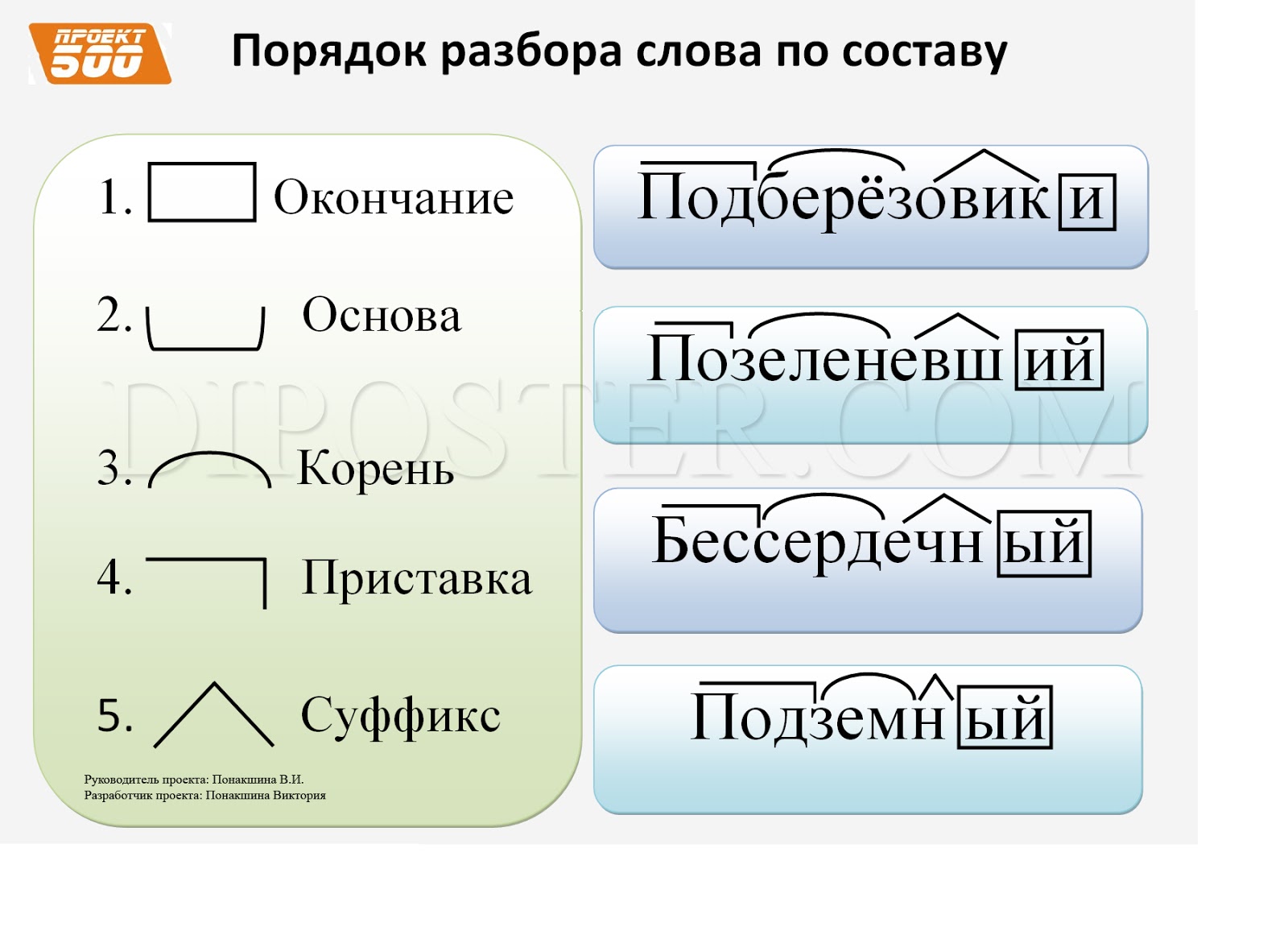
Разбор слова «урожай» по составу (морфемный разбор)
Чтобы разобрать по составу слово «урожай», изменим его по падежам и рассмотрим происхождение слова.
Словом «урожай» называют все то, что уродилось на земле: зерновые культуры (пшеницу, рожь, ячмень, гречиху), овощи, фрукты, грибы и т. д.
В этом году хороший урожай картофеля.
Агрохозяйства стремятся собрать урожай зерновых без потерь.
Нас порадовал богатый урожай помидоров и огурцов.
Чтобы разобрать по составу слово «урожай», сначала выделим в нем словоизменительную морфему — окончание. Для этого изменим это существительное мужского рода по падежам:
- сбор чего? урожа-я
- горжусь чем? урожа-ем
- забочусь о чём? об урожа-е.

После корневого гласного «а» падежные окончания, выраженные буквами «я» и «е», обозначают два звука, поэтому фонетически эту запись представим вот так:
- урожа[й’-а]
- урожа[й’-э]м
- об урожа[й’-э],
где звук [й’] принадлежит суффиксу.
Значит, в форме именительного падежа в его составе выделим нулевое окончание как у существительного мужского рода второго склонения.
Приставка у- и суффикс -ай создали это слово, о чем узнаем, если обратимся к его этимологии.
Происхождение слова
УРОЖАЙ. Искон. Преф. производное от «рожай» < rodjajь, суф. образования от той же основы, что и родить, урод.
Родственными словами с корнем род-/рож-/рожд- являются следующие:
- роды
- уродиться
- переродиться
- роженица
- рождение
- зарождение
- перерождение.

В результате наших исследований морфемный состав этого существительного соответствует схеме:
урожай — приставка/корень/суффикс/окончание.
Скачать статью: PDFКонспект урока по русскому языку, 2 класс. Состав слова.
Тема: Как собрать и разобрать слово.
(Урок введения нового знания)
Цель: дать общее представление о морфемном составе слова, о единообразном написании морфем; учить выделять
корень в родственных словах с опорой на смысловую связь однокоренных слов и на общность написания корней.
Планируемые результаты
Предметные:
сформировать вместе с детьми определение корень слова;
познакомить с понятием «морфема»;
находить и подбирать родственные слова, выделять в них общую часть.
Метопредметные
Личностные УУД:
формирование уважительного отношения к иному мнению, иной точке зрения;
развитие мотивов учебной деятельности и формирование личностного смысла учения;
формировать представление о значении русского языка в жизни человека. Регулятивные УУД:
формировать умение принимать и сохранять учебную задачу;
формировать умение оценивать совместную с учителем или одноклассником результат своих действий
формировать умение высказывать свои предположения.
Познавательные УУД:
развитие речи, мышления, воображения школьников, умения выбирать средства языка в соответствии с
целями, задачами и условиями общения;
освоение первоначальных знаний о грамматике русского языка;
овладение умениями правильно читать и писать, участвовать в диалоге, составлять несложные
монологические высказывания. Коммуникативные УУД:
умение выражать свою точку зрения; адекватно воспринимать позицию одноклассника.
Ход учебного занятия
Формирование УУД
Этапы учебного
занятия
I. Организационный
момент
Стадия вызов.
Цель: включение детей
в деятельность на
личностно значимом
уровне
Утром солнышко проснулось,
Улыбнулось, потянулось.
И, отбросив одеяло
На зарядку побежало.
II. Актуализация
знаний.
Регулятивные УУД:
формировать умение принимать и сохранять учебную задачу;
формировать умение оценивать совместную с учителем или одноклассником результат своих действий
формировать умение высказывать свои предположения.
Познавательные УУД:
развитие речи, мышления, воображения школьников, умения выбирать средства языка в соответствии с
целями, задачами и условиями общения;
освоение первоначальных знаний о грамматике русского языка;
овладение умениями правильно читать и писать, участвовать в диалоге, составлять несложные
монологические высказывания. Коммуникативные УУД:
умение выражать свою точку зрения; адекватно воспринимать позицию одноклассника.
Ход учебного занятия
Формирование УУД
Этапы учебного
занятия
I. Организационный
момент
Стадия вызов.
Цель: включение детей
в деятельность на
личностно значимом
уровне
Утром солнышко проснулось,
Улыбнулось, потянулось.
И, отбросив одеяло
На зарядку побежало.
II. Актуализация
знаний.

 Коммуникативные:
уметь формулировать
высказывание, обосновывать
собственные позиции; работать
в группе.
Регулятивные:
выделять и формулировать
познавательные цели с
помощью учителя, планировать
совместно с учителем свои
действия для достижения
целей.
деятельности.
Цель: обсуждение
затруднений,
проговаривание
задач урока
1 группа: Задание: разобрать
картинку из готовых пазлов и
собрать из этих частиц новую
картинку.
Дети проделывая работу делают
вывод: что можно разобрать любую
картинку и собрать новую из этих
же частей. Части не меняются, а
сюжет поменялся.
2 группа: Разобрать готовый
дом из конструктора и собрать
из этих же частей новый
предмет.
3. Группа: Помочь Ане и Ване
решить спор при написании
слов в предложении.
Ваня предлагает написать: В
лису ребята увидели рыжую
лесу.
А Аня наоборот: В лису ребята
увидели рыжую лису.
Разбор предложения.
4. Группа: Работа на
интерактивной доске со
строками:
Дети делают вывод: можно
разобрать предмет и из этих же
деталей собрать новый предмет.
Коммуникативные:
уметь формулировать
высказывание, обосновывать
собственные позиции; работать
в группе.
Регулятивные:
выделять и формулировать
познавательные цели с
помощью учителя, планировать
совместно с учителем свои
действия для достижения
целей.
деятельности.
Цель: обсуждение
затруднений,
проговаривание
задач урока
1 группа: Задание: разобрать
картинку из готовых пазлов и
собрать из этих частиц новую
картинку.
Дети проделывая работу делают
вывод: что можно разобрать любую
картинку и собрать новую из этих
же частей. Части не меняются, а
сюжет поменялся.
2 группа: Разобрать готовый
дом из конструктора и собрать
из этих же частей новый
предмет.
3. Группа: Помочь Ане и Ване
решить спор при написании
слов в предложении.
Ваня предлагает написать: В
лису ребята увидели рыжую
лесу.
А Аня наоборот: В лису ребята
увидели рыжую лису.
Разбор предложения.
4. Группа: Работа на
интерактивной доске со
строками:
Дети делают вывод: можно
разобрать предмет и из этих же
деталей собрать новый предмет.
 В одном случае надо вписать букву
е, проверочное слово – спешка; в
другом надо писать и , проверочное
слово спишет. Дети доказывают, что
написание слов различно,
лексическое значение разное, а
звуковая транскрипция будет
одинакова.
Делают вывод: что слово состоит из
слогов, звуков и буков.
Разбирать и собирать слово –
подбирая родственные слова –
однокоренные.
Личностные:
понимание глобального
значения корня для любого
предмета.
Познавательные:
использовать графические
средства, строить логические
цепи рассуждения.
Коммуникативные:
уметь слушать, уметь
формировать высказывания.
Регулятивные:
аргументировать свои мнения,
уметь делать умозаключение.
Предметные: формирование определений
корень слова, однокоренные
слова, знакомство с понятием
морфема.
частей. Выполнять разбор слова
по составу.
Работа по учебнику и
интерактивной доске.
Как называется раздел?
Как звучит тема урока?
Послушайте, что сообщает
профессор Самоваров. Какой
секрет он вам открыл?
Почему надо знать эти части?
Упр.
В одном случае надо вписать букву
е, проверочное слово – спешка; в
другом надо писать и , проверочное
слово спишет. Дети доказывают, что
написание слов различно,
лексическое значение разное, а
звуковая транскрипция будет
одинакова.
Делают вывод: что слово состоит из
слогов, звуков и буков.
Разбирать и собирать слово –
подбирая родственные слова –
однокоренные.
Личностные:
понимание глобального
значения корня для любого
предмета.
Познавательные:
использовать графические
средства, строить логические
цепи рассуждения.
Коммуникативные:
уметь слушать, уметь
формировать высказывания.
Регулятивные:
аргументировать свои мнения,
уметь делать умозаключение.
Предметные: формирование определений
корень слова, однокоренные
слова, знакомство с понятием
морфема.
частей. Выполнять разбор слова
по составу.
Работа по учебнику и
интерактивной доске.
Как называется раздел?
Как звучит тема урока?
Послушайте, что сообщает
профессор Самоваров. Какой
секрет он вам открыл?
Почему надо знать эти части?
Упр.
 Проверка на интерактивной доске.
Работа с интерактивной
доской.
Собрать слова. Соотнести с
правильной схемой.
Какую цель мы с вами ставили на уроке?
Как вы считаете, мы справились с поставленной задачей?
Что вам больше всего понравилось?
Что нового узнали?
Чему научились?
Оцените свою работу на уроке с помощью наших Светофорчиков.
V. Итог урока.
Рефлексия
деятельности.
Цель: оценить свою
работу на уроке.
выполнение учебного
действия.
Познавательные:
уметь структурировать знание.
Коммуникативные:
грамотно строить речевые
высказывания.
Регулятивные:
выполнять учебные задания в
соответствии с целью; умение
соотносить учебные действия с
известными правилами.
Предметные:
Знать части слова.
Л.: определить свою степень
усвоения данной темы, степень
эмоционального
удовлетворения от процесса
работы на уроке.
П.: умение анализировать
свою деятельность.
Р.: адекватно понимать
причины успеха/ не успеха в
учебной деятельности.
Проверка на интерактивной доске.
Работа с интерактивной
доской.
Собрать слова. Соотнести с
правильной схемой.
Какую цель мы с вами ставили на уроке?
Как вы считаете, мы справились с поставленной задачей?
Что вам больше всего понравилось?
Что нового узнали?
Чему научились?
Оцените свою работу на уроке с помощью наших Светофорчиков.
V. Итог урока.
Рефлексия
деятельности.
Цель: оценить свою
работу на уроке.
выполнение учебного
действия.
Познавательные:
уметь структурировать знание.
Коммуникативные:
грамотно строить речевые
высказывания.
Регулятивные:
выполнять учебные задания в
соответствии с целью; умение
соотносить учебные действия с
известными правилами.
Предметные:
Знать части слова.
Л.: определить свою степень
усвоения данной темы, степень
эмоционального
удовлетворения от процесса
работы на уроке.
П.: умение анализировать
свою деятельность.
Р.: адекватно понимать
причины успеха/ не успеха в
учебной деятельности.Как в Минске судят студентов: 12 обвиняемых и задержания в день суда | Беларусь: взгляд из Европы — спецпроект DW | DW
На первое заседание суда Октябрьского района Минска по «делу студентов», которое началось в пятницу, 14 мая, пустили только близких родственников обвиняемых и журналистов государственных СМИ.
«История знает множество примеров, когда людей преследовали, сажали в тюрьмы и просто уничтожали только за то, что их мнение отличалось от мнения правящих элит. Это мы наблюдаем и в нашей стране в наше время. И та же история прекрасно иллюстрирует, что бывает, когда безмолвная жертва говорит «нет» своим мучителям», — заявила во время судебного заседания по «делу студентов» Ольга Филатченкова и ходатайствовала об изменении меры пресечения всем обвиняемым и вынесении оправдательного приговора.
Протест студентов Белорусского государственного университета в Минске, октябрь, 2020 год
Во время процесса запретили фото- и видеосъемку. ОМОН разогнал десятки людей, пришедших поддержать обвиняемых. 14 человек, в том числе, политика Анатолия Лебедько и журналистку TUT.BY Любовь Касперович,
14 человек, в том числе, политика Анатолия Лебедько и журналистку TUT.BY Любовь Касперович,
задержали. Во время судебного заседания фигурантам дела предъявили обвинения, были рассмотрены несколько ходатайств. Следующее заседание состоится 15 мая. Судебные слушания будут длиться до 7 июня.
Представительнице Тихановской не доходят письма
После президентских выборов 2020 года белорусские студенты массово выступили против фальсификации результатов голосования и насилия в отношении протестующих. Они участвовали в маршах протеста, проводили акции солидарности в вузах.
12 ноября, в так называемый «черный четверг», к пяти студентам минских вузов, преподавательнице БГУИР и выпускнице медуниверситета Алане Гебремариам пришли из КГБ. У них дома и в офисе Ассоциации белорусских студентов были проведены обыски, молодых людей задержали. Следственный комитет завершил расследование по делу об организации «маршей студентов» 16 марта и сообщил о 12 обвиняемых. Они более полугода провели в заключении, правозащитники признали их политическими заключенными.
Алана Гебремариам
Алану Гебремариам задержали 12 ноября 2020 года. 24-летняя активистка и координаторка Ассоциации белорусских студентов входит в состав Координационного совета белорусской оппозиции и представляет Светлану Тихановскую в вопросах по делам молодежи и студентов. Общественной деятельностью Алана занимается с 2018 года, а в 2019 году она участвовала в парламентских выборах. Первое время после ареста к ней в СИЗО не пускали адвоката и не передавали письма даже от родителей.
Алана и сейчас не получает почти никакой корреспонденции, находясь практически в полной информационной изоляции, говорит DW ее приятель Валерий. «Со сложившейся ситуацией Алана справляется с переменным успехом, она привыкла к определенному уровню комфорта и уважения к себе. Понятно, что в СИЗО ничего этого нет. К тому же ей почти не приходят письма, с начала года она получила их не более десяти. Это несколько подрывает ее боевой дух, она не понимает, что происходит на воле, кто ей пишет, а кто нет», — рассказывает молодой человек.
Близкие не верят в оправдательный приговор
Среди обвиняемых и девушка Валерия, 20-летняя студентка Белорусского государственного педагогического университета, участница «Ассоциации белорусских студентов» Яна Оробейко. «Яна очень скромная, ей все время казалось, что она ничем важным не занимается. Хотя она, например, очень долго добивалась, чтобы возле одного из корпусов педагогического положили пешеходную дорожку. К слову, дорожка там появилась, — говорит Валерий. — Яна верила, что переговоры и петиции — путь к изменению общества, что диалог между властью и обществом возможен».
Яна Оробейко со своим другом Валерием
По словам парня, в конце марта Яна пять суток провела в карцере. Это надломило ее психическое состояние, перед судом она была подавлена, почти не писала писем, переживала и часто плакала. Валерий говорит, что и Алана, и Яна ждут завершения судебного процесса, чтобы появилась хоть какая-то определенность: «Девушки писали, что даже если будет тюремный срок, им будет проще. В СИЗО испытания кажутся бесконечными, люди просто сидят и ждут».
В СИЗО испытания кажутся бесконечными, люди просто сидят и ждут».
Валерий не надеется на оправдательный приговор — считает, что в нынешней ситуации в Беларуси это вряд ли возможно. Наиболее реальным, по его словам, может стать «домашняя химия» — ограничение свободы без направления в исправительное учреждение открытого типа.
«Нет оснований для применения такого уровня санкций»
На это же рассчитывает и Виталий Трахтенберг — отец еще одного из подсудимых, 19-летнего студента БГУ Ильи. За время заключения сына он виделся с ним всего три раза. Илья, по словам отца, держался хорошо, писал бодрые письма, но в последнее время настроение несколько изменилось.
«На Володарского (СИЗО №1 на улице Володарского в Минске — Ред.) сейчас становится душно, а это ни бодрости, ни радости не прибавляет, хотя на прогулки в последнее время стали выводить почти каждый день», — говорит Виталий. Двое бывших соседей Ильи по СИЗО рассказали отцу парня об условиях содержания: «Площадь камеры на пятнадцать человек — 24 на два метра, есть большое окно, но его вынуждены закрывать из-за того, что прямо напротив стоит орущий целый день громкоговоритель — «музыкальное сопровождение СИЗО». Слушать это нереально, общаться под такой ор тоже».
Слушать это нереально, общаться под такой ор тоже».
В последний месяц Илья получает одно-два письма в неделю — только от родителей. Виталий расценивает это как фактор психологического давления: студентам хотят показать, что о них, якобы, все забыли и они никому не нужны.
Если Илье и остальным фигурантам «дела студентов» и можно предъявить какие-либо обвинения, то лишь в нарушении правил внутреннего распорядка вузов, считает Виталий. Он уверен: молодые люди не совершили никаких действий, подпадающих под уголовную статью. «На такую ситуацию никто не рассчитывал хотя бы потому, что не было оснований для применения такого уровня санкций. Более-менее реалистичный сценарий сегодня — это год-два ограничения свободы с направлением или без направления в учреждения открытого типа», — убежден Виталий Трахтенберг.
Смотрите также:
Протесты в Беларуси: «партизанский» формат
Цепи солидарности
Несмотря на преследования и жесткие действия со стороны силовиков, минчане продолжают выходить на улицы и выстраиваться в цепи солидарности.
Теперь выход даже такой небольшой группы требует подготовки и больших человеческих ресурсов — чтобы обеспечить безопасность всех участников.Протесты в Беларуси: «партизанский» формат
Дворовые протесты
Популярные еще недавно чаепития и концерты во дворах теперь стали слишком опасны для их участников. Но, договариваясь в закрытых чатах, минчане по-прежнему собираются по вечерам в своих дворах, чтобы сфотографироваться и показать в соцсетях, что протесты не прекращаются.
Протесты в Беларуси: «партизанский» формат
Политические граффити
В этом году исполнилось 35 лет аварии на ЧАЭС. Проведение традиционного «Чернобыльского шляха» в Минске власти так и не разрешили, ссылаясь на отсутствие у организаторов договоров с городскими службами, а также на ситуацию с коронавирусом. Одному из организаторов несогласованной акции, председателю партии «Зеленые» Дмитрию Кучуку, дали 15 суток ареста.
Протесты в Беларуси: «партизанский» формат
Видео-ролики
К годовщине чернобыльской катастрофы минчане сделали видеоролик.
Заклеенные красно-зеленой лентой глаза снявшихся в нем символизируют слепоту белорусов. «Нам и раньше не говорили правду, и с тех пор ничего не изменилось. Теперь наши глаза открылись, и это уже не вернуть назад», — говорят авторы ролика.Протесты в Беларуси: «партизанский» формат
Цепи свободы в других городах Беларуси
На улицы выходит не только Минск, но и другие города Беларуси. Многим активистам из Смолевич пришлось уехать из страны этой весной после того, как на концерт группы РСП ворвался ОМОН и большинство музыкантов и зрителей оказались за решеткой.
Протесты в Беларуси: «партизанский» формат
Бело-красно-белые флаги в небе
В районе Минского камвольного комбината регулярно запускают в небо флаги с бело-красно-белыми воздушными шарами. Раньше их тут вешали на здания, однако теперь такие флаги довольно быстро снимают работники ЖЭСа или МЧС. В планах креативных минчан и другие способы демонстрации национальной символики, справиться с которыми городским службам будет непросто.
Протесты в Беларуси: «партизанский» формат
Акции солидарности с политзаключенными
Политическим заключенными в Беларуси на сегодняшний день признаны 370 человек. Дмитрия Янковского 4 мая осудили на год лишения свободы за то, что в сентябре прошлого года он заступился за женщину, которую милиционер ударил в лицо. Яновского признали виновным в насилии в отношении сотрудника правоохранительных органов.
Протесты в Беларуси: «партизанский» формат
Символика в лифтах
Жители одного из минских домов научились разбирать металлические панели в лифтах. Достаточно приклеить на световую полосу красный скотч, и получится бело-красно-белый флаг — главный символ протестов в Беларуси.
Протесты в Беларуси: «партизанский» формат
Рисунки на асфальте
«Мы разам», «Жыве Беларуь», «97%», принты с гербом «Пагоня» и бело-красно-белый флаг — такие надписи и рисунки на асфальте можно встретить во многих городах Беларуси.
Протесты в Беларуси: «партизанский» формат
Наклейки в подъездах
Генпрокуратура Беларуси подготовила пакет документов о признании бело-красно-белого флага экстремистской символикой. Если это случится, то за хранение такой наклейки у себя дома будет грозить административная ответственность. Свою первую присягу в качестве президента Александр Лукашенко в 1994 году принимал под бело-красно-белым флагом.
Протесты в Беларуси: «партизанский» формат
Бело-красно-белый маникюр
Герб «Пагоня», орнамент, белые и красные сердечки и даже миниатюрная Нина Багинская — мода на маникюр с национальными символами в Беларуси не прекращается. Маникюр в этом стиле — новый тренд среди белорусок. И не только — в марте российский видеоблогер Юрий Дудь тоже накрасил ногти в белый и красный цвета в знак солидарности с белорусами.
Протесты в Беларуси: «партизанский» формат
Символы на деревьях
Красное сердечко на белом фоне — минчане оставляют такие знаки на деревьях, чтобы напомнить друг другу о том, что мирный протест не закончился и что люди, готовые поддержать друг друга, всегда рядом.
Автор: Ольга Верасович
 Теперь выход даже такой небольшой группы требует подготовки и больших человеческих ресурсов — чтобы обеспечить безопасность всех участников.
Теперь выход даже такой небольшой группы требует подготовки и больших человеческих ресурсов — чтобы обеспечить безопасность всех участников. Заклеенные красно-зеленой лентой глаза снявшихся в нем символизируют слепоту белорусов. «Нам и раньше не говорили правду, и с тех пор ничего не изменилось. Теперь наши глаза открылись, и это уже не вернуть назад», — говорят авторы ролика.
Заклеенные красно-зеленой лентой глаза снявшихся в нем символизируют слепоту белорусов. «Нам и раньше не говорили правду, и с тех пор ничего не изменилось. Теперь наши глаза открылись, и это уже не вернуть назад», — говорят авторы ролика.

Как привести гардероб в порядок, если вам опять нечего надеть
Разбираем завалы по методу Мари Кондо
1. Избавляемся от лишнего
Мари Кондо, автор книги «Магическая уборка», предлагает разобрать шкаф за один раз. Так вы точно не забудете о каких-то вещах на дальней полке и доведёте дело до конца. Ведь что-то же мешало вам все эти годы разобрать вещи? Выложите всю одежду, что хранится у вас в шкафу, на антресолях и комоде, на пол, чтобы оценить объёмы нажитого.
Как понять, что из одежды оставить, а от чего избавиться? Мари Кондо предлагает расстаться с вещами, которые не приносят вам радости. Да-да, если у вас есть старая майка с детским принтом, которую уже и надеть-то стыдно, но с ней связаны очень приятные воспоминания, значит, её можно оставить.
Избавьтесь от вещей, которые вы не носили в течение последнего года. Оправдания «вдруг похудею» или «мне сказали, что я в ней отпадно выгляжу, но носить не решаюсь» не подходят. Это кандидаты на выкидывание.
Это кандидаты на выкидывание.
Когда будете сортировать одежду, постарайтесь устроить так, чтобы свидетелями вашей уборки не стали родные, которым подобное расточительство, вероятно, будет совсем не по душе.
Не переносите сомнительного вида футболки и растянутые штаны в категорию «для дома», особенно это касается мам в декрете и фрилансеров. Домашняя одежда должна быть удобной, бесспорно, но она должна быть ещё и красивой. Настолько, чтобы в ней было не стыдно открыть соседям дверь, выйти в ближайший магазин или пойти на вечернюю прогулку.
То ненужное, которое ещё вполне можно носить, отдайте на благотворительность или сдайте на переработку. Многие из сетевых магазинов принимают старую одежду в обмен на небольшую скидку.
2. Сортируем и складываем
Рассортируйте одежду по типам (футболки и майки, джинсы, бельё) и сложите особым образом, как показано в этом видео.
На узкие полки убираем футболки и джинсы, на широкие — кладём сложенные вещи в невысоких контейнерах.
Зачем так мучиться и делать из одежды рулеты? Когда мы храним одежду в стопке, на самые нижние вещи приходится значительное давление, они сильнее мнутся. Одежду из нижних рядов очень неудобно доставать, поэтому при хранении стопкой мы носим от силы 3–4 верхние вещи, а нижние продолжают всё больше и больше сминаться и окончательно теряют шанс быть надетыми.
Этот же способ прекрасно подходит для складывания нижнего белья и носков. Бельё, занимавшее целый комод, теперь поместится в одном ящике, максимум — в двух.
Если вам не достаёт терпения складывать вещи вручную, можете воспользоваться готовым решением в стиле Шелдона Купера.
3. Используем вакуумные пакеты
Для хранения сезонных вещей прекрасно подходят вакуумные пакеты. В них можно хранить как обычные вещи, так и зимние куртки и одеяла. Это существенно экономит место в квартире и очень удобно при переездах.
Пакет при откачивании воздуха может принять любую форму, поэтому если планируете уместить несколько вакуумных пакетов в сумке или коробке, то сначала вложите вакуумный пакет с вещами в нужный контейнер и только потом откачайте воздух.
Единственный минус вакуумных пакетов — то, что даже самая маленькая дырочка запустит воздух обратно. И тут только два выхода: или чинить, если дырочка небольшая, или выкидывать.
Покупаем грамотно
1. Скажите «нет» импульсивным покупкам
Вы пошли в магазин за новой футболкой для тренировок, но по пути к спортивному отделу вынуждены были пройти мимо чудесных и таких необходимых платьев и классных брюк? Продавцы давно усвоили, что базовые вещи надо располагать как можно дальше от входа, чтобы каждый покупатель прошёл по всему магазину.
Есть хоть малейшее сомнение в том, что вам нужна эта вещь? Не берите её в тот же день! Если она стоит того, чтобы за ней вернуться, то вы обязательно это сделаете. Этот способ прекрасно спасает от импульсивных покупок. А значит, экономит деньги в вашем кошельке и бережёт место в шкафу для более достойных вещей.
А значит, экономит деньги в вашем кошельке и бережёт место в шкафу для более достойных вещей.
2. Будьте внимательнее на распродажах
Главная опасность распродаж — потратить больше, чем мы планировали, вместо предполагаемой экономии. Все эти «3 по цене 2», «вторая вещь в подарок» провоцируют нас на покупку совершенно ненужных футболок и сомнительного качества кофточек.
Сохраняйте трезвую голову.
Избежать соблазна помогает предварительный просмотр коллекций в онлайн-каталоге: так вы существенно сэкономите себе время в самих магазинах и отсеете сомнительные предложения.
Самое спокойное время в магазинах в горячий сезон — утро с 10 до 12 в выходные и последние 1,5 часа до закрытия в будни. В это время вы точно не нахватаете лишнего из-за очередей в примерочные.
3. Ходите по магазинам с подругой
Верная подруга убережёт вас от ненужных трат и уж точно не постесняется отметить, что какой-то наряд вам не идёт. Совместный поход по магазинам позволяет иначе взглянуть на свой гардероб.
Шопинг с подругой расширит ваши взгляды и остановит от покупки ещё одной такой же кофточки.
4. Загляните в секонд-хенды
Неслучайно все известные фэшн-блогеры не гнушаются барахолок, гаражных распродаж и секонд-хендов. Если в вашей голове засели представления о больших ангарах, где на раскладушках навалена грудой мятая одежда, то вы просто очень давно не были в секонд-хендах.
Сегодня большинство секонд-хендов — крупные магазины с аккуратно отсортированной и отпаренной одеждой.
Вся одежда проходит обязательную химчистку. Нередко встречаются и совершенно новые товары с бирками. Как правило, в сетевых магазинах всё наполнение меняется полностью каждую неделю, а по мере приближения дня поставки новинок действуют прогрессирующие скидки.
Секонд-хенды могут выручить, если предстоит какая-то вечеринка и нужно купить наряд на одну ночь, если у вас есть дети, которые очень быстро растут, если вы беременны, хочется побаловать себя новыми нарядами, а цены в обычных магазинах кусаются.
5. Инвестируйте в одежду
Всегда делайте акцент на качестве вещи, если носить её вы планируете долго и часто. Отдавайте предпочтение проверенным производителям и натуральным тканям.
Натуральные материалы хорошо испаряют влагу и позволяют коже дышать. Синтетические нейлоновые волокна (капрон), полиэфирные (полиэстер) и полиуретановые волокна (спандекс) намного дешевле и проще в производстве, поэтому их часто используют для изготовления одежды. Не надо бояться, если в понравившейся вам кофточке будет спандекс или полиэстер. В качестве примеси эти материалы улучшают качества трикотажа, делают его более прочным и красивым.
Главное, чтобы одежда, которая контактирует с телом, не состояла из одной синтетики.
Хлопковый трикотаж идеально подходит для нижнего белья. Если хлопок вас категорически не вдохновляет, то при выборе кружевного белья, которое в основном делается из синтетики, проверьте наличие отверстий в переплетении нитей и хлопковой ластовицы. Тогда даже синтетическое бельё будет безопасно в носке.
Тогда даже синтетическое бельё будет безопасно в носке.
В магазинах масс-маркета в составе свитеров часто встречается акрил, его количество в вязаных изделиях может быть от 5 до 100%. И если внешне вы с трудом распознаёте 100-процентный акрил, то не поленитесь взглянуть на этикетку. Чем больше процент акрила, тем жарче вам будет в тёплую погоду и холоднее при низких температурах.
Особняком стоит одежда из микрофибры и мембранных тканей, которые представляют собой высокотехнологичную синтетику. Эти материалы дышат, пропускают пар и воздух из-под одёжного пространства, не промокают и не продуваются.
Из микрофибры делают качественное бельё. Особенно хорошо этот материал подходит для спортивного белья, так как ткань отводит влагу от кожи и остаётся сухой. Мембранные ткани в основном применяются для туристической и спортивной одежды, где вещи используются в экстремальных условиях.
Вкладывайтесь в покупку базовых вещей, которые составят основу вашего гардероба. Обращайте внимание на состав и структуру ткани. Однако вещи, которые покупаются на один сезон, могут быть недорогими и любого качества.
Однако вещи, которые покупаются на один сезон, могут быть недорогими и любого качества.
Бережём любимые вещи
Соблюдайте инструкции по стирке и глажке. Лучше стирать при чуть меньшей температуре, чем указано на этикетке, тогда вещь не полиняет и не растянется.
Если на ярлычке рекомендована химчистка, то такую одежду категорически нельзя стирать.
Например, пальто и костюмы из натуральной шерсти или с eё примесью при стирке неизбежно потеряют форму. Шерсть впитывает в себя очень много влаги и при высыхании одежду может перекосить на какую-то сторону. Отчасти ситуацию можно исправить с помощью утюга, но даже его использование не даёт гарантии, что вещь примет такую же форму, как до стирки.
В попытке сэкономить многие стирают в машине пуховики. Неважно, постираете вы его со специальными шариками или без, со специальным шампунем для верхней одежды или без него, результат будет один: после стирки пух сваляется в комки и вы получите продуваемый пуховик. Лучше отнесите любимую куртку или пальто в химчистку.
Лучше отнесите любимую куртку или пальто в химчистку.
Кстати, куртки на синтепоне стирать можно, но помните, что синтепон может оторваться на уровне швов, если он плохо пристёган.
Одежду ни в коем случае нельзя сушить под прямыми солнечными лучами или на батарее.
Ультрафиолет — главный враг не только цветной, но и белой одежды.
Синтетические материалы могут не выдержать высоких температур, изделие сильно растянется и потеряет свой первоначальный вид. Так, например, купальники из лайкры (спандекса) очень боятся прямых солнечных лучей и хлорированной воды. Это помогает производителям каждый год выпускать новую коллекцию купальников, не опасаясь низкого спроса. 🙂
Ежегодный слет волоколамских отрядов Юнармии прошел на Мемориале 28 героям-панфиловцам
Мероприятие прошло в рамках 76-й годовщины Победы в Великой Отечественной Войне. В слёте приняли участие восемь команд — отряды школ и других учебных заведений округа.
Приветствовала участников заместитель главы Волоколамского городского округа по социальным вопросам Ольга Буракова:
— Для Волоколамского округа патриотические мероприятия и празднование Дней Воинской Славы России всегда имели немаловажное значение.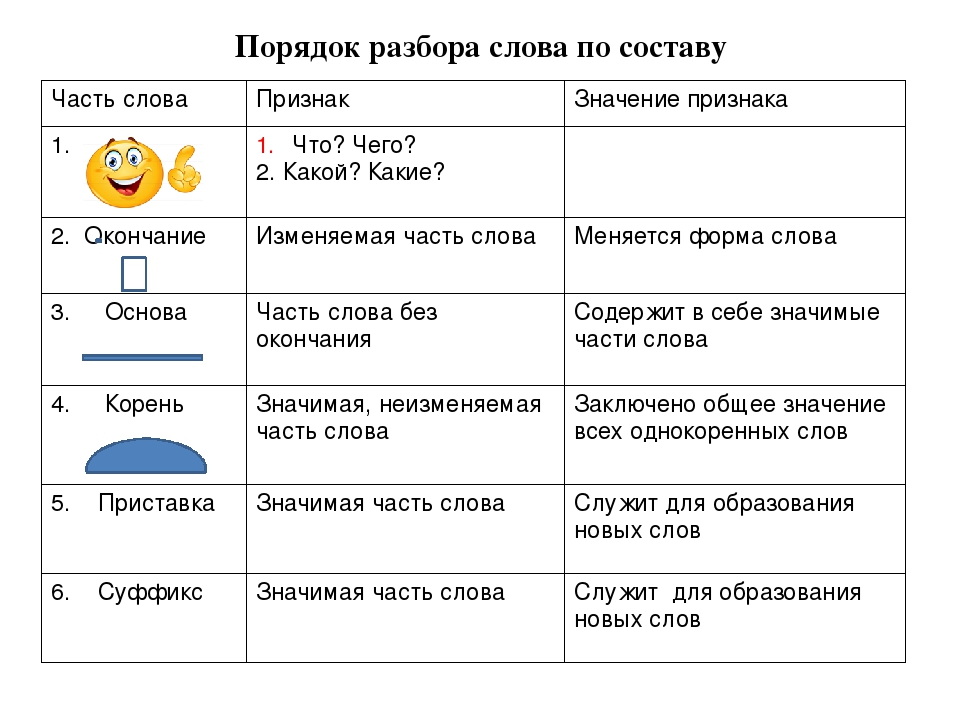 С 2010 года Волоколамск — город Воинской славы. Мы все — потомки Победителей, мы помним и чтим Великий подвиг наших дедов и прадедов. И также должны уметь защищать нашу Родину, как делали это русские и советские воины прошлых лет.
С 2010 года Волоколамск — город Воинской славы. Мы все — потомки Победителей, мы помним и чтим Великий подвиг наших дедов и прадедов. И также должны уметь защищать нашу Родину, как делали это русские и советские воины прошлых лет.
И вот соревнованиям дан старт.
На протяжении первого этапа конкурса юнармейцы продемонстрировали свои навыки в строевой подготовке: марше, построении и даже исполнении строевой песни.
Принимал этот своеобразный мини-экзамен Юрий Сенькин, военный комиссар города Волоколамск, рабочих поселков Шаховская и Лотошино. Остальные конкурсы слета также оценивало строгое жюри, в состав которого вошли известные жители округа.
Во втором и третьем этапах команды соревновались в умении оказывать первую помощь, собирать и разбирать винтовку, завязывать морские узлы, ориентироваться на местности.
Команды действовали дружно и сплочённо, помогая и поддерживая друг друга. Не оставались в стороне и их руководители, к которым участники всегда могли обратиться за советом. Но не за помощью, ведь выполнять все задания юнармейцы должны были самостоятельно.
Не оставались в стороне и их руководители, к которым участники всегда могли обратиться за советом. Но не за помощью, ведь выполнять все задания юнармейцы должны были самостоятельно.
В военном музее-бункере для участников был подготовлен особый конкурс: здесь ребята демонстрировали свои знания истории, географии и литературы.
На следующем этапе – физподготовке – участники выполняли задания на силу, выносливость и дисциплину.
Победителями ежегодного слета в этот раз стали ребята из военно-патриотического клуба «Смелый» имени Владимира Кузьмича Ватагина. А наградой им стал сертификат на десять комплектов юнармейской формы.
Напомним, что данное мероприятие проводится ежегодно с 2016 года. Региональные штабы движения открыты в 85 субъектах Российской Федерации. С момента создания Юнармии в ее ряды вступили 803 тысячи детей и подростков по всей России. Сегодня в рядах юнармейцев более 170 волоколамских школьников.
Источник: http://involokolamsk.ru/novosti/molodezhnaya_politika/ezhegodnyy-slet-volokolamskih-otryadov-yunarmii-proshel-na-memoriale-28-geroyam-panfilovcam
смешные картинки и другие приколы: комиксы, гиф анимация, видео, лучший интеллектуальный юмор.
Догнать и перегнать
Рязань в экономической истории XX века можно поставить в один ряд с Южной Кореей, Японией или Сингапуром – там тоже было своё экономическое чудо. Что, неужели вы о нём не слышали?
Вскоре после смерти Сталина партийные вожди решили больше заботиться не о рекордах выплавок стали и прочих цифрах в отчётах, а о реальном уровне жизни населения. Маленков в этом плане проводил довольно толковую работу и в народе запомнился по поговорке «Пришёл Маленков – поели блинков». Сменивший его Никита Сергеевич продолжил заботиться о населении, но методы у него были специфические.
Успехи Хрущёва в сельском хозяйстве отложились в народной памяти мемами про кукурузу и освоением целины, едва не разорившим сельское хозяйство Советского союза. Подчинённые Никиты Сергеевича посыл уловили и стали заниматься не менее безумными вещами.
Подчинённые Никиты Сергеевича посыл уловили и стали заниматься не менее безумными вещами.
Сигнал им был подан соответствующий: коровы и свиньи должны были внять политической воле партии и направить все усилия на обеспечение страны советов мясом и молоком. Вот текст послания обкомам КПСС от 1958 года: «Среди экономистов есть скептики, которые не верят в возможности нашего сельского хозяйства утроить производство мяса. Но как они подошли к этому делу? Как водится, взяли карандашик и подсчитали, какой может быть прирост скота и за сколько лет. Товарищи, надо же понимать, какие сейчас силы накопились у советского народа. Это же политическое явление, результат долголетней работы нашей партии…»
Лучше всех уловил посыл начальник Рязанской области А.Н. Ларионов. В начале 1959 года он пообещал за год утроить заготовки мяса в области, за что в феврале область получила орден Ленина, а сам Ларионов в декабре (ещё до окончания года) стал Героем соцтруда.
Обещание добиться рекордных заготовок мяса сперва выполнялось вполне ожидаемо и предсказуемо: в области забили бóльшую часть скота, причём не только мясного, но и молочного – и приплод, и животных-производителей, и даже личных животных колхозников, которых принудительно «взяли в долг» под расписку. Самое весёлое началось, когда выяснилось, что и этого недостаточно.
Самое весёлое началось, когда выяснилось, что и этого недостаточно.
В Советском союзе была такая штука как общественные фонды потребления – на них строили школы, детсады и прочие общественные блага. На эти средства великий комбинатор Ларионов придумал закупать скот в соседних областях, чтобы всё-таки выполнить данные обещания. Всё это сопровождалось овацией Хрущёва в течение всего года, который требовал, чтобы все остальные области брали пример с Рязанской.
В итоге обещание с горем пополам всё-таки выполнили, заготовив 150 тысяч тонн мяса. Цели на следующий 1960 год стояли ещё более амбициозные: 180 тысяч тонн. Убитое во всех смыслах животноводство смогло выдать лишь 30 тысяч. Колхозники, у которых «взяли в долг» их скот, отказывались обрабатывать землю, поэтому сбор зерна упал на 50%.
Ларионов, поняв, что был пойман за руку, как дешёвка, не выдержал и в сентябре 1960 умер – по официальной версии от сердечной недостаточности, но в народе была молва, что он застрелился.
По итогам всей аферы были наказаны невиновные и награждены непричастные: у Ларионова не отобрали звание Героя соцтруда, а Хрущёв, чтобы скинуть вину, объявил виновным главу Бюро ЦК КПСС по РСФСР А.Б. Аристова. Казалось бы, а при чём здесь Аристов? А не при чём, просто Хрущёву нужен был виновный. Никаких организационных выводов из катастрофы областного масштаба не сделали. К счастью, уже через 4 года сумасшедшего кукурузника сместили. В народе часто принято считать, что сделали это исключительно в интересах аппаратчиков, но всё тот же народ от таких перестановок только выиграл.
Via https://t.me/lettersfromvladivostok/
Пивной фольклор от Дмитрия Булдакова/ Пивной сомелье / Подкаст на PodFM.ru
Ольга Зацепина: Добрый день! Вы слушаете 13-выпуск вкусного ток-шоу «Пивной сомелье», первый в очередном сезоне – наша команда отдохнула, надегустировалась новых сортов пива в путешествиях и готова к подвигам! В виртуальной студии программы Ольга Зацепина, мне помогают звукорежиссер Юрий Берингов и продюсер Стас Жураковский.
 И мы с большой радостью открываем новый сезон «Пивного сомелье», где для вас, дорогие слушатели, припасено несколько сюрпризов, основанных на анализе статистики. Мы наблюдали, какие выпуски вы слушали больше всего и будем продолжать и развивать эти темы!
И мы с большой радостью открываем новый сезон «Пивного сомелье», где для вас, дорогие слушатели, припасено несколько сюрпризов, основанных на анализе статистики. Мы наблюдали, какие выпуски вы слушали больше всего и будем продолжать и развивать эти темы!Еще одна хорошая новость – теперь программа доступна для скачивания не только на Подфм.ру и Арпод.ру, но и на новом подкаст-терминале Подстер.ру. Кстати, в айтюнс мы тоже по-прежнему есть 🙂
Начинаем как всегда с новостей, а после – интервью с большим пивным знатоком и коллекционером пивного фольклора Дмитрием Булдаковым.
Обнародован рецепт фирменного пива Обамы – американский президент, как известно, является большим поклонником пива. Теперь на сайте Белого дома опубликованы рецепты двух сортов, незабываемым вкусом которых неоднократно хвастался сам Обама. Помощник шеф-повара Белого дома Сэмюел Кас назвал напитки «неподражаемыми», выразив сожаление в том, что «мощности слабоваты, поэтому мы не можем напоить всех желающих».
Составными частями медового эля являются две примерно полуторалитровых банки легкой солодовой вытяжки, 450 граммов сухого экстракта солода, немного экстракта светлого и бисквитного солода, полкило специально приготовленного в Белом доме меда, несколько видов гранулированного хмеля, две чайных ложки сульфата кальция, пивные дрожжи и немножко кукурузного сахара. Темное медовое пиво в Белом доме готовят с использованием примерно тех же ингредиентов. На сайте Белого дома также даны подробные инструкции, как готовить эти напитки.
О том, что Обама купил на свои деньги мини-пивоварню и установил ее в Белом доме, весь мир узнал осенью прошлого года, когда президент угостил своим пивом американского сержанта, награжденного медалью за отвагу. А не так давно стало известно, что глава государства регулярно запасается своим пивом на время предвыборных поездок по стране.
Ароматизированное пиво пользуется особой популярностью в Великобритании. По данным компании Nielsen, занимающейся исследованиями рынков, продажи ароматизированного пива в Соединенном Королевстве в прошлом году выросли на 80%. Данный сегмент аналитики называют самым быстроразвивающимся на британском рынке пива. По прогнозам экспертов, в ближайшие несколько лет спрос на ароматизированное пиво в Великобритании будет постоянно расти, а рынок, соответственно, продолжит развиваться.
Данный сегмент аналитики называют самым быстроразвивающимся на британском рынке пива. По прогнозам экспертов, в ближайшие несколько лет спрос на ароматизированное пиво в Великобритании будет постоянно расти, а рынок, соответственно, продолжит развиваться.
Первая в Великобритании женщина-пивной сомелье Софи Атертон отмечает, что ароматизированное пиво было разработано давно, но популярным оно становится только сейчас. Она связывает это с тем, что пиво стали продавать крупнейшие в стране супермаркеты. «Еще 10 лет назад нужно было сильно постараться, чтобы найти нечто подобное в местном гастрономе, а теперь оно есть в любом магазине». По мнению Атертон, многие потребители впервые пробуют ароматизированное пиво где-нибудь на отдыхе и, возвращаясь в Великобританию, хотят вспомнить отпуск и покупают подобную продукцию. Кстати, напиток хорошо подавать с фруктовыми десертами и шоколадом, считает пивной сомелье.
В Америке тем временем появилась пивная художница. Карен Эланд прославилась в интернете кофейными картинами, а теперь занялась бир-артом. Искусство основано на том, что пиво разных сортов, как и кофе разной крепости, оставляет на бумаге и ткани следы разных оттенков. Благодаря Карен интерес пивной живописи распространился далеко за пределы ее родного города Бенд в штате Орегон. Многие работы художница делает на заказ для дегустационных домов и элитных пивоварен со всего мира.
Искусство основано на том, что пиво разных сортов, как и кофе разной крепости, оставляет на бумаге и ткани следы разных оттенков. Благодаря Карен интерес пивной живописи распространился далеко за пределы ее родного города Бенд в штате Орегон. Многие работы художница делает на заказ для дегустационных домов и элитных пивоварен со всего мира.
ОЗ: Гостем «Пивного Сомелье» сегодня становится Дмитрий Булдаков. Дима, привет.
Дмитрий Булдаков: Привет, Оля.
ОЗ: Мы этим разговором будет продолжать такую этнографическую серию, которая у нас в прошлом сезоне началась, будем говорить о культуре потребления пива, исторических всяких разных моментах, о том, как пиво закрепляется в общественном сознании и ты для этого человек, конечно, безумно подходящий. Потому что кроме того, что ты пивной путешественник и экскурсовод на пивоваренном заводе, ты ещё и собиратель пивного фольклора.
ДБ: Я надеюсь.
ОЗ: Ты-то надеешься, а я вообще, знаешь, когда мне об этом рассказали в питерской пивной тусовке, я подумала: «Ммм, пивной фольклор существует». Как ты первый раз с ним соприкоснулся и как ты понял что вот это что-то интересно и стоит это коллекционировать, собирать и показывать.
Как ты первый раз с ним соприкоснулся и как ты понял что вот это что-то интересно и стоит это коллекционировать, собирать и показывать.
ДБ: Я не к тому, речь не идёт о том, что я собираю в книгу, в файлик, в запись, ещё как-то. Он просто накапливается как-то в голове, потому что, в принципе, пивной фольклор есть всегда. Он вокруг нас, это то, чем мы общаемся о пиве, то, как мы пиво интерпретируем и может быть, в форме пивного фольклора мы храним какие-то свои знания о пиве, это наш опыт.
ОЗ: Что ты относишь? Какие жанры ты относишь к этому фольклору? Я думаю, что какие-то анекдоты явно.
ДБ: Пивной фольклор – это вся информация, весь опыт, который получил человек о пиве, который не является научной информацией, не издан где-то, передаётся, в основном, устно, подлежит записи только с точки наблюдения как анекдот, его интересно рассказывать, но когда ты его записал, передал, что-то теряется, потому что часть рассказчика – это и есть часть анекдота. Это моё такое убеждение, может, кто-то так не считает – любители читать анекдоты в Интернете, что сейчас тоже популярно. Может быть, есть в Интернете пивной фольклор, вне всякого сомнения, тоже об этом можно поговорить, но я считаю, что в основном это всё-таки устно. Начинается всё в голове, высказывается всё ртом, голосом и, собственно говоря, из этого образовывается какая-то картинка.
Может быть, есть в Интернете пивной фольклор, вне всякого сомнения, тоже об этом можно поговорить, но я считаю, что в основном это всё-таки устно. Начинается всё в голове, высказывается всё ртом, голосом и, собственно говоря, из этого образовывается какая-то картинка.
ОЗ: У тебя какой топ-3 анекдотов о пиве? Так сложно выбрать сразу?
ДБ: Это сложно, может быть, это какие-то байки о пиве, может быть, они не очень приличные в какой-то степени, поэтому, давайте их не будем озвучивать. Если получится, то есть замечательный сайт биркульт.ru на котором периодически эта информация возникает. Возможно, если будет время, я это буду выкладывать. Пока попытки такие скромные всё это систематизировать тяжеловато.
ОЗ: Ну хорошо, вернёмся к анекдоту, всё-таки какой-то анекдот о пиве я должна из тебя извлечь, для того, чтобы повеселить наших слушателей.
ДБ: Я постараюсь попозже.
ОЗ: Хорошо, давай. Вернёмся к вопросу о том, как ты с этой темой соприкоснулся впервые, после чего у тебя вот эта матрица начала формироваться? Какой-то это был случай или ты просто в какой-то момент обнаружил, что, да, этой информации много в моей голове?
ДБ: Здесь больше немножко в подходе отношений ко всему, т.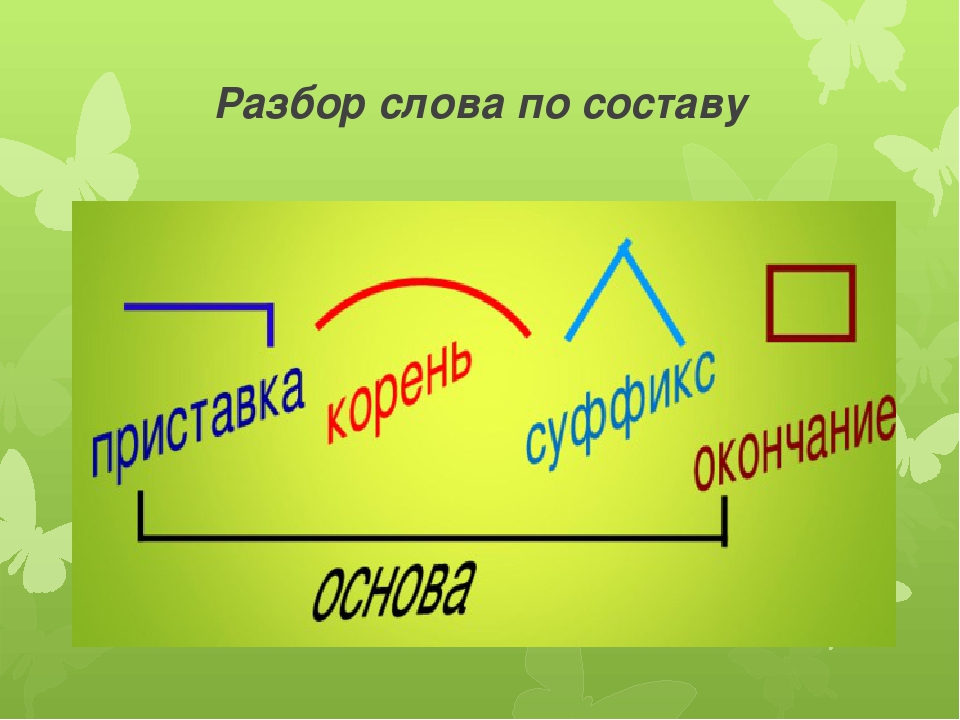 е. мне не очень нравится серьёзное накопление какой-то информации, мне больше нравятся всегда какие-то шутки-прибаутки и даже. Скажем, водим экскурсии по пивоваренному заводу нашему любимому – Балтика, всегда интереснее подавать информацию с юмором. Её невозможно подать сухую, нельзя рассказывать о ферментах, о сложении, не знаю, брожения, созревании – это будет очень сухо. Люди устанут через пять секунд, а проводить какие-то аналогии, например, рассказывать о том, что дрожжи, они как маленькие люди, они тоже образуют колонии, у них есть труженик, у них есть лентяй, можно даже с пчёлами – трутни провести аналогии. И когда ты рассказываешь эту картинку, она ложиться хорошо в сознании неподготовленного человека и тогда он уже пусть пока один грамм из будущего килограмма он усвоит, но потом, в дальнейшем, у него будет некая матрица, он будет усваивать и переваривать информацию в что-то, в чём сможет пользоваться в жизни.
е. мне не очень нравится серьёзное накопление какой-то информации, мне больше нравятся всегда какие-то шутки-прибаутки и даже. Скажем, водим экскурсии по пивоваренному заводу нашему любимому – Балтика, всегда интереснее подавать информацию с юмором. Её невозможно подать сухую, нельзя рассказывать о ферментах, о сложении, не знаю, брожения, созревании – это будет очень сухо. Люди устанут через пять секунд, а проводить какие-то аналогии, например, рассказывать о том, что дрожжи, они как маленькие люди, они тоже образуют колонии, у них есть труженик, у них есть лентяй, можно даже с пчёлами – трутни провести аналогии. И когда ты рассказываешь эту картинку, она ложиться хорошо в сознании неподготовленного человека и тогда он уже пусть пока один грамм из будущего килограмма он усвоит, но потом, в дальнейшем, у него будет некая матрица, он будет усваивать и переваривать информацию в что-то, в чём сможет пользоваться в жизни.
Потому что, ещё раз говорю, этот фольклор пивной, можно собирателем-любителем меня назвать, мне больше эта сторона нравится, потому что именно через него человек – это первое приближение его к пониманию пива и здесь даже можно, я по образованию искусствовед. Когда мы говорим о понимании человеком чего-либо есть несколько пластов. Первый уровень приближения у нас будет мифы, фольклор. Как вижу, так и понимаю. Т.е. я вижу, что пиво пенится, наверное, это чудо. Я сварил сусло, я поставил его в определённое место и не знаю что там какая-то микрофлора, какие-то дрожжи там поселились. Я вижу, что оно потом стало бродить, появились пузырьки, появились пенные завитки. Потом, раз, получилось пиво. Либо чудо, либо фокус.
Когда мы говорим о понимании человеком чего-либо есть несколько пластов. Первый уровень приближения у нас будет мифы, фольклор. Как вижу, так и понимаю. Т.е. я вижу, что пиво пенится, наверное, это чудо. Я сварил сусло, я поставил его в определённое место и не знаю что там какая-то микрофлора, какие-то дрожжи там поселились. Я вижу, что оно потом стало бродить, появились пузырьки, появились пенные завитки. Потом, раз, получилось пиво. Либо чудо, либо фокус.
ОЗ: Мы к такому интересному моменту подходим, во многих местах земли, пиво – это вообще часть какого-то эпоса национального и давай об этом поговорим. Безумно интересная тема, в каких местах, в каких странах какие легенды о пиве ты знаешь и возможно как они сложились расскажешь?
ДБ: В основном, пивоварение возникало в тех странах, где похолоднее. Прижилось, возникало оно практически везде. Если говорить кто первый создал пиво, то, в принципе, какой первый народ появился – тот и создал. Все народы в стадии своей юности, детства, если хотите, может быть чуть попозже – отрочества, какой-то цивилизации, они всегда варили пиво. У них всегда что-то росло. Как правило, это в том числе это было зерно, соответственно, кто-то его забывал в какой-то влажной среде, оно начинало бродить, там создавалась своя микрофлора и из этого сбраживалось пиво.
Потом кто-то увлекался больше виноградорством, у кого-то виноград не рос и они занимались больше пивоварением. И очень часто, поскольку пиво является питательным источником, этот вариант обеззараживать воду в условиях если у вас эпидемия, холера, потому что эту воду кипятите. В пиве есть небольшое количество алкоголя, углекислого газа, хмель или какие-то травы в зависимости от региона и возникают микробы и получается такой напиток, который безопасен.
Например, представьте, вы живёте в пустыне, все болеют, у всех холера, очень неприятная атмосфера складывается из этого. Единственное, что вы можете пить – это пиво, у единиц возникает такое предположение, что это произошло не просто так. Возможно на него влияла некая сила, Бог, Дух, Священное животное, всё что угодно.
ОЗ: Сколько богов разных, которые покровительствуют пивоварению или создают пивоварение, ты можешь так спонтанно вспомнить?
ДБ: Опять же, у каждого народа была своя. Религия до тех пор, по крайней мере, не выливались в какие-то более крупные религиозные течения. Египет — Осирис, скандинавские страны в мифологии, например, Тор это мог быть. В России он не очень.., его звали , я не очень уверен в этом. Тоже такое было, квас, квасило, квасить, заквасить, не в смысле квасить как некоторые понимают.
ОЗ: Да, не в смысле квасить.
ДБ: А больше заквашивания, потому что люди не разделяли брожение, скисание продукта, видели что оно меняется. Получается что-то вкусное и что-то невкусное, собственно говоря. Этимология слова была такая.
ОЗ: Хорошо.
ДБ: У меня на эту тему есть маленькая статейка на том же биркульте, десяток покровителей пивоварения. Если брать уже ближе к нам, к русской культуре, 18-19 века, когда все регионы России были уже христианизированы за редким исключением. На Никльщину, ко Дню Святого Николая люди всегда готовили пиво, к зиме и в другое время года. Праздник? Праздник. Религиозный? Религиозный вне всякого сомнения. Бабушка у меня, откуда вообще какой-то интерес появился? Сначала к пиво появился интерес, потом уже к фольклору, но связь тем не менее была.
У меня бабушка жила в средней полосе, тогда ещё Калининская область, сейчас мы её называем Тверской областью, они на все праздники летом, на Ивана Купала обязательно готовили пиво. Детям давали сусло – оно сладкое, оно питательное, оно вкусное. Взрослые набирались немножко побольше терпения, пока сусло сбродится, пока получится пиво. Всем хорошо, всем приятно.
Религия в советские годы не была так актуальна, тем не менее, у нас народ готовит пиво. И даже недавно на экскурсии встретил человека, он, получается, земляк моей бабушки и мамы, он с Тверской области. Он рассказал, что до сих пор они готовят пиво, ржаное, ячменное, у него в огороде растёт хмель, они это устраивают под праздник. Не сказал бы что человек верующий, какой-то религиозный фанатик или ещё что-то.
ОЗ: Это вообще удивительный случай, когда сохранились действительно очень-очень старые традиции, вековые, когда они живут и чуть-чуть наблюдаем.
ДБ: Более того, при широком выборе различных кастрюль, половников, тёрок, мясорубок и прочего, что можно применять дома для варки пива, люди продолжали использовать для этого бабушкин инструмент, который, может быть, сделан её прадедушкой. Они деревянные, они старенькие у них, оказывается даже очень хорошо. Они все в действии, они работают. Может быть починены с помощью современных средств, но всё это существует, всё это хранится. Если получится когда-нибудь, такая мечта – выбраться в свободное, не по работе путешествие, объехать всё это, просто поговорить с людьми, чтобы их сильно не пугать и посмотреть как они дома делают. Потому что делают очень-очень много людей. Говорят об этом не все, может быть, кто-то боится, что их будут за это критиковать, типа: «Что ты готовишь пиво, есть же красивое, с красивой этикеткой, которое уже проверено, уже сделано», тем не менее, пусть делают дома – это тоже хорошо.
ОЗ: То-то своё, это знаешь как огурчики и помидорчики, которые есть в супермаркете, они тоже могут быть нормальные, но ведь есть свои такие домашние, с любовью выращенные.
ДБ: И даже не смотря на работу в большой компании, в компании Балтика, я всё равно считаю, что домашнее пивоварение должно развиваться, потому что оно в какой-то степени стимулирует и большие компании к новым открытиям. Потому что хорошо когда в одном регионе кто-то варит вкусное пиво, если оно становится популярным, то в принципе, на это обращают внимание и более серьёзные производители и готовы донести эту интересную вещь уже до более широкой аудитории. Хотелось чтобы это было так, по крайней мере.
ОЗ: Вот у нас недавно в пивном сомелье был гостем Дмитрий Чередниченко, который на пивоваренном конкурсе…
ДБ: Известный домашний пивовар.
ОЗ: Победил одним из своих сортов, он действительно тоже очень интересно рассказывал как домашние косятся на его кастрюли и всё-таки скрепя сердце говорят: «Ладно, что ж, принимаем мы тебя со всем пивом». С мешком солода на балконе.
ДБ: Да, это своего рода спорт, сначала ты покупаешь попроще оборудование, потом побольше и соответственно растут и навыки. Потом ты становишься человеком, который в этом плане независимый, который имеет своё собственное суждение. Мы говорим не о том, что он посмотрел рекламный ролик или его свозили на экскурсию и за ручку свозили в те или иные месте уже известные. Он сам варит, он сам знает что из чего происходит. Его уже не купишь рекламной какой-то картинкой, он действительно дисциплинирует всю пивную сообщество, если хороший пивовар. Дима – хороший пивовар, я пробовал его пиво, я с ним знаком, дай Бог каждому в той или иной степени готовить своё пиво. Хорошо.
ОЗ: Да, он конечно очень увлечённый парень и это чувствуется, чувствовалось по нашему разговору. А я предлагаю тебе двинуться дальше по историческому лайнапу виртуальному, который мы представили, мы начали с древнейших времён, поговорили немного о пивной мифологии, я кстати, буду ждать чтобы ты мне прислал ссылку на свой пост о 10-и покровителях пива. Мы его покажем в шоу нотах, чтобы наши слушатели могли прочитать, познакомиться с этой информацией. Возможно, это им будет интересно.
Вот, давай от мифологии двигаться дальше, когда стали возникать ещё какие-то форматы такого фолка и народного творчества узкого и коллективного бессознательного, связанного с пивом?
ДБ: Я бы продолжил эту мысль, которую минуты три с половиной назад я начал озвучивать о том, что фольклор – устная традиция. Байки, прибаутки – это приближение нашего понимания пива, потому что нам так проще. Мы пытаемся разобрать пиво, исходя из опытна не пивного, мы рассуждаем о пиве на уровне аналогии с другими вещами. После того как появляется более глубокое понимание, человек начинает относится к пиву, если оно понравилось, то с уважением. Если даже не понравилось, но он видит, что это нравится другим, это всё равно достойный продукт, он уважает его как противника, своего оппонента в мире напитков. И здесь бы я сказал, что вступают религиозные отношения.
Человек не просто понял, осознал, начинаешь уважать, начинаешь продвигать эту идею в массы, начинаешь систематизировать эти знания и здесь очень хороший пример опять же с брожением, не знаю от чего пиво бродит, откуда появляются эти пенные завитки, что в нём поселяется? Это либо чудо, любо фокус, любо что-то случилось. Дело происходило в средневековой Европе, например, и тут же это привлекло внимание, угадайте кого?
ОЗ: Кого?
ДБ: Католической церкви, или протестантской, в зависимости от того в какое время эта ситуация возникала. И происходит чудо, мы понимаем, что все чудеса – это действия какой-то сверхъестественной силы, а поскольку в христианской традиции сверхъестественные силы делятся на чёрное и белое, то церковь как представитель белой стороны должна защищать пиво от чёрной. Потому что если церковь не защитит, тогда скорее всего, чудо в вашем подвале происходило, извините, с очень большой вероятностью под воздействием дьявола. Соответственно, платите церкви определённую таксу, сдаёте определённое количество пива, назовём это на сертификацию, на экспертизу. Но, она была религиозной, скорее всего, просто употребление шло к столу той или иной монастырской общины. Вешались распятья в пивоварнях, какие-то сакральные символы и так далее.
После этого, техническая революция, масса открытий, открытия в том числе, в микробиологии, пивоварение становится уже на научные рельсы, уже не очень понятно зачем платить церкви тот или иной налог, зачем вешать какие-то крестики в тех или иных местах, где готовится пиво, Давать церкви эту бочку пива, приглашать монахов, именно в монастырях открывать пивоварню и пиво становится таким хорошо изученным продуктом, который можно повторять. Рецепты, которого можно переносить по всему миру, не обязательно только в определённом священном месте готовить. В большей степени, потому что понятно, что это какие-то редкие сорта, которые привязаны к одному месту. И вот это уже третий уровень приближения. Первый был такой миф, он же фольклор, назовём его так. И мифы до сих пор существуют, твои собеседники неоднократно здесь озвучивали.
ОЗ: У нас даже, знаешь, есть в каждом выпуске такой традиционный вопрос, который мы всем задаём: какой миф о пиве вам чаще всего приходится слышать и как вы его опровергаете, как вы объясняете?
ДБ: С эти проще, если ты не против, я вот сейчас это закончим и про миф.
ОЗ: Да, вернёмся к этому.
ДБ: Без проблем, с этим всё в порядке, потому что это будни в какой-то степени наши. И когда вы переводите пиво на научную вещь, может быть, оно становится скучнее, зато, по крайней мере, по нему всё понятно и мы можем создавать пиво не каким-то интуитивным путём, сегодня это положу и получится вот то. А уже просчитывать вариант заблаговременно, тиражировать, писать об этом книжки. Может быть, что-то теряется, поэтому дай Бог, чтобы всё-таки фольклор и религиозная составляющая пива присутствовали и тоже это в какой-то степени радует.
ОЗ: Это, знаешь, такие иные сторонники, они могут объяснить и тем, что мысли материальны, когда мы о чём-то думаем, мы некие сущности создаём и конечно, вот это большое количество увлечённых пивоварением людей, которые коллективно постоянно думают и говорят о пиве, бесспорно создают какие-то некие мыслительные сущности о которых в том числе мы сейчас и будем разговаривать. Ну что, к вопросу о мифе вернёмся тогда?
ДБ: Миф, ну сейчас, пару секунд на размышление. Самый частый, это всё просто, я думаю, их озвучивали постоянно – это в том, что в пиво добавляется спирт, что пиво крепче 5,5 %-6% в зависимости от персонального опыта отвечающего, что пива крепче 5-6% не существует, обязательно нужно добавить спирт, чтобы оно стало крепче. Я лично на работе, я провожу параллель с вином. Никого не удивляет, что вино может 13,14,15 % алкоголя, бывает и побольше, потому что оно было всегда таким. Потому что привыкли, вот если вино подашь 53% алкоголя, вот это скорее всего, вызовет у человека какие-то вопросы. А пиво всегда было 4,5, 4-6%, ну 7% алкоголя появляется, там Балтика 9, целый ряд сортов и привозятся они в Россию.
ОЗ: Тактический ядерный пингвин.
ДБ: Тактический ядерный пингвин – нет, я помню, когда я был студентом, не буду никакой рекламы делать, было одно пиво, оно было значительно крепче 9, оно было в свободном доступе, ещё когда таможенники, так скажем, когда у нас не выработалось в стране новое законодательство на счёт ввоза тех или иных напитков, оно было значительно крепче. Многие забыли, кто постарше, если бы я озвучил сейчас. На правах рекламы, многие бы сразу вспомнили.
ОЗ: Да ладно, скажи шепотом. Мы же говорим про исторические сорта про всякие разные тихонечко.
ДБ: Это не отечественное пиво сразу скажу, название говорить не буду.
ОЗ: Ну ладно, договорились.
ДБ: Воздержимся, хорошо, что мы тренировались, пускай эти воспоминания, которые уже отошли на задний план. Сейчас там у всех, понятно, голова забита живым, неживым пивом и чем-то в этом роде, пускай обратятся к тому, что радовало когда-то, потому что, в принципе, все стереотипы, которые складываются о современном пиве, они складываются на базе прошлый переживаний. И пускай человек вспомнит, что первые сорта, самые простые, которые просто банками, контейнерами привозились к нам из-за рубежа, на столько радовали человека и прошло, например, 15 лет и сейчас те же самые сорта, в тех же баночках, в тех же самых коробочках, они наоборот стали предметом осуждения, что поменялось?
ОЗ: Слушай…
ДБ: Пиво наврятли.
ОЗ: Возможно, немножко поменялось оборудование на котором оно всё варится, но мне кажется, что рецепты и пиво осталось тем же, поменялись люди, которые говорят.
ДБ: Есть объективные вещи, которые в пиве, у него вкус, как урожайность, качество воды, с годами оно, к сожалению, лучше не становится и тоже это нужно учитывать. Но, самое-то главное – меняется субъект.
ОЗ: И массовое сознание меняется.
ДБ: Может быть, отношения с пивом, они глубоко интимны, они у каждого индивидуальны складываются и каждый будет отстаивать свою любовь к конкретному пиву и только потом уже рухнет под напором какого-то общественного мнения, а в целом, поменялся сам человек. Т.е. меняется его миф.
Что касается самого популярного мифа, который сейчас существует – живое пиво. Уже да, тут несколько раз это всё рассказывалось. Это всё очень интересно, обычно как я рассказываю об этом, это то, что не бывает пиво живого или неживого, а бывает зараженное и незаражённое. Объясняю, рассказывал об этом кто-нибудь из присутствующих? Вот именно с этой точки зрения.
ОЗ: Мы довольно много говорим о живом и неживом пиве, но давай про заражённое и незаражённое пиво, ещё никто не блестел чешуёй.
ДБ: Как я объясняю, два таких ключевых, глобальных фактора, которые, с которыми сталкивается человек, когда дома варит пиво или когда он покупает пиво на розлив там бутылку, которую ему дают, это первый фактор – кислород. Т.е. если ваше пиво наливается так, что в него попадает кислород, оно будет окисляться, т.е. в нём будет происходит простая химическая реакция. Можете открыть любую бутылку магазинного пива, вскрыть эту упаковку и снова закрыть и попробовать это пиво на утро. Оно не будет точно таким же, произойдёт, это будет как раз эффект быстрого изменения вкуса этого пива.
А второй фактор – это посторонняя микрофлора, поскольку пиво очень питательная среда на только для человека, да, но и для микроорганизмов, которые там существуют. Если мы возьмём грязную посуду, если мы возьмём туже самую экспериментальную бутылку дунем туда.
ОЗ: Ещё добавить туда организмов.
ДБ: Закроем, поставим, но не в холодильник, а в то место, где им будет приятно размножаться, вести свои эти процессы, оно тоже будет портится значительно быстрее, чем пиво, которое было в целостной упаковке. Вот это первое. Честно говоря, целый ряд точек, которые раньше занимались живым пивом, но сейчас они отходят от этой концепции, отходят от этой парадигмы и стараются всё-таки просто предлагать пиво, потому что оно вкуснее. Вкуснее не потому что, да, бывают вкусные сорта пива разливных, я ничего не говорю, такое бывает. Но, они вкусные не потому что они живые.
ОЗ: Потому что они просто хорошие.
ДБ: Они просто другие, человек сравнивает тёплое с мягким.
ОЗ: Мы с тобой, по-моему, дегустировали, а нет, мы с тобой неживой сорт дегустировали в «Дегустационном зале», ты к нам приходил раньше.
ДБ: Не мёртвый, я бы так сказал, учитывая, что к этим понятиям я отношусь глубоко скептически.
ОЗ: Ну вот, наши гости они предлагают такую ироническую концепцию, что не бывает мёртвого пива, что это живой напиток, который создаётся из природных всяких разных ингредиентов и точно также как вино, как оно может быть, когда в нём и характер винограда и то и сё и пятое-десятое ив пиве тоже есть и вклад зерна и вклад дрожжей, у людей не поднимается язык называть это мёртвым, но а живые массовое сознание так причудливо выдаёт эту историю.
ДБ: Это пройдёт, это первый уровень знакомства потребителя с микробиологией, потому что, на самом деле, если там глубоко вникать, если человек из лаборатории, конечно, на много больше всё это рассказал, на много более развёрнуто все эти факты раскрыл, в целом, я думаю, что это пройдёт. Это нормально, хорошо, что вообще это есть, это стимулирует какой-то интерес к пиву и поэтому человек два года попивший живое пиво, потом вдруг он уже начнёт понимать, что в целом дело не в том, жизнь, не жизнь, короткий срок годности, длинный срок годности.
ОЗ: Пастеризация, не пастеризация.
ДБ: Пастеризация, её почему-то называют постерилизацией – это какой-то совершенно новый процесс, наверное, пройдёт, нормально всё, человек поездит, человек по магазинам походит. Если кто-то это слышит, уважаемые слушатели, я думаю, что всё не зря здесь говориться, вы не бойтесь пробовать новое пиво, если привыкли пить светлое пиво – попробуйте тёмное. Самое простое, если привыкли пить лёгкое пиво – попробуйте крепкое пиво. Если привыкли пить пиво только из воды, солода и хмеля – попробуйте из воды, солода с базиликом, с чередой и хмель или вместо хмеля может быть это будет акация или что-то ещё. Это, в конце концов, получите удар по носу за такую смелость, но будите знать, что это пиво не варится. Но пива огромное количество сортов, там несколько десятков тысяч сортов существует в мире и почему бы себя ограничивать каким-то одним?
ОЗ: Я думаю, что завершать этот разговор стоит таким современным срезом пласта массового сознания, что ты можешь сказать, как сейчас люди смотрят на пиво, как они его видят, как они его осмысляют?
ДБ: Слава Богу, появляется большое количество людей, которые относятся к пиву не как к алкоголю, т.е. покупая в магазине пиво они не смотрят на то, сколько в нём процентов алкоголя содержится по объёму и сколько это пиво стоит. И в зависимости от этого, производя не хитрую калькуляцию сколько стоит такое-то количество алкоголя, они выбирают не то, что более меняет потом их замечательное сознание, а всё-таки они интересуются чем-то необычным. И здесь уже появляется группа людей, не группа, скажем, большой, значимый, ощутимый процент, который воспринимает пиво как продукт питания. Один из продуктов питания, напиток, который может пользоваться ежедневно, главное уметь им пользоваться.
Поскольку есть такая тенденция, что человек выбирает из продуктов максимально здоровые, он же читает этикетку, он же читает состав. Слава Богу, кстати, в России на пиве очень содержательная этикетка, например, сравнить с американской этикеткой, наша этикетка – она позволяет очень много чего получить, если не полениться повернуть бутылочку не только красивой стороной, а информативной и эту информацию прочитать. Как продукты питания, молоко, колбасы, не знаю, мясо, сыры и прочее многим интересно из чего сделаны, более того масса народу приходит на экскурсии и интересуется как это всё происходило. Действительно ли это всё правда, что рассказывают в своём рекламном ролике. Тоже самое отношение и к пиву, они тоже интересуются как это было сделано, некоторые пробуют это сделать дома, они уже делают ставку на здоровье. Т.е. они не говорят о том, что я не буду пить пиво никогда, да, я собственно уйду в монастырь и буду питаться водой и хлебом. Пиво нормальное – оно занимает достойное место у них на столе и люди готовы покупать пиво за большие деньги.
Скажем, 10 лет назад что человек будет покупать пиво по цене 20 долларов за бутылку, мало кто бы увлёкся на это и откликнулся, а сейчас эта категория людей тоже появляется. Люди проходят в ресторан, они уже начинают выбирать какое пиво им интересно, там пока не будем углубляться сильно, пока сложно говорить действительно ли человек хорошо разбирается в пиве или не хорошо, потому что интерес есть и интерес углублять свои знания в пиве – это очень хорошо. Где-то я слышал, что один человек, читавший исследования, что пиво сейчас входит в десятку крупнейших мировых трендов то, чем интересуется человек, то, чему хочет учиться. Т.е. существует большой спрос на информацию о пиве. Если вы будите просто готовить пиво – это будет уже за пределами этого интереса, если вы будите делать интересное пиво, если вы будите красиво украшать, если вы будите не просто его продавать, а ещё и рассказывать о том какое это пиво, как им пользоваться, учить им и вот «Пивной сомелье», который у нас организовался в прошлом году – замечательный проект, тоже, собственно говоря, наши пять копеек в эти мировые весы, которые всё-таки склоняют чащу в сторону пива, нежели просто алкоголя такого. Мне кажется, это очень важно и дай Бог.
ОЗ: По этому мы собственно здесь и сидим, я думаю, что мы сегодня нагнали достаточно интриги, чтобы уже рассказать классный, интересный, весёлый анекдот о пиве, ну, пожалуйста, сделай это.
ДБ: Ну, он может быть не классный и не интересный.
ОЗ: Но, весёлый хоть?
ДБ: Скажем, на тему того, что я вспомнил.
ОЗ: Давай.
ДБ: Учёные наконец-то добавили к числу ПИ число ВО и ходят безумно счастливые, чего и вам желаю.
ОЗ: Да, спасибо большое, Дима, это был пивной этнограф, путешественник, бирофил.
ДБ: Любитель пивного фольклора, потому что этнограф, бирофил – какие-то страшные все названия, может быть, пугающие человека, может быть, действительно завышающие.
ОЗ: И хороший, весёлый парень, который действительно любит пиво и любит рассказывать о нём интересные вещи – Дмитрий Булдаков, пока.
ДБ: Спасибо, Оля. Пока, пока.
Артикул: Композиционные объекты | Slack
Объекты композиции могут использоваться внутри элементов блока и определенных полей полезной нагрузки сообщения. Это просто общие шаблоны объектов JSON, с которыми вы часто будете сталкиваться при построении блоков или составлении сообщений.
В нашем руководстве по Block Kit в приложениях показано, где можно использовать блоки.
Списки полей и значений ниже описывают JSON, который приложения могут использовать для создания каждого объекта:
Текстовый объект
Объект, содержащий некоторый текст в формате plain_text или с использованием mrkdwn , нашего собственного вклада в столь любимый стандарт Markdown.
Поля
| Поле | Тип | Обязательно? | Описание |
|---|---|---|---|
тип | Строка | Есть | Форматирование, используемое для этого текстового объекта. Может быть одним из plain_text или mrkdwn . |
текст | Строка | Есть | Текст для блока.Это поле принимает любую стандартную разметку форматирования текста, если type — mrkdwn . |
смайликов | логический | Нет | Указывает, следует ли преобразовывать смайлы в текстовом поле в формат смайликов с двоеточием. Это поле можно использовать, только если тип — plain_text . |
дословно | логический | Нет | Если установлено значение false (по умолчанию) URL-адреса будут автоматически преобразованы в ссылки, имена бесед будут привязаны к ссылкам, а некоторые упоминания будут автоматически проанализированы.Использование значения true пропустит любую предварительную обработку такого рода, хотя вы все равно можете включить строки синтаксического анализа вручную. Это поле можно использовать, только если тип — mrkdwn . |
Пример
{
"тип": "mrkdwn",
"text": "Сообщение * с полужирным шрифтом * и _ некоторым курсивом_."
}
Посмотреть пример
Подтверждение диалогового объекта
Объект, определяющий диалог, который обеспечивает шаг подтверждения для любого интерактивного элемента.В этом диалоговом окне пользователя попросят подтвердить свое действие, предложив кнопки подтверждения и отказа.
Поля
| Поле | Тип | Обязательно? | Описание |
|---|---|---|---|
титул | Объект | Есть | plain_text — только текстовый объект, определяющий заголовок диалогового окна. Максимальная длина этого поля — 100 символов. |
текст | Объект | Есть | Текстовый объект, определяющий пояснительный текст, который появляется в диалоговом окне подтверждения.Максимальная длина текста в этом поле составляет 300 символов. |
подтвердить | Объект | Есть | plain_text — только текстовый объект для определения текста кнопки, подтверждающей действие. Максимальная длина текста в этом поле составляет 30 символов. |
отказать | Объект | Есть | plain_text — только текстовый объект для определения текста кнопки, отменяющей действие.Максимальная длина текста в этом поле составляет 30 символов. |
стиль | Строка | Нет | Определяет цветовую схему, применяемую к кнопке подтверждения . Значение опасность отобразит кнопку с красным фоном на рабочем столе или красным текстом на мобильном телефоне. Значение primary отобразит кнопку с зеленым фоном на рабочем столе или синим текстом на мобильном устройстве. Если это поле не указано, значением по умолчанию будет первичный . |
Пример
{
"заглавие": {
"тип": "простой_текст",
"text": "Вы уверены?"
},
"text": {
"тип": "mrkdwn",
"text": "Вы бы предпочли хорошую игру в _chess_?"
},
"подтверждать": {
"тип": "простой_текст",
"текст": "Сделай это"
},
"отказываться от": {
"тип": "простой_текст",
"text": "Стой, я передумал!"
}
}
Посмотреть пример
Опционный объект
Объект, который представляет один выбираемый элемент в меню выбора, меню с множественным выбором, группе флажков, группе переключателей или дополнительном меню.
Поля
| Поле | Тип | Обязательно? | Описание |
|---|---|---|---|
текст | Объект | Есть | Текстовый объект, определяющий текст, отображаемый в параметре меню. Меню переполнения, выбора и множественного выбора могут использовать только объекты plain_text , тогда как переключатели и флажки могут использовать текстовые объекты mrkdwn .Максимальная длина текста в этом поле составляет 75 символов. |
значение | Строка | Есть | Уникальное строковое значение, которое будет передано вашему приложению при выборе этого параметра. Максимальная длина этого поля — 75 символов. |
описание | Объект | Нет | plain_text — только текстовый объект, который определяет строку описательного текста, показанную под полем text рядом с переключателем.Максимальная длина объекта text в этом поле составляет 75 символов. |
url | Строка | Нет | URL-адрес для загрузки в браузере пользователя при нажатии этой опции. Атрибут url доступен только в меню переполнения . Максимальная длина этого поля — 3000 символов. Если вы используете url , вы все равно будете получать полезные данные взаимодействия, и вам нужно будет отправить ответ с подтверждением. |
Пример
{
"text": {
"тип": "простой_текст",
"текст": "Мару"
},
"значение": "мару"
}
Посмотреть пример
Объект группы опций
Предоставляет способ группировать параметры в меню выбора или меню с множественным выбором.
Поля
| Поле | Тип | Обязательно? | Описание |
|---|---|---|---|
этикетка | Объект | Есть | plain_text — только текстовый объект, который определяет метку, показанную над этой группой параметров.Максимальная длина текста в этом поле составляет 75 символов. |
варианты | Объект [] | Есть | Массив объектов параметров, принадлежащих к этой конкретной группе. Максимум 100 предметов. |
Пример
"option_groups": [
{
"метка": {
"тип": "простой_текст",
"текст": "Группа 1"
},
"параметры": [
{
"text": {
"тип": "простой_текст",
"текст": "* это простой_текст *"
},
"значение": "значение-0"
},
{
"text": {
"тип": "простой_текст",
"текст": "* это простой_текст *"
},
"значение": "значение-1"
},
{
"text": {
"тип": "простой_текст",
"text": "* это простой_текст *"
},
"значение": "значение-2"
}
]
},
{
"метка": {
"тип": "простой_текст",
"текст": "Группа 2"
},
"параметры": [
{
"text": {
"тип": "простой_текст",
"текст": "* это простой_текст *"
},
"значение": "значение-3"
}
]
}
]
Посмотреть пример
Конфигурация действия отправки
Определяет, когда элемент ввода обычного текста будет возвращать полезные данные взаимодействия block_actions .
Поля
| Поле | Тип | Обязательно? | Описание |
|---|---|---|---|
trigger_actions_on | Строка [] | Нет | Массив типов взаимодействий, для которых вы хотите получить полезную нагрузку block_actions . Должен быть один или оба из следующих: |
Пример
{
тип: "вход",
dispatch_action: истина,
element: {
тип: "plain_text_input",
многострочный: правда,
dispatch_action_config: {
trigger_actions_on: ["on_character_entered"]
}
},
метка: {
тип: "plain_text",
text: "Это многострочный текстовый ввод",
смайлики: правда
}
}
Объект фильтра для списков разговоров
Предоставляет способ фильтрации списка опций в меню выбора бесед или меню с множественным выбором бесед.
Поля
| Поле | Тип | Обязательно? | Описание |
|---|---|---|---|
включая | Строка [] | Нет | Указывает, какой тип разговоров должен быть включен в список . Если это поле указано, любые разговоры, которые не соответствуют, будут исключены. Вы должны предоставить массив строк из следующих вариантов: |
exclude_external_shared_channels | логический | Нет | Указывает, следует ли исключить внешние общие каналы из списков разговоров. По умолчанию false . |
exclude_bot_users | логический | Нет | Указывает, следует ли исключать пользователей-ботов из списков бесед. По умолчанию false . |
Обратите внимание, что хотя ни одно из вышеперечисленных полей не является обязательным по отдельности, вы должны указать хотя бы одно из этих полей .
Пример
{
"тип": "диалог_выбрать",
"placeholder": {
"тип": "простой_текст",
"text": "Выберите беседу",
«эмодзи»: правда
},
"filter": {
"включать": [
"общественный",
"mpim"
],
"exclude_bot_users": правда
}
}
Посмотреть пример
Известные проблемы
В iOS текст заполнителя заменяется на «0 выделено», когда нет выбранных бесед.
В iOS возникают несоответствия пользовательского интерфейса, когда пользователи выбирают элементы в меню с множественным выбором.
Как использовать методы сопоставления, фильтрации и сбора Java Stream API | автор: javinpaul | Ява посетил
Привет, ребята! Если вы изучаете функциональное программирование на Java и хотите научиться использовать методы map, filter и collect в Java, то вы попали в нужное место.
В прошлом я поделился лучшими курсами функционального программирования Java, а также некоторыми книгами по Java по Lambda и Stream, а сегодня я собираюсь научить вас, как использовать методы map, filter и collect для создания вашего потока. конвейер для преобразования ваших данных из одной формы в другую.
Несмотря на то, что я ранее писал как о map (), так и о filter (), я снова пишу этот пост, чтобы расширить концепцию на языке непрофессионала, чтобы обеспечить лучшее понимание для моих читателей и коллег-разработчиков Java.
Функция map () — это метод в классе Stream, который представляет концепцию функционального программирования. Проще говоря, map () используется для преобразования одного объекта в другой, применяя функцию .
Вот почему Stream.map (Function mapper) принимает функцию в качестве аргумента. Например, используя функцию map () , вы можете преобразовать список String в List of Integer, применив метод Integer.valueOf () к каждой строке во входном списке.
Все, что вам нужно, это функция отображения для преобразования одного объекта в другой. Затем функция map () выполнит преобразование за вас. Это также промежуточная операция Stream, что означает, что вы можете вызывать другие методы Stream, такие как фильтр, или собирать их для создания цепочки преобразований.
Теперь, переходя к методу фильтрации, как следует из названия, он фильтрует элементы на основе условия , которое вы ему задали. Например, если ваш список содержит числа, а вам нужны только числа, то вы можете использовать метод фильтрации, чтобы выбрать только число, которое полностью делится на два.
Метод фильтрации по существу выбирает элементы на основе заданного вами условия. По этой причине фильтр (условие Predicate, ) принимает объект Predicate, который предоставляет функцию, которая применяется к условию.Если условие оценивается как истинное, объект выбирается. В противном случае он будет проигнорирован.
Подобно карте, фильтр также является промежуточной операцией, что означает, что вы можете вызывать другие методы Stream после вызова фильтра.
filter () метод также lazy , что означает, что он не будет оцениваться, пока вы не вызовете метод сокращения, например collect, и он остановится, как только достигнет цели.
Если вы не знакомы с поведением Stream, я предлагаю вам ознакомиться с Learn Java Functional Programming with Lambdas & Streams от Ранга Рао Карнама на Udemy, где подробно объясняются основы Stream.
Чтобы понять любую новую концепцию, вам нужен хороший пример. Вот почему вы читаете эту статью. Поскольку String и Integer являются наиболее распространенными типами данных в Java, я выбрал простой и интересный пример.
У меня есть список строк: числа вроде {«1», «2», «3», «4», «5», «6»} . Я хочу обработать этот список, и мне нужен еще один список целых чисел с четными числами .
Чтобы найти четные числа, мне сначала нужно преобразовать список строк в список целых чисел.Для этого я могу использовать метод map () класса java.util.Stream. Но перед этим нам нужен Stream как map (), как определено в классе java.util.stream.
Это совсем несложно, так как вы можете получить поток из любой коллекции, например List или Set путем вызова метода stream (), который определен в интерфейсе java.util.Collection .
Метод map (Function mapper) принимает Function, технически говоря, объект интерфейса java.util.function.Function.Затем эта функция применяется к каждому элементу Stream, чтобы преобразовать его в нужный вам тип.
Поскольку нам нужно преобразовать String в Integer, мы можем передать метод Integer.parseInt () или Integer.valueOf () в функцию map ().
Я выбрал метод valueOf () по причинам, упомянутым в статье parseInt vs valueOf, то есть производительности и кешированию. Кстати, это не только я. Даже Джошуа Блох посоветовал предпочесть статические фабричные методы, такие как valueOf () , а не конструктору в Effective Java .
Затем map () вернет поток целых чисел, который содержит как четные, так и нечетные числа. Чтобы выбрать только четные числа, мы можем использовать метод filter ().
Требуется объект предиката, который технически является функцией для преобразования объекта в логическое значение . Мы передаем объект, и он вернет true или false. Затем фильтр использует эту информацию для включения объекта в поток результатов.
Итак, чтобы включить только четные числа, мы вызываем фильтр (число -> число% 2 == 0) , что означает, что каждое число будет разделено на два, и, если нет остатка, оно будет выбрано.Это та же самая логика, которую мы использовали при решении задач кодирования, чтобы проверить, является ли данное число четным или нечетным в Java.
Мы почти закончили. Но пока у нас есть только поток четных целых чисел, а не список четных целых чисел, и поэтому нам нужно их использовать.
Поскольку нам нужен список, я вызвал collect (Collectors.toList ()) , , который соберет все четные числа в список и вернет результат.
Теперь вы можете подумать: как он узнает, что нужно вернуть список целых чисел? Что ж, нам нужно получить эту информацию путем вывода типа, потому что мы уже указали эту информацию, сохранив результат в List .
Если вы хотите узнать больше о выводе типа в лямбда-выражении, неплохо начать с Complete Java MasterClass .
Вот программа на Java, реализующая все, что я сказал в предыдущем разделе. Вы можете запустить эту программу в IDE или из командной строки и увидеть результат.
Вы также можете поэкспериментировать с использованием большего количества функций map () или большего количества вызовов filter () , чтобы сделать композицию более длинной и сложной.Вы даже можете поиграть с методом collect () , чтобы собрать результат в список, набор, карту или любую другую коллекцию.
Вы можете видеть, что исходный список содержит числа от 1 до 6, а отфильтрованный список содержит только четные числа, то есть 2, 4 и 6.
Наиболее важным кодом в этом примере являются следующие четыре строки обработки потока. код:
Этот код начинается с карты, затем фильтра и, наконец, сбора. Вам может быть интересно, будет ли порядок иметь значение.Что ж, это так.
Поскольку для нашего условия фильтрации требуется переменная типа int, нам сначала нужно преобразовать Stream of String в Stream of Integer . Вот почему мы сначала вызвали функцию map () .
Когда у нас есть поток целых чисел, мы можем применить математику, чтобы найти четные числа. Мы передали это условие методу фильтра. Если бы нам нужно было отфильтровать строку, например, выбрать всю строку, длина которой > 2 , то мы бы вызвали фильтр перед картой.
Вот и все о том, как использовать карту и фильтр в Java 8 . Мы видели интересный пример того, как мы можем использовать карту для преобразования одного объекта в другой и как использовать фильтр для выбора объекта на основе условия. Мы также научились составлять операции в потоке для написания ясного и лаконичного кода.
Дальнейшее обучение
Полный Java MasterClass
От коллекций до потоков в Java 8 Использование лямбда-выражений
Java SE 8 для программистов (книга)
Рефакторинг для Java 8 Streams and Lambdas Семинар для самообучения
Другое Учебные пособия по Java вам может понравиться
Если вам интересно узнать больше о новых функциях Java 8, вот мои предыдущие статьи, охватывающие некоторые из важных концепций Java 8:
- Полная дорожная карта разработчика Java (см.)
- Как отсортировать может по значениям в Яве 8? (пример)
- Разница между map () и flatMap в Java 8 (ответ)
- Как использовать класс Stream в Java 8 (учебник)
- 10 курсов для углубленного изучения Java (курсы)
- Как форматировать / проанализировать дату с помощью LocalDateTime в Java 8? (учебник)
- 5 книг по изучению Java 8 с нуля (книги)
- Какой метод используется по умолчанию в Java 8? (пример)
- Как присоединиться к String в Java 8 (пример)
- Разница между абстрактным классом и интерфейсом в Java 8? (ответ)
- 20 примеров даты и времени в Java 8 (учебник)
- Как отсортировать карту по ключам в Java 8? (пример)
- 15 вопросов на собеседовании по потоку Java и функциональному программированию (список)
- Как преобразовать список в карту в Java 8 (решение)
- 10 примеров дополнительных функций в Java 8? (пример)
Спасибо, что прочитали эту статью.Если вы найдете это руководство по Java полезным, поделитесь им со своими друзьями и коллегами. Если у вас есть какие-либо вопросы или отзывы, напишите нам.
П.С. — Если вы серьезно настроены улучшить свои навыки функционального программирования на Java и хотите узнать больше о Java Stream API, я настоятельно рекомендую вам пройти Изучите функциональное программирование на Java с помощью Lambdas & Streams курс от Ранга Рао Карнама на Udemy , который подробно объясняет основы Stream.
Угловая компоновка Составьте полное руководство
В этой статье мы исследуем множество способов компоновки макета в угловом формате.
Фото Глена Кэрри на Unsplash
Что такое компоновка макета?
Во многих отношениях макет и композиция являются строительными блоками дизайна. Они придают вашей работе структуру и упрощают навигацию, от полей по бокам до содержимого между ними.Композицию макета формируют пять основных принципов
.- Близость
- Белое пространство
- Выравнивание
- Контрастность
- Иерархия
Примечания: Я не собираюсь объяснять здесь каждый принцип, поскольку это выходит за рамки нашей компетенции, но вы можете прочитать эту замечательную статью для получения дополнительной информации.
Как это сделать в угловом?
- Компонент должен отображаться на
{x: 0, y: 0} - Компонент
: стиль хостадолжен бытьdisplay: blockПочему это важно? чтобы упростить внешнему компоненту установку полей и ширины, если мы используем компонент внутри другого компонента. - Создавайте как можно крошечный и многоразовый компонент. Как я могу узнать, следует ли разделять эту часть как компонент ?. Компонент должен делать одно и только одно.
Какие предусмотрены приемы компоновки макетов угловой?
Этот пост исследует множество способов комбинирования, смешивания и смешивания компонентов Angular, в том числе:
- Компоненты проекции содержимого внутри пользовательского элемента (Компонент Layout & Style).
Проекция контента
Что такое проекция контента?
В Angular проекция контента используется для проецирования контента в компоненте (angular.io).
Почему мы его используем?
- Многие компоненты в вашем приложении используют ту же структуру и стиль, но содержимое отличается, другими словами Возможность повторного использования .
- Вы создаете компонент только для отображения, а другой компонент — для обработки действий пользователя, другими словами Разделение проблем .
Как я могу им пользоваться?
Угловое усиление с использованием селекторов CSS, атрибутов html и элементов html для достижения композиции макета.
С одним слотом
По сути, вы просто добавляете в свой html, и он заменяется содержимым извне компонента
Войти в полноэкранный режимВыйти из полноэкранного режима
<компонент-контейнер>
Контент здесь
Войти в полноэкранный режимВыйти из полноэкранного режимаМногослотовая (целевая проекция)
ng-contentпринимает атрибутselect, который позволяет нам установить конкретное имя селектора css для этого слота.
Войти в полноэкранный режимВыйти из полноэкранного режима
<компонент-контейнер>
Контент для первого слота
Войти в полноэкранный режимВыйти из полноэкранного режима Если вы используете его в обычной настройке angular cli, вы получите ошибку, если сейчас используете тег .
Отклонение необработанного обещания: ошибки синтаксического анализа шаблона: ‘slot-one’ не является известным элементом, Angular не распознает тег
slot-one.slot-oneне является ни директивой, ни компонентом
Быстрый способ обойти эту ошибку — добавить свойство метаданных схемы в ваш модуль, установить значение NO_ERRORS_SCHEMA в вашем файле модуля.
// app.module.ts
импортировать {NgModule, NO_ERRORS_SCHEMA} из '@ angular / core'; //
импортировать {BrowserModule} из '@ angular / platform-browser';
импортировать {AppComponent} из './app.component ';
import {ContainerComponent} из './container-component';
@NgModule ({
импорт: [BrowserModule],
объявления: [AppComponent, ContainerComponent],
бутстрап: [AppComponent],
схемы: [NO_ERRORS_SCHEMA], // добавляем эту строку
})
класс экспорта AppModule {}
Войти в полноэкранный режимВыйти из полноэкранного режима- Использование атрибутов
[имя]|[имя] [другое имя]
Войти в полноэкранный режимВыйти из полноэкранного режима
<компонент-контейнер>
Контент для первого слота
Контент для второго слота
Войти в полноэкранный режимВыйти из полноэкранного режима- Использование атрибута со значением
[name = "value"]
Войти в полноэкранный режимВыйти из полноэкранного режима
<компонент-контейнер>
Контент для первого слота
Контент для второго слота
Войти в полноэкранный режимВыйти из полноэкранного режима- Использование класса (ов)
.имя|.name.another-name
Войти в полноэкранный режимВыйти из полноэкранного режима
<компонент-контейнер>
Контент для первого слота
Контент для первого и второго слотов
Войти в полноэкранный режимВыйти из полноэкранного режима- Без упаковки div
, как вы можете видеть в предыдущем примере, вы можете использовать целевой слот, обернув свой контент с помощью div или element и прикрепив к нему селектор, но в некоторых случаях вы просто хотите поместить его туда.
Использование
ngProjectAsangular атрибута в теге ng-container или любом другом теге, который вы хотите
Войти в полноэкранный режимВыйти из полноэкранного режима
Очень важный текст с тегами.
Очень важный текст с тегами.
Войти в полноэкранный режимВыйти из полноэкранного режимаВнутри
* нг для // Компонент контейнера
@Составная часть({
...
шаблон: `
`
})
class TabsComponent {
@ContentChild (TemplateRef) templateRef: TemplateRef;
@Input () элементы;
}
Войти в полноэкранный режимВыйти из полноэкранного режима
<контейнер-компонент [items] = "данные">
{{ пункт }}
Войти в полноэкранный режимВыйти из полноэкранного режимаField Sensor: вычисление состава и цели запросов PubMed | База данных
Аннотация
PubMed ® — это поисковая система, обеспечивающая доступ к коллекции из более чем 27 миллионов биомедицинских библиографических записей по состоянию на 2017 год.PubMed обрабатывает миллионы запросов в день, и понимание этих запросов является одним из основных строительных блоков для успешного поиска информации. В этой работе мы представляем Field Sensor, предметно-ориентированный инструмент для понимания состава и прогнозирования намерений пользователя запросов PubMed. Получив запрос, датчик поля определяет поле для каждого токена или последовательности токенов в запросе в многоэтапном процессе, который включает синтаксическое разбиение на фрагменты, тегирование на основе правил и вероятностное предсказание поля.В этой работе интересующие поля связаны с элементами (мета) данных каждой записи PubMed, такими как название статьи, аннотация, имя (имена) автора, название журнала, том, выпуск, страница и дата. Мы оцениваем точность нашего алгоритма на аннотированном человеком корпусе из 10 000 запросов PubMed, а также на новом наборе из 103 000 запросов PubMed с машинными аннотациями. Датчик поля обеспечивает точность 93 и 91% на двух соответствующих корпусах и обнаруживает, что почти половина всех поисков является навигационной (например.грамм. поиск авторов, поиск заголовков статей и т. д.), а половина — информационные (например, тематические поиски). Датчик поля был интегрирован в PubMed с июня 2017 года для обнаружения информационных запросов, для которых результаты, отсортированные по релевантности, могут быть предложены в качестве альтернативы тем, которые отсортированы по дате по умолчанию. Кроме того, состав запросов PubMed, вычисленный датчиком поля, оказывается важным для понимания того, как пользователи запрашивают PubMed.
Введение
PubMed (www.pubmed.gov) — это поисковая машина, разработанная и поддерживаемая Национальным центром биотехнологической информации NLM. PubMed работает с MEDLINE ® , коллекцией из более чем 27 миллионов биомедицинских библиографических записей по состоянию на 2017 год, и в последние десятилетия наблюдается неуклонный рост научной информации. PubMed обрабатывает в среднем 3 миллиона запросов в день и признан основным инструментом для ученых в области биомедицины (1–3). Учитывая важность PubMed, улучшение понимания запросов пользователей открывает огромные возможности для улучшения результатов поиска.
Для обычных поисковых систем проблема понимания запроса охватывает весь спектр исследований, начиная от определения цели запроса высокого уровня (информационного, навигационного или транзакционного) (4–8) до определения более детальной информации запроса, такой как человек, возраст, фильм, путешествия, рабочие области (9), для понимания семантики запросов (10–12). Многие запросы, задаваемые в Интернете, нацелены на структурированные или полуструктурированные веб-данные, такие как коммерческие продукты, фильмы и т. Д. Отображение неструктурированного языка этих запросов в структурированное представление было тщательно изучено и показало, что оно улучшает результаты поиска (13-15).Другие подходы, используемые для понимания запросов, включают статистическое машинное обучение (7), глубокое обучение (9, 12), сопоставление с семантическим пространством Википедии (10, 11), использование журналов запросов (11, 16) и информации о кликах (17).
Несмотря на обширные исследования в области общего поиска в Интернете, было опубликовано меньше исследований о моделях использования биомедицинских информационных ресурсов в Интернете. Однако известно, что между ними есть важные различия (18–21). В биомедицинской области проводится несколько исследований, направленных на понимание того, как осуществляется поиск информации о здоровье, и информационных потребностей пользователей предметной области, таких как клиницисты, медицинские исследователи или пациенты (18, 19, 22–25).Два наиболее полных анализа журнала биомедицинских запросов — это изучение запросов PubMed за 1 день (19) и изучение запросов PubMed за 1 месяц (18). Оба анализируют статистические свойства журналов запросов, такие как длина запроса, пользовательские сеансы, размер набора результатов, и пытаются охарактеризовать запросы с точки зрения семантики и цели. Работа, описанная в (18), вручную аннотирует случайный набор из 10 000 запросов из журналов PubMed путем сопоставления сегментов запросов с шестнадцатью предопределенными категориями семантических типов.В исследовании (19) предпринимается попытка семантического анализа запросов путем сопоставления их со словарем, контролируемым MeSH.
Одним из основных аспектов запросов, исследуемых как общим, так и биомедицинским доменом поиска, является цель запроса. Согласно определению Бродера (5), общие веб-запросы можно охарактеризовать как информационные, навигационные или транзакционные (обычно не наблюдаемые в научных поисках). Распространяя это определение на PubMed, информационные запросы, также известные как тематические поиски, такие как рак толстой кишки или семейная средиземноморская лихорадка , предназначены для удовлетворения информационных потребностей по определенной теме.Навигационные запросы, также известные как запросы известных элементов (26), такие как Katanaev AND Cell 2005, 120 (1): 111–22, , предназначены для поиска конкретной публикации. В PubMed навигационные запросы могут состоять из элементов цитирования, включая имя автора, заголовок, том, выпуск, страницу и / или дату, или быть полными цитатами. Лишь небольшой процент запросов PubMed включает явные поля, назначенные пользователем, и их легко понять. Подавляющее большинство запросов не имеют назначений полей, хотя предполагается скрытая структурная информация.Для этих запросов бремя отображения сегментов запроса в поля перекладывается на поисковую систему.
Причина важности прогнозирования намерения запроса заключается в том, что оно часто определяет поведение поисковой системы (27). Информационные запросы сосредоточены на доступе к свободному тексту, который имеет тенденцию извлекать множество документов, а функция сортировки имеет решающее значение для отображения результатов. Напротив, навигационные запросы требуют синтаксических анализаторов и доступа к структурированным данным цитирования и представляют намерение пользователя найти конкретный документ или веб-сайт.Это различие особенно важно для поиска в базах данных научного цитирования, таких как PubMed, где навигационные запросы составляют значительно большую часть всех запросов по сравнению с общей поисковой областью. Как мы демонстрируем в этом исследовании, навигационные запросы составляют примерно половину всех поисков, в то время как в общей поисковой области они, как сообщается, составляют 10% запросов (6).
Хотя запросы, связанные со здоровьем, и поиск информации о состоянии здоровья привлекли внимание к разработке новых инструментов и методов, специфичных для этой области (28), насколько нам известно, нет приложений, которые могут вывести цель запросов PubMed алгоритмически.Два недавних исследования рассматривают возможность прогнозирования намерений академических запросов (29, 30). В исследовании (29) сообщается, что в академических поисковых системах навигационные запросы составляют 7,6% запросов, однако при вычислении используются явные подсказки, такие как номер ISBN, DOI или другие теги, связанные с цитированием, для классификации запросов. Учитывая, что только небольшой процент запросов PubMed включает явные поля, назначенные пользователем, для классификации намерения запроса необходимы более чувствительные методы. В исследовании (30) представлен подход бинарной классификации для прогнозирования целей научных запросов, авторы которых сообщают, что оценка F1 равна 0.677 на наборе из 579 вручную аннотированных научных запросов с использованием их лучшего метода (Gradient Boosted Trees). Они используют такие функции, как количество токенов в запросе, соотношение терминов запроса, идентифицированных как имена авторов, есть ли в запросе знаки препинания или нет, и т. Д. Для управления обучением. Чтобы решить проблему прогнозирования цели биомедицинских запросов, мы разработали Field Sensor, инструмент веб-масштаба, который присваивает поле каждому токену или последовательности токенов в запросе, вычисляя сопоставление между сегментом запроса и полем вдоль с вероятностью этого отображения.Например, учитывая запрос апноэ во сне, cushing он определяет, что apnea во сне — это текст, а cushing — это имя автора, и предсказывает отображение apnea во сне [текст], cushing [автор] . На основе назначений полей намерение запроса выводится следующим образом: запрос считается информационным, если он состоит из текстовых полей только , в противном случае мы называем его навигационным.
Датчик поля — это механизм вероятностного прогнозирования поля, оснащенный двумя модулями предварительной обработки на основе правил.Система начинается с модуля синтаксического разделения запросов, который разбивает запрос на основе логических операторов и скобок. Сегменты запроса, помеченные пользователем, также идентифицируются на этом этапе и остаются неизменными. За ним следует модуль маркировки запросов на основе правил, предназначенный для распознавания элементов цитирования в запросах, исходящих из полей тома, выпуска, страницы и даты, с учетом шаблонов между числами и знаками препинания. И, наконец, третий модуль — это модуль вероятностного предсказания поля, который по заданному сегменту запроса предсказывает поле сегмента.Модель основана на байесовском подходе, который предполагает соответствие между сегментом запроса и полем в PubMed на основе статистики сбора. Наш модуль прогнозирования вероятностного поля связан с моделью вероятностного поиска для полуструктурированных данных (PRMS) (13) способом вычисления сопоставлений между словами запроса и полями. Однако PRMS представляет собой модель набора слов с униграммой, в то время как наша модель учитывает зависимости терминов и пытается предсказать поля для сегментов запроса, содержащих до пяти токенов.
Термин запроса для сопоставления полей, прогнозируемый датчиком поля, может использоваться несколькими способами. Важной функцией нашего метода является классификация запроса как информационного или навигационного. Датчик поля был развернут в PubMed с июня 2017 года для выявления информационных запросов, для которых пользователям предлагаются результаты поиска, отсортированные по релевантности, в качестве альтернативы обратному временному порядку по умолчанию (31). Дополнительным применением могут быть смешанные запросы, содержащие как информационные, так и навигационные компоненты.Идентификация этих полей может усилить процесс поиска, применяя различные стратегии поиска к информационным и навигационным компонентам запроса. Кроме того, датчик поля незаменим при исследованиях журнала запросов. Это позволяет нам изучать, как осуществляется поиск биомедицинской информации. Для запросов, которые не извлекают никаких документов, инструмент может помочь нам лучше понять, какие поля с большей вероятностью могут быть причиной. И, наконец, поскольку базовая модель Field Sensor вычисляется на основе данных Medline, ее можно использовать для любой другой специализированной базы данных биомедицинского цитирования, такой как bioRxiv (http: // biorxiv.org /) или может быть переобучен для применения в других академических поисковых системах.
Материалы и методы
В этом разделе мы описываем нашу модель, лежащую в основе Field Sensor, инструмента для определения поля для каждого токена или последовательности токенов в запросе. Статьи в PubMed заносятся в базу данных в единой структурированной форме: аннотация статьи, название статьи, имя (имена) автора, название журнала, том, выпуск, страница и дата. Это те поля, которые нас интересуют в отображении.Мы пометим сегменты запроса, которые сопоставляются с восемью полями, как текст , заголовок , автор , журнал , том , выпуск , дата и страница , соответственно. Обратите внимание, что текстовое поле соответствует словарю, найденному в рефератах. Хотя статьи содержат дополнительные поля базы данных, например принадлежность, мы считаем, что выделенные восемь областей наиболее актуальны для нашей работы.
На рисунке 1 показан общий поток обработки запросов и прогнозирования поля в терминах трех основных модулей: синтаксического разбиения запросов, маркировки цитирования на основе правил и вероятностного прогнозирования поля.В этом разделе мы ссылаемся на пример запроса Katanaev AND Cell 2005, 120 (1): 111 — 22 , чтобы проиллюстрировать функциональность каждого модуля, демонстрируя, как сегменты запроса интерпретируются на каждом этапе.
Рисунок 1.
Конвейер обработки запросов Field Sensor. Система состоит из трех основных модулей: синтаксического разбиения запросов, тегирования цитирования на основе правил и вероятностного прогнозирования поля. Рядом с каждым модулем мы показываем, как сегменты запроса интерпретируются каждым из этих трех модулей.
Рисунок 1.
Конвейер обработки запросов Field Sensor. Система состоит из трех основных модулей: синтаксического разбиения запросов, тегирования цитирования на основе правил и вероятностного прогнозирования поля. Рядом с каждым модулем мы показываем, как сегменты запроса интерпретируются каждым из этих трех модулей.
Синтаксические фрагменты запроса
Первым шагом в процессе понимания запроса является поиск сегментов запроса, связанных логическими операторами (И, ИЛИ), круглыми скобками и скобками.Скобки и скобки устанавливают порядок работы, но пока мы обрабатываем запрос линейным образом. Сегменты запроса, помеченные пользователем, также идентифицируются на этом этапе и остаются неизменными. На рисунке 1 показан ввод и вывод запроса, когда синтаксическое разбиение на фрагменты применяется в красном поле. В этом примере запрос разделен на два сегмента, разделенных логическим И. В общей сложности 12,66% запросов выигрывают от этого модуля.
Цитирование на основе правил
Тегер цитирования на основе правил предназначен для обнаружения элементов цитирования в запросе путем интерпретации знаков препинания и цифр, которые указывают на информацию о цитировании, такую как объем, выпуск, страница и дата.Это подход, основанный на правилах, который снабжен множеством шаблонов, используемых для идентификации этих элементов цитирования. Например, модуль:
распознает, что page, pp, p — это индикаторы страниц, v или vol — индикаторы объема;
интерпретирует шаблоны, указывающие диапазон страниц, например 1860–73;
идентифицирует шаблоны, указывающие объем и информацию о выпуске, например 83 (2) или 351: 18.
Синий прямоугольник на рисунке 1 иллюстрирует выходные данные запроса, когда применяется теггер цитирования.В общей сложности 8,8% запросов выигрывают от этого модуля, и это запросы, содержащие информацию о цитировании. Большинство запросов, изменяемых этим модулем, отличаются от запросов, на которые влияет первый модуль синтаксического фрагментирования запросов, предполагающий, что синтаксическое фрагментирование запросов в основном нацелено на информационные запросы, то есть последовательности текстовых элементов, связанных логическими операторами. Из всех запросов, которые изменяются либо синтаксическим разбиением запросов, либо тегами цитирования на основе правил, только ~ 2% изменяются обоими, что указывает на то, что эти процессы дополняют друг друга.
Наш теггер цитирования на основе правил обрабатывает текстовую строку в три этапа. На первом этапе алгоритм ищет совпадающие скобки, квадратные скобки или кавычки. Если найдены совпадающие круглые скобки, строка между скобками помечается как , в скобках . Точно так же строка между квадратными скобками обозначается Tag , а строка, предшествующая тегу Tag , помечена как Tagged . Строка, заключенная между совпадающими кавычками, помечена как Quoted и не предназначена для разделения этим модулем.
Шаг второй состоит в присвоении более определенных меток токенам, которые представляют информацию о цитировании. Для этого токены рассматриваются в порядке появления и проверяются на соответствие известному набору терминов, которые являются сокращениями для месяцев (например, января , декабря ), индикаторами номеров страниц (например, p , pp ) и индикаторы количества томов (например, v , vol ). Когда такие токены распознаются и появляются в соответствующем контексте, мы маркируем их Месяц , PageIndicator или VolumeIndicator .Если токен не распознается как один из них, мы исследуем отдельные символы. Если первый символ — это цифра или второй символ — это цифра, а маркер содержит дефис, метка изменяется на Numeric . В противном случае мы проверяем, является ли строка алфавитной, и передаем ее для обработки следующему модулю.
На третьем этапе снова исследуются теги в том порядке, в котором они встречаются. Если найден токен с меткой PageIndicator , это означает, что следующий токен должен иметь метку Page .Точно так же после метки VolumeIndicator должна следовать метка Volume . Этикетка Numeric подвергается особой обработке. Если соответствующий токен представляет собой целое число от 1900 до текущего года, метка изменяется на Год . Если токен содержит «–», например 111 — 22 , имеет маркировку Page . Если маркер с меткой Numeric представляет собой целое число в диапазоне 1 – 31 и следует за маркером с меткой Месяц , метка Numeric изменяется на Day .Целое число в скобках рассматривается далее. Если он находится в диапазоне от 1900 до текущего года, он помечается как Год . В противном случае, если ему предшествует метка Numeric , он проверяется на соответствие одному из шаблонов тома и выпуска, например 83 (2) , и ему присвоен ярлык Issue . Наконец, делается попытка пометить Numeric жетонов, которые появляются рядом с жетонами, не помеченными Numeric как Volume или Issue , если эти метки еще не приняты.Кроме того, если назначены обе метки, они должны располагаться рядом и в следующем порядке: , том , за которым следует , выпуск . Здесь включены не все подробности, но выше описаны основные функции.
Вероятностное предсказание поля
Запросы, не содержащие информации о синтаксическом анализе или индикаторов полей, составляют 78,54% всех запросов. Модуль вероятностного прогнозирования поля прогнозирует поля запроса, устанавливая отношения между токенами запроса и полями в базе данных PubMed.Наш метод предполагает, что запрос имеет неявное отображение каждого термина запроса или последовательности терминов в одно из восьми полей и что распределение слов в полях базы данных обеспечивает основу для процесса вывода.
После обработки с помощью первых двух модулей прогнозирование вероятностного поля применяется к сегментам запроса, где нет другой информации синтаксического анализа. Поля, которые мы рассматриваем для расчета, — это аннотация статьи, название статьи, имя автора, название журнала, том, выпуск, страница и дата.Мы предполагаем, что запрос Q состоит из м члена Q = ( т 1, …, т м ), и мы хотим предсказать вероятность того, что член т в запрос следует интерпретировать как исходящий из поля F и в записи PubMed.
Начнем с применения теоремы Байеса. Чтобы получить оценку левой части, мы оценим каждый множитель правой части. Фактор P (t | Fi) — это вероятность наблюдения термина t в поле F i записи PubMed.Мы вычисляем P (t | Fi) для каждого из восьми полей, используя языковую модель (32) следующим образом:P (t | Fi) = freq (t∈Fi) freq (Fi).
(2)Фактор PFi — это априорная вероятность того, что поле является источником терминов. Мы получаем оценки P (Fi) из набора из 10 000 аннотированных вручную запросов PubMed, обсуждаемых в следующем разделе. В предположении, что этот список полей является исчерпывающим и взаимоисключающим, данная интерпретация запроса будет назначать только одно поле каждому термину.Это позволяет нам вычислить P (t) = ∑i = 18p (t | Fi) p (Fi) . Затем мы можем применить (1), чтобы предсказать наиболее вероятное присвоение полей терминам в запросе.
Языковая модель обычно вычисляет распределение вероятностей по последовательностям слов. Данной последовательности длиной м она присваивает вероятность Pt1,…, tm всей последовательности. Модель униграммы предполагает независимость членов и вычисляет вероятность как Punit1, t2 = Pt1Pt2. Модель языка unigram часто используется в распознавании речи, машинном переводе и тегах POS.Полезным расширением модели униграммы является модель биграмм, которая предполагает, что вероятность наблюдения члена t2 зависит от предыдущего члена, и вычисляет вероятность биграммы t1 t2 как P2-gramt1, t2 = Pt1Pt2t1.
Сначала мы вычисляем вероятности на основе модели языка униграмм, затем мы расширяем анализ до последовательностей пар слов. Мы используем модель языка биграмм, чтобы вычислить вероятность пары терминов P2-gramt1, t2 = Pt1Pt2t1, и сравнить ее значение с Punit1, t2 = Pt1Pt2. Для каждого поля, в котором найдена пара токенов, если P2-gramt1, t2> Punit1, t2 для этого поля, мы объединяем два термина t1 и t2 во фразу t1 t2, и для пары предсказывается поле с наибольшей вероятностью.Когда два термина объединяются во фразу t1 t2, процесс итеративно продолжает проверять последующие пары t2 t3, t3 t4 и t4 t5 и расширяет прогнозируемый сегмент запроса до тех пор, пока он больше не сможет быть расширен или не достигнет пяти токенов в длину ( оперативное решение). Для каждой длины сегмента записывается поле с наибольшей вероятностью. В наших языковых моделях мы не используем сглаживание, потому что мы ограничиваем наш подход поиском терминов, которые фактически появляются в базе данных, из которой получены модели.Затем мы вычисляем путь через запрос, чем-то похожий на этап декодирования в алгоритме Витерби (33). Начиная с первого токена, мы используем жадный метод, итеративно перемещая указатель в конец самого длинного прогнозируемого сегмента. Хотя это не дает оптимальных границ сегментации, это дает разумное приближение.
На рисунке 2 мы разрабатываем пример, демонстрирующий, как вычисляются вероятности для образца запроса интраоперационная эндоскопия . Прогноз, основанный на модели языка униграммы, назначает поле с наибольшей вероятностью отдельным токенам и приводит к предсказанию эндоскопия в качестве имени журнала.Однако, когда мы применяем модель языка биграмм и вычисляем вероятность интраоперационной эндоскопии , мы правильно предсказываем фразу интраоперационная эндоскопия как текстовое поле . В этом примере текст оказывается единственным полем, в котором находится эта биграмма.
Рисунок 2.
Пример вероятностных назначений полей с использованием моделей языков униграмм и биграмм.
Рисунок 2.
Пример вероятностных назначений полей с использованием моделей языков униграмм и биграмм.
Учитывая корреляцию между словами в аннотации статей и заголовками статей, определение того, намерен ли пользователь выполнить поиск по ключевым словам или запрос заголовка статьи, может иметь решающее значение для получения соответствующих результатов поиска. После стандартного прогнозирования поля датчик поля включает дополнительную проверку, чтобы убедиться, что сегмент запроса является полным заголовком или является значительной частью заголовка. Мы используем обозначение поля title , чтобы соответствовать полному заголовку или значительной части заголовка в запросе.Обозначение поля text предназначено для сегментов запроса текстового слова, представляющих интересующую тему, встречающихся либо в заголовке, либо в аннотации. Также присутствует сильная корреляция между названиями журналов и текстовыми терминами, особенно для коротких названий журналов, таких как рак , кровь и тираж . Многие названия журналов совпадают с часто встречающимися терминами и представляют собой проблему. Кроме того, расчет вероятности на основе языковой модели может отдавать предпочтение полю с меньшим объемом словаря, и journal field является примером такого.Когда термин можно интерпретировать и как текстовый термин, и как название журнала, модель с большей вероятностью предскажет его как название журнала. Мы публикуем исходные прогнозы поля для одного токена, прогнозируемого как журнал , чтобы проверить, содержит ли запрос дополнительную информацию о цитировании, такую как объем, выпуск, дата или страница и / или имя автора. В противном случае, если вероятность предсказания поля журнала ниже 0,8, мы помечаем термин как текст .
Индексация базы данных, подготовка и внедрение данных
Важным компонентом Field Sensor является этап индексации базы данных.Данные PubMed предварительно обрабатываются отдельно для каждого из восьми интересующих полей. В каждом поле мы собираем вероятности отдельных терминов для каждого члена, а также совместные и условные вероятности для пар терминов. Эти значения хранятся отдельно для каждого поля в легкодоступном формате, чтобы облегчить быстрый доступ к значениям. Важной деталью этого процесса является токенизация, которая определяет правила обработки пробелов и неалфавитно-цифровых символов при разделении текста на токены.Крайне важно, чтобы токенизация базы данных согласовывалась с токенизацией запроса для оптимального извлечения записей базы данных.
Датчик поля реализован на C ++ как общий инструмент для понимания состава медицинских и биомедицинских запросов. Текущая реализация имеет среднюю пропускную способность ∼800 запросов в секунду в одном потоке, что соответствует максимальному поисковому трафику PubMed. Датчик поля был интегрирован и развернут в PubMed, чтобы отличать информационные запросы от навигационных.Подробности использования PubMed выделены в (31).
Данные оценки
Золотой стандарт 10K запросов PubMed с ручными аннотациями
Мы используем общедоступный набор данных из 10К аннотированных вручную запросов, описанных в (18). В этом исследовании был проведен семантический анализ запросов, в котором содержание запроса было помечено одной из 16 семантических категорий: Часть тела, Компонент клетки, Ткань, Химическое вещество / лекарство, Устройство, Беспорядок, Ген / белок, Живое существо, Процедура исследования, Медицинская процедура. , Биологический процесс, Название, Имя автора, Название журнала, Цитирование и Аббревиатура .Для аннотирования набора запросов были привлечены семь аннотаторов, обладающих опытом в различных областях биомедицины и / или информатики.
Чтобы использовать эти аннотированные вручную данные для оценки датчика поля, мы немного изменим определения категорий, чтобы они соответствовали нашей настройке. Четыре семантических класса Название, Имя автора, Название журнала и Цитата используются, как определено. Остальные двенадцать категорий объединены в один класс текст , поскольку мы не намерены проводить различие между этими категориями и идентифицировать их как текстовые элементы.Обратите внимание, что категория Citation включает том, выпуск, страницу и дату, которые помечены как Citation . Следовательно, для этого набора мы оцениваем, насколько хорошо мы выделяем четыре элемента цитирования из остальных категорий, но не измеряем эффективность для каждого класса отдельно. На рисунке 3 представлен состав набора 10K с точки зрения полей. Как мы упоминали в разделе «Методы», состав набора 10K также используется для оценки фактора PFi, представляющего априорную вероятность поля в (1).Мы получаем оценки P (Fi) из этого набора для пяти полей: Текст , Заголовок, Имя автора, Название журнала, Цитата ; и поскольку категория Citation включает том, выпуск, страницу и дату, мы равномерно распределяем вероятность категории Citation между этими четырьмя полями.
Рисунок 3.
Распределение полей, вычисленных для 10K запросов, аннотированных пятью полями: Ключевое слово, Автор, Цитата, Имя журнала и Заголовок.
Рисунок 3.
Распределение полей, вычисленных для 10 000 запросов, аннотированных пятью полями: Ключевое слово, Автор, Цитата, Название журнала и Заголовок.
Серебряный стандарт запросов PubMed с машинными аннотациями 103K
Надежный способ автоматического создания высококачественного аннотированного набора запросов — это создание уникального сопоставления между запросом и документом. Здесь мы описываем набор из 103K машинных аннотированных запросов. Набор получается автоматически и не подвергался ручной аннотации, поэтому мы называем его Серебряным стандартом.Использование этого автоматизированного процесса позволяет нам надежно аннотировать произвольно большое количество запросов.
При построении этого набора мы рассматриваем, как токены запроса могут быть сопоставлены с полями записи PubMed. В этом сопоставлении мы используем следующие поля статьи PubMed: название, имена авторов, название журнала, том, выпуск, страница и дата. Тезисы не рассматриваются. При вычислении сопоставления мы оцениваем, какая часть запроса нашла совпадение с информацией в документе PubMed, и вычисляем оценку, отражающую уровень совпадения.Основываясь на этой оценке, мы вычисляем вероятность того, что ответ будет правильным. Был выполнен вероятностный анализ по большому количеству запросов, и на основе анализа была откалибрована функция оценки. Подробности этого метода в настоящее время излагаются в отдельной работе. Однако у нас есть результирующий высококачественный аннотированный набор данных, который можно использовать для оценки датчика поля.
Этот подход сопоставления был разработан, чтобы обеспечить более эффективное решение запросов с единичной цитатой.Запросы одиночного цитирования — это те навигационные запросы, которые можно сопоставить с уникальной статьей PubMed. Запросы с одиночным цитированием обычно представляют собой длинные запросы и содержат полное название и / или некоторую комбинацию названия журнала, автора и тома, выпуска, страницы и даты. Обратите внимание, что текстовое поле не представлено в этом наборе данных. Текстовый сегмент запроса может соответствовать части заголовка, однако сопоставление сегмента запроса и аннотации недоступно в этом анализе. Причина двоякая.Первая причина — эффективность: сопоставление по абстрактам с помощью этого алгоритма занимает значительно больше времени, чем сопоставление по заголовкам. Во-вторых, пользователи редко используют термины, отсутствующие в названии, при построении единственного запроса цитирования.
Для этой оценки мы обработали около 3 миллионов запросов, собранных за один день 12 октября 2016 года, и сократили его до набора из 102 971 запроса, который с очень высокой вероятностью сопоставляется с уникальным документом PubMed. Мы будем называть этот набор набором 103K Silver.При ручном просмотре 500 случайно выбранных запросов из этого набора мы обнаружили, что их синтаксический анализ имеет точность 99%.
Эксперименты и результаты
Мы оцениваем производительность датчика поля по золотому стандарту 10K запросов и серебряному стандарту 103K запросов. Два набора тестов демонстрируют взаимодополняющие свойства. Набор 10K не различает четыре элемента цитирования из тома , выпуска , страницы и даты , которые все объединены в одно поле цитирования .Набор 103K, с другой стороны, обогащен аннотациями цитирования для каждого из этих четырех, что позволяет нам оценить производительность датчика поля на этих полях. По сравнению с набором 10K набор 103K также обогащен полем title . Это объясняется тем, что это поля, которые помогают установить уникальное сопоставление между запросом и статьей PubMed. Другой аспект набора данных 103K заключается в том, что аннотации text отсутствуют, потому что абстрактное поле не было включено для сопоставления.
Результаты и анализ на наборе 10К
Золотой стандартный набор из 10K запросов, содержащий 9490 аннотированных запросов и 510 запросов, для которых не было найдено разумных аннотаций (эти запросы исключаются из рассмотрения). Мы будем называть набор 10K_GS. 9490 аннотированных запросов содержат 29 426 токенов. Некоторые сегменты запросов золотого стандарта не аннотированы, что сокращает количество аннотированных токенов до 25 195.
Для оценки производительности Field Sensor мы применили его к набору 10K.Анализ Field Sensor представлен на уровне запроса (9490 запросов) и уровне токена (на основе 25 195 аннотированных токенов). Мы называем набор прогнозируемых аннотаций 10K_FS и сравниваем их с ручными аннотациями 10K_GS. Для анализа на уровне запроса последовательность предсказанных полей является правильной, если она соответствует аннотации золотого стандарта. В противном случае, если хотя бы одно из полей не соответствует аннотации золотого стандарта, прогноз считается неверным. При анализе на уровне токенов прогнозируемое поле сравнивается с полем золотого стандарта на токеновой основе.Из 9490 полевой датчик правильно аннотировал 8798 запросов, что составляет 93,28% общей точности инструмента. В таблице 1 представлены параметры Precision, Recall и F для пяти полей, вычисленных на уровне токена и запроса.
Таблица 1.Анализ полевого датчика на основе токенов и запросов
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| . | п. . | р . | Ф . | п. . | р . | Ф . |
| Автор | 0,980 | 0,967 | 0,974 | 0,969 | 0,969 | 0,969 |
| Текст | 0.932 | 0,957 | 0,944 | 0,957 | 0,980 | 0,968 |
| Цитирование | 0,953 | 0,918 | 0,935 | 0,964 | 0,935 | 0,949 |
Журнал| 0,949 | | |||||
| Журнал 0,882 | 0,926 | 0,904 | 0,796 | 0,891 | 0,841 | |
| Название | 0.882 | 0,789 | 0,833 | 0,767 | 0,741 | 0,753 |
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| . | п. . | р . | Ф . | п. . | р . | Ф . | ||||||
| Автор | 0,980 | 0,967 | 0,974 | 0,969 | 0,969 | 0,969 | ||||||
| Текст | 0,932 | 0,957 | 0,944 | 0,957 | 0,957 | 0,944 | 0,957 | 0,957 | 0,944 | 0,957 | 0,957 | 0,968 |
| Цитирование | 0.953 | 0,918 | 0,935 | 0,964 | 0,935 | 0,949 | ||||||
| Журнал | 0,882 | 0,926 | 0,904 | 0,796 | 0,891 | 0,841 | ||||||
| Название 0,882 | 0,789 | 0,833 | 0,767 | 0,741 | 0,753 | |||||||
Анализ полевого датчика на основе токенов и запросов
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| . | п. . | р . | Ф . | п. . | р . | Ф . |
| Автор | 0.980 | 0,967 | 0,974 | 0,969 | 0,969 | 0,969 |
| Текст | 0,932 | 0,957 | 0,944 | 0,957 | 0,980 | 0,968 |
| Цитирование 0,953 | 0,918 | 0,935 | 0,964 | 0,935 | 0,949 | |
| Журнал | 0.882 | 0,926 | 0,904 | 0,796 | 0,891 | 0,841 |
| Заголовок | 0,882 | 0,789 | 0,833 | 0,767 | 0,741 | 0,753 |
| Сравнение на основе токенов . | Сравнение на основе запросов . | |||||
|---|---|---|---|---|---|---|
| . | п. . | р . | Ф . | п. . | р . | Ф . |
| Автор | 0,980 | 0,967 | 0,974 | 0,969 | 0,969 | 0,969 |
| Текст | 0.932 | 0,957 | 0,944 | 0,957 | 0,980 | 0,968 |
| Цитирование | 0,953 | 0,918 | 0,935 | 0,964 | 0,935 | 0,949 |
Журнал| 0,949 | | |||||
| Журнал 0,882 | 0,926 | 0,904 | 0,796 | 0,891 | 0,841 | |
| Название | 0.882 | 0,789 | 0,833 | 0,767 | 0,741 | 0,753 |
Орфографические ошибки
При вычислении прогнозов полей для набора из 10 КБ мы обнаружили, что 431 запрос содержал токены, не найденные в PubMed. Большинство этих ненайденных терминов представляют собой орфографические ошибки, такие как « хирургическая маска в действии t h eater » или « ростовой хрящ ». Поиск PubMed оснащен функцией автозамены, которая потенциально может помочь в этих случаях орфографии, но проверка орфографии выходит за рамки этого исследования.
Мы проанализировали распределение полей слов с ошибками, сравнив их с вручную назначенными тегами в 10K_GS. Анализ показывает, что в 60% случаев орфографическая ошибка — это текстовый элемент, в 33% — имя автора, в 4% — токен заголовка. Ошибки в названии журнала и цитировании составляют по 1,3%. Основываясь на этой статистике, датчик поля помечает маркеры с ошибками как текст . Показатели отзыва / точности и измерения F , представленные в таблице 1, вычислены на основе этого предположения.
Из 9490 запросов 692 содержат по крайней мере один неверно аннотированный токен, и в следующем разделе представлен подробный анализ обнаруженных ошибок. Анализ показал, что 187 из 692 запросов (27%) содержали орфографические ошибки, то есть токен, не найденный в PubMed. Прогноз датчика поля на жетоне с ошибкой никоим образом не демонстрирует производительность инструмента. Более того, наличие жетонов с ошибками затрудняет оценку Field Sensor. Например, если фамилия автора написана с ошибкой, инициалы автора после фамилии не будут связаны с фамилией.Или жетон заголовка с ошибкой приводит к тому, что полное название не распознается. Для анализа ошибок мы не рассматриваем 187 запросов, содержащих токены с ошибками, и внимательно изучаем оставшиеся 505 запросов, в которых ошибка возникла по какой-либо причине, кроме неправильного написания.
Подробный анализ ошибок на наборе 10K
Мы определяем четыре источника ошибок, которые составляют большинство различий, обнаруженных в запросах 505. Больше всего различий между текстовыми словами и именами авторов (32.26%), затем следуют текстовые слова и заголовки статей (24,71%), текстовые слова и названия журналов (24,15%), а также текстовые слова и цитаты (13,2%). Эти четыре класса покрывают ~ 95% ошибок, и для них мы предоставляем подробный анализ ошибок. Остальные случаи весьма незначительны и касаются всего тридцати запросов.
Различия между словами текста и именами авторов
Эти типы различий встречаются в именах авторов, которые также являются часто используемыми английскими словами. Например, sweet чаще всего интерпретируется как text , но при поиске в PubMed по фамилии sweet [автор] извлекает 3923 документа PubMed.Такие ошибки также наблюдаются при одноименных заболеваниях, таких как болезнь Альцгеймера , где фамилия используется в названии болезни. В наборе 10K для 110 запросов текстовое слово предсказывается как имя автора, а в 61 запросе имя автора предсказывается как текст. Примеры запросов в этой категории представлены на рисунке 4.
Рисунок 4.
Различие между текстовыми словами и именами авторов.
Рисунок 4.
Различие между текстовыми словами и именами авторов.
Различие слов текста и заголовков
Учитывая корреляцию между словами в аннотации статей и заголовками, определение того, намерен ли пользователь выполнить поиск по ключевым словам или запрос заголовка статьи, может иметь решающее значение для получения ожидаемых результатов поиска. Количество случаев, когда текст предсказывается как заголовок, составляет 66 запросов. Количество случаев, когда заголовок предсказывается как текст, составляет 65 запросов.
По некоторым запросам может быть не совсем понятно, выполняет ли пользователь поиск по ключевым словам или заголовку статьи. Например, поиск PubMed с запросом «, шизофрения и рассеянный склероз » возвращает 518 статей при интерпретации запроса по ключевому слову и ровно 1 результат [PMID: 3059470] при интерпретации как заголовок. Более того, изучая различия между результатами Field Sensor и ручными аннотациями, мы заметили, что аннотаторы не всегда последовательно различали поля текста и заголовка.Примеры запросов в этой категории представлены на рисунке 5.
Рисунок 5.
Различие между текстовыми словами и заголовками.
Рисунок 5.
Различия между текстовыми словами и заголовками.
Различие слов текста и названия журнала
Также присутствует сильная корреляция между названиями журналов и текстовыми словами, особенно для однозначных названий журналов, таких как рак, диабет, кровообращение, кровь, лекарства и т. Д.Многие названия журналов совпадают с частыми текстовыми словами и представляют собой проблему. Количество запросов, в которых текстовое слово предсказывается как заголовок журнала / часть заголовка журнала, составляет 86 запросов, а количество запросов, в которых заголовок журнала предсказывается как текст, составляет 37.
Отличительные текстовые слова и информация о цитировании
Число случаев, когда текстовое слово предсказывается как цитата, равно 24, а количество случаев, когда элемент цитирования предсказывается как текстовое слово, равно 46.Эта ошибка может возникать с числами, которые законно являются частью текста, но интерпретируются как элемент цитирования. Например, в запросе QUERY = KLN 47 мы прогнозируем, что 47 будет элементом цитирования. Еще одним источником различий в этой группе являются запросы, содержащие такие термины, как review , где термин интерпретируется как информация о цитировании в 10K_GS, а мы интерпретируем его как текст. Другой пример в этой группе — QUERY = учебник педиатрии и Nelson .Учебник мы интерпретируем как текстовый элемент, а в 10K_GS он интерпретируется как цитируемая информация.
Результаты и анализ для набора 103K
Набор данных 103K Silver Standard содержит 102 971 запрос, а общее количество аннотированных терминов в наборе составляет 828 078. На рисунке 6 показано распределение полей в этом наборе данных. Эти навигационные запросы сильно обогащены заголовками статей, которые полностью или частично появляются в более чем 91% запросов. Имена авторов присутствуют в 25.5% запросов, за которыми следует дата в 10,23% запросов и название журнала в 9,17% запросов. Даже в запросах на цитирование объем, проблема и страница все еще незначительны.
Рисунок 6.
Распределение полей, вычисленных для 103K запросов, аннотированных семью полями цитирования: заголовок, имя автора, дата, страница, том, выпуск и имя журнала.
Рисунок 6.
Распределение полей, вычисленных для 103K запросов, аннотированных семью полями цитирования: заголовок, имя автора, дата, страница, том, выпуск и имя журнала.
Из 102 971 запроса датчик поля полностью соответствует аннотациям стандарта Silver по 93 716 запросам, что составляет 91,01% общей точности инструмента. Что касается токенов, то для 98,23% токенов (813 404) мы согласны с аннотацией Silver Standard и не согласны с оставшимися 1,77%.
Далее мы вычисляем Precision, Recall и F -score на уровне токена и запроса для каждого из семи полей. Вычисление уровня токена оценивает долю правильно идентифицированных токенов в поле.Вычисление уровня запроса оценивает долю запросов с правильно идентифицированными диапазонами полей. В таблице 2 представлена точность. Напомним, и F — мера для семи полей, вычисленных на уровне токена и запроса.
Таблица 2.Анализ на основе токенов и запросов датчика поля в наборе 103K
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | |||||
|---|---|---|---|---|---|---|---|
| п. . | р . | Ф . | п. . | р . | Ф . | ||
| Название | 0,990 | 0,993 | 0,991 | 0,986 | 0,987 | 0,986 | |
| Автор | 0.972 | 0,940 | 0,956 | 0,987 | 0,942 | 0,964 | |
| Дата | 0,910 | 0,955 | 0,932 | 0,978 | 0,955 | 0,967 | |
| Страница | 0,9690,898 | 0,932 | 0,980 | 0,902 | 0,939 | ||
| Объем | 0.928 | 0,838 | 0,881 | 0,947 | 0,841 | 0,891 | |
| Выпуск | 0,983 | 0,686 | 0,808 | 0,994 | 0,685 | 0,811 | |
| Журнал | 0,742 | 0,725 | 0,733 | 0,821 | 0,637 | 0,717 | |
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| п. . | р . | Ф . | п. . | р . | Ф . | |
| Название | 0.990 | 0,993 | 0,991 | 0,986 | 0,987 | 0,986 |
| Автор | 0,972 | 0,940 | 0,956 | 0,987 | 0,942 | 0,964 |
| Дата 0,910 | 0,955 | 0,932 | 0,978 | 0,955 | 0,967 | |
| Страница | 0.969 | 0,898 | 0,932 | 0,980 | 0,902 | 0,939 |
| Объем | 0,928 | 0,838 | 0,881 | 0,947 | 0,841 | 0,891 |
| Выпуск 0,983 | 0,686 | 0,808 | 0,994 | 0,685 | 0,811 | |
| Журнал | 0.742 | 0,725 | 0,733 | 0,821 | 0,637 | 0,717 |
Анализ полевого датчика на основе маркеров и запросов на основе набора 103K
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | |||||
|---|---|---|---|---|---|---|---|
| п. . | р . | Ф . | п. . | р . | Ф . | ||
| Название | 0,990 | 0,993 | 0,991 | 0,986 | 0,987 | 0,986 | |
| Автор | 0,972 | 0,940 | 0,956 | 0.987 | 0,942 | 0,964 | |
| Дата | 0,910 | 0,955 | 0,932 | 0,978 | 0,955 | 0,967 | |
| Стр. 0,980 | 0,902 | 0,939 | |||||
| Объем | 0,928 | 0,838 | 0,881 | 0.947 | 0,841 | 0,891 | |
| Выпуск | 0,983 | 0,686 | 0,808 | 0,994 | 0,685 | 0,811 | |
| Журнал | 0,742 | 0,725 | 0,742 | 0,725 | 0,821 | 0,637 | 0,717 |
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| п. . | р . | Ф . | п. . | р . | Ф . | |
| Название | 0,990 | 0,993 | 0,991 | 0.986 | 0,987 | 0,986 |
| Автор | 0,972 | 0,940 | 0,956 | 0,987 | 0,942 | 0,964 |
| Дата | 0,910 | 0,955 | 0,9 0,978 | 0,955 | 0,967 | |
| Страница | 0,969 | 0,898 | 0,932 | 0.980 | 0,902 | 0,939 |
| Объем | 0,928 | 0,838 | 0,881 | 0,947 | 0,841 | 0,891 |
| Выпуск | 0,983 | 0,686 | 0,80 0,994 | 0,685 | 0,811 | |
| Журнал | 0,742 | 0,725 | 0,733 | 0.821 | 0,637 | 0,717 |
Для трех наиболее часто встречающихся полей в наборе данных 103K (Заголовок, Имена авторов и Дата) производительность Field Sensor весьма впечатляющая. В настоящее время наши усилия направлены на улучшение распознавания названий журналов, однако, поскольку названия журналов встречаются в 9,19% запросов в этом наборе с большим количеством цитирований, общее влияние этого поля невелико.
Утилита датчика поля: прогнозирование цели запроса и состав запроса
Журналы PubMed регистрируют взаимодействия пользователей с PubMed, такие как поиск, извлечение и переход по ссылкам.В этом разделе мы демонстрируем применение датчика поля в журналах запросов PubMed. Мы прогнозируем намерение запроса, исследуем состав и длину запросов PubMed и выделяем шаблоны поиска информации о цитировании в качестве примеров использования Field Sensor. Анализ выполняется в случайный день запросов PubMed, зарегистрированных в системе в среду, 12 октября 2016 года, который содержит 3 054 498 анонимных запросов.
Используя датчик поля, мы можем предсказать намерение запроса с высокой точностью и скоростью веб-масштаба (обработка около 800 запросов в секунду в одном потоке).Обработка в веб-масштабе позволяет применять датчик поля к произвольно большому набору запросов и классифицировать их как информационные или навигационные на основе прогнозов датчика поля. Применительно к 1 дню запросов мы прогнозируем, что 47,68% запросов будут информационными, а 52,31% — навигационными. Для справки, точность, достигнутая в наборе данных 10K, составляет 95,24% в этой задаче двоичной классификации, где прогнозируется, что 53,08% запросов будут информационными, а 46,91% — навигационными. Разделение по золотому стандарту — 53.69% информационных и 46.31% навигационных. Обратите внимание, что производительность нашего метода в задаче двоичной классификации выше, чем в задаче прогнозирования всех восьми полей.
Возможность различать информационные и навигационные запросы позволяет нам лучше понять, как пользователи запрашивают PubMed. Например, мы наблюдали заметный рост размера запроса по сравнению со средним размером запроса 3,54 и средней длиной 3, о которых сообщалось в более ранних исследованиях 2009 г. (18, 19). По данным на 12 октября 2016 года, среднее количество токенов на запрос составляет 5.18, а медиана — 3. Для вычисления этих средних значений мы токенизировали запросы, определяя токены как последовательности символов, разделенных пробелами, и исключили из анализа зашумленные запросы, содержащие более 100 токенов. Чтобы понять причины увеличения длины, мы вычисляем среднюю длину запроса за шесть моментов времени. Эти точки представляют собой 1 день журналов PubMed, собранных в один и тот же день 20 января в течение шести последовательных лет с 2012 по 2017 год. Как показано на рисунке 7, мы наблюдаем, что информационные запросы в среднем остаются примерно того же размера, однако длина и доля навигационных запросов соответствуют растущей тенденции.Средний размер навигационных запросов увеличился с 5,3 в 2012 году до 7,0 в 2017 году. По сравнению с набором 10 КБ, доля навигационных запросов также увеличилась. Это может отражать то, что поисковые системы становятся лучше при синтаксическом анализе длинных запросов, и пользователям становится комфортно копировать заголовок статьи или всю цитату.
Рисунок 7.
Средняя длина запроса, вычисленная по журналам запросов, собранным 20 января за шесть лет подряд в период с 2012 по 2017 год.
Рисунок 7.
Средняя длина запроса, вычисленная по журналам запросов, собранным 20 января в течение шести последовательных лет в период с 2012 по 2017 год.
Доступность прогнозируемых полевых данных позволяет нам лучше понять сложность процесса поиска информации пользователей, ищущих информацию о цитировании. Мы анализируем поля запроса, чтобы выявить наиболее частые способы доступа к информации о цитировании. Анализ полей проводится по навигационным запросам с 12 октября 2016 года.Чтобы получить шаблоны, мы группируем последовательности токенов из одного поля в одну сущность. Например, запросы, состоящие из двух авторов author1, author2, будут считаться запросом автора. На рисунке 8 представлены 13 наиболее частых шаблонов, на которые приходится> 80% навигационных запросов. Около 28% навигационных запросов — это запросы имени автора. Это запросы, состоящие из одного или нескольких имен авторов. Следующей по величине категорией являются запросы заголовков, которые составляют около 24% всех навигационных запросов, а вместе с запросами авторов составляют более половины всех навигационных запросов.Другие популярные шаблоны поиска — это имя автора, за которым следует текст, и текст, за которым следует имя автора. Эти две категории вместе составляют около 12,5% навигационных запросов. Запросы, состоящие только из PMID, также оказываются популярным способом доступа к статье и вносят 4,5% в навигационный поиск. Обилие запросов с длинными заголовками, средняя длина которых составляет 11,57 токенов, объясняет длину навигационных запросов. На рисунке 8 представлено распределение размеров запросов в каждой из обозначенных категорий.
Рисунок 8.
13 наиболее частых шаблонов доступа к информации о цитировании в PubMed, на которые приходится> 80% навигационных запросов. Процент запросов в каждом шаблоне отражается на гистограмме относительно основной оси Y , а средняя длина запросов в этом шаблоне отражается на диаграмме рассеяния, измеренной относительно вторичной оси Y .
Рисунок 8.
13 наиболее частых шаблонов доступа к информации о цитировании в PubMed, на которые приходится> 80% навигационных запросов.Процент запросов в каждом шаблоне отражается на гистограмме относительно основной оси Y , а средняя длина запросов в этом шаблоне отражается на диаграмме рассеяния, измеренной относительно вторичной оси Y .
Выводы и обсуждение
Здесь мы представляем Field Sensor, новый вероятностный инструмент для вычисления композиции запроса и прогнозирования цели запроса. Инструмент помечает каждый сегмент запроса полем записи PubMed (текст, заголовок, автор, журнал, том, выпуск, страница и дата).Мы оцениваем инструмент на аннотированном вручную наборе данных из 10К запросов, а также на машинном аннотированном наборе данных из 103К запросов и демонстрируем его превосходную производительность. Программное обеспечение обеспечивает скорость производственного уровня для PubMed.
Основная функция датчика поля — определить цель запроса. Как часть поисковой системы PubMed, он используется для обнаружения информационных запросов и направления пользователя к результатам поиска с ранжированием по релевантности. Применительно к случайному дню запросов PubMed, Field Sensor предсказывает, что 48% будут информационными, а 52% — навигационными.Насколько нам известно, датчик поля — это первый инструмент веб-масштабирования для определения намерений и вычисления состава биомедицинских запросов. Кроме того, полевые прогнозы позволяют нам в широком масштабе изучать, как биомедицинская информация ищется в PubMed. Базовая модель Field Sensor обучается на данных Medline, а Field Sensor может быть адаптирован к запросам в другом домене путем переобучения на соответствующих данных домена.
В будущем мы планируем изучить альтернативный метод вычисления вероятностей.В текущих настройках вероятностное предсказание поля основано на языковой модели, где вероятность термина в поле вычисляется как частота термина в поле, деленная на размер поля по всей базе данных, как измеряется числа терминов. Другой правдоподобный подход к вычислению вероятности — вычислить вероятность термина как отношение количества документов, в которых встречается этот термин, и размера коллекции PubMed (около 27 миллионов документов). Мы считаем, что это может нейтрализовать некоторые проблемы, которые мы наблюдаем с названиями журналов, но может привести к другим ошибкам.В будущем мы также планируем уделять больше внимания ошибкам в написании токенов. Они представляют собой источник ошибок не только потому, что маркер с ошибкой не помечен точно, но и потому, что он мешает анализу оставшейся части запроса. Хотя обработка орфографических ошибок как текста была разумной, первым логическим шагом для улучшения обработки этих запросов было бы исправление орфографии. Мы планируем включить проверку орфографии в следующее поколение Field Sensor.
Благодарности
Это исследование было поддержано Программой внутренних исследований Национальной медицинской библиотеки NIH.
Конфликт интересов . Ничего не объявлено.
Список литературы
1Falagas
M.
,Pitsouni
E.
,Malietzis
G.
et al. (2008
)Сравнение PubMed, Scopus, Web of Science и Google Scholar: сильные и слабые стороны
.FASEB J
.,22
,338
—342
,2Lu
Z.
(2011
)PubMed и не только: обзор веб-инструментов для поиска биомедицинской литературы
.База данных
,2011
,baq036
.3Wildgaard
L.E.
,Лунд
H.
(2016
)Продвижение PubMed? Сравнение сторонних инструментов PubMed / MEDLINE
.Библиотека Hi Tech
,34
,669
—684
.4Ашкан
A.
,Clarke
C.L.
,Agichtein
E.
et al. (2009
) Классификация и характеристика цели запроса.In : Материалы 31-й Европейской конференции по исследованиям в области IR по достижениям в области информационного поиска .5Broder
A.
(2002
) Таксономия веб-поиска. В : Труды ACM SIGIR. 6Янсен
B.J.
,Стенд
D.L.
,Spink
A.
Определение намерения пользователя при запросах поисковых систем. In: WWW 2007. 7Mendoza
M.
,Zamora
J.
(2009
) Определение цели пользовательского запроса с использованием машин векторов поддержки. In: Proceedings of 16th International Symposium on String Processing and Information Retrieval, 2009. Springer-Verlag Berlin, Heidelberg, Saariselkä, Finland, pp. 131–142.8Figueroa
A.
,Atkinson
J.
(2016
)Классификаторы ансамбля для определения намерений пользователей, стоящих за веб-запросами
.IEEE Internet Comput
.,20
.9Hashemi
H.B.
,Asiaee
A.
,Kraft
R.
(2016
) Обнаружение намерения запроса с использованием сверточных нейронных сетей. In : Международная конференция по веб-поиску и интеллектуальному анализу данных, семинар по пониманию запросов, 2016 .10Hu
J.
,Wang
G.
,Lochovsky
F.
et al.(2009
) Понимание намерений пользователя с помощью Википедии. В: Труды 18-й Международной конференции по всемирной паутине, 2009 г. . ACM New York, New York, NY, USA, Madrid, Spain.11Ren
X.
,Wang
Y.
,Yu
X.
et al. (2014
) Гетерогенное изучение намерений на основе графов с помощью запросов, веб-страниц и концепций википедии. В: Труды 7-й Международной конференции ACM по веб-поиску и интеллектуальному анализу данных (WSDM’14) .ACM New York, New York, NY, USA, стр. 23–32.12Kale
A.
,Taula
T.
,Hewavitharana
S.
et al. (2017
)На пути к семантической сегментации запросов. В: Семинар SIGIR 2017 по поиску нейронной информации (Neu-IR’17)
,Tokyo
,Japan
,13Kim
J.
,Xue
X.
,Croft
W.B.
(2009
) Вероятностная модель поиска для полуструктурированных данных.In: European Conference on Information Retrieval .14Nikolaev
F.
,Kotov
A.
,Zhiltsov
N.
(2016
) Параметризованные полевые модели временной зависимости для ad-hoc извлечение сущности из графа знаний. В: Труды 39-й Международной конференции ACM SIGIR по исследованиям и разработкам в области информационного поиска . ACM New York, New York, NY, USA, Pisa, Italy, стр.435
—444
.15Sarkas
N.
,Paparizos
S.
,Tsaparas
P.
(2010
) Структурированная аннотация веб-запросов. ACM SIGMOD Международная конференция по управлению данными (SIGMOD’10) . ACM New York, New York, NY, USA, Indianapolis, IN, USA.16Radlinski
F.
,Szummer
M.
,Craswell
N.
Определение цели запроса на основе переформулировок и щелчков. WWW 2010 . 17Pitler
E.
,Church
K.
(2009
) Использование словесных методов устранения неоднозначности для классификации веб-запросов по намерениям. В: 2009 Conference on Empirical Methods in Natural Language Processing , pp. 1428–1436.18Islamaj Dogan
R.
,Murray
C.
,Névéol
A.
et al. (2009
)Понимание поведения пользователей PubMed при поиске посредством анализа журналов
.База данных
,2009
,bap018
.19Herskovic
J.
,Tanaka
L.Y.
,Hersh
W.
et al. (2007
)Один день из жизни PubMed: анализ обычного дневного журнала запросов
.J. Am. Med. Поставить в известность. Assoc
.,14
,212
—220
.20Wilbur
W.J.
,Kim
W.
,Xie
N.
(2006
)Исправление орфографии в поисковой системе PubMed
.Инф. Retr
.,9
,543
—564
.21Hersh
W.
,Voorhees
E.
(2009
)Обзор специального выпуска TREC genomics
.Инф. Retr
.,12
,1
—15
.22Bampoulidis
A.
,Lupu
M.
,Palotti
J.
et al. (2016
) Интерактивное изучение медицинских запросов. В: 14-й Международный семинар по индексированию мультимедиа на основе контента (CBMI) . IEEE, Бухарест, Румыния.23Цикрика
T.
,Muller
H.
,Kahn
C.E.J.
(2012
) Анализ журнала для понимания поведения медицинских работников при поиске изображений. В: Труды 24-й Европейской конференции по медицинской информатике (MIE2012) .Европейская федерация медицинской информатики и IOS Press, Пиза, Италия, стр. 1020–1024.24Белый
R.
,Horvitz
E.
(2014
)От поиска здоровья к здравоохранению: исследования намерений и использование через журналы запросов и опросы пользователей
.J. Am. Med. Инф. Assoc
.,21
,49
—55
.25Zhang
Y.
(2014
)Поиск конкретной информации о здоровье в MedlinePlus: модели поведения и пользовательский опыт
.J. Assoc. Инф. Sci. Technol
.,65
,53
—68
.26Ogilvie
P.
,Callan
J.
Объединение представлений документов для поиска известных предметов. В: СИГИР 2003 . 27Bernstam
E.
,Herskovic
J.
,Hersh
W.
(2009
) Справочник по исследованиям в области анализа веб-журналов 28Hersh W.
(2009
) Поиск информации: здоровье и биомедицина.29Li
X.
,Schijvenaars
B.J.A.
,De Rijke
M.
(2017
)Расследование запросов и ошибок поиска в академическом поиске
.Инф. Процесс. Manag
.,53
,666
—683
.30Khabsa
M.
,Wu
Z.
,Giles
C.L.
(2016
) На пути к лучшему пониманию академического поиска. В: JCDL 2016, 16-я совместная конференция ACM / IEEE-CS по электронным библиотекам . ACM, Ньюарк, Нью-Джерси, США 31Fiorini
N.
,Lipman
D.J.
,Lu
Z.
(2017
)Передний край: на пути к PubMed 2.0
.eLife
,6
:e28801
.32Укомплектование персоналом
C.
,Raghavan
P.
,Schütze
H.
(2009
)Введение в поиск информации
.Cambridge University Press
.33Viterbi
A.J.
(1967
)Границы ошибок для сверточных кодов и асимптотически оптимальный алгоритм декодирования
.IEEE Trans. Инф. Теория
,13
,260
—269
.Заметки автора
Опубликовано Oxford University Press, 2018 г.Эта работа написана служащими правительства США и находится в открытом доступе в США.
Как план администрации Трампа повлияет на состав иммиграции: первые численные оценки
Поскольку администрация США настаивает на самом широком пересмотре иммиграционного законодательства с 1965 года, с самым значительным сокращением легальной иммиграции с 1924 года в предложенном документе «Обеспечение будущего Америки» Действуйте », новый анализ CGD впервые дает количественную оценку того, как предлагаемые сокращения повлияют на этнического, религиозного и образовательного состава иммиграционных потоков.
Находим:
- У латиноамериканцев и чернокожих иммигрантов будет примерно в два раза больше шансов попасть под сокращение иммиграции, чем у белых иммигрантов;
- Сокращения не позволят большинству иммигрантов-мусульман и католиков; а также
- Сокращения существенно сократят количество иммигрантов с высшим образованием. Расширенные рабочие визы добавили бы только одного выпускника университета на каждые семь удаленных низкоквалифицированных рабочих за счет отмены семейных виз и Diversity Visa.
Ниже мы предоставляем инструмент, который может использовать каждый, чтобы приблизительно оценить этнические последствия предложения по иммиграционной реформе США.
Этнические воздействия
Здесь мы даем первые количественные оценки того, как последнее предложение по иммиграционной реформе повлияет на этнический состав иммиграционных потоков США. Мы анализируем «Закон об обеспечении будущего Америки» (H.R. 4760), представленный в Конгрессе ранее в этом месяце и полностью соответствующий приоритетам иммиграционной политики администрации.По нашим оценкам, этот закон вызовет следующие изменения в этническом составе новых иммиграционных потоков:
То есть, в годовом потоке иммигрантов после такой реформы по сравнению с до реформы количество неиспаноязычных белых сократилось бы примерно на 34,6 процента. Количество нелатиноамериканских чернокожих упадет на 63,9 процента, а количество выходцев из Латинской Америки любой расы — на 58,2 процента. Другими словами, сравнивая иммиграционный поток с реформой и без нее, вероятность того, что реформа воспрепятствует тому или иному чернокожему или латиноамериканскому иммигранту, примерно вдвое выше для белого иммигранта.Это прямое следствие высокой представленности этих групп в категориях виз, которые будут сокращены или исключены в результате реформы: визы для воссоединения семей для латиноамериканских иммигрантов и визы для разногласий или визы беженцев для чернокожих иммигрантов, особенно чернокожих иммигрантов из Африки.
Как мы получили эти результаты : Начнем с иммиграционных потоков по каждому классу виз в предлагаемых визовых квотах в Законе и фактических иммиграционных потоков каждого типа за последний год, по которому имеются статистические данные (2016).Затем мы оцениваем этнический состав получателей виз с помощью единственно доступных оценок этнического состава новых иммигрантов в каждой категории виз. Они взяты из уникального обзора репрезентативной выборки всех иммигрантов в США за типичный недавний год: когорта новых иммигрантов из США за 2003 год, составленный Гильерминой Яссо и дополненный нашим собственным анализом базовых данных Обзора новых иммигрантов. (Ни одна другая когорта не опрашивалась подобным образом.) Мы опускаем относительно небольшое количество людей, сообщающих о нескольких расах, мы опускаем людей, которые сообщают о своей расе как американские индейцы, и мы опускаем несколько очень маленьких категорий виз (EB- 4/5).Результаты являются оценочными, а не точными прогнозами, поскольку они основаны на этническом составе одной прошлой когорты иммигрантов.
Наряду с приведенными выше результатами мы предлагаем инструмент, который может использовать каждый, чтобы понять и скорректировать эти оценки для себя. Расчеты в электронной таблице для всех цифр в этом посте доступны здесь. Таблицу можно использовать в качестве инструмента для оценки этнических последствий любого предложения по иммиграционной реформе, просто заполнив пересмотренные визовые квоты в этом предложении.Мы также публикуем его, чтобы показать предположения и источники данных, лежащие в основе цифр. Код Stata для получения некоторых этнических долей в этой таблице с использованием необработанных данных опроса новых иммигрантов находится здесь.
Религиозные воздействия
Мы используем тот же метод для оценки воздействия предложений администрации по реформе на этнический состав иммиграции:
То есть, в годовом потоке иммигрантов после такой реформы по сравнению с дореформенным число мусульман сократилось бы примерно на 53.2 процента, а число католиков уменьшится примерно на 53,8 процента. Другими словами, реформа устранит большинство мусульман и католиков из потока новых иммигрантов в США. Это прямое следствие того факта, что эти группы непропорционально представлены получателями виз, число которых будет сокращено или исключено в результате реформы: мусульмане — среди разнопрофильных виз и виз беженцев, а католики — среди виз для воссоединения семей.
Воздействие на образование
Администрация заявила, что экономика США нуждается в более квалифицированной иммиграции.Таким же образом мы можем проанализировать влияние предложений по реформе на уровень образования иммигрантов из США:
То есть, в годовом потоке иммигрантов после такой реформы по сравнению с дореформенным, количество иммигрантов с университетским дипломом или ученой степенью на упало бы на примерно на 17,6 процента. Спад для других образовательных групп был бы больше. Предложение об отмене нескольких категорий виз для воссоединения семей приведет к отстранению около 267000 рабочих с уровнем образования ниже среднего от годового иммиграционного потока, в то время как предложение о расширении виз на основе трудоустройства для высококвалифицированных рабочих добавит около 38000 рабочих с университетом или более к ежегодному притоку иммиграции.Другими словами, расширенные рабочие визы добавят только одного выпускника университета на каждые семь низкоквалифицированных рабочих, уволенных из-за отмены семейных виз и виз для разногласий. Таким образом, это предложение мало повлияет на иммиграцию в сторону повышения квалификации, но значительно снизит иммиграцию в целом.
Уменьшение числа иммигрантов с университетским образованием является следствием того факта, что, хотя администрация предлагает поднять квоты на получение виз для трудоустройства, требующих университетского образования, она также сокращает другие категории виз, которые включают большое количество выпускников университетов.Например, около 41 процента иммигрантов, участвовавших в опросе новых иммигрантов, получивших вид на жительство по программе Diversity Visa, имеют высшее или более высокое образование, и реформы направлены на отмену этой визы.
Эти оценки являются предварительными и приблизительными, поскольку основываются на предположениях. Мы считаем предположения разумными для этой цели, но они, безусловно, спорны. Дальнейший анализ может и должен улучшить их. Во-первых, базовый уровень иммиграции для каждой категории визы — это фактический уровень иммиграции на 2016 финансовый год.Это предположение будет менее разумным, поскольку анализ распространяется дальше в будущее. Второе предположение состоит в том, что состав иммигрантов из когорты, изучаемой New Immigrant Survey, в ближайшем будущем будет аналогичным для когорт. Мы считаем это разумным для расы и религии; Что касается образования, очевидно, что уровень образования среди категорий сокращенных виз сегодня выше, чем для иммигрантов в Обследовании новых иммигрантов, как показал Дэвид Бир, что подразумевает, что снижение квалификации среди иммигрантов будет даже больше, чем предполагалось выше.Третье предположение заключается в том, что несовершеннолетние дети в категориях виз F2A и F4 имеют такое же распределение характеристик, как и взрослые, которые получают эти визы. (Исследование новых иммигрантов не сообщает о расе или религии для репрезентативной выборки несовершеннолетних детей, получающих эти визы, и, очевидно, не может указать уровень образования несовершеннолетних детей.)
Мы считаем разумным предположить, что расовый и религиозный состав несовершеннолетних детей, спонсируемых по этим визам, аналогичен составу взрослых детей и других взрослых, спонсируемых по этим визам, но мы не можем проверить точность этого предположения.Что касается результатов образования, это предположение, как правило, создает небольшую предвзятость, поскольку конечный образовательный уровень людей, иммигрирующих в раннем детстве, почти наверняка будет выше, чем образовательный уровень взрослых, иммигрирующих по этой визе — в категориях виз, где образование взрослых является очень низкий. Но такая предвзятость несущественна для выводов анализа, потому что это означало бы, что влияние иммиграционной реформы на типичный уровень образования в потоке иммигрантов будет даже менее положительным, чем описано выше.Например, в категории визы F2A в 2016 финансовом году насчитывается 62 644 несовершеннолетних ребенка, а в категории F4 — 27 073 несовершеннолетних ребенка. Средний уровень образования взрослых в категории F2A составляет 8 лет. Вышеупомянутый анализ рассматривает удаление детей из притока F2A так, как если бы несовершеннолетние дети тоже имели 8-летнее образование, и удаление таких малообразованных иммигрантов из притока существенно повысило бы средний уровень образования среди иммигрантов. Но если их конечный уровень образования будет в среднем выше 8 лет в Соединенных Штатах, что почти наверняка, исключение их из притока иммигрантов повысит средний уровень образования среди иммигрантов на минус , чем показано выше.Короче говоря, выводы анализа вряд ли будут существенно чувствительны к этим предположениям.
Мы призываем политиков, журналистов и всех, кто заинтересован в оценке последствий других предложений по иммиграционной реформе в будущем, использовать созданный нами инструмент.
Этот пост был обновлен 6 февраля и включает подробное обсуждение предположений, лежащих в основе анализа, в ответ на вопросы читателей (спасибо!) И исправление ошибок в тексте, описывающем охват населения и влияние на образование.
Что такое bind | F # для удовольствия и прибыли
Это второй пост в серии. В предыдущем посте я описал некоторые основные функции для поднятие ценности из нормального мира в возвышенный мир.
В этом посте мы рассмотрим функции «пересечения мира» и то, как их можно приручить с помощью функции bind .
Вот список ярлыков для различных функций, упомянутых в этой серии:
- Часть 1: Подъем в возвышенный мир
- Часть 2: Как составить функции пересечения мира
- Часть 3: Практическое использование основных функций
- Часть 4: Смешанные списки и повышенные значения
- Часть 5: Реальный пример, использующий все методы
- Часть 6: Создание собственного возвышенного мира
- Часть 7: Резюме
Часть 2: Как составить функции пересечения мира
Общие имена : привязать , flatMap , и затем , собрать , SelectMany
Общие операторы : >> = (слева направо), = << (справа налево)
Что он делает : Позволяет составлять функции пересечения мира («монадические»)
Подпись : (a-> E ) -> E -> E .В качестве альтернативы с измененными параметрами: E -> (a-> E ) -> E
Нам часто приходится иметь дело с функциями, которые пересекаются между нормальным миром и возвышенным миром.
Например: функция, которая анализирует строку в int , может возвращать Option вместо обычного int ,
функция, которая читает строки из файла, может вернуть IEnumerable ,
функция, которая выбирает веб-страницу, может вернуть Async и так далее.
Эти виды функций «пересечения мира» можно распознать по их сигнатуре a -> E ; их вход находится в нормальном мире, но их выход находится в возвышенном мире.
К сожалению, это означает, что функции такого типа нельзя связать вместе с помощью стандартной композиции.
«bind» преобразует функцию пересечения мира (обычно известную как «монадическая функция») в приподнятую функцию E -> E .
Преимущество этого заключается в том, что полученные в результате повышенные функции живут исключительно в мире возвышенных, и поэтому их можно легко комбинировать с помощью композиции.
Например, функция типа a -> E не может быть напрямую скомпонована с функцией типа b -> E , но после использования bind вторая функция
становится типа E -> E , из которого может быть составлен из .
Таким образом, bind позволяет связать вместе любое количество монадических функций.
Альтернативная интерпретация
Альтернативная интерпретация bind заключается в том, что это функция с двумя параметрами , которая принимает повышенное значение ( E ) и «монадическую функцию» ( a -> E ),
и возвращает новое повышенное значение ( E), сгенерированное «разворачиванием» значения внутри ввода и запуском для него функции a -> E.Конечно, метафора «разворачивания» работает не для каждого возвышенного мира, но все же часто бывает полезно думать об этом таким образом.
Вот несколько примеров определения bind для двух разных типов в F #:
Опция =
// Функция привязки для параметров
позвольте привязать f xOpt =
сопоставить xOpt с
| Некоторые x -> f x
| _ -> Нет
// имеет тип: ('a ->' b option) -> 'a option ->' b option
список модулей =
// Функция привязки для списков
пусть bindList (f: 'a ->' b список) (xList: 'список) =
[для x в xList выполните
для y в f x do
yield y]
// имеет тип: ('a ->' b list) -> 'a list ->' b list
Примечания:
- Конечно, в этих двух частных случаях функции уже существуют в F # под названием
Option.привязатьиList.collect. - Для
List.bindЯ снова обманываю и используюдля..в..до, но я думаю, что эта конкретная реализация ясно показывает, как привязка работает со списками. Есть более чистая рекурсивная реализация, но я не буду ее здесь показывать.
Как объяснялось в начале этого раздела, привязка может использоваться для создания межмирных функций.
Давайте посмотрим, как это работает на практике, на простом примере.
Сначала предположим, что у нас есть функция, которая анализирует определенную строку s в int s.Вот очень простая реализация:
пусть parseInt str =
сопоставить str с
| «-1» -> Некоторые -1
| "0" -> Некоторые 0
| «1» -> Некоторые 1
| "2" -> Некоторые 2
// так далее
| _ -> Нет
// подпись - строка -> параметр int
Иногда возвращает int, иногда нет. Итак, подпись - это строка -> int option - кросс-мировая функция.
Допустим, у нас есть другая функция, которая принимает int в качестве входных данных и возвращает тип OrderQty :
тип OrderQty = OrderQty int
пусть toOrderQty qty =
если qty> = 1, то
Некоторые (OrderQty кол-во)
еще
// разрешены только положительные числа
Никто
// подпись int -> опция OrderQty
Опять же, он может не вернуть OrderQty , если вход не положительный.Таким образом, подпись - int -> OrderQty option - еще одна межмирная функция.
Теперь, как мы можем создать функцию, которая начинается со строки и возвращает OrderQty за один шаг?
Вывод parseInt не может быть передан непосредственно в toOrderQty , поэтому здесь на помощь приходит bind !
Выполнение Option.bind toOrderQty поднимает его до функции int option -> OrderQty option , и поэтому вывод parseInt может использоваться как ввод, как и нам нужно.
пусть parseOrderQty str =
parseInt str
|> Option.bind toOrderQty
// подпись - строка -> опция OrderQty
Сигнатура нашего нового parseOrderQty - это строка -> параметр OrderQty , еще одна функция для разных стран. Итак, если мы хотим что-то сделать с выводимым OrderQty Возможно, нам придется снова использовать bind для следующей функции в цепочке.
Как и в случае с apply , использование именованной функции bind может быть неудобным, поэтому обычно создают инфиксную версию,
обычно называется >> = (для потока данных слева направо) или = << (для потока данных справа налево).
С его помощью вы можете написать альтернативную версию parseOrderQty следующим образом:
пусть parseOrderQty_alt str =
str |> parseInt >> = toOrderQty
Вы можете видеть, что >> = выполняет ту же роль, что и конвейер ( |> ), за исключением того, что он работает для передачи «повышенных» значений в функции перекрестного мира.
Привязать как «программируемую точку с запятой»
Bind можно использовать для объединения в цепочку любого количества функций или выражений, поэтому вы часто видите код, выглядящий примерно так:
выражение1 >> =
выражение2 >> =
выражение3 >> =
выражение4
Это не слишком отличается от того, как может выглядеть императивная программа, если вы замените >> = на ; :
statement1;
оператор2;
statement3;
statement4;
Из-за этого привязку иногда называют «программируемой точкой с запятой».
Языковая поддержка привязки / возврата
Большинство функциональных языков программирования имеют синтаксическую поддержку bind , которая позволяет избежать написания серии продолжений или использования явных привязок.
В F # это (один из компонентов) вычислительных выражений, поэтому следующая явная цепочка связывает :
initialExpression >> = (fun x ->
выражениеUsingX >> = (весело y ->
выражениеUsingY >> = (весело z ->
x + y + z))) // возврат
становится неявным, используя let! синтаксис:
повышенный {
позволять! х = начальное выражение
позволять! y = выражениеUsingX x
позволять! z = выражениеUsingY y
вернуть x + y + z}
В Haskell эквивалентом является «нотация do»:
сделать
x <- начальное выражение
y <- выражениеUsingX x
z <- выражениеUsingY y
вернуть x + y + z
А в Scala эквивалент «для понимания»:
для {
x <- начальное выражение
y <- выражениеUsingX (x)
z <- выражениеUsingY (y)
} урожай {
х + у + г
}
Важно подчеркнуть, что у вас нет , у вас нет для использования специального синтаксиса при использовании bind / return.Вы всегда можете использовать bind или >> = так же, как и любую другую функцию.
Комбинация bind и return считается даже более мощной, чем apply и return ,
потому что если у вас есть bind и return , вы можете построить map и применить из них, но не наоборот.
Вот как можно использовать привязку для эмуляции карты , например:
- Сначала вы создаете функцию пересечения мира из нормальной функции, применяя
returnк выходу. - Затем преобразуйте эту функцию пересечения мира в приподнятую функцию, используя привязку
mapв первую очередь.
Точно так же привязка может имитировать применить . Вот как map и применяются. можно определить с помощью bind и return для параметров в F #:
// карта определена в терминах привязки и возврата (некоторые)
пусть карта f =
Вариант.привязать (f >> Некоторые)
// применить, определенное в терминах привязки и возврата (некоторые)
позвольте применить fOpt xOpt =
fOpt |> Option.bind (весело f ->
let map = Option.bind (f >> Некоторые)
карта xOpt)
В этот момент люди часто спрашивают: «Почему я должен использовать , применить вместо , привязать , если привязка более эффективна?»
Ответ заключается в том, что только потому, что применимо может быть эмулировано привязкой , не означает, что должен быть .Например, можно реализовать применить таким образом, который не может быть эмулирован реализацией bind .
Фактически, использование apply («аппликативный стиль») или bind («монадический стиль») может сильно повлиять на работу вашей программы!
Мы обсудим эти два подхода более подробно в части 3 этого поста.
Свойства правильной реализации привязки / возврата
Как и с картой , и как с применить / return , правильная реализация пары bind / return должна иметь
некоторые свойства верны независимо от того, с каким возвышенным миром мы работаем.
Есть три так называемых «Закона Монад»,
и один из способов определения монады (в смысле программирования) состоит в том, чтобы сказать, что она состоит из трех вещей: конструктора универсального типа E плюс пары
функции ( связывают и возвращают ), которые подчиняются законам монад. Это не единственный способ определить монаду, и математики обычно используют несколько иной
определение, но это наиболее полезно для программистов.
Как и в случае с законами функтора и аппликатива, которые мы видели ранее, эти законы вполне разумны.
Во-первых, обратите внимание, что return функция сама по себе является перекрестной функцией:
Это означает, что мы можем использовать bind , чтобы превратить его в функцию в повышенном мире. А что делает эта поднятая функция? Надеюсь, ничего!
Он должен просто вернуть свой ввод.
Итак, это в точности первый закон монады: он говорит, что эта поднятая функция должна быть такой же, как функция id в повышенном мире.
Второй закон аналогичен, но с bind и return поменяли местами.Скажем, у нас есть нормальное значение a и функция перекрестного мира f , которая превращает a в E .
Давайте поднимем их обоих в возвышенный мир, используя bind на f и return на a .
Теперь, если мы применим повышенную версию f к повышенной версии a , мы получим некоторое значение E .
С другой стороны, если мы применим нормальную версию f к нормальной версии a , мы также получим некоторое значение E .
Второй закон монады гласит, что эти два повышенных значения ( E) должны быть одинаковыми. Другими словами, вся эта привязка и возврат не должны искажать данные.
Третий закон монады касается ассоциативности.
В нормальном мире композиция функций ассоциативна.
Например, мы могли бы передать значение функции f , а затем взять этот результат и передать его другой функции g .
В качестве альтернативы, мы можем сначала объединить f и g в одну функцию, а затем передать ей и .
пусть groupFromTheLeft = (a |> f) |> g
пусть groupFromTheRight = a |> (f >> g)
В нормальном мире мы ожидаем, что обе эти альтернативы дадут одинаковый ответ.
Третий закон монад гласит, что после использования bind и возврата группировка также не имеет значения. Два примера ниже соответствуют примерам выше:
пусть groupFromTheLeft = (a >> = f) >> = g
пусть groupFromTheRight = a >> = (fun x -> f x >> = g)
И снова мы ожидаем, что оба они дадут одинаковый ответ.
Список - это не монада. Вариант - это не монада.
Если вы посмотрите на определение выше, монада имеет конструктор типа (он же «универсальный тип») и , две функции, и - набор свойств, которые должны быть удовлетворены.
Таким образом, тип данных List является лишь одним из компонентов монады, как и тип данных Option . Список и Опция сами по себе не являются монадами.
Было бы лучше думать о монаде как о преобразовании , так что «монада списка» - это преобразование, которое преобразует нормальный мир в повышенный «мир списка», а «Монада опций» - это преобразование, которое преобразует нормальный мир в повышенный «мир опций».
Я думаю, что здесь возникает большая путаница. Слово «Список» может означать много разных вещей:
- Конкретный тип или структура данных, например
List. - Конструктор типа (универсальный тип):
List. - Конструктор типа и некоторые операции, например класс или модуль
List. - Конструктор типа и некоторые операции удовлетворяют законам монад.
Только последняя монада! Остальные значения допустимы, но вносят путаницу.
Также два последних случая трудно отличить друг от друга, глядя на код. К сожалению, были случаи, когда реализации не удовлетворял законам монад.То, что это «монада», не означает, что это монада.
Лично я стараюсь избегать использования слова «монада» на этом сайте и вместо этого сосредотачиваюсь на функции bind , как части набора функций для решения проблем.
а не абстрактное понятие.
Так что не спрашивайте: у меня есть монада?
Спросите: есть ли у меня полезные функции связывания и возврата? И правильно ли они реализованы?
Теперь у нас есть набор из четырех основных функций: map , return , apply и bind , и я надеюсь, что вы понимаете, что делает каждая из них.
Но есть некоторые вопросы, которые еще не решены, например, «почему я должен выбрать , применить вместо , привязать ?»,
или «как я могу иметь дело с несколькими возвышенными мирами одновременно?»
В следующем посте мы ответим на эти вопросы и продемонстрируем, как использовать набор инструментов, на ряде практических примеров.
ОБНОВЛЕНИЕ: Исправлена ошибка в законах монад, указанная @joseanpg. Спасибо!
Как мы анализировали результаты поиска Google - разметка
В последние годы Google значительно расширил предоставление результатов поиска, которые предназначены для ответов на запросы пользователей прямо на странице поиска, без необходимости переходить по ним, используя информацию, которую Google извлекал из Интернета или собирал у партнеров.Он также расширил результаты, которые выделяют принадлежащие Google продукты, такие как YouTube, Google Images, Google Maps, Google Flights, и, казалось бы, нескончаемый поток «связанных» поисковых запросов, которые уводят пользователей все глубже и глубже в самый ценный продукт Google. Поиск. Эти типы результатов, которые мы называем «модулями», часто отображаются в прямоугольниках и обычно визуально отличаются от результатов традиционного ранжированного поиска Google, хотя эти различия начинают стираться.
Мы разработали эксперимент, чтобы измерить количество и размещение этих результатов поиска, созданных Google и самостоятельно ссылающихся на них, и сравнить их с другими типами результатов и ссылок.В частности, мы хотели сравнить их с результатами и ссылками на веб-сайты, не принадлежащие Google. В данном случае мы будем называть это ведро лидирующего за пределы контента контента в результатах поиска как «не относящееся к Google».
Поскольку в настоящее время не существует рандомизированной выборки общедоступных поисковых запросов Google, мы создали выборку из 15 269 запросов по всем темам, фигурирующим в Google Trends, в период с ноября 2019 года по январь 2020 года. Мы использовали разделение поисков Google на корневые слова и выполнили каждый из них через поиск Google на мобильном эмуляторе для iPhone X.
Затем мы использовали новую технику, чтобы измерить, сколько места Google выделил различным типам результатов и ссылок на первой странице результатов поиска. (Подробности в Приложении 1.)
Мы классифицировали результаты поиска по четырем категориям: Google, не-Google, реклама и AMP (первоначально аббревиатура от «ускоренных мобильных страниц»), которые представляют собой страницы, написанные третьими сторонами (часто новостными сайтами) на языке разметки, созданном Google и кешируется на серверах Google для быстрой загрузки на мобильных устройствах.Мы отнесли к категории «Google» те результаты или ссылки, которые отправляют пользователей на сайты Google и YouTube, а также текст внутри «модулей» Google, на который не ссылаются. (См. Более подробную информацию в разделе «Категоризация» ниже.)
Мы обнаружили, что результаты Google преобладают на первом экране, занимая 62,6% его в нашей выборке. Этот процент падает при рассмотрении всей первой страницы, где доля Google составляла 41 процент. Для сравнения, Google распределил 44,8% первой страницы результатов на сторонние сайты, 13.3 процента на AMP-страницы и один процент на рекламу.
Кроме того, мы обнаружили, что результаты, не относящиеся к Google, были сдвинуты вниз до середины и ниже середины страницы, в то время как Google предоставил своим собственным результатам самые избранные места в верхней части результатов поиска, как показано на этом графике.
Что отображается на странице поиска Google при прокрутке вниз?
Процент недвижимости в нашей выборке, нормализованная длина страницы
Не Google
AMP
Ответ Google
Продукт Google
Объявления
Процент страницы, покрытой категорией
На этом графике по оси X отложен процент раздела страницы, занятого каждой категорией.(Обратите внимание, что Google делится на две категории.) Каждая горизонтальная линия сетки проходит на 10 процентов вниз по странице. Чем шире цвет, тем большую площадь занимает эта категория. Источник: 15 269 поисковых запросов.
Мы обнаружили, что более чем в половине поисков в нашей выборке контент Google занимал не менее 75 процентов первого экрана. В каждом пятом запросе на первом экране полностью отсутствовал контент, не принадлежащий Google.
Размещение на странице поиска имеет значение. Данные, полученные с помощью инструментов аналитики поисковых систем от компаний-разработчиков программного обеспечения Advanced Web Ranking и Sistrix, показывают, что CTR резко падает сверху вниз на странице результатов поиска на мобильных устройствах.(Такая же динамика имеет место на рабочем столе.)
Невозможно переоценить влияние действий Google на поведение в Интернете. По оценкам, в Соединенных Штатах Google обслуживает почти девять из десяти поисковых запросов в Интернете. Компания заявляет, что каждую секунду получает более 63 000 запросов.
Важно отметить, что мы использовали новый метод категоризации, чтобы определить, какие результаты считать «Google», а какие - «не Google». Не существует общепринятых стандартов.
Представитель Google Лара Левин сказала, что, поскольку наша выборка не случайна, наши результаты могут содержать больше «ответов» Google и результатов AMP, чем было бы в действительно случайной выборке.
Она раскритиковала наш выбор категоризации, заявив, что AMP-контент следует считать не принадлежащим Google, и что не все результаты, которые мы обозначили как «Google», приносят пользу компании. «Предоставление ссылок для обратной связи, помощь людям в переформулировке запросов или изучении тем, а также краткое изложение фактов не предназначены для предпочтения Google.Эти функции в основном отвечают интересам пользователей, и мы проверяем это в процессе тщательного тестирования ». (См. Дальнейшие комментарии в разделе Google Response.)
Когда мы измерили влияние множественных возможных интерпретаций результатов Google и не Google, наша система классификации оказалась не самой строгой и не самой щедрой ни для того, ни для другого, вместо этого она оказалась посередине. В каждом варианте определения, который мы исследовали, Google по-прежнему предоставлял себе больше всего места на желанном первом экране.
В 1997 году Сергей Брин и Ларри Пейдж зарегистрировали Google.com как базу для инновационной поисковой системы, которая поможет людям находить в Интернете то, что они ищут.
Он быстро завоевал долю рынка у существующих поисковых систем, таких как Yahoo и MSN. По данным Statcounter, к концу 2004 года Google был самой популярной поисковой системой в США, и теперь она занимает 88 процентов рынка поисковых систем США.
В 2004 году, когда Google стал публичным, Пейдж изложил свое видение Google как чистого справочного инструмента:
«Большинство порталов показывают свое собственное содержание над контентом в других местах сети.Мы считаем, что это конфликт интересов, аналогичный получению денег за результаты поиска. Их поисковая система не обязательно обеспечивает наилучшие результаты; он предоставляет результаты портала », - сказал Пейдж Playboy. «Google сознательно старается держаться подальше от этого. Мы хотим вывести вас из Google в нужное место как можно быстрее ».
Тем не менее, за последнее десятилетие Google переориентировался на ответы на запросы самостоятельно, собирая и извлекая информацию из других источников и представляя их непосредственно на странице поиска, а также направляя пользователей к другим доходным объектам, которыми он владеет: Google Maps, YouTube, Google Travel и т. Д. .
«Наши продукты прошли долгий путь с момента основания компании более двух десятилетий назад», - говорится в заявлении Google в SEC за 2019 год. «Вместо того, чтобы просто показывать десять синих ссылок в наших результатах поиска, мы все чаще можем давать прямые ответы - даже если вы говорите свой вопрос с помощью голосового поиска - что позволяет быстрее, проще и естественнее находить то, что вы ищете. для."
В марте 2018 года Google даже экспериментировал с выдачей только ответа и отсутствия результатов поиска по некоторым запросам.
В 2010 году Google приобрела компанию под названием Metaweb, которая стала основой для базы данных об отношениях между сущностями и информацией - в основном людьми, местами и вещами - называемой «графом знаний». Граф знаний используется для многих модулей ответов, иногда называемых «панелями знаний», которые Google создает и занимает видное место в результатах поиска.
Казалось особенно важным изучить изменения Google в его результатах поиска, поскольку Google сталкивается с антимонопольным надзором в США.С. и Европа.
В 2017 году Европейская комиссия оштрафовала Google на 2,42 миллиарда евро после того, как обнаружила, что Google «злоупотребил своим доминированием на рынке в качестве поисковой системы, предоставив незаконные преимущества другому продукту Google», имея в виду свою службу сравнения покупок, которая теперь называется Google Покупки. В 2018 году комиссия разослала вопросы конкурентам Google по поиску местных компаний. А в прошлом году он подтвердил, что начал предварительное расследование относительно того, незаконно ли Google уделяет приоритетное внимание своему продукту Google for Jobs в результатах поиска.Google заявила, что не согласна с решением комиссии по Google Покупкам, которое она обжаловала.
В Соединенных Штатах Федеральная торговая комиссия в 2013 году закрыла расследование относительно того, незаконно ли Google собирал контент и уделял приоритетное внимание свойствам компании при поиске после того, как Google согласился разрешить веб-сайтам отказаться от извлечения их контента для своих свойств, включая Google Авиабилеты. , Отели Google и списки местных предприятий. Агентство также пришло к выводу, что приоритет Google для собственного контента «может быть правдоподобно оправдан как нововведения, которые улучшили продукт Google и улучшили качество обслуживания его пользователей.”
В 2019 году Министерство юстиции и 50 генеральных прокуроров штатов и территорий по отдельности начали антимонопольные расследования в отношении Google. FTC также рассматривает приобретения у крупных технологических компаний, включая Google, чтобы определить, сдерживают ли они конкуренцию. Многие результаты типа ответов Google, которые стремятся ответить на вопросы на странице поиска, возникли в результате покупок. К ним относятся «граф знаний», как упоминалось ранее. Google Авиабилеты также выросли в результате приобретения.
Некоторые исследователи попытались количественно оценить влияние приоритета Google своего контента в результатах поиска. Moz, компания, которая продает инструменты для индустрии поисковой оптимизации, на протяжении многих лет запускала список поисковых запросов в браузере для настольных ПК с различными интервалами, глядя на размещение первого «традиционного органического результата», который они определяют как «десять синих ссылки »- результаты в стиле.
Эти неоплачиваемые результаты со временем смещались вниз по странице, заменяясь сначала рекламой, а теперь - контентом Google, обнаружил Моз.В 2013 году первый «органический» результат отображался в среднем на 375 пикселей вниз по странице. В 2020 году оно было еще ниже, в среднем на 616 пикселей. В отличие от нашего исследования, Moz не считал ссылки в модулях, созданных Google, как «обычные». В то время в Твиттере официальный представитель Google Дэнни Салливан раскритиковал исследование как «устаревшую оценку».
В 2019 году анализ, проведенный аналитиком поисковых систем Рэндом Фишкином, показал, что половина всех поисковых запросов Google по его данным завершается без нажатия пользователем на что-либо.Из тех, кто что-то нажимал, 12 процентов перешли по ссылкам на Google Images, YouTube или другие ресурсы Google. Исследование было основано на более чем миллиарда поисковых запросов с более чем 10 миллионов настольных компьютеров и мобильных и настольных устройств без iOS, собранных Jumpshot, ныне несуществующим поставщиком данных о «потоках посещений».
Google признал в комментариях Конгрессу в ноябре 2019 года, что одна из основных причин, по которой люди прекращают поиск, заключается в том, что модули Google предоставляют ответ на странице поиска.
Другие поисковые системы, включая Bing и DuckDuckGo, также иногда предоставляют результаты типа «ответы» на своих страницах поиска. По данным Statcounter и SimilarWeb, вместе Bing и Duck Duck Go получают менее 10 процентов веб-трафика.
В исследовании Эрика Энджа, проведенного в 2019 году, выяснялось, увеличивает или уменьшало ли включение в модули Google количество переходов на веб-сайты, и были получены неоднозначные результаты. Исследование Sistrix 2020 года показало, что панели знаний и избранные фрагменты сокращают переходы на другие веб-сайты.
В исследовании, опубликованном в этом году северо-западными исследователями Николасом Винсентом и Брентом Хехтом, измерялось наличие и размещение ссылок на Википедию из нескольких поисковых систем, не только из Google. В исследовании использовался пространственный подход к аудиту поисковых страниц, помимо подсчета результатов в традиционном стиле или в стиле «десять синих ссылок». Они обнаружили, что ссылки на Википедию часто появляются на видных местах, предполагая, что «мощные технологии, такие как поисковые системы, в значительной степени зависят от бесплатного контента, созданного добровольцами.”
The Wall Street Journal проверил, предпочитает ли Google YouTube конкурентам в модуле «видео», и обнаружил, что при поиске точных названий видео, размещенных на конкурирующих платформах DailyMotion, Facebook и Twitch, YouTube в подавляющем большинстве оказался первым и занял большую часть слоты в видео-карусели. Представитель Google Левин сказал журналам и The Markup, что не отдает предпочтения YouTube.
Различные новостные агентства сообщали о проблемах с модулями Google, начиная от сексизма и неточностей в избранных фрагментах до потери трафика, который угрожает существованию небольших веб-сайтов.В The Outline в 2017 и 2018 годах было опубликовано несколько статей о влиянии модулей на онлайн-издателей, написанных одним из авторов этого исследования. В одной из этих статей сообщалось, что Google без разрешения извлек информацию с CelebrityNetWorth.com и отобразил ее в избранных фрагментах, что привело к падению посещаемости сайта. Другой исследовал влияние модулей Google на посещаемость веб-сайтов, посвященных афроамериканской литературе. The Outline также опубликовал статью о неточной информации в избранных фрагментах, а The Guardian сообщил, что Google дает прямой сексистский ответ на вопрос: «Являются ли женщины злом?» в избранном фрагменте.Google изменил последний вариант после публикации статьи и заявил, что не несет ответственности за «контент в Интернете», который попадает в результаты поиска. Представитель Google Салливан, бывший журналист, в то время как он был репортером, много писал о модулях и о том, что он назвал Google «проблемой одного истинного ответа», - что поисковая система хочет дать один ответ на каждый запрос, но часто ошибается.
Подобно исследованиям Sparktoro и Moz, в нашем исследовании изучается, какая часть страницы результатов поиска Google направляет пользователей на сторонний контент по сравнению с содержанием Google.Тем не менее, он идет дальше, измеряя, какая часть первой страницы занята результатами поиска и ссылками Google и сторонних источников, и использует более точное определение. Он также измеряет, какая часть первого экрана и первой полной страницы занята результатами и ссылками поиска Google и сторонних поставщиков, а также двумя другими категориями. Таким образом, он обеспечивает более глубокий анализ результатов, созданных Google и со ссылками на себя, а также их сравнение с результатами, полученными не в Google.
Категоризация
Мы разделили результаты поиска на четыре типа: реклама, AMP, Google и сторонние.
Категоризация результатов была самой серьезной проблемой, с которой мы столкнулись в этом проекте. Не существует общепринятых определений того, что такое результат «Google» или «не Google». Некоторые до сих пор называют последние результаты «обычными» результатами поиска, но не все. И ссылки на внешние веб-сайты, не принадлежащие Google, появляются вне этих «обычных» результатов, что делает это определение менее полезным для наших целей.
Сложность категоризации результатов частично связана с усложнением внешнего вида и происхождения самих результатов.Когда он был запущен, Google давал только традиционные результаты. Два года спустя, с изобретением AdWords, компания добавила рекламу, которая не выглядела так, как традиционные результаты.
Совсем недавно Google представил еще одну категорию, которую в индустрии SEO называют «функции поисковой выдачи». (SERP - это аббревиатура от Search Engine Results Page.) Функции SERP включают в себя то, что мы называем модулями, а также традиционные «органические» результаты, которые выходят за рамки заголовка и стиля описания исходных «десяти синих ссылок» и могут иметь несколько интерактивных компонентов. в них, например текстовые ссылки и изображения.Google называет эти более привлекательные традиционные результаты «богатыми результатами».
Еще больше разбавив некогда четкие визуальные маркеры, Google даже начал размещать ссылки на Google Scholar внутри некоторых традиционных результатов. Они появлялись в академических статьях по истории, компьютерным системам и медицине в нашей выборке.
Многие модули Google не работают и не выглядят одинаково. Некоторые относятся только к контенту Google, а некоторые полностью ссылаются на внешнюю сеть. Другие, например панели знаний, обычно содержат текст, не вызывающий клика, и ссылки как на сайты Google, так и на сторонние сайты.Тем не менее, другие, как и многие «избранные фрагменты», в основном состоят из неактивного текста, за исключением ссылки на источник на внешний веб-сайт, с которого был извлечен текст, часто без явного ведома веб-сайта.
Google еще больше запутал воду, когда решил, что если ссылка на веб-сайт, не принадлежащий Google, появится в очищенном модуле «избранного фрагмента», он удалит этот сайт из традиционных результатов ниже (если он там появится), чтобы избежать дублирования.
Для проведения нашего исследования мы изучили исходный код страниц результатов поиска Google, чтобы определить, откуда берется информация, отображаемая в результатах, и где связанные ссылки ведут пользователя, что является основой для наших определений.(Технические подробности того, как мы это сделали, изложены в Приложении 2.)
Мы классифицировали результаты, которые приводят пользователей к продуктам и службам Google, включая YouTube, Google Maps, Google Авиабилеты, Google Images, а также к дополнительным поисковым запросам Google как «Google», независимо от того, где они появляются на странице. В эту категорию также входят необычный контент, созданный Google, например животные дополненной реальности.
Мы посчитали интерактивную часть результатов, которые ведут на веб-сайты, не упомянутые выше, как «не принадлежащие Google».В случае с традиционными результатами мы также посчитали сопроводительный текст, не вызывающий клика, как не связанный с Google, потому что этот текст и заголовки для традиционных «обычных» результатов поиска написаны самими этими веб-сайтами (хотя Google может переопределить его).
Если результат в модуле был смешанным - например, модуль Google Hotels, содержащий рекламу, ссылку «проверить доступность» и информацию об отелях, мы подсчитывали площадь интерактивных ссылок для любой категории, к которой они принадлежали. Например, в панелях знаний мы считали ссылки на вышеупомянутые продукты Google как «Google», а ссылки на другие сайты как «не принадлежащие Google».”
В случае избранных фрагментов и других модулей, содержащих текст, не имеющий ссылки, мы засчитали текст, не вызывающий клика, как Google, потому что модуль был создан - и его текст выбран - Google. Модули типа «панель знаний» упоминают конкретные базы данных Google в коде, из которого они, по-видимому, взяты.
Google не согласен с этим определением и ранее не соглашался с аналогичными определениями избранных фрагментов, заявляя, что считает их высокоценным «органическим» содержанием.
На этой вкладке
Книги вы попадете в список дополнительных поисковых запросов Google.Переход к
Википедия .Эта вкладка
Видео - это в основном результаты YouTube.Эти ссылки ведут к более
поисковым запросам Google .Поскольку мы решили гибридизировать нашу обработку модулей, следуя нашим руководящим принципам источников и ссылок, небольшое количество пустого пространства, которое обычно учитывается в других модулях, не учитывается в конкретном случае гибридных результатов.Это приводит к небольшому сокращению области, отнесенной к Google в нашем исследовании.
РезультатыAMP также вызвали трудности с категоризацией. AMP - это HTML-подобный язык разметки с открытым исходным кодом, который Google внедрил четыре года назад и потребовал от издателей новостей размещать свой контент в модуле «Главные новости».
Издатели могут показывать объявления на AMP-страницах из любой рекламной сети, если они соответствуют стандартам AMP. Google заявил, что более 100 рекламных сетей поддерживают AMP.Сайты, не поддерживающие AMP, теперь могут появляться в модуле «Главные новости».
Результаты AMP не выводят пользователей на внешние веб-сайты. Когда пользователи нажимают на результат AMP из поиска Google (и Gmail), они попадают на кэшированную страницу, которая является клоном страницы веб-сайта и находится на серверах Google. Однако, если пользователи нажимают дальше на странице, они переходят по ссылкам на исходном веб-сайте, куда бы они ни вели.
AMP-страницы теперь отображаются в других модулях и в традиционных результатах поиска на мобильных устройствах.И его разработчики поощряют использование AMP за пределами веб-страниц и мобильных устройств.
Из-за сложной природы AMP - контент создается внешними веб-сайтами, но доставляется с серверов Google и должен соответствовать спецификациям Google - мы выделили эти результаты в отдельную категорию. Мы включаем AMP в знаменатель при определении объема страницы, занимаемой любой категорией контента.
Выбор включения или исключения AMP из категории значительно изменил бы результаты, как это показано в 80.7 процентов поисковых запросов с мобильных устройств и занимает 13,3 процента доступного места в результатах поиска.
Левин, представитель Google, возразил против нашего решения, заявив, что результаты AMP должны быть отнесены к категории не относящихся к Google. «Это исходящие ссылки на издателей и других создателей Интернета. Утверждать иное не соответствует действительности », - сказала она.
Наконец, мы разделили объявления на отдельные категории. Сюда входила не только реклама вверху и внизу страницы, но и спонсируемый контент, например, некоторые платные результаты покупок.
Сбор данных
Поскольку в настоящее время не существует рандомизированной выборки общедоступных поисковых запросов Google, мы создали выборку из 15 269 поисковых запросов на основе тем, представленных в Google Trends, в период с ноября 2019 года по январь 2020 года.
Мы собрали тренды по всем доступным темам: бизнес, развлечения, наука и технологии, спорт и главные новости. (Подробности см. В Приложении 1.)
Мы запустили эти запросы в поиске Google на мобильном эмуляторе iPhone X за тот же период времени.
Анализ
Мы измерили процент недвижимости для нашей выборки из 15 269 популярных поисковых запросов, которые были заняты каждой категорией, как определено выше, как для первой страницы (все результаты загружаются на первой странице), так и для первого экрана. (Исследователи называют первый экран «над сгибом».)
Мы опустили панель поиска и область над ней, а также область под кнопкой «дополнительные результаты». Это исключило стандартные элементы, которые появляются на каждой странице результатов, но не являются результатами и в противном случае были бы засчитаны как «Google.”
Этот раздел страницы опущен.
Анализ ограничен этим разделом.
Мы нормализовали длину каждой страницы поиска, чтобы она начиналась под панелью поиска и заканчивалась под кнопкой «дополнительные результаты».
Этот раздел страницы опущен.
В нашем примере длина первой страницы варьировалась в зависимости от запроса: от 1400 до 9100 пикселей с колоколообразным распределением и в среднем 5000 пикселей.
Мы нормализовали длину каждой страницы поиска, чтобы можно было изучить размещение элементов как вверху, так и внизу первой страницы.
Верхние 15 процентов нормализованной страницы примерно равны длине первого экрана iPhone X, поэтому мы называем эту часть «первым экраном».
Затем мы использовали новую технику веб-синтаксического анализа, чтобы измерить присутствие и положение элементов на странице. (См. Подробности в Приложении 1.) Этот метод включал «окрашивание» результатов поиска и связывание одного из пяти цветов на основе нашей категоризации, а затем измерение количества места, выделенного Google для каждой категории.(Подробности см. В Приложении 2.)
1. Анализировать
Анализируйте результаты поиска и классифицируйте каждый модуль и раздел на странице.
2. Пятно
Измерьте количество пикселей каждой категории на странице и закрасьте ее цветом в соответствии с ее категорией.
3. Совокупный
Объедините пиксели для каждой категории на странице и разделите на сумму пикселей во всех категориях.
Процентные доли в совокупном изображении основаны на результатах поиска по всей странице по запросу «Джон Чо».
Чтобы вычислить процент площади, покрытой различными категориями результатов поиска, мы разделили общее количество пикселей, покрытых каждой категорией в нашей выборке, на общее количество пикселей, покрытых всеми категориями. Этот расчет не включает пробелы между результатами или разделы, удаляемые при нормализации длины страницы, такие как панель поиска, логотип вверху или другие элементы нижнего колонтитула внизу, ни один из которых не является результатом.
Это формула для процента доступной площади, покрытой результатами, которые мы классифицировали как «Google», как определено в разделе «Определения»:
- г г процент недвижимости, занятой Google
- грамм это сумма пикселей недвижимости, занятых продуктами и ответами Google.
- нг это сумма пикселей недвижимости, занятых сторонними
- усилитель это сумма пикселей недвижимости, занятых AMP
- объявление это сумма пикселей недвижимости, занятых рекламой.
Где
Мы обнаружили, что собственные результаты Google преобладают на первом экране (первые 15 процентов нормализованной страницы).
| Зона покрытия | Частота в выборке | Зона покрытия | Частота в выборке | |
| 62,6% | 95,9% | 41% | 100% | |
| Не из Google | 19.2% | 80% | 44,8% | 100% |
| AMP | 12,1% | 22,6% | 13,3% | 80,7% |
| Ads | 6,1% | 8,1% | 1% | 9,5% |
Google выделила только 19,2 процента первого экрана на результаты и ссылки, не относящиеся к Google, по сравнению с 62,6 процента первого экрана на свой собственный. Для всей первой страницы доля сторонних пользователей выше, но все же меньше половины - 44.8 процентов.
Что касается частоты, результаты Google появлялись на первом экране в 95,9% случаев. В каждом пятом поиске в нашей выборке ни один результат или ссылка, не относящаяся к Google, не появлялись на первом экране; все было либо Google, либо рекламой, либо AMP.
Если посмотреть на распределение площадей, охватываемых каждой категорией, почти в трех из четырех наших поисковых запросов (72,3%) Google выделил не более четверти первого экрана для результатов и ссылок, не относящихся к Google.В 54,8% поисковых запросов Google отдавал себе львиную долю первого экрана - 75% и более.
Как показано на приведенном ниже графике с областями с накоплением, который также является абстрактным, Google разместил большую часть результатов и ссылок, не относящихся к Google, в середине первой страницы, в значительной степени ближе к нижней средней части. Он размещал результаты, которые мы отнесли к категории Google, в основном вверху и внизу страницы.
Что отображается на странице поиска Google при прокрутке вниз?
Процент недвижимости в нашей выборке, нормализованная длина страницы
Не Google
AMP
Ответ Google
Продукт Google
Объявления
Процент страницы, покрытой категорией
На этом графике по оси X отложен процент раздела страницы, занятого каждой категорией.(Обратите внимание, что Google делится на две категории.) Каждая горизонтальная линия сетки проходит на 10 процентов вниз по странице. Чем шире цвет, тем большую площадь занимает эта категория.
Хорошо зарекомендовавшие себя исследования в области психологии показывают, что размещение информации на странице, а именно начало и конец списка, благоприятно влияет на запоминание и оценку. Другие исследования используют это предположение в качестве основы для анализа ранжирования традиционных результатов поиска.
Google предоставил результаты AMP в подавляющем большинстве из нашей поисковой выборки, 80.7 процентов. В 22,6% поисков результаты AMP были размещены на первом экране.
Google показывал рекламу менее чем в 10 процентах результатов нашего выборочного поиска. Когда они появлялись, реклама была сгруппирована вверху. Процент объявлений зависит от типа поиска. Google сказал, что реклама встречается редко, но отказался указать, как часто она появлялась.
Некоторые из наших результатов зависят от типа поиска. Изучив меньшую выборку из 700 поисковых страниц по каждой из пяти тем популярных поисковых запросов, мы обнаружили некоторые различия между категориями.Например, для запросов о состоянии здоровья в нашей выборке Google занял почти половину первого экрана, 43,5 процента, с «ответами».
результатов AMP появились в девяти из 10 поисковых запросов в категориях «развлечения», «спорт» и «популярные новости» в нашей выборке.
Рекламы (включая спонсируемый контент) появлялись примерно в 19 процентах популярных поисковых запросов, связанных с бизнесом и технологиями, и лишь в двух-трех процентах случаев из спорта, развлечений и главных новостей. Ниже приведены два примера.(Чтобы увидеть все примеры, обратитесь к нашему Github.)
Бизнес
| Зона покрытия | Частота в выборке | Зона покрытия | Частота в выборке | |
| Не из Google | 32.6% | 84,4% | 49,9% | 100% |
| AMP | 4,7% | 10,3% | 8,7% | 65,9% |
| Продукт Google | 27,8% | 83,6% | 25,5% | 100% |
| Google Answer | 19,5% | 64,1% | 13,2% | 99,3% |
| Объявления | 15,4% | 17,4% | 2,7% | 18.9% |
Развлечения
| Зона покрытия | Частота в выборке | Зона покрытия | Частота в выборке | |
| Не из Google | 16,7% | 90.4% | 41,6% | 100% |
| AMP | 12,6% | 25,7% | 15,6% | 90,3% |
| Продукт Google | 42,7% | 97,1% | 31% | 100% |
| Ответ Google | 26,7% | 83,4% | 11,7% | 99,9% |
| Объявления | 1,2% | 1,7% | 0,2% | 2,4% |
В дополнение к графику с накоплением площадей мы использовали метаданные пространственных элементов, чтобы вычислить, как далеко пользователю нужно прокрутить, чтобы увидеть различные виды результатов поиска.
В нашем примере пользователю придется прокручивать первый экран не менее 75 процентов времени, чтобы получить первый традиционный результат (подмножество «не Google»).
ответов и продуктов Google часто появлялись на первом экране, подтверждая наши основные выводы. Например, когда в нашей выборке появлялись изображения Google, они почти всегда отображались на первом экране (75 процентов времени).
Среднее расстояние вниз по странице до первого контакта элементов страницы
Не Google
AMP
Ответ Google
Продукт Google
Объявления
В процентах вниз по странице
Результат
Традиционный результат
Каждая точка представляет собой среднее расстояние, при этом 50 процентов результатов (межквартильный диапазон) находятся между планками ошибок.
Каждый из сделанных нами выборов, от размера экрана до выборки и категоризации, несет с собой ограничения. Некоторые из них оказали бы незначительное влияние на результаты. Другие значительно изменили бы их. Ниже приведены выявленные нами ограничения, разделенные на разделы.
Категоризация
Наш выбор учитывать некоторые модули или части модулей как Google, а некоторые как не относящиеся к Google, в зависимости от того, откуда поступает контент и куда он ведет, является оригинальным подходом, который должен быть точным и справедливым.Вряд ли он полностью понравится ни защитникам Google, ни его критикам. Google не согласен с некоторыми из наших категорий. (См. Раздел Google Response ниже.)
Кроме того, наше решение разделить результаты AMP, вероятно, будет спорным, так как некоторые сочтут их «органическими», а другие будут рассматривать их как свидетельство растущего влияния Google на открытую сеть. Google заявил, что считает их органическими.
Согласно нашим определениям, Google распределил 62.6 процентов первого экрана и 41 процент всей первой страницы для себя; 19,2% первого экрана и 44,8% всей первой страницы были распределены на результаты и ссылки, не относящиеся к Google.
Если бы мы выбрали другие определения, наши результаты также изменились бы. Когда мы измерили влияние нескольких интерпретаций того, что можно было считать Google и не-Google, Google смог покрыть диапазон от 48,6 до 83,1 процента первого экрана, а не-Google - от 10.8 и 33,2 процента первого экрана:
- Если бы мы посчитали все AMP как Google и оставили все остальное без изменений, площадь Google увеличилась бы до 74,7 процента первого экрана и 54,3 процента первой полной страницы. Если бы мы считали, что все AMP-страницы не принадлежат Google , то количество не-Google увеличилось бы до 31,3 процента первого экрана и 58,1 процента первой полной страницы. (AMP покрывает 12,1 процента площади на первом экране и 13 процентов.3 процента первой полной страницы.)
- Если бы мы не гибридизировали модули в стиле «ответы», а скорее считали любой результат с внешней ссылкой как «не относящийся к Google », независимо от того, какая часть контента была интерактивной, это сместило бы результаты первого экрана на 14 процентов. . Если оставить все остальные определения прежними, это изменение увеличит результаты, не относящиеся к Google, до 33,2 процента и опустит Google до 48,7 процента от первого экрана. Это привело бы к сдвигу результатов на всей странице всего на 3.1 процент.
- Использование «традиционных» результатов - «десять синих ссылок» - стиля - в качестве единственной метрики для результатов, не относящихся к Google. и только «модули», поскольку результаты Google имели бы значительный эффект. Согласно этому определению, область, не относящаяся к Google, будет составлять только 10,8 процента первого экрана, а Google поднимется до 83,1 процента верхнего экрана. Для полной первой страницы не-Google будет увеличиваться до 47,1 процента первой страницы, а Google - до 51,9 процента.Одна из причин, по которой оба будут расти, заключается в том, что AMP больше не будет отдельной категорией.
- Если бы мы рассмотрели все «традиционные» результаты как «не относящиеся к Google », но продолжили бы гибридизацию модулей , это привело бы к небольшому увеличению до категории не относящихся к Google, в общей сложности 19,5% от первого экрана и 53,7 процента первой полной страницы. Около 27 процентов результатов в традиционном стиле или в стиле «десять синих ссылок» - это AMP, а один процент ведет на YouTube или Google.com.
- Рекламные объявления занимают 6,1% площади первого экрана и 1% всей площади первой страницы. Если бы мы считали объявления частью категории Google, это увеличилось бы до 68,7% первого экрана.
Используя любое из приведенных выше определений, получается, что Google предоставил себе наибольшую область на первом экране. (См. Таблицу в Github.)
По сравнению с другими возможностями, наша интерпретация попала в середину
Первая область экрана, посвященная Google и не Google
Устный перевод с большинством пользователей, не относящихся к Google
Наша интерпретация
Интерпретация с большинством Google
Google раскритиковал наш выбор включить ссылки обратной связи как Google, заявив, что они предназначены исключительно для разработки продукта.Но эти ссылки не являются косвенными и составляют всего 0,05 процента всей области на первом экране и 0,03 процента всей области на первой полной странице, поэтому они не повлияли бы ни на один из наших результатов.
Выбор образца
Невозможно получить действительно случайную выборку современных поисковых запросов. Самой последней общедоступной выборке репрезентативных поисковых запросов 14 лет. Это набор из 20 миллионов запросов от 650 000 пользователей AOL, который подвергся критике за неэтичный характер, поскольку позволял идентифицировать отдельных пользователей.
В заявлении Google говорится, что 15 процентов запросов, которые он получает каждый день, являются новыми.
Поскольку наша выборка из 15 269 поисковых запросов была создана на основе популярных поисковых запросов, она не может охватить уникальные поисковые запросы, часто выполняемые отдельными пользователями.
Наша выборка состоит из всех доступных категорий (бизнес, здоровье, технологии и наука, развлечения, спорт, главные новости) из Google Trends для США в период с ноября 2019 года по январь 2020 года (более подробную информацию см. В Приложении 1.) Он может отличаться от действительно случайной выборки неизвестными нам способами.
Например, реклама появлялась менее чем в 10% выборочных поисковых запросов и еще реже использовалась при поиске по развлечениям и спорту. Мы подозревали, что это низкий показатель по сравнению со всеми поисковыми запросами Google. Когда мы спросили Google, пресс-секретарь Левин сказал только, что реклама «не показывается по большинству запросов».
В нашей выборке много новостей и результатов СМИ, которые, как мы обнаружили, часто возвращают результаты AMP на мобильных устройствах. Мы подозревали, что это может отличаться от того, что мы нашли бы со случайной выборкой, если бы она была доступна.Левин подтвердил это - и сказал, что популярные поисковые запросы также с большей вероятностью будут содержать панели знаний. Панели знаний появлялись в трех из четырех поисковых запросов в нашей выборке.
Около 1539 записей из нашей выборки - около одного процента не дублированных поисков - были повреждены в результате использования ресурсов и JavaScript в исходном коде, срок действия которых истек между временем, когда мы собрали условия поиска, и временем, когда мы запустили более поздние тесты мы усовершенствовали нашу методологию. Мы удалили их из нашего образца.
Расположение и персонализация
Мы зафиксировали местоположение для поиска как Нью-Йорк. Исследования, проведенные Брауновским университетом и Северо-Восточным университетом, показывают, что геолокация больше всего влияет на запросы местных заведений, тогда как общие термины практически не имеют персонализации.
Мы не входили ни в одну учетную запись Google при выполнении поиска, и мы выполняли поиск группами по 300, последовательно, с интервалом в несколько секунд между ними. Это также могло повлиять на количество показанных нами объявлений.
Дисплей
Мы выбрали мобильный формат для наших результатов, потому что Google сообщает, что более половины поисковых запросов выполняется на мобильных устройствах, а по другим оценкам, 60 процентов.
Результаты поиска на рабочем столе будут другими. Например, результаты поиска Google на компьютере содержат два столбца информации, а результаты для мобильных устройств - только один. Дополнительный столбец приведет к различиям в размещении страниц.
Чтобы стандартизировать размер экрана, мы использовали размеры iPhone X.Размер экрана iPhone немного превышает средний размер экранов современных смартфонов. Нормализация длины страницы снижает влияние изменения экрана между моделями смартфонов.
Выбор iPhone X привел к появлению некоторых ссылок на магазин приложений Apple в нашем образце, который мы отнесли к категории не принадлежащих Google. Если бы мы выбрали устройство Android, ссылки вели бы в магазин приложений Google, который был бы отнесен к категории Google.
Пустое пространство и стандартные элементы страницы
При подсчете процента результатов в любой категории мы учитывали только площадь самих результатов.Мы не добавляли пробелы между результатами, самой панелью поиска или другими стандартными объектами на странице.
Эти элементы и пустое пространство вместе занимают 28,7% всей первой страницы.
Google не согласился с нашей категоризацией в следующих отношениях:
- Левин возражал против нашего решения поместить AMP в отдельную категорию, заявив, что эти результаты должны были быть отнесены к категории «не относящиеся к Google»: «Это исходящие ссылки на издателей и других веб-разработчиков.Утверждать иное не соответствует действительности ».
- Левин возражал против нашей категоризации прямых ответов, включая панели знаний и избранные фрагменты, как Google, заявив, что некоторые богатые традиционные результаты содержат аналогичную информацию, и мы посчитали последние не принадлежащими Google.
- Левин возражал против нашей классификации ссылок «обратной связи», которые побуждают пользователей отправлять отзывы о рекомендуемых фрагментах, как Google. Эти ссылки составляют всего 0,03 процента страницы.
- Левин возражал против того, чтобы мы относили избранные фрагменты к категории Google.«Неправильно изображать избранные фрагменты как простые ответы на вопрос, которые никогда не приводят к клику - многие сайты стремятся выделить свое содержание в виде фрагментов, так как это может привлечь значительный трафик на их сайты». Она отказалась предоставить данные о том, сколько трафика из избранных фрагментов отправляют на веб-сайты. (С другой стороны, она также сказала, что ответы на запросы путем размещения панелей знаний на странице результатов поиска, без отправки трафика на веб-сайты, полезны для пользователей. «Непосредственный ответ на запросы, основанный на такой информации, не« отвлекает трафик »; это выполняем свою работу в качестве поисковой службы », - сказала она.)
«Эта методология, основанная на нерепрезентативной выборке поисковых запросов, ошибочна и вводит в заблуждение», - сказал Левин в заявлении по электронной почте. «Предоставление ссылок для обратной связи, помощь людям в переформулировке запросов или изучении тем, а также краткое изложение фактов не предназначены для предпочтения Google. Эти функции в основном отвечают интересам пользователей, и мы проверяем это в процессе тщательного тестирования ».
Она сказала, что многие из модулей, которые мы назвали Google, являются разработками, обслуживающими пользователей, например, панели знаний и модули «люди также спрашивают» и «связанные поисковые запросы», которые приводят к увеличению количества поисков в Google.
«Это не имеет ничего общего с« удержанием людей в поиске », а всего лишь для того, чтобы помочь им найти то, что они действительно ищут, не тратя время на нажатие на нерелевантные ссылки или повторный ввод результатов поиска», - говорится в ее заявлении.
Левин также возражал против выделения Google. «Эта методология также не рассматривает сравнение Google с любыми другими поисковыми системами, многие из которых используют аналогичный подход с точки зрения предоставления полезных функций, которые отображают быстрые факты или помогают людям исследовать связанные темы.”
Google занимает 90 процентов рынка США
Мы обнаружили, что Google помещает результаты, которые он создает, в том числе те, которые относятся к его собственным свойствам, на самых избранных позициях: 62,6 процента первого экрана было занято контентом Google, а в нашей выборке только 19,2 процента приходилось на контент, не относящийся к Google. .
Мы обнаружили, что более чем в половине поисков контент Google занимал не менее 75 процентов первого экрана. В каждом пятом запросе на первом экране полностью отсутствовал контент, не принадлежащий Google.
Собственный контент Google настолько повсеместен на странице результатов поиска, что конкурирует с контентом, не принадлежащим Google, за доминирование на всей первой странице, причем категории занимают 41 и 44,8 доступной области соответственно, согласно нашим определениям.
Доминирование Google на поисковом рынке, обеспечивающее 88% запросов в США, означает, что этот выбор имеет огромные потенциальные последствия. Владельцы веб-сайтов зависят от трафика от Google.
СоучредительGoogle Ларри Пейдж сказал в 2004 году, что конфликт интересов, возникающий, когда поисковая система также владеет контентом, может ухудшить качество поискового рейтинга, хотя в то время он критиковал конкуренцию за редакционный контент, который он размещал на своих страницах поиска. , согласно заявлению Google.
Google продолжает выпускать и приобретать продукты, которые конкурируют с другими компаниями. К ним относятся YouTube - второй по популярности веб-сайт в мире; Google Авиабилеты и отели, которые в 2019 году превзошли своих американских конкурентов Expedia.com и Booking.com; и модули ответов, которые конкурируют с издателями, включая Википедию.
Мы обнаружили, что Google обычно показывает свои продукты в результатах поиска и выделяет их на видном месте.
↩ ссылка
Приложение 1: Сбор и предварительная обработка данных
Мы создали наш образец, используя недокументированный API для сбора данных в реальном времени из Google Trends каждые шесть часов, начиная с ноября.С 5 по 7 января 2020 г. Мы собрали все популярные запросы по всем темам, которые предоставляет Google: бизнес, здоровье, развлечения, спорт, технологии и популярные новости, локализованные в США.
Каждый вызов API возвращал запись JSON, которую мы анализировали, чтобы вернуть поле «сущностей» (например, кожная сыпь, аллергия, медицина, молекула), которое мы использовали для поиска в мобильном эмуляторе. Это давало в среднем 300 уникальных поисковых запросов в день.
Для создания мобильного эмулятора мы использовали Selenium для запуска безголового браузера Firefox.Браузер был параметризован пользовательским агентом iPhone X и его размерами экрана (375 на 812 пикселей). Сосредоточение нашего исследования на мобильных устройствах позволило нам стандартизировать и ограничить размеры экрана.
Каждые 10 минут на сервере в Нью-Йорке запускался новый эмулятор. Эмулятор посетил Google.com и выполнил 50 последовательных поисков, введя и отправив запросы в строку поиска. Для каждого поиска эмулятор сохранял исходный код страницы как HTML, а также снимок экрана первой полной страницы.Эти серии поисков выполнялись последовательно с интервалом в несколько секунд.
Мы использовали исходный код HTML как основу для определения различных единиц анализа в нашем исследовании. Мы собрали в общей сложности 42 104 записи, но наш окончательный набор данных содержит 15 269 записей HTML (каждая запись представляет собой один поиск) после удаления повторяющихся условий поиска и фильтрации 1539 поврежденных записей. Мы определили, что запись была повреждена, если она содержала элементы размером более 700 пикселей (86 процентов экрана) при предварительной обработке данных в марте 2020 года.Это было результатом истекших ресурсов или JavaScript из исходного исходного кода.
Чтобы идентифицировать и количественно оценить различные типы результатов и ссылок на страницах поиска, мы использовали традиционный интерфейсный веб-парсинг для выделения элементов DOM на основе характеристик HTML.
Мы считываем HTML-код каждого результата поиска в BeautifulSoup и написали более 60 настраиваемых веб-парсеров для идентификации каждого типа результата и его xpath (уникальный идентификатор элементов CSS на веб-странице).Наши веб-парсеры использовали атрибуты HTML (тип тега, data- *, текст и обработчики JavaScript, такие как jsaction) и функции доступности (доступные полнофункциональные интернет-приложения [ARIA], альтернативный текст), чтобы назначить каждому результату категоризацию рекламы, AMP, не- Google, продукт Google или ответ Google (подробнее об этом в следующем разделе). Продукт Google и ответ Google вместе составляют категорию «Google» в наших выводах.
Мы отказались от заголовков, таких как панель поиска или вкладок, для таких вещей, как «изображения» или «покупки».«Мы также отказались от нижних колонтитулов, которые также являются стандартными и содержат ссылки на настройки, справку, отзывы, конфиденциальность и условия. Наконец, мы отказались от значков, которые ведут к телефонным звонкам. Эти значки не ссылаются на веб-сайты, ресурсы Google и не удерживают вас на странице поиска. Вместо этого мы смотрим только на результаты поиска, включая модули.
Однако, поскольку эти методы были ограничены статическими веб-страницами, они не предоставляли важных пространственных метаданных о видимости, местоположении и размерах каждого результата.
Чтобы решить эту проблему, мы разработали новый подход, который позволил нам «запятнать» результаты и измерить их присутствие и положение на мобильной веб-странице. Подход, который мы здесь будем называть «веб-анализом», был основан на лабораторном методе идентификации и измерения присутствия клеточных компонентов и других веществ с помощью целевого окрашивания или окрашивания, называемого анализами. Мы переосмыслили эту технику для Интернета.
Кроме того, наш выбор для анализа выбранных элементов отображаемой страницы был вдохновлен двумя расширениями браузера: Perceptual ad blocker, проект исследователей из Принстонского университета, который использует видимые функции для выбора и показа рекламы, и Abstract browsing, плагин Chrome для визуального отображения. художника Рафаэля Розендаля, который «показывает вам скелет сети», выделяя композицию веб-страниц.
Используя веб-анализ, мы вернули HTML-код каждой страницы результатов поиска в мобильный эмулятор и использовали Selenium для выбора каждого элемента на основе xpath. Выбор элементов в Selenium дал нам дополнительную информацию, которую мы искали, например, видим ли элемент, а также расположение, длину и ширину элемента.
Используя дополнительные пространственные метаданные из Selenium, мы смогли вычислить площадь, занимаемую каждым результатом на первом экране, а также всей первой страницей.Мы сделали это, отрегулировав длину и ширину каждого результата в соответствии с смещением x и y от местоположения и вырезав значения за пределами размеров первого экрана (375 пикселей по оси x и 15 процентов вниз по нормализованной странице) на iPhone X и полная первая страница.
Мы использовали эти пространственные метаданные вместе с категоризацией, присвоенной нашими пользовательскими анализаторами, для оценки площади или недвижимости, занимаемой каждой категорией. Мы выполнили один и тот же расчет на каждой странице поиска в нашем наборе данных.
↩ ссылкаПриложение 2: Как мы разбирали каждую категорию
Мы классифицировали результаты мобильного поиска как не относящиеся к Google (серый), рекламный (красный), AMP (синий) или Google (желтый и зеленый).
Для этого мы создали 68 веб-парсеров, используя визуальные и программные маркеры, чтобы фиксировать уникальные результаты, которые мы часто встречаем в нашем наборе данных. Чтобы увидеть все наши парсеры, обратитесь к нашему репозиторию GitHub. Мы использовали одни и те же идентификаторы для проверки производительности каждого парсера. (Подробнее об этом читайте в нашем разделе анализа ошибок.)
Не из Google
Наши парсеры выявляли результаты, не относящиеся к Google, путем поиска тегов , которые включали атрибут «href» (который указывает на гиперссылку) и исключали атрибут «data-amp» и вели на веб-сайты, отличные от YouTube и Google.
В этих случаях мы гибридизировали обработку модулей, считая внешние ссылки как не относящиеся к Google, а несвязанный текст - как Google. Это означает, что отбрасывается небольшое количество пустого пространства, что отличается от результатов, относящихся к одной категории.
Недвижимость, не принадлежащая Google, в примерах ниже выделена серым. В примере справа показаны ссылки, не относящиеся к Google, встроенные в модули Google, такие как «избранный фрагмент» или другие результаты типа «ответы».
Слева: серая заштрихованная область является примером ссылки атрибуции в избранном фрагменте, которая ведет на веб-сайт, не принадлежащий Google. Мы посчитали это не-Google. Мы считали текст над ним как Google. Справа: серая заштрихованная область является примером интерактивных списков результатов поиска, которые ведут на сайты, отличные от Google и YouTube.Мы посчитали их не принадлежащими Google.Объявления
Мы в первую очередь идентифицировали рекламные объявления по значкам «реклама» и «спонсируемые», которые Google включает на них. . Объявления включают в себя платные списки объявлений в текстовом поиске и платные списки отелей Google. Спонсируемые списки включают определенные продукты Google Покупок и местные услуги.
После января 2020 года компания Google Flights больше не принимает сборы от авиакомпаний и больше не помечается как «рекламная» или «спонсируемая». По этой причине мы считаем Google Авиабилеты продуктом Google, а не рекламой.
Наши парсеры искали раскрытие рекламы в специальных возможностях, ссылки, ведущие на Google Ad Services, и прослушиватели событий, такие как «jsaction», запускающие функции JavaScript при нажатии. Для расчетов, связанных с недвижимостью, мы измерили целые карточки в каруселях (слева) и спонсируемых элементах (справа).
Вот пример нескольких видов рекламы, выделенный красным:
Слева: эти текстовые объявления выглядят как обычные результаты. Справа: это реклама продуктов со ссылками на розничных продавцов и «спонсируемые» результаты.AMP
Наши парсеры идентифицировали контент AMP на основе атрибута data-amp в тегах . Для расчетов, связанных с недвижимостью, мы использовали те же критерии, что и другие категории, измеряя весь поисковый лист, а также интерактивный модуль.
Общие элементы AMP выделены синим цветом ниже:
Слева: ссылки AMP часто появляются в модуле «Главные новости». Они также могут отображаться как традиционные результаты поиска. Ссылки AMP можно определить по маленькому значку молнии в правом верхнем углу результатов поиска.Справа: AMP-сайты выходят за рамки новостных издателей. Такие сайты, как Reddit, теперь используют язык разметки для своих страниц.Мы классифицировали результаты, которые либо связывают с другими продуктами Google при нажатии, либо предоставляют ответ на странице поиска, как полностью или частично Google.
Мы использовали подкатегорию «продуктов» Google для результатов, которые приводят пользователя к Картам Google, видеороликам YouTube, Картинкам Google, рейсам Google, другим поисковым запросам Google или отелям Google.Мы также посчитали специализированный контент, такой как созданные Google модели животных с дополненной реальностью, которые попали в нашу выборку, как Google.
Эта подкатегория включает встроенные видео YouTube, которые воспроизводятся на странице поиска, и изображения в результатах поиска, при нажатии на которые запускается обратный поиск изображений в Картинках Google.
Не существует единого визуального флага, который мы использовали для идентификации «продуктов» Google, поэтому наши парсеры использовали несколько методов для их идентификации. Они просмотрели все элементы тега со ссылками, не относящиеся к AMP, и проверили домен гиперссылки на известные домены Google.Если URL-адрес начинается с обратной косой черты или любого другого символа, мы обнаружили, что он ведет к свойству Google.
Естественно, у Google есть более сложные элементы с гиперссылками, чем просто теги . Чтобы зафиксировать их, мы рассмотрели атрибуты HTML, такие как специальные возможности (такие как ARIA), JavaScript и атрибуты данных.
Для результатов, содержащих связанные «продукты» Google, мы измерили область, на которую можно нажимать. Примеры результатов поиска «продукта» Google выделены желтым цветом ниже:
Слева: все вкладки на этой «панели знаний» ведут к другим поисковым запросам Google.Изображения открывают визуально похожие изображения в Картинках Google. Справа: карта и данные о местных компаниях прямо на Google Maps. Кнопки фильтра приводят к более тонкому поиску.Google «ответы» - это подкатегория Google. Это относится к модулям, которые содержат отобранный Google текст и визуализации данных, часто извлекаемые из открытого Интернета, но иногда с разрешения владельцев веб-сайтов. «Ответ» Google может быть представлен в виде визуализации данных, таких как цены на акции и популярные времена в вашем любимом ресторане.
Наши парсеры обнаруживали ответы, используя специальные возможности, такие как ARIA, невидимые заголовки и атрибуты данных в исходном коде, а именно « data-attrid», атрибуты, такие как « kc: / music / record_cluster: lyrics. »Эти разборчивые, организованные источники данных являются эксклюзивными для« ответов »и ясно показывают, что Google извлекает контент из названной частной базы данных. Мы нашли в коде ссылки на «ответы» на другие именованные источники данных, такие как ss, hw, wg и okra. Эти ссылки всегда представляют собой иерархические запросы, характерные для графовых баз данных.
Мы измерили область ответов Google с большим количеством текста по прямоугольнику, окружающему текст. Расширяемые ответы измеряются всем интерактивным элементом, а визуализация данных измеряется границами рисунка.
Примеры ответов Google выделены зеленым цветом:
Слева: дата является ответом на поисковый запрос. Выпадающие вопросы расширяются, чтобы показать ответы на связанные вопросы, удерживая пользователя на странице. Справа: абзац вверху представляет собой избранный фрагмент, взятый из MIT Technology Review.Мы считаем весь прямоугольник, ограничивающий края, как ответ Google. Как и в предыдущем примере (слева), вопросы в разделе «люди также задают» расширяются и отображаются ответы, подготовленные Google.Мы использовали несколько подходов для проверки ошибок.
Отладка
Чтобы проверить производительность нашего метода веб-синтаксического анализа во время разработки, мы использовали Selenium для внедрения атрибутов CSS для «окрашивания» визуализированных элементов в соответствии с категорией и сохранили исходный код страницы. Этот метод изменял внешний вид элементов на веб-странице, четко разграничивая категории результатов.Мы также внедрили настраиваемый атрибут, называемый «категория разметки», который изменил базовый исходный код и подключил каждый окрашенный элемент к синтаксическому анализатору. Это был важный инструмент отладки для разработки каждого из наших пользовательских парсеров.
Выборочная проверка окрашенных изображений
Чтобы оценить производительность наших веб-парсеров и точность наших расчетов, мы выборочно проверили 741 испорченную страницу поиска. Мы использовали графическую библиотеку p5.js, чтобы визуализировать нашу технику окрашивания прямо на полностраничных снимках экрана страниц поиска.
Используя снимок экрана, мы нарисовали границы результатов и ссылок для каждой категории на основе пространственных метаданных, возвращенных веб-анализом.
Каждой категории был присвоен цвет, соответствующий предыдущим примерам в нашем документе: серый для ответов, не относящихся к Google, зеленый для ответов Google, желтый для продуктов Google, синий для AMP и красный для рекламы.
Примеров окрашенных изображений:
Пятна этих результатов поиска показали, что они были правильно проанализированы.Используя инструмент аннотации Prodigy, мы создали пользовательский интерфейс и руководство кодировщика для двух аннотаторов для выборочной проверки 741 окрашенного изображения, произвольно взятого из нашего набора данных.Мы попросили аннотаторов искать два типа ошибок.
1. Классификация: неклассифицированные или неправильно классифицированные элементы.
2. Измерение: ошибка измерения площади элемента.
Два автора статьи были аннотаторами. Для результатов поиска с ошибками мы определили, сколько пикселей было переоценено или занижено для каждой категории.
Мы обнаружили ошибки в 74 изображениях с пятнами (9,99% изображений, прошедших выборочную проверку).
Мы нашли 14 окрашенных изображений (1.89 процентов изображений, прошедших выборочную проверку) с ошибками классификации, восемь из которых возникли в результате неправильной классификации кнопок и фильтров «Google», которые должны были считаться рекламными.
Ошибки измерения произошли в 65 изображениях (8,77% выборочно проверенных изображений), большинство из которых были недооценены. Это произошло главным образом из-за отсутствия текста в списках традиционного поиска AMP. Это произошло в 23 поисковых запросах, при этом в среднем 44,52 тыс. Пикселей, или 3,85% площади первой полной страницы, не учитывались.
Когда мы скомпилировали корректировки на уровне пикселей для исправления 74 ошибок измерения и классификации, мы обнаружили, что все категории были занижены. Учет этих ошибок не изменил наши проценты для любой категории в нашей выборке более чем на одну десятую процента на первой полной странице. Мы не рассматривали эффект на какой-либо части страницы.
Мы благодарим Кристо Уилсона и Рональда Э. Робертсона (Северо-Восточный университет), Пита Мейерса (Моз) и Ребекку Голдин (Sense About Science USA и Университет Джорджа Мейсона) за комментарии к предыдущему проекту.
Коррекция
В более ранней версии этой истории процент AMP в нашей выборке был изменен в двух случаях.