Образовательный тест на оценку грамотности «На уроке русского языка» — какие знания остались в памяти?. Dropi
/ Автор: Мария
В этом тесте мы проверим, какие знания остались у Вас со школы и насколько грамотно Вы пишете. Например, помните ли Вы чем отличаются причастные и деепричастные обороты? Не случалось ли Вам задумываться, а правильно ли Вы написали слово, к которому нельзя подобрать проверочное? Убедитесь, что ничего не забыли и наберите как минимум 9 баллов.
Тесты по русскому языку #русский язык
Вопрос 1 из 15
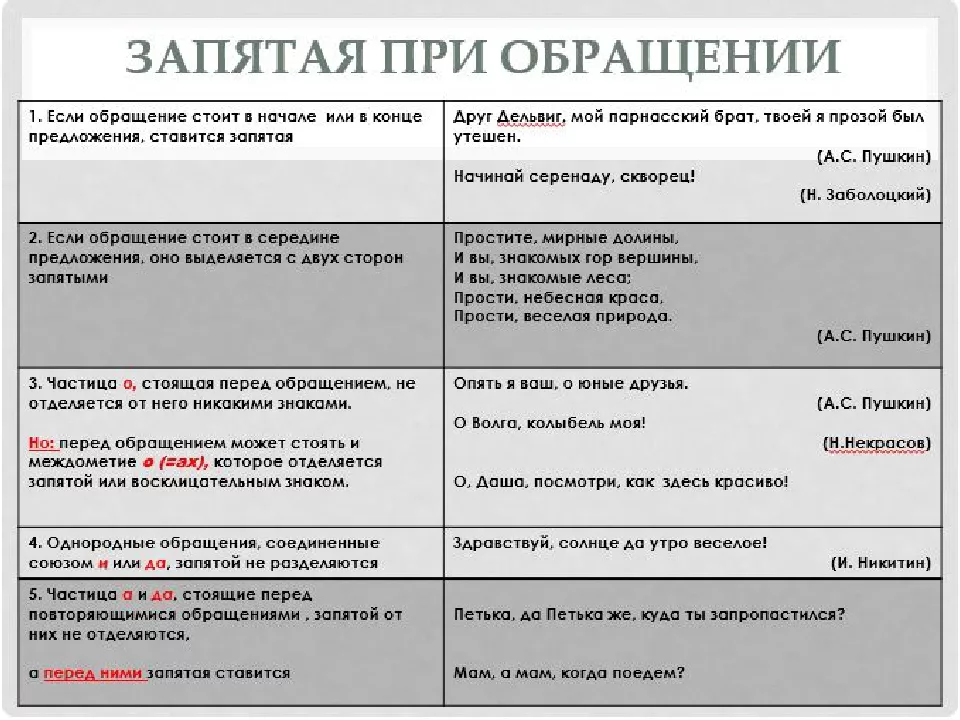
В каком случае причастный оборот выделяется с двух сторон запятыми?
Если стоит перед определяемым словом
Если стоит после определяемого слова
Всегда выделяется двумя запятыми
Вопрос 2 из 15
Выберите ряд с причастиями, которые пишутся через -ущ-, -ющ-:
та_щий, хвал_щий
бор_щийся, дыш_щий
колыш_щийся, стел_щийся
Вопрос 3 из 15
На какие вопросы отвечает деепричастие?
Что делающий? Какой?
Что делая? Что сделав?
Каким образом?
Вопрос 4 из 15
Как правильно пишется слово в.
 m1r4j&v(» data-test-id=»4511″ data-post-id=»9121″ data-answer-count=»1561″> Пиренеи
m1r4j&v(» data-test-id=»4511″ data-post-id=»9121″ data-answer-count=»1561″> ПиренеиВопрос 11 из 15
Выберите правильное утверждение:
Причастие соединило в себе признаки глагола и прилагательного
Причастие соединило в себе признаки глагола и наречия
Причастие соединило в себе признаки глагола и деепричастия
Вопрос 12 из 15
Определите, какое наречие относится к разряду образа действия?
вблизи
вчера
втайне
Вопрос 13 из 15
В каком из словосочетаний слова соединены типом связи примыкание?
Наука наблюдать
Первый звонок
Писать книгу
Вопрос 14 из 15
Выберите наречное словосочетание:
Бег на месте
Каша в горшочке
Вверх ногами
Вопрос 15 из 15
Укажите вариант, в котором во всех словах пропущена буква «е»:
угн. ..тение, см…риться, вы…вление
..тение, см…риться, вы…вление
отл…чительный, ч…столюбивый, конс…рвировать
изм…нение, оч…рстветь, запр…щать
Комментарии
sql server — Как создать список, разделенный запятыми, с помощью SQL-запроса?
спросил
Изменено 1 год, 7 месяцев назад
Просмотрено 191 тысяч раз
У меня есть 3 таблицы с именами:
- Приложения (идентификатор, имя)
- Ресурсы (идентификатор, имя)
- ApplicationsResources (id, app_id, resource_id)
Я хочу отобразить в графическом интерфейсе таблицу всех имен ресурсов. В одной ячейке в каждой строке я хотел бы перечислить все приложения (через запятую) этого ресурса.
В одной ячейке в каждой строке я хотел бы перечислить все приложения (через запятую) этого ресурса.
Итак, вопрос в том, как лучше всего сделать это в SQL, поскольку мне нужно получить все ресурсы, а также мне нужно получить все приложения для каждого ресурса?
Должен ли я сначала запустить выбор * из ресурсов, а затем выполнить цикл по каждому ресурсу и выполнить отдельный запрос для каждого ресурса, чтобы получить список приложений для этого ресурса?
Можно ли это сделать одним запросом?
- sql
- sql-сервер
- tsql
- агрегация строк
5
MySQL
SELECT r.name,
GROUP_CONCAT(a.name SEPARATOR ',')
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К APPLICATIONSRESOURCES ar ON ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ПРИЛОЖЕНИЯМ a ON a.id = ar.app_id
СГРУППИРОВАТЬ ПО r.name
SQL Server (2005+)
ВЫБЕРИТЕ r.имя,
STUFF((SELECT ',' + a. name
ИЗ ПРИЛОЖЕНИЙ
ПРИСОЕДИНЯЙТЕСЬ К РЕСУРСАМ ПРИЛОЖЕНИЯ ar ON ar.app_id = a.id
ГДЕ ar.resource_id = r.id
СГРУППИРОВАТЬ ПО имени
FOR XML PATH(''), TYPE).value('text()[1]','NVARCHAR(max)'), 1, LEN(','), '')
ИЗ РЕСУРСОВ
name
ИЗ ПРИЛОЖЕНИЙ
ПРИСОЕДИНЯЙТЕСЬ К РЕСУРСАМ ПРИЛОЖЕНИЯ ar ON ar.app_id = a.id
ГДЕ ar.resource_id = r.id
СГРУППИРОВАТЬ ПО имени
FOR XML PATH(''), TYPE).value('text()[1]','NVARCHAR(max)'), 1, LEN(','), '')
ИЗ РЕСУРСОВ
 name
ИЗ ПРИЛОЖЕНИЙ
ПРИСОЕДИНЯЙТЕСЬ К РЕСУРСАМ ПРИЛОЖЕНИЯ ar ON ar.app_id = a.id
ГДЕ ar.resource_id = r.id
СГРУППИРОВАТЬ ПО имени
FOR XML PATH(''), TYPE).value('text()[1]','NVARCHAR(max)'), 1, LEN(','), '')
ИЗ РЕСУРСОВ
name
ИЗ ПРИЛОЖЕНИЙ
ПРИСОЕДИНЯЙТЕСЬ К РЕСУРСАМ ПРИЛОЖЕНИЯ ar ON ar.app_id = a.id
ГДЕ ar.resource_id = r.id
СГРУППИРОВАТЬ ПО имени
FOR XML PATH(''), TYPE).value('text()[1]','NVARCHAR(max)'), 1, LEN(','), '')
ИЗ РЕСУРСОВ
SQL Server (2017+)
SELECT r.name,
STRING_AGG(имя, ',')
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К APPLICATIONSRESOURCES ar ON ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ПРИЛОЖЕНИЯМ a ON a.id = ar.app_id
СГРУППИРОВАТЬ ПО r.name
Oracle
Я рекомендую прочитать об агрегации/конкатенации строк в Oracle.
3ПРИМЕЧАНИЕ:Этот метод не рекомендуется, поскольку он может давать неверные или недетерминированные результаты.
Это было задокументировано в StackOverflow и DBA
Использование COALESCE для создания строки с разделителями-запятыми в SQL Server
http://www. sqlteam.com/article/using-coalesce-to-build-comma-delimited-string
sqlteam.com/article/using-coalesce-to-build-comma-delimited-string
Пример:
DECLARE @EmployeeList varchar(100) SELECT @EmployeeList = COALESCE(@EmployeeList + ', ', '') + CAST(Emp_UniqueID AS varchar(5)) ОТ ПродажЗвонкиСотрудников ГДЕ SalCal_UniqueID = 1 ВЫБЕРИТЕ @EmployeeList
3
Я не знаю, есть ли какое-либо решение, позволяющее сделать это независимо от базы данных, поскольку вам, скорее всего, потребуется какая-то форма манипуляции со строками, а они обычно различаются у разных поставщиков.
Для SQL Server 2005 и выше можно использовать:
SELECT
r.ID, r.Name,
Ресурсы = МАТЕРИАЛ(
(ВЫБЕРИТЕ ','+a.Имя
ОТ dbo.Applications a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.ApplicationsResources ar ON ar.app_id = a.id
ГДЕ ar.resource_id = r.id
ДЛЯ ПУТИ XML('')), 1, 1, '')
ОТ
dbo.Resources r
Он использует конструкцию SQL Server 2005 FOR XML PATH для перечисления подэлементов (приложений для данного ресурса) в виде списка, разделенного запятыми.
Марк
2
Я считаю, что вам нужно:
ВЫБЕРИТЕ ItemName, GROUP_CONCAT(DepartmentId) FROM table_name GROUP BY ItemName
Если вы используете MySQL
Ссылка
- http://dev. /refman/5.0/en/group-by-functions.html#function_group-concat
4
Предполагая, что SQL Server:
Структура таблицы:
CREATE TABLE [dbo].[item_dept](
[ItemName] char(20) NULL,
[DepartmentID] целое NULL
)
Запрос:
SELECT ItemName,
STUFF((SELECT ',' + rtrim(convert(char(10),DepartmentID))
ОТ item_dept b
ГДЕ a.ItemName = b.ItemName
FOR XML PATH('')),1,1,'')
ОТ item_dept a
СГРУППИРОВАТЬ ПО названию элемента
Результаты:
ItemName DepartmentID пункт1 21,13,9,36 п.2 4,9,44
2
Я думаю, что мы могли бы написать следующий способ для извлечения (приведенный ниже код является просто примером, пожалуйста, измените при необходимости):
Create FUNCTION dbo.ufnGetEmployeeMultiple(@DepartmentID int) ВОЗВРАЩАЕТ VARCHAR(1000) КАК НАЧИНАТЬ DECLARE @Employeelist varchar(1000) SELECT @Employeelist = COALESCE(@Employeelist + ', ', '') + E.LoginID ОТ отдела кадров. Сотрудник Е Left ПРИСОЕДИНЯЙТЕСЬ к HumanResources.EmployeeDepartmentHistory H ON E.BusinessEntityID = H.BusinessEntityID INNER JOIN HumanResources.Department D ON H.DepartmentID = D.DepartmentID Где H.DepartmentID = @DepartmentID Возврат @Employeelist КОНЕЦ ВЫБЕРИТЕ D.name в качестве отдела, dbo.ufnGetEmployeeMultiple (D.DepartmentID) в качестве сотрудников ОТ HumanResources.Отдел D SELECT Distinct (D.name) в качестве отдела, dbo.ufnGetEmployeeMultiple (D.DepartmentID) в качестве Сотрудники ОТ HumanResources.Отдел D

В следующей версии SQL Server вы сможете делать
SELECT r.name,
STRING_AGG(имя, ',')
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К РЕСУРСАМ ПРИЛОЖЕНИЙ ar
ПО ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ЗАЯВКАМ
ПО a.id = ar.app_id
СГРУППИРОВАТЬ ПО r. name
 name
name
Для предыдущих версий продукта существует достаточно большое количество различных подходов к этой проблеме. Отличный их обзор содержится в статье: Объединение значений строк в Transact-SQL.
MySQL
SELECT r.name,
GROUP_CONCAT(a.name SEPARATOR ',')
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К APPLICATIONSRESOURCES ar ON ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ПРИЛОЖЕНИЯМ a ON a.id = ar.app_id
СГРУППИРОВАТЬ ПО r.name
**
MS SQL Server
SELECT r.name,
STUFF((SELECT ','+ a.name
ИЗ ПРИЛОЖЕНИЙ
ПРИСОЕДИНЯЙТЕСЬ К РЕСУРСАМ ПРИЛОЖЕНИЯ ar ON ar.app_id = a.id
ГДЕ ar.resource_id = r.id
СГРУППИРОВАТЬ ПО имени
FOR XML PATH(''), TYPE).value('.','VARCHAR(max)'), 1, 1, '')
ИЗ РЕСУРСОВ
СГРУППИРОВАТЬ ПО deptno;
Oracle
SELECT r.name,
LISTAGG(a.name SEPARATOR ',') ВНУТРИ ГРУППЫ (ПОРЯДОК ПО a. name)
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К APPLICATIONSRESOURCES ar ON ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ПРИЛОЖЕНИЯМ a ON a.id = ar.app_id
СГРУППИРОВАТЬ ПО r.name;
 name)
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К APPLICATIONSRESOURCES ar ON ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ПРИЛОЖЕНИЯМ a ON a.id = ar.app_id
СГРУППИРОВАТЬ ПО r.name;
name)
ИЗ РЕСУРСОВ
ПРИСОЕДИНЯЙТЕСЬ К APPLICATIONSRESOURCES ar ON ar.resource_id = r.id
ПРИСОЕДИНЯЙТЕСЬ К ПРИЛОЖЕНИЯМ a ON a.id = ar.app_id
СГРУППИРОВАТЬ ПО r.name;
Невозможно сделать это независимо от БД. Таким образом, вам нужно получить весь набор данных следующим образом:
выберите r.name как ResName, a.name как AppName из Ресурсы как г, Приложения как, ПриложенияРесурсы as ar где ar.app_id = a.id и ar.resource_id = r.id
А затем объединить AppName программно при группировке по ResName .
Чтобы быть агностиком, откинься назад и ударь плоскодонкой.
Выберите a.name как a_name, r.name как r_name из ApplicationsResource ar, Applications a, Resources r где a.id = ar.app_id и r.id = ar.resource_id порядок по r.name, a.name;
Теперь используйте язык программирования вашего сервера, чтобы соединить a_names, в то время как r_name такое же, как и в прошлый раз.
Это будет сделано в SQL Server:
DECLARE @listStr VARCHAR(MAX) SELECT @listStr = COALESCE(@listStr+',' ,'') + Convert(nvarchar(8),DepartmentId) ИЗ таблицы ВЫБЕРИТЕ @listStr
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Преобразование запятых или других разделителей в таблицу или список в SQL Server с использованием T-SQL
Разработчикам баз данных часто требуется преобразовать значение, разделенное запятыми, или другие элементы с разделителями в табличный формат. Разделители включают вертикальную черту «|», решетку «#», доллар «$» и другие символы. Уровень совместимости SQL Server 130 и
последующие версии поддерживают функцию string_split() для преобразования значений, разделенных разделителями, в строки (формат таблицы).
Для уровней совместимости ниже 130 разработчики ранее делали это с помощью определяемой пользователем функции, которая
включает цикл While или курсор для извлечения данных.
Разделители включают вертикальную черту «|», решетку «#», доллар «$» и другие символы. Уровень совместимости SQL Server 130 и
последующие версии поддерживают функцию string_split() для преобразования значений, разделенных разделителями, в строки (формат таблицы).
Для уровней совместимости ниже 130 разработчики ранее делали это с помощью определяемой пользователем функции, которая
включает цикл While или курсор для извлечения данных.
Выполнение программы в итерации с использованием цикла является распространенным методом как во внутреннем приложении, так и в базе данных. Когда количество итераций меньше ожидаемого, время выполнения может быть меньше, однако количество итераций больше, что приводит к увеличению времени обработки. Например, если приложение получает данные из
базу данных с выполнением части программы в цикле путем анализа различных входных параметров. Приложению необходимо будет обернуть ответ базы данных каждой итерации. Чтобы справиться с ситуацией такого типа, мы можем выполнить ту же программу за один раз с анализом значений, разделенных запятыми или разделителями, в качестве входного параметра в базе данных и преобразовать его в табличный формат в программе T-SQL, чтобы продолжить дальнейшую логику.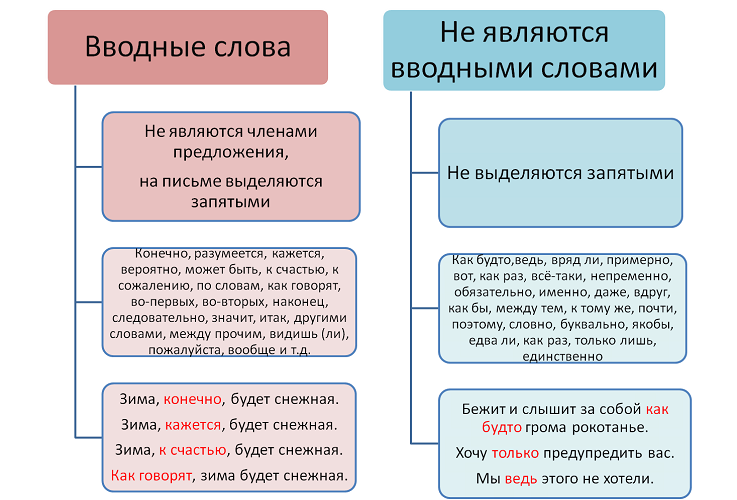
Сегодня многие платформы перешли на микросервисную архитектуру. Не только приложение, но и дизайн базы данных также могут быть структурированы в архитектуре на основе микросервисов, и большая часть внутренней связи между базами данных осуществляется только с целочисленными ссылками. Это причина, чтобы получить какой-то хитрый способ добиться лучшего выполнения со стороны базы данных.
Несколько входных данных для одного и того же параметра можно выполнить с помощью разделенных запятыми значений во входном параметре хранимой процедуры или входных данных для табличной функции и использовать с таблицей в операторе T-SQL. При использовании T-SQL может быть больше ситуаций для этой стратегии. При программировании с помощью SQL Server разработчик должен разбивать строку на элементы с помощью разделителя. Использование функции split для строки определяет разделитель как входной параметр. Вся строка будет разделена и возвращена в виде таблицы. В определенных обстоятельствах входной параметр может быть комбинацией двух или более значений, разделенных символами, для каждого набора входных данных. Например:
Например:
N’203616, 198667, 193718, 188769,…» N’1021|203616$1021|198667$1022|193718$1022|188769$…’ N’1021|203616,198667$1022|193718,188769$…’
Есть преимущества однопоточного выполнения со значениями, разделенными запятыми, по сравнению с многопоточным выполнением в SQL. Сервер:
- Однократное выполнение части программы, в результате чего количество входных данных
- Одна операция чтения или записи над таблицами базы данных вместо нескольких итераций с использованием цикла
- Разовое использование ресурсов сервера
- Больше никаких препятствий в серверном приложении для настройки ответа из нескольких наборов результатов.
- Однократная фиксация означает, что база данных/SQL Server не будет блокировать транзакцию и замедлять работу. Таким образом, нет возможности блокировки
- Легко контролировать согласованность транзакций
Функция разделения с использованием петли
В большинстве случаев разработчик пишет табличную функцию с циклом для извлечения данных из разделенных запятыми
значения в виде списка или таблицы. Цикл извлекает кортеж один за другим с помощью рекурсии. Проблемы с производительностью могут возникнуть при работе с большим входным параметром, поскольку его извлечение займет больше времени. Здесь у нас есть простая функция с именем split_string, которая использует цикл внутри функции с табличным значением. Эта функция позволяет
два аргумента или входных параметра (1 – входная строка и 2 – разделитель):
Цикл извлекает кортеж один за другим с помощью рекурсии. Проблемы с производительностью могут возникнуть при работе с большим входным параметром, поскольку его извлечение займет больше времени. Здесь у нас есть простая функция с именем split_string, которая использует цикл внутри функции с табличным значением. Эта функция позволяет
два аргумента или входных параметра (1 – входная строка и 2 – разделитель):
1 2 3 4 5 6 7 8 10 110005 12 13 14 2009111000 9000 900014 000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 21000 9000 9000 15 9000 9000 9000 9000 210009 9000 | СОЗДАТЬ ФУНКЦИЮ split_string ( @in_string VARCHAR(MAX), @delimeter VARCHAR(1) ) RETURNS (91 VARCHAR TABLE @list @list TABLE)0005 AS BEGIN В то время как LEN (@IN_STRING)> 0 BEGIN INSERT в @List (Tuple) Выберите LEAND (@IN_STRING, Charindex (@delimiter,@in_string+’,’) -1) В качестве Tuple SET @In_String = материал (@in_string, 1, charindex (@delimiter, @in_string + @delimiter), ») Конец Возврат Конец |
Таблица набора результатов, возвращаемая этой функцией, содержит каждую подстроку строки входного параметра, разделенную разделителем. Подстроки в таблице расположены в том порядке, в котором они встречаются во входном параметре. Если разделитель или разделитель не согласуется ни с одной частью входной строки, то выходная таблица будет иметь только один компонент. Табличная функция вернет набор результатов в формате строки-столбца из строки, разделенной запятыми.
Подстроки в таблице расположены в том порядке, в котором они встречаются во входном параметре. Если разделитель или разделитель не согласуется ни с одной частью входной строки, то выходная таблица будет иметь только один компонент. Табличная функция вернет набор результатов в формате строки-столбца из строки, разделенной запятыми.
SELECT * FROM split_string(‘1001,1002,1003,1004’, ‘,’) |
Последние версии SQL Server предоставляют встроенную функцию string_split() для выполнения той же задачи с входными данными. параметры входной строки и разделителя. Но есть и другой эффективный способ выполнить эту задачу с помощью XML.
Функция разделения с использованием XML
Функция Split, использующая логику XML, является полезным методом для отделения значений от строки с разделителями. Использование логики XML с подходом XQUERY на основе T-SQL приводит к тому, что T-SQL не характеризуется как рекурсия с использованием цикла или курсора. По сути, строка входного параметра преобразуется в XML путем замены узла XML в T-SQL.
артикуляция. Полученный XML используется в XQUERY для извлечения значения узла в формат таблицы. Это также приводит к лучшей производительности.
По сути, строка входного параметра преобразуется в XML путем замены узла XML в T-SQL.
артикуляция. Полученный XML используется в XQUERY для извлечения значения узла в формат таблицы. Это также приводит к лучшей производительности.
Например, у нас есть значение, разделенное запятыми, с переменной @user_ids в приведенном ниже операторе T-SQL. В переменная, запятая заменяется тегами XML, чтобы сделать его документом типа данных XML, а затем извлекается с помощью XQUERY. с XPATH как ‘/root/U’:
1 2 3 4 5 6 7 8 10 500025 | DECLARE @user_ids NVARCHAR(MAX) = N’203616, 198667, 193718, 188769, 183820, 178871, 173922, 168973, 164024, 159075, 154126, 149177, 144228, 139279, 134330, 129381, 124432, 119483, 114534, 109585, 104636, 99687, 94738, 89789, 84840, 79891, 74942, 69993, 65044, 60095, 55146′
DECLARE @sql_xml Replace(‘>
SELECT f. INTO #users FROM @sql_xml.nodes(‘/root/U’) f(x)
SELECT * FROM #users |
 x.value(‘.’, ‘BIGINT’) AS user_id
x.value(‘.’, ‘BIGINT’) AS user_idВ приведенной выше функции мы использовали тип данных VARCHAR (100) для извлеченного значения, а не BIGINT. Также могут быть изменения в строке входных параметров. Например, если во входной строке есть один лишний «,» в начало или конец строки, он возвращает одну дополнительную строку с 0 для типа данных BIGINT и ” для ВАРЧАР.
Например,
DECLARE @user_ids VARCHAR(MAX) = N’203616, 198667, 193718, 188769, 183820, 178871,’ DECLARE @sql_xml XML = Cast(‘
SELECT f.x.value(‘.’, ‘BIGINT’) AS user_id ИЗ @sql_xml. узлы(‘/корень/U’) f(x) |
Чтобы обработать этот тип данных ” или 0 в наборе результатов, мы можем добавить условие ниже в T-SQL заявление:
1 2 3 4 5 6 | DECLARE @user_ids VARCHAR(MAX) = N’203616, 198667, 193718, 188769, 183820, 178871,’ DECLARE @sql_xml XML = Cast(‘
ВЫБРАТЬ f. ОТ @sql_xml.nodes(‘/root/U’) f(x) ГДЕ f.x.value(‘.’, ‘BIGINT’ ) <> 0 |
 x.value(‘.’, ‘BIGINT’) AS user_id
x.value(‘.’, ‘BIGINT’) AS user_idЗдесь f.x.value(‘.’, ‘BIGINT’) <> 0 исключает 0, а f.x.value(‘.’, ‘VARCHAR(100)’) <> ” исключает ” в наборе результатов запроса. Это условие T-SQL может быть добавлено в функции с табличным значением с количеством входной параметр для обработки этого дополнительного разделителя.
Функция:
1 2 3 4 5 6 7 8 10 110005 12 13 14 2009111000 9000 900014 000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 21000 9000 9000 15 9000 9000 9000 9000 210009 9000 | СОЗДАТЬ ФУНКЦИЮ split_string_XML ( @in_string VARCHAR(MAX), @delimeter VARCHAR(1) ) ВОЗВРАТ @list TABLE(tuple VARCHAR(100)) AS BEGIN DECLARE @sql_xml XML = Cast(‘
INSERT INTO @list(tuple) SELECT f. FROM @sql_xml.nodes(‘/root/U’) f(x) WHERE f.x.value(‘.’, ‘BIGINT’) <> 0
ВОЗВРАТ КОНЕЦ |
 x.value(‘.’, ‘VARCHAR(100)’) AS tuple
x.value(‘.’, ‘VARCHAR(100)’) AS tupleИсполнение:
ВЫБЕРИТЕ * ИЗ split_string_XML(‘203616,198667,193718,188769,183820,178871,173922,’, ‘,’) |
Комбинация символов в строке, разделенной разделителями
Но что делать, если входной параметр представляет собой комбинацию двух значений с несколькими разделителями? В этом случае входной параметр должен быть извлечен дважды с помощью подзапроса, как показано ниже:
1 2 3 4 5 6 7 8 10 110005 12 | DECLARE @in_string VARCHAR(MAX) = ‘1021|203616$1021|198667$1022|193718$1022|188769$’ DECLARE @sql_xml XML = Cast(‘
SELECT X. X.Y.value(‘(U)[2]’, ‘VARCHAR(20)’) AS user_id FROM ( SELECT Cast(‘ ОТ @sql_xml.nodes(‘/root/U’) f(x) ГДЕ f.x.value(‘.’, ‘VARCHAR(MAX)’ ) <> » )T ВНЕШНЕЕ ПРИМЕНЕНИЕ T.xml_.nodes(‘root’) as X(Y) |
 Y.value(‘(U)[1]’, ‘VARCHAR(20)’) AS role_id,
Y.value(‘(U)[1]’, ‘VARCHAR(20)’) AS role_id,Этот пример похож на приведенный выше пример, но мы использовали вертикальную черту «|». как разделитель со вторым разделителем, доллар «$». Здесь входным параметром является комбинация двух столбцов, role_id и user_id. Как мы видим ниже, user_id и role_id находятся в отдельном столбце в наборе результатов таблицы:
Мы можем использовать любой символ в приведенной выше функции, например, одну строку, разделенную символами, или комбинацию строк, разделенных символами. Разработчик должен просто заменить символ в операторах T-SQL выше.