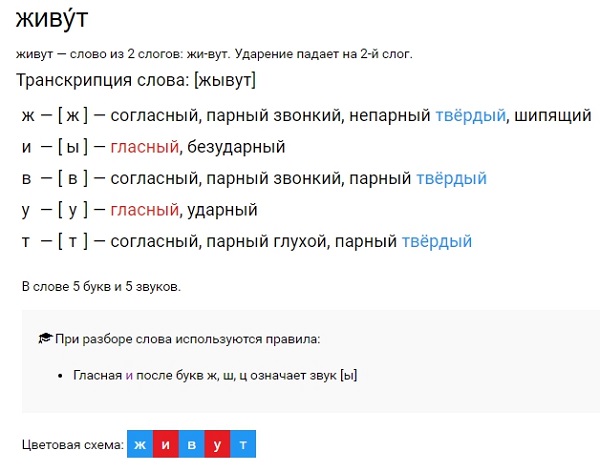
“Счастливый” фонетический разбор | Грамота
План — это то, что является сутью фонетического разбора слова “счастливый” и не только. Определённой последовательности необходимо придерживаться, так как это в разы упростит понимание смысла анализа.
Основные моменты, которые включены в фонетический анализ — это транскрипционная запись слова по звуковым и буквенным составляющим, правильное произношение и соотношения количества букв и звуков. Предлагаем проанализировать слово “счастливый” с точки звуко-буквенного разбора.
Фонетический разбор
- Как правило, данный этап следует начинать с определения местоположения ударения: счастлИвый.
- Языковая единица “счастливый” – трёхсложное слово, так как имеет три гласных. Правильно подсчитаем количество звуков и букв в анализируемом слове: 10 букв (3 гласных, 7 согласных) и 8 звуков.
- Слоговое деление выглядит следующим образом: счаст/ли/вый.
- Перенос слова “счастливый” через строку проводится по слоговому делению: счаст-ливый, счастли-вый.


Транскрипция слова
Перед тем, как записывать транскрипцию нужно несколько раз произнести единицу языка вслух. Итак, запишем все услышанные звуки: [щ’асл’ивый’].
Звуко-буквенный разбор
- с — [щ’] — по правилам звучания, относится к глухим всегда мягким согласным
- ч — с письменной единицей “с” образует совместный звук [щ’]
- а — [а] — данная гласная не имеет акцента в виде ударения
- с — [с] — согласно фонетике, относится к глухим твёрдым согласным
- т — не звучит при произношении, поэтому не имеет звуковой единицы, в данном случае
- л — [л’] —по правилам звучания, принадлежит к звонким мягким согласным
- и — [и] — данная гласная имеет акцент в виде ударения
- в — [в] — согласный, в звонкой твёрдой форме
- ы — [ы] — данная гласная не имеет акцента в виде ударения
- й — [й’] —по правилам звучания, относится к звонким всегда мягким согласным
Проверь себя: “Жёлтый” фонетический разбор слова
Звуко-буквенный разбор слова “счастливый” подразумевает описание признаков тех или иных звуков. Исходя из анализа, не все буквы соответствуют таким же звукам.
Исходя из анализа, не все буквы соответствуют таким же звукам.
Согласно правилам фонетики, сочетания букв -сч- обозначают звуковую единицу [щ’]. Так как согласная “л” стоит перед буквой “и”, то она смягчается, образуя звук [л’].
Раздел: ФонетикаПоп-группа или поп группа как правильно?
Правильно Поп-группа – правильный вариант написания сложного существительного, пишется через дефис. Согласно правилам русского языка, сложные существительные с несклоняемой первой частью, выраженной существительным в именительном падеже с нулевым окончанием, пишутся через дефис: поп-группа, рок-группа, джаз-оркестр. Известная поп-группа приезжает… Читать дальше »
Международный фонетический алфавит — изучайте и понимайте его онлайн
Есть ли какие-либо языки, которые вы хотели бы выучить? Было бы здорово, если бы вы знали, как произносить слова на любом языке?
На самом деле это возможно благодаря Международному фонетическому алфавиту! Если вы не знаете, что это такое, не волнуйтесь… Мы изучим Международный фонетический алфавит, зачем он был создан и что он может рассказать нам о звуках речи. Мы также рассмотрим фонематическую таблицу английского языка, которая показывает характерные для английского языка звуки речи. Наконец, мы опишем, как транскрибировать телефоны и фонемы.
Мы также рассмотрим фонематическую таблицу английского языка, которая показывает характерные для английского языка звуки речи. Наконец, мы опишем, как транскрибировать телефоны и фонемы.
Что такое Международный фонетический алфавит?
Международный фонетический алфавит (сокращенно IPA) представляет собой набор символов, обозначающих фонетические звуки. Эти звуки известны как телефоны. IPA используется, чтобы помочь нам понять и транскрибировать различные звуки речи на разных языках.
Чем полезен Международный фонетический алфавит?
IPA помогает нам правильно произносить слова. Вместо того, чтобы полагаться на письменное написание слов, которое не всегда совпадает с тем, как мы их произносим, фонетический алфавит описывает звуки слов (без привязки к буквам языка). Итак, когда что-то написано с использованием IPA, оно всегда будет соответствовать произношению. Это особенно полезно для людей, изучающих новый язык, так как они смогут правильно произносить слова.
Кто создал Международный фонетический алфавит?
Международный фонетический алфавит был создан в 1888 году французским лингвистом Полем Пасси.
Символы международного фонетического алфавита (МФА)
Он был основан на латинском алфавите и первоначально представлял звуки речи на разных языках, чтобы их можно было легко записать. Он также был создан с целью замены множества ранее использовавшихся отдельных систем транскрипции; единая система для представления звуков на всех языках была бы проще в использовании.
Каковы различные качества речи?
МФА представляет все различные качества и звуки речи на разных языках. К ним относятся:
- Телефоны
- Фонемы
- Интонация
- Разделение между словами
- Слоги.
Давайте рассмотрим их более подробно!
Что такое телефоны?
Телефоны различаются звуками. Когда мы говорим, мы производим телефоны. Телефоны не привязаны к какому-либо языку, поэтому используются во всем мире. Когда мы транскрибируем телефоны, они пишутся в квадратных скобках [ ].
Когда мы говорим, мы производим телефоны. Телефоны не привязаны к какому-либо языку, поэтому используются во всем мире. Когда мы транскрибируем телефоны, они пишутся в квадратных скобках [ ].
Что такое фонемы?
Фонемы — это мысленные представления и значения звука слова. Изменение фонемы в слове может изменить его значение. Например, замена фонемы /t/ в слове лист на фонему /p/ создает слово овца . В отличие от телефонов, фонемы зависят от языка, поэтому их нельзя применить ко всем языкам. Когда мы транскрибируем фонемы, они пишутся между косыми чертами / /.
Что такое интонация?
Интонация — это изменение тона голоса во время разговора. Интонация может использоваться по разным причинам, например:
, чтобы показать эмоции или отношение говорящего.
, чтобы показать разницу между утверждением и вопросом.
, чтобы указать, закончил ли говорящий свое предложение.
для добавления ударения к определенным частям предложения, что может немного изменить смысл.

Что такое разделение между словами?
Когда мы говорим, не каждое слово льется и не каждый слог оканчивается на чистый звук. Таким образом, между звуками, которые мы произносим, могут быть промежутки. Например, в слове «крайний» буква «т» часто произносится нечетко. При расшифровке звук «т» можно заменить символом, называемым гортанной смычкой, который выглядит так: ʔ. Он используется для обозначения блокировки воздушного потока, что мешает нам воспроизводить чистый звук.
Что такое слоги?
Слоги — это единицы разговорной речи, которые должны содержать гласный звук, а иногда и согласные. Например, если мы посмотрим на следующие слова:
Книга — 1 слог
Стол — 2 слога
Садоводство — 3 слога
используется для обозначения разрывов между разными слогами.
Таблица 9 Международного фонетического алфавита (IPA)0007
Таблица IPA показывает все звуки и качества речи в системе репрезентативных символов. — Wikimedia Commons (рис. 1)
Есть много информации, которую нужно принять, но не волнуйтесь! Мы просто разберем каждый раздел и рассмотрим каждую часть по очереди. Затем мы больше сосредоточимся на фонематическом алфавите английского языка, так как это поможет объяснить звуки, характерные для английского языка.
МФА можно разделить на:
Легочные согласные
Неупольмонные концентраты
гласных (монофтхонгс и дифтонгс)
Suprasementals
TONE давлением воздуха из легких и блокировкой пространства между голосовыми связками. Все согласных в английском языке являются легочными, но есть и некоторые в других языках (см. ниже).
В таблице IPA легочные согласные классифицируются тремя способами:
Звонкость — это относится к тому, издают ли голосовые связки звук.
Звонкие согласные возникают в результате вибрации голосовых связок при воспроизведении звука. Например, согласные: Б, Д, Г, Ж, Л. При глухих согласных голосовые связки не производят звук, вместо этого через них проходит воздух. Например, согласные: с, р, т, ф, ф.
Место сочленения — это относится к тому, где во рту издаются звуки.
Способ артикуляции — это относится к тому, как наши органы речи используются для воспроизведения звука, в частности, как блокируется воздушный поток для того, чтобы издавать разные звуки.
Например, звук произносимый / б/ называется звонким двугубным взрывным . Это означает, что для произнесения звука /b/:
Голосовые связки вибрируют, издавая звук (звонкий).
Обе губы сжаты (двугубные).
Голосовой тракт заблокирован, воздух выталкивается через губы (взрывной).
Нелегочные согласные
Это согласные, которые не образуются с потоком воздуха из легких. В английском языке нет нелегочных согласных.
Три типа непульмональных согласных:
Извлекательные
Имплозивные
Щелчки
Койсанские языки известны тем, что в них используются щелкающие согласные, которые можно записать с помощью таких символов, как ǃ и ǂ.
Гласные
Гласные — это звуки, которые произносятся без ограничения воздушного потока, и звук зависит от положения рта и языка.
Например, когда мы произносим гласную «а» в слове «выпекать», наши языки находятся далеко от нёба и направлены к передней части рта.
Но когда мы произносим гласную «у» в слове «музыка», язык становится близко к нёбу и расположен по направлению к спине .Типы гласных
Гласные можно разделить на две категории:
- Монофтонги
- Дифтонги
Моногласные звуки в одном слоге 9004. Например, гласный «i» в слове «hit» — это один гласный звук, который можно записать как /ɪ/.
Дифтонги — две гласные в слоге. Например, в слове «играть» гласная «а» состоит из двух звуков, которые транскрибируются как /eɪ/. Дифтонги также называют скользящими гласными, так как один гласный звук плавно переходит в другой.
Надсегментарии
Группа символов, обозначающих просодические признаки речи, в том числе
Ударение — ударение на определенных частях слова или высказывания.
Тон — изменение высоты голоса.
Длительность — Продолжительность звука, измеряемая в миллисекундах (не путать с длиной гласной)
Разрывы слогов — где заканчивается один слог и начинается другой.
Связывание — отсутствие разрыва слога
Тоны и словесные акценты
Тоны и акценты используются при транскрипции тональных языков, в которых слова могут иметь различное значение в зависимости от используемой интонации (высоты тона) . Примеры тональных языков включают китайский, тайский, вьетнамский.
Диакритические знаки
Диакритические знаки — это знаки, добавляемые к фонетическим знакам (например, ударениям или седилам), которые показывают небольшие различия в звуках, слегка изменяющие произношение.
Например, в слове «ручка» после буквы «р» слышно выдыхание воздуха. Это можно показать с помощью диакритического знака [ʰ], поэтому будет выглядеть как [pʰen].
Диакритические символы и их значения показаны в таблице на диаграмме IPA. — Wikimedia Commons (рис. 2)
Звуки МФА
Международный фонетический алфавит используется для представления всех возможных звуков речи. Это звуки, встречающиеся как в английском языке, так и в других языках. Эти звуки можно разделить на телефоны и фонемы. Мы рассмотрим эти термины и звуки английского языка ниже.
Международный фонетический алфавит (IPA) звуки английского языка
Звуки английского языка (или любого другого языка) показаны в фонематической таблице.
Эта фонематическая таблица основана на IPA и специфична для английского языка. Ниже показаны 44 английские фонемы:
Английский фонематический алфавит показывает все фонемы, используемые в английском языке.
— Викисклад (рис. 3).Расшифровка телефонов
При расшифровке телефоны записываются в квадратных скобках [ ]. Фонетическая транскрипция детализирована, в том числе многие элементы звуков речи, чтобы уточнить варианты произношения. Это так называемые «узкие транскрипции».
Ниже приведены некоторые примеры фонетической транскрипции. Все они написаны в соответствии с британским принятым произношением.
Булавка — [pʰɪn]
Крыло — [wɪ̃ŋ]
Порт — [pʰɔˑt]
Диакритические знаки используются в транскрипциях выше, чтобы показать определенные различия в произношении. [ʰ] указывает на аспирацию — слышимый выдох воздуха. [ h ] указывает на назализацию — воздух выходит из носа.
Транскрипция фонем
При транскрипции фонемы пишутся между косыми чертами / /. В фонематических транскрипциях упоминаются только наиболее очевидные и важные элементы звуков речи.
Это так называемые «широкие транскрипции».Ниже приведены некоторые примеры фонематических транскрипций. Все они написаны в соответствии с британским принятым произношением.
Булавка — /pɪn/
Крыло — /wɪŋ/
Порт — /pɔːt/
Поскольку фонематическая транскрипция не так подробна, как фонетическая транскрипция, диакритические знаки не нужны, поскольку они не нужны для понимания значения слов.
Международный фонетический алфавит. Ключевые выводы
- Международный фонетический алфавит (IPA) представляет собой набор символов, обозначающих фонетические звуки.
- IPA помогает нам транскрибировать слова на разных языках и произносить слова точно независимо от языка.
- IPA был создан в 1888 году французским лингвистом Полем Пасси.
- Телефоны — это звуки слов, тогда как фонемы — это мысленные представления звуков.
- Различными частями диаграммы IPA являются: легочные согласные, непульмональные согласные, монофтонги, дифтонги, надсегментарные звуки, тона и словесные ударения, диакритические знаки.
- Таблица фонематического алфавита английского языка предназначена для английского языка и содержит 44 фонемы английского языка.
- Фонетические транскрипции известны как узкие транскрипции. Они пишутся между скобками.
- Фонематическая транскрипция известна как широкая транскрипция. Они пишутся между косыми чертами.
Ссылки
- Рис. 1. Международная фонетическая ассоциация, CC BY-SA 3.0, через Wikimedia Commons
- Рис. 2. Пользователи Grendelkhan, Nohat на en.wikipedia, CC BY-SA 3.0, через Wikimedia Commons
- Рис. 3. Белоснежка, 1991, CC BY-SA 3.0, Wikimedia Commons
PowerShell разбирает файл Json — Stack Overflow
Я пытался искать, но нашел только одно сообщение, описывающее тот же метод, который я использую для анализа JSON, поэтому мне было интересно, есть ли лучший способ сделать это.
Я написал небольшую функцию для генерации случайного пароля и, используя таблицу Json ACII, чтобы определить, какие символы будут частью пароля, я выбрал этот подход, так как хочу также распечатать написание пароля.
Сейчас у меня есть это:
[строка]$asciiJson = @" [ {"Индекс": "1","Число": "33","AsciiCode": "!","Фонетический": "Восклицательный знак","Тип": "Символ"}, {"Индекс": "2","Число": "34","AsciiCode": "\"","Фонетический":"Двойные кавычки","Тип": "Символ"}, {"Индекс": "3","Число": "35","AsciiCode": "#","Фонетический": "Знак решетки","Тип": "Символ"}, {"Индекс": "4", "Число": "36", "AsciiCode": "$", "Фонетический": "Знак доллара", "Тип": "Символ"}, {"Индекс": "5","Число": "37","AsciiCode": "%","Фонетический": "Знак процента","Тип": "Символ"}, {"Индекс": "6", "Число": "38", "AsciiCode": "&", "Фонетический": "Амперсанд", "Тип": "Символ"}, {"Индекс": "7","Число": "39","AsciiCode": "'","Фонетический": "Одинарная кавычка","Тип": "Символ"}, {"Индекс": "8","Число": "40","AsciiCode": "(","Фонетический": "Открывающая скобка","Тип": "Символ"}, {"Индекс": "9","Число": "41","AsciiCode": ")","Фонетический": "Закрывающая скобка","Тип": "Символ"}, {"Индекс": "10","Число": "42","AsciiCode": "*","Фонетический": "Звездочка","Тип": "Символ"}, {"Индекс": "11","Число": "43","AsciiCode": "+","Фонетический": "Знак плюс","Тип": "Символ"}, {"Индекс": "12","Число": "44","AsciiCode": ",","Фонетический": "Запятая","Тип": "Символ"}, {"Индекс": "13","Число": "45","AsciiCode": "-","Фонетический": "Знак минус -Дефис","Тип": "Символ"}, {"Индекс": "14","Число": "46","AsciiCode": ".Это часть, где я генерирую таблицу различных символов
# Генерация таблиц символов $charsTable = ConvertFrom-Json-InputObject $asciiJson $symbolsTable = $charsTable | Где-Объект {$_.
 Звонкие согласные возникают в результате вибрации голосовых связок при воспроизведении звука. Например, согласные: Б, Д, Г, Ж, Л. При глухих согласных голосовые связки не производят звук, вместо этого через них проходит воздух. Например, согласные: с, р, т, ф, ф.
Звонкие согласные возникают в результате вибрации голосовых связок при воспроизведении звука. Например, согласные: Б, Д, Г, Ж, Л. При глухих согласных голосовые связки не производят звук, вместо этого через них проходит воздух. Например, согласные: с, р, т, ф, ф.
 Но когда мы произносим гласную «у» в слове «музыка», язык становится близко к нёбу и расположен по направлению к спине .
Но когда мы произносим гласную «у» в слове «музыка», язык становится близко к нёбу и расположен по направлению к спине .

 — Викисклад (рис. 3).
— Викисклад (рис. 3). Это так называемые «широкие транскрипции».
Это так называемые «широкие транскрипции».