Тест на определение личности по Юнгу и Бриггс-Майерс
Этот бесплатный личностный тест позволит определить Ваш тип личности в виде четырех букв по типологии Юнга, которую совершенствовали Майерс, Бриггс, фон Франц и ван дер Хооп. Наш тест — это один из нескольких способов определить свой тип личности по типологии Юнга, который похож, однако не идентичен , с тестом MBTI (Индикатор типов Майерс-Бриггс ) ® MBTI), индикатором типов Юнга и похожими материалами.
Тест на определение типа личности от IDR Labs является собственностью IDR Labs International.
Наш тест — это один из немногих бесплатных тестов этого типа, который проходит статистический контроль и является достоверным. Несмотря на это, просим обратить Ваше внимание, что тест служит лишь своеобразным индикатором, который только примерно может определить присущие Вам качества.
Права на товарный знак Индикатора типов Майерс-Бриггс и теста MBTI принадлежат компании the Myers & Briggs Foundation, Соединенным Штатам Америки и другим странам. Тест MBTI был опубликован компанией The Myers-Briggs. Индикатор типов Юнга принадлежит Psytech International.
Тест MBTI был опубликован компанией The Myers-Briggs. Индикатор типов Юнга принадлежит Psytech International.
Все личностные тесты, независимо от того, являются ли они официальными тестами как тест MBTI® (Индикатор типов Майерс-Бриггс) и Индикатор типов Юнга, или такими бесплатными онлайн-тестами как данный, служат лишь индикаторами, которые только предположительно могут определить Ваш тип личности. Ни один из тестов не может определить Ваш тип личности с абсолютной точностью и достоверностью и заменить детальное изучение работ Майерс, Бриггс, фон Франц, ван дер Хоопа и Юнга.
Как издатели данного бесплатного онлайн-теста, который позволяет определить Ваш тип личности по типологии Юнга, Майерс, Бриггс, фон Франц и ван дер Хоопа, мы приложили все усилия, чтобы этот тест отличался точностью, завершенностью и достоверностью.
Как и «официальные» тесты на основе типологии Юнга и другие профессионально разработанные тесты, наш бесплатный онлайн-тест прошел статистический контроль и многочисленные проверки для того, чтобы обеспечить максимальную точность результатов.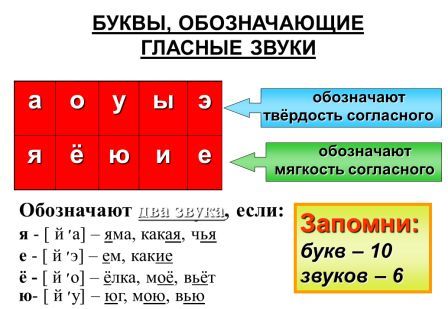
Для создания данного теста мы использовали типологию психологических типов К. Г. Юнга, представленную в его работе Психологические типы и типологию Изабелл Бриггс Майерс, соавтора теста MBTI®, которую она опубликовала в своем труде У каждого свой дар. Кроме того, работы ван дер Хоопа Ориентация сознания и Характер и подсознание также оказали значительное влияние на создание этого теста.
Этот тест основан на широко признанных теориях, а именно на подтвержденных теориях типов личности Юнга, Майерс, фон Франц и ван дер Хоопа, а не на приближенной версии типологии Юнга.
Наш бесплатный онлайн-тест также использует работы ван дер Хоопа и пытается точно определить психологические типы личности в соответствии с его трудами.
Разработчики этого бесплатного онлайн-теста являются дипломированными специалистами, которые имели опыт работы с многочисленными тестированиями личности, а также работали на профессиональном уровне с тестированием типологии личности. Перед прохождением нашего бесплатного онлайн-теста, обратите, пожалуйста, внимание, что хотя полученный результат в виде четырех букв может совпадать с другими результатами официальных тестов, его не следует путать с Индикатором типов Бриггс-Майерс, Грей-Уилрайт и Юнга. Результаты нашего личностного онлайн-теста предоставляются «как есть» и не должны толковаться как предоставление профессиональной или сертифицированной консультации любого рода. Для получения дополнительной информации о нашем личностном онлайн-тесте ознакомьтесь, пожалуйста, с нашими Условиями предоставления услуг.
Перед прохождением нашего бесплатного онлайн-теста, обратите, пожалуйста, внимание, что хотя полученный результат в виде четырех букв может совпадать с другими результатами официальных тестов, его не следует путать с Индикатором типов Бриггс-Майерс, Грей-Уилрайт и Юнга. Результаты нашего личностного онлайн-теста предоставляются «как есть» и не должны толковаться как предоставление профессиональной или сертифицированной консультации любого рода. Для получения дополнительной информации о нашем личностном онлайн-тесте ознакомьтесь, пожалуйста, с нашими Условиями предоставления услуг.
Бесплатный онлайн инструмент OCR (Распознавание текста) — Convertio
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Выберите файлы
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
Выберите все языки, используемые в документе
Выберите основной язык. ..РусскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТатарскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
..РусскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТатарскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
Выберите дополнительные языки…РусскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТатарскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
Формат и настройки выбора
Документ Microsoft Word (. docx)Microsoft Excel Workbook (.xlsx)Microsoft Excel 97-2003 Workbook (.xls)Microsoft PowerPoint Presentation (.pptx)Searchable PDF Document (.pdf)Text Document (.txt)RTF Document (.rtf)CSV Document (.csv)Electornic Publication (.epub)Xml формат хранения книг (.fb2)DjVu Document (.djvu)
docx)Microsoft Excel Workbook (.xlsx)Microsoft Excel 97-2003 Workbook (.xls)Microsoft PowerPoint Presentation (.pptx)Searchable PDF Document (.pdf)Text Document (.txt)RTF Document (.rtf)CSV Document (.csv)Electornic Publication (.epub)Xml формат хранения книг (.fb2)DjVu Document (.djvu)
Все страницы
Номера страниц
Как распознать текст с изображения?
Шаг 1
Загрузите изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, по ссылке или перетащив их на страницу
Шаг 2
Язык и формат
Выберите все языки, используемые в документе. Кроме того, выберите .doc или любой другой формат, который вам нужен в результате (поддерживается больше 10 текстовых форматов)
Шаг 3
Конвертируйте и скачивайте
Нажмите «Распознать», и вы можете сразу загрузить распознанный текстовый файл
python – Как анализировать строковые даты с двузначным годом?
спросил
Изменено 2 года, 3 месяца назад
Просмотрено 69 тысяч раз
Мне нужно проанализировать строки, представляющие 6-значные даты в формате ггммдд , где гг находится в диапазоне от 59до 05 (с 1959 по 2005 год). Согласно документам модуля
Согласно документам модуля time , базовым годом Python по умолчанию является 1969, что мне не подходит.
Есть ли простой способ переопределить опорный год или вы можете предложить другое решение? Я использую Python 2.7. Спасибо!
- python
- date
- y2k
- 2-значный год
Я бы использовал datetime и нормально разобрал его. Затем я бы использовал datetime.datetime.replace для объекта, если он истек с вашей максимальной датой — настраивая его на 100 лет:
импорт даты и времени дд = datetime.datetime.strptime (дата, '% г% м% д') если дд.год > 2005: дд = дд.заменить(год=дд.год-100)
Добавьте столетие к дате, используя собственный свод:
year = int(date[0:2])
если 59 <= год <= 99:
дата = '19' + дата
еще
дата = '20' + дата
, а затем используйте strptime с директивой %Y вместо %y .
1
91953 г.
Вы также можете выполнить следующее:
today=datetime.datetime.today().strftime("%m/%d/%Y")
сегодня=сегодня[:-4]+сегодня[-2:]
Недавно был аналогичный случай, закончившийся этим базовым расчетом и логикой:
pivotyear = 1969
век = int(str(pivotyear)[:2]) * 100
def year_2to4_digit (год):
вернуть век + год, если век + год > ось года, иначе (столетие + 100) + год
Если вы имеете дело с очень недавними датами, а также с очень старыми датами и хотите использовать текущую дату в качестве опорной (а не только текущий год), попробуйте этот код:
импорт даты и времени
определение parse_date (date_str):
проанализировано = datetime.datetime.strptime(date_str,'%y%m%d')
текущая_дата = дата/время.дата/время.сейчас()
если проанализировано > current_date:
проанализировано = проанализировано.заменить (год = проанализировано.год - 100)
вернуть проанализированный
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Методы парсера, операторы и комбинаторы — документация parsy 2.
 0
0Методы парсера
Объекты синтаксического анализатора возвращаются любым из встроенных примитивов синтаксического анализа синтаксического анализа. Они можно использовать и манипулировать, как показано ниже.- класс parsy.Parser[источник]
- __init__( wrap_fn )[источник]
Это функция низкого уровня для создания новых парсеров, которые используются внутри но редко требуется пользователям библиотеки parsy. Следует пройти функция синтаксического анализа, которая принимает два аргумента — строку/список для анализа и текущий индекс в список — и возвращает
Результатобъект, как описано в разделе Создание новых экземпляров Parser.
Следующие методы фактически используют анализаторы, которые у вас есть создано:
- синтаксический анализ ( string_or_list ) [источник]
Попытки проанализировать данную строку (или список).

Возникла ошибка ParseError.Вместо строки вы можете передать список токенов. Почти все примеры предполагают строки для простоты. Некоторые из примитивов также явно зависит от строки, и некоторые комбинаторы (такие как
Parser.concat()) зависят от строки, но большинство остальных библиотека будет работать и с токенами. См. Отдельные этапы лексирования/токенизации для Дополнительная информация.
- parse_partial ( string_or_list ) [источник]
Аналогичен
разбору, за исключением того, что он не требует всего строка (или список) для использования. Возвращает кортеж(результат, остаток), гдеостатокчасть строка (или список), которая осталась.
Следующие методы по сути являются комбинаторами , которые производят новые парсеры из существующего.
Они предоставляются как методы на Parserдля удобство. Другие комбинаторы описаны ниже.- описание( строка )[источник]
Добавляет в парсер описание, которое используется в сообщении об ошибке если разбор не удался.
>>> year = regex(r'[0-9]{4}').desc('4-значный год') >>> год.parse('123') ParseError: ожидаемый 4-значный год в 0:0
- тогда( other_parser )[источник]
Возвращает синтаксический анализатор, который, если исходный синтаксический анализатор завершится успешно, продолжит синтаксический анализ с
other_parser. Это создаст стоимость, произведеннуюдругой_парсер.>>> строка('x').затем(строка('y')).parse('xy') 'у'См. также >> оператор.
- пропустить( other_parser )[источник]
Аналогично
Parser.then(), за исключением того, что результирующий парсер будет использовать значение, созданное первым синтаксическим анализатором.>>> строка('x').skip(строка('y')).parse('xy') 'Икс'См. также оператор <<.
- много()[источник]
Возвращает синтаксический анализатор, который ожидает исходный синтаксический анализатор 0 или более раз, и выдает список результатов. Обратите внимание, что этот синтаксический анализатор не дает сбой, если ничего не соответствует, но вместо этого ничего не потребляет и создает пустой список.
>>> parser = регулярное выражение (r'[a-z]').many() >>> parser.parse('') [] >>> parser.parse('abc') ['а', 'б', 'в']
- раз( мин [ макс=мин ])[источник]
Возвращает синтаксический анализатор, который ожидает исходный синтаксический анализатор не менее
мин.раз, и не болеемакс.раз, и выводит список результатов. Если только один задан аргумент, парсер ожидает ровно столько раз.
- at_most( n )[источник]
Возвращает синтаксический анализатор, который ожидает исходный синтаксический анализатор не более
nраз, и выдает список результатов.
- по крайней мере ( n ) [источник]
Возвращает синтаксический анализатор, который ожидает исходный синтаксический анализатор не менее
nраз, и выдает список результатов.
Возвращает синтаксический анализатор, который ожидает исходный синтаксический анализатор, за которым следует
other_parser. Начальный синтаксический анализатор ожидается не менеемин.раз и не болеемакс.раз. По умолчанию он не используетother_parserи создает список результаты исключаяother_parser. ЕслиConsumer_otherравноTrue, тоother_parserпотребляется, и его результат включается в список результатов.>>> seq(string('A').until(string('B')), string('BC')).parse('AAABC') [['А','А','А'], 'БК'] >>> строка('A'). until(строка('B')).then(строка('BC')).parse('AAABC')
'ДО НАШЕЙ ЭРЫ'
>>> строка ("A").
['А', 'А', 'А', 'БК']
Новое в версии 2.0.
- необязательно ( по умолчанию = Нет ) [источник]
Возвращает синтаксический анализатор, который ожидает начальный синтаксический анализатор ноль или один раз, и отображает результат к заданному значению по умолчанию в случае несоответствия. Если нет по умолчанию указано значение,
Нет Используется.>>> строка('A').Необязательный().parse('A') «А» >>> строка('A').необязательный().parse('') Никто >>> string('A').Optional('Oops').parse('') "Ой"
- карта ( map_function ) [источник]
Возвращает синтаксический анализатор, который преобразует полученное значение исходного синтаксического анализатора с
map_function.>>> регулярное выражение (r'[0-9]+').map (int).parse ('1234') 1234Это самый простой способ преобразовать проанализированные строки в типы данных.
comb()иcomb_dict()ниже.
- объединить ( comb_fn ) [источник]
Возвращает синтаксический анализатор, который преобразует полученные значения исходного синтаксического анализатора с
comb_fn, передавая аргументы с использованием синтаксиса*args.Если текущий синтаксический анализатор создает итерацию значений, это может быть более удобный способ их объединения, чем
map().Пример 1 — порядок аргументов нашего вызываемого объекта уже соответствует:
>>> с даты импорта даты и времени >>> yyyymmdd = seq(regex(r'[0-9]{4}').map(int), ... регулярное выражение (r'[0-9] {2}').map (целое число), ... регулярное выражение (r'[0-9] {2}').map (int)).combine (дата) >>> ггггммдд.parse('20140506') datetime.date(2014, 5, 6)Пример 2 — порядок аргументов нашего вызываемого объекта не совпадает, и нам нужно настроить параметр, поэтому мы можем исправить его с помощью лямбды.
>>> ddmmyy = regex(r'[0-9]{2}').map(int).times(3).combine( ... лямбда d, m, y: date(2000 + y, m, d)) >>> ddmmyy.parse('060514') datetime.date(2014, 5, 6)Эквивалент
lambdaдля использования с картойlambda res: date(2000 + res[2], res[1], res[0]), что менее читабельно. Версия собъединениетакже гарантирует, что ровно 3 предмета будут сгенерированы предыдущий парсер, иначе вы получитеTypeError.
- comb_dict( fn )[источник]
Возвращает синтаксический анализатор, который преобразует значение, полученное исходным синтаксическим анализатором. используя предоставленную функцию/вызываемый, передавая аргументы с помощью
**kwargsсинтаксис.Значение, созданное исходным синтаксическим анализатором, должно быть отображением/словарем из имена значениям, или список из двух кортежей, или что-то еще, что может быть передан конструктору
dict.Если
Нетприсутствует в качестве ключа в словаре, он будет удален перед переходом кfn, как и все ключи, начинающиеся с_.Мотивация:
Для строительства сложных объектов это может быть более удобным, гибким и читабельнее
map()илиCombine(), потому что, избегая позиционные аргументы, мы можем избежать зависимости от порядка компонентов в анализируемой строке и в порядке аргументов вызываемых объектов использовал. Он специально разработан для использования в сочетании сseq(). итег().Мы можем использовать
**kwargsверсиюseq()для создания очень читаемое определение:>>> ддммгггг = последовательность( ... день = регулярное выражение (r'[0-9]{2}').map(целое число), ... месяц = регулярное выражение (r'[0-9] {2}').map (целое число), ... год = регулярное выражение (r'[0-9] {4}').map (целое число), . .. ).combine_dict(дата)
>>> ддммгггг.parse('04052003')
datetime.date(2003, 5, 4)
(если это трудно понять, используйте Python REPL и изучите результат вызова
parse, если вы удалите вызовcomb_dict).Здесь мы использовали
datetime.date, который принимает аргументы ключевого слова. Для тебя собственные потребности синтаксического анализа, вы часто будете использовать пользовательские типы данных. Вы можете создать как вам угодно, но мы предлагаем классы данных (stdlib), attrs или pydantic. Вы также можете использовать именованный кортеж для простых случаев.В следующем примере показано использование
_в качестве префикса для удаления элементы, которые вас не интересуют, и использованиеnamedtupleдля создать простую структуру данных.>>> из коллекций импортировать namedtuple >>> Пара = namedtuple('Пара', ['имя', 'значение']) >>> имя = регулярное выражение ("[A-Za-z]+") >>> int_value = regex("[0-9]+"). map(int)
>>> логическое_значение = строка ("истина"). Результат (истина) | строка («ложь»). результат (ложь)
>>> пара = последовательность(
... имя=имя,
... __eq=строка('='),
... значение=целое_значение | логическое_значение,
... __sc=строка(';'),
... ).combine_dict(Пара)
>>> пара.parse("foo=123;")
Пара (имя = 'foo', значение = 123)
>>>pair.parse("BAR=true;")
Пара (имя = 'BAR', значение = Истина)
Вы также можете использовать
<<или>>для ненужных частей (но в некоторых случаях это менее удобно):>>> пара = последовательность( ... имя=имя << строка ('='), ... значение = (целое_значение | логическое_значение) << строка (';') ... ).combine_dict(Пара)Изменено в версии 1.2: Разрешить использование списков и словарей и отфильтровать
Нет.Изменено в версии 1.3: Удаление аргументов, начинающихся с
_
- тег( имя )[источник]
Возвращает синтаксический анализатор, который упаковывает полученное значение исходного синтаксического анализатора в 2 кортеж, содержащий
(имя, значение). Это обеспечивает очень простой способ
пометить проанализированные компоненты. например:>>> день = регулярное выражение (r'[0-9]+').map (целое число) >>> month = string_from("Январь", "Февраль", "Март", "Апрель", "Май", ..."Июнь", "Июль", "Август", "Сентябрь", "Октябрь", ... "Ноябрь декабрь") >>> день.parse("10") 10 >>> day.tag("день").parse("10") («день», 10) >>> seq(day.tag("день") << пробел, ... месяц.тег("месяц") ... ).parse("10 сентября") [('день', 10), ('месяц', 'сентябрь')]Также хорошо работает в сочетании с
.map(dict)для получения словаря. значений:>>> seq(day.tag("имя") << пробел, ... месяц.тег("месяц") ... ).map(dict).parse("10 сентября") {'день': 10, 'месяц': 'сентябрь'}… и с
comb_dict()для создания других объектов.Обычно лучше использовать
seq()с аргументами ключевого слова, если вы хотите составить словарь.
- concat () [источник]
Возвращает синтаксический анализатор, который объединяет (в виде строки) ранее произведенные ценности.
Обычно используется после many()и подобных методы, которые производят несколько значений.>>> letter.at_least(1).parse("привет") ['Привет'] >>> letter.at_least(1).concat().parse("привет") 'Привет'
- результат( значение )[источник]
Возвращает синтаксический анализатор, который, если первоначальный синтаксический анализатор завершается успешно, всегда производит
значение.>>> строка('foo').result(42).parse('foo') 42
- should_fail( описание )[источник]
Возвращает синтаксический анализатор, который не работает, когда первоначальный синтаксический анализатор завершается успешно, и завершается успешно когда первоначальный синтаксический анализатор дает сбой (не потребляя входных данных). Описание должно быть передано, которое используется в сообщениях об ошибках синтаксического анализа.
По сути, это отрицательный прогноз:
>>> p = буква << строка (" "). should_fail ("не пробел")
>>> p.parse('A')
«А»
>>> p.parse('A')
ParseError: ожидается «не пробел» в 0:1
Это также полезно для реализации таких вещей, как повторный синтаксический анализ до тех пор, пока маркер:
>>> (string(";").should_fail("not;") >> letter).many().concat().parse_partial('ABC;') («Азбука», «;»)
- привязать( fn )[источник]
Возвращает синтаксический анализатор, который, если первоначальный синтаксический анализатор прошел успешно, приводит к
fnи продолжает работу с парсером, возвращенным изfn. Этот является монадической операцией связывания. Однако, поскольку у нас нет Haskell 9Нотация 0011 do в Python, использование которой очень неудобно. Вместо этого вы должны посмотрите Создание синтаксического анализатора, который обеспечивает гораздо более приятный синтаксис для этого случаях, когда вам понадобилось бы обозначениеdoв парсеке.
- sep_by( сен , мин=0 , макс=инф )[источник]
Подобно
Parser., это возвращает новый парсер, который повторяется начальный парсер и собирает результаты в список, но в этом случае разделенный парсером times() сен(чье возвращаемое значение отбрасывается). По умолчанию это повторяется без ограничений, но можно указать минимальное и максимальное значения.>>> csv = letter.at_least(1).concat().sep_by(string(",")) >>> csv.parse("abc,def") ['абв', 'определ.']
- отметка () [источник]
Возвращает синтаксический анализатор, который заключает исходный результат синтаксического анализатора в значение содержащий информацию о столбцах и строках совпадения, а также исходное значение. Новое значение представляет собой 3-кортеж:
((начало_строки, начало_столбца), исходное_значение, (конец_строки, конец_столбца))
Это полезно для возможности сообщить о проблемах с разбором более точно, особенно если вы используете parsy в качестве лексера и хотите, чтобы последующий анализ потока токенов был возможность сообщать об исходных позициях в сообщениях об ошибках и т.
д.

 Они предоставляются как методы на
Они предоставляются как методы на 

 until(строка('B')).then(строка('BC')).parse('AAABC')
'ДО НАШЕЙ ЭРЫ'
>>> строка ("A").
['А', 'А', 'А', 'БК']
until(строка('B')).then(строка('BC')).parse('AAABC')
'ДО НАШЕЙ ЭРЫ'
>>> строка ("A").
['А', 'А', 'А', 'БК']



 .. ).combine_dict(дата)
>>> ддммгггг.parse('04052003')
datetime.date(2003, 5, 4)
.. ).combine_dict(дата)
>>> ддммгггг.parse('04052003')
datetime.date(2003, 5, 4)
 map(int)
>>> логическое_значение = строка ("истина"). Результат (истина) | строка («ложь»). результат (ложь)
>>> пара = последовательность(
... имя=имя,
... __eq=строка('='),
... значение=целое_значение | логическое_значение,
... __sc=строка(';'),
... ).combine_dict(Пара)
>>> пара.parse("foo=123;")
Пара (имя = 'foo', значение = 123)
>>>pair.parse("BAR=true;")
Пара (имя = 'BAR', значение = Истина)
map(int)
>>> логическое_значение = строка ("истина"). Результат (истина) | строка («ложь»). результат (ложь)
>>> пара = последовательность(
... имя=имя,
... __eq=строка('='),
... значение=целое_значение | логическое_значение,
... __sc=строка(';'),
... ).combine_dict(Пара)
>>> пара.parse("foo=123;")
Пара (имя = 'foo', значение = 123)
>>>pair.parse("BAR=true;")
Пара (имя = 'BAR', значение = Истина)
 Это обеспечивает очень простой способ
пометить проанализированные компоненты. например:
Это обеспечивает очень простой способ
пометить проанализированные компоненты. например: Обычно используется после
Обычно используется после  should_fail ("не пробел")
>>> p.parse('A')
«А»
>>> p.parse('A')
ParseError: ожидается «не пробел» в 0:1
should_fail ("не пробел")
>>> p.parse('A')
«А»
>>> p.parse('A')
ParseError: ожидается «не пробел» в 0:1
 times()
times()  д.
д.Операторы парсера
В этом разделе описываются операторы, которые можно использовать с объектами Parser для
создавать новые парсеры.
| оператор парсер | other_parser
Возвращает синтаксический анализатор, который пытается синтаксический анализатор и, в случае сбоя, откатывается
и пытается other_parser . Их можно связать вместе.
Результирующий синтаксический анализатор выдаст значение, созданное первым удачный парсер.
>>> parser = строка('x') | строка ('у') | строка ('г')
>>> parser.parse('x')
'Икс'
>>> parser.parse('у')
'у'
>>> parser.parse('z')
'г'
Обратите внимание, что other_parser будет использоваться только в том случае, если анализатор не может потреблять
ввод и терпит неудачу. other_parser не используется в случае, если позже парсера
компоненты выходят из строя. Это означает, что порядок операндов имеет значение - для
пример:
Это означает, что порядок операндов имеет значение - для
пример:
>>> ((строка('A') | строка('AB')) + строка('C')).parse('ABC')
ParseEror: ожидается «C» в 0:1
>>> ((строка('AB') | строка('A')) + строка('C')).parse('ABC')
«Азбука»
>>> ((строка('AB') | строка('A')) + строка('C')).parse('AC')
'переменный ток'
<< оператор парсер << other_parser
То же, что и parser.skip(other_parser) - см. Parser.skip() .
(Подсказка - стрелки указывают на важный парсер!)
>>> (строка ('x') << строка ('y')).parse ('xy')
'Икс'
>> оператор парсер >> other_parser
То же, что и parser.then(other_parser) - см. Parser.then() .
(Подсказка - стрелки указывают на важный парсер!)
>>> (строка ('x') >> строка ('y')).parse ('xy')
'у'
+ оператор парсер1 + парсер2
Требует, чтобы оба синтаксических анализатора совпадали по порядку, и складывает два результата вместе, используя
оператор +. Это будет работать только в том случае, если результаты поддерживают оператор плюс
(например, строки и списки):
Это будет работать только в том случае, если результаты поддерживают оператор плюс
(например, строки и списки):
>>> (строка ("x") + регулярное выражение ("[0-9]")).разобрать("x1")
"х1"
>>> (string("x").many() + regex("[0-9]").map(int).many()).parse("xx123")
['х', 'х', 1, 2, 3]
Оператор "плюс" является удобным сокращением для:
>>> seq(parser1, parser2).combine(лямбда a, b: a + b)
* оператор парсер1 * число
Это ярлык для выполнения Parser.times() :
>>> (строка("x") * 3).parse("xxx")
["х", "х", "х"]
Вы также можете установить верхнюю и нижнюю границы путем умножения на диапазон:
>>> (строка ("x") * диапазон (0, 3)).parse ("xxx")
ParseError: ожидаемый EOF в 0:2
(Обратите внимание, что нормальная семантика диапазона соблюдается - второе число является исключая верхнюю границу, не включительно).
Комбинаторы парсеров
- parsy. alt( *парсеры )[источник]
Создает синтаксический анализатор из переданного списка аргументов альтернативных синтаксических анализаторов, которые пробуются по порядку, переходя к следующему, если текущий терпит неудачу, как за | оператор - другими словами, он соответствует любому из альтернативные парсеры.
Пример использования синтаксиса
*argsдля передачи списка синтаксических анализаторов, которые были генерируется путем сопоставленияstring()со списком символов:>>> hexdigit = alt(*map(string, "0123456789abcdef"))
(В этом случае лучше использовать
char_from())Обратите внимание, что порядок аргументов имеет значение, как описано в разделе | оператор.
 alt( *парсеры )[источник]
alt( *парсеры )[источник]- parsy.seq( * парсеры , ** kw_parsers )[источник]
Создает синтаксический анализатор, который запускает последовательность синтаксических анализаторов по порядку и объединяет их результаты в виде списка.
>>> x_bottles_of_y_on_the_z = \ ... seq(regex(r"[0-9]+").map(int) << строка ("бутылки"), ... регулярное выражение (r"\S+") << строка ("на"), ... регулярное выражение (r"\S+") ... ) >>> x_bottles_of_y_on_the_z.parse("99 бутылок пива на стене") [99, 'пиво', 'стена']Вы также можете использовать
seq()с ключевыми словами вместо позиционных аргументы. В этом случае произведенное значение является словарем индивидуума. значения, а не последовательность. Это может облегчить получение произведенной стоимости. потреблять.>>> name = seq(first_name=regex("\S+") << пробел, ... last_name=regex("\S+") >>> name.parse("Джейн Смит") {'first_name': 'Джейн', 'last_name': 'Смит'}Изменено в версии 1.1: Добавлена опция
**kwargs.Примечание
В качестве альтернативы см.
Parser.tag()способ маркировки проанализированного компоненты и создание словарей.

Прочие комбинаторы
Parsy не пытается включить все возможные комбинаторы - нет причин, почему
нельзя создавать свои под свои нужды с помощью встроенных комбинаторов и
примитивы.