Слова «налево» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «налево» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «налево» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «налево».
Содержимое:
- 1 Слоги в слове «налево» деление на слоги
- 2 Как перенести слово «налево»
- 3 Морфологический разбор слова «налево»
- 4 Разбор слова «налево» по составу
- 5 Сходные по морфемному строению слова «налево»
- 6 Синонимы слова «налево»
- 7 Антонимы слова «налево»
- 8 Ударение в слове «налево»
- 9 Фонетическая транскрипция слова «налево»
- 10 Фонетический разбор слова «налево» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «налево»
- 12 Значение слова «налево»
- 13 Как правильно пишется слово «налево»
- 14 Ассоциации к слову «налево»
Слоги в слове «налево» деление на слоги
Количество слогов: 3
По слогам: на-ле-во
Как перенести слово «налево»
на—лево
нале—во
Морфологический разбор слова «налево»
Часть речи:
Наречие
Грамматика:
часть речи: наречие;
отвечает на вопрос: Как?
Начальная форма:
налево
Разбор слова «налево» по составу
| на | приставка |
| лев | корень |
| о | суффикс |
налево
Сходные по морфемному строению слова «налево»
Сходные по морфемному строению слова
Синонимы слова «налево»
1. влево
влево
2. слева
3. ошуюю
4. в левую сторону
5. по левую руку
6. по левую сторону
7. незаконно
8. противозаконно
9. неправомерно
10. беззаконно
11. в нарушение закона
Антонимы слова «налево»
1. направо
2. справа
Ударение в слове «налево»
нале́во — ударение падает на 2-й слог
Фонетическая транскрипция слова «налево»
[нал’`эва]
Фонетический разбор слова «налево» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| н | [н] | согласный, звонкий непарный (сонорный), твёрдый | н |
| а | [а] | гласный, безударный | а |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| е | [`э] | гласный, ударный | е |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| о | [а] | гласный, безударный | о |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 6 букв и 6 звуков.
Буквы: 3 гласных буквы, 3 согласных букв.
Звуки: 3 гласных звука, 3 согласных звука.
Предложения со словом «налево»
Имечко новое взял, машет теперь этой острой железкой направо и налево!
Источник: Юлия Галанина, Пропавшая шпага.
Создавалось впечатление, что боги просто не в силах удержать руки, лапы, клювы или что там у них при себе: только и знают, что насиловать смертных женщин направо и налево.
Источник: Маргарет Этвуд, Пенелопиада, 2011.
Напротив сверкают «Сахара» и «Хилтон», налево — огромная башня «Стратосферы».
Источник: Ольрика Хан, Пока Майдан не разлучит нас.
Значение слова «налево»
НАЛЕ́ВО , нареч. 1. В левую сторону; противоп. направо. (Малый академический словарь, МАС)
Как правильно пишется слово «налево»
Орфография слова «налево»Правильно слово пишется: нале́во
Нумерация букв в слове
Номера букв в слове «налево» в прямом и обратном порядке:
- 6
н
1 - 5
а
2 - 4
л
3 - 3
е
4 - 2
в
5 - 1
о
6
Ассоциации к слову «налево»
Рубило
Развилка
Светофор
Поворот
Проулок
Авеню
Указатель
Оплеуха
Улочка
Ответвление
Коридор
Переулок
Бульвар
Отворот
Квартал
Шоссе
Стрит
Автострада
Арк
Разворот
Аллея
Гуща
Пересечение
Набережная
Ведущая
Проспект
Тропинка
Палица
Тропа
Просек
Руль
Проход
Тропка
Тупик
Флигель
Узенький
Подъездной
Асфальтовый
Тенистый
Перпендикулярный
Раздавать
Свернуть
Разить
Сворачивать
Крушить
Повернуть
Поворачивать
Сыпать
Разбрасывать
Рубить
Швырять
Косить
Заворачивать
Проехать
Наносить
Молотить
Расталкивать
Флиртовать
Рассыпать
Трепаться
Вильнуть
Трахаться
Доехать
Лупить
Размахивать
Притормозить
Миновать
Палить
Разделиться
Огибать
Изменять
Крутануть
Покатить
Выехать
Прокладывать
Поводить
Завернуть
Уклоняться
Езжать
Промчаться
Петлять
Обогнуть
Хвастаться
Поворачиваться
Пересечь
Трубить
Скомандовать
Кланяться
Скосить
Вертеть
Хлестать
Въехать
Направо
Справа
Слева
Вправо
Круто
Кругом
Щедро
Вдоль
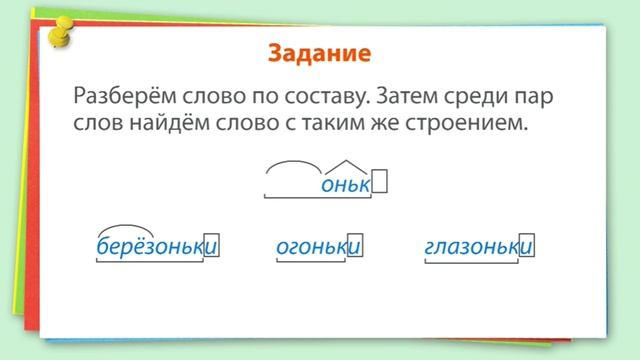
Разобрать слово по составу.
 Вскоре, справа, слева, направ… -reshimne.ru
Вскоре, справа, слева, направ… -reshimne.ruНовые вопросы
Ответы
Приставки:в,с,с,на,на,с,в,в
Корни:скор,права,лева,право,лево,права,лева,верху,низу
В-приставка, скор-корень, е-суффикс (окончание полностью отсутствует).
С-приставка, прав-корень, а-суффикс (окончание полностью отсутствует).
С-приставка, лев-корень, а-суффикс (окончание полностью отсутствует).
На-приставка, прав-корень, о- суффикс (окончание полностью отсутствует).
На-приставка, лев-корень, о-суффикс (окончание полностью отсутствует).
С-приставка, прав-корень, а-суффикс (окончание полностью отсутствует).
В-приставка, верх-корень, у-суффикс (окончание полностью отсутствует).
В-приставка, низ-корень, у-суффикс (окончание полностью отсутствует).
Похожие вопросы
На лугу ручей. Быстрый и звонкий.Там плещут хвостиками караси. У ручья трава. Густая. Высокая.
Определите виды связи словосочетании: ливневые дожди,обещает быть,ожидается,ранняя осень,по прогнозам синоптиков,осенью происходят,сухая пора,первые признаки осени,предметы осени,холодное дыхание…
Ночью был шторм.Дул сильный ветер.Весь дом дрожал. Грозно ухали волны.К утру шторм стих.Наташа и Сережа пошли к морю.Наташа подняла с песка маленького рачка. Волны выбросили его на берег.Он слабо шевелил лапками. Девочка бросила рачка в воду.Он закувыркался в зеленой воде и уплыл. В луже на боку плавала рыбка.Сережа поймал ее и выпустил в море.Пото…
Помогите срочноНайдите примыкание.
 ..
..Сочинение по пословице «Всякое дорога вместе веселее»…
Составить план на тему:летний день….
Математика
Литература
Алгебра
Русский язык
Геометрия
Английский язык
Химия
Физика
Биология
Другие предметы
История
ОбществознаниеОкружающий мир
География
Українська мова
Українська література
Қазақ тiлi
Беларуская мова
Экономика
Музыка
Право
Французский язык
Немецкий язык
МХК
ОБЖ
Психология
Тест по русскому языку по теме «Морфемика» (5 класс)
Морфемика 5 класс
1 вариант
1. Подчеркните слова, имеющие
нулевое окончание.
Подчеркните слова, имеющие
нулевое окончание.
Спелый,
шарфы, мышь, повторял, перекресток, медведь, облако, вверх.
2. Выделите окончания
Пишем, умного, лыжня, сани, сверху.
3. Выберите пары слов, в которых представлены
формы одного и того же слова.
1)
художник – художница;
2) берег – береговой;
3) спать – спал;
4) белый – беловатый;
5) читать – читают,
6) грубое – грубая.
4. В каком ряду верно перечислены все морфемы, входящие в основу слова?
1) приставка, корень, окончание
2) корень, суффикс
3) приставка, корень, суффикс, окончание
4) приставка, корень, суффикс
5. Выделите корень
Заплетать, вкусненький, записался, подлокотник, желтоватый,
налево.
6. Закончи предложение: «Главная
значимая часть слова, в которой заключено общее лексическое значение всех
однокоренных слов – это…»
1)
Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке лишнее
слово, подчеркните его
1.
Приморский, уморить, море.
2. Росток, растение, растерять.
3. Губа, загубить, губастый.
4. Утихнет, тихий, утешать.
5. Развевается, развитие, веять.
8. Обозначьте приставки
Сверхзвуковой, наименьший, перезагрузка, пробираться,
антифашист.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -ушк-, -к-, -ок, -ышк-, -ёк, -ик.
Зуб___________, гнездо____________, зонт________, тетрадь_________, зерно___________, парень______________
10. Выделите
уменьшительно-ласкательные суффиксы.
Деревушка,
гвоздик, ящик, осинка, сынок, лепесток,
пенёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Учительская, налево, присоединила, пришкольный, заоблачный.
Морфемика 5 класс
2 вариант
1. Выберите слова, имеющие нулевое
окончание.
Выберите слова, имеющие нулевое
окончание.
Слева,
завтрак, легкий, читаешь, взрыв, днем, пень, учился.
2. Выделите окончания
Бегают, красивым, улицу, вприпрыжку,
мысли.
3. Выберите пары слов, в которых
представлены формы одного и того же слова.
1)
красивый – красив;
2) решаем – решаете;
3) ресницы – ресниц;
4) бумага – бумажный,
5) делать – сделать;
6) ходить – переходить.
4. Какая часть слова служит для образования форм слова?
1) окончание
2) приставка
3) корень
4) суффикс
5. Выделите корень
Забирать,
справа, преподнести, хитрющий, бельчонок,
поздороваться.
6. Закончи предложение: «Значимая
часть слова, которая находится после корня и служит для образования новых слов
– это…»
1)
Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке
однокоренные слова. Обозначьте корень
1.
Переселить, пересилить, сильный.
2. Город, горожанин, загородка.
3. Липовый, липнет, липа.
4. Любитель, любовь, любой.
5. Нос, переносить, переносица.
8. Обозначьте приставки
Бесполезный, отрывать, суперскачки, алогичный, приступить.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -юшк-, -инк, -еньк-, -ик, -чик.
Белый___________, хозяйка____________, заяц________, пароход_________, снег___________, добрый______________
10. Выделите
уменьшительно-ласкательные суффиксы.
Девушка,
ключик, ластик, рябинка, доченька, потолок, паренёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Настольный, приморский, справа, подорожник, парашютистка.
ОТВЕТЫ
1 вариант
1. Подчеркните слова, имеющие
нулевое окончание.
Подчеркните слова, имеющие
нулевое окончание.
Спелый,
шарфы, мышь, повторял, перекресток, медведь, облако, вверх.
2. Выделите окончания
Пишем, умного,
лыжня, сани, сверху.
3. Выберите пары слов, в которых
представлены формы одного и того же слова.
1)
художник – художница;
2) берег – береговой;
3) спать – спал;
4) белый – беловатый;
5) читать – читают,
6) грубое – грубая.
4. В каком ряду верно перечислены все морфемы, входящие в основу слова?
1) приставка, корень, окончание
2) корень, суффикс
3) приставка, корень, суффикс, окончание
4) приставка, корень, суффикс
5. Выделите корень
Заплетать, вкусненький, записался,
подлокотник, желтоватый, налево.
6. Закончи предложение: «Главная
значимая часть слова, в которой заключено общее лексическое значение всех
однокоренных слов – это…»
1)
Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке
лишнее слово, подчеркните его
1.
Приморский, уморить, море.
2. Росток, растение, растерять.
3. Губа, загубить, губастый.
4. Утихнет, тихий, утешать.
5. Развевается, развитие, веять.
8. Обозначьте приставки
Сверхзвуковой, наименьший, перезагрузка, пробираться, антифашист.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -ушк-, -к-, -ок, -ышк-, -ёк, -ик.
Зуб – зубок (ик),
гнездо — гнездышко, зонт — зонтик, тетрадь — тетрадка,
Егор – Егорушка (ка), парень – паренёк.
10. Выделите уменьшительно-ласкательные
суффиксы.
Деревушка,
гвоздик, ящик, осинка,
сынок, лепесток, пенёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Учительская, налево, присоединила, пришкольный, петербуржец, заоблачный.
учитель учить
левый
присоединить соединить единый
школьный школа
облачный облако
ОТВЕТЫ
2 вариант
1. Выберите слова, имеющие нулевое
окончание.
Слева, завтрак, легкая, читаешь, взрыв, днем, пень, учился.
2. Выделите окончания
Выделите окончания
Бегают, красивым,
улицу, вприпрыжку, мысли.
3. Выберите пары слов, в которых
представлены формы одного и того же слова.
1)
красивый – красив;
2) решаем – решаете;
3) ресницы – ресниц;
4) бумага – бумажный,
5) делать – сделать;
6) ходить – переходить.
4. Какая часть слова служит для образования форм слова?
1) окончание
2) приставка
3) корень
4) суффикс
5. Выделите корень
Забирать,
справа, преподнести, хитрющий,
бельчонок, поздороваться.
6. Закончи предложение: «Значимая
часть слова, которая находится после корня и служит для образования новых слов
– это…»
1)
Приставка;
2) корень;
3) суффикс;
4) окончание;
5) основа.
7. Выберите в каждой строчке
однокоренные слова. Обозначьте корень
1. Переселить, пересилить, сильный.
2. Город, горожанин, загородка.
3. Липовый, липнет, липа.
4. Любитель, любовь, любой.
5. Нос, переносить, переносица.
8. Обозначьте приставки
Бесполезный, отрывать, суперскачки, алогичный, приступить.
9. Образуйте слова с уменьшительно-ласкательным значением, используя суффиксы -юшк-, -инк, -еньк-, -ик, -чик.
Белый — беленький, хозяйка — хозяюшка, заяц – заинька (чик), пароход — пароходик, снег — снежинка, добрый — добренький
10. Выделите
уменьшительно-ласкательные суффиксы.
Девушка,
ключик, ластик, рябинка,
доченька, потолок, паренёк.
11. Разберите по составу слова и сделайте цепочку из слов, от которых оно образовано
Настольный, подорожник, справа, приморский, парашютистка.
стол
море
правый
дорожник дорожный дорога
парашютист парашют
Диктанты 6 класс — русский язык, уроки
Контрольные диктанты для 6 класса
1четверть
Кедр
Кедр растет высоко в горах, ветры его набок клонят, стараются к земле наклонить. А он –высок, могуч, вцепился корнями в землю и тянется все выше и выше к солнцу.
На концах веток кедровые шишки висят. Орешки еще не поспели, но вокруг много зверьков и птиц живет. Кедр всех кормит.
Белка свалит шишку на землю, вынет орешки, два-три съест, но один уронит. Этот орешек утащит к себе в норку мышь. Она по деревьям взбираться не умеет, а вкусных орешков ей хочется.
Поздней осенью еще больше зверьков и птиц на кедре. Они собирают и прячут кедровые орешки под камни, зарывают про запас в землю.
Они собирают и прячут кедровые орешки под камни, зарывают про запас в землю.
(По Г.Снегиреву,103 слова)
Грамматическое задание.
1.Синтаксический разбор предложения
1в.-На концах веток кедровые шишки висят.
2в.-Кедр растет высоко в горах.
2.Выписать из разобранных предложений словосочетания и сделать их разбор.
3.Разобрать слова по составу.
1в.-Собирают,орешки,поздней
2в.-Уронит,норку,кедровые
4.Определить ,сколько звуков и букв в словах
1в.-Еще,умеет
2в.-Его,осенью
Серые разбойники
Я подтащил свое суденышко , сразу забрал из лодки снасти ,часть рыбы и подошел к дому. Открылась и закрылась за мной дверь . Но я не вошел в дом, а остался в коридоре ,заглянул в дверную щель.
Вороны появились мгновенно. Метнулись серые крылья, птицы молча кружили над лодкой. Наконец весь разбойничий отряд расселся вокруг моего суденышка.
Первой начала грабеж только одна ворона. Она прыгнула на борт, повертела головой направо, налево и быстро схватила со дна рыбу. Тут и другие вороны ухватили по большой плотве.
Она прыгнула на борт, повертела головой направо, налево и быстро схватила со дна рыбу. Тут и другие вороны ухватили по большой плотве.
Проходит минута ,и птицы исчезают. Теперь можно появляться и мне…
Такие набеги вороны совершают каждый день, когда я возвращался с рыбалки. (По А.Снегову,105 слов)
Грамматические задания.
1.Подобрать антонимы к словам
1в.-Открылась, появились
2в.-Подтащил , возвращался
2.Составить схему предложения
1в.- Такие набеги вороны совершали каждый день, когда я возвращался домой.
2в.-Метнулись серые крылья, птицы молча кружили над лодкой.
3.Морфемный разбор слов
1в.- Подтащил, закрылась, прыгнула
2в.- Открылась, кружили, повертела
4. Найти в тексте однокоренные слова
2 четверть
Азбука тайги
Третьи сутки мы шли по тайге. До станции было еще далеко.
Я выбрал для ночлега сухое, высокое местечко, но мой спутник , который всю жизнь прожил в лесной деревушке, отказался от удобной стоянки и увел меня на болото.
Наступила полночь. Вдруг смерчем пронесся тяжелый ветер, начался бурелом. Вокруг раздался грохот, вой, треск ,но нас все это обошло стороной. К утру появилось солнце, и мы побрели кипятить чай туда ,где я хотел расположиться. Это место было завалено грудой стволов.
Как таежник догадался об опасности?
За чаем старичок сознался, что с вечера заметил следы медведя, который ушел из тайги на болото. Он доверился предчувствию животного. «Медведь все знает, слушайся в тайге медведя»,- закончил он свой рассказ.
Грамматическое задание.
1.Морфемный разбор слов
1в-спутник,старичок,опасности
2в.-таежник,предчувствие,местечко
2.Разобрать по членам предложения и указать части речи .
1в.-Вдруг смерчем пронесся тяжелый ветер, начался бурелом.
2в.-Вокруг раздался грохот, вой, треск, но нас все это обошло стороной.
3.Выписать 3 слова словосочетания с окончанием -Е или -И у существительных. Объяснить написание.
4. Выписать 2 слова с правописанием О или Е в окончаниях существительных. Объяснить написание .
Объяснить написание .
3четверть
На реке Великой
Солнечным июльским утром наша туристская группа прибыла на станцию Насва.
Через три минуты около пятидесяти рюкзаков с вещами и продуктами и восемнадцать тюков с байдарками большой кучей лежат на перроне.
Но до реки еще километров тридцать пять. В ближайшей деревне мы договариваемся о машине, и к середине дня наш палаточный лагерь уже разбит в одиннадцати километрах за деревней Луково на поляне возле берега Великой.
Великая – главная река Псковской области. Ее протяженность –более четырехсот километров. На своем пути она принимает сорок семь протоков . Она то мирно журчит вдоль поросших ивой берегов, то превращается в горную речку, которая пробивает себе путь сквозь нагромождение камней. Здесь начинается наш водный поход на байдарках.
Грамматическое задание
1.Синтаксический разбор предложения
1в.-В ближайшей деревне мы договариваемся о машине.
2в. -Великая-главная река Псковской области.
-Великая-главная река Псковской области.
2.Морфемный разбор слов
1в.-Туристская,прибыла
2в.-Июльским,принимает
3.Выписать словосочетания с числительными и определить падеж имен числительных.
1в.-из 3 абзаца
2в.-из 4 абзаца
Дуб и ветер
Красивый и необыкновенный дуб рос на высокой горе. Ни у кого не было сил покорить его.
Однажды налетел на него ветер, дунул с одной стороны, с другой, старался пригнуть к земле. А дуб стоит и смеется каждым своим листиком. Кто-то подсказал ветру ,что погубить дуб может молния. Побежал ветер звать на помощь молнию.
Раскололось небо ,грянул гром, блеснула саблями молния. Загорелась вершина дуба, но пошел дождь и залил огонь. А дуб продолжал расти , даже крепче стал.
Спросил тогда ветер у величественного дуба: « Почему я не могу погубить тебя?»
Дуб ответил, что не ствол его держит, как думают некоторые . Сила его в том, что он в землю родную врос, корнями за нее держится . «Потому никто мне не страшен»,-добавил дуб.
«Потому никто мне не страшен»,-добавил дуб.
Грамматическое задание.
1.Разбор по составу слов
1в.-побежал,листиком
2в.-налетел, вершина
3.Разобрать по членам предложение, указать части речи и составить схему данного предложения
1в.- Спросил тогда ветер у величественного дуба»Почему я не могу погубить тебя?»
2в.- «Потому никто мне не страшен»,- добавил дуб
4.Морфологический разбор слов
1в.-Каждым(листиком)
2в.-Некоторые
4 четверть
Битва во ржи
Высокая густая рожь-это для многих животных густой лес.
Солнце давно уже село, догорает короткая летняя зорька, какие-то тени реют над полем. Это совы вылетели за добычей. В лунную ночь будут они присматриваться, ловить мышей и полевок. Надо много ловкости ,чтобы словить их в высокой ржи.
Но во ржи живет множество других вредителей. Это насекомые и их прескверные гусеницы. Если бы их никто не трогал, то от хлебного поля ничего бы не осталось. Однако есть у поля ценные друзья, которые стараются сберечь урожай. Это землеройки , ежи, летучие мыши, птицы, жабы, лягушки. Мы их часто не видим и знать не хотим, тогда как они самоотверженно спасают наши хлеба от истребления.
Однако есть у поля ценные друзья, которые стараются сберечь урожай. Это землеройки , ежи, летучие мыши, птицы, жабы, лягушки. Мы их часто не видим и знать не хотим, тогда как они самоотверженно спасают наши хлеба от истребления.
Грамматическое задание.
1.Разобрать по членам предложения и указать части речи
1в.-Солнце давно уже село.
2в.-Это совы вылетели за добычей.
2.Разобрать слова по составу
1в.- догорает, высокая, присматриваться
2в.- вылетели, ловкости, стараются
3.Морфологический разбор слова
1в.-спасают
2в.-догорает
4.Выписать 3-4 слова с орфограммами и объяснить их
Какими частями речи являются слова (направо, налево)
Русский язык, 2021-06-18 21:38:26, andrey451
Ответ
Ответ разместил: Romays
Наречиями думаю так
Ответ
Ответ разместил: Møŝķá56
1.Лес за деревенькой
2.Как чудесен и свеж необЪятный лес,в который вЪезжаем мы за деревенькой!Направо и налево над нами высятся болЬшие столетние сосны. В голубое небо возносятся их темно-зеленые вершины,сквозь которые лЬются красноватые солнечные лучи.Соскочив с экипажа,мы идем по обочине песчаной лесной дороги.Толстые,изЪезженные колесами корни стелются над землей.В лесу пахнет смолой,земляникой,а на березах пересвистываются невидимые соловьи,барабанят дятлы.
В голубое небо возносятся их темно-зеленые вершины,сквозь которые лЬются красноватые солнечные лучи.Соскочив с экипажа,мы идем по обочине песчаной лесной дороги.Толстые,изЪезженные колесами корни стелются над землей.В лесу пахнет смолой,земляникой,а на березах пересвистываются невидимые соловьи,барабанят дятлы.
3.въезжаем-езж-въехать,лесу-лес-лес,соловей-солов,барабанят-барабан
4.Направо(куда?),налево(куда?)-наречие
5.Чудесен-ужасен,свеж-гнил,большие-маленькие,толстые-тонкие,невидимые-заметные.
6.Пахнет-сказуемое,пересвистываются соловьи(сказ.,подл.,),барабанят дятлы(сказ.,подл.).
Ответ
Ответ разместил: Iraeuroset3
1тема текста . как чудесен и свеж необъятный лес.
2необЪятный, въезжаем большие льются изъезженные .
3
4 наречия , куда?
5чудесен- ужасен
свеж-…
необъятный-…
6Сказуемое пахнет. сказуемое и подлежащее пересвистываются соловьи , барабанят дятлы. Потому что в предложении говорится сразу и о дятлах и о соловьях
Ответ
Ответ разместил: leloneltt
Как чудесен и свеж необъятный лес, в который въезжаем мы за деревенькой! Направо и налево над нами высятся большие столетние сосны. В голубое небо возносятся их тёмно-зеленые вершины,сквозь которые льются красноватые солнечные лучи. Соскочив с экипажа, мы идём по обочине песчаной лесной дороги. Толстые, изъезженные колесами корни стелятся над землёй. В лесу пахнет смолой, земляникой, а на берёзах пересвистываются невидимые соловьи, барабанят дятлы.
В голубое небо возносятся их тёмно-зеленые вершины,сквозь которые льются красноватые солнечные лучи. Соскочив с экипажа, мы идём по обочине песчаной лесной дороги. Толстые, изъезженные колесами корни стелятся над землёй. В лесу пахнет смолой, земляникой, а на берёзах пересвистываются невидимые соловьи, барабанят дятлы.
1. Автор хотел показать все красоты леса. Все звуки, запахи. Главная мысль ( я думаю ), что человек должен беречь природу, чтобы она оставалась такой же красивой.
2.Разделительные ъ и ь знаки.
3.Красноватые:
красн-корень.
оват-суффикс.
ые-окончание.
деревенькой:
деревень-корень
к-суффикс
ой-окончание.
необъятный;
не-приставка
объя-корень
т и н-суффиксы
ый-окончание
5. Направо и налево-обстоятельство (куда?)
6. чудесен-ужасен.
свеж-старый.
и т д.
7. Пахнет (глагол) (односостав).
пересвистываются соловьи ( ———+ глагол основа)
барабанят дятлы ( ———+ глагол )
Это сложное предложение, потому что в нем больше одной грамматической основы.
Прости у меня на телефоне 4% если есть вопросы я позже напишу.
Ответ
Ответ разместил: Nastasia13z
Как чудесен и свеж необЪятный лес,в который вЪезжаем мы за деревенькой!Направо и налево над нами высятся болЬшие столетние сосны.В голубое небо возносятся их темно-зеленые вершины,сквозь которые лЬются красноватые солнечные лучи.Соскочив с экипажа,мы идем по обочине песчаной лесной дороги.Толстые,изЪезженные колесами корни стелются над землёй. В лесу пахнет смолой,земляникой,а на березах пересвистываются невидимые соловьи,барабанят дятлы.
№1.
Лес за деревенькой.
№3.
въезжаем — езж — въехать, лесу — лес — лес, соловей — солов, барабанят — барабан
№4.
Направо (куда?), налево (куда?) — наречие.
№5.
чудесен — ужасен, свеж — гнил, большие — маленькие, толстые — тонкие, невидимые — заметные
№6.
пахнет — сказуемое, пересвистываются соловьи (сказ.,подл.), барабанят дятлы (сказ., под.) . Здесь 3 грамматические основы, поэтому предложение является сложным.
Здесь 3 грамматические основы, поэтому предложение является сложным.
Ответ
Ответ разместил: Реноша
Наречие.Вопрос куда?Налево и направо
Ответ
Ответ разместил: Chvrv
Наречия — признак действия и отвечают на вопросы: где, куда, зачем, откуда, почему, когда и как?
Идут (КУДА? ) налево, направо
Ответ
Ответ разместил: KoteikaOneLove
хотя бы с одним заданием!
Как чудесен и свеж необъятный лес, в который въезжаем мы за деревенькой! Направо и налево над нами высятся большие столетние сосны. В голубое небо возносятся их тёмно(?)зелёные вершины, сквозь которые льются красноватые солнечные лучи. Соскочив с экипажа, мы идём по обочине песчаной лесной дороги. Толстые, изъезженные колёсами корни стелются над землёй. В лесу пахнет смолой, земляникой, а на берёзах пересвистываются невидимые соловьи, барабанят дятлы.
Тема : Рассказывается про жизнь природы , в данном случаи про лес
Основная мысль : Показать красоту природы , восхищение
Красноватый
корень [красн] + суффикс [оват] + окончание [ый]
Основа(ы) слова: красноват
образования слова: суффиксальный
Деревенькой
корень [деревень] + суффикс [к] + окончание [ой]
Основа(ы) слова: деревеньк
образования слова: суффиксальный
Необъятный
: приставка [не] + корень [объя] + суффикс [т] + суффикс [н] + окончание [ый]
Основа(ы) слова: необъятн
образования слова: префиксально-суффиксальный
4 ) Необъятный — подчеркиваешь о , корень [объя]
Экипаж , подчеркиваешь и , корень [экипаж]
5) направо , налево — наречие
куда ?
Ответ
Ответ разместил: ImagineDragonsUA
ЭТИ СЛОВА ЯВЛЯЮТСЯ НАРЕЧИЕМ
Ответ
Ответ разместил: Snezhana200511
Это наречия,т. к. мы задаем вопрос куда?
к. мы задаем вопрос куда?
Другие вопросы по: Русский язык
Твір на тему як я розумію поняття честь…
Опубликовано: 28.02.2019 16:00
Ответов: 3
Знайти критичні точки функції f(x)=3x в кубе-x квадрат !…
Опубликовано: 02.03.2019 02:30
Ответов: 1
Сочинение «мой режим дня в один из дней недели»…
Опубликовано: 02.03.2019 02:40
Ответов: 3
Решить 1. наследство для близнецов : завещание в пользу жени и ребенка , которий должен родиться -если родить мальчик, то он получит 2/3, а жена 1/3 , если родиться девочка , то он…
Опубликовано: 02.03.2019 04:40
Ответов: 1
Найдите все натуральные значения х, при которых верно неравенство: 4 целых и 3 восьмых меньше чем икс восьмых меньше чем 5 целых и 1 восьмых….
Опубликовано: 02.03.2019 21:20
Ответов: 1
Какую часть составляют: 23м2 от ара,47мин от суток, 39см от 7 м. ..
..
Опубликовано: 02.03.2019 22:40
Ответов: 2
Популярные вопросы
Плотность некоторого газообразного вещ-ва по водороду=17.чему равна его плотность по воздуху (мвозд=29 г/моль? )…
Опубликовано: 01.03.2019 10:10
Ответов: 1
Мини-сообщение о различных мнениях происхождения человека…
Опубликовано: 02.03.2019 01:40
Ответов: 2
Завтра экзамен реакция между нитрат алюминия и фосфат натрия, соляная кислота и сульфид калия, соляная кислота и гидроксид калия…
Опубликовано: 02.03.2019 06:20
Ответов: 1
Как называется вещество, транспортирующее кислород из легочныхальвеол в ткани и находящиеся в эритроцитах( полный ответ)? заранее !…
Опубликовано: 02.03.2019 08:20
Ответов: 1
Написать на qbasic программу для вычисления произведения наибольшего и наименьшего из трех чисел. числа вводятся с клавиатуры….
Опубликовано: 02.03.2019 13:40
Ответов: 2
Составьте уравнение реакции гидроксид меди(2) и сульфат натрия…
Опубликовано: 03.03.2019 01:00
Ответов: 2
Диаметр шара равен 524 км. каков радиус этого шара?…
Опубликовано: 03.03.2019 03:20
Ответов: 1
The usa. because of its huge size the us climate is incredibly varied. if there is a ‘general’ climate then it is temperate, but it is also tropical in florida and hawaii, arctic i…
Опубликовано: 03.03.2019 03:40
Ответов: 3
Низменность северной америки — крупнейший район добычи нефти и газа?…
Опубликовано: 03.03.2019 04:50
Ответов: 3
Мотоциклист выехал из одног города в 7 ч утра и приехал в другой город в 12 ч дня. каждый час он проезжал 65 км .какое расстояние между ?. ..
..
Опубликовано: 03.03.2019 22:40
Ответов: 1
Больше вопросов по предмету: Русский язык Случайные вопросы
Пандемия популяризирует множество слов и фраз
Глобальный коронавирус быстро изменил наш язык, включив в него множество слов и фраз, которые не были частью нашего повседневного лексикона, такие как «социальное дистанцирование» и «карантин».
Пандемия COVID-19 изменила нашу повседневную жизнь больше, чем мы могли себе представить.
Возьмем, к примеру, слова, добавленные в наш словарный запас, которые мы теперь используем каждый день. Термины, которые когда-то были для нас чужими или почти не использовались, теперь являются частью основного набора, который помог нам пройти через этот глобальный кризис.
«Это действительно показало, что язык имеет значение, что язык обладает силой», — сказал Николас Пичи, преподаватель программы письма и сочинения Колледжа искусств и наук Университета Майами.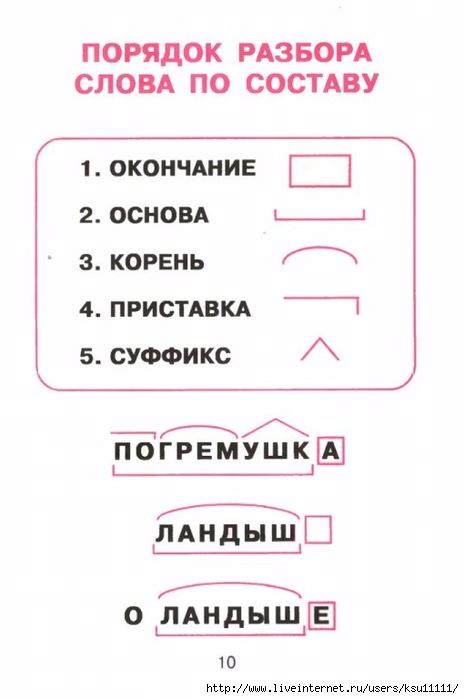 «Сегодня наши новые глоссарии, связанные с COVID, заставили нас учиться и проходить ускоренные курсы в любом количестве непредвиденных областей — от биологии и иммунологии до статистической риторики, государственных операций и гражданского права».
«Сегодня наши новые глоссарии, связанные с COVID, заставили нас учиться и проходить ускоренные курсы в любом количестве непредвиденных областей — от биологии и иммунологии до статистической риторики, государственных операций и гражданского права».
Пичи указал на некоторые из широко используемых словарей, которые сейчас популярны в нашем повседневном языке.
Медицинские термины
В начале марта, когда мир начал больше узнавать о вирусе, нам быстро пришлось ознакомиться с целым рядом слов, в том числе с самим термином «COVID-19».
«Если вы помните, когда все это началось, мы все пытались понять настоящее название этого вируса. Большинство людей сначала называли это коронавирусом, а затем им пришлось выучить технический термин и то, что он означает. Было много информации сразу», — объяснил Пичи. «Я предполагаю, что этот учебный процесс изучения новых лексических единиц стал дополнительным стрессом в и без того напряженное время. Но язык, однажды выученный, может быть способом вырвать контроль над хаотическими ситуациями — мощная особенность языкового творчества, письменного и устного».
По мере развития пандемии такие слова и термины, как «изоляция», «распространение среди населения», «передача», «инкубационный период», «уровень летальности», «бессимптомное течение», «вентилятор» и «карантин», стали часто использоваться при ссылаясь на вирус.
«Эти слова вошли в наш повседневный лингвистический режим через унаследованные платформы и платформы социальных сетей, а также из уст в уста сообщества. Их быстрое и плавное внедрение довольно удивительно и свидетельствует о гибкости человеческого языка в целом и английского в частности», — сказал Пичи. «До того, как разразилась пандемия, такое слово, как карантин — с его экзотическими, но клиническими фонемами, вызывающими ощущение «чужеземного захватчика» как по слогам, так и по этимологическому происхождению — казалось чем-то из фильма ужасов. Это слово вы готовы услышать в таких фильмах, как «Заражение », «», но уж точно не в нашем реальном социальном мире. Однако по мере развития пандемии она начала терять свои коннотации страха, поскольку все больше людей, в том числе наши соседи и члены семьи, вынуждены были отправиться на карантин. Это просто стало частью жизни».
Это просто стало частью жизни».
Социальные и правительственные термины
Пока мы путешествовали по этому новому миру пандемии, в нас также бросали другие социальные и политические термины. Например, по мере быстрого распространения COVID-19 в обществе был введен термин «социальная дистанция», чтобы помочь остановить распространение
«До марта большинство людей — за пределами антикризисных или медицинских кругов — вероятно, никогда не слышали этот лязг- звучащая идиома, произнесенная вслух или напечатанная», — сказал Пичи. «Теперь мы постоянно слышим и видим его в наших словесно-зрительных ландшафтах и в различных грамматических формах: мы видим его как существительное (9).0021 социальная дистанция ), в форме прилагательного, которая включает наречие ( социально дистанцированная ), как глагольная (от до социальной дистанции ). Его вездесущность предполагает как игру языковых изобретений, так и адаптивную гибкость английского языка».
В нашем список словарного запаса, который помог нам понять сложность вируса.
«Теперь мы все знаем определение СИЗ, — сказал Пичи. — Более того, у всех нас есть некоторые из них. До пандемии средний человек не знал, что такое маска N95, хирургическая маска или тканевая маска, но теперь мы используем эти предметы везде, куда бы мы ни пошли, и ссылаемся на них в наших самых обыденных повседневных разговорах. Они стали частью нашего разговорного языка, чтобы соответствовать нашей социальной реальности».
Когда в начале марта Соединенные Штаты были закрыты, жители также начали постоянно получать уроки гражданского права, настраиваясь на брифинги для прессы ежедневной рабочей группы по коронавирусу Белого дома. Многим пришлось быстро узнать о Законе CARES и о том, как он повлияет на них лично. Мы также узнали, что у Соединенных Штатов есть Стратегический национальный запас (важнейшие предметы медицинского назначения).
— Я снова предполагаю, что большинство американских граждан смутно, если вообще не знали, что наше правительство хранит такой запас, — сказал Пичи. — В любом случае, это была интересная новость для меня.
— В любом случае, это была интересная новость для меня.
Модные слова
Хотя многие слова, которые мы сейчас используем, не новы, другие были созданы как побочный продукт пандемии. Например, потребность в сохранении виртуального подключения привела к появлению таких разговорных терминов, как «масштабирование» (с использованием платформы для видеоконференций) или «зумбомбирование» (нежелательное разрушительное вторжение, которое обычно вызывается интернет-троллями и хакерами, взламывающими виртуальный компьютер). встреча прошла в Zoom).
Словарь Merriam-Webster Dictionary даже принял экстраординарное решение включить сокращения, связанные с COVID-19, такие как WFH (работа на дому). Ники объяснила, что это отражает то, насколько быстро язык адаптируется к окружающим нас ситуациям.
«Английский язык оказался удивительно устойчивым и адаптивным языком, начиная с его германских истоков и значительной латиноамериканской экспансии и заканчивая тем, что мы заимствовали из множества других языков мира. Когда вы объединяете эту лингвистическую инклюзивность с возможностями наших цифровых медиа по распространению меметической информации, вы получаете потенциал для распространения языка, который не имеет аналогов в истории», — сказал он.
Когда вы объединяете эту лингвистическую инклюзивность с возможностями наших цифровых медиа по распространению меметической информации, вы получаете потенциал для распространения языка, который не имеет аналогов в истории», — сказал он.
Люди также развлекались со словами, чтобы придать им другие значения. Примеры включают «quaranteam», который относится к пузырю людей, которые создают свой собственный сплоченный круг общения, и «quarantini», который представляет собой любой коктейль, который вы смешиваете дома, находясь в изоляции.
Пичи отмечает, что «изобретение языка и творческие образы и фигуры, используемые для комического облегчения, могут помочь людям проявить свою устойчивость в темные времена».
Хотя сложно уследить за всеми популярными словами и фразами, связанными с пандемией, Пичи считает, что людям важно быть в курсе.
« Чтобы выжить в этом новом сложном мире, вам всегда нужно обновлять свой интеллектуальный банк данных», — объяснил он. «Вы всегда должны быть готовы принять эти новые слова. Потому что, если вы их не понимаете, вы можете стать частью более крупной проблемы. Истина и знание в значительной степени являются предметом торговли и передачи через язык. Если, как говорится, знание — это сила, то язык — это сила. А знание важных и текущих языковых изменений может дать вам возможность внести позитивные изменения».
«Вы всегда должны быть готовы принять эти новые слова. Потому что, если вы их не понимаете, вы можете стать частью более крупной проблемы. Истина и знание в значительной степени являются предметом торговли и передачи через язык. Если, как говорится, знание — это сила, то язык — это сила. А знание важных и текущих языковых изменений может дать вам возможность внести позитивные изменения».
ВСТРОЕННАЯ РЕКЛАМА В ТЕКСТЕ — Microsoft Corporation
Предмет рассмотрения в целом относится к встраиванию рекламных объявлений в текст веб-страницы и, более конкретно, к изменению исходного текста веб-страницы путем включения рекламы в текст без ухудшения качества смысл веб-страницы.
Интернет-реклама стала основным источником дохода для большинства СМИ и издательских веб-сайтов. По мере того, как значение онлайн-рекламы возрастало, методы онлайн-рекламы претерпели драматическую эволюцию. Одной из тенденций этой продолжающейся эволюции является более тесная интеграция рекламы в веб-страницы.
Подобно другим видам рекламы, интернет-реклама стремится представить релевантную рекламу пользователям таким образом, чтобы привлечь внимание пользователей. Многие пользователи заинтересованы в нерекламном содержании веб-страницы и предпочитают игнорировать рекламу. Соответственно, об эффективности рекламы можно судить по релевантности рекламы интересам пользователя, а также по способности рекламы привлечь внимание пользователя.
Реклама может быть в значительной степени отделена от основного текста веб-страницы, например реклама на баннере или боковой панели. Рекламные объявления, относящиеся к содержанию веб-страницы, могут быть идентифицированы путем сравнения ключевых слов с веб-страницы с ключевыми словами, связанными с рекламой. Однако при таком методе рекламы пользователю относительно легко сосредоточиться только на нерекламном контенте и игнорировать баннерную или боковую рекламу, поскольку рекламные объявления размещаются на веб-странице отдельно от нерекламного контента.
Последующая эволюция онлайн-рекламы размещает рекламу внутри нерекламного контента. Например, слово в текстовом поле веб-страницы может быть гиперссылкой на рекламу. Нажатие на слово или прокрутка слова может привести к всплывающей рекламе. Эта модель рекламы встраивает рекламу в нерекламный контент веб-страницы. Однако, несмотря на то, что реклама связана с нерекламным содержанием веб-страницы, пользователи могут отказаться от просмотра рекламы, и исходный текст остается неизменным.
Соответственно, желательно найти способы глубоко внедрить рекламу в нерекламный контент таким образом, чтобы пользователям было трудно его игнорировать и при этом не снижалась ценность нерекламного контента.
Это краткое изложение предназначено для ознакомления с рядом концепций в упрощенной форме, которые более подробно описаны ниже в подробном описании. Это краткое изложение не предназначено для определения ключевых признаков или существенных признаков заявленного предмета, а также не предназначено для использования для ограничения объема заявленного предмета.
Ввиду вышеизложенного, это раскрытие описывает различные иллюстративные компьютерные программные продукты, способы и устройства для создания встроенной рекламы. В этом раскрытии описывается новая рекламная стратегия, которая связывает релевантные рекламные объявления с ключевыми словами на веб-странице и добавляет рекламные объявления к существующему тексту без ухудшения исходного значения существующего текста. Эта стратегия рекламы дополняет существующую рекламу на основе ключевых слов и контекстную рекламу. Встроенная реклама «скрывает» рекламу в контексте, вставляя рекламу в исходный контент, не ухудшая смысла исходного контента. Анализируя язык исходного контента, можно выбрать соответствующую рекламу для вставки и соответствующие методы изменения исходного текста для вставки соответствующей рекламы.
Исходное сообщение, например веб-страница, является источником ключевых слов, которые можно извлечь из сообщения. Ключевые слова, извлеченные из сообщения, могут быть связаны с ключевыми словами, связанными с рекламой. В некоторых реализациях ассоциация может выполняться специализированным компьютером-сервером. Композиция извлеченного ключевого слова, рекламы и слов-модификаторов может быть создана компьютером-сервером. Композиция может быть встроена в сообщение таким образом, что композиция заменяет часть текста сообщения без ухудшения исходного значения сообщения.
В некоторых реализациях ассоциация может выполняться специализированным компьютером-сервером. Композиция извлеченного ключевого слова, рекламы и слов-модификаторов может быть создана компьютером-сервером. Композиция может быть встроена в сообщение таким образом, что композиция заменяет часть текста сообщения без ухудшения исходного значения сообщения.
Подробное описание представлено со ссылкой на прилагаемые рисунки. На фигурах самая левая(ые) цифра(ы) ссылочного номера идентифицирует фигуру, на которой ссылочный номер появляется впервые. Использование одних и тех же ссылочных номеров на разных фигурах указывает на сходные или идентичные элементы.
РИС. 1 представлена схема системы для встраивания рекламы в веб-страницы.
РИС. 2 представляет собой схематическое представление, показывающее примерный сервер веб-страницы.
РИС. 3 представляет собой схематическую диаграмму, показывающую примерную базу данных рекламы.
РИС. 4 представляет собой схематическую диаграмму, показывающую примерный композиционный сервер.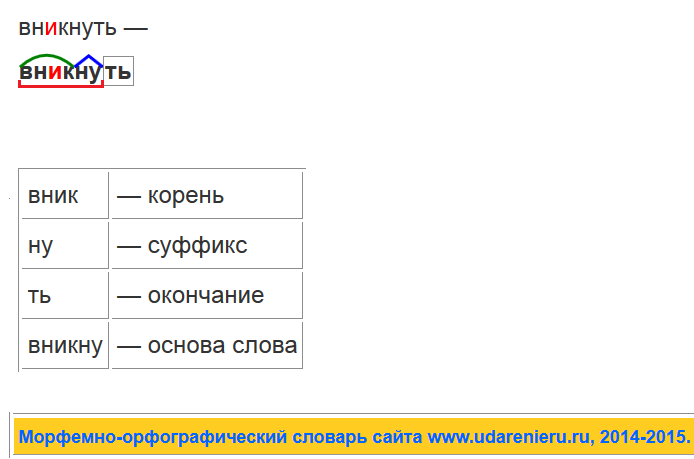
РИС. 5 представляет собой схематическую диаграмму, показывающую примерный процесс внедрения рекламных объявлений в веб-страницу.
РИС. 6 представляет собой схематическую диаграмму, показывающую текст веб-страницы до и после внедрения рекламы.
РИС. 7 представляет собой блок-схему, показывающую примерный способ воспроизведения веб-страницы со встроенной рекламой.
РИС. 8 представляет собой схематическое представление, показывающее примерное вычислительное устройство для встраивания рекламных объявлений в текст.
Это раскрытие направлено на различные иллюстративные компьютерные программы, способы и устройства для внедрения рекламы в сообщение. Например, рекламодатель может пожелать приобрести размещение рекламы на определенной веб-странице. Веб-страница может содержать текст, изображения и другие рекламные объявления, при этом одна из текстовых областей является основной текстовой областью, например новостной статьей. Наиболее желательно размещение рекламы в новостной статье, потому что это часть веб-страницы, которую пользователь, скорее всего, прочитает. Вместо того, чтобы просто добавлять ссылку на рекламу в новостной статье, в этом раскрытии обсуждается изменение фактического содержания новостной статьи, чтобы реклама была включена в текст новостной статьи.
Вместо того, чтобы просто добавлять ссылку на рекламу в новостной статье, в этом раскрытии обсуждается изменение фактического содержания новостной статьи, чтобы реклама была включена в текст новостной статьи.
Для удобства в этом раскрытии используются термины, относящиеся к конкретной реализации, а именно к тексту на веб-страницах. Однако идеи этого раскрытия не ограничиваются этим, но применимы к любому сообщению, текстовому, звуковому, визуальному, анимационному или в любой другой форме. В визуальном сообщении, таком как фильм или изображение, реклама может быть встроена путем размещения изображения поверх другого изображения. Например, изображение автомобиля может быть изменено, чтобы включить логотип бренда на двери автомобиля. В слуховом сообщении такой звук, как звонок в дверь, может быть заменен звуковым знаком рекламодателя.
РИС. 1 показана схема системы 100 для взаимодействия пользователя 102 с вычислительным устройством 104 для просмотра веб-страниц, содержащих встроенную рекламу. Вычислительное устройство 104 может быть подключено к сети 106 , такой как Интернет. В этой реализации содержимое веб-страницы предоставляется сервером веб-страницы 108 , рекламное содержимое предоставляется базой данных объявлений 110 , а сопоставление ключевого слова с рекламой, а также создание модифицированной веб-страницы со встроенной рекламой осуществляется выполняется составным сервером 112 . Серверы и базы данных могут быть реализованы отдельно или попеременно объединены для выполнения описанных функций.
Вычислительное устройство 104 может быть подключено к сети 106 , такой как Интернет. В этой реализации содержимое веб-страницы предоставляется сервером веб-страницы 108 , рекламное содержимое предоставляется базой данных объявлений 110 , а сопоставление ключевого слова с рекламой, а также создание модифицированной веб-страницы со встроенной рекламой осуществляется выполняется составным сервером 112 . Серверы и базы данных могут быть реализованы отдельно или попеременно объединены для выполнения описанных функций.
РИС. 2 показана схема 200 примерного сервера 108 веб-страницы. Сервер веб-страницы 108 содержит процессор 202 и память 204 . Память 204 содержит содержимое веб-страницы 206 . Веб-страницы могут содержать текст, изображения, видео или другой контент. Этот контент существует в виде, созданном автором веб-страницы без встроенной рекламы. Сервер веб-страниц 108 также содержит соединения связи 208 . Коммуникационные соединения 208 сконфигурированы для предоставления содержимого веб-страницы серверу 112 компоновки, где реклама из базы данных 110 рекламы может быть встроена в содержимое 206 веб-страницы. Контент веб-страницы может предоставляться через сеть 106 или через другое коммуникационное соединение между сервером 108 веб-страницы и сервером 9 компоновки.0110 112 .
Коммуникационные соединения 208 сконфигурированы для предоставления содержимого веб-страницы серверу 112 компоновки, где реклама из базы данных 110 рекламы может быть встроена в содержимое 206 веб-страницы. Контент веб-страницы может предоставляться через сеть 106 или через другое коммуникационное соединение между сервером 108 веб-страницы и сервером 9 компоновки.0110 112 .
РИС. 3 показана схема 300 примерной базы данных 110 рекламы. База данных 110 содержит множество рекламных объявлений 302 и множество описаний 304 . Для каждого объявления может быть соответствующее описание. Рекламные объявления 302 могут включать информацию, относящуюся к продукту, такую как имя, ключевое слово, описание, логотип или ссылку на страницу продукта. Описание 304 рекламы может включать текст из самой рекламы или текст, сгенерированный для описания содержания рекламы. Например, пометка изображения, видео или аудио с текстовой строкой упрощает сопоставление этого контента с текстом веб-страницы. В некоторых реализациях описание 304 может включать звуковую, визуальную или числовую информацию, связанную с рекламой. Описание 304 может также включать слова, которые были предложены рекламодателем или куплены им. Купленные слова могут иным образом не иметь связи с рекламой. Однако возможность назначать слова без ограничения по описанию 304 позволяет явно настроить описание 304 рекламного объявления 302 .
В некоторых реализациях описание 304 может включать звуковую, визуальную или числовую информацию, связанную с рекламой. Описание 304 может также включать слова, которые были предложены рекламодателем или куплены им. Купленные слова могут иным образом не иметь связи с рекламой. Однако возможность назначать слова без ограничения по описанию 304 позволяет явно настроить описание 304 рекламного объявления 302 .
РИС. 4 показана схема 400 примерного сервера 112 составления. Составной сервер включает в себя процессор 402 , коммуникационное(ые) соединение(я) 404 и память 406 . В некоторых реализациях коммуникационное(ые) соединение(я) , 404, может быть настроено на получение содержимого веб-страницы и отправку измененного содержимого веб-страницы на вычислительное устройство, такое как вычислительное устройство 9.0110 104 , показанный на РИС. 1.
Память 406 может включать в себя модуль 408 сканирования веб-страниц, сконфигурированный для сканирования веб-страниц в режиме реального времени. Веб-страницы могут включать в себя веб-страницы с сервера 108 веб-страниц. В некоторых реализациях сканирование также включает в себя создание копии просканированных веб-страниц в памяти 406 составного сервера 112 .
Веб-страницы могут включать в себя веб-страницы с сервера 108 веб-страниц. В некоторых реализациях сканирование также включает в себя создание копии просканированных веб-страниц в памяти 406 составного сервера 112 .
Память 406 может также включать модуль сегментации веб-страниц 410 . Модуль , 410, сегментации веб-страницы может быть сконфигурирован для сегментации веб-страницы на несколько блоков. Каждый из блоков может быть смысловой частью веб-страницы. Исходные веб-страницы могут содержать такие элементы, как изображения, видео, баннеры, контактную информацию, руководства по навигации и другую рекламу. Пользователи рассматривают веб-страницу как несколько разных семантических объектов, а не как один объект. Пространственные и визуальные подсказки позволяют пользователям разделить веб-страницу на несколько смысловых частей. Многочисленные элементы могут затруднить машинный анализ основного текста веб-страницы. Однако машина также может разделить веб-страницу на семантические части, используя информацию, закодированную в языке разметки, лежащем в основе веб-страницы.
В одной реализации модуль сегментации веб-страницы 410 использует алгоритм сегментации страницы на основе зрения (VIPS) для сегментации веб-страницы на блоки. Алгоритм VIPS настроен на извлечение семантической структуры веб-страницы на основе визуального представления веб-страницы. Алгоритм VIPS извлекает информацию о структуре из дерева объектной модели документа веб-страницы. Дерево объектной модели документа веб-страницы идентифицирует дискретные объекты на веб-странице на основе кодирования или тегов языка разметки, описывающего веб-страницу. Далее находятся разделители между блоками извлечения. Разделители могут обозначать горизонтальные или вертикальные линии на веб-странице, которые не пересекают ни один из блоков. Таким образом, веб-страница может быть представлена семантическим деревом, в котором каждый конечный узел дерева соответствует блоку веб-страницы. Блок веб-страницы может быть дополнительно разделен на более мелкие блоки. Таким образом, реализации алгоритма VIPS могут повторяться, рекурсивно разделяя веб-страницу из более крупных блоков на более мелкие блоки.
Модуль сегментации веб-страницы 410 может также идентифицировать основной текстовый блок веб-страницы. Основной текстовый блок может быть текстовым блоком, который содержит больше слов, чем другой текстовый блок на той же веб-странице, и находится в фокусе веб-страницы. Фокус веб-страницы можно определить, идентифицируя текстовый блок, ближайший к центру веб-страницы. В других реализациях фокус веб-страницы может определяться тегами или метками на языке разметки, связанными с блоком. В некоторых реализациях основной текстовый блок идентифицируется путем фильтрации других блоков, таких как блоки, содержащие изображения, рекламу или нетекстовое содержимое. Блоки, содержащие изображения или рекламные объявления, могут быть идентифицированы путем анализа меток, ссылок или аналогичной информации на языке разметки, описывающем блоки.
Память 406 может также включать модуль извлечения предложений 412 . Модуль извлечения предложений 412 идентифицирует отдельные предложения из текста веб-страницы. В некоторых реализациях предложения извлекаются только из текста основного текстового блока. После получения всех предложений из блока веб-страницы к каждому из предложений применяется статистическая модель синтаксического анализа, чтобы сгенерировать лексическое дерево синтаксического анализа для каждого предложения. В общем случае статистическая модель синтаксического анализа определяет условную вероятность для каждого дерева синтаксического анализа-кандидата, сгенерированного из предложения. Сам синтаксический анализатор представляет собой алгоритм, который ищет наилучшее дерево, которое максимизирует вероятность результирующего предложения.
В некоторых реализациях предложения извлекаются только из текста основного текстового блока. После получения всех предложений из блока веб-страницы к каждому из предложений применяется статистическая модель синтаксического анализа, чтобы сгенерировать лексическое дерево синтаксического анализа для каждого предложения. В общем случае статистическая модель синтаксического анализа определяет условную вероятность для каждого дерева синтаксического анализа-кандидата, сгенерированного из предложения. Сам синтаксический анализатор представляет собой алгоритм, который ищет наилучшее дерево, которое максимизирует вероятность результирующего предложения.
Память 406 может также включать в себя модуль 414 сопоставления ключевых слов рекламы. Модуль 414 сопоставления ключевых слов рекламы получает ключевые слова с веб-страницы и сопоставляет эти ключевые слова с рекламой. В некоторых реализациях ключевые слова веб-страницы идентифицируются путем анализа текста веб-страницы. В частности, анализируемый текст веб-страницы может быть текстом основного текстового блока. Модуль сопоставления рекламы и ключевых слов 414 связывает описания 304 рекламных объявлений 302 , хранящихся в базе данных объявлений 110 , с ключевыми словами с веб-страницы на основе журналов пользователей, кластеризации слов или правил торгов.
В частности, анализируемый текст веб-страницы может быть текстом основного текстового блока. Модуль сопоставления рекламы и ключевых слов 414 связывает описания 304 рекламных объявлений 302 , хранящихся в базе данных объявлений 110 , с ключевыми словами с веб-страницы на основе журналов пользователей, кластеризации слов или правил торгов.
Пользовательские журналы могут быть записью других веб-страниц, просматриваемых тем же пользователем. Использование пользовательских журналов для определения потенциально релевантной рекламы может быть лучше, чем использование одних только ключевых слов, поскольку совокупность информации, используемой для идентификации потенциально релевантной рекламы, основана на фактическом поведении пользователя. Если пользователь при просмотре веб-страницы определенного типа выбрал рекламу, вполне вероятно, что аналогичная реклама будет интересна пользователю, когда пользователь снова просматривает веб-страницу этого типа. Например, если пользователь щелкнул рекламу авиакомпании при просмотре веб-страницы о путешествиях, вполне вероятно, что пользователь заинтересуется рекламой авиакомпаний при просмотре других веб-страниц о путешествиях.
Например, если пользователь щелкнул рекламу авиакомпании при просмотре веб-страницы о путешествиях, вполне вероятно, что пользователь заинтересуется рекламой авиакомпаний при просмотре других веб-страниц о путешествиях.
Пользовательские журналы могут быть проанализированы для определения взаимосвязей между веб-страницами и рекламными объявлениями, представляющими интерес для пользователя. В некоторых реализациях для кластеризации информации, содержащейся в пользовательских журналах, используется метод кластеризации на основе плотности. Одним из примеров метода кластеризации на основе плотности является алгоритм пространственной кластеризации приложений с шумом на основе плотности (DBSCAN). Алгоритм DBSCAN использует структуру пространственного индексирования для определения местоположения точек в данных на определенном расстоянии от центральной точки кластера. Все кластеры, состоящие из количества точек меньше минимального, считаются «шумом» и отбрасываются.
Кластеризация слов определяет вероятную взаимосвязь между двумя словами, основываясь на частоте их совместного употребления в эталонном корпусе текста. Из эталонного корпуса текста можно рассчитать попарное сходство между всеми существительными, всеми глаголами и всеми прилагательными/наречиями. Базовым корпусом текстов могут быть, например, архивные газетные статьи. Список похожих слов, включая меру сходства, создается для каждого слова в корпусе текста на основе попарного сходства. Рекламное объявление может быть связано с ключевым словом с веб-страницы, если слова в описании рекламного объявления входят в число слов, идентифицированных как похожие на ключевое слово.
Из эталонного корпуса текста можно рассчитать попарное сходство между всеми существительными, всеми глаголами и всеми прилагательными/наречиями. Базовым корпусом текстов могут быть, например, архивные газетные статьи. Список похожих слов, включая меру сходства, создается для каждого слова в корпусе текста на основе попарного сходства. Рекламное объявление может быть связано с ключевым словом с веб-страницы, если слова в описании рекламного объявления входят в число слов, идентифицированных как похожие на ключевое слово.
Правила назначения ставок могут связывать рекламу с ключевым словом в зависимости от того, сколько денег рекламодатель готов заплатить за связь с данным ключевым словом. В одной реализации правил торгов рекламодатель, делающий самую высокую ставку, может создать связь между ключевым словом и рекламой.
Связь между ключевым словом и рекламой может основываться на сочетании журналов пользователей, группировки слов и правил назначения ставок. Анализ каждого из пользовательских журналов, кластеризация слов и правила торгов могут генерировать три разных значения силы ассоциации. Каждое из трех значений силы связи может быть объединено в линейно-взвешенное или среднее слияние для получения единого комбинированного значения силы связи. В некоторых реализациях взвешивание может быть изменено на основе эмпирического наблюдения за соответствием рекламного слова ключевому слову. Рекламное объявление с наивысшим комбинированным значением силы ассоциации может быть связано с ключевым словом. В некоторых реализациях несколько рекламных объявлений могут быть связаны с одним ключевым словом, например, когда несколько рекламных объявлений имеют одинаковое значение силы ассоциации. Также возможно создать ассоциацию между ключевым словом и несколькими рекламными объявлениями, имеющими, например, первое, второе и третье наивысшее объединенное значение силы связи.
Каждое из трех значений силы связи может быть объединено в линейно-взвешенное или среднее слияние для получения единого комбинированного значения силы связи. В некоторых реализациях взвешивание может быть изменено на основе эмпирического наблюдения за соответствием рекламного слова ключевому слову. Рекламное объявление с наивысшим комбинированным значением силы ассоциации может быть связано с ключевым словом. В некоторых реализациях несколько рекламных объявлений могут быть связаны с одним ключевым словом, например, когда несколько рекламных объявлений имеют одинаковое значение силы ассоциации. Также возможно создать ассоциацию между ключевым словом и несколькими рекламными объявлениями, имеющими, например, первое, второе и третье наивысшее объединенное значение силы связи.
Память 406 может также включать в себя модуль 416 составления рекламного предложения. Реклама, выбранная для вставки в предложение, может быть рекламой, идентифицированной модулем , 414 сопоставления ключевых слов рекламы. Предложение уже было разложено в дерево синтаксического анализа модулем извлечения предложений 412 . Следовательно, задача модуля составления рекламного предложения 416 состоит в том, чтобы определить, как объединить предложение и рекламу. Реклама может содержать элементы, отличные от текста; однако с целью определения того, как сочетать предложение с рекламой, анализируются только текстовые элементы рекламы или рекламный текст. Рекламный текст вставляется в дерево разбора и создается новое дерево разбора. Это повторяется для создания нескольких деревьев синтаксического анализа, каждое дерево синтаксического анализа соответствует вставке рекламного текста в другое место в исходном предложении. Благодаря этому процессу создается множество различных композиций.
Предложение уже было разложено в дерево синтаксического анализа модулем извлечения предложений 412 . Следовательно, задача модуля составления рекламного предложения 416 состоит в том, чтобы определить, как объединить предложение и рекламу. Реклама может содержать элементы, отличные от текста; однако с целью определения того, как сочетать предложение с рекламой, анализируются только текстовые элементы рекламы или рекламный текст. Рекламный текст вставляется в дерево разбора и создается новое дерево разбора. Это повторяется для создания нескольких деревьев синтаксического анализа, каждое дерево синтаксического анализа соответствует вставке рекламного текста в другое место в исходном предложении. Благодаря этому процессу создается множество различных композиций.
Память 406 может также включать в себя модуль фильтрации композиции 418 . Модель 418 фильтрации композиции выбирает одну композицию из множества различных композиций, созданных модулем 416 составления рекламного предложения. Фильтрация основана на методах сглаживания. Каждое новое дерево синтаксического анализа, созданное путем вставки рекламного текста в исходное предложение, имеет вероятность быть естественным и грамматически правильным предложением. Вероятность слов и фраз определяется путем сравнения с языковой моделью. Произведение вероятности слов и фраз каждого нового дерева синтаксического анализа является вероятностью предложения в целом. Из многочисленных потенциальных композиций композиция с наибольшей вероятностью по сравнению с другими потенциальными композициями, скорее всего, будет соответствовать естественному и грамматически правильному предложению. Таким образом, модуль 9 фильтрации композиции0110 418 выбирает новое дерево синтаксического анализа с наибольшей вероятностью. При этом сервер композиции 112 определяет, где в предложении следует вставить рекламу.
Фильтрация основана на методах сглаживания. Каждое новое дерево синтаксического анализа, созданное путем вставки рекламного текста в исходное предложение, имеет вероятность быть естественным и грамматически правильным предложением. Вероятность слов и фраз определяется путем сравнения с языковой моделью. Произведение вероятности слов и фраз каждого нового дерева синтаксического анализа является вероятностью предложения в целом. Из многочисленных потенциальных композиций композиция с наибольшей вероятностью по сравнению с другими потенциальными композициями, скорее всего, будет соответствовать естественному и грамматически правильному предложению. Таким образом, модуль 9 фильтрации композиции0110 418 выбирает новое дерево синтаксического анализа с наибольшей вероятностью. При этом сервер композиции 112 определяет, где в предложении следует вставить рекламу.
Память 406 может также включать в себя модуль рендеринга веб-страницы 420 . Этот модуль 420 отображает окончательные результаты встраивания рекламы. Текст веб-страницы изменен таким образом, что композиция, идентифицированная модулем фильтрации композиции 418 , отображается пользователю 102 вместо отображения исходного текста веб-страницы. В некоторых реализациях это достигается тем, что составной сервер 112 перехватывает передачи веб-страниц с сервера веб-страниц 108 и модифицирует веб-страницу путем внедрения рекламы перед доставкой веб-страницы на вычислительное устройство 104 .
Текст веб-страницы изменен таким образом, что композиция, идентифицированная модулем фильтрации композиции 418 , отображается пользователю 102 вместо отображения исходного текста веб-страницы. В некоторых реализациях это достигается тем, что составной сервер 112 перехватывает передачи веб-страниц с сервера веб-страниц 108 и модифицирует веб-страницу путем внедрения рекламы перед доставкой веб-страницы на вычислительное устройство 104 .
В некоторых реализациях составной сервер 112 содержит языковую модель 422 . Языковая модель 422 может включать в себя большой корпус текста, такой как справочный корпус, рассмотренный выше. В некоторых реализациях большой объем текста автоматически собирается с других веб-страниц. Этот корпус текста предоставляет набор данных, которые можно анализировать, чтобы определить статистическую вероятность порядка слов и отношений между словами. Если в корпусе текста встречается сочетание слов или словосочетание, вероятно, это сочетание слов или словосочетание является естественным сочетанием. Ссылаясь на языковую модель 422 , машина может создавать новые предложения и порядок слов, которые, вероятно, будут естественными и грамматически правильными. Языковая модель 422 может зависеть от темы. Корпус текстов, основанный на публикациях по экономике, может давать более точные оценки естественных и грамматических предложений для содержания веб-страницы, связанной с экономикой, чем корпус текстов, основанный на общих новостных статьях. Например, составной сервер 112 может содержать множество языковых моделей, каждая из которых связана с разными темами. В некоторых реализациях составной сервер 112 может определить тему веб-страницы и выбрать языковую модель, соответствующую этой теме.
Ссылаясь на языковую модель 422 , машина может создавать новые предложения и порядок слов, которые, вероятно, будут естественными и грамматически правильными. Языковая модель 422 может зависеть от темы. Корпус текстов, основанный на публикациях по экономике, может давать более точные оценки естественных и грамматических предложений для содержания веб-страницы, связанной с экономикой, чем корпус текстов, основанный на общих новостных статьях. Например, составной сервер 112 может содержать множество языковых моделей, каждая из которых связана с разными темами. В некоторых реализациях составной сервер 112 может определить тему веб-страницы и выбрать языковую модель, соответствующую этой теме.
Показан на РИС. 5 представляет собой процесс 500 для встраивания рекламы в предложение с веб-страницы. Сервер веб-страниц 108 является источником исходной веб-страницы 502 . Исходная веб-страница 502 может содержать блок панели инструментов, несколько рекламных блоков Ad 1 , Ad 2 и несколько текстовых блоков. Исходная веб-страница 502 может быть сегментирован на блоки с помощью процесса, описанного выше в отношении модуля сегментации веб-страницы 410 . Сегментация веб-страницы 504 выгодна тем, что позволяет идентифицировать отдельный текстовый блок для дальнейшего анализа, тем самым уменьшая объем информации, которую необходимо обработать, чтобы встроить рекламу в предложение.
Исходная веб-страница 502 может быть сегментирован на блоки с помощью процесса, описанного выше в отношении модуля сегментации веб-страницы 410 . Сегментация веб-страницы 504 выгодна тем, что позволяет идентифицировать отдельный текстовый блок для дальнейшего анализа, тем самым уменьшая объем информации, которую необходимо обработать, чтобы встроить рекламу в предложение.
Предложение взято с веб-страницы 506 . Проиллюстрировано извлечение только одного предложения; однако более одного предложения или даже все предложения с веб-страницы могут быть извлечены и проанализированы по отдельности.
Далее процесс 500 переходит к созданию статистического дерева разбора предложения 508 . На этом рисунке первые пять слов предложения (например, другие/популярные/общение/системы/подобные) и слово «являются» показаны как узлы дерева. Каждый узел в дереве обозначает одно слово. Разбор статистического дерева предложения сочетается с рекламой из базы данных объявлений 110 . Реклама или рекламные объявления, выбранные из базы данных объявлений 110 для комбинации с предложением из анализа статистического дерева 508 может быть выбран методом, подобным тому, который выполняется модулем 414 сопоставления ключевых слов рекламы. На этом рисунке реклама представлена словом «Microsoft».
Реклама или рекламные объявления, выбранные из базы данных объявлений 110 для комбинации с предложением из анализа статистического дерева 508 может быть выбран методом, подобным тому, который выполняется модулем 414 сопоставления ключевых слов рекламы. На этом рисунке реклама представлена словом «Microsoft».
Вставка рекламы рядом с узлом для слова «нравится» создает модифицированное статистическое древовидное представление предложения. Эта позиция для вставки рекламы выбирается через предложение-рекламу фильтрации 512 . Процесс фильтрации предложений-рекламы 512 может быть аналогичен процессу, выполняемому модулем 418 фильтрации композиции. Языковая модель 514 предоставляет критерий фильтрации для фильтрации предложения-рекламы 512 . Другими словами, место вставки слова «Microsoft» зависит от того, где в извлеченном предложении оно будет наиболее вероятным в соответствии с языковой моделью 514 .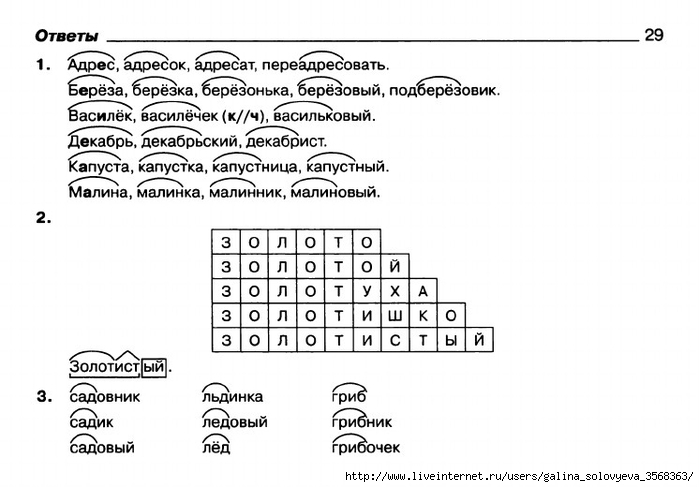 Языковая модель 514 , показанный на РИС. 5 может быть такой же, как языковая модель , 422 , показанная на фиг. 4. В некоторых реализациях языковая модель может существовать отдельно от сервера 112 составления.
Языковая модель 514 , показанный на РИС. 5 может быть такой же, как языковая модель , 422 , показанная на фиг. 4. В некоторых реализациях языковая модель может существовать отдельно от сервера 112 составления.
РИС. 6 более подробно показаны синтаксический анализ , 508, статистического дерева и фильтрация , 512 рекламы предложений на фиг. 5. Процесс 600 , показанный на фиг. 6 начинается с предложения 602 , взятого с веб-страницы. Это то же самое предложение, показанное на фиг. 5. Лексическое дерево синтаксического анализа 604 предложения создается моделью синтаксического анализа, такой как марковский процесс 0 th порядка. Модель синтаксического анализа идентифицирует лексическое заглавное слово или заглавное слово. В некоторых реализациях заглавное слово является ключевым словом из предложения. На этой иллюстрации заглавным словом является «связь», которое показано в верхней части дерева лексического разбора 604 . Вероятность заглавного слова равна P H (H|P, h). Где H — главный дочерний элемент фразы, P H — вероятность H, P — родитель заглавного слова, а h — заглавное слово.
Вероятность заглавного слова равна P H (H|P, h). Где H — главный дочерний элемент фразы, P H — вероятность H, P — родитель заглавного слова, а h — заглавное слово.
Модификаторы генерируются справа от заглавного слова с вероятностью, показанной как:
∏i=1…m+1PH(Ri(ri)|P,h,H) .
R m+1 (r m+1 ) определяется как STOP — символ STOP добавляется в словарь нетерминалов, и модель синтаксического анализа прекращает генерировать правые модификаторы, когда генерируется символ STOP. Р 1 . . . R m являются правыми модификаторами H. Модификаторы также генерируются слева от заглавного слова с вероятностью, показанной как:
∏i=1…n+1PL(Li(li)|P,h,H).
Для модификаторов, сгенерированных слева, L n+1 (l n+1 ) определяется как STOP. Л 1 . . . L n — левые модификаторы H. Либо n, либо m могут быть равны 0, и n=1=0 для унарных правил.
При наличии дерева лексического анализа 604 , полученного для предложения 602 , и рекламного слова (например, Microsoft), слово объявления вставляется рядом с узлом в дереве лексического анализа 604 . В некоторых реализациях рекламное слово вставляется рядом с каждым узлом в дереве лексического разбора 9.0110 604 . Рекламное слово может быть вставлено рядом с узлом, соответствующим слову «нравится» 606 , узлом, соответствующим слову «другое» 608 , узлом, соответствующим слову «системы» 610 , или любым другим узел 612 . Детали других возможных деревьев лексического разбора не показаны на фиг. 6 для краткости.
Одно дерево синтаксического анализа выбирается из нескольких деревьев синтаксического анализа 606 — 612 , которые создаются путем объединения предложения и рекламного слова. В одной реализации выбор основан на вероятности вставки, рассчитанной языковой моделью n-грамм. В этом примере выбранным деревом синтаксического анализа является лексическое дерево синтаксического анализа 9. 0110 606 слева на РИС. 6.
0110 606 слева на РИС. 6.
В языковой модели с n-граммами вероятность предложения P(s) выражается как произведение вероятности слов, составляющих предложение, при этом вероятность каждого слова зависит от идентичности последних n-1 слов. Таким образом, для предложения s, состоящего из слов w i . . . w l, вероятность предложения P(s) отображается как:
P(s)=∏i=1lP(wi|w1i-1)≈∏i=1l P(wi|w1-n+1i-1)
Обычно n принимается равным 2 или 3, что соответствует модели биграммы или триграммы соответственно. Каждое возможное предложение, сгенерированное вставкой рекламного слова в дерево лексического разбора 604 будет иметь вероятность, связанную с этим предложением. Из возможных предложений в этом примере, 606 — 612 , дерево лексического разбора 606 в левой части фиг. 6 имеет более высокую вероятность, чем любое другое возможное лексическое дерево синтаксического анализа 608 — 612 . Таким образом, этот алгоритм выбирает точку вставки для рекламного слова с максимальным P(s).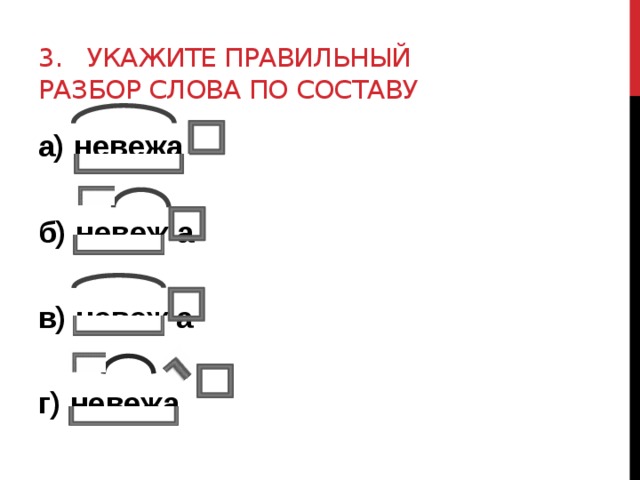 В этом примере «Другие популярные коммуникационные системы, такие как Microsoft . . . 606 более вероятен, чем «другие популярные коммуникационные системы Microsoft, такие как . . . 608 или «Другие популярные коммуникационные системы Microsoft, такие как . . . 610 .
В этом примере «Другие популярные коммуникационные системы, такие как Microsoft . . . 606 более вероятен, чем «другие популярные коммуникационные системы Microsoft, такие как . . . 608 или «Другие популярные коммуникационные системы Microsoft, такие как . . . 610 .
Как обсуждалось ранее, реклама может быть больше, чем просто рекламное слово. В этом примере рекламное слово «Microsoft», но реклама содержит текст «Microsoft Outlook, MSN Messenger» и изображения, представляющие MICROSOFT OUTLOOK™ и MSN MESSENGER™. Реклама также содержит гиперссылки или ссылки на другой веб-сайт. Ссылки обозначены подчеркиванием «Microsoft Outlook» и «MSN Messenger». Исходное предложение 602 изменяется путем включения рекламы в позицию, указанную языковой моделью n-грамм, что приводит к новому предложению 614 , которое представляет собой композицию исходного предложения 602 и рекламы.
Показан на РИС. 7 представлена примерная блок-схема процесса 700 создания веб-страницы со встроенной рекламой. Для простоты понимания способ 700 представлен отдельными этапами, представленными в виде независимых блоков на фиг. 7. Однако эти отдельно очерченные этапы не следует рассматривать как обязательно зависящие от порядка их выполнения. Порядок, в котором описан процесс, не следует рассматривать как ограничение, и любое количество описанных блоков процесса может быть объединено в любом порядке для реализации способа или альтернативного метода. Кроме того, также возможно, что один или несколько из предусмотренных шагов будут опущены.
Для простоты понимания способ 700 представлен отдельными этапами, представленными в виде независимых блоков на фиг. 7. Однако эти отдельно очерченные этапы не следует рассматривать как обязательно зависящие от порядка их выполнения. Порядок, в котором описан процесс, не следует рассматривать как ограничение, и любое количество описанных блоков процесса может быть объединено в любом порядке для реализации способа или альтернативного метода. Кроме того, также возможно, что один или несколько из предусмотренных шагов будут опущены.
Блок-схема процесса 700 представляет собой пример метода, который может быть выполнен сервером составления 112 . В других реализациях процесс может выполняться другим специализированным устройством, отличным от сервера 112 составления. В качестве альтернативы процесс 700 также может выполняться на множестве устройств.
Показанный в блоке 702 процесс 700 идентифицирует веб-страницу. Веб-страница может храниться в памяти сервера веб-страницы, такого как сервер 9 веб-страницы. 0110 108 , показанный на РИС. 2.
0110 108 , показанный на РИС. 2.
Показанный в блоке 704 процесс 700 сканирует веб-страницу. Сканирование веб-страницы может выполняться любой программой или сценарием, которые систематически и автоматически просматривают веб-страницы коллекции, такие как World Wide Web. Некоторыми примерами сканеров веб-страниц являются программы, используемые для автоматического индексирования веб-страниц для поисковых систем.
Показанный в блоке 706 процесс 700 сегментирует веб-страницу. Веб-страница может быть сегментирована с помощью алгоритма машинного зрения, такого как описанный выше в отношении модуля 9 сегментации веб-страницы.0110 410 . В некоторых реализациях алгоритмом машинного зрения является алгоритм VIPS.
Показанный в блоке 708 процесс 700 идентифицирует основной текстовый блок. Основной текстовый блок может быть идентифицирован после сегментации веб-страницы. В других реализациях, которые не сегментируют веб-страницу, основной текстовый блок может быть извлечен из веб-страницы без сегментации. Идентификация основного текстового блока может быть выполнена способом, аналогичным описанному выше в отношении модуля 9 сегментации веб-страницы.0110 410 .
Идентификация основного текстового блока может быть выполнена способом, аналогичным описанному выше в отношении модуля 9 сегментации веб-страницы.0110 410 .
Показанный в блоке 710 процесс 700 извлекает предложения из основного текстового блока. Извлечение предложений может быть аналогично извлечению предложений 506 , показанному на фиг. 5. В некоторых реализациях отдельные предложения идентифицируются с помощью знаков окончания предложений (например, «.», «?», «!» и т. д.) и начальных заглавных букв. Извлечение предложений может включать выделение отдельных предложений как отдельных элементов для дальнейшей обработки или анализа.
Показанный в блоке 712 процесс 700 анализирует предложения. В некоторых реализациях синтаксический анализ предложений включает идентификацию отдельных слов в предложениях. Первым шагом анализа предложений может быть разложение предложений на дерево с использованием языковой модели. Разбор предложений также может быть выполнен путем создания дерева синтаксического анализа предложения, аналогичного лексическому дереву синтаксического анализа , 604, , описанному выше в отношении фиг. 6.
6.
Показанный в блоке 714 процесс 700 идентифицирует пару реклама-ключевое слово. Идентификация пары «реклама-ключевое слово» может выполняться аналогично тому, как это делает модуль , 414, сопоставления «реклама-ключевое слово». В некоторых реализациях ключевое слово связано с конкретным предложением, и, таким образом, связывание рекламы с ключевым словом также связывает рекламу с предложением. Если данное ключевое слово появляется в предложении или блоке текста более одного раза, реклама может иметь ассоциации с несколькими местами в предложении или несколькими предложениями в блоке текста. Подобно другим видам рекламы, встроенная реклама позволяет показывать одну и ту же рекламу несколько раз на одной веб-странице.
Показанный в блоке 716 процесс 700 создает композиции из рекламы и предложения. Композиции могут быть созданы способом, подобным описанному выше в отношении модуля , 416 составления рекламных предложений. Как правило, но не всегда, для данной пары ключевое слово-предложение создается несколько композиций. Композиции могут создавать новые предложения, вставляя рекламу в различные места исходного предложения, подобно тому, как это показано на фиг. 6. Выбор места и способа вставки рекламы в исходные предложения может производиться случайным образом и/или без знания грамматики или правил построения предложений. Таким образом, вполне возможно, что многие из композиций покажутся читателю неестественными или неграмотными.
Как правило, но не всегда, для данной пары ключевое слово-предложение создается несколько композиций. Композиции могут создавать новые предложения, вставляя рекламу в различные места исходного предложения, подобно тому, как это показано на фиг. 6. Выбор места и способа вставки рекламы в исходные предложения может производиться случайным образом и/или без знания грамматики или правил построения предложений. Таким образом, вполне возможно, что многие из композиций покажутся читателю неестественными или неграмотными.
Показанный в блоке 718 процесс 700 выбирает грамматическую композицию. Если создается только одна композиция, эта композиция будет автоматически выбрана в качестве грамматической композиции. Если имеется несколько композиций для выбора, процесс выбора может быть аналогичен процессу, выполняемому модулем , 418, фильтрации композиции. В процессе выбора грамматической композиции предпринимается попытка выбрать одно предложение, которое будет казаться грамматически логичным и естественным для читателя, из нескольких предложений, созданных с помощью алгоритма, реализованного на вычислительном устройстве.
Показанный в блоке 720 процесс 700 отображает веб-страницу со встроенной рекламой. Рендеринг может быть аналогичен тому, который выполняется модулем , 420, рендеринга веб-страницы. Встраивание рекламы в исходный текст веб-страницы создает встроенную рекламу. Рекламу представляют пользователю в той части веб-страницы, которую пользователь может просмотреть, и реклама интегрирована с содержимым веб-страницы, так что пользователю трудно игнорировать рекламу. Как обсуждалось в отношении изменения предложения 614 , текст, изображения, видео, гиперссылки или другая реклама могут быть встроены в веб-страницу.
РИС. 8 представляет собой блок-схему, показывающую примерное вычислительное устройство , 800, для создания встроенной рекламы. Вычислительное устройство , 800, может быть сконфигурировано как любая подходящая система, способная создавать композицию рекламного предложения. В одной примерной конфигурации система содержит по меньшей мере один процессор 802 и память 804 . Процессор 802 может быть реализован соответствующим образом в оборудовании, программном обеспечении, прошивке или их комбинации. Программные или микропрограммные реализации процессора , 802, могут включать в себя исполняемые компьютером или машиной инструкции, написанные на любом подходящем языке программирования для выполнения различных описанных функций.
Процессор 802 может быть реализован соответствующим образом в оборудовании, программном обеспечении, прошивке или их комбинации. Программные или микропрограммные реализации процессора , 802, могут включать в себя исполняемые компьютером или машиной инструкции, написанные на любом подходящем языке программирования для выполнения различных описанных функций.
Например, вычислительное устройство 800 иллюстрирует архитектуру этих компонентов, находящихся в одной системе или одном сервере, которые могут быть коммуникативно связаны с сетью, такой как сеть 106 , показанный на РИС. 1. В качестве альтернативы эти компоненты могут находиться в нескольких других местах, серверах или системах. Например, все компоненты могут существовать на стороне клиента. Кроме того, два или более из показанных компонентов могут быть объединены в единый компонент в одном месте. Проиллюстрированные компоненты могут также находиться в вычислительном устройстве без подключения к сети, таком как автономная база данных. Вычислительное устройство 800 не ограничено составным сервером 112 . В некоторых реализациях вычислительное устройство , 800, может быть похоже на вычислительное устройство , 104, , показанное выше на фиг. 1.
Вычислительное устройство 800 не ограничено составным сервером 112 . В некоторых реализациях вычислительное устройство , 800, может быть похоже на вычислительное устройство , 104, , показанное выше на фиг. 1.
Память 804 может хранить программы инструкций, загружаемых и исполняемых на процессоре, а также данные, генерируемые при выполнении этих программ. В зависимости от конфигурации и типа вычислительного устройства 800 память 804 может быть энергозависимой (например, ОЗУ) и/или энергонезависимой (например, ПЗУ, флэш-память и т. д.). Вычислительное устройство 800 может также включать дополнительное съемное запоминающее устройство 806 и/или несъемное запоминающее устройство 808 , включая, помимо прочего, магнитные накопители, оптические диски и/или ленточные накопители. Дисководы и связанные с ними машиночитаемые носители могут обеспечивать энергонезависимое хранение машиночитаемых инструкций, структур данных, программных модулей и других данных для устройств связи.
Переходя к содержимому памяти 804 подробнее память 804 может включать в себя операционную систему 810 и модуль составления рекламных предложений 416 для создания композиций рекламных объявлений и предложений. Память 804 может также, в некоторых реализациях, содержать языковую модель 812 , которая может быть аналогична языковой модели 422 или языковой модели 514 . Многоязычные модели, такие как языковая модель 812 , языковая модель 422 и языковая модель 514 , могут быть одинаковые или разные языковые модели. Кроме того, вычислительное устройство , 800, может включать в себя базу данных, размещенную на процессоре , 802, (не показан).
Компьютерные носители данных включают энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым методом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Память 804 , съемное хранилище и несъемное хранилище — все это примеры компьютерных носителей данных. Дополнительные типы компьютерных носителей информации, которые могут присутствовать, включают, помимо прочего, RAM, ROM, EEPROM, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические носители, магнитные кассеты, магнитные лента, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения желаемой информации и к которому может получить доступ вычислительное устройство 800 .
Память 804 , съемное хранилище и несъемное хранилище — все это примеры компьютерных носителей данных. Дополнительные типы компьютерных носителей информации, которые могут присутствовать, включают, помимо прочего, RAM, ROM, EEPROM, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические носители, магнитные кассеты, магнитные лента, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения желаемой информации и к которому может получить доступ вычислительное устройство 800 .
Вычислительное устройство 800 может также содержать коммуникационное(ые) соединение(я) 812 , которое позволяет процессору 802 связываться с серверами, пользовательскими терминалами и/или другими устройствами в сети. Соединение(я) связи 812 является примером средства связи. Среда связи обычно представляет собой машиночитаемые инструкции, структуры данных и программные модули. В качестве примера, но не ограничения, средства связи включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Используемый здесь термин машиночитаемый носитель включает как носители данных, так и носители связи.
В качестве примера, но не ограничения, средства связи включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Используемый здесь термин машиночитаемый носитель включает как носители данных, так и носители связи.
Вычислительное устройство 800 может также включать устройство(а) ввода 814 , такое как клавиатура, мышь, перо, устройство голосового ввода, устройство сенсорного ввода, стилус и т.п., и устройство(а) вывода, 816 , такие как дисплей, монитор, громкоговорители, принтер и т. д. Все эти устройства хорошо известны в данной области техники и не нуждаются в подробном обсуждении.
Предмет, описанный выше, может быть реализован аппаратно, программно или как аппаратно, так и программно. Хотя реализации встроенной рекламы были описаны на языке, специфичном для структурных признаков и/или методологических действий, следует понимать, что предмет, определенный в прилагаемой формуле изобретения, не обязательно ограничивается конкретными признаками или действиями, описанными выше. Скорее конкретные признаки и действия раскрыты как примерные формы примерных реализаций создания встроенной рекламы. Например, нет необходимости, чтобы методологические действия выполнялись в порядке или комбинациях, описанных в данном документе, и могут выполняться в любой комбинации одного или нескольких действий.
Скорее конкретные признаки и действия раскрыты как примерные формы примерных реализаций создания встроенной рекламы. Например, нет необходимости, чтобы методологические действия выполнялись в порядке или комбинациях, описанных в данном документе, и могут выполняться в любой комбинации одного или нескольких действий.
знак доллара
Знак доллара, $ , является спорным маленьким оператором Haskell. Семантически это не имеет большого значения, и его сигнатура типа не дает вам намека на то, почему его следует использовать так часто, как сейчас. Его лучше всего понять не по его типу, а по его приоритету . Мы полагаем, что относительная семантическая пустота этого оператора в сочетании с относительной неясностью приоритета делает его таким запутанным на первый взгляд.
Приложение функции
Оператор $ является инфиксным оператором для … применения функции?
($) :: (a -> b) -> a -> b
Учитывая функцию a -> b и a для ее применения, мы получаем b .
λ> sort $ "джули" "eijlu"
Странный инфикс, но ладно. Haskell не нуждается в операторе для применения функции; белого места достаточно.
е :: а -> б х :: а f $ x = f x
λ> сортировать "джули" "эйджлу"
Это кажется совершенно бессмысленным, пока вы не посмотрите дальше типа. Здесь и далее в этой статье мы упростили тип по сравнению с тем, что вы можете увидеть, если запросите эту информацию в своем собственном REPL. Дополнительные биты информации, которые может дать REPL, не важны для понимания этого, поэтому мы их проигнорировали.
λ> :информация ($) ($) :: (а -> б) -> а -> б -- Определено в «GHC.Base» infixr 0 $
Это маленькое замечание, которое так легко упустить из виду, в конце содержит ключ к пониманию вездесущности числа 9.0686 ($) : инфикср 0 .
-
infixrговорит нам, что это инфиксный оператор с правой ассоциативностью. -
0говорит нам, что у него самый низкий приоритет.
Напротив, обычное применение функции (через пробел)
- является левоассоциативным и
- имеет наивысший возможный приоритет (10).
Таким образом, роль оператора $ состоит в том, чтобы дать нам приложение функции с другой — на самом деле противоположной — ассоциативностью и приоритетом.
Это означает, что вы обычно видите $ , где стандартное приложение функции не имеет необходимой ассоциативности и приоритета для контекста. И что означает , так это то, что вы обычно видите, что он используется вместо круглых скобок для связывания вещей, которые в противном случае не были бы связаны.
Это будет более понятно на некоторых примерах. Сравните:
λ> сортировать "джули"++ "моронуки" "эйджлуморонуки" λ> сортировать $"джули"++"моронуки" "eiijklmnooruu"
В первом случае заявка 9Сортировка 0686 к «julie» является самой жесткой привязкой, поэтому аргументом сортировки является только первая строка «julie», а отсортированная строка «eijlu» является первым аргументом (++) . Во втором случае использование
Во втором случае использование $ меняет ассоциативность, точно так же, как если бы мы использовали скобки:
λ> sort("julie"++"moronuki")
"eiijklmnooruu" Таким образом, аргументом sort является объединение двух строк, а не только «julie».
Состав
Один шаблон, в котором иногда используется знак доллара, находится между цепочкой составных функций и аргументом, передаваемым (первому из) этих функций.
λ> голова . сортировать $ "Джули" 'e'
Это немного странно, поскольку мы только что сказали, что $ является правоассоциативным; справа особо нечего оценивать. Таким образом, ключ здесь — приоритет. Мы не можем сделать это:
λ> голова. sort "julie"
Это не будет правильно оценено, потому что
- оператор
(.)имеет приоритет 9, но приложение функции - (
sort "julie") имеет более высокий приоритет.
Это означает, что применение сорта к его аргументу произойдет до композиции головы и сорта .
(.) ожидает два аргумента функции:
(.) :: (b -> c) -> (a -> b) -> a -> c
Но применение sort к аргументу означает, что это больше не функция.
λ> :type (сортировка "julie") (sort "julie") :: [Char]
Второй аргумент (.) может быть sort , но не может быть sort "julie" ; sort — это функция a -> b , но sort "julie" — нет.
Но, как ни странно, это не единственный способ использования $ в отношении композиции функций. В некоторых случаях $ может заменить оператора композиции, (.) . Итак, оба из них действительны Haskell:
λ> голова . сортировать $ "Джули" 'е' λ> head $ sort "джули" 'e'
В первом случае важнее всего 0-старшинство $ ; во втором случае важна правая ассоциативность. Во втором случае сначала оценивается все, что справа, а затем к этому результату применяется головка . Так что в этом случае мы в любом случае получим один и тот же результат.
Так что в этом случае мы в любом случае получим один и тот же результат.
Однако они не всегда могут использоваться взаимозаменяемо. Оба хороши:
λ> headSort xs = head $ sort xs λ> headSort "Джули" 'е' λ> headSort = голова. Сортировать λ> headSort "Джули" 'e'
Но это не так:
λ> headSort = head $ sort
В данном случае, на этот раз, это из-за типа, а не из-за приоритета. sort сама по себе не подходит для использования в качестве второго аргумента $ .
Большие аргументы
Бывают случаи, когда знак доллара используется перед особенно большой аргумент функции. Это наиболее распространено, возможно, с блоками от до , но иногда появляется, когда есть большая анонимная функция, передаваемая в качестве аргумента другой функции. Давайте посмотрим на действительно типичный пример; это из документации для scotty Beam me up. веб-фреймворк.
{-# LANGUAGE OverloadedStrings #-}
импортировать Web. Scotty
импортировать Data.Monoid (mconcat)
основной = Скотти 3000$
получить "/: слово" $
делать
луч <- параметр "слово"
html $ mconcat [" Скотти, ", beam, " я поднимаюсь!
"]  Scotty
импортировать Data.Monoid (mconcat)
основной = Скотти 3000$
получить "/: слово" $
делать
луч <- параметр "слово"
html $ mconcat ["
Scotty
импортировать Data.Monoid (mconcat)
основной = Скотти 3000$
получить "/: слово" $
делать
луч <- параметр "слово"
html $ mconcat [" Мы немного изменили макет, чтобы он лучше соответствовал эстетике наших типовых классов do -block, но в остальном это прямо из документации. В этом коротком фрагменте два оператора долларов. И scotty , и получают , каждый из которых нуждается в некотором большом действии в качестве второго аргумента, поэтому правая ассоциативность $ позволяет всему большому фрагменту после него действовать как один аргумент функции. Вы можете заменить скобки для точно такого же эффекта.
{-# LANGUAGE OverloadedStrings #-}
импортировать Web.Scotty
импортировать Data.Monoid (mconcat)
главный = Скотти 3000
(получить "/:слово"
(делать
луч <- параметр "слово"
html $ mconcat [" Scotty, ", beam, " me up!
"])) Но обычно Хаскеллеры не предпочитают заключать такие большие фрагменты в круглые скобки.
Начиная с GHC 8.6.1, существует также языковое расширение BlockArguments , которое, если оно включено, может сделать оператор $ ненужным во многих из этих контекстов.
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE BlockArguments #-}
импортировать Web.Scotty
импортировать Data.Monoid (mconcat)
главный = Скотти 3000
(получить "/:слово"
делать
луч <- параметр "слово"
html $ mconcat [" Scotty, ", beam, " me up!
"]) Это то же самое, что и первые два фрагмента. Вы можете заметить, что вам нужно сохранить круглые скобки (или использовать $ ) вокруг блока, который начинается с получить , потому что получить не является одним из ключевых слов, которые работают с Аргументы Блока .
И раритет
Наконец, отметим раритет про $ . Его тип
($) :: (a -> b) -> a -> b
также можно записать как
($) :: (a -> b) -> (a -> b)
На самом деле именно так следует читать и понимать тип, но поскольку Haskell по умолчанию каррирован, второй набор скобок не нужен и поэтому обычно не пишется. Но это означает, что
Но это означает, что $ — это просто тождественная функция для … функций.
идентификатор :: а -> а -- а ~ (а -> б) id @(_ -> _) :: (a -> b) -> (a -> b)
Это означает, что при желании вы можете иногда заменить функцию id на $ . id позволяют использовать его в инфиксной позиции; обратные кавычки вокруг обычных префиксных функций позволяют использовать их как инфиксные функции, если хотите.
λ> head $ sort "julie" 'е' λ> head `id` сортировать "julie" 'e'
Конечно, если вам , инфиксирующий id , вы могли бы добавить к нему префикс, верно?
λ> id head (сорт "julie") 'e'
И это то же самое, что и это:
λ> голова (сорт "julie") 'e'
Конечно, вы не можете сделать это во всех контекстах, в которых используется $ , потому что инфикс id и $ не имеют одинакового… как вы уже догадались, ассоциативности и приоритета. Когда вы создаете префиксную функцию, такую как инфикс
Когда вы создаете префиксную функцию, такую как инфикс id , отмечая ее, но не указываете иначе ассоциативность и приоритет для ее использования инфикса, по умолчанию она имеет левоассоциативность и приоритет 9, что делает его таким же приоритетом, как композиция функций, но ниже (на единицу), чем обычное применение функции префикса. Вы можете заменить инфикс id на знаки доллара в примерах scotty , но вам также нужно добавить несколько круглых скобок. Мы оставим понимание того, где именно и почему, в качестве упражнения для читателя.
Хотя это небольшое любопытство о взаимосвязи $ и id интересно, пожалуйста, не начинайте писать на Haskell с большим количеством инфикса идентификатор . Это приведет вас в плохие места и заставит ваших коллег ненавидеть вас.
Как оформить резюме Раздел «Образование»: примеры и шаблоны
Поиск Многие соискатели вкладывают свою энергию в составление резюме, создавая основную часть своего резюме: разделы с опытом и навыками. В результате раздел образования становится чем-то вроде запоздалой мысли. Но когда системы отслеживания кандидатов разбирают резюме и анализируют требования к описанию работы, следует уделять больше внимания (и лучшему форматированию). Мы здесь, чтобы внести ясность в вопрос о том, как форматировать образовательный раздел вашего резюме.
В результате раздел образования становится чем-то вроде запоздалой мысли. Но когда системы отслеживания кандидатов разбирают резюме и анализируют требования к описанию работы, следует уделять больше внимания (и лучшему форматированию). Мы здесь, чтобы внести ясность в вопрос о том, как форматировать образовательный раздел вашего резюме.
Что включить в раздел «Образование» резюме
Прежде всего. Что должно быть включено в раздел образования вашего резюме? Вот основные сведения:
- Название учреждения
- Степень
- Местонахождение школы
- Годы обучения
Отсюда вы можете добавить академические награды, стипендии и другие достижения, если это применимо. Вы можете также включать курсовую работу, но только в том случае, если она абсолютно уместна для работы, на которую вы претендуете. Если вы включаете курсовую работу, используйте названия каждого курса в качестве описания вместо номеров курсов.
Если курсовая работа кажется вам неподходящей, подумайте о том, чтобы включить соответствующие проекты или группы, в которых вы действительно преуспели. Например, дипломная работа, инициатива по изменению школьной политики или впечатляющая группа в кампусе, которую вы возглавляли. . Все, что иллюстрирует ваши увлечения и относится к работе, заслуживает внимания.
Например, дипломная работа, инициатива по изменению школьной политики или впечатляющая группа в кампусе, которую вы возглавляли. . Все, что иллюстрирует ваши увлечения и относится к работе, заслуживает внимания.
Добавление дополнительных сведений, таких как курсовая работа и проекты, лучше всего подходит для соискателей, которые недавно закончили учебу или имеют минимальный опыт работы. Подробнее о форматировании проектов и курсов мы поговорим позже.
Сопроводительное письмо также является прекрасным местом для расширения вашей соответствующей курсовой работы.
Что касается названия вашего раздела образования? Компания Jobscan проверила коллекцию резюме и обнаружила, что 35% из них использовали нетрадиционные заголовки для заголовка своего образования. Это может привести к ошибкам синтаксического анализа в ATS, что приведет к ненужным дисквалификациям. Простой заголовок «Образование» — лучший вариант. Он не занимает много места, и ATS точно знает, как его анализировать.
Jobscan анализирует ваше резюме на соответствие описанию работы, чтобы убедиться, что ваш раздел об образовании соответствует требованиям, среди прочих проверок названий должностей, специальных навыков, измеримых результатов и других рекомендаций ATS и рекрутеров.
Jobscan анализирует ваше резюме, как ATS, и сообщает вам, узнаваемо ли ваше образование.Где указать средний балл в резюме
Вы должны указать свой средний балл в разделе «Образование» рядом со своей специальностью. Если вы получили награды в своем университете (с отличием или с отличием), эти награды должны быть перечислены ниже вашей специальности курсивом, а рядом с ними — ваш средний балл.
Вот как это должно выглядеть:
Университет ДеПоля | Чикаго, Иллинойс | декабрь 2009 г. – март 2013 г.
Бакалавр гуманитарных наук по английской композиции (средний балл: 3.75)
Имейте в виду, что вы должны указывать свой средний балл в своем резюме только в том случае, если он выше 3. 5 и если вы недавно закончили вуз. Если вы недавно закончили учебу и ваш средний балл ниже 3,5, вместо этого используйте место, чтобы рассказать о впечатляющем дипломном проекте (или о чем-то в этом роде).
5 и если вы недавно закончили вуз. Если вы недавно закончили учебу и ваш средний балл ниже 3,5, вместо этого используйте место, чтобы рассказать о впечатляющем дипломном проекте (или о чем-то в этом роде).
Как указать несовершеннолетнего в вашем резюме
Если ваш несовершеннолетний имеет непосредственное отношение к работе, на которую вы претендуете, возможно, стоит указать его в своем резюме. Указание вашего несовершеннолетнего может помочь выделить соответствующие навыки, которые помогут вам опередить конкурентов.
В резюме необходимо указать несовершеннолетнюю специальность рядом с основной специальностью. Например:
Университет ДеПола, Чикаго, Иллинойс, декабрь 2009 г. – март 2013 г.
Бакалавр искусств, основная английская композиция, небольшая журналистика
несовершеннолетний, например:
Университет ДеПола, Чикаго, Иллинойс, декабрь 2009 г. – март 2013 г.
Бакалавр гуманитарных наук, основная английская композиция, дополнительная журналистика (средний балл: 3,75)
Формат раздела «Образование резюме»
Многие ATS анализируют информацию из резюме кандидата в цифровом профиле заявителя. Если ваше образование оформлено неправильно, велика вероятность того, что информация будет неправильно проанализирована или вообще пропущена.
Если ваше образование оформлено неправильно, велика вероятность того, что информация будет неправильно проанализирована или вообще пропущена.
Обычно степень указывается перед школой, но если вы поступили во впечатляющий университет Лиги плюща, имя школы не повредит.
Помните, что в разделе «Полное образование» будет указано название школы, полученная степень (или основная/незначительная), местонахождение школы и дата окончания. Например:
Bachelor of Arts: Theatre, Shakespearean, 2016
Колумбийский колледж, Чикаго, IL
или
Магистр делового администрирования, 2014
Университет Вирджинии, Шарлоттсвилл, VA 2
9 . сообщества, мероприятия или соответствующие курсы, если это имеет смысл для работы, на которую вы претендуете. Эту информацию можно указать в нижней части раздела «Образование», например:
Степень бакалавра, начальное образование и преподавание, 2013 г.
Университет Индианы в Блумингтоне, Блумингтон, IN
Общества: Delta Delta Delta, Habitat for Humanity, Группа поддержки студентов
Если вы все еще получаете степень, вы можете указать «ожидаемую дату выпуска», но будьте ясны что вы еще не закончили. Как и в приведенных выше примерах, вам не нужно указывать дату начала (хотя вы можете, если хотите). Например:
Бакалавр наук: гражданское строительство
Вашингтонский университет, Сент-Луис, Миссури.
Ожидаемая дата выпуска в 2019 г.
Если вы учились в колледже, но не закончили его, допустимо указать ваше высшее образование, если оно соответствует требованиям работы — просто укажите количество полученных кредитов. Например:
Университет Майами, Корал-Гейблс, Флорида
Сочинение на английском языке, получено 65 кредитных часов
Куда идет образовательная секция?
Где в разделе вашего резюме вы решите указать свое образование, зависит от того, где вы находитесь в своей карьере. Например, если вы недавно закончили учебу и практически не имеете опыта, раздел «Образование» — ваш лучший актив, и его следует разместить в верхней части вашего резюме (выше «Опыт работы»).
Например, если вы недавно закончили учебу и практически не имеете опыта, раздел «Образование» — ваш лучший актив, и его следует разместить в верхней части вашего резюме (выше «Опыт работы»).
С другой стороны, если у вас есть некоторый профессиональный опыт, вы должны сосредоточиться на нем, решив разместить раздел об образовании ниже Опыт работы.
Если вы недавно вернулись в школу, вы можете поместить раздел «Образование» в самом верху. Например, ветеранам, которые пошли в школу после увольнения из армии, рекомендуется ставить свое образование выше своего опыта в резюме из военного в гражданское.
Однако, если вы вернулись в школу, готовясь к смене карьеры, но все еще хотите работать в своей нынешней области, продолжайте подчеркивать свой прошлый опыт.
В конечном счете, место, где вы разместите свой раздел об образовании, зависит от того, насколько ваше образование соответствует должности по сравнению с другим опытом в вашем резюме.
Организация нескольких степеней в резюме
При перечислении различных школ, которые вы посещали, перечислите их в обратном хронологическом порядке. Другими словами, высшая степень должна быть на вершине. Например, ваша степень магистра должна быть указана выше вашей степени бакалавра.
Другими словами, высшая степень должна быть на вершине. Например, ваша степень магистра должна быть указана выше вашей степени бакалавра.
Вы учились в колледже? Если это так, вам не нужно указывать свое высшее образование. Информация о вашей средней школе должна быть включена только в том случае, если вы все еще посещаете среднюю школу или колледж. Если вы закончили колледж, высшая степень может заменить диплом средней школы в вашем резюме.
Как включить обучение за границей в свое резюме
Добавление семестра или года обучения за границей в ваше резюме может показать работодателям, что вы предприимчивы. Эта информация не должна занимать много места и должна быть включена в раздел образования.
Правильным местом для указания учебы за границей в вашем резюме будет название университета, который вы окончили. Вы можете отформатировать его так же, как вы форматируете другие посещаемые учреждения. Например:
Университет ДеПола, Чикаго, Иллинойс, декабрь 2009 г. — март 2013 г.
— март 2013 г.
Бакалавр гуманитарных наук, специальность английская композиция, небольшая журналистика
Università degli Studi di Firenze, Флоренция, Италия (обучение за рубежом) сентябрь 2010 г. — декабрь 2010 г.
- Завершенная курсовая работа по журналистике и международным отношениям.
- Стал свободно говорить на итальянском языке
Все, что вы включаете в свое резюме, должно иметь отношение к работе, на которую вы претендуете. Хорошо упомянуть курсовую работу и другие виды деятельности, которые относятся к этой работе, включая ваш опыт обучения за границей.
8 Примеры раздела «Образование в резюме»
Независимо от того, какое учебное заведение вы посещали или какую степень получили, один из следующих восьми примеров раздела «Образование» должен указать вам правильное направление при обновлении вашего резюме.
- Бакалавр прикладных наук (B.A.Sc.), международный бизнес, 2013 г. 0022
Бакалавр искусств, бухгалтерский учет/Финансы - Майами Университет, Корал Гейблс, FL
Bachelor of Arts (B.A.) Social Psychology, 2013 - Бакалавр инженерных наук, гражданской и экологической инженерии, 2009 г.0022
Степень бакалавра, маркетинг и финансы, 2011 г. - Университет Пердью, Западный Лафайет, в
. NY
Бакалавр делового администрирования, финансы, 2007-2011
 0022
0022 Drock of Pharm.nafer (Pharm.na Magde), Pharm.na Magde), Pharm.na Magde), Pharm.na Magde), Pharm.na Magde), Pharm.na), Pharm.
Университет Батлера, Индианаполис, Индиана Посетите наш Учебный центр, чтобы узнать больше о форматах резюме.
Версия этой статьи была первоначально опубликована 24 ноября 2014 г. Тристой Винни. Он был переписан 15 июня 2021 года.
Извлечение информации о качестве медицинской помощи из неструктурированных данных
- Список журналов
- AMIA Annu Symp Proc
- v. 2017; 2017
- PMC5977624
 2017; 2017
2017; 2017AMIA Annu Symp Proc. 2017; 2017: 1243–1252.
Published online 2018 Apr 16.
, PhD, 1, 2 , DDS, DMSc, 1, 2 , MD, 1, 2 , 1 , MA, 3 и , MD, MS 1, 2
Информация об авторе Информация об авторских правах и лицензии Отказ от ответственности
Исследование качества медицинской помощи является фундаментальной задачей, которая включает в себя оценку моделей лечения и измерение связанных с ними результатов лечения пациентов для выявления потенциальных областей для улучшения здравоохранения. Несмотря на то, что используются как качественный, так и количественный подходы, основным препятствием для количественного подхода является то, что многие полезные индикаторы качества здравоохранения скрыты в примечаниях к врачу, что требует дорогостоящего и трудоемкого ручного просмотра диаграмм для их выявления и измерения. Извлечение информации является ключевой задачей обработки естественного языка (NLP) для обнаружения и извлечения важных знаний, скрытых в неструктурированных клинических данных. Тем не менее, широкое распространение НЛП еще не материализовалось; технические навыки, необходимые для разработки или использования такого программного обеспечения, представляют собой серьезное препятствие для медицинских исследователей, желающих использовать эти методы. В этой статье мы представляем Canary, бесплатное решение с открытым исходным кодом, предназначенное для пользователей без НЛП и технических знаний, и применяем его к четырем задачам, стремясь измерить частоту: (1) снижения инсулина; (2) снижение приема статинов; (3) побочные реакции на статины; и (3) консультирование по бариатрической хирургии. Наши результаты показывают, что этот подход облегчает добычу неструктурированных данных с высокой точностью, позволяя извлекать полезную информацию о качестве здравоохранения из источников данных с произвольным текстом.
Извлечение информации является ключевой задачей обработки естественного языка (NLP) для обнаружения и извлечения важных знаний, скрытых в неструктурированных клинических данных. Тем не менее, широкое распространение НЛП еще не материализовалось; технические навыки, необходимые для разработки или использования такого программного обеспечения, представляют собой серьезное препятствие для медицинских исследователей, желающих использовать эти методы. В этой статье мы представляем Canary, бесплатное решение с открытым исходным кодом, предназначенное для пользователей без НЛП и технических знаний, и применяем его к четырем задачам, стремясь измерить частоту: (1) снижения инсулина; (2) снижение приема статинов; (3) побочные реакции на статины; и (3) консультирование по бариатрической хирургии. Наши результаты показывают, что этот подход облегчает добычу неструктурированных данных с высокой точностью, позволяя извлекать полезную информацию о качестве здравоохранения из источников данных с произвольным текстом.
Повышение качества медицинской помощи – фундаментальная, но сложная задача в любой системе здравоохранения. Первым шагом к таким улучшениям является выявление конкретных недостатков производительности. Этого можно достичь путем измерения качества здравоохранения путем использования и/или разработки показателей эффективности, которые могут служить индикаторами качества. Такие показатели варьируются от простых показателей (например, время ожидания пациента) до более сложных (например, время до введения антибиотиков пациенту с пневмонией).
Методы исследования качества здравоохранения можно в целом разделить на качественные и количественные по своей природе. «Качество» — это не простое определение понятия, а гораздо более сложный и изощренный вопрос. Следовательно, вопросы исследования, которые могут возникнуть, не всегда имеют количественные ответы. Качественные исследования оказались эффективным способом ответа на некоторые из этих сложных вопросов с использованием подходов, основанных на интервью, наблюдении и анализе данных.
Количественные методы, с другой стороны, направлены на измерение явлений и их статистическую оценку. Общие меры включают распространенность, заболеваемость, частоту и тяжесть. Это исследование генерирует числовые данные, применяя определенные методы к предварительно выбранным данным. Следует также отметить, что смешанные методы, сочетающие как качественный, так и количественный подходы, продолжают получать все более широкое распространение в исследовательском сообществе. 1 Независимо от исследовательской парадигмы информатика играет важную роль в получении правильных данных.
Одна из проблем, связанных с количественными исследованиями, заключается в том, что помимо статистики, полученной из структурированных данных (например, историй болезни или результатов лабораторных исследований), разработка показателей для более сложных вопросов оказалась более сложной. 2 Серьезным препятствием является то, что хотя часть целевой информации легкодоступна в виде структурированных данных, большая ее часть хранится в виде неструктурированных данных, таких как свободный текст, написанный медицинскими работниками. Такое использование свободного текста обусловлено гибкостью, требуемой профессионалами при описании своих наблюдений, диагнозов и стратегий лечения. Однако неструктурированные данные на естественном языке, которые они производят, нельзя напрямую использовать в крупномасштабном количественном анализе. Чтобы использовать эти описательные данные, их необходимо вручную абстрагировать посредством трудоемкого просмотра диаграмм. Действительно, ретроспективный обзор диаграмм является широко используемым методом для выявления проблем, недостаточно хорошо задокументированных другими методами. 3 Хотя широко считается, что это трудоемкий процесс, также было сказано, что «просмотр карт сложнее, чем кажется на первый взгляд». 4 Наглядный пример этих проблем можно увидеть в работе Пивоварова и др., 5 , которые утверждают:
Такое использование свободного текста обусловлено гибкостью, требуемой профессионалами при описании своих наблюдений, диагнозов и стратегий лечения. Однако неструктурированные данные на естественном языке, которые они производят, нельзя напрямую использовать в крупномасштабном количественном анализе. Чтобы использовать эти описательные данные, их необходимо вручную абстрагировать посредством трудоемкого просмотра диаграмм. Действительно, ретроспективный обзор диаграмм является широко используемым методом для выявления проблем, недостаточно хорошо задокументированных другими методами. 3 Хотя широко считается, что это трудоемкий процесс, также было сказано, что «просмотр карт сложнее, чем кажется на первый взгляд». 4 Наглядный пример этих проблем можно увидеть в работе Пивоварова и др., 5 , которые утверждают:
«Показатели, используемые для оценки качества медицинской помощи, часто скрыты в историях болезни. Чтобы точно абстрагироваться от этих показателей качества, специально обученные медсестры вручную просматривают записи пациентов, чтобы найти соответствующую информацию.
 В нашем учреждении на 2600 коек работают 35 штатных специалистов по абстрагированию данных, которые составляют отчеты о показателях качества для 30 баз данных, охватывающих 13 болезненных состояний и процессов оказания помощи».
В нашем учреждении на 2600 коек работают 35 штатных специалистов по абстрагированию данных, которые составляют отчеты о показателях качества для 30 баз данных, охватывающих 13 болезненных состояний и процессов оказания помощи».Учитывая, что эти заметки с произвольным текстом содержат жизненно важные клинические данные и что их ручное рассмотрение является дорогостоящим процессом, это привело к разработке вычислительных методов для обработки и извлечения из них интересующей информации. 6 Это часто делается с помощью извлечения информации (IE), задачи идентификации и извлечения соответствующих фрагментов текста из более крупного неструктурированного документа. Исследователи разрабатывают такие методы для извлечения необходимой им информации из собственных источников данных. После извлечения эта информация используется для количественных исследований, поддержки принятия клинических решений, доказательной медицины или дальнейшей обработки.
Главной целью настоящей статьи является показать, как исследователи могут использовать неструктурированные данные для количественных исследований в области здравоохранения. Мы подходим к этому, представляя новую платформу для извлечения информации из данных произвольного текста и демонстрируя ее применение в четырех различных проектах, ориентированных на качество здравоохранения.
Мы подходим к этому, представляя новую платформу для извлечения информации из данных произвольного текста и демонстрируя ее применение в четырех различных проектах, ориентированных на качество здравоохранения.
Внедрение программного обеспечения для извлечения информации является важным аспектом проведения более сложных количественных исследований качества здравоохранения. Это связано с тем, что, несмотря на важность, стоимость и трудоемкость этой задачи, как мы подчеркивали выше, для биомедицинских исследователей не существует готовых к использованию инструментов. В идеале такие инструменты должны быть просты в использовании исследователям, даже тем, у кого нет опыта НЛП или разработки программного обеспечения. Однако такого бесплатного решения или решения с открытым исходным кодом не существует. В этой статье мы представляем Canary, платформу извлечения информации на основе НЛП, разработанную с учетом этих критериев. Canary был разработан для обработки клинических документов для поддержки извлечения данных с использованием определяемых пользователем параметров поиска информации и словаря. Описаны различные компоненты, образующие конвейер Canary NLP, и система захвата текстовых фрагментов, после чего следует эмпирическая оценка клинических данных из четырех проектов.
Описаны различные компоненты, образующие конвейер Canary NLP, и система захвата текстовых фрагментов, после чего следует эмпирическая оценка клинических данных из четырех проектов.
В этом разделе мы описываем ряд различных подходов, которые использовались для извлечения информации, выделяя их преимущества и недостатки. При этом мы стремимся позиционировать Canary в более широком контексте литературы по извлечению информации.
Простое сопоставление текста : Самый элементарный и прямой подход к IE основан на определении конкретных слов или последовательностей слов, которые должны сопоставляться и выводиться. Хотя это может работать в самых простых случаях, таких как идентификация конкретных наркотиков, это нецелесообразно для более сложных задач.
Сопоставление с образцом : Некоторые недостатки метода сопоставления строк можно устранить, используя более выразительные и мощные методы сопоставления с образцом. Регулярные выражения — распространенный метод, обычно используемый для этой цели. Они могут быть полезны при расширении шаблонов для соответствия вариантам (например, , различные шаблоны выражения лекарств и дозировки) или для учета других шаблонов, таких как типографские ошибки. К недостаткам можно отнести большое количество правил, необходимых для охвата всех возможных вариантов, а также трудности с поддержанием и обновлением правил. Они также не могут захватить структуру, как мы обсудим в следующем разделе.
Они могут быть полезны при расширении шаблонов для соответствия вариантам (например, , различные шаблоны выражения лекарств и дозировки) или для учета других шаблонов, таких как типографские ошибки. К недостаткам можно отнести большое количество правил, необходимых для охвата всех возможных вариантов, а также трудности с поддержанием и обновлением правил. Они также не могут захватить структуру, как мы обсудим в следующем разделе.
Синтаксический анализ языка Методы, описанные до сих пор, можно рассматривать как методы «поверхностной» обработки текста, основанные исключительно на словах в том виде, в каком они появляются в тексте. Другой подход предполагает использование «более глубокого» понимания текста путем его анализа для создания синтаксических представлений данных; это может включать синтаксический анализ группы или зависимости. Процесс синтаксического анализа может добавлять лингвистическую информацию, такую как теги частей речи для каждого слова, а также структурную информацию, такую как словосочетания с существительными или предложными словосочетаниями. Затем эта информация может быть включена в правила IE для создания более точных и обобщаемых правил. Эти методы успешно применяются в недавних исследованиях. Например, Ван и др. . показали, что такие методы на основе парсеров могут быть полезны для автоматического извлечения информации об употреблении психоактивных веществ из клинических записей. 7 Одним из недостатков этого подхода является то, что процесс синтаксического анализа может быть медленным.
Затем эта информация может быть включена в правила IE для создания более точных и обобщаемых правил. Эти методы успешно применяются в недавних исследованиях. Например, Ван и др. . показали, что такие методы на основе парсеров могут быть полезны для автоматического извлечения информации об употреблении психоактивных веществ из клинических записей. 7 Одним из недостатков этого подхода является то, что процесс синтаксического анализа может быть медленным.
Обучение под наблюдением Недавно разработанное семейство методов, основанных на статистическом анализе текста, называется машинным обучением под наблюдением. Это включает использование помеченных обучающих данных для обучения алгоритма обучения выявлению интересующих элементов. Хотя он не требует ручного проектирования правил извлечения информации, как в предыдущих подходах, затраты на создание помеченных данных для контролируемого обучения также значительны. Более того, для эффективного обучения алгоритмам обучения требуются большие объемы данных, а также соответствующий опыт их настройки. Тем не менее, был разработан ряд успешных и популярных наборов инструментов на основе машинного обучения для обработки клинической информации. Automated Retrieval Console (ARC) — один из таких инструментов, который пытается исключить создание правил посредством контролируемого обучения. 8 В последние годы система Apache cTAKES также получила широкое распространение среди клинических исследователей. 9 Однако существует группа исследователей-клиницистов без необходимых навыков НЛП и/или компьютерных наук, которые не могут использовать эти решения. В связи с этим решение, которое мы здесь представляем, является дополнительным и призвано помочь вышеупомянутым исследователям в самостоятельном проведении своих исследований.
Тем не менее, был разработан ряд успешных и популярных наборов инструментов на основе машинного обучения для обработки клинической информации. Automated Retrieval Console (ARC) — один из таких инструментов, который пытается исключить создание правил посредством контролируемого обучения. 8 В последние годы система Apache cTAKES также получила широкое распространение среди клинических исследователей. 9 Однако существует группа исследователей-клиницистов без необходимых навыков НЛП и/или компьютерных наук, которые не могут использовать эти решения. В связи с этим решение, которое мы здесь представляем, является дополнительным и призвано помочь вышеупомянутым исследователям в самостоятельном проведении своих исследований.
3.1. Дизайн
Мы разработали метод извлечения информации и разработали программу НЛП, реализующую его. Эта платформа была оценена путем проведения четырех количественных экспериментов по качеству здравоохранения с использованием неструктурированных клинических записей.
3.2. Гибридный метод извлечения информации на основе пользовательских параметров
Программное обеспечение Canary использует гибридный подход к задаче IE, сочетая подходы сопоставления с образцом и синтаксического анализа для устранения их недостатков. Подходы не исключают друг друга и могут дополнять друг друга, как мы показываем.
Регулярные выражения могут быть очень полезны для распознавания слов или фрагментов текста, но они не предназначены для фиксации структуры текста. Хотя они могут быть полезны для идентификации текста в предварительно заданном формате, такого как даты, числа, адреса электронной почты или измерения, 10 они не подходят для более сложных структур с большим разнообразием их состава. Например, написание регулярного выражения для сопоставления текстовых фрагментов, описывающих часть тела, может быть громоздкой и подверженной ошибкам задачей, учитывая большое количество возможных вариантов. Давайте рассмотрим следующие примеры интересующих фраз:
| (1) Левая рука | (2) Передняя крестообразная связка | |||
| (3) область нижней спины | (4) Латерал Анкл Лигал | (4) Латерал Лейгл Лигал | (4) Латерал Лейгал | (4). (6) верхний левый квадрант живота (6) верхний левый квадрант живота |
Открыть в отдельном окне
Основным недостатком регулярных выражений является их неспособность захватывать рекурсивные структуры, такие как вложенные компоненты в древовидную структуру. Например, они не могут сопоставлять вложенные скобки в строке.
Фраза (5) выше является примером такой вложенной структуры, в которой один объект состоит из двух меньших объектов: правой руки и указательного пальца. Захват таких вложенных конструкций требует определения рекурсивных правил, некоторые из которых регулярные выражения по своей сути не способны.
С другой стороны, обнаружение вложенных конструкций может быть достигнуто с помощью подхода, основанного на синтаксическом анализе, в котором могут быть определены рекурсивные грамматические правила. Хотя все аспекты регулярных выражений могут быть реализованы с помощью синтаксического анализа, только некоторые функции синтаксического анализа могут быть выполнены с использованием регулярных выражений.
Еще одним недостатком использования регулярных выражений является то, что правила охватывают как слова, так и их возможный порядок. Однако, учитывая размер целевого словаря, который используют исследователи (особенно в области медицины), было бы выгодно разделить лексические статьи и способы их комбинирования. Другими словами, разделите правила на словарь (набор распознаваемых слов и их категорий) и грамматику (правила, определяющие, как можно комбинировать слова). Эту проблему можно легко решить с помощью решения на основе синтаксического анализа путем определения словаря терминов и грамматических правил, которые определяют, как их можно комбинировать.
Проблема, связанная с регулярными выражениями, заключается в том, что они могут быстро усложняться, что приводит к громоздкому набору загадочных правил, которые бывает очень трудно понять. Обновление таких правил также сопряжено с трудностями. Исследователи отмечают, что модификация и документирование регулярных выражений являются источником трудностей в их работе. 11 Изоляция словарного запаса и правил грамматики может помочь решить эти проблемы, как мы продемонстрируем.
11 Изоляция словарного запаса и правил грамматики может помочь решить эти проблемы, как мы продемонстрируем.
Использование полного синтаксического анализатора языка потребует, чтобы пользователи определяли свои правила поверх лингвистических правил, управляющих целевым языком (т. е. ., сначала распределите слова по их грамматическим категориям, а затем создайте интересующие подмножества). Альтернативный подход, используемый Canary, заключается в том, чтобы позволить пользователям создавать простую настраиваемую грамматику, которая позволяет им моделировать свою целевую информацию, например, ., части тела или что-то более широкое, включающее части тела. Полный синтаксический анализ языка также требует больших вычислительных ресурсов.
Теперь обратимся к конкретному примеру, чтобы проиллюстрировать, как работает этот подход. Первым шагом является определение словаря или лексики, которая представляет собой набор слов, организованных в классы слов. Класс — это группа слов из одной семантической категории. Для нашего примера частей тела мы можем определить два класса, относящиеся к частям тела и анатомическим прилагательным, которые можно определить как:
Класс — это группа слов из одной семантической категории. Для нашего примера частей тела мы можем определить два класса, относящиеся к частям тела и анатомическим прилагательным, которые можно определить как:
АНАТОМИЧЕСКИЙ → (двух)?-?латеральный(еральный)?, передний, каудальный, верхний, нижний, левый, правый, […]
ЧАСТЬ ТЕЛА → (гастро)?кишечный, (гастро)?о?пищеводный (musculo)?скелет, брюшная полость.?, брюшная полость, […]
Пользователи могут определить столько классов, сколько необходимо, и слова, принадлежащие каждому классу, могут быть сопоставлены с использованием регулярного выражения, как показано в приведенном выше примере. Это позволяет пользователям создавать настраиваемые онтологии в соответствии со своими потребностями.
Второй шаг включает в себя определение грамматических правил, которые определяют, как эти классы слов могут быть объединены для форм фраз. Фраза может быть отдельным словом или комбинацией слов, как разрешено грамматикой.
ЧАСТЬ ТЕЛА → ЧАСТЬ ТЕЛА ЧАСТЬ ТЕЛА
ЧАСТЬ ТЕЛА → АНАТОМИЧЕСКАЯ ЧАСТЬ ТЕЛА
Приведенные выше правила гласят, что фраза части тела может быть отдельной частью тела или анатомическим прилагательным, за которым следует часть тела. Затем эти правила обрабатываются синтаксическим анализатором для сопоставления всех фрагментов текста, которые соответствуют любому из предоставленных правил. Слова, которых нет в словаре, игнорируются. Некоторые примеры, соответствующие этой простой грамматике, показаны на .
Открыть в отдельном окне
Примеры фрагментов текста с описанием частей тела, соответствующих нашей простой грамматике.
Мы также можем расширить грамматику для соответствия вложенным частям тела, просто добавив рекурсивное правило:
BODYPARTPHRASE → BODYPARTPHRASE BODYPARTPHRASE
Рекурсивное правило выражает, что фраза может включать подфразу того же типа, что и ее собственная составляющая, что позволяет нам зафиксировать рекурсивное свойство естественного языка. Это важно, потому что, например, английские существительные и предложения могут быть бесконечно рекурсивными. В приведенном выше примере это расширение позволяет захватывать одну или несколько смежных фраз частей тела. Проиллюстрируем это примерами в.
Это важно, потому что, например, английские существительные и предложения могут быть бесконечно рекурсивными. В приведенном выше примере это расширение позволяет захватывать одну или несколько смежных фраз частей тела. Проиллюстрируем это примерами в.
Открыть в отдельном окне
Примеры рекурсивных фраз частей тела, которые содержат другие части тела (отмечены синим цветом) в качестве составляющих.
Мы видим, что это простое расширение позволяет захватывать более сложные фразы. Это невозможно с регулярными выражениями. С другой стороны, синтаксический анализатор может найти произвольное количество таких вложенных элементов.
Кроме того, эти правила грамматики групп можно использовать для построения более сложных фраз, содержащих несколько рекурсивных элементов, как мы покажем в следующем разделе.
3.2.1. Создание более длинных фраз
Исследователям часто приходится извлекать сложные фразы, которые содержат больше информации, чем просто часть тела. С этой целью простые правила, которые мы видели до сих пор, могут служить строительными блоками для формирования более длинных и сложных фраз. Опираясь на предыдущий пример, теперь мы расширяем правила для обнаружения состояния здоровья, связанного с частью тела. Сначала добавим в наш словарь дополнительные слова:
С этой целью простые правила, которые мы видели до сих пор, могут служить строительными блоками для формирования более длинных и сложных фраз. Опираясь на предыдущий пример, теперь мы расширяем правила для обнаружения состояния здоровья, связанного с частью тела. Сначала добавим в наш словарь дополнительные слова:
АРТИКУЛ → the, a, ПРЕДЛОГ → of, in, […]
POSSPRONOUN → его, ее, ваше, мое СОСТОЯНИЕ → (hepato)?(to)?токсичность, боли?, боль, […]
Мы также добавляем некоторые правила грамматики, чтобы зафиксировать фразу, указывающую на состояние, связанное с телом часть:
CONDITIONPHRASE → BODYPARTPHRASE CONDITION
CONDITIONPHRASE → CONDITION PREPOSITION BODYPARTPHRASE
Применяя эти правила, мы можем сопоставить фразы, показанные в . Мы также можем заметить, что фраза части тела в левом примере имеет три уровня вложенных фраз. Этот пример демонстрирует, что преимущество подхода, основанного на грамматике, заключается в том, что на элементы нашего словаря можно легко ссылаться и использовать их для построения более крупных и содержательных фраз, что невозможно при использовании регулярных выражений.
Открыть в отдельном окне
Два дерева синтаксического анализа для фраз условий, которые включают рекурсивные фразы частей тела.
3.3. Canary: Платформа извлечения информации на основе NLP
Чтобы облегчить исследователям анализ текстовых документов, мы создали бесплатную программу под названием Canary, 12 , как показано ниже. Программное обеспечение, которое можно загрузить бесплатно (http://canary.bwh.harvard.edu/), было разработано для извлечения информации с использованием подхода, описанного в разделе 3.2. Программное обеспечение также включает в себя многочисленные примеры проектов, которые демонстрируют, как описанный выше подход на основе грамматики используется на практике. При разработке платформы Canary учитывался ряд факторов, некоторые из которых мы выделяем здесь.
Открыть в отдельном окне
Обзор программы Canary.
Простота использования : Canary был разработан для пользователей, не имеющих опыта разработки программного обеспечения или инженерного дела, что позволяет определять словарь и правила грамматики через унифицированный графический интерфейс пользователя (GUI). Вывод генерируется в текстовом формате для удобства анализа.
Вывод генерируется в текстовом формате для удобства анализа.
Easy Setup : Canary доступна в виде готового программного решения. Его можно установить в локальную папку без прав администратора и даже запустить с флешки. Он был разработан для работы из коробки.
Проблемы безопасности и конфиденциальности : Исследователи в области информатики здравоохранения часто работают с данными, которые включают защищенную медицинскую информацию, что требует соблюдения соответствующих правовых мер и мер безопасности для защиты этой информации (например, ., соответствие HIPAA). Эти данные могут храниться в локальных сетях и за брандмауэрами со строгими правилами, регулирующими их передачу. Хотя был предложен ряд облачных решений для обработки данных и извлечения информации, вышеупомянутые ограничения могут исключить их использование для многих клинических исследователей. В таких случаях использование автономных программных пакетов, которые можно запускать на локальных компьютерах, может быть лучшим вариантом. Это одна из мотивирующих причин, лежащих в основе дизайна Canary.
Это одна из мотивирующих причин, лежащих в основе дизайна Canary.
Первая задача, которую мы демонстрируем, это количественная оценка снижения уровня инсулина. Неподтвержденно известно, что пациенты часто отказываются от лекарств, рекомендованных их лечащими врачами. Однако систематических данных об этом явлении немного. Неизвестно, как часто пациенты отказываются от лекарств и как часто они в конечном итоге получают лекарства, от которых изначально отказались. Эта информация, если она будет извлечена, будет иметь большое значение для исследования качества здравоохранения и результатов.
Инсулин считается одним из препаратов, от которых пациенты особенно часто отказываются. Многие пациенты не хотят начинать инъекционные препараты; другие выражают опасения, что «однажды начав принимать инсулин, вы уже не сможете от него отказаться». Исследования показывают, что пациентам, чей диабет плохо контролируется пероральными препаратами, требуется очень много времени, чтобы начать принимать инсулин; 13 снижение уровня инсулина у пациентов может быть одной из причин этого. Однако данные о снижении уровня инсулина остаются крайне ограниченными. 14
Однако данные о снижении уровня инсулина остаются крайне ограниченными. 14
Одной из причин недостатка исследований в этой области является то, что информация о пациентах, отказывающихся от приема лекарств, недоступна. Поскольку эти пациенты отказались от лекарства до того, как был выписан какой-либо рецепт, в источниках данных, которые обычно используются для изучения назначений лекарств, таких как заявления о страховании аптеки или записи о лекарствах EMR, не создается никакого следа. Вместо этого снижение приема лекарств в основном регистрируется в описательных заметках, что требует трудоемкого просмотра диаграмм. С этой целью программное обеспечение NLP, такое как Canary, имеет большие перспективы, позволяя клиническим исследователям получать доступ к ценным фрагментам соответствующей информации, спрятанным среди миллионов неструктурированных медицинских записей. Соответственно, мы оцениваем наше программное обеспечение по данным для этой задачи, используя его для извлечения этой информации, и проводим исследование для оценки распространенности пациентов, отказывающихся от инсулина.
4.1. Сбор данных
Данные для этого исследования получены из историй болезни всех взрослых пациентов с диабетом, получавших лечение в учреждениях первичной медико-санитарной помощи, связанных с Массачусетской больницей общего профиля и Бригамом и Женской больницей, в период с 2000 по 2014 год. Количество просмотренных заметок для каждой задачи варьировалось от 600. и 50000.
4.2. Языковая модель снижения уровня инсулина
Для выявления случаев снижения уровня инсулина у пациентов был проведен ручной анализ подмножества собранных данных, содержащих 50 000 заметок. Эта задача требовала наибольшего набора заметок из-за крайне малой распространённости информации. Затем канарский словарь и критерии извлечения информации были созданы исследователем-клиницистом, не имевшим формальной подготовки в области НЛП или разработки программного обеспечения. Они были разработаны для определения языка, используемого для документирования снижения инсулина в случаях, идентифицированных вручную, с максимальной точностью и обобщаемостью.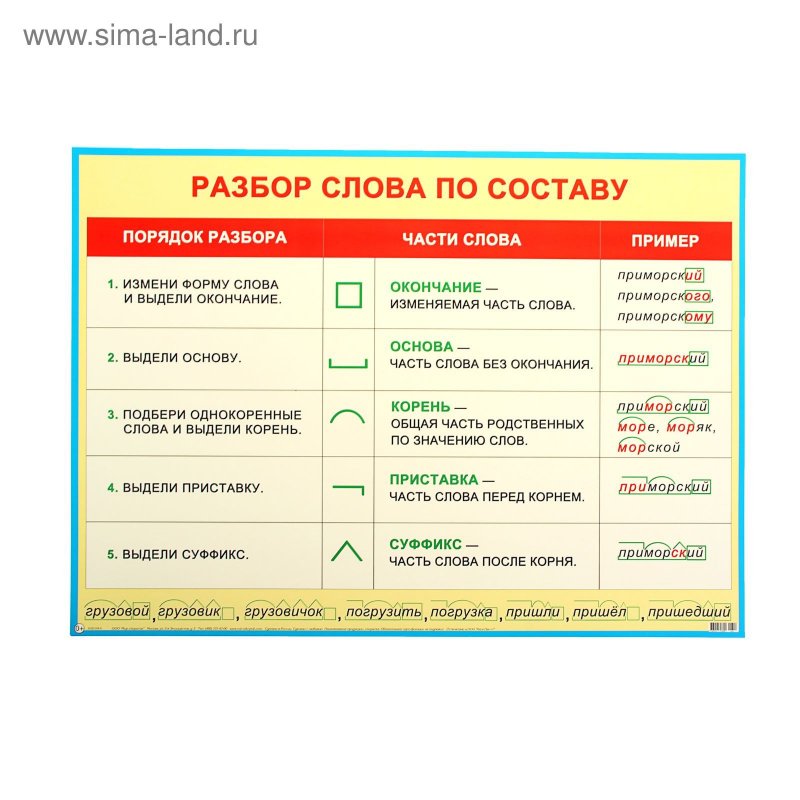 После многократного уточнения языковой модели был получен набор из 148 классов слов и 284 правил.
После многократного уточнения языковой модели был получен набор из 148 классов слов и 284 правил.
4.3. Оценка
Основной целью нашей оценки является оценка точности, с которой случаи снижения инсулина могут быть обнаружены с помощью Canary. Эта оценка была проведена на основе золотого стандарта набора данных, состоящего из 1501 заметки о поставщике медицинских услуг, которые были выбраны случайным образом и независимо прокомментированы подготовленными студентами-фармацевтами и студентами-медиками. Рецензенты отметили все предложения, описывающие пациентов, которые отказываются принимать инсулин. Затем мы сравниваем аннотацию рецензента с выводом, созданным Canary. Мы провели нашу оценку этого аннотированного золотого стандарта на двух уровнях детализации:
Уровень примечаний: обнаружение примечаний, содержащих любое упоминание о снижении уровня инсулина в любом месте документа.
Уровень предложения: обнаружение предложений, в которых упоминается снижение инсулина, во всех примечаниях.

Оценка на уровне предложения является более сложной задачей. На уровне примечаний рассчитывались чувствительность (отзыв), специфичность и положительная прогностическая ценность (PPV/точность). Специфичность не имеет значения на уровне предложений из-за произвольного характера процесса токенизации (т. е. границы токенов в свободном тексте зависят от реализации), поэтому рассчитывались только чувствительность и PPV. Результаты этого эксперимента будут использованы для оценки распространенности снижения уровня инсулина в неструктурированных данных, относящихся к пациентам с диабетом.
4.4. Результаты
Аннотированный вручную тестовый набор включал всего 19 предложений с упоминанием снижения уровня инсулина всего в 14 примечаниях. Это распространенность на уровне примечаний, равная 0,93%, что подчеркивает трудности, связанные с идентификацией этой информации посредством ручного просмотра. Следует также отметить, что с учетом длины средней ноты эта распространенность значительно ниже на уровне предложений, т. е. ., менее 1% предложений.
е. ., менее 1% предложений.
Затем мы применили Canary к тем же данным. Результаты этой оценки перечислены в . Мы видим, что на уровне нот Canary достигла чувствительности 100,0% и PPV 9.3,3%, с еще лучшими результатами на уровне предложений.
Таблица 1.
Результаты оценки тестового набора из 1 501 банкноты золотого стандарта с добавленными вручную аннотациями. В скобках указан 95% доверительный интервал.
| Sensitivity | Specificity | PPV | |
|---|---|---|---|
| Note-level | 100.0% (76.8–100.0) | 99.9% (99.6–100) | 93.3% (68.0–99. 8) 8) |
| Уровень предложения | 100,0% (82,4–100,0) | Н/Д | 95,0% (74,4–99,9) |
Открыть в отдельном окне, банку, указанную в описании отказа от лекарств
распространяться на другие классы наркотиков. Сердечно-сосудистые заболевания являются причиной смерти номер один как в Соединенных Штатах, так и во всем мире, а гиперхолестеринемия является наиболее распространенным фактором риска. Ингибиторы ГМГ-КоА-редуктазы (статины) снижают риск сердечно-сосудистых событий у пациентов с гиперхолестеринемией. Тем не менее, многие пациенты с высоким сердечно-сосудистым риском не принимают статины, что, вероятно, приводит к тысячам предотвратимых смертей. Причины этого до конца не выяснены, но считается, что отказ от приема лекарств может сыграть свою роль.
Наша методология может быть использована для эмпирического изучения этого явления и анализа начальных показателей отказа от приема статинов, того, как часто пациенты в конечном итоге начинают терапию статинами после первоначального отказа от нее, и может ли поставщик, который в конечном итоге прописывает статины, отличаться от того, кто рекомендует статины. изначально было отказано в популяции пациентов с высоким сердечно-сосудистым риском.
С этой целью мы провели предварительное исследование для оценки специфичности и PPV нашего метода при выявлении случаев снижения приема статинов.
5.1. Сбор данных
Данные для этого исследования получены из историй болезни всех взрослых пациентов с ишемической болезнью сердца, получавших лечение в учреждениях первичной медико-санитарной помощи, связанных с Массачусетской больницей общего профиля и Brigham and Women’s Hospital в период с 2000 по 2013 год.
5.2. Языковая модель снижения приема статинов
Исследователь-клиницист, не имеющий формального обучения НЛП или разработке программного обеспечения, использовал набор из 8800 заметок для создания канареечной модели для выявления случаев снижения приема статинов. Канарская лексика и правила грамматики были созданы для сопоставления текстовых фрагментов с максимальной точностью и обобщаемостью. В результате получилась модель с 97 семантических классов слов и 88 структур.
5.3. Оценка и результаты
Для оценки использовали набор из 4000 протянутых банкнот. Модель достигла чувствительности (истинная положительная частота) 88% и PPV (точность) 92%. Эти предварительные результаты подчеркивают полезность нашего подхода к изучению этой проблемы здравоохранения. Сейчас мы находимся в процессе создания дополнительных ресурсов для измерения специфичности наших моделей, чтобы применить их для ответов на исследовательские вопросы, изложенные в разделе 5.
EMR широко используются для документирования побочных реакций на лекарства. Было показано, что системы поддержки принятия клинических решений, которые анализируют предыдущие аллергии и реакции, значительно уменьшают количество ошибок при назначении, что делает эту область широко исследуемой. Однако значительная часть этих реакций не документируется в структурированном формате, а вместо этого сохраняется в виде свободного текста. С этой целью мы применили нашу методологию для количественного извлечения этой информации и провели исследование для оценки распространенности информации о побочных реакциях, которая не представлена в структурированном формате. Более конкретно, мы изучили это для ингибиторов 3-гидрокси-3-метилглутарил-КоА-редуктазы 9.0021 (т.е. ., статины), так как считается, что они имеют высокий уровень побочных реакций, о которых сообщают пациенты.
6.1. Сбор данных
Это исследование проводилось в Partners HealthCare System, сети оказания медицинских услуг в восточном Массачусетсе. Partners Healthcare поддерживает общесетевой репозиторий аллергий на лекарства под названием Partners Enterprise Allergy Repository (PEAR). Система EMR, используемая в Partners, позволяет вводить данные в PEAR. Данные для нашего исследования были получены от всех пациентов, которым были назначены статины в период с 2000 по 2010 год.
6.2. Языковая модель побочных эффектов статинов
Обученные студенты-фармацевты вручную просмотрели набор из 3175 описательных заметок поставщика, аннотирующих случаи побочных реакций на статины. Эти примечания были выбраны случайным образом из набора всех примечаний, написанных по данным, в которых статин был отмечен как прекращенный в системе EMR. После аннотации была создана канарская лексика и грамматические правила, позволяющие максимально точно и обобщающе сопоставить текстовые фрагменты.
6.3. Оценка и результаты
Оценка осуществляется по той же схеме, что описана в разделе 4.3 выше, за исключением того, что набор данных золотого стандарта из 242 заметок о поставщиках услуг был выбран случайным образом и независимо прокомментирован двумя обученными студентами-фармацевтами. Результаты первого этапа оценки перечислены в . Мы видим, что на уровне нот Canary достигла чувствительности 87,4% и PPV 99,4%. Как и ожидалось, обнаружение на уровне предложений оказалось более сложным, с немного более низкими результатами.
Таблица 2.
Результаты оценки тестового набора из 242 банкнот золотого стандарта с добавленными вручную аннотациями. В скобках указан 95% доверительный интервал.
| Sensitivity | Specificity | PPV | |
|---|---|---|---|
| Note-level | 87. 4% (83.0–91.8) | 98.3% (96.5–100) | 99.4% (98.2–100 |
| Уровень предложения | 80,6% (75,4–84,9 | Н/Д | 98,6% (96,9–100) |
Открыть в отдельном окне
Проверив модель и продемонстрировав, что она может достигать высоких уровней точности, мы перешли ко второму этапу нашей оценки. Canary использовался для обработки полного набора из 4,7 миллионов заметок, собранных для исследования. Это привело к выявлению 224 421 пациента, которым были назначены статины в течение периода исследования, причем 31 531 из них были отмечены нашим программным обеспечением как имеющие побочные реакции на статины. Однако только 9У 20,020 (28,6%) пациентов реакция на статины регистрировалась в структурированном формате (в PEAR). 15 Этот результат показывает, что подавляющее большинство поставщиков медицинских услуг регистрируют информацию о реакции на лекарство только в неструктурированных данных.
Бариатрическая хирургия является единственным наиболее эффективным методом лечения значительной и устойчивой потери веса у пациентов с ожирением и значительно улучшает многочисленные сопутствующие ожирению заболевания, включая риск сердечно-сосудистых заболеваний, гипертонию, инфаркты миокарда, инсульты и смертность от сердечно-сосудистых заболеваний.
Важным шагом в принятии пациентом решения о проведении бариатрической операции является обсуждение с врачом и рекомендация бариатрической операции пациенту. Имеется мало систематических данных об эпидемиологических рекомендациях бариатрической хирургии. Неизвестно, как часто врачи обсуждают и рекомендуют бариатрическую операцию пациентам с ожирением, которые являются кандидатами на операцию. Одна из причин нехватки исследований в этой области заключается в том, что информация о рекомендациях врачей бариатрической хирургии не всегда доступна. Эта информация, как правило, не отражается ни в административных, ни в структурированных электронных клинических данных, поскольку данные о рецептах или страховых исках не генерируются. Вместо этого рекомендации бариатрической хирургии в основном записываются в описательных примечаниях, требующих трудоемкого просмотра карт.
Методология, которую мы использовали до сих пор, может быть использована для эмпирического изучения этого вопроса. При попытке дать количественную оценку рекомендации по бариатрической хирургии в примечаниях любой подход должен уметь различать обсуждение процедуры и упоминания о предшествующих процедурах. Следовательно, идентификация заметок, содержащих эти две категории информации, является целью нашего предварительного проекта.
7.1. Сбор данных
Данные для этого исследования получены из историй болезни всех взрослых пациентов с индексом массы тела (ИМТ) > 35 кг/м 2 лечился в учреждениях первичной медико-санитарной помощи при Массачусетской больнице общего профиля и больнице Brigham and Women’s Hospital в период с 2000 по 2014 год.
7.2. Языковая модель консультирования по бариатрической хирургии
Набор из 300 заметок был вручную прокомментирован обученным студентом-фармацевтом и впоследствии использован другим исследователем, не имеющим формальной подготовки в области НЛП или разработки программного обеспечения, для создания канареечной модели для четкого обнаружения случаев предшествующей операции и обсуждения операции. . Канарская лексика и правила грамматики были созданы для сопоставления текстовых фрагментов с максимальной точностью и обобщаемостью. В результате была создана модель с 17 семантическими классами слов и 160 структурами.
7.3. Оценка и результаты
Продвинутый тестовый набор из 300 банкнот был вручную прокомментирован обученным студентом-фармацевтом и использован для оценки, которая проводится в соответствии с процедурой, описанной в разделе 4.3. Результаты для обеих категорий на уровне примечаний и предложений перечислены в . Эта предварительная оценка очень многообещающая, поскольку она показывает, что наши модели способны достигать высокой точности и демонстрировать обобщаемость новых данных.
Таблица 3.
Результаты оценки для обеих категорий на тестовом наборе из 300 вручную аннотированных банкнот золотого стандарта.
| Sensitivity | PPV | |
|---|---|---|
| Bariatric Surgery Discussion (Note-level) | 90% | 90% |
| Bariatric Surgery Discussion (Sentence-level) | 85% | 69% |
| Prior Bariatric Surgery (Note-level) | 83% | 90% |
| Prior Bariatric Surgery (Sentence-level) | 44% | 96% |
Открыть в отдельном окне
Мы описали и продемонстрировали применение извлечения информации для выявления полезных идей путем анализа клинических документов. Мы показали, что этот подход может помочь ответить на вопросы количественного исследования качества здравоохранения, ответы на которые нелегко получить из структурированных источников данных.
В рамках этого подхода мы также представили Canary, инструмент для извлечения информации, основанный на пользовательских параметрах и онтологиях. Основным преимуществом нашего инструмента является то, что это программное обеспечение на основе графического интерфейса пользователя, которое не требует каких-либо технических знаний. В этом исследовании это было подчеркнуто тем фактом, что его использовали несколько исследователей без какой-либо технической подготовки для успешного создания языковых моделей важных клинических явлений. Отзывы этих пользователей были положительными, и затем модели были протестированы на крупномасштабном наборе заметок поставщика.
Этот подход также полезен для исследования исходов, которое включает количественную оценку схем лечения и измерение связанных с ними исходов для пациентов, и является важной областью исследования для выявления потенциальных областей для улучшения качества здравоохранения. С этой целью описанную здесь методологию можно использовать для количественного измерения сложных социальных и демографических проблем в исследованиях служб здравоохранения.
1. Джик ТД. Смешение качественных и количественных методов: триангуляция в действии. Управленческая наука ежеквартально. 1979;24(4):602–611. [Google Scholar]
2. Поуп К., Ван Ройен П., Бейкер Р. Качественные методы исследования качества здравоохранения. Качество и безопасность в здравоохранении. 2002;11(2):148–152. [Бесплатная статья PMC] [PubMed] [Google Scholar]
3. Beckmann U, Bohringer C, Carless R, et al. Оценка двух методов улучшения качества интенсивной терапии: упрощенный мониторинг инцидентов и ретроспективный анализ медицинских карт. Медицина интенсивной терапии. 2003;31(4):1006–1011. [PubMed] [Академия Google]
4. Allison JJ, Wall TC, Spettell CM, et al. Искусство и наука обзора диаграмм. Журнал Объединенной комиссии по улучшению качества. 3// 2000;26(3):115–136. [PubMed] [Google Scholar]
5. Пивоваров Р., Копплсон Ю.Дж., Горман С.Л., Водри Д.К., Эльхадад Н. Может ли обобщение записей пациентов поддерживать абстракцию показателей качества? Документ представлен на: Материалы ежегодного симпозиума AMIA. 2016 [бесплатная статья PMC] [PubMed] [Google Scholar]
6. Xu H, Stenner SP, Doan S, Johnson KB, Waitman LR, Denny JC. MedEx: система извлечения информации о лекарствах для клинических повествований. Журнал Американской ассоциации медицинской информатики. 2010;17(1):19–24. [Бесплатная статья PMC] [PubMed] [Google Scholar]
7. Wang Y, Chen ES, Pakhomov S, et al. Автоматизированное извлечение информации об употреблении психоактивных веществ из клинических текстов. Документ представлен на: Материалы ежегодного симпозиума AMIA. 2015 [бесплатная статья о PMC] [PubMed] [Google Scholar]
8. D’Avolio LW, Nguyen TM, Farwell WR, et al. Оценка обобщенного подхода к поиску клинической информации с использованием автоматизированной консоли поиска (ARC) Журнал Американской ассоциации медицинской информатики. 2010;17(4):375–382. [Бесплатная статья PMC] [PubMed] [Google Scholar]
9. Савова Г.К., Масанц Дж.Дж., Огрен П.В., и соавт. Mayo Clinical Text Analysis and Knowledge Extraction System (cTAKES): архитектура, оценка компонентов и приложения. Журнал Американской ассоциации медицинской информатики. 2010;17(5):507–513. [Бесплатная статья PMC] [PubMed] [Google Scholar]
10. Турчин А., Колаткар Н.С., Грант Р.В., Махни Э.К., Пендерграсс М.Л., Эйнбиндер Дж.С. Использование регулярных выражений для извлечения информации об артериальном давлении и интенсификации лечения из текста заметок врача. J Am Med Inform Assoc. 2006;13(6):691–695. [Бесплатная статья PMC] [PubMed] [Google Scholar]
11. Kraus S, Blake C, West SL. Извлечение информации из медицинских записей. Документ представлен на: Medinfo 2007: Материалы 12-го Всемирного конгресса по медицинской (медицинской) информатике; Создание устойчивых систем здравоохранения. 2007 [Google Scholar]
12. Мальмаси С., Сандор Н. , Хосомура Н., Голдберг М., Скентзос С., Турчин А. Канарейка: платформа НЛП для клиницистов и исследователей. Прикладная клиническая информатика. 2017;8(2):447–453. [Бесплатная статья PMC] [PubMed] [Google Scholar]
13. Rubino A, McQuay L, Gough S, Kvasz M, Tennis P. Отсроченное начало подкожной инсулинотерапии после неэффективности пероральных сахароснижающих препаратов у пациентов с диабетом 2 типа: популяционный анализ в Великобритании. Диабетическая медицина. 2007;24(12):1412–1418. [PubMed] [Google Scholar]
14. Хан Х., Ласкер С., Чоудхури Т. Распространенность и причины отказа от инсулина у бангладешских пациентов с плохо контролируемым диабетом 2 типа в Восточном Лондоне. Диабетическая медицина. 2008;25(9):1108–1111. [PubMed] [Академия Google]
15. Скентцос С., Шубина М., Плуцкий Дж., Турчин А. Структурированные и неструктурированные: факторы, влияющие на документирование побочных реакций на лекарства в репозитории EMR. Документ представлен на: Материалы ежегодного симпозиума AMIA. 2011 [бесплатная статья PMC] [PubMed] [Google Scholar]
Статьи с материалов ежегодного симпозиума AMIA предоставлены здесь с разрешения Американской ассоциации медицинской информатики
Учебное пособие по формату
YAML | Кантера
Учебное пособие по формату YAML
Здесь мы описываем синтаксис и структуру файлов Cantera YAML, как размерные значения в файлах Cantera YAML обрабатываются, и как понять некоторые сообщения об ошибках, которые могут возникнуть при чтении эти входные файлы.
Синтаксис
Файлы Cantera YAML используют подмножество спецификации YAML 1.2. Файлы Cantera YAML состоят из отдельных значений, которые могут быть строками, числами или логическими значениями, которые затем составляются как элементы вложенных отображений и последовательностей.
Строки
Строки обычно могут быть написаны без кавычек, но могут быть заключены в одиночные
кавычки или двойные кавычки, если это необходимо, чтобы избежать определенных неоднозначностей при синтаксическом анализе.
Строка Еще одна «строка» "Строка: которая требует кавычек"
Числа
Числа могут быть записаны как целые числа, десятичные значения или с использованием E-нотации
3 3.14 6.022e23
Логические значения
Логические значения в YAML записываются как слова true или ложь .
Последовательности
Последовательность из нескольких элементов указывается путем разделения элементов запятыми и заключив их в квадратные скобки. Отдельные элементы могут иметь любой тип -- строки, целые числа, числа с плавающей запятой, сопоставления или последовательности.
элементов: [O, H, C, N, Ar] диапазоны температур: [200,0, 1000,0, 3500,0]
Приведенный выше синтаксис с использованием квадратных скобок для определения списка называется стилем потока в ЯМЛ. Последовательности также могут быть записаны в стиль блока , используя одну строку для каждого элемента в последовательности, где каждая строка начинается с дефиса:
элементов: - О - Н - С - Н - Ар
Последовательности также могут быть вложенными. Все следующие примеры эквивалентны:
данные: [[1, 2], [3, 4]] данные: - - 1 - 2 - - 3 - 4 данные: - - 1 - 2 - - 3 - 4
Сопоставления
Сопоставление — это контейнер, состоящий из пар ключ-значение. Ключи в отображении Должно быть уникальным. Как и в случае с последовательностями, существует два способа записи отображения. в стиль потока , сопоставление заключено в фигурные скобки, двоеточие (за которым следует пробелы) используются для разделения ключей и значений, а пары ключ-значение разделяются через запятую:
состав: {H:2, C:1, O:1}
В блочном стиле каждая клавиша записывается на новой строке, за которой следует двоеточие. Значение может быть размещено либо на той же строке, либо на следующей строке, с отступом на один уровень:
состав:
Ч: 2
С:
1
О: 1
Все ключи в файлах Cantera YAML обрабатываются как строки. Файл Cantera YAML
само отображение, обычно в стиль блока . Мы ссылаемся на ключи в этом
сопоставление верхнего уровня в виде разделов входного файла.
Последовательности отображений
Общая структура входных файлов Cantera представляет собой вложенную последовательность отображений. Этот можно записать в блочном стиле как:
- уравнение: O2 + CO <=> O + CO2
константа скорости: {A: 2,5e+12, b: 0, Ea: 47800}
- уравнение: O2 + Ch3O <=> HO2 + HCO
константа скорости: {A: 1.0e+14, b: 0, Ea: 40000}
- уравнение: H + O2 + M <=> HO2 + M
тип: трехкорпусный
константа скорости: {A: 2,8e+18, b: -0,86, Ea: 0}
эффективность: {AR: 0, C2H6: 1,5, CO: 0,75, CO2: 1,5, h3O: 0, N2: 0, O2: 0}
Ключи в каждом сопоставлении могут не совпадать. В этом примере каждый из
три отображения в последовательности имеют уравнений и констант скорости ключей,
в то время как только третья запись имеет ключей типа и ключей эффективности .
Размерные значения
Многие поля имеют числовые значения, представляющие размерные величины---a
давление или плотность, например. Если они введены без указания
единицы, единицы измерения по умолчанию (устанавливаются 93 # ошибка (отсутствует пробел между значением и единицами измерения)
См. API единиц измерения документацию для получения дополнительной информации, включая полный набор поддерживаемых единиц измерения.
Единицы по умолчанию
Единицы по умолчанию, которые применяются ко всему входному файлу или его части, могут быть
установить с использованием единиц отображения . Отображение единиц , размещенное на верхнем уровне
входной файл применяется ко всему файлу. Отображение единиц , размещенное как член
другое сопоставление применяется к этому сопоставлению и любым вложенным сопоставлениям или последовательностям и переопределяет более высокий уровень 93
Единицы по умолчанию могут быть установлены для массы , длины , времени , количества , давление , энергия и активация-энергия .
Обработка ошибок
Во время обработки входного файла могут возникнуть ошибки. Это может быть синтаксические ошибки или могут быть ошибки, которые Cantera помечает как ошибки из-за какая-то явная нестыковка в данных --- нефизическая величина, вид, который содержит незадекларированный элемент, реакция, содержащая незадекларированный вид, отсутствующие определения видов или элементов, несколько определений элементов, виды или реакции и так далее.
Синтаксические ошибки
Синтаксические ошибки обнаруживаются синтаксическим анализатором YAML и должны быть исправлены перед продолжаем дальше. При обнаружении синтаксической ошибки Cantera выдает исключение, которое включает в себя местоположение ошибки. Дополнительная информация, такая как трассировка, показывающая, где в коде читался входной файл, может быть также напечатано.
Например, рассмотрим следующий входной файл, предназначенный для создания
газ с видами и реакциями GRI-Mech 3.0, но отсутствует двоеточие
который нужен после термо ключ:
фазы:
- название: газ
термоидеальный газ
кинетика: газ
элементы: [Н, О]
виды: [{gri30. yaml/species: все}]
реакции: [gri30.yaml/reactions]
Когда это определение импортируется в приложение, появляется сообщение об ошибке, подобное следующее будет напечатано на экране, и выполнение программы или скрипта завершится:
Трассировка (последний последний вызов): Файл "", строка 1, в Файл "/some/path/cantera/base.pyx", строка 25, в cantera._cantera._SolutionBase.__cinit__ self._init_yaml (файл, фаза, фазы, yaml) Файл "/some/path/cantera/base.pyx", строка 49| 5 | элементы: [Н, О] | 6 | виды: [{gri30.yaml/species: все}] | 7 | реакции: [gri30.yaml/reactions] ******************************************************* *********************
В верхней части сообщения об ошибке показана цепочка функций, которые были вызваны
до появления ошибки. По большей части это внутренние Кантеры
функции, не имеющие здесь прямого отношения. Соответствующая часть этого сообщения об ошибке
часть между линиями звездочек. Это сообщение говорит о том, что синтаксический анализатор YAML
столкнулся с проблемой в строке 4 из газ. . Во многих случаях, в том числе и в этом,
парсер выйдет из строя где-то после собственно проблема с входным файлом,
поскольку он должен продолжать синтаксический анализ, пока не найдет что-то, что не может быть
действительный синтаксис YAML. В этом случае проблема с точки зрения парсера
что ключ, который начался в строке 3, продолжается через новую строку, прежде чем он найдет
двоеточие, которое можно рассматривать как разделитель. Поскольку ключ нельзя сломать
через такие строки синтаксический анализатор указывает на ошибку в том месте, где она
нашел двоеточие. Оглядываясь назад от указанной точки ошибки, мы можем
видите, что проблема в отсутствующем двоеточии в предыдущей строке. ямл
Ошибки Cantera
Теперь давайте рассмотрим другой класс ошибок, которые сам Cantera обнаруживает. Продолжая приведенный выше пример, предположим, что отсутствует двоеточие. исправлено, и входной файл снова обработан. Опять выдает сообщение об ошибке, но на этот раз из Кантеры:
Traceback (последний последний звонок): Файл "", строка 1, в Файл "/some/path/cantera/base.