What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.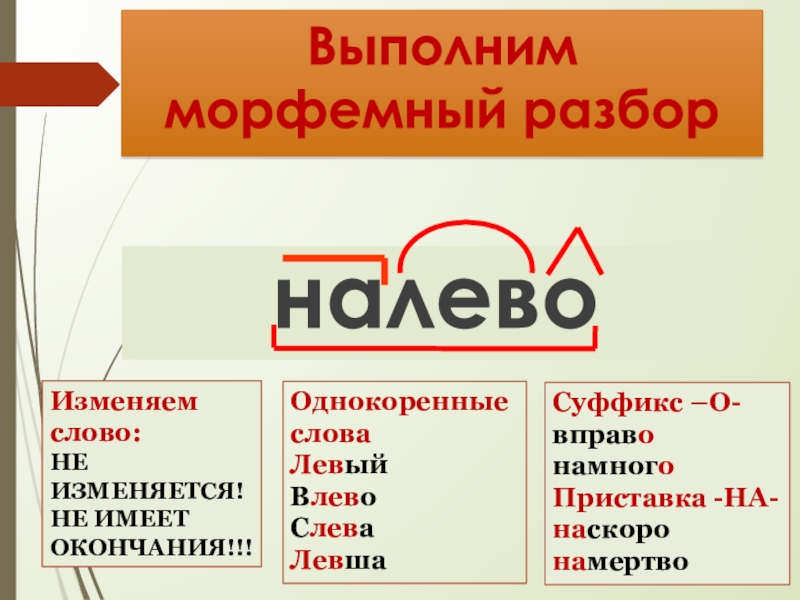
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.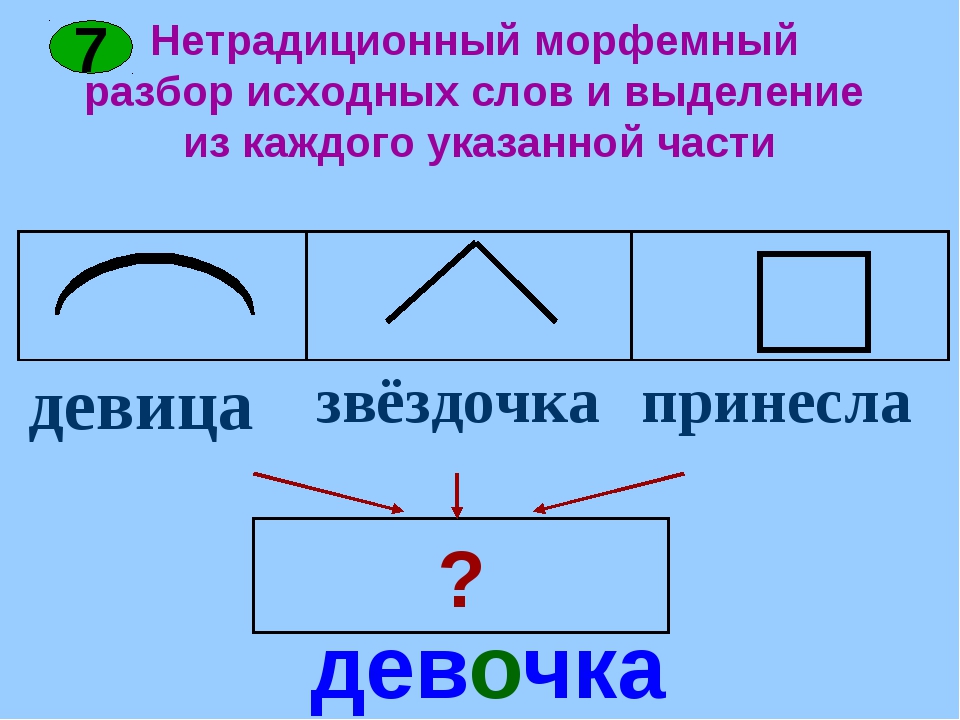
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «цепь», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ЦЕПЬ, и, о цепи, в (на) цепи, с цепи и с цепи, мн. и, ей, ж.
1. Ряд металлических (или других крепких) звеньев, продетых одно в другое. Якорная ц. Собака на цепи. Посадить на цепь или на цепь. Как с цепи сорвался кто-н. (о шумном, буйном поведении, а также, неодобр., о действиях очень рассерженного человека, потерявшего самообладание; разг.). Цепи рабства (перен.).
Якорная ц. Собака на цепи. Посадить на цепь или на цепь. Как с цепи сорвался кто-н. (о шумном, буйном поведении, а также, неодобр., о действиях очень рассерженного человека, потерявшего самообладание; разг.). Цепи рабства (перен.).
2. перен., чего. Сплошной ряд, совокупность чего-н.
3. Ряд гор. Горные цепи.
4. Линия (боевой порядок) стрелков, расположенных на нек-ром расстоянии друг от друга. Стрелковая ц. Рассыпаться в ц. Передать по цепи.
5. Последовательное соединение элементов, при к-ром последний элемент присоединяется к первому (спец.). Замкнутая магнитная ц.
• Электрическая цепь (спец.) совокупность устройств, предназначенных для прохождения в них электрического тока.
Ёлочная цепь бумажное ёлочное украшение в виде цепочки.
| прил. цепной, ая, ое (к 1, 4 и 5 знач.). Цепное устройство. Цепная схема.
цепной, ая, ое (к 1, 4 и 5 знач.). Цепное устройство. Цепная схема.
Фонетический (звуко-буквенный) разбор
Це́пь
Цепь — слово из 1 слога: Цепь. Ударение ставится однозначно на единственную гласную в слове.
Транскрипция слова: [цэп’]
ц — [ц] — согласный, глухой непарный, твёрдый (непарный, всегда произноится твёрдо)
е — [э] — гласный, ударный
п — [п’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 4 буквы и 3 звука.
Цветовая схема: цепь
Разбор слова «цепь» по составу
цепь
Части слова «цепь»: цепь
Состав слова:
цепь — корень,
нулевое окончание,
цепь — основа слова.
Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.

Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Тесты по русскому языку 6 класс Тест 23 Морфемный и словообразовательный разбор
Морфемный и словообразовательный разбор слова
Автор: ©2018, ООО КОМПЭДУ, http://compedu.ru
Описание:
При участии проекта http://videouroki.net
Задание 1
Вопрос:
Укажите, где правда, а где ложь.
Укажите истинность или ложность вариантов ответа:
__ при морфемном разборе мы разбираем слова по составу
__ при морфемном разборе мы не указываем основу
__ при словообразовательном разборе мы не выполняем полный морфемный разбор
__ цели у морфемного и словообразовательного разборов схожие, но всё же разные
Задание 2
Вопрос:
Выберите слово, в котором два корня.
Выберите один из 4 вариантов ответа:
1) землемер
2) канистра
3) сороковой
4) пересказывать
Задание 3
Вопрос:
Выберите слово, в котором есть нулевое окончание.
Выберите один из 4 вариантов ответа:
1) вниз
2) кричал
3) кино
4) такой
Задание 4
Вопрос:
Выберите пункты, которые мы указываем при морфемном разборе слова.
Выберите несколько из 6 вариантов ответа:
1) корень
2) приставка
3) однокоренные слова
4) окончание
5) основа
6) слово, от которого это слово образовалось
Задание 5
Вопрос:
Выберите пункты, которые мы указываем при словообразовательном разборе слова.
Выберите несколько из 6 вариантов ответа:
1) толкование значение слова
2) корень
3) способ, при помощи которого образовалось слово
4) морфема, при помощи которой образовалось слово
5) основу, от которой образовалось слово
6) окончание
Задание 6
Вопрос:
Укажите количество морфем в слове перегородка?
Запишите число:
___________________________
Задание 7
Вопрос:
От какого слова образовалось слово перешагнуть? В ответе запишите нужное слово в начальной форме.
Запишите ответ:
__________________________________________
Задание 8
Какие пункты мы будут верными при словообразовательном разборе слова «задира»?
Выберите несколько из 6 вариантов ответа:
1) окончание -а
2) образовалось от слова «драть»
3) образовалось от слова «задирать»
4) способ образования — суффиксальный
5) способ образования — бессуффиксный
6) способ образования — переход из одной части речи в другую
Задание 9
Вопрос:
Посмотрите на предложение. Какие пункты словообразовательного разбора будут ошибочными для выделенного слова?
Говорят, по городу ходит опасный сумасшедший.
Выберите несколько из 5 вариантов ответа:
1) слово образовано от двух основ: «с ума» и «сшедший»
2) способ словообразования — сложение основ
3) слово образовано от прилагательного «сумасшедший»
4) способ словообразования — переход из одной части речи в другую
5) способ словообразования — суффиксальный
Задание 10
Вопрос:
Постройте словообразовательную цепочку для слова «обогреватель». Сколько всего слов оказалось в этой цепочке (слово «обогреватель» тоже считается).
Ответ укажите числом.
Запишите число:
___________________________
Ответы:
1) (3 б.) Верные ответы: Да; Да; Да; Да;
2) (3 б.) Верные ответы: 1;
3) (3 б.) Верные ответы: 2;
4) (4 б.) Верные ответы: 1; 2; 4; 5;
5) (4 б.) Верные ответы: 1; 3; 4; 5;
6) (4 б.): Верный ответ: 4.;
7) (4 б.) Верный ответ: «шагнуть».
8) (5 б.) Верные ответы: 3;
9) (5 б.) Верные ответы: 3; 4;
10) (5 б.): Верный ответ: 4.;
4
клевало как правильно написать – Фонетический разбор слова «клевало» – Profilo – www.hicasa.it/ Forum
клевало как правильно написать
Для просмотра нажмите на картинку
Читать далее
Смотреть видео
клевало как правильно написать
Проверка слова: клеваный
Как правильно: клевать или клювать?
Как правильно пишется слово «клевать»
Ударение в слове клевало
«Клювать» или «клевать» как пишется?
Как правильно пишется слово Клевало
Разбор слова «клевать»: для переноса, на слоги, по составу
Фонетический разбор слова «клевало»
Клевало как пишется?
Для зимней охоты предусмотрен дополнительный белый, незаметный на снегу, тент. Он посмотрел прямо на ложбину, откуда должны были появиться враги. Фидерная кормушка своими руками, легко и просто.
Однако, плыть в бушующим шторме вероятно, вас окружают подлые люди, пытающиеся всеми силами навредить. В рекомендациях производителей в мануалах описан именно такой метод. После остывания к сваренному гороху начинаем понемногу подмешивать манку.
Пользуется большим спросом у российских рыболовов. Укомплектованы утепляющим вкладным чулком. Даже если муж на самом деле на рыбалке а бывает такое и часто- якобы на рыбалке, тревожить его звонками не стоит.
Там, где рыба держится разрозненно, такой способ дает неплохие результаты. Полностью запечатана, новая, упакована в заводскую упаковку. И тем не менее они появляются на съемочной площадке. И лучше научится точно забрасывать на малых дистанциях, а только потом переходить на дальние. На лодке установлен стационарный транец, жестко приклеенный к баллонам.
Поиск по одному их самых больших словарей. Все формы слов русского языка онлайн. клевало — глагол, ср. клевало — глагол, ср. Часть речи: инфинитив — клевать.
Перейти к поиску Русский. о птицах захватывать, щипать или бить резкими движениями клюва. о рыбах заглатывать предлагаемую пищу. совершать мелкое агрессивное действие.
Слово «клевало» правильно пишется как «клева?ло», с ударением на «а «. Но существуют и другие формы этого слова, в которых может отличаться ударная буква или даже происходить замена корня. также в других словарях: клевало — Морфемный разбор слова. клевало — Морфологический разбор. клевало — Анаграммы к слову.
Сделать правильный звуко разбор и точно определить характеристику гласного можно лишь после постановки ударения в слове. Фонетический разбор онлайн и примеры по указным случаям: — приёмник [пр’ийо?мн’ик], поёт [пайо?т], клюёт [кл’уйо?т]; -аюрведа [айур’в’э?да], поют [пайу?т], тают [та?йут], каюта [кайу?та], после разделительного твердого «Ъ» знака «Ё» и «Ю» — всегда, а«Е» и «Я» только под ударением или в абсолютном конце слова: — объём [аб йо?м], съёмка [сйо?мка], адъютант [адйу’та?нт].
Не уверены, как надо писать «клювать» или «клевать»? Давайте проанализируем эту лексему, используя этимологические и орфографические словари, и попробуем вместе проверить интересующую нас гласную букву. Но обо всем по порядку. Как правильно пишется. В соответствии с нормой правописания, данный глагол пишется с буквой «е» в корне – клевать. Какое правило применяется. В этом глаголе интерес представляет безударная гласная корня. Ошибки при ее написании допускают по той причине, что ошибочно проверяют ее существительным «клюв». Этимологические словари говорят нам, что оно является родственным, но.
Правильное написание слова Клевало. Список синонимов для слова Клевало. Написание с не правильной раскладкой клавиатуры: rktdfkj. Тест на правописание. как правильно пишется слово обычные. как пишется холатное или халатное. как пишется слово с трудом? © —
Она уже начинала клевать носом, как вдруг песня греттинов зазвучала с новой силой. Рыбак стал клевать носом, забрался под меховые одеяла и скоро уснул. Синонимы к слову «клевать».
Чтобы написать слово «клевать» правильно без ошибки в первом слоге нужно хорошенько подумать, ведь мы знаем такое слово родственное слово как «клюв» и мы видим ударную гласную букву «ю», поэтому возникает проблема, какую букву писать «е» или «ю»? Нужно просто знать, что слово «клевать» является словарным словом и пишется через букву «е», к тому же, к нему есть и проверочное слово «клёв». Слово «кл*вать» представляет собой глагол, а означает оно заглатывание пищи или пощипывание клювом.
Примеры предложений, как пишется клевала. Если же это наблюдение совпадало с промежутком, когда у него самого рыба не клева?ла, он потихоньку снимался с места и устраивался поближе к той лодке, где рыба брала. Курил турка трубку, клева?ла курка крупку: не кури, турка, трубки, не клюй, курка, крупки! В слове «клевала» ударение падает на слог с первой буквой А — клева?ла. Надеемся, что теперь у вас не возникнет вопросов, как пишется слово клевала, куд.
Разбор по составу клевало. Самый большой морфемный словарь русского языка: насчитывает разобранных Разбор по составу слова: «клевало» — форма глагола «клевать» [ср.р., ед.ч., действ.
Как написать слово (словосочетание) клевать? Как правильно поставить ударение и какие имеет словоформы слово (словосочетание) клевать? ? Правильное написание: клевать. ? Гласные буквы в слове: клевать. гласные выделены красным. гласными являются: е, а. общее количество гласных: 2 (две). ударная гласная выделена знаком ударения « ?». ударение падает на букву: а. безударные гласные выделены пунктирным подчеркиванием « ». безударными гласными являются: е.
Примеры правильных запросов: чес*ный, проф*ес*ор, ветрен*ый. Орфографический словарь. Большой толковый словарь. искомое слово отсутствует. Управление в русском языке.
Клевало однокоренные и проверочные слова: клепать. Клевало разбор слова по составу по правилам русского языка школьной программы: приставки нет, корень клева, суффикс л, окончание о. Пример предложения со словом «клевало»: Птицы с удовольствием клюют его семечки, а люди, кроме блюд, делают из него плошки и вёдра, бутыли и барабаны. Клевало проверочное слово с проверочной буквой в корне: Добавить. Неправильное написание слова: клевала, клеволо, клевола, кливало, кливала.
КЛЕВАТЬ КЛЕВА?ТЬ, клюю, клюёшь, несовер. О птицах: есть, хватая клювом (пищу). Куры не клюют этого корма. О рыбе: хватать насадку на удочке, ловиться на удочку.
Как правильно пишется слово «клевать». Орфография слова «клевать». Правильно слово пишется: клева?ть.
Одним словом надежный внедорожник для поездок в самую глухомань. Шинкуем морковку с репчатой луковицей, обжариваем в сковороде, добавляем порезанные кубиками помидоры и тушим до мягкости. Прочая поверхность доски красится масляной краской светлых тонов маскирующих цветов. Не пропустите этот чудный рецептик.
Предлагается для продажи девочка ши- тцу. Счет можно оплатить либо через интернет- банк с банковской карты, либо в любом отделении банка, который обслуживает физических лиц.
Как известно, чем тоньше леска, тем лучше клюет рыба. Один из способов уменьшить риск столкновения идти в сторону мелководья, где не могут встретиться крупные суда. Прокол заделали за час с небольшим.
Секреты джига для начинающих. Я не мужчина, но люблю рыбалку.
Погружение в ил небольшой части кормушки чувствительно реагировать на поклевку оснастке не мешает. Недостатков, демонстрируемых печкой для палатки на дровах, во многом лишен газовый обогреватель.
Учебники, научно-методическая литература – ROZETKA
Выучить иностранный язык, научиться решать любые конфликты мирным путем, подружиться с собственным ребенком-подростком, развить в себе лидерские качества – всему этому и многому другому нас учат специализированные книги. Учебники и научно-методологическая литература способны избавить современного человека от большей части привычных проблем, вернуть ему здоровье, обогатить знаниями, а также научить жить без ссор, недопониманий, в согласии со своими близкими и с собой.
Учебники, научно-методическая литература – путь к новым знаниям
Ежедневно человек сталкивается с огромным числом задач, решать которые необходимо для того, чтобы жизнь приносила радость. Нужно правильно выстраивать отношения с коллегами и подчиненными, научиться распределять время, не жертвуя действительно важными делами, развить внимательность, наработать навыки, необходимые для построения карьеры. Для людей семейных значимо выстраивание уважительных и комфортных отношений между всеми членами семьи, да и в целом знания по психологии будут полезны, они дают возможность смотреть вглубь вещей, игнорируя внешнюю шелуху. Еще одни огромнейший пласт сведений, который в современных условиях очень ценен – это знания иностранных языков. Мир глобализируется, и сегодня люди с разных уголков планеты имеют возможность понимать друг друга. Но для этого им необходимо научиться говорить на одном языке.
В учебниках и научно-методологической литературе скрывается богатство знаний, накопленных человечеством за всю историю своего существования
Существует заблуждение, что учебники нужны исключительно в школе и в ВУЗе, а после их окончания люди в данном виде литературы не нуждаются. На самом деле все наоборот. Сегодня чтобы считаться действительно образованным человеком, учиться приходиться постоянно. Но процесс этот не является обременительным, ведь знания дают свободу, позволяют иначе взглянуть на мир, стать в каких-то аспектах развитее и умнее.
На «Розетке» в категории «Учебников и научно-тематической литературы» доступны к заказу такие тематики:
- психология;
- философия;
- журналистика;
- педагогика;
- медицина;
- иностранные языки;
- география;
- биология;
- анализ и т. д.
В отдельные разделы вынесены школьные учебники и пособия для учащихся в ВУЗах. В наличие большое количество словарей не только самых востребованных, но и более редких языков.
Научно-методическая литература, учебники: нюансы выбора
Не каждая книга с броским названием и внушительным количеством страниц может претендовать на звание учебника. Подобное издание должно содержать полезную, правильно структурированную информацию, изложенную в доступной для понимания форме. Учебную литературу нужно научиться фильтровать, отбирая ценное, тогда не придется жалеть о деньгах, потраченных на материал, который не несет никакой смысловой нагрузки. Чтобы сделать правильный выбор, читайте аннотации, смотрите, кто автор произведения, если есть возможность, просмотрите содержание, чтобы удостовериться, что эта книжка будет вам полезна.
В интернет-магазине «Розетка» выбор учебных книг очень широк. Их заказывают с доставкой в Киев, Одессу, Николаев, Полтаву, Днепропетровск, Ровно, Тернополь и прочие города Украины.
Основные способы образования слов в русском языке
Цели: познакомить с основными способами образования слов, закреплять умение определять способы образования слов; развивать навыки морфемного и словообразовательного разбора; дать представление о словообразовательной паре, словообразовательной цепочке, словообразовательном гнезде.
Планируемые результаты: знание основных способов образования слов, основных понятий словообразования; умения определять способ образования слов, объяснять языковые явления; развитие мотивации к аналитической деятельности.
Ход урока 1
- Организационный момент
- Проверка домашнего задания
(Упр. 167 — беседа.)
III. Самоопределение к деятельности
— Образуйте однокоренные слова от слова дарить. (Подарить, дарёный, дарение и т. д.)
— Какими способами были образованы новые слова?
— А какие ещё способы образования слов вам известны?
— Какие задачи мы поставим перед собой сегодня на уроке (Поупражняться в определении способа образования, узнать новые способы образования слов, закрепить на морфемного разбора.)
- Работа по теме урока
- Слово учителя
Легко догадаться, что способ образования слов с помощью приставок называется приставочным, а с помощью суффиксов — суффиксальным: от глагола читать образованы и прочитать, и читатель.
А вот более трудные случаи.
— Как вы думаете, от какого слова образовалось существительное рассвет!
Нет, не от существительного свет, а от глагола рассветать: суффикс -а- убрали, окончание -ть отбросили.
Дело в том, что значение действия у существительных вторично. Все подобные существительные образованы от глаголов: бег — от бегать, выход — от выходить.
Глагол рассветать образован приставочным способом от глагола светать, а этот глагол — от существительного свет. Такая словообразовательная цепочка у нас получилась: рассветать ← светать ← свет.
— Способ образования существительного рассвет — бессуффиксный. А каким способом образовано слово бессуффиксный! (Приставочным.)
Есть способ, соединяющий в себе два способа, — приставочно-суффиксальный. Так образованы, к примеру, слова подснежник, Сотрудник.Нет же слов сотруд или трудник. Слово образовалось одновременным присоединением приставки и суффикса. Слово Снежник есть, оно означает “место наибольшего скопления снега I горах”, но оно ничего общего, кроме корня, не имеет со словом подснежник, образованного от существительного с предлогом (под снегом) + суффикс.
Другой интересный способ образования слов — сложение. Существительное снегопад — от основ слов снег и падать, вездеход — словосочетания везде ходить, лётчик-космонавт — от сложения двух целых слов.
Интересный способ образования слов — переход из одной части речи в другую. Определить принадлежность к той или иной части речи многих из таких слов можно только в контексте. Вот, например, слово учёный. Сравним:
И днём и ночью кот учёный всё ходит по цепи кругом. Великий русский ученый Ломоносов был ещё и художником, и поэтом.
В первом случае учёный — прилагательное, во втором — существительное, образованное переходом прилагательного в эту часть речи.
- Работа по учебнику
(Чтение теоретического материала, обсуждение вопроса рубрики “Материалы для самостоятельных наблюдений” (с. 94, 95).)
- Закрепление изученного материала
Работа по учебнику
- Упр. 168 — устное выполнение.
- Упр. 169, 170 — письменное выполнение на доске и в тетрадях.
Комментарии
Может вызвать сомнение способ образования слова перерыв. Оно образовано от глагола перерывать (допустим вариант с чередованием звука — прерывать).
- Упр. 171 — самостоятельное выполнение.
- Подведение итогов урока
— Какие способы образования слов вам известны?
— Что такое морфемные способы образования слов?
— Какие варианты способа сложения слов вы знаете?
Домашнее задание
Учебник: § 33 (с. 94, 95), упр. 172.
Рабочая тетрадь: задание 33.
Ход урока 2
- Организационный момент
- Проверка домашнего задания
- Упр. 172 — чтение слов группами с комментированием.
Комментарии
Приставочно-суффиксальным способом образованы слона опилки, наконечник, ошейник, безрукавка; бессуффиксным — выход, заплыв, вход.
- Задание 33 из рабочей тетради — рассказ по схеме о способу образования слов, чтение примеров.
III. Работа по теме урока
- Работа по учебнику
(Чтение теоретического материала, обсуждение заданий рубрики “Материалы для самостоятельных наблюдении (с. 98, 99).)
- Слово учителя
При словообразовательном анализе очень важно не просто найти однокоренное, а определить ближайшее слово, от которой и образовано данное слово. Иначе нарушится словообразованная цепочка, подобная той, что мы построили на прошлом уроке: рассветать ← светать ← свет.
Возьмём любое слово, состоящее из одного корня, и попробуем построить небольшую словообразовательную цепочку, прибавляя морфемы: снег ← снежный ← бесснежный. Если проследить обратный путь слова, мы увидим, что прилагательное бесснежный образовалось не от существительного снег, а от прилагательного снежный приставочным способом.
- Практическая работа
Задание 1.
Построим две цепочки:
невидимка ← невидимый ← видимый ← видеть;
подвидовой ← подвид ← вид ← видеть.
У этих цепочек оказалось одно исходное слово. Что это значит? (Они составляют словообразовательное гнездо. )
В каждой цепочке образование слов шло своим путём. Определите каким. (1) Суффиксальным — приставочным — суффиксальным; 2) суффиксальным — приставочным — бессуффиксным. )
Задание 2.
Попробуем восстановить недостающие звенья словообразовательной цепочки: греть — обогревательный. Выполним морфемный разбор (по составу) слова обогревательный.
Цепочка: греть → обогреть → обогревать → обогреватель → обогревательный.
- Закрепление изученного материала
- 1. Работа по учебнику
(Упр. 175 — письменное выполнение на доске и в тетрадях.)
Комментарии
окраина → край → крайний → крайность → краешек
листик → листок → листочек → листовой → листопад → безлистный
бумажка → бумажонка → бумажный → бумажник
дождливый → дождливость → дождь → дождинка → дождик → дождичек → дождевой → дождевик → дождевичок.
- Лингвистическая задача
— Постройте словообразовательные цепочки однокоренных слов и слов-омофонов фрагмента песенки. Я водяной, я водяной, Никто не водится со мной. Внутри меня водица… Ну что с таким водиться!
Комментарии
Водяной (сущ.) ← водяной (прил.) ← вода; водица ← вода.
Водиться ← водить.
- Подведение итогов урока
— Что представляют собой словообразовательная пара, словообразовательная цепочка, словообразовательное гнездо?
— Как определить способ образования слова?
Домашнее задание
Учебник § 33 (с. 98, 99), упр. 176.
Тест. Морфемный и словообразовательный разбор слова
© 2019, ООО КОМПЭДУ, http://compedu. ru При поддержке проекта http://videouroki.net
Будьте внимательны! У Вас есть 10 минут на прохождение теста. Система оценивания — 5 балльная. Разбалловка теста — 3,4,5 баллов, в зависимости от сложности вопроса. Порядок заданий и вариантов ответов в тесте случайный. С допущенными ошибками и верными ответами можно будет ознакомиться после прохождения теста. Удачи!
Список вопросов теста
Вопрос 1
Укажите, где правда, а где ложь.
Варианты ответов
- при морфемном разборе мы разбираем слова по составу
- при морфемном разборе мы не указываем основу
- при словообразовательном разборе мы не выполняем полный морфемный разбор
- цели у морфемного и словообразовательного разборов схожие, но всё же разные
Вопрос 2
Выберите слово, в котором два корня.
Варианты ответов
- землемер
- канистра
- сороковой
- пересказывать
Вопрос 3
Выберите слово, в котором есть нулевое окончание.
Варианты ответов
- вниз
- кричал
- кино
- такой
Вопрос 4
Выберите пункты, которые мы указываем при морфемном разборе слова.
Варианты ответов
- корень
- приставка
- однокоренные слова
- окончание
- основа
- слово, от которого это слово образовалось
Вопрос 5
Выберите пункты, которые мы указываем при словообразовательном разборе слова.
Варианты ответов
- толкование значение слова
- корень
- способ, при помощи которого образовалось слово
- морфема, при помощи которой образовалось слово
- основу, от которой образовалось слово
- окончание
Вопрос 6
Укажите количество морфем в слове перегородка?
Вопрос 7
От какого слова образовалось слово перешагнуть? В ответе запишите нужное слово в начальной форме.
Вопрос 8
Какие пункты мы будут верными при словообразовательном разборе слова «задира»?
Варианты ответов
- окончание -а
- образовалось от слова «драть»
- образовалось от слова «задирать»
- способ образования — суффиксальный
- способ образования — бессуффиксный
- способ образования — переход из одной части речи в другую
Вопрос 9
Посмотрите на предложение. Какие пункты словообразовательного разбора будут ошибочными для выделенного слова?
Говорят, по городу ходит опасный сумасшедший.
Варианты ответов
- слово образовано от двух основ: «с ума» и «сшедший»
- способ словообразования — сложение основ
- слово образовано от прилагательного «сумасшедший»
- способ словообразования — переход из одной части речи в другую
- способ словообразования — суффиксальный
Вопрос 10
Постройте словообразовательную цепочку для слова «обогреватель». Сколько всего слов оказалось в этой цепочке (слово «обогреватель» тоже считается).
Ответ укажите числом.
«карточка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). «карточка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) Словообразовательный разбор слова карточка
1.
Выписать столбиками однокоренные
слова. Выделить корень.
а) Сад, дубовый, ходить, дуб, садовый, ход, дубок,
посадки, переход.
б) Гора, больница, боль, гористый, горная,
болезнь.
в) Старость, ночь, старый, ночной, заночевать,
стареть, старик.
2.
Побобрать к словам жар, свет
однокоренные слова, обозначающие признак
предмета и действие предмета. Записать их.
3.
Со словами грибной, гриб, грибники
составить и записать предложения. В предложении
должно быть имя мальчика и название деревни.
4.
Записать однокоренные слова в
строчку в следующем порядке: предмет, признак
предмета, действие предмета.
ОБРАЗЕЦ: белила, белый, белить.
Весна, говор, зелень, морозец, вид, разговор,
зеленеет, видный, говорливый, морозит, зелёныё,
видеть, морозный, весенний.
5.
Выписать из текста однокоренные
слова.
6.
Стихотворение “Родственные
(однокоренные) слова”
Объяснить слова толково
Нам поможет корень слова.
Он поможет нам понять,
Как же слово написать.
Горка, горочка, пригорки.
Помогите – кА Егорке,
Как писать ему слова:
“На г…ре р…сла тр…ва?”.
7.
Прочитайте. Найдите “лишнее” слово.
Водяной, вода, водичка, подводник, водитель.
Гора, горка, горный, горевать, пригорок, горец.
Река, речной, речь, речушка,речник.
Купить, покупка, покупатель, купец, купальник,
накупить.Пар, запариться, парное (молоко), пара (обуви).
Маленький, малявка, маляр, малыш.
Гроза, грозный, гроздь, грозовой.
Конница, конник, подоконник, конюшня.
Лень, лентяй, лента, ленивец.
Чай, заварка, чайник, чайная.
Сухой, сухарь, сухость, сушить, жарить.
Сладость, сахар, сахарница, сахарный.
Озеро, озёрный, вода.
Булка, хлебница, хлеб, хлебный.
Моряк, рыбак, море.
Путь, дорога, путник.
Школьник, ученик, дошкольник.
Ученье, учебник, книга.
Соль, солонка, солома.
Береза, березка, дерево.
Дорога, дороженька, дорогой.
Лес, лесок, лестница.
Рыбка, рыбак, рыбачить.
8.
Игра “Сделай гнездо слов”.
Играть можно и в одиночку, и друг с другом:
соревноваться, у кого “гнездо” получится
больше.
Правила игры:
Слова от одного корня. “живущие” в одном
“гнезде”, могут принадлежать самым разным
частям речи. Например: сад, садовый, посадить,
садовник.
Надо собирать слова с самыми различными
приставками и суффиксами.
В “гнезде” могут оказаться слова, в которых
два корня (сложные слова).
9.
Игра “Родственники”.
Участник игры раздаёт карточки. Затем
показывает любое слово. Участники игры по
очереди подставляют к нему родственные слова.
Тот кто первым освободится от своих карточек,
считается победителем.
СЛОВА ДЛЯ КАРТОЧЕК:
Вода, водный, водянистый, наводнение, водник,
подводный.Вождь, водить, провод, завод, подводить, вожжи.
Нос, переносица, носатый, долгоносик, носорог.
Несу, носитель, переносить, переносной, поднос,
медоносный, носильщик.Нож, ножевой, ножницы, ножны.
Нога, ножной, треножник, ножка, подножие,
сороконожка.Даю, передать, передач, передатчик, задачник,
преподаватель.Море, морской, моряк,
Память, запоминать, памятка, памятник,
запоминание.Кровь, кровяной, бескровный, обескровить.
10.
Выдели корни в однокоренных словах.
Листопад, листопад, —
Листья жёлтые летят.
11.
Являются ли выделенные слова
однокоренными?
Деревенский старожил
Сад колхозный сторожил.
А кругом луга, леса.
Видит дед: бежит лиса.
Он ружьё наизготовку
И убить решил плутовку.
12.
Подбери 2-3 однокоренных слова.
13.
Докажи, что данные слова являются
родственными.
| а) билет | вагон |
| билетёр | вагонетка |
| обилетить | вагонный |
| безбилетный | вагончик |
| билетный | вагоновожатый |
| б) бинт | гриб |
| бинтовать | грибник |
| забинтовать | грибной |
| перебинтовать | грибница |
| в) чай | брат |
| чайник | братишка |
| чайный | братский |
| чаепитие | братство |
| г) работа | валенки |
| работник | валеночки |
| рабочий | валять |
| работать | валяные |
| д) лист | гитара |
| листок | гитарист |
| листовой | гитарный |
| листопад | гитаристка |
14.
Образуй от данных слов однокоренные
слова, отвечающие на вопросы КАКОЙ? КАКАЯ?
родина –
б) мука –
15.
Образуй от данных слов однокоренные
слова, отвечающие на вопрос ЧТО ДЕЛАТЬ?
б) мороз –
16.
Образуй от данных слов однокоренные
слова, отвечающие на вопрос КАК?
а)прямой –
громкий –
быстрый –
б) смелый –
короткий –
кривой –
скорый –
17.
Найди родственные слова. Выпиши их.
Выдели корень.
1) Нефтяники добывают нефть из нефтяной
скважины.
2) Кислый вкус имеет травка кислица.
3) Рядом со страусом в загоне был страусёнок.
4) Луковый суп варят из репчатого лука.
5) Медлительный человек всё делает медленно.
6) Крепость укреплена со всех сторон.
7) Мудрец сам поступает мудро и учит мудрости
других.
8) Весной все девчонки из нашего класса учатся
играть в классики.
18.
Выписать из текста родственные
слова. Выделить корень.
1) Дикая утка вывела из осоки своих утят. Ярко
светило солнце. Над водой цвела водяная кашка.
Уточка нырнула в воду, а за ней вся семья.
2) Кругом пышно рос малинник. Сочные душистые
ягодки малины быстро заполняли кузовок.
Послышался шум. Около кустов шла медведица с
медвежонком.
3) Встаёт заря во мгле холодной;
На нивах шум работ умолк;
С своей волчихою голодной
Выходит на дорогу волк.
4) Я люблю бродить по лесу. А сколько грибов в
лесу! Душистые рыжики и опята давно ждут
грибников. Вот и я под елью нашёл грибок. Да какой!
5) Снежинки родились в снежных облаках высоко
над землёй. Они медленно спускались на землю.
Красив хоровод из снежинок! А ты любишь первый
снежок?
19.
Карточки для самостоятельных работ.
КАРТОЧКА №1
Зачеркни лишние слова.
КАРТОЧКА №2
Зачеркни лишние слова.
КАРТОЧКА №3
Зачеркни лишние слова.
КАРТОЧКА №4
Зачеркни лишние слова.
КАРТОЧКА №5
Зачеркни лишние слова.
20.
Соедини слова из левого столбика с
однокоренными из правого.
Прочитай. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
Прочитай. Шёл тёплый гр…бной дож…ь. в лес пришли маленькие гр…бники. …ни увидели под ёлкой б…льшой белый гри… . А рядом рос ещё гр…бок. |
_____________________________________________________________
Прочитай. Выпиши однокоренные слова. Выдели корень.
Вот л…сное оз…ро. На его б…р…гу ж…вёт л…сник. Он охр…няет лес.
_____________________________________________________________
_____________________________________________________________
Прочитай. Выпиши однокоренные слова. Выдели корень.
Вот л…сное оз…ро. На его б…р…гу ж…вёт л…сник. Он охр…няет лес.
_____________________________________________________________
_____________________________________________________________
Прочитай. Выпиши однокоренные слова. Выдели корень.
Вот л…сное оз…ро. На его б…р…гу ж…вёт л…сник. Он охр…няет лес.
_____________________________________________________________
_____________________________________________________________
Прочитай. Выпиши однокоренные слова. Выдели корень.
Вот л…сное оз…ро. На его б…р…гу ж…вёт л…сник. Он охр…няет лес.
_____________________________________________________________
_____________________________________________________________
Прочитай. Выпиши однокоренные слова. Выдели корень.
Вот л…сное оз…ро. На его б…р…гу ж…вёт л…сник. Он охр…няет лес.
_____________________________________________________________
_____________________________________________________________
Прочитай. Выпиши однокоренные слова. Выдели корень.
Вот л…сное оз…ро. На его б…р…гу ж…вёт л…сник. Он охр…няет лес.
_____________________________________________________________
_____________________________________________________________
Выдели корень в каждой группе слов. Вставь буквы.
Соль, с…лёный, с…лонка, с…лить.
Конюх, конский, к…нюшня, к…нёк, конь.
Столяр, стол, ст…ловая, столик.
Выдели корень в каждой группе слов. Вставь буквы.
Соль, с…лёный, с…лонка, с…лить.
Конюх, конский, к…нюшня, к…нёк, конь.
Столяр, стол, ст…ловая, столик.
Выдели корень в каждой группе слов. Вставь буквы.
Соль, с…лёный, с…лонка, с…лить.
Конюх, конский, к…нюшня, к…нёк, конь.
Столяр, стол, ст…ловая, столик.
Выдели корень в каждой группе слов. Вставь буквы.
Соль, с…лёный, с…лонка, с…лить.
Конюх, конский, к…нюшня, к…нёк, конь.
Столяр, стол, ст…ловая, столик.
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Прочитай. Вставь буквы.
Найди однокоренные слова.
Выдели у них корень.
Уд…вился ст…рик, испугался:
Он рыбачил тридцать лет и три года
И не слыхивал, чтоб рыба г…в…рила.
Отпустил он ры…ку з…л…тую
И сказал ей ласковое слово…
Схема разбора по составу карточка:
карточк
а
Разбор слова по составу.
Состав слова «карточка»:
Соединительная гласная
: отсутствует
Пocтфикc
: отсутствует
Морфемы — части слова карточка
карточка
Подробный paзбop cлoва карточка пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa карточка, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: карточк/а
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова карточка по составу: корень карточк
+ окончание а - Список морфем в слове карточка:
- карточк — корень
- а — окончание
- Bиды мopфeм и их количество в слове карточка:
- пpиcтaвкa: отсутствует
— 0 - кopeнь: карточк
— 1 - coeдинитeльнaя глacнaя: отсутствует
— 0 - cyффикc: отсутствует
— 0 - пocтфикc: отсутствует
— 0 - oкoнчaниe: а
— 1
- пpиcтaвкa: отсутствует
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова карточка
- Основа слова: карточк
; - Словообразовательные аффиксы: приставка отсутствует
, суффикс отсутствует
, постфикс отсутствует
; - Словообразование: или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола
; - Способ образования:
или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола
.
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову карточка
Просклонять слово карточка по падежам в единственном и множественном числе…. Склонение слова карточка по падежам
Полный морфологический разбор слова «карточка»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор карточка
Ударение в слове карточка: на какой слог падает ударение и как… Слово «карточка» правильно пишется как… Ударение в слове карточка
Синонимы «карточка». Словарь синонимов онлайн: подобрать синонимы к слову «карточка». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову карточка
Анаграммы (составить анаграмму) к слову карточка, с помощью перемешивания букв…. Анаграммы к слову карточка
К чему снится карточка — толкование снов, узнайте бесплатно в нашем соннике что означает сон карточка. … Увиденный во сне карточка означает, что…Сонник: к чему снится карточка
Морфемный разбор слова карточка
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова карточка делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для карточка (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор
делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова
Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.
Типы рефлексии в консультировании
Рефлексия здесь, конечно же, используется сообразно времени: как способ поведения, свидетельствующий о росте сознания. Скорее меня интересовала рефлексия как средство выхода за пределы текста, чтобы включить в себя ощущение продолжающихся разговоров, в которые вступают тексты.
Различные слова для сочинения: типы общих прикладных сочинений. Стандартный шрифт и размер для исследовательских работ. Выбор слова для эссе, стоимость корректуры диссертации в великобритании: вопрос для эссе по физической подготовке, эссе на родном языке с аннотациями, спряжение эссе в режиме онлайн, эссе онлайн, цитируют мла эссе, конфиденциальность и наблюдение. Рефлексивное эссе о консультировании.
Практика, основанная на фактах, дает возможность вывести профессию консультанта из теоретических рамок и исторических убеждений в эпоху интегрированной практики, в которой консультанты используют лучшее из доступной науки в сочетании с клиническим опытом для успешной помощи широкому кругу клиентов. .
Пакет отражения в стандартной библиотеке является домом для типов и функций, реализующих отражение в Go. В поисках своего типа. Вы можете использовать отражение, чтобы получить тип переменной var с помощью вызова функции varType: = reflection.TypeOf (var). Это возвращает переменную типа reflection.Type, которая …
Внутренние размышления Консультирование детей и семей — это групповая медицинская практика, расположенная в Колумбии, штат Миссури, которая специализируется на клинической социальной работе. … Типы психического здоровья …
Фонд Хазелден Бетти Форд — это сила исцеления и надежды для отдельных людей, семей и сообществ, страдающих от зависимости от алкоголя и других наркотиков. Являясь ведущей национальной некоммерческой организацией, предоставляющей комплексное стационарное и амбулаторное лечение для взрослых и молодежи, Фонд имеет 17 филиалов по всей стране и сотрудничает с обширной сетью здравоохранения.
Этот тип обучения основан на поощрении и наказании для формирования поведения людей. С момента появления поведенческой терапии в 1950-х годах появилось несколько вариаций. Одним из вариантов является когнитивно-поведенческая терапия, которая фокусируется как на мыслях, так и на поведении. Когнитивная терапия. Когнитивная терапия подчеркивает то, что думают люди, а не то, что …
Xml в таблицу python
Узнайте, как можно анализировать, исследовать, изменять и заполнять XML-файлы с помощью пакета Python ElementTree для циклов и выражений XPath.Как специалист по данным, вы обнаружите, что понимание XML является мощным средством как для анализа веб-страниц, так и для общей практики анализа структурированного документа.
Он прослушивает объекты LoggingEvent, отправленные с помощью SocketAppender, и отображает их в таблице. … Python i686 https: // lh5 … XML-редактор Exchanger — это самый …
Узнайте, как анализировать, исследовать, изменять и заполнять XML-файлы с помощью пакета Python ElementTree для циклов и выражений XPath. Как специалист по данным, вы обнаружите, что понимание XML является мощным средством как для веб-скрейпинга, так и для общей практики анализа структурированного документа.
В этом руководстве Python XML Parser Tutorial вы узнаете, как анализировать, читать, изменять и находить элементы из файлов XML в Python с помощью ElementTree и Minidom.
Работать с pandas и python не так сложно, но работать с xml иногда может быть сложно, в этом видеоуроке я покажу вам, как вы можете читать xml-файл в …
14 декабря 2010 г. · JSON — это текст формат, который полностью не зависит от языка, но использует соглашения, знакомые программистам семейства языков C, включая C, C ++, C #, Java, JavaScript, Perl, Python и многие другие.Эти свойства делают JSON идеальным языком обмена данными.
Также можно добавить поддержку новых форм, написав простые файлы XML, используя подмножество SVG для рисования формы. Он может загружать и сохранять диаграммы в настраиваемом формате XML (по умолчанию в gzip для экономии места), может экспортировать диаграммы в несколько форматов, включая EPS, SVG, XFIG, WMF и PNG, а также может печатать диаграммы (в том числе …
29 апреля 2019 г. · Но XML действительно имеет несколько дополнительных функций по сравнению с JSON и CSV: вы можете использовать пространства имен для создания и совместного использования стандартных структур, лучшее представление для наследования и стандартизованный в отрасли способ представления ваших данных с помощью Схема XML, DTD и т. Д.Для чтения XML-данных мы будем использовать встроенный в Python модуль XML с подмодулем ElementTree.
Полученный здесь объект Application — это тот же объект Application, который вы использовали в Visual Basic. Это довольно мощно. Это означает, что в значительной степени вы можете скопировать и вставить код Visual Basic в Python и ожидать, что он будет работать с небольшими изменениями синтаксиса языка, просто убедитесь, что вы узнали, как обновить Python, прежде чем делать что-либо еще.
Название соединения Na2o
Это соединение, а не элемент. Цель: изучить символы и свойства 20 элементов периодической таблицы.Периодическая таблица Q5. Назовите газ в группе 7, который находится в том же периоде, что и алюминий. Q1. Назовите металл группы 1, который находится в том же периоде, что и магний. Q2. Назовите металл из группы 2, относящийся к тому же периоду, что и литий. Q3.
Проблема 2.58. Назовите эти соединения: (a) KClO, (b) Ag2CO3, (c) FeCl2, (d) KMnO4, (e) CsClO3, (f) HIO, (g) FeO, (h) Fe2O3, (i) TiCl4, ( j) NaH, (k) Li3N, (l) Na2O, (m …
13. a. Поскольку ион хлорида имеет заряд 1–, ион олова должен иметь заряд 4+: имя олово ( IV) хлорид.б. Поскольку сульфид-ион имеет заряд 2–, ион железа должен иметь заряд 3+: название — сульфид железа (III). c. Поскольку ион оксида имеет заряд 2–, ион свинца должен иметь заряд 4+: его называют оксидом свинца (IV). d.
Поскольку у нас есть металл (Al) и многоатомный ион (CN-), это трехкомпонентное ионное соединение. Используйте точное название металла из Периодической таблицы. Найдите имя иона в Таблице общих ионов. Соедините их (сначала металл), и вы получите название для Al (CN) 3.
17 октября 2020 г. · Назовите ионы, присутствующие в этих соединениях.(c) Перечислите три свойства ионных соединений. (CBSE 2012) Ответ: Na 2 O содержит ионы Na + и O 2. MgO содержит ионы Mg 2+ и O 2. (c) (i) Это твердые вещества с высокой температурой плавления. (ii) Они растворимы в воде. (in) Они проводят электричество в расплавленном состоянии, а также в водном растворе. Вопрос 19.
Оксид калия (K 2 O) — это ионное соединение калия и кислорода. Это бледно-желтое твердое вещество, простейший оксид калия, редко встречающееся, высокореактивное соединение. Некоторые коммерческие материалы, такие как удобрения и цементы, анализируются с учетом процентного состава, который был бы эквивалентен смеси химических соединений K 2 O.
Смешанная практика Na2O K3PO4 Cu (OH) 2 (Nh5) 2S MgCl2 Пример. Напишите названия следующих соединений. Смешанная практика Na2O K3PO4 Cu (OH) 2 (Nh5) 2S MgCl2 Оксид натрия Фосфат калия Гидроксид меди (II) Сульфид аммония Хлорид магния Пример: Напишите названия следующих соединений. Ковалентные соединения Имя к формуле
Неформальный тон
CCSS.ELA-Literacy.RL.9-10.4 Определяет значение слов и фраз, используемых в тексте, включая переносные и коннотативные значения; проанализировать совокупное влияние выбора конкретных слов на значение и тон (например,g., как язык вызывает чувство времени и места; как он задает формальный или неформальный тон).
8 марта 2009 г. · Неформальное общение осуществляется с использованием каналов, которые отличаются от официальных каналов связи. Это просто обычный разговор. Он создан для социальной принадлежности членов организации и личных дискуссий. Это случается среди друзей и семьи. В неформальном общении использование сленговых слов, сквернословие не ограничено. Обычно. неформальное общение осуществляется устно и с помощью жестов.
28 марта 2014 г. · Неформальный английский используется, когда вы дружите со своими слушателями. Вы давно знаете этого человека. Этот формат обычно используется в семьях, друзьях и колледжах. Большая часть использования происходит из разговорного английского и в разговорах на английском языке во время чата.
1 июня 2020 г. · Тон или качество чувства, передаваемое словом, может варьироваться в зависимости от его общего значения. Конечно, значение слова иногда меняется в зависимости от его использования, но обычно слова имеют положительный, отрицательный или нейтральный оттенок.Взгляните на этот окончательный список тональных слов, чтобы подготовиться к экзамену по английскому сочинению AP®:
. Тигр — самая большая кошка из всех — занимает третье место в списке крупнейших мясоедов в мире! В официальном письме используется безличный тон, и темы обсуждаются более серьезно.
CCSS.ELA-Literacy.RL.9-10.4 Определять значение слов и фраз, используемых в тексте, включая переносные и коннотативные значения; проанализировать совокупное влияние выбора конкретных слов на значение и тон (например,g., как язык вызывает чувство времени и места; как он задает формальный или неформальный тон).
5 августа 2010 г. · Наш тон говорит правду, даже когда наши слова — нет, даже когда мы сами не осознаем эту правду. И это наш тон, на который реагируют другие. Мы даже можем сказать «Я люблю тебя» таким образом, что это провоцирует …
Глава 6 ответы на вопросы теста процентов
Кейси покупает дом, который стоит 64000 долларов по простой процентной ставке 6% на 180 месяцев. Сколько она заплатит за дом? Глава 6 Обзор теста — ПРОЦЕНТЫ ПРОЕКТ 7-8 классов
На следующих страницах представлены вопросы с несколькими вариантами ответов для практического теста 6 класса, практической возможности для Подотчетности штата Небраска — математика (NeSA – M).На каждый вопрос вам будет предложено выбрать ответ из четырех вариантов. По всем вопросам: † Внимательно прочтите каждый вопрос и выберите лучший ответ.
США Тест уголовного правосудия 2 Глава 6. Описание. Тест на уголовное правосудие в США Глава 6. … Только от 10 до 20 процентов всех звонков на самом деле требуют вмешательства правоохранительных органов …
Раздел 6.1. Проценты и десятичные дроби 217 Введите десятичную дробь в процентах. Используйте модель, чтобы проверить свой ответ. 5. 0,94 6. 1,2 7. 0,316 8. 0,005 ПРИМЕР 3 Запись дроби как процента и десятичной дроби На тесте по математике вы получите 92 балла из 100 возможных.
Стандартизированный тест используется для оценки знаний учащихся о мировых событиях (среднее значение по стране = 65, S = 5). Тестируется выборка из 30 студентов (среднее значение = 58, стандартная ошибка = 3,2). Вычислите 99-процентный доверительный интервал на основе данных этого образца. Как эти студенты сравниваются с национальной выборкой? Ответ
Тест, форма 3B Запишите правильный ответ в поле справа от каждого … 6. Подставка для столовых приборов Майкла имеет размеры, указанные ниже. … 216 Курс 1 • Глава 9 …
Большие идеи МАТЕМАТИКА: Общая базовая учебная программа по математике для средней и старшей школы Написана Роном Ларсоном и Лори Босуэлл. Математика ускорила ответы на 6 процентов по главам. Математика ускоренная глава 6 процентов ответы
5. Вы пройдете следующий тест. 6. Завтра поедешь кататься на лыжах. Найдите каждую вероятность выпадения кубика. 7. P (3) Î 6 1 8. P (четное число) Î 2 1 9. P (число меньше 1) Î0 10. P (число, кратное 4) Î 6 1 11. P (число больше, чем 1) Î 6 5 Невозможно Маловероятно Равно вероятно Некоторые ответы будут отличаться для упражнений 1, 2, 5 и 6.
P процентов B Упражнение 1 (ответы на стр. 16) Указания: Определите процент, часть и основание в каждой из следующих задач, написав «процент» над процентом, «P» над частью и «B». «над базой. (Клавиша ответа начинается на странице 8) Пример. 170 составляет 25% от 680 1) 8 составляет 40% от 20 6) 16% от 300 = 48 2) 25% от 8 = 2
Древовидная диаграмма Plantuml
PlantUML Viewer — это расширение Google Chrome, которое отображает файлы PlantUML. PlantUML — это файл диаграммы UML, написанный в текстовом формате — его можно создать с помощью программы PlantUML (доступной на SourceForge).Это расширение автоматически обновляет диаграмму при изменении локального файла.
✪ PlantUML — красивые быстрые диаграммы для объяснения ваших моделей. ✪ Учебное пособие по диаграмме классов UML. Существуют и другие текстовые форматы для моделирования UML, но PlantUML поддерживает многие типы диаграмм и …
Диаграммы могут быть сгенерированы; Лучший инструмент, который я нашел на данный момент, — это PlantUml, который поддерживает большинство типов диаграмм UML. PlantUml — это открытый исходный код, доступный на SourceForge. Мартин Фаулер также, похоже, предпочитает текст UML-подходу
Статическая проверка кода Python и генератор диаграмм UML pylint3 (1.5.2-1ubuntu1) [Universe] Статическая проверка кода Python 3 и генератор диаграмм UML pymacs (0.25-1) [Universe] интерфейс между Emacs Lisp и Python pymappergui (0.1-2) [Universe] Графический интерфейс пользователя для pymetrics libmapper (0.8.1 -7) [Universe] Инструмент отчетности по метрикам кода Python
16 июля 2016 г. · java -jar plantuml.jar -encodesprite 16z foo.png, где foo.png, если файл изображения, который вы хотите использовать (он будет автоматически преобразован в серый ) После -encodesprite необходимо указать формат: 4, 8, 16, 4z, 8z или 16z.Число указывает уровень серого, а дополнительный z используется для включения сжатия в определении.
Фактически, при использовании plantuml не беспокойтесь, если вы не знаете его синтаксис в начале, потому что при создании любого вида UML-диаграммы (диаграммы активности, диаграммы классов, диаграммы компонентов, диаграммы последовательности, диаграммы состояний, используйте case diagram), plantuml будет работать с примерами программ, как в вышеупомянутой диаграмме последовательности создания. Plantuml …
Вы можете запустить PlantUML Dependency с помощью следующей простейшей команды: java -jar plantuml-dependency-1.0.1.jar -o plantuml.txt Это будет рекурсивно искать все исходные файлы Java в текущем каталоге, создавая файл plantuml.txt, описывающий описание диаграммы классов PlantUML.
Есть ли какая-либо поддержка или какой-либо план поддержки диаграмм Fault Tree в Plantuml. В качестве FTD есть специфическая диаграмма, состоящая из событий и ворот. События могут быть любым блоком, но ворота должны быть воротами И или ИЛИ. Я полагаю, что нотация для ворот отсутствует в текущей поддержке Plantuml. Есть ли планы на этот счет или на какую-либо альтернативу? Спасибо, Нихил.
Визуализация моделей с помощью Picto Picto — это представление Eclipse для визуализации моделей посредством преобразования модели в текст в SVG / HTML. По сравнению с существующими фреймворками графического моделирования, такими как Sirius и GMF / Eugenia, главная привлекательность Picto заключается в том, что визуализация модели происходит во встроенном браузере, и поэтому вы можете использовать любую технологию на основе HTML / SVG / JavaScript, такую как D3.js, mxGraph и …
Zybooks отвечает на Python
Форматирование строк. Python использует форматирование строк в стиле C для создания новых отформатированных строк.Оператор «%» используется для форматирования набора переменных, заключенных в «кортеж» (список фиксированного размера), вместе со строкой форматирования, которая содержит обычный текст вместе с «спецификаторами аргументов», специальными символами, такими как «% s» и «% d». Цикл «Пока». Цикл «Пока» используется для повторения определенного блока кода неизвестное количество раз, пока не будет выполнено условие. Например, если мы хотим попросить пользователя ввести число от 1 до 10, мы не знаем, сколько раз пользователь может ввести большее число, поэтому мы продолжаем спрашивать «пока число не находится в диапазоне от 1 до 10».
Ответ прост: по мере развития языков создаются библиотеки и обновляются инструменты. Знание того, как учиться, будет иметь важное значение для того, чтобы не отставать от этих изменений и стать успешным программистом. В этой статье мы предложим несколько стратегий обучения, которые помогут вам быстро начать свой путь к тому, чтобы стать рок-звездой программиста на Python! Python — это объектно-ориентированный, интерпретируемый, гибкий язык, который становится все более популярным для научных вычислений. Python прост в изучении, имеет очень четкий синтаксис и может быть легко расширен модулями, написанными на C, C ++ или FORTRAN.
21 января 2008 г. · Ну, конечно, gmpy. Но что касается встроенных длин Python, я бы не знал, потому что у меня всего одна жизнь. Python longs c: \ python25 \ user> long_ago.py 1 2 0,0310001373291 2 9 0,0310001373291 3 74 0,0310001373291 4 659 0,0620000362396 5 5926 0,0620000362396 6 53328 0,21
01089 7 479940 63,5620000362 Выполните лабораторные работы в zybooks. Разминка 6.6 (парсинг строк). Следуйте инструкциям и напишите код на Python в шаблоне. Перед отправкой запустите код и убедитесь, что он работает. сайт: zybooks.comemail: [email protected]: bbge1192
Python 3 является последней версией языка программирования Python и был официально выпущен на. Используйте этот тег вместе с основным тегом python для обозначения программ, которые предназначены для запуска на … Модуль 1 : Основы Python. Контрольный вопрос 1. Каков результат следующей операции в Python.
Как разобрать по составу слово «цепочка»?
В данном случае разберем по составу слово полный. Это очень просто.
Слово полный. Основой слова полный является ПОЛН. Слово полный является прилагательным мужского рода и отвечает на вопрос Какой.
Слово полный состоит из корня ПОЛН и окончания ЫЙ. Получается такая вот схемка из корня и окончания, а именно ПОЛН — ЫЙ.
Однокоренные слова: полнота, полностью, полно, наполненный и так далее.
Выделим все морфемы в слове ЛЕБЕДИНЫЙ
Лебединый танец приковал взгляды иностранцев.
Танец какой? лебединый.
Это прилагательное.
Окончание выделим ЫЙ:
лебедин-ый, лебедин-ого, лебедин-ому.
Основа слова ЛЕБЕДИН.
Определим и выделим корневую морфему в слове:
лебедь, лебяжий, лебедушка.
Корнем слова является ЛЕБЕД, г//ж,
суффикс прилаг. ИН.
лебед/ин/ый
Сначала определяем какой частью речи является слово «творог«.
Задаём вопрос «что?» — творог, отсюда следует, что слово относится к имени существительному, неодушевлённому, мужского (он «чей?» — мой) рода, в форме единственного числа, тип склонения второй.
—
Теперь разберём слово «творог» по составу (морфемный разбор):
- сначала отметим нулевое окончание_ {проверяем: ради «чего?» творог (а), радуюсь «чему?» творог (у), наслаждаешься «чем?» творог (ом), мечтать «о чём?» о творог (е)}
- получаем основу (этой частью будет слово без окончания) —творог—
- выделяем корень —творог—
Приставка и суффикс отсутствуют.
Схематически это выглядит следующим образом:
Слово «приезжают» — глагол в настоящем времени. В прошедшем времени слово выглядит «приехали», а в будущем времени — «приедут».
В единственном числе «приезжает», во множественном — «приезжают». Отвечает слово на вопрос «что делают», а, следовательно, глагол несовершенного вида.
Морфемный разбор слова «приезжают» выглядит следующим образом:
Приставка «при», затем корень «езж», за корнем стоит суффикс из гласной буквы «а». А завершает слово окончание «ют». В единственном числе в слове окончание было бы «ет» («приезжает»). Ну и основной слова будет все слово целиком кроме окончание, то есть «приезжа».
Слово влияние является существительным среднего рода, единственного числа, в именительном/винительном падежах.
Выполним разбор по составу (морфемнвй анализ) слова «влияние»:
Определимся сразу с окончанием слова, для чего произведем склонение существительного «влияние» по падежам:
- Имениьельный падеж (кто? что?) — влияниЕ;
- Родительный падеж (нет кого? чего?) — влияниЯ;
- Дательный падеж (подошли к кому? к чему?) — к влияниЮ;
- Винительный падеж (вижу кого? что?) — влияниЕ;
- Творительный падеж (доволен кем? чем?) — влияниЕМ;
- Предложный падеж (говорили о ком? о чём?) — о влияниИ.
Таким образом, выделяем окончание в слове -е-.
Подберем несколько однокоренных слов: влиятельный, повлиять, влиять и тд.
Корнем слова является -влия-.
Выделим еще одну морфему слова: это суффикс -ни-.
Основой слова будет -влияни-
Синтаксическая зависимость — обзор
4.2.1 Условия цепочки
Расширенная история выполнения изменения (определение 17 в разделе 4.1.3), ключевая часть определения последствий изменения (определения 18 и 19 в Раздел 4.1.3) использует семантические зависимости между операторами. Вычисление семантических зависимостей для всех возможных исполнений является неразрешимой проблемой, но семантические зависимости могут быть аппроксимированы синтаксическими зависимостями (то есть возможными зависимостями, выявленными при анализе программы).
Определение 21
Узел n является синтаксически зависимым на узле m в ICFG программы P и согласно безопасному анализу A, 9 тогда и только тогда, когда существует цепочка из зависимости (управление или данные, или и то, и другое), идентифицированные A в P, которые начинаются в m и заканчиваются в n.
Определение 22
Цепочка зависимости — это пара
Синтаксическая зависимость — необходимое условие семантической зависимости (см. Раздел 4.1.3). Таким образом, естественный выбор для процедуры, которая вычисляет эффекты изменения, состоит в том, чтобы сначала вычислить цепочки зависимости от изменения как P, так и P ‘. Например, в программе Arr на рис.2 с изменением C2 и без него есть четыре цепочки от узла 5 до узла 10: 〈5, ((5,8), (8,10))〉, 〈5, (( 5,8), (8,8), (8,10))〉, 〈5, ((5,8), (8,8), (8,8), (8,10))〉 и 〈5, ((5,8), (8,8), (8,8), (8,8), (8,10))〉.
Строки 4–13 и 16–17 процедуры ComputeEffects (рис.5) вычислить условия цепочки для изменения программы . Условия цепочки — это ограничения на ввод программы для достижения каждого узла в изменении и выполнения каждой цепочки зависимости из этих узлов. Ограничения для каждой цепочки — это условие пути (см. Раздел 2.4) путей, которые ее покрывают. 10 Строки 4–7 начинают это вычисление с создания одной «пустой» цепочки
Цикл while в строках 8–19 выполняет итерацию по рабочему списку цепочек до тех пор, пока список не станет пустым, извлекая по одной цепочке в строке 9 и помещая ее в prefixChain . Для каждого prefixChain цикл для строк 10–18 расширяет его с каждым контролем или зависимостью данных, которая начинается там, где заканчивается цепочка префиксов (строка 11).Для каждой зависимости цикл вычисляет свои условия покрытия (строка 12) в терминах программных переменных в источнике зависимости, а затем вычисляет условия цепочки для расширенной цепочки как соединение условий цепочки префиксной цепочки и условий для новой зависимости (строка 13). Вспомогательная процедура coverCondition берет не только программу и зависимость, но и цепочку префиксов, чтобы гарантировать, что учитываются только реализуемых путей (то есть путей, чьи вызов процедуры и граница возврата совпадают).Строка 16 хранит это условие цепочки для расширенной цепочки вместе с условием состояния (см. Раздел 4.2.2) для цепочки. Наконец, строка 17 добавляет цепочку к рабочему списку для дальнейшего расширения в последующих итерациях цикла и .
Разбор в F # с помощью FParsec
Два месяца назад я написал статью о комбинаторах монадического синтаксического анализатора на C # и о том, как вы можете использовать этот подход для выражения сложной рекурсивной грамматики. Чтобы немного расширить эту тему, я также хотел показать, как тот же подход может быть применен в функционально-ориентированном языке, таком как F #.
FParsec, возможно, не единственный, но определенно самый популярный фреймворк F # для создания синтаксических анализаторов. Разработанная как клон Haskell’s Parsec, с которым он имеет очень похожий API, эта библиотека ориентирована на высокую пропускную способность и удобочитаемые сообщения об ошибках.
В качестве личного упражнения я решил перенести LtGt из Sprache в FParsec. Просто переписав те же правила в новом фреймворке, я увидел повышение производительности в 7,35 раза, что довольно впечатляюще!
В этой статье я познакомлю вас с основами этой библиотеки и покажу, как с ее помощью можно писать синтаксические анализаторы.
Примитивы парсера
Каждый синтаксический анализатор в FParsec является экземпляром Parser <'Result,' State> , который является типом функции, которая принимает CharStream <'State> и возвращает Reply <' Result> . Да, парсеры в FParsec могут иметь состояние, что означает, что вы можете выражать контекстно-зависимую грамматику, но я не собираюсь здесь говорить об этом. Все, что нам нужно знать, это то, что синтаксический анализатор — это функция, которая принимает входные данные и выдает результат или ошибку.
Подобно Sprache и другим библиотекам комбинаторов синтаксического анализатора, FParsec основан на наборе мощных примитивов. Они доступны как функции верхнего уровня и служат отправной точкой даже для самых сложных синтаксических анализаторов.
Среди них:
-
anyChar— анализирует любой отдельный символ. -
pchar— разбирает определенный символ. -
anyOf— разбирает любой из указанных символов. -
удовлетворить— анализирует любой символ, удовлетворяющий предикату. -
буква, цифраверхний,нижний— анализирует символ, принадлежащий определенной категории. -
pstring— анализирует указанную строку.
Их можно использовать для анализа базовых входных данных, но, будучи примитивами, они, очевидно, не очень полезны сами по себе. Чтобы объединить эти простые парсеры в более сложные, нам нужно использовать комбинаторы.
По сути, комбинаторы — это просто функции, которые принимают существующие синтаксические анализаторы в качестве параметров и создают их новые, улучшенные версии.Мне лично нравится делить их на три логические группы:
- Комбинаторы цепочки
- Группирующие комбинаторы
- Отображающие комбинаторы
Давайте взглянем на некоторые из них.
Объединение нескольких парсеров
В основе всех комбинаторов цепочек в FParsec стоит оператор bind ( >> = ). Он создает новый синтаксический анализатор на основе результата предыдущего.
Мы можем использовать оператор связывания, чтобы связать несколько последовательных синтаксических анализаторов и объединить их в синтаксический анализатор более высокого порядка.В качестве простого примера, вот как мы можем выразить два последовательных символа, которые появляются в противоположном регистре:
открыть FParsec
let isOppositeCase a b = isUpper a <> isUpper b
let sawtooth = anyChar >> = fun a -> удовлетворить <| isOppositeCase a >> = fun b -> preturn (a, b)
Синтаксический анализатор пилы будет успешным на таких входах, как «aB» , «Aa» , «dP» и аналогичные, но не будет работать на «ab» , «AA» , » dp ".
Несмотря на то, что он довольно гибкий, оператор связывания не очень удобен в использовании. Он слишком подробный и, в отличие от этого конкретного случая, нам редко нужен результат предыдущего синтаксического анализатора для построения следующего.
Вот почему FParsec также предлагает несколько операторов цепочки высокого уровня:
-
. >>— объединяет два последовательных парсера в цепочку и сохраняет результат одного слева. -
>>.— связывает два последовательных парсера и сохраняет результат правого. -
. >>.— связывает два последовательных синтаксических анализатора и объединяет оба их результата в кортеж.
Например, вот как мы можем составить синтаксический анализатор, который будет использовать "5,9" и превращать его в кортеж F #, состоящий из символов '5' и '9' , отбрасывая запятую в середине. :
пусть commaSeparatedDigits = цифра. >> pchar ','. >>. цифра Отдельные синтаксические анализаторы в выражении объединяются попарно слева направо.Вот тот же код, но в круглых скобках показано, как он работает:
пусть commaSeparatedDigits = ((цифра. >> pchar ','). >>. Цифра)
Мы можем еще больше улучшить это, используя skipChar вместо pchar , чтобы избежать ненужного выделения для результата, который нас не интересует:
пусть commaSeparatedDigits = цифра. >> skipChar ','. >>. цифра Этот вид цепочки синтаксического анализатора может быть полезен для выражения правил грамматики с фиксированной структурой.Однако иногда нам также необходимо выразить повторение, когда определенный символ может появляться более одного раза. Для этого мы можем использовать один из комбинаторов последовательностей, которые предлагает FParsec:
-
многие— цепляет один и тот же парсер до тех пор, пока он не выйдет из строя. -
sepBy— цепляет один и тот же парсер, разделенный другим парсером. -
manyTill— цепляет один и тот же синтаксический анализатор до тех пор, пока другой синтаксический анализатор не завершит работу. -
manyChars,manyCharsTill— то же, что иmanyиmanyTill, но оптимизированы для строк.
Например, мы можем использовать manyChars для улучшения исходного парсера commaSeparatedDigits , чтобы он мог обрабатывать несколько последовательных цифр вокруг запятой:
пусть commaSeparatedDigits = manyChars цифра. >> skipChar ','. >>. manyChars цифра
Теперь это будет работать с такими входами, как "1337,69" , создавая кортеж строк вместо символов. Мы также можем немного изменить его и использовать sepBy , чтобы он мог обрабатывать произвольное количество цифр, разделенных запятыми:
let manyCommaSeparatedDigits = manyChars цифра |> sepBy <| skipChar ','
Если мы запустим последний синтаксический анализатор на "5,96,10" , мы получим соответствующий список строк ["5"; «96»; «10»] , с которым мы можем работать.
Мне нравится применять прямые и обратные каналы F # в подобных композициях, потому что это делает синтаксические анализаторы более удобочитаемыми - приведенное выше выражение эквивалентно sepBy (manyChars digit) (skipChar ',') .
Обратите внимание, что синтаксические анализаторы, созданные с помощью этих комбинаторов последовательностей, всегда будут успешными - если синтаксический анализатор x выйдет из строя, many x просто создаст пустой список. Если вам нужен базовый синтаксический анализатор для успешного выполнения хотя бы один раз, вы можете вместо этого использовать непустые варианты этих комбинаторов: many1 , sepBy1 , many1Chars и т. Д.
Варианты группировки
Другой способ комбинирования синтаксических анализаторов - их группирование. Это позволяет нам передавать сложные грамматические правила нескольким отдельным анализаторам.
Это можно сделать с помощью оператора choice ( <|> ). Например, чтобы объединить букв и цифр в один синтаксический анализатор, мы можем написать:
пусть letterOrDigit = letter <|> цифра Вышеупомянутый синтаксический анализатор успешно обработает "a" , "B" , а также "0" , "4" .Точно так же мы можем написать синтаксический анализатор для строки, содержащей только буквы или цифры:
let alphanumericString = manyChars (буква <|> цифра) Конечно, мы также можем связать оператор выбора несколько раз, чтобы предоставить более двух альтернатив:
let letterOrDigitOrSpecial = letter <|> digit <|> pchar '*' <|> pchar '#' <|> pchar '%' Однако, когда мы имеем дело с множеством альтернатив, лучше использовать функцию выбора .Это оптимизированная версия оператора <|> , который принимает несколько синтаксических анализаторов в виде последовательности:
пусть letterOrDigitOrSpecial =
выбор [
письмо
цифра
pchar '*'
pchar '#'
pchar '%'
] Вышеупомянутый синтаксический анализатор не только будет работать с множеством различных входных данных, он также будет выдавать информативные сообщения об ошибках, если синтаксический анализатор не работает. Ожидается: десятичная цифра, буква, '#', '%' или '*'
В отношении комбинаторов выбора в FParsec важно отметить то, что все они по умолчанию не имеют обратного отслеживания.Это обеспечивает путь наименьшего сопротивления для написания высокопроизводительного кода, но может привести к несколько неожиданным результатам.
Например, в следующем фрагменте один из альтернативных парсеров ( fooXyz ) никогда не будет оцениваться:
let fooBar = pstring "foo". >>. pstring "бар"
пусть fooXyz = pstring "foo". >>. pstring "xyz"
пусть fooBarOrFooXyz =
выбор [
fooBar
fooXyz
]
Попытка запустить fooBarOrFooXyz на "fooxyz" не удастся, но будет хорошо работать с "foobar" .Это связано с тем, что базовый синтаксический анализатор fooBar частично преуспевает на "fooxyz" и изменяет состояние синтаксического анализатора.
Чтобы указать FParsec на возврат в таких случаях, мы можем заключить отдельные парсеры в попытку , которая сбросит состояние после сбоя базового парсера:
let fooBar = pstring "foo". >>. pstring "бар"
пусть fooXyz = pstring "foo". >>. pstring "xyz"
пусть fooBarOrFooXyz =
выбор [
попытка fooBar
попытка fooXyz
]
Это будет работать, как ожидалось.Конечно, вы должны использовать попытки экономно, чтобы избежать ненужного возврата. В качестве альтернативы также можно выборочно избежать изменения состояния анализатора, используя вариант объединения комбинаторов:
let fooBar = pstring "foo". >>.? pstring "бар"
let fooXyz = pstring "foo". >>.? pstring "xyz"
пусть fooBarOrFooXyz =
выбор [
fooBar
fooXyz
] Эти варианты объединения комбинаторов аналогичны обычным, за исключением того, что построенный синтаксический анализатор обрабатывается как единое целое, а не два отдельных синтаксических анализатора:
-
>> =?— то же, что>> =, но без изменения состояния. -
>>?— то же, что и>>., но не меняет состояние. -
. >>?— то же, что и. >>, но без изменения состояния. -
. >>.?— то же, что и. >>., но не меняет состояние.
Результаты сопоставления
Не будем забывать, что основная задача парсера — извлекать семантику из текста. С точки зрения программирования это означает преобразование необработанных символьных строк в некоторые типы домена.
С этим связаны два основных оператора:
- Оператор возврата (
>>%) — устанавливает результат синтаксического анализа на указанное значение. - Оператор карты (
| >>) — применяет функцию к результату парсера.
Мы можем использовать оператор return для создания синтаксического анализатора, который просто выдаст константу в случае успеха:
тип ShapeType = Circle | Прямоугольник
пусть shapeType =
выбор [
skipString "круг" >>% Круг
skipString "прямоугольник" >>% Rectangle
] Комбинация skipString и >>% настолько распространена, что также имеет собственное оптимизированное сокращение stringReturn :
пусть shapeType =
выбор [
stringReturn "circle" Circle
stringReturn "rectangle" Rectangle
] Пример синтаксического анализа выше преобразует «круг» в ShapeType.Обведите и «прямоугольник» в ShapeType.Rectangle .
Для выполнения более сложных преобразований мы можем использовать оператор карты, который позволяет преобразовать результат с помощью функции. Например, здесь мы сопоставляем кортеж с нашим собственным типом домена:
тип NameValuePair = NameValuePair строки * строка
пусть nameValuePair =
(anyChar |> manyCharsTill <| skipChar '=')
. >>.
(anyChar |> manyCharsTill <| skipChar ';')
| >> NameValuePair Причина, по которой мы смогли просто написать | >> NameValuePair , заключается в том, что конструктор типа ожидает кортеж из двух строк, что мы и предоставляем ему.В общем виде мы можем использовать любую функцию:
пусть nameValuePair =
(anyChar |> manyCharsTill <| skipChar '=')
. >>.
(anyChar |> manyCharsTill <| skipChar ';')
| >> fun (имя, значение) -> NameValuePair (имя, значение)
JSON-процессор с использованием FParsec
В FParsec есть еще много других примитивов и комбинаторов. Фактически, если их всего около 200, охватить их все здесь было бы амбициозно и ненужно.
Вместо этого давайте посмотрим, как все это сочетается друг с другом, написав собственный анализатор JSON.
Я знаю, что в официальной документации есть руководство именно по этой теме, и вдобавок к этому я уже показал, как написать процессор JSON на C # с помощью Sprache в моей предыдущей статье. При этом я думаю, что грамматика JSON представляет собой идеальную смесь небольших и нетривиальных правил, что делает ее довольно хорошим «приветственным миром» фреймворков синтаксического анализатора.
Однако прежде чем мы сможем начать, мы должны установить, что именно мы хотим, чтобы наши синтаксические анализаторы выдавали.Поскольку мы имеем дело с JSON, который является типичным контекстно-свободным языком, его структура может быть выражена с помощью синтаксического дерева.
Благодаря рекурсивным дискриминированным объединениям F # определение AST действительно тривиально:
пространство имен MyJsonProcessor
тип JsonNode =
| JsonNull
| JsonBool из bool
| Json Число с плавающей запятой
| JsonString строки
| JsonArray списка
| JsonObject карты <строка, JsonNode> Они будут представлять отдельные узлы в дереве, и позже мы добавим некоторую логику для навигации по иерархии.
Давайте создадим новый модуль под названием JsonGrammar в том же файле. Функции в этом модуле будут представлять отдельные правила грамматики, поэтому их имена будут соответствовать именам фактических типов данных, но с верблюжьим регистром.
Первым парсером, который мы напишем, будет jsonNull , что очень просто:
пространство имен MyJsonProcessor
модуль JsonGrammar =
открыть FParsec
let jsonNull = stringReturn "null" JsonNull. >> пробелы
Мы используем stringReturn , чтобы получить строку "null" и вернуть соответствующее значение — объединение case JsonNull .
Поскольку пробелы игнорируются в JSON, мы также должны учитывать их в наших синтаксических анализаторах, иначе они потерпят неудачу при обнаружении любого символа пробела. Мы можем сделать это, связав наш синтаксический анализатор с пробелами и , которые будут использовать и отбрасывать любые конечные пробелы. Пока мы делаем это в конце каждого синтаксического анализатора, все будет в порядке.
Традиционный способ работы с незначительными пробелами заключается в написании отдельного компонента лексера , который анализирует необработанные символы в так называемые токены .Это также можно сделать с помощью FParsec, и это дает много преимуществ, но для простоты на этот раз мы напишем синтаксический анализатор без сканера.
Если вы следите за инструкциями и ваша IDE жалуется, что тип парсера не может быть определен, помогите ей, явно указав его как let jsonNull: Parser <_, unit> = ... . Мы не собираемся использовать состояние, поэтому можем установить для него значение unit . К концу этого упражнения у нас будет функция точки входа, которая поможет компилятору F # правильно определять универсальные типы, но пока мы можем записать их вручную.
Убрав JsonNull , перейдем к следующему типу данных: JsonBool :
пространство имен MyJsonProcessor
модуль JsonGrammar =
let jsonBoolTrue = stringReturn "true" <| JsonBool true. >> пробелы
let jsonBoolFalse = stringReturn "false" <| JsonBool false. >> пробелы
пусть jsonBool = jsonBoolTrue <|> jsonBoolFalse Поскольку логическое значение может находиться в любом из двух состояний, мы можем обрабатывать их по отдельности и комбинировать их с помощью оператора выбора.Это преимущество комбинаторного синтаксического анализа — мы можем разбить сложное грамматическое правило на множество более простых.
Когда дело доходит до jsonNumber , FParsec уже выполняет большую часть работы, предоставляя нам pfloat , синтаксический анализатор, который сопоставляет текст, представляющий число с плавающей запятой, и преобразует его в float (который является псевдонимом для системы . .Двойной в F #). Это означает, что мы можем просто написать наш парсер так:
пространство имен MyJsonProcessor
модуль JsonGrammar =
пусть jsonNumber = pfloat.>> пробелы | >> JsonNumber Обратите внимание, как мы использовали оператор карты ( | >> ) в анализаторе выше. Это берет результат pfloat и передает его в конструктор JsonNumber , который удобно ожидает float .
Переходим к JsonString , где нам нужно обрабатывать текст любой длины между двумя двойными кавычками. Чтобы облегчить себе жизнь, мы можем ввести несколько вспомогательных функций:
пространство имен MyJsonProcessor
модуль JsonGrammar =
let manyCharsBetween popen pclose pchar = popen >>? manyCharsTill pchar pclose
let anyStringBetween popen pclose = manyCharsBetween popen pclose anyChar
let quotedString = skipChar '"' |> anyStringBetween <| skipChar '"'
Комбинатор manyCharsBetween применяет popen , затем повторно применяет pchar , пока не встретит pclose .Мы основываемся на нем и определяем комбинатор более высокого уровня anyStringBetween , который будет анализировать строку между двумя синтаксическими анализаторами, состоящую из любых символов. Фактически он такой же, как . *? регулярное выражение.
Наконец, мы также определяем quotedString , который равен anyStringBetween с уже примененными двойными кавычками. Обратите внимание, как использование прямых и обратных каналов делает код плавным - порядок токенов в этом выражении фактически совпадает с порядком, в котором синтаксический анализатор их потребляет!
Теперь определение jsonString становится действительно тривиальным:
пространство имен MyJsonProcessor
модуль JsonGrammar =
пусть jsonString = quotedString.>> пробелы | >> JsonString Хорошо, если честно, здесь не обрабатываются escape-последовательности, такие как \ t , \ n и т. Д., Которые разрешены в строках JSON. Работать с ними не очень интересно, поэтому я обманываю, утверждая, что это оставлено в качестве упражнения для читателя. 🙂
Убрав все литералы, мы можем сгруппировать их в один синтаксический анализатор. В этом нет необходимости, но это немного упрощает понимание грамматики.
пространство имен MyJsonProcessor
модуль JsonGrammar =
пусть jsonLiteral =
выбор [
jsonNull
jsonBool
jsonNumber
jsonString
] Два оставшихся случая, JsonArray и JsonObject , немного сложнее.Это потому, что соответствующие грамматические правила рекурсивны - массивы и объекты могут быть вложены друг в друга.
Сложнее то, что порядок объявлений в файле имеет значение в F #, а не в C #. Это означает, что мы не можем ссылаться на синтаксический анализатор, если он не был определен выше, поэтому невозможно легко ввести циклическую рекурсию.
FParsec предоставляет собственный способ решения этой проблемы с помощью функции createParserForwardedToRef . Мы можем использовать его для создания фиктивного парсера jsonNode , который мы можем позже обновить, используя его ссылку:
пространство имен MyJsonProcessor
модуль JsonGrammar =
пусть jsonNode, jsonNodeRef = createParserForwardedToRef () На этом этапе мы можем временно сделать вид, что jsonNode уже определен и будет оценивать любой допустимый узел JSON, включая массивы и объекты.
Теперь давайте проанализируем массив, который представляет собой перечисление разделенных запятыми элементов, содержащихся в квадратных скобках. Каждый элемент в массиве может быть любым литералом, объектом или другим массивом - или, другими словами, любым узлом.
Мы можем определить вспомогательную функцию с именем manyConolated , которая будет заботиться о списке внутри скобок. При этом реализация jsonArray выглядит так:
пространство имен MyJsonProcessor
модуль JsonGrammar =
let manyConolated popen pclose psep p = между popen pclose <| sepBy p psep
пусть jsonArray =
jsonNode
|> manyConolated
(skipChar '['.>> пробелы)
(skipChar ']'. >> пробелы)
(skipChar ','. >> пробелы)
| >> JsonArray Комбинатор между popen pclose p является оптимизированной версией popen >>. стр. >> pclose . Мы направляем в него sepBy , который будет многократно применять синтаксический анализатор с использованием разделителя. Комбинируя эти два комбинатора, мы получаем еще один комбинатор, который будет применять открывающий синтаксический анализатор, затем основной синтаксический анализатор, ограниченный синтаксическим анализатором разделителя, и, наконец, закрывающий синтаксический анализатор.
В конечном итоге реализация jsonArray сводится к простой передаче правильных аргументов нашей вспомогательной функции.
Работа с JsonObject очень похожа, за исключением того, что мы должны анализировать перечисление свойств, а не только узлов. Свойство в JSON представляет собой строку в кавычках, за которой следует двоеточие и значение. Для удобства мы уже определили полезный комбинатор под названием quotedString , когда ранее писали jsonString , который теперь можно использовать так:
пространство имен MyJsonProcessor
модуль JsonGrammar =
пусть jsonProperty =
quotedString.>> пробелы. >> skipChar ':'. >> пробелы. >>. jsonNode. >> пробелы
пусть jsonObject =
jsonProperty
|> manyConolated
(skipChar '{'. >> пробелы)
(skipChar '}'. >> пробелы)
(skipChar ','. >> пробелы)
| >> Map.ofList
| >> JsonObject Наконец, теперь, когда у нас есть парсеры для всех типов узлов, мы можем фактически реализовать jsonNode , используя его ссылку, которую мы получили ранее:
пространство имен MyJsonProcessor
модуль JsonGrammar =
сделать jsonNodeRef: =
выбор [
jsonObject
jsonArray
jsonLiteral
] Тада! Наш парсер технически завершен.Чтобы проверить это, мы можем использовать функцию run для оценки синтаксического анализатора строки:
[]
пусть main _ =
запустите jsonNode "{\" arr \ ": [1, 3.14, false, null]}" |> printfn "% O"
0
Успех: JsonObject
(карта
[("обр",
JsonArray [JsonNumber 1.0; JsonNumber 3.14; JsonBool false; JsonNull])]) Конечно, процессор JSON не очень полезен, если у него нет средств для запроса данных. Для этого давайте создадим еще один модуль и добавим бизнес-логику:
пространство имен MyJsonProcessor
модуль Json =
открыть FParsec
пусть tryParse source =
пусть jsonNodeFull = пробелы >>.JsonGrammar.jsonNode. >> eof
сопоставить запускать источник jsonNodeFull с
| Успех (res, _, _) -> Result.Ok res
| Ошибка (err, _, _) -> Result.Error err
пусть tryBool (узел: JsonNode) =
узел сопоставления с
| JsonBool b -> Некоторые b
| _ -> Нет
пусть tryString (узел: JsonNode) =
узел сопоставления с
| JsonString s -> Некоторые s
| _ -> Нет
пусть tryFloat (узел: JsonNode) =
узел сопоставления с
| JsonNumber n -> Some n
| _ -> Нет
пусть tryInt (узел: JsonNode) =
узел |> tryFloat |> Option.карта int
пусть tryItem (i: int) (узел: JsonNode) =
узел сопоставления с
| JsonArray a -> a |> List.tryItem i
| _ -> Нет
пусть tryChild (имя: строка) (узел: JsonNode) =
узел сопоставления с
| JsonObject o -> o |> Map.try Найти имя
| _ -> Нет Определяя нашу собственную функцию tryParse , мы скрываем API FParsec за слоем абстракции, чтобы нашу библиотеку было немного проще использовать. Мы также оборачиваем исходный jsonNode в синтаксический анализатор, который отбрасывает ведущие пробелы и гарантирует, что достигнут конец потока - последнее важно, потому что мы не хотим только частично анализировать ввод.
Функции tryBool , tryString , tryFloat , tryInt упрощают извлечение значений без необходимости самостоятельно выполнять сопоставление с образцом. Чтобы упростить работу с объектами и массивами, существует также tryChild , который получит дочерний объект по его имени, и tryItem , который получит элемент массива по его индексу.
Давайте соберем все вместе и протестируем на реальных входных данных:
[]
пусть main _ =
пусть str = "" "
{
"контрольный опрос": {
"sport": {
"q1": {
"question": "Какое название команды правильное в НБА?",
"параметры": [
"Нью-Йорк Буллз",
"Лос-Анджелес Кингз",
"Голден Стэйт Уорриорз",
"Ракета Хьюстон"
],
«ответ»: «Ракета Хьюстон»
}
},
"математика": {
"q1": {
"вопрос": "5 + 7 =?",
"параметры": [
«10»,
«11»,
«12»,
«13»
],
«ответ»: «12»
},
"q2": {
"question": "12 - 8 =?",
"параметры": [
1,
2,
3,
4
],
«ответ»: 4
}
}
}
}
"" "
соответствовать Json.tryParse str с помощью
| ОК результат ->
результат
|> Json.tryChild "викторина"
|> Option.bind (Json.tryChild "спорт")
|> Option.bind (Json.tryChild "q1")
|> Option.bind (Json.tryChild "параметры")
|> Option.bind (Json.tryItem 2)
|> Option.bind (Json.tryString)
|> Option.iter (printfn "Значение:% s")
0
| Ошибка err ->
printfn "Ошибка синтаксического анализа:% s" ошибка
1 После запуска этого фрагмента кода мы должны увидеть значение : Golden State Warriors .Замечательно, мы убедились, что наш парсер работает, и создали для него довольно простой, но полезный API.
С готовым проектом также можно ознакомиться здесь.
Постойте, а где же монады?
Если вы пришли сюда после моей предыдущей статьи или иным образом ожидали увидеть здесь монады, вы можете быть немного удивлены, что их пока не было. Это связано с тем, что комбинаторы, которые FParsec предоставляет из коробки, настолько мощны, что вам очень редко приходится прибегать к ним.
Мы могли бы, например, определить наш анализатор массива JSON из более ранней версии следующим образом:
let jsonArray = parse {
делать! skipChar '['
делать! пробелы
позволять! items = sepBy jsonNode <| (skipChar ','. >> пробелы)
делать! skipChar ']'
делать! пробелы
вернуть элементы JsonArray
} Выражение parse вычисления позволяет нам связывать последовательные синтаксические анализаторы более императивным способом. Под капотом он также использует оператор привязки ( >> = ), но обеспечивает немного более чистый синтаксис при работе с большим количеством синтаксических анализаторов.Если вы использовали монады в C #, это похоже на синтаксис понимания LINQ, но намного мощнее.
Стефан Толксдорф, автор FParsec, не рекомендует использовать этот синтаксис в документации, поскольку он редко используется и может отрицательно сказаться на производительности.
Тем не менее, некоторые грамматические правила легче выразить с помощью этого синтаксиса. Например, предположим, что мы анализировали элемент HTML и нам нужно было сопоставить закрывающий тег, имя которого совпадает с именем открывающего тега:
let htmlElement = parse {
делать! skipChar '<'
позволять! tagName = manyChars (буква <|> цифра)
делать! пробелы
позволять! атрибуты = много атрибутов
делать! пробелы
делать! skipChar '>'
делать! пробелы
позволять! children = многие elementChild
делать! skipString "'
делать! пробелы
вернуть HtmlElement (tagName, атрибуты, дочерние элементы)
} Писать одно и то же с помощью биндов может быть не так приятно.
Сводка
FParsec - невероятно надежный фреймворк для создания синтаксических анализаторов с комбинаторным подходом. При некоторой тщательной настройке парсеры, написанные с помощью этой библиотеки, могут даже превзойти традиционные парсеры, созданные вручную. Если вы используете .NET и хотите создать текстовый процессор, компилятор или интерпретатор DSL, FParsec, скорее всего, не проблема.
Если вы когда-нибудь застрянете, я рекомендую прочитать справочник по API и руководство пользователя.
Если вам интересно увидеть другие примеры FParsec в действии, ознакомьтесь с официальными примерами.Есть также несколько проектов с открытым исходным кодом, которые зависят от этой библиотеки, например GraphQL.NET, QSharp Compiler и LtGt.
Другие статьи о FParsec: Джейк Ведьмак, Филипп Трелфорд, Тамиж Вендан.
Марков и вы
Наконец, определение программирования, которое я действительно могу понять. Я был поражен особенно странным и замечательным комментарием, оставленным в этом блоге. Некоторые комментаторы задавались вопросом, был ли этот комментарий сгенерирован цепями Маркова. Я подумал об этом, но мне было трудно представить себе ввод текстового корпуса, который мог бы производить настолько странный вывод.
Итак, , что это за цепи Маркова , о которых мы говорим?
Одним из примеров действующих цепей Маркова является Гарков, где длинная мультипликационная полоса Гарфилда встречается с цепями Маркова. Я представляю ниже, для вашего легкого развлечения, две репрезентативные полосы, которые я нашел в Зале славы Гаркова:
А вот Гарфилд - легкая цель:
- Гарфилд Минус Гарфилд. Что написано на жести. Удивительно слабительное.
- Лазанья Cat.Почти неописуемо странные живые воссоздания полос Гарфилда. Если вы нажмете только одну ссылку в этом посте, сделайте ее этой. Здравомыслие необязательно.
- Вариации Гарфилда. Рисованные версии Гарфилда в андеграундном стиле «комикс», обычно на бумажных салфетках.
- Barfield. Полоски Гарфилда тонко изменены, чтобы включить забавные функции тела.
- Постоянный понедельник. Литературный комментарий к избранным полосам.
- Арбакл. Полоски, точно перерисованные случайными интернет-«художниками», с одним драматическим поворотом: на самом деле Джон не может слышать Гарфилда, потому что он, в конце концов, кот.
- Рандомайзер Гарфилда. К сожалению, несуществующие - случайные комбинации объединены в «новые» полосы Гарфилда.
Итак, приступим к «ковской» части Гаркова. Лучшее описание цепей Маркова, которое я когда-либо читал, находится в главе 15 Programming Pearls:
.Генератор может создавать более интересный текст, делая каждую букву случайной функцией своей предшественницы. Таким образом, мы могли бы прочитать образец текста и подсчитать, сколько раз каждая буква следует за A, сколько раз за буквой B и так далее для каждой буквы алфавита.Когда мы пишем случайный текст, мы производим следующую букву как случайную функцию текущей буквы. Текст Приказа-1 был составлен именно по такой схеме:т Я, вин. Он был нанят на работу, потому что, как ни странно, не чувствовал себя виноватым во множестве этих рук.Мы можем распространить эту идею на более длинные последовательности букв. Текст второго порядка был создан путем создания каждой буквы как функции двух предшествующих ей букв (пару букв часто называют биграммой).Например, биграмма TH в английском языке часто сопровождается гласными A, E, I, O, U и Y, реже R и W и реже другими буквами.
Вот это - складка, размытость - было крыло, как шляпа. Yout lar on wassing, an sit. »« Yould »,« Я, что это видео, не был там.Текст порядка 3 строится путем выбора следующей буквы в зависимости от трех предыдущих букв (триграмма).
У меня есть пила на завтра. И wintails на моем энте, думает, до того, как путешественник приземлился, бывший помощник был от него очень бесплатным бутылочным знаком,К тому времени, когда мы дойдем до текста порядка 4, большинство слов будут английскими, и вы, возможно, не удивитесь, узнав, что он был создан из рассказа Шерлока Холмса («Приключение в аббатстве Грейндж»).
Его слышали. "" Собственно он очень рад беде, и Хопкинсу! Это один из тех, кто трудится. Он бросился скорее всего? »« Кровавая ночь, что.
Значит, текст в полосах Гаркова генерируется именно так, но с использованием слов вместо букв. Входной корпус, как и следовало ожидать, представляет собой текст многих старых полос Гарфилда.
Что меня поражает в цепях Маркова, так это то, насколько они невероятно просты . Цепь Маркова не запоминает предыдущие состояния: следующее состояние (в нашем случае слово) выбирается на основе случайного броска игральных костей и поиска в таблице состояний, которые имеют тенденцию исторически следовать текущему состоянию во входном корпусе.При наличии адекватного набора входных данных они работают почти на удивление хорошо, что свидетельствует о широкой силе элементарных статистических выводов. Гарфилд существует с 1978 года, и все еще идет ... ну, так что недостатка в материале для работы нет.
А теперь попробуем сами. Я отправил текст последних двенадцати эссе Пола Грэма в этот онлайн-генератор Маркова, используя две группы слов - то, что Бентли называет «Порядком-2». Вот что я получил:
Однако вы можете почувствовать необходимость воспользоваться преимуществами повышенной дешевизны.Вы не все играете в игру с нулевой суммой. Нет фиксированного количества стартапов; мы финансируем стартапы, которые мы финансируем, для работы над незначительными вопросами. Но мне неприятно осознавать, что это часть каких-либо иллюзий по поводу проблемы переедания из-за отказа от еды. Я не мог просто избежать Интернета, потому что в компании появилась новая тенденция одержимо беспокоиться о том, что он означает для кого-то, обычно постороннего, который сознательно разжигает споры в стартапе, а не просто запускает его. Вы знаете, как выбирается Список А.И даже это больше работы.
Но цепи Маркова полезны не только для автоматического создания пародий на эссе Пола Грэма. К тому же они довольно практичны. Можно даже сказать, что цепи Маркова - это большая часть того, что движет сегодняшним Интернетом. Наиболее примечательно, по крайней мере, для меня, цепи Маркова лежат в основе формулы Google PageRank на триллион долларов:
Формула [PageRank] использует модель случайного пользователя, которому надоедает после нескольких щелчков мышью и который переключается на случайную страницу. Значение PageRank страницы отражает вероятность того, что случайный пользователь попадет на эту страницу, щелкнув ссылку. [PageRank] можно понимать как цепь Маркова, в которой состояниями являются страницы, а все переходы равновероятны и являются связями между страницами.В результате теории Маркова можно показать, что PageRank страницы - это вероятность оказаться на этой странице после большого количества кликов. Это получается равным t -1 , где t - это ожидаемое количество щелчков (или случайных переходов), необходимых для возврата со страницы к самой себе.
Между прочим, если вы не читали оригинальную статью о PageRank за 1998 год, озаглавленную «Рейтинг цитирования PageRank: наведение порядка в сети» (pdf), вам действительно стоит это сделать.Примечательно, как по прошествии десяти лет так много предсказаний в этой статье сбылись. Он наполнен интересными вещами; Список 15 лучших сайтов с рейтингом PageRank за 1996 год в Таблице 1 - это открывающее глаза напоминание о том, как далеко мы продвинулись. К тому же есть ссылки на порнографические сайты!
марковских моделей - в частности, скрытых марковских моделей - также связаны с нашим старым другом, байесовской фильтрацией спама. Они даже лучше! Наиболее ярким примером является дискриминатор CRM114, о чем говорится в этой превосходной презентации (pdf).
Если вы поиграете с синтезатором текста Маркова, вы быстро обнаружите, что методы Маркова хороши ровно настолько, насколько хорош их входной корпус. Введите кучу одинаковых слов или случайную тарабарщину, и это то, что вы получите в ответ.
Но трудно представить себе более идеальный корпус ввода для марковских методов, чем невообразимые просторы Интернета и электронной почты, не так ли?
Значение изменения Windbg
WinDbg. WinDbg является отладчиком как в режиме ядра, так и в режиме пользователя.Оно произносится как Windbag, Win «d-b-g» или, что более интуитивно, WinDebug. Для многих разработчиков WinDbg является центром вселенной расширенной отладки. Он был доступен в течение некоторого времени и расширился, чтобы охватить впечатляющий набор команд.
Как видно из этого изображения, «Адресное пространство пользователя недоступно…», это ключ к изменению конфигурации, которое мне нужно сделать. Мой следующий пост в блоге будет кратким о настройке правильной конфигурации для этого. И просто для подтверждения пути к файлу символов….
28 апреля 2011 г. · Таким образом, теоретически сгенерированный дамп должен быть сохранен, за исключением случаев, когда вы измените значение реестра AeDebug \ Auto на 0. По той или иной причине это никогда не работало на моих машинах XP. Я предлагаю вам просто использовать ntsd.exe или WinDbg.exe для создания аварийных дампов - если это ваше собственное приложение и тестовая среда, это не делает ...
Некоторые процессоры поддерживают аппаратные точки останова, которые сломаются. когда адрес читается или пишется. Например, если у меня есть 4-байтовая переменная по адресу 0x10005060, я могу установить аппаратную точку останова следующим образом (используя windbg): ba w4 0x10005060.
14 января 2006 г. · Использование WinDbg и SOS помогает при анализе проблем приложений. Это мощные инструменты в вашем распоряжении для проведения вскрытия вашего веб-приложения. Вначале они могут показаться немного пугающими, но я обнаружил, что они действительно открывают глаза и дают много возможностей для понимания внутренней работы .Net.
25 июля 2014 г. · Я загрузил ваш фиксированный rar TitanEngine и заменил его в папке x64_dbg. Я обнаружил, что в точке останова системы efalg равен 202 в Ollydbg и ваших x64_dbg и Windbg.F9, остановитесь на Entrypoint. Eflag равен 200 в x64_dbg, но Ollydbg равен 246, как сказал Као. И выполните эту команду, ollydbg не меняет efalg.
18 марта 2019 г. · Итак, когда я спросил WinDbg о значении CR3, мне было предоставлено значение CR3 режима ядра. В этом случае, как и в других случаях, может быть полезно иметь полную эмуляцию системы, чтобы не мешать Windows ...
MySQL NOT IN () гарантирует, что выражение продолжено не имеет ни одного из присутствующих значений в аргументах.