Выполните полный синтаксический разбор предложения №1. (разбор по членам, характеристика, схема). 1)Свет луны таинстве…ый и…
М
Синтаксический разбор предложения Просто о синтаксическом разборе предложения Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное. По эмоциональной окраске: восклицательное или невосклицательное. По наличию грамматических основ: простое или сложное. Затем, в зависимости от того, простое предложение или сложное: Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. Пример синтаксического разбора простого предложения Устный разбор: Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими. Письменный: Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. Пример синтаксического разбора простого предложения Устный разбор: Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими. Письменный: Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими. Пример разбора сложного предложения Устный разбор: Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено. Письменный: Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП. 1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено. 2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено. Пример схемы (предложение, после него схема) Другой вариант синтаксического разбора Синтаксический разбор. Порядок при синтаксическом разборе. В словосочетаниях: Выделяем из предложения нужное словосочетание. Рассматриваем строение – выделяем главное слово и зависимое.
Пример разбора сложного предложения Устный разбор: Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено. Письменный: Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП. 1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено. 2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено. Пример схемы (предложение, после него схема) Другой вариант синтаксического разбора Синтаксический разбор. Порядок при синтаксическом разборе. В словосочетаниях: Выделяем из предложения нужное словосочетание. Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание. И, наконец, обозначаем каким является его грамматическое значение. В простом предложении: Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное. Находим основу предложения, устанавливаем, что предложение простое. Далее, необходимо рассказать о том, как построено данное предложение. Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное. Распространённое или нераспространённое Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает. Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить. Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются.
Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание. И, наконец, обозначаем каким является его грамматическое значение. В простом предложении: Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное. Находим основу предложения, устанавливаем, что предложение простое. Далее, необходимо рассказать о том, как построено данное предложение. Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное. Распространённое или нераспространённое Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает. Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить. Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются.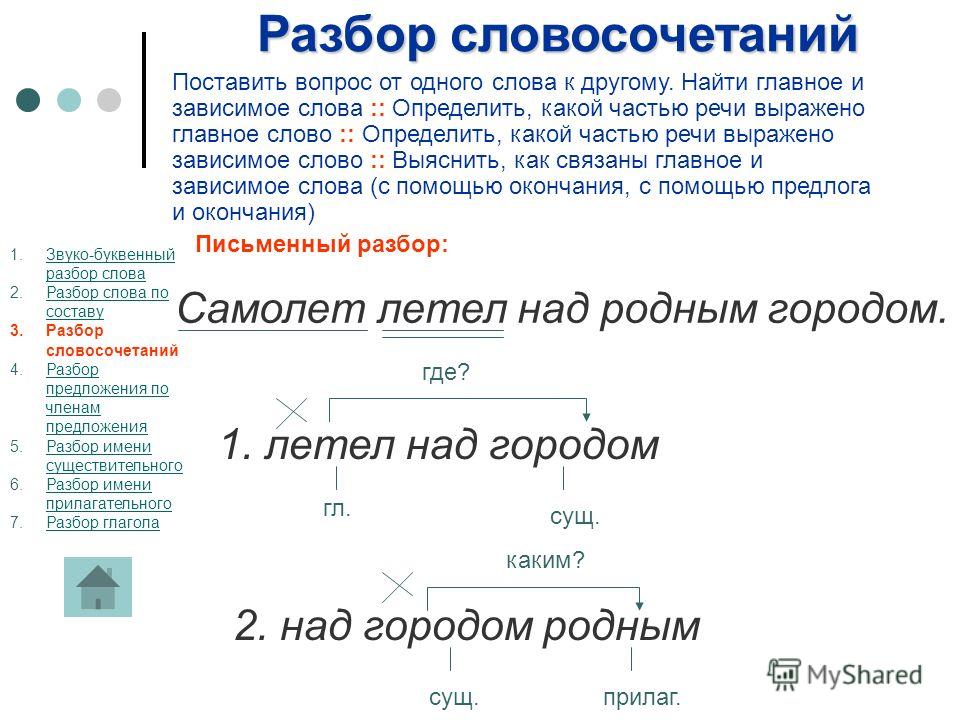 Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого. Объясняем, почему так или иначе расставлены знаки препинания в предложении. https://uchim.org/russkij-yazyk/sintaksicheskij-razbor — uchim.org Сказуемое Отмечаем, чем является сказуемое — простым глагольным или составным (именным или глагольным). Указать, чем выражено сказуемое: простое — какой формой глагола; составное глагольное — из чего оно состоит; составное именное — какая употреблена связка, чем выражается именная часть. В предложении, имеющем однородные члены. Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами. В предложениях с обособленными членами: Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого. Объясняем, почему так или иначе расставлены знаки препинания в предложении. https://uchim.org/russkij-yazyk/sintaksicheskij-razbor — uchim.org Сказуемое Отмечаем, чем является сказуемое — простым глагольным или составным (именным или глагольным). Указать, чем выражено сказуемое: простое — какой формой глагола; составное глагольное — из чего оно состоит; составное именное — какая употреблена связка, чем выражается именная часть. В предложении, имеющем однородные члены. Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами. В предложениях с обособленными членами: Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения. В предложениях с обособленными членами речи: Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения. В сложносочиненном предложении: Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу. Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение. В сложноподчинённом предложении с придаточным (одним) Сначала, указываем, каким предложение является по цели высказывания.
В предложениях с обособленными членами речи: Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения. В сложносочиненном предложении: Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу. Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение. В сложноподчинённом предложении с придаточным (одним) Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их. Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится. Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения. В сложноподчинённом предложении с придаточными (несколькими) Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить.
Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их. Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится. Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения. В сложноподчинённом предложении с придаточными (несколькими) Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений. В сложном бессоюзном предложении: Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение. Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. В сложном предложении, в котором присутствуют разные виды связи. Называем, каким по цели высказывания, является данное предложение.
Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений. В сложном бессоюзном предложении: Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение. Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. В сложном предложении, в котором присутствуют разные виды связи. Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие. По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложения
Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие. По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложения
Как делать полный синтаксический разбор предложения
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.

- Затем, в зависимости от того, простое предложение или сложное:

| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
 Далее указываем, каким синтаксическим способом связано данное словосочетание.
Далее указываем, каким синтаксическим способом связано данное словосочетание.В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
 Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.Сказуемое
- Отмечаем, чем является сказуемое – простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое – какой формой глагола;
- составное глагольное – из чего оно состоит;
- составное именное – какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение.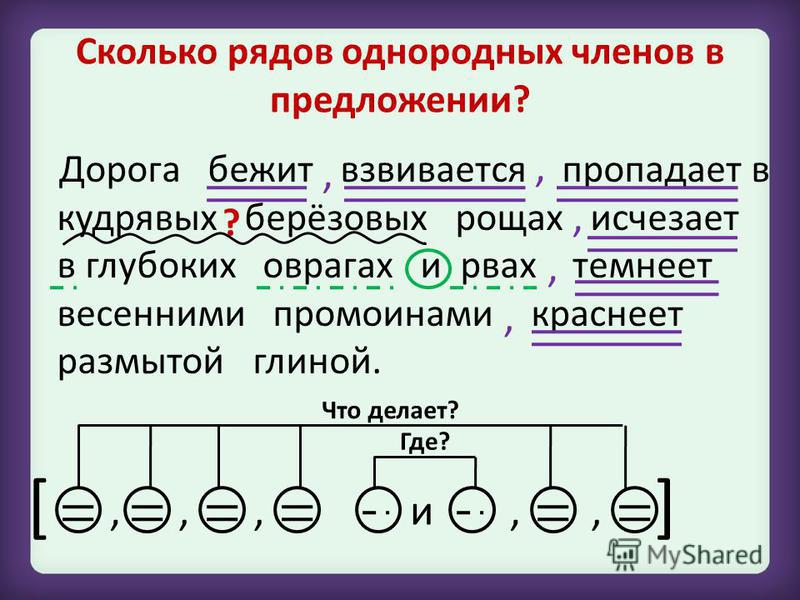 Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» – как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Вопросы
Кого? чего? кому? чему? кем? чем? о ком? о чем?
Какой? чей? который по счету?
Где? когда? куда? откуда? почему? зачем? как? в какой степени?
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка – прилагательное;
юбка из шерсти – существительное;
юбка отглаженная – причастие;
привычка побеждать – инфинитив…
Пример синтаксического разбора предложения
Подчеркнем грамматические основы. Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т.д.
Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т.д.
Теперь подчеркиваем второстепенные члены:
Переехала откуда? из деревни – обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику. Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
Синтаксический разбор предложения без. Разбор предложения по частям речи онлайн
Для начала разберемся с терминологией: для предложения существует только синтаксический разбор. В этом разборе указывается подлежащее, сказуемое и другие члены предложения. Указать часть речи можно только для слова. Тем не менее, в синтаксический разбор предложения часто входит задача указать часть речи для каждого слова. И есть сервисы, где можно ввести либо предложение целиком, либо по одному слову. И они дают вам информацию по частям речи для каждого слова.
Goldlit
В этом сервисе можно ввести предложение целиком и получить морфологический разбор каждого слова. В который, конечно же, входит и часть речи. Например:
Как видите, обнаруженное слово ставится в начальную форму и для него указывается:
- Начальная форма.
- Часть речи.
- Грамматика – что тут указывается зависит от части речи.
- Формы слова.

Нас интересует часть речи. Но будьте внимательны сервис недостаточно умен, чтобы всегда корректно его определить. Например, частица «уж». В приведенном предложении это частица, а никакое не существительное «уж». Про ужей тут речи не идет. Так что результаты пословного разбора предложения надо перепроверять вручную. В этом смысле он ничуть не выигрывает у сервисов, где вводится одно слово. Если б он мог из контекста определить значение, то выигрывал бы, а так – нет. Так что обратите внимание обычные на онлайн-сервисы морфологического разбора, они работают также. У меня один такой сервис описан тоже дальше.
Возьмем другой пример, повествовательное предложение «Времени нет».
Что скажет нам Goldlit?
Начальная форма : ВРЕМЕНИТЬ
Часть речи : глагол в личной форме
Грамматика : второе лицо, действительный залог, единственное число, переходный, несовершенный вид, повелительное наклонение (императив)
То есть слово «времени» он понял как глагол «повремени». Что явно неправда. Дальше правда указывается второе значение:
Что явно неправда. Дальше правда указывается второе значение:
Начальная форма : ВРЕМЯ
Часть речи : существительное
Грамматика : единственное число, неодушевленное, родительный падеж, средний род
Формы : время, времени, временем, времена, времён, временам, временами, временах
Это уже правильно, существительное. В общем будьте внимательны при использовании подобных сервисов.
Чтобы воспользоваться сервисом:
- Перейдите по адресу http://goldlit.ru/component/slog
- Введите предложение.
- Вы получите морфологический разбор каждого слова.
Викислово
Здесь вы можете указать только одно слово. При этом дополнительно вам скажут, каким членом предложения может быть это слово. Либо один вариант, либо, если их несколько, то так и пишут. Разбор слова «времени» выглядит примерно так же:
А вот разбор слова «добавив». Тут уже однозначно указан член предложения. Это обстоятельство. Потому что деепричастия всегда являются обстоятельствами.
Morphologyonline
Этот сервис мне нравится даже больше: дизайн чище, рекламы меньше, работает не хуже.
Чтобы воспользоваться:
- Перейдите на сайт http://morphologyonline.ru/
- Введите слово в пустое поле.
- Щелкните кнопку «Разобрать».
Вы получите разбор:
Здесь третьей строкой идет «Синтаксическая роль». Это то же самое, что «Член предложения» в сервисе Викислово.
А второй строкой идут «Морфологические признаки», которые в первом сервисы обозначены как «Грамматика». Тут они прописаны лучше, так как разделены на постоянные и непостоянные. Имеется в виду, что в зависимости от формы слова, какие-то признаки могут меняться, а какие-то нет. Например, существительное «время» всегда нарицательное, неодушевленное, среднего рода и 2 склонения. Это постоянные признаки. А падеж и число могут меняться в зависимости от формы слова: «нет времени», «дай время», «с давних времен». Тут родительный, дательный, снова родительный падеж. И единственное, снова единственное и множественное число. Какую форму слова «время» употребишь, такой падеж и число и будет. Потому это непостоянные признаки.
И единственное, снова единственное и множественное число. Какую форму слова «время» употребишь, такой падеж и число и будет. Потому это непостоянные признаки.
Морфологический vs Морфемный
Морфологический разбор слова следует отличать от морфемного. В морфемный разбор слова входит определение корня, суффикса, окончания, основы слова. Для морфемного разбора тоже есть много сервисов, они описаны .
Если вам надо определить не только части речи всех слов предложения, но и разобрать предложение в целом: по цели высказывания, подчеркнуть члены предложения, то используйте шпаргалки, коих полно в интернете. Кое-где можно даже поупражняться онлайн. Сравнение подобный сервисов у меня .
Чтобы правильно ставить знаки препинания, необходимо четко представлять себе структуру предложения. Осознать ее призван помочь синтаксический разбор, то есть разбор предложения по членам. Именно синтаксическому разбору предложения посвящена наша статья.
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое . Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое , более одной — сложное .
Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое , более одной — сложное .
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное . Если же присутствуют оба главных члена — двусоставное .
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым . В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.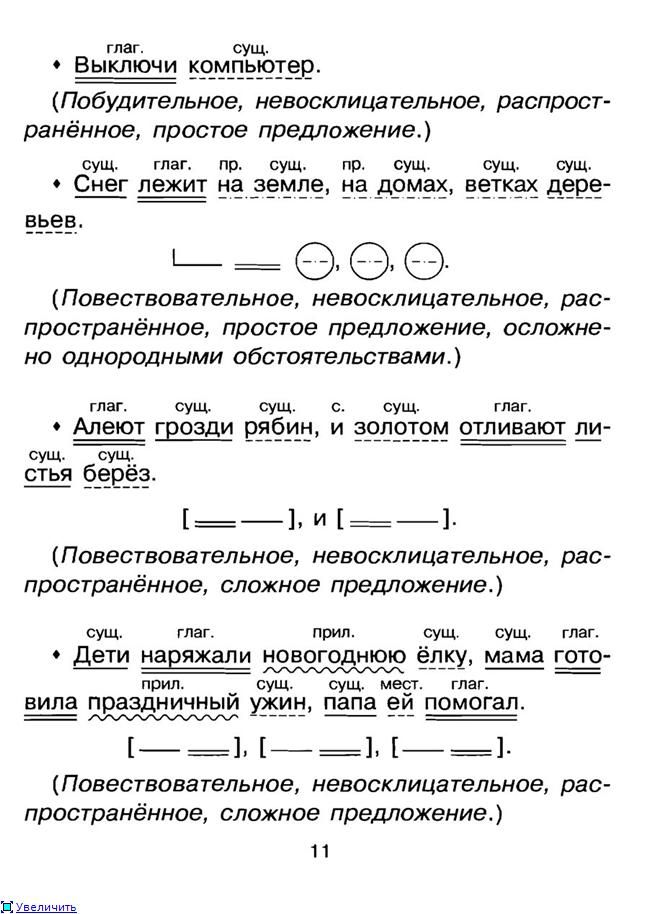
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
По количеству главных членов в грамматической основе : односоставное или двусоставное.
Если предложение односоставное, надо определить его вид : назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Например , предложение “Ребята, давайте жить дружно!” осложнено обращением «ребята».
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка — прилагательное;
юбка из шерсти — существительное;
юбка отглаженная — причастие;
привычка побеждать — инфинитив…
Пример синтаксического разбора предложения
Разберем предложение «Не знал, что ты, Маша, переехала из деревни в город» .
Подчеркнем грамматические основы . Их две: знал и ты переехала . Определим части речи: знал — сказуемое, выражено глаголом в личной форме и т.д.
Теперь подчеркиваем второстепенные члены :
Переехала откуда? из деревни — обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику . Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
Тест по теме
Оценка статьи
Средняя оценка: 4.5 . Всего получено оценок: 638.
Синтаксический разбор предложения является наиболее часто задаваемым заданием из школы, которое у некоторых не получается сделать. Сегодня я расскажу, как обхитрить училку и сделать всё правильно.
Я приведу сегодня ТОП-5 сервисом, которые помогут Вам провести разбор предложения на члены речи.
Все они могут выполнить какой-то синтаксический разбор предложений или слов. В каждом из них есть какие-то плюсы и минусы.
Данные сервисы будут специализированы как для русского, так и для английского языка.
И скажу сразу, они работают не великолепно само собой, но они помогут Вам справиться с большей частью Вашего задания.
Сравнение
В таблицы выше я перечислил лучшие из лучших сервисов, которые могут помочь Вам в выполнении ваших заданий по синтаксическому разбору предложений.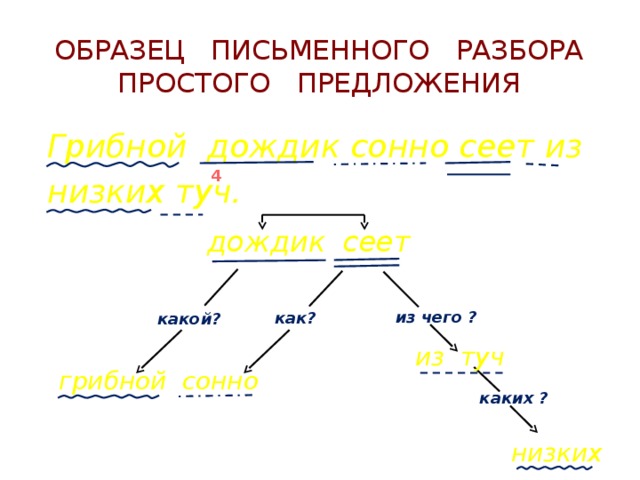
Если Вы ознакомились с таблицей, я предлагаю начать разбирать каждый из сервисов и начнем мы с самой последней строчки нашего списка и постепенно дойдем до лидера нашего ТОПа.
| Название сервиса | Язык сервиса | Слово/предложение | Ссылка |
|---|---|---|---|
| GoldLit | Русский | Предложение | http://goldlit.ru/component/slog |
| Грамота.ру | Русский | Слово | http://gramota.ru/slovari/dic |
| Морфология онлайн | Русский | Слово | http://morphologyonline.ru |
| Delph-in | Английский | Предложение | http://erg.delph-in.net/logon |
| Lexis Res | Английский | Предложение | http://www.lexisrex.com/English/Sentence-Study/ |
№5 Lexis Res
По этой ссылке Вы можете попасть на данный сервис и сами оценить его работу: http://www.lexisrex. com/English/Sentence-Study .
com/English/Sentence-Study .
Что же это за сайт? Для людей, которые изучают английский язык – это просто клад. Эта страница позволяет анализировать английский текст. Его может использовать человек с любым уровнем знаний.
Это сервис, который позволяет Вам провести синтаксический разбор предложения полностью на английском языке. Предложения могут быть как простыми, сложными, сложносочиненными и сложноподчиненными.
Помимо того, что сайт делает этот разбор любого вида предложения, он еще объясняет каждое слово по значениям. То есть, если Вы не знаете точное значение какого-нибудь слова, то этот ресурс Вам отлично подойдет.
Вам просто нужно написать нужный Вам текст в поле или нажать кнопку «Random sentences» (т.е. «Случайное предложение»), и затем нажать кнопку «Analyse», и затем Вы получите подробный анализ каждого слова в предложении: объяснение значения слова, часть речи.
Какие же преимущества у этого сайта перед другими? Прежде всего, сервис очень прост в использовании, Вам не нужно будет тратить уйму времени, чтобы понять, что к чему.
Во-вторых, сайт имеет огромную базу, которая позволяет делать синтаксический разбор текста любой сложности и тематики.
Помимо этого, сайт имеет огромный функционал, он будет полезен еще многими своими фишками для людей, которые занимаются изучением английского языка.
- простой в освоении сайт;
- практически нет рекламы, которая бы отвлекала;
- простой интерфейс сайта;
- огромный функционал;
- очень хороший синтаксический разбор.
Негатив:
- если Вы не владейте удовлетворимым уровнем знания английского языка, будет немного трудновато читать все объяснения на сайте;
- слова при разборе не подчеркиваются линиями частей речи;
- нету адаптации сайта под русский язык.
Как видите, соотношения плюсов и минусов позволяет назвать этот сайт хорошим, но не отличным, поэтому он на пятом месте.
№4 Delph-in
На четвертом месте расположен сервис под названием « Delph- in».
По этой ссылке Вы можете его опробовать: http://erg. delph-in.net/logon . Этот сайт – настоящий монстр для людей, которые изучают английский язык. Этот сервис позволяет иметь онлайн-доступ к LinGO English Resource Grammar (ERG).
delph-in.net/logon . Этот сайт – настоящий монстр для людей, которые изучают английский язык. Этот сервис позволяет иметь онлайн-доступ к LinGO English Resource Grammar (ERG).
Здесь используется платформа разработки грамматики Linguistic Knowledge Builder.
Данный интерфейс позволяет вводить одно предложение, используя систему ERG и визуализировать результаты разбора в различных формах.
Сразу скажу, что сайт подойдет для тех, кто достаточно опытен в английском языке, но этот сайт просто великолепен и необходим для таких людей.
Какие же преимущества есть у этого сервиса? Прежде всего этот сайт имеет более хорошую степень разбора предложение по методу, который используется в университете в Осло, а если быть точно, то Языковой технологической группе.
Здесь используется европейская система синтаксического разбора предложения. Помимо использования этого метода, данный сайт показывает разные способы разбора предложения, что делает разбор более гибким и удобным.
Теперь же мы рассмотрим, как плюсы, так и минусы этого сервиса.
Позитив:
- очень гибкая система синтаксического разбора предложения;
- можно писать предложения на самые различные тематики;
- неограниченное количество символов в предложении можно использовать.
Негатив:
- первый из них — это то, что сервис достаточно сложный для использования людям, с низким и средним уровнем английского;
- чтобы понять, как работает сервис и разобрать, чтобы понять, что к чему, нужно уделить сайту несколько часов.
Мы ознакомились с четвертой позицией и теперь перейдем к третьему месту нашего ТОПа.
№3 MorphologyOnline
Этот сайт идеально подойдет для тех, кому нужно качественно разобрать предложение поэтапно, слово за словом, чтобы точно не ошибиться и правильно подобрать каждую часть речи к каждому слову в разбираемом предложении.
Сервис так же полезен тем, что у него очень широкое описание каждого искомого слова.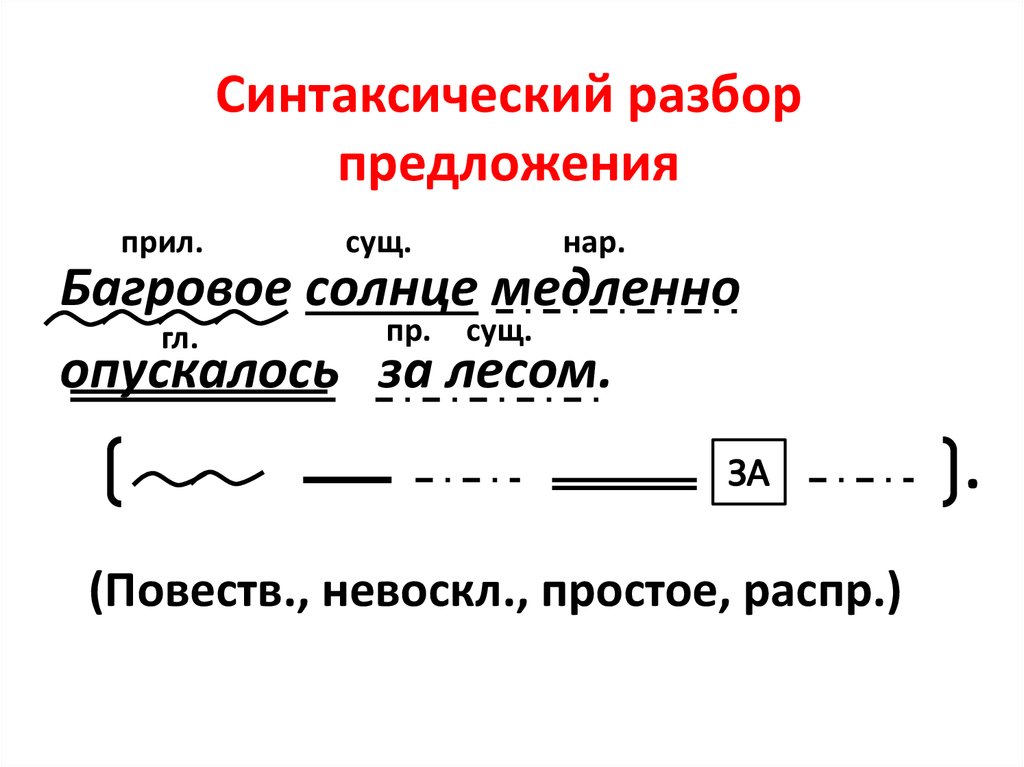
Какие же преимущества есть у данного сервиса? Давайте их разберем.
Прежде всего, это то, что он очень прост в использовании. Его интерфейс не имеет никаких отвлекающих элементов, что позволит Вам полностью сосредоточиться на написанной информации.
Еще, помимо того, что сервис указывает часть речи слова, он еще описывает морфологический анализ, что делает анализ слова более глубоким и тщательным.
Это поможет Вам никогда не ошибиться в синтаксическом анализе Вашего предложения. Так же, если Вы захотите сами детально ознакомиться с частями речи, Вы можете найти информацию на этом сайте, которая очень удобно и понятно объяснена.
Теперь же рассмотрим сервис с двух стороны и увидим, как плюсы, так и минусы. Начнем с положительной стороны.
Позитив:
- очень прост – с ним справится даже самый юный пользователь;
- нет никаких назойливых реклам, что делает использование сервиса комфортным;
- глубокий анализ;
- огромное количество информации для самостоятельного синтаксического разбора предложения.

Негатив:
- этот сервис может анализировать только одно слово за раз, что делает весь процесс медлительным;
- данный сайт больше акцентирован на морфологический разбор слова, но он так же прекрасно делает и синтаксический разбор;
- отсутствуют еще какие-либо другие инструменты, что делает сайт узким для использования в разных сферах.
Именно из-за этих минусов и плюсов сервис занимает лишь третье место. А теперь настало время для второго места.
№2 «Грамота.ру»
Почему именно этот сервис расположен на 4 месте? Данный сайт позволяет проанализировать одно слово за раз по всем русским словарям, которые не только указывают часть речи, но и объясняют значение искомого слова, синонимы, антонимы, различные формы.
Здесь даже можно найти правильное ударение для любого русского слова.
Помимо этого сервиса полного разбора слова, здесь есть множество материалов по изучению русского языка, например: самые различные словари, журналы, азбуки, книги, репетиторы, различные полезные ссылки.
Поэтому, если Вы хотите полностью провести анализ слова или же увеличить свой уровень знаний русского языка, Вы можете смело пользоваться данным ресурсом.
Давайте рассмотрим более подробно преимущества сайта. Прежде всего, здесь очень приятный интерфейс, всё понятно, ничего не нужно искать. Всё нужное можно сразу же увидеть на дисплее монитора. Сам же сайт не имеет рекламы.
Всё оформление сайта выполнено в простых цветах, то есть от длительного чтения этого сайта глаза у Вас не так сильно устают.
С этим сервисом сможет разобрать абсолютно любой человек: от первого класса до пожилого возраста.
Поскольку я описал все возможные плюсы очень подробно, можно теперь составить целый краткий список и так же добавить негативные стороны, чтобы увидеть полную картинку.
Почему именно этот сервис занял первое место в нашем ТОПе? Прежде всего, сайт может выполнить синтаксический разбор предложения, вне зависимости от количества символ и слов.
Анализ на сайте построен очень удобно. Сервис создан именно для синтаксического разбора предложений.
Сервис создан именно для синтаксического разбора предложений.
Этот сайт имеет ряд преимуществ. Как и говорилось, сайт может анализировать целые предложения, а не только лишь по слову.
Синтаксический анализ проводится очень удобно: сначала пишется начальные формы слова, затем части речи, затем идет грамматический анализ, и потом склонение по падежам.
Из всего ТОПа, у этого сервиса самый удобный и приятный для глаза интерфейс.
Помимо этих достоинств, сайт так же имеет разделы с различной литературой разных периодов, различные поэзии, как русские, так и зарубежные. Сайт имеет информацию о многих поэтах, множество удобно написанных биографий. Всё это так же поможет Вам изучить различную литературу, если Вам будет нужно это.
Но не смотря на все эти плюсы, у сайта есть так же некоторые минусы. О них мы поговорим после того, как подобьем все достоинства.
Позитив:
- выполняет полный разбор именно предложения, вне зависимости от тематики, количества слов и символов;
- минимальное количество рекламы, но даже она не мешает использовать сайт;
- очень просто в освоении;
- множество информации по литературе;
- прекрасный интерфейс и хорошая цветовая гамма.

Негатив:
- абсолютное отсутствие материалов по русском языку;
- сайт заточен под литературу больше, но всё равно имеет инструмент для разбора предложений.
Итог
Давайте же подобьем итоги. Проанализировав целый ТОП, Вы можете понять, что, если Вам нужен сайт для синтаксического разбора предложений на русском, я рекомендую Вам использовать именно ресурс «Goldlit».
Простота сайта, прекрасный анализ предложения, множество интересных материалов – именно эти ключевые факторы повлияли на расположение сайта в нашем топе.
Он является абсолютным лидером в нашем ТОПе и лучших онлайн сервисом по синтаксическому разбору предложений на русском в русских сетях Интернета.
Это ресурс, который поможет Вам не только выполнить домашнее задание, но и ознакомиться с различной литературой. Используйте сервис «Goldlit».
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:

| Если простое : 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное : 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся , распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся , распространенное, осложненное однородными подлежащими.
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что , сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что , СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
Сказуемое
- Отмечаем, чем является сказуемое — простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое — какой формой глагола;
- составное глагольное — из чего оно состоит;
- составное именное — какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Ссылка: https://сайт/russkij-yazyk/sintaksicheskij-razbor
Запомни:
Член предложения | Обозначает/ показывает | Отвечает на вопросы | Подчеркивается | |
Подлежащее | главные члены предложения | о ком или о чем говорится в предложении | кто? что? | |
Сказуемое | называет то, что совершает предмет, его состояние, каков он | что делает? что делал? что будет делать? каков? | ||
Определение | второстепенные члены предложения | признак предмета | какой? какая? какое? какие? чей? чья? | |
Дополнение | на какой предмет или явление направлено действие | кого? чего? кому? чему? кого? что? кем? чем? о ком? о чём? | ||
Обстоятельство | как совершается действие, когда совершается действие, где совершается действие, по какой причине совершается действие, с какой целью совершается действие | где? куда? когда? откуда? почему? зачем? и как? |
Выпиши
предложение.
Делай так : С высоких гор побежали звонкие ручейки .
1.Основа предложения:
в предложении говорится о ручейках , следовательно, ручейки — это подлежащее,
побежали , следовательно, побежали – это сказуемое.
2.В предложении есть второстепенные члены.
Задаю вопрос от подлежащего:
ручейки какие?- звонкие – это определение.
Задаю вопрос от сказуемого:
побежали откуда? –с гор – это обстоятельство места.
с гор каких? – высоких – это определение.
39. Схема разбора предложения (синтаксический разбор).
I. Вид предложения по цели высказывания.
II. Вид предложения по интонации.
III. Основа предложения (подлежащее и сказуемое).
IV. Вид предложения по наличию второстепенных членов.
V. Второстепенные члены предложения.
Выпиши
предложение.
Делай так : С высоких гор побежали звонкие ручейки . (Повеств., невоскл., распр.)
Это предложение
I. Повествовательное.
II. Невосклицательное.
III.Основа предложения:
в предложении говорится о ручейках , следовательно, ручейки — это подлежащее,
о ручейках говорится, что они побежали , следовательно, побежали – это сказуемое.
IV. В предложении есть второстепенные члены, поэтому оно распространённое.
V. Задаю вопрос от подлежащего:
ручейки какие?- звонкие – это определение.
Задаю вопрос от сказуемого:
побежали откуда? – с гор – это обстоятельство места.
Задаю вопрос от второстепенных членов предложения:
С гор каких? – высоких – это определение.
Запомни:
III. Пунктуация
40.Знаки
препинания в конце предложений(. ?!).
Выпиши предложение правильно. Придумай свое или найди в учебнике предложение с таким же знаком. Подчеркни знак препинания.
Делай так : Слава нашей Родине ! Слава труду !
41. Однородные члены предложения.
Выпиши предложение. Правильно расставь знаки. Подчеркни однородные члены предложения. Начерти схему предложения.
Делай так : Грачи , скворцы и жаворонки улетели в теплые края. (О,О и О)
Знаки препинания при однородных членах:
О да (=и) О
О, да (= но) О
и О, и О,и О,и О
или О, или О,или О,или О
О, и О,и О,и О
42.Сложное предложение.
Выпиши правильно предложение. Подчеркни грамматические основы. Начерти схемы.
Делай так:
Дремлют рыбы под водой, почивает сом седой.
[ ], [ ].
43. Предложения
с прямой речью.
Запиши правильно предложение. Составь схему.
Делай так :
1) Олег успокаивал мать: «Все будет хорошо».
2) Он крикнул: «Вперёд, ребята!»
3) Он спросил: «Ты откуда, парень?»
4) «Я тебя не выдам», — обещал Иван.
5)»Пожар!» – крикнула Таня.
6) «Кто это был?» – спросила Оля.
7) «Я врач, — сказал он,- сегодня дежурю».
«П, — а, — п».
8) «Наше присутствие необходимо, — закончил Петров.- Выезжаем утром».
«П, — а. — П».
9) «Почему в пять? – спросил брат.- Это очень рано».
«П? — а. — П».
10) «Ну и отлично! – воскликнула Аня.- Поедем вместе».
«П! — а. — П».
11) «Он из нашей группы, – сказал Иван.- Садись, Пётр!»
«П, — а. – П!»
УЧИТЕЛЮ И РОДИТЕЛЯМ
«Памятка по выполнению работы над ошибками по русскому языку» состоит из трёх разделов: «Правила правописания», «Виды разборов», «Пунктуация».
В
первом и третьем разделе даны указания
о том, какие операции и в какой
последовательности необходимо произвести
учащимся при выполнении работы над
ошибками. Для того чтобы ученик мог
быстро и легко найти в памятке нужную
орфограмму, каждое правило имеет свой
порядковый номер.
Работу по памятке мы предлагаем проводить следующим образом. К традиционным обозначениям ошибок на полях приписывать номер орфограммы, помещенной в памятке. После проверенной работы пропускать две строчки и на последующих строчках указывать эти номера.
Ученик, получив тетрадь, должен выполнить работу над ошибками строго по памятке. Каждую работу учитель проверяет и оценивает, при этом учитывается правильность и точность исправления.
Например: на улице сильный морос – на полях ученик видит| №20. Он открывает книжку-памятку и читает алгоритм работы:
№20 Мороз – мороз ы .
Таким образом, основными видами самостоятельной работы учащихся над ошибками являются:
Самостоятельное исправление (потом можно предложить самостоятельное отыскивание) ошибок;
Самостоятельное выписывание слов, в которых допущена ошибка;
Подбор проверочных слов;
Повторение правил.
Учитывая необходимость преемственности начальной и средней ступени обучения при составлении третьего раздела «Виды разборов» (морфемный, фонетический, морфологический, синтаксический) мы опирались на учебник для 5 класса общеобразовательных учреждений, авторы Т.А. Ладыженская, М.Т. Баранов, Л.А. Тростенцова и др.
«Памятка по выполнению работы над ошибками по русскому языку» может быть использована в учебной работе по любой программе начальной школы, как при групповой форме работы, так и при индивидуальной, самостоятельной работе ученика в классе или дома.
Литература
1.Русский язык: 3 класс: комментарии к урокам/ С.В. Иванов, М.И. Кузнецова.- М.: Вентана-Граф, 2011.-464 с.- (Начальная школа XXI века).
2.Русский язык: Теория: Учебник для 5-9 кл. общеобразоват. учеб. заведений /В.В. Бабайцева, Л.Д. Чеснокова- М.: Просвещение,1994.-256 с.
3.
Русский язык: учеб.для 5 кл. общеобразоват.
учреждений / Т.А.Ладыженская, М.Т.Баранов,
Л.А. Тростенцова и др.- М. : Просвещение,
2007.-317 с.
4. Справочник для начальных классов. Пособие для учащихся 3-5 классов, их родителей и учителей. /Т.В. Шклярова — М.: «Грамотей», 2012, 128 с.
План «Синтаксический разбор предложения» (9 класс)
План «Синтаксический разбор предложения»
Простое предложение
План разбора
1. Вид предложения по цели высказывания ( повествовательное, вопросительное, побудительное).
2. Вид эмоциональной окраске по интонации ( восклицательное или невосклицательное).
3. По наличию грамматических основ ( простое, сложное).
4. Вид по составу грамматической основы ( двусоставное или односоставное;
если односоставные –какого типа ( определенно- личное. неопределенно- личное, безличное назывное )).
5. По наличию
второстепенных членов предложения ( распространённое или нераспространённое).
6. По наличию или отсутствию необходимого члена предложения( полное или неполное)
7. Осложненное ( чем?) или неосложненное.
8. Разобрать предложение по членам и указать, чем они выражены ( сначала разбирается подлежащее и сказуемое, потом – второстепенные члены, относящиеся к подлежащему, затем – к сказуемому).
9. Объяснить расстановку знаков препинания.
10. Составить схему предложения.
План разбора сложного предложения.
1.Вид предложения по цели высказывания.
2.Вид предложения по эмоциональной окраске.
3. По наличию грамматических основ( простое или сложное)количество простых).
4. По видам связи
простых предложений:союзное (сочинительный, подчинительный), бессоюный.
5. По виду связывающего союза ( ССП или СПП ), (каждое предложение разбирается отдельно)
ССП | СПП | БСП |
6. Определить тип союза и смысловые отношения между предложениями. 7. Начертить схему предложения. 8. Разобрать части как простые предложения | 6. Определить тип придаточного. 7. Начертить схему предложения, указать позицию придаточного (или способ присоединения придаточных) 8. Разобрать как простое предложение (ПП).
| 6. Определить
смысловые отношения между частями , БСП. 7. Начертить схему предложения. 8. Разобрать как простое предложение (ПП).
|
Синтаксический разбор сложного предложения.
Но вот однажды, в оттепельный мартовский день, когда аэродром за одно
утро вдруг потемнел, а пористый снег осел так, что самолеты оставляли
на нём глубокие борозды, Алексей поднялся на своём истребителе.
( Это предложение повествотельное, невосклицательное,сложное, состоит из 4-х простых предложений . Между 1 и 2 предложениями подчинительная связь;
1- главное, 2-придаточное; оно присоединяется к главному с помощью союза когда, относитсяк слову день, отвечает на вопрос какой?
2 предложения – придаточное определение,
3 предложения относится к 1 предложению как придаточное определительное,
2 и 3 предложения находятся в однородном подчинении,
соединены противительным союзом а . Между 3 и 4 предложениями – подчинительная
связь.
3 предложение по отношению к 4-му главное, 4 предложение придаточное;оно связано с ним союзом что и относится к указательному слову так, отвечает на вопрос в какой мере? 4 предложение придаточное меры и степени.
1 предложение – Но вот однажды, в оттепельный мартовский день,
…,Алексей поднялся на своем истребителе. (повествовательное, невосклицательное, простое, двусоставное, распростроненное, полное, осложнено уточняющим распространенным обстоятельством).
2 предложение – придаточное определительное. Когда аэродром за одно утро вдруг потемнел, (повествовательное,невосклицательное, простое, двусоставное, распространенное, полное).
3 предложение – придаточное определительное… а пористый снег осел так, (повествовательное, невосклицательное, простое, двусоставное, распространенное)
4 предложение – придаточное меры и степени. .. что самолеты
оставляли на нем глубокие борозды (повествовательное, невосклицательное, простое, двусоставное,
распространенное,полное)
день
придаточное определительное
придаточное определительное а …
когда… ,
придаточное меры и степени
что…
Это СПП с однородным и последовательным подчинением придаточное ( или комбинированное подчинение)
Сложные предложения с разными видами связи.
1. Сочинение и подчинение
2. Сочинение и бессоюзная связь
3. Подчинение и бессоюзная связь
4. Сочинение, подчинение и бессоюзная связь.
В саду росли одни только дубы; они стали распускаться только недавно, так что теперь сквозь молодую листву виден был весь сад с его эстрадой , столиками, качелями, видны были все вороньи гнезда, похожие на большие шапки.
(это предложение повествовательное, невосклицательное, сложное с бессоюзной и союзной связью, состоит из 3 частей; 1 часть – простое предожение, 2 часть – СПП
с придаточным следствия, 3 часть – простое предложение.)
1 предложение. В саду росли одни только дубы (повествовательное,
І часть невосклицательное,
простое, двусоставное, распространенное, полное).
2 предложение главное…они стали распускаться только недавно (повествовательное, невосклицательное, простое, двусоставное,
ІІ часть распространенное,полное)
3 предложение придаточное следствия… что теперь сквозь молодую
листву виден был весь сад с его эстрадой, столиками, качелями, (повествовательное, невосклицательное, простое, двусоставное, распространенное, полное осложнено обособленным определением).
4 предложение. .. видны были все вороньи гнезда, похожие
на
III часть большие шапки. (повествовательное, невосклицательное, простое,
двусоставное, распространенное, полное, осложнено обособленными
определениями)
1 2 3 4
; , что… , .
1-2 предложение – бессоюзная связь.
2-3 предложение – подчинительная связь. (СПП с придаточным следствием)
3-4 предложение — бессоюзная связь.
Синтаксический разбор простого предложения.
Обычно народные праздники, митинги и демонстрации проводят на
главной площади города.
(Предложения повествовательное, невосклицательное, простое, односоставное, неопределенно – личное, распространенное, полное, осложненное однородными дополнениями).
Синтаксический разбор сложного предложения.
Лодка колыхалась на волнах, шаловливо плескавшихся об ее борта,
еле двигалась по темному морю, а
оно играло все резвей и резвей.
(Предложение повествовательное, невосклицательное, сложное, союзное состоит их двух простых предложений)
1 предложение – Лодка колыхалась на волнах, шаловливо плескавшихся
об ее борта, еле двигалась по темному морю.
(Предложение повествовательное,невосклицательное, простое, двусоставное, распространенное, полное,осложнено однородными сказуемыми и причастным оборотом).
2 предложение – оно играло все резвей и резвей
(Предложение певествовательное, невосклицательное, простое, двусоставное, распространенное, полное).
1 2
, , а .
(Предложение
сложносочиненное; между предложениями выражено противопоставление. Простые
предложения связаны противительным союзом а)
Морфемный словообразовательный разбор слова.
Морфемный разбор по составу
| Словообразовательный | ||||||
1.Окончание. 2.Основа. 3.Суффикс (суффиксы). 4.Приставки. 5.Корень.
двигатель
раскрасавица | 1. 2.Выявить словообразующую часть (двигатель двигать) ( суффиксальный способ образования). 3. Определить, от какой основы образовано слово
|
Упражнения по теме «Двусоставные предложения»
Предикативное ядро предложения. Подлежащее и сказуемое
ДП1. Выпишите сначала предложения с простым глагольным сказуемым, затем — с составным глагольным сказуемым. Выделите грамматические основы в каждом предложении.
1. В ответ на все упрёки в праздности он бил баклуши.
2. Наконец-то мы начали изучать синтаксис простого предложения!
3. Скоро будем сдавать экзамены.
4. Он попросил меня похлопотать об отъезде (Чаковский).
5. Великий национальный поэт умеет заставить говорить и барина, и мужика их языком (Белинский).
6. И пусть развивается и процветает родная страна!
7. Ни при каких усилиях человек не сможет передать очарование этого дня (Паустовский).
8. В Москве я не буду ни видеть вас, ни писать вам, ни звонить (Паустовский).
9. Чиновники несколько недель водили за нос просителя.
10. Долго будет моросить осенний дождь (Паустовский).
11. Там, где вечно дремлет тайна, есть нездешние поля (Есенин).
12. За калиткой сразу начинались густые, запущенные аллеи (Паустовский).
13. Стали носиться зловещие слухи о необходимости не только знания грамоты, но и других, до тех пор неслыханных в том быту наук (Гончаров).
14. Они продолжали целые десятки лет сопеть, дремать и зевать (Гончаров).
15. А пурга, словно издеваясь, не хотела униматься (Лавренев).
ДП2. Перепишите предложения, выделите грамматические основы. Укажите, какой частью речи выражено подлежащее.
1. Многое изменилось в Марьине за прошедший год.
2. Мы с Тамарой ходим парой: санитары мы с Тамарой (Барто).
3. Пусть другие кричат от отчаянья, от обиды, от боли и холода; мы-то знаем: доходней молчание, потому что молчание — золото (Галич).
4. Входящие должны предъявить билеты.
5. Только в то мятежное время пятнадцатилетний мог стать членом партии (Николай Островский).
6. Семеро одного не ждут (Пословица).
7. А, но, зато, однако — противительные союзы.
8. Далече грянуло «ура» — полки увидели Петра (Пушкин).
ДП3. Перепишите предложения, расставляя знаки препинания. Выделите грамматические основы. Укажите, чем выражено сказуемое. Обозначьте вид сказуемого.
1. Что помнится? Он славно пересмеять умеет всех болтает шутит мне забавно делить со всяким можно смех (Грибоедов).
2. «Ах!» — и легче тени Татьяна прыг в другие сени с крыльца на двор и прямо в сад (Пушкин).
3. Нам Алексей Степаныч с вами не удалось сказать двух слов (Грибоедов).
4. Вздумала было на ночь загадать на картах после молитвы да видно в наказание-то бог и наслал его (Гоголь).
5. У вас тут крыльцо давно уж ходуном ходит.
6. Не в прошлом ли году в конце в полку тебя я знал? Лишь утро: ногу в стремя и носишься на борзом жеребце; осенний ветер дуй хоть спереди хоть с тыла (Грибоедов)
7. Вошедши в зал Чичиков должен был на минуту зажмурить глаза потому что блеск от свечей ламп и дамских платьев был страшный (Гоголь)
8. Несколько пушек между коих узнал я и нашу поставлены были на походные лафеты (Пушкин).
9. Я спешил в дом священника увидеться с Марьей Ивановной (Пушкин).
10. Ещё не зная будет ли она петь я попросил её спеть.
ДП4. Перепишите предложения, расставляя знаки препинания. Выделите грамматические основы. Укажите, чем выражены подлежащее и сказуемое. Обозначьте вид сказуемого.
1. Один и тот же сон мне повторяться стал мне снится будто я от поезда отстал (Левитанский).
2. А всё же давайте сначала подумаем стоит ли начинать такой дорогостоящий проект.
3. Пускай заманит и обманет не пропадёшь не сгинешь ты и лишь забота затуманит твои прекрасные черты (Блок).
4. Прилёг вздремнуть я у лафета и слышно было до рассвета как ликовал француз (Лермонтов).
5. Пять плюс четыре будет восемь.
6. Владимир и писал бы оды да Ольга не читала их (Пушкин).
7. Случалось ли поэтам слезным читать в глаза своим любезным свои творенья? (Пушкин)
8. Пусть юноши своей не разгадав судьбы постигнуть не хотят предназначенье века и не готовятся для будущей борьбы за угнетённую свободу человека (Рылеев).
9. Ей туфли оказались впору что не могло не радовать меня.
10. Когда я сказал ему что он пляшет под чужую дудку его это явно задело.
11. Ягнёнок в жаркий день зашел к ручью напиться и надобно ж беде случиться что около тех мест голодный рыскал Волк (Крылов).
12. «Урок окончен», — хотел произнести учитель однако ученики уже устремились к выходу.
13. Летит летит взглянуть назад не смеет мигом обежала куртины мостики лужок аллею к озеру лесок кусты сирен переломала по цветникам летя к ручью и задыхаясь на скамью упала… (Пушкин).
14. Быть может, чувствий пыл старинный им на минуту овладел но обмануть он не хотел доверчивость души невинной (Пушкин).
15. Он съехал уж у нас ему казалось скучно и редко посещал наш дом потом опять прикинулся влюблённым взыскательным и огорчённым! (Грибоедов)
ДП5. Выпишите, расставляя знаки препинания, сначала предложения с простым глагольным, затем с составным глагольным сказуемым, затем с составным именным сказуемым. Выделите грамматические основы. Обозначьте, чем выражены подлежащее и сказуемое.
1. Владимир всегда готов помочь другу.
2. Книги могут рассказать о многом даже о том о чём нам с вами никогда не доводилось слышать.
3. Изредка порывами налетал ветер.
4. У входа в купе стояло несколько человек бурно обсуждавших результаты прошедшего матча который передавали по радио.
5. Я хотел бы посетить этот город известный мне и по рассказам побывавших там и по литературным произведениям.
6. Закат тяжело пылает на склонах деревьев.
7. Леса в Мещёре глухие непроходимые дремучие.
8. Мы долго говорили о случившемся.
9. Телеграмма была отправлена утром с ближайшего к посёлку телеграфного отделения.
10. Природа и в рассказах Владимира Короленко и в повестях Михаила Пришвина изображена с большим мастерством.
11. Встретившая нас улыбчивая женщина оказалась заведующей местной библиотекой.
12. Рад видеть вас!
13. У вас в провинции каждому новому лицу были рады.
14. Девятью девять восемьдесят один.
15. И жизнь хороша и жить хорошо а в нашей буче боевой кипучей и того лучше! (Маяковский)
16. Он артист и этим всё сказано.
17. Всё лето Митя провалял дурака и опомнился только к началу сентября.
18. Пусть Наталья зайдёт завтра к начальнику отдела.
19. Пока полежи отдохни.
20. А князь Гвидон с берега душой печальной провожает бег их дальный глядь поверх текучих вод лебедь белая плывёт (Пушкин).
Второстепенные члены предложения
ДП6. Заполните правую колонку таблицы собственными примерами.
| Способы выражения согласованных определений | Примеры |
| Полное прилагательное | Отличник пришёл в любимую школу. |
| Полное причастие / причастный оборот | Сегодня встретил пришедшего в школу отличника. Вчера встретил отличника, пришедшего в школу. |
| Определительное местоимение | Отличники есть в каждом классе. |
| Указательное местоимение | И в этом, и в том классе есть отличники. |
| Изменяемое ритяжательное местоимение | Много отличников в нашем классе. |
| Порядковое числительное, количественное числительное | В восьмом классе учатся только отличники. Один отличник внезапно получил четвёрку. |
| Существительное, согласованное в падеже (согласованное приложение) | Восхищаюсь учениками-отличниками. |
| Способы выражения несогласованных определений | Примеры |
| Наречие | Я заказал в ресторане макароны по-флотски и яйца всмятку. |
| Существительное без предлога (несогласованное приложение) | Учусь в школе «НИКА«. Посетил город Ярославль. Помню радость бабушки при виде города. |
| Существительное с предлогом | Пью компот из вишен. Купила платье в полоску. Меня одолевали мысли о судьбе. |
| Инфинитив | Меня всегда отличало желание учиться. |
| Сравнительная степень прилагательного | Видел я дома побогаче вашего. |
| Синтаксически неделимое словосочетание | Женщина бальзаковского возраста. |
| Неизменяемое притяжательное местоимение | В его доме много гостей. Их желания всегда исполняются. |
ДП7. Перепишите предложения, выделите грамматические основы и определения. Укажите, чем выражены определения. Образуйте, где это возможно, вместо согласованных определений формы несогласованных (см. выделенные слова и словосочетания).
Образец:
Варвара относилась к Наталье с материнской любовью — Варвара относилась к Наталье с любовью матери. Детская одежда продаётся в тридцать пятом магазине — Одежда для детей продаётся в магазине номер тридцать пять.
- Графиня на светских приёмах носила только золотые украшения и только шёлковые платья.
- Славен был каретник Михеев своими золотыми руками и невероятно красивыми каретами.
- Темноволосая женщина выразительным взглядом зелёных глаз оказалась хозяйкой деревенской усадьбы.
- Спортсмену на районных соревнованиях была предоставлена вторая попытка.
- Зимняя погода в южных регионах отличается неустойчивостью: первые заморозки сменяются оттепелями.
- Сельские жители нелегко привыкают к городскому образу жизни.
- Зимой на севере России можно наблюдать более длинные ночи, чем на юге.
ДП8. Перепишите предложения, вставляя пропущенные буквы и знаки препинания. Выделите грамматические основы и определения. Укажите, чем выражено определение.
- Свою давнюю мечту путешествовать Миша отл..чавш..йся с ра..его де..ства богатой ф..нтазией реал..зовал сразу по окончани.. ун..верситета в городе Воронеже.
- У братских могил нет заплака..ых вдов — сюда ходят люди (по)крепче на братских могилах не ставят крестов… Но разве от этого легче?! (В.С. Высоцкий)
- Обл..мав у края лёд погрузился на понтоны первый взвод. Погрузился о. .толкнулся и пошёл. Второй за ним. Пр..готовился пригнулся третий следом за вторым (А.Т. Твардовский)
- Эти господа любят засматриват..ся на луну да слушать щ..лканье соловьёв. Любят они луну-кокетку которая бы нар..жалась в палевые обл..ка да сквозила таинстве..о через ветви дерев или сыпала снопы серебря..ых лучей в глаза своим покло..икам (И.А. Гончаров)
- (Н..)перед..ваемо слепящий свет со..нца (не)сколько раз см..няла огромная тень от гр..ды проб..гавших по небу туч.. и обл..ков.
- Б..седа (на)ед..не как и (в)целом многоч..совое общение (с)глазу(на)глаз дост..вляли уд..вольствие нам обоим.
- Прит..ившаяся в роднике под сосной ключевая вода холодная и м..нящая была прозрач..на и чиста.
- Голова японца (не)защ..щает..ся (н..)чем н.. от жары в два..цать пять градусов н.. от холода в один градус (И.Ф. Крузенштерн)
- Два..цать первого числа мы перес..кали гр..ницу России и пред..являли погр..ничникам стопкой сложе..ые документы.
- Ю..ый Пушкин-лицеист нач..нал с произв..дений подр..жательского характера и на его способность писать стихи многие обр..тили вн..мание но всё(же) не смогли уг..дать в нём будущего гения.
ДП9. Составьте по одному предложению с каждым из данных словосочетаний. Выделите дополнения, укажите, чем они выражены. Дайте письменный ответ на вопрос: от чего зависит выбор падежа при таких дополнениях?
Вижу цели, не вижу целей, принёс книгу, не принёс книги, выполнил упражнение, не выполнил упражнения, обеспечил порядок, не обеспичил порядка.
ДП10. Перепишите предложения, расставляя знаки препинания. Выделите все члены предложения, укажите, чем они выражены.
1) Очнувшись я несколько времени не мог опомниться и не понимал что со мною сделалось.
2) Я лежал в незнакомой горнице и чувствовал большую слабость.
3) Передо мною стоял Савельич со свечкою в руках.
4) Кто-то бережно развивал перевязи которыми грудь и плечо были у меня стянуты.
5) Проснувшись подозвал я Савельича и вместо него увидел перед собою Марью Ивановну ангельский голос её меня приветствовал.
6) Не могу выразить сладостного чувства овладевшего мною в эту минуту.
7) Я схватил её руку и прильнул к ней обливая слезами умиления.
8) Милая добрая Марья Ивановна сказал я ей будь моею женою согласись на моё счастие.
9) Чтение сего письма возбудило во мне разные чувствования.
10) Бог видит, бежал я заслонить тебя своею грудью от шпаги Алексея Иваныча!
11) Нет Пётр Андреич отвечала Маша я не выйду за тебя без благословения твоих родителей.
12) Мысль потерят её навсегда была для меня совершенно невыносимой.
(По А.С. Пушкину)
ДП11. Перепишите текст, вставляя пропущенные буквы и знаки препинания.
Сделайте полный синтаксический разбор выделенных предложений 8, 15, 16, 21: подчеркните все члены предложения; укажите части речи над каждым словом; дайте характеристику каждому предложению
- по структуре,
- по цели высказывания,
- по эмоциональной окраске,
- по количеству главных членов,
- по наличию второстепенных членов,
- по наличию осложняющих элементов.
Выпишите номера односоставных предложений, в том числе сложных предложений, содержащих односоставные части.
(1) (По)утру старую графиню героиню(П,п)ушкинской «Пиковой дамы» од…вали три девушки. (2) «Одна держала банку румян другая к..робку со шпильками третья высокий чепец с лентами огне…ого цвета». (3) Вошел м…лодой офицер Томский внук графини и нач..лась светская б..лтовня о прошедш..м вчера бале. (4) «…Пришли мне какой(нибудь) новый роман, только пожалуйста не из нынешних» попросила графиня внука. (5) И по..снила: (6) «То есть такой роман где бы герой (н..) давил (н..) отца (н..) матери и где бы (н..)было утопле..ых тел. (7) Я ужасно боюсь утопле..иков!» (8) Выр..жаясь нын..шним языком графиня просит внука не пр..сылать ей три(лл,л)еров ужастиков и романов со сценами насилия.
(9) (Во)все времена всегда одно и то(же). (10) Мы порой думаем что книги и фильмы с убийствами и насилием это беда лиш… нашего времени. (11) Однако даже сто пят..десят лет назад всё это было.
(12) А(за)чем пишут страшные книги? (13) И (по)чему их читают? (14) Ответить (не)трудно: (за)тем же (за)чем в парке катают..ся на аттракционах. (15) Пережить и..огда сильные ощущения потребность человека. (16) Ему хочет..ся испытать чу..ство ужаса. (17) Если книга не вызыва..т (н..)каких чувств мы говорим что она скучная и откладыва..м её в сторону. (18) Но все эти три..еры опас..ны другим: человек пр..выкает только к приключенческим или детективным соч..нениям и мимо него проходят лу..шие книги мировой литературы. (19) Кто начитался три..еров тому Тургенев покажет..ся прес..ным и жизнь пройдёт без Тургенева. (20) Один за другим отвергают. .ся классики и человек остаёт..ся (не)образова..ым и (не)разб..рающ..мся в литературе хотя он с утра до вечера чита..т. (21)Не такой уж плохой вкус был у графини боявшейся утопленников.
(По С.Соловейчику)
Русский язык полный синтаксический разбор
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:
| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |
Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
Сказуемое
- Отмечаем, чем является сказуемое – простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое – какой формой глагола;
- составное глагольное – из чего оно состоит;
- составное именное – какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т. е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» – как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т. е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Вопросы
Кого? чего? кому? чему? кем? чем? о ком? о чем?
Какой? чей? который по счету?
Где? когда? куда? откуда? почему? зачем? как? в какой степени?
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка – прилагательное;
юбка из шерсти – существительное;
юбка отглаженная – причастие;
привычка побеждать – инфинитив…
Пример синтаксического разбора предложения
Подчеркнем грамматические основы. Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т. д.
Теперь подчеркиваем второстепенные члены:
Переехала откуда? из деревни – обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику. Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
Синтаксический анализ | Руководство по освоению обработки естественного языка (часть 11)
Расширенный NLP
Эта статья была опубликована в рамках блога Data Science Blogathon
Введение Эта статья является частью продолжающейся серии блогов по обработке естественного языка (NLP). В предыдущей статье мы обсудили технику извлечения сущностей под названием «Распознавание именованных сущностей». Существует также еще одна техника извлечения сущностей, которая также является популярной техникой под названием 9.0007 Тема Моделирование , которую мы обсудим в последующих статьях нашего цикла блогов.
Итак, в этой статье мы углубимся в синтаксический анализ, который является одним из важнейших уровней НЛП.
Это одиннадцатая часть серии блогов, посвященных пошаговому руководству по обработке естественного языка.
Содержание
1. Что такое синтаксический анализ?
2. В чем разница между синтаксическим и лексическим анализом?
3. Что такое синтаксический анализатор?
4. Каковы различные типы синтаксических анализаторов?
5. Что такое деривация и ее виды?
6. Какие типы парсинга основаны на деривации?
7. Что такое дерево разбора?
Синтаксический анализ определяется как анализ, сообщающий нам логическое значение определенных предложений или частей этих предложений. Нам также необходимо учитывать правила грамматики, чтобы определить логическое значение, а также правильность предложений.
Или, говоря простыми словами, синтаксический анализ — это процесс анализа естественного языка с использованием правил формальной грамматики. Мы применяли грамматические правила только к категориям и группам слов, а не к отдельным словам.
Синтаксический анализ в основном присваивает тексту семантическую структуру. Он также известен как синтаксический анализ или синтаксический анализ. Слово «разбор» происходит от латинского слова «pars», что означает «часть». Синтаксический анализ имеет дело с синтаксисом естественного языка. В синтаксическом анализе использовались грамматические правила.
Давайте рассмотрим пример, чтобы лучше понять:
Рассмотрим следующее предложение:
Приговор: в школу, мальчик
Приведенное выше предложение логически не передает его смысла, а его грамматическая структура неверна. Итак, синтаксический анализ говорит нам, передает ли то или иное предложение свое логическое значение или нет, и является ли его грамматическая структура правильной или нет.
Как мы уже обсуждали этапы или различные уровни НЛП, третий уровень НЛП — это синтаксический анализ, или синтаксический анализ, или синтаксический анализ. Основная цель этого уровня — извлечь точное значение, или, говоря простыми словами, можно сказать, найти словарное значение из текста. Синтаксический анализ проверяет текст на осмысленность по сравнению с правилами формальной грамматики.
Например, рассмотрим следующее предложение
Предложение: «горячее мороженое»
Приведенное выше предложение будет отклонено семантическим анализатором.
Теперь давайте формально определим синтаксический анализ,
В приведенном выше смысле синтаксический анализ или синтаксический анализ можно определить как процесс анализа строк символов на естественном языке в соответствии с правилами формальной грамматики.
Целью лексического анализа является очистка данных и извлечение признаков с помощью таких методов, как
.- Штемминг,
- Лемматизация,
- Исправление слов с ошибками и т. д.
Но, наоборот, в синтаксическом анализе наша цель:
- Найти роль слов в предложении,
- Интерпретация отношений между словами,
- Интерпретировать грамматическую структуру предложений.
Рассмотрим следующий пример с двумя предложениями:
Предложения: Патна — столица Бихара. Является ли Патна столицей Бихара?
В обоих предложениях все слова одинаковы, но только первое предложение синтаксически правильное и легко понятное.
Но мы не можем провести эти различия, используя основные методы лексической обработки. Поэтому нам требуются более сложные методы обработки синтаксиса, чтобы понять отношения между отдельными словами в предложении.
Синтаксический анализ рассматривает в предложении следующие аспекты, которых нет в лексике:
Порядок слов и значениеЦелью синтаксического анализа является выявление зависимости слов от других слов в документе. Если мы изменим порядок слов, то это затруднит понимание предложения.
Сохранение стоп-словЕсли убрать стоп-слова, то это может вообще изменить смысл предложения.
Морфология словФормирование стемминга, лемматизация приведет слова к их базовой форме, тем самым изменив грамматику предложения.
Части речи слов в предложенииОчень важно определить правильную часть речи в слове.
Например, Рассмотрим следующие фразы:
‘порезы на руке’ (Здесь ‘порезы’ — существительное) ‘он режет ананас’ (Здесь ‘режет’ — глагол)Что такое синтаксический анализатор?
Парсер используется для реализации задачи разбора.
Теперь давайте посмотрим, что такое парсер?
Он определяется как программный компонент, который предназначен для приема входных текстовых данных и дает структурное представление ввода после проверки правильности синтаксиса с помощью формальной грамматики. Он также генерирует структуру данных, как правило, в форме дерева синтаксического анализа, абстрактного синтаксического дерева или другой иерархической структуры.
Источник изображения: Google Images
Мы можем понять актуальность синтаксического анализа в НЛП с помощью следующих точек:
- Анализатор может использоваться для сообщения о любой синтаксической ошибке.
- Помогает исправить часто возникающие ошибки, чтобы можно было продолжить обработку оставшейся части программы.
- Дерево синтаксического анализа создается с помощью парсера.
- Парсер используется для создания таблицы символов, которая играет важную роль в НЛП.
- Парсер также используется для создания промежуточных представлений (IR).
Как уже говорилось, синтаксический анализатор — это процедурная интерпретация грамматики. Он пытается найти оптимальное дерево для конкретного предложения после поиска в пространстве множества деревьев.
Давайте обсудим некоторые из доступных парсеров:
- Анализатор рекурсивного спуска
- Анализатор сдвига-уменьшения
- Анализатор диаграмм
- Парсер регулярных выражений
Это одна из самых простых форм синтаксического анализа. Ниже приведены некоторые важные моменты, касающиеся синтаксического анализатора рекурсивного спуска:
- Процесс осуществляется сверху вниз.
- Пытается проверить правильность синтаксиса входного потока.
- Сканирует вводимый текст слева направо.
- Необходимая операция для этих типов парсеров — сканирование символов из входного потока и сопоставление их с терминалами с помощью грамматики.
Вот некоторые из важных моментов парсера сдвига и уменьшения:
- Это следует простому восходящему процессу.
- Он направлен на поиск последовательности слов и фраз, которая соответствует правой части грамматического произведения, и заменяет их левой частью произведения.
- Он пытается найти последовательность слов, которая продолжается до тех пор, пока не будет сокращено все предложение.
- Проще говоря, этот синтаксический анализатор начинается с входного символа и стремится построить дерево синтаксического анализа до начального символа.
Вот некоторые из важных моментов парсера диаграмм:
- В основном этот синтаксический анализатор полезен для неоднозначных грамматик, включая грамматики естественных языков.
- Он применяет концепцию динамического программирования к задачам синтаксического анализа.
- Из-за динамического программирования он сохраняет частичные гипотетические результаты в структуре, называемой «диаграммой».
- «Диаграмму» также можно повторно использовать в различных сценариях.
Это один из наиболее часто используемых парсеров. Ниже приведены некоторые важные моменты, касающиеся синтаксического анализатора регулярных выражений:
.- Он использует регулярное выражение, которое определено в форме грамматики поверх строки с POS-тегом.
- По сути, он использует эти регулярные выражения для разбора входных предложений и создания из них дерева разбора.
Нам нужна последовательность продукционных правил, чтобы получить входную строку. Вывод – это набор правил производства. Во время синтаксического анализа мы должны определить нетерминал, который подлежит замене, а также определить продукционное правило, с помощью которого нетерминал будет заменен.
Типы происхожденияВ этом разделе мы обсудим два типа производных, которые можно использовать для решения, какой нетерминал заменить продукционным правилом:
Самая левая производная В крайнем левом выводе сентенциальная форма ввода сканируется и заменяется слева направо. В этом случае сентенциальная форма известна как левая сентенциальная форма.
В крайнем левом выводе сентенциальная форма ввода сканируется и заменяется справа налево. В этом случае сентенциальная форма называется право-сентенциальной формой.
Типы анализа
Наследование делит синтаксический анализ на следующие два типа:
Источник изображения: Google Images
Анализ сверху внизПри синтаксическом анализе сверху вниз синтаксический анализатор начинает создавать дерево синтаксического анализа из начального символа, а затем пытается преобразовать начальный символ во входные данные. Наиболее распространенная форма анализа сверху вниз использует рекурсивную процедуру для обработки ввода, но ее главный недостаток — 9.0007 возврат .
Анализ снизу вверх При анализе снизу вверх анализатор начинает работать с входным символом и пытается построить дерево анализатора до начального символа.
Представляет собой графическое изображение деривации. Начальный символ вывода считается корневым узлом дерева синтаксического анализа, а конечные узлы являются конечными, а внутренние узлы нетерминальными.
Наиболее полезным свойством дерева синтаксического анализа является то, что Обход дерева по порядку создаст исходную входную строку.
Например, Рассмотрим следующее предложение:
Приговор: собака увидела человека в парке
После анализа предложения сформированное дерево разбора показано ниже:
Источник изображения: Google Images
На этом мы заканчиваем часть 11 серии блогов по обработке естественного языка! Другие записи моего блогаВы также можете проверить мои предыдущие сообщения в блоге.
Предыдущие записи блога Data Science.
LinkedIn Вот мой профиль Linkedin на случай, если вы захотите связаться со мной. Я буду счастлив быть связанным с вами.
По любым вопросам вы можете написать мне на Gmail .
Конечные примечанияСпасибо за внимание!
Надеюсь, вам понравилась статья. Если вам это нравится, поделитесь им с друзьями тоже. Что-то не упомянуто или хотите поделиться своими мыслями? Не стесняйтесь комментировать ниже, и я свяжусь с вами. 😉
Медиафайлы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
blogathonСинтаксический анализ
Содержание
Об авторе
Скачать Приложение Analytics Vidhya для последнего блога/статьи
Предыдущий пост Линейные прогностические модели. Часть 1
Следующий пост Часть 12: Пошаговое руководство по освоению НЛП — Грамматика в НЛП
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Примите
Политику конфиденциальности и использования файлов cookie
Пройдите обучение у экспертов отрасли
Эксперты отрасли станут вашими наставниками, проведут вас через проекты и помогут вам становиться лучше каждый день! Проверить ПрограммаОбъяснение структуры предложений и синтаксиса
Содержание
- Что такое английский язык?
- VCE English Language Study Design
- Что входит в экзамен?
- Как изучать английский язык
- Список метаязыков
- Образец эссе
- Категории тем эссе для 12 класса
1. Что такое английский язык?
Study Design Stuff
Английский язык является одним из 4 различных предметов английского языка, предлагаемых как часть Victorian Certificate of Education (VCE). В этом предмете вы узнаете, как люди и группы с разной идентичностью используют разные варианты английского языка и как это связано с отражением их ценностей и убеждений. Английский язык даст вам существенное представление о влиянии языка на общество, о том, что он сообщает о нас самих и о группах, с которыми мы идентифицируем себя, и о том, как общество, в свою очередь, также может влиять на язык.
Если вы не уверены в том, что именно влечет за собой эта тема, не волнуйтесь! Давайте рассмотрим, что входит в каждый модуль, и что вы должны делать в каждом из них.
2. План исследования английского языка VCE
Примечание. План исследования содержит список метаязыков для модулей 1 и 2, а также для модулей 3 и 4. Они очень похожи, за исключением списка модулей 3 и 4. включает в себя несколько новых функций, таких как добавление паттернов (фонологических, синтаксических и семантических), а также значительное дополнение к подсистеме дискурса (когерентность, связность, особенности разговорного дискурса и стратегии разговорного дискурса).
Блок 1
Область исследования (AoS1)
AoS1 называется «природа и функция языка». Вы узнаете о функциях разных типов текстов, различиях между устными и письменными текстами, о том, как ситуационные и контекстуальные факторы могут влиять на тексты, и, самое главное, вы узнаете о метаязыке согласно списку метаязыков Блоков 1 и 2.
Область исследования (AoS2)
AoS2 называется «овладение языком». Здесь вы узнаете о теориях, предложенных различными лингвистами и социологами относительно того, как дети усваивают языки. Кроме того, вы также расскажете, как усваиваются вторые языки. Один из самых важных навыков, который вы приобретете в этом AoS, — это умение применять метаязык в дискуссиях и эссе.
Unit 2
AoS1
English Across Time» предоставит вам исторический контекст того, как мы пришли к форме английского языка, которую мы используем сегодня. Вы узнаете о процессах, которые привели к развитию современного английского языка из древнеанглийского, об изменениях, которые произошли во всех подсистемах (узнайте о синтаксической подсистеме здесь), а также о различных подходах к языковым изменениям.
AoS2
«Englishes in contact», вы узнаете о процессах, которые привели к глобальному распространению английского языка, пересечениях между культурой и языком, а также об отличительных чертах пиджинов, креолов и английского языка как лингва-франка.
Блок 3
AoS1
«Неформальный язык» даст вам представление о роли неформального языка в современном австралийском контексте. Вы узнаете, что делает тексты неформальными, чем они отличаются для устных и письменных текстов, и какие социальные цели могут быть достигнуты с помощью неформального языка, например, поддержание или угроза потребностям лица, установление близости или солидарности, создание группы или поддержка языковых инноваций.
АоС2
«Формальный язык» предоставит вам подробное представление о том, что делает тексты формальными, отличительных чертах устных и письменных текстов, а также о том, каких социальных целей можно достичь с помощью формального языка, таких как укрепление авторитета, установление опыта, уточнение, запутывание, или поддержание и вызов положительных и отрицательных потребностей лица.
В обоих этих AoS вы будете применять Метаязык Модулей 3 и 4 в своих кратких ответах и аналитических комментариях. Дополнительный метаязык обычно преподается в 1-м семестре 12-го класса, пока вы изучаете содержание 3-го раздела.
Unit 4
AoS1
«Языковые вариации в австралийском обществе» представляет собой подробное исследование того, как стандартный и нестандартный австралийский английский используется в современном обществе. Вы узнаете, как идентичность создается с помощью языка, как варианты английского языка различаются в зависимости от культуры (например, этнолекты или английский язык австралийских аборигенов), а также какое отношение к различным вариантам имеют разные группы.
AoS2
В разделе «Индивидуальная и групповая идентичность» вы увидите, как язык меняется в зависимости от различных факторов, таких как возраст, пол, род занятий, интересы, стремления или образование, и как все эти факторы влияют на нашу идентичность. Вы узнаете больше о своих и чужих группах, а также о том, как их можно создавать и поддерживать с помощью языка. Кроме того, вы узнаете о взаимосвязи между социальными установками и языком и о том, как язык может формироваться, а также влиять на социальные установки и ожидания сообщества.
Для получения дополнительной информации ознакомьтесь с планом исследования.
3. Что входит в экзамен?
Экзамен для 12 классов включает 2 часа письма и 15 минут чтения. Он состоит из трех разделов:
- Раздел A: 15 баллов (рекомендуется потратить на этот раздел примерно 20-25 минут)
- Раздел B: 30 баллов (рекомендуется потратить примерно 40-45 минут, и написать 600-700 слов)
- Раздел C: 30 баллов (рекомендуется потратить примерно 45-50 минут и написать 700-800 слов)
Убедитесь, что вы прочитали критерии оценки для каждого раздела.
Раздел A
Раздел A — 15 баллов за вопросы с кратким ответом. Вам дается текст, и вы должны ответить на вопросы о стилистических и дискурсивных особенностях, используемых в тексте, при этом убедившись, что вы демонстрируете детальное знание метаязыка, тщательно выбирая соответствующие примеры из текста.
Глубокое понимание метаязыка действительно важно как с точки зрения знания значений каждого металингвистического термина, так и с точки зрения знания того, к какой категории подходит каждый термин (например, знание того, что вывод является частью когерентности, а не связности). Поэтому важно, чтобы вы изучали свой метаязык с точки зрения того, что означает каждая терминология, а также с точки зрения того, к какой категории относится каждый термин.
В качестве общего руководства:
- 1 балл – одна идея или один пример или одно объяснение
- 2 балла – одна идея плюс один или два примера с пояснениями объяснения
- 4 балла – две или три идеи плюс один или два примера каждой с пояснениями
- 5 баллов – три идеи плюс один или два примера каждой с пояснениями
правильно вопросы. Учащиеся иногда упускают из виду, сколько примеров указано в вопросах для идентификации (эта информация часто дается как «определить 2 примера» или «определить цели» во множественном числе), забывают проверить, сколько баллов стоит вопрос, или путают определенные метаязыковые термины, например, путать типы предложений со структурами предложений. Поэтому будьте очень осторожны, отвечая на эти вопросы.
Вот несколько примеров вопросов с краткими ответами, которые возникали на прошлых экзаменах VCAA:
[Вопрос 2, VCAA 2017] — определите и прокомментируйте использование двух разных просодических элементов. (4 балла).
Здесь вы должны определить 2 различных просодических признака (высота тона, ударение, громкость, интонация или темп) и обсудить, какое влияние они оказывают на текст, принимая во внимание контекстуальные факторы. Например, ударение может использоваться для акцентирования внимания, а интонация может влиять на передаваемые эмоции.
[Вопрос 1, VCAA 2015] — Какие типы предложений используются в строках с 15 по 36? Как они усиливают цели этого текста? (3 балла)
Здесь вы должны определить соответствующие типы предложений (повествовательные, повелительные, вопросительные и восклицательные) и объяснить их роль в тексте. Вы также хотели бы, чтобы ваши объяснения соответствовали контексту текста.
[Вопрос 9, VCAA, 2010 г.] — Обсудите функцию двух разных функций, не связанных с беглостью речи, между строками 70 и 9.6. (4 балла)
Здесь вы должны определить два признака отсутствия беглости (такие как паузы, фальстарт, исправления, повторение) и дать объяснение в 1 предложении их роли или того, на что они указывают.
[Вопрос 1, 2012 VCAA] — Определите регистр текста. (1 балл)
Этот вопрос достаточно прямолинеен, и в своем ответе вы можете использовать такие термины, как формальный, неформальный, преимущественно формальный/неформальный.
[Вопрос 4, VCAA 2012] — Какое время глагола в строках 9–34 поддерживает цель этого раздела текста? (2 балла)
Здесь вы должны определить, в каком времени глагол стоит в прошедшем, настоящем или будущем времени, и объяснить, почему он используется таким образом, исходя из контекстуальных факторов.
[Вопрос 3, 2017 VCAA] — Используя соответствующий метаязык, определите и объясните две особенности языка, отражающие личность говорящего. (4 балла) идентичности, такие как жаргон, разговорные выражения, семантика некоторых шуток, ругательства или уничижительные выражения.
Примечание: На экзаменах до 2012 года было 2 набора вопросов с кратким ответом, потому что аналитические комментарии не были частью экзамена в то время. Это оставляет вас с большим количеством практических вопросов! Однако имейте в виду, что списки метаязыков различались, и некоторые функции классифицировались по-разному. Например, во втором вопросе экзамена VCAA 2013 вас просят рассказать о просодических особенностях, однако в отчете экзаменатора в качестве варианта предлагаются паузы. Мы знаем, что в настоящем исследовании паузы классифицируются как особенности разговорного дискурса в подсистеме дискурса, тогда как просодические особенности классифицируются в рамках подсистемы фонетики и фонологии.
Узнайте, как отвечать на вопросы с краткими ответами на английском языке VCE, если вам нужна дополнительная помощь в решении раздела A экзамена.
Раздел Б
Раздел Б представляет собой аналитический комментарий (АК) стоимостью 30 баллов. Введение для AC — это объяснение контекстуальных факторов, социальной цели и регистра текста. В основных абзацах (обычно их три) вы группируете примеры из текста по темам и объясняете их роль.
Существует два основных подхода к основным абзацам; подсистемный подход и целостный подход. При подсистемном подходе вы должны организовать свои примеры так, чтобы каждый абзац касался определенной подсистемы. Например, ваш AC может состоять из введения, затем абзаца по лексикологии, одного по синтаксису и одного по дискурсу. Этот подход проще, когда вы начинаете с AC, но одна из проблем с ним заключается в том, что вы в конечном итоге ограничиваете себя только одной частью текста для одного абзаца. При целостном подходе вы обычно делаете абзац, посвященный социальной цели, регистрации и дискурсу. При таком подходе вы можете сгруппировать примеры из нескольких подсистем и рассказать о том, как они работают вместе для достижения определенных ролей в текстах.
Убедитесь, что вы пытаетесь использовать ряд различных типов текстов, таких как авторские статьи, рецепты, клятвы, редакционные статьи, рекламные объявления, хвалебные речи, сообщения в социальных сетях, публичные объявления, стенограммы телепередач, стенограммы радиопередач, письма, речи, юридические документы. контракты, разговоры, рассказы и многое другое.
Для получения дополнительной информации посмотрите это видео:
Раздел C
Раздел C представляет собой сочинение стоимостью 30 баллов. Существует ряд тем, которые потенциально могут возникнуть на экзамене, и очень важно, чтобы вы практиковались в написании различных эссе.
В сочинениях очень важно убедиться, что вы изложили четкую аргументацию во вступлении. Это в основном скажет оценщику, что вы делаете в своем эссе, а также поможет вам вспомнить, в каком направлении двигаться со своим эссе. После вашего утверждения, вы должны обозначить свои идеи. Это означает, что вам нужно обобщить те 3 пункта, которые вы указываете в основных абзацах.
Вот упражнение, которое очень полезно для уточнения введения. Когда вы пишете свое утверждение, напишите: «В этом эссе я буду утверждать, что [Вставьте утверждение]. Я сделаю это, указав следующие пункты [Вставьте указатели]». Когда вы довольны своим введением, вы можете удалить подчеркнутые части. Это поможет вам действительно понять, чем отличаются роли для разногласий и указателей. Вы также хорошо поймете, какую позицию занимаете в эссе.
Абзацы основного текста имеют структуру TEEL. Вы начинаете с тематического предложения, излагаете свои доказательства, объясняете их, а затем связываете их со своим утверждением. У вас есть три варианта типа доказательств, которые вы будете использовать (стимулирующий материал, современные примеры и цитаты лингвистов), и важно использовать их комбинацию. Согласно рубрике экзамена, вы должны использовать как минимум 1 часть стимулирующего материала. Современные примеры в идеале должны быть из текущего и предыдущего года. Цитаты лингвистов не имеют ограничений по времени, но неплохо попытаться найти последние цитаты.
Одна из самых важных вещей в основных абзацах — убедиться, что вы можете связать свой пример с утверждением. Если вы не можете этого сделать, это означает, что ваши примеры не имеют отношения к тому, что вы пытаетесь донести.
В заключении убедитесь, что вы не вводите новые примеры или пункты. Роль заключения состоит в том, чтобы обобщить и подкрепить ваши пункты и ваше общее утверждение.
Если вам нужны дополнительные разъяснения, взгляните на этот пост в эссе по английскому языку.
4. Как учиться английскому языку
Тайм-менеджмент и организация
Расписание занятий сделает учебу менее напряженной, чем она должна быть. В своем расписании убедитесь, что вы выделяете достаточно времени для всех своих предметов, а также времени для отдыха, внеклассных занятий, работы и общения. Реалистичный график также будет означать, что вы с меньшей вероятностью будете тратить время, пытаясь решить, какие предметы изучать. Например, каждое воскресенье вы можете потратить 15 минут на планирование своей недели, исходя из того, какие у вас оценки и каким предметам вы хотели бы уделить время. Это становится особенно полезным в SWOTVAC, где вы будете нести ответственность за то, чтобы уделять достаточно времени каждому предмету, а также сбалансировать все остальное за пределами школы.
Вот несколько дополнительных ресурсов, которые помогут вам в тайм-менеджменте:
SWOTVAC: Планирование вашей жизни
10 советов по тайм-менеджменту
Как выжить VCE — мотивация и подход наиболее важные методы изучения английского языка.
Основы метаязыка рассматриваются в Разделе 1. Убедитесь, что у вас есть четкий набор заметок для этого содержания, чтобы вы могли оглянуться назад и пересмотреть его в течение года. Прежде чем начнется 12-й год, вы должны убедиться, что все в списке метаязыков 11-го года имеет для вас смысл. Проведение летних каникул до начала 12-го класса для закрепления основ поможет вам в течение 12-го года, так как вы сможете намного быстрее освоить новый метаязык. Одна из первых вещей, которые вы затронете, — это согласованность и сплоченность, поэтому, если вы хотите получить преимущество, взгляните на этот пост.
В течение 12-го года вашей обязанностью будет постоянное пересмотр метаязыка. Вполне вероятно, что вы будете проводить большую часть учебного времени за изучением содержания и написанием кратких ответов, аналитических комментариев или эссе. Поэтому очень важно найти способ, который лучше всего подходит для вас, чтобы иметь возможность часто пересматривать метаязык. Флэш-карты очень полезны для повторения, а также для создания ассоциативных карт, чтобы вы могли визуализировать, как все изложено в дизайне исследования.
Одна из проблем, с которой сталкиваются учащиеся, заключается в том, что они могут дать определения и привести примеры терминов метаязыка, однако они не могут понять, как они соотносятся с категориями каждой подсистемы. Например, учащийся может вспомнить, что такое метафора, но не может вспомнить, что она соответствует семантическому паттерну. Точно так же учащийся может знать, что такое пауза, но не знать, является ли она частью просодических или дискурсивных особенностей. Важно знать, что представляют собой все категории, потому что вопросы с кратким ответом обычно просят вас определить функции в определенной категории. Следовательно, тратить время только на повторение определений недостаточно для изучения метаязыка. Вы также должны быть в состоянии убедиться, что вы можете вспомнить, к какой категории подходит каждый термин.
Чтение новостей
Для эссе вы должны использовать примеры из современных СМИ в качестве доказательства (наряду со стимулирующим материалом и цитатами лингвистов). Для вас действительно важно начать этот процесс как можно раньше, чтобы вы могли начать использовать примеры в эссе как можно раньше. Советы о том, как находить, анализировать и хранить ваши примеры, см. в нашей публикации «Создание банков доказательств для эссе для английского языка» .
Знакомство с историческим, политическим и социальным контекстом Австралии даст вам более полное представление о современных примерах. Итак, если вы еще этого не сделали, попробуйте выработать привычку читать новости (хорошее место для начала — The Conversation или The Guardian). Телевизионные программы, такие как Q and A, The Drum и Media Watch, помогут вам понять австралийский контекст, и часто в этих программах также обсуждаются роли языка, которые напрямую связаны с тем, что вы ищете, в качестве примеров для эссе. Особенно важно начать рано и развивать эти навыки с течением времени, чтобы вы могли создать целостную основу.
Дополнительные практические занятия и поиск отзывов
Выполнение дополнительных практических занятий — действительно эффективный способ развития и совершенствования ваших аналитических навыков. Убедитесь, что вы получаете отзывы о своей работе от своего учителя или репетитора, так как это единственный способ узнать, движетесь ли вы в правильном направлении.
Если у вас мало времени, даже составление плана AC или сочинения или просто выполнение 1 абзаца — это эффективный способ пересмотреть.
Учебные цитаты и примеры
Поначалу запоминание нескольких страниц, полных цитат лингвистов и современных примеров, может показаться сложным, но как только вы начнете использовать их в эссе, их станет намного легче запомнить. С самого начала yr12 убедитесь, что вы создали документ для компиляции цитат и примеров лингвистов в подзаголовки. Например, такие подзаголовки, как «культурная самобытность», «жаргон», «разжигание ненависти», «свобода слова» или «австралийские ценности», облегчат вам навигацию по заметкам при планировании эссе.
Если вы начнете рано, вы сможете вспомнить все по крупицам в течение года, что определенно проще, чем пытаться вспомнить улики накануне экзамена. Кроме того, вы будете готовы к цитатам и примерам, как только начнете писать эссе в классе, поэтому вы сможете использовать свои примеры раньше, следовательно, выучить их раньше и, следовательно, сможете заранее запомнить свои цитаты и примеры. Если вы учитесь в 12-м классе, приближаетесь к концу года и все еще с трудом запоминаете свои примеры и цитаты, попробуйте использовать карточки для запоминания своих доказательств. Убедитесь, что вы делаете ряд эссе на разные темы, чтобы вы могли применять и анализировать свои доказательства.
Учиться на своих ошибках
Часто повторять одни и те же ошибки и продолжать терять оценки может быть неприятно. Таким образом, сбор ошибок, которые вы совершаете в течение года, в отдельном блокноте или документе — это отличный способ отслеживать ключевые вещи, которые вам нужно помнить. У вас также будет меньше шансов повторить эти ошибки.
Групповые занятия
Групповые занятия по английскому языку — очень эффективный способ улучшить понимание материала и увидеть различные точки зрения на применение определенных идей. Повторение метаязыка и проверка знаний ваших друзей может быть легким и увлекательным способом убедиться, что вы и ваши друзья находитесь на правильном пути. Обмен способами, которыми вы и ваша группа подошли к конкретному AC, также является эффективным способом узнать о различных подходах. Обсуждение тем эссе — полезный способ уточнения ваших аргументов, поскольку вы ознакомитесь с разными мнениями и сможете работать над тем, чтобы ваши аргументы были актуальными и сильными.
См. Как расширить свои возможности в VCE English Language для получения дополнительных советов!
5. Список метаязыков
Пожалуйста, обратитесь к страницам 9-10 для списка 11-го класса и 17-18 для списка 12-го года!
6. Образец эссе
Тема
Язык имеет основополагающее значение для идентичности, и, следовательно, мы используем наш лингвистический репертуар для проецирования различных аспектов нашей идентичности в зависимости от контекста. Обсудите это утверждение в контексте современной Австралии, сославшись по крайней мере на две подсистемы в своем ответе.
(Тема этого эссе относится к Разделу 4 — AoS1, «Языковая изменчивость в австралийском обществе». )
Введение
Язык играет ключевую роль в установлении и передаче различных аспектов идентичности. Таким образом, люди могут изменить свой языковой репертуар, чтобы установить членство в группе. Teenspeak является эффективным механизмом выражения подростковой идентичности, но также может использоваться старшим поколением для обращения к молодежи. Переключение кода между этнолектами и стандартным австралийским английским также иллюстрирует, как люди могут манипулировать своим языковым выбором в соответствии со своей средой, одновременно отражая этническую идентичность. Кроме того, жаргон играет решающую роль в установлении профессиональной идентичности и обозначении опыта или авторитета. Следовательно, языковой выбор способен выражать разнообразную и многогранную идентичность.
Body Paragraph
Teenspeak способен выражать идентичность и устанавливать членство в группе среди подростков, однако он также может использоваться теми, кто находится вне группы, чтобы обратиться к подросткам. Профессор Пэм Питерс утверждает, что «подростки используют язык как своего рода идентификационный знак, который исключает взрослых». Следовательно, подростки могут установить исключительность и членство в группе. Владелец пекарни Морган Хипворт, у которого в основном есть подростки сам является подростком, использует подростковый язык в видео-рецепте, где он отвечает на вопрос «Можете ли вы сделать 10-слойный тост с сыром?» словами «Спорим, поехали». общаться и общаться со своей молодой аудиторией, продолжая утверждать свою идентичность в подростковом возрасте. Это демонстрирует, как подростковая речь может быть эффективной как для установления членства в группе, так и для выражения идентичности. Точно так же ютубер Эшли Мешиа широко использует подростковые инициализмы в подписях в Instagram, таких как как «ootd» для «наряда дня», «grwm» для «приготовься со мной» и «ngl» для «не буду лгать», позволяет ей общаться со своими преимущественно подростками, что позволяет ей большая солидарность и членство в группе. Это также указывает на то, что подростковая речь является эффективным механизмом выражения идентичности и формирования членства в группе. Напротив, подростковый язык также может использоваться пожилыми людьми, чтобы привлечь внимание подростков. Например, в 2019 г., ведущий ABC «Вопросы и ответы» Тони Джонс закончил рекламный ролик о возможности для старшеклассников появиться на панели фразой «Это будет освещено семьей». когда пожилые люди говорят на подростковом языке, это часто вызывает раздражение. Лингвист Кейт Берридж утверждает, что «пожилые люди, использующие современный подростковый сленг, часто звучат неискренне и фальшиво», и Джонс знал об этом, однако его целью было обратиться к этому, чтобы иметь возможность дальнейшего продвижения видео. Таким образом, подростковая речь эффективна как для установления членства в группе, так и для выражения идентичности, а также для обращения к своей группе и члену чужой группы.
7. Категории тем сочинений для 12-х классов
1: Австралийский английский
- Австралийский английский отличается от других национальных разновидностей – эта тема посвящена тому, что делает австралийский английский уникальным, и факторам, которые со временем способствовали его развитию. Вы можете узнать больше, прочитав наш блог о культурных ценностях Австралии
- Что делает этот сорт уникальным как национальный сорт
- Широкий, общий, культивируемый акцент
- Ethnolects
- Английский язык аборигенов
- Отношение к разновидностям австралийского языка
- Стандартный австралийский английский и его престижность
- Нестандартные варианты, действующие в Австралии
- Региональные различия в Австралии
- Роль языка в формировании национальной идентичности (читайте блог)
2: Индивидуальная и групповая идентичность
- Социальные и личностные различия (возраст, пол, род занятий, интересы, образование, происхождение, устремления)
- Индивидуальная идентичность и групповая принадлежность
- Стандартный и нестандартный английский и престижные варианты
- Ингруппы и исключение
- Социальное отношение к нестандартным акцентам и диалектам
- Потребности лица (читать блог) 6 3 9 : Регистрация
- Отношения между говорящим/писающим и собеседниками/аудиторией
- Физическая обстановка, ситуационный и культурный контекст
- Предмет/тема/область/поле
- Способ (разговорный, письменный, электронный)
- Цель/функция взаимодействия
- Социальные установки и убеждения участников
- Включение и исключение; ингруппы и аутгруппы; социальная дистанция и близость
- Как язык может использоваться для поддержки или угрозы положительным или отрицательным потребностям лица (читать блог)
- Престижные формы языка
- Политкорректность (Читайте блог)
- Дискриминация и Hatespeech
- Эвфемизм и дисфемизм (Смотреть видео)
- ТАБОР, уничижительные и клятвенные районы 9010
- и то, как языковой учет
- 1001
- и то, как языковой экологически чистый. запутывание, двусмысленность, тарабарщина)
- Стратегии вежливости и социальная гармония
- Язык в общественном достоянии; общественный язык
- Лингвистические инновации
- Как язык представляет или формирует социальные и культурные ценности, убеждения, взгляды
- Как язык может выражать идентичность
- Другие функции языка, такие как запись, разъяснение, развлечение, продвижение, убеждение, памятование, празднование, обучение, информирование
- Австралийский английский и его развитие и эволюция во времени
- Табу, сквернословие и дисфемизм и роль в изменении социальных ценностей
- Политическая корректность, недискриминационный язык и изменение социальных ценностей
- Лингвистические инновации и неформальный язык
- Технологические достижения и их влияние на язык — сюда входят смайлики и текстовая речь
- Глобальные контакты и другие социальные изменения и их влияние на современный австралийский английский
- Этнолекты мигрантов и аборигенов Английский
- Размышления лингвиста
- Решение: Извлечение синтаксических признаков на основе правил
- Пример: Извлечение типа вопроса с использованием spaCy
- Больше экспериментируйте с синтаксическими функциями в наших повседневных усилиях по машинному обучению и инвестируйте в оптимизацию этого процесса, чтобы он стал повторяющейся частью конвейера.
- Создайте больше кода с открытым исходным кодом для извлечения лингвистических признаков.
- Наймите больше лингвистов и при необходимости помогите им повысить свои технические навыки. Инвестируйте в них ради уникальной отдачи, которую они принесут.
- Предварительной маркировки больших наборов данных для создания зашумленных обучающих данных во время подготовки данных (функция маркировки )
- Исключения определенных аннотаций во время предварительная обработка данных ( предварительный фильтр )
- Отфильтровывать ложные срабатывания из выходных данных классификатора до/во время оценки модели (постфильтр )
- Придумайте одно или два больших лингвистических обобщения по каждой категории.
- Придумайте несколько контрпримеров к обобщениям и при необходимости измените/расширьте их.
- Напишите правила, отражающие новые обобщения.
- Проверьте правила на нескольких примерах.
- Доработайте правила, устранив все ложные срабатывания и протестировав новые примеры.
-
pos_: Обобщенный тег части речи. -
tag_: Детализированный тег части речи. -
dep_: Тег синтаксической зависимости, т. е. связь между токенами. -
head: синтаксический регулятор или непосредственно доминирующая лексема - Ссылаясь на теги spaCy (например,
"WDT","WP"и т. д.) делает ваши правила более общими, чем обращение к отдельным wh-словам (строка 3). - Pied-piping может быть захвачен отношением зависимости
prepмежду wh-словом и его заголовком (синтаксическим родителем или «управляющим» токеном) (строка 8). - Псевдоклева исключаются путем возврата
False, если слово wh находится в отношенииcsubjилиadvclк его заголовку (строки 11–13). - Вопрос возникает в несвязной конструкции, в которой «есть» (или другая форма «быть», например «был») функционирует как вспомогательное , например, « она использует spaCy?» (основной глагол здесь «использование». )
- Вопрос возникает в связной конструкции, в которой «есть» функционирует как основной глагол , « мышь мертва?»
- Тип 1 зафиксирован в строках 14–16, а инверсия подлежащего по отношению к вспомогательному. (Те же строки кода могут также отвечать за предметную область).0399 модальная инверсия , типа «Вы можете прочитать статью?»).
- Тип II фиксируется в строках 20–22, а инверсия субъекта происходит по отношению к корню, т. е. единственному токену, чей тег зависимости
«ROOT»в документе. - Взаимоисключающие вопросы полярных и белых вопросов отражены в строках 9–10.
- Одно за другим предложения (устные или письменные) передают идеи, которые складываются в смысл.
- Для полного понимания необходима эффективная обработка структуры предложения. 90–100 Уровень синтаксиса текста является одним из предикторов понятности текста (Snow et al., 2005). 90–100 Эффективные читатели знают структуры фраз, части предложений и то, как они работают (Скотт, 2004).
- Используйте предложения из текста, используемого для чтения или чтения вслух.
- Включите слова, которые недавно встречались на уроках фонетики или правописания.
- Включить недавно выученные словарные термины.
- Введите скремблирование предложений, состоящее всего из нескольких слов — максимум из трех или четырех. Затем постепенно увеличивайте количество слов, а также сложность структуры предложения. Старайтесь не использовать слишком много слов, которые могут утомить учащихся.
- Составьте задание, начав первое слово предложения с заглавной буквы и поставив знаки препинания после последнего слова.
Улучшенный человеко-компьютерный интерфейс, который может преобразовывать естественный язык в компьютерный и наоборот. Система естественного языка может быть интерфейсом к системе базы данных, например, для использования туристическим агентом при бронировании. Слепые люди могли бы использовать систему естественного языка (с распознаванием речи) для взаимодействия с компьютерами, и Стивен Хокинг использует ее для создания речи из своего печатного текста.
Программа перевода, которая может переводить с одного человеческого языка на другой (например, с английского на французский). Даже если программы, которые переводят между человеческими языками, несовершенны, они все равно будут полезны, поскольку они могут сначала выполнить рудиментарный перевод, с проверкой их работы и исправлением переводчиком-человеком. Это сокращает время на перевод.
Программы, которые могут проверять грамматику и приемы письма в текстовом документе.
Компьютер, который может читать на человеческом языке, может читать целые книги, чтобы пополнять свою базу данных данными. Это, безусловно, было бы проще, чем то, что Дуг Ленат пытается сделать с CYC.
- Обработка сигналов
- Синтаксический анализ
- Семантический анализ
- Прагматика
- Фонетические и фонологические знания: как слова соотносятся со звуками.
- Морфологическое знание: как слова строятся из более примитивных морфем (например, как «дружественный» происходит от «друг»). глагол может иметь разное время и т. д. Морфемы включают «бег», «смех», «не-», «-s» и «-es». уровень морфем.
- Синтаксические знания: как последовательности слов образуют правильные предложения. Знание правил грамматики.
- Семантические знания: как слова имеют «значение»; как слова имеют ссылку (обозначение) и связанные понятия (коннотации)
- Прагматическое знание: «как предложения используются в разных ситуациях и как употребление влияет на интерпретацию предложения», это касается намерений и контекста разговора.
- Знание дискурса: как предшествующие предложения определяют значение предложения, например, в случае референта местоимения.
- Мировые знания: общие знания, например, о убеждениях и целях других пользователей в разговоре.
- Парсеры шумоподавления
- Парсеры конечного автомата (парсеры конечного автомата)
- Анализаторы грамматики определенного предложения (аналогичные анализаторам грамматики структуры фраз)
4: Социальная цель языка
5: Отношение к разновидностям
6: Изменение языка
Хотя изменение языка в большей степени проявляется в модулях 1 и 2, по-прежнему важно знать, как язык меняется в повседневной жизни, отражая социальные потребности, установки и ценности. Обратите внимание на следующее:
Написание лингвистических правил для обработки естественного языка | by Jenny Lee
С руководством по извлечению типа вопроса с помощью spaCy
Источник: This LA Times articleСодержание
Когда я впервые начал изучать науку о данных ближе к концу своей докторской диссертации. программы по лингвистике, я был рад открыть для себя роль лингвистики, в частности, лингвистики особенности — в разработке моделей НЛП. В то же время я был немного озадачен тем, почему об использовании синтаксических признаков (например, уровень клаузальной вложенности, наличие согласования, тип речевого акта и т. д.) говорится относительно мало по сравнению с другими типами признаков, , например, сколько раз определенное слово встречается в тексте (лексические признаки), меры сходства слов (семантические признаки) и даже место в документе, где встречается слово или фраза (позиционные признаки).
Например, в задаче анализа настроений мы можем использовать список содержательных слов (прилагательных, существительных, глаголов и наречий) в качестве признаков для прогнозирования семантической ориентации отзывов пользователей (т. е. положительных или отрицательных). В другой задаче классификации обратной связи мы можем курировать списки слов или фраз для конкретной области, чтобы обучить модель, которая может направлять комментарии пользователей в соответствующий отдел поддержки, например, в отдел выставления счетов, технический отдел или отдел обслуживания клиентов.
Обе эти задачи требуют предварительно созданных словарей для извлечения функций, и существует множество таких словарей для публичного использования, таких как SocialSent и эти словари, созданные автором Medium. (Также ознакомьтесь с этой исследовательской статьей, в которой обсуждаются различные методы построения лексикона настроений). Пока лексические признаки сыграли важную роль в разработке многих приложений НЛП, было относительно мало работы, связанной с использованием синтаксических признаков (одно большое исключение, возможно, относится к области обнаружения грамматических ошибок).
Это сбивало с толку (и немного утомляло) меня как представителя лингвистической традиции, придающей синтаксису некое «превосходство» над семантикой и фонологией в общей архитектуре грамматики. Это, конечно, не означает, что лингвисты считают синтаксис в каком-то смысле более важным, чем другие разделы лингвистики, а просто то, что он занимает главенствующее положение во многих моделях грамматики, утверждающих, что синтаксическая форма является производной 9 . 0399 до достигается семантическая или фонетическая интерпретация. Привыкнув к этой «центральности» синтаксического модуля в лингвистической теории, я изо всех сил пытался понять прохладное отношение к синтаксической структуре в НЛП, которое резко контрастировало с большим доверием, которое разработчики НЛП придавали лексическому содержанию как характеристикам.
Язык, представленный НЛП, временами заставлял меня думать о фрагментарном Мистере Картофельная Голова — двухмерные части тела, разбросанные по странице книжки-раскраски, слова, не имеющие отношения друг к другу.
Источник: https://www.pixar.com/feature-films/toy-story Некоторое беспокойство, которое я чувствовал в связи с этим очевидным упрощением языка (как набор слов в моем самом раннем понимании), в конце концов исчезло. рассеяться, когда я уловил «магию» машинного обучения/глубокого обучения: даже без явного кодирования «он также изучает синтаксис». (И, по иронии судьбы, именно так ребенок овладевает языком — без явных указаний. )
Как лингвист (в частности, специалист по морфосинтаксии), я все еще, честно говоря, немного зациклен на реальности, что синтаксические особенности не получили такого большого внимания. внимание как лексические признаки в НЛП/ОД, и я склонен объяснять эту асимметрию следующими причинами:
1. Повторное знакомство с конвейером предварительной обработки и его нормализация, в котором структура преуменьшается. -представление слов. Эти методы полезны во многих случаях, но по своей сути являются субтрактивными: они удаляют фрагменты синтаксической (и/или морфологической) информации, присутствующей в исходном тексте. Удаление стоп-слов удаляет служебные слова, которые кодируют информацию об отношениях между составляющими/фразами, например, в, из, в, , и и т. д. Лемматизация и выделение корня удаляют важные флективные особенности, такие как время и согласование, а также производные аффиксы, которые могут иметь решающее значение для определения точного значения слова (например, — эр в учитель , — мент в — хищение ). И, конечно же, представления «мешок слов» не учитывают порядок слов, что является значительной потерей для такого языка, как английский, который не использует морфологический падеж для обозначения порядка слов. Когда эти шаги становятся обычными и повторяющимися частями нашего повседневного конвейера НЛП, это может скрыть или свести к минимуму роль, которую на самом деле играет синтаксическая структура.0399 не играет роли в обработке естественного языка, следовательно, препятствует или препятствует любым попыткам систематически измерять его влияние на модели НЛП. 2. Практические проблемы написания сложных лингвистических правил Я также предполагаю, что относительная неясность синтаксических особенностей в значительной степени связана с практическими трудностями написания достаточно сложных правил. Эксперты НЛП приходят в эту область с разной степенью знаний в области синтаксиса, и без четкого понимания основ и универсалий синтаксической структуры, лежащих в основе каждого языка, а также, в некоторой степени, ограничений на межъязыковые вариации, может быть трудно чтобы знать, какие синтаксические особенности имеют отношение к конкретному языку, не говоря уже о написании эвристик для их извлечения. В отличие от лексических особенностей, которые во многих случаях сводятся к простому подсчету слов, разработка хорошо продуманных лингвистических правил на уровне предложений (синтаксических) является гораздо более сложной задачей, требующей значительных знаний предметной области.
Я также пришел к выводу, что некоторые из наших самых популярных и коммерческих продуктов НЛП не требуют очень сложных синтаксических представлений входного текста или речи — создание синтаксических характеристик менее чем незаменимы при разработке моделей, которые их приводят в действие. Я думаю, причины в том, что (1) человеческая речь при взаимодействии человека и машины имеет тенденцию быть упрощенной с самого начала («Привет, Google, погода в Сан-Франциско» вместо «Эй, Джон, не могли бы вы сказать мне, какая сегодня погода в Сан-Франциско? ») и (2) простой синтаксический анализ лучше подходит для систем с меньшими вычислительными затратами, чем сложный синтаксический анализ, поэтому мы вынуждены работать с этими ограничениями.
Чтобы было ясно, три вещи, которые я обрисовал выше, являются проблемами/препятствиями для использования синтаксических функций, оправданий для их исключения в разработке функций. Хотя я не уверен, насколько синтаксические функции могут повлиять на производительность модели по сравнению с другими функциями, я верю, что, поскольку мы стремимся создавать машины, которые могут взаимодействовать с людьми гораздо более тонкими, естественными и изощренными способами. , синтаксический ввод и представление будут играют все более заметную роль в будущем НЛП. Я думаю, что мы получили бы большую пользу, если бы сделали эти три вещи в ответ:
Во всех этих трех задачах, я думаю, мы получим наибольшую отдачу, используя, в частности, систему , основанную на правилах . Синтаксис — это область, требующая точных знаний о конкретном языке, и поэтому она хорошо подходит для представления на основе правил (то есть в НЛП), возможно, в большей степени, чем любая другая область грамматики. Предложение использовать подход, основанный на правилах, конкурирует с подходом, полностью основанным на машинном обучении, для создания наборов функций. В последнем вы обучаете модель, которая предсказывает значение определенной функции 9От 0399 до подаются в модель, которая прогнозирует выходные данные некоторой целевой переменной. Однако этот процесс, вероятно, будет очень трудоемким и дорогостоящим, поскольку вы обучаете модель –, обучая модель. И именно поэтому я бы рекомендовал использовать правила как часть гибридной системы почти во всех случаях. Гибридные подходы сочетают в себе базовую модель, основанную на алгоритмах машинного обучения, с системой, основанной на правилах, которая служит своего рода фильтром постобработки, и они устарели. Было много успешных применений их, как это и на моей собственной работе.
Использование правил
Еще одно преимущество правил и систем, основанных на правилах, заключается в том, что их можно гибко использовать различными способами и, таким образом, повысить ценность и строгость почти на каждом этапе конвейера машинного обучения. Помимо использования их для извлечения признаков на этапе разработки признаков, их также можно использовать для:
некоторые могут быть склонны делать. Скорее, мы должны признать, что они очень убедительно дополняют друг друга, добавляя серьезное преимущество общей архитектуре.
В этом заключительном разделе я дам практическое руководство по написанию некоторых синтаксических правил для извлечения признаков. Я буду использовать spaCy для этого, сосредоточившись на извлечении тип вопроса . Я выбрал тип вопроса, потому что эта категория может особенно хорошо проиллюстрировать невероятную ценность лингвистических знаний при построении частично управляемой правилами модели НЛП. Кроме того, вероятно, есть много вариантов использования для извлечения типа вопроса (и, соответственно, типа предложения), поэтому, надеюсь, кому-то будет полезен приведенный ниже код. Некоторые приложения, которые я могу придумать, это: точная классификация вопросов (является ли предложение wh-вопросом, вопросом «да» или «нет» или теговым вопросом?), обнаружение речевого акта (является ли комментарий вопросом, просьбой или требование?), сравнительный речевой анализ (какой человек или группа использует в своей речи больше стратегий вежливости?) и т. д.
В этом заключительном разделе я, в конечном счете, надеюсь, довел до сознания как уместность лингвистических знаний для разработчиков НЛП, так и уместность правил или систем, основанных на правилах, в задачах НЛП/МО .
Написание лингвистических правил: итеративный процесс
При написании лингвистических правил я обычно выполняю следующие шесть шагов: ).
Часто эти шаги не являются идеально последовательными. Например, определение категорий, на которые вы хотите ориентироваться (шаг 1), в основном сводится к формулированию некоторых обобщений о них (шаг 2), поэтому вы можете выполнять эти шаги одновременно. Прежде чем я проиллюстрирую, как этот поток может направлять наше написание правил, давайте немного углубимся в spaCy.
Начало работы с spaCy
spaCy — это высокопроизводительная библиотека Python, которая может похвастаться многочисленными функциями и возможностями, которые помогут вам создать ваше любимое приложение НЛП, включая токенизацию, распознавание именованных сущностей, тегирование частей речи, анализ зависимостей, предварительное -обученные векторы слов и подобия, а также встроенные визуализаторы. Ознакомьтесь с полным набором его функций здесь, но здесь нас будут интересовать только два его компонента обработки, которые позволят нам представить синтаксическую структуру любого предложения, а именно теггер и парсер . Основной процесс использования spaCy выглядит следующим образом: сначала загрузите модель по вашему выбору (например, "en_core_web_sm" ). Затем вы можете проверить компоненты конвейера, позвонив по номеру pipe или pipe_name на nlp .
Затем вызовите nlp , передав строку и преобразовав ее в spaCy Doc , последовательность токенов (строка 2 ниже). Синтаксическая структура документа Doc может быть построена путем доступа к следующим атрибутам токенов его компонентов:
Я считаю полезным распечатать значения этих атрибутов вместе с именами лексем и индексами в кортежах, например:
Если вы хотите визуализировать синтаксический анализ, введите свое предложение во встроенный визуализатор spaCy. помечен POS-тегом грубого уровня (точный уровень ( tag_ ) здесь не показан).
Шаги 1–2: Определите категории, о которых вы хотите написать правила, и придумайте одно или два лингвистических обобщения для каждой категории
Эти два шага часто идут рука об руку. Разрабатывая правила извлечения типов вопросов, мы должны признать, что в любом языке есть два типа вопросов: wh-вопросы и полярные вопросы. Внимательно прочитайте эти обобщения:
Обобщения о типах вопросов: (1) Wh-вопросы (иначе содержательные вопросы): начните с вопросительного слова («wh-фразы»), например кто, что , где , и как, и позвоните для получения конкретной информации.(2) Полярные вопросы (также известные как вопросы «да» или «нет»): на них можно ответить утвердительно или отрицательно (с ответом «да» или «нет»), и они начинаются со вспомогательного ( сделал, сделал ) или модального ( будет, может ) глагол.
Вам может быть полезно визуализировать эти типы вопросов с помощью displaCy. Последний снимок экрана содержит синтаксический анализ для wh-вопроса, а вот один для полярного вопроса:
В дополнение к визуальному синтаксическому анализу мне нравится видеть тройку pos-tag-dep для каждого жетон, вот так:
Используя свое знание соглашений об аннотациях Penn Treebank (поскольку именно их использует spaCy), вы можете попробовать написать функции v1, которые будут отражать приведенные выше обобщения. Обычно я предпочитаю писать отдельные функции для разных категорий, а не одну функцию, содержащую сложную логику if/then. Вот краткая первая версия, в которой делается попытка зафиксировать обобщения в (1)-(2).
v1 правила извлечения двух типов вопросовШаг 3: Придумайте контрпримеры и пересмотрите свои обобщения
Придумывать контрпримеры к вашим первоначальным обобщениям очень важно, потому что они бросят вызов вашим основным предположениям о рассматриваемом лингвистическом феномене (здесь — формирование вопросов) и заставят вас выявить общую нить между различными примерами, чтобы выразить их поведение и характеристики в единый, обобщенный способ. В конечном счете, это поможет вам написать более простые, но более надежные и исчерпывающие правила.
Два приведенных выше обобщения воспроизведены здесь, чтобы избавить вас от прокрутки:
(1) Wh-вопросы (также известные как вопросы по содержанию): начните с вопросительного слова («wh-фразы»), например кто, что , где и как, и позвоните для получения конкретной информации .(2) Полярные вопросы (также известные как вопросы «да» или «нет»): на них можно ответить утвердительно или отрицательно (с ответом «да» или «нет»), и они начинаются со вспомогательного ( сделал, сделал ) или модального ( будет, может ) глагол.
Вот первая пара контрпримеров к обобщению в (1):
(3) То, что вы говорите , невероятно.
(4) Кого ты собираешься убивать, это не моя проблема.
Мы видим, что (1) не подтверждается этими предложениями, потому что, несмотря на то, что они начинаются с wh-слова, они не являются wh-вопросами! Это то, что лингвисты называют wh-расщелинами, или псевдорасщелинами . Псевдолевые часто описываются как придающие ударение или «фокус» части предложения и имеющие форму в (5):
(5) свободный относительный + «быть» + сфокусированный компонент
Свободный родственник — это предложение wh-relative, в котором (очевидно) отсутствует заглавное существительное (то есть «что вы говорите» вместо «то, что вы говорите»). Эта часть псевдорасщелины вводит тему (о чем идет речь в предложении) и связана с сфокусированным компонентом, который вводит новую информацию («невероятно») посредством глагола «быть».
Вот еще несколько контрпримеров к (1):
(5) В какой статье говорили о spaCy?
(6) Кому вы читали статью?
Эти предложения не подтверждаются (1) по другой причине: Хотя они не начинают с wh-фразы, как говорится в обобщении, они по-прежнему являются wh-вопросами в том смысле, что на них можно дать конкретную информацию (например, ответ на (6) может быть таким: «Я прочитал статью своей сестре. »). Эти предложения представляют собой так называемые «пестрые» конструкции и характеризуются тем, что слово wh появляется вместе с предлогом, как если бы оно «перетащило» другое слово в начало предложения. (6) в частности, можно противопоставить другому предложению, которое «связывает» предлог: « Кто вы читали статью по ?».
Наконец, вот два контрпримера к обобщению о полярных вопросах, изложенному в (2):
(7) Будет ли сегодня дождь?
(8) Вам было грустно из-за ее ухода?
Эти предложения показывают, что в дополнение к вспомогательным и модальным глаголам связка («быть») как основной глагол (в отличие от вспомогательного) должна быть включена в категорию глаголов, которые могут стоять в начале полярных вопросов. . Проще говоря, глагол и подлежащее подвергаются инверсии в полярных вопросах, когда глагол является вспомогательным, модальным или формой «быть», который служит основным глаголом. Это подводит нас к следующим пересмотренным обобщениям:
(1') Wh-вопросы (иначе содержательные вопросы): содержат вопросительное слово («wh-фразу»), например кто, что , где и как, и призывают к более конкретная информация.
Я думаю, что этот шаг наглядно демонстрирует, что лингвистические знания необходимы для написания сложных правил извлечения признаков. Знание того, что в английском языке используются различные стратегии для обозначения вопросительных предложений, таких как инверсия подлежащего-глагол и wh-движение, а также распознавание (и наличие названий) интересных лингвистических явлений, таких как pied-piping и clefting, может помочь вам сформулировать обобщения, которые могут в очередь поможет вам написать всеобъемлющие правила, которые не слишком специфичны.
Шаг 4: Напишите правила
Теперь мы можем изменить более ранние версии функций, is_wh_question_v1 и is_polar_question_v1 , чтобы они соответствовали новым обобщениям (1′) и (2′). Эта часть потребует некоторого времени и практики, прежде чем мы сможем чувствовать себя очень уверенно и комфортно, так что наберитесь терпения! Ниже я выделю несколько основных вещей, которые характеризуют каждую из функций v2:
In is_wh_question_v2 :
В is_polar_question_v2 , нам необходимо учитывать две ситуации:
Шаги 5–6. Проверьте правила на множестве примеров и повторяйте!
Наконец, чтобы объединить все вышеперечисленное, мы можем написать тестовую функцию, которая берет список примеров предложений и печатает тип вопроса для каждого предложения.
Когда я запускаю get_question_type(sentences) , я получаю следующий вывод:
В [352]: get_question_type(sentences)
Это правда? -- полярный
Ты можешь остановиться? -- полярный
Вы любите Джона? -- полярный
Тебе грустно? -- полярный
Она пела? -- polar
Вы не придете на ужин? -- полярный
Не могли бы вы мне помочь? -- полярный
Кого ты любишь? -- wh
Чей это ребенок? -- wh
Откуда вы его знаете? -- wh
Кому она читала книгу? -- ч
Я голоден.
Spacy это так весело! -- не вопрос
Скажи мне, что ты имеешь в виду. -- не вопрос
Буду рад вам помочь. -- не вопрос
Не грусти. -- не вопрос
Как хотите. -- wh # ложное срабатывание
То, что вы говорите, невозможно. -- не вопрос
Куда ты, туда и я. -- не вопрос
Все верно, кроме предпоследнего предложения «Все, что хочешь». С функциями v2 мы достигли точности 18/19 = 94,7% . Неплохо! Обратите внимание, что эти правила действительно чувствительны к лежащей в основе синтаксической структуре каждого предложения, а не к некоторым поверхностным свойствам, таким как наличие вопросительного знака (что иллюстрируется правильной классификацией примера «Чей это ребенок . ») .
И на всякий случай:
из sklearn.metrics importclassification_reportcr = classification_report(true_values, rules_predictions)
print(cr) точность отзыва f1-score supportне вопрос 1,00 0,88 0,93 8
полярный 1,00 1,00 1,00 7
белый 0,80 1,00 0,89 4
В качестве последнего шага вам нужно уточнить правила, устранив все ложные срабатывания для повышения точности (например, «Все, что вы хотите» было неправильно классифицировано как wh-вопрос) и тестирование с большим количеством примеров (и более сложных примеров), чтобы улучшить память. Когда вы будете удовлетворены, примените правила к новым данным и используйте результаты на любом этапе вашего рабочего процесса, который вы считаете целесообразным. Например, вы можете включить их в качестве функций во время разработки функций или использовать их уже в конвейере данных для создания зашумленных данных для аннотации.
Написание лингвистических правил для НЛП/машинного обучения — сложный итеративный процесс, требующий глубокого понимания языка и способности систематизировать эти знания в форме общих эвристик на языке программирования. Хотя правил, вероятно, недостаточно для того, чтобы их можно было использовать отдельно в большинстве приложений NLP, а хорошее написание правил почти всегда требует экспертных знаний, они имеют много преимуществ и являются отличным дополнением к алгоритмам ML. Если я убедил вас во всей их ценности, попробуйте spaCy и не стесняйтесь предлагать функцию версии 3 ниже или добавить запрос правил для других функций. 🙂
Синтаксическая осведомленность: обучение структуре предложения (часть 1)
Способность понимать на уровне предложения во многом является основой для способности понимать текст. То, как авторы выражают свои идеи в предложениях, сильно влияет на способность читателя получить доступ к этим идеям и идентифицировать их. Сложные предложения, содержащие большое количество идей (также называемых пропозициями) или имеющие необычный порядок слов, затрудняют понимание учащимися того, что они читают, особенно учащимся, которые поступают в школу с ограниченным знакомством с устной речью или для которых английский язык является второй язык.
Подумайте об этом:
Знание предложений также важно для сочинения учащимися (устно или письменно). Как объясняет это Сэддлер (2012): «Из многих трудностей, с которыми сталкиваются писатели, когда участвуют в сложном акте письма, создание предложений, которые точно передают смысл, является особенно сложной задачей…. манипулирование предложениями требует усилий и критичности».
Знание синтаксиса
Синтаксис — это изучение и понимание грамматики — системы и расположения слов, фраз и предложений, составляющих предложения. Чтобы понять предложение, читатель должен обрабатывать, хранить (в рабочей памяти) и интегрировать разнообразную информацию о синтаксисе и значении слов (Paris & Hamilton, 2009).
Синтаксическая осведомленность означает способность отслеживать взаимосвязь между словами в предложении, чтобы понимать его при чтении или сочинении в устной или письменной форме. Учащиеся развивают синтаксическую осведомленность посредством общения с устной речью, когда они маленькие, и особенно благодаря знакомству с письменной речью, которую они слышат при чтении вслух или самостоятельном чтении (примерно в 3 классе).
Упражнения для развития синтаксической осведомленности
Существует несколько учебных занятий, которые могут помочь учащимся развить «чувство предложения» (т. е. синтаксическую осведомленность), предоставляя учащимся возможность манипулировать и добавлять слова в предложения.
Скремблирование предложений
Во время упражнения по скремблированию предложений учащиеся составляют предложения из слов. Учащимся дается набор слов из предложения, которые расположены не по порядку. Затем они должны составить из слов полное предложение, соответствующее правильной английской грамматике. Слова не могут быть удалены. Вот два примера:
Вот несколько советов по использованию скремблирования предложений с вашими учениками:
Составление предложений: вопросы на букву «W»
Упражнения по составлению предложений помогают учащимся использовать и манипулировать растущим числом слов в предложениях (Мэрилин Адамс, 2011). Они особенно полезны для развития синтаксической осведомленности о придаточных предложениях, предложных фразах и наречных фразах. В основном упражнении по составлению предложений используются шесть вопросительных слов: кто, что, где, почему, что, как . Занятие начинается с простого предмета (например, черепаха ). Затем задается ряд вопросов, чтобы побудить студентов расширить и уточнить. Это задание можно выполнять всей группой, когда учащиеся вносят предложения, а учитель пишет предложения. Для старших школьников это задание можно выполнять в малых группах или с партнерами. Подготовьте, дав учащимся всего два-три вопросительных слова, а затем постепенно расширяйте задание.
Вот пример:
Источниками для этих занятий являются две программы профессионального развития «Ключи к грамотности»: Программа «Ключевое понимание: классы K-3 » и «Ключи к раннему письму» . Щелкните здесь, чтобы узнать больше об этих программах и заказать книги. В посте следующего месяца я поделюсь еще двумя действиями по развитию синтаксической осведомленности: Разработка ядра предложения и Объединение предложений .
Ссылки:
Адамс, MJ (2011). Чтение, язык и разум. Презентация PowerPoint в NYSED Network Team Institute, 29 ноября 2011 г., Олбани, штат Нью-Йорк.
Саддлер Б. (2012). Пособие для учителя по эффективному предложению
по письму . Нью-Йорк: Гилфорд Пресс.
Скотт, К. (2004). Синтаксический вклад
в развитие грамотности. В C. Stone, E. Stillman, B. Ehren,
& K. Apel (Eds.) Справочник по языку
и грамотности стр. 340-363. Нью-Йорк:
Гилфорд Пресс.
Сноу, К., Гриффин, П., и Бернс, М.С. (ред.). (2005). Знания для поддержки обучения чтению . Сан-Франциско: Джосси-Басс.
Джоан Седита — основатель организации «Ключи к грамотности» и автор программ профессионального развития «Ключи к грамотности». Она опытный педагог, признанный в стране спикер и педагог-тренер. Она проработала более 35 лет в сфере обучения грамоте и выступала перед тысячами учителей и смежных специалистов в школах, колледжах, клиниках и на профессиональных конференциях.
Win Phillip’s Papers
Вернуться на СТРАНИЦУ МОДУЛЯ
Уинфред Филлипс: Автор
апрель 1999 г.
Введение
В этой статье я представляю общее введение в обработку естественного языка. В первую очередь это обсуждение того, как заставить компьютер обрабатывать естественный язык. Я также описываю, как ProtoThinker обрабатывает английский язык.
«Обработка естественного языка» здесь относится к использованию и способности систем обрабатывать предложения на естественном языке, таком как английский, а не на специализированном искусственном компьютерном языке, таком как C++. Системы, представляющие здесь реальный интерес, — это цифровые компьютеры того типа, который мы думаем как персональные компьютеры и мейнфреймы (а не цифровые компьютеры в том смысле, в котором «мы все — цифровые компьютеры», если это вообще так). Конечно, люди могут обрабатывать естественные языки, но для нас вопрос заключается в том, смогут ли цифровые компьютеры и когда-либо будут обрабатывать естественные языки.
К сожалению, есть некоторая путаница в использовании терминов, и нам нужно разобраться с этим, прежде чем продолжить. Во-первых, иногда фраза «естественный язык» используется не для реальных языков, как они используются в обычном дискурсе, например, наше фактическое использование английского языка для общения в повседневной жизни, а для более ограниченного подмножества такого человеческого языка, один очищен от конструкций и двусмысленностей, которые компьютеры не могли разобрать. Поэтому один писатель утверждает, что «человеческие языки допускают аномалии, которых не могут допустить естественные языки»2. Может быть, потребность в таком языке и существует, но естественный язык, ограниченный таким образом, является искусственным, а не естественным. Я не использую фразу «естественный язык» в этом ограниченном смысле искусственного естественного языка. Когда я использую эту фразу, я имею в виду человеческий язык во всей его беспорядочности и разнообразном использовании.
Во-вторых, фраза «обработка естественного языка» не всегда используется одинаково. Существует широкий смысл и узкий смысл.1 Эта фраза иногда понимается широко, включая обработку сигналов или распознавание речи, вопросы контекстной ссылки, планирование и генерацию дискурса, а также синтаксический и семантический анализ и обработку (значение этих терминов будет рассмотрено более подробно позже). В других случаях эта фраза используется более узко, чтобы включать только синтаксический и семантический анализ и обработку.
В-третьих, даже если эта путаница преодолена, фраза «обработка естественного языка » может или не может восприниматься как синоним «понимания естественного языка». «Обработка» наиболее естественно используется как для интерпретации , так и для поколения , в то время как можно было бы подумать, что «понимание» лучше использовать только для части интерпретации . Для меня утверждение, что система способна понимать естественный язык, не означает, что система может генерировать естественный язык, а только то, что она может интерпретировать естественный язык. Сказать, что система может обрабатывать естественный язык, можно как для понимания (интерпретации), так и для генерации (производства). Но фраза «понимание естественного языка», кажется, используется некоторыми авторами как синоним «обработки естественного языка», и это использование включает интерпретацию и генерацию. В этой статье я буду использовать термин «обработка естественного языка», но имейте в виду, что в основном я обсуждаю интерпретацию, а не генерацию.
В-четвертых, еще одна проблема заключается в том, что фраза «понимание естественного языка» иногда используется в смысле исследования того, как работают естественные языки, и попытки разработать вычислительную модель этой работы, где «обработка естественного языка» относится к системе. интерпретация и генерация естественных языков. Это использование фразы намекает на две разные цели этой области исследований. Одна цель — понять, как работает обработка естественного языка; здесь «понимание естественного языка» — это человеческое стремление понять обработку естественного языка, кто бы ни занимался обработкой. Другая цель состоит в том, чтобы заставить компьютер обрабатывать естественные языки, и, конечно же, в этой попытке построить процессор естественного языка может быть полезно выполнение первой цели понимания того, как работает процессор. Другой способ разграничить эти две цели состоит в том, чтобы отметить, что при разработке вычислительной модели обработки (или понимания) естественного языка необходимо проводить различие между научная цель и техническая цель. В этой попытке разработать вычислительную модель есть научная цель или мотивация понимания понимания и воспроизведения естественного языка ради самого понимания. Также обычно связывают техническую цель — заставить компьютер обрабатывать предложения на естественном языке.3 Аллен сначала, кажется, различает понимание естественного языка как человеческое научное усилие от обработки естественного языка как того, что пытается исследовать и моделировать, но иногда даже он использует «понимание естественного языка» таким образом, что требуется выяснить, какой смысл имеется в виду.
Существует пятая путаница, которую необходимо устранить, и она заключается в том, что термин «понимание» нагружен значениями или коннотациями, которых нет в термине «обработка», хотя большинство пользователей фразы «понимание естественного языка» либо не осознают, либо не заботятся о них. об этих загруженных коннотациях. Люди, конечно, способны обрабатывать и понимать естественные языки, но настоящий интерес к обработке естественного языка здесь заключается в том, сможет ли компьютер это сделать или сможет ли это сделать. Из-за коннотации термина «понимание» его использование в контексте компьютерной обработки должно быть уточнено или объяснено. Сирл, например, утверждает, что цифровые компьютеры, такие как персональные компьютеры и мейнфреймы, какими мы их знаем в настоящее время, вообще ничего не могут понять, и ни один такой цифровой компьютер будущего никогда не сможет что-либо понять только благодаря вычислениям. Другие не согласны. Ввиду этого противоречия по поводу того, могут ли цифровые компьютеры рассматриваемого типа когда-либо что-либо понимать, использование фразы «понимание естественного языка», кажется, искажает проблему, если не оговорить использование фразы «понимание». Но многие авторы используют фразу «понимание», как будто у этого термина не было спорной истории по отношению к компьютерам. Я думаю, что утверждения Сёрла, верны они или нет, имеют большое значение и нуждаются в рассмотрении, и не следует метаться вокруг термина «понимание», не отметив, что не обязательно подразумевается, что компьютеры могут понимать в том смысле, в котором объекты. Термин «обработка», возможно, предпочтительнее термина «понимание» в этом контексте, но «понимание» здесь имеет свою историю, и я не призываю прекратить использование этого термина. Конечно, в этой статье, если я метафорически использую термины «понимание» или «знание» по отношению к компьютерам, я ничего не имею в виду относительно того, смогут ли они или будут ли когда-либо действительно понимать или знать в каком-либо философски интересном смысле.
Сколько способностей будет считаться способностью обработки естественного языка? Не все люди могут обрабатывать естественный язык на одном уровне, поэтому мы не можем точно ответить на этот вопрос, но целью была бы способность интерпретировать и общаться с людьми в обычном, обычном человеческом дискурсе. Это было бы немалым подвигом. «Обработка» означает перевод с или на естественный язык (интерпретация или генерация). Чтобы иметь возможность общаться с другими людьми, даже если они ограничиваются текстовым взаимодействием, а не речью, компьютеру, вероятно, потребуется не только обрабатывать предложения на естественном языке, но и обладать знаниями о мире. Приличный разговор будет включать интерпретацию и генерацию предложений на естественном языке, и, предположительно, ответы на комментарии и вопросы потребуют некоторого знания здравого смысла. Как мы увидим, такое знание здравого смысла было бы необходимо даже для понимания значения многих предложений естественного языка. Например, если бы компьютеру сказали: «У Мэри был маленький ягненок», знание здравого смысла позволило бы компьютеру понять, что Мэри, возможно, съела баранину на обед, а не владела бараниной, но тот же тип знания здравого смысла показал бы эта интерпретация невозможна для «У Мэри была маленькая стиральная машина». Нужен здравый смысл, чтобы знать, что люди едят баранину, а не стиральные машины.
Я не собираюсь обсуждать все возможные варианты использования компьютера, способного обрабатывать естественный язык, но упомяну здесь некоторые из них. Типичные приложения для обработки естественного языка включают следующее. 4
Очевидно, что было бы легче заставить компьютер выполнить задачу, если бы вы могли говорить с ним нормальными английскими предложениями, а не изучать специальный язык, понятный только компьютеру и другим программистам. Я говорю «вероятно», потому что языки программирования обычно требуют, чтобы вы излагали вещи более точно, чем это происходит в типичных английских предложениях, и обычному человеку может быть трудно заставить компьютер выполнять какую-то математически точную задачу, если он или она должна была сформулировать задание на разговорном английском языке. Но на первый взгляд, по крайней мере, было бы здорово, если бы мы могли общаться с компьютерами так же, как друг с другом.
Что включает в себя обработка естественного языка?
В широком смысле считается, что обработка естественного языка (с точки зрения интерпретации) включает как минимум следующие подтемы5:
По большей части существует согласие относительно того, что вписывается в каждую из этих категорий. Я использую здесь термин «прагматика» в широком смысле; некоторые авторы используют его более узко и добавляют категории, которые я считаю широко относящимися к прагматике.
Обработка сигналов принимает произнесенные слова в качестве входных данных и превращает их в текст. Синтаксический анализ касается структуры или грамматики предложений. Семантический анализ имеет дело со значением слов и предложений, способами, которыми слова и предложения относятся к элементам в мире. «Значение» в этих обсуждениях обычно связано с семантикой, но в других контекстах я видел синтаксис, связанный с «синтаксическим значением». Прагматика касается того, как значение предложения зависит от его функции в повседневной жизни, то есть от более широкого контекста разговора и т. д., и поэтому кажется, что она тоже связана со значением. Так что, возможно, было бы лучше не думать о проблемах «значения» как об ограниченных только семантикой.
В этой статье я в основном буду игнорировать тему обработки сигналов. Компьютеры чаще всего вводят текст напрямую, будь то с клавиатуры или считывают из файла или другого источника, а не интерпретируют устную речь. Есть некоторые сложные системы, и даже менее дорогие, которые может купить каждый, которые более или менее успешно обрабатывают произносимые слова, чтобы перевести их в текстовую форму.
Я расскажу о некоторых основах других тем. У Джеймса Аллена есть второе издание того, что здесь считается стандартным произведением, Понимание естественного языка , и я часто черпаю из этого источника.
Прежде чем продолжить, я должен отметить, однако, два других процесса, которые должны происходить для обработки естественного языка: токенизация и обработка на машинном уровне. Некоторые авторы упоминают токенизацию как еще один компонент обработки естественного языка, и мне кажется, что вы могли бы рассматривать ее как часть обработки сигналов, между обработкой сигналов и синтаксическим анализом или, что менее просто, даже как часть синтаксического анализа.7 Токенизация это преобразование входного сигнала в части (токены), чтобы компьютер мог его обработать. Например, даже когда машина получает текст с клавиатуры, текст поступает в машину в виде потока символов ASCII, которые должны быть классифицированы по отдельным единицам, таким как слова или буквы/цифры6. Компьютер не знает, как рассмотрите в нем типы символов ASCII, если только ему не сказано ожидать символы, целые числа, числа с плавающей запятой, строку и т. д. Это типы данных. Например, когда вы набираете букву на клавиатуре, эффект заключается в передаче кода символа ASCII для конкретной набранной буквы. «А», например, равно 41 (это будет передано в двоичном формате). Но компьютер должен взять этот символ ASCII и соединить его с другими, чтобы интерпретировать их вместе как слово, целое число или единицу другого типа; короче, жетон. Поскольку некоторые авторы говорят об обработке сигналов как о преобразовании речи в текст, а текст распознается как слово, возможно, уже задействована некоторая токенизация. Однако вместо этого можно было бы думать об обработке сигнала как о чистом преобразовании звука в какой-то текстовый поток без обработки потока как слов или отдельных символов как таковых, то есть без ввода данных со стороны компьютера. В этом случае токенизация может показаться дополнительным компонентом обработки естественного языка, а не просто частью обработки сигналов. Таким образом, некоторые авторы пишут о токенизации как о первом шаге разбора и предшествующего синтаксического анализа. В этом смысле токенизация необходима не только для обработки естественного языка, но и для любой обработки языка со стороны компьютера. Или, если кто-то имеет действительно широкое представление о синтаксическом анализе, он может даже рассматривать его как включающий токенизацию, поскольку распознавание слов в отличие от чисел уже включает грамматику языка.
Другой темой, которая обычно не рассматривается при обсуждении обработки естественного языка в компьютерах, является обработка на машинном уровне: тот факт, что по мере обработки сигнала и выполнения синтаксического, семантического и прагматического анализа происходит непрерывный перевод в машинный язык или даже сигналы напряжения. Это произойдет для анализируемого предложения на естественном языке, а также для всех команд обработки, которым компьютер следует при анализе. То, как это происходит, зависит от конкретного языка программирования, на котором написана программа обработки естественного языка. Но это 9Генерация кода 0398
При обсуждении обработки естественного языка компьютерами просто предполагается, что обработка на машинном уровне происходит по мере того, как происходит обработка языка, и это не рассматривается как тема обработки естественного языка как таковая. Но я думаю, что если предпринимается попытка понять, как у людей происходит обработка естественного языка, с целью использования этого понимания для создания цифровой компьютерной системы, которая выполняет удовлетворительную обработку естественного языка, то вопрос о том, как на самом деле низкоуровневая обработка обработка на самом деле происходит у людей, и цифровые компьютеры могут иметь значение. Если люди обрабатывают естественные языки, используя параллельную, распределенную обработку на базовом уровне, и это не просто реализация сентенциального ИИ на более высоком уровне, а, скорее, включает в себя другой тип представления или вообще не представляет, тогда это может быть, а может и не быть. Можно построить адекватный процессор естественного языка, который использует исключительно тип последовательной обработки современных цифровых компьютеров. Мне кажется, что может оказаться, что то, как компьютер на самом деле работает на самом низком уровне, может оказаться актуальной проблемой для обработки естественного языка. В нынешнем виде обычное обсуждение обработки естественного языка в компьютерах, по-видимому, в значительной степени связано с интерпретацией сентенциалов ИИ. Обычная цель состоит в том, чтобы преобразовать предложения естественного языка в своего рода представление знаний, которое легче всего интерпретировать как соответствующее внутреннему представлению смысла или предложению у людей. Машины и программы, используемые для моделирования или программ обработки естественного языка, обычно ориентированы на последовательную обработку на традиционных цифровых компьютерах, поэтому понятно, почему это должно быть так.
Таким образом, синтаксический анализ, семантический анализ и прагматика остаются сердцевиной большинства дискуссий об обработке естественного языка. Мы склонны предполагать, что компьютеру можно было бы дать словарные значения слов, а также тип речи для каждого из них и правила грамматики, и, используя эту информацию, обработать предложение на естественном языке. Это должен быть чисто механический процесс поиска в базе данных и классификации частей предложения. Но все не так просто, в основном из-за проблемы неоднозначности на многих уровнях. Чтобы правильно интерпретировать предложения на естественном языке, система должна будет не только грамматически разобрать предложения, но и связать слова с вещами в мире и с общим контекстом произнесения предложения. В то время как «разбор» обычно ассоциируется с синтаксическим анализом, правильный разбор предложений может даже потребовать прояснения любых семантических и прагматических проблем, которые стоят на пути правильного синтаксического анализа (например, вам может понадобиться знать контекст, чтобы решить, является ли « воздействие» является существительным или глаголом; в последние годы он стал все чаще использоваться как глагол). И затем, когда есть синтаксический анализ, необходимы семантика и прагматика, чтобы понять полное значение предложения.
Таким образом, происходит осознание того факта, что понимание естественного языка гораздо сложнее, чем просто сортировка слов по частям речи и поиск их определений. Аллен упоминает различные типы знаний, имеющих отношение к пониманию естественного языка8:
Учитывая эту разбивку характеристик или типов знаний в наших предыдущих четырех подтемах обработки естественного языка, мы бы сказали, что синтаксический анализ включает рассмотрение морфологических и синтаксических знаний со стороны процессора естественного языка, семантический анализ включает рассмотрение семантических знаний и прагматика. включает рассмотрение прагматических, дискурсивных и мировых знаний. Поскольку я и некоторые другие используют «прагматику», она содержит довольно много, причем один автор перечисляет «ссылку на контекст дискурса (включая анафору, вывод референтов и более расширенные отношения когерентности дискурса и структуры повествования), вывод разговора и импликатура. , а также планирование и генерация дискурса». Я думаю, что Аллен использует его в более узком смысле.
Результатом обработки человеком предложения на естественном языке является то, что человек понимает смысл предложения. Мы игнорируем рассмотрение того, имеет ли книга, пьеса или какой-либо другой рассказ или повествование единственное «значение», задуманное автором, которое является 90 398 значением 90 401. Скажем так, предложение имеет смысл, понятный процессору. Кроме того, мы не собираемся решать проблему между точками зрения сентенциального ИИ и PDP/коннекционистского ИИ относительно формы этого значения у людей, будь то какое-то внутреннее предложение или представление в уме или мозге процессора. Исследователи в области искусственного интеллекта, философии, когнитивных наук, лингвистики, компьютерной лингвистики и т. д. могли бы рассмотреть то, как это происходит у людей, под рубрикой понимания естественного языка. Вместо этого наш непосредственный вопрос заключается в том, как мы должны рассматривать эту тему для компьютера.
Обычно я следую использованию терминов Алленом здесь, хотя многие другие авторы придерживаются аналогичного понимания. Поскольку мы пытаемся смоделировать обработку естественного языка, если мы хотим изобразить или представить значение предложения для такой модели, мы не можем просто использовать само предложение, потому что могут присутствовать двусмысленности. Слова имеют несколько значений или смыслов. Итак, в модели для представления смысла предложения нам нужен более точный, недвусмысленный способ представления. Мы будем использовать формальные языки . Начиная с предложения на естественном языке, результат синтаксического анализа даст синтаксическое представление в грамматике; эта форма часто отображается в виде древовидной диаграммы или определенного способа написания ее в виде текста. Этот тип синтаксического представления можно также назвать «структурным описанием». Синтаксические представления языка используют контекстно-свободных грамматик , которые показывают, какие фразы являются частями других фраз в том, что может считаться контекстно-свободной формой. Тогда результат семантического анализа даст логическая форма предложения. Логическая форма используется для фиксации семантического значения и отображения этого значения независимо от любых таких контекстов. Затем мы перейдем к рассмотрению прагматики, и поэтому, наконец, нам нужно общее представление знаний , которое позволяет контекстуальную интерпретацию контекстно-свободного анализа формы и логической формы. Имейте в виду, что я пишу так, как если бы общий анализ проходил в виде дискретных этапов, каждый из которых дает результаты, которые служат входными данными для следующего этапа. Можно логически рассматривать это таким образом, но некоторые реальные формы обработки естественного языка выполняют несколько стадий одновременно, а не последовательно.
Вот еще несколько терминов. Процесс интерпретации отображает предложения естественного языка на формальный язык или с одного формального языка на другие. Но существуют разные типы процесса интерпретации, в зависимости от того, какой формальный язык и стадия рассматриваются. Анализатор представляет собой процесс интерпретации, который отображает предложения естественного языка в их синтаксическую структуру или представление (результат синтаксического анализа) и их логическую форму (результат семантического анализа). Парсер использует правила грамматики и значения слов (в лексиконе). Это отображение может быть последовательным или одновременным. А контекстная интерпретация сопоставляет логическую форму с ее окончательным представлением знаний.
Как уже упоминалось, существуют разные способы (раздельные или одновременные) выполнения синтаксического и семантического анализа, короче говоря, синтаксического анализа, но в любом таком синтаксическом анализе будут общие элементы. Сначала будет грамматика . Грамматика определяет допустимые способы объединения единиц (синтаксически и семантически) для получения других составляющих. Также будет использоваться лексикон, указывающий типы речи для слов; иногда это считается частью грамматики. Во-вторых, процессор будет иметь алгоритм , который, используя правила грамматики, производит структурные описания для конкретного предложения. Например, алгоритм решает, следует ли проверять токены слева направо или наоборот, использовать ли метод поиска в глубину или в ширину, действовать ли методом сверху вниз или снизу вверх и т. д. Но он возможно, что у алгоритма возникнут проблемы, если будет применено более одного правила, что приведет к неоднозначности, и, таким образом, третьим компонентом является оракул , механизм для разрешения таких неоднозначностей. Типом неоднозначности здесь может быть лексическая синтаксическая неоднозначность (например, слово может быть существительным или глаголом) или структурная синтаксическая неоднозначность. Этот последний тип двусмысленности связан с тем фактом, что может быть более одного способа комбинировать одни и те же лексические категории, чтобы получить юридическое предложение.
Чтобы увидеть, как можно иметь противоречивый синтаксический анализ фразы и, следовательно, нуждаться в способе их разрешения (оракул), рассмотрим пример структурной синтаксической двусмысленности Стидмана во фразе «Положи книгу на стол». Один из способов проанализировать это — рассмотреть его как законченную глагольную фразу с глаголом «положить», именной фразой «книга», и предложной фразой «на столе». Другой способ анализа — рассмотреть «книга на столе» как собственно именная группа без дополнительной предложной группы. Предложение «Положи книгу на стол» наиболее естественно вызывает предыдущую интерпретацию, другими словами, указание взять книгу и положить ее на стол. Но все же, если фраза включена в более длинное предложение «Положи книгу на столе в карман», то она предполагает последний анализ, поскольку относится к книге, уже лежащей на столе. В зависимости от того, как фраза используется в том или ином конкретном предложении, грамматика сама по себе может не решить, как правильно анализировать эту фразу синтаксически. (Здесь возникает дополнительная двусмысленность относительно того, лежит ли книга уже на столе или стол у вас в кармане.)
Синтаксический анализ
Перейдем к синтаксическому анализу. Эта тема слишком велика, чтобы подробно осветить ее здесь, поэтому я просто попытаюсь обобщить основные вопросы и использовать примеры, чтобы дать представление о некоторых возникающих проблемах.
Парсинг может показаться довольно простым механическим процессом. Имея лексикон, сообщающий компьютеру часть речи слова, компьютер сможет просто прочитать входное предложение слово за словом и, в конце концов, произвести структурное описание. Но проблемы возникают по нескольким причинам. Во-первых, слово может функционировать как разные части речи в разных контекстах (например, иногда существительное, иногда глагол). Например, «лиса бежит по лесу» относится к «лисе» как к существительному, тогда как «лиса бежит по лесу, за которой гончим легко следовать» использует его как прилагательное. Вы не узнаете, как используется слово «лиса», пока не прочитаете предложение целиком.
Таким образом, мы должны определить, какая часть речи уместна в данном конкретном контексте. Во-вторых, и в связи с этим, может быть несколько возможных интерпретаций структуры предложения. Как мы должны решить, какой анализ является правильным? В-третьих, при поиске интерпретации предложения могут быть разные способы сделать это, некоторые из них более эффективны, чем другие. Подобные проблемы и вопросы усложняют то, что на первый взгляд может показаться простой задачей.
Синтаксическая обработка предложения включает в себя определение подлежащего и сказуемого, а также места существительных, глаголов, местоимений и т. д. Учитывая разнообразие способов построения предложений в естественном языке, очевидно, что сам по себе порядок слов мало что скажет вам об этих вопросах. и в зависимости от порядка слов в любом случае будет разочарован тем фактом, что предложения различаются по длине и могут содержать несколько предложений.
Я должен еще раз упомянуть, что токенизация должна произойти, чтобы добраться до точки включения синтаксического анализа. Каждый компилятор или интерпретатор языка программирования должен иметь какой-либо встроенный токенизатор, который позволяет распознавать символы ASCII, набранные с клавиатуры или введенные из файла, как данные или команды определенного типа. Язык будет иметь определенные предопределенные типы данных, которые он может распознавать: целые числа, числа с плавающей запятой, символы и, возможно, строки, представляющие собой кластеры неинтерпретируемых символов. Если мы создаем процессор естественного языка, написав программу на определенном языке, то мы должны создать токенизатор естественного языка, который будет принимать строки и преобразовывать их в отдельные слова (в ASCII пробел также представлен кодом ASCII, поэтому не думайте о пробелах как о чем-то пустом, что компьютер может просто «знать» отдельные слова. ) Вот почему токенизацию со стороны процессора естественного языка можно рассматривать как первый шаг в синтаксическом анализе.
Кроме того, отметим, что Пролог, как и любой другой язык программирования, имеет встроенный токенизатор, который позволяет ему распознавать допустимые типы данных, существующие в Прологе. Поскольку Пролог может распознавать их не только как токены, но и как команды Пролога, это не просто токенизатор, а встроенный считыватель. Встроенное средство чтения можно использовать для создания токенизатора естественного языка Prolog, который может размечать строки, состоящие из допустимых терминов Prolog. Используя эту программу чтения Пролога и встроенный предикат «оператор» для определения других операторов, которые могут соединять существительные, например, можно построить элементарный процессор естественного языка, который может анализировать простые предложения. Так что, возможно, у Пролога есть преимущество перед другими языками, когда дело доходит до создания простого процессора естественного языка. Однако типы предложений, которые можно анализировать, настолько ограничены, что для чего-либо, напоминающего полезный процессор естественного языка для обычного разговора, необходимо использовать другой подход.
Отбросив эти предварительные вопросы, давайте обсудим понятие грамматики. Мы также обсудим способы представления синтаксической структуры и различные алгоритмы и типы синтаксического анализа.
Грамматика содержит правила построения предложений в языке. Аллен упоминает, что несколько компонентов отличают хорошую грамматику от плохой. Общность включает в себя диапазон предложений, которые грамматика правильно анализирует. Избирательность включает в себя ряд не-предложений, которые он идентифицирует как проблематичные. Понятность — это простота грамматики. Таким образом, хорошая грамматика будет обладать общностью, избирательностью и понятностью.
Мы должны отметить, что здесь рассматриваются две разные грамматики или значения слова «грамматика». Во-первых, как метод или набор правил построения предложений на конкретном языке, грамматика определяет, правильно ли построено предложение (возможно, предполагаемое предложение даже не является предложением, если оно не следует грамматике). Таким образом, английская грамматика существует независимо от того, сооружу ли я компьютер для обработки естественных языков или нет. Но во-вторых, есть грамматика, которую я строю в своем процессоре естественного языка. Эти две грамматики не совпадают, или, возможно, они не являются одним и тем же использованием термина «грамматика». Грамматика в первом смысле определяет язык, и в этом смысле термина «грамматика» нет смысла говорить о том, что грамматика анализирует предложение правильно или неправильно; грамматика в этом смысле ничего не анализирует. Если он определяет сам язык, он не может ошибиться. Только во втором случае «грамматика», где это означает метод анализа или правила, используемые в моем процессоре естественного языка, может быть хорошим или плохим при определении того, является ли предложение правильным или неправильным. Язык имеет свою собственную грамматику (первого смысла), и грамматика (второй смысл), которую я разрабатываю, будет или не будет хорошей, если она выносит правильные суждения, соответствующие принятым предложениям, определенным собственной грамматикой языка.
Обсуждения синтаксического анализа различают различные типы грамматики, то есть грамматику в этом втором смысле правил, которым следуют в строящемся процессоре естественного языка. Таким образом, некоторые грамматики оказываются более полезными при анализе предложений естественного языка, чем другие. Обсуждения также различают различные типы синтаксических анализаторов. Здесь все становится сложным и иногда неясным в литературе. Напомним, что мы различали различные компоненты, которые будут иметь любой парсер: грамматику, алгоритм и оракул. Поскольку каждый из этих компонентов может варьироваться в зависимости от парсера, кажется, что может быть несколько различных способов классификации парсеров. Например, парсеры можно классифицировать по грамматике, или по алгоритму, или по сочетанию грамматика-алгоритм, или, возможно, как-то иначе. Есть несколько аспектов алгоритма синтаксического анализатора, поэтому можно даже допустить, что эти различия еще больше повлияют на классификацию. Таким образом, кажется, что потенциально существует множество различных способов классификации синтаксических анализаторов, и это оставляет человека в замешательстве из-за такой фразы, как «существует три типа синтаксических анализаторов». Чтобы кто-то утверждал, что существует три типа синтаксических анализаторов, должна быть принята конкретная схема классификации. неявно, или нужно говорить об общих типах, которые исторически были приняты и идентифицированы как таковые.
Например, иногда говорят, что существует три типа синтаксических анализаторов:
Это может быть точным, но типы кажутся перемешанными. Анализатор шумоподавления даже не использует правильную грамматику. Сказать, что синтаксический анализатор — это конечный автомат, значит классифицировать его по тому, как он работает, а не по используемой грамматике. Сказать, что синтаксический анализатор является синтаксическим анализатором грамматики с определенным предложением, означает классифицировать его на основе типа используемой им грамматики. Если мы иногда пропустим в последующем обсуждении, это потому, что различные типы классификации часто объединяются в дискуссиях по литературе.
Вернемся к грамматикам. Чтобы увидеть, как работает грамматика естественного языка, многие исследователи в качестве предварительного изучения сначала пытаются понять контекстно-свободную грамматику (CFG) . Как это ни звучит, контекстно-свободная грамматика состоит из правил, которые применяются независимо от контекста, будь то контекст других элементов или частей предложения или более широкий дискурсивный контекст предложения. Считается, что естественные языки не поддаются полному анализу с использованием контекстно-свободных грамматик, поскольку некоторые влияния могут иметь место между различными частями предложения, например, время и лицо различных частей предложения должны согласовываться. Но контекстно-свободные грамматики — хорошая отправная точка для понимания темы. Мы еще не обсуждали синтаксические анализаторы, но я отмечу, что контекстно-свободные синтаксические анализаторы используются практически во всех компьютерных языках, и поэтому синтаксический анализатор естественного языка может использовать некоторые методы синтаксического анализа, разработанные для таких контекстов. И этот тип синтаксического анализа может анализировать целые фразы, а не только слова, что позволяет ему работать со связанными группами слов.
Правила грамматики позволяют заменить один вид элемента определенными частями, которые могут его составлять. Например, предложение состоит из именной группы и глагольной группы, поэтому для анализа предложения эти два типа могут заменить предложение. Это разложение может продолжаться за пределами именной и глагольной групп, пока не закончится. Таким образом, на любом этапе анализа каждая часть предложения может рассматриваться как терминальная или нетерминальная 9.0401 . Терминалы будут фактически отдельными словами (вы не можете их анализировать дальше), а нетерминалы будут предложениями или фразами, которые еще не полностью разбиты. Таким образом, нетерминал может быть определен в терминах других элементов, обычно рекурсивно, до тех пор, пока не будут достигнуты терминалы. Например, рассмотрим конкретное предложение, которое можно определить с помощью словосочетания существительного и словосочетания глагола. Именное словосочетание является нетерминалом, которое затем определяется в терминах определителя, за которым следует существительное. Существительное является терминалом, поэтому оно далее не определяется, но определитель — это нетерминал, определяемый терминами «the», «a» и «an», которые являются терминалами и далее не определяются. Эти правила для такой замены переписать правила или правила производства того, как каждая из частей может быть построена из других.
В следующих примерах мы будем использовать два выражения декомпозиции. Первое выражение встречается в формулировке самих правил. Это правила грамматики; они допускают подстановку при любом разборе. Второе выражение возникает, когда мы используем правила для выражения фактического анализа конкретного предложения; это и есть разбор. В любом случае, упомянутом ниже, мы собираемся ввести некоторые общие обозначения, которые используются при обсуждении синтаксического анализа.
Существует множество обозначений, которые можно использовать для представления правил перезаписи грамматики; эти обозначения включают деревья и списки, в которых используются различные символы. Примером контекстно-свободной грамматики является следующий пример использования оператора стрелки для выражения допустимой декомпозиции:
с -> нп, вп.
в.п. -> тв, н.
вп -> iv.
нп -> прон.
прон -> [он].
п -> [яблоки].
тв -> [ест].
IV -> [спит].
Используются также сокращения. Здесь «s» относится к «предложению», «np» к «именной фразе», «vp» к «глагольной фразе», «tv» к «переходному глаголу», «n» к «существительному», «iv» к « непереходный глагол», «pron» на «местоимение», а термины в скобках являются фактическими словами словаря. Таким образом, это могут быть некоторые из допустимых правил в грамматике, и их можно применять в качестве перезаписи при синтаксическом анализе.
Обычное обозначение, используемое для написания контекстно-свободных грамматик, — 9.0398 Бэкус-Наур форма. В форме Бэкуса-Наура:
- Имя элемента находится слева, а его определение — справа
- Имя только одного элемента отображается слева
- Символ «::=» отделяет имя от определения
- Определение состоит из терминалов и/или нетерминалов, разделенных запятыми
- Вертикальная черта в определении со значением с обеих сторон и выражением, заключенным в квадратные скобки, действует как «или», чтобы указать, что можно использовать любое значение
- Вертикальная черта справа может разделять определения, любое из которых можно использовать.
- Грамматические правила устанавливают допустимые формы предложений и т. д.
Например, число может быть определено как цифра или знак плюс или минус, за которым следует число:
число :: = цифра | [ + | - ] количество
Вот представления Бэкуса-Наура предложений «сюзан бежит» и «мальчик играет»:
:: = :: = | :: = Сьюзан
:: = а
:: = мальчик
:: = работает | игры
Чтобы сделать их более ясными, мы можем преобразовать приведенное выше в набор правил грамматики с немного другим обозначением:
предложение -> словосочетание существительное, глагол.
словосочетание -> имя.
словосочетание -> определитель, существительное.
имя -> [сьюзан].
определитель -> [а].
существительное -> [мальчик].
глагол -> [бежит].
глагол -> [играет].
Это должно быть довольно легко читать. Предложение может быть переписано как словосочетание существительное и глагол. Словосочетание может быть именем, определителем и существительным и т. д.
Другой способ представить предложение, анализируемое в соответствии с контекстно-свободной грамматикой, — это структура списка. В нотации списка пример Аллена «Джон съел кошку»:
(S (НП (ИМЯ Джон))
(ВП (В ел)
(НП (АРТ)
(Н кот))))
Здесь предложение (S) представлено в крайнем левом углу, а каждый этап справа разбивает его на несколько строк. Таким образом, переходя от предложения, мы разбиваем его на именную группу (NP) и глагольную группу (VP), при этом именная группа состоит из имени «Джон», глагольная группа состоит из глагола «съел» и именная группа , и эта именная группа, состоящая из артикля «the» и существительного «кошка».
Опять же, чтобы построить дерево или список, подобный приведенному выше, мы должны знать правила перезаписи, которые позволяют нам заменять одну часть ее компонентами. Напомним, что грамматика — это формальная спецификация допустимых в языке структур. Техника синтаксического анализа — это метод анализа предложения для определения его структуры в соответствии с грамматикой.
Поговорим подробнее о методах парсинга. Как можно заметить выше, в грамматиках есть специальный символ, называемый начальным символом, которым может быть S для предложения. Можно сказать, что грамматика выводит предложение, если последовательность правил позволяет вам переписать начальный символ в предложение. На таких выводах основаны два процесса: генерация и синтаксический анализ. Генерация — это когда вы начинаете с символа S и получаете последовательность слов, применяя правила перезаписи. Их можно применять случайным образом, если вы хотите сгенерировать любое старое предложение. Как мы видели, синтаксический анализ идентифицирует структуру предложения с учетом конкретной грамматики, поэтому он не будет проводиться путем случайного применения правил, а скорее систематическим образом. И он должен сверять результаты с фактическим рассматриваемым предложением по ходу дела.
Помимо использования правил грамматики, синтаксический анализ будет включать в себя особый метод попытки применить правила к предложениям. Это алгоритм разбора. Аллен определяет алгоритм синтаксического анализа как процедуру, которая просматривает различные способы объединения грамматических правил и находит комбинацию этих правил, которая генерирует дерево или список, который может быть структурой анализируемого входного предложения.
Мне кажется, что в этом алгоритме задействованы два аспекта. Во-первых, синтаксический анализ методов поиска может быть сверху вниз или снизу вверх . Стратегия «сверху вниз» начинается с S и ищет различные способы перезаписи символов, пока не сгенерирует входное предложение (или не потерпит неудачу). Таким образом, S является началом, и оно проходит серию переписываний, пока не будет найдено рассматриваемое предложение.
С
НП ВП
ИМЯ ВП
Джон вице-президент
Джон В НП
Джон НП
Джон ART N
Джон съел N
Джон съел кошку
В восходящей стратегии каждый начинает со слов предложения и использует правила перезаписи в обратном порядке, чтобы уменьшить символы предложения, пока не останется S.
Джон съел кошку
ИМЯ съел кота
ИМЯ В кот
ИМЯ V АРТ кошка
НАЗВАНИЕ V АРТ N
НП В АРТ Н
НП В НП
НП ВП
С
Синтаксический анализатор «сверху вниз» будет «думать» следующим образом: «Чтобы найти предложение, означающее S: vp np, найдите именную фразу, означающую np, слева от глагольной фразы, означающей vp». Снизу вверх будет: «Если вы найдете именное словосочетание, означающее np, слева от глагольного выражения, означающего vp, превратите их в предложение, означающее S: vp np». Конечно, восходящий анализатор, вероятно, будет , начиная с на более низком уровне, чем этот.
Помимо выбора направления стратегии (сверху вниз или снизу вверх), существует также аспект того, следует ли действовать в глубину или в ширину. Чтобы понять разницу между этими двумя стратегиями, полезно изучить алгоритмы поиска в курсе по структурам данных, но я попытаюсь объяснить основную идею. Давайте применим его к нисходящему экземпляру другого типа. Представьте себе различные способы разбиения числа шестнадцать на шестнадцать отдельных. Предположим, мы попытаемся разбить это, построив древовидную структуру с числом шестнадцать наверху. При этом пишем две восьмерки. Затем пишем две четверки под первой восьмеркой. Что теперь делать? Мы можем взять первые четыре и разбить их на две двойки. Это была бы стратегия «сначала в глубину», потому что мы пытаемся углубиться, прежде чем идти вширь. Или мы можем взять вторую восьмерку и разбить ее на две четверки. Это сначала в ширину, потому что он пытается пройти по ширине дерева, прежде чем углубиться.
По сути, синтаксический анализатор может работать любым из этих двух способов при синтаксическом анализе. Алгоритм возьмет предложение и рассмотрит для него различные грамматические возможности. Например, он рассматривает первое возможное переписывание, которое интерпретирует его определенным образом, скажем, как имеющее две составляющие. Дальше будет два пути. Он может взять первую составляющую и рассмотреть возможности для этого, что может разбить ее на две составляющие, а затем взять первую составляющую этой части и т. д. Она проходит весь путь вниз по этим первым возможностям, прежде чем вернуться на один уровень назад и пробует вторую возможность перезаписи самого низкого уровня. Это будет стратегия «сначала в глубину». Или, после первоначального рассмотрения первой возможности с переписыванием, он может перейти непосредственно к следующей части предложения, а не рассматривать все возможности, порожденные для первой части первой части первой части и т. д. Это будет стратегия «сначала вширь».
Другой способ понять это —
Стандартный алгоритм интерпретации PROLOG имеет ту же стратегию поиска, что и алгоритм разбора в глубину сверху вниз. Это позволяет ПРОЛОГу переформулировать правила контекстно-свободной грамматики в виде предложений в ПРОЛОГе, если кто-то хочет следовать этой стратегии.
Итак, у нас есть понятие грамматики и синтаксического анализатора, а также представление о том, что синтаксические анализаторы могут использовать различные стратегии синтаксического анализа. Давайте сделаем шаг назад и отметим некоторые фактические методы синтаксического анализа, обсуждаемые во многих книгах по ИИ. Мы уже упоминали, что в книгах обычно обсуждаются три типа синтаксических анализаторов, используемых в процессорах естественного языка:
- Парсеры шумоподавления
- Парсеры конечного автомата (парсеры конечного автомата)
- Анализаторы грамматики определенного предложения (аналогичные анализаторам грамматики структуры фраз)
Парсер для удаления шума просматривает предложение в поисках выбранных слов, которые входят в его определенный словарь. Когда одно из слов найдено, компьютер инициирует нужное действие. При прочтении любые слова, не входящие в список искомых компьютером, считаются «шумом» и отбрасываются. Мне кажется, что этот тип синтаксического анализатора на самом деле не использует грамматику в каком-либо реалистичном смысле, поскольку здесь не задействованы правила, а только словарный запас.
Очевидно, что синтаксический анализатор шумоподавляющего типа имеет ограниченное применение. Возможно, его можно использовать, чтобы указать компьютеру открыть определенный файл, когда компьютер ищет любой ввод со словом «открыть» и именем файла, указанным в его текущем каталоге. Но даже такая простая система может дать сбой, поскольку может привести к нежелательному действию, если пользователь введет предложение, в котором слова из выбранного списка используются не так, как предполагал программист. Например, синтаксический анализатор, настроенный на «очистить данные», когда он видит эти два термина в предложении, таком как «Очистить данные из базы данных», может инициировать такое действие при чтении «Очистить верхнюю часть рабочей области операций с данными». Здесь пользователь имел в виду нечто иное, чем совершенное действие.
Следующий тип синтаксического анализатора в приведенном выше списке — это синтаксический анализатор конечного автомата . Он начинается с чтения первого слова во входном предложении. Прочитанные слова сравниваются со словарным запасом, и после определения типа слова машина предсказывает возможные варианты следующего слова. Таким образом, после выбора одного слова ваш выбор для следующего слова будет ограничен тем, что является грамматически правильным. Выбор этого второго слова ограничивает то, что может быть использовано в качестве третьего и т. д. Таким образом, синтаксический анализатор конечного автомата меняет свое состояние каждый раз, когда он читает следующее слово предложения, пока не будет достигнуто конечное состояние.
Этот подход к грамматике с конечным числом состояний рассматривает построение и анализ предложений как переход через ряд состояний. Один из способов представить эти состояния в виде узлов на диаграмме с линиями (дугами) со стрелками, соединяющими их. Состояния и переходы составляют грамматику с конечным числом состояний, которую можно назвать сетью переходов .
Мы видим, что для такого синтаксического анализатора необходимы две базы данных: одна содержит словарь слов и их типов, а другая содержит текущее состояние проанализированного предложения. Например, предположим, что машина читает слово, и ее словарь распознает его как существительное. Это переводит машину в определенное состояние, ожидая, что за ней последуют только определенные виды слов, например глагол. Затем считывается следующее слово, и машина переходит из одного состояния в другое. В конце концов машина сможет сообщать части предложения и устранять некоторые виды возможной двусмысленности. Машина сможет судить о том, является ли предложение грамматически правильным или нет, потому что она знает допустимый тип речи для определенных позиций. Если эта программа написана на Прологе, когда машина достигает определенного места в предложении и не анализирует его, она может вернуться к более раннему месту и попробовать другую интерпретацию предыдущего слова. Это использует способность Пролога возвращаться назад.
Парсер конечного автомата основан на синтаксисе конечного состояния, который «предполагает», что люди создают предложения по одному слову за раз. Некоторые авторы, кажется, думают, что этот тип синтаксического анализатора основан на особом понимании того, как люди создают предложения. Может быть, так и было изначально, но я думаю, что теперь можно построить синтаксический анализатор конечного автомата для конкретного приложения, потому что он полезен, и в то же время утверждать, что люди на самом деле строят предложения совершенно по-другому. В качестве примера того, как люди меняют состояния при разборе предложений, рассмотрим следующие предложения «садовой дорожки».
- Транспортировка стальных кораблей стоит дорого.
- Старик лодки.
Сначала спотыкаешься на первом предложении, пока не понимаешь, что главное существительное в подлежащем — «сталь». Возможно, вы решили, что это предложение касается стальных кораблей, а затем, когда остальную часть предложения не удалось правильно разобрать, вы отступили и переклассифицировали «сталь» из прилагательного в существительное. Во втором предложении вы, вероятно, подумали, что речь идет о старике, но это заставило вас ожидать глагол после «мужчина». Обнаружение «the» заставило вас вернуться назад и изменить категорию «old» на существительное, а «man» на глагол.
Мне кажется, что этот тип синтаксического анализатора следует стратегии «снизу вверх, в ширину». Критики жалуются, что проблема этого типа синтаксического анализатора заключается в том, что он должен включать очень много слов и их лексическую категоризацию. Многие слова, как в приведенном выше примере, попадают более чем в одну категорию, что требует хранения дополнительной информации и увеличивает сложность и время поиска. Но большой словарь, по-видимому, в любом случае понадобится, если мы попытаемся разработать синтаксический анализатор для полной обработки естественного языка, поэтому будет ли это особой проблемой, вызванной этим типом синтаксического анализатора, будет зависеть от того, что мы пытаемся сделать.
Мне кажется, что тот факт, что машина способна предсказывать следующие слова только как один из возможных типов, может позволить устранить некоторую двусмысленность и дать ей возможность классифицировать слова, не входящие в ее словарь. Но это будет редко, поэтому список словаря должен быть довольно большим, чтобы сделать что-то полезное. А сложные предложения могут запутать типичный анализатор конечного автомата. Например, Хомский заметил, что любое предложение в английском языке можно расширить, добавив или включив другую структуру или предложение. Таким образом, «Мышь убежала в свою нору» становится «Кошка знает, что мышь убежала в свою нору», а затем «Кошка, которую преследовала собака, знает, что мышь убежала в свою нору целиком» и т. д. до бесконечности. Грамматики с конечными состояниями не являются рекурсивными и поэтому могут наткнуться на длинные предложения, расширенные таким образом, возможно, застрявшие на обширном возврате.
Мне кажется, что при наличии бесконечно быстрого компьютера с бесконечным объемом памяти и бесконечным временем для программирования словаря синтаксический анализатор конечного автомата правильно интерпретирует многие предложения на языке своего рода методом грубой силы. Каждое прочитанное слово переводило компьютер в состояние, исключающее многие возможности, до тех пор, пока точное предложение не было прочитано, и компьютер не оказывался в состоянии, обеспечивающем интерпретацию именно этого конкретного предложения. (Некоторые типы двусмысленности, которые нельзя разрешить, кроме как путем ссылки на более широкий контекст, не будут разрешены. Это касается прагматики). Конечно, моя машина не такая быстрая и большая, и у меня не так много времени. Невозможность построить именно такую программу и компьютер показывает неосуществимость такого подхода.
Один автор отмечает два противоположных подхода к обработке естественного языка. Один подход пытается использовать всю информацию в предложении, как это сделал бы человек, с целью сделать компьютер способным обрабатывать до такой степени, чтобы он мог общаться с человеком. Другой подход позволяет компьютеру воспринимать предложения на естественном языке, но стремится извлечь только ту информацию, которая необходима для распознавания команды. Первые два типа синтаксических анализаторов, которые мы только что обсудили, следуют этому последнему подходу.
Мы уже упоминали, что, хотя контекстно-свободные грамматики полезны при разборе искусственных языков, остается спорным, в какой степени естественный язык, такой как английский, можно смоделировать с помощью контекстно-свободных правил. Но дополнительные сложности связаны с различиями между естественными и искусственными языками. Количество правил грамматики для естественного языка велико. А контекстуальная информация внутри предложения может быть полезна при анализе естественного языка. Так много синтаксических анализаторов естественного языка используют другую грамматику и другой синтаксический анализатор, чтобы работать с этой грамматикой.
Синтаксический анализатор грамматики с определенным предложением, который мне кажется своего рода синтаксическим анализатором грамматики структуры фраз, который использует грамматику с определенным предложением, считается более сложным, чем синтаксический анализатор конечного автомата. Грамматика структуры фраз восходит к Зелигу Харрису (1951), который считал предложения состоящими из структур. Разбор таких предложений требует рекурсивного анализа компонентов сверху вниз до тех пор, пока не будут достигнуты завершающие единицы (слова). Таким образом, синтаксический анализатор грамматики определенного предложения будет нисходящим, скорее всего, синтаксическим анализатором в глубину.
Процессор естественного языка, использующий DCG, сначала разбивает предложение на составные части. Он начинается с основной словосочетания существительного и словосочетания глагола и, в конечном итоге, определяет существительные, глаголы, предлоги и т. Д. Таким образом, он продолжается сверху вниз, с каждым проходом, разбивая каждую единицу дальше рекурсивным образом, пока не будет проанализировано все предложение. . Например, «Джек быстро побежал к дому» разбито на именную группу «Джек», а остальное — на глагольную группу. Глагольная фраза затем разбивается на глагол «побежал», наречие «быстро» и именную фразу «в дом». Эта именная группа далее разбивается на предлог и именную группу, а именная группа — на артикль и существительное. Для начала у программы есть словарь слов, и она просматривает предложение в поисках именной группы. Он обнаруживает, что первое слово в предложении является существительным, а остальное считается глагольной фразой. Очевидно, однако, что словарный запас должен быть достаточно большим, чтобы подобрать все возможные существительные и т. д.
Как мы уже отмечали, строго говоря, грамматика с определенным предложением является грамматикой, а не синтаксическим анализатором, и, как и другие грамматики, DCG может использоваться с любым алгоритмом/оракулом для создания синтаксического анализатора. Для упрощения мы предполагаем определенные понятия об алгоритме, обычно используемом в парсерах, использующих DCG, и мы получаем эти предположения из литературы, описывающей парсеры DCG.
DCG аналогичен форме Бэкуса-Наура, но оператор «—>» заменяет «::=». Этот символ —> является стандартным оператором в Прологе, и Пролог преобразует предложение DCG в предложение Пролога таким образом, что левая часть завершается успешно, если выполняется правая часть, и правая часть завершается успешно, если и т. д. Таким образом, в Прологе есть встроенный в него метод разбора грамматики определенного предложения (DCG). (DCG не используют возможности чтения Prolog, поэтому входной поток должен быть токенизирован.) Теперь можно увидеть преимущество использования Prolog в этом типе приложений. На самом деле один автор утверждает, что контекстно-свободные грамматики и грамматики с определенными предложениями на самом деле являются программами на Прологе.
Мы пытались провести различие между частью грамматики определенного предложения анализатора грамматики определенного предложения и частью алгоритма анализа грамматики структуры фразы анализатора грамматики определенного предложения. Обратимся к первому аспекту. Одним из улучшений, которые DCG допускает по сравнению с формой контекстно-свободной грамматики (Бэкуса-Наура) в Прологе, является то, что DCG может содержать другую информацию, такую как время, число и род, о частях предложения. Напомним, что их пришлось исключить из контекстно-свободной грамматики, поскольку CFG требует, чтобы каждую часть предложения можно было анализировать независимо от других частей. DCG позволяет включать дополнительные аргументы для обработки этой информации; затем синтаксический анализатор может сказать, являются ли фраза-существительное и фраза-глагол единственной или множественной, например, так, чтобы синтаксический анализатор мог убедиться, что они совпадают. (Кроме того, DCG может содержать исполняемые цели в фигурных скобках; эти цели не выполняются до тех пор, пока оператор не будет проанализирован. Это связано с тем, как Пролог читает операторы, и не может быть объяснено, не углубляясь здесь в Пролог.)
Это, очевидно, дает DCG преимущество перед контекстно-свободной грамматикой при обработке естественного языка. Грамматика естественного языка включает в себя части предложения, согласующиеся во времени, лице, роде и т. д. Эта дополнительная информация может считаться контекстной информацией, и контекстно-свободные грамматики ее не включают. Таким образом, грамматики с определенным предложением улучшают контекстно-свободные грамматики в этом отношении, позволяя хранить такую информацию. Поскольку определения грамматики анализируются рекурсивным образом, информация, интерпретируемая в любой момент, может быть передана вперед или назад для сравнения с такой информацией для других частей предложения. И другая информация может быть сохранена тоже. Переменные могут быть квалифицированы или определены количественно (например, использование «любого»). Глаголы могут быть определены как переходные или непереходные (принимать прямое дополнение или нет).
Но даже синтаксический анализатор DCG не решит всех проблем неоднозначности. Возможны несколько интерпретаций (альтернативный синтаксический анализ) предложения из-за того, что отдельный термин может быть, например, существительным или глаголом, или из-за того, что местоимения могут иметь любой из нескольких референтов. Использование эвристики может помочь в выборе между альтернативными синтаксическими анализами, хотя эти эвристические принципы может быть трудно закодировать в виде правил в программе. Вот два примера таких принципов, основанных на психологических принципах, которым, похоже, следуют люди:
- Принцип минимального вложения: предпочитайте синтаксический анализ, который создает наименьшее количество узлов в дереве синтаксического анализа. Таким образом, в «человек держал собаку в доме» толкование состоит в том, что «в доме» относится к «держал», а не к «собаке». Это связано с тем, что предыдущая интерпретация создает меньше узлов, разбивая глагольную фразу «держал собаку в доме» на глагол (держал), именную фразу (собака) и предложную фразу (в доме), а не на глагол. (держал) и именное словосочетание (собака в доме), при этом последнее именное словосочетание требует дополнительной разбивки на именное словосочетание (собака) и предложное словосочетание (в доме).
- Правильная ассоциация (позднее закрытие): при прочих равных интерпретировать новые составляющие как часть строящейся текущей составляющей, а не как часть какой-либо составляющей выше в дереве синтаксического анализа. Таким образом, в «Джордж сказал, что Генри уехал на своей машине» интерпретация состоит в том, что Генри уехал в машине, а не Джордж говорил в машине.
Другая попытка избежать двусмысленности основана не на кодировании эвристических правил, а на теории вероятностей. Основная идея состоит в том, что альтернативному синтаксическому анализу может быть предоставлена вероятность, а алгоритм может быть направлен на поиск интерпретаций, имеющих наибольшую вероятность.
Конечным результатом синтаксического анализа является то, что компьютер получит представление о синтаксической структуре входного предложения. Точная форма этого представления будет зависеть от природы НЛП и языка, на котором оно написано, но, скорее всего, оно будет состоять из серии операторов перезаписи, которые, вероятно, будут нести некоторые дополнительные параметры или аргументы, указывающие на некоторый сентенциальный контекст. информация о лице, времени и т.д.
Семантический анализ
После того, как компьютер приступил к анализу синтаксической структуры входного предложения, необходим семантический анализ, чтобы установить значение предложения. Прежде чем я продолжу, необходимо сделать две оговорки. Во-первых, как и прежде, тема более сложная, чем может быть подробно рассмотрено здесь, поэтому я продолжу, описав то, что мне кажется главным, и приведу несколько примеров. Во-вторых, я действую так, как будто синтаксический анализ и семантический анализ — это две разные и отдельные процедуры, тогда как в системе НЛП они на самом деле могут быть переплетены.
Из синтаксической структуры предложения система НЛП попытается создать логическую форму предложения. Логическая форма является контекстно-свободной в том смысле, что она не требует, чтобы предложение интерпретировалось в его общем контексте в дискурсе или разговоре, в котором оно встречается. А логическая форма пытается изложить смысл предложения без привязки к конкретному естественному языку. Таким образом, цель, по-видимому, состоит в том, чтобы сделать его ближе к понятию пропозиции, чем к исходному предложению.
Здесь я следую различиям Аллена. Этот независимый от контекста смысл, или логическая форма, представляет собой , означающее . Фактический смысл, зависящий от контекста, который в конечном итоге должен быть рассмотрен после семантического анализа, — это использование . Аллен отмечает, что неясно, действительно ли существует какое-либо независимое от контекста значение, но для НЛП полезно попытаться его развить. Сопоставление предложения с его логической формой или значением называется «семантической интерпретацией», а сопоставление логической формы с окончательным представлением знаний (KR) называется «контекстуальной интерпретацией». Однако мы не должны переоценивать важность контекста; очевидно, это не вся история. Большая часть семантического значения не зависит от контекста, и тип информации, найденной в словарях, например, может использоваться в семантическом анализе для создания логической формы. Соответствующая информация здесь включает основные семантические свойства слов (они относятся к отношениям, объектам и т. д.) и различные возможные значения слова.
Базовой или примитивной единицей значения для семантики будет не слово, а смысл, потому что слова могут иметь разные значения, подобные приведенным в словаре для одного и того же слова. Одна из попыток помочь в этом состоит в том, что различные чувства могут быть организованы в набор классов объектов; это представление называется онтологией. Аристотель отмечал классы субстанции, количества, качества, отношения, места, времени, положения, состояния, действия и привязанности, а Аллен отмечает, что мы можем добавлять события, идеи, концепции и планы. Действия и события имеют особое влияние. События важны во многих теориях, потому что они обеспечивают структуру организации интерпретации предложений. Действия осуществляются агентами. Также важным является уже упомянутое понятие ситуации.
Простое отмечание различных значений слова, конечно, не говорит вам, какое из них используется в конкретном предложении, и поэтому двусмысленность по-прежнему является проблемой для семантической интерпретации. (Аллен отмечает, что некоторые значения более конкретны (менее 90 398 расплывчатых 90 401 ), чем другие, и практически все значения предполагают некоторую степень расплывчатости, поскольку теоретически их можно сделать более точными.) Говорят, что слово с разными значениями имеет 90 398 лексических 90 401 двусмысленность. На семантическом уровне следует также отметить возможность структурная неоднозначность. «Каждый мальчик любит собаку» неоднозначно между многими собаками или одной собакой. Этот вид семантической структурной неоднозначности будет включать в себя область действия квантификатора.
Таким образом, для языка логической формы нам нужно что-то, что может улавливать смысловые значения, а также то, как они применяются к объектам и могут комбинироваться в более сложные выражения. Аллен представляет язык, напоминающий исчисление предикатов первого порядка (FOPC), который позволяет это сделать. Я не собираюсь пытаться объяснить все об этом языке, но я расскажу о некоторых его основах и приведу примеры.
В этом языке логической формы значения слов будут атомами или константами, и они классифицируются по типу вещей, которые они описывают. Константы, описывающие объекты, представляют собой терминов , а константы, описывающие отношения и свойства, представляют собой предикатов . Предложение формируется из предиката, за которым следует соответствующее количество терминов, служащих его аргументами. «Фидо — это собака» переводится как «(DOG1 FIDO1)» с использованием термина FIDO1 и предикатной константы DOG1. Могут быть унарные предикаты (один аргумент), бинарные предикаты (два аргумента) и n-арные предикаты. «Сью любит Джека» — это (LOVES1 SUE1 JACK1). Собственные имена (Фидо) имеют смысл слов, которые являются терминами, тогда как нарицательные существительные (собака) имеют смысл слов, которые являются унарными предикатами. Глаголы обычно имеют значения, соответствующие n-арным сказуемым. Аллен указывает, что в других системах семантической репрезентации, помимо используемого им типа, есть способы проводить аналогичные различия.
Продолжая сходство с FOPC, также используются логические операторы. Оператор отрицания НЕ, как в (НЕ (ЛЮБОВ1 СЬЮ1 Джек1)) для «Сью не любит Джека». Язык логической формы позволит использовать операторы, подобные функциональным связкам истины в FOPC, для дизъюнкции, конъюнкции и условного оператора («того, что часто называют импликацией»). Поскольку английские термины для и, или, но и т. д. могут иметь коннотации, не улавливаемые операторами и связками FOPC, язык логической формы допускает и это. Он также вводит квантификаторы, как два в FOPC (универсальный и экзистенциальный), так и английские для some, most, many и т. д. Переменные тоже используются, но не совсем так, как в FOPC. В FOPC назначение переменной распространяется только на область действия квантификатора, но в естественных языках, где местоимения относятся к вещам, введенным ранее, нам нужны переменные, чтобы продолжать свое существование за пределами исходной области действия квантификатора. Каждый раз, когда вводится дискурсивная переменная, ей присваивается уникальное имя, и последующие предложения могут ссылаться на этот термин.
Существует также ряд расширений базового FOPC, которые должны быть выполнены на языке логической формы. К ним относятся обобщенные кванторы, модальные операторы и предикатные операторы, которые мы сейчас опишем. Мы уже упоминали, что язык логической формы будет иметь больше кванторов, чем два FOPC. Кванторы, используемые в естественных языках, отличаются от квантификаторов в FOPC более узким диапазоном и большей сложностью. Чтобы зафиксировать это, Аллен может использовать обобщенные квантификаторы, которые имеют форму:
(переменная-квантификатор: ограничение-предложение тело-предложение)
«Большинство собак лают» интерпретируется как имеющее логическую форму:
(БОЛЬШИНСТВО1 d1 : (СОБАКА1 d1) (БАРКС1 d1))
это означает, что большинство объектов «d1», которые удовлетворяют «(DOG1 d1)», также удовлетворяют «(BARKS1 d1)».
Тип обобщенного квантификатора используется для артиклей «the» и «a». Чтобы уловить смысл предложения, очевидно, что-то должно делать работу этих артиклей. Например, обратите внимание, что «Собака лает» верно только в том случае, если есть конкретная собака, которая лает, и использование контекста будет важно для идентификации этой конкретной собаки, поскольку утверждение может относиться к любой из многих собак в мире. На языке логической формы утверждение будет таким:
(THE x : (СОБАКА1 x) (BARKS1 x))
Модальные операторы используются для представления значения интенциональных глаголов, таких как верить и хотеть, для представления времени и для других целей. Например, «Сью считает, что Джек счастлив» становится:
(ВЕРЮ СЬЮ1 (СЧАСТЛИВЫЙ ДЖЕК1))
Мы также можем использовать модальные операторы для захвата напряженной информации. Операторы модального времени включают PAST, PRES и FUT. «Джон видит Фидо», «Джон видел Фидо» и «Джон увидит Фидо» переводятся таким образом:
(ПРЕСС (ВИДИТ1 ДЖОН1 ФИДО1))
(ПРОШЛОЕ (ВИДИТ1 ДЖОН1 ФИДО1))
(FUT (ВИДИТ1 ДЖОН1 ФИДО1))
Теперь давайте снова обратимся к предикатам в этом языке логической формы. Мы уже упоминали, что будут унарные, бинарные и n-арные предикаты. Мы также будем использовать понятие предикатного оператора. Оператор предиката принимает предикат в качестве аргумента и создает новый предикат; это используется для работы с формами множественного числа, например, в «собачьем лае». Если DOG1 является предикатом, истинным для любой собаки, то (PLUR DOG1) является предикатом, истинным для любого набора собак. «Собачий лай» это:
(THE x : ((PLUR DOG1) x) (BARKS1 x))
Таким образом, вы можете видеть, что язык логической формы действительно имеет сходство с FOPC, с некоторыми дополнениями, необходимыми для того, чтобы уловить богатство естественного языка, который часто игнорируется FOPC. Вернемся снова к вопросу неоднозначности. Напомним, что язык логической формы должен иметь возможность справляться с двусмысленностью, которую не всегда можно разрешить без рассмотрения более широкого контекста дискурса, недоступного на данном этапе анализа. Он не обязательно сможет разрешить двусмысленность, но он должен быть в состоянии ее представить. Язык логической формы сможет кодировать многие формы двусмысленности, позволяя перечислять альтернативные смыслы в случаях, когда разрешен один смысл. Предложение может иметь несколько возможных синтаксических структур, и каждая из них может иметь несколько возможных логических форм. Слова в предложении могут даже иметь несколько значений. При всей этой двусмысленности число возможных логических форм, с которыми приходится иметь дело, может быть огромным. Это можно уменьшить, сведя некоторые распространенные неоднозначности и представив их в логической форме. Эти неоднозначности могут быть устранены позже, когда станет доступна дополнительная информация из остальной части предложения и дополнительная контекстная информация. Некоторые авторы рассматривают язык, который фиксирует эту кодировку неоднозначности, как квазилогическая форма .
В качестве примера этой способности улавливать двусмысленность (без ее разрешения) рассмотрим слово «мяч», которое может быть круглым предметом или социальным событием. «Сью смотрела на мяч» неоднозначно и не может быть устранено без учета более широкого дискурсивного контекста. , недоступной на этапе семантического анализа Мы можем представить это предложение с помощью единой логической формы, которая захватывает оба смысла мяча:
(THE b1 : ({BALL1 BALL2} b1) (ПРОШЛОЕ (WATCh2 SUE1 b1)))
Мы упоминали, что такое предложение, как «Каждый мальчик любит собаку», неоднозначно относится к тому, есть ли одна собака или много. Эта двусмысленность фиксируется с помощью угловых скобок, которые обозначают аббревиатуру области видимости:
(ЛЮБИТ1 <КАЖДОГО b1 (МАЛЬЧИКА1 b1)> )
Это заменяет две отдельные возможности:
(КАЖДЫЙ b1 : (МАЛЬЧИК1 b1) (A d1 : (СОБАКА1 d1) (ЛЮБИТ1 b1 d1)))
(A d1 : (СОБАКА1 d1) (КАЖДЫЙ b1 : (МАЛЬЧИК1 b1) (ЛЮБИТ b1 d1)))
Язык логической формы также использует переменные событий и состояний для предикатов и тематических ролей. Основная идея здесь заключается в том, что одно слово, такое как «перерыв», может иметь разные значения в разных языках.
Джон разбил окно молотком.
Молоток разбил окно.
Окно разбилось.
Эти употребления слова «разрыв» имеют разную арность (первое — троичное между Джоном, молотком и окнами, а остальные — бинарными и унарными соответственно). Переменные события могут использоваться для обозначения различных типов событий, связанных с тремя ситуациями. Или можно использовать тематические роли, в которых Джон играет роль агента, окно — роль темы, а молоток — роль инструмента. В других ситуациях могут потребоваться роли «из локации», «в локацию», «путь по локации», и даже больше ролей может быть символизировано. Описание и символизация этих событий и тематических ролей слишком сложны для этого. введение.
До сих пор мы писали так, как если бы процесс синтаксического анализа, приводящий к синтаксическому представлению в контекстно-свободной грамматике или грамматике с определенным предложением, и процесс семантического анализа, который берет это синтаксическое представление и дает утверждение в языке логической формы, были два отдельных процесса. Мы свободно использовали фразу «семантическая интерпретация» для последнего процесса; на самом деле мы могли бы думать о семантической интерпретации как о переходе от предложения к логической форме или от синтаксической структуры или репрезентации к логической форме. Существует более специализированное использование «семантической интерпретации», связанное с использованием различных методов для ссылка синтаксический и семантический анализ. В этом особом смысле метод семантической интерпретации позволяет вычислять логические формы при разборе. Популярная версия этого использует стиль «правило за правилом», при этом каждое синтаксическое правило соответствует семантическому правилу, так что каждая правильно сформированная синтаксическая составляющая будет иметь соответствующую правильно сформированную семантическую (логическую форму) составляющую значения. Но возможны и другие подходы, в том числе те, которые пытаются произвести семантическую интерпретацию непосредственно из предложения без использования синтаксического анализа, и те, которые пытаются анализировать на основе семантической структуры. Как и в случае синтаксического анализа, статистика может использоваться для устранения неоднозначности слов в наиболее вероятном смысле.
Прагматика
До сих пор мы обсуждали процессы достижения синтаксического представления предложения или предложения и семантического значения, логической формы или предложения или предложения. На уровне логической формы могут оставаться некоторые типы неоднозначности, поскольку логическая форма является контекстно-независимым представлением. Поэтому нам нужно пойти дальше в нашем анализе. При обработке естественного языка возникают некоторые виды неоднозначности, которые невозможно разрешить без учета контекста произнесения предложения. Могут быть задействованы общие знания о мире, а также конкретные знания о ситуации. Это знание может также понадобиться, чтобы понять намерения говорящего и дать возможность выдвинуть исходные предположения, предполагаемые говорящим. Таким образом, кроме нашего представления синтаксической структуры и логической формы, нам нужен способ представления таких фоновых знаний и рассуждений. Новый уровень репрезентации — репрезентация знаний. (KR), а языком, который мы для этого используем, будет язык представления знаний (KRL).
Обратите внимание, что некоторые подходы отличаются от Аллена тем, что они используют один и тот же язык для логической формы и представления знаний, но Аллен считает, что использование двух языков лучше, поскольку логическая форма и представление знаний не будут делать все то же самое. Например, логическая форма зафиксирует неоднозначность, но не разрешит ее, в то время как представление знаний направлено на ее устранение. Конечно, в очень простых системах НЛП не может быть никакого способа обрабатывать общее знание мира, конкретный дискурс или знание ситуации, поэтому логическая форма — это то, на что способна система.
Для представления знаний Аллен использует абстрактное представление, основанное на FOPC, но отмечает, что возможны и другие средства представления. Ему не нужно напрямую представлять логические формулы или использовать методы доказательства теорем в качестве модели вывода. Скорее, система представления знаний может быть семантической сетью, коннекционистской моделью или любым другим формализмом, обладающим надлежащей выразительной силой. Я не собираюсь подробно обсуждать его KRL, а просто отмечу, что он действительно напоминает символизацию FOPC с универсальной и экзистенциальной квантификацией, а также функциональными связями или операторами истинности для конъюнкции, дизъюнкции, условного выражения и отрицания.
Обратимся к некоторым примерам места общих знаний. Общие знания о мире могут быть определены в терминах типов объектов в мире без упоминания конкретных индивидуумов. (Информация о конкретных людях будет включена в знания о конкретной обстановке или ситуации.) Общие знания важны для разрешения многих неясностей. Например, рассмотрим следующие предложения:
Я прочитал рассказ об эволюции за десять минут.
Я читал рассказ об эволюции за последний миллион лет.
Очевидно, что предложная фраза, заканчивающаяся первым предложением, относится ко времени, которое потребовалось для прочтения рассказа, а предложная фраза, заканчивающая второе предложение, относится к самому периоду эволюции. Но откуда ты это узнал? Предложения имеют одинаковую основную структуру. Ваши базовые общие знания о продолжительности человеческой жизни, скорости чтения и теории эволюции позволили вам разобраться в этом.
Когда местоимение используется в предложении, мы должны определить его референт. Это известно как разрешение анафоры . Простой метод состоит в том, чтобы найти самую последнюю использованную возможную ссылку и использовать ее. Некоторая информация о домене может быть полезна для определения того, какие недавно использованные существительные действительно могут соответствовать местоимению. Например:
Фред пошел в супермаркет. Он нашел бутылку молока в
молочный отдел, заплатил за него и ушел.
Словосочетание «это», которое в последний раз использовалось в слове «it», — это молочная секция, но информация из базы знаний может подсказать нам, что люди не платят за молочные секции, поэтому нам следует поискать другой референт.
Или подумайте, как ваши знания о мире могут быть использованы для определения правильного значения предложений в следующем классическом примере:
Время летит как стрела
Плодовые мушки, как банан.
В этих предложениях все еще может скрываться двусмысленность, но мы используем общие знания о времени и плодовых мушках, чтобы, вероятно, по-разному интерпретировать слово «мухи» в этих предложениях. Конечно, общее знание — не единственный вид знания, полезный для устранения неоднозначности. Иногда конкретное знание ситуации позволяет разобраться в референте именной фразы или разрешить другие двусмысленности.
Возвращаясь к общим знаниям, отметим, что возможность представления знаний будет включать в себя базу данных предложений (базу знаний (КБ)) и набор из методов вывода , которые будут использоваться для получения новых предложений из текущей базы знаний и информации во входном предложении. Без методов вывода знания в базе знаний будут бесполезны. Как уже упоминалось, языком, используемым для определения базы знаний, будет язык представления знаний, и хотя он может совпадать с языком логической формы, Аллен считает, что он должен быть другим из соображений эффективности. Язык представления знаний можно сделать кратким, чтобы можно было быстро делать выводы, а функция сопоставления свяжет язык логической формы с KRL.
Вот некоторые другие важные различия, связанные с представлением знаний. Отношения следствия следует отличать от отношений следствия. Когда формула P должна быть истинной, учитывая формулы в базе знаний, KB влечет за собой P. Импликации, с другой стороны, — это выводы, которые обычно могут быть получены из предложения, но могут быть отвергнуты при определенных обстоятельствах. Например, предложение «У Джека две машины» влечет за собой , что у Джека есть машина, но только подразумевает, что не владеет тремя машинами.
Чтобы понять естественный язык, необходимо различать дедуктивный и недедуктивный вывод, причем последний включает в себя индуктивный вывод и абдуктивный вывод. Система может разрешать использование правил по умолчанию, которые могут допускать исключения (они могут быть изменены). Предположение о замкнутом мире утверждает, что база знаний содержит полную информацию о некоторых предикатах. Если для такого предиката содержащее его предложение не может быть доказано истинным, то его отрицание предполагается истинным.
Мы уже упоминали, что KRL Аллена напоминает FOPC тем, что включает в себя количественную оценку и функциональные связки или операторы истинности. Напомним, что язык логической формы включал в себя больше кванторов, чем в FOPC. Вот конкретное различие между языком логической формы и языком представления знаний. Язык логической формы содержит широкий набор кванторов, в то время как KRL, как и FOPC, использует только кванторы существования и всеобщности. Аллен отмечает, что если онтологии KRL разрешено включать наборы, конечные наборы могут использоваться для придания приблизительного значения различным кванторам языка логической формы.
Язык представления знаний также использует способ представления стереотипной информации об объектах и ситуациях, потому что многие выводы, которые мы делаем при понимании естественного языка, включают предположения о том, что обычно происходит в обсуждаемой ситуации. Способ обеспечить это состоит в том, чтобы закодировать эту информацию в структурах, известных как кадры . Фрейм — это совокупность фактов и объектов о некотором типичном объекте, ситуации или действии, а также определенные стратегии вывода для рассуждений о такой ситуации. Части кадра, факты и объекты, называются слотами или ролями. Так, например, рама для дома может иметь слоты кухни, гостиной и т. д. Фрейм также задает отношения между слотами и объектом, представленным самим фреймом. Обозначение слота может быть расширено, чтобы показать отношения между фреймом и другими предложениями или событиями, особенно предпосылками, эффектами и декомпозицией (способом, которым обычно выполняется действие). Мне кажется, что информация в этих кадрах фиксирует наши знания здравого смысла о вещах и событиях в мире.
KRL также должен включать метод представления и рассуждений о временных событиях, таких как информация, содержащаяся во временах глаголов и в наречиях (например, «вчера»). Ранее мы приводили несколько примеров важности общих знаний. Но некоторые проблемы с интерпретацией предложения на естественном языке связаны не с общим знанием, а с более конкретным локальным дискурсивным контекстом (разговором). Например, что касается входного предложения, синтаксическая и семантическая структура предшествующего предложения или предшествующего предложения, а также список объектов, упомянутых в этом предложении или предложении, могут содержать важную информацию. Мы уже упоминали, что простой алгоритм разрешения анафоры может заставить программу искать существительное в непосредственно предшествующем предложении или предложении. Помимо местоимений, разрешение может потребоваться и для других выражений. Другие ссылочные выражения могут быть интерпретированы с использованием методов сопоставления с образцом, которые находят синтаксическое сходство между текущим предложением и предыдущими. Например, подумайте, как интерпретировать третье предложение в этом примере диалога от Аллена: Шаблон последнего предложения можно сопоставить с предыдущим шаблоном, где мороженое отображается на бананы, а холодильник на полку. Затем может быть предоставлен недостающий аспект клерка, кладущего такие предметы. Обратите внимание, что релевантным локальным дискурсивным контекстом может быть не просто предыдущее предложение, а более широкий набор, как в примере с бананами. Чтобы подготовить тему, которую мы вскоре рассмотрим более подробно, отметим, что более тщательный анализ дискурса включает в себя определение предполагаемой направленности части языка, чтобы понять ее. Мы часто переключаем внимание, когда говорим, и процессоры естественного языка должны видеть это, чтобы понять, о чем мы говорим. Когда мы разговариваем, мы иногда совершаем краткий экскурс, который на мгновение смещает фокус, и мы должны быть в состоянии увидеть, что, например, именное словосочетание отсылает к более раннему фокусу, а не к экскурсу. К чему относится «более широкий план»? Словосочетание не является местоимением, но все же нам нужно определить, к чему оно относится. Наиболее непосредственно предшествующим кандидатом является «маркетинговый план», но использование подсказки «хотя» связано с тем фактом, что фраза «маркетинговый план» находится в середине краткого экскурса из предыдущей основной темы обсуждения, которая была о бизнес-плане. Таким образом, мы видим, что упомянутый более широкий план является бизнес-планом, а не маркетинговым планом. Один аспект, который здесь важен, заключается в том, что мы предполагаем связность дискурса, что позволяет нам определить, как предложения соотносятся друг с другом. Мы исходим из того, что дискурс обычно не состоит из несвязанных между собой предложений. Например, рассмотрим: Поскольку мы предполагаем, что дискурс связен, «он» должен относиться к Джеку, «зажженный» должен означать «зажечь», а не «зажечь» свечу, а инструмент, используемый для зажигания свечи, должен быть спичкой. Конечно, это предполагает, что приведенное выше изображает нормальный набор событий. Многие такие интерпретации когерентности будут скорее импликациями, чем следствиями; другими словами, они могут быть опровергнуты и могут быть переопределены более поздней информацией. Теперь мы можем еще более конкретно определить понятие локального дискурса. Локальная дискурсивная ситуация включает в себя локальные связи между предложениями. Но, как уже упоминалось в приведенном выше примере, тема обсуждения может сдвигаться, изменяться и возвращаться к предыдущим темам, при этом высказывания группируются в единицы, называемые дискурсивными сегментами , имеющими иерархическую структуру. Часто вносятся изменения в дискурсивный сегмент, но ключевых фраз , таких как «кстати». Обработка естественного языка должна учитывать этот расширенный контекст дискурса, включая несколько сегментов. Например, местоимение может относиться к референту, не упомянутому в предыдущем сегменте, но в более раннем сегменте. Представьте, что два человека говорят о том, что один из них ведет третьего человека в аэропорт, чтобы сесть на самолет. Разговор временно переходит в обсуждение новой машины, которую водитель недавно купил. Аллен отмечает, что нет единого мнения о том, как следует проводить сегментацию или о том, что представляют собой сегменты конкретного дискурса, хотя почти все исследователи разделяют интуицию о том, что некоторые предложения объединяются в такие единицы. Но остаются еще два важных нерешенных вопроса: во-первых, методы анализа предложений внутри сегмента и, во-вторых, отношение сегментов друг к другу. Мы можем кратко прокомментировать их. В НЛП структурным требованием к сегменту является то, что предложения внутри сегмента должны обладать такими свойствами, как: Существует два подхода к дальнейшему разграничению сегментов. Интенциональный подход предполагает, что предложения внутри сегмента способствуют достижению общей цели или коммуникативной цели. Информационный подход предполагает, что предложения связаны временными, причинными или риторическими отношениями. В НЛП, имеющем дело с наличием сегментов, отдельные сегменты могут быть захвачены в дискурсивных состояниях, что позволяет временно приостановить один сегмент, пока преследуется новый. Состояние дискурса состоит из: Затем НЛП может обрабатывать предложения как принадлежащие к определенному сегменту, а затем использовать эту информацию для разрешения двусмысленности и предоставления подразумеваемой информации. Итак, мы предполагаем, что дискурсивные сегменты связаны сами по себе и вместе могут составлять дискурсивное состояние, и НЛП может использовать эту информацию для интерпретации. Дальнейшие возможности системы НЛП интерпретировать разговоры на естественном языке включают понятия ожиданий, сценариев и планов. Сначала поговорим об ожиданиях. По отношению к входному предложению содержание предыдущих предложений и любые выводы, сделанные при интерпретации этих предложений, образуют то, что можно было бы назвать «конкретной установкой». Эта конкретная информация о настройках может генерировать набор ожиданий. Ожидания могут быть порождены информацией, среди прочего, о действии и причинности, причинах и следствиях, предварительных условиях, включении, декомпозиции и порождении. Есть много возможных ситуаций и сценариев, которые будут генерировать ожидания. Один из способов контролировать формирование ожиданий — хранить большие блоки информации, идентифицирующие типичные ситуации. Это скриптов . Сценарии могут быть описаны в терминах действий или состояний как целей, таких как «сесть на поезд до Рочестера» или «доехать до Рочестера», и эти цели могут использоваться системой для поиска соответствующего сценария. Распознавание плана также связано с тем, что понимание естественного языка часто требует понимания намерений вовлеченных агентов. Мы предполагаем, что люди действуют не хаотично, а имеют цели и их действия являются частью плана по достижению цели. Когда мы читаем «Дэвид отчаянно нуждался в деньгах. Он подошел к своему столу и достал пистолет», мы делаем вывод, что у Дэвида есть некий план использовать пистолет, чтобы совершить преступление и получить немного денег, хотя это прямо не указано. Или когда мы спрашиваем билетного агента: «Вы знаете, когда отправляется следующий поезд?» мы ожидаем, что агент сообщит нам время, если он его знает, а не просто скажет нам, что он знает его, сказав «Да». Все эти разговоры об ожиданиях, сценариях и планах звучат великолепно, но человеческий опыт настолько обширен, что системе НЛП будет трудно включить все это в свою базу знаний. Ясно, что еще предстоит проделать большую работу в области развития и совершенствования вышеуказанных методов. Как говорит Аллен, «необходимо проделать значительную работу, прежде чем эти методы можно будет успешно применять в реальных областях». Эта статья посвящена пониманию или интерпретации естественного языка. Процессор естественного языка в полном смысле должен уметь не только интерпретировать или понимать предложения на естественном языке, но также генерировать их и участвовать в диалоге (естественном диалоге) с другим процессором естественного языка, будь то человек или компьютер. Главный вопрос, на который нужно ответить при определении разговорного агента, заключается в том, почему агент вообще должен говорить? Что побуждает его говорить что-либо или пытаться понять высказывания, которые ему говорят? Очень простое НЛП, участвующее в разговоре, может делать это, потому что оно было запрограммировано на это, подобно агенту базы данных, отвечающему на вопросы. Получив входной вопрос, агент будет интерпретировать его, искать ответ в базе данных и генерировать выходные данные, содержащие ответ. Но, конечно же, отмечает Аллен, этот тип простого агента нельзя считать очень умным или разговорчивым. У этого типа агента не было бы шансов пройти тест Тьюринга, например, потому что он не был бы гибким и, казалось бы, вообще не мог генерировать независимый ответ или инициировать линию диалога. Аллен отмечает, что мы можем наделить систему разумом, если будем действовать таким образом, который более точно соответствует тому, что мотивирует поведение человека. Люди действуют для достижения целей. Способ моделирования этого заключается в использовании концепций восприятия (мира), которые включают: Приведенный выше набор понятий называется моделью BDI (вера, желание и намерение). Чтобы упомянутая ранее база знаний функционировала как убеждения агента, лучше всего разделить базу знаний на области убеждений. Каждое предложение может быть убеждением. Два пространства были бы полезны для беседы, одно для убеждений агента, а другое для представления его убеждений относительно убеждений другого агента. В частности, агент должен уметь распознавать намерения другого агента, и для этого можно использовать распознавание плана. Аллен обсуждает понятие речевых актов, обсуждая понятие плана дискурса, который мог бы управлять диалогом. Компьютер будет действовать детерминированным образом в соответствии со своей программой, так что он должен быть запрограммирован, например, когда начинать разговор. Ранние попытки НЛП включают в себя попытку Национального исследовательского совета в конце сороковых или начале пятидесятых годов разработать систему, которая могла бы переводиться между человеческими языками. Полная беглость речи прогнозировалась в течение пяти лет. (в, в, в, на, на) (последний, последний, новый, последний, низший, наихудший) (время, время) для анализа и синтеза релейно-контактные электрические (схема, схема, схема) параллельные-(последовательные, последовательные , последовательный, непротиворечивый) (связь, соединение, сочетание) (с, от) (успех, удача) (использовать, использовать) аппарат булевой алгебры. В 1966 году, потратив 20 миллионов долларов, Консультативный комитет NRC по автоматизированной обработке языков рекомендовал прекратить дальнейшее финансирование проекта. Вместо этого, по их мнению, фокус финансирования должен быть смещен на изучение понимания языка. Мы не будем углубляться в прогресс в распознавании речи. Возможно, следующим часто упоминаемым шагом в других аспектах обработки естественного языка была ELIZA, разработанная Джозефом Вейценбаумом в шестидесятых годах. В семидесятых годах Роджер Шанк разработал MARGIE, которая сократила все английские глаголы до одиннадцати семантических примитивов (таких как ATRANS, или Абстрактная передача, и PTRANS, или Физическая передача). Такого рода редукция позволяет MARGIE делать выводы о последствиях полученной информации, потому что она будет знать, какие события произойдут в зависимости от семантического примитива, задействованного во входном предложении. Это получило дальнейшее развитие в понятии скриптов, о котором мы упоминали выше. Идея заключалась в том, что компьютеру можно было дать справочную информацию (СЦЕНАРИЙ) о том, какие вещи происходят в типичных повседневных сценариях, и затем он мог бы вывести информацию, не предоставленную явно. Люди делают это все время. MARGIE уступила место SAM (механизм применения сценариев), который мог переводить ограниченное количество предложений с разных языков (английский, китайский, русский, голландский и испанский). В конце семидесятых Сценарии привели к PAM для Механизма Планирования, основанному на работе Шанка, Абельсона и Виленски. PAM интерпретировал истории с точки зрения целей различных участников. Позже последовали различные варианты студентов этих ребят, в том числе FRUMP, который использовался для обобщения новостей UPI. Тем не менее адекватного последовательного перевода не хватало, как, например, когда ФРУМП прочитал рассказ о том, как политическое убийство потрясло Америку, и резюмировал рассказ как о землетрясении. В настоящее время разработан ряд программ обработки естественного языка как университетскими исследовательскими центрами (по искусственному интеллекту или компьютерной лингвистике), так и частными компаниями. Большинство из них имеют очень ограниченные домены, то есть они могут обрабатывать разговоры только на ограниченные темы. Достаточно сказать, что относительно системы обработки естественного языка, которая может разговаривать с человеком на любую тему, которая может возникнуть в разговоре, мы еще не достигли этого. Одна из проблем состоит в том, что утомительно пытаться загрузить в компьютер большой словарь, а также поддерживать и обновлять этот словарь. Структурирование правил грамматики естественного языка также является большой задачей. Но есть и проблема общего познания мира. Большая часть проблемы связана с отсутствием знаний здравого смысла со стороны компьютера. Возможно, поможет база данных CYC Дуга Лената, если она вся «закончена». Но мне кажется, что несколько достаточно компетентных философов могли бы быстро найти знания здравого смысла, не закодированные в базе данных. Что нам нужно, как мне кажется, так это способ, с помощью которого компьютер мог бы изучать знания здравого смысла так же, как это делаем мы, познавая мир. Некоторые исследователи тоже в это верят, поэтому работа над темой машинного обучения продолжается. Более свежую информацию о состоянии дел по вышеупомянутым темам можно получить, выполнив поиск во всемирной паутине с использованием таких ключевых слов, как обработка естественного языка, понимание естественного языка, машинное обучение, компьютерная лингвистика и т. ProtoThinker имеет ограниченные возможности обработки английских предложений, поэтому я кратко прокомментирую, как работает его парсер. Я сомневаюсь, что ProtoThinker имеет много общих знаний о мире, но у него есть возможность разобраться в элементарных английских предложениях. Насколько я могу судить, синтаксический анализатор в ProtoThinker сначала пытается удалить знаки препинания и такие термины, как «пожалуйста», и преобразует прописные буквы в строчные. Он имеет большой список общеупотребительных терминов, классифицированных по частям речи. Он ищет такие термины, сопоставляет их с соответствующей частью речи, а затем пытается классифицировать большую фразу, включающую этот термин. Используя эту информацию и наилучшее совпадение со структурой, ProtoThinker может затем принять утверждение и сообщить вам об этом, а затем ответить на вопросы, относящиеся к этому утверждению. Таким образом, он может расширить свою базу данных информации для последующего использования в сеансе. Поскольку ProtoThinker написан на Прологе, предположительно, он использует нисходящий алгоритм поиска в глубину, но лично я не могу убедиться в этом, просканировав код синтаксического анализатора. Похоже, что у него есть возможность отслеживать некоторую контекстную информацию внутри предложения, такую как лицо (первое, второе и т. д.) и время, так что в этом смысле его грамматика не выглядит контекстно-свободной. Откровенно говоря, мне нужно было бы увидеть больше комментариев в коде и изучить больше подобных программ, чтобы понять тонкости того, как это работает. Я знаю, как тяжело комментировать программу после того, как она сделана, и Джон Баркер прокомментировал некоторые из ранних частей программы. Аллен, Джеймс, Понимание естественного языка , второе издание (Редвуд-Сити: Бенджамин/Каммингс, 1995). Братко, Иван, Prolog , второе издание (Workingham: Addison-Wesley, 1990). Гинзберг, Мэтт, Основы искусственного интеллекта (Сан-Матео: Морган Кауфманн, 19 лет)93). Хоган, Джеймс П., Mind Matters (Нью-Йорк: Баллантайн, 1997). Лазарев Григорий Л. Маркус, Клаудия, Программирование на прологе (чтение: Addison-Wesley, 1986). Шильдт, Герберт, Advanced Turbo Prolog (Беркли: Osborne McGraw-Hill, 1987). Шохам, Уоав, Методы искусственного интеллекта в Прологе (Сан-Франциско: Морган Кауфманн, 1994). Стидман, Марк, «Обработка естественного языка», в Маргарет А. Боден, редактор, Искусственный интеллект (Сан-Диего: Academic Press, 1996). Стерлинг, Леон, и Шапиро, Эхуд, Искусство Пролога (Кембридж: MIT Press, 1986). Тефт, Ли, Программирование на Турбо-Прологе (Englewood Cliffs: Prentice-Hall, 1989). Таунсенд, Карл, Передовые методы в Turbo Prolog (Сан-Франциско: Sybex, 1987) 1 Маркус, с. 2 Стидман, с. 229. [назад] Синтаксический анализ и семантическая интерпретация Синтаксический анализ: отнесение слов к грамматическим категориям и определение структурных отношений между составными частями Семантическая интерпретация: интеграция информации, передаваемой синтаксическим разбором, и интерпретация общего смыслового (пропозиционального) содержания предложения Обработка предложений в режиме онлайн и в автономном режиме В режиме онлайн: обрабатывать слова одно за другим по мере их прослушивания, не дожидаться конца предложения для разбора предложения, не дожидаться конца предложения предложение интерпретировать предложение в автономном режиме: дождитесь конца предложения перед доступом к словам, дождитесь конца предложения, чтобы разобрать предложение, дождитесь конца предложения, чтобы интерпретировать предложение Затенение речи повторение другого человека, чем ближе это грамматическое предложение, тем быстрее вы сможете его затенить. Синхронный перевод перевод с 1 языка на другой: слышать один язык, говорить на другом одновременная онлайн обработка двух языков RSVP (быстрая последовательная визуальная обработка) предложений читать слова, мигающие в середине экрана, может ли человек читать слово, Предсказания: синтаксический анализ : если онлайн: грамматически быстрее, чем неграмматически, если офлайн: грамматически = неграмматически семантическая интерпретация : если онлайн: семантически правдоподобно быстрее, чем неправдоподобно Исследования движения глаз Исследования чтения: предложение на экране, где люди фиксируют/останавливают/возвращают назад Разговорный пассив: слушайте предложение, принимайте решение: какая картинка соответствует предложению, в какой момент человек берет на себя обязательство смотреть на одну картинку : Активный: девушка толкала мальчика, пассивный: мальчик толкал девушку, если бы люди ждали конца предложения, люди смотрели бы на правильную картинку в половине случаев, НО люди смотрели бы на правильную картинку до того, как они закончили ее слушать > на -линейная обработка предложения садовой дорожки временно двусмысленные предложения, и вы изначально построили неправильное дерево, более интуитивное значение является неправильным Предсказание: обработка в автономном режиме , обработка садовой дорожки = предложение без садовой дорожки, будет только одно значение , обработка онлайн : обработка предложений садовой дорожки медленнее (постоянно) Неоднозначные предложения несколько грамматических синтаксических анализов (т. часто второй разбор остается незамеченным Синтаксическая неоднозначность: привязанность PP > высокая привязанность (к VP), низкая привязанность (к NP) EX: Дон упомянул служанку актрисы , которая была на балконе> высокая привязанность: слуга был на балконе, низкая привязанность: актриса была на балконе Структурная эвристика Garden Path Структурная эвристика, используемая для синтаксического анализа Позднее закрытие минимальное приложение Основное утверждение Garden Path Двухэтапная модель обработки предложений Синтаксический анализ : немедленный, автоматический > доступ к словам из лексикона (все значения), определение синтаксической категории слов, размещение слов в синтаксическом дереве с использованием категории слова/структурной эвристики Семантическая (тематическая) интерпретация : интерпретация слов (правильная значение), интерпретировать значения слов для определения пропозиционального содержания всего предложения Пошаговое : каждое слово обрабатывается по мере его поступления, синтаксический анализ выполняется до семантической интерпретации Восходящее : контекстно-независимый Модульный : используется только структурная информация Последовательный : один синтаксический анализ формируется за раз с наименьшим количеством (разветвленных) узлов минимизировать количество узлов ветвящейся фразовой структуры, присоединяя входящие слова к узлу, который уже разветвляется Пример: доктор Фил обсуждал секс с Рашем Лимбо (минимальное присоединение PP) Эвристика позднего закрытия не постулировать ненужную структуру. Эвристика основного утверждения при наличии двух структур на выбор, постройте структуру, в которой новые элементы относятся к основному утверждению предложения, например: Доктор Фил обсуждал секс с Рашем Лимбо, приложение к основному утверждению: доктор Фил разговаривает с Рашем Лимбо Модели удовлетворения ограничений обработки предложений Каскадирование: синтаксический анализ и семантическая интерпретация происходят одновременно, сверху вниз и снизу вверх: контекст влияет на интерпретацию, немодульный: высокоинтерактивный: информация из нескольких источников ограничивать интерпретацию, лексических предубеждений: частотность слов, класс слов (относительная недавность хлопка как существительного по сравнению с прилагательным) аргументная структура глаголов, контекст: референтный и визуальный, просодия , ограниченная параллельная обработка: если вся информация сходится в одном анализе, то последовательный, если нет, то может поддерживаться несколько анализов Критика подхода, основанного на ограничениях сначала наиболее часто встречающаяся структура, например. «Достаточно хорошая» модель обработки предложений Делайте минимальную > используйте простую лексическую информацию, когда это возможно, затем используйте простые правила, такие как 1-й NP = Агент, выполняйте синтаксический анализ только при необходимости, то, что «достаточно хорошо», зависит от ситуации > если ставки высоки, создавайте синтаксические структуры, лицензированные грамматикой, пересматривайте структуру, если первоначальный синтаксический анализ неверен, являются ли ошибки просто ошибками или результатом достаточно хорошей обработки? Обработка предложений с зависимостями на большом расстоянии (заполнение пробелов) Зависимость на расстоянии: Девочка была поцелована ___ мальчиком Доказательство того, что заполняющий пробел психологически «реален»: кросс-модальные эксперименты: «Ребенок пролил сок, который ____ испачкал ковер» «Сок, который пролил ребенок ___, испачкал ковер» > имя «сок» быстрее в пробеле «Сомнительные» предложения с пробелами — это садовая дорожка > «Это мальчик, который понравился девушке [возможное место разрыва], чтобы игнорировать [фактическое место пробела], наполнители связаны с глаголами (т. В языке логической формы использовались модельные операторы (PAST, PRES, FUT) и временные связки (BEFORE, DURING). Расширения FOPC используются в KRL для представления такого типа информации. Например, «t1 Эта информация может позволить указать референт местоимения или другой определенной именной фразы, встречающейся во входном предложении, или она может предоставить значение многоточия глагольной фразы во входном предложении, которое относится к ранее описанному событию. Пример Аллена разрешения анафоры, а также пример интерпретации многоточия глагола:
Джек потерял бумажник в машине.
Он искал его несколько часов.
(местоимение «это», относящееся к «бумажнику» в предыдущем предложении)
Джек забыл свой бумажник.
Сэм тоже.
(многоточие глагола, относящееся к забыванию кошелька в
предыдущее предложение)
Система НЛП может отслеживать их, группируя возможные антецеденты местоимений в список сущностей дискурса или список истории. Затем можно использовать уже упомянутый простой алгоритм, чтобы потребовать, чтобы самое последнее в списке проверялось как возможный референт рассматриваемого местоимения. Эта проверка будет более сложной, если она будет включать в себя проверку ограничений, таких как те, которые основаны на правильном роде и числе, чтобы исключить некоторые референты как возможности. (Могли бы быть разработаны и другие, более сложные алгоритмы.)
Продавец положил бананы на полку?
Да.
Мороженое в холодильнике?
Термины, которые являются ключом к такому экскурсу, — это «хотя», «кстати» и «кстати», в то время как такие фразы, как «в любом случае» и «возвращение», указывают на возврат к предыдущему фокусу. Чтобы адаптировать пример из Гинзберга, рассмотрим: Бизнес-план будет включать в себя гораздо больше, чем маркетинговый план. Хотя разработка маркетингового плана была основной темой этого курса, в этот более широкий план включены и другие важные области.
Джек достал спичку.
Он зажег свечу.
Затем слушатель вмешивается: «Кстати, вы успели вовремя доставить ее к самолету?» Очевидно, что «она» относится не к возможному продавцу, который продал водителю новую машину, а к человеку, которого везут в аэропорт. Сегмент о поездке в аэропорт сменился на сегмент о покупке новой машины. Затем возможная интерпретация входного предложения может быть сопоставлена/сопоставлена с ожиданиями. Цель состоит в том, чтобы только одна из интерпретаций соответствовала ожиданиям. В приведенном выше примере процесс сопоставления будет использовать ожидания для сопоставления истории с интерпретацией того, что спичка зажгла свечу, а не с интерпретацией того, что спичка зажгла свечу, поскольку обычно ожидается, что спичка зажжет свечу, а не сделает что-то еще. к этому. Но если точное совпадение невозможно, потребуются другие соображения. Со сценарием связана более богатая структура, называемая плановая модель . План, набор действий, используется для достижения цели, и это понятие может использоваться НЛП для вывода плана агента на основе действий агента. Это распознавание плана или вывод о плане. Возможные ожидания могут быть сформированы на основе знания таких планов. Мы предполагаем, что агент осознает, что наша цель – фактически узнать время, а не только то, знает ли он его. Чтобы процессор естественного языка мог правильно интерпретировать такие предложения, он должен иметь много исходной информации о таких сценариях и уметь ее применять. Поколение естественного языка
Но инициирование разговора — это больше, чем просто указание понять его: Восприятие, планирование, обязательство и действие являются процессами, в то время как убеждения, желания и намерения являются частью когнитивного состояния агента. Таким образом, это не так уж далеко от простой программы базы данных, о которой упоминалось ранее. Конечно, в программу можно было бы встроить некую рандомизирующую функцию, чтобы она могла «выбирать» из нескольких альтернатив при ответе или инициировании диалога. Учитывая, что в отношении темы человеческой свободы воли и выбора мы, по-видимому, не разрешили спор между либертарианством, компатибилизмом и жестким детерминизмом, тот факт, что даже очень сложный компьютер для обработки естественного языка, вероятно, будет действовать детерминированным образом, может не мешать ему участвовать в разговоре так же, как это делает человек. Могут ли компьютеры уже понимать естественные языки?
Теория, лежащая в основе этого оптимизма, возникла из-за успеха усилий по взлому кодов во время Второй мировой войны, которые заставили людей поверить в то, что человеческие языки — это просто разные системы кодирования для одного и того же значения. Применение соответствующих правил преобразования должно обеспечивать возможность преобразования с одного языка на другой. В этом методе использовался автоматический поиск в словаре и применение правил грамматики для перестановки эквивалентов слов, полученных из словаря. Было некоторое понимание того, что двусмысленность и идиомы могут создавать проблемы, требующие участия некоторого ручного редактирования. Математик Уоррен Уивер из Фонда Рокфеллера считал, что, возможно, необходимо сначала перевести на промежуточный язык (вне зависимости от того, существует ли такая вещь в основе естественных языков или ее нужно создать). Но усилия не увенчались реальным успехом. Например, из середины 50-х годов вышел такой перевод: «В последнее время булева алгебра успешно применяется при анализе релейных сетей последовательно-параллельного типа». Программа перечисляла альтернативы, когда не была уверена в переводе. ELIZA могла вводить текст, использовать сопоставление с образцом и замену «я» и «вы» там, где это необходимо, вставлять некоторые готовые вводные фразы, такие как «Расскажите мне об этом подробнее» и «Почему вы так думаете», и производить вывод, который появился. пользователю исходить от недирективного роджерианского терапевта. Эта программа могла создать видимость обработки естественного языка, но ее синтаксический, семантический и прагматический анализ были примитивными или практически отсутствовали, так что на самом деле это была просто умная игра для вечеринок, которая в любом случае, кажется, близка к первоначальному замыслу Вейценбаума. . Поскольку ELIZA действовала как «клиент-центрированный» терапевт, она могла выплевывать вам в ответ все, что вы ей давали, что она не могла обработать. С точки зрения прорывов в НЛП, мне кажется, что это не так уж важно, за исключением, может быть, комментария по поводу заменяемости терапевтов, использующих клиентоцентрированные методы Карла Роджерса. д. Многие университеты в США проводят исследования по У НЛП есть информация и ссылки, например, Техасский университет на http://www.cs.utexas.edu\users\ml. ProtoThinker как процессор естественного языка
Это подсказывает ему структуру предложения. Так, например, он ищет общие вопросы, в которых начинаются термины, такие как «что», «как», «кто», «когда» и т. д. Он может искать связки, такие как «тогда», «либо», «оба, «и» и т. д., чтобы попытаться разбить предложение на предложения. Он может распознавать распространенные приветствия, такие как «Привет». Он также может распознавать общие предлоги и местоимения. Распознавание этих подсказок помогает ему попытаться сопоставить образец фразы или предложения с некоторыми общими структурами, которые он ищет. Может потребоваться предлог в качестве подсказки для поиска предложной фразы или вспомогательный глагол в качестве подсказки для поиска глагольной фразы. У него есть большой список глаголов и существительных, с которыми он может обращаться, включая некоторые неправильные формы глаголов. По-видимому, если у него возникают проблемы с определением референта местоимения, он может попросить пользователя уточнить, кто или что является референтом. Он не обязан комментировать это или даже показывать кому-либо, так что он действительно забавно показывает мне код синтаксического анализатора. Существует множество доступных книг по Прологу, которые помогут вам построить синтаксический анализатор, но даже с учетом этого достижение Джона Баркера в том, что эта штука действительно работает, заслуживает похвалы. Список литературы и библиография
, Почему Пролог? (Энглвудские скалы: Прентис-Холл, 1989). Сноски
236. [назад] Карточки для обработки предложений | Chegg.com
Доказательство того, что обработка предложения происходит в режиме онлайн Прогнозы: синтаксический анализ : если в режиме онлайн: грамматически быстрее, чем неграмматически если офлайн: грамматически = неграмотно семантическая интерпретация : если онлайн: семантически правдоподобно скорее, чем неправдоподобно, если офлайн: правдоподобно = неправдоподобно е. несколько деревьев) и, следовательно, несколько возможных интерпретаций если возможно, продолжайте работать над одной и той же фразой или предложением как можно дольше, присоединяйте поступающие лексические единицы к обрабатываемому в данный момент предложению или фразе, преимущества: автоматически и снижает требования к памяти, например: пока Сьюзен одевала ребенка, он играл на полу , позднее заключительное приложение : Ребенок является объектом одетого Спортсменка поняла, что ее туфли остались в автобусе > понимает, что обычно принимает S, поэтому у нее должны быть трудности с обувью, нет никаких доказательств того, что более простая структура когда-либо усложняется для обработки контекстом, делает ли это проверяемый прогноз? > что считается свидетельством против гипотезы, основанной на ограничениях, всегда можно сказать, что один тип доказательств превосходит другой, почему подход, основанный на ограничениях, когда-либо терпит неудачу?