Слова «английский» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «английский» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «английский» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «английский».
Содержимое:
- 1 Слоги в слове «английский»
- 2 Как перенести слово «английский»
- 3 Морфемный разбор слова «английский» по составу
- 4 Сходные по морфемному строению слова «английский»
- 5 Синонимы слова «английский»
- 6 Ударение в слове «английский»
- 7 Фонетическая транскрипция слова «английский»
- 8 Фонетический разбор слова «английский» на буквы и звуки (Звуко-буквенный)
- 9 Предложения со словом «английский»
- 10 Сочетаемость слова «английский»
- 11 Значение слова «английский»
- 12 Склонение слова «английский» по подежам
- 13 Как правильно пишется слово «английский»
Слоги в слове «английский»
Количество слогов: 3
По слогам: а-нглий-ский
н — непарная звонкая согласная (сонорная), примыкает к текущему слогу
й всегда примыкает к предшествующей гласной
й — непарная звонкая согласная (сонорная), примыкает к текущему слогу
с примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «английский»
ан—глийский
анг—лийский
англий—ский
английс—кий
Морфемный разбор слова «английский» по составу
| англий | корень |
| ск | суффикс |
| ий | окончание |
английский
Сходные по морфемному строению слова «английский»
Сходные по морфемному строению слова
Синонимы слова «английский»
1. великобританский
великобританский
2. британский
3. аглицкий
4. англосаксонский
5. инглиш
6. гловерный
Ударение в слове «английский»
англи́йский — ударение падает на 2-й слог
Фонетическая транскрипция слова «английский»
[англ’`ий’ск’ий’]
Фонетический разбор слова «английский» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| а | [а] | гласный, безударный | а |
| н | [н] | согласный, звонкий непарный (сонорный), твёрдый | н |
| г | [г] | согласный, звонкий парный, твёрдый, шумный | г |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| и | [`и] | гласный, ударный | и |
| й | [й’] | согласный, звонкий непарный (сонорный), мягкий | й |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| к | [к’] | согласный, глухой парный, мягкий, шумный | к |
| и | [и] | гласный, безударный | и |
| й | [й’] | согласный, звонкий непарный (сонорный), мягкий | й |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 10 букв и 10 звуков.
Буквы: 3 гласных буквы, 7 согласных букв.
Звуки: 3 гласных звука, 7 согласных звуков.
Предложения со словом «английский»
Чтобы книгу, скажем, русского писателя прочли на английском языке, её надо прежде перевести и издать.
Источник: Сергий Чернец, Собрание сочинений. Том третий. Рассказы и эссе.
Созданная под их руководством невиданная доселе армия нежити в 1314 году вторглась во владения
Источник: Ренард Фиерци, Чародейская Академия. Книга 1. Санта-Ралаэнна, 2015.
Вот что подразумевает английское слово meditation: концентрация и созерцание — это два полюса, ровно посередине находится медитация.
Источник: Б. Ш. Раджниш (Ошо), Осознанность сегодня. Как сделать медитацию частью своей повседневной жизни?.
Сочетаемость слова «английский»
1. английский язык
2. английский король
3. английское правительство
4. уроки английского языка
5. преподаватель английского языка
6. курсы английского языка
7. знать английский
8. говорить на английском
9. владеть английским
10. (полная таблица сочетаемости)
Значение слова «английский»
АНГЛИ́ЙСКИЙ , -ая, -ое. Прил. к англичане, к А нглия. Английский язык. (Малый академический словарь, МАС)
Склонение слова «английский» по подежам
| Падеж | Единственное числоЕд.ч. | Множественное числоМн.ч. | ||
|---|---|---|---|---|
| Мужской родМ.р. | Женский родЖ.р. | Средний родС.р. | ||
| ИменительныйИм. | какой? | какая? | какое? | какие? |
| английский | английская | английское | английские | |
РодительныйРод. | какого? | какой? | какого? | каких? |
| английского | английской | английского | английских | |
| ДательныйДат. | какому? | какой? | какому? | каким? |
| английскому | английской | английскому | английским | |
| Винительный (одушевленное)Вин. одуш. | какого? | какую? | какого? | каких? |
| английского | английскую | английское | английских | |
| Винительный (неодушевленное)Вин. неодуш. | какой? | какую? | какое? | какие? |
| английский | английскую | английское | английские | |
| ТворительныйТв. | каким? | какой? | каким? | какими? |
| английским | английской, английскою | английским | английскими | |
ПредложныйПред. | о каком? | о какой? | о каком? | о каких? |
| английском | английской | английском | английских | |
Как правильно пишется слово «английский»
Правописание слова «английский»
Орфография слова «английский»
Правильно слово пишется: англи́йский
Нумерация букв в слове
Номера букв в слове «английский» в прямом и обратном порядке:
- 10
а
1 - 9
н
2 - 8
г
3 - 7
л
4 - 6
и
5 - 5
й
6 - 4
с
7 - 3
к
8 - 2
и
9 - 1
й
10
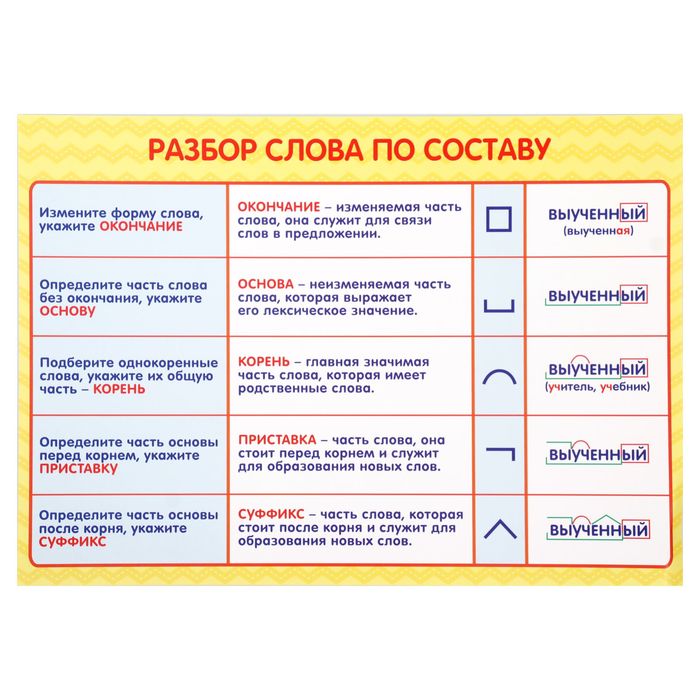
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква. Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н., Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову.
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: карамелька сейчас ироавпв сейчас парниквед сейчас и н т а р а с к сейчас о б с т о к сейчас я е птриа сейчас ч о к с т т сейчас уфцанзр сейчас атабор сейчас макушппа сейчас згаро сейчас ньспшоест сейчас с о б а к а сейчас енлхараг сейчас г о с т ь р 1 секунда назад
[PDF] Извлечение многословных словосочетаний с использованием синтаксической композиции биграмм
- Идентификатор корпуса: 17069599
title={Извлечение словосочетаний с использованием синтаксической композиции биграмм},
автор={Виолета Серетан, Лука Нерима и Эрик Верли},
год = {2003}
} - Виолета Серетан, Л.
 Нерима, Э. Верли
Нерима, Э. Верли - Опубликовано в 2003 г.
- Лингвистика, информатика
 Нерима, Э. Верли
Нерима, Э. ВерлиИзвлечение словосочетаний на основе синтаксического разбора
- Виолета Серетан
Компьютерные науки, лингвистика
- 2008
методологическую базу для их идентификации на основе синтаксических критериев, показывающую, что полученные результаты более надежны, чем результаты стандартных методов, основанных на ограничениях линейной близости.
Ориентированный на трансляцию. Идентификация и экстракция коллокации.
 , который может извлекать больше словосочетаний с более высокой точностью, чем базовый уровень, что важно для задач обработки естественного языка, связанных с предложениями.
, который может извлекать больше словосочетаний с более высокой точностью, чем базовый уровень, что важно для задач обработки естественного языка, связанных с предложениями.Извлечение памяти для избирательного перевода на основе статистической и лингвистической информации
- Томас С. Чуанг, Цзя-Янь Цзянь, Юй-Чиа Чанг, Джейсон Дж. С. Чанг
Лингвистика, информация
Rocling/IJClclp
- 999 2009 2009 2009 2009 20099 2009
- 9999 20099 200999009
/IJClclp
- 999 2009 2009 2009 2009 2009 2009 2009 2009 20099 20099 2009
.
Экспериментальные результаты показывают, что память фразового перевода может быть эффективно использована для компьютерного обучения языку (CALL) и компьютерного перевода (CAT).
Инструмент для извлечения и визуализации многословных словосочетаний в многоязычных корпусах
- Виолета Серетан, Л. Нерима, Э. Верли
Информатика
- 2004
Подход, лежащий в основе этой системы, является гибридным, поскольку метод извлечения сочетает синтаксический анализ текстов со статистической мерой для тест релевантности (т. е. для кандидатов, ранжируемых в соответствии с коллокационной силой).
е. для кандидатов, ранжируемых в соответствии с коллокационной силой).
Распознавание фреймов словосочетаний из предложений
В этом исследовании сначала извлекаются словосочетания биграмм с помощью метода, основанного на семантике распределения, путем введения шаблонов словосочетаний и интеграции некоторых современных мер ассоциации, а также получения самых длинных словосочетаний в соответствии с рекурсивной природой и лингвистическими правилами. словосочетаний.
Точная извлечение коллокации с использованием многоязычного анализатора
- Violeta Seretan, E. Wehrli
Компьютерная наука
ACL
- 2006
Гибская система. из английских, французских, испанских и итальянских корпусов.
Знакомство с сложными именами и именами собственными
- Г. Протазюк, Маржена Кришкевич, Х. Рыбински, А. Делтейл
Информатика
RSEISP
- 2007
В данной статье предлагается T-GSP как его модификация для извлечения часто встречающихся текстовых шаблонов и, в частности, часто встречающихся последовательностей слов, которые удовлетворяют заданным грамматическим правилам.
Синтаксическое согласование и обнаружение многословных выражений
В этой статье представлен усовершенствованный тип согласователя, который объединяет синтаксическую информацию о структуре предложения, а также статистическую информацию о совпадении слов для обнаружения и отображения тех слов из контекста, которые наиболее сильно относящийся к исследуемому слову.
Collocation Candidate Extraction from Dependency-Annotated Corpora: Exploring Differences across Parsers and Dependency Annotation Schemes
- P. Uhrig, S. Evert, Thomas Proisl
Computer Science
- 2018
This chapter evaluates a total of 8 синтаксических анализаторов на 2 корпуса с 20 различными показателями ассоциации плюс несколько пороговых значений частоты для 6 различных типов словосочетаний по сравнению с Оксфордским словарем словосочетаний для студентов, изучающих английский язык (2-е издание; 2009 г. ).).
).).
Приобретение перевода коллокации с использованием монолингальных корпораций
- Yajuan Lü, M. Zhou
Компьютерная наука
ACL
- 2004
. знаний и достигает многообещающих результатов в извлечении перевода словосочетаний.
ПОКАЗАНЫ 1-10 ИЗ 28 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантностьНаиболее влиятельные статьиПоследность
Извлечение словосочетаний из корпусов текстов
- Л. Деканг
Информатика
- 1998
Представлен метод извлечения словосочетаний из корпусов текстов с высокой точностью и широким охватом коллокаций описывается вычисление сходства слов.
Создание многоязычного словаря словосочетаний из больших корпусов текстов
- Л. Нерима, Виолета Серетан, Э. Верли
Компьютерные науки, лингвистика
EACL
- 2003
В этой статье описывается система терминологического извлечения, способная обрабатывать многословные выражения с использованием мощного синтаксического анализатора. Система включает в себя инструмент согласования, позволяющий пользователю…
Система включает в себя инструмент согласования, позволяющий пользователю…
Извлечение словосочетаний из текста: Xtract
- Frank Smadja
Информатика
Comput. Лингвистика
- 1993
Описан набор методов, основанных на статистических методах извлечения и идентификации словосочетаний из больших текстовых корпусов, основанных на некоторых оригинальных методах фильтрации, которые позволяют производить более богатые и более точные выходные данные.
Словосочетания и словари общего назначения
- М. Бенсон
Лингвистика
- 1990
В последние годы лексикографы уделяют словосочетаниям повышенное внимание. 1 До сих пор обсуждение словосочетаний в основном касалось той роли, которую они могут играть в…
DEC dictionnaire explicatif et combinatoire du français contemporain
- Игорь А. Мельчук, А. Клас
Языкознание
- 1984 900 Описание каждой словарной статьи.
Информатика
ACL
- 1996
 Он пытается дать явные и недвусмысленные определения и использовать их в качестве основы для описания синтаксических и…0004
Он пытается дать явные и недвусмысленные определения и использовать их в качестве основы для описания синтаксических и…0004Новый статистический синтаксический анализатор, основанный на вероятностях зависимостей между заглавными словами в дереве синтаксического анализа, который обучается на 40 000 предложений менее чем за 15 минут и может быть улучшен до более 200 предложений в минуту с незначительной потерей точности.
Нормы словесных ассоциаций, взаимная информация и лексикография
- Кеннет Уорд Чёрч, П. Хэнкс
Лингвистика
ACL
- 1989
Предлагаемая мера, коэффициент ассоциации, оценивает нормы словесных ассоциаций непосредственно из машиночитаемых корпусов, позволяя оценивать нормы для десятков тысяч слов.
Обобщение автоматически сгенерированных схемы отбора
- R. Grishman, J. Sterling
Компьютерная наука
Coling
- 1994
 Grishman, J. Sterling
Grishman, J. SterlingИзмерения степени отбора, полученного с различными положениями корпорации, и A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A является ИРКА описывается метод использования корпуса для идентификации похожих по выборке терминов и использования этого сходства для расширения охвата по выборке для фиксированного размера корпуса.
Функции обучения и масштабирования для устранения неоднозначности
- Х. Алшави, Д. Картер
Информатика
Вычисл. Лингвистика
- 1994
Представлен автоматический метод взвешивания вкладов функций предпочтения, используемых в устранении неоднозначности, и определена функция, которая работает значительно лучше, чем функции, основанные на взаимной информации и отношениях правдоподобия лексических ассоциаций.
Надежные методы анализа данных на естественном языке
Автоматизированный анализ данных на естественном языке стал центральной проблемой при проектировании интеллектуальных информационных систем, и в последнее время интерес был сосредоточен на предоставлении методов приближенного анализа, предполагая, что, когда точный анализ невозможен, частичные результаты могут быть очень полезными.
Клитики | Microsoft Узнайте
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 2 минуты на чтение
Примечание
Служба индексирования больше не поддерживается в Windows XP и недоступна для использования в Windows 8. Вместо этого используйте Windows Search для поиска на стороне клиента и Microsoft Search Server Express для поиска на стороне сервера.
Вместо этого используйте Windows Search для поиска на стороне клиента и Microsoft Search Server Express для поиска на стороне сервера.
Клитика — это безударное слово, которое не может стоять самостоятельно и присоединяется к ударному слову, образуя единое целое. Клитики нельзя легко классифицировать как фонологические, синтаксические или морфологические.
Клитики бывают двух типов: проклитики и энклитики . Проклитики прикрепляются к началу слова. Энклитики прикрепляются к концу слова. Например, во французском языке проклитики включают местоимения «я» и «лес» в «il me les a donnés» («он дал их мне»). Энклитики включают «les» в «donnez-les-moi» («дайте их мне»). Другие примеры французских клитик включают случаи, когда артикль связан с существительным с апострофом, например «l’orange» («апельсин»). В этом случае рекомендуется рассматривать апостроф как разделитель между клитикой и словом, к которому присоединяется клитика. Средство разбиения по словам генерирует «l» и «orange», так что запросы на «orange» соответствуют «l’orange».
Клитики сложнее анализировать в таких языках, как испанский. Испанский глагол может образовывать множество поверхностных форм, в зависимости от времени. Например, вы можете спрягать неправильный глагол «ir» («идти») как «nosotros [или nosotras] vamos» («мы идем», «пойдем»). Вы также можете написать «vamos» как «vamanos», где местоимение «nosotros (или nosotras)» представлено в клитической форме. В этом случае клитики должны оставаться нетронутыми как при создании индекса, так и при запросе. Следует рассмотреть вопрос об удалении клитики во время создания индекса и создании поверхностных форм путем поиска корней во время запроса. Удаление клитик в случаях неоднозначной морфологии состава клитик может привести к непредсказуемым результатам. Создание большого количества поверхностных форм для слова увеличивает размер полнотекстового индекса и может отрицательно сказаться на производительности запроса. Рекомендуется, чтобы стеммер генерировал только небольшое количество поверхностных форм.