Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
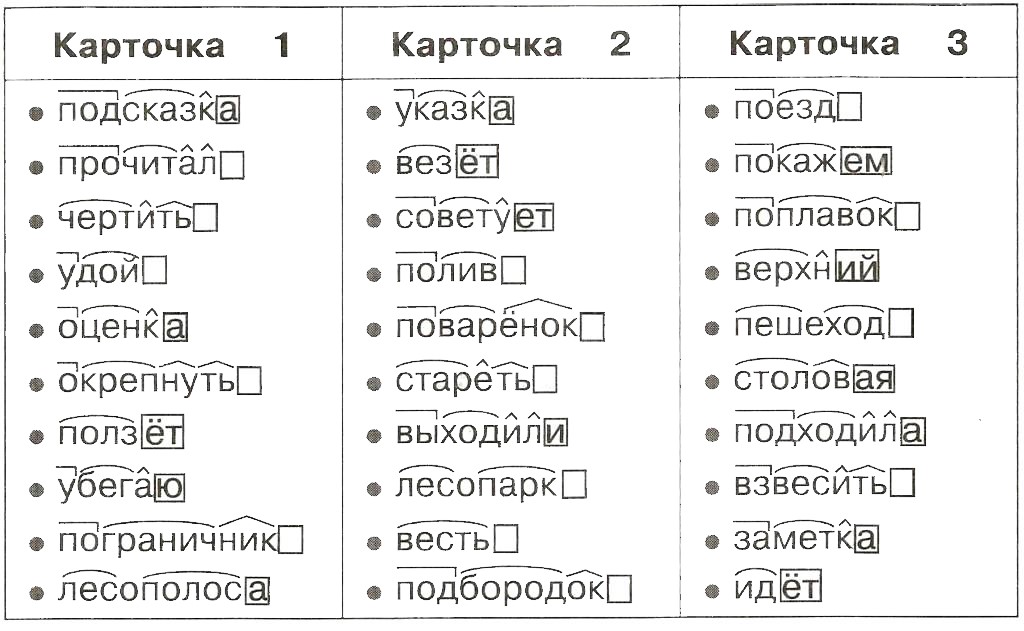
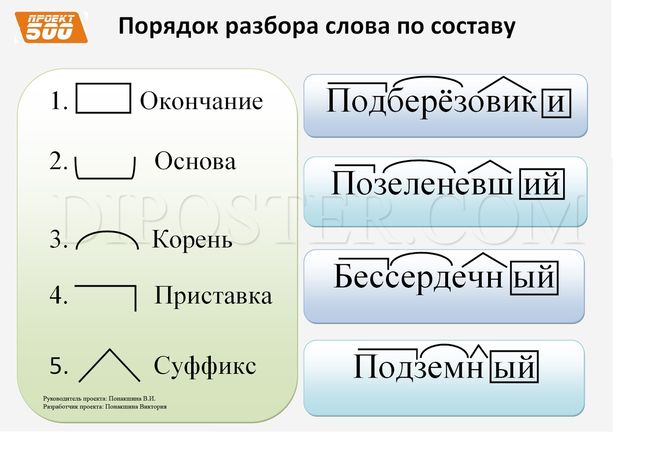
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: у г ч о н г е сейчас оекнлси сейчас оултяпк сейчас тотаева сейчас кумвыда сейчас б р о т у сейчас ртезка 1 секунда назад у ч а с т и е 1 секунда назад пенсия 1 секунда назад мтнмёио 1 секунда назад косметика 1 секунда назад мастер 1 секунда назад вваривающий 1 секунда назад н п р ь л р с ь о з е е 1 секунда назад колгяда 1 секунда назад
словообразование — Приставки в словах «участие» и «вкусный»
Вопрос задан
Изменён 8 месяцев назад
Просмотрен 571 раз
Подскажите, пожалуйста, есть ли приставки в словах участие и вкусный?
- словообразование
- морфемика
- морфемный-разбор
- приставка
1
Исторически — да, в современном языке — нет.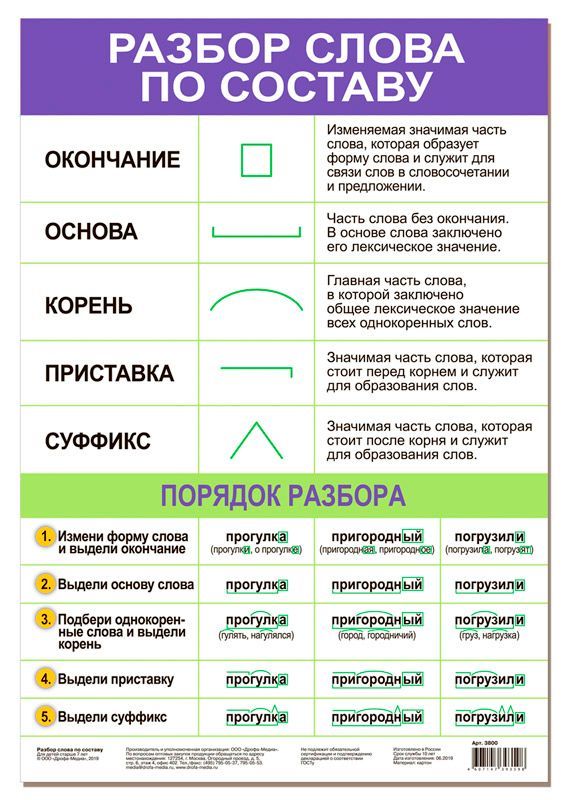
На синхронном (современном) уровне слово участие непроизводно, то есть считается не производным ни от какого другого слова; исторически же это существительное пришло к нам из старославянского языка, где оно было образовано с помощью суффикса -иj- от слова
Похожая история и у слова вкусный: в современном русском это слово образовалось от существительного вкус, которое, в свою очередь, непроизводно. Этимологически оно заимствовано из старославянского въкусъ (корень здесь тот же, что и в словах кушать, кусать).
О том, почему участие я не считаю образованным от глагола участвовать:
«В системе исконной русской апеллятивной аффиксации усечение как языковая техника отсутствует» — пишет лингвист А. А. Кретов.
В нашем случае slava1947 предлагается именно эта модель: 1) от глагола отсекается суффикс -ова-, 2) к получившейся основе прибавляется суффикс -иj-, однако я с ней не согласен.
1
Подскажите, пожалуйста, есть ли приставки в словах участие, вкусный?
При обращении к истории слов могут обнаруживаться связи, которые уже не осознаются всеми или значительной частью носителей языка. Однако когда-то эти связи были, и кем-то они еще могут ощущаться.
Вот с этой-то, «исторической» точки зрения в словах вкусный и участие приставки могут быть выделены. Вот какое членение этих слов представлено в «Словаре морфем русского языка» А.И. Кузнецовой и Т.Ф. Ефремовой:
в-кус-н-ый,
у-част-и-е.
В словарях, опирающихся на идеи современного словообразования, приставки в этих словах не выделяются.
В слове участие обычно теперь выделяется корень участ-, суффикс отвлечённого существительного -и- (вернее: -иj-) и окончание -е (вернее: -э). По мнению большинства словаристов с точки зрения современного языка это предел членения.
В слове вкусный – корень вкус-, суффикс -н- и окончание -ый.
НИКЕМ из известных мне исследователей слово участие в синхронном анализе не считается непроизводным. Обычно его производят от слова участвовать (см. его первое значение в «Новом словаре русского языка» Ефремовой: УЧАСТИЕ ср. 1. Процесс действия по знач. глаг. участвовать
(1)… ).Участие от участвовать образуют и Морковкин, и Тихонов, и …
Из «Словообразовательного словаря русского языка» Тихонова (М., 1990):
15
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Корень слова: плавник (корень) | Membean
Латинское корневое слово fin означает «конец», как «граница» или «предел».
Все студенты знают, что экзамен fin al сдается в «конце» курса. Точно так же все те, кто идет на музыкальный концерт, знают, что эль fin знаменует собой «конец» композиции. Когда вы вступаете в гонку, линия fin ish отмечает ее «конец».
То, что имеет размер fin ite, вообще не имеет «конца». Идея позади в fin
состоит в том, что для него нет никакого «конца» или «предела»! В то время как в fin ity указывает на непостижимо безграничный размер, что-то, что не имеет «конца» относительно того, насколько маленьким оно может быть, в fin itesimal. Однако когда что-то имеет размер con fin ed, оно имеет основательный «конец», поскольку вокруг него установлена «граница». Итак, что такое fin ition? Словарь de fin ition отмечает «конец» или «предел» значений, которые имеет данное слово! Если описание чего-либо является неопределенным fin ite, с другой стороны, у него нет видимого «конца» или «границы», и поэтому он неясен.
Давайте продолжим с еще несколькими примерами английской лексики, которые иллюстрируют, что латинский корень слова
Масло re fin ery re fin es или перерабатывает нефть до ее пригодного для использования «конца». Масло re fin eries не будет существовать вечно.
Вы когда-нибудь встречали кого-то, кто действительно разборчив, или действительно плавник неприглядный? fin «границы» неприятного человека слишком fin e, поскольку им очень трудно угодить — нет «конца» fin требования противного человека!
Хорошо, теперь я подведу «конец» к этому обсуждению, так как мы fin ally сделали! Теперь вы будете хорошо подготовлены к fin словам, которые используют fin , точно зная, каковы их «концы» или «пределы»!
- окончательный : относящийся к «концу»
- финал : «конец» чего-то
- отделка : «конец»
- бесконечный : не имеющий «конца» или «предела»
- бесконечность : математическая сущность, не имеющая «конца»
- бесконечно малый : относящийся к чему-то, что не имеет «конца» своей малости
- ограничить : обеспечить тщательную «границу» или «конец», за который нельзя выйти
- определение : «граница» или «конец» значения слова
- неопределенный : не имеющий «конца» или «границы»
- штраф : довести до «хорошего конца»
- нефтеперерабатывающий завод : промышленное предприятие, на котором сырое вещество тщательно перерабатывается до пригодного для использования «конца»
- конечное : качество наличия «конца» чего-то
- привередливый : относится к тому, у кого слишком много «ограничивающих» границ
[PDF] Deep Unordered Composition Rivals Syntactic Methods for Text Classification
- title={Глубокая неупорядоченная композиция конкурирует с синтаксическими методами классификации текста},
автор = {Мохит Ийер и Варун Манджунатха и Джордан Л.
 Бойд-Грабер и Хэл Даум {\’e}},
booktitle={Ежегодное собрание Ассоциации компьютерной лингвистики},
год = {2015}
}
Бойд-Грабер и Хэл Даум {\’e}},
booktitle={Ежегодное собрание Ассоциации компьютерной лингвистики},
год = {2015}
} Многие существующие модели глубокого обучения для задач обработки естественного языка сосредоточены на изучении композиционности их входных данных, что требует большого количества дорогостоящих вычислений. [] Ключевой результат Мы показываем, что наша модель допускает те же ошибки, что и модели с учетом синтаксиса, указывая на то, что для рассматриваемых нами задач нелинейное преобразование входных данных важнее, чем адаптация сети к порядку слов и синтаксису.
Просмотр в ACL
cs.colorado.eduНа пути к универсальным вложениям парафрастических предложений
- J. Wieting, Mohit Bansal, Kevin Gimpel, Karen Livescu
Computer Science
ICLR
- 2016
Database и сравнивает шесть композиционных архитектур, обнаружив, что наиболее сложные архитектуры, такие как рекуррентные нейронные сети с долговременной кратковременной памятью (LSTM), лучше всего работают с данными в предметной области.
Явная модель взаимодействия к классификации текста
- . (названный EXAM), оснащенный механизмом взаимодействия для включения сигналов соответствия на уровне слов в задачу классификации текста.
- Simeng Sun, Mohit Iyyer
Компьютерные науки
NAACL
- 2021
- Xin Dong, Gerard de Melo
Информатика
EMNLP
- 2019
- Chongyu Pan, Jian Huang, Jianxing Gong, Xingsheng Yuan
Информатика
IEEE Access
- 2019
- Руи Чжан, Хонглак Ли, Драгомир Р. Радев
Информатика
NAACL
- 2016
- Dinghan Shen, Guoyin Wang, L. Carin
Информатика
ACL
- 2018
- Нэнси Фульда
Компьютерная наука
SAI
- 2020
- Калпеш Кришна, П. Джёти, Мохит IYYER
Компьютерная наука
Annlp
- 2018
- R. Socher, Alex Perelygin, Christopher Potts
Computer Science
EMNLP
- 2013
- Nal Kalchbrenner, Edward Grefenstette, P. Blunsom
Компьютерная наука
ACL- 2014
- Ozan Irsoy, Claire Cardie
Компьютерная наука
NIPS
- 2014
- Mohit Iyyer, Jordan L. Boyd-Graber, L. Claudino, R. Socher, Hal Daumé
Computer Science
EMNLP
- 2014
- Р. Сочер, Джеффри Пеннингтон, Э. Хуанг, А. Нг, Кристофер Д. Мэннинг
Информатика
EMNLP
- 2011
- R. Socher, E. Huang, Jeffrey Pennington, A. Ng, Christopher D. Manning
Computer Science
NIPS
- 2011
- Кай Шэн Тай, Р. Сочер, Кристофер Д. Мэннинг
Информатика
ACL
- 2015
- Илья Суцкевер, Ориол Виньялс, Куок В. Ле
Информатика
NIPS
- 2014
- Yoon Kim
Информатика
EMNLP
- 2014
Новый взгляд на простые нейронно-вероятностные языковые модели
(2003), который просто объединяет вложения слов в фиксированном окне и передает результат через сеть прямой связи для предсказания следующего слова, что приводит к небольшому, но последовательному уменьшению недоумения в трех наборах данных моделирования языка на уровне слов.
Надежная самообучающаяся платформа для межъязыковой классификации текстов
модели многоязычного представления и наблюдает значительное повышение эффективности классификации документов и тональностей для целого ряда различных языков.
Метод глубокого обучения для встраивания предложений на основе матричного кодирования Адамара
Этот метод использует встраивание слов, синтаксический анализ зависимостей, матрицу Адамара с алгоритмом расширенного спектра и нейронную сеть глубокого обучения, обученную на корпусе Sentences Involving Compositional Knowledge (SICK) для кодирования предложений любого размера.
Обучение переносу нескольких кадров для классификации текста с помощью моделей на основе облегченного встраивания слов
Модифицированная иерархическая стратегия объединения предварительно обученных вложений слов предлагается для классификации текста методом обучения с переносом за несколько шагов и демонстрирует значительную эффективность классификации в задачах обучения с переносом за несколько шагов по сравнению с другими альтернативными методами.
Чувствительные к зависимостям сверточные нейронные сети для моделирования предложений и документов
DSCNN иерархически строит текстовые представления, обрабатывая предварительно обученные вложения слов через сети с долговременной кратковременной памятью и впоследствии извлекая признаки с помощью операторов свертки, и не полагается на синтаксические анализаторы и дорогостоящую маркировку фраз, и, таким образом, не ограничивается задания на уровне предложения.
Базовый уровень нуждается в большей любви: о простых моделях на основе встраивания слов и связанных с ними механизмах объединения
основанных на встраивании моделей RNN/CNN, и предлагает две дополнительные стратегии объединения по сравнению с вложениями изученных слов: операция максимального объединения для улучшения интерпретируемости и операция иерархического объединения, которая сохраняет пространственную информацию в текстовых последовательностях.
Переосмысление наших предположений об оценке языковой модели
Утверждается, что предварительно обученные лингвистические вводящие вкладчики имеют ценность, и вводящие в силу, и вводящие в силу, и вводящие в силу, а не вводящие в силу, а не в инициалистии, и в условиях, и в условиях, что они не связаны с подсудимыми. задач и принял парадигму, в которой они вместо этого рассматриваются как хранилища неявных знаний, которые можно использовать для решения задач рассуждений на основе здравого смысла с помощью линейных операций над встроенным текстом.
Пересмотр важность правил кодирования логики в классификации настроений
9013 9015 9015 7015 8. синтаксически сложные входные данные, такие как предложения A-но-B, и краудсорсинговый анализ показывают, как ELMo превосходит базовые модели даже в предложениях с неоднозначными ярлыками тональности.
SHOWING 1-10 OF 42 REFERENCES
SORT BYRelevanceMost Influenced PapersRecency
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
Дерево настроений, которое включает в себя подробные метки настроений для 215 154 фраз в деревьях синтаксического анализа 11 855 предложений и ставит новые задачи для композиционности настроений, а также представляет рекурсивную нейронно-тензорную сеть.
Свожденная нейронная сеть для моделирования предложений
8 ARITELUSTRELICE DINELUSLER DINELERICE DINELUSTER DINELUSLER DINELURELENAL DINELELERICURE DINELULER DINELURELERICURE DINELERICE DINELERICE DINELULER.
который используется для семантического моделирования предложений и индуцирует граф признаков над предложением, который способен явно фиксировать короткие и долгосрочные отношения.Глубокие рекурсивные нейронные сети для композиции на языке
. и превосходит предыдущие базовые показатели в задаче анализа настроений, включая мультипликативный вариант RNN, а также недавно введенные векторы абзацев.
A Neural Network for Factoid Question Answering over Paragraphs
This work представляет модель рекурсивной нейронной сети, qanta, которая может рассуждать о вводе текста вопроса, моделируя текстовую композиционность, и применяет ее к набору данных вопросов из соревнования по викторинам, называемого викториной.
Рекурсивные автоэнкодеры с полууправлением для прогнозирования распределения настроений
Каркас машинного обучения на основе рекурсивного кодирования предложений для романов прогнозирование распределения меток тональности, которое превосходит другие современные подходы к широко используемым наборам данных, без использования какой-либо предопределенной лексики тональности или правил смещения полярности.
Динамическое объединение и развертывание рекурсивных автоэнкодеров для обнаружения парафраз
RAE) и неконтролируемые RAE, основанные на новой раскрывающейся цели, и изучают векторы признаков для фраз в синтаксических деревьях, чтобы измерить сходство слов и фраз между двумя предложениями.
Улучшенные семантические представления из древовидных сетей долговременной кратковременной памяти
Введено дерево-LSTM, которое превосходит LSTM по производительности в отношении древовидной структуры. существующие системы и сильные базовые показатели LSTM по двум задачам: прогнозирование семантической связи двух предложений и классификация настроений.
Обучение последовательностям с помощью нейронных сетей
предложения заметно улучшили производительность LSTM, потому что это привело к появлению множества краткосрочных зависимостей между исходным и целевым предложением, что упростило задачу оптимизации.
Сверточные нейронные сети для классификации предложений
Модели CNN, обсуждаемые здесь, улучшают современное состояние в 4 из 7 задач, которые включают анализ настроений и предложенную классификацию вопросов.
 Бойд-Грабер и Хэл Даум {\’e}},
booktitle={Ежегодное собрание Ассоциации компьютерной лингвистики},
год = {2015}
}
Бойд-Грабер и Хэл Даум {\’e}},
booktitle={Ежегодное собрание Ассоциации компьютерной лингвистики},
год = {2015}
} 



 который используется для семантического моделирования предложений и индуцирует граф признаков над предложением, который способен явно фиксировать короткие и долгосрочные отношения.
который используется для семантического моделирования предложений и индуцирует граф признаков над предложением, который способен явно фиксировать короткие и долгосрочные отношения.

