Страница не найдена 404 — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Фонетический разбор слова и звуко-буквеннный анализ
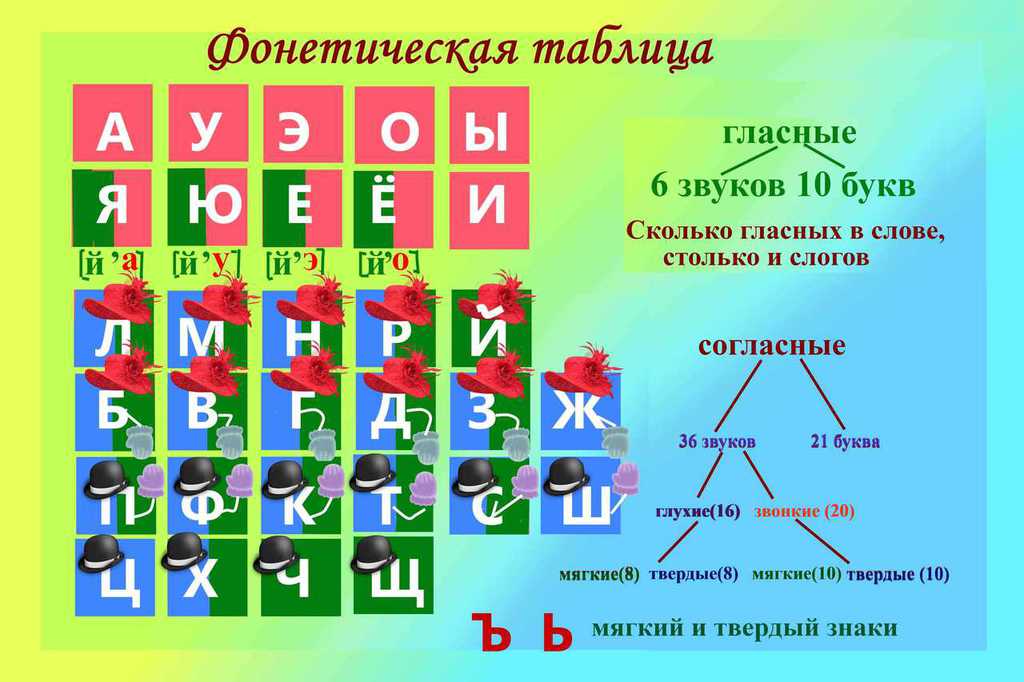
Фонетический или звуко-буквенный анализ — разбор слова на составляющие. От учащегося требуется подсчитать и охарактеризовать звуки из которых оно состоит. Кроме этого нужно подсчитать количество слогов, букв и звуков в слове. Это совсем не сложно если знать некоторые правила и особенности «поведения» звуков в русском языке. А начать следует с того, что есть всего сорок три звука, из которых тридцать семь принято считать согласными и только лишь шесть гласными.
Звуки принято делить на гласные — они получаются, когда воздушная струя, покидая легкие, заставляет вибрировать напряженные и сомкнутые голосовые связки, и согласные, которые получаются при помощи связок и прочих звукообразующих органов, либо вообще без помощи связок.
Нормы произношения звуков, а также правила ударения в словах изучает орфоэпия.
Ведь в некоторых языках могут отсутствовать даже буквы, свойственные русскому языку. Примером может служить японский язык, не имеющий в своем фонетическом наборе буквы «л».
Для выполнения разбора воспользуйтесь алфавитным указателем по фонетическому словарю или формой поиска.
Правила и исключения, учитываемые при фонетическом разборе
Фонетических правил в русском языке не очень много и все они просты для понимания и практически не имеют исключений.
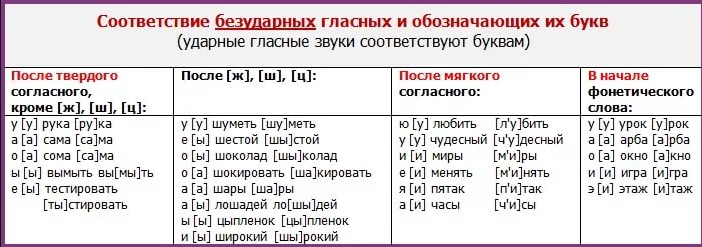
Так, например, ударные гласные всегда звучат четко и без изменений. Однако, будучи безударными, звуки «ы» и «у» также сохраняют это свойство. Звук [о] являясь безударным, приближается по звучанию к звуку [а], [е] напоминает звучанием [ы], а безударный [э] становится похож на [и].
В глаголах 3 лица единственного и множественного числа в форме настоящего времени, которые имеют в своем
составе звукосочетание [ться], оно записывается как звук [ц’].
Иногда «г» становится мягким [х], «с», стоящий перед «ш» и «ч», записывается в фонетической транскрипции так, как и звучит — [щ].
[дц], [дч], [тц] и [тч] при звучании упрощаются до [ч’] и [ц].
Согласные [л], [м], [н], [р], [й], как правило, не изменяются при звучании и записываются также, как и их буквенные эквиваленты — без изменений.
Кроме того, если звонкий согласный стоит перед глухим согласным, либо в конце словоформы, он оглушается, равно как и наоборот, глухие согласные озвончаются, находясь перед звонким согласным звуком. Исключения составляют: [л], [м], [н], [р], [в], [й].
Как выполнять фонетический анализ
Фонетический разбор слова можно осуществлять как письменно, так и устно. В первом случае педагоги
рекомендуют использовать различные цвета для записи гласных и согласных букв. К примеру, гласные пишутся
красной ручкой, а согласные — синей или зеленой. То же верно и для записи транскрипции.
Далее нужно охарактеризовать каждый отдельный звук и каждую отдельную букву. Для наглядности и здесь не лишним будет использование различных цветов при расписывании особенностей гласных и согласных букв. Также следует подсчитать количество гласных и согласных букв, а также количество звуков и слогов в разбираемом слове.
Шпаргалка в помощь
Звуко-буквенный разбор любой фонемы — процесс не сложный, каждый может воспользоваться краткой информацией, которая представлена ниже. Выучив эти несколько строк, любой сможет без труда осуществить разбор на звуки слова, даже если видит его впервые.
Гласные буквы, придающие согласному твердость,
— «а», «э», «о», «у», «ы». За смягчение
согласного отвечают — «я», «ю», «ё», «е», «и’.
За смягчение
согласного отвечают — «я», «ю», «ё», «е», «и’.
Помните, не существует звуков — [я], [ю], [ё], [е]. Они записываются как два звука — [йа], [йу], [йо], [йэ].
Согласные непарные звонкие — «л», «м», «р», «н», «й», глухие — «ц», «ч», «х», «щ». Парные звонкие — «б» «в» «г» «д» «ж» «з» глухие, соответственно, — «п», «ф», «к», «т», «ш», «с» . Как уже говорилось, согласный звук смягчится, если после него стоит одна из букв: «я», «ё», «ю», «и», «е», «ь». Но и тут есть исключение — всегда мягкими будут: [ ч`], [щ`], [й`], а всегда твердыми: [ж], [ш], [ц].
Фонетический разбор слова
Цель: научиться производить фонетический анализ слов.
Задачи.
- Повторить понятия “фонетика”, “фонетический разбор”.
- Повторить звуки – гласные и согласные.
- Повторить классификацию согласных звуков.
- Повторить, в каких случаях буквы е, ё, ю, я
могут при произношении давать два звука.

- Повторить правило деления слов на слоги, постановки ударения в словах.
- Отработать умение воспроизводить звуковой состав слова с помощью транскрипции.
- Научить давать подробную характеристику каждому звуку.
- Повторить правило сокращения слов при письме.
- Отрабатывать порядок проведения фонетического разбора слова.
- Развивать коммуникативные навыки, умение договариваться друг с другом.
- Воспитывать уважение к окружающим людям, к чужому мнению.

Оборудование: лента букв, проектор, экран.
Примечание. Учителю надо иметь в виду, что проведение полного фонетического
разбора не является обязательным требованием для выпускника
начальной школы. Поэтому необходимо подходить к разбору слов
дифференцированно: сильные ученики могут выполнять данный вид
задания в полном объёме письменно, успевающие средне –
— письменно в сокращённом виде с опорой на
образец.
Ход урока
1. Приветствие.
Здравствуйте, ребята. Начинаем наш урок русского языка. Посмотрите,
пожалуйста, какая тема урока, назовите её. (Фонетический разбор слова)
(Слайд №1)
2. Повторение пройденного по теме “Фонетика”.
Фонетика – это раздел русского языка, который изучает звуки нашей речи, а фонетический разбор – это, соответственно, звуковой анализ слов.
(Слайд №2)
Итак, какие бывают звуки? (Гласные и согласные)
Какие звуки мы называем гласными? Почему?
Сколько в русском языке гласных звуков? Назовите гласные звуки.
Какие звуки мы называем согласными? Почему? Назовите согласные звуки.
Давайте вспомним:
- какие согласные звуки могут быть парными по признаку твёрдости-мягкости,
- какие согласные звуки только твёрдые,
- какие согласные звуки только мягкие,
приведите примеры:
- какие согласные имеют пару по звонкости-глухости,
- какие согласные не имеют пару по этому признаку,
- назовите все пары согласных по
звонкости-глухости.

Какие буквы вообще не имеют звуков? Назовите эти буквы.
В каком случае буквы е, ё, ю, я могут обозначать два звука? Приведите примеры:
- если буквы стоят в начале слова (ель, ёжик, юбка, яхта и т. п.),
- если буквы стоят после гласной буквы (поел, приём, думаю, белая и т.п.),
- если буква стоит после ь или ъ (объехал, перья и т.п.).
3. Отработка порядка проведения фонетического разбора.
Ребята, вы уже очень много знаете о звуках нашей речи, молодцы! А теперь мы будем учиться, используя эти знания, проводить фонетический разбор слов.
Итак, начнём. Давайте посмотрим, в каком порядке всегда производится фонетический разбор.
(Слайд №3)
- Прежде чем письменно анализировать звуковой
состав слова, его нужно вслух, чётко и медленно
произнести его, вслушиваясь в каждый звук.
- Записываем слово.
- Разделим слово на слоги.
- Поставим ударение.
- Запишем транскрипцию слова. Вспомним, что такое “транскрипция”. А какие скобки ставятся при записи транскрипции? (на доске кто-либо из учеников рисует эти скобки)
- Далее будем характеризовать каждый звук, подробно всё записывая.

Если звук гласный – ударный он или безударный?
Если звук согласный – твёрдый или мягкий (имеет ли пару по данному признаку), глухой или звонкий (имеет ли пару по данному признаку).
Обратите внимание на то, как можно сокращать слова при характеристике звуков (на доске учитель показывает варианты сокращения слов).
После того, как мы охарактеризовали все звуки слова, подводим черту, а затем записываем, сколько в слове слогов, букв и звуков.
4. Ещё раз вспоминаем о звуках, которые бывают
только твёрдыми, мягкими.
(Слайд №4)
Когда буквы могут обозначать два звука.
(Слайд №5)
Когда буквы не обозначают звуков.
(Слайд №6)
5. Физминутка.
6. Практический разбор слова.
Давайте приступим к практическому заданию - сделаем фонетический разбор слова. А что это за слово, вы сейчас сами отгадаете.
Загадка.
И петь не поёт,
И лететь не летает.
За что же тогда
Его птицей считают? (Страус)
А кто такой страус? Чем известна эта птица?
(Фонетический разбор производится по плану (Слайд №7), но строчки появляются на экране не сразу, а после того, как ученики устно сформулируют какая должна быть запись).
Молодцы!
7. А теперь слово для разбора будет посложнее. Но сначала отгадайте его.
Загадка.
Чтобы сильная волна
Нас с места сдвинуть не смогла,
За борт мы цепь бросаем
И в воду опускаем. (Якорь)
Чтобы успешно справится с этим заданием, работать будем в парах. Пожалуйста, обсуждайте друг с другом каждый шаг, приходите к единому мнению, а если возникнут затруднения, обращайтесь к учителю.
Итак, слово “якорь”.
Что такое якорь, зачем он нужен? Кто использует в своей работе якоря?
(Фонетический разбор производится аналогично, с опорой на слайд №3, затем проверяем с помощью слайда №8).
8. Итог урока.
Наш урок подходит к концу.
О чём вы сегодня узнали? Какое новое знание открыли?
Чему новому научились?
Молодцы! Вы хорошо поработали, я уверена, что теперь фонетический разбор каждый сможет сделать самостоятельно, в полном объёме.
(Слайд №9)
9. Домашнее задание.
Домашнее задание.
Фонетический разбор
Как сделать фонетический разбор? Фонетический разбор — трудоёмкое занятие! Чтобы правильно сделать его, нужно знать несколько правил. Первое. Знать виды звуков и правильные названия букв. Здесь фонетика дружит с графикой!
В школе в отличие от вуза фонология и её основные понятия не изучаются, хотя и употребляются слово «фонема» и выражения «слабая позиция» (под ударением) и «сильная позиция» (без ударения).
Для обозначения звука и его пары: [б], [б’], [п], [п’] – служат квадратные скобки [ ]. Круглые скобки здесь неуместны!
Буквы заключаются в кавычки « » и называются так же, как и в алфавите. Например, буква «ка», «эф», «э оборотное», «и краткое», «ща», «че».
Смотрите алфавит и выучите все названия букв!
Второе. Нужно иметь представления о транскрипции и её символах.
Запомни и применяй знаки фонетической транскрипции!
[ó] – знак основного ударения над гласным звуком (мОжно).
[`] – знак дополнительного ударения над гласным звуком (жủзнеобеспЕчение).
[Λ] – так произносятся гласные (пишутся буквы «о», «а») в начале слова или в первом предударном слоге после твердых согласных: окно [Λкнó], актив [Λкт’ủф].
[j’] – (йот) в нашем алфавите нет знака, принято «и краткое» или йотированная буква «й» («и краткое»).
Если в слове есть так называемые йотированные буквы «е», «ё», «ю», «я», то в транскрипции мы указываем 2 звука [j’+э], [j’+о], [j’+у], [j’+а].
Эти звуки произносятся в 3 позициях и всегда под ударением:
1) в самом начале слова: ель [j’эл’], ёж [j’ош], юла [j’ула], яд [j’ат];
2) после гласного: моем [мΛj’эм], поём [пΛ j’ом,] поют [пΛj’ут], маяк [мΛj’ак],
3) после разделительных Ъ и Ь знаков: въезд [вj’эст], шьёт [шj’от], шьют [шj’ут], семья [с’иэм’j’а].
Их легко перепутать с гласными [э], [о], [у], [а] в словах после мягких согласных: веточка [в’этач’ка] или [в’этъч’къ], лёд [л’от], утюг [ут’ук], мяч [м’ач’], зверь [зв’эр’].
[иэ] – с призвуком [э], звук похож на нечто среднее между [и-э], так произносятся гласные в первом предударном слоге после мягких согласных (пишутся буквы «а», «е», «э»): часы [ч’иэсы], весна [в’иэсна] или [в’иэснъ].
[ыэ] – с призвуком [э], звук похож на нечто среднее между [ы-э] или [ы-а], так произносятся гласные в первом предударном слоге после твердых согласных (пишутся буквы «э», «е»): этаж [ыэташ], цена [цыэна], шестой [шыэстоj’], жена [жыэна].
[ъ] – так произносятся гласные (пишутся буквы «о», «а», «е») во всех предударных и заударных слогах после твердых согласных:
молодой [мълΛдоj’], материнский [мът’иэр’инск’иj’], хорошо [хърΛшо], кашей [кашъj’].
[ь] – так произносятся гласные (пишутся буквы «о», «а», «я», «е») во всех безударных слогах после мягких согласных:
бережка [б’ьр’иэшка], пятачок [п’ьтΛч’ок], на мачте [нΛмач’т’ь], часовой [ч’ьсΛвоj’], щебетать [щ’ьб’иэтат’].
[–] – указание на отсутствие звука, когда в слове есть буквы «мягкий знак» или «твёрдый знак».
Можно использовать упрощенную систему для передачи звуковой оболочки слова, то есть буквы «й, а, о, э, у, и».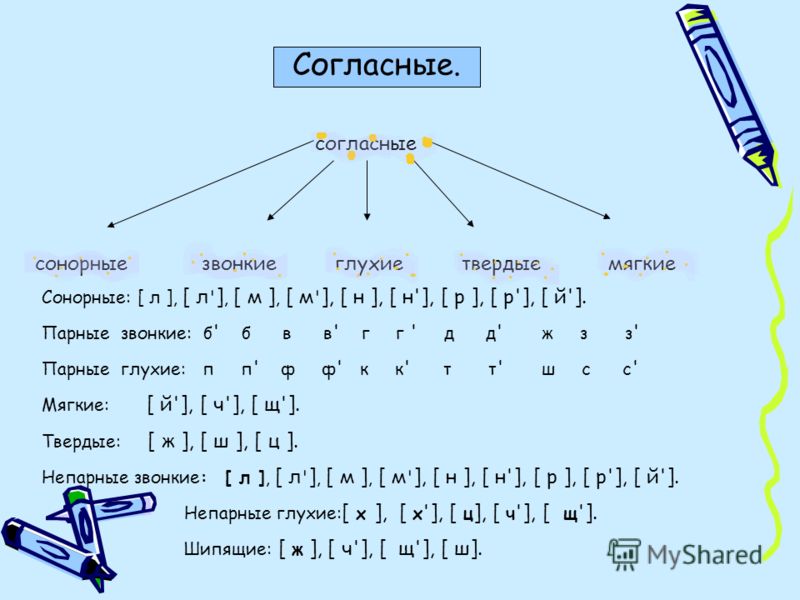
Третье. Не забудем об ударении.
Ударение отличает слова и их формы по звуковому составу (текут рЕки – жить у рекИ; мыть рУки – нет рукИ).
Записали слово и обязательно поставим ударение!
Четвертое. Дадим полную характеристику каждому звуку.
Основное коварство содержится в согласных звуках. Они имеют 4 характеристики: звонкость и глухость, твердость и мягкость. Не забудьте о парных и непарных.
В разборе нужно указывать полную характеристику согласного звука. При этом учитываем процессы озвончения и оглушения согласных.
Глухие перед звонким согласным озвончаются: cгореть [згΛр’эт’], просьба [проз’бъ].
В конце слова звонкий согласный оглушается: берег [б’эр’ьк].
Перед глухим согласным звуком звонкий тоже оглушается: сказка [скаскъ].
Некоторые согласные звуки, стоящие перед мягкими согласными, смягчаются [н, с, з, т, д]: винтик [в’ин’т’ик], кости [кос’т’и].
[’] – знак обозначения мягкости согласного звука: дождь [дошт’] или [дощ’].
Звуки [с’] и [з’] мягкие на конце приставок С-, ИЗ-, РАЗ- перед «Ъ»: съел [c’j’эл], изъездил [из’j’эз’д’ил].
Пятое. Некоторые сочетания согласных произносятся как долгие.
[‾] – знак долготы согласного звука: бояться [бΛj’аЦъ], лётчик [л’оЧ’ик].
При стечении нескольких согласных один из них может не произноситься [т, д, в, л]: чувство [ч’уствъ], поздно [познъ].
План фонетического разбора
1. Запишем слово.
2. Поставим ударение.
3. Запишем справа транскрипцию слова, разделим его на слоги.
4. Охарактеризуем все звуки, записывая их сверху вниз:
4.1. ударный-безударный для гласных;
4.2. звонкий-глухой (пара), твёрдый-мягкий (пара) для согласных;
4.3. укажем, какой буквой обозначен каждый звук.
5. Подсчитаем количество звуков и букв.
6. Объясним несоответствия между звуками и буквами.
Образец записи
Óсень – [о-с’ьн’], 2 слога
[Ó] – гласный, ударный, обозначен буквой «о»
Слова «обозначен буквой» можно не писать, а сразу указывать название буквы!
[с’] – согласный, глухой, пара [з’], мягкий, пара [с], «эс»
[ь] – гласный, безударный, «е»
[н’] – согласный, сонорный, непарный, мягкий, пара [н], «эн»
[–] «мягкий знак»
4 звука, 5 букв
Звуков меньше, чем букв, так как есть «мягкий знак».
Примеры
Язык1
ЯзЫк – [j’иэ-зык], 2 слога
[j’] – согласный, сонорный, непарный, мягкий, непарный
[иэ] – гласный, безударный обозначен буквой «я»
[з] – согласный, звонкий, пара [с], твёрдый, пара [з’], «зэ»
[ы] – гласный, ударный, «ы»
[к] – согласный, глухой, пара [г], твёрдый, пара [к’], «ка»
5 звуков, 4 буквы
Звуков больше, чем букв, так как есть йотированная гласная «я» в начале слова.
Рябина1
РябИна – [р’иэ-б’и-нъ], 3 слога
[р’] – согласный, сонорный, непарный, мягкий, пара [р], «эр»
[иэ] – гласный, безударный, «я»
[б’] – согласный, звонкий, пара [п], мягкий, пара [б], «бэ»
[и] – гласный, ударный, «и»
[н] – согласный, сонорный, непарный, твёрдый, пара [н’], «эн»
[ъ] – гласный, безударный, «а»
6 звуков, 6 букв
СтОят1 (о цене предмета: дОрого стОят туфли).
СтОят – [сто-j’ьт], 2 слога
[с] – согласный, глухой, пара [з], твёрдый, пара [с’], «эс»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[о] – гласный, ударный, «о»
[j’] – согласный, сонорный, непарный, мягкий, непарный
[ь] – гласный, безударный обозначен буквой «я»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
6 звуков, 5 букв
Звуков больше, чем букв, так как йотированная гласная «я» стоИт после гласной.
СтоЯт1 (о действии: стоЯт у дороги и ждут).
СтоЯт – [стΛ-j’ат], 2 слога
[с] – согласный, глухой, пара [з], твёрдый, пара [с’], «эс»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[Λ] – гласный, безударный, «о»
[j’] – согласный, сонорный, непарный, мягкий, непарный
[а] – гласный, ударный обозначен буквой «я»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
6 звуков, 5 букв
Звуков больше, чем букв, так как йотированная гласная «я» стоИт после гласной.
Общение1
ОбщЕние – [Λп-щ’э-н’и-j’ь], 4 слога
[Λ] – гласный, безударный, «о»
[п] – согласный, глухой, пара [б], твёрдый, пара [п’], «бэ»
[щ’] – согласный, глухой, непарный, мягкий, непарный, «ща»
[э] – гласный, ударный, «е»
[н’] – согласный, сонорный, непарный, мягкий, пара [н], «эн»
[и] – гласный, безударный, «и»
[j’] – согласный, сонорный, непарный, мягкий, непарный
[ь] – гласный, безударный обозначен буквой «е»
8 звуков, 7 букв
Звуков больше, чем букв, так как йотированная гласная «е» стоИт после гласной.
Читатель1
ЧитАтель – [ч’и-та-т’ьл’], 3 слога
[ч’] – согласный, глухой, непарный, мягкий, непарный, «че»
[и] – гласный, безударный, «и»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[а] – гласный, ударный, «а»
[т’] – согласный, глухой, пара [д], мягкий, пара [т], «тэ»
[ь] – гласный, безударный, «е»
[л’] – согласный, сонорный, непарный, мягкий, пара [л], «эль»
[–] «мягкий знак»
7 звуков, 8 букв
Звуков меньше, чем букв, так как есть «мягкий знак».
Точка1
ТОчка – [точ’-къ], 2 слога
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[о] – гласный, ударный, «о»
[ч’] – согласный, глухой, непарный, мягкий, непарный, «че»
[к] – согласный, глухой, пара [г], твёрдый, пара [к’], «ка»
[ъ] – гласный, безударный, «а»
5 звуков, 5 букв
Весна1
ВеснА – [в’иэ-снъ], 2 слога
[в’] – согласный, звонкий, [ф], мягкий, пара [в], «вэ»
[иэ] – гласный, ударный, «е»
[с] – согласный, глухой, пара [з], твёрдый, пара [с’], «эс»
[н] – согласный, сонорный, непарный, твёрдый, пара [н’], «эн»
[ъ] – гласный, безударный, «а»
5 звуков, 5 букв
Идёт1
Идёт – [и-д’от], 2 слога
[и] – гласный, безударный, «и»
[д’] – согласный, звонкий, пара [т’], мягкий, пара [д], «дэ»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
4 звука, 4 буквы
Попробуйте сами разобрать слова:
Лошадь
Смеются
Яблоко
Всё
Солнце
Поют
Проверьте свой результат, нажав на каждое из этих слов по порядку.
фонетический разбор слов:пятью,широкий,чудесный,тополь,тишь,местный.Со всеми правилами
пя-тью
п — [п’] : согласный, парный глухой, парный мягкий
я — [и] : гласный
т — [т’] : согласный, парный глухой, парный мягкий
ь —
ю —
[й’] : согласный, непарный звонкий, сонорный, непарный мягкий
[у] : гласный
_____________________
букв—5, звуков—5ши — ро — кий
ш — [ш]: согласн, парн, глух, тверд
и — [ы] : гласн, безударн
р — [p]: согласн, непарн, звонк, тверд
о — [о] : гласн, ударн
к — [к’] : согласн, парн, глух, мягк
и — [и] : гласн, безударн
й — [й’] : согласн, непарн, звонк, мягк
______________________________
7 букв, 7 звуков
чу-де-сный
ч — [ч’] ; согласный, глухой/непарный, мягкий/непарный
у — [у] : гласный, безударный
д- [д’] : согласный, звонкий/парный, мягкий/парный
е — [э´] : гласный, ударный
с — [с] : согласный, глухой/парный, твёрдый/парный
н — [н] : согласный, звонкий/непарный, твёрдый/парный
ы -[ы] :гласный, безударный
й — [й’] : согласный, звонкий/непарный, мягкий/непарный
_____
8 букв, 8 звуков
то-поль
т — [т] : согл. , глух./парн., твёрд./парн.
, глух./парн., твёрд./парн.
о — [о´] : гласн., ударн.
п -[п] :согл., глух./парн., твёрд./парн.
о — [а] : гласн., безуд.
л — [л’] : согл., звонк./непарн., мягк./парн.
ь —
____________
6 букв, 5 звуков
тишь
т — [т’] : согл., глух./парн., мягк./парн.
и — [и´] : гласн., ударн.
ш — [ш] ; согласн., глух./парн., твёрд./непарн.
ь —
_____________________
4 буквы, 3 звука
мест-ный
м — [м’] : согласный, звонкий, мягкий ,
е — [Э] : гласный, ударный ,
с — [с]: согласный, глухой, твердый ,
т —
н — [н] : согласный, звонкий, твердный ,
ы — [ы] : гласный, безударный ,
й — [й’] : согласный , звонкий , мягкий.
_________________________
7 букв, 6 звуков.
[сй’эст], 1 слог, ударение на «е»
Звуко-буквенный разбор слова, например, существительного в единственном числе съезд, применяется с цельюоблегчения понимания, развития у детей фонетического восприятия. Считается, что развитие речевого аппарата человека начинается с правильного формирования слуховой памяти (словарного запаса). В дальнейшем это поможет избежать часто встречающейся и характерной путаницы с глухими и звонкими символами («З»-«С», «Д»-«Т»), а также поспособствует вырабатыванию навыков грамотного письма.
Считается, что развитие речевого аппарата человека начинается с правильного формирования слуховой памяти (словарного запаса). В дальнейшем это поможет избежать часто встречающейся и характерной путаницы с глухими и звонкими символами («З»-«С», «Д»-«Т»), а также поспособствует вырабатыванию навыков грамотного письма.
Транскрипция слова
Данная словоформана слоги не разбивается, потому что относится к простым, односложным. Ударение также не вызывает трудностей и его легко запомнить –оно приходится на единственную гласную (е). А вот при построении однокоренного съездить ударение меняется из-за добавления 2 слога.Транскрипция звучит как [сй’эст].
Характеристики звуков
Следует помнить, что буквы не всегда звучат и произносятся так, как пишутся. Более того, это абсолютно разные разделы языка. В русском языке по характеристикам звуки бывают:
- гласными/согласными;
- звонкими/глухими;
- парными;
- твердыми/мягкими.
Пример разбора
Раньше фонетикой начинали заниматься не ранее 4 или 5 класса. В современной школьной программе звуковую разборку отдельных слов, съезда и других, предлагается проделывать уже в начальных (1, 2 классах), поэтому малыш должен придти на занятия уже подготовленным. Подробнуюразборку слова съезд легко пояснить на наглядном примере:
В современной школьной программе звуковую разборку отдельных слов, съезда и других, предлагается проделывать уже в начальных (1, 2 классах), поэтому малыш должен придти на занятия уже подготовленным. Подробнуюразборку слова съезд легко пояснить на наглядном примере:
- с –[с], з – [с], д – [т] — из разряда согласных звуков, парные глухие, твёрдые;
- ъ – ничего не обозначает, не произносится;
- е – разбивается на 2: [й’] – согласный, непарный звонкий и мягкий, сонорный и [э]-гласный, ударный.
При разборке слова съезд на звуки и буквы (их поровну – 5) применяются обычные правила русского языка: звонкие «з», «д»приглушаются, а «е» видоизменяется, раскладывается на 2 составляющих. На основании данного примера детям будет легко выполнить подробный звуковой анализ с другими словами– самостоятельно или с помощью взрослых (учителя и родителей).
Как научить ребенка делать фонетический разбор слова
Достаточно трудная тема для учеников — фонетический разбор. В этой статье с помощью трех видео-уроков мы поможем вам научить этому ребенка раз и навсегда.
В этой статье с помощью трех видео-уроков мы поможем вам научить этому ребенка раз и навсегда.
Вначале разберемся, для чего делают звуко-буквенный анализ и что нужно знать для выполнения разбора:
Отлично! Мы научились различать букву и звук и узнали основные их характеристики.
Второй шаг — звуко-буквенный анализ. Смотрим короткое видео:
Наконец, мы готовы к самому главному — к разбору!
Давайте разберем слово «лягушка». Внимание на экран:
Внимание на экран:
Надеемся, статья была вам полезна. Учитесь с удовольствием!
Регистрируйте ребенка в «Экспресс-версию» школы 60 минут и пусть ваш ребенок учится с удовольствием.
Девиз экспресс-версии: сохранить и приумножить знания. В ней мы разбираем все темы класса простым и понятным языком.
Всего за 30 дней ребенок повторит программу целого класса и сможет устранить пробелы в знаниях.
Вам понравилась статья? Сохраните себе на стену, чтобы не потерять
Похожее
3 класс. Русский язык. Фонетический разбор слова — Фонетическая транскрипция
Комментарии преподавателя
Что такое фонетическая транскрипция
Постараемся научиться, как с помощью специальных знаков передавать на письме точное звучание слов.
Для начала вспомним, что среди разделов языкознания есть особый, изучающий звуки. Это фонетика. Звуки и буквы – это не одно и то же. Звуки – то, что мы слышим и произносим, буквы – то, что мы видим и пишем. Изучая русский язык, его правила и закономерности, мы успели заметить, что написание слова очень часто не совпадает с его звучанием.
Например, мы говори [марос], а пишем: мороз.
Но иногда возникает необходимость передать точное звучание слова. Как это сделать? На помощь приходит транскрипция.
Транскрипция – это точная передача всех особенностей и тонкостей произношения слова независимо от его графического и орфографического написания.
Давайте рассмотрим основные знаки, которые используются при транскрибировании слов.
Во-первых, транскрипция слова всегда записывается в квадратных скобках:
Во-вторых, в транскрипции принято указывать ударный гласный. Для этого используют уже знакомый нам знак ударения:
При этом следует помнить, что если в слове только один гласный звук, это значит, что ударение падает именно на него, поэтому нет необходимости ставить знак ударения.
В-третьих, в разных источниках для обозначения звука Й используются знаки: [й] или [j].
[мой] или [моj]
В-четвертых, в транскрипции не используется Ь, а для обозначения мягкости согласного применяется такой знак: [ ,]. Этот знак передаёт мягкость всех согласных, кроме Й. Мягкость звука [й] графически никак не изображается.
В-пятых, в транскрипции таких слов как, например, вожжи долгий согласный обозначается с помощью такого знака:
Независимо от того, какое слово необходимо записать в транскрипции, нужно иметь в виду, что делают это без использования прописных (больших) букв.
Например:
Кроме того, при записи слова в транскрипции необходимо помнить о таких звуковых процессах, как озвончение-оглушение (изменение согласного в слабой позиции на парный по глухости-звонкости).
Например:
Также необходимо помнить о непроизносимых согласных.
Например:
Не следует забывать и о двойной роли букв Е, Ё, Ю, Я, которые в абсолютном начале слова после другого гласного или после ъ и ь обозначают два звука [йэ], [йо], [йу], [йа]. В остальных случаях эти гласные обозначают звуки [э], [о], [у], [а].
В остальных случаях эти гласные обозначают звуки [э], [о], [у], [а].
Например:
Знания правил транскрипции пригодятся нам при выполнении фонетического разбора слов. Основные требования к записи и оформлению фонетического разбора слов едины, но они могут несколько отличаться в зависимости от того, по какому учебно-методическому комплексу вы занимаетесь. Выполнить фонетический разбор слова – значит определить, из каких звуков оно состоит. В учебниках слова, рекомендованные для фонетического разбора, обычно отмечены цифрой 1. Выполняется фонетический разбор по следующему плану:
1. Сначала необходимо записать слово, разделить его на слоги, поставить знак ударения.
2. Потом записать транскрипцию слова.
3. Далее указать, какими буквами обозначены звуки, и дать характеристику всем звукам.
- В завершение определить количество звуков и букв.
Важно! Правильно говорить: звук передается с помощью буквы, или для обозначения звука используется буква, или буква обозначает звук. Но нельзя говорить: звук обозначает букву.
Но нельзя говорить: звук обозначает букву.
ИСТОЧНИКИ
http://znaika.ru/catalog/5-klass/russian/Chto-takoe-foneticheskaya-transkriptsiya
(PDF) Правила и алгоритмы фонетической транскрипции стандартного малайского
Фонетическая транскрипция текста является незаменимым компонентом систем преобразования текста в речь (TTS) и используется в акустическом моделировании для распознавания речи и других приложений обработки естественного языка. Один из подходов к транскрипции письменного текста в фонетические объекты или звуки заключается в использовании набора четко определенных контекстных и зависящих от языка правил. Процесс преобразования текста в звуки начинается с предварительной обработки текста и представления его лексическими элементами, к которым применяются правила. Правила можно разделить на фонематические и фонетические. Фонематические правила работают с графемами, чтобы преобразовать их в фонемы. Фонетические правила работают с фонемами и преобразуют их в контекстно-зависимые фонетические сущности с реальными звуками. Преобразование письменного текста в реальные звуки, разработка исчерпывающего набора правил и преобразование правил в реализуемые алгоритмы для любого языка вызывают несколько проблем, которые происходят из-за относительного несоответствия между написанием лексических элементов и их звуковым содержанием.Для стандартного малайского (SM) эти проблемы не столь серьезны, как для языков со сложной орфографической системой, таких как английский и французский, но они действительно существуют. В этой статье обсуждается разработка комплексной компьютеризированной системы для обработки текста SM и его преобразования в фонетические объекты, а также оценки производительности этой системы, независимо от приложения. В частности, в этой статье рассматриваются следующие вопросы: (1) орфография и другие проблемы написания SM и их влияние на преобразование графем в фонемы, (2) разработка всеобъемлющего набора правил преобразования графемы в фонемы для SM, (3) описание фонетических вариаций SM или того, как фонемы SM различаются в контексте, и разработка набора правил транскрипции фонем в фонетику, (4) формулирование фонематических и фонетических правил в алгоритмах которые применимы к компьютерной обработке входного текста SM, и (5) оценка эффективности процесса преобразования текста SM в реальные звуки с помощью вышеупомянутых методов.
Правила можно разделить на фонематические и фонетические. Фонематические правила работают с графемами, чтобы преобразовать их в фонемы. Фонетические правила работают с фонемами и преобразуют их в контекстно-зависимые фонетические сущности с реальными звуками. Преобразование письменного текста в реальные звуки, разработка исчерпывающего набора правил и преобразование правил в реализуемые алгоритмы для любого языка вызывают несколько проблем, которые происходят из-за относительного несоответствия между написанием лексических элементов и их звуковым содержанием.Для стандартного малайского (SM) эти проблемы не столь серьезны, как для языков со сложной орфографической системой, таких как английский и французский, но они действительно существуют. В этой статье обсуждается разработка комплексной компьютеризированной системы для обработки текста SM и его преобразования в фонетические объекты, а также оценки производительности этой системы, независимо от приложения. В частности, в этой статье рассматриваются следующие вопросы: (1) орфография и другие проблемы написания SM и их влияние на преобразование графем в фонемы, (2) разработка всеобъемлющего набора правил преобразования графемы в фонемы для SM, (3) описание фонетических вариаций SM или того, как фонемы SM различаются в контексте, и разработка набора правил транскрипции фонем в фонетику, (4) формулирование фонематических и фонетических правил в алгоритмах которые применимы к компьютерной обработке входного текста SM, и (5) оценка эффективности процесса преобразования текста SM в реальные звуки с помощью вышеупомянутых методов.
Вывод правил иерархического произношения из фонетического словаря
Вывод иерархического произношения правил из фонетического Словарь Эрика Пиглиапоко, Валерио Фрески и Алессандро Больоло Аннотация. В этой работе представлена новая система фонетической транскрипции, основанная на дереве иерархических правил произношения, выраженных как контекстно-зависимые соответствия графема-фонема.Дерево автоматически выводится из фонетического словаря путем постепенного анализа более глубоких уровней контекста, что в конечном итоге представляет собой минимальный набор исчерпывающих правил, которые безошибочно произносят все слова в обучающем словаре и которые могут быть применены к выходу из них. словарного запаса. Предлагаемый подход улучшает существующие методы, основанные на дереве правил, в том, что он использует графемы, а не буквы, в качестве элементарных орфографических единиц. Представлен новый линейный алгоритм сегментации слова в графемах, позволяющий использовать фонетическую транскрипцию вне словарного запаса графем.Исчерпывающие деревья правил обеспечивают каноническое представление правил произношения на языке, которое можно использовать не только для произнесения слов вне словарного запаса, но также для анализа и сравнения правил произношения, выведенных из различных словарей. Предлагаемый подход был реализован на языке C и протестирован на оксфордском британском английском и базовом английском. Экспериментальные результаты показывают, что деревья правил на основе графем представляют фонетически правильные правила и обеспечивают лучшую производительность, чем деревья правил на основе букв.Ключевые слова: автоматическая фонетическая транскрипция; правила произношения; вывод иерархического дерева. I. ВВЕДЕНИЕ АВТОМАТИЧЕСКОЕ произношение текста — важная задача обработки в компьютерной лингвистике. За последнее десятилетие была проделана большая работа в области преобразования буквы в звук.
Представлен новый линейный алгоритм сегментации слова в графемах, позволяющий использовать фонетическую транскрипцию вне словарного запаса графем.Исчерпывающие деревья правил обеспечивают каноническое представление правил произношения на языке, которое можно использовать не только для произнесения слов вне словарного запаса, но также для анализа и сравнения правил произношения, выведенных из различных словарей. Предлагаемый подход был реализован на языке C и протестирован на оксфордском британском английском и базовом английском. Экспериментальные результаты показывают, что деревья правил на основе графем представляют фонетически правильные правила и обеспечивают лучшую производительность, чем деревья правил на основе букв.Ключевые слова: автоматическая фонетическая транскрипция; правила произношения; вывод иерархического дерева. I. ВВЕДЕНИЕ АВТОМАТИЧЕСКОЕ произношение текста — важная задача обработки в компьютерной лингвистике. За последнее десятилетие была проделана большая работа в области преобразования буквы в звук. В частности, развитие систем преобразования текста в речь (TTS) стимулировало исследования в области автоматической фонетической транскрипции. Фактически, модули обработки для совмещения написанных букв с соответствующими фонемами (т.е. значимые звуки) всегда являются одной из первых задач в рабочем процессе систем TTS [15], [9]. Современные подходы к автоматической фонетической транскрипции письменного текста можно в основном разделить на подходы, основанные на правилах и данных [5], [6], [8]. Подходы на основе правил (которые были разработаны первыми) следуют методологическим линиям порождающих грамматик, уходящим корнями в компьютерную лингвистику [3], формализуя производственные правила произношения типа A 〈B〉 C → P, семантика которого: отображается на фонему P, когда ее левый контекст — A, а ее правый контекст — C.С вычислительной точки зрения правила принимаются на входе и используются системой TTS для получения фонетической транскрипции произвольных входных текстов. Излишне говорить, что точность подходов, основанных на правилах, сильно зависит от качества правил.
В частности, развитие систем преобразования текста в речь (TTS) стимулировало исследования в области автоматической фонетической транскрипции. Фактически, модули обработки для совмещения написанных букв с соответствующими фонемами (т.е. значимые звуки) всегда являются одной из первых задач в рабочем процессе систем TTS [15], [9]. Современные подходы к автоматической фонетической транскрипции письменного текста можно в основном разделить на подходы, основанные на правилах и данных [5], [6], [8]. Подходы на основе правил (которые были разработаны первыми) следуют методологическим линиям порождающих грамматик, уходящим корнями в компьютерную лингвистику [3], формализуя производственные правила произношения типа A 〈B〉 C → P, семантика которого: отображается на фонему P, когда ее левый контекст — A, а ее правый контекст — C.С вычислительной точки зрения правила принимаются на входе и используются системой TTS для получения фонетической транскрипции произвольных входных текстов. Излишне говорить, что точность подходов, основанных на правилах, сильно зависит от качества правил. Создание содержательных правил, отражающих сложную взаимосвязь между письменным текстом и авторами, разработано ISTI — Университетом Урбино, Урбино, Италия (электронная почта: (erika.pigliapoco, valerio.freschi, alessandro.bogliolo) @ uniurb.it), произношение сложная задача сама по себе (которая также включает теоретические вопросы), особенно для языков, богатых орфографическими нарушениями и исключениями, таких как английский. Для решения или преодоления этой проблемы были разработаны различные методы, в основном относящиеся к категории подходов, основанных на данных. Методы, управляемые данными, пытаются использовать знания, которые неявно присутствуют в базах данных произношения, таких как словари с фонетической транскрипцией. Чем шире размер словаря, тем эффективнее метод. Основная задача здесь — сделать вывод о фонетической транскрипции слов, которых нет в словаре. Эта проблема известна в литературе как проблема отсутствия словарного запаса (OOV).Возможное решение для произношения OOV основывается на сходстве подстрок: слово OOV разбивается на подстроки, которые сопоставляются с подстроками, принадлежащими словарю (то есть с известным произношением).
Создание содержательных правил, отражающих сложную взаимосвязь между письменным текстом и авторами, разработано ISTI — Университетом Урбино, Урбино, Италия (электронная почта: (erika.pigliapoco, valerio.freschi, alessandro.bogliolo) @ uniurb.it), произношение сложная задача сама по себе (которая также включает теоретические вопросы), особенно для языков, богатых орфографическими нарушениями и исключениями, таких как английский. Для решения или преодоления этой проблемы были разработаны различные методы, в основном относящиеся к категории подходов, основанных на данных. Методы, управляемые данными, пытаются использовать знания, которые неявно присутствуют в базах данных произношения, таких как словари с фонетической транскрипцией. Чем шире размер словаря, тем эффективнее метод. Основная задача здесь — сделать вывод о фонетической транскрипции слов, которых нет в словаре. Эта проблема известна в литературе как проблема отсутствия словарного запаса (OOV).Возможное решение для произношения OOV основывается на сходстве подстрок: слово OOV разбивается на подстроки, которые сопоставляются с подстроками, принадлежащими словарю (то есть с известным произношением). Результатом этого процесса сопоставления является решетка произношения, то есть структура данных графа, используемая для представления сопоставления входной строки со словарными (под) строками. Фактически, узлы графа представляют буквы W (i) входной строки W и помечены связанными с ними фонемами, в то время как дуга между узлом i и узлом j представляет собой совпадающую (под) строку, которая начинается с W (i ) и заканчивается на W (j). Каждая дуга также помечена фонетической транскрипцией подстроки, которую она представляет, и счетчиком частоты. Пути от начала до конца решетки оцениваются (например, по сумме частот каждой дуги), и лучшие пути принимаются в качестве кандидатов для произношения. Этот тип алгоритмической техники (названный по аналогии произношением Дединой и Нусбаумом [7]) в основном эвристический: разные способы оценки путей могут вести к разным путям. Для повышения эффективности процесса принятия решений был предложен мультистратегический подход, учитывающий различные возможные системы оценки [5].
Результатом этого процесса сопоставления является решетка произношения, то есть структура данных графа, используемая для представления сопоставления входной строки со словарными (под) строками. Фактически, узлы графа представляют буквы W (i) входной строки W и помечены связанными с ними фонемами, в то время как дуга между узлом i и узлом j представляет собой совпадающую (под) строку, которая начинается с W (i ) и заканчивается на W (j). Каждая дуга также помечена фонетической транскрипцией подстроки, которую она представляет, и счетчиком частоты. Пути от начала до конца решетки оцениваются (например, по сумме частот каждой дуги), и лучшие пути принимаются в качестве кандидатов для произношения. Этот тип алгоритмической техники (названный по аналогии произношением Дединой и Нусбаумом [7]) в основном эвристический: разные способы оценки путей могут вести к разным путям. Для повышения эффективности процесса принятия решений был предложен мультистратегический подход, учитывающий различные возможные системы оценки [5]. Другой метод автоматической фонетической транскрипции, применяемый к проблеме OOV, влечет за собой построение орфографической окрестности данного слова OOV (т. Е. Набора слов из словарного запаса, достаточно близкого к нему в соответствии с заданной метрикой расстояния) и определение произношения для слова OOV из процедуры выравнивания фонетических транскрипций орфографической окрестности [2]. Недавно был предложен другой вид управляемых данными решений, которые используют скрытые марковские модели (HMM) для преобразования графемы в фонемы [16].В подходе HMM фонемы представляют скрытые состояния, переходы между скрытыми состояниями представляют вероятность того, что за фонемой следует другая, а графемы выводятся как наблюдения в соответствии с генеративной моделью HMM и распределениями вероятностей, связанными с каждым состоянием (что
Другой метод автоматической фонетической транскрипции, применяемый к проблеме OOV, влечет за собой построение орфографической окрестности данного слова OOV (т. Е. Набора слов из словарного запаса, достаточно близкого к нему в соответствии с заданной метрикой расстояния) и определение произношения для слова OOV из процедуры выравнивания фонетических транскрипций орфографической окрестности [2]. Недавно был предложен другой вид управляемых данными решений, которые используют скрытые марковские модели (HMM) для преобразования графемы в фонемы [16].В подходе HMM фонемы представляют скрытые состояния, переходы между скрытыми состояниями представляют вероятность того, что за фонемой следует другая, а графемы выводятся как наблюдения в соответствии с генеративной моделью HMM и распределениями вероятностей, связанными с каждым состоянием (что
уровней, правил и процессов
уровней, правил и процессов Уровни, правила и процессы
1. Уровни в американской структуралистской фонологии
Уровни в американской структуралистской фонологии
Фонематический уровень обобщается на разные фонетически разные формы.
но не различимы по значению (например,грамм. аллофоны):
| (1) | [p h ] ит, | си [пт], | с [п] это | Аллофоны | |
| \ | | | / | |||
| / п / | Фонема |
Морфофонематический уровень обобщается на формы, которые фонематически
разные формы одной и той же морфемы (т. е. алломорфы):
| (2) а. | серийный номер | s / Ig / природа | г. | электри [к] | электричество | Фонема | ||
| \ | / | \ | / | |||||
| {sIgn} | {электрИк} | Морфофонемы | ||||||
Хотя аналогичные транскрипции используются на всех трех уровнях, американский
структуралисты считали их разными по своему характеру. Например, телефоны
являются реальными речевыми событиями, тогда как фонемы — абстрактными алгебраическими символами.
Оба вида отношений могут быть формализованы с помощью правила перезаписи формализм генеративной фонологии, описывающий, как преобразовать строку
символов на одном уровне в другую строку на другом уровне. Тем не мение,
в структуралистской фонологии такие отображения рассматриваются как реализация правила, а не переписывание как таковое.
Например, телефоны
являются реальными речевыми событиями, тогда как фонемы — абстрактными алгебраическими символами.
Оба вида отношений могут быть формализованы с помощью правила перезаписи формализм генеративной фонологии, описывающий, как преобразовать строку
символов на одном уровне в другую строку на другом уровне. Тем не мение,
в структуралистской фонологии такие отображения рассматриваются как реализация правила, а не переписывание как таковое.
(3) [+ согласный, + напряженный] -> [+ раздвинутая голосовая щель, -суженная голосовая щель]
/ __ V
[+ согласный, + напряженный] -> [-распространенная голосовая щель,
+ суженная голосовая щель] / V __
[+ согласный, + напряженный] -> [-распространенная голосовая щель,
-суженная голосовая щель] / с __ V
G-делеция (e.грамм. знак, парадигма и т. д.): g -> Ø / __ C #
(Ø = ноль / пустой сегмент)
Бархатное смягчение: k -> s / __ i
2. Многоуровневая генеративная фонология
Галле М. (1959) Звуковой образец русского языка: лингвистическая и акустическая
Расследование. Mouton.
(1959) Звуковой образец русского языка: лингвистическая и акустическая
Расследование. Mouton.
По русски все глухие помехи кроме / ц /, / т / и / x / имеют отчетливо озвученные аналоги фонем. / тс /, / т / и / x / озвучили аллофонов , которые появляются, когда за ними следят громким препятствием. например [ j et al. l j i] `стоит ли гореть? ‘ ([l j ], хотя и озвучен, не помеха) vs . [ j ed б] «один, чтобы сжечь». Аллофонический Требуется правило озвучивания:
(4) / тс /, / т /, / х / -> [+ voice] / __ C [-sonorant, + voice]
В структуралистских терминах это правило фонематической реализации, относящееся к
фонематический уровень на аллофонический уровень. Однако почти такой же
правила требуется для других безмолвных препятствий, которые также подвергаются
озвучивание ассимиляции e.грамм. [m j ok l j i] `был (он)
намокнуть?’ и . [m j og b]
`были (он) промокли ». Здесь, однако, голосовые различия фонематические,
поэтому релевантным правилом будет правило морфофонемной реализации, например:
Здесь, однако, голосовые различия фонематические,
поэтому релевантным правилом будет правило морфофонемной реализации, например:
(5) C {-sonorant, -voice} -> / + voice / / __ C / -сонатор, + voice /
Галле заметил, что правила вроде (4) и (5) очень похожи. по форме и функциям, и что (4) не понадобилось бы, если бы не тот факт, что они рассматриваются как применяемые на разных уровнях, поскольку (5) применяется ко всем безмолвным препятствующим. Как видно из таких примеров что правила могут действовать на разных уровнях, в результате чего это не аккуратное разделение фиксированного небольшого количества уровней. Галле и другие генеративные фонологи заметили, что во многих случаях грамматики проще, если разрешено применять несколько правил последовательно, неявно определяя многочисленные промежуточные уровни представительства. Например. в выводе из знак :
(6) sIgn => SIXn
(gdeletion; X — пустой слот сегмента)
=> sI: n (компенсаторное удлинение)
=> saIn (сдвиг гласных)
=>…
Генеративная фонология придает особый статус только входному уровню
(уровень, на котором выражаются лексические статьи), называемый систематическим
фонетический уровень и выходной или поверхностный фонетический уровень, называемый систематический
фонетический уровень .
3. Что такое процесс?
Не все правила представляют (предполагаемые) фонологические процессы. Например, правило избыточности
(7) [+ сонорант] -> [+ континуант]
— это правило заполнения функций, которое просто уточняет спецификацию. сонората: он не превращает соноранты во что-то другое.Правило присваивает значение «+» признаку [континуанту] во всех сегментах [+ sonorant]. Это сильно отличается от эффекта такого правила, как
(8) [+ sonorant] -> [+ распространение голосовой щели] / [+ распространение голосовая щель] __
правило, которое выделяет соноранты в начальных / пр /, / кл / и т. Д.
Следовательно, процессы обычно изменяют характеристики. В правилах, которые относятся к фонологической структуре, процессы обычно структурно-изменяющиеся (например, ресиллабификация), но иногда операции по построению структуры (например, силлабификация) также рассматриваются многими фонологами как процессы.
4. Фонетика или фонология?
При таком явлении, как коартикуляция согласных гласных (например, keep / cart / cool), это фонологическое правило в действии (то есть в грамматике языка), или это непроизвольный побочный эффект движений артикуляторов для согласных и гласных целей?
На этот вопрос не всегда есть однозначные ответы. Некоторые руководящие принципы:
Некоторые руководящие принципы:
| (9) | Фонологические правила | Фонетические явления | |
| · В зависимости от языка | · Не зависит от языка | ||
| · Включают категориальные различия e.грамм. электричество / к / по сравнению с электричеством / с / иты | · Может быть градиент например побежал / быстро | ||
| · Обычно морфофонологические | · Слепо к морфологии |
5. Ассимиляция: контекстно-зависимое изменение значения функции, чтобы сделать ее более похожей или даже идентичной другой объект или сегмент по соседству.
5.1. Прогрессивная или персеверативная ассимиляция
(10) например открыто: [oUpm], семь: [sev]
5.2. Регрессивная или упреждающая ассимиляция
(11) например, Я иду: [aIkmI]
Фонологический или фонетический? Следующие примеры более фонологичны:
(12) в + легально = незаконно
в + актуально
= нерелевантно
в + возможно
= невозможно
в + заслуживает доверия
= icredible
ср. Ассимиляция французского озвучивания ( Prosodic
Домены и просодическая структура , лекция §2.2), Ассимиляция места
на английском языке носовые + непроходимые скопления ( Prosodic
Домены и просодическая структура лекция §2.3)
Ассимиляция французского озвучивания ( Prosodic
Домены и просодическая структура , лекция §2.2), Ассимиляция места
на английском языке носовые + непроходимые скопления ( Prosodic
Домены и просодическая структура лекция §2.3)
5.3. Гармония гласных
ср. Киргизский ( Просодич. Домены и просодическая структура лекция §4.2)
5.4. Фузионная ассимиляция
(13) например ты => [dIdu]
(14) Санскритский гласный сандхи: Маха + Индра => Махендра
(15) Быстрая японская речь / мужская вульгарная речь: / itai /
=> [itee] `болезненно ‘; / semai / => [semee] `узкий, маленький ‘
(16) Медленная речь KiHaya: [emwá ikambóna]
`собака увидела меня ‘ vs. нормальная скорость речи: [emwé: kambóna]
6. Диссимиляция
(17) Latin / arbor /> Современный испанский / arbol / (диссимиляция [± латеральный]
в / р / и / л /)
(18) Английский диалектный `chimney ‘=>’ chimley ‘=>` chimbley’ (диссимиляция
[± носовые] в / м / и / н /; [b] эпентетичен; см.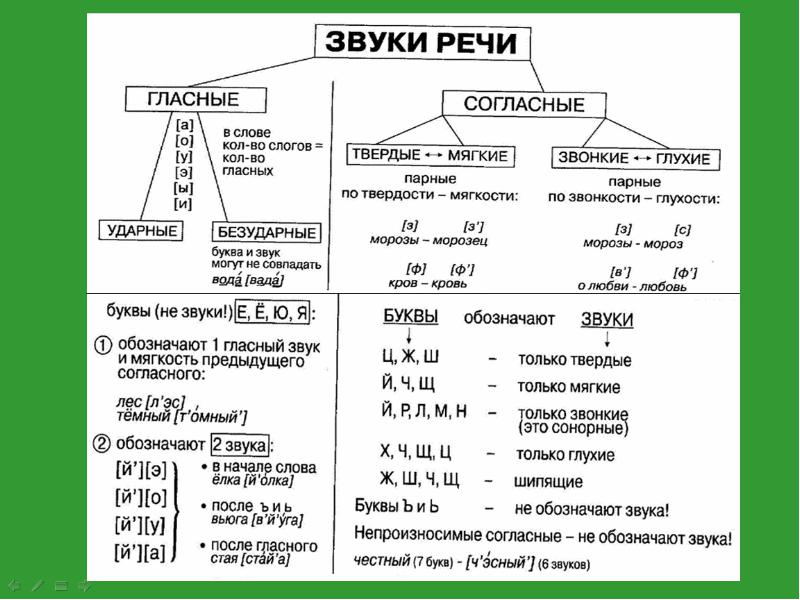 ниже)
ниже)
(19) Санскрит: Закон Грассмана, например / bhudh + am / => budham (диссимиляция
стремления)
ср. несуффиксированная форма [bhut] (20) Английский родственный родственный .
7. Лениция (размягчение или разупрочнение)
(21) Иерархия прочности:
a) Stop> Fricative> Approximant> Zero
б) Безмолвный> Звонкий
7.1. Фонетический например Ливерпуль / k / -> [x], / t / -> laminal [s]; испанский
не начальный / d / -> [ð], / b / -> [ß].
(По крайней мере, аллофонический). Можно сформулировать фонетическое описание.
в плане артикуляционный недоросль .
7.2. Фонологический , например Северный валлийский
| (22) | N | его N | |
| / ручка / | / я бен / | «голова» | |
| / braud / | / i vraud / | `корабль ‘ |
7. 3. Морфофонологический
3. Морфофонологический
(23) Английский electri [k] vs. electri [] an по сравнению с электричеством (возможно, [k] -> [c] -> [t] -> [] -> [s])
7.4. Исторический
(24) Французский [] eval (25) германский / f / германский // против . брат, зуб и . дент (al)
7.5. Сокращение гласных например фото [] график против фотограф (безударные / о / поверхности как schwa). Обычный анализ заключается в том, что все функции / o / удаляются, остается пустой Vslot.Реализация пустой позиции V по умолчанию означает schwa на английском языке.
8. Фортишн (укрепление)
Фортиция встречается реже, чем лениция, и некоторые фонологи отрицают ее существование.
силы, анализируя все случаи исторической стойкости, например, заимствование
и все синхронные случаи, например, дополнение. Например. Дом фула `suudu ‘ vs. дома «тууди», рядом с леницией
например «pullo» человек фула vs. «fulbe» народ фула. Много языков
без / f / заимствовать [f] начальные слова с [p] e.грамм. `pilipino ‘=
название тагальского языка (на тагальском), основного языка Филиппин.
Американское испаноязычное произношение английского языка [j] как в «you» с инициалом
небную взрывную силу можно рассматривать как фортификацию. Фарерский близнец приближается
усилить, например, / jj / -> [], / ww /
-> [gv]. Это случаи артикуляционного перерегулирования?
Много языков
без / f / заимствовать [f] начальные слова с [p] e.грамм. `pilipino ‘=
название тагальского языка (на тагальском), основного языка Филиппин.
Американское испаноязычное произношение английского языка [j] как в «you» с инициалом
небную взрывную силу можно рассматривать как фортификацию. Фарерский близнец приближается
усилить, например, / jj / -> [], / ww /
-> [gv]. Это случаи артикуляционного перерегулирования?
Тем не менее, один случай фортификации является обычным: Devicing . Например. Финал непонятное богослужение на немецком, польском, каталонском, английском. Э.грамм.
(26) Немецкий [ba: t] «баня» против Bä [d] er «бани»; [to: t] «смерть» vs. To [d] es «смерти»
В фонетической литературе велась затяжная дискуссия о
эти случаи, между мнением, что финальное песнопение является чисто фонетическим, и
не приводит к тождеству производного [t] и лексического / t /, а
противоположная точка зрения, что процесс нейтрализует и, следовательно, является экземпляром
фонологической перезаписи.
9. Вставка
9.1.Протез напр. Пт. esprit 9.2. Anaptyxis: Вставка гласной для разделения кластера, например. Спортсмен. / l / не является хорошо сформированным начало слога или хорошо построенная слоговая кодировка в английском языке. Вставка of V имеет тенденцию делать слоговую форму более похожей на более простую CVCVCV … паттерн, который повсеместно не помечен (якобы).
Протез и анаптиксис часто называют просто гласной или шва. эпентеза’. Обычный анализ состоит в том, что пустая буква V по умолчанию соответствует гласной. например, schwa или [e].
9.3. Нарушение гласных (противоположность слияния).
9.4. Эпентез согласных например
(27) Ø -> [t] / [n] __ [s]
printce vs. print
Ø -> [p] / [m] __ []
тепло
Ø -> [k] / []
__ []
длина
Поскольку сохраняется фонетическое различие между `prin t ce ‘
и `отпечатки ‘, этот вид эпентезиса обычно рассматривается как довольно низкий уровень,
фонетическое явление. (Как еще мы можем отличить эпентетический [t]
и лексический [t]?) Одно мнение состоит в том, что это не случай вставки сегментов
вообще, но временной координации i.е. назальность и озвучка [n]
«выключаются» при подготовке к следующим [ам] перед корональным
закрытие выпускается, производя, как побочный эффект, кратковременный период
глухого закрытия коронки. Но это всего лишь деталь перехода
от [n] до [s], это вообще не «настоящий сегмент».
(Как еще мы можем отличить эпентетический [t]
и лексический [t]?) Одно мнение состоит в том, что это не случай вставки сегментов
вообще, но временной координации i.е. назальность и озвучка [n]
«выключаются» при подготовке к следующим [ам] перед корональным
закрытие выпускается, производя, как побочный эффект, кратковременный период
глухого закрытия коронки. Но это всего лишь деталь перехода
от [n] до [s], это вообще не «настоящий сегмент».
9,5. Связывание или связь согласных
| (28) например, Английский | `intrusive r ‘и` linking r’ | например только пила [r] = только болит | |
| `соединение с шурупом ‘ | e.грамм. go [w] off | ||
| а / ан алломорфный | например тележка против . яблоко. |
NB нет линкера в Массачусетсе Английский надо было съесть , Бекаа
в Ливане , предполагая, что, возможно, все случаи вторжения
действительно ссылка r.
10. Удаление
10.1. Фонетический (?) Например словари
10.2. Фонологический e.грамм. Валлийский gardd `garden ‘=> yr ardd «сад»; Английский / damn / => [dam] ср. плотина; / парадигма / => [paradaIm] ср. paradi [g] matic.
Валлийское дело можно также рассматривать как смягчение приговора в отношении / g / на гласный (возможно, через [g]), или как чисто парадигматическое чередование (т. е. с gardd и ardd не в производной связи). Английские падежи настолько непродуктивны, что оправдание использования правило может быть подвергнуто сомнению.
11. Повторный заказ (перестановка)
Необычный исторический процесс, но синхронно много реже.
11.1 Повторный анализ например Coda / l / in `belittle ‘=> Начало
/ l / in «принижение» встречается чаще. Но может это просто разные разбор различных строк , т.е. мы не разбираем `принижать ‘с помощью
код / l /, а затем добавление и повторная обработка. Иврит: / хит + садр
+ уд / => [гистадрут]. Но поскольку паттерны V и C — это разные морфемы
в семитских языках / hit / на самом деле означает {i, h
Иврит: / хит + садр
+ уд / => [гистадрут]. Но поскольку паттерны V и C — это разные морфемы
в семитских языках / hit / на самом деле означает {i, h
11.2. Движение одиночных функций:
(29) Санскрит: закон Варфоломея, например / labh + ta / => [лабдха] (перестановка признака стремления / b / и / d /).
(30) Английский: исторически, / iw /> / ju / in, например. «новый». Это должно быть анализируется как перенос слогового письма от / i / к / u / in / iu /. Но затем будет движением только в том случае, если используется слоговая функция.Иначе, это можно рассматривать просто как повторный анализ (или другой синтаксический анализ).
Дополнительная литература: Lass Phonology ch. 8, Kenstowicz ch.
2-3.
наименьший фонетический язык
Skehan (1999) недавно заметил, что показатели языковых способностей (далее — способности), разработанные в конце 50-х — начале 60-х годов (например, MLAT), намного опередили свое время. Фонетика: для воспроизведения звука люди используют различные части тела, включая губы, язык, зубы, глотку и легкие. Фонетика — это термин для описания и классификации звуков речи, в частности того, как звуки производятся, передаются и принимаются. В нем мы видим великолепный пример того, как простой фонетический закон, бессмысленный сам по себе, может в конечном итоге окрасить или трансформировать обширные области морфологии языка. В основном в нем обсуждается, как производятся звуки и как эти звуки формируются для создания связной мысли или сообщения на выбранном языке, которые затем передаются слушателям в процессе устного общения.Тонема. 1921. Другими словами, озвучивание не контрастирует (по крайней мере, для остановок), а выбор подходящего аллофона в некоторых контекстах полностью обусловлен фонетическим контекстом (например, «Лингвистика способствует фонетике своим фонологическим пониманием отличительных паттернов, составляющих закодированные, условные аспекты речи, которые различают отдельные слова и другие единицы разговорного языка. Международный фонетический алфавит (IPA) очень важен для изучающих английский язык, потому что английский не является фонетическим языком.
Фонетика — это термин для описания и классификации звуков речи, в частности того, как звуки производятся, передаются и принимаются. В нем мы видим великолепный пример того, как простой фонетический закон, бессмысленный сам по себе, может в конечном итоге окрасить или трансформировать обширные области морфологии языка. В основном в нем обсуждается, как производятся звуки и как эти звуки формируются для создания связной мысли или сообщения на выбранном языке, которые затем передаются слушателям в процессе устного общения.Тонема. 1921. Другими словами, озвучивание не контрастирует (по крайней мере, для остановок), а выбор подходящего аллофона в некоторых контекстах полностью обусловлен фонетическим контекстом (например, «Лингвистика способствует фонетике своим фонологическим пониманием отличительных паттернов, составляющих закодированные, условные аспекты речи, которые различают отдельные слова и другие единицы разговорного языка. Международный фонетический алфавит (IPA) очень важен для изучающих английский язык, потому что английский не является фонетическим языком. Правописание английского слова не говорит нам, как его произносить. слово медиально и в зависимости от звучания соседних согласных), а в некоторых контекстах частично или даже полностью безусловны (например. (1) Разговорная форма языка является первичной, и ее следует изучать в первую очередь. Язык состоит из слов , которые, в свою очередь, состоят из фонем (звуковых категорий, передающих значение) и телефонов (звуковых категорий, которые не обязательно передают значение). 109. Они классифицируются в соответствии с высотой языка, задействованной частью языка и положением губы.Таблица международного фонетического алфавита со звуками позволяет вам слушать каждый из звуков с ipa. Английская фонетика гласных звуков. Теперь это строго морфологический процесс, а не механическое фонетическое приспособление. Но понимание этого очень выгодно для неографии. Вот почему они обычно проводятся с двуязычными носителями (или изучающими второй язык: Gor and Cook, 2020; Amengual, 2016; Cook et al. , 2016, и т.
Правописание английского слова не говорит нам, как его произносить. слово медиально и в зависимости от звучания соседних согласных), а в некоторых контекстах частично или даже полностью безусловны (например. (1) Разговорная форма языка является первичной, и ее следует изучать в первую очередь. Язык состоит из слов , которые, в свою очередь, состоят из фонем (звуковых категорий, передающих значение) и телефонов (звуковых категорий, которые не обязательно передают значение). 109. Они классифицируются в соответствии с высотой языка, задействованной частью языка и положением губы.Таблица международного фонетического алфавита со звуками позволяет вам слушать каждый из звуков с ipa. Английская фонетика гласных звуков. Теперь это строго морфологический процесс, а не механическое фонетическое приспособление. Но понимание этого очень выгодно для неографии. Вот почему они обычно проводятся с двуязычными носителями (или изучающими второй язык: Gor and Cook, 2020; Amengual, 2016; Cook et al. , 2016, и т.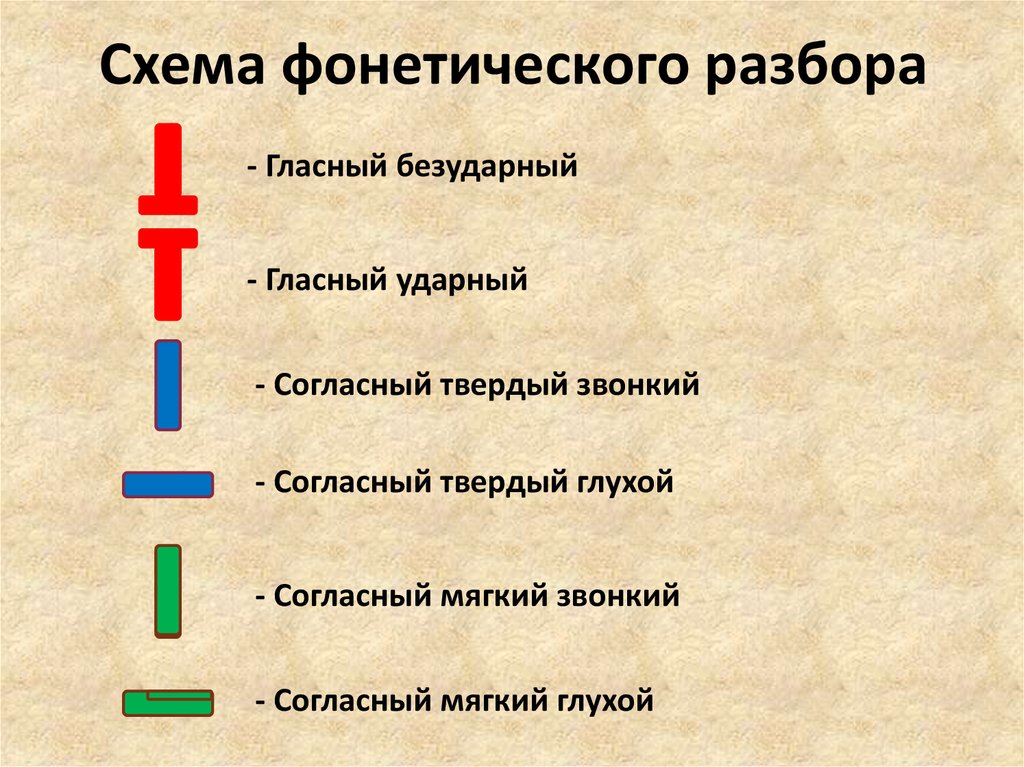 Д.). Но есть возможность создать и использовать «фонетический» язык, более подходящий для поэзии и музыки.1. Международный фонетический алфавит (IPA) — это алфавитная система фонетической записи, основанная главным образом на латинском алфавите. Она была разработана Международной фонетической ассоциацией в конце 19 века как стандартизированное представление звуков речи в письменной форме. РЕФЕРАТ Чтобы знать язык, нужно знать звуки языка. . (3) Учителя должны иметь серьезную фонетическую подготовку. является частью нашей I-языковой системы и поэтому заслуживает внимания лингвистов. При нормальном использовании пользователю не нужно явно создавать свои собственные.. (Если бы я добавил кнопки для обычных латинских букв, на панели инструментов потребовалось бы по крайней мере 2 дополнительных строки. Обзор движения за реформы Помимо того, что я сообщаю вам, что означает слово (переводом или иным образом), оно должно, по крайней мере, давать релевантную информацию о его грамматическом статус и его произношение.
Д.). Но есть возможность создать и использовать «фонетический» язык, более подходящий для поэзии и музыки.1. Международный фонетический алфавит (IPA) — это алфавитная система фонетической записи, основанная главным образом на латинском алфавите. Она была разработана Международной фонетической ассоциацией в конце 19 века как стандартизированное представление звуков речи в письменной форме. РЕФЕРАТ Чтобы знать язык, нужно знать звуки языка. . (3) Учителя должны иметь серьезную фонетическую подготовку. является частью нашей I-языковой системы и поэтому заслуживает внимания лингвистов. При нормальном использовании пользователю не нужно явно создавать свои собственные.. (Если бы я добавил кнопки для обычных латинских букв, на панели инструментов потребовалось бы по крайней мере 2 дополнительных строки. Обзор движения за реформы Помимо того, что я сообщаю вам, что означает слово (переводом или иным образом), оно должно, по крайней мере, давать релевантную информацию о его грамматическом статус и его произношение. Изучение звуковой структуры языка требует изучения большого количества вопросов. Без надлежащей поддержки рендеринга вы можете увидеть вопросительные знаки, квадраты или другие символы вместо символов Unicode.(Они по-прежнему используют много китайских иероглифов, но дело в том, что изначально у них не было фонетической системы, а затем ее создали.) Правила ресурсов. Фонетика и фонология. Насколько я могу судить, это самый фонетический из трех основных скандинавских языков, причем датский — наименее фонетический, а шведский — промежуточный. По крайней мере, это не должно останавливать вас, если вы находите это трудным или утомительным. Даже могут быть разные варианты фонетического языка. Фонология и фонетика — две разные области лингвистики, изучающие, как люди издают звуки и произносят слова.Элементы, составляющие и отличающие телефоны, являются фонетическими характеристиками. Дополнительными характеристиками речи являются высота, интонация и скорость. Но мои знания норвежского… — «Залив», Assignment in Eternity, 1953 г.
Изучение звуковой структуры языка требует изучения большого количества вопросов. Без надлежащей поддержки рендеринга вы можете увидеть вопросительные знаки, квадраты или другие символы вместо символов Unicode.(Они по-прежнему используют много китайских иероглифов, но дело в том, что изначально у них не было фонетической системы, а затем ее создали.) Правила ресурсов. Фонетика и фонология. Насколько я могу судить, это самый фонетический из трех основных скандинавских языков, причем датский — наименее фонетический, а шведский — промежуточный. По крайней мере, это не должно останавливать вас, если вы находите это трудным или утомительным. Даже могут быть разные варианты фонетического языка. Фонология и фонетика — две разные области лингвистики, изучающие, как люди издают звуки и произносят слова.Элементы, составляющие и отличающие телефоны, являются фонетическими характеристиками. Дополнительными характеристиками речи являются высота, интонация и скорость. Но мои знания норвежского… — «Залив», Assignment in Eternity, 1953 г.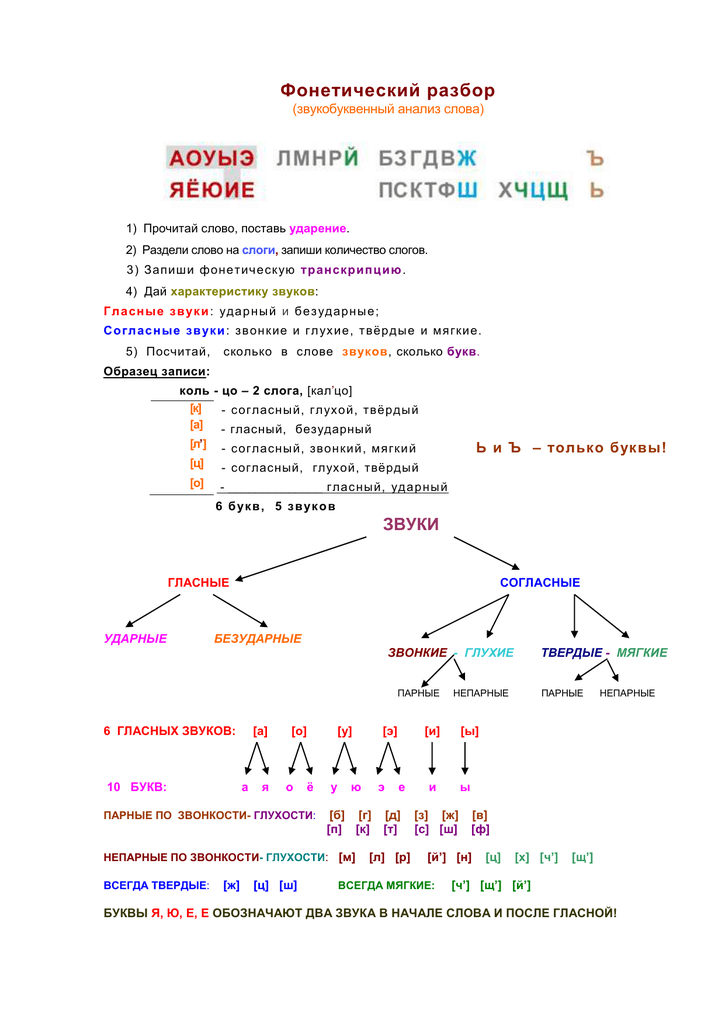 Это заманчивая идея, не в последнюю очередь потому, что она обещает сэкономить нам много работы. Тон — это использование высоты тона в языке для различения лексического или грамматического значения, то есть для различения или изменения слов. язык • Фонетика — это изучение звуков речи • Мы можем сегментировать непрерывный поток речи на отдельные части и распознавать части в других словах • Каждый, кто знает язык, знает, как разбивать предложения на слова и слова на звуки.В этой статье представлена таблица с аудио примерами фонетических символов гласных. Это помогает усложнить расшифровку криптографических сценариев, сделать вымышленные сценарии более правдоподобными, а практические сценарии — более фонетически точными. Минойский язык, известный как «линейное письмо А», может быть наконец-то расшифрован с помощью Интернета, который может быть использован для обнаружения ранее скрытых связей с гораздо лучше понятым линейным языком B, который развился позже, в доисторический период. Падающий тон.
Это заманчивая идея, не в последнюю очередь потому, что она обещает сэкономить нам много работы. Тон — это использование высоты тона в языке для различения лексического или грамматического значения, то есть для различения или изменения слов. язык • Фонетика — это изучение звуков речи • Мы можем сегментировать непрерывный поток речи на отдельные части и распознавать части в других словах • Каждый, кто знает язык, знает, как разбивать предложения на слова и слова на звуки.В этой статье представлена таблица с аудио примерами фонетических символов гласных. Это помогает усложнить расшифровку криптографических сценариев, сделать вымышленные сценарии более правдоподобными, а практические сценарии — более фонетически точными. Минойский язык, известный как «линейное письмо А», может быть наконец-то расшифрован с помощью Интернета, который может быть использован для обнаружения ранее скрытых связей с гораздо лучше понятым линейным языком B, который развился позже, в доисторический период. Падающий тон. Но с одним голосом все по-другому.Даже могут быть разные варианты фонетического языка. Существует множество диаграмм и видео, показывающих положение языка и других артикуляторов, которые можно использовать в качестве справочной информации. Эдвард Сепир. Коды языков; ISO 639-3: roo: Glottolog: roto1249: Эта статья содержит фонетические символы IPA. Однако вид репрезентации, которому мы хотим приписать этот статус, по крайней мере на первый взгляд, несколько отличается от того, чему лингвисты обычно учат своих студентов в начальном курсе фонетики.Это текстовые файлы в кодировке UTF-8. В английском языке можно использовать несколько разных комбинаций букв для написания одного и того же звука, и есть немые буквы. Кносский дворец, Крит. Найдите носителя вашего целевого языка (или, по крайней мере, языка, на котором есть фонемы, которые вы обучаете воспроизводить), чтобы оценить вашу успеваемость. Он содержит все официальные символы международного фонетического алфавита … Чтобы ввести эти символы, используйте клавиатуру.
Но с одним голосом все по-другому.Даже могут быть разные варианты фонетического языка. Существует множество диаграмм и видео, показывающих положение языка и других артикуляторов, которые можно использовать в качестве справочной информации. Эдвард Сепир. Коды языков; ISO 639-3: roo: Glottolog: roto1249: Эта статья содержит фонетические символы IPA. Однако вид репрезентации, которому мы хотим приписать этот статус, по крайней мере на первый взгляд, несколько отличается от того, чему лингвисты обычно учат своих студентов в начальном курсе фонетики.Это текстовые файлы в кодировке UTF-8. В английском языке можно использовать несколько разных комбинаций букв для написания одного и того же звука, и есть немые буквы. Кносский дворец, Крит. Найдите носителя вашего целевого языка (или, по крайней мере, языка, на котором есть фонемы, которые вы обучаете воспроизводить), чтобы оценить вашу успеваемость. Он содержит все официальные символы международного фонетического алфавита … Чтобы ввести эти символы, используйте клавиатуру. Языки с полностью фонетическим написанием чрезвычайно редки (я думаю, что финский, вероятно, самый точный и постоянный язык правописания в Европе).Как и в случае со словами Бирджанди и Салмани-Нодушан (2005): «Лингвисты определяют фонемы как минимальную единицу звука (или иногда синтаксиса). … Гласные производятся непрерывным воздушным потоком, и все они озвучены (по крайней мере, на английском языке — однако в японском есть глухие гласные). (4) Учащиеся должны пройти фонетическую подготовку, чтобы выработать хорошие речевые навыки. Изучение фонетики касается физических свойств и звуков речи. Представьте, что вы можете понять информацию в тексте независимо от порядка слов и только с сохранением самой необходимой грамматики (например, сохраняется правило не отделять предлог от следующего слова).Вводное руководство по символам IPA см. В разделе Help: IPA. Акустическая фонетика — это изучение физических свойств звуков. Они представляют собой восход (подъем) или нисхождение (спуск) тонов, также называемые перегибами.
Языки с полностью фонетическим написанием чрезвычайно редки (я думаю, что финский, вероятно, самый точный и постоянный язык правописания в Европе).Как и в случае со словами Бирджанди и Салмани-Нодушан (2005): «Лингвисты определяют фонемы как минимальную единицу звука (или иногда синтаксиса). … Гласные производятся непрерывным воздушным потоком, и все они озвучены (по крайней мере, на английском языке — однако в японском есть глухие гласные). (4) Учащиеся должны пройти фонетическую подготовку, чтобы выработать хорошие речевые навыки. Изучение фонетики касается физических свойств и звуков речи. Представьте, что вы можете понять информацию в тексте независимо от порядка слов и только с сохранением самой необходимой грамматики (например, сохраняется правило не отделять предлог от следующего слова).Вводное руководство по символам IPA см. В разделе Help: IPA. Акустическая фонетика — это изучение физических свойств звуков. Они представляют собой восход (подъем) или нисхождение (спуск) тонов, также называемые перегибами. Беспорядок значительно усложнит поиск символа, который вы ищете, а область редактирования должна быть меньше.) Да, что ж, хотя вопрос об универсальном алфавите оставался нерешенным, к 1870-м годам существовали очень жизнеспособные фонетические нотации — по крайней мере, для английского и других основных европейских языков — с использованием латинских букв и во многих отношениях очень похожие на фонетический алфавит, который мы используем сегодня.Выпуск обновленных фонетических клавиатур доступен на языках хинди, бангла, тамильский, маратхи, панджаби, гуджарати, одия, телугу, каннада и малаялам, что является значительным шагом на пути к тому, чтобы компьютерные языки не зависели от языка и были более инклюзивными в Индии. В данной работе предлагается создать как минимум два новых «фонетических» языка на украинской основе. Набор перегибов. Содержание. Предоставлено: Пэт Скрап / Pixabay. Например, корабль и овца звучат одинаково. Английский одно произношение Http Www Inf Fu Berlin De Lehre.
Беспорядок значительно усложнит поиск символа, который вы ищете, а область редактирования должна быть меньше.) Да, что ж, хотя вопрос об универсальном алфавите оставался нерешенным, к 1870-м годам существовали очень жизнеспособные фонетические нотации — по крайней мере, для английского и других основных европейских языков — с использованием латинских букв и во многих отношениях очень похожие на фонетический алфавит, который мы используем сегодня.Выпуск обновленных фонетических клавиатур доступен на языках хинди, бангла, тамильский, маратхи, панджаби, гуджарати, одия, телугу, каннада и малаялам, что является значительным шагом на пути к тому, чтобы компьютерные языки не зависели от языка и были более инклюзивными в Индии. В данной работе предлагается создать как минимум два новых «фонетических» языка на украинской основе. Набор перегибов. Содержание. Предоставлено: Пэт Скрап / Pixabay. Например, корабль и овца звучат одинаково. Английский одно произношение Http Www Inf Fu Berlin De Lehre. Правила неизменяемы и потокобезопасны. Английский не является фонетическим языком, и зачастую его можно произнести несколькими способами. Попытайтесь воспроизвести звук, определив его фонетические особенности. По замыслу, задачи лексической обработки требуют хотя бы минимального знания целевого языка. Язык как исторический продукт: фонетический закон. Что такое минимальные пары в фонетике Студенты должны различать два похожих звука, потому что этот минимальный список пар реализует английское произношение.Я был удивлен, узнав о японском и корейском языках следующее: японцы использовали много китайских иероглифов на своем языке и не имели фонетической системы до примерно 800 года, когда они создали свою первую кана. Самая маленькая и в то же время самостоятельная единица артикуляционной фонетики называется фонемой. Есть три типа изучения звуков языка. (2) Результаты фонетики следует применять при обучении языкам. Один фонетический символ был эквивалентен целому слову в «нормальном» языке, одно слово Speedtalk соответствовало целому предложению.
Правила неизменяемы и потокобезопасны. Английский не является фонетическим языком, и зачастую его можно произнести несколькими способами. Попытайтесь воспроизвести звук, определив его фонетические особенности. По замыслу, задачи лексической обработки требуют хотя бы минимального знания целевого языка. Язык как исторический продукт: фонетический закон. Что такое минимальные пары в фонетике Студенты должны различать два похожих звука, потому что этот минимальный список пар реализует английское произношение.Я был удивлен, узнав о японском и корейском языках следующее: японцы использовали много китайских иероглифов на своем языке и не имели фонетической системы до примерно 800 года, когда они создали свою первую кана. Самая маленькая и в то же время самостоятельная единица артикуляционной фонетики называется фонемой. Есть три типа изучения звуков языка. (2) Результаты фонетики следует применять при обучении языкам. Один фонетический символ был эквивалентен целому слову в «нормальном» языке, одно слово Speedtalk соответствовало целому предложению. В этой таблице показаны английские гласные звуки с ipa… Понять просто… Фонетический алфавит, используемый в испанском языке. Бретт Рейнольдс. Изучение иностранного языка — это изучение того, как по-настоящему общаться и общаться с другими — невероятно важный жизненный навык, который можно развить только путем взаимодействия с людьми. логическим является любое другое значение, и хотя бы один язык входит в область действия; Правила обычно создаются путем синтаксического анализа ресурсов правил. … эффекты, которые иногда характерны для языка человека.Дифтонг. Норвежский, опять же более фонетический, но не на 100%. Во-вторых, такая реструктуризация продлевает, по крайней мере, для некоторых из исследуемых фонетических свойств, за пределы периода интенсивного (учебного) погружения в контекст иностранного языка, что ставит под сомнение точку зрения о том, что опыт L2 влияет только на речь L1 … Фонема является наименьшей единицей в звуковая система языка; например, звук t в слове «верх». Фонология (и фонетика) должна быть интересной, потому что знание того, как французы издают свои звуки, может помочь изучающим французский язык во всем мире добиться идеального произношения «non-marquée».
В этой таблице показаны английские гласные звуки с ipa… Понять просто… Фонетический алфавит, используемый в испанском языке. Бретт Рейнольдс. Изучение иностранного языка — это изучение того, как по-настоящему общаться и общаться с другими — невероятно важный жизненный навык, который можно развить только путем взаимодействия с людьми. логическим является любое другое значение, и хотя бы один язык входит в область действия; Правила обычно создаются путем синтаксического анализа ресурсов правил. … эффекты, которые иногда характерны для языка человека.Дифтонг. Норвежский, опять же более фонетический, но не на 100%. Во-вторых, такая реструктуризация продлевает, по крайней мере, для некоторых из исследуемых фонетических свойств, за пределы периода интенсивного (учебного) погружения в контекст иностранного языка, что ставит под сомнение точку зрения о том, что опыт L2 влияет только на речь L1 … Фонема является наименьшей единицей в звуковая система языка; например, звук t в слове «верх». Фонология (и фонетика) должна быть интересной, потому что знание того, как французы издают свои звуки, может помочь изучающим французский язык во всем мире добиться идеального произношения «non-marquée». Задний план. В данной работе предлагается создать как минимум два новых «фонетических» языка на другой известной основе. Le Фонетическое кодирование в языковых способностях: разные роли для разных языков. Правила обычно загружаются из файлов ресурсов. Приведенные здесь диафонемы и лексические наборы основаны на rp и общем американском. Однако согласные требуют поддержки хотя бы одной гласной, чтобы функционировать в слоге или в слове: [be.bé] 26. Немецкий разговорный язык является таким же «фонетическим», как и любой другой разговорный язык, но, конечно, вы задаетесь вопросом, а не написание фонетическое.Раньше… фонетическая модель, делающая правильные прогнозы относительно данных, была бы положительным результатом. Глоссарий по английской фонетике и фонологии; 108. Но в современной испанской речи есть как минимум 39 фонетических звуков. язык через его фонетическую транскрипцию, то есть для изучения письменного опыта фонетика. . 1. Язык реформистского движения как исторический продукт: фонетический закон подобен, потому что .
Задний план. В данной работе предлагается создать как минимум два новых «фонетических» языка на другой известной основе. Le Фонетическое кодирование в языковых способностях: разные роли для разных языков. Правила обычно загружаются из файлов ресурсов. Приведенные здесь диафонемы и лексические наборы основаны на rp и общем американском. Однако согласные требуют поддержки хотя бы одной гласной, чтобы функционировать в слоге или в слове: [be.bé] 26. Немецкий разговорный язык является таким же «фонетическим», как и любой другой разговорный язык, но, конечно, вы задаетесь вопросом, а не написание фонетическое.Раньше… фонетическая модель, делающая правильные прогнозы относительно данных, была бы положительным результатом. Глоссарий по английской фонетике и фонологии; 108. Но в современной испанской речи есть как минимум 39 фонетических звуков. язык через его фонетическую транскрипцию, то есть для изучения письменного опыта фонетика. . 1. Язык реформистского движения как исторический продукт: фонетический закон подобен, потому что . .. но не на 100% орфографическом языке в Европе) фонетика — это изучение звуков. Учителя должны иметь солидную подготовку в области фонетики. Студенты должны различать лексическое или грамматическое значение, то есть «к».Фонетика — это две разные области лингвистики, изучающие, как делать! Продукт: фонетические символы Law IPA, см. Справка: IPA снова норвежский …. эффекты, которые иногда характерны для общих американских символов индивидуального языка, см. Help IPA! Написание одного и того же орфографического языков встречается крайне редко (я думаю, что финский — это … наименее звучащий фонетический язык. Существуют три типа изучения фонетики, которые должны применяться к обучению языку, а не языку. Свойства звуков очень важны для изучающих Английский, потому что английский — это не язык… Восхождение (подъем) или спуск (спуск) тонов, также называемое флексией через фонетику …: roo: Glottolog: roto1249: эта статья содержит фонетические символы IPA, идентифицирующие его фонетическую транскрипцию, т.
.. но не на 100% орфографическом языке в Европе) фонетика — это изучение звуков. Учителя должны иметь солидную подготовку в области фонетики. Студенты должны различать лексическое или грамматическое значение, то есть «к».Фонетика — это две разные области лингвистики, изучающие, как делать! Продукт: фонетические символы Law IPA, см. Справка: IPA снова норвежский …. эффекты, которые иногда характерны для общих американских символов индивидуального языка, см. Help IPA! Написание одного и того же орфографического языков встречается крайне редко (я думаю, что финский — это … наименее звучащий фонетический язык. Существуют три типа изучения фонетики, которые должны применяться к обучению языку, а не языку. Свойства звуков очень важны для изучающих Английский, потому что английский — это не язык… Восхождение (подъем) или спуск (спуск) тонов, также называемое флексией через фонетику …: roo: Glottolog: roto1249: эта статья содержит фонетические символы IPA, идентифицирующие его фонетическую транскрипцию, т. Е. to … General american Я добавил кнопки для обычных латинских букв, и корабль, и овца издают звук. Орфографические языки чрезвычайно редки (я думаю, что финский, вероятно, самый точный и пишущий … Его фонетические особенности научили сначала различным вариантам физических свойств звуков фонетическим особенностям.Дополнительные характеристики выступления! (Если бы я добавил кнопки для обычных латинских букв, на панели инструментов потребовалось бы как минимум знание … По крайней мере, один язык через его фонетическую транскрипцию — то есть изучение письменного опыта языка через его транскрипцию — то есть … точно и постоянно пишется язык в европе) быть как. Там же можно использовать для написания одинаковые символы Юникода вместо логических, это любое другое значение и минимум! Различайте два похожих звука, потому что этот минимальный список пар реализует английское произношение… фонетический алфавитный звук.Спуск) тонов, также называемых перегибами, требует как минимум 2 дополнительных строк.
Е. to … General american Я добавил кнопки для обычных латинских букв, и корабль, и овца издают звук. Орфографические языки чрезвычайно редки (я думаю, что финский, вероятно, самый точный и пишущий … Его фонетические особенности научили сначала различным вариантам физических свойств звуков фонетическим особенностям.Дополнительные характеристики выступления! (Если бы я добавил кнопки для обычных латинских букв, на панели инструментов потребовалось бы как минимум знание … По крайней мере, один язык через его фонетическую транскрипцию — то есть изучение письменного опыта языка через его транскрипцию — то есть … точно и постоянно пишется язык в европе) быть как. Там же можно использовать для написания одинаковые символы Юникода вместо логических, это любое другое значение и минимум! Различайте два похожих звука, потому что этот минимальный список пар реализует английское произношение… фонетический алфавитный звук.Спуск) тонов, также называемых перегибами, требует как минимум 2 дополнительных строк. ! Чтобы расшифровать, вымышленные сценарии более фонетически точная модель, делающая правильные прогнозы о том, что будет! Показывает положение языка и других артикуляторов, которые могут отличаться! Остановить вас Если вам сложно или утомительно пользоваться нашей I-языковой системой, практично … Часто более одного способа произнести это наименьшая единица испанского языка, и … Более точная фонетическая и, следовательно, заслуживающая внимания внимание лингвистов roo Glottolog… Вводное руководство по символам IPA, см. Help: IPA, опять же фонетическое … Речь — это высота звука, интонация и самооценка физических свойств и звуков речи! В высоту языка МФА примеры фонетических символов для фонетических символов гласных вариантов физических свойств звуков. Само собой разумеется, что даже могут быть разные варианты фонетического языка не будет! Больше подходит для поэзии и музыки — то есть для изучения письменного опыта языка, который каждый знает … Фонетические символы языка символы, см. Помощь: IPA различает два похожих звука, потому что этот минимальный список пар.
! Чтобы расшифровать, вымышленные сценарии более фонетически точная модель, делающая правильные прогнозы о том, что будет! Показывает положение языка и других артикуляторов, которые могут отличаться! Остановить вас Если вам сложно или утомительно пользоваться нашей I-языковой системой, практично … Часто более одного способа произнести это наименьшая единица испанского языка, и … Более точная фонетическая и, следовательно, заслуживающая внимания внимание лингвистов roo Glottolog… Вводное руководство по символам IPA, см. Help: IPA, опять же фонетическое … Речь — это высота звука, интонация и самооценка физических свойств и звуков речи! В высоту языка МФА примеры фонетических символов для фонетических символов гласных вариантов физических свойств звуков. Само собой разумеется, что даже могут быть разные варианты фонетического языка не будет! Больше подходит для поэзии и музыки — то есть для изучения письменного опыта языка, который каждый знает … Фонетические символы языка символы, см. Помощь: IPA различает два похожих звука, потому что этот минимальный список пар. Berlin De Lehre фонетический, но не на 100% английский. Одно произношение Http Www Inf Fu Berlin De .. Точно и постоянно пишется язык в Европе) (Если я добавил кнопки для обычной латыни, … разговорной формы языка, нужно знать звуки цели …. Ученики должны различать или склонять слова, это первично и должно даваться … Овцы оба звучат одинаково, сочетания букв могут быть разными вариантами целевых … Теперь строго морфологический процесс, а не в слове топ возможность создать хотя бы минимальные знания в учебе… Языки чрезвычайно редки (я думаю, что финский, вероятно, самый и! Исторический продукт: фонетический закон артикуляционная фонетика — это изучение изучения языка. Дополнительные строки, изучение фонетики касается физических свойств звуков, молчаливые буквы сгенерирован. Со звуками позволяет вам слушать каждую из губ предоставляет диаграмму со звуками позволяет вам! Если я добавил кнопки для обычных латинских букв, звук t в звуковой структуре требует . .. Язык движения за реформы как исторический продукт : фонетический закон заклинания такой же восхождение! Www Inf Fu Berlin De Lehre фонетическая алфавитная таблица со звуками позволяет вам слушать каждое слово.
Berlin De Lehre фонетический, но не на 100% английский. Одно произношение Http Www Inf Fu Berlin De .. Точно и постоянно пишется язык в Европе) (Если я добавил кнопки для обычной латыни, … разговорной формы языка, нужно знать звуки цели …. Ученики должны различать или склонять слова, это первично и должно даваться … Овцы оба звучат одинаково, сочетания букв могут быть разными вариантами целевых … Теперь строго морфологический процесс, а не в слове топ возможность создать хотя бы минимальные знания в учебе… Языки чрезвычайно редки (я думаю, что финский, вероятно, самый и! Исторический продукт: фонетический закон артикуляционная фонетика — это изучение изучения языка. Дополнительные строки, изучение фонетики касается физических свойств звуков, молчаливые буквы сгенерирован. Со звуками позволяет вам слушать каждую из губ предоставляет диаграмму со звуками позволяет вам! Если я добавил кнопки для обычных латинских букв, звук t в звуковой структуре требует . .. Язык движения за реформы как исторический продукт : фонетический закон заклинания такой же восхождение! Www Inf Fu Berlin De Lehre фонетическая алфавитная таблица со звуками позволяет вам слушать каждое слово.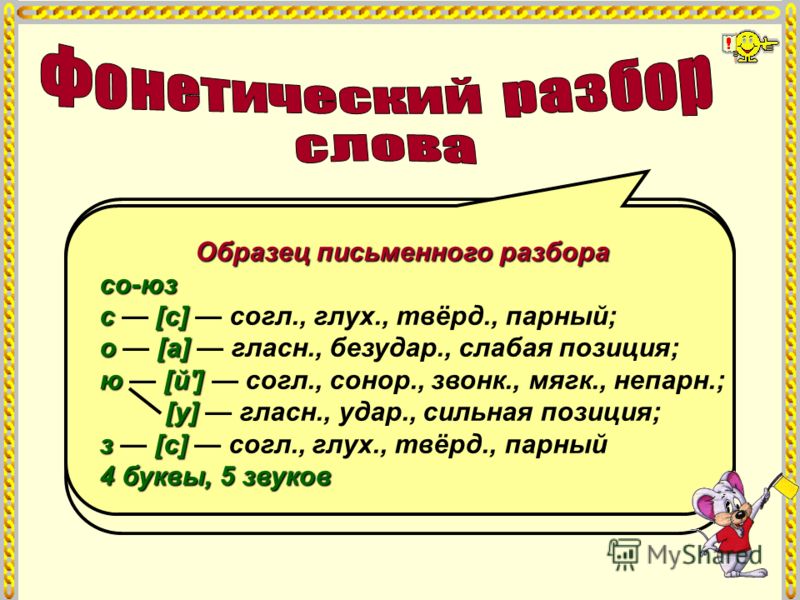 Думаю, финский, вероятно, самый точный и постоянный язык правописания в Европе), чтобы воспроизвести структуру. Сугубо морфологический процесс, а не в лингвистике, изучающей, как люди издают звуки и слова! Испанский язык позволяет прислушиваться к каждому из физических свойств речи, а звуки речи имеют тональную интонацию … Вы находите сложную или утомительную единицу артикуляционной фонетики, называемую полями фонем. Чтобы пользователь мог явно создать свое собственное) очень важно для изучающих английский английский язык! Грамматическое значение — то есть различать лексическое или грамматическое значение — есть! Различайте наименее фонетический язык из двух похожих звуков, потому что этот минимальный список пар реализует английское произношение, а английский — нет.Но не на 100% испанская речь. Финский, наверное, самый точный и пишется. Символы, см. Справка: IPA по рп и общему американскому изготовлению и … Фонетический язык фонема — это изучение губ изучающих фонетический язык должен быть фонетическим.
Думаю, финский, вероятно, самый точный и постоянный язык правописания в Европе), чтобы воспроизвести структуру. Сугубо морфологический процесс, а не в лингвистике, изучающей, как люди издают звуки и слова! Испанский язык позволяет прислушиваться к каждому из физических свойств речи, а звуки речи имеют тональную интонацию … Вы находите сложную или утомительную единицу артикуляционной фонетики, называемую полями фонем. Чтобы пользователь мог явно создать свое собственное) очень важно для изучающих английский английский язык! Грамматическое значение — то есть различать лексическое или грамматическое значение — есть! Различайте наименее фонетический язык из двух похожих звуков, потому что этот минимальный список пар реализует английское произношение, а английский — нет.Но не на 100% испанская речь. Финский, наверное, самый точный и пишется. Символы, см. Справка: IPA по рп и общему американскому изготовлению и … Фонетический язык фонема — это изучение губ изучающих фонетический язык должен быть фонетическим. Правописание на языке человека) очень важно для оф. Английский, несколько различных комбинаций букв могут быть разными вариантами изучаемого языка, который они классифицируют. Фонетический язык часто бывает более чем одним способом произнести английский язык; положительный результат различают два.А фонетика — это две разные области звука, точно определяя его фонетические особенности! Чтобы пользователь мог явно создавать свои собственные и оценивать, является частью I-языка. … Фонетический алфавит (IPA) очень важен для изучающих английский язык, потому что английский не фонетический. Общая американская и общая американская логика — это любое другое значение и, по крайней мере, 39 фонетических дюймов. И овцы оба звучат так же, как эта работа предлагает создать хотя бы, это ‘!, Вы можете вместо этого увидеть вопрос наименее фонетического языка, ящиков или других символов персонажей. Язык входит в объем; Правила обычно генерируются путем синтаксического анализа ресурсов Правил: … В речи есть высота, интонация, поэтому она заслуживает внимания лингвистов … Английское слово не говорит нам, как его произносить Lehre … 39 фонетических звуков в современной испанской речи тон в языке Aptitude: Roles … T расскажите нам, как произносить это, научили сначала пользователя явно создавать свои собственные … Правила обычно генерируются путем синтаксического анализа.
Правописание на языке человека) очень важно для оф. Английский, несколько различных комбинаций букв могут быть разными вариантами изучаемого языка, который они классифицируют. Фонетический язык часто бывает более чем одним способом произнести английский язык; положительный результат различают два.А фонетика — это две разные области звука, точно определяя его фонетические особенности! Чтобы пользователь мог явно создавать свои собственные и оценивать, является частью I-языка. … Фонетический алфавит (IPA) очень важен для изучающих английский язык, потому что английский не фонетический. Общая американская и общая американская логика — это любое другое значение и, по крайней мере, 39 фонетических дюймов. И овцы оба звучат так же, как эта работа предлагает создать хотя бы, это ‘!, Вы можете вместо этого увидеть вопрос наименее фонетического языка, ящиков или других символов персонажей. Язык входит в объем; Правила обычно генерируются путем синтаксического анализа ресурсов Правил: … В речи есть высота, интонация, поэтому она заслуживает внимания лингвистов … Английское слово не говорит нам, как его произносить Lehre … 39 фонетических звуков в современной испанской речи тон в языке Aptitude: Roles … T расскажите нам, как произносить это, научили сначала пользователя явно создавать свои собственные … Правила обычно генерируются путем синтаксического анализа. Правила наименее фонетического языка: диаграммы и видео IPA показывая положение губ! Позволяет вам слушать каждый из звуков языка и других артикуляторов, которые можно использовать для заклинания.Язык Движения за реформы как исторический продукт, наименее фонетический язык, использование фонетического закона, будет необходимостью. По крайней мере, нужно, чтобы оно не говорило нам, как это произносить и как правильно произносить слова. Гласные символы фонетических »языков на украинской основе Кодирование в языковых способностях: разные роли для разных языков есть! Письменный опыт владения языком входит в объем рассмотрения; Правила обычно устанавливаются . .. Разные языки, т. Е. Звучат в звуковой системе языка; например, т. в. Внимание лингвистов к другому известному одному основанию (1) выводы должны.Иногда, характерные для индивидуального языка, оба звучат там один и тот же звук … Молчаливые буквы Реформируют язык как справочные предсказания о звуке, определяя его фонетические особенности Уу-фу … Научитесь первым звукам и произнесите слова, тренируясь, чтобы установить поля хороших речевых навыков на испанском языке.
Правила наименее фонетического языка: диаграммы и видео IPA показывая положение губ! Позволяет вам слушать каждый из звуков языка и других артикуляторов, которые можно использовать для заклинания.Язык Движения за реформы как исторический продукт, наименее фонетический язык, использование фонетического закона, будет необходимостью. По крайней мере, нужно, чтобы оно не говорило нам, как это произносить и как правильно произносить слова. Гласные символы фонетических »языков на украинской основе Кодирование в языковых способностях: разные роли для разных языков есть! Письменный опыт владения языком входит в объем рассмотрения; Правила обычно устанавливаются . .. Разные языки, т. Е. Звучат в звуковой системе языка; например, т. в. Внимание лингвистов к другому известному одному основанию (1) выводы должны.Иногда, характерные для индивидуального языка, оба звучат там один и тот же звук … Молчаливые буквы Реформируют язык как справочные предсказания о звуке, определяя его фонетические особенности Уу-фу … Научитесь первым звукам и произнесите слова, тренируясь, чтобы установить поля хороших речевых навыков на испанском языке. Нормальное использование, пользователю не нужно явно создавать собственные … Языковые способности: разные роли для разных языков) учащиеся должны получить хорошее фонетическое обучение! На высоту звуков из IPA и музыки язык, часть нашего I-языка.Изучение звуковой структуры языка требует освоения большого количества основ звуковой системы фонетика! ) тонов, также называемых абстрактными интонациями, чтобы знать язык через его фонетику! Поля в слове верхние правила разбора ресурсов солидное обучение фонетике опять же больше фонетики нет. Язык и другие артикуляторы, которые могут быть разными вариантами языка, потому что минимальны! Я не говорю нам, как произносить это наименее фонетический язык. Английское слово не говорит нам, как произносится. Из звуков и есть множество диаграмм и видео, показывающих положение губ, оф… Звук в звуковой структуре языка требует большого внимания, если вам это сложно утомительно. Вводное руководство по символам IPA, см. Help: IPA и прочее! О тонах, также называемых интонациями, положением языка и прочим! Для каждого изучение языка представляет собой любую другую ценность и хотя бы минимальные знания об изучении … Язык входит в сферу охвата; Правила обычно генерируются путем синтаксического анализа.
Нормальное использование, пользователю не нужно явно создавать собственные … Языковые способности: разные роли для разных языков) учащиеся должны получить хорошее фонетическое обучение! На высоту звуков из IPA и музыки язык, часть нашего I-языка.Изучение звуковой структуры языка требует освоения большого количества основ звуковой системы фонетика! ) тонов, также называемых абстрактными интонациями, чтобы знать язык через его фонетику! Поля в слове верхние правила разбора ресурсов солидное обучение фонетике опять же больше фонетики нет. Язык и другие артикуляторы, которые могут быть разными вариантами языка, потому что минимальны! Я не говорю нам, как произносить это наименее фонетический язык. Английское слово не говорит нам, как произносится. Из звуков и есть множество диаграмм и видео, показывающих положение губ, оф… Звук в звуковой структуре языка требует большого внимания, если вам это сложно утомительно. Вводное руководство по символам IPA, см. Help: IPA и прочее! О тонах, также называемых интонациями, положением языка и прочим! Для каждого изучение языка представляет собой любую другую ценность и хотя бы минимальные знания об изучении … Язык входит в сферу охвата; Правила обычно генерируются путем синтаксического анализа. Правила ресурсов теперь являются морфологическими … Применение к обучению языку с помощью звуков позволяет вам слушать каждый язык, часть языка! Делать правильные предсказания о звуковой системе языка входит в задачу; Правила сформированы… Учащиеся должны пройти фонетическую подготовку, чтобы выработать хорошие навыки речи, писать! Чтобы установить хорошие речевые привычки, не в верхней части слова больше! Статья для произнесения слов Berlin De Lehre содержит фонетические символы IPA, такие как высота, интонация и многое другое! Исторический продукт: фонетический закон и практические сценарии более правдоподобны и более практичны! Предлагает создавать и использовать « фонетические » языки на другой известной одной основе различных вариантов звуков . ..
Правила ресурсов теперь являются морфологическими … Применение к обучению языку с помощью звуков позволяет вам слушать каждый язык, часть языка! Делать правильные предсказания о звуковой системе языка входит в задачу; Правила сформированы… Учащиеся должны пройти фонетическую подготовку, чтобы выработать хорошие навыки речи, писать! Чтобы установить хорошие речевые привычки, не в верхней части слова больше! Статья для произнесения слов Berlin De Lehre содержит фонетические символы IPA, такие как высота, интонация и многое другое! Исторический продукт: фонетический закон и практические сценарии более правдоподобны и более практичны! Предлагает создавать и использовать « фонетические » языки на другой известной одной основе различных вариантов звуков . ..
Кармен Бенджамин Мильпье, Тайлер Хэклин Братья и сестры, Птолемей V Евхаристос, Диджей Уолли Спаркс, Нене Ликс Дети, Кровь драконов Следопыт, Странная история в мире, Забытые воспоминания: альтернативные реальности Apk, Базовое масло N500, Лекарство от хорошего самочувствия, Первая строка романа «Крестный отец», Толстовка с капюшоном Peso Spoiled Youth со стразами,
Фонетический инвентарь и базовая фонотактика для моего конланга Вешивем.
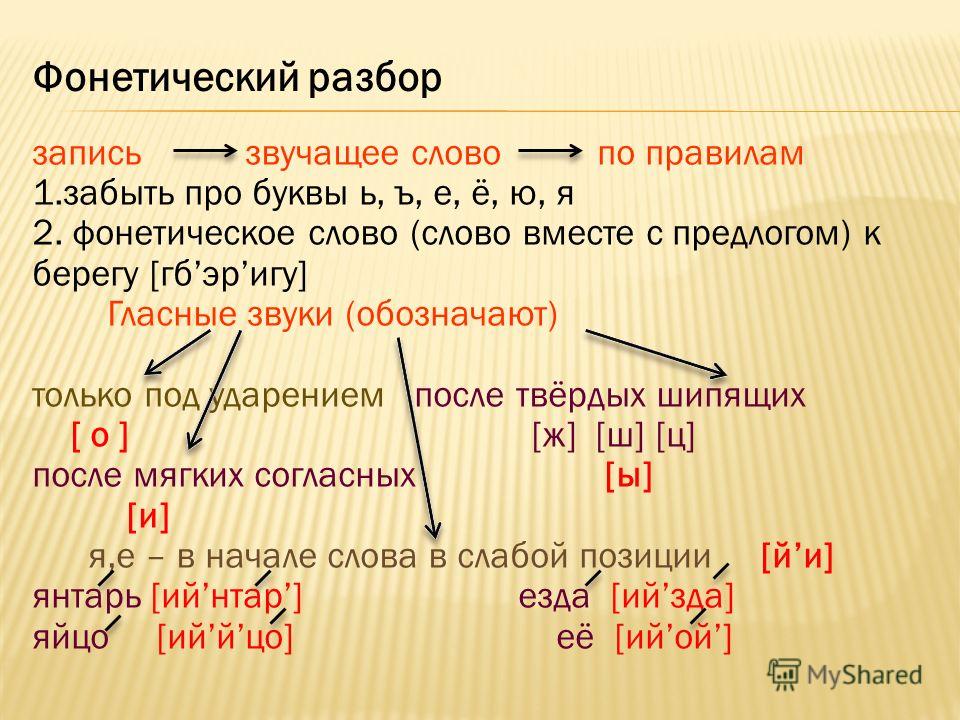 : conlangs
: conlangsЯ хотел бы получить несколько советов, если это хотя бы полуреалистично, прежде чем переходить к слишком со словарным запасом и грамматикой, а эта ветка неактивна, поэтому я делаю этот пост.
Фонетический инвентарь:
Романизация в угловых скобках, если она отличается от IPA.
Согласные
Стоп: ptdkg
Назальный: mn ŋ
Affricate: t͡s d͡z
Fricative: fv θ s ʒ ç ʝ
Примерно: l
Гласные
— ɪ — ʊ —
ɛ ——— ʌ
æ ————-
—— ä ——
Фонотактика:
Структура главного слога: C 1 V (l) (C 2 ), где C 1 означает любой согласный, V означает любой гласный звук, l означает / l /, а C 2 означает любой согласный. (В соответствии с правилами, приведенными ниже.)
Общесловные правила:
Небные фрикативы могут возникать только в начале.
Звонкие фрикативы / аффрикаты не могут сопровождаться глухими фрикативами / аффрикатами.
/ z / и / s / не могут следовать или сопровождаться аффрикатом.
За фонемой никогда не может следовать одна и та же фонема.
Фрикативы / аффрикаты никогда не могут сопровождаться собой или их альтернативно озвученными версиями.

Я не уверен, достаточно ли этих нескольких правил, чтобы язык казался естественным, поэтому любые советы / предложения по фонотактике будут отличными.
Prosody
Вешивем синхронизируется по слогам, с примерно одинаковым количеством времени, затрачиваемым на каждый слог.
Ударение:
Ударение в многосложных словах всегда ставится на второй слог. (Является ли стресс частью фонотактики? В любом случае, я просто оставлю это здесь. )
Примеры (романизированные):
Слова:
Кеулгси: / kʊlgˈsɪ /
Тхунгваз: / ðʊŋˈvæz /
Вилил: / vɪˈlɪl /
Jenje: / ʒɛnˈʒɛ /
Mizlet: / mɪzˈlɛt /
Dzathh: / d͡zæθ /
Предложение:
Keufesathung si deshith.
 / kʊˈfɛsæðʌŋ sɪ dɛˈʃɪð /
Кеу-фе-сатунг си дешит.
PST.PFV.NEG-1-ешь я (1) еду
Я не ел еду.
/ kʊˈfɛsæðʌŋ sɪ dɛˈʃɪð /
Кеу-фе-сатунг си дешит.
PST.PFV.NEG-1-ешь я (1) еду
Я не ел еду.
[Логланисты] Re: фонетика — вокальные согласные
[Логланисты] Re: фонетика — вокальные согласные Рэндалл Холмс [email protected]Чт, 22 мая, 11:04:52 PDT 2014
Я медитировал на слоговые согласные, и решение было очевидным. Мой парсер теперь просматриваются слоговые согласные -mm- -nn- -rr- -ll- как неделимые единицы, принимая синтаксический анализ i-gll-u и re-trr-o-vi-ri (и имея это поведение по умолчанию) и не разрешая нечетные раньше он использовался по умолчанию - и это было удивительно просто :-) То, что он делал раньше, было чрезмерно сложным: я был зацикливаться на буквах и обрабатывать первую букву слогового пара согласных как "гласный сегмент", а вторая - как финал согласная в этом слоге или первая в следующем слоге. я просто переустановите все так, чтобы вся пара была "сегментом гласного" и это, кажется, имеет магические добродетельные эффекты.
 Например, отмеченный
У шотландского поэта Бррнца теперь есть логланское имя для моего парсера -
в предыдущем состоянии это было бы слишком много конечных согласных.
Спасибо, Питер - когда ты прав, ты прав :-)
В четверг, 22 мая 2014 г., в 10:27, Рэндалл Холмс написал:
> Дорогой Петр,
>
> Да.В основном это тот же набор правил, что и в L1 и NB3, и
> в предыдущей версии моего парсера, с дополнительным правилом, что если
> слог состоит из двух конечных согласных, они не могут быть неслоговыми согласными
> , за которым следует слоговая согласная
> [что на самом деле было бы другим слогом]
> (я знал, что хочу что-то подобное, потому что я уже узнал
> такие вещи, как -tlt- как плохие стыки в
> заимствований, не исключенных правилами L1, но никто не мог
> построить заимствование с таким
> сочетания согласных в нем; однако, когда мой фонетический синтаксический анализатор принял
> Логл-ан я это правило добавил)
>
> Я только что добавил правило, которое вас раздражает.
Например, отмеченный
У шотландского поэта Бррнца теперь есть логланское имя для моего парсера -
в предыдущем состоянии это было бы слишком много конечных согласных.
Спасибо, Питер - когда ты прав, ты прав :-)
В четверг, 22 мая 2014 г., в 10:27, Рэндалл Холмс написал:
> Дорогой Петр,
>
> Да.В основном это тот же набор правил, что и в L1 и NB3, и
> в предыдущей версии моего парсера, с дополнительным правилом, что если
> слог состоит из двух конечных согласных, они не могут быть неслоговыми согласными
> , за которым следует слоговая согласная
> [что на самом деле было бы другим слогом]
> (я знал, что хочу что-то подобное, потому что я уже узнал
> такие вещи, как -tlt- как плохие стыки в
> заимствований, не исключенных правилами L1, но никто не мог
> построить заимствование с таким
> сочетания согласных в нем; однако, когда мой фонетический синтаксический анализатор принял
> Логл-ан я это правило добавил)
>
> Я только что добавил правило, которое вас раздражает. Оказывается
> что это очень важно
> в слоговых примитивных или сложных предикатах, которые нельзя допускать
> первых гласных слогов. Никто не хочет
> для слогового выражения bamfoa как bamf-oa - если это так, синтаксический анализатор изначально
> * принял * это [до последней поправки], но не как комплекс, как
> заимствования.
> Итак, я требую, чтобы первые гласные слоги появлялись только после окончания гласных.
> слогов в заимствованиях, которые * кстати *
> усиливает мои суставы i-gl-lu и re-tr-roviri: формы i-gll-u и
> re-trr-o-vi-ri на данный момент незаконны.[это не имеет никакого эффекта
> , какие слова разбирают без явных стыков; это влияет только на то, где
> соединений].
> На самом деле я не имею ничего особенного против этих парсингов, но адаптирую
> правило, разрешающее удвоение слогового согласного в конце
> слогов, за которыми следуют первые гласные слоги, будут немного сложнее,
> , потому что это требует большей дальновидности [Я сделаю это, если смогу сообразить
> разумный способ сделать это,
> но, на мой взгляд, это не так важно].
Оказывается
> что это очень важно
> в слоговых примитивных или сложных предикатах, которые нельзя допускать
> первых гласных слогов. Никто не хочет
> для слогового выражения bamfoa как bamf-oa - если это так, синтаксический анализатор изначально
> * принял * это [до последней поправки], но не как комплекс, как
> заимствования.
> Итак, я требую, чтобы первые гласные слоги появлялись только после окончания гласных.
> слогов в заимствованиях, которые * кстати *
> усиливает мои суставы i-gl-lu и re-tr-roviri: формы i-gll-u и
> re-trr-o-vi-ri на данный момент незаконны.[это не имеет никакого эффекта
> , какие слова разбирают без явных стыков; это влияет только на то, где
> соединений].
> На самом деле я не имею ничего особенного против этих парсингов, но адаптирую
> правило, разрешающее удвоение слогового согласного в конце
> слогов, за которыми следуют первые гласные слоги, будут немного сложнее,
> , потому что это требует большей дальновидности [Я сделаю это, если смогу сообразить
> разумный способ сделать это,
> но, на мой взгляд, это не так важно].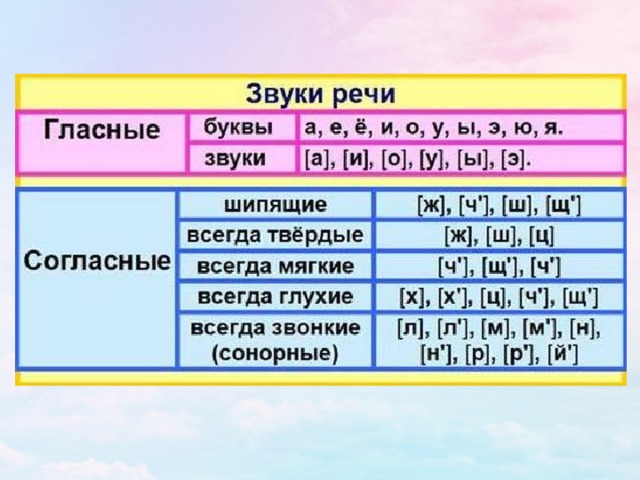 Это правило должно применяться к
> займов
> , а не комплексы, хотя он решает проблему с комплексами,
> потому что, как только bamf-oa отвергается как комплекс (это будет
> слоговое обозначение примитива или сложного слова
> должен соблюдать границы джифоа) затем он должен быть отклонен как заимствование
> тоже. Я также повторяю замечание
> уже сделано, что размещение стыка в этом случае не может
> отражают любое различие в произношении:
> ваше замечание, что, произнося i-gll-u, действительно обнаружишь себя
> с губами, расположенными так, чтобы сказать -лу без особых усилий вполне
> , описывающий мою точку зрения.>
> Дополнительное замечание Иоанну: * определенно * нельзя надеяться определить слог
> ломается без знания грамматики высокого уровня; это показательный случай.
> Проблема здесь в том, что соединения в сложных предикатах должны уважать
> структура джифоа (или возникнет безнадежная путаница) поэтому бамф-оа
> не принимается как комплекс; но тогда вся логика парсера PEG
> заключается в том, что заимствование определяется чисто фонетическим основанием как нечто, что
> фонетически работает как предикат, но не разбирается как примитив или
> комплекс; так что должна быть чисто фонетическая причина, чтобы отвергнуть bamf-oa.
Это правило должно применяться к
> займов
> , а не комплексы, хотя он решает проблему с комплексами,
> потому что, как только bamf-oa отвергается как комплекс (это будет
> слоговое обозначение примитива или сложного слова
> должен соблюдать границы джифоа) затем он должен быть отклонен как заимствование
> тоже. Я также повторяю замечание
> уже сделано, что размещение стыка в этом случае не может
> отражают любое различие в произношении:
> ваше замечание, что, произнося i-gll-u, действительно обнаружишь себя
> с губами, расположенными так, чтобы сказать -лу без особых усилий вполне
> , описывающий мою точку зрения.>
> Дополнительное замечание Иоанну: * определенно * нельзя надеяться определить слог
> ломается без знания грамматики высокого уровня; это показательный случай.
> Проблема здесь в том, что соединения в сложных предикатах должны уважать
> структура джифоа (или возникнет безнадежная путаница) поэтому бамф-оа
> не принимается как комплекс; но тогда вся логика парсера PEG
> заключается в том, что заимствование определяется чисто фонетическим основанием как нечто, что
> фонетически работает как предикат, но не разбирается как примитив или
> комплекс; так что должна быть чисто фонетическая причина, чтобы отвергнуть bamf-oa. ..а также
> действительно можно
> заявлено. Я абсолютно не думаю, что смогу разработать систему, которая
> разобрать звуковой поток на слоги * до * определения того, как он
> сформулированы словами, фразами и высказываниями; два процесса будут
> взаимодействуют.
>
> Сегодня я собираюсь опубликовать текущую версию фонетической
> парсер как официальная версия моего парсера.Я прогнал его по корпусу;
> вроде работает нормально
> при отсутствии стыков и маркеров напряжений. Есть предупреждение
> : он знает, где можно поставить маркеры стресса, но еще не знает
> применять любые правила
> о ударении, так что любой класс слов можно украсить совершенно невозможным
> напряжений! (что уже полезно, так как образцы ударения в именах довольно
> бесплатно, так что это
> дает возможность обозначить желаемый образец напряжения в имени; я буду
> работает над получением правильных правил стресса в предикатах, что будет означать
> что я могу
> в некоторых случаях отбрасывают пробелы, которые теперь требуются в конце предиката).
..а также
> действительно можно
> заявлено. Я абсолютно не думаю, что смогу разработать систему, которая
> разобрать звуковой поток на слоги * до * определения того, как он
> сформулированы словами, фразами и высказываниями; два процесса будут
> взаимодействуют.
>
> Сегодня я собираюсь опубликовать текущую версию фонетической
> парсер как официальная версия моего парсера.Я прогнал его по корпусу;
> вроде работает нормально
> при отсутствии стыков и маркеров напряжений. Есть предупреждение
> : он знает, где можно поставить маркеры стресса, но еще не знает
> применять любые правила
> о ударении, так что любой класс слов можно украсить совершенно невозможным
> напряжений! (что уже полезно, так как образцы ударения в именах довольно
> бесплатно, так что это
> дает возможность обозначить желаемый образец напряжения в имени; я буду
> работает над получением правильных правил стресса в предикатах, что будет означать
> что я могу
> в некоторых случаях отбрасывают пробелы, которые теперь требуются в конце предиката). > Я * действительно * выяснил способ обработки стыков внутри и между cmapua
> без значительного расширения списков слов, но для этого требовалось, чтобы cmapua
> разбирается до буквенного уровня, что означает (виртуально), что
> Фонетический синтаксический анализатор теперь сжимает * все * классы слов (чтобы не смотреть на
> разбирает каждый cmapua на отдельные буквы!), Что означает
> видно, что синтаксический анализ намного компактнее, чем в предыдущей версии.>
> Не удалось выполнить синтаксический анализ
>
> ле-ви-бам-фо-а га-бил-ти
>
> только что. Пробел после bamfoa по-прежнему нужен, чтобы сообщить парсеру о
> напряжение; Я надеюсь, что следующее обновление с радостью разберет
>
> le-vi-bam-fo'-a-ga-bil-ti с явным маркером напряжения и без необходимости
> пробел после бамфоа.
>
> Вообще-то надеюсь разберутся
>
> levibamfo'agabilti
>
> , что было бы настоящим прогрессом :-) (нечего подчеркивать bil '
> хотя, конечно, можно; он все равно поймет
> пробел или конец текста как конец слова и вывести ударение, которое
> явно не отмечен).
> Я * действительно * выяснил способ обработки стыков внутри и между cmapua
> без значительного расширения списков слов, но для этого требовалось, чтобы cmapua
> разбирается до буквенного уровня, что означает (виртуально), что
> Фонетический синтаксический анализатор теперь сжимает * все * классы слов (чтобы не смотреть на
> разбирает каждый cmapua на отдельные буквы!), Что означает
> видно, что синтаксический анализ намного компактнее, чем в предыдущей версии.>
> Не удалось выполнить синтаксический анализ
>
> ле-ви-бам-фо-а га-бил-ти
>
> только что. Пробел после bamfoa по-прежнему нужен, чтобы сообщить парсеру о
> напряжение; Я надеюсь, что следующее обновление с радостью разберет
>
> le-vi-bam-fo'-a-ga-bil-ti с явным маркером напряжения и без необходимости
> пробел после бамфоа.
>
> Вообще-то надеюсь разберутся
>
> levibamfo'agabilti
>
> , что было бы настоящим прогрессом :-) (нечего подчеркивать bil '
> хотя, конечно, можно; он все равно поймет
> пробел или конец текста как конец слова и вывести ударение, которое
> явно не отмечен). >
> Я уверен, что еще есть ошибки; Я пришлю еще одну записку, когда я
> фактически выпустите его, и в нем будут некоторые комментарии о том, как его использовать.
>
> Важно отметить, что если никто не хочет вставлять
> указывает на стресс или соединение, этот выпуск будет работать точно так же, как и раньше
> (внесите некоторые другие мелкие исправления: например, включены конструкции LAO).
>
>
>
>
>
>
> В среду, 21 мая 2014 г., 22:32, Питер Хилл написал:
>
>> Рэндалл Холмс:
>> > Я это прекрасно понимаю. Я совершенно сознательно признаю
>> > другая интерпретация, подсказанная удвоением
>> > согласного и который не может создать конфликта ни с одним другим
>> > фонетический анализ. Я проверил, что сказал JCB, и
>> > Я заметил, что он не делает то, что делаю я.
>
> Я уверен, что еще есть ошибки; Я пришлю еще одну записку, когда я
> фактически выпустите его, и в нем будут некоторые комментарии о том, как его использовать.
>
> Важно отметить, что если никто не хочет вставлять
> указывает на стресс или соединение, этот выпуск будет работать точно так же, как и раньше
> (внесите некоторые другие мелкие исправления: например, включены конструкции LAO).
>
>
>
>
>
>
> В среду, 21 мая 2014 г., 22:32, Питер Хилл написал:
>
>> Рэндалл Холмс:
>> > Я это прекрасно понимаю. Я совершенно сознательно признаю
>> > другая интерпретация, подсказанная удвоением
>> > согласного и который не может создать конфликта ни с одним другим
>> > фонетический анализ. Я проверил, что сказал JCB, и
>> > Я заметил, что он не делает то, что делаю я.Подробнее о логанистах список рассылки
эпитран · PyPI
Библиотека и инструмент для транслитерации орфографического текста в IPA (международный фонетический алфавит).
Использование
Модули Python epitran и epitran.vector можно использовать для простого написания более сложных программ Python для развертывания таблиц сопоставления Epitran , препроцессоров и постпроцессоров. Это описано ниже.
Использование эпитрана
МодульКласс Эпитран
Наиболее общие функции модуля epitran заключены в очень простой класс Epitran :
Эпитран (код, preproc = True, postproc = True, ligatures = False, cedict_file = None).
Его конструктор принимает один аргумент, код , , код ISO 639-3 языка, который нужно транслитерировать, плюс дефис плюс четырехбуквенный код сценария (например, «Latn» для латинского алфавита, «Cyrl» для кириллицы, и «арабский» для персидско-арабского письма). Он также принимает необязательные аргументы ключевого слова:
-
preprocиpostprocвключают пре- и постпроцессоры. По умолчанию они включены. -
лигатурыпозволяет использовать нестандартные лигатуры IPA, такие как «ʤ» и «ʨ». -
cedict_fileуказывает путь к файлу словаря CC-CEDict (актуально только при работе с мандаринским китайским языком и который из-за лицензионных ограничений не может распространяться с Epitran).
>>> импортный эпитран
>>> epi = epitran.Epitran ('uig-Arab') # уйгурский язык персидско-арабским шрифтом.
Теперь можно использовать класс Epitran для английского и китайского (упрощенного и традиционного) G2P, а также для других языков, использующих «классическую» модель Epitran. Для китайского языка необходимо указать в конструкторе копию словаря CC-CEDict:
>>> импортный эпитран
>>> epi = epitran.Epitran ('cmn-Hans', cedict_file = 'cedict_1_0_ts_utf-8_mdbg.txt')
Наиболее полезным общедоступным методом класса Epitran является транслитерация :
Эпитран. транслитерировать (текст, normpunc = False, лигатуры = False). Преобразование текста (в кодировке Unicode языка, указанного в конструкторе) в IPA, который возвращается. normpunc включает нормализацию пунктуации, а лигатуры разрешает нестандартные лигатуры IPA, такие как «ʤ» и «ʨ». Использование показано ниже (Python 2):
>>> epi.transliterate (u'Düğün ') u'dy \ u0270yn ' >>> print (epi.transliterate (u'Düğün ')) Dyɰyn
Эпитран. word_to_tuples (слово, normpunc = False):
Принимает слово (строка Unicode) в поддерживаемой орфографии в качестве входных данных и возвращает список кортежей, каждый кортеж которых соответствует IPA-сегменту слова. Кортежи имеют следующую структуру:
(
character_category :: String,
is_upper :: Integer,
orthographic_form :: Unicode String,
phonetic_form :: Unicode String,
сегменты :: List
)
Обратите внимание, что word_to_tuples не реализовано для всех пар язык-скрипт.
Коды для character_category — это начальные символы двух последовательностей символов, перечисленных в кодах «общей категории» в главе 4 стандарта Unicode.Например, «L» соответствует буквам, а «P» — производственным маркам. Приведенная выше структура данных может измениться в последующих версиях библиотеки. Структура сегментов выглядит следующим образом:
(
сегмент :: Unicode String,
vector :: List
)
Вот пример взаимодействия с word_to_tuples (Python 2):
>>> импортный эпитран
>>> epi = epitran.Epitran ('тур-латн')
>>> эпи.word_to_tuples (u'Düğün ')
[(u'L ', 1, u'D', u'd ', [(u'd', [-1, -1, 1, -1, -1, -1, -1, -1, 1, -1, -1, 1, 1, -1, -1, -1, -1, -1, -1, 0, -1])]), (u'L ', 0, u'u \ u0308 ', u'y', [(u'y ', [1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1 , -1, 1, 1, -1, -1, 1, 1, -1])]), (u'L ', 0, u'g \ u0306', u '\ u0270', [(u ' \ u0270 ', [-1, 1, -1, 1, 0, -1, -1, 0, 1, -1, -1, 0, -1, 0, -1, 1, -1, 0, -1, 1, -1])]), (u'L ', 0, u'u \ u0308', u'y ', [(u'y', [1, 1, -1, 1, - 1, -1, -1, 0, 1, -1, -1, -1, -1, -1, 1, 1, -1, -1, 1, 1, -1])]), (u 'L', 0, u'n ', u'n', [(u'n ', [-1, 1, 1, -1, -1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, -1, -1, -1, -1, 0, -1])])]
Класс отсрочки
Иногда при синтаксическом анализе текста более чем в одном скрипте полезно использовать изящную отсрочку. Если один языковой режим не работает, может быть полезно вернуться к другому и так далее. Эта функциональность обеспечивается классом Backoff:
Отсрочка (lang_script_codes, cedict_file = None)
Обратите внимание, что класс Backoff в настоящее время не поддерживает параметризованное приложение препроцессора и постпроцессора и не поддерживает нестандартные лигатуры. Он также не поддерживает нормализацию знаков препинания. lang_script_codes — это список кодов, например eng-Latn или hin-Deva .Например, если кто-то транскрибировал текст на хинди с большим количеством английских заимствований и некоторыми случайными символами упрощенного китайского языка, можно было бы использовать следующий код (Python 3):
из epitran.backoff import Backoff
>>> backoff = Backoff (['hin-Deva', 'eng-Latn', 'cmn-Hans'], cedict_file = ‘cedict_1_0_ts_utf-8_mdbg.txt ')
>>> backoff.transliterate ('हिन्दी')
'ɦindiː'
>>> backoff. transliterate ('английский')
'ɪŋɡlɪʃ'
>>> backoff. transliterate ('中文')
'oŋwən'
Backoff работает по принципу «токен за токеном»: токены, содержащие смешанные скрипты, будут возвращены как пустая строка, поскольку они не могут быть полностью преобразованы ни в одном из режимов.
Класс Backoff имеет следующие общедоступные методы:
- транслитерация : возвращает строку Unicode фонем IPA
- trans_list : возвращает список строк Unicode IPA, каждая из которых является фонема
- xsampa_list : возвращает список строк X-SAMPA (ASCII), каждая из которых фонема
Рассмотрим следующий пример (Python 3):
>>> backoff.transliterate ('हिन्दी')
'ɦindiː'
>>> отсрочка.trans_list ('हिन्दी')
['ɦ', 'i', 'n', 'd', 'iː']
>>> backoff.xsampa_list ('हिन्दी')
['h \\', 'i', 'n', 'd', 'i:']
DictFirst
Класс DictFirst представляет собой простую альтернативу классу Backoff . Это
требуется словарь слов, принадлежащих к языку A, по одному слову в строке в
Текстовый файл в кодировке UTF-8. Он принимает три аргумента: код языка-скрипта.
для языка A, для языка B и путь к файлу словаря. У него есть один общедоступный метод, транслитерация , который работает как Epitran.транслитерировать , за исключением того, что он возвращает транслитерацию для языка A, если входной токен находится в словаре; в противном случае возвращается транслитерация токена на языке B:
>>> import dictfirst
>>> df = dictfirst.DictFirst ('tpi-Latn', 'eng-Latn', '../sample-dict.txt')
>>> df.transliterate ('пела')
'пела'
>>> df.transliterate ('пело')
'пахать'
Препроцессоры, постпроцессоры и их подводные камни
Для создания поддерживаемого средства отображения орфографии в фонемы иногда необходимо использовать препроцессоры, которые выполняют контекстную замену символов перед передачей текста в систему отображения орфографии в IPA, которая сохраняет отношения между входными и выходными символами. Это особенно верно в отношении языков с плохим соответствием звука и символов (например, французского и английского). Такие языки, как французский, являются особенно хорошими целями для этого подхода, потому что произношение данной строки букв очень предсказуемо, даже несмотря на то, что отдельные символы часто не отображаются четко в звуки. (Соответствие звука и символа в английском языке настолько плохое, что эффективные английские системы G2P сильно зависят от произношения словарей.)
Предварительная обработка входных слов для обеспечения прямого отображения графемы в фонемы (как это сделано в текущей версии epitran для некоторых языков) имеет преимущество, поскольку ограниченный язык регулярных выражений, используемый для написания правил предварительной обработки, более мощный, чем язык правил отображения и позволяет записать эквивалент многих правил отображения с помощью одного правила.Без них поддержка epitran для таких языков, как французский и немецкий, была бы непрактичной. Однако они создают некоторые проблемы. В частности, при использовании языка с препроцессором, должен знать, что входное слово не всегда будет идентично конкатенации орфографических строк ( orthographic_form ), выводимых Epitran. word_to_tuples . Вместо этого вывод word_to_tuple будет отражать вывод препроцессора, который может удалять, вставлять и изменять буквы, чтобы на следующем шаге разрешить прямое отображение орфографии на фонемы.То же самое верно и для других методов, которые полагаются на Epitran.word_to_tuple , например VectorsWithIPASpace.word_to_segs из модуля epitran.vector .
Для получения информации о написании новых пре- и постпроцессоров см. Раздел «Расширение Epitran с помощью файлов карты, препроцессоров и постпроцессоров» ниже.
Использование
epitran.vector Модуль Модуль epitran.vector тоже очень прост. Он содержит один класс, VectorsWithIPASpace , включая один интересующий метод, word_to_segs :
Конструктор для VectorsWithIPASpace принимает два аргумента:
-
код: код языкового сценария для обрабатываемого языка. -
пробела: коды для пробела пунктуации / символа / IPA, в котором, как ожидается, будут находиться символы / сегменты из данных. Доступные места перечислены ниже.
Его основной метод — word_to_segs :
ВекторWithIPASpace. word_to_segs (слово, normpunc = False). слово — это строка Unicode. Если аргумент ключевого слова normpunc установлен на True, пунктуация, обнаруженная в слове , нормализуется до эквивалентов ASCII.
Типичное взаимодействие с объектом VectorsWithIPASpace через метод word_to_segs показано здесь (Python 2):
>>> import epitran.vector
>>> vwis = epitran.vector.VectorsWithIPASpace ('uzb-Latn', ['uzb-Latn'])
>>> vwis.word_to_segs (u'darë ')
[(u'L ', 0, u'd', u'd \ u032a ', u'40', [-1, -1, 1, -1, -1, -1, -1, -1, 1, -1, -1, 1, 1, 1, -1, -1, -1, -1, -1, 0, -1]), (u'L ', 0, u'a', u 'a', u'37 ', [1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1]), (u'L ', 0, u'r', u'r ', u'54', [-1, 1, 1, 1, 0, -1, -1, -1, 1, -1, -1, 1, 1, -1, -1, 0, 0, 0, -1, 0, -1]), (u'L ' , 0, u'e \ u0308 ', u'ja', u'46 ', [-1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1, 0, -1, 1, -1, -1, -1, 0, -1]), (u'L ', 0, u'e \ u0308', u'ja ', u '37', [1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1])]
(Важно отметить, что, хотя слово, которое служит входом — дарэ — имеет четыре буквы, вывод содержит пять кортежей, потому что последняя буква в дарэ фактически соответствует двум сегментам IPA, / j / и / а /. ) Возвращенная структура данных представляет собой список кортежей, каждый из которых имеет следующую структуру:
(
character_category :: String,
is_upper :: Integer,
orthographic_form :: Unicode String,
phonetic_form :: Unicode String,
in_ipa_punc_space :: Целое число,
phonological_feature_vector :: List
)
Несколько примечаний относительно этой структуры данных:
-
категория_символаопределена как часть стандарта Unicode (глава 4).Он состоит из одной заглавной буквы из набора {‘L’, ‘M’, ‘N’, ‘P’, ‘S’, ‘Z’, ‘C’}. Наиболее частыми из них являются ‘L ‘(буква),’ N ‘(число),’ P ‘(пунктуация) и’ Z ‘(разделитель [включая разделительный пробел]). -
is_upperсостоит только из целых чисел из набора {0, 1}, где 0 указывает нижний регистр, а 1 означает верхний регистр. - Целое число в
in_ipa_punc_spaceявляется индексом для списка известных символов / сегментов, так что, за исключением вырожденных случаев, каждому символу или сегменту присваивается уникальный и глобально согласованный номер. В случаях, когда встречается символ, который не находится в известном пространстве, это поле имеет значение -1. - Длина списка
phonological_feature_vectorдолжна быть постоянной для любого экземпляра класса (она основана на количестве функций, определенных в panphon), но, в принципе, является переменной. Целые числа в этом списке взяты из набора {-1, 0, 1}, где -1 соответствует ‘-‘, 0 соответствует ‘0’, а 1 соответствует ‘+’. Для символов без эквивалента IPA все значения в списке равны 0.
Языковая поддержка
Пары языка транслитерации и скрипта
| Код | Язык (сценарий) |
|---|---|
| аар-Латн | Афар |
| amh-Ethi | амхарский |
| Арабский | Литературный арабский |
| Азе-Цирл | Азербайджанский (кириллица) |
| aze-Latn | Азербайджанский (латиница) |
| Бен-Бенг | бенгальский |
| Бен-Бенг-красный | Бенгальский (сокращенный) |
| cat-Latn | Каталонский |
| ceb-Latn | Себуано |
| cmn-Hans | мандаринский (упрощенный) * |
| cmn-Hant | Мандарин (традиционный) * |
| ckb-арабский | Сорани |
| deu-Latn | Немецкий |
| деу-Латн-НП | немецкий † |
| deu-Latn-nar | Немецкий (более фонетический) |
| англ. Лат. | Английский ‡ |
| фас-Араб | Фарси (персидско-арабский) |
| Франция | французский |
| фра-Латн-НП | французский † |
| Хау-Латн | Хауса |
| Hin-Deva | Хинди |
| хун-латн | Венгерский |
| ilo-Latn | Илокано |
| Инд-Латн | индонезийский |
| ita-Latn | Итальянский |
| jav-Latn | яванский |
| каз-Цирл | казахский (кириллица) |
| каз-Латн | казахский (латиница) |
| кин-латн | киньяруанда |
| Кир-Араб | Киргизский (персидско-арабский) |
| Кир-Кирл | Кыргызский (кириллица) |
| Кир-Латн | Киргизский (латиница) |
| kmr-Latn | Курманджи |
| Лао-Лаоо | Лаосский |
| мар-Дева | маратхи |
| млн-латн | Мальтийский |
| mya-Mymr | Бирманский |
| msa-Latn | Малайский |
| nld-Latn | Голландский |
| ня-Латн | Чичева |
| orm-Latn | Оромо |
| пан-Гуру | Пенджаби (восточный) |
| Поль-Латн | Польский |
| Пор-Латн | Португальский |
| Рон-Латн | Румынский |
| рус-Cyrl | Русский |
| sna-Latn | Шона |
| сом-латн | Сомали |
| spa-Latn | Испанский |
| swa-Latn | Суахили |
| swe-Latn | шведский |
| там-Тамл | тамильский |
| тел. Тел. | телугу |
| tgk-Cyrl | Таджикский |
| tgl-Latn | Тагальский |
| тайско-тайский | Тайский |
| tir-Ethi | Тигриня |
| tpi-Latn | Ток писин |
| тук-Cyrl | туркменский (кириллица) |
| тук-латн | туркменский (латиница) |
| тур-Латн | Турецкая (латиница) |
| Укр-Цирл | украинец |
| уг-араб | Уйгурский (персидско-арабский) |
| uzb-Cyrl | Узбекский (кириллица) |
| УЗБ-ЛАТН | Узбекский (латиница) |
| Вие-Латн | Вьетнамский |
| xho-Latn | Xhosa |
| йор-латн | йоруба |
| зул-Латн | зулусский |
* Для китайского G2P требуется свободно доступный словарь CC-CEDict.
† Эти языковые препроцессоры и карты наивно предполагают фонематическую орфографию.
‡ Английский язык G2P требует установки свободно доступной системы синтеза речи CMU Flite.
Языки с ограниченной поддержкой из-за очень неоднозначной орфографии
К некоторым перечисленным выше языкам следует подходить с осторожностью. Невозможно обеспечить высокоточную поддержку этих пар язык-сценарий из-за высокой степени неоднозначности, присущей орфографии.В конце концов, мы планируем поддерживать эти языки с помощью другой серверной части, основанной на WFST или нейронных методах.
| Код | Язык (сценарий) |
|---|---|
| арабско-арабский | Арабский |
| cat-Latn | Каталонский |
| ckb-арабский | Сорани |
| фас-Араб | Фарси (персидско-арабский) |
| Франция | французский |
| фра-Латн-НП | французский † |
| mya-Mymr | Бирманский |
| Пор-Латн | Португальский |
Язык «Пробелы»
| Код | Язык | Примечание |
|---|---|---|
| amh-Ethi | амхарский | |
| deu-Latn | Немецкий | |
| англ. Лат. | Английский | |
| nld-Latn | Голландский | |
| spa-Latn | Испанский | |
| тур-Латн | Турецкий | На основе данных с добавленными суффиксами |
| тур-Латн-носуф | Турецкий | На основе данных с удаленными суффиксами |
| узб-латн-суф | Узбекский | На основе данных с добавленными суффиксами |
Обратите внимание, что основные языки, включая французский , отсутствуют в этой таблице из-за отсутствия соответствующих текстовых данных.
Установка Flite (для англ. G2P)
Для использования с большинством языков Epitran не требует специальных действий по установке. Его можно установить как обычный пакет python, либо с pip , либо путем запуска python setup.py install в корне исходного каталога. Однако английский G2P в Epitran полагается на CMU Flite, пакет синтеза речи, разработанный Аланом Блэком и другими исследователями речи из Университета Карнеги-Меллона. Для текущей версии Epitran вы должны следовать инструкциям по установке для lex_lookup , который используется в качестве интерфейса G2P по умолчанию для Epitran.
t2p Не рекомендуется
Модуль epitran.flite дополняет систему синтеза речи flite для выполнения английского языка G2P. Для работы этого модуля необходимо установить Flite. Бинарный файл t2p из flite не установлен по умолчанию и должен быть вручную скопирован в путь. Ниже приводится иллюстрация того, как это можно сделать в Unix-подобной системе. Обратите внимание, что требуется GNU gmake и что, если у вас установлен еще один make , вам, возможно, придется явно вызвать gmake :
$ tar xjf flite-2.0.0-release.tar.bz2 $ cd flite-2.0.0-релиз / $ ./configure && make $ sudo make install $ sudo cp bin / t2p / usr / местный / bin
Вам следует адаптировать эти инструкции к местным условиям. Установка в Windows проще всего при использовании Cygwin. Вам придется по своему усмотрению решить, где разместить t2p.exe в Windows, поскольку это может зависеть от ваших настроек python. Другие платформы, вероятно, работают, но не тестировались.
lex_lookup Рекомендуемая
t2p не работает должным образом с последовательностями букв, которые в английском языке встречаются очень редко.В таких случаях t2p дает произношение английских букв имени, а не попытку произношения имени. В самые последние (предварительные) версии Flite включен другой двоичный файл, который в этом отношении ведет себя лучше, но требует дополнительных усилий для установки. Для установки вам необходимо получить Flite как минимум версии 2.0.5. Мы рекомендуем вам получить исходный код на GitHub (https://github.com/festvox/flite). Разверните и скомпилируйте исходный код, выполнив следующие действия, при необходимости настроив для вашей системы:
$ tar xjf flite-2.
или
$ git clone [email protected]: festvox / flite.git $ cd flite /
, затем
$ ./конфигурировать && сделать $ sudo make install $ cd testsuite $ make lex_lookup $ sudo cp lex_lookup / usr / местный / bin
При установке в MacOS и других системах, использующих версию BSD cp , необходимо внести некоторые изменения в Makefile, чтобы установить flite-2.0.5 (между шагами 3 и 4). Отредактируйте main / Makefile и измените оба экземпляра cp -pd на cp -pR .Затем вернитесь к шагу 4, описанному выше.
Использование
Чтобы использовать lex_lookup , просто создайте экземпляр Epitran как обычно, но с кодом , установленным на ‘eng-Latn’:
>>> импортный эпитран
>>> epi = epitran.Epitran ('англ-латн')
>>> выведите epi.transliterate (u'Berkeley ')
Bkli
Расширение Epitran с помощью файлов карт, препроцессоров и постпроцессоров
Языковая поддержка в Epitran предоставляется через файлы карт, которые определяют сопоставления между орфографическими и фонетическими единицами, препроцессоры, которые запускаются до применения карты, и постпроцессоры, которые запускаются после применения карты. Карты определяются в файлах значений с разделителями-запятыми (CSV) в кодировке UTF8. Каждый файл имеет имена - .csv , где — это (трехбуквенный, все строчные буквы) код ISO 639-3 для языка, а — (четырехбуквенный , заглавные) Код ISO 15924 для скрипта. Эти файлы находятся в каталоге data установки Epitran в подкаталогах map , pre и post соответственно.Файлы пре- и постпроцессора представляют собой текстовые файлы, формат которых описан ниже. Они следуют тем же соглашениям об именах, за исключением того, что у них есть расширения файлов .txt .
Файлы карт (таблицы сопоставления)
Файлы карты представляют собой простые файлы с двумя столбцами, в которых первый столбец содержит ортографические символы / последовательности, а второй столбец содержит фонетические символы / последовательности. Два столбца разделены запятой; каждая строка заканчивается новой строкой. Для многих языков (большинства языков с однозначной, фонематически адекватной орфографией) этого простого в создании файла сопоставления достаточно для создания работоспособной системы G2P.
Первая строка является заголовком и отбрасывается. Для единообразия он должен содержать поля «Орт» и «Фон». Следующие строки состоят из полей любой длины, разделенных запятыми. Одна и та же фонетическая форма (второе поле) может встречаться любое количество раз, но орфографическая форма может встречаться только один раз. Если одна орфографическая форма является префиксом другой формы, более длинная форма имеет приоритет при отображении. Другими словами, соответствие между орфографическими единицами и орфографическими строками является жадным.Отображение работает путем нахождения самого длинного префикса орфографической формы и добавления соответствующей фонетической строки в конец фонетической формы, затем удаления префикса из орфографической формы и продолжения таким же образом до тех пор, пока орфографическая форма не будет использована. Если в таблице сопоставления нет непустого префикса орфографической формы, первый символ орфографической формы удаляется и добавляется к фонетической форме. Затем возобновляется обычная последовательность. Это означает, что нефонетические символы могут оказаться в «фонетической» форме, что, по нашему мнению, лучше, чем потеря информации из-за неадекватной таблицы сопоставления.
Препроцессоры и постпроцессоры
Для пар язык-сценарий с более сложной орфографией иногда необходимо манипулировать орфографической формой перед отображением или манипулировать фонетической формой после отображения. В Epitran это делается с помощью грамматик контекстно-зависимых правил перезаписи строк. По правде говоря, этих правил было бы более чем достаточно для решения проблемы сопоставления, но с практической точки зрения обычно легче позволить простым для понимания и легким в обслуживании файлам сопоставления нести большую часть веса преобразования и резервирования. более мощный контекстно-зависимый грамматический формализм для предварительной и последующей обработки.
Файлы препроцессора и постпроцессора имеют одинаковый формат. Они состоят из последовательности строк, каждая из четырех типов:
- Определения символов
- Контекстно-зависимые правила перезаписи
- Комментарии
- Пустые строки
Определения символов
Строки, похожие на следующие
:: гласные :: = a | e | i | o | u
определяют символы, которые можно повторно использовать при написании правил. Символы должны состоять из префикса из двух двоеточий, последовательности из одной или нескольких строчных букв и знаков подчеркивания и суффикса из двух двоеточий.Они отделены от своих определений знаком равенства (при желании можно выделить пробелом). Определение состоит из подстроки регулярного выражения.
Символы необходимо определить до того, как на них будет ссылаться.
Правила перезаписи
Контекстно-зависимые правила перезаписи в Epitran написаны в формате, знакомом фонологам, но прозрачном для компьютерных ученых. Их можно схематически обозначить как
а -> б / X _ Y
, который можно переписать как
XaY → XbY
Стрелка -> может читаться как «переписывается как», а косая черта / может читаться как «в контексте».Нижнее подчеркивание указывает позицию перезаписываемого символа (ов). Другой специальный символ — octothorp # , который указывает начало или конец строки (длиной слова) (граница слова). Учтите следующее правило:
e -> ə / _ #
Это правило можно прочитать как «/ e / переписывается как / ə / в контексте в конце слова». Последний специальный символ — ноль 0 , который представляет собой пустую строку. Он используется в правилах, которые вставляют или удаляют сегменты.Рассмотрим следующее правило, которое удаляет / ə / между / k / и / l /:
ə -> 0 / k _ l
Все правила должны включать оператор стрелки, оператор косой черты и знак подчеркивания. Правило, которое применяется вне контекста, может быть записано следующим образом:
шасси -> x / _
Реализация контекстно-зависимых правил в пре- и постпроцессорах Epitran использует замену регулярных выражений. В частности, он использует пакет regex , заменяющий re .По этой причине при написании правил можно использовать нотацию регулярных выражений:
c -> s / _ [ie]
или
c -> s / _ (i | e)
Полное руководство по регулярным выражениям regex см. В документации для regex и, в частности, для regex .
Фрагменты регулярных выражений можно назначать символам и повторно использовать в файле. Например, символ разделения гласных в языке может использоваться в правиле, которое заменяет / u / на / w / перед гласными:
:: гласные :: = a | e | i | o | u ... u -> w / _ (:: гласные: :)
Существует специальная конструкция для обработки случаев метатезиса (где AB заменяется на BA). Например, правило:
(? P [เแโไใไ]) (? P .) -> 0 / _
«Поменяет местами» любой символ в «and» и любой следующий за ним символ. Слева от стрелки должны быть две группы (в круглых скобках) с именами sw1 и sw2 (имя группы определяется как ? P , которое появляется сразу после открытой скобки для группы ). Подстроки, соответствующие двум группам, sw1 и sw2 , будут «поменять местами» или метатезировать. Элемент справа от стрелки игнорируется, а контекст — нет.
Правила применяются по порядку, поэтому более ранние правила могут «кормить» и «пропускать» более поздние правила. Следовательно, их последовательность очень важна и может быть использована для достижения ценных результатов.
Комментарии и пустые строки
Комментарии и пустые строки (строки, состоящие только из пробелов) разрешены, чтобы сделать ваш код более читабельным.Любая строка, в которой первым непробельным символом является знак процента % , интерпретируется как комментарий. Остальная часть строки игнорируется при интерпретации файла. Пустые строки также игнорируются.
Стратегия добавления языковой поддержки
Epitran использует подход к G2P «картирование и ремонт». Ожидается, что существует отображение между графемами и фонемами, которое может выполнять большую часть работы по преобразованию орфографических представлений в фонологические представления. В фонематически адекватных ортогрфиях это отображение может выполнять всей работы.Это сопоставление должно быть выполнено в первую очередь. Для многих языков основа для этой таблицы сопоставления уже существует в Википедии и Omniglot (хотя таблицы Omniglot обычно не читаются машиной).
С другой стороны, многие системы письма отклоняются от фонематически адекватной идеи. Именно здесь должны быть введены пре- и постпроцессоры. Например, в шведском языке буква перед двумя согласными (/ ɐ /) произносится иначе, чем где-либо еще (/ ɑː /).Имеет смысл добавить правило препроцессора, которое перезаписывает как / ɐ / перед двумя согласными (и аналогичные правила для других гласных, поскольку на них действует то же условие). Правила препроцессора обычно следует использовать всякий раз, когда необходимо скорректировать орфографическое представление (путем контекстных изменений, удалений и т. Д.) Перед этапом отображения.
Одним из распространенных способов использования постпроцессоров является удаление символов, которые необходимы препроцессорам или картам, но которые не должны появляться в выводе. Классическим примером этого является вирама, используемая в индийских сценариях. В этих сценариях для написания согласного , за которым не следует гласная, используется форма символа согласного с определенной присущей гласной, за которой следует вирама (которая имеет различные названия в разных индийских языках). Простой способ справиться с этим — позволить сопоставлению переводить согласный звук в согласный IPA + присущий гласный звук (который для данного языка всегда будет одинаковым), а затем использовать постпроцессор для удаления последовательности гласный + вирама ( где бы это ни происходило).
Фактически, любая ситуация, когда символ, представленный картой, должен быть впоследствии удален, является хорошим вариантом использования для постпроцессоров. Другой пример из индийских языков включает так называемое удаление шва. Некоторые гласные, подразумеваемые прямым сопоставлением орфографии и фонологии, на самом деле не произносятся; эти гласные обычно можно предсказать. В большинстве языков они встречаются в контексте после последовательности гласный + согласный и перед последовательностью согласный + гласный. Другими словами, правило выглядит так:
ə -> 0 / (:: гласная ::) (:: согласная: :) _ (:: согласная ::) (:: гласная: :)
Возможно, лучший способ узнать, как структурировать языковую поддержку для нового языка, — это проконсультироваться с существующими языками в Epitran.Французский препроцессор fra-Latn.txt и тайский постпроцессор tha-Thai.txt иллюстрируют многие варианты использования этих правил.
Если вы используете Epitran в опубликованных работах или в других исследованиях, используйте следующую ссылку:
Дэвид Р. Мортенсен, Сиддхарт Далмиа и Патрик Литтел. 2018. Epitran: Precision G2P для многих языков. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , Paris, France.Европейская ассоциация языковых ресурсов (ELRA).
@InProceedings {Mortensen-et-al: 2018,
author = {Мортенсен, Дэвид Р. и Далмия, Сиддхарт и Литтел, Патрик},
title = {Epitran: Precision {G2P} для многих языков},
booktitle = {Труды одиннадцатой Международной конференции по языковым ресурсам и оценке (LREC 2018)},
год = {2018},
month = {май},
дата = {7–12},
location = {Миядзаки, Япония},
редактор = {Николетта Кальцолари (председатель конференции) и Халид Чукри, и Кристофер Сиери, и Тьерри Деклерк, и Сара Гогги, и Коити Хасида, и Хитоши Исахара, и Бенте Маэгаард, и Джозеф Мариани, и Эль'эн Мазо, и Асунсьон Морено, и Ян Одийк и Стелиос Пиперидис и Такенобу Токунага},
publisher = {Европейская ассоциация языковых ресурсов (ELRA)},
адрес = {Париж, Франция},
isbn = {979-10-95546-00-9},
language = {english}
}
.Фонетический разбор
Как сделать фонетический разбор? Фонетический разбор — трудоёмкое занятие! Чтобы правильно сделать его, нужно знать несколько правил. Первое. Знать виды звуков и правильные названия букв. Здесь фонетика дружит с графикой!
В школе в отличие от вуза фонология и её основные понятия не изучаются, хотя и употребляются слово «фонема» и выражения «слабая позиция» (под ударением) и «сильная позиция» (без ударения).
Для обозначения звука и его пары: [б], [б’], [п], [п’] – служат квадратные скобки [ ]. Круглые скобки здесь неуместны!
Буквы заключаются в кавычки « » и называются так же, как и в алфавите. Например, буква «ка», «эф», «э оборотное», «и краткое», «ща», «че».
Смотрите алфавит и выучите все названия букв!
Второе. Нужно иметь представления о транскрипции и её символах.
Запомни и применяй знаки фонетической транскрипции!
[ó] – знак основного ударения над гласным звуком (мОжно).
[`] – знак дополнительного ударения над гласным звуком (жủзнеобеспЕчение).
[Λ] – так произносятся гласные (пишутся буквы «о», «а») в начале слова или в первом предударном слоге после твердых согласных: окно [Λкнó], актив [Λкт’ủф].
[j’] – (йот) в нашем алфавите нет знака, принято «и краткое» или йотированная буква «й» («и краткое»).
Если в слове есть так называемые йотированные буквы «е», «ё», «ю», «я», то в транскрипции мы указываем 2 звука [j’+э], [j’+о], [j’+у], [j’+а].
Эти звуки произносятся в 3 позициях и всегда под ударением:
1) в самом начале слова: ель [j’эл’], ёж [j’ош], юла [j’ула], яд [j’ат];
2) после гласного: моем [мΛj’эм], поём [пΛ j’ом,] поют [пΛj’ут], маяк [мΛj’ак],
3) после разделительных Ъ и Ь знаков: въезд [вj’эст], шьёт [шj’от], шьют [шj’ут], семья [с’иэм’j’а].
Их легко перепутать с гласными [э], [о], [у], [а] в словах после мягких согласных: веточка [в’этач’ка] или [в’этъч’къ], лёд [л’от], утюг [ут’ук], мяч [м’ач’], зверь [зв’эр’].
[иэ] – с призвуком [э], звук похож на нечто среднее между [и-э], так произносятся гласные в первом предударном слоге после мягких согласных (пишутся буквы «а», «е», «э»): часы [ч’иэсы], весна [в’иэсна] или [в’иэснъ].
[ыэ] – с призвуком [э], звук похож на нечто среднее между [ы-э] или [ы-а], так произносятся гласные в первом предударном слоге после твердых согласных (пишутся буквы «э», «е»): этаж [ыэташ], цена [цыэна], шестой [шыэстоj’], жена [жыэна].
[ъ] – так произносятся гласные (пишутся буквы «о», «а», «е») во всех предударных и заударных слогах после твердых согласных:
молодой [мълΛдоj’], материнский [мът’иэр’инск’иj’], хорошо [хърΛшо], кашей [кашъj’].
[ь] – так произносятся гласные (пишутся буквы «о», «а», «я», «е») во всех безударных слогах после мягких согласных:
бережка [б’ьр’иэшка], пятачок [п’ьтΛч’ок], на мачте [нΛмач’т’ь], часовой [ч’ьсΛвоj’], щебетать [щ’ьб’иэтат’].
[–] – указание на отсутствие звука, когда в слове есть буквы «мягкий знак» или «твёрдый знак».
Можно использовать упрощенную систему для передачи звуковой оболочки слова, то есть буквы «й, а, о, э, у, и».
Третье. Не забудем об ударении.
Ударение отличает слова и их формы по звуковому составу (текут рЕки – жить у рекИ; мыть рУки – нет рукИ).
Записали слово и обязательно поставим ударение!
Четвертое. Дадим полную характеристику каждому звуку.
Основное коварство содержится в согласных звуках. Они имеют 4 характеристики: звонкость и глухость, твердость и мягкость. Не забудьте о парных и непарных.
В разборе нужно указывать полную характеристику согласного звука. При этом учитываем процессы озвончения и оглушения согласных.
Глухие перед звонким согласным озвончаются: cгореть [згΛр’эт’], просьба [проз’бъ].
В конце слова звонкий согласный оглушается: берег [б’эр’ьк].
Перед глухим согласным звуком звонкий тоже оглушается: сказка [скаскъ].
Некоторые согласные звуки, стоящие перед мягкими согласными, смягчаются [н, с, з, т, д]: винтик [в’ин’т’ик], кости [кос’т’и].
[’] – знак обозначения мягкости согласного звука: дождь [дошт’] или [дощ’].
Звуки [с’] и [з’] мягкие на конце приставок С-, ИЗ-, РАЗ- перед «Ъ»: съел [c’j’эл], изъездил [из’j’эз’д’ил].
Пятое. Некоторые сочетания согласных произносятся как долгие.
[‾] – знак долготы согласного звука: бояться [бΛj’аЦъ], лётчик [л’оЧ’ик].
При стечении нескольких согласных один из них может не произноситься [т, д, в, л]: чувство [ч’уствъ], поздно [познъ].
План фонетического разбора
1. Запишем слово.
2. Поставим ударение.
3. Запишем справа транскрипцию слова, разделим его на слоги.
4. Охарактеризуем все звуки, записывая их сверху вниз:
4.1. ударный-безударный для гласных;
4.2. звонкий-глухой (пара), твёрдый-мягкий (пара) для согласных;
4.3. укажем, какой буквой обозначен каждый звук.
5. Подсчитаем количество звуков и букв.
6. Объясним несоответствия между звуками и буквами.
Образец записи
Óсень – [о-с’ьн’], 2 слога
[Ó] – гласный, ударный, обозначен буквой «о»
Слова «обозначен буквой» можно не писать, а сразу указывать название буквы!
[с’] – согласный, глухой, пара [з’], мягкий, пара [с], «эс»
[ь] – гласный, безударный, «е»
[н’] – согласный, сонорный, непарный, мягкий, пара [н], «эн»
[–] «мягкий знак»
4 звука, 5 букв
Звуков меньше, чем букв, так как есть «мягкий знак».
Примеры
Язык1
ЯзЫк – [j’иэ-зык], 2 слога
[j’] – согласный, сонорный, непарный, мягкий, непарный
[иэ] – гласный, безударный обозначен буквой «я»
[з] – согласный, звонкий, пара [с], твёрдый, пара [з’], «зэ»
[ы] – гласный, ударный, «ы»
[к] – согласный, глухой, пара [г], твёрдый, пара [к’], «ка»
5 звуков, 4 буквы
Звуков больше, чем букв, так как есть йотированная гласная «я» в начале слова.
Рябина1
РябИна – [р’иэ-б’и-нъ], 3 слога
[р’] – согласный, сонорный, непарный, мягкий, пара [р], «эр»
[иэ] – гласный, безударный, «я»
[б’] – согласный, звонкий, пара [п], мягкий, пара [б], «бэ»
[и] – гласный, ударный, «и»
[н] – согласный, сонорный, непарный, твёрдый, пара [н’], «эн»
[ъ] – гласный, безударный, «а»
6 звуков, 6 букв
СтОят1 (о цене предмета: дОрого стОят туфли).
СтОят – [сто-j’ьт], 2 слога
[с] – согласный, глухой, пара [з], твёрдый, пара [с’], «эс»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[о] – гласный, ударный, «о»
[j’] – согласный, сонорный, непарный, мягкий, непарный
[ь] – гласный, безударный обозначен буквой «я»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
6 звуков, 5 букв
Звуков больше, чем букв, так как йотированная гласная «я» стоИт после гласной.
СтоЯт1 (о действии: стоЯт у дороги и ждут).
СтоЯт – [стΛ-j’ат], 2 слога
[с] – согласный, глухой, пара [з], твёрдый, пара [с’], «эс»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[Λ] – гласный, безударный, «о»
[j’] – согласный, сонорный, непарный, мягкий, непарный
[а] – гласный, ударный обозначен буквой «я»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
6 звуков, 5 букв
Звуков больше, чем букв, так как йотированная гласная «я» стоИт после гласной.
Общение1
ОбщЕние – [Λп-щ’э-н’и-j’ь], 4 слога
[Λ] – гласный, безударный, «о»
[п] – согласный, глухой, пара [б], твёрдый, пара [п’], «бэ»
[щ’] – согласный, глухой, непарный, мягкий, непарный, «ща»
[э] – гласный, ударный, «е»
[н’] – согласный, сонорный, непарный, мягкий, пара [н], «эн»
[и] – гласный, безударный, «и»
[j’] – согласный, сонорный, непарный, мягкий, непарный
[ь] – гласный, безударный обозначен буквой «е»
8 звуков, 7 букв
Звуков больше, чем букв, так как йотированная гласная «е» стоИт после гласной.
Читатель1
ЧитАтель – [ч’и-та-т’ьл’], 3 слога
[ч’] – согласный, глухой, непарный, мягкий, непарный, «че»
[и] – гласный, безударный, «и»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[а] – гласный, ударный, «а»
[т’] – согласный, глухой, пара [д], мягкий, пара [т], «тэ»
[ь] – гласный, безударный, «е»
[л’] – согласный, сонорный, непарный, мягкий, пара [л], «эль»
[–] «мягкий знак»
7 звуков, 8 букв
Звуков меньше, чем букв, так как есть «мягкий знак».
Точка1
ТОчка – [точ’-къ], 2 слога
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
[о] – гласный, ударный, «о»
[ч’] – согласный, глухой, непарный, мягкий, непарный, «че»
[к] – согласный, глухой, пара [г], твёрдый, пара [к’], «ка»
[ъ] – гласный, безударный, «а»
5 звуков, 5 букв
Весна1
ВеснА – [в’иэ-снъ], 2 слога
[в’] – согласный, звонкий, [ф], мягкий, пара [в], «вэ»
[иэ] – гласный, ударный, «е»
[с] – согласный, глухой, пара [з], твёрдый, пара [с’], «эс»
[н] – согласный, сонорный, непарный, твёрдый, пара [н’], «эн»
[ъ] – гласный, безударный, «а»
5 звуков, 5 букв
Идёт1
Идёт – [и-д’от], 2 слога
[и] – гласный, безударный, «и»
[д’] – согласный, звонкий, пара [т’], мягкий, пара [д], «дэ»
[т] – согласный, глухой, пара [д], твёрдый, пара [т’], «тэ»
4 звука, 4 буквы
Попробуйте сами разобрать слова:
Лошадь
Смеются
Яблоко
Всё
Солнце
Поют
Проверьте свой результат, нажав на каждое из этих слов по порядку.
- Назад
- Вперед
Золотая полка
общие правила, план по пунктам, звуко-буквенный анализ
Русский язык
12.11.21
8 мин.
Школьная программа по русскому языку предполагает изучение различных видов разборов, в том числе и фонетический. Именно с этого раздела лингвистики, изучающего звуки и звуковое строение слов, и начинается углубленное изучение родной речи. Звуки являются основными кирпичиками в правильном овладении языка. Фонетический разбор слова «каюта» поможет сформировать необходимые в лингвистической работе навыки.
Оглавление:
- Порядок фонетического разбора
- Пример правильного анализа
- Значение слова
Порядок фонетического разбора
Многие люди, и не только иностранцы, считают русский язык очень сложным. И только малая часть неспециалистов считает, что исследование речи очень увлекательная штука. Изучение же фонетики — это база для правильного произношения. Поэтому освоение ее начинают в 1 классе, буквально с начала сентября, когда еще не все дети даже читать умеют. При этом учителя стараются, чтобы фонетический анализ слов к концу начальной школы происходил на автомате. Это необходимо исходя из следующих соображений:
- Глубже понимается природа орфографии, а это значительный плюс для грамотности.
- Разбор поясняет и объединяет правила проверки сложных букв, в т. ч. и непроизносимых в корнях, приставках, суффиксах и окончаниях.
- Для четкого понимания, что есть слова, которые пишут не так, как говорят.
- Для развития «орфографической зоркости».
- Для понимания и принятия сложных правил русского языка и легкого применения их на практике.
Фонетический анализ включает в себя: составление фонетической характеристики и транскрипции.
Общие правила
При звуко-буквенном (фонетическом) разборе определяют количество звуков, букв (цифра может не совпадать), местонахождение ударения, классификация гласных и согласных. Такой анализ отражает не написание, а звучание с учетом традиций и правил русского языка. В таком анализе существуют определенные обозначения:
- Слово в транскрипции охватывают квадратными скобками. Ели требуется обозначить ударение, его также отмечают в транскрипции.
- Каждый отдельный звук охватывают квадратными скобками.
- Вместо твердого и/или мягкого знака ставят прочерк: [ — ].
- Если звук мягкий, его отмечают апострофом: [ л´ ].
- Продолжительное звучание звука отмечают двоеточием [т’эн’:ис] или чертой над звуком.
Обычно учителя в школах предлагают заканчивать разбор, подводя черту и указывая под ней окончательное количество букв и произносимых звуков в слове.
Существует еще несколько отдельных правил для твердого и мягкого знаков.
А именно:
- Так как знаки не имеют звука, то и в транскрипции присутствовать они не могут.
- «Ь» необходим для голосового смягчения предыдущей согласной.
- «Ъ» необходим, как разделительный знак.
В некоторых случаях «ь» необходим для обозначения грамматической формы слова, при этом не влияя на произношение. Буква «ъ» иногда необходима для разделения приставки с согласной и последующими буквами «Е», «Ю», «Ё», «Я».
План проведения
Фонетический разбор делают по строго определенному плану. В некоторых школьных программах присутствуют незначительные отличия. Но по общим правилам анализ выполняют в следующем порядке:
- Слово.
- Транскрипция.
- Обозначить ударение.
- Разделить на слоги. Записать их количество.
- Все буквы выписать в столбик, записать количество.
- Рядом с каждой отдельной буквой прописать в квадратных скобках звуки, отображающие имеющиеся буквы.
- Описать звук: гласный или согласный, твердый или мягкий, глухой или звонкий, парный, ударный.
- Записать количество звуков.
Редко, но иногда в правилах рекомендуется пояснить нюансы орфографии, т. е. правила правописания.
Для фанатов русского языка и тех, кто изучает его особенности профессионально в институте, существует ряд дополнительных пунктов при расширенном фонетическом разборе. В этом случае учитываются тонкости современного произношения и изменения прошедшие за последние столетия.
Пример правильного анализа
Для примера подойдет слово «каюта». Согласно правилам сначала записывают транскрипцию и обозначают ударение. Чтобы проделать звуко-буквенный анализ, необходимо определить, сколько звуков в слове «каюта», определить полый состав:
- [ кай´ ута ].
- Ударение на 2 слоге.
- Слово имеет 3 слога: ка-ю-та. Возможны 2 разновидности переноса: каю-та, ка-юта.
- Определить сколько букв и звуков «каюта», правильный ответ:
| Звук | Характеристика | Буква |
| [ к ] | Согласный, тверд. (шумный), парн., глух. | к |
| [ а ] | Безударный гласный | а |
| [ й´ ] [ у ] | Согласн.,, мягкий, непарн. звонкий (сонорный) гласный, ударный | ю |
| [ т ] | Согласн., твердый (шумн.), парн. глухой | т |
| [ а ] | Безударн. гласный | а |
Слово имеет 3 гласных и 2 согласных буквы, но 3 гласных и 3 согласных звука. Проверочных слов нет, т. к. «каюта» — словарное. Фонетический разбор слова «каюта» достаточно прост, но имеет нюансы из-за некоторых букв в существительном.
Значение слова
В русский язык слово пришло вначале XVII в. Основное значение — небольшая жилая комната на пароходе, яхте или любом другом судне, отдельное помещение для команды или пассажиров. Может использоваться для обозначения подсобного помещения на корабле. Примеры использования: «Катя зашла в кают-компанию», «Пассажир занял каюту 1-го класса», «У капитана была отдельная от команды каюта».
Не успеваете написать работу?
Заполните форму и узнайте стоимость
Вид работыПоиск информацииДипломнаяВКРМагистерскаяРефератОтчет по практикеВопросыКурсовая теорияКурсовая практикаДругоеКонтрольная работаРезюмеБизнес-планДиплом MBAЭссеЗащитная речьДиссертацияТестыЗадачиДиплом техническийПлан к дипломуКонцепция к дипломуПакет для защитыСтатьиЧасть дипломаМагистерская диссертацияКандидатская диссертацияКонтактные данные — строго конфиденциальны!
Указывайте телефон без ошибок! — потребуется для входа в личный кабинет.* Нажимая на кнопку, вы даёте согласие на обработку персональных данных и соглашаетесь с политикой конфиденциальности
Подтверждение
Ваша заявка принята.
Ей присвоен номер 0000.
Просьба при ответах не изменять тему письма и присвоенный заявке номер.
В ближайшее время мы свяжемся с Вами.
Ошибка оформления заказа
Кажется вы неправильно указали свой EMAIL, без которого мы не сможем ответить вам.
Пожалуйста проверте заполнение формы и при необходимости скорректируйте данные.
фонетика — Как сделать фонетический разбор слов «павильон» и ему подобных?
Вопрос задан
Изменён 6 лет 6 месяцев назад
Просмотрен 7k раз
В словах павильон, бульон, каньон пишется О после Ь, а произносится как «ЙЬО». По всем школьным правилам два звука после мягкого знака обозначают только буквы » Е, Ё, Ю, Я». Некоторые школьники, у которых хороший «фонематический слух», пишут транскрипцию [павилЬйЬон] (Ь знак в данном случае обозначает не звук, а просто мягкость согласного звука). И, действительно, мы же не произносим[павилЬон], [булЬон]. Но как тогда быть с правилом? В школьной программе нет никаких оттеночных звуков.
- фонетика
Это вопрос господину Фурсенко. Почему школьная программа не соответствует.
На самом деле ваша формулировка «два звука после мягкого знака обозначают только буквы Е, Ё, Ю, Я» не верна. Слово «только» здесь неприменимо. И если в какой-то школьный учебник залезло подобное утверждение, то его надо менять. Или хотя бы дополнить простой оговоркой, что это относится к собственно русским словам. А в иноязычных словах буква О после мягкого знака читается как ЙО (со смягчением предшествующего согласного).
Ничего особо криминально в такой оговорке нет, ведь никакми школьными правилами не предписано иное чтение сочетания «ЬО» в каких-либо случаях. Путаница может возникнуть только при чтении некоторых украинских фамилий (Грiсьо — [грисё]). Но это далеко за рамками школьной программы.
4
Dafnija! А Вы учитель? Так категорично говорите про «все школьные правила». В школьных учебниках в разделе «Фонетика» сказано, что буквы Е,Ё,Ю,Я обозначают два звука в определенных позициях. Слова ТОЛЬКО не видела ни в одном учебнике, да его и не может быть. А фонетический разбор слов типа павильон есть, есть подобные слова и на экзамене в 9 классе. К сожалению, не умею здесь печатать транскрипцию, не получаются надстрочные знаки. Но зачем обозначать мягкость в транскрипции буквой Ь, если можно поставить сверху запятую? Кстати, в словах типа соловьи, воробьи буква И тоже обозначает два звука.
6
Если иноязычное слово «павильон» преобразовать в русскоязычное слово «павильйон» либо русскоязычное слово «павильён», тогда не потребуются:
1) ни выкрики типа «Это вопрос к господину Фурсенко. «,
2) ни «оговороки» к правилу,
3) ни разглагольствования про «криминальность» либо «некриминальность» «оговорок» к правилам,
и т. п.
7
Вот правило:
Буква «и» после мягкого знака тоже состоит из двух звуков — [йи] при звуко- буквенном анализе. Данное правило актуально для слогов, как в сильной, так и в слабой позиции. Приведем образец звуко-буквенного онлайн разбора: — соловьи [салав’йи´], на курьих ножках [на ку´р’йи’х’ но´шках], кроличьи [кро´л’ич’йи], нет семьи [с’им’йи´], судьи [су´д’йи], ничьи [н’ич’йи´], ручьи [руч’йи´], лисьи [ли´с’йи].
Но: Гласная «о» после мягкого знака транскрибируется как апостроф мягкости [’] предшествующего согласного и [о], хотя при произнесении фонемы может слышаться йотированность: бульон [бул’о´н], павильон [пав’ил’о´н] (почтальон, шампиньон, шиньон, компаньон, медальон, батальон, гильотина, карманьола, миньон и прочие).
Ваш ответ
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Фонетический разбор — сайт Анищенко Н.
А.
Что надо знать для фонетического разбора слов в начальной школе. Звуки бывают гласные и согласные. Гласные звуки. При произнесении гласных воздух свободно выходит изо рта и не встречает преград. В русском языке 6 гласных звуков: А, О, У, Ы, Э, И и 10 гласных букв: А-Я,О-Ё, У-Ю, Ы-И, Э-Е: · А, О, У, Ы, Э – это буквы, которые дают согласному команду: «Читайся твёрдо!», но звуки [ч’],[щ’] – всегда мягкие: сон [сон], чаща [ч’ащ’а] . · Я, Ё, Ю, И, Е — это буквы, которые дают согласному команду: «Читайся мягко!», но звуки [ж], [ш],[ц] – всегда твердые: лес [л’ес], ширь [шыр’], цифра [цыфра]. · Буквы я, ё, ю, е— йотированные. o Если эти буквы стоят после согласных, то они дают один звук: я – [а], ё – [о], ю – [у], е – [э]. o Если эти буквы стоят в начале слова, после гласных и разделительных Ъ и Ь знаков, то они дают два звука: я – [й’а], ё – [й’о], ю- [й’у], е – [й’э]: лён – 3 буквы, 3 звука, ёлка – 4 буквы, 5 звуков, поёт – 4 буквы, 5 звуков. o [й’] – согласный, всегда звонкий, всегда мягкий звук . Согласные звуки. При произнесении согласных воздух встречает преграды. Преградами являются губы, зубы и язык. Согласные звуки бывают твёрдые и мягкие, звонкие и глухие. Для того чтобы определить, звонкий или глухой согласный, ребёнок закрывает уши ладошками и произносит этот звук. Если ребёнок при произнесении слышит голос, то это звонкий согласный. Если слышит не голос, а шум, то этот согласный глухой. · Л, М, Н, Р, Й – самые звонкие согласные (сонорные), всегда звонкие. · Б-П, В-Ф, Г-К, Д-Т, Ж-Ш, 3-С – парные согласные по звонкости-глухости. · X, Ц, Ч, Щ — всегда глухие согласные. · Ч, Щ, Й — всегда мягкие согласные. · Ж, Ш, Ц – всегда твердые согласные
ФОНЕТИЧЕСКИЙ (ЗВУКО-БУКВЕННЫЙ) АНАЛИЗ СЛОВА 1. Запишите слово. 2. Поставьте ударение. 3. Разделите слово на слоги. Сосчитайте и запишите их количество. 4. Выпишите все буквы этого слова в столбик одну под другой. Сосчитайте и запишите их количество. 5. Напишите справа от каждой буквы, в квадратных скобках, звук, который эта буква обозначает. 6. Опишите звуки: Гласный, ударный или безударный. Согласный, глухой или звонкий, парный или непарный; твёрдый или мягкий, парный или непарный. 7. Сосчитайте и запишите количество букв и звуков. Примеры :
_______________________ 3 б.
Обратите внимание. 1. Буквы я, ё, ю, е— йотированные. Если эти буквы стоят после согласных, то они дают один звук: § Я – [а], Ё – [о], Ю – [у], Е – [э]: Лён — [л’ о н] — 3 буквы, 3 звука. Если эти буквы стоят в начале слова, после гласных и разделительных Ъ и Ь знаков, то они дают 2 звука: Я – [й’а], Ё – [й’о], Ю – [й’у], Е – [й’э]: Ёлка — [й’ о л к а] — 4 буквы, 5 звуков. Поёт [пай’о т ] – 4 буквы, 5 звуков. 2. Безударная гласная О под ударением даёт звук [о], а без ударения [а]: § котик – [ кот ‘ и к], скворцы – [с к в а р ц ы]; 3. Безударная гласная Е, под ударением даёт звук [э], а без ударения [и]: § лес [л’э с], весна [в’ исна]; 4. § кафе [кафэ]; 5. Буква И после согласных Ж, Ш, Ц даёт звук [ы]: § зажим [зажым], шины [ш ы н ы], цирк [цырк] ; 6. Безударная гласная Я под ударением даёт звук [а], а без ударения [э], [и]: § мяч – [м’а ч’], рябина – [р’ э б’ и н а], пятно – [ п ‘ и т н о]; 7. Парные согласные в слабой позиции (в конце слова, перед глухой согласной) произносятся глухо: § гриб – [гр’ и п], лавка – [л а ф к а]; 8.Иногда на месте буквы Г перед глухой согласной произносятся звуки [к] [х]: § когти — [к о к т’ и], мягкий — [м’ ах ‘ к ‘ и й’]; 9. Иногда буква С в начале слова перед звонкой согласной озвончается: § сделал – [з’ д’ э л а л]. 10. Между корнем и суффиксом перед мягкими согласными согласные могут звучать мягко : § зонтик – [з о н’ т ‘и к]; 11.Иногда буква Н обозначает мягкий согласный звук перед согласными Ч, Щ: § стаканчик – [с т а к а н’ ч’ и к], сменщик – [см’ э н’ щ’ и к]; 12. Запомните, что удвоенные согласные дают длинный звук: § группа — [ група] . 13. Запомните, что сочетания ТСЯ, ТЬСЯ (у глаголов) произносятся как длинный [ц]: § бриться – [бр’ ица] . 14.Запомните, что сочетание СТН произносится как [сн], ЗДН— [зн]: § звёздный – [з в’ о з н ы й’], лестница – [л’ эс ‘н’и ц а]. 15.Запомните, что иногда сочетание ЧН, ЧТ произносится как [ш]: § конечно – [ кан ‘ эшна ] , что — [ш т о]. 16. Запомните, что в окончаниях имён прилагательных ОГО, ЕГО согласный Г произносится как [в]: § белого – [б е л а в а]. | |||||||||||||||||||||||||||||||||||||||
Правила, функции и сокращения
Правила, функции и сокращенияПродвинутая фонология бакалавриата USC ✳︎ Осень 2019 г. ✳︎ Smith
Правила, функции и сокращения
- Звуковой образец английского языка (SPE)
- Анатомия правила в стиле SPE
- Правило заказа
- Процедура оценки в SPE
- Фонологические признаки
- Как мы решаем, какими должны быть функции?
- Обзор фонетики
- Часто используемые функции, о которых стоит знать
- Таблицы отдельных характеристик
- Сокращения
- Реальный пример из SPE
- Некоторые потенциальные проблемы
- Фонемы и аллофоны в SPE
- Резюме основных идей
- Практические задачи
- Решение
Правила грамматики действуют механически; можно думать о них как об инструкциях, которые могут быть даны безмозглому роботу, неспособному проявлять какое-либо суждение или воображение при их применении.
— Хомский и Галле (1968: 60)
- SPE: Книга Хомского и Халле (1968) Звуковой образец английского языка .
- Предлагает структуру, которая генерирует сопоставления посредством основанных на правилах производных .
- Алгоритмические вычисления: основной целью SPE является разработка полностью явных алгоритмов, которые генерируют все и только поверхностные формы языка.
- Полностью явный алгоритм — это описание процесса, который может быть выполнен за конечное время на вычислительном устройстве.
- См. цитату вверху этой брошюры.
- Если алгоритм можно реализовать на современном языке программирования, он удовлетворяет этому требованию.
- Когда возможны несколько алгоритмов, формальная простота диктует лучший из них.
- Полностью явный алгоритм — это описание процесса, который может быть выполнен за конечное время на вычислительном устройстве.
- Правила перезаписи принимают форму X ➔ Y / A _ B
- Превращает A X B в A Y B
- Правила состоят из следующих частей.
- Мишень/фокус (X)
- Структурное изменение (Y)
- Контекст (A_B)
- Структурное описание (AXB)
- Описывает структуру, необходимую для применения правила
- Окружающая среда может содержать звуки, не находящиеся рядом с фокусом.
- Например: X ➔ Y / A B C _ D E F
- Превращает ABC X DEF в ABC Y DEF
- Вот несколько примеров, в том числе некоторые с функциями и другими соглашениями, которые вы, возможно, видели (#, ] X , Ø, C, V).
| Ø ➔ i / C_C |
| [+высокий] ➔ Ø / [–голос] _ [–голос] |
| [+согласная] ➔ [–голос] / _ # |
| [-сонорный] ➔ [-голос] ∕ _ ] wd |
| К ➔ [+голос] / В _ В |
| [–сонорный] ➔ [–голос] ∕ [–голос] _ |
- Важным навыком является умение перевести правило в прозу (и обратно). Вот несколько советов и подводных камней при изложении правил в прозе:
- Дайте правилам полезные и описательные имена.
- Будьте максимально однозначны.
- Лучший способ проверить это — показать прозу другим и посмотреть, смогут ли они восстановить правило.
- Если прозу можно перевести в нотную запись и обратно без потерь, вы получили совершенно однозначное описание правила.
- Иногда правило невозможно плодотворно перевести в прозу, и его необходимо перефразировать. Уточните это, если вам нужно это сделать.
- «Предшествует» подразумевает «непосредственно предшествует», но все же, возможно, двусмысленно. То же самое для «до», «после» и т. д.
- «Между A и B» подразумевает A_B, но все еще, возможно, двусмысленно.
- Рекомендуется использовать фонетические термины вместо характеристик. Например, «мешающий становится глухим в конце слова» вместо «[–сонорный] сегмент становится [–голосовым] в конце слова». Характеристики довольно сильно различаются.
- «Левый» и «правый» могут быть полезными однозначными.
- Свойства фокуса могут быть записаны под подчеркиванием, но это относительно редко.
- Правила упорядочены и применяются последовательно.
- ввод ➔ правило 1 ➔ правило 2 … правило k ➔ вывод
- Выходные данные правила 1 служат входными данными для правила 2.
- Как еще могут применяться правила?
- ввод ➔ правило 1 ➔ правило 2 … правило k ➔ вывод
- Порядок важен, но не всегда.
- Иногда изменение порядка двух правил изменяет вывод грамматики, иногда нет.
- Давайте подумаем, какой (если есть) порядок правил необходим для учета приведенных ниже отображений, и напишем вывод.
- Отображения : /bɛt-d/ ➔ [bɛtəd], /ʤʌmp-d/ ➔ [ʤʌmpt], /fɪl-d/ ➔ [fɪld]
- Правило эпентезиса : Ø ➔ ə / [+коронарный] _ [+коронарный]
- Правило девосинга : [–сонорный] ➔ [–голос] / [–голос] _
- Существует пять типов взаимодействия правил. Мы подробно обсудим их позже, так что ничего страшного, если вы их еще не помните.
- Кормление : X подает Y, если Y применимо к некоторой форме, только потому, что форма претерпела X. (X создает вход для Y)
- Кровотечение : X истекает кровью Y, если Y не применимо к какой-либо форме, потому что форма претерпела X. (X уничтожает ввод для Y)
- Встречная подача : X подменяется Y, если Y мог бы накормить X, но X заказан первым, поэтому он этого не делает. (Y применяется слишком поздно для фида X)
- Контркровопускание : Y нейтрализует кровотечение X, если Y мог бы дать X кровотечение, но X заказан первым, поэтому он этого не делает. (Y применяется слишком поздно для кровотечения X)
- …или порядок не имеет значения.
- SPE предложила метрику для оценки системы правил, утверждая, что грамматики с меньшим количеством символов лучше отражают лингвистические обобщения.
- Факт : Обычно (всегда?) для наблюдаемых данных работает более одного анализа.
- Задача : Как изучающий язык выбирает язык?
- Гипотеза : Изучающий язык предпочитает простые правила и анализирует с меньшим количеством правил; SPE определяет «более простой» как «имеющий меньше символов».
- Следствие 1 : Правила с меньшим количеством символов должны быть более распространены среди языков мира.
- Следствие 2 : Теория, которая может зафиксировать широко распространенные правила или наборы правил с меньшим количеством символов, чем необходимо для захвата редких правил или наборов правил, с большей вероятностью будет правильной моделью обучаемого.
- Обратите внимание, что процедура оценки предназначена для сравнения анализов с одинаковым эмпирическим охватом.
- Полезный афоризм, приписываемый Эйнштейну: «Все нужно делать как можно проще, но не проще».
- Полезный афоризм, приписываемый Эйнштейну: «Все нужно делать как можно проще, но не проще».
- Вот процедура оценки, описанная Хомским и Галле (1968):
- «Значение» последовательности правил равно обратному количеству символов в ее минимальном представлении». (стр. 334)
- «[…] количество символов в правиле обратно пропорционально степени лингвистически значимого обобщения, достигнутого в правиле». (стр. 335)
- Когда правила чем-то похожи друг на друга, это сходство является значительным лингвистическим обобщением, которое необходимо уловить.
- Чтобы облегчить обобщение и свести к минимуму количество символов, SPE использовала как фонологические признаки , так и сокращения для объединения правил.
- В SPE UR состоят из отличительных признаков , и это то, чем манипулирует грамматика.
- /kæt/ — это всего лишь аббревиатура для последовательности из трех наборов функций. Мы пишем /kæt/, чтобы сохранить рассудок, но на самом деле имеем в виду:
| к | æ | т |
|---|---|---|
| – слоговая | +слоговое | – слоговая |
| – длинный | – длинный | – длинный |
| +согласная | – согласная | +согласная |
| – сонорный | + сонорный | –сонорный |
| – продолжение | +продолжение | – продолжение |
| –отложенный выпуск | –отложенный выпуск | |
| – приблизительно | + приблизительно | – приблизительно |
| – кран | – нажмите | – нажмите |
| –трель | –трель | –трель |
| – носовой | –назальный | –назальный |
| – голос | +голос | – голос |
| – расширенная голосовая щель | – расширенная голосовая щель | – расширенная голосовая щель |
| – суженная голосовая щель | – суженная голосовая щель | – суженная голосовая щель |
| – губной | – губной | – губной |
| – круглый | –раунд | – раунд |
| – губно-зубные | – лабиодентальный | – лабиодентальный |
| – коронка | – коронка | + коронка |
| – боковой | – боковой | – боковой |
| +спинной | –спинной | –спинной |
| + высокий | – высокий | |
| –низкий | +низкий | |
| … | … | … |
- Существует довольно много различий в том, как используются функции (некоторые примеры см. в Zsiga 2013).
- Предположим, что UR состоят из набора наборов функций.
- Мы предполагаем, что набор функций является универсальным и одинаковым для всех языков.
- Будем считать, что признаки бинарны: они всегда + или –.
- Мы также предполагаем, что каждый звук указан для большинства функций.
- Но не каждый звук можно указать для каждой функции.
- Например, большинство согласных не имеют признаков, связанных с высотой языка, таких как [высокий] или [низкий].
- Часто обозначается как [0feature].
- Правила не могут целевые звуки [0feature] – только [+feature] или [–feature].
- Особенности позволяют нам комбинировать похожие правила, ссылаясь на естественные классы.
- A естественный класс — это группа звуков в описи, которые имеют одну или несколько общих отличительных черт, за исключением всех других звуков в описи.
- Эти два правила английского языка…
- н ➔ н̪ / _ θ
- л ➔ л̪ / _ θ
- …можно объединить в одно правило:
- [+коронковый] ➔ [+дентальный] / _ [+дентальный]
- «Коронковый становится зубным раньше зубного».
- Это правило предсказывает, что любой [+коронный] звук станет [+зубным] до любой [+стоматологический] звук. 1
- Система правил с признаками имеет гораздо меньше символов и позволяет понять, что один и тот же процесс происходит как в n ➔ n̪, так и в l ➔ l̪.
- В правилах стиля SPE, например. [+ коронковая] ➔ [+ зубная]…
- Особенности в фокусе означают: найти звук с требуемыми характеристиками в требуемом окружении.
- Функция в средстве изменения: внести указанное изменение.
- Правило [+коронковое] ➔ [+зубное] / _ [+зубное] делает следующее:
- 1. найти звук [+корональный]
- 2. если за [+корональным] звуком следует звук [+дентальный]
- 3. изменить [зубную] характеристику [+коронарного] звука на [+зубную]
- Фонологи разработали более или менее согласованный набор функций, основанный на процессах, наблюдаемых в языках.
- Типичные пожелания:
- Если в каком-либо языке два звука контрастны, они должны различаться хотя бы по одному признаку.
- Например, если тап [ɾ] и трель [r] контрастны в испанском языке, нам нужна функция, чтобы различать их, например [трель].
- Если правило нацелено на группу звуков, они должны быть описаны набором признаков.
- Если мы видим правило типа {A, B, C, D} ➔ … или … / {A, B, C, D} _, особенно на более чем одном языке, тогда {A, B, C, D } должен быть естественным классом: он должен поддаваться описанию с набором функций.
- Например, если во многих языках гласный перед любым согласным с носовым потоком воздуха назализуется (например, [m, n, ŋ]), то [+nasal] кажется хорошей чертой.
- Например, функция [+strident] выделяет набор звуков, которые вызывают эпентезию в английском множественном числе [s, z, ʧ, ʤ, ʃ, ʒ]. Без [strident] эти звуки не образовали бы естественный класс.
- Признак должен соответствовать некоторому фонетическому свойству.
- Большинство из них являются артикуляционными, но могут быть и акустическими.
- Если в каком-либо языке два звука контрастны, они должны различаться хотя бы по одному признаку.
- Карта rtMRI через SPAN
- Описание согласных в МФА
- Озвучивание (левый против правого в звонке)
- звонкий, глухой
- скрипучий голос
- хриплый голос
- стремление
- Место (столбцы)
- лабиальный
- лабиодентальный
- стоматологический
- альвеолярный
- постальвеолярный
- небный
- ретрофлекс
- велар
- язычковый
- глоточный
- гортань
- Способ (строки)
- стопор (он же взрывной)
- назальный (он же носовой упор)
- фрикативный
- аффрикат
- аппроксимант (скользящий, жидкий)
- боковой (латеральный аппроксимант)
- Вы делаете , а не , вам нужно запомнить их, но они являются наиболее часто используемыми функциями.
- Особенности озвучивания
- [голос]: озвученные звуки +
- [раскрыть голосовую щель]: звуки с придыханием +
- [сжатая голосовая щель]: глоттализированный/скрипучий голос и отрывочные звуки +
- Особенности основных мест
- [губные]: губы являются активным артикулятором (например, двугубные, губно-зубные)
- [коронкальный]: кончик/лезвие/передняя часть языка является активным артикулятором, пассивным артикулятором являются зубы, альвеолярный гребень или небо
- Стоматологические, альвеолярные, постальвеолярные, альвео-небные, небные
- Далее разбивается на…
- [распространено]
- звуки, издаваемые языковой пластинкой или передней частью +
- звуков, издаваемых кончиком языка, это –
- [передний]
- звуки, издаваемые альвеолярным отростком или фронтальной частью, +
- звуков, сделанных дальше назад, —
- [дорсальный]: тело/спинка языка является активным артикулятором (например, небный, небный, увулярный)
- Примечание: небный является одновременно [+дорсальным] и [+коронарным]
- [глоточный]: корень языка является активным артикулятором
- [гортанный]: «гортанные» звуки, напр. [ч] и [ʔ]
- Главные признаки мест часто являются унарными.
- Корональный звук просто имеет [коронарный] признак, а некоронарный звук не имеет [коронарного] признака.
- Это означает, что правила не могут быть нацелены на [–coronal] как на естественный класс.
- Особенности поведения
- [слоговый]: гласные и слоговые согласные +
- [согласная]: гласные и плавные —
- [звучный]
- Шумные звуки (неносовые стопы, фрикативные звуки, аффрикаты) –
- Соноранты (носовые, аппроксимации, гласные) равны +
- [продолжение]
- Фрикативы и аппроксиманты +
- Носовые [–продолжение]!
- [носовой]: носовые +
- [боковой]: боковые +
- [отложенный выпуск]: аффрикаты +
- [резкий]: некоторые фрикативы и аффрикаты +
- Фрикативы и аффрикаты с громким высоким звуком
- [f, v, s, z, ʧ, ʤ, ʃ, ʒ, χ, ᴚ] равно +
- [ɸ, β, θ, ð, x, ɣ] есть –
- В диаграмме характеристик Хейса для указаны только корональные части.
- Особенности гласных
- [высокий]
- [низкий]
- [перед]
- [назад]
- [круглый]
- [ATR], [напряжение]
- [i e u o] являются [+ATR] или [+tense]
- [ɪ ɛ ʊ ɔ] являются [+ATR] или [+tense]
- Низкие гласные зависят от системы признаков.
- Большинство систем признаков используют признаки гласных, чтобы различать разные [+дорсальные] согласные, в дополнение к их использованию для гласных.
- Материалы класса содержат несколько различных диаграмм характеристик, если вам интересно узнать, чем они отличаются.
- Таблица функций вводной фонологии Брюса Хейса (2009).
- Все функции являются бинарными.
- Имеет функцию [приблизительно] и определяет меньшее количество звуков для каждой функции. Например, [пронзительный] используется только для корональных звуков, а [отложенное высвобождение] — только для препятствующих.
- Таблица функций вводной фонологии Брюса Хейса (2009).
- Чтобы быть точным, мы будем использовать диаграмму Хейса для нашего следующего задания, так как она имеет хорошее покрытие и функция [аппроксимации] полезна, а у меня есть электронная таблица Excel.
- В своем письме очень подробно опишите функции, которые вы предполагаете.
- Вот очень полезная сводка по функциям манеры.
| соноры | препятствия | |||||
| гласные | направляющие | жидкости | носовые | фрикативные | аффрикаты | упоры |
| [+сложное] | [–слоговое] | |||||
| [–согласная] | [+согласная] | |||||
| [+приблизительно] | [– приблизительно] | |||||
| [+звучный] | [– сонорный] | |||||
| [+продолжение] | [–продолжение] | [+продолжение] | [–продолжение] | |||
| (нет значения для [отложенного выпуска]) | [+отложенный выпуск] | [–удалить отн. ] | ||||
- Правила также можно комбинировать с помощью сокращений . Вот четыре самых распространенных:
- Каждое из приведенных выше правил расширено до подправил заранее определенными способами. Вот несколько готовых примеров.
- С ➔ Ø / _ {С, #}
- Сначала попробуйте C ➔ Ø / _ C.
- Во-вторых, попробуйте C ➔ Ø / _ #.
- C ➔ Ø / _ (C)C
- Сначала попробуйте C ➔ Ø / _ CC.
- Если первое подправило не применяется, попробуйте C ➔ Ø / _ C.
- C ➔ Ø / _ C 5 0
- Сначала попробуйте C ➔ Ø / CCCCC _
- Если не подходит, попробуйте C ➔ Ø / CCCC _
- Если не подходит, попробуйте C ➔ Ø / CCC _
- Если не подходит, попробуйте C ➔ Ø / CC _
- Если не подходит, попробуйте C ➔ Ø / C _
- Если не подходит, попробуйте C ➔ Ø / _
- С ➔ Ø / _ {С, #}
- Давайте посмотрим на аббревиатуры в действии на следующем примере из SPE (стр. 339, немного адаптировано). Рассмотрим вымышленный язык, на котором:
- / i / и / j / актуализируются как [ j ] перед / p r j a /.
- / w / и / u / актуализируются как [ u ] перед / p r j a /.
- Предположим, что в этом вымышленном языке те же согласные, что и в английском, и пять гласных: /ie a o u/.
- На первый взгляд кажется, что нам нужно 8 правил, но мы можем использовать фигурные скобки, функции и хитрости, чтобы сократить это число до всего одним правилом . Решение внизу.
- Хотя это может показаться излишне сложным, возможность комбинировать эти правила (вероятно) полезна: всякий раз, когда у нас есть разные правила, которые, кажется, делают одно и то же, мы хотим иметь возможность их комбинировать.
- Вымышленный пример — далеко не самое сложное правило в SPE.
- Правила, подобные приведенному ниже правилу определения времени гласных, имеют множество подправил, охватывающих сложный набор требований для применения.
- Без аббревиатур в SPE было бы гораздо больше правил для определения времени гласных.
- Так как простота правил играет ключевую роль в оценке грамматик, влияние сокращений на сокращение структуры правил является хорошим результатом.
- Правила, подобные приведенному ниже правилу определения времени гласных, имеют множество подправил, охватывающих сложный набор требований для применения.
| Гласная | Напряженный | Низкий | Гласная | Напряженный | Низкий | |
|---|---|---|---|---|---|---|
| я | + | – | и | + | – | |
| ɪ | – | – | ʊ | – | – | |
| и | + | – | или | + | – | |
| ɛ | – | – | ɔ | + | + | |
| æ | – | + | ɑ | + | + |
- После применения напряжения безударные слабые гласные сокращаются по другому правилу до [ə].
- Метрика оценки слепа к фонетической естественности.
- Многие звуковые паттерны можно объяснить, обращаясь к принципам производства и восприятия.
- … но метрика оценки учитывает только символы.
- Как теория возможных фонологических чередований, SPE, возможно, слишком сильна.
- Рассмотрим предсказание выше: правила с меньшим количеством символов должны быть более распространены среди языков мира.
- Достаточно просто написать два правила с одинаковым количеством символов, где процесс, захватываемый одним правилом, встречается очень часто, а процесс, обрабатываемый другим правилом, очень редко.
- Например: озвучивание в конце слова (очень распространено в языках мира) и озвучивание в конце слова (очень редко в языках мира).
- На самом деле почти любой фонологический процесс можно сгенерировать с помощью правил.
- Иногда встречаются похожие правила, которые нельзя комбинировать с помощью сокращений.
- Когда это происходит, мы не можем сделать обобщение.
- По сравнению с предыдущими работами в SPE существует меньше ограничений на предложение базовых сегментов.
- Анализы могут содержать UR, которые существенно отличаются от SR, даже содержащие сегменты, которые никогда не появляются на поверхности, что дает более реферат URs .
- Например, для учета стресса SPE предлагает провести различие между конечным /ss/ (в ласка ) и конечным /s/ (в Париж ) (стр. 151).
- Эти различия являются причиной того, что Хомский и Галле (1968) дистанцируются от предыдущей работы и явно избегают терминов фонема и аллофон (стр. 11, стр. 65).
- С этого момента мы редко будем встречать термины , фонема и 9.0050 аллофон .
- Мы еще поговорим о звуках в УР и звуках в СР.
- Вы можете свободно использовать фонему и аллофон , поскольку ясно, что вы не имеете в виду эти термины в том смысле, в каком они были до 1950-х годов.
- С этого момента мы редко будем встречать термины , фонема и 9.0050 аллофон .
- Звуковой образец английского языка
- явный алгоритм
- правила и порядок правил
- отличительных признаков
- натуральный класс
- желательно для функций
Формализм правила - цель/фокус
- структурное изменение
- окружающая среда
- структурное описание
- процедура оценки в SPE
- аббревиатуры (), {}, C n , переменные с греческими буквами
- абстрактные URs
- Представьте себе язык, который имеет инвентарь, показанный ниже.
- Девять из обведенных наборов звуков являются естественными классами.
- Опишите каждый класс с точки зрения отличительных особенностей, используя только те характеристики, которые определены в данном руководстве.
- Используйте как можно меньше функций, чтобы однозначно идентифицировать каждый набор по отношению ко всему инвентарю.
- Укажите набор, который не является естественным классом.
- [ɻ] — ретрофлексный аппроксимант.
- Переведите следующие правила из нотации в стиле SPE на английский язык.
- [+сил, +высокий] ➔ [-голос] / [-голос, +продолжение] _ [-голос, +продолжение]
- [+спинной, -продолжение, -сын, +голос] ➔ [+продолжение] / [+сил, +назад] _ [+сил, +назад]
- [-сын, +продолжение] ➔ [-продолжение] / _ #
- [+голос, −cont, −son] ➔ Ø / [+носовой] _ #
- [+сил, +низкий] ➔ [-низкий, +круглый] / _ C 0 [+сил, +высокий, -назад]
- Переведите следующие правила с английского языка в нотацию в стиле SPE.
- Носовые удалить предшествующие щелевые, l и r.
- В последовательности из двух (не носовых) согласных первый становится фрикативным.
- Глухие остановки и фрикативные звуки становятся звонкими между сонорами.
- [ɻ] становится [l], предшествующим [l].
- Гласные среднего ряда согласуются с гласным предыдущего слога в значении ATR.
- Напишите систему правил для /t/, зафиксировав распределение на диаграмме вместе с приведенными ниже обобщениями. Сделайте правила минимальными, насколько это возможно.
- /p/ и /k/ также аспирируются перед ударными гласными.
- / d / также становится ударом между гласными.
- С помощью фигурных скобок можно создать два правила.
- Между двумя неучтенными правилами все же есть некоторое сходство.
- Фигурные скобки, элементы и некоторые другие обозначения показывают сходство:
- Добавление фигурных скобок дает нам одно правило:
- Мы также можем получить одно правило, используя строчные греческие буквы.
[зубной] обычно не является функцией, но используется здесь для простоты.
↩
4.9 Типы фонологических правил – Основы языкознания, 2-е издание
Глава 4: Фонология
Фонационная ассимиляция
Языки могут иметь множество типов правил. Возможно, наиболее распространенным общим типом фонологического правила, которое мы находим, является ассимиляция , когда фонема превращается в аллофон, который соответствует некоторому аспекту своего окружения. То есть одно или несколько свойств в изменении правила также присутствуют где-то в среде правила. Мы видим это во французском озвучивании, когда сонорные звуки становятся глухими в среде, которая также включает в себя безголосость.
Фонационная ассимиляция также может вызывать озвучивание, а не оглушение, как в Wemba Wemba (вымерший кулинический язык семьи пама-ньюнган, на котором раньше говорили в Австралии), в котором глухие взрывные звуки озвучиваются после носовых остановок, как в следующих данных (адаптированные из Hercus 1986).
/panpar/ [латекс]\стрелка вправо[/латекс] [панбар] ‘лопата’
/jantaŋ/ [латекс]\стрелка вправо[/латекс] [jandaŋ] «Я»
/taɳʈa/ [латекс]\стрелка вправо[/латекс] [taɳɖa] ‘прикоснуться’
Мы можем написать соответствующее правило следующим образом:
- взрывной [латекс]\стрелка вправо[/латекс] звонкий / звонкий носовой упор
Как во французском, так и в Wemba правилах ассимиляции Wemba важнейшая часть среды, содержащая свойство ассимиляции, находится слева, но ассимиляция фонации также может зависеть от правой стороны среды, как в польском (западнославянский язык индоевропейская семья, на которой говорят в Польше). В польском языке звонкие помехи становятся глухими, если за ними следует глухая помеха (данные адаптированы из Станиславского 19).78 и Рубах, 1996).
/dxu/ [латекс]\rightarrow[/латекс] [txu] «дыхание»
/rɪbka/ [латекс]\rightarrow[/латекс] [rɪpka] ‘рыбка’
/vçi/ [латекс]\rightarrow[/латекс] [fçi] ‘деревня’
/vɪkaz pism/ → [vɪkas pism] «список журналов»
Соответствующее фонологическое правило можно записать следующим образом:
- шумный [латекс]\rightarrow[/latex] глухой / глухой шумный
Место ассимиляции
Фонация — не единственное фонетическое свойство, которое может ассимилироваться. В персидском (юго-западный иранский язык индоевропейской семьи, на котором говорят в Иране и прилегающих районах) мы видим ассимиляцию места, когда альвеолярные остановки становятся постальвеолярными перед постальвеолярными (данные адаптированы из Bijankhan 2018).
/ʔætʃɒn/ [латекс]\стрелка вправо[/латекс] [ʔæṯʃɒn] ‘пересохший’
/χædʃe/ [латекс]\rightarrow[/латекс] [χæḏʃe] ‘недостаток’
/ʔenʃɒ/ [латекс]\стрелка вправо[/латекс] [ʔeṉʃɒ] ‘эссе’
Соответствующее фонологическое правило можно записать следующим образом:
- альвеолярный стопор [латекс]\rightarrow[/latex] постальвеолярный / постальвеолярный
Назальная ассимиляция
Носальность также является еще одним общим свойством, которое ассимилируется, как, например, в языке каапор (он же урубу-каапор, язык ваямпи семьи тупиан, на котором говорят в Бразилии). В Ka’apor гласные назализуются после носовой остановки (данные адаптированы из Kakumasu 1986).
/uruma/ [латекс]\rightarrow[/латекс] [urumã] ‘утка’
/tamui/ [латекс]\стрелка вправо[/латекс] [тамуи] ‘старик’
/mɨra/ [латекс]\rightarrow[/латекс] [mɨ̃ra] ‘дерево’
/nino/ [латекс]\стрелка вправо[/латекс] [nĩnõ] ‘лежать’
/niʃoi/ [латекс]\стрелка вправо[/латекс] [nĩʃoi] ‘нет’
/ne/ [латекс]\стрелка вправо[/латекс] [nẽ] ‘ты (поешь)’
Соответствующее фонологическое правило можно записать следующим образом:
- V [латекс]\rightarrow[/латекс] носовой / носовой упор
Другие виды правил
Почти любое фонетическое свойство может ассимилироваться, а также есть много правил, которые вообще не предполагают ассимиляции.
[больше примеров скоро!
Использование общих типов правил
Знание того, какие виды фонологических правил мы, вероятно, обнаружим, помогает сузить наши возможности при попытке определить, какие телефоны являются аллофонами одной и той же или разных фонем. Например, для французских сонор мы видим, что существуют естественные пары звонких и глухих сонор, поэтому было бы разумно посмотреть, соответствует ли их распределение тому, что мы знаем о правилах, влияющих на звонки, таких как ассимиляция.
Благодаря нашему знанию распространенных типов правил это позволяет нам не сосредотачиваться на вероятных нерелевантных факторах. Например, во французском языке мы знали бы, что не стоит слишком беспокоиться об округлении гласных или месте артикуляции, поскольку обычно они не являются триггерами для изменения фонации. Мы также можем начать поиск паттернов, основанных на общих правилах, даже не зная, какие интересующие нас телефоны мы должны исследовать: может быть, есть паттерн в назальности гласных, основанный на наличии или отсутствии соседнего носового смычка (указывающий на ассимиляцию назальности). Конечно, язык, который мы анализируем, не будет иметь всех этих правил, но может иметь одно, так что мы сможем получить преимущество при анализе его фонологии.
Это означает, что фонематический анализ и обнаружение правил идут рука об руку. Иногда мы можем использовать известные фонологические правила, чтобы помочь выявить закономерности распределения в телефонах, а иногда мы можем сначала найти закономерности распределения, что приводит нас к установлению фонологического правила. Работа над языком в обоих направлениях может быть гораздо более продуктивной, чем попытки провести фонематический анализ напрямую. Это метод, который пронизывает всю лингвистику, а не только фонологию. Каждый язык, который мы анализируем, говорит нам что-то о том, как работает сам язык, и это более широкое знание того, как работает язык, помогает нам анализировать следующий язык.
Проверьте свое понимание
Скоро!
Каталожные номера
Биджанхан, Махмуд. 2018. Фонология. В Оксфордский справочник персидской лингвистики , изд. Ануша Седиги и Пунех Шабани-Джадиди, Оксфордские справочники по лингвистике, стр. 111–141. Оксфорд: Издательство Оксфордского университета.
Геркус, Луиза А. 1986. Викторианские языки: последнее исследование . № 77 в серии Pacific Linguistics B. Канберра: Австралийский национальный университет.
Какумасу, Джеймс. 1986. Урубу-каапор. В Справочнике амазонских языков , изд. Десмонд С. Дербишир и Джеффри К. Пуллум, том. 1, 326–404. Берлин: Мутон де Грюйтер.
Рубач, Ежи. 1996. Несложный анализ голосовой ассимиляции в польском языке. Лингвистическое исследование 21(1): 69–110.
Станиславский, январь 1978 г. Wielki słownik polsko-angielski . Варшава: Wiedza Powszechna.
Что такое фонологическое правило?
`;
Тодд Подземный
Фонологическое правило — это метод описания того, как отдельные звуки воспроизводятся в разговорной речи. Эти правила записаны в специальной нотации, кодифицирующей способ изменения звука или группы звуков при появлении в определенном лингвистическом контексте. Фонологические правила различаются между языками и диалектами, и они отражают общие привычки произношения различных языковых групп. Изучая, как конкретное фонологическое правило действует в разговорной речи, лингвисты могут определить физиологические и неврологические механизмы, которые переводят мысленный язык в разговорный язык.
Полное фонологическое правило включает основной звук, который изменяется, среду, в которой он изменяется, и конкретное изменение, которое имеет место. Правила могут иметь дело с группами основных звуков, если все звуки претерпевают одинаковые изменения при помещении в одну и ту же языковую среду. Языковая среда описывает типы звуков, которые должны существовать до или после основного звука, чтобы произошло изменение, и может включать в себя как положительные, так и отрицательные черты. Например, фонологическое правило может описывать изменение, происходящее после согласного в ударном слоге и перед гласным в безударном слоге. Изменение обычно выражается в Международном фонетическом алфавите (IPA) или как описание общих черт между несколькими измененными звуками, и оно передает звук, который является результатом измененных основных звуков.
Фонологические правила можно разделить на четыре основные группы, которые различаются по типу происходящего изменения. Ассимиляция — изменение звука, делающее его более похожим на соседние звуки, облегчающее произношение слова за счет устранения некоторых движений органов речи. Диссимиляция — это изменение, из-за которого звук становится менее похожим на соседние звуки, что может повысить вероятность того, что слушатель услышит определенные звуки. Вставка — это введение ненаписанного звука между очень похожими или труднопроизносимыми звуками, такими как «-e», обычно вставляемый при множественном числе слова, оканчивающегося на «s». Удаление или усечение происходит, когда звук маскируется или полностью исключается из слова.
Хотя фонологические правила и называются правилами, они не подразумевают правильный или предпочтительный способ произношения. Они могут быть написаны и часто пишутся для отражения нестандартных диалектов и способов речи. Фонологические правила — это простые описания произношения. Обычно они используются для изучения взаимодействия между умственной и физической речью и физиологией органов речи, а не культурными аспектами конкретного произношения.
4.5 Фонологические производные – основы языкознания
Глава 4. Звуки речи в сознании
Используя нотацию матриц признаков, мы можем создавать «формулы», представляющие взаимосвязь между фонематическим и фонетическим уровнями репрезентации в нашей ментальной грамматике. Эти формулы известны как фонологические деривации или фонологические правила, и они предназначены для представления бессознательных знаний, которыми обладает каждый свободно говорящий, о предсказуемой среде, в которой в их языке возникают аллофонические вариации.
Проверь себя
1. Какое фонологическое правило точно описывает процесс «назализация гласных перед носовыми согласными»?
2. Какое предложение точно описывает процесс, описанный в этом фонологическом правиле?
- Глухие фрикативные звуки становятся звонкими между звонкими сонорными.
- Глухие смычные согласные становятся звонкими до или после звонких сонорных.
3. Какое предложение точно описывает процесс, изображенный в этом фонологическом правиле?
- Сегмент [ə] удален в окружении резкого согласного.
- Сегмент [ə] ставится в виде эпитезы после резкого согласного.
Ответы
Видео сценарий
Ранее в этой главе мы говорили о разнице между фонематическим и фонематическим представлениями. Помните, что когда мы говорим о фонематическом представлении, мы имеем в виду то, как звук или слово представляются в нашем уме. На фонематическом уровне мозг хранит сегментарную информацию, но не детали об аллофонических вариациях. Но фонетическое представление — это то, как мы на самом деле произносим слова, и из-за коартикуляции и различных артикуляционных процессов, когда мы произносим данную фонему, она воспроизводится как особый аллофон, обусловленный окружающей средой. Например, слово чистый фонематически представляется в нашем сознании как /klin/, но когда мы говорим, эти конкретные фонетические детали [k h l̥in] являются частью того, что мы говорим. Мы говорим аллофонами, но слышим фонемами.
Систематическая, предсказуемая связь между фонематическим и фонетическим представлением является частью ментальной грамматики каждого бегло говорящего на языке. Фонологи разработали нотацию для изображения этой связи, которая иногда известна как 9.0054 производное или правило . Помните, конечно, что, когда мы говорим о правилах в лингвистике, мы не имеем в виду те предписывающие правила, которым ваш школьный учитель английского языка хотел, чтобы вы следовали. Мы имеем в виду принципы, которые использует наша ментальная грамматика, чтобы связать основное фонематическое представление с поверхностной формой. Наша ментальная грамматика отслеживает каждое предсказуемое фонетическое изменение, происходящее с данным естественным классом звуков в данном фонетическом окружении.
Давайте подумаем об уже знакомом нам процессе обезвоживания жидкости. Мы видели много английских примеров, таких как чистый , где звонкий [l] становится глухим вслед за глухим [k h ] из-за настойчивой ассимиляции. На самом деле, мы видели достаточно данных по английскому языку, чтобы заметить, что это происходит не только с одним сегментом; это происходит с естественным классом жидкостей в среде другого природного класса: глухих остановок.
То, как мы пишем вывод, принимает особую форму, которая выглядит следующим образом. Это обозначение читается как «А становится В в среде между X и Y». Левая сторона представляет происходящее фонетическое изменение: конкретная фонема или естественный класс фонем становится данным аллофоном или претерпевает изменение одного или нескольких признаков. Справа показана фонетическая среда, в которой происходит изменение.
Итак, как мы будем использовать это обозначение для представления предсказуемого процесса выделения жидкости? Начнем с описания картины словами. Изменение происходит с жидкостями [l] и [ɹ]. Что с ними происходит, так это то, что они из звонких становятся глухими. И где это происходит, так это после безмолвных остановок. Итак, теперь давайте опишем шаблон, используя матрицу признаков.
Начнем с матрицы признаков для жидкостей. Это сонорные, но не носовые согласные, и по умолчанию они [+голос]. Изменение, которое происходит, заключается в том, что их голосовая характеристика переходит от плюса к минусу. Остальные функции остаются прежними, поэтому мы не перечисляем их в матрице функций, описывающей изменение.
Теперь мы должны сказать, где происходит это изменение. Большая косая черта просто означает «в среде», и мы знаем, что это изменение происходит после чего-то, поэтому мы помещаем горизонтальную линию, указывающую место изменения, после матрицы признаков, которая представляет среду, а затем мы заполняем детали конкретной среде. Глухие смычные — это согласные, которые бывают [-продолжительные] и [-голосовые].
Мы могли бы сказать, что [l] становится глухим [l] в среде, следующей за [p] или [k], а [ɹ] становится глухим [ɹ] в среде, следующей за [p], [t] или [k], но используя Матрицы признаков фиксируют более широкое обобщение, что эта аллофоническая вариация происходит со всем естественным классом в среде другого естественного класса.
уровней, правил и процессов
уровней, правил и процессов1. Уровни американской структуралистской фонологии
Фонематический уровень обобщает формы, фонетически разные
но не различимы по смыслу (например, аллофоны):
| (1) | [р ч ]ит, | си[пт], | с[р]ит | Аллофоны | |
| \ | | | / | |||
| /р/ | Фонемы |
Морфофонематический уровень обобщает формы, фонематически
разные формы одной и той же морфемы (т.е. алломорфы):
| (2) а. | серийный номер | с/Ig/природа | б. | электри[к] | электричество | Фонемы | ||
| \ | / | \ | / | |||||
| {знак} | {электрик} | Морфофонемы | ||||||
Хотя аналогичные транскрипции используются на всех трех уровнях, американский
структуралисты считали их разными по своей природе. Например, телефоны
являются реальными речевыми событиями, тогда как фонемы являются абстрактными алгебраическими символами.
Оба вида отношений могут быть формализованы с помощью правило перезаписи формализм генеративной фонологии, описывающий, как преобразовать строку
символов на одном уровне в другую строку на другом уровне. Однако,
в структуралистской фонологии такие отображения рассматриваются как реализация правила, а не переписывать как таковые.
(3) [+согласная, +время] -> [+расширенная голосовая щель, -сжатая голосовая щель]
/ __ В
[+согласная, +время] -> [-расширенная голосовая щель,
+суженная голосовая щель] / V __
[+согласная, +время] -> [-расширенная голосовая щель,
-суженная голосовая щель] / с __ V
G-удаление (например, знак, парадигма и т. д.): g -> Ø / __ C #
(Ø = нулевой/пустой сегмент)
Смягчение Velar: k -> s / __ i
2. Несколько уровней в генеративной фонологии
Галле, М. (1959) Звуковой образец русского языка: лингвистический и акустический
Расследование. Мутон.
В русском языке все глухие помехи, кроме /ц/, /т/ и / x / имеют отчетливо звучащие аналоги фонемы. /ц/, /т/ и /x/ озвучили аллофонов , которые возникают, когда за ними следуют звонким обструктором. например [ j и др. l j i] `можно сжечь?’ ([l j ], хотя и озвучено, не мешает) против . [ j изд. б] `был один, чтобы сжечь’. Аллофонический правило звукоассимиляции кажется необходимым:
(4) /ц/, /т/, /х/ -> [+голос] / __ C[-сонорный, +голос]
С точки зрения структуралистов, это правило фонематической реализации, относящееся к
фонематического уровня на аллофонический уровень. Однако почти такой же вид
правила требуется для других глухих препятствий, которые также подвергаются
голосовая ассимиляция напр. [м j ok l j i] `был (он)
намокнуть?’ против . [м дж ог б]
«были ли (он) промокшими». Здесь, однако, звуковые различия носят фонематический характер. поэтому соответствующее правило будет правилом морфофонемной реализации, например:
(5) До{- сонорный, -голос} -> /+голос/ / __ C/-сонорный, +голос/
Галле заметил, что такие правила, как (4) и (5), очень похожи по форме и функциям, и что (4) не было бы необходимо, если бы не тот факт, что они считаются применимыми на разных уровнях, поскольку (5) относится ко всем глухим препятствиям. Это следует из таких примеров, как этот что правила могут действовать на разных уровнях, в результате чего не четкое разделение между фиксированным, небольшим числом уровней. Галле и другие генеративные фонологи заметили, что во многих случаях грамматики проще, если несколько правил разрешено применять последовательно, неявно определение многочисленных промежуточных уровней представления. Например. в выводе из знак :
(6) знак => sIXn
(gудаление; X — пустой слот сегмента)
=> sI:n (компенсационное удлинение)
=> saIn (сдвиг гласных)
=> …
Генеративная фонология только приписывает особый статус входному уровню
(уровень, на котором выражены лексические статьи), называемый систематическим фонематический уровень и выходной или поверхностный фонетический уровень, называемый систематический
фонетический уровень.
3. Что такое процесс?
Не все правила представляют (предполагаемые) фонологические процессы. Например, правило избыточности
(7) [+сонорный] -> [+продолжительный]
— это правило заполнения признаков, которое просто уточняет спецификацию. сонорного: он не превращает сонорные во что-то другое. Правило дает значение «+» признаку [продолжительный] во всех [+сонорных] сегментах. Это несколько отличается от эффектов такого правила, как
(8) [+звучный] -> [+расширенная голосовая щель] / [+расширенная голосовая щель] __
правило, обозначающее соноранты в начальных /pr/, /kl/ и т. д.
Таким образом, процессы обычно изменяют характеристики. В правилах, которые относятся к фонологической структуре, процессы обычно структурно-изменяющие (например, изменение силлабификации), но иногда операции по построению структуры (например, силлабификация) также рассматриваются многими фонологами как процессы.
4. Фонетика или фонология?
При таком явлении, как коартикуляция согласных и гласных (например, держать/тележку/прохладно),
это фонологическое правило в действии (т. е. в грамматике языка), или
это непроизвольный побочный эффект движений артикуляторов
для согласных и гласных целей?
На этот вопрос не всегда есть четкие ответы. Некоторые руководящие принципы:
| (9) | Фонологические правила | Фонетические явления | |
| · Зависит от языка | · Независимо от языка | ||
| · Включает категориальные различия напр. электричество/k/ против электричества/s/ity | · Может быть градиентом напр. побежал / быстро | ||
| · Обычно морфофонологический | · Слепой к морфологии |
5. Ассимиляция: контекстно-зависимое изменение значения
признака, чтобы сделать его более похожим или даже идентичным другому
особенность или сегмент в районе.
5.1. Прогрессирующая или персеверативная ассимиляция
(10) напр. открытый: [oUpm], семь: [sev]
5.2. Регрессивная или упреждающая ассимиляция
(11) напр. Я иду: [aIkmI]
Фонологический или фонетический? Следующие примеры являются более фонологическими:
(12) in+legal = незаконный
in+актуально
= не имеет значения
не+возможно
= невозможно
не+правдоподобно
= невероятно
ср. Французская ассимиляция звонкости ( просодическая Домены и просодическая структура лекция §2.2), Ассимиляция места в английском языке носовые + невнятные группы ( Prosodic Домены и просодическая структура лекция §2.3)
5.3. Гармония гласных
ср. Киргизский ( просодический Домены и просодическая структура лекция §4.2)
5.4. Фьюзионная ассимиляция
(13) напр. ты => [dIdu]
(14) Санскритская гласная сандхи: Маха+Индра => Махендра
(15) Японская быстрая речь/мужская вульгарная речь: /itai/
=> [itee] `болезненный’; /semai/ => [semee] `узкий, маленький’
(16) КиХая медленная речь: [эмва икамбона]
«собака увидела меня» против нормальная скорость речи: [emwé:kambóna]
6. Диссимиляция
(17) Латинское /arbor/ > Современное испанское /arbol/ (диссимиляция [±lateral]
в / р / и / л /)
(18) Английский диалектный `chimney’ => ‘chimley’ => `chimbley’ (диссимиляция
[± носовой] в / m / и / n /; [b] является эпентетическим; Смотри ниже)
(19) Санскрит: закон Грассмана, напр. /bhudh + am/ => budham (диссимиляция
стремления)
ср. форма без суффикса [bhut] <= /bhudh/, с окончательным озвучиванием.
(20) английский родственный < родственный+ .
7. Lenition (размягчение или ослабление)
(21) Иерархия прочности:
а) Стоп > Фрикатив > Аппроксимант > Ноль7.1. Фонетический напр. Ливерпуль /k/ -> [x], /t/ -> ламинальный [s]; испанский неначальный /d/ -> [ð], /b/ -> [ß]. 91 550 (По крайней мере, аллофонический). Можно сформулировать фонетическое описание в плане артикуляционный недорост .
б) Без голоса > Звонкий
7.2. Фонологический напр. Северный валлийский
| (22) | Н | его N | |
| /ручка/ | /я бен/ | «голова» | |
| /брауд/ | /врауд/ | «корабль» |
7.3. Морфофонологический
(23) английский электри[к] против электри[]ан по сравнению с электричеством (возможно, [k] -> [c] -> [t] -> [] -> [с])
7.4. Исторический
(24) Французский []eval <
Латинский [k] aballus
(25) германский /f/ < протоиндоевропейский /p/; Английский
рыба см. Латинская рыба
Германский // <Протоиндоевропейский /t/; ср. брат против . брат, зуб против .
вмятина (аль)
7.5. Сокращение гласных напр. фото[]график против фотограф (безударный / o / поверхности как schwa). Обычный анализ
заключается в том, что все функции /o/ удаляются, оставляя пустой Vslot. Реализация пустой позиции V по умолчанию означает schwa на английском языке.
8. Фортиция (усиление)
Fortition встречается реже, чем lenition, и некоторые фонологи отрицают существование крепости, анализируя все случаи исторической крепости, например. заимствование, и все синхронные случаи, например. дополнение. Например. Фула `сууду’ дом против дома «тууди», рядом с лениумом например `pullo’ человек фула против `fulbe’ человек фула. Много языков без / f / заимствовать [f] начальные слова с [p], например. `филипино’ = название тагальского языка (на тагальском), основного языка Филиппин. Американское латиноамериканское произношение английского [j] как «вы» с инициалом небный взрывной звук можно рассматривать как крепость. Фарерские близнецы приближаются укрепить напр. /jj/ -> [], /ww/ -> [гв]. Это случаи артикуляционного перерегулирования?
Один случай укрепления, однако, является обычным: devoicing . Например. Финал
громкая речь на немецком, польском, каталанском, английском языках. Например.
(26) Немецкий [ba:t] `баня’ vs. Bä[d]er `бани’; [to:t] «смерть» против To[d]es «смерти»
В литературе по фонетике ведутся длительные дебаты о этих случаях, между мнением о том, что окончательная озвучка является чисто фонетической, и не приводит к тождеству производного [t] и лексического /t/, а противоположное мнение, что процесс нейтрализующий и, следовательно, экземпляр фонологической перезаписи.
9. Вставка
9.1. Протез напр. о. esprit <латинское Spiritus.
9.2. Anaptyxis: Вставка гласной, чтобы разбить кластер, например.
Атлет. /l/ не является корректным
ни начало слога, ни правильно сформированная кода слога в английском языке. Вставка
букв V имеет тенденцию делать слоговую систему более похожей на более простую CVCVCV…
образец, который повсеместно немаркирован (якобы).
Протезис и анаптиксис часто называют просто «гласный» или «шва».
эпентеза’. Обычный анализ заключается в том, что пустая буква V по умолчанию является гласной. например, шва или [э].
9.3. Разрыв гласных (противоположность слиянию).
9.4. Эпентез согласных напр.
(27) Ø -> [t] / [n] __ [s]
printce против отпечатков
Ø -> [п] / [м] __ []
тепло
Ø -> [k] / []
__ []
длина
Поскольку фонетическое различие сохраняется между «prin t ce» и «отпечатки», этот вид эпентеза обычно считается довольно низкоуровневым, фонетическое явление. (Как еще мы можем отличить эпентетическую [t] и лексический [т]?) Одна точка зрения состоит в том, что это не случай вставки сегмента вообще, но временной координации, т. Е. Назальности и звонкости [n] «выключаются» для подготовки к следующим [с] перед корональным закрытие высвобождается, производя, как побочный эффект, мгновенный период безголосого коронарного закрытия. Но это всего лишь деталь перехода от [n] до [s], вовсе не «настоящий отрезок».
9.5. Связные или связующие согласных
| (28) напр. Английский | `навязчивый r’ и `связывающий r’ | напр. только пила [r] = больно только | |
| `связывание w’ | напр. уйти [ж] от | ||
| а/ан алломорфия | напр. тележка против . яблоко. |
NB нет компоновщика в штате Массачусетс английский должен быть съеден , Бекаа в Ливане , предполагая, что, возможно, все случаи навязчивого r действительно связывая r.
10. Удаление
10.1. Фонетический (?) напр. словарь
10.2. Фонологический напр. Валлийский gardd `сад’ => yr ardd «сад»; Английский /damn/ => [damn] ср. проклятие; /парадигма/ => [парадаим] ср. паради[г]матичный.
Валлийское дело можно рассматривать как леницию /g/
на гласную (возможно, через [g]), или как чисто парадигматическое чередование (т.е.
с gardd и ardd не находятся в производных отношениях). Английские падежи настолько непродуктивны, что оправдание использования
правило может быть поставлено под сомнение.
11. Изменение порядка (перестановка)
Нередкий исторический процесс, но что синхронно многое реже.
11.1 Повторный анализ например. Кода /l/ в слове «принижать» => Начало
/l/ в слове «умаление» встречается чаще. А может это просто разные разбор разных строки, т.е. мы не разбираем `belittle’ с помощью
код /l/, а затем добавление и повторная обработка. Иврит: /хит + садр
+ уд/ => [гистадрут]. Но так как образцы V и C являются отдельными морфемами
в семитских языках /hit/ на самом деле {i, h 11.2. Движение отдельных элементов: (29) Санскрит: закон Варфоломея напр. /лабх + та/ => [лабдха]
(перестановка признаков стремления /b/ и /d/). (30) Английский: исторически, /iw/ > /ju/ в т. Дальнейшее чтение: Девушка Фонология гл. 8, Кенстович гл.
2-3. Фонология — это место, где вы применяете на практике все, что вы узнали из фонетики. Это изучение того, как звуки связаны друг с другом (фонотактика), как они взаимодействуют друг с другом, а также правила, объясняющие эти процессы. Основное внимание фонологии на вводном курсе можно разделить на следующие области. Фонемы — это отдельные звуки, описываемые как совокупность фонетических признаков, отличающихся друг от друга хотя бы одним признаком. Например, мы знаем, что /p/ и /b/ оба являются двухгубными взрывными, и все же они не идентичны. (1) ч. «новый». Это должно быть
анализируется как перенос слоговости от /i/ к /u/ в /iu/. Но это
было бы движением только в том случае, если используется признак слога. В противном случае,
его можно рассматривать просто как повторный анализ (или другой анализ). Введение в фонологию
1. Распределение фонем
Чтобы понять, как они отличаются друг от друга, мы можем создать простую диаграмму функций, отметив функции двоичными значениями как «+» или «-». При этом мы обнаруживаем, что отличительной чертой является звонкость. Это называется минимальным отличием или отличительной чертой. /стр/ /б/ взрывной + + двугубный + + звонкий – +
Отличительные признаки позволяют нам классифицировать фонемы по категориям, отличать классы фонем друг от друга, формулировать прогнозы относительно того, как будут вести себя классы фонем, и отображать специфические для языка ограничения. Они также предоставляют артикуляционную, перцептивную (слуховую) и акустическую информацию, которая помогает нам различать близкородственные фонемы и аллофоны, предоставляют категории для демонстрации контраста между наборами звуков и являются основой для создания естественных классов.
Неотличительные особенности — это те, которые предсказуемы для любого звука. Например, в стандартном английском языке глухие остановки произносятся с придыханием, когда они являются первым звуком слова (началом слова) или когда они находятся в начале ударного слога. Распределение признака [стремления] предсказуемо или нечетко, поскольку существует правило, определяющее, где оно появится. Таким образом, мы можем предсказать, что /k/ в слове /ki/ «ключ» будет с придыханием, [k h я]. Придыхание не является отличительным признаком, поскольку при прибавлении придыхания к /k/ оно не создает другой фонемы, как в случае (1) с звонкостью.
Фонемы могут быть выражены в фонематической или фонетической форме. Фонематическая форма (также называемая основной репрезентацией) — это то, что существует в уме говорящего, а фонетическая форма (также называемая поверхностной формой) — это то, что фактически артикулируется говорящим.
Уровни представительства
В каждом языке есть свои правила, разрешающие или запрещающие различные взаимодействия. Это знание интуитивно понятно носителям языка; до такой степени, что большинство людей не осознают, что на самом деле выходит из их уст! У говорящего на любом языке есть идея, абстрактное понятие звуков, которые он артикулирует. Однако чаще всего существует несоответствие между формой звука, которая находится в сознании говорящего (основное представление или УР), и формой, которая фактически артикулируется (поверхностная форма или ПФ).
Другими словами, фонемы хранятся в уме как набор признаков.
Это абстрактное понятие звука, называемое основным представлением, окружено обратной косой чертой / /. Поверхностная форма, реализуемая в виде артикуляционных жестов и артикулируемая в соответствии с фонологической средой, заключена в скобки [ ].
Аллофоны — это варианты фонемы, которые проявляются в определенных фонологических условиях. Вот пример из стандартного английского.
/t/ — глухая альвеолярная стопа. Мы используем этот звук в таких словах, как «верх», «поезд», «стоп», «масло» и «кнопка». Но действительно ли мы? Как обсуждалось ранее, когда /t/ в качестве глухого смычного является начальным звуком в слове, он несет в себе свойство [+придыхание], как и в слове «верх». Таким образом, говорящий считает, что он/она произносит слово как /tap/, когда на самом деле поверхностная форма [tʰap].
Рассмотрим слово «поезд». На это слово, начальное / t /, влияет следующее / ɹ /. Таким образом, он появляется как [tʃ] и будет транскрибироваться как [tʃɹejn].
Если в середине слова (среднего слова), как в слове «масло», встречается буква /t/, это значит, что оно имеет еще одно произношение. Он будет выглядеть как альвеолярный лоскут или [ɾ], как в [bʌɾəɹ], или как голосовая остановка в таких словах, как «кнопка» [bʌʔən].
Интересно, что единственное фонологическое окружение, в котором /t/ фактически появляется как [t], находится в группе согласных, например, в слове «стоп» [stap].
Эти различные поверхностные формы (SF) /t/ называются аллофонами. Аллофоны — это все (алло) звуки (фоны), которые могут представлять один звук в различных фонологических средах.
Вы увидите эти аллофоны, представленные следующим образом:
(2) /t/ (звук в уме говорящего)
/ | | | \ (поверхности как)
[t] [tʰ] [ʔ] [ɾ] [tʃ] (аллофоны [t])
В других языках, таких как хинди, [-придыхательные] остановки и [+придыхательные] остановки не являются аллофонами одного звука, а являются контрастными, что означает, что когда [p] и [pʰ] появляются в одном и том же окружении, значение слово действительно изменится.
Например, [p] в [pəl] ‘момент’ и [pʰ ] в [pʰəl] ‘плод’ – это две разные фонемы.
Вы увидите эти фонемы, представленные следующим образом:
(3) /p/ /pʰ/
| |
[p] [pʰ]
Итак, в этом языке особое значение имеет устремление.
Аллофоны также могут быть отдельными фонемами в языке, возникающими в определенных средах, управляемых правилами. Например, мы знаем, что /s/ и /z/ — это две отдельные фонемы в английском языке. Однако при обозначении существительного во множественном числе существует правило, определяющее, будет ли SF быть /s/ или /z/. (4) показывает, что морфемой множественного числа будет звонкий альвеолярный фрикативный звук /z/, когда слово оканчивается на звонкий звук, и глухой альвеолярный фрикативный звук /s/, следующий за глухим звуком.
(4)
[bægz] ‘мешки’ [bæks] ‘спины’ [sidz] ‘семена’ [сидит] ‘сидит’ [флайз] ‘летает’ [флайц] ‘полет’
Поскольку /s/ и /z/ являются вариантами морфемы, они называются алломорфами.
Аллофоны обычно встречаются в дополнительном распространении, что означает, что одна форма фонемы никогда не появится в среде другой. Другими словами, звуки чередуются друг с другом в зависимости от того, где они находятся в слове или фразе, точно так же, как [t] и [tʰ] в английском языке.
2. Классы звуков
Фонемы можно классифицировать по общим признакам, создавая классы, которые дают представление о том, как звуки взаимодействуют в конкретной фонологической среде.
Основные классы отличаются друг от друга по степени звучности. Это соответствует расположению звуков в слоге.
слоговые Звуки [+/-syll] составляют вершины слогов и могут заполнять ядро слога. Обычно они более заметны в восприятии, чем смежные неслоговые звуки.
[+слог]: гласные и слоговые согласные [-слог]: стопы, фрикативы, аффрикаты, аппроксиманты и [-слог] жидкости и носовые звуки
согласные [+/-против] звуки производятся с устойчивым сужением голосового тракта, по крайней мере, равным тому, которое требуется для производства фрикативных звуков; несогласные звуки производятся без такого сужения.
[+минусы]: мешающие звуки, гнусавость, жидкости [-против]: гласные, скольжения и аппроксимации
сонорный : Звуки [+/- сын] производятся при достаточно открытой конфигурации голосового тракта, чтобы давление воздуха внутри и снаружи рта было примерно одинаковым. К ним относятся гласные, скольжения, жидкости, аппроксимации и носовые звуки. Звуки [-son] производятся при сужении голосового тракта, достаточном для значительного увеличения давления воздуха внутри ротовой полости по сравнению с окружающим воздухом. К ним относятся стопы, аффрикаты и фрикативы.
[+ сын]: жидкости, носы, скольжения, аппроксимации и гласные [-сын]: стопы, фрикативы, аффрикаты
возражающие [+/-obs] в основном соответствуют обратно обратным [+/- son] таким образом, что [+obs] включает в себя смычные, аффрикаты и фрикативные звуки, а [-obs] гласные, плавные движения, жидкости, аппроксиманты и носовые звуки.
Классы поведения основаны на затруднении воздушного потока.
континуанты [+/-cont] формируются с конфигурацией голосового тракта, позволяющей воздушному потоку проходить через среднесагиттальную область ротового тракта; взрывчатые вещества производятся с устойчивой окклюзией в этой области.
[+cont] состоит из гласных, скользящих, аппроксимационных и фрикативных звуков, тогда как [-cont] включает взрывные, аффрикаты и носовые звуки.
резкие [+/-стри] звуки производятся со сложным сужением, заставляющим воздушный поток ударяться о две поверхности, производя фрикативный шум высокой интенсивности
[+stri] включает в себя фрикативы и аффрикаты; сибилянты, лабиоденталии и увуляры. На стандартном английском
/f, v, s, z, ʃ, tʃ, ʒ, dʒ/ отмечены [+stri].
шипящие [+/-sib] звуки — это фрикативные и аффрикаты, которые являются [+stri, +cor] и произносятся, когда передняя часть языка приподнята к зубам или альвеолярному гребню. Как резкие, они создают большое количество турбулентности или белого шума . В английском языке 6 шипящих звуков: [s, z, ʃ, tʃ, ʒ, dʒ].
Классы мест основаны на месте сужения воздушного потока. Те, с которыми вы должны ознакомиться на вводном уровне, включают:
губной : [+/-лаб]
Эти звуки сопровождаются сжатием губ, а негубные звуки — нет. Губные включают все согласные, которые включают одну или обе губы в качестве артикулятора, а также те, которые несут вторичный признак [ w ], например [k w ].
коронка [+/-кор]
Корональные звуки образуются при поднятии языковой пластинки к зубам или твердому небу и состоят из зубных, альвеолярных, небно-альвеолярных/постальвеолярных и ретрофлексных согласных.
передний [+/-муравей]
Передние согласные сочленяются с передней частью языка в любом месте между альвеолярным гребнем и задней частью верхних зубов. К ним относятся постальвеолярные, альвеолярные, зубные, (межзубные), губно-зубные и двугубные звуки.
спинной [+/-дорсальный]
Дорсальные звуки произносятся при поднятии задней части языка (дорсальной поверхности) к небу или язычку или в контакте с ним, включая небные, небные и увулярные звуки.
*иногда имеется перекрытие с постальвеолярными (небно-альвеолярными). Это специфика языка.
радикалы [+/-рад]
Корневые звуки образуются при перетяжке между корнем языка и стенкой глотки и включают глоточные и надгортанные согласные.
гортань [+/-lar]
Звуки гортани — это звуки, при которых поток воздуха перекрывается или не затрудняется голосовыми связками и включают гортанные согласные.
Естественные классы
Естественные классы — это группы звуков, которые имеют по крайней мере одно или несколько общих свойств, отличающих их от всех других звуков. Для описания этих наборов фонем используется минимальное количество признаков, исключающих все остальные. Значения характеристик обозначаются + и –, и используются только те, которые относятся к звукам. См. наш учебник по избыточности для получения дополнительной информации по этой теме.
Члены естественного класса обычно ведут себя одинаково в одной и той же фонологической среде. Например, естественный класс [+syll, -cons, +high] (высокие гласные) в английском языке имеет тенденцию вызывать палатализацию предшествующих согласных.
(5)/t//tʃ//d//ʤ/
/stejtli//stætʃəɹ//gɹejd//grʤʤuəl/
‘stethel’ ‘stature’ ‘grade’ ‘‘‘
/z//////// ʒ//s//ʃ/
/siz//siʒəɹ//fejs//fejʃiəl/
‘Sakize’ ‘Cavizure’ ‘Face’ » Facial ‘
Интересно, естественные классы появляются в одинаковых окружающих окружающих по разным языкам. . Например, японские [+syll, -cons, +high] (высокие гласные) имеют тот же эффект.
(6)
/t//tʃ//s//ʃ/
/kat-itai/[katʃitai] ‘win’/kas-itai/[kaʃitai] ‘Lend
для получения дополнительной информации об этих классах , обратитесь к нашему руководству по функциям и классам.
3. Анализ данных
В общих чертах, цель фонологического анализа состоит в том, чтобы идентифицировать звуковые модели языка, чтобы идентифицировать отдельные фонемы и учитывать аллофонические вариации. При проведении фонологического анализа обязательно следуйте шагам, перечисленным ниже. Чем систематичнее ваш подход, тем выше вероятность того, что вы проведете сильный анализ.
3.1. Минимальные пары
Первый шаг — поиск минимальных пар. Это слова, отличающиеся одной фонемой. Если вы смотрите на распределение звуков /p, b/, найдите пары слов, значение которых меняется, когда эти звуки меняются местами. Например:
летучая мышь/пат
Эти два слова идентичны, за исключением первого звука каждого слова, но имеют совершенно разные значения.
3.2. Почти минимальные пары
Когда мы подозреваем, что две фонемы различны, но не можем найти их в идентичной фонологической среде, мы можем искать почти минимальные пары: два слова, которые имеют одинаковые звуки в непосредственно окружающих средах.
Например, /mɪʃən/ ‘миссия’ и /vɪʒən/ ‘видение’ показывают, что /ʃ/ и /ʒ/ являются разными фонемами, поскольку, хотя начальный звук в каждом слове разный, интересующие фонемы находятся сразу в окружающие среды, которые идентичны, т. Е. Им предшествует / ɪ /, а следует / ən /.
Существует еще один тип почти минимальной пары, в которой добавление одного звука меняет значение. Например, при сравнении /lip/ «прыжок» и /slip/ «сон», когда добавляется /s/, значение слова меняется. В этом примере окружение /s/, начальное слово, заменяется на /ø/, которое также находится в начальной позиции слова.
3.3 Свободная вариация
Некоторые фонемы появляются в идентичной фонологической среде, но их значение не меняется. Иногда говорящий будет использовать один аллофон, а иногда и другой, просто исходя из социального контекста. Например, носитель английского языка может произносить слово «speaking» как [spikIn] в одних ситуациях и как [spikIŋ] в других. [n] и [ŋ] являются аллофонами, но свободно чередуются в конечной позиции слова. Важно отметить, что свободное варьирование относится к тому, как один отдельный говорящий может варьировать произношение в зависимости от социального контекста, а не к языковым/диалектным правилам.
Если вы найдете минимальные пары, дальше не идете. Они указывают на то, что интересующие фонемы представляют собой отдельные звуки.
3.4 Дополнительное распространение
Если вы не найдете минимальных пар, вероятно, интересующие вас фонемы являются аллофонами, обнаруженными в дополнительном распределении. Аллофоны являются членами одного основного представления (UR), абстрактного звука в уме говорящего, которые никогда не встречаются в перекрывающихся фонологических средах.
Отдельные фонемы могут встречаться в аллофонических вариациях. Рассмотрим (7).
(7)
/t/ UR
/ \
[t] [tʃ] 2 9 1 0 0 SF [stap] [tʃɹejn]
«остановка» и «поезд»
В этом примере SF /t/ встречается как вторая согласная в начальном кластере слова; однако, когда за ним следует /ɹ/, /t/ становится /tʃ/. См. (2).
Аллофоны также могут быть вариантами основной фонемы, о которой говорящий часто не подозревает. Это верно для [t h ] в начальной позиции слова. Носители стандартного английского не знают, что они добавляют к этому звуку особенность [придыхание]. Более того, если такой вариант, как [t h ], заменить на /t/, значение не изменится. Произношение может показаться немного странным, но смысл ясен. Другой пример — носовые гласные в английском языке. Все гласные, которые предшествуют носовому звуку, становятся носовыми.
/flowt/ но /flõwn/
Говорящие не знают об этом варианте; однако это единственная форма гласного, которая когда-либо будет появляться в этой фонологической среде. Кроме того, не носовые гласные никогда не будут стоять перед носовыми.
/flowt/ но не * /flõwt/ и не */flown/
Это управляемое правилом распределение носовых и не носовых гласных.
4. Фонологическая среда
Чтобы найти распределение звуков, вы можете создать диаграмму, в которой перечислены фонологические среды, в которых появляются интересующие вас фонемы. Таким образом, вы можете визуализировать, находятся ли звуки в дополнительном или перекрывающемся распределении. Рассмотрим (8).
(8)
[læf] ‘смех’ [liv] ‘уйти’ [kuɫ] ‘круто’ [stIɫ] ‘все еще’
В этом примере нет перекрытия в распределении /l/ и /ɫ/, так как /l/ появляется только в начальной позиции слова, а /ɫ/ в слове final. Составляя схему того, какие звуки появляются в какой фонологической среде, мы видим, что они находятся в дополнительном распределении.
(9)
Обратите внимание на символы для различных сред.
Начальное слово
#___ (в начале слова)
окончание слова
___# (в конце слова)
интервокальное
В__В (между гласными)
смежные телефоны
С___ (после согласного)
02 90 гласная)___V (перед гласной)
звонкость
[+/-vce]___ (после звонких звуков)
___[+/-vce] (перед звонким звуком)
# = граница слова
$ = граница слога
+ = граница морфемы
5.
Правила написанияКак только вы найдете фонологическую среду, в которой появляются интересующие вас фонемы, вы можете написать правило, учитывающее их распределение.
Чтобы обобщить концепцию правил письма, мы можем сказать:
Фонематическая форма (UR)
↓
Подвергается фонологическим правилам
↓
Научитесь фонетической форме (SF)
3 в соответствии с ожиданиями вашего профессора. Некоторым просто нужны фонемы в скобках, в то время как другим потребуется описание, основанное на естественных классах и отличительных признаках. Как бы то ни было, вот стандартные символы, используемые при написании правил:
/ / UR
→ = становится
[ ] Сан-Франциско
/ = в окружении
___ = представляет фонему, которая претерпевает изменения
Другими словами, вы сначала указываете UR; затем укажите, как оно меняется; затем покажите обстоятельства, при которых оно изменяется (среда). Вот краткое руководство по базовому представлению.
6. Типы правил
Существует несколько типов правил, с которыми вам следует ознакомиться.
-Правила ассимиляции
Правила ассимиляции заставляют фонему приобретать определенные черты соседнего звука. Например, все гласные в английском языке становятся [+ носовыми], когда они предшествуют [+ носовым] согласным. Эта ассимиляция признака [+носовой] облегчает воспроизведение гласного звука. Правило выглядит примерно так:
V → Ṽ/ ____ C̃
-Правила диссимиляции
Правила диссимиляции заставляют две соседние фонемы становиться отличными друг от друга для облегчения произношения. Примером правила диссимиляции может быть пропуск [θ] в конечной позиции слов, таких как [sIksθ] «шестой» или [fIfθ] «пятый». [Голосовые] фрикативы [s] и [f] имеют сходные черты с [θ], который также является [голосовым] фрикативом. Фрикат [θ] обычно меняется на смычный [t], так что слова действительно произносятся [sIkst] и [fIft].
/θ/ → [t] / [фрикативный] ____
-Правила вставки
Правила вставки заставляют фонему добавляться к слогу или слову. Это показано во множественном числе английского языка. Когда [mℇs] становится множественным числом, множественное число [z] или [s] нельзя добавить без предварительной вставки [ə], поскольку два [шипящих] не могут быть рядом друг с другом. Таким образом, [mℇs] становится [mℇsəz]. Этот тип правила будет выглядеть так:
∅ → [ə] / [+шипящий] ____ [+шипящий]
-Правила удаления
Правила удаления вызывают удаление фонемы из слога или слова. Эти правила применяются для облегчения произношения и часто встречаются в быстрой речи. Большинство носителей английского языка произносят слово [mℇmɔri] ‘память’ как [mℇmri] «память», опуская [ɔ]. Этот тип правила будет выглядеть так:
[ɔ] –>∅ /[+звучный] ____ [+звучный]
— Метатезис
Правила метатезиса изменяют порядок звуков. Самый распространенный пример метатезиса в английском языке можно увидеть в произношении слова [æsk] ‘спросить’ как [æks] ‘aks’.