Откуда берутся гласные
9.11.2020
Откуда берутся гласные
Полина Меньшова
Гласные звуки образуются, когда в речевом тракте нет существенного сужения. Воздушная струя не встречает препятствия на своём пути. Устраняем преграды, которые мешают понимать фонетику, и знакомимся с самыми артикуляционно свободными звуками русского языка.
Гласные произносятся только с голосом. Отсюда и название, ведь «глас» и «голос» — одно и то же. Чтобы описать любой гласный звук, достаточно знать три его признака, каждый из которых несложно «почувствовать».
1. Ряд — горизонтальное положение языка при произнесении звука. Протяните «и» и обратите внимание на то, где находится ваш язык. Он упирается кончиком в нижние зубы, правильно? [и] и [э] — гласные переднего ряда, поскольку язык при их произнесении максимально продвинут вперёд. Лучше понять и представить положение органов речи помогут артикуляционные профили.
Гласные звуки образуются, когда в речевом тракте нет существенного сужения. Воздушная струя не встречает препятствия на своём пути. Устраняем преграды, которые мешают понимать фонетику, и знакомимся с самыми артикуляционно свободными звуками русского языка.
Гласные произносятся только с голосом. Отсюда и название, ведь «глас» и «голос» — одно и то же. Чтобы описать любой гласный звук, достаточно знать три его признака, каждый из которых несложно «почувствовать».
1. Ряд — горизонтальное положение языка при произнесении звука. Протяните «и» и обратите внимание на то, где находится ваш язык. Он упирается кончиком в нижние зубы, правильно? [и] и [э] — гласные переднего ряда, поскольку язык при их произнесении максимально продвинут вперёд. Лучше понять и представить положение органов речи помогут артикуляционные профили.
Теперь попробуйте произнести звуки [ы] и [а]. Язык находится чуть дальше от зубов, чем при [и]. Это особенность гласных среднего ряда.
Это особенность гласных среднего ряда.
Теперь попробуйте произнести звуки [ы] и [а]. Язык находится чуть дальше от зубов, чем при [и]. Это особенность гласных среднего ряда.
Гласные [о] и [у] заставляют язык отодвигаться назад ещё сильнее. Именно поэтому они относятся к гласным заднего ряда.
Гласные [о] и [у] заставляют язык отодвигаться назад ещё сильнее. Именно поэтому они относятся к гласным заднего ряда.
Чтобы лучше почувствовать разницу между разными гласными звуками, можно медленно произнести последовательность от гласного переднего ряда к гласному заднего ряда. Например: [и], [ы], [у].
2. Подъём — минимальное расстояние между верхней точкой языка и нёбом, или вертикальное положение языка. Но подъём можно определить и по тому, насколько задействуется нижняя челюсть при произнесении гласного звука.
Когда мы произносим гласные нижнего подъёма, нижняя челюсть опускается и рот открывается широко.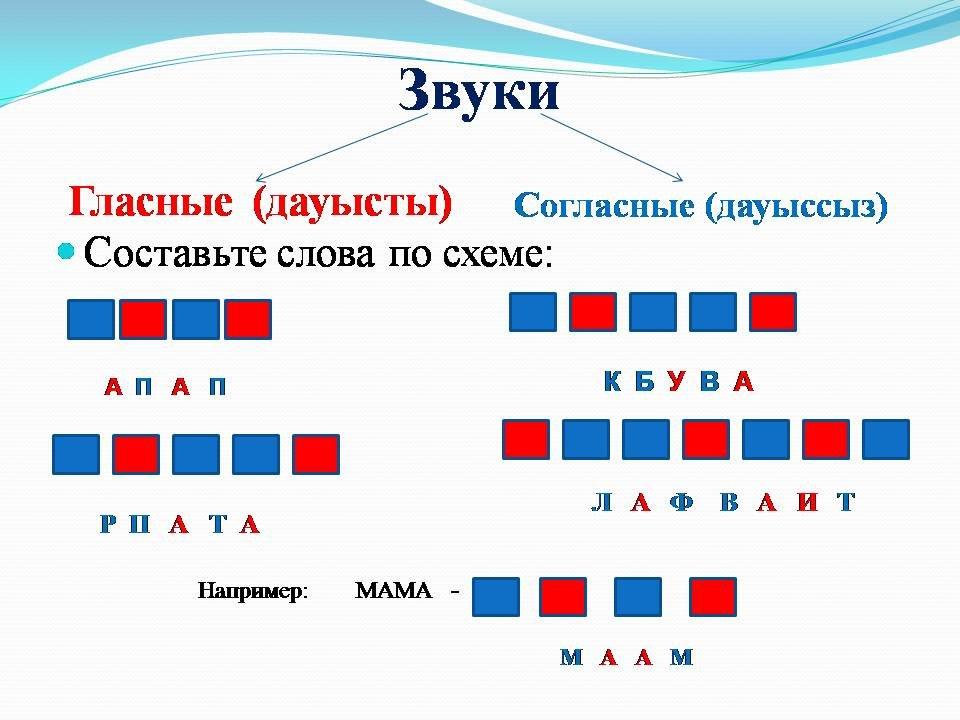 Доктора не просто так просят пациентов сказать «а»: артикуляция этого звука такова, что даже самый застенчивый больной скорее всего откроет рот так, как нужно врачу.
Доктора не просто так просят пациентов сказать «а»: артикуляция этого звука такова, что даже самый застенчивый больной скорее всего откроет рот так, как нужно врачу.
Чтобы лучше почувствовать разницу между разными гласными звуками, можно медленно произнести последовательность от гласного переднего ряда к гласному заднего ряда. Например: [и], [ы], [у].
2. Подъём — минимальное расстояние между верхней точкой языка и нёбом, или вертикальное положение языка. Но подъём можно определить и по тому, насколько задействуется нижняя челюсть при произнесении гласного звука.
Когда мы произносим гласные нижнего подъёма, нижняя челюсть опускается и рот открывается широко. Доктора не просто так просят пациентов сказать «а»: артикуляция этого звука такова, что даже самый застенчивый больной скорее всего откроет рот так, как нужно врачу.
При произнесении гласных среднего подъёма челюсть тоже опускается, но не так сильно, как в случае с гласными нижнего подъёма. Попробуйте сказать [о] и [э].
Попробуйте сказать [о] и [э].
При произнесении гласных среднего подъёма челюсть тоже опускается, но не так сильно, как в случае с гласными нижнего подъёма. Попробуйте сказать [о] и [э].
Когда мы произносим гласные верхнего подъема, нижняя челюсть практически не меняет своего положения. Звуки [и], [ы] и [у] позволят в этом убедиться.
Когда мы произносим гласные верхнего подъема, нижняя челюсть практически не меняет своего положения. Звуки [и], [ы] и [у] позволят в этом убедиться.
3. Лабиализация — огубление звука, то есть участие губ в его артикуляции. Когда мы произносим огублённые, или лабиализованные, гласные, губы вытягиваются в «трубочку». Это характерная черта звуков [о] и [у].
3. Лабиализация — огубление звука, то есть участие губ в его артикуляции. Когда мы произносим огублённые, или лабиализованные, гласные, губы вытягиваются в «трубочку». Это характерная черта звуков [о] и [у].
Когда мы произносим гласные верхнего подъема, нижняя челюсть практически не меняет своего положения. Звуки [и], [ы] и [у] позволят в этом убедиться.
Звуки [и], [ы] и [у] позволят в этом убедиться.
Когда мы произносим гласные верхнего подъема, нижняя челюсть практически не меняет своего положения. Звуки [и], [ы] и [у] позволят в этом убедиться.
Характеристика каждого гласного звука русского языка — уникальный набор перечисленных признаков. Например, гласные [и] и [ы] нелабиализованные и имеют одинаковый подъём, но различаются по ряду. Для лабиализованных звуков [у] и [о] ряд не будет различительным признаком, зато у них неодинаковый подъём.
Характеристика каждого гласного звука русского языка — уникальный набор перечисленных признаков. Например, гласные [и] и [ы] нелабиализованные и имеют одинаковый подъём, но различаются по ряду. Для лабиализованных звуков [у] и [о] ряд не будет различительным признаком, зато у них неодинаковый подъём.
Классификационная таблица основных гласных звуков русского языка (полужирным курсивом выделены лабиализованные гласные)
Чем левее гласный в ячейке, тем ближе к зубам находится язык при его произнесении.
Запомнить характеристики гласных звуков русского языка поможет также треугольник Л. В. Щербы:
Чем левее гласный в ячейке, тем ближе к зубам находится язык при его произнесении.
Запомнить характеристики гласных звуков русского языка поможет также треугольник Л. В. Щербы:
Треугольник Щербы
|
 portal-slovo.ru/philology/37379.php%3felement_id%3d37379%26pagen_1%3d4
portal-slovo.ru/philology/37379.php%3felement_id%3d37379%26pagen_1%3d4 Ру
Руpython — Как посчитать гласные и согласные в кадре данных pandas (как в верхнем, так и в нижнем регистре)?
Вот мои данные
Нет тела 1 Данные, Аналитика 2 StackOver.
Вот мой ожидаемый результат
Нет согласных гласных тела 1 Данные, Аналитика. 5 8 2 StackOver. 3 6
- python
- regex
- pandas
- текст
- извлечение признаков
вы можете подсчитать количество гласных, используя очень простое регулярное выражение, а количество согласных — это количество всех букв минус0003
В [121]: df['Гласные'] = df.Body.str.lower().str.count(r'[aeiou]') В [122]: df['Consonant'] = df.Body.str.lower().str.count(r'[az]') - df['Vowels'] В [123]: дф Выход[123]: Нет согласных гласных тела 0 1 Данные, Аналитика 5 8 1 2 StackOver. 3 6
 Body.str.lower().str.count(r'[aeiou]')
В [122]: df['Consonant'] = df.Body.str.lower().str.count(r'[az]') - df['Vowels']
В [123]: дф
Выход[123]:
Нет согласных гласных тела
0 1 Данные, Аналитика 5 8
1 2 StackOver. 3 6
Body.str.lower().str.count(r'[aeiou]')
В [122]: df['Consonant'] = df.Body.str.lower().str.count(r'[az]') - df['Vowels']
В [123]: дф
Выход[123]:
Нет согласных гласных тела
0 1 Данные, Аналитика 5 8
1 2 StackOver. 3 6
PS y может быть как гласным, так и согласным …
4
Другой вариант — применить str.extractall с условием or’d, чтобы эффективно разбить данные на два столбца, затем сгруппировать по индексу и подсчитать количество столбцов, например:
counts = (
df.Body.str.extractall('(?i)(?P<гласные>[aeiou])|(?P<согласные>[az])')
.groupby(уровень=0).count()
)
Это работает, потому что (?i) регулярного выражения указывает, что выражение должно быть нечувствительным к регистру, а [aeiou] захватывает все гласные в первую группу соответствия (или столбец), а затем [a-z] захватит все остальные буквы, которые не захватила первая группа (все, кроме гласных).
Дает вам:
гласных согласных 0 5 8 1 3 6
Затем назначьте/присоединитесь к исходному DF.
Использовать str.count с параметром re.I для игнорирования регистра:
import re df['Гласные'] = df['Тело'].str.count(r'[aeiou]', flags=re.I) df['Consonant'] = df['Body'].str.count(r'[bcdfghjklmnpqrstvwxzy]', flags=re.I) печать (дф) Нет согласных гласных тела 0 1 Данные, Аналитика 5 8 1 2 StackOver. 3 6
Попробуйте так:
гласных = set("AEIOUAeiou")
минусы = установить ("bcdfghjklmnpqrstvwxyzBCDFGHJKLMNPQRSTVWXYZ")
df['Vowels'] = [sum(1 для c в x, если c в гласных) для x в df['Body']]
df['Consonents'] = [sum(1 для c в x, если c в cons) для x в df['Body']]
печать (дф)
3
Зарегистрируйтесь или войдите
Зарегистрироваться через GoogleЗарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Подсчет гласных в строке Python
спросил
Изменено 1 год, 7 месяцев назад
Просмотрено 228 тысяч раз
Я пытаюсь подсчитать количество вхождений определенных символов в строку, но результат неверный.
Вот мой код:
inputString = str(input("Пожалуйста, введите предложение: "))
а = "а"
А = "А"
е = "е"
Э = "Э"
я = "я"
Я = "Я"
о = "о"
О = "О"
ты = "ты"
У = "У"
счет = 0
есчет = 0
счет = 0
счет = 0
счет = 0
если A или a в строке:
счет = счет + 1
если E или e в строке:
эсчет = эсчет + 1
если я или я в полосе:
счет = счет + 1
если o или O в строке:
количество = количество + 1
если u или U в строке:
счет = счет + 1
печать (счет, ecount, icount, ocount, ucount)
Если я ввожу букву A вывод будет: 1 1 1 1 1
- python
То, что вы хотите, можно сделать очень просто:
>>> mystr = input("Пожалуйста, введите предложение: ")
Пожалуйста, введите предложение: abcdE
>>> print(*map(mystr.lower().count, "aeiou"))
1 1 0 0 0
>>>
Если вы их не знаете, то вот ссылка на карту и одна на карту * .
определение количества гласных (строка):
число_гласных = 0
для символа в строке:
если char в "aeiouAEIOU":
число_гласных = число_гласных+1
вернуть num_vowels
(помните пробел s)
>>> предложение = ввод («Предложение:»)
Предложение: это предложение
>>> counts = {i:0 для i в 'aeiouAEIOU'}
>>> для char в предложении:
... если char в количестве:
... counts[char] += 1
...
>>> для k,v в counts.items():
... печать (к, v)
...
1
д 3
ты 0
У 0
О 0
я 2
Е 0
о 0
А 0
я 0
data = str(input("Пожалуйста, введите предложение: "))
гласные = "аиоу"
для v в гласных:
печать (v, данные.нижний (). Количество (v))
0
Использовать счетчик
>>> из коллекций импортировать счетчик
>>> c = Счетчик('галлахад')
>>> напечатать с
Counter({'a': 3, 'l': 2, 'h': 1, 'g': 1, 'd': 1})
>>> c['a'] # количество символов "a"
3
Счетчик доступен только в Python 2. 7+. Решение, которое должно работать на Python 2.5, будет использовать
7+. Решение, которое должно работать на Python 2.5, будет использовать defaultdict
>>> from collections import defaultdict
>>> d = defaultdict(int)
>>> для c в s:
... д[с] = д[с] + 1
...
>>> напечатать словарь(d)
{'a': 3, 'h': 1, 'l': 2, 'g': 1, 'd': 1}
1 , если A или a in stri означает , если A или (a in stri) , что равно , если True, или (in stri) , что всегда равно True , и то же самое для каждого из ваших утверждений , если .
То, что вы хотели сказать, это , если A in stri или a in stri .
Это твоя ошибка. Не единственный — вы на самом деле не считаете гласные, так как проверяете, содержит ли строка их только один раз.
Другая проблема заключается в том, что ваш код далеко не лучший способ сделать это, см., например, это: Подсчет гласных из необработанного ввода. Там вы найдете несколько хороших решений, которые можно легко применить для вашего конкретного случая.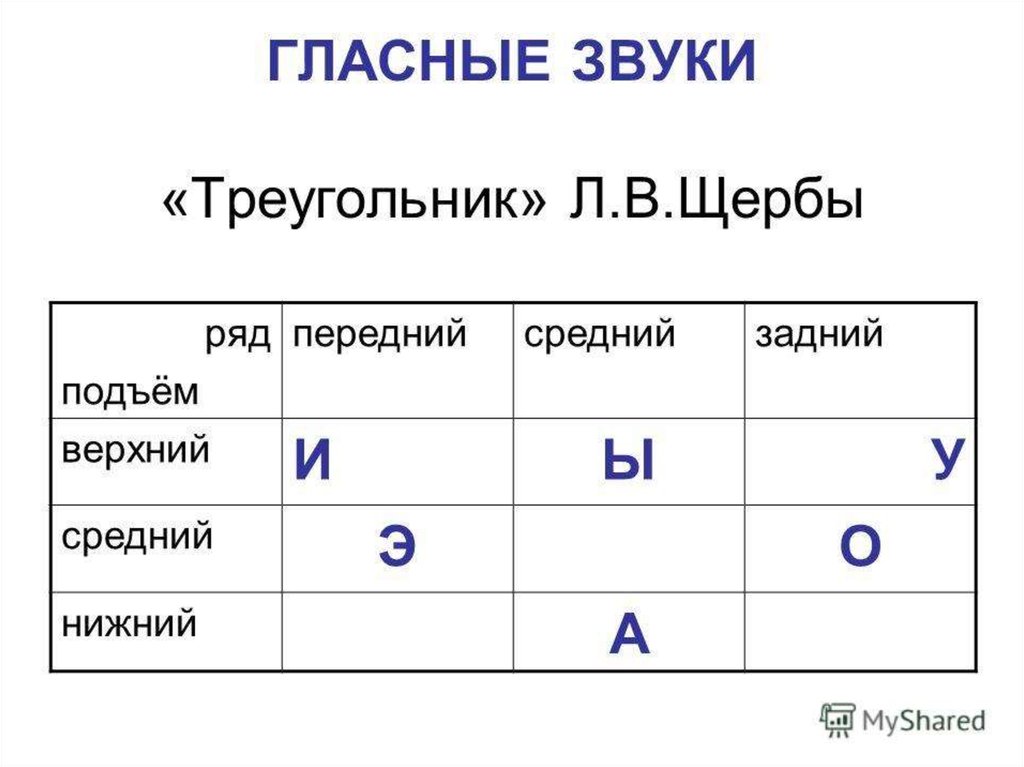 Я думаю, что если вы подробно изучите первый ответ, вы сможете правильно переписать свой код.
Я думаю, что если вы подробно изучите первый ответ, вы сможете правильно переписать свой код.
Для тех, кто ищет самое простое решение, вот оно:
гласная = ['a', 'e', 'i', 'o', 'u']
Sentence = input("Введите фразу:")
количество = 0
на букву в предложении:
если буква в гласной:
количество += 1
распечатать (количество)
2
Другое решение со списком:
гласных = ["a", "e", "i", "o", "u"]
def vowel_counter (ул):
return len([char для char в строке, если char в гласных])
print(vowel_counter("абракадабра"))
№ 5
>>> строка = "aswdrtio" >>> [string.lower().count(x) для x в "aeiou"] [1, 0, 1, 1, 0]
1
количество = 0
string = raw_input("Введите предложение, и я посчитаю гласные!").lower()
для символа в строке:
если char в 'aeiou':
количество += 1
количество печатей
2
Я написал код для подсчета гласных.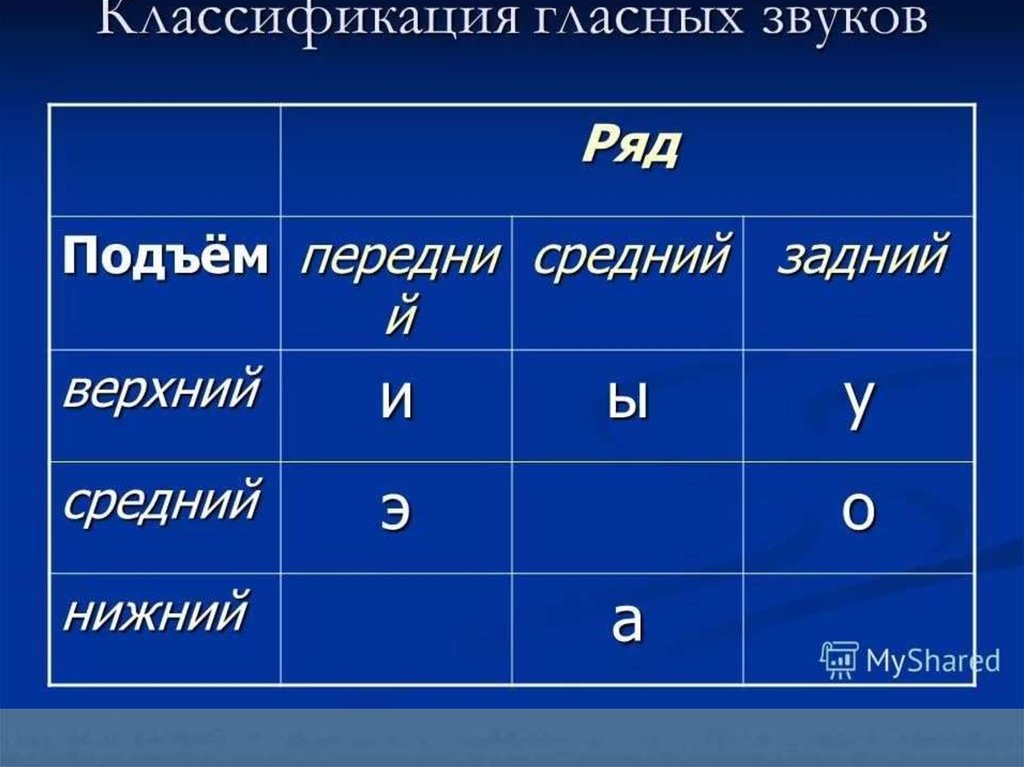 Вы можете использовать это для подсчета любого символа по вашему выбору. Надеюсь, это поможет! (закодировано на Python 3.6.0)
Вы можете использовать это для подсчета любого символа по вашему выбору. Надеюсь, это поможет! (закодировано на Python 3.6.0)
пока (правда):
фраза = ввод('Введите фразу, в которой вы хотите подсчитать гласные:')
if фраза == 'end': #Это будет использоваться для завершения цикла
quit() #Вы можете использовать команду break, если не хотите выходить
lower = str.lower(phrase) #Сделает строку строчной
convert = list(lower) #Преобразовать строку в список
a = convert.count('a') # Это подсчитает букву для буквы a
е = convert.count('e')
я = конвертировать.счет('я')
о = конвертировать.счет('о')
u = convert.count('u')
гласный = a + e + i + o + u # Используется для нахождения общей суммы гласных
print('Всего гласных = ', гласный)
напечатать ('а = ', а)
напечатать ('е = ', е)
напечатать ('я = ', я)
напечатать ('о = ', о)
напечатать ('и = ', и)
Предположим,
S = «Комбинация»
импорт ре
напечатать re.findall('a|e|i|o|u', S)
Распечатки: [‘о’, ‘и’, ‘а’, ‘и’, ‘о’]
Для вашего падежа в предложении (Case1):
txt = «бла-бла-бла. ..»
..»
import re
txt = re.sub('[\r\t\n\d\,\.\!\?\\\/\(\)\[\]\{\}]+', " ", txt)
txt = re.sub('\s{2,}', " ", txt)
txt = txt.strip()
слова = txt.split(' ')
для w словами:
напечатать w, len(re.findall('a|e|i|o|u', w))
Случай 2
импорт повторно из nltk.tokenize import word_tokenize
для w в work_tokenize(txt):
напечатать w, len(re.findall('a|e|i|o|u', w))
из коллекции Счетчик импорта
количество = счетчик ()
inputString = str(input("Пожалуйста, введите предложение: "))
для я в inputString:
если я в "aeiouAEIOU":
count.update(i)
распечатать (количество)
предложение = ввод ("Введите предложение: ").upper()
#создать два списка
гласные = ['A', 'E', "I", "O", "U"]
число = [0,0,0,0,0]
#перебрать каждый символ
для i в диапазоне (len (предложение)):
#для каждого символа перебираем гласные
для v в диапазоне (len (гласные)):
#если символ соответствует гласным, увеличьте число
если предложение[i] == гласные[v]:
число[v] += 1
для i в диапазоне (len (гласные)):
печать (гласные [i], "", число [i])
количество = 0 s = "azcbobobEgghakl" с = с.
 нижний ()
для i в диапазоне (0, len (s)):
если s[i] == 'a'или s[i] == 'e'или s[i] == 'i'или s[i] == 'o'или s[i] == 'u' :
количество += 1
print("Количество гласных: "+str(count))
нижний ()
для i в диапазоне (0, len (s)):
если s[i] == 'a'или s[i] == 'e'или s[i] == 'i'или s[i] == 'o'или s[i] == 'u' :
количество += 1
print("Количество гласных: "+str(count))
1
Это работает для меня, а также подсчитывает согласные (считайте это бонусом), однако, если вы действительно не хотите подсчитывать согласные, все, что вам нужно сделать, это удалить последний цикл for и последнюю переменную в вершина.
Это код Python:
data = input('Пожалуйста, дайте мне строку:')
данные = данные.нижний()
гласные = ['a','e','i','o','u']
согласные = ['b','c','d','f','g','h','j','k','l','m','n','p' ,'q','r','s','t','v','w','x','y','z']
количество гласных = 0
количество согласных = 0
для строки в данных:
для я в гласных:
если строка == я:
количество гласных += 1
для я в согласных:
если строка == я:
количество согласных += 1
print('Ваша строка содержит %s гласных и %s согласных. ' %(vowelCount, consonantCount))
 ' %(vowelCount, consonantCount))
' %(vowelCount, consonantCount))
Самый простой ответ:
inputString = str(input("Пожалуйста, введите предложение: "))
количество_гласных = 0
inputString = inputString.lower()
vowel_count+=inputString.count("а")
vowel_count+=inputString.count("e")
vowel_count+=inputString.count("i")
vowel_count+=inputString.count("о")
vowel_count+=inputString.count("u")
печать (vowel_count)
1
из коллекций import defaultdict
определение count_vowels (слово):
гласные = 'aeiouAEIOU'
count = defaultdict(int) # счетчик инициализации
для char в слове:
если char в гласных:
количество [знак] += 1
количество возвратов
Питонический способ подсчета гласных в слове, не такой как в java или c++ , на самом деле нет необходимости предварительно обрабатывать строку слова, нет необходимости в str.strip() или str.lower() . Но если вы хотите считать гласные без учета регистра, то перед тем, как войти в цикл for, используйте str. . lower()
lower()
1
гласных = ["a", "e", "i", "o", "u"]
def checkForVowels (some_string):
#сохранит все подсчитанные переменные гласных как ключ/значение
количествогласных = {}
для я в гласных:
# проверить переменные нижних гласных
если я в some_string:
количествогласных[i] = some_string.count(i)
#проверка переменных верхних гласных
elif i.upper() в some_string:
количествогласных[i.upper()] = some_string.count(i.upper())
возвращаемое количество гласных
print(checkForVowels("какая-то строка"))
Вы можете протестировать этот код здесь: https://repl.it/repls/BlueSlateblueDecagons
Так что получайте удовольствие, надеюсь, немного помогло.
…
гласных = "aioue"
text = input("Пожалуйста, введите текст:")
количество = 0
для я в тексте:
если я в гласных:
количество += 1
print("Есть", count, "гласные в вашем тексте")
…
1
определяющих гласных():
количество гласных = 0
user=input("введите предложение:")
для гласной в user:
если гласная в "aeiouAEIOU":
числогласных=числогласных+1
вернуть numOfVowels
print("Количество гласных: "+str(vowels()))
1
Вы можете использовать регулярное выражение и понимание dict:
import re s = "аиоууаааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааа его его его его его его он его ему его ему его"
Функция регулярного выражения findall() возвращает список, содержащий все совпадения
Здесь x — это ключ, а длина списка, возвращаемого регулярным выражением, — это количество каждой гласной в этой строке, обратите внимание, что регулярное выражение найдет любой введенный вами символ в строку «aeiou».
foo = {x: len(re.findall(f"{x}", s)) для x в "aeioou"}
печать (фу)
возвращает:
{'a': 3, 'e': 9, 'i': 2, 'o': 1, 'u': 2}
string1='Я люблю свою Индию' гласная = 'aeiou' для я в гласной: напечатать i + "->" + str(string1.count(i))
1
Это просто, не думайте, что это сложно, ищите троичный цикл for в python, вы его получите.
print(sum([1 for ele in input() if ele in "aeiouAEIOU"]))
1
по определению vowel_count(строка):
строка = строка.нижний()
количество = 0
vowel_found = Ложь
для символа в строке:
if char in 'aeiou': #проверка, является ли char гласной
количество += 1
vowel_found = Истина
если vowel_found == False:
print(f"В строке нет гласных: {string}")
количество возвратов
строка = "привет мир"
результат = vowel_count(string) # вызывающая функция
print("Нет гласных: ", результат)
по определению count_vowel():
цент = 0
s = 'abcdiasdeokiomnguu'
s_len = длина (ы)
s_len = s_len - 1
в то время как s_len >= 0:
если s[s_len] в ('aeiou'):
цент += 1
s_len -= 1
print 'количество гласных: ' + str(cnt)
возврат центов
деф основной():
печать (count_vowel())
основной()
1
количество = 0
name=raw_input("Введите ваше имя:")
на букву в имени:
if(буква в ['A','E','I','O','U','a','e','i','o','u']):
количество = количество + 1
выведите «У вас есть», посчитайте, «гласные в вашем имени».