Аудиоанализ с помощью машинного обучения: создание приложения для обнаружения звука на основе ИИ
Время чтения: 15 минут
Мы живем в мире звуков: приятные и надоедливые, низкие и высокие, тихие и громкие, они влияют на наше настроение и наши решения. Наш мозг постоянно обрабатывает звуки, чтобы дать нам важную информацию об окружающей среде. Но акустические сигналы могут сказать нам еще больше, если анализировать их с помощью современных технологий.
Сегодня у нас есть искусственный интеллект и машинное обучение для извлечения информации, неслышимой для людей, из речи, голосов, храпа, музыки, промышленного и дорожного шума и других типов акустических сигналов. В этой статье мы поделимся тем, что узнали при создании решений для распознавания звука на основе ИИ для проектов в области здравоохранения.
В частности, мы объясним, как получить аудиоданные, подготовить их к анализу и выбрать правильную модель машинного обучения для достижения максимальной точности предсказания. Но сначала давайте рассмотрим основы: что такое анализ звука и что делает работу с аудиоданными такой сложной задачей.
Но сначала давайте рассмотрим основы: что такое анализ звука и что делает работу с аудиоданными такой сложной задачей.
Что такое аудиоанализ?
Аудиоанализ — это процесс преобразования, изучения и интерпретации аудиосигналов, записанных цифровыми устройствами. Стремясь понять звуковые данные, он применяет ряд технологий, в том числе современные алгоритмы глубокого обучения. Аудиоанализ уже получил широкое распространение в различных отраслях, от развлечений до здравоохранения и производства. Ниже мы приведем самые популярные варианты использования.
Распознавание речи
Распознавание речи касается способности компьютеров различать произносимые слова с помощью методов обработки естественного языка. Это позволяет нам управлять ПК, смартфонами и другими устройствами с помощью голосовых команд и диктовать тексты машинам вместо ручного ввода. Siri от Apple, Alexa от Amazon, Google Assistant и Cortana от Microsoft — популярные примеры того, насколько глубоко технология проникла в нашу повседневную жизнь.
Распознавание голоса
Распознавание голоса предназначено для идентификации людей по уникальным характеристикам их голоса, а не для выделения отдельных слов. Подход находит применение в системах безопасности для аутентификации пользователей. Например, биометрический движок Nuance Gatekeeper проверяет сотрудников и клиентов по их голосам в банковском секторе.
Распознавание музыки
Распознавание музыки — это популярная функция таких приложений, как Shazam, которая помогает вам идентифицировать неизвестные песни по короткому образцу. Еще одним применением музыкального аудиоанализа является классификация жанров: скажем, Spotify использует собственный алгоритм для группировки треков по категориям (их база данных содержит более 5000 жанров)9.0003
Распознавание звуков окружающей среды
Распознавание звуков окружающей среды фокусируется на идентификации окружающих нас шумов, обещая множество преимуществ для автомобильной и производственной промышленности. Это жизненно важно для понимания окружения в приложениях IoT.
Это жизненно важно для понимания окружения в приложениях IoT.
Такие системы, как Audio Analytic, «прислушиваются» к событиям внутри и снаружи вашего автомобиля, позволяя автомобилю вносить коррективы для повышения безопасности водителя. Другим примером является технология SoundSee от Bosch, которая может анализировать шумы машин и упрощает профилактическое обслуживание для контроля состояния оборудования и предотвращения дорогостоящих отказов.
Здравоохранение — еще одна область, где может пригодиться распознавание звуков окружающей среды. Он предлагает неинвазивный тип удаленного мониторинга пациента для обнаружения таких событий, как падение. Кроме того, анализ кашля, чихания, храпа и других звуков может облегчить предварительный скрининг, определение статуса пациента, оценку уровня заражения в общественных местах и так далее.
Примером такого анализа в реальной жизни является Sleep.ai, который обнаруживает скрежетание зубами и звуки храпа во время сна. Решение, созданное AltexSoft для голландского стартапа в области здравоохранения, помогает стоматологам выявлять и контролировать бруксизм, чтобы в конечном итоге понять причины этой аномалии и лечить ее.
Независимо от того, какие звуки вы анализируете, все начинается с понимания аудиоданных и их специфических характеристик.
Что такое аудиоданные?
Аудиоданные представляют аналоговые звуки в цифровом виде, сохраняя основные свойства оригинала. Как мы знаем из школьных уроков физики, звук — это волна колебаний, проходящая через среду, такую как воздух или вода, и достигающая в конце концов наших ушей. Он имеет три ключевые характеристики, которые необходимо учитывать при анализе аудиоданных: период времени, амплитуда и частота.
Время Период — это то, как долго длится определенный звук или, другими словами, сколько секунд требуется для завершения одного цикла колебаний.
Амплитуда — это интенсивность звука, измеряемая в децибелах (дБ), которую мы воспринимаем как громкость.
Частота , измеряемая в герцах (Гц), показывает, сколько звуковых колебаний происходит в секунду. Люди интерпретируют частоту как низкий или высокий тон .
Люди интерпретируют частоту как низкий или высокий тон .
Хотя частота является объективным параметром, высота тона субъективна. Диапазон человеческого слуха лежит между 20 и 20 000 Гц. Ученые утверждают, что большинство людей воспринимают как низкий тон все звуки ниже 500 Гц — например, рев двигателя самолета. В свою очередь, высоким тоном для нас является все, что выше 2000 Гц (например, свист.)
Форматы файлов аудиоданных
Подобно текстам и изображениям, аудио представляет собой неструктурированные данные, что означает, что они не организованы в таблицы со связанными строками и столбцами. Вместо этого вы можете хранить аудио в различных форматах файлов, таких как
- WAV или WAVE (формат аудиофайла Waveform), разработанных Microsoft и IBM. Это формат файла без потерь или необработанный, что означает, что он не сжимает исходную звуковую запись;
- AIFF (формат файла обмена аудио), разработанный Apple. Как и WAV, он работает с несжатым звуком;
- FLAC (бесплатный аудиокодек без потерь), разработанный Xiph.
 Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.
Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука. - MP3 (mpeg-1 audio layer 3), разработанный Обществом Фраунгофера в Германии и поддерживаемый во всем мире. Это наиболее распространенный формат файлов, поскольку он позволяет легко хранить музыку на портативных устройствах и пересылать туда и обратно через Интернет. Хотя mp3 сжимает звук, он по-прежнему обеспечивает приемлемое качество звука.
 Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.
Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.Мы рекомендуем использовать файлы aiff и wav для анализа, так как они не пропускают информацию, присутствующую в аналоговых звуках. В то же время имейте в виду, что ни те, ни другие аудиофайлы нельзя напрямую скармливать моделям машинного обучения. Чтобы сделать звук понятным для компьютеров, данные должны быть преобразованы.
Основы преобразования аудиоданных, которые нужно знать
Прежде чем углубиться в обработку аудиофайлов, нам нужно ввести определенные термины, с которыми вы столкнетесь почти на каждом этапе нашего пути от сбора звуковых данных до получения прогнозов машинного обучения. Стоит отметить, что аудиоанализ предполагает работу с изображениями, а не прослушивание.
Стоит отметить, что аудиоанализ предполагает работу с изображениями, а не прослушивание.
Форма сигнала — это базовое визуальное представление аудиосигнала, отражающее изменение амплитуды во времени. График отображает время по горизонтальной оси (X) и амплитуду по вертикальной оси (Y), но не говорит нам, что происходит с частотами.
Пример сигнала. Источник: Обработка звуковых сигналов для машинного обучения
Спектр или спектральный график представляет собой график, на котором по оси X показана частота звуковой волны, а по оси Y — ее амплитуда. Этот тип визуализации звуковых данных помогает вам анализировать частотный контент, но пропускает временную составляющую.
Пример графика спектра. Источник: Analytics Vidhya
Спектрограмма представляет собой подробное представление сигнала, которое охватывает все три характеристики звука.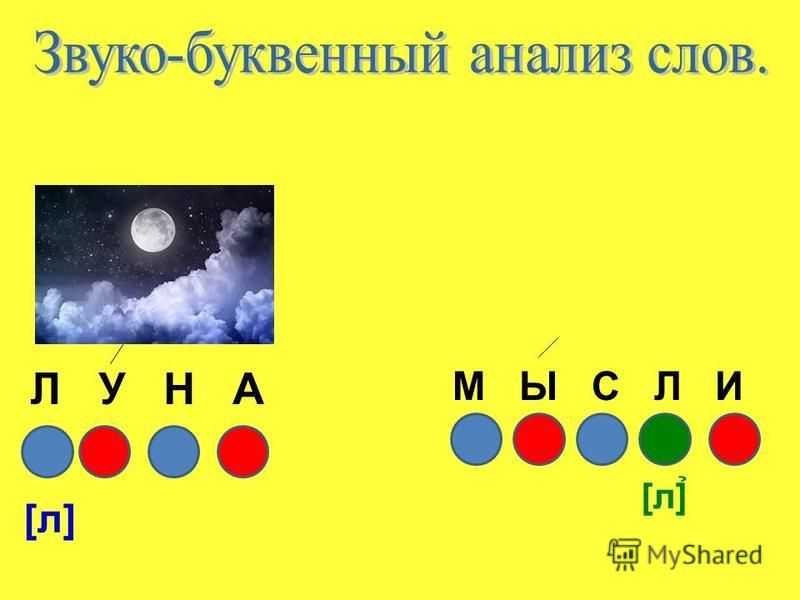 Вы можете узнать о времени по оси x, частоте по оси y и амплитуде по цвету. Чем громче событие, тем ярче цвет, а тишина представлена черным цветом. Очень удобно иметь три измерения на одном графике: это позволяет отслеживать, как меняются частоты во времени, исследовать звук во всей его полноте, на глаз выявлять различные проблемные места (например, шумы) и паттерны.
Вы можете узнать о времени по оси x, частоте по оси y и амплитуде по цвету. Чем громче событие, тем ярче цвет, а тишина представлена черным цветом. Очень удобно иметь три измерения на одном графике: это позволяет отслеживать, как меняются частоты во времени, исследовать звук во всей его полноте, на глаз выявлять различные проблемные места (например, шумы) и паттерны.
Пример спектрограммы. Источник: iZotope
Спектрограмма мела , где мел означает мелодия, представляет собой разновидность спектрограммы, основанную на шкале мела, которая описывает, как люди воспринимают звуковые характеристики. Наше ухо различает низкие частоты лучше, чем высокие. Вы можете проверить это сами: Попробуйте сыграть тоны от 500 до 1000 Гц, а затем от 10 000 до 10 500 Гц. Первый диапазон частот, казалось бы, намного шире второго, хотя на самом деле они одинаковы. Спектрограмма мела включает в себя эту уникальную особенность человеческого слуха, преобразуя значения в герцах в шкалу мела. Этот подход широко используется для классификации жанров, обнаружения инструментов в песнях и распознавания речевых эмоций.
Этот подход широко используется для классификации жанров, обнаружения инструментов в песнях и распознавания речевых эмоций.
Пример мел спектрограммы. Источник: Devopedia
Преобразование Фурье (FT) — это математическая функция, которая разбивает сигнал на пики различной амплитуды и частоты. Мы используем его для преобразования сигналов в соответствующие графики спектра, чтобы посмотреть на тот же сигнал под другим углом и выполнить частотный анализ. Это мощный инструмент для понимания сигналов и устранения ошибок в них.
Быстрое преобразование Фурье (БПФ) — это алгоритм, вычисляющий преобразование Фурье.
Применение БПФ для просмотра того же сигнала с точки зрения времени и частоты. Источник: NTi Audio
Кратковременное преобразование Фурье (STFT) представляет собой последовательность преобразований Фурье, преобразующих сигнал в спектрограмму.
Программное обеспечение для анализа звука
Конечно, вам не нужно выполнять преобразования вручную. Вам также не нужно понимать сложную математику, лежащую в основе FT, STFT и других методов, используемых в аудиоанализе. Все эти и многие другие задачи выполняются автоматически программным обеспечением для анализа звука, которое в большинстве случаев поддерживает следующие операции:
- импорт аудиоданных
- добавить аннотации (метки),
- редактировать записи и разбивать их на части,
- удалить шум,
- преобразовывать сигналы в соответствующие визуальные представления (формы сигналов, графики спектра, спектрограммы, мел-спектрограммы),
- выполнять операции предварительной обработки,
- анализ временного и частотного содержания,
- извлечение аудиофункций и многое другое.
Самые передовые платформы также позволяют обучать модели машинного обучения и даже предоставляют предварительно обученные алгоритмы.
Вот список самых популярных инструментов, используемых для анализа звука.
Audacity — это бесплатный аудиоредактор с открытым исходным кодом, позволяющий разделять записи, удалять шумы, преобразовывать сигналы в спектрограммы и маркировать их. Audacity не требует навыков программирования. Тем не менее, его набор инструментов для анализа звука не очень сложен. Для дальнейших шагов вам необходимо загрузить свой набор данных в Python или переключиться на платформу, специально предназначенную для анализа и/или машинного обучения.
Разметка аудиоданных в Audacity. Источник: Towards Data Science
Пакет Tensorflow-io для подготовки и аугментации аудиоданных позволяет выполнять широкий спектр операций — удаление шумов, преобразование волновых форм в спектрограммы, частотную и временную маскировку, чтобы сделать звук отчетливо слышимым, и более. Инструмент принадлежит экосистеме TensorFlow с открытым исходным кодом, охватывающей сквозной рабочий процесс машинного обучения.
Librosa — это библиотека Python с открытым исходным кодом, в которой есть почти все, что вам нужно для анализа звука и музыки. Он позволяет отображать характеристики аудиофайлов, создавать все типы визуализации аудиоданных и извлекать из них функции, и это лишь некоторые из возможностей.
Audio Toolbox от MathWorks предлагает множество инструментов для обработки и анализа аудиоданных, от маркировки до оценки показателей сигнала и извлечения определенных функций. Он также поставляется с предварительно обученными моделями машинного обучения и глубокого обучения, которые можно использовать для анализа речи и распознавания звука.
Этапы анализа аудиоданных
Теперь, когда у нас есть общее представление о звуковых данных, давайте взглянем на ключевые этапы сквозного проекта анализа аудио.
- Получите аудиоданные для конкретных проектов, сохраненные в стандартных форматах файлов.
- Подготовка данных для вашего проекта машинного обучения с использованием программных средств
- Извлечение звуковых характеристик из визуальных представлений звуковых данных.
- Выберите — модель машинного обучения, а — обучать аудиофункциям.
Этапы анализа звука с помощью машинного обучения
Сбор голосовых и звуковых данных
У вас есть три варианта получения данных для обучения моделей машинного обучения: использовать бесплатные звуковые библиотеки или наборы аудиоданных, приобрести их у поставщиков данных или собрать его с привлечением экспертов предметной области.
Бесплатные источники данных
В сети много таких источников. Но что мы в данном случае не контролируем, так это качество и количество данных, а также общий подход к записи.
Библиотеки звуков — это бесплатные аудиофайлы, сгруппированные по темам. Такие источники, как Freesound и BigSoundBank, предлагают голосовые записи, звуки окружающей среды, шумы и, честно говоря, всевозможные вещи. Например, вы можете найти саундскейп аплодисментов и набор со звуками скейтборда.
Такие источники, как Freesound и BigSoundBank, предлагают голосовые записи, звуки окружающей среды, шумы и, честно говоря, всевозможные вещи. Например, вы можете найти саундскейп аплодисментов и набор со звуками скейтборда.
Самое главное, что звуковые библиотеки не готовятся специально для проектов машинного обучения. Таким образом, нам необходимо выполнить дополнительную работу по комплектованию комплектов, маркировке и контролю качества.
Наборы аудиоданных , напротив, созданы с учетом конкретных задач машинного обучения. Например, набор данных Bird Audio Detection Лаборатории машинного прослушивания содержит более 7000 отрывков, собранных в ходе проектов биоакустического мониторинга. Другим примером является набор данных ESC-50: Классификация звуков окружающей среды, содержащий 2000 помеченных аудиозаписей. Каждый файл длится 5 секунд и принадлежит к одному из 50 семантических классов, организованных в пять категорий.
Одна из крупнейших коллекций аудиоданных — AudioSet от Google. Он включает более 2 миллионов 10-секундных звуковых клипов с человеческими метками, извлеченных из видео на YouTube. Набор данных охватывает 632 класса, от музыки и речи до звуков осколков и зубной щетки.
Он включает более 2 миллионов 10-секундных звуковых клипов с человеческими метками, извлеченных из видео на YouTube. Набор данных охватывает 632 класса, от музыки и речи до звуков осколков и зубной щетки.
Коммерческие наборы данных
Коммерческие аудио наборы для машинного обучения определенно более надежны с точки зрения целостности данных, чем бесплатные. Мы можем порекомендовать ProSoundEffects продавать наборы данных для обучения моделей для распознавания речи, классификации звуков окружающей среды, разделения источников звука и других приложений. Всего у компании 357 000 файлов, записанных экспертами по звуку фильмов и классифицированных по 500+ категориям.
Но что, если звуковые данные, которые вы ищете, слишком специфичны или редки? Что делать, если вам нужен полный контроль над записью и маркировкой? Что ж, тогда лучше делайте это в партнерстве с надежными специалистами из той же отрасли, что и ваш проект по машинному обучению.
Экспертные наборы данных
При работе с Sleep. ai нашей задачей было создание модели, способной идентифицировать скрежещущие звуки, которые люди с бруксизмом обычно издают во время сна. Понятно, что нужны были специальные данные, недоступные в открытых источниках. Кроме того, надежность и качество данных должны были быть самыми лучшими, чтобы мы могли получить достоверные результаты.
ai нашей задачей было создание модели, способной идентифицировать скрежещущие звуки, которые люди с бруксизмом обычно издают во время сна. Понятно, что нужны были специальные данные, недоступные в открытых источниках. Кроме того, надежность и качество данных должны были быть самыми лучшими, чтобы мы могли получить достоверные результаты.
Чтобы получить такой набор данных, стартап сотрудничал с лабораториями сна, где ученые наблюдают за людьми, пока они спят, чтобы определить здоровый режим сна и диагностировать нарушения сна. Эксперты используют различные устройства для записи мозговой активности, движений и других событий. Для нас они подготовили размеченный набор данных, содержащий около 12 000 образцов скрежещущих и храпящих звуков.
Подготовка аудиоданных
В случае Sleep.io наша команда пропустила этот шаг, доверив специалистам по сну задачу подготовки данных для нашего проекта. То же самое относится и к тем, кто покупает аннотированные звуковые коллекции у поставщиков данных. Но если у вас есть только необработанные данные, то есть записи, сохраненные в одном из форматов аудиофайлов, вам необходимо подготовить их для машинного обучения.
Но если у вас есть только необработанные данные, то есть записи, сохраненные в одном из форматов аудиофайлов, вам необходимо подготовить их для машинного обучения.
Маркировка аудиоданных
Маркировка или аннотация данных — это пометка необработанных данных с правильными ответами для запуска контролируемого машинного обучения. В процессе обучения ваша модель научится распознавать закономерности в новых данных и делать правильные прогнозы на основе меток. Таким образом, их качество и точность имеют решающее значение для успеха проектов машинного обучения.
Хотя маркировка предполагает помощь программных инструментов и некоторую степень автоматизации, по большей части она по-прежнему выполняется вручную профессиональными аннотаторами и/или экспертами в предметной области. В нашем проекте по обнаружению бруксизма эксперты по сну прослушали аудиозаписи и пометили их ярлыками скрежета или храпа.
Узнайте больше о подходах к аннотированию из нашей статьи Как организовать маркировку данных для машинного обучения
Предварительная обработка аудиоданных
Помимо обогащения данных значимыми тегами, мы должны предварительно обработать звуковые данные, чтобы повысить точность предсказания. Вот самые основные шаги для проектов по распознаванию речи и классификации звуков.
Вот самые основные шаги для проектов по распознаванию речи и классификации звуков.
Кадрирование означает разрезание непрерывного звукового потока на короткие фрагменты (кадры) одинаковой длины (обычно 20-40 мс) для дальнейшей посегментной обработки.
Работа с окнами — это фундаментальный метод обработки звука, позволяющий свести к минимуму спектральную утечку — распространенную ошибку, приводящую к искажению частоты и ухудшению точности амплитуды. Существует несколько оконных функций (Хемминга, Хэннинга, Плоской вершины и т. д.), применяемых к разным типам сигналов, хотя вариант Хэннинга хорошо работает в 95% случаев.
По сути, все окна делают одно и то же: уменьшают или сглаживают амплитуду в начале и конце каждого кадра, увеличивая ее в центре, чтобы сохранить среднее значение.
Форма сигнала до и после работы с окнами. Источник: National Instruments .
Метод Overlap-Add (OLA) предотвращает потерю жизненно важной информации, которая может быть вызвана работой с окнами . OLA обеспечивает 30-50-процентное перекрытие между соседними кадрами, что позволяет изменять их без риска искажения. В этом случае исходный сигнал можно точно восстановить по окнам.
OLA обеспечивает 30-50-процентное перекрытие между соседними кадрами, что позволяет изменять их без риска искажения. В этом случае исходный сигнал можно точно восстановить по окнам.
Пример работы с окнами с перекрытием. Источник: Wiki Университета Аалто
Узнайте больше об этапе предварительной обработки и методах, которые он использует, из нашей статьи Подготовка ваших данных для машинного обучения и видео ниже.
https://youtu.be/P8ERBy91Y90
Аудиофункции или дескрипторы — это свойства сигналов, вычисленные на основе визуализации предварительно обработанных аудиоданных. Они могут принадлежать к одному из трех доменов
- временных доменов, представленных осциллограммами,
- частотная область, представленная графиками спектра, и
- временная и частотная области, представленные спектрограммами.
Визуализация аудиоданных: форма сигнала для временной области, спектр для частотной области и спектрограмма для частотно-временной области. Источник: Типы аудиофункций для машинного обучения.
Источник: Типы аудиофункций для машинного обучения.
Характеристики во временной области
Как мы упоминали ранее, характеристики во временной области или временные характеристики извлекаются непосредственно из исходных сигналов. Обратите внимание, что волновые формы не содержат много информации о том, как на самом деле будет звучать произведение. Они показывают только то, как амплитуда изменяется со временем. На изображении ниже мы видим, что сигналы состояния воздуха и сигналов сирены выглядят одинаково, но, конечно же, эти звуки не будут похожими.
Примеры сигналов. Источник: Towards Data Science
Теперь давайте перейдем к некоторым ключевым характеристикам, которые мы можем извлечь из сигналов.
Огибающая амплитуды (AE) отслеживает пики амплитуды в пределах кадра и показывает, как они изменяются во времени. С помощью AE вы можете автоматически измерять продолжительность отдельных частей звука (как показано на рисунке ниже). AE широко используется для обнаружения начала, чтобы указать, когда начинается определенный сигнал, а также для классификации музыкальных жанров.
AE широко используется для обнаружения начала, чтобы указать, когда начинается определенный сигнал, а также для классификации музыкальных жанров.
Амплитуда огибающей тико-тико пения птиц. Источник: Seewave: Принципы анализа звука
Кратковременная энергия (STE) показывает изменение энергии в коротком речевом кадре.
Это мощный инструмент для разделения вокализованных и невокализованных сегментов.
Среднеквадратическая энергия (RMSE) дает вам представление о средней энергии сигнала. Его можно вычислить по форме волны или спектрограмме. В первом случае вы получите результат быстрее. Тем не менее, спектрограмма обеспечивает более точное представление энергии во времени. RMSE особенно полезен для сегментации звука и классификации музыкальных жанров.
Скорость пересечения нуля (ZCR) подсчитывает, сколько раз сигнальная волна пересекает горизонтальную ось в кадре. Это одна из наиболее важных акустических характеристик, широко используемая для обнаружения присутствия или отсутствия речи и отличия шума от тишины и музыки от речи.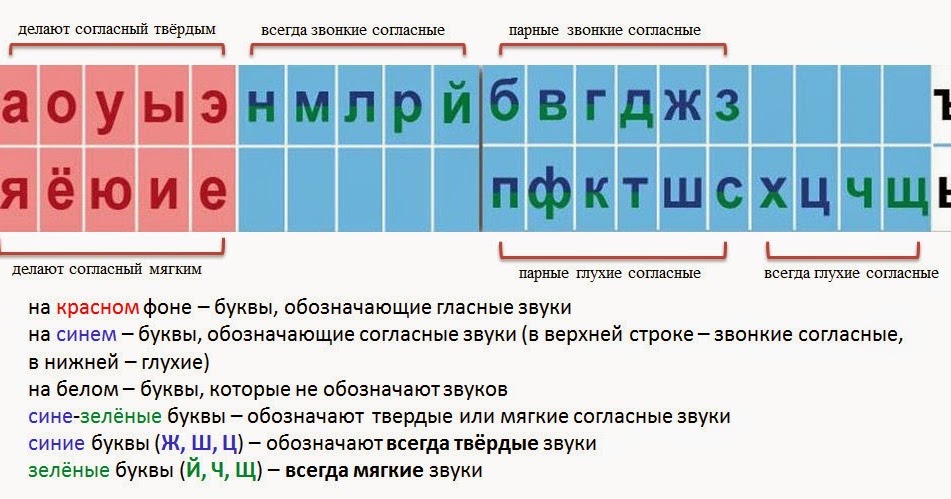
Характеристики частотной области
Признаки частотной области извлечь труднее, чем временные, поскольку процесс включает преобразование сигналов в графики спектра или спектрограммы с использованием FT или STFT. Тем не менее, именно частотное содержание раскрывает многие важные звуковые характеристики, невидимые или трудноразличимые во временной области.
Наиболее распространенные характеристики частотной области включают
- среднюю или среднюю частоту,
- медианная частота при разделении спектра на две области с одинаковой амплитудой,
- отношение сигнал-шум (SNR) при сравнении силы желаемого звука с фоновым носом, Отношение энергии полосы
- (BER), изображающее отношения между более высокими и более низкими частотными диапазонами. Другими словами. он измеряет, насколько низкие частоты преобладают над высокими.
Конечно, в этом домене есть множество других свойств, на которые стоит обратить внимание. Напомним, что он говорит нам, как звуковая энергия распространяется по частотам, а временная область показывает, как сигнал изменяется во времени.
Характеристики частотно-временной области
Эта область объединяет как временные, так и частотные компоненты и использует различные типы спектрограмм для визуального представления звука. Вы можете получить спектрограмму из сигнала, применяя кратковременное преобразование Фурье.
Одна из самых популярных групп характеристик частотно-временной области — мел-частотные кепстральные коэффициенты (MFCC) . Они работают в диапазоне человеческого слуха и, как таковые, основаны на мел-шкале и мел-спектрограммах, которые мы обсуждали ранее.
Неудивительно, что первоначальное применение MFCC — это распознавание речи и голоса. Но они также оказались эффективными для обработки музыки и акустической диагностики в медицинских целях, в том числе для обнаружения храпа. Например, одна из недавних моделей глубокого обучения, разработанная Инженерной школой (Университет Восточного Мичигана), была обучена на 1000 MFCC-изображениях (спектрограммах) звуков храпа.
Форма волны звука храпа (a) и ее спектрограмма MFCC (b) по сравнению с формой волны звука смыва унитаза (c) и соответствующим изображением MFCC (d). Источник: Модель глубокого обучения для обнаружения храпа ( Electronic Journal, Vol.8, Issue 9 )
временная и частотная области. В сочетании они создавали богатые профили скрежещущих и храпящих звуков.
Выбор и обучение моделей машинного обучения
Поскольку звуковые функции представлены в визуальной форме (в основном в виде спектрограмм), это делает их объектом распознавания изображений, основанного на глубоких нейронных сетях. Существует несколько популярных архитектур, показывающих хорошие результаты в обнаружении и классификации звука. Здесь мы сосредоточимся только на двух обычно используемых для выявления проблем со сном по звуку.
Сети с долговременной кратковременной памятью (LSTM)
Сети с долговременной кратковременной памятью (LSTM) известны своей способностью выявлять долгосрочные зависимости в данных и запоминать информацию из многочисленных предыдущих шагов. Согласно исследованию обнаружения апноэ во сне, LSTM могут достигать точности 87 процентов при использовании функций MFCC в качестве входных данных для отделения нормальных звуков храпа от ненормальных.
Согласно исследованию обнаружения апноэ во сне, LSTM могут достигать точности 87 процентов при использовании функций MFCC в качестве входных данных для отделения нормальных звуков храпа от ненормальных.
Другое исследование показывает еще лучшие результаты: LSTM классифицировал нормальный и ненормальный храп с точностью 95,3%. Нейронная сеть была обучена с использованием пяти типов функций, включая MFCC и кратковременную энергию из временной области. Вместе они представляют различные характеристики храпа.
Сверточные нейронные сети (CNN)
Сверточные нейронные сети лидируют в области компьютерного зрения в здравоохранении и других отраслях. Их часто называют , что является естественным выбором для задач распознавания изображений . Эффективность архитектуры CNN при обработке спектрограмм еще раз доказывает справедливость этого утверждения.
В вышеупомянутом проекте Инженерной школы (Университет Восточного Мичигана) модель глубокого обучения на основе CNN достигла точности 96 процентов в классификации храпящих и нехрапящих звуков.
Почти такие же результаты получены для комбинации архитектур CNN и LSTM. Группа ученых из Технологического университета Эйндховена применила модель CNN для извлечения признаков из спектрограмм, а затем запустила LSTM, чтобы классифицировать выходные данные CNN на события, связанные с храпом и без храпа. Значения точности варьируются от 94,4 до 95,9 процентов в зависимости от расположения микрофона, используемого для записи звуков храпа.
Для проекта Sleep.io команда специалистов по данным AltexSoft использовала две CNN (для обнаружения храпа и скрипа) и обучила их на платформе TensorFlow. После того, как модели достигли точности более 80 процентов, они были запущены в производство. Их результаты постоянно улучшались по мере роста числа входных данных, полученных от реальных пользователей.
Создание приложения для обнаружения храпа и скрежетания зубами
Чтобы сделать наши алгоритмы классификации звуков доступными для широкой аудитории, мы упаковали их в приложение для iOS Do I Snore or Grind, которое вы можете бесплатно загрузить из App Store.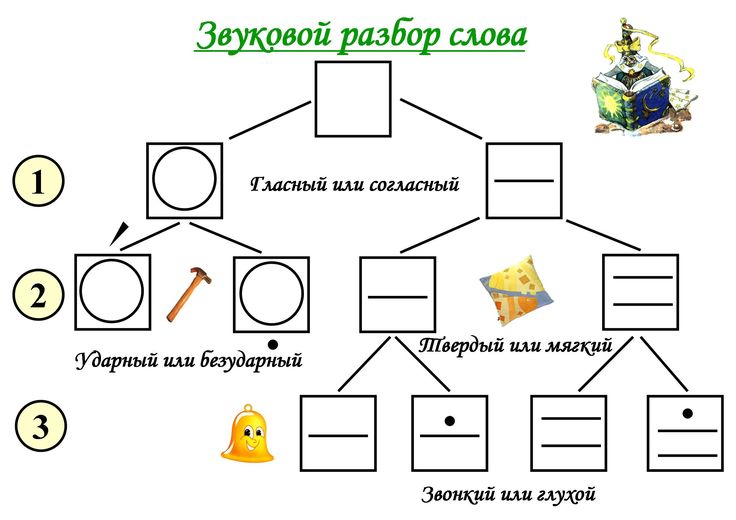 Наша команда UX создала единый поток, позволяющий пользователям записывать шумы во время сна, отслеживать свой цикл сна, отслеживать события вибрации и получать информацию о факторах, влияющих на сон, и советы о том, как они могут изменить свои привычки. Весь анализ аудиоданных выполняется на устройстве, поэтому вы получите результаты даже при отсутствии подключения к Интернету.
Наша команда UX создала единый поток, позволяющий пользователям записывать шумы во время сна, отслеживать свой цикл сна, отслеживать события вибрации и получать информацию о факторах, влияющих на сон, и советы о том, как они могут изменить свои привычки. Весь анализ аудиоданных выполняется на устройстве, поэтому вы получите результаты даже при отсутствии подключения к Интернету.
Интерфейс приложения Do I Snore or Grind.
Имейте в виду, однако, что никакое приложение для здоровья, каким бы умным оно ни было, не может заменить настоящего врача. Вывод, сделанный ИИ, должен быть проверен вашим стоматологом, врачом или другим медицинским экспертом.
Если вы хотите узнать еще больше подробностей, прочитайте наши тематические исследования
AltexSoft и Bruxlab: использование современного машинного обучения и науки о данных для диагностики и борьбы с бруксизмом
AltexSoft и SleepScore Labs: Building iOS-приложение для обнаружения храпа и скрежета зубов
Руководство по концепции синтаксического анализа
Руководство по концепции синтаксического анализаЗачем нужен синтаксический анализ
Важным аспектом соответствия данных назначению является их структура.
- В системе сбора данных нет полей для каждая отдельная часть информации с различным использованием, что приводит к тому, что пользователь обходные пути, такие как ввод большого количества отдельных фрагментов информации в единственное свободное текстовое поле или использование неправильных полей для информации, которая не имеет очевидного места (например, размещение информации о компании в отдельных полях контактов).
- Данные необходимо перенести в новую систему с другая структура данных.
- Необходимо удалить дубликаты из данных, и трудно определить и удалить дубликаты из-за структуры данных (например, идентификаторы ключевых адресов, такие как номер помещения, не разделяются от остальной части адреса).
В качестве альтернативы структура данных может быть правильной, но использование
оно недостаточно контролируется или подвержено ошибкам. Например:
Например:
- Пользователи не обучены собирать все необходимые информацию, вызывая такие проблемы, как ввод контактов с помощью «читов данных», а не реальных имена в полях имени
- Приложение отображает поля в нелогичном порядок, что приводит к тому, что пользователи вводят данные не в те поля
- Пользователи вводят повторяющиеся записи способами, трудно обнаружить, например, ввод неточных данных в несколько записей, представляющих один и тот же сущности, либо введя точные данные, но не в те поля.
Все эти проблемы приводят к ухудшению качества данных, что во многих случаях может дорого обходиться бизнесу. Поэтому для бизнеса важно быть в состоянии анализировать данные для этих проблем, и решить их там, где необходимый.
Анализатор OEDQ
Процессор OEDQ Parse предназначен для использования разработчиками.
процессов качества данных для создания пакетных парсеров для понимания
и преобразование конкретных типов данных — например, данных имен,
Адресные данные или описания продуктов. Тем не менее, это общий парсер
в котором нет правил по умолчанию, специфичных для любого типа данных. Зависит от данных
правила могут быть созданы путем анализа самих данных и установки Parse
конфигурация.
Тем не менее, это общий парсер
в котором нет правил по умолчанию, специфичных для любого типа данных. Зависит от данных
правила могут быть созданы путем анализа самих данных и установки Parse
конфигурация.
Терминология
Синтаксический анализ — часто используемый термин как в области качества данных, и в вычислительной технике в целом. Это может означать что угодно, от простого «нарушения данные до полного синтаксического анализа естественного языка (NLP), который использует сложные искусственный интеллект, позволяющий компьютерам «понимать» человеческий язык. Также часто используется ряд других терминов, связанных с синтаксическим анализом. Опять таки, они могут иметь немного разные значения в разных контекстах. это поэтому важно определить, что мы подразумеваем под синтаксическим анализом и связанным с ним термины в OEDQ.
Обратите внимание на следующие термины и определения:
Срок | Определение |
Разбор | В OEDQ синтаксический анализ определяется как применение заданных пользователем
бизнес-правила и искусственный интеллект, чтобы понимать и
проверять массивы любых типов данных и, при необходимости, улучшать их структуру
для того, чтобы сделать его пригодным для использования. |
Жетон | Маркер — это часть данных, которая распознается как единица синтаксическим анализом. процессор с помощью правил. Заданное значение данных может состоять из одного или нескольких токенов. Маркер может быть распознан с помощью синтаксического или семантического анализа данных. |
Токенизация | Первоначальный синтаксический анализ данных с целью их разделения на
наименьшие единицы (базовые токены) с использованием правил. Каждому базовому токену присваивается тег,
например , который используется для представления непрерывной последовательности буквенных символов. |
Базовый токен | Начальный токен, распознаваемый Tokenization. Последовательность базы Жетоны позже могут быть объединены для формирования нового Токена в Классификации или Реклассификация. |
Классификация | 905:30|
Проверка токена | 905:30|
Реклассификация | Необязательный дополнительный этап классификации, который позволяет классифицированные токены и неклассифицированные (базовые) токены, подлежащие реклассификации как один новый токен. |
Образец токена | Объяснение строки данных с использованием шаблона тегов токена, либо в одном атрибуте или в нескольких атрибутах. Строка данных может быть представлена с использованием нескольких различных токенов. узоры. |
Выбор | Процесс, с помощью которого процессор Parse пытается выбрать «лучший»
объяснение данных с использованием настраиваемого алгоритма, где запись имеет
множество возможных объяснений (или шаблонов токенов). |