Презентация «Звуко-буквенный разбор слова»
Звуко- буквенный разбор слова
- Одной из причин пропуска букв является:
-недостаточное развитие фонетического слуха.
- Для этого обращаем внимание на устный звуко-буквенный разбор.
- Устный разбор можно провести легко и интересно с помощью условных схем.
- Работу можно начинать с 1 класса. Учащимся очень нравится.
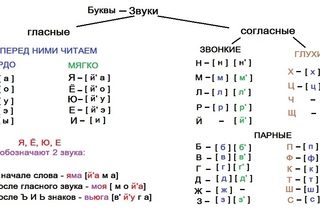
Гласный, безударный
Гласный , ударный
Согласный, звонкий парный, твердый парный
Согласный, звонкий парный, твердый непарный
Согласный, звонкий непарный, твердый парный
Согласный, звонкий парный, мягкий парный
Согласный, звонкий непарный, мягкий парный
Согласный, глухой парный, твердый парный
Согласный, глухой непарный, твердый парный
Согласный, глухой парный, мягкий парный
Согласный, глухой парный, мягкий парный
Согласный, глухой непарный, мягкий парный
Согласный, звонкий непарный, мягкий непарный
Согласный, глухой непарный, мягкий непарный
Согласный, глухой непарный, твердый непарный
Лис [а]
[а] – гласный, ударный.
[в] олк
[в] – согласный, звонкий парный, твёрдый парный.
[р]ак
[р] – согласный, звонкий непарный, твёрдый парный.
[к]от
[к] – согласный, глухой парный, твёрдый парный.
[ж]ираф
[ж] – согласный, звонкий парный, твёрдый непарный.
Ло [ш]ка[ш] – согласный, глухой парный, твёрдый непарный.
[ц]ыплёнок
[ц] – согласный, глухой непарный, твёрдый непарный.
[з´]ебра
[з´] – согласный, звонкий парный, мягкий парный.
[р´]епа
[р´] – согласный, звонкий непарный, мягкий парный.
[п´]ила
[п´] – согласный, глухой парный, мягкий парный.
Ле [й´]ка
[й´] – согласный, звонкий непарный, мягкий непарный.
[ч´]айник
[ч´] – согласный, глухой непарный, мягкий непарный.
- Когда учащийся хорошо освоил устный разбор, он переходит к письменному.
- 1. Произнеси слово
- 2.Сколько в слове слогов, произнеси ударный слог.
- Если гласный звук, то какой он- ударный или безударный;
- Если согласный звук, то какой он – глухой или звонкий, твердый или мягкий, парный или непарный.
- 4. Сделай вывод о количестве букв и звуков в слове
Лошадь
Лошадь — [лошат´] – 2 слога
Л — [л] – согл., звонк. непарн., твёрд. парн.
О — [о] – гласн., ударн.
Ш- [ш] – согл., глух. парн., твёрд.непарн.
А — [а] – гласн.,безударн.
Д- [т ´] – согл., глух.парн., мягк.парн.
Ь —————
_____________________
6 б.5 зв.
Спасибо за внимание
«Печенье» фонетический звуко-буквенный разбор слова
Фонетическим анализом слова “печенье” называют характеристику звуковых и буквенных составляющих.
Помимо этого, он включает в себя транскрипцию анализируемого слова, определение правильного местоположения ударного слога, сравнение буквенного и звукового анализа, дробление на слоги, возможные варианты переноса слова через строку.
Что нужно делать, чтобы не допускать ошибок? Просто следует придерживаться плана, которые прослеживает логическую связь между пунктами разбора. В качестве примера проделаем фонетический разбор языковой единицы “печенье”.
Фонетический разбор
- Начнём с самой трудной задачи в этом этапе разбора слова “печенье” определим звуковой и буквенный состав по количеству: 7 букв (3 гласных, 3 согласных и мягкий знак), 7 звуков.
- Далее проанализируем место ударения: печЕнье. Ударность акцентирует второй слог.
- Всего в слове “печенье” три слога по количеству слогообразующих гласных. Произведём дробление на слоги: пе/че/нье.
- Способы переноса через строку соответствуют слоговому делению.
Транскрипция слова
Это, возможно, самый сложный этап всего разбора, потому что имеет больше всего нюансов, на которые в дальнейшем делает упор звуко-буквенный анализ.
Повторим анализируемое слово несколько раз вслух, после запишем все звуки в квадратных скобках: [п’ич’ин’й’э].
Звуко-буквенный разбор
- п — [п’] — принято определять как согласный, здесь представлен в глухой мягкой форме
- е — [и] — имеет признаки гласного, ударность не делает акцент
- ч — [ч’] — принято определять как согласный, здесь представлен в глухой мягкой форме
- е — [и] — имеет признаки гласного, ударность не делает акцент
- н — [н’] — принято относить к согласным, здесь представлен в звонкой мягкой форме
- ь — не произносится
- е — [й’] — принято относить к согласным, здесь представлен в звонкой мягкой форме
- — [э] — имеет признаки гласного, ударность делает акцент
Проверь себя: “Хлопья” фонетический разбор слова
Звуки [п] и [ч] смягчаются последующим гласным “е”, который, не имея ударность, представляется звуком [и].
Так как вторая гласная буква “е” стоит после мягкого знака, её принято обозначать звуком [й’э].
Звуко-буквенный разбор слова «снег» — tarologiay.ru
Фонетический разбор слова «снег» — это звуко-буквенный анализ слова, характеристика звуков и итоговый подсчет количества букв и звуков в этом слове.
Чтобы выполнить звуко-буквенный разбор (фонетический) разбор слова «снег», определим количество слогов, запишем его звучание, охарактеризуем каждый звук и подсчитаем количество букв и звуков.
В слове «снег» содержится один гласный звук, который образует один фонетический слог. Выполняя звуко-буквенный разбор, учтем, что в русском языке написание и звучание слов не всегда совпадают. Учтём, что исследуемое слово имеет некоторые фонетические особенности.
При произношении этого существительного конечный звонкий, обозначенный буквой «г», по закону русской фонетики оглушается и заменяется парным ему глухим согласным. Выяснив эту фонетическую закономерность, звучание анализируемого слова запишем так:
снег [с н’ э к].
Также учтем, что буквы «е», «ё», «ю», «я» после согласных обозначают их мягкость и соответствуют одному звуку:
- буква «е» под ударением обозначает звук [э],
- буква «ё» — это ударный звук [о],
- буква «ю» — это звук [у],
- буква «я» — это ударный звук [а].
Понаблюдаем:
- лето [л’ э т а],
- полёт [п а л’ о т],
- сюда [с’ у д а],
- лямка [л’ а м к а].
Эти буквы обозначают два звука только в определенных позициях.
Запишем буквы и звуки исследуемого слова вертикально и дадим каждому звуку фонетическую характеристику:
- буква «с» — это звук [с] — согласный глухой парный, твердый парный,
- буква «н» обозначает звук [н’] — согласный звонкий непарный, мягкий парный,
- буква «е» — это звук [э] — гласный ударный,
- букве «г» соответствует звук [к] — согласный глухой парный, твердый парный.


Завершим звуко-буквенный разбор рассматриваемого существительного подсчётом букв и звуков:
В слове «снег» содержится 4 буквы и 4 звука.
Как произвести фонетический (звуково-буквенный) разбор слов «зеленый», «зеленый»?
Фонетический анализ слова quot; greenquot ;.
Word quot; greenquot; состоит из 3-х слогов — ze — л — ny . Второй слог подчеркнут.
Буква z — звук 3 — согласный, звонкий, парный, мягкий.
Буква е — звук И — гласный безударный.
Буква А — звук Л — согласный, звонкий, мягкий.
Буква — звук О — гласная, ударная.
Буква H — звук H — согласный, звонкий, твердый.
Буква Y — звук S — гласный, безударный.
Буква J — звук — согласный, звонкий, мягкий.
Слово состоит из 7 букв, 7 звуков.
Напишем транскрипцию слова — зилоны .
Фонетический анализ слова quot; greenquot ;.
Word quot; greenquot; состоит из 3-х слогов — ze — л — ная . Второй слог подчеркнут.
Буква z — звук 3 — согласный, звонкий, парный, мягкий.
Буква е — звук И — гласный безударный.
Буква А — звук Л — согласный, звонкий, мягкий.
Буква — звук О — гласная, ударная.
Буква H — звук H — согласный, звонкий, твердый.
Буква А — звук А — гласная, безударная.
Буква i — звук — согласный, звонкий, мягкий; звук А — гласный безударный.
Слово состоит из 7 букв, 8 звуков.
Напишем транскрипцию слова — зилоная .
Свободное владение
- Свободное владение
- Как оценить беглость — метод 1 и метод 2 ,
- Оцените просодию
- Руководство по подсчету очков Prosody
- Контрольный список Prosody
- Этапы развития беглости
- Учебные идеи
- Использование техники для обучения
Беглость — Свободное владение — это способность читать текст, как устно, так и без слов, с соответствующей скоростью, точностью и выражением.Однако беглость не гарантирует понимания. Три измерения — это точность, автоматическая обработка и просодия.
- При отсутствии беглости кажется, что у читателя нет навыков в переводе текста в звуки, предназначенные для того, чтобы их услышал автор, чтобы читатель мог понять предполагаемое и непреднамеренное значение.
- Свободные читатели лучше видят и распознают слово или слова при фиксации одного взгляда и не нуждаются в таком большом количестве исправлений или регрессов.
- Они также делают более короткие фиксации, более длинные переходы между фиксациями и меньше регрессий, чем более медленные читатели.
- Иметь алфавитный принцип , способность связывать звуки с буквами и смешивать звуки для образования слов и знать часто встречающиеся слова.
- Низкая точность чтения слов оказывает очевидное негативное влияние на понимание прочитанного и беглость чтения из-за неточного чтения слов, что приводит к неправильной интерпретации текста.
- Ошибки, не влияющие на смысл, встречаются редко.
- Существует сильная корреляция между скоростью чтения и более высоким уровнем понимания прочитанного у среднего и плохого читателя.

Нужно уметь
- Определять звуки, представленные буквами или комбинациями букв
- Смешанные фонемы
- Чтение фонограмм (общие закономерности в словах)
Используйте как буквенно-звуковые, так и смысловые подсказки, чтобы точно определить произношение и значение слова в тексте (зная, как правильно произносить слова в контексте.
- «У собаки был бант в волосах.”
- «Носовая часть корабля была черной».
Недостаточно правильно сказать слово. Это должно быть сделано правильно, используя только достаточно умственных способностей, чтобы иметь достаточно когнитивных способностей для понимания текста.
Если для этого требуется слишком много времени, понимание и чтение не будут достигнуты, работа останется незавершенной, теряется интерес к чтению и школе.
Автоматическая обработка (без сознательного обдумывания), определяемая с точки зрения скорости, точности распознавания слов, скорости распознавания слов, и просодии — правильное выражение с точки зрения фразировки, высоты тона… является важной частью умелого чтения.
Это не имеет ничего общего с устным чтением.
Неисправные читатели вынуждены сосредотачивать свое внимание на распознавании слов, оставляя меньше возможностей для понимания.
Метод 1
- Decode — озвучивает слова с минимальными ошибками (точность 90-95%).
- Автоматическая обработка — оценка со скоростью чтения.Прочтите отрывок для уровня класса в течение 60 секунд, а затем подсчитайте количество правильно прочитанных слов (включая исправления, которые занимают более 3 секунд, как ошибки). Сравните баллы учащихся с целевыми показателями на уровне класса.
- Просодическое чтение разбирает текст на синтаксически и семантически подходящие единицы. Слушайте и оценивайте по рубрике, оценивающей экспрессию, объем, фразировку, плавность и темп.
Если ученики прочитают отрывок об уровне своего класса в течение одной минуты, учитель может быстро понять эти три.Учащиеся, набравшие меньше баллов, находятся в группе риска.
Метод 2
- Попросите учащихся прочитать 100 слов отрывка на их уровне. Если они имеют точность 90% или больше (90 слов).
- Оценка автоматичности считывания при декодировании может быть определена как скорость. Когда студенты читают отрывок, запишите количество слов, прочитанных точно за минуту.
- Сравните оценки учащихся с целевыми показателями. На 20-30% ниже целевого обычно требуется дополнительная инструкция.
 Если они имеют точность 90% или больше (90 слов).
Если они имеют точность 90% или больше (90 слов).Однако помните — Fast не говорит бегло. Такие утверждения, как «Увеличь темп», «Посмотрим, сможешь ли ты побить свой предыдущий результат». или другое утверждение, в котором скорость важнее понимания, не следует делать.
Беглость речи может составлять около 30% их отклонений в результатах тестов.
Оценить просодию Prosody — это ритмический и тональный аспекты речи. Высота (интонация), ударение (выделение слога), продолжительность, способствующая выразительному прочтению текста.Сигнальные вопросы, удивление, восклицание и другие значения, выходящие за рамки семантики произносимых слов.
Просодия в устном чтении должна сигнализировать о понимании прочитанного читателем и улучшать понимание слушателя на слух. То есть, просодические читатели понимают то, что они читают, и облегчают чтение другим.
Просодию можно измерить, только наблюдая за устным чтением связного текста. Во время чтения отрывка учитель может слушать от до
.
интонация, выражение и границы фраз учащегося.
Следующая рубрика может быть использована для оценки беглости читателя в областях выражения и объема, фразировки, плавности и темпа по этой четырехбалльной шкале. Поддающаяся количественной оценке шкала дает оценку, которую можно использовать для сравнения ученика с самим собой во времени или между учениками в классе или школе.
Exp r и объем
• Читает слова, как будто просто чтобы их выудить. Мало смысла пытаться заставить текст звучать как естественный язык. Читает тихим голосом.
Читает тихим голосом.
• Начинает использовать голос, чтобы текст звучал как естественный язык в некоторых … областях текста, но не в других. Основное внимание уделяется произношению слов. По-прежнему читает тихим голосом.
• Делает текст естественным на протяжении большей части отрывка. Иногда скатывается к невыразительному чтению. Громкость голоса обычно соответствует всему тексту.
Телефонный звонок
• Читает монотонно, плохо понимая границы фраз; часто читает слово за словом.
• Часто читает фразы из двух и трех слов, создавая впечатление прерывистого чтения; неправильное ударение и интонация не выделяют концов предложений и предложений.
• Читает с перерывами, паузами в середине предложения для дыхания и некоторой нервозностью; разумное ударение и интонация.
• Как правило, читает с хорошей формулировкой, в основном с помощью предложений и предложений, уделяя должное внимание выражению.
Гладкость
• Делает частые продолжительные паузы, колебания, фальстарты, звуковые сигналы, повторения и / или множественные попытки.
• Встречается несколько «грубых пятен» в тексте, где длительные паузы или колебания более часты и мешают.
• Иногда нарушает плавный ритм из-за трудностей с определенными словами и / или структурами.
• Обычно читает плавно с небольшими перерывами, но быстро решает трудности со словами и структурой, обычно путем самокоррекции.
Темп
• Читает медленно и кропотливо.
• Читает умеренно медленно.
• Читает неравномерно, в быстром и медленном темпе.
• Последовательно читает в разговорном темпе; соответствующий рейтинг на протяжении всего чтения.
Диапазон оценок 4-16. Как правило, оценка ниже 8 указывает на то, что беглость речи может быть проблемой.Оценка 8 или выше указывает на то, что учащийся хорошо владеет языком.
Как правило, оценка ниже 8 указывает на то, что беглость речи может быть проблемой.Оценка 8 или выше указывает на то, что учащийся хорошо владеет языком.
По материалам Zutell & Rasinski, 1991.
Контрольный список Prosody
1. Студент сделал акцент на соответствующих словах.
2. Тон голоса студента повышался и понижался в соответствующих местах текста.
3. Сгибание ученика отражало пунктуацию в тексте (например, тон голоса повышался в конце вопроса).
4.В повествовательном тексте с диалогами ученик использовал соответствующий голосовой тон для представления психических состояний персонажей, таких как возбуждение, печаль, страх или уверенность.
5. Студент использовал знаки препинания, чтобы правильно делать паузы на границах фраз.
6. Студент использовал предложные фразы, чтобы сделать паузу на границах фраз.
7. Студент использовал деление на подлежащее и глагол, чтобы сделать паузу на границах фраз.
8. Студент использовал союзы, чтобы сделать паузу на границах фраз.
Для развития беглости чтения используйте вспомогательное чтение и повторное чтение.
Студенты должны слышать, как звучит беглое чтение и как интерпретировать текст своим голосом. Исследования показывают, что такая практика улучшает их способности в этих областях, а также понимание. Четыре элемента, которые следует учитывать: 1. Иметь необходимые предварительные навыки, 2. выбрать подходящее вмешательство, 3. реализовать учебные компоненты и выбрать подходящие материалы для чтения.
Отрывки для перформанса — стихи, сценарии, речи, монологи, диалоги, анекдоты и загадки отлично подходят для этого. Поэтические кафе и читательские театральные фестивали. Комедийные клубы.
Взаимодействия, используемые учителями для повышения просодии —
• «Ты правильно сказал все слова, Томас, но ты читал слишком быстро. Мне было трудно понять то, что ты пытался мне сказать».
• «Элиза, то, как вы заставили каждого персонажа звучать по-разному в этом диалоге, было фантастически.Было легко и весело слушать, как спорят эти персонажи ».
• «Мне очень нравится, как вы делали паузу между предложениями. это дало мне возможность подумать над сообщением автора. А теперь подумайте о том, чтобы найти места, где можно сделать паузу еще на секунду в более длинных предложениях».
• «Мне понравилось, как вы сделали свой голос сильным и громким в этом разделе. Он действительно сказал мне, что этот раздел отрывка был важен».
• «Попробуй здесь притормозить и сделать свой голос немного тише.Помните, вы пытаетесь рассказать мне о чем-то загадочном. Расскажите историю не только словами, но и голосом ».
Стр. 34 ***
Этапы развития беглости
- Начальный уровень
- Приобретение
- Уровень владения
- Техническое обслуживание
- Обобщение
- Адаптация
Повторное чтение не рекомендуется ученикам младше первого класса, так как у них нет буквенно-звукового соответствия и словосочетания.
Совместное обучение было продемонстрировано как гибкое и эмпирически обоснованное.
Компоненты многократного чтения | |
1. Отрывки следует читать вслух компетентному преподавателю. | Репетиторы должны быть обучены контролировать устное чтение учащихся и обеспечивать обратную связь. |
2. Должна быть предоставлена корректирующая обратная связь. | Отзыв о словарных ошибках |
3. Отрывки следует читать до тех пор, пока не будет достигнут критерий эффективности. | Читайте отрывки, пока ученик не достигнет заданного уровня беглости. |

Последовательность команд
- Объедините учащихся в пары и предоставьте им отрывок из 100–200 слов на их учебном уровне, прозрачность отрывка, маркер и лист данных.
- Каждый ученик по очереди работает в качестве регистратора.
- Диктофон записывает время и отмечает неправильные или пропущенные слова. Пропущенные слова определяются как неправильное произношение. Если читатель колеблется более 3 секунд, диктофон произносит пропущенное слово, заставляет читателя повторить его и продолжает читать.Диктофон отмечает X на прозрачной пленке над пропущенным словом, помещенным на копию отрывка.
- Диктофон объявляет об окончании периода времени в одну минуту, предоставляет читателю обратную связь и предлагает читателю произнести их.
- Регистратор записывает количество прочитанных слов, ошибок и правильных слов в минуту на листе выполнения.
- Студенты меняются ролями и повторяют процесс не более четырех раз за сеанс.
- Положительный конец.

- Модель беглого устного чтения (Blevins, 2001; Rasinski, 2003) с использованием учителя, читающего вслух, и в рамках повторяющихся интервенций по чтению (Chard et al., 2002).
- Предоставлять прямые инструкции и обратную связь для обучения расшифровке неизвестных слов, правильному выражению и фразе, обратному движению глаз и стратегиям, которые используют беглые читатели (NICHD, 2000; Snow et al., 1998).
- Обеспечить устную поддержку и моделирование для читателей (Rasinski, 2003), используя вспомогательное чтение, хоровое чтение, парное чтение, аудиокассеты и компьютерные программы.
- Обеспечьте учащихся большим количеством материалов на их уровне самостоятельного чтения, чтобы они могли читать самостоятельно (Allington, 2000).
- Предлагает много возможностей для практики, используя многократное чтение все более сложного текста (Chard et al., 2002, Meyer & Felton, 1999; Rasinski, 2003; Samuels, 1979).
- Поощряйте развитие просодии через границы контрольной фразы (Rasinski, 2003; Schreiber, 1980).

QuickReads Modern Curriculum Press
Компьютерные руководства Soliloquy Learning…
Книги с записью Carbo, Национальный институт стилей чтения,
Как узнать, когда двигаться дальше? Точность 95–100% на уровне класса по количеству слов в минуту из таблицы оценок.
Марка | Время | Правильных слов в минуту |
Первая | Зима | 39 |
Второй | Осень | 53 |
Третий | Осень | 79 |
Четвертый | Осень | 90-99 |
Пятый | Осень | 105 |
Прочие вмешательства :
Практика изоляции с помощью флеш-карт может быть полезна для начинающих и испытывающих трудности читателей
Читательский театр
Радио чтение
Самозаписи
Телефоны Whisper пвх пап
Явное обучение интонации
ABCD? EFG! ПРИВЕТ? JKL.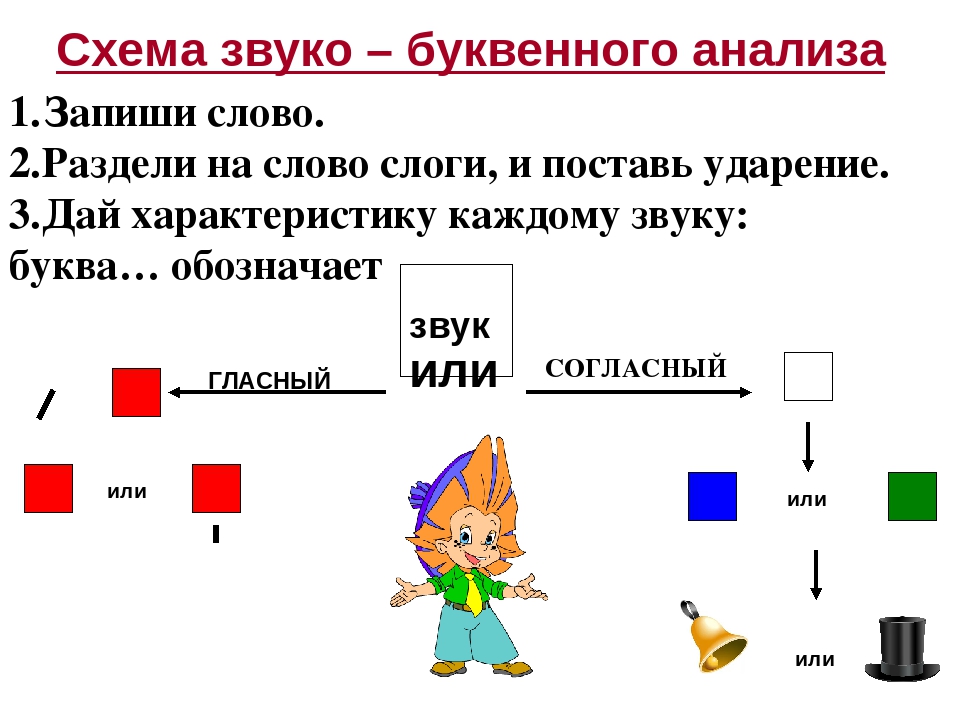 MN? OPQ. RST! UVWXY. Z!
MN? OPQ. RST! UVWXY. Z!
ГРАНИЦЫ ПРЕДЛОЖЕНИЯ
Мое любимое время года / года — лето .//
Я так рад / мы собрались / вчера вечером .//
Было хорошо выйти, / поесть, / пойти в кино / и провести время вместе .//
Реализация Elm задачи «Word Count» с помощью Elm-Parser | tkshill | GistLog
24 октября 2020
Кирк Шиллингфорд
Tl; dr
Это краткая заметка о том, как я использовал библиотеку elm-parser для решения задачи кодирования упражнений.io. Это заняло у меня намного больше времени, чем я ожидал, потому что на данный момент не так много ресурсов по синтаксическому анализу в Elm, поэтому я надеюсь, что эта статья может добавить к доступным ресурсам для других. Чтобы перейти непосредственно к реализации, щелкните здесь, чтобы увидеть, как я это сделал. Чтобы увидеть полный код и тесты, щелкните здесь.
Содержание
Введение
Итак, в эти выходные я попробовал задачу подсчета слов на упражнениях в рамках еженедельного задания, которое я выполняю с друзьями. Мы только начали, но это было весело, так как я получил возможность отточить свои навыки вяза, а также познакомить других с языком. Я очень рекомендую это.
Мы только начали, но это было весело, так как я получил возможность отточить свои навыки вяза, а также познакомить других с языком. Я очень рекомендую это.
Подробности задачи приведены ниже, но, по сути, она требует извлечения некоторой информации из строки текста.
Зачем использовать синтаксические анализаторы вместо регулярных выражений?
Моей первоначальной и непосредственной мыслью было использовать регулярные выражения, так как раньше я всегда выполнял сопоставление с образцом в строках.Каково же было мое удивление, когда я просмотрел библиотеку elm-regex и увидел следующую строку как первый элемент в библиотеке Readme.md :
«Вообще говоря, будет проще и приятнее использовать вместо этой библиотеки синтаксического анализа, например elm / parser».
Какая библиотека предлагает вам использовать другую библиотеку?
Что ж, сообщество Вязов очень сосредоточено на двух вещах; пытается все исправить , но также является практичным. А иногда это означает, что вам нужно предоставить решение, признавая, что это не лучшее решение. Автор продолжает объяснять, почему он считает, что elm-regex не должен быть вашим первым выбором для большинства вещей, и это, безусловно, был интересный аргумент. Это определенно стоит прочитать в исходном документе, но грубое резюме будет таким:
А иногда это означает, что вам нужно предоставить решение, признавая, что это не лучшее решение. Автор продолжает объяснять, почему он считает, что elm-regex не должен быть вашим первым выбором для большинства вещей, и это, безусловно, был интересный аргумент. Это определенно стоит прочитать в исходном документе, но грубое резюме будет таким:
- В целом регулярное выражение сложно понять, поддерживать и тестировать
- Относительная простота использования регулярного выражения означает, что оно часто используется для приложений, для обработки которых оно никогда не предназначалось.), за которым следует любая строчная буква (a-z), цифра (0-9), знак подчеркивания или дефис. Затем {6,18} проверяет, что таких символов не менее 6, но не более 18. Наконец, нам нужен конец строки ($).
И это … нормально? Но очевидно ли это из выражения регулярного выражения? Может быть, если вы знакомы. Но если вы не знакомы с регулярным выражением, можете ли вы определить, правильно ли вы ввели строку? Если вы знакомы с регулярным выражением и сделаете ошибку, сможете ли вы ее обнаружить?
Regex не может сказать, правильно это или неправильно.
Таким образом, нам осталось использовать модульные тесты как единственную реальную защиту от ошибок, которая может быть громоздкой.Итак, учитывая все это, я подумал, почему бы не попробовать elm-parser. Конечно, это не может быть так уж плохо. *
* На самом деле это было довольно плохо 😬, но на самом деле это не вина библиотеки. Библиотека Elm-parser вполне разумна, если вы знаете, что делаете, а я — нет. Мне потребовалось несколько часов, чтобы получить рабочее решение, которое включает в себя бесчисленное количество возвратов, правок и прочтения, перечитывания и перечитывания этой статьи Алекса Корбана (будь здоров, Алекс) и документации, потому что я пытался оба изучают библиотеку и изучают концепцию синтаксического анализа и решения конкретной проблемы.Может быть, это не лучшая идея, но вот и мы.
Методология
Остальная часть этой статьи будет попыткой объяснить мою методологию, если бы я знал, что делаю с самого начала, потому что, если бы я попытался провести вас по моему фактическому пути, это заняло бы 50 страниц.
Инструкции по подсчету слов на сайтеexperience.io
Давайте рассмотрим актуальные требования к программе.
Для данной фразы подсчитайте количество вхождений каждого слова в этой фразе.
В этом упражнении вы можете ожидать, что слово всегда будет одним из:
- Число, состоящее из одной или нескольких цифр ASCII (например, «0» или «1234») ИЛИ
- Простое слово, состоящее из одной или нескольких букв ASCII (т. Е. «А» или «они») ИЛИ
- Сокращение двух простых слов, соединенных одним апострофом (например, «это» или «они»).
При подсчете слов можно принять следующие правила:
- При подсчете учитывается регистр (т. Е. «You», «you» и «YOU» — это 3 использования одного и того же слова)
- Счетчик неупорядочен; тесты будут игнорировать порядок слов и счетчиков
- Все формы пунктуации, кроме апострофа в сокращении, игнорируются
- Слова могут быть разделены пробелами в любой форме (например, «\ t», «\ n», «»)
В конце мы предоставляем единственную функцию
WordCountс сигнатурой типа:
WordCount: String -> Dict String Int, что означает, что функция примет некоторую строку текста и вернет словарь с ключами строк и значений. целых чисел, представляющих наши слова и частоту их появления соответственно.Как мы это реализуем, полностью зависит от нас.Итак, какова наша стратегия
Давайте рассмотрим проблему. Наша программа должна создать функцию, которая принимает строку символов и возвращает
Dictionary со словами из строки в качестве ключей и частотой их появления в качестве значений.Мы можем разбить нашу программу на два отдельных этапа:
- Разобрать строку на список допустимых слов
- Преобразуем список слов в наш словарь
Вкратце: что вообще такое парсер?
Синтаксический анализатор можно определить как «компьютерную программу, которая разбивает текст на распознанные строки символов для дальнейшего анализа» .Синтаксический анализ можно рассматривать как альтернативу проверке. Вместо того, чтобы проверять , находятся ли данные в состоянии, которое может быть использовано вашей программой / процессом, синтаксический анализ пытается преобразовать входящих данных в это допустимое состояние; если данные не могут быть преобразованы, значит, данные недействительны и анализ не выполняется.
Это мощный метод, поскольку он гарантирует, что после этапа синтаксического анализа у вас будет либо:
- Данные, которые являются именно той формой, которая вам нужна для вашей бизнес-логики (и вам не нужно снова проверять их без вашей программной логики)
- Представление несовместимого объекта, с которым ваша программа может иметь дело. до , это может вызвать ошибки во внутренней логике.
Парсеры можно разбить на три отдельных этапа / части:
Токенизатор разбивает поток текста на токены, обычно ища пробелы (табуляции, пробелы, новые строки).
Лексер в основном является токенизатором, но обычно он присоединяет дополнительный контекст к токенам — этот токен является числом, этот токен является строковым литералом, этот другой токен является оператором равенства.
Анализатор берет поток токенов из лексера и превращает его в абстрактное синтаксическое дерево, представляющее (обычно) программу, представленную исходным текстом.
В этом примере наше основное внимание уделяется токенизации и лексированию , поскольку мы на самом деле не строим абстрактное синтаксическое дерево. Мы просто напрямую потребляем список допустимых слов, возвращаемый нашим лексером.
Так как мы это делаем?
Реализация
Определение наших токенов
псевдоним типа Contraction = Может быть, строка тип ValidWord = Числовая строка | Сокращение буквенной строкиВо-первых, давайте воспользуемся системой типов, чтобы определить тип токенов, которые мы хотим возвращать из нашего синтаксического анализатора.Согласно инструкциям, мы можем ожидать два типа допустимых слов. Один — это последовательность всех числовых символов, а другой — последовательность всех буквенных символов, которые могут иметь или не иметь одного апострафа. Наш тип
ValidWordбудет представлять эти два варианта. Обратите внимание на то, что ветвьAlphabeticпринимает два аргумента; первая — это строка, представляющая последовательность символов. Второе сокращение String. Поэтому слова с апострофами будут иметь сокращениеJust somestring, а слова без него будут иметь сокращениеNothing.Создание синтаксического анализатора числовых допустимых слов
isIgnorable: Char -> Bool isIgnorable = not << Char.isAlphaNum numericWord: синтаксический анализатор ValidWord numericWord = преуспеть числовой |, chompWhile isIgnorable | = (getChompedString <| успешная идентичность |, chompIf Char.isDigit |, chompWhile Char.isDigit ) |, chompWhile isIgnorableХорошо, я знаю, что это много. Я постараюсь изо всех сил объяснить, что здесь происходит.
-
isIgnorable- это просто вспомогательная функция, которая возвращает истину, если символ не является буквенным или числовым. Мы собираемся использовать его, когда нам нужно проверить наличие пробелов и случайных символов между словами . -
numericWord- это наш синтаксический анализатор ValidWord. В частности, он пытается создать ветвьNumericтипаValidWord. Он не обрабатывает случайAlphabetic(для этого у нас будет другой парсер).- успешно - это первая функция, которую мы видим из библиотеки синтаксического анализатора, и пока мы можем рассматривать ее как функцию, которая помогает нам начать определение последовательности шагов синтаксического анализа
- |. - это вспомогательная функция из библиотеки синтаксического анализа, которая позволяет анализировать часть потока без передачи содержимого. Это отлично подходит, когда вы хотите убедиться, что что-то существует, но не хотите передавать это своим конструкторам токенов
- chomp В то время как делает именно то, на что похоже.Он будет потреблять поток текста, пока выполняется переданное в него условие. В сочетании с (|.) Мы, по сути, говорим, что «в начале могут быть какие-то не буквенно-цифровые символы, нас это не волнует
- | = - противоположность
|.Это передает независимо от результата парсера, который идет после него - getChompedString - обычно chompers ничего не возвращают. Они просто потребляют и проверяют.
getChompedStringпревращает результат всего, что вы перекусили, как строкуString. ( Примечание , что мне потребовалась целая вечность, чтобы понять, что это лучший способ вернуть такие странно определенные строки, как эта. Это не единственный способ - см. Parser.variable - но это лучший способ для данной конкретной ситуации). Мы передаемgetChompedStringеще одну подкатегорию парсеров, которая на самом деле является тем, что мы хотим использовать для создания нашего числового токена.-
identity- это обычная вспомогательная функция в функциональном программировании, которая просто возвращает то, что ей передано. - chompIf - chomps только char в точности соответствует следующей функции. В этом случае мы хотим «пережевывать», только если символ является цифрой.
- Далее идет chomp
В то время какговорит: «После идентификации хотя бы одной цифры вы можете ввести последовательность из любого количества цифр, сколько хотите.
-
- Наконец, мы добавляем еще одну проверку на наличие не буквенно-цифровых символов.
- В целом мы можем прочитать этот парсер как:
"Эй, проверь, нет ли в начале этого текста каких-то не буквенно-цифровых символов.Мне все равно, сколько. Тогда вы должны увидеть не менее на одну цифру . Возьмите эту последовательность цифр. Затем вы должны увидеть еще несколько не буквенно-цифровых символов. Конец » ❤️
Это было много! Но, по сути, теперь у нас есть парсер, который может обрабатывать числовые допустимые слова.
Создание синтаксического анализатора буквенных допустимых слов
апостроф: Char апостроф = Char. fromCode 39
сокращение: Parser (Maybe String)
сжатие =
(getChompedString <|
успешная идентичность
|,chompIf ((==) апостроф)
|, chompIf Char.isAlpha
|, chompWhile Char.isAlpha
)
|> Parser.map Just
alphabeticWord: синтаксический анализатор ValidWord
alphabeticWord =
преуспеть по алфавиту
|, chompWhile isIgnorable
| = (getChompedString <|
успешная идентичность
|, chompIf Char.isAlphaNum
|, chompWhile Char.isAlpha
)
| = oneOf [сокращение с возможностью возврата, ничего не добиться]
|, chompWhile isIgnorable "О нет, это даже сложнее, чем числовое."Если вы так думаете, вы правы. Но основная техника та же самая. Основное различие заключается в том, что Alphabetic ValidWords принимает две части данных: первая строка для буквенного текста перед апострофом и вторая
Maybe Stringкоторый представляет собой вторую часть соединения. Давайте рассмотрим здесь то, что отличается от числовой версии.-
апостроф- Во-первых, мы видим, что мы определили константу, называемую апострофом, которая представляет апострофный символ.Я сделал это, потому что Elm представляет символы, используя апостофы / одинарные кавычки. Итак,"n"- это строка'n'- этоCharn. Обычно это нормально, но в случае самого апострофа мы видим, что это представлениеCharдолжно быть'' ', что компилятору, похоже, не понравилось. 😬 Итак, мы использовали ссылочный номер кодовой точки из библиотеки Unicode для создания символа апострофа. Могут быть и другие способы сделать это, но в то время это казалось ясным и разумным. -
сокращение- это синтаксический анализатор сокращения нашего действительного слова. Обратите внимание, что в первую очередь он проверяет, является ли первый символ апострофом.- Затем мы проверяем, следует ли за апострофом буквенный символ. Это означает, что завершающие апострофы отклоняются.
- Parser.map - это вспомогательная функция с сигнатурой типа
Parser.map: (a -> b) -> Parser a -> Parser b. Это позволяет нам преобразовывать значения внутри парсера и возвращать новый парсер преобразованного значения.В этом случае мы оборачиваем строкуStringизgetChompedStringв значениеMaybe. - В целом мы можем интерпретировать сокращение как:
«Эй, проверьте, есть ли апостроф, за которым следует хотя бы один буквенный символ. Оберните это в« Может быть ».
-
alphabeticWord- основная функция для создания синтаксического анализатора для ветвиAlphabeticтипаValidWord. Его структура похожа наnumericWord, проверяя наличие пробелов, а затем ища последовательность буквенных символов.- oneOf - это функция, которую мы раньше не видели.
oneOfприменяет список синтаксических анализаторов к последовательности, пробуя их один за другим, пока один из них не будет принят.- с возможностью отслеживания с возвратом - это вспомогательная функция в библиотеке синтаксического анализатора, которая сообщает, что в случае сбоя синтаксического анализатора выполняется возврат к тому месту, где он был начат, для следующей части синтаксического анализатора.
- altogther, oneOf пробует наш синтаксический анализатор сокращения, и если он терпит неудачу (потому что никакого сокращения не существует), он возвращает синтаксический анализатор другого случая нашего, возможно,
Nothing.
- Обратите внимание, что буквенное слово имеет два оператора
| =, каждый из которых принимает входные данные для конструктораAlphabetic.Мы можем прочитать весь синтаксический анализатор как:
«Эй, проверьте, есть ли какие-то не буквенно-цифровые символы. Затем возьмите последовательность хотя бы из одного алфавитного символа. Затем, если вы видите последовательность апострофа, за которой следуют другие буквенные символы, верните Just, иначеничего не вернет. "
- oneOf - это функция, которую мы раньше не видели.
Если честно, мне кажется, что эти концепции трудно объяснить, если вы не начинаете с первых принципов, поэтому я могу только надеяться, что примеры и описание имеют достаточно контекста, чтобы помочь людям.
Преобразование списка в словарь
Прежде чем завязать узел на наших парсерах, давайте на секунду перескочим и поговорим о преобразовании списка допустимых слов в словарь строковых ключей и целых чисел
validWordToString: ValidWord -> Строка validWordToString vw = чехол vw из Цифровое слово -> слово Буквенное сокращение слова_ -> сжатие_ |> Может быть.withDefault "" |> String.append word dictUpdate: String -> Dict String Int -> Dict String Int dictUpdate ключ dict = case Dict. получить ключевой диктат
Просто посчитайте ->
Dict. Вставить ключ (count + 1) dict
Ничего ->
Dict. Вставить ключ 1 dict
Для этого мы должны определить две вспомогательные функции:
validWordToStringиdictUpdate.validWordToStringделает именно то, что говорит, и может преобразовать любой экземплярValidWordв простую строкуString. Мы используем операторы case, чтобы определить, с каким типомValidWordмы имеем дело.Обратите внимание, что в то время как случайNumericпредставляет собой довольно простую декомпозицию шаблона, случайAlphabeticимеет это надоедливое сокращение, которое представляет собойMaybe String. Здесь мы используем Maybe.withDefault, чтобы предоставить значение по умолчанию в случае, если сокращение -Ничего(по умолчанию - пустая строка""), и мы используем String. append, чтобы прикрепить его к первой части строки.dictUpdate- это функция, которая принимает ключ и Словарь и выполняет следующие действия:- , если ключ уже существует в словаре, замените значение в этом ключе самим собой плюс еще один
- , если ключ не существует, вставьте ключ в словарь со значением 1.
Эти две функции будут объединены с несколькими последними функциями, которые мы должны собрать вместе.
Собираем все вместе петлями
validWordHelper: List ValidWord -> Parser (Step (List ValidWord) (Dict String Int)) validWordHelper revValidWords = позволять continueLooping: ValidWord -> Step (Список ValidWord) (Dict String Int) continueLooping vw = Цикл (vw :: revValidWords) stopLooping: a -> Step (Список ValidWord) (Dict String Int) stopLooping _ = revValidWords |> Список.карта (validWordToString >> String.toLower) |> List. foldl dictUpdate Dict.empty
|> Готово
в
один из
[успешно продолжить
| = oneOf [алфавитное слово с возможностью возврата, числовое слово]
, success () |> Parser.map stopLooping
]
validWord: Parser (Dict String Int)
validWord =
цикл [] validWordHelper Мы почти на финишной черте нашего парсера. Мы создали два синтаксических анализатора, которые могут обрабатывать любой случай наших действительных токенов,
numericWordиalphabeticWord, но оба они производят только один токен .Нам все еще нужно определить способ преобразования строки в последовательность токенов.Войдите в функцию Parser.loop. Это, безусловно, самая грубая часть этого приложения.
петляимеет обозначение типацикл
: состояние -> (состояние -> синтаксический анализатор (состояние шага а)) -> синтаксический анализатор аНе беспокойтесь, если эта подпись вас немного пугает.
Я буквально понял это только во время написания этого документа. 😅 Это также помогает, если вы привыкли складывать функции для последовательностей.Что может помочь, это если вы заметите, что функция цикла
Шаг определяется по:
тип Step state a = Состояние цикла | СделаноПо сути, цикл
Loopтипа Step определяет, что делать дальше, а ветвьDoneопределяет, что делать, если больше нет токенов для захвата.В нашем случае наше «состояние», которое мы обновляем, - это
List ValidWords, а наша «a», форма данных после завершения цикла, - этоDict String Int, который мы хотим в качестве нашего конечного продукта.По мере того, как мы перебираем нашу строку, мы переносим это постоянно обновляемое состояние, а затем, наконец, когда мы
stopLooping, мы используем функциюvalidWordToStringиdictUpdate, которую мы определили ранее, чтобы преобразовать состояние
List ValidWordв состояниеList String, а затем «сворачиваем» этот список в словарь, используя нашу функциюdictUpdateдля правильного добавления каждой строки из нашего списка в словарь.Если вас это все еще сбивает с толку, ничего страшного. Это определенно не самая интуитивная вещь, если вы раньше не работали с функциональными парсерами. Я написал эту статью, чтобы люди могли изучить этот код на досуге, используя документацию и другие ресурсы для справки.
И наконец ...
И последнее, но не менее важное: мы определяем фактическую функцию, которая определяет наш API
wordCount.wordCount: String -> Dict String Int wordCount предложение = case Parser. выполнить предложение действительного слова
Хорошо разобрано ->
разобранный
Err _ ->
Dict.empty До сих пор мы только конструировали парсеры.
Parser.run - это функция, которая может фактически приниматьParserи возвращать значение. Чтобы быть более конкретным,Parser.runимеет подпись:запустить: Parser a -> String -> Result (List DeadEnd) aЗдесь мы видим еще один печально известный тип функционального программирования, тип результата!
Результатимеет подписьтип Результат значение ошибки = ОК значение | Ошибка ошибкиКак
Возможно,Результатиспользуется для инкапсуляции данных из операций, которые могут быть успешными или неудачными.В отличие отMaybe, который просто возвращаетNothing,ResultимеетErr acase, гдеaможет быть любым типом данных, который мы хотим, который вы можете использовать для хранения дополнительного контекста для вашей ошибки.В банке с функцией
run, связанный с ней тип ошибки -List DeadEnd, в то время как в основном это список всех причин сбоя вашего парсера.Все это, чтобы сказать, когда мы запускаем наш синтаксический анализатор в
wordCount, мы должны обрабатывать оба случаяResult, случай, когда он успешен (в этом случае мы возвращаем успешно проанализированный словарь), и случай, когда он не работает ( мы решили игнорировать тип ошибки и просто вернуть пустой словарь)Заключение
Резюме
- Нам нужно было создать функцию, которая принимает строку и конвертирует ее в словарь ключевых слов и количество раз, когда они встречаются
- допустимых слов могут быть последовательностью цифр, букв или букв со встроенным в них апострофом - мы создали тип «токен»
ValidWordsдля представления двух способов создания допустимого слова - Мы определили синтаксический анализатор для каждого случая
ValidWord, предназначенный для извлечения из строки текста - Мы определили цикл, который будет продолжать попытки отобрать
ValidWordиз нашей текстовой строки - Мы определили несколько вспомогательных функций для преобразования между или основными типами,
ValidWord,String,ListиDict
Последние мысли
Я потратил слишком много времени на этот проект, но он мне очень понравился.
Парсинг - это основополагающий метод разработки программного обеспечения, а библиотека elm-parser на самом деле чрезвычайно надежна. Я мог бы потратить много времени на настройку этого решения для повышения производительности или более строгого соблюдения правил типов, но я думаю, что пока могу оставить это в этом месте. Я не берусь думать, что это идеальная статья. Но совершенство - враг хорошего.Дополнительные ресурсы
- Вот суть полного решения и соответствующие тесты
- Вот ссылка на онлайн-редактор Elm, где я сделал очень очень грубый интерфейс для опробования некоторых тестовых образцов.
Если вы можете придумать, что я могу сделать для улучшения этой статьи, напишите мне по адресу [email protected]. Я также в слабых группах
ElmиF #под именем @kirk ShillingfordСпасибо за уделенное время. 🙏🏾
Создано 6 месяцев назад | Обновлено 6 месяцев назад
Программа, развивающаяся вместе с вашими детьми
Программа, развивающаяся вместе с вашими детьми
Наша ведущая программа, Jolly Phonics, обучает детей чтению и письму с использованием синтетической фонетики, которая широко признана наиболее эффективным способом обучения детей чтению и письму на английском языке.Это было более 25 лет назад. С тех пор наш огромный прогресс был изучен в многочисленных исследовательских проектах, результаты которых привели к тому, что акустика стала центральным элементом учебной программы Великобритании. Сегодня нас используют более чем в 100 странах мира. Как ведущее и наиболее опытное издательство по синтетической фонетике мы предлагаем 7-летнюю школьную программу, в которой преподаются не только фонетика, но и орфография, пунктуация и грамматика.
- Систематическое обучение фонетике, грамматике, орфографии и пунктуации в течение школьных лет
- Обучение мультисенсорное и активное, с забавными действиями, рассказами и песнями
- Независимые исследования подтверждают выдающиеся результаты, достигнутые во всем мире с помощью программы
- Продолжает пересматривать и расширять звуковые знания детей
- Гибкость и простота внедрения в школе
- Разработано учителями для учителей
Щелкните здесь, чтобы открыть для себя наш великолепный ассортимент совершенно новых и обновленных ресурсов на 2021 год!
Теперь вы можете присоединиться к нам для двух БЕСПЛАТНЫХ онлайн-сессий с невероятными соавторами Jolly Phonics, Сью Ллойд и Сарой Вернем.
В течение мая, июня и июля мы будем проводить две бесплатные сессии: «Начни с Jolly Phonics», с Сью Ллойд и «Расширяйся с Jolly Phonics» через KS1 с Сарой Вернхам.
Вы можете зарегистрироваться для участия в этих мероприятиях, нажав здесь.
Эмма Инс - заместитель директора начальной школы Тюдоров в Саффолке, Англия. Она следила за развитием грамотности в школе, используя программу Jolly Phonics в течение последних 8 лет.В этом коротком видео она рассказывает о том, как они используют программу, и об их успехах.Как работает Jolly Phonics
Jolly Phonics - это комплексная программа, основанная на проверенном, увлекательном и мультисенсорном методе синтетической фонетики, которая помогает детям читать и писать с раннего возраста. Это означает, что мы обучаем звукам букв, а не алфавиту. Эти звуки из 42 букв являются звуковыми строительными блоками, которые дети с правильными инструментами используют для декодирования английского языка.Читая слово, они узнают буквы и смешивают соответствующие звуки; при написании слова идентифицируют звуки и записывают соответствующие буквы. Эти навыки называются смешиванием и сегментацией. Вот два из пяти навыков, которые необходимы детям для овладения фонетикой:
- Изучение звуков букв: Детей учат звукам 42 букв, которые представляют собой смесь звуков алфавита (1 звук - 1 буква) и диграфов (1 звук - 2 буквы), таких как sh, th, ai и ue.Используя мультисенсорный подход, каждый звук букв представлен забавными действиями, рассказами и песнями. Мы обучаем звукам букв в 7 группах по 6 букв в темпе 4-5 звуков в неделю. Дети могут начать читать после того, как выучили первую группу букв, и должны были быть ознакомлены со всеми звуками из 42 букв после 9 недель в школе.
- Формирование обучающего письма: Этому учат вместе с введением звука каждой буквы. Обычно дети учатся формировать и записывать буквы в ходе урока.
- Смешивание: После того, как первые несколько звуков букв усвоены, дети начинают смешивать звуки, чтобы помочь им читать и писать новые слова.
- Сегментирование: Когда дети начинают читать слова, им также необходимо начать определять звуковые компоненты, которые заставляют слово звучать так, как оно есть. Обучая смешиванию и сегментированию одновременно, дети учатся собирать и разбирать звуки в словах.
- Хитрые слова Это слова с неправильными частями, такими как «кто» и «я». Дети изучают это как исключения из правил фонетики. Использование общих сложных слов в начале года увеличивает беглость чтения (поскольку они часто встречаются в тех первых простых предложениях, которые вы могли бы ожидать, что они прочитают).
Наряду с этими навыками детей также знакомят с основным альтернативным написанием гласных. Эти пять навыков составляют основу, которую дети развивают с каждым годом обучения грамматике. Вы можете просматривать видео по каждому из пяти ключевых навыков, нажимая кнопки ниже.
Jolly Phonics работает - проверенные результаты!
По всему миру было проведено множество исследований Jolly Phonics, которые можно посмотреть здесь. Исследование показывает, что успехи, достигнутые детьми, использующими Jolly Phonics, намного превышают успехи детей, не обучающихся с использованием синтетического метода фонетики. Он эффективен во всем диапазоне способностей: мальчики справляются не хуже, чем девочки, тогда как те, у кого английский является вторым языком, могут справляться так же хорошо, как дети, у которых он является первым.
Начальная школа Rush Green в Эссексе, Англия, обратилась к Jolly Phonics, чтобы повысить уровень грамотности в школе. Увидев значительный прогресс в способностях своих детей, они с тех пор расширили свое обучение с помощью программы грамматики на протяжении многих лет.«Jolly Phonics - это потрясающе, когда дети учат звуки букв и помогают произносить слова, чтобы перейти к следующему этапу их речи и языка».
Jolly Phonics продлится следующие 6 лет
Программа продолжается в течение школьных лет, расширяя предыдущее преподавание фонетики дополнительными концепциями орфографии, грамматики и пунктуации.Каждый год обучения предусматривает постоянный пересмотр и закрепление тем, изученных в предыдущие годы. Детей также учат основным понятиям грамматики и пунктуации, начиная с простых соответствующих возрасту определений, которые постепенно вырабатываются с каждым годом обучения. Обучение по-прежнему носит мультисенсорный характер с действиями и цветовым кодированием (в соответствии с Монтессори) для частей речи, чтобы помочь детям развить понимание того, как работает язык. Систематическая программа означает, что детям даются инструменты, необходимые для самостоятельного написания того, что они хотят, ясно и выразительно.
С учетом того, что орфография, пунктуация и грамматика (или SPaG) стали более заметными в учебных планах по всему миру, мы расширили нашу программу обучения грамоте до возраста 11 лет (6-й класс / P7 в Великобритании). Наша программа находится в авангарде этого обучения и отвечает целям как национальной учебной программы Великобритании, так и общих основных государственных стандартов США.
«Систематическое обучение орфографии, грамматике, пунктуации и лексике проявляется в ежедневном письме учащихся. Они могут распознавать и использовать части грамматики при чтении и письме.”
Прогресс программы
Щелкните здесь, чтобы просмотреть все ресурсы в магазине в Великобритании.
Щелкните здесь, чтобы просмотреть все ресурсы в магазине в США.
Алфавит Пламени Бена Маркуса
«Сегодня я получил 500 000 дискретных битов информации, из которых, возможно, 25 являются важными». - Дэвид Фостер УоллесСлова убивают.
Иоанна 1: 1 может быть мифологической выдумкой, но в конце будет слово, какое-то слово и затем конец.Освещает человечество. Некоторое ненавистное слово, или риторика, или нижняя строка отчета о прибыли, или слова о мнимом превосходстве, (неверно) воспринимаемых угрозах, словах вымышленных богов, передаваемых через книги, наполненные словами, словами, которые отравляют и убивают. Люди умирают каждый день от слов, сказанных глупостей, мыслей, обдумываемых словами, да, есть много других способов сделать это, но, может быть, почти все, что действительно хреново, сводится к словам. Все эти гребаные слова.
Практически все в мире, принятые в слишком высоких дозах, вредны для нас.Что, если бы это было буквально, я имею в виду с медицинской точки зрения, истинным языком, что, если бы мы прошли точку, когда мы стали пьяными с DT на языке? Об этом упрощенно и говорится в этой книге. Как мы живем в мире, где мы должны быть пост-языком, пост-смыслом, где члены нашей семьи имеют возможность отравить нас своим языком.
Язык убивает. Может быть, я меньшинство, может быть, я аномалия, но я единственный человек, у которого лично есть опыт относительно того, что на самом деле происходит в голове.Я не причастен к чужим мыслям (к счастью. Я с трудом вынесу свои собственные). Все, что со мной не так, кроме некоторых физических болей и грядущих болезней (скорее всего), происходит от слов. Слова, которые испортили мой образ мышления, слова, которые побеждают и режут меня, слова, искажающие мое восприятие мира, слова, которыми дразнит меня мой мозг, слова, которые говорят другие люди, слова в песнях, в книгах. Палки и камни могли сломать мне кости, но слова меня серьезно испортили.
Мышление - первая отрава ... Почему сам человек не выпотрошен от мысли? Кого волнует слово, обнародованное, это частное слово, которое наносит более длительный ущерб, от человека к человеку. Сначала нужно было прекратить думать. Мышление . Возможно, это следующий шаг в долгом, ползучем победе над этой токсичностью, еще одной основной деятельностью человека, которую мы будем постепенно забирать.
О, я нахрен на это надеюсь.
И даже если они не облажались напрямую, их так много, столько слов орут на вас из самых разных источников.Почти белый шум бесконечной болтовни со смешанным смыслом. Бесконечные цепочки предупреждений, новостей и попыток привлечь к ним ваше внимание, невнятные разговоры в общественных местах, преднамеренные слова, которые вы ищете, и все те, которых вы не можете избежать. Слова, написанные случайными битами, смело кричат: ПОСМОТРИТЕ НА МЕНЯ !!! ПОСМОТРИ НА МЕНЯ!!! ОБРАТИТЕ НА МЕНЯ ВНИМАНИЕ !!! Я ВАЖНЕЕ ЧЕМ ДРУГОЕ !!! КТО ЗАБОТЕТСЯ, ЕСЛИ У МЕНЯ НИЧЕГО НЕ ДОЛЖНО СКАЗАТЬ, ТОЛЬКО, Блядь, ОБРАТИТЕ ВНИМАНИЕ НА МЕНЯ !!!!! ВОЗМОЖНАЯ ВЫСОКАЯ РЕКОМЕНДАЦИЯ !!!!
Просто заткнись уже и прекрати свою постоянную бомбардировку, пытаясь привлечь мое внимание.И здесь я добавляю больше слов. Еще больше грязной чуши информации, которую я прошу вас тщательно изучить, чтобы увидеть, не содержится ли в ней что-то важное, что-то стоящее. Какая чертовски тщеславная с моей стороны. Полезное сообщение? Ха!
"Распространение сообщений разбавляет их. Даже понимание их является компромиссом. Язык убивает себя, истекает срок действия своего носителя. Язык действует как кислота над своим сообщением. Если вас больше не волнуют идеи или чувства, тогда поставьте это на язык.Это, безусловно, будет последним, достойным концом. Язык - еще одно название гроба ».
Подобные строки часто встречаются в книге. Я читал эту цитату, наверное, более пятидесяти раз. Я уже несколько недель мучился с этим обзором. Глядя на цитаты, которые я отбирал , пытаюсь понять, что я имею в виду сказать о них, что я думаю, они имеют в виду. Прочтите это еще раз, я только что прочитал, и это затруднительно, что это за сообщение без языка? Первоначальный, или a priori , или что-то еще чертовски громкое слово, которое ты хочешь использовать, сообщение, которое стоит перед словом.Ощущение неосознанности, мысль, которая трепещет без осознания, момент действия против мышления? Я думаю о том, как что-то сделать, и застываю в бездействии, не в силах пошевелиться. Слишком часто я бормочу себе под нос после жалкого выступления в драке, о котором я начал слишком много думать. Когда я не думаю, что все просто течет, происходит невероятное дерьмо, когда я думаю, все разваливается, я бормочу извинения, связанные с мышлением. Бен Маркус не мог иметь это в виду, не так ли?
"'Само понимание не имеет значения... Не превращайте это в фетиш, потому что это ничего не окупает. Эта привычка должна быть нарушена. Понимание усыпляет нас. Темный и нежелательный сон. Подобные вопросы не подлежат разрешению. Мы никогда не должны верить, что знаем свои роли. Мы всегда должны задаваться вопросом, что нужно для этого момента? » делал, и я хотел остановиться, я хотел заняться чем-нибудь еще, я устал от того, что повторения разрушения воспроизводятся снова и снова, я хотел, чтобы образы вышли из моей собственной головы, но вместо этого я их встраивали дальше, изменяя, казалось бы, бесконечными повторяющимися выстрелами лично засвидетельствованного разрушения.Я продолжал смотреть, потому что мне нужны были ответы, я хотел, чтобы кто-нибудь сказал мне, кто это сделал, поэтому я продолжал смотреть, как будто я досмотрел фильм до конца, который мне надоел только потому, что я чувствовал себя так, как будто я нужно было вознаградить некоторым пониманием, чтобы знать почему. Я думал, что мне нужны эти слова, чтобы привести все в порядок, собрать все сломанное и разрушенное, но не на улицах центра города, а во мне самом, чтобы я знал, что слова, которые пронеслись в моей голове, не сделали меня Полное дерьмо, что была причина, пусть и плохая, но причина того, что произошло.
С пониманием разницы не было.
Сократ, или Платон, или кто-то, пишущий с этими именами, проболтались о «Познай себя, пойми себя». Я потратил как минимум два десятилетия своей жизни, пытаясь понять себя, пытаясь проанализировать себя, искать ответы на вопросы, почему, выяснять то и это, и все, что я сделал, это утонул в обратной связи самосознательный и самореферентный шум. Было бы лучше, если бы я никогда не думал «о себе». Неисследованная жизнь, возможно, и не стоит того, чтобы жить, но исследованная жизнь - это чертовски ад.Понимание? Ха!
Когда Эстер, наконец, стала достаточно взрослой, чтобы ходить в школу одна, она все еще хотела одобрения простых вещей, которые можно было бы считать талантами. Есть яблоко. Стоя на одной ноге. Скоро она захочет, чтобы ее поздравили с тем, что она проснулась и вышла из комнаты. Однажды она села у нас на подоконнике - ей, должно быть, было восемь или девять лет. Она была очень довольна собой, раскачивая ногами взад и вперед.
Папа, ты знаешь, что я могу сделать трюк?
Ах да?
Ага!
Я могу делать ноги то и то, то и то!
Я это вижу.
Вы видите?
Верю.
Вы не смотрите. Почему ты не смотришь?
Ищу. Я вижу это.
Но нет. Ты не.
Надо было ее поздравить. Кто сказал, что в этом нет ничего необычного? Что я действительно знал о необычных вещах?
Иногда я шучу о детях и о том, за что их поздравляют, о простых вещах, таких как ходьба, вставание, произнесение слов, гадание в туалете, о том, что мы с вами делаем каждый день без особой помпы.Я шучу, что мне нужна такая похвала, я хочу, чтобы меня хорошо относили к себе добрыми словами за то, что они делали невзрачное, и я шучу, что детей не следует хвалить за подобные вещи, потому что они не такие уж и сложные , они в конечном итоге поймут, как делать все эти вещи, так что оставьте похвалу за действительно достойные дела, такие как решение проблемы мирового голода или лечение рака или что-то в этом роде.
Я шучу.
Я улыбнулся и даже немного посмеялся, когда нашел этот отрывок в книге.Может быть, шутка заключается не в том, что нам следует воздерживаться от похвалы за важные вещи, а в том, что просто жить и иметь возможность так раскачивать ногу, стоит похвалить. Может быть, эти добрые слова - просто противоядие от всех дерьмовых словечек, с которыми нам ничего не нужно делать, кроме как продолжать дышать, чтобы встретиться с ними. Я не знаю. Я, наверное, просто засранец из-за того, что «шучу» о том, что хочу, чтобы меня хвалили каждый раз, когда мне удается не гадить на себя и задерживать дефекацию, пока не доберусь до ванной.
Надо было ее поздравить. Кто сказал, что в этом нет ничего необычного? Что я действительно знал о необычных вещах?
Этот гребаный обзор не дает мне покоя уже несколько недель. Это не единственный, у меня есть четыре незавершенных обзора, которые я вижу на своем рабочем столе, все они открываются своими словами, дразня меня, чтобы я добавил к ним больше слов, чтобы они что-то значили, и, возможно, их прочитали и заработали столь желанные голоса хороших читателей.
Я хотел сказать очень важные вещи в этом обзоре, но потом мне помешали другие слова, я хотел использовать несколько тщательно подобранных цитат, чтобы вызвать мысли, которые будут интересны мне и, надеюсь, другим людям, вместо этого я получил в нарциссическую бессвязность, используя книгу как трамплин для самой скучной темы, которую только можно вообразить.Чертовы слова. Винить их. Я ухожу без промедления на этом.
Ниже приведены еще несколько цитат, с которыми я собирался что-то сделать. Вы должны их прочитать, и если они вызывают какие-либо мысли, то, вероятно, они лучше, чем то, что я написал бы.
Потому что восстановление языка для людей было всего одним маленьким кусочком его работы. Бьюсь об заклад, это детская игра. Мелкая работа - это правильно. В конце концов, это тоже маленький , не так ли? Достаточно легко расстрелять всех жидкостью, чтобы они снова могли выкрикивать оскорбления друг другу, начинать свою кампанию по громкому обвинению. Легко . Он сделает больше, чем это. ЛеБов также стирает систему убеждений, удаляет любовь из воздуха, как если бы он был всего лишь атмосферным загрязнителем. Любовь - это просто загрязнение, которое можно очистить от человека, верно, ЛеБов? Если бы только у вас были подходящие инструменты.
Если вы так внимательно слушаете ничего, используя подобное оборудование, вы можете услышать все, что захотите. Это заставило вас думать, что нас все еще тошнит от какого-то языка, о существовании которого мы даже не знали. Неслышно, тихо шепотом, изрекает враг издалека, это невозможно даже измерить.Тем не менее, он источал какой-то яд, который заставлял всех нас ползать по животу и задыхаться.
10 потрясающих книг по алфавиту для Национального месяца грамотности - плюс советы учителям!
Научиться читать - одна из самых сложных задач, которые когда-либо выполняются ребенком. Помимо того, что для чтения требуется хорошая рабочая память, отличное понимание звуков и понимание условностей задачи, чтение также зависит от параллельной обработки в мозгу. И это то, что мы не можем торопить. Мозгу нужно время для развития.
С другой стороны, действительно не существует такой вещи, как слишком раннее начало обучения чтению, если вы понимаете этапы развития чтения. Самые первые этапы не похожи на , когда учатся читать . Эти этапы включают в себя интенсивный языковой обмен между детьми и родителями и много рассказов, как через чтение вслух, так и через словесную игру. На ранних этапах также выгодна богатая печатная среда, что не обязательно означает владение большим количеством книг (хотя владение книгами обычно связано с более высокими успехами в развитии грамотности).
В рамках Национального месяца грамотности я попросил библиотекарей, учителей и специалистов по грамотности по всей стране поделиться своими простейшими советами по обучению чтению, а также своими любимыми книгами по алфавиту. Результат был обнадеживающим и восхитительным. Во-первых, советы:
1. Погрузите детей в изучение алфавита через игры, развлечения и исследования. Игры, стишки, музыка, игра пальцами и повседневные дела - все в счет. (Энн Сейка, детский библиотекарь, Публичная библиотека Льюистона) Говоря о повседневных делах, специалист по чтению Кэрол Салливан Свирски, которой нравится книга Alphabet City, предлагает: «Ищите буквы, созданные в естественном окружении.Может быть, найти палку, похожую на K , или след самолета, похожий на W . Если присмотреться, буквы будут спрятаны вокруг вас ». (Свирский, Woodland Elementary, Milford Public Schools)
2. Много смейтесь, присутствуйте и помогайте ребенку быть искренне счастливым во время чтения. Они будут помнить, как они себя чувствуют (счастливы!), И это поможет привить раннюю любовь к чтению. (Даниэль Томас, старший преподаватель дошкольного образования в системе государственных школ Гросс-Пуэнт)
3.Обращайтесь к естественному любопытству ребенка и сделайте обучение значимым. Выберите письмо дня. Затем попробуйте поиски сокровищ, приключения «Я шпионю» и воображаемое путешествие с «покупками» для предметов, которые начинаются с буквы дня. (Патрисия Сазерленд, специалист по двуязычной грамотности и дислексии и автор книги «Алфавит во всем мире»)
4. Читайте вслух младенцам (даже коробки с хлопьями!), А когда ребенок подрастет, не бойтесь читать упражнения, которые могут показаться повторяющимися. Поскольку грамотность требует множества навыков, таких как острота зрения, распознавание звуков, понимание того, что печатный текст имеет значение, мелкая моторика (потому что письмо и чтение тесно связаны) и даже социальное развитие, вы действительно не можете начать слишком рано или повторять что-то слишком часто. "Очередной раз!" должно быть любимым словом, которое вы хотите услышать от ребенка, который хочет слышать, как вы говорите, читаете и делитесь. Однако речь идет не о тренировках с детьми. Речь идет о том, чтобы разделить жизнь чтения с течением времени и понять, что многие переменные должны стать на свои места, прежде чем произойдет независимое чтение.(Джоэл Бангилан, лингвист, молодежная служба и библиотекарь, публичная библиотека округа Харрис)
5. Произнесите несколько букв вместе во время рассказов по алфавиту. Просто укажите на букву и попросите ребенка сказать это письмо вместе с вами, затем сделайте еще один шаг и спросите, какая буква стоит до или после буквы, которую вы только что сказали. Если ребенок не уверен, предложите вместе произнести алфавит, чтобы узнать, что, например, G следует после F . (Хиллари Хиггинс, помощник детского библиотекаря в публичной библиотеке Гейлсберга)
(Это, кстати, дает дополнительное преимущество - знакомство с математическим языком.«До» и «после» - важнейшие понятия и язык для развития математики!)
6. Приукрасите буквы или украсьте их. Сделайте M запоминающимся, например, нарядив его в образ монстра. (Сьюзан Эрхардт, специалист по работе с молодежью районной библиотеки Кента) Попросите детей старшего возраста написать стихотворение об их преобразованном письме. (Калли Фейен, специалист по распространению грамотности в государственных школах Ипсиланти)
7. Сделайте изучение алфавита увлекательным процессом, связав буквы с жизнью ребенка. Тот факт, что алфавит начинается с буквы А, не означает, что вам нужно начинать с нее. Чему учить в первую очередь? Выберите буквы, которые используются в имени ребенка, или буквы, обозначающие любимые игрушки или продукты ребенка. И подчеркните соответствие буквы и звука, а не просто научите распознавать буквы. (Дженнифер Уильямс, специалист по грамотности в Calliope Global и член правления Международной ассоциации грамотности)
8. Используйте любимую куклу или фигурку, чтобы создать коллекцию сюрпризов для письма недели и сыграйте в угадайку. Представьте, что кукла или фигурка любит собирать коллекции и снова собрала пять предметов, которые начинаются с одной буквы. Положите предметы в специальную коробку и вытаскивайте их по одному, прося ребенка назвать предметы. После того, как элемент назван, повторите его имя и подчеркните звук, с которого элемент начинается. Повторите для всех пяти пунктов, а затем попросите ребенка угадать, о какой букве кукла думает в течение недели. Последним предметом в коробке может быть большая картонная версия письма недели.Пусть ребенок вытащит письмо, чтобы закончить игру. (Сара Вивиани, детский библиотекарь, Публичная библиотека Манделя, Уэст-Палм-Бич)
9. Используйте алфавитные книги с самого раннего возраста. Хотя чтение вслух вслух ребенку важно для процесса обучения чтению, вы можете начать говорить о строительных блоках слов, читая и просматривая множество книг по алфавиту. (Дженнифер Нунан, библиотекарь детской службы MLIS публичная библиотека Льюиса)
10.Спойте песню ABC и поделитесь детскими стишками. (МэриЭнн Миноцци, библиотекарь города Йонкерс) Это о том, как весело провести время со звуками языка и использовать его музыку для укрепления памяти. Мозг любит учиться через музыкальные шаблоны! Вы также можете использовать новые песни ABC, такие как «The Alphabet of Nations» и «E Eats Everything». (Розмари Киладитис, детский библиотекарь Королевской библиотеки)
11. Используйте распознавание букв для поиска книг в библиотеке. Начните с совместного чтения книги с алфавитом, затем используйте определенную букву в качестве буквы для поиска, чтобы найти новые книги, названия или имена авторов которых начинаются с этой буквы.(Николь Уилкинсон, специалист по СМИ начальной библиотеки, школьный округ Quaker Valley)
12. Используйте визуальные и тактильные приемы. Повесьте алфавит на стену, чтобы дети могли легко сориентироваться в письме. Держите коробки для писем с пластиковыми буквами и предметы, начинающиеся с букв (они есть и на испанском языке!), Или лотки для трассировки, чтобы играть с ними; пусть дети издают звуки букв, держа предметы в руках или обводя буквы. Контейнеры для коммерческих писем и лотки для копий уже готовы к употреблению, но вы можете сделать их версии с предметами домашнего обихода.(Эмили Бертон, менеджер по работе с молодежью)
Когда вы просите библиотекарей, учителей и специалистов по грамотности по всей стране рассказать вам свои любимые книги по алфавиту, вы очень быстро понимаете: в мире существует много книг по алфавиту! Вот только 10, до которых я сузил список, выбранных на основе того, сколько раз они были рекомендованы ( Chicka Chicka Boom Boom возглавили список), или просто из-за их забавы или красоты.
1. Chicka Chicka Boom Boom.Захватывающая гонка по кокосовой пальме, полная рифм, кувырков и падений.
2. Гашликрамские крошки. Не для ребенка, который не умеет разбирать иронию, эта тщательно (каламбурная) подробная алфавитная книга ведет хронику безвременных и странно забавных смертей Тини, от Эми до Зиллы.
3. Азбука Эрика Карла. Классический Эрик Карл, от Муравьев до Зебры. В особенности тигр может заставить вас улыбнуться.
4. Горох LMNO. Кроме того, что эту много раз рекомендовали, мне пришлось включить ее из-за поэтов.(См. Страницу P, где маленькая зеленая горошина пишет, вероятно, пантум.)
5. Письма от дрожи: Пиратская азбука. Для любителя пиратов в каждом ребенке. Есть что-то особенное в B, проплывающем в кристально чистой бухте. (Может быть, это наивно напоминает мне дни супа с алфавитом, когда все буквы проплывали мимо!)
6. Тайна алфавита. В котором теряется маленький x, и буквы отправляются его искать. Ну да, есть упоминания о алфавитном супе! И поцелуи.
7.Однажды в алфавите: рассказы на все буквы. На этом стоит остановиться, от умных иллюстраций до таких слов, как daft и enigma (плюс аллитерационная фраза почти девять тысяч ).
8. Сонный алфавит. Помимо того, что эта книга очень милая и, как говорит специалист по грамотности Калли Фейен, в ней есть «шутка о хороших трусах»: вам действительно просто нужно сшить маленькие одеяла.
9.Алфавитный зал. Наблюдайте, как переделывают комнату (иногда с юмором), когда поднимается каждая створка и добавляются буквы! Плюс яблоки очаровательны.
10. Скрытый алфавит. Прекрасная графическая обработка алфавита, в которой объекты становятся частью букв, когда вы поднимаете черные рамки, закрывающие все изображения. (Например, острие стрелки становится центром большой буквы A.) Отлично подходит для развития зрительной проницательности.
Еще о писателе Л.Л. Баркат
Л.Л. Баркат - сертифицированный учитель и преподаватель английского языка K-12, который преподавал в начальной, средней школе и колледже. Автор шести книг для взрослых и двух для детей, она также является издателем, стремящимся освещать прекрасные работы и налаживать связи между поколениями, особенно с помощью «посвящения поэзии» и других инициатив по обучению грамоте. Ее последнее увлечение - математическое образование и помощь учителям и родителям в укреплении чувства числа детей за счет их естественной склонности к физическим упражнениям, играм, строительству и творчеству, а также созданию музыки.Свяжитесь с ней в LinkedIn и найдите ее работу в Edutopia. Затем, если вас интересует еще одна книга с алфавитом, посмотрите ее заголовок A Is for Azure: Alphabet in Colors!
Обращаемся ко всем фанатам HuffPost!
Подпишитесь на членство, чтобы стать одним из основателей и помочь сформировать следующую главу HuffPost
Загрузите аудиоконтент для "Korean Made Simple" бесплатно!
Особая благодарность моему другу Джереми из Spongemind.org и YouTube-каналу MotivateKorean за помощь в организации аудиозаписи трех книг "Korean Made Simple" носителями корейского языка.Я не смог бы сделать аудиофайлы, если бы не он и его корейские знакомые, говорящие на родном языке, взяли на себя это задание.
Вот что вы получите:
- Примерно два часа корейского контента из трех книг, записанных носителями языка.
- Практические разделы хангыль ( Korean Made Simple 1 )
- Введение в хангыль
- Подробнее Хангыль
- Введение в изменения звука
- Разговор каждой главы из всех трех книг ( Korean Made Simple 1, 2 и 3 ).
Эти аудиофайлы предназначены для использования вместе с "Korean Made Simple" 1, 2 и 3.
Файлы были тщательно созданы, чтобы их можно было использовать как дома, так и вне дома. Вы можете слушать их во время учебы за рабочим столом, по дороге на работу или во время тренировки.
Еще раз спасибо всем, кто поддерживал меня через этот веб-сайт, мой канал на YouTube и эти книги. Я с нетерпением жду продолжения обучения и создания новых уроков и видео.
Щелкните здесь, чтобы загрузить аудиофайлы для "Korean Made Simple".
Щелкните здесь, чтобы загрузить аудиофайлы для "Korean Made Simple 2".
Щелкните здесь, чтобы загрузить аудиофайлы для "Korean Made Simple 3".
 Таким образом, нам осталось использовать модульные тесты как единственную реальную защиту от ошибок, которая может быть громоздкой.
Таким образом, нам осталось использовать модульные тесты как единственную реальную защиту от ошибок, которая может быть громоздкой.
 целых чисел, представляющих наши слова и частоту их появления соответственно.Как мы это реализуем, полностью зависит от нас.
целых чисел, представляющих наши слова и частоту их появления соответственно.Как мы это реализуем, полностью зависит от нас.

 Второе сокращение
Второе сокращение 
 В сочетании с (|.) Мы, по сути, говорим, что «в начале могут быть какие-то не буквенно-цифровые символы, нас это не волнует
В сочетании с (|.) Мы, по сути, говорим, что «в начале могут быть какие-то не буквенно-цифровые символы, нас это не волнует
 fromCode 39
сокращение: Parser (Maybe String)
сжатие =
(getChompedString <|
успешная идентичность
|,chompIf ((==) апостроф)
|, chompIf Char.isAlpha
|, chompWhile Char.isAlpha
)
|> Parser.map Just
alphabeticWord: синтаксический анализатор ValidWord
alphabeticWord =
преуспеть по алфавиту
|, chompWhile isIgnorable
| = (getChompedString <|
успешная идентичность
|, chompIf Char.isAlphaNum
|, chompWhile Char.isAlpha
)
| = oneOf [сокращение с возможностью возврата, ничего не добиться]
|, chompWhile isIgnorable
fromCode 39
сокращение: Parser (Maybe String)
сжатие =
(getChompedString <|
успешная идентичность
|,chompIf ((==) апостроф)
|, chompIf Char.isAlpha
|, chompWhile Char.isAlpha
)
|> Parser.map Just
alphabeticWord: синтаксический анализатор ValidWord
alphabeticWord =
преуспеть по алфавиту
|, chompWhile isIgnorable
| = (getChompedString <|
успешная идентичность
|, chompIf Char.isAlphaNum
|, chompWhile Char.isAlpha
)
| = oneOf [сокращение с возможностью возврата, ничего не добиться]
|, chompWhile isIgnorable  Давайте рассмотрим здесь то, что отличается от числовой версии.
Давайте рассмотрим здесь то, что отличается от числовой версии.

 Затем возьмите последовательность хотя бы из одного алфавитного символа. Затем, если вы видите последовательность апострофа, за которой следуют другие буквенные символы, верните
Затем возьмите последовательность хотя бы из одного алфавитного символа. Затем, если вы видите последовательность апострофа, за которой следуют другие буквенные символы, верните  получить ключевой диктат
Просто посчитайте ->
Dict. Вставить ключ (count + 1) dict
Ничего ->
Dict. Вставить ключ 1 dict
получить ключевой диктат
Просто посчитайте ->
Dict. Вставить ключ (count + 1) dict
Ничего ->
Dict. Вставить ключ 1 dict
 append, чтобы прикрепить его к первой части строки.
append, чтобы прикрепить его к первой части строки. foldl dictUpdate Dict.empty
|> Готово
в
один из
[успешно продолжить
| = oneOf [алфавитное слово с возможностью возврата, числовое слово]
, success () |> Parser.map stopLooping
]
validWord: Parser (Dict String Int)
validWord =
цикл [] validWordHelper
foldl dictUpdate Dict.empty
|> Готово
в
один из
[успешно продолжить
| = oneOf [алфавитное слово с возможностью возврата, числовое слово]
, success () |> Parser.map stopLooping
]
validWord: Parser (Dict String Int)
validWord =
цикл [] validWordHelper  Я буквально понял это только во время написания этого документа. 😅 Это также помогает, если вы привыкли складывать функции для последовательностей.
Я буквально понял это только во время написания этого документа. 😅 Это также помогает, если вы привыкли складывать функции для последовательностей.
 выполнить предложение действительного слова
Хорошо разобрано ->
разобранный
Err _ ->
Dict.empty
выполнить предложение действительного слова
Хорошо разобрано ->
разобранный
Err _ ->
Dict.empty 
 Парсинг - это основополагающий метод разработки программного обеспечения, а библиотека elm-parser на самом деле чрезвычайно надежна. Я мог бы потратить много времени на настройку этого решения для повышения производительности или более строгого соблюдения правил типов, но я думаю, что пока могу оставить это в этом месте. Я не берусь думать, что это идеальная статья. Но совершенство - враг хорошего.
Парсинг - это основополагающий метод разработки программного обеспечения, а библиотека elm-parser на самом деле чрезвычайно надежна. Я мог бы потратить много времени на настройку этого решения для повышения производительности или более строгого соблюдения правил типов, но я думаю, что пока могу оставить это в этом месте. Я не берусь думать, что это идеальная статья. Но совершенство - враг хорошего.