Разбор слов по составу, морфемный разбор
wordmap
Разбор слов по составу
Каждое слово состоит из составных частей. Выделение этих частей – и есть разбор слов по составу. Его также называют «морфемный разбор слов». Чтобы научиться делать такой разбор быстро и безошибочно, необходимо первым делом понять, какие части слов бывают, и как они определяются.
Кстати, чтобы сделать грамотный морфемный разбор слов, особенно если вы столкнулись со сложными словами, будет нелишним использовать специальные словари морфемных разборов. Они могут быть электронными, ими легко и удобно пользоваться в режиме онлайн, например – на нашем сайте.
Разбираем поэтапно
Морфемный разбор слова необходимо делать в определенной последовательности:
- Для начала, выпишите слово и выясните, к какой части речи оно относится. Если это, к примеру, наречие – знайте, что оно не будет иметь окончания и других частей, так как не изменяется.
- Определите окончание, если оно вообще есть.

- Далее стоит определить основу. Это та часть, у которой нет окончания. Например, слово «городской»: тут окончание «ой», и основа «городск».
- Как видите, основа может содержать в себе суффикс и даже приставку.
- Находим приставку, если таковая имеется. К примеру, слово «застолье»: после того, как вы определили основу «стол», вы безтруда найдете приставку «за».
- Определяем суффикс. Эта часть слова стоит сразу после основы (корня» и нужна, чтобы образовать новое слово. Например, был стол – стал столик. В этом случае «ик» — суффикс (окончания нет). Был лес – стал лесок, или лесник.
- Последний этап – найти корень слова. Это та часть, которая не изменяется. В случае со столом, «стол» и есть корень. Чтобы определить корень, найдите однокоренные слова.

Каждая часть выделяется графически, с помощью особых значков. Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Особенности, которые следует знать
Морфемный анализ – процесс, который может показаться слишком простым, а может и наоборот, вызывать ряд сложностей. Вот, что стоит всегда знать и учитывать:
- Нельзя начинать разбор с поиска корня, даже если на первый взгляд он очевиден. Это может привести к ошибке, так что начинать всегда следует с окончания. Часто этап определения корня стоит вторым в плане, но все же вернее именно заканчивать разбор этим этапом, так как это – наиболее безошибочный путь.
- Не стоит путать слова с нулевым окончанием, и те, которые не имеют окончаний. Ведь нулевое окончание – это по сути такая же часть речи, а слово, не имеющее окончаний – не изменяется вовсе. Например, это наречия, деепричастия, сравнительные степени прилагательных и некоторые исключения.

Чтобы научиться делать морфемный разбор грамотно, не забывайте пользоваться электронными словарями, которые доступны на нашем сайте. Это удобно, и позволит вам научиться разбирать слова безошибочно!
Только что искали:
цветы апельсина 2 секунды назад
понакидала 3 секунды назад
слизский 3 секунды назад
жорнгел 6 секунд назад
ревец 9 секунд назад
рутина 11 секунд назад
невма 14 секунд назад
монен смит 14 секунд назад
ксаерн 16 секунд назад
бомботари 27 секунд назад
зильберинг 27 секунд назад
наблко 27 секунд назад
захолустье 41 секунда назад
стягивается 43 секунды назад
возглавить роту 48 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | деселерометр | 27 слов | 5 часов назад | 178.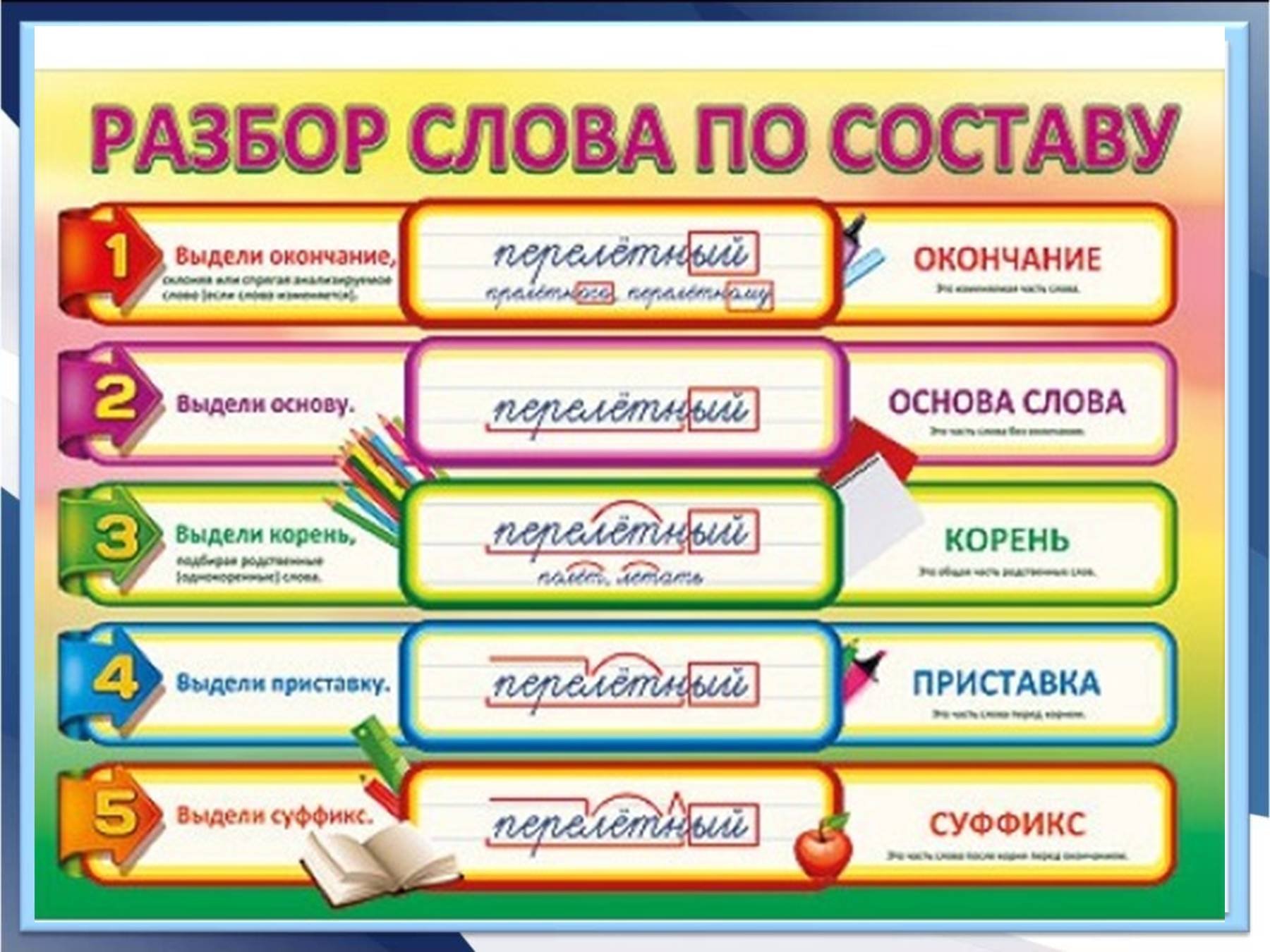 176.79.226 176.79.226 |
| Игрок 2 | кинообъектив | 15 слов | 6 часов назад | 46.187.4.53 |
| Игрок 3 | круиз | 3 слова | 10 часов назад | 93.80.182.13 |
| Игрок 4 | переворот | 24 слова | 10 часов назад | 93.80.182.13 |
| Юленька | менструация | 1 слово | 15 часов назад | 178.176.67.205 |
| Юлия | переворот | 5 слов | 15 часов назад | 178.176.67.205 |
| Игрок 7 | заплевывание | 26 слов | 16 часов назад | 85.254.74.198 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | немного | 50:48 | 5 часов назад | 217. 66.156.154 66.156.154 |
| Игрок 2 | подарок | 48:47 | 5 часов назад | 217.66.156.154 |
| Игрок 3 | красава | 47:54 | 5 часов назад | 46.187.4.53 |
| Игрок 4 | закреплен | 55:52 | 5 часов назад | 217.66.156.154 |
| Игрок 5 | сиротка | 18:28 | 5 часов назад | 46.187.4.53 |
| Игрок 6 | постоянно | 62:53 | 5 часов назад | 217.66.156.154 |
| Игрок 7 | волнограф | 22:27 | 5 часов назад | 46.187.4.53 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Юля | На одного | 10 вопросов | 5 часов назад | 46. 187.4.53 187.4.53 |
| Й | На одного | 10 вопросов | 6 часов назад | 83.217.201.60 |
| Krasskina | На двоих | 5 вопросов | 9 часов назад | 178.176.74.84 |
| Кристина | На одного | 10 вопросов | 13 часов назад | 46.216.168.145 |
| Кристина | На одного | 10 вопросов | 13 часов назад | 46.216.168.145 |
| Анна Никитина | На двоих | 5 вопросов | 1 день назад | 31.173.84.152 |
| Анастасия Ратникова | На двоих | 5 вопросов | 1 день назад | 31.173.84.152 |
| Играть в Чепуху! | ||||
Морфологический разбор слова «семью»
Слово можно разобрать в 3 вариантах, в
зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Наречие
2 вариант разбора
Часть речи: Существительное
СЕМЬЮ — неодушевленное
Начальная форма слова: «СЕМЬЯ»
| Слово | Морфологические признаки |
|---|---|
| СЕМЬЮ |
|
Все формы слова СЕМЬЮ
СЕМЬЯ, СЕМЬИ, СЕМЬЕ, СЕМЬЮ, СЕМЬЕЙ, СЕМЬЕЮ, СЕМЕЙ, СЕМЬЯМ, СЕМЬЯМИ, СЕМЬЯХ
3 вариант разбора
Часть речи: Числительное
Разбор слова по составу семью
| Основа слова | семью |
|---|---|
| Корень | семь |
| Суффикс | ю |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СЕМЬЮ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «семью»
Примеры предложений со словом «семью»
1
Она вернулась домой с семью картофелинами среднего размера, семью куриными филе и семью морковками примерно одинаковой длины.
Поступки во имя любви, Роушин Мини, 2011г.
2
Любовь к женщине он не только не мог себе представить без брака, но он прежде представлял себе семью, а потом уже ту женщину, которая даст ему семью.
Анна Каренина, Лев Толстой, 1878г.
3
Не найти счастья ни за семью морями, ни за семью горами.
Богомолье. Повести и рассказы, Иван Шмелев, 2008г.
4
если ты выйдешь за него, он войдет в нашу семью как сын, тогда как с другим тебе самой, нашей дочери, придется войти в чужую семью.
Жизнь, Ги де Мопассан, 1883г.
5
Он не изображает человеческую семью на фоне природы – он делает человеческую семью частью природы.
Книги в моей жизни (сборник), Генри Миллер, 1952г.
Найти еще примеры предложений со словом СЕМЬЮ
«В чем разница между доходом и богатством?» и другие распространенные вопросы об экономических концепциях | Pew Research Center
Pew Research Center illustration В Pew Research Center мы изучаем экономическую жизнь людей — от того, кто считается безработным, до того, что значит быть представителем среднего класса. Но экономические концепции не всегда так понятны остальным из нас, как экономистам, и жаргон может быть труден для понимания.
Но экономические концепции не всегда так понятны остальным из нас, как экономистам, и жаргон может быть труден для понимания.
Вот некоторые из наиболее распространенных терминов и понятий, которые встречаются в нашей работе по экономике, и их значение.
В чем разница между доходом и богатством?Доход и благосостояние являются ключевыми показателями финансовой безопасности семьи или отдельного человека. Доход – это сумма заработка от работы или собственного бизнеса, процентов по сбережениям и инвестициям, выплат по социальным программам и многих других источников. Обычно он рассчитывается на годовой или ежемесячной основе.
Богатство, или собственный капитал, представляет собой стоимость активов, принадлежащих семье или физическому лицу (например, дом или сберегательный счет), за вычетом непогашенной задолженности (например, ипотечного кредита или студенческого кредита). Это относится к сумме, накопленной за всю жизнь или более (поскольку она может передаваться из поколения в поколение). Это накопленное богатство является источником пенсионного дохода, защищает от краткосрочных экономических потрясений и обеспечивает безопасность для будущих поколений. По состоянию на 2016 год семьи с высоким доходом в США имели в среднем в 7,4 раза больше богатства, чем семьи со средним доходом, и в 75 раз больше богатства, чем семьи с низким доходом. Эти коэффициенты выросли с 3,4 до 28 в 1983 соответственно, как показано на диаграмме ниже:
Это накопленное богатство является источником пенсионного дохода, защищает от краткосрочных экономических потрясений и обеспечивает безопасность для будущих поколений. По состоянию на 2016 год семьи с высоким доходом в США имели в среднем в 7,4 раза больше богатства, чем семьи со средним доходом, и в 75 раз больше богатства, чем семьи с низким доходом. Эти коэффициенты выросли с 3,4 до 28 в 1983 соответственно, как показано на диаграмме ниже:
Экономическое неравенство — это широкий термин, который может относиться к неравенству в доходах и/или богатстве, помимо других показателей уровня жизни.
Неравенство доходов измеряет распределение доходов среди населения. В Соединенных Штатах, например, большая доля совокупного дохода в настоящее время приходится на домохозяйства с более высокими доходами, а доля домохозяйств со средними и низкими доходами снижается, что означает увеличение неравенства в доходах.
Точно так же имущественное неравенство измеряет распределение собственного капитала среди населения. В Америке разрыв в уровне благосостояния между домохозяйствами с более высокими и низкими доходами острее, чем разрыв в доходах, и в последние десятилетия он рос более быстрыми темпами.
Неравенство в доходах можно также измерить с помощью коэффициента 90/10 — отношения дохода, необходимого для попадания в число 10% самых высокооплачиваемых работников в США (90-й процентиль), к доходу на пороге 10% самых бедных наемные работники (10-й процентиль).
Другим распространенным показателем является коэффициент Джини, единственное число, предназначенное для измерения степени неравенства в распределении. Обычно он используется для измерения того, насколько сильно распределение доходов в стране отклоняется от абсолютно равного распределения. Коэффициент Джини, равный 0, представляет собой абсолютное равенство (все люди имеют одинаковый доход), а 1 — полное неравенство (все доходы страны принадлежат только одному человеку). В 2017 году в США коэффициент Джини составлял 0,434 (на основе валового дохода до уплаты налогов), что представляет собой самый высокий уровень неравенства среди стран G7.
В 2017 году в США коэффициент Джини составлял 0,434 (на основе валового дохода до уплаты налогов), что представляет собой самый высокий уровень неравенства среди стран G7.
Гендерный разрыв в оплате труда измеряет разницу в доходах мужчин и женщин. Исторически сложилось так, что мужчины в США в среднем зарабатывали больше, чем женщины, но со временем этот разрыв постепенно сокращался, особенно среди молодых работников.
Эксперты не совсем понимают, почему существует разрыв. В то время как некоторые факторы, способствующие гендерному разрыву в оплате труда, поддаются количественной оценке (различия в профессиональных навыках, уровне образования, опыте работы, членстве в профсоюзах, количестве отработанных часов, отрасли и роде занятий), другие измерить труднее. К ним относятся обязанности материнства и семьи и их влияние на участие женщин в работе по сравнению с мужчинами; гендерные стереотипы и дискриминация; и различия в профессиональных сетях и склонности вести переговоры о повышении и продвижении по службе.
Центр рассчитывает гендерный разрыв в оплате труда на основе среднего почасового заработка работников, занятых полный и неполный рабочий день. Подробнее о почему мы рассчитываем разрыв в оплате труда таким образом.
Как измеряется бедность? Черта бедности, также называемая порогом бедности, устанавливается федеральным правительством и ежегодно используется для определения права на участие в федеральных программах, таких как SNAP (ранее называвшаяся «продовольственные талоны») и Medicaid. Черта бедности определяется на основе того, сколько стоит купить продукты первой необходимости по плану экономного питания 9.0007 , а затем умножить эту сумму на три. Эти показатели рассчитываются на основе размера и состава семьи и ежегодно корректируются с учетом инфляции с использованием индекса потребительских цен. Например, в 2020 году черта бедности в США составляла 26 246 долларов на семью из четырех человек. Узнайте больше о том, когда и как была разработана черта бедности.
В Центре мы часто используем этот показатель в нашей работе по таким темам, как жизнь американцев, живущих в бедности.
Как определяется средний класс или средний доход?Наше исследование рассматривает средний класс как в США, так и в глобальном контексте.
Для США мы определяем, кто попадает в средний класс, используя относительные доходы домохозяйств. Например, американцы со средним доходом – это взрослые, чей годовой доход домохозяйства составляет две трети и удваивает средний показатель по стране после того, как доходы были скорректированы с учетом размера домохозяйства. Наш анализ среднего класса в мегаполисах и штатах США также принимает во внимание разную стоимость жизни по всей стране.
В глобальном контексте люди со средним доходом живут на 10,01-20 долларов в день, что соответствует годовому доходу от 14 600 до 29 200 долларов на семью из четырех человек (в ценах 2011 года). Это скромно по меркам стран с развитой экономикой. Фактически, он находится за официальной чертой бедности в США. Наш анализ глобального среднего класса обязательно учитывает паритет покупательной способности, в котором обменные курсы валют корректируются с учетом различий в ценах на товары и услуги в разных странах.
Фактически, он находится за официальной чертой бедности в США. Наш анализ глобального среднего класса обязательно учитывает паритет покупательной способности, в котором обменные курсы валют корректируются с учетом различий в ценах на товары и услуги в разных странах.
Изучение среднего класса говорит нам о тенденциях, связанных с экономическим неравенством, и добавляет контекст к другим изучаемым нами тенденциям, включая рынок труда, личные и домашние финансы.
Узнайте больше о нашей методологии для среднего класса в США и о том, как мы рассчитываем уровни доходов в США, о нашей глобальной методологии среднего класса за 2015 год и о нашей глобальной методологии среднего класса за 2021 год. Используйте наш калькулятор дохода среднего класса в США или наш глобальный калькулятор среднего класса , чтобы узнать, попадает ли ваша семья в эту группу.
Почему данные о доходах часто корректируются с учетом количества членов домохозяйства? Мы корректируем данные о доходах домохозяйств, потому что домохозяйство из четырех человек с доходом 50 000 долларов сталкивается с более жесткими бюджетными ограничениями, чем домохозяйство из двух человек с тем же доходом.
В самом простом случае поправка на размер домохозяйства может означать преобразование дохода домохозяйства в доход на душу населения. Таким образом, домохозяйство из двух человек с доходом 50 000 долларов будет иметь доход на душу населения в размере 25 000 долларов, что вдвое больше, чем доход на душу населения домохозяйства из четырех человек с таким же общим доходом.
Мы используем несколько более точную корректировку, в которой доход домохозяйства делится на квадратный корень из числа людей в домохозяйстве. Затем для целей отчетности мы масштабируем полученный доход, чтобы он отражал размер домохозяйства, равный трем, целое число ближе всего к среднему размеру домохозяйства в США, который в 2020 году составлял 2,5.
Узнайте больше о нашей методологии для этой корректировки.
Почему так много разных метрик для оценки состояния рынка труда? Короткий ответ: каждый из них говорит нам что-то свое о рынке труда. Бюро трудовой статистики производит множество показателей, в том числе шесть показателей того, что оно называет «недоиспользованием рабочей силы», наряду со многими другими показателями, включая уровень участия в рабочей силе, соотношение занятости и численности населения, среднюю недельную заработную плату, среднее количество отработанных часов и многое другое. . В своей работе по теме Центр использует три основных показателя.
Бюро трудовой статистики производит множество показателей, в том числе шесть показателей того, что оно называет «недоиспользованием рабочей силы», наряду со многими другими показателями, включая уровень участия в рабочей силе, соотношение занятости и численности населения, среднюю недельную заработную плату, среднее количество отработанных часов и многое другое. . В своей работе по теме Центр использует три основных показателя.
· Уровень безработицы : Простого отсутствия работы недостаточно для того, чтобы правительство считало человека безработным; он или она также должны быть готовы к работе и активно искать работу (или временно уволены). Уровень безработицы — это доля рабочей силы, состоящей из лиц в возрасте 16 лет и старше, имеющих работу, временно уволенных или активно ищущих работу, которые являются безработными. В любой конкретный месяц уровень безработицы может расти или падать в зависимости не только от того, сколько людей находят или теряют работу, но и от того, сколько людей присоединяются к активной рабочей силе или покидают ее.
· Соотношение занятости и численности населения : Это соотношение отражает процентную долю трудоустроенного гражданского неинституционального населения данной группы в возрасте 16 лет и старше. Например, мы использовали этот показатель для сравнения занятости среди различных возрастных групп в США. увольнение или активный поиск работы. На это может повлиять то, что все больше людей отказываются от поиска работы, временно увольняются по личным или семейным причинам, выходят на пенсию или решают вернуться к учебе.
Что означает сезонная корректировка показателей занятости? Вы когда-нибудь использовали данные, которые не были скорректированы с учетом сезонных колебаний? Сезонная корректировка — это статистический метод, который учитывает и устраняет сезонные колебания численности рабочей силы и уровней занятости и безработицы из-за предсказуемых месячных моделей, включая погоду, урожай, праздники и школьные расписания.
Поскольку эти события происходят довольно регулярно, сезонная корректировка позволяет более точно измерить, как занятость и безработица изменяются от месяца к месяцу. Как правило, мы используем цифры, не скорректированные с учетом сезонных колебаний, при сравнении одного и того же месяца в разные годы. В последнее время это было полезно для понимания COVID-19.медленное восстановление рынка труда. Мы также используем данные без сезонной поправки для постов, в которых измеряем летнюю занятость.
Сезонные корректировки не требуются для среднегодовых оценок.
Что означает поправка на инфляцию и зачем вы это делаете?Инфляция — это общий рост цен на товары и услуги в экономике. В результате инфляции потребители могут приобрести меньше товаров и услуг за ту же сумму денег.
Поправка на инфляцию позволяет нам сравнивать стоимость валюты с течением времени, чтобы понять такие тенденции, как потеря покупательной способности минимальной заработной платы в США с течением времени, и сравнить стоимость заработной платы рабочих за несколько десятилетий.
Это статистический метод, который позволяет нам сравнивать разницу в покупательной способности с течением времени. Это говорит нам больше, чем простое сравнение разницы в количестве долларов, стоимость которых снижается по мере инфляции.
В чем разница между государственным дефицитом и государственным долгом?Дефицит бюджета и государственный долг – это два взаимосвязанных, но очень разных понятия. Бюджетный дефицит – это 90 119 годовой 90 120 расчет, который относится к разнице между тем, что правительство тратит в данном году, и тем, сколько оно получает, обычно в виде налогов.
Государственный долг США – это 90 119 общая 90 120 сумма, непогашенная задолженность правительства с течением времени для таких вещей, как покрытие федерального дефицита за предыдущие годы. Государственный долг США составляет 28,5 триллионов долларов США по состоянию на конец июня, и, по прогнозам, этот долг будет расти в ближайшие годы.
Семейство моделей Transformer
С момента своего появления в 2017 году оригинальная модель Transformer вдохновила на создание множества новых интересных моделей, выходящих за рамки задач обработки естественного языка (NLP). Существуют модели для предсказания складчатой структуры белков, обучения гепарда бегу и прогнозирования временных рядов. Имея так много доступных вариантов трансформеров, можно легко упустить большую картину. Общим для всех этих моделей является то, что они основаны на оригинальной архитектуре Transformer. Некоторые модели используют только кодер или декодер, а другие используют оба. Это обеспечивает полезную таксономию для классификации и изучения высокоуровневых различий между моделями семейства Transformer и поможет вам понять Transformers, с которыми вы раньше не сталкивались.
Если вы не знакомы с оригинальной моделью трансформера или вам нужно освежить в памяти знания, ознакомьтесь с главой «Как работают трансформеры» из курса «Обнимающее лицо».
Компьютерное зрение
Сверточная сеть
Долгое время сверточные сети (CNN) были доминирующей парадигмой для задач компьютерного зрения, пока Vision Transformer не продемонстрировал свою масштабируемость и эффективность. Даже в этом случае некоторые из лучших качеств CNN, такие как неизменность перевода, настолько сильны (особенно для определенных задач), что некоторые трансформеры включают свертки в свою архитектуру. ConvNeXt перевернул этот обмен и включил варианты дизайна от Transformers для модернизации CNN. Например, ConvNeXt использует неперекрывающиеся скользящие окна для исправления изображения и большее ядро для увеличения его глобального рецептивного поля. ConvNeXt также предлагает несколько вариантов дизайна слоев для более эффективного использования памяти и повышения производительности, поэтому он выгодно конкурирует с Transformers!
Кодер
Vision Transformer (ViT) открыл двери для задач компьютерного зрения без извилин. ViT использует стандартный кодировщик Transformer, но его главный прорыв заключается в том, как он обрабатывает изображение. Он разбивает изображение на патчи фиксированного размера и использует их для создания встраивания, точно так же, как предложение разбивается на токены. Компания ViT использовала эффективную архитектуру Transformers, чтобы в то время демонстрировать конкурентоспособные результаты с CNN, при этом требуя меньше ресурсов для обучения. Вскоре за ViT последовали другие модели зрения, которые также могли справляться с задачами плотного зрения, такими как сегментация и обнаружение.
ViT использует стандартный кодировщик Transformer, но его главный прорыв заключается в том, как он обрабатывает изображение. Он разбивает изображение на патчи фиксированного размера и использует их для создания встраивания, точно так же, как предложение разбивается на токены. Компания ViT использовала эффективную архитектуру Transformers, чтобы в то время демонстрировать конкурентоспособные результаты с CNN, при этом требуя меньше ресурсов для обучения. Вскоре за ViT последовали другие модели зрения, которые также могли справляться с задачами плотного зрения, такими как сегментация и обнаружение.
Одной из таких моделей является Swin Transformer. Он строит иерархические карты объектов (как CNN 👀 и в отличие от ViT) из патчей меньшего размера и объединяет их с соседними патчами в более глубоких слоях. Внимание вычисляется только в локальном окне, и окно перемещается между слоями внимания, чтобы создать связи, чтобы помочь модели лучше учиться. Поскольку Swin Transformer может создавать иерархические карты признаков, он является хорошим кандидатом для сложных задач прогнозирования, таких как сегментация и обнаружение. SegFormer также использует кодировщик Transformer для построения иерархических карт признаков, но добавляет сверху простой декодер многослойного персептрона (MLP), чтобы объединить все карты признаков и сделать прогноз.
SegFormer также использует кодировщик Transformer для построения иерархических карт признаков, но добавляет сверху простой декодер многослойного персептрона (MLP), чтобы объединить все карты признаков и сделать прогноз.
Другие модели зрения, такие как BeIT и ViTMAE, черпали вдохновение из цели предварительной тренировки BERT. BeIT предварительно обучается с помощью моделирования маскированных изображений (MIM) ; патчи изображения маскируются случайным образом, а изображение также разбивается на визуальные токены. BeIT обучен предсказывать визуальные маркеры, соответствующие замаскированным участкам. ViTMAE имеет аналогичную цель предварительной подготовки, за исключением того, что он должен предсказывать пиксели вместо визуальных токенов. Что необычно, так это то, что 75% участков изображения замаскированы! Декодер восстанавливает пиксели из замаскированных маркеров и закодированных фрагментов. После предварительной подготовки декодер выбрасывается, а кодировщик готов к использованию в последующих задачах.
Декодер
Модели машинного зрения, использующие только декодер, встречаются редко, потому что большинство моделей машинного зрения полагаются на кодировщик для изучения представления изображения. Но для таких случаев использования, как генерация изображений, декодер подходит естественным образом, как мы видели на примере моделей генерации текста, таких как GPT-2. ImageGPT использует ту же архитектуру, что и GPT-2, но вместо того, чтобы предсказывать следующий токен в последовательности, он предсказывает следующий пиксель изображения. Помимо создания изображений, ImageGPT также можно настроить для классификации изображений.
Кодер-декодер
Модели Vision обычно используют кодировщик (также известный как магистраль) для извлечения важных характеристик изображения перед их передачей в декодер Transformer. DETR имеет предварительно обученную основу, но также использует полную архитектуру кодера-декодера Transformer для обнаружения объектов. Кодер изучает представления изображений и комбинирует их с объектными запросами (каждый объектный запрос представляет собой изученное встраивание, фокусирующееся на области или объекте в изображении) в декодере. DETR прогнозирует координаты ограничивающей рамки и метку класса для каждого объектного запроса.
DETR прогнозирует координаты ограничивающей рамки и метку класса для каждого объектного запроса.
Обработка естественного языка
Кодер
BERT — это преобразователь только для кодировщика, который случайным образом маскирует определенные токены на входе, чтобы не видеть другие токены, что позволяет ему «мошенничать». Цель предварительной подготовки — предсказать замаскированный токен на основе контекста. Это позволяет BERT полностью использовать левый и правый контексты, чтобы помочь ему изучить более глубокое и богатое представление входных данных. Тем не менее, в стратегии предварительной подготовки BERT еще оставалось место для улучшения. RoBERTa улучшила это, представив новый рецепт предварительной подготовки, который включает в себя обучение на более длительных и больших партиях, случайное маскирование токенов в каждой эпохе, а не только один раз во время предварительной обработки, и удаление цели прогнозирования следующего предложения.
Основной стратегией повышения производительности является увеличение размера модели. Но обучение больших моделей требует больших вычислительных ресурсов. Одним из способов снижения вычислительных затрат является использование модели меньшего размера, такой как DistilBERT. DistilBERT использует дистилляцию знаний — метод сжатия — для создания уменьшенной версии BERT, сохраняя при этом почти все свои возможности понимания языка.
Но обучение больших моделей требует больших вычислительных ресурсов. Одним из способов снижения вычислительных затрат является использование модели меньшего размера, такой как DistilBERT. DistilBERT использует дистилляцию знаний — метод сжатия — для создания уменьшенной версии BERT, сохраняя при этом почти все свои возможности понимания языка.
Тем не менее, большинство моделей Трансформеров по-прежнему стремились к большему количеству параметров, что привело к появлению новых моделей, ориентированных на повышение эффективности тренировок. ALBERT уменьшает потребление памяти, уменьшая количество параметров двумя способами: разделяя встраивание большого словаря на две меньшие матрицы и позволяя слоям совместно использовать параметры. ДеБЕРТа добавил механизм распутанного внимания, в котором слово и его позиция отдельно кодируются в двух векторах. Внимание вычисляется из этих отдельных векторов вместо одного вектора, содержащего вложения слов и позиций. Longformer также сосредоточился на повышении эффективности внимания, особенно при обработке документов с более длинными последовательностями. Он использует комбинацию локального оконного внимания (внимание рассчитывается только на основе фиксированного размера окна вокруг каждого маркера) и глобального внимания (только для определенных маркеров задач, таких как 9).0167 [CLS] для классификации), чтобы создать разреженную матрицу внимания вместо полной матрицы внимания.
Он использует комбинацию локального оконного внимания (внимание рассчитывается только на основе фиксированного размера окна вокруг каждого маркера) и глобального внимания (только для определенных маркеров задач, таких как 9).0167 [CLS] для классификации), чтобы создать разреженную матрицу внимания вместо полной матрицы внимания.
Декодер
GPT-2 — это только декодер Преобразователь, который предсказывает следующее слово в последовательности. Он маскирует жетоны справа, поэтому модель не может «обмануть», глядя вперед. Предварительно обучив большой объем текста, GPT-2 стал действительно хорошо генерировать текст, даже если текст только иногда точен или верен. Но в GPT-2 отсутствовал двунаправленный контекст предварительной подготовки BERT, что делало его непригодным для определенных задач. XLNET сочетает в себе лучшее из целей предварительного обучения BERT и GPT-2, используя цель моделирования языка перестановок (PLM), которая позволяет обучаться в двух направлениях.
После GPT-2 языковые модели стали еще больше и теперь известны как больших языковых моделей (LLM) . LLM демонстрируют небольшое или даже нулевое обучение, если они предварительно обучены на достаточно большом наборе данных. GPT-J — это LLM с параметрами 6 млрд, обученный на токенах 400 млрд. За GPT-J последовала OPT, семейство моделей, предназначенных только для декодирования, самая большая из которых имеет размер 175 миллиард и обучена на токенах 180 миллиард. BLOOM был выпущен примерно в то же время, и самая большая модель в семействе имеет 176 миллиардов параметров и обучена на 366 миллиардах токенов на 46 языках и 13 языках программирования.
Кодер-декодер
BART сохраняет исходную архитектуру Transformer, но изменяет цель предварительной подготовки с помощью текста , заполняющего искажение, где некоторые текстовые диапазоны заменяются одним маркером маски . Декодер предсказывает неповрежденные токены (будущие токены маскируются) и использует скрытые состояния кодировщика, чтобы помочь ему. Pegasus похож на BART, но Pegasus маскирует целые предложения, а не фрагменты текста. В дополнение к моделированию замаскированного языка, Pegasus предварительно обучается с помощью генерации предложений с пропусками (GSG). Цель GSG маскирует целые предложения, важные для документа, заменяя их
Pegasus похож на BART, но Pegasus маскирует целые предложения, а не фрагменты текста. В дополнение к моделированию замаскированного языка, Pegasus предварительно обучается с помощью генерации предложений с пропусками (GSG). Цель GSG маскирует целые предложения, важные для документа, заменяя их маска токен. Декодер должен генерировать выходные данные из оставшихся предложений. T5 — более уникальная модель, которая превращает все задачи NLP в задачу преобразования текста в текст с использованием определенных префиксов. Например, префикс Суммировать: указывает на задачу суммирования. T5 предварительно обучен с помощью обучения с учителем (GLUE и SuperGLUE) и обучения с самоконтролем (случайная выборка и отбрасывание 15% токенов).
Аудио
Кодер
Wav2Vec2 использует кодировщик Transformer для изучения речевых представлений непосредственно из необработанных аудиосигналов. Предварительно обучается сопоставительной задачей на определение истинного речевого представления из набора ложных. HuBERT похож на Wav2Vec2, но имеет другой процесс обучения. Целевые метки создаются на этапе кластеризации, на котором сегменты похожего звука назначаются кластеру, который становится скрытым блоком. Скрытый блок сопоставляется с вложением, чтобы сделать прогноз.
HuBERT похож на Wav2Vec2, но имеет другой процесс обучения. Целевые метки создаются на этапе кластеризации, на котором сегменты похожего звука назначаются кластеру, который становится скрытым блоком. Скрытый блок сопоставляется с вложением, чтобы сделать прогноз.
Кодер-декодер
Speech3Text — это модель речи, предназначенная для автоматического распознавания речи (ASR) и перевода речи. Модель принимает функции банка логарифмических фильтров, извлеченные из формы аудиосигнала и предварительно обученные авторегрессивно для создания стенограммы или перевода. Whisper также является моделью ASR, но, в отличие от многих других речевых моделей, она предварительно обучена на огромном количестве ✨ помеченных ✨ данных транскрипции аудио для нулевой производительности. Большая часть набора данных также содержит неанглийские языки, а это означает, что Whisper также можно использовать для языков с низким уровнем ресурсов. Структурно Whisper похож на Speech3Text. Аудиосигнал преобразуется в логарифмическую спектрограмму, закодированную кодером. Декодер генерирует расшифровку авторегрессивно из скрытых состояний кодировщика и предыдущих токенов.
Декодер генерирует расшифровку авторегрессивно из скрытых состояний кодировщика и предыдущих токенов.
Мультимодальный
Кодер
VisualBERT — мультимодальная модель для задач языка зрения, выпущенная вскоре после BERT. Он сочетает в себе BERT и предварительно обученную систему обнаружения объектов для извлечения функций изображения в визуальные вложения, которые передаются вместе с вложениями текста в BERT. VisualBERT предсказывает маскированный текст на основе немаскированного текста и визуальных вложений, а также должен предсказать, выровнен ли текст с изображением. Когда ViT был выпущен, ViLT принял ViT в своей архитектуре, потому что таким образом было проще получить встраивание изображений. Встраивания изображений обрабатываются совместно с вложениями текста. Оттуда ViLT предварительно обучается путем сопоставления текста изображения, моделирования маскированного языка и маскирования целых слов.
CLIP использует другой подход и делает парное предсказание ( изображение , текст ). Кодировщик изображений (ViT) и кодировщик текста (Transformer) совместно обучаются на наборе данных из 400 миллионов (
Кодировщик изображений (ViT) и кодировщик текста (Transformer) совместно обучаются на наборе данных из 400 миллионов ( изображений , текстов ) парных данных, чтобы максимизировать сходство между изображениями и текстовыми вложениями ( изображений , текстов ) пар. После предварительной подготовки вы можете использовать естественный язык, чтобы указать CLIP предсказывать текст по изображению или наоборот. OWL-ViT строится поверх CLIP, используя его в качестве основы для обнаружения объектов с нулевым выстрелом. После предварительной подготовки добавляется головка обнаружения объектов, чтобы сделать заданный прогноз по ( класс , ограничительная рамка ) пар.
Кодер-декодер
Оптическое распознавание символов (OCR) — это давняя задача распознавания текста, которая обычно включает несколько компонентов для понимания изображения и создания текста. TrOCR упрощает процесс с помощью сквозного трансформатора. Кодер представляет собой модель в стиле ViT для понимания изображения и обрабатывает изображение как патчи фиксированного размера. Декодер принимает скрытые состояния кодировщика и авторегрессивно генерирует текст. Пончик — это более общая модель визуального понимания документов, которая не опирается на подходы, основанные на OCR. Он использует Swin Transformer в качестве кодера и многоязычный BART в качестве декодера. Donut предварительно обучен читать текст, предсказывая следующее слово на основе изображения и текстовых аннотаций. Декодер генерирует последовательность маркеров по запросу. Приглашение представлено специальным токеном для каждой нижестоящей задачи. Например, синтаксический анализ документов имеет специальный
Кодер представляет собой модель в стиле ViT для понимания изображения и обрабатывает изображение как патчи фиксированного размера. Декодер принимает скрытые состояния кодировщика и авторегрессивно генерирует текст. Пончик — это более общая модель визуального понимания документов, которая не опирается на подходы, основанные на OCR. Он использует Swin Transformer в качестве кодера и многоязычный BART в качестве декодера. Donut предварительно обучен читать текст, предсказывая следующее слово на основе изображения и текстовых аннотаций. Декодер генерирует последовательность маркеров по запросу. Приглашение представлено специальным токеном для каждой нижестоящей задачи. Например, синтаксический анализ документов имеет специальный синтаксический анализ маркера , который в сочетании со скрытыми состояниями кодировщика выполняет синтаксический анализ документа в формате структурированного вывода (JSON).
Обучение с подкреплением
Декодер
Преобразователь решений и траекторий рассматривает состояние, действие и награду как задачу моделирования последовательности.