Сплин подборы аккордов для гитары
Запретили песни Цоя, Агата Кристи, Наутилус Помпилиус, Зиверт
Отвечаем в отдельной теме
| Название композиции | Видео | Просмотров |
|---|---|---|
| 3007 | 16,897 | |
| 3007-й | 11,152 | |
| Mama Mia (Мама миа) | 46,290 | |
| Mamma Mia | 23,194 | |
| SOS | 23,940 | |
| Undenied | 20,295 | |
| Аделаида | 171,590 | |
| Ай Лав Ю | 24,334 | |
| Алиса | 81,628 | |
| Алкоголь | 41,649 | |
| Алкоголь | 14,921 | |
| Алкоголь | 24,096 | |
| Алкоголь | 21,120 | |
| Алкоголь | 12,620 | |
| Алкоголь | 46,764 | |
| Альтависта | 29,787 | |
| Альтависта (Другая точка зрения) | 41,330 | |
| Альтависта (Другая точка зрения) | 87,642 | |
| Альтависта (Другая точка зрения) | 8,488 | |
| Альтависта (Другая точка зрения) | 10,734 | |
| Альтависта (Другая точка зрения) | 10,240 | |
| Альтависта (Другая точка зрения) | 10,387 | |
| Англо-русский словарь (Давай, лама) | 35,613 | |
| Англо-русский словарь (Давай, лама) | 59,374 | |
| Англо-русский словарь (Давай, Лама) | 39,638 | |
| Англо-русский словарь (Давай, Лама) | 146,460 | |
| Атом | 12,325 | |
| Беги, моя жизнь | 13,386 | |
| Без тормозов | 25,598 | |
| Бездыханная легкость моя | 24,538 | |
| Бездыханная легкость моя | 2,208 | |
| Бездыханная легкость моя | 69,628 | |
| Бериллий | 34,179 | |
| Бериллий | 63,181 | |
| Бериллий | 15,616 | |
| Бетховен | 11,806 | |
| Бетховен | 14,816 | |
| Блатная про Хипа | 40,632 | |
| Блокада | 15,178 | |
| Бог устал нас любить | 128,833 | |
| Бог устал нас любить | 85,972 | |
| Бог устал нас любить | 286,704 | |
| Больше никакого рок-н-ролла | 14,940 | |
| Больше никакого рок-н-ролла | 16,719 | |
| Бони и Клайд | 125,956 | |
| Бонни и Клайд | 32,063 | |
| Бонни и Клайд | 293,836 | |
| Брокгауз и Ефрон | 9,439 | |
| Будь моей тенью | 22,331 | |
| Будь моей тенью | 81,775 | |
| Будь моей тенью | 35,938 | |
| В мире иллюзий | 28,009 | |
| В мире иллюзий | 9,267 | |
| Важная вещь | 4,643 | |
| Валдай | 14,559 | |
| Вальс | 24,552 | |
| Вальс | 11,351 | |
| Весь этот бред | 121,576 | |
| Весь этот бред | 113,646 | |
| Весь этот бред | 4,630 | |
| Весь этот бред | 290,308 | |
| Винсент | 19,821 | |
| Вирус | 3,513 | |
| Вниз головой | 25,621 | |
| Вниз головой | 27,149 | |
| Воздушный шар | 12,709 | |
| Война | 44,671 | |
| Волк | 69,990 | |
| Волк | 9,823 | |
| Волк | 8,589 | |
| Волна | 32,219 | |
| Волна | 10,634 | |
| Волшебная скрипка | 19,600 | |
| Волшебное слово | 11,825 | |
| Время назад | 64,227 | |
| Время назад | 77,017 | |
| Время назад | 53,447 | |
| Время, назад | 10,900 | |
| Время, назад | 39,870 | |
| Время, назад | 10,041 | |
| Всадник | 20,183 | |
| Всадник | 17,727 | |
| Все включено | 12,390 | |
| Все включено | 5,012 | |
| Всё наоборот | 6,877 | |
| Все так странно | 9,696 | |
| Всё так странно | 7,954 | |
| Всего хорошего | 49,507 | |
| Всего хорошего | 39,371 | |
| Встретимся завтра | 22,989 | |
| Встречная полоса | 4,682 | |
| Выпусти меня отсюда | 27,249 | |
| Выпусти меня отсюда | 47,155 | |
| Выхода нет | 283,391 | |
| Выхода нет | 5,674,024 | |
| Выхода нет | 43,732 | |
| Выхода нет | 3,248,486 | |
| Выхода нет | 106,736 | |
| Выхода нет | 66,056 | |
| Выхода нет | 45,129 | |
| Гандбол | 47,759 | |
| Гандбол | 133,448 | |
| Гандбол | 25,690 | |
| Где ты была | 28,943 | |
| Гимн | 46,669 | |
| Гни свою линию | 262,728 | |
| Гроза | 11,012 | |
| Гроза | 3,887 | |
| Грузовик (Без тормозов) | 14,281 | |
| Давайте делать паузы в словах | 70,274 | |
| Далеко домой | 53,666 | |
| Два плюс один | 5,282 | |
| Дверной глазок | 2,091 | |
| Двое не спят | 107,551 | |
| Двое не спят | 264,919 | |
| Двое не спят | 34,026 | |
| Двое не спят | 576,282 | |
| Двое не спят | 39,865 | |
| Двуречье | 126,122 | |
| Двуречье (Я ничего не скрыл) | 41,528 | |
| Девятиэтажный дом | 12,538 | |
| Дежавю | 5,941 | |
| День за днём | 14,580 | |
| Джа играет джаз | 7,927 | |
| Джим | 35,402 | |
| Джин | 21,276 | |
| Джин | 59,801 | |
| Джин | 11,757 | |
| Джин | 8,757 | |
| До встречи | 13,679 | |
| До встречи | 9,750 | |
| Добро пожаловать | 16,995 | |
| Добрых дел мастер | 49,601 | |
| Добрых дел мастер | 13,587 | |
| Добрых дел мастер | 10,836 | |
| Добрых дел мастер | 24,251 | |
| Домовой | 41,088 | |
| Домовой | 8,025 | |
| Достань гранату | 16,894 | |
| Достань гранату | 23,928 | |
| Достань гранату (Нажми на кнопку) | 11,412 | |
| Дочь самурая | 270,247 | |
| Дыши легко | 12,583 | |
| Дыши легко | 5,627 | |
| Дыши легко | 8,166 | |
| Есть кто-нибудь живой | 7,567 | |
| Жертва талого льда | 45,808 | |
| Жертва талого льда | 15,379 | |
| Жертва талого льда | 12,287 | |
| За семью печатями | 38,480 | |
| За стеной | 6,188 | |
| Загладь вину свою | 40,982 | |
| Звезда рок-н-ролла | 23,678 | |
| Звезда рок-н-ролла | 78,722 | |
| Звери | 17,943 | |
| Звери | 56,087 | |
| Зеленая песня | 4,964 | |
| Земля уходит из-под ног | 29,086 | |
| Золотые сны | 3,748 | |
| Иди через лес | 54,086 | |
| Иди через лес | 14,500 | |
| Иди через лес | 82,828 | |
| Иди через лес | 13,843 | |
| Император | 10,560 | |
| Испанская инквизиция | 4,609 | |
| Исчезаем в темноте | 16,004 | |
| Исчезаем в темноте | 12,320 | |
| Исчезаем в темноте | 13,333 | |
| Йог спокоен | 15,645 | |
| Йог спокоен | 14,165 | |
| Йог спокоен | 8,833 | |
| Камень | 19,689 | |
| Камень | 24,168 | |
| Камень | 13,614 | |
| Катись, колесо | 26,841 | |
| Катись, колесо | 9,557 | |
| Катись, колесо | 38,060 | |
| Катись, колесо | 8,183 | |
| Катится камень | 18,638 | |
| Кесарь | 4,341 | |
| Кит | 52,301 | |
| Ковчег | 8,605 | |
| Ковчег | 3,682 | |
| Ковчег | 8,568 | |
| Ковш | 17,559 | |
| Ковш | 22,473 | |
| Когда пройдет сто лет | 18,333 | |
| Кое-что еще | 19,092 | |
| Кое-что еще | 10,036 | |
| Кое-что еще | 14,336 | |
| Кокаинетка | 31,465 | |
| Коктейли третьей мировой | 21,286 | |
| Колокол | 10,841 | |
| Колокол | 4,159 | |
| Конец прекрасной эпохи | 83,233 | |
| Корабль ждет | 10,446 | |
| Корабль ждет | 14,743 | |
| Корень Мандрагоры | 36,501 | |
| Кофейня | 2,445 | |
| Кошмары | 2,525 | |
| Красота | 12,229 | |
| Кто-то не успел | 46,292 | |
| Куда летит мой самолёт | 7,603 | |
| Куда летит мой самолёт | 2,796 | |
| Лабиринт | 22,971 | |
| Лабиринт | 6,240 | |
| Ленинград — Амстердам | 58,784 | |
| Ленинград-Амстердам | 14,245 | |
| Ленинград-Амстердам | 109,513 | |
| Ленинград-Амстердам | 33,768 | |
| Ленинград-Амстердам | 13,025 | |
| Лепесток | 24,929 | |
| Лепесток | 7,096 | |
| Лестница | 22,878 | |
| Лестница | 9,214 | |
| Летела жизнь | 49,043 | |
| Линия жизни | 49,045 | |
| Линия жизни | 91,362 | |
| Линия жизни | 39,092 | |
| Линия жизни | 118,876 | |
| Линия жизни | 50,740 | |
| Линия жизни | 91,020 | |
| Любовь идет по проводам | 43,783 | |
| Любовь идет по проводам | 22,037 | |
| Любовь идет по проводам | 8,695 | |
| Люди на ладони | 5,427 | |
| Люся сидит дома | 6,849 | |
| Люся сидит дома | 20,123 | |
| Мама Миа | 44,936 | |
| Мамма Миа | 10,676 | |
| Мамма миа | 7,885 | |
| Мария и Хуана | 55,396 | |
| Матч | 20,097 | |
| Матч | 9,030 | |
| Маяк | 224,277 | |
| Маяк | 19,687 | |
| Маяк | 38,961 | |
| Маяк | 16,619 | |
| Маяк | 45,654 | |
| Маяк (Вместо письма) | 106,215 | |
| Маяк (Вместо письма) | 14,961 | |
| Маяк (вступление) | 20,305 | |
| Мелькнула чья-то тень | 22,018 | |
| Мне 20 лет | 189,668 | |
| Мне сказали слово | 19,188 | |
| Мобильный | 10,056 | |
| Мобильный | 20,027 | |
| Мое сердце | 154,553 | |
| Мое сердце | 3,377,097 | |
| Моё сердце | 118,383 | |
| Мое сердце | 38,111 | |
| Мое сердце | 78,644 | |
| Моё сердце (Соло) | 38,069 | |
| Молоко и мед | 35,447 | |
| Молоко и мёд | 13,872 | |
| Мороз по коже | 74,449 | |
| Мороз по коже | 36,978 | |
| Мороз по коже | 146,527 | |
| Мороз по коже | 10,950 | |
| Мороз по коже | 13,108 | |
| Мотоциклетная цепь | 13,593 | |
| Мотоциклетная цепь | 6,448 | |
| Моя любовь | 128,295 | |
| Моя любовь | 27,725 | |
| Моя любовь | 12,070 | |
| Мы сидели и курили | 183,174 | |
| Мы чужие здесь | 7,910 | |
| Мысль | 22,353 | |
| Мысль | 31,108 | |
| Мысль | 7,258 | |
| На счастье | 7,393 | |
| На утро | 5,607 | |
| Нам, мудрецам | 11,015 | |
| Настройка звука | 7,627 | |
| Настройка звука | 4,189 | |
| Небесный хор | 5,311 | |
| Небо в алмазах | 43,847 | |
| Небо в алмазах | 6,592 | |
| Небо в алмазах | 5,565 | |
| Небо в алмазах | 89,704 | |
| Невский проспект | 66,578 | |
| Невский проспект | 21,739 | |
| Невский проспект | 14,476 | |
| Нервное сердце | 10,361 | |
| Нервное сердце | 10,384 | |
| Нефть | 7,302 | |
| Нечего делать внутри | 53,467 | |
| Никто не хочет войны | 10,841 | |
| Новые люди | 124,382 | |
| Новые люди | 365,764 | |
| Новые люди | 239,284 | |
| Новые люди | 18,253 | |
| Новые люди | 53,188 | |
| Новые люди | 46,855 | |
| Окраины | 23,263 | |
| Она была так прекрасна | 181,223 | |
| Орбит без сахара | 427,192 | |
| Орбит без сахара | 7,680 | |
| Орбит без сахара | 263,345 | |
| Орбит без сахара | 36,272 | |
| Орбит без сахара | 64,760 | |
| Орбит без сахара | 39,101 | |
| Оркестр | 163,978 | |
| Оркестр | 28,966 | |
| Оркестр | 19,174 | |
| Остаемся зимовать | 146,661 | |
| Остаемся зимовать | 23,219 | |
| Остаёмся зимовать | 146,079 | |
| Остаемся зимовать | 31,309 | |
| Остаемся зимовать | 129,989 | |
| Паузы | 35,977 | |
| Паузы | 33,139 | |
| Паузы | 28,654 | |
| Паузы | 12,079 | |
| Паузы | 23,939 | |
| Паузы | 303,097 | |
| Пепел | 7,085 | |
| Передайте это Гарри Поттеру, если вдруг его встретите | 43,800 | |
| Передайте это Гарри Поттеру, если вдруг его встретите | 19,823 | |
| Передайте это Гарри Поттеру, если вдруг его встретите | 434,286 | |
| Передайте это Гарри Поттеру, если вдруг его встретите | 9,786 | |
Передайте это Гарри Поттеру, если вдруг его встретите. | 14,545 | |
| Песенка про хипа | 8,444 | |
| Песня на одном аккорде | 84,632 | |
| Песня о звездах | 21,742 | |
| Песня о звёздах | 147,514 | |
| Песня про продюсера | 14,183 | |
| Петербургская свадьба | 18,545 | |
| Петербургская свадьба | 42,644 | |
| Пил — курил | 70,534 | |
| Пил, курил | 13,909 | |
| Пил-курил | 11,162 | |
| Пил-курил | 26,470 | |
| Пил-курил | 11,919 | |
| Пирамиды | 11,487 | |
| Пирамиды | 13,806 | |
| Письмо | 77,077 | |
| Письмо | 27,484 | |
| Письмо | 5,034 | |
| Письмо | 155,085 | |
| Пластмассовая жизнь | 192,400 | |
| Пластмассовая жизнь | 68,877 | |
| Пластмассовая жизнь | 14,444 | |
| Пластмассовая жизнь | 11,484 | |
| Пластмассовая жизнь | 24,309 | |
| Пластмассовая жизнь | 16,830 | |
| Пластмассовая жизнь | 13,927 | |
| Пластмассовая жизнь | 46,060 | |
| Пластмассовая жизнь | 21,119 | |
| Под сурдинку | 24,391 | |
| Под сурдинку | 8,939 | |
| Подводная лодка | 35,205 | |
| Подводная лодка | 12,692 | |
| Подводная песня | 8,186 | |
| Пожар | 4,980 | |
| Пой мне еще | 352,400 | |
| Пой мне еще | 26,366 | |
| Пой мне ещё | 14,581 | |
| Пой мне ещё (правильный вид) | 52,675 | |
| Полная луна | 16,964 | |
| Полная луна | 10,235 | |
| Полная луна | 9,293 | |
| Помолчим немного | 10,021 | |
| Праздник | 13,277 | |
| Праздник | 9,366 | |
| Праздник | 5,475 | |
| Праздник | 1,279 | |
| Праздник (Другая точка зрения) | 10,877 | |
| Праздник (Другая точка зрения) | 6,623 | |
| Призрак | 3,409 | |
| Прирожденный убийца | 7,842 | |
| Приходи | 52,606 | |
| Приходи | 127,143 | |
| Пробки | 17,968 | |
| Пробки | 4,644 | |
| Прочь из моей головы | 238,310 | |
| Прочь из моей головы | 27,684 | |
| Прочь из моей головы | 21,808 | |
| Пурга-кочерга | 16,284 | |
| Пурга-кочерга | 2,139 | |
| Пурга-кочерга | 7,805 | |
| Пусть играет музыка | 8,973 | |
| Пусть играет музыка | 7,515 | |
| Пусть играет музыка | 5,359 | |
| Путь на восток | 10,397 | |
| Пыльная быль (Сказка) | 20,676 | |
| Пыльная быль (Сказка) | 13,358 | |
| Рай в шалаше | 93,731 | |
| Рай в шалаше | 27,312 | |
| Рай в шалаше | 18,937 | |
| Рай в шалаше | 9,987 | |
| Рай в шалаше | 10,015 | |
| Рай в шалаше | 12,193 | |
| Рай в шалаше | 195,301 | |
| Рай в шалаше | 8,128 | |
| Рай в шалаше | 13,914 | |
| Рики-тики-тави | 26,275 | |
| Рождество | 34,806 | |
| Романс | 152,464 | |
| Романс | 239,146 | |
| Романс | 1,690,595 | |
| Романс | 53,322 | |
| Романс | 28,958 | |
| Романс | 16,005 | |
| Романс | 20,573 | |
| Романс | 25,794 | |
| Романс (Мы будем счастливы теперь) | 33,037 | |
| Русский словарь (Давай, Лама, давай) | 28,085 | |
| Рыба без трусов | 38,440 | |
| Рыба без трусов | 13,351 | |
| РЭП (Нервное сердце) | 9,432 | |
| Самовар | 11,508 | |
| Самый первый снег (Три цвета) | 18,617 | |
| Самый первый снег (Три цвета) | 13,359 | |
| Самый первый снег (Три цвета) | 16,620 | |
| Санкт-Петербургское небо | 14,312 | |
| Санкт-Петербургское небо | 39,064 | |
| Свет горел всю ночь | 25,385 | |
| Свет горел всю ночь | 24,029 | |
| Свет горел всю ночь | 6,595 | |
| Свет горел всю ночь | 5,175 | |
| Северо-запад | 9,380 | |
| Северо-Запад | 2,945 | |
| Семь восьмых | 9,668 | |
| Семь восьмых | 22,756 | |
| Семь восьмых | 9,422 | |
| Сердце зимы | 3,705 | |
| Серебряные реки | 9,246 | |
| Сиануквилль | 16,079 | |
| Сиануквиль | 9,536 | |
| Сиануквиль | 13,506 | |
| Сиануквиль | 52,769 | |
| Симфония | 4,556 | |
| Скажи | 202,733 | |
| Скажи | 30,285 | |
| Сказка | 74,924 | |
| Сказочный леший | 8,404 | |
| Скоро будет солнечно | 71,409 | |
| Скоро будет солнечно | 13,692 | |
| Скоро будет солнечно | 19,708 | |
| Скоро будет солнечно | 2,408 | |
| Сломано все | 29,938 | |
| Сломано все | 5,270 | |
| Совсем другой | 30,536 | |
| Совсем другой | 12,879 | |
| Совсем другой | 8,503 | |
| Солнце взойдет | 10,104 | |
| Солнце взойдет | 24,121 | |
| Солнце взойдет | 22,182 | |
| Спи в заброшенном доме | 75,991 | |
| Спи в заброшенном доме | 10,888 | |
| Спи в заброшенном доме | 16,411 | |
| Спи в заброшенном доме | 10,542 | |
| Спи в заброшенном доме | 14,319 | |
| Спи в заброшеном доме | 7,260 | |
| Спи, дитя | 10,100 | |
| Среди зимы | 5,634 | |
| Старый дом | 8,581 | |
| Страшная тайна | 28,529 | |
| Страшная тайна | 9,921 | |
| Страшная тайна | 8,830 | |
| Страшная тайна | 1,741 | |
| Сумасшедший автобус | 8,546 | |
| Сумасшедший автобус | 5,925 | |
| Сумасшедший дом | 5,784 | |
| Сухари и сушки | 7,901 | |
| Сын | 11,228 | |
| Сын | 15,868 | |
| Тайком | 6,715 | |
| Танцуй | 46,562 | |
| Танцуй | 75,014 | |
| Танцуй | 663,196 | |
| Танцуй | 54,755 | |
| Твое разбитое пенсне | 7,740 | |
| Тебе это снится | 23,552 | |
| Тебе это снится | 41,241 | |
| Тебе это снится | 30,279 | |
| Тебе это снится (Special Version) | 1,120 | |
| Тепло родного дома | 36,475 | |
| Тепло родного дома | 23,197 | |
| Тепло родного дома | 82,142 | |
| Терпсихора | 22,532 | |
| Терпсихора | 14,681 | |
| Терпсихора | 8,279 | |
| Топай! | 38,591 | |
| Тревога | 12,595 | |
| Три цвета | 16,627 | |
| Три цвета (Первый снег) | 27,854 | |
| Увертюра | 5,548 | |
| Урок географии | 15,993 | |
| Урок географии | 42,153 | |
| Фаза | 3,148 | |
| Феллини | 30,369 | |
| Феллини | 236,616 | |
| Феллини | 84,255 | |
| Феллини | 18,171 | |
| Феллини | 16,283 | |
| Феллини | 18,057 | |
| Феллини | 12,985 | |
| Феллини | 12,232 | |
| Фибоначчи | 6,754 | |
| Фильм ужасов | 2,758 | |
| Фюрер, фюрер | 8,689 | |
| Фюрер, фюрер | 13,254 | |
| Холодные зимы | 16,860 | |
| Храм | 36,040 | |
| Храм | 13,500 | |
| Храм | 235,557 | |
| Храм | 10,743 | |
| Храм | 20,744 | |
| Храм | 10,113 | |
| Частушки | 33,715 | |
| Человек и дерево | 6,029 | |
| Человек не спал | 7,477 | |
| Человек, что продал мир | 25,342 | |
| Чердак | 20,303 | |
| Черная волга | 94,015 | |
| Черный цвет солнца | 20,611 | |
| Чёрный цвет солнца | 11,251 | |
| Чёрный цвет солнца | 9,638 | |
| Черный цвет солнца | 62,316 | |
| Что ты будешь делать | 68,206 | |
| Что ты будешь делать? | 28,288 | |
| Чудак | 40,986 | |
| Чудак | 228,213 | |
| Чудак | 30,392 | |
| Шаман | 11,858 | |
| Шато Марго | 42,551 | |
| Шато-Марго | 9,307 | |
| Шахматы | 11,523 | |
| Шпионы | 3,711 | |
| Я был влюблён в Вас | 80,367 | |
| Я должен успеть | 14,126 | |
| Я должен успеть | 7,195 | |
| Я должен успеть (Кто-то не успел) | 10,483 | |
| Я не хочу домой | 17,772 | |
| Я не хочу домой | 10,776 | |
| Яблоко | 2,773 |
10 популярных кодов и шифров
Коды и шифры — не одно и то же: в коде каждое слово заменяется другим, в то время как в шифре заменяются все символы сообщения.
В данной статье мы рассмотрим наиболее популярные способы шифрования, а следующим шагом будет изучение основ криптографии.
- Стандартные шифры
- Цифровые шифры
- Как расшифровать код или шифр?
Стандартные шифры
ROT1
Этот шифр известен многим детям. Ключ прост: каждая буква заменяется на следующую за ней в алфавите. Так, А заменяется на Б, Б — на В, и т. д. Фраза «Уйрйшоьк Рспдсбннйту» — это «Типичный Программист».
Попробуйте расшифровать сообщение:
Лбл еёмб, рспдсбннйту?
Сумели? Напишите в комментариях, что у вас получилось.
Шифр транспонирования
В транспозиционном шифре буквы переставляются по заранее определённому правилу. Например, если каждое слово пишется задом наперед, то из hello world получается dlrow olleh. Другой пример — менять местами каждые две буквы. Таким образом, предыдущее сообщение станет eh ll wo ro dl.
Ещё можно использовать столбчатый шифр транспонирования, в котором каждый символ написан горизонтально с заданной шириной алфавита, а шифр создаётся из символов по вертикали.
Из этого способа мы получим шифр holewdlo lr. А вот столбчатая транспозиция, реализованная программно:
def split_len(seq, length):
return [seq[i:i + length] for i in range(0, len(seq), length)]
def encode(key, plaintext):
order = {
int(val): num for num, val in enumerate(key)
}
ciphertext = ''
for index in sorted(order.keys()):
for part in split_len(plaintext, len(key)):
try:ciphertext += part[order[index]]
except IndexError:
continue
return ciphertext
print(encode('3214', 'HELLO'))Азбука Морзе
В азбуке Морзе каждая буква алфавита, цифры и наиболее важные знаки препинания имеют свой код, состоящий из череды коротких и длинных сигналов:
Чаще всего это шифрование передаётся световыми или звуковыми сигналами.
Сможете расшифровать сообщение, используя картинку?
•−− −•− −−− −• −•−• • ••• − •− − −••− •• • ••• − −••− −•• • −−−− •• ••−• •−• •− − −−− •−• −•−−
Шифр Цезаря
Это не один шифр, а целых 26, использующих один принцип. Так, ROT1 — лишь один из вариантов шифра Цезаря. Получателю нужно просто сообщить, какой шаг использовался при шифровании: если ROT2, тогда А заменяется на В, Б на Г и т. д.
Так, ROT1 — лишь один из вариантов шифра Цезаря. Получателю нужно просто сообщить, какой шаг использовался при шифровании: если ROT2, тогда А заменяется на В, Б на Г и т. д.
А здесь использован шифр Цезаря с шагом 5:
Иербэй йюк ёурбэй нтчйхйцтаъ энщхуж
Моноалфавитная замена
Коды и шифры также делятся на подгруппы. Например, ROT1, азбука Морзе, шифр Цезаря относятся к моноалфавитной замене: каждая буква заменяется на одну и только одну букву или символ. Такие шифры очень легко расшифровываются с помощью частотного анализа.
Например, наиболее часто встречающаяся буква в английском алфавите — «E». Таким образом, в тексте, зашифрованном моноалфавитным шрифтом, наиболее часто встречающейся буквой будет буква, соответствующая «E». Вторая наиболее часто встречающаяся буква — это «T», а третья — «А».
Однако этот принцип работает только для длинных сообщений. Короткие просто не содержат в себе достаточно слов.
Шифр Виженера
Представим, что есть таблица по типу той, что на картинке, и ключевое слово «CHAIR». Шифр Виженера использует принцип шифра Цезаря, только каждая буква меняется в соответствии с кодовым словом.
Шифр Виженера использует принцип шифра Цезаря, только каждая буква меняется в соответствии с кодовым словом.
В нашем случае первая буква послания будет зашифрована согласно шифровальному алфавиту для первой буквы кодового слова «С», вторая буква — для «H», etc. Если послание длиннее кодового слова, то для (k*n+1)-ой буквы, где n — длина кодового слова, вновь будет использован алфавит для первой буквы кодового слова.
Чтобы расшифровать шифр Виженера, для начала угадывают длину кодового слова и применяют частотный анализ к каждой n-ной букве послания.
Попробуйте расшифровать эту фразу самостоятельно:
зюм иэлруй южжуглёнъ
Подсказка длина кодового слова — 4.
Шифр Энигмы
Энигма — это машина, которая использовалась нацистами во времена Второй Мировой для шифрования сообщений.
Есть несколько колёс и клавиатура. На экране оператору показывалась буква, которой шифровалась соответствующая буква на клавиатуре. То, какой будет зашифрованная буква, зависело от начальной конфигурации колес.
То, какой будет зашифрованная буква, зависело от начальной конфигурации колес.
Существовало более ста триллионов возможных комбинаций колёс, и со временем набора текста колеса сдвигались сами, так что шифр менялся на протяжении всего сообщения.
Цифровые шифры
В отличие от шифровки текста алфавитом и символами, здесь используются цифры. Рассказываем о способах и о том, как расшифровать цифровой код.
Двоичный код
Текстовые данные вполне можно хранить и передавать в двоичном коде. В этом случае по таблице символов (чаще всего ASCII) каждое простое число из предыдущего шага сопоставляется с буквой: 01100001 = 97 = «a», 01100010 = 98 = «b», etc. При этом важно соблюдение регистра.
Расшифруйте следующее сообщение, в котором использована кириллица:
110100001001101011010000101111101101000010110100
Шифр A1Z26
Это простая подстановка, где каждая буква заменена её порядковым номером в алфавите. Только нижний регистр.
Попробуйте определить, что здесь написано:
15-6-2-16-13-30-26-16-11 17-18-10-14-6-18
Шифрование публичным ключом
Алгоритм шифрования, применяющийся сегодня буквально во всех компьютерных системах. Есть два ключа: открытый и секретный. Открытый ключ — это большое число, имеющее только два делителя, помимо единицы и самого себя. Эти два делителя являются секретным ключом, и при перемножении дают публичный ключ. Например, публичный ключ — это 1961, а секретный — 37 и 53.
Есть два ключа: открытый и секретный. Открытый ключ — это большое число, имеющее только два делителя, помимо единицы и самого себя. Эти два делителя являются секретным ключом, и при перемножении дают публичный ключ. Например, публичный ключ — это 1961, а секретный — 37 и 53.
Открытый ключ используется, чтобы зашифровать сообщение, а секретный — чтобы расшифровать.
Как-то RSA выделила 1000 $ в качестве приза тому, кто найдет два пятидесятизначных делителя числа:
1522605027922533360535618378132637429718068114961380688657908494580122963258952897654000350692006139
Как расшифровать код или шифр?
Для этого применяются специальные сервисы. Выбор такого инструмента зависит от того, что за код предстоит расшифровать. Примеры шифраторов и дешифраторов:
- Азбука Морзе
- RSA (криптографический алгоритм с открытым ключом)
- Двоичный код
- Другие онлайн-дешифраторы
Адаптированный перевод «10 codes and ciphers»
Переводчик азбуки Морзе — Азбука Морзе перевод
Параметры
Скрыть параметры
Азбука Морзе СОС
Остановить Азбука Морзе СОС
Азбука Морзе алфавит
Кириллица
| А | . — — | Б | -… | В | .— | Г | —. | Д | -.. | Е | . |
| Ж | …- | З | —.. | И | .. | Й | .— | К | -.- | Л | .-.. |
| М | — | Н | -. | О | — | П | .—. | Р | .-. | С | … |
| Т | — | У | ..- | Ф | ..-. | Х | …. | Ц | -.-. | Ч | —. |
| Ш | —- | Щ | —.- | Ъ | —.— | Ы | -.— | Ь | -..- | Э | ..-.. |
| Ю | ..— | Я | .-.- | Ї | .—. | Є | ..-.. | І | .. | Ґ | —. |
Число
| 0 | —— | 1 | .—- | 2 | ..— | 3 | …— | 4 | … .- .- | 5 | ….. |
| 6 | -…. | 7 | —… | 8 | —.. | 9 | —-. |
Пунктуация
| . | .-.-.- | , | —..— | ? | ..—.. | ‘ | .—-. | ! | -.-.— | / | -..-. |
| ( | -.—. | ) | -.—.- | & | .-… | : | —… | ; | -.-.-. | = | -…- |
| + | .-.-. | — | -….- | _ | ..—.- | « | .-..-. | $ | …-..- | @ | .—.-. |
| ¿ | ..-.- | ¡ | —…- |
Что такое азбука Морзе?
Азбука Морзе — это способ кодирования символов, позволяющий операторам отправлять сообщения, используя серию длинных и коротких электрические сигналы или, другими словами, используя точки и тире.
Кто изобрел азбуку Морзе?
Изобретателями азбуки Морзе считаются Сэмюэл Ф. Б. Морзе и его помощник Альфред Вейл.
Б. Морзе и его помощник Альфред Вейл.
Когда была изобретена азбука Морзе?
Азбука Морзе была разработана в 1830-х годах, а в 1840-х годах — усовершенствована.
Какое первое сообщение было отправлено с помощью азбуки Морзе?
Первое официальное сообщение было таким: «What hath God wrought» (на русском: Чудны дела Твои, Господи!). Его отправил Сэмюэл Ф. Б. Морзе 24 мая 1844 года при открытии телеграфной линии Балтимор — Вашингтон.
Для чего используется азбука Морзе?
В прошлом азбука Морзе применялась очень широко, особенно в армии. Сегодня азбука Морзе имеет ограниченную область применения, но она всё еще используется в авиации, в среде радиолюбителей и в качестве вспомогательной технологии для людей с ограниченными физическими возможностями.
Как использовать азбуку Морзе?
Код Морзе можно использовать различными способами, например, с помощью ручки и бумаги, с помощью света и звука или даже с помощью глаз или пальцев.
Как учить азбуку Морзе?
Вы можете изучить азбуку Морзе, слушая аудиозаписи с кодом, а также применяя методы запоминания слов, которые можно найти на различных сайтах. Одним из лучших методов обучения азбуке Морзе в 2022 году стала клавиатура Gboard от компании Google. Вы можете заниматься онлайн бесплатно с помощью упражнений для изучения кода Морзе, предоставляемых лабораторией Google Creative Lab.
Одним из лучших методов обучения азбуке Морзе в 2022 году стала клавиатура Gboard от компании Google. Вы можете заниматься онлайн бесплатно с помощью упражнений для изучения кода Морзе, предоставляемых лабораторией Google Creative Lab.
Как читать код Морзе?
Если вам не хватает опыта в чтении кода Морзе, вы можете найти соответствующие коду символы в таблице с азбукой Морзе, или просто использовать переводчик азбуки Морзе.
Как перевести код Морзе?
Если вы хотите перевести или расшифровать код Морзе и не умеете его читать, то можете просто использовать переводчик азбуки Морзе онлайн. С помощью переводчика азбуки Морзе вы можете легко расшифровать код и прочитать текст на русском языке.
Что такое переводчик азбуки Морзе?
Переводчик азбуки Морзе позволяет любому человеку переводить код Морзе в текст и легко декодировать сообщение, записанное кодом. С помощью онлайн-переводчика кода Морзе любой человек может перевести простой текст на русском или другом языке в код Морзе и наоборот. Помните ли вы мелодию SMS-сигнала Nokia? Если хотите испытать ностальгию, попробуйте расшифровать код «… — …», а затем воспроизвести звук. Что если вам потребуется расшифровать секретное сообщение на азбуке Морзе или вы наткнетесь в игре на пасхальное яйцо с кодом? Переводчик азбуки Морзе к вашим услугам 7/24, если у вас есть интернет-соединение и желание выучить азбуку Морзе.
Помните ли вы мелодию SMS-сигнала Nokia? Если хотите испытать ностальгию, попробуйте расшифровать код «… — …», а затем воспроизвести звук. Что если вам потребуется расшифровать секретное сообщение на азбуке Морзе или вы наткнетесь в игре на пасхальное яйцо с кодом? Переводчик азбуки Морзе к вашим услугам 7/24, если у вас есть интернет-соединение и желание выучить азбуку Морзе.
Как будет СОС на азбуке Морзе?
СОС на азбуке Морзе выглядит так: «… — …»
Как будет «Я люблю тебя» на азбуке Морзе?
«Я люблю тебя» на азбуке Морзе: «.-.- / .-.. ..— -… .-.. ..— / — . -… .-.-»
Переводите аудио в текст — автоматическое транскрибирование и перевод — VEED.IO
Транскрибируйте ваши аудио файлы в текст. Автоматический перевод на любой язык.
НачатьПеревод аудио в текст
Хотите перевести аудио или голосовые заметки в текст? Теперь Вы можете сделать это и многое другое с помощью простого аудиопереводчика VEED! Транскрибируйте голосовые записи, подкасты, выступления, диалоги и многое другое. Мощный звуковой переводчик VEED может автоматически определить любой язык в ваших аудиофайлах (mp3, wav, m4a и др.) и транскрибировать его в текст одним нажатием мыши! Просто загрузите свой файл, перейдите в «Субтитры» и мгновенно транскрибируйте аудио в текст. Не стесняйтесь редактировать и перефразировать транскрипцию, когда она будет готова. Используйте аудио переводчик VEED, чтобы ускорить переход от распознавания речи к транскрипции. Наш сервис транскрипции работает онлайн, автоматически. Нет необходимости в ручной печати. Не нужно полагаться на Google переводчика. С VEED транскрипция и перевод никогда не были проще.
Мощный звуковой переводчик VEED может автоматически определить любой язык в ваших аудиофайлах (mp3, wav, m4a и др.) и транскрибировать его в текст одним нажатием мыши! Просто загрузите свой файл, перейдите в «Субтитры» и мгновенно транскрибируйте аудио в текст. Не стесняйтесь редактировать и перефразировать транскрипцию, когда она будет готова. Используйте аудио переводчик VEED, чтобы ускорить переход от распознавания речи к транскрипции. Наш сервис транскрипции работает онлайн, автоматически. Нет необходимости в ручной печати. Не нужно полагаться на Google переводчика. С VEED транскрипция и перевод никогда не были проще.
Различные форматы. VEED позволяет сохранять транскрипцию в виде текста (.txt) и SRT (.srt), чтобы упростить ее совместное использование и открытие на разных платформах. Загружайте аудио или видео файлы в любом формате. И это еще не все — VEED может перевести Ваш текст более чем на 100 языков!
Как автоматически перевести аудио в текст:
Загрузите видео
Загрузите аудио (или видео), которое Вы хотите транскрибировать, просто перетащите на VEED —это очень просто.
Транскрибируйте
Нажмите «Субтитры» > «Авто Транскрипция». Выберите язык для распознавания. Нажмите «Начать», и ваша транскрипция появится автоматически.
Переведите
Просто нажмите «Настройки» и выберите, на какой язык перевести скрипт. Или оставьте на языке оригинала. Когда Вы закончили, выберите «Загрузить .txt».
Инструкция «Как перевести аудио в текст»
Быстро, автоматически и точно
С VEED Вы можете транскрибировать видео за считанные секунды. Один щелчок, несколько нажатий на клавиатуру, — и Ваша транскрипция готова к работе! Наша программа для распознавания речи автоматически расшифрует Ваше видео, сэкономив Вам часы на ручном транскрибировании. Точность автоматической транскрипции VEED – одна из лучших в своем классе, и является фаворитом для создателей видео, которые ищут транскрипцию «на ходу». Для 100% точности просто отредактируйте и переформулируйте текст. Кроме того, благодаря нашему программному обеспечению распознавания речи на основе искусственного интеллекта не будет отображаться слишком много текста! И, если у Вас когда-нибудь возникнут трудности, просто обратитесь к нам в чат, и мы будем рады помочь! Больше не нужно тратить драгоценное время на ручной ввод транскрипцию и перевод. VEED сделает все это быстрее, чем когда-либо.
VEED сделает все это быстрее, чем когда-либо.
Подкасты, выступления и интервью
Аудио Переводчик VEED может транскрибировать широкий спектр аудиоконтента — выступления TED, подкасты для Spotify, интервью, выступления и многое другое. Наличие текстовой версии аудио- или видеоконтента делает его более доступным для разных аудиторий, включая глухих, слабослышащих или тех, кто просматривает Ваш контент в общественном месте. Создание транскрипции позволяет переформулировать аудио- или видеоконтент в блоги и статьи. Вы также можете редактировать для краткости, ясности и в случаях неправильного произношения. Это займет всего минуту, но для такого количества людей это действительно необходимо!
Иностранные языки
Хотите представить свой контент не англоязычной аудитории? С VEED перевод аудио еще никогда не был таким простым! VEED может перевести Ваше аудио на более чем 100 языков — китайский, голландский, немецкий, испанский, американский английский, британский английский и многие другие — выбор за Вами! Более того,, Вы также можете выбрать свой английский акцент и переводить с разных акцентов! С испанского на английский? От солнечного австралийца до британца старой школы? Что бы это ни было, предоставьте это мощному инструменту транскрибирования VEED. Используйте VEED, чтобы сделать Ваш контент приятным для любого уголка земного шара.
Используйте VEED, чтобы сделать Ваш контент приятным для любого уголка земного шара.
Часто Задаваемые Вопросы
Что говорят про VEED
Больше, чем переводчик аудио!
Наш аудио переводчик — лишь один из многих инструментов, которые Вы можете использовать на VEED. Вы можете создавать свои собственные титры, GIF-файлы, видео-гайды, музыкальные ремиксы, — вариантов множество! Используйте VEED для редактирования видео, добавления фоновой музыки, стикеров, индикаторов выполнения и многого другого. Или просто вырезайте, разделяйте и сжимайте видео для более быстрого рендеринга. VEED — это браузерный инструмент, который помогает таким создателям, как Вы, производить привлекательный контент для своих подписчиков. Мы создали VEED, чтобы Вы могли сосредоточиться на создании впечатляющего контента, не тратя время и энергию на сложные программы. Неважно, новичок Вы в редактировании видео или профессионал, VEED — это понятный инструмент, который сделает Вашу работу всего за несколько кликов.
Главный альбом года, возможно, вышел уже в феврале. Его записала 37-летняя Кэролайн Полачек Певицу называют «новой Кейт Буш» — хотя ей самой это не нравится
Кэролайн Полачек
Jason Kempin / Getty Images
В текстах и разговорах о Кэролайн Полачек нередко употребляется выражение «sleeper hit». То есть песня, которая вроде бы не должна была стать популярной и поначалу не стала, но сделала для музыкального процесса что-то значительное и через некоторое время после выхода все-таки получила признание. Это описание отчасти применимо ко всей карьере Полачек: музыке певица, которой в этом году будет 38, посвятила всю жизнь, но по-настоящему громким стал лишь вышедший 14 февраля этого года альбом «Desire, I Want to Turn Into You» — всего второй под ее именем. Рейтинг записи на сайте — агрегаторе рецензий Metacritic — 95, на редкость высокий. Почему Полачек теперь называют «Кейт Буш этого поколения», притом что сама она от таких сравнений открещивается?
Япония, кони и айподКэролайн Полачек родилась на Манхэттене, но раннее детство провела в Токио, куда переехали родители из-за работы. Что-то японское, минорное, навсегда засело в подсознании певицы.
Что-то японское, минорное, навсегда засело в подсознании певицы.
Ее отец Джеймс, всю жизнь боровшийся с биполярным расстройством и депрессией, был не только финансовым аналитиком, но и классическим пианистом и скрипачом, а также ученым-китаистом, работавшим в Принстоне и Колумбийском университете. Чтобы маленькая Кэролайн, которая очень любила петь, вдобавок не стучала по фортепиано, Джеймс подарил ей синтезатор Yamaha. Когда Полачек было семь, семья переехала в Коннектикут, где обожавшая лошадей Кэролайн училась верховой езде — благодаря этому у нее развилось чувство ритма. Когда ей было девять, родители развелись.
В 17 Полачек пела одновременно то ли в четырех, то ли в пяти хорах. И еще в группе а капелла. И еще в двух ню-метал-группах. В то же время Полачек долго не верила, что музыка может стать основой ее жизни. Хотя со стороны казалось, что она очень быстро добилась успеха. Уже в 2008 году песня «Bruises» инди-поп-группы Chairlift, где была солисткой Кэролайн, попала в рекламу плеера iPod Nano четвертого поколения — в тот момент Полачек сдавала выпускные экзамены. Следующий альбом Chairlift, «Something» 2012 года, приняли очень хорошо, и группа объехала с концертами весь мир (заезжала даже в Москву).
Следующий альбом Chairlift, «Something» 2012 года, приняли очень хорошо, и группа объехала с концертами весь мир (заезжала даже в Москву).
Кэролайн Полачек в составе трио Chairlift
Wendy Redfern / Redferns / Getty Images
В 2013 году Полачек поработала над песней Бейонсе «No Angel», но не стремилась уйти с головой в коммерцию — и в 2014-м выпустила сольный альбом «пасторальной электроники» под именем Ramona Lisa.
Все это время она, по собственному признанию, жила с «чувством отстраненного неверия» — и только недавно приняла, что собирается заниматься музыкой всю жизнь.
Свое имяВ 2015 году Полачек нашла нового музыкального партнера — Дэнни Л. Харла, одного из ранних участников экспериментально-футуристичного поп-лейбла PC Music. С Харлом они «по-братски и по-сестрински, иногда очень жестко, выводили друг друга из зоны комфорта» — так Полачек «очеловечила» его киберэмоциональную композицию «Ashes of Love».
2017 год стал в жизни Полачек рубежным.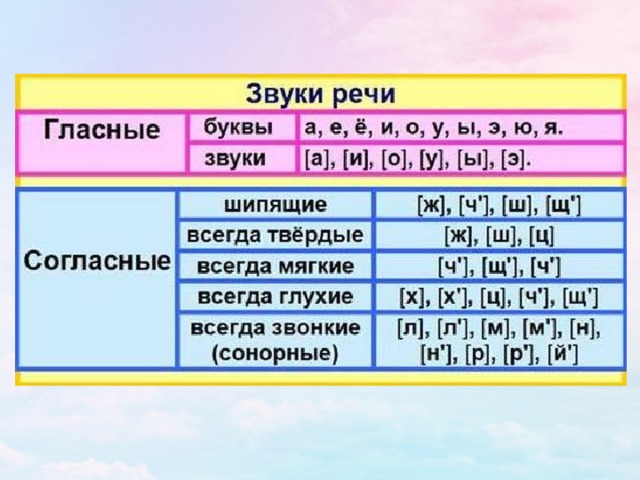 Во-первых, Chairlift, еще между первым и вторым альбомом превратившиеся из трио в дуэт, мирно распались. Во-вторых, Полачек пережила развод. В-третьих, выпустила инструментальный альбом «Drawing The Target Around The Arrow» под инициалами CEP. В-четвертых — и это главное, — вдохновленная работой с Харлом, задумала сольную пластинку, в итоге названную «Pang» по «загадочным всплескам адреналина и приступам бессонницы». По меткому выражению авторов издания RA, «Pang» — запись о том, как «выйти из кокона расставания и найти новое головокружительное счастье».
Во-первых, Chairlift, еще между первым и вторым альбомом превратившиеся из трио в дуэт, мирно распались. Во-вторых, Полачек пережила развод. В-третьих, выпустила инструментальный альбом «Drawing The Target Around The Arrow» под инициалами CEP. В-четвертых — и это главное, — вдохновленная работой с Харлом, задумала сольную пластинку, в итоге названную «Pang» по «загадочным всплескам адреналина и приступам бессонницы». По меткому выражению авторов издания RA, «Pang» — запись о том, как «выйти из кокона расставания и найти новое головокружительное счастье».
Полачек тогда уже было 30 с лишним — и впервые выпускать альбом под своим именем казалось рискованным, но ей очень нравилась получавшаяся с Харлом музыка. «Pang» вышел в 2019-м, и на 2020-й у Полачек были планы выступить на крупнейших в карьере фестивалях «Гластонбери» и Primavera. Все отменила пандемия.
Ее Полачек застала в Лондоне. Отец, с которым они долго не общались и вновь начали разговаривать, когда Полачек было уже под 30, и который никогда не ходил ни на один ее концерт, был в США. В апреле 2020-го он заболел ковидом и умер от осложнений. Прощание с ним по фейстайму Полачек называет одним из самых болезненных событий в жизни.
В апреле 2020-го он заболел ковидом и умер от осложнений. Прощание с ним по фейстайму Полачек называет одним из самых болезненных событий в жизни.
Она долго ничего не писала, потом сбежала в красоту Средиземноморья, попутешествовав по Италии и Испании, а одновременно вдохновлялась «раскрепощающей» ролью женщин в фильмах Педро Альмодовара — все это нашло отражение в ее новом альбоме, который начинается с почти полуминутного воя Кэролайн.
Остров сокровищПервая, заглавная и открывающая пластинку песня «Welcome to My Island» не подошла для «Pang», зато задала тон всей новой записи. Полачек то ли зовет на свой остров, то ли хочет удостовериться, что на нем никого нет, то ли, по красивой теории, приветствует, будто Калипсо, Одиссея. А еще читает речитатив, начиная со слов: «Я дочь своего отца, в конце концов». Впрочем, сама Полачек не любит буквализма и верит, что во всем искусстве важно неназываемое. «Я ищу что-то, что никто не может увидеть» — это строчка из седьмой песни альбома, «Fly to You», записанной с Граймс и Дайдо, героиней детства Полачек.
Caroline Polachek — Welcome To My Island [Official Music Video]
Caroline Polachek
Раньше Полачек на недели запиралась в студии, но «Welcome to My Island» — гораздо более «экстравертный» альбом, на котором она «играет с бессмыслицей и абстракцией», — записывался короткими промежутками во время поездок, в том числе в турне с Дуа Липой. Эти вспышки творчества тщательно организованы — и фантазийная одиссея Полачек на редкость изысканно детализирована. Полачек не только сама монтирует видео и курирует все, что касается дизайна, но и может, по словам Харла, по полтора часа слушать один такт хай-хэта, «маниакально покачивая головой».
Каждая песня на «Desire, I Want to Turn Into You» — звуковой мир в себе, и, хотя альбом таит удивительное разнообразие, Полачек зачаровывает единой эстетикой и сцепляет все потрясающим вокалом (не зря же она столько лет училась бельканто). Вот фламенко в «Sunset», вот гэридж в посвященной ее покойной подруге Софи «I Believe» с рефреном «Загляни за край, но не слишком далеко», вот брейкбит в той же «Fly to You», а вот трип-хоповая поступь в «Crude Drawing of an Angel» — и еще повсюду акустическая гитара.
Caroline Polachek — Sunset [Official Music Video]
Caroline Polachek
Единственная возможная претензия — что приемы Полачек, в общем, проверены и не новы: «Desire…» — это во многом дань музыке девяностых. В припеве «I Believe» сигналит будто бы тот же синтезатор, что в великой «Youʼre Not Alone» Olive; блип-клавиши в «Blood and Butter» напоминают о приемах Уильяма Орбита со знакового альбома Мадонны «Ray of Light», которому на днях исполнилось 25 лет; «Pretty in Possible» отзовется поклонникам «Unfinished Sympathy» Massive Attack. Но прежде всего альбом Полачек — сокровищница мелодий: что в величественных треках вроде «Hopedrunk Everasking» с переходящим в эфемерность вокалом, что в более радийных хитах вроде «Bunny Is a Rider», названной Pitchfork лучшей песней 2021-го.
В припеве «I Believe» сигналит будто бы тот же синтезатор, что в великой «Youʼre Not Alone» Olive; блип-клавиши в «Blood and Butter» напоминают о приемах Уильяма Орбита со знакового альбома Мадонны «Ray of Light», которому на днях исполнилось 25 лет; «Pretty in Possible» отзовется поклонникам «Unfinished Sympathy» Massive Attack. Но прежде всего альбом Полачек — сокровищница мелодий: что в величественных треках вроде «Hopedrunk Everasking» с переходящим в эфемерность вокалом, что в более радийных хитах вроде «Bunny Is a Rider», названной Pitchfork лучшей песней 2021-го.
Вокруг творчества Полачек и правда рождается много сравнений: и с Кейт Буш, и с Мадонной, и с Cocteau Twins. «Я такая нефизическая», — воспевает Кэролайн в «Bunny Is a Rider» ту же нематериальность, что и Софи на альбоме «Oil of Every Pearlʼs Un-Insides», где довела эстетику электронного композиторства до совершенства. «Desire…» — идеал из того же мира: лучше, кажется, не напишешь. Главный фокус, который проделала Полачек и не проделал больше никто (разве что та же Буш, чья «Running Up That Hill» попала в саундтрек «Очень странных дел»), — это соединение в атомизированном обществе и миллениалов, следящих за ней с Chairlift, и зумеров, открывающих Полачек благодаря тиктоку, где у нее больше миллиона лайков. Все хотят сбежать на ее остров — на 45 минут, которые, впрочем, можно повторить еще, и еще, и еще раз. И потом с этого острова уже не выбраться.
Все хотят сбежать на ее остров — на 45 минут, которые, впрочем, можно повторить еще, и еще, и еще раз. И потом с этого острова уже не выбраться.
«Медуза»
Переводчик азбуки Морзе онлайн
- Главная
- Инструменты
- Работа с текстом
- Переводчик азбуки Морзе онлайн
Азбука Морзе — код Морзе, «Морзянка» — способ кодирования букв алфавита, цифр, знаков препинания и других символов при помощи длинных и коротких сигналов, так называемых «тире» и «точек» (а также пауз, разделяющих буквы).
За единицу времени принимается длительность одной точки. Длительность тире равна трём точкам. Пауза между знаками в букве — одна точка, между буквами в слове — 3 точки, между словами — 7 точек.
На этой странице Вы можете бесплатно воспользоваться сервисом для конвертерования текста в Азбуку Морзе или наоборот.
| Русский символ | Латинский символ | Код |
|---|---|---|
| А | A | •− |
| Б | B | −••• |
| В | W | •−− |
| Г | G | −−• |
| Д | D | −•• |
| Е и Ё | E | • |
| Ж | V | •••− |
| З | Z | −−•• |
| И | I | •• |
| Й | J | •−−− |
| К | K | −•− |
| Л | L | •−•• |
| М | M | −− |
| Н | N | −• |
| О | O | −−− |
| П | P | •−−• |
| Р | R | •−• |
| С | S | ••• |
| Т | T | − |
| У | U | ••− |
| Ф | F | ••−• |
| Х | H | •••• |
| Ц | C | −•−• |
| Ч | Ö | −−−• |
| Ш | CH | −−−− |
| Щ | Q | −−•− |
| Ъ | Ñ | −−•−− |
| Ы | Y | −•−− |
| Ь | X | −••− |
| Э | É | ••−•• |
| Ю | Ü | ••−− |
| Я | Ä | •−•− |
| Русский символ | Латинский символ | Код Морзе |
|---|---|---|
| 1 | •−−−− | |
| 2 | ••−−− | |
| 3 | •••−− | |
| 4 | ••••− | |
| 5 | ••••• | |
| 6 | −•••• | |
| 7 | −−••• | |
| 8 | −−−•• | |
| 9 | −−−−• | |
| 0 | −−−−− | |
. | •••••• | |
| , | . | •−•−•− |
| ! | , | −−••−− |
| ! | −•−•−− | |
| ? | ••−−•• | |
| ‘ | •−−−−• | |
| « | •−••−• | |
| ; | −•−•−• | |
| : | −−−••• | |
| — | −••••− | |
| + | •−•−• | |
| = | −•••− | |
| _ (подчёркивание) | ••−−•− | |
| / | −••−• | |
| ( | −•−−• | |
| ( или ) | ) | −•−−•− |
| & | •−••• | |
| $ | •••−••− | |
| @ | •−−•−• | |
| Ошибка | Error | •••••••• |
| Конец связи | End contact | ••−•− |
P. S. Следует отметить, что хотя русская азбука Морзе частично совпадает с латинской, но всё же есть некоторые отличия (сравнивал на русской и английской страницах Википедии — там же можно посмотреть таблицы кодов). Например:
S. Следует отметить, что хотя русская азбука Морзе частично совпадает с латинской, но всё же есть некоторые отличия (сравнивал на русской и английской страницах Википедии — там же можно посмотреть таблицы кодов). Например:
- символ «точка» в русском варианте: · · · · · · , а в латинском: · – · – · –
- запятая в русском: · − · − · − , а в латинском: – – · · – –
- восклицательный знак в русском: − − · · − − , а в латинском: – · – · – –
- открывающая скобка в латинском: – · – – · , а закрывающая – · – – · – , а в русском обе скобки одинаковые: – · – – · –
- некоторые символы вроде & + _ $ есть только в латинском варианте
Поэтому при спорных моментах, например, конвертировать код − − · · − − в восклицательный знак (по-русской версии) или в запятую (по латинской), предпочтение отдаётся русской версии, поскольку раз Вы читаете это сообщение на русском, то предполагается, что для Вас важнее именно русский вариант.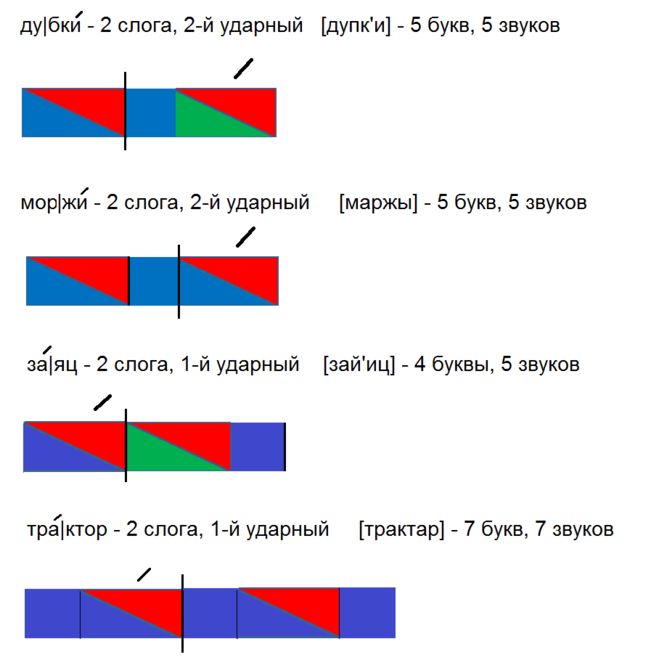
Чтобы произвести расчеты, необходимо разрешить элементы ActiveX!
Работа с текстом Инструмент Текст 6161113
Существует множество вариантов расшифровок сигнала бедствия SOS — «Save Our Souls», «Save Our Ship», «Swim Or Sink», «Stop Other Signals», «Спасите От Смерти». Но все они являются лишь мнемониками, придуманными для лучшего запоминания, тогда как во время принятия этого сигнала в качестве стандартного на Международной радиотелеграфной конференции 1906 года никакого смысла в аббревиатуру не закладывалось. Даже сами буквы SOS к последовательности азбуки Морзе (. . . — — — . . .) можно отнести весьма условно, ведь в ней нет межбуквенных интервалов. А приняли эту комбинацию точек и тире из-за того, что она оказалась удобнее других для распознавания и выделения в общем потоке сигналов благодаря достаточной длине и симметричности.
Сэмюэл Морзе до 34 лет был художником и не интересовался техникой.
 В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.
В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.Азбуку Морзе в привычном нам виде изобрёл не Морзе, а немецкий инженер Герке. Оригинальная азбука Морзе была неудобной, хотя и использовалась на некоторых американских железных дорогах вплоть до 1960-х годов.
6 февраля 1900 года расположенная в финском городе Котка радиостанция передала на ледокол «Ермак» беспроводную телеграмму с приказом спасти находящихся на оторвавшейся льдине 50 рыбаков. Это была первая в истории передача радиосигнала о бедствии на море. Спасательная операция завершилась успешно.
Современные субмарины оснащены более эффективными средствами коммуникации с «наземным миром». Связь ведется на сверхдлинных волнах, которые способны проникать на океанскую глубину до 300 метров. Это очень дорогостоящая «мобильная связь», которая требует содержания мощных наземных антенных полей, потребляющих мощность до 30 МВт, и постоянно барражирующих в небе связных самолетов.
Сигнал SOS передается на частоте 600 метров лишь в случае крайней необходимости, когда экипажу судна и пассажирам угрожает реальная опасность для жизни. В случае нарушения этого правила на виновников необоснованной паники может быть наложено взыскание. Либо моральное, что в морском сообществе не пустой звук. Либо материальное — когда пришедшие на помощь суда понесут значительные материальные потери. Однако существует исключение из этого непреложного правила. Капитан судна в некоторых случаях может передавать на «сосовой частоте» в три фиксированных «минуты молчания» информацию о возникновении серьезной угрозы для находящихся в регионе кораблей.
Это могут быть сообщения о неисправности маяков, о вулканической деятельности, об активности пиратов, о затонувших судах…Для ускорения радиообмена в широкое использование были введены аббревиатуры, трёхбуквенные «Q-коды» и многочисленные жаргонные выражения. От того передается Q код в виде вопроса или утверждения, меняется его значение. В голосовой связи сигнал SOS не применяется, сигналом бедствия служит Mayday. Запрещено подавать сигнал SOS, если на то нет реальной угрозы для жизни людей или судна на море.
 В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.
В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.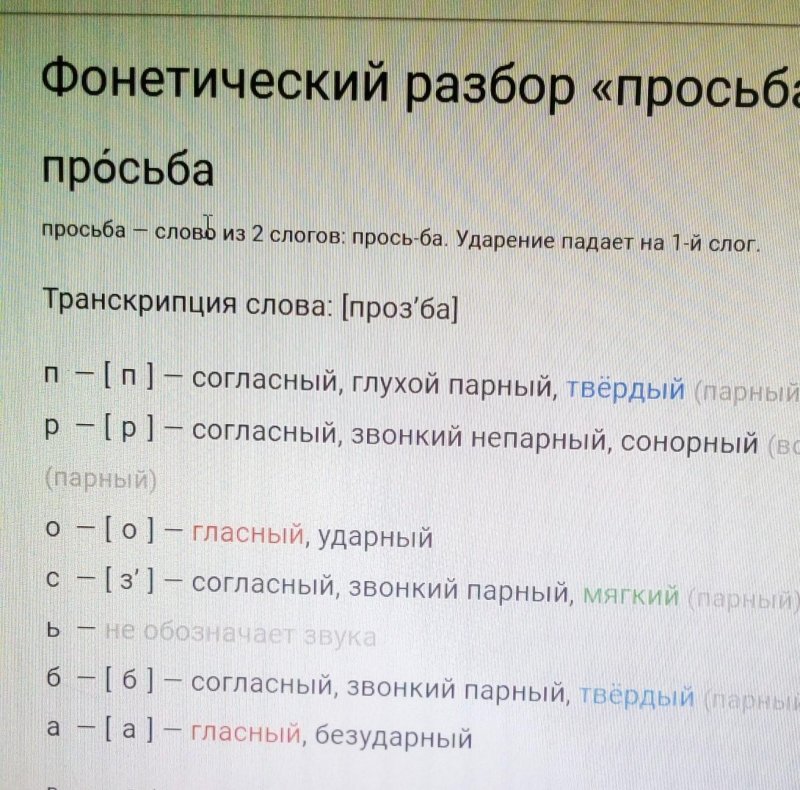
 Это могут быть сообщения о неисправности маяков, о вулканической деятельности, об активности пиратов, о затонувших судах…
Это могут быть сообщения о неисправности маяков, о вулканической деятельности, об активности пиратов, о затонувших судах…Если материал понравился Вам и оказался для Вас полезным, поделитесь им со своими друзьями!
Сумма прописью. Перевод числа в пропись
Перевод числа в пропись.
Работа с текстом Инструмент Текст
Конвертер текста в цифровой код
Онлайн калькулятор преобразует символы в их цифровые коды.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Подсчет количества символов
Подсчет количества символов.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Подсчет количества символов в тексте
Сколько символов, строк и количество слов находятся в строке.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер текста в юникод
Конвертер для перевода любого текста (не только кириллицы) в Юникод.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер букв в HTML-коды
Конвертер для перевода любого текста в HTML-коды.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер регистра букв
Сервис по изменению написания букв с заглавных на строчные или строчных на заглавные.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер HTML кодов в текст
Конвертер для перевода ASCII кодов в текст
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст

Сколько весит ребенок?
Согласно нормам Всемирной Организацией Здравоохранения (ВОЗ)
Масса и вес Масса Теория Единицы измерения
Назначение и структура операционных систем
Операционные системы Информатика
Что такое дюйм? Чему равен 1 дюйм?
Дюйм — это длина, которая соответствует 2,54 сантиметра (приблизительно 25 миллиметров)
Размеры и расстояния Длина Формулы
Процент / доля от числа
Арифметика Калькулятор Расчёт Проценты
Основные тригонометрические тождества
Тригонометрические тождества — это равенства, которые устанавливают связь между синусом, косинусом, тангенсом и котангенсом одного угла, которая позволяет находить любую из данных функций при условии, что будет известна какая-либо другая.
Тригонометрия Математика Тригонометрия Формулы Теория
Формула объема цилиндра
Объем цилиндра равен произведению квадрата радиуса основания, высоты цилиндра и числа пи (3.1415)
Формулы объема Расчёт Объем Тригонометрия Формулы Геометрия Фигуры
Закон сохранения электрических зарядов
Алгебраическая сумма электрических зарядов в замкнутой системе остается постоянной.
Законы сохранения Формулы Физика Теория 8 класс Закон Динамика Механика
Сколько соток, квадратных метров, километров и аров в одном гектаре земли? Метры, сотки, ары, гектары: значение, таблица. Как рассчитать, сколько гектаров в одной сотке или в одном квадратном метре, аре: перевод соток в гектары
Гектар — это площадь квадрата со стороной 100 м. Ар — площади квадрата со стороной в 10 м. 1 сотка это 100 квадратных метров
Площади и объемы Площадь Математика Формулы Геометрия

Все о синтаксическом анализе: что это такое и как он связан с программным обеспечением для преобразования текста в речь | Алекс Кителингер | Voice Tech Podcast
В мире распознавания речи — как и в любой лингвистической области — слово «анализ» часто используется, имея более чем пару значений и приложений.
В самом базовом определении «разбор» означает «анализ (в данном случае предложения) с точки зрения грамматических составляющих, определение частей речи, синтаксических отношений и т. д.». Для нас это означает, что мы берем предложение как единое целое и разбиваем его на понятные фрагменты с их собственным значением и контекстом, а также описываем их отношение друг к другу. Традиционно вы можете увидеть это как «дерево» предложения после того, как оно тем или иным образом проанализировано. Возьмем мой любимый пример, сказанный Граучо Марксом: «Сегодня утром я застрелил слона в пижаме…»
Теперь, если принять это предложение за чистую монету (без спойлеров, те, кто это знает), мы посмотрим на типичную интерпретацию основной части этого предложения. Мы опустим «сегодня утром», потому что это немного усложняет ситуацию. У нас осталось следующее:
Я был в пижаме, я застрелил слона. Просто обычное воскресенье! (Источник) Это дерево предложений в очень простом смысле; представление того, как мы могли бы классически разобрать это. Но тот факт, что анализ, подобный этому, настолько специфичен и информативен, может быть сложной проблемой при ограниченной информации, как мы увидим на полном примере этой цитаты: «Этим утром я застрелил слона в пижаме. Как он оказался в моей пижаме, я не знаю!»
Но тот факт, что анализ, подобный этому, настолько специфичен и информативен, может быть сложной проблемой при ограниченной информации, как мы увидим на полном примере этой цитаты: «Этим утром я застрелил слона в пижаме. Как он оказался в моей пижаме, я не знаю!»
Мне не хочется слишком объяснять шутку 90-летней давности, поэтому я позволю ей усвоиться, предоставив альтернативный (и правильный, в данном случае) разбор вышеизложенного.
Действительно маловероятный сценарий! Немного садовой дорожки.Создавайте лучшие голосовые приложения. Получите больше статей и интервью от экспертов по голосовым технологиям на voicetechpodcast.com
Смысл этого, помимо прекрасного предлога, чтобы заставить вас всех услышать немного классической игры слов, состоит в том, чтобы показать, что наличие всех слов во фразе недостаточно, чтобы получить его полное значение во многих случаях. Мы, люди, чертовски хорошо интерпретируем значение предложения из контекста (вперёд, люди!), но для машин это сложный процесс. Когда мы говорим о синтаксическом анализе в компьютерной лингвистике, эти предложения должны интерпретироваться в соответствии с установленной грамматикой: установленным набором правил того, как работает данный язык, чтобы определить, что является «грамматическим», а что нет. Это используется в качестве основы для структурирования предложения в возможных интерпретациях. я говорю «возможно» здесь очень преднамеренно, поскольку человеческие языки в целом (особенно английский) имеют большую тенденцию к двусмысленности. Обычно это обходится с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или подобного предложения и будет просто давать вероятность каждой данной интерпретации.
Когда мы говорим о синтаксическом анализе в компьютерной лингвистике, эти предложения должны интерпретироваться в соответствии с установленной грамматикой: установленным набором правил того, как работает данный язык, чтобы определить, что является «грамматическим», а что нет. Это используется в качестве основы для структурирования предложения в возможных интерпретациях. я говорю «возможно» здесь очень преднамеренно, поскольку человеческие языки в целом (особенно английский) имеют большую тенденцию к двусмысленности. Обычно это обходится с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или подобного предложения и будет просто давать вероятность каждой данной интерпретации. С тех пор мы прошли долгий путь, но там есть что рассказать… так что я не буду! По крайней мере, не сегодня.
С тех пор мы прошли долгий путь, но там есть что рассказать… так что я не буду! По крайней мере, не сегодня.
Возможно, более интересной является текущая реализация того, как работают наши голосовые помощники. Alexa, например, не выполняет всю эту тяжелую работу локально (как и другие, хотя это может быть не всегда так…) Ваше устройство Echo возьмет полученный звуковой файл (прочитайте мой последний пост, если вы любопытно, как работает это волшебство), и передайте его в службу Alexa, размещенную в облаке Amazon, и основная часть обработки будет выполняться там. Даже в этом случае работа сильно урезана по сравнению с этой увесистой моделью сравнения. Alexa действует на основе нескольких ключевых элементов, которые она ищет в запросе, и использует их для определения основного значения того, что вы ищете. Пример запроса показан ниже из отличного руководства для тех, кто ищет краткий обзор начала разработки для устройств с поддержкой Alexa:
Способ анализа запроса Alexa (вверху) и данные, которые она отправляет в навык (внизу) (Источник) нужно определить, каковы названия призыва и навыка, а затем проанализировать, где находится «высказывание», и действовать, основываясь только на этом небольшом фрагменте. Даже в этом случае гораздо проще разобрать, когда структура запроса уже известна; вы просите свое устройство выполнить задачу за вас, и это серьезно ограничивает возможности того, что вы могли бы сказать.
Даже в этом случае гораздо проще разобрать, когда структура запроса уже известна; вы просите свое устройство выполнить задачу за вас, и это серьезно ограничивает возможности того, что вы могли бы сказать.В этом много всего, и я только начинаю царапать поверхность, но суть в том, что «разбор» того, что вы говорите, за рамками виртуальных помощников — это огромное испытание, полное ошибок и несоответствий, особенно если учесть, что то, как мы, люди, говорим, откровенно говоря, состоит из ошибок и несоответствий. Даже в этом ограниченном контексте, который мы оцениваем с помощью Alexa, предстоит проделать большую работу. Я определенно планирую продолжить копаться в мельчайших подробностях того, что происходит, чтобы добраться из пункта А в пункт Б, но я надеюсь, что этот небольшой обзор был хотя бы немного проницательным!
Полное руководство по распознаванию речи с помощью Python — Real Python
Смотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Распознавание речи с помощью Python
Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Распознавание речи с помощью Python
Вы когда-нибудь задумывались, как добавить распознавание речи в свой проект Python? Если да, то продолжайте читать! Это проще, чем вы думаете.
Огромный успех продуктов с голосовой поддержкой, таких как Amazon Alexa, далеко не причуда, доказал, что некоторая степень поддержки речи будет важным аспектом бытовой техники в обозримом будущем. Если подумать, причины довольно очевидны. Включение распознавания речи в ваше приложение Python обеспечивает уровень интерактивности и доступности, с которым могут сравниться немногие технологии.
Улучшения доступности уже заслуживают внимания. Распознавание речи позволяет пожилым людям, а также людям с физическими и зрительными нарушениями взаимодействовать с современными продуктами и услугами быстро и естественно — без графического интерфейса!
Лучше всего то, что включить распознавание речи в проект Python очень просто. В этом руководстве вы узнаете, как это сделать. Вы узнаете:
В этом руководстве вы узнаете, как это сделать. Вы узнаете:
- Как работает распознавание речи,
- Какие пакеты доступны в PyPI; и
- Как установить и использовать пакет SpeechRecognition — полнофункциональную и простую в использовании библиотеку распознавания речи Python.
В конце концов, вы примените полученные знания к простой игре «Угадай слово» и увидите, как все это сочетается.
Бесплатный бонус: Щелкните здесь, чтобы загрузить пример проекта распознавания речи Python с полным исходным кодом, который вы можете использовать в качестве основы для своих собственных приложений распознавания речи.
Как работает распознавание речи — обзор
Прежде чем мы приступим к распознаванию речи в Python, давайте поговорим о том, как работает распознавание речи. Полное обсуждение заняло бы целую книгу, поэтому я не буду утомлять вас всеми техническими подробностями. На самом деле, этот раздел не является обязательным для остальной части учебника. Если вы хотите сразу перейти к делу, не стесняйтесь пропустить вперед.
Если вы хотите сразу перейти к делу, не стесняйтесь пропустить вперед.
Распознавание речи берет свое начало в исследованиях, проведенных в Bell Labs в начале 1950-х годов. Ранние системы были ограничены одним говорящим и имели ограниченный словарный запас примерно в дюжину слов. Современные системы распознавания речи прошли долгий путь по сравнению со своими древними аналогами. Они могут распознавать речь нескольких говорящих и обладают огромным словарным запасом на многих языках.
Первым компонентом распознавания речи является, конечно же, речь. Речь должна быть преобразована из физического звука в электрический сигнал с помощью микрофона, а затем в цифровые данные с помощью аналого-цифрового преобразователя. После оцифровки можно использовать несколько моделей для преобразования аудио в текст.
Большинство современных систем распознавания речи основаны на так называемой скрытой марковской модели (СММ). Этот подход основан на предположении, что речевой сигнал, рассматриваемый в течение достаточно короткого промежутка времени (скажем, десять миллисекунд), может быть разумно аппроксимирован как стационарный процесс, то есть процесс, в котором статистические свойства не меняются во времени.
В типичном HMM речевой сигнал делится на 10-миллисекундные фрагменты. Спектр мощности каждого фрагмента, который по сути представляет собой график зависимости мощности сигнала от частоты, отображается в вектор действительных чисел, известный как кепстральные коэффициенты. Размерность этого вектора обычно невелика — иногда всего 10, хотя более точные системы могут иметь размерность 32 и более. Конечным результатом HMM является последовательность этих векторов.
Для декодирования речи в текст группы векторов сопоставляются с одной или несколькими фонемами — фундаментальной единицей речи. Этот расчет требует тренировки, поскольку звучание фонемы варьируется от говорящего к говорящему и даже варьируется от одного высказывания к другому одним и тем же говорящим. Затем применяется специальный алгоритм для определения наиболее вероятного слова (или слов), которые образуют заданную последовательность фонем.
Можно себе представить, что весь этот процесс может быть дорогостоящим в вычислительном отношении. Во многих современных системах распознавания речи нейронные сети используются для упрощения речевого сигнала с использованием методов преобразования признаков и уменьшения размерности до распознавания HMM. Детекторы голосовой активности (VAD) также используются для сокращения звукового сигнала до тех частей, которые могут содержать речь. Это предотвращает трату времени распознавателем на анализ ненужных частей сигнала.
Во многих современных системах распознавания речи нейронные сети используются для упрощения речевого сигнала с использованием методов преобразования признаков и уменьшения размерности до распознавания HMM. Детекторы голосовой активности (VAD) также используются для сокращения звукового сигнала до тех частей, которые могут содержать речь. Это предотвращает трату времени распознавателем на анализ ненужных частей сигнала.
К счастью, как программисту Python вам не нужно ни о чем беспокоиться. Ряд служб распознавания речи доступен для использования в Интернете через API, и многие из этих служб предлагают Python SDK.
Удаление рекламы
Выбор пакета распознавания речи Python
В PyPI существует несколько пакетов для распознавания речи. Вот некоторые из них:
- апиай
- в сбореai
- Google-облачная речь
- кармансфинкс
- Распознавание речи
- watson-developer-cloud
- остроумие
Некоторые из этих пакетов, такие как wit и apiai, предлагают встроенные функции, такие как обработка естественного языка для определения намерений говорящего, которые выходят за рамки простого распознавания речи. Другие, такие как google-cloud-speech, сосредоточены исключительно на преобразовании речи в текст.
Другие, такие как google-cloud-speech, сосредоточены исключительно на преобразовании речи в текст.
Существует один пакет, отличающийся простотой использования: SpeechRecognition.
Для распознавания речи требуется аудиовход, и SpeechRecognition делает получение этого ввода очень простым. Вместо того, чтобы создавать сценарии для доступа к микрофонам и обработки аудиофайлов с нуля, SpeechRecognition позволит вам начать работу всего за несколько минут.
Библиотека SpeechRecognition выступает в качестве оболочки для нескольких популярных речевых API и, таким образом, является чрезвычайно гибкой. Один из них — Google Web Speech API — поддерживает ключ API по умолчанию, который жестко запрограммирован в библиотеке SpeechRecognition. Это означает, что вы можете встать с ног, не подписываясь на услугу.
Гибкость и простота использования пакета SpeechRecognition делают его отличным выбором для любого проекта Python. Однако не гарантируется поддержка каждой функции каждого API-интерфейса, который он обертывает.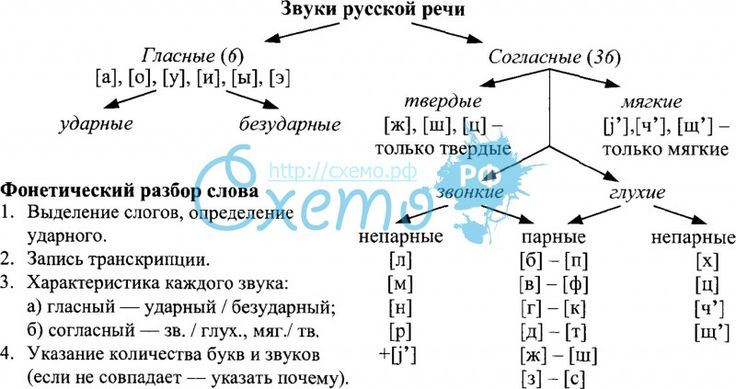 Вам нужно будет потратить некоторое время на изучение доступных вариантов, чтобы выяснить, будет ли работать SpeechRecognition в вашем конкретном случае.
Вам нужно будет потратить некоторое время на изучение доступных вариантов, чтобы выяснить, будет ли работать SpeechRecognition в вашем конкретном случае.
Итак, теперь, когда вы убеждены, что вам нужно попробовать SpeechRecognition, следующим шагом будет его установка в вашей среде.
Установка распознавания речи
SpeechRecognition совместим с Python 2.6, 2.7 и 3.3+, но требует некоторых дополнительных шагов по установке для Python 2. В этом руководстве я предполагаю, что вы используете Python 3.3+.
Вы можете установить SpeechRecognition с терминала с помощью pip:
$ pip установить SpeechRecognition
После установки вы должны проверить установку, открыв сеанс интерпретатора и введя:
>>>
>>> импортировать voice_recognition как sr >>> ср.__версия__ «3.8.1»
Примечание: Номер версии, который вы получите, может отличаться. Версия 3.8.1 была последней на момент написания.
Держите этот сеанс открытым. Вы начнете работать с ним чуть позже.
SpeechRecognition будет работать из коробки , если все, что вам нужно сделать, это работать с существующими аудиофайлами. Однако для конкретных случаев использования требуется несколько зависимостей. Примечательно, что пакет PyAudio необходим для захвата микрофонного входа.
Вы увидите, какие зависимости вам нужны, когда будете читать дальше. А пока давайте погрузимся и изучим основы пакета.
Распознаватель
Класс Вся магия в SpeechRecognition происходит с классом Recognizer .
Основной целью экземпляра Recognizer , конечно же, является распознавание речи. Каждый экземпляр поставляется с различными настройками и функциями для распознавания речи из источника звука.
Создать экземпляр Recognizer очень просто. В текущем сеансе интерпретатора просто введите:
>>>
>>> r = ср.
 Распознаватель()
Распознаватель()
Каждый экземпляр Recognizer имеет семь методов распознавания речи из аудиоисточника с использованием различных API. Это:
-
распознать_bing(): Microsoft Bing Speech -
распознать_google(): Google Web Speech API -
распознать_google_cloud(): Google Cloud Speech — требуется установка пакета google-cloud-speech . -
распознать_houndify(): Houndify от SoundHound -
распознать_ibm(): Преобразование речи IBM в текст -
распознать_sphinx(): CMU Sphinx — требуется установка PocketSphinx -
распознать_wit(): Wit.ai
Из семи только распознать_sphinx() работает в автономном режиме с двигателем CMU Sphinx. Остальные шесть требуют подключения к Интернету.
Полное обсуждение функций и преимуществ каждого API выходит за рамки данного руководства. Поскольку SpeechRecognition поставляется с ключом API по умолчанию для Google Web Speech API, вы можете сразу начать работу с ним. По этой причине в этом руководстве мы будем использовать API Web Speech. Остальные шесть API требуют аутентификации либо с помощью ключа API, либо с помощью комбинации имени пользователя и пароля. Для получения дополнительной информации обратитесь к документации SpeechRecognition.
Поскольку SpeechRecognition поставляется с ключом API по умолчанию для Google Web Speech API, вы можете сразу начать работу с ним. По этой причине в этом руководстве мы будем использовать API Web Speech. Остальные шесть API требуют аутентификации либо с помощью ключа API, либо с помощью комбинации имени пользователя и пароля. Для получения дополнительной информации обратитесь к документации SpeechRecognition.
Внимание! Ключ по умолчанию, предоставляемый SpeechRecognition, предназначен только для целей тестирования и .0021 Google может отозвать его в любое время . , а не — хорошая идея для использования Google Web Speech API в производстве. Даже с действительным ключом API вы будете ограничены только 50 запросами в день, и увеличить эту квоту невозможно. К счастью, интерфейс SpeechRecognition практически идентичен для каждого API, поэтому то, что вы сегодня изучите, будет легко применить в реальном проекте.
Каждый метод cognition_*() вызовет ошибку speech_recognition. RequestError 9Исключение 0142, если API недоступен. Для
RequestError 9Исключение 0142, если API недоступен. Для распознать_sphinx() это может произойти в результате отсутствия, повреждения или несовместимости установки Sphinx. Для других шести методов может быть выдано сообщение RequestError , если достигнуты пределы квоты, сервер недоступен или отсутствует подключение к Интернету.
Ладно, хватит болтать. Давайте испачкаем руки. Продолжайте и попробуйте вызвать распознать_google() в сеансе интерпретатора.
>>>
>>> r.recognize_google()
Что случилось?
Вы, вероятно, получили что-то вроде этого:
Traceback (последний последний вызов): Файл "", строка 1, в Ошибка типа: в системе распознавания_google() отсутствует 1 обязательный позиционный аргумент: 'audio_data'
Вы могли догадаться, что это произойдет. Как можно что-то узнать из ничего?
Все семь распознавать_*() методов распознавателя требуется аргумент audio_data . В каждом случае
В каждом случае audio_data должен быть экземпляром класса AudioData SpeechRecognition.
Существует два способа создания экземпляра AudioData : из аудиофайла или из аудиозаписи, записанной с микрофона. С аудиофайлами немного проще начать работу, поэтому давайте сначала рассмотрим их.
Удаление рекламы
Работа с аудиофайлами
Прежде чем продолжить, вам нужно скачать аудиофайл. Тот, который я использовал для начала, «harvard.wav», можно найти здесь. Убедитесь, что вы сохранили его в том же каталоге, в котором запущен ваш сеанс интерпретатора Python.
SpeechRecognition упрощает работу с аудиофайлами благодаря удобному классу AudioFile . Этот класс может быть инициализирован путем к аудиофайлу и предоставляет интерфейс менеджера контекста для чтения и работы с содержимым файла.
Поддерживаемые типы файлов
В настоящее время SpeechRecognition поддерживает следующие форматы файлов:
- WAV: должен быть в формате PCM/LPCM
- АИФФ
- AIFF-C
- FLAC: должен быть собственный формат FLAC; OGG-FLAC не поддерживается
Если вы работаете в Linux, macOS или Windows на базе x-86, вы сможете без проблем работать с файлами FLAC. На других платформах вам потребуется установить кодировщик FLAC и убедиться, что у вас есть доступ к инструменту командной строки
На других платформах вам потребуется установить кодировщик FLAC и убедиться, что у вас есть доступ к инструменту командной строки flac . Вы можете найти дополнительную информацию здесь, если это относится к вам.
Использование
record() для захвата данных из файлаВведите в сеанс интерпретатора следующее, чтобы обработать содержимое файла «harvard.wav»:
>>>
>>> гарвард = sr.AudioFile('harvard.wav')
>>> с Гарвардом в качестве источника:
... аудио = r.record(источник)
...
Менеджер контекста открывает файл и считывает его содержимое, сохраняя данные в экземпляре AudioFile с именем source. Затем метод record() записывает данные из всего файла в экземпляр AudioData . Вы можете подтвердить это, проверив тип аудио :
>>>
>>> тип(аудио) <класс 'speech_recognition.
 AudioData'>
AudioData'>
Теперь вы можете вызвать распознавание_google() , чтобы попытаться распознать любую речь в аудио. В зависимости от скорости вашего интернет-соединения вам, возможно, придется подождать несколько секунд, прежде чем вы увидите результат.
>>>
>>> r.recognize_google(аудио) 'Несвежий запах старого пива задерживается, требуется тепло чтобы вывести запах, холодное купание восстанавливает здоровье и цедра соленый огурец вкус прекрасный с ветчиной тако аль Пасторе - моя любимая пикантная еда - горячая перекрестная булочка
Поздравляем! Вы только что записали свой первый аудиофайл!
Если вам интересно, откуда берутся фразы в файле «harvard.wav», это примеры Гарвардских предложений. Эти фразы были опубликованы IEEE в 1965 году для использования при тестировании разборчивости речи на телефонных линиях. Они до сих пор используются при тестировании VoIP и сотовой связи.
Гарвардские предложения состоят из 72 списков из десяти фраз. Вы можете найти в свободном доступе записи этих фраз на веб-сайте Open Speech Repository. Записи доступны на английском, китайском, французском и хинди. Они представляют собой отличный источник бесплатных материалов для тестирования вашего кода.
Вы можете найти в свободном доступе записи этих фраз на веб-сайте Open Speech Repository. Записи доступны на английском, китайском, французском и хинди. Они представляют собой отличный источник бесплатных материалов для тестирования вашего кода.
Захват сегментов со смещением
и длительностью Что делать, если вы хотите записать в файл только часть речи? Метод record() принимает аргумент ключевого слова продолжительность , который останавливает запись по истечении заданного количества секунд.
Например, следующая запись захватывает любую речь в первые четыре секунды файла:
>>>
>>> с Гарвардом в качестве источника: ... аудио = r.record (источник, продолжительность = 4) ... >>> r.recognize_google(аудио) 'застоялся запах старого пива'
Метод record() при использовании внутри блока с всегда перемещается вперед в файловом потоке.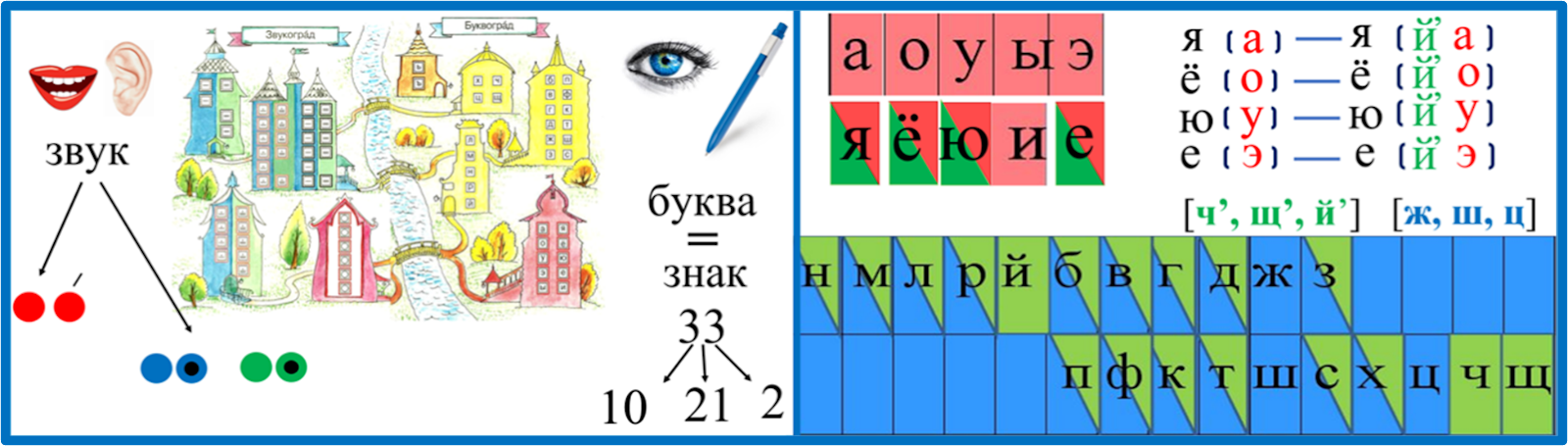 Это означает, что если вы записываете один раз в течение четырех секунд, а затем снова записываете в течение четырех секунд, второй раз возвращает четыре секунды звука после первых четырех секунд.
Это означает, что если вы записываете один раз в течение четырех секунд, а затем снова записываете в течение четырех секунд, второй раз возвращает четыре секунды звука после первых четырех секунд.
>>>
>>> с Гарвардом в качестве источника: ... audio1 = r.record (источник, продолжительность = 4) ... audio2 = r.record (источник, продолжительность = 4) ... >>> r.recognize_google(аудио1) 'застоялся запах старого пива' >>> r.recognize_google(аудио2) «Требуется тепло, чтобы вызвать запах холодного купания»
Обратите внимание, что audio2 содержит часть третьей фразы в файле. При указании длительности запись может остановиться на середине фразы или даже на середине слова, что может снизить точность транскрипции. Подробнее об этом чуть позже.
В дополнение к указанию продолжительности записи методу record() можно задать конкретную начальную точку с помощью ключевого аргумента offset . Это значение представляет собой количество секунд от начала файла, которое следует игнорировать перед началом записи.
Это значение представляет собой количество секунд от начала файла, которое следует игнорировать перед началом записи.
Чтобы захватить только вторую фразу в файле, вы можете начать со смещения в четыре секунды и записать, скажем, три секунды.
>>>
>>> с Гарвардом в качестве источника: ... аудио = r.record (источник, смещение = 4, продолжительность = 3) ... >>> r.recognize_google(аудио) «Требуется тепло, чтобы вывести запах»
Аргументы ключевого слова offset и duration полезны для сегментации аудиофайла , если вы предварительно знаете структуру речи в файле. Однако их поспешное использование может привести к плохой транскрипции. Чтобы увидеть этот эффект, попробуйте в интерпретаторе следующее:
>>>
>>> с Гарвардом в качестве источника: ... аудио = r.record (источник, смещение = 4,7, продолжительность = 2,8) ... >>> r.recognize_google(аудио) 'Мескит, чтобы вывести запах Айко'
Начав запись с 4,7 секунды, вы пропустили часть «it t» в начале фразы «требуется тепло, чтобы выделить запах», поэтому API получил только «akes heat», которое было сопоставлено с «мескитовым оттенком». ».
».
Точно так же в конце записи вы записали «a co», которое является началом третьей фразы «холодное купание восстанавливает здоровье и бодрость духа». Это было сопоставлено с «Айко» по API.
Есть еще одна причина, по которой вы можете получить неточные транскрипции. Шум! Приведенные выше примеры работали хорошо, потому что аудиофайл достаточно чистый. В реальном мире, если у вас нет возможности предварительно обработать аудиофайлы, вы не можете ожидать, что звук будет бесшумным.
Удаление рекламы
Влияние шума на распознавание речи
Шум - это факт жизни. Все аудиозаписи содержат некоторую степень шума, а необработанный шум может нарушить точность приложений распознавания речи.
Чтобы понять, как шум может повлиять на распознавание речи, загрузите файл «jackhammer.wav» здесь. Как всегда, убедитесь, что вы сохранили это в рабочий каталог вашего сеанса интерпретатора.
В этом файле есть фраза «затхлый запах старого пива», произнесенная на фоне громкого отбойного молотка.
Что происходит, когда вы пытаетесь расшифровать этот файл?
>>>
>>> jackhammer = sr.AudioFile('jackhammer.wav')
>>> с отбойным молотком в качестве источника:
... аудио = r.record(источник)
...
>>> r.recognize_google(аудио)
'запах улиток от старых продавцов снаряжения'
Прочь!
И как ты с этим справляешься? Вы можете попробовать использовать метод Adjust_for_ambient_noise() класса Recognizer .
>>>
>>> с отбойным молотком в качестве источника: ... r.adjust_for_ambient_noise (источник) ... аудио = r.record(источник) ... >>> r.recognize_google(аудио) "до сих пор пахнет старыми торговцами пивом"
Это немного приблизило вас к настоящей фразе, но она все еще не идеальна. Кроме того, в начале фразы отсутствует «the». Почему это?
Метод Adjust_for_ambient_noise() считывает первую секунду файлового потока и калибрует распознаватель по уровню шума аудио. Следовательно, эта часть потока потребляется до того, как вы вызовете
Следовательно, эта часть потока потребляется до того, как вы вызовете record() для захвата данных.
Вы можете настроить временной интервал, который Adjust_for_ambient_noise() использует для анализа, с помощью ключевого аргумента duration . Этот аргумент принимает числовое значение в секундах и по умолчанию равен 1. Попробуйте уменьшить это значение до 0,5.
>>>
>>> с отбойным молотком в качестве источника: ... r.adjust_for_ambient_noise (источник, продолжительность = 0,5) ... аудио = r.record(источник) ... >>> r.recognize_google(аудио) «улитки пахнут, как старые торговцы пивом»
Что ж, вы получили "the" в начале фразы, но теперь у вас есть новые проблемы! Иногда невозможно удалить эффект шума — сигнал слишком шумный, чтобы с ним можно было успешно справиться. Именно так обстоит дело с этим файлом.
Если вы часто сталкиваетесь с этими проблемами, возможно, вам придется прибегнуть к некоторой предварительной обработке звука. Это можно сделать с помощью программного обеспечения для редактирования аудио или пакета Python (например, SciPy), который может применять фильтры к файлам. Подробное обсуждение этого выходит за рамки этого руководства — если вам интересно, ознакомьтесь с книгой Allen Downey Think DSP. На данный момент просто имейте в виду, что окружающий шум в аудиофайле может вызвать проблемы и должен быть устранен, чтобы максимизировать точность распознавания речи.
Это можно сделать с помощью программного обеспечения для редактирования аудио или пакета Python (например, SciPy), который может применять фильтры к файлам. Подробное обсуждение этого выходит за рамки этого руководства — если вам интересно, ознакомьтесь с книгой Allen Downey Think DSP. На данный момент просто имейте в виду, что окружающий шум в аудиофайле может вызвать проблемы и должен быть устранен, чтобы максимизировать точность распознавания речи.
При работе с зашумленными файлами может быть полезно увидеть фактический ответ API. Большинство API возвращают строку JSON, содержащую множество возможных транскрипций. Метод cognition_google() всегда будет возвращать наиболее вероятную транскрипцию , если вы не заставите его дать вам полный ответ.
Это можно сделать, установив аргументу ключевого слова show_all метода распознать_google() значение True.
>>>
>>> r.
 recognize_google(аудио, show_all=True)
{'альтернатива': [
{'транскрипт': 'улитки пахнут, как старые торговцы пивом'},
{'транскрипт': 'неподвижный запах старых торговцев пивом'},
{'транскрипт': 'улитки пахнут старыми торговцами пивом'},
{'транскрипт': 'затхлый запах старых торговцев пивом'},
{'транскрипт': 'улитки пахнут старыми торговцами пивом'},
{'транскрипт': 'неприятный запах старых продавцов пива'},
{'транскрипт': 'до сих пор пахнет старыми торговцами пивом'},
{'транскрипт': 'запах бастилии старых торговцев пивом'},
{'транскрипт': 'до сих пор пахнет старыми пивоварами'},
{'транскрипт': 'неподвижный запах старых пивных лавок'},
{'расшифровка': 'все еще вонючие старые продавцы пива'},
{'транскрипт': 'затхлый запах старых торговцев пивом'},
{'транскрипт': 'неподвижный запах старого торговца пивом'}
], 'финал': Истина}
recognize_google(аудио, show_all=True)
{'альтернатива': [
{'транскрипт': 'улитки пахнут, как старые торговцы пивом'},
{'транскрипт': 'неподвижный запах старых торговцев пивом'},
{'транскрипт': 'улитки пахнут старыми торговцами пивом'},
{'транскрипт': 'затхлый запах старых торговцев пивом'},
{'транскрипт': 'улитки пахнут старыми торговцами пивом'},
{'транскрипт': 'неприятный запах старых продавцов пива'},
{'транскрипт': 'до сих пор пахнет старыми торговцами пивом'},
{'транскрипт': 'запах бастилии старых торговцев пивом'},
{'транскрипт': 'до сих пор пахнет старыми пивоварами'},
{'транскрипт': 'неподвижный запах старых пивных лавок'},
{'расшифровка': 'все еще вонючие старые продавцы пива'},
{'транскрипт': 'затхлый запах старых торговцев пивом'},
{'транскрипт': 'неподвижный запах старого торговца пивом'}
], 'финал': Истина}
Как видите, распознавание_google() возвращает словарь с ключом 'alternative' , указывающим на список возможных расшифровок. Структура этого ответа может варьироваться от API к API и в основном полезна для отладки.
Структура этого ответа может варьироваться от API к API и в основном полезна для отладки.
К настоящему моменту у вас есть довольно хорошее представление об основах пакета SpeechRecognition. Вы видели, как создать экземпляр AudioFile из аудиофайла и использовать метод record() для захвата данных из файла. Вы узнали, как записывать сегменты файла, используя смещение и продолжительность ключевое слово аргументы record() , и вы испытали пагубное влияние шума на точность транскрипции.
А теперь самое интересное. Давайте перейдем от расшифровки статических аудиофайлов к интерактивности вашего проекта, принимая входные данные с микрофона.
Удаление рекламы
Работа с микрофонами
Чтобы получить доступ к микрофону с помощью SpeechRecognizer, вам необходимо установить пакет PyAudio. Идите вперед и закройте текущий сеанс интерпретатора, и давайте сделаем это.
Установка PyAudio
Процесс установки PyAudio зависит от вашей операционной системы.
Дебиан Линукс
Если вы используете Linux на основе Debian (например, Ubuntu), вы можете установить PyAudio с apt :
$ sudo apt-get установить python-pyaudio python3-pyaudio
После установки вам может понадобиться запустить pip install pyaudio , особенно если вы работаете в виртуальной среде.
macOS
Для macOS сначала необходимо установить PortAudio с Homebrew, а затем установить PyAudio с pip :
$ заварить установить портаудио $ pip установить pyaudio
Windows
В Windows вы можете установить PyAudio с pip :
$ pip установить pyaudio
Проверка установки
После установки PyAudio вы можете протестировать установку из консоли.
$ python -m распознавание речи
Убедитесь, что ваш микрофон по умолчанию включен и включен. Если установка прошла успешно, вы должны увидеть что-то вроде этого:
Если установка прошла успешно, вы должны увидеть что-то вроде этого:
Минуту молчания, пожалуйста... Установите минимальный порог энергии на 600,4452854381937. Скажите что-то!Идите вперед и немного поиграйте с ним, говоря в микрофон и наблюдая, насколько хорошо SpeechRecognition расшифровывает вашу речь.
Примечание: Если вы используете Ubuntu и получаете какой-то странный вывод, например «ALSA lib… Unknown PCM», обратитесь к этой странице за советами по подавлению этих сообщений. Эти выходные данные получены из пакета ALSA, установленного вместе с Ubuntu, а не из SpeechRecognition или PyAudio. На самом деле эти сообщения могут указывать на проблему с вашей конфигурацией ALSA, но, по моему опыту, они не влияют на функциональность вашего кода. В основном они неприятны.
Удалить рекламу
Микрофон Класс Откройте другой сеанс интерпретатора и создайте экземпляр класса распознавателя.
>>>
>>> импортировать voice_recognition как sr >>> r = sr.Recognizer()
Теперь вместо аудиофайла в качестве источника вы будете использовать системный микрофон по умолчанию. Вы можете получить к нему доступ, создав экземпляр класса Microphone .
>>>
>>> mic = sr.Microphone()
Если в вашей системе нет микрофона по умолчанию (например, на Raspberry Pi) или вы хотите использовать микрофон, отличный от микрофона по умолчанию, вам нужно будет указать, какой из них использовать, указав индекс устройства. Вы можете получить список имен микрофонов, вызвав статический метод list_microphone_names() класса Microphone .
>>>
>>> sr.Microphone.list_microphone_names() ['HDA Intel PCH: аналог ALC272 (hw:0,0)', 'HDA Intel PCH: HDMI 0 (hw:0,3)', 'по умолчанию', 'передний', 'объем40', 'объем51', 'объем71', 'HDMI', 'пульс', 'дмикс', 'по умолчанию']
Обратите внимание, что ваш вывод может отличаться от приведенного выше примера.
Индекс устройства микрофона — это индекс его имени в списке, возвращаемом функцией list_microphone_names(). Например, с учетом приведенного выше вывода, если вы хотите использовать микрофон с именем «передний», который имеет индекс 3 в списке, вы должны создать такой экземпляр микрофона:
>>>
>>> # Это просто пример; не беги >>> mic = sr.Microphone(device_index=3)
Однако для большинства проектов вы, вероятно, захотите использовать системный микрофон по умолчанию.
Использование
listen() для захвата микрофонного входа Теперь, когда у вас есть экземпляр Microphone , готовый к работе, пришло время записать некоторые данные.
Как и класс AudioFile , Microphone является менеджером контекста. Вы можете захватить ввод с микрофона, используя метод listen() класса Recognizer внутри с блоком . Этот метод принимает источник звука в качестве первого аргумента и записывает ввод от источника до тех пор, пока не будет обнаружена тишина.
Этот метод принимает источник звука в качестве первого аргумента и записывает ввод от источника до тех пор, пока не будет обнаружена тишина.
>>>
>>> с микрофоном в качестве источника: ... аудио = r.listen(источник) ...
После того, как вы выполните блок с , попробуйте сказать «привет» в микрофон. Подождите немного, пока приглашение интерпретатора не отобразится снова. Как только появится подсказка «>>>», вы готовы распознать речь.
>>>
>>> r.recognize_google(аудио) 'привет'
Если подсказка никогда не появляется, ваш микрофон, скорее всего, улавливает слишком много окружающего шума. Вы можете прервать процесс с помощью Ctrl + C , чтобы вернуть подсказку.
Для обработки окружающего шума вам потребуется использовать метод Adjust_for_ambient_noise() класса Recognizer , точно так же, как вы делали это при попытке разобраться в шумном аудиофайле. Поскольку ввод с микрофона гораздо менее предсказуем, чем ввод из аудиофайла, рекомендуется делать это каждый раз, когда вы прослушиваете ввод с микрофона.
Поскольку ввод с микрофона гораздо менее предсказуем, чем ввод из аудиофайла, рекомендуется делать это каждый раз, когда вы прослушиваете ввод с микрофона.
>>>
>>> с микрофоном в качестве источника: ... r.adjust_for_ambient_noise (источник) ... аудио = r.listen(источник) ...
После запуска приведенного выше кода подождите секунду, пока Adjust_for_ambient_noise() сделает свое дело, затем попробуйте сказать «привет» в микрофон. Опять же, вам придется подождать некоторое время, пока не вернется приглашение переводчика, прежде чем пытаться распознать речь.
Напомним, что Adjust_for_ambient_noise() анализирует источник звука в течение одной секунды. Если это кажется вам слишком длинным, не стесняйтесь регулировать это с помощью продолжительность аргумент ключевого слова.
В документации SpeechRecognition рекомендуется использовать продолжительность не менее 0,5 секунды. В некоторых случаях вы можете обнаружить, что длительности больше, чем одна секунда по умолчанию, дают лучшие результаты. Минимальное необходимое значение зависит от окружающей среды микрофона. К сожалению, эта информация обычно неизвестна во время разработки. По моему опыту, длительности по умолчанию в одну секунду достаточно для большинства приложений.
В некоторых случаях вы можете обнаружить, что длительности больше, чем одна секунда по умолчанию, дают лучшие результаты. Минимальное необходимое значение зависит от окружающей среды микрофона. К сожалению, эта информация обычно неизвестна во время разработки. По моему опыту, длительности по умолчанию в одну секунду достаточно для большинства приложений.
Удалить рекламу
Обработка нераспознаваемой речи
Попробуйте ввести предыдущий пример кода в интерпретатор и издать какие-то неразборчивые звуки в микрофон. В ответ вы должны получить что-то вроде этого:
Traceback (последний последний вызов): Файл "", строка 1, в Файл "/home/david/real_python/speech_recognition_primer/venv/lib/python3.5/site-packages/speech_recognition/__init__.py", строка 858, в распознавании_google если не isinstance(actual_result, dict) или len(actual_result.get("alternative", [])) == 0: поднять UnknownValueError() speech_recognition.
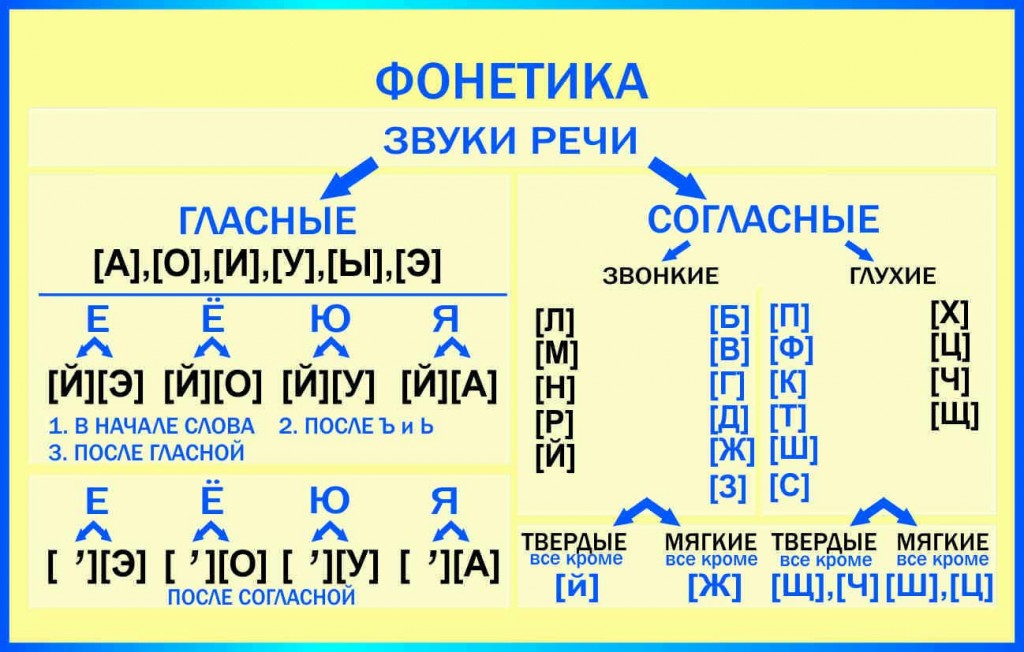 UnknownValueError
UnknownValueError
Звук, который не может быть сопоставлен с текстом с помощью API, вызывает исключение UnknownValueError . Вы всегда должны оборачивать вызовы API блоками try и за исключением блоков для обработки этого исключения.
Примечание : Возможно, вам придется приложить больше усилий, чем вы ожидаете, чтобы получить исключение. API очень усердно работает, чтобы транскрибировать любые вокальные звуки. Даже короткое ворчание было для меня расшифровано как слова вроде «как». Кашель, хлопки в ладоши и щелканье языком постоянно вызывают исключение.
Собираем все вместе: игра «Угадай слово»
Теперь, когда вы ознакомились с основами распознавания речи с помощью пакета SpeechRecognition, давайте воспользуемся вашими новыми знаниями и напишем небольшую игру, которая выбирает случайное слово из списка и дает пользователю три попытки угадать слово.
Вот полный скрипт:
случайный импорт
время импорта
импортировать speech_recognition как sr
defcognition_speech_from_mic(распознаватель,микрофон):
"""Транскрибируйте речь с записи с `микрофона`.
Возвращает словарь с тремя ключами:
"success": логическое значение, указывающее, был ли запрос API
успешный
"error": `None`, если ошибки не произошло, в противном случае строка, содержащая
сообщение об ошибке, если API не может быть достигнут или
речь была неузнаваема
"транскрипция": `Нет`, если речь не может быть расшифрована,
в противном случае строка, содержащая расшифрованный текст
"""
# проверяем, что аргументы распознавателя и микрофона соответствуют типу
если не isinstance (распознаватель, sr.Recognizer):
поднять TypeError («`распознаватель` должен быть экземпляром `распознавателя`»)
если не экземпляр(микрофон, ср.микрофон):
поднять TypeError («`микрофон` должен быть экземпляром `Микрофон`»)
# настроить чувствительность распознавателя к окружающему шуму и записать звук
# с микрофона
с микрофоном в качестве источника:
распознаватель.adjust_for_ambient_noise (источник)
аудио = распознаватель. слушай(источник)
# настроить объект ответа
ответ = {
"успех": Правда,
"ошибка": Нет,
"транскрипция": нет
}
# попробуй распознать речь в записи
# если перехвачено исключение RequestError или UnknownValueError,
# соответствующим образом обновить объект ответа
пытаться:
ответ["транскрипция"] = распознаватель.recognize_google(аудио)
кроме sr.RequestError:
# API недоступен или не отвечает
ответ["успех"] = Ложь
ответ["ошибка"] = "API недоступен"
кроме sr.UnknownValueError:
# речь была неразборчива
response["error"] = "Не удалось распознать речь"
вернуть ответ
если __name__ == "__main__":
# установить список слов, максимальное количество догадок и лимит подсказок
СЛОВА = ["яблоко", "банан", "виноград", "апельсин", "манго", "лимон"]
NUM_GUESSES = 3
ПРОМТ_ЛИМИТ = 5
# создать экземпляры распознавателя и микрофона
распознаватель = sr.Recognizer()
микрофон = ср. Микрофон()
# получить случайное слово из списка
слово = случайный.выбор(СЛОВА)
# отформатировать строку инструкций
инструкция =(
"Я думаю об одном из этих слов:\n"
"{слова}\n"
"У вас есть {n} попыток угадать, какой из них.\n"
).format(words=', '.join(WORDS), n=NUM_GUESSES)
# показать инструкции и подождать 3 секунды перед запуском игры
распечатать (инструкции)
время сна(3)
для i в диапазоне (NUM_GUESSES):
# получить предположение от пользователя
# если возвращается транскрипция, выйти из цикла и
# продолжать
# если транскрипция не возвращена и запрос API не выполнен, прерываем
# зациклить и продолжить
# если запрос API прошел успешно, но транскрипция не была возвращена,
# повторно предложить пользователю высказать свою догадку еще раз. Сделай это
# до PROMPT_LIMIT раз
для j в диапазоне (PROMPT_LIMIT):
print('Угадай {}. Произнеси!'.format(i+1))
угадать = распознать_речь_из_микрофона (распознаватель, микрофон)
если угадать["транскрипция"]:
перерыв
если не угадать["успех"]:
перерыв
print("Я не расслышал. Что ты сказал?\n")
# если произошла ошибка, остановить игру
если предположить["ошибка"]:
print("ОШИБКА: {}".format(догадка["ошибка"]))
перерыв
# показать пользователю транскрипцию
print("Вы сказали: {}".format(угадайте["транскрипция"]))
# определить правильность догадки и остались ли попытки
угадай_есть_правильно = угадай["транскрипция"].нижний() == слово.нижний()
user_has_more_attempts = я < NUM_GUESSES - 1
# определить, выиграл ли пользователь игру
# если нет, повторить цикл, если у пользователя есть еще попытки
# если попыток не осталось, пользователь проигрывает игру
если предположение_верно:
print("Верно! Вы выиграли!".format(word))
перерыв
Элиф user_has_more_attempts:
print("Неверно. Попробуйте еще раз.\n")
еще:
print("Извините, вы проиграли!\nЯ думал о '{}'.".format(word))
перерыв
 Возвращает словарь с тремя ключами:
"success": логическое значение, указывающее, был ли запрос API
успешный
"error": `None`, если ошибки не произошло, в противном случае строка, содержащая
сообщение об ошибке, если API не может быть достигнут или
речь была неузнаваема
"транскрипция": `Нет`, если речь не может быть расшифрована,
в противном случае строка, содержащая расшифрованный текст
"""
# проверяем, что аргументы распознавателя и микрофона соответствуют типу
если не isinstance (распознаватель, sr.Recognizer):
поднять TypeError («`распознаватель` должен быть экземпляром `распознавателя`»)
если не экземпляр(микрофон, ср.микрофон):
поднять TypeError («`микрофон` должен быть экземпляром `Микрофон`»)
# настроить чувствительность распознавателя к окружающему шуму и записать звук
# с микрофона
с микрофоном в качестве источника:
распознаватель.adjust_for_ambient_noise (источник)
аудио = распознаватель.
Возвращает словарь с тремя ключами:
"success": логическое значение, указывающее, был ли запрос API
успешный
"error": `None`, если ошибки не произошло, в противном случае строка, содержащая
сообщение об ошибке, если API не может быть достигнут или
речь была неузнаваема
"транскрипция": `Нет`, если речь не может быть расшифрована,
в противном случае строка, содержащая расшифрованный текст
"""
# проверяем, что аргументы распознавателя и микрофона соответствуют типу
если не isinstance (распознаватель, sr.Recognizer):
поднять TypeError («`распознаватель` должен быть экземпляром `распознавателя`»)
если не экземпляр(микрофон, ср.микрофон):
поднять TypeError («`микрофон` должен быть экземпляром `Микрофон`»)
# настроить чувствительность распознавателя к окружающему шуму и записать звук
# с микрофона
с микрофоном в качестве источника:
распознаватель.adjust_for_ambient_noise (источник)
аудио = распознаватель. слушай(источник)
# настроить объект ответа
ответ = {
"успех": Правда,
"ошибка": Нет,
"транскрипция": нет
}
# попробуй распознать речь в записи
# если перехвачено исключение RequestError или UnknownValueError,
# соответствующим образом обновить объект ответа
пытаться:
ответ["транскрипция"] = распознаватель.recognize_google(аудио)
кроме sr.RequestError:
# API недоступен или не отвечает
ответ["успех"] = Ложь
ответ["ошибка"] = "API недоступен"
кроме sr.UnknownValueError:
# речь была неразборчива
response["error"] = "Не удалось распознать речь"
вернуть ответ
если __name__ == "__main__":
# установить список слов, максимальное количество догадок и лимит подсказок
СЛОВА = ["яблоко", "банан", "виноград", "апельсин", "манго", "лимон"]
NUM_GUESSES = 3
ПРОМТ_ЛИМИТ = 5
# создать экземпляры распознавателя и микрофона
распознаватель = sr.Recognizer()
микрофон = ср.
слушай(источник)
# настроить объект ответа
ответ = {
"успех": Правда,
"ошибка": Нет,
"транскрипция": нет
}
# попробуй распознать речь в записи
# если перехвачено исключение RequestError или UnknownValueError,
# соответствующим образом обновить объект ответа
пытаться:
ответ["транскрипция"] = распознаватель.recognize_google(аудио)
кроме sr.RequestError:
# API недоступен или не отвечает
ответ["успех"] = Ложь
ответ["ошибка"] = "API недоступен"
кроме sr.UnknownValueError:
# речь была неразборчива
response["error"] = "Не удалось распознать речь"
вернуть ответ
если __name__ == "__main__":
# установить список слов, максимальное количество догадок и лимит подсказок
СЛОВА = ["яблоко", "банан", "виноград", "апельсин", "манго", "лимон"]
NUM_GUESSES = 3
ПРОМТ_ЛИМИТ = 5
# создать экземпляры распознавателя и микрофона
распознаватель = sr.Recognizer()
микрофон = ср. Микрофон()
# получить случайное слово из списка
слово = случайный.выбор(СЛОВА)
# отформатировать строку инструкций
инструкция =(
"Я думаю об одном из этих слов:\n"
"{слова}\n"
"У вас есть {n} попыток угадать, какой из них.\n"
).format(words=', '.join(WORDS), n=NUM_GUESSES)
# показать инструкции и подождать 3 секунды перед запуском игры
распечатать (инструкции)
время сна(3)
для i в диапазоне (NUM_GUESSES):
# получить предположение от пользователя
# если возвращается транскрипция, выйти из цикла и
# продолжать
# если транскрипция не возвращена и запрос API не выполнен, прерываем
# зациклить и продолжить
# если запрос API прошел успешно, но транскрипция не была возвращена,
# повторно предложить пользователю высказать свою догадку еще раз. Сделай это
# до PROMPT_LIMIT раз
для j в диапазоне (PROMPT_LIMIT):
print('Угадай {}. Произнеси!'.format(i+1))
угадать = распознать_речь_из_микрофона (распознаватель, микрофон)
если угадать["транскрипция"]:
перерыв
если не угадать["успех"]:
перерыв
print("Я не расслышал.
Микрофон()
# получить случайное слово из списка
слово = случайный.выбор(СЛОВА)
# отформатировать строку инструкций
инструкция =(
"Я думаю об одном из этих слов:\n"
"{слова}\n"
"У вас есть {n} попыток угадать, какой из них.\n"
).format(words=', '.join(WORDS), n=NUM_GUESSES)
# показать инструкции и подождать 3 секунды перед запуском игры
распечатать (инструкции)
время сна(3)
для i в диапазоне (NUM_GUESSES):
# получить предположение от пользователя
# если возвращается транскрипция, выйти из цикла и
# продолжать
# если транскрипция не возвращена и запрос API не выполнен, прерываем
# зациклить и продолжить
# если запрос API прошел успешно, но транскрипция не была возвращена,
# повторно предложить пользователю высказать свою догадку еще раз. Сделай это
# до PROMPT_LIMIT раз
для j в диапазоне (PROMPT_LIMIT):
print('Угадай {}. Произнеси!'.format(i+1))
угадать = распознать_речь_из_микрофона (распознаватель, микрофон)
если угадать["транскрипция"]:
перерыв
если не угадать["успех"]:
перерыв
print("Я не расслышал. Что ты сказал?\n")
# если произошла ошибка, остановить игру
если предположить["ошибка"]:
print("ОШИБКА: {}".format(догадка["ошибка"]))
перерыв
# показать пользователю транскрипцию
print("Вы сказали: {}".format(угадайте["транскрипция"]))
# определить правильность догадки и остались ли попытки
угадай_есть_правильно = угадай["транскрипция"].нижний() == слово.нижний()
user_has_more_attempts = я < NUM_GUESSES - 1
# определить, выиграл ли пользователь игру
# если нет, повторить цикл, если у пользователя есть еще попытки
# если попыток не осталось, пользователь проигрывает игру
если предположение_верно:
print("Верно! Вы выиграли!".format(word))
перерыв
Элиф user_has_more_attempts:
print("Неверно. Попробуйте еще раз.\n")
еще:
print("Извините, вы проиграли!\nЯ думал о '{}'.".format(word))
перерыв
Что ты сказал?\n")
# если произошла ошибка, остановить игру
если предположить["ошибка"]:
print("ОШИБКА: {}".format(догадка["ошибка"]))
перерыв
# показать пользователю транскрипцию
print("Вы сказали: {}".format(угадайте["транскрипция"]))
# определить правильность догадки и остались ли попытки
угадай_есть_правильно = угадай["транскрипция"].нижний() == слово.нижний()
user_has_more_attempts = я < NUM_GUESSES - 1
# определить, выиграл ли пользователь игру
# если нет, повторить цикл, если у пользователя есть еще попытки
# если попыток не осталось, пользователь проигрывает игру
если предположение_верно:
print("Верно! Вы выиграли!".format(word))
перерыв
Элиф user_has_more_attempts:
print("Неверно. Попробуйте еще раз.\n")
еще:
print("Извините, вы проиграли!\nЯ думал о '{}'.".format(word))
перерыв
Давайте немного разберемся.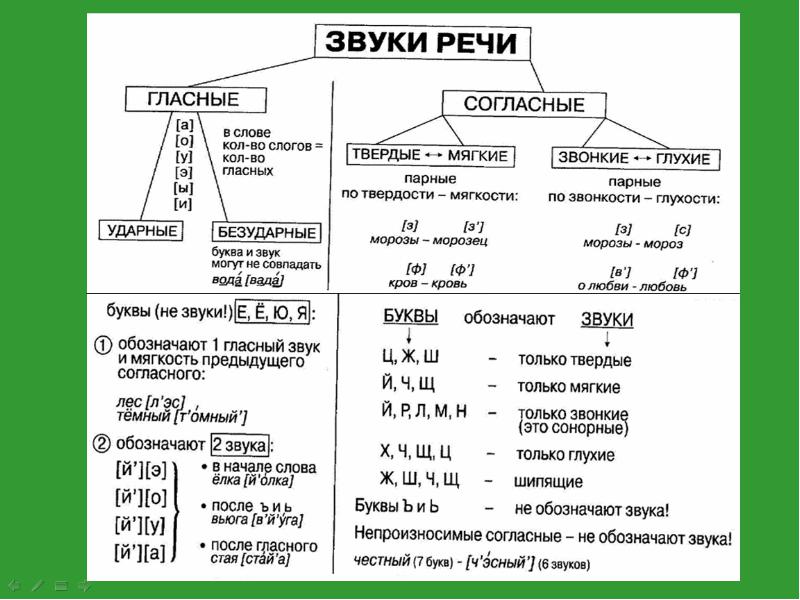
Функция cognition_speech_from_mic() принимает экземпляр Recognizer и Microphone в качестве аргументов и возвращает словарь с тремя ключами. Первый ключ, "success" , является логическим значением, указывающим, был ли запрос API успешным. Второй ключ, «ошибка» , — это либо None , либо сообщение об ошибке, указывающее, что API недоступен или речь неразборчива. Наконец, "транскрипция" ключ содержит транскрипцию звука, записанного микрофоном.
Функция сначала проверяет, что аргументы распознавателя и микрофона имеют правильный тип, и вызывает TypeError , если любой из них недействителен:
, если не isinstance(recognizer, sr.Recognizer):
поднять TypeError («распознаватель» должен быть экземпляром «распознавателя»)
если не экземпляр(микрофон, ср.микрофон):
поднять TypeError («микрофон» должен быть экземпляром «Микрофон»)
Затем используется метод listen() для записи микрофонного входа:
с микрофоном в качестве источника:
распознаватель. adjust_for_ambient_noise (источник)
аудио = распознаватель.слушай(источник)
 adjust_for_ambient_noise (источник)
аудио = распознаватель.слушай(источник)
adjust_for_ambient_noise (источник)
аудио = распознаватель.слушай(источник)
Метод Adjust_for_ambient_noise() используется для калибровки распознавателя для изменения шумовых условий каждый раз, когда вызывается функция распознавать_речи_от_микрофона() .
Затем вызывается распознавание_google() для расшифровки любой речи в записи. А 9Блок 0141 try...except используется для перехвата исключений RequestError и UnknownValueError и их соответствующей обработки. Успех запроса API, любые сообщения об ошибках и расшифрованная речь сохраняются в ключах Success , error и Transcription словаря response , который возвращается функцией распознать_speech_from_mic() .
ответ = {
"успех": Правда,
"ошибка": Нет,
"транскрипция": нет
}
пытаться:
ответ["транскрипция"] = распознаватель.recognize_google(аудио)
кроме sr. RequestError:
# API недоступен или не отвечает
ответ["успех"] = Ложь
ответ["ошибка"] = "API недоступен"
кроме sr.UnknownValueError:
# речь была неразборчива
response["error"] = "Не удалось распознать речь"
вернуть ответ
 RequestError:
# API недоступен или не отвечает
ответ["успех"] = Ложь
ответ["ошибка"] = "API недоступен"
кроме sr.UnknownValueError:
# речь была неразборчива
response["error"] = "Не удалось распознать речь"
вернуть ответ
RequestError:
# API недоступен или не отвечает
ответ["успех"] = Ложь
ответ["ошибка"] = "API недоступен"
кроме sr.UnknownValueError:
# речь была неразборчива
response["error"] = "Не удалось распознать речь"
вернуть ответ
Вы можете протестировать функцию распознать_речь_из_микрофона() , сохранив приведенный выше сценарий в файл с именем «guessing_game.py» и запустив в сеансе интерпретатора следующее:
>>>
>>> импортировать voice_recognition как sr
>>> из угадайки импортировать распознать_речь_из_микрофона
>>> r = sr.Recognizer()
>>> m = ср.Микрофон()
>>> распознать_речь_из_микрофона(р, м)
{'успех': Истина, 'ошибка': Нет, 'транскрипция': 'привет'}
>>> # Ваш вывод будет зависеть от того, что вы говорите
Сама игра довольно проста. Во-первых, объявляется список слов, максимально допустимое количество догадок и лимит подсказок:
.СЛОВ = ['яблоко', 'банан', 'виноград', 'апельсин', 'манго', 'лимон'] NUM_GUESSES = 3 ПРОМТ_ЛИМИТ = 5
Затем создается экземпляр Recognizer и Microphone и выбирается случайное слово из WORDS :
распознаватель = sr.
 Recognizer()
микрофон = ср.Микрофон()
слово = случайный.выбор(СЛОВА)
Recognizer()
микрофон = ср.Микрофон()
слово = случайный.выбор(СЛОВА)
После печати некоторых инструкций и ожидания в течение 3 трех секунд используется цикл для для управления каждой попыткой пользователя угадать выбранное слово. Первым делом в цикле for является еще один цикл for , который запрашивает у пользователя не более PROMPT_LIMIT раз для предположения, каждый раз пытаясь распознать ввод с помощью функции cognition_speech_from_mic() и сохраняя словарь, возвращенный в локальная переменная догадка .
Если "транскрипция" ключ предположения не равен None , то речь пользователя была расшифрована, и внутренний цикл завершается с break . Если речь не была расшифрована и ключ "успех" установлен на False , то произошла ошибка API и цикл снова завершается с break . В противном случае запрос API был выполнен успешно, но речь была неузнаваема. Пользователь предупрежден, и
Пользователь предупрежден, и для цикл повторяется, давая пользователю еще один шанс на текущую попытку.
для j в диапазоне (PROMPT_LIMIT):
print('Угадай {}. Произнеси!'.format(i+1))
угадать = распознать_речь_из_микрофона (распознаватель, микрофон)
если угадать["транскрипция"]:
перерыв
если не угадать["успех"]:
перерыв
print("Я не расслышал. Что ты сказал?\n")
После завершения внутреннего цикла for словарь предположения проверяется на наличие ошибок. Если таковая возникла, отображается сообщение об ошибке и внешний for Цикл завершается break , который завершит выполнение программы.
, если предположить ['ошибка']:
print("ОШИБКА: {}".format(догадка["ошибка"]))
перерыв
Если ошибок не было, транскрипция сравнивается со случайно выбранным словом. Метод lower() для строковых объектов используется для обеспечения лучшего соответствия предположения выбранному слову. API может возвращать речь, соответствующую слову «яблоко», как «яблоко» или «яблоко», и любой ответ должен считаться правильным ответом.
API может возвращать речь, соответствующую слову «яблоко», как «яблоко» или «яблоко», и любой ответ должен считаться правильным ответом.
Если предположение было правильным, пользователь выигрывает и игра прекращается. Если пользователь ошибся и у него остались попытки, внешний цикл for повторяется и извлекается новое предположение. В противном случае пользователь проигрывает игру.
предположение_верно_правильное = предположение["транскрипция"].нижний() == слово.нижний()
user_has_more_attempts = я < NUM_GUESSES - 1
если предположение_верно:
print('Верно! Вы выиграли!'.format(word))
перерыв
Элиф user_has_more_attempts:
print('Неверно. Попробуйте еще раз.\n')
еще:
print("Извините, вы проиграли!\nЯ думал о '{}'.".format(word))
перерыв
При запуске вывод будет выглядеть примерно так:
Я думаю об одном из этих слов: яблоко, банан, виноград, апельсин, манго, лимон У вас есть 3 попытки угадать, какой из них.
 Угадай 1. Говори!
Вы сказали: банан
Неправильно. Попробуйте еще раз.
Угадай 2. Говори!
Вы сказали: лимон
Неправильно. Попробуйте еще раз.
Угадай 3. Говори!
Вы сказали: Апельсин
Правильный! Ты победил!
Угадай 1. Говори!
Вы сказали: банан
Неправильно. Попробуйте еще раз.
Угадай 2. Говори!
Вы сказали: лимон
Неправильно. Попробуйте еще раз.
Угадай 3. Говори!
Вы сказали: Апельсин
Правильный! Ты победил!
Удалить рекламу
Резюме и дополнительные ресурсы
В этом руководстве вы узнали, как установить пакет SpeechRecognition и использовать его Recognizer , чтобы легко распознавать речь как из файла — с помощью record() — так и из микрофонного ввода — с помощью listen(). Вы также видели, как обрабатывать сегменты аудиофайла, используя смещение и длительность ключевые аргументы метода record() .
Вы увидели, как шум может влиять на точность транскрипции, и узнали, как настроить чувствительность экземпляра Recognizer к окружающему шуму с помощью настроить_для_окружающего_шума(). Вы также узнали, какие исключения может создавать экземпляр Recognizer — RequestError для неправильных запросов API и UnkownValueError для неразборчивой речи — и как обрабатывать их с помощью try. блоков. ..кроме
..кроме
Распознавание речи — это глубокая тема, и то, что вы здесь узнали, едва касается поверхности. Если вы хотите узнать больше, вот несколько дополнительных ресурсов.
Бесплатный бонус: Щелкните здесь, чтобы загрузить пример проекта распознавания речи Python с полным исходным кодом, который вы можете использовать в качестве основы для своих собственных приложений распознавания речи.
Дополнительные сведения о пакете распознавания речи:
.- Справочник по библиотеке
- Примеры
- Страница устранения неполадок
Несколько интересных интернет-ресурсов:
- За микрофоном: наука общения с компьютерами. Короткометражный фильм об обработке речи Google.
- Исторический взгляд на распознавание речи Хуанга, Бейкера и Редди. Сообщения ACM (2014). В этой статье представлен глубокий и научный взгляд на эволюцию технологии распознавания речи.
- Прошлое, настоящее и будущее технологии распознавания речи Кларка Бойда из The Startup. В этом сообщении блога представлен обзор технологии распознавания речи с некоторыми мыслями о будущем.
 В этом сообщении блога представлен обзор технологии распознавания речи с некоторыми мыслями о будущем.
В этом сообщении блога представлен обзор технологии распознавания речи с некоторыми мыслями о будущем.Несколько хороших книг по распознаванию речи:
- Голос в машине: создание компьютеров, понимающих речь, Pieraccini, MIT Press (2012). Доступная для широкой аудитории книга, охватывающая историю и современные достижения в области обработки речи.
- Основы распознавания речи, Рабинер и Хуанг, Прентис Холл (1993). Рабинер, исследователь из Bell Labs, сыграл важную роль в разработке некоторых из первых коммерчески жизнеспособных распознавателей речи. Этой книге уже более 20 лет, но многие основы остались прежними.
- Автоматическое распознавание речи: подход к глубокому обучению, Ю и Дэн, Спрингер (2014). Ю и Дэн — исследователи в Microsoft, оба активно работают в области обработки речи. Эта книга охватывает множество современных подходов и передовых исследований, но не для математически слабонервных.
Приложение: Распознавание речи на языках, отличных от английского
В этом руководстве мы распознавали речь на английском языке, который является языком по умолчанию для каждого распознать_*() метод пакета SpeechRecognition. Однако распознать речь на других языках вполне возможно, и сделать это довольно просто.
Однако распознать речь на других языках вполне возможно, и сделать это довольно просто.
Чтобы распознавать речь на другом языке, установите аргумент ключевого слова language метода распознать_*() в строку, соответствующую нужному языку. Большинство методов принимают языковой тег BCP-47, например 'en-US' для американского английского или 'fr-FR' для французского. Например, следующее распознает французскую речь в аудиофайле:
импортировать voice_recognition как sr
г = ср.Распознаватель()
с sr.AudioFile('path/to/audiofile.wav') в качестве источника:
аудио = r.record(источник)
r.recognize_google (аудио, язык = 'fr-FR')
Только следующие методы принимают аргумент ключевого слова языка :
-
распознать_bing() -
распознать_google() -
распознать_google_cloud() -
распознать_ibm() -
распознать_сфинкс()
Чтобы узнать, какие языковые теги поддерживаются используемым вами API, вам необходимо обратиться к соответствующей документации. Список тегов, принятых
Список тегов, принятых cognition_google() , можно найти в этом ответе на переполнение стека.
Смотреть сейчас Это руководство содержит связанный с ним видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Распознавание речи с помощью Python
IBE — Портал науки об обучении — Создание мозга, способного читать, часть 1: Звук и зрение
Человеческий мозг не предназначен для чтения. Чтобы научиться читать, мы должны построить и соединить нейронные системы для разговорной речи и визуальной обработки.
Этот отчет подготовлен стипендиями Science of Learning Fellowships, финансируемыми Международной организацией по исследованию мозга (IBRO) в партнерстве с Международным бюро образования (IBE) Организации Объединенных Наций по вопросам образования, науки и культуры (ЮНЕСКО). Стипендия IBRO/IBE-UNESCO Science of Learning Fellowship направлена на поддержку и распространение ключевых исследований нейронауки в области обучения и мозга для педагогов, политиков и правительств.
Резюме
- Чтение — относительно недавнее культурное изобретение: человеческий мозг не предназначен для чтения
- Чтобы читать, мы должны заимствовать и опираться на другие нейронные системы; мы строим на
- Системы обработки устной речи для обработки звуков речи
- Системы для соединения печатных букв с произносимыми звуками
- Области визуальной обработки для восприятия печатных слов
- Системы визуальной обработки, позволяющие перемещать взгляд по тексту на странице
- Обучение чтению не происходит естественным путем
- Детей надо учить читать
- Мозги, которые могут читать, должны быть построены
Человеческий мозг не предназначен для чтения
Чтение является относительно недавним культурным изобретением. Биологически это означает, что человеческий мозг не предназначен для чтения. То есть мозг не наделен врожденной частью, которая «занимается чтением». Действительно, с точки зрения эволюции не было достаточно времени для развития части мозга, которая «занимается чтением». И все же вы читаете эти слова. Как это возможно?
Действительно, с точки зрения эволюции не было достаточно времени для развития части мозга, которая «занимается чтением». И все же вы читаете эти слова. Как это возможно?
Вы построили мозг, который может читать, заимствуя, наращивая и «перерабатывая» другие нейронные системы например, 1,2 . Со временем и с практикой чтения вы и ваш мозг соединили эти системы для совместной работы на службе чтения. Для тех, кто не имел возможности сделать это, социальные и экономические издержки неграмотности, особенно для женщин и девочек, ошеломляют, например, 3 . Этот краткий обзор состоит из двух частей (см. также Создание мозга, способного читать, часть 2: словарный запас и значение 9).0004), рассматривает некоторые системы, участвующие в построении мозга, способного читать слова.[1]
[1] В обеих частях этого краткого руководства в качестве примера алфавитного языка используется английский (язык, в котором печатные символы алфавита отображаются на звуки разговорной речи).
 Чтение на всех языках включает преобразование печатного текста в речь, но на разных уровнях (зернистости). Обе части этого обзора также относятся к начинающим читателям как к маленьким детям, но те же самые принципы применимы к начинающим читателям старшего возраста и взрослым.
Чтение на всех языках включает преобразование печатного текста в речь, но на разных уровнях (зернистости). Обе части этого обзора также относятся к начинающим читателям как к маленьким детям, но те же самые принципы применимы к начинающим читателям старшего возраста и взрослым.Обработка разговорной речи: фонематическое осознание
Фонологическое осознание — это чувствительность к звуковой структуре разговорной речи например, 4,5 . Он включает в себя способности обнаруживать, идентифицировать и манипулировать звуками разговорной речи. Наименьшие единицы разговорной речи, отличающие одно слово от другого, называются фонемами . Например, звук, который издает буква p , является фонемой в английском языке. С этого момента я буду использовать косые черты, чтобы указать, что я имею в виду звуки, а не буквы; Итак, звук, что буква p делает это /p/.
Рисунок 1. Некоторые задания на фонематическую грамотность с примерами от менее сложных (внизу) к более сложным (вверху). Обратите внимание, что самая сложная задача, замена фонем, зависит от многих других навыков. Также вспомните, что фонематическое восприятие включает в себя обработку звука, поэтому в этих задачах не задействована печать — только произносимые слова и звуки.
Обратите внимание, что самая сложная задача, замена фонем, зависит от многих других навыков. Также вспомните, что фонематическое восприятие включает в себя обработку звука, поэтому в этих задачах не задействована печать — только произносимые слова и звуки.
Фонологическое сознание на уровне фонем называется фонематическим сознанием . Например, зная, какое из произнесенных слов швабра , машина, и мат начинаются с одного и того же звука, отражающего фонематическое восприятие. То же самое можно сказать и о возможности смешивать отдельные звуки /m/ /a/ /t/ в произнесенное слово mat . То же самое можно сказать и о возможности замены /b/ на /m/ в произносимом слове mat для создания нового произнесенного слова bat . Фонематическая осведомленность является одним из лучших предикторов обучения чтению на алфавитных языках , например, 6,7 . Действительно, фонематическая осведомленность предсказывает способность читать в школьные годы, от детского сада до 12 класса 9. 0969 8 .[2] Явное обучение учащихся распознаванию фонем и управлению ими (например, посредством игр с выделением и сопоставлением, смешиванием и заменой, как в приведенных выше примерах) считается передовой практикой, основанной на убедительных научных данных , например, 10, 11, с. 2 . Рисунок 1 суммирует некоторые задачи фонематического восприятия.
0969 8 .[2] Явное обучение учащихся распознаванию фонем и управлению ими (например, посредством игр с выделением и сопоставлением, смешиванием и заменой, как в приведенных выше примерах) считается передовой практикой, основанной на убедительных научных данных , например, 10, 11, с. 2 . Рисунок 1 суммирует некоторые задачи фонематического восприятия.
[2] В частности, лингвистическая природа и фонологическая сложность стимулов, наряду с требованием произвести вербальный ответ, являются компонентами задач на фонематическую осведомленность, которые были связаны с более поздней способностью к чтению (с точки зрения декодирования)
9 . К сожалению, разобрать произносимые слова на фонемы непросто. Например, рассмотрим произносимое слово box . Сколько и каких фонем в этом слове? В произнесенном слове box четыре фонемы: /b/ /o/ /k/ /s/. Если вы ошиблись в своем фонематическом анализе, вы не одиноки. Попробуйте это: сколько и какие фонемы есть в произнесенном слове туфелька ? В туфельке всего две фонемы: /sh/ и /oo/. Многие учителя до начала работы и в процессе работы не могут точно выполнять задачи по подсчету фонем и манипулированию ими, такие как эти примеры сегментации фонем например, 12,13,14 . Учителям трудно обучать маленьких детей фонемам в произносимых словах без адекватного понимания самих фонем. К счастью, есть ресурсы, которые помогут учителям улучшить фонематическую осведомленность и обучение , например, 11,15,16 .
Многие учителя до начала работы и в процессе работы не могут точно выполнять задачи по подсчету фонем и манипулированию ими, такие как эти примеры сегментации фонем например, 12,13,14 . Учителям трудно обучать маленьких детей фонемам в произносимых словах без адекватного понимания самих фонем. К счастью, есть ресурсы, которые помогут учителям улучшить фонематическую осведомленность и обучение , например, 11,15,16 .
Рис. 2. Левое полушарие головного мозга человека с задней верхней височной областью, окрашенной розовым цветом. Изменено из Хью Гейни (добавлено затенение) на Викискладе, CC BY-SA
Разговорная речь обрабатывается во многих областях мозга. Например, одна область в верхней части височной доли (называемая задней верхней височной извилиной/бороздой, см. , рис. 2 ) предназначена для обработки речи , например, 17 . У взрослых, слушающих речь, определенные группы нейронов в этой области активируются определенными звуками речи, такими как /p/ или /m/ 18,19 . То есть этот регион кодирует и обрабатывает разговорную речь на уровне фонем. Эта же верхняя височная область также активна во время чтения про себя у беглых читателей, когда нет звукового ввода из внешней среды например, 20,21 . Таким образом, мы заимствуем из системы обработки разговорного языка для чтения , например, 22 .
То есть этот регион кодирует и обрабатывает разговорную речь на уровне фонем. Эта же верхняя височная область также активна во время чтения про себя у беглых читателей, когда нет звукового ввода из внешней среды например, 20,21 . Таким образом, мы заимствуем из системы обработки разговорного языка для чтения , например, 22 .
Но в этой истории есть еще кое-что: эта система обработки языка коренным образом изменяется в ходе обучения чтению , например, 23,24,25 . То есть обучение чтению фактически меняет способ обработки речи в мозгу. После обучения чтению «обработка речи автоматически включает в себя разбиение звука речи на составляющие фонемы… Язык уже никогда не будет прежним» 26, стр. 1010-1011 . После всего лишь одного года чтения инструкций уровень активации в верхней височной области повышается, когда дети слушают устную речь 27 . То, что дети могут определить один и тот же звук /м/ в произносимых словах мат и маленький и джем является результатом обучения чтению.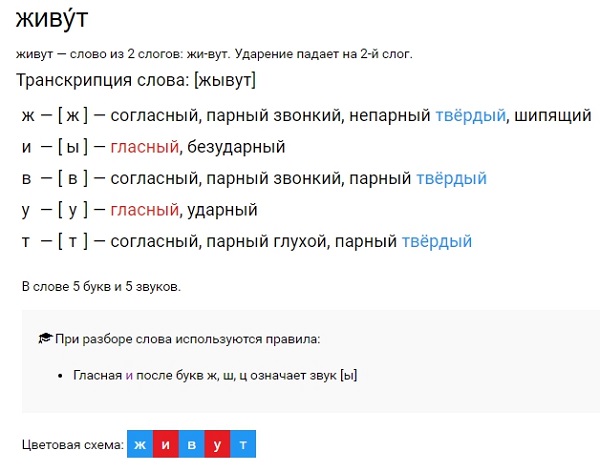 В алфавитных языках обучение чтению — это то, что позволяет нам обрабатывать речь на фонемном уровне и реорганизует нейронные системы обработки речи, лежащие в основе этого навыка 2 .
В алфавитных языках обучение чтению — это то, что позволяет нам обрабатывать речь на фонемном уровне и реорганизует нейронные системы обработки речи, лежащие в основе этого навыка 2 .
Соединение речи с печатным текстом: расшифровка
Таким образом, обучение чтению на алфавитных языках предполагает осознание фонем в речи. Это также включает в себя знание букв и комбинаций букв в печати. Важно отметить, что это также включает осознание того, что эти две вещи связаны: что звуки языка отображаются на письменные буквы. Алфавитный принцип — это понимание того, что существуют особые отношения между произносимыми звуками и печатными буквами. Обучение чтению и фонологическое осознание взаимно усиливают друг друга, потому что «фонологическое осознание помогает детям открыть для себя алфавитный принцип… [и] обучение чтению алфавитного письма также развивает фонологическое и фонематическое осознание» 28, с. 9 . Задача начинающего читателя состоит в том, чтобы узнать, какие буквы сочетаются с какими звуками, что называется графемо-фонемными соответствиями .
[3] Для получения информации о развитии знаний о буквах, см. краткое изложение в этой серии
Возникающая грамотность: создание основы для обучения чтению .Изучение сопоставлений между буквами (графемами) и звуками (фонемами) является основой декодирования в начале чтения. Декодирование — это трудоемкий процесс рассмотрения каждой буквы в печатном слове, сопоставления ее со звуком, а затем смешивания звуков вместе, чтобы прочитать слово. Например, в начале чтения написанное слово cat на странице читается как /kuh/ /ahh/ /tuh/ , а затем эти звуки сливаются в произнесенное слово cat . Побуквенное декодирование частично зависит от краткосрочной вербальной памяти, которая предсказывает начало чтения на уровне слов 29 .
Рис. 3. Пример декодируемого текста (художественная литература). Взято с http://www.freereading.net/w/images/f/f5/Decodable_Fiction_6.pdf, CC-BY SA 3.0 US
«Декодируемые тексты » — это книги, предназначенные для того, чтобы обеспечить достаточную практику озвучивания на основе шаблонов. слов (например, кошка, шляпа, коврик, сидел, летучая мышь ) и часто используются в учебных программах по фонетике. См. пример Рисунок 3 . Фонетические методы обучения чтению сосредоточены на построении знаний о соответствии графемы и фонемы явным, систематическим и структурированным образом и считаются передовой практикой в обучении начальному чтению на алфавитных языках , например, 10,31 . Имеются убедительные доказательства в пользу обучения учащихся декодированию в начале чтения, чтобы распознавать отдельные слова, в качестве основополагающего навыка, поддерживающего чтение для понимания 11 .
слов (например, кошка, шляпа, коврик, сидел, летучая мышь ) и часто используются в учебных программах по фонетике. См. пример Рисунок 3 . Фонетические методы обучения чтению сосредоточены на построении знаний о соответствии графемы и фонемы явным, систематическим и структурированным образом и считаются передовой практикой в обучении начальному чтению на алфавитных языках , например, 10,31 . Имеются убедительные доказательства в пользу обучения учащихся декодированию в начале чтения, чтобы распознавать отдельные слова, в качестве основополагающего навыка, поддерживающего чтение для понимания 11 .
[4] Декодируемые тексты знакомят детей с повторяющимися буквенно-звуковыми моделями (например,
-at ), так что с практикой начинающие читатели в конечном итоге узнают эту схему и им не нужно будет озвучивать каждый элемент (например, / at/, а не /a/ /t/). Из-за контролируемого (и, следовательно, ограниченного) словарного запаса и сюжетной линии в декодируемых текстах учителя могут захотеть рассмотреть возможность дополнения другими повествовательными и информационными текстами, которые учитель может читать с поддержкой или вслух. Такие тексты могут способствовать расширению словарного запаса и могут повысить интерес и мотивацию к чтению 9.0969 30 .
Такие тексты могут способствовать расширению словарного запаса и могут повысить интерес и мотивацию к чтению 9.0969 30 .Рисунок 4. Орфографическая глубина, представленная в виде трех уровней, хотя на самом деле это спектр, для языков по всему миру. Атрибуция: Р. Перейра, https://linguisticmaps.tumblr.com/post/187856489343/orthographic-depth-languages-have- Different-Levels
Насколько быстро дети учатся декодировать и читать слова, зависит от характера используемого языка. например, 32,33,34 . Это связано с тем, что регулярность соответствия графема-фонема варьируется в зависимости от языка. Эта регулярность или ее отсутствие упоминается как орфографическая глубина языка; орфографическая информация о глубине нанесена по всему миру в Рисунок 4 . Когда сопоставления очень последовательны (данная графема почти всегда соответствует одной и той же фонеме), как в языках с неглубокой орфографией , таких как итальянский, дети могут выучить все соответствия, которые будут применяться ко всем словам в течение первого года (или четные месяцы) обучения. Но когда сопоставления менее последовательны (данная графема может сопоставляться с несколькими фонемами, такими как c в английском языке отображается либо в /k/, либо в /s/, например, cat или city ) в языках с глубокой орфографией требуется больше времени для изучения. Например, детям, которые учатся читать на английском языке, требуется как минимум еще два года обучения чтению на том же уровне, что и детям, которые учатся читать на итальянском языке 32 .
Но когда сопоставления менее последовательны (данная графема может сопоставляться с несколькими фонемами, такими как c в английском языке отображается либо в /k/, либо в /s/, например, cat или city ) в языках с глубокой орфографией требуется больше времени для изучения. Например, детям, которые учатся читать на английском языке, требуется как минимум еще два года обучения чтению на том же уровне, что и детям, которые учатся читать на итальянском языке 32 .
Рис. 5. (A) Вид левого полушария человеческого мозга с верхней височной областью, заштрихованной розовым цветом. (B) Внутренний вид сверху левой височной доли с удаленными теменными областями, чтобы показать борозду Хешля (HS) и височную плоскость (PT). Изменено по материалам Мишель Мёрель, Федерико Де Мартино и Элии Формисано, 2014 г., Wikimedia Commons, CC-BY 3.0
Как у детей, так и у взрослых визуальная буквенная и слуховая речевая звуковая информация интегрируются в нейронных областях, расположенных вдоль верхней части височной доли 35-38 . Верхняя височная борозда и височная плоскость/область борозды Хешля завернуты в складки в верхней части височной доли, как показано на рис. 5 . Это области, которые кодируют соответствия графема-фонема, когда дети учатся читать. Хотя в последовательных языках можно выучить, какие буквы и какие звуки сочетаются в течение нескольких месяцев, переход от построения ассоциаций к автоматической интеграции букв и звуков в новые аудиовизуальные нейронные репрезентации может занять годы опыта чтения 37,39 .
Верхняя височная борозда и височная плоскость/область борозды Хешля завернуты в складки в верхней части височной доли, как показано на рис. 5 . Это области, которые кодируют соответствия графема-фонема, когда дети учатся читать. Хотя в последовательных языках можно выучить, какие буквы и какие звуки сочетаются в течение нескольких месяцев, переход от построения ассоциаций к автоматической интеграции букв и звуков в новые аудиовизуальные нейронные репрезентации может занять годы опыта чтения 37,39 .
Визуальная обработка: восприятие слов
Рис. 6. Вентральный (фиолетовый цвет) и дорсальный (зеленый цвет) потоки визуальной обработки (обозначения добавлены). Selket/Wikimedia Commons, лицензия GNU Free Documentation License, CC BY-SA 3.0
Вентральный зрительный путь, идущий от затылочной доли вдоль нижней части височной доли (см. рис. 6), специализирован для обработки текстуры, цвета, узора. , форма и мелкие детали например, 40 . Эти характеристики любой поступающей визуальной информации обрабатываются по этому пути. Нейронная обработка букв и слов во многом зависит от специализаций этой части зрительной системы. Например, мелкие детали, отличающие G от C, форма буквы B в виде одной вертикальной линии и двух кривых в определенном расположении, а также образцы графем, которые составляют значимые последовательности, такие как cat или -ing. , все извлекают выгоду из особенностей этого пути.
Эти характеристики любой поступающей визуальной информации обрабатываются по этому пути. Нейронная обработка букв и слов во многом зависит от специализаций этой части зрительной системы. Например, мелкие детали, отличающие G от C, форма буквы B в виде одной вертикальной линии и двух кривых в определенном расположении, а также образцы графем, которые составляют значимые последовательности, такие как cat или -ing. , все извлекают выгоду из особенностей этого пути.
Чтение не только заимствует вентральный зрительный путь, но также строит и изменяет его. В одном из первых исследований исследователи предъявляли взрослым, свободно читающим, четыре типа стимулов: настоящие слова (например, ANT), выдуманные слова (например, GEEL), цепочки букв (например, VSHFFT) и цепочки букв. подобные символы 41 . Сравнивая нейронные реакции на эти различные типы стимулов, исследователи заметили одну область вдоль вентрального зрительного пути, которая была активна только для настоящих и выдуманных слов. Поскольку это были стимулы, которые визуально принимали форму слов на английском языке, исследователи назвали эту область «областью визуальной словоформы». Это был один из первых отчетов о нейровизуализации области мозга, специализирующейся на обработке визуальных объектов, которые принимали форму — «выглядели как» — слова. Этот крошечный кусочек коры, казалось, был настроен на орфография слов (см. рисунок 7 ). С тех пор это открытие повторялось много раз, и область визуальной словоформы постоянно ассоциировалась с автоматической орфографической обработкой текста у беглых читателей , например, 42,43-46 .
Поскольку это были стимулы, которые визуально принимали форму слов на английском языке, исследователи назвали эту область «областью визуальной словоформы». Это был один из первых отчетов о нейровизуализации области мозга, специализирующейся на обработке визуальных объектов, которые принимали форму — «выглядели как» — слова. Этот крошечный кусочек коры, казалось, был настроен на орфография слов (см. рисунок 7 ). С тех пор это открытие повторялось много раз, и область визуальной словоформы постоянно ассоциировалась с автоматической орфографической обработкой текста у беглых читателей , например, 42,43-46 .
Рис. 7. Вид левого полушария человеческого мозга с приблизительным расположением области визуальной словоформы, окрашенной фиолетовым цветом. Изменено из Hugh Geiney (добавлено затенение) на Wikimedia Commons, CC BY-SA
Область визуальной словоформы не активируется печатными буквами у людей, не умеющих читать 2 . Обучение чтению стимулирует развитие и специализацию области визуальной словоформы. Эта область становится все более настроенной на слова с опытом чтения , например, 42,44 . По сути, область визуальной словоформы формируется внутри вентрального зрительного пути по мере увеличения навыков чтения , например, 44,47 . 47,49,50 . Действительно, уровни активации в области визуальной словоформы связаны со способностью к декодированию у читателей в возрасте от 7 до 18 лет.0969 например, 51 . Из этого следует, что специализация области визуальной словоформы для автоматической обработки орфографических слов распространяется за пределы начальной школы , например, 52,53 , до подросткового возраста , например, 54 .
Эта область становится все более настроенной на слова с опытом чтения , например, 42,44 . По сути, область визуальной словоформы формируется внутри вентрального зрительного пути по мере увеличения навыков чтения , например, 44,47 . 47,49,50 . Действительно, уровни активации в области визуальной словоформы связаны со способностью к декодированию у читателей в возрасте от 7 до 18 лет.0969 например, 51 . Из этого следует, что специализация области визуальной словоформы для автоматической обработки орфографических слов распространяется за пределы начальной школы , например, 52,53 , до подросткового возраста , например, 54 .
[5] Подобно другим областям вдоль вентрального зрительного пути, специализированным для птиц у опытных орнитологов или автомобилей у автомобильных экспертов
48 .Визуальная обработка: движения глаз
Дорсальный зрительный путь, идущий от затылочной доли через заднюю височную долю вверх в теменную долю (см. Рисунок 6 ), предназначен для обработки движения и восприятия глубины например, 40 . Вклад этого пути визуальной обработки в чтение может быть менее очевидным, учитывая, что на стандартной странице текста нет ничего движущегося, а печать не имеет глубины. Тем не менее, глазам читателя необходимо перемещаться по тексту на странице тщательно откалиброванным и скоординированным образом. Например, попытка читать по-английски справа налево или пропуск каждой второй строки текста наверняка создаст проблемы для понимания. Из-за своих основных особенностей дорсальный зрительный путь также участвует в глазодвигательном контроле (движениях глаз) например, 55 . Таким образом, обучение чтению также заимствует дорсальный путь обработки зрительной информации.
Рисунок 6 ), предназначен для обработки движения и восприятия глубины например, 40 . Вклад этого пути визуальной обработки в чтение может быть менее очевидным, учитывая, что на стандартной странице текста нет ничего движущегося, а печать не имеет глубины. Тем не менее, глазам читателя необходимо перемещаться по тексту на странице тщательно откалиброванным и скоординированным образом. Например, попытка читать по-английски справа налево или пропуск каждой второй строки текста наверняка создаст проблемы для понимания. Из-за своих основных особенностей дорсальный зрительный путь также участвует в глазодвигательном контроле (движениях глаз) например, 55 . Таким образом, обучение чтению также заимствует дорсальный путь обработки зрительной информации.
Рис. 8. Карикатура предложения, прочитанного с отмеченными фиксациями (синие точки, когда глаза ненадолго останавливаются) и саккадами (оранжевые линии, когда глаза двигаются по тексту). У опытных читателей фиксации длятся около 200-250 миллисекунд, а средняя длина саккады составляет от 7 до 9 знаков. Для начинающих читателей фиксации могут длиться более 300 миллисекунд, а средняя длина саккады намного короче, иногда всего 1 или 2 пробела между буквами. Фиксация и длина саккады также зависят от знакомства и сложности текста.
Для начинающих читателей фиксации могут длиться более 300 миллисекунд, а средняя длина саккады намного короче, иногда всего 1 или 2 пробела между буквами. Фиксация и длина саккады также зависят от знакомства и сложности текста.
Глаза читателей перемещаются по странице, делая серию остановок и прыжков. Остановки называются фиксациями , периоды, в течение которых глаза относительно неподвижны, а скачки называются саккадами , периоды, когда глаза переходят к следующей фиксации , например, 56 . Это показано на рис. 8 . Наблюдение за движениями глаз начинающих читателей показывает, что навыки, связанные с плавным перемещением глаз по тексту на странице, требуют некоторого времени для развития! По сравнению со беглым читателем, начинающие читатели имеют более длительную фиксацию (их взгляд дольше остается на одном месте страницы), более короткие саккады (они переводят взгляд на следующую фиксацию всего на одну-две буквы, а не на семь-девять, как при беглом чтении). читатели) и больше регрессий (они чаще возвращают взгляд на уже просмотренный текст) например, 56,57,58 . В среднем «начинающим читателям требуется две фиксации, чтобы определить слово, тогда как взрослым читателям достаточно одной фиксации» 58, с. 232 . Важно отметить, что незафиксированные буквы по-прежнему видны в пределах так называемого диапазона восприятия , например, 58 .[6] Каждая буква на странице визуально обрабатывается во время чтения. С практикой чтения движения глаз во время чтения становятся более взрослыми. Вероятно, это происходит, когда дорсальная зрительная система обучается «специальным движениям глаз и паттернам зрительного внимания, необходимым для чтения» 9.0969 60, с. 72 . Таким образом, обучаясь чтению, мы одновременно заимствуем и изменяем обработку в дорсальном зрительном пути.
читатели) и больше регрессий (они чаще возвращают взгляд на уже просмотренный текст) например, 56,57,58 . В среднем «начинающим читателям требуется две фиксации, чтобы определить слово, тогда как взрослым читателям достаточно одной фиксации» 58, с. 232 . Важно отметить, что незафиксированные буквы по-прежнему видны в пределах так называемого диапазона восприятия , например, 58 .[6] Каждая буква на странице визуально обрабатывается во время чтения. С практикой чтения движения глаз во время чтения становятся более взрослыми. Вероятно, это происходит, когда дорсальная зрительная система обучается «специальным движениям глаз и паттернам зрительного внимания, необходимым для чтения» 9.0969 60, с. 72 . Таким образом, обучаясь чтению, мы одновременно заимствуем и изменяем обработку в дорсальном зрительном пути.
[6] Если вы бегло читаете, ваш диапазон восприятия позволяет вам видеть от 7 до 9 пробелов справа от вашей фиксации, хотя и не так четко, как буквы в пределах фиксации, поскольку вы читаете на алфавитном языке, который читается слева направо, как в английском.
 В алфавитных языках, которые читаются справа налево, диапазон восприятия простирается влево на то же расстояние, на которое бегло читает 59 .
В алфавитных языках, которые читаются справа налево, диапазон восприятия простирается влево на то же расстояние, на которое бегло читает 59 .Заключение, часть 1
Поскольку мозг не предназначен для чтения, обучение чтению не происходит естественным путем, без обучения ср. 61 . Иными словами, чтение не является врожденным, и дети должны усвоить систематические отношения между звуками речи и визуальными символами в своем языке (языках): детей нужно учить читать. Из этого следует, что обучение чтению — это не только набор технических навыков, но и социальная практика, находящаяся в культурном контексте школьного образования и других учебных сред 62 .
В начале формального обучения обучение чтению на алфавитных языках зависит от структурированного опыта со звуками языка (фонемы) и печатными буквами и словами (графемами), понимания алфавитного принципа и большого количества практики сопоставления графем с фонемами. пока слова не смогут распознаваться и читаться автоматически.[7] Как обсуждалось в этом кратком изложении, этот опыт заимствует, строит и изменяет множество сетей обработки в мозгу. Обучение должно затрагивать все эти навыки, чтобы воспитать ребенка, умеющего читать, и все эти нейронные сети, чтобы сформировать мозг, способный читать.
пока слова не смогут распознаваться и читаться автоматически.[7] Как обсуждалось в этом кратком изложении, этот опыт заимствует, строит и изменяет множество сетей обработки в мозгу. Обучение должно затрагивать все эти навыки, чтобы воспитать ребенка, умеющего читать, и все эти нейронные сети, чтобы сформировать мозг, способный читать.
[7] Из этого следует, что основные проверки зрения и слуха рекомендуются задолго до начала формального обучения чтению; если ребенок не может четко видеть графемы или четко слышать фонемы, процесс будет нарушен.
Однако обучение чтению слов требует еще большего; многие процессы должны происходить согласованно. Некоторые другие важные аспекты начала чтения обсуждаются во второй части этого краткого обзора, Создание мозга, способного читать, часть 2: словарный запас и смысл .
Список литературы
- Dehaene, S. Чтение в мозгу: наука и эволюция человеческого изобретения . (Викинг, 2009).
- Dehaene, S. и др. Как обучение чтению меняет корковые сети, отвечающие за зрение и язык. Science 330, 1359-1364, doi:10.1126/science.1194140 (2010).
- Всемирный фонд грамотности. Экономические и социальные издержки неграмотности. (Всемирный фонд грамотности, Мельбурн, Австралия, 2018 г.).
- Трейман, Р. Основы грамотности. Современные направления психологической науки 9, 89-92, doi:10.1111/1467-8721.00067 (2000).
- Энтони, Дж. Л. и Фрэнсис, Д. Дж. Развитие фонологического сознания. Текущие направления в психологии 14, 255-259, doi:10.1111/j.0963-7214.2005.00376.x (2005).
- Хойен Т., Лундберг И., Станович К. Э. и Бьяалид И.-К. Компоненты фонологического сознания. Чтение и письмо 7, 171-188, doi:10.1007/BF01027184 (1995).
- Мелби-Лервог, М., Халаас, С.-А. Х. и Халм, К. Фонологические навыки и обучение чтению: метааналитический обзор. Психология. Бык. 138, 322-352, doi:10. 1037/a0026744 (2012).
- Калфи, Р. К., Линдамуд, П. и Линдамуд, К. Акустико-фонетические навыки и чтение — от детского сада до двенадцатого класса. J. Образование. Психол. 64, 293-298, doi:10.1037/h0034586 (1973).
- Каннингем, А. Дж., Уиттон, К., Талкотт, Дж. Б., Берджесс, А. П. и Шапиро, Л. Р. Деконструкция фонологических задач: вклад стимула и типа реакции в прогнозирование навыков раннего декодирования. Познание 143, 178-186, doi:10.1016/j.cognition.2015.06.013 (2015).
- Национальный институт детского здоровья и развития человека. Отчет Национальной комиссии по чтению. Обучение детей чтению: основанная на фактических данных оценка научно-исследовательской литературы по чтению и ее значение для обучения чтению (публикация NIH № 00-4769). (Правительственная типография США, Вашингтон, округ Колумбия, 2000 г.).
- Форман, Б. и др. Базовые навыки для поддержки чтения для понимания в детском саду до 3-го класса. (Национальный центр оценки образования и региональной помощи (NCEE), Институт педагогических наук, Министерство образования США, Вашингтон, округ Колумбия, 2016 г. ).
- Бос, К., Мазер, Н., Диксон, С., Подхайски, Б. и Чард, Д. Восприятие и знания дослужебных и неработающих педагогов об обучении чтению в раннем возрасте. Annals of Dyslexia 51, 97-120, doi: 10.1007/s11881-001-0007-0 (2001).
- Чизман, Э. А., Макгуайр, Дж. М., Шанквейлер, Д. и Койн, М. Знания учителей-первокурсников в области фонематического восприятия и его обучения. Педагогическое образование и специальное образование 32, 270-289, doi: 10.1177/0888406409339685 (2009 г.).
- Стейнторп, Р. Используй или потеряешь. Грамотность сегодня , 16-17 (2003).
- Moats, L.C. Speech to print: основы языка для учителей . (Пол Х. Брукс, 2000).
- Линдамуд, П., Белл, Н. и Линдамуд, П. Сенсорно-когнитивные факторы в полемике по поводу обучения чтению. Journal of Developmental and Learning Disorders 1, 143-182 (1997).
- Биндер, Дж. Р. и др. Активация височной доли человека речевыми и неречевыми звуками. Церебр. Cortex 10, 512-528, doi:10.1093/cercor/10.5.512 (2000).
- Mesgarani, N., Cheung, C., Johnson, K. & Chang, EF. Кодирование фонетических признаков в верхней височной извилине человека. Science 343, 1006-1010, doi:10.1126/science.1245994 (2014).
- Чанг, Э. Ф. и др. Репрезентация категориальной речи в верхней височной извилине человека. Нац. Неврологи. 13, 1428-1433, doi:10.1038/nn.2641 (2010).
- Жубер, С. и др. Нейронные корреляты лексических и подлексических процессов при чтении. Брэйн Ланг. 89, 9-20, doi:10.1016/S0093-934X(03)00403-6 (2004).
- Симос, П. Г. и др. Мозговые механизмы чтения: роль верхней височной извилины в назывании слов и псевдослов. Нейроотчет 11, 2443-2447, doi:10.1097/00001756-200008030-00021 (2000).
- Moats, L.C. Speech to print: основы языка для учителей . 2-е изд. (Пол Х. Брукс, 2010 г.).
- Бреннан, К. , Као, Ф., Педроарена-Лил, Н., Макнорган, К. и Бут, Дж. Р. Овладение чтением реорганизует сеть фонологической осведомленности только в алфавитных системах письма. Гул. Карта мозга. 34, 3354-3368, doi:10.1002/hbm.22147 (2013).
- Кастро-Калдас, А., Петерссон, К.М., Рейс, А., Стоун-Эландер, С. и Ингвар, М. Неграмотный мозг: обучение чтению и письму в детстве влияет на функциональную организацию мозга взрослого человека. Мозг 121, 1053-1063, doi:10.1093/brain/121.6.1053 (1998).
- Нейшн, К. и Халм, К. Обучение чтению меняет фонологические навыки детей: данные латентного переменного лонгитюдного исследования чтения и повторения слов. Наука о развитии , doi:10.1111/j.1467-7687.2010.01008.x (2010).
- Frith, U. Буквальное изменение мозга. Мозг 121, 1011-1012, doi: 10.1093/brain/121.6.1011 (1998).
- Монзальво, К. и Дехане-Ламбертц, Г. Как овладение чтением меняет сеть разговорной речи детей. Брэйн Ланг. 127, 356-365, doi:10. 1016/j.bandl.2013.10.009 (2013).
- Панг Э.С., Муака А., Бернхардт Э.Б. и Камил М.Л. Обучение чтению. Серия «Образовательная практика» — 12. (Международное бюро образования, Международная академия образования, Женева, Швейцария, 2003 г.).
- Каннингем, А. Дж., Берджесс, А. П., Уиттон, К., Талкотт, Дж. Б. и Шапиро, Л. Р. Динамические отношения между фонологической памятью и чтением: пятилетнее лонгитюдное исследование в возрасте от 4 до 9 лет.. Наука о развитии , 1–18, doi: 10.1111 / desc.12986 (2020).
- Templeton, S. & Gehsmann, K.M. Обучение чтению и письму: развивающий подход . (Пирсон, 2014).
- Национальный исследовательский совет. Предотвращение затруднений при чтении у детей младшего возраста . (Издательство Национальной академии, 1998).
- Сеймур, П. Х. К., Аро, М. и Эрскин, Дж. М. Фонд повышения грамотности в европейских орфографиях. руб. Дж. Психол. 94, 143-174, doi:10.1348/000712603321661859 (2003).
- Зиглер, Дж. К. и Госвами, У. Грамотность на разных языках: похожие проблемы, разные решения. Наука о развитии 9, 429-453 (2006).
- Караволас, М., Лервог, А., Дефиор, С., Малкова, Г. С. и Хьюм, К. Различные модели, но эквивалентные предикторы роста чтения в последовательных и непоследовательных орфографиях. Психологические науки 24, 1398-1407, doi:10.1177/0956797612473122 (2013 г.).
- Блау, В. и др. Девиантная обработка букв и звуков речи как непосредственная причина нарушения чтения: исследование функциональной магнитно-резонансной томографии детей с дислексией. Brain 133, 868-879, doi: 10.1093/brain/awp308 (2010).
- ван Аттевельдт, Н., Формисано, Э., Гебель, Р. и Бломерт, Л. Интеграция букв и звуков речи в человеческом мозгу. Neuron 43, 271-282, doi:10.1016/j.neuron.2004.06.025 (2004).
- Бломерт, Л. Нейронная подпись орфографо-фонологического связывания при успешном и неудачном развитии чтения. Neuroimage 57, 695-703, doi:10.1016/j.neuroimage.2010.11.003 (2011).
- Richlan, F. Функциональная нейроанатомия звуковой интеграции букв и речи и ее связь с аномалиями мозга при дислексии развития. Frontiers in Human Neuroscience 13, 1–8, doi:10.3389/fnhum.2019.00021 (2019).
- Фройен, Д.Дж.В., Бонте, М.Л., ван Аттевельдт, Н. и Бломерт, Л. Долгий путь к автоматизации: нейрокогнитивное развитие обработки букв и речи. J. Cogn. Неврологи. 21, 567-580, doi:10.1162/jocn.2009.21061 (2009).
- Ливингстон, М. и Хьюбел, Д. Разделение формы, цвета, движения и глубины: анатомия, физиология и восприятие. Science 240, 740-749, doi:10.1126/science.3283936 (1988).
- Петерсен, С.Э., Фокс, П.Т., Познер, М.И., Минтун, М. и Райхл, М.Е. Позитронно-эмиссионные томографические исследования анатомии коры при обработке отдельных слов. Природа 331, 585-589, doi:10.1038/331585a0 (1988).
- Cohen, L. & Dehaene, S. Специализация внутри вентрального потока: случай для области визуальной словоформы. Neuroimage 22, 466-476, doi:10.1016/j.neuroimage.2003.12.049 (2004).
- Коэн, Л. и др. Языковая настройка зрительной коры? Функциональные свойства области формы визуального слова. Brain 125, 1054-1069, doi: 10.1093/brain/awf094 (2002).
- McCandliss, B.D., Cohen, L. & Dehaene, S. Область визуальной формы слова: опыт чтения в веретенообразной извилине. Trends in Cognitive Sciences 7, 293-299, doi: 10.1016/S1364-6613(03)00134-7 (2003).
- Глезер, Л. С., Цзян, X. и Ризенхубер, М. Доказательства высокоизбирательной настройки нейронов на целые слова в «визуальной области словоформы». Neuron 62, 199-204, doi:10.1016/j.neuron.2009.03.017 (2009).
- Dehaene, S. & Cohen, L. Уникальная роль визуальной области словоформы в чтении. Trends in Cognitive Sciences 15, 254-262, doi:10.1016/j.tics.2011.04.003 (2011).
- Ванделл, Б. А., Раушекер, А. М. и Йетман, Дж. Д. Учимся видеть слова. год. Преподобный Психолог. 63, 31-53, doi:10.1146/annurev-psych-120710-100434 (2012).
- Готье, И., Скудларски, П., Гор, Дж. К. и Андерсон, А. В. Экспертиза автомобилей и птиц задействует области мозга, участвующие в распознавании лиц. Нац. Неврологи. 3, 191-197, doi:10.1038/72140 (2000).
- Брем, С. и др. Чувствительность мозга к печатным текстам возникает, когда дети усваивают звуковые соответствия букв и речи. Proceedings of the National Academy of Sciences 107, 7939-7944, doi:10.1073/pnas.02107 (2010).
- Centanni, T. и др. Раннее развитие буквенной специализации в левой веретенообразной форме связано с лучшим чтением слов и меньшей площадью лица веретенообразной формы. Наука о развитии 21, e12658, doi: 10.1111 / desc.12658 (2018).
- Shaywitz, B.A. et al. Нарушение задних отделов мозга при чтении у детей с дислексией развития. Биол. Психиатрия 52, 101-110, doi:10.1016/S0006-3223(02)01365-3 (2002).
- Coch, D. & Meade, G. N1 и P2 к словам и словесным стимулам у детей позднего начального школьного возраста и взрослых. Психофизиология 53, 115-128, doi:10.1111/psyp.12567 (2016).
- Эдди, М. Д., Грейнджер, Дж., Холкомб, П. Дж., Митра, П. и Габриэли, Дж. Д. Э. Маскированный прайминг и ERP диссоциируют созревание орфографических и семантических компонентов визуального распознавания слов у детей. Психофизиология 51, 136-141, doi:10.1111/psyp.12164 (2014).
- Брем, С. и др. Доказательства изменений в развитии сети визуальной обработки текстов после подросткового возраста. Neuroimage 29, 822-837, doi:10.1016/j.neuroimage.2005.09.023 (2006).
- Boden, C. & Giaschi, D. Дефицит M-потока и зрительные процессы, связанные с чтением, при дислексии развития. Психология. Бык. 133, 346-366, doi:10.1037/0033-2909.133.2.346 (2007).
- Райнер К., Форман Б. Р., Перфетти К. А., Песецкий Д. и Зайденберг М. С. Как психологическая наука влияет на обучение чтению. Психологическая наука в интересах общества 2, 31-74, doi: 10.1111/1529-1006.00004 (2001).
- Блайт, Х.И. Изменения в развитии движений глаз и кодирования визуальной информации, связанные с обучением чтению. Современные направления психологической науки 23, 201-207, doi: 10.1177/0963721414530145 (2014).
- Райнер, К. Движения глаз и диапазон восприятия у начинающих и опытных читателей. Дж. Экспл. Детская психология. 41, 211-236, doi:10.1016/0022-0965(86)
-8 (1986).
- Jordan, TR и др. Направление чтения и центральный диапазон восприятия: данные из арабского и английского языков. Psychonomic Bulletin & Review 21, 505-511, doi: 10.3758/s13423-013-0510-4 (2014).
- Ванделл, Б. А. Нейробиологические основы видения слов. Энн. Н. Я. акад. науч. 1224, 63-80, doi:10. 1111/j.1749-6632.2010.05954.x (2011).
- Гудман, К. С. и Гудман, Ю. М. Учиться читать — это естественно. В Теория и практика раннего чтения Том. 1 (под редакцией Л.Б. Резника и П.А. Уивера) 137–154 (Эрлбаум, 1979).
- Street, B. Обучение чтению с точки зрения социальной практики: этнография, школьное образование и обучение взрослых. Проспекты 46, 335-344, doi:10.1007/s11125-017-9411-z (2016).
 1037/a0026744 (2012).
1037/a0026744 (2012). ).
). Церебр. Cortex 10, 512-528, doi:10.1093/cercor/10.5.512 (2000).
Церебр. Cortex 10, 512-528, doi:10.1093/cercor/10.5.512 (2000). , Као, Ф., Педроарена-Лил, Н., Макнорган, К. и Бут, Дж. Р. Овладение чтением реорганизует сеть фонологической осведомленности только в алфавитных системах письма. Гул. Карта мозга. 34, 3354-3368, doi:10.1002/hbm.22147 (2013).
, Као, Ф., Педроарена-Лил, Н., Макнорган, К. и Бут, Дж. Р. Овладение чтением реорганизует сеть фонологической осведомленности только в алфавитных системах письма. Гул. Карта мозга. 34, 3354-3368, doi:10.1002/hbm.22147 (2013). 1016/j.bandl.2013.10.009 (2013).
1016/j.bandl.2013.10.009 (2013).
Анализ набора данных UrbanSound8K с помощью TensorFlow | Паскаль Янецки
От необработанного аудио к TFRecord к пакетам заполнения
Существует несколько способов подачи данных в нейронную сеть. Чаще всего используются массивы Numpy и файлы CSV/Pandas. Кроме того, TensorFlow предлагает собственный формат хранения TFRecord. Это удобно, но не очень удобно для новичков.
Photo by Richard Horvath on Unsplash Несмотря на то, что многие наборы данных, такие как MNIST или CIFAR, легко доступны, иногда вам приходится создавать собственные наборы данных самостоятельно. К счастью, перевести другие наборы данных в формат TFRecord не так сложно, если вы сделали это несколько раз. Здесь мы проанализируем набор данных UrbanSound8K, сохраним его в формате TFRecord и, наконец, пройдемся по его образцам. Если вы совершенно не знакомы с этим форматом, вы можете получить практический обзор здесь, в котором также рассказывается, как мы можем анализировать данные текста и изображения.
Описание набора данных
Набор данных UrbanSound8K [1] (доступен бесплатно только для некоммерческого использования; CC BY-NC 3.0) содержит 8732 аудиофайла различной продолжительности. Максимум 4 секунды каждый образец принадлежит к одному из 10 классов. Файлы поставляются в десятикратном порядке и хранятся в формате WAVE. Каждый файл может иметь разную частоту дискретизации, разрядность и количество каналов. С ~ 7 ГБ это набор данных среднего размера. Таким образом, если вы ищете меньший по размеру и более доступный набор аудиоданных, взгляните на ESC50.
Загрузка и извлечение
Перейдите на веб-страницу набора данных и щелкните ссылку для загрузки внизу, чтобы загрузить набор данных. Как уже упоминалось, вы можете использовать данные бесплатно, но только для некоммерческих проектов — для этого пояснительного сообщения в блоге, демонстрирующего синтаксический анализ данных и связанные с ним концепции, все в порядке.
В зависимости от вашего подключения загрузка может занять несколько минут. После скачивания распакуйте архив. Теперь у вас есть две папки, аудио и метаданные . Нам нужен только первый.
В этой папке файлы предварительно распределены по десяти папкам, от fold1 до fold10 . Все файлы именуются по следующей схеме:
{SOURCE_ID}-{LABEL}-{TAKE}-{SLICE}.wav
Первая часть используется для идентификации ID исходного файла, LABEL для метка класса и TAKE и SLICE используются для различения нескольких семплов, взятых из одного исходного файла.
Разбор аудиоданных в TFRecords
Заранее, если вы впервые работаете с TFRecords, собственным форматом TensorFlow для эффективного хранения данных, или вам нужно освежить знания, взгляните на этот блокнот Google Colab и сопроводительное описание здесь.
Нам не нужен файл метаданных, потому что метка аудиосэмпла вписана в его имя файла. Таким образом, мы можем начать непосредственно с записи данных в файлы TFRecord. Для этого мы сначала импортируем несколько пакетов и пару вспомогательных функций:0005
Затем мы определяем функцию, которая загружает звук с диска. Для этого используем библиотеку librosa . Хотя есть альтернативы, такие как scipy , я нашел его наиболее удобным. Кроме того, мы можем быстро извлечь метку, разделив имя файла сначала на «/», а затем на «-». В конце мы возвращаем аудиоданные, их частоту дискретизации, метку и имя файла:
Затем мы определяем функцию, которая делает извлеченные данные готовыми к сохранению. Здесь мы будем использовать вспомогательную функцию, реализованную ранее. Как я описал во вводном практическом руководстве по формату TFRecord, эти функции используются для подготовки целых чисел, чисел с плавающей запятой, строк и байтов к записи на диск. Присвоение функциям подходящих имен поможет нам извлечь их позже. Наконец, мы заворачиваем их в Пример объекта, похожего на коробку с некоторым содержимым и свойствами. Следующее изображение иллюстрирует эту концепцию:
Теперь у нас определены две основные функции: загрузка аудиоданных с диска и преобразование их в формат, совместимый с TFRecord. Следовательно, мы можем реализовать метод, объединяющий оба. Для этого мы создаем объект TFRecordWriter , отвечающий за запись данных на диск, и перебираем все найденные аудиофайлы. Затем каждый аудиофайл анализируется, упаковывается в Пример объекта и записан в файл TFRecord.
Несмотря на то, что набор данных относительно велик, отдельный файл TFRecord, в котором хранится одна полная складка, имеет подходящий размер, около 550 МБ. Для больших наборов данных вы хотите использовать больше файлов. Для таких случаев в документации есть несколько советов.
Наконец, мы реализуем следующую основную функцию для перебора всех сгибов:
Чтобы завершить наш небольшой сценарий, мы определяем синтаксический анализатор аргументов. Он ведет к audio каталог, упомянутый в начале, и выходной каталог. Если этот каталог еще не существует, он будет создан:
Запуск скрипта выполняется вызовом python /path/to/script.py
С скриптом, определенным для создания файлов TFRecord, мы, вероятно, хотим прочитать файлы обратно позже. Вот это мы сейчас и реализуем.
Чтение аудиоданных из TFRecords
После того, как вы сделали это пару раз, на самом деле очень просто получить данные из файлов TFRecord. Нам просто нужно инвертировать процедуру сохранения. Предварительно мы поставили функции, названные sr , len , y , и так далее, в коробку. Таким образом, мы используем одни и те же имена для получения данных.
Единственное замечание касается аудиоданных. Поскольку это массив, мы должны изменить его форму. Вот почему мы сохранили свойство len . Точно так же имя файла должно быть преобразовано в строку:
Мы используем следующую функцию для чтения содержимого одного или нескольких файлов TFRecord. Он возвращает набор данных объект:
Мы можем перебрать первые несколько элементов, используя цикл for, проверяя их на наличие ошибок. Каждый образец состоит из четырех компонентов: фактических аудиоданных, метки, частоты дискретизации и исходного имени файла:
Одно предостережение — неравномерная продолжительность файла. Обычная пакетная операция завершится ошибкой. Таким образом, мы должны заполнить партии. Мы можем сделать это следующим образом:
Примечание. Мы дополняем образец до 178017 записей, потому что самый длинный аудиофайл чуть больше 4 секунд, и мы не хотим усекать эти данные. Максимальное время всех остальных файлов составляет 4 секунды * 44 100 Гц = 176 400 сэмплов.
Вот оно! Теперь дело за вами.
В этом посте мы преобразовали набор данных UrbanSound8K в TFRecord. Для этого мы использовали 9Библиотека Python 0003 librosa и несколько вспомогательных функций. Затем мы перебрали заранее определенные складки и проанализировали каждую отдельно.
В конце концов, мы извлекли данные, а также заполнили пакет. Это дало нам набор данных, который мы можем повторить.
Литература
[1] Дж. Саламон, К. Джейкоби и Дж. П. Белло, « Набор данных и таксономия для исследования городского звука », 22-я Международная конференция ACM по мультимедиа, Орландо, США, ноябрь 2014 г.
Аудиоанализ С помощью машинного обучения: создание приложения для обнаружения звука на основе искусственного интеллекта
Время чтения: 15 минут
Мы живем в мире звуков: приятные и раздражающие, низкие и высокие, тихие и громкие, они влияют на наше настроение и наши решения. Наш мозг постоянно обрабатывает звуки, чтобы дать нам важную информацию об окружающей среде. Но акустические сигналы могут сказать нам еще больше, если анализировать их с помощью современных технологий.
Сегодня у нас есть искусственный интеллект и машинное обучение для извлечения информации, неслышимой для людей, из речи, голосов, храпа, музыки, промышленного и дорожного шума и других типов акустических сигналов. В этой статье мы поделимся тем, что узнали при создании решений для распознавания звука на основе ИИ для проектов в области здравоохранения.
В частности, мы объясним, как получить аудиоданные, подготовить их к анализу и выбрать правильную модель машинного обучения для достижения максимальной точности предсказания. Но сначала давайте рассмотрим основы: что такое анализ звука и что делает работу с аудиоданными такой сложной задачей.
Что такое аудиоанализ?
Аудиоанализ — это процесс преобразования, исследования и интерпретации аудиосигналов, записанных цифровыми устройствами. Стремясь понять звуковые данные, он применяет ряд технологий, в том числе современные алгоритмы глубокого обучения. Аудиоанализ уже получил широкое распространение в различных отраслях, от развлечений до здравоохранения и производства. Ниже мы приведем самые популярные варианты использования.
Распознавание речи
Распознавание речи связано со способностью компьютеров различать произносимые слова с помощью методов обработки естественного языка. Это позволяет нам управлять ПК, смартфонами и другими устройствами с помощью голосовых команд и диктовать тексты машинам вместо ручного ввода. Siri от Apple, Alexa от Amazon, Google Assistant и Cortana от Microsoft — популярные примеры того, насколько глубоко технология проникла в нашу повседневную жизнь.
Распознавание голоса
Распознавание голоса предназначено для идентификации людей по уникальным характеристикам их голоса, а не для выделения отдельных слов. Подход находит применение в системах безопасности для аутентификации пользователей. Например, биометрический движок Nuance Gatekeeper проверяет сотрудников и клиентов по их голосам в банковском секторе.
Распознавание музыки
Распознавание музыки — это популярная функция таких приложений, как Shazam, которая помогает вам идентифицировать неизвестные песни по короткому образцу. Еще одним применением музыкального аудиоанализа является классификация жанров: скажем, Spotify использует собственный алгоритм для группировки треков по категориям (их база данных содержит более 5000 жанров)9.0005
Распознавание звуков окружающей среды
Распознавание звуков окружающей среды фокусируется на идентификации окружающих нас шумов, обещая множество преимуществ для автомобильной и обрабатывающей промышленности. Это жизненно важно для понимания окружения в приложениях IoT.
Такие системы, как Audio Analytic, «прислушиваются» к событиям внутри и снаружи автомобиля, позволяя автомобилю вносить коррективы для повышения безопасности водителя. Другим примером является технология SoundSee от Bosch, которая может анализировать шумы машин и упрощает профилактическое обслуживание для контроля состояния оборудования и предотвращения дорогостоящих отказов.
Здравоохранение — еще одна область, где может пригодиться распознавание звуков окружающей среды. Он предлагает неинвазивный тип удаленного мониторинга пациента для обнаружения таких событий, как падение. Кроме того, анализ кашля, чихания, храпа и других звуков может облегчить предварительный скрининг, определение статуса пациента, оценку уровня заражения в общественных местах и так далее.
Примером такого анализа в реальной жизни является Sleep.ai, который обнаруживает скрежетание зубами и звуки храпа во время сна. Решение, созданное AltexSoft для голландского стартапа в области здравоохранения, помогает стоматологам выявлять и контролировать бруксизм, чтобы в конечном итоге понять причины этой аномалии и лечить ее.
Независимо от того, какие звуки вы анализируете, все начинается с понимания аудиоданных и их специфических характеристик.
Что такое аудиоданные?
Аудиоданные представляют аналоговые звуки в цифровом виде, сохраняя основные свойства оригинала. Как мы знаем из школьных уроков физики, звук — это волна колебаний, проходящая через среду, такую как воздух или вода, и достигающая в конце концов наших ушей. Он имеет три ключевые характеристики, которые необходимо учитывать при анализе аудиоданных: период времени, амплитуда и частота.
Время Период - это то, как долго длится определенный звук или, другими словами, сколько секунд требуется для завершения одного цикла колебаний.
Амплитуда — это интенсивность звука, измеряемая в децибелах (дБ), которую мы воспринимаем как громкость.
Частота , измеряемая в герцах (Гц), показывает, сколько звуковых колебаний происходит в секунду. Люди интерпретируют частоту как низкий или высокий тон .
В то время как частота является объективным параметром, высота звука субъективна. Диапазон человеческого слуха лежит между 20 и 20 000 Гц. Ученые утверждают, что большинство людей воспринимают как низкий тон все звуки ниже 500 Гц — например, рев двигателя самолета. В свою очередь, высоким тоном для нас является все, что выше 2000 Гц (например, свист.)
Форматы файлов аудиоданных
Подобно текстам и изображениям, аудио представляет собой неструктурированные данные, что означает, что они не организованы в таблицы со связанными строками и столбцами. Вместо этого вы можете хранить аудио в различных форматах файлов, таких как
- WAV или WAVE (формат аудиофайла Waveform), разработанных Microsoft и IBM. Это формат файла без потерь или необработанный, что означает, что он не сжимает исходную звуковую запись;
- AIFF (формат файла обмена аудио), разработанный Apple. Как и WAV, он работает с несжатым звуком;
- FLAC (бесплатный аудиокодек без потерь), разработанный Xiph.Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.
- MP3 (аудиослой mpeg-1 3), разработанный Обществом Фраунгофера в Германии и поддерживаемый во всем мире. Это наиболее распространенный формат файлов, поскольку он позволяет легко хранить музыку на портативных устройствах и пересылать туда и обратно через Интернет. Хотя mp3 сжимает звук, он по-прежнему обеспечивает приемлемое качество звука.
Мы рекомендуем использовать файлы aiff и wav для анализа, так как они не пропускают информацию, присутствующую в аналоговых звуках. В то же время имейте в виду, что ни те, ни другие аудиофайлы нельзя напрямую скармливать моделям машинного обучения. Чтобы сделать звук понятным для компьютеров, данные должны быть преобразованы.
Основы преобразования аудиоданных, которые нужно знать
Прежде чем углубиться в обработку аудиофайлов, нам нужно ввести определенные термины, с которыми вы столкнетесь почти на каждом этапе нашего пути от сбора звуковых данных до получения прогнозов машинного обучения. Стоит отметить, что аудиоанализ предполагает работу с изображениями, а не прослушивание.
Форма волны — это базовое визуальное представление аудиосигнала, отражающее изменение амплитуды во времени. График отображает время по горизонтальной оси (X) и амплитуду по вертикальной оси (Y), но не говорит нам, что происходит с частотами.
Пример сигнала. Источник: Обработка звуковых сигналов для машинного обучения
Спектр или спектральный график представляет собой график, на котором ось X показывает частоту звуковой волны, а ось Y представляет ее амплитуду. Этот тип визуализации звуковых данных помогает вам анализировать частотный контент, но пропускает временную составляющую.
Пример графика спектра. Источник: Analytics Vidhya
Спектрограмма представляет собой подробное представление сигнала, которое охватывает все три характеристики звука. Вы можете узнать о времени по оси x, частоте по оси y и амплитуде по цвету. Чем громче событие, тем ярче цвет, а тишина представлена черным цветом. Иметь три измерения на одном графике очень удобно: это позволяет отслеживать, как меняются частоты во времени, исследовать звук во всей его полноте, на глаз выявлять различные проблемные места (например, шумы) и паттерны.
Пример спектрограммы. Источник: iZotope
Спектрограмма мела , где мел означает мелодия, представляет собой разновидность спектрограммы, основанную на шкале мела, которая описывает, как люди воспринимают звуковые характеристики. Наше ухо различает низкие частоты лучше, чем высокие. Вы можете проверить это сами: Попробуйте сыграть тоны от 500 до 1000 Гц, а затем от 10 000 до 10 500 Гц. Первый диапазон частот, казалось бы, намного шире второго, хотя на самом деле они одинаковы. Спектрограмма мела включает в себя эту уникальную особенность человеческого слуха, преобразуя значения в герцах в шкалу мела. Этот подход широко используется для классификации жанров, обнаружения инструментов в песнях и распознавания речевых эмоций.
Пример мел спектрограммы. Источник: Devopedia
Преобразование Фурье (FT) — это математическая функция, которая разбивает сигнал на пики различной амплитуды и частоты. Мы используем его для преобразования сигналов в соответствующие графики спектра, чтобы посмотреть на тот же сигнал под другим углом и выполнить частотный анализ. Это мощный инструмент для понимания сигналов и устранения ошибок в них.
Быстрое преобразование Фурье (БПФ) — это алгоритм вычисления преобразования Фурье.
Применение БПФ для просмотра того же сигнала с точки зрения времени и частоты. Источник: NTi Audio
Кратковременное преобразование Фурье (STFT) представляет собой последовательность преобразований Фурье, преобразующих сигнал в спектрограмму.
Программное обеспечение для анализа звука
Конечно, вам не нужно выполнять преобразования вручную. Вам также не нужно понимать сложную математику, лежащую в основе FT, STFT и других методов, используемых в аудиоанализе. Все эти и многие другие задачи выполняются автоматически программным обеспечением для анализа звука, которое в большинстве случаев поддерживает следующие операции:
- импорт аудиоданных
- добавить аннотации (метки),
- редактировать записи и разбивать их на части,
- удалить шум,
- преобразовывать сигналы в соответствующие визуальные представления (формы сигналов, графики спектра, спектрограммы, мел-спектрограммы),
- выполнять операции предварительной обработки,
- анализ временного и частотного содержания,
- извлечения аудиофункций и многое другое.
Самые передовые платформы также позволяют обучать модели машинного обучения и даже предоставляют предварительно обученные алгоритмы.
Вот список самых популярных инструментов, используемых для анализа звука.
Audacity — это бесплатный аудиоредактор с открытым исходным кодом, позволяющий разделять записи, удалять шумы, преобразовывать сигналы в спектрограммы и маркировать их. Audacity не требует навыков программирования. Тем не менее, его набор инструментов для анализа звука не очень сложен. Для дальнейших шагов вам необходимо загрузить свой набор данных в Python или переключиться на платформу, специально предназначенную для анализа и/или машинного обучения.
Разметка аудиоданных в Audacity. Источник: Towards Data Science
Пакет Tensorflow-io для подготовки и аугментации аудиоданных позволяет выполнять широкий спектр операций — удаление шумов, преобразование волновых форм в спектрограммы, частотную и временную маскировку для четкой слышимости звука, и более. Инструмент принадлежит экосистеме TensorFlow с открытым исходным кодом, охватывающей сквозной рабочий процесс машинного обучения. Таким образом, после предварительной обработки вы можете обучать модель машинного обучения на той же платформе.
Librosa — это библиотека Python с открытым исходным кодом, в которой есть почти все, что вам нужно для анализа звука и музыки. Он позволяет отображать характеристики аудиофайлов, создавать все типы визуализации аудиоданных и извлекать из них функции, и это лишь некоторые из возможностей.
Audio Toolbox от MathWorks предлагает множество инструментов для обработки и анализа аудиоданных, от маркировки до оценки метрик сигнала и извлечения определенных функций. Он также поставляется с предварительно обученными моделями машинного обучения и глубокого обучения, которые можно использовать для анализа речи и распознавания звука.
Этапы анализа аудиоданных
Теперь, когда у нас есть общее представление о звуковых данных, давайте взглянем на ключевые этапы сквозного проекта анализа аудио.
- Получите аудиоданные проекта , сохраненные в стандартных форматах файлов.
- Подготовьте данные для вашего проекта машинного обучения с помощью программных средств
- Извлечение звуковых характеристик из визуальных представлений звуковых данных.
- Выберите — модель машинного обучения, а — обучать аудиофункциям.
Этапы анализа звука с помощью машинного обучения
Сбор голосовых и звуковых данных
У вас есть три варианта получения данных для обучения моделей машинного обучения: использовать бесплатные звуковые библиотеки или наборы аудиоданных, приобрести их у поставщиков данных или собрать его с привлечением экспертов предметной области.
Бесплатные источники данных
В Интернете есть много таких источников. Но что мы в данном случае не контролируем, так это качество и количество данных, а также общий подход к записи.
Библиотеки звуков — это бесплатные аудиофайлы, сгруппированные по темам. Такие источники, как Freesound и BigSoundBank, предлагают голосовые записи, звуки окружающей среды, шумы и, честно говоря, всевозможные вещи. Например, вы можете найти саундскейп аплодисментов и набор со звуками скейтборда.
Самое главное, что звуковые библиотеки не готовятся специально для проектов машинного обучения. Таким образом, нам необходимо выполнить дополнительную работу по комплектованию комплектов, маркировке и контролю качества.
Наборы аудиоданных , напротив, создаются с учетом конкретных задач машинного обучения. Например, набор данных Bird Audio Detection Лаборатории машинного прослушивания содержит более 7000 отрывков, собранных в ходе проектов биоакустического мониторинга. Другим примером является набор данных ESC-50: Классификация звуков окружающей среды, содержащий 2000 помеченных аудиозаписей. Каждый файл длится 5 секунд и принадлежит к одному из 50 семантических классов, организованных в пять категорий.
Одна из крупнейших коллекций аудиоданных — AudioSet от Google. Он включает более 2 миллионов 10-секундных звуковых клипов с человеческими метками, извлеченных из видео на YouTube. Набор данных охватывает 632 класса, от музыки и речи до звуков осколков и зубной щетки.
Коммерческие наборы данных
Коммерческие аудио наборы для машинного обучения определенно более надежны с точки зрения целостности данных, чем бесплатные. Мы можем порекомендовать ProSoundEffects продавать наборы данных для обучения моделей для распознавания речи, классификации звуков окружающей среды, разделения источников звука и других приложений. Всего у компании 357 000 файлов, записанных экспертами по звуку фильмов и классифицированных по 500+ категориям.
Но что, если звуковые данные, которые вы ищете, слишком специфичны или редки? Что делать, если вам нужен полный контроль над записью и маркировкой? Что ж, тогда лучше делайте это в партнерстве с надежными специалистами из той же отрасли, что и ваш проект по машинному обучению.
Экспертные наборы данных
При работе с Sleep.ai нашей задачей было создать модель, способную идентифицировать скрежещущие звуки, которые люди с бруксизмом обычно издают во время сна. Понятно, что нужны были специальные данные, недоступные в открытых источниках. Кроме того, надежность и качество данных должны были быть самыми лучшими, чтобы мы могли получить достоверные результаты.
Чтобы получить такой набор данных, стартап сотрудничал с лабораториями сна, где ученые наблюдают за людьми, пока они спят, чтобы определить здоровый режим сна и диагностировать нарушения сна. Эксперты используют различные устройства для записи мозговой активности, движений и других событий. Для нас они подготовили размеченный набор данных, содержащий около 12 000 образцов скрежещущих и храпящих звуков.
Подготовка аудиоданных
В случае Sleep.io наша команда пропустила этот шаг, доверив специалистам по сну задачу подготовки данных для нашего проекта. То же самое относится и к тем, кто покупает аннотированные звуковые коллекции у поставщиков данных. Но если у вас есть только необработанные данные, то есть записи, сохраненные в одном из форматов аудиофайлов, вам необходимо подготовить их для машинного обучения.
Маркировка аудиоданных
Маркировка или аннотация данных — это пометка необработанных данных с правильными ответами для запуска контролируемого машинного обучения. В процессе обучения ваша модель научится распознавать закономерности в новых данных и делать правильные прогнозы на основе меток. Таким образом, их качество и точность имеют решающее значение для успеха проектов машинного обучения.
Хотя маркировка предполагает помощь программных средств и некоторую степень автоматизации, по большей части она по-прежнему выполняется вручную профессиональными аннотаторами и/или экспертами в предметной области. В нашем проекте по обнаружению бруксизма эксперты по сну прослушали аудиозаписи и пометили их ярлыками скрежета или храпа.
Узнайте больше о подходах к аннотированию из нашей статьи Как организовать маркировку данных для машинного обучения
Предварительная обработка аудиоданных
Помимо обогащения данных значимыми тегами, мы должны предварительно обработать звуковые данные, чтобы повысить точность предсказания. Вот самые основные шаги для проектов по распознаванию речи и классификации звуков.
Кадрирование означает разрезание непрерывного звукового потока на короткие фрагменты (кадры) одинаковой длины (обычно 20-40 мс) для дальнейшей посегментной обработки.
Работа с окнами — это фундаментальный метод обработки звука, позволяющий свести к минимуму спектральную утечку — распространенную ошибку, приводящую к искажению частоты и ухудшению точности амплитуды. Существует несколько оконных функций (Хемминга, Хэннинга, Плоской вершины и т. д.), применяемых к разным типам сигналов, хотя вариант Хэннинга хорошо работает в 95% случаев.
По сути, все окна делают одно и то же: уменьшают или сглаживают амплитуду в начале и конце каждого кадра, увеличивая ее в центре, чтобы сохранить среднее значение.
Форма сигнала до и после работы с окнами. Источник: National Instruments .
Метод Overlap-Add (OLA) предотвращает потерю жизненно важной информации, которая может быть вызвана работой с окнами . OLA обеспечивает 30-50-процентное перекрытие между соседними кадрами, что позволяет изменять их без риска искажения. В этом случае исходный сигнал можно точно восстановить по окнам.
Пример работы с окнами с перекрытием. Источник: Wiki Университета Аалто
Узнайте больше об этапе предварительной обработки и методах, которые он использует, из нашей статьи Подготовка ваших данных для машинного обучения и видео ниже.
https://youtu.be/P8ERBy91Y90
Аудиофункции или дескрипторы — это свойства сигналов, вычисленные на основе визуализации предварительно обработанных аудиоданных. Они могут принадлежать к одному из трех доменов
- временных доменов, представленных осциллограммами,
- частотных областей, представленных графиками спектра, и
- временных и частотных областей, представленных спектрограммами.
Визуализация аудиоданных: форма сигнала для временной области, спектр для частотной области и спектрограмма для частотно-временной области. Источник: Типы аудиофункций для машинного обучения.
Характеристики во временной области
Как мы упоминали ранее, характеристики во временной области или временные характеристики извлекаются непосредственно из исходных сигналов. Обратите внимание, что волновые формы не содержат много информации о том, как на самом деле будет звучать произведение. Они показывают только то, как амплитуда изменяется со временем. На изображении ниже мы видим, что сигналы состояния воздуха и сигналов сирены выглядят одинаково, но, конечно же, эти звуки не будут похожими.
Примеры сигналов. Источник: Towards Data Science
Теперь давайте перейдем к некоторым ключевым функциям, которые мы можем извлечь из сигналов.
Огибающая амплитуды (AE) отслеживает пики амплитуды в кадре и показывает, как они изменяются во времени. С помощью AE вы можете автоматически измерять продолжительность отдельных частей звука (как показано на рисунке ниже). AE широко используется для обнаружения начала, чтобы указать, когда начинается определенный сигнал, а также для классификации музыкальных жанров.
Амплитуда огибающей тико-тико птичьего пения. Источник: Seewave: Принципы анализа звука
Кратковременная энергия (STE) показывает изменение энергии в коротком речевом кадре.
Это мощный инструмент для разделения вокализованных и невокализованных сегментов.
Среднеквадратическая энергия (RMSE) дает вам представление о средней энергии сигнала. Его можно вычислить по форме волны или спектрограмме. В первом случае вы получите результат быстрее. Тем не менее, спектрограмма обеспечивает более точное представление энергии во времени. RMSE особенно полезен для сегментации звука и классификации музыкальных жанров.
Скорость пересечения нуля (ZCR) подсчитывает, сколько раз сигнальная волна пересекает горизонтальную ось в кадре. Это одна из наиболее важных акустических характеристик, широко используемая для обнаружения присутствия или отсутствия речи и различения шума и тишины, а музыки и речи.
Характеристики частотной области
Признаки частотной области извлечь труднее, чем временные, поскольку процесс включает преобразование сигналов в графики спектра или спектрограммы с использованием FT или STFT. Тем не менее, именно частотное содержание раскрывает многие важные звуковые характеристики, невидимые или трудноразличимые во временной области.
Наиболее распространенные характеристики частотной области включают
- среднюю или среднюю частоту,
- медианная частота при разделении спектра на две области с одинаковой амплитудой,
- отношение сигнал-шум (SNR) при сравнении силы желаемого звука с фоновым носом, Отношение энергии полосы
- (BER), изображающее отношения между более высокими и более низкими частотными диапазонами. Другими словами. он измеряет, насколько низкие частоты преобладают над высокими.
Конечно, в этом домене есть множество других свойств, на которые стоит обратить внимание. Напомним, что он говорит нам, как звуковая энергия распространяется по частотам, а временная область показывает, как сигнал изменяется во времени.
Характеристики частотно-временной области
В этой области сочетаются временные и частотные компоненты и используются различные типы спектрограмм для визуального представления звука. Вы можете получить спектрограмму из сигнала, применяя кратковременное преобразование Фурье.
Одна из самых популярных групп характеристик частотно-временной области — мел-частотные кепстральные коэффициенты (MFCC) . Они работают в диапазоне человеческого слуха и, как таковые, основаны на мел-шкале и мел-спектрограммах, которые мы обсуждали ранее.
Неудивительно, что первоначальное применение MFCC — это распознавание речи и голоса. Но они также оказались эффективными для обработки музыки и акустической диагностики в медицинских целях, в том числе для обнаружения храпа. Например, одна из недавних моделей глубокого обучения, разработанная Инженерной школой (Университет Восточного Мичигана), была обучена на 1000 MFCC-изображениях (спектрограммах) звуков храпа.
Форма волны звука храпа (a) и ее спектрограмма MFCC (b) по сравнению с формой волны звука смыва унитаза (c) и соответствующим изображением MFCC (d). Источник: Модель глубокого обучения для обнаружения храпа ( Electronic Journal, Vol.8, Issue 9 )
временная и частотная области. В сочетании они создавали богатые профили скрежещущих и храпящих звуков.
Выбор и обучение моделей машинного обучения
Поскольку звуковые функции представлены в визуальной форме (в основном в виде спектрограмм), они становятся объектом распознавания изображений, основанного на глубоких нейронных сетях. Существует несколько популярных архитектур, показывающих хорошие результаты в обнаружении и классификации звука. Здесь мы сосредоточимся только на двух обычно используемых для выявления проблем со сном по звуку.
Сети с долговременной кратковременной памятью (LSTM)
Сети с долговременной кратковременной памятью (LSTM) известны своей способностью выявлять долгосрочные зависимости в данных и запоминать информацию из многочисленных предыдущих шагов. Согласно исследованию обнаружения апноэ во сне, LSTM могут достигать точности 87 процентов при использовании функций MFCC в качестве входных данных для отделения нормальных звуков храпа от ненормальных.
Другое исследование показывает еще лучшие результаты: LSTM классифицировал нормальный и ненормальный храп с точностью 95,3%. Нейронная сеть была обучена с использованием пяти типов функций, включая MFCC и кратковременную энергию из временной области. Вместе они представляют различные характеристики храпа.
Сверточные нейронные сети (CNN)
Сверточные нейронные сети лидируют в области компьютерного зрения в здравоохранении и других отраслях. Их часто называют , что является естественным выбором для задач распознавания изображений . Эффективность архитектуры CNN при обработке спектрограмм еще раз доказывает справедливость этого утверждения.
В вышеупомянутом проекте Инженерной школы (Университет Восточного Мичигана) модель глубокого обучения на основе CNN достигла точности 96 процентов в классификации храпящих и нехрапящих звуков.
Почти такие же результаты получены для комбинации архитектур CNN и LSTM. Группа ученых из Технологического университета Эйндховена применила модель CNN для извлечения признаков из спектрограмм, а затем запустила LSTM, чтобы классифицировать выходные данные CNN на события, связанные с храпом и без храпа. Значения точности варьируются от 94,4 до 95,9 процентов в зависимости от расположения микрофона, используемого для записи звуков храпа.
Для проекта Sleep.io команда специалистов по данным AltexSoft использовала две CNN (для обнаружения храпа и скрипа) и обучила их на платформе TensorFlow. После того, как модели достигли точности более 80 процентов, они были запущены в производство. Их результаты постоянно улучшались по мере роста числа входных данных, полученных от реальных пользователей.
Создание приложения для обнаружения храпа и скрежетания зубами
Чтобы сделать наши алгоритмы классификации звуков доступными для широкой аудитории, мы упаковали их в приложение для iOS Do I Snore or Grind, которое вы можете бесплатно загрузить из App Store. Наша команда UX создала единый поток, позволяющий пользователям записывать шумы во время сна, отслеживать свой цикл сна, отслеживать события вибрации и получать информацию о факторах, влияющих на сон, и советы о том, как они могут изменить свои привычки. Весь анализ аудиоданных выполняется на устройстве, поэтому вы получите результаты даже при отсутствии подключения к Интернету.
Интерфейс приложения Do I Snore or Grind.
Имейте в виду, однако, что никакое приложение для здоровья, каким бы умным оно ни было, не может заменить настоящего врача. Вывод, сделанный ИИ, должен быть проверен вашим стоматологом, врачом или другим медицинским экспертом.
Если вы хотите узнать еще больше подробностей, прочитайте наши тематические исследования
AltexSoft и Bruxlab: использование современного машинного обучения и науки о данных для диагностики и борьбы с бруксизмом
AltexSoft и SleepScore Labs: Building iOS-приложение для обнаружения храпа и скрежета зубов
Программные продукты - SIL Language Technology
Компания SIL разработала программное обеспечение, которое позволяет людям во всем мире использовать компьютер на своем родном языке.
Для того, чтобы иметь полный указатель, здесь охвачен весь спектр программного обеспечения SIL, от самой современной программы лингвистического анализа до древних инструментов обработки текста, которые представляют только исторический интерес. Поиск программного обеспечения по лингвистической задаче, языку интерфейса, лицензии или операционной системе можно выполнить с помощью LingTranSoft, который включает в себя все программное обеспечение SIL, а также другое программное обеспечение, используемое для поддержки языковой разработки и задач перевода.
Если у вас есть вопросы или вам нужна помощь, обратитесь в отдел языковых технологий.
На отдельной странице перечислены шрифты, производимые SIL.
Рекомендуемые продукты
Andika Шрифт Unicode без засечек, разработанный специально для грамотного использования и нужд начинающих читателей. Основное внимание уделяется четким буквенным формам, которые нельзя легко спутать друг с другом. | |
Менеджер аудио проектов Audio Project Manager (ранее SIL Transcriber) можно использовать как веб-приложение или настольное приложение с функциями локального управления аудио- и текстовыми материалами. Он также имеет функции для совместной работы в Интернете и работает вместе с такими инструментами, как Paratext и Render, обеспечивая гибкое управление целыми аудио- и аудио-текстовыми проектами. | |
Awami Nastaliq Awami Nastaliq — это арабский шрифт в стиле насталик, поддерживающий широкий спектр языков Юго-Западной Азии, включая, помимо прочего, урду. | |
Блум Чтобы научиться читать, нужны книги. Чтобы научиться хорошо читать и развить любовь к чтению, нужно много книг. Книги для всех уровней подготовки. Но как малограмотным языковым сообществам получить все эти книги на своем языке? Они могут сделать это с Блум. | |
FLEx (FieldWorks Language Explorer) Позволяет лингвистам работать очень продуктивно при составлении словарного запаса и интерлинеаризации текстов. Мощные инструменты массового редактирования могут сэкономить часы работы. FLEx позволяет контролировать, какие поля и записи будут отображаться в публикации словаря. | |
Keyman Позволяет вводить текст на более чем 1000 языках на планшетах и телефонах с ОС Windows, iPhone, iPad, Android и даже мгновенно в веб-браузере. Клавиатуры для конкретных языков можно найти на сайте Keyman и на scripts. | |
Паратекст Позволяет вводить, редактировать, проверять и публиковать перевод Священных Писаний на основе оригинальных текстов (греческий, иврит) и версий на основных языках. | |
SayMore Запись носителей языков мира — это весело и полезно, но хранить все полученные файлы и метаданные в порядке? Преобразование файлов в архивные форматы? Транскрипция? Болезненный. Вот почему мы создали SayMore — чтобы сделать задачи документирования на общих языках увлекательными и поддерживать вашу продуктивность. | |
Конструктор приложений Писания Помогает создавать индивидуальные приложения Писания для смартфонов и планшетов Android. Вы указываете файлы Писания для использования, имя приложения, шрифты, цвета, звук и значок. Конструктор приложений для Писания соберет все вместе и создаст приложение для вас. | |
Tagmukay Высококачественный шрифт Shifinagh, поддерживающий тавалламматский диалект тамаджака. | |
Translators Workplace Коллекция библейских ресурсов, отобранных SIL специально для переводчиков Библии и предлагаемых через партнерство в качестве библиотеки в Logos Bible Software. |
top
Веб-приложения
Language Forge Совместный лексический онлайн-редактор, который синхронизируется с FLEx. Он хорошо выглядит на мобильных устройствах, поддерживает совместную работу, комментирование и обзор, роли пользователей и обрабатывает множество лексических полей. Посмотрите краткий обзор. | |
ScriptSource Динамический, совместный справочник по системам письменности мира, с подробной информацией о сценариях, символах, языках - и остальных потребностях для их поддержки в вычислительной сфере. | |
Scriptoria Scriptoria — это платформа управления рабочими процессами, которая позволяет любому пользователю создавать и обновлять приложения для мобильных устройств на любом языке. | |
Кузница Писаний Веб-инструмент для облегчения проверки Писания онлайн-сообществом. Взаимодействуйте с языковым сообществом, загружая отрывки из Писания, задавая целевые вопросы и импортируя ответы обратно в Paratext. Посмотрите краткий обзор. | |
Webonary Дает языковым группам возможность публиковать двуязычные или многоязычные словари в Интернете с минимальной технической помощью. | |
Справка IPA - веб-версия Полезный и простой инструмент для обучения распознаванию, расшифровке и воспроизведению звуков Международного фонетического алфавита (IPA). |
top
Другое поддерживаемое программное обеспечение
SIL International рекомендует людям использовать это программное обеспечение для выполнения своих задач по обработке языка. Это программное обеспечение поддерживается и обновляется. Кроме того, техническую поддержку можно получить от разработчика(ов) приложения.
Adapt It Помогает переводить тексты между родственными языками (процесс, называемый адаптацией). Используя Adapt It, переводчики смогли значительно сократить общее время, затрачиваемое на переводческие проекты. | |
Ашенинка: анализатор слогов Инструмент, который исследует различные алгоритмы для разбора орфографических слов на слоги и вставки произвольных дефисов в слова. | |
BART Анализ библейского анализа и исследования (BART) | |
Cog помогает вам CompareStististics с использованием LAICESISISISISISISISISISISISTIISTIISTIESS с использованием LAICESISISISISTIISTIISTIESTIISTIISTIESS. Его можно использовать для автоматизации большей части процесса сравнения списков слов из разных языковых вариантов. | |
Dictionary App Builder Помогает создавать собственные словарные приложения для смартфонов и планшетов Android. | |
Набор инструментов полевого лингвиста Инструмент управления и анализа данных для полевых лингвистов. Он особенно полезен для хранения лексических данных, а также для синтаксического анализа и интерлинеаризации текста, но его можно использовать для управления практически любыми данными. | |
FLExTrans Основанная на правилах система машинного перевода, простая в использовании для обычных лингвистов. Он использует FLEx (Fieldworks Language Explorer) и мощный язык правил передачи для получения высококачественных результатов. Возможно, в вашем проекте уже есть лексиконы в FLEx, так что у вас есть преимущество! | |
Средства разработки шрифтов Полный список средств разработки шрифтов, разработанных и используемых SIL. К ним относятся скрипт для создания составных глифов в FontLab (FLGlyphBuilder), версия TypeTuner для командной строки и другие инструменты. | |
Glyssen Поможет вам создать высококачественную инсценированную аудиозапись Писания. | |
Graphite Пакет, который можно использовать для создания «умных шрифтов», способных отображать системы письма с наиболее сложным поведением. | |
HearThis Запись Библии стала проще! HearThis предлагает самостоятельную альтернативу для сообществ, желающих получить переведенный текст Священных Писаний на свой родной язык. | |
Клавиатуры IPA Предоставляет различные клавиатуры для ввода данных IPA. Доступны решения для Windows, Linux и Mac OS X. | |
Конструктор приложений для клавиатуры Помогает создавать индивидуальные приложения для клавиатуры для смартфонов и планшетов Android. Клавиатурное приложение позволяет пользователям добавлять системную клавиатуру на свое устройство, что позволяет им вводить текст на своем языке в других приложениях, таких как Gmail, Facebook и WhatsApp. | |
LingTree Инструмент, позволяющий описать лингвистическое дерево и создать его графическое изображение. LingTree Helper может облегчить работу. | |
Библиотека LinguaLinks, издание Logos Библиотека LinguaLinks представляет собой набор электронных справочных материалов, предназначенных для поддержки языковых полевых исследований. Библиотека использует возможности компьютеров для предоставления информации, инструкций, обучения и советов. | |
OneStory Editor OneStory Editor — это программное обеспечение для документирования устных библейских историй. | |
Стартовый набор PAWS Экспертная система, которая создает согласованную грамматику PC-PATR, которая охватывает подавляющее большинство синтаксиса данного языка. Он также создает черновик описания грамматики на основе ответов пользователя. | |
Ассистент фонолога Помогает обнаружить и проверить правила звучания в языке. | |
Primer Pro Помогает грамотным работникам, упрощая разработку букварей. Он выполняет утомительную работу, которую традиционно должны были выполнять сами местные авторы и специалисты по грамотности. | |
PTXprint Разработанная как дополнение к Paratext, PTXprint представляет собой отдельную программу, позволяющую создавать высококачественные PDF-файлы для пробных публикаций Священных Писаний. Он имеет множество легко настраиваемых параметров, позволяющих получить целый ряд выходных данных. | |
Reading App Builder Помогает создавать индивидуальные приложения для смартфонов и планшетов. | |
Преобразователи SIL Предоставляет инструменты, с помощью которых вы можете изменить кодировку, шрифт и/или сценарий текста в документах. | |
SIL ViewGlyph Программа просмотра шрифтов для Windows, позволяющая увидеть содержимое шрифта глазами другого приложения или операционной системы. | |
Трансселератор Плагин Paratext, который добавляет функцию, помогающую проверять понимание. | |
TypeTuner Web Позволяет пользователям легко изменять определенные шрифты SIL, чтобы активировались различные глифы или поведение смарт-шрифтов (вместе называемые функциями шрифта). пользователи. | |
Ukelele Редактор раскладки клавиатуры Unicode для macOS версии 10.2 и выше. | |
XLingPaper Способ создания и архивирования лингвистических статей или книг с использованием XML. |
top
Неподдерживаемое программное обеспечение
Неподдерживаемое программное обеспечение доступно для использования на условиях «как есть». Программное обеспечение может быть полезным для выполнения задач, для которых оно было разработано. Однако из-за ограниченных ресурсов SIL не будет предоставлять поддержку или устранять ошибки для программного обеспечения.
Компаралекс Онлайновая лексическая база данных списков языковых слов с аудиосэмплами для лингвистического анализа и исторической и сравнительной лингвистической реконструкции. |
Dekereke Инструмент Windows для фонологических полевых исследований. Это полезно для исследования фонотактических обобщений путем создания различных диаграмм согласных, гласных, тональных мелодий и слоговых моделей. |
Flashgrid Дополнение к популярной программе карточек Anki. Он добавляет возможность детализации, выбирая из сетки (аналогично Rosetta Stone или Vocabulary Manager). |
Haiola Преобразование файлов Unicode USFM, разархивированных пакетов ETEN DBL или файлов USFX в файлы HTML, EPUB3, модули проекта Crosswire Sword, Microsoft Word XML, файлы PDF или другие форматы. |
Справка IPA — версия для загрузки Полезный и простой инструмент для обучения распознаванию, расшифровке и воспроизведению звуков Международного фонетического алфавита (IPA). |
KeyLayoutMaker Сценарий Perl, позволяющий быстро создать хотя бы первый черновой вариант XML-файла раскладки клавиатуры (.keylayout) для Mac OS X версии 10.2 или более поздней. |
Lexique Pro Не держите свой лексикон при себе! Поделитесь этим с другими! Вы потратили годы на работу над своим словарем, но насколько легко другим воспользоваться им? Целью Lexique Pro является сделать ваши данные удобными для использования, доступными и удобными для обмена с другими. |
LIFT Tools Набор разнообразных утилит для файлов LIFT, которые позволяют вносить определенные виды массовых изменений в данные, используемые FLEx, WeSay и Lexique Pro. |
myWorkSafe Предназначен для создания системы резервного копирования с нулевой конфигурацией, в первую очередь для разработчиков языков. |
Лингвистические инструменты OpenOffice Дополнение, предоставляющее меню инструментов для лингвистических рецензий и других документов, написанных на малоизвестных языках. |
Pathway Обрабатывает языковые данные из FieldWorks и Paratext в привлекательные и подходящие форматы для черновой печати или публикации. |
Браузер PC-PATR Инструмент, который значительно упрощает просмотр результатов синтаксического анализа, произведенного программой PC-PATR. |
PDFDroplet Простой маленький инструмент, с помощью которого можно легко создавать буклеты! Создавайте документ как обычно, не беспокоясь о проблемах с макетом буклета. |
PrimerPrep Инструмент, который помогает грамотным работникам быстро и легко выполнять основные этапы подготовки грунтовки. |
SheetSwiper Преобразует электронные таблицы, содержащие лингвистические данные, в стандартный формат (для использования с Linguist's Toolbox, Phonology Assistant, Lexique Pro и т. |
SILAS Шаблон Microsoft Word для более удобного и безопасного размещения файлов RTF, экспортируемых из Paratext, Adapt It или Fieldworks Translation Editor. |
SILKin Помогает полевым работникам анализировать и документировать структуру родства и терминологию, используемую в языке другой культуры. |
Solid Используется для проверки и очистки данных лексикона стандартного формата и, при необходимости, преобразования их в LIFT. |
Анализатор речи Облегчает акустический анализ звуков речи. |
Количество символов Юникода Быстрая и грязная замена Unicode для Ccount, утилиты подсчета символов. Программа доступна как в виде исходного кода Perl, так и в виде отдельного исполняемого файла Windows. |
Vocabulary Manager Мультимедийный инструмент для изучения словарного запаса. |
WeSay Помогает нелингвистам составить словарь на своем родном языке. У него есть различные способы помочь носителям языка думать о словах на их языке и вводить некоторые основные данные о них (без обратной косой черты, только формы для заполнения). |
WordSurv Помогает в сборе и анализе списков слов. Это в первую очередь инструмент для исследователя диалектов, который заинтересован в получении современной картины языковой ситуации в данной области. |
XeTeX Система набора текста, основанная на слиянии системы TeX Дональда Кнута с Unicode и современными технологиями шрифтов. |
top
Программное обеспечение, снятое с производства
Программное обеспечение, снятое с производства, доступно для использования на условиях «как есть». Программное обеспечение может быть полезным для выполнения задач, для которых оно было разработано.