Разбор слов по составу
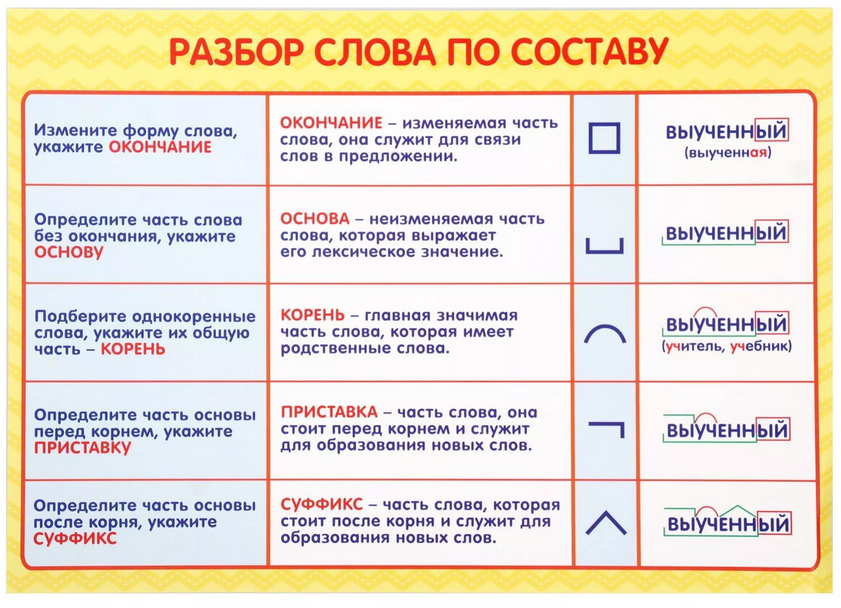
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: оттемл сейчас к е р п о а ч 1 секунда назад овраозг 1 секунда назад я б л о к о с 1 секунда назад наша служба и опасна и трудна 1 секунда назад т а и с к о л 1 секунда назад а а а н л ф г 1 секунда назад риедвео 2 секунды назад натиск 2 секунды назад наукми 2 секунды назад музыковед 2 секунды назад амтареогл 2 секунды назад редиска 2 секунды назад т е х н и к а 3 секунды назад портг 3 секунды назад
Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Использование некоторых словоформ тоже имеет несколько вариаций.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- определить его корректное написание;
- понять, как правильно в нем ставить ударение.
Площадка предлагает ознакомиться с историей возникновения слова. Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.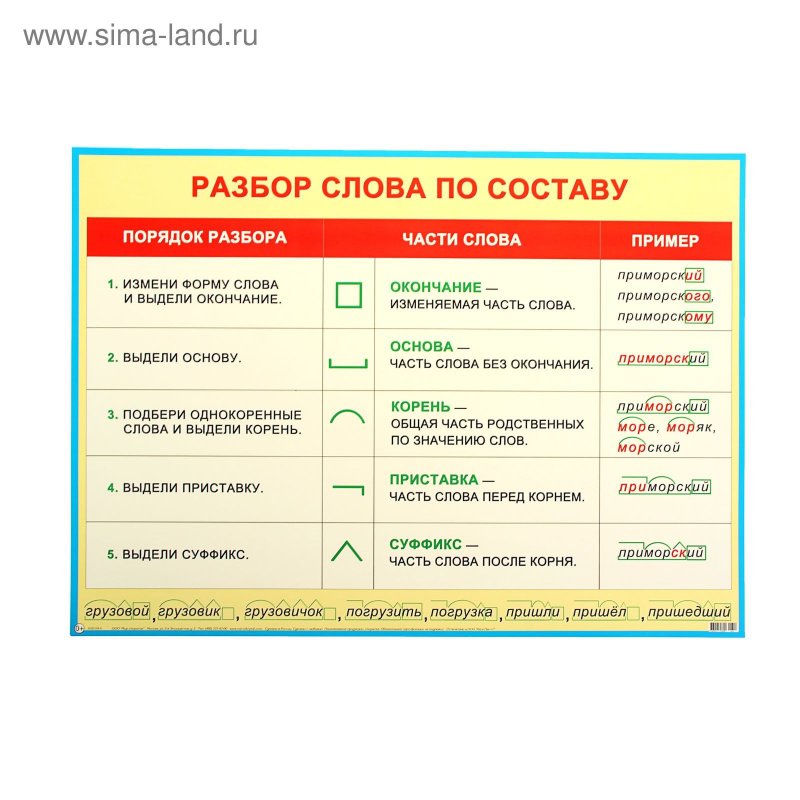
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций. Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
уьпроиск 6 секунд назад
мнящее 15 секунд назад
правота 17 секунд назад
ерасыл 22 секунды назад
естествознание 24 секунды назад
спортак 32 секунды назад
деж 36 секунд назад
вилла 37 секунд назад
воспользоваться магией 37 секунд назад
онд 37 секунд назад
грабельки 41 секунда назад
коробка 49 секунд назад
ледубр 56 секунд назад
доеторп 57 секунд назад
василек 1 минута 8 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | разветвленность | 27 слов | 8 часов назад | 176. 59.121.171 59.121.171 |
| Игрок 2 | фантастика | 52 слова | 8 часов назад | 93.80.181.223 |
| Арпине | вагоностроитель | 34 слова | 8 часов назад | 176.59.121.171 |
| Арпине | надругательство | 35 слов | 8 часов назад | 176.59.121.171 |
| Арпине | колесопрокатчик | 33 слова | 9 часов назад | 176.59.121.171 |
| Арпине | пангерманист | 15 слов | 9 часов назад | 176.59.121.171 |
| Игрок 7 | трансфузиология | 222 слова | 9 часов назад | 93.80.181.223 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | вейка | 55:52 | 4 часа назад | 94. 245.134.239 245.134.239 |
| Игрок 2 | вейка | 11:13 | 4 часа назад | 94.245.134.239 |
| Игрок 3 | побед | 50:51 | 5 часов назад | 94.245.134.239 |
| Игрок 4 | удача | 9:11 | 5 часов назад | 94.245.134.239 |
| Игрок 5 | отрез | 49:53 | 8 часов назад | 176.59.42.174 |
| Игрок 6 | аршин | 49:56 | 8 часов назад | 176.98.51.142 |
| Игрок 7 | дебил | 51:53 | 8 часов назад | 176.59.120.138 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Дарина | На двоих | 20 вопросов | 7 часов 7 секунд назад | 80. 34.126.178 34.126.178 |
| Дарина | На двоих | 20 вопросов | 80.34.126.178 | |
| Иван | На двоих | 10 вопросов | 18 часов назад | 188.170.86.112 |
| Иван | На двоих | 10 вопросов | 19 часов назад | 188.170.86.112 |
| Иван | На двоих | 10 вопросов | 19 часов назад | 188.170.86.112 |
| Ле | На одного | 10 вопросов | 20 часов назад | 84.22.133.138 |
| Все | На одного | 20 вопросов | 1 день назад | 176.59.8.68 |
| Играть в Чепуху! | ||||
Предварительная обработка текста: Удаление стоп-слов | Chetna
Удобное руководство по удалению английских стоп-слов в Python
Изображение Kai на Unsplash Мы хорошо понимаем тот факт, что компьютеры могут легко обрабатывать числа, если они хорошо запрограммированы. 🧑🏻💻 Однако большая часть информации, которой мы располагаем, представлена в виде текста. 📗 Мы общаемся друг с другом, напрямую разговаривая с ними или используя текстовые сообщения, сообщения в социальных сетях, телефонные звонки, видеозвонки и т. д. Чтобы создавать интеллектуальные системы, нам нужно использовать эту информацию, которой у нас в избытке.
🧑🏻💻 Однако большая часть информации, которой мы располагаем, представлена в виде текста. 📗 Мы общаемся друг с другом, напрямую разговаривая с ними или используя текстовые сообщения, сообщения в социальных сетях, телефонные звонки, видеозвонки и т. д. Чтобы создавать интеллектуальные системы, нам нужно использовать эту информацию, которой у нас в избытке.
Обработка естественного языка (НЛП) — это ветвь искусственного интеллекта, которая позволяет машинам интерпретировать человеческий язык. 👍🏼 Однако то же самое не может быть использовано машиной напрямую, и нам нужно сначала предварительно обработать то же самое.
Предварительная обработка текста — это процесс подготовки текстовых данных, чтобы машины могли использовать их для выполнения таких задач, как анализ, прогнозирование и т. д. Предварительная обработка текста включает множество различных шагов, но в этой статье мы рассмотрим только познакомьтесь со стоп-словами, почему мы их удаляем и с различными библиотеками, которые можно использовать для их удаления.
Итак, приступим. 🏃🏽♀️
Что такое стоп-слова? 🤔Слова, которые обычно отфильтровываются перед обработкой естественного языка, называются стоп-словами . На самом деле это самые распространенные слова в любом языке (такие как артикли, предлоги, местоимения, союзы и т. д.), и они не добавляют много информации к тексту. Примеры нескольких стоп-слов в английском языке: «the», «a», «an», «so», «what».
Почему мы удаляем стоп-слова? 🤷♀️
Стоп-слова доступны в изобилии на любом человеческом языке. Удаляя эти слова, мы удаляем низкоуровневую информацию из нашего текста, чтобы уделить больше внимания важной информации. По порядку можно сказать, что удаление таких слов не оказывает негативного влияния на модель, которую мы обучаем для нашей задачи.
Удаление стоп-слов определенно уменьшает размер набора данных и, следовательно, сокращает время обучения из-за меньшего количества токенов, участвующих в обучении.
Всегда ли мы удаляем стоп-слова? Всегда ли они бесполезны для нас? 🙋♀️
Нет! 🙅♂️
Мы не всегда удаляем стоп-слова. Удаление стоп-слов сильно зависит от задачи, которую мы выполняем, и цели, которую мы хотим достичь. Например, если мы обучаем модель, которая может выполнять задачу анализа настроений, мы можем не удалять стоп-слова.
Обзор фильма: «Фильм совсем не понравился».
Текст после удаления стоп-слов: « фильм хороший»
Мы ясно видим, что отзыв о фильме был отрицательным. Однако после удаления стоп-слов отзыв стал положительным, что не соответствует действительности. Таким образом, удаление стоп-слов здесь может быть проблематичным.
В таких задачах, как классификация текста, обычно не требуются стоп-слова, поскольку другие слова, присутствующие в наборе данных, более важны и дают общее представление о тексте. Поэтому стоп-слова в таких задачах мы обычно убираем.
Короче говоря, в НЛП есть много задач, которые невозможно выполнить должным образом после удаления стоп-слов. Итак, подумайте, прежде чем выполнять этот шаг. Загвоздка здесь в том, что ни одно правило не является универсальным, и ни один список стоп-слов не является универсальным. Список, не передающий никакой важной информации одной задаче, может передать много информации другой задаче.
Предостережение: Прежде чем удалять стоп-слова, немного изучите свою задачу и проблему, которую вы пытаетесь решить, а затем примите решение.
Какие существуют библиотеки для удаления стоп-слов? 🙎♀️ Сегодня НЛП является одной из наиболее изучаемых областей, и в этой области было сделано много революционных разработок. НЛП опирается на передовые вычислительные навыки, и разработчики по всему миру создали множество различных инструментов для работы с человеческим языком. Из такого большого количества библиотек некоторые довольно популярны и очень помогают в выполнении множества различных задач НЛП.
Некоторые из библиотек, используемых для удаления английских стоп-слов, список стоп-слов вместе с кодом приведены ниже.
Natural Language Toolkit (NLTK):
NLTK — замечательная библиотека для игры с естественным языком. Когда вы начнете свое путешествие по НЛП, это будет первая библиотека, которую вы будете использовать. Шаги для импорта библиотеки и списка английских стоп-слов приведены ниже:
import nltk
from nltk.corpus import стоп-слов )
Вывод:
['я', 'мне', 'мой', 'сам', 'мы', 'наш', 'наш', 'нас', 'ты', 'ты', 'ты', «ты», «ты», «твой», «твой», «себя», «себя», «он», «его», «его», «сам», «она», «она». ", 'она', 'ее', 'сама', 'это', 'это', 'его', 'сама', 'они', 'их', 'их', 'их', 'себя', 'что', 'который', 'кто', 'кому', 'этот', 'тот', 'этот', 'эти', 'те', 'есть', 'есть', 'есть', 'был', 'были', 'быть', 'был', 'быть', 'иметь', 'имеет', 'иметь', 'иметь', 'делать', 'делает', 'делал', 'делает ', 'а', 'а', 'то', 'и', 'но', 'если', 'или', 'потому что', 'как', 'до', 'пока', 'из', 'в', 'по', 'за', 'с', 'о', 'против', 'между', 'в', 'через', 'во время', 'до', 'после', 'сверху' ', 'ниже', 'до', 'от', 'вверху', 'внизу', 'в', 'вне', 'вкл.', 'выкл.', 'сверху', 'под', 'снова', «дальше», «тогда», «один раз», «здесь», «там», «когда», «где», «почему», «как», «все», «каждый», «оба», «каждый». ', 'несколько', 'больше', 'большинство', 'другой', 'некоторые', 'такой', 'нет', 'ни', 'не', 'только', 'свой', 'такой же', 'так', 'та п', 'тоже', 'очень', 'с', 'т', 'может', 'будет', 'просто', 'не'т', 'не надо', 'должен', "должен был" , 'сейчас', 'д', 'лл', 'м', 'о', 'ре', 'ве', 'у', 'аин', 'арен', 'не', 'может' , «не мог», «не сделал», «не сделал», «не делает», «не имеет», «имел», «не имел», «имеет», «не имеет», «имеет» , «не», «не», «не», «ма», «может», «не может», «должен», «не должен», «нужно», «не нужно» , 'шань', 'не должен', 'должен', 'не должен', 'был', 'не был', 'был', 'не был', 'выиграл', 'не будет' , 'было бы', "не было бы"]
 ', 'выкл.', 'сверху', 'под', 'снова', «дальше», «тогда», «один раз», «здесь», «там», «когда», «где», «почему», «как», «все», «каждый», «оба», «каждый». ', 'несколько', 'больше', 'большинство', 'другой', 'некоторые', 'такой', 'нет', 'ни', 'не', 'только', 'свой', 'такой же', 'так', 'та п', 'тоже', 'очень', 'с', 'т', 'может', 'будет', 'просто', 'не'т', 'не надо', 'должен', "должен был" , 'сейчас', 'д', 'лл', 'м', 'о', 'ре', 'ве', 'у', 'аин', 'арен', 'не', 'может' , «не мог», «не сделал», «не сделал», «не делает», «не имеет», «имел», «не имел», «имеет», «не имеет», «имеет» , «не», «не», «не», «ма», «может», «не может», «должен», «не должен», «нужно», «не нужно» , 'шань', 'не должен', 'должен', 'не должен', 'был', 'не был', 'был', 'не был', 'выиграл', 'не будет' , 'было бы', "не было бы"]
', 'выкл.', 'сверху', 'под', 'снова', «дальше», «тогда», «один раз», «здесь», «там», «когда», «где», «почему», «как», «все», «каждый», «оба», «каждый». ', 'несколько', 'больше', 'большинство', 'другой', 'некоторые', 'такой', 'нет', 'ни', 'не', 'только', 'свой', 'такой же', 'так', 'та п', 'тоже', 'очень', 'с', 'т', 'может', 'будет', 'просто', 'не'т', 'не надо', 'должен', "должен был" , 'сейчас', 'д', 'лл', 'м', 'о', 'ре', 'ве', 'у', 'аин', 'арен', 'не', 'может' , «не мог», «не сделал», «не сделал», «не делает», «не имеет», «имел», «не имел», «имеет», «не имеет», «имеет» , «не», «не», «не», «ма», «может», «не может», «должен», «не должен», «нужно», «не нужно» , 'шань', 'не должен', 'должен', 'не должен', 'был', 'не был', 'был', 'не был', 'выиграл', 'не будет' , 'было бы', "не было бы"] Проверим, сколько стоп-слов в этой библиотеке.
print ( len (sw_nltk))
Вывод:
179
Удалим из текста стоп-слова.
text = "Когда я впервые встретил ее, она была очень тихой.
новый_текст = " ". join (слов) print (new_text)
print ("Старая длина: ", len (текст))
print ("Новая длина: ", len (new_text)) 0 Приведенный выше код довольно прост, но я все же объясню его для начинающих. У меня есть текст, и я разбиваю этот текст на слова, так как стоп-слова — это список слов. Затем я изменил слова на строчные, так как все слова в списке стоп-слов написаны строчными буквами. Затем я создал список всех слов, которых нет в списке стоп-слов. Затем полученный список объединяется, чтобы снова сформировать предложение.Вывод:
сначала встретил тишину. молчал все два часа пути Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 82Мы можем ясно видеть, что удаление стоп-слов сократило длину предложения со 129 до 82.
Пожалуйста, обратите внимание, что я буду использовать аналогичный код для объяснения стоп-слов в каждой из библиотек.
spaCy:
spaCy — это библиотека программного обеспечения с открытым исходным кодом для продвинутого НЛП. Эта библиотека сейчас довольно популярна, и практикующие НЛП используют ее для наилучшего выполнения своей работы.
import spacy
#загрузка маленькой модели spacy на английском языке
en = spacy.load ('en_core_web_sm')
sw_spacy = en. Defaults.stop_words
print (sw_spacy)Вывод:
{'те', 'на', 'свои', ''ва', 'себя', 'вокруг', 'между', 'четыре ', 'был', 'один', 'от', 'я', 'тогда', 'другой', 'может', 'относительно', 'в дальнейшем', 'передний', 'тоже', 'использованный', 'причем', 'буду', 'делаю', 'все', 'вверх', 'на', 'никогда', 'либо', 'как', 'до', 'все равно', 'с', ' через», «количество», «сейчас», «он», «был», «иметь», «в», «потому что», «не», «поэтому», «они», «не», « даже', 'кого', 'это', 'видеть', 'где-то', 'после этого', 'ничего', 'в то время как', 'много', 'всякий раз', 'кажется', 'пока', 'почему' , 'в', 'также', 'некоторые', 'последний', 'чем', 'получить', 'уже', 'наш', 'когда-то', 'будет', 'никто', 'м', 'что', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что угодно', 'хотя', 'хотя', 'который', 'будет', 'там ', 'ни', 'как-то', 'после этого', 'к тому же', 'кто-либо', 'нас', 'несколько', 'сделал', 'без', 'третий', 'что-нибудь', 'двенадцать', 'против', 'пока', 'двадцать', 'если', 'однако', ' сама', 'когда', 'может', 'наш', 'шесть', 'сделано', 'кажется', 'иначе', 'звонить', 'возможно', 'было', 'все же', 'где' , 'иначе', 'еще', 'внутри', 'его', 'для', 'вместе', 'где-то еще', 'на протяжении', 'из', 'другие', 'показать', 'с', 'где-либо', 'во всяком случае', 'как', 'есть', 'тот', 'следовательно', 'что-то', 'настоящим', 'нигде', 'в последнее время', 'говорить', 'не делает', 'ни ', 'его', 'идти', 'сорок', 'положить', 'их', 'по', 'а именно', 'может', 'пять', 'если', 'сам', 'есть', 'девять', 'потом', 'внизу', 'дно', 'тем самым', 'такой', 'оба', 'она', 'становиться', 'целое', 'кто', 'себя', 'каждый ', 'через', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'далее', 'не', 'здесь', 'во время ', 'почему', 'с', 'просто', 'ы', 'становится', 'буду', 'о', 'а', 'использование', 'кажется', 'г', ' 'll', 're', 'должен', 'где угодно', 'заранее', 'пятьдесят', 'становление', 'может', 'среди', 'мой', 'пустой', 'оттуда', ' после этого», «почти», «наименее», «кто-то», «часто», «от», «держать», «его», «или», «м», «сверху», «она», «никто ', 'когда-то', «поперек», «с», «ре», «сотня», «только», «через», «имя», «восемь», «три», «назад», «к», «все», 'стал', 'двигаться', 'я', 'мы', 'прежде', 'так', 'я', 'откуда', 'под', 'всегда', 'сам', 'в', 'здесь ', 'больше', 'после', 'себя', 'вы', 'выше', 'шестьдесят', 'их', 'ваш', 'сделано', 'действительно', 'большинство', 'везде', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'сторона', 'бывший', 'кто-либо', 'полный', 'имеющий', 'твой', 'чей ', 'за', 'пожалуйста', 'десять', 'казалось', 'иногда', 'должен', 'сверху', 'брать', 'каждый', 'то же самое', 'скорее', 'действительно', 'последний', 'и', 'ок', 'вследствии этого', 'часть', 'за', 'одиннадцать', 'когда-либо', ''ре', 'достаточно', 'не', 'снова' , ''d', 'нас', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'там', 'к', 'м', ", ''d', 'дать', 'делать', 'ан', 'вполне', 'эти', 'каждый', 'навстречу', 'это', 'нельзя', 'потом', 'за' , 'делать', 'были', 'ли', 'хорошо', 'другой', 'ниже', 'первый', 'на', 'любой', 'никто', 'многие', 'серьезный', ' различные', 'ре', 'два', 'меньше', 'ве '}Довольно длинный список.
печать ( len (sw_spacy))Вывод:
326Ого, 326! Давайте удалим стоп-слова из нашего предыдущего текста.
слов = [слово для слов в тексте . split() , если слов. ниже() нет в sw_spacy]
new_text = " ". присоединиться (слова)
печать (новый_текст)
печать ("Старая длина: ", длин (текст))
печать ("Новая длина: ", длин (новый_текст))Вывод:
мет тихо. оставался тихим весь час пути в Стоуни-Брук, Нью-Йорк.
Старая длина: 129
Новая длина: 72Мы ясно видим, что удаление стоп-слов сократило длину предложения со 129 до 72, что даже короче, чем в NLTK, потому что в библиотеке spaCy больше стоп-слов, чем в NLTK.
Gensim:
Gensim (Generate Similar) — это программная библиотека с открытым исходным кодом, использующая современное статистическое машинное обучение. Согласно Википедии, Gensim предназначен для обработки больших текстовых коллекций с использованием потоковой передачи данных и добавочных онлайн-алгоритмов, что отличает его от большинства других пакетов программного обеспечения для машинного обучения, предназначенных только для обработки в памяти.
импорт gensim
из gensim.parsing.preprocessing import remove_stopwords, СТОП-СЛОВА
print (СТОП-СЛОВА)Вывод:
frostset({'те', 'на', 'свои', 'ваши', 'т.е.', 'вокруг', 'между', 'четыре', 'был', 'один', 'выкл', 'ам', 'тогда', 'другой', 'может', 'плакать', 'относительно', 'в будущем', 'перед', 'слишком ', 'используется', 'при этом', 'делает', 'все', 'вверх', 'никогда', 'на', 'как', 'либо', 'до', 'все равно', 'с тех пор', 'через', 'количество', 'сейчас', 'он', 'не могу', 'был', 'против', 'иметь', 'в', 'потому что', 'вкл.Опять длинный список.
печать ( len (СТОП-СЛОВА))Вывод:
337Уммм! Такой же счет, как spaCy. Удалим стоп-слова из нашего текста.
new_text = remove_stopwords (текст)9 ))
print (new_text) print ("Старая длина: ", len (текст))
print ("Новая длина: ",
 Она молчала в течение всего двухчасового пути от Стоуни-Брук до Нью-Йорка."words = [word for word in text. split() , если слов. ниже() нет в sw_nltk]
Она молчала в течение всего двухчасового пути от Стоуни-Брук до Нью-Йорка."words = [word for word in text. split() , если слов. ниже() нет в sw_nltk] 
 Проверим, сколько стоп-слов в этой библиотеке.
Проверим, сколько стоп-слов в этой библиотеке.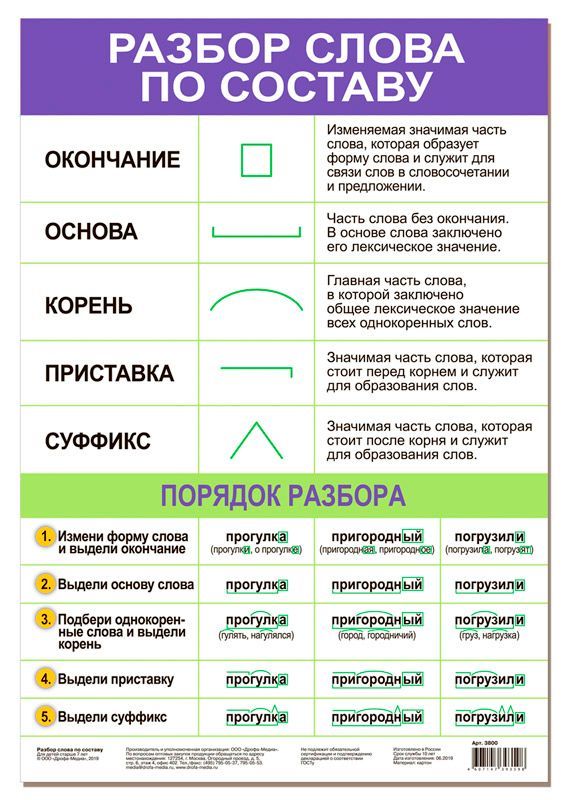 Хотя результаты в этом случае очень похожи.
Хотя результаты в этом случае очень похожи. ', 'не', 'поэтому ', 'они', 'даже', 'кого', 'это', 'видеть', 'где-то', 'интерес', 'вследствие этого', 'толстый', 'ничего', 'тогда как', 'много', 'всякий раз', 'найти', 'кажется', 'пока', 'в силу чего', 'в', 'лтд', 'огонь', 'также', 'некоторые', 'последний', 'чем', 'получить ', 'уже', 'наш', 'не делает', 'когда-то', 'будет', 'никто', 'тот', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что-либо', 'хотя', 'хотя', 'и т. д.', 'который', 'будет', 'там', 'ни', 'каким-то образом', 'после этого', 'кроме того', 'кто бы ни ', 'тонкий', 'себя', 'fe ж', 'делал', 'третий', 'без', 'двенадцать', 'что угодно', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама' , 'когда', 'может', 'шесть', 'наше', 'сделано', 'кажется', 'иначе', 'звонить', 'возможно', 'было', 'все же', 'заполнить', ' где', 'иначе', 'все еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показать' , 'искренний', 'где угодно', 'во всяком случае', 'как', 'есть', 'тот', 'следовательно', 'что-то', 'настоящим', 'нигде', 'в последнее время', 'де', ' сказать', 'делает', 'ни', 'его', 'идти', 'сорок', 'положить', 'их', 'по', 'а именно', 'км', 'могл', 'пять' , 'если', 'сама', 'есть', 'девять', 'потом', 'внизу', 'дно', 'таким образом', 'такая', 'оба', 'она', 'становиться', ' весь', 'кто', 'себя', 'каждый', 'через', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'дальше' , 'здесь', 'во время', 'почему', 'с', 'просто', 'становится', 'около', 'а', 'со', 'использование', 'кажущееся', 'должное', ' где», «заранее», «деталь», «пятьдесят», «становление», «может быть», «среди», «мой», «пустой», «отсюда», «там после', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'не сделал', 'никто' , 'когда-то', 'через', 'сотня', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к', 'все', 'стало', ' двигаться», «я», «мы», «ранее», «так», «я», «откуда», «описывать», «под», «всегда», «сам», «больше», «здесь» , 'в', 'после', 'себя', 'вы', 'их', 'выше', 'шестьдесят', 'не', 'твой', 'сделал', 'везде', 'действительно', ' самый', 'кг', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'компьютер', 'бок', 'бывший', 'полный', 'кто-нибудь' , 'имеет', 'ваш', 'чей', 'за', 'пожалуйста', 'мельница', 'среди', 'десяти', 'казалось', 'иногда', 'должен', 'над', ' взять', 'каждый', 'дон', 'тот же', 'скорее', 'действительно', 'последний', 'и', 'часть', 'вследствии этого', 'пер', 'одиннадцать', 'когда-либо' , 'достаточно', 'снова', 'нам', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'там', 'к', 'дать', ' система', 'делать', 'вполне', 'ан', 'эти', 'все', 'по направлению', 'это', 'счет', 'не может', 'не', 'потом', ' за», «делать», «были», «ли», «ну», «другой», «ниже», «первый», «на», «любой», «никто», «многие», «различные» , 'серьезно', 'ре', 'два', 'меньше', 'не мог'})
', 'не', 'поэтому ', 'они', 'даже', 'кого', 'это', 'видеть', 'где-то', 'интерес', 'вследствие этого', 'толстый', 'ничего', 'тогда как', 'много', 'всякий раз', 'найти', 'кажется', 'пока', 'в силу чего', 'в', 'лтд', 'огонь', 'также', 'некоторые', 'последний', 'чем', 'получить ', 'уже', 'наш', 'не делает', 'когда-то', 'будет', 'никто', 'тот', 'что', 'таким образом', 'нет', 'сам', 'вне', 'следующий', 'что-либо', 'хотя', 'хотя', 'и т. д.', 'который', 'будет', 'там', 'ни', 'каким-то образом', 'после этого', 'кроме того', 'кто бы ни ', 'тонкий', 'себя', 'fe ж', 'делал', 'третий', 'без', 'двенадцать', 'что угодно', 'против', 'пока', 'двадцать', 'если', 'однако', 'нашла', 'сама' , 'когда', 'может', 'шесть', 'наше', 'сделано', 'кажется', 'иначе', 'звонить', 'возможно', 'было', 'все же', 'заполнить', ' где', 'иначе', 'все еще', 'внутри', 'его', 'для', 'вместе', 'в другом месте', 'на протяжении', 'из', 'например', 'другие', 'показать' , 'искренний', 'где угодно', 'во всяком случае', 'как', 'есть', 'тот', 'следовательно', 'что-то', 'настоящим', 'нигде', 'в последнее время', 'де', ' сказать', 'делает', 'ни', 'его', 'идти', 'сорок', 'положить', 'их', 'по', 'а именно', 'км', 'могл', 'пять' , 'если', 'сама', 'есть', 'девять', 'потом', 'внизу', 'дно', 'таким образом', 'такая', 'оба', 'она', 'становиться', ' весь', 'кто', 'себя', 'каждый', 'через', 'кроме', 'очень', 'несколько', 'среди', 'существование', 'быть', 'моё', 'дальше' , 'здесь', 'во время', 'почему', 'с', 'просто', 'становится', 'около', 'а', 'со', 'использование', 'кажущееся', 'должное', ' где», «заранее», «деталь», «пятьдесят», «становление», «может быть», «среди», «мой», «пустой», «отсюда», «там после', 'почти', 'наименее', 'кто-то', 'часто', 'от', 'держать', 'его', 'или', 'сверху', 'ее', 'не сделал', 'никто' , 'когда-то', 'через', 'сотня', 'только', 'через', 'имя', 'восемь', 'три', 'назад', 'к', 'все', 'стало', ' двигаться», «я», «мы», «ранее», «так», «я», «откуда», «описывать», «под», «всегда», «сам», «больше», «здесь» , 'в', 'после', 'себя', 'вы', 'их', 'выше', 'шестьдесят', 'не', 'твой', 'сделал', 'везде', 'действительно', ' самый', 'кг', 'пятнадцать', 'но', 'должен', 'вместе', 'рядом', 'ее', 'компьютер', 'бок', 'бывший', 'полный', 'кто-нибудь' , 'имеет', 'ваш', 'чей', 'за', 'пожалуйста', 'мельница', 'среди', 'десяти', 'казалось', 'иногда', 'должен', 'над', ' взять', 'каждый', 'дон', 'тот же', 'скорее', 'действительно', 'последний', 'и', 'часть', 'вследствии этого', 'пер', 'одиннадцать', 'когда-либо' , 'достаточно', 'снова', 'нам', 'еще', 'к тому же', 'в основном', 'один', 'тем временем', 'куда', 'там', 'к', 'дать', ' система', 'делать', 'вполне', 'ан', 'эти', 'все', 'по направлению', 'это', 'счет', 'не может', 'не', 'потом', ' за», «делать», «были», «ли», «ну», «другой», «ниже», «первый», «на», «любой», «никто», «многие», «различные» , 'серьезно', 'ре', 'два', 'меньше', 'не мог'})  Проверим, сколько стоп-слов в этой библиотеке.
Проверим, сколько стоп-слов в этой библиотеке.Мы видим, что удалить стоп-слова с помощью библиотеки Gensim довольно просто.
Вывод:
Когда я встретил тишину. Она молчала весь час долгого путешествия Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 83
Удаление стоп-слов уменьшило длину предложения со 129 до 83. Мы видим, что хотя длина стоп-слов в spaCy и Gensim одинакова, результирующий текст довольно другой.
Scikit-Learn:
Scikit-Learn не нуждается в представлении. Это бесплатная библиотека машинного обучения для Python. Это, пожалуй, самая мощная библиотека для машинного обучения.
Это, пожалуй, самая мощная библиотека для машинного обучения.
от Sklearn.feature_extraction.Text Импорт English_stop_words
Print (English_stop_words)
‘вокруг’, ‘между’, ‘четыре’, ‘был’, ‘один’, ‘выкл’, ‘ам’, ‘тогда’, ‘другой’, ‘может’, ‘плакать’, ‘в будущем’, ‘передний ‘, ‘тоже’, ‘при этом’, ‘все’, ‘вверху’, ‘на’, ‘никогда’, ‘либо’, ‘как’, ‘до’, ‘все равно’, ‘с’, ‘через’, ‘количество’, ‘сейчас’, ‘он’, ‘не может’, ‘было’, ‘против’, ‘иметь’, ‘в’, ‘потому что’, ‘вкл.’, ‘не’, ‘поэтому’, ‘они ‘, ‘даже’, ‘кого’, ‘это’, ‘видеть’, ‘где-то’, ‘интерес’, ‘поэтому’, ‘ничего’, ‘толстый’, ‘тогда как’, ‘много’, ‘всякий раз’, ‘найти’, ‘казаться’, ‘пока’, ‘посредством чего’, ‘в’, ‘ооо’, ‘огонь’, ‘также’, ‘некоторые’, ‘последний’, ‘чем’, ‘получить’, ‘уже ‘, ‘наш’, ‘когда-то’, ‘будет’, ‘никто’, ‘тот’, ‘что’, ‘таким образом’, ‘нет’, ‘сам’, ‘вне’, ‘следующий’, ‘что угодно’, ‘хотя’, ‘хотя’, ‘и т. д.’, ‘который’, ‘было бы’, ‘там’, ‘ни’, ‘каким-то образом’, ‘после этого’, ‘кроме того’, ‘кто бы ни ‘, ‘тонкий’, ‘самим’, ‘мало’, ‘третий’, ‘без’, ‘ничего’, ‘двенадцать’, ‘против’, ‘пока’, ‘двадцать’, ‘если’, ‘однако’, ‘нашла’, ‘сама’, ‘когда’, ‘может’, ‘наш’, ‘шесть’, ‘сделано’, ‘кажется’, ‘еще’, ‘звонок’, ‘возможно’, ‘было’, ‘все же ‘, ‘заполнить’, ‘где’, ‘иначе’, ‘до сих пор’, ‘внутри’, ‘его’, ‘для’, ‘вместе’, ‘в другом месте’, ‘на протяжении’, ‘из’, ‘например’, ‘другие’, ‘показать’, ‘искренний’, ‘где угодно’, ‘во всяком случае’, ‘как’, ‘являются’, ‘тот’, ‘следовательно’, ‘что-то’, ‘настоящим’, ‘нигде’, ‘de ‘, ‘впоследствии’, ‘ни’, ‘его’, ‘идти’, ‘сорок’, ‘положить’, ‘их’, ‘по’, ‘а именно’, ‘могл’, ‘пять’, ‘сам’, ‘есть’, ‘девять’, ‘после’, ‘внизу’, ‘дно’, ‘тем самым’, ‘такой’, ‘оба’, ‘она’, ‘становиться’, ‘целое’, ‘кто’, ‘себя’ ‘, ‘каждый’, ‘через’, ‘кроме’, ‘очень’, ‘несколько’, ‘среди’, ‘существующий’, ‘быть’, ‘мой’, ‘дальше’, ‘здесь’, ‘во время’, ‘почему’, ‘с’, ‘становится’, ‘около’, ‘а’, ‘со’, ‘кажущийся’, ‘должен’, ‘где угодно’, ‘заранее’, ‘подробно’, ‘пятьдесят’, ‘становящийся ‘, ‘может’, ‘среди’, ‘мой’, ‘пустой’, ‘отсюда’, ‘потом’, ‘почти’, ‘наименее’, ‘ кто-то’, ‘часто’, ‘от’, ‘держать’, ‘его’, ‘или’, ‘сверху’, ‘ее’, ‘никто’, ‘когда-нибудь’, ‘через’, ‘сотня’, ‘только’ , ‘через’, ‘имя’, ‘восемь’, ‘три’, ‘назад’, ‘к’, ‘все’, ‘стало’, ‘движение’, ‘я’, ‘мы’, ‘ранее’, ‘ так’, ‘я’, ‘откуда’, ‘описывать’, ‘под’, ‘всегда’, ‘сам’, ‘в’, ‘здесь’, ‘больше’, ‘после’, ‘сами’, ‘вы’ , ‘выше’, ‘шестьдесят’, ‘их’, ‘не’, ‘твой’, ‘сделал’, ‘действительно’, ‘большинство’, ‘везде’, ‘пятнадцать’, ‘но’, ‘должен’, ‘ вдоль’, ‘рядом’, ‘ее’, ‘сторона’, ‘бывший’, ‘кто-нибудь’, ‘полный’, ‘имеет’, ‘твой’, ‘чей’, ‘за’, ‘пожалуйста’, ‘среди’ , ‘мельница’, ‘десять’, ‘казалось’, ‘иногда’, ‘должен’, ‘свыше’, ‘брать’, ‘каждый’, ‘то же самое’, ‘скорее’, ‘последний’, ‘и’, ‘ вслед за этим’, ‘часть’, ‘за’, ‘одиннадцать’, ‘когда-либо’, ‘достаточно’, ‘снова’, ‘нас’, ‘еще’, ‘к тому же’, ‘в основном’, ‘один’, ‘тем временем’ , ‘куда’, ‘там’, ‘по направлению’, ‘дать’, ‘система’, ‘делать’, ‘эти’, ‘каждый’, ‘по направлению’, ‘это’, ‘счет’, ‘ не может», «не», «потом», «за», «были», «ли», «ну», «другой», «ниже», «первый», «над», «какой-либо», ‘нет’, ‘много’, ‘серьезно’, ‘ре’, ‘два’, ‘не мог’, ‘меньше’})
Опять длинный список.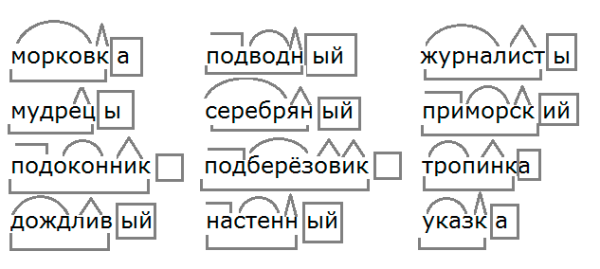 Проверим, сколько стоп-слов в этой библиотеке.
Проверим, сколько стоп-слов в этой библиотеке.
print ( len (ENGLISH_STOP_WORDS))
Вывод:
318
Удалим стоп-слова из нашего текста.
слов = [слово для слов в тексте . split() , если слов. ниже() нет в ENGLISH_STOP_WORDS]
new_text = " ". присоединиться (слова)
печать (новый_текст)
печать ("Старая длина: ", длин (текст))
печать ("Новая длина: ", длин (новый_текст))
Вывод:
мет тихо. молчал весь час долгого пути Стоуни-Брук в Нью-Йорк.
Старая длина: 129
Новая длина: 72
Удаление стоп-слов уменьшило длину предложения со 129 до 72. Мы видим, что и Scikit-learn, и spaCy дали одинаковые результаты.
Могу ли я добавить в список свои стоп-слова? ✍️
Да, мы также можем добавить собственные стоп-слова в список стоп-слов, доступных в этих библиотеках, для нашей цели.
Вот код для добавления некоторых пользовательских стоп-слов в список стоп-слов NLTK:
sw_nltk. extend (['первый', 'второй', 'третий', 'я'])
print ( len (sw_nltk))
Вывод:
183
Мы видим, что длина Стоп-слов NLTK теперь 183 вместо 179. И теперь мы можем использовать тот же код для удаления стоп-слов из нашего текста.
Могу ли я удалить стоп-слова из готового списка? 👋
Да, если мы хотим, мы также можем удалить стоп-слова из списка, доступного в этих библиотеках.
Вот код, использующий библиотеку NLTK:
sw_nltk. удалить ("не") Стоп-слово «не» теперь удалено из списка стоп-слов.
В зависимости от используемой библиотеки вы можете выполнять соответствующие операции для добавления или удаления стоп-слов из готового списка. Я указываю на это, потому что NLTK возвращает список стоп-слов, в то время как другие библиотеки возвращают набор стоп-слов.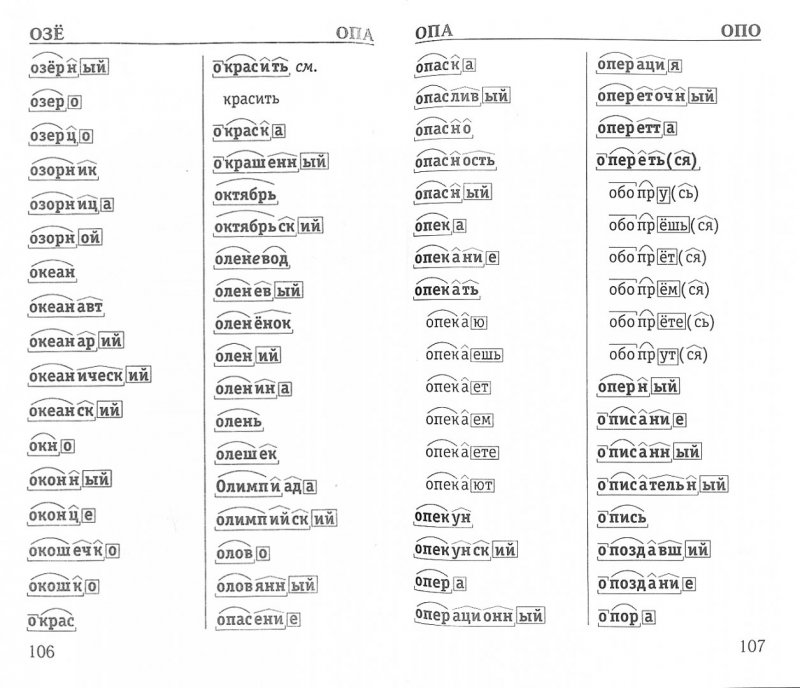
Если мы не хотим использовать какую-либо из этих библиотек, мы также можем создать собственный список стоп-слов и использовать его в нашей задаче. Обычно это делается, когда у нас есть опыт в предметной области в нашей области и когда мы знаем, каких слов следует избегать при выполнении нашей задачи.
Посмотрите на приведенный ниже код, чтобы увидеть, насколько это просто.
# создайте свой собственный список стоп-слов
my_stop_words = ['her','me','i','she','it']words = [word for word in text .split() если слово .lower() не в my_stop_words]
new_text = " ". join (words)
print (new_text)
print ("Старая длина: ", len (текст))
print ("Новая длина: ", len 0 (090text))Результат:
При первой встрече было очень тихо.
Старая длина: 129
Новая длина: 115Аналогичным образом вы можете создать свой список стоп-слов в соответствии с вашей задачей и использовать его. 🤟
В этой статье мы заметили, что разные библиотеки имеют разный набор стоп-слов, и мы можем четко сказать, что стоп-слова — это наиболее часто используемые слова в любом языке.
Хотя вы можете использовать любую из этих библиотек для удаления стоп-слов из текста, настоятельно рекомендуется использовать одну и ту же библиотеку для всей задачи предварительной обработки текста.
Спасибо всем, что прочитали это. Поделитесь своим ценным отзывом или предложением относительно этого поста! Приятного чтения! 📗 🖌
анализ - Предупреждение: "правило бесполезно в парсере из-за конфликтов" в Bison
Вот значительно упрощенный (но полный) отрывок из вашей грамматики. Я объявил
выражениетерминалом, чтобы не определять его:%token expression IF %% предложение: отправленоСоставлено |sentSelection |sentExpression отправленоСоставлено: список предложений список предложений: предложение |предложениеСписок предложений sendExpression: выражение ';' |';' sentSelection: IF '(' выражение ')' предложение 9Когда bison находит конфликт в грамматике, он разрешает его в соответствии с простой процедурой:
 оставался тихим в течение всего двухчасового путешествия из Стоуни-Брук в Нью-Йорк.
оставался тихим в течение всего двухчасового путешествия из Стоуни-Брук в Нью-Йорк. - конфликты сдвига-свертки разрешаются в пользу сдвига
- конфликты редукции разрешаются в пользу продукции, которая встречается в грамматике ранее.

Как только это произойдет, может оказаться, что какое-то производство больше нельзя будет использовать, потому что оно было исключено из каждого контекста, в котором оно могло бы быть сокращено. Это явный признак того, что грамматика проблематична. [Примечание 1]
Основная проблема здесь в том, что sendComposed означает, что операторы можно просто соединить вместе, чтобы получился более длинный оператор. Итак, что произойдет, если вы напишете:
IF (e) оператор1 оператор2
Возможно, оператор1 оператор2 предназначен для сокращения в один sendComposed который является целью IF , поэтому два оператора выполняются только в том случае, если e истинно. Или может быть, что отправили Compposed состоит из оператора IF с целевым оператором 1 , за которым следует оператор 2 . В терминах C разница между:
if (e) { statement1; заявление2; }
и
{ если (e) { оператор1; } заявление2; }
Так что это настоящая двусмысленность, и вам, вероятно, нужно переосмыслить отсутствие фигурных скобок, чтобы исправить это.
Но это не единственная проблема; у вас также есть куча конфликтов уменьшения-уменьшения. Это происходит гораздо проще, потому что частью приведенной выше грамматики является следующий цикл:
предложение: отправленоСоставлено отправленоСоставлено: список предложений список предложений: предложение
Этот цикл означает, что ваша грамматика позволяет оборачивать одно предложение произвольным числом единичных сокращений. Вы, конечно, не хотели этого; Я уверен, что вы намеревались использовать sentComposed только в случае действительной необходимости. Но бизон не знает ваших намерений; оно знает только то, что вы говорите.
Опять же, вы, вероятно, решите эту проблему, когда выясните, как вы на самом деле хотите определить границы отправленоСоставлено .
Примечания:
В некоторых случаях конфликты на самом деле не являются проблемой. Например, между этими двумя постановками существует конфликт сдвига-уменьшения; так называемая двусмысленность "висячее другое":
sentSelection: предложение IF '('выражение')' |ЕСЛИ '('выражение')' предложение ИНАЧЕ предложениеВо вложенном выражении
IF:ЕСЛИ (e) ЕСЛИ (f) s1 ИНАЧЕ s2
не понятно будет ли
ELSEследует применять к внутреннему или внешнемуIF.
