Тексты для списывания с грамматическими заданиями 1 класс
Закрепление тем: слова действия, слова предметы. Отработка звуко-буквенного разбора слова.
Списать текст.
Подчеркнуть слова, обозначающие действие зеленым цветом (что делать?)
Выпиши отдельно слова, отвечающие на вопрос кто? Что?
Кто? | Что? |
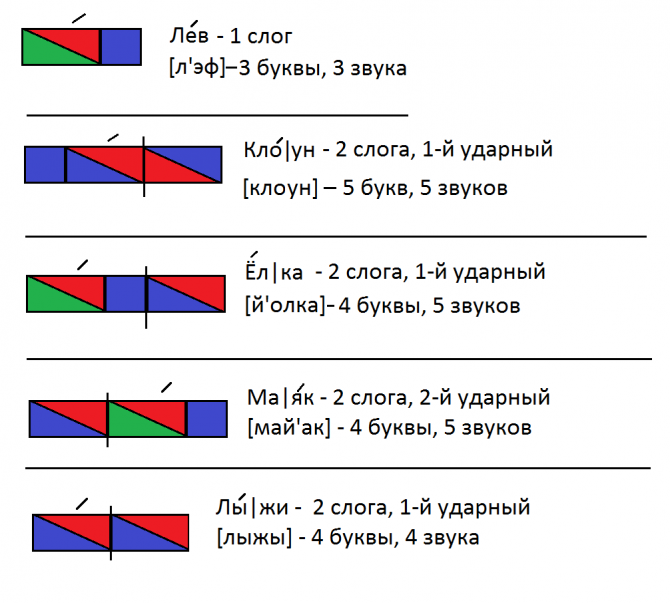
Сделать разбор слова Анисья, земля.
В саду
Солнышко устало и ушло за рощу. Земля хорошо прогрелась за день. Бабушка Анисья и её внучка Ольга были в саду. Они поливали грядки с луком и укропом. У дома стояло ведро с тёплой водой.
Работа с текстом
Ответить на вопросы:
Куда ушло солнышко?
Кто был в саду?
Что поливали бабушка и внучка?
Что стояло у дома?
Закрепление тем: слова действия, повторение орфограммы жи/ши, отработка навыков звуко-буквенного разбора.
1.Списать текст
2.Подчеркнуть орфограмму ЖИ/ШИ (простым карандашом)
3 Подчеркнуть зелёным цветом слова действия.
Выполнить звуко-буквенный разбор слов: ШИПОВНИК, ЦВЁЛ.
В лесу рос красивый куст. Куст цвёл яркими цветами. Это был шиповник. Хороши душистые розы. Стала Ася рвать розы. А там шипы. У Аси заноза.
Работа с текстом. Ответь на вопросы письменно.
Где рос куст?
Как назывался куст?
Что стала рвать Ася?
Почему у Аси заноза?
Закрепление тем: слова признаки предмета, повторение орфограммы жи/ши, отработка навыков звуко-буквенного разбора.
1.Списать текст
2.Подчеркнуть орфограмму ЖИ/ШИ (простым карандашом)
3 Подчеркнуть волной слова, отвечающие на вопрос Какой? Какая?
Выполнить звуко-буквенный разбор слов: БОЛЬШАЯ, РЫСЬ.
На дереве лежит большая рыжая кошка. У кошки зелёные глаза и пушистые кисточки на ушах. Сильные лапы зверя впились в ствол. Это рысь.
Работа с текстом. Ответь на вопросы письменно.
Где была кошка? Какого цвета у кошки глаза? Как называлась такая кошка? |
Закрепление тем: слова действия, слова предметы, слова признаки предмета. Отработка навыков звуко-буквенного разбора.
1. Списать текст
2. В последнем предложение подчеркни слова, отвечающие на вопрос:
— что? – одной линией,
— что делает? – двумя линиями
— какой? – волнистой линией
Сделай разбор слов: ЗАЯЦ, ЦВЕТЫ
Весной.
Хороша роща весной. Слышны песни птиц. Дятлы звонко стучат по стволу. Вот прыгнул под куст заяц. Кругом цветы. Вот цветет душистый ландыш.
Работа с текстом
Чьи песни слышны?
Кто стучит по стволу?
Куда прыгнул заяц?
Какой цветок цвёл?
Тема предлоги
Списать текст
Обвести местоимения в кружок
Предлоги подчеркнуть одной линией
Сделать звуко-буквенный разбор слова ДЕРЕВО
На островке.
Заяц жил на островке. По ночам он глодал кору с осин. Днем прятался в кустах. Вода в реке стала прибывать. Заяц спокойно спал под кустом. Он проснулся. Вокруг зайчишки была вода. Зайцу прыгнул на толстый сук дерева.
Работа с текстом:
О ком говорится в тексте?
Где прятался заяц?
Что случилось, когда заяц проснулся?
Как он спасся?
Тема предлоги
Спиши текст.
Подчеркни орфограмму ЧК/ЧН
Подчеркни синим цветом предлоги, красным цветом местоимение
Подчеркни простым карандашом двумя линиями слова действия.
Сделать звуко-буквенный разбор слова СИНИЧКА.
К окну подлетела синичка. У окна стояли дети. Ребята открыли форточку. Синичка влетела в комнату. Птичка была голодна. Дети накормили её.
Правописание -Н- и -НН- в различных частях речи
Все для самостоятельной подготовки к ЕГЭ
Зарегистрироваться
Русский язык Математика (профильная) Математика (базовая) Обществознание Физика История Биология Химия Английский язык Литература Информатика География
Задания Варианты Теория
Список терминов Морфологические нормы Лексические нормы (паронимы) Орфоэпические нормы Синтаксические нормы Написание н/нн в суффиксах Пунктуация в простом и сложносочиненном предложении Пунктуация при обособленных членах предложения Пунктуация при вводных словах и обращениях Пунктуация в сложноподчиненном предложении Пунктуация в сложном предложении с разными видами связи Пунктуационный анализ текста Лексическое значение слова (задание 2) Правописание корней Правописание приставок Правописание суффиксов Правописание суффиксов и окончаний глагольных форм Написание не и ни с разными частями речи Слитное, дефисное, раздельное написание слов Функционально-смысловые типы речи Лексическое значение слова Средства связи предложений в тексте Языковые средства выразительности
Разбор сложных заданий в тг-канале:
Посмотреть
Правописание Н и НН в существительных
НН пишется:
1) если корень слова оканчивается на н, а суффикс начинается с н:
Например: конница, бесприданница, малинник
2) если существительное образовано от прилагательного или от причастия, имеющего нн:
Например: современник, торжественность
Н пишется:
Если существительное образовано от основы прилагательного с одним н
Например: песчаник, пряности, юность
Правописание Н и НН в суффиксах отыменных прилагательных (образованных от имени существительного)
НН пишется:
1) в прилагательных, образованных от имен существительных и прилагательных с помощью суффиксов -енн-, -онн-.

Например: революционный, временный, здоровенный
Исключение: ветреный
2) в прилагательных, образованных от существительных с основой на
Например: длинный, туманный, чугунный
Прилагательные бараний, тюлений, свиной и подобные пишутся с одной н, так как они образованы от существительных с основой на н путем прибавления суффикса-j-.
Прилагательные пряный, румяный, юный пишутся с одной н, так как это непроизводные прилагательные.
Н пишется:
Н пишется в прилагательных, образованных от существительных с помощью суффиксов -ин-, -ан-,-ян-.
Например: мышиный, гусиный, водяной
Исключения: стеклянный, оловянный, деревянный
Правописание Н и НН в отглагольных прилагательных и причастиях
НН пишется:
1) полные страдательные причастия прошедшего времени.
Например: закрученный, откопанный, купленный
2) в прилагательных на -ованный, -ёванный, -еванный.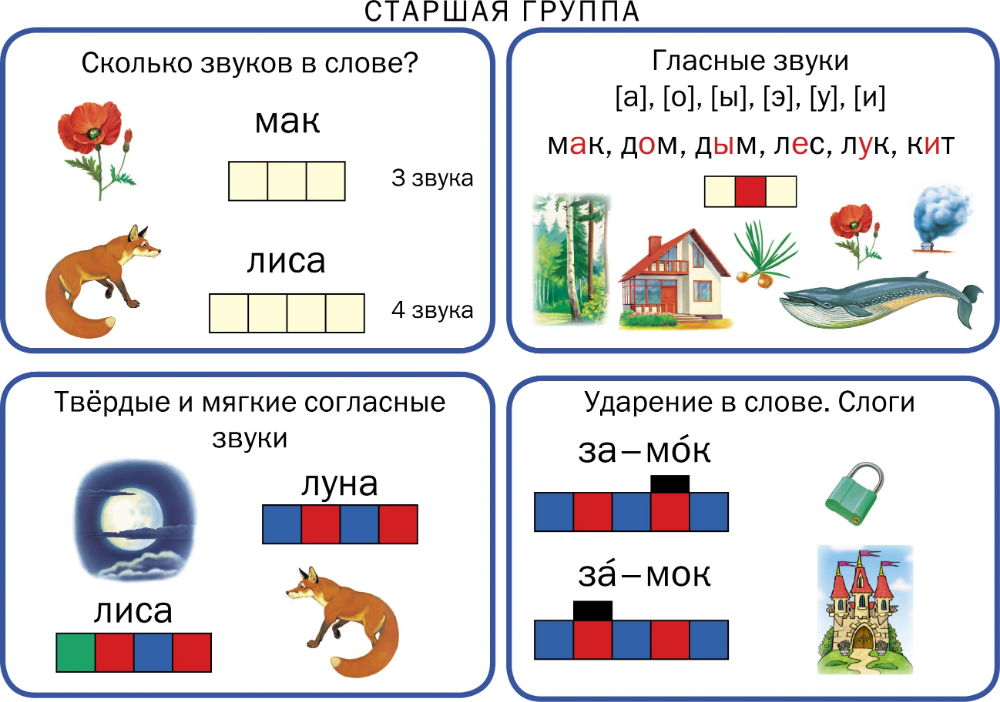
Например: маринованный, корчёванный, асфальтированный
Н пишется:
1) в отглагольных прилагательных
Например: беленые стены, груженый вагон
2) в кратких причастиях
Например: сделан, освоены, окрашено
конченый человек, названый брат, названая сестра, посажёный отец, посажёная мать, Прощёное воскресенье, гладкокрашеный, домотканый, мелкодроблёный, самозваный, тяжелораненый, цельнокроеный, латаный-перелатаный, стираный-перестираный, чиненый-перечиненый, читаный-перечитаный, штопаный-перештопаный, желанный, жданный, надёванный, неведанный, невиданный, негаданный, нежеланный, нежданный, ненадёванный, неожиданный, неслыханный, нечаянный, долгожданный, доморощенный.
Правописание Н и НН в наречиях
В наречиях пишется столько н, сколько их пишется в слове, от которого наречие образовано.
Например: нечаянно (нечаянный), путано (путаный), ветрено (ветреный)
Практика: решай 15 задание и тренировочные варианты ЕГЭ по русскому языку
Составим твой персональный план подготовки к ЕГЭ
рабочих листов по структуре предложений и онлайн-упражнений
| Структура предложения Класс/уровень: A1 учительиссима | Порядок слов Класс/уровень: Класс 2, класс 3, средний от quickbrooker | ОТЧЕТНАЯ РЕЧЬ WH ВОПРОС Класс/уровень: 8/9 по MRPHUOC |
Такие. .. что .. что Класс/уровень: 8/9 по MRPHUOC | Письмо для домашних животных 1 Класс/уровень: 12 по фанбич | Написание простых предложений — звук Класс/уровень: элементарный по Ротембоарон |
| Структура предложения Класс/уровень: 9 класс от дафназа | Строение предложения Класс/уровень: 3 класс от Джордана | Простые и сложные предложения Класс/уровень: 5 по Нураиншахира |
| Составьте предложения по мотивам Класс/уровень: Начальная школа от учитель_Сильвия | Структура предложения Класс/уровень: A2 по МануэлаБ | Класс/уровень: 1 по Hanneliejp9 |
| Структура Toefl itp CH5 Класс/уровень: Пятикурсник МИЛАГРОСКАЛДЕРОН | Структура предложения (3) Класс/уровень: A1 по МануэлаБ | Множественный выбор условных предложений и пожеланий Класс/уровень: 9 по MRPHUOC |
| отчетная речь да- нет вопрос Класс/уровень: 8/9 по MRPHUOC | Мой счет за коммунальные услуги — часть 2 Класс/уровень: 9 класс Промкван | Объединение предложений Класс/уровень: взрослое издание от temry_latrop |
| Картины — структура предложения Класс/уровень: A1 от марианоэльбарберо | Структура предложения Класс/уровень: A1 по МануэлаБ | Маленькая девочка, которую забыли абсолютно все Ранг/уровень: 3° de Secundaria Паулинабетанкур |
| Расшифруй слова Класс/уровень: Начальный от Хосемарал | Оценка английского языка (4 класс) Класс/уровень: 4 класс по КристоферТео | ОТЧЕТНАЯ РЕЧЬ ДА- НЕТ ВОПРОСЫ Класс/уровень: 8/9 по MRPHUOC |
| Простые, составные, сложные, сложносложные предложения от MissEliseSix | Изменение порядка предложений и пунктуация Класс/уровень: Средний от katiem8 | Итак. .. что .. что Класс/уровень: 8/9 по MRPHUOC |
| Весна: Зашифрованные предложения Класс/уровень: CLB Грамотность / 1 от Шеррик | Строитель предложений Класс/уровень: 5 от taniaceballos84 | Год за годом из Класс/уровень: ГОД 3 от амирахадила |
| Моя рутина: порядок предложений Класс/уровень: A1 от pau_86 | Закажи слова и сопоставь с правильным учителем Класс/уровень: 2 класс iciargomez | Переставьте слова Класс/уровень: 4 класс по Tc_Arifah |
| Полный тест структуры Toefl1 Ранг/уровень: и от чудострел | Если — Если не Класс/уровень: 8/9 по MRPHUOC | И-или-но-так Класс/уровень: 7 по MRPHUOC |
| Порядок слов Класс/уровень: 4 класс от anazaloa_2020 | TOEFL практика — Структура 1 Класс/уровень: 9 nhiptischoolht | Мохандас Махатма Ганди Класс/уровень: 8 по mpe5 |
| Рабочий лист 5 — Завершение предложения Класс/уровень: uni по Minh_HUCE | Расставь слова по порядку Класс/уровень: детей 1 по впторрес94 | GE BK6U5 Совет по предложению + тот пункт Класс/уровень: 12 класс по Вики0513 |
БТС G8 9.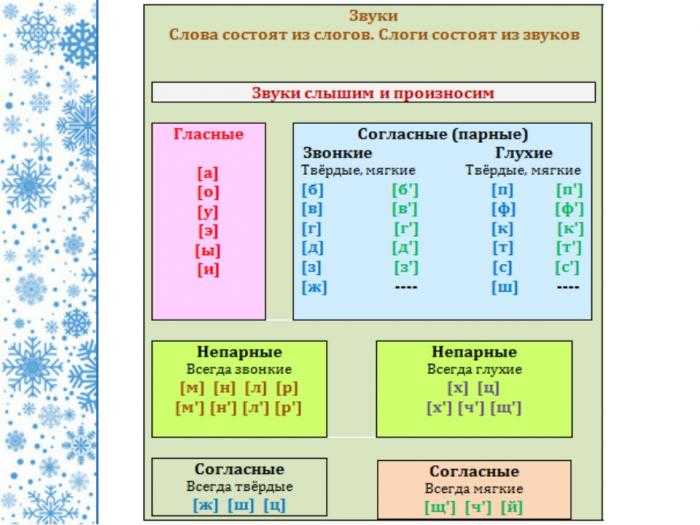 1 Соответствие предложения 1 Соответствие предложения Класс/уровень: 8 класс от файелинч | Переписать предложения 2 Класс/уровень: B1 по 17040371 | Предложение Класс/уровень: Детский сад миалозано |
| Упражнение на соответствие структуры предложения Класс/уровень: 10-й класс по uranix09 | Слоны не умеют танцевать Класс/уровень: класс 3 по Джойцекуо | Предложения Класс/уровень: Cuarto de Primaria по маримардлко |
Введение в набор слов в НЛП с использованием Python
Содержание
Мешок слов — это метод обработки естественного языка для моделирования текста. В этом блоге мы узнаем больше о том, почему используется Bag of Words, мы поймем концепцию с помощью примера, узнаем больше о ее реализации в Python и многое другое.
В этом блоге мы узнаем больше о том, почему используется Bag of Words, мы поймем концепцию с помощью примера, узнаем больше о ее реализации в Python и многое другое.
- Что такое мешок слов в НЛП?
- Для чего используется алгоритм Bag of Words?
- Понимание Bag of Words на примере
- Реализация Bag of Words с помощью Python
- Создайте модель «мешок слов» с помощью Sklearn
- Что такое N-граммы?
- Что такое Tf-Idf (термин частота-обратная частота документа)?
- Извлечение признаков с помощью векторизатора Tf-Idf
- Ограничения Bag of Word
Используя обработку естественного языка, мы используем текстовые данные, доступные в Интернете, для получения информации для бизнеса. Чтобы понять этот огромный объем данных и сделать из них выводы, нам нужно сделать их пригодными для использования. Обработка естественного языка помогает нам в этом.
Что такое мешок слов в НЛП? Мешок слов — это метод обработки естественного языка для моделирования текста. С технической точки зрения можно сказать, что это метод извлечения признаков с помощью текстовых данных. Этот подход представляет собой простой и гибкий способ извлечения признаков из документов.
С технической точки зрения можно сказать, что это метод извлечения признаков с помощью текстовых данных. Этот подход представляет собой простой и гибкий способ извлечения признаков из документов.
Набор слов — это представление текста, описывающее встречаемость слов в документе. Мы просто следим за количеством слов и игнорируем грамматические детали и порядок слов. Он называется «мешком» слов, потому что любая информация о порядке или структуре слов в документе отбрасывается. Модель касается только того, встречаются ли известные слова в документе, а не где в документе.
Итак, почему набор слов, что плохого в простом и легком тексте?
Одна из самых больших проблем с текстом заключается в том, что он беспорядочный и неструктурированный, а алгоритмы машинного обучения предпочитают структурированные, четко определенные входные данные фиксированной длины, а с помощью метода Bag-of-Words мы можем преобразовать тексты переменной длины в фиксированную длину. -длина вектора.
-длина вектора.
Кроме того, на более детальном уровне модели машинного обучения работают с числовыми данными, а не с текстовыми данными. Итак, чтобы быть более конкретным, с помощью метода мешка слов (BoW) мы преобразуем текст в эквивалентный ему вектор чисел.
Понимание набора слов на примереДавайте посмотрим на пример того, как метод набора слов преобразует текст в векторы
Пример(1)
без предварительной обработки: Отличное обучение , Теперь приступайте к обучению»Предложение 2: «Обучение — это хорошая практика»
| Предложение 1 | Предложение 2 |
| Добро пожаловать | Обучение |
| до | есть |
| Великий | a |
| Обучение | хороший | 90 028
| , | Практика |
| Сейчас | |
| начало | | 9002 8
| обучение | |
Шаг 1: Просмотрите все слова в приведенном выше тексте и составьте список всех слов в нашем модельном словаре.
- Добро пожаловать
- В
- Отлично
- Обучение
- ,
- Сейчас
- начало
- обучение
- a
- хорошо
- практика
Обратите внимание, что слова «обучение» и «обучение ‘ здесь не совпадают из-за различия падежей и, следовательно, повторяются. Также обратите внимание, что запятая ‘ , ’ также взята в списке.
Поскольку мы знаем, что словарь состоит из 12 слов, мы можем использовать документ фиксированной длины для представления 12 слов с одной позицией в векторе для оценки каждого слова.
Используемый здесь метод подсчета очков заключается в подсчете присутствия каждого слова и отметке 0 в случае отсутствия. Этот метод оценки используется более широко.
Оценка предложения 1 будет выглядеть следующим образом:
| Слово | Частота |
| Добро пожаловать 90 011 | 1 |
| до | 1 |
| Большой | 1 |
| Обучение | 1 |
| , | 1 |
| Сейчас | 1 |
| начало | 1 | 9002 8
| обучение | 1 |
| это | 0 |
| a | 0 | хорошо | 0 |
| практика | 0 |
Запись вышеуказанных частот в вектор
Предложение 1 ➝ 90 453 [ 1,1,1,1,1,1,1,1,0, 0,0 ]
Теперь для предложения 2 оценка будет выглядеть так:
| Слово | Частота |
| 0 | |
| в | 0 |
| Великий | 0 |
| Обучение | 1 |
| , | 0 |
| Сейчас | 0 | 900 28
| начало | 0 |
| обучение | 0 |
| is | 1 |
| a | 1 |
| хорошо | 1 |
| практика | 1 |
Аналогичным образом, записав вышеуказанные частоты в векторная форма
Предложение 2 ➝ [ 0,0,0,0,0,0,0,1,1,1,1,1 ]
| Предложение | 9 0490 Добро пожаловатьв | Большой | Обучение | , | Сейчас | начать | обучение | это | хорошо | практика 900 11 | ||
| Предложение1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| Предложение2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 90 011 |
Но это лучший способ выполнить мешок слов.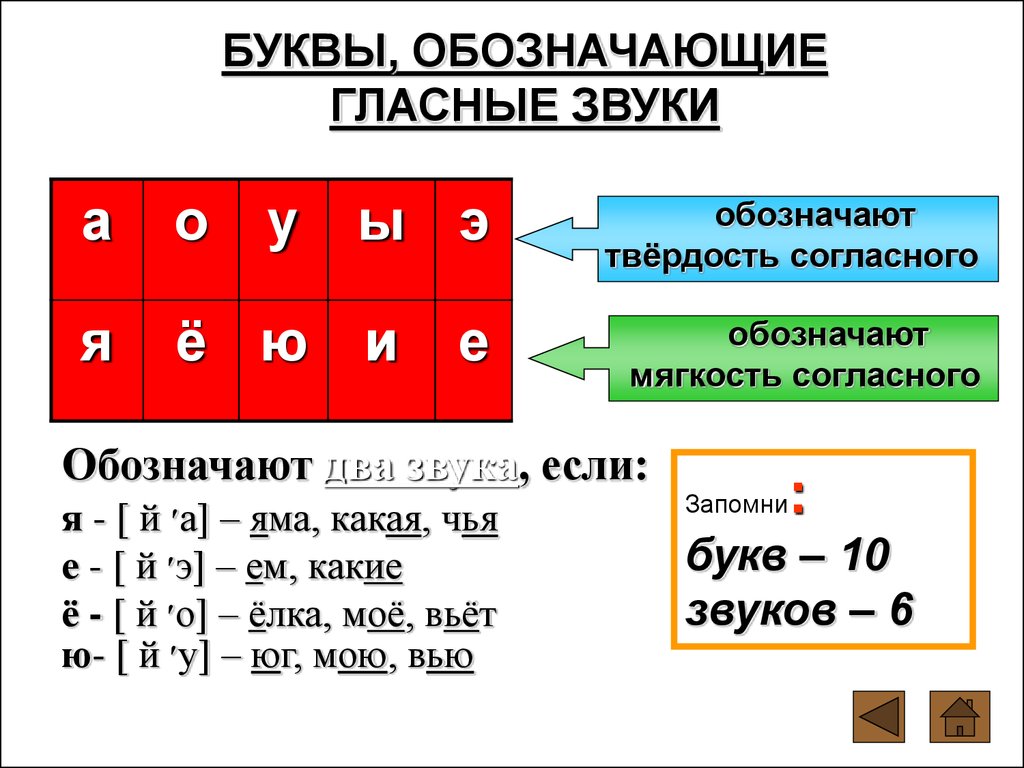 Приведенный выше пример был не лучшим примером того, как использовать набор слов. Слова Обучение и обучение, хотя и имеют одно и то же значение, взяты дважды. Также в словарь включается запятая ‘,’, которая не несет никакой информации.
Приведенный выше пример был не лучшим примером того, как использовать набор слов. Слова Обучение и обучение, хотя и имеют одно и то же значение, взяты дважды. Также в словарь включается запятая ‘,’, которая не несет никакой информации.
Давайте внесем некоторые изменения и посмотрим, как можно более эффективно использовать «мешок слов».
Пример (2) с предварительной обработкой :Предложение 1: «Добро пожаловать в отличное обучение, приступайте к обучению»
Предложение 2: «Обучение — это хорошая практика»
Шаг 1 : Преобразование вышеприведенные предложения строчными буквами, так как регистр слова не несет никакой информации.
Шаг 2 : Удалите из текста специальные символы и стоп-слова. Стоп-слова — это слова, которые не содержат много информации о тексте, такие как «is», «a», «the и многие другие».
После выполнения описанных выше шагов предложения меняются на
Предложение 1: «приветствуем вас, отличное обучение, теперь начните учиться»
Предложение 2: «изучаем передовой опыт»
Хотя приведенные выше предложения не имеют особого смысла, максимальная информация содержится только в этих словах.
Шаг 3 : Просмотрите все слова в приведенном выше тексте и составьте список всех слов в нашем модельном словаре.
- добро пожаловать
- отлично
- обучение
- сейчас
- начало
- хорошо
- практика
Теперь, когда в словаре всего 7 слов, мы можем использовать документ фиксированной длины, представляющий 7, с одной позицией в векторе для оценки каждого слова .
Используемый здесь метод оценки тот же, что и в предыдущем примере. Для предложения 1 количество слов следующее:
| Word | Частота |
| welcome | 1 |
| great | 1 |
| learning | 2 |
| now | 1 |
| start | 1 |
| good | 0 |
| практика | 0 |
Запись приведенных выше частот в векторе
Предложение 1 ➝ [ 1,1,2,1,1,0,0 ]
Теперь предложение 2, оценка примерно
| Word | Частота |
| приветствие | 0 | отличный | 0 |
| обучение | 1 |
| сейчас | 0 |
| 0 | |
| хорошо | 1 |
| практика | 1 |
Аналогично, записав вышеуказанные частоты в векторной форме
Предложение 2 ➝ [ 0,0,1,0,0,1,1 ]
| Предложение | welcome | 90 490 отличноучится | сейчас | начало | хорошо | практика | |
| Предложение1 | 1 | 1 | 2 | 1 | 1 9001 1 | 0 | 0 |
| Предложение2 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
Подход, использованный во втором примере, обычно используется в методе Bag-of-Words, поскольку наборы данных, используемые в Machine обучения чрезвычайно велики и могут содержать словарный запас в несколько тысяч или даже миллионов слов. Следовательно, предварительная обработка текста перед использованием набора слов — лучший способ.
Следовательно, предварительная обработка текста перед использованием набора слов — лучший способ.
Существуют различные этапы предварительной обработки, которые могут повысить производительность Bag-of-Words. Некоторые из них очень подробно описаны в этом блоге.
В приведенных выше примерах мы используем все слова из словаря для формирования вектора, что не является ни практичным, ни лучшим способом реализации модели BoW. На практике для формирования вектора используются только несколько слов из словаря, более предпочтительно самые распространенные слова.
Реализация алгоритма мешка слов с помощью PythonВ этом разделе мы собираемся реализовать алгоритм мешка слов с помощью Python. Кроме того, это очень простая реализация для понимания того, как работает алгоритм набора слов, поэтому я бы не рекомендовал использовать его в вашем проекте, вместо этого используйте метод, описанный в следующем разделе.
def векторизовать (токены):
''' Эта функция принимает список слов в предложении в качестве входных данных
и возвращает вектор размера filtered_vocab. Он ставит 0, если
слово отсутствует в токенах и количество токенов, если они есть.'''
вектор=[]
для w в filtered_vocab:
vector.append (токены.count (w))
обратный вектор
Уникальная защита (последовательность):
'''Эта функция возвращает список, в котором порядок остается
то же самое, и ни один элемент не повторяется. Использование функции set() не
сохранить исходный порядок, поэтому я не использовал его вместо этого '''
видел = установить ()
вернуть [x вместо x в последовательности, если нет (x в увиденном или увиденном.add(x))]
#создать список стоп-слов. Вы также можете импортировать стоп-слова из nltk
стоп-слова=["к","является","а"]
#список специальных символов. Вы также можете использовать регулярные выражения
special_char=[",",":"," ",";",".","?"]
#Запишите предложения в корпус,в нашем случае всего два
string1="Добро пожаловать в отличное обучение, теперь приступайте к обучению"
string2="Обучение - это хорошая практика"
#преобразовать их в нижний регистр
строка1=строка1. нижний()
строка2=строка2.нижний()
#разбить предложения на токены
токены1=string1.split()
токены2=string2.split()
печать (токены1)
печать (токены2)
#создать список слов
vocab=уникальный(токены1+токены2)
печать (словарь)
#отфильтровать список словарного запаса
filtered_vocab=[]
для w в словаре:
если w не в стоп-словах и w не в special_char:
filtered_vocab.append(w)
печать (filtered_vocab)
#конвертировать предложения в векторные файлы
vector1 = векторизовать (токены1)
печать (вектор1)
vector2 = векторизовать (токены2)
печать (вектор2)
Он ставит 0, если
слово отсутствует в токенах и количество токенов, если они есть.'''
вектор=[]
для w в filtered_vocab:
vector.append (токены.count (w))
обратный вектор
Уникальная защита (последовательность):
'''Эта функция возвращает список, в котором порядок остается
то же самое, и ни один элемент не повторяется. Использование функции set() не
сохранить исходный порядок, поэтому я не использовал его вместо этого '''
видел = установить ()
вернуть [x вместо x в последовательности, если нет (x в увиденном или увиденном.add(x))]
#создать список стоп-слов. Вы также можете импортировать стоп-слова из nltk
стоп-слова=["к","является","а"]
#список специальных символов. Вы также можете использовать регулярные выражения
special_char=[",",":"," ",";",".","?"]
#Запишите предложения в корпус,в нашем случае всего два
string1="Добро пожаловать в отличное обучение, теперь приступайте к обучению"
string2="Обучение - это хорошая практика"
#преобразовать их в нижний регистр
строка1=строка1. нижний()
строка2=строка2.нижний()
#разбить предложения на токены
токены1=string1.split()
токены2=string2.split()
печать (токены1)
печать (токены2)
#создать список слов
vocab=уникальный(токены1+токены2)
печать (словарь)
#отфильтровать список словарного запаса
filtered_vocab=[]
для w в словаре:
если w не в стоп-словах и w не в special_char:
filtered_vocab.append(w)
печать (filtered_vocab)
#конвертировать предложения в векторные файлы
vector1 = векторизовать (токены1)
печать (вектор1)
vector2 = векторизовать (токены2)
печать (вектор2)
 Он ставит 0, если
слово отсутствует в токенах и количество токенов, если они есть.'''
вектор=[]
для w в filtered_vocab:
vector.append (токены.count (w))
обратный вектор
Уникальная защита (последовательность):
'''Эта функция возвращает список, в котором порядок остается
то же самое, и ни один элемент не повторяется. Использование функции set() не
сохранить исходный порядок, поэтому я не использовал его вместо этого '''
видел = установить ()
вернуть [x вместо x в последовательности, если нет (x в увиденном или увиденном.add(x))]
#создать список стоп-слов. Вы также можете импортировать стоп-слова из nltk
стоп-слова=["к","является","а"]
#список специальных символов. Вы также можете использовать регулярные выражения
special_char=[",",":"," ",";",".","?"]
#Запишите предложения в корпус,в нашем случае всего два
string1="Добро пожаловать в отличное обучение, теперь приступайте к обучению"
string2="Обучение - это хорошая практика"
#преобразовать их в нижний регистр
строка1=строка1.
Он ставит 0, если
слово отсутствует в токенах и количество токенов, если они есть.'''
вектор=[]
для w в filtered_vocab:
vector.append (токены.count (w))
обратный вектор
Уникальная защита (последовательность):
'''Эта функция возвращает список, в котором порядок остается
то же самое, и ни один элемент не повторяется. Использование функции set() не
сохранить исходный порядок, поэтому я не использовал его вместо этого '''
видел = установить ()
вернуть [x вместо x в последовательности, если нет (x в увиденном или увиденном.add(x))]
#создать список стоп-слов. Вы также можете импортировать стоп-слова из nltk
стоп-слова=["к","является","а"]
#список специальных символов. Вы также можете использовать регулярные выражения
special_char=[",",":"," ",";",".","?"]
#Запишите предложения в корпус,в нашем случае всего два
string1="Добро пожаловать в отличное обучение, теперь приступайте к обучению"
string2="Обучение - это хорошая практика"
#преобразовать их в нижний регистр
строка1=строка1.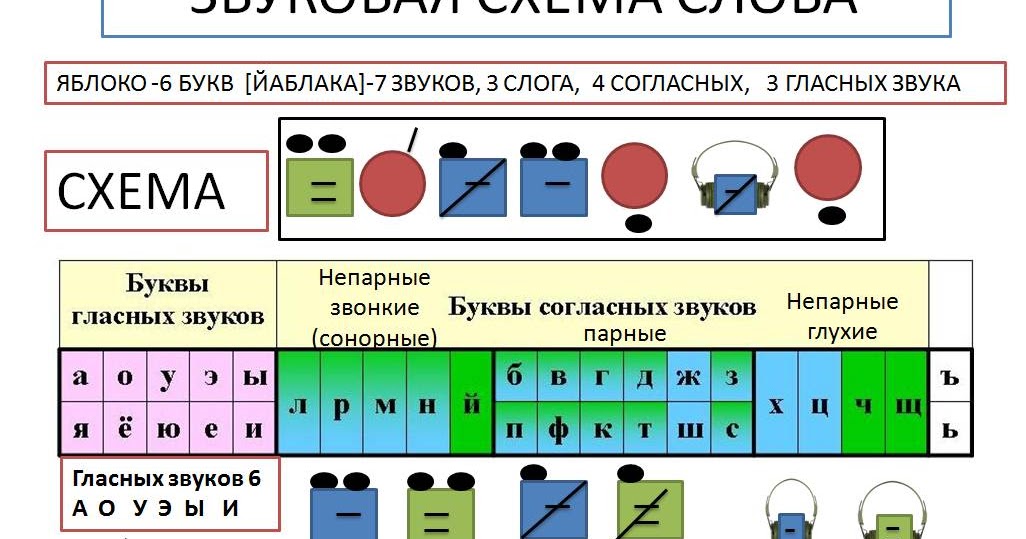 нижний()
строка2=строка2.нижний()
#разбить предложения на токены
токены1=string1.split()
токены2=string2.split()
печать (токены1)
печать (токены2)
#создать список слов
vocab=уникальный(токены1+токены2)
печать (словарь)
#отфильтровать список словарного запаса
filtered_vocab=[]
для w в словаре:
если w не в стоп-словах и w не в special_char:
filtered_vocab.append(w)
печать (filtered_vocab)
#конвертировать предложения в векторные файлы
vector1 = векторизовать (токены1)
печать (вектор1)
vector2 = векторизовать (токены2)
печать (вектор2)
нижний()
строка2=строка2.нижний()
#разбить предложения на токены
токены1=string1.split()
токены2=string2.split()
печать (токены1)
печать (токены2)
#создать список слов
vocab=уникальный(токены1+токены2)
печать (словарь)
#отфильтровать список словарного запаса
filtered_vocab=[]
для w в словаре:
если w не в стоп-словах и w не в special_char:
filtered_vocab.append(w)
печать (filtered_vocab)
#конвертировать предложения в векторные файлы
vector1 = векторизовать (токены1)
печать (вектор1)
vector2 = векторизовать (токены2)
печать (вектор2)
Вывод:
Создайте модель Bag of Words с помощью SklearnМы можем использовать функцию CountVectorizer() из библиотеки Sk-learn, чтобы легко реализовать описанную выше модель BoW с помощью Python.
импортировать панд как pd из sklearn.feature_extraction.text импортировать CountVectorizer, TfidfVectorizer предложение_1 = "Это хорошая работа.
 Я ни за что не пропущу ее"
предложение_2 = «Это совсем не хорошо»
CountVec = CountVectorizer(ngram_range=(1,1), # для использования биграмм ngram_range=(2,2)
stop_words='английский')
#трансформировать
Count_data = CountVec.fit_transform([sentence_1,sentence_2])
#создать фрейм данных
cv_dataframe=pd.DataFrame(Count_data.toarray(),columns=CountVec.get_feature_names())
печать (cv_dataframe)
Я ни за что не пропущу ее"
предложение_2 = «Это совсем не хорошо»
CountVec = CountVectorizer(ngram_range=(1,1), # для использования биграмм ngram_range=(2,2)
stop_words='английский')
#трансформировать
Count_data = CountVec.fit_transform([sentence_1,sentence_2])
#создать фрейм данных
cv_dataframe=pd.DataFrame(Count_data.toarray(),columns=CountVec.get_feature_names())
печать (cv_dataframe)
Вывод:
Что такое N-грамм?Опять те же вопросы, что такое n-граммы и зачем мы их используем? Давайте разберемся в этом на примере ниже:
Предложение 1: «Это хорошая работа. Я ни за что не пропущу это»
Предложение 2: «Это совсем нехорошо»
Для этого примера возьмем словарный запас только из 5 слов. Пять слов:
- хорошо
- работа
- скучаю
- не
- все
Итак, соответствующие векторы для этих предложений:
«Это хорошая работа. Я ни за что не пропущу» = [1,1,1,1,0]
Я ни за что не пропущу» = [1,1,1,1,0]
«Это совсем нехорошо» = [1,0,0,1,1]
Можете ли вы угадайте, в чем здесь проблема? Предложение 2 является отрицательным предложением, а предложение 1 является положительным предложением. Отражается ли это каким-либо образом в приведенных выше векторах? Нисколько. Итак, как мы можем решить эту проблему? Здесь нам на помощь приходят N-граммы.
N-грамма — это последовательность слов, состоящая из N символов: 2-грамма (чаще называемая биграммой) — это последовательность из двух слов, таких как «действительно хорошо», «не очень хорошо» или «ваша домашняя работа». , а 3-грамма (чаще называемая триграммой) представляет собой последовательность из трех слов, таких как «совсем нет» или «выключить свет».
Например, биграммы в первой строке текста в предыдущем разделе: «Это совсем нехорошо» выглядят следующим образом:
- «Это»
- «не является»
- «нехорошо»
- «хорошо»
- «совсем»
Теперь вместо того, чтобы использовать только слова в приведенном выше примере, мы используем биграммы (Bag-of-bigrams), как показано выше.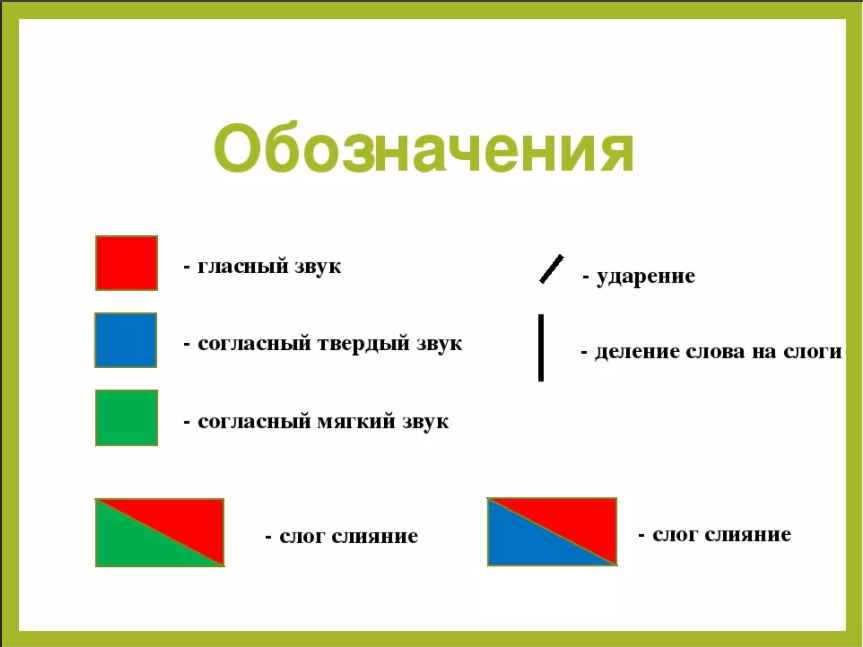 Модель может различать предложение 1 и предложение 2. Таким образом, использование биграмм делает токены более понятными (например, «макет HSR» в Бангалоре более информативен, чем «HSR» и «макет»)
Модель может различать предложение 1 и предложение 2. Таким образом, использование биграмм делает токены более понятными (например, «макет HSR» в Бангалоре более информативен, чем «HSR» и «макет»)
Таким образом, мы можем пришли к выводу, что представление в виде мешка биграмм намного мощнее, чем в виде мешка слов, и во многих случаях его очень сложно превзойти.
Что такое Tf-Idf (термин частота-обратная частота документа)?Используемый выше метод подсчета очков берет количество каждого слова и представляет слово в векторе количеством отсчетов этого конкретного слова. Что означает слово с большим количеством слов?
Означает ли это, что слово важно для получения информации о документах? Ответ — нет. Позвольте мне объяснить, если слово встречается в документе много раз, а также во многих других документах в нашем наборе данных, может быть, это потому, что это слово является просто частым словом; не потому, что это актуально или значимо.
Один из подходов заключается в изменении масштаба частоты слов в зависимости от того, как часто они появляются во всех документах, чтобы баллы за часто встречающиеся слова, такие как «the», которые также часто встречаются во всех документах, снижались. Этот подход называется частотно-инверсивной частотой документа термина или сокращенно известен как подход оценки Tf-Idf. TF-IDF предназначен для отражения того, насколько релевантен термин в данном документе. Так как же рассчитывается Tf-Idf документа в наборе данных?
TF-IDF для слова в документе вычисляется путем умножения двух разных показателей:
Частота термина (TF) слова в документе. Есть несколько способов подсчета этой частоты, самый простой из которых — это необработанный подсчет случаев появления слова в документе. Кроме того, есть другие способы регулировки частоты. Например, путем деления необработанного количества экземпляров слова либо на длину документа, либо на необработанную частоту наиболее часто встречающегося слова в документе. Формула для расчета Term-Frequency:
Формула для расчета Term-Frequency:
TF(i,j)=n(i,j)/Σ n(i,j)
Где,
n(i,j )= количество раз, когда n-е слово встречается в документе. Σn(i,j) = общее количество слов в документе.
обратная частота документа (IDF) слова в наборе документов. Это говорит о том, насколько часто или редко встречается слово во всем наборе документов. Чем он ближе к 0, тем слово встречается чаще. Этот показатель можно рассчитать, взяв общее количество документов, разделив его на количество документов, содержащих слово, и вычислив логарифм.
Таким образом, если слово очень распространено и встречается во многих документах, это число будет приближаться к 0. В противном случае оно будет приближаться к 1.
Умножение этих двух чисел дает оценку TF-IDF для слова в документе. . Чем выше оценка, тем более релевантным является это слово в данном конкретном документе.
. Чем выше оценка, тем более релевантным является это слово в данном конкретном документе.
Говоря математическим языком, показатель TF-IDF рассчитывается следующим образом:
IDF=1+log(N/dN)
Где
N=общее количество документов в наборе данных dN=общее количество документов, в которых встречается n-е слово
Также обратите внимание, что единица, добавленная в приведенную выше формулу, нужна для того, чтобы термины с нулевым IDF не подавлялись полностью. Этот процесс известен как сглаживание IDF.
TF-IDF получен
TF-IDF=TF*IDF
Это кажется слишком сложным? Не волнуйтесь, этого можно добиться всего несколькими строками кода, и вам даже не нужно запоминать эти страшные формулы.
Мы можем использовать функцию TfidfVectorizer() из библиотеки Sk-learn, чтобы легко реализовать описанную выше модель BoW(Tf-IDF).
импортировать панд как pd из sklearn.feature_extraction.text импортировать CountVectorizer, TfidfVectorizer предложение_1 = "Это хорошая работа.
 Я ни за что не пропущу ее"
предложение_2 = «Это совсем не хорошо»
#без гладкой ИДФ
print("Без сглаживания:")
# определить tf-idf
tf_idf_vec = TfidfVectorizer (use_idf = Истина,
smooth_idf = Ложь,
ngram_range=(1,1),stop_words='english') # использовать только биграммы ngram_range=(2,2)
#трансформировать
tf_idf_data = tf_idf_vec.fit_transform ([предложение_1, предложение_2])
#создать фрейм данных
tf_idf_dataframe=pd.DataFrame(tf_idf_data.toarray(),columns=tf_idf_vec.get_feature_names())
печать (tf_idf_dataframe)
печать("\n")
#с гладью
tf_idf_vec_smooth = TfidfVectorizer (use_idf = Истина,
smooth_idf = Верно,
ngram_range=(1,1),stop_words='английский')
tf_idf_data_smooth = tf_idf_vec_smooth.fit_transform([sentence_1,sentence_2])
print("Со сглаживанием:")
tf_idf_dataframe_smooth=pd.DataFrame(tf_idf_data_smooth.toarray(),columns=tf_idf_vec_smooth.get_feature_names())
печать (tf_idf_dataframe_smooth)
Я ни за что не пропущу ее"
предложение_2 = «Это совсем не хорошо»
#без гладкой ИДФ
print("Без сглаживания:")
# определить tf-idf
tf_idf_vec = TfidfVectorizer (use_idf = Истина,
smooth_idf = Ложь,
ngram_range=(1,1),stop_words='english') # использовать только биграммы ngram_range=(2,2)
#трансформировать
tf_idf_data = tf_idf_vec.fit_transform ([предложение_1, предложение_2])
#создать фрейм данных
tf_idf_dataframe=pd.DataFrame(tf_idf_data.toarray(),columns=tf_idf_vec.get_feature_names())
печать (tf_idf_dataframe)
печать("\n")
#с гладью
tf_idf_vec_smooth = TfidfVectorizer (use_idf = Истина,
smooth_idf = Верно,
ngram_range=(1,1),stop_words='английский')
tf_idf_data_smooth = tf_idf_vec_smooth.fit_transform([sentence_1,sentence_2])
print("Со сглаживанием:")
tf_idf_dataframe_smooth=pd.DataFrame(tf_idf_data_smooth.toarray(),columns=tf_idf_vec_smooth.get_feature_names())
печать (tf_idf_dataframe_smooth)
Вывод:
Несмотря на то, что Bag-of-Words довольно эффективен и прост в реализации, все же у этой техники есть некоторые недостатки, которые приведены ниже:
- Модель игнорирует информацию о местоположении слова. Информация о местоположении — это часть очень важной информации в тексте. Например, «сегодня выходной» и «Сегодня выходной» имеют одинаковое векторное представление в модели BoW.
- Сумка словесных моделей не учитывает семантику слова. Например, слова «футбол» и «футбол» часто используются в одном и том же контексте. Однако векторы, соответствующие этим словам, сильно различаются в модели мешка слов. Проблема становится более серьезной при моделировании предложений. Пример: «Купить подержанные автомобили» и «Купить старые автомобили» представлены совершенно разными векторами в модели Bag-of-words.
- Спектр словарного запаса — большая проблема, с которой сталкивается модель Bag-of-Words. Например, если модель встречает новое слово, которое она еще не видела, мы говорим редкое, но информативное слово, такое как Библиоклепт (означает тот, кто ворует книги). Модель BoW, вероятно, в конечном итоге проигнорирует это слово, поскольку оно еще не было замечено моделью.
 Информация о местоположении — это часть очень важной информации в тексте. Например, «сегодня выходной» и «Сегодня выходной» имеют одинаковое векторное представление в модели BoW.
Информация о местоположении — это часть очень важной информации в тексте. Например, «сегодня выходной» и «Сегодня выходной» имеют одинаковое векторное представление в модели BoW. Это подводит нас к концу этой статьи, где мы узнали о Bag of words и его реализации с помощью Sk-learn.