What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
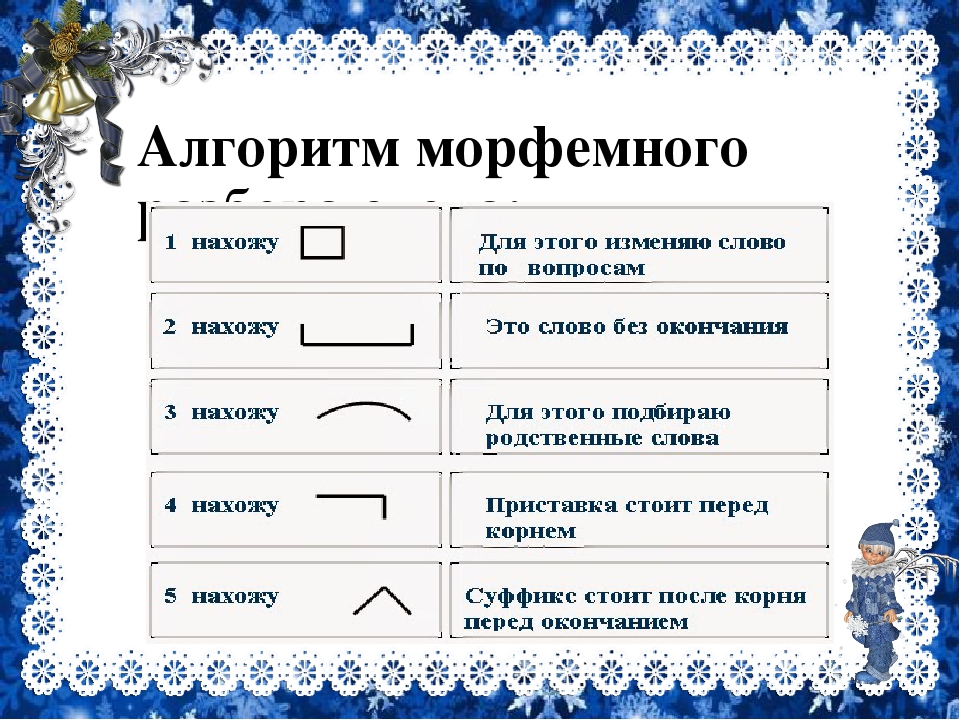
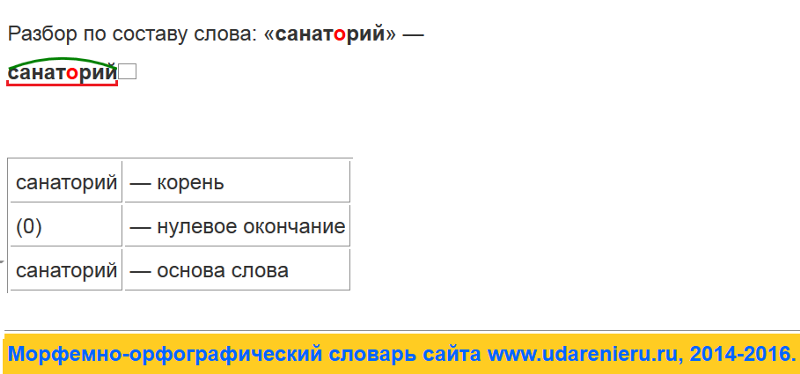
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Разбор предложений по шаблонам русского языка / Хабр
Существует несколько парсеров, подходящих для русского языка. Некоторые из них могут даже выполнять синтаксический анализ, как SyntaxNet, MaltParser и AOT:… или выявлять факты, как Tomita.
Глядя на эти парсеры, я вижу какую-то огромную сложность вычислений, требования к памяти, лицензионные ограничения и… ограниченность каждого решения, увы.
Чтобы понять, что же там такого сложного, мне захотелось сделать собственный парсер. Благо выходные оказались длинными.
Основная идея
Я подумал, как мы сами разбираем текст? Как выделяем из фразы ключевые элементы, строим в голове отношения между словами?
Говорят, что Tomita построен на основе GLR-парсера, который, в свою очередь расширяет LR-парсер, который читает слова по порядку, пытается строить дерево отношений между ними.
У меня же была мысль, что текст надо рассматривать как набор штампов, на которые у нас наметан глаз. «
Далее, находя штампы, получившееся кусочки фразы соединяем в другие штампы, и так, пока не поймем всю фразу целиком — «мотылек на розе» (мотылек — белый, роза — красная), «небо над морем» (небо — темное, море — синее).
Выбор правильного инструмента
То есть, для поиска шаблона (прилагательное, существительное) мне нужно искать пару слов в том же падеже, числе и роде. Как? Естественным решением определения характеристик (граммем) в Python использовать pymorphy2 by kmike
import pymorphy2 as py
def tags(word):
morph = py. MorphAnalyzer()
return morph.parse(word)
>>> print(tags('красной')[0])
Parse(word='красной', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='красный', score=0.125, methods_stack=((<DictionaryAnalyzer>, 'красной', 86, 8),))
>>> print(tags('красной')[0].tag.grammemes)
frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'})
MorphAnalyzer()
return morph.parse(word)
>>> print(tags('красной')[0])
Parse(word='красной', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='красный', score=0.125, methods_stack=((<DictionaryAnalyzer>, 'красной', 86, 8),))
>>> print(tags('красной')[0].tag.grammemes)
frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'})
 MorphAnalyzer()
return morph.parse(word)
>>> print(tags('красной')[0])
Parse(word='красной', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='красный', score=0.125, methods_stack=((<DictionaryAnalyzer>, 'красной', 86, 8),))
>>> print(tags('красной')[0].tag.grammemes)
frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'})
MorphAnalyzer()
return morph.parse(word)
>>> print(tags('красной')[0])
Parse(word='красной', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='красный', score=0.125, methods_stack=((<DictionaryAnalyzer>, 'красной', 86, 8),))
>>> print(tags('красной')[0].tag.grammemes)
frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'})
Слова ‘femn’, ‘ADJF’, ‘sing’, ‘gent’, ‘Qual’ — это обозначения для граммем, принятых в pymorphy2. Обозначения уникальны, их можно использовать для однозначного определения нужных характеристик слова.
Первые штрихи на холсте
Теперь, имея инструмент, составим простой шаблон:
source = '''
Вася ест кашу
# сущ глагол сущ
# что/кто делает с_чем-то
NOUN,nomn VERB NOUN,accs
'''
Здесь ищем существительное (NOUN) в именительном падеже (nomn), за ним глагол (VERB), далее существительное в винительном падеже (accs). Не описанные в шаблоне характеристики нам не важны.
class PPattern:
def __init__(self):
super(). __init__()
import io
def parseSource(src):
def parseLine(s):
nonlocal arr, last
s = s.strip()
if s == '':
last = None
return
if s[0] == '#':
return
if last is None:
last = PPattern()
arr.append(last)
last.example = s
else:
last.tags = s.split()
arr = []
last = None
buf = io.StringIO(src)
s = buf.readline()
while s:
parseLine(s)
s = buf.readline()
return arr
s = parseSource(source)
 __init__()
import io
def parseSource(src):
def parseLine(s):
nonlocal arr, last
s = s.strip()
if s == '':
last = None
return
if s[0] == '#':
return
if last is None:
last = PPattern()
arr.append(last)
last.example = s
else:
last.tags = s.split()
arr = []
last = None
buf = io.StringIO(src)
s = buf.readline()
while s:
parseLine(s)
s = buf.readline()
return arr
s = parseSource(source)
__init__()
import io
def parseSource(src):
def parseLine(s):
nonlocal arr, last
s = s.strip()
if s == '':
last = None
return
if s[0] == '#':
return
if last is None:
last = PPattern()
arr.append(last)
last.example = s
else:
last.tags = s.split()
arr = []
last = None
buf = io.StringIO(src)
s = buf.readline()
while s:
parseLine(s)
s = buf.readline()
return arr
s = parseSource(source)
Пусть вас здесь не пугает работа через StringIO — я хотел сделать потоковое чтение, просто на всякий случай, если понадобится читать большие тексты.
Приведенный кусок кода лишь считывает шаблоны, но более ничего не делает. Добавим анализируемый текст и его парсинг:
source = '''
Вася ест кашу
# сущ гл сущ
# что/кто делает с_чем-то
NOUN,nomn VERB NOUN,accs
Красивый цветок
ADJF NOUN
Птица сидит на крыше
# сущ гл предлог сущ
NOUN,nomn VERB NOUN,loct
'''
text = '''
Мама мыла раму
Вася разбил окно
Лара сама мыла раму
Мама мыла пластиковые окна
'''
import pymorphy2 as py
class PPattern:
def __init__(self):
super(). __init__()
def checkPhrase(self,text):
def checkWordTags(tags, grams):
for t in tags:
if t not in grams:
return False
return True
def checkWord(tags, word):
variants = morph.parse(word)
for v in variants:
if checkWordTags(self.tags[nextTag].split(','), v.tag.grammemes):
return (word, v)
return None
morph = py.MorphAnalyzer()
words = text.split()
nextTag = 0
result = []
for w in words:
res = checkWord(self.tags[nextTag].split(','), w)
if res is not None:
result.append(res)
nextTag = nextTag + 1
if nextTag >= len(self.tags):
return result
return None
def parseText(pats, text):
def parseLine(line):
was = False
for p in pats:
res = p.checkPhrase(line)
if res:
print('+',line, p. tags, [r[0] for r in res])
was = True
if not was:
print('-',line)
buf = io.StringIO(text)
s = buf.readline()
while s:
s = s.strip()
if s != '':
parseLine(s)
s = buf.readline()
patterns = parseSource(source)
parseText(patterns, text)
 __init__()
def checkPhrase(self,text):
def checkWordTags(tags, grams):
for t in tags:
if t not in grams:
return False
return True
def checkWord(tags, word):
variants = morph.parse(word)
for v in variants:
if checkWordTags(self.tags[nextTag].split(','), v.tag.grammemes):
return (word, v)
return None
morph = py.MorphAnalyzer()
words = text.split()
nextTag = 0
result = []
for w in words:
res = checkWord(self.tags[nextTag].split(','), w)
if res is not None:
result.append(res)
nextTag = nextTag + 1
if nextTag >= len(self.tags):
return result
return None
def parseText(pats, text):
def parseLine(line):
was = False
for p in pats:
res = p.checkPhrase(line)
if res:
print('+',line, p.
__init__()
def checkPhrase(self,text):
def checkWordTags(tags, grams):
for t in tags:
if t not in grams:
return False
return True
def checkWord(tags, word):
variants = morph.parse(word)
for v in variants:
if checkWordTags(self.tags[nextTag].split(','), v.tag.grammemes):
return (word, v)
return None
morph = py.MorphAnalyzer()
words = text.split()
nextTag = 0
result = []
for w in words:
res = checkWord(self.tags[nextTag].split(','), w)
if res is not None:
result.append(res)
nextTag = nextTag + 1
if nextTag >= len(self.tags):
return result
return None
def parseText(pats, text):
def parseLine(line):
was = False
for p in pats:
res = p.checkPhrase(line)
if res:
print('+',line, p.
Pymorphy2 при анализе слова возвращает массив всех возможных вариантов, что это за слово может быть: «мыла» — это существительное или глагол. Поэтому наша задача проверить все эти варианты и выбрать из них такой, что характеристики слова подойдут под шаблон. Это делается в функции checkWord.
Получаем результат разбора:
+ Мама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'раму']
+ Вася разбил окно ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Вася', 'разбил', 'окно']
+ Лара сама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Лара', 'мыла', 'раму']
+ Лара сама мыла раму ['ADJF', 'NOUN'] ['сама', 'мыла']
+ Мама мыла пластиковые окна ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'окна']
+ Мама мыла пластиковые окна ['ADJF', 'NOUN'] ['пластиковые', 'окна']
Ну что же, неплохо для начала.
И что, это всё?
Нет, конечно, теперь надо описать соответствие падежей, родов и т.д. между словами. Модифицируем описание шаблона:
source = '''
# Красивый цветок
ADJF NOUN
-a- -b-
# Правила выведения, разделяющие пробелы обязательны
= a.case = b.case
= a.number = b.number
= a.gender = b.gender
'''Появилась строка определения переменных
-a- -b- и строки правил, начинающиеся с «=». Вообще я не заморачивался с синтаксисом шаблонов, поэтому каждый оператор живет в одной строке, а тип оператора определяется по первому символу.Добавляем разбор правил в парсинг шаблонов. Правило компилируется в две лямбды — для получения значения до символа «=», и для для получения второго значения.
def parseFunc(v, names):
dest = v.split('.')
index = names.index(dest[0])
dest = (eval('lambda a: a.' + '.'.join(dest[1:])), index)
return dest
def parseLine(s):
...
elif s[0] == '-': # внутренние имена
s = [x. strip('-') for x in s.split()]
last.names = s
elif s[0] == '=': # правила
s = [x for x in s[1:].split() if x != '']
dest = parseFunc(s[0],last.names)
src = parseFunc(s[2],last.names)
last.rules.append(((dest[1],src[1]), dest, src))
else:
...
 strip('-') for x in s.split()]
last.names = s
elif s[0] == '=': # правила
s = [x for x in s[1:].split() if x != '']
dest = parseFunc(s[0],last.names)
src = parseFunc(s[2],last.names)
last.rules.append(((dest[1],src[1]), dest, src))
else:
...
strip('-') for x in s.split()]
last.names = s
elif s[0] == '=': # правила
s = [x for x in s[1:].split() if x != '']
dest = parseFunc(s[0],last.names)
src = parseFunc(s[2],last.names)
last.rules.append(((dest[1],src[1]), dest, src))
else:
...
И добавляем проверку правил в парсинг текста — просто вычисление лямбд и сравнение их результатов:
...
res = checkWord(self.tags[nextTag].split(','), w)
if res is not None:
result.append(res)
usedP.add(wi)
if not self.checkRules(usedP, result):
result.remove(res)
usedP.remove(wi)
else:
nextTag = nextTag + 1
if nextTag >= len(self.tags):
return (result, usedP)
...
def checkRules(self, used, result):
for r in self.rules:
if max(r[0]) < len(result):
destRes = result[r[0][0]]
destV = destRes[1]
destFunc = r[1][0]
srcRes = result[r[0][1]]
srcFunc = r[2][0]
srcV = srcRes[1]
if not self. checkPropRule(destFunc,destV, srcFunc, srcV):
return False
return True
def checkPropRule(self, getFunc, getArgs, srcFunc, srcArgs, \
op = lambda x,y: x == y):
v1 = getFunc(getArgs)
v2 = srcFunc(srcArgs)
return op(v1,v2)

Прогоним на классике
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['Эти', 'типы']
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['нашем', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['типы', 'стали', 'на', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['стали', 'есть', 'на', 'складе']
Еще введем правило для имен:
# хомяк Коля
NOUN Name
-a- -b-
= a.tag.case = b.tag.case
= a.tag.number = b.tag.number
Это дает разбор:
+ Сестра Татьяна - учительница ['NOUN', 'Name'] ['Сестра', 'Татьяна']Больше правил, хороших и разных
Все было так хорошо, что означало, что мы чего-то не заметили.
 Парсер сломался на фразе «Младшие братья Миша и Вова ходят в детский сад» — он не смог подтвердить правило
Парсер сломался на фразе «Младшие братья Миша и Вова ходят в детский сад» — он не смог подтвердить правило = a.gender = b.gender, потому что «младшие» не имеет родовой принадлежности и может относиться как к слову мужского рода «братья», так и к женскому «сестры».= a.tag.gender is None or a.tag.gender == b.tag.genderМне показалось, что у Python должно быть встроенное средство получения имен «a» и «b», задействованных в выражении. Предчувствие не обмануло, небольшое чтение help и документации привело меня к парсеру AST, в котором было все необходимое, и следующему коду:
import ast
def parseSource(src):
def parseFunc(expr, names):
m = ast.parse(expr)
# Получим список уникальных задействованных имен
varList = list(set([ x. id for x in ast.walk(m) if type(x) == ast.Name]))
# Найдем их позиции в грамматике
indexes = [ names.index(v) for v in varList ]
lam = 'lambda %s: %s' % (','.join(varList), expr)
return (indexes, eval(lam), lam)
 id for x in ast.walk(m) if type(x) == ast.Name]))
# Найдем их позиции в грамматике
indexes = [ names.index(v) for v in varList ]
lam = 'lambda %s: %s' % (','.join(varList), expr)
return (indexes, eval(lam), lam)
id for x in ast.walk(m) if type(x) == ast.Name]))
# Найдем их позиции в грамматике
indexes = [ names.index(v) for v in varList ]
lam = 'lambda %s: %s' % (','.join(varList), expr)
return (indexes, eval(lam), lam)
Все правила переписал на выражения Python. Кстати, если правило записано неправильно, то оно не компилируется еще при чтении словаря шаблонов и программа вылетает по exception, так что если словарь прочитался, то правила выполнимы.
И все получилось:+ Младшие братья Миша и Вова ходят в детский сад ['ADJF', 'NOUN'] ['Младшие', 'братья']
# Текст, который будем парсить
text = '''
Мама мыла раму
Вася разбил окно
Лара сама мыла раму
Рано ушла наша Шура
Мама мыла пластиковые окна
Наша семья
У нас большая семья
Папа и брат Илья работают на заводе
Мама ведет хозяйство
Сестра Татьяна - учительница
Я учусь в школе
Младшие братья Миша и Вова ходят в детский сад
Эти типы стали есть на нашем складе
'''
Словарь шаблонов
# Описания шаблонов
source = '''
# Вася ест кашу
# сущ гл сущ
# что/кто делает с_чем-то
NOUN,nomn VERB NOUN,accs
# определения внутренних имен
-a- -b- -c-
= a. tag.number == b.tag.number
# Именованная сущность
:SNOUN
# Красивый цветок
ADJF NOUN
-a- -b-
# Правила сооответствия шаблону
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
= a.tag.gender is None or a.tag.gender == b.tag.gender
# Птица сидит на крыше
# сущ гл предлог сущ
NOUN,nomn VERB PREP NOUN,loct
-a- -b- -c- -d-
= a.tag.number == b.tag.number
# стали есть
VERB INFN
# хомяк Коля
NOUN Name
-a- -b-
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
# серп и молот
NOUN CONJ NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
#
NOUN PNCT NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
= c.normal_form == '-'
'''
 tag.number == b.tag.number
# Именованная сущность
:SNOUN
# Красивый цветок
ADJF NOUN
-a- -b-
# Правила сооответствия шаблону
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
= a.tag.gender is None or a.tag.gender == b.tag.gender
# Птица сидит на крыше
# сущ гл предлог сущ
NOUN,nomn VERB PREP NOUN,loct
-a- -b- -c- -d-
= a.tag.number == b.tag.number
# стали есть
VERB INFN
# хомяк Коля
NOUN Name
-a- -b-
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
# серп и молот
NOUN CONJ NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
#
NOUN PNCT NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
= c.normal_form == '-'
'''
tag.number == b.tag.number
# Именованная сущность
:SNOUN
# Красивый цветок
ADJF NOUN
-a- -b-
# Правила сооответствия шаблону
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
= a.tag.gender is None or a.tag.gender == b.tag.gender
# Птица сидит на крыше
# сущ гл предлог сущ
NOUN,nomn VERB PREP NOUN,loct
-a- -b- -c- -d-
= a.tag.number == b.tag.number
# стали есть
VERB INFN
# хомяк Коля
NOUN Name
-a- -b-
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
# серп и молот
NOUN CONJ NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
#
NOUN PNCT NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
= c.normal_form == '-'
'''
Разбор
+ Мама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'раму']
+ Вася разбил окно ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Вася', 'разбил', 'окно']
+ Лара сама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Лара', 'мыла', 'раму']
+ Рано ушла наша Шура ['ADJF', 'NOUN'] ['наша', 'Шура']
+ Мама мыла пластиковые окна ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'окна']
+ Мама мыла пластиковые окна ['ADJF', 'NOUN'] ['пластиковые', 'окна']
+ Наша семья ['ADJF', 'NOUN'] ['Наша', 'семья']
+ У нас большая семья ['ADJF', 'NOUN'] ['большая', 'семья']
+ Папа и брат Илья работают на заводе ['NOUN', 'Name'] ['Папа', 'Илья']
+ Папа и брат Илья работают на заводе ['NOUN', 'Name'] ['и', 'Илья']
+ Папа и брат Илья работают на заводе ['NOUN', 'Name'] ['брат', 'Илья']
+ Папа и брат Илья работают на заводе ['NOUN', 'CONJ', 'NOUN'] ['Папа', 'и', 'брат']
+ Мама ведет хозяйство ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'ведет', 'хозяйство']
+ Сестра Татьяна - учительница ['NOUN', 'Name'] ['Сестра', 'Татьяна']
+ Сестра Татьяна - учительница ['NOUN', 'PNCT', 'NOUN'] ['Сестра', '-', 'учительница']
+ Сестра Татьяна - учительница ['NOUN', 'PNCT', 'NOUN'] ['Татьяна', '-', 'учительница']
+ Я учусь в школе ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Я', 'учусь', 'в']
+ Я учусь в школе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['Я', 'учусь', 'в', 'школе']
+ Младшие братья Миша и Вова ходят в детский сад ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['братья', 'ходят', 'в']
+ Младшие братья Миша и Вова ходят в детский сад ['ADJF', 'NOUN'] ['Младшие', 'братья']
+ Младшие братья Миша и Вова ходят в детский сад ['ADJF', 'NOUN'] ['детский', 'сад']
+ Младшие братья Миша и Вова ходят в детский сад ['NOUN', 'CONJ', 'NOUN'] ['братья', 'и', 'Вова']
+ Младшие братья Миша и Вова ходят в детский сад ['NOUN', 'CONJ', 'NOUN'] ['Миша', 'и', 'Вова']
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['Эти', 'типы']
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['нашем', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['типы', 'стали', 'на', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['стали', 'есть', 'на', 'складе']
+ Эти типы стали есть на нашем складе ['VERB', 'INFN'] ['стали', 'есть']
Что дальше?
1.
 Как видите, я остановился на поиске отдельных шаблонов, но не стал результат разбора объединять в дерево синтаксического разбора. Тому есть несколько причин, и одна из них — я не уверен, что стоит это делать. Каждый вариант разбора дает нам маленькую крупицу информации. Объединяя их в дерево, мы пытаемся втиснуть знания в искусственную структуру. Ребенок может читать и понимать предложения, не зная, какое слово в нем подлежащее, а какое — сказуемое. Он берет крупицы и создает в своей голове картину (описываемого) мира. Зачем же нам требовать от машины большего?
Как видите, я остановился на поиске отдельных шаблонов, но не стал результат разбора объединять в дерево синтаксического разбора. Тому есть несколько причин, и одна из них — я не уверен, что стоит это делать. Каждый вариант разбора дает нам маленькую крупицу информации. Объединяя их в дерево, мы пытаемся втиснуть знания в искусственную структуру. Ребенок может читать и понимать предложения, не зная, какое слово в нем подлежащее, а какое — сказуемое. Он берет крупицы и создает в своей голове картину (описываемого) мира. Зачем же нам требовать от машины большего?2. Очевидно не хватает правила, насколько одно слово может быть удалено в тексте от другого. Так «Папа» стал «Ильей», хотя между ними стоят слова «и брат».
3. Так же очевидно, что нужно сортировать результаты между собой и отбрасывать маловероятные. Определение релевантности — вопрос открытый, как минимум можно измерять удаленность слов друг от друга.
4. В правилах, помимо остальных частей речи, не хватает знаков пунктуации. Можно ввести константные литералы «NOUN ‘-‘ NOUN», а можно, как выше в примере с учительницей, проверять знак в правиле.
Можно ввести константные литералы «NOUN ‘-‘ NOUN», а можно, как выше в примере с учительницей, проверять знак в правиле.
5. Pymorphy2 умеет предполагать принадлежность слов к частям речи, поэтому возможны даже такие варианты:>>> parseText(patterns, 'бятые пуськи')
+ бятые пуськи ['ADJF', 'NOUN'] ['бятые', 'пуськи']
+ бятые пуськи ['NOUN', 'Name'] ['бятые', 'пуськи']
Однако здесь пришлось оригинальные слова Петрушевской поменять местами, т.к. нет шаблона с обратным порядком слов. Не то, чтобы это проблема, шаблон ввести недолго, но перестановки слов в русском языке случаются часто и всех их шаблонами не покрыть. Поэтому имеет смысл ввести в описания шаблонов какие-то модификаторы, допускающие перестановку.
Код лежит на GitHub.
Код Маркировки Обуви, Состав и Примеры кода маркировки обуви — ЭкоПринт
Обязательные к заполнению атрибуты кода GTIN при описании обуви в GS1- Штрих-код/GTIN
- Модель производителя
- Дата публикации (план)
- Наименование товара на этикетке
- Бренд (торговая марка)
- ИНН производителя/импортёра
- Вид обуви
- Материал верха
- Материал подкладки
- Материал низа
Описание обязательных атрибутов обуви для получения кода GS1 GTIN на обувь
Штрих-код/GTIN
Определение: Глобальный идентификационный номер товара в Системе GS1.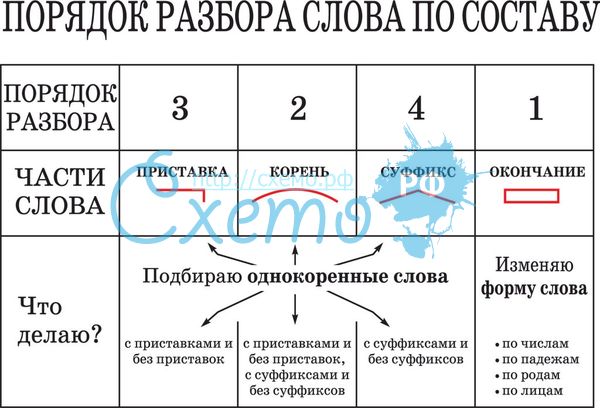
Рекомендации по заполнению: Если необходимо получить новый идентификатор GTIN, то полеследует оставить пустым.
При обработке файла система выдаст первый свободный номер из диа-
пазона префикса, закреплённого за предприятием.
Если идентификатор GTIN уже присвоен производителем/импортёром (из диапазона национальных префиксов 460-469), указать его.
Пример: 4680018660012
Модель производителя
Определение: Идентификатор изделия, используемый во внутренней системе производителя, чаще всего, артикул.
Рекомендации по заполнению: Текстовое поле, длина не более 50 символов.
Пример: МН-0416
Дата публикации (план)
Определение: Дата, до наступления которой пользователь может редактировать все поля у зарегистрированного изделия. До наступления указанной даты информация об изделии не будет передаваться в информационную систему «Маркировка». После наступления указанной даты можно редактировать только необязательные к заполнению атрибуты.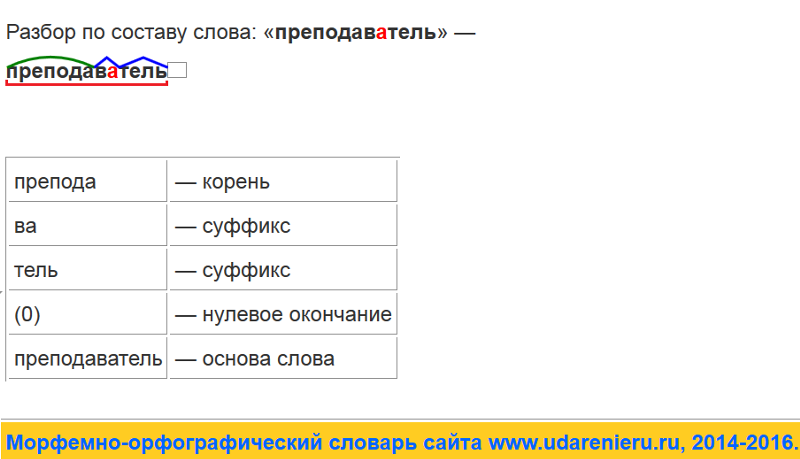
Рекомендации по заполнению: Дата в формате дд.мм.гггг. Если пользователь уверен, что исправлять ничего не потребуется, то необходимо указать текущую дату.
В этом случае описаниетовара и соответствующий номер GTIN будут переданы в ИС Маркировка в тот же день.
Пример: 20.04.2016
Наименование товара на этикетке
Определение: Наименование изделия, которое отражает все отличительные характеристики,по которым потребитель может отличить одно изделие от другого. Допускаются сокращения.
Рекомендации по заполнению: Текстовое поле, длина 1024 символа.
Пример: Женские туфли, синие, модель ЗАСМ, р. 38.
Бренд (торговая марка)
Определение: Зарегистрированная торговая марка, под которой изделие реализуется на рынке.
Рекомендации по заполнению: Текстовое поле длиной не более 128 символов. В случае отсутствия торговой марки следует указать «отсутствует».
Пример: ECCO
ИНН производителя/импортёра
Определение: ИНН российского производителя или импортёра
Рекомендации по заполнению: Цифровое поле длиной от 10 до 12 цифр.
Пример: 3715449091
Вид обуви
Определение: Вид обуви.
Рекомендации по заполнению: Справочник видов обуви.
Пример: <310000020> САПОГИ
Материал верха
Определение: Поле для указания материала верха изделия.
Рекомендации по заполнению: Текстовое поле длиной не более 128 символов.
Пример: Текстиль.
Материал подкладки
Определение: Поле для указания материала подкладки изделия.
Рекомендации по заполнению: Текстовое поле длиной не более 128 символов.
Пример: Натуральная кожа.
Материал низа
Определение: Поле для указания материала низа изделия.
Рекомендации по заполнению: Текстовое поле длиной не более 128 символов.
Пример: Резина
Истории за 26 мая — Задолба!ли
Здесь на сайте нередко ругают женщин, которые хотят феминизма, но чуть что — прикидываются беспомощными кисоньками. Так вот у меня обратная проблема: задолбали мужчины, которые хотят быть хозяевами в жизни и в отношениях, но когда им надо — припоминают феминизм.
Так вот у меня обратная проблема: задолбали мужчины, которые хотят быть хозяевами в жизни и в отношениях, но когда им надо — припоминают феминизм.
Я из тех женщин, которые благодарны феминисткам прошлого за возможность читать, писать и голосовать, но дальнейшую борьбу за эмансипацию лично для себя считаю нецелесообразной. С подросткового возраста хотела себе жизнь как у домохозяйки из американского пригорода: я буду красивой, полностью возьму на себя быт и воспитание детей, а муж должен быть «каменной стеной». Поэтому вот вам моя модель идеальной жизни.
Нет, никакого раздельного счёта в ресторане. Ты платишь за меня. Ах, ты вспомнил феминизм? Ну так иди на свидание с йетиподобной феминисткой Светой: она сэкономила пару тысяч на шугаринге и сама заплатит за ужин.
Да, я жду от тебя не только внимания, но и подарков. Не обязательно дорогих, но уж на букет изволь раскошелиться. Что-что ты говоришь, я меркантильная? Скажу по секрету: ты употребляешь слово в неправильном значении.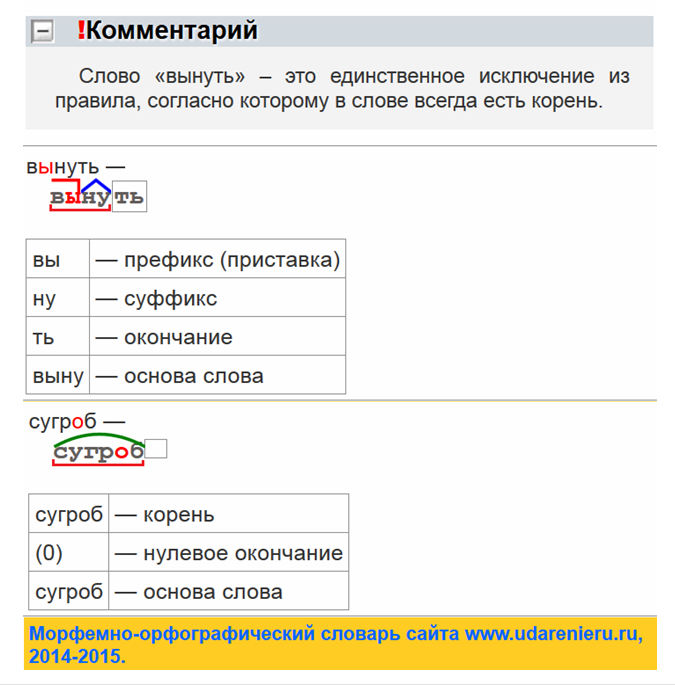 Меркантильность — это стремление получить из всего выгоду, а какая мне выгода из цветов? Я их не перепродам и на еду не обменяю. Меркантильностью меня упрекнуть не получилось, и ты вспоминаешь о феминизме? Окей, удачи тебе с феминисткой Олей, у неё на цветы аллергия. Она толстая, говоришь? Не беда: сэкономишь на цветах за год — ко дню рождения подаришь ей абонемент на фитнес.
Меркантильность — это стремление получить из всего выгоду, а какая мне выгода из цветов? Я их не перепродам и на еду не обменяю. Меркантильностью меня упрекнуть не получилось, и ты вспоминаешь о феминизме? Окей, удачи тебе с феминисткой Олей, у неё на цветы аллергия. Она толстая, говоришь? Не беда: сэкономишь на цветах за год — ко дню рождения подаришь ей абонемент на фитнес.
Безусловно, после свадьбы ты должен обеспечивать меня и наших детей. У меня есть небольшая удалённая занятость и зарплата, которая в данный момент обеспечивает мне приемлемую жизнь. После свадьбы я в общий бюджет ни копейки не вложу — все деньги пойдут на счёт, который будет кормить меня в старости — если с тобой что-то случится, ну или если ты решишь обменять меня на молодуху. Что значит «Ты мне всё, а я тебе только писечку»? Я готова взять на себя быт, разнообразно готовить, делать твой дом красивым и уютным, воспитывать детей — это по-твоему «писечка»? Держи расценки повара, клинера, дизайнера по интерьерам и няни — и охреневай от того, как мало я на самом деле прошу. Так что да: мои деньги — это мои деньги, а твои деньги — это наши деньги. Что, не нравится? Ты опять вспоминаешь феминизм? Вперёд, женись на Яне. Только по дому вы всё будете делать вместе и в декрет пойдёте тоже вместе, другие варианты её не устраивают.
Так что да: мои деньги — это мои деньги, а твои деньги — это наши деньги. Что, не нравится? Ты опять вспоминаешь феминизм? Вперёд, женись на Яне. Только по дому вы всё будете делать вместе и в декрет пойдёте тоже вместе, другие варианты её не устраивают.
Ах да, твою маму я хочу видеть пореже. Желательно — не чаще раза в год. Вы можете встречаться с ней на нейтральной территории, без проблем, но в квартире, куда ты приведёшь меня хозяйкой, я другую женщину терпеть не буду. Не нравится — знакомься с феминисткой Ирой. Она за girl power и сестринство, может наладить контакт с любой женщиной, обе бывшие свекрови в ней души не чают, и с твоей мамой она обязательно подружится. Что значит «Ты не на помойке себя нашёл, чтобы встречаться с дважды разведённой»? Ну, а я не на помойке себя нашла, чтобы встречаться с корзинкой, который до двадцати семи не смог перерезать пуповину от любимой мамы. Аривидерчи!
Если мы разведёмся — я не попытаюсь обобрать тебя до нитки, но и гордо уходить с голым задом и детьми подмышкой, как сделала бы «сильная и независимая», тоже не стану. Как минимум я потребую обеспечить нас с детьми жилплощадью и алиментами, по которым я готова ежемесячно предоставлять отчёт. Не нравится? Ок, раздела жилплощади требовать не буду, но дети остаются у тебя. Кстати, если наш ребёнок вдруг родится нездоровым и проблемным, то после развода он априори останется с тобой. Что за круглые глаза: ты же хотел патриархальный брак, а «патриархат» — это «власть отца», вот и властвуй. А я — всего лишь слабая женщина, от меня многого требовать не стоит, и больного ребёнка я точно не потяну.
Как минимум я потребую обеспечить нас с детьми жилплощадью и алиментами, по которым я готова ежемесячно предоставлять отчёт. Не нравится? Ок, раздела жилплощади требовать не буду, но дети остаются у тебя. Кстати, если наш ребёнок вдруг родится нездоровым и проблемным, то после развода он априори останется с тобой. Что за круглые глаза: ты же хотел патриархальный брак, а «патриархат» — это «власть отца», вот и властвуй. А я — всего лишь слабая женщина, от меня многого требовать не стоит, и больного ребёнка я точно не потяну.
Помимо вышеперечисленных пунктов мне многого не надо. Хочешь встречаться с друзьями — встречайся. Хочешь чтобы я заткнулась — заткнусь. Даже измену пропущу мимо глаз и ушей — только предохраняйся и желательно изменяй так, чтобы я не узнала. Красота же!
Вот только мужчинам это не нужно. Я не понимаю, где те самые богачи, которые дают жене «приличную сумму» в обмен на уборку и готовку. В интернете таких 99%, ну, а в жизни их фиг найдёшь. Вокруг не «мужчины-каменные стены», а какие-то полусгнившие перегородки из ДСП — ни защиты, ни опоры.
Я буквально каждый день читаю и слышу от мужчин, что феминизм не нужен, что феминистки уже добились всех прав и хотят привилегий, что феминистки разрушают семью. Но как только я предлагаю мужчине абсолютно антифеминисткую модель семьи, где он будет главой не на словах, а на деле, так тут же у всех отрастают лапки. И когда такой мужчина обрисовывает мне своё видение брака, оказывается, что ему нужна баба-ломовая лошадь, которая будет вкалывать на работе и дома. И я всё больше прихожу к выводу, что это не женщины, а именно мужчины живут по принципу — ты мне всё, а я тебе писечку.
Если уж говорить о феминизме, то я во многом не согласна с современными представительницами данного движения. Но я всё больше солидарна с ними в одной мысли: иногда легче и приятнее завести котика, чем выходить замуж. А что вы требуете от слабой женщины? Я ничего не хочу решать, я хочу платье. Чего я точно не хочу — так это связываться с мужчиной, который немножко поделает вид, что он главный, а потом под шумок присядет мне на шею.
Птичь — Атланты прогноз специалиста 25.05.21
br>
После трех выездных поединков подряд футбольный клуб Птичь возвращается домой и 25.05.2021 проведет первый матч в родных стенах. А в гости приезжают футболисты клуба Атланты, так что встреча не обещает быть легкой. Свисток главного арбитра о начале игры прозвучит в 19:30 по Москве. Если брать всю историю данного противостояния, то в нем было уже 34 матча, по итогам которых лучше себя проявил футбольный клуб Атланты, одержавший пятнадцать побед при шести поражениях. Гости также смогли выиграть три из последних четырех встреч.
Команда Птичь и команда Атланты, судя из стартовой заявки, выйдут на поле сильнейшими составами. Напомним, что ранее в СМИ говорилось о том, что в составе хозяев поля будут отсутствовать несколько ведущих футболистов. Эта информация существенным образом повлияла на котировки букмекеров, выставленных на этот матч. Наши прогнозисты считали, что оснований для такого завышенного коэффициента на победу команды Птичь в этом матче нет, так как отсутствие двух лидеров для такого клуба, каким является команда Птичь – не критично, так как глубина скамейки позволяет провести ротацию состава, без существенной потери качества игры. Тем более что сейчас стало известно о том, что лидеры все же сыграют. Мы думаем, что команда Птичь сегодня добьется уверенной победы над своими соперниками, так что, рекомендуем играть не только победу хозяев поля в этом матче, но и делать ставки на фору команды Птичь. Учитывая, что команды будут действовать основными составами, нам также кажутся вполне играбельными ставки на общий тотал больше в матче, так как хозяева вряд ли забьют менее двух голов, да и гостям вполне по силам наиграть на забитый мяч. Также здесь можно рассмотреть ставку на индивидуальный тотал голов команды Птичь на больше, исходя из того, что хозяева поля очень активно действуют в родных стенах. К примеру, в прошлом сезоне команда Птичь только в трех домашних матчах забила менее двух голов.
Тем более что сейчас стало известно о том, что лидеры все же сыграют. Мы думаем, что команда Птичь сегодня добьется уверенной победы над своими соперниками, так что, рекомендуем играть не только победу хозяев поля в этом матче, но и делать ставки на фору команды Птичь. Учитывая, что команды будут действовать основными составами, нам также кажутся вполне играбельными ставки на общий тотал больше в матче, так как хозяева вряд ли забьют менее двух голов, да и гостям вполне по силам наиграть на забитый мяч. Также здесь можно рассмотреть ставку на индивидуальный тотал голов команды Птичь на больше, исходя из того, что хозяева поля очень активно действуют в родных стенах. К примеру, в прошлом сезоне команда Птичь только в трех домашних матчах забила менее двух голов.
СТАВКИ/КОЭФФИЦИЕНТЫ БУКМЕКЕРСКИХ КОНТОР НА МАТЧ Птичь — Атланты:
В случае выигрыша футбольного клуба Птичь сыграет коэффициент 2.06, при победе ФК Атланты букмекеры выплатят выигрыш по ставкам на 2.36, а вероятность ничьи составляет 6. 2.
2.
История личных встреч
Большой выбор ставок, предложенный букмекерами на матч команды Птичь и команды Атланты, можно объяснить тем, что обе команды относят к элите современного футбола, и их противостояние – это матч, который, несомненно, привлечет внимание любителей футбола во всем мире. Команды тщательно готовятся к этому матчу, так как победа в нем позволит не только набрать три очка, необходимые для турнирной таблицы, но эта победа будет очень сильным моральным подспорьем, ведь победа, добытая в матчах с прямым конкурентом в борьбе за чемпионство – лучшее, о чем можно только мечтать. В плане кадровых потерь команды подходят к предстоящему матчу в отличной форме. Все ключевые футболисты готовы помочь клубу со стартовых минут матча, а наставники смогли приобрести на трансферном рынке еще ряд перспективных футболистов, которые могут усилить игру клубов со скамейки. Так что, с исполнителями у команды Птичь и команды Атланты – полный порядок. Тактику наставники тоже не меняли по сравнению с прошлым сезоном. Действительно, зачем ломать и менять то, что приносит результат. Напомним, что оба клуба играют в атакующий футбол, причем, можно сказать, что даже в остро атакующий, когда вся команда может угрожать воротам соперника при быстром переходе из обороны в атаку, либо при стандартах. Это означает, что сегодня команды не будут отсиживаться в обороне, а постараются создать максимум голевых моментов.
Поклонники футбола уже давно ожидают, когда 25.05.2021 на поле выйдут команды Птичь и Атланты. По московскому времени прямая трансляция данного поединка пройдет в 19:30. Интерес к данной встрече возникает еще и потому, что уже два года команды между собой не играли. А в последнем очном противостоянии команды разошлись миром, завершив встречу со счетом 3-3.
Предматчевый анализ и прогнозы букмекеров
Чемпионат находится в самом разгаре, поэтому футболистам команды Птичь и команды Атланты нельзя расслабляться, ведь борьба за высокие места в чемпионате – это необходимость демонстрировать футбол высшего качества в каждом матче, особенно в матчах с прямыми конкурентами. А в том, что именно команда Птичь и команда Атланты будут конкурировать между собой за высокие места в чемпионате, у экспертов нашего ресурса нет никаких сомнений. Команды отлично укомплектованы на нынешний сезон, причем, отличительной чертой обеих команд является наличие хорошей скамейки запасных, футболисты которой могут в любой момент усилить игру команд. Вообще, позволить игрокам такого уровня выходить на замену могут далеко не каждые футбольные команды. Однако, к слову, менеджеры обеих команд постоянно экспериментируют с составом, предоставляя игровое время всем футболистам. Но, по мнению экспертов нашего ресурса, в сегодняшнем матче экспериментов не будет. Обеим командам необходим результат, поэтому менеджеры постараются задействовать всех ведущих футболистов, использовав максимально неудобную тактику для соперника. Отличительными качеством команды Птичь и команды Атланты является атакующий стиль игры, так как львиная доля выигрышных матчей команд приходиться на активные действия у ворот соперника. Учитывая, что сегодняшние соперники умеют активно действовать не только в атаке, но и в обороне, наши эксперты полагают, что матч будет очень интересным, а прогнозы от наших экспертов позволят сделать просмотр этого противостояния еще более зрелищным.
Для экспертов нашего ресурса преимущество команды Птичь в противостоянии с футболистами команды Атланты очевидно. Хозяева поля проводят лучший сезон, демонстрируя слаженную, результативную игру во всех матчах. Особенно уверенно футболисты команды Птичь чувствуют себя в родных стенах, где забивают соперникам по несколько мячей. Гости существенно уступают в классе своим соперникам. При этом, футболисты команды Атланты не отличаются стабильностью в выездных матчах. Да и оборона у команды Атланты частенько проваливается, из-за этого гости много пропускают. Мы думаем, что всеми этими проблемами гостей футболисты команды Птичь должны воспользоваться сполна. А это означает, что команда Птичь уверенно победит в этом матче. Таким образом, наш прогноз на матч команды Птичь и команды Атланты – уверенная победа хозяев поля, причем, более рисковые бетторы могут делать ставки на то, что команда Птичь пробьет фору, заявленную букмекерами. Индивидуальный тотал хозяев поля, как и общий тотал забитых голов в матче мы рекомендуем ставить на больше. В родных стенах команда Птичь никому не забивала менее двух голов, а учитывая проблемы гостей в обороне, мы полагаем, что победа команды Птичь будет разгромной. Желтые карточки и нарушения правил в этом матче мы советуем играть на меньше, так как командам не за чем совершать грубые фолы в таком матче. А вот индивидуальный тотал угловых команды Птичь мы рассматриваем на больше, так как клуб активно использует фланги во время атак, а атаковать хозяева поля в этом матче будут много, поэтому и ставка эта видится уверенной.
Птичь
Болельщики футбольного клуба Птичь уже смирились с тем, что он в последние годы постоянно перемещается между дивизионами. В начале сезона все также шло к тому, что команду ожидает понижение в классе, но после того, как был уволен главный тренер и на его место пришел опытный иностранный специалист, результаты команды постепенно стали улучшаться. Хозяева смогли выбраться из зоны вылета, а сейчас вообще идут десятыми, так что оторваться от аутсайдеров получилось уже на четырнадцать очков. В данный момент футбольный клуб Птичь вообще пребывает в великолепной форме, одержав три победы в последних четырех поединках, а также один раз сыграв вничью. Дома команда чаще выигрывает, чем проигрывает, а также новый тренер заставил игроков больше думать об обороне, так что существенно сократилось количество пропущенных мячей. Восстановились от повреждений сразу трое полузащитников, так что в лазарете остаются только центральный защитник и левый нападающий.
Атланты
Из-за провального начала сезона длительное время футбольный клуб Атланты пребывал в зоне вылета, так что многие уже начали думать, что по завершении чемпионата ему грозит понижение в классе. Но, два месяца назад руководство сменило главного тренера, пригласив молодого амбициозного специалиста, с которым команда начала показывать более атакующий футбол, а не просто сидеть в обороне, надеясь на то, что удастся не пропустить. С данным наставником футбольный клуб Атланты сыграл восемь матчей, в которых потерпел только одно поражение, но зато одержав шесть побед. Это позволило гостям выбраться из зоны вылета, так что сейчас команда уже идет четырнадцатой, на четыре очка оторвавшись от аутсайдеров. Футболисты стали больше самоотдачи демонстрировать на поле, и это касается не только домашних, но и выездных матчей, где команда пытается грамотно действовать в обороне, но еще и постоянно атаковать. В лазарете ФК Атланты пребывают двое защитников, а также может пропустить игру левый вингер.
Интересные факты перед матчем Птичь – Атланты
Эксперты нашего ресурса в матче команды Птичь и команды Атланты видят фаворитами хозяев поля. Вообще, если рассматривать успехи клубов в нынешнем сезоне, то это противостояние равных соперников. В принципе, букмекеры и предлагают практически равные коэффициенты на победы команд в этом матче. Однако, при тщательном изучении статистических и прочих данных эксперты нашего ресурса смогли найти несколько факторов, которые говорят о том, что в этом матче команда Птичь должна побеждать своих соперников. Календарь у хозяев поля более щадящий, чем у команды Атланты. При этом, у хозяев поля в строю все ключевые футболисты, в отличии от гостей, которые вынуждены использовать футболистов резерва, не имеющих достаточного опыта выступлений в таких матчах. Да и победа футболистам команды Птичь в этом матче гораздо нужнее, чем их соперникам. Так что, все факторы говорят о том, что сегодня стоит играть победу команды Птичь, и именно это советуют делать эксперты нашего ресурса. Относительно общего тотала забитых голов в этом матче. Оба клуба играют в атакующий футбол, а учитывая проблемы с составом у гостей, мы не видим причин, чтобы команда Птичь не забила своим соперникам несколько голов. Так что, неплохой ставкой в этом матче является еще и ставка на общий тотал забитых голов на больше. Относительно нарушений правил и желтых карточек, то футболисты обеих команд играют грубо, поэтому предложенный букмекерами тотал должны пробивать. Угловые обе команды подают, причем, в личных встречах, эти клубы всегда пробивают заявленный тотал, поэтому мы не видим причин для того, чтобы и сегодня команды не подали много угловых.
Игра завершится победой Птичь — 2.06, в игре будет ничья — 6.2, игра завершится победой Атланты — 2.36.
Букмекеры полагают, что у команды Атланты нет особых шансов против более мотивированного соперника, и наши эксперты полностью с этим согласны. Напомним, что хозяевам поля сейчас необходимы очки, да и по уровню игры они заметно превосходят своих соперников, которые вдобавок ко всему уже потеряли мотивацию в этом чемпионате. Напомним, что команда Атланты еще раньше стала основным неудачником чемпионата, когда не смогла выиграть ни одного выездного матча. Да и вообще, гости в этом чемпионате действительно выглядят слабо, уступая даже откровенно слабым командам, видно, команда потратила последние силы на выход в элитный дивизион. Нет необходимости лишний раз напоминать о том, что в составе команды Птичь выступают настоящие профессионалы, которые успели зарекомендовать себя не только на клубном уровне, но и на уровне национальных сборных, эти футболисты умеют решать исходы матчей одним касанием, поэтому у гостей просто нет шансов в матче с таким грозным и мотивированным соперником. Так что, здесь мы солидарны с букмекерами, которые прогнозируют уверенную победу хозяев поля. Поэтому наш прогноз – фора команды Птичь в этом матче. Общий тотал тоже должен быть пробит, причем, необходимо делать ставки и на общий тотал забитых голов на больше и на индивидуальный тотал хозяев поля. В родных стенах команда Птичь играет очень мощно, особенно со слабыми соперниками, которым забивает не менее двух-трех мячей. Индивидуальный тотал угловых команды Птичь мы тоже советуем играть на больше, так как хозяева поля не перестают атаковать даже после нескольких забитых голов.
«Птичь»
Еще недавно футбольный клуб Птичь находился на последнем месте в чемпионате, и не было никаких надежд, что удастся спастись от вылета. Но, после того как поменялся главный тренер, игра аутсайдера намного улучшилась, так что в пяти турах под его руководством было лишь одно поражение, причем от представителя ТОП-5 чемпионата, а в остальных матчах хозяева одержали две победы над более сильными соперниками и дважды сыграли вничью. Это позволило подняться с последнего места и футбольный клуб Птичь даже покинул зону вылета, но остальных аутсайдеров команда опережает исключительно за счет лучшей разницы по забитым и пропущенным мячам. Главное, чтобы эффект от смены наставника продержался как можно дольше, тогда хозяева смогут набрать больше очков и отдалиться от опасной зоны. Но, даже, несмотря на то, что форма футбольного клуба Птичь улучшилась, он все равно остается самой малозабивающей командой в чемпионате.
Этим летом футбольный клуб Атланты провел громкую трансферную кампанию, так что болельщики ожидали высоких результатов. Но, сезон начался совершенно не так, как хотелось, ведь большинство матчей было проиграно, а главный тренер все равно пытался ввести в игру новичков, хотя они явно не улучшали игру команды. Такое упрямство стоило наставнику работы, так что быстро руководство гостей пригласило другого специалиста, обладающего не меньшим опытом в данной лиге. Он сразу же внес коррективы в состав, так что сейчас футбольный клуб Атланты уже является крепким середняком и не позволяет легко отбирать у себя очки. Из зоны вылета гости поднялись на десятую строчку, так что от вылета уже себя обезопасили, но побороться за квалификацию в Лигу Европы не получится, ведь из-за слабого начала сезона отставание от лидеров очень большое. Кроме того, сейчас у команды снова начался спад, так как в последних шести турах получилось набрать только четыре очка. А ведь серьезных проблем с составом у гостей нет.
Статистика и личные встречи
Наши эксперты постоянно мониторят линии букмекерских контор в поисках интересных матчей. Если рассматривать футбольные матчи с практической точки зрения, то составить прогноз можно на любой футбольный матч, независимо от того, к какому чемпиону он относится. Это может быть даже самая неизвестная лига третьесортного чемпионата. Однако наши эксперты занимаются тем, что прогнозируют исходы и статистику тех футбольных матчей, смотреть которые предпочитают все любители футбола. Матчи топ-чемпионатов, которые собирают целые стадионы преданных болельщиков, а также многомиллионную армию болельщиков у экранов телевизоров – вот настоящая страсть наших экспертов. Нельзя сказать, что прогнозировать легко – нет, это тяжелый труд, требующий концентрации и тщательно анализа многочисленных факторов, которые могут оказать влияние на результат матча, однако нам нравится заниматься своим делом и делиться своими трудами с любителями футбола. Сегодня мы решили разобрать матч, соперниками в котором будут команда Птичь и команда Атланты. Для обеих команд результат матча чрезвычайно важен, поэтому команды будут играть на встречных курсах, тем более что защита – не самая сильная сторона обеих команд. В текущем сезоне оба клуба сыграли большинство своих матчей на тотал больше, поэтому вряд ли в принципиальной игре они станут использовать защитную тактику, скорее всего, тренеры вновь будут играть в атакующий футбол, поэтому болельщиков ждет большое количество забитых мячей.
Птичь — Атланты. Прогноз на футбол (25.05.21)
Благодаря любопытной информации, которую удалось найти экспертам нашего ресурса, мы смогли верно оценить шансы команд, встречающихся между собой в очередном туре известного футбольного чемпионата. Речь идет о противостоянии команды Птичь и команды Атланты. Напомним, что в настоящий момент оба клуба обладают неплохими шансами на то, чтобы по итогам сезона занять высокое место в турнирной таблице, дающее право выступать в престижном клубном турнире в будущем сезоне. Однако, наши эксперты смогли найти любопытную информацию, благодаря которой мы выяснили, что гости не горят желанием выступать одновременно на несколько фронтов. Из этого следует, что победа команды Птичь в этом матче выглядит отличной ставкой, которую мы рекомендуем всем любителям футбола. Общий тотал забитых голов в этой игре мы тоже рассматриваем на больше. Скорее всего, оба клуба забьют в этой игре, однако хозяева в итоге окажутся сильнее. Так что, можно делать и ставки на то, что в матче забьют обе команды. Общий тотал желтых карточек стоит рассмотреть на больше, так как это принципиальный матч, а все принципиальные матчи играются на больше. А вот угловых в этом матче не будет много, так как букмекеры весьма завысили общий тотал, забыв, видимо, что и команда Птичь, и команда Атланты не используют фланги, предпочитая атаковать через центр. Так что, общий тотал угловых на меньше – тоже отличная ставка, которую можно смело заигрывать в этом матче. Хотя, все же, лучше играть победу команды Птичь.
Несколько лет назад футбол был более прогнозирован, команды демонстрировали стабильные результаты, а прогнозировать статистику было совсем легко. Однако все течет и все меняется, меняемся мы, меняется и футбол. Сегодня эта игра становится более динамичной, команды предпочитают более активно действовать у чужих ворот, не выстраивая глубоко эшелонированную оборону у собственной штрафной площадки. Времена игры на удержание нужного результата проходят. Тем не менее, новые времена, с молодыми тренерами и молодыми талантливыми футболистами, не менее интересны. Теперь в моде атакующий футбол, с большим количеством ударов и забитых голов, когда стадион ревет от восторга, а один футболист может забивать пять раз в ворота своих соперников, и это уже никого не удивляет. Изменения пошли на пользу этой игры. Наши эксперты надеются, что и в будущем футбол будет только прогрессировать, а наши прогнозы при этом будут оставаться такими же четкими, и будут также стабильно приносить прибыль. Всем удачи!
По мнению футбольных аналитиков, победа ФК Птичь или ничья должны зайти в качестве ставки на данный поединок, так как Атланты сейчас находится не в лучшей форме и не всегда стабильно играет на выезде.
Птичь – Атланты: статистика и история личных встреч
Эксперты нашего ресурса всегда тщательно отслеживают статистические данные футбольных матчей. Это позволяет нам проводить более тщательный анализ линии букмекерских контор в поисках интересных ставок с высоким процентом проходимости. В матче команды Птичь и команды Птичь, наши эксперты смогли найти ряд интересных предложений в букмекерских конторах. Все наши соображения относительно этого матча мы изложили ниже. Мы думаем, что в этом матче можно будет сделать интересные ставки не только до его начала, но и по ходу игры. Напомним, что сейчас практически все букмекерские конторы предлагают большой выбор ставок по ходу игры, среди которых есть ставки не только на основные исходы матча, но и на статистику. Учитывая мнения наших экспертов, а также зная предложения букмекерских контор до начала матча, можно выгодно сделать ставки по ходу игры. При некоторых раскладах, можно рискнуть небольшой суммой, но в итоге поднять солидный выигрыш. Относительно ожиданий от игры, мы думаем, что футболисты обеих команд постараются сыграть на максимум своих возможностей, поэтому мы ждем интересный и результативный матч, тем более что в СМИ говорят о том, что существенных проблем с составом нет ни у одной, ни у другой команды. Так что, ждем интересного матча, исход которого будет напрямую зависеть от желания и старания футболистов команды Птичь и команды Атланты.
Орландо Прайд (жен) — Портленд Торнс (жен) прогноз профессионала на футбол 27.05.21
br>
Футбольный матч Орландо Прайд (жен) — Портленд Торнс (жен) будет завершать тур национального первенства, и пройдет данный поединок в 27-го мая 2021 года, так что посетить его сможет большое количество болельщиков. Для этого организаторы турнира даже специально сдвинули начало матча до 02:00 по МСК. В последних десяти матчах лучше проявили себя футболисты клуба Орландо Прайд (жен), одержавшие пять побед при трех поражениях, но в поединке этого сезона ФК Портленд Торнс (жен) одержал победу со счетом 4-1.
Команда Орландо Прайд (жен) и команда Портленд Торнс (жен), судя из стартовой заявки, выйдут на поле сильнейшими составами. Напомним, что ранее в СМИ говорилось о том, что в составе хозяев поля будут отсутствовать несколько ведущих футболистов. Эта информация существенным образом повлияла на котировки букмекеров, выставленных на этот матч. Наши прогнозисты считали, что оснований для такого завышенного коэффициента на победу команды Орландо Прайд (жен) в этом матче нет, так как отсутствие двух лидеров для такого клуба, каким является команда Орландо Прайд (жен) – не критично, так как глубина скамейки позволяет провести ротацию состава, без существенной потери качества игры. Тем более что сейчас стало известно о том, что лидеры все же сыграют. Мы думаем, что команда Орландо Прайд (жен) сегодня добьется уверенной победы над своими соперниками, так что, рекомендуем играть не только победу хозяев поля в этом матче, но и делать ставки на фору команды Орландо Прайд (жен). Учитывая, что команды будут действовать основными составами, нам также кажутся вполне играбельными ставки на общий тотал больше в матче, так как хозяева вряд ли забьют менее двух голов, да и гостям вполне по силам наиграть на забитый мяч. Также здесь можно рассмотреть ставку на индивидуальный тотал голов команды Орландо Прайд (жен) на больше, исходя из того, что хозяева поля очень активно действуют в родных стенах. К примеру, в прошлом сезоне команда Орландо Прайд (жен) только в трех домашних матчах забила менее двух голов.
СТАВКИ/КОЭФФИЦИЕНТЫ БУКМЕКЕРСКИХ КОНТОР НА МАТЧ Орландо Прайд (жен) — Портленд Торнс (жен):
Вероятность победы футбольного клуба Орландо Прайд (жен) сопоставима с коэффициентом 2.5, а котировкой 2.3 букмекерские конторы оценили ФК Портленд Торнс (жен). Шансы на ничейный результат составляют 3.24.
История личных встреч
Чтобы проанализировать и найти интересные прогнозы на матч команды Орландо Прайд (жен) и команды Портленд Торнс (жен) нашим экспертам потребовалось проработать большой объем информации. Сюда вошли и матчи прошлого сезона, сыгранные клубами, и товарищеские матчи, в которых команды принимали участие в межсезонье. Помимо этого, мы поработали с составами команд, выяснив полезность ушедших, оставшихся и пришедших футболистов. Все это позволило нам сделать определенные выводы, которые наши свое отражение в наших прогнозах. Команда Орландо Прайд (жен) и команда Портленд Торнс (жен) – клубы, которые в прошлом сезоне играли в атакующей манере. Однако сейчас для одной из команд такой стиль игры окажется неприемлемым, так как клуб покинуло ряд футболистов, отвечавших за креатив и реализацию. На их место были взяты новые исполнители, однако вряд ли наставник сходу будет строить игры всей команды через новичков. Скорее всего, клуб выберет защитный стиль, пытаясь угрожать воротом соперника на контратаках. Другая команда сохранила своих лидеров, поэтому мы полагаем, что здесь тренер не стал трогать прежнюю тактическую схему, оставив ее без изменений. Так что, наши прогнозисты видят в этом матче несколько вариантов развития событий, но наиболее реальным будет такой, когда одна команда будет постоянно атаковать, а другая будет стараться разрушать атаки, переходя в молниеносные контратаки. Независимо от тактики, которую наставники выберут для своих подопечных, мы полагаем, что игра получится интересной, и позволит утолить «голод» болельщиков, соскучившихся по футболу.
Поклонники футбола уже давно ожидают, когда 27-го мая 2021 года на поле выйдут команды Орландо Прайд (жен) и Портленд Торнс (жен). По московскому времени прямая трансляция данного поединка пройдет в 02:00. Интерес к данной встрече возникает еще и потому, что уже два года команды между собой не играли. А в последнем очном противостоянии команды разошлись миром, завершив встречу со счетом 3-3.
Предматчевый анализ и прогнозы букмекеров
В прошлом сезоне команда Орландо Прайд (жен) и команда Портленд Торнс (жен) выдали отличный матч, результат которого до сих пор в памяти у многих любителей футбола. В преддверии очного матча между этими футбольными клубами, в СМИ активно напоминают, какие именно соперники будут встречаться, и что футболисты обеих команд умеют творить на футбольном поле. Вообще, результат этого противостояния будет решающим и для одной, и для другой команды. Напомним, что сейчас команда Орландо Прайд (жен) и команда Портленд Торнс (жен) находятся в числе лидеров чемпионата, команды занимают места в верхней части турнирной таблицы, что говорит о серьезности намерений относительно нынешнего сезона. Естественно, впереди у команд непростые матчи, однако сейчас все внимание менеджеров и футболистов приковано к предстоящей игре, в которой соперниками будут ближайшие конкуренты. По словам менеджеров обеих команд, за исключением травмированных футболистов, которые уже на протяжении длительного времени не могут помочь своему клубу, все остальные игроки готовы выйти на поле со стартовых минут. Благодаря этому у менеджеров обеих команд есть возможность выбирать, кому именно из футболистов доверить выступать с первых минут матча. В связи с этим, встает вопрос тактической схемы, которую будут использовать менеджеры обеих команд на ближайший матч. Наши эксперты тщательно изучили статистику матчей команд в текущем сезоне, а также статистику личных встреч между этими футбольными клубами за последние сезоны. Это позволило нам найти интересные закономерности, на которых и основаны наши прогнозы, с которыми можно ознакомиться ниже.
Для экспертов нашего ресурса преимущество команды Орландо Прайд (жен) в противостоянии с футболистами команды Портленд Торнс (жен) очевидно. Хозяева поля проводят лучший сезон, демонстрируя слаженную, результативную игру во всех матчах. Особенно уверенно футболисты команды Орландо Прайд (жен) чувствуют себя в родных стенах, где забивают соперникам по несколько мячей. Гости существенно уступают в классе своим соперникам. При этом, футболисты команды Портленд Торнс (жен) не отличаются стабильностью в выездных матчах. Да и оборона у команды Портленд Торнс (жен) частенько проваливается, из-за этого гости много пропускают. Мы думаем, что всеми этими проблемами гостей футболисты команды Орландо Прайд (жен) должны воспользоваться сполна. А это означает, что команда Орландо Прайд (жен) уверенно победит в этом матче. Таким образом, наш прогноз на матч команды Орландо Прайд (жен) и команды Портленд Торнс (жен) – уверенная победа хозяев поля, причем, более рисковые бетторы могут делать ставки на то, что команда Орландо Прайд (жен) пробьет фору, заявленную букмекерами. Индивидуальный тотал хозяев поля, как и общий тотал забитых голов в матче мы рекомендуем ставить на больше. В родных стенах команда Орландо Прайд (жен) никому не забивала менее двух голов, а учитывая проблемы гостей в обороне, мы полагаем, что победа команды Орландо Прайд (жен) будет разгромной. Желтые карточки и нарушения правил в этом матче мы советуем играть на меньше, так как командам не за чем совершать грубые фолы в таком матче. А вот индивидуальный тотал угловых команды Орландо Прайд (жен) мы рассматриваем на больше, так как клуб активно использует фланги во время атак, а атаковать хозяева поля в этом матче будут много, поэтому и ставка эта видится уверенной.
Орландо Прайд (жен)
В межсезонье руководство футбольного клуба Орландо Прайд (жен) не смогло удержать многих своих лидеров, которые начали покидать команду, как только у нее появились финансовые трудности. В составе осталось мало опытных игроков, так что нынешний главный тренер вынужден задействовать на футбольном поле игроков из молодежной академии, для которых этот сезон является дебютным в высшем дивизионе. Так что, если ранее футбольный клуб Орландо Прайд (жен) был крепким середняком, то очень быстро он превратился в аутсайдера, и хозяева сейчас занимают последнюю строчку, не показывая обнадеживающей игры. Пока футбольный клуб Орландо Прайд (жен) может похвастаться только двумя победами, а шансов на спасение от вылета практически нет, ведь у команды как самая дырявая оборона, так и самое малорезультативное нападение. За последних шесть туров удалось набрать всего одно очко, а смена наставника в прошлом месяце не принесла желаемого результата. В лазарете хозяев атакующий полузащитник и правый вингер.
Портленд Торнс (жен)
Из-за провального начала сезона длительное время футбольный клуб Портленд Торнс (жен) пребывал в зоне вылета, так что многие уже начали думать, что по завершении чемпионата ему грозит понижение в классе. Но, два месяца назад руководство сменило главного тренера, пригласив молодого амбициозного специалиста, с которым команда начала показывать более атакующий футбол, а не просто сидеть в обороне, надеясь на то, что удастся не пропустить. С данным наставником футбольный клуб Портленд Торнс (жен) сыграл восемь матчей, в которых потерпел только одно поражение, но зато одержав шесть побед. Это позволило гостям выбраться из зоны вылета, так что сейчас команда уже идет четырнадцатой, на четыре очка оторвавшись от аутсайдеров. Футболисты стали больше самоотдачи демонстрировать на поле, и это касается не только домашних, но и выездных матчей, где команда пытается грамотно действовать в обороне, но еще и постоянно атаковать. В лазарете ФК Портленд Торнс (жен) пребывают двое защитников, а также может пропустить игру левый вингер.
Интересные факты перед матчем Орландо Прайд (жен) – Портленд Торнс (жен)
Букмекеры видят явным фаворитом в матче команды Орландо Прайд (жен) и команды Портленд Торнс (жен) хозяев поля. Дело в том, что футболистам команды Орландо Прайд (жен) необходимо побеждать в этом матче, чтобы сохранять шансы в борьбе за высокие места в чемпионате. Гости уже решили свои задачи в турнирной таблице, поэтому они могут просто доигрывать сезон. По словам менеджера хозяев поля, он планирует выставить сильнейший состав с первых минут матча. Из этого следует, что хозяева будут атаковать на протяжении всей игры, и вряд ли удовлетворяться несколькими забитыми мячами. Так что, наши эксперты советуют в этом матче делать ставки на победу команды Орландо Прайд (жен) и на победу команды Орландо Прайд (жен) по форе. Отдельно стоит упомянуть о тотале. Естественно, мы рекомендуем играть заявленный тотал забитых голов на больше. При этом более надежной выглядит ставка на то, что хозяева поля пробьют свой тотал голов. Относительно угловых, то здесь тоже стоит исходить от команды Орландо Прайд (жен). Так как хозяева поля будут действовать в этом матче первым номером, то, скорее всего, команда пробьет свой индивидуальный тотал угловых. Желтых карточек и нарушений правил в матче не должно быть много. Оба клуба относятся к корректными командам, а в матчах между собой совершают мало фолов и получают мало желтых карточек, поэтому эти события мы рекомендуем играть на меньше, тем более что для гостей поражение в этом матче не будет значить ничего, вряд ли они будут упираться и совершать грубые фолы.
Победу в матче одержит Орландо Прайд (жен) — 2.5, ничья по результатам противостояния — 3.24, победу в матче одержит Портленд Торнс (жен) — 2.3.
Команда Орландо Прайд (жен) и команда Портленд Торнс (жен), которые примут участие в матче в ближайшем туре, выйдут на поле сильнейшими составами. Об этом стало известно со слов менеджеров команд, которые подтвердили, что у обеих команд еще остаются шансы на то, чтобы занять более высокие места в чемпионате, поэтому каждая игра – это отличный шанс улучшить свои турнирные позиции. Вообще, на старте сезона оба клуба являлись одними из претендентов на попадание в престижные клубные турниры. Однако по ряду причин эти команды забуксовали на старте чемпионата, поэтому теперь они вынуждены стараться наверстать упущенное в концовке. Букмекеры выкатили примерное равные коэффициенты на победу команды Орландо Прайд (жен) и команды Портленд Торнс (жен) в этом матче, наши эксперты придерживаются такого же мнения, так как мы полагаем, что обеим командам необходим еще сезон для того чтобы закончить перестройку, и начать двигаться к намеченным целям. В связи с этим, мы полагаем, что участие в клубных турнирах в будущем году не пойдет на пользу ни одной, ни другой команде. Исходя из этого, наиболее вероятным исходом противостояния мы считаем ничью, на что и предлагаем делать ставки. Общий тотал голов матча мы рассматриваем на меньше. Так как оба соперника будут выступать сильнейшими составами, то они будут максимально собранно действовать в защите, да и сам матч будет проходить, скорее всего, в неспешном темпе, что исключает большое количество забитых голов. Общий тотал угловых в матче мы тоже рекомендуем играть на меньше, так как оба клуба атакуют через центр, практически не используя фланги. А вот нарушений и предупреждений в матче ожидается много, поэтому общий тотал этих статистических параметров мы рекомендуем заигрывать на больше.
«Орландо Прайд (жен)»
Этот сезон футбольный клуб Орландо Прайд (жен) проводит на неплохом уровне, ведь получилось пройти групповой этап Лиги Чемпионов, а сейчас команда имеет отличные шансы на то, чтобы снова квалифицироваться в самый престижный европейский турнир. Хозяева идут третьими в чемпионате, но на две последние путевки в Лигу Чемпионов претендует сразу четыре команды, так что до конца сезона предстоит еще упорная борьба. На своем поле Орландо Прайд (жен) играет очень хорошо, так как поражений еще не было в этом сезоне, но ничьи все же случаются довольно часто. По количеству забитых мячей хозяева уступают только лидеру чемпионата, но оборона команды не самая надежная, что связано со слишком атакующим стилем футбольного клуба Орландо Прайд (жен). Сейчас хозяева находятся в хорошей форме, ведь в шести последних турах хоть и было неожиданное гостевое поражение от аутсайдера, но в остальных пяти матчах были уверенные победы. Левый вингер перебрал желтых карточек, так что вынужден пропустить этот поединок.
Этим летом футбольный клуб Портленд Торнс (жен) провел громкую трансферную кампанию, так что болельщики ожидали высоких результатов. Но, сезон начался совершенно не так, как хотелось, ведь большинство матчей было проиграно, а главный тренер все равно пытался ввести в игру новичков, хотя они явно не улучшали игру команды. Такое упрямство стоило наставнику работы, так что быстро руководство гостей пригласило другого специалиста, обладающего не меньшим опытом в данной лиге. Он сразу же внес коррективы в состав, так что сейчас футбольный клуб Портленд Торнс (жен) уже является крепким середняком и не позволяет легко отбирать у себя очки. Из зоны вылета гости поднялись на десятую строчку, так что от вылета уже себя обезопасили, но побороться за квалификацию в Лигу Европы не получится, ведь из-за слабого начала сезона отставание от лидеров очень большое. Кроме того, сейчас у команды снова начался спад, так как в последних шести турах получилось набрать только четыре очка. А ведь серьезных проблем с составом у гостей нет.
Статистика и личные встречи
Наши эксперты постоянно мониторят линии букмекерских контор в поисках интересных матчей. Если рассматривать футбольные матчи с практической точки зрения, то составить прогноз можно на любой футбольный матч, независимо от того, к какому чемпиону он относится. Это может быть даже самая неизвестная лига третьесортного чемпионата. Однако наши эксперты занимаются тем, что прогнозируют исходы и статистику тех футбольных матчей, смотреть которые предпочитают все любители футбола. Матчи топ-чемпионатов, которые собирают целые стадионы преданных болельщиков, а также многомиллионную армию болельщиков у экранов телевизоров – вот настоящая страсть наших экспертов. Нельзя сказать, что прогнозировать легко – нет, это тяжелый труд, требующий концентрации и тщательно анализа многочисленных факторов, которые могут оказать влияние на результат матча, однако нам нравится заниматься своим делом и делиться своими трудами с любителями футбола. Сегодня мы решили разобрать матч, соперниками в котором будут команда Орландо Прайд (жен) и команда Портленд Торнс (жен). Для обеих команд результат матча чрезвычайно важен, поэтому команды будут играть на встречных курсах, тем более что защита – не самая сильная сторона обеих команд. В текущем сезоне оба клуба сыграли большинство своих матчей на тотал больше, поэтому вряд ли в принципиальной игре они станут использовать защитную тактику, скорее всего, тренеры вновь будут играть в атакующий футбол, поэтому болельщиков ждет большое количество забитых мячей.
Орландо Прайд (жен) — Портленд Торнс (жен). Прогноз на футбол (27.05.21)
Менеджеры команды Орландо Прайд (жен) и команды Портленд Торнс (жен) накануне матча сделали много громких заявлений. Напомним, что команда Орландо Прайд (жен) и команда Портленд Торнс (жен) будут встречаться между собой в рамках чемпионата. Оба клуба сейчас ведут борьбу за возможность улучшить свои турнирные позиции и, в принципе, время для этого еще есть, так как в чемпионате еще достаточно матчей. К очному противостоянию клубы подходят без существенных потерь, да, раньше команды лишились некоторых футболистов, однако уже научились действовать без них. Преимущество родного поля – основной фактор, которые вынуждает букмекеров и экспертов нашего ресурса рассматривать хозяев поля фаворитами этого матча. В принципе, в текущем сезоне команда Портленд Торнс (жен) выступает ничуть не хуже, и вполне способна нанести неприятное поражение в родных стенах своим соперникам. Так что, в этом матче мы рекомендуем ждать начала игры, а потом, определившись с формой и готовность команд, делать ставки на победителя в этом матче. Общий тотал: здесь, скорее всего, лучше играть на больше. В составе команды Орландо Прайд (жен) и команды Портленд Торнс (жен) достаточно футболистов, обладающих отличной индивидуальной техникой, которая может в любой момент привести к забитому голу. Нарушений и желтых карточек в матче тоже ожидается много, так как, вне зависимости от того, какая команда первой откроет счет в матче, футболисты будут грубо действовать друг против друга, провоцировать и симулировать, а все это способствует большому количеству желтых карточек. Так как обе команды используют фланги, и подают много угловых по статистике, то и здесь мы рекомендуем делать ставки на тотал больше угловых в этой игре.
Для большинства любителей футбол, которые отправляются на стадионы, чтобы поддержать любимую команду, ставки на спорт – развлечение. Болельщик идет на футбол, и по пути заходит в кассу букмекерской конторы, где выбирает одно или несколько событий, на которые делает ставку. Причем, общий анализ и выбор ставки занимает не более нескольких минут. Всего за несколько минут человек успевает проанализировать и выбрать наиболее оптимальную ставку на тот или иной исход футбольного матча. Это поразительно. Экспертам нашего ресурса для этого требуется не менее нескольких часов, так как мы должны определить риски, взвесить все за и против, тщательно проанализировать все доступные статистические данные. Именно это отличает профессионалов от любителей. Прогнозы наших экспертов имеют высокую вероятность проходимости, а на длительной дистанции ставки по нашим прогнозам способны принести солидный плюс. Ставки же для развлечения, подобные тем, которые мы описали выше – приведут лишь к пустой трате времени и денег. Вам выбирать, во что вкладывать свои время и деньги.
Ведущие отечественные прогнозисты в футбольном матче Орландо Прайд (жен) — Портленд Торнс (жен) ожидают доминирования гостей, из-за чего настроены поставить на их победу по угловым ударам.
Орландо Прайд (жен) – Портленд Торнс (жен): статистика и история личных встреч
Эксперты нашего ресурса всегда тщательно отслеживают статистические данные футбольных матчей. Это позволяет нам проводить более тщательный анализ линии букмекерских контор в поисках интересных ставок с высоким процентом проходимости. В матче команды Орландо Прайд (жен) и команды Орландо Прайд (жен), наши эксперты смогли найти ряд интересных предложений в букмекерских конторах. Все наши соображения относительно этого матча мы изложили ниже. Мы думаем, что в этом матче можно будет сделать интересные ставки не только до его начала, но и по ходу игры. Напомним, что сейчас практически все букмекерские конторы предлагают большой выбор ставок по ходу игры, среди которых есть ставки не только на основные исходы матча, но и на статистику. Учитывая мнения наших экспертов, а также зная предложения букмекерских контор до начала матча, можно выгодно сделать ставки по ходу игры. При некоторых раскладах, можно рискнуть небольшой суммой, но в итоге поднять солидный выигрыш. Относительно ожиданий от игры, мы думаем, что футболисты обеих команд постараются сыграть на максимум своих возможностей, поэтому мы ждем интересный и результативный матч, тем более что в СМИ говорят о том, что существенных проблем с составом нет ни у одной, ни у другой команды. Так что, ждем интересного матча, исход которого будет напрямую зависеть от желания и старания футболистов команды Орландо Прайд (жен) и команды Портленд Торнс (жен).
pywordform — модуль Python для анализа форм MS Word (docx) для извлечения значений полей и тегов
pywordform — это модуль Python для анализа форм Microsoft Word в формате docx и извлечения всех значений полей с их тегами в словарь Python.
Новости
- 2012-04-19 v0.02 : добавлена поддержка многострочных текстовых полей
- 04.03.2012 v0.01 : опубликована начальная версия
Загрузить:
Архив доступен на странице проекта.
Лицензия
BSD, с открытым исходным кодом. См. LICENCE.txt для получения дополнительной информации.
Как использовать этот модуль:
Откройте файл sample_form.docx (предоставленный с исходным кодом) в MS Word и отредактируйте значения полей. Вы также можете добавлять или редактировать поля и создавать свою собственную форму Word (см. Ниже).
Из оболочки вы можете использовать модуль как инструмент для извлечения всех полей с тегами:
> Python pywordform.py sample_form.docx field1 = "привет, мир." field2 = "привет," field3 = "значение B" field4 = "04-03-2012"
В сценарии Python функция parse_form возвращает словарь значений полей, индексированных тегами:
импортировать pywordform
fields = pywordform. parse_form ('sample_form.docx')
поля печати
Выход:
{'field2': 'hello, \ nworld.', 'field3': 'value B', 'field1': 'hello, world.', 'field4': '04 -03-2012 '}
Для получения дополнительной информации см. Основную программу в конце модуля, а также строки документации.
Как создавать свои собственные формы MS Word:
- В MS Word (2007 или более поздней версии) перейдите на вкладку разработчика (вам может потребоваться включить «показывать вкладку разработчика на ленте» в параметрах Word).
- включить режим проектирования.
- щелкните один из значков, например «Aa», чтобы вставить поле.
- , когда поле выбрано, нажмите кнопку свойств и убедитесь, что вы установили уникальный идентификатор в качестве тега. Он будет использоваться, когда pywordform анализирует форму.
- по завершении отключите режим разработки, чтобы ввести значения в поля.
- , вы также можете защитить документ (на вкладке разработчика), чтобы пользователи могли только вводить значения в поля и не изменять остальную часть документа.
Известные ограничения:
- Поддерживается только последний формат «docx», но не устаревший формат «doc» MS Word.
- Поддерживаются только поля формы Word нового стиля. Поля устаревшей формы имеют другую структуру, этот модуль еще не анализирует их.
- На данный момент многострочные текстовые поля не анализируются правильно.
- Пока нельзя редактировать значения полей и сохранять документ.
Как внести свой вклад:
Код доступен в репозитории Mercurial на bitbucket.Вы можете использовать его, чтобы отправлять улучшения или сообщать о любых проблемах.
Чтобы сообщить об ошибке, воспользуйтесь страницей отчетов о проблемах или отправьте мне электронное письмо.
Учебное пособие поExcel: как импортировать и анализировать сложные данные
Импорт данных в Excel из других источников может стать настоящей головной болью, особенно если вы копируете и вставляете данные из Интернет-источника. Данные, экспортированные с мэйнфрейма; из другой программы, такой как Microsoft Access, Lotus, Word или Word Perfect, Adobe Acrobat; или из любого другого текстового источника — это, как правило, несложный процесс, потому что все можно свести к простому текстовому файлу ASCII.
В параметрах импорта и анализа Excel используется мастер, который проведет вас через эти процессы. Просто следуйте инструкциям на экранах. После импорта данных проблема состоит в том, как правильно проанализировать данные, особенно если информация в каждом анализируемом поле содержит несколько слов, много знаков препинания, специальных символов или других сложностей.
Импорт данных
1. Откройте пустую электронную таблицу Excel и следуйте инструкциям из «Советы по Excel pro: импорт и анализ данных.Обратите внимание, что вся информация импортируется в одно поле, поэтому вы должны проанализировать данные, чтобы разбить эту строку текста на отдельные поля. Обратите внимание, что синтаксический анализ данных, использованных в справочной статье, был легким, потому что каждое поле содержало похожие записи.
2. В нашем примере мы просто введем дюжину записей, которые вы сможете отредактировать вручную за несколько минут. Но техника, которую я вам покажу, подойдет для редактирования тысяч записей. Примечание. В оставшейся части статьи предположим, что ваша таблица содержит 1000 записей.Поля для этой базы данных: Имя, Заголовок, Местоположение филиала, Город и Штат; это пять столбцов (или полей).
PC World / JD SartainВсе шесть полей импортированы в один столбец
Перед синтаксическим анализом базы данных
Если вы проанализируете базу данных сейчас, результаты будут беспорядочными, потому что у некоторых имен есть приветствия или титулы. У некоторых есть отчество или инициалы, у некоторых есть суффиксы и / или аккредитации. Кроме того, другие поля содержат от одного до пяти слов на запись.А поскольку единственным разделителем является пробел, Excel создает новое поле или столбец для каждого слова. Очистка этого беспорядка включает в себя несколько шагов.
PC World / JD SartainБаза данных проанализирована перед реорганизацией.
A. Сначала извлеките последнее слово
1. Давайте извлечем последнее слово в каждой строке текста, а затем удалим это слово из исходной базы данных. В данном случае это состояние.
2. Переместите курсор в ячейку P5 и введите следующую формулу:
= ОБРЕЗАТЬ (ВПРАВО (ПОДСТАВИТЬ (A5, «», ПОВТОР («», 100)), 100))
3.Скопируйте формулу с P5 на P6 через P1000.
4. Затем выделите диапазон, выберите Копировать , переместите один столбец вправо и выберите Вставить значения . Если вы этого не сделаете, извлеченная вами информация о «состоянии» изменится в зависимости от новой проанализированной информации в A5.
5. Удалить столбец P.
PC World / JD SartainИзвлечь последнее слово в каждой строке текста.
B. Удалить последнее слово в каждой записи / строке текста
1.Переместите курсор в столбец B и введите следующую формулу:
= LEFT (TRIM (A5), FIND («~», SUBSTITUTE (A5, »«, »~», LEN (TRIM (A5)) — LEN (SUBSTITUTE) (TRIM (A5), ”“, ””)))) — 1)
Обратите внимание, что все данные из A5 , кроме State, теперь находятся в B5.
2. Скопируйте эту формулу из B5 в B6 через B1000.
3. Обратите внимание, что столбец B теперь является формулой, которую необходимо преобразовать в текст.
4. Затем выделите диапазон (B5: B1000), выберите Копировать , переместите один столбец вправо (столбец C) и выберите Вставить значения .
5. Удалите столбцы A и B. Все сдвинется влево, и база данных снова окажется в столбце A.
PC World — JD SartainУдалите последнее слово в каждой строке текста.
C. Используйте повторяющиеся данные для извлечения города
Единственным непротиворечивым фрагментом информации в этой базе данных является слово Branch. Давайте воспользуемся этой информацией, чтобы извлечь город. Есть несколько способов выполнить эту функцию. Это всего лишь один вариант.
1.Во-первых, давайте вставим в нашу формулу такой символ, как знак плюса (+), чтобы упростить процедуру поиска и замены.
2. Переместите курсор в исходную позицию.
3. На вкладке «Главная» нажмите кнопку Найти и выбрать . Выберите Заменить из списка.
4. В диалоговом окне Find & Replace введите слово Branch , а затем пробел в поле Find What .
5. В поле Заменить на введите слово Branch , затем пробел и знак + .
6. Чтобы проверить результаты, нажмите кнопку Найти следующий , затем нажмите кнопку Заменить . Если вы уверены, что ваши результаты будут точными, просто нажмите кнопку Заменить все .
7. Обратите внимание, что Excel поместил знак + между каждым городом и словом Branch.
8. Затем введите эту формулу в ячейку M5: = RIGHT (A5, LEN (A5) -FIND («+», A5)) .
9. Выделите диапазон и скопируйте формулу в M5 вниз от M6 до M1000.
10. Обратите внимание, что столбец M теперь является формулой, которую необходимо преобразовать в текст.
11. Затем выделите диапазон (M5: M1000), выберите Копировать , переместите один столбец влево (столбец L) и выберите Вставить значения .
12. Удалите столбец M (все перемещается влево), затем разверните столбец L, чтобы разместить самый длинный город в диапазоне.
PC World / JD SartainИспользуйте повторяющиеся данные для извлечения города.
D. Удалить город из базы данных строка текста
1.Переместите курсор в ячейку B5 и введите эту формулу:
= LEFT (A5, FIND («+», A5 & «+») — 1)
Обратите внимание, что все данные из A5 , кроме , теперь город в B5
2. Скопируйте эту формулу из B5 в B6 через B1000.
3. Обратите внимание, что столбец B теперь является формулой, которую необходимо преобразовать в текст.
4. Выделите диапазон (B5: B1000), выберите Копировать , переместите один столбец вправо (столбец C) и выберите Вставить значения .
5. Удалите столбцы A и B. Все перемещается влево, и база данных снова находится в столбце A.
Обратите внимание, что город переместился в столбец J, а штат находится в столбце K.
PC World / JD SartainУдалить город из строки базы данных.
E. Перед синтаксическим анализом подсчитайте столбцы
Используйте эту формулу для подсчета количества столбцов / полей, которые Excel потребуется для анализа ваших данных.
Примечание. Просто для того, чтобы убедиться, что в вашей электронной таблице достаточно рабочего места для работы с данными.Вы всегда можете вставить или удалить столбцы и строки позже.
1. Перед анализом данных переместите курсор в ячейку M5 и введите следующую формулу:
= IF (LEN (TRIM (A5)) = 0,0, LEN (TRIM (A5)) — LEN ( ЗАМЕНА (A5, ”“, ””)) + 1).
2. Скопируйте формулу из M5 (первая ячейка в вашей базе данных) в M6 и до последней ячейки в вашей базе данных; например, M1000.
3. Выделите диапазон, выберите Копировать , переместите один столбец вправо и выберите Вставить значения .
4. Затем удалите столбец M (формулы), и все переместится на один столбец влево.
5. Отсортируйте значения в новом столбце M в порядке убывания (от наибольшего к наименьшему). Наибольшее число в этом диапазоне показывает количество столбцов, которые вам понадобятся (для работы) при анализе данных. В данном случае это 11 столбцов: от A до K, начиная со строки 5.
Примечание: поскольку столбцы J и K уже используются, и нам нужно несколько столбцов для работы, вставьте шесть новых столбцов в любом месте между B и K. , выталкивая Город и Штат в столбцы P и Q.
PC World / Jd SartainИспользуйте формулу, чтобы узнать, сколько столбцов после анализа данных.
И теперь мы анализируем данные
Затем анализируем данные с помощью мастера преобразования текста в столбцы.
1. Выделите базу данных (в данном случае только столбец A).
2. Выберите Данные > Текст в столбцы .
3. В мастере преобразования текста в столбцы (шаг 1) нажмите кнопку с разделителями, , затем нажмите Далее.
PC World / JD SartainВыберите с разделителями из текста в столбцы, шаг 1 мастера настройки
4.Установите флажок Пробел в мастере (шаг 2), затем щелкните Далее .
5. На шаге 3 щелкните первый столбец и на панели «Формат данных столбца » нажмите кнопку Текст . Щелкните следующий столбец и снова нажмите кнопку Текст и так далее до конца, затем щелкните Готово .
Примечание. Если столбец содержит даты, нажмите кнопку Дата . Для текста нажмите кнопку Текст ; для чисел нажмите кнопку General .Если вы не уверены, используйте кнопку General для всех полей, потому что эта кнопка преобразует поля даты в даты, числовые значения в числа, а все остальное — в текст. Также обратите внимание, что вы можете нажать кнопку Do Not Import Column (Skip) button, чтобы пропустить ненужные поля.
Также обратите внимание на адрес ячейки в поле «Назначение». По умолчанию это первая ячейка в первом столбце выделенного диапазона; например, $ A $ 5. По умолчанию это нормально. Однако вы можете выбрать другой адрес ячейки, если, например, вы хотите, чтобы база данных располагалась где-то еще на этом листе, другом листе или в другой книге.
PC World / JD SartainВыберите разделитель пробелов и текст — или общий — для формата данных столбца.
Затем систематизируйте данные
Это все еще беспорядок, но намного лучше, чем было! Теперь у вас есть шесть полей, распределенных по 11 столбцам. Почему? Поскольку единственным логическим разделителем был пробел, поэтому всякий раз, когда Excel обнаруживал пробел, он создавал новый столбец. Теперь нам нужно собрать все это вместе в логической последовательности.
A. Сортировка и СЦЕПИТЬ
1.Отсортируйте базу данных по столбцу A. Обратите внимание, что поле имени никогда не превышает четырех столбцов.
2. Переместите курсор на L5. Выберите Формулы > Текст > СЦЕПИТЬ . На панели «Объединение» в диалоговом окне «Аргументы функции », «» есть несколько текстовых полей. Заполните их следующим образом:
- Щелкните A5 в Text1 .
- Введите пробел в кавычках в Text2 .
- Затем щелкните B5 в Text3.
- Введите другой пробел в кавычках в Text4.
- Щелкните C5 в Text5 .
- Введите еще один пробел в кавычках в Text6.
- Наконец, щелкните D5 в Text7 , затем щелкните OK.
- Или введите эту формулу в L5: = СЦЕПИТЬ (A5, ”“, B5, ”“, C5, ”“, D5) .
Некоторые результаты будут содержать все поля имени. Другие будут включать имена плюс часть заголовка.
4. Вставьте новую электронную таблицу (New WS) и скопируйте столбец L. Перейдите на новый лист и вставьте значения в A5.
5. Также скопируйте столбцы P (Город) и Q (Штат) в столбцы D и E в Новом WS.
PC World / JD SartainИспользуйте функцию Concatenate для объединения анализируемых полей
Обратите внимание, что существует всего девять должностей: генеральный директор, технический директор, финансовый директор, главный операционный директор, президент, старший менеджер, менеджер, директор и руководитель.Некоторые из названий прикреплены к отделам, таким как руководитель отдела маркетинга, директор по связям с общественностью, технический директор по информационным наукам и т. Д. Итак, на всякий случай мы добавим соответствующие отделы в наши формулы.
Также Примечание. Я не знаю максимально допустимое количество замещающих функций для одной формулы. Я знаю, что в 2003 году их было ограничено семью, но в версиях Office 2007, 2010 и 2016 их больше. Для моих целей я ограничиваю его до 10, потому что что-либо большее, чем это, становится слишком запутанным для редактирования.
B. Используйте функцию ЗАМЕНА для извлечения заголовков и статей
Тем не менее, введите следующую формулу в ячейку D5 новой электронной таблицы WS:
= ЗАМЕНИТЬ (ПОДСТАВИТЬ (ПОДСТАВИТЬ (ПОДСТАВИТЬ (ПОДСТАВИТЬ ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (A5, «COO», «»), «Финансовый директор», «»), «Технический директор», «»), «Генеральный директор», «»), «Президент», «»), «Старший», «»), «Президент», «»), «Руководитель», «»), «Менеджер», «»), «Маркетинг», «»)
6. Введите эту формулу в ячейку G5. :
= ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (ЗАМЕНИТЬ (D5, «Внутренние дела», «»), «Связи с общественностью», «»), «Связи с общественностью», ””), ”) , «Финансы», «»), «Реклама», «»), «Информация», «»), «Наука», «»), «и», «»), «из», «»)
7.Первая формула (которая относится к A5) вводится в D5 и удаляет заголовки. Вторая формула (которая относится к D5) вводится в G5 и удаляет отделы и статьи (и, из, и т. Д.)
8. Скопируйте формулу из G5 в G6 через G1000.
9. Выделите диапазон, выберите Копировать , перейдите к ячейке A5 и выберите Вставить значения . Теперь у вас есть имена, отделенные от заголовков.
10. Удалите столбцы D и G.
PC World / JD SartainИспользуйте функцию ЗАМЕНА для удаления заголовков и статей
С.СОЕДИНИТЕ оставшиеся поля
1. Вернитесь к исходной проанализированной базе данных. Поля простираются от A5 до K5.
2. Переместите курсор на L5 и введите следующую формулу: = СЦЕПИТЬ (C5, ”“, D5, ”“, E5, ”“, F5, ”“, G5, ”“, H5, ”“, I5, ”“, J5, ”“, K5) . Эта функция объединяет заголовки и ветки.
3. Скопируйте формулу из L5 в L6 через L1000.
4. Затем переместите курсор в ячейку R5 и введите следующую формулу: = TRIM (RIGHT (SUBSTITUTE (TRIM (L5), ”“, REPT (““, 60)), 180)]
Важное примечание : Эти две формулы также работают для этого шага:
= MID (L5, (LEN (R5) +2), 99)
= IF (ISERROR (SEARCH (R5, L5,1)), L5, ПРАВЫЙ (L5, LEN (L5) -LEN (R5)))
5.Скопируйте эту формулу из R5) в R6 через R1000. И теперь у вас есть информация о филиале.
6. Выделите от R5 до R1000 и выберите Копировать . Перейдите в электронную таблицу New WS и Вставьте значения в столбец C.
PC World / JD SartainИзвлеките информацию о ветвях из базы данных
D. Извлечь заголовок, и готово
Все, что осталось сделать, это извлечь заголовки и скопировать их в Новую WS.
1.Переместите курсор в ячейку T5. (Обратите внимание, что расположение ячеек произвольное).
2. Введите эту формулу: = ПОДСТАВИТЬ (L5, R5, ””)
3. Скопируйте формулу из T5 в T6 через T1000.
4. Обратите внимание, что заголовки извлекаются из объединенных заголовков и названий веток в столбце L.
PC World / JD SartainИзвлекают заголовки из объединенных полей в столбце L
5. Скопируйте заголовки из столбца T в столбец B новой WS.Обязательно используйте Paste > Special > Values .
Теперь все столбцы с несколькими словами разделены на правильные поля, поэтому вы можете работать с данными по полям — создать список рассылки для слияния почты, распечатать конверты или этикетки, объединить в Outlook или использовать информацию в другой базе данных.
PC World / JD SartainПолностью проанализированная база данных
Примечание. Когда вы покупаете что-то после перехода по ссылкам в наших статьях, мы можем получить небольшую комиссию.Прочтите нашу политику партнерских ссылок для получения более подробной информации.8.5 Откройте файл mbox-short.txt и прочтите его построчно. Когда вы найдете строку, начинающуюся с ‘From’, как следующая строка: From [email protected] Сб, 5 января, 09:14:16 2008, вы проанализируете строку From с помощью split () и распечатаете вторую слово в строке (т.е. полный адрес человека, отправившего сообщение). Затем распечатайте счетчик в конце. Подсказка: не включайте строки, начинающиеся с «От:».Вы можете загрузить образцы данных по адресу http://www.py4e.com/code3/mbox-short.txt · GitHub
8.5 Откройте файл mbox-short.txt и прочтите его построчно. Когда вы найдете строку, начинающуюся с «От», например, следующую строку: From [email protected] Сб, 5 января, 09:14:16 2008, вы проанализируете строку From с помощью split () и распечатаете вторую слово в строке (т.е. полный адрес человека, отправившего сообщение). Затем распечатайте счетчик в конце. Подсказка: не включайте строки, начинающиеся с «От:».Вы можете загрузить образцы данных по адресу http://www.py4e.com/code3/mbox-short.txt · GitHubМгновенно делитесь кодом, заметками и фрагментами.
8.5 Откройте файл mbox-short.txt и прочтите его построчно. Когда вы найдете строку, начинающуюся с ‘From’, как следующая строка: From [email protected] Сб, 5 января, 09:14:16 2008, вы проанализируете строку From с помощью split () и распечатаете вторую слово в строке (т.е. полный адрес человека, отправившего сообщение). Затем распечатайте…
| fhand = open («mbox-short.txt») | |
| количество = 0 | |
| для линии в fhand: | |
| строка = line.rstrip () | |
| , если строка == «»: продолжить | |
| слов = строка.сплит () | |
| if words [0]! = «From»: продолжить | |
| печать (слова [1]) | |
| count = count + 1 | |
| print («Были», count, «строки в файле, в которых From в качестве первого слова») |
Анализируйте предсказуемые шаблоны с помощью привязки
- Последнее обновление
- Сохранить как PDF
- Синтаксис
- Опции
- Правила
- Инструмент пользовательского интерфейса синтаксического анализа привязки
- Примеры
- Поля имен со специальными символами
- Использовать разрывы строк в качестве привязки
Оператор синтаксического анализа (также называемый привязкой синтаксического анализа) выполняет синтаксический анализ строки в соответствии с указанными начальными и конечными привязками, а затем помечают их как поля для использования в последующих функциях агрегирования в запросе, таких как сортировка, группировка или другие функции.
В этом разделе описывается, как использовать инструмент пользовательского интерфейса привязки синтаксического анализа для добавления синтаксического анализа к запросу, а также подробно описывается структура оператора привязки синтаксического анализа.
Синтаксис
-
| проанализировать "* " как -
| проанализировать "* " как [nodrop] -
| проанализировать [field =] " * " как
Опции
- Параметр
nodropпринудительно включает в результаты также сообщения, не соответствующие какому-либо сегменту синтаксического термина.Дополнительные сведения см. В разделе «Разбор nodrop». - Параметр
field = fieldnameпозволяет указать поле для синтаксического анализа, отличное от сообщения по умолчанию. Дополнительные сведения см. В разделе «Поле синтаксического анализа».
Правила
- Поля, созданные пользователем, например извлеченные или проанализированные поля, могут быть названы с использованием буквенно-цифровых символов и подчеркиваний (
_). Поля должны начинаться с буквенно-цифрового символа. - Если поле не указано, используется весь текст входящих сообщений.
- Подстановочный знак используется в качестве заполнителя для извлеченного поля. Подстановочные знаки должны быть разделены пробелом или другим символом.
**недействителен. Вместо этого используйте другой оператор синтаксического анализа, например регулярное выражение синтаксического анализа. - Количество подстановочных знаков в строке шаблона должно соответствовать количеству переменных.
- Для одного оператора синтаксического анализа разрешено несколько извлечений.
- Символы, заключенные в двойные кавычки (не в одинарные), являются строковыми литералами.Используйте обратную косую черту, чтобы избежать двойных кавычек в строке. Например:
-
| проанализировать "\" уровень \ ": *," как уровень
-
Инструмент синтаксического анализа привязки
Вы можете использовать инструмент пользовательского интерфейса привязки синтаксического анализа, чтобы выделить текст сообщения для синтаксического анализа, определить поля синтаксического анализа и выполнить действие синтаксического анализа.
Для синтаксического анализа с помощью инструмента привязки синтаксического анализа:
- Запустить поиск.
- В результатах поиска найдите сообщение с текстом, который нужно проанализировать.
- Выделите текст, щелкните правой кнопкой мыши и выберите Анализировать выделенный текст .
Откроется диалоговое окно Parse Text , в котором отображается выделенный вами текст.
- Выделите текст для первого поля синтаксического анализа и щелкните Щелкните, чтобы извлечь это значение .
Выделенный текст заменен звездочкой (*).
В этом примере снимка экрана GET является привязкой синтаксического анализа, а выделенный текст, который следует за ним, является первым полем синтаксического анализа. - Введите имя (без пробелов) для поля анализа в области Поля .
- Если вы хотите проанализировать дополнительные поля, добавьте запятую после имени поля и повторите действие синтаксического анализа. На следующем снимке экрана показаны три проанализированных поля: url , status_code и size (в указанном порядке). Обратите внимание, что три поля соответствуют трем звездочкам в тексте синтаксического анализа.
- Нажмите Отправить .
Снова откроется страница поиска, на которой будет показан созданный вами оператор синтаксического анализа, добавленный в поиск. - Щелкните Start , чтобы отобразить результаты поиска, которые теперь показывают проанализированное сообщение.
Примеры
Пример сообщения журнала:
2 августа 04:06:08: host = 10.1.1.124: local / ssl2 notice mcpd [3772]: [email protected]: severity = warning: 01070638: 5: член пула 172.31.51.22:0 состояние монитора отключено.
В следующих примерах start_anchor — это «user =» , а stop_anchor — «:» , которым заканчивается адрес электронной почты.Звездочка ( * ) — это глобус, представляющий проанализированный термин. В примерах создается новое поле для каждого сообщения с именем «user» , и это поле будет содержать значение адреса электронной почты, в данном случае jsmith @ demo.com .
... | проанализируйте "user = *:" как пользователь
Оператор синтаксического анализа также позволяет извлекать несколько полей одной командой:
... | проанализировать "user = *: severity = *:" как user, severity | ...
В этом примере создаются два поля из примера сообщения журнала: user = jsmith @ demo.com и серьезность = предупреждение .
Поля имен со специальными символами
Вы можете создавать имена полей, содержащие специальные символы, например пробелы, дефисы, обратные или прямые косые черты, используя следующий синтаксис:
... | проанализировать "<строка>" как% "<имя поля со специальными символами>"
Например, этот запрос позволит вам разобрать фразу «ID класса», включая пробел:
... | проанализировать "[Классификация: *]" как% "ID класса"
extract "\ [Классификация :(? . *) \]" | class_id как% "ID класса" Использовать разрывы строк в качестве привязки
Если ваши журналы доставляются в многострочном формате, вы можете выполнить синтаксический анализ до разрыва строки в сообщении. Для этого используйте следующие регулярные выражения в качестве якоря остановки на разрыве строки:
Журналы Linux: \ n
Журналы Windows: \ r
Например, если у нас в журналах есть следующее сообщение:
12: 08: 10,651 INFO sample_server ReportEmailer: 178 - ОТЛАДКА ОТПРАВКИ СООБЩЕНИЯ:
Кому: example @ sumologic.ком
Тема: Новые разрывы строк в сообщении
, чтобы получить адрес «Кому:», вы можете использовать следующие запросы:
... | проанализировать "To: * \ n" как toAddress
или
... | проанализировать "To: * \ r" как toAddress
, который возвращает [email protected] в столбце toAddress.
Ввод текста / ключевого слова — Octoparse
Обновленное руководство для последней версии 8.1 доступно здесь.Пойдите, чтобы проверить сейчас!
Иногда может потребоваться взаимодействие с веб-страницей при извлечении данных. Например:
· Вы хотите очистить данные с веб-сайта, для которого требуется вход в систему. Поэтому вам нужно ввести свое имя пользователя и пароль для входа в систему, прежде чем получить доступ к нужным данным.
· У вас есть список ключевых слов для поиска в поле поиска, но вы не хотите вводить их одно за другим.
В этом уроке мы покажем вам, как работать с одним или несколькими текстами / ключевыми словами, вводимыми на веб-страницу с помощью Octoparse.
1) Введите одно ключевое слово в текстовое поле
2) Введите несколько ключевых слов в поле поиска
1) Введите одно ключевое слово в текстовое поле
Вводить текст или ключевое слово в Octoparse очень просто. С помощью встроенного браузера вы можете взаимодействовать с веб-страницей, просто указывая и щелкая, как и в любом обычном браузере.
Давайте посмотрим на самые простые шаги для ввода текста в Octoparse.
1. Выбрать поле ввода на странице во встроенном браузере
Когда вы щелкаете поле ввода во встроенном браузере, Octoparse может определить, что вы выбрали текстовое поле. Действие «Введите текст» автоматически появится в «Подсказках к действию».
2. Выберите «Ввести текст»
После того, как вы нажмете «Ввести текст», появится текстовое поле в «Подсказках к действию».
3. Введите текст / ключевое слово
Введите текст или ключевое слово в текстовое поле и нажмите «ОК».
Вы можете видеть, что то, что вы только что вводите, также отображается в поле ввода на странице во встроенном браузере.
Octoparse сообщит вам «Ввод текста сохранен» в «Подсказках действий», и вы также можете заметить, что действие «Ввести текст» добавлено в рабочий процесс.
2) Введите несколько ключевых слов в поле поиска
Если у вас есть ряд заранее определенных и определенных текстовых значений, вы можете добавить их в «Текстовый список», чтобы создать действие поиска цикла.Octoparse будет автоматически вводить каждое слово в списке в поле поиска, по одному слову за раз.
Давайте посмотрим, как создать режим цикла «Текстовый список» для очистки данных путем поиска по нескольким ключевым словам на веб-сайте.
1. Перетащите действие «Элемент цикла» в конструктор рабочего процесса
2. Перейдите в «Режим цикла» и выберите «Текстовый список»
3. Перейдите к «Текстовому списку» ниже и нажмите «A», чтобы ввести ключевые слова, которые вы хотите искать, в текстовое поле
Нажмите «ОК», когда закончите ввод.Затем Вы можете увидеть свои ключевые слова в поле «Элемент цикла».
4. Щелкните поле поиска на странице во встроенном браузере и выберите «Введите текст» в «Подсказки действий»
5. Введите первое ключевое слово из «Текстового списка» в текстовое поле
6. Перетащите действие «Ввести текст» в «Элемент цикла» в конструкторе рабочего процесса
7.Щелкните действие «Ввести текст» в дизайнере рабочего процесса
Перейдите в «Текст цикла» и выберите «Использовать текст в элементе цикла для заполнения текстового поля»
8. Нажмите кнопку поиска на веб-странице и выберите «Нажмите кнопку» в «Советы по действию»
После нажатия кнопки «Щелкнуть» вы заметите, что действие «Щелкнуть элемент» добавлено в рабочий процесс.
9.Нажмите «Сохранить», чтобы завершить создание цикла поиска «Текстовый список».
Наконец, не забудьте проверить рабочий процесс .
Давайте посмотрим, как Octoparse будет вводить эти ключевые слова для поиска в поле поиска и взаимодействовать с веб-сайтом.
1. Щелкните поле «Элемент цикла»
Вы можете видеть, что ключевые слова, которые вы только что ввели, отображаются в «Элементе цикла».
2.Выберите одно ключевое слово и щелкните действие «Ввести текст»
Во встроенном браузере видно, что выбранное слово введено в поле поиска.
3. Щелкните «Щелкните элемент»
Octoparse имитирует реальные действия при просмотре веб-страниц при нажатии кнопки поиска. Вы можете увидеть результаты поиска по выбранному слову на веб-странице во встроенном браузере.
日本語 記事 :
テ キ ス ト / キ ー ワ ー ド の 入 力 Интернет ス ク レ イ ピ ン グ に つ い て の 記事 は 公式 サ イ ト で も 読 む と が で き ま す。Artículo en español:
Entrada de texto / palabra claveTambién puede leer artículos de
web scraping en el sitio web oficial .Статьи по теме:
Выписка за логином
От: https://www.octoparse.com/tutorial-7/text-input
Как очистить результаты поиска от списка ключевых слов
Самым сложным в веб-парсинге может быть получение данных, которые вы хотите очистить.
Например, вам может потребоваться очистить данные со страницы результатов поиска по ряду ключевых слов.
Вы можете настроить отдельные проекты парсинга для каждого ключевого слова.
Однако существуют мощные парсеры, которые могут автоматизировать процесс поиска и очищать нужные данные.
Сегодня мы настроим веб-парсер для поиска по списку ключевых слов и сбора данных по каждому из них.
Бесплатный и мощный веб-скребок
Для этого проекта мы будем использовать ParseHub. Бесплатный и мощный веб-скребок, который может собирать данные с любого веб-сайта.
Перед тем, как мы начнем, убедитесь, что вы загрузили и установили ParseHub бесплатно.
Мы также будем извлекать данные со страницы результатов поиска Amazon для краткого списка ключевых слов.
Видеоурок по очистке результатов по ключевым словамПоиск и извлечение данных из списка ключевых слов
Теперь пора настроить наш проект и начать сбор данных.
- Установите и откройте ParseHub. Нажмите «Новый проект» и введите URL-адрес веб-сайта, с которого вы будете выполнять парсинг. В этом случае мы будем извлекать данные из Amazon.ca. Затем страница отобразится внутри приложения и позволит вам начать извлечение данных.
- Теперь нам нужно передать ParseHub список ключевых слов, по которым мы будем выполнять поиск для извлечения данных. Для этого щелкните значок настроек в левом верхнем углу и выберите «Настройки».
- В разделе «Начальное значение» вы можете ввести свой список ключевых слов либо в виде файла CSV, либо в формате JSON прямо в текстовое поле под ним.
- Если вы используете файл CSV для загрузки ключевых слов, убедитесь, что у вас есть ячейка заголовка. В данном случае это будет слово «ключевые слова».
- После того, как вы отправите свой список ключевых слов, нажмите «Назад к командам», чтобы вернуться к своему проекту. Щелкните значок «ПЛЮС» (+) рядом с выбранной «страницей», щелкните «Дополнительно» и щелкните команду «Цикл».
- По умолчанию ваш список ключевых слов будет выбран как список элементов для циклического просмотра. Если нет, не забудьте выбрать «ключевые слова» в раскрывающемся списке.
- Щелкните значок ПЛЮС (+) рядом с выбранным вами «Для каждого элемента в ключевых словах» и выберите команду «Начать новую запись».По умолчанию эта команда будет называться «список1».
- Щелкните значок ПЛЮС (+) рядом с инструментом «list1» и выберите команду «Выбрать».
- С помощью команды выбора щелкните прямо в строке поиска Amazon, чтобы выбрать ее.
- Это создаст команду ввода, под ней выберите «выражение» из раскрывающегося списка и введите слово «элемент» в текстовое поле.
- Теперь мы сделаем так, чтобы ParseHub добавлял ключевое слово для каждого результата рядом с ним.Для этого щелкните значок ПЛЮС (+) рядом с командой «list1» и выберите команду «Извлечь».
- Под командой извлечения введите слово «элемент» в первое текстовое поле.
- Теперь позвольте ParseHub выполнить поиск по ключевым словам в списке. Щелкните значок «ПЛЮС» (+) рядом с выбранным вами «list1» и выберите команду выбора.
- Щелкните кнопку поиска, чтобы выбрать его и переименовать в «search_bar»
- Щелкните значок ПЛЮС (+) рядом с выбранным элементом «search_bar» и выберите «Щелкните» команда
- Появится всплывающее окно с вопросом, является ли это кнопкой «следующая страница».Нажмите «Нет» и переименуйте новый шаблон в «search_results»
- Теперь давайте перейдем на страницу результатов поиска первого ключевого слова в списке и извлечем некоторые данные.
- Начните с переключения в режим просмотра в левом верхнем углу и поиска по первому ключевому слову в списке.
- После отображения страницы убедитесь, что вы все еще работаете над своим новым шаблоном search_results, выбрав его на вкладках слева.
- Теперь выключите режим обзора и щелкните имя первого результата на странице, чтобы выбрать его.Он будет выделен зеленым, чтобы указать, что он был выбран.
- Остальные товары на странице будут выделены желтым цветом. Щелкните второй в списке, чтобы выбрать их все.
- ParseHub теперь извлекает название продукта и URL-адрес для каждого продукта на первой странице результатов для каждого ключевого слова.
Хотите получать больше данных по каждому продукту? Ознакомьтесь с нашим руководством о том, как собирать данные о товарах с Amazon, включая цены, коды ASIN и многое другое.
Хотите извлечь больше данных на страницы? Ознакомьтесь с нашим руководством о том, как добавить нумерацию страниц к вашему проекту и извлекать данные из нескольких страниц результатов.
Запуск вашего парсера
Пришло время запустить ваш проект и экспортировать его как файл Excel.
Для этого нажмите зеленую кнопку «Получить данные» на левой боковой панели.
Здесь вы сможете протестировать, запустить или запланировать задание очистки. В этом случае мы сразу его запустим.
Заключительные мысли
ParseHub отключен для извлечения всех выбранных вами данных.После завершения обработки вы сможете загрузить его в виде файла CSV или JSON.
Теперь вы знаете, как выполнять поиск по списку ключевых слов и извлекать данные из каждого результата.
Какой веб-сайт вы очистите в первую очередь?
Загрузите и установите ParseHub бесплатно
Как перенести данные из форм Word на лист Excel
Избегайте хлопот, связанных с ручным импортом данных формы Word в Excel. С помощью мастера Excel вы можете быстро выполнить этот процесс.
Примечание редактора: В видео Брэндон Вильяроло проведет вас по этапам переноса данных из форм Word на рабочий лист Excel в Microsoft Office 365.
Формы Word предоставляют удобный способ сбора информации из пользователей или клиентов, чтобы вы могли проанализировать его позже. Но перенос данных в Excel может оказаться сложной задачей. Чтобы не вводить данные на лист вручную, позвольте мастеру импорта текста Excel внести их за вас.Для демонстрации предположим, что вы попросили сотрудников заполнить форму, показанную на рис. , рис. A .
ПОДРОБНЕЕ: цены и возможности Office 365 для потребителей
Рисунок A
Выполните следующие действия, чтобы сохранить данные каждой заполненной формы в текстовый файл, который можно импортировать в Excel:
- Откройте одну из заполненных форм.
- Перейти к инструментам | Параметры, щелкните вкладку «Сохранить» и установите флажок «Сохранить данные только для форм».(В Word 2007 нажмите кнопку «Office», нажмите «Дополнительно», прокрутите до «Сохранить точность при совместном использовании этого документа» и установите флажок «Сохранить данные как текстовый файл с разделителями».)
- Нажмите «ОК».
- Сохраните файл как файл .txt.
- Когда появится диалоговое окно «Преобразование файла» (, рис. B ), нажмите «ОК».
Рисунок B
Теперь вы можете импортировать данные из текстовых файлов в электронную таблицу, выполнив следующие действия:
- Откройте пустой рабочий лист в Excel.
- Перейти к данным | Импортировать внешние данные | Импортировать данные. (В Excel 2007 перейдите на вкладку «Данные», нажмите «Получить внешние данные», а затем выберите «Из текста».)
- Щелкните текстовый файл, который нужно импортировать, затем нажмите «Импорт».
- Выберите вариант с разделителями (, рис. C ) и нажмите «Далее».
Рисунок C
- Для этого примера снимите флажок «Вкладка», а затем установите флажок «Запятая» ( Рисунок D ).
Рисунок D
- Нажмите «Далее», а затем — «Готово».
- Щелкните ячейку A1 и затем щелкните OK.
На рисунке E показаны полученные данные. Обратите внимание, что заголовки были вставлены над данными в первой строке.
Рисунок E
Чтобы импортировать второй текстовый файл, просто откройте тот же рабочий лист Excel и щелкните во второй строке под последней строкой данных; в данном случае A4. (Мастер заставляет вас пропускать строку каждый раз, когда вы добавляете новую строку данных. Эти пустые строки можно удалить позже.)
СМОТРЕТЬ: Сравнительная таблица: офисные пакеты (Tech Pro Research)
Важное примечание : Если вам нужно вводить более нескольких форм в день, вам следует рассмотреть возможность использования ADO (объекта данных ActiveX) для создания соединения кода с рабочим листом, которое автоматизирует процесс передачи данных.