ТОП-7 Онлайн-Сервисов: Синтаксический Разбор Предложения
Иногда просто жизненно необходимо разобрать предложение на синтаксические составляющие. Но что делать, если немного подзабыл правила, а нужной программы под рукой нет? Подтянуть знания синтаксиса можно за несколько уроков на онлайн-курсах русского языка в школе Skysmart, но когда времени в обрез — выручат специальные онлайн-сервисы для синтаксического разбора предложений.
Как правило, этими сервисами пользуются студенты и ученики старших классов. Но иногда даже взрослые люди туда заглядывают. Стоит отметить, что некоторые из них способны быстро и качественно произвести требуемый анализ.
Стоит заметить, что некоторые сервисы, которые рекламируют услуги такого типа могут быть просто фишинговыми сайтами, предназначенными для кражи личных данных пользователя. А анализировать текст или предложение они не умеют.
Поэтому важно выбрать действительно качественный сервис, которому можно доверять. В этом материале мы собрали наиболее адекватные ресурсы, который предоставляют пользователям услуги такого плана.
И сейчас мы их рассмотрим подробнее.
 И сейчас мы их рассмотрим подробнее.
И сейчас мы их рассмотрим подробнее.Содержание
- GoldLit
- Seosin
- Морфология онлайн
- Грамота
- Lexis Res
- Delph-in
- ProgaOnline
- Заключение
GoldLit
GoldLit
Первой в нашем списке значится платформа GoldLit. Это действительно весьма неплохой сервис, который позволяет произвести глубокий анализ предложения. Вообще, платформа заточена под морфологию. Но синтаксический анализ тоже производится.
К особенностям сервиса стоит отнести полный разбор каждого слова. Как морфологический, так и синтаксический. Но при этом нет никаких условных обозначений вроде подчеркиваний, акцентуаций и прочего. И это не совсем удобно.
Зато для тех, кто изучает литературу ресурс будет незаменим, так как снабжает практически каждое слово обширным литературным комментарием. Но использовать его для подготовки не рекомендуется, так как справочного материала по поводу синтаксиса очень мало.
Тем не менее, работает ресурс довольно быстро. Однако со сложными предложениями и большими кусками текста он не справляется. Тем не менее, для разового использования сервис вполне подходит, ибо обладает всем необходимым функционалом.
ПЛЮСЫ:
- Синтаксический и морфологический разбор каждого слова
- Обширный литературный комментарий
- Быстрая работа ресурса
- Русский язык в интерфейсе
МИНУСЫ:
- Нет никаких обозначений
- Скудный справочный материал в плане синтаксиса
- Не справляется со сложными предложениями
Сайт
Читайте также: Места, где я был. ТОП-10 сервисов для туристов (+бонус)Seosin
Seosin
Проект Seosin задумывался именно как платформа для синтаксического разбора предложения. Поэтому никаких проблем с этим нет. Но такой анализ – единственное, на что способен ресурс. Никаких дополнительных опций не предусмотрено.
Принцип работы у сервиса простой. Пользователь вводит в окошко текст и через несколько секунд получает полный синтаксический разбор всех его составляющих. Ключевой особенностью является возможность подчеркивания определенных частей речи и прочего.
Ресурс работает очень быстро и способен даже анализировать сложные приложения и целые тексты. Именно поэтому многие пользователи выбирают именно этот сервис. Ведь он действительно способен быстро выдать требуемый анализ.
Однако не стоит забывать, что и у него есть недостатки. Первый – отсутствие справочного материала. Его вообще нет. Поэтому использовать ресурс для самостоятельной подготовки нельзя. Второй недостаток – нет никаких настроек. Просто окно для ввода текста.
ПЛЮСЫ:
- Отличная работа со сложными предложениями
- Полный синтаксический анализ текста
- Подчеркивание частей речи и прочих элементов
- Очень быстрая работа
МИНУСЫ:
- Нет справочного материала
- Скудный интерфейс
Сайт
Читайте также: Бесплатные онлайн-курсы.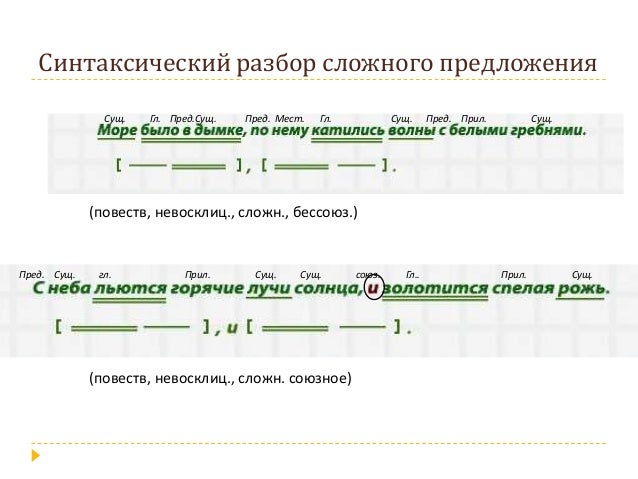 ТОП-100 в 2022 году
ТОП-100 в 2022 годуМорфология онлайн
Морфология онлайн
Вообще-то эта платформа придумана для морфологического разбора слов. Но она способна произвести и синтаксический анализ. Однако для этого придется серьезно попотеть. Ибо все нужные настройки глубоко спрятаны.
Сервис отличается приятным оформлением и весьма простым интерфейсом. Он позволяет на лету выполнить морфологический анализ. А если немного поиграть с настройками, то и синтаксический вполне можно получить.
Платформа снабжена обширным справочным материалом, но не имеет обыкновения как-то обозначать части речи и прочее. К тому же, работать с синтаксисов на этом ресурсе новичку будет очень сложно.
Тем не менее, это весьма неплохой проект, который могут использовать студенты для подготовки. Работает Морфология онлайн только с русским языком. Зато не нужна никакая регистрация. Просто нужно ввести слово и нажать на Enter.
ПЛЮСЫ:
- Полный морфологический анализ
- Можно выполнить синтаксический разбор
- Много справочного материала
- Очень быстрая работа
МИНУСЫ:
- Нет подчеркиваний частей речи
- Производить синтаксический анализ очень сложно
Сайт
Читайте также: ТОП-14 Бесплатных сервисов с обоями на Рабочий стол высокого качестваГрамота
Грамота
Весьма необычный ресурс, который обладает тоннами справочного материала. И умеет неплохо разбирать слова. Но совершенно не может работать с предложениями. Сказывается морфологическая направленность.
Тем не менее, ресурс весьма удобен для тех, кто постигает русский языке. Его вполне можно использовать для самостоятельной подготовки. Что, собственно, и делают студенты и школьники. Это один из самых популярных сервисов такого плана в Рунете.
Сайт обладает весьма неплохим оформлением и может похвастаться продуманным интерфейсом. Здесь можно настроить практически все, что вы хотите узнать о том или ином слове. Такая гибкость играет только на руку платформе.
Здесь можно настроить практически все, что вы хотите узнать о том или ином слове. Такая гибкость играет только на руку платформе.
Однако для синтаксического анализа ресурс не очень подходит. Конечно, какую-то информацию получить можно, но она будет не настолько полной, как при использовании предыдущих вариантов. Зато справочного материала много.
ПЛЮСЫ:
- Огромное количество справочного материала
- Всесторонний разбор слова
- Быстрая работа
- Интуитивно понятный интерфейс
МИНУСЫ:
- Не умеет работать с предложениями
- Не особо подходит для синтаксического анализа
Сайт
Читайте также: Обучение Big Data | ТОП-10 Лучших Курсов для Начинающих — Включая БесплатныеLexis Res
Lexis Res
А вот этот проект очень пригодится тем, кто углубленно изучает английский язык. Платформа предназначена для синтаксического и морфологического анализов слов и предложений. И она превосходно справляется со своими функциями.
И она превосходно справляется со своими функциями.
У ресурса есть одно неоспоримое преимущество: он способен предоставить подробное описание всех значений конкретного слова. Имеется обширный справочный материал. Но он исключительно на английском языке. Как и весь сервис.
К отличительным чертам проекта стоит также отнести опцию подчеркивания различных частей речи и прочих составляющих предложения. Это весьма неплохо, так как повышает уровень комфорта при работе с проектом.
Но использовать Lexis Res смогут только те, кто уже достаточно хорошо знает английский язык, поскольку на этой платформе нет ни одного русского слова. Да и создавалась она западными разработчиками. Однако отрицать ее полезность нельзя.
ПЛЮСЫ:
- Полный морфологический и синтаксический анализ английских слов и предложений
- Обширный справочный материал
- Очень быстрая работа
- Подчеркивание частей речи
МИНУСЫ:
- Отсутствие русского языка
Сайт
Читайте также: ВПН (VPN) на Андроид (Android) — ТОП-25 Лучших которые можно бесплатно скачать и установить на ваш смартфонDelph-in
Delph-in
Отличная платформа для разбора английских слов и предложений.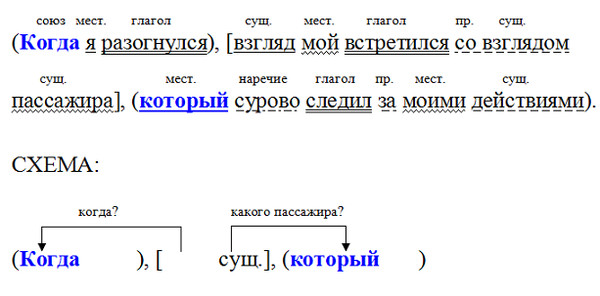 Умеет производить полный синтаксический и морфологический анализ, обладает обозначениями частей речи и очень быстро работает благодаря примитивному интерфейсу.
Умеет производить полный синтаксический и морфологический анализ, обладает обозначениями частей речи и очень быстро работает благодаря примитивному интерфейсу.
Однако для работы с ней придется выучить все условные обозначения, научиться управлять громоздким интерфейсом и неплохо выучить английский язык, поскольку в интерфейсе нет ни одного слова на русском.
Тем не менее, если вы хорошо знаете английский, то этот сервис станет для вас незаменимым помощником. Если, конечно, вы научитесь обращаться с ресурсом. А сделать это довольно сложно даже тем, кто знает язык.
Преимуществом платформы является тот факт, что она построена на примитивном движке, который не обвешан ненужными «свистелками». Поэтому и работает сервис гораздо быстрее других. Но к нему нужно привыкнуть.
ПЛЮСЫ:
- Полный морфологический анализ слова и предложения
- Опция синтаксического анализа
- Есть обозначения частей речи и прочего
- Очень высокая скорость работы
МИНУСЫ:
- Очень неудобный интерфейс
- Нет русского языка
- Новички не разберутся в управлении
Сайт
ProgaOnline
ProgaOnline
Очень простая платформа, которая предназначена именно для синтаксического анализа. Отличается предельно простым управлением. Достаточно ввести нужное предложение в окно и нажать на кнопку «Enter».
Отличается предельно простым управлением. Достаточно ввести нужное предложение в окно и нажать на кнопку «Enter».
Помимо этого, имеется опция подчеркивания частей речи и прочие обозначения. Все это облегчает восприятие текстового комментария. Причем работает сервис очень быстро. По причине того, что сайт не перегружен ненужными элементами.
Однако использовать платформу для самостоятельной подготовки не выйдет, поскольку нет почти никакого справочного материала. И это существенный недостаток. Зато для работы с ProgaOnline не требуется регистрация.
В общем, для качественного синтаксического анализа фраз и предложений данный сервис вполне подходит. Тем более, что именно для этого он и сделан. А справочный материал можно найти и в другом месте.
ПЛЮСЫ:
- Быстрый и качественный синтаксический анализ
- Подчеркивание частей речи и другие обозначения
- Очень быстрая работа ресурса
- Предельно простое управление
МИНУСЫ:
- Нет справочного материала
Сайт
Заключение
А теперь подведем итоги. В данном материале мы рассмотрели самые лучшие онлайн-сервисы, предназначенные для синтаксического анализа предложений и слов. Среди них есть многофункциональные комбайны. Но их объединяет одно: они совершенно бесплатны. Вам нужно только выбрать наиболее подходящий.
В данном материале мы рассмотрели самые лучшие онлайн-сервисы, предназначенные для синтаксического анализа предложений и слов. Среди них есть многофункциональные комбайны. Но их объединяет одно: они совершенно бесплатны. Вам нужно только выбрать наиболее подходящий.
4.5 Оценка
ТОП лучших сервисов для синтаксического разбора предложений
А какой сервис используете Вы? Возможно, вы знаете хорошую и функциональную программу которую мы не указали в нашем ТОПе, мы будем благодарны если вы расскажите нам о ней в комментариях.
8.8Экспертная оценка
GoldLit
7.5
Delph-in
8
Грамота
9
Морфология онлайн
9
Seosin
9
Lexis Res
9.5
ProgaOnline
9.5
0.2Оценка пользователей
GoldLit
Delph-in
Грамота
Морфология онлайн
Seosin
Lexis Res
ProgaOnline
1.5
Добавить отзыв | Читать отзывы и комментарии
ГДЗ Русский язык 6 класс Ладыженская, Баранов в 2 ч на Решалка
 org/BreadcrumbList»>
org/BreadcrumbList»>ГДЗ Русский язык 6 класс Ладыженская, Баранов в 2 ч
авторы: Ладыженская, Баранов.
издательство: Просвещение
Задачи
- ЧАСТЬ 1
- ЯЗЫК. РЕЧЬ. ОБЩЕНИЕ
- §1. Русский язык — один из развитых языков мира.
- 1
- 2
- 3
- §2. Язык, речь, общение
- 4
- 5
- 6
- §3. Ситуация общения
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- §1. Русский язык — один из развитых языков мира.
- ПОВТОРОЕНИЕ ИЗУЧЕННОГО В 5 КЛАССЕ
- §4. Фонетика
- */1
- 14
- 15
- 16
- 17
- */2
- 18
- 19
- */3
- 20
- 21
- 22
- §5. Морфемы в слове.Орфограммы в приставках и в корнях слов
- *
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- §6. Часть речи
- *
- 31
- 32
- 33
- §7. Орфограммы в окончаниях слов
- *
- 34
- 35
- 36
- 37
- 38
- §8. Словосочетание
- *
- 39
- 40
- 41
- 42
- 43
- §9. Простое предложение
- *
- 44
- 45
- 46
- 47
- 48
- §10. Сложное предложение. Запятые в сложном предложении
- *
- 49
- 50
- 51
- 52
- §11. Синтаксический разбор предложений
- 53
- 54
- §12. Прямая речь. Диалог
- *
- 55
- 56
- 57
- 58
- 59
- §4.
- ТЕКСТ
- §13. Текст и его особенности
- *
- 60
- 61
- 62
- 63
- §14. Тема и основная мысль текста. Заглавие текста
- 64
- 65
- 66
- 67
- 68
- §15. Начальные и конечные предложения текста
- *
- 69
- 70
- 71
- 72
- 73
- §16. Ключевые слова
- 74
- 75
- 76
- 77
- 78
- 79
- §17. Основные признаки текста
- 80
- 81
- 82
- 83
- §18. Текст и стили речи
- *
- 84
- 85
- 86
- 87
- §19. Официально-деловой стиль речи
- 88
- 89
- 90
- 91
- §13. Текст и его особенности
- ЛЕКСИКА. КУЛЬТУРА РЕЧИ
- §20. Слово и его лексическое значение
- *
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- §21. Собирание материалов к сочинению
- 103
- 104
- 105
- 106
- §22. Общеупотребительные слова
- 107
- 108
- 109
- 110
- §23. Профессионализимы
- 111
- 112
- 113
- 114
- 115
- 116
- §24. Диалектизмы
- *
- 117
- 118
- 119
- 120
- §25. Исконно русские и заимствованные слова
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- §26. Новые слова (неологизмы)
- 129
- 130
- 131
- 132
- §27. Устаревшие слова
- *
- 133
- 134
- 135
- 136
- §28. Словари
- 137
- 138
- 139
- ПОВТОРЕНИЕ
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 5
- 6
- 140
- 141
- 142
- Контрольные вопросы и задания
- §20. Слово и его лексическое значение
- ФРАЗЕОЛОГИЯ. КУЛЬТУРА РЕЧИ
- §29. Фразеологизмы
- */1
- */2
- 143
- 144
- 145
- */3
- 146
- 147
- 148
- §30. Источники фразеологизмов
- 149
- 150
- 151
- 152
- ПОВТОРЕНИЕ
- Контрольные вопросы и задания
- 1
- 2
- 3
- 153
- 154
- 155
- Контрольные вопросы и задания
- §29. Фразеологизмы
- СЛОВООБРАЗОВАНИЕ. ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ
- §31. Морфемика и словообразование
- *
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- §32. Описание помещения
- *
- 164
- 165
- 166
- 167
- §33. Основные способы образования слов в русском языке
- */1
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- */2
- 175
- 176
- §34. Этимология слов
- 177
- *
- 178
- 179
- §35. Систематизация материалов к сочинению. Сложный план
- 180
- 181
- 182
- 183
- §36. Буквы а и о в корне -кас- — -кос-
- *
- 184
- 185
- 186
- §37. Буквы а и о в корне -гар- — -гор-
- *
- 187
- 188
- 189
- 190
- 191
- §38. Буквы а и о в корне -зар- — -зор-
- *
- 192
- 193
- 194
- 195
- 196
- §39. Буквы ы и и после приставок
- 197
- 198
- 199
- 200
- §40. Гласные в приставках пре- и при-
- *
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- §41. Соединительные о и е в сложных словах
- *
- 215
- 216
- 217
- §42. Сложносокращенные слова
- */1
- 218
- 219
- 220
- 221
- */2
- 222
- 223
- 224
- 225
- §43. Морфемный и словообразовательный разбор слова
- *
- 226
- 227
- 228
- 229
- 230
- ПОВТОРЕНИЕ
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- Контрольные вопросы и задания
- §31. Морфемика и словообразование
- МОРФОЛОГИЯ. ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ
- ИМЯ СУЩЕСТВИТЕЛЬНОЕ
- §44. Повторение изученного в 5 классе
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- §45. Разноскланяемые имена существительные
- */1
- 254
- */2
- 255
- 256
- 257
- 258
- §46. Буква е в суффиксе -ен- существительных на -мя
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- §47. Несклоняемые имена существительные
- 266
- 267
- 268
- 269
- 270
- 271
- §48. Род несклоняемых имен существительных
- 272
- 273
- 274
- 275
- 276
- §49. Имена существительные общего рода
- 277
- 278
- 279
- 280
- 281
- §50. Морфологический разбор имени существительного
- 282
- 283
- 284
- §51. Не с существительными
- *
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- §52. Буквы ч и щ в суффиксе существительных -чик (-щик)
- *
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- §53. Гласные в суффиксах существительных -ек и -ик
- 299
- 300
- 301
- §54. Гласные о и е после шипящих в суффиксах существительных
- 302
- 303
- 304
- 305
- 306
- 307
- ПОВТОРЕНИЕ
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- Контрольные вопросы и задания
- §44. Повторение изученного в 5 классе
- ИМЯ СУЩЕСТВИТЕЛЬНОЕ
- ЯЗЫК. РЕЧЬ. ОБЩЕНИЕ
- ЧАСТЬ 2
- МОРФОЛОГИЯ. ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ
- ИМЯ ПРИЛАГАТЕЛЬНОЕ
- §55. Повторение изученного в 5 классе
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- §56. Описание природы
- *
- 326
- 327
- 328
- 329
- §57. Степени сравнения имен прилагательных
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- §58. Разряды имен прилагательных по значению. Качественные прилагательные
- 340
- 341
- 342
- §59. Относительные прилагательные
- 343
- 344
- 345
- 346
- 347
- §60. Притяжательные прилагательные
- 348
- *
- 349
- 350
- §61. Морфологический разбор имени прилагательного
- *
- 351
- 352
- 353
- 354
- §62. Не с прилагательными
- *
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- §63. Буквы о и е после щипящих и ц в суффмксах прилагательных
- 362
- 363
- 364
- §64. Одна и две буквы н в суффиксах прилагательных
- 365
- 366
- 367
- *
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- §65. Различение на письме суффиксов прилагательных -к- и -ск-
- 376
- 377
- 378
- §66. Дефисное и слитное написание сложных прилагательных
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- Повторение
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- Контрольные вопросы и задания
- §55.
- ИМЯ ЧИСЛИТЕЛЬНОЕ
- §67. Имя числительное как часть речи
- */1
- */2
- 394
- 395
- */3
- 396
- 397
- §68. Простые и составные числительные
- 398
- 399
- 400
- §69. Мягкий знак на конце и в середине числительных
- *
- 401
- 402
- 403
- §70. Порядковые числительные
- 404
- 405
- 406
- 407
- §71. Разряды количественных числительных
- 408
- 409
- 410
- §72. Числительные, обозначающие целые числа
- 411
- 412
- 413
- *
- 414
- 415
- 416
- 417
- §73. Дробные числительные
- 418
- 419
- 420
- §74. Собирательные числительные
- *
- 421
- 422
- 423
- 424
- 425
- 426
- §75. Морфологический разбор имени числительного
- 427
- 428
- Повторение
- *
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 429
- 430
- 431
- 432
- §67. Имя числительное как часть речи
- МЕСТОИМЕНИЕ
- §76. Местоимение как часть речи
- *
- 433
- 434
- 435
- 436
- §77. Личные местоимения
- */1
- 437
- 438
- 439
- 440
- 441
- */2
- 442
- 443
- 444
- §78. Возвратное местоимение себя
- 445
- 446
- 447
- 448
- 449
- §79. Вопросительные и относительные местоимения
- */1
- 450
- */2
- 451
- */3
- 452
- */4
- 453
- 454
- 455
- 456
- 457
- §80. Неопределенные местоимения
- */1
- */2
- 458
- 459
- */3
- 460
- 461
- §81. Отрицательные местоимения
- 462
- 463
- 464
- 465
- 466
- *
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- §82. Притяжательные местоимения
- */1
- 474
- */2
- 475
- 476
- 477
- 478
- 479
- §83. Рассуждение
- 480
- 481
- §84. Указательные местоимения
- */1
- 482
- */2
- 483
- 484
- 485
- 486
- 487
- 488
- §85. Определительные местоимения
- 489
- 490
- 491
- *
- 492
- 493
- 494
- §86. Местоимения и другие части речи
- 495
- 496
- §87. Морфологический разбор местоимения
- 497
- 498
- 499
- Повторение
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- Контрольные вопросы и задания
- §76. Местоимение как часть речи
- ГЛАГОЛ
- §88. Повторение изученного в 5 классе
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- *
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- §89. Разноспрягаемые глаголы
- */1
- 522
- 523
- */2
- 524
- 525
- 526
- 527
- §90. Глаголы переходные и непереходные
- */1
- */2
- */3
- 528
- 529
- 530
- */4
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- §91. Наклонение глагола. Изъявительное наклонение
- 538
- 539
- 540
- 541
- 542
- §92. Условное наклонение
- */1
- */2
- 543
- 544
- 545
- 546
- 547
- §93. Повелительное наклонение
- */1
- */2
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- */3
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- §94. Употребление наклонений
- *
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- §95. Безличные глаголы
- */1
- 569
- 570
- */2
- 571
- 572
- 573
- 574
- 575
- §96. Морфологический разбор глагола
- 576
- §97. Рассказ на основе услышенного
- 577
- 578
- §98. Правописание гласных в суффиксах глаголов
- *
- 579
- 580
- 581
- 582
- 583
- 584
- Повторение
- Контрольные вопросы и задания
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- Контрольные вопросы и задания
- §88.
- ПОВТОРЕНИЕ И СИСТЕМАТИЗАЦИЯ ИЗУЧЕННОГО В 5 и 6 КЛАССАХ
- §99. Разделы науки о языке
- *
- 594
- 595
- §100. Орфография
- *
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- §101. Пунктуация
- *
- 608
- 609
- 610
- §102. Лексика и фразеология
- *
- 611
- 612
- 613
- 614
- §103. Словообразование
- *
- 615
- 616
- 617
- 618
- §104. Морфология
- *
- 619
- 620
- §105. Синтаксис
- *
- 2
- §99.
- ИМЯ ПРИЛАГАТЕЛЬНОЕ
- МОРФОЛОГИЯ. ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ
 Фонетика
Фонетика Простое предложение
Простое предложение Начальные и конечные предложения текста
Начальные и конечные предложения текста Собирание материалов к сочинению
Собирание материалов к сочинению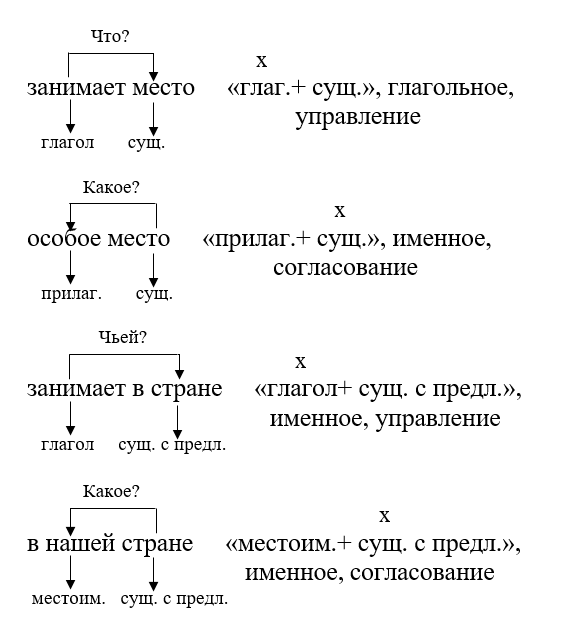 Устаревшие слова
Устаревшие слова ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ
ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ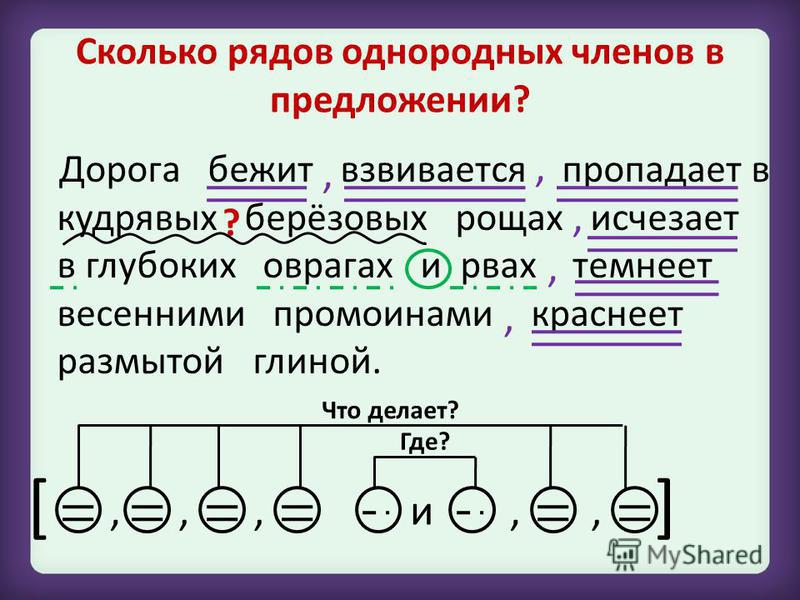 Сложный план
Сложный план Соединительные о и е в сложных словах
Соединительные о и е в сложных словах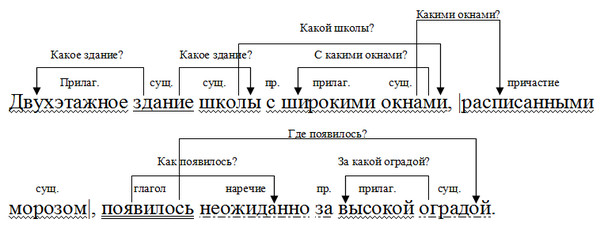 ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ
ОРФОГРАФИЯ. КУЛЬТУРА РЕЧИ Род несклоняемых имен существительных
Род несклоняемых имен существительных Гласные в суффиксах существительных -ек и -ик
Гласные в суффиксах существительных -ек и -ик Повторение изученного в 5 классе
Повторение изученного в 5 классе Притяжательные прилагательные
Притяжательные прилагательные Различение на письме суффиксов прилагательных -к- и -ск-
Различение на письме суффиксов прилагательных -к- и -ск- Простые и составные числительные
Простые и составные числительные Собирательные числительные
Собирательные числительные Возвратное местоимение себя
Возвратное местоимение себя Притяжательные местоимения
Притяжательные местоимения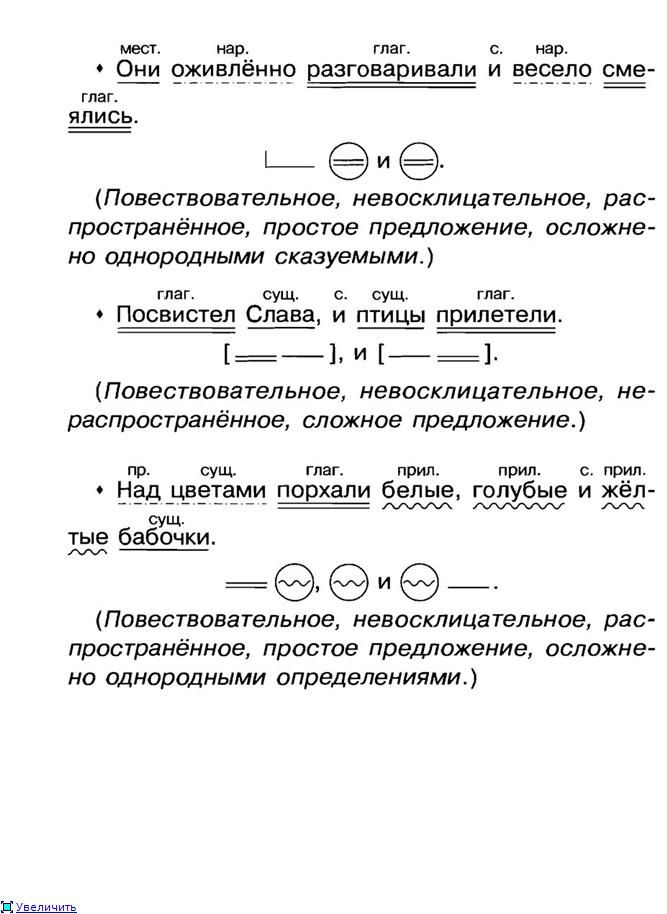 Повторение изученного в 5 классе
Повторение изученного в 5 классе Наклонение глагола. Изъявительное наклонение
Наклонение глагола. Изъявительное наклонение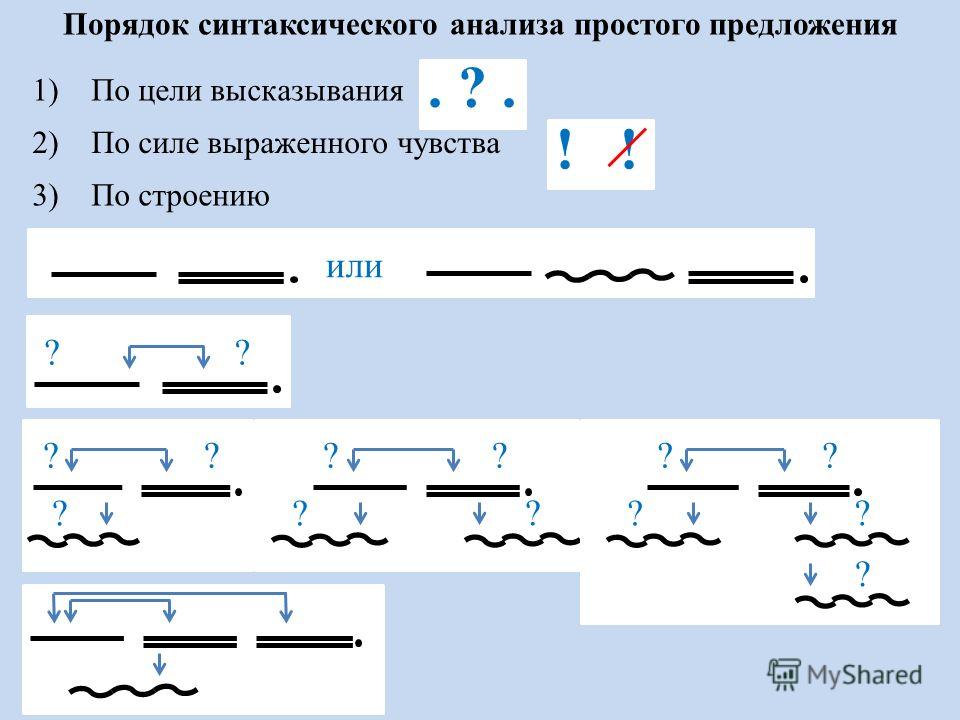 Безличные глаголы
Безличные глаголы Разделы науки о языке
Разделы науки о языке Синтаксис
СинтаксисЧасто бывают трудности с домашними заданиями по русскому? Это, наверное, один из самых сложных предметов, в котором даже для самого опытного учителя найдутся вопросы, приводящие в ступор. Кроме того, правила периодически меняются, а школьники уж точно за ними не успевают. Мы за то, чтобы подрастающее поколение было грамотным, но иногда упражнения в учебниках направлены вовсе не на это. Поэтому при необходимости есть смысл обратиться к ГДЗ по русскому языку за 6 класс Ладыженской, Барановой. Не обязательно слепо переписать решение и забыть. Если на готовом примере рассмотреть алгоритм выполнения задания, то есть все шансы подтянуть тему и общую успеваемость по предмету. Но даже самое банальное переписывание заданий принесет свою пользу, ведь грамотное написание слов отложится в памяти.
Готовые домашние задания без ошибок
ГДЗ – не новинка на рынке. Но популярные ранее печатные издания грешили не только опечатками в тексте, но и откровенно неправильными решениями заданий. В наших решебниках за 6 класс такие недочеты исключены. Мы вручную решаем все упражнения и повторно проверяем, чтобы Ваш ребенок уверенно себя чувствовал на уроке. Решения подробно и понятно расписываются для лучшего понимания алгоритма, а интерфейс сайта удобен для быстрого и эффективного поиска нужной информации. Используйте готовые домашние задания по русскому за 6 класс с пользой, и пусть Ваши школьные будни станут намного проще, веселее, продуктивнее.
В наших решебниках за 6 класс такие недочеты исключены. Мы вручную решаем все упражнения и повторно проверяем, чтобы Ваш ребенок уверенно себя чувствовал на уроке. Решения подробно и понятно расписываются для лучшего понимания алгоритма, а интерфейс сайта удобен для быстрого и эффективного поиска нужной информации. Используйте готовые домашние задания по русскому за 6 класс с пользой, и пусть Ваши школьные будни станут намного проще, веселее, продуктивнее.
Разбор предложения с союзом а. Предложения. Пример синтаксического разбора простого предложения
Поставить ударение в слове Играть в города
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить:)
При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить:)
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.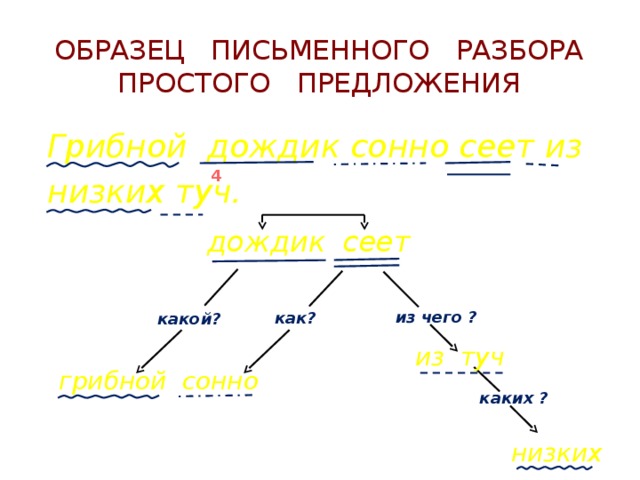
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса.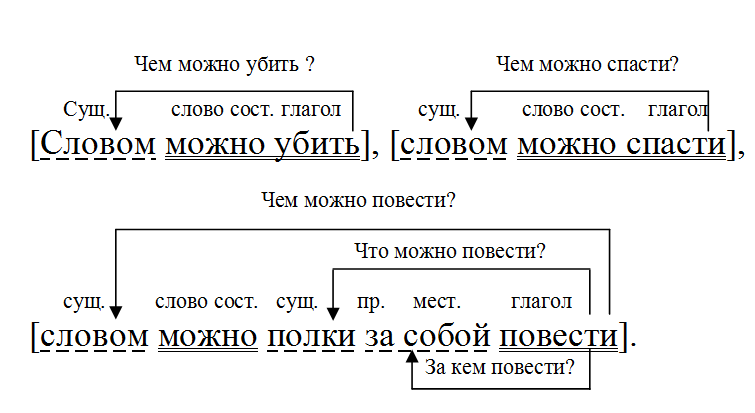 Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие — это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи — это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое — это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое — это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение — второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта — было бы скучно, уж поверьте. Итак, обстоятельство — это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной — важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» — как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая — придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой — как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй — «мы не сделали».
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется — оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола — действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Слова и словосочетания — это составляющие каждого предложения на письме и в устной речи. Для его построения следует четко понимать, какая должна быть между ними связь, чтобы построить грамматически правильное высказывание. Именно поэтому одной из важных и сложных тем в школьной программе русского языка является синтаксический разбор предложения. При таком разборе проводится полный анализ всех компонентов высказывания и устанавливается имеющаяся между ними связь. Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Правила разбора словосочетаний
Анализ определенного словосочетания, взятого из контекста, является относительно простым в разделе синтаксиса русского языка. Для того чтобы его произвести, определяют, какое из слов выступает главным, а какое — зависимым, и определяют, к какой части речи каждое из них относится. Далее необходимо определить синтаксическую связь между этими словами. Всего их выделяют три:
- Согласование — это своего рода подчинительная связь, при которой род, число и падеж для всех элементов словосочетания определяет главное слово. Например: отдаляющийся поезд, летящая комета, светящее солнце.
- Управление также является одним из видов подчинительной связи, оно может быть сильным (когда падежная связь слов необходима) и слабым (когда падеж зависимого слова не предопределен). Например: поливать цветы — поливать из лейки; освобождение города — освобождение армией.
- Примыкание — это также подчинительный вид связи, однако он относится лишь к неизменяемым и не склоняемым по падежам словам. Зависимость такие слова выражают лишь смыслом. Например: езда верхом, непривычно грустный, очень страшно.

Пример синтаксического разбора словосочетаний
Синтаксический разбор словосочетания должен выглядеть примерно так: «красиво говорит»; главное слово — «говорит», зависимое — «красиво». Эту связь определяют посредством вопроса: говорит (как?) красиво. Слово «говорит» использовано в настоящем времени в единственном числе и третьем лице. Слово «красиво» — это наречие, а потому в данном словосочетании выражается синтаксическая связь — примыкание.
Схема синтаксического разбора простого предложения
Синтаксический разбор предложения немного похож на анализ словосочетания. Состоит он из нескольких этапов, которые позволят изучить структуру и отношение всех составляющих его компонентов:
- В первую очередь определяют цель высказывания отдельно взятого предложения, все они делятся на три вида: повествовательные, вопросительные и восклицательные, или побудительные. Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного — восклицательный.
- Далее следует выделить грамматическую основу предложения — подлежащее и сказуемое.
- Следующий этап — описание строения предложения. Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.
- Далее синтаксический разбор предложения предусматривает разбор всех слов по их принадлежности к частям речи, роду, числу и падежу.
- Завершающий этап — объяснение поставленных в предложении знаков препинания.
 Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного — восклицательный.
Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного — восклицательный.
Пример синтаксического разбора простого предложения
Теория теорией, но без практики нельзя закрепить ни одной темы. Именно поэтому в школьной программе много времени уделяется синтаксическим разборам словосочетаний и предложений. И для тренировки можно брать самые простые предложения. Например: «Девушка лежала на пляже и слушала прибой».
- Предложение повествовательное и невосклицательное.
- Главные члены предложения: девушка — подлежащее, лежала, слушала — сказуемые.
- Данное предложение двусоставное, полное и распространенное. В качестве осложнений выступают однородные сказуемые.
- Разбор всех слов предложения:
- «девушка» — выступает в роли подлежащего и является существительным женского рода в единственном числе и именительном падеже;
- «лежала» — в предложении является сказуемым, относится к глаголам, имеет женский род, единственное число и прошедшее время;
- «на» — это предлог, служит для связи слов;
- «пляже» — отвечает на вопрос «где?» и является обстоятельством, в предложении выражено существительным мужского рода в предложном падеже и единственном числе;
- «и» — союз, служит для соединения слов;
- «слушала» — второе сказуемое, глагол женского рода в прошедшем времени и единственном числе;
- «прибой» — в предложении является дополнением, относится к имени существительному, имеет мужской род, единственное число и употреблено в винительном падеже.

Обозначение частей предложения на письме
При синтаксическом разборе словосочетаний и предложений используются условные подчеркивания, которые обозначают принадлежность слов к тому или иному члену предложения. Так, например, подлежащее подчеркивают одной линией, сказуемое — двумя, определение обозначают волнистой линией, дополнение — пунктиром, обстоятельство — пунктиром с точкой. Для того чтобы правильно определить, какой именно член предложения перед нами, следует поставить к нему вопрос от одной из частей грамматической основы. К примеру, на вопросы имени прилагательного отвечает определение, дополнение определяется вопросами косвенных падежей, обстоятельство указывает на место, время и причину и отвечает на вопросы: «где?» «откуда?» и «почему?»
Синтаксический разбор сложного предложения
Порядок разбора сложного предложения немного отличается от вышеприведенных примеров, а потому не должен вызвать особых трудностей. Однако все должно быть по порядку, и поэтому учитель усложняет задачу лишь после того, как дети научились разбирать простые предложения. Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
- Сначала определяют цель высказывания и эмоциональную окраску.
- Далее выделяют грамматические основы в предложении.
- Следующий шаг — определение связи, которая может осуществляться при помощи союза или без него.
- Далее следует указать, посредством какой связи соединены две грамматических основы в предложении. Это могут быть интонация, а также сочинительные или подчинительные союзы. И тут же сделать вывод, каким является предложение: сложносочиненным, сложноподчиненным или бессоюзным.
- Следующий этап разбора — это синтаксический анализ предложения по его частям. Производят его по схеме для простого предложения.
- В заключение анализа следует построить схему предложения, на которой будет видна связь всех его частей.
Связь частей сложного предложения
Как правило, для связи частей в сложных предложениях употребляются союзы и союзные слова, перед которыми обязательно ставится запятая.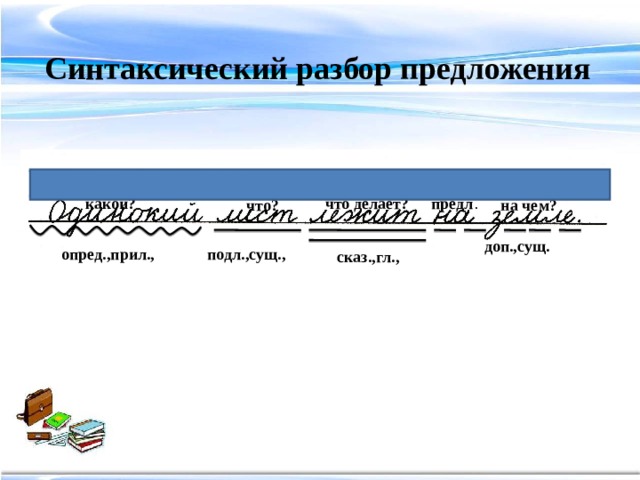 Такие предложения называются союзными. Делятся они на два вида:
Такие предложения называются союзными. Делятся они на два вида:
- Сложносочиненные предложения, соединенные посредством союзов а, и, или, то, но . Как правило, обе части в таком высказывании равноправны. Например: «Солнце светило, а облака плыли».
- Сложноподчиненные предложения, в которых используются такие союзы и союзные слова: чтобы, как, если, где, куда, так как, хотя и другие. В таких предложениях всегда одна часть зависит от другой. Например: «Солнечные лучи заполнят комнату, как только пройдет туча».
Синтаксический разбор предложения является наиболее часто задаваемым заданием из школы, которое у некоторых не получается сделать. Сегодня я расскажу, как обхитрить училку и сделать всё правильно.
Я приведу сегодня ТОП-5 сервисом, которые помогут Вам провести разбор предложения на члены речи.
Все они могут выполнить какой-то синтаксический разбор предложений или слов. В каждом из них есть какие-то плюсы и минусы.
Данные сервисы будут специализированы как для русского, так и для английского языка.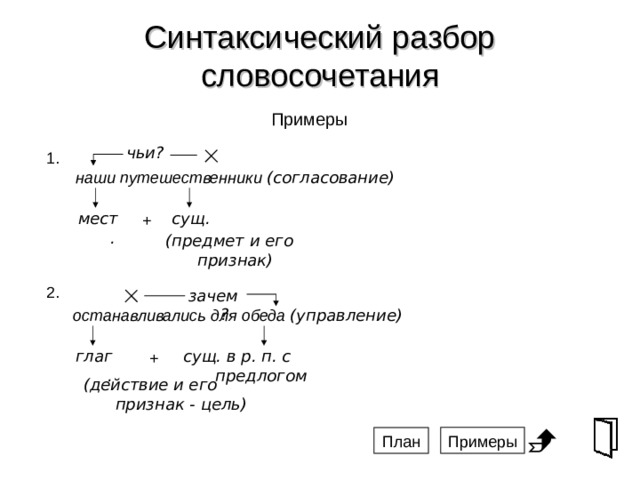
И скажу сразу, они работают не великолепно само собой, но они помогут Вам справиться с большей частью Вашего задания.
Сравнение
В таблицы выше я перечислил лучшие из лучших сервисов, которые могут помочь Вам в выполнении ваших заданий по синтаксическому разбору предложений.
Если Вы ознакомились с таблицей, я предлагаю начать разбирать каждый из сервисов и начнем мы с самой последней строчки нашего списка и постепенно дойдем до лидера нашего ТОПа.
| Название сервиса | Язык сервиса | Слово/предложение | Ссылка |
|---|---|---|---|
| GoldLit | Русский | Предложение | http://goldlit.ru/component/slog |
| Грамота.ру | Русский | Слово | http://gramota.ru/slovari/dic |
| Морфология онлайн | Русский | Слово | http://morphologyonline.ru |
| Delph-in | Английский | Предложение | http://erg. delph-in.net/logon delph-in.net/logon |
| Lexis Res | Английский | Предложение | http://www.lexisrex.com/English/Sentence-Study/ |
№5 Lexis Res
По этой ссылке Вы можете попасть на данный сервис и сами оценить его работу: http://www.lexisrex.com/English/Sentence-Study .
Что же это за сайт? Для людей, которые изучают английский язык – это просто клад. Эта страница позволяет анализировать английский текст. Его может использовать человек с любым уровнем знаний.
Это сервис, который позволяет Вам провести синтаксический разбор предложения полностью на английском языке. Предложения могут быть как простыми, сложными, сложносочиненными и сложноподчиненными.
Помимо того, что сайт делает этот разбор любого вида предложения, он еще объясняет каждое слово по значениям. То есть, если Вы не знаете точное значение какого-нибудь слова, то этот ресурс Вам отлично подойдет.
Вам просто нужно написать нужный Вам текст в поле или нажать кнопку «Random sentences» (т. е. «Случайное предложение»), и затем нажать кнопку «Analyse», и затем Вы получите подробный анализ каждого слова в предложении: объяснение значения слова, часть речи.
е. «Случайное предложение»), и затем нажать кнопку «Analyse», и затем Вы получите подробный анализ каждого слова в предложении: объяснение значения слова, часть речи.
Какие же преимущества у этого сайта перед другими? Прежде всего, сервис очень прост в использовании, Вам не нужно будет тратить уйму времени, чтобы понять, что к чему.
Во-вторых, сайт имеет огромную базу, которая позволяет делать синтаксический разбор текста любой сложности и тематики.
Помимо этого, сайт имеет огромный функционал, он будет полезен еще многими своими фишками для людей, которые занимаются изучением английского языка.
- простой в освоении сайт;
- практически нет рекламы, которая бы отвлекала;
- простой интерфейс сайта;
- огромный функционал;
- очень хороший синтаксический разбор.
Негатив:
- если Вы не владейте удовлетворимым уровнем знания английского языка, будет немного трудновато читать все объяснения на сайте;
- слова при разборе не подчеркиваются линиями частей речи;
- нету адаптации сайта под русский язык.

Как видите, соотношения плюсов и минусов позволяет назвать этот сайт хорошим, но не отличным, поэтому он на пятом месте.
№4 Delph-in
На четвертом месте расположен сервис под названием « Delph- in».
По этой ссылке Вы можете его опробовать: http://erg.delph-in.net/logon . Этот сайт – настоящий монстр для людей, которые изучают английский язык. Этот сервис позволяет иметь онлайн-доступ к LinGO English Resource Grammar (ERG).
Здесь используется платформа разработки грамматики Linguistic Knowledge Builder.
Данный интерфейс позволяет вводить одно предложение, используя систему ERG и визуализировать результаты разбора в различных формах.
Сразу скажу, что сайт подойдет для тех, кто достаточно опытен в английском языке, но этот сайт просто великолепен и необходим для таких людей.
Какие же преимущества есть у этого сервиса? Прежде всего этот сайт имеет более хорошую степень разбора предложение по методу, который используется в университете в Осло, а если быть точно, то Языковой технологической группе.
Здесь используется европейская система синтаксического разбора предложения. Помимо использования этого метода, данный сайт показывает разные способы разбора предложения, что делает разбор более гибким и удобным.
Теперь же мы рассмотрим, как плюсы, так и минусы этого сервиса.
Позитив:
- очень гибкая система синтаксического разбора предложения;
- можно писать предложения на самые различные тематики;
- неограниченное количество символов в предложении можно использовать.
Негатив:
- первый из них — это то, что сервис достаточно сложный для использования людям, с низким и средним уровнем английского;
- чтобы понять, как работает сервис и разобрать, чтобы понять, что к чему, нужно уделить сайту несколько часов.
Мы ознакомились с четвертой позицией и теперь перейдем к третьему месту нашего ТОПа.
№3 MorphologyOnline
Этот сайт идеально подойдет для тех, кому нужно качественно разобрать предложение поэтапно, слово за словом, чтобы точно не ошибиться и правильно подобрать каждую часть речи к каждому слову в разбираемом предложении.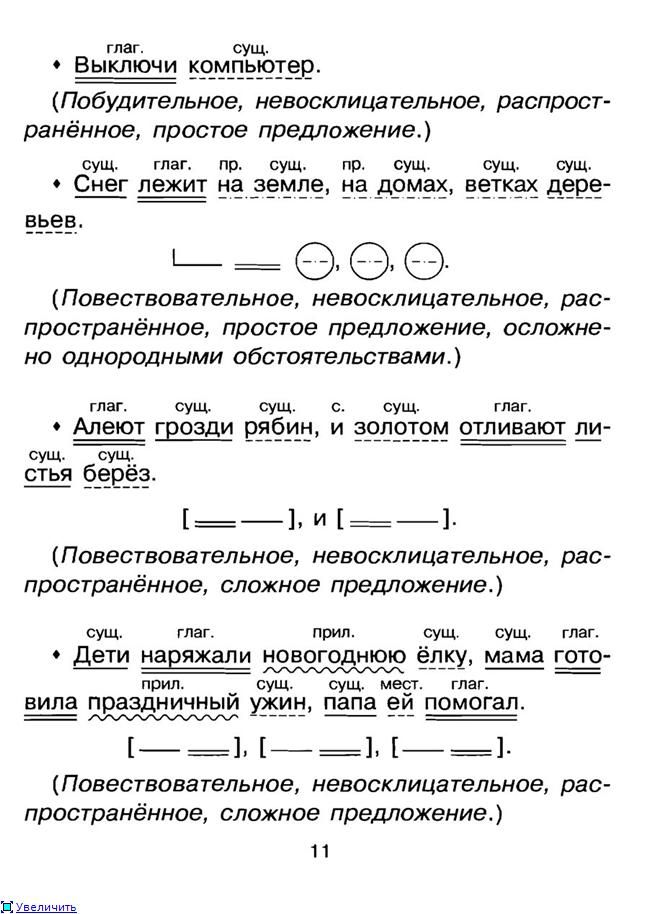
Сервис так же полезен тем, что у него очень широкое описание каждого искомого слова.
Какие же преимущества есть у данного сервиса? Давайте их разберем.
Прежде всего, это то, что он очень прост в использовании. Его интерфейс не имеет никаких отвлекающих элементов, что позволит Вам полностью сосредоточиться на написанной информации.
Еще, помимо того, что сервис указывает часть речи слова, он еще описывает морфологический анализ, что делает анализ слова более глубоким и тщательным.
Это поможет Вам никогда не ошибиться в синтаксическом анализе Вашего предложения. Так же, если Вы захотите сами детально ознакомиться с частями речи, Вы можете найти информацию на этом сайте, которая очень удобно и понятно объяснена.
Теперь же рассмотрим сервис с двух стороны и увидим, как плюсы, так и минусы. Начнем с положительной стороны.
Позитив:
- очень прост – с ним справится даже самый юный пользователь;
- нет никаких назойливых реклам, что делает использование сервиса комфортным;
- глубокий анализ;
- огромное количество информации для самостоятельного синтаксического разбора предложения.

Негатив:
- этот сервис может анализировать только одно слово за раз, что делает весь процесс медлительным;
- данный сайт больше акцентирован на морфологический разбор слова, но он так же прекрасно делает и синтаксический разбор;
- отсутствуют еще какие-либо другие инструменты, что делает сайт узким для использования в разных сферах.
Именно из-за этих минусов и плюсов сервис занимает лишь третье место. А теперь настало время для второго места.
№2 «Грамота.ру»
Почему именно этот сервис расположен на 4 месте? Данный сайт позволяет проанализировать одно слово за раз по всем русским словарям, которые не только указывают часть речи, но и объясняют значение искомого слова, синонимы, антонимы, различные формы.
Здесь даже можно найти правильное ударение для любого русского слова.
Помимо этого сервиса полного разбора слова, здесь есть множество материалов по изучению русского языка, например: самые различные словари, журналы, азбуки, книги, репетиторы, различные полезные ссылки.
Поэтому, если Вы хотите полностью провести анализ слова или же увеличить свой уровень знаний русского языка, Вы можете смело пользоваться данным ресурсом.
Давайте рассмотрим более подробно преимущества сайта. Прежде всего, здесь очень приятный интерфейс, всё понятно, ничего не нужно искать. Всё нужное можно сразу же увидеть на дисплее монитора. Сам же сайт не имеет рекламы.
Всё оформление сайта выполнено в простых цветах, то есть от длительного чтения этого сайта глаза у Вас не так сильно устают.
С этим сервисом сможет разобрать абсолютно любой человек: от первого класса до пожилого возраста.
Поскольку я описал все возможные плюсы очень подробно, можно теперь составить целый краткий список и так же добавить негативные стороны, чтобы увидеть полную картинку.
Почему именно этот сервис занял первое место в нашем ТОПе? Прежде всего, сайт может выполнить синтаксический разбор предложения, вне зависимости от количества символ и слов.
Анализ на сайте построен очень удобно. Сервис создан именно для синтаксического разбора предложений.
Сервис создан именно для синтаксического разбора предложений.
Этот сайт имеет ряд преимуществ. Как и говорилось, сайт может анализировать целые предложения, а не только лишь по слову.
Синтаксический анализ проводится очень удобно: сначала пишется начальные формы слова, затем части речи, затем идет грамматический анализ, и потом склонение по падежам.
Из всего ТОПа, у этого сервиса самый удобный и приятный для глаза интерфейс.
Помимо этих достоинств, сайт так же имеет разделы с различной литературой разных периодов, различные поэзии, как русские, так и зарубежные. Сайт имеет информацию о многих поэтах, множество удобно написанных биографий. Всё это так же поможет Вам изучить различную литературу, если Вам будет нужно это.
Но не смотря на все эти плюсы, у сайта есть так же некоторые минусы. О них мы поговорим после того, как подобьем все достоинства.
Позитив:
- выполняет полный разбор именно предложения, вне зависимости от тематики, количества слов и символов;
- минимальное количество рекламы, но даже она не мешает использовать сайт;
- очень просто в освоении;
- множество информации по литературе;
- прекрасный интерфейс и хорошая цветовая гамма.

Негатив:
- абсолютное отсутствие материалов по русском языку;
- сайт заточен под литературу больше, но всё равно имеет инструмент для разбора предложений.
Итог
Давайте же подобьем итоги. Проанализировав целый ТОП, Вы можете понять, что, если Вам нужен сайт для синтаксического разбора предложений на русском, я рекомендую Вам использовать именно ресурс «Goldlit».
Простота сайта, прекрасный анализ предложения, множество интересных материалов – именно эти ключевые факторы повлияли на расположение сайта в нашем топе.
Он является абсолютным лидером в нашем ТОПе и лучших онлайн сервисом по синтаксическому разбору предложений на русском в русских сетях Интернета.
Это ресурс, который поможет Вам не только выполнить домашнее задание, но и ознакомиться с различной литературой. Используйте сервис «Goldlit».
Слова и словосочетания — это составляющие каждого предложения на письме и в устной речи. Для его построения следует четко понимать, какая должна быть между ними связь, чтобы построить грамматически правильное высказывание. Именно поэтому одной из важных и сложных тем в школьной программе русского языка является синтаксический разбор предложения. При таком разборе проводится полный анализ всех компонентов высказывания и устанавливается имеющаяся между ними связь. Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Именно поэтому одной из важных и сложных тем в школьной программе русского языка является синтаксический разбор предложения. При таком разборе проводится полный анализ всех компонентов высказывания и устанавливается имеющаяся между ними связь. Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Правила разбора словосочетаний
Анализ определенного словосочетания, взятого из контекста, является относительно простым в разделе синтаксиса русского языка. Для того чтобы его произвести, определяют, какое из слов выступает главным, а какое — зависимым, и определяют, к какой части речи каждое из них относится. Далее необходимо определить синтаксическую связь между этими словами. Всего их выделяют три:
- Согласование — это своего рода подчинительная связь, при которой род, число и падеж для всех элементов словосочетания определяет главное слово. Например: отдаляющийся поезд, летящая комета, светящее солнце.
- Управление также является одним из видов подчинительной связи, оно может быть сильным (когда падежная связь слов необходима) и слабым (когда падеж зависимого слова не предопределен). Например: поливать цветы — поливать из лейки; освобождение города — освобождение армией.
- Примыкание — это также подчинительный вид связи, однако он относится лишь к неизменяемым и не склоняемым по падежам словам. Зависимость такие слова выражают лишь смыслом. Например: езда верхом, непривычно грустный, очень страшно.
 Например: отдаляющийся поезд, летящая комета, светящее солнце.
Например: отдаляющийся поезд, летящая комета, светящее солнце.Пример синтаксического разбора словосочетаний
Синтаксический разбор словосочетания должен выглядеть примерно так: «красиво говорит»; главное слово — «говорит», зависимое — «красиво». Эту связь определяют посредством вопроса: говорит (как?) красиво. Слово «говорит» использовано в настоящем времени в единственном числе и третьем лице. Слово «красиво» — это наречие, а потому в данном словосочетании выражается синтаксическая связь — примыкание.
Схема синтаксического разбора простого предложения
Синтаксический разбор предложения немного похож на анализ словосочетания. Состоит он из нескольких этапов, которые позволят изучить структуру и отношение всех составляющих его компонентов:
- В первую очередь определяют цель высказывания отдельно взятого предложения, все они делятся на три вида: повествовательные, вопросительные и восклицательные, или побудительные. Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного — восклицательный.
- Далее следует выделить грамматическую основу предложения — подлежащее и сказуемое.
- Следующий этап — описание строения предложения. Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.
- Далее синтаксический разбор предложения предусматривает разбор всех слов по их принадлежности к частям речи, роду, числу и падежу.
- Завершающий этап — объяснение поставленных в предложении знаков препинания.
 А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.
А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.Пример синтаксического разбора простого предложения
Теория теорией, но без практики нельзя закрепить ни одной темы. Именно поэтому в школьной программе много времени уделяется синтаксическим разборам словосочетаний и предложений. И для тренировки можно брать самые простые предложения. Например: «Девушка лежала на пляже и слушала прибой».
- Предложение повествовательное и невосклицательное.
- Главные члены предложения: девушка — подлежащее, лежала, слушала — сказуемые.
- Данное предложение двусоставное, полное и распространенное. В качестве осложнений выступают однородные сказуемые.
- Разбор всех слов предложения:
 В качестве осложнений выступают однородные сказуемые.
В качестве осложнений выступают однородные сказуемые.- «девушка» — выступает в роли подлежащего и является существительным женского рода в единственном числе и именительном падеже;
- «лежала» — в предложении является сказуемым, относится к глаголам, имеет женский род, единственное число и прошедшее время;
- «на» — это предлог, служит для связи слов;
- «пляже» — отвечает на вопрос «где?» и является обстоятельством, в предложении выражено существительным мужского рода в предложном падеже и единственном числе;
- «и» — союз, служит для соединения слов;
- «слушала» — второе сказуемое, глагол женского рода в прошедшем времени и единственном числе;
- «прибой» — в предложении является дополнением, относится к имени существительному, имеет мужской род, единственное число и употреблено в винительном падеже.
Обозначение частей предложения на письме
При синтаксическом разборе словосочетаний и предложений используются условные подчеркивания, которые обозначают принадлежность слов к тому или иному члену предложения.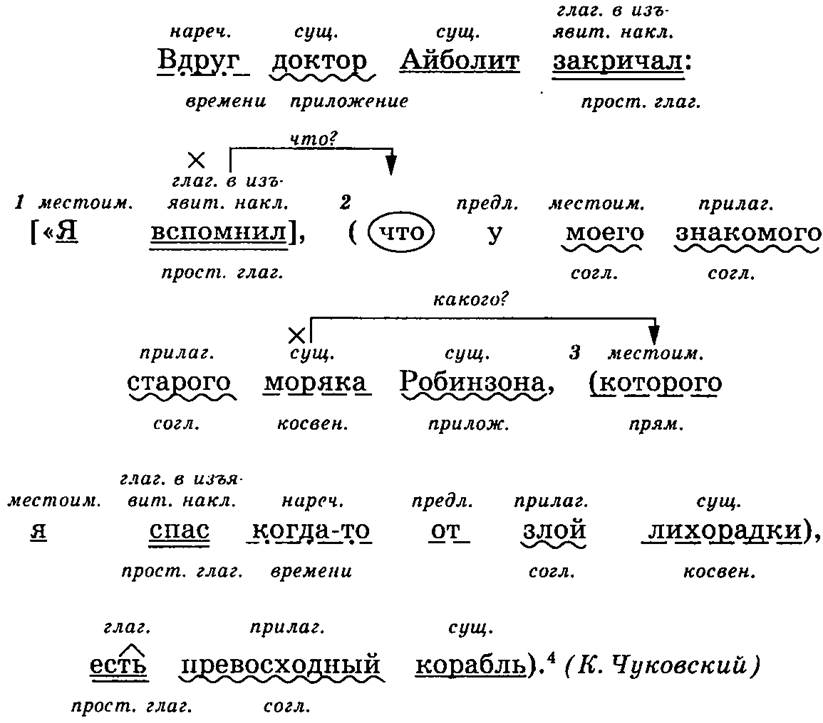 Так, например, подлежащее подчеркивают одной линией, сказуемое — двумя, определение обозначают волнистой линией, дополнение — пунктиром, обстоятельство — пунктиром с точкой. Для того чтобы правильно определить, какой именно член предложения перед нами, следует поставить к нему вопрос от одной из частей грамматической основы. К примеру, на вопросы имени прилагательного отвечает определение, дополнение определяется вопросами косвенных падежей, обстоятельство указывает на место, время и причину и отвечает на вопросы: «где?» «откуда?» и «почему?»
Так, например, подлежащее подчеркивают одной линией, сказуемое — двумя, определение обозначают волнистой линией, дополнение — пунктиром, обстоятельство — пунктиром с точкой. Для того чтобы правильно определить, какой именно член предложения перед нами, следует поставить к нему вопрос от одной из частей грамматической основы. К примеру, на вопросы имени прилагательного отвечает определение, дополнение определяется вопросами косвенных падежей, обстоятельство указывает на место, время и причину и отвечает на вопросы: «где?» «откуда?» и «почему?»
Синтаксический разбор сложного предложения
Порядок разбора сложного предложения немного отличается от вышеприведенных примеров, а потому не должен вызвать особых трудностей. Однако все должно быть по порядку, и поэтому учитель усложняет задачу лишь после того, как дети научились разбирать простые предложения. Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
- Сначала определяют цель высказывания и эмоциональную окраску.
- Далее выделяют грамматические основы в предложении.
- Следующий шаг — определение связи, которая может осуществляться при помощи союза или без него.
- Далее следует указать, посредством какой связи соединены две грамматических основы в предложении. Это могут быть интонация, а также сочинительные или подчинительные союзы. И тут же сделать вывод, каким является предложение: сложносочиненным, сложноподчиненным или бессоюзным.
- Следующий этап разбора — это синтаксический анализ предложения по его частям. Производят его по схеме для простого предложения.
- В заключение анализа следует построить схему предложения, на которой будет видна связь всех его частей.

Связь частей сложного предложения
Как правило, для связи частей в сложных предложениях употребляются союзы и союзные слова, перед которыми обязательно ставится запятая. Такие предложения называются союзными. Делятся они на два вида:
- Сложносочиненные предложения, соединенные посредством союзов а, и, или, то, но . Как правило, обе части в таком высказывании равноправны. Например: «Солнце светило, а облака плыли».
- Сложноподчиненные предложения, в которых используются такие союзы и союзные слова: чтобы, как, если, где, куда, так как, хотя и другие. В таких предложениях всегда одна часть зависит от другой. Например: «Солнечные лучи заполнят комнату, как только пройдет туча».
 Как правило, обе части в таком высказывании равноправны. Например: «Солнце светило, а облака плыли».
Как правило, обе части в таком высказывании равноправны. Например: «Солнце светило, а облака плыли».Синтаксический разбор простого предложения прочно вошёл в практику начальной и средней школы. Это самый трудный и объёмный вид грамматического разбора. Он включает характеристику и схему предложения, разбор по членам с указанием частей речи.
Строение и значение простого предложения изучается начиная с 5 класса. Полный набор признаков простого предложения обозначается в 8 классе, а в 9 классе основное внимание уделяется сложным предложениям.
В этом виде разбора соотносятся уровни морфологии и синтаксиса: ученик должен уметь определять части речи, узнавать их формы, находить союзы, понимать способы связи слов в словосочетании, знать признаки главных и второстепенных членов предложения.
Начнём с самого простого: поможем ребятам подготовиться к выполнению синтаксического разбора в 5 классе. В начальной школе ученик запоминает последовательность разбора и выполняет его на элементарном уровне, указывая грамматическую основу, синтаксические связи между словами, вид предложения по составу и цели высказывания, учится составлять схемы и находить однородные члены.
В начальной школе используются разные программы по русскому языку, поэтому уровень требований и подготовка учащихся разные. В пятом классе я принимала детей, обучавшихся в начальной школе по программам образовательной системы «Школа 2100», «Школа России» и «Начальная школа XXI века». Отличия есть и большие. Учителя начальной школы проделывают колоссальную работу, чтобы компенсировать недостатки своих учебников, и сами «прокладывают» преемственные связи между начальной и средней школой.
В 5 классе материал по разбору предложения обобщается, расширяется и выстраивается в более полную форму, в 6-7 классах совершенствуется с учётом вновь изученных морфологических единиц (глагольные формы: причастие и деепричастие; наречие и категория состояния; служебные слова: предлоги, союзы и частицы).
Покажем на примерах отличия между уровнем требований в формате синтаксического разбора.
В 4 классе | В 5 классе |
В простом предложении выделяется грамматическая основа, над словами обозначаются знакомые части речи, подчёркиваются однородные члены, выписываются словосочетания или рисуются синтаксические связи между словами. Схема: [О -, О]. Повествовательное, невосклицательное, простое, распространённое, с однородными сказуемыми. Сущ.(главное слово)+прил., Гл.(главное слово)+сущ. Гл.(главное слово)+мест. Нареч.+гл.(главное слово) | Синтаксические связи не рисуются, словосочетания не выписываются, схема и основные обозначения такие же, но характеристика иная: повествовательное, невосклицательное, простое, двусоставное, распространённое, осложнено однородными сказуемыми. Разбор постоянно отрабатывается на уроках и участвует в грамматических заданиях контрольных диктантов. |
В сложном предложении подчёркиваются грамматические основы, нумеруются части, над словами подписываются знакомые части речи, указывается вид по цели высказывания и эмоциональной окраске, по составу и наличию второстепенных членов. Схема разбора: [О и О] 1 , 2 , и 3 . Повествовательное, невосклицательное, сложное, распространённое. | Схема остаётся той же, но характеристика иная: повествовательное, невосклицательное, сложное, состоит из 3 частей, которые связаны бессоюзной и союзной связью, в 1 части есть однородные члены, все части двусоставные и распространённые. Разбор сложного предложения в 5 классе носит обучающий характер и не является средством контроля. |
Схемы предложения с прямой речью: А: «П!» или «П,» — а. Вводится понятие цитаты, совпадающее по оформлению с прямой речью. | Схемы дополняются разрывом прямой речи словами автора: «П, — а. — П.» и «П, — а, — п». Вводится понятие диалога и способы его оформления. Схемы составляют, но характеристика предложений с прямой речью не производится. |


План разбора простого предложения
1. Определить вид предложения по цели высказывания (повествовательное, вопросительное, побудительное).
2. Выяснить тип предложения по эмоциональной окраске (невосклицательное или восклицательное).
3. Найти грамматическую основу предложения, подчеркнуть её и обозначить способы выражения, указать, что предложение простое.
4. Определить состав главных членов предложения (двусоставное или односоставное).
5. Определить наличие второстепенных членов (распространённое или нераспространённое).
6. Подчеркнуть второстепенные члены предложения, указать способы их выражения (части речи): из состава подлежащего и состава сказуемого.
7. Определить наличие пропущенных членов предложения (полное или неполное).
8. Определить наличие осложнения (осложнено или не осложнено).
9. Записать характеристику предложения.
10. Составить схему предложения.
Для анализа мы использовали предложения из прекрасных сказок Сергея Козлова про Ёжика и Медвежонка.
1) Это был необыкновенный осенний день!
2) Обязанность каждого — трудиться.
3) Тридцать комариков выбежали на поляну и заиграли на своих писклявых скрипках.
4) У него нет ни папы, ни мамы, ни Ёжика, ни Медвежонка.
5) И Белка взяла орешков и чашку и поспешила следом.
6) И они сложили в корзину вещи: грибы, мёд, чайник, чашки — и пошли к реке.
7) И сосновые иголки, и еловые шишки, и даже паутина — все распрямились, заулыбались и затянули изо всех сил последнюю осеннюю песню травы.
8) Ёжик лежал, по самый нос укрытый одеялом, и глядел на Медвежонка тихими глазами.
9) Ёжик сидел на горке под сосной и смотрел на освещённую лунным светом долину, затопленную туманом.
10) За рекой, полыхая осинами, темнел лес.
11) Так до самого вечера они бегали, прыгали, сигали с обрыва и орали во всё горло, оттеняя неподвижность и тишину осеннего леса.
12) И он прыгнул, как настоящий кенгуру.
13) Вода, куда ты бежишь?
14) Может, он с ума сошёл?
15) Мне кажется, он вообразил себя… ветром.
Образцы разбора простых предложений
[PDF] Разбор деревьев арабских предложений с помощью набора инструментов естественного языка
- Идентификатор корпуса: 15681173
title={Синтаксический анализ деревьев арабских предложений с помощью набора инструментов для естественного языка},
автор = {Маад Шатнави и Бумедьен Белхуш},
год = {2012}
} - M. Shatnawi, B. Belkouche
- Опубликовано в 2012 г.
- Информатика
Мы разрабатываем основу для использования Natural Language Toolkit (NLTK) для анализа арабских предложений Корана. Эта структура поддерживает строительство дерева для Священного Корана. Предлагаемая модель успешно анализирует различные главы Корана (суры) в дополнение к предложениям на современном стандартном арабском языке (MSA). Наличие такого синтаксического анализатора будет полезно в различных приложениях обработки естественного языка, таких как машинный перевод, синтез речи и поиск информации.
Эта структура поддерживает строительство дерева для Священного Корана. Предлагаемая модель успешно анализирует различные главы Корана (суры) в дополнение к предложениям на современном стандартном арабском языке (MSA). Наличие такого синтаксического анализатора будет полезно в различных приложениях обработки естественного языка, таких как машинный перевод, синтез речи и поиск информации.
Синтаксический анализ современного стандартного арабского языка с использованием ресурсов Treebank
В этом документе рассматривается проблема использования ресурсов Treebank для статистического анализа предложений на современном стандартном арабском языке путем проведения эксперимента на Pen Arabic Treebank (PATB) и производительности синтаксического анализа, полученной с точки зрения Точность, полнота и F-мера составили 82,4, 86,6, 84,6 и 84,4% соответственно.
Улучшение синтаксического анализа зависимостей словесных арабских предложений с использованием семантических функций
В этой работе предлагается подход к анализу зависимостей для устных предложений современного стандартного арабского языка с использованием анализатора зависимостей, управляемого данными, а именно, MaltParser, использующего семантическую информацию, доступную в лексической арабской VerbNet (AVN), для дополнения существующей морфо-синтаксической информации, уже имеющейся в данных. .
.
Статистический анализ с помощью машинного обучения из банка деревьев классического арабского языка
- К. Дюкс
Информатика
ArXiv
- 2015
Эта работа направлена на продвижение современного гибридного синтаксического анализа путем введения формального представления аннотаций и ресурса для машинного обучения на классическом арабском языке, с первым банком деревьев для классического арабского языка и первым статистическим парсер на основе зависимостей на любом языке для многоточия, отброшенных местоимений и гибридных представлений.
Обзор лексико-функциональной грамматики в арабском контексте
- С. Саллум
Информатика
- 2016
Усилия, которые LFG приложила для решения различных проблем НЛП, учитываются, и новые тенденции были выявлены при проведении этого опроса и продемонстрированы для проведения дальнейших исследований.
Интерактивная проверка слов Корана в реальном времени в веб-контенте
- Т. Эль-Сакка
Информатика
2013 Университет Тайба Международная конференция по достижениям в области информационных технологий для Священного Корана и наук о нем
- 2013
Реализован веб-сервис для веб-браузеров, включающий эффективные алгоритмы поиска в настраиваемый пользовательский интерфейс, который поддерживает интерактивную проверку выделенных слов в Коране с/без диакритических знаков и может считаться аккредитацией цифровое содержание Корана в Интернете.
Международный журнал по электротехнике и вычислительной технике (IJECE)
- Х. Абдулкадхим, Дж. Н. Шехаб
Информатика
- 2021
Предлагаемая система под названием «Извлечение открытой информации на арабском языке» (AOIE) может извлекать высокомасштабируемые текстовые отношения на арабском языке, будучи независимой от предметной области, и достигает высокой эффективности при извлечении предложений из больших объемов текста.
Геймификация для обработки арабского естественного языка: идеи на практике
- I. Zeroual, Anoual El Kah, A. Lakhouaja
Информатика
- 2017
Освещены преимущества использования игрового подхода в аннотации корпуса, распознавании именованных сущностей и устранении неоднозначности смысла слов для НЛП арабского языка.
SHOWING 1-10 OF 36 REFERENCES
SORT BYRelevanceMost Influenced PapersRecency
A chart parser for analyzing modern standard Arabic sentence
- E. Othman, K. Shaalan, A. Rafea
Computer Science
MTSUMMIT
- 2003
В этой статье сообщается о попытке разработать эффективный анализатор диаграмм для анализа предложений современного стандартного арабского языка (MSA), а также объясняется арабский морфологический анализатор, основанный на методе ATN.
Treebank Depertion Bank: слово о миллионах слов
- Otakar Smrž viktor bielický iveta kouřilová jakub kráčmar Zemánek
Компьютерная наука
- 2008
.
проверенные и пересмотренные аннотации, а также вычислительные инструменты с открытым исходным кодом, разработанные в рамках проекта, рассматриваются для публикации в этом году.CATiB: The Columbia Arabic Treebank
- Nizar Habash, Ryan Roth
Computer Science
ACL
- 2009
The Columbia Arabic Treebank (CATiB) is a database of syntactic analyses of Arabic sentences using representations and терминология, вдохновленная традиционным арабским синтаксисом.
Синтаксическая аннотация в базе данных Columbia Arabic Treebank
- Низар Хабаш, Рим Фарадж, Райан Рот
Лингвистика
- 2009
CATiB использует лингвистическое представление и терминологию, вдохновленную давней традицией синтаксических исследований арабского языка, чтобы упростить обучение комментаторов и не ограничиваться наймом комментаторов со степенью в области лингвистики.
Улучшение синтаксического анализа арабских зависимостей с помощью лексических и флективных морфологических признаков
- Юваль Мартон, Низар Хабаш, Оуэн Рэмбоу
Информатика
SPMRL@NAACL-HLT
- 2010
Показано, что обучение синтаксического анализатора с использованием простого регулярного экспрессивного расширения бедного набора POS-тегов с высокой точностью предсказания дает лучшие результаты, чем использование высокоинформативного набора POS-тегов только со средней точностью предсказания, хотя последний лучше всего работает на ввод золота.
Дерево зависимостей Корана с использованием традиционной арабской грамматики
Представлено дерево зависимостей Корана на арабском языке (QADT) и сообщается о том, как совместная онлайн-аннотация использовалась для объединения коранистов и экспертов по арабскому языку для обеспечения высокого уровня точность грамматического анализа всего Корана.
Изменение состояния конструкции в арабском дереве деревьев
- Райан Габбард, С. Кулик
Компьютерные науки
ACL
- 2008
- 2008
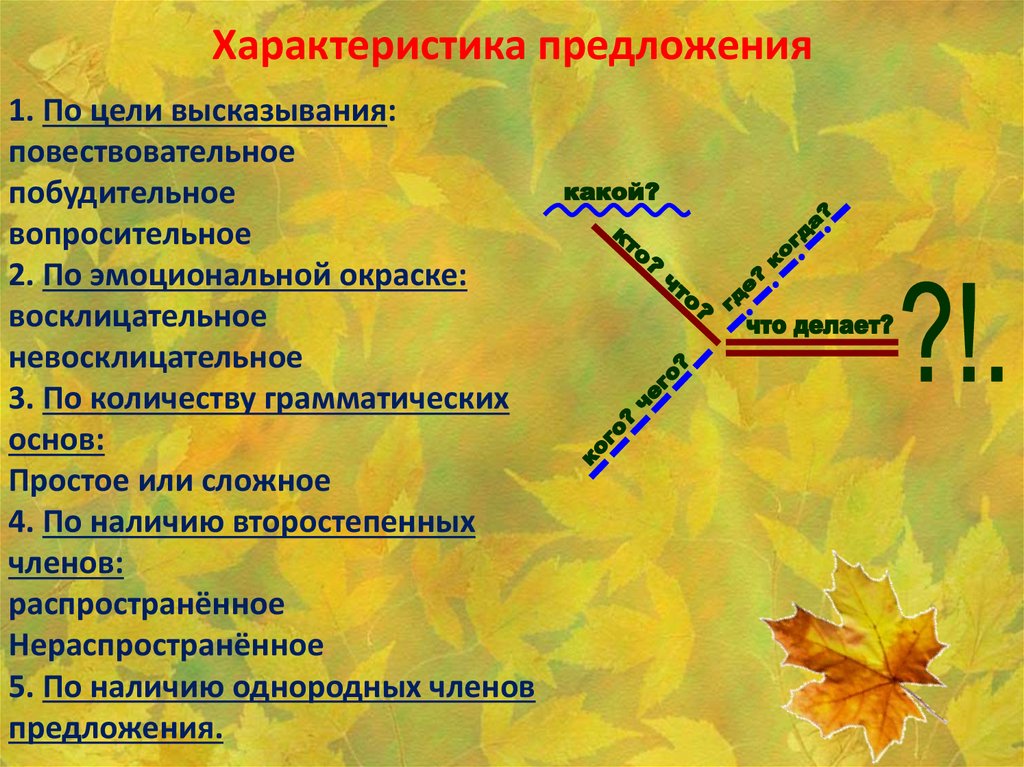 проверенные и пересмотренные аннотации, а также вычислительные инструменты с открытым исходным кодом, разработанные в рамках проекта, рассматриваются для публикации в этом году.
проверенные и пересмотренные аннотации, а также вычислительные инструменты с открытым исходным кодом, разработанные в рамках проекта, рассматриваются для публикации в этом году.

Проблема определения и присоединения конструкций к деревьям арабских деревьев в первых банках деревьев представлены статистические данные, которые количественно определяют проблему, обеспечивая базовый уровень и результаты первой попытки дискриминационной процедуры обучения для этой задачи.
NP Обнаружение подлежащего в арабских предложениях с началом глагола
- Спенс Грин, Конал Сати, Кристофер Д. Мэннинг
Информатика, лингвистика
MTSUMMIT
- 2009
Условная фраза случайных существительных определяет полный объем последовательности арабских глаголов. — начальные предложения на уровне Fβ=1 61,3%, абсолютное улучшение на 5,0% по сравнению с базовым уровнем статистического анализатора.
Анализ арабского банка деревьев: анализ и улучшения
- С. Кулик, Райан Габбард, М. Маркус
Информатика
- 2006
Обсуждаются некоторые вопросы, связанные с оценкой, и показано, что текущая производительность синтаксического анализа арабского языка не так плоха, как считалось ранее, и некоторые модификации представлены синтаксические анализаторы, которые обеспечивают скромное увеличение производительности.
MaltParser: независимая от языка система анализа зависимостей на основе данных
- Юдзи Мацумото
Информатика
- 2005
Экспериментальная оценка подтверждает, что MaltParser может обеспечить надежный, эффективный и точный синтаксический анализ для широкого спектра языков без специфичных для языка улучшений и с довольно ограниченным объемом обучающих данных.
Учебник № 18. Синтаксический анализ II: WCFG, внутренний алгоритм и взвешенный анализ
В первой части этого руководства мы представили контекстно-свободные грамматики (CFG) и способы их преобразования в нормальную форму Хомского. Мы представили алгоритм CYK для задачи распознавания. Этот алгоритм оценивает, допустимо ли предложение в соответствии с грамматикой, и его можно легко адаптировать для возврата допустимых деревьев синтаксического анализа.
Мы представили алгоритм CYK для задачи распознавания. Этот алгоритм оценивает, допустимо ли предложение в соответствии с грамматикой, и его можно легко адаптировать для возврата допустимых деревьев синтаксического анализа.
В этом блоге мы представим взвешенных контекстно-свободных грамматик или WCFG . Они присваивают неотрицательный вес каждому правилу в грамматике. Отсюда мы можем присвоить вес любому дереву синтаксического анализа, перемножив вместе веса составляющих его правил. Мы представляем два варианта алгоритма CYK, применимых к WCFG. (i) внутренний алгоритм вычисляет сумму весов всех возможных анализов (деревьев синтаксического анализа) для предложения. (ii) Взвешенный синтаксический анализ Алгоритм находит дерево синтаксического анализа с наибольшим весом.
В части III этого руководства мы познакомимся с вероятностными контекстно-свободными грамматиками. Это особый случай WCFG, когда веса всех правил с одинаковой левой частью в сумме равны единице. Затем мы обсудим, как узнать эти веса из корпуса текста. Мы увидим, что внутренний алгоритм является важной частью этого процесса.
Затем мы обсудим, как узнать эти веса из корпуса текста. Мы увидим, что внутренний алгоритм является важной частью этого процесса.
Контекстно-свободные грамматики и распознавание CYK
Прежде чем мы начнем обсуждение, давайте кратко рассмотрим, что мы узнали о контекстно-свободных грамматиках и алгоритме распознавания CYK в части I этого руководства. Напомним, что мы определили контекстно-свободную грамматику как кортеж $\langle S, \mathcal{V}, \Sigma, \mathcal{R}\rangle$ с начальным символом $S$, нетерминалы $\mathcal{V }$, терминалы $\Sigma$ и, наконец, правила $\mathcal{R}$.
В наших примерах нетерминалы представляют собой набор $\mathcal{V}=\{\mbox{VP, PP, NP, DT, NN, }\ldots\}$, содержащий подпункты (например, глагол- фраза $\mbox{VP}$ ) и части речи (например, существительное $\mbox{NN}$). Терминалы содержат слова. Мы будем рассматривать грамматики в нормальной форме Хомского, где правила либо отображают один нетерминал в два других нетерминала (например, $\text{VP} \rightarrow \text{V} \; \text{NP})$, либо один терминальный символ (например, $\text{V}$-> eats). {th}$ строки диаграммы существует $l-1$ способов разделить подпоследовательность на две части. Например, строка в сером прямоугольнике в позиции (4,2) может быть разделена 4-1 = 3 способами, которые соответствуют синим, зеленым и красным заштрихованным прямоугольникам, и эти разбиения индексируются переменной $s$.
{th}$ строки диаграммы существует $l-1$ способов разделить подпоследовательность на две части. Например, строка в сером прямоугольнике в позиции (4,2) может быть разделена 4-1 = 3 способами, которые соответствуют синим, зеленым и красным заштрихованным прямоугольникам, и эти разбиения индексируются переменной $s$.
Рис. 2. Алгоритм распознавания CYK. а) Сначала рассмотрим подпоследовательности длины $l=1$. Для каждой позиции $p$ мы проверяем, существует ли правило, порождающее слово, и устанавливаем соответствующий элемент диаграммы в значение TRUE. Например, в позиции (1,3) мы устанавливаем NP в TRUE, так как у нас есть правило $\mbox{NP}\rightarrow\mbox{him}$. б) Затем мы рассматриваем подпоследовательности длины $l=2$ и устанавливаем элементы в позиции как истинные, если существует бинарное нетерминальное правило, объясняющее эту подпоследовательность. Например, в позиции (2,2) мы устанавливаем VP в TRUE, поскольку у нас есть правило $\mbox{VP}\rightarrow\mbox{VBD NP}$. c) Мы продолжаем таким же образом, работая через все более и более длинные подпоследовательности, пока не достигнем позиции (1,1), которая представляет всю строку. Если мы можем установить $S$ в TRUE в этой позиции, то предложение может быть сгенерировано грамматикой. Дополнительные сведения см. в части I этого руководства.
Если мы можем установить $S$ в TRUE в этой позиции, то предложение может быть сгенерировано грамматикой. Дополнительные сведения см. в части I этого руководства.
Алгоритм CYK сначала находит действительные унарные правила, которые отображают претерминалы, представляющие части речи, в терминалы, представляющие слова (например, DT$\rightarrow$ the). Затем он рассматривает подпоследовательности возрастающей длины и идентифицирует применимые бинарные нетерминальные правила (например, $\mbox{NP}\rightarrow \mbox{DT NN})$. Правило применимо, если ниже на диаграмме есть два поддерева, корни которых совпадают с его правой частью. Если алгоритм может поместить начальный символ в верхний левый угол диаграммы, то общее предложение верно. Псевдокод дается:
0 # Инициализировать структуру данных 1 диаграмма[1...n, 1...n, 1...V] := FALSE 2 3 # Используйте унарные правила, чтобы найти возможные части речи на претерминалах 4 for p := 1 to n # начальная позиция 5 для каждого унарного правила A -> w_p 6 диаграмма[1, p, A] := ИСТИНА 7 8 # Основной цикл синтаксического анализа 9 для l := 2 to n # длина подпоследовательности 10 for p := 1 to n-l+1 # начальная позиция 11 for s := 1 to l-1 # ширина разделения 12 для каждого бинарного правила A -> B C 13 диаграмма[l, p, A] = диаграмма[l, p, A] ИЛИ (диаграмма [s, p, B] И диаграмма [l-s, p+s, C]) 14 15 обратная диаграмма[n, 1, S]
Более подробное обсуждение этого алгоритма см. в первой части этого блога.
в первой части этого блога.
Взвешенные контекстно-свободные грамматики
Взвешенные контекстно-свободные грамматики (WCFG) — это контекстно-свободные грамматики, каждое правило которых имеет неотрицательный вес. Точнее, мы добавляем функцию $g: \mathcal{R} \mapsto \mathbb{R}_{\geq 0}$, которая отображает каждое правило в неотрицательное число. Тогда вес полного дерева вывода $T$ равен произведению весов каждого правила $T_t$:
\begin{equation}\label{eq:weighted_tree_from_rules} \mbox{G}[T] = \prod_{t \in T} g[T_t]. \tag{1} \end{equation}
Контекстно-свободные грамматики генерируют строки, тогда как взвешенные контекстно-свободные грамматики генерируют строки с соответствующим весом.
Мы будем интерпретировать вес $g[T_t]$ как степень предпочтения правила, поэтому мы «предпочитаем» деревья разбора $T$ с более высокими общими весами $\mbox{G}[T]$. В конечном счете, мы изучим эти веса таким образом, что реальные наблюдаемые предложения будут иметь большие веса, а неграмматические предложения будут иметь меньшие веса. С этой точки зрения веса можно рассматривать как параметры модели.
С этой точки зрения веса можно рассматривать как параметры модели.
Поскольку веса дерева $G[T]$ неотрицательны, их можно интерпретировать как ненормированные вероятности. Чтобы создать допустимое распределение вероятностей по возможным деревьям синтаксического анализа, мы должны нормализовать общий вес $Z$ всех производных деревьев:
\begin{eqnarray} Z &=& \sum_{T \in \mathcal{T}[\ mathbf{w}]} \mbox{G}[T] \nonumber \\ &=& \sum_{T \in \mathcal{T}[\mathbf{w}]} \prod_{t \in T} \mbox {g}[T_t], \tag{2} \end{eqnarray}
где $\mathcal{T}[\mathbf{w}]$ представляет собой набор всех возможных деревьев синтаксического анализа, из которых наблюдаемые слова $\mathbf{w}=[x_{1},x_{2},\ldots x_{L}]$ можно получить. Мы будем называть нормализующую константу $Z$ статистической суммой . Тогда условное распределение возможного вывода $T$ для наблюдаемых слов $\mathbf{w}$ будет следующим:
\begin{equation} Pr(T|\mathbf{w}) = \frac{\mbox{G} [Т] {Z}.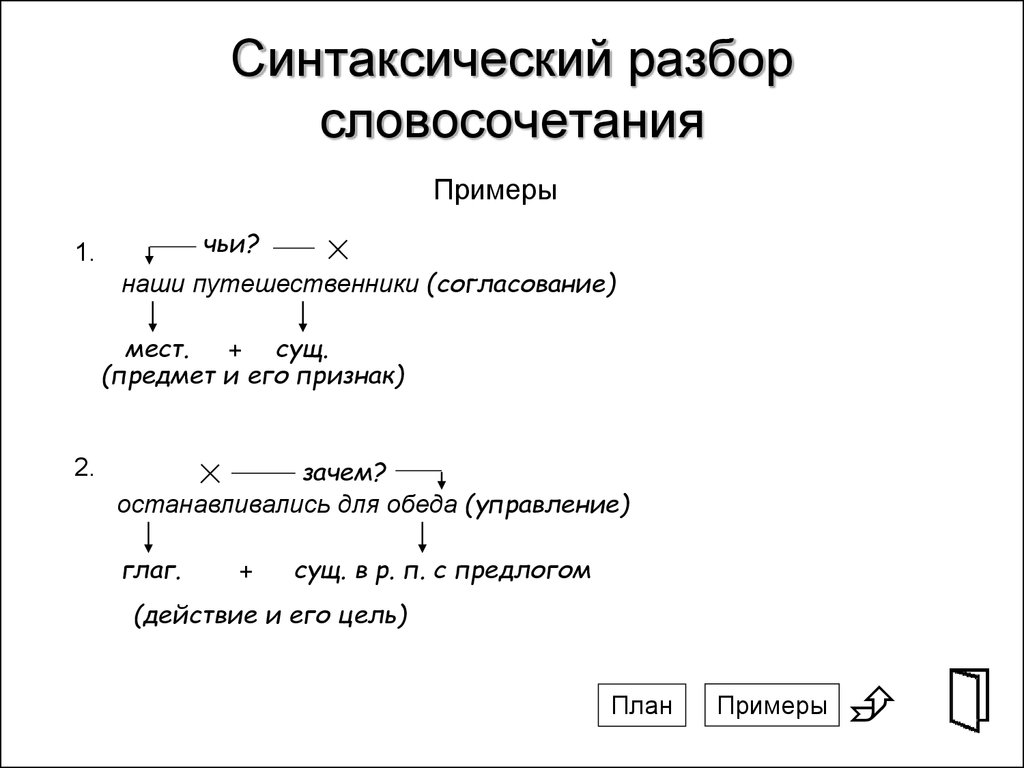 \tag{3} \end{equation}
\tag{3} \end{equation}
Вычисление статистической суммы
Мы определили статистическую сумму $Z$ как сумму весов всех деревьев $\mathcal{T}[\mathbf{w}]$, из которых могут быть получены наблюдаемые слова $\mathbf{w}$. Однако в первой части этого руководства мы увидели, что количество возможных бинарных деревьев синтаксического анализа очень быстро увеличивается с увеличением длины предложения.
Алгоритм распознавания CYK использовал динамическое программирование для поиска в этом огромном пространстве возможных деревьев за полиномиальное время и определения наличия хотя бы одного действительного дерева. Чтобы вычислить статистическую сумму, мы будем использовать аналогичный прием для поиска по всем возможным деревьям и одновременного суммирования их весов. Это известно как внутри алгоритма .
Полукольца Прежде чем представить внутренний алгоритм, нам нужно ввести полукольцо . Эта абстрактная алгебраическая структура поможет нам адаптировать алгоритм CYK для вычисления различных величин. Полукольцо — это множество $\mathbb{A}$, на котором мы определили два бинарных оператора:
Полукольцо — это множество $\mathbb{A}$, на котором мы определили два бинарных оператора:
1. $\oplus$ — это коммутативная операция с единичным элементом 0, которая ведет себя как сложение $+$:
- $x \oplus y = y \oplus x$
- $(x \oplus y) \oplus z = x \oplus (y \oplus z)$
- $x \oplus 0 = 0 \oplus x = x$
2. $\otimes$ является ассоциативным операция, которая (справа) распределяет по $\oplus$ точно так же, как умножение $\times$. Он имеет единичный элемент 1 и поглощающий элемент 0:
- $(x \otimes y) \otimes z = x \otimes (y \otimes z)$
- $x \otimes (y \oplus z) = (x \otimes y) + (x \otimes z)$
- $x \otimes 1 = 1 \otimes x = x$
- $x \otimes 0 = 0 \otimes x = 0$
Аналогично грамматикам мы будем обозначать полукольца просто кортежами: $\langle\mathbb{A}, \oplus, \otimes, 0, 1\rangle$. Вы можете думать о полукольце как об обобщении понятий сложения и умножения. 1
Внутренний алгоритм вычисления $Z$ Вычисление статистической суммы $Z$ для условного распределения $Pr(T|\mathbf{w})$ может показаться трудным, поскольку оно суммирует по большому пространству возможных выводов предложения $\mathbf{w}$. Однако мы уже видели, как алгоритм распознавания CYK принимает или отклоняет предложение за полиномиальное время, перебирая все возможные производные. Внутренний алгоритм использует вариант того же трюка для вычисления статистической суммы.
Однако мы уже видели, как алгоритм распознавания CYK принимает или отклоняет предложение за полиномиальное время, перебирая все возможные производные. Внутренний алгоритм использует вариант того же трюка для вычисления статистической суммы.
При использовании для распознавания $\texttt{chart}$ содержит значения $\texttt{TRUE}$ и $\texttt{FALSE}$ и вычисление основано на двух логических операторах ИЛИ и И, и мы можем думать из них как часть полукольца $\langle\{\texttt{TRUE}, \texttt{FALSE}\}, OR, AND, \texttt{FALSE}, \texttt{TRUE}\rangle$.
Внутренний алгоритм заменяет это полукольцо полукольцом суммы произведений $\langle\mathbb{R}_{\geq 0} \cup \{+\infty\} , +, \times, 0, 1\rangle$ на получить следующую процедуру:
0 # Инициализировать структуру данных
1 диаграмма[1...n, 1...n, 1...|V|] := 0
2
3 # Используйте унарные правила, чтобы найти возможные части речи на претерминалах
4 for p := 1 to n # начальная позиция
5 для каждого унарного правила A -> w_p
6 диаграмма[1, p, A] := g[A-> w_p]
7
8 # Основной цикл синтаксического анализа
9 для l := 2 to n # длина подпоследовательности
10 for p := 1 to n-l+1 # начальная позиция
11 for s := 1 to l-1 # ширина разделения
12 для каждого бинарного правила A -> B C
13 диаграмма[l, p, A] = диаграмма[l, p, A] +
(g[A -> B C] x диаграмма [s, p, B] x диаграмма [l-s,p+s, C] )
14
15 обратная диаграмма[n, 1, S] 9{th}$ non-terminal — это корень. Интуиция для правила обновления в строке 13 проста. Дополнительным весом для добавления правила $A\rightarrow BC$ в диаграмму является вес $g[A\rightarrow BC]$ для этого правила, умноженный на сумму весов всех возможных левых поддеревьев с корнями в B, умноженный на сумму весов всех возможных правых поддеревьев с корнем в C. Как и раньше, может быть несколько возможных правил, которые помещают нетерминал $A$ в положение, соответствующее различным разбиениям подпоследовательности, и здесь мы выполняем это вычисление для каждого правила и суммировать результаты вместе.
Рабочий пример На рисунках 3 и 4 показан рабочий пример внутреннего алгоритма для того же предложения, которое мы использовали для алгоритма распознавания CYK. Рисунок 3а соответствует строкам 4-6 алгоритма, где мы инициализируем первую строку диаграммы на основе весов унарного правила. Рисунок 3b соответствует основному циклу в строках 9–13 для длины подпоследовательности $l=2$. Здесь мы назначаем бинарные нетерминальные правила и вычисляем их веса как (стоимость правила $\times$ веса левой ветви $\times$ веса правой ветви).
Рисунок 3. Пример работы внутреннего алгоритма 1. а) Вес (число над частью речи) для подпоследовательностей длины $l=1$ определяется соответствующим весом правила (вверху справа). Например, позиции $1,3$ мы присваиваем вес 1,5, потому что применимо правило «$\mbox{NP}\rightarrow\mbox{him}$», которое имеет вес 1,5. б) Вес для подпоследовательностей длины 2 вычисляется как вес правила, умноженный на вес левой ветви, умноженный на правую ветвь. Например, в позиции (2,2) вес равен 3,36 на основе умножения веса 1,6 правила «$\mbox{VP}\rightarrow\mbox{VBD NP}$» на вес 1,4 левой ветви, умноженный на вес 1,5 правой ветви.
Рисунок 4а соответствует основному циклу в строках 9-13 для длины подпоследовательности $l=5$. В позиции (5,2) применимы два возможных правила, оба из которых приводят к одному и тому же нетерминалу. Мы вычисляем веса для каждого правила, как и раньше, и суммируем результаты так, чтобы окончательный вес в этой позиции суммировался по всем поддеревьям. На рис. 4b показан окончательный результат алгоритма. Вес, связанный с начальным символом $S$ в позиции (6,1), представляет собой статистическую сумму.
Рисунок 4. Пример работы внутреннего алгоритма 2 а) Когда мы достигаем позиции (5,2), есть два возможных правила, которые оба назначают нетерминал $VP$ этой позиции на графике (красное и синее разделение). Мы рассчитываем вес каждого правила, как и раньше, и складываем их вместе, чтобы сгенерировать новый вес. б) Когда мы достигаем верхнего левого угла, вес 441,21, связанный с начальным символом, представляет собой статистическую сумму Z. Если мы отследим пути, по которым мы достигли этой точки, мы сможем реконструировать все деревья, которые способствовали это значение. 9k]$ для нетерминала A (см. уравнение 4).
Взвешенный анализ
В предыдущем разделе мы видели, что можем преобразовать алгоритм распознавания CYK во внутренний алгоритм, просто изменив базовое полукольцо. С его небольшой корректировкой мы показали, что можем вычислить статистическую сумму (сумму весов всех производных дерева) за полиномиальное время. В этом разделе мы применяем аналогичный прием к взвешенному анализу .
Напомним, что статистическая сумма $Z$ была определена как сумма всех возможных дифференцирований: 9{*} &=& \underset{T \in \mathcal{T}[\mathbf{w}]}{\text{arg} \, \text{max}} \; \left[\mbox{G}[T]\right] \nonumber \\ &=& \underset{T \in \mathcal{T}[\mathbf{w}]}{\text{arg} \, \text {max}} \left[\prod_{t \in T} \mbox{g}[T_t]\right], \tag{6} \end{eqnarray}
, где $\mbox{G}[T]$ — это вес дерева вывода, который вычисляется путем произведения весов $\mbox{g}[T_t]$ правил.
Еще раз изменим полукольцо в алгоритме CYK для выполнения задачи. Заменим полукольцо сумм-произведений $\langle\mathbb{R}_{\geq 0} \cup \{+\infty\} , +, \times, 0, 1\rangle$ на полукольцо макс-произведений $ <\mathbb{R}_{\geq 0} \cup \{+\infty\} , \max[\bullet], \times, 0, 1>$, чтобы найти оценку «лучшего» вывода. Это дает нам следующий алгоритм:
0 # Инициализировать структуру данных
1 диаграмма[1...n, 1.. .n, 1...|V|] := 0
2
3 # Используйте унарные правила, чтобы найти возможные части речи на претерминалах
4 for p := 1 to n # начальная позиция
5 для каждого унарного правила A -> w_p
6 диаграмма [1, р, А] := г [А -> w_p]
7
8 # Основной цикл разбора
9 for l := 2 to n # длина подпоследовательности
10 for p := 1 to n-l+1 # начальная позиция
11 for s := 1 to l-1 # ширина разделения
12 для каждого бинарного правила A -> B C
13 диаграмма[l,p,A] = max[диаграмма[l,p,A],
(g[A -> B C] x диаграмма[s, p, B] x диаграмма[l-s,p+s, C]]
14
15 обратная диаграмма[n, 1, S]
Отличия от алгоритма распознавания CYK окрашены в зеленый цвет, а единственное отличие как от внутреннего алгоритма, так и от алгоритма распознавания CYK окрашено в оранжевый цвет.
Еще раз: каждая позиция $(p,l)$ в $\texttt{chart}$ представляет собой подпоследовательность, которая начинается с позиции $p$ и имеет длину $l$. Во внутреннем алгоритме каждая позиция содержала вектор с одной записью для каждого из правил $|V|$. Каждый элемент этого вектора содержит сумму весов всех поддеревьев, которые входят в этот привязанный нетерминал. В этом варианте каждый элемент имеет максимальный вес среди всех поддеревьев, которые поступают в этот привязанный нетерминал. Позиция (n,1) представляет всю строку, поэтому значение $\texttt{chart[n, 1, S]}$ является максимальным весом среди всех допустимых деревьев синтаксического анализа. Если это ноль, то нет действительного вывода.
Правило обновления в строке 13 для веса в $\texttt{chart[l, p, A]}$ теперь имеет следующую интерпретацию. Для каждого правила $\texttt{A -> B C}$ и для каждого возможного разделения $\texttt{s}$ данных мы умножаем вес правила $\texttt{g[A -> B C]}$ на два веса $\texttt{chart[s, p, B]}$ и $\texttt{chart[l-s, p+s, B]}$, связанные с двумя дочерними подпоследовательностями. Если результат больше, чем текущее максимальное значение, мы обновляем его. Если нас интересует само дерево синтаксического анализа, то мы можем сохранить обратные указатели, указывающие, какое разделение дало максимальное значение в каждой позиции, и пройти назад, чтобы получить лучшее дерево.
Рабочий пример На рисунке 6 показан рабочий пример взвешенного синтаксического анализа. Алгоритм начинается с присвоения весов претерминалам точно так же, как на рисунке 3а. Вычисление весов для подпоследовательностей длины $l=2$ также точно такое же, как на рисунке 3b, и алгоритм также работает одинаково для $l=3$ и $l=4$.
Единственная разница возникает для подпоследовательности длины $l=5$ в позиции $p=2$ (рис. 6). Есть два возможных правила, каждое из которых назначает неконечную VP диаграмме в этой позиции. Во внутреннем алгоритме мы вычислили веса этих правил и суммировали их. При взвешенном анализе мы сохраняем наибольший из этих весов, и эта операция соответствует функции $\mbox{max}[\bullet,\bullet]$ в строке 13 алгоритма.
Рис. 6. Пример работы взвешенного синтаксического анализа. а) Когда мы получаем длину строки $l=5$, позиция $p=2$, возможны два правила, которые назначают нетерминальные VP этой позиции, соответствующей красному и синему поддеревьям соответственно. Мы вычисляем вес для каждого как обычно (вес правила $\times$ вес левого дерева $\times$ вес правого дерева), но затем присваиваем максимальное из них текущей позиции. b) По завершении значение, связанное с начальным символом S в верхнем левом углу, является максимальным весом всех деревьев синтаксического анализа. Отслеживая, какие поддеревья способствовали этому (т. е. синее поддерево, а не красное), мы можем получить это максимально взвешенное дерево, которое является «лучшим» синтаксическим анализом предложения согласно взвешенному контекстно-свободному анализу. грамматика.
В конце процедуры вес, связанный с начальным символом в позиции (6,1), соответствует дереву с максимальным весом и поэтому считается «лучшим». Отслеживая, какое поддерево дало максимальный вес при каждом разделении, мы можем получить это дерево, которое соответствует нашему лучшему предположению при разборе предложения.
Резюме
Мы видели, что можно добавлять веса к CFG и заменять полукольцо $И, ИЛИ$ на $+, \times$, чтобы найти общий вес всех возможных дифференцирований (т. е. вычислить статистическую сумму с внутренним алгоритм). Дальше больше, но вместо этого мы можем использовать $\max, \times$, чтобы найти дерево разбора с наибольшим весом. 9k], \tag{7} \end{equation}
, где для распознавания $\mbox{g}[A \rightarrow B C]$ просто возвращается $\texttt{TRUE}$ для всех существующих правил.
Читатели, знакомые с графическими моделями, несомненно, заметят сходство между этими методами и распространением убеждений по сумме и по максимальному произведению. В самом деле, мы могли бы альтернативно представить весь этот аргумент в терминах графических моделей, но полукольцевая формулировка более краткая.
В заключительной части этого блога мы рассмотрим вероятностные контекстно-свободные грамматики, которые являются частным случаем взвешенно-контекстно-свободных грамматик. Мы разработаем алгоритмы для изучения весов (i) корпуса предложений с известными деревьями синтаксического анализа и (ii) только предложений. Последний случай приведет к обсуждению знаменитого внутри-снаружи алгоритм .
1. Если вам интересно, почему это «полу», то это потому, что великолепные кольца также имеют аддитивную обратную для каждого элемента: $x \oplus (-x) = 0$.
Работайте с нами!
Впечатлена работой команды? Borealis AI ищет сотрудников на различные должности в разных командах. Посетите нашу страницу вакансий прямо сейчас и откройте для себя возможности присоединиться к аналогичным важным проектам!
Карьера в Borealis AI Получение и анализ данных из Интернета с помощью OpenRefine
Содержание

 Здесь мы назначаем бинарные нетерминальные правила и вычисляем их веса как (стоимость правила $\times$ веса левой ветви $\times$ веса правой ветви).
Здесь мы назначаем бинарные нетерминальные правила и вычисляем их веса как (стоимость правила $\times$ веса левой ветви $\times$ веса правой ветви).  На рис. 4b показан окончательный результат алгоритма. Вес, связанный с начальным символом $S$ в позиции (6,1), представляет собой статистическую сумму.
На рис. 4b показан окончательный результат алгоритма. Вес, связанный с начальным символом $S$ в позиции (6,1), представляет собой статистическую сумму.  В этом разделе мы применяем аналогичный прием к взвешенному анализу .
В этом разделе мы применяем аналогичный прием к взвешенному анализу .  .n, 1...|V|] := 0
2
3 # Используйте унарные правила, чтобы найти возможные части речи на претерминалах
4 for p := 1 to n # начальная позиция
5 для каждого унарного правила A -> w_p
6 диаграмма [1, р, А] := г [А -> w_p]
7
8 # Основной цикл разбора
9 for l := 2 to n # длина подпоследовательности
10 for p := 1 to n-l+1 # начальная позиция
11 for s := 1 to l-1 # ширина разделения
12 для каждого бинарного правила A -> B C
13 диаграмма[l,p,A] = max[диаграмма[l,p,A],
(g[A -> B C] x диаграмма[s, p, B] x диаграмма[l-s,p+s, C]]
14
15 обратная диаграмма[n, 1, S]
.n, 1...|V|] := 0
2
3 # Используйте унарные правила, чтобы найти возможные части речи на претерминалах
4 for p := 1 to n # начальная позиция
5 для каждого унарного правила A -> w_p
6 диаграмма [1, р, А] := г [А -> w_p]
7
8 # Основной цикл разбора
9 for l := 2 to n # длина подпоследовательности
10 for p := 1 to n-l+1 # начальная позиция
11 for s := 1 to l-1 # ширина разделения
12 для каждого бинарного правила A -> B C
13 диаграмма[l,p,A] = max[диаграмма[l,p,A],
(g[A -> B C] x диаграмма[s, p, B] x диаграмма[l-s,p+s, C]]
14
15 обратная диаграмма[n, 1, S]  Каждый элемент этого вектора содержит сумму весов всех поддеревьев, которые входят в этот привязанный нетерминал. В этом варианте каждый элемент имеет максимальный вес среди всех поддеревьев, которые поступают в этот привязанный нетерминал. Позиция (n,1) представляет всю строку, поэтому значение $\texttt{chart[n, 1, S]}$ является максимальным весом среди всех допустимых деревьев синтаксического анализа. Если это ноль, то нет действительного вывода.
Каждый элемент этого вектора содержит сумму весов всех поддеревьев, которые входят в этот привязанный нетерминал. В этом варианте каждый элемент имеет максимальный вес среди всех поддеревьев, которые поступают в этот привязанный нетерминал. Позиция (n,1) представляет всю строку, поэтому значение $\texttt{chart[n, 1, S]}$ является максимальным весом среди всех допустимых деревьев синтаксического анализа. Если это ноль, то нет действительного вывода.
 Мы вычисляем вес для каждого как обычно (вес правила $\times$ вес левого дерева $\times$ вес правого дерева), но затем присваиваем максимальное из них текущей позиции. b) По завершении значение, связанное с начальным символом S в верхнем левом углу, является максимальным весом всех деревьев синтаксического анализа. Отслеживая, какие поддеревья способствовали этому (т. е. синее поддерево, а не красное), мы можем получить это максимально взвешенное дерево, которое является «лучшим» синтаксическим анализом предложения согласно взвешенному контекстно-свободному анализу. грамматика.
Мы вычисляем вес для каждого как обычно (вес правила $\times$ вес левого дерева $\times$ вес правого дерева), но затем присваиваем максимальное из них текущей позиции. b) По завершении значение, связанное с начальным символом S в верхнем левом углу, является максимальным весом всех деревьев синтаксического анализа. Отслеживая, какие поддеревья способствовали этому (т. е. синее поддерево, а не красное), мы можем получить это максимально взвешенное дерево, которое является «лучшим» синтаксическим анализом предложения согласно взвешенному контекстно-свободному анализу. грамматика. е. вычислить статистическую сумму с внутренним алгоритм). Дальше больше, но вместо этого мы можем использовать $\max, \times$, чтобы найти дерево разбора с наибольшим весом. 9k], \tag{7} \end{equation}
е. вычислить статистическую сумму с внутренним алгоритм). Дальше больше, но вместо этого мы можем использовать $\max, \times$, чтобы найти дерево разбора с наибольшим весом. 9k], \tag{7} \end{equation}
- Цели урока
- Зачем использовать OpenRefine?
- План урока
- Пример 1. Получение и анализ HTML
- Запуск проекта «Сонеты»
- Получить HTML
- Разобрать HTML
- Разделенные ячейки
- Отменить побег
- Очистка и экспорт
- Пример 2: URL-запросы и анализ JSON
- Запуск проекта «Хроника Америки»
- Создать запрос
- Получить URL-адреса
- Анализ JSON для получения элементов
- Разделить многозначные ячейки
- Анализ значений JSON
- Пример 3: расширенные API
- Jython в окне выражений
- Jython GET-запрос
- Почтовый запрос
- Сравните настроение
OpenRefine — это мощный инструмент для изучения, очистки и преобразования данных. В предыдущем уроке Programming Historian «Очистка данных с помощью OpenRefine» были представлены базовые функции Refine для эффективного обнаружения и исправления несогласованности в наборе данных.
Основываясь на этих основных навыках обработки данных, этот урок посвящен способности Refine извлекать URL-адреса и анализировать веб-контент.
В примерах представлены некоторые расширенные функции для преобразования и улучшения набора данных, в том числе:
В предыдущем уроке Programming Historian «Очистка данных с помощью OpenRefine» были представлены базовые функции Refine для эффективного обнаружения и исправления несогласованности в наборе данных.
Основываясь на этих основных навыках обработки данных, этот урок посвящен способности Refine извлекать URL-адреса и анализировать веб-контент.
В примерах представлены некоторые расширенные функции для преобразования и улучшения набора данных, в том числе:
- выборка URL-адресов с помощью Refine
- создавать URL-запросы для получения информации из простого веб-API
- анализировать ответы HTML и JSON для извлечения соответствующих данных
- использовать функции массива для управления строковыми значениями
- использовать Jython для расширения функциональности Refine
Для выполнения этого урока будет полезно иметь базовые знания OpenRefine, HTML и таких концепций программирования, как переменные и циклы.
Зачем использовать OpenRefine?
Возможность создавать наборы данных из неструктурированных документов, доступных в Интернете, открывает возможности для исследований с использованием оцифрованных первичных материалов, веб-архивов, текстов и современных медиапотоков. Уроки Programming Historian знакомят с рядом методов сбора и взаимодействия с этим содержимым, от wget до Python.
При работе с текстовыми документами Refine особенно подходит для этой задачи, позволяя пользователям получать URL-адреса и напрямую обрабатывать результаты итеративным исследовательским образом.
Уроки Programming Historian знакомят с рядом методов сбора и взаимодействия с этим содержимым, от wget до Python.
При работе с текстовыми документами Refine особенно подходит для этой задачи, позволяя пользователям получать URL-адреса и напрямую обрабатывать результаты итеративным исследовательским образом.
Дэвид Хьюн, создатель Freebase Gridworks (2009 г.), который стал GoogleRefine (2010 г.), а затем OpenRefine (2012+), описывает Refine как:
- более мощный, чем электронная таблица
- более интерактивный и наглядный, чем скрипты
- более предварительный / исследовательский / экспериментальный / игривый, чем база данных 1
Refine — это уникальный инструмент, сочетающий мощь баз данных и языков сценариев в интерактивном и удобном визуальном интерфейсе.
Из-за этой гибкости он был принят журналистами, библиотекарями, учеными и другими людьми, которым необходимо преобразовать данные из различных источников и форматов в структурированную информацию.
Терминал OpenRefine и графический интерфейс
OpenRefine — это бесплатное приложение Java с открытым исходным кодом. Пользовательский интерфейс отображается вашим веб-браузером, но Refine не является веб-приложением. Никакая информация не отправляется онлайн, и подключение к Интернету не требуется. Полная документация доступна на официальной вики. Для установки и запуска Refine зайдите на эту страницу мастерской.
Примечание: этот урок был написан с использованием openrefine-2.7. Хотя почти все функции взаимозаменяемы между версиями, я предлагаю использовать самую новую версию.
План урока
В этом уроке представлены три примера, демонстрирующие рабочие процессы для сбора и обработки данных из Интернета:
- Пример 1. Получение и анализ HTML преобразует электронную книгу в структурированный набор данных путем анализа HTML и использования массива строк. функции.
- Пример 2: URL-запросы и синтаксический анализ JSON взаимодействует с простым веб-API для создания полнотекстового набора данных первых страниц исторических газет.
- Пример 3: расширенные API демонстрирует использование Jython для реализации запроса POST к веб-службе обработки естественного языка.

В этом примере одна веб-страница загружается и анализируется в структурированную таблицу с помощью встроенных функций Refine. Аналогичный рабочий процесс можно применить к списку URL-адресов, часто сгенерированному путем анализа другой веб-страницы, создавая гибкий инструмент для сбора данных в Интернете.
Необработанные данные для этого примера — это HTML-копия сонетов Шекспира из Project Gutenberg. Преобразование сборника стихов в структурированные данные открывает новые способы чтения текста, позволяя нам сортировать, обрабатывать и связывать другую информацию.
Обратите внимание, что Project Gutenberg предоставляет каналы для массовой загрузки данных каталога.
Их общедоступный веб-сайт не следует использовать для веб-скрапинга.
Копия электронной книги в формате HTML для этого примера размещена на GitHub, чтобы избежать перенаправлений, встроенных в сайт Gutenberg.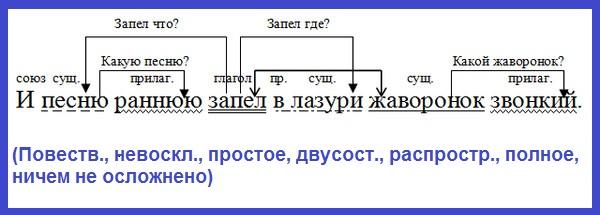
Запустить проект «Сонеты»
Запустить OpenRefine и выбрать Создать проект . Refine может импортировать данные из самых разных форматов и источников, из локального файла Excel в доступный через Интернет RDF. Одним из часто упускаемых из виду методов является Буфер обмена , который позволяет вводить данные с помощью копирования и вставки. В разделе «Получить данные из» щелкните Буфер обмена и вставьте этот URL-адрес в текстовое поле:
https://programminghistorian.org/assets/fetch-and-parse-data-with-openrefine/pg1105.html.
Запустить проект с буфером обмена
После нажатия Далее функция Уточнить должна автоматически идентифицировать содержимое как построчный текстовый файл, а параметры синтаксического анализа по умолчанию должны быть правильными.
Добавьте название проекта «Сонеты» вверху справа и нажмите 9.0249 Создать проект .
В результате получится проект с одним столбцом и одной строкой.
Fetch HTML
Встроенная функция Refine для получения списка URL-адресов выполняется путем создания нового столбца. Щелкните стрелку меню Столбец 1 > Редактировать столбец > Добавить столбец, выбрав URL-адреса .
Изменить столбец > Добавить столбец, выбрав URL-адрес
Назовите новый столбец «выборка». Параметр Throttle delay устанавливает время паузы между запросами, чтобы избежать блокировки сервером. По умолчанию консервативен.
Добавить столбец в диалоговом окне выборки
После нажатия «ОК» функция «Уточнить» начнет запрашивать URL-адреса из базового столбца, как если бы вы открывали страницы в своем браузере, и будет сохранять каждый ответ в ячейках нового столбца. В этом случае имеется один URL-адрес в столбце 1 , в результате чего одна ячейка в столбце fetch содержит полный исходный код HTML для веб-страницы Sonnets.
Получение результатов
Анализ HTML
Большая часть веб-страницы не является текстом сонета и должна быть удалена для создания чистого набора данных. Во-первых, необходимо определить шаблон, который может выделить нужный контент.
Элементы часто будут вложены в уникальный контейнер или получат осмысленный класс или идентификатор.
Во-первых, необходимо определить шаблон, который может выделить нужный контент.
Элементы часто будут вложены в уникальный контейнер или получат осмысленный класс или идентификатор.
Чтобы упростить изучение HTML, щелкните URL-адрес в столбце 1 , чтобы открыть ссылку в новой вкладке, затем щелкните правой кнопкой мыши страницу, чтобы «Просмотреть исходный код страницы».
В этом случае страница сонетов не имеет отличительной семантической разметки, но каждое стихотворение содержится внутри одного элемента
Каждый сонет представляет собой
со строками, разделенными
На выборка столбца , щелкните стрелку меню > изменить столбец > Добавить столбец на основе этого столбца . Дайте новому столбцу имя «parse», затем щелкните в текстовом поле Expression .
Изменить столбец > Добавить столбец на основе этого столбца
Данные в Refine можно преобразовать с помощью языка General Refine Expression Language (GREL).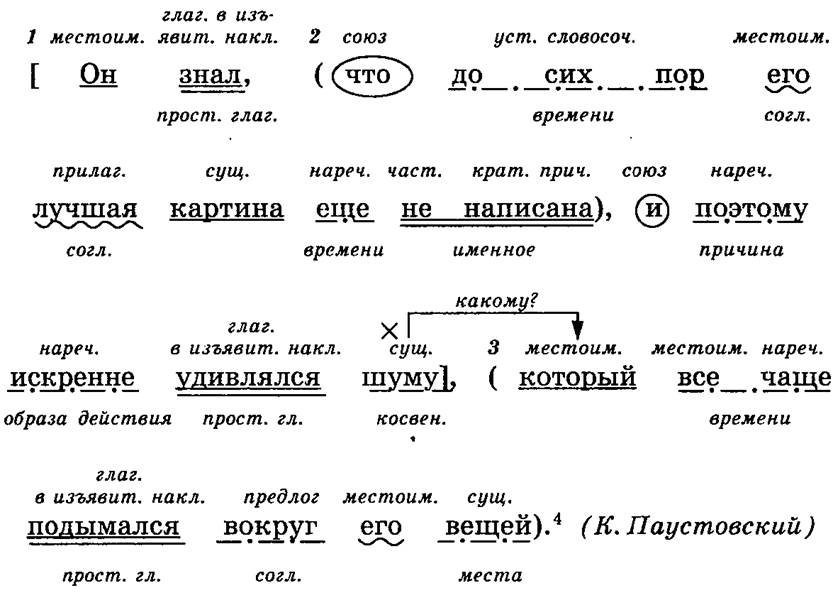 Блок Expression принимает функции GREL, которые будут применяться к каждой ячейке в существующем столбце для создания значений для нового.
9Окно 0249 Preview под полем Expression отображает текущее значение слева и значение для нового столбца справа.
Блок Expression принимает функции GREL, которые будут применяться к каждой ячейке в существующем столбце для создания значений для нового.
9Окно 0249 Preview под полем Expression отображает текущее значение слева и значение для нового столбца справа.
Выражение по умолчанию: значение , переменная GREL, представляющая текущее содержимое ячейки.
Это означает, что каждая ячейка просто копируется в новый столбец, что отражается в Preview .
Переменные и функции GREL последовательно выстраиваются вместе с использованием точки, называемой точечной нотацией.
Это позволяет создавать сложные операции, передавая результаты каждой функции следующей.
Функция parseHtml() GREL может читать HTML-контент, позволяя получать доступ к элементам с помощью функции select() и синтаксиса селектора jsoup.
Начиная со значения , добавьте функции parseHtml() и select("p") в поле Expression , используя запись через точку, в результате чего:
value.
 parseHtml().select("p")
parseHtml().select("p")
Не нажимайте OK в этот момент, просто посмотрите на Preview , чтобы увидеть результат выражения.
Изменить выражение GREL, функцию parseHtml
Обратите внимание, что вывод справа больше не начинается с корневых элементов HTML ( и т. д.), видимых слева.
Вместо этого он начинается с квадратной скобки [ , отображающей массив всех p элементов, найденных на странице.
Уточнить представляет массив в виде списка, разделенного запятыми, заключенного в квадратные скобки, например, [ "один", "два", "три" ] .
Уточнение является визуальным и итеративным; обычно постепенно создают выражение, проверяя предварительный просмотр, чтобы увидеть результат.
Помимо помощи в отладке GREL, это дает возможность узнать больше о наборе данных, прежде чем добавлять дополнительные функции.
Попробуйте следующие операторы GREL в Выражение окно без щелчка ОК . Посмотрите окно предварительного просмотра, чтобы понять, как они работают:
Посмотрите окно предварительного просмотра, чтобы понять, как они работают:
- Добавление порядкового номера к выражению выбирает один элемент из массива, например
value.parseHtml().select("p")[0]. Начало файла сонетов содержит много абзацев лицензионной информации, которые не нужны для набора данных. Пропуская порядковые номера, первый сонет находится по адресуvalue.parseHtml().select("p")[37]. - GREL также поддерживает использование отрицательных индексов, поэтому
value.parseHtml().select("p")[-1]вернет последний элемент в массиве. В обратном порядке последний сонет имеет индекс[-3]. - Используя эти порядковые номера, можно разрезать массив, извлекая только диапазон
p, содержащий сонеты. Добавьте функциюslice()в выражение для предварительного просмотра подмножества:value.parseHtml().select("p").slice(37,-2).
Нажатие OK с приведенным выше выражением приведет к появлению пустого столбца, что является частой причиной путаницы при работе с массивами. Refine не сохраняет объект массива как значение ячейки.
Необходимо использовать
Refine не сохраняет объект массива как значение ячейки.
Необходимо использовать toString() или join() для преобразования массива в строковую переменную.
Функция join() объединяет массив с указанным разделителем.
Например, выражение [ "один", "два", "три" ].join(";") приведет к строке «один;два;три».
Таким образом, окончательное выражение для создания разбор столбца :
value.parseHtml().select("p").slice(37,-2).join("|")
Щелкните OK , чтобы создать новый столбец с использованием выражения.
Протестируйте трансформацию и посмотрите, что получится — ее очень легко отменить! Полная история операций записывается во вкладке «Отменить/Повторить».
Split Cells
Столбец parse теперь содержит все сонеты, разделенные символом «|», но проект по-прежнему содержит только одну строку.
Отдельные строки для каждого сонета могут быть созданы путем разделения ячейки.
Щелкните стрелку меню на разбор столбца > Редактировать ячейки > Разделить многозначные ячейки . Введите разделитель
Введите разделитель | , который использовался для соединения с на последнем шаге.
Редактировать ячейки > Разделить многозначные ячейки
После этой операции в верхней части таблицы проекта теперь должно быть 154 строки. Под номером находится опция переключения «Показать как: строк, , записей, ». Щелкнув по записям , вы сгруппируете строки на основе исходной таблицы, в этом случае она будет читаться как 1. Отслеживание этих чисел является важной «проверкой работоспособности» при преобразовании данных в Refine. 154 строки имеют смысл, потому что электронная книга содержит 154 сонета, а 1 запись представляет исходную таблицу только с одной строкой. Непредвиденное число указывало бы на проблему с преобразованием.
Строки проекта
Каждая ячейка в столбце parse теперь содержит один сонет, окруженный тегом  Это вызовет диалоговое окно, похожее на создание нового столбца.
Преобразование перезапишет ячейки текущего столбца, а не создаст новый.
Это вызовет диалоговое окно, похожее на создание нового столбца.
Преобразование перезапишет ячейки текущего столбца, а не создаст новый.
В поле выражения введите значение.parseHtml() .
Предварительный просмотр покажет полное дерево HTML, начиная с элемента .
Важно отметить, что parseHtml() автоматически заполнит отсутствующие теги, что позволит проанализировать эти значения ячеек, несмотря на то, что они не являются действительными HTML-документами.
Выберите тег p , добавьте порядковый номер и используйте функцию innerHtml() для извлечения текста сонета:
value.parseHtml().select("p")[0].innerHtml()
Нажмите OK для преобразования всех 154 ячеек в столбце.
Редактировать ячейки > Преобразовать
В приведенном выше выражении select возвращает массив из p элементов, хотя в каждой ячейке есть только один элемент. Попытка передать массив в
Попытка передать массив в innerHtml() вызовет ошибку.
Таким образом, номер индекса необходим для выбора первого (и единственного) элемента в массиве для передачи правильного типа объекта в innerHtml() .
Не забывайте о типах объектов данных при отладке выражений GREL!
Unescape
Обратите внимание, что каждая ячейка имеет десятки , объект HTML, используемый для представления «неразрывного пробела», поскольку браузеры игнорируют лишние пробелы в исходном коде.
Эти объекты часто встречаются при сборе веб-страниц и могут быть быстро заменены соответствующими символами простого текста с помощью функции unescape() .
В столбце анализировать выберите Редактировать ячейки > Преобразовать и введите следующее в поле выражения:
значение.unescape('html')
Объекты будут заменены обычными пробелами.
Функции массива GREL обеспечивают мощный способ манипулирования текстовыми данными и могут использоваться для завершения обработки сонетов. Любое строковое значение можно преобразовать в массив с помощью функции
Любое строковое значение можно преобразовать в массив с помощью функции split() , предоставив символ или выражение, которое разделяет элементы (в основном противоположность join() ).
В сонетах каждая строка заканчивается на , обеспечивающий удобный разделитель для разделения.
Выражение
value.split(" создаст массив строк каждого сонета.
Затем номера индексов и срезы можно использовать для заполнения новых столбцов.
Имейте в виду, что Refine не выводит массив непосредственно в ячейку.
Обязательно выберите один элемент из массива, используя номер индекса, или преобразуйте его обратно в строку с помощью
") join() .
Кроме того, текст сонета содержит огромное количество ненужных пробелов, которые использовались для размещения стихов в электронной книге.
Это можно вырезать из каждой строки, используя функция обрезки() .
Trim автоматически удаляет все начальные и конечные пробелы в ячейке, что необходимо для очистки данных.
Используя эти концепции, можно выделить и обрезать одну строку для создания чистых столбцов, представляющих номер сонета и первую строку. Создайте два новых столбца из столбца parse , используя следующие имена и выражения:
Следующий столбец, который нужно создать, — это полный текст сонета, который содержит несколько строк.
Однако trim() очистит только начало и конец ячейки, оставив ненужные пробелы в теле сонета.
Для обрезки каждой строки по отдельности используйте регулятор GREL 9.0639 forEach() , удобный цикл, перебирающий массив.
Из столбца синтаксического анализа создайте новый столбец с именем «текст» и щелкните в поле Expression .
Оператор forEach() запрашивает массив, имя переменной и выражение, применяемое к переменной.
Следуя форме forEach(массив, переменная, выражение) , постройте цикл, используя следующие параметры:
- array:
value.split(", создайте массив из строк сонета в каждая ячейка.
") - переменная:
строка, каждый элемент массива затем представляется как переменная (это может быть что угодно, часто используетсяи). - выражение:
line.trim(), затем каждый элемент оценивается отдельно с указанным выражением. В этом случаеtrim()удаляет пробелы из каждой строки сонета в массиве.

В этот момент выражение должно выглядеть так: forEach(value.split(" в коробке Expression .
Обратите внимание, что в Preview теперь отображается массив, в котором первым элементом является номер сонета.
Поскольку результаты
"), line, line.trim()) forEach() возвращаются в виде нового массива, можно применять дополнительные функции массива, такие как срез и объединение.
Добавьте slice(1) , чтобы удалить номер сонета, и join("\n") , чтобы объединить строки в строковое значение ( \n - это символ новой строки в обычном тексте). Таким образом, окончательное выражение для извлечения и очистки полного текста сонета:
Таким образом, окончательное выражение для извлечения и очистки полного текста сонета:
forEach(value.split("
"), line, line.trim()).slice(1).join("\n")
GREL для каждого выражения
Нажмите «ОК», чтобы создать столбец. Следуя той же методике, добавьте еще один новый столбец из синтаксического анализа с именем «последний», чтобы представить последние двустишие строки, используя:
forEach(value.split("
"), line, line.trim()). срез(-3).присоединиться("\n")
Наконец, числовые столбцы можно добавить с помощью функции length() .
Создать новые столбцы из текст с именами и выражениями ниже:
- «символы»,
value.length() - «линий»,
value.split(/\n/).length()
Очистка и экспорт
В этом примере мы использовали ряд операций для создания новых столбцов с чистыми данными.
Это типичный рабочий процесс уточнения, позволяющий легко сверить каждое преобразование с существующими данными. На этом этапе ненужные столбцы можно удалить.
Нажмите на Все столбцы > Редактировать столбцы > Переупорядочить/удалить столбцы .
На этом этапе ненужные столбцы можно удалить.
Нажмите на Все столбцы > Редактировать столбцы > Переупорядочить/удалить столбцы .
Все > Изменить столбцы
Перетащите имена ненужных столбцов в правую часть диалогового окна, в данном случае Столбец 1 , выборка и разбор . Перетащите оставшиеся столбцы в нужном порядке с левой стороны. Щелкните Ok , чтобы удалить и изменить порядок набора данных.
Изменить порядок/удалить столбцы
Используйте фильтры и фасеты для изучения и подмножества коллекции сонетов. Затем нажмите кнопку экспорта, чтобы создать версию новой таблицы сонетов для использования вне Refine. Будет экспортировано только текущее выбранное подмножество.
Экспорт CSV
Многие учреждения культуры предоставляют веб-API, позволяющие пользователям получать доступ к информации о своих коллекциях с помощью простых HTTP-запросов.
Эти источники позволяют создавать новые запросы и агрегировать текст, которые ранее были невозможны, преодолевая границы репозиториев и коллекций для поддержки крупномасштабного анализа как контента, так и метаданных. В этом примере будут собраны данные из проекта Chronicling America, чтобы собрать небольшой набор первых страниц газет с полным текстом.
Следуя обычному рабочему процессу парсинга веб-страниц, Refine используется для создания URL-адреса запроса, извлечения информации и анализа ответа JSON.
В этом примере будут собраны данные из проекта Chronicling America, чтобы собрать небольшой набор первых страниц газет с полным текстом.
Следуя обычному рабочему процессу парсинга веб-страниц, Refine используется для создания URL-адреса запроса, извлечения информации и анализа ответа JSON.
Chronicling America полностью открыта, поэтому для доступа к API не требуется ключ или учетная запись, и нет никаких ограничений на использование. Другие агрегаторы часто являются частными и ограниченными. Пожалуйста, ознакомьтесь с конкретными условиями использования перед просмотром веб-страниц или использованием информации в исследованиях.
Начать проект «Хроники Америки»
Чтобы начать работу после завершения Пример 1 , нажмите кнопку Открыть в правом верхнем углу. Откроется новая вкладка с представлением проекта Refine start. Вкладку с проектом Sonnets можно оставить открытой без ущерба для производительности. Создать проект из Буфер обмена , вставив этот CSV-файл в текстовое поле:
штат,год Айдахо, 1865 г.
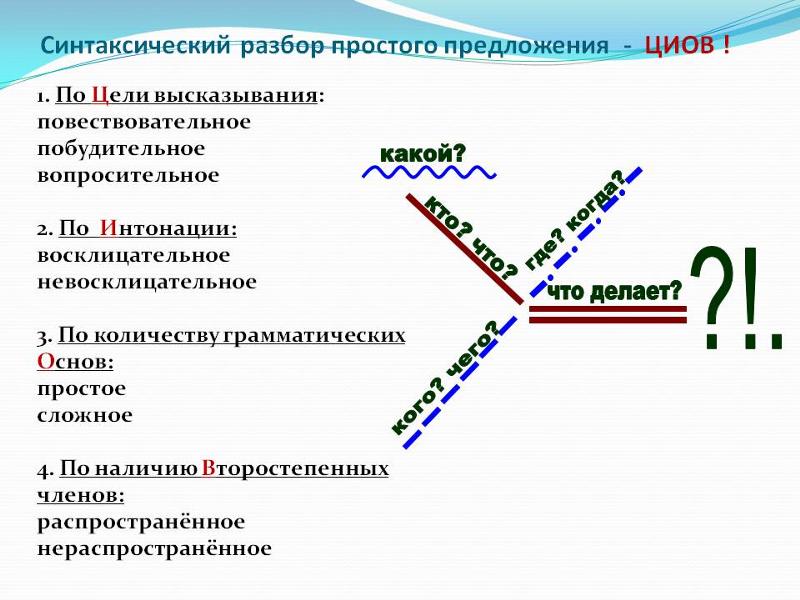 Монтана, 1865 г.
Орегон, 1865 г.
Вашингтон, 1865 г.
Монтана, 1865 г.
Орегон, 1865 г.
Вашингтон, 1865 г.
После нажатия Далее функция «Уточнить» должна автоматически идентифицировать содержимое как файл CSV с правильными параметрами синтаксического анализа. Добавьте имя проекта «ChronAm» в правом верхнем углу и нажмите «Создать проект ».
Создать проект
Создание запроса
Chronicling America предоставляет документацию по своим шаблонам API и URL.
В дополнение к официальной документации информация об альтернативных форматах и API поиска иногда приводится в элемент веб-страницы.
Проверьте , или