Фонетический разбор слов варежки, игра, книга, коньки,метель,мир, снег, снежки,спор,успех
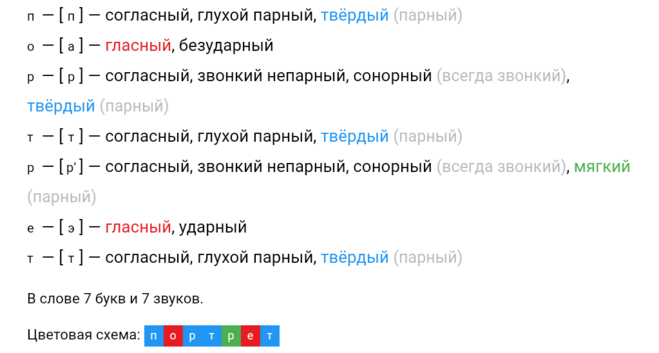
Транскрипция слова: [вар’ишк’и]
в — [в] — согласный, звонкий парный, твёрдый (парный)
а — [а] — гласный, ударный
р — [р’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
е — [и] — гласный, безударный
ж — [ш] — согласный, глухой парный, твёрдый (непарный, всегда произноится твёрдо), шипящий
к — [к’] — согласный, глухой парный, мягкий (парный)
и — [и] — гласный, безударный
В слове 7 букв и 7 звуков.
Транскрипция слова: [игра]
и — [и] — гласный, безударный
г — [г] — согласный, звонкий парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
а — [а] — гласный, ударный
В слове 4 буквы и 4 звука.
Транскрипция слова: [кн’ига]
к — [к] — согласный, глухой парный, твёрдый (парный)
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
и — [и] — гласный, ударный
г — [г] — согласный, звонкий парный, твёрдый (парный)
а — [а] — гласный, безударный
В слове 5 букв и 5 звуков.
Транскрипция слова: [кан’к’и]
к — [к] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
ь — не обозначает звука
к — [к’] — согласный, глухой парный, мягкий (парный)
и — [и] — гласный, ударный
В слове 6 букв и 5 звуков.
Транскрипция слова: [м’ит’эл’]
м — [м’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
е — [и] — гласный, безударный
т — [т’] — согласный, глухой парный, мягкий (парный)
е — [э] — гласный, ударный
л — [л’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
ь — не обозначает звука
В слове 6 букв и 5 звуков.
Транскрипция слова: [м’ир]
м — [м’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
и — [и] — гласный, ударный
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
В слове 3 буквы и 3 звука.
Транскрипция слова: [сн’эк]
с — [с] — согласный, глухой парный, твёрдый (парный)
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
е — [э] — гласный, ударный
г — [к] — согласный, глухой парный, твёрдый (парный)
В слове 4 буквы и 4 звука.
Транскрипция слова: [сн’ишк’и]
с — [с] — согласный, глухой парный, твёрдый (парный)
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
е — [и] — гласный, безударный
ж — [ш] — согласный, глухой парный, твёрдый (непарный, всегда произноится твёрдо), шипящий
к — [к’] — согласный, глухой парный, мягкий (парный)
и — [и] — гласный, ударный
В слове 6 букв и 6 звуков.
Транскрипция слова: [спор]
с — [с] — согласный, глухой парный, твёрдый (парный)
п — [п] — согласный, глухой парный, твёрдый (парный)
о — [о] — гласный, ударный
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
В слове 4 буквы и 4 звука.
Транскрипция слова: [усп’эх]
у — [у] — гласный, безударный
с — [с] — согласный, глухой парный, твёрдый (парный)
п — [п’] — согласный, глухой парный, мягкий (парный)
е — [э] — гласный, ударный
х — [х] — согласный, глухой непарный, твёрдый (парный)
В слове 5 букв и 5 звуков.
Преобразование текста фонетической нотации IPA в речь
Требуется современный браузер с поддержкой JavaScript. В качестве альтернативы рассмотрите возможность использования lexconvert в сочетании с eSpeak.
Пример команды для Мумбаи:
python lexconvert.py —try unicode-ipa «/mʊmˈbaɪ/»
Преобразование IPA фонетической записи в речь
как это работает?
Используя вычислительные возможности процессора JavaScript вашего браузера, Фонетическая нотация IPA переводится в фонемы, понятные eSpeak, с использованием соответствий и логики, найденных в lexconvert. Переведенные фонемы (например, [[mUm’baI]] для /mʊmˈbaɪ/) затем передаются для вывода в meSpeak.js, исправленную Emscripten версию eSpeak. После создания вывода произношение в формате WAV можно загрузить.
Переведенные фонемы (например, [[mUm’baI]] для /mʊmˈbaɪ/) затем передаются для вывода в meSpeak.js, исправленную Emscripten версию eSpeak. После создания вывода произношение в формате WAV можно загрузить.
Поскольку эта обработка происходит в вашем браузере, эта страница может быть загружена и использована в автономном режиме. Кроме того, запрошенные произношения не регистрируются.
улучшите этот инструмент
Внесите свой вклад через GitHub.
Сообщить об ошибке. Обязательно укажите проблемный ввод, версию вашего браузера (Справка > О программе), версию операционной системы и тип устройства. Сообщите о проблеме на GitHub или отправьте электронное письмо.
Дополнить список соответствий IPA -фонемам. Для английского языка eSpeak распознает 96 фонем (dictsource/dict_phonemes). В настоящее время с помощью lexconvert отображается только 55, и, возможно, были ошибки в интерпретации схемы преобразования lexconvert. Дополнительные соответствия должны улучшить произношение.
Дополнительные соответствия должны улучшить произношение.
Внести вклад в базовые библиотеки. eSpeak, meSpeak.js или самый последний вариант Emscripten для повышения производительности/размера. В настоящее время meSpeak.js занимает более двух мегабайт.
about
Этот инструмент на основе браузера интегрирует meSpeak.js под лицензией GPL (пересмотренная версия eSpeak от Emscripten) и соответствия от lexconvert для анализа фонетической нотации IPA и ее преобразования в речь.
Этот инструмент также доступен по адресу
контакт
лицо в 0n0e точка ком
примечание
Было странно, что этого инструмента не существовало; базовые компоненты были бесплатными (как в пиве и свободе) и легкодоступными в течение многих лет (eSpeak был Emscripten’ed в 2011 году: speak.js) наряду с явным спросом (например, в 2013 году r/linguistics и Linguistics Stack Exchange).
Демо-версия Natural Voices от AT&T была размещена на книжном рынке, но конечная точка больше недоступна.
eSpeak, к сожалению, не разбирает IPA фонетическая запись напрямую, требующая преобразования с помощью lexconvert. Хотя версия eSpeak, созданная Emscripten, довольно велика, два мегабайта стали менее заметными, поскольку размеры страниц со временем увеличились. В качестве побочного эффекта, без обработки на стороне сервера и без автоматической обработки, соображения конфиденциальности и безопасности были упрощены (с предположением, что meSpeak.js заслуживает доверия).
Последнее обновление: 04.01.2017
[PDF] ПРЕОБРАЗОВАНИЕ БУКВЫ В ЗВУК ДЛЯ СИСТЕМ TTS GALICIAN
- Идентификатор корпуса: 6362871
@inproceedings{Braga2006LETTERTOSOUNDCF,
title={ПРЕОБРАЗОВАНИЕ БУКВЫ В ЗВУК ДЛЯ ГАЛИЦКИХ СИСТЕМ TTS},
автор = {Даниэла Брага и Л. М. С. Коэльо},
год = {2006}
}
М. С. Коэльо},
год = {2006}
}  М. С. Коэльо},
год = {2006}
}
М. С. Коэльо},
год = {2006}
} - Д. Брага, Л. Коэльо
- Опубликовано в 2006 г.
В этой статье для галисийского языка описан основанный на лингвистических правилах алгоритм преобразования букв в звуки (LTS). Представлен полный набор фонологических правил транскрипции относительно стандартного галисийского варианта. Также предлагается машиночитаемый фонетический алфавит SAMPA для галисийского языка. Алгоритм был реализован и протестирован с использованием текстовых материалов CORGA. Полученные экспериментальные результаты позволили получить 98,5% от точности. Были выявлены основные ошибки и возможные решения…
jth3006.unizar.esАвтоматическая фонетическая транскрипция на основе правил для румынского языка
- Тома Стефан-Адриан, Мунтяну Дору-Петру
Future Linguistics
Computing World 2009 , сервисное вычисление, когнитивное, адаптивное, содержание, шаблоны
- 2009
Очевидно, что даже для преимущественно фонетических языков, таких как румынский, основанные на правилах буквозвуковые системы с введенными вручную правилами ограничены человеческой неспособностью определить важные закономерности в произношении.
Преобразование букв в звуки для румынского языка: сравнение пяти алгоритмов
Оценка 5 систем преобразования букв в звуки (LTS) для румынского языка показывает, что деревья решений и нейронные сети дают наилучшие результаты для преобразования букв в звуки в румынском языке. .
Диалектная вариация в языке боро и правила преобразования графемы в фонему для обработки лексического поиска в системе Boro TTS
- C. Сарма, П. Талукдар
Лингвистика
- 2012
Невозможно включить все слова естественного языка для общей системы преобразования текста в речь. Система преобразования графемы в фонему необходима для произнесения слова, которого нет в словаре.…
Автоматизированная система преобразования графемы в фонему для румынского языка
- Дж. Домокос, О. Буза, Г. Тодерян
Лингвистика
SpeD
- 2011
Представлена новая автоматизированная система преобразования графемы в фонему для румынского языка, основанная на искусственных нейронных сетях вместе с некоторыми результатами транскрипции, основанными на словаре произношений, составленном вручную из 1004 слов.
Автоматическая фонетическая транскрипция с помощью фонологического происхождения
- Маркос Гарсия, Исаак Дж. Гонсалес
Лингвистика
Пропор , и оценивает несколько лингвистических процессов, происходящих во время деривации, для создания транскрипций, специфичных для диалекта.
РАЗРАБОТКА СЛОВАРА ПРОИЗНОШЕНИЯ ДЛЯ РУМЫНСКОГО ЯЗЫКА
- Г. Тодерян
Лингвистика
- 2012
Цель этой статьи состоит в том, чтобы представить новую автоматизированную систему преобразования графем в фонемы для румынского языка, основанную на искусственных нейронных сетях, вместе с некоторыми результатами транскрипции, основанными на на…
Conversión Fonética Automática con Información Fonológica para el Gallego
- Marcos Garcia, Isaac J. González
Computer Science, Art
Proces. дель Ленг. натуральный
- 2011
Преобразователь позволяет оценить различные фонологические процессы, связанные с силабификацией фонологического происхождения, а также автоматически транскрибировать лексику с фонетической информацией различных языков.
Автоматизированная система преобразования графем в фонемы для румынского языка
Представлена новая автоматизированная система преобразования графем в фонемы для румынского языка, основанная на искусственных нейронных сетях вместе с некоторыми результатами транскрипции, основанными на словаре произношений, составленном вручную из 1004 слов. .
ПОКАЗАНЫ 1–10 ИЗ 31 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные статьиНедавность
Основанный на правилах преобразователь графемы в телефон для систем tts на европейском португальском языке
Алгоритм транскрипции графемы в телефон (G2P) на основе лингвистических правил описан для европейского португальского языка с целью разработки модуля/инструмента, который может улучшить синтетическую естественность речи в европейском португальском языке и доказал исключительную важность лингвистических знаний для разработки систем преобразования текста в речь (TTS).
Статистически обученные орфографические и звуковые модели для тайского языка
- А. Чотимонгкол, А. Блэк
Лингвистика
INTERSPEECH
- 2000
- R. Damper, Y. Marchand, M. Adamson, K. Gustafson
Computer Science
SSW
- 1998
- H. Meng, S. Seneff, V. Zue
Physics
HLT
- 1994
- Luís C. Oliveira, C. Viana, I. Trancoso
Информатика
[Материалы] ICASSP-92: 1992 Международная конференция IEEE по акустике, речи и обработке сигналов
- 1992
- А. Блэк, К. Ленцо, В. Пагель
Лингвистика
SSW
- 1998
- C. Coker, Kenneth Ward Church, M. Y. Liberman
Лингвистика
SSW
- 1990
- Антал ван ден Бош, Вальтер Далеманс
Компьютерные науки, лингвистика
EACL
13
- Yves Schabes
Лингвистика
- 1995
автоматически обучается из словарей, которые объединяют n-грамм модели телефона с деревьями решений, чтобы достичь точности слов лучше, чем 65,15% в подходе, основанном на правилах.
Сравнительная оценка методов преобразования букв в звуки для синтеза английского текста в речь
аналогия, нейронные сети с прямой связью и метод k-ближайших соседей в отношении их успеха в автоматической фонемизации.
Фонологический анализ для двунаправленного преобразования букв в звук/звук в буквы
Стратегия иерархического синтаксического анализа для обеспечения иерархического лексического анализа слова, ударения, силлабологии фонематика и графемика, основанные на подходе, сочетающем формализм, основанный на правилах, с методами, основанными на данных.
Система преобразования текста в речь на основе правил для португальского языка
Последние достижения в разработке системы преобразования текста в речь для португальского языка на формантном синтезаторе Klatt80 добились многообещающих результатов, а именно в том, что касается выполнения назначения ударения, фонетической транскрипции и просодического разбора.
Вопросы построения общего письма к звуковым правилам
Общая структура для построения правил букво-звука (LTS) языка из списка слов в быть полностью автоматическим, хотя небольшое количество ручного посева может дать лучшие результаты.
Морфология и рифмование: две мощные альтернативы правилам преобразования букв в звуки для синтеза речи
Большинство синтезаторов речи склонны полагаться на правила преобразования букв в звуки для большинства слов и прибегают к небольшому «словарю исключений» примерно из 5000 слов, чтобы охватить более серьезные пробелы в…
Методы преобразования графем в фонемы, ориентированные на данные
Показано, что с помощью методов обучения с учителем, основанных на корпусе транскрибированных слов, можно достичь таких же и даже лучших результатов без явного моделирования лингвистических знаний.
Точное обобщение трансдукций конечных состояний: применение к транскрипции графы к фонеме
Мы представляем два метода для построения Nite-State State, который общий AniteSditates Auction.