Морфологический разбор слова «решение»
Часть речи: Существительное
РЕШЕНИЕ — неодушевленное
Начальная форма слова: «РЕШЕНИЕ»
| Слово | Морфологические признаки |
|---|---|
| РЕШЕНИЕ |
|
| РЕШЕНИЕ |
|
Все формы слова РЕШЕНИЕ
РЕШЕНИЕ, РЕШЕНЬЕ, РЕШЕНИЯ, РЕШЕНЬЯ, РЕШЕНИЮ, РЕШЕНЬЮ, РЕШЕНИЕМ, РЕШЕНЬЕМ, РЕШЕНИИ, РЕШЕНЬИ, РЕШЕНИЙ, РЕШЕНИЯМ, РЕШЕНЬЯМ, РЕШЕНИЯМИ, РЕШЕНЬЯМИ, РЕШЕНИЯХ, РЕШЕНЬЯХ
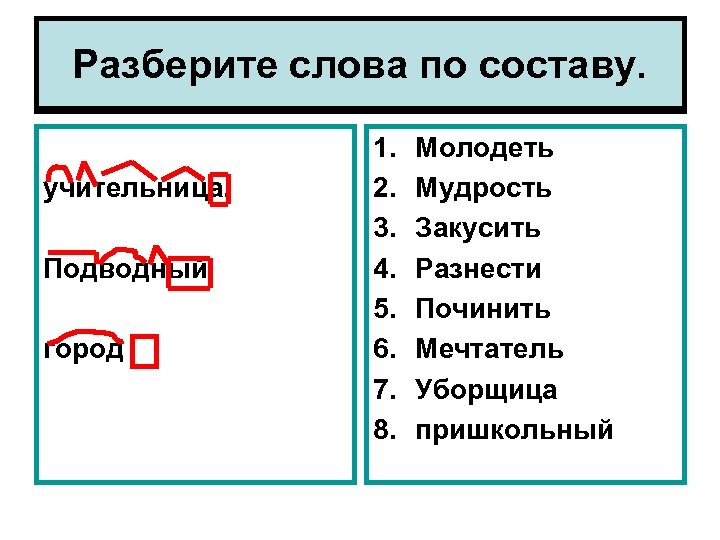
Разбор слова по составу решение
решени
е
| Основа слова | решени |
|---|---|
| Корень | реш |
| Суффикс | ени |
| Окончание | е |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «РЕШЕНИЕ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «решение»
Примеры предложений со словом «решение»
1
В общем, когда вы примете какое-то решение по этому делу, это должно быть ваше решение, а не решение судьбы или «сволочей» – начальников.
Хроники пикирующего менеджера. Увольнение, V. Smolensky
2
Решение этого вопроса им кажется очень просто, как просто всегда кажется решение трудного вопроса тому человеку, который не понимает его.
Полное собрание сочинений. Том 26. Произведения 1885–1889 гг. О жизни, Лев Толстой, 1886-1887г.
3
стали кричать рядовые кролики, потому что в трудную минуту решение не принимать никакого решения было для кроликов самым желанным решением.
Кролики и удавы. Созвездие Козлотура. Детство Чика (сборник), Фазиль Искандер, 2016г.
4
Сдается мне, это гораздо более здравое решение, – сказал Говард, хотя в действительности это решение его тогда сильно задело.
О красоте, Зэди Смит, 2005г.
5
Это мое решение – справедливое решение».
Исход, Игорь Шенфельд, 2012г.
Найти еще примеры предложений со словом РЕШЕНИЕ
Слова «решение» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «решение» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «решение» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «решение».
Содержимое:
- 1 Слоги в слове «решение»
- 2 Как перенести слово «решение»
- 3 Морфемный разбор слова «решение» по составу
- 4 Сходные по морфемному строению слова «решение»
- 5 Синонимы слова «решение»
- 6 Антонимы слова «решение»
- 7 Ударение в слове «решение»
- 8 Фонетическая транскрипция слова «решение»
- 9 Фонетический разбор слова «решение» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «решение»
- 11 Сочетаемость слова «решение»
- 12 Значение слова «решение»
- 13 Склонение слова «решение» по подежам
- 14 Как правильно пишется слово «решение»
Слоги в слове «решение»
Количество слогов: 4
Как перенести слово «решение»
ре—шение
реше—ние
Морфемный разбор слова «решение» по составу
| реш | корень |
| ени | суффикс |
| е | окончание |
решение
Сходные по морфемному строению слова «решение»
Сходные по морфемному строению слова
Синонимы слова «решение»
1. приговор
приговор
2. вердикт
3. разрешение
4. резолюция
5. постановление
6. заключение
7. разгадка
8. намерение
9. разгадывание
10. отгадка
11. урегулирование
12. определение
13. вывод
14. ответ
15. усмотрение
16. уступка
17. вотум
18. иджма
19. соломоново решение
20. декрет
21. расшивка
Антонимы слова «решение»
1. тупик
2. наведение
Ударение в слове «решение»
реше́ние — ударение падает на 2-й слог
Фонетическая транскрипция слова «решение»
[р’иш`эн’ий’э]
Фонетический разбор слова «решение» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| р | [р’] | согласный, звонкий непарный (сонорный), мягкий | р |
| е | [и] | гласный, безударный | е |
| ш | [ш] | согласный, глухой парный, твёрдый, шипящий, шумный | ш |
| е | [`э] | гласный, ударный | е |
| н | [н’] | согласный, звонкий непарный (сонорный), мягкий | н |
| и | [и] | гласный, безударный | и |
| е | [й’] | согласный, звонкий непарный (сонорный), мягкий | е |
| [э] | гласный, безударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 7 букв и 8 звуков.
Буквы: 4 гласных буквы, 3 согласных букв.
Звуки: 4 гласных звука, 4 согласных звука.
Предложения со словом «решение»
Люди с крупным большим пальцем обладают способностью находить правильные решения проблем.
Источник: В. В. Калюжный, Большая книга хиромантии, 2015.
Сейчас не лучшее время для принятия ответственных решений, поэтому звёзды рекомендуют просто переждать.
Источник: Татьяна Борщ, Лунный календарь для женщин на 2016 год + календарь стрижек, 2015.
Вместе с тем, подобное сценическое решение поднимало вопросы о месте бокса в жизни современного общества и о роли зрителя в постановке.
Источник: Майк О’Махоуни, Сергей Эйзенштейн, 2008.
Сочетаемость слова «решение»
1. правильное решение
2. окончательное решение
окончательное решение
3. верное решение
4. решение проблемы
5. решение задачи
6. решение вопроса
7. принятие решения
8. в правильности принятого решения
9. поиск решения
10. решение пришло
11. решение созрело
12. решение нашлось
13. принять решение
14. найти решение
15. изменить своё решение
16. (полная таблица сочетаемости)
Значение слова «решение»
РЕШЕ́НИЕ , -я, ср. 1. Действие по глаг. решить1—решать (в 1, 2 и 3 знач.). Решение вопроса. Решение дела. Участвовать в решении чьей-л. судьбы. (Малый академический словарь, МАС)
Склонение слова «решение» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | что? | решение, решенье | решения, решенья |
| РодительныйРод. | чего? | решения, решенья | решений |
ДательныйДат. | чему? | решению, решенью | решениям, решеньям |
| ВинительныйВин. | что? | решение, решенье | решения, решенья |
| ТворительныйТв. | чем? | решением, решеньем | решениями, решеньями |
| ПредложныйПред. | о чём? | решенье, решении, решеньи | решениях, решеньях |
Как правильно пишется слово «решение»
Правописание слова «решение»
Правильно слово пишется: реше́ние
Нумерация букв в слове
Номера букв в слове «решение» в прямом и обратном порядке:
- 7
р
1 - 6
е
2 - 5
ш
3 - 4
е
4 - 3
н
5 - 2
и
6 - 1
е
7
[PDF] Разбор зависимостей в памяти | Semantic Scholar
- Идентификатор корпуса: 974611
@inproceedings{Nivre2004MemoryBasedDP,
title={Синтаксический анализ зависимостей в памяти},
автор={Иоаким Нивр, Йохан Холл и Йенс Нильссон},
booktitle={Конференция по компьютерному изучению естественного языка},
год = {2004}
} В этом документе приводятся результаты экспериментов с использованием обучения на основе памяти для управления синтаксическим анализатором детерминированных зависимостей для неограниченного текста на естественном языке.
View on ACL
stp.lingfil.uu.seDeterministic Dependency Parsing of English Text
- Joakim Nivre, Mario Scholz
Computer Science
COLING
- 2004
В этой статье представлен детерминированный синтаксический анализатор зависимостей, основанный на обучении на основе памяти, который анализирует текст на английском языке за линейное время и создает помеченные графы зависимостей, используя в качестве меток дуг комбинацию меток скобок и меток грамматических ролей, взятых из схемы аннотаций Penn Treebank II. .
Дискриминативные классификаторы для анализа детерминированных зависимостей
- Йохан Холл, Йоаким Нивр, Йенс Нильссон
Информатика
ACL
- 2006
Систематическое сравнение методов обучения на основе памяти и машин опорных векторов для создания классификаторов для разбора детерминированных зависимостей с использованием данных из китайского, английского и шведского языков вместе с различными моделями признаков показывает, что SVM обеспечивает более высокую точность для богато сформулированные модели функций на всех языках, хотя и со значительно более длительным временем обучения.
Разбор зависимостей между языками с использованием шаблонов частей речи
- P. Bednar
Информатика
TSD
- 2016
обучающие данные для прямой оценки прогностической способности паттернов частей речи на основе данных оценки из банков деревьев в Чехии и Словакии.
Придание формы синтаксическому анализатору зависимостей N-версии — повышение точности синтаксического анализа зависимостей для испанского языка с использованием Maltparser
- Miguel Ballesteros, J. Herrera, Virginia Francisco, Pablo Gervás
Информатика
KDIR
- 2010
Существует n-версия, которая работает следующим образом: набор слов, которые чаще всего анализируются неправильно, поэтому синтаксический анализатор зависимостей n-версии состоит из n различных синтаксических анализаторов, специально обученных для синтаксического анализа этих сложных слов.
Улучшение анализа зависимостей на основе графов с помощью истории решений
- Вэньлян Чен, Дзюнъити Казама, Ёсимаса Цуруока, Кентаро Торисава
Информатика
COLING
- 2010
короткие зависимости, вычисляемые на более ранних этапах синтаксического анализа, для повышения точности длинных зависимостей на более поздних этапах.
Интеграция парсеров зависимостей на основе графов и переходов
- Joakim Nivre, Ryan T. McDonald
Computer Science
ACL
- 2008
для повышения точности синтаксического анализа за счет интеграции модели на основе графа и модели на основе перехода.
Анализаторы зависимостей стекирования
- Андре Ф. Т. Мартинс, Дипанджан Дас, Ноа А. Смит, Э. Син
Информатика
EMNLP
- 2008
Эксперименты на двенадцати языках показывают, что наложение синтаксических анализаторов на основе переходов и графов повышает производительность по сравнению с существующими современными синтаксическими анализаторами зависимостей.
Многословные единицы в синтаксическом разборе
- Йоаким Нивре, Йенс Нильссон
Информатика
- 2004
Исследовано влияние обучения на основе синтаксического анализа на точность определения термина MWU на основе синтаксического анализа и анализ некоторых из наиболее важных типов ошибок, которые устраняются за счет распознавания MWU.
Анализатор зависимостей на основе данных для болгарского языка
- Светослав Маринов, Йоаким Нивре
Информатика
- 2005
Этот документ считается первым надежным синтаксическим анализатором данных, подготовленным для болгарского языка и прошедшим оценку от BulTreeBank, который использует представления на основе зависимостей и применяет детерминированный алгоритм для создания структур зависимостей за один проход по входной строке.
Анализ зависимостей на основе переходов с подключаемыми классификаторами
- Алекс Рудник
Информатика
ArXiv
- 2012
Представлены расширения к MaltParser, которые позволяют использовать любой классификатор для обучения машины, обертки, соответствующей интерфейсу обертки Обучение на основе памяти TiMBL для этого интерфейса и эксперименты по анализу многоязычных зависимостей с помощью различных классификаторов.
ПОКАЗЫВАЮТСЯ 1-10 ИЗ 35 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантностьНаиболее влиятельные статьиНовости
Управляемые головой статистические модели для анализа естественного языка
- М. Коллинз
Компьютерные науки
CL
- 2003
- 2003 представляется как последовательность решений, соответствующих центрированному нисходящему построению дерева.
Парсер, вдохновленный максимальной энтропией
- Евгений Чарняк
Информатика
ANLP
- 2000
Новый синтаксический анализатор для синтаксического анализа до деревьев синтаксического анализа в стиле Penn tree-bank, который обеспечивает среднюю точность/отзыв 90,1% для предложений длиной 40 и менее и 89,5% при обучении и представлена апробация на ранее созданных разделах дерева Wall Street Journal.
Три новые вероятностные модели анализа зависимостей: исследование
- Джейсон Эйснер
Информатика
COLING
- 1996
Предварительные эмпирические результаты оценки производительности синтаксического анализа трех моделей на аннотированном обучающем тексте Wall Street Journal (полученном из Penn Treebank) показывают, что генеративная модель работает значительно лучше, чем другие, и делает примерно одинаково хорошо при назначении тегов части речи.

Статистический синтаксический анализатор для чешского языка
- М. Коллинз, Ян Хаич, Л. Рэмшоу, К. Тилманн
Информатика
ACL
- 1999
В этой статье рассматривается статистический анализ чешского языка, который радикально отличается от английского как минимум в двух отношениях: (1) это язык с высокой степенью флективности и (2) в нем относительно свободный порядок слов. …
Основанная на памяти альтернатива коннекционистскому синтаксическому анализу сдвига и сокращения рядом с моделями нейронных сетей.
Строительство большого аннотированного корпуса английского языка: Penn Treebank
- M. Marcus, Beatrice Santorini, Mary Ann Marcinkiewicz
Компьютерная наука
CL
- 1993
В результате этого гранта, исследования, исследования, исследования, исследования, исследования, исследования, исследования, исследования, исследования, исследования, исследования опубликовали на компакт-диске корпус из более чем 4 миллионов слов непрерывного текста, аннотированного тегами частей речи (POS), который включает полностью проанализированную вручную версию классического корпуса Брауна.
Руководства и оракулы для анализа линейного времени
- М. Кей
Информатика
IWPT
- 2000
Стратагема отделения считывания от построения диаграмм также может быть применена к другим типам синтаксических анализаторов, в частности к анализаторам левого входа. использовать раннюю композицию.
Руководство Earley Parsing
- Pierre Boullier
Компьютерная наука
IWPT
- 2003
Метод, который может ускорить Эрли Парсерс на практике, предсказанный, чей предсказатель является немного модифицированным в таком виде, как это предсказано, и чьи предсказание является слегка модифицированным таким образом, что это так. выбирает начальный элемент только в том случае, если этот элемент находится в справочнике.
Эффективный алгоритм для проектного анализа зависимости
- Joakim Nivre
Компьютерные науки
IWPT
- 2003
.
Этот документ представляет собой детерминированный пассажирский альгарирование. , достигая точности выше 85% с очень простой грамматикой.Забывание исключений вредно для изучения языка
- Walter Daelemans, Antal van den Bosch, Jakub Zavrel
Информатика
Машинное обучение
- 2004
Показано, что при изучении языка, в отличие от полученной мудрости, сохранение в памяти исключительных учебных примеров может быть полезным для точности обобщения, и что обучение на основе дерева решений часто работает хуже, чем обучение на основе памяти.
⚖ Структурирование юридических документов с помощью Deep Learning | Полин Шавальяр | Внутри доктрины
Арно Мирибель и Полин Шавальяр
Почти 4 миллиона решений выносятся ежегодно французскими судами. Прецедентное право, которым они руководствуются, имеет решающее значение для юристов, которые используют его в суде для защиты своих клиентов.
Юридические исследования утомительны, и миссия Doctrine — — помочь им перейти прямо к делу. Судебные решения традиционно представляют собой длинных и сложных документов. В довершение всего, например, адвоката может интересовать только резолютивная часть решения, то есть итоги судебного разбирательства. На самом деле, в таком длинном тексте довольно часто ищут конкретный юридический аспект, и это может быстро показаться поиском иголки в стоге сена. Наша цель здесь — определить структуру решений по доктрине (т. е. оглавление) до помочь пользователям легче перемещаться по ним.
Решение обычно имеет следующую структуру:
- Метаданные («En-tête» по-французски): суд, номер, дата и т. д. судебного разбирательства.
- Стороны («Стороны» на французском языке): сведения об истцах и ответчиках
- Состав суда («Состав суда» на французском языке): имя председателя суда, секретаря и т. д.
- Факты («Faits» по-французски): что случилось?
- Заявление в суде и основные аргументы («Moyens» по-французски): аргументы, представленные истцом и ответчиком.
- Основания («Мотивы» на французском языке): причины и аргументы, использованные судом для вынесения окончательного решения.
- Резолютивная часть решения («Dispositif» на французском языке): окончательное решение суда.
Это обычные разделы, однако в решениях нет системной структуры. Суды могут использовать различные стили , как с точки зрения написания, так и организации документов. Например, у некоторых есть заголовки, которые выделяют определенную часть, а у некоторых нет. Причем у некоторых есть все описанные выше разделы, у некоторых только некоторые.
Пример оглавления решения по Доктрине. Это решение не включает ни метаданные, ни иски.Французский апелляционный суд обычно имеет очень унифицированный способ написания.
Выдержка из решения французского апелляционного суда с четким названием раздела «Факты». Извлечено из https://www.doctrine.fr/d/CA/Orleans/2007/SKDD824CCFE8D8D9D93128 . См. английский перевод . Около 55% их решений (среди тех, что размещены на Doctrine) имеют явные заголовки для каждой категории:Для остальных 45% у нас нет явного заголовка для всех разделов.
Пример неструктурированного текста, предоставленный Апелляционным судом Франции. Извлечено из https://www.doctrine.fr/d/CA/Metz/2015/RAC1261A1563690C06B77 . См. английский перевод .Решения можно рассматривать как небольшие истории, и хотя люди могут их понять, потому что они понимают контекст и имеют некоторые ожидания, как поступит алгоритм?
Итак, как мы можем автоматически генерировать оглавления для судебных решений?
Для каждого входного абзаца из решения мы хотим предсказать, какой раздел он должен быть помечен (тот, к которому он принадлежит).
Давайте немного подумаем о том, как человек может понять переход между двумя разделами на рисунке выше (от «Фактов» к «Основаниям»).
- Постановление по пунктам — большая подсказка: суд всегда будет напоминать нам о фактах, прежде чем давать основания.
- Словарь , используемый , также выглядит по-разному в этих разделах. В приведенном выше неструктурированном примере первый абзац суммирует 90 384 события 9.0385 , тогда как второй абзац цитирует некоторые точные законодательные пункты и кажется авторитетным аргументом . Но не так-то просто увидеть разницу, только взглянув на используемые слова. Действительно, в данном случае оба абзаца цитируют аспект законодательства, и, таким образом, оба абзаца содержат семантику здравоохранения и санитарной среды.
Наш первый подход заключался в использовании набора слов (BoW) для кодирования словарной информации абзаца, а также условных случайных полей (CRF) над абзацами для кодирования последовательной информации.
К сожалению, эта попытка быстро оказалась недостаточной, особенно из-за ее простоты, учитывая сложность задачи. Как подчеркивалось ранее, словарей среди абзацев 9.0337 недостаточно отличается от , чтобы BoW работал хорошо.Чтобы решить эту сложную проблему, мы обучили более сложную модель: нейронную сеть (bi-LSTM с вниманием), использующую PyTorch, чтобы помочь нам предсказать оглавление с учетом решения произвольного текста.
В этом разделе мы сначала подробно описываем данные, которые мы использовали, и то, как мы их предварительно обработали. Затем мы объясняем, какие модели мы пробовали, и почему. Наконец, мы предоставляем ретроспективный обзор результатов и интерпретаций 👀.
💣 Спойлер: наши модели работают хорошо!
Как подробно описано во введении, наша задача состоит в том, чтобы классифицировать каждый абзац (назовем его X) решения в одну из 7 наиболее распространенных категорий (назовем его y ).
Эти категории следующие: Метаданные, Стороны, Состав, Факты, Заявления в законе, Основания и Постановляющая часть.
Определение X
Ниже абзац (отмеченный ¶) представляет собой отдельный раздел текста, обозначенный новой строкой
Разделение на пункты ¶1, ¶2 и ¶3.\nсимволов. Посмотрите ниже, как мы получаем их в наших решениях.Настройка и поиск y
Мы хотим иметь контролируемую настройку классификации (с истинным или ожидаемым y ), поэтому нам нужны помеченные данные для наших абзацев.
На самом деле, это довольно просто. Для многих решений французского апелляционного суда существует четкое и ясное оглавление. Эти решения используют заголовки для структурирования документов, поэтому мы можем искать эти заголовки, чтобы аннотировать наш набор данных (9).0384 y ), а затем удалите их. Наш набор данных теперь помечен как .
Чтобы избежать слишком большого словарного запаса, мы:
- Строчный текст
- Основы слов
- Заменим все числа на ноль . В нашем случае очень важно сохранить редкие слова даже под одним единственным представлением, потому что оно часто будет соответствовать фамилиям. И мы предположили, что можем узнать что-то по фамилиям (что в конечном итоге оказалось правдой).
В этом разделе мы кратко опишем, какие модели мы выбрали, и интуицию, стоящую за этим выбором.
Подождите… это распознавание именованных объектов?
Одна вещь, которую мы быстро заметили, — это сходство нашей задачи (классификация абзацев) с распознаванием именованных сущностей (NER). NER — это традиционная задача в обработке естественного языка, где алгоритм обучается обнаруживать объекты в предложении.
Распознавание названных лиц: поиск юристов, дат и других лиц в решении.В нашем случае мы работаем не в масштабе слов , а в масштабе абзаца . Тем не менее, идея остается прежней, мы можем вывести метку слова/абзаца с помощью:
- его присущих свойств
- его контекста (соседство дает понимание метки).
Итак, изучение литературы по NER дало нам несколько отличных идей по архитектуре модели (а именно нейронные сети bi-LSTM с вниманием — мы скоро это увидим).
Выбранная нами архитектура сильно вдохновлена этой статьей.Вложения абзаца
Так же, как NER, модели используют слова вложения в качестве начального представления для своих входных данных, нам нужно представить наши абзацы с вложениями абзаца .
Объединение вложений слов
В Doctrine мы обучили наши собственные вложения слов на 2 миллионах юридических документов с помощью wang2vec. Мы можем использовать эти вложения слов для вычисления вложений абзацев, например, путем агрегирования вложений слов абзаца. Мы пробовали две агрегации:
- Среднее вложений слов абзаца, инициализированных нашими предварительно обученными векторами.
- Сумма вложений слов абзаца, инициализированных нашими предварительно обученными векторами.
Обучение с помощью bi-LSTM
Одна из проблем предыдущего метода (усреднение и сумма) заключается в том, что он не фиксирует последовательную информацию о порядке слов во вложениях абзаца, и мы можем повредить обучению.
Одним из решений является использование bi-LSTM, который хранить информацию слева направо и справа налево. Мы обучили их, используя наши предварительно обученные вложения слов.- bi-LSTM над абзацем и чтением слов, сохраняя последнее скрытое состояние слева направо и справа налево.
- bi-LSTM с механизмом самоконтроля, сильно вдохновлен этой статьей Bengio et al, 2017. Будет очень полезно для интерпретации того, какие слова влияют на окончательную классификацию.
Классификатор
Теперь, когда у нас есть хороший дизайн для вложений абзацев, мы можем определить операции над этими вложениями, чтобы предсказать, к какому классу они принадлежат.
- Выбор кодировщика
Мы также хотим классифицировать один абзац на основе информации о соседних абзацах, чтобы зафиксировать последовательность абзацев.
Здесь мы снова выбрали би-LSTM.- Выбор декодера
Мы выбрали CRF, потому что они позволяют моделировать вероятности перехода между классами . И в нашем случае наши классы имеют последовательную информацию (т.е. класс «Мотивы» должен идти после класса «Факты» и перед классом «Диспозитив»), поэтому просмотр матрицы переходов помогает проверить, хорошо ли учится модель.
Архитектура сети классификации параграфов.Обратите внимание, что мы также попробовали простой softmax для части декодера и сравнили результаты (мы увидим это позже).
Мы разделились на обучающие и тестовые наборы и учились с помощью оптимизатора Adam со скоростью обучения = 0,0025 и бета = 0,85. Наша потеря — это отрицательная логарифмическая вероятность.
Ниже приведены характеристики наших лучших моделей:
Результаты наших лучших моделей по классификации абзацев.Обратите внимание, что обучение моделей с агрегацией средних для встраивания абзацев занимает примерно на 30% меньше времени, чем с bi-RNN!
Обратите внимание, что f1-оценка относится ко всем тегам.
Однако мы углубились в результаты и заметили, что модели было сложнее предсказать конкретный тег «Moyens». Они действительно не всегда присутствуют в решениях, а иногда смешиваются с частью «Факты».Производительность лучшей модели
Наша лучшая модель набрала 0,98 балла f1!
Благодаря CRF мы можем взглянуть на нормализованные оценки перехода между классами и увидеть, где модель работает хорошо, а где нет.
Матрица переходов, представляющая оценки переходов между различными разделами. Красный означает низкий балл перехода, зеленый — высокий балл перехода.Некоторые интерпретации:
- Каждый класс, вероятно, будет , за которым следует сам (потому что каждый класс почти всегда состоит из нескольких абзацев).
- За разделом «Метаданные», скорее всего, последует «Стороны» или «Состав».
- Как правило, нижний треугольник зеленый и верхний треугольник красный , что является хорошей проверкой работоспособности, гарантирующей, что разделы обычно не переходят от метки к предыдущей!
- Вероятность перехода между классами «Земля» и «Стороны» действительно мала, потому что они далеко друг от друга в решении.
Визуализация с вниманием
Мы использовали веса внимания, чтобы проанализировать, какие слова помогают модели предсказывать правильные классы. В следующих примерах очень интересно отметить, что слова с высоким вниманием имеют общий смысл.
Выделены слова, очень характерные для раздела сторон: avocat (адвокат) и barreau (бар). Выделены слова, очень характерные для состава судебной секции: président (председатель), conseiller (советник), délibéré (совещался) и Greffier (клерк). Выделены слова, очень характерные для постановляющей части: Confirme (подтвердить), déféré (упомянутый), излишек (остаток).Этот проект предоставил прекрасную возможность протестировать встраивание абзацев и механизмы внимания в Doctrine. Мы получили фантастические результаты, и сегодня наша модель развернута для наших пользователей.

 Этот документ представляет собой детерминированный пассажирский альгарирование. , достигая точности выше 85% с очень простой грамматикой.
Этот документ представляет собой детерминированный пассажирский альгарирование. , достигая точности выше 85% с очень простой грамматикой. Юридические исследования утомительны, и миссия Doctrine — — помочь им перейти прямо к делу.
Юридические исследования утомительны, и миссия Doctrine — — помочь им перейти прямо к делу.  д.
д. Около 55% их решений (среди тех, что размещены на Doctrine) имеют явные заголовки для каждой категории:
Около 55% их решений (среди тех, что размещены на Doctrine) имеют явные заголовки для каждой категории:
 К сожалению, эта попытка быстро оказалась недостаточной, особенно из-за ее простоты, учитывая сложность задачи. Как подчеркивалось ранее, словарей среди абзацев 9.0337 недостаточно отличается от , чтобы BoW работал хорошо.
К сожалению, эта попытка быстро оказалась недостаточной, особенно из-за ее простоты, учитывая сложность задачи. Как подчеркивалось ранее, словарей среди абзацев 9.0337 недостаточно отличается от , чтобы BoW работал хорошо.
 И мы предположили, что можем узнать что-то по фамилиям (что в конечном итоге оказалось правдой).
И мы предположили, что можем узнать что-то по фамилиям (что в конечном итоге оказалось правдой). Выбранная нами архитектура сильно вдохновлена этой статьей.
Выбранная нами архитектура сильно вдохновлена этой статьей. Одним из решений является использование bi-LSTM, который хранить информацию слева направо и справа налево. Мы обучили их, используя наши предварительно обученные вложения слов.
Одним из решений является использование bi-LSTM, который хранить информацию слева направо и справа налево. Мы обучили их, используя наши предварительно обученные вложения слов. Здесь мы снова выбрали би-LSTM.
Здесь мы снова выбрали би-LSTM. Однако мы углубились в результаты и заметили, что модели было сложнее предсказать конкретный тег «Moyens». Они действительно не всегда присутствуют в решениях, а иногда смешиваются с частью «Факты».
Однако мы углубились в результаты и заметили, что модели было сложнее предсказать конкретный тег «Moyens». Они действительно не всегда присутствуют в решениях, а иногда смешиваются с частью «Факты».
