Слова «традиция» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «традиция» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «традиция» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «традиция».
Содержимое:
- 1 Слоги в слове «традиция» деление на слоги
- 2 Как перенести слово «традиция»
- 3 Морфологический разбор слова «традиция»
- 4 Разбор слова «традиция» по составу
- 5 Сходные по морфемному строению слова «традиция»
- 6 Синонимы слова «традиция»
- 7 Ударение в слове «традиция»
- 8 Фонетическая транскрипция слова «традиция»
- 9 Фонетический разбор слова «традиция» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «традиция»
- 11 Сочетаемость слова «традиция»
- 12 Значение слова «традиция»
- 13 Склонение слова «традиция» по подежам
- 14 Как правильно пишется слово «традиция»
- 15 Ассоциации к слову «традиция»
Слоги в слове «традиция» деление на слоги
Количество слогов: 4
По слогам: тра-ди-ци-я
Как перенести слово «традиция»
тра—диция
тради—ция
Морфологический разбор слова «традиция»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: единственное;
падеж: именительный;
отвечает на вопрос: (есть) Что?
Начальная форма:
традиция
Разбор слова «традиция» по составу
| традици | корень |
| я | окончание |
традиция
Сходные по морфемному строению слова «традиция»
Сходные по морфемному строению слова
Синонимы слова «традиция»
1. обычай
обычай
2. норма
3. обыкновение
4. наследие
5. установление
6. ценность
7. неписанный закон
8. заведено
9. повелось
10. принято
11. так заведено
12. так повелось
13. так принято
14. итихаса
Ударение в слове «традиция»
тради́ция — ударение падает на 2-й слог
Фонетическая транскрипция слова «традиция»
[трад’`ицый’а]
Фонетический разбор слова «традиция» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| а | [а] | гласный, безударный | а |
| д | [д’] | согласный, звонкий парный, мягкий | д |
| и | [`и] | гласный, ударный | и |
| ц | [ц] | согласный, глухой непарный, твёрдый, шумный | ц |
| и | [ы] | гласный, безударный | и |
| я | [й’] | согласный, звонкий непарный (сонорный), мягкий | я |
| [а] | гласный, безударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 8 букв и 9 звуков.
Буквы: 4 гласных буквы, 4 согласных букв.
Звуки: 4 гласных звука, 5 согласных звуков.
Предложения со словом «традиция»
По пунктам, шаг за шагом, в лучших традициях, с примерами и разбором ситуаций.
Источник: Л. В. Петрановская, Если с ребенком трудно, 2013.
Неравномерность, поливариантность сценариев в какой-то мере является гарантом формирования областей нового и сохранения культурных традиций.
Источник: А. Ю. Демшина, Визуальные искусства в ситуации глобализации культуры: институциональный аспект, 2010.
Возможно, современное название отражает древнюю традицию.
Источник: Х. Э. Дэвидсон, Древние скандинавы. Сыны северных богов.
Сочетаемость слова «традиция»
1. семейная традиция
семейная традиция
2. древние традиции
3. старые традиции
4. традиции народа
5. традиции предков
6. традиции семьи
7. в рамках традиции
8. сила традиции
9. дух традиции
10. традиция требовала
11. традиция сохранилась
12. традиция утверждает
13. продолжить традицию
14. стать традицией
15. нарушить традицию
16. (полная таблица сочетаемости)
Значение слова «традиция»
ТРАДИ́ЦИЯ , -и, ж. 1. Исторически сложившиеся и передаваемые из поколения в поколение обычаи, нормы поведения, взгляды, вкусы и т. п. Традиции русского флота. Революционные традиции пролетариата. Ломка традиций. (Малый академический словарь, МАС)
Склонение слова «традиция» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
ИменительныйИм. | что? | традиция | традиции |
| РодительныйРод. | чего? | традиции | традиций |
| ДательныйДат. | чему? | традиции | традициям |
| ВинительныйВин. | что? | традицию | традиции |
| ТворительныйТв. | чем? | традицией | традициями |
| ПредложныйПред. | о чём? | традиции | традициях |
Как правильно пишется слово «традиция»
Правописание слова «традиция»
Орфография слова «традиция»
Правильно слово пишется: традиция
Нумерация букв в слове
Номера букв в слове «традиция» в прямом и обратном порядке:
- 8
т
1 - 7
р
2 - 6
а
3 - 5
д
4 - 4
и
5 - 3
ц
6 - 2
и
7 - 1
я
8
Ассоциации к слову «традиция»
Дань
Буддизм
Современность
Уклад
Фольклор
Обычай
Верование
Почитание
Устой
Возрождение
Иудаизм
Сохранение
Следование
Культура
Канон
Приверженец
Празднование
Соответствие
Ритуал
Древние
Соблюдение
Эпос
Православие
Ислам
Наследие
Условность
Средневековье
Жанр
Йог
Стереотип
Становление
Аристократия
Хранительница
Чтить
Соблюдаться
Возродить
Восходить
Установиться
Предписывать
Соблюсти
Придерживаться
Сохраняться
Сочетать
Впитать
Соблюдать
Сложиться
Отражать
Перенять
Нарушать
Символизировать
Освятить
Воспитать
Воспитываться
Заимствовать
Исторически
Согласно
Наперекор
«Основные типы звуков в русском языке».
 Народные традиции, обычаи, праздники.
Народные традиции, обычаи, праздники.Тема урока: «Основные типы звуков в русском языке». Народные традиции, обычаи, праздники.
Цель урока:
систематизировать знания учащихся о фонетике и орфоэпии как разделах лингвистики, о системе гласных и согласных звуков русского языка, о способах их обозначения на письме, показать соотношение звукового и буквенного (орфографического) облика слова;
повторить основные правила произношения гласных и согласных звуков.
совершенствовать умения находить в слове основные звуковые процессы, производить фонетический разбор слова;
оценивать свою и чужую речь с точки зрения соблюдения орфоэпических норм современного русского языка;
воспитывать в детях чувство любви к русскому языку, чувство глубокой ответственности за чистоту и правильность русской речи.
Оборудование к уроку: интерактивная доска,
Раздаточный материал для индивидуальной и групповой работы.
Ход урока :
І.Оргмомент.
Преподаватель: Дорогие ребятиа! Сегодня у нас необычный урок. К нам на урок пришли гости. Я хочу пожелать Вам хорошего настроения и удачи. Что бы вы пожелали друг другу?
ІІ. Проверка домашнего задания.
Работа с текстом. Определите стиль текста.
Есть очень интересное рассуждение ученого-лингвиста А. А. Леонтьева о категории рода в русском языке. Он утверждает, что в русском языке нет никакого рода. А во всех учебниках говорится, что он есть.
Женщин мы обозначаем при помощи женского, а мужчин — при помощи мужского рода: он (Иван Иванович), она (Марья Антоновна). Девочка читала, мальчик спал.
Но есть «оно». Среднее — нечто неодушевлённое.
Почему-то по-русски нож — мужского рода, вилка — женского, ну а блюдце — среднего. Чем ножик более «мужествен», чем вилка?
Чем ножик более «мужествен», чем вилка?
То ли дело английский язык! Там нельзя сказать про ножик (knife) — he «он», а про ложку (spoon) — she «она», нужно говорить только it «оно». He — это только «он — мужчина», а she — «она — женщина». И чтобы сказать кошка, англичанин прибавляет к слову cat «она»: she — cat.
Таким образом, говоря словами Н. В. Гоголя, «постижение законов русского языка есть тяжкая обязанность, но и наслаждение». Действительно, всегда интересно открывать новые, страницы.
ІІІ. Этап актуализаций знаний.
ЭПИГРАФ К УРОКУ:
…Язык имеет свои краски, то есть звуки. Он ими воображению нашему может весьма часто рисовать или живописать предметы…
Бестужев- Марлинский.
Преподаватель: Дорогие ребята, прочитайте эпиграф к нашему сегодняшнему уроку. Это слова Бестужева- Марлинского. Попробуйте самостоятельно сформулировать тему нашего сегодняшнего урока. Какому разделу лингвистики он будет посвящен?
Это слова Бестужева- Марлинского. Попробуйте самостоятельно сформулировать тему нашего сегодняшнего урока. Какому разделу лингвистики он будет посвящен?
( Учащиеся, опираясь на эпиграф к уроку и на данное к уроку домашнее задание, формулируют тему урока и записывают ее в тетрадь).
Проблемный вопрос: Нужно ли изучать фонетику и орфоэпию?
Задание опережающего характера:
1 группа- ученическмй уровень опираясь на материалы учебника «Русский язык» составить вопросы для фонетической разминки.
Раздел науки о языке, изучающий звуки речи | Фонетика |
Предмет изучения фонетики | Звуки речи |
В чем различие звука и буквы? | Буква обозначает звуки на письме |
На какие две группы делятся все звуки речи? | Гласные и согласные. |
Какие звуки обозначают буквы е, ё, ю, я? | [й’э], [й’о], [й’у], [й’а] |
Когда буквы е, ё, ю, я дают два звука? Когда буквы е, ё, ю, я дают один звук? Приведите примеры. | В начале слова; после разделительных ъ, ь; в конце слова; после гласных букв. Яма — [й’а]ма; юла — [й’у]ла; вьюга — в[й’у]га; съезд — с[й’э]зд; армия — арми[й’а]; знаем — зна[й’э]м. |
Назовите характеристики согласных звуков. | Твёрдые, мягкие, звонкие, глухие. |
Составьте пары согласных звуков по признаку звонкости и глухости. | [б-п], [б’-п’], [г-к], [г’-к’], [в-ф], [в’-ф’], [д-т], [д’-т’], [з-с], [з’-с’], [ж-ш] |
Какие звонкие и глухие звуки являются непарными? | Звонкие — [р], [р’], [л], [л’], [м], [м’], [н], [н’], [й’] Глухие — ([ц], [ч’], [х]) |
Какие звуки всегда твёрдые? | [ж], [ш], [ц] |
Назовите непарные звуки по признаку мягкости. | [ч’], [й’], [щ’] |
Какие звуки называют шипящими? | [ш] [щ’] [ч’] |
Сколько звуков в русском языке? | ? |


2 группа – алгоритмический уровень подготовить фонетические задачи по изучаемой теме.
Уровень культуры каждого человека проявляется уже на уровне произношения. Неточное произнесение звуков затрудняет понимание между людьми, создает препятствия для общения. Неверное ударение в слове, неправильное произношения режет слух, поэтому необходимо владеть нормами правильного произношения. Правильное произношение слова имеет не меньшее значение, чем верное написание.
Задача 1. Вставьте пропущенные буквы в словах, укажите в транскрипции сложные случаи произношения согласных. Что такое транскрипция?
Сформулируйте правило. Обоснуйте свой ответ по схеме: Дано – решение – вывод.
Обоснуйте свой ответ по схеме: Дано – решение – вывод.
Бо[…] , празднуе[…], исповедова[…, до[…] и […] , ску[…]о, коне[…]о, наро[..]о, чт […] обы, […] о , не [..]о, мя[…’] , (л [..] сок, в[….] сна, пл[…] сать.
Задача 2. Спишите слова, поставьте в них ударения. Ответье на следующие вопросы: В чём особенности русского ударения? С выделенными словами составьте предложения.
Афе́ра (не афёра!), аэропо́рты, обеспе́чение, звони́шь хозя́ева, пуло́вер, коне[шн]о, ту́фля, авто́бус, догово́р, катало́г, простыня́, сре́дство, язык.
Язык народа — цвет всей его духовной жизни.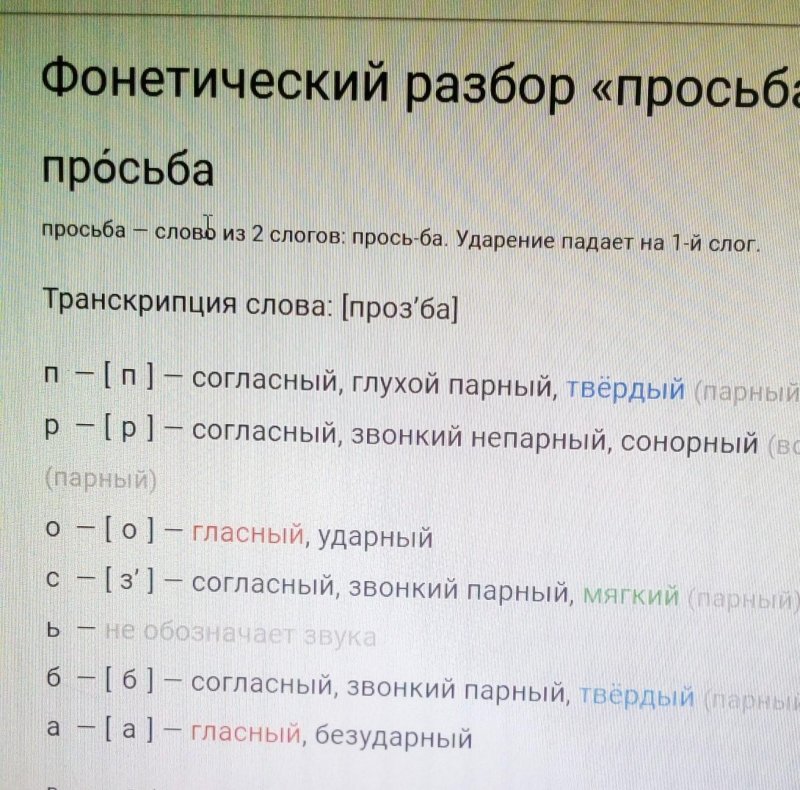
Язык каждого народа создан самим народом.
Язык – отражение национальной культуры обшества.
III. Проверка знаний. Отработка умений и навыков.
Культура. Язык, традиции, обычаи.
Ребята, сегодня мы поговорим об обычаях и традициях казахского, русского, британского народа, закрепляя свои знания по теме «Основные типы звуков в русском языке». Народные традиции, обычаи, праздники.
Работа с текстом.
Текст №1. Задание: Прочитайте текст, переведите выделенный отрывок текста на английский язык.
У каждой нации и в каждой стране есть свои обычаи и традиции.В Великобритании традиции играют более важную роль в жизни людей, чем в других странах. Англичане гордятся своими традициями и тщательно сберегают их. Праздники особенно богаты старыми традициями. Рождество — большой английский национальный праздник. Люди приглашают своих друзей к себе домой, чтобы проводить Старый год и встретить Новый год. Когда часы начинают бить двенадцать , глава семьи идет ко входной двери и открывает ее широко и держит ее до последнего удара. Затем он закрывает дверь. Он выпустил Старый год и впустил Новый год.
Люди приглашают своих друзей к себе домой, чтобы проводить Старый год и встретить Новый год. Когда часы начинают бить двенадцать , глава семьи идет ко входной двери и открывает ее широко и держит ее до последнего удара. Затем он закрывает дверь. Он выпустил Старый год и впустил Новый год.
Еще одна английская традиция — сырная гонка. Это мероприятие проводится ежегодно в последний понедельник мая ровно в полдень на холме Купера в Глостаре., все участники буквально гонятся за головкой сыра, которую спускают с очень крутого холма. В этой погоне за сыром принимают участие люди со всего мира.
Масленица в Англии празднуется в марте. Масленица в Англии продолжается всего лишь один день-последний вторник перед Великим постом.Называется этот день «Покаянным вторником» из-за церковной традиции исповедоваться перед началом поста. В Англии в этот день принято устраивать множество развлечений и шутливых соревнований. В этот день проходят разнообразные соревнования, кулачные битвы. Самым известным мужским состязанием является футбол. Масленица в Англии не обходится без блинов. Рецепты приготовления блинов в Англии такие же, как и в России. Однако наполнять их начинками не принято. Но кульминацией всего шутливого действа является традиционный «Блинный забег». В соревнованиях участвуют и женщины. Так в этот день проходят ежегодные состязания в беге женщин с блинами. Женщины мчатся с горячей сковородой и блином на ней. Каждая из участниц держит в руках сковородку с блином , который надо подбрасывать на бегу и пытаться не уронить на землю Первый кто прибегает к стоящему у церкви звонарю, считается победителем гонок.
В Англии в этот день принято устраивать множество развлечений и шутливых соревнований. В этот день проходят разнообразные соревнования, кулачные битвы. Самым известным мужским состязанием является футбол. Масленица в Англии не обходится без блинов. Рецепты приготовления блинов в Англии такие же, как и в России. Однако наполнять их начинками не принято. Но кульминацией всего шутливого действа является традиционный «Блинный забег». В соревнованиях участвуют и женщины. Так в этот день проходят ежегодные состязания в беге женщин с блинами. Женщины мчатся с горячей сковородой и блином на ней. Каждая из участниц держит в руках сковородку с блином , который надо подбрасывать на бегу и пытаться не уронить на землю Первый кто прибегает к стоящему у церкви звонарю, считается победителем гонок.
Текст №2.Задание: Прочитайте текст. Прескажите. Составьте вопросы к тексту. Расставьте ударение в выделенных словах. Произведите фонетический разбор согласных в слове: Чудная
Наурыз в Казахстане справляют 22 марта. В этот чудный день происходит обновление природы: бурно растет трава, набухают почки на деревьях, проходят первые дожди. В этот день принято приводить в порядок свое жилье, отдать долги, прощать все ссоры и обиды. Празднование Наурыза начинается со встречи рассвета. Люди берут грабли, лопаты и идут к роднику для его чистки. Затем под наблюдением старших отправляются на посадку деревьев. По традиции при посадке деревьев нужно приговаривать «Пусть останется в памяти от человека дерево, нежели стадо. В этот день готовится очень много еды, являющейся символом изобилия. Дастархан накрывается в каждом доме. У казахов особое значение имеет цифра 7. Напроимер, наурыз-коже, изготовляемый на 7 ингредиентов. Это мясо, соль, жир, лук, пшеница, курт, иримшик.По мифологическим представлениям казахов Наурыз- это день, когда на земле устанавливается добро.
В этот чудный день происходит обновление природы: бурно растет трава, набухают почки на деревьях, проходят первые дожди. В этот день принято приводить в порядок свое жилье, отдать долги, прощать все ссоры и обиды. Празднование Наурыза начинается со встречи рассвета. Люди берут грабли, лопаты и идут к роднику для его чистки. Затем под наблюдением старших отправляются на посадку деревьев. По традиции при посадке деревьев нужно приговаривать «Пусть останется в памяти от человека дерево, нежели стадо. В этот день готовится очень много еды, являющейся символом изобилия. Дастархан накрывается в каждом доме. У казахов особое значение имеет цифра 7. Напроимер, наурыз-коже, изготовляемый на 7 ингредиентов. Это мясо, соль, жир, лук, пшеница, курт, иримшик.По мифологическим представлениям казахов Наурыз- это день, когда на земле устанавливается добро.
Текст №3. Задание: Прочитайте, перескажите. Сделайте фонетический разбор слова: солнце.
Масленица — древнейший народный праздник проводов зимы и встречи весны.
Для всего русского населения семь масленичных дней были самым веселым и любимым временем в году. Народ ласково называл этот праздник «касаточка», «сахарные уста», «целовальница», «честная масленица», «веселая», «пеpепелочка», «объедуха».
Масленица на протяжении многих веков сохранила характер народного гулянья. Все традиции Масленицы направлены на то, чтобы прогнать зиму и разбудить природу ото сна. Масленицу встречали с величальными песнями на снежных горках. Символом Масленицы было чучело из соломы, обряженное в женские одежды, с которым вместе веселились, а затем хоронили или сжигали на костре вместе с блином, которое чучело держало в руке.
Неотъемлемой частью праздника были катания на лошадях , распространено было катание молодежи с ледяных гор. Среди обычаев сельской молодежи на Масленицу были также прыжки через костер и взятие снежного городка.
Основным угощением и символом Масленицы являются блины. Их пекут каждый день с понедельника, но особенно много — с четверга по воскресенье. Круглый румяный блин очень похож на летнее солнце. Ели блины со сметаной, яйцами, икрой и другими вкусными начинками с утра до вечера, чередуя с другими блюдами. Вся неделя на масленицу именовалась не иначе как «честная, широкая, веселая, боярыня‑масленица, госпожа масленица
Круглый румяный блин очень похож на летнее солнце. Ели блины со сметаной, яйцами, икрой и другими вкусными начинками с утра до вечера, чередуя с другими блюдами. Вся неделя на масленицу именовалась не иначе как «честная, широкая, веселая, боярыня‑масленица, госпожа масленица
Понедельник — устраивали и раскатывали ледяные горки. Дети делали утром соломенное чучело.
Вторник — в этот день начинаются веселые игры.
Среда — «лакомка». На первом месте в ряду угощений, конечно же, блины.
Четверг — чтобы помочь солнцу прогнать зиму, люди устраивают по традиции катание на лошадях «по солнышку» — то есть по часовой стрелке вокруг деревни.
Пятница — » зять едет «к теще на блины».
Суббота — в этот день ходят в гости ко всем родственникам и угощаются блинами.
Воскресенье — это заключительный, «прощеный день», когда просят прощения у родных и знакомых за обиды и после этого, как правило, весело поют и пляшут, тем самым провожая широкую Масленицу.
В этот день на огромном костре сжигают соломенное чучело. Этим и завершается праздник Масленицы.
Работа с пословицами. Задание: Продолжи пословицы о Масленице.
1.Не житье-бытье,а Масленица
2.Масленица семь дней гуляет.
3.Без блина не масляна
4.Масленица без блинов,именины без пирогов не бывают.
Работа с поговорками. Задание:
1. Как много стран,так много обычаев. So many countries so many customs
2. У традиции седая борода. Tradition wears a snowy beard.
3. Обычай сильнее закона. Custom rules the law.
4. всякую привычку есть отвычка. Break the legs of an evil customНа
Творческая работа. Составьте небольшой текст на тему: Нужно ли изучать фонетику и орфоэпию? Докажите свою точку зрения, опираясь на мнения ученых и писателей.
Преподаватель : Ребята, вы подобрали очень яркие примеры, отвечая на проблемный вопрос. Действительно, чтобы овладеть орфоэпией, то есть правильным литературным произношением, надо уметь слышать и анализировать звучащее слово. Именно звучащая речь является основной формой существования языка. Даже когда мы читаем про себя, слова воспринимаются нами в их звуковом составе.
Время нашего урока истекло. Благодарю всех за работу. Очень надеюсь, что урок был вам не только в удовольствие, но и на пользу.
Домашнее задание.
Написать рекламный текст, призывающий изучать фонетику и бережно относиться к языку (не менее 150 слов).
что это такое, для чего нужен, порядок проведения, а также пример
Одни и те же буквы могут читаться по-разному, в зависимости от их расположения в слове и ряда других факторов. Поэтому, чтобы понять, как должно звучать слово, проводят его фонетический разбор, иначе называемый звуко-буквенным анализом. Эта процедура проводится по определенному алгоритму, изучение которого входит в базовую школьную программу.
Читайте в статье
- Что это такое?
- Порядок
- Пример
- Заключение
Что это такое?
Звуко-буквенным или фонетическим разбором лексемы называют анализ ее звукового состава. В процессе анализа слово разделяют на звуки, для каждого из которых определяют базовые характеристики. Результатом такого разбора является полная характеристика лексемы с фонетической точки зрения. По ней можно понять, как произносить слово корректно, с учетом правил фонетики и сложившихся традиций русской речи.
Для проведения фонетического анализа необходимо в первую очередь знать классификацию звуков, существующих в нашем языке. А именно – помнить, что звуки делятся на две большие категории:
- гласные – состоящие только из голоса: [а], [о], [и], [у];
- согласные – состоящие из голоса и шума, производимого выдыхаемым воздухом: [н], [с], [т], [щ].

Согласные, в свою очередь, подразделяются на твердые и мягкие, звонкие и глухие. У большинства из них есть пары по признакам твердости/мягкости и звонкости/глухости, но не у всех. Список непарных согласных невелик:
- всегда произносимые звонко (сонорные) – Н, Л, М и Р;
- всегда звучащие глухо – Х, Ц, Ч и Щ;
- всегда читаются мягко – Й, Ч и Щ;
- всегда произносятся твердо – Ж, Ц и Ш.
Мягкость звука при разборе отмечается апострофом после его буквенного обозначения, например: «боль» — [бол’], «роль» — [рол‘], «калий» — [калий‘].
При проведении звуко-буквенного анализа нужно помнить, что фонетическая запись слова редко совпадает с его орфографической записью. Несовпадение может быть количественным и качественным. В первом случае, число фонем в слове может быть:
- равным числу букв, использованных для его записи, например: «хлеб» — [хлеп];
- меньшим, чем количество букв, использованных в записи слова, к примеру: «ложь» — [лош];
- большим, чем количество букв в слове, как, например: «ялик» — [й’алик].
Количественная разница возникает по нескольким причинам.
- В нашем языке есть буквы Ь и Ъ, которые не фиксируют никаких звуков, а используются на письме либо как разделители, либо для обозначения твердости/мягкости стоящих пред ними согласных.
- Гласные буквы Е, Ё, Ю и Я образуют два звука, когда находятся после букв Ь или Ъ, гласных звуков или в начале слова. Их транскрипция в этом случае будет выглядеть как [й‘э], [й‘о], [й‘у] и [й‘а], соответственно.
- Транскрипция глагольных постфиксов –тся и –ться будет выглядеть как [ца]: «бриться» — бри[ца], «готовится» — готови[ца].
- Буквосочетание ЗЖ обычно произносится как смягченный протяженный звук [ж]: «брюзжит» — [б’р’уж’ит].
Качественные расхождения орфографической и фонетической записей слова связаны с правилами чтения и традициями русской речи. Гласные под ударением и в безударной позиции могут звучать по-разному, например, буквы Е и Я без ударения будут читаться как [и], а буква О в аналогичной ситуации будет звучать как [а].
Звонкие согласные, стоящие перед глухими или перед набором согласных и Ь на конце лексемы, оглушаются, то есть, заменяются на парные им глухие согласные. И наоборот, глухие согласные в определенных позициях озвончаются, то есть, заменяются парными звонкими. Например:
- боб – бо[п];
- ложка – ло[ш]ка;
- вокзал – [вагзал] и т.д.
Все эти нюансы необходимо помнить и учитывать, проводя фонетический анализ лексемы. Также нужно иметь ввиду, что перед гласными И, Е, Ё и Я могут стоять только мягкие согласные звуки, а гласные фонемы [а], [у], [о], [ы] и [э] могут звучать исключительно после твердых согласных.
И, конечно, для проведения фонетического анализа необходимо уметь проставлять в слове ударение и разделять его на слоги. Все это, включая перечисленные выше правила, входит в программу русского языка в младшей школе.
Порядок
Фонетический или звуко-буквенный разбор слова проводят по следующему алгоритму.
- Выписывают слово, предназначенное для анализа.
- Записывают транскрипцию слова в квадратных скобках, мягкие звуки отмечают апострофом.
- Записывают слово по слогам, рядом отмечают количество слогов и номер ударного слога.
- Выписывают поочередно все звуки, содержащиеся в слове. Для каждого из них указывают соответствующую ему букву (при наличии).
- Рядом с каждым звуком пишут его характеристику. Отмечают, является ли он гласным или согласным. Для первых указывают, стоит звук под ударением или нет. Для вторых – записывают значение признаков твердости/мягкости и звонкости/глухости, отмечают, имеет ли звук пару по последнему признаку.
- В конце характеристики указывают количество букв и количество звуков в анализируемом слове.
Пример
Для примера проведем разбор по звукам слова «свечка».
Свечка – [с’в’эч’ка].
Свеч-ка – 2 слога, первый слог ударный.
- [с‘] – согласный, соответствует букве С, мягкий, глухой парный;
- [в‘] – согласный, соответствует букве В, мягкий, звонкий парный;
- [э] – гласный, соответствует букве Е, ударный;
- [ч‘] – согласный, соответствует букве Ч, всегда мягкий, глухой непарный;
- [к] – согласный, соответствует букве К, твердый, глухой парный;
- [а] – гласный, соответствует букве А, безударный.
В слове «свечка» 6 букв и 6 звуков.
Заключение
Проведение фонетического разбора слова требует знания базовых правил классификации звуков и основных фонетических принципов. Только с помощью этой информации можно выполнить корректную звуковую запись слова и понять его фонетический состав.
Lexibank, общедоступный репозиторий стандартизированных списков слов с вычисленными фонологическими и лексическими характеристиками
Abstract
В последние десятилетия наблюдается значительный рост цифровых данных о языках мира. В то же время растет спрос на кросс-лингвистические наборы данных, о чем свидетельствуют многочисленные исследования, посвященные разным вопросам предыстории человека, культурной эволюции и человеческого познания. К сожалению, большинство опубликованных наборов данных не стандартизированы, что затрудняет их сравнение. Здесь мы представляем новый подход к повышению сопоставимости кросс-лингвистических лексических данных. Мы разработали рабочие процессы для компьютерного перевода наборов данных в кросс-лингвистические форматы данных, набор стандартов, которые делают эти наборы данных более доступными, интероперабельными и пригодными для повторного использования (FAIR). Мы тестируем рабочий процесс Lexibank на 100 наборах лексических данных, из которых мы получаем агрегированную базу данных списков слов в унифицированной фонетической транскрипции, охватывающую более 2000 языковых разновидностей. Мы иллюстрируем преимущества нашего подхода, показывая, как можно автоматически выводить фонологические и лексические признаки, дополняя и расширяя существующие кросс-лингвистические наборы данных.
Предыстория и резюме
Сравнение языков мира открывает новые окна в предысторию, культуру и познание человека. Сравнивая языки исторически, мы можем проследить их эволюцию во времени и сравнить ее с данными археологии и генетики 1,2 . Сравнивая языки типологически, мы можем узнать об универсальных тенденциях и культурных различиях, лежащих в основе распределения языковых черт 3,4 , и исследовать степень, в которой языковые тенденции формируются внешними факторами 5,6 . Сравнивая лингвистические данные, полученные на многих языках, с данными когнитивной науки и психологии, мы можем способствовать более широкому пониманию человеческого познания и поведения 7,8,9 .
Для сравнения языков мира лингвистические данные должны быть собраны таким образом, чтобы обеспечить максимальную сопоставимость отдельных точек данных по ресурсам и языковым семьям. Хотя количество доступных в цифровом виде данных для языков мира резко возросло за последние десятилетия 10 количество сопоставимых данных все еще относительно невелико. Эта проблема еще более усугубляется тем, что более обширные коллекции данных, собранные в прошлом, часто не архивируются для обеспечения долгосрочной устойчивости. В результате довольно много наборов данных исчезло из Интернета и больше не доступно 11,12 , хотя они играли существенную роль в предыдущих публикациях.
Вдохновившись базой данных GenBank 13 , где ученые могут публично депонировать нуклеотидные последовательности, мы создали Lexibank, набор кросс-лингвистических наборов данных в стандартизированных форматах 14 , который предлагает доступ к словоформам, звукозаписи и лексическим особенностям для более чем 2000 языковых разновидностей, полученных из 100 отдельных высококачественных наборов данных 15 .
Коллекция словарей Lexibank — это первая попытка объединить богатство языковых данных, собранных за прошедшие столетия. Хотя это далеко не полное собрание, мы убеждены, что оно станет богатым источником для будущих исследований истории, разнообразия и психологии языков мира.
Существует множество способов анализа и использования данных Lexibank. Собирая лексические данные для большого количества языков, Lexibank предлагает множество возможностей для исследователей, изучающих кросс-лингвистические аспекты лексики человеческих языков. Таким образом, в отношении конкретных семантических доменов Lexibank позволяет ученым расширить предыдущие исследования по эволюции цветовых терминов 16 , терминологии частей тела 17 или семантике эмоций 4 . Что касается отношения между лексической формой и значением, Lexibank предлагает самую большую коллекцию лексических данных со стандартизированными транскрипциями и семантическими толкованиями, что позволяет ученым проверять отдельные гипотезы о звуковой символике в языках мира 18 . Что касается исследования общих аспектов лексической организации, Лексибанк предлагает одну из крупнейших кросс-лингвистических коллекций пар форма-значение, позволяющую исследователям искать различные факторы, формирующие лексику языков мира 9.0009 8 . Для целей сравнения исторических языков коллекция словарей Lexibank предлагает самую большую коллекцию экспертных суждений об исторически связанных (родственных) словах, доступных на сегодняшний день. Учитывая, что вычислительные методы обнаружения родственных кодов пока не могут конкурировать с экспертами 19 , наша коллекция, таким образом, предлагает богатый материал для тестирования и обучения новых методов в будущем. Точно так же, учитывая, что коллекция Lexibank объединяет данные на глобальной основе, ученые могут использовать коллекцию данных для тестирования новых методов автоматической идентификации заимствований 9.0009 20,21 или расширить предыдущие подходы к автоматическому обнаружению контактных зон 22,23,24 . Кроме того, мы показываем, как данные можно использовать для автоматического извлечения различных фонологических и лексических характеристик для отдельных языковых разновидностей.
Предоставляя подробный воспроизводимый рабочий процесс, с помощью которого наборы лексических данных в различных форматах могут быть унифицированы и приведены в соответствие с общими стандартами, коллекция Lexibank также способствует повышению «справедливости» кросс-лингвистических наборов данных, делая данные доступными для поиска, интероперабельными. и Многоразовые 25 , выполняя первоначальную цель инициативы по кросс-лингвистическим форматам данных 14 и способствуя воспроизводимым исследованиям в области лингвистики 26 .
Учитывая успех открытых стандартизированных данных в эволюционной биологии и генетике 27 , есть надежда, что активизация будущих совместных усилий по стандартизации и обработке данных может спровоцировать аналогичный бум новых методов и идей в языковых науках. Наш план на будущее состоит не только в дальнейшем расширении этого сбора данных путем предоставления новых наборов данных самим, но и в поощрении коллег во всем мире, которые собирают кросс-лингвистические данные, внести свой вклад в эту продолжающуюся работу и делиться своими данными в открытом, стандартизированном формате. форма.
Методы
Общие сведения о кросс-лингвистических наборах лексических данных
Структурные наборы данных , такие как Всемирный атлас языковых структур, являются одним из ключевых типов данных, используемых в кросс-лингвистических исследованиях. (https://wals.info) 28 . Структурные наборы данных собирают точки лингвистических данных в виде функций, которые отвечают на конкретные вопросы о конкретных характеристиках языка. Вопросы могут быть адресованы различным лингвистическим областям, начиная от фонологии (например, Есть ли в языке губно-зубные звуки? ) 6 , через синтаксис (например, Каков основной порядок слов в языке? ) 29,30 и лексикон (например, Использует ли язык одно и то же слово для выражения «страха» и «удивления»? ) 4 . Преимущество структурных наборов данных заключается в том, что отдельные признаки можно сравнивать непосредственно между языками и что ответы, которые, как правило, имеют числовую или категориальную форму, обычно легко интерпретируются. Однако недостатком структурных наборов данных является то, что их сложно собрать, поскольку лингвистам обычно приходится создавать их из словарей и справочных грамматик, а также то, что их извлечение подвержено ошибкам, поскольку оно напрямую зависит от интерпретации и анализа человеком 31 .
Альтернативными формами данных, применимыми для кросс-лингвистических исследований, являются многоязычные списки слов и параллельные тексты . Списки слов предлагают переводы наборов понятий (обычно отражающих словарь повседневного использования) на различные целевые языки. Коллекции параллельных текстов обеспечивают переводы одних и тех же базовых текстов на несколько языков. И параллельные тексты, и словари собирались давно, по крайней мере, с конца XVIII в. 32,33 . Однако, поскольку автоматизированные методы сравнения текстов и последовательностей требуют цифровых данных, только недавно ученые начали использовать их для крупномасштабных кросс-лингвистических исследований 34,35,36 .
В прошлом предпринимались различные попытки составить кросс-лингвистические списки слов. Проект Comparative Bantu OnLine Dictionary (CBOLD, http://www.cbold.ish-lyon.cnrs.fr/), начатый в 1994 году, представляет собой одну из первых цифровых попыток представить лексические данные, но не обновлялся. с 2000 года 37 . Проект PanLex (https://www.panlex.org/) предоставляет обширную коллекцию списков Сводеша — списков слов, в которых используются списки понятий, первоначально составленные Моррисом Сводешем в качестве вопросника 38,39 — почти для 2000 языковых разновидностей 40 .
Недостатком сборника является то, что его источники плохо документированы, а формы не представлены в стандартизированных фонетических транскрипциях. База данных ASJP (https://asjp.clld.org) представляет собой самую обширную коллекцию списков слов с точки зрения межъязыкового охвата, предлагая списки слов, содержащие около 40 элементов для более чем 5000 языковых разновидностей в единой системе фонетической транскрипции 9.0009 41 . Недостаток базы данных ASJP, однако, заключается в том, что охват с точки зрения понятий очень низок, и даже цель предоставления переводов для небольшого списка из 40 понятий достигнута только для примерно 86% разновидностей в текущей версии. Кроме того, система транскрипции объединяет многие различия, предусмотренные в традиционном Международном фонетическом алфавите, и поэтому предлагает лишь ограниченные возможности для кросс-лингвистических исследований фонологических вариаций.
Напротив, в The Intercontinental Dictionary Series (IDS, https://ids.clld.org) имеется гораздо меньше языков, но гораздо больший список понятий с переводами более 1400 понятий на более чем 300 языковых разновидностей 42 . К сожалению, основная проблема IDS заключается не в отсутствии межъязыкового охвата, а в том, что языковые формы не представлены в унифицированных фонетических транскрипциях. В результате данные могут использоваться только для внутриязыкового сравнения, такого как кросс-лингвистическое исследование паттернов колексификации 43 , где одна и та же словоформа выражает несколько понятий в одном и том же языке 44 . Русская русскаярука ( рука ) обычно относится как к «руке», так и к «руке», что отражает образец, который можно найти во многих языках мира.
В дополнение к глобальным коллекциям списков слов существуют также обширные коллекции списков слов, ориентированные на определенные лингвистические «макрообласти», такие как, например, база данных NorthEuralex (http://northeuralex.org), которая предлагает стандартизированные списки слов для более чем 1000 концепты, переведенные более чем на 100 евразийских языков 45 , или базу данных Hunter-Gatherer (https://huntergatherer. la.utexas.edu/), в которой собраны списки слов различного размера и структуры для более чем 400 языковых разновидностей 46 . В таблице 1 представлен обзор основных лексических баз данных, которые были опубликованы в прошлом.
Полноразмерная таблица
До сих пор основной стратегией крупномасштабных коллекций списков слов была сборка данных язык за языком. Следуя языковым или региональным стандартам документации по концепциям и орфографиям, ученые стремятся собрать как можно больше списков слов для как можно большего количества языков, в конечном итоге достигая точки, когда становится все труднее добавлять больше данных или когда регион был достаточно охвачен. . Поскольку коллекции неизбежно будут использовать существующие наборы данных, процесс сбора данных включает в себя значительный объем переформатирования, корректировки и модификации независимо опубликованных наборов данных. Этот процесс несет в себе опасность внесения ошибок в производные данные, особенно когда источник интерпретируется и преобразуется для его адаптации к новым ресурсам. Другая проблема возникает из-за недостаточной гибкости закрытых коллекций данных с фиксированным количеством понятий и фиксированной системой фонетической транскрипции. Поскольку решения об игнорировании или перекодировании частей исходных данных во время сбора данных не могут быть легко отменены, при сборе данных часто упускаются более важные части исходной информации, из которой они взяты.
Альтернатива сборке данных по языку состоит из приведения отдельных наборов данных к общим стандартам, из которых впоследствии можно агрегировать пользовательские наборы данных. Для этой стратегии решающее значение имеет наличие справочных каталогов (описывающих основные лингвистические конструкции, такие как разновидности языка, понятия и звуки речи) и стандартных форматов для обмена данными (структуры таблиц, метаданные). Первоначальные идеи по решению проблемы, связанной с отсутствием стандартов и форматов обмена кросс-лингвистическими данными, были представлены в рамках инициативы «Форматы кросс-лингвистических данных» (CLDF) (https://cldf.clld.org 9).0009 14 ). CLDF предложила первые спецификации для списков слов и наборов структурных данных и рассказала, как можно стандартизировать межъязыковые лексические и структурные данные и как пакеты программного обеспечения могут помочь проверить, соответствуют ли данные новым предложенным стандартам. Опираясь на CLDF, мы разработали улучшенные способы преобразования кросс-лингвистических лексических данных в новые стандарты. Мы протестировали эти рабочие процессы, поднимая различные наборы данных, опубликованные за последние десятилетия, и сотрудничая с активными сборщиками данных. В целом, эта коллекция, которую мы называем Lexibank, состоит из 100 отдельных наборов данных CLDF, охватывающих более 4000 списков слов из более чем 2400 языковых разновидностей. Чтобы проиллюстрировать потенциал взаимодействия и повторного использования этого сбора данных, мы разрабатываем новый набор программных инструментов, которые позволяют нам автоматически извлекать из данных различные фонологические и лексические особенности.
Межъязыковые форматы данных
Инициатива CLDF была запущена в 2014 году исследователями из разных учреждений для решения общих проблем повторного использования и переносимости цифровых межъязыковых данных 47 . Решение, предложенное инициативой CLDF, состояло в том, чтобы унифицировать кросс-лингвистические наборы данных, предложив относительно простые табличные форматы для представления лексических, структурных и параллельных текстовых данных 14 . В то время как более ранние усилия по стандартизации часто стремились к полноте (в смысле выразительная адекватность 48 ), CLDF выбрала повторное использование вычислений в качестве основной цели дизайна. Таким образом, спецификация CLDF сравнительно невелика, но поставляется с четкими примерами, показывающими, как данные могут быть проанализированы с помощью вычислений 49 . Начиная с 2018 года, мы дополнительно усовершенствовали исходные спецификации, расширив их, чтобы лучше учитывать фонетические транскрипции. Важным шагом стала интеграция расширенных стандартов фонетической транскрипции, предоставленных Cross-Linguistic Transcription Systems (CLTS, https://clts.clld.org), справочным каталогом, который сопоставляет фонетические транскрипции со звуками речи 50,51 . За последние два года все три основных справочных каталога, на которые ссылается CLDF — Glottolog для языков 52 , Concepticon для понятий 53 и CLTS для звуков речи — были радикально усовершенствованы, чтобы обеспечить более детальную интеграцию кросс- лингвистические данные. Были предприняты первые попытки моделирования дополнительных кросс-лингвистических типов данных, таких как текст с подстрочным глянцем 54 . Подробности этого процесса можно найти на веб-сайте проекта инициативы CLDF (https://cldf.clld.org). Для будущих усовершенствований CLDF мы приняли практику сначала представлять их в специальных исследованиях вместе с примерами, а затем обсуждать, следует ли интегрировать их в последующие новые версии спецификации CLDF 9. 0009 55 .
(Ретро) Стандартизация наборов лексических данных
Стандартизация наборов лексических данных с помощью CLDF осуществляется в двух формах. Во-первых, CLDF можно использовать для повышения сопоставимости существующих наборов данных в форме ретро-стандартизации. Во-вторых, CLDF можно использовать в процессе сбора и обработки данных для обеспечения проверки согласованности необработанных лингвистических данных. Чтобы улучшить обе формы стандартизации, мы создали пакет PyLexibank Python 9.0009 56 поверх универсального пакета CLDFBench 57 . CLDFBench позволяет пользователям с помощью нескольких строк кода преобразовывать свои данные в форматы CLDF, но в нем отсутствуют специальные решения, важные для создания лексических данных. PyLexibank опирается на CLDFBench, чтобы облегчить и более целенаправленно курировать лексические данные, обеспечивая интегрированную поддержку Concepticon 53 и справочных каталогов CLTS 58 . Основная услуга, предлагаемая пакетом PyLexibank, — это явная интеграция справочных каталогов, которые важны для обеспечения сопоставимости лексических данных, а именно Concepticon, для стандартизации идентификаторов понятий, полученных из толкований извлечения в лексических словарях 59 и CLTS для стандартизации фонетических транскрипций 50 .
Связывание лексических данных с проектом Concepticon организовано в рамках специального рабочего процесса, поддерживаемого редакцией проекта Concepticon. Рабочий процесс подробно описан в предыдущих исследованиях 60,61,62 . Преобразование фонетических транскрипций в стандарты, предусмотренные проектом CLTS, организовано с помощью профилей орфографии 63 . Профили орфографии представляют собой простые справочные таблицы, которые определяют отдельные графемы в заданной орфографии (графема представляет собой единицу, состоящую из одного или нескольких символов) вместе с их целевым значением в стандартизированной системе транскрипции. PyLexibank облегчает создание и курирование профилей орфографии, позволяя пользователям создавать черновой профиль из своих необработанных данных. Он использует метод автоматической сегментации фонетических транскрипций, изначально разработанный для программного пакета LingPy 9.0009 64 . Таким образом, можно создать первый «черновой профиль», который пользователи могут затем систематически уточнять. Пакет PyLexibank предлагает дополнительные процедуры для предварительной обработки лексических форм с общими процедурами очистки (удаление скобок, разделение записей и т. д.). Уточнив профиль, данные можно сегментировать с помощью пакета Segments 65 и проверить с помощью пакета PyCLTS 66 . Подробности процесса создания профиля орфографии обсуждались в предыдущих исследованиях 67,68 . В таблице 2 приведены основные операции. Как пакеты программного обеспечения, на основе которых строится репозиторий Lexibank, интегрируются и применяются на практике, было задокументировано в нескольких практических руководствах членов команды и первых пользователей, которые иллюстрируют, как наборы данных могут быть подняты в CLDF и добавлены в репозиторий Lexibank 69,70 .
Полноразмерный стол
Автоматическое извлечение функций
Хотя языковые функции часто определяются по-разному, основные типы функций могут быть легко идентифицированы и часто даже вычислены обычным способом. Подобно процессу агрегации признаков , лежащему в основе базы данных AUTOTYP для структурных признаков 71,72 , мы предлагаем вычислительные методы для извлечения фонологических и лексических признаков из коллекции списков слов Lexibank. Например, рассмотрим функцию «Размер согласного», которая включает в себя количество согласных в данном языке. Как только данные представлены в списке слов в фонетической транскрипции и сегментированы таким образом, чтобы можно было идентифицировать уникальные звуки, нижняя граница количества согласных в данном языке может быть аппроксимирована путем подсчета различных звуков в образце списка слов. Хотя этот подход может не выявить все согласные, поскольку нет гарантии, что меньший набор слов будет содержать все звуки языка 73 , он достаточно хорошо аппроксимирует реальное количество звуков. Поскольку все данные в подмножестве LexiCore нашей коллекции Lexibank связаны со звуковыми идентификаторами, предоставленными проектом CLTS 58 , каждый из которых, в свою очередь, определяет звук набором отличительных признаков, мы можем легко извлечь дополнительные подмножества звуков в зависимости от их отличительные черты. Таким образом, наш код для извлечения признаков, реализованный как часть специального программного пакета (CL Toolkit, https://pypi.org/project/cltoolkit 74 ), определяет различные функции с помощью простых программных операций. Эти операции проверяют, имеют ли подмножества звуков в звуковом инвентаре данного языка определенную функцию или определенную комбинацию функций (см. Раздел Техническая проверка ).
Для некоторых фонологических характеристик, таких как просодия или звуковая символика, требуются дополнительные данные или функции. Просодические признаки, вычисляемые CL Toolkit, например, используют автоматическую процедуру слогового преобразования, основанную на звучности отдельных звуков 75 реализуется программным пакетом LingPy 64 . Особенности звуковой символики, которые определяются путем проверки наличия у слова, выражающего определенное понятие, определенных фонетических свойств, дополнительно необходимо учитывать информацию из справочника Concepticon 53 , который стандартизирует понятия в коллекции Lexibank.
При извлечении лексических признаков проверяется полная или частичная идентичность словоформ, выражающих выделенные понятия. Таким образом, чтобы проверить, объединены ли слова «рука» и «кисть» в данном языке, способ сначала просматривает наборы понятий Concepticon «РУКА» 1637, «РУКА» 1277 и «РУКА ИЛИ РУКА» 2121, а затем проверяет присутствуют ли словоформы для «РУКА» и «РУКА», и если да, то идентичны ли они. Если они идентичны, он идентифицирует колексификацию, если нет, он проверяет, присутствует ли словоформа для «РУКА ИЛИ РУКА», которая повлечет за собой колексификацию, идентифицируя колексификацию, если это так, или иным образом давая отрицательный результат. Аналогичным образом метод проверяет наличие общих подстрок или колексификаций аффиксов.
Код для автоматического извлечения фонологических и лексических признаков написан таким образом, чтобы пользователи могли легко расширять его в будущем. Поскольку объекты, из которых извлекаются функции, представляют собой стандартизированные дескрипторы для звуков или понятий, расширения нашей текущей кодовой базы могут быть легко написаны и интегрированы или применены путем создания облегченных плагинов для наших текущих решений, представленных в пакете CL Toolkit.
Записи данных
Коллекция словарей Lexibank
Lexibank 15 — это мета-коллекция стандартизированных списков слов, составленных из различных отдельных наборов данных. Сами стандартизированные списки слов составляются независимо. Их курирование следует рабочему процессу курирования данных проекта Lexibank, в котором используется библиотека PyLexibank Python 56 для преобразования лексических данных в пользовательских форматах в списки слов CLDF. Редколлегия проекта Lexibank принимает решение о включении отдельных наборов данных в коллекцию словарей Lexibank. Наборы данных, включенные в эту коллекцию, необходимо заархивировать с помощью Zenodo (https://zenodo.org/) и курировать в репозитории GIT (https://git-scm.com/). Наборы данных, включенные в коллекцию словарей Lexibank, снабжены ссылками на их DOI Zenodo и URL-адресом их репозитория GIT и классифицированы по уровню стандартизации (файл etc/lexibank.csv в репозитории Lexibank.
Коллекция словарей Lexibank предоставляется в виде самого набора данных CLDF. Набор данных дополнен кодом Python, который можно вызвать из командной строки и который позволяет пользователям загружать все отдельные наборы данных из своих архивов (Zenodo и GitHub). Кроме того, код позволяет вычислять из данных фонологические и лексические признаки и сохранять их в форматах CLDF. Все отдельные списки слов, на которые есть ссылки в репозитории Lexibank, а также сам репозиторий Lexibank находятся под лицензией Creative Commons 4. 0. Репозиторий Lexibank курируется на GitHub (https://github.com/lexibank/lexibank-analysed) и архивируется с помощью Zenodo (https://doi.org/10.5281/zenodo.5227817) 15 . Текущая версия репозитория — Версия 0.2.
Lexibank (версия 0.2) в настоящее время собирает лексические данные из 100 различных наборов данных, которые вместе предлагают списки слов для 4069 языковых разновидностей, соответствующих 2456 различным языкам и диалектам (согласно Glottolog 52 ), и предоставляют информацию в общей сложности для 3110 лексических концепций, всего 1 912 952 слова. Списки слов в коллекции Lexibank показывают различные степени стандартизации, отражающие уровень, до которого они могут быть подняты. Для 3320 словарей взяты из 94 набора данных, полностью стандартизированные фонетические транскрипции могут быть предоставлены как минимум для 80 словоформ. Мы называем этот набор данных подмножеством LexiCore Lexibank (см., например, набор данных chingelong 76 ). Для 1806 списков слов из 52 наборов данных могут быть предоставлены большие списки слов, содержащие не менее 250 стандартизированных понятий, но отдельные списки слов не обязательно предлагают полностью стандартизированные фонетические транскрипции. Мы называем этот набор данных подмножеством ClicsCore Lexibank (для примера см. набор данных diacl 77 ). 1441 словарь из 49наборы данных доступны не только в стандартизированных фонетических транскрипциях, но также предлагают информацию об этимологически связанных словах (родственные наборы), предоставленную экспертами. Мы называем этот набор данных подмножеством CogCore Lexibank (для примера см. набор данных liusinitic 78 ). Небольшое подмножество из 18 списков слов из 4 наборов данных даже предлагает протоформы — формы, выведенные для неподтвержденных языков предков с использованием традиционных методов сравнительного метода 79 — в стандартизированных фонетических транскрипциях. Этот набор данных называется подмножеством ProtoCore Lexibank (см. набор данных davletshinaztecan 9).0009 80 например).
На рисунке 1 показано распределение данных для списков слов LexiCore (списки слов со стандартизированной транскрипцией) и ClicsCore (списки слов с большим охватом с точки зрения понятий) в нашей коллекции. Хотя мы видим, что некоторые регионы мира менее хорошо освещены, чем другие, мы также можем видеть, что текущая коллекция уже достигла значительного охвата во всем мире. В таблице 3 представлена общая статистика по наборам данных, собранным как часть коллекции Lexibank.
Рис. 1Распределение лексических ресурсов с фонетической транскрипцией (LexiCore) и лексических ресурсов с большим количеством лексических форм (ClicsCore) в коллекции словарей Lexibank.
Изображение в полный размер
Таблица 3. Сравнение коллекций лексических списков слов, опубликованных за последние десятилетия.Полноразмерная таблица
Коллекция фонологических и лексических характеристик
Коллекция данных Lexibank предоставляет данные в форматах, которые облегчают как агрегация лексических данных из разных источников и интеграция агрегированных данных с другими видами лингвистической и неязыковой информации. Интеграция гарантируется стандартами, предусмотренными спецификацией CLDF, и справочными каталогами, которые предоставляют большие коллекции метаданных для стандартных конструкций в лингвистических исследованиях, таких как языки (Glottolog 52 , https://glottolog.org), концепции (Concepticon 53 , https://concepticon.clld.org) и звуки речи (Cross-Linguistic Transcription Systems, CLTS 9).0009 58 , https://clts.clld.org). Поскольку все справочные каталоги предоставляют дополнительную обширную информацию о лингвистических конструкциях, которые они определяют, связывание данных со справочными каталогами позволяет значительно обогатить существующие наборы данных. Кроме того, поскольку идентификаторы объектов (для языков, понятий, звуков речи), предоставляемые справочными каталогами, могут быть интегрированы в любой дополнительный ресурс, существует множество способов дальнейшей интеграции данных. Через языковые идентификаторы Glottolog, например, культурные данные из D-PLACE 9Базу данных 0009 81 можно сравнить с лексическими данными в нашей коллекции Lexibank. С помощью идентификаторов понятий Concepticon различные виды речевых норм, рейтингов и концептуальных отношений могут быть получены через межъязыковую базу данных Норм, Рейтингов и Отношений (NoRaRe 62 , https://digling.org/norare/) база данных. С помощью звуковых идентификаторов каталога CLTS можно получить и сравнить информацию о звуковых инвентаризациях из многочисленных баз звуковых инвентаризаций 82 . На рис. 2 показано, как можно интегрировать данные, представленные в форматах CLDF, путем расширения базовых данных с помощью справочных каталогов, а также путем анализа и визуализации данных с помощью специальных программных инструментов.
Справочные каталоги, инструменты для анализа и инструменты для визуализации, интегрированные наборами данных CLDF. Предоставляя активные ссылки на идентификаторы Glottolog, Concepticon и преобразовывая фонетические транскрипции в стандартные транскрипции, предоставляемые каталогом CLTS, наборы данных CLDF можно интегрировать с другими существующими наборами данных, такими как D-PLACE 9. 0009 81 , NORaRE 62 и PHOIBLE 89 . С помощью специальных пакетов для анализа наборов данных CLDF данные можно легко агрегировать с помощью CLDFBench 57 , а функции можно автоматически извлекать с помощью CL Toolkit 74 . Для визуализации наборов данных CLDF данные можно нанести на географические карты с помощью CLDFViz 91 и опубликовать на интерактивных веб-сайтах с помощью CLLD 110 .
Полноразмерное изображение
В дополнение к справочным наборам данных, которые содержат списки слов в стандартах, соответствующих стандартам обработки и интеграции данных Lexibank, справочный каталог Lexibank предоставляет набор фонологических и лексических признаков, которые были автоматически извлечены из данных списка слов. Для вычислений используется пакет CL Toolkit Python 74 , и его можно вызывать через командную строку как часть рабочего процесса Lexibank для агрегации и обработки данных. Полученные наборы функций обеспечивают автоматически извлекаемые реестры фонем и фонологические характеристики для всех языковых разновидностей в подмножестве LexiCore Lexibank, а также автоматически извлекаемые лексические особенности для всех языковых разновидностей в подмножестве ClicsCore. Сами наборы функций хранятся в формате CLDF, а также совместно используются и архивируются с каждым выпуском репозитория Lexibank.
Техническая проверка
Благодаря высокому уровню интеграции и стандартизации списков слов коллекция Lexibank имеет высокий потенциал для повторного использования. Эти данные могут быть использованы в качестве отправной точки для различных филогенетических исследований отдельных языковых семей. Учитывая большое количество наборов данных, в которых этимологические отношения слов между языками были аннотированы экспертами, эти данные также могут служить ориентиром для продвижения разработки новых методов автоматического сравнения слов 9.0009 19 и автоматическое предсказание родственных слов 83,84 , что значительно превышает размер ранее опубликованных эталонных наборов данных 85 . Кроме того, данные можно использовать для вычисления различных видов фонологических и лексических особенностей отдельных языковых разновидностей и, таким образом, активно способствовать будущим исследованиям языкового разнообразия, предыстории человека и человеческого познания. Далее мы сосредоточимся на этом последнем аспекте и покажем, как фонологические и лексические признаки могут быть автоматически вычислены из коллекции Lexibank. Таким образом, мы способствуем недавним попыткам повысить прозрачность кросс-лингвистических коллекций структурных данных. Мы ожидаем, что роль, которую формальное извлечение дискретных и непрерывных признаков из языковых данных играет в настоящее время, приобретет гораздо большее значение в будущем.
Вывод фонологических признаков
В сравнительной лингвистике в прошлом для сравнения языков использовались различные виды фонологических признаков. Фонологические признаки включают в себя различные характеристики, связанные со звуками разговорных языков или их комбинацией, начиная от дискретных признаков, таких как размер фонемы, отражающих количество различных звуков в данном языке 86,87 , до непрерывных признаков, таких как отношение согласных и гласных размер 82 , и категориальные признаки, такие как наличие и тип лексического тона в языке 5 , вплоть до бинарных признаков, таких как наличие губно-зубных звуков 6,88 . Как правило, они собираются путем извлечения соответствующей информации непосредственно из лингвистической литературы (справочные грамматики, фонологические описания, грамматические зарисовки).
Поскольку коллекция LexiCore из коллекции списков слов Lexibank содержит словоформы в стандартизированных фонетических транскрипциях, многие фонологические характеристики могут быть автоматически вычислены на основе данных. Это имеет три основных преимущества. Во-первых, это экономит много времени и труда, поскольку извлечение признаков может выполняться автоматически. Во-вторых, это повышает гибкость аннотации признаков, поскольку мы не обязаны выбирать одно представление (категориальное, непрерывное и т. д.) значений признаков перед началом сбора данных, но можем экспериментировать с различными представлениями при разработке методов вывода признаков. В-третьих, он гораздо более прозрачен, так как предполагаемые признаки могут быть проверены напрямую путем обращения к исходным данным.
Наш рабочий процесс для извлечения фонологических признаков из списка слов в нашей коллекции LexiCore Lexibank в настоящее время позволяет нам вычислить 30 различных фонологических признаков. Некоторые функции также предлагаются в больших наборах структурных данных 28 и могут быть напрямую с ними сопоставлены, в то время как другие функции до сих пор не были собраны в общедоступных наборах данных и, следовательно, могут предложить интересную информацию для языковых типологов.
В таблице 4 показаны 30 фонологических признаков, которые мы автоматически извлекли из данных. Как видно из таблицы, признаки можно разделить на четыре группы. Есть дискретные признаки по размерам звукового инвентаря (1–7, количество гласных, согласных и т. д.), есть разные признаки по особым типам звуков или отдельным специфическим звукам (8–19).), имеется три просодических признака (20–22) и восемь признаков, относящихся к конкретным звукосмысловым отношениям (также называемых «звуковой символикой», 23–30).
Таблица 4 Фонологические характеристики, автоматически извлекаемые из данных LexiCore в Lexibank.Полноразмерная таблица
Чтобы оценить полезность нашего подхода к автоматическому извлечению признаков из наборов лексических данных, мы сравнили, насколько хорошо предполагаемые значения для пяти выбранных признаков в LexiCore коррелируют с признаками, представленными в базе данных WALS 28 и функции, полученные из PHOIBLE 89 . Как видно из результатов этого сравнения в таблице 5, наш подход получает достаточно высокие корреляции как с функциями в WALS, так и с функциями, извлеченными из PHOIBLE, хотя PHOIBLE и WALS обычно показывают более высокую корреляцию друг с другом. Это, однако, неудивительно, учитывая, что оба набора данных основаны на очень похожих источниках от одного и того же участника (большая часть PHOIBLE была взята из базы данных инвентаризации фонологических сегментов Калифорнийского университета в Лос-Анджелесе 9).0009 90 , автор которого Ян Мэддисон также написал главу о фонологии в WALS, см. подробное исследование Anderson et al . 51 для подробного обсуждения сравнения базы данных инвентаризации фонем).
Полноразмерная таблица
Для изучения особенностей, полученных с помощью наших рабочих процессов, требуются инструменты для исследовательского анализа данных. Один из способов изучения больших коллекций объектов для кросс-лингвистических данных — нанести их на географическую карту, чтобы увидеть, возникают ли определенные территориальные закономерности. CLDF поставляется со специальным набором программных инструментов для визуализации данных, которые значительно облегчают эту часть (CLDFViz 91 ), позволяя пользователям создавать высококачественные статические и интерактивные карты, в которых функции могут комбинироваться по желанию. Пример такой карты показан на рис. 3, где мы нанесли объекты 28 и 29.в нашей коллекции, которые спрашивают, начинаются ли слова для «мать» и «отец» с [m] и [p] соответственно, что отражает хорошо известную тенденцию, которую можно наблюдать в языках мира и обычно связывают со звуками, которые изучают дети. во время овладения первым языком 92 . Как видно из карты, наши данные подтверждают общемировую тенденцию. Во многих неродственных языках, на которых говорят в разных географических регионах, есть слова для «матери», которые начинаются с [m], и слова для «отца», которые начинаются с [p] или подобных звуков (включая губно-зубные фрикативы, такие как [f]). Более подробные исследования потребуют углубленного анализа со стороны языковых типологов, для которых наш набор данных является полезной отправной точкой.
Сравнение межъязыковых паттернов звуковой символики, включающих слова «мать» и «отец» в языках мира. На рисунке показаны четыре набора данных, из которых взяты четыре примера, показывающие актуальные формы для отдельных языковых разновидностей.
Изображение в натуральную величину
Вывод лексических признаков
Языки различаются по способу построения их словарей. Одним из наиболее важных аспектов различий языков является то, в какой степени они используют одни и те же словоформы для обозначения разных понятий. русский 9Например, 0035 ruka может означать «рука» и «кисть», а немецкое Decke может означать «потолок» и «одеяло». с одной стороны и омофония с другой стороны 44 ), в последнее время привлек более широкое внимание лингвистов 93 , психологов 4 и ученых-компьютерщиков 94 , и наиболее заметно представлен в базе данных кросс-лингвистических колексификаций ( КЛИКС, https://clis.clld.org 60,61,95 ), который объединяет колексификации из наборов данных CLDF для более чем 2000 языковых разновидностей. В то время как исходная база данных CLICS была создана из 30 наборов данных, коллекция ClicsCore в Lexibank расширяет эту коллекцию на 20 дополнительных наборов данных. Сохраняя только те языки, которые предоставляют не менее 250 понятий, которые можно связать со справочным каталогом Concepticon, ClicsCore содержит 1806 различных языковых разновидностей, соответствующих 1114 различным языкам (что отражено уникальными глоттокодами в справочном каталоге Glottolog).
В то время как исходные данные CLICS идентифицируют как колексификации только те случаи, когда идентичная словоформа обозначает два разных смысла, мы расширяем понятие колексификации в нашей процедуре извлечения признаков, добавляя еще два типа колексификации, которые до сих пор лишь спорадически обсуждались в литература. Во-первых, мы добавляем метод идентификации частичных колексификаций, определяемых как те случаи, в которых две словоформы, выражающие два разных понятия, не идентичны, но имеют общую подстроку, и аффиксальные колексификации, где одно слово появляется как префикс или суффикс. другого слова (см. Таблицу 6 для примеров и полных определений). Систематический поиск этих колексификаций в наших данных позволяет нам выявить общие черты в языках мира и исследовать, обусловлены ли они территориальной близостью, общим происхождением или, скорее, общими когнитивными принципами.
Таблица 6 Шаблоны колексификации, которые можно вычислить на основе подмножества ClicsCore коллекции списков слов Lexibank. Полноразмерная таблица
30 функций, которые мы вычисляем из подмножества ClicsCore нашей коллекции списков слов, приведены в таблице 7. Хотя мы могли бы легко расширить эту коллекцию, мы ограничили функции теми случаями, которые ранее обсуждались в литературы и собраны вручную в наборы структурных данных.
Таблица 7 30 лексических признаков, которые могут быть автоматически извлечены из подмножества ClicsCore Lexibank.Полноразмерная таблица
В качестве первого примера потенциала больших агрегированных наборов данных на рис. 4 показано, какие языки в нашей коллекции объединяют слова «рука» с «кистью» и «нога» с «ступней» соответственно. Предыдущие исследования были почти исключительно сосредоточены на глобальном распространении языков, объединяющих слова «рука» и «кисть», предполагая, что существует географическая тенденция к объединению этих терминов тем чаще, чем ближе человек подходит к экватору 96 . Сопоставление паттерна колексификации с его логическим аналогом дает интересные паттерны, поскольку наш анализ предполагает довольно сильную системную тенденцию в языках из разных языковых семей и областей выражать как «рука/кисть», так и «нога/нога» с помощью одно слово каждый, или различать их оба. Необходимы дополнительные исследования по этой теме. Данные, которые мы собрали здесь, являются полезной отправной точкой.
Глобальное распределение языков в подмножестве ClicsCore Lexibank, которые объединяют слова «рука» и «кисть» и «нога» и «ступня» соответственно.
Полноразмерное изображение
На рис. 5 представлен еще один пример функций, которые частично встречаются в коррелированной форме. На этот раз мы сравним, обозначают ли языки «женщину» и «мужчину» посредством частичной колексификации (сравните 女人 nǚ-rén «женщина → женщина» и 男人nan-ren «мужчина → мужчина» в китайском языке). ), с одной стороны, и «дочь» и «сын» (ср. 女兒 nǚ- ě r ‘потомство женского пола → дочь’ vs. 兒子 ě rzĭ ‘потомство-сын → сын’), с другой стороны. Анализ предполагает большой территориальный кластер в Юго-Восточной Азии, где хорошо известна тенденция языков к использованию сложных слов в довольно аналитическом ключе, а также некоторые языки на севере Южной Америки, но картина показывает менее глобальный характер. 4.
Частичные колексификации между «женщиной» и «мужчиной», а также между «дочерью» и «сыном».
Полноразмерное изображение
В качестве последнего примера на рис. 6 сравниваются аффиксальные колексификации, в которых слова повторяются в начале другого слова, что указывает на сильные семантические отношения. В конкретном примере мы проверяем, в какой степени слово «слеза» в языках нашей выборки состоит из слова «глаз» и слова «вода» соответственно. То, что «слезы» обозначаются как «глазная вода», является распространенным паттерном, который можно найти во многих языках Юго-Восточной Азии (сравните Younuo [ki 55 mo 32 -ʔŋ 44 ] ‘глазная вода’ 68,97 ), но также и в нескольких языках Южной Америки (сравните гуарани esa-ɨ ‘глазная вода’) 49000 . Как видно из рисунка, мы находим, что языки Юго-Восточной Азии действительно в подавляющем большинстве случаев выражают «слезы» как «глазная вода», поскольку они демонстрируют ассоциацию аффиксов «глаз» и «вода» со «слезой». ‘, но, кроме этого, эта функция встречается только спорадически.
Сравнение языков, выражающих слово «слеза» как «слезы из глаз» в выборке Lexibank с помощью ClicsCore.
Полноразмерное изображение
Замечания по использованию
Распространение наборов данных lexibank
Для распространения наборов данных CLDF в целом и наборов данных Lexibank в частности мы используем существующие решения для долгосрочного архивирования, предоставляемые Zenodo (https://zenodo.org). ). Как только набор данных Lexibank создан и создатели считают, что данные готовы к публичному обмену, новая версия данных создается и архивируется с помощью Zenodo, используя автоматическую интеграцию Zenodo с GitHub. Кроме того, новая версия помечена как часть сообщества Lexibank на Zenodo (https://zenodo.org/communities/lexibank), что позволяет пользователям удобно просматривать большую коллекцию доступных наборов данных. Zenodo является партнером OpenAIRE (https://www. openaire.eu/) и индексируется re3data (https://www.re3data.org) и, в конечном итоге, поисковыми системами, такими как 9.0035 Google Dataset Search , тем самым решив проблему нахождения академических ресурсов 98 .
Продвижение lexibank
Lexibank и лексические данные в форматах CLDF продвигались несколькими способами. Во-первых, мы провели подробные исследования, в которых форматы CLDF используются вместе с CLDFBench и пакетом программного обеспечения PyLexibank, иллюстрируя, как можно успешно выполнять агрегацию данных 60,61 , или показывая, как данные могут быть дополнены в прозрачных форматах CLDF 21,68 Во-вторых, мы создали несколько флагманских проектов, которые демонстрируют определенные аспекты CLDF и преимущества использования интегрированных данных 99,100 . В-третьих, мы проводили проекты со студентами и молодыми учеными, которых обучали использованию наших новых ресурсов и поощряли делиться своими знаниями в виде небольших сообщений в блогах (опубликованных на https://calc. hypotheses.org) вместе с новыми наборами данных. какие студенты бакалавриата, докторантуры и магистратуры поднялись с помощью нашей команды 70 101 102 103 .
Lexibank — это непрерывная совместная работа, и мы очень приветствуем участие более широкого сообщества. Наша команда основных участников оказывает активную поддержку тем, кто хочет узнать, как подготовить свои данные для включения в Lexibank. В то время как надлежащее включение набора данных в выпуск Lexibank требует включения в сообщество Lexibank на Zenodo (https://zenodo.org/communities/lexibank), бесплатная доступность соответствующего программного обеспечения и стандарт CLDF позволяют объединить внешние — или даже частные — данные с Lexibank. Надеемся, что эта низкая планка для взаимодействия с Lexibank как потребителем данных, а также производителем данных будет способствовать активному сообществу.
Доступность кода
Основной программный пакет, лежащий в основе Lexibank, курируется на GitHub (https://github. com/lexibank/lexibank-analysed/tree/v0.2) и заархивирован в Zenodo (https://doi.org/ 10.5281/zenodo.5227817) 15 . Отдельные наборы данных, принадлежащие коллекции словарей Lexibank, курируются в отдельных репозиториях на GitHub (см. наш основной список на https://github.com/lexibank/lexibank-analysed/blob/v0.2/etc/lexibank.csv), а также все заархивировано с Zenodo (см. https://zenodo.org/communities/lexibank/).
Ссылки
Грей, Р. Д., Драммонд, А. Дж. и Гринхилл, С. Дж. Языковые филогении обнаруживают импульсы и паузы расширения в Тихоокеанском поселении. Science 323 , 479–483, https://doi.org/10.1126/science.1166858 (2009).
Артикул ОБЪЯВЛЕНИЯ КАС пабмед Google Scholar
Сагарт, Л. и др. . Датированные языковые филогении проливают свет на происхождение китайско-тибетского языка.
Proceedings of the National Academy of Science of the United States of America 116 , 10317–10322, https://doi.org/10.1073/pnas.1817972116 (2019).Артикул КАС Google Scholar
Blasi, D. E., Søren, W., Hammarström, H., Stadler, P. F. & Christiansen, M. H. Предвзятость звуковых ассоциаций, обнаруженная в тысячах языков. Труды Национальной академии наук Соединенных Штатов Америки 113 , 10818–10823, https://doi.org/10.1073/pnas.1605782113 (2016).
Артикул КАС Google Scholar
Джексон, Дж. К. и др. . Семантика эмоций демонстрирует как культурные различия, так и универсальную структуру. Science 366 , 1517–1522, https://doi.org/10.1126/science.aaw8160 (2019).
Артикул ОБЪЯВЛЕНИЯ КАС пабмед Google Scholar
Blasi, D. E. и др. . Звуковые системы человека сформированы постнеолитическими изменениями в конфигурации прикуса. Science 363 , 1–10, https://doi.org/10.1126/science.aav3218 (2019).
Артикул КАС Google Scholar
Маджид, А. и др. . Дифференциальное кодирование восприятия в языках мира. Труды Национальной академии наук Соединенных Штатов Америки 115 , 11369–11376, https://doi.org/10.
1073/pnas.1720419115 (2018).Артикул КАС пабмед ПабМед Центральный Google Scholar
Томпсон Б., Робертс С. Г. и Лупьян Г. Влияние культуры на значения слов, выявленное посредством крупномасштабного семантического выравнивания. Nature Human Behavior 4 , 1029–1038, https://doi.org/10.1038/s41562-020-0924-8 (2020).
Артикул пабмед Google Scholar
Кройманс И., Аршамян А., Спид Л. Дж. и Маджид А. Распознавание винных запахов винными экспертами не опосредовано словесно. Journal of Experimental Psychology 150 , 545–559, https://doi.org/10.1037/xge0000949 (2021).
Артикул пабмед Google Scholar
Дедиу, Д. Типология для масс. Лингвистическая типология 20 , 579–581, https://doi.
org/10.1515/lingty-2016-0029(2016).Артикул Google Scholar
Донохью, М., Хетерингтон, Р., МакЭлвенни, Дж. и Доусон, В. Всемирная фонотактическая база данных . Набор данных больше не доступен (кафедра лингвистики Австралийского национального университета, Канберра, 2013 г.).
Дайен, И., Крускал, Дж. Б. и Блэк, П. Сравнительная индоевропейская база данных: Файл IE-data1. Набор данных больше не доступен по исходной ссылке http://www.wordgumbo.com/ie/cmp/iedata.txt (1997).
Бенсон, Д. А. и др. . ГенБанк. Рез. нуклеиновых кислот. 41 , 36–42, https://doi.org/10.1093/nar/gks1195 (2013).
Артикул КАС Google Scholar
Форкель, Р. и др. . Кросс-лингвистические форматы данных, продвигающие совместное использование и повторное использование данных в сравнительной лингвистике.
Scientific Data 5 , 1–10, https://doi.org/10.1038/sdata.2018.205https://cldf.clld.org (2018).Лист, Ж.-М. и др. . Lexibank, общедоступный репозиторий стандартизированных наборов лексических данных с автоматически вычисляемыми фонологическими и лексическими характеристиками для более чем 2000 языковых разновидностей [версия 0.2]. Зенодо https://doi.org/10.5281/zenodo.5227817 (2021).
Хейни, Х. Дж. и Бауэрн, К. Филогенетический подход к эволюции цветовых терминологических систем. Труды Национальной академии наук Соединенных Штатов Америки 113 , 13666–13671 (2016).
Артикул КАС Google Scholar
Маджид, А. и ван Стаден, М. Можно ли объяснить номенклатуру тела теориями воплощения? Темы когнитивных наук 7 , 570–594 (2015).
Артикул Google Scholar
Лист, Дж.-М., Гринхилл, С.Дж. и Грей, Р.Д. Возможности автоматического сравнения слов для исторической лингвистики. PLOS ONE 12 , 1–18, https://doi.org/10.1371/journal.pone.0170046 (2017).
Артикул КАС Google Scholar
Чжан, Л., Фабри, Р., Нербонн, Дж. и Нербонн, Дж. Обнаружение заимствованных слов с помощью вычислений. In Aboh, EO & Vigouroux, CB (ред.) Вариация бросает кости: всемирный коллаж в честь Саликоко С. Муфвене , 269–288, https://doi.org/10.1075/coll.59.11zha (John Benjamins, 2021).
Лист, Ж.-М. и Форкель, Р. Автоматическая идентификация заимствований в многоязычных словарях [версия 2; экспертная оценка: одобрено 4].
Open Research Europe 1 , 79, https://doi.org/10.12688/openreseurope.13843.1 (2021).Артикул Google Scholar
Гаст В., Коптьевская-Тамм М. Ареалный фактор в лексической типологии. Некоторые данные из лексических баз данных. В Ван Олмен, Д., Мортельманс, Т. и Брисар, Ф. (ред.) Аспекты языковых вариаций , 43–81 (де Грюйтер, Берлин, 2018).
Мацумаэ, Х. и др. . Изучение корреляций в генетических и культурных различиях между языковыми семьями в Северо-Восточной Азии. Science Advances 7 , https://doi.org/10.1126/sciadv.abd9223 (2021).
Раначер, П. и др. . Отслеживание контактов в культурной эволюции: байесовская смешанная модель для выявления географических областей языковых контактов. Journal of the Royal Society Interface 18 , 20201031, https://doi.org/10.
1098/rsif.2020.1031 (2021).Артикул пабмед ПабМед Центральный Google Scholar
Wilkinson, MD et al . Руководящие принципы FAIR по управлению и управлению научными данными. Scientific Data 3 , 1–9, https://doi.org/10.1038/sdata.2016.18 (2016).
Артикул Google Scholar
Берез-Крекер, А. Л. и др. . Воспроизводимые исследования в лингвистике: заявление о цитировании и атрибуции данных в нашей области. Лингвистика 56 , 1–18, https://doi.org/10.1515/ling-2017-0032 (2018).
Артикул Google Scholar
Йестон, Дж. С. Прогресс в размещении данных и кода. Блог научных редакторов https://blogs.sciencemag.org/editors-blog/2021/07/15/progress-in-data-and-code-deposition/ (2021).
Драйер, М. и Хаспелмат, М. (ред.) WALS Online https://wals.info (Институт эволюционной антропологии Макса Планка, Лейпциг, 2013 г.).
Данн, М., Гринхилл, С. Дж., Левинсон, С. К. и Грей, Р. Д. Эволюционная структура языка показывает специфические для происхождения тенденции в универсалиях порядка слов. Nature 473 , 79–82, https://doi.org/10.1038/nature09923 (2011).
Артикул ОБЪЯВЛЕНИЯ КАС пабмед Google Scholar
Jäger, G. & Wahle, J. Филогенетическая типология. Frontiers in Psychology 12 , 1–15, https://doi.org/10.3389/fpsyg.2021.682132 (2021).
Артикул Google Scholar
Хаммарстрём, Х. Измерение префиксов и суффиксов в языках мира. В Материалы третьего семинара по вычислительной типологии и многоязычному НЛП , 81–89 (Ассоциация вычислительной лингвистики, Страудсбург, 2021 г.
).фон Лейбниц, G.W. Desiderata circa linguas populorum, ad Dn. Подеста [Desiderata относительно языков мира]. В Dutens, L. (ред.) Godefridi Guilielmi Leibnitii opera omnia, nic primum collecta, in class distributa, praefationibus et indicibus exornata [Собрание сочинений Готфрида Вильгельма Лейбница, теперь впервые собранное, разделенное на классы и обогащенное введениями и указателями ] , 228–231 (Fratres des Tournes, Женева, 1768 г.).
фон Аделунг, Ф. Catherinens der Grossen Verdienste um die vergleichende Sprachenkunde [Достижения Екатерины Великой в области сравнительного языкознания] (Фридрих Дрекслер, Санкт-Петербург, 1815).
Холман, Э. В. и др. . Автоматизированное датирование языковых семей мира на основе лексического сходства. Текущая антропология 52 , 842–875, https://doi.org/10.1086/662127 (2011).
Артикул Google Scholar
Эстлинг, Р. Изучение колексификации с помощью массивно-параллельных корпусов. В Schapper, A., Roque, LS & Hendery, R. (eds.) Лексическая типология семантических сдвигов , 157–176 (De Gruyter, Berlin and Boston, 2016).
Хайман, Л. и Лоу, Дж. (ред.) Сравнительный онлайн-словарь банту (CBOLD) http://www.cbold.ish-lyon.cnrs.fr/ (DDL, Lyon, 1994-2000) ).
Сводеш, М. Лексико-статистическое датирование доисторических этнических контактов. Особое внимание уделяется североамериканским индейцам и эскимосам.
Труды Американского философского общества 96 , 452–463 (1952).Google Scholar
Сводеш, М. На пути к большей точности лексикостатистического датирования. Международный журнал американской лингвистики 21 , 121–137 (1955).
Артикул Google Scholar
Камхольц, Д. и др. . (ред.) Материалы девятой Международной конференции по языковым ресурсам и оценке , 3145–3150 http://www.lrec-conf.org/proceedings/lrec2014/pdf/1029_Paper.pdf (Европейская ассоциация языковых ресурсов, Рейкьявик, 2014 г.).
Wichmann, S., и др. . База данных ASJP [Версия 16 (Институт эволюционной антропологии Макса Планка, Лейпциг, https://asjp.clld.org 2013).
Ки, М. Р. и Комри, Б. Серия межконтинентальных словарей (Институт эволюционной антропологии Макса Планка, Лейпциг, https://ids.
clld.org 2016).Лист, Дж.-М., Терхалле, А. и Урбан, М. Использование сетевых подходов для улучшения анализа межъязыковой полисемии. In Proceedings of the Ten International Conference on Computational Semantics — Short Papers , 347–353 (Association for Computational Linguistics, Stroudsburg, 2013).
Франсуа, А. Семантические карты и типология колексификаций: переплетение многозначных сетей в разных языках. В Ванхове, М. (ред.) От полисемии к семантическим изменениям , Studies in Language Companion, 163–215 (Бенджаминс, Амстердам, 2008 г.).
Деллерт, Дж. и др. . NorthEuraLex: обширная лексическая база данных Северной Евразии. Языковые ресурсы и оценка 54 , 273–301, https://doi.org/10.1007/s10579-019-09480-6 (2019).
Артикул пабмед ПабМед Центральный Google Scholar
Берд, С. и Саймонс, Г. Семь аспектов переносимости языковой документации и описания. Язык 79 , 557–582 (2003).
Артикул Google Scholar
Ромари, Л. и Иде, Н. Международный стандарт для фреймворка лингвистических аннотаций. Репозиторий компьютерных исследований abs/0707.3269 , 1–11, http://arxiv.org/abs/0707.3269 (2007).
ОБЪЯВЛЕНИЕ Google Scholar
Лист, Ж.-М. Представление структурных данных в CLDF. Компьютерное сравнение языков на практике 1 , 18–21, https://calc.hypotheses.org/445 (2018).
Google Scholar
Андерсон, К. и др. . Измерение вариаций в инвентаре фонем. Research Square 1–16, https://doi.org/10.21203/rs.3.rs-8
- /v1. Препринт в настоящее время находится на рассмотрении (2021 г.).
Хаммарстрем, Х., Хаспелмат, М., Форкель, Р. и Банк, С. Glottolog [версия 4.4] https://glottolog.org (Институт эволюционной антропологии Макса Планка, Лейпциг, 2021 г.).
Лист, Ж.-М. и др. . Концептикон. Ресурс для связывания списков понятий [Версия 2.5.0] https://concepticon.clld.org (Институт истории человечества им. Макса Планка, Йена, 2021 г.).
Швейкхард, Н. Э. и Лист, Дж.-М. Разработка системы аннотаций для процессов словообразования в сравнительной лингвистике. Журнал теоретической лингвистики SKASE 17 , 2–26 (2020).
Google Scholar
Форкель, Р., Гринхилл, С.Дж., Бибико, Х.-Дж., Тресолди, Т. и Лист, Ж.-М. ПиЛексибанк. Кураторская библиотека Python для Lexibank [версия 2.8.2] https://pypi.org/pylexibank/ (Институт эволюционной антропологии Макса Планка, Лейпциг, 2021 г.).
Форкель, Р. и Лист, Дж.-М. CLDFBench.
Поднимите ваши кросс-лингвистические данные. В материалах Proceedings of the Twelfth International Conference on Language resources and Evaluation , 6997–7004, https://pypi.org/project/cldfbench/ (Европейская ассоциация языковых ресурсов, Люксембург, 2020 г.).List, J.-M., Anderson, C., Tresoldi, T. & Forkel, R. Межъязыковые системы транскрипции [Версия 2.1.0] https://clts.clld.org (макс. Институт истории человечества Планка, Йена, 2021 г.).
Лист, Ж.-М. и др. . (ред.) Proceedings of the Ten International Conference on Language Resources and Evaluation , 2393–2400 (Европейская ассоциация языковых ресурсов, Люксембург, 2016 г.).
Лист, Ж.-М. и др. . CLICS 2 : улучшенная база данных кросс-лингвистических колексификаций, собирающая лексические данные с помощью кросс-лингвистических форматов данных. Лингвистическая типология 22 , 277–306, https://doi.
org/10.1515/lingty-2018-0010 (2018).Артикул Google Scholar
Ржимски, К. и др. . База данных кросс-лингвистических колецификаций, воспроизводимый анализ кросс-лингвистических полисемий. Scientific Data 1–12, https://doi.org/10.1038/s41597-019-0341-xhttps://clis.clld.org (2020).
Тьюка А., Форкель Р. и Лист Ж.-М. Связывание норм, рейтингов и отношений слов и понятий в различных языковых вариантах. Методы исследования поведения 1–21, https://doi.org/10.3758/s13428-021-01650-1 (2021).
Moran, S. & Cysouw, M. Поваренная книга Unicode для лингвистов: управление системами письма с использованием профилей орфографии (Language Science Press, Берлин, 2018 г.).
Лист, Ж.-М. & Форкель, Р. LingPy. Библиотека Python для количественных задач в исторической лингвистике [версия 2.
6.8] https://pypi.org/project/lingpy/ (Институт эволюционной антропологии Макса Планка, Лейпциг, 2021 г.).Форкель, Р. и др. . сегментов. Стандартные процедуры токенизации Unicode и сегментация профиля орфографии [версия 2.1.3] https://pypi.org/project/segments (Институт истории человечества им. Макса Планка, Йена, 2019 г.).
Лист, Дж.-М., Андерсон, К., Тресольди, Т. и Форкель, Р. PyCLTS. Библиотека Python для работы с системами фонетической транскрипции [версия 3.0.0] https://pypi.org/project/pyclts/ (Институт истории человечества им. Макса Планка, Йена, 2020 г.).
Гейслер, Х.-Дж., Форкель, Р. и Лист, Дж.-М. Цифровое стандартизированное ретро-издание Tableaux phonétiques des patois suisses romands (TPPSR). Ин Аванци, М., ЛоВеккио, Н., Миллур, А. и Тибо, А. (ред.) Nouveaux рассматривает диалектную вариацию , 13–36 (Éditions de Linguistique et de Philologie, Страсбург, 2021 г.
).Ву, М.-С., Швейкхард, Н.Э., Бодт, Т.А., Хилл, Н.В. и Лист, Дж.-М. Компьютерное сравнение языков. Уровень развития. Journal of Open Humanities 6 , 1–14, https://doi.org/10.5334/johd.12 (2020).
Артикул Google Scholar
Лист, Ж.-М. Преобразование набора данных Vietic Сидвелла и Алвеса с 2021 года в CLDF. Компьютерное сравнение языков на практике 3 , 1–15, https://calc.hypotheses.org/2954 (2021).
Google Scholar
Блюм, Ф. Сбор данных во время пандемии: переработка данных Констенлы Уманья о языковых семьях чибчан, ленкан и мисумалпам. Компьютерное сравнение языков на практике 4 , 1–6, https://calc.hypotheses.org/2751 (2021).
Google Scholar
Бикель, Б.
9 (2022). и др. . База данных AUTOTYP [Версия 1.0.0] Zenodo https://doi.org/10.5281/zenodo.5Витцлак-Макаревич А., Николс Дж., Хильдебрандт К. А., Захарко Т. и Бикель Б. Управление данными AUTOTYP: принципы проектирования и реализация. In The Open Handbook of Linguistic Data Management , 631–642, https://doi.org/10.7551/mitpress/12200.003.0061 (MIT Press, 2022).
Докум, Р. и Бауэрн, К. Сводеш списки недостаточно длинные: Делая фонологические обобщения на основе ограниченных данных. В Остине, П.К. (ред.) Языковая документация и описание , 16 , 35–54 (EL Publishing, Лондон, 2018 г.).
Лист, Ж.-М. & Forkel, R. CL Toolkit. Библиотека Python для обработки кросс-лингвистических данных [версия 0.1.1] https://pypi.org/project/cltoolkit (Институт эволюционной антропологии Макса Планка, Лейпциг, 2021 г.).
Чин, А. С. 海南島的哥隆話. Язык гелонг в многоязычном центре Хайнаня. Бюллетень китайской лингвистики 8 , 140–156, https://doi.org/10.1163/2405478x-00801008 (2015).
Артикул Google Scholar
Carling, G. и др. . Диахронический атлас сравнительной лингвистики (DiACL). База данных по типологии древних языков. PLOS ONE 1–20, https://doi.org/10.1371/journal.pone.0205313 (2018).
Лю, Лилу 刘俐李, Ван, Хунчжун 王洪钟 и Буй Ин 柏莹. Xiandài Hànyŭ fāngyán héxnc, tèzhēng cíjí 现代汉语方言核心词·特征词集 [Сборник основных словарных слов и характерных диалектных слов в современных китайских диалектах] (Fèngshuáng, Nánjng, 2007).
Давлетшин А. Прото-уто-ацтеки на пути к прото-ацтекской родине: лингвистические свидетельства. Journal of Language Relationship 1 , 75–92, https://doi.org/10.31826/jlr-2012-080106 (2020).
Артикул Google Scholar
Кирби, К. Р. и др. . D-PLACE: глобальная база данных культурного, языкового и экологического разнообразия. PLOS ONE 11 , 1–14, https://doi.org/10.1371/journal.pone.0158391 (2016).
Артикул КАС Google Scholar
Мэддисон, И., Флавьер, С., Марсико, Э., Купе, К. и Пеллегрино, Ф. LAPsyD: База данных фонологических систем Лиона-Альбукерке. В материалах Interspeech https://lapsyd.
huma-num.fr/lapsyd/ (ISCA, Лион, 2013 г.).Бодт, Т. А. и Лист, Дж.-М. Рефлекторный прогноз. Тематическое исследование Западной Хо-Бва. Diachronica 39 , 1–38, https://doi.org/10.1075/dia.20009.bod (2022).
Артикул Google Scholar
Лист, Дж.-М., Хилл, Н.В. и Форкель, Р. Новая структура для быстрой автоматической фонологической реконструкции с использованием усеченных выравниваний и шаблонов звукового соответствия В Материалы 3-го семинара по вычислительным подходам к историческому изменению языка , 1–8 https://aclanthology.org/2022.lchange-1.9.pdf (Ассоциация вычислительной лингвистики, Дублин, 2022 г.).
Лист, Ж.-М. и Прокич, Дж. Эталонная база данных фонетических выравниваний в исторической лингвистике и диалектологии. В Calzolari, N. и др. . (ред.) Материалы девятой Международной конференции по языковым ресурсам и оценке , 288–294 http://www.
lrec-conf.org/proceedings/lrec2014/pdf/299_Paper.pdf (Европейская ассоциация языковых ресурсов, Рейкьявик, 2014 г.).Аткинсон, К. Д. Фонематическое разнообразие поддерживает последовательную модель эффекта основателя языковой экспансии из Африки. Наука 332 , 346–349, https://doi.org/10.1126/science.1199295 (2011).
Артикул ОБЪЯВЛЕНИЯ КАС Google Scholar
Моран С., Гроссман Э. и Веркерк А. Исследование диахронических тенденций в фонологических инвентаризациях с использованием BDPROTO. Языковые ресурсы и оценка 55 , 79–103, https://doi.org/10.1007/s10579-019-09483-3 (2020).
Артикул Google Scholar
Everett, C. & Chen, S. Речь адаптируется к различиям в зубном ряду внутри и между популяциями. Scientific Reports 11 , 1–10, https://doi.
org/10.1038/s41598-020-80190-8 (2021).Артикул КАС Google Scholar
Моран, С. и Макклой, Д. PHOIBLE [Версия 2.0] https://phoible.org (Институт истории человечества им. Макса Планка, Йена, 2019 г.).
Мэддисон И. Звуковые паттерны . (Издательство Кембриджского университета, Кембридж и Нью-Йорк, 1984).
Книга Google Scholar
Форкель, Р. CLDFВиз. Библиотека Python, предоставляющая инструменты для визуализации данных из наборов данных CLDF [версия 0.5.0] https://pypi.org/project/cldfviz/ (Институт эволюционной антропологии Макса Планка, Лейпциг, 2021 г.).
Якобсон Р. Почему «мама» и «папа»? В Kaplan, B. & Wapner, S. (eds.) Перспективы психологической теории: Очерки в честь Хайнца Вернера , 124–134 (International University Press, Нью-Йорк, 1960).
Шаппер, А. Этнолингвистическая связь между обонянием и поцелуями: пример из Юго-Восточной Азии. Океаническая лингвистика 58 , 92–109, https://doi.org/10.1353/ol.2019.0004 (2019).
Артикул Google Scholar
Бао Х., Хауэр Б. и Кондрак Г. Об универсальных колексификациях. В материалах Proceedings of the Eleventh Global Wordnet Conference , 1–7 (Global Wordnet Association, Online, 2021).
Лист, Ж.-М., Майер, Т., Терхалле, А. и Урбан, М. CLICS: База данных кросс-лингвистических колексификаций [Версия 1.0] https://lingpy.org/clis/ (Forschungszentrum Deutscher Sprachatlas, Марбург, 2014 г.).
Браун, Ч. Х. Рука и рука. В Dryer, MS и Haspelmath, M. (eds.) The World Atlas of Language Structures Online https://wals.info/chapter/129 (Институт эволюционной антропологии Макса Планка, Лейпциг, 2013).
Чен, Цигуан 陳其光. Miàoyáo yŭwén 妙药语文 [Язык мяо и яо] (Zhōngyāng Mnzú Dàxué 中央民族大学 [Центральный институт меньшинств], Пекин, 2012).
Блумтритт, Дж. и Рау, Ф. Метаданные в Zeitalter поиска набора данных Google. Зенодо https://doi.org/10.5281/ZENODO.2613444 (2019).
Гейслер, Х.-Дж., Форкель, Р. и Лист, Дж.-М. The tableaux phonétiques des patois suisses romands online [Версия 1.0] https://tppsr.clld.org (Институт истории человечества им. Макса Планка, Йена, 2020 г.).
Джерарди Ф. Ф., Райхерт С. и Арагон С. С. TuLeD: Лексическая база данных Tupan [Версия 0.11 ] https://tular.clld.org (Институт эволюционной антропологии Макса Планка, Лейпциг, 2021 г.).
Тьюка, А. Добавление списков понятий в Concepticon: руководство для начинающих. Компьютерное сравнение языков на практике 3 , 1–10, https://calc.
hypotheses.org/2225 (2020).Google Scholar
Гронд, Ф. Р. и Тюфекчи, А. Компьютерное сравнение Gelong и Hlai с использованием кросс-лингвистических форматов данных. Компьютерное сравнение языков на практике 4 , 1–7, https://calc.hypotheses.org/2827 (2021).
Google Scholar
Мартинович, В. Преобразование готического словаря Штрейтберга в список слов CLDF в системе Windows. Компьютерное сравнение языков на практике 5 , 1–9, https://calc.hypotheses.org/3318 (2022).
Google Scholar
Гринхилл, С. Дж., Баст, Р. и Грей, Р. Д. База данных австронезийского базового словаря: от биоинформатики к лексомике. Эволюционная биоинформатика 4 , 271–283 (2008).
Артикул Google Scholar
Старостин Г. С., Крылов П. Глобальная лексикостатистическая база данных: Составление, уточнение, соединение базовой лексики по всему миру: от свободной формы к древовидной https://starlingdb.org/new100/ (рус. ГУ, Москва, 2011).
Сегерер, Г. и Флавье, С. RefLex: Справочный словарь Африки http://reflex.cnrs.fr (DDL, Lyon, 2015).
Матисофф, Дж. А. Китайско-тибетский этимологический словарь и тезаурус Проект https://stedt.berkeley.edu/ (Калифорнийский университет, Беркли, 2015 г.).
Greenhill, SJ TransNewGuinea.org: онлайн-база данных языков Новой Гвинеи. PLOS ONE 10 , 1–17, https://doi.org/10.1371/journal.
pone.0141563https://transnewguina.org (2015).Форкель Р., Банк С., Ржимски С. и Бибико Х.-Дж. CLLD: набор инструментов для межъязыковых баз данных [версия 7.2.0] https://pypi.org/project/clld/ (Институт эволюционной антропологии Макса Планка, Лейпциг, 2020 г.).
Эверетт К., Блази Д. Э. и Робертс С. Г. Климат, голосовые связки и тональные языки: соединение физиологических и географических точек. Proceedings of the National Academy of Sciences of the United States of America 112 , 1322–1327, https://doi.org/10.1073/pnas.1417413112 (2015).
Артикул ОБЪЯВЛЕНИЯ КАС пабмед ПабМед Центральный Google Scholar
Винтер, Б., Соскути, М., Перлман, М. и Дингеманс, М. Трель /r/ ассоциируется с шероховатостью, связывая звук и осязание в разговорных языках. Scientific Reports 12 , https://doi.org/10.1038/s41598-021-04311-7 (2022).
Бенц, К., Веркерк, А., Киела, Д., Хилл, Ф. и Баттери, П. Адаптивная коммуникация: Языки с большим количеством не носителей языка, как правило, имеют меньше словоформ. PLOS ONE 10 , e0128254, https://doi.org/10.1371/journal.pone.0128254 (2015).
Артикул КАС пабмед ПабМед Центральный Google Scholar
Бауэрн, К., Эппс, П., Хилл, Дж. и МакКонвелл, стр. Языки охотников-собирателей и их соседей [Версия от 27 апреля 2021 г.] https://huntergatherer.la.utexas.edu/ (Йельский университет, Нью-Хейвен, 2021 г.).
Андерсон, К. и др. . Межъязыковая база данных систем фонетической транскрипции. Ежегодник Познанско-лингвистической встречи 4 , 21–53, https://doi.org/10.2478/yplm-2018-0002 (2018).
Артикул Google Scholar
Лист, Дж.-М., Симс, Н.А. и Форкель, Р. На пути к устойчивой обработке текста с подстрочным глянцем в языковой документации. ACM Transactions on Asian and Low Resource Language Processing Information 20 , 1–15, https://doi.org/10.1145/3389010 (2021).
Артикул Google Scholar
Лист, Ж.-М. Сравнение последовательностей в исторической лингвистике https://sequencecomparison.github.io (Düsseldorf University Press, Düsseldorf, 2014).
Weiss, M. Сравнительный метод. В Бауэрн, К. и Эванс, Б. (ред.) Справочник Routledge по исторической лингвистике , 127–145 (Routledge, Нью-Йорк, 2015).
Бауэрн, К. Чирила: Современные и исторические ресурсы для языков коренных народов Австралии [Набор данных]. Языковая документация и сохранение 1–43 http://chirila.yale.edu/ (2016).
Скачать ссылки
Благодарности
Многие люди участвовали в подготовке отдельных наборов данных, которые были интегрированы в коллекцию Lexibank. Мы очень благодарны им за помощь в стандартизации наборов лексических данных. Эти участники перечислены как авторы, редакторы или в определенных ролях вместе с отдельными наборами данных Lexibank, заархивированными в Zenodo. Мы выражаем особую благодарность Тьяго Тресольди, Мей-Шин Ву, Юнфан Лаю и Хансу-Йоргу Бибико за помощь в подготовке отдельных наборов данных с использованием наших рабочих процессов, Квентину Аткинсону за обмен идеями в ходе первоначальных обсуждений сбора данных и Эбби Хантган. , Александр Савельев, Кэтрин Янг, Клэр Бауэрн, Дамиан Саттертуэйт-Филлипс, Фабрисио Ферраз Герарди, Фенг Ван, Фредерик Блюм, Герхард Ягер, Джордж С. Старостин, Гийом Сегерер, Джессика К. Ивани, Йоханнес Деллерт, Кай Сирьянен, Магнус Фарао Хансен , Мария Коптьевская-Тамм, Мэри Уолворт, Маурицио Серва, Майкл Данн, Мухаммад Закария, Наталья Морозова, Натан В. Хилл, Натаниэль А. Симс, Улоф Лундгрен, Пол Сидвелл, Шон Ли, Тиаго Ч. Чакон, Тимотеус А. Бодт, и Volker Gast за щедрый обмен данными и помощь в подготовке отдельных наборов данных. Особая благодарность также выражается различным командам, участвующим в поддержании и дальнейшем развитии наших трех основных справочных каталогов: Glottolog (Харальд Хаммарстрём, Мартин Хаспелмат и Себастьян Банк), Concepticon (Натанаэль Швайхард, Анника Тьюка, Кристина Пьяных, Каролин Хундт, Мей -Шин Ву, Тиаго Тресольди) и CLTS (Кормак Андерсон, Тиаго Тресольди). В рамках проекта CLLD (см. https://clld.org) и проекта Glottobank (см. https://glottobank.org) работа была поддержана Обществом Макса Планка, Институтом науки Макса Планка. истории человечества и Королевского общества Новой Зеландии (грант Фонда Марсдена 13-UOA-121). JML финансировался стартовым грантом ERC 715618 «Сравнение языков с помощью компьютера» (см. https://digling.org/calc/). SJG поддерживалась схемой финансирования Discovery Projects Австралийского исследовательского совета (номер проекта DE 1201019).54) и грант Центра передового опыта ARC по динамике языка (CE140100041).
Финансирование
Финансирование открытого доступа организовано и разрешено Projekt DEAL.
Информация об авторе
Авторы и организации
Департамент лингвистической и культурной эволюции, Институт эволюционной антропологии им. Макса Планка, Лейпциг, Германия
Иоганн-Маттис Лист, Роберт Форкель, Саймон Дж. и Рассел Д. Грей
Institut für Orientalistik, Indogermanistik, Ur- und Frühgeschichtliche Archäologie, Университет им. Фридриха Шиллера, Йена, Германия
Johann-Mattis List
ARC Center of Excellence for the National Dynamics of Language, Австралия Австралия
Саймон Дж.
ГринхиллШкола психологии Оклендского университета, Окленд, Новая Зеландия
Рассел Д. Грей
Авторы
- Johann-Mattis List
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
- Robert Forkel
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
- Simon J. Greenhill
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
- Christoph Rzymski
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
- Johannes Englisch
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
- Russell D. Gray
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
Взносы
Р. Д.Г. инициировал проект Lexibank в рамках более крупной инициативы Glottobank отдела лингвистической и культурной эволюции Института эволюционной антропологии им. Макса Планка в Лейпциге (бывший Институт истории человечества им. концептуальное сопровождение развития Лексибанка. Дж.М.Л., Р.Ф. и С.Дж.Г. последовательно разработали основные аспекты спецификации CLDF для обработки многоязычных списков слов, которые позже были расширены C.R., J.M.L., R.F. и С.Дж.Г. РФ написал первую версию программного пакета PyLexibank, а C.R., J.M.L. и С.Дж.Г. способствовало его дальнейшему развитию. Дж.М.Л. и Р.Ф. написал C.L. Пакет Toolkit, используемый для вычисления фонологических и лексических характеристик из списков слов в этом исследовании. Дж.М.Л. и Р.Ф. написал первую версию анализов, представленных в составе репозитория lexibank-analysed, а C.R. и J.E. внесли свой вклад в его дальнейшее развитие. Дж.М.Л. и Р.Ф. сделал графику для этого исследования. C.R., J.E., J.M.L., R.F. и С.Дж.Г. создавал, курировал, тестировал и архивировал наборы данных, опубликованные как часть коллекции Lexibank. Дж.М.Л. написали первый черновик, а J.M.L., R.D.G., R.F. и С.Дж.Г. расширил первый вариант. Все авторы переработали второй вариант и согласны с окончательным вариантом.
Авторы переписки
Переписка с Иоганн-Маттис Лист или Роберт Форкель.
Заявление об этике
Конкурирующие интересы
Авторы не заявляют об отсутствии конкурирующих интересов.
Дополнительная информация
Примечание издателя Springer Nature остается нейтральной в отношении юрисдикционных претензий в опубликованных картах и институциональной принадлежности.
Права и разрешения
Открытый доступ Эта статья находится под лицензией Creative Commons Attribution 4.0 International License, которая разрешает использование, совместное использование, адаптацию, распространение и воспроизведение на любом носителе или в любом формате при условии, что вы укажете автора(ов) оригинала и источник, ссылку на лицензию Creative Commons и указать, были ли внесены изменения. Изображения или другие сторонние материалы в этой статье включены в лицензию Creative Commons для статьи, если иное не указано в кредитной строке материала. Если материал не включен в лицензию Creative Commons статьи, а ваше предполагаемое использование не разрешено законом или выходит за рамки разрешенного использования, вам необходимо получить разрешение непосредственно от правообладателя. Чтобы просмотреть копию этой лицензии, посетите http://creativecommons.org/licenses/by/4.0/.
Перепечатка и разрешения
Об этой статье
Эту статью цитирует
Культурная эволюция эмоций
- Кристен А. Линдквист
- Джошуа Конрад Джексон
- Мария Гендрон
Обзоры природы Психология (2022)
Что такое классический подход к фонике?
Традиционный метод Либо пир, либо голод. Когда я учила своих детей читать, программ по фонетике было так мало, что я не знала, где их найти.
Обучение акустике почти исчезло в 1930-х годах и начало возрождаться только в 1970-х. Сейчас так много звуковых программ на выбор, что голова идет кругом. Как вы оцениваете и сравниваете все эти программы, чтобы решить, какая из них лучше для вас? И что более важно для нас, классических педагогов, существует ли классический подход к фонетике, и если да, то какой?
В движении классического образования было два ответа на этот последний вопрос. С одной стороны, есть те, кто считает, что Путь письма к чтению (WRTR) Ромальды Спалдинг — это настоящий классический подход, а все остальное лучше всего можно описать как «облегченная акустика». С другой стороны, ведущие издательские компании движения — Veritas Press, Memoria Press и Peace Hill Press — не используют метод Сполдинга, и фактически все они написали свои собственные фонические программы.
Я утверждаю, что метод Сполдинга настолько уникален, что первое разделение фонетических программ в мире домашнего обучения находится между программами типа Сполдинга и всем остальным. Все остальное, я думаю, можно точно описать как традиционную фонетику. Какой подход лучше, или они оба одинаково эффективны? Я опишу каждый, а затем приведу сравнение, чтобы дать читателю инструменты для ответа на этот вопрос.
Во-первых, давайте рассмотрим традиционную акустику, из которой можно выбрать множество программ. Это правда, что у каждого есть немного разные акценты и разные навороты. Некоторые написаны для матери, обучающейся на дому, в неформальной обстановке; некоторые написаны для класса. Некоторые включают инструкцию по печати; некоторые нет. Некоторые программы фонетики продолжаются на протяжении всей начальной школы и включают правописание и грамматику; другие просто охватывают основы. Некоторые учат смешиванию гласных и согласных, а другие — смешению согласных и гласных. В некоторых есть много песен, джинглов и веселых занятий; другие — голые кости. Некоторые из них лечебные; другие ускоряются. У некоторых есть специальные системы маркировки. Но, за немногими исключениями, все они используют ту или иную версию традиционного масштаба и последовательности, поэтому все они могут быть классифицированы как традиционные.
Какие характеристики традиционной фонетики являются общими для всех этих программ?
Первый принцип традиционной фонетики заключается в том, чтобы научиться различать буквы и звуки, которые представляет каждая буква. Традиционная фонетика — это синтетическая фонетика: она начинается с букв, а не со слов. Студенты сначала учат один звук для каждого согласного и краткий звук для каждой гласной, чтобы строить (синтезировать) слова. Звуки, которые представляют буквы, изучаются изолированно, прежде чем начинать смешивание и чтение.
Второй принцип традиционной фонетики – это обширная практика со словами «согласная-короткая гласная-согласная» (CVC) в качестве основы чтения. Именно со словами CVC учащиеся учатся смешивать звуки букв в словах слева направо. Именно со словами CVC студенты продолжают практиковать и осваивать наиболее распространенный звук каждой из 26 букв. Именно со словами CVC учащиеся тренируются различать эти очень важные, но очень нюансированные короткие гласные звуки (9). 1549 сумка, попрошайка, большая, болотная, жучок ). Кроме того, шаблон CVC является строительным блоком многих многосложных слов.
Третий принцип традиционной фонетики — это систематическое представление английских орфографических моделей в логической и проверенной временем последовательности, от более простого к более сложному. Несмотря на то, что после слов CVC порядок несколько гибкий, типичная последовательность основных орфографических (фонических) паттернов, описанных в начальной фонетике, будет следующей:
- CVC слова: согласные-краткие гласно-согласные слова ( pat, pet, pit, pot, put )
- сочетания начальных/конечных согласных ( s/l/r -сочетания: sc, sl, sm, bl, cl, fl, dr, gr, pr и т. д.)
- 4 ч -орграфы ( ч, ш, ч, ч )
- долгие гласные с немыми e ( ат-ат, мат-мат и т.д.)
- команды долгих гласных (ay, ai, oa, ee и т. д.)
- три звука у
- мягкий и твердый c и g
Хотя точный порядок и выбор звуковых паттернов могут различаться, важно то, что каждый из них практикуется в семействе слов, которое иллюстрирует этот паттерн. Примером семейства слов являются 45 общеупотребительных слов, которые пишутся как long a с командой гласных ai : maid, nail, brain и т. д. Благодаря этому систематическому изучению орфографических моделей и семейств слов учащиеся изучают тысячи слов и навыки декодирования, чтобы прочитать еще тысячи. Традиционная фонетическая последовательность эффективна, потому что она систематична, а не случайна. Он раскрывает основной порядок большого разнообразия английских орфографических моделей, по одной модели за раз. Это упорядоченное представление помогает памяти и является сердцем фонетики. Без него многие учащиеся не в состоянии распознавать, осваивать и бегло читать английские слова, поскольку в английском языке самое неправильное написание из всех современных языков.
Кроме того, учащиеся развивают зрительную память, необходимую для написания английских слов, которые имеют несколько вариантов написания одного и того же звука (существует семь распространенных способов написания длинного звука o ). Если вы можете произнести слово лодка с помощью oa вместо bote , то это не потому, что вы запомнили правило, а потому, что выучили его в семействе слов и видели, как оно пишется правильно тысячу раз. Существует очень мало полезных правил, которые помогут вам выбрать один из возможных вариантов правописания в английском языке.
Однако в традиционной фонетике правописание является вторичным по отношению к чтению. Учащиеся могут читать раньше своих орфографических способностей. Хотя правописание важно, оно не должно замедлять беглость чтения или мешать ему. Образцы правописания преподаются сначала с целью декодирования, а затем с целью кодирования (орфографии).
Пока учащиеся изучают основы фонетики, они тренируют свои новые фонетические навыки, читая рассказы с высоким процентом простых фонетических слов, например, «Кошка на коврике». После достаточной практики и освоения наиболее распространенных шаблонов учащиеся переходят от фонетического чтения к книгам с более богатым и естественным словарным запасом. В какой-то момент в первом или втором классе чтение начинает налаживаться, и большинство учеников начинают читать задолго до того, как начнутся занятия по фонетике. В этот момент уроки фонетики начинают переходить в уроки орфографии, которые продолжают закреплять навыки чтения и правописания на протяжении всей начальной школы.
Некоторые ведущие программы традиционной фонетики
- Word Mastery , Флоренс Акин, 1913 г., является примером фонетики до появления чтения целиком. (отредактировано и перепечатано MP как Classical Phonics )
- A Guide to Teaching Phonic s, Джун Лайдей Ортон, 1964, Акустика Ортона-Джиллингема для учащихся с дислексией
- Профессор акустики дает совет по звуку , сестра Моника Фолцер, 1966 г., является одной из первых звуковых программ, вновь появившихся после исчезновения акустики в XIX веке. 30 с. Это была программа, которую использовала Марва Коллинз.
- Взрывайте код, 1976, Издательская служба для преподавателей
- АБека Фоникс
- Alpha Phonics , Сэмюэл Блюменфельд, 1985
- Phonics Pathways , Долорес Хискес
- SRA Phonics , Макгроу Хилл
- Руководство для обычных родителей по обучению чтению , Джесси Уайз и Сара Баффингтон, 2005 г.
- Начальная акустика , 2005 г., Издательская служба преподавателей .
- Музей акустики , Veritas Press
- Первое чтение , 2010, Memoria Press
Метод Сполдинга
Метод Сполдинга ( Путь письма к чтению ) настолько уникален, что я разделил все звуковые программы на две категории: традиционный метод и метод Сполдинга.
Метод Сполдинга (WRTR) был очень популярен в классическом образовании, и, хотя он не так широко используется среди домашних школьников из-за его сложности, он может быть наиболее часто используемой фонетической программой в классических школах.
Программа Spalding была создана г-жой Ромальдой Spalding, которая имела диплом Педагогического колледжа Колумбийского университета и обучала нескольких студентов с нарушениями чтения. Затем она разработала свою собственную программу, предназначенную для обучения всех учащихся, а не только тех, у кого дислексия. В 1957 г. миссис Сполдинг опубликовала свой метод в 300-страничном руководстве «Письменный путь к чтению » (WRTR), работе, которая оказалась слишком сложной для расшифровки средним родителем/учителем и, следовательно, породила ряд побочные продукты, программы, предназначенные либо для помощи в реализации WRTR как есть, либо модифицированные программы WRTR.
Хотя существует два более поздних издания WRTR, я ссылаюсь на издание 1990 года, поскольку оно является последним, подготовленным самой миссис Сполдинг, и поэтому должно быть наиболее точным описанием ее метода. WRTR трудно понять, и я потратил много времени и сил на то, чтобы понять его и представить точно и честно. Без сомнения, между этим описанием и ответвлениями, упомянутыми выше, будут различия.
Краткое изложение WRTR
Фонограммы : Фонограмма представляет собой букву или группу букв, обозначающую звук. Студенты изучают общие звуки 70 фонограмм изолированно, 54 до начала чтения и 16 после. 46 фонограмм содержат только один звук, 11 – два звука, 13 – три и более звуков. Первые 54 фонограммы — это 26 букв алфавита плюс эр, ир, ур, вор, ухо, ш, ее, й, ай, ай, ой, оу, ой, ой, ав, ау, ью, уй, оо , ch, ng, ea, ar, ck, ed или, wh, oa .
Фонограммы преподаются с помощью дидактических карточек и диктантов. Уроки являются мультисенсорными, то есть учащиеся слышат, говорят, видят и пишут фонограммы и пишут слова.
Правописание слов: Учащиеся изучают правописание наиболее распространенных слов на основе расширенного списка английских слов 1915 года Айерса в порядке частоты использования. Студенты изучают 30 орфографических слов в неделю путем анализа с использованием фонограмм и правил правописания/фоники. Перед началом чтения учащиеся изучают 150 наиболее распространенных слов и продолжают изучать правописание 780 слов в 1 классе и 1700 слов в 4–6 классах.
Чтение: Поскольку орфография является основным направлением программы Spalding, обучение чтению напрямую не рассматривается. Однако чтение начинается через 2-3 месяца после начала программы, после того как выучены 54 фонограммы и 150 высокочастотных слов.
Правила правописания/орфографии: Учащиеся изучают 29 правил правописания/орфографии по мере необходимости на еженедельных уроках правописания. Студенты не должны запоминать правила, но должны уметь их распознавать или применять.
Записная книжка по правописанию: Каждый год учащиеся создают свою собственную тетрадь для правописания, в которую они записывают слова и правила правописания каждого года и предыдущего года. Слова маркируются в соответствии с системой маркировки Spalding.
Система выставления оценок: В системе выставления оценок краткие гласные отсутствуют, для долгих гласных подчеркивание, а для дополнительных гласных — число. Система маркировки остальных фонограмм – номер звука на оборотной стороне карточки фонограммы, если это не первый звук. Все двухбуквенные фонограммы подчеркиваются один раз, а если звук фонограммы не один на карточках фонограмм, то подчеркиваются два раза.
Оценка: Часто проводятся оценки с использованием тестов Моррисона-Макколла для проверки орфографии и тестов Макколла-Краббса для понимания прочитанного.
Сравнение традиционной акустики и метода Сполдинга
- Сполдинг обучает 45 фонограммам под диктовку перед началом чтения.
Традиционная фонетика обучает только 26 буквам алфавита, прежде чем смешивать и произносить слова. Многие программы начинают смешивание, как только вы выучите звуки нескольких букв. - Spalding обучает всем основным звукам для каждой из фонограмм с самого начала.
Традиционная акустика изначально обучает только одному звуку для каждой буквы, особенно для кратких гласных звуков. - Spalding не рекомендует слова-подсказки для запоминания звуков фонограммы.
Традиционная фонетика использует слова-подсказки, такие как яблоко, яйцо, иглу, осьминог, зонтик для коротких гласных или еда и футов для оо . - Spalding уделяет особое внимание анализу; учащиеся анализируют целые слова, используя фонограммы и правила правописания.
Традиционная акустика делает упор на синтез; учащиеся начинают с отдельных звуков букв, которые смешиваются в слова слева направо. - Spalding обучает 29 правилам правописания/фоники, которые используются для анализа 1700 наиболее распространенных слов английского языка.
Орфографические/фонические правила минимальны в большинстве традиционная акустических программы. - Spalding обучает звуковым паттернам в том виде, в каком они встречаются в высокочастотных словах, порядок которых, по необходимости, является случайным.
Традиционная акустика обучает звуковым моделям в логическом порядке, начиная с самых обычных слов CVC и переходя от более простых к более сложным. - Spalding включает все слова в уроки орфографии, а не идентифицирует некоторые из них как слова с листа (см. ниже).
Традиционная фонетика вводит слова, необходимые для написания и чтения простых предложений. - Согласно WRTR, ученики Spalding начинают читать с настоящих книг и пропускают базовые и фонетические чтения.
Традиционный Студенты, изучающие фонетику, начинают чтение с простых фонетических чтений. - Spalding специально избегает семейств слов.
В традиционной акустике учащиеся практикуют каждый новый фонический образец в семействах слов. - Spalding обучает правильному написанию часто употребляемых слов как основе чтения.
Традиционная фонетика обучает распознаванию орфографических моделей, начинающихся со слов CVC, в качестве основы для чтения.
Что такое визуальные слова?
Некоторые родители боятся «видящих слов». Они были настолько дискредитированы методом обучения чтению «посмотри-скажи», что любое появление видящего слова является признаком компромисса с дьяволом «посмотри-скажи». Но в традиционной фонетике они необходимы.
Для того, чтобы составлять простые предложения с фонетическими словами, необходимо попутно учить зрительные слова. Причина в том, что многие из наших самых распространенных слов являются неправильными и, следовательно, не встречаются в начале звуковой последовательности.
Многие из этих общеупотребительных слов, таких как the, as, she и go , на самом деле не являются неправильными, но часто изучаются вне последовательности, до того, как будет изучена их фонетическая модель. Изучение отдельных слов, не входящих в орфограмму конкретного урока, не вызывает у учащихся затруднений и не отвлекает от систематического изложения фонетики.
Другие слова, такие как come, some и say , нарушают правила, но все же содержат фонетические элементы, которые можно произнести. Лишь несколько слов, таких как of, eye, и one , настолько нефонетичны, что лучше просто выучить их наизусть.
Spalding & Orton-Gillingham
Почему Spalding и Orton-Gillingham так тесно связаны и какова истинная связь между ними? Ромальда Сполдинг действительно обучала нескольких студентов под руководством доктора Ортона, и она действительно ссылается и приписывает ему список фонограмм, которые она использует в WRTR.
Более важным является утверждение миссис Сполдинг во введении к WRTR, что ее вклад «главным образом заключался в том, чтобы превратить обучение доктора Ортона в метод преподавания в классе». Поскольку Академия Ортона малоизвестна, утверждение Ромальды Сполдинг никогда не подвергалось сомнению.
Я внимательно изучил «Руководство по преподаванию фонетики » миссис Ортон , а также другие программы с логотипом Orton — Explode the Code и Primary Phonics — и нашел их в каждом из десяти пунктов. сравнения на предыдущей странице, чтобы быть четко в традиционной колонке.
Гид миссис Ортон, например, начинает смешивать слова CVC на первом уроке, когда выучены только пять согласных и короткая гласная a. Первоначально для каждой буквы преподается только один звук, и каждый новый образец правописания отрабатывается в семействах слов. Зрительные слова преподаются по мере необходимости, чтобы учащиеся могли читать предложения. В руководстве нет ни одной уникальной функции Spalding; нет ни списка правил правописания, ни орфографической тетради, ни системы оценок, ни правописания высокочастотных слов. Метод Ортона во всех отношениях является традиционной фонетической программой.
В заключение следует отметить, что WRTR является собственным творением миссис Сполдинг, имеющим слабое отношение к методу Ортона-Гиллингема или ко всей традиции традиционной фонетики.
Первоначально опубликовано в летнем выпуске The Classical Teacher за 2014 год.
Фонетика — Лингвистика — Oxford Bibliographies
Введение
Фонетику можно определить как науку о речи. Он касается всех аспектов производства, передачи и восприятия звуков языка. Согласно одному взгляду на объем термина «лингвистика», фонетику можно рассматривать как самостоятельную дисциплину наряду с лингвистикой или, альтернативно, как ее компонент, хотя вторая интерпретация может подразумевать сужение предмета только теми аспектами, которые рассматриваются непосредственно. имеет отношение к лингвистическому анализу и теории. Термины «наука (науки) о речи» или «фонетическая наука (науки)», встречающиеся в названиях книг или в названиях академических программ и кафедр, эквивалентны фонетике в ее более широком смысле, используемой для того, чтобы настаивать на широком круге задач и научной основе науки. дисциплина. Слово «фонетический» и его производные начали использоваться в английском языке в 1840-х годах, и хотя значительные открытия в науке о речи можно проследить в целом ряде культурных традиций (и в истории вплоть до античности), современная форма предмета в основном 19Европейское творение го века. Вклад британских пионеров А. Дж. Эллиса (р. 1814–ум. 1890) и А. М. Белла (р. 1819–ум. 1905) был особенно важен, а последующее установление фонетики как основы лингвистической науки в целом можно объяснить, в частности, влияние Генри Свита (р. 1845–ум. 1912) и Эдуарда Сиверса (р. 1850–ум. 1932). Доминировавшая в то время сравнительно-историческая лингвистика с тех пор уступила место нескольким изменениям парадигмы, хотя фонетика сохранила свою позицию того, что Свит назвал «необходимой основой» изучения языка. С середины 19Поэтому фонетика имеет непрерывную и кумулятивную историю как междисциплинарная область, расположенная на трехстороннем пересечении биомедицинских наук (сначала, в основном физиологии), физических наук (в первые дни, главным образом, акустики) и лингвистических наук. . Каждая из этих областей претерпела радикальную диверсификацию и развитие, в результате чего общее поле фонетики теперь огромно. Поэтому любая попытка библиографии должна быть очень избирательной.
Учебники и введение
Предмет фонетики хорошо обеспечен многочисленными превосходными учебниками. На протяжении более чем одного поколения выдающийся курс Питера Ладефогеда по фонетике был наиболее широко используемым учебным пособием и остается единственной лучшей отправной точкой для всех, кто плохо знаком с предметом. Первое издание вышло в 1975 г. и сразу же стало эталоном благодаря четкому изложению, множеству примеров из оригинальных полевых исследований, великолепным диаграммам и упражнениям по решению задач. Он охватывает традиционную описательную фонетику (включая обучение практическим навыкам производства и аудирования), акустику и связь с фонологией через систему фонетических признаков. Этот последний аспект был связан с более ранней работой Ладефогеда над системами признаков, изложенной в Ladefoged 19.71 (цитируется в разделе «Фонологические особенности и процессы») и вызвал бурную дискуссию в фонологическом климате того времени, но был значительно изменен и уменьшен в более поздних изданиях. При жизни автора вышло пять изданий, шестое было посмертно исправлено и дополнено К. Джонсоном (Ladefoged, Johnson, 2011). Ладефогед был самым энергичным и плодовитым фонетиком своего времени. Его письмо ясное и дружелюбное к ученикам, а с годами его стиль становился все более личным и увлекательным. Кларк и др. 2007 — третье издание содержательного учебника, впервые появившегося в 1989. Он имеет широкий охват, включая фонологию, а также многие аспекты фонетики; он также содержит исчерпывающие ссылки и обширную библиографию. Несколько других общих работ следуют тому же всеобъемлющему плану, в некоторой степени охватывая артикуляцию, транскрипцию, производство речи и акустику речи, иногда с четкой целью предоставить текст, который может поддержать программу получения степени в области клинических наук о речи: примеры: Hewlett and Beck 2006. и Рафаэль и др. 2007. На более вводном уровне Ashby and Maidment 2005 представляет собой широко распространенный текст, целью которого является объединение традиционных описательных и экспериментальных подходов. Среди успешных текстов с небольшим экспериментальным содержанием или без него — Collins and Mees 2008 и Roach 2009. . На вводном уровне Ashby 2005 был особенно успешным. Он касается только традиционной описательной фонетики и использования фонетических символов.
Эшби, Майкл и Джон А. Мейдмент. 2005. Введение в фонетику . Кембриджское введение в язык и лингвистику. Кембридж, Великобритания: Кембриджский унив. Нажимать.
DOI: 10.1017/CBO9780511808852
Вводный текст, объединяющий описательный и экспериментальный подходы. В дополнение к основным темам фонетического описания и классификации это включает краткое освещение фонологии, надсегментов и восприятия речи. Имеет упражнения (с ответами) и вспомогательный веб-сайт.
Эшби, Патрисия. 2005. Звуков речи . 2 изд. Языковые рабочие тетради. Лондон: Рутледж.
Популярное и очень удобное для студентов введение в основы фонетической классификации и транскрипции до уровня, подходящего для первого экзамена (например, сертификационного экзамена Международной фонетической ассоциации).
Многочисленные упражнения (с ответами) и могут быть использованы для самообучения. Первоначально опубликовано в 1995 году; второе издание также доступно в виде электронной книги (2008 г.).Кларк, Джон, Колин Яллоп и Джанет Флетчер. 2007. Введение в фонетику и фонологию . 3-е изд. Учебники Блэквелла по лингвистике 9. Малден, Массачусетс: Wiley-Blackwell.
Самый содержательный комбинированный фонетико-фонологический текст. Последующие издания издаются уже более двадцати лет. Довольно большая библиография и, таким образом, хорошая отправная точка для более углубленного изучения.
Коллинз, Беверли и Ингер М. Мис. 2008. Практическая фонетика и фонология: Пособие для студентов . 2 изд. Лондон: Рутледж.
Основное заглавие дает мало информации о содержании, хотя «книга ресурсов» ближе к исключительно широкому кругу тем и материалов. Включает артикуляционную фонетику и много информации об акцентах английского языка (как британского, так и мирового).
В разделе «Дополнения» представлены хорошо подобранные чтения, устанавливающие фонетику в более широком контексте. Глоссарий технических терминов, аннотированная библиография и отличный компакт-диск.Хьюлетт, Найджел и Дж. Маккензи Бек. 2006. Введение в науку о фонетике . Махва, Нью-Джерси: Лоуренс Эрлбаум.
Очень содержательный текст от двух уважаемых учителей и исследователей.
Ладефогед, Питер и Кит Джонсон. 2011. Курс фонетики . 6-е изд. Бостон: Cengage.
Последнее издание лучшего вступительного текста. К книге прилагается компакт-диск с речевыми примерами, большая часть которых также находится в свободном доступе в Интернете.
Рафаэль, Лоуренс Дж., Глория Дж. Борден и Кэтрин С. Харрис. 2007. Учебник по речевым наукам: физиология, акустика и восприятие речи . 5-е изд. Балтимор: Липпинкотт, Уильямс и Уилкинс.
Первоначально опубликовано в 1980 году под авторством Бордена и Харриса и широко используется в качестве учебника для курсов по патологии речи и терапии.
Сосредоточены на различных конституирующих науках. Его избегание термина «фонетика» может означать, что искусство и навык распознавания и транскрипции звуков принадлежат к другому типу дисциплины.Роуч, Питер. 2009. Фонетика и фонология английского языка: Практический курс . 4-е изд. Кембридж, Великобритания: Кембриджский унив. Нажимать.
Простой, но точный отчет, предназначенный в основном для изучающих английский язык, но полезный для любого начинающего студента, регулярно пересматриваемый и обновляемый. В первом издании (1983 г.) была отдельная книга для наставников.
наверх
Пользователи без подписки не могут видеть весь контент на эта страница. Пожалуйста, подпишитесь или войдите.
Как подписаться
Oxford Bibliographies Online доступен по подписке и с бессрочным доступом к учреждениям. Чтобы получить дополнительную информацию или связаться с торговым представителем Oxford, нажмите здесь.
Греко-римская традиция | Оксфордская история фонологии
Фильтр поиска панели навигации Oxford AcademicОксфордская история фонологииФонетика и фонологияПсихолингвистикаКнигиЖурналы Мобильный телефон Введите поисковый запрос
Закрыть
Фильтр поиска панели навигации Oxford AcademicОксфордская история фонологииФонетика и фонологияПсихолингвистикаКнигиЖурналы Введите поисковый запрос
Расширенный поиск
Иконка Цитировать Цитировать
Разрешения
- Делиться
- Твиттер
- Подробнее
Укажите
Сен, Ранджан, «Греко-римская традиция», в Б. Элан Дрешер и Гарри ван дер Халст (ред.), The Oxford History of Phonology (
, 2022; онлайн-издание, Oxford Academic, 19 мая 2022 г.), https://doi.org/10.1093/oso/9780198796800.003.0006, по состоянию на 4 марта 2023 г.
Выберите формат Выберите format.ris (Mendeley, Papers, Zotero).enw (EndNote).bibtex (BibTex).txt (Medlars, RefWorks)
Закрыть
Фильтр поиска панели навигации Oxford AcademicОксфордская история фонологииФонетика и фонологияПсихолингвистикаКнигиЖурналы Мобильный телефон Введите поисковый запрос
Закрыть
Фильтр поиска панели навигации Oxford AcademicОксфордская история фонологииФонетика и фонологияПсихолингвистикаКнигиЖурналы Введите поисковый запрос
Advanced Search
Abstract
Греко-римская грамматическая традиция выкристаллизовала большую часть лингвистического метаязыка, используемого сегодня, либо в виде греческих форм, либо в виде латинских кальк. Грамматика стала объяснять любой случай языка, устного или письменного, и превратилась из практической в научную дисциплину (греч. τέχνη 9).1549 техне , лат. ars ), со своим набором правил. Решающие наблюдения и аналитические инструменты в организации звуков — аллофония, естественные классы, акцентуация, слоговая структура и вес, фонологические процессы, морфофонологическое чередование и абстрактные основные основы — могут быть причислены к вкладу древних западных грамматиков, а фонологическое изменение было отмечается путем цитирования старых форм или осуждения новых. Впоследствии эта традиция легла в основу средневековой и более поздней лингвистики в Европе и на востоке, и многие из ее тем сохранялись на протяжении всей лингвистической истории.
Ключевые слова: Древнегреческий язык, латынь, грамматики, произношение, аллофония, просодия, ударение, слог, фонологические процессы, морфофонологическое чередование
Предмет
Фонетика и фонологияПсихолингвистика
В настоящее время у вас нет доступа к этой главе.
Войти
Получить помощь с доступом
Получить помощь с доступом
Доступ для учреждений
Доступ к контенту в Oxford Academic часто предоставляется посредством институциональных подписок и покупок. Если вы являетесь членом учреждения с активной учетной записью, вы можете получить доступ к контенту одним из следующих способов:
Доступ на основе IP
Как правило, доступ предоставляется через институциональную сеть к диапазону IP-адресов. Эта аутентификация происходит автоматически, и невозможно выйти из учетной записи с IP-аутентификацией.
Войдите через свое учреждение
Выберите этот вариант, чтобы получить удаленный доступ за пределами вашего учреждения. Технология Shibboleth/Open Athens используется для обеспечения единого входа между веб-сайтом вашего учебного заведения и Oxford Academic.
- Нажмите Войти через свое учреждение.
- Выберите свое учреждение из предоставленного списка, после чего вы перейдете на веб-сайт вашего учреждения для входа.
- Находясь на сайте учреждения, используйте учетные данные, предоставленные вашим учреждением. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если вашего учреждения нет в списке или вы не можете войти на веб-сайт своего учреждения, обратитесь к своему библиотекарю или администратору.
Войти с помощью читательского билета
Введите номер своего читательского билета, чтобы войти в систему. Если вы не можете войти в систему, обратитесь к своему библиотекарю.
Члены общества
Доступ члена общества к журналу достигается одним из следующих способов:
Войти через сайт сообщества
Многие общества предлагают единый вход между веб-сайтом общества и Oxford Academic. Если вы видите «Войти через сайт сообщества» на панели входа в журнале:
- Щелкните Войти через сайт сообщества.
- При посещении сайта общества используйте учетные данные, предоставленные этим обществом. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если у вас нет учетной записи сообщества или вы забыли свое имя пользователя или пароль, обратитесь в свое общество.
Вход через личный кабинет
Некоторые общества используют личные аккаунты Oxford Academic для предоставления доступа своим членам. См. ниже.
Личный кабинет
Личную учетную запись можно использовать для получения оповещений по электронной почте, сохранения результатов поиска, покупки контента и активации подписок.
Некоторые общества используют личные аккаунты Oxford Academic для предоставления доступа своим членам.
Просмотр учетных записей, вошедших в систему
Щелкните значок учетной записи в правом верхнем углу, чтобы:
- Просмотр вашей личной учетной записи и доступ к функциям управления учетной записью.
- Просмотр институциональных учетных записей, предоставляющих доступ.
Выполнен вход, но нет доступа к содержимому
Oxford Academic предлагает широкий ассортимент продукции. Подписка учреждения может не распространяться на контент, к которому вы пытаетесь получить доступ. Если вы считаете, что у вас должен быть доступ к этому контенту, обратитесь к своему библиотекарю.
Ведение счетов организаций
Для библиотекарей и администраторов ваша личная учетная запись также предоставляет доступ к управлению институциональной учетной записью. Здесь вы найдете параметры для просмотра и активации подписок, управления институциональными настройками и параметрами доступа, доступа к статистике использования и т. д.
Покупка
Наши книги можно приобрести по подписке или купить в библиотеках и учреждениях.
Информация о покупке
Фонетическое правописание для лучшего произношения
Правописание означает составление слова из букв по установленным правилам. Обычно под орфографией мы понимаем, какие буквы использовать и в каком порядке при написании слова. Но фонетическое написание служит нам немного больше. Он учит нас произносить слова!
Для человека, изучающего новый язык или борющегося с произношением имени, фонетическая орфография бесценна. В этой статье вы узнаете больше о том, как использовать этот метод, чтобы улучшить не только свои навыки правописания, но и навыки говорения и восприятия на слух.
Определение фонетического правописания
Давайте начнем с основ. Что такое фонетическая орфография? Это устройство для произношения, которое требует написания слов в соответствии с тем, как произносится каждый слог. Проще говоря, фонетическое написание — это способ написать слово так, как оно звучит.
В фонетическом методе правописания каждому звуку присваивается по крайней мере одна буква или сочетание букв. Но бывают случаи, когда буква или сочетание букв звучит по-разному или один и тот же звук пишется по-разному. В этих случаях пригодится фонетическая орфография.
Рассмотрим слово «Бумага». Букве P соответствует звук /p/. Но если P в паре с H, например, в Photo, ph звучит как /f/.
Аналогично T в Table присваивается звук /t/. Но в сочетании с h, например, в This, он создает новый звук. Но опять же, th в this и th в thin звучат по-разному. Трудно понять разницу, если вы изучаете слово, читая.
Теперь подумайте о слове «Картофель». Возможно, вы хотите произнести его как «po-ta-to», но на самом деле это слово произносится как «puh-tei-tow».
Точно так же, согласно фонетическому написанию, «банан» должно быть «бух-нАн-ух». Это написание говорит вам сделать ударение на букве А в середине слова, которая не может быть известна из традиционного написания.
Чем полезна фонетическая орфография?
Английский язык непростой. Существует множество правил и моделей правописания и столько же исключений из этих правил. Общая проблема, с которой мы все сталкиваемся, заключается в том, что написание слова часто отличается от того, как оно звучит, что затрудняет как устную, так и письменную речь.
Но как фонетическая орфография может помочь в этой ситуации?
Вот несколько случаев, которые помогут вам лучше понять:
- В случаях публичных выступлений, таких как выступления, чтение новостей, объявление имен на выпускных церемониях или спортивных мероприятиях, фонетическая орфография очень помогает.
- Это звуковое руководство по произношению, которое особенно полезно для необычных терминов, таких как медицинская или инженерная терминология, кулинарные термины и т. д.
- Международный фонетический алфавит (IPA) содержит символы для различных звуков, которые являются общими для всех языков. Так что если вы изучаете новый язык помимо родного, это во многом вам поможет.
- Фонетическая орфография проста в использовании для всех уровней учащихся.
- Ученики детского сада легко пишут слова с фонетической орфографией. Например: «Летучая мышь» звучит именно так, как пишется.
- Учащиеся ESL могут разложить слова на звуки, чтобы выучить слова.
- Если вы являетесь носителем языка или находитесь на продвинутом уровне, попробуйте этот метод, чтобы улучшить беглость речи и словарный запас.
- Наряду с улучшением произношения вы получаете более четкое представление о стиле речи на языке. Таким образом, вы сможете улучшить свои разговорные навыки во время изучения нового языка.
- Фонетическая орфография также поможет вам улучшить навыки слушания. Вы будете иметь лучшее представление об акцентах и сможете лучше понимать речь. Этот конкретный навык пригодится в тестах на прослушивание.
Например, предположим, что вы используете тест правописания SpellQuiz для проверки своих навыков правописания. В этом тесте вам нужно написать слова, которые вы слышите. Поэтому, если вы знаете, как звучит слово и с каким акцентом говорит говорящий, у вас не возникнет проблем с ответом, и вы быстро повысите уровень!
Фонетический этап развития правописания является очень важным этапом для любого нового ученика. Ознакомьтесь с нашей дополнительной статьей по теме!
Фонетический алфавит правописания
Международный фонетический алфавит (IPA) — это система, в которой каждому звуку в английском языке соответствует символ. С помощью этого метода вы можете научиться правильно произносить определенное слово на английском языке.
Вот несколько примеров алфавитов:
Краткие гласные
Символ IPA | Примеры слов |
и | Согните, господа, десять, лучше. |
æ | Кошка, а, кепка, толстая, у. |
? | Беги, любовь, дорогая, раз, приходи, уходи |
? | Положить, Книга, мог бы, уголок, бы, настроение, ботинок |
? | Початок, поп, спичка, приседание, колбаса. |
? | Жива, опять мама. |
Долгие гласные
Символ IPA | Примеры слов |
я: | Бесплатно, аккуратно, луч, команда |
?: | Прокляни, услышь, птица, сожги. |
?: | Разговор, лапа, скучно, рассвет, челюсть. |
и: | Мало, сапог, терять, хмурый, фрукты, жевать. |
?: | Быстро, машина, жестко, ванна. |
Гласные дифтонга
Символ IPA | Примеры слов |
?? | Рядом, ухо, ясно, слеза, пиво, страх |
е? | Волосы, там, уход, лестница, груша |
е? | Лицо, космос, дождь, чехол, восьмерка |
?? | Радость, найм, игрушка, катушка, устрица. |
а? | Мой, взгляд, гордость, добрый, полет |
?? | Нет, не надо, камни, одни, отверстие |
а? | Рот, дом, коричневый, корова, снаружи |
Щелевые согласные
Символ IPA | Примеры слов |
ф | Полный, пятница, рыба, нож. |
против | Жилет, деревня, вид, пещера. |
? | Подумай, подумай, Баня. |
ð | Там, те, братцы, другие. |
Зоопарк, сумасшедший, ленивый, зигзаг, нос. | |
? | Рубашка, спешка, магазин, нал. |
? | Телевидение, бред, случайный |
ч | Высокий, помогите, привет. |
Взрывные согласные
Символ IPA | Примеры слов |
р | Штифт, колпачок, цель, пауза. |
б | Сумка, пузырь, сборка, халат. |
т | Время, поезд, буксир, поздно. |
д | Дверь, день, диск, вниз, подача. |
к | Наличные, быстро, крикет, носок. |
г | Девушка, зелень, трава, флаг. |
Аффрикаты согласных
Символ IPA | Примеры слов |
?? | Выбирай, сыр, церковь, часы. |
д? | Радость, жонглирование, сок, сцена. |
Носовые согласные
Символ IPA | Примеры слов |
м | Комната, мать, сумасшедшая, больше. |
п | Теперь, никто, не знал, очередь. |
? | Король, вещь, песня, плавание. |
Аппроксимантные согласные
Символ IPA | Примеры слов |
р | Дорога, розы, река, кольцо, катание. |
и | Жёлтый, обычный, мелодия, вчерашний, дворовый. |
с | Стена, прогулка, вино, мир. |
л и ? | Закон, жребий, прыжок, длинный, пилюля, холод, холод, таяние. |
Многие взрослые сталкиваются с трудностями, связанными с правописанием. Узнайте больше о проблемах правописания у взрослых прямо сейчас!
Таблица фонетического правописания
Таблицы фонетического правописания чрезвычайно полезны для обучения и личного использования. Вы можете сделать свой собственный с помощью этих простых шагов:
- Узнайте звуки на вашем языке. Например, в британской английской речи 44 звука.
- Узнайте IPA-символы этого звука.
- Запишите их в одну колонку, а примерные слова в другую.
- Вы можете повесить эту таблицу в своем классе, чтобы научить учащегося, или рядом со своим столом для быстрого ознакомления.
Ниже вы можете найти список фонетических символов, используемых для звуков в английском языке. Есть также слова в качестве примера включены. Они делятся на гласные и согласные.
Таблица фонетического правописания: согласные
Фонетический знак согласного звука | Звучит как | Символ IPA |
Б | б один, бул б | /б/ |
Ч | ch icken, рис. | /т?/ |
Д | d одже, форби д | /д/ |
| дирхамов | au th или th en | /р/ |
Ф | ф эзер, ту гх , ру и далее ле | /ф/ |
Г | г рен, бэ г , е г | /?/ |
Х | h внутренний, красный h край | /ч/ |
Дж | д утра, г entle, le dg er | /д?/ |
К | c ot, k ettle, s k ip, pi ck le | /ч/ |
Х | lo ч, H анука | /х/ |
Таблица фонетического правописания: Гласные
Фонетический символ гласного звука | Звучит как | Символ IPA |
А | С а р, сл а р | /æ/ |
а/ч или аа | м o далее, f a далее | /??/ |
Воздух | сп ар е, р воздух | /??р/ |
ау или аи | с а пэ, б ай т | /э?/ |
е или е | n e st, бл e ssings | /?/ |
ее | Fl ee t, pl ea d | /и/ |
или | Р ушко , б эер | /??р/ |
Фонетический орфографический словарь
Вам может быть интересно, как использовать фонетические символы для изучения слов. Вы когда-нибудь пытались погуглить, как произносится слово или значение слова? Они используют символы IPA для обучения произношению.
Существуют словари, такие как Oxford Learners Dictionary for Academic English или Oxford Advanced Learners Dictionary, которые включают фонетическое написание слова наряду с традиционным написанием и определением.
Вы можете проверить tophonetics, который представляет собой веб-сайт, который преобразует любое текстовое слово, данное в фонетической транскрипции IPA.
Кроме того, easypronunciation дает вам возможность выбирать между американским английским и британским английским и предлагает фонетическое правописание в обоих. Это полезный инструмент для лучшего понимания акцентов. Macmillandictionary — это онлайн-словарь, предлагающий ту же услугу.
Вот несколько примеров фонетического правописания, чтобы вы могли понять использование фонетических символов из словарей фонетического правописания:
Гласные
я? | см. | /си?/ |
я | счастливый | /?hæpi/ |
? | сидеть | /с?т/ |
и | кровать | /кровать/ |
æ | кот | /кэт/ |
?? | отец | /?ф??р?(р)/ |
? | получил | /??т/ |
?? | пила | /с??/ |
? | поставить | /т?т/ |
и | фактический | /?ækt?u?l/ |
ты? | тоже | /ту?/ |
? | чашка | /к?п/ |
?? | мех | /ф??(р)/ |
? | о | /??ба?т/ |
е? | скажем | /се?/ |
?? | перейти | /???/ |
а? | мой | /ма?/ |
?? | мальчик | /б??/ |
а? | теперь | /нет?/ |
?? | рядом с | /н??(р)/ |
е? | волосы | /он?(р)/ |
?? | чистый | /pj??(r)/ |
Есть и другие способы научиться произношению каждого слова.
Согласные
р | ручка | /ручка/ |
б | плохой | /bæd/ |
т | чай | /ти?/ |
д | сделал | /д?д/ |
к | кот | /кэт/ |
? | получить | /?et/ |
т? | цепь | /т?е?н/ |
д? | варенье | /d?æm/ |
ф | осень | /ф??л/ |
против | фургон | /væn/ |
? | тонкий | /??н/ |
ð | это | /р?с/ |
с | см. | /си?/ |
г | зоопарк | /зу?/ |
? | башмак | /?у?/ |
? | зрение | /?в??н/ |
ч | шляпа | /шет/ |
м | человек | /мэн/ |
п | теперь | /нет?/ |
? | петь | /с??/ |
л | ножка | /ле?/ |
р | красный | /красный/ |
и | да | /jes/ |
с | мокрый | /мокрый/ |
Дополнительные примеры
яблоко | Ап-уль | /?æp. |
бутылка | бОт-л | /?б?.т?л/ |
закусочная | DIN-UHR | /?д?н?/ |
съел | Eet-n | /?итн?/ |
забор | фЭнты | /?ф?нц/ |
Ханна | ХАН-э-э | /час?/ |
Джон | Джон | /д????н/ |
щенок | PUH·моч. | /?п?пи/ |
Сара | сер-э-э | /с?????/ |
Теперь, когда вы получили общее представление о том, как работает фонетическая орфография и чем она может быть вам полезна, изучите ее подробнее, чтобы укрепить свои навыки произношения. Не забывайте вести блокнот для того, что вы выучили, и время от времени просматривайте его. Проверьте словарный запас SpellQuiz, чтобы оценить диапазон своего словарного запаса. Вы также можете пройти тест SpellQuiz’s Spelling Bee Online (SBO), чтобы проверить свой истинный потенциал правописания. Удачи!
3.6 Международный фонетический алфавит. Основы лингвистики, 2-е издание
Перейти к содержанию
Глава 3: Фонетика
Сегментация
Заметьте, мы говорили о телефонах так, как будто очевидно, что они из себя представляют, но это не всегда так. Иногда легко найти четкое разделение между телефонами в заданном слове, то есть разделить слово на составляющие его телефоны, но иногда это бывает очень сложно. Мы можем увидеть эту разницу, взглянув на сигналов , представляющих собой специальные изображения, которые графически представляют воздушные колебания звуковых волн. Две формы волны на рис. 3.19 показывают заметную разницу в том, насколько легко сегментировать английские слова nab и шерсть.
Сигнал для nab содержит резкие переходы между тремя очень разными областями, соответствующими трем телефонам. Для сравнения, форма сигнала для шерсть имеет плавные переходы от начала к концу, без явных делений между телефонами. Для целей этого учебника все слова будут для вас сегментированы, но важно помнить, что при работе с необработанными данными из разговорного языка может быть не так ясно, где проходят границы между телефонами.
Транскрипция
Когда мы можем идентифицировать отдельные фонемы в слове, мы хотим иметь подходящий способ их обозначения, который можно было бы легко и последовательно понимать, чтобы соответствующая информация о произношении могла быть однозначно передана другим лингвистам. Такое обозначение называется транскрипция , которая может быть очень широкой (дающей только минимальную информацию, необходимую для сопоставления одного слова с другим), или очень узкой (давая большое количество тонких фонетических деталей), или где-то в между. Будь то широкая, узкая или промежуточная, фонетическая транскрипция обычно дается в квадратных скобках [ ] , так что, например, согласная в начале английского слова nab может быть транскрибирована как [n], с понимая, что символ [n] предназначен для обозначения звонких альвеолярных носовых упоров.
Как лингвисты, мы заинтересованы в изучении и описании как можно большего количества языков, поэтому для разговорных языков мы в идеале хотим использовать систему транскрипции, которую можно использовать для всех возможных телефонов на любом разговорном языке. Это означает, что мы не можем просто использовать систему письма одного существующего языка, потому что она будет оптимизирована для представления телефонов этого языка и не будет иметь простых способов представления телефонов других языков.
Кроме того, многие системы письма полны несоответствий и неточностей, что делает их непригодными для какой-либо строгой и однозначной транскрипции, даже для связанного с ними разговорного языка. Например, буква в английской системе письма используется для обозначения разных телефонов, таких как неокругленная гласная нижнего переднего ряда в 9.1549 nab , неокругленная гласная нижнего заднего ряда в , отец , неокругленная гласная среднего переднего времени в halo , и неокругленная гласная среднего центра в diva . И наоборот, неокругленная гласная высокого переднего ряда в английском языке может быть представлена разными буквами и сочетаниями букв: в diva ,
Обратите внимание, что символы системы письма представлены здесь с заключенными в них угловыми скобками < > . Это общепринятое обозначение в лингвистике, которое помогает визуально отличить символы в системе письма от символов, используемых для транскрипции телефонов, которые заключены в квадратные скобки [ ].
Кроме того, даже если бы английское написание было совершенно правильным, многие конкретные английские слова имеют разное одинаково правильное произношение, например .либо , данные и маршрут . Но даже слова, которые, кажется, имеют только одно последовательное произношение, на самом деле могут произноситься разными говорящими по-разному, более тонко. Например, в Лос-Анджелесе и Лондоне гласная в слове швабра обычно имеет низкое положение языка, а лондонская гласная также имеет некоторое округление губ, которое не используется в произношении Лос-Анджелеса. В Чикаго гласная в слове швабра артикулируется больше в центре рта, что составляет 9.1549 mop звучат почти как map для других динамиков. Если бы мы попытались письменно описать, как произносится гласная из другого языка, и сказали бы, что она произносится так же, как гласная в английском слове mop , мы не могли бы гарантировать, что читатель узнает, является ли рассматриваемая гласная сзади и без закруглений (как в Лос-Анджелесе , швабра ), сзади и по кругу (как в Лондоне, , швабра ) или по центру и без закруглений (как в Чикаго, , швабра ).
Международный фонетический алфавит
Чтобы избежать этих проблем, лингвисты разработали более подходящие системы транскрипции для разговорных языков, каждая из которых имеет свои сильные и слабые стороны. В этом учебнике мы будем использовать широко распространенную стандартную систему транскрипции, называемую International Phonetic Alphabet (сокращенно IPA ). IPA был создан Международной фонетической ассоциацией (бесполезно также сокращенно IPA). Организация IPA была основана в 1886 году, и вскоре после этого была опубликована первая версия их системы транскрипции. С тех пор система транскрипции IPA претерпела множество изменений по мере развития нашего понимания разговорных языков мира. Самый последний символ был добавлен в IPA в 2005 году: [ⱱ] для лабиодентального крана, телефона, встречающегося во многих языках Центральной Африки, таких как моно (центральный язык банда убангийской семьи, на котором говорят в Демократической Республике Демократическая Республика Конго).
Для справки полная диаграмма IPA приведена на рис. 3.20. Эта диаграмма доступна под лицензией Creative Commons Attribution-Sharealike 3.0 Unported, авторские права © 2020 Международной фонетической ассоциации. Он также доступен в Интернете на домашней странице IPA, а также есть несколько онлайн-версий, доступных для программ чтения с экрана, например, эта, созданная Уэстоном Рутером.
Рисунок 3.20. Полная таблица всех символов Международного фонетического алфавита.Изучение IPA требует много времени, практики и рекомендаций, и речь идет не только о запоминании символов. Основная структура и принципы организации стола — вот что действительно важно. Таким образом, IPA подобен периодической таблице химических элементов. Итак, полезно знать, что Na — это химический символ элемента натрия с атомным номером 11, а [m] — это IPA-символ звонких двугубных носовых смычек, но гораздо важнее знать, что это за понятия и что означают эти термины. Что такое натрий? Что означает, что атомный номер элемента равен 11? Что значит озвучить телефон? Как устроен голосовой тракт для двугубной носовой остановки?
Вот почему в этой главе основное внимание уделяется определению концепций, чтобы вы могли заложить прочную основу для понимания того, как устроены телефоны . Обозначение также важно, но оно не имеет ценности без соответствующего концептуального осмысления.
Использование ИПС
Полное обсуждение того, как использовать IPA для транскрипции, выходит за рамки вводного учебника, подобного этому. Здесь мы обсудим несколько рекомендаций и несколько конкретных примеров из английского языка. Для любой транскрипции важно помнить, кто ваша аудитория и какова цель транскрипции. В большинстве случаев нам обычно нужна довольно широкая транскрипция, чтобы передать основное представление о наиболее важных аспектах артикуляции.
Одна из важных руководящих рекомендаций IPA для широкой транскрипции состоит в том, чтобы использовать типографически простейшую нотацию , которая по-прежнему передает наиболее важную информацию. Например, когда это возможно, мы должны выбирать такие символы, как вертикальные [a] и [r], а не их повернутые аналоги [ɐ] и [ɹ]. Эти вертикальные символы легче набирать, легче читать и они более надежны в том, как они отображаются разными шрифтами.
Другой аспект типографской простоты — избегать диакритических знаков , которые представляют собой специальные знаки, такие как [ ̪ ] и [ʰ], которые помещаются над, под, через или рядом с символом, чтобы придать ему немного другое значение. Они часто необходимы для определенных контекстов, но иногда они излишни и могут затруднить понимание читателем. Таким образом, вы должны использовать диакритические знаки, когда их значение имеет решающее значение, но избегать их в других случаях.
Типографская простота также является хорошей практикой, когда речь идет о большом количестве различий между говорящими, которые не имеют отношения к основной мысли. Например, английская согласная, обычно обозначаемая буквой У некоторых говорящих может быть округление губ, что обозначено в IPA диакритическим знаком [ʷ] после символа. У некоторых говорящих может быть как фарингализация, так и округление!
Это приводит как минимум к двенадцати различным возможным артикуляциям, каждая со своей собственной транскрипцией в IPA, в зависимости от места артикуляции, наличия или отсутствия фарингализации и округления губ. Символы IPA для этих двенадцати возможностей приведены в списке ниже. Для каждого символы расположены по месту артикуляции: альвеолярный, постальвеолярный и ретрофлексный.
- без фарингализации и без округления: [ɹ], [ɹ̱] или [ɻ]
- фарингализация без округления: [ɹˁ], [ɹ̱ˁ] или [ɻˁ]
- округление и отсутствие фарингализации: [ɹʷ], [ɹ̱ʷ] или [ɻʷ]
- как фарингализация, так и округление: [ɹˁʷ], [ɹ̱ˁʷ] или [ɻˁʷ]
Кроме того, существует множество других ротических произношений помимо североамериканских разновидностей, таких как альвеолярный постукивание [ɾ] или трель [r] в Шотландии, звонкий увулярный фрикативный звук [ʁ] в Нортумбрии и лабиодентальный аппроксимант [ʋ] В Лондоне.
Таким образом, при расшифровке английского языка в целом не существует единого символа, точно представляющего произношение этого согласного, поэтому для широкой транскрипции разумным выбором является простое вертикальное [r] без диакритических знаков, что соответствует рекомендации IPA по типографской простоте. . Конечно, при расшифровке конкретной артикуляции конкретного говорящего может иметь смысл использовать более точный символ, особенно если важны детали артикуляции. Но, вообще говоря, простой прямой [r] обычно подходит для английского языка, хотя некоторые лингвисты могут предпочесть использовать [ɹ] или [ɻ] для североамериканского английского, хотя существует по крайней мере дюжина одинаково допустимых североамериканских произношений. Если вы изучаете курс лингвистики, обязательно следуйте стандартам и правилам, установленным вашим преподавателем.
Почему так много вариантов произношения английского В разговорных языках мира мы находим множество вариаций в ротике. Во многих языках есть только один ротик, но какой именно ротик у них может быть очень разным даже между близкородственными языками. Произношение ротиков в языке также может меняться со временем, особенно если в языке есть только одно. Похоже, что в различных ротических звуках нет единого всеобъемлющего фонетического сходства, и лингвисты все еще пытаются выяснить, что делает этот класс согласных таким особенным.
Даже когда произношение данного телефона довольно одинаково для всех говорящих, многие лингвисты по-прежнему выбирают типографически более простую транскрипцию. Рассмотрим согласную в начале английского слова chin , которая является глухой постальвеолярной аффрикатой. Аффрикаты в IPA обычно транскрибируются путем написания соответствующего взрывного символа, обозначающего стоп-закрытие, за которым следует соответствующий фрикативный символ, представляющий фрикативное высвобождение, оба объединены под изогнутой 9. 1541 соединительная планка [ ͡ ] , чтобы показать, что они объединены в единый телефон.
Итак, для представления глухой постальвеолярной аффрикаты в подбородке нам нужно подобрать правильные взрывные и фрикативные символы. Во-первых, давайте рассмотрим глухой постальвеолярный фрикативный звук. Мы можем найти его символ в таблице IPA, заглянув в раздел, посвященный согласным. Места артикуляции перечислены вверху, а способы артикуляции перечислены внизу слева. В данной ячейке, если есть два символа, тот, что слева, глухой, а тот, что справа, звонкий. Итак, просматривая постальвеолярный столбец и фрикативный ряд, мы находим символы [ʃ] и [ʒ], и, поскольку нас интересует глухой фрикативный звук, мы выбираем символ [ʃ].
Однако в IPA нет аналогичного базового символа для глухого постальвеолярного взрывного звука. Эта часть таблицы пуста, поэтому нам нужно создать собственный символ, используя базовый символ для аналогичного согласного и добавив один или несколько диакритических знаков. В этом случае мы можем использовать альвеолярный [t] и поставить под ним ретракционный диакритический знак [ ̱ ], чтобы указать, что его место артикуляции находится немного дальше назад, как мы делали ранее для постальвеолярного центрального аппроксиманта [ɹ̱]. Таким образом, мы получаем [ṯ] как символ глухого постальвеолярного взрывного звука.
Итак, начнем с того, что соединим эти два символа под перекладиной: [ṯ͡ʃ]. Однако большинство носителей английского языка также произносят эту аффрикату с некоторым округлением губ, поэтому полностью точная транскрипция будет больше похожа на [ṯ͡ʃʷ] с диакритическим знаком [ʷ] для обозначения округления.
Но вряд ли какой-либо лингвист транскрибирует эту аффрикату с таким количеством фонетических подробностей. Почти никогда не уместно указывать, что он круглый, а постальвеолярное расположение стопорного смыкания подразумевается тем фактом, что он имеет постальвеолярный выход. Вы не можете открыть стопорное закрытие в положении, отличном от того, где оно сделано: если есть постальвеолярное освобождение, оно обязательно должно исходить из постальвеолярного закрытия. Таким образом, для типографской простоты аффриката чаще транскрибируется просто как [t͡ʃ] без какого-либо из двух диакритических знаков. Как и в случае с [r] для английского rhotic, [t͡ʃ] технически не является точной транскрипцией для большинства говорящих, но типографически проще и передает всю важную информацию, необходимую для понимания основ артикуляции. Перекладина на аффрикате также иногда может быть опущена в транскрипциях, поэтому [tʃ] также является распространенной транскрипцией для этой аффрикаты, что делает ее еще более типографически простой.
Даже без этих проблем, как правило, не существует такого понятия, как «тот самый» правильный вариант транскрипции слова. Два произношения одного и того же слова одним и тем же говорящим всегда будут иметь некоторые различия, потому что мы живем в физическом мире, где мы не можем избежать незначительных несовершенств и колебаний. Даже если бы мы хотели зафиксировать все эти возможные различия с помощью IPA, он просто не предназначен для такого уровня фонетической детализации. Когда такая деталь важна, ее необходимо передать другими способами, например, с помощью изображений (таких как формы волны и среднесагиттальные диаграммы) и числовых измерений (таких как громкость в децибелах и продолжительность в миллисекундах). Таким образом, в транскрипции IPA всегда отсутствуют некоторые детали, поэтому мы должны решить, сколько деталей необходимо, а сколько следует опустить для простоты.
Расшифровка английского языка с помощью IPA
Несмотря на все эти ловушки, все же важно получить некоторые базовые навыки транскрипции для будущей работы в области лингвистики. Поскольку этот учебник представлен на английском языке, английский язык является хорошей отправной точкой, чтобы дать вам что-то конкретное, на чем можно закрепить свое понимание того, как делать транскрипцию. Однако в английском языке существует множество диалектных вариаций, поэтому предлагаемые здесь транскрипции носят очень общий характер и могут отличаться от разновидностей английского языка, с которыми вы знакомы.
Начнем с согласных, где в разных диалектах меньше различий. В таблице 3.2 перечислены некоторые взрывные звуки и аффрикаты английского языка с их символом IPA (с учетом типографской простоты) и примеры слов, содержащих каждый согласный звук в разных позициях, где это возможно. Для каждого слова часть написания, соответствующая телефону, выделена жирным шрифтом. Наконец, также дается фонетическое описание каждого согласного.
| символ | пример (начало) | пример (средний) | пример (конец) | описание |
|---|---|---|---|---|
| [п] | р и | ра р ид | ла р | глухой двугубный взрывной |
| [б] | б и | ра б удостоверение личности | ла б | звонкий двугубный взрывной |
| [т] | т и | а т оп | ле т | глухой альвеолярный взрывной |
| [д] | д ан | a d опция | ле д | звонкий альвеолярный взрывной |
| [т] | ч в | ба тч эс | ри ч | глухая постальвеолярная аффриката |
| [д] | г в | ба дг эс | ри дг е | звонкий постальвеолярный аффрикат |
| [к] | с и | би ск э | ла ск | глухой велярный взрывной |
| [ɡ] | г и | би гг эр | ла г | звонкий велярный взрывной |
| [ʔ] | — | – | — | глухой гортанный взрывной |
Большинство из них простые, но, как обсуждалось в разделе 3. 3, альвеолярные согласные обычно апикоальвеолярные, хотя некоторые говорящие могут произносить их кончиком языка. Если эта деталь необходима, эти согласные можно записать как [t̻] и [d̻], используя ламинальный диакритический знак [̻]. Независимо от активного артикулятора, некоторые говорящие могут произносить эти согласные на задней части зубов, а не на альвеолярном гребне, и в этом случае они будут транскрибироваться как [t̪] и [d̪] с использованием зубного диакритического знака [ ̪ ].
Гортанная взрывная (также часто называемая гортанной смычкой ) является лишь маргинальной согласной в английском языке. Его можно найти как зацепиться за горло в середине междометия uh-oh . Некоторые носители также используют его в другом месте, например, в середине некоторых британских английских произношений слова Bottle . Он артикулируется путем полного смыкания голосовых связок, блокируя весь поток воздуха через голосовую щель.
В таблице 3. 3 перечислены некоторые фрикативы английского языка.
| символ | пример (начало) | пример (средний) | пример (конец) | описание |
|---|---|---|---|---|
| [ф] | и и | ва ф э | левый f | глухой губно-зубной фрикативный звук |
| [в] | против и | и против или | леа v и | звонкий губно-зубной фрикативный звук |
| [θ] | й в | е е е | истинный -й | глухой межзубный фрикативный звук |
| [ð] | й и | еи й еи | сму й | звонкий межзубный фрикативный звук |
| [с] | с в | мю ск ле | бу с | глухой альвеолярный фрикативный звук |
| [з] | z один | мю зз ле | бу зз | звонкий альвеолярный фрикативный звук |
| [ʃ] | ш в | Хай и и | ру ш | глухой постальвеолярный фрикативный звук |
| [ʒ] | — | А и и | роу г е | звонкий постальвеолярный фрикативный звук |
| [ч] | ч и | а ч эд | — | глухой гортанный фрикативный звук |
Наиболее заметным отличием здесь является то, что некоторые говорящие не используют [θ] и [ð], а вместо этого используют [t] и [d] или [f] и [v], в зависимости от диалекта и положения в слове. Как и в случае постальвеолярных аффрикатов, упомянутых ранее, постальвеолярные фрикативы также обычно несколько округлены, поэтому их можно было бы более узко транскрибировать как [ʃʷ] и [ʒʷ]. Звонкий постальвеолярный фрикативный звук [ʒ] также является одним из самых редких согласных в английском языке, и многие говорящие произносят его в некоторых позициях как аффрикат, а не как фрикативный. Например, вы можете услышать, как говорящие произносят последнюю согласную в числе 9.1549 гараж как аффриката [d͡ʒ], а не фрикативный [ʒ].
В таблице 3.4 перечислены некоторые соноранты английского языка. Во всех разговорных языках мира сонорные звуки, как правило, озвучиваются по умолчанию, потому что их высокая степень воздушного потока заставляет голосовые связки спонтанно вибрировать, если не прилагаются дополнительные усилия, чтобы удержать их от вибрации. Это верно для английского языка, поэтому звучание сонорантов здесь не указано.
| символ | пример (начало) | пример (средний) | пример (конец) | описание |
|---|---|---|---|---|
| [м] | м и | и мм или | ра м | двугубная носовая пробка |
| [н] | n и | и нн эр | ра п | альвеолярный носовой упор |
| [ŋ] | — | и нг или | ра нг | велярная назальная пробка |
| [л] | л ане | для ll у | ба ll | альвеолярный латеральный аппроксимант |
| [р] | р и | так рр у | ба р | (разные! см. ранее обсуждение) |
| [дж] | у ость | на и на | — | небный центральный аппроксимант |
| [ш] | с на | и с или | — | губно-велярная центральная аппроксимация |
Некоторые из этих сонорантов требуют дополнительного обсуждения. Альвеолярный носовой упор [n] имеет почти те же вариации, что и альвеолярные взрывные звуки, при этом некоторые говорящие имеют ламиноальвеолярное сочленение [n̻], а некоторые — зубное сочленение [n̪]. Велярный носовой упор часто является одним из самых удивительных телефонов для англоязычных носителей английского языка, которые плохо знакомы с фонетикой, потому что его нелегко идентифицировать как собственный телефон. Многих людей вводит в заблуждение написание, и они думают, что произносят такие слова, как 9.1549 певец с [ɡ], но на самом деле у большинства говорящих там только носовой упор, так что певец отличается от пальцем, с певец имеет только [ŋ] и палец с [ŋɡ] . Тем не менее, есть носители, которые действительно произносят все подобные слова с [ɡ] после носовой остановки, но даже в этом случае носовая остановка у них все еще велярная [ŋ], а не альвеолярная [n].
Примечательным согласным здесь является [w], который выделяется среди согласных английского языка тем, что двушарнирный , что означает, что он имеет два равных места сочленения. Он бывает двугубным (с аппроксимирующей перетяжкой между двумя губами) и небной (со второй аппроксимирующей перетяжкой между спинкой языка и небной занавеской). Его место сочленения обычно называют лабиально-велярным . Раньше в английском языке постоянно было два лабиально-велярных приближения: звонкий [w] и глухой [ʍ]. Сегодня очень немногие говорящие обладают обоими этими качествами, но те, кто произносит слова, ведьма и которая по-разному, со звонким [w] в ведьма и глухим [ʍ] в которая .
Теперь мы можем перейти к гласным. Именно здесь большая часть различий в произношении встречается в английских диалектах, и полное описание всех гласных в английском языке заняло бы целый учебник. Обратите внимание, что это не общее свойство разговорных языков в целом. Некоторые из них похожи на английский, с наибольшим диалектным разнообразием гласных, но другие имеют гораздо большее диалектное разнообразие согласных, в то время как третьи могут иметь относительно равномерную смесь вариаций как согласных, так и гласных.
В таблице 3.5 перечислены некоторые монофтонги английского языка с акцентом на английские гласные, поскольку они широко произносятся в диалектах Северной Америки. Тем не менее, только в Северной Америке все еще существует много вариаций, и это обсуждение не следует рассматривать как представление какого-либо конкретного говорящего или региона, не говоря уже о каком-либо идеализированном стандарте или целевом произношении. Это просто удобная абстракция, которая обеспечивает полезную основу, хотя это все еще лишь очень приблизительное руководство, и отдельные говорящие могут довольно сильно отличаться от того, что здесь обсуждается. Обратите также внимание, что безударные гласные очень нестабильны, особенно в быстрой речи, поэтому, например, безударный [u] может произноситься скорее как [ʊ] или [ə], даже если один и тот же говорящий произносит одно и то же слово. Как и в большинстве разговорных языков, гласные в английском обычно все звонкие, поэтому их звучание здесь не приводится. Приведены примеры слов, которые показывают гласную в ударном слоге, безударном слоге и в конце слова (подробнее о слогах и ударении см. Разделы 3.10 и 3.11).
| символ | Пример (напряженный) | Пример (без ударения) | пример (конец) | описание |
|---|---|---|---|---|
| [и] | б шт. тер | соль и или | с ее | высокий передний неокругленный напряженный |
| [ɪ] | б и ттер | — | — | высокий передний незакругленный свободный |
| [е] | б а кер | — | с ай | среднее переднее неокругленное время |
| [ɛ] | б д ттер | — | — | средний передний незакругленный свободный |
| [æ] | б а ттер | — | — | низкая передняя часть без закруглений |
| [ɑ] | ф и и | — | сп а | низкая спинка без закругления |
| [ɒ] | б о нетто | — | — | полукруглая спинка |
| [ɔ] | б или рдер | — | с ав | свободная круглая спинка посередине |
| [о] | б оа тер | — | с ев | среднее круглое время назад |
| [ʊ] | б оо кер | — | — | высокая спинка с круглым вырезом |
| [у] | б оо мер | мужчина и ал | с уе | высокая спина круглая напряженная |
| [ʌ] | б и ттер | — | — | средняя центральная неокруглая рыхлая (напряженная) |
| [ə] | — | и и мал | софт и | средняя центральная неокруглая рыхлая (безударная) |
Как отмечалось ранее, существует множество вариаций, которые невозможно здесь подробно обсудить, поэтому мы рассмотрим лишь несколько заметных отклонений. Во-первых, в то время как многие говорящие произносят четыре напряженных гласных как монофтонги, как здесь транскрибировано, большинство говорящих вместо этого произносят некоторые или все из них как дифтонги, возможно, даже имея в конце аппроксимацию, а не гласную. Например, неокругленное время высокого переднего ряда [i] может произноситься некоторыми говорящими больше как [ɪi] или [ij]. Особенно часто две напряженные средние гласные произносятся как дифтонги, что-то вроде [eɪ] и [oʊ] или, возможно, [ej] и [ow].
Многие гласные заднего ряда, особенно [ʊ], являются передними и/или неокругленными для некоторых говорящих на некоторых диалектах.
Гласные заднего ряда в родили и , купленном , некоторые североамериканцы произносят одинаково друг с другом, поэтому они часто обозначаются одним и тем же символом [ɔ], хотя обратите внимание, что могут быть некоторые различия, с [ɔ] перед ротиком часто произносится несколько выше, ближе к [о]. Однако у многих говорящих в Канаде и на западе США гласная в 9-м разряде звучит совсем по-другому. 1549 купил из расточил . Их купил гласный намного ниже, а у некоторых динамиков он еще и неокругленный. Эти динамики используют ту же самую низкую гласную в купили , что и в бот . Для большинства жителей Северной Америки нижние гласные в bot и balm произносятся одинаково: либо как back round [ɒ], либо как back unrounded [ɑ]; в некоторых диалектах это может быть центральный неокругленный [а]. У других есть две разные гласные для этих слов, обычно [ɒ] в 9.1549 bot и [ɑ] или [a] в бальзаме . Излишне говорить, что эта часть системы гласных в английском языке вызывает особые затруднения, и даже многие опытные лингвисты неправильно понимают ее аспекты.
Две средние гласные [ʌ] и [ə] часто рассматриваются как связанные произношения одной и той же гласной в зависимости от того, встречаются ли они в ударном слоге (опять же, см. разделы 3.10 и 3.11 для получения дополнительной информации о слогах и ударении) . А пока просто обратите внимание, что некоторые гласные английского языка произносятся громче и длиннее, чем другие, которые мы называем 9.1541 ударный , в то время как другие более мягкие и короткие гласные называются безударными . Мы можем видеть разницу в ударении в таких парах, как вал и ниже , которые различаются главным образом тем, какой слог подвергается ударению: первый слог в вал и второй слог в ниже . Две центральные гласные в английском языке имеют разное ударение: первый слог в имени Bubba ударный, а второй безударный, поэтому мы можем записать это имя как [bʌbə]. Хотя эти две гласные звучат очень похоже для многих говорящих и могут быть легко обозначены одним и тем же символом, существует давняя традиция обозначать безударную среднюю гласную в английском языке с помощью [ə], а ударную среднюю центральную гласную с [ʌ], основанную на об историческом произношении, в котором ударная гласная произносилась намного дальше назад (и до сих пор произносится в некоторых диалектах).
Символ [ə] имеет специальное имя, schwa . Среди лингвистов распространена шутка, что их любимая гласная — шва или что они хотели бы больше походить на шва, потому что она безударная, имея в виду желание избежать типично большого количества стресса в академических кругах. Однако, хотя шва всегда безударна в английском и некоторых других разговорных языках, во многих других [ə] является обычной гласной, как и любая другая гласная, и может быть ударной. Например, ударение [ə] можно найти в таких языках, как Sḵwx̱wú7mesh (прибрежный салишский язык семьи салишан, на котором говорят в Британской Колумбии), румынский (западный романский язык индоевропейской семьи, на котором говорят в Румынии) и мандарин. (китайский язык китайско-тибетской семьи, на котором говорят в Китае и близлежащих районах). Таким образом, нет ничего, что требовало бы, чтобы [ə] был безударным в целом, поэтому вы не должны думать об этом как о безударной гласной по своей сути.
Наконец, мы рассматриваем дифтонги и слоговые согласные , которые являются фонами, имеющими сужения, подобные согласным, в голосовом тракте, но которые функционируют скорее как гласные в английском языке. Некоторые дифтонги и слоговые согласные английского языка приведены в таблице 3.5.
| символ | Пример (напряженный) | Пример (без ударения) | пример (конец) | описание |
|---|---|---|---|---|
| [аɪ] | б и тер | — | с хай | от низкого центрального неокругленного до высокого переднего неокругленного дифтонга |
| [а] | бр вл нер | — | ч вл | низкий центральный неокругленный дифтонг с высокой спинкой круглый |
| [ɔɪ] | б или лер | — | с ой | округлый дифтонг от середины спины до неокругленного дифтонга спереди |
| [r̩] | б ур нинг | внутр. er знач. | с ир | слоговый ротик |
| [л̩] | — | haz el гайка | садд ле | силлабический альвеолярный латеральный аппроксимант |
| [н̩] | — | от до от | внезапный en | слоговая альвеолярная носовая пробка |
| [м̩] | — | дно ом меньше | продан ом | слоговый двугубный носовой упор |
Используемые здесь символы для дифтонгов представляют собой грубое среднее значение того, где они обычно начинаются и заканчиваются, но фактическое произношение довольно сильно варьируется от говорящего к говорящему и даже для одного и того же говорящего. Низкая начальная точка для [aɪ] и [aʊ] может быть ближе к задней [ɑ] или передней [æ], в то время как средняя начальная точка для [ɔɪ] может быть ближе к напряженному [o]. Кроме того, передняя конечная точка hiɡh для [aɪ] и [ɔɪ] может быть ближе к времени [i] или аппроксимации [j], в то время как конечная точка hiɡh для [aʊ] также может быть ближе к времени [u] или аппроксимация [w].
Слоговые согласные транскрибируются с использованием слогового диакритического знака [ˌ] под соответствующим символом согласной. Однако иногда они транскрибируются с предшествующим [ə] вместо этого, так что фундук можно было бы транскрибировать либо как [hezl̩nʌt], либо как [hezəlnʌt]. Слоговая ротатика (также называемая ротацированными гласными или r-окрашенными гласными ) настолько распространена, что у них есть свои специальные символы: [ɝ] в ударных слогах и [ɚ] в безударных слогах. Таким образом, сжигание может быть расшифровано как [br̩nɪŋ] или [bɝnɪŋ], а интервал может быть расшифрован как [ɪntr̩vl̩] или [ɪntɚvl̩].
Со всеми этими различиями, не только в произношении разных носителей, но и в выборе транскрипции разными лингвистами, может быть трудно понять, что на самом деле подразумевает данная транскрипция.