Слова «плюс» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «плюс» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «плюс» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «плюс».
Содержимое:
- 1 Как перенести слово «плюс»
- 2 Морфологический разбор слова «плюс»
- 3 Разбор слова «плюс» по составу
- 4 Сходные по морфемному строению слова «плюс»
- 5 Синонимы слова «плюс»
- 6 Антонимы слова «плюс»
- 7 Ударение в слове «плюс»
- 8 Фонетическая транскрипция слова «плюс»
- 9 Фонетический разбор слова «плюс» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «плюс»
- 11 Сочетаемость слова «плюс»
- 12 Значение слова «плюс»
- 13 Как правильно пишется слово «плюс»
- 14 Ассоциации к слову «плюс»
Как перенести слово «плюс»
Плюс
Морфологический разбор слова «плюс»
Часть речи:
Союз
Грамматика:
часть речи: союз;
отвечает на вопрос:
Начальная форма:
плюс
Разбор слова «плюс» по составу
| плюс | корень |
| ø | нулевое окончание |
плюс
Сходные по морфемному строению слова «плюс»
Сходные по морфемному строению слова
Синонимы слова «плюс»
1. достоинство
достоинство
2. преимущество
3. добродетель
4. совершенство
5. знак
6. крестик
7. да
8. выгода
9. сильная сторона
10. положительный момент
Антонимы слова «плюс»
1. минус
Ударение в слове «плюс»
Плю́с — ударение падает на слог с единственной гласной в слове
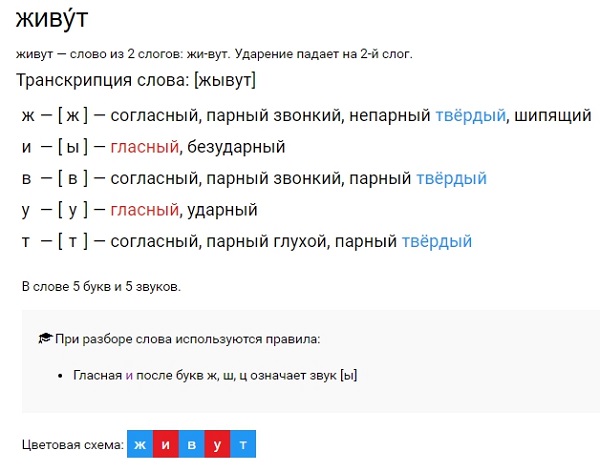
Фонетическая транскрипция слова «плюс»
[пл’`ус]
Фонетический разбор слова «плюс» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | |
|---|---|---|---|
| П | [п] | согласный, глухой парный, твёрдый, шумный | П |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| ю | [`у] | гласный, ударный | ю |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 4 буквы и 4 звука.
Буквы: 1 гласная буква, 3 согласных букв.
Звуки: 1 гласный звук, 3 согласных звука.
Предложения со словом «плюс»
Но при всех плюсах май больше подходит для общения со старыми друзьями, а новые персоны, появившиеся в вашем окружении в период с 27 апреля по 22 мая, пользы вам не принесут.
Источник: Татьяна Борщ, Лунный календарь для женщин на 2016 год + календарь стрижек, 2015.
В такой холод (а были примерно плюс десять) нас встретили полуобнажённые служанки.
Источник: Александр Маяков, Летописи межмирья. Книга четвертая. Осколки.
Плюс отряд «Вергилий» и десяток рыцарей.
Источник: Александр Маяков, Летописи межмирья. Книга четвертая. Осколки.
Сочетаемость слова «плюс»
1. большой плюс
большой плюс
2. единственный плюс
3. огромный плюс
4. до плюс бесконечности
5. множество плюсов
6. масса плюсов
7. со знаком плюс
8. плюсы перевешивают
9. иметь свои плюсы и минусы
10. взвешивать плюсы и минусы
11. найти свои плюсы
12. (полная таблица сочетаемости)
Значение слова «плюс»
ПЛЮС , -а, м. 1. Мат. Знак (+), обозначающий действие сложения или положительность величины; противоп. минус. Поставить плюс. (Малый академический словарь, МАС)
Как правильно пишется слово «плюс»
Правописание слова «плюс»
Орфография слова «плюс»
Правильно слово пишется: плюс
Нумерация букв в слове
Номера букв в слове «плюс» в прямом и обратном порядке:
- 4
п
1 - 3
л
2 - 2
ю
3 - 1
с
4
Ассоциации к слову «плюс»
Минус
Балл
Ноль
Очко
Шкала
Процент
Баланс
Сложение
Стоимость
Нуль
Аккумулятор
Двойка
Чаевые
Издержка
Оклад
Градус
Аглая
Расход
Гонорар
Погост
Тройка
Температура
Зарплата
Телепатия
Оплата
Страховка
Варианта
Компенсация
Ооо
Оценка
Возмещение
Бакс
Гравитация
Штраф
Жалованье
Стипендия
Радиостанция
Пенс
Обозреватель
Плата
Взнос
Дизайн
Скидка
Льгота
Аванс
Авто
Налог
Гражданка
Авторские
Доллар
Внезапность
Сумма
Комплект
Имидж
Питание
Котов
Сбережение
Вещание
Литр
Недостаток
Влажность
Несомненный
Балловый
Безусловный
Дополнительный
Бесплатный
Кое-какой
Неоспоримый
Центовый
Долларовый
Чеченский
Бесспорный
Годовой
Очевидный
Евро
Пике
Фунтовый
Сюжетный
Гарантированный
Существенный
- Отрицательный
Выпуклый
Заработный
Призовой
Пожизненный
Стерлинговый
Обслуживающий
Ежемесячный
Взвешивать
Взвесить
Равняться
Прикинуть
Перечислять
Сочетать
Отнести
Оценить
Прикидывать
Обозначаться
Итого
Объективно
Опубликовано: 2020-07-08
Популярные слова
воспитанник , беседами , взбежавшие , взъерошив , выскребу , высчитанною , вытравлявшей , вячеславом , гемолизом , геннадиевичи , гимнастерочку , домоустройство , завибрируют , завинчивающимся , павлиньего , парабеллумами , парковавшемся , перебираемыми , плакатная , подающее , подлетать , подросту , положительнейшего , помпонах , поохотившимся , пражского , прогульном , прокашливаться , проституируя , противогазовые , развернувшее , разделе , раскрутилось , раскусывают , расторгну , резервированного , реорганизовавшем , респонсорною , сильванер , солея
Стандартный синтаксический анализатор запросов | Справочное руководство Apache Solr 6.
 6
6 Парсер запросов Solr по умолчанию также известен как парсер « lucene ».
Основным преимуществом стандартного анализатора запросов является то, что он поддерживает надежный и довольно интуитивно понятный синтаксис, позволяющий создавать разнообразные структурированные запросы. Самым большим недостатком является то, что он очень нетерпим к синтаксическим ошибкам по сравнению с чем-то вроде парсера запросов DisMax, который разработан так, чтобы выдавать как можно меньше ошибок.
Стандартные параметры синтаксического анализатора запросов
В дополнение к общим параметрам запроса, параметрам фасетирования, параметрам выделения и параметрам MoreLikeThis стандартный синтаксический анализатор запросов поддерживает параметры, описанные в таблице ниже.
| Параметр | Описание |
|---|---|
q | Определяет запрос, используя стандартный синтаксис запроса. |
ежеквартально | Указывает оператор по умолчанию для выражений запроса, переопределяя оператор по умолчанию, указанный в схеме. Возможные значения: «И» или «ИЛИ». |
дф | Указывает поле по умолчанию, переопределяя определение поля по умолчанию в схеме. |
свиноматки | Разделить по пробелам: если установлено значение |
Значения параметров по умолчанию указаны в solrconfig. или переопределены значениями времени запроса в запросе. xml
xml
Ответ стандартного анализатора запросов
По умолчанию ответ стандартного анализатора запросов содержит один безымянный блок . Если используется параметр debug , то дополнительно будет возвращен блок с именем «debug». Он будет содержать полезную информацию для отладки, включая исходную строку запроса, проанализированную строку запроса и информацию объяснения для каждого документа в блоке объяснениеДругое , то для всех документов, соответствующих этому запросу, будет предоставлена дополнительная информация объяснения.
Примеры ответов
В этом разделе представлены примеры ответов стандартного анализатора запросов.
Приведенный ниже URL-адрес отправляет простой запрос и запрашивает модуль записи ответов XML для использования отступов, чтобы сделать ответ XML более удобочитаемым.
http://localhost:8983/solr/techproducts/select?q=id:SP2514N
Результаты:
<ответ><результат numFound="1" start="0"> <док> 0 1 электроника жесткий диск 7200 об/мин, 8 МБ кэш-памяти, IDE Ultra ATA-133 NoiseGuard, технология SilentSeek, двигатель с гидродинамическим подшипником (FDB) SP2514N true Samsung Electronics Co. Ltd. Samsung SpinPoint P120 SP2514N — жесткий диск — 250 ГБ — ATA-133 6 <плавающее имя="цена">92.0SP2514N
Вот пример запроса с ограниченным списком полей.
http://localhost:8983/solr/techproducts/select?q=id:SP2514N&fl=id+name
Результаты:
<ответ><результат numFound="1" start="0"> <док> 0 2 SP2514N Samsung SpinPoint P120 SP2514N — жесткий диск — 250 ГБ — ATA-133
Указание терминов для стандартного анализатора запросов
Запрос к стандартному анализатору запросов разбит на термины и операторы. Есть два типа терминов: отдельные термины и словосочетания.
Есть два типа терминов: отдельные термины и словосочетания.
Несколько терминов можно комбинировать с логическими операторами для формирования более сложных запросов (как описано ниже).
Важно, чтобы анализатор, используемый для запросов, разбирал термины и фразы таким же образом, как и анализатор, используемый для индексации, разбирает термины и фразы; в противном случае поиск может дать неожиданные результаты. |
Модификаторы терминов
Solr поддерживает различные модификаторы терминов, которые при необходимости повышают гибкость или точность поиска. Эти модификаторы включают подстановочные знаки, символы для «нечеткого» или более общего поиска и так далее. Разделы ниже подробно описывают эти модификаторы.
Поиск с подстановочными знаками
Стандартный синтаксический анализатор запросов Solr поддерживает односимвольный и многосимвольный поиск с подстановочными знаками в пределах одного термина. Подстановочные знаки можно применять к отдельным терминам, но не к поисковым фразам.
Подстановочные знаки можно применять к отдельным терминам, но не к поисковым фразам.
| Тип поиска с подстановочными знаками | Специальный символ | Пример |
|---|---|---|
Один символ (соответствует одному символу) | ? | Строка поиска |
Несколько символов (соответствует нулю или более последовательным символам) | * | Поиск с подстановочными знаками: |
Нечеткий поиск
Стандартный анализатор запросов Solr поддерживает нечеткий поиск на основе алгоритма расстояния Дамерау-Левенштейна или алгоритма редактирования расстояния. Нечеткий поиск обнаруживает термины, похожие на указанный термин, но не обязательно являющиеся точным совпадением. Чтобы выполнить нечеткий поиск, используйте символ тильды ~ в конце термина, состоящего из одного слова. Например, чтобы найти термин, похожий по написанию на «бродить», используйте нечеткий поиск:
Нечеткий поиск обнаруживает термины, похожие на указанный термин, но не обязательно являющиеся точным совпадением. Чтобы выполнить нечеткий поиск, используйте символ тильды ~ в конце термина, состоящего из одного слова. Например, чтобы найти термин, похожий по написанию на «бродить», используйте нечеткий поиск:
бродить~
Этот поиск будет соответствовать таким словам, как бродить, пена и пена. Оно также будет соответствовать самому слову «бродить».
Необязательный параметр расстояния определяет максимально допустимое количество правок от 0 до 2, по умолчанию 2. Например:
бродить~1
расстояние редактирования «2».
Во многих случаях поиск по основам (приведение терминов к общей основе) может привести к эффектам, подобным нечеткому поиску и поиску с подстановочными знаками. |
Поиск по близости
Поиск по близости ищет термины, находящиеся на определенном расстоянии друг от друга.
Чтобы выполнить поиск по близости, добавьте символ тильды ~ и числовое значение в конце поисковой фразы. Например, для поиска слов «апач» и «джакарта» в пределах 10 слов друг от друга в документе используйте поиск:
«апач джакарта»~10
Расстояние, которое здесь указано, — это номер термина. движения, необходимые для соответствия заданной фразе. В приведенном выше примере, если «apache» и «jakarta» находятся на расстоянии 10 пробелов друг от друга в поле, но «apache» стоит перед «jakarta», потребуется более 10 перемещений терминов, чтобы переместить термины вместе и расположить «apache» на справа от «джакарты» с пробелом между ними.
Поиск в диапазоне
Поиск в диапазоне задает диапазон значений для поля (диапазон с верхней и нижней границей). Запрос сопоставляет документы, значения которых для указанного поля или полей попадают в диапазон. Запросы диапазона могут включать или исключать верхнюю и нижнюю границы. Сортировка выполняется лексикографически, за исключением числовых полей. Например, приведенный ниже запрос диапазона соответствует всем документам, в которых
Например, приведенный ниже запрос диапазона соответствует всем документам, в которых поле популярности имеет значение от 52 до 10 000 включительно.
популярность:[52 TO 10000]
Запросы диапазона не ограничиваются полями даты или даже числовыми полями. Вы также можете использовать диапазонные запросы с полями без даты:
title:{Aida TO Carmen}
Это найдет все документы, заголовки которых находятся между Aida и Carmen, но не включая Aida и Carmen.
Скобки вокруг запроса определяют его включенность.
Квадратные скобки
[и]обозначают включающий запрос диапазона, который соответствует значениям, включая верхнюю и нижнюю границу.Фигурные скобки
{и}обозначают запрос исключительного диапазона, который сопоставляет значения между верхней и нижней границами, но исключает сами верхнюю и нижнюю границы.Вы можете смешивать эти типы, чтобы один конец диапазона был включающим, а другой — исключающим.
 Вот пример:
Вот пример: count:{1 TO 10] 9=1.0 text:shoes
 Вот пример:
Вот пример: Указание полей в запросе к стандартному синтаксическому анализатору запросов
Данные, проиндексированные в Solr, организованы в поля, которые определены в схеме Solr. Поиск может использовать преимущества полей для повышения точности запросов. Например, вы можете искать термин только в определенном поле, например в поле заголовка.
Схема определяет одно поле как поле по умолчанию. Если вы не укажете поле в запросе, Solr ищет только поле по умолчанию. Кроме того, вы можете указать другое поле или комбинацию полей в запросе.
Чтобы указать поле, введите имя поля, затем двоеточие «:», а затем искомый термин в поле.
Например, предположим, что индекс содержит два поля, заголовок и текст, и этот текст является полем по умолчанию. Если вы хотите найти документ под названием «Правильный путь», который содержит текст «не идите этим путем», вы можете включить в поисковый запрос любой из следующих терминов:
заголовок: «Правильный путь» И text:go
title:"Делай правильно" AND go
Поскольку текстовое поле является полем по умолчанию, индикатор поля не требуется; следовательно, второй запрос выше пропускает его.
Поле допустимо только для термина, которому оно непосредственно предшествует, поэтому запрос title:Do it right найдет только «Do» в поле заголовка. Он найдет «это» и «правильно» в поле по умолчанию (в данном случае в текстовом поле).
Логические операторы позволяют применять логическую логику к запросам, требующим наличия или отсутствия определенных терминов или условий в полях для сопоставления документов. В таблице ниже приведены логические операторы, поддерживаемые стандартным анализатором запросов.
| Логический оператор | Альтернативный символ | Описание |
|---|---|---|
И | | Для совпадения требуется присутствие обоих терминов по обе стороны от логического оператора. |
НЕ | | Требует отсутствия следующего термина. |
ИЛИ | | Требуется, чтобы для совпадения присутствовал один термин (или оба термина). |
| Требуется наличие следующего термина. | |
| Запрещает следующий термин (то есть совпадения в полях или документах, не содержащих этот термин). 9Оператор 0003 — функционально аналогичен логическому оператору |

Логические операторы позволяют комбинировать термины с помощью логических операторов. Lucene поддерживает И, «+», ИЛИ, НЕ и «-» в качестве логических операторов.
При указании логических операторов с такими ключевыми словами, как И или НЕ, ключевые слова должны быть указаны в верхнем регистре. |

Стандартный анализатор запросов поддерживает все логические операторы, перечисленные в таблице выше. Анализатор запросов DisMax поддерживает только |
Оператор ИЛИ является оператором соединения по умолчанию. Это означает, что если между двумя терминами нет логического оператора, используется оператор ИЛИ. Оператор ИЛИ связывает два термина и находит совпадающий документ, если какой-либо из терминов существует в документе. Это эквивалентно объединению с использованием множеств. Символ || можно использовать вместо слова ИЛИ.
Для поиска документов, содержащих «jakarta apache» или просто «jakarta», используйте запрос:
«jakarta apache» jakarta
или
«jakarta apache» OR jakarta 54 504 +
Символ + (также известный как «обязательный» оператор) требует, чтобы термин после символа + существовал где-то в поле хотя бы в одном документе, чтобы запрос вернул совпадение.
Например, для поиска документов, которые должны содержать слово «jakarta» и могут содержать или не содержать слово «lucene», используйте следующий запрос:
+jakarta lucene
Этот оператор поддерживается как стандартным парсером запросов, так и парсером запросов DisMax. |
Логический оператор И (
&& )Оператор И сопоставляет документы, в которых оба термина присутствуют в любом месте в тексте одного документа. Это эквивалентно пересечению с использованием множеств. Символ 9Вместо слова AND можно использовать 0003 && .
Для поиска документов, содержащих «jakarta apache» и «Apache Lucene», используйте любой из следующих запросов:
«jakarta apache» И «Apache Lucene»
«jakarta apache» && «Apache Lucene»
Булев оператор НЕ (
! ) Оператор НЕ исключает документы, содержащие термин после НЕ. Это эквивалентно различию с использованием наборов. Символ
Это эквивалентно различию с использованием наборов. Символ ! Вместо слова NOT можно использовать .
Следующие запросы выполняют поиск документов, содержащих фразу «jakarta apache», но не содержащих фразу «Apache Lucene»:
"jakarta apache" НЕ "Apache Lucene"
"jakarta apache" ! "Apache Lucene"
Логический оператор
- Символ - или оператор «запретить» исключает документы, содержащие термин после символа - .
Например, для поиска документов, содержащих «jakarta apache», но не «Apache Lucene», используйте следующий запрос:
«jakarta apache» - «Apache Lucene»
Экранирование специальных символов
Solr дает особое значение следующих символов при их появлении в запросе:
+ - && || ! ( ) { } [ 9 " ~ * ? : /
Чтобы Solr интерпретировал любой из этих символов буквально, а не как специальный символ, поставьте перед ним обратную косую черту 0. Например, 90 \0003 символ обратной косой черты 90. , чтобы найти (1+1):2, не заставляя Solr интерпретировать знак плюс и круглые скобки как специальные символы для формулировки подзапроса с двумя терминами, экранируйте символы, ставя перед каждым из них обратную косую черту:
Например, 90 \0003 символ обратной косой черты 90. , чтобы найти (1+1):2, не заставляя Solr интерпретировать знак плюс и круглые скобки как специальные символы для формулировки подзапроса с двумя терминами, экранируйте символы, ставя перед каждым из них обратную косую черту:
\(1\+1\)\:2
Группировка условий для формирования подзапросов
Lucene/Solr поддерживает использование круглых скобок для группирования предложений для формирования подзапросов. Это может быть очень полезно, если вы хотите управлять булевой логикой запроса.
Приведенный ниже запрос ищет либо «jakarta», либо «apache» и «веб-сайт»:
(jakarta ИЛИ apache) И веб-сайт
Это повышает точность запроса, требуя, чтобы термин «веб-сайт» существовал, наряду с любым термином «джакарта» и «апач».
Группировка предложений внутри поля
Чтобы применить два или более логических оператора к одному полю при поиске, сгруппируйте логические предложения в круглых скобках. Например, приведенный ниже запрос ищет поле заголовка, содержащее слово «возврат» и фразу «розовая пантера»:
Например, приведенный ниже запрос ищет поле заголовка, содержащее слово «возврат» и фразу «розовая пантера»:
title:(+return +»pink panther»)
Поддерживаются комментарии C-Style. в строках запроса.
Пример:
"jakarta apache" /* это комментарий в середине обычной строки запроса */ ИЛИ jakarta
Комментарии могут быть вложенными.
Различия между синтаксическим анализатором запросов Lucene и стандартным синтаксическим анализатором запросов Solr
Стандартный синтаксический анализатор запросов Solr отличается от синтаксического анализатора запросов Lucene следующим образом:
A * может использоваться для одной или обеих конечных точек, чтобы указать открытый запрос диапазона
field:[* TO 100]находит все значения поля меньше или равные 100поле: [100 ДО *]находит все значения поля больше или равные 100field:[* TO *]соответствует всем документам с полем
Чисто отрицательные запросы (все предложения запрещены) разрешены (только как предложение верхнего уровня)
Перехват синтаксиса FunctionQuery.
Вам нужно будет использовать кавычки для инкапсуляции функции, если она включает круглые скобки, как показано во втором примере ниже:Поддержка использования анализатора запросов любого типа в качестве вложенного предложения.
Поддержка специального синтаксиса
filter(…)для указания того, что некоторые предложения запроса должны кэшироваться в кэше фильтра (как логический запрос с постоянной оценкой). Это позволяет кэшировать подзапросы и повторно использовать их в других запросах. Например,inStock:trueбудет кэшировано и повторно использовано во всех трех следующих запросах:q=функции:песни ИЛИ фильтр(на складе:true)q=+manu:Apple +фильтр(на складе:true)q=+manu:Apple & fq=inStock:trueЭто можно использовать даже для кэширования отдельных предложений сложных запросов с фильтрацией. В приведенном ниже первом запросе в кеш фильтра будут добавлены 3 элемента (верхний уровень
fqи оба предложенияfilter(…)), а во втором запросе будет 2 попадания в кеш и один новый кеш. вставка (для нового верхнего уровня fq):q=features:songs & fq=+filter(inStock:true) +filter(price:[* TO 100])q=manu:Apple & fq=-filter(inStock:true) -filter(price:[* TO 100])
Запросы диапазона («[a TO z]»), префиксные запросы («a*») и запросы с подстановочными знаками («a*b») имеют постоянную оценку (все соответствующие документы получают одинаковую оценку). Факторы оценки TF, IDF, повышение индекса и «координация» не используются. Количество совпадающих терминов не ограничено (как это было в прошлых версиях Lucene).
- 9=
, который устанавливает для всего предложения указанную оценку для любых документов, соответствующих этому предложению:
 Вам нужно будет использовать кавычки для инкапсуляции функции, если она включает круглые скобки, как показано во втором примере ниже:
Вам нужно будет использовать кавычки для инкапсуляции функции, если она включает круглые скобки, как показано во втором примере ниже: вставка (для нового верхнего уровня
вставка (для нового верхнего уровня Указание даты и времени
Запросы к полям с использованием типа TrieDateField (обычно запросы диапазона) должны использовать соответствующий синтаксис даты:
метка времени: [* ДО СЕЙЧАС]createdate:[1976-03-06T23:59:59. 999Z TO *] создано:[1995-12-31T23:59:59.999Z К 2007-03-06T00:00:00Z]публикация: [СЕЙЧАС-1ГОД/ДЕНЬ ДО СЕЙЧАС/ДЕНЬ+1ДЕНЬ]createdate:[1976-03-06T23:59:59.999Z TO 1976-03-06T23:59:59.999Z+1YEAR]createdate:[1976-03-06T23:59:59.999Z/ГОД ДО 1976-03-06T23:59:59.999Z]
 999Z TO *]
999Z TO *] Локальные параметры в запросах
Другие парсеры
Общие параметры запроса Парсер запросов DisMax
Пьер Дивеньи о фонетическом восстановлении
Дата:
Пт, 26.04.2013 – 13:15–14:30
Адрес:
Зал для семинаров CCRMA
Тип мероприятия:
Семинар по слуху
aaaaaaaaa BUZZ aaaaaaaaaaaaa
Если жужжание достаточно громкое, люди будут слышать непрерывный гласный звук. Это известно как фонетическая реставрация. Эл Брегман (автор тома «Анализ слуховых сцен») говорит, что это пример сочетания старого и нового. Я подозреваю, что это пример нисходящего влияния. Все примеры одного и того же процесса, которые помогают нам понять слуховой мир вокруг нас.
Это известно как фонетическая реставрация. Эл Брегман (автор тома «Анализ слуховых сцен») говорит, что это пример сочетания старого и нового. Я подозреваю, что это пример нисходящего влияния. Все примеры одного и того же процесса, которые помогают нам понять слуховой мир вокруг нас.
Пьер Дивеньи будет просматривать литературу и рассказывать об экспериментах, которые он провел по восстановлению фонетики. Как получается, что мы можем слышать звуки, которых нет? Как наш мозг анализирует мир, даже перед лицом громких шумов, которые затуманивают информацию, которую мы хотим услышать?
Кто: Пьер Дивеньи (CCRMA)
Что: Фонематическая реставрация с артикуляционным поворотом
Когда: четверг, 26 апреля, 13:15
Где: Зал для семинаров CCRMA (верхний этаж холма)
Почему: Потому что это волшебство 🙂
Не пропустите… Фонетическое восстановление мощно, но трудно восстановить целый час, пропущенный на семинаре по слухопротезированию.
— Malcolm
CCRMA Hearing Seminar April 26, 2013
Pierre Divenyi
Phonemic restoration with an articulatory twist
“Phonemic restoration” – перцептивное восстановление сегментов речи, замененных случайным шумом — впервые было обнаружено Уорреном в 19 году.70 и время от времени исследовались психологами-экспериментаторами, фонетиками, аудиологами и специалистами по вычислительной технике. Однако похоже, что его механизмы до настоящего времени в значительной степени оставались скрытыми. Обычно предполагается, что это некий нисходящий поток (генерирующий либо правильные, либо неправильные ответы), который заполняет недостающие сегменты, но природа этого потока неизвестна. Является ли это процессом поиска слов или фонем, которые имеют смысл в данном контексте, или это поток некоторых основных базовых функций, из которых отсутствующий сегмент восстанавливается в более высоком центре? Чтобы решить эту головоломку, мы сначала составили список «спондиев», соединив пары односложных слов с длинными гласными (небольшая часть которых включала настоящие спондиевские слова), а затем заменили их среднюю часть либо тишиной, либо плоской огибающей Гаусса. шум, или тот же шум, модулированный огибающей вырезаемой речи, или гул (низкочастотная пилообразная волна), имеющий контур f0 вырезаемого сегмента. Слушателям сказали, что исходным стимулом всегда была пара английских слов, и попросили напечатать то, что, по их мнению, представляла собой эта пара. Пары стимулов и ответов были фонематически выровнены для создания фонематических и фонетических матриц путаницы. Они также были повторно синтезированы с использованием артикуляционного синтезатора Haskins Labs TaDA (task dynamic application), построенного на восьми функциях жестов. Синтезированные пары сигналов были выровнены по времени, и вычислено расстояние между парами функций жестов. Данные показывают, что для всех четырех наполнителей фонематические и фонетические ошибки были примерно на один порядок больше, чем расстояние между жестами. Таким образом, результаты поддерживают теорию, согласно которой речь воспринимается путем ее разложения на некоторый набор разреженных базисных функций.
шум, или тот же шум, модулированный огибающей вырезаемой речи, или гул (низкочастотная пилообразная волна), имеющий контур f0 вырезаемого сегмента. Слушателям сказали, что исходным стимулом всегда была пара английских слов, и попросили напечатать то, что, по их мнению, представляла собой эта пара. Пары стимулов и ответов были фонематически выровнены для создания фонематических и фонетических матриц путаницы. Они также были повторно синтезированы с использованием артикуляционного синтезатора Haskins Labs TaDA (task dynamic application), построенного на восьми функциях жестов. Синтезированные пары сигналов были выровнены по времени, и вычислено расстояние между парами функций жестов. Данные показывают, что для всех четырех наполнителей фонематические и фонетические ошибки были примерно на один порядок больше, чем расстояние между жестами. Таким образом, результаты поддерживают теорию, согласно которой речь воспринимается путем ее разложения на некоторый набор разреженных базисных функций. Один такой набор будет состоять из артикуляционных жестов, и мы воспринимаем речь, когда наш мозг восстанавливает эти жесты — процесс, который фактически подтвержден нейробиологическими наблюдениями.
Один такой набор будет состоять из артикуляционных жестов, и мы воспринимаем речь, когда наш мозг восстанавливает эти жесты — процесс, который фактически подтвержден нейробиологическими наблюдениями.
Профиль – Пьер Дивеньи, профессор-консультант, CCRMA, факультет музыки
Пьер Дивеньи начал свою карьеру как пианист, давая сольные концерты в Европе и США. Будучи аспирантом Вашингтонского университета, его интересы обратились к науке, и он получил докторскую степень в области систематического музыковедения, написав диссертацию о восприятии ритма в микромелодиях. Эта работа привела его к исследованиям психоакустики последовательностей тонов, временных интервалов и слуховой локализации. Он работал исследователем сначала в Центральном институте глухих в Сент-Луисе, а затем в Лаборатории исследования речи и слуха Медицинского центра Мартинеса (Калифорния) штата Вирджиния, которой он руководил с 19с 79 по 2012 год. Его исследования в течение последних двух десятилетий были сосредоточены на анализе слуховой сцены и, в частности, на слуховых процессах, лежащих в основе отделения речи от фонового шума — так называемом «эффекте коктейльной вечеринки» — и его дисфункции.