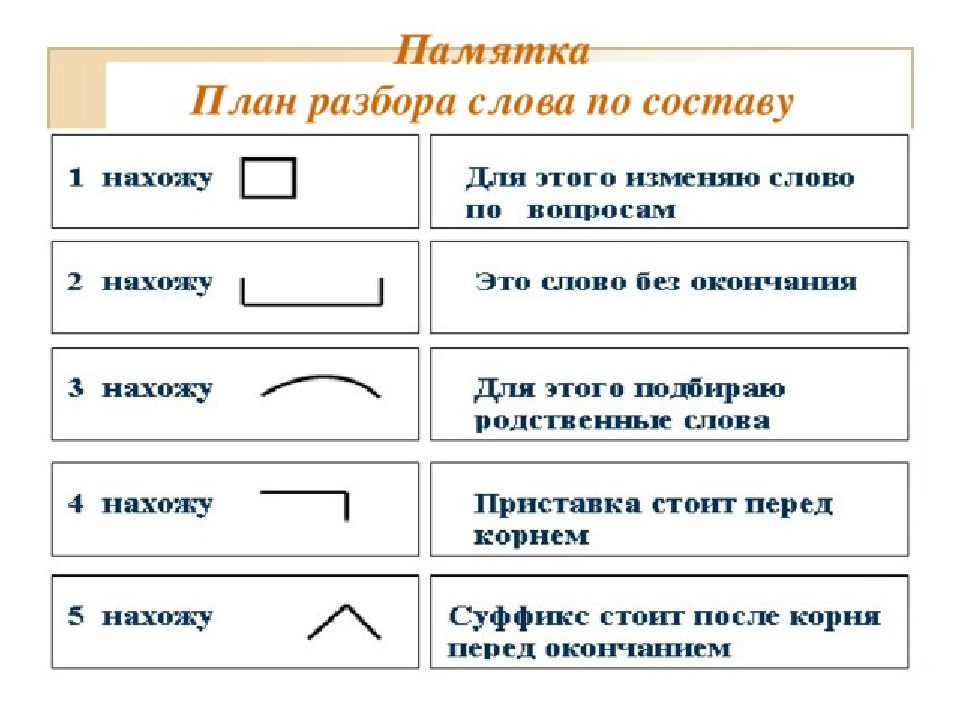
Постановка учебной задачи и её решение Практич.: работа в парах над заданием. Словесн.: формулировка темы и цели урока. | ≈10 | — Посмотрите на доску. — Какие части слова вам напоминают эти сочетания букв? (по,за,ок,про,онок,а,ек,ик,ое,пере,у) — Вместе с соседом по парте придумайте и запишите слова, выделите эти части слова. — Какие части слова вы еще знаете? — Что такое корень? — Может ли слово быть без суффикса, окончания, а корня? — Как вы полагаете, о чём пойдёт речь на нашем уроке? — Определите тему сегодняшнего урока. — Какие задания мы будем выполнять? — Откройте учебник на странице 58. -Правильно мы определили тему урока? — Сформулируйте цель нашего урока. | В парах придумывать и записывать слова с некоторыми перечисленными приставками. Определять тему и цель урока. | Л: учебно-познавательный интерес к новому учебному материалу и способам решения новой задачи. Р: учитывать установленные правила в планировании и контроле, способе решения. Р: целеполагание. | Решение частных задач Практич.: работа с учебником, чтение правила. Практич: работа над упражнением, работа в парах. Словесн.: анализ правила. Практич.: письменное задание. Практич.: работа с правилом. Практич.: работа с письменным успражнением. | ≈20 | — Посмотрите на плакат на странице 58. — Это порядок разбора слов по составу. Лучше всего он подходит для разбора существительных и прилагательных. — Прочитайте. — Что нового вы узнали из этого плаката? (1 пункт – раньше не выполняли) — А теперь посмотрите на страницу 59. — Кто-нибудь один прочитает вслух образец устного рассуждения. — А теперь посмотрите на образец письменного разбора. — Для того, чтобы проверить, умеете ли вы рассуждать и письменно выполнять разбор слов разных частей речи, выполним упражнение 52. — Сделайте разбор слов из списка устно вместе со своим соседом по парте, опираясь на образец на странице 59. — После этого письменно разберите эти слова по составу. — Кто-нибудь хочет устно разобрать слова по составу? — Слова каких частей речи вы только что разбирали? (сущ.,прилаг.) — А как вы думаете, глагол по составу разбирается так же, как существительное и прилагательное? (нет) — Прочтите текст и правило на странице 60. — Что нового вы узнали? Как разбирается глагол? (меняется порядок разбора – если глагол в н.ф., то сначала выделяется суффикс н.ф., а затем глагольный суффикс; если глагол стоит в форме настоящего или будущего времени, то сначала выделяют окончание, а затем глагольный суффикс; если глагол стоит в форме прошедш. времени, то сначала выделяется окончание, затем суффикс глагола прош. — Теперь давайте приведём примеры. — Для этого возьмём любой глагол с суффиксом –ть- в н.ф. и запишем его в трёх разных формах: начальной, в форме настоящего времени и в форме прошедшего времени. — Давайте возьмём глагол бегать. — Разберём его по составу. — Кто-то один разбирает на доске, остальные в тетрадях. — Глагол бегать стоит в какой форме? (н.ф.) — Как разбираем глагол начальной формы? Откуда начинаем? (суффикс) — Какие суффиксы у этого глагола? (суффикс н.ф. -а- и глагольный суффикс -ть-). — Теперь выделяем корень (бег-) — Теперь поставим глагол бегать в форму настоящего времени – бегаешь. — Откуда начинаем разбирать глагол в форме наст.времени? (окончание) — Какое окончание у глагола бегаешь? (-ешь) — Что выделяем дальше? (суффикс) — Какой суффикс? (-а-) — Теперь выделяем корень (-бег-). — Поставим глагол в форму прошедшего времени (бегал) — Откуда начинаем разбирать глагол прошедшего времени? (окончание) — Какое окончание у глагола бегал? (нулевое) — Теперь выделяем суффикс прош. — Теперь выделим глагольный суффикс (-а-) — Теперь выделим корень (-бег-) — Ребята, а чего не хватает в разборе этих слов? (основы) — Откройте страницу 62 и прочитайте правило. — Какие суффиксы начальной формы глагола не входят в основу? (-ть-, — ти-, -чь-) — Какие суффиксы прошедшего времени не входят в основу глагола? (-л-) — А что ещё не входит в основу глагола? (частицы –ся, -сь) — Хорошо, вы изучили новое правило, а теперь давайте вернёмся к тем глаголам, которые мы разбирали и выделим у них основу. — Какая основа будет у глагола в н.ф. — бегать? (бегать) — Какая основа будет у глагола в форме настоящего времени -бегаешь? (бегаешь) — Какая основа будет у глагола прошедшего времени — бегал? (бегал) — Теперь вы знаете, как разбирать по составу все части речи. — Выполните упражнение 56. — Вам нужно будет списать текст, вставляя нужные буквы. — После того, как вы спишите текст, вам нужно будет разобрать любую пару одинаково выделенных слов (скалил – бездельник, либо рычал – намордник). — Договоритесь с соседом по парте, кто какую пару слов будет разбирать. — Давайте проверим, кто-то один выйдет к доске и покажет, как разобрал слова по составу. — Кто не согласен? – У кого по-другому? | Читать правило в учебнике. Читать образец устного рассуждения. Выполнять упражнение, работать в парах. Отвечать на вопросы. Читать правило в учебнике. Анализировать правило. Работать над письменным заданием у доски и в тетрадях. Читать и анализировать правило. Выполнять письменное упражнение в тетрадях. Работать у доски. | Р: принимают и сохраняют учебную задачу, учитывают выделенные учителем ориентиры действия в новом учебном материале, в сотрудничестве с учителем. П: дополняют и расширяют знания. Р: осмысляют учебный материал. П.: выполнение действий по алгоритму; осознанное построение речевого высказывания; построение логической цепи рассуждений, доказательств. |


 времени, а затем глагольный суффикс)
времени, а затем глагольный суффикс) времени (-л-)
времени (-л-)

python — быстрый анализ NLTK в синтаксическом дереве
спросил
Изменено 8 лет, 10 месяцев назад
Просмотрено 5к раз
Я пытаюсь разобрать несколько сотен предложений в их синтаксические деревья, и мне нужно сделать это быстро, проблема в том, что если я использую NLTK, мне нужно определить грамматику, и я не могу знать, что я только знаю, что это будет английский. Я пытался использовать этот статистический парсер, и он отлично работает для моих целей, однако скорость могла бы быть намного лучше. Есть ли способ использовать синтаксический анализ nltk без грамматики? В этом фрагменте я использую пул обработки для «параллельной» обработки, но скорость оставляет желать лучшего.
соленья импортные импортировать повторно из stat_parser.\x00-\x7F]+','',each)))]) p.map (несколько, в списке)

- питон
- нлп
- нлтк
1
Синтаксический анализ — операция, требующая значительных вычислительных ресурсов. Вы, вероятно, можете получить гораздо лучшую производительность с более совершенным синтаксическим анализатором, таким как bllip. Он написан на C++ и выигрывает от того, что команда работала над ним в течение длительного периода времени. Есть модуль python, который с ним взаимодействует.
Вот пример сравнения bllip и используемого вами синтаксического анализатора:
время импорта
# настроить stat_parser
из stat_parser импортировать парсер
парсер = парсер()
# установка блипа
из импорта bllipparser RerankingParser
из bllipparser.ModelFetcher import download_and_install_model
# скачать модель (нужно сделать только один раз)
model_dir = download_and_install_model('WSJ', '/tmp/models')
# Загрузка модели медленная, но это нужно сделать только один раз
rrp = RerankingParser. from_unified_model_dir(model_dir)
предложение = «В лингвистике грамматика — это набор структурных правил, управляющих составом предложений, фраз и слов на любом данном естественном языке».
если __name__=='__main__':
Таймер импорта из timeit
t_bllip = Таймер (лямбда: rrp.parse (предложение))
t_stat = Таймер (лямбда: parser.parse (предложение))
напечатать "bllip", t_bllip.timeit(число=5)
распечатать "stat", t_stat.timeit(число=5)
from_unified_model_dir(model_dir)
предложение = «В лингвистике грамматика — это набор структурных правил, управляющих составом предложений, фраз и слов на любом данном естественном языке».
если __name__=='__main__':
Таймер импорта из timeit
t_bllip = Таймер (лямбда: rrp.parse (предложение))
t_stat = Таймер (лямбда: parser.parse (предложение))
напечатать "bllip", t_bllip.timeit(число=5)
распечатать "stat", t_stat.timeit(число=5)
 from_unified_model_dir(model_dir)
предложение = «В лингвистике грамматика — это набор структурных правил, управляющих составом предложений, фраз и слов на любом данном естественном языке».
если __name__=='__main__':
Таймер импорта из timeit
t_bllip = Таймер (лямбда: rrp.parse (предложение))
t_stat = Таймер (лямбда: parser.parse (предложение))
напечатать "bllip", t_bllip.timeit(число=5)
распечатать "stat", t_stat.timeit(число=5)
from_unified_model_dir(model_dir)
предложение = «В лингвистике грамматика — это набор структурных правил, управляющих составом предложений, фраз и слов на любом данном естественном языке».
если __name__=='__main__':
Таймер импорта из timeit
t_bllip = Таймер (лямбда: rrp.parse (предложение))
t_stat = Таймер (лямбда: parser.parse (предложение))
напечатать "bllip", t_bllip.timeit(число=5)
распечатать "stat", t_stat.timeit(число=5)
На моем компьютере он работает примерно в 10 раз быстрее:
(vs)[jonathan@ ~]$ python /tmp/test.py блип 2.57274985313 статистика 22.748554945
Кроме того, ожидается запрос на включение синтаксического анализатора bllip в NLTK: https://github.com/nltk/nltk/pull/605
Кроме того, вы заявляете: «Я не могу знать, что я только знаю, что это будет английский» в вашем вопросе. Если под этим вы подразумеваете, что ему нужно анализировать и другие языки, это будет намного сложнее. Эти статистические синтаксические анализаторы обучаются на некоторых входных данных, часто анализируя контент из WSJ в Penn TreeBanks.