Как правильно разобрать слово «Мамулечка» по составу?
Подберите пример каждому типу предложения.1. сложное предложение с союзной сочинительной и союзной подчинительной связью.2. сложное предложение с союз … ной сочинительной и бессоюзной связью.3. сложное предложение с союзной подчинительной и бессоюзной связью.4. сложное предложение с союзной сочинительной, союзной подчинительной и бессоюзной связью.ответ должен быть с доказательствомА) одни друзья хороши вдали, а другие-вблизи; кто не очень пригоден для беседы, бывает превосходен в переписке.Б) истинная дружба-медленно растущее растение, которая должна быть испытана в беде и несчастье, прежде чем заслужить такое название.В) друг должен быть у нас всегда в душе, а душа всегда с нами: она может хоть каждый день видеть кого захочет.Г) не думаю, что можно заставить всех людей любить друг друга, но я желал бы уничтожить ненависть между людьми.Д) дружба подобна сокровищнице: из неё невозможно почерпнуть больше, чем ты в неё вложил.
Помогите пожалуйста очень срочно нужно
Все высказывания являются предложениями с союзной сочинительной и союзной подчинительной связью, кроме…ответ должен быть с доказательством.А) Беда, … коль пироги начнёт печь сапожник, а сапоги тачать пирожник, и дело не пойдет на лад.Б) Всякая работа трудно до времени, пока её не полюбишь, а потом она возбуждает и становится легче.В) Выбери профессию, которую ты любишь, и тебе не придется работать ни дня в твоей жизни.Г) человек, который работает руками, — рабочий; человек, работающий руками и головой,-ремесленник; но человек, которая работает и руками, и головой, и сердцем,-мастер своего дела.
на месте вопросительного знака нужно поставить запятую между сочинительным и подчинительным союзом в предложении. Ответ должен быть с доказательством
Укажите ряды, в которых все наречия пишутся через дефис.
1) убеждал по..хорошему, на..оборот, по..прежнему не готово
2)явился нежданно..негаданно, по.
номер 7, пожалуйста, никак не могу определить
Прочитайте высказывания Антуана ее Сент-Экзюпери и укажите то, которое представляет собой сложное предложение с разными видами союзной и бессоюзной св … язи. Ответы должны быть доказательствами.
Пожалуйста, очень прошу, бошка уже не соображает
Самостоятельная работа. Причастные и деепричастные обороты.А) Подчеркните подлежащее и сказуемое (в каждом предложении).Б) Найдите причастия и дееприч
… астия, обозначьте в них суффиксы.В) Поставьте крестик над главным словом и проведите стрелку (вопрос НЕ писать!)Г) Выделите графически причастные и деепричастные обороты.Д) Расставьте знаки препинания.1)Интерес…но сидя зимним вечером у камина поговорить с возвративш…мся из похода туристом.2)Только изредка на Волге подплывая к родной пристани вдруг закричит хриплым голосом старый пароход простуже(н,нн)ый от осенних ветров.3)(Кое)где на опушках пасутся дикие козы; стройно и чутко стоят они на своих тонких ножках и пр…слушиваются красиво повернув голову и насторожив уши к незнакомым звукам.4)Каштанка отскочила и приседая на все четыре лапы залилась громким лаем разбудивш… весь дом. 5)Кот противно шипя ударил несчастную Каштанку (не)ожидавшую такого подлого нападения лапой по голове.6)Ра(з,с)пряжё(н,нн)ые на ночь лошади опустив головы погрузились в чуткую дремоту.7)Вдруг один из охотников чутко пр…слушивавшийся к подозрительному ш…роху встал и заслонив рукой свет костра посмотрел направо.8)Печорин закута(н,нн)ый в шинель старался пробраться к дверям надвинув на глаза офицерскую фуражку.9)Однажды в лесу я провалился в глубокую яму распоров себе острой корягой бок и повредив кожу на затылке.10)Гуляя с псом во дворе дома Николай Иванович даже не подозревал об огорчениях подстерегающ… их у соседнего подъезда.
сочинение на тему Первая любовь. Какое влияние оказывает первая любовь на детскую душу. ОГЭ
мормышка разобрать по составу – Profile – Jett Hitt – Composer Forum
Для просмотра нажмите на картинку
Читать далее
Смотреть видео
мормышка — разбор по составу и морфменый анализ слова
Как разобрать по составу слово мормышка?
Разбор по составу (морфемный) слова «мормышка»
Разбор по составу слова «мормышка»
Разбор слова «Мормышка»
Разбор слова «мормышка» по составу (Морфемный разбор)
«мормышка» по составу
Весла для лодки пвх купить в нижнем новгороде
Разбор по составу слова МОРМЫШКА: мормыш/к/а. Предложения со словом «мормышка». Упомянутых рыб на безнасадочную мормышку уже можно ловить с частотой колебаний гораздо меньшей, чем при ловле окуня. Юрий Юсупов, Рыбалка на мормышку без насадок, Существует много приёмов игры мормышкой, рассчитанных как на привлечение рыбы к месту ловли, так и на то, чтобы спровоцировать её на поклёвку.
 Разборы слов на букву: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Разборы слов на букву: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.Чтобы правильно разобрать слово «мормышка» по составу, нужно определить его значение. Может показаться, что однокоренное для него — слово «мышка». Слово «мормышка» образовано от слова «мормыш», и оно имеет значение «снасть для зимней рыбалки». Мормыш — это рачок, похожий на креветку, около сантиметра длиной. Живёт в озере Байкал. Мормыша используют как насадку на удочку при ловле некоторых рыб: окуня, плотвы, ерша и других. Это означает, что морфемный состав слова «мормышка» таков: -мормыш- корень, -к- суффикс (суффикс.
Как выполнить разбор слова мормышка по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, суффикс, окончание . Схема разбора по составу: мормыш ка Строение слова по морфемам: мормыш/к/а Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень [мормыш] + суффикс [к] + окончание [а] Основа слова: мормышк. ? Список морфем: мормыш — корень.
Разобрать слово по составу, что это значит? Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор. План: Как разобрать по составу слово? При проведении морфемного разбора соблюдайте определённую последовательн.
Онлайн разбор слова «Мормышка» по составу ? Части слова ? Морфемный анализ ? Разобрать другое слово по составу.
 Все разделы Антонимы Деление на слоги Однокоренные слова Перенос слова Предложения со словом Разбор слова по составу Синонимы Склонение слова по падежам Ударение в слове Фонетический разбор слова Любую Корень Окончание Приставку Суффикс.
Все разделы Антонимы Деление на слоги Однокоренные слова Перенос слова Предложения со словом Разбор слова по составу Синонимы Склонение слова по падежам Ударение в слове Фонетический разбор слова Любую Корень Окончание Приставку Суффикс.Разбор по составу мормышка. Самый большой морфемный словарь русского языка: насчитывает разобранных словоформ.
2) Морфологический разбор слова «Мормышка». Существительное: единственное число, женский род, именительный падеж, неодушевленное.
Как разобрать слово мормышка по составу? Какой корень слова, его основа и строение? Морфемный разбор слова мормышка, его схема и части слова (морфемы). ? Схема разбора по составу: мормыш ка.
Самое длинное слово в русском языке
Русский язык устанавливает свои личные рекорды по длине слов и аббревиатур, количеству гласных и согласных внутри слов. И кто бы мог подумать, что в русском языке есть даже слова на букву «ы».
• В Книге рекордов Гиннесса самое длинное слово в русском языке — превысокомногорассмотрительствующий (35 букв),
а в орфографическом словаре РАН –водогрязеторфопарафинолечение (29 букв).
• К самым длинным существительным в русском языке также относят человеконенавистничество и высокопревосходительство.
• Самые длинные одушевлённые существительные – одиннадцатиклассница и делопроизводительница.
• Самое длинное наречие, фиксируемое словарём, – неудовлетворительно.
• Слово соответственно является одновременно самым длинным предлогом и самым длинным союзом.
• Самые длинные глаголы – переосвидетельствоваться, субстанционализироваться, и интернационализироваться.
Однако все эти рекорды безосновательны, ведь некоторые правила русского языка позволяют легко их побить. Так, в словах, обозначающих родство, нет ограничений на количество приставок «пра-», поэтому слово для обозначения далёкого предка или потомка может содержать огромное количество букв. Для обозначения возраста человека, который на настоящий момент еще жив, самым длинным является слово восьмидесятичетырёхлетний (25 букв).
Для обозначения возраста человека, который на настоящий момент еще жив, самым длинным является слово восьмидесятичетырёхлетний (25 букв).
Но по этому же принципу можно строить гораздо более длинные прилагательные для возраста деревьев или даже космических объектов. А если вместо основы «-летний» использовать основы «-килограммовый», «-миллиметровый», «-миллисекундный», то слова будут еще длиннее.
• Например, тысячадевятьсотвосьмидесятидевятимиллиметровый (46 букв). Названия химических веществ, строящиеся по определённым принципам, могут достигать большой длины.
Так, например, в патенте РФ №2285004, имеется словотетрагидропиранилциклопентилтетрагидропиридопиридиновые (55 букв), но кто с уверенностью скажет, что это предел?
• А еще в русском языке есть слово с 7 согласными подряд – контрвстреча, а также слово, в котором подряд идут три пары одинаковых букв – телеграммааппарат.
• Самая длинная аббревиатура (из реально существовавших) – НИИОМТПЛАБОПАРМБЕТЖЕЛБЕТРАБСБОРМОНИМОНКОНОТДТЕХСТРОМОНТ (56 букв). Расшифровывается как: «Научно-исследовательская лаборатория операций по армированию бетона и железобетонных работ по сооружению сборно-монолитных и монолитных конструкций отдела технологии строительно-монтажного управления Академии строительства и архитектуры СССР».
• Слова на «ы» в русском языке тоже есть. Это названия российских городов и рек: Ыгыатта, Ыллымах, Ынахсыт, Ыныкчанский, Ытык-кюёль.
• Большинство слов, которые начинаются с буквы “ф” в русском языке, заимствованные. Александр Сергеевич Пушкин гордился тем, что в “Сказке о царе Салтане” было всего лишь одно слово с буквой “ф” – флот.
И напоследок интересный «исторический» рекорд:
Буква «твердый знак» или, как его раньше называли, «ер» сейчас ведет себя тихо и смирно. Но еще недавно школьники, учившиеся грамоте, терпели от этой буквы страшные несчастья. До 1917 года во фразе «Тогда о твердомъ знаке съ гневомъ и негодованiемъ писали…» пришлось бы поставить 4 «ера». В издании «Война и мир» 1897 года на каждую страницу приходится 54–55 твердых знаков. Это 70 с лишним страниц!
Но еще недавно школьники, учившиеся грамоте, терпели от этой буквы страшные несчастья. До 1917 года во фразе «Тогда о твердомъ знаке съ гневомъ и негодованiемъ писали…» пришлось бы поставить 4 «ера». В издании «Война и мир» 1897 года на каждую страницу приходится 54–55 твердых знаков. Это 70 с лишним страниц!
Если посчитать все книги, получится, что в царской России ежегодно печаталось около восьми с половиной миллионов страниц, сверху донизу покрытых только твердыми знаками.
Наш язык таит в себе неисчерпаемый запас интересных и необычных фактов. И мы представили вашему вниманию далеко не полный их перечень.
Автор: Дарья Волкова
Моих читателей интересует:
с вами Школа XXI векКак избежать ошибок параллелизма при написании
Распространенная проблема при написании статей для многих авторов эссе и исследовательских работ — использование параллельной структуры . Английский язык во многом похож на математику. Когда мы соединяем слова или фразы вместе, мы должны убедиться, что все части имеют «одинаковую ценность». То есть все они должны быть в одной форме.
Что такое параллелизм и почему это проблема в письменной форме?
Выявление параллельных структур предложений в любом письме может быть трудным.Итак, давайте начнем с нескольких примеров.
- Я люблю яблоки, апельсины и хожу в зоопарк.
- Тренер посоветовал мне правильно питаться, регулярно заниматься спортом и что посещение тренажерного зала облегчит мне задачу.
- Мэри — знаменитый писатель, танцор и пишет отличные песни.
Заметили ли вы какие-либо проблемы с приведенными выше предложениями? Если нет, не волнуйтесь. Прочитав эту статью, вы станете экспертом в выявлении проблем параллелизма!
Давайте еще раз взглянем на предложения, написанные выше.На этот раз изучите цветные слова и фразы ниже. Подчеркнутые части указывают на части предложения, которые служат триггерами для параллельных структур.
- Я люблю яблоки, апельсины и хожу в зоопарк.
- Тренер посоветовал мне правильно питаться, регулярно заниматься спортом и что посещение тренажерного зала облегчит мне задачу.
- Мэри — знаменитый писатель, танцор и пишет отличные песни.
Почему красные части выше неправильные?
- В предложении 1 говорится: «Мне нравятся существительное, существительное и -ing-фраза.”
- Предложение 2 гласит: «Тренер посоветовал мне: (1) глагол; (2) глагол; (3) эта фраза.
- Предложение 3 гласит: «Мария — существительное, существительное и глагол».
Эти три предложения нарушают параллельную структуру. Каждое из красных слов в приведенных выше примерах имеет грамматическую форму, отличную от других слов в соответствующих списках.
Как решить эту проблему?
Есть три способа решить проблему с параллельной структурой. В каждом случае идея состоит в том, чтобы все части совпадали в грамматической форме.Мы будем использовать приведенные выше примеры предложений, чтобы проиллюстрировать каждый метод.
Метод №1: Согласуйте грамматически несоответствующую часть с другими частями.
Этот метод часто оказывается самым простым, когда вы имеете дело с непараллельными словами или простыми фразами. Соответственно, мы рекомендуем метод №1 для большинства случаев, связанных с проблемами параллелизма. Однако со сложными фразами или предложениями вы можете потерять какой-то смысл, поэтому для таких ситуаций мы рекомендуем метод № 3 (ниже).
| Непараллельная структура | Правильная параллельная структура | |
| 1 | Я люблю яблоки, апельсины и хожу в зоопарк. | Я люблю яблоки, апельсины и зоопарки. |
| 2 | Тренер посоветовал мне правильно питаться, регулярно заниматься спортом и что посещение тренажерного зала облегчит мне задачу.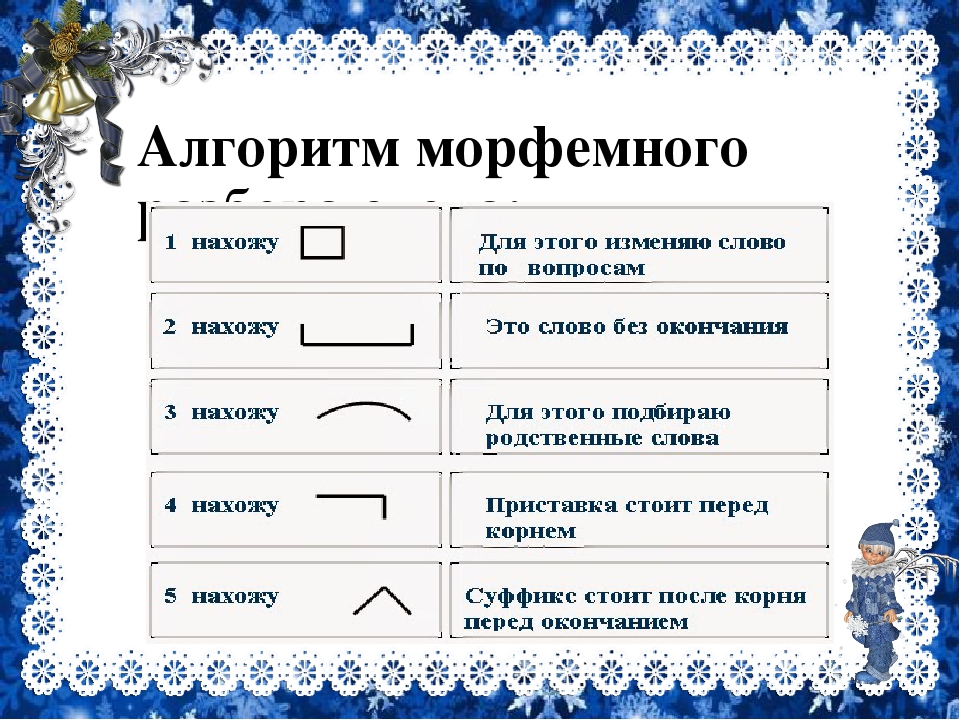 | Тренер посоветовал мне правильно питаться, регулярно заниматься спортом и ходить в спортзал. (Здесь мы теряем смысл в том, что посещение тренажерного зала облегчило бы выполнение упражнений.) |
| 3 | Мэри — знаменитый писатель, танцор и пишет отличные песни. | Мэри — знаменитый писатель, танцовщица и автор песен. |
Метод № 2: Сделайте так, чтобы другие части соответствовали грамматически непараллельной части.
Будьте осторожны при использовании этого метода. Изменение предыдущих частей может привести к повторяющимся фразам (как в примере 1 ниже), и в этом случае мы рекомендуем изменить непараллельную часть, а не остальную часть предложения! Этот метод также не решит проблему потери смысла в более сложных предложениях.
| Непараллельная структура | Правильная параллельная структура | |
| 1 | Я люблю яблоки, апельсины и хожу в зоопарк. | Я люблю есть яблоки, апельсины и ходить в зоопарк («есть» — это одно и то же). |
| 2 | Тренер посоветовал мне правильно питаться, регулярно заниматься спортом и что посещение тренажерного зала облегчит мне задачу. | Тренер рекомендовал регулярно заниматься спортом, правильно питаться и посещать тренажерный зал. (Здесь мы теряем смысл в том, что посещение тренажерного зала облегчило бы выполнение упражнений.) |
| 3 | Мэри — знаменитый писатель, танцор и пишет отличные песни. | Мэри знаменита, потому что она пишет книги, танцует и сочиняет отличные песни. |
Метод № 3: РАЗДЕЛИТЬ предложение.
Иногда изменение части предложения может потребовать существенной реструктуризации, иначе вы можете случайно изменить значение исходного предложения.В таких случаях мы рекомендуем создавать несколько предложений.
| Непараллельная структура | Правильная параллельная структура | |
| 1 | Я люблю яблоки, апельсины и хожу в зоопарк. | Я люблю есть яблоки и апельсины. Еще я люблю ходить в зоопарк. |
| 2 | Тренер посоветовал мне правильно питаться, регулярно заниматься спортом и что посещение тренажерного зала облегчит мне задачу. | Тренер посоветовал мне правильно питаться и регулярно заниматься спортом. Он также сказал мне, что посещение спортзала облегчит тренировки. |
| 3 | Мэри — знаменитый писатель, танцор и пишет отличные песни. | Мария — знаменитый писатель и танцовщица. Еще она пишет отличные песни. |
Остерегайтесь сложных сравнительных фраз!
Большинство простых стилей предложений, использующих параллельные структуры, соединяются союзами типа «и», «или» или «но».Однако существует около сложных конструкций, которые часто беспокоят многих авторов: параллелизм в модифицирующих предложениях (например, относительные придаточные предложения и придаточные предложения) и сравнительные фразы (например, коррелятивные союзы) . Остерегайтесь сложных сравнительных фраз!
- В относительных предложениях используются слова «that» или «which».
- Причастные предложения — это фразы, состоящие из глаголов и используемые как прилагательные. Например, «Эта машина построена на долгий срок».
- Корреляционные союзы включают такие термины, как «не только… но также», «либо… или», «ни… ни», «если… то» и т. Д.
- Структуры сравнения включают типичные «чем» или «как».
Все эти типы выражений требуют параллельных грамматических форм!
При исправлении таких утверждений относитесь к сравнительным фразам или второй половине коррелятивного союза как к знакам равенства и спрашивайте себя: «У меня одинаковая грамматическая структура с обеих сторон?»
| Непараллельная структура | Правильная параллельная структура |
Мне нравится большой дом 1910 года постройки, в котором есть две большие гостиные. | Мне нравится большой дом 1910 года постройки, в котором есть две большие гостиные. (Устраните проблемную параллельную структуру, удалив соединение.) |
| Мэри владеет PR-компанией, местом, дающим много возможностей для роста и где люди получают вознаграждение на основе заслуг (причастная фраза + придаточное предложение). | Мэри владеет PR-компанией, местом, дающим множество возможностей для роста, где люди получают вознаграждение на основе заслуг. (Удаление «и» устраняет проблему параллелизма.Этот метод работает в большинстве случаев, когда причастная фраза и придаточное предложение связаны союзом.) |
| Я не только люблю играть на скрипке, но и танцевать. | Я не только люблю играть на скрипке, но и танцевать. OR Мне нравится не только играть на скрипке, но и танцевать. |
| Либо пойдем в магазин сейчас, либо подождем до следующей недели. | Либо пойдем в магазин сейчас, либо подождем до следующей недели. |
| Я предпочитаю в отпуск уйти, чем бонус. | Я предпочитаю уехать в отпуск, чем получать бонус. |
Еще один удар: следите за временами глаголов!
Еще одна параллельная структура, с которой мы боремся, — это глагольное смещение времени! Поднимите руку, если вы когда-либо говорили что-то вроде следующего:
- «Мне очень нравится этот фильм, поэтому я его и купил».
- Мы знали, что у нас мало времени, работу надо заканчивать и нужно спешить.
Поднимает руку Что случилось, спросите вы? Посмотрим еще раз:
- «Мне очень нравится этот фильм, поэтому я его и купил.”
- Мы знали, что у нас мало времени, работу надо заканчивать и нужно спешить.
Приведенное выше предложение 1 переключается с настоящего времени на прошедшее, в то время как второе предложение добавляет пассивную голосовую структуру в середину списка «то». Не делай этого! Как бы они выглядели, если бы их исправили?
Не делай этого! Как бы они выглядели, если бы их исправили?
- «Мне очень нравится этот фильм, поэтому я его и купил».
- Мы знали, что у нас мало времени, надо закончить работу и нужно спешить.
Контрольный список параллелизма
- Определите любые союзы или списки в вашем предложении.
- Посмотрите на структуру ваших слов и фраз по обе стороны от этих союзов. У вас есть существительные, глаголы, прилагательные, фразы -ing и т. Д. С обеих сторон?
- Посмотрите на предложения, которые у вас есть в предложении. Есть ли в ваших списках такие же статьи? Есть ли у вас описательные предложения того же типа, описывающие одно и то же?
- Находятся ли ваши глаголы в одном и том же времени по обе стороны от союза и в модифицирующих предложениях?
- Если у вас есть список, выполняет ли каждая часть списка (A, B, C и т. Д.) имеют одинаковую грамматическую форму?
Мы надеемся, что эти советы научили вас решать проблемы, связанные с параллелизмом при написании. Теперь вы готовы приступить к написанию сочинения или статьи с уверенностью.
И если вы все еще не уверены в том, что в вашем письме нет ошибок, мы рекомендуем воспользоваться нашими услугами по корректуре и редактированию, чтобы довести ваш текст до совершенства. ВНИМАНИЕ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Мы подберем для вашей работы профессиональных редакторов, разбирающихся в предметной области вашей статьи.
А пока желаю удачи в написании!
Как создать сбалансированные макеты для ваших надписей — Жуан Невес
Приоритетом номер один для всего, что вы создаете, должно быть , четкость .Нет смысла иметь действительно классную и стильную надпись, если люди не могут ее правильно прочитать. Я также виноват в том, что слишком зацикливаюсь на стиле, из-за чего конечный результат иногда оказывается неясным.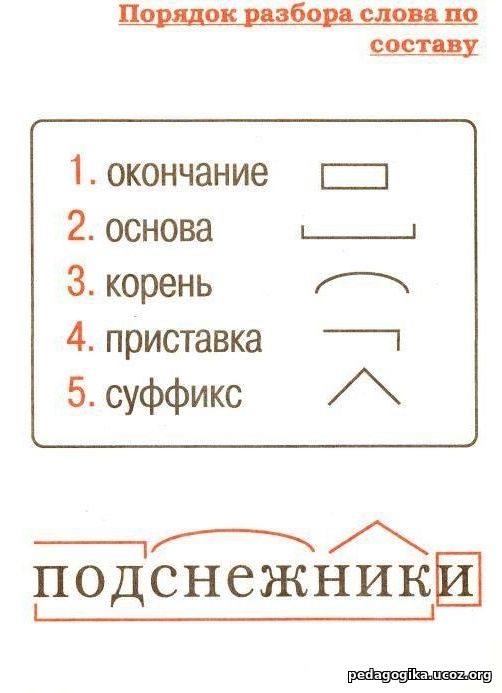 Иерархия также чрезвычайно важна для любого предмета дизайна. Помните, что латинский алфавит читается слева направо, поэтому наши глаза стремятся следовать в этом направлении. Главные слова вашей цитаты должны быть в центре внимания статьи, но имейте в виду, что это не должно мешать созданию хорошего потока.
Иерархия также чрезвычайно важна для любого предмета дизайна. Помните, что латинский алфавит читается слева направо, поэтому наши глаза стремятся следовать в этом направлении. Главные слова вашей цитаты должны быть в центре внимания статьи, но имейте в виду, что это не должно мешать созданию хорошего потока.
Вам также необходимо выяснить соотношение вашей фигуры. Будет ли это пейзаж, портрет или квадрат? Иногда вы поймете, какой вариант лучше, во время работы над ним, но вы также можете быть ограничены кратким изложением или конкретным форматом, поэтому вам придется адаптировать композицию к этому. Если вы создаете в основном для Instagram, вертикальные изображения (4: 5), как правило, работают лучше, потому что они занимают больше места на экране.
Есть несколько приемов, которые сделают вашу композицию интересной. Вы можете использовать кривые, наклонить шрифт и подумать о симметрии.Делать вещи симметричными — всегда хороший способ выровнять вашу композицию, потому что это всегда будет делать ее сбалансированной. Эта симметрия может быть горизонтальной, вертикальной или даже и той, и другой! Еще одна вещь, о которой часто забывают, — это пустое пространство. Белое пространство — это не пустое пространство, и оно чрезвычайно полезно для установления иерархии и выравнивания вещей. Мне нравится поворачивать свои работы и размывать глаза, чтобы увидеть, правильно ли распределен вес изображения (инвертирование цветов изображения также хорошо, если вы работаете в цифровом формате).Если вы чувствуете, что есть некоторые пустые места, которые необходимо заполнить, вы можете попробовать использовать лигатуры из слов или даже добавить дополнительные элементы, такие как линии или небольшие иллюстрации, которые относятся к вашей цитате. Вы также можете использовать ленты или фигуры, чтобы вставить слова. Это не только поможет вам создать более интересную композицию, но и станет отличным способом придать вес.
Итак, основные концепции, которые вам следует запомнить: четкость , иерархия , шкала и баланс . Это четыре основных принципа, которые я помню при разработке, но важно помнить, что иногда правила предназначены для того, чтобы их нарушать. Отличный совет — спросить мнение других людей о том, как они читают вашу цитату. Мы можем настолько увлечься своей работой, что предполагаем, что все будут интерпретировать ее так же, как и мы, что не всегда так.
Это четыре основных принципа, которые я помню при разработке, но важно помнить, что иногда правила предназначены для того, чтобы их нарушать. Отличный совет — спросить мнение других людей о том, как они читают вашу цитату. Мы можем настолько увлечься своей работой, что предполагаем, что все будут интерпретировать ее так же, как и мы, что не всегда так.
Ни слова не остров — модель взвешивания трансформации для семантической композиции | Труды Ассоциации компьютерной лингвистики
Фразы черный автомобиль и фиолетовый автомобиль очень похожи — за исключением их частоты.В большом корпусе, описанном в более В разделе 4.1 фраза черный автомобиль встречается 131 раз, что позволяет смоделировать целая фраза по распределению. Но фиолетовый автомобиль гораздо реже, всего с пятью вхождениями и, следовательно, вне досягаемости для моделей распределения на основе количества совпадений.
Распределительные представления слов, полученные из больших неаннотированных корпусов (Коллоберт и др., 2011; Миколов и др., 2013; Pennington et al., 2014) собирают информацию об отдельных такие слова, как фиолетовый и автомобиль и могут выразить, в векторном пространстве разные типы сходства слов (схожесть цветов прилагательные вроде черный и фиолетовый , между автомобиль и грузовик и т. д.).
Создание фразовых представлений, в частности представление низкочастотных
фразы типа фиолетовый автомобиль , это задание для композиции моделей
распределительная семантика. Композиционная модель — это функция f , которая
объединяет векторы отдельных слов, например, u для черный и v для автомобиль во фразу
Представительство р . p — результат применения
композиционная функция f к векторам слов u , v : p = f ( u , v ).
Композиционная модель — это функция f , которая
объединяет векторы отдельных слов, например, u для черный и v для автомобиль во фразу
Представительство р . p — результат применения
композиционная функция f к векторам слов u , v : p = f ( u , v ).
Наша цель — найти функцию f , которая учится составлять фразы представления путем обучения по набору фраз. Целевое представление целая фраза, p ~ , заучивается непосредственно из корпуса, при необходимости объединение сначала интересующих пар слов, например, black_car . Функция f стремится максимизировать косинусное подобие составного представления p и цели представление p ~ , arg maxp⋅p ~ || p || 2 || p ~ || 2.
В этом документе представлены следующие материалы:
- •
Мы предоставляем подробный обзор и оценку существующего состава. модели. Оценка проводится параллельно по трем синтаксическим конструкции с использованием английских, немецких и голландских берегов деревьев: прилагательное-существительное фразы ( черный автомобиль , schwarz Auto , zwart auto ), именные соединения ( яблоко tree , Apfelbaum , appelboom ) и фразы наречия-прилагательное ( очень большой , sehr groß , zeer groot ).Эти конструкции служат корпусом исследования в области анализа обобщающего потенциала композиции модели.

Оценка существующих подходов показывает, что композиционные модели лежат на противоположных концах спектра. С одной стороны, они используют одно и то же матричное преобразование (Socher et al., 2010) для всех слов, что приводит к очень общий состав.С другой стороны, есть композиционные модели. которые используют отдельные векторы (Дима, 2015) или матрицы (Socher et al., 2012) для каждого словарного слова, что приводит к словесные композиции с множеством параметров. Хотя последние работают лучше, они требуют обучающих данных для каждого слова. Эти лексикализованные модели композиции страдают от проклятия размерность (Bengio et al., 2003): Индивидуальные преобразования слов изучаются исключительно по примерам, содержащим эти слова, и не извлекать пользу из информации, содержащейся в учебных примерах, включающих разные, но семантически связанные слова. В этом примере векторы / матрицы для черный и фиолетовый будут обучаться независимо, несмотря на схожесть слов и соответствующие им векторные представления.
- •
Предлагаем вес трансформации — новый модель композиции, где «нет слова — остров» (Донн, 1624). Модель опирается на подобие векторов слов, чтобы вызвать аналогичные преобразования. Его формулировка, представленная в разделе 3, позволяет адаптировать композицию функция даже для примеров, которые не были замечены во время обучения: Для Например, даже если фиолетовый автомобиль встречается нечасто, композиция по-прежнему может создавать подходящее представление на основе других фразы, содержащие цветные прилагательные, встречающиеся на тренировках.
- •
Мы исправляем ошибку в методике ранжирования, предложенной Барони. и Зампарелли (2010) и впоследствии использовался в качестве стандарта оценки в других публикациях (Dinu et al., 2013; Дима, 2015). Исправленная методика, описано в Разделе 4.4, использует исходные фразы в качестве ориентира, а не составленные представления.Это справедливое сравнение между возможны результаты различных композиционных моделей.
- •
Мы предоставляем эталонные реализации TensorFlow (Abadi et al., 2015) всей композиции модели, исследованные в этой статье 1 и наборы данных для английского и Составные части немецкого языка, фразы прилагательное и существительное, а также фразы наречия и прилагательные и для словосочетаний «прилагательное-существительное» и «наречие-прилагательное» в голландском языке. 2


Представления Word широко используются в современной обработке естественного языка. Они
улучшить лексический охват систем НЛП путем экстраполяции информации о словах
замечено при обучении семантически похожим словам, которые не были частью обучения
данные. Еще одно преимущество состоит в том, что представления слов можно обучать на больших,
неаннотированные корпуса с использованием неконтролируемых методов, основанных на совпадении слов.Однако та же парадигма моделирования не может быть легко использована для моделирования фраз. Так как
продуктивности построения фраз, лишь малая часть всех
грамматически правильные фразы действительно встречаются в корпусах.
Композиционные модели пытаются решить эту проблему с помощью восходящего подхода, где фразовое представление строится из его частей.Композиционные модели имеют удалось построить представления для английских фраз прилагательного и существительного, таких как red car (Baroni and Zamparelli, 2010), именные соединения на английском языке ( phone номер ; Mitchell and Lapata, 2010) и немецком языке ( Apfelbaum, «яблоня»; Дима, 2015), определяющие фразы типа no memory (Dinu et al., 2013), а также для моделирования деривационной морфологии на английском языке (например,, перестроить- + сборка → перестроить ; Lazaridou et al., 2013) и немецкий (например, taub «глухой» + -heit → Taubheit «глухота»; Padó et al., 2016).
В этом разделе мы обсудим несколько композиционных моделей из литературы,
приведены в таблице 1. Они варьируются от простых
аддитивные модели к многослойным моделям для конкретных слов.В наших описаниях
входными данными для композиционных функций являются два вектора: u , v ∈ℝ n , где n —
размерность словесного представления. u и v есть
представления первого и второго элемента фразы и фиксируются
во время тренировочного процесса. В данной работе составное представление имеет то же
размерность в качестве входных данных, p ∈ℝ n .Это позволяет нам тренировать
композиционные функции, такие, что составные представления находятся в одном векторе
пространство как представления слова.
Матричная модель, предложенная Socher et al. (2010) выполняет аффинное преобразование конкатенированные входные векторы, [ u ; v ] ∈ℝ 2 n , используя матрицу W ∈ℝ n × 2 n и смещение b ∈ℝ n .
Хотя матричная модель более мощная, чем аддитивные модели, она преобразует все возможные пары u , v в одну манера. Этот подход «один размер подходит всем» нелогично: можно было бы ожидать, например, что прилагательные цвета изменять существительные иначе, чем прилагательные, описывающие физическое качество ( черная машина против быстрой машины ).А одиночное преобразование обязательно для моделирования общей композиции, которая работает достаточно хорошо для большинства обучающих примеров, но не может охватить больше конкретные словесные взаимодействия.
Модель FullLex 3 , предложенная Socher et al. (2012) представляет собой комбинацию модели Matrix с Baroni и
Зампарелли (2010)
модель линейной карты, специфичная для прилагательного.FullLex захватывает конкретные слова
взаимодействия с использованием обучаемого тензора A ∈ℝ | V | × n × n ,
где | V | размер словарного запаса. u и v преобразуются крест-накрест с помощью преобразования
матрицы A u , A v ∈ℝ n × n .Тогда преобразованные представления A v u и A u v вход матричной модели. Каждая матрица A w в модели FullLex
инициализируется с использованием единичной матрицы I с некоторыми небольшими
возмущения. Поскольку I u = u , модель FullLex начинается как
приближение матричной модели.Матрицы слов, которые встречаются
в обучающих данных обновляются во время оценки параметров, чтобы лучше
предсказывать фразовые представления.
u и v преобразуются крест-накрест с помощью преобразования
матрицы A u , A v ∈ℝ n × n .Тогда преобразованные представления A v u и A u v вход матричной модели. Каждая матрица A w в модели FullLex
инициализируется с использованием единичной матрицы I с некоторыми небольшими
возмущения. Поскольку I u = u , модель FullLex начинается как
приближение матричной модели.Матрицы слов, которые встречаются
в обучающих данных обновляются во время оценки параметров, чтобы лучше
предсказывать фразовые представления.
Модель FullLex страдает двумя недостатками, вызванными устранением каждого из них.
слово как остров: (1) Модель FullLex изучает только специализированные
матрицы для слов, которые были замечены в обучающих данных.Слова не в
обучающие данные преобразуются с использованием единичной матрицы, тем самым
эффективное сокращение модели FullLex до модели Matrix для неизвестных
слова. (2) Поскольку модель хранит матрицы для конкретных слов, FullLex
модель имеет чрезмерно большое количество параметров даже для скромных
словари. Например, в наших экспериментах с английским
Фразы прилагательное-существительное в модели FullLex использовалось ∼740 M параметров
для словарного запаса 18 481 слова. Большое количество параметров делает
модель чувствительна к переобучению.
Большое количество параметров делает
модель чувствительна к переобучению.
Размер модели FullLex можно уменьшить, используя матрицу низкого ранга. приближения для A w (Socher и др., 2012). Однако это вариация решает только проблему размера модели, но не улучшить обработку неизвестных слов.
Модель BiLinear была предложена Socher et al. (2013а, б) в качестве альтернативы модели FullLex. Эта модель позволяет
для более сильного взаимодействия между представлениями слов, чем Матрица
модель. При этом у BiLinear меньше параметров, чем у FullLex,
потому что он избегает матриц для слов. Socher et al.(2013a; 2013b) цель — построить модель, которая
лучше умеет обобщать различные исходные данные. Ядро
Модель билинейной композиции представляет собой тензор E ∈ℝ n × d × n , который хранит d билинейных форм. Каждый из билинейных
форм умножается на на и на (u⊺Ev), чтобы сформировать составной вектор
размерность d .Потому что размер фразы
представление — n , в этой статье мы предполагаем, что d = n . Каждая билинейная форма может быть
рассматривается как захват другого взаимодействия между u и v . Затем модель добавляет векторное представление
вычисляется с использованием билинейных форм для вывода модели Matrix.
Модель BiLinear решает обе проблемы модели FullLex.Это не применять резервное преобразование для каждого невидимого слова, в то же время время резко сокращает количество параметров. К сожалению, в наши эксперименты с композицией, модель BiLinear в целом работает хуже чем модель FullLex. Следовательно, можно привести сильный аргумент в пользу модели, которая изучает информацию о конкретных словах или группах слов.
Другая альтернатива, которая обучает преобразования для конкретных слов, но использует
меньше параметров, чем у FullLex — это модель WMask, предложенная Димой
(2015). Снижение
количество параметров достигается обучением, на каждое слово всего два
векторы маски, u m , u h ∈ℝ n , вместо матрицы n × n .Маска
векторы являются позиционными: если u является вектором для листа , первая маска u m используется для представления листа во фразах, где лист является
первое слово (т.е. воздуходувка ), а в осень
лист , где лист — второе слово,
используется вторая маска, u h .В
обучаемые параметры хранятся в двух матрицах W m , W h ∈ℝ | V | × n ,
где | V | размер словарного запаса.
Векторы маски u m и u h инициализируются с использованием векторов единиц, 1 , и разрешить начальное слово представления должны быть адаптированы для каждой отдельной композиции.Для слова, которых нет в обучающих данных. WMask сводится, как и FullLex, к Матричная модель. В отличие от модели FullLex, в которой используется поперечное преобразования входных векторов, A v u и A u v , Дима (2015) использует прямой преобразований: u , вектор первого слова, есть преобразуется поэлементным умножением на свою первую позицию маска, u m , u ⊙ u m .Вектор второе слово, v , преобразуется аналогичным образом, на этот раз используя вторую маску положения, v ⊙ v h . В преобразованные векторы затем составляются с использованием матричной модели. У нас есть экспериментировали как с прямым, так и с перекрестным нанесением масок. В прямое нанесение масок, предложенное Димой (2015), давало неизменно лучшие результаты чем крест-накрест.
Хотя WMask использует меньше параметров, он по-прежнему имеет линейную зависимость от
количество слов в словарном запасе, | В |. Как в
в случае FullLex маски только улучшают состав увиденных слов
во время обучения и не приносят пользы от похожих слов, которые не были
в обучении.
Как в
в случае FullLex маски только улучшают состав увиденных слов
во время обучения и не приносят пользы от похожих слов, которые не были
в обучении.
Большинство моделей, описанных в этом разделе, можно использовать с нелинейная функция активации, такая как гиперболический тангенс или ReLU (Hahnloser et al., 2000).
Мы экспериментировали с этими нелинейностями. хуже с г = ReLU, а там не было ощутимого улучшения производительности модели с использованием g = tanh.
Мы предполагаем, что нелинейность не нужна, потому что в нашем эксперименты исходное и целевое представления происходят из вектора пространство, обученное захвату линейных субструктур (Миколов и др., 2013). У ReLU есть дополнительный недостаток, заключающийся в том, что он не может создавать отрицательные компоненты вектора в целевом представлении.Результаты, представленные в разделе 5 используйте функцию идентичности, g ( x ) = x , для всех составные модели в таблице 1.
Предпосылка нашей модели состоит в том, что слова с похожими значениями сочетаются с другими словами. аналогичным образом. В теоретической лингвистике это понимание было зафиксировано понятие избирательных ограничений.Например, цветные прилагательные, такие как черный , зеленый и фиолетовый , комбинировать с бетонными объектами, такими как яблоко , велосипед и автомобиль . Модель FullLex включает черный , зеленый и фиолетовый с
номинальная головка вагон с тремя различными композиционными функциями,
рассматривать каждое слово как остров:
Модель FullLex включает черный , зеленый и фиолетовый с
номинальная головка вагон с тремя различными композиционными функциями,
рассматривать каждое слово как остров:pblack_car = W [Acaru; Ablackv] + bpgreen_car = W [Acaru; Agreenv] + bppurple_car = W [Acaru; Apurplev] + b
(1) Потому что каждое прилагательное преобразован через отдельный матрица — A черный , A зеленый , и A фиолетовый в уравнении 1 — например, модель не учитывает схожесть лексического значения цвета прилагательные.То же отсутствие обобщения справедливо и для лексического значения слова конкретные объекты, потому что их составные матрицы также полностью независимы друг друга. Более подходящая модель должна иметь возможность обобщать лексические значения слов, входящих в фразовый состав. Предлагаемая нами модель, преобразование и весовой коэффициент , решает эту проблему.
путем выполнения фразового сочинения в два этапа: этап преобразования , этап и этап взвешивания , этап .На этапе трансформации модель
диверсифицирует свою обработку входных данных, применяя несколько различных
матрицы преобразования к одним и тем же входным векторам. Потому что количество
преобразований намного меньше, чем количество слов в словаре,
Модель рекомендуется повторно использовать преобразования для аналогичных входных данных. Результат
шаг преобразования H ∈ℝ t × n , a
набор тн -мерных сборных представлений. Каждая строка H , H i представляет собой комбинацию
входные векторы u и v параметризованы матрицей преобразования i .
Каждая строка H , H i представляет собой комбинацию
входные векторы u и v параметризованы матрицей преобразования i .
На втором этапе процесса композиции H 1 , H 2 ,…, H t объединяются в финальную составленное представление р .Мы поэкспериментировали с несколькими вариантами для объединения преобразований t в один вектор.
Мы экспериментировали с четырьмя различными способами комбинирования строк t из H в p . Первый вариант, TransWeight-feat, использует вектор веса w feat ∈ℝ n и вектор смещения b feat ∈ℝ n для взвешивания индивидуума особенности каждого из преобразованных векторов t .Взвешенный затем векторы суммируются. Каждый компонент p получается через pc = wcfeat [∑i = 1tHi, c] + bcfeat.
Другой вариант взвешивания, TransWeight-trans, использует вектор весов w trans ∈ℝ t и смещение b trans ∈ℝ n для взвешивания t преобразованных вектора.Каждые p c представляют собой взвешенную сумму
соответствующий столбец H , pc = [∑i = 1tHi, cwitrans] + bctrans.
Третий вариант, коврик TransWeight, взвешивает элементы H , используя матрица W мат ∈ℝ t × n и смещение b мат ∈ℝ n .Результат Произведение Адамара W mat ⊙ H суммируется по столбцам, в результате получается вектор, компоненты задаются как pc = [∑i = 1t (wmat⊙H) i, cbcmat.
Несмотря на то, что эти три процедуры взвешивания отличаются друг от друга, они имеют общую систематическую ошибку: выполнить локальное взвешивание из t строк H .Локальное взвешивание означает, что c -й компонент окончательного составного представления, p c , основан только на значениях в c -й столбец H , и не интегрируется информация из остальных n — 1 столбец. По результатам в Таблице 3 далее в этой статье будет показано, местные взвешивания не могут использовать дополнительную информацию в H .
При взвешивании трансформации, TransWeight, мы используем глобальное значение . взвешивание тензор W ∈ℝ t × n × n и смещение b ∈ℝ n to объединить элементы H . Взвешивание выполняется с помощью тензорное двойное сжатие (:), как показано в уравнении (3).
В данной постановке c -й компонент финального представление получается как p c = ∑i = 1n∑j = 1twc, i, jHj, i. Операция двойного точечного произведения приводит к глобальное взвешивание, потому что вся матрица преобразований H учтены для каждого компонента p , хотя и с использованием компонентно-зависимое взвешивание.
TransWeight устраняет выявленные недостатки существующих композиционных моделей. в разделе 2. Поскольку матрицы преобразования не зависят от слова, количество необходимых параметры резко снижены. Более того, обучение повторному использованию преобразований для слов с похожими векторными представлениями является неотъемлемой частью обучения модель.Это делает TransWeight особенно подходящим для создания составных представления фраз, содержащих новые слова. Пока новые слова подобно некоторым словам, которые можно увидеть во время обучения, модель может повторно использовать выучил преобразования для построения новых фразовых представлений.
Мы оценили модели композиции, описанные в этой статье, по трем типам фраз:
соединения; фразы прилагательное-существительное; и наречия-прилагательные для трех языков:
Английский, немецкий и голландский.Как обсуждалось в разделе 1, наша цель — обучить и оценить композиционные функции
форма p = f ( u , v ), например
что косинусное сходство между предсказанным представлением p и
целевое представление p ~ максимизируется. Для этого нам нужна цель
представление p ~ для каждой фразы, а также представления
их составные слова, u и v .
Для этого нам нужна цель
представление p ~ для каждой фразы, а также представления
их составные слова, u и v .
В разделе 4.1 мы описываем группы деревьев которые использовались для тренировки представлений слов и фраз u , v и p ~ . Раздел 4.2 показывает, как были получены наборы фраз для каждого языка. В Разделе 4.3 мы объясняем, как были обучены представления слов / фраз и модели композиции. Наконец, в разделе 4.4 мы описываем нашу оценку методология.
Для каждого типа фразы каждое целевое представление p ~ было обучено совместно с представлениями составляющие слова u и v с использованием word2vec (Миколов et al., 2013) и гиперпараметры в Приложении 6. Для фраз, в которых слова разделены пробелом (прилагательное-существительное фразы, наречия-прилагательные и английские составные части), мы сначала объединили фразу в единое целое.Это обеспечивает обучение с использованием word2vec, в котором используется токены как его основная единица.
Каждая модель композиции p = f ( u , v ) (за исключением
немасштабированная аддитивная модель) была обучена с использованием обратного распространения ошибки с помощью Adagrad
алгоритм (Duchi et al., 2011). Так как
наша цель — максимизировать косинусное сходство между предсказанной фразой
представление p и целевое представление p ~ , мы использовали косинусное расстояние 1 − p⋅p ~ ∥p∥2∥p ~ ∥2 в качестве функции потерь. Тренировка
гиперпараметры приведены в Приложении 6.
Тренировка
гиперпараметры приведены в Приложении 6.
Baroni and Zamparelli (2010) представлены идея использования ранжирования для оценки эффективности различных составные модели. Рисунок 1 иллюстрирует процесс оценки двух составных представлений, p 1 и p 2 , соединение яблоня , полученное двумя различными композициями функции, f 1 и f 2 .В упрощенная установка, показанная на Рисунке 1, исходные векторы, обозначенные сплошными синими стрелками, — это против , вектор дерева и p ~ вектор яблони . p 1 и p 2 , представления, составленные с использованием f 1 и f 2 , изображены с использованием пунктирных оранжевых стрелок.
Рисунок 1:
Исправленная оценка. Исходное изображение соединения яблоко дерево — вектор ссылки; оба оригинальные ( v ) и составлен ( п. 1 , п. 2 ) представления сравниваются с p ~ с точки зрения косинусного подобия.
Рисунок 1:
Исправленная оценка. Исходное изображение соединения яблоко
дерево — вектор ссылки; оба оригинальные
( v ) и составлен
( п. 1 , п. 2 )
представления сравниваются с p ~ с точки зрения косинусного подобия.
p 1 происходит следующим образом: Сначала сравнивается p 1 с точки зрения косинусного сходства, к исходным представлениям всех слов и соединений в словаре.Затем исходные векторы сортируются таким образом, чтобы были найдены наиболее похожие векторы. первый. На рисунке 1, v , вектор дерева , ближе к p 1 , чем p ~ , исходный вектор apple дерево . Ранг, присвоенный составному представлению, — это позиция соответствующего исходного вектора в списке с сортировкой по подобию.В случае p 1 ранг равен 2, потому что Первоначальное изображение яблони , p ~ , было вторым в заказе.
Затем такая же процедура выполняется для p 2 . p 2 сравнивается с исходными векторами p ~ и v и получает ранг 1, потому что p ~ , исходный вектор для яблока дерево , является его ближайшим соседом.
В этом и заключается проблема: хотя p 1 ближе к
исходное представление p ~ чем p 2 , p 1 положение хуже. Это потому, что
вектор ссылки — это составное представление, которое изменяет от одной функции композиции к другой. Барони
и Зампарелли (2010)
формулировка процедуры присвоения рангов может привести к ситуациям, когда
составные представления оцениваются лучше, даже если расстояние между составленными
и исходный вектор увеличивается, как показано на рисунке 1.
Мы предлагаем простое решение этой проблемы: вычисляем все сходства косинусов. относительно p ~ исходное представление каждого соединения или фраза. Наличие фиксированной точки отсчета позволяет правильно оценить и сравнить производительность разных композиционных моделей. В новом формулировка p 1 правильно оценена как лучшая составное представление и присвоенный ранг 1, тогда как p 2 присвоен ранг 2.
Композиционные модели оцениваются на тестовой выборке каждой набор данных. Во-первых, ранг каждого составного представления определяется с помощью процедура, описанная выше. Затем сортируются ранги всех записей тестового набора. Сообщаем о первом (Q 1 ), второй (Q 2 ) и третий (Q 3 ) квартили, где Q 2 — это медиана отсортированного рангового списка, Q 1 — это медиана первой половины и Q 3 — медиана второй половины список.Мы сообщаем два дополнительных показателя эффективности: среднее значение косинусное расстояние (cos-d) между составленным и исходным представления каждой записи тестового набора и процент тестируемых соединений с рангом ≤5 . Как правило, составное представление может иметь близкие соседи, которые разные, но семантически похожи на составную фразу. А ранг ≤5 указывает на хорошо построенное представление, совместимое с соседство исходной фразы.
Еще одна особенность нашей оценки заключается в том, что ранги рассчитываются относительно
полный словарь каждого набора вложения. Это в отличие от предыдущих
оценок (Baroni, Zamparelli, 2010; Дима, 2015), где ранг
был вычислен по ограниченному словарю, содержащему только слова и
фразы в наборе данных.Ограниченный словарь упрощает оценку
потому что многие похожие слова исключены. В нашем случае аналогичные слова из
все исходное векторное пространство может стать фольгой для модели композиции, даже если
они не являются частью набора данных. Например, набор данных по английским соединениям
имеет ограниченный словарный запас 25 807 слов, тогда как полный словарный запас
содержит 270 941 слово.
Это в отличие от предыдущих
оценок (Baroni, Zamparelli, 2010; Дима, 2015), где ранг
был вычислен по ограниченному словарю, содержащему только слова и
фразы в наборе данных.Ограниченный словарь упрощает оценку
потому что многие похожие слова исключены. В нашем случае аналогичные слова из
все исходное векторное пространство может стать фольгой для модели композиции, даже если
они не являются частью набора данных. Например, набор данных по английским соединениям
имеет ограниченный словарный запас 25 807 слов, тогда как полный словарный запас
содержит 270 941 слово.
Различные вариации весов, оцененные на наборе данных о соединениях (32 246 номинальных соединений). Во всех вариантах используется t = 100 преобразования, представления слов с n = 200 Измерения и частота отсева, которые наблюдались лучше всего для набора данных разработчика (подробности см. в Приложении 6).Результаты по 6442 соединениям в тестовой выборке набор данных по немецким соединениям.
| Модель . | Вт парам. . | Cos-d . | Q 1 . | Q 2 . | Q 3 . | ≤5 . |
|---|---|---|---|---|---|---|
| TransWeight-feat | n + n | 0.344 | 2 | 5 | 28 | 50,82% |
| TransWeight-trans | t + n | 0,338 | 2 | 5 | 24 | 52,90% |
| Коврик TransWeight | тн + н | 0,338 | 2 | 5 | 25 | 53,24% |
| TransWeight | тн 2 + н 9281 9281 0. 310 310 | 1 | 3 | 11 | 65,21% |
| Модель . | Вт парам. . | Cos-d . | Q 1 . | Q 2 . | Q 3 . | ≤5 . |
|---|---|---|---|---|---|---|
| TransWeight-feat | n + n | 0.344 | 2 | 5 | 28 | 50,82% |
| TransWeight-trans | t + n | 0,338 | 2 | 5 | 24 | 52,90% |
| Коврик TransWeight | тн + н | 0,338 | 2 | 5 | 25 | 53,24% |
| TransWeight | тн 2 + н 9281 9281 0.310 | 1 | 3 | 11 | 65,21% |
TransWeight-feat, который суммирует преобразованные представления, а затем взвешивает каждый компонент суммированного представления имеет самую слабую производительность, с только 50,82% тестируемых соединений получили оценку ниже 5.
Более высокая производительность — 52,90% — достигается при применении того же
взвешивание для каждого столбца матрицы преобразований H . В
Результаты TransWeight-trans интересны в двух отношениях: во-первых, это
превосходит вариант функции TransWeight-feat, несмотря на обучение меньшего
количество параметров (300 vs. 400 в нашей настройке). Во-вторых, он работает наравне с
вариант коврика TransWeight, хотя последний имеет большее количество
параметры (20 200 в нашей настройке). Это говорит о том, что эффективное сочетание
Метод должен учитывать полные преобразования (т.е. целые строки H ) и систематически их комбинировать.
400 в нашей настройке). Во-вторых, он работает наравне с
вариант коврика TransWeight, хотя последний имеет большее количество
параметры (20 200 в нашей настройке). Это говорит о том, что эффективное сочетание
Метод должен учитывать полные преобразования (т.е. целые строки H ) и систематически их комбинировать.
TransWeight основывается на этом понимании, делая каждый элемент окончательной композиции представление p в зависимости от каждого компонента преобразованного представительство H .Результат — заметное увеличение качество прогнозов, на ∼12% больше тестовых представлений с рангом ≤5.
Хотя это взвешивание использует значительно больше параметров, чем предыдущее весов (4 000 200 параметров), количество параметров относительно количество преобразований т и не растет с размером словарь.Как показывают результаты в следующем подразделе, относительно небольшая количество преобразований достаточно даже для больших тренировок словари.
Таблица 5: Результаты с использованием метода оценки Baroni and Zamparelli (2010) для наиболее эффективных моделей для Английский, немецкий и голландский по составу именных соединений, фразы прилагательно-существительные и наречия-прилагательные.| . | Номинальные соединения . | Фразы прилагательного и существительного
. | Наречие-прилагательные Фразы . | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Модель . | Cos-d . | Q 1 . | Q 2 . | Q 3 . | ≤5 . | Cos-d . | Q 1 . | Q 2 . | Q 3 . | ≤5 . | Cos-d . | Q 1 . | Q 2 . | Q 3 . | ≤5 . | ||||||
| Английский | |||||||||||||||||||||
| WMask + | 0.344 | 3 | 9 | 43 | 39,84% | 0,342 | 4 | 11 | 41 | 33,23% | 0,335 | 3 | 8 | 33 | 40,86% | ||||||
| BiLinear | 0,335 | 3 | 7 | 33 | 43,81% | 0,332 | 3 | 9 | 33 | 39,14% | 0,331 | 2 | 7 | 25 | 45.84% | ||||||
| FullLex + | 0,338 | 3 | 9 | 41,5 | 40,53% | 0,309 | 2 | 6 | 20 | 48,41% | 48,41% | 2 | 7 | 25 | 45,45% | ||||||
| TransWeight | 0,30 | 2 | 7 | 34 | 44.43% | ||||||||||||||||
| Немецкий | |||||||||||||||||||||
| WMask + | 0,34 | 3 | 12 | 89 | 37,01% | 0. 35 35 | 5 | 19 | 92 | 25,52% | 0,387 | 8 | 40 | 219,5 | 18,32% | ||||||
| Билинейный | 0,334 | 3 | 11 | 97 | 38,73 % | 0,34 | 5 | 15 | 74 | 29,51% | 0,383 | 7 | 29 | 163 | 21,83% | ||||||
| FullLex + | 0.328 | 3 | 10 | 72 | 39,89% | 0,343 | 4 | 12 | 58 | 32,49% | 0,383 | 7 | 35 | 7 | 35 | 20,55% | |||||
| TransWeight | 0,31 | 2 | 10 | 76 | 40.10% | 0,324 | 4 | 14 | 68 | 30,24% | 0,367 | 6 | 24 | 130 | 23,21%3 | ||||||
| Голландский | |||||||||||||||||||||
| WMask + | 0,393 | 7 | 39 | 307 | 21.09% | 0.378 | 6 | 20 | 132 | 24,87% | 0,429 | 9 | 44 | 315 | 17,42% | ||||||
| Билинейный | 0,396 | 6 | 34 | 284 | 24,37 % | 0,375 | 5 | 19 | 140 | 27,40% | 0,426 | 8 | 34 | 239 | 19,18% | ||||||
| FullLex + | 0.388 | 6 | 37 | 313,5 | 22,93% | 0,362 | 4 | 13 | 80 | 31,57% | 0,433 | 10 | 50 | 16,65% | |||||||
| TransWeight | 0,376 | 5 | 28 | 235,5 | 25. 25% 25% | 0,349 | 5 | 18 | 16 | 26,92% | 0,423 | 8 | 29 | 238 | 18,9698 | ||||||
 5
50 32.49%
 65%
65%TransWeight, составная модель, предложенная в этой статье, обеспечивает последовательную результаты, являясь лучшей моделью для всех языков и фраз Типы .Разница в производительности с моделью, занявшей второе место, FullLex +, переводит на большее количество тестовых фраз, близких к оригиналу представления (т. е. достижение ранга ≤ 5). Эта разница колеблется от 8% тестовых фраз в данных о немецких соединениях составляют менее 1% для Английские словосочетания «прилагательное-существительное». Однако важно отметить существенное разница в количестве параметров, используемых двумя моделями: Все TransWeight модели используют 100 преобразований и, следовательно, имеют постоянное количество 12 020 200 параметров.Напротив, количество параметров, используемых FullLex + увеличивается с увеличением словарного запаса, достигая 739 320 200 параметры в случае набора данных английское прилагательное-существительное.
Самая сложная задача для всех композиционных моделей в любой из трех
языки — составная композиция. Мы считаем, что эта трудность может быть в основном
объясняется сложностью, вносимой должностью. Например, в
состав прилагательное-существительное, прилагательное всегда занимает первое место, а
существительное второе. Однако в составных словах одно и то же существительное может встречаться в обоих
позиции в различных обучающих примерах. Рассмотрим, например,
соединения дом-лодка и дом-лодка . В лодочном домике (дом для хранения лодок) значение дома смещено в сторону убежища для неодушевленных.
объект , тогда как дом-лодка выбирает из дома аспектов, связанных с людьми и их повседневной жизнью
происходит на лодке.Эти различия в позициях могут сделать его более
сложно создавать составные представления.
Например, в
состав прилагательное-существительное, прилагательное всегда занимает первое место, а
существительное второе. Однако в составных словах одно и то же существительное может встречаться в обоих
позиции в различных обучающих примерах. Рассмотрим, например,
соединения дом-лодка и дом-лодка . В лодочном домике (дом для хранения лодок) значение дома смещено в сторону убежища для неодушевленных.
объект , тогда как дом-лодка выбирает из дома аспектов, связанных с людьми и их повседневной жизнью
происходит на лодке.Эти различия в позициях могут сделать его более
сложно создавать составные представления.
Другой аспект, который делает наборы данных наречие-прилагательное и прилагательное-существительное проще — высокая частота набора данных некоторых наречий / прилагательных. Для Например, в английском наборе данных прилагательное-существительное небольшое подмножество из 52 прилагательных например, новый , хороший , маленький , общественный и т.д. более 500 раз в обучающей части набора данных прилагательное-существительное.Поскольку прилагательное всегда является первым элементом композиции, фразы, содержащие эти часто встречающиеся прилагательные, составляют около 24,8% от набора тестовых данных. Частые составляющие более вероятны быть правильно смоделированным по композиции, что приведет к лучшему полученные результаты.
Аддитивные модели (Addition, SAddition, VAddition) наименее конкурентоспособны
модели в нашей оценке на всех наборах данных. Результаты убедительно доказывают, что
указывают на то, что аддитивные модели слишком ограничены для состава . An
адекватное составное представление не может быть получено просто как (взвешенное)
среднее значение входных компонентов.
Результаты убедительно доказывают, что
указывают на то, что аддитивные модели слишком ограничены для состава . An
адекватное составное представление не может быть получено просто как (взвешенное)
среднее значение входных компонентов.
Модель Matrix явно превосходит аддитивные модели. Однако его результаты скромнее по сравнению с такими моделями, как WMask +, BiLinear, FullLex + и TransWeight.Этого и следовало ожидать: наличие единственного аффинного преобразования ограничивает способность модели адаптироваться ко всем возможным входным векторам u и v . Из-за небольшого количества параметров, матричная модель может отражать только общие тенденции в данные.
Больше взаимодействия между u и v способствует Билинейная модель через билинейные формы d в тензоре E ∈ℝ n × d × n .Эта способность поглощать больше информации из обучающих данных означает: лучшие результаты — модель BiLinear превосходит модель Matrix по всем наборы данных.
При оценке FullLex мы пытались смягчить трактовку неизвестных слов.
Вместо использования неизвестных матриц для моделирования композиции фраз, не входящих в
данные для обучения, мы используем подход ближайшего соседа к композиции.Взять для
Например, фраза небесно-голубое платье , где небесно-голубое не встречается в шлейфе.
Наша реализация, FullLex +, ищет ближайшего соседа небесно-голубой , который появляется в поезде ( синий ), и использует связанную с ним матрицу для построения
составленное представление. Такой же подход используется и для модели WMask,
который называется WMask +.
Такой же подход используется и для модели WMask,
который называется WMask +.
Использование наборов данных с диапазоном различных размеров показало, что наборы данных с меньшее количество фраз на уникальное слово может быть успешно смоделировано с помощью только векторы трансформации. Однако наборы данных с большим количеством фраз на слово требуют использования матриц преобразования для обобщения. Для Например, набор данных по голландским соединениям содержит 5317 уникальных слов и 17773 словосочетаний, в результате чего 3.3 фразы в слове. На этом наборе данных стоимость билетов WMask + незначительна. хуже, чем FullLex + (0,70%), это признак того, что FullLex + страдает от данных редкость в таких сценариях и не может дать хороших результатов без адекватного количество обучающих данных. Напротив, разрыв между двумя моделями увеличивается. значительно на наборах данных с большим количеством фраз на слово — например, FullLex + превосходит WMask + с показателем 8.07% по данным английских словосочетаний «прилагательное-существительное» набор, который содержит 11,6 фраз на слово. 5
Мы сравнили FullLex + и TransWeight с точки зрения их способности моделировать фразы.
где хотя бы одна из составляющих не является частью обучающих данных. Для
Например, 16,2% тестовой части набора данных по английским соединениям, 563
соединения, имеют по крайней мере один компонент, который не виден во время тренировки.Мы
оценили FullLex + и TransWeight на этом подмножестве данных: 59,15%
представления, составленные с помощью FullLex +, получают ранг ≤ 5. При использовании
TransWeight рейтинг ≤ 5 получен для 67,50% представлений.
Разница между двумя результатами является показателем превосходного
обобщающие возможности TransWeight.
При использовании
TransWeight рейтинг ≤ 5 получен для 67,50% представлений.
Разница между двумя результатами является показателем превосходного
обобщающие возможности TransWeight.
TransWeight — самая эффективная модель композиции для малых и больших наборов данных. одинаково.Это показывает, что относиться к похожим словам одинаково, а не к каждому слову как семантический остров — имеет двоякое преимущество: (i) приводит к хорошему возможности обобщения, когда обучающих данных недостаточно, и (ii) дает моделировать возможность размещения большого количества обучающих примеров без увеличение количества параметров.
Результаты в Разделе 5.2 показали что стратегия обобщения на основе преобразований, используемая TransWeight, работает хорошо для разных языков и типов фраз. Однако, понимая, что кодирование преобразований требует сделать шаг назад и снова обдумать архитектура модели.
Каждое преобразование, используемое моделью, можно рассматривать как отдельное приложение аффинное преобразование конкатенированных входных векторов [ u ; v ] ∈ℝ 2 n — по сути, одна матрица модель — в результате получается вектор в ℝ n .Сто преобразований предоставляют 100 способов объединения одной и той же пары входных данных. векторов.
Можно выдвинуть две конкурирующие гипотезы о том, как каждое преобразование
способствует окончательному представлению. Специализация гипотеза предполагает, что каждое преобразование специализируется на
определенные типы ввода (например,g., биграммы, составленные из цветных прилагательных и похожие на артефакты
существительные вроде черная машина ). Напротив, распределение гипотеза предполагает, что параметры, отвечающие за определенные
биграммы распределяются по пространству преобразований, а не
ограничены какой-либо отдельной трансформацией.
Специализация гипотеза предполагает, что каждое преобразование специализируется на
определенные типы ввода (например,g., биграммы, составленные из цветных прилагательных и похожие на артефакты
существительные вроде черная машина ). Напротив, распределение гипотеза предполагает, что параметры, отвечающие за определенные
биграммы распределяются по пространству преобразований, а не
ограничены какой-либо отдельной трансформацией.
Если гипотеза специализации верна, удаление преобразований, которые адаптированный к конкретному типу ввода, резко снизит производительность на экземпляры этого типа ввода.Чтобы проверить эту гипотезу, мы оценили TransWeight при случайном отбрасывании полных преобразований с отсевами от 0% до 90% во время прогнозирования. 6 Эта процедура также удаляет от 0% до 90% специализированные преобразования — при условии, что они существуют.
Работоспособность модели с выпадением трансформации трудно интерпретировать в
изоляция, потому что можно ожидать, что производительность модели
уменьшается как побочный эффект удаления параметров.Таким образом, любая потеря производительности
можно отнести к удалению конкретных преобразований или к уменьшению количества параметров в целом. Чтобы сделать
результаты интерпретируемы, мы создали эталонную модель, которая позволяет исключить отдельные
параметры преобразованных представлений, а не отбрасывать полные
трансформации. Эталонная модель удаляет то же количество параметров, что и
модель с выпадением трансформации, но сохраняет определенные трансформации
частично цела.Это позволяет нам проверить, есть ли потеря производительности
выпадение преобразований больше, чем ожидаемая потеря при удалении (любых)
параметры. Если это действительно так, то удаление определенных преобразований более целесообразно.
вреднее, чем удаление случайных параметров, и гипотеза специализации должна
быть принятым. С другой стороны, если нет ощутимой разницы между
две модели, то гипотезу специализации следует отклонить в пользу
гипотеза распределения.
Эталонная модель удаляет то же количество параметров, что и
модель с выпадением трансформации, но сохраняет определенные трансформации
частично цела.Это позволяет нам проверить, есть ли потеря производительности
выпадение преобразований больше, чем ожидаемая потеря при удалении (любых)
параметры. Если это действительно так, то удаление определенных преобразований более целесообразно.
вреднее, чем удаление случайных параметров, и гипотеза специализации должна
быть принятым. С другой стороны, если нет ощутимой разницы между
две модели, то гипотезу специализации следует отклонить в пользу
гипотеза распределения.
Результаты этого эксперимента с набором английских прилагательных и существительных показаны на рис. занимает ≤5 место по сравнению с показателем отсева. Потому что практически нет разница в потерях между моделью, в которой используется выпадение преобразования, и эталонной модели мы отвергаем гипотезу специализации. Однако, отвергая гипотеза специализации не исключает возможности семантического свойства определенных классов слов фиксируются распределенными параметрами через преобразования.
Рисунок 2:
Процент рангов ≤5 модели, в которой отбрасываются преобразования. случайным образом и модель отражения, которая отбрасывает отдельные параметры преобразованные представления случайным образом.
Рисунок 2:
Процент рангов ≤5 модели, которые отбрасывают преобразования
случайным образом и модель отражения, которая отбрасывает отдельные параметры
преобразованные представления случайным образом.
В этой статье мы представили TransWeight, новую композиционную модель, в которой используется набор взвешенных преобразований, как золотую середину между полностью лексикализованной моделью и модели, основанные на единственном преобразовании. TransWeight превосходит все другие модели в наших экспериментах.
В этой работе мы обучили TransWeight работе с определенными типами фраз.В будущем, мы хотели бы исследовать, можно ли использовать одну модель TransWeight для исполнять композиции разных типов фраз, возможно, при интеграции информация о структуре фраз и их контексте, как в Hermann и Blunsom (2013), Yu et al. (2014), Ю и Дредзе (2015).
Еще одно расширение, которое нас интересует, — это использование TransWeight для составления большего количества чем два слова.Мы планируем последовать примеру Socher et al. (2012) здесь, кто использует функцию композиции FullLex в рекурсивная нейронная сеть для составления произвольного количества слов. Точно так же мы может использовать TransWeight в рекурсивной нейронной сети, чтобы составить более два слова.
В наших экспериментах 100 преобразований дали оптимальные результаты для всех наборов фраз.Однако необходимы дальнейшие исследования, чтобы определить, является ли это число оптимальным.
для любой комбинации классов слов, или зависит ли это от класса слов
тип (т.е. открытый или закрытый), разнообразие классов слов в наборе данных или
свойства пространства вложения, которые присущи методу, используемому для построения
векторное пространство.
(PDF) Вычисление схожести исходного кода программы по составу дерева синтаксического анализа и графа вызовов
Математические проблемы в инженерии
T : Окончательная 1-мера обнаружения плагиата.
Метод 1-мера
JPlag .
CCFinder .
Модифицированное ядро дерева синтаксического анализа ( = 0,95) [] .—-
Graphkernel ( = 0,99) .Ц
Ядро модифицированного графа (= 0,97) .
Предлагаемый метод ( = 0,96) 0,87
обнаружения, мера сходства ()
должна учитывать не только синтаксическую структурную информацию, но и
динамическая структура вызова одновременно.
8. Заключение
В этой статье мы предложили новый метод сравнения исходного кода программы
.Предлагаемый метод вычисляет
подобия между двумя исходными кодами с составом
двух видов структурной информации, извлеченной из исходных
кодов. То есть, метод использует как синтаксическую информацию
, так и динамическую информацию. Синтаксическая информация, которую
предоставляет структурное представление на локальном уровне, включается в дерево синтаксического анализа
. Для сравнения деревьев синтаксического анализа в этой статье используется
— специализированное древовидное ядро для деревьев синтаксического анализа исходных кодов.Динамическая информация
, которая содержится в графике вызова функции
, дает структурное представление высокого и глобального уровня. Ядро графа
с учетом имен функций принимается для отражения структуры графа
. Наконец, предлагаемый метод
использует составное ядро ядер для использования обоих видов
информации. Кроме того, веса ядер в составном ядре
определяются автоматически с цикломатической сложностью
.
В экспериментах по обнаружению плагиа-
ризма из исходного кода Java-программы с реальным набором данных показано, что предложенный метод
превосходит существующие методы в обнаружении плагиат-
ризм-пар. В частности, эксперименты с различными числами
В частности, эксперименты с различными числами
показывают, что предложенный метод всегда работает хорошо, независимо от размера исходных кодов.
Одним из преимуществ предложенного метода является то, что
можно использовать с другими языками, такими как C, C ++ и Python
, даже если эксперименты проводились только с Java.
Поскольку предлагаемый метод требует только деревьев синтаксического анализа и
графов вызовов функций исходных кодов, он может быть применен к любым
другим языкам, если доступен синтаксический анализатор для этих языков. Вся информация
предлагаемого метода доступна по адресу
http://ml.knu.ac.kr/plagiarism.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов
относительно публикации данной статьи.
Благодарности
Это исследование было поддержано проектом BK Plus (SW
HumanResourceDevelopmentProgram forSupporting
Smart Life), финансируемым Министерством образования, Школа
компьютерных наук и инженерии, Национальный университет Кёнпук
, Корейский национальный университет
(A), а также ICT R&D pro-
грамма MSIP / IITP (, WiseKB: Big data based self-
эволюционирует база знаний и платформа рассуждений).
Ссылки
[] J.-W. Сын и С.-Б. Парк, «Дискриминация веб-таблицы с позицией com-
с богатой структурной и содержательной информацией», Applied
So Computing, том , №, стр. –,.
[] Д. Л. МакКейб, «Обман среди студентов колледжей и университетов:
с точки зрения Северной Америки», Международный журнал образовательной этики
tional Integrity, vol. , нет. , стр. – , .
[] С. Хорвиц, «Выявление семантических и текстовых различий
между двумя версиями программы», в Proceedings of the ACM
SIGPLAN Conference on Programming Language Design and
Implementation, pp. - – -,.
- – -,.
[] В. Ян, «Выявление синтаксических различий между двумя про
граммов», Программное обеспечение: практика и опыт, том , №, стр. –
, .
[] J.-W. Сын Т.-Г. Но, Х.-Дж. Сонг, С.-Б. Парк, «Приложение
для обнаружения плагиата исходного кода на основе дерева синтаксического анализа ядра
», Engineering Applications of Articial Intelligence, vol.,
no. , стр. – , .
[] М.Л. Каммер, Обнаружение плагиата в программах haskell с использованием сопоставления графа вызовов
[M.S. thesis], Утрехтский университет, .
[] Хаусслер Д. Ядра свертки на дискретных структурах // ЖТФ.
Представитель UCS-CRL--, Калифорнийский университет, Санта-Крус,
Калифорния, США, .
[] B. Sch
olkopf, K.Tsuda, and J.-P.Vert, Kernel Methods in
Computational Biology, MIT Press, –.
[] М. Коллинз и Н. Дуи, «Ядра свертки для естественного языка
», в «Достижения в системах обработки нейронной информации»,
с. – , .
[] T. G¨
artner, P. Flach и S. Wrobel, «Об ядрах графов: твердость
результатов и эффективные альтернативы», в материалах 16-й ежегодной конференции по обучению
. Eory, pp. – , август
.
[] Д. Хиндл, «Классификация существительных на основе структур предикат-аргумент —
структур», в Трудах 28-го Ежегодного собрания Ассоциации
для компьютерной лингвистики (ACL ’90), стр. – , Strouds-
burg, Pa, USA, июнь .
[] П. Резник, «Использование информационного содержания для оценки семантического сходства
в таксономии», в материалах 13-й Международной
совместной конференции по искусственному интеллекту, стр. , .
[] Б.Гипп, Н. Меушке и К. Брайтингер, «Обнаружение гиата на основе цитирования
: осуществимость в крупномасштабном научном исследовании
pus», Журнал Информационной ассоциации Наука и техника —
нология, т. , №, стр. – ,.
, №, стр. – ,.
[-] Г. Варелас, Э. Воутсакис, П. Ратопулу, Э. Г. Петракис и
Э. Э. Милиос, «Методы семантического сходства в Wordnet и
их применение для поиска информации в Интернете», в Pro —
потолков 7-го ежегодного международного семинара ACM по сети
Управление информацией и данными, стр. – , .
[] K. Williams, H.-H. Чен и К. Л. Джайлз, «Классификация и ранжирование результатов поисковых систем
как потенциальных источников плагиата», в
Proceedings of the ACM Symposium on Document Engineering,
pp. – , Форт-Коллинз, Коло, США, сентябрь.
Посвящается другим людямУ нас также есть множество примеров музыкальных композиций, посвященных другим людям, их чествованию или памяти. В честь определенного годаЭто не так часто, как все, что мы обсуждали до сих пор, но примеры все же существуют. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


 Он может прояснить значение тематического предложения, переформулируя его в других формах, определяя его термины, отрицая обратное, давая иллюстрации или конкретные примеры; он может установить это доказательствами; или он может развить его, показывая его значения и последствия.В длинном абзаце он может выполнить несколько из этих процессов.
Он может прояснить значение тематического предложения, переформулируя его в других формах, определяя его термины, отрицая обратное, давая иллюстрации или конкретные примеры; он может установить это доказательствами; или он может развить его, показывая его значения и последствия.В длинном абзаце он может выполнить несколько из этих процессов.

 Разрыв между ними служит риторической паузой, выделяя некоторые детали действия.
Разрыв между ними служит риторической паузой, выделяя некоторые детали действия.
 Исправленная версия, следовательно, просто предположение о намерениях автора.
Исправленная версия, следовательно, просто предположение о намерениях автора.

 Интерес, вызванный серией, очень порадовал Комитет, и в дальнейшем планируется выпускать аналогичную серию ежегодно. Четвертый концерт состоится во вторник, 10 мая, когда будет представлена не менее интересная программа.
Интерес, вызванный серией, очень порадовал Комитет, и в дальнейшем планируется выпускать аналогичную серию ежегодно. Четвертый концерт состоится во вторник, 10 мая, когда будет представлена не менее интересная программа.
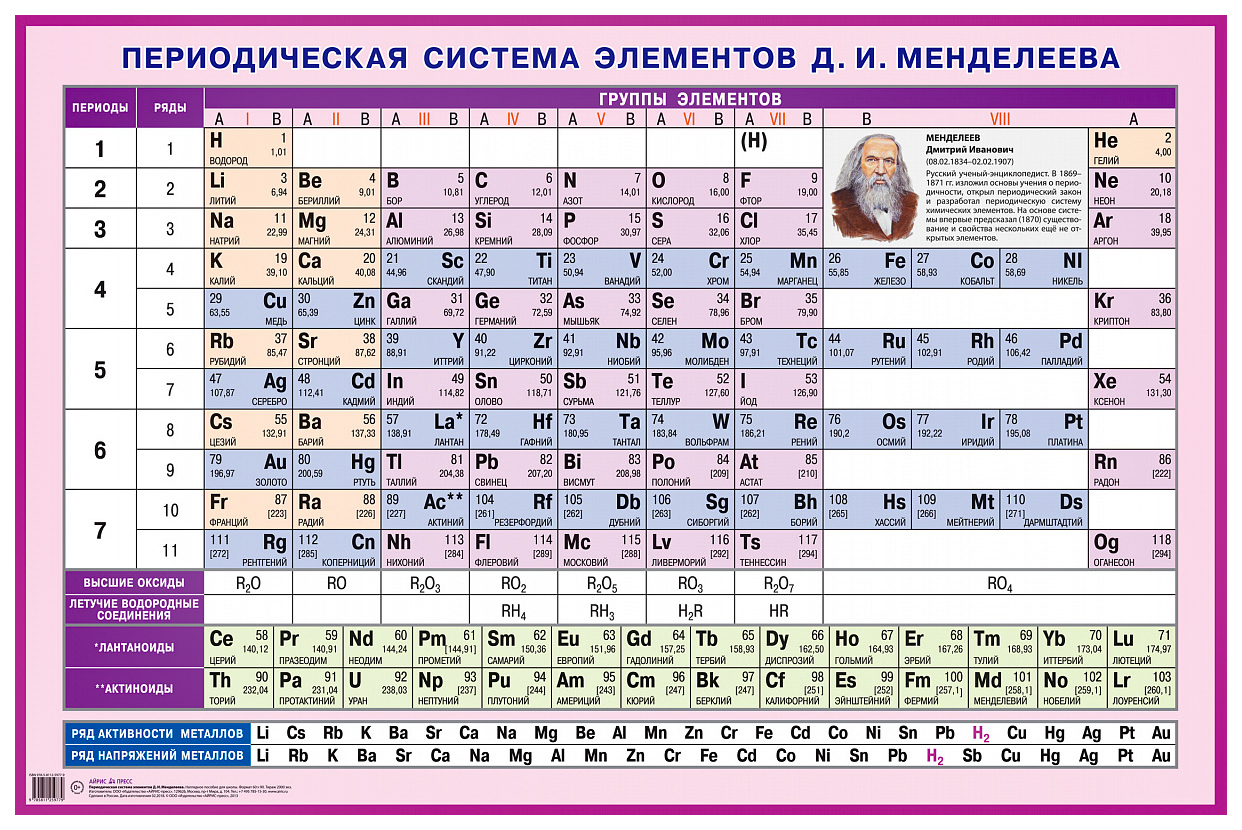
 Это возражение, однако, обычно не выполняется, когда порядок прерывается только относительным предложением или выражением в приложении.Это также не относится к периодическим предложениям, в которых прерывание является преднамеренно используемым средством создания неопределенности (см. Примеры в Правиле 18).
Это возражение, однако, обычно не выполняется, когда порядок прерывается только относительным предложением или выражением в приложении.Это также не относится к периодическим предложениям, в которых прерывание является преднамеренно используемым средством создания неопределенности (см. Примеры в Правиле 18).