Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: анрду сейчас кодиса сейчас стивпррее сейчас арабм сейчас в у р з а слава из букв сейчас рымашоз сейчас щелочь сейчас закупка сейчас где есть л т е а сейчас диктатр 1 секунда назад кнаосып 1 секунда назад в о д п о н к и д 1 секунда назад колепасил 1 секунда назад тесимфан 1 секунда назад где есть буквы к т а 1 секунда назад
Морфологический разбор слова «выучить»
Часть речи: Инфинитив
ВЫУЧИТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ВЫУЧИТЬ»
| Слово | Морфологические признаки |
|---|---|
| ВЫУЧИТЬ |
|
Все формы слова ВЫУЧИТЬ
ВЫУЧИТЬ, ВЫУЧИЛ, ВЫУЧИЛА, ВЫУЧИЛО, ВЫУЧИЛИ, ВЫУЧУ, ВЫУЧИМ, ВЫУЧИШЬ, ВЫУЧИТЕ, ВЫУЧИТ, ВЫУЧАТ, ВЫУЧИВ, ВЫУЧИВШИ, ВЫУЧИМТЕ, ВЫУЧИ, ВЫУЧИВШИЙ, ВЫУЧИВШЕГО, ВЫУЧИВШЕМУ, ВЫУЧИВШИМ, ВЫУЧИВШЕМ, ВЫУЧИВШАЯ, ВЫУЧИВШЕЙ, ВЫУЧИВШУЮ, ВЫУЧИВШЕЮ, ВЫУЧИВШЕЕ, ВЫУЧИВШИЕ, ВЫУЧИВШИХ, ВЫУЧИВШИМИ, ВЫУЧЕННЫЙ, ВЫУЧЕННОГО, ВЫУЧЕННОМУ, ВЫУЧЕННЫМ, ВЫУЧЕННОМ, ВЫУЧЕН, ВЫУЧЕННАЯ, ВЫУЧЕННОЙ, ВЫУЧЕННУЮ, ВЫУЧЕННОЮ, ВЫУЧЕНА, ВЫУЧЕННОЕ, ВЫУЧЕНО, ВЫУЧЕННЫЕ, ВЫУЧЕННЫХ, ВЫУЧЕННЫМИ, ВЫУЧЕНЫ
Разбор слова по составу выучить
выучи
ть
| Основа слова | выучи |
|---|---|
| Приставка | вы |
| Корень | уч |
| Суффикс | и |
| Глагольное окончание | ть |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ВЫУЧИТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «выучить»
1
Однажды он не выучил два урока сряду и завтра должен был остаться без обеда, если не выучит их к утру, а выучить было некогда, все легли спать.
Обрыв, Иван Гончаров, 1869г.
2
Буквы Ваня еще выучил в школе, и мне оставалось самое трудное – выучить его складам.
Записки сироты, Лидия Чарская, 1907г.
3
Язык мне всё равно не выучить, да, если даже выучу, всё равно не хочу.
Детородный возраст, Наталья Земскова
4
Решила английский язык выучить так, чтобы свободно на нем разговаривать и понимать, про что нерусские рок-группы поют – выучила.
Зачердачный мир, Владимир Царицын, 2013г.
5
Выучила испанский язык – точнее, попыталась выучить, потому что он мне не нравится.
Спрятанные реки, Анна Матвеева, 2019г.
Найти еще примеры предложений со словом ВЫУЧИТЬ
Что такое синтаксический анализ зависимостей?
Техрим Муштак
Устали от LeetCode? 😩
Изучите 24 шаблона, чтобы решить любой вопрос на собеседовании по кодированию, не заблудившись в лабиринте практических задач в стиле LeetCode. Практикуйте свои навыки в практической среде кодирования, не требующей настройки. 💪
Введение
Обработка естественного языка (NLP) — это междисциплинарная концепция, которая использует синтетический интеллект и основы компьютерной лингвистики, чтобы увидеть, как человеческие языки взаимодействуют с технологиями.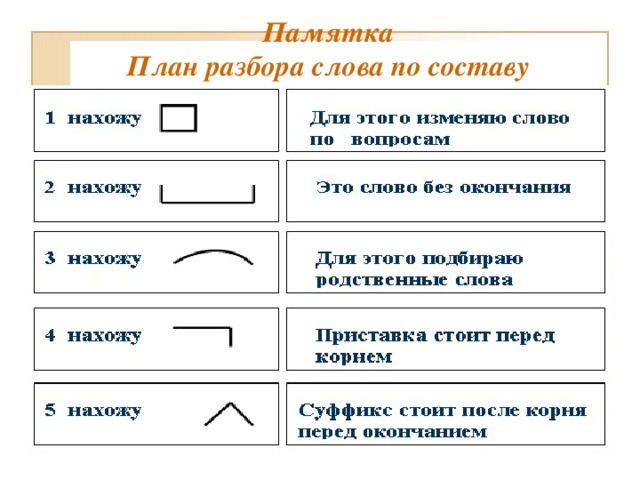 Существует много методов, используемых с НЛП, в которых синтаксис и семантика используются для синтаксического анализа. Разбор — это грамматический анализ предложения. Например, если предложение передается в НЛП, синтаксический анализ включает в себя разбиение предложения на части речи, например, существительное, глагол и т. д.
Существует много методов, используемых с НЛП, в которых синтаксис и семантика используются для синтаксического анализа. Разбор — это грамматический анализ предложения. Например, если предложение передается в НЛП, синтаксический анализ включает в себя разбиение предложения на части речи, например, существительное, глагол и т. д.
Анализ зависимостей
Анализ зависимостей относится к изучению зависимостей между фразами предложения для определения грамматической структуры предложения. Грамматика зависимостей обеспечивает представление языка в виде графов. Узлы — это слова, а ребра — это зависимости. При этом предполагается, что между каждой языковой единицей в предложении существует прямая связь. Отношения между каждой языковой единицей или фразой в предложении выражаются направленными дугами, называемыми 9.0011 структуры зависимостей .
Структура зависимостей
Структуры зависимостей представляют собой ориентированные графы, которые удовлетворяют следующим ограничениям:
- Они имеют один назначенный корневой узел, который не имеет входящих дуг.

- Каждый узел имеет одно входящее ребро, кроме корневого узла.
- Существует уникальный путь к каждому узлу от корневого узла.

Пример
Пример синтаксического анализа зависимостей
В этом примере мы видим, что можем перейти от оценки корневого слова к любому другому слову в структуре. Если нам нужно перейти от «оценки» к «хорошо», мы перейдем от «оценки» к «оценкам», а затем от «оценок» к «хорошо».
Теги зависимостей
Важным элементом разбора зависимостей является тег зависимости. Тег зависимости указывает на связь между двумя фразами. Это слово, которое изменяет значение другого слова. Если мы посмотрим на приведенный выше пример, слово «интеллектуальный» является прилагательным к слову «студенты». Используемый здесь тег зависимости — amod , , что означает модификатор прилагательного. Начало стрелки представляет родительский элемент, а конец — дочерний или зависимый.
Некоторые общие теги используются для синтаксических отношений между словами. Они описаны ниже:
Они описаны ниже:
Часто используемые теги зависимостей
Реализация
Теперь давайте создадим анализатор зависимостей в Python. Анализ зависимостей в Python очень прост и понятен. Нам нужно установить несколько библиотек. Реализация кода для приведенного выше примера приведена ниже:
import spacy
nlp=spacy.load('en_core_web_sm')
text='Умные ученики легко получают хорошие оценки.'
для токена в nlp(text):
print(token.text,'->',token.dep_,'->',token.head.text)
Разбор зависимостей
Объяснение кода
- Строки 1–2: Мы импортируем библиотеку Python
spacy, а затем загружаем конвейерspacyдля поддержки английского языка. - Строка 4: Образец текста на английском языке.
- Строка 6: У нас есть Цикл для каждой лексемы в тексте.
- Строка 7:
token.textвозвращает токен предложения,token.возвращает тег зависимости для слова, а dep_ token.head.textвозвращает соответствующее заглавное слово (к которому стрелка указывает).
 dep_
dep_ СВЯЗАННЫЕ ТЭГИ
nlp
машинное обучение
УЧАСТНИК
Tehreem Mushtaq
Copyright ©2022 Educative, Inc. Все права защищены
Learning context-dependent word embeddings based on dependency parsing
No Access
- Ke Yan,
- Jie Chen,
- Wenhao Zhu,
- Xin Jin and
- Guannan Hu
Ke Yan
,
Jie Chen
,
Wenhao Zhu
,
Xin Jin
и
Guannan Hu
Опубликовано онлайн: 22 апреля, 2020pp 334-346HTTPS: //doi. org/10.150.150.0003
org/10.150.150.0003
Abstract
Вложение слов представляет собой основной метод представления текста. Независимо от того, являются ли они входными данными для алгоритма машинного обучения или функциями, используемыми в приложении для обработки естественного языка, встраивания оказались полезными в решении различных задач обработки текста. В текстах на естественном языке контекстная информация оказывает решающее влияние на семантику представления слов. В текущих исследованиях большинство моделей обучения основаны на поверхностной текстовой информации и не полностью используют глубокие отношения в предложениях. Чтобы преодолеть эту проблему, в этой статье предлагается модель непрерывного набора слов на основе зависимостей, которая интегрирует отношения зависимости между словами и предложениями в контекст с весами, тем самым увеличивая влияние конкретной контекстной информации на предсказание целевых слов. Этот метод увеличивает изобилие контекстной информации слова и улучшает семантику встраивания слов. Экспериментальные результаты показывают, что предложенный метод подчеркивает семантические отношения и повышает производительность представления слов.
Экспериментальные результаты показывают, что предложенный метод подчеркивает семантические отношения и повышает производительность представления слов.
Keywords
word embedding, context-dependent, dependency parsing, semanticsPrevious article
Volume 19Issue 42020
- ISSN: 1461-4111
- eISSN: 1741-5179
History
- Опубликовано онлайн 22 апреля 2020 г.
Copyright © 2020 Inderscience Enterprises Ltd.0028
Authors and Affiliations
- Ke Yan 1
- Jie Chen 2
- Wenhao Zhu 3
- Xin Jin 4
- Guannan Hu 5
- 1. Школа компьютерной инженерии и науки, Шанхайский университет, 99 Shangda Road, BaoShan District, Шанхай 20444, Китай
- 2.
