Алгоритм фонетического разбора строки | PHPClub
Alexander_Saven
Новичок
- #1
Алгоритм фонетического разбора строки
Добрый день!
Встал вопрос выборки данных из MySQL по схожему звучанию. Операторы soundex(), metaphone() и т.д подходят, но только для латинских полей, поэтому переписал с VB на PHP получилась функция аналог metaphone()….какие идеи может есть у кого по дальнейшей реализации вопроса? может уже кто-нибудь сталкивался с подобным!
Alexander_Saven
Новичок
- #2
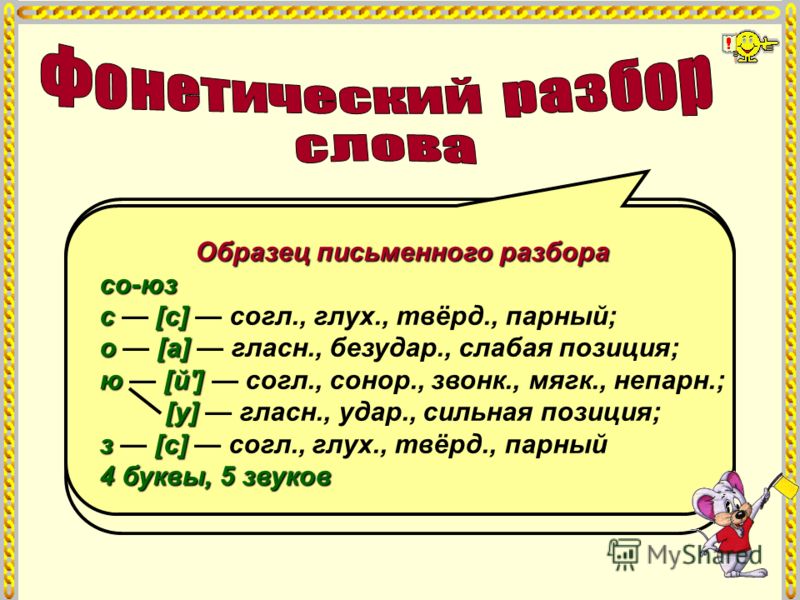
Фонетический разбор строки
Добрый день!
Встал вопрос выборки данных из MySQL по схожему звучанию. Операторы soundex(), metaphone() и т.д подходят, но только для латинских полей, поэтому переписал с VB на PHP получилась функция аналог metaphone()….какие идеи может есть у кого по дальнейшей реализации вопроса? может уже кто-нибудь сталкивался с подобным!
Операторы soundex(), metaphone() и т.д подходят, но только для латинских полей, поэтому переписал с VB на PHP получилась функция аналог metaphone()….какие идеи может есть у кого по дальнейшей реализации вопроса? может уже кто-нибудь сталкивался с подобным!
Фанат
oncle terrible
- #3
кросспостинг запрещён правилами форума.
Alexander_Saven
Новичок
- #4
Автор оригинала: Фанат
кросспостинг запрещён правилами форума.Нажмите для раскрытия…
Изначально не туда написал, хотел в PHP&Mysql…..просто смотрю реакции людей никакой ((( неужели никто не сталкивался с подобным?
Saturn
Новичок
- #5
примеры вариантов того, что тебе надо получить, можешь привести?
чтобы понять, чего именно надо тебе.
Alexander_Saven
Новичок
- #6
Автор оригинала: Saturn
примеры вариантов того, что тебе надо получить, можешь привести?чтобы понять, чего именно надо тебе.
Нажмите для раскрытия…

Предположим, база данных MySQL состоит из таблицы, в которой записаны некоторые имена (не имена и фамилии), а названия компаний, т.е это могут быть либо вымышленные названия, либо нет…вводим запрос на получение всех записей ПОХОЖИХ (но не по как синтаксис LIKE)…и алгоритм выдает все созвучные, схожие по звучанию, написанию, в которых даже на слух можно определить сходство друг c другом (громкая согласная, схожие ударения и т.д)…как я полагаю реализовать такую вещь достаточно сложно…у меня есть аналог metaphone пхпешного, который успешно создает сигнатуру каждого слова…но весь вопрос, что с этим делать?
!diss
Новичок
- #7
как я полагаю реализовать такую вещь достаточно сложно.
..у меня есть аналог metaphone пхпешного, который успешно создает сигнатуру каждого слова…но весь вопрос, что с этим делать?Нажмите для раскрытия…

Да идея хороша…например для поиска по запросу с несколькими ошибками. Как реализовать — раз Вы хотите найти созвучность, то работать надо с фонемами. Соответствие слогов фонемам где-то видел в нете. Потом построить таблицу связей между фонемами с учетом уровня схожести и далее дело техники….
Saturn
Новичок
- #8
Alexander_Saven
теперь понятно.
идея действительно интересная, но совсем не легкоосуществимая…
Основные методы и приемы обучения. особенности фонетического анализа в начальной школе — Информатика, информационные технологии
Дидактические игры и занимательные упражнения при изучении фонетики и графики в начальных классах
План
Введение
Глава 1. Особенности изучения фонетики и графики в начальных классах
1.1Содержание и структура школьного курса фонетики,графики
1.2Основные методы и приемы обучения. Особенности фонетического анализа в начальной школе.
Глава 2.Дидактические игры и занимательные упражнения как средство активизации познавательной деятельности младших школьников
2.1 Место и роль дидактических игр и занимательных упражнений в образовательном процессе
2. Методические приемы организации деятельности в рамках выделенной проблемы
Заключение
Список использованной литературы
Приложение
Введение
Фонетические знания очень важны для школьников, так как они тесно связаны с графикой и проявляются в орфографической грамотности и орфоэпических нормах, а также способствуют осмысленному и глубокому усвоению родной речи.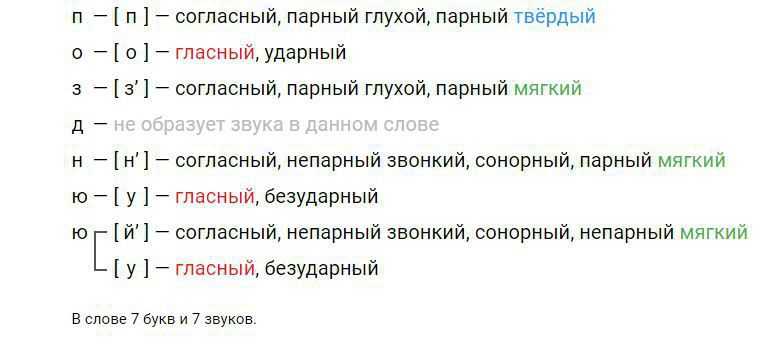 Этим обусловлена актуальность нашего исследования.
Этим обусловлена актуальность нашего исследования.
Как сформировать фонетические представления учащихся начальной школы так, чтобы они стали прочной базой для дальнейшего освоения языковой системы – вот проблема над которой работает каждый учитель начальной школы.
Теоретической основой работы являются труды Т.П. Сальниковой, С.Л. Соловейчик, К.Д. Ушинского, Л.В. Щербы, Б.Т. Панова и др.
Объектом исследования является фонетическая система русского языка.
Предмет — приемы формирования фонетических представлений на уроках русского языка в начальной школе
Цель работы — рассмотреть приемы формирования фонетических представлений учащихся на уроках русского языка в начальной школе.
Для достижения указанной цели в работе представлены следующие задачи:
— изучить теоретическую литературу по теме исследования; выявить объем фонетических сведений, изучаемых в начальной школе;
— проанализировать программы «Гармония», «Начальная школа XXI века» в рамках изучаемой проблемы;
— проследить связь фонетических знаний с орфографией и орфоэпией;
— создать и апробировать систему фонетических упражнений, направленных на совершенствование фонетических представлений учащихся 3 класса гимназии №4 «Ступени»
Для решения поставленных задач использованы следующие научно – исследовательские методы:
— теоретический анализ методической литературы по проблемам исследования;
— формирующий этап, констатирующая и контрольная работа,-
наблюдение;
— анализ документации;
— методы статистической обработки данных.
В соответствии с задачами исследования разработана структура дипломной работы. Она состоит из введения, теоретической главы, в которой рассматриваются понятия звук речи, фонетические процессы, описывается классификация звуков русской речи, разграничиваются понятия «звук» и «буква»; во второй главе представлен анализ методической литературы, посвященной работе со звуком и буквой в начальной школе, представлен сравнительный анализ двух программ обучения «Гармония» и «Начальная школа 21 века», а также описала опытно-практическую работу, проведенную с целью совершенствования фонетический представлений учащихся 3 класса гимназии №4 «Ступени». Заключение представляет основные выводы по теме исследования, к которым пришел автор дипломной работы. Приложение содержит комплект заданий для опытно-практической работы.
Глава 1.
Особенности изучения фонетики и графики в начальных классах
Содержание и структура школьного курса фонетики,графики
Фонетика как отрасль языкознания изучает содержание первого, нижнего уровня языковой системы-произносительного. Теоретический материал этого уровня составляют учения о звуках речи, их характеристика, классификация, учение о слогоделении, об ударении в слове, представления о других произносительных средствах, о громкости речи, ее темпе, о повышении и понижении голоса, о паузах, об интонациях. Программы обычно представляют тщательную отработку практических умений: от фонетического (а затем и звуко-буквенного) анализа до выразительной речи, до развития дикции и усвоения орфоэпии. Фонетика составляет основной материал 1 класса; в последующих классах материал углубляется, усложняются примеры, закрепляются практические умения. Трудность для детей представляют выделение звуков из некоторых сочетаний, различие твердости/мягкости согласных; в процессе дальнейшего обучения детей нередко затрудняет соотношение звука и буквы: чтение и письмо выдвигают в глазах детей букву в сравнении со звуком (но это уже графика).
Теоретический материал этого уровня составляют учения о звуках речи, их характеристика, классификация, учение о слогоделении, об ударении в слове, представления о других произносительных средствах, о громкости речи, ее темпе, о повышении и понижении голоса, о паузах, об интонациях. Программы обычно представляют тщательную отработку практических умений: от фонетического (а затем и звуко-буквенного) анализа до выразительной речи, до развития дикции и усвоения орфоэпии. Фонетика составляет основной материал 1 класса; в последующих классах материал углубляется, усложняются примеры, закрепляются практические умения. Трудность для детей представляют выделение звуков из некоторых сочетаний, различие твердости/мягкости согласных; в процессе дальнейшего обучения детей нередко затрудняет соотношение звука и буквы: чтение и письмо выдвигают в глазах детей букву в сравнении со звуком (но это уже графика).
Основой усвоения графики служат четкие умения в области фонетики. Каждый звук (точнее каждая фонема) должен иметь свой знак, т. е. букву. Но вскоре дети узнают, что звук и буква совпадают не всегда. Система правил обозначения звуков (фонем)составляют предмет графики. В содержание графики так же входят заглавные буквы, знаки препинания, средства выделения абзацев.
е. букву. Но вскоре дети узнают, что звук и буква совпадают не всегда. Система правил обозначения звуков (фонем)составляют предмет графики. В содержание графики так же входят заглавные буквы, знаки препинания, средства выделения абзацев.
Изучение фонетики и графики во времени совмещают с обучением грамоте, т.е. с работой по букварю. В этот период уроки объединяют звук и его букву, т.е. фонетика и графика объединяются в одном уроке. Но в дальнейшем в курсе языка встречаются темы фонетико-графического содержания, связанные с правописанием и культурой речи: «Сочетания жи-ши», «Разделительный Ь», «Употребление ъ в середине слова», и т.д.
Фонетико-графические темы, как и орфографические, подчас «вклиниваются» в грамматический материал. Кроме того, фонетико-графическая линия, сливаясь с орфографической, не прерывается, а вплетается в общую систему на протяжении всех лет начального обучения. Непрерывность этой линии обеспечивается так же фонетическим (фонетико-графическим) разбором в системе звукового анализа.
Дети с I класса практически владеют понятием «слог» и в простейших случаях могут правильно произвести слогоделение. Курс фонетики IV класса в теоретическом плане ничего нового к этим начальным знаниям не добавляет, поскольку учащимся не дается ни определения слога, ни правил слогоделения.
Исключительно важным элементом звукового строя русского языка является словесное ударение, изучению которого в школе уделяется большое внимание. Русское словесное ударение носит количественно-динамический характер, т. е. ударный гласный отличается большей длительностью и силой. На первом из этих свойств основан используемый в начальных классах способ определения ударного слога путем его протягивания (ру-кааа). На второе свойство ударного гласного — силу его, которое также знакомо детям с начальных классов, еще раз указывается в учебнике для IV класса. Здесь же дается представление еще об одной особенности ударного слога, обусловленной его силой,— об отчетливом произнесении в нем гласных звуков [а], [о], [э], которые в безударном слоге меняют свое произношение. Никаких других теоретических сведений об ударении раздел «Фонетика» не содержит.
Никаких других теоретических сведений об ударении раздел «Фонетика» не содержит.
Между тем русское ударение обладает двумя характерными особенностями, определяющими его функцию в языке, — разноместностью и подвижностью. Разноместность русского ударения проявляется в том, что оно не закреплено в языке за определенным слогом или морфемой и в принципе может падать на любой слог, на любую морфологическую часть слова.
Разноместность ударения делает его важным смыслоразлочительным средством. «В русском языке,— писал Л. В. Щерба,— можно приводить сотнями слова, которые различаются друг от друга только ударением» (ср.: полки — полки, уха — уха и др.). Подвижность же русского ударения состоит в том, что при словоизменении и словообразовании оно может перемещаться с одной морфемы на другую в пределах одного слова или гнезда родственных слов, например: нога — ногу — ногой, новый — заново — обновить. В силу этой особенности ударение становится вспомогательным средством при словоизменении и словообразовании. Свойствами русского ударения обусловлена и особенность его как предмета лингвистического изучения. Так, разноместность ударения делает его индивидуальным признаком слова и потому является предметом не только фонетики, но и лексикологии. Подвижность же ударения, проявляющаяся при словоизменении и словообразовании, относит его к сфере соответствующих наук — словообразования и морфологии. Соответственно и в школьном курсе сведения об особых свойствах русского ударения, отсутствующие в разделе «Фонетика», сообщаются детям в связи с изучением лексики, словообразования, морфологии.
Свойствами русского ударения обусловлена и особенность его как предмета лингвистического изучения. Так, разноместность ударения делает его индивидуальным признаком слова и потому является предметом не только фонетики, но и лексикологии. Подвижность же ударения, проявляющаяся при словоизменении и словообразовании, относит его к сфере соответствующих наук — словообразования и морфологии. Соответственно и в школьном курсе сведения об особых свойствах русского ударения, отсутствующие в разделе «Фонетика», сообщаются детям в связи с изучением лексики, словообразования, морфологии.
Так, на разноместность ударения обращается внимание в связи с наблюдением над лексическим значением слов, различающихся только ударением (омографов). Подвижность же ударения является предметом специальных наблюдений в курсе морфологии при изучении таких, например, тем, как образование множественного числа некоторых существительных (адреса, выборы, шофёры и др.), образование кратких форм прилагательных и глагольных форм прошедшего времени. На слово — и формообразовательной подвижности ударения основан хорошо известный учащимся способ проверки безударных гласных — путем подбора однокоренных слов и изменения слова. Нетрудно заметить, что рассмотрение этого материала в школе подчинено практическим целям: орфографической и орфоэпической . Однако полезно в данном случае усилить и теоретический аспект, обращая внимание детей на смыслоразличительную роль русского ударения, на его участие в словоизменении и словообразовании.
На слово — и формообразовательной подвижности ударения основан хорошо известный учащимся способ проверки безударных гласных — путем подбора однокоренных слов и изменения слова. Нетрудно заметить, что рассмотрение этого материала в школе подчинено практическим целям: орфографической и орфоэпической . Однако полезно в данном случае усилить и теоретический аспект, обращая внимание детей на смыслоразличительную роль русского ударения, на его участие в словоизменении и словообразовании.
При изучении же фонетики в IV классе ударение рассматривается только как один из элементов звуковой формы слова. Фонетический разбор в качестве обязательного требования включает определение ударного гласного. Здесь отрабатывается, закрепляется умение быстро и правильно определять место ударения в каждом слове — умение, совершенно необходимое и для дальнейших наблюдений над особенностями русского ударения, и для прочного овладения орфоэпической нормой, и для сознательного усвоения и использования всех орфографических правил, связанных с обозначением безударных гласных.
Основные методы и приемы обучения. Особенности фонетического анализа в начальной школе
В области методов обучения обращается внимание на такие условия:
-опора на практическое усвоение языка до изучения теории, на языковое чутье в этой области;
-постоянное сопоставление звукового и буквенного составов единиц языка;
-установка на фиксацию всех расхождений в ситуациях звук/буква;
-проговаривание, артикуляция, скандирование, отработка голоса;
-тренировка слуха, тренировка пишущей руки;
-образцы хорошего произношения и каллиграфического письма и пр.
Далеко не каждое слово, может стать объектом звукового разбора. При отборе слов, учителю необходимо учитывать фонематические особенности слов, и меру сложности, которую представляют для ученика каждое анализируемое слово. Все слова можно разделить на 3 группы:1) Слова состоящие из звуков в сильных позициях.(сын,день,тюльпан.)2) Слова состоящие из звуков в сильных позициях и слабых практически совпадающих по своим акустическим характеристикам сильными позициями, тех же фонем. (трава, лиса, суп). Слова 1-й и 2-й группы не представляют сложности для звукового разбора.3) Слова которые имеют в своем составе звуки в сильных и слабых позициях при чем,последние отличаются по звучанию от сильных позиций тех же фонем(мороз). Среди слов 3-й группы есть такие, которые необходимо анализировать в младших классах(двусложные слова с ударением на вторые слоги:нога,бегун,пятно и т.п), но есть и такие котрые лучше не использовать для фонетического анализа. Не рекомендуется брать:
(трава, лиса, суп). Слова 1-й и 2-й группы не представляют сложности для звукового разбора.3) Слова которые имеют в своем составе звуки в сильных и слабых позициях при чем,последние отличаются по звучанию от сильных позиций тех же фонем(мороз). Среди слов 3-й группы есть такие, которые необходимо анализировать в младших классах(двусложные слова с ударением на вторые слоги:нога,бегун,пятно и т.п), но есть и такие котрые лучше не использовать для фонетического анализа. Не рекомендуется брать:
1. Слова с редуцированными гласными( во 2,3-м предударном и в заударном слогах есть буквы е,а,о,я,э.Например: вечер,грохот.
2. Слова с непроизносимыми буквами согласных.Например: солнце, лестница.
3. Слова с упрощением и ассимиляцией.счастье,сшить и др.
4. Слова с удвоенными буквами согласных.:сумма,гамма.
Виды звукового анализа в начальной школе. В методике различают собственно-фонетический (звуковой) разбор и звукобуквенный разбор. Цель первого определение звуковой последовательности в слове без обращения к буквам. 2-й включает в себя выяснение соотношения выделенных звуков с буквами. Собственно-фонетический разбор практикуется на начальном этапе обучения языку в период обучения граммоте и является начальной ступенью любого вида фонетического разбора. Собственно-фонетическийй разбор целесообразно проводить по такому плану:
2-й включает в себя выяснение соотношения выделенных звуков с буквами. Собственно-фонетический разбор практикуется на начальном этапе обучения языку в период обучения граммоте и является начальной ступенью любого вида фонетического разбора. Собственно-фонетическийй разбор целесообразно проводить по такому плану:
1. Произнеси и послушай слово.
2.Найди ударный слог, а затем скажи слово по слогам.
3. Протяни (выдели голосом) первый звук в полном слове, назови его и охактеризуй.
4.Обозначь выделенный звук условным знаком.
5. Протяни(выделив голосом второй звук в полном слове, назови его и охарактеризуй и т.д.
6.Произнеси подряд все названные звуки и послушай не искажается ли слово(проверь получилось ли слово). Развитие умения проводить звуковой анализ связано с расширением круга анализируемых слов. Если в начале разбираются слова 1-й и 2-й групп, то по мере взросления детей все большее место начинают занимать слова 3-й группы. Как только младшие школьники приступают к анализу слов, в которых есть звуки в слабых позициях не совпадающие с основным вариантом фонем, они на практике убеждаются в том,что в русском языке не в любой позиции возможен весь набор гласных и согласных звуков. Например:На конце только глухие согласные без ударения нет звука «о» и т.д. Таким образом обучения фонетики связано с обучением орфоэпии. С момента знакомства с буквами, основным видом упражнения на уроках по изучению фонетики и графики становится звукобуквенный разбор в своих 2-х разновидностям: фонетико-графическй и фонетико-орфографический. Преобразование собственно-звукового разбора в звукобуквенный потребует дополнение плана одним пунктом, а именно какой буквой обозначаетсяся каждый звук и почему.
Например:На конце только глухие согласные без ударения нет звука «о» и т.д. Таким образом обучения фонетики связано с обучением орфоэпии. С момента знакомства с буквами, основным видом упражнения на уроках по изучению фонетики и графики становится звукобуквенный разбор в своих 2-х разновидностям: фонетико-графическй и фонетико-орфографический. Преобразование собственно-звукового разбора в звукобуквенный потребует дополнение плана одним пунктом, а именно какой буквой обозначаетсяся каждый звук и почему.
Главная задача фонетико-графического разбора – это проследить действие слогового принципа русской графики, который находит свое закрепление в правилах передачи на письме твердости, мягкости согласных и фонемы «й».
Задачей фонетико-орфографического разбора отмечается тем, что он нацелен на развитие орфографической зоркости и на освоении правил правописания.В школе как правило все 3 вида звукового анализа сливаются в один(фонетический):
–Звукобуквенный: ученик проводит сначала собственно-фонетический разбор, затем обозначает звуки буквами и анализируя не совпадения обозначает орфограммы. Из алгоритма фонетического анализа постепенно уходят графические обозначения звуков. [йо/жы/ки][й’]согл.,звонк.,непарн.,мягк,непарн.,[о]гл.,ударн.,[жсогл.,звонк.,парн.,тверд,непарн.[ы]-гл.,безуд.,[к’]-согл,глух.,парн.,мягк., парн.,[и]гл.,безуд., 6 зв,5букв.
Из алгоритма фонетического анализа постепенно уходят графические обозначения звуков. [йо/жы/ки][й’]согл.,звонк.,непарн.,мягк,непарн.,[о]гл.,ударн.,[жсогл.,звонк.,парн.,тверд,непарн.[ы]-гл.,безуд.,[к’]-согл,глух.,парн.,мягк., парн.,[и]гл.,безуд., 6 зв,5букв.
Статьи к прочтению:
- А) алгоритм, записанный на языке программирования
- Абораторная работа №2. исследование двумерных преобразований графических объектов.
Интерактивные методы обучения в условиях современного урока (ФГОС)
Похожие статьи:
Основные методы и приемы защиты от компьютерных вирусов
Во-первых, это профилактические меры. Профилактических мер не так много, но они понизят вероятность заражения информации на десятки процентов. Следует…
Изучение основных приемов работы с ms excel.
Цель работы — Изучить основные приемы работы с электронной таблицей MS Excel.
 Научиться создавать электронные таблицы средней сложности Основные понятия…
Научиться создавать электронные таблицы средней сложности Основные понятия…
 Научиться создавать электронные таблицы средней сложности Основные понятия…
Научиться создавать электронные таблицы средней сложности Основные понятия…Распознавание непрерывной речи, зависящей от говорящего, с помощью KEAL
- Мерсье, Г. ;
- Бигорн, Д. ;
- Миклет, Л. ;
- Ле Геннек, Л. ;
- Керре, М.
Аннотация
Дано описание системы распознавания непрерывной речи KEAL, зависящей от диктора. Неизвестное высказывание распознается с помощью следующих процедур: акустического анализа, фонетической сегментации и идентификации, анализа слов и предложений. Сочетание основанной на признаках, независимой от говорящего грубой фонетической сегментации с методами статистической классификации, зависящей от говорящего, является одной из основных конструктивных особенностей акустико-фонетического декодера.
- Публикация:
Протоколы IEE: коммуникационная речь и видение
- Дата публикации:
- Апрель 1989 г.
- Биб-код:
- 1989IPCSV.136..145M
- Ключевые слова:
- Динамическое программирование;
- Фонетика;
- Распознавание речи;
- Декодеры;
- Человеко-машинные системы;
- сегмента;
- Связь и радар

СИСТЕМА ФОНЕТИЧЕСКОГО ПЕРЕВОДА НА ЕСТЕСТВЕННЫЙ ЯЗЫК
Система фонетического перевода на естественный язык получает аудиовыход от электроакустического устройства, которое подключено в качестве компонента к аудиосистеме, представленной в театре или аудитории, чтобы идентифицировать любой речевой сигнал, содержащийся в пределах аудио выход.

Настоящее изобретение в целом относится к системе перевода на естественный язык и, более конкретно, к системе фонетического перевода на естественный язык, способной переводить слышимый звук из любого устройства вывода звука на множество предпочитаемых аудиторией языков.
В последнее время количество людей, которые смотрят зарубежные фильмы с целью получения удовольствия и/или развлечения, сокращается из-за языкового барьера. Иностранные фильмы могут доставлять удовольствие при просмотре, за исключением понимания языка. Люди в разных частях региона обычно предпочитают смотреть фильмы или мероприятия на разных языках. Во время просмотра таких фильмов или мероприятий зрителям может быть трудно понять язык звуковой программы.
Чтобы преодолеть такие проблемы с пониманием, аудитория может использовать человека-переводчика, внимательно искать субтитры фильма и читать до конца или комбинацию подобных инструментов. Однако переводчики-люди обычно обходятся очень дорого; а читать субтитры из фильма очень сложно и не позволяет быстро понять.
Из-за языкового барьера иностранные фильмы дублируются или имеют субтитры. Если идея «прочитать» фильм отталкивает пользователя, его единственный выбор — посмотреть дублированную версию оригинального фильма на предпочитаемом им языке. Для того, чтобы дублировать оригинальный фильм с одного иностранного фильма на другой фильм, потребовалось бы вдвое больше кинопроизводства, особенно озвучивания, перезаписи песен.
На кинофестивалях, таких как Канны, люди хотят смотреть хорошие иностранные фильмы; особенно они хотели бы знать о том, как они использовали современные технологии, сюжет и сценарий в зарубежных фильмах. Что касается музыкальных концертов, люди хотели бы видеть концерты зарубежных композиторов. Из-за языкового барьера качество музыки недоступно людям во всем мире. № 6,356,865, выданный Franz et al., озаглавленный «Способ и устройство для выполнения устного перевода»; патент США. № 5,758,023, выданный Бордо, под названием «Многоязычная система распознавания речи»; патент США. № 5,293584, выданный Brown et al., озаглавленный «Система распознавания речи для перевода на естественный язык»; патент США. № 5,963,892, выданный Tanaka et al., озаглавленный «Устройство перевода и способ для облегчения операции ввода речи и получения ее правильного перевода»; патент США. № 7,162,412, выданный Yamada et al., озаглавленный «Многоязычная система помощи при разговоре»; патент США. № 6917920, выданный Koizumi et al., озаглавленный «Устройство перевода речи и машиночитаемый носитель»; патент США. №4,984,177/выданный Rondel et al., озаглавленный «Переводчики голосового языка; и патент США. № 4,507,750, выданный Frantz et al., озаглавленный «Электронное устройство с принимающего языка».
№ 5,293584, выданный Brown et al., озаглавленный «Система распознавания речи для перевода на естественный язык»; патент США. № 5,963,892, выданный Tanaka et al., озаглавленный «Устройство перевода и способ для облегчения операции ввода речи и получения ее правильного перевода»; патент США. № 7,162,412, выданный Yamada et al., озаглавленный «Многоязычная система помощи при разговоре»; патент США. № 6917920, выданный Koizumi et al., озаглавленный «Устройство перевода речи и машиночитаемый носитель»; патент США. №4,984,177/выданный Rondel et al., озаглавленный «Переводчики голосового языка; и патент США. № 4,507,750, выданный Frantz et al., озаглавленный «Электронное устройство с принимающего языка».
Согласно патенту США. В патенте № 5,615,301, выданном Rivers et al., под названием «Автоматизированная система языкового перевода», каждое предложение переводится на универсальный язык, а затем переводит предложения с универсального языка на родной язык пользователя, указанный пользователем. Но фонетическая система естественного языка по настоящему изобретению использует языковые словари 6700 языков, которые содержат все возможные слова и наборы грамматических правил, представленные на 6700 языках, которые используются в 228 странах. Используя 6700 языковых словарей, система фонетического естественного языка по настоящему изобретению переводит слышимую речь на одном языке непосредственно на множество предпочитаемых аудиторией языков и распределяет аудиовыход на подлокотнике сиденья каждой аудитории. Таким образом, зрители могут наслаждаться прослушанной программой, не держа в руках никакого устройства для перевода на внешний язык.
Но фонетическая система естественного языка по настоящему изобретению использует языковые словари 6700 языков, которые содержат все возможные слова и наборы грамматических правил, представленные на 6700 языках, которые используются в 228 странах. Используя 6700 языковых словарей, система фонетического естественного языка по настоящему изобретению переводит слышимую речь на одном языке непосредственно на множество предпочитаемых аудиторией языков и распределяет аудиовыход на подлокотнике сиденья каждой аудитории. Таким образом, зрители могут наслаждаться прослушанной программой, не держа в руках никакого устройства для перевода на внешний язык.
Соответственно, существует потребность в системе для перевода с аудиовыхода любого устройства аудиовывода на множество желаемых аудиторией языков быстрым, простым, надежным и экономичным способом. Кроме того, существует потребность в системе перевода, которая могла бы заменить переводчиков и субтитры.
Система фонетического перевода на естественный язык является конечной целью перевода аудиовыхода электроакустического устройства на язык, предпочитаемый каждой отдельной аудиторией, и доставляет переведенную речь в виде аудиосигнала, соответствующего динамику подлокотника сиденья аудитории. Настоящее изобретение системы фонетического перевода естественного языка имеет возможность понимать взаимодействия на уровне знания дискурса, предсказывать следующие высказывания, понимать ссылки на местоимения и обеспечивать высокоуровневые ограничения для создания контекстуально подходящих предложений, включающих различные контекстно-зависимые явления. Система принимает аудиовыход от электроакустических устройств, независимых от входов непрерывной речи, через инструмент, который способен преобразовывать звуковые волны в электромагнитные сигналы.
Настоящее изобретение системы фонетического перевода естественного языка имеет возможность понимать взаимодействия на уровне знания дискурса, предсказывать следующие высказывания, понимать ссылки на местоимения и обеспечивать высокоуровневые ограничения для создания контекстуально подходящих предложений, включающих различные контекстно-зависимые явления. Система принимает аудиовыход от электроакустических устройств, независимых от входов непрерывной речи, через инструмент, который способен преобразовывать звуковые волны в электромагнитные сигналы.
Настоящее изобретение системы фонетического перевода на естественный язык решает две основные задачи; один переводит язык слышимой речи непосредственно на предпочитаемый каждым человеком язык аудитории; и во-вторых, передает переведенную слышимую речь на предпочтительном языке каждой аудитории на соответствующий аудиовыход подлокотника сиденья аудитории.
Ввиду вышеупомянутых недостатков, присущих известному уровню техники, общая цель настоящего изобретения состоит в том, чтобы предоставить систему перевода на естественный язык, сконфигурированную так, чтобы включать все преимущества предшествующего уровня техники и преодолеть присущие ей недостатки.
Таким образом, целью настоящего изобретения является создание фонетической системы естественного языка, которая способна обеспечивать перевод звукового вывода звуковой программы с одного языка на предпочтительный язык каждой отдельной аудитории, таким образом, аудитория может слушать звуковую речь. программы на иностранном языке без использования языковых переводчиков или внимательного чтения субтитров программы на иностранном языке.
Настоящее изобретение также обеспечивает пользовательский интерфейс для аудитории, где он/она может выбрать предпочтительный язык для прослушивания слышимой речи. Пользовательский интерфейс настоящего изобретения предоставляет аудитории возможность узнать о рекламных предложениях по бронированию билетов, иметь возможность бронирования билетов по городу, новые выпуски и позволяет аудитории выбирать места. Пользовательский интерфейс также доступен через устройства с поддержкой WAP или в киосках бронирования билетов.
Настоящее изобретение раскрывает модуль распознавания речи, который способен идентифицировать последовательности на уровне фонем из звукового вывода с высокой точностью в режиме реального времени в условиях независимой от говорящего непрерывной речи и большого словарного запаса. Модуль распознавания речи принимает электромагнитные сигналы и обеспечивает вывод фонемных последовательностей в режиме реального времени, исключая нежелательные шумы, и отправляет их в модуль перевода. Модуль языкового перевода, используемый для синтаксического анализа и генерации, способен интерпретировать эллиптические, неправильно сформированные предложения, которые появляются в аудиовыходе аудиопрограммы. Кроме того, интерфейс между синтаксическим анализатором и модулем распознавания речи должен передавать необходимую информацию синтаксическому анализатору и давать соответствующую обратную связь модулю распознавания речи для повышения точности распознавания. После трансляции алгоритм распределения связывает различные переведенные аудиосигналы с местом для зрителей и отправляет их в блок распределения. Это устройство выполняет последнюю задачу по передаче переведенного аудиосигнала на каждое отдельное зрительское место.
Модуль распознавания речи принимает электромагнитные сигналы и обеспечивает вывод фонемных последовательностей в режиме реального времени, исключая нежелательные шумы, и отправляет их в модуль перевода. Модуль языкового перевода, используемый для синтаксического анализа и генерации, способен интерпретировать эллиптические, неправильно сформированные предложения, которые появляются в аудиовыходе аудиопрограммы. Кроме того, интерфейс между синтаксическим анализатором и модулем распознавания речи должен передавать необходимую информацию синтаксическому анализатору и давать соответствующую обратную связь модулю распознавания речи для повышения точности распознавания. После трансляции алгоритм распределения связывает различные переведенные аудиосигналы с местом для зрителей и отправляет их в блок распределения. Это устройство выполняет последнюю задачу по передаче переведенного аудиосигнала на каждое отдельное зрительское место.
Они вместе с другими аспектами настоящего изобретения, наряду с различными признаками новизны, которые характеризуют настоящее изобретение, конкретно указаны в прилагаемой формуле изобретения и составляют часть настоящего изобретения. Для лучшего понимания настоящего изобретения, его эксплуатационных преимуществ и конкретных целей, достигаемых при его использовании, следует сделать ссылку на прилагаемые чертежи и описательные материалы, на которых проиллюстрированы примерные варианты осуществления настоящего изобретения.
Для лучшего понимания настоящего изобретения, его эксплуатационных преимуществ и конкретных целей, достигаемых при его использовании, следует сделать ссылку на прилагаемые чертежи и описательные материалы, на которых проиллюстрированы примерные варианты осуществления настоящего изобретения.
Преимущества и особенности настоящего изобретения станут более понятными при обращении к следующему подробному описанию и формуле изобретения в сочетании с прилагаемыми чертежами, на которых одинаковые элементы обозначены одинаковыми символами и на которых:
РИС. 1 — известная система фонетического перевода на естественный язык согласно варианту осуществления настоящего изобретения;
РИС. 2 иллюстрирует пользовательский интерфейс для бронирования билетов, где зрители выбирают предпочитаемый ими язык для просмотра/прослушивания звуковой программы;
РИС. 3 показано, как транслируемые аудиосигналы распределяются по множеству выходных аудиоразъемов подлокотников зрительских мест с использованием блока распределения;
РИС. 4 иллюстрирует место для аудитории предшествующего уровня техники;
4 иллюстрирует место для аудитории предшествующего уровня техники;
РИС. 5 иллюстрирует блок-схему системы фонетического перевода на естественный язык согласно варианту осуществления настоящего изобретения.
Настоящее изобретение раскрывает автоматизированный способ, помогающий зрителям получать удовольствие от публичных мероприятий, таких как закрытая зона для проведения драматических презентаций, сценических представлений, хирургических демонстраций или кинопоказов на их естественном языке. Система фонетического перевода на естественный язык согласно настоящему изобретению включает в себя онлайн-приложение для бронирования билетов, в котором хранится предпочитаемый аудиторией язык вместе с номером места. На фиг. 1, аудитория 102 бронирует билеты на публичное мероприятие, которое представляет собой драматическое представление, сценическое представление, хирургическую демонстрацию или кинопоказ на естественном иностранном языке. Аудитория 102 может использовать свое устройство 104 с поддержкой WAP, онлайн-приложение устройства 106 для бронирования билетов или использовать стороннего поставщика 108 для бронирования билетов на публичные мероприятия. Система фонетического перевода на естественный язык в соответствии с настоящим изобретением предоставляет аудитории возможность выбора языка для просмотра/прослушивания публичных мероприятий, как показано на фиг. 1 . а.
Система фонетического перевода на естественный язык в соответствии с настоящим изобретением предоставляет аудитории возможность выбора языка для просмотра/прослушивания публичных мероприятий, как показано на фиг. 1 . а.
Как показано на РИС. 1, система фонетического перевода на естественный язык в соответствии с настоящим изобретением предоставляет возможность выбора языка, предпочитаемого аудиторией, когда аудитория покупает билет в билетной кассе 120 . Продавец запрашивает предпочтительный язык аудитории, чтобы ввести языковые предпочтения вместе с номером места в систему с помощью пользовательского интерфейса. Если для конкретного места не выбран предпочтительный язык, то настоящее изобретение выбирает язык по умолчанию, то есть «английский», в качестве предпочтительного языка для конкретной аудитории.
Система фонетического перевода на естественный язык по настоящему изобретению включает в себя графический интерфейс пользователя, устройство захвата аудиовыхода в качестве блока ввода, модуль перевода на естественный язык, блок распределения и блок вывода. Модуль перевода на естественный язык включает в себя модуль распознавания речи, модуль языкового перевода, модуль голосового синтезатора и алгоритм распространения.
Модуль перевода на естественный язык включает в себя модуль распознавания речи, модуль языкового перевода, модуль голосового синтезатора и алгоритм распространения.
Как показано на РИС. 1 . a , пользовательский интерфейс 10 для системы бронирования билетов по настоящему изобретению включает в себя элемент 9 графического интерфейса пользователя.0103 14 , который содержит 6700 названий естественных языков, используемых в 228 странах, что позволяет аудитории либо вводить название предпочитаемого языка непосредственно в поле управления, либо выбирать один из естественных языков в качестве предпочтительного языка из списка существующих вариантов, чтобы насладиться событием. Когда аудитория нажимает кнопку «Купить сейчас» 16 , алгоритм онлайн-приложения пользовательского интерфейса строит двумерную хеш-таблицу для выбранного значения элемента 14 и номера места из элемента 9.0103 12 , где номер места из элемента 12 является ключом, а выбранное значение элемента 14 является значением. Алгоритм онлайн-приложения пользовательского интерфейса сохраняет двумерную хеш-таблицу на сервер , 120, базы данных системы бронирования билетов, как показано на фиг. 1.
Алгоритм онлайн-приложения пользовательского интерфейса сохраняет двумерную хеш-таблицу на сервер , 120, базы данных системы бронирования билетов, как показано на фиг. 1.
Как показано на РИС. 2, устройство захвата аудиовыхода , 202, представляет собой инструмент, способный преобразовывать звуковые волны в электромагнитные волны, т. е. микрофон, который функционально соединен с системой фонетического перевода на естественный язык по настоящему изобретению.
Модуль перевода на естественный язык включает в себя модуль распознавания речи, синтаксический анализ, генерацию, голосовой синтезатор и алгоритм распределения. Такая система раскрыта в «DM-Dialog: экспериментальная система преобразования речи в речь» Hironki Kitano et al., журнал IEEE 0018-9162/91/0600-003, сделанный официально и включенный в настоящий документ посредством ссылки.
Модуль перевода на естественный язык системы фонетического перевода на естественный язык идентифицирует последовательности на уровне фонем из звукового вывода звуковой программы и строит информационное содержание на основе наиболее подходящих гипотез о последовательности на уровне фонем с использованием языковых словарей. Языковые словари представляют собой базу знаний, которая содержит все возможные слова, представленные на 6700 естественных языках, которые используются в 228 странах, и предоставляет лексический, фразовый, синтаксический фрагменты для модуля генерации при создании эквивалентного предложения каждого предпочитаемого языка аудитории для слышимого. речь с аудиовыхода.
Языковые словари представляют собой базу знаний, которая содержит все возможные слова, представленные на 6700 естественных языках, которые используются в 228 странах, и предоставляет лексический, фразовый, синтаксический фрагменты для модуля генерации при создании эквивалентного предложения каждого предпочитаемого языка аудитории для слышимого. речь с аудиовыхода.
Алгоритм распределения модуля перевода на естественный язык тесно интегрирован с модулем распределения, который предоставляет двумерную хэш-таблицу переведенного аудиосигнала с соответствующим номером места, где хеш-таблица представляет собой двумерный массив, который имеет формат ссылки номера места и переведенный звуковой сигнал, который позволяет блоку распределения подавать звуковой сигнал на основе номера места.
Распределительный блок функционально соединен с настоящим изобретением Системы перевода фонетических естественных языков и соединен с гнездовым разъемом подлокотника каждого сиденья, как показано на РИС. 2. Блок распределения получает двумерную хеш-таблицу 230 , который содержит аналоговые аудиосигналы для звуковой программы, представляемой аудитории, а затем передается по физической кабельной распределительной сети 208 на каждое зрительское место. Распределительная кабельная сеть от распределительного блока проложена внутри каждого кинозала, а разъем типа «мама» 210 размещен в подлокотнике зрительского кресла. Штекерный разъем «папа» вставляется в разъем «мама» для контакта с кабельной распределительной сетью для приема аналоговых аудиосигналов. Штекерный разъем подключается к кабелю, который подключается к комплекту наушников. В комплекте наушников есть левый и правый динамик, которые размещаются соответственно на левом и правом ушах аудитории для прослушивания аналогового аудиосигнала.
2. Блок распределения получает двумерную хеш-таблицу 230 , который содержит аналоговые аудиосигналы для звуковой программы, представляемой аудитории, а затем передается по физической кабельной распределительной сети 208 на каждое зрительское место. Распределительная кабельная сеть от распределительного блока проложена внутри каждого кинозала, а разъем типа «мама» 210 размещен в подлокотнике зрительского кресла. Штекерный разъем «папа» вставляется в разъем «мама» для контакта с кабельной распределительной сетью для приема аналоговых аудиосигналов. Штекерный разъем подключается к кабелю, который подключается к комплекту наушников. В комплекте наушников есть левый и правый динамик, которые размещаются соответственно на левом и правом ушах аудитории для прослушивания аналогового аудиосигнала.
Модуль перевода на естественный язык системы фонетического перевода на естественный язык работает, как показано на фиг. 5. Устройство захвата аудиовыхода 202 принимает звуковой сигнал от электроакустического устройства, которое подключено в качестве компонента к аудиосистеме в помещении для проведения драматических презентаций, сценических развлечений, хирургических демонстраций или киношоу. Как показано на фиг. 5 модуль реорганизации речи , 502, идентифицирует последовательности на уровне фонем из звукового сигнала 500 и оперативно связан с синтаксическим анализатором 510 , где модуль распознавания речи 502 получает обратную связь о гипотезе фонемы и предсказании гипотезы слова от синтаксического анализатора. Точность распознавания речи улучшена за счет интерфейса, созданного между модулем распознавания речи 502 и синтаксическим анализатором 510 , поскольку он отфильтровывает ложные первые варианты выбора модуля распознавания речи и выбирает грамматически и семантически правдоподобные вторые или третьи лучшие гипотезы. Парсер 510 способен обрабатывать несколько гипотез параллельно, а не одну последовательность слов, как это видно в системах машинного перевода с вводом текста. Последовательность фонем содержит замену, вставку и удаление фонем по сравнению с правильной транскрипцией, которая содержит только ожидаемые фонемы, такая последовательность фонем представляет собой зашумленную последовательность фонем.
Как показано на фиг. 5 модуль реорганизации речи , 502, идентифицирует последовательности на уровне фонем из звукового сигнала 500 и оперативно связан с синтаксическим анализатором 510 , где модуль распознавания речи 502 получает обратную связь о гипотезе фонемы и предсказании гипотезы слова от синтаксического анализатора. Точность распознавания речи улучшена за счет интерфейса, созданного между модулем распознавания речи 502 и синтаксическим анализатором 510 , поскольку он отфильтровывает ложные первые варианты выбора модуля распознавания речи и выбирает грамматически и семантически правдоподобные вторые или третьи лучшие гипотезы. Парсер 510 способен обрабатывать несколько гипотез параллельно, а не одну последовательность слов, как это видно в системах машинного перевода с вводом текста. Последовательность фонем содержит замену, вставку и удаление фонем по сравнению с правильной транскрипцией, которая содержит только ожидаемые фонемы, такая последовательность фонем представляет собой зашумленную последовательность фонем. Задача обработки на фонологическом уровне синтаксического анализатора 510 состоит в том, чтобы активировать гипотезу о правильной последовательности фонем из этой зашумленной последовательности фонем. Парсер 510 делает прогноз наилучшей гипотезы, используя языковые словари 512 для гипотез фонем и слов, полученных от модуля распознавания речи 502 . Таким образом, выбираются наилучшие гипотезы для построения информационного содержания, которое представляет собой предложение слышимой речи.
Задача обработки на фонологическом уровне синтаксического анализатора 510 состоит в том, чтобы активировать гипотезу о правильной последовательности фонем из этой зашумленной последовательности фонем. Парсер 510 делает прогноз наилучшей гипотезы, используя языковые словари 512 для гипотез фонем и слов, полученных от модуля распознавания речи 502 . Таким образом, выбираются наилучшие гипотезы для построения информационного содержания, которое представляет собой предложение слышимой речи.
Одновременно модуль перевода на естественный язык 204 получает двумерную хэш-таблицу 508 из базы данных онлайн-бронирования билетов 506 , в которой каждый предпочтительный язык отдельной аудитории связан с номером места. Модуль генерации 516 способен генерировать соответствующие предложения с правильным контролем артикуляции. Генерирующий модуль 516 создает грамматическое предложение для каждого отдельного предпочтительного языка, который определен в хэш-таблице 508 , с использованием набора грамматических правил, определенных в языковых словарях. В настоящем изобретении системы перевода фонетического естественного языка используется схема параллельной инкрементной генерации, и процесс генерации и обработка синтаксического анализа выполняются почти одновременно. Таким образом, часть высказывания может быть сгенерирована во время синтаксического анализа. Настоящее изобретение использует общие принципы вычислений как при синтаксическом анализе, так и при генерации, и, таким образом, позволяет интегрировать эти процессы. Почти параллельный синтаксический анализ и генерация: в отличие от традиционных методов машинного перевода, в которых процесс генерации запускается после завершения синтаксического анализа, это изобретение одновременно выполняет процесс генерации во время синтаксического анализа. Как в процессах синтаксического анализа, так и в процессах генерации используются параллельные инкрементные алгоритмы. Это позволяет мультимедийной системе перевода на родной язык генерировать часть входного высказывания во время синтаксического анализа остальной части высказывания.
В настоящем изобретении системы перевода фонетического естественного языка используется схема параллельной инкрементной генерации, и процесс генерации и обработка синтаксического анализа выполняются почти одновременно. Таким образом, часть высказывания может быть сгенерирована во время синтаксического анализа. Настоящее изобретение использует общие принципы вычислений как при синтаксическом анализе, так и при генерации, и, таким образом, позволяет интегрировать эти процессы. Почти параллельный синтаксический анализ и генерация: в отличие от традиционных методов машинного перевода, в которых процесс генерации запускается после завершения синтаксического анализа, это изобретение одновременно выполняет процесс генерации во время синтаксического анализа. Как в процессах синтаксического анализа, так и в процессах генерации используются параллельные инкрементные алгоритмы. Это позволяет мультимедийной системе перевода на родной язык генерировать часть входного высказывания во время синтаксического анализа остальной части высказывания. Таким образом, слышимое речевое предложение переводится на несколько естественных языков, а затем предоставляется хэш-таблица сгенерированных предложений 9.0103 514 на Голосовой синтезатор 520 . Модуль голосового синтезатора 520 предоставляет звуковые сигналы для переведенных предложений в виде хэш-таблицы 518 для алгоритма распределения 522 .
Таким образом, слышимое речевое предложение переводится на несколько естественных языков, а затем предоставляется хэш-таблица сгенерированных предложений 9.0103 514 на Голосовой синтезатор 520 . Модуль голосового синтезатора 520 предоставляет звуковые сигналы для переведенных предложений в виде хэш-таблицы 518 для алгоритма распределения 522 .
Алгоритм распространения 522 оперативно связан с блоком распределения 524 , который использует хеш-функцию для эффективного сопоставления номера места с соответствующим звуковым сигналом на предпочтительном языке каждой отдельной аудитории. Хэш-функция используется для преобразования номера места в индекс театра 130 или зрительный зал (как показано на фиг. 4) место (как показано на фиг. 3), где необходимо искать аудиосигнал на соответствующем предпочтительном языке.
Как показано на РИС. 2, устройство распределения принимает массив аудиосигналов с номером места. Блок распределения использует хеш-функцию для извлечения аудиосигналов для разъемов подлокотников сидений в каждом ряду зрительного зала или театра. Как показано на фиг. 2, блок распределения получает аудиосигналы 232 , 234 , 236 из выходных данных модуля перевода на естественный язык для разъема подлокотника сидений A-1, A-2, A-3 в ряду A.
Как показано на фиг. 2, блок распределения получает аудиосигналы 232 , 234 , 236 из выходных данных модуля перевода на естественный язык для разъема подлокотника сидений A-1, A-2, A-3 в ряду A.
Как показано на РИС. 3, система фонетического перевода на естественный язык по настоящему изобретению включает в себя стул, на котором зритель или слушатель сидит для просмотра звуковой программы, представляемой в театре или аудитории, обычно имеющий четыре ножки для поддержки и опору для спины 302 и часто с упорами для рук 304 . Двухгнездовой разъем типа «мама» 306 в подлокотнике зрительского места. Двухконтактный штекерный разъем 310 , 312 308 вставляется в гнездовой разъем для обеспечения контакта с кабельной распределительной сетью для приема аналоговых аудиосигналов. Штекерный разъем подключается к кабелю 314 , который подключается к комплекту наушников. В комплект наушников входит левый динамик 316 и правый динамик 318 , которые размещаются соответственно на левом и правом ушах аудитории для прослушивания аналогового аудиосигнала.