Государственное казенное учреждение социального обслуживания Ростовской области центр помощи детям, оставшимся без попечения родителей, "РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7"
Синтетический разбор это: Синтаксический разбор простого предложений — Правила и примеры
SoftCraft: разработка трансляторов (конспект лекций)
Тема 6. Общие принципы организации синтаксического разбора
[
содержание
| предыдущая тема
| следующая тема
]
Содержание темы
Назначение синтаксического разбора. Классификация методов синтаксического разбора.
Назначение синтаксического разбора
Синтаксический разбор (распознавание) является первым этапом синтаксического анализа. Именно при его выполнении осуществляется подтверждение того, что входная цепочка символов является программой, а отдельные подцепочки составляют синтаксически правильные программные объекты.
Вслед за распознаванием отдельных подцепочек осуществляется анализ их семантической корректности на основе накопленной информации. Затем проводится добавление новых объектов в объектную модель программы или в промежуточное представление.
Разбор предназначен для доказательства того, что анализируемая входная цепочка, записанная на входной ленте, принадлежит или не принадлежит множеству цепочек порождаемых грамматикой данного языка. Выполнение синтаксического разбора осуществляется распознавателями, являющимися автоматами. Поэтому данный процесс также называется распознаванием входной цепочки. Цель доказательства в том, чтобы ответить на вопрос: принадлежит ли анализируемая цепочка множеству правильных цепочек заданного языка. Ответ «да» дается, если такая принадлежность установлена. В противном случае дается ответ «нет». Получение ответа «нет» связано с понятиям отказа. Единственный отказ на любом уровне ведет к общему отказу.
Чтобы получить ответ «да» относительно всей цепочки, надо его получить для каждого правила, обеспечивающего разбор отдельной подцепочки.
Так как множество правил образуют иерархическую структуру, возможно с рекурсиями, то процесс получения общего положительного ответа можно интерпретировать как сбор по определенному принципу ответов для листьев, лежащих в основе дерева разбора, что дает положительный ответ для узла, содержащего эти листья. Далее анализируются обработанные узлы, и уже в них полученные ответы складываются в общий ответ нового узла. И так далее до самой вершины. Данный принцип обработки сильно напоминает бюрократическую систему, используемую в организационном управлении любого предприятия. Так поднимается наверх информация, подтверждающая выполнение указания начальника организации. До этого, теми же путями, вниз спускалось и разделялось исходное указание.
Классификация методов синтаксического разбора
Если попытаться формализовать задачу на уровне элементарного метаязыка, то она будет ставиться следующим образом. Дан язык L(G) с грамматикой G, в которой S — начальный нетерминал. Построить дерево разбора входной цепочки
a = a1a2a3…an.
Естественно, что существует огромное количество путей решения данной задачи, и целью разработчика распознавателя является выделение приемлемых вариантов его реализации. Для того, чтобы понять, что, и каким образом, влияет на принципы функционирования распознавателя, а следовательно, и на организацию разбора, рассмотрим некоторые возможные варианты. Общая классификация рассматриваемых вариантов построения распознавателя представлена на рис. 6.1.
На самом верхнем уровне выделяются:
методы разбора;
последовательность разбора;
использование просмотра вперед;
использование возвратов.
Методы разбора
Выделяются два основных метода синтаксического разбора:
нисходящий разбор;
восходящий разбор.
Кроме этого можно использовать комбинированный разбор, сочетающий особенности двух предыдущих.
Нисходящие и восходящие подходы широко используются в различных областях человеческой деятельности, особенно в тех из них, которые связаны с анализом и синтезом искусственных систем. В частности, можно отметить методы разработки программного обеспечения сверху вниз (нисходящий) и снизу вверх (восходящий).
Нисходящий разбор заключается в построении дерева разбора, начиная от корневой вершины. Разбор заключается в заполнении промежутка между начальным нетерминалом и символами входной цепочки правилами, выводимыми из начального нетерминала. Подстановка основывается на том факторе, что корневая вершина является узлом, состоящим из листьев, являющихся цепочкой терминалов и нетерминалов одного из альтернативных правил, порождаемых начальным нетерминалом. Подставляемое правило в общем случае выбирается произвольно. Вместо новых нетерминальных вершин осуществляется подстановка выводимых из них правил. Процесс протекает до тех пор, пока не будут установлены все связи дерева, соединяющие корневую вершину и символы входной цепочки, или пока не будут перебраны все возможные комбинации правил. В последнем случае входная цепочка отвергается. Построение дерева разбора подтверждает принадлежность входной цепочки данному языку. При этом, в общем случае, для одной и той же входной цепочки может быть построено несколько деревьев разбора. Это говорит о том, что грамматика данного языка является недетерминированной.
Эти рассуждения иллюстрируются следующим примером. Пусть будет дана грамматика G:
G6 = ({S}, {a, +, *}, P, S)
,
Где P определяется как:
S → a
S → S + S
S → S * S
Цепочки, порождаемые данной грамматикой можно интерпретировать как выражения, состоящие из операндов «a», а также операций «+» и «*». Недетерминированность грамматики позволяет порождать одну и ту же терминальную цепочки с использованием различных выводов. Например, выражение
И так далее. В этом пример число вариантов одной и той же произвольной цепочки вывода настолько велико, что не имеет и смысла говорить о практическом применении данной грамматики. Но в данном случае она позволяет показать, каким образом могут порождаться различные деревья при нисходящем разборе. Пошаговое построение различных деревьев показано на рис. 6.2, 6.3, 6.4. Можно отметить, что процесс построения дерева совпадает с последовательностью шагов вывода входной цепочки.
При восходящем разборе дерево начинает строиться от терминальных листьев путем подстановки правил, применимых к входной цепочке, опять таки, в общем случае, в произвольном порядке. На следующем шаге новые узлы полученных поддеревьев используются как листья во вновь применяемых правилах. Процесс построения дерева разбора завершается, когда все символы входной цепочки будут являться листьями дерева, корнем которого окажется начальный нетерминал. Если, в результате полного перебора всех возможных правил, мы не сможем построить требуемое дерево разбора, то рассматриваемая входная цепочка не принадлежит данному языку.
Восходящий разбор также непосредственно связан с любым возможным выводом цепочки из начального нетерминала. Однако, эта связь, по сравнению с нисходящим разбором, реализуется с точностью до «наоборот».
На рис. 6.5, 6.6, 6.7 приведены примеры построения деревьев разбора для грамматики G6 и процессов порождения цепочек, представленных выражениями (6.1). Из рисунков видно, что шаги порождения дерева соответствуют движению по представленным цепочкам вывода справа налево.
Комбинированный разбор может быть реализован тогда, когда процесс распознавания разбивается на два этапа. На одном из них осуществляется нисходящий, а на другом — восходящий разбор. Этапов может быть и больше, а порядок их применения — произвольным. Комбинированным можно считать разбор в любом трансляторе, если фазу лексического анализа принять за первый этап, а синтаксического — за второй. При этом лексический анализатор нельзя считать истинным распознавателем, так как осуществляется формирование только одного слоя ветвей в дереве разбора, расположенного над символами входной цепочки (рис.
6.8).
Прямой лексический анализатор будет являться восходящим распознавателем, который может сочетаться с нисходящим. Непрямой же лексический анализ можно рассматривать как нисходящий разбор некоторой подцепочки (осуществляются проверки версий). Поэтому комбинированный разбор будет при его совместном использовании с восходящим распознавателем. В синтаксическом же анализаторе комбинация различных видов разборов обычно не используются, так как в этом нет особого смысла.
Последовательность разбора.
Последовательность разбора определяет, каким образом осуществляется формирование фрагмента дерева разбора на каждом шаге подстановки. Эти подстановки могут осуществляться слева направо, справа налево, произвольно. Различные последовательности разбора можно рассмотреть на примере грамматики G6 и выводов одной и той же цепочки, описанных выражениями 6.1. В первом примере представлен вывод слева направо, когда порождение новой цепочки на каждом шаге осуществляется для самого левого нетерминала. Как только из самого левого нетерминала порождается терминальная цепочка, осуществляется переход к нетерминалу, расположенному правее. Второй пример иллюстрирует выполнение вывода справа налево. Третий и четвертый пример иллюстрируют произвольный порядок вывода. Следует отметить, что использование упорядоченного разбора ускоряет его выполнение за счет уменьшения числа перебираемых правил.
Последовательность разбора непосредственно сочетается с методом разбора. Так, при нисходящем разборе слева направо, подстановка правил вместо самых левых нетерминалов ведет к тому, что входная цепочка распознается с ее начала (рис. 6.2). Нисходящий разбор справа налево ведет к первоначальному подтверждению символов с конца цепочки (рис. 6.3). Наоборот, восходящий разбор слева направо осуществляет замену на нетерминал символов, расположенных в конце цепочки (рис. 6.5). Замена начальных символов производится при восходящем разборе справа налево (рис. 6.6). Произвольный разбор не оговаривает последовательность подстановки правил (рис 6. 4, 6.7). Это ведет к большему количеству переборов.
Повышение эффективности разбора осуществляется разработкой грамматик, специально поддерживающих согласованные между собой метод и последовательность. Так, например, Грамматики, предназначенные для нисходящего разбора, обычно используются для вывода слева направо. Следовательно, и входная цепочка будет разбираться слева направо. Это позволяет быстрее получать нужные символы, а не ждать конца цепочки и лишь потом осуществлять разбор (можно, конечно, саму цепочку разбирать от конца к началу, но это уже из области симметрии). Грамматики, ориентированные на восходящий разбор, обычно оптимизированы под правый вывод входной цепочки, что позволяет, при синтаксическом разборе, опять-таки осуществлять подстановки нетерминалов слева направо.
Использование просмотра вперед.
Языки (как и другие системы) бывают различными по сложности. Ряд из них практически невозможно описать с помощью простых грамматик. Поэтому, в грамматиках могут встречаться альтернативные правила, начинающиеся с одинаковых цепочек символов. Возникающая неоднозначность может быть разрешена путем предварительного просмотра правила на n символов вперед до той границы, начиная с которой данное правило можно будет отличить от других. В контекстно свободных (КС) грамматиках число, определяющее количество символов, анализируемых перед выбором подстановки (1, 2…), используется для классификации. По этому критерию КС грамматики, задаются следующим образом: КС(1), КС(2),…
Просмотр вперед — это один из возможных вариантов упорядочивания подстановок, обеспечивающий решение проблемы недетерминированности. Наряду с ним используются: преобразование грамматик к детерминированным и анализ с возвратами.
Использование возвратов
Синтаксический разбор с возвратами выполняется аналогично тому, как осуществляется непрямой лексический анализ. Возвраты производятся для альтернативных правил, начинающихся с одинаковых подцепочек. В этом случае появление отказа при разборе правила ведет к восстановлению входной головки в то положение, в котором она была да входа в данное правило. Использование возвратов может выступать в качестве альтернативы просмотру вперед. Приоритет правил, определяющий порядок их обхода, назначается также как и при лексическом анализе и зависит от того, является ли некоторое правило подмножеством другого. Метод универсален и легок для понимания и реализации. Однако, такой подход замедляет разбор и может вести к дополнительным издержкам во время семантического анализа и построения объектной модели.
Резюме.
Приведенные варианты организации синтаксического разбора могут встречаться в разнообразных сочетаниях. Однако, при разработке языка программирования всегда необходимо искать разумный компромисс. Несмотря на разнообразие факторов, влияющих на особенности организации разрабатываемого языка программирования, всегда надо учитывать, что:
чем сложнее синтаксис языка программирования, тем сложнее его грамматика;
чем сложнее грамматика, тем больше сложность и универсальность методов разбора;
универсальные методы разбора ведут к более медленному его выполнению.
Поэтому, от начала процесса разработки языка программирования до его реализации постоянно необходимо обеспечивать баланс между сложностью замысла и простотой реализации. Следует также отметить, что усложнение синтаксиса не всегда обеспечивает более удобное восприятие конструкций языка пользователем. Зачастую можно иметь простой синтаксис и удобный для использования язык, поддерживаемый очень быстрым транслятором.
Контрольные вопросы и задания
Назначение синтаксического разбора.
Что является результатом синтаксического разбора?
Назовите основные критерии классификации синтаксического разбора.
Какие существуют методы разбора?
Связь методов разбора с выводом входной цепочки.
Особенности нисходящего разбора.
Особенности восходящего разбора.
Особенности комбинированного разбора.
Какие существуют последовательности разбора?
Связь между методами разбора и последовательностью разбора.
Синтаксический разбор слова и словосочетания, разбор простого и сложного предложения
Среди существующих разборов синтаксический разбор слова, входящего в состав предложения и словосочетания, занимает не последнюю роль: он позволяет дать полную характеристику этих единиц синтаксиса. При этом важно понимать разницу между ними, уметь определять характерные признаки для каждой синтаксической единицы в отдельности. Другими словами, синтаксический разбор – это грамматическая характеристика словосочетания и предложения (как простого, так и сложного).
Среди существующих разборов синтаксический разбор слова, входящего в состав предложения и словосочетания, занимает не последнюю роль: он позволяет дать полную характеристику этих единиц синтаксиса. При этом важно понимать разницу между ними, уметь определять характерные признаки для каждой синтаксической единицы в отдельности. Другими словами, синтаксический разбор – это грамматическая характеристика словосочетания и предложения (как простого, так и сложного).
При таком виде работы очень важно владеть умением различать основные синтаксические единицы и знать характерные признаки каждой из них. Требуются определенные знания и умения в области изучения синтаксиса:
– знание различий между словосочетанием и предложением;
– умение отличить простое предложение от сложного, определить способ синтаксической связи;
– владение знанием характерных признаков предложений и словосочетаний, понимание разницы между грамматической основой и словосочетанием.
Из курса русского языка известно, что основные единицы речи – это слова, словосочетания и предложения. Синтаксический разбор слова (отдельного) не проводится, слова разбираются фонетически и морфологически. А вот другие единицы с точки зрения синтаксиса рассматриваются, и начинается все со словосочетания.
Выполняя синтаксический разбор слова в словосочетании, принято делить слова на главные и зависимые (определяется главное и от него ставится вопрос к зависимому), попутно определяя, к каким частям речи они относятся. Следующий шаг – это выяснение общего грамматического значения (предмет и его признак, действие и его признак, действие и предмет и так далее). Дальше определяется синтаксический способ связи, при помощи которого слова соединяются между собой. В русском языке различают согласование, примыкание и управление. В первом случае зависимое слово стоит при главном в тех же формах, во втором, связывается только по смыслу, в третьем – стоит в определенных формах, которые не меняются.
По порядку синтаксический разбор словосочетания, точнее, его план, выглядит следующим образом:
— определить главное слово и зависимое, поставить вопрос.
— выяснить вид словосочетания (именное, наречное, глагольное).
— указать синтаксическую связь слов в словосочетании.
— при разборе предложения, в первую очередь, выясняется, какое это предложение, простое или сложное, так как для каждого их вида существует свой порядок.
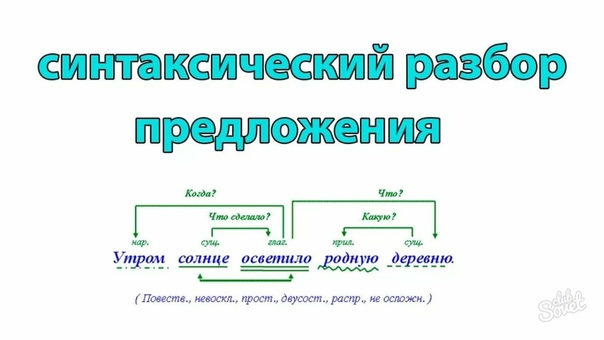
Итак, синтаксический разбор слова (слов), составляющих простое предложение, начинается с определения главных членов, сказуемого и подлежащего. Затем надо выяснить вид предложение по цели высказывания (повествовательное, вопросительное или побудительное), эмоциональной окрашенности (восклицательное или нет). Следующий шаг – определение типа предложения по количеству грамматических основ (односоставное или двусоставное), есть ли в нем второстепенные члены, или нет (распространенное или нераспространенное). Кроме того, следует выяснить наличие однородных или обособленных членов, то есть осложнено оно чем-то или нет.
Анализ сложного предложения несколько отличается от анализа простого. В этом случае надо не только определить грамматические основы и тип предложения, но и доказать, что оно сложное, установить, при помощи какой связи (союзной или бессоюзной) связываются простые предложения в составе сложного. Если синтаксический разбор слов в сложном предложении показывает, что связь союзная, то необходимо определить его принадлежность к типу сложносочиненного или сложноподчиненного. В первом случае это определяется на основе союза – соединительного, разделительного или противительного. Во втором случае нужно найти главное и придаточное предложения, определить, при помощи чего они связаны друг с другом, поставить вопрос и указать тип. В бессоюзном предложении, прежде всего, выясняется смысловая связь между частями и правильность постановки знаков препинания. И, наконец, заключительный этап любого синтаксического разбора – это составление схемы предложения или словосочетания, иными словами – графическое обозначение выполненного действия.
С# — Что такое синтаксический анализ?
спросил
Изменено
3 года, 2 месяца назад
Просмотрено
93 тысячи раз
Синтаксический анализ — это то, с чем я часто сталкиваюсь в процессе разработки, но, будучи младшим, я предполагаю, что в какой-то момент освою его, когда это понадобится. В моем текущем проекте мне сказали найти и использовать синтаксический анализатор HTML для определенной функции, я нашел пару в Интернете.
Но что на самом деле делает анализатор HTML? И что значит парсить объект?
С#
разбор
HTML-разбор
1
Синтаксический анализ обычно применяется к тексту — акт чтения текста и преобразования его в более полезный формат в памяти, «понимание» того, что он означает в некоторой степени. Так, например, синтаксический анализатор XML возьмет последовательность символов (или байтов) и преобразует их в элементы, атрибуты и т. д.
В некоторых случаях (особенно в компиляторах) существует разделение между лексическим анализом и синтаксическим анализом, поэтому реальная «понимающая» часть синтаксического анализатора работает с последовательностью токенов (идентификаторы, операторы и т. д.), а не с необработанными символами.
Синтаксический анализ берет набор данных и извлекает из него содержательную информацию. При синтаксическом анализе HTML вы хотите прочитать HTML-код и вернуть структурированный набор тегов и текста
. Вы можете начать здесь: http://en.wikipedia.org/wiki/Parsing. Краткий отрывок:
Разбор или синтаксический анализ — это процесс анализа строки
символы на естественном языке или на компьютерных языках,
в соответствии с правилами формальной грамматики. Термин разбор приходит
от латинского pars (orationis), что означает часть (речи).
0
Parse (компьютеры) , Dictionary.com:
Анализировать (строку символов), чтобы связать группы символов с синтаксическими единицами базовой грамматики.
2
Синтаксический анализатор — это компонент компилятора/интерпретатора, который разбивает данные на более мелкие элементы для облегчения перевода на другой язык. Синтаксический анализатор принимает входные данные в виде последовательности токенов или программных инструкций и обычно строит структуру данных в виде дерева синтаксического анализа или абстрактного синтаксического дерева.
В информатике и лингвистике синтаксический анализ или, более формально, синтаксический анализ — это процесс анализа текста, составленного из последовательности токенов (например, слов), для определения его грамматической структуры по отношению к заданному ( более или менее) формальная грамматика.
:0)
Википедия
1
Это процесс идентификации токенов [тегов, атрибутов] внутри HTML.
Не пытайтесь самостоятельно написать что-либо, кроме тривиального синтаксического анализатора. Есть хорошие инструменты для этого использования ANTLR и bison — два, о которых я могу думать.
Если вы используете инструменты, вы сможете обратиться за помощью, когда столкнетесь с проблемой.
ура,
Мартин.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
peg — Как обрабатывать семантические ошибки в TatSu при правильном разборе?
Задавать вопрос
спросил
Изменено
1 год, 11 месяцев назад
Просмотрено
203 раза
Я пытаюсь создать анализатор TatSu для языка, содержащего C-подобные выражения. ‘<{bitwise_and_expr}+
;
побитовое_и_выражение =
'&'<{equality_expr}+
;
равенство_выражение =
('==' | '!=')<{comparison_expr}+
;
сравнение_выражение =
('<' | '<=' | '>‘ | ‘>=’)<{bitshift_expr}+
;
битовое_выражение =
('<<' | '>>’)<{additive_expr}+
;
add_expr =
('+' | '-')<{multiplicative_expr}+
;
мультипликативное_выражение =
('*' | '/' | '%')<{unary_expr}+
;
унарное_выражение =
'+' ~ атом
| '-' ~ атом
| '~' ~ атом
| '!' ~ атом
| атом
;
атом =
буквальный
| helper_call
| в скобках
| var_or_param
;
буквальный =
значение: тип с плавающей запятой: `поплавок`
| значение: целое число тип: `int`
| значение: char тип: `char`
| значение: строка тип: `строка`
| значение: bool тип: `int`
| значение: null тип: `null`
;
helper_call =
функция: идентификатор '(' ~ params:expression_list ')'
;
var_or_param =
идентификатор
;
в скобках =
'(' ~ @:выражение ')'
;
9helper_call
атом
unary_expr
мультипликативное_выражение
. ..
Попытка подогнать его под правило helper_call не увенчалась успехом, тогда как правило var_or_param должно было подойти. Оказывается, причиной стал ошибочный FailedSemantics , поднятый семантическими действиями по var_or_param . Как только я это исправил, синтаксический анализ заработал, как и ожидалось.
В связи с этим возникает вопрос: если FailedSemantics влияет на логику синтаксического анализа, как правильно предупредить пользователя о семантической ошибке, но в остальном логика синтаксического анализа верна и не должна пытаться использовать другие варианты или правила? Например, несоответствие типов или использование переменных перед объявлением? (В идеале таким образом, чтобы по-прежнему отображался номер строки, в которой произошла ошибка.)


 Построить дерево разбора входной цепочки
Построить дерево разбора входной цепочки
 Вместо новых нетерминальных вершин осуществляется подстановка выводимых из них правил. Процесс протекает до тех пор, пока не будут установлены все связи дерева, соединяющие корневую вершину и символы входной цепочки, или пока не будут перебраны все возможные комбинации правил. В последнем случае входная цепочка отвергается. Построение дерева разбора подтверждает принадлежность входной цепочки данному языку. При этом, в общем случае, для одной и той же входной цепочки может быть построено несколько деревьев разбора. Это говорит о том, что грамматика данного языка является недетерминированной.
Вместо новых нетерминальных вершин осуществляется подстановка выводимых из них правил. Процесс протекает до тех пор, пока не будут установлены все связи дерева, соединяющие корневую вершину и символы входной цепочки, или пока не будут перебраны все возможные комбинации правил. В последнем случае входная цепочка отвергается. Построение дерева разбора подтверждает принадлежность входной цепочки данному языку. При этом, в общем случае, для одной и той же входной цепочки может быть построено несколько деревьев разбора. Это говорит о том, что грамматика данного языка является недетерминированной. Недетерминированность грамматики позволяет порождать одну и ту же терминальную цепочки с использованием различных выводов. Например, выражение
Недетерминированность грамматики позволяет порождать одну и ту же терминальную цепочки с использованием различных выводов. Например, выражение 


 Как только из самого левого нетерминала порождается терминальная цепочка, осуществляется переход к нетерминалу, расположенному правее. Второй пример иллюстрирует выполнение вывода справа налево. Третий и четвертый пример иллюстрируют произвольный порядок вывода. Следует отметить, что использование упорядоченного разбора ускоряет его выполнение за счет уменьшения числа перебираемых правил.
Как только из самого левого нетерминала порождается терминальная цепочка, осуществляется переход к нетерминалу, расположенному правее. Второй пример иллюстрирует выполнение вывода справа налево. Третий и четвертый пример иллюстрируют произвольный порядок вывода. Следует отметить, что использование упорядоченного разбора ускоряет его выполнение за счет уменьшения числа перебираемых правил. 4, 6.7). Это ведет к большему количеству переборов.
4, 6.7). Это ведет к большему количеству переборов. Поэтому, в грамматиках могут встречаться альтернативные правила, начинающиеся с одинаковых цепочек символов. Возникающая неоднозначность может быть разрешена путем предварительного просмотра правила на n символов вперед до той границы, начиная с которой данное правило можно будет отличить от других. В контекстно свободных (КС) грамматиках число, определяющее количество символов, анализируемых перед выбором подстановки (1, 2…), используется для классификации. По этому критерию КС грамматики, задаются следующим образом: КС(1), КС(2),…
Поэтому, в грамматиках могут встречаться альтернативные правила, начинающиеся с одинаковых цепочек символов. Возникающая неоднозначность может быть разрешена путем предварительного просмотра правила на n символов вперед до той границы, начиная с которой данное правило можно будет отличить от других. В контекстно свободных (КС) грамматиках число, определяющее количество символов, анализируемых перед выбором подстановки (1, 2…), используется для классификации. По этому критерию КС грамматики, задаются следующим образом: КС(1), КС(2),…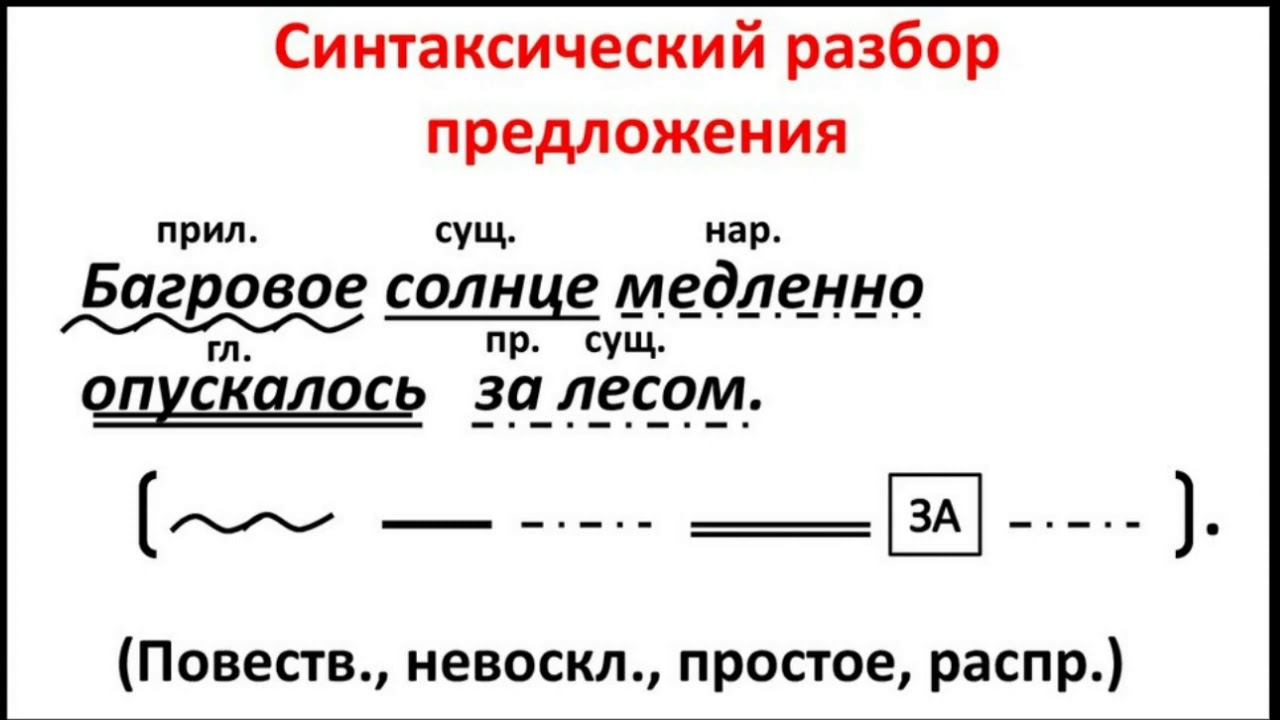 В этом случае появление отказа при разборе правила ведет к восстановлению входной головки в то положение, в котором она была да входа в данное правило. Использование возвратов может выступать в качестве альтернативы просмотру вперед. Приоритет правил, определяющий порядок их обхода, назначается также как и при лексическом анализе и зависит от того, является ли некоторое правило подмножеством другого. Метод универсален и легок для понимания и реализации. Однако, такой подход замедляет разбор и может вести к дополнительным издержкам во время семантического анализа и построения объектной модели.
В этом случае появление отказа при разборе правила ведет к восстановлению входной головки в то положение, в котором она была да входа в данное правило. Использование возвратов может выступать в качестве альтернативы просмотру вперед. Приоритет правил, определяющий порядок их обхода, назначается также как и при лексическом анализе и зависит от того, является ли некоторое правило подмножеством другого. Метод универсален и легок для понимания и реализации. Однако, такой подход замедляет разбор и может вести к дополнительным издержкам во время семантического анализа и построения объектной модели.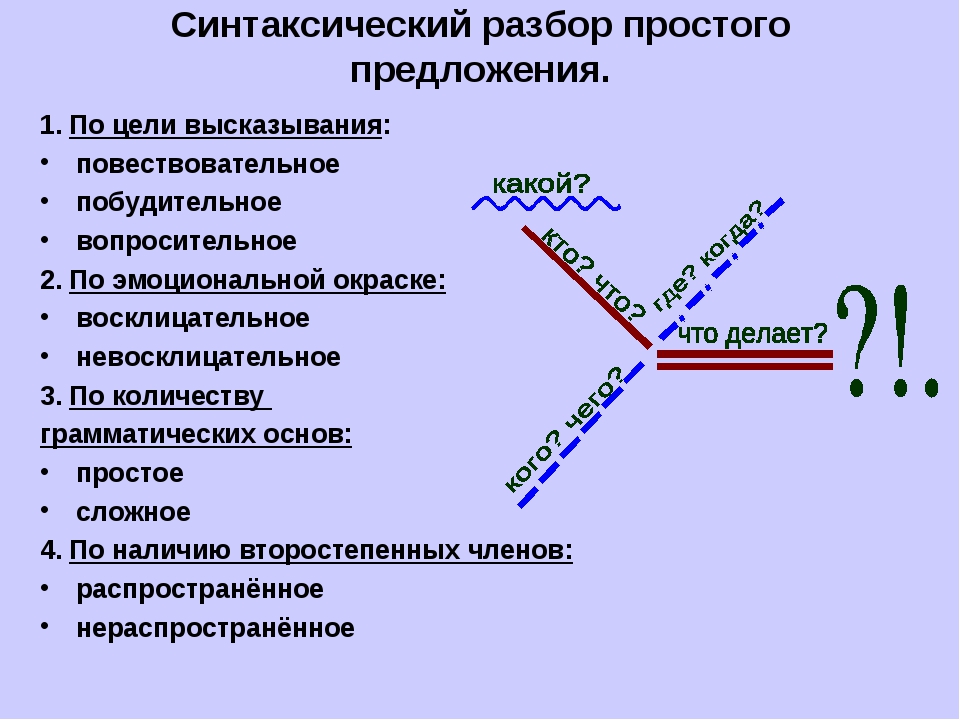



 Кроме того, следует выяснить наличие однородных или обособленных членов, то есть осложнено оно чем-то или нет.
Кроме того, следует выяснить наличие однородных или обособленных членов, то есть осложнено оно чем-то или нет.
 Так, например, синтаксический анализатор XML возьмет последовательность символов (или байтов) и преобразует их в элементы, атрибуты и т. д.
Так, например, синтаксический анализатор XML возьмет последовательность символов (или байтов) и преобразует их в элементы, атрибуты и т. д.

 ‘<{bitwise_and_expr}+
;
побитовое_и_выражение =
'&'<{equality_expr}+
;
равенство_выражение =
('==' | '!=')<{comparison_expr}+
;
сравнение_выражение =
('<' | '<=' | '>‘ | ‘>=’)<{bitshift_expr}+
;
битовое_выражение =
('<<' | '>>’)<{additive_expr}+
;
add_expr =
('+' | '-')<{multiplicative_expr}+
;
мультипликативное_выражение =
('*' | '/' | '%')<{unary_expr}+
;
унарное_выражение =
'+' ~ атом
| '-' ~ атом
| '~' ~ атом
| '!' ~ атом
| атом
;
атом =
буквальный
| helper_call
| в скобках
| var_or_param
;
буквальный =
значение: тип с плавающей запятой: `поплавок`
| значение: целое число тип: `int`
| значение: char тип: `char`
| значение: строка тип: `строка`
| значение: bool тип: `int`
| значение: null тип: `null`
;
helper_call =
функция: идентификатор '(' ~ params:expression_list ')'
;
var_or_param =
идентификатор
;
в скобках =
'(' ~ @:выражение ')'
;
9helper_call
атом
unary_expr
мультипликативное_выражение
.
‘<{bitwise_and_expr}+
;
побитовое_и_выражение =
'&'<{equality_expr}+
;
равенство_выражение =
('==' | '!=')<{comparison_expr}+
;
сравнение_выражение =
('<' | '<=' | '>‘ | ‘>=’)<{bitshift_expr}+
;
битовое_выражение =
('<<' | '>>’)<{additive_expr}+
;
add_expr =
('+' | '-')<{multiplicative_expr}+
;
мультипликативное_выражение =
('*' | '/' | '%')<{unary_expr}+
;
унарное_выражение =
'+' ~ атом
| '-' ~ атом
| '~' ~ атом
| '!' ~ атом
| атом
;
атом =
буквальный
| helper_call
| в скобках
| var_or_param
;
буквальный =
значение: тип с плавающей запятой: `поплавок`
| значение: целое число тип: `int`
| значение: char тип: `char`
| значение: строка тип: `строка`
| значение: bool тип: `int`
| значение: null тип: `null`
;
helper_call =
функция: идентификатор '(' ~ params:expression_list ')'
;
var_or_param =
идентификатор
;
в скобках =
'(' ~ @:выражение ')'
;
9helper_call
атом
unary_expr
мультипликативное_выражение
. ..
.. 