это что? Что такое морфемный разбор?
Наверняка каждый школьник сталкивался с таким определением, как морфема. Это понятие довольно тесно связано с составом слова, и его знание помогает выполнить морфемный анализ. Давайте поговорим о том, что это такое. Разберемся также и с тем, что такое морфемный разбор.
Что такое морфема?
Морфема – это наименьшая значимая часть слова. Впервые термин был введен известным ученым Бадуэном де Куртенэ еще в середине XIX века и используется в лингвистике до сих пор.
Все слова состоят из морфем. Они — кирпичики, из которых составляются слова. Каждая составляющая имеет имеет свое значение и роль. Выделяют следующие типы морфем: обязательные и необязательные. Обязательная всегда присутствует в слове и называется корнем. Необязательные могут как входить в состав лексемы, так и не входить в него. Эти морфемы называются аффиксами. Давайте рассмотрим каждый вид в отдельности.
Узнаем как ие существуют слова, не имеющие окончания?. ..
..
Словообразование принято считать сложнейшим разделом в русском языке. По статистике, в России…
Обязательные морфемы
Как уже упоминалось, обязательная морфема в русском языке всего одна, и она называется корнем. Нет такого слова, которое бы существовало без данной морфемы. Слова без корня (исключение — некоторые служебные части речи) отсутствуют в русском языке.
Она главная, так как несет основное лексического значение. К примеру, лексема лес, лесной, лесник объединяет один корень — лес. Все эти слова имеют схожее значение, связанное с лесом. Единственное — их различие в оттенках. Так, лес – пространство, покрытое деревьями; лесной – относящийся к лесу; лесник – человек, который сторожит его.
В сложных словах есть несколько корней, к примеру, в слове светлоликий два корня – свет и лик. Не забывайте об этом при разборе слова. В основном сложные слова имеют два корня, в некоторых случаях могут встречаться слова с большим набором.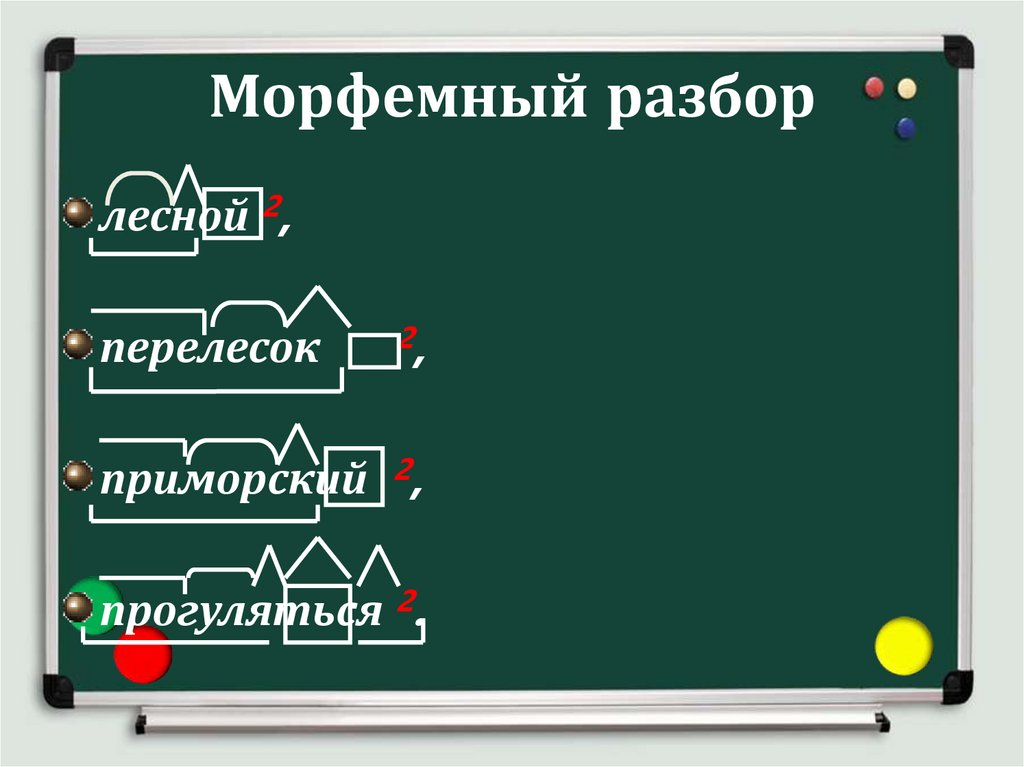
Морфемный состав слова современный и исторический: пример….
Морфемный состав слова в ходе развития языка не всегда оставался неизменным. Исторические…
Необязательные морфемы
Необязательные морфемы русского языка — аффиксы. Среди них выделяют следующие:
- префиксы, или приставки;
- постфиксы, или суффиксы;
- флексии, или окончания;
- интерфиксы.
Они могут присутствовать в слове или же нет. При этом каждая новая необязательная морфема придает ему новое значение.
Первые два вида морфем передают лексическое и грамматическое значение. Флексии же выражают только грамматическое значение слова. Даже нулевое, то есть не имеющее звукового выражения, окончание показывает, какое грамматическое значение имеет лексема.
Префиксы и постфиксы
Разберем для начала те морфемы, которые придают новые лексические и грамматические оттенки.
Префиксы всегда располагаются в начале слова и изменяют его значение. В русском языке насчитывается около 70 префиксов. Большинство их образовано от предлогов. В школе зачастую их называют приставками. Каждая приставка имеет свое значение и меняет оттенок слова. К примеру, ехать – двигаться куда-то; подъехать – приблизиться к чему-либо.
В русском языке насчитывается около 70 префиксов. Большинство их образовано от предлогов. В школе зачастую их называют приставками. Каждая приставка имеет свое значение и меняет оттенок слова. К примеру, ехать – двигаться куда-то; подъехать – приблизиться к чему-либо.
При этом меняется лексическое значение слова, но часть речи, к которой оно принадлежит, остается неизменной.
Постфиксы всегда располагаются между корнем и флексией (если она есть в слове). Они служат не только для образования нового значения, но и для того, чтобы образовать новую часть речи. Так, с помощью суффикса -н- от существительного лес обрадовалось прилагательное лесной.
Морфемный разбор слова по составу
Для формирования орфографических навыков очень важен морфемный разбор слова или некий…
Некоторые суффиксы образовывают новый оттенок значения. Так, есть уменьшительно-ласкательные суффиксы, такие как: -ушк-, -чик-, -очк- и другие. С помощью них образуются лексемы с новым оттенком значения. Например: ухо – ушко, палец – пальчик, корзина – корзиночка.
С помощью них образуются лексемы с новым оттенком значения. Например: ухо – ушко, палец – пальчик, корзина – корзиночка.
В слове может быть несколько приставок и суффиксов. Все зависит от строения лексемы, ее значения. Поэтому, делая разбор по морфемам слова, следует обратить на это особое внимание.
Интерфиксы
Данные морфемы служат для связи нескольких корней в сложных словах. К примеру, слово лоботряс состоит из двух слов — лоб и тряс. Они связаны между собой интерфиксом –о-. Интерфиксы не всегда изучаются в школе, зачастую о них говорят лишь в старших классах, и то мельком.
Основа слова
Узнав, что морфема — это значима часть лексемы, следует вспомнить и еще об одной немаловажной части – основе. Это неизменяемая часть слова, то есть его часть без окончания. Основа заключает в себе основное лексическое значение и может состоять из одного лишь корня или корня и аффикса (аффиксов). В глаголах основа может прерываться окончанием, если есть постфикс –ся или -сь. Например, в слове покупалась основа будет прерываться окончанием и выглядеть как покупал-а-сь.
В глаголах основа может прерываться окончанием, если есть постфикс –ся или -сь. Например, в слове покупалась основа будет прерываться окончанием и выглядеть как покупал-а-сь.
Флексии
Данные морфемы употребляются для того, чтобы выразить грамматическое значение. В школьной программе они носят название окончаний. С их помощью определяется грамматическое значение. Для существительных это род, число, падеж. Флексии присутствуют во всех частях речи, исключая неизменяемые, такие как наречие, союз, предлог. В этих частях речи они не выделяются. Во всех остальных частях речи при отсутствии окончания оно принимается за нулевое.
К примеру, в слове лес окончание будет нулевым, в слове леса окончание будет –а. При этом окончание данного слова будет выражать то, что данное существительное относится к множественному числу и находится в именительном падеже.
Морфемный разбор слова
Итак, мы выяснили, что морфема — это наименьшая значимая часть лексемы. Теперь поговорим о морфемном разборе. Для того чтобы правильно сделать морфемный разбор, необходимо придерживаться следующих правил.
Теперь поговорим о морфемном разборе. Для того чтобы правильно сделать морфемный разбор, необходимо придерживаться следующих правил.
1. Сначала анализируемую лексему выписываем из предложения или текста в том виде, в котором она там присутствует.
2. Определяем часть речи и то, изменяемая ли она. Если да, переходим к пункту 3, если нет — к пункту 4.
3. Находим окончание. Для этого склоняем по родам или падежам, числам. Изменяемая часть и будет окончанием.
4. Выделяем основу. Основа — это все слово без окончания.
5. Находим корень. Для этого подбираем однокоренные слова из разных частей слова.
6. Выделяем приставку, которая стоит перед корнем .
7. Выделяем суффиксы. Для этого подбираем слова со схожими суффиксами, но разными корнями. Помните, что некоторые слова могут иметь несколько приставок и суффиксов. К примеру, слово пренеприятный имеет две приставки: пре-не-приятный. А в слове мечтательница три суффикса: мечт-а-тель-ница.
Вот и весь разбор по составу.
Пример морфемного разбора
Давайте разберем одно слово, чтобы вы увидели принцип морфемного разбора и запомнили последовательность действий. Возьмем для при мера предложение: «Давно не видел старика».
1. Выписали слово «старика».
2. Просклоняли: старик, старику – существительное, изменяемое.
3. Просклоняли еще раз: старик, старику, стариками, окончание слова старика – а.
4. Отбрасываем окончание. Основа — старик.
5. Подбираем однокоренные лексемы: старость, стареть – корень стар.
6. У нас нет ничего перед корнем, значит, приставки в слове нет.
7. Подбираем слова с суффиксом -ик-, если они есть. Мужик, носик – суффикс – ик.
Как видите, ничего сложного в разборе слова нет. Главное, строго следовать алгоритму, чтобы не сбиться и правильно все определить, а также понимать, что такое морфема. Примеры с различными морфемами следует также научиться правильно подбирать.
Если же вы сомневаетесь в правильности разбора, вы всегда можете найти морфемный словарь русского языка и посмотреть в нем, из каких морфем состоит то или иное слово, как именно оно образовано. Вы можете воспользоваться словарями под редакцией Потихи З. А. или Тихонова А. Н.
Итак, мы узнали, что морфема – это наименьшая значимая часть слова, определили, какие бывают морфемы, поговорили о каждой из них. Также выяснили, как правильно делать морфемный разбор слова и рассмотрели пример этого разбора. Вспомнили о словарях, которые помогут вам проверить правильность разбора слова. Надеемся, статья была вам полезна.
Разбор: значение и примеры | StudySmarter
На каком-то этапе изучения языка вы могли столкнуться с устрашающими «языковыми деревьями». В лингвистике эти деревья называются деревьями синтаксического анализа (или иногда синтаксическими деревьями), и они являются важным компонентом синтаксического анализа, формы синтаксического анализа.
В этой статье вы найдете информацию о синтаксическом анализе, его корнях в лингвистике и о том, как анализировать предложения.
Разбор Значение
Разбор, иногда называемый синтаксическим анализом, представляет собой процесс разделения языка (например, предложения) на его грамматические компоненты. В области языкознания и синтаксиса грамматические компоненты предложения называются составляющие.
Составные части являются «строительными блоками» предложений и могут варьироваться от отдельных слов до предложений.
Термин , анализирующий , является глаголом (инфинитив = для разбора ), происходящим от латинского слова pars (означающего часть, как в часть речи ).
Сам процесс синтаксического анализа может быть выполнен с помощью визуальных диаграмм, известных как деревья синтаксического анализа или синтаксического дерева, или с помощью компьютерного программного обеспечения. Создание деревьев синтаксического анализа помогает нам увидеть синтаксические отношения между составляющими.
Создание деревьев синтаксического анализа помогает нам увидеть синтаксические отношения между составляющими.
Рис. 1. Составные части являются строительными блоками языка
Определение синтаксического анализа
Таким образом, синтаксический анализ можно определить как:
Синтаксический анализ (для разбора) — Разделение предложения на его грамматические компоненты и описание их синтаксических ролей.
Синтаксический анализ в лингвистике
Синтаксический анализ — это междисциплинарный метод, используемый в лингвистике, ИИ (искусственном интеллекте), анализе данных, обработке естественного языка и разработке программного обеспечения. Хотя синтаксический анализ сегодня обычно ассоциируется с информационными технологиями (ИТ), он уходит своими корнями в лингвистика .
Синтаксический анализ в лингвистике включает в себя выделение всех составляющих в предложении и замечание таких вещей, как спряжения времен и глаголов. Подобный анализ языка помогает нам понять предполагаемое значение и цель предложения, а также отношения между словами.
Подобный анализ языка помогает нам понять предполагаемое значение и цель предложения, а также отношения между словами.
Например, наиболее распространенная составляющая связь в предложении — это подлежащее + его сказуемое . Субъект — это то, о ком/чем идет речь в предложении, а его сказуемое — это часть предложения, которая добавляет подробности или информацию к подлежащему (сказуемые обычно содержат глагол).
» Женщина с блестящим черным рюкзаком — моя сестра .»
В этом примере мы видим две основные составляющие: подлежащее ( Женщина с блестящим черным рюкзаком ) и его сказуемое ( моя сестра ).
Разбор помогает нам распознать, какая группа слов является подлежащим, а какие — сказуемым.
Вы, наверное, уже поняли, что составляющие играют жизненно важную роль в синтаксическом анализе. Итак, давайте теперь познакомимся с ними поближе.
Составные части
Составные части — это языковые единицы, которые вместе составляют предложение. Это могут быть морфемы, фразы и предложения. Меньшие составляющие (например, морфемы) объединяются, образуя более крупные составляющие (например, фразы), которые снова могут объединяться, образуя более крупные составляющие (например, предложения или сказуемые).
Это могут быть морфемы, фразы и предложения. Меньшие составляющие (например, морфемы) объединяются, образуя более крупные составляющие (например, фразы), которые снова могут объединяться, образуя более крупные составляющие (например, предложения или сказуемые).
Например, в приведенном выше примере ( Женщина с блестящим черным рюкзаком — моя сестра) мы выделили две основные составляющие, но эти более крупные составляющие можно разделить на отдельные составляющие.
Составляющая « Th женщина с блестящим черным рюкзаком» является именной группой, которая также содержит предложную составляющую фразы « с блестящей сумкой «, которая содержит прилагательную составляющую фразы « блестящая черный».
Составляющая словосочетания = T h e женщина с блестящим черным рюкзаком
Составляющая предложной фразы = с блестящей сумкой
Составляющая прилагательной фразы = блестящий черный
Методы синтаксического анализа
). Деревья синтаксического анализа содержат ветвей, и корневых узлов, узлов ветвления, и конечных узлов.
Деревья синтаксического анализа содержат ветвей, и корневых узлов, узлов ветвления, и конечных узлов.
Как правило, основное предложение является корневым узлом , поскольку над ним нет ветвей, фразы являются узлами ветвления , а отдельных слова являются конечными узлами . Ветви — это линии, которые показывают взаимосвязь между узлами.
Связь между узлами может быть описана в терминах родитель и ребенок или мать и дочь.
Примеры синтаксического анализа
Теперь, когда вы знаете все о деревьях синтаксического анализа, давайте внимательно рассмотрим пример. Вы должны знать, что деревья синтаксического анализа обычно следуют одному и тому же ключу:
S = предложение
NP = существительная фраза
VP = глагольная фраза
Adjp = прилагательная фраза
Advp = Adverb фраза
PP = предлогальная фраза
D = DEGRINER
n = noun V = verb = verb = verb = verb = verb = verb = verb = verb = verb = verb = verb = verb = verb = verb = verb v = verbe verbaze
.
Adj = Прилагательное
ADV = Adverb
P = Предлог
Рис. 2. Пример дерева Parse
Узлы листьев —
(DETRIGINER)0005
Женщина (существительное)
с (предлог)
( (Digeriner)
- 9191918
(DEGRINIRE).7777.777918. 8
(DEGRINIRIN
Backpack (существительное)
IS (глагол)
My (Detrber)
- 70019191920 (DEGRINER)
- 77 191919 (DEGRINER)
7 (DIRSIRIN0005
Разбор предложений
Вот еще несколько примеров проведения составного анализа предложений с использованием деревьев разбора.
Пример 1.
Рис. 3. Дерево синтаксического анализа
Пример 2.
Рис. 3. Простое дерево синтаксического анализа
Помните: фраза может содержать только одно слово. Например, именная группа может состоять из существительного в единственном числе.
Например, именная группа может состоять из существительного в единственном числе.
Activity
Почему бы не взять ручку и бумагу и не попробовать создать собственное дерево синтаксического анализа?
Начните с простого предложения, например:
«Молодой человек устроился на новую работу».
- Начните с определения подлежащего (обычно существительного/именного словосочетания) и его сказуемого (обычно глагольного словосочетания).
- Определите все различные узлы ветвей, которые существуют внутри (ниже) двух основных узлов ветвей.
- Определите конечные узлы, которые появляются в узлах ответвления.
Анализ электронных писем
Языковой анализ играет важную роль во многих аспектах нашей повседневной жизни, возможно, мы даже не осознаем этого. Один аспект заключается в фильтрации электронной почты.
Анализ электронной почты — это процесс использования компьютерного программного обеспечения для идентификации определенных слов или фраз в электронной почте. Этот процесс может автоматически фильтровать электронные письма по папкам, таким как «спам» или «социальные сети», и помогает нам быстро находить и сортировать электронные письма.
Этот процесс может автоматически фильтровать электронные письма по папкам, таким как «спам» или «социальные сети», и помогает нам быстро находить и сортировать электронные письма.
Синтаксический анализ — основные выводы
- Синтаксический анализ, иногда называемый синтаксическим анализом, представляет собой процесс разделения языка (например, предложения) на его грамматические компоненты.
- При изучении синтаксиса предложения мы смотрим на его составляющие и их отношения друг к другу.
- Синтаксический анализ — это междисциплинарный метод, используемый в лингвистике, ИИ (искусственном интеллекте), анализе данных, обработке естественного языка и разработке программного обеспечения.
- Наиболее распространенный способ проведения синтаксического анализа — создание дерева синтаксического анализа (также известного как синтаксическое дерево). Деревья синтаксического анализа состоят из корней и корневых узлов, узлов ветвей и конечных узлов.
- Отношения между узлами можно описать как родительский и дочерний или материнский и дочерний.


Лекции CS440
Лекции CS440 CS 440/ECE 448
Маргарет Флек
Естественный язык 3
Боати МакБотфейс (от BBC)
Нахождение морфем
Итак, теперь давайте предположим, что у нас есть чистая последовательность слов. Под словом я подразумеваю кусок размера, удобного для более поздних алгоритмов (например, синтаксический анализ, перевод). Это может быть вывод распознавателя речи. Или, поскольку многие системы естественного языка не начинаются с речи, поток слов может быть (очищенным) письменным текстом.
Затем эти слова необходимо разделить на морфемы с помощью алгоритма «морфологии». Слова в некоторых языках могут быть очень длинными (например, в турецком), что усложняет задачу. выполнять дальнейшую обработку, если они (по крайней мере, частично) не подразделяются в морфемы. Например:
без ответа —> без ответа
предварительные условия —> предварительные условия
Или рассмотрим следующее известное китайское слово:
Чжун + Го
В современном китайском языке это одно слово («Китай»).
Иногда родственные слова образуются с помощью процессов, отличных от конкатенации, например. внутренняя смена гласных в английском «фут» против «ноги». Когда это распространено в языке, мы можем захотеть использовать более абстрактное представление на основе признаков, например.
фут —> фут+ЕДИНСТВЕННОЕ ЧИСЛО
фута —> фут+МНОЖЕСТВЕННОЕ ЧИСЛО
Иногда соответствующее разделение зависит от приложения. Итак, английский притяжательный
окончание «s» традиционно пишется как часть предшествующего слова. Однако часто бывает
удобно отделить его как отдельное слово при последующей обработке.
Однако часто бывает
удобно отделить его как отдельное слово при последующей обработке.
Маркировка POS
Чтобы сгруппировать слова в более крупные единицы (например, предложные фразы), Первым шагом обычно является присвоение тега «части речи» (POS) каждому слову. Вот пример текста из корпуса Брауна, который содержит очень чистые письменный текст.
Северные либералы являются главными сторонниками гражданских прав и интеграция. Они также вели нацию в направлении государство всеобщего благосостояния.
Вот версия с тегами. Например, «либералы» — это ННС, которые
является существительным во множественном числе. «Северный» — прилагательное (JJ).
Наборы тегов должны различать основные типы слов.
(например, существительные и прилагательные) и основные варианты, например.
существительные в единственном и множественном числе, глаголы в настоящем и прошедшем времени.
Есть также несколько специальных тегов
ключевые функциональные слова, такие как HV для «иметь»,
и знаки препинания (например, точка).
Северные/jj либералы/nns являются/ber the/вождем/jjs сторонники/nns в/в гражданских/жж прав/ннс и/сс/в интеграции/нн ./. Они/ппсс Иметь/hv также/rb привело/vbn the/в нации/nn в/в/в направлении/nn из/в а/в благополучии/нн состояние/нн ./.
Большинство слов имеют только одну общую часть речи. Таким образом, мы можем подняться до
около 91% точности с использованием простого «базового» алгоритма, который
всегда угадывает наиболее распространенную часть речи для каждого слова.
Однако некоторые слова имеют более одного возможного тега, например. «либеральный»
может быть как существительным, так и прилагательным. Чтобы сделать это правильно, мы можем
использовать алгоритмы, подобные скрытым марковским моделям (следующая лекция).
На чистом тексте хорошо настроенный POS-тегер может получить около 9точность 7%.
Другими словами, POS-теггеры достаточно надежны и в основном используются в качестве
стабильной отправной точкой для дальнейшего анализа.
Мелководные системы
Многие полезные системы можно построить, используя только простой локальный анализ. словесного потока, например слова, словесные биграммы, морфемы, POS-теги, возможно поверхностный анализ (см. ниже). Эти алгоритмы обычно делают «марковское предположение», т. е. предполагают, что только несколько последних пунктов имеют значение для следующего решения. Например.
- Решаете, вставлять ли границу слова? Посмотрите на последние 5-7 символов.
- Решаете, какой POS-тег добавить к следующему слову? Посмотрите на последние 1-3 слова.
Конкретные методы включают автоматы с конечным числом состояний, скрытые марковские модели (HMM) и рекуррентные нейронные сети (RNN). Позже в этом курсе мы увидим скрытые марковские модели.
Один очень старый тип мелководья
система исправления правописания.
Полезные обновления (которые часто работают)
включать обнаружение грамматических ошибок, добавление гласных или диакритических знаков
в языке (например, арабском), где они часто опускаются. Передовые исследовательские задачи включают в себя автоматическую оценку
ответы на стандартизированные тесты.
Распознавание речи использовалось для оценки английского языка.
беглость речи и дети учатся читать (например, вслух).
Успех зависит от очень сильных ожиданий относительно того, что
скажет человек.
Передовые исследовательские задачи включают в себя автоматическую оценку
ответы на стандартизированные тесты.
Распознавание речи использовалось для оценки английского языка.
беглость речи и дети учатся читать (например, вслух).
Успех зависит от очень сильных ожиданий относительно того, что
скажет человек.
Перевод часто выполняется с помощью неглубоких алгоритмов. Чтобы научиться переводить, мы могли бы выровнять пары предложений на разных языках, сопоставив соответствующие слова.
Русский: 18-летним нельзя покупать алкоголь.
Французский: Les 18 ans ne peuvent pas acheter d’alcool
| 18 | год | старые | может | т | купить | спирт | |||
| Лес | 18 | и | и | пёвент | за | ачетер | д’ | алкоголь |
Обратите внимание, что некоторые слова не имеют соответствий на другом языке.
Корпус совпадающих пар предложений можно использовать для создания словарей перевода (для фразы, а также слова) и извлекать общие сведения об изменениях в порядке слов.
Анализ
Если у нас есть POS-теги для слов, мы можем собрать слова в дерево разбора. Существует множество стилей построения деревьев синтаксического анализа. Здесь представляет собой дерево избирательного округа из пенсильванского дерева (от Митча Маркуса).
Дерево синтаксического анализа в стиле Penn treebank (от Митча Маркуса)
Альтернативой является дерево зависимостей , как показано ниже из Гугл лаборатории. Достаточно свежий парсер от них называется «Парси Макпарсфейс» после Великобритании Boaty McBoatface показан выше.
В этом примере левое дерево показывает
правильная приставка для «в своей машине», т.е. модификация «поехала».
Дерево справа показывает интерпретацию, в которой улица
находится в машине.
Лингвисты (вычислительные и другие) ведут длительные споры о лучший способ нарисовать эти деревья. Однако закодированная информация всегда довольно похожи и в основном включают в себя группировку слов которые образуют связные фразы, например. «государство всеобщего благоденствия». Это довольно похоже к разбору языков программирования, за исключением того, что программирование языки были разработаны, чтобы упростить синтаксический анализ.
«Поверхностный синтаксический анализатор» строит только самые нижние части такого дерева. Так что может группировать слова в словосочетания с существительными, предложными словосочетаниями и сложные глаголы (например, «идет»). Извлекать эти фразы намного проще чем построение всего дерева синтаксического анализа, и может быть чрезвычайно полезным для построение неглубоких систем.
Подобно низкоуровневым алгоритмам, синтаксические анализаторы часто принимают решения, используя только
небольшое количество предшествующего (и, возможно, прогнозного) контекста. Однако «один элемент» контекста может быть целым
кусок дерева синтаксического анализа. Например, «юная леди» может считаться
единое целое. Алгоритмы синтаксического анализа обычно должны учитывать широкий спектр параметров, например.
множество вариантов частично построенного дерева. Поэтому они обычно используют
поиск луча, т.е.
оставить только фиксированное количество гипотез с лучшим рейтингом. Более новые методы также
попытаться разделить древовидную структуру между конкурирующими альтернативами (например, динамическое программирование)
чтобы они могли хранить больше гипотез и избегать дублирования работы.
Однако «один элемент» контекста может быть целым
кусок дерева синтаксического анализа. Например, «юная леди» может считаться
единое целое. Алгоритмы синтаксического анализа обычно должны учитывать широкий спектр параметров, например.
множество вариантов частично построенного дерева. Поэтому они обычно используют
поиск луча, т.е.
оставить только фиксированное количество гипотез с лучшим рейтингом. Более новые методы также
попытаться разделить древовидную структуру между конкурирующими альтернативами (например, динамическое программирование)
чтобы они могли хранить больше гипотез и избегать дублирования работы.
Парсеры делятся на три категории
- Нелексикализованный: используйте только теги POS для построения дерева.
- На основе класса: вне части речи, определите общий тип объект или действие (например, человек против транспортного средства)
- Лексикализованный: также включает некоторую информацию о слове идентичность/значение
Значение лексической информации иллюстрируется предложениями вот так, в котором меняется именное словосочетание изменяет то, что предложное словосочетание изменяет:
Она шла по улице.в ее грузовике. (меняет ход)
в новом наряде. (меняет тему)
в Южном Чикаго. (меняет улицу)
 .
. Лучшие синтаксические анализаторы лексикализированы (точность до 94% от Google). Парсер «Parsey McParseface»). Но неясно, сколько информации включать о слова и их значения. Например, должен ли «автомобиль» всегда вести себя как «грузовик»? Более подробная информация помогает принимать решения (особенно приложение) но требует больше обучающих данных.
Подробнее о наборах бирок
Обратите внимание, что набор тегов для корпуса Брауна был несколько специализированным.
для английского языка, в котором формы have и to be
играют важную синтаксическую роль.
Наборы тегов для других языков потребуют одних и тех же тегов (например, для
существительные), но и категории для
типы служебных слов, которые не используются в английском языке.
Например, для набора тегов для китайского языка или языка майя потребуется тег для числа.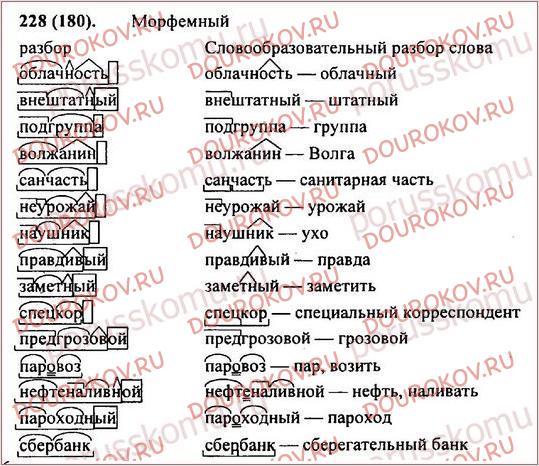 классификаторы, которые представляют собой слова, которые идут с числами (например, «три»)
для указания приблизительного типа перечисляемого объекта (например,
«таблице» может потребоваться классификатор для больших плоских объектов).
Не ясно, лучше ли иметь специализированные наборы тегов
для конкретных языков или один универсальный набор тегов, включающий
основные функциональные категории для всех языков.
классификаторы, которые представляют собой слова, которые идут с числами (например, «три»)
для указания приблизительного типа перечисляемого объекта (например,
«таблице» может потребоваться классификатор для больших плоских объектов).
Не ясно, лучше ли иметь специализированные наборы тегов
для конкретных языков или один универсальный набор тегов, включающий
основные функциональные категории для всех языков.
Наборы тегов различаются по размеру в зависимости от теоретических предубеждений люди, делающие аннотированные данные. Меньшие наборы этикеток передают только основная информация о типе слова. Большие наборы содержат информацию о том, какую роль слово играет в окружающем контексте. Образец размеры
- Пенн Трибэнк 36
- Коричневый корпус 87
- «универсальный» 12
Разговорный разговорный язык также включает в себя черты, которых нет в письменном языке.
В приведенном ниже примере (из корпуса Switchboard)
можно увидеть заполненную паузу «ух», а также обломанное слово «т-«. Кроме того, обратите внимание, что первое предложение разбивается парантетической
комментарий («вы знаете»), и третье предложение обрывается в конце.
Такие особенности затрудняют анализ устной беседы, чем
письменный текст.
Кроме того, обратите внимание, что первое предложение разбивается парантетической
комментарий («вы знаете»), и третье предложение обрывается в конце.
Такие особенности затрудняют анализ устной беседы, чем
письменный текст.
Я был бы очень-очень осторожен и, ну, вы знаете, проверил бы их. Э-э, наш, надо было т-, поместить маму в дом престарелых. У нее был довольно массивный инсульт о, ммм, о —
I/PRP ‘d/MD be/VB очень/RB очень/RB осторожный/JJ и/CC ,/, эм/UH ,/, вы /прп знаете/вбп ,/, проверяя/вбг их/прп вых/рп./. Ух/Ух,/, наш/прп$ ,/, имел/вбд т-/к ,/, место/вб мой/прп$ мать/нн в/в а/дт дом престарелых/NN дом/NN ./. Она/PRP имела/VBD a/DT скорее/RB массивная/JJ ход/н.н.о/рб ,/,э/ух ,/,о/рб —/:
Семантика
Представление смысла менее понятно. В современных системах значение индивидуального
основы слов (например, «кошка» или «прогулка») основаны на их наблюдаемом контексте. мы увидим подробности
позже в срок. Но эти значения не связаны или связаны лишь слабо с
Физический мир. Приемы объединения значений отдельных слов в единое
значение (например, «рыжий кот») так же хрупки.
Очень немногие системы пытаются понять
сложные конструкции с использованием кванторов
(«Сколько стрел не попали в цель?»)
или относительные предложения. (Примером относительного предложения является «что дало бы…» в
приведенный выше пример синтаксического анализа Penn treebank.)
Но эти значения не связаны или связаны лишь слабо с
Физический мир. Приемы объединения значений отдельных слов в единое
значение (например, «рыжий кот») так же хрупки.
Очень немногие системы пытаются понять
сложные конструкции с использованием кванторов
(«Сколько стрел не попали в цель?»)
или относительные предложения. (Примером относительного предложения является «что дало бы…» в
приведенный выше пример синтаксического анализа Penn treebank.)
Специфическая проблема даже для простых приложений заключается в том, что отрицание легко для человека, но трудно для него. компьютеры. Например, запрос Google для «Африка, а не франкоязычный» возвращает информацию во франкоязычных частях Африки. И это пример кругового перевода показывает, как Google выполняет следующую конверсию, которая меняет полярность советов.
- Ввод: «так что ой, как пробовать через 3 часа.»
- Вывод: «Попробуйте попробовать через 3 часа.»
Приложения, которые могут хорошо работать с ограниченным пониманием включают
- группировка документов по темам, разделение документов в местах смены темы
- анализ настроений: нравится ли писателю этот фильм или этот ресторан?
Три типа поверхностного семантического анализа оказались полезными и почти в пределах текущих возможностей:
- классы слов: какие слова похожи друг на друга (например, люди или овощи)?
- значение слова значение неоднозначности: какое было предполагаемое прочтение слова с несколькими значениями (например, «банк»)?
- семантическая ролевая маркировка: мы знаем, что именное словосочетание X относится
к глаголу Y. Является ли X субъектом/действующим лицом? объект, что действие
было сделано? инструмент, используемый, чтобы помочь с действием?
- совместное разрешение (см. ниже)
 Является ли X субъектом/действующим лицом? объект, что действие
было сделано? инструмент, используемый, чтобы помочь с действием?
Является ли X субъектом/действующим лицом? объект, что действие
было сделано? инструмент, используемый, чтобы помочь с действием?Семантическая ролевая маркировка включает в себя определение того, как основные именные фразы в предложение относится к глаголу. Например, в «Джон вел машину». «Джон» — это субъект/агент, а «машина» — управляемый объект. Эти отношения не всегда являются объектами, т.е. кто ест кого в «мост, пожирающий грузовики»? (Погугли это.)
В настоящее время наиболее популярным представлением классов слов является «вложение слов». Вложения слов дают каждому слову уникальное местоположение в многомерном евклидовом пространстве, устроенном так, что подобные слова находятся близко друг к другу. Подробности увидим позже. популярный алгоритм word2vec.
Текущий текст содержит ряд «именованных сущностей», т. е. существительных, местоимений и т.
словосочетания, относящиеся к людям, организациям и местам. Совместная резолюция пытается идентифицировать
какие именованные сущности относятся к одному и тому же.
Например, в этом тексте из Википедии у нас есть
определил три сущности, относящиеся к Мишель Обаме,
два как Барак Обама и три как места, которые не являются ни тем, ни другим.
из них. Одним из источников трудностей являются такие предметы, как
последний «Обама», который внешне выглядит так, как будто это может быть
любой из них.
Совместная резолюция пытается идентифицировать
какие именованные сущности относятся к одному и тому же.
Например, в этом тексте из Википедии у нас есть
определил три сущности, относящиеся к Мишель Обаме,
два как Барак Обама и три как места, которые не являются ни тем, ни другим.
из них. Одним из источников трудностей являются такие предметы, как
последний «Обама», который внешне выглядит так, как будто это может быть
любой из них.
[Мишель ЛаВон Робинсон Обама] (родился 17 января 1964 г.) американский юрист, администратор университета и писатель который служил в качестве [Первая леди США] от с 2009 по 2017 год. Замужем за [44-й президент США], [Барак Обама], и была первой афроамериканской первой леди. Выросший на южной стороне [Чикаго, Иллинойс], [Обама] является выпускник [Университет Принстон] и [Гарвардская школа права].
Согласованность диалога
С самого раннего возраста люди обладают сильной способностью управлять
взаимодействия в течение длительного периода времени.