Разбор слов по составу
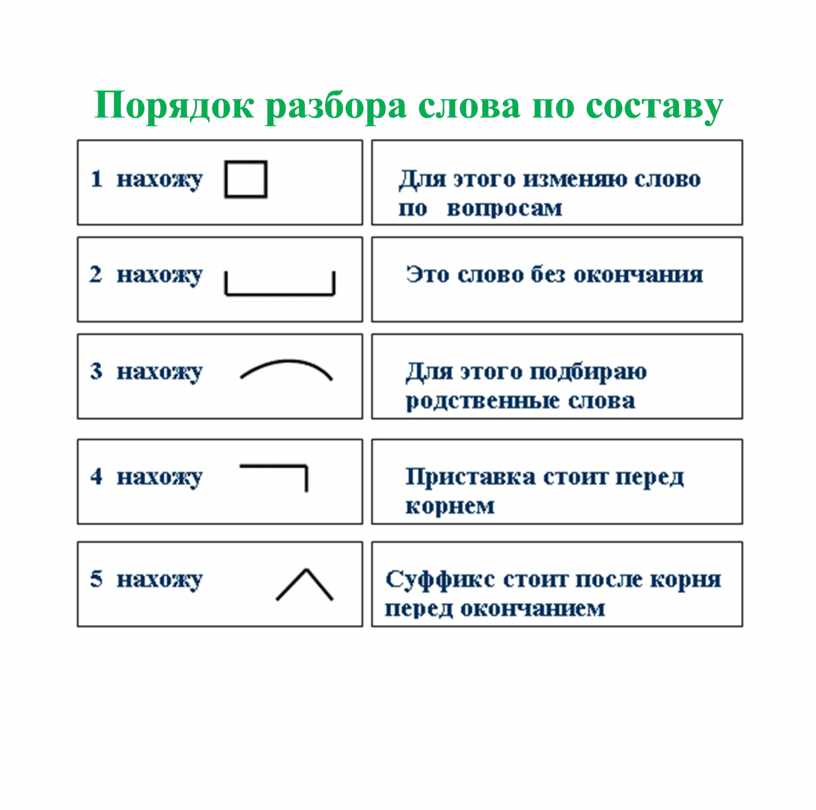
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: меловайс сейчас катание сейчас мирешка сейчас пинмекг сейчас тропа сейчас йанорам 1 секунда назад кнзитрвоа 1 секунда назад москит 1 секунда назад о т б л е с к 1 секунда назад схутра 1 секунда назад с а д р е т л 1 секунда назад у с т я ы п н 2 секунды назад с б р о у л е 2 секунды назад гиолка 2 секунды назад рондо 2 секунды назад
Предложение. Члены предложения: главные и второстепенные
- Члены предложения
- Главные члены: подлежащее и сказуемое
- Типы сказуемых
- Второстепенные члены предложения
- Определение
- Дополнение
- Обстоятельство
Предложение — это сочетание слов или отдельное слово, выражающее законченную мысль.
В устой речи окончание предложения выражается голосом (интонацией), между предложениями делается остановка (пауза). На письме одно предложение отделяется от другого точкой (.), вопросительным (?) или восклицательным знаком (!). Первое слово в каждом предложении пишется с большой буквы.
Чашка стоит на столе.
Сегодня выходной!
Как долго нам ещё ждать?
Слова в предложении связаны грамматически, то есть с помощью окончаний и предлогов, а также по смыслу.
Не является предложением:
- Группа слов, не связанных по смыслу: стол, чашка, стоит.
- Группа слов, не выражающих законченную мысль: чашка стоит на.
Члены предложения
Члены предложения — это слова, входящие в состав предложения, которые отвечают на какой-нибудь вопрос.
Пример. В предложении
Наша семья осенью переезжает из деревни в город
шесть членов.
- Чья семья? — Наша.
- Кто переезжает? — Семья.
- Когда переезжает? — Осенью.
- Семья что делает? — Переезжает.
- Откуда переезжает? — Из деревни .
- Куда переезжает? — В город.
Слова из и в не отвечают на вопросы и поэтому самостоятельными членами предложения не являются, а входят в состав тех членов, к которым относятся.
Члены предложения делятся на главные и второстепенные.
Главные члены: подлежащее и сказуемое
Главные члены предложения — это подлежащее и сказуемое. Подлежащее и сказуемое составляют грамматическую основу предложения. Грамматическая основа предложения — это основная часть предложения, которая состоит из его главных членов: подлежащего и сказуемого.
Подлежащее — это главный член предложения, который отвечает на вопрос кто? или что? Подлежащее называет объект, который производит действие, испытывает какое-либо состояние, обладает определённым признаком. Подлежащее подчёркивается одной чертой: подлежащее.
Подлежащее подчёркивается одной чертой: подлежащее.
Подлежащее обычно выражается именем существительным или местоимением в именительном падеже.
Пример.
Дождь шёл весь день. Что шло? — Дождь.
Мы идём в кино. Кто идёт? — Мы.
Сказуемое — это главный член предложения, который отвечает на один из вопросов: что делает? что делается? каков? кто он? что такое? Сказуемое связано с подлежащим и называет его действие, состояние или признак. Сказуемое подчёркивается двумя чертами: сказуемое.
Сказуемое обычно выражается глаголом, но оно может также быть выражено именем существительным и именем прилагательным. От подлежащего к сказуемому можно задать вопрос.
Пример.
Солнце ярко (что делает?) светит.
На улице (что делается?) темнеет.
Цветок (каков?) красив.
Менделеев – (кто он?) учёный.
Золото – (что такое?) металл.
Подлежащее и сказуемое связаны друг с другом по смыслу и грамматически.
Типы сказуемых
Сказуемое может быть простым и составным. Составные сказуемые делятся на глагольные и именные.
| Простое глагольное сказуемое | работают боится |
| Составное глагольное сказуемое | продолжают работать стал бояться |
| Составное именное сказуемое | стали рабочими остался трусом |
Второстепенные члены предложения
Второстепенные члены предложения — это слова, которые поясняют сказуемое, подлежащее или один из второстепенных членов.
Пример. В предложении
Озорной щенок любопытно разглядывал новую игрушку
подлежащее щенок и сказуемое разглядывал; второстепенные члены предложения: озорной, любопытно, новую, игрушку.
- Слово озорной поясняет подлежащее щенок, показывая какой щенок разглядывал.

- Слово любопытно поясняет сказуемое разглядывал и показывает, как разглядывал щенок.
- Слово игрушку поясняет сказуемое разглядывал и показывает, что разглядывал щенок.
- Слово новую поясняет второстепенный член предложения игрушку и показывает, какую игрушку разглядывал щенок.

Отношение членов предложения друг к другу можно изобразить такой схемой:
Любой второстепенный член зависит от какого-либо другого слова в предложении, а подлежащее и сказуемое ни от каких других слов не зависят и являются таким образом основой всего предложения. Подлежащее и сказуемое и без второстепенных членов могут составить предложение.
Второстепенные члены предложения в зависимости от того, как они поясняют другие члены предложения, делятся на определения, дополнения и обстоятельства.
Определение
Определение — это второстепенный член предложения, который обозначает признак предмета и отвечает на вопросы: какой? который? чей? Определение подчёркивается волнистой линией: определение.
Определение относится к имени существительному.
Пример.
Яркие звёзды сияли в ночном небе.
Звёзды какие? — Яркие. Небо какое? — Ночное.
Моя шапка упала в лужу.
Чья шапка? — Моя.
Марине пошёл восьмой год.
Который год? — Восьмой.
Дополнение
Дополнение — это второстепенный член предложения, который обозначает предмет и отвечает на вопросы косвенных падежей: кого? чего? кому? чему? кого? что? кем? чем? о ком? о чём? Дополнение подчёркивается пунктирной линией: дополнение.
Дополнение обычно относится к глаголу.
Пример.
Я интересуюсь географией.
Интересуюсь чем? — Географией.
На вокзале мы встречали папу.
Встречали кого? — Папу.
Миша позвонил другу.
Позвонил кому? — Другу.
Обстоятельство
Обстоятельство — это второстепенный член предложения, который обозначает, как и при каких обстоятельствах (то есть где? когда? почему? и т. п.) совершается действие. Обстоятельство отвечает на вопросы: как? каким образом? где? когда? куда? откуда? почему? зачем?. Обстоятельство подчёркивается пунктиром с точкой: обстоятельство.
п.) совершается действие. Обстоятельство отвечает на вопросы: как? каким образом? где? когда? куда? откуда? почему? зачем?. Обстоятельство подчёркивается пунктиром с точкой: обстоятельство.
Обстоятельство обычно относится к глаголу.
Пример.
Зимой мы катаемся на лыжах.
Катаемся когда? — Зимой.
Из уютного магазинчика мы вышли на шумную улицу.
Вышли откуда? — Из магазинчика. Вышли куда? — На улицу.
Лисица подкрадывалась тихо и осторожно.
Подкрадывалась как? — Тихо и осторожно.
python — Преобразование псевдоалгебраической строки в команду
Регулярные выражения по своей сути не подходят для задач, связанных со скобками для вложенной группировки — ваш псевдоалгебраический язык (PAL) не является обычным языком. Вместо этого следует использовать настоящий синтаксический анализатор, такой как PyParsing (анализатор PEG).
Хотя для этого по-прежнему требуется преобразование исходного кода в операции, это можно выполнить непосредственно во время синтаксического анализа.
Нам нужно несколько языковых элементов, которые напрямую транслируются в примитивы Python:
- Числовые литералы, такие как
1.3, asint/floatлитералы илидроби. Дробь. - Ссылки на имена, такие как
A3, в качестве ключей к пространству именобъектов. - Скобки, такие как
(...), как группировка с помощью скобок для:- Варианты, такие как
(1.3 или A3), какмакс.вызовов. - Диапазоны имен, например, от
A4 до A6, какмакс.звонки - Бинарный оператор
+, как бинарный оператор+.
- Варианты, такие как
- Неявное умножение, например,
2(...), как2 * (...).
Такой простой язык одинаково подходит и для транспилятора, и для интерпретатора — нет побочных эффектов и интроспекции, так что подойдет наивный перевод без первоклассных объектов, промежуточного представления или AST.
Для транспилятора нам нужно преобразовать исходный код PAL в исходный код Python. Мы можем использовать pyparsing для прямого чтения PAL и использования действия синтаксического анализа для генерации Python.
Примитивные выражения
Простейшим случаем являются числа — исходный код PAL и Python идентичны. Это идеально, чтобы посмотреть на общую структуру транспиляции:
import pyparsing as pp
# Правило грамматики PAL: одно "слово" из знака, цифры, точки, цифры
ЧИСЛО = pp.Regex(r"-?\d+\.?\d*")
# PAL -> преобразование Python: вычисление соответствующего кода Python
@NUMBER.setParseAction
def translate (результат: pp.ParseResults) -> str:
вернуть результат[0]
Обратите внимание, что setParseAction обычно используется с lambda вместо декорирования def . Однако более длинный вариант легче комментировать/аннотировать.
Ссылка на имя похожа на синтаксический анализ, но требует незначительного перевода на Python. Мы по-прежнему можем использовать регулярные выражения, так как здесь тоже нет вложенности. Все имена будут ключами к единому глобальному пространству имен, которое мы произвольно называем
Мы по-прежнему можем использовать регулярные выражения, так как здесь тоже нет вложенности. Все имена будут ключами к единому глобальному пространству имен, которое мы произвольно называем объектами .
ИМЯ = pp.Regex(r"\w+\d+")
@NAME.setParseAction
def translate (результат: pp.ParseResults) -> str:
return f'objects["{result[0]}"]' # интерполировать ключ в пространство имен
Обе части грамматики уже работают независимо для транспиляции. Например, NAME.parseString("A3") предоставляет исходный код objects["A3"] .
Составные выражения
В отличие от терминальных/примитивных грамматических выражений, составные выражения должны ссылаться на другие выражения, возможно, на самих себя (на этом этапе регулярные выражения не работают). PyParsing упрощает это с помощью выражений Forward — это заполнители, которые определяются позже.
# заполнитель для любого допустимого элемента грамматики PAL ВЫРАЖЕНИЕ = pp.
 Forward()
Forward()
Без приоритета оператора и просто группировки через (...) , все + , или и от до работают одинаково. В качестве демонстратора мы выбираем или .
Теперь грамматика усложняется: мы используем pp. Подавляем для соответствия, но отбрасываем чисто синтаксические ( / ) и или . Мы используем + / - для объединения нескольких грамматических выражений ( - означает отсутствие альтернатив при разборе). Наконец, мы используем прямую ссылку ВЫРАЖЕНИЕ для ссылки на каждое другое выражение и это выражение .
SOME_OR = pp.Suppress("(") + ВЫРАЖЕНИЕ + pp.OneOrMore(pp.Suppress("или") - ВЫРАЖЕНИЕ) - pp.Suppress(")")
@SOME_OR.setParseAction
def translate (результат: pp.ParseResults) -> str:
элементы = ', '.join(результат)
вернуть f "макс ({элементы})"
Диапазоны имен и сложение в основном работают одинаково, меняется только разделитель и форматирование вывода. Неявное умножение проще тем, что оно работает только с парой выражений.
Неявное умножение проще тем, что оно работает только с парой выражений.
На данный момент у нас есть транспилятор для каждого типа элемента языка. Отсутствующие правила могут быть созданы таким же образом. Теперь нам нужно на самом деле прочитать исходный код и запустить транспилированный код.
Начнем с того, что соберем воедино то, что у нас есть: вставим все элементы грамматики в прямую ссылку. Мы также предоставляем удобную функцию для абстрагирования от PyParsing.
ВЫРАЖЕНИЕ << (ИМЯ | НОМЕР | НЕКОТОРОЕ_ИЛИ)
def transpile (приятель: улица) -> улица:
"""Перенести исходный код PAL в исходный код Python"""
вернуть EXPRESSION.parseString(приятель, parseAll=True)[0]
Чтобы запустить некоторый код, нам нужно транспилировать код PAL и оценить код Python с некоторым пространством имен. Так как наша грамматика допускает только безопасный ввод, мы можем напрямую использовать eval :
def execute(pal, **objects):
"""Выполнить исходный код PAL с заданными значениями объекта"""
код = транспортировать (приятель)
вернуть оценку (код, {"объекты": объекты})
Эту функцию можно запустить с заданным исходным кодом PAL и значениями имени для оценки эквивалентного значения Python:
>>> выполнить("(A4 или A3 или 13)", A3=42, A4=7)
42
Для полной поддержки PAL определите отсутствующие составные правила и добавьте их вместе с другими в EXPRESSION .
python — разобрать строку, разделенную точками, в переменную словаря
спросил
Изменено 3 года, 3 месяца назад
Просмотрено 5к раз
У меня есть строковые значения как,
"a" "а.б" "BCD"
Как преобразовать их в переменные словаря Python как,
a а["б"] б["в"]["д"]
Первая часть строки (до точки) станет именем словаря, а остальные подстроки станут ключами словаря.0195 4
Я столкнулся с этой же проблемой при разборе ini-файлов с ключами, разделенными точками, в разных разделах. например:
[приложение] site1.ftp.host = имя хоста site1.ftp.username = имя пользователя site1.database.hostname = db_host ; и т. д..
Итак, я написал небольшую функцию для добавления «add_branch» к существующему дереву словаря:
def add_branch(дерево, вектор, значение):
"""
Учитывая словарь, вектор и значение, вставьте значение в словарь
на листе дерева, заданном вектором. Рекурсивный!
Параметры:
data (dict): структура данных, в которую вставляется вектор.
вектор (список): список значений, представляющих путь к конечному узлу.
значение (объект): объект, который будет вставлен в лист
Пример 1:
дерево = {'а': 'яблоко'}
вектор = ['b', 'c', 'd']
значение = 'собака'
дерево = add_branch (дерево, вектор, значение)
Возвращает:
дерево = { 'a': 'яблоко', 'b': { 'c': {'d': 'собака'}}}
Пример 2:
вектор2 = ['б', 'с', 'е']
значение2 = 'яйцо'
дерево = add_branch (дерево, вектор2, значение2)
Возвращает:
tree = { 'a': 'яблоко', 'b': { 'c': {'d': 'собака', 'e': 'яйцо'}}}
Возвращает:
dict: словарь со значением, помещенным по указанному пути.
Алгоритм:
Если мы находимся на листе, добавьте его как ключ/значение в дерево
Иначе: если поддерево не существует, создайте его.
Рекурсия с поддеревом и сдвинутым влево вектором.
Верните дерево.
"""
ключ = вектор[0]
дерево[ключ] = значение \
если len(вектор) == 1 \
else add_branch(tree[key] if key in tree else {},
вектор[1:],
ценить)
дерево возврата
9. ]+ # один или несколько символов, не являющихся точкой
) # конец именованной группы 'dict'
\. # буквальная точка
(?P # начало именованной группы 'keys'
.* # остальная часть строки!
) # конец именованной группы 'keys'""",
в_,
флаги = re.X)
d = vars()[match.group('dict')]
для ключа в match.group('keys'):
d = d.get (ключ, нет)
если d равно None:
# обрабатывать случай, когда в словаре нет этого (под)ключа!
print("Ой!")
перерыв
результат = д
# результат == Истина
 Рекурсивный!
Параметры:
data (dict): структура данных, в которую вставляется вектор.
вектор (список): список значений, представляющих путь к конечному узлу.
значение (объект): объект, который будет вставлен в лист
Пример 1:
дерево = {'а': 'яблоко'}
вектор = ['b', 'c', 'd']
значение = 'собака'
дерево = add_branch (дерево, вектор, значение)
Возвращает:
дерево = { 'a': 'яблоко', 'b': { 'c': {'d': 'собака'}}}
Пример 2:
вектор2 = ['б', 'с', 'е']
значение2 = 'яйцо'
дерево = add_branch (дерево, вектор2, значение2)
Возвращает:
tree = { 'a': 'яблоко', 'b': { 'c': {'d': 'собака', 'e': 'яйцо'}}}
Возвращает:
dict: словарь со значением, помещенным по указанному пути.
Алгоритм:
Если мы находимся на листе, добавьте его как ключ/значение в дерево
Иначе: если поддерево не существует, создайте его.
Рекурсия с поддеревом и сдвинутым влево вектором.
Верните дерево.
"""
ключ = вектор[0]
дерево[ключ] = значение \
если len(вектор) == 1 \
else add_branch(tree[key] if key in tree else {},
вектор[1:],
ценить)
дерево возврата
9.
Рекурсивный!
Параметры:
data (dict): структура данных, в которую вставляется вектор.
вектор (список): список значений, представляющих путь к конечному узлу.
значение (объект): объект, который будет вставлен в лист
Пример 1:
дерево = {'а': 'яблоко'}
вектор = ['b', 'c', 'd']
значение = 'собака'
дерево = add_branch (дерево, вектор, значение)
Возвращает:
дерево = { 'a': 'яблоко', 'b': { 'c': {'d': 'собака'}}}
Пример 2:
вектор2 = ['б', 'с', 'е']
значение2 = 'яйцо'
дерево = add_branch (дерево, вектор2, значение2)
Возвращает:
tree = { 'a': 'яблоко', 'b': { 'c': {'d': 'собака', 'e': 'яйцо'}}}
Возвращает:
dict: словарь со значением, помещенным по указанному пути.
Алгоритм:
Если мы находимся на листе, добавьте его как ключ/значение в дерево
Иначе: если поддерево не существует, создайте его.
Рекурсия с поддеревом и сдвинутым влево вектором.
Верните дерево.
"""
ключ = вектор[0]
дерево[ключ] = значение \
если len(вектор) == 1 \
else add_branch(tree[key] if key in tree else {},
вектор[1:],
ценить)
дерево возврата
9. ]+ # один или несколько символов, не являющихся точкой
) # конец именованной группы 'dict'
\. # буквальная точка
(?P
]+ # один или несколько символов, не являющихся точкой
) # конец именованной группы 'dict'
\. # буквальная точка
(?PИли еще проще: разбить на точки.
in_ = 'a.b.c'
input_split = in_.split('.')
d_name, ключи = input_split[0], input_split[1:]
d = варс()[d_name]
для ключей в ключах:
d = d.get (ключ, нет)
если d равно None:
# то же, что и выше
результат = д
0
с = "a.b.c"
s = s.replace(".", "][")+"]" # 'a][b][c]'
i = s.find("]") # найти первое "]"
s = s[:i]+s[i+1:] # удалить 'a[b][c]'
s = s.