Звуковой и буквенный состав слова
Главная > Справочник по образованию > Энциклопедия де-факто > Языкознание, филология, лингвистика > Русский язык > Фонетика и графика > Звуковой и буквенный состав слова
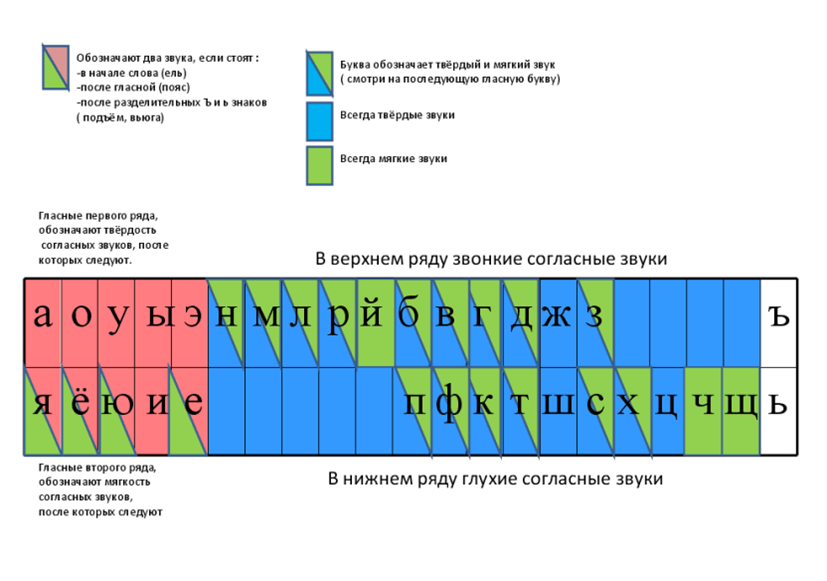
Звуки мы произносим и слышим, буквы – видим и пишем. Обозначение звуков речи буквами на письме изучает графика (от греч «графо» – пишу).
Чтобы отличить при изучении фонетики звук от буквы, звуки заключаются в квадратные скобки. Например, буква а обозначает звук [а], буква эл обозначат звук [л] и т.д.
В некоторых словах все звуки обозначаются «своей» буквой, например:
[с] [т] [о] [л] – стол,
[ш] [к] [а] [ф] – шкаф,
[с] [к] [а] [з] [а] [л] – сказал.
Однако буква не всегда соответствует «своему» звуку. Одна буква может обозначать разные звуки, например в словах дом – д [о]м, дома’ – д[а]ма’ (мн.ч.). Буква о обозначает звук [о] и [а].
Один звук может обозначаться разными буквами: в словах клад и плот в конце слова произносится один звук [т], а обозначают его разные буквы: д и т .
Нужно различать звуковой и буквенный составы слов.
Так, звуковой и буквенный составы слов дом соответствуют друг другу, а в форме дома’ есть несоответствие: пишем букву о – произносим звук [а]; в слове винегре’т в безударных слогах пишем буквы и и е – произносим почти одинаковый звук [и].
Количество букв и звуков в словах иногда не совпадают, например в слове честный пишется 7 букв, а произносится 6 звуков. Буква т не обозначает звука (непроизносимый согласный). По нормам орфоэпии при стечении согласных в некоторый словах звуки . [в], [д], [л], [т] не произносятся, а буквы пишутся: солнце, сердце и др.
Чтобы не ошибиться в написании слов с непроизносимыми согласными [в], [д], [л], [т], нужно подобрать проверочное слово, в котором эти согласные отчетливо: здравствуйте – здравие (здоровье), сердце – сердечный, солнце – солнышко, участник – участие.
1. В словах лестница, чувство, чувствовать, праздник, сверстник есть непроизносимый согласный.
2. В словах вкусный, чудесный, опасный, ровесник, участвовать непроизносимого согласного нет.
Другие записи
10.06.2016. Фонетический разбор
Цель этого вида лингвистического анализа слова состоит в выявлении звукового состава последнего. При этом необходимо: определить количество слогов, установить качественно-количественное соотношение…
10.06.2016. Русский алфавит
Буквы, расположенные в определенной последовательности составляют алфавит, или азбуку. А а Б бэ В вэ Г Гэ Д дэ Е е Ё ё Ж жэ З зэ И и Й и и-краткое К…
10.06.2016. Ударение
Если слово состоит из нескольких слогов, то одни из них звучит более четко (произносится с большей силой), чем остальные. Так, в слове лётчик с большей силой произносится первый слог, а в слове космонавт –…
Rust + Tauri / Хабр
В чём-то сочинение стихов похоже на написание кода — имеет значение только «чистый» текст, и этот текст, как и код, подчиняется определенным правилам. Поэту могли бы пригодиться те самые «автоподсказки» и подсветка
Поэту могли бы пригодиться те самые «автоподсказки» и подсветка кода стихов. Может, даже с какой-то поддержкой рефакторинга, помочь поэту найти слабое место. Но найти что-то подобное (особенно на русском языке) у меня не вышло. Например, на запрос poetry editor в основном выпадают сервисы по найму редакторов-людей. Проекты, конечно, есть, но они либо слабые, либо мёртвые (поправьте меня, если я неправ).
Значит, задумал я на коленках склепать IDE для поэтов…
Слева — сляпанная на коленках иконка Справа — арт от MidjourneyЯ сразу отсёк мысль делать что-то «тяжелое» с нейронными сетями, дописывающее стихи за поэта. Это круто, конечно, но это совсем другая задача. В каком-то смысле это как раз забирает у поэта его основную работу (баловался я недавно с chatGPT-подобными штуками в области поэзии, ощущения неоднозначные). Content-generator на основе нейронной сети — непредсказуемая и в целом на текущем этапе развития плохо управляемая вещь. Одним словом, создавать Copilot-поэт у меня не было ни желания, ни ресурсов.
Итак, что нужно поэту из того, с чем ему может помочь программа?
Самый очевидный ответ — рифмы. Пожалуй, поиск рифм чем-то похож на автодополнение в IDE: IDE предлагает подходящее продолжение кода, ориентируясь на синтаксис и внутреннюю структуру. При подборе рифм же мы ищем слова, подходящие по каким-то сложным, но в принципе формализуемым критериям. С поиском рифм, в принципе, справляются и онлайн-сервисы, но его можно сделать лучше, интегрировать в редактор, дать поэту возможность настроить «стиль рифм», разумно ранжировать их по качеству и смыслу.
Что дальше? Ритм. Чередование ударных-безударных в правильном порядке. Но выдавать «ошибки» (или предупреждения) не стоит — ритм может быть очень своеобразным, например, некоторые «сбои» в ритме делаются специально для привлечения внимания. А вот сделать ритм более наглядным может быть полезно — если мы правильно подсветим ударные/безударные слоги, поэту будет проще найти и исправить «сломанный ритм». Как правило, это основная проблема новичков, еще не сумевших хорошо «прочувствовать» стих. Стих звучит коряво, а что исправлять — непонятно.
Стих звучит коряво, а что исправлять — непонятно.
Что ещё? Ещё звучание стихотворение сильно задается ассонансами и  </p><p></p><p>(рекомендую произнести вслух, чтобы прочувствовать)</p>» data-abbr=»аллитерациями «>аллитерациями — сочетания звуков, при правильном использовании которых стихотворение может звучать волшебно даже при полном отсутствии смысла. Напрашивается их подсветить, авось что-то хорошее получится.
</p><p></p><p>(рекомендую произнести вслух, чтобы прочувствовать)</p>» data-abbr=»аллитерациями «>аллитерациями — сочетания звуков, при правильном использовании которых стихотворение может звучать волшебно даже при полном отсутствии смысла. Напрашивается их подсветить, авось что-то хорошее получится.
Ну, поехали.
Рифмы
Может быть, кто-то помнит страдания Цветика из «Незнайки», когда тот попросил его самого придумать рифму к слову «пакля»:
Он остановился посреди комнаты, сложил на груди руки, голову наклонил набок и стал думать. Потом поднял голову кверху и стал думать, глядя на потолок. Потом ухватился руками за собственный подбородок и стал думать, глядя на пол. Проделав всё это, он стал бродить по комнате и потихоньку бормотал про себя:
— Пакля, бакля, вакля, гакля, дакля, макля… — Он долго так бормотал, потом сказал: — Тьфу! Что это за слово? Это какое-то слово, на которое нет рифмы.
Поиск «идеальной рифмы» в ключевом месте может заставить перебрать сотни вариантов, просидеть уйму времени и пойти переписывать всю строфу заново. Или удовлетвориться тем, что есть, и потом каждый раз корёжиться, перечитывая. Это основной «камень преткновения» нейронок вроде chatGPT — концепцию рифмы, особенно на русском языке, они зачастую ещё не могут «понять», стихи исключительно белые (с ритмом там тоже возникают определенные проблемы — чат-бот обычно ничего не знает про ударения).
Или удовлетвориться тем, что есть, и потом каждый раз корёжиться, перечитывая. Это основной «камень преткновения» нейронок вроде chatGPT — концепцию рифмы, особенно на русском языке, они зачастую ещё не могут «понять», стихи исключительно белые (с ритмом там тоже возникают определенные проблемы — чат-бот обычно ничего не знает про ударения).
Казалось бы, поиск рифмы легко формализовать, компьютеры с ним должны легко справляться. Да что там париться — забиваем в поиск «рифма к слову пакля» и наслаждаемся…
…наслаждаемся выводом по типу «набрякла, сакля, тентакли, накрахмаля, универмага» и подобным. Конечно, там встречаются и «качественные» рифмы — например, столь напрашивающаяся «капля» (лучшая по моему мнению, если не знать контекста стиха — универсальный поэтический образ, отличающийся от «пакли» одной перестановкой букв). Но в онлайн-сервисах приходится продираться сквозь тонны редко используемых, крайне экзотических и просто неподходящих слов. Да и звучат они как-то не очень. Если задуматься, задача формализации критериев рифмы в терминах строк становится не такой очевидной: вроде бы полученные слова и похожи на исходное, а всё равно что-то не то…
Если задуматься, задача формализации критериев рифмы в терминах строк становится не такой очевидной: вроде бы полученные слова и похожи на исходное, а всё равно что-то не то…
Насколько я понимаю, работают подобные поисковики достаточно просто — в первую очередь индексируют все слова по ударным гласным (не та ударная гласная — сразу откидываем), а дальше смотрят на какое-то подобие редакционного расстояния (сайты почти мгновенно выдают результаты даже для выдуманных слов, так что алгоритм там не может быть тяжёлым — как видно из выдачи, словари у них весьма объёмные). На Github есть open-source репозитории, но они либо строятся на нейронках, либо на ещё более простых алгоритмах. Нейронки — это хорошо, но им не так хорошо даются рифмы (наш мозг тому пример), да и давать они будут скорее «избитые» рифмы — рифмы, которые будут строиться по тем же принципам, что и в обучающей выборке. Не будем даже думать о том, что получится, если обучить такую сеть на стихах из интернета.
Итак, пусть мы хотим создать свой алгоритм поиска рифм. Не дающий явного мусора, и (важно) — стилистически настраиваемый.
Не дающий явного мусора, и (важно) — стилистически настраиваемый.
Если открыть Википедию, то окажется, что рифм существует куча разных видов, что, например, слава-слово-слева — тоже рифма, только за счёт согласных, а не гласных, и так далее. Нет однозначного определения, что такое хорошая рифма. Кто-то считает «хорошими» строгие рифмы, любой компромисс — признак слабины поэта. Кто-то говорит, что «хорошая» рифма должна быть похожа на хорошую загадку — ответ должен быть неожиданным, но подходящим. Нерушимое правило только одно — рифма должна быть как-то похожа на исходное слово. Я решил выделить несколько метрик похожести слов, вклад и параметры которых можно настроить. Мне показалось очень важным, чтобы человек мог сам указать, что именно для него в рифме важно.
В моем случае метрики дают по слагаемому с некоторым настраиваемым весом. Перечислю их с небольшими упрощениями:
Метрики, оценивающие «ошибку» рифмы
Гласные. Метрика, возведённая сайтами с рифмами в абсолют.
 В случае сайтов все просто — если ударение падает на гласные, то гласные должны совпадать. Если нет — не обязательно, но желательно. Я хочу убрать это «должны» в случае ударных, заменив жёсткие ограничения на мягкие (настраиваемый штраф). Я ввел фиксированное расстояние между гласными «в вакууме» (например, а-о ближе друг к другу, чем а-и). Расстояние считается через набор субъективных фонетических характеристик произношения — к сожалению, у меня нет данных по «векторам звучания» для каждой буквы. Если ударение падает — умножаю расстояние на достаточно большой коэффициент (можем его уменьшить, если для нас нормальны рифмы вида слава-слово). Понятно, что это не даёт нам индексировать слова по ударным гласным, поэтому во много раз увеличивает работу поиска. В этом нет ничего страшного, это всё равно будет занимать немного времени, для чего-то интересного его не жалко (тем не менее, строгий поиск по ударным гласным можно сделать опциональным — в десятки раз увеличивающий скорость за счёт потери рифм вида слава-слово).
В случае сайтов все просто — если ударение падает на гласные, то гласные должны совпадать. Если нет — не обязательно, но желательно. Я хочу убрать это «должны» в случае ударных, заменив жёсткие ограничения на мягкие (настраиваемый штраф). Я ввел фиксированное расстояние между гласными «в вакууме» (например, а-о ближе друг к другу, чем а-и). Расстояние считается через набор субъективных фонетических характеристик произношения — к сожалению, у меня нет данных по «векторам звучания» для каждой буквы. Если ударение падает — умножаю расстояние на достаточно большой коэффициент (можем его уменьшить, если для нас нормальны рифмы вида слава-слово). Понятно, что это не даёт нам индексировать слова по ударным гласным, поэтому во много раз увеличивает работу поиска. В этом нет ничего страшного, это всё равно будет занимать немного времени, для чего-то интересного его не жалко (тем не менее, строгий поиск по ударным гласным можно сделать опциональным — в десятки раз увеличивающий скорость за счёт потери рифм вида слава-слово).Согласные. Использовать что-то вроде редакционного расстояния (минимальное количество операций замены-добавления-вставки букв) плохо: например, с ним сложно работать с близкими по звучанию согласными (р-л-н, п-т-с и тп). Конечно, можно сделать редакционное расстояние с весами (ссылка на вики), сделав “дешевой” замену близких по звучанию букв, но все равно будут возникать проблемы с дублирующимися согласными (например, лак – мрак, буква «л» одновременно близка и к «м», и к «р», но низкий вес замены применится только к одной из букв, если дополнительно не усложнять метрику). А еще сильно хуже будут оцениваться перестановки (пакля-капля). Поэтому сделаем проще: пройдемся по всем парам согласных, и будем складывать расстояния между согласными с тем меньшим весом, чем дальше они друг от друга и конца слова. Это O(n²), но слова у нас не слишком длинные, а времени для интересных комбинаций не жалко. Ну и бонус для перестановок обеспечим дополнительным штрафом на “новые буквы”, пропорциональному размеру симметрической разницы множеств букв, встречающихся в словах.
Если у нас одно слово — перестановка другого, мы не добавили новых букв, значит, слагаемое обнулится.Структура согласных. Количество подряд идущих согласных после соответствующей гласной (рака-арка, из-за изменения структуры рифма не такая строгая, как, например, рака-лака — согласные тоже требуют время, чтобы себя произнести). Считаем соответствующее изменения длины после каждой гласной, возводим в степень, складываем.
 В случае сайтов все просто — если ударение падает на гласные, то гласные должны совпадать. Если нет — не обязательно, но желательно. Я хочу убрать это «должны» в случае ударных, заменив жёсткие ограничения на мягкие (настраиваемый штраф). Я ввел фиксированное расстояние между гласными «в вакууме» (например, а-о ближе друг к другу, чем а-и). Расстояние считается через набор субъективных фонетических характеристик произношения — к сожалению, у меня нет данных по «векторам звучания» для каждой буквы. Если ударение падает — умножаю расстояние на достаточно большой коэффициент (можем его уменьшить, если для нас нормальны рифмы вида слава-слово). Понятно, что это не даёт нам индексировать слова по ударным гласным, поэтому во много раз увеличивает работу поиска. В этом нет ничего страшного, это всё равно будет занимать немного времени, для чего-то интересного его не жалко (тем не менее, строгий поиск по ударным гласным можно сделать опциональным — в десятки раз увеличивающий скорость за счёт потери рифм вида слава-слово).
В случае сайтов все просто — если ударение падает на гласные, то гласные должны совпадать. Если нет — не обязательно, но желательно. Я хочу убрать это «должны» в случае ударных, заменив жёсткие ограничения на мягкие (настраиваемый штраф). Я ввел фиксированное расстояние между гласными «в вакууме» (например, а-о ближе друг к другу, чем а-и). Расстояние считается через набор субъективных фонетических характеристик произношения — к сожалению, у меня нет данных по «векторам звучания» для каждой буквы. Если ударение падает — умножаю расстояние на достаточно большой коэффициент (можем его уменьшить, если для нас нормальны рифмы вида слава-слово). Понятно, что это не даёт нам индексировать слова по ударным гласным, поэтому во много раз увеличивает работу поиска. В этом нет ничего страшного, это всё равно будет занимать немного времени, для чего-то интересного его не жалко (тем не менее, строгий поиск по ударным гласным можно сделать опциональным — в десятки раз увеличивающий скорость за счёт потери рифм вида слава-слово).
 Если у нас одно слово — перестановка другого, мы не добавили новых букв, значит, слагаемое обнулится.
Если у нас одно слово — перестановка другого, мы не добавили новых букв, значит, слагаемое обнулится.В принципе, этих основных метрик может быть достаточно для простого подбора, но вот ещё несколько, которые помогут найти именно нужную нам рифму:
Длина слова — хочется дать штраф подбираемым словам, которые слишком короткие/длинные. Совсем короткие человеку и самому подобрать несложно, а слишком длинные часто сложно запихнуть в стих (как правило, они еще не будут подходить по стилю).
Популярность. Помните те «сакля, набрякла» в начале статьи? Не думаю, что эти слова известны большинству.
Это частично лечится фильтрацией словаря от устаревших, неупотребляемых и прочих слов, но что-то обязательно останется. Подобные слова хочется учитывать, но накладывать штраф, чтобы мы в первую очередь получали “нормальные слова”. Берём индекс слова по популярности, возводим в некоторую степень.
 Это частично лечится фильтрацией словаря от устаревших, неупотребляемых и прочих слов, но что-то обязательно останется. Подобные слова хочется учитывать, но накладывать штраф, чтобы мы в первую очередь получали “нормальные слова”. Берём индекс слова по популярности, возводим в некоторую степень.
Это частично лечится фильтрацией словаря от устаревших, неупотребляемых и прочих слов, но что-то обязательно останется. Подобные слова хочется учитывать, но накладывать штраф, чтобы мы в первую очередь получали “нормальные слова”. Берём индекс слова по популярности, возводим в некоторую степень.И last, but not least:
Значение слова. Есть такая хорошая штука — word2vec, позволяющая каждому слову с помощью нейросети сопоставить вектор (массив), описывающий «смысл» слова. Это позволяет удобно считать «расстояния» между словами как векторами. Берём готовый словарь для русского языка (результат работы нейронной сети), ловкость рук, и человек уже может указывать, какая должна быть «тематика» нужного слова. Укажет тематику «про любовь», и с меньшей вероятностью будут лезть слова вроде «автоматизация», «канализация» и так далее. Сопоставляем каждой теме набор слов, считаем среднее и стандартное отклонение значений по каждому измерению (задаём тематику), потом суммируем расстояния от среднего и сопоставляем с отклонением по каждому измерению.
Здесь можно было бы применить много статистических методов, например, работать со всей матрицей ковариации, а не только с её диагональю.
 Здесь можно было бы применить много статистических методов, например, работать со всей матрицей ковариации, а не только с её диагональю.
Здесь можно было бы применить много статистических методов, например, работать со всей матрицей ковариации, а не только с её диагональю.Разумеется, работать здесь мы будем уже с транскрипциями, а не самими словами. Русский язык удобен тем, что большинство правил чтения очевидны, если не вдаваться в фонетические тонкости. Это значит, что мы можем генерировать транскрипции при старте программы вместо того, чтобы хранить их в отдельном файле. Идеи генерации транскрипции я опущу, думаю, они интуитивно понятны большинству, кто умеет читать вслух.
Итоговое представление — набор «звуков», объектов, хранящих в себе идентификатор и набор «модификаторов»: мягкость, звонкость, ударность (у гласных) — они будут немного влиять на оцениваемое расстояние между звуками.
Реализация рифматора
Использовал словарь Зализняка (есть в свободном доступе, и в нем есть все возможные склонения-спряжения слов), пересёк его с word2vec, обученном на литературе из открытого доступа. Получил базу из 30 000 семейств слов, 700 000 словоформ. Не слишком много — нет многих современных и специализированных слов, но оно нам и не особо надо.
Получил базу из 30 000 семейств слов, 700 000 словоформ. Не слишком много — нет многих современных и специализированных слов, но оно нам и не особо надо.
Прототип «рифматора» с основными метриками писал на питоне, скорость была соответствующая — процесс поиска рифмы растягивался на несколько минут. Конечно, процесс можно было ускорить за счет разных оптимизаций, но язык явно неподходящий.
Я как раз планировал освоить Rust, поэтому решил попробовать переписать на него (заодно окунуться в язык). Rust — язык, безусловно, очень интересный и приятный, про него в целом на Хабре написано много. Скорость сравнима с плюсами, но из-за четкой системы «правил» язык не допускает проблем с памятью, в целом гарантируется более предсказуемое поведение (потребность в дебаге практически отпадает, практически всё ловится на этапе компиляции с приличным объяснением, что именно не так). К слову, на базовом уровне освоить его достаточно легко даже без серьезного опыта работы с C-подобными языками, если не лезть в самом начале в самые лютые внутренности.
Rust хорош в оптимизации, так что возможность задавать пользовательские расстояния между буквами пришлось сделать опциональной (в дефолтной сборке отключены) — функция расчета расстояния вызывается абсолютно безумное число раз, и отказ от статически заданных коэффициентов уменьшает скорость примерно в 1.5 раза. Все остальные коэффициенты полностью настраиваются через файл.
Повозившись с оптимизацией памяти, я за счёт переиспользования данных довел потребление памяти поиска до <200 Мб — для быстрого поиска требуется хранить сгенерированные транскрипции всех слов, все значения слов (напомню, каждый — вектор над 32-битным float с размерностью 150), части речи и подобное. Добавил ту самую опциональную индексацию (достаточно выставить indexation: true в конфигурационном файле) — время поиска уменьшается с ~ 600 мс до 50-150 мс (зависит от «популярности» ударной комбинации; тестировал на относительно приличном ноутбуке).
Добавил ту самую опциональную индексацию (достаточно выставить indexation: true в конфигурационном файле) — время поиска уменьшается с ~ 600 мс до 50-150 мс (зависит от «популярности» ударной комбинации; тестировал на относительно приличном ноутбуке).
К поиску рифмы очень близка задача вида «подобрать слово, подходящее по ритму». Допустим, что для ритмической структуры необходимо слово из трёх слогов со смыслом «сильный, твёрдый», но чтобы ударение падало на последний слог. Я решил встроить такой поисковик внутрь «рифматора». Используя индексацию ударных слогов, мы легко можем найти слова с нужной комбинацией слогов. Немного регулярных выражений — и можно создавать свои «словесные паттерны» с нужными ударными слогами. Из подходящих остается только выделить наиболее близкие по смыслу. Обозначим «+» за безударный слог, «!» — за ударный. Задачу выше можно сформулировать запросом «++!», или двумя запросами «++и’й», «++о’й», если нам важна часть речи и окончание (и вуаля, мы получили «волевой»).
Код подборщика лежит в отдельном репозитории, можно использовать и как библиотеку, и как самостоятельную консольную утилиту. Итак, вот мой вывод из консоли рифм к слову «пакля» на текущих стандартных настройках (без использования фильтра по смыслу, с ним можно получить гораздо более полезные результаты):
["палка", "балка", "капля", "лапка", "пакля", "блага", "пугала", "копала", "поляка", "бокала", "купала", "покупала", "погибала", "полагала", "погуляла", "убегала", "огибала", "облегала", "кляпа", "копала", "колебала", "облекала", "опекала", "обегала", "попугала", "углубляла", "поколебала", "плакал", "капал", "поплакал", "оплакал", "покалякал", "глобальна", "бланка", "купальна", "планка", "рыбалка", "полянка", "лубянка", "напугала", "капрала", "пробегала", "набегала", "беглянка", "покарала", "обругала", "пролегала", "балагана", "поиграла", "понукала", "пеликана", "прогуляла", "накопала", "баклана", "бабка", "обыграла", "поругала", "капеллана", "обокрала", "бака", "вбегала", "капилляра", "помогала", "выбегала", "покивала", "выкупала", "выгибала", "обмякла", "прялка", "паковала", "помыкала", "купальня", "обмякла", "клапан", "упаковала", …]
Может, само по себе оно не очень впечатляет, но попробуйте поиграть настройками, добавлять смысловые требования, поискать хорошую рифму в реальном примере. Настройки можно менять до безумия, например, вместо того, чтобы сильнее учитывать похожесть согласных в конце слова, требовать похожести в начале (сделать коэффициент важности концовки отрицательным). Будет что-то новое и забавное.
Настройки можно менять до безумия, например, вместо того, чтобы сильнее учитывать похожесть согласных в конце слова, требовать похожести в начале (сделать коэффициент важности концовки отрицательным). Будет что-то новое и забавное.
Графическая оболочка
Для разработки самого редактора нашел интересный фреймворк на Rust: Tauri. Позволяет использовать веб-технологии для пользовательского интерфейса (js, css, говорят о поддержке практически всех веб-фреймворков), а тяжелую логику выносить на Rust-backend. Tauri позволяет вызывать команды, прописанные в Rust
Serialize / Deserialize из serde (популярная, почти стандартная библиотека для чтения/записи чего только можно). Rust, в свою очередь, способен «триггерить» события, которые сможет обработать JS. Вся эта химера оборачивается в аккуратный установщик с минимумом усилий и кучей настроек.
Увы, я не владею серьезными веб-фреймворками, поэтому реализовал для начала совсем примитивный GUI на голом JS+CSS. Так как код уже набирает вес, начинаю задумываться о том, чтобы переписать на что-нибудь вроде React+TS+SASS, но руки пока не дошли.
Я сначала хотел сделать подбор рифмы в качестве автоподсказки, но потом решил, что поэту виднее, когда, какая и к чему она ему нужна. Автоподсказка почти наверняка будет отвлекать и раздражать. Я встроил поиск в нижнюю панельку, рядом поместил выбор смысла и настроек.
Следующий этап — подсветка. К сожалению, обычные библиотеки для подсветки кода мне не подходят — моя подсветка принципиально отличается от “обычной” — никаких ключевых слов, каждую букву нужно подсвечивать отдельно по непримитивным правилам (например, поиск ударения в каждом слове с правильным учётом модификаторов вроде пользовательского ударения). Покопался я в библиотеках, плюнул, пошел заниматься велосипедостроением — написал на коленке свой contentedible элемент, прописав руками операции вроде вставки или отмены. Меня до сих пор коробит от этого решения, так что если кто-то знает, как это сделать более адекватно — я был бы очень рад об этом услышать.
Меня до сих пор коробит от этого решения, так что если кто-то знает, как это сделать более адекватно — я был бы очень рад об этом услышать.
Итак, с цветами разобрались, посмотрим, что получается (подсветим ударения жёлтым, отсутствие — зелёным, односложные слова — красным, незнакомые — фиолетовым):
Общий вид редактора Поле ввода снизу — поле для поиска рифмНе очень наглядно, ничего непонятно. Нужно сделать как-то так, чтобы все гласные были друг под другом одного размера, а согласные куда-то исчезли. Сами буквы тоже отвлекают внимание. Попробуем убрать вообще все (разумеется, как и для других похожих действий, для это есть хоткеи), оставим только квадратики цвета, соответствующие гласным:
Воу, выглядит прикольно. Очень хорошо видно ритмическую структуру.Здесь я взял «чудное мгновенье» Пушкина, для сравнения — кусочек сказки о рыбаке и рыбке (большинство отклонений от ритма вызваны неоднозначностями в ударениях, их легко проставить руками):
Видно, что ритм бывает разным, выдавать ошибки/предупреждения было бы очень плохо.
Для более точной структуры пришлось проставлять ударения, программа пока не умеет определять их, исходя из контекста (у мо’ря-моря’). Чтобы стихи с рваным ритмом тоже можно красиво было отобразить (для аккуратного чтения которых нужно тянуть некоторые гласные, быстро проговаривать другие, и делать паузы после третьих), я добавил возможность использовать «модификаторы длины звучания». Вот посмотрите, это:
Обратите внимание на спецсимволы в первых двух словахОтобразится как
Внимание на первую клеткуОтлично, мы «починили» ритм в первой строчке. Не уверен, что этим реально кто-то сможет пользоваться, но однозначно полезно.
Ассонансы (созвучие гласных) и аллитерации (согласных) могут быть менее полезными непосредственно для «поимки» кривостей звучания, но всегда можно просто полюбоваться своими/чужими созвучиями. Такой метод позволяет увидеть много неявных вещей (я думаю, что-то подобное наверняка должно использоваться у профессиональных литературоведов).
Вот например, посмотрите на этот интересный переход в гласных в последних трёх строфах «чудного мгновения»:
Во первых двух строфах нарастает и возвращается большое количество «а», а в третьей — резко выстраиваются соседние линии из «и» и «о», что делает последнюю строфу по звучанию именно «финальным аккордом» всего стихотворения.
А вот аллитерации в той же последней строфе (да, оно пока немного кашеобразное, но видно):
Номенклатура соответствий цвета и букв достаточно сложная — опустим её. Будем наслаждаться картинкой без понимания, что за ней стоит.Очень много созвучий б-в-г (тёмно-красный/коричневый), подчеркивающие финальное слово «любовь».
Реальная полезность такого «цветового анализа» может быть под вопросом, но кажется забавным.
Фишки «классического редактора» я не реализовывал. Пока там нет даже классического блокнотского «Save as» и «Open» (зато есть автосохранение, без него было бы грустно). В случае редактирования стиха мне кажется приемлемой практикой работать через «вырезать-вставить нужную строфу». Конечно, рано или поздно такими вещами озаботиться надо будет, но для «Proof of concept» пойдёт.
Выводы
Итак, мы умеем круто искать рифму. Можем искать рифму, больше всего подходящую по смыслу — выбирая из нескольких встроенных, определив её из контекста стиха автоматически или задав «руками», перечислив характерные слова. Можем копаться в огромной куче настроек звучания подбираемой рифмы, ища идеальную комбинацию или настраивая под себя. Умеем легко определять ритмические ошибки из приятного визуального представления, не нужно занудно расставлять ударения и высчитывать ритм. Можем добавить модификаторы и по-прежнему пользоваться благами визуализации, если наш стих нужно читать по-особенному (если нужно сделать паузу, что-то быстро проговорить, что-то медленно). Ну и в качестве приятного бонуса — можем насладиться «цветовым звучанием» стиха по гласным и согласным.
В целом я доволен и тем, что выбрал Rust, и конкретно Tauri — работать быстро, удобно, приятно. Приложение потребляет чуть больше 300 Мб оперативки, установщик со всеми встроенными сжатыми словарями весит 14 Мб, загрузка и транскрипция словарей при старте приложения занимает <3-5 с, поиск рифмы — 15-600 ms (зависит от слова и наличия индексации), скорость работы вполне приличная.
Приложение ни в коем случае не пишет стихи за человека. Оно не указывает ему, как писать. Это просто инструмент, с которым может быть немного проще найти и исправить свои ошибки. Может быть, с его помощью можно удобнее шлифовать «стихи» от нейронных чат-ботов. Ни в коем случае программа не уменьшает ценность труда «настоящих поэтов» — настоящая поэзия заключается отнюдь не в построении правильного ритма и подбора хорошей рифмы. Я надеюсь, что такой инструмент просто поможет уменьшить количество откровенно плохих стихов.
Я не претендую на идеальность моих метрик, их реализаций, разумности подсветки и, в особенности — на качество GUI. Это скорее именно «Proof of concept». Но мне кажется, идея забавная, и если её правильным образом развить и доработать, на выходе можно получить что-то крутое. Я несчастный голодный студент-физик, особо времени-сил заниматься этим нет, так что весь код лежит в репозитории под лицензией GPL, если кто вдруг заинтересовался — можно попробовать подобрать свои коэффициенты для настроек или помутить что-то своё, я буду в любом случае рад.
В репозитории в релизах лежат установщики. Всё полностью упаковано в bundle, благодаря Github Actions в большинстве случаев собирать под себя не надо. Под Виндой проблем не должно быть, под Линуксом могут возникнуть заминки с зависимостями на некоторых версиях. Мне удалось с моими разобраться, но там были какие-то очень грязные методы, в сём благочестивом святилище им не место. Они вроде общие для всего Tauri, но почему-то инструкции по их обходу найти у меня не получилось. Под Mac оно почти наверняка работать не будет, благо не тестировалось.
Tauri недавно выпустило возможность деплоить под Android, чем я хочу воспользоваться — в реальности очень немногие пишут стихи на рабочем месте за компьютером — в этой ситуации обычно возникают совсем другие мысли, очень тяжело настроиться на “возвышенное”. Совсем другое дело — сидя с телефоном на лавочке у пруда под опадающими листьями (хотя тут тоже возможны варианты). К сожалению, для Androidтребуется как минимум полная переработка GUI, так что одними моими силами оно появится нескоро.
Конечно, сейчас IDE очень минималистичное, но с ним можно сделать кучу всего интересного. В первую очередь — увеличить количество метрик, создать коллекцию полезных настроек, глубже закопаться в качество. Можно, например, руками или с помощью оптимизационных алгоритмов подобрать настройки, выдающие рифмы, характерные для известных авторов. Можно оптимизировать, распараллелить подбор рифм. Можно адаптировать код для сайта. Мне кажутся лишними в таком приложении такие вещи, как, например, ассистент-нейронная сеть. Не очень хорошо делать и анализ стиха — количественные характеристики вряд ли смогут быть объективными, привязка к конкретным «показателям качества» ни к чему хорошему не приводила. Впрочем, кто знает?
В принципе, ничто не мешает адаптировать такой редактор и на другие языки — на русском просто заметно проще создавать транскрипции и напрямую связывать букву-звук на уровне подсветки. Если найти нужные словари с транскрипциями, не очень тяжело создать версии и для других языков.
На самом деле дискуссионный вопрос — а возможны ли в принципе популярные среди поэтов специализированные редакторы для поэзии? Само наличие такого инструмента ставит свои морально-этические вопросы. Будут ли ими пользоваться, даже если они станут по-настоящему крутыми? А главное — кто, профессиональные поэты или сочинители рекламных слоганов? Как поэты будут относиться к такой «редактуре»? До какой степени редактор «вправе» помогать поэту?
В моём случае помощь минимальная, которая просто помогает сократить немного «механической» работы, но что будет, если/когда появятся редакторы, проникающие в структуру гораздо глубже? Время покажет…
4 буквы — один звук: Улучшите правописание с помощью 5 списков слов из 4-буквенных графем
Научиться правильному написанию больших слов может быть легко с помощью этих 5 списков слов из графем , состоящих из 4 букв. Наличие всех этих слов в одном месте, включая графемы из 4 букв, делает изучение правописания новых слов очень увлекательным.
Важно научиться правильно писать слова, в которых есть графема, так как это необходимо для беглого чтения. Наши списки включают повседневные слова, которые дети могут использовать при написании стихов, коротких рассказов и создании заметок в своем дневнике.
Дети могут создавать свои собственные плакаты, карточки, диаграммы и проекты с этими словами, чтобы улучшить свои навыки правописания во время учебы.
НАЖМИТЕ ЗДЕСЬ, чтобы улучшить навыки правописания и чтения с помощью 10 КНИГ КОРОТКИХ ИСТОРИЙ с рифмами .
барабаны
Овальные голубые очки
US 6,00 $
Купить сейчас
Что такое графема с 4 буквами
График с 4 буквами, представляющими один звук в словом. У него нет официального названия, но многие учителя называют его «квадрографом».
Буквы «ау» в слове «поймал» считаются «квадраграфом», так как звучат как слово «или».
Но «смех» в «смехе» — это не «квадрограф». Его можно описать как комбинацию двух диграфов «au», звучащих как «ah», и «gh», звучащих как «f», как в «laf».
Точно так же «ough» в «хотя» считается «квадраграфом», так как звучит как «о» в «холодном».
Но «ough» в «жестком» и «засухе» не является «квадрографом».
В слове «tough» его можно описать как комбинацию двух диграфов «ou», звучащих как «uh», и «gh», звучащих как «f», как в «tuf».
В слове «засуха» «ou» — это дифтонг, звучащий как «ow», а «ght» — это триграф, звучащий как «t».
Чтобы лучше понять графемы, состоящие из 4 букв, вы можете прочитать, что такое фонема , графема , диграф и триграф .
Для дальнейшего чтения вы даже можете узнать о гласных , согласных , правил правописания , аффиксах и взглянуть на эту статью на интервенция чтения для отстающих учащихся.
Списки слов для графем из 4 букв
Вот 5 списков слов для графем из 4 букв. Это augh, eigh, ough, ngue и heir.
A TUGHпоймал, ни была, дочь, обезумевшая, бойня, непослушная, неважно, чревала, преподавана, аухт, дистринг, божеучка, пачина, внучка
Eught 9, Eight Eight, Eight Eight, Eight Eight, Eight Eight, Eight Eight, Eight Eight, Eight Eight, Eight Eight, Eight. восемнадцать, восемьдесят, взвешивать, вес, перевешивать, фрахт, ржать, сосед, соседство, сани, высота, увеличивать, легкий, тяжеловес, недостаточный вес, избыточный вес, пресс-папье, дедвейт тьфухотя, хотя, основательный, проходной, тесто, пончик, район
думал, задумался, необдуманно, запоздало, купил, принес, должен, искал, ноль, боролся, ковырял
через, на протяжении, прорыв
ngueязык, язык, жила, язык, меренга
наследникнаследник, реликвия, наследство, наследство, сонаследники 05 90 заключение0029
Эти 5 списков слов для графем с 4 буквами очень полезны для упражнений по правописанию. Студенты могут использовать их для создания плакатов, карточек, диаграмм, стихов, рассказов и заметок в журнале. Сделайте время обучения веселым с помощью этих слов и быстро освойте правописание и чтение.
Study Zone Institute
Когда вы покупаете что-либо через наши розничные каналы связи, мы можем получать комиссионные, а розничный продавец может получать определенные данные, подлежащие проверке, для целей бухгалтерского учета.
См. также:
Алфавит: 7 Основных вещей, которые нужно знать о буквах и звуках ТРЕЗИ Words -an ending: Загрузите 6 бесплатных рабочих листов для трассировки Words -at ending: Загрузите 8 бесплатных рабочих листов для трассировки Words -am ending: Загрузите 5 бесплатных рабочих листов для трассировки Двух букв Слова: Скачать 5 бесплатных рабочих листов для отслеживания ТРЕБОВЫ Гласные – слоги, диграфы, триграфы, долгие, краткие и немые Согласные – диграфы, триграфы, твердые, мягкие, смешанные, немые звуки Spelling rules for ch, tch, ck, k, oi, oy, ou, ow, ie, ei Affixes – rules for adding prefixes and suffixes Phonological and фонематическая осведомленность: помогите читателю, испытывающему затруднения, со звукамиНравится:
Нравится Загрузка. ..
Расшифровать ЗВУК — Расшифровать 47 слов из букв в ЗВУК
ЗВУК расшифровывает и составляет 47 слов!Начинается с
Заканчивается на
Содержит
Реклама:
47 Расшифрованные слова из букв ЗВУКСлова из 5 букв, составленные из расшифровки букв ЗВУК
- узел
- звук
- удон
- отменяет
- сырой
Слова из 4 букв, образованные расшифровкой букв ЗВУК
- доны
- Доун
- серовато-желтые
- дуэты
- кивает
- ноус
- ответственность
- звуки
- шлепать
- удон
- удос
- отменить
Слова из 3 букв, образованные расшифровкой букв ЗВУК
- дон
- душ
- дсо
- серый
- дуэт
- кивок
- нет
- нус
- ОД
- ons
- уд
- мы
- дерн
- сын
- су
- суд
- солнце
- ты делаешь
- удс
- uns
Слова из 2 букв, образованные расшифровкой букв ЗВУК
- делать
- нет
- ню
- од
- на
- Операционные системы
- ОУ
- так
- ООН
- нас
Сколько слов можно составить из звука?
Выше приведены слова, полученные путем расшифровки S O U N D (DNOSU) . Наш поисковик слова расшифровал эти буквы, используя различные методы, чтобы сгенерировать 47 слов ! Наличие такого инструмента для расшифровки, как наш, поможет вам во ВСЕХ играх со словами!
Сколько слов можно составить из ЗВУКА?
Чтобы еще больше помочь вам, вот несколько списков слов, связанных с буквами ЗВУК.
- Слова из 5 букв
- слов, начинающихся с S
- Слов, Оканчивающихся на D
- Слова, начинающиеся со ЗВУКА
- Слова, содержащие ЗВУК
- Слова, оканчивающиеся на ЗВУК
- Различные способы кодирования ЗВУКА
S O U N D Значения букв в Word Scrabble и Words With Friends
Вот значения букв S O U N D в двух самых популярных играх со словами.
Эрудит
Буквы ЗВУК стоят 6 очков в Эрудит
- S 1
- О 1
- У 1
- Н 1
- Д 2
Слова с друзьями
Буквы ЗВУК стоят 8 баллов в Words With Friends
- S 1
- О 1
- У 2
- Н 2
- Д 2
Если расшифровать ЗВУК.
.. Что это значит?Определение ЗВУКА в расшифрованном виде
Если расшифровать эти буквы, ЗВУК, то из них и получится несколько слов. Вот одно из определений слова, в котором используются все незашифрованные буквы:
узел
- Извините. У меня нет значения этого слова.
- Нажмите здесь, чтобы увидеть полное значение слова nodus
- Является ли nodus словом Scrabble?
- является ли nodus словом Words With Friends?
Дополнительная информация о буквах
ЗВУК- Перестановки ЗВУКА
- Анаграммы ЗВУКА
- слов с буквами
Звук расшифровки для других игр Word Scramble
- Звук расшифровки для игр Word Scramble
- Расшифровать звуковые буквы для анаграмм
- ЗВУК в текстовом повороте
- ЗВУК в Эрудит
- ЗВУК в словах с друзьями
- ЗВУК в беспорядке
- Расшифруй слово ЗВУК
- Звук расшифровать для всех словесных игр
Шифрование букв в SOUND
По словам нашего другого создателя скремблирования, SOUND можно скремблировать разными способами. Различные способы перестановки слова называются «перестановками» слова.
Согласно Google, это определение перестановки:
способ, особенно один из нескольких возможных вариантов, в котором можно упорядочить или расположить набор или количество вещей.
Чем это полезно? Что ж, он показывает вам анаграммы звука , зашифрованные по-разному, и помогает вам легче распознавать набор букв. Это поможет вам в следующий раз, когда эти буквы S O U N D появятся в игре со словами.
СОНУД ОНСУД УСНОД ЮНСОД СУНОД СУОНД OUSND УОСНД НСОУД НУСОД СНАУД СНУОД НОСУД НСУОД USOND НУОСД ОСНУД ОСУНД
Мы остановились на 18, но есть так много способов зашифровать ЗВУК !
Word Scramble Words
- nsapmesat
- жирное
- нтохрисег
- дсепкоаэс
- нет жизни
- герсбупус
- эркселонр
- cmaatiins
- оценка
- gbbcinirs
- птатнуар
- ехальргтис
- годовщина
- нмафтирог
- sppgieolt
- нурисибмг
- еантизмы
- телолабме
- нтеснифог
- нлидкапуд
Расшифруй эти буквы, чтобы получились слова.