Слова «свою» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «свою» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «свою» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «свою».
Содержимое:
- 1 Слоги в слове «свою» деление на слоги
- 2 Как перенести слово «свою»
- 3 Синонимы слова «свою»
- 4 Антонимы слова «свою»
- 5 Ударение в слове «свою»
- 6 Фонетическая транскрипция слова «свою»
- 7 Фонетический разбор слова «свою» на буквы и звуки (Звуко-буквенный)
- 8 Предложения со словом «свою»
- 9 Сочетаемость слова «свою»
- 10 Значение слова «свою»
- 11 Как правильно пишется слово «свою»
- 12 Ассоциации к слову «свою»
Слоги в слове «свою» деление на слоги
Количество слогов: 2
По слогам: сво-ю
Как перенести слово «свою»
свою
Синонимы слова «свою»
1. частный
частный
2. личный
3. нестандартный
4. нечужой
5. своеобычный
6. своеобразный
7. оригинальный
8. характерный
9. домашний
10. близкий
11. собственный
12. свойский
13. собственноличный
14. нашенский
15. родимый
16. родной
17. являющийся личной собственностью
18. находящийся в личной собственности
19. отечественный
20. наш
21. неординарный
22. специфический
23. специфичный
24. характеристический
25. характеристичный
26. индивидуальный
27. особый
28. неповторимый
29. особенный
30. нетрадиционный
31. неизбитый
32. неповторяемый
33. нетривиальный
34. самобытный
35. своебытный
36. своебычливый
37. кровный
38. мазёвый
39. свояк
40. находящийся в личном владении
41. находящийся в частных руках
42. единоличный
43. являвшийся личной собственностью
44. принадлежащий
принадлежащий
Антонимы слова «свою»
1. чужой
Ударение в слове «свою»
свою́ — ударение падает на 2-й слог
Фонетическая транскрипция слова «свою»
[свай’у]
Фонетический разбор слова «свою» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| о | [а] | гласный, безударный | о |
| ю | [й’] | согласный, звонкий непарный (сонорный), мягкий | ю |
| [у] | гласный, ударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 4 буквы и 5 звуков.
Буквы: 2 гласных буквы, 2 согласных букв.
Звуки: 2 гласных звука, 3 согласных звука.
Предложения со словом «свою»
Однако плакал после разорения дела своей жизни целую неделю, даже заболел от расстройства ветрянкой.Майя Кучерская, Современный патерик. Чтение для впавших в уныние.
Время сделало своё дело – перед ним стояла пожилая женщина, которую можно было сравнить разве что с розой из гербария.Максим Шахов, Ген разведчика, 2012.
Высокоодарённые, можно сказать, талантливые люди, они были тесно связаны с духовной жизнью своего времени.Вальтер Гёрлиц, Германский Генеральный штаб. История и структура. 1657-1945.
Сочетаемость слова «свою»
1. руки свои
2. на веку своём
3. под ноги свои
4. думать о своём
5. настоять на своём
6. стоять на своём
7. (полная таблица сочетаемости)
Значение слова «свою»
СВОЙ , своего́, м. ; своя́, свое́й, ж.; своё, своего́, ср.; мн. свои́, свои́х. 1. притяжат. мест. Принадлежащий себе, свойственный самому себе; собственный. Сделать своими руками. Не верить своим глазам. Своя голова на плечах. Своя жизнь, свои заботы у каждого. Свои мысли. К своему удивлению. (Малый академический словарь, МАС)
; своя́, свое́й, ж.; своё, своего́, ср.; мн. свои́, свои́х. 1. притяжат. мест. Принадлежащий себе, свойственный самому себе; собственный. Сделать своими руками. Не верить своим глазам. Своя голова на плечах. Своя жизнь, свои заботы у каждого. Свои мысли. К своему удивлению. (Малый академический словарь, МАС)
Как правильно пишется слово «свою»
Правописание слова «свою»Орфография слова «свою»
Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «свою» в прямом и обратном порядке:
Ассоциации к слову «свою»
Усмотрение
Правота
Пожитки
Собрат
Питомец
Нагота
Мучитель
Паства
Невиновность
Очередь
Согражданин
Сбережение
Спутница
Соплеменник
- Ручища
Обыкновение
Возлюбленная
Сородич
Подданный
Делишки
Обязанность
Долг
Сверстник
Соотечественник
Предшественник
Любимец
Любимица
Кумир
Возлюбленный
Вол
Похождение
Благодетель
Горесть
Карьер
Ноша
Притязание
Вассал
Обидчик
Преданность
Беспомощность
Мемуары
Детище
Первенец
Правильность
Вотчина
Воспитанница
Признательность
Единомышленник
Краса
Разумение
Неспособность
Отпрыск
Подопечный
Ненаглядный
Ревностный
Излюбленный
Искупить
Загладить
Доживать
Почтить
Изливать
Излить
Устыдиться
Отстаивать
Славиться
Умерить
Навязывать
Поделиться
Подчинять
Посвящать
Дорожить
Излагать
Участить
Утрачивать
Высказывать
Подкрепить
Завещать
Гордиться
Стыдиться
Обуздать
Прославиться
Оплакивать
Пожертвовать
Совать
Жертвовать
-
Расширять
Демонстрировать
Отречься
Подчинить
Продемонстрировать
Вкладывать
Изложить
Упиваться
Диктовать
Хвастаться
Пересмотреть
Выставлять
Чередом
Напоказ
Сообразно
Опубликовано: 2020-09-09
Популярные слова
воспитанник , беседами , взбежавшие , взъерошив , выскребу , высчитанною , вытравлявшей , вячеславом , гемолизом , геннадиевичи , гимнастерочку , домоустройство , завибрируют , завинчивающимся , павлиньего , парабеллумами , парковавшемся , перебираемыми , плакатная , подающее , подлетать , подросту , положительнейшего , помпонах , поохотившимся , пражского , прогульном , прокашливаться , проституируя , противогазовые , развернувшее , разделе , раскрутилось , раскусывают , расторгну , резервированного , реорганизовавшем , респонсорною , сильванер , солея
морфологический и фонетический разбор слова
Русский язык является одним из самых удивительных и интересных языков в мире. Система русской грамматики и сложное строение слова порой могут сбить с толку не только иностранцев, но и родных говорящих. Одним из таких примеров является слово «петербургской». В зависимости от контекста оно может быть написано по-разному.
Система русской грамматики и сложное строение слова порой могут сбить с толку не только иностранцев, но и родных говорящих. Одним из таких примеров является слово «петербургской». В зависимости от контекста оно может быть написано по-разному.
Изучение морфологии поможет понять, почему это слово имеет свою форму, а фонетический разбор позволит оценить звуковую картину и правильно произнести слово. Рассмотрим каждый аспект подробнее.
Слово «петербургской» представляет собой прилагательное в женском роде, в родительном падеже, единственном числе. То есть оно обозначает принадлежность к Санкт-Петербургу. В своей основе оно состоит из двух частей: «петербург» и «ской».
Содержание
- Как правильно пишется «петербургской»: морфологический анализ слова
- Понятие словоформы
- Морфологическое значение окончания «ской» в прилагательных
- Фонетический аспект словообразования «петербургской»
- Ударение в словоформе «петербургской»
- Звуковая структура слова «петербургской»
Как правильно пишется «петербургской»: морфологический анализ слова
Слово «петербургской» является прилагательным и образовано от названия города Санкт-Петербург. Оно имеет окончание -ской, что указывает на принадлежность к чему-либо.
Оно имеет окончание -ской, что указывает на принадлежность к чему-либо.
Морфологически слово «петербургской» относится к женскому роду, единственному числу и третьему склонению. При этом оно является полным прилагательным, что означает, что оно может употребляться в качестве определения без основного слова.
Изучив морфологический анализ слова «петербургской», можно сделать вывод о том, что его правильное написание с большой вероятностью будет заканчиваться на букву «й». Это следует из того, что название Санкт-Петербурга пишется с буквой «й», а прилагательные от географических названий, как правило, сохраняют эту букву в основе.
Таким образом, написание «петербургской» сочетает в себе написание основы по образцу названия города и окончания, указывающего на принадлежность.
Понятие словоформы
В русском языке каждое слово имеет несколько форм, которые изменяются в зависимости от различных грамматических категорий (рода, числа, падежа и т.д.). Эти формы называются словоформами.
Например, слово «петербургской» является словоформой от слова «петербургский». В данном случае словоформа изменяется по роду женскому и падежу родительный.
Существительные, прилагательные, глаголы и причастия имеют большое количество словоформ. Например, глагол «брать» имеет формы: беру, берешь, берет, берем, берете, берут. В этом случае глагол изменяется по лицу и числу.
Каждая словоформа имеет свою ударную гласную, которая может изменяться в зависимости от словоформы и происхождения слова. В слове «петербургской» ударением является гласная о, которая в основе слова «петербургский» звучит более громко.
Изучение словоформ и ударных гласных является важной частью изучения русского языка и помогает говорящему правильно использовать слова в речи.
Морфологическое значение окончания «ской» в прилагательных
Окончание «ской» в прилагательных образуется от существительного в женском роде на -ская. Оно имеет морфологическое значение, обозначающее принадлежность к указанному существительному. Например, «петербургская» — прилагательное, обозначающее принадлежность к городу Санкт-Петербургу.
Например, «петербургская» — прилагательное, обозначающее принадлежность к городу Санкт-Петербургу.
Прилагательные с окончанием «ской» могут образовываться от различных существительных, как абстрактных, так и конкретных. Например, «историческая» — обозначает связь с историей, «водная» — связь со водой, «кожаная» — материал из кожи.
Окончание «ской» может не только указывать на принадлежность, но и привносить значения качественного признака. Например, «железнодорожная» — обозначает не только принадлежность к железной дороге, но и характеризует объект как связанный с железом и прочным.
В русском языке окончание «ской» является морфологически значимым, и применяется широко в образовании прилагательных. Оно позволяет точнее и яснее выражать принадлежность и качественные характеристики объектов, что делает язык более выразительным и разнообразным.
Фонетический аспект словообразования «петербургской»
Слово «петербургской» — это прилагательное, образованное от географического названия Петербург. Фонетически, это слово состоит из четырех слогов: «пе-теp-буpг-ской». Начинается оно со звука «пе» и заканчивается на звуке «ой».
Фонетически, это слово состоит из четырех слогов: «пе-теp-буpг-ской». Начинается оно со звука «пе» и заканчивается на звуке «ой».
В этом слове есть несколько интересных моментов. Первое — это буква «г» в середине слова. Обычно она произносится как звонкий глухой звук, но в слове «петербург» эта буква произносится как глухой звук «к». Это связано с историческим развитием этого названия.
Еще один интересный момент — это сочетание двух согласных звуков «т» и «б» в середине слова. Обычно такие сочетания трудно произносятся, но здесь эти звуки соседствуют друг с другом.
В целом, слово «петербургской» имеет приятное звучание и является хорошо читаемым и произносимым словом.
Ударение в словоформе «петербургской»
Слово «петербургская» относится к женскому роду существительных и образовано от названия города Санкт-Петербург. Ударение в словоформе «петербургской» падает на последний слог «ской», то есть это окончание является ударным.
Правильное произношение слова «петербургская» важно для грамотной речи и письма, особенно если вы являетесь жителем Санкт-Петербурга или намерены общаться с петербуржцами.
Чтобы запомнить ударение в словоформе «петербургской», можно прибегнуть к технике запоминания через ассоциации. Например, представьте себе картину с Петром I, который стоит на улице Петербурга и держит в руках большую булаву. Слово «ской» в окончании «петербургской» звучит как «ской», что часто ассоциируется с булавой.
Звуковая структура слова «петербургской»
Слово «петербургской» состоит из 12 букв и имеет 3 слога. Фонетически слово можно разбить на следующие звуки: /п/, /е/, /т/, /е/, /р/, /б/, /у/, /р/, /г/, /с/, /к/, /о/, /й/. В слове присутствуют все гласные звуки русского языка: /а/, /е/, /ё/, /и/, /о/, /у/, /ы/, /э/, /ю/, /я/. Также в слове есть две согласные: /б/ и /г/ соответственно в начале и конце слова.
В слове «петербургской» ударение падает на 5 слог: /пэ-тэр-бу?рг-ской/. Второй слог идет безударным и содержит гласный звук /е/. Также в слове есть две мягкие согласные: /т/ и /г/, которые образуют соответствующие пары с твёрдыми согласными: /д/ и /к/.
Звучание слова «петербургской» зависит от произношения говорящего и может отличаться в разных регионах. Например, в Петербурге слово часто произносят смягченным звуком /г/ в конце слова, в то время как в других регионах России может звучать твёрдый звук /к/.
- Слово «петербургской» является прилагательным в женском роде.
- Слово содержит две корневые морфемы: «Петербург-» и «-ской».
- Петербург — это название города, столицы России с 1712 по 1918 год.
- Морфема «-ской» образуется от мужского рода «-ский».
| Падеж | Единственное число | Множественное число |
|---|---|---|
| Именительный | петербургская | петербургские |
| Родительный | петербургской | петербургских |
| Дательный | петербургской | петербургским |
| Винительный | петербургскую | петербургские |
| Творительный | петербургской | петербургскими |
| Предложный | петербургской | петербургских |
В зависимости от падежа слово «петербургской» может изменять свою форму. Например, в винительном падеже единственного числа слово будет звучать как «петербургскую», а в предложном падеже множественного числа — как «петербургских».
Например, в винительном падеже единственного числа слово будет звучать как «петербургскую», а в предложном падеже множественного числа — как «петербургских».
Как установить и использовать плагины Elasticsearch | Linode Docs
 results match 
 results
Нет результатов
Фильтры
Фильтры ( )
Все
0, ‘текст-белый’: checkbox.checked, ‘текст-серый-400’: !checkbox.checked && checkbox.count === 0 }» style=letter-spacing:.07px x-text=checkbox.title>
Добавить теги
Все
0, ‘текст-белый’: checkbox.checked, ‘текст-серый-400’: !checkbox.checked && checkbox.count === 0 }» style=letter-spacing:.07px x-text=checkbox.title>
Добавить авторов
Все
0, ‘текст-белый’: checkbox. checked, ‘текст-серый-400’: !checkbox.checked && checkbox.count === 0 }» style=letter-spacing:.07px x-text=checkbox.title>
checked, ‘текст-серый-400’: !checkbox.checked && checkbox.count === 0 }» style=letter-spacing:.07px x-text=checkbox.title>
Traducciones al EspañolСоздать учетную запись Linode чтобы попробовать это руководство с кредитом в долларах США.Estamos traduciendo nuestros guías y tutoriales al Español. Эс posible que usted esté viendo una traducción generada автоматический. Estamos trabajando con traductores profesionales пункт verificar лас traducciones де нуэстро ситио сети. Эсте проект es un trabajo en curso.
Этот кредит будет применяться к любым действительным услугам, использованным во время вашего первого дней.
Что такое плагины Elasticsearch?
Elasticsearch — масштабируемая поисковая система с открытым исходным кодом. Хотя Elasticsearch поддерживает большое количество готовых функций, его также можно расширить с помощью различных плагинов для обеспечения расширенной аналитики и обработки различных типов данных.
В этом руководстве показано, как установить следующие подключаемые модули Elasticsearch и взаимодействовать с ними с помощью API Elasticsearch:
- ingest-attachment : позволяет Elasticsearch индексировать и искать документы в кодировке base64 в таких форматах, как RTF, PDF и PPT.
- фонетический анализ : идентифицирует результаты поиска, которые звучат похоже на поисковый запрос.
- ingest-geoip : добавляет информацию о местоположении в проиндексированные документы на основе любых IP-адресов в документе.
- ingest-user-agent : анализирует заголовок
User-AgentHTTP-запросов, чтобы предоставить идентифицирующую информацию о клиенте, который отправил каждый запрос.
sudo . Если вы не знакомы с командой sudo , вы можете ознакомиться с нашим руководством по пользователям и группам.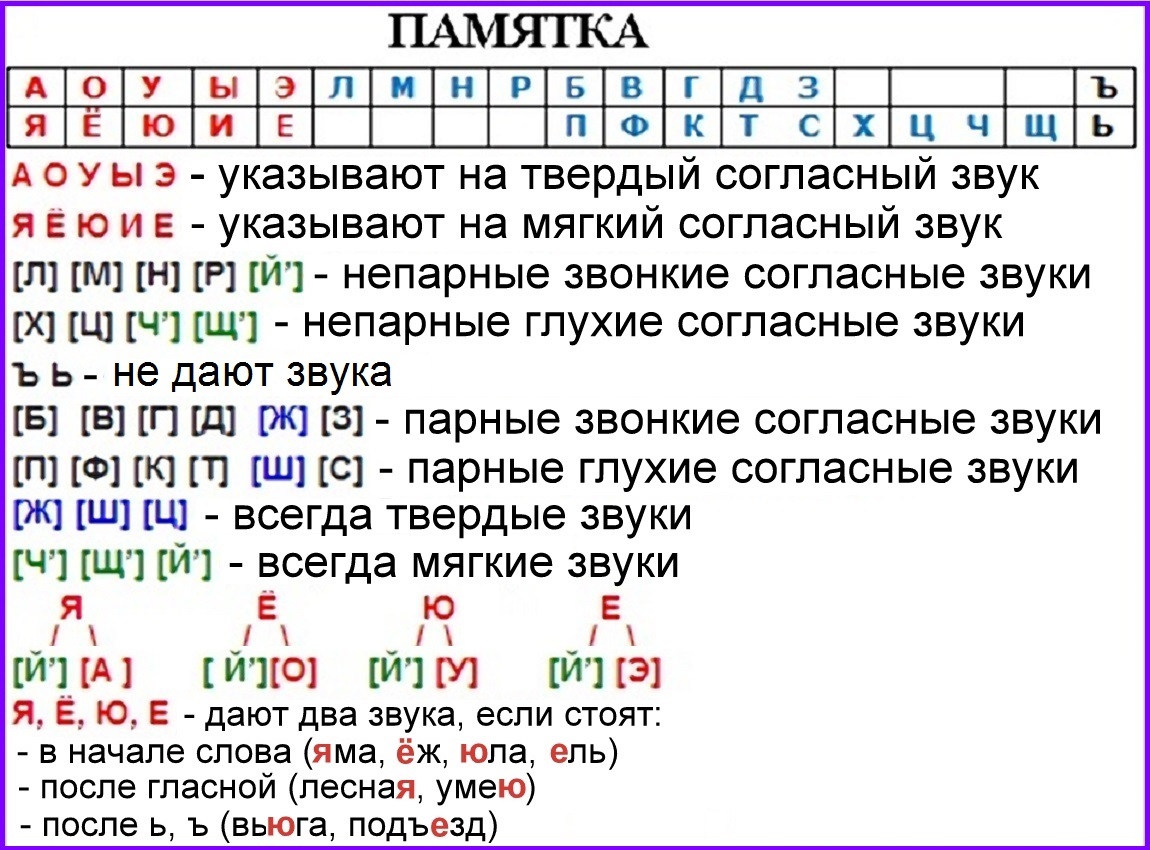
Прежде чем начать
Если вы еще этого не сделали, создайте учетную запись Linode и вычислительный экземпляр. См. наши руководства «Начало работы с Linode» и «Создание вычислительного экземпляра».
Следуйте нашему руководству по настройке и защите вычислительного экземпляра, чтобы обновить свою систему. Вы также можете установить часовой пояс, настроить имя хоста, создать ограниченную учетную запись пользователя и усилить доступ по SSH.
Установка
Java
На момент написания этой статьи для Elasticsearch требуется Java 8.
OpenJDK 8 доступен в официальных репозиториях. Установите безголовый пакет OpenJDK 8:
sudo apt install openjdk-8-jre-headless
Подтвердите, что Java установлена:
java -версия
Вывод должен быть похож на:
версия openjdk "1.8.0_151" Среда выполнения OpenJDK (сборка 1.8.0_151-8u151-b12-1~deb9у1-б12) 64-разрядная виртуальная машина сервера OpenJDK (сборка 25.
 151-b12, смешанный режим)
151-b12, смешанный режим)
 151-b12, смешанный режим)
151-b12, смешанный режим)
Elasticsearch
Установите официальный ключ подписи пакета Elastic APT:
wget -qO — https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-ключ добавить -
Установите пакет
apt-transport-https, который требуется для получения пакетов deb, обслуживаемых через HTTPS:sudo apt-get install apt-transport-https
Добавьте информацию о репозитории APT в список источников вашего сервера:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic.list
Обновите список доступных пакетов:
sudo apt-get update
Установите пакет
elasticsearch:sudo apt-get install -y elasticsearch
Установите размер кучи JVM примерно равным половине доступной памяти вашего сервера. Например, если на вашем сервере 1 ГБ ОЗУ, измените
XmsиXmxзначений в файле/etc/elasticsearch/jvm.на options 512m. Остальные значения в этом файле оставьте без изменений:- Файл: /etc/elasticsearch/jvm.options
-Xms512m -Xmx512m
Включить и запустить службу
elasticsearch:sudo systemctl enable elasticsearch sudo systemctl начать поиск elastics
Подождите несколько секунд, пока служба запустится, затем подтвердите, что Elasticsearch API доступен:
завиток локальный: 9200
REST API Elasticsearch должен вернуть ответ JSON, подобный следующему:
{ "имя": "Sch2T0D", "имя_кластера": "докер-кластер", "cluster_uuid": "MH6WKAm0Qz2r8jFK-TcbNg", "версия": { "номер": "6.1.1", "build_hash": "bd92e7f", "build_date": "2017-12-17T20:23:25.338Z", "build_snapshot": ложь, "lucene_version": "7.1.0", "минимальная_версия_совместимости_провода": "5. 6.0",
"минимальная_индексная_совместимая_версия": "5.0.0"
},
«слоган»: «Знаешь, для поиска»
} Чтобы определить, успешно ли запущена служба, просмотрите самые последние журналы:
systemctl status elasticsearch
 options
options  6.0",
"минимальная_индексная_совместимая_версия": "5.0.0"
},
«слоган»: «Знаешь, для поиска»
}
6.0",
"минимальная_индексная_совместимая_версия": "5.0.0"
},
«слоган»: «Знаешь, для поиска»
} Теперь вы готовы установить и использовать плагины Elasticsearch.
Плагины Elasticsearch
В оставшейся части этого руководства мы рассмотрим несколько плагинов и распространенные варианты их использования. Многие из следующих шагов будут включать взаимодействие с API Elasticsearch. Например, чтобы проиндексировать образец документа в Elasticsearch, Запрос POST с полезной нагрузкой JSON должен быть отправлен по адресу /{имя индекса}/{тип}/{идентификатор документа} :
POST /exampleindex/doc/1
{
"message": "это значение для поля сообщения"
}
Существует ряд инструментов, которые можно использовать для отправки этого запроса. Самый простой подход — использовать curl из командной строки:
curl -H'Content-Type: application/json' -XPOST localhost:9200/exampleindex/doc/1 -d '{ "message": "this значение поля сообщения" }'
Другие альтернативы включают vim-rest-console, подключаемый модуль Emacs es-mode или подключаемый модуль консоли для Kibana. Используйте любой удобный для вас инструмент.
Используйте любой удобный для вас инструмент.
Подготовьте индекс
Перед установкой каких-либо подключаемых модулей создайте тестовый индекс.
Создайте индекс с именем
testс одним сегментом и без реплик:POST /test { "настройки": { "индекс": { "количество_реплик": 0, "количество_осколков": 1 } } }ПримечаниеЭти настройки подходят для тестирования, но в производственной среде следует использовать дополнительные сегменты и реплики.
Добавить пример документа в индекс:
POST /test/doc/1 { "message": "это пример документа" }Поиск можно выполнять с помощью конечной точки URL
_search. Найдите «пример» в поле сообщения во всех документах:POST /_search { "запрос": { "условия": { "сообщение": ["пример"] } } }API Elasticsearch должен вернуть соответствующий документ.
Плагин вложения Elasticsearch
Плагин вложения позволяет Elasticsearch принимать документ в кодировке base64 и индексировать его содержимое для облегчения поиска. Это полезно для поиска в PDF или документах с форматированным текстом с минимальными затратами.
Это полезно для поиска в PDF или документах с форматированным текстом с минимальными затратами.
Установите подключаемый модуль
ingest-attachmentс помощью инструмента elasticsearch-plugin :sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-attachment
Перезапустить elasticsearch:
sudo systemctl перезапустить elasticsearch
Подтвердите, что подключаемый модуль установлен должным образом, используя API
_cat:GET /_cat/plugins
Плагин
ingest-attachmentдолжен быть в списке установленных плагинов.
Для использования подключаемого модуля вложения необходимо использовать конвейер для обработки данных в кодировке base64 в поле документа. Конвейер приема — это способ выполнения дополнительных шагов при индексировании документа в Elasticsearch. В то время как Elasticsearch поставляется с предустановленным конвейером процессоров (которые могут выполнять такие действия, как удаление или добавление полей), плагин вложения устанавливает дополнительный процессор, который можно использовать при определении конвейера.
Создайте конвейер с именем
doc-parser, который берет данные из поля с именемencoded_docи выполняет процессор приложения в поле:PUT /_ingest/pipeline/doc-parser { "description": "Извлечь текст из документов в кодировке base-64", «процессоры»: [ { «вложение»: { «поле»: «encoded_doc» } } ] }Конвейер
Примечание По умолчанию обработчик вложений создает новое поле с именемdoc-parserтеперь можно указать при индексации документов для извлечения данных из поляencoded_doc.вложениес проанализированным содержимым целевого поля. Дополнительную информацию см. в документации процессора вложений.Индексировать пример документа RTF (форматированный текст). Следующая строка представляет собой документ RTF, содержащий текст, который мы хотели бы найти. Он состоит из текста в кодировке base64 «Привет из документа RTF с форматированным текстом»:
e1xydGYxXGFuc2kKSGVsbG8gZnJvbSBpbnNpZGUgb2YgYSByaWNoIHRleHQgUlRGIGRvY3VtZW50LgpccGFyIH0K
Добавьте этот документ в тестовый индекс, используя параметр
?pipeline=doc_parserдля указания нового конвейера:PUT /test/doc/rtf?pipeline=doc-parser { "encoded_doc": "e1xydGYxXGFuc2kKSGVsbG8gZnJvbSBpbnNpZGUgb2YgYSByaWNoIHRleHQgUlRGIGRvY3VtZW50LgpccGFyIH0K" }Поиск термина «богатый», который должен вернуть проиндексированный документ:
ПОЧТОВЫЙ /_поиск { "запрос": { "условия": { "attachment. content": ["богатый"]
}
}
}
Этот метод можно использовать для индексации и поиска других типов документов, включая PDF, PPT и XLS. Дополнительные поддерживаемые форматы файлов см. в проекте Apache Tika (в котором реализована базовая реализация извлечения текста).
 content": ["богатый"]
}
}
}
content": ["богатый"]
}
}
}
Плагин фонетического анализа
Elasticsearch отлично справляется с анализом текстовых данных. Несколько анализаторов поставляются в комплекте с Elasticsearch, который может выполнять мощный анализ текста.
Одним из таких анализаторов является плагин Phonetic Analysis. С помощью этого плагина можно искать термины, похожие по звучанию на другие слова.
Установить плагин
-фонетический анализплагин:sudo /usr/share/elasticsearch/bin/elasticsearch-plugin установить фонетический анализ
Перезапустить Elasticsearch:
sudo systemctl перезапустить elasticsearch
Подтвердите, что плагин был успешно установлен:
ПОЛУЧИТЬ /_cat/плагины
Чтобы использовать этот плагин, необходимо внести следующие изменения в тестовый индекс:
- Необходимо создать фильтр . Этот фильтр будет использоваться для обработки токенов, созданных для полей проиндексированного документа.
- Этот фильтр будет использоваться анализатором . Анализатор определяет, как токенизировано поле и как эти токенизированные элементы обрабатываются фильтрами.
- Наконец, мы настроим тестовый индекс, чтобы использовать этот анализатор для поля в индексе с сопоставление .
 Этот фильтр будет использоваться для обработки токенов, созданных для полей проиндексированного документа.
Этот фильтр будет использоваться для обработки токенов, созданных для полей проиндексированного документа.Перед добавлением анализаторов и фильтров необходимо закрыть индекс.
Закрыть тестовый индекс:
POST /test/_close
Определите анализатор и фильтр для тестового индекса в
_settingsAPI:PUT /test/_settings { "анализ": { "анализатор": { "мой_фонетический_анализатор": { «токенизатор»: «стандартный», "фильтр": [ "стандарт", "нижний регистр", "мой_фонетический_фильтр" ] } }, "фильтр": { "мой_фонетический_фильтр": { "тип": "фонетический", "кодер": "метафон", «заменить»: ложь } } } }Повторно открыть индекс, чтобы включить поиск и индексацию:
POST /test/_open
Определите сопоставление для поля с именем
phonetic, которое будет использовать анализаторmy_phonetic_analyzer:POST /test/_mapping/doc { "характеристики": { "фонетический": { "тип": "текст", "анализатор": "my_phonetic_analyzer" } } }Индексируйте документ с полем JSON под названием
phoneticс содержимым, которое должно быть передано через фонетический анализатор:POST /тест/документ { "фонетический": "черный кожаный пуфик" }Выполните
совпадениепоиска по термину «оттоманка». Однако вместо правильного написания термина напишите слово с ошибкой, чтобы слово с ошибкой было фонетически похоже:POST /_search { "запрос": { "соответствовать": { «фонетический»: «отомен» } } }Плагин фонетического анализа должен уметь распознавать, что «отомэн» и «оттоманка» фонетически похожи, и возвращать правильный результат.
 Однако вместо правильного написания термина напишите слово с ошибкой, чтобы слово с ошибкой было фонетически похоже:
Однако вместо правильного написания термина напишите слово с ошибкой, чтобы слово с ошибкой было фонетически похоже:Плагин Geoip Processor
При индексировании документов, таких как файлы журналов, некоторые поля могут содержать IP-адреса. Плагин Geoip может обрабатывать IP-адреса, чтобы обогатить документы данными о местоположении.
Установите плагин:
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-geoip
Перезапустить Elasticsearch:
sudo systemctl перезапустить elasticsearch
Подтвердите, что плагин установлен, проверив API:
ПОЛУЧИТЬ /_cat/плагины
Как и подключаемый модуль конвейера ingest-attachment , подключаемый модуль ingest-geoip используется в качестве процессора в конвейере приема. В документации плагина Geoip описаны доступные настройки при создании процессоров в конвейере.
В документации плагина Geoip описаны доступные настройки при создании процессоров в конвейере.
Создайте конвейер с именем
parse-ip, который использует IP-адрес из поля с именемipи создает региональную информацию под полем по умолчанию (geoip):PUT /_ingest/pipeline/parse-ip { "description": "Геолокация IP-адреса", "процессоры" : [ { "geoip" : { "поле" : "ip" } } ] }Добавьте сопоставление в индекс, чтобы указать, что поле
ipдолжно храниться как IP-адрес в базовом механизме хранения:POST /test/_mapping/doc { "характеристики": { "айпи": { "тип": "ip" } } }Индекс документа с
ipполе установите пример адреса и передайтеpipe=parse-ipв запросе на использование конвейераparse-ipдля обработки документа:PUT /test/doc/ipexample?pipeline=parse-ip { "ip": "8.8.8.8" }Получить документ для просмотра полей, созданных конвейером:
GET /test/doc/ipexample
Ответ должен включать ключ
geoipJSON с такими полями, какcity_name, полученными из исходного IP-адреса. Плагин должен корректно определять, что IP-адрес находится в Калифорнии.
 Плагин должен корректно определять, что IP-адрес находится в Калифорнии.
Плагин должен корректно определять, что IP-адрес находится в Калифорнии.Плагин процессора агента пользователя
Обычный вариант использования Elasticsearch — индексирование файлов журналов. Анализируя определенные поля из журналов доступа к веб-серверу, можно более эффективно искать запросы по коду ответа, URL-адресу и другим параметрам. ingest-user-agent добавляет возможность анализа содержимого заголовка User-Agent веб-запросов для более точного создания дополнительных полей, идентифицирующих клиентскую платформу, которая выполнила запрос.
Установите плагин:
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-user-agent
Перезапустить Elasticsearch:
sudo systemctl перезапустить elasticsearch
Подтвердите, что плагин установлен:
GET /_cat/plugins
Создайте конвейер загрузки, который указывает Elasticsearch, на какое поле ссылаться при анализе строки пользовательского агента:
PUT /_ingest/pipeline/useragent { "description": "Проанализировать содержимое User-Agent", «процессоры»: [ { «user_agent»: { «поле»: «агент» } } ] }Индексировать документ с полем агента
User-Agentstring:PUT /test/doc/agentexample?pipeline=useragent { "agent": "Mozilla/5. 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/60.0.3112.113 Safari/537.36"
}
Получить документ для просмотра полей, созданных конвейером:
GET /test/doc/agentexample
Индексированный документ будет включать пользовательские данные под
user_agentКлюч JSON. Плагин User Agent понимает множество строкUser-Agentи может надежно анализироватьполей User-Agentиз журналов доступа, созданных веб-серверами, такими как Apache и NGINX.
 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/60.0.3112.113 Safari/537.36"
}
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/60.0.3112.113 Safari/537.36"
}
Заключение
Плагины, описываемые в этом руководстве, представляют собой небольшое подмножество тех, которые доступны в Elastic или написаны сторонними организациями. Дополнительные ресурсы, касающиеся Elasticsearch и использования подключаемых модулей, см. по ссылкам в Дополнительная информация 9раздел 0038 ниже.
Вы можете обратиться к следующим ресурсам для получения дополнительной информации
на эту тему. Хотя они предоставляются в надежде, что они будут
полезно, обратите внимание, что мы не можем ручаться за точность или своевременность
материалы внешнего размещения.
Хотя они предоставляются в надежде, что они будут
полезно, обратите внимание, что мы не можем ручаться за точность или своевременность
материалы внешнего размещения.
- Документация по Elastic
- Справочник по Elasticsearch
- Справочник по плагинам Elasticsearch
Эта страница была первоначально опубликована на
убунту дебиан база данных java
Присоединяйтесь к беседе.
Прочитайте другие комментарии или разместите свои ниже. Комментарии должны быть уважительными, конструктивны и соответствуют теме руководства. Не публиковать внешние ссылки или реклама. Прежде чем публиковать, подумайте, комментарий будет лучше адресован, связавшись с нашим Служба поддержки или запрос на наш Сайт сообщества.
Система комментариев Disqus для Linode Docs требует принятия
Функциональные файлы cookie, которые позволяют нам анализировать использование сайта, чтобы мы могли
измерять и улучшать производительность. Для просмотра и создания комментариев к этому
статью, пожалуйста
обновить настройки файлов cookie
на этом веб-сайте и обновите эту веб-страницу. Обратите внимание: у вас должен быть
В вашем браузере включен JavaScript.
Для просмотра и создания комментариев к этому
статью, пожалуйста
обновить настройки файлов cookie
на этом веб-сайте и обновите эту веб-страницу. Обратите внимание: у вас должен быть
В вашем браузере включен JavaScript.
Создать собственный анализатор | Elasticsearch Guide [8.8]
Если встроенные анализаторы не удовлетворяют ваши потребности, вы можете создать специальный анализатор , в котором используется соответствующая комбинация:
- ноль или более фильтров символов
- токенизатор
- ноль или более фильтров токенов.
Конфигурация
пользовательский анализатор принимает следующие параметры:
Пример конфигурации редактирования
Вот пример, который сочетает в себе следующее:
- Фильтр персонажей
- Фильтр символов полосы HTML
- Токенизатор
- Стандартный токенизатор
- Фильтры токенов
- Фильтр токенов нижнего регистра
- ASCII-складной токен-фильтр
ПОЛОЖИТЬ мой-индекс-000001
{
"настройки": {
"анализ": {
"анализатор": {
"my_custom_analyzer": {
"тип": "пользовательский",
«токенизатор»: «стандартный»,
"char_filter": [
"html_strip"
],
"фильтр": [
"нижний регистр",
"асцифолдинг"
]
}
}
}
}
}
POST мой-индекс-000001/_analyze
{
"анализатор": "my_custom_analyzer",
"text": "Это дежавю?"
} Для анализаторов |

В приведенном выше примере создаются следующие термины:
[ is, this, deja, vu ]
В предыдущем примере использовались токенизатор, фильтры токенов и фильтры символов с их конфигурации по умолчанию, но можно создавать настроенные версии каждого и использовать их в пользовательском анализаторе.
Вот более сложный пример, который сочетает в себе следующее:
- Фильтр персонажей
- Mapping Character Filter, настроенный на замену
:)на_happy_и:(на_sad_
- Mapping Character Filter, настроенный на замену
- Токенизатор
- Pattern Tokenizer, настроенный для разделения на знаки препинания
- Фильтры токенов
- Фильтр токенов нижнего регистра
- Stop Token Filter, настроенный на использование предопределенного списка английских стоп-слов.
Вот пример:
PUT my-index-000001
{
"настройки": {
"анализ": {
"анализатор": {
"my_custom_analyzer": {
"char_filter": [
"смайлики"
],
"токенизатор": "пунктуация",
"фильтр": [
"нижний регистр",
"english_stop"
]
}
},
"токенизатор": {
"пунктуация": {
"тип": "шаблон",
"шаблон": "[ . ,!?]"
}
},
"char_filter": {
"смайлики": {
"тип": "сопоставление",
"сопоставления": [
":) => _счастливый_",
":( => _sad_"
]
}
},
"фильтр": {
"english_stop": {
"тип": "стоп",
"стоп-слова": "_english_"
}
}
}
}
}
POST мой-индекс-000001/_analyze
{
"анализатор": "my_custom_analyzer",
"text": "Я человек :), а вы?"
}  ,!?]"
}
},
"char_filter": {
"смайлики": {
"тип": "сопоставление",
"сопоставления": [
":) => _счастливый_",
":( => _sad_"
]
}
},
"фильтр": {
"english_stop": {
"тип": "стоп",
"стоп-слова": "_english_"
}
}
}
}
}
POST мой-индекс-000001/_analyze
{
"анализатор": "my_custom_analyzer",
"text": "Я человек :), а вы?"
}
,!?]"
}
},
"char_filter": {
"смайлики": {
"тип": "сопоставление",
"сопоставления": [
":) => _счастливый_",
":( => _sad_"
]
}
},
"фильтр": {
"english_stop": {
"тип": "стоп",
"стоп-слова": "_english_"
}
}
}
}
}
POST мой-индекс-000001/_analyze
{
"анализатор": "my_custom_analyzer",
"text": "Я человек :), а вы?"
} Назначает индексу пользовательский анализатор по умолчанию, | |
Определяет пользовательский токенизатор |
