Как разобрать по составу слово «загар»?
Выполним морфемный разбор слова «загар» и выясним, что в его составе имеются четыре значимых морфемы вместо визуально видимых двух. В этом слове, кроме приставки и корня, присутствуют две морфемы-«невидимки» — нулевой суффикс и нулевое окончание.
Мне очень нравится, когда волосы слегка выгорают, они становятся золотыми, но сильного загара я опасаюсь (Джек Лондон. Маленькая хозяйка Большого дома).
Для того чтобы правильно выяснить морфемный состав слова «загар», следует обратиться к словообразованию. Это поможет нам «увидеть» ту морфему, которая участвовала в образовании слова, но в слове визуально не видна. Речь идет, конечно, о нулевом суффиксе.
Слово «загар» является отглагольным. Оно образовано от однокоренного глагола «загорать».
При словообразовании от глагола отсечены за ненадобностью суффикс и окончание
загор/ать.
В корне этих слов произошло чередование гласных а//о.
При образовании от глагола нового слова — существительного, причём произошла смена части речи, — принял участие нулевой суффикс.
Аналогично образованы отглагольные существительные:
- обменять → обмен о;
- сплавить → сплав о;
- обмануть → обман о.
На конце нового слова «загар», являющегося существительным мужского рода единственного числа, в форме именительного падежа есть еще одна невидимая морфема — нулевое окончание.
Проверим это, изменив слово по падежам:
- цвет (чего?) загара;
- стремлюсь к чему? к загару;
- любуюсь чем? загаром;
- забочусь о чем? о загаре.
В косвенных падежных формах нулевое окончание проявляется в виде букв. Основой слова является часть загар- без окончания.
Основой слова является часть загар- без окончания.
В начале исследуемого слова укажем приставку за-, как и в составе слов:
- заболеть
- заработок
- застроить
Корнем является значимая часть -гар-, которая прослеживается в морфемном составе родственных слов:
- огарок
- угарный
- пригарь
Следовательно, анализируемое слово имеет следующий морфемный состав:
- за — приставка
- -гар- корень
- нулевой суффикс
- нулевое окончание.
Закончим разбор по составу и запишем морфемный состав слова в виде итоговой схемы:
загар 0 — приставка/корень/ нулевой суффикс/нулевое окончание
Аналогичное морфемное строение имеют отглагольный существительные «взрыв», «испуг», «закат».
Отметим, что в школьной практике принят упрощенный вариант разбора по составу (морфемного состава) этого слова:
загар — приставка/корень/нулевое окончание.
Скачать статью: PDF1. Разобрать слова по составу. I Вариант: беспорядочные, тропинка II вариант: бесконечная, усеянные. 2.Морфологический разбор: I Вариант: камней II вариант: лесом. 3. Синтаксический разбор предложения.
Контрольный диктант в 8 классе № 1
Цель: проверить знания, умения и навыки учащихся на начало учебного года.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— написание сложных прилагательных;
— н-нн в причастиях и прилагательных;
— не с прилагательными и причастиями.
— написание производных предлогов;
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при причастном и деепричастном обороте
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков.

Поход
Утром участники похода снова отправляются в путь, рассчитывая сегодня подняться на вершину горы. Она невысокая, но с четырьмя уступами.
Едва приметная извилистая тропинка вьётся по берегу неширокой горной речонки, берущей начало у ледника, а затем резко взбирается влево. Путешественники с трудом преодолевают крутой подъём.
Тропинка огибает беспорядочные нагромождения камней, осложняющие путь. Приходится преодолевать и эти препятствия. Мешают и заросли дикой малины, усеянные ещё неспелыми ягодами. Её колючие ветви цепляются за рюкзаки, одежду.
Вот и вершина. Здесь туристы располагаются на отдых. Отсюда открывается чудесная панорама. Слева от подножия горы расстилается долина, покрытая тёмно-зелёным лесом. Кое-где блестят на солнце зеркала небольших озёр. В течение тысячелетий зарастали их берега густой растительностью. Справа простирается бесконечная цепь холмов, сплошь покрытых зеленью.
Весь день туристы наслаждались красотой гор, загорали, распевали под аккомпанемент гитары песни. Только к вечеру, боясь заблудиться в темноте, они вернулись на тропу, ведущую в лагерь, делясь своими впечатлениями о походе. (147 слов)
Грамматические задания.
1. Разобрать слова по составу.
I Вариант: беспорядочные, тропинка II вариант: бесконечная, усеянные
2.Морфологический разбор: I Вариант: камней II вариант: лесом
3. Синтаксический разбор предложения.
I Вариант: Тропинка огибает беспорядочное нагромождение камней, осложняющих путь.
II Вариант: Справа у подножия горы расстилается долина, покрытая тёмно-зелёным лесом.
Критерии оценки знаний учащихся
Диктант
• «5» – за работу, в которой нет ошибок.

• «4» – за работу, в которой допущено 1 – 2 ошибки.
• «3» – за работу, в которой допущено 3 – 4 ошибки.
• «2» – за работу, в которой допущено более 5 ошибок.
Грамматическое задание
«5» — безошибочное выполнение всех заданий;
«4» — если учеником выполнено 4 задания с небольшими погрешностями;
«3» — правильно выполнил не менее 3-х заданий с небольшим недочетами
«2» — если ученик не справляется с большинством грамматических заданий.
Приложенные файлы
- 5171361
Размер файла: 16 kB Загрузок: 0
Найди слово, которое соответствует схеме. Задание 11 ВПР 4 класс. » Рустьюторс
ВПР по русскому языку 4 класс. Соответствие слова схеме (морфемный состав слова)1) В 10-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(10)Он стал военным.
военным (воен-н-ым)
2) В 7-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(7)Она замирает в позе охотницы и настораживается.
охотницы (охот-ниц-ы)
3) В 5-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
Так мы эти созревшие цветки срывали лишь для забавы.
цветки (цвет-к-и)
4) В 7-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(7)Известно, что «серебряная» вода губит многие бактерии.
серебряная (серебр-ян-ая)
5) В 12-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(12)Например, в родном Вьетнаме бамбук прибавляет в росте до двух метров в день.
родном (род-н-ом)
6) В 3-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(3)Потом в гнезде появляются длинноногие аистята.
аистята (аист-ят-а)
7) В 6-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(6)От первых же утренних морозов в начале осени они погибают.
утренних (утр-енн-их)
8) В 6-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(6)Зацветает берёзка на исходе апреля.
берёзка (берёз-к-а)
9) В 12-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(12)Бабушка вытряхивает незваного гостя, а он не вытряхивается.
бабушка (баб-ушк-а)
10) В 6-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(6)А из них должны вырасти молодые крепкие дубки, которым нужен свет и воздух.
дубки (дуб-к-и)
11) В 6-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(6)Именно с правой стороны их пришивали на рыцарскую одежду.
рыцарскую (рыцар-ск-ую)
12) В 7-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
Ком этот двигался по земле, причём не катился, а перемещался на невидимых ножках.
ножках (нож-к-ах)
13) В 1-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(1)На одном корабле «служил» ручной медведь Михаил.
ручной (руч-н-ой)
14) В 6-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(6)Он заставил своих моряков… качаться!
моряков (мор-як-ов)
15) В 8-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(8)В конце концов Аякса выпустили, и он стремглав помчался к месту снежного обвала.
снежного (снеж-н-ого)
16) В 11-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(11)Пирогов принёс мешочек с гипсом домой.
мешочек (мешоч-ек-нулевое)
17) В 11-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(11)Ночью просыпаюсь от протяжного тигриного воя.
тигриного (тигр-ин-ого)
18) В 11-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(11)Ты лежебока, за день ни разу не повернёшься, а я и снег растапливаю, и лёд просверливаю, и деревья живой водицей напою.
водицей (вод-иц-ей)
19) В 14-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(14)Особенно рано распускается подснежник белоцветный.
подснежник (под-снеж-ник-нулевое)
20) В 12-м предложении найди слово, состав которого соответствует схеме:
Выпиши это слово, обозначь его части.
(12)Поднесли к ране кашицу из лука, подержали 10 минут, взяли пробу: в ране почти не осталось микробов!
кашицу (каш-иц-у)
Дело о клевете на ветерана. Навальный в суде
2 июня телеканал RT выпустил ролик о голосовании по поправкам в Конституцию. В тот же день руководитель ФБК Алексей Навальный опубликовал это видео в своих соцсетях, назвав героев ролика «голубчиками», «продажными холуями», «предателями» и «людьми без совести».
В середине июня Следственный комитет возбудил против Навального уголовное дело по части 2 статьи 128.1 УК. Следственный комитет считает, что комментарий политика «содержал заведомо ложные сведения, порочащие честь и достоинство ветерана». Потерпевшим по делу признали участника Великой Отечественной войны Игната Артеменко, который стал одним из героев агитационного ролика. В ведомстве сообщили, что своим комментарием Навальный якобы подорвал здоровье ветерана.
После возбуждения дела в офисе ФБКФБК и у самого Навального прошли обыски, политик рассказывал, что расследованием дела занимаются 15 следователей. Уголовное дело было возбуждено после жалобы члена Общественной палаты, юриста Ильи Ремесло, выступающего в СМИ и соцсетях с провластных позиций. Причем экспертиза усмотрела клевету в комментарии, где сам ветеран Артеменко не упоминается, более того на момент возбуждения дела он реакции политика на видеоролик не видел.Обвинительное заключение прокуратура утвердила в начале августа, в конце декабря суд возобновил производство по делу. Сам Алексей Навальный после возвращения в Россию находится в СИЗО «Матросская тишина». 2 февраля судья Симоновского районного суда Москвы Наталья Репникова отправила политика в колонию на 2 года 8 месяцев.
Перед началом процесса у ворот в Бабушкинский суд собрались несколько десятков журналистов. Как передает корреспондент «Медиазоны», на заседании будут присутствовать минимум два иностранных дипломата.
Тем временем в зал суда пригласили стороны процесса.
Навальный стоит в аквариуме. Политик спросил корреспондента «Медиазоны» о главном редакторе издания Сергее Смирнове, который отбывает 25 суток ареста за твит, и передал ему привет.
В зал зашла судья Вера Акимова и проверяет явку. Сторону обвинения представляет прокурор Екатерина Фролова, которая ранее участвовала в заседании по замене политику условного срока на реальный.
Судья разъясняет участникам процесса их права. Адвокатов Навального пока нет в зале. «Я исключаю, что мои защитники не явились», — говорит он.
«Я исключаю, что мои защитники не явились», — говорит он.
Потерпевший ветеран участвует в заседании по видеосвязи. На экране под потолком зала включили трансляцию, вероятно, из квартиры Артеменко. На пенсионере надеты ордена. Рядом с ним стоит женщина.
Исправлено в 10:17. В первоначальной версии публикации было неверно указано имя судьи.
На лице Артеменко надета маска. «Ваша честь, может, вы прекратите издеваться над пожилым человеком», — обращается Навальный к судье. Политик недоумевает, зачем пенсионер в маске, если он находится дома.
В зал заходит адвокат Навального Вадим Кобзев.
В зал зашла вторая адвокат политика Ольга Михайлова.
Судья объявляет заседание открытым и устанавливает личность подсудимого. Навальный спрашивает, хорошо ли его слышно и называет свой год рождения, место рождения, место работы и прочие данные.
Судья спрашивает, ознакомился ли обвиняемый с материалами дела. «Я материалы дела не видел», — отвечает политик. Судья отмечает, что дело передали в суд еще в августе. Навальный говорит, что у него в августе было «много дел», намекая на отравление. Он просит полчаса на общение с адвокатами.
Судья Акимова оговорилась и назвала ветерана по фамилии Игнатенко:
— Он не Игнатенко, а Артеменко, — поправил ее Вадим Кобзев.
— Да какая разница, — ехидничает Навальный.
Судья разъясняет ветерану его права. Тому они понятны.
Навальный настаивает, что родственники ветерана «торгуют им». «У меня ходатайство и протест», — говорит он. Навальный предлагает разрешить ветерану снять маску и отвечать лежа. «Вы просто издеваетесь над ним», — настаивает политик.
«Я смотрю на это все, и реально мне противно и невыносимо. Мало того, что вы этого несчастного человека, который, в соответствии с материалами дела, находится в беспомощном состоянии. Его несколько месяцев используют как куклу. Вы еще сейчас его посадили, маску на него нацепили. Поэтому я ходатайствую, чтобы ему дали возможность хотя бы не сидя, а дали лечь и дали возможность снять эту идиотскую маску», — говорит он.
«Раз уж вы решили его использовать для этого омерзительного пиар-процесса, — продолжает обвиняемый. — Вы издеваетесь над 95-летним человеком, который вообще не понимает, что его используют. Просто издеваетесь. К вопросу о том, кто такие предатели, фашисты и политические проститутки — это те люди, которые сидят напротив. Дайте ему лечь и снимите с него маску <…> Если он сейчас, через какое-то время схватится за сердце, вы в этом будете виноваты».
Женщина, сидящая с ветераном говорит, что тот недавно перенес операцию и ему нужно отвечать в горизонтальном положении.
Затем Навальный говорит, что хотел бы, чтобы на процессе велась видеосъемка.
— Это процесс в целом затевался, как некий пиаровский процесс. Потому что кремлю нужны заголовки «Навальный оклеветал ветерана». Раз вам это нужно, пожалуйста, приглашайте сюда средства массовой информации, — настаивает политик. Однако судья говорит, что съемка запрещена.
Теперь Навальный и его адвокат просят пообщаться друг с другом конфиденциально. «Он же не сбежит из аквариума», — аргументирует Кобзев и просит удалить конвой. Адвокат также отмечает, что во время прошлого заседания по замене срока на реальный судья позволял это сделать.
— Есть такая штука как право на защиту. Есть адвокаты, и я бы хотел с ними пообщаться, — говорит Навальный.
— Алексей, — обращается Кобзев к Навальному. — Судья спросила у кого-то, можно ли или нельзя [приватно пообщаться адвокатам и политику ]. Не судья самый главный, а судья у кого-то спросил у более главного.
Корреспондент «Медиазоны» передает, что Акимова действительно несколько минут размышляла над ходатайством Навального об общении с адвокатами, при этом, считает корреспондент, Кобзеву могло показаться, что она что-то пишет в телефоне за кафедрой.
Однако Акимова удовлетворяет ходатайство и разрешает политику поговорить с защитниками. Судья объявляет перерыв до 11:30.
В зал пустили журналистов. Судья Акимова вернулась с перерыва и объявила, что на обсуждение сторон ставится вопрос о начале судебного следствия.
Адвокат Ольга Михайлова говорит, что защитникам так и не дали пообщаться наедине с Навальным, без конвоя.
«Я хотел бы обратить внимание суда, что потерпевший не понимает, что происходит», — отмечает политик.
Несмотря на возражения, судья постановила начать разбирательство при данной явке.
Слово берет прокурор Фролова. Навальный обвиняется в том, что совершил клевету. Она говорит, что Навальный разместил ролик с ветераном, в котором Артеменко выразил свою гражданскую позицию по поводу принятия поправок в Конституцию, и подписал его «О, вот они голубчики, команда холуев». Также Навальный, продолжает прокурор, написал в комментарии о «продажных холуях», «предателях» и «людях без совести». По мнению Фроловой, в высказываниях Навального есть фразы, содержащие негативное отношение к ветерану и подрывающие его репутацию.
Навальный говорит, что обвинение ему непонятно. «Я не знаю ничего об Артеменко. Кроме того, что им торгуют, словно он какая-то кукла на цепи», — настаивает обвиняемый.
«Я не знаю Артеменко», — еще раз подчеркивает Навальный. Вину он не признает.
Адвокат Кобзев говорит, что сейчас будет «бубнить свое отношение защиты к обвинению по делу о клевете» и предлагает журналистам зайти в его твиттер.
Кобзев начинает свою речь с краткого пересказа постановления о возбуждении уголовного дела. По версии следствия, разместив твит и пост в телеграме, Навальный, «будучи осведомленным о несоответствующих действительности фактах», распространил сведения, не имеющие место в действительности, порочащие честь и достоинство ветерана.
По словам Кобзева, защита категорически не согласна с утверждениями следствия, так как в высказываниях Навального приведены оценочные суждения. Чтобы предъявить политику обвинение в клевете, следствию пришлось провести две лингвистических экспертизы.
«И только после получения заключения эксперта, утверждавшей, что в публичных выступлениях Алексея Анатольевича Навального «имеются высказывания, в которых получили речевое выражение какие-либо факты действительности или положение дел, имеющие отношение к Артеменко И. С.», следствие привлекло А.А.Навального к уголовной ответственности», — отмечает адвокат.
С.», следствие привлекло А.А.Навального к уголовной ответственности», — отмечает адвокат.
По мнению защиты, с утверждением следствия и экспертов «невозможно согласиться».
Кобзев ссылается на диспозицию статьи о клевете, согласно которой ответственность за это правонарушение наступает, если виновный заранее знал, что сведения им сообщаемые ложны.
Адвокат также рассказывает о постановлении Пленума Верховного суда, согласно которому сведениями, не соответствующими действительности, являются утверждения о фактах или событиях, которые не имели места в реальности во время, к которому относятся оспариваемые сведения. При этом порочащими считаются сведения о нарушении потерпевшим закона или неэтичном поведении.
Кобзев также ссылается на статью 10 Конвенции о защите прав человека и основных свобод и статью 29 Конституции, которые гарантируют каждому право на свободу мысли и слова.
«Согласно законодательству, для законного привлечения лица к уголовной ответственности, необходимо установление всех признаков состава преступления. В данном деле признаки состава преступления отсутствуют», — читает Кобзев.
Корреспондент «Медиазоны» передает, что ветеран практически неподвижно сидит в кадре. За его спиной — телевизор и портрет (либо фото) мужчины и женщины. Слева от него женщина в розовом. Именно она до этого подсказывала Артеменко, когда судья задавала ему вопросы.
По мнению защиты, в деле Навального отсутствует объективная сторона преступления, поскольку негативная информация передавалась в форме оценочных суждений, а текст не содержит фактов, которые могли бы быть действительными или недействительными.
Кобзев ссылается на лингвистическое заключение, составленное заведующим отделом экспериментальной лексикографии Института русского языка имени Виноградова РАН Анатолием Барановым. Адвокат отмечает, что эксперты СК, которые нашли в публикациях Навального признаки клеветы, в своих работах ссылались на Баранова.
По мнению профессора, сообщения Навального содержали негативную информацию, которая передается в форме оценочных суждений.
«Приведенные слова и словосочетания в составе исследованных комментариев не передают (не сообщают) каких бы то ни было фактов и не могут быть проверены на соответствие действительности», — пришел к выводу эксперт.
Кобзев также говорит о нарушении обвинением УПК. Также в постановлении о привлечении Навального в качестве обвиняемого не описаны конкретные действия последнего, образующие состав клеветы.
«Конкретные слова или фразы, которые по версии обвинения порочат честь и достоинство Артеменко в постановлении и обвинительном заключении не указаны. Следователь лишь полностью процитировал тексты публикаций Навального. При таких обстоятельствах совершенно непонятно, от обвинения в чем должен защищаться Навальный и какое обвинение опровергать. Обвинение в том, что он назвал лиц голубчиками? Обвинение в том, что он считает команду слабоватой, а она, на самом деле, сильная или это не команда вовсе? Обвинение в том, что он назвал лиц холуями или продажными холуями, позором, людьми без совести или предателями?» — задается вопросом адвокат.
Также Кобзев говорит, что следствие нарушило правило территориальной подсудности и не указало, когда и где свидетели ознакомились с публикациями Навального.
«Какими правовыми положениями руководствовался заместитель прокурора г. Москвы Бурко при направлении данного уголовного дела мировому судье судебного участка №320 города Москвы, совершенно непонятно», — недоумевает Кобзев.
Кобзев говорит о политической мотивированности дела против Навального.
«Единственной целью является привлечение к уголовной ответственности политика и общественного деятеля Навального, чтобы остановить его антикоррупционные расследования и исключить возможность его участия в выборах как в Государственную Думу РФ, так и в выборах Президента РФ», — читает адвокат.
Адвокат отмечает, что дело против Навального возбудили после проверки, которая длилась несколько часов.
«Подобная срочность и незамедлительность вынесения постановления о возбуждении уголовного дела в совокупности с его неконкретностью однозначно свидетельствует о его незаконности, необоснованности, немотивированности, политической подоплеке уголовного преследования, а также о влиянии на следователя извне», — считает Кобзев.
Он также говорит, что расследованием таких дел должен заниматься дознаватель, а не следователь ГСУ СК по Москве, что также свидетельствует о политической мотивированности.
Кобзев также уверен, что в отношении Навального был нарушен принцип презумпции невиновности. В частности, следователь писал в постановлениях на обыск фразу: «Таким образом, следствием установлено, что данное преступление совершено Навальным Алексеем Анатольевичем…». То есть следователь уже признал политика виновным.
Также, отмечает адвокат, обвинение политику было предъявлено с нарушением УПК.
«Постановление о привлечении в качестве обвиняемого Навального не содержит таких существенных обстоятельств, характеризующих его личность, как образование, место работы, адрес места жительства, сведения о наличии или отсутствии судимостей, о состоянии на учете в наркологических и психоневрологических диспансерах и иных важных обстоятельств», — говорит адвокат.
Защита заканчивает свое выступление.
Судья приобщает письменное возражение Кобзева.
— Вы отказываете мне в праве выразить отношение к обвинению? — спрашивает Навальный.
Судья говорит, что по УПК это не положено, но разрешает политику говорить. «Обещаете, что не будете меня перебивать?» — уточняет политик и продолжает:
— Я очень хорошо понимаю, как вообще возникло это дело, почему его сфабриковали. Его сфабриковал даже не Следственный комитет, все это дело изобрели пиарщики, ну журналисты RT, какая-нибудь Маргарита Симоньян, потому что сама конструкция этого дела очень пиаровская. Все дело в том, что против меня всегда фабрикуют уголовные дела, но власти наши всегда испытывают большие проблемы, когда эти дела доходят до судов, потому что когда здесь происходит какая-то процедура, всем ясно, что правда на моей стороне не потому, что я какой-то очень хороший, а потому, что я говорю простые вещи, с которыми все согласны.
Я говорю: «Cледователи фабрикуют дела». И все знают, все люди вне зависимости от политических взглядов знают, что следователи фабрикуют дела. Я говорю: «Прокуроры — бессовестные люди». И все знают — да, прокуроры в нашей стране бессовестные люди. Я говорю: «Суды продажные». И все говорят: «Да, суды продажные». На меня подает в суд «Единая Россия», и все уже заранее на моей стороне, поэтому понадобилась какая-то более хитрая штука. Нужно, чтобы в зале суда я противостоял не бессовестным прокурорам, или продажным судьям, или следователям, а чему-то более важному, чему-то более святому, и возникла идея: а давайте найдем ветерана, наденем на него медали, посадим и будем его просто беспринципно и нагло использовать, чтобы получилось, что Навальный против ветерана и его медалей.
Я говорю: «Прокуроры — бессовестные люди». И все знают — да, прокуроры в нашей стране бессовестные люди. Я говорю: «Суды продажные». И все говорят: «Да, суды продажные». На меня подает в суд «Единая Россия», и все уже заранее на моей стороне, поэтому понадобилась какая-то более хитрая штука. Нужно, чтобы в зале суда я противостоял не бессовестным прокурорам, или продажным судьям, или следователям, а чему-то более важному, чему-то более святому, и возникла идея: а давайте найдем ветерана, наденем на него медали, посадим и будем его просто беспринципно и нагло использовать, чтобы получилось, что Навальный против ветерана и его медалей.
Политик говорит, что кампания за поправки в Конституцию была «абсолютно холуйская, подлая».
— Цель их была одна: чтобы Путин, который находится у власти 20 лет, остался еще пожизненным президентом. И в рамках этой кампании было сделано много отвратительных вещей. Одна из таких вещей был мерзкий холуйский ролик, где много разных людей рассказывали, что, конечно, нужно внести поправки, чтобы Путин остался пожизненным президентом. В этом ролике был много кто. Там был дизайнер Артемий Лебедев, там был актер Охлобыстин и так далее.
Судья прерывает Навального и говорит, что «достаточно». Они пару минут спорят. Навальный убеждает судью, что «недостаточно» и продолжает свою речь.
«Почему получается, что высказавшись об этом ролике, что в нем холуи и предатели, я не вижу здесь ни Артемия Лебедева, ни актера Охлобыстина? — задается вопросом политик — Было бы не очень удобно вам, правильно, говорить, что Навальный оклеветал Лебедева, Охлобыстина и Артеменко, потому что у Артеменко — медали, а у Лебедева зеленые волосы, а у Охлобыстина, не знаю, что у него вместо медалей, мешочек с кокаином, наверное, находится. И это уже не так круто».
Политик говорит, что поэтому обвинению понадобилось «притащить ветерана» в суд.
«Ведь наша власть и Путин считают, что они лично выиграли в Отечественной войне, поэтому они притащили ветерана. Я хочу сказать, что клевета, ваша честь, записывайте, пожалуйста, вы, видимо, пропустили, когда в институте учились. Клевета — это умышленное деяние в отношении конкретного человека.
Я хочу сказать, что клевета, ваша честь, записывайте, пожалуйста, вы, видимо, пропустили, когда в институте учились. Клевета — это умышленное деяние в отношении конкретного человека.
Когда я вам говорю, если я скажу, что вы, ваша честь, согласились такого-то числа сфабриковать это уголовное дело, потому что вам за это дадут квартиру, а вам за это обещали, например, дачу, то тогда можно сказать: «Навальный оклеветал» — он говорил о квартире, но вам за это дают дачу, но я сказал ваше имя и место», — говорит Навальный.
Он продолжает:
«Когда я сказал: «Это сборище продажных холуев» — я не знаю ничего ни про какого Артеменко, да, я знаю, что люди, которые участвуют в этой кампании — омерзительны, особенно родственники этого человека, которые, повторю, торгуют своим дедом, который ничего не соображает, за которого какая-то женщина отвечает на вопросы все, это просто отвратительно — [эти слова] даже с формальной юридической точки зрения нельзя [интерпретировать так, как это делает прокурор].
Понимаете, прокурорша в лицо всем здесь говорит: «Навальный умышленно распространил сведения об Артеменко». Да я его фамилии не упоминал. Да прочитайте, что я написал. Когда я говорю, что «»Единая Россия» — партия жуликов и воров» — это мое отношение ко всей партии «Единая Россия». Что же, это теперь означает, каждый может подавать на меня в суд, потому что я его оклеветал?
Когда я говорю, что на Russia Today работают бессовестные продажные журналисты, я их что, оклеветал? Нет, хотя они, конечно, все индивидуально продажные и бессовестные. В этом суть процесса. Вы полностью извратили вообще уголовное право, врете, что я оклеветал Артеменко, хотя его в глаза не видел никогда, еще и используете его сейчас, чтобы его медалями защищать вора Путина и его всех остальных друзей — воров. Вот и все мое отношение к обвинению».
Прокурор Фролова предлагает судье допросить потерпевшего и свидетелей, а потом исследовать письменные доказательства.
«Ваша честь, если у вас не получается руководить процессом, давайте я попробую», — говорит Навальный. Он отмечает, что ветеран не понимает, где находится, и надо выяснить, способен ли он вообще отвечать.
Он отмечает, что ветеран не понимает, где находится, и надо выяснить, способен ли он вообще отвечать.
Михайлова спрашивает у судьи, кем была организована видеосвязь и кто находится в комнате помимо ветерана и его сиделки. Навальный тоже интересуется, кто же организовал трансляцию.
Ветерана очень плохо слышно в зале, на что обращают внимание Навальный и адвокат Кобзев.
Защита Навального возражает против видеоконференцсвязи.
— Кто обеспечивает это все, ваша честь? — спрашивает Михайлова судью. Она также возражает против допроса по видеоконференции.
Выясняется, что женщина в розовом это дочь ветерана, а не сиделка. Сиделка, по словам прокурора, находится в другом помещении.
Навальный просит, чтобы ему раскрыли, кто подсказывает ответы ветерану. «Следователь, сотрудник ФСБ или Маргарита Симоньян, которая ест бобра?» — ерничает политик.
Акимова говорит, что по поручению суда рядом с потерпевшим находится другая судья.
— Она подсказывает ему? — спрашивает Навальный.
Навальный просит, чтобы судья показалась в кадре. «Она что там, голая?» — спрашивает обвиняемый.
Акимова возражает, что у судьи рядом с ветераном тоже есть «тайна на изображение».
В кадре на экране действительно ненадолго появляется третья женщина, передает корреспондент «Медиазоны». Акимова уточняет, что это и есть та судья, направленная к ветерану, чтобы объяснить ему порядок судопроизводства и его права.
Никто не может расслышать, что говорит ветеран и женщина рядом с ним. Судья объявляет технический перерыв пять минут, чтобы наладить связь.
Технический перерыв продлевают еще на десять минут. По его окончанию судья объявляет допрос ветерана Артеменко.
Корреспондент «Медиазоны» передает, что из динамиков исходят «странные звуки». Ветеран поднял на лоб очки и слушает.
Права потерпевшему понятны. Рядом с ним сидит судья. Она представляется, но ее имя нельзя расслышать. Она говорит, что личность ветерана установлена по паспорту, а подписка у него отобрана. Она прощается. Слово передают ветерану.
Она прощается. Слово передают ветерану.
Судья просит рассказать Артеменко, что ему известно по настоящему уголовному делу.
Артеменко рассказывает, что он ветеран войны, получил ранение при форсировании реки Одер, участвовал в партизанском движении, воевал на Белорусском фронте, потом 39 лет служил в армии.
«В июне я узнал, что Навальный назвал меня предателем Родины, это меня очень огорчило. Я вынужден защищать свою честь», — говорит он.
Корреспондент «Медиазоны» предполагает, что все эти слова ветеран читает с листа. Его глаза опущены вниз.
«Я хочу, чтобы Навальный публично принес извинения передо мной и перед памятью актера Ланового», — говорит Артеменко.
Ветеран попросил прекратить устный допрос. Прокурор Фролова его поддержала и ходатайствовала об оглашении его письменных показаний.
Кобзев выступает против удовлетворения ходатайства.
Фролова говорит, что ветеран просит прекратить допрос в устной форме, потому что плохо помнит события того лета.
Адвокат Ольга Михайлова также возражает. Она говорит, что письменные показания могут быть оглашены только в случае существенных противоречий. То, что ветеран не помнит события — это не противоречия.
Навальный снова говорит, что родственники используют Артеменко как куклу. «Вы будете гореть в аду, что взяли деда 95-летнего и надели на него медали. Он же ничего не понимает», — возмущается политик.
Судья удовлетворяет ходатайство обвинения, несмотря на возражения Навального и его защитников. Ветерану так и не был задан ни один вопрос.
Фролова озвучивает протокол показаний Артеменко. Прокурор очень долго и обстоятельно рассказывает фронтовую биографию Артеменко, а также события из послевоенной карьеры ветерана. По ее словам, в ролике RT он снялся в марте 2020 года «из патриотических целей», денег не просил.
Дальше оглашаются показания Артеменко, в которых рассказывается, что ветеран сильно обиделся на Навального за слова из твита. Артеменко говорит, что долго переживал и ему стало плохо. «Я попросил внука помочь мне наказать Навального за его слова», — цитирует Фролова его показания.
«Я попросил внука помочь мне наказать Навального за его слова», — цитирует Фролова его показания.
Теперь прокурор Фролова озвучивает дополнительный протокол допроса Артеменко. Там снова содержатся его воспоминания о войне, например, как «фашисты прибыли в деревню на лошадях».
Судья, которая находится в квартире с ветераном, просит перерыв из-за плохого самочувствия Артеменко. Объявляется 10 минут перерыва.
«Я же вам говорил», — обращается Навальный к судье.
Секретарь объявила, что по состоянию здоровья потерпевшего перерыв продлевается, насколько — неизвестно.
Журналистов запустили в зал заседаний. На экране видеоконференцсвязи пожилая женщина, кто это — пока неясно. О судьбе ветерана также ничего неизвестно.
В аквариум завели Навального. Судья Акимова говорит, что исследование показаний потерпевшего было прервано, потому что ему стало плохо — ветерану вызвали скорую помощь. Участвовать в заседании он сегодня больше не может.
Навальный говорит:
— Я хотел бы ходатайствовать о том, чтобы вы записали в протокол, поскольку я же говорил, что так и будет — приедет к нему скорая помощь. Так и запишите: поскольку Навальный нас всех видит насквозь — а я вам говорил, что они просто придушат этого деда подушкой сегодня ночью — вы, уважаемые журналисты, пожалуйста, запишите, что я так и говорю: они его убьют, чтобы потом говорить, что его этот процесс доконал. Спасибо.
Прокурор Фролова в ответ просит суд внести в протокол ее слова о том, что «до такого состояния его довел Навальный Алексей Анатольевич».
По словам политика, еще в августе было известно о нотариально заверенном обращении Артеменко в суд, в котором тот просил не присутствовать на заседании. Однако, считает Навальный «кто-то отвратительный, мерзкий и жестокий написал в сценарии, что обязательно нам нужно поставить дедушку, чтоб он тряс своими медалями».
— Вам нужно было на кого-то надеть китель? Вот на нее и можно было надеть, — продолжает Навальный, указывая на прокурора.
Судья перебивает Навального, напоминая ему, что потерпевший — ветеран войны.
— Именно! Это я и говорю: зачем вы его сюда тащите, если ему 95 лет и он просил вас его сюда не приводить? — восклицает Навальный.
Судья говорит, что так как допрос ветерана прерван, она меняет порядок процесса и просит приступить к допросу соседки потерпевшего по подъезду Галины Маргулис, она выступает свидетелем обвинения. Ей тоже 95 лет.
— Состояние здоровья позволит ей участвовать? — спрашивает адвокат Михайлова.
— Надеюсь, — отвечает судья.
У Михайловой и Кобзева те же вопросы, что прозвучали ранее. Их интересует, кто организовал эту видеоконференцсвязь. Однако судья не прислушивается к адвокатам и приступает к допросу свидетельницы.
Маргулис, говорит, что она «коренная москвичка» и знает Артеменко с 1973 года. По словам соседки, ветерана «оболгали».
Теперь вопросы задает прокурор Фролова. Ответы Маргулис нельзя расслышать из-за плохого качества связи.
Адвокат Михайлова отмечает, что она, сидя в зале, не может «разобрать ни слова» из того, что говорит свидетельница. А прокурор, по мнению защитницы, «делает вид, что все понимает».
Прокурор спрашивает у свидетельницы, известно ли ей о том, как оклеветали Артеменко и кто это сделал. Та отвечает, что слышала по телевизору, что оболгали «хорошего человека, который живет в моем доме».
Прокурор спрашивает у Маргулис, принимал ли Артеменко участие в Великой Отечественной войне.
Та с первого раза не может понять вопрос. Прокурор Фролова повторяет вопрос, а потом перефразирует его:
— Он защищал Родину?
— Он ветеран, участник войны и ветеран, — отвечает соседка Артеменко.
— Скажите пожалуйста, когда-то Игнат Сергеевич выступал против своей чести и против своей Родины? — интересуется Фролова.
— Ой, о чем говорить-то? Такого не могло быть! — отвечает Маргулис.
— Он когда-то предавал свою страну? — продолжает Фролова.
— Я даже не могу ответить вам на этот вопрос.
— Вам известно о том, что Игнат Сергеевич снимался в патриотическом ролике? — продолжает допрос прокурор Фролова.
— Я слышала, что в этом ролике его оболгали, — путается Маргулис.
— Ужасный ролик, — отзывается Навальный.
После небольшой паузы Фролова продолжает:
— Вы сами видели ролик, где Игнат Сергеевич выступает и поясняет о том, что поправки в Конституцию… пропагандирует принятие поправок в Конституцию?
— Нет, такого не видела.
— То есть вы видели ролик, где его уже оболгали? — уточняет Фролова.
— Да.
На этом у прокурора вопросы заканчиваются. Теперь вопросы свидетельнице задает Навальный. Он уточняет, действительно ли она много общалась с Артеменко в Совете ветеранов и знает о том, что тот был белорусским партизаном. Маргулис подтверждает.
— Как вы считаете, что белорусские партизаны сделали бы с теми людьми, которые украли их пенсии и построили на них дворец?
Фролова просит снять этот вопрос как не относящийся к обвинению.
— Я возражаю категорически, потому что прокурор задает какие-то странные абстрактные вопросы,— отвечает ей Навальный.
Судья просит Навального задавать следующий вопрос, но «по существу предъявленного обвинения».
— Значит прокурор спрашивала абстрактные вопросы. Я спрашиваю те вопросы, которые относятся к существу обвинения. Мне интересно, что бы сделали партизаны? Расстреляли бы они тех людей, которые на их пенсии построили дворец? Как считаете, Галина Андреевна?
Этот вопрос тоже не устраивает ни прокурора, ни судью.
Дальше Навальный интересуется у соседки потерпевшего, хорошо ли живут пенсионеры в России. Этот вопрос снова снимается, прокурор говорит Навальному, что «здесь не митинг, а процесс».
— Скажите, пожалуйста, Галина Андреевна, Артеменко же ваш сосед по дому, вы его хорошо знаете? — спрашивает Навальный.
— Он на втором этаже, я на третьем, — отвечает свидетельница.
— Игнат Сергеевич живет богатой жизнью?
Прокурор требует отклонить вопрос. Кобзев просит не снимать вопрос. Судья говорит, что вопрос нужно переформулировать.
Кобзев просит не снимать вопрос. Судья говорит, что вопрос нужно переформулировать.
Навальный продолжает задавать вопросы Маргулис.
— Скажите, считаете ли вы предателями нашей страны тех, кто поднял пенсионный возраст? — спрашивает Навальный свидетельницу.
Прокурор просит снять вопрос, поскольку он не относится к делу. Судья снимает. Навальный настаивает, что относится.
— Хорошо, следующий вопрос, — продолжает Навальный. — Правильно ли я понимаю, что Геннадий Сергеевич ваш сосед по дому, вы его хорошо знаете?
— Да, — отвечает Маргулис.
— Вопрос: Геннадий Сергеевич живет хорошей, богатой жизнью?
Прокурор просит снять вопрос. Навальный и адвокаты настаивают, что он задает вопрос, характеризующий потерпевшего. Судья просит сформулировать «более ясно».
— Галина Андреевна, можете ли вы сказать, что Геннадия Сергеевич Артеменко живет хорошей, богатой жизнью, как положено жить ветерану войны.
— Он живет как человек.
— Скажите, пожалуйста, какая у него пенсия.
Прокурор снова просит снять вопрос. Навальный спорит, говорит, что хочет знать о материальном благополучии, поскольку в заявлении он говорит, что не получал деньги за участие в ролике. Судья просит сформулировать вопрос иначе. Тогда Навальный спрашивает, какая пенсия у свидетельницы, она отказывается отвечать.
— А Геннадий Сергеевич какую пенсию получает, знаете? — снова спрашивает Навальный.
Прокурор вновь вмешивается. «Не задавайте мне вопросы, которые ко мне не относятся», — жалуется свидетельница.
— А вам кто посоветовал это мне сейчас так сказать, вот эта женщина, которая рядом? — интересуется политик.
— Я ищу правду, — отвечает свидетельница.
— Вы огромный молодец. Мой вопрос к вам такой: как вы думаете, то, что пенсия ветеранов войны в России примерно в 12 раз меньше, чем пенсия немецкого солдата, который проиграл, в этом виноваты те оккупанты, которые захватили нашу страну, или кто?
Прокурор просит снять вопрос. Пока Навальный спорит, свидетельница спрашивает его, какая у него пенсия и на что он живет. Навальный отвечает, что ему пенсию не платят, его кормит государство кашей, пока он сидит в СИЗО.
Пока Навальный спорит, свидетельница спрашивает его, какая у него пенсия и на что он живет. Навальный отвечает, что ему пенсию не платят, его кормит государство кашей, пока он сидит в СИЗО.
— Смотрите, ваша честь, что происходит, — говорит Навальный. — Вы мне все тычете, говорите: ветеран, ветеран. А как я задаю вопрос, почему вы пенсию не платите этим ветеранам, сразу вам мои вопросы не нравятся. Когда здесь читают мемуары про форсирование Днепра, так это отлично, а как начали обсуждать пенсию ветеранов, так вам не нравится.
— Вы считаете, что много пенсию платят или мало? — обращается Навальный к свидетельнице.
— Не ко мне вопрос. Я довольна.
— А я знаю, что большинство пенсионеров пенсией не довольны. Как думаете, почему?
Судья вновь прерывает.
— Хорошо. Галина Андреевна, последний вопрос. Вы сказали представителю обвинения, что в ролике, в котором снялся Артеменко, его оклеветали?
Свидетельница не слышит, и Навальный повторил вопрос.
— Правильно, — соглашается пенсионерка.
— Вы устроили издевательство над пожилым человеком, — обращается политик к судье. Потому что вы сюда вывели пожилого человека, который видел что-то по телевизору и все, и запрещаете задавать мне любые вопросы».
Судья уточняет, что ему вменяют распространение в сети интернет.
— Вы сетью интернет пользуетесь? — Навальный снова обращается к свидетельнице.
— Чем? — спрашивает пенсионерка и просит повторить.
— Спасибо большое, Галина Андреевна, всего вам хорошего, — говорит Навальный.
— Больше не обижайте людей заслуженных, — говорит в ответ пенсионерка.
Навальный в ответ обещает повысить пенсию всем ветеранам.
Теперь адвокат Михайлова спрашивает свидетельницу, кто с ней в комнате. Та отвечает, что сиделка и техник.
Слово снова берет Навальный. Он говорит, что прокурор несет «любую отсебятину», а ему не позволяют задавать вопросы.
Допрос Маргулис завершают.
В зал суда заходит второй свидетель обвинения по фамилии Акимов. Как передает корреспондент «Медиазоны», это мужчина лет 35. Он одет в джинсы и темно-синюю кофту, руки держит за спиной. Судья быстро устанавливает его личность и приступает к допросу.
Как передает корреспондент «Медиазоны», это мужчина лет 35. Он одет в джинсы и темно-синюю кофту, руки держит за спиной. Судья быстро устанавливает его личность и приступает к допросу.
Судья просит Акимова рассказать все, что известно ему по этому делу. Свидетель говорит, что в июне 2020 года в «политической группе» «ВКонтакте» нашел запись, которая ссылается на твиттер Навального, а именно на его твит с высказыванием о тех, кто снялся в ролике RT.
— Особенно меня задело, что слово «предатель» применялось к Игнатенко Артему… кхе-кхе… Артеменко Игнату Сергеевичу. Так как этот человек прошел Великую отечественную войну, он никак не может быть предателем своей страны, продажным холуем, — рассказывает Акимов.
Судья обращается к прокурору Фроловой: задавайте вопросы свидетелю. Та говорит, что вопрос у нее только один: обращался ли свидетель в правоохранительные органы после того, что увидел?
— Да, я дал заявление через онлайн-форму Следственного комитета.
— Еще такой вопрос. Вас кто-то просил писать заявление, кто-то вам угрожал?
— Нет.
— То есть, это ваша гражданская позиция была?
— Это моя гражданская позиция, — отвечает Акимов и объясняет, что его дед по материнской линии — тоже ветеран, и для него тема уважения ветеранов крайне важна.
— Спасибо большое, нет вопросов.
Теперь судья предлагает допросить свидетеля защитникам Навального. Встает адвокат Ольга Михайлова:
— Скажите пожалуйста, я так понимаю, вы проживаете в Кемеровской области?
— Да.
— А каким образом вы сегодня оказались в судебном заседании?
— Мне пришла телеграмма от судьи Акимовой.
— Вы за свой счет сюда приехали?
— Да.
— Все, исчерпывающий дал ответ? — вмешивается судья. Михайлова ей не отвечает.
— Вы часто участвуете в судебных заседаниях? — продолжает защитница.
— Нет.
— Скажите пожалуйста, у вас есть юридическое образование?
— Юридического образования нет.
— Но, тем не менее, вы написали заявление…
— Пожалуйста, вопросы задавайте, — снова подает голос судья Акимова.
— В этом заявлении вы указывали, [по какой статье проверять Навального?].
— Да, указывал. Просил проверить на содержание клеветы.
— Почему вы решили, что в этом тексте есть клевета?
— А вы думаете, что ее там не было? То есть по отношению к человеку, который… за свою страну, и он делает это добровольно, его никто не заставляет. И вы считаете, что этот человек предатель и продал свою страну?!
— А вы были знакомы с Артеменко?
— Нет.
— А откуда вы знали, что он ветеран?
— Вам свидетель пояснил, что он обратился в правоохранительные органы, — в третий раз вмешивается судья.
— Вы вопрос слышали вообще? — негодует Михайлова. Судья просит ее задавать вопросы яснее.
Акимов говорит, что проверил Игнатенко — ошибаясь в фамилии ветерана — на сайте «Память народа».
Михайлова спрашивает про остальных участников ролика: «За их честь и достоинство вы не стали [обращаться в СК]»?
— Я в своих показаниях сказал, что Алексей Анатольевич оскорбил всех. Но особенно акцентировал внимание на то, что он оскорбил ветерана.
— Вы заявление писали в правоохранительные органы — в связи с клеветой на ветерана или на всех участников?
Акимов отвечает что-то невнятное. Следом Михайлова пытается узнать, как именно и куда Акимов обратился с заявлением; тот внезапно заявляет, что отправил его почтой. На помощь свидетелю приходит прокурор Фролова:
— Ваша честь, свидетель пояснял, что обратился в электронном виде в свободном рассказе.
— Ваша честь, сейчас допрос стороной защиты, можно меня избавить от прокурора? — не выдерживает Михайлова.
Теперь вопросы задает Навальный. Акимов отвечает, что обнаружил твит Навального в группе «Мировая политика».
— За Артемия Лебедева вам не было обидно? — спрашивает Навальный.
— Мне за всех обидно, — отвечает Акимов.
Свидетель объясняет, что остальные люди из ролика — самостоятельные, и, если надо, могут сами обратиться в правоохранительные органы.
— Скажите пожалуйста, вы слышали такую фразу «Единая Россия — партия жуликов и воров»? — продолжает Навальный.
— Слышал.
— Вы считаете, что я этой фразой оклеветал каждого члена партии «Единая Россия»?
Прокурор Фролова просит снять вопрос. Навальный возражает и пускается в спор о том, что такое клевета.
— Я прошу вас послушать, послушайте меня, — горячится он, когда судья его прерывает.
— Слушать здесь будете вы, — обижается судья Акимова.
— Нет, вы будете меня слушать! Потому что вы — человек, который изображает судью! Не делайте вид, будто вы здесь что-то решаете! — кричит Навальный из «аквариума».
— Алексей Анатольевич, я вас призываю к порядку.
— Я в порядке полном, — успокаивается подсудимый и возвращается к допросу свидетеля.
Навальный спрашивает, как Акимов понял, что Навальный оклеветал конкретно ветерана, а не всех, кто снялся в ролике. Свидетель пускается в путанные объяснения и рассказывает про ютуб-канал SmileFace, в одном из видео ведущий канала цитирует оппозиционера. Навальный тоже просит его процитировать; свидетель говорит, что ему нужен телефон.
— Несите, несите, я вам разрешаю, — командует Навальный из «аквариума».
— Подсудимый, вы хорошо себя чувствуете? — ошарашенно спрашивает судья. — Может, перерыв объявить?
— Я хорошо себя чувствую.
В зале заседания смотрят ролик, в котором содержатся вырезки из видео Навального, где тот критикует кампанию за поправки в Конституцию.
Политик спрашивает Акимова, произносил ли он в своей речи фамилию Артеменко. Свидетель говорит, что нет.
Адвокат Кобзев спрашивает, понимает ли свидетель разницу между клеветой и оскорблением. Тот говорит, что да и что он увидел в сообщении Навального и то, и другое.
Перед тем, как покинуть зал, свидетель зачитывает ответ из МВД на его заявление о клевете в адрес ветерана. Навальный спрашивает, как так вышло, что ответ пришел из МВД, хотя Акимов до этого говорил, что обращался в СК. В итоге свидетель говорит, что не смог сразу вспомнить, куда именно он писал заявление.
В итоге свидетель говорит, что не смог сразу вспомнить, куда именно он писал заявление.
Следующей вызывают на допрос сиделку ветерана по фамилии Тимурова. На экране видеоконференцсвязи появляется женщина в хиджабе и медицинской маске.
Тимурова представляется и начинает что-то рассказывать о деле.
— Она зачитывает заученный текст, — обращает внимание Навальный.
Судья останавливает Тимурову, чтобы разъяснить ей ее права и обязанности.
Адвокат Михайлова говорит, что возражает против допроса свидетеля по видеосвязи. Защитница отмечает, что Тимурова родилась в 1978-м году и не настолько пожилая, чтобы не присутствовать в суде. Прокурор возражает: свидетельница должна сидеть с потерпевшим.
— Молодая женщина не явилась в зал суда, потому что работает сиделкой?! — возмущается Навальный. Он говорит, что очевидно прямо сейчас Тимурова «не занимается сидением» с кем-либо.
Корреспондент «Медиазоны» передает, что ни одно слово из сказанного свидетельницей не разобрать, судья просит подойти ее ближе к микрофону и говорить помедленнее.
Навальный пеняет судье, что если бы Тимурову вызвали в суд, то такого бы не случилось. Судья делает Навальному два замечания. Акимова предупреждает, что после третьего она удалит политика из зала.
Михайлова задает вопрос, как судья, которая находится в квартире ветерана, могла удостоверить паспорт гражданки Таджикистана. Судья игнорирует вопрос.
— Можете меня удалить, я ничего не понимаю, — возмущается Навальный.
Корреспондент «Медиазоны» подтверждает, что слова сиделки действительно не разобрать. Суд объявляет технический перерыв на 10 минут.
Журналистов снова пустили в зал. Судья спрашивает свидетельницу, хорошо ли она понимает русский язык и не нужен ли ей переводчик. Та говорит, что не нужен. Корреспондент «Медиазоны» отмечает, что Тимурову стало лучше слышно, но ее ответы все равно трудно понять.
Свидетельница рассказывает, что в марте прошлого года к ним в квартиру приезжало телевидение. Она говорит с сильным акцентом. После съемок, рассказывает сиделка, они с ветераном уехали на дачу, где Артеменко почувствовал себя плохо. Потерпевшего она называет «полковник».
Она говорит с сильным акцентом. После съемок, рассказывает сиделка, они с ветераном уехали на дачу, где Артеменко почувствовал себя плохо. Потерпевшего она называет «полковник».
«Скорый помощь уехал, а полковник переживает до сих пор», — рассказывает Тимурова.
Свидетельница говорит, что она ухаживает за «полковником» уже четыре года, постоянно слушает его рассказы о войне и плачет. «Он сказал, что предатель Родина — это не обо мне», — рассказывает она.
Тимурова добавляет, что ветеран очень уважает Таджикистан и не считает граждан из этой страны людьми второго сорта.
Слово берет прокурор Фролова. Тимурова рассказывает ей, что 8 июня они посмотрели ролик RT, в котором снимался ветеран, и под ним он увидел «комментарий» Навального. 9 июня за ним приехала «скорая помощь». Алексея Навального свидетельница назвала Александром.
Теперь вопросы свидетельнице задает Навальный.
— Как в вашем телефоне оказался ролик и комментарий?
— Я узнала от его внук Игор, — говорит она.
— Каким образом вы узнали?
Та повторяет, что узнала от внука Артеменко. Тимурова говорит, что видео ей отправил внук, а комментарий был под видео.
— Там прям было написано, что Алексей Анатольевич Навальный оклеветал ветерана?
— Да, да, — отвечает сиделка.
Навальный спрашивает, почему она оглядывается, кто там с ней. Та отвечает, что с ней оператор, технический работник. Политик пытается уточнить у сиделки, что же именно оказалось у нее в телефоне и о каком комментарии идет речь, но она очень запутанно изъясняется.
— Прям было написано Алексей Анатольевич Навальный? — спрашивает политик.
Сиделка кивает и повторяет слова о комментарии под видео.
— Полковник когда плакал, его внук приехал. «Меня на весь мир оклеветали, что я предатель Родина», — вспоминает она события тех дней.
В итоге она говорит, что заявление в полицию писал внук полковника.
— Все документы в вашем деле — вранье. Ваши материалы дела фальшивки. Почему ее допрашивали в школе? Меня ни разу в школе не допрашивали, — возмущается Навальный.
Почему ее допрашивали в школе? Меня ни разу в школе не допрашивали, — возмущается Навальный.
Сиделку спрашивают, почему ее допрашивали в школе, но та говорит, что не понимает этого.
— Это необычно, когда человека допрашивают в школе, — продолжает Навальный, настаивая, чтобы та все же ответила, как она оказалась в школе. Судья снимает вопрос
— Получали ли вы повестку, чтобы вы явились в школу? — спрашивает политик, но этот вопрос снова снимают.
Судья требует задавать вопросы по существу.
Михайлова настаивает, что вопрос о том, почему сиделку допрашивали в школе — корректный.
Во время допроса Тимурова говорит, что Артеменко сейчас находится где-то в комнате.
В свою очередь, адвокат Михайлова настаивает, что необходимо установить личность сиделки ветерана. Защита хочет огласить материалы дела, но судья не позволяет.
— Вы даже не помогаете прокурору, вы пляшете под его дудку! — говорит Навальный.
Допрос Тимуровой завершают.
Судья вызывает в зал еще одного свидетеля — Игоря Колесникова, внука ветерана, который написал на политика заявление.
— Вы торговец своим дедом! — обвиняет Навальный свидетеля.
В результате между обвиняемым и свидетелем завязывается словесная перепалка, они спорят и перекрикивают друг друга.
Судья Акимова предупреждает Навального, что выгонит его из зала, если политик продолжит так себя вести.
Внук говорит, что после съемок ролика ему начали звонить журналисты и спрашивать, что он думает о твите Навального.
Отвечая на вопросы Фроловой, он говорит, что ссылки с комментарием Навального ему присылали во «ВКонтакте». «Возможно был скриншот [из твиттера]», — предполагает он.
Колесников настаивает, что деньги за ролик и свидетельства в суде ему не платили.
«Дедушке стало нехорошо с сердцем», — продолжает внук ветерана, но уточнить, какой конкретный диагноз ему поставили он не может, точнее не помнит.
Колесников говорит, что ни дедушка, ни он сам никуда не обращались. Это журналисты начали просить комментарии у ветерана.
Это журналисты начали просить комментарии у ветерана.
«Сегодня читал новости, что там было написано, что я буду гореть в аду, о том что я с дедушкой сделал, что мы получали за это деньги, я очень надеюсь что Навальный сможет это доказать», — говорит внук.
Он кричит, чтобы политик принес публичные извинения и доказал, что внук хотя бы «копейку» получил, а «не только кучу расходов».
— Скажите пожалуйста, навязывал ли вам кто-то требование обратиться в правоохранительные органы? — спрашивает прокурор.
— Прямого навязывания никакого не было.
Вопросы начинает задавать Навальный.
— Зина это кто?
— Зина это сиделка, — отвечает Колесников
Политик интересуется, знает ли свидетель фамилию сиделки. Тот говорит, что не знает ее.
— Не знаете фамилию сиделки, которая четыре года работает с вашим дедушкой? — недоумевает обвиняемый.
— Нет. У меня есть фотография… Когда женщина приходила к нам на данный участок я проверил где она, что она, чтобы она нас не обокрала и так далее, и после этого у нас с ней нормальные отношения, — отвечает внук.
— Свидетель, вы только что сказали, что просили Зину дедушке ничего не говорить, чтобы оградить его от неприятной информации. Верно?
— Да.
— Зина 15 минут назад сказала нам, что вы ей отправили видео и попросили показать его дедушке. Кто из вас лжет?
— Когда Зина рассказала дедушке, он носился с тем, чтобы она ему показала. После этого я ей все это отправлял, потому что Зина не умеет пользоваться интернетом, она заходила, но не могла найти источник.
— Зина говорит, что показала по вашей просьбе. Вы лжете или Зина лжет?
Прокурор просит переформулировать: «Поскольку в его вопросе содержится оскорбление в адрес свидетеля».
— Вы почему просто не извинились перед дедушкой, ну у вас же был шанс? — спрашивает свидетель у Навального.
— Я считаю, что вы просто ничтожество, которое позорится… — политик срывается на крик.
— Я считаю, что после этого предатель не имеет мужества просто извиниться! — кричит в ответ Колесников.
— Свидетель, успокойтесь, и не вам говорить про мужество. Вы торгуете своим дедушкой, — обвиняет Навальный.
— Будьте добры, доказательства, я торгую своим дедушкой, будьте добры доказательства! — просит свидетель.
— Вы торгуете своим дедушкой. Доказательства сейчас узнаете. Я только что, как и все присутствующие в зале, видел противоречия в показаниях. Свидетель Зина говорит нам о том, что ее внук попросил показать дедушке информацию. Внук говорит, что наоборот просил Зину не показывать дедушке информацию. Я хотел бы знать кто из них лжет. Что происходит?
Навальный отмечает затянувшееся молчание и спрашивает: «У нас перерыв в заседании или что?». Судья подтверждает — перерыв по просьбе свидетеля.
— У меня в горле пересохло на вас кричать, — говорит Колесников.
— А я кричу на вас без всякого стакана. Если вы хотите высказаться, вы можете высказаться когда будете отвечать. Не надо здесь строить возмущенного… Вы позорите свою… — кричит Навальный.
— Адвокаты, я даю вам ровно пять минут, если вы не приведете в чувства своего подзащитного, он будет удален, — говорит судья.
— Я могу задать вопрос, ваша честь? — спрашивает Навальный.
— Сторона защиты, пять минут вам переговорить, если вам интересно принимать участие в процессе, — предупреждает судья.
После перерыва судья просит Навального задавать вопросы и уточняет, что это нужно делать «четко, конкретно и уважительно». Политик просит занести в протокол протест судье, потому что Акимова не позволила ему задавать вопросы внуку Артеменко.
— Этот протест связан с тем, что как только я поймал свидетеля на лжи, вы сняли мой вопрос и объявили перерыв под выдуманным предлогом, чтобы свидетель мог проконсультироваться, как отвечать на этот вопрос, — считает политик.
Навальный снова говорит свидетелю, что он и сиделка дают противоречивые показания и спрашивает, кто из них лжет.
— Никто из нас не лжет. Позвонил Зине я, о том, что появилась информация в интернете о дедушке, сказал тоже я, информацию отправил ей тоже я. Показала она самовольно, — настаивает внук.
Показала она самовольно, — настаивает внук.
Навальный подчеркивает, что сиделка говорила, что показала Артеменко информацию по просьбе родственника ветерана. Свидетель объясняет, что они платят сиделке зарплату и она могла испугаться, что ее за это уволят.
— То, что она сказала, это неважно. Она сказала, как она эту ситуацию видит, то, как я вижу эту ситуацию, говорю я, — говорит свидетель.
Судья пеняет адвокатам, что они бездействуют и не призывают своего подзащитного к порядку.
— Скажите, пожалуйста, свидетель, вы нам сказали, что ни вы, ни ваш дедушка, ваши родственники с заявлениям в правоохранительные органы не обращались, — говорит Навальный. Свидетель подтверждает.
— Вы также сказали, что чтобы оградить своего дедушку, вы взяли все на себя, что вы имеете в виду, — продолжает политик.
Свидетель говорит, что дедушке начали звонить журналисты, а потом «товарищи» Навального нашли данные Колесникова, и на его номер стали приходить сообщения с угрозами, его поджидали у дома.
— Я стал отвечать на все звонки, которые поступали от всех источников, — говорит свидетель.
Далее Навальный пытается выяснить, кто именно написал заявление.
— Сиделка показала, что заявление в правоохранительные органы дедушка писал, но не сам, а вы помогали, — говорит политик.
— Мы на вас заявление не писали, — отвечает свидетель.
Навальный и его адвокаты просят суд «обозреть, зачитать свидетелю» заявление, которое находится в материалах дела, поскольку Колесников говорит, что его дедушка не писал заявление. Судья отмечает, что сейчас не «стадия исследования материалов».
— Господи боже мой, — негодует Навальный. — Вы еще меня останавливаете. Вы понимаете, как суд устроен вообще?
Адвокат Кобзев говорит: «Нам его потом еще раз что ли вызывать, чтобы он мог обозреть материалы?»
— Ваша честь, вы знаете отлично, что все в этом деле сфабриковано, и там есть заявление Артеменко, я его видел. И его внук врет, что заявления не было. Может, дело даже не в том, что врет, они все придумали. Следователь сам написал заявление, подписался дедом, а этот врет здесь. Поэтому покажите этот лист дела.
Может, дело даже не в том, что врет, они все придумали. Следователь сам написал заявление, подписался дедом, а этот врет здесь. Поэтому покажите этот лист дела.
Навальный вступает в перепалку с судьей: «Вы делаете вид, что вы судья, мало того, что вы по сути не судья, и решение принимаете не вы. Вы даже не понимаете, как процесс устроен. Вы даже не можете сфабриковать дело правильно. Меня это оскорбляет».
Гособвинитель просит отложить процесс, поскольку заседание длится с 10 утра и рабочее время закончилось. Навальный возражает: «В тот момент, когда я вас прижал к стенке, вы снова объявляете перерыв». В перепалку вступает и свидетель, и прокурор, и адвокаты Навального.
Судья обещает, что все листы дела будут рассмотрены на другом заседании.
Адвокат Михайлова отмечает, что они хотят предъявить документ свидетелю, пока он здесь, судья отмечает, что они могут сделать это в следующий раз, если свидетель явится.
— Когда вы его подготовите, — говорит Навальный.
— Не надо меня готовить, — отвечает свидетель.
Навальный уточняет, готов ли он отвечать на вопросы. Тот отвечает, что готов. Тогда политик снова спрашивает, кто написал заявление, которое лежит в материалах дела.
— Я могу отвечать? — спрашивает свидетель.
Судья откладывает заседание.
— Вы не можете оборвать просто так! Было мое ходатайство об обозрении материалов дела! — кричит Навальный.
В результате судья объявляет перерыв до 12 февраля.
Кто есть кто в YUNGRUSSIA
Гид по московскому шоукейсу молодых и дерзких.
9 мая на арт-заводе «Флакон» представители движения YUNGRUSSIA устраивают смотр своих достижений. Мы подготовили краткий гид по артистам, выступающим на шоукейсе популярного молодежного объединения.
PHARAOH
Кто это: Если вы зашли на наш сайт не впервые, то наверняка знаете. Негласный лидер объединения; новая рэп- (а, может быть, даже и рок-) звезда; 20-летний москвич с футбольным прошлым, благодаря которому “Молодая Россия” стала вербовать в свои ряды тысячи и тысячи слушателей.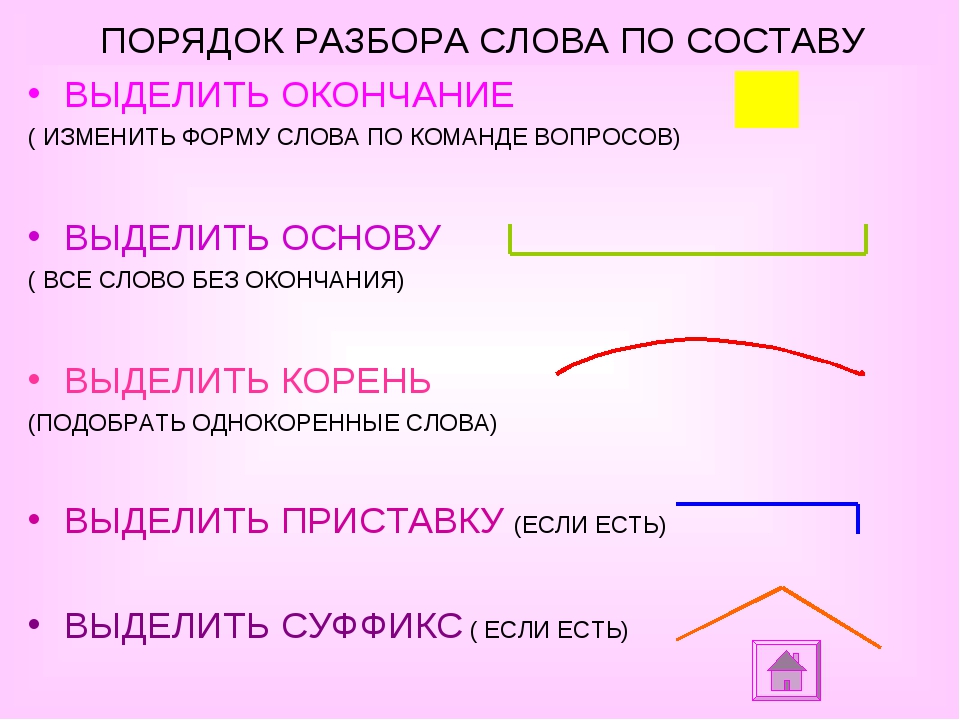 Невеселый загробный рэп и до него существовал в России, но благодаря ему захватил умы молодежи.
Невеселый загробный рэп и до него существовал в России, но благодаря ему захватил умы молодежи.
Подписаться: твиттер / инстаграм / саундклауд
Что слушать: Несмотря на то, что от главных хитов (“Black Siemens”, “Champagne Squirt”) автор методично открещивается, называя их самыми примитивными в своем репертуаре, не упомянуть о них как о песнях, разделивших историю Pharaoh на “до” и “после”, нельзя. Им в противовес — совместный с Boulevard Depo боевик “5 минут назад”, которому скоро станет тесновато в статусе интернет-хита, и наивно-романтичная “Бойсбэнд”, которая полтора года назад несправедливо прошла мимо всех радаров. Стилеформирующим же для Pharaoh стал прошлогодний микстейп “Dolor“, который не столько о суицидальных настроениях (альбом поставлялся с буклетом, содержащим предсмертное письмо), сколько о тревожном мироощущении вчерашних детей нулевых.
BOULEVARD DEPO
Кто это: Петербургский (а до этого — уфимский) рэпер-абсурдист, автор интернет-хитов “Сквирт шампанского в лицо” и “Мое имя Топский Павел” и термина weedwave, которым он описывает свою музыку. Песни Depo — непонятно куда ведущий поток сознания, иногда без рифм и структуры, но с обилием веб-сленга, перечислением разных сортов марихуаны и жаргонизмов собственного сочинения. Чтобы вы понимали: у него есть песня про то, как герой застрял внутри jpeg-файла, и песня, написанная от лица куста марихуаны в теплице. Название YungRussia, кстати, тоже его авторства.
Подписаться: твиттер / инстаграм / саундклауд / вконтакте
Что слушать: Прошлогодний микстейп “Otricala” и недавний “Плакшери”, совместный с Pharaoh. На них вальяжный и неторопливый стиль Depo раскрывается в полной мере. Естественно, без песен “OCB”, “Champagne Squirt” и “Мамина куртка” список будет неполным.
i61
Кто это: Создатель уфимского объединения Dopeclvb, звукорежиссер, обладатель кибер-очков и автор такой же кибернетической, музыки, вдохновением для которой служит пиксельно-восьмибитная романтика 80-х.
 В его песнях нарочно лоуфайный, кассетный звук, а голос пропускается через все возможные эффекты: так, что иногда сложно разобрать слова. Впечатление дополняют видеоклипы, которые выглядят как слегка безумный калейдоскоп. Он же стал инициатором создания комикса про YUNGRUSSIA.
В его песнях нарочно лоуфайный, кассетный звук, а голос пропускается через все возможные эффекты: так, что иногда сложно разобрать слова. Впечатление дополняют видеоклипы, которые выглядят как слегка безумный калейдоскоп. Он же стал инициатором создания комикса про YUNGRUSSIA.Подписаться: твиттер / инстаграм / вконтакте / саундклауд
Что слушать: Микстейпы “Shelby” (2014) и “Shelby 2: Infinity» (2015). Оба они записаны под впечатлением от компьютерной игры “Hotline Miami”, по словам автора, сильно на него повлиявшей, и нуарового синтипопа 20-летней давности. Особое внимание песням “Серпантин”, “Сестра” и “Neon City”.
BASIC BOY И GLEBASTA SPAL
Кто это: Если i61 — приверженец ностальгической электроники, то другие два человека из Dopeclvb тяготеют к автотьюновой и сиропной “новой Аланте”. Первый, кто приходит на ум после прослушивания — Young Thug, любитель сочинять двусмысленные и, на первый взгляд, дурацкие строчки. Главный тег для творчества Glebasta и Basic Boy — пост-ирония, именно она позволяет им сочинять прилипчивый стрит-поп про пусси-пиццу, факбоев и тамагочи.
Подписаться: вконтакте / твиттер Basic Boy / твиттер Glebasta Spal / саундклауд Glebasta Spal
Что слушать: Два прошлогодних микстейпа — “Вишневый сок” и “Dopetap3” — второй, как можно понять, демонстрирует совместные достижения уфимской “спортивной команды”. На нем же обнаруживается обезоруживающий неймдроппингом интернет-хит тандема “Стас Пьеха” и недавно ставшая дерганым клипом “Девочка-интернет”.
TECHNO
Кто это: Несмотря на название формирования, география участников YungRussia распространяется и за пределы страны. Яркий пример — 20-летний одессит, прежде скрывавшийся под именем Ca$$xttx (читается “Кассета”), теперь же выбрал моникер Techno (в Dead Dynasty состоят и другие украинцы — битмейкер-харьковчанин Southgarden, а также участники продюсерского коллектива FrozenGangBeatz).
 Не верьте: техно тут, конечно, нет и в помине. А что есть? Кодеиново-заторможенная музыка в стиле ранних Three 6 Mafia и песни молодого злодея.
Не верьте: техно тут, конечно, нет и в помине. А что есть? Кодеиново-заторможенная музыка в стиле ранних Three 6 Mafia и песни молодого злодея.Подписаться: вконтакте / твиттер / инстаграм
Что слушать: У Techno пока есть только одна песня, в скором времени обещан и микстейп. С музыкой, выпущенной под именем Ca$$xttx, легче — Вконтакте можно найти треков столько, что хватило бы и на дебютный релиз. Смена никнейма возникла не на пустом месте: если песни “позднего” Techno и соответствуют дэд-рэп пейзажам Dead Dynasty, то подписанные именем Ca$$xttx — совсем наоборот. Они наивны, ранимы, в таких если кто-то и умирает, то только внутренний ребенок, как в песне “Зеркала”. Цитата: “Эти дети так хотели кем-то стать и что-то значить, их учили бить ножом, спать с нелюбимыми телами”.
THOMAS MRVZ
Кто это: Простая аналогия: Мраз в YUNGRUSSIA — как Фрэнк Оушн в Odd Future. Мастер томного R&B, он одинаково успешно пробует себя и в мрачноватых балладах, и в духоподъемных песнях вроде прошлогодней “May13”. Важный момент: если творчество других “молодороссиян” требует какой-то предварительной подготовки, то песням Мраза легко сдаться безо всякого боя. Уже сейчас он — желанный гость на фитах, треками с ним в этом году отметились Яникс и Мезза.
Подписаться: твиттер / инстаграм / саундклауд
Что слушать: Недавний альбом “May13” — от начала и до конца. “Гимны романтика, из которых, как из распахнутой форточки, веет духом юности”, — вот что мы о них писали, и от слов своих не отступимся. Если вам станет мало, есть и двухлетней давности релиз “Emotional-8”.
ACID DROP KING
Кто это: Длинноволосый юноша, появляющийся почти в каждом клипе Pharaoh. Его можно увидеть и в самом первом видео Глеба “Ничего не изменилось”, и в самом, на текущий момент, последнем “Фосфоре”. Там он вместе со звездой Dead Dynasty исполняет странные танцы вдвоем посреди темного леса.

Подписаться: вконтакте / твиттер
Что слушать: А нечего слушать! Точнее, как — сольных песен у Ефима нет, зато есть нескольких совместок с Pharaoh. Одна из таких, «Russtrell», стала клипом и к сегодняшнему времени набрала больше миллиона просмотров. Цитата: «Чуваки говорят, я сдвинутый напрочь. Ты столько не видел, сколько снюхали за ночь».
JEEMBO
Кто это: артист из Уфы, тембром голоса напоминающий Schoolboy Q. Часто выступает в роли бэк-эмси на концертах Pharaoh. Возможно, самый техничный рэпер отряда. Пока коллеги стремятся выйти за рамки жанра, Jeembo играет по его правилам, но отыгрывает в техническом плане на совесть.
Подписаться: твиттер / инстаграм / вконтакте
Что слушать: И снова: сольного релиза нет, но дюжина фитов с Pharaoh, Boulevard Depo и другими есть. Буквально вчера вышла новая песня «Tommy». Нам нравится “Skate & Destroy” — такая “Kick Push” наоборот, песня о причастности к группировке единомышленников, о деструктивной юности и ломающихся при падении с доски костях. Скоро Jeembo обещает выпустить и дебют, спродюсированный одним из главных саунддизайнеров Dead Dynasty, продюсером stereoRYZE. Одно но: обещания о дебютном релизе звучат уже где-то года два.
УЧАСТНИКИ SABBAT CULT
Кто это: Группа Sabbat Cult изначально базировалась в Подмосковье, но постепенно состав расширился и до других городов. Песни — сами понимаете, не о цветочках и радугах. В здешних сюжетах уживаются психоделия и духовность, налёт мистики и отсылки к хоррорам. Что слушать: У влившегося в ряды Sabbat Cult относительно недавно уфимца Killah TVETH — альбом “Killin Hillz”.
У негласного лидера формации, Превосходного кота Протея, слушать том тягучего, будто перегнанного с жеванных кассет, трилла “Горе проигравшим”. Там есть песня “Живот”, в тексте которой постулируется круг интересов Sabbat: “Я смеюсь так долго, когда я покурю.
 Третье око бога у меня во лбу”. Ещё можно посмотреть единственный пока клип с факельными танцами в кадре.
Третье око бога у меня во лбу”. Ещё можно посмотреть единственный пока клип с факельными танцами в кадре.У называющего себя «проповедник черной мессы» рэпера GONE.Fludd — альбом «Формы и пустота» с многорукой Шивой на обложке, где сэмплируется Алина Орлова, а рэп читают так, будто заклятья накладывают.
PADILLION
Кто это: Битмейкеры — в принципе работники невидимого фронта, в случае с YUNGRUSSIA эта невидимость начинает расти в геометрической прогрессии. Что известно о Padillion: базируется во Флориде, но сейчас активно играет сеты в городах России. По сравнению с другими битмейкерами “молодой России” его музыка — светлая и успокоительная. Она ближе не к клауду и триллу, а к новым мутациям соула и электроники, которые продвигает калифорнийский лейбл Soulection (не так давно поставивший треки Padillion в своем подкасте). “Fuck 808s”, — пишет он в своем твиттере, это что-то вроде девиза.
Подписаться: твиттер / инстаграм / бэндкэмп / саундклауд
Что слушать: Песня с музыкой Padillion есть на альбоме Thomas Mrvz (“The Dome”). Как и любой саундклауд-продюсер, он выпускает много разрозненного материала, достаточно заглянуть к нему на страницу. Если вам нужны релизы, то можем посоветовать двухлетней давности EP “Feline” с котиками на обложке.
WHITE PUNK
Кто это: Прежде аффилиат продюсерской группы FrozenGangBeatz из Пензы, диджей и продюсер Dead Dynasty, писавший среди прочих музыку для резидентов Raider Klan. Его тяжелые тревожные биты как нельзя лучше подходят бунту молодых и злых: за замедленными яростными полотнами, где сэмплированы стоны и рёв из хорроров, вынырывающий из звукового тумана грохот стрельбы и взрывов, скрываются неожиданно летящие минорные синтезаторные мелодические линии. Получается контраст красоты и цветения со смертью и разложением.
Подписаться: твиттер / инстаграм / саундклауд
Что слушать: Спродюсированную им для Pharaoh “Идол” (почти 3 миллиона просмотров на YouTube), которой тот открывает свои концерты. Дебютный инструментальный альбом “Quintillian” — панихидный фонк, одного взгляда на треклист которого достаточно, чтобы уловить не самый лучистый настрой (названия треков: “Ворот из шипов”, “Запах измены”, “Из вен”). Ещё ремикс-альбом “Remixes Are Dead”, где на атомы расщепляются песни Drake и FKA twigs.
Дебютный инструментальный альбом “Quintillian” — панихидный фонк, одного взгляда на треклист которого достаточно, чтобы уловить не самый лучистый настрой (названия треков: “Ворот из шипов”, “Запах измены”, “Из вен”). Ещё ремикс-альбом “Remixes Are Dead”, где на атомы расщепляются песни Drake и FKA twigs.
Голландским журналистам «слили» новую «сенсацию» по делу рейса Mh27
Нидерландская вещательная корпорация NOS опубликовала запись переговоров, которые якобы велись после крушения малайзийского Boeing (рейс Mh27) под Донецком в июле 2014 года.
Как утверждается, на записи присутствует голос одного из обвиняемых по данному делу Сергея Дубинского, телефон которого прослушивался украинскими спецслужбами.
В распоряжении журналистов оказались сотни разговоров обвиняемого в июле и августе 2014 г. Как следует из опубликованных расшифровок, Дубинский обсуждал 16 июля по телефону переброску «Бука» на один из фронтовых участков под селом Мариновка.
Стоит отметить, что данная «утечка», опубликованная голландскими журналистами, вовсе не доказывает вину России, как это пытаются сделать представители следственной группы.
В одной из расшифровок можно разобрать слова о том, то пассажирский лайнер был сбит истребителем, который в разговоре назван «сушкой». А уже эта самая «сушка» после своей атаки была сбита «Буком».
Авторы «сенсации» настаивают, что говоривший о «сушке» — это гражданин России Сергей Дубинский. Однако в расследовании не говорится о том, что Дубинский ранее предлагал пройти детектор лжи, чтобы доказать свою невиновность.
Как передает агентство ТАСС, прокуратура Нидерландов отказалась комментировать «слив» материалов расследования в прессу. В надзорном ведомстве заявили, что не знают, каким образом журналисты получили записи.
Малайзийский Boeing 777, летевший из Амстердама в Куала-Лумпур, разбился 17 июля 2014 года под Донецком. Все 298 пассажиров, находившиеся на борту самолета, погибли. Следователи считают, что лайнер был сбит представителями ополчения ДНР из «Бука».
Все 298 пассажиров, находившиеся на борту самолета, погибли. Следователи считают, что лайнер был сбит представителями ополчения ДНР из «Бука».
Нидерланды утверждают, что за гибель людей ответственна именно Россия. Обвиняемыми по делу, кроме Дубинского, проходят россияне Игорь Гиркин (Стрелков), Олег Пулатов и украинец Леонид Харченко.
В концерне «Алмаз-Антей» признают, что сбившая самолет ракета применялась на «Буке», но настаивают, что она была устаревшей модели, которая не использовалась Российской армией с 2011 г., в то же время продолжая состоять на вооружении армии Украины.
Как сообщало EADaily, голландское следствие уже заранее во всем обвинило Россию и вся работа сводится к поиску доказательств этой версии. А возможную вину украинской стороны Нидерланды расследовать не будут. Невиновность Украины признана аксиомой, не требующей доказательств.
«Есть книги, для которых просто перевода недостаточно». Учёный, нашедший неизданные поэмы Набокова, — о его снах — Афиша Plus — Новости Санкт-Петербурга
Фото: из личного архива Андрея БабиковаПоделитьсяСочетание слов «Набоков» и «Супермен» оказалось настолько взрывным, что в марте 2021 года сообщение о том, что российский учёный Андрей Бабиков обнаружил стихотворение, написанное автором «Лолиты» от лица влюблённого супергероя, захватило средства массовой информации. Впрочем, автору находки не впервой открывать новое о писателе — в своей книге «Прочтение Набокова» в 2019 году Бабиков уже публиковал неизвестные стихи и письма, а последние полгода помогал с изданием работы об эксперименте со снами Набокова. Среди того, что, вероятно, скоро увидят читатели, — поэма о Севере с отблеском революции и новый перевод «романа-квинтэссенции».
— В Издательстве Ивана Лимбаха вышла составленная набоковедом, переводчиком Геннадием Барабтарло книга «Я\сновидения Набокова», которую вы редактировали. Что найдёт в ней читатель?
— Эта книга — результат пристального изучения набоковского «эксперимента» над собственным сознанием или, вернее, подсознанием. В октябре 1964 года живший в это время в Швейцарии Набоков решил проверить теорию английского авиатора, философа и инженера Джона Уильяма Дунна, который полагал, что во снах время движется вспять, и потому в них можно видеть отражение событий, которые ещё не произошли. Суть эксперимента в том, чтобы подробно и точно записывать свои сны сразу после пробуждения, а потом в течение нескольких дней стараться заметить какие-либо переклички увиденных во снах деталей, имен, явлений с реальными.
В октябре 1964 года живший в это время в Швейцарии Набоков решил проверить теорию английского авиатора, философа и инженера Джона Уильяма Дунна, который полагал, что во снах время движется вспять, и потому в них можно видеть отражение событий, которые ещё не произошли. Суть эксперимента в том, чтобы подробно и точно записывать свои сны сразу после пробуждения, а потом в течение нескольких дней стараться заметить какие-либо переклички увиденных во снах деталей, имен, явлений с реальными.
Дневник с изложением эксперимента на 118 карточках (Набоков пользовался для сочинения книг и для записей небольшого размера каталожными карточками, которые воспроизводятся в «Я/сновидениях Набокова». — Прим. ред.) хранится в Нью-Йоркской публичной библиотеке, в коллекции рукописей братьев Генри и Альберта Бергов (врачей, учёных, коллекционеров архивных материалов. — Прим. ред.). Геннадий Александрович [Барабтарло] стал их разбирать, сравнивать записи с событиями в жизни Набокова и его близких, с его произведениями и составлять к этому дневнику комментарии.
Некоторые совпадения снов и последующих деталей в реальности отметил сам Набоков в более поздних примечаниях на тех же карточках, но Барабтарло значительно расширил временные и тематические границы, исследовал его письма и записи более раннего и более позднего периода — обратил внимание на те вещи, о которых писатель ещё не мог знать. Барабтарло дополнил дневник коллекцией снов в произведениях Набокова, их множество в романах, рассказах, других дневниках. А далее в книге следуют эссе самого Геннадия Александровича, в которых он классифицирует набоковские сны, разбирает особенности его творчества сквозь призму набоковской концепции времени.
Сначала, в 2018 году, книга вышла на английском языке под выразительным названием «Insomniac Dreams» («Сны страдающего бессонницей». — Прим. ред.). Русское название не менее удачно и более многогранно.
— Барабтарло успел русифицировать свою английскую книгу, но окончательно готовить ее русский вариант к публикации пришлось уже без него?
— Он был уже очень болен и работу над русской версией последние два года вёл в состоянии все усиливавшейся слабости. Ему помогала жена, она указана в книге соавтором перевода, она же продолжила подготовку книги к печати после его смерти. Кроме того, переводы нескольких отрывков из произведений Набокова и целиком четвертой главы из второй части романа «Ада» я сделал по просьбе Геннадия Александровича специально для этого издания. Большую работу проделала главный редактор издательства Ивана Лимбаха Ирина Кравцова. Несколько месяцев мы с ней состояли в очень интенсивной переписке и много часов беседовали по телефону, поскольку оставалось еще много вопросов, на которые уже некому было ответить. Я внес небольшие уточнения в собственно перевод дневников, в текст цитат из произведений Набокова, проверил точность примечаний, дат, указаний, ссылок.
Ему помогала жена, она указана в книге соавтором перевода, она же продолжила подготовку книги к печати после его смерти. Кроме того, переводы нескольких отрывков из произведений Набокова и целиком четвертой главы из второй части романа «Ада» я сделал по просьбе Геннадия Александровича специально для этого издания. Большую работу проделала главный редактор издательства Ивана Лимбаха Ирина Кравцова. Несколько месяцев мы с ней состояли в очень интенсивной переписке и много часов беседовали по телефону, поскольку оставалось еще много вопросов, на которые уже некому было ответить. Я внес небольшие уточнения в собственно перевод дневников, в текст цитат из произведений Набокова, проверил точность примечаний, дат, указаний, ссылок.
Русское издание отличается от английского не только в отношении примечаний — не все понятное английскому читателю понятно русскому и наоборот. Было добавлено эссе составителя «Три времени глагола», включенное в раздел «Возвратный ветер». Разбирая дневник Набокова, Геннадий Александрович попутно рассмотрел особенности позднего набоковского стиля — в романах «Ада», «Сквозняк из прошлого» и «Взгляни на арлекинов!», которые практически не изучаются в России. Он оставил нам широкое поле для размышлений о природе набоковского искусства. Созданная книга уникальна, она совмещает в себе архивную публикацию, научное исследование, биографический очерк, философское рассуждение и дает материал для небывалого эксперимента над собственным сознанием, который может проделать любой желающий, следуя инструкциям Набокова и Дунна.
Фото: «Издательство Ивана Лимбаха»Поделиться— Прочитав книгу, сама утром поймала себя на мысли, что пытаюсь запомнить мельчайшие детали сна, чтобы потом сравнить их с реальностью. Вы сами пробовали повторить эксперимент Дунна?
— Записывать свои сны первым делом после пробуждения, чтобы они не забылись, запоминать детали, образы — не такое лёгкое занятие, как кажется. В течение дня есть опасность что-то домыслить, а этого делать нельзя. К записям нужно возвращаться и вносить пояснения, отмечать, что происходит в твоей жизни. Нет, я еще не повторил эксперимент Дунна — Набокова, хотя, конечно, в разное время замечал, что сны бывают необыкновенно артистичными, и записывал удивительные сюжеты так называемых вещих снов.
К записям нужно возвращаться и вносить пояснения, отмечать, что происходит в твоей жизни. Нет, я еще не повторил эксперимент Дунна — Набокова, хотя, конечно, в разное время замечал, что сны бывают необыкновенно артистичными, и записывал удивительные сюжеты так называемых вещих снов.
— Какой сон Набокова из этой книги вам особенно запомнился?
— На одной из карточек он пишет, что видел себя в кабинете директора музея, на столе у которого лежали рассыпчатые брикеты. Набоков машинально стал их есть, приняв их за печенье, а оказалось, что это были ценные образцы почв. Несколько дней спустя Набоков по телевизору посмотрел программу с разговором почвоведов в Африке, обсуждавших разные виды почв. Он заметил мешочки и кирпичики с образцами, похожие на те, которые он съел во сне. Тут-то Набоков и увидел точное подтверждение теории Дунна о «возвратном времени», о чем и написал на карточке: «Отмечаю абсолютное ясное ощущение, что этот фильм вызвал мой сон, если бы сон следовал за фильмом!»
— Верите ли вы в то, что дело здесь в движении времени, а не просто в совпадениях?
— Я полагаю, что само время — это и есть потенциальная возможность осуществления всего чего угодно, что только мы можем себе вообразить. Если мы будем рассуждать о времени в привычных категориях движения, мы будем его тем или иным способом сопрягать с пространством. Набоков писал, что, поскольку прошлого уже нет, будущего — ещё нет, а настоящее — только переход из одного состояния в другое, то времени не существует. Есть ощущение данности, момента, только и всего. Люди привыкли видеть, как стрелка часов бежит по кругу. Но ведь это олицетворение пространственных изменений — она лишь меняет своё положение в пространстве на циферблате, а то, как мы сами меняем свое положение в отношении своего прошлого и будущего, никто объяснить не может.
У Ходасевича есть изумительные стихи о времени: «Как птица в воздухе, как рыба в океане, / Как скользкий червь в сырых пластах земли, / Как саламандра в пламени — так человек / Во времени». Вот этот образ саламандры, не гибнущей в пламени, — человека, способного жить в испепеляющей стихии времени, по-моему, очень близок был представлениям Набокова, который, как известно, восхищался Ходасевичем.
Вот этот образ саламандры, не гибнущей в пламени, — человека, способного жить в испепеляющей стихии времени, по-моему, очень близок был представлениям Набокова, который, как известно, восхищался Ходасевичем.
— Могли ли вы представить, что найдёте и переведёте утерянное стихотворение Набокова о Супермене?
— Это только кажется, что такие открытия происходят вдруг. Об этом стихотворении впервые написал Эндрю Фильд — первый биограф Набокова, — не указав даже его названия. Позже автор замечательной двухтомной биографии писателя, «Русские годы» и «Американские годы», Брайан Бойд написал об этих стихах с поздних слов самого Набокова и наконец впервые привёл их название — «The Man of To-morrow’s Lament». Буквально «Горькая жалоба человека будущего». Человек будущего или Человек из стали — официальные названия Супермена в комиксах. Разумеется, я давно хотел найти это стихотворение.
Мои поиски были связаны с изучением малоисследованного периода первых лет Набокова в Америке, а также со всем, что могло раскрыть замысел и обстоятельства создания второй части «Дара». Я приехал в библиотеку Йельского университета и в архиве Эдмунда Уилсона — друга и патрона Набокова — среди стихотворений и рассказов 1940-х годов, которые тот ему посылал, обнаружил этот листок.
Было известно, что стихи писатель посылал в журнал New Yorker, поэтому я обратился к Ольге Ворониной (исследователь творчества Набокова. — Прим. ред.), которая изучала переписку Набокова с журналом. И она прислала мне письмо, в котором Набоков предложил стихотворение редактору журнала Чарльзу Пирсу, выразил надежду на то, что его «английский не слишком плох» и он сможет получить гонорар, окупающий его «мучения» от перехода с русского языка на английский. Но Пирс отказал, посчитав стихи слишком сложными и скабрезными, и они не были опубликованы и считались утерянными. А ведь, возможно, это первое в мире стихотворение о Супермене. Затем еще одна большая удача — мне удалось найти ту самую обложку комикса о Супермене за 1942 год, с которой Набоков заимствовал свой сюжет.
— Как вы поняли, что историю прогулки Супермена с Лоис Лейн в парке писатель не придумал и нужно искать источник?
— Догадаться об этом было невозможно, кто мог подумать, что Набоков настолько хорошо знаком с комиксами? Но меня заинтересовали начальные строки, которые в моем переводе звучат так: «Я вынужден носить очки, иначе / Состав ее для суперглаз прозрачен», то есть вожделеющий свою подругу по «Дейли Плэнет» (вымышленная газета, в которой работала Лоис. — Прим. ред.) Кларк Кент видит её буквально насквозь. Я решил проверить, есть ли где-нибудь в комиксах до мая 1942 года, когда было написано это стихотворение, изображение Супермена, использующего свое рентгеновское зрение, и стал пролистывать все выпуски подряд.
Таких рисунков было несколько: он смотрел сквозь стены, подслушивал и подсматривал козни злодеев. Так я дошёл до майского выпуска 1942 года — и вуаля! Вот же источник, вот эта сценка в парке, и слова Лоис Лейн, которая видит статую Супермена и спрашивает: «О Кларк, разве он не чудесен!?!» — не зная, что её спутник и есть этот самый супергерой. Слова Лоис Набоков слово в слово повторил в своем стихотворении. Это открытие, возможно, не менее важное, чем находка самого стихотворения: мы впервые сталкиваемся с тем, что Набоков в качестве основы своего произведения использует абсолютно реальный источник, никак его не скрывает, берет целую фразу из комикса и даже сохраняет знаки препинания. Поразительно, ведь Набоков всегда иронично относился к популярной культуре, держался от неё в стороне!
— Чем его так вдохновил Супермен?
— Тут совпало очень много обстоятельств, и в первую очередь — увлечение его восьмилетнего сына Мити комиксами. Уже позже я обратил внимание на письмо Набокова к жене Вере, в котором он пишет, что читал сыну перед сном гоголевский «Нос», а потом комиксы. Когда мальчик слушал «Нос», «он очень смеялся, но предпочитает Супермана» (Набоков произносил «Суперман»). Заметьте, как всё замкнулось: и находка, и источник, и биографическая основа. Человек будущего — одно из названий Супермена, о чем Набоков не мог бы узнать, не прочитав комикс.
Заметьте, как всё замкнулось: и находка, и источник, и биографическая основа. Человек будущего — одно из названий Супермена, о чем Набоков не мог бы узнать, не прочитав комикс.
К слову, тут возникает двусмысленность: автор написал «Жалобную песнь Супермена» в 1942 году, когда Гитлер, возомнив себя сверхчеловеком, пытался создать «мир будущего». И тут у Набокова, как всегда, есть второй план. Первый — история от лица Супермена о его отношениях с Лоис Лейн, с которой он не может иметь детей, потому что сила его страсти убьёт её в первую же брачную ночь. А второй план таков, что человек будущего — Супермен — парадоксальным образом оказывается лишённым будущего. Как и «сверхчеловеку» Гитлеру, ему остается только мечтать «быть нормальным парнем» и завести семью.
— Насколько хорошо исследователи знают Набокова-человека?
— В последние годы благодаря публикации «Писем к Вере», осуществленной Ольгой Ворониной и Брайаном Бойдом, благодаря публикации «Я\сновидений», переписки Набокова с Михаилом Карповичем, его близким американским другом, благодаря книге Максима Шраера о сложных отношениях Набокова и Бунина, благодаря другим исследованиям, русскому переводу большой книги Бойда «По следам Набокова», я надеюсь, читатели начинают несколько по-новому смотреть на разные обстоятельства его жизни, на некоторые черты его характера. Изменится, надеюсь, угол зрения. Многое ещё нужно разыскать, объяснить, прокомментировать и опубликовать, чтобы восстановить выпавшие страницы его биографии и внести уточнения в наше представление о нём как о человеке.
Долгие годы это представление оставалось очень грубым даже вопреки множеству фактов, собранных Бойдом и другими учеными: Набокова считали снобом, нарциссом, лицемером, капризным и неприятным субъектом. Занятная черта: в американской глуши этот нарцисс-аристократ мог подружиться со случайным соседом по гостинице, а проживая в Палас-отеле Монтре, он многое знал об окружающих его служащих, у кого какие беды, у кого жена скоро должна родить, был добр с открытыми и прямыми людьми и не прощал низости. Стремление его фигуру «разъяснить», упростить — ведь Набоков не вписывается не только в литературные рамки, — это стремление, вероятно, неосознанное, но действительно пагубное. Такие любительские занятия психоанализом по отношению к Набокову часто просто уморительны.
Стремление его фигуру «разъяснить», упростить — ведь Набоков не вписывается не только в литературные рамки, — это стремление, вероятно, неосознанное, но действительно пагубное. Такие любительские занятия психоанализом по отношению к Набокову часто просто уморительны.
— Есть ли шанс, что в архивах найдутся другие материалы, интересные не только набоковедам, но и широкому кругу читателей? Или же после «Лауры», а теперь и стихотворения о Супермене уже точно ничего не осталось?
— Именно это сейчас и происходит: коллеги публикуют или готовят к публикации ценные научные материалы по энтомологии, по переводческой его работе, его интервью, эссе. Мне недавно удалось обнаружить совершенно неизвестные сочинения Набокова на русском языке, которые не упоминаются ни в одном источнике, ни в одной биографии. Недавно я опубликовал его спортивную поэму «Олимпикум», готовлю к изданию и другие неизвестные поэмы. Некоторые вещи ждали своего часа, пока их рукописи расшифруют, как, например, рукопись «Солнечного сна» — самого крупного произведения Набокова до «Трагедии господина Морна», то есть до 1924 года. Эту поэму я опубликовал во втором номере роскошного альманаха Ивана Толстого «Connaisseur».
— Набоков не упоминал эти поэмы и, возможно, не хотел, чтобы они увидели свет. Насколько этично их публиковать теперь?
— Но Набоков не упоминал и некоторые ранние свои рассказы, которые, тем не менее, были опубликованы Дмитрием Владимировичем, его сыном. Мы же не знаем, почему он не говорил о них: может быть, полагал, что они не сохранились. И здесь нет его прямого запрета публиковать эти произведения. Я уверен, что Набоков не считал их своими лучшими достижениями в области поэзии, ни в коем случае, но, тем не менее, после публикации рассказов, после публикации «Оригинала Лауры» — романа, который он прямо запретил печатать, а сын его издал, посчитав, что его репутация классика, великолепного стилиста, оригинального мыслителя уже не может пострадать.
Напротив, с обнаружением неизвестных поэм 1920-х годов, о которых я пишу в своей книге «Прочтение Набокова», изданной Иваном Лимбахом, мы теперь видим такое разнообразие тем и сюжетов, о котором и не подозревали. Оказывается, ранний Сирин (псевдоним, которым Набоков пользовался с 1921 года. — Прим. ред.) писал не только «аккуратные», часто «банальные» эмигрантские стихи, как было принято думать. Он писал сказочные, фантастические, страшные, смелые вещи, не всегда, однако, удовлетворявшие его критериям технического совершенства. Я уверен, что Дмитрий Набоков, который прекрасно знал, ценил и переводил стихи отца на английский язык и с которым мы переписывались долгие годы, одобрил бы этот проект.
— Я знаю, что вы готовите свой перевод «Ады». Расскажите, пожалуйста, об этом.
— «Аду» на русский переводили несколько раз. Была «Ада, или Радости страсти», «Ада, или Эротиада». Название в оригинале — «Ada or Ardor», и для слова «ardor» — пыл, жар — я избираю «отрада», то есть у меня «Ада, или Отрада». Я долго думал, как лучше перевести название, ведь богатое латинское слово ardor есть во многих романских языках, но в русском его нет. Идеального переводческого решения для этой задачи нет. Вариант с «усладой» был «отбрит», и я несколько лет тому назад избрал рабочее название с «отрадой», которое стало постоянным после того, как я заметил, что сам Набоков в переводе одного из своих стихотворений «отраду» перевел как «ardor».
«Ада» — самый большой роман Набокова, вырастающий из всей набоковской писательской жизни. Книга требует большой сосредоточенности, основательного знания предыдущих его произведений. Это сложный, литературоцентричный, философский роман, наполненный разного рода загадками. Брайан Бойд уже 30 лет составляет подробные комментарии к нему на английском языке, публикует их частями, и я надеюсь, что этот труд он скоро доведет до конца.
— Чем текст «Ады» в новом переводе будет отличаться от предыдущих вариантов?
— Могу сказать коротко, что стихи, которых немало в этом романе, я перевожу в рифму, как в оригинале. Я не стараюсь ни «перенабоковить» Набокова, ни навязать ему свой стиль.
Я не стараюсь ни «перенабоковить» Набокова, ни навязать ему свой стиль.
— Как вы проверяете точность своего перевода? Как подбираете верные выражения для набоковского слога?
— Набоков сам великолепным образом отредактировал и авторизировал французский перевод «Ады» и раскрыл в нем несколько загадок. Работая над переводом, я постоянно сверяюсь с французским текстом. В 1965 году, приступая к «Аде», Набоков переводил на русский свою «Лолиту». Я специально занимался изучением лексики, оборотов, пунктуации русской версии романа, то, как он передавал в ней игру слов, какие термины использовал, какие нет. При этом, однако, события в «Аде» относятся главным образом к условному XIX веку, поэтому лексический состав в ней особенный. В русской версии «Лолиты» Набоков несколько модернизировал свой старый сиринский слог, но можно ли так же поступить с «Адой»? Вставленные Набоковым в английский текст русские слова и выражения написаны по правилам дореформенной орфографии. Ни о какой русской революции 1917 года живущие на Антитерре герои романа не знают.
Тут еще помогает изучение его писем к Вере 1970-х годов — в них мы видим тот самый романтический и точный русский, на который он сам хотел перевести «Аду» в поздние годы. Есть книги, для которых просто перевода недостаточно. Конечно, я использую его излюбленные обороты и словечки: «панель», «снедь», «жовиальный», «баснословный», но стараюсь не превращать свой перевод в антикварную лавку.
Беседовала Ольга Минеева, «Фонтанка.ру»
— WordReference.com Словарь английского языка
- Преобразование в ‘ parse ‘ (v): (⇒ сопряженное)
- parses
- v 3-е лицо единственного числа
- parsing
- v pres p глагол — настоящее причастие : глагол ing используется описательно или для образования прогрессивного глагола — например, « поет, птица», «Это поет, ».
 «
«
- проанализировано
- v прошедшее глагол, прошедшее простое : Прошедшее время — например,« Он увидел человека ».« Она засмеялась ».
- проанализировано
- v past p глагол, причастие прошедшего времени : Форма глагола, используемая описательно или для образования глаголов — например, « заперта, дверь», «Дверь была заперта , ».
 «
«WordReference Словарь американского английского языка для учащихся Random House © 2021
parse / pɑrs, pɑrz / USA произношение v.[~ + Объект], проанализировано, синтаксический анализ.
- Грамматика, лингвистика для анализа (предложения) с точки зрения его грамматических частей.
Полный словарь американского английского WordReference Random House © 2021
parse (pärs, pärz), США произношение v., parsed, pars • ing.
в.т.
- Грамматика, лингвистика для анализа (предложения) с точки зрения грамматических составляющих, определения частей речи, синтаксических отношений и т. Д.
- Грамматика, лингвистика для описания (слова в предложении) грамматически, идентифицируя часть речи, словоизменительную форму, синтаксическую функцию и т. Д.
- Computing: анализировать (строку символов), чтобы связать группы символов с синтаксическими единицами базовой грамматики.
в.
- Грамматика, лингвистика, чтобы допустить анализ.
парс ′ эр, н.
- Latin pars часть, как в pars ōrātiōnis часть речи
- 1545–55
Краткий английский словарь Коллинза © HarperCollins Publishers ::
синтаксический анализ / pɑːz / vb- для присвоения составной структуры (предложению или словам в предложении)
‘ parse ‘ также встречается в этих записях (примечание: многие из них не являются синонимами или переводами):
Анализ зависимостей | НЛП-прогресс
Синтаксический анализ зависимостей — это задача извлечения синтаксического анализа зависимости предложения, представляющего его грамматические
структура и определяет отношения между «головными» словами и словами, которые изменяют эти заголовки.
Пример:
корень
|
| + ------- dobj --------- +
| | |
nsubj | | + ------ det ----- + | + ----- nmod ------ +
+ - + | | | | | | |
| | | | | + -nmod- + | | | + -case- + |
+ | + | + + || + | + | |
Я предпочитаю утренний рейс через Денвер
Отношения между словами проиллюстрированы над предложением направленным, помеченным дуги от голов к иждивенцам (+ указывает на иждивенцев).
Penn Treebank
Модели оцениваются по Стэнфордской зависимости преобразование ( v3.3.0 ) Penn Treebank с предсказанных POS-тегов. Знаки препинания исключены из оценки. Метрики оценки — это немаркированная оценка привязанности (UAS) и маркированная оценка привязанности (LAS). UAS не учитывает семантическое отношение (например, Subj), используемое для маркировки вложения между головкой и дочерним элементом, в то время как LAS требует семантически правильную метку для каждого вложения.Здесь мы также упоминаем прогнозируемую точность маркировки POS.
| Модель | POS | UAS | LAS | Бумага / Источник | Код |
|---|---|---|---|---|---|
| Label Attention Layer + HPSG + XLNet (Mrini et al., 2019) | 97,3 | 97,42 | 96,26 | Переосмысление собственного внимания: к интерпретируемости для нейронного анализа | Официальный |
| Парсер HPSG (совместный) + XLNet (Чжоу и др., 2020) | 97.3 | 97,20 | 95,72 | Головной анализ грамматики структуры фраз на Penn Treebank | Официальный |
| Синтаксический анализатор HPSG (совместный) + BERT (Чжоу и Чжао, 2019) | 97,3 | 97,00 | 95,43 | Головной анализ грамматики структуры фраз на Penn Treebank | Официальный |
CVT + многоцелевой (Clark et al.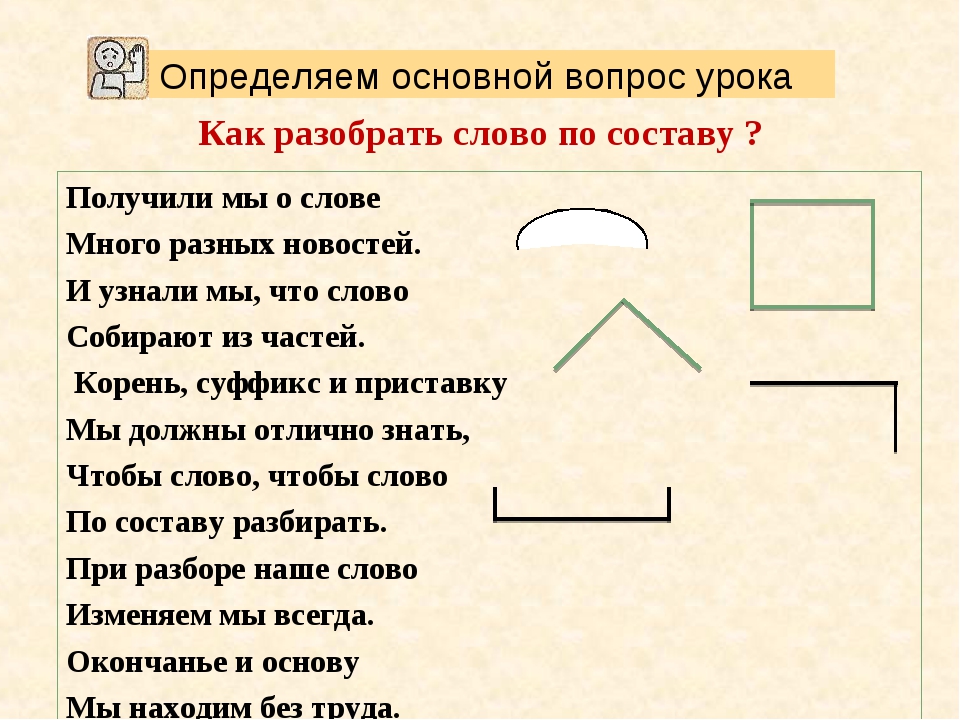 , 2018) , 2018) | 97.74 | 96,61 | 95,02 | Полу-контролируемое моделирование последовательности с перекрестным обучением | Официальный |
| CRF Parser (Zhang et al., 2020) | – | 96,14 | 94,49 | Эффективное дерево второго порядка CRF для анализа нейронных зависимостей | Официальный |
| Сеть указателей слева направо (Фернандес-Гонсалес и Гомес-Родригес, 2019) | 97.3 | 96,04 | 94,43 | Разбор зависимостей слева направо с сетями указателей | Официальный |
| Графический синтаксический анализатор с GNN (Ji et al., 2019) | 97,3 | 95,97 | 94,31 | Анализ зависимостей на основе графов с помощью графических нейронных сетей | |
| Deep Biaffine (Дозат и Мэннинг, 2017) | 97.3 | 95,74 | 94,08 | Deep Biaffine Attention для анализа нейронной зависимости | Официальный |
| jPTDP (Нгуен и Верспур, 2018) | 97,97 | 94,51 | 92,87 | Улучшенная модель нейронной сети для совместной маркировки POS и анализа зависимостей | Официальный |
| Andor et al. (2016) | 97.44 | 94,61 | 92,79 | Глобально нормализованные нейронные сети на основе переходов | |
| Дистиллированный нервный ВОГ (Kuncoro et al., 2016) | 97,3 | 94,26 | 92,06 | Преобразование ансамбля жадных анализаторов зависимостей в один синтаксический анализатор MST | |
Синтаксический анализатор на основе дистиллированных переходов (Liu et al. , 2018) , 2018) | 97.3 | 94,05 | 92,14 | Получение знаний для структурированного прогнозирования на основе поиска | Официальный |
| Weiss et al. (2015) | 97,44 | 93,99 | 92,05 | Структурированное обучение для анализа нейронной сети на основе переходов | |
| Анализатор на основе переходов BIST (Kiperwasser and Goldberg, 2016) | 97.3 | 93,9 | 91,9 | Простой и точный анализ зависимостей с использованием двунаправленных представлений функций LSTM | Официальный |
| Arc-гибрид (Ballesteros et al., 2016) | 97,3 | 93,56 | 91,42 | Обучение с исследованием улучшает жадный синтаксический анализатор Stack-LSTM | |
| Анализатор на основе графов BIST (Кипервассер и Голдберг, 2016) | 97.3 | 93,1 | 91,0 | Простой и точный анализ зависимостей с использованием двунаправленных представлений функций LSTM | Официальный |
Универсальные зависимости
В центре внимания задачи — изучение синтаксических анализаторов зависимостей, которые могут работать в реальных условиях, начиная с необработанного текста, и которые могут работать со многими типологически разными языками, даже с языками с низким уровнем ресурсов, для которых мало или совсем нет обучающих данных. , используя общий стандарт синтаксической аннотации.Эта задача стала возможной благодаря инициативе Universal Dependencies (UD, http://universaldependencies.org), которая разработала древовидные банки для 60+ языков с кросс-лингвистически согласованной аннотацией и возможностью восстановления исходных исходных текстов.
Участвующие системы должны будут найти помеченные синтаксические зависимости между словами, то есть синтаксический заголовок для каждого слова и метку, классифицирующую тип отношения зависимости. Помимо синтаксических зависимостей, будет оцениваться прогноз морфологии и лемматизации.Будет несколько наборов тестов на разных языках, но все наборы данных будут соответствовать общему стилю аннотаций UD. Участников попросят проанализировать необработанный текст, если предварительная обработка по золотому стандарту (токенизация, леммы, морфология) недоступна. Данные, предварительно обработанные базовой системой (UDPipe, https://ufal.mff.cuni.cz/udpipe), были предоставлены, чтобы участники могли сосредоточиться на улучшении только одной части конвейера обработки. Организаторы считали, что это делает задачу доступной для всех.
Следующие результаты приведены только для справки:
Межъязычный синтаксический анализ с нулевым выстрелом — это задача вывести синтаксический анализ зависимостей предложений на одном языке без каких-либо помеченных деревьев обучения для этого языка.
Банк деревьев универсальных зависимостей
Модели сравниваются с Universal Dependency Treebank v2.0. Для каждого из 6 целевых языков модели могут использовать деревья всех других языков и английского языка и оцениваются UAS и LAS на целевом объекте.Итоговая оценка — это средний балл по 6 целевым языкам. Наиболее распространенная установка для оценки — использовать золотые POS-теги.
Неконтролируемый синтаксический анализ зависимостей — это задача определения синтаксического анализа зависимостей предложений без каких-либо помеченных обучающих данных.
Penn Treebank
Как и в случае контролируемого синтаксического анализа, модели сравниваются с Penn Treebank. Наиболее распространенная установка для оценки — использовать золотые POS-теги в качестве входных данных и для оценки систем с использованием немаркированной оценки вложений (также называемой «направленной зависимостью точность’).
Вернуться к README
Что такое анализатор электронной почты? Определение парсинга электронной почты
Сильвестр Дюпон
6 минут чтения
Анализатор электронной почты — это программный инструмент, который преобразует необработанное электронное письмо в читаемый формат. На самом деле существует две основные категории парсеров электронной почты. Во-первых, низкоуровневые парсеры MIME электронной почты декодируют необработанные электронные письма в читаемый текстовый формат . Во-вторых, высокоуровневые парсеры содержимого электронной почты преобразуют содержимое электронных писем в структурированные данные .Структурированные данные — это формат данных со структурным значением, то есть понятный для машины. Структурированные данные обычно можно визуализировать в Excel или использовать в качестве входных данных для другого программного обеспечения (например, как часть автоматизированного бизнес-процесса).
Мы более подробно рассмотрим парсеры электронной почты. Но сначала …
Определим парсинг, что такое парсинг и что делают парсеры
Погодите, может, вас в первую очередь привлекло слово «синтаксический анализатор».
Так что же такое парсер?
Даже Гарри Поттер использует язык синтаксического анализатора, чтобы говорить на Python
Определение синтаксического анализа
Этимологически глагол to parse происходит от латинского pars , что означает множественное число , часть .Итак, синтаксический анализатор имеет какое-то отношение к идентификации частей чего-либо.
Фактически, синтаксический анализатор — это инструмент, который может анализировать и идентифицировать значимые части в тексте . В случае с причудливыми словами синтаксический анализ данных означает процесс анализа строки символов на естественном языке или на компьютерных языках в соответствии с правилами формальной грамматики (спасибо, Википедия, за то, что заставили нас здесь выглядеть умными).
Синтаксический анализатор — это компьютерная программа, которая определяет набор инструкций в своем исходном коде для анализа входных предложений и преобразования их в структуры данных. Обычно это делается с помощью деревьев синтаксического анализа для лексического и синтаксического анализа.
Давайте возьмем пример, если это все еще слишком неясно. Пока вы читаете именно это предложение, последовательность букв на экране, ваш мозг понимает его значение. Ваш мозг действует как парсер:
- он сначала определяет последовательность букв, составляющих слова. Это называется лексическим анализом.
- , то он использует грамматику и контекст, чтобы понять значение слов, соединенных в предложение.Это синтаксический анализ.
Прямо сейчас вы занимаетесь синтаксическим анализом!
Синтаксические анализаторы в информатике
В информатике синтаксический анализатор — это то, что позволяет машине понять, что имеет в виду программист, когда он набирает код на выбранном им языке программирования. Синтаксический анализатор считывает код и, через несколько уровней синтаксического анализа, в конечном итоге преобразует его в набор нулей и единиц, который запускает то, что появляется на экране, данные отправляются через Интернет или запускает Yo !.
Мир синтаксического анализа в информатике имеет глубокую и богатую теоретическую базу, а также такие жаргоны, как Lexical Analysis , грамматика Хомского , Backus – Naur form и т.д. по грамматике и методам синтаксического анализа. Это очень весело!
Теперь, когда мы надеемся, что это прояснилось, давайте вернемся к нашим анализаторам электронной почты.
Что такое парсер MIME?
Аудитория: Парсеры MIME предназначены для людей с техническим / программным образованием .
MIME (для многоцелевых расширений электронной почты в Интернете) — это стандартный формат Интернета , в котором сообщения электронной почты кодируются . Формат MIME поддерживает обработку различных наборов символов, нетекстовых вложений (таких как изображения, аудио) и составного тела сообщения, что позволяет объединить все это вместе. Как и большинство интернет-стандартов, MIME был определен IETF посредством набора RFC (запросов на комментарии): в основном RFC 2045, RFC 2046, RFC 2047, RFC 4288, RFC 4289 и RFC 2049.
Электронные сообщения MIME-анализаторы используются для декодирования электронных писем, закодированных в MIME.Такой синтаксический анализатор может извлекать заголовок (который включает электронную почту отправителя, электронную почту получателя, тему, дату и т. Д.), Извлекать тело письма и любое вложение.
Существует большое количество библиотек с открытым исходным кодом, которые обеспечивают анализ электронной почты MIME на большинстве языков программирования. Например:
Существует также ряд онлайн-платформ SaaS, которые предлагают синтаксический анализ MIME в качестве услуги, например:
Что такое анализатор электронной почты?
Аудитория: парсеров электронной почты предназначены для людей с опытом автоматизации бизнес-процессов .Парсеры электронной почты отлично подходят для автоматизации процессов ввода данных электронной почты.
Основная проблема с электронными письмами заключается в том, что они по своей природе представляют собой просто поток неструктурированного текста. Машины обычно не любят неструктурированные данные, из-за которых кому-то сложно включить входящие электронные письма в рабочий процесс автоматизации.
Парсер электронной почты (он же парсер электронной почты, или средство извлечения данных электронной почты, или анализатор электронной почты содержимого) предназначен для людей, которым необходимо извлечь некоторый фрагмент текста из своих электронных писем и поместить их в электронную таблицу Excel или передать его другому программному обеспечению для обработки / отслеживания. .Другими словами, анализатор электронной почты извлекает неструктурированный текст из электронного письма и преобразует его в структурированные данные .
Пример парсера электронной почты, преобразующего электронное письмо с уведомлением Twitter в структурированные данные
Эти парсеры электронной почты особенно полезны для обработки большого количества электронных писем, сгенерированных компьютером.
Когда использовать анализатор электронной почты?
Существует множество доменов, которые используют парсеры электронной почты, чтобы помочь им автоматизировать свой бизнес.
Вот некоторые примеры использования парсера электронной почты:
- Анализировать электронные письма с подтверждением электронной коммерции (с таких торговых площадок, как Amazon, Ebay, Etsy, Craiglist и т. Д.). Затем загрузите их в простую электронную таблицу или сложное программное обеспечение для управления логистикой, такое как SAP, чтобы управлять обработкой заказов и отслеживать ее
- Анализируйте электронных писем с уведомлениями о недвижимости, поступающих с разных веб-сайтов с объявлениями о недвижимости. Затем объедините их все в электронную таблицу или в предпочитаемое программное обеспечение CRM (например, Salesforce, Pipedrive, Zoho).
- Анализируйте электронные письма с подтверждением поездки (например, подтверждения рейсов, подтверждения отелей, подтверждения аренды).И скормить их в программное обеспечение для корпоративного управления поездками или просто создать карту путешествий
- Анализировать отчеты мониторинга сети и системы (например, Pingdom, NewRelic, Dynatrace). Объедините все предупреждения в одном хранилище данных, чтобы отслеживать и обнаруживать любые проблемы автоматически и централизованно
- Анализировать электронные письма с уведомлениями из социальных сетей (например, из Twitter, Facebook, LinkedIn, Pinterest). Затем отслеживайте их и в конечном итоге убедитесь, что следующих пользователей благодарили / принимали / поддерживали
- И многие другие , небо — предел! Электронные письма, сгенерированные компьютером, повсюду и содержат множество данных, на которые полагаются предприятия.
Последнее обновление:
CoNLL 2018 Общая задача
Сценарий оценки (версия 2018) доступен для Скачать здесь.
Все системы должны будут генерировать допустимые выходные данные в Формат CoNLL-U для всех тестов наборы.
Определение «действительного» не такое строгое, как для выпущенных древовидных банков UD. Например, неизвестная метка отношения зависимости будет стоить всего один в отмеченной оценке точности, но не будет отображать всю файл недействителен.Однако циклы, несколько корневых узлов, неправильное количество столбцы или неправильная индексация узлов будут считаться недопустимым выводом. После этого оценка конкретного тестового файла будет установлена на 0. (но общая макро-оценка все равно будет отличной от нуля, если результаты для других тестовые файлы действительны).
Системы будут знать язык и код банка дерева набор тестов, но они должны реагировать даже на неизвестный язык / древовидный набор коды (для которых нет обучающих данных). Системы будут возможность выбрать либо необработанный текст в качестве ввода, либо файл, предварительно обработанный UDPipe.Каждая система должна выдавать действительные выходные данные для каждого набора тестов.
Несколько разных показателей, оценивающих разные аспекты аннотации, будет вычисляться и публиковаться для каждого выхода системы. Три основные системы Рейтинг будет основан на трех основных показателях. Ни один из них не важнее чем другие, и мы не будем объединять их в один рейтинг. Участники, желающие снизить сложность задачи, могут сосредоточиться на улучшения всего по одной метрике; однако все участвующие системы будут оцениваться по всем трем показателям, и участникам настоятельно рекомендуется для вывода всех соответствующих аннотаций (синтаксис + морфология + леммы), даже если они просто копируют значения, предсказанные базовой моделью.Три основных показателя являются:
- LAS (оценка привязанности) будет вычисляться так же, как и в задача 2017 года, чтобы можно было сравнить результаты двух задач.
- MLAS (оценка прикрепления с учетом морфологии) основана на Показатель CLAS рассчитан в 2017 г. и расширен за счет оценки тегов POS и морфологические особенности.
- BLEX (оценка двулексической зависимости) объединяет отношения содержания и слова с лемматизацией (но не с тегами и функциями).
Все три показателя отражают сегментацию слов и отношения между контентом слова; это остается основным направлением совместной задачи. LAS также включает отношения между другими словами, но игнорирует морфологию и леммы. В две другие метрики ближе к содержанию и значению; Оценки MLAS должны также быть более сопоставимыми между типологически разными языками.
Сегментация слов должна быть отражена в показателях, потому что системы не имеют доступа к сегментация по золотому стандарту, и определение слов является предварительное условие для оценки зависимости.
Оценка начинается с сопоставления слов, произведенных системой, с золотым стандартные; отношение не может считаться правильным, если одно из связанных узлы не могут быть выровнены по соответствующему узлу золотого стандарта. Согласование алгоритм требует, чтобы системы сохранили входную последовательность непробельные символы. Если в системе используется токенизатор или морфологический анализатор, который нормализует или иным образом повреждает входные символы, то система должна запомнить исходные непробельные символы и восстановить их на этапе постобработки.Любые токены, состоящие из нескольких слов, которые производит система, должны быть должным образом отмеченными как таковые, а поверхностная струна, которой они соответствуют должно быть указано.
Оценка прикрепления с маркировкой (LAS) стандартная метрика оценки при разборе зависимостей: процент
слов, которым присвоены как правильный синтаксический заголовок, так и
правильная метка зависимости. Для целей подсчета очков только универсальный
метки зависимостей будут приняты во внимание, что означает, что
специфичные для языка подтипы, такие как acl: relcl (относительный
clause), подтип универсального отношения acl (adnominal clause), будет усечено до acl как в
золотой стандарт и в выводе парсера в оценке.(Парсерам по-прежнему рекомендуется выводить специфичные для языка отношения, если они могут их предсказать, поскольку это делает парсеры более полезными вне общей задачи.)
Как и в 2017 году, все узлы, включая знаки препинания, будут отражены в LAS.
Этот показатель учитывает несоответствия сегментации слов в
учетная запись. Таким образом, зависимость считается правильной, только если оба
узлы отношения соответствуют существующим узлам золотого стандарта. Точность P
количество правильных отношений, деленное на количество
узлы системного производства; напомним, R — количество правильных соотношений
делится на количество узлов золотого стандарта.Затем мы определяем
LAS как оценка F 1 = 2PR / (P + R).
Системы будут ранжироваться на основе среднего макроса LAS по всем тестам.
Оценка прикрепления с указанием морфологии (MLAS) нацелен на кросс-лингвистическую сопоставимость оценок. Это расширение CLAS (опубликовано экспериментально в 2017 г.) в сочетании с оценкой UPOS теги и морфологические признаки. Основная часть идентична описанной LAS выше: для выровненных системных и золотых узлов их соответствующие родительские узлы считается; если системный родитель не выровнен с золотым родителем или если метка отношения отличается, слово не считается правильно прикрепленным.в отличие в LAS определенные типы отношений не оцениваются напрямую. Слова прилагаются через такие отношения (как в системе, так и в данных о золоте) не считаются самостоятельные слова. Однако они рассматриваются как особенности слов содержания. они принадлежат. Следовательно, слово S, произведенное системой, считается правильным, если все соблюдены следующие условия:
- Соответствует золотому стандарту слова G.
- Их соответствующие родительские узлы правильно выровнены друг относительно друга.
- Универсальные части их отношений зависимости находятся в списке «отношений содержания» и совпадают.
- Теги UPOS слов S и G идентичны.
- Для выбранных морфологических признаков (см. Список ниже) их значения в точках S и G идентичны (отсутствующие признаки считаются пустым значением). В случае использования нескольких значений (например,
Gender = Masc, Neut) все строки значений должны быть идентичны. И S, и G могут также иметь другие функции, но они игнорируются при оценке. - «Функциональные дочерние элементы» узла — это дочерние узлы, присоединенные через отношение, которое находится в списке «функциональных отношений».Если они присутствуют, они определяют дополнительные условия, при которых узел S будет считаться правильным:
- Каждый функциональный дочерний элемент S должен быть согласован с функциональным дочерним элементом G.
- Каждый функциональный дочерний элемент G должен соответствовать функциональному дочернему элементу S.
- Для каждой пары выровненных функциональных детей FS и FG:
- Универсальная часть метки их отношения к S (соответственно G) должна совпадать.
- Их теги UPOS должны быть идентичными.
- Значения перечисленных морфологических признаков должны соответствовать аналогично тому, как сравниваются признаки слов содержания.
- Когда вычисляется точность P, количество правильных слов делится на общее количество созданных системой слов содержания, то есть тех, которые присоединены через «отношение содержания».
- При вычислении отзыва R количество правильных слов делится на общее количество слов содержания золотого стандарта, т.е.е., те, которые прикреплены через «отношение содержания».
- «Контентные отношения»:
nsubj,obj,iobj,csubj,ccomp,xcomp,obl,вокативный падеж, 901 adv40 ,развернутый,advmod,discourse,nmod,appos,nummod,acl,amod,conc,fixed,flat,complexсирота,идет с,reparandum,root,dep. - «Функциональные отношения»:
aux,cop,mark,det,clf,case,cc. - Обратите внимание, что отношение
точкане является ни содержательным, ни функциональным. Это игнорируется в MLAS. - «Выбранные функции»:
PronType,NumType,Poss,Reflex,Foreign,Abbr,Gender,Animacy,Number, DefiniteCaseградусов,VerbForm,Mood,Tense,Aspect,Voice,Evident,Polarity,Person,Polite.Примечание. Все эти функции определены как «универсальные» в рекомендациях UD v2. Тем не менее, оценка будет отражать все значения этих функций, которые появляются в данных, включая дополнительные значения, зависящие от языка.
Оценка билексической зависимости (BLEX) похож на MLAS в том, что он фокусируется на отношениях между словами содержания. Вместо морфологических признаков он включает лемматизацию в оценка. Таким образом, он ближе к семантическому содержанию и оценивает два аспекта аннотаций UD, которые важны для понимания языка: зависимости и лексемы.В BLEX слово S, созданное системой, является правильным, если оно выровнено к золотому стандарту слова G, их родители выровнены, универсальные части их типов отношений идентичны и перечислены как «отношения содержания» (как и в MLAS), и их леммы совпадают. «Соответствующие леммы» обычно означают одинаковые строки в столбце леммы; однако, если золотая лемма - единственная символ подчеркивания («_»), любая системная лемма считается правильной. Как и в случае с MLAS, количество правильных слов делится на общее количество содержательные слова в соответствующем наборе данных для вычисления точности, вспомнить и счет F1.Обратите внимание, что функциональные дочерние элементы игнорируются и не внести свой вклад в BLEX.
Помимо показателей, описанных выше, мы будем оценивать системы по различные другие размеры. Участникам предлагается предсказывать даже морфологические признаки и подтипы отношений, которые не оцениваются в LAS / MLAS / BLEX; такая система более полезна для реального развертывания, поэтому мы планируйте оценивать все функции в одной из вторичных метрик. Кроме того, мы можем публиковать дополнительные рейтинги для подзадач (например,г., выступление на малоресурсные языки).
Мы используем платформу Tira для оценки участвующих систем. Следовательно, участники будут представлять системы, а не проанализированные данные, что увеличивает проверяемость и воспроизводимость результатов.
Формат данных и подробные сведения об оценке
Формат данных CoNLL-U, используемый для универсального Дерево зависимостей более подробно описано на http://universaldependencies.org/format.html. Он намеренно похож на формат CoNLL-X, который использовался в CoNLL 2006 Shared Task и с тех пор стала стандартом де-факто.У каждого слова есть собственная строка, и есть столбцы, разделенные табуляцией для словоформа, лемма, тег POS и т. д. Например, следующий фрагмент кодирует английское предложение Они покупают и продают книги .
1 Они PRON PRP Case = Nom | Number = Plur 2 nsubj _ _
2 купить купить ГЛАГОЛ VBP Number = Plur | Person = 3 | Tense = Pres 0 root _ _
3 и и CONJ CC _ 2 cc _ _
4 продавать продавать ГЛАГОЛ VBP Number = Plur | Person = 3 | Tense = Pres 2 cons _ _
5 книг книга СУЩЕСТВУЕТ NNS Число = Plur 2 dobj _ Пробел = Нет
6. . ПУНКТ._ 2 пункта _ _
Синтаксические слова и токены из нескольких слов
Однако есть несколько важных расширений w.r.t. формат CoNLL-X. Возможно, наиболее важным является понятие из синтаксических слов против многословных лексем . Это делает этап токенизации в UD сложнее, чем относительно простой В других областях НЛП процедура называется токенизацией. Например, Немецкий zum - это сокращение предлога zu «К», и артикул dem «The».В UD это многословный токен, состоящий из двух синтаксические слова, zu и dem . Эти синтаксические слова - это узлы в отношениях зависимости. Изучение этого сложнее, чем отделить знаки препинания от слов, потому что сокращение не является чистым соединением участвующих слов. CoNLL-U формат использует здесь два разных механизма: пунктуацию, обычно пишется рядом со словом - это отдельный одно слово" токен, а атрибут в последнем столбце сообщает, что не было пробел между знаком препинания и словом.На с другой стороны, сокращение - это токен из нескольких слов, который имеет отдельная строка, начинающаяся с ряда следующих синтаксических слов, которые принадлежат ему. Рассмотрим немецкую фразу zur Stadt, zum Haus «to город, к дому ». Соответствующий раздел CoNLL-U может выглядеть так:
1-2 zur _ _ _ _ _ _ _ _
1 zu _ ADP _ _ 3 случая _ _
2 der _ DET _ _ 3 det _ _
3 Stadt _ NOUN _ _ 0 root _ SpaceAfter = Нет
4, _ ТОЧКА _ _ 3 точки _ _
5-6 зум _ _ _ _ _ _ _ _
5 zu _ ADP _ _ 7 case _ _
6 dem _ DET _ _ 7 det _ _
7 Haus _ СУЩЕСТВИТЕЛЬНОЕ _ _ 3 cons _ _
Мы не будем оценивать, правильно ли сгенерирована система SpaceAfter = Нет атрибута .Но созданный системой файл CoNLL-U должен быть токенизированным.
исходного текста; если система решит разделить zum в zu и dem , не забудьте также сгенерировать
строка с несколькими словами 5-6 zum .
Придется выровнять узлы (синтаксические слова), выводимые системой в соответствии с золотым стандартом данные. Таким образом, если система не распознает zur как сокращение и выводит
мы будем обрабатывать любые отношения, идущие к узлу или от узла zur как неверно.То же самое произойдет с узлом « Stadt, »,
если система не сможет отделить пунктуацию от слова Stadt .
Если система ошибочно разбивает слово Haus и выходы
отношения, включающие Hau или das , будут рассматриваться
неверно.
Даже если система распознает zur как сокращение, но выводит неверные синтаксические словоформы, токены будет считаться неверным:
Отношения с участием узла 1 неверны, но отношения с участием узла 2 может быть правильным.Исключение: совпадение нечувствительно к регистру, поэтому разделение Zum - zu dem или zum to Zu dem оба в порядке.
Согласование системных слов с золотым стандартом
Простая часть: предположим, что нет токенов, состоящих из нескольких слов (схватки). Обе последовательности токенов (золото, система) имеют одинаковые основной текст (без пробелов). Токены могут быть представлены как диапазоны символов. Мы можем найти пересечения системного характера диапазоны с золотыми диапазонами символов и найдите мировоззрение за один проход.
Предположим, что есть несколько слов жетоны. Они могут содержать что угодно, не похожее на Первоначальный текст; однако данные по-прежнему содержат исходную поверхность форме, и мы знаем, какой части основного текста они соответствуют к. Таким образом, нам нужно только выровнять отдельные слова между золотом и системный токен из нескольких слов. Мы используем LCS (самый длинный из распространенных подпоследовательность) для этого.
Границы предложений будут проигнорированы во время выравнивания токенов, т.е.е. весь набор тестов будет выровняться сразу. Системы должны будут исполнить приговор сегментация для создания действительных файлов CoNLL-U, но предложение границы будут оцениваться только косвенно, через зависимость связи. Отношение зависимости, которое встречается в золотом приговоре граница неверна. Если, с другой стороны, система генерирует ложный разрыв предложения, он не будет наказан напрямую, но там обязательно будет хотя бы одно золотое отношение, которое система упустила; отсутствие баллов за такие отношения будет косвенным наказание за неправильную сегментацию предложения.
Мы стремимся исследовать, насколько хорошо различаются внутренние оценки показатели коррелируют со сквозной производительностью в нисходящем NLP приложения, которые, как считается, получают пользу от грамматического анализа: извлечение биологических событий, детальный анализ мнений и разрешение области отрицания.
Сотрудничаем с Инициатива по оценке внешнего парсера (EPE) и предоставит нашим участникам возможность принять участие в этом задача с минимумом дополнительных усилий. Будет дополнительный "тест" установлен на синтаксический анализ (только на английском языке, 1.1 миллион токенов, тот же формат ввода, что и UD data) доступны в TIRA. Когда наши участники успешно обработали стандартные наборы тестов UD, им рекомендуется вызывать другую систему, работающую на TIRA, обработка входных данных EPE. Чтобы не мешать основной задаче синтаксического анализа, Срок подачи заявок на запуск системы EPE истекает через неделю. Организаторы EPE затем соберут выходные данные парсера из TIRA и определять внешние, последующие результаты; этот шаг вычислительно интенсивно, поскольку требует переподготовки трех приложений EPE на каждом набор выходов парсера.Следовательно, результаты EPE будут публиковаться только незадолго до истечения первоначального срока подачи описаний систем.
См. Информация для участников EPE 2018 для дополнительные детали.
NLPwin - Microsoft Research
Введение Люси Вандервенде *
* от имени всех, кто внес вклад в разработку NLPwin
NLPwin - это программный проект Microsoft Research, целью которого является предоставление инструментов обработки естественного языка для Windows (отсюда и NLPwin).Проект был начат в 1991 году, когда Microsoft открыла исследовательскую группу Microsoft; хотя активное развитие NLPwin продолжалось в течение 2002 года, он все еще регулярно обновляется, в основном для обслуживания машинного перевода.
NLPwin использовался и до сих пор используется в ряде продуктов Microsoft, среди которых Index Server (1992-3), Word Grammar Checker (анализ каждого предложения в логической форме с 1996 года), функция запросов на английском языке для SQL Server (SQL Server 1998 - 2000), интерфейс запросов на естественном языке для Encarta (1999, 2000), Intellishrink (2000) и, конечно же, Bing Translator.
Поскольку мы знали, что разрабатываем NLPwin частично для поддержки средства проверки грамматики, грамматика NLPwin разработана так, чтобы обеспечивать широкий охват (т.е. не зависящую от предметной области) и быть устойчивой, в частности, устойчивой к грамматическим ошибкам. Хотя большинство грамматик изучается из данных, аннотированных в PennTreeBank, интересно учитывать, что такие грамматики могут быть не в состоянии анализировать неграмматическую или фрагментированную грамматику, поскольку эти грамматики не имеют обучающих данных для такого ввода. Грамматика NLPwin производит синтаксический анализ для любого ввода, и если охватывающий синтаксический анализ не может быть назначен, он создает «подобранный» синтаксический анализ, объединяющий самые большие составляющие, которые он смог построить.
Радуга НЛП: мы предвидели, что с еще более сложными возможностями анализа можно будет создавать самые разнообразные приложения. Как вы можете видеть ниже, компонент генерации не был хорошо разработан, и мы постулировали приложения NL для генерации так же, как надеются на горшок с золотом в конце радуги. Наши первые модели машинного перевода передавались на семантическом уровне (статьи до 2002 г.), в то время как сегодня наши машинные переводы в основном передаются на синтаксическом уровне, используя смесь моделей, основанных на синтаксисе и фразе.
Рис. 1. Радуга НЛП (1991), наше первоначальное видение необходимых компонентов НЛП и возможных приложений.
Архитектура следует конвейерному подходу, как показано на рисунке 2, где каждый компонент обеспечивает дополнительные уровни анализа / аннотации входных данных. Мы спроектировали систему как относительно бедную вначале, используя при этом все более богатые и богатые источники данных, поскольку потребность в большем количестве семантической информации возрастала; Одна из наших целей этой архитектуры - сохранить неоднозначность до тех пор, пока нам не понадобится разрешить эту неоднозначность или пока ресурсы данных не существуют, чтобы разрешить разрешение.Таким образом, синтаксический анализ проходит в два этапа: синтаксический набросок (который сегодня можно описать как плотный лес) и синтаксический портрет, где мы «распаковываем» лес и конструируем составляющий уровень анализа, который является синтаксическим, но также и семантическим. действительный. Дерево клиентов продолжает уточняться даже во время обработки логической формы, поскольку может использоваться более глобальная информация.
Рисунок 2: Компоненты NLPwin и схема их выходного представления.
Стоит сделать несколько замечаний по поводу синтаксического анализатора (термин, который в общих чертах объединяет модули морфологии, эскиза и портрета). Во-первых, парсер состоит из правил, созданных человеком. Это вызовет недоверие у тех, кто знаком только с машинно-обученными парсерами, обученными на PennTreeBank. Следует иметь в виду, что синтаксический анализатор NLPwin был создан до того, как первый синтаксический анализатор был обучен на PennTreeBank, что синтаксический анализатор должен быть быстрым (для поддержки средства проверки грамматики) и что написание правил грамматики было нормой для грамматик до PennTreeBank.Кроме того, грамматик, которому было поручено писать правила, поддерживался сложным набором инструментов разработчика НЛП (созданным Джорджем Хайдорном), так же, как программист теперь поддерживается в Visual Studio, где правила грамматики могут запускаться в определенные точки кода и из них. , переменные могут быть изменены в интерактивном режиме для целей исследования, и, что наиболее важно, среда разработчика поддерживала запуск набора тестовых файлов с интерфейсами для грамматика для обновления целевых файлов с помощью улучшенного синтаксического анализа.Во-вторых, ведущий грамматист Карен Дженсен нарушила неявную традицию, согласно которой составляющая структура подразумевается применением правил синтаксического анализа [1]. Дженсен заметил, что бинарные правила необходимы даже для того, чтобы справляться даже с обычными языковыми явлениями, такими как свободный порядок слов и размещение наречных и предложных фраз. Таким образом, в NLPwin мы используем двоичные правила в формализме расширенной грамматики структуры фраз (APSG), вычисляя структуру фразы как часть действий правил, тем самым создавая узлы с неограниченными модификаторами, сохраняя при этом двоичные правила, как показано на рисунке 3.
Рисунок 3: Дерево вывода отображает историю применения правил, а вычисленное дерево обеспечивает полезную визуализацию структуры фраз.
Еще одним важным аспектом NLPwin является то, что именно структура записи, а не деревья, является основным результатом работы компонента анализа (показано на рисунке 4). Деревья - это просто удобная форма отображения, использующая только 5 из множества атрибутов, составляющих представление анализа (предварительные модификаторы (PRMODS), HEAD, постмодификаторы (PSMODS), тип сегмента (SEGTYPE) и строковое значение.Вот запись, набор атрибутов и значений для узла DECL1:
Рис. 4. Структура записи любого компонента является сердцем анализа NLPwin.
Как только основная форма дерева округа определена, можно вычислить, что такое логическая форма. У логической формы двоякая цель: вычислить структуру предиката-аргумента для каждого предложения («кто что сделал, с кем, когда, где и как?») И нормализовать различные синтаксические реализации того, что можно считать одним и тем же «значением».Поступая таким образом, концепции, которые, возможно, далеки в предложении и в составной структуре, могут быть сведены вместе, в значительной степени потому, что логическая форма представлена в виде графа, где линейный порядок больше не является первичным. Логическая форма - это ориентированный помеченный граф, где дуги помечены теми отношениями, которые определены как семантические, а поверхностные слова, передающие только синтаксическую информацию, представлены не как узлы в графе, а как аннотации к узлам, сохраняя их синтаксис. информация (не показана на графике ниже).Рассмотрим следующую логическую форму:
Рисунок 5: Пример логической формы.
График логической формы на рисунке 5 представляет прямую связь между «слонами» и «иметь», которая прерывается относительным предложением в поверхностном синтаксисе. Более того, при анализе относительного придаточного предложения логическая форма выполнила две операции: логическая форма нормализует пассивную конструкцию, а также назначает референт относительного местоимения «который». Другие операции, обычно выполняемые логической формой, включают (но не ограничиваются ими): неограниченные зависимости, функциональный контроль, косвенное перефразирование объекта, назначение модификаторов.
Рисунок 5 также демонстрирует некоторые недостатки логической формы: 1) должен ли «иметь» быть концептуальным узлом в этом графе или его следует интерпретировать как дугу с пометкой «Часть» между «слоном» и «бивнем»? В более общем плане: каким должен быть перечень меток отношений и как его определять? И 2) следует ли нам делать вывод из этого предложения только о том, что «на африканских слонов охотились» и что «у африканских слонов большие бивни», или мы можем сделать вывод, что «на слонов охотились» и что они оказались «африканскими слонами».Решение этого вопроса об объеме было отложено до обработки дискурса [2], когда такие вопросы могут быть рассмотрены, и логическая форма не представляет двусмысленности в области видимости.
Во время разработки конвейера NLPwin (см. Рисунок 2) мы считали, что будет отдельный компонент, определяющий смыслы слов после синтаксического анализа входных данных. Этот компонент предназначался для выбора и / или сопоставления лексической информации из нескольких словарей для представления и расширения лексического значения каждого слова содержимого.Такой взгляд на устранение неоднозначности слов (WSD) контрастировал с зарождавшимся тогда интересом к WSD в академическом сообществе, которое формулировало задачу WSD как выбор одного смысла из фиксированного перечня смыслов слов как правильного. Наше основное возражение против этой формулировки состоит в том, что любой фиксированный перечень обязательно не будет достаточным в качестве основы для грамматики широкого охвата (см. Dolan, Vanderwende and Richardson, 2000). По тем же причинам мы решили отказаться от использования Word Senses и в NLPwin.Сегодня эта область добилась больших успехов в изучении более гибкого понятия лексического значения с появлением векторного пространства, которое было бы многообещающим для объединения с выводом этого синтаксического анализатора.
Хотя мы не рассматривали устранение неоднозначности в словах как отдельную задачу, мы разработали наш синтаксический анализатор и последующие компоненты так, чтобы использовать все более обширную лексическую информацию. Грамматика эскиза опирается на рамки подкатегории и другие синтаксико-семантические коды, доступные из двух словарей: Longman Dictionary of Contemporary English (LDOCE) и American Heritage Dictionary, 3 rd edition, права на которые Microsoft приобрела в цифровом виде.LDOCE, в частности, предоставляет богатую лексическую информацию, которая облегчает построение логической формы [3]. Такие коды, какими бы богатыми они ни были, не поддерживают полную семантическую обработку, которая необходима, например, при определении правильного присоединения предложных фраз или номинальной со-ссылки. Возник вопрос: можно ли получить такие семантические знания автоматически, чтобы поддерживать синтаксический анализатор с широким охватом?
В начале и середине 90-х был значительный интерес к словарям и другим справочным материалам для семантической информации в широком смысле.По этой причине мы предполагали, что там, где лексической информации было недостаточно для поддержки решений, которые необходимо было принять в компоненте портрета, мы могли бы получить такую информацию в машиночитаемых справочниках.
В то время было доступно несколько анализаторов с широким охватом, поэтому основной упор делался на разработку строковых шаблонов (регулярных выражений), которые можно было бы использовать для идентификации конкретных типов семантической информации; Херст (1992) описывает использование таких паттернов для приобретения Гипернимия (это термины).Alshawi (1989) анализирует словарные определения, используя грамматику, специально разработанную для этого словаря («Longmanese»). Мы столкнулись с двумя проблемами при использовании этого подхода: во-первых, по мере того, как возрастает потребность в большем вспоминании, написание и уточнение строковых шаблонов становится все более и более сложным, в пределе приближаясь к сложности написания полной грамматики и, таким образом, далеко отклоняясь от простой строки. паттерны, с которых вы начали, и, во-вторых, при извлечении семантических отношений за пределами Hypernymy мы обнаружили, что строковых паттернов недостаточно (см. Montemagni and Vanderwende 1992).
Вместо этого мы предложили анализировать текст словаря с использованием уже разработанных лингвистических компонентов, эскиза, портрета и логической формы, обеспечивая доступ к надежному синтаксическому анализу, чтобы ускорить получение знаний семантической информации, необходимой для улучшения портрета. Эта самонастройка возможна, потому что некоторые лингвистические выражения недвусмысленны, и поэтому на каждой итерации мы можем извлекать из однозначного текста, чтобы улучшить анализ неоднозначного текста (см. Vanderwende 1995).
По мере того, как каждое определение в словаре и онлайн-энциклопедии обрабатывалось, а семантическая информация сохранялась для доступа к Portrait, картинка возникала из соединения всех фрагментов графа. Если рассматривать их как базу данных, а не как справочную таблицу (как люди используют словари), фрагменты графа связаны между собой и возникают интересные пути / выводы. Чтобы еще больше обогатить данные, мы предприняли шаг к просмотру каждого фрагмента графа с точки зрения каждого узла содержимого.Представьте, что вы смотрите на граф как на мобильный телефон и берете его за каждый из объектов по очереди - узлы под объектом остаются такими же, но узлы над этим объектом становятся инвертированными (показано на рисунке 6). Например, для определения слона :: животное с бивнями из слоновой кости »MindNet хранит не только фрагмент графика« ЧАСТЬ слона (бивень MATR из слоновой кости) », но также« ЧАСТЬ бивня слона »и« MATR-OF из слоновой кости ». бивень »[4].
Рисунок 6: Логическая форма и ее инверсии.
Мы назвали этот набор пересекающихся графов MindNet.Рисунок 7 отражает картину, которую мы видели для слова «птица», когда смотрели на все части информации, которые были автоматически почерпнуты из словарного текста:
Рис. 7. Фрагмент NLPwin MindNet, сосредоточенный на слове «птица»
Как человеку, использующему только словарь, было бы очень сложно составить список всех различных типов птиц, всех частей птицы, всех мест, где птица может быть найдена, или типов действий. что птица может сделать. Но путем преобразования словаря в базу данных и инвертирования всех семантических отношений, как показано на рисунке 6, MindNet содержит обширную семантическую информацию для любого понятия, встречающегося в тексте, особенно.потому что он создается автоматическими методами с использованием грамматики с широким охватом, грамматики, которая анализирует фрагменты, а также анализирует полный грамматический ввод.
Мы вычислили показатель сходства для MindNet, используя тезаурус Роджера в качестве аннотированных обучающих данных. Получив пару слов от Roget, мы вычислили все пути в MindNet между этими синонимами, а затем наблюдали, как часто встречаются паттерны путей (паттерны типов отношений с конкретными концепциями, связывающими эти типы отношений, и без них).Таким образом, мы узнаем, что если X и Y связаны с использованием шаблона пути: ( X - Hypernym - z - HypernymOf Y ) или ( X - HasObject - z - ObjectOf - Y ) , что X и Y считаются похожими с большим весом. Затем мы можем запросить произвольные пары слов на предмет их сходства, обнаружив, что «золото» и «цинк» похожи, а «золото» и «велосипед» - нет.
Априори нет причин, по которым MindNet нельзя создать из текста, отличного от текста словаря или энциклопедии.Действительно, если бы MindNet разрабатывалась сегодня, мы бы стремились автоматически получать семантическую информацию из Интернета. Заметной инженерной проблемой является время обработки, хотя доступность массово-параллельных веб-сервисов в значительной степени смягчает эту проблему. Другая важная задача - установить достоверность исходного материала (часть успеха IBM Watson в игре Jeopardy можно отнести к тщательному отбору источников информации). Что должно произойти с (очевидными) противоречиями даже в том случае, если источники одинаково надежны? Веса, вычисленные для определенных частей графа знаний, можно использовать для балансировки частоты встречаемости этой информации, но сам источник также следует учитывать в схеме весов.Более того, MindNet - это не просто база данных троек; мы сохраняем контекст, из которого были извлечены семантические отношения, и поэтому теоретически мы могли бы разрешить очевидные противоречия, принимая во внимание контекст. Мы не столкнулись с этими проблемами, поскольку MindNet был рассчитан только из источников, которые категорически правдивы (словари и энциклопедии), но эти проблемы следует решать в дальнейшем путем получения знаний из Интернета.
Первоначальная цель, как показано на рисунке 2, состояла в том, чтобы сократить пересказы до канонического представления в модуле, который мы предварительно назвали «Концепции», хотя «Определение концепций» было бы более наглядным.Как и в случае с устранением неоднозначности слов, мы отказались от этого модуля, поскольку были недовольны лежащим в основе предположением о том, что одно представление концепции или сложного события будет преобладать над другими, в то время как в действительности оба выражения эквивалентны; эквивалентность должна быть плавной и позволять варьироваться в зависимости от потребности приложения. Здесь мы снова считаем, что текущее исследование, целью которого является представление фрагментов синтаксического анализа в векторном пространстве, является многообещающим подходом, при этом подчеркивая важность учета синтаксического анализа и структуры логической формы.
Наконец, несколько слов о грамматике генерации (показана справа от радуги на рисунке 1). В NLPwin мы разработали два типа грамматик генерации: компоненты генерации на основе правил (в том числе те, которые поставляются с Microsoft Word, например, для перезаписи пассивного в активный) и Amalgam, набор модулей генерации с машинным обучением. Оба типа грамматик генерации использовались в производстве для машинного перевода.
Вкратце…
Мы описали некоторые аспекты проекта NLPwin в Microsoft Research [5].Компоненты лексической и синтаксической обработки предназначены для широкого охвата и устойчивости к грамматическим ошибкам, что позволяет создавать синтаксические анализы для фрагментированных, неграмматических, а также грамматических входов. Эти компоненты в основном представляют собой грамматики, основанные на правилах, использующие богатые лексические и семантические ресурсы, полученные из онлайн-словарей. Выходные данные компонента синтаксического анализа, древовидного анализа, преобразуются в графическое представление, называемое логической формой. Цель логической формы - вычислить структуру предиката-аргумента для каждого предложения и нормализовать различные синтаксические реализации того, что можно считать одним и тем же «значением».При этом расстояние между концептами отражает семантическое расстояние, а не линейное расстояние в поверхностной реализации, сближая связанные концепции, чем они могут появиться на поверхности. MindNet - это автоматическое построение базы данных связанных логических форм. Когда справочные ресурсы являются исходным текстом для MindNet, MindNet можно рассматривать как традиционный метод и объект получения знаний, но когда MindNet создается путем обработки произвольного ввода текста, MindNet представляет собой глобальное представление всех логических форм этого текста, что позволяет просмотр понятий и их семантических связей в этом тексте.Фактически, MindNet считался наиболее привлекательным средством для просмотра и изучения конкретных отношений, извлеченных из текстовой коллекции.
[1] см. Дженсен, Карен. 1987. Бинарные правила и небинарные деревья: Разрушение концепции фразовой структуры. В Математика языка , изд. А. Манастер-Рамер, 65-86. Амстердам: John Benjamins Pub.Co.
[2] Фактически, система NLPwin (пока) не решала эту проблему до сегодняшнего дня.
[3] Коды ящиков LDOCE, например, предоставляют информацию об ограничениях типов и аргументах для глаголов.В LDOCE «убедить» помечено как ObjC, что указывает на то, что «убедить» имеет объектный контроль (т.е. что объект «убедить» понимается как подлежащее дополнения глагола). Таким образом, можно построить логическую форму с «Джон» в качестве субъекта «перейти в библиотеку» из входного предложения: «Я убедил Джона пойти в библиотеку», а для входного предложения «Я обещал Джону иди в библиотеку », логическая форма строится с« я »в качестве предмета« перейти в библиотеку ».
[4] Алгоритм, конечно, также идентифицирует отношение «слон ГИПЕРНИМ животное», но при обработке словаря информация, извлеченная из различий определения (спецификации гиперонима), верна для определяемого слова, а не верно для гипернима, и поэтому мы извлекаем не то, что «у животных есть бивни», а скорее то, что «у слонов есть бивни».
[5] На момент написания этой статьи (2014 г.) NLPwin считался зрелой системой с ограниченным развитием компонентов генерации и логической формы.
Среда разработки
Морфология
Синтаксис
- Дженсен, Карен, Джордж Э. Хейдорн и Стивен Д. Ричардсон (ред.). 1993. Обработка естественного языка: подход PLNLP. Kluwer : Бостон.
- ПРИМЕЧАНИЕ. Хотя приведенное выше не является справочным материалом для работы, проделанной в Microsoft, подход PLNLP дает хороший обзор мотивации и структуры синтаксической системы, а также ряда других ключевых компонентов полной системы NLP.
- Стивен Д. Ричардсон. 1994. Загрузка статистической обработки в синтаксический анализатор естественного языка на основе правил. В материалах семинара The Balancing Act: сочетание символического и статистического подходов к языку, спонсируемого ACL.
- Майкл Гамон и Том Ройтер. 1997. Анализ разделимых префиксных глаголов немецкого языка в системе обработки естественного языка Microsoft. Технический отчет Microsoft Research, MSR-TR-97-15, сентябрь 1997 г.
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер.1997. Практический опыт совместного использования грамматики в многоязычном НЛП, Технический отчет Microsoft Research, No. MSR-TR-97-16
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер. 1997. От исследований к коммерческим приложениям: как заставить НЛП работать на практике. В материалах семинара ACL «От исследования к коммерческим приложениям: как заставить НЛП работать на практике»
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер. 1997. Практический опыт обмена грамматикой в многоязычном НЛП, № 2, с.MSR-TR-97-16
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер. 1997. От исследований к коммерческим приложениям: как заставить НЛП работать на практике. В материалах семинара ACL «От исследования к коммерческим приложениям: как заставить НЛП работать на практике»
- Такако Айкава, Крис Квирк и Ли Шварц. 2003. Изучение предлогного присоединения из выровненных по предложению двуязычных корпусов, Американская ассоциация машинного перевода.
- Ли Шварц; Такако Айкава.2004. Многоязычный корпусный подход к разрешению английского языка. В трудах LREC.
Логическая форма
- Люси Вандервенде. 1994. Алгоритм автоматической интерпретации последовательностей существительных. В материалах 15-й Международной конференции по компьютерной лингвистике, том 2.
- Люси Вандервенде. 1996. Анализ последовательностей существительных с использованием семантической информации, извлеченной из он-лайн словарей, докторская диссертация, Джорджтаунский университет, технический отчет Microsoft Research, нет.MSR-TR-95-57, октябрь 1996 г.
- Ричард Кэмпбелл и Хисами Судзуки. 2002. Нейтральный к языку синтаксис: обзор . Технический отчет Microsoft Research, MSR-TR-2002-76
- Ричард Кэмпбелл. 2002. Вычисление области видимости модификатора в NP языково-нейтральным методом. В материалах 19 -й Международной конференции по компьютерной лингвистике, COLING-2002.
- Ричард Кэмпбелл и Хисами Судзуки. 2002. Языко-нейтральное представление синтаксической структуры.В материалах Первого международного семинара по масштабируемому пониманию естественного языка (SCANALU 2002), Гейдельберг, Германия
- Ричард Кэмпбелл, Такако Айкава, Зиксин Цзян, Кармен Лозано, Майте Мелеро и Анди Ву. 2002. Независимое от языка представление временной информации. В LREC 2002 Workshop Proceedings: Annotation Standards for Temporal Information in Natural Language. 13-21.
- Ричард Кэмпбелл и Эрик Ринггер. 2004. Преобразование аннотаций банка деревьев в нейтральный к языку синтаксис, в трудах LREC.
- Ричард Кэмпбелл. 2004. Использование лингвистических принципов для восстановления пустых категорий. В материалах ACL.
Устранение неоднозначности в словах
- Уильям Б. Долан. 1994. Неоднозначность смысла слова: объединение связанных смыслов. Труды 15-й Международной конференции по компьютерной лингвистике, COLING’94, 5-9 августа 1994 г., Киото, Япония, 712-716.
- Уильям Долан, Люси Вандервенде и Стивен Д. Ричардсон. 2000. Многозначность в системе обработки естественного языка с широким охватом.В Многозначность: теоретические и вычислительные подходы . Ред. Яэль Рэвин и Клаудия Ликок. Oxford University Press, июль 2000 г.
Дискурс
MindNet - Автоматическое построение базы знаний
- Симонетта Монтемагни и Люси Вандервенде. 1992. Структурные шаблоны против строковых шаблонов для извлечения семантической информации из словарей, в трудах четырнадцатой Международной конференции по компьютерной лингвистике, COLING-1992
- Уильям Долан, Стивен Д.Ричардсон и Люси Вандервенде. 1993. Автоматическое извлечение структурированных баз знаний из он-лайн каталогов, нет. MSR-TR-93-07, май 1993 г.
- Уильям Долан, Стивен Д. Ричардсон и Люси Вандервенде. 1993. Объединение основанных на словарях и основанных на примерах методов для анализа естественного языка, нет. MSR-TR-93-08, июнь 1993 г.
- Люси Вандервенде. 1995. Неопределенность в получении лексической информации. В симпозиуме AAAI по представлению и приобретению лексических знаний : TR SS-95-01, AAAI, 1995
- Стивен Д.Ричардсон, Уильям Б. Долан и Люси Вандервенде. 1998. MindNet: получение и структурирование семантической информации из текста. В материалах COLING-ACL 1998
- Люси Вандервенде, Гэри Качмарчик, Хисами Судзуки и Арул Менезес. 2005. MindNet: автоматически создаваемый лексический ресурс. In Proceedings of the HLT / EMNLP Interactive Demonstrations, October 2005
Поколение
- Саймон Корстон-Оливер, Майкл Гамон, Эрик Ринггер и Роберт Мур. 2002. Обзор Amalgam: модуль поколения с машинным обучением.В материалах ACL
- Майкл Гамон, Эрик Ринггер и Саймон Корстон-Оливер. 2002. Амальгама: модуль поколения с машинным обучением. Технический отчет Microsoft Research No. MSR-TR-2002-57, июнь 2002 г.
- Чжу Чжан, Майкл Гамон, Саймон Корстон-Оливер, Эрик Ринггер. 2002. Вставка знаков препинания внутри предложения в генерации естественного языка. Технический отчет Microsoft Research No. MSR-TR-2002-58
Немецкий
Французский
- Мартина Сметс, Майкл Гамон, Саймон Корстон-Оливер и Эрик Ринггер.2003. Адаптация системы реализации предложений с машинным обучением к французскому языку, в материалах европейской главы ACL .
- Мартина Сметс, Майкл Гамон, Саймон Корстон-Оливер и Эрик Ринггер. 2003. French Amalgam: система реализации предложений с машинным обучением, Association pour le Traitement Automatique des Langues, TALN 2003
Испанский
китайский
Японский
Проверка грамматики
- Джордж Э. Хайдорн. 2000. Интеллектуальная помощь при письме.В A Справочник обработки естественного языка : Методы и приложения для обработки языка как текста. Марсель Деккер, Нью-Йорк. С. 181-207.
Машинный перевод
- Майкл Гамон, Хисами Судзуки и Саймон Корстон-Оливер. 2001. Использование машинного обучения для внутренней оценки переданных языковых представлений, Европейская ассоциация машинного перевода, январь 2001 г.
- Саймон Корстон-Оливер, Майкл Гамон и Крис Брокетт.2001. Подход машинного обучения к автоматической оценке машинного перевода, Ассоциация компьютерной лингвистики
- Арул Менезес и Стивен Д. Ричардсон. 2001. Алгоритм выравнивания «лучший первый» для автоматического извлечения отображений переноса из двуязычных корпусов, Association for Computational Linguistics .
- Уильям Долан, Стивен Д. Ричардсон, Арул Менезес и Моника Корстон-Оливер. 2001. Преодоление узких мест в настройке с использованием машинного перевода на основе примеров, Association for Computational Linguistics .
- Стивен Д.Ричардсон, Уильям Б. Долан, Арул Менезес и Джесси Пинкхэм. 2001. Достижение коммерческого качества перевода с помощью методов, основанных на примерах. В материалах конференции MT Summit VIII, Сантьяго-де-Компостела, Испания. 293-298.
- Ричард Кэмпбелл, Кармен Лозано, Джесси Пинкхэм и Мартина Сметс. 2002. Машинный перевод как испытательная площадка для многоязычного анализа. In Proceedings of COLING 2002
- Джесси Пинкхэм и Мартина Сметс. 2002. Модульный МП с изученным двуязычным словарем: быстрое развертывание новой языковой пары.In Proceedings of COLING 2002
- Джесси Пинкхэм и Мартина Сметс. 2002. Машинный перевод без двуязычного словаря. В материалах 9-й конференции по теоретико-методологическим вопросам машинного перевода.
- Крис Брокетт, Такако Айкава, Энтони Ауэ, Арул Менезес, Крис Куирк и Хисами Судзуки. 2002. Англо-японский машинный перевод на основе примеров с использованием абстрактных семантических представлений, Труды семинара Coling 2002 по машинному переводу в Азии, COLING-2002
- Мартина Сметс, Джозеф Пентероудакис и Арул Менезес.2002. Перевод словесных идиом. В трудах международного семинара по вычислительным подходам к словосочетаниям, Colloc-02, Вена, Австрия
- Арул Менезес. 2002. Улучшенный контекстный перевод с использованием машинного обучения. На 5-й конференции Ассоциации машинного перевода в Северной и Южной Америке, AMTA 2002 г. Тибурон, Калифорния, США, 8–12 октября 2002 г. Proceedings, Springer, Verlag
- Мартина Сметс, Майкл Гамон, Джесси Пинкхэм, Том Ройтер и Мартина Петтанаро. 2003. Высококачественный машинный перевод с использованием компонента реализации предложения с машинным обучением.В материалах Ассоциации машинного перевода в Северной и Южной Америке
- Саймон Корстон-Оливер и Майкл Гамон. 2003. Объединение деревьев решений и обучения на основе преобразований для исправления перенесенных языковых представлений. В материалах Ассоциации машинного перевода в Северной и Южной Америке
- Энтони Ауэ, Арул Менезес, Роберт Мур, Крис Квирк и Эрик Ринггер. 2004. Статистический машинный перевод с использованием помеченных графов семантических зависимостей. В материалах 10-й Международной конференции по теоретическим и методологическим вопросам машинного перевода (TMI ‐ 2004).Балтимор, Мэриленд.
- Саймон Корстон-Оливер и Майкл Гамон. 2004. Нормализация немецкой и английской флективной морфологии для улучшения статистического выравнивания слов. В материалах Ассоциации машинного перевода в Северной и Южной Америке
- Крис Куирк, Арул Менезес и Колин Черри. 2004. Перевод дерева зависимостей: синтаксически сформированный фразовый SMT, нет. MSR-TR-2004-113, ноябрь 2004 г.
- Эрик Ринггер, Майкл Гамон, Роберт С. Мур, Дэвид Рохас, Мартин Сметс и Саймон Корстон-Оливер.2004. Лингвистически обоснованные статистические модели составной структуры для упорядочивания в реализации предложения. В материалах 20 -й Международной конференции по компьютерной лингвистике.
- Дунхуэй Фэн, Яцзюань Лю, Мин Чжоу. 2004. Новый подход к согласованию англо-китайских именованных сущностей. В материалах ЕМНЛП-2004
- Яцзюань Лю и Мин Чжоу. 2004. Приобретение совместных переводов с использованием одноязычных корпусов. In Proceedings of the 42 nd Annual Meeting on Association for Computational Linguistics.
- Арул Менезес и Крис Квирк. 2005 г. Система перевода Treelet от Microsoft Research: оценка IWSLT. В материалах международного семинара по устному переводу, октябрь 2005 г.
- Крис Куирк, Арул Менезес и Колин Черри. 2005. Зависимый перевод Treelet: синтаксически сформированный фразовый SMT. В материалах ACL
- Арул Менезес и Крис Квирк. 2005. Перевод дерева зависимостей: конвергенция статистического и основанного на примерах машинного перевода.В материалах 10-го семинара по машинному переводу на высшем уровне по машинному переводу на основе примеров
- Майкл Гамон, Энтони Ауэ и Мартина Сметс. 2005. Оценка машинного перевода на уровне предложения без справочных переводов: помимо языкового моделирования. В трудах Европейской ассоциации машинного перевода.
- Крис Куирк и Саймон Корстон-Оливер. 2006. Влияние качества синтаксического анализа на синтаксически обоснованный статистический машинный перевод. В материалах ЕМНЛП 2006
- Сяодун Хэ, Арул Менезес, Крис Куирк, Энтони Ауэ, Саймон Корстон-Оливер, Цзяньфэн Гао и Патрик Нгуен.2006. Система перевода Microsoft Research Treelet: оценка NIST MT 06, Национальный институт стандартов и технологий, март 2006 г.
- Крис Куирк и Арул Менезес. 2006. Зависимость Treelet Translation: Конвергенция статистического и основанного на примерах машинного перевода ?. В машинном переводе, т. 20, стр. 43–65, март 2006 г.
- Арул Менезес, Кристина Тутанова и Крис Куирк. 2006. Система перевода дерева исследований Microsoft: оценка NAACL 2006 Europarl. В WMT 2006
- Арул Менезес и Крис Квирк.2007. Использование шаблонов порядка зависимостей для повышения универсальности перевода. В материалах второго семинара по статистическому машинному переводу в ACL 2007
- Арул Менезес и Крис Квирк. 2008. Синтаксические модели для структурной вставки и удаления слов при переводе. В материалах ЕМНЛП 2008
Обобщение
- Кристина Тутанова, Крис Брокетт, Майкл Гамон, Джагадиш Джагарламунди, Хисами Судзуки и Люси Вандервенде. 2007. Система обобщения Pythy: исследования Microsoft на DUC 2007.В материалах дела DUC-20077
- Люси Вандервенде, Хисами Судзуки, Крис Брокетт и Ани Ненкова. 2007. За пределами SumBasic: сфокусированное на задачах обобщение с упрощением предложений и лексическим расширением. In Information Processing and Management, Volume 43, Issue 6, pages 1606-1618 .
- Эдуард Хови, Чин-Ю Линь и Лян Чжоу. 2005. Оценка DUC 2005 с использованием базовых элементов. В материалах семинара DUC-2005.
- Юрий Лесковец, Наташа Милич-Фрайлинг, Марко Гробельник.2005. Влияние лингвистического анализа на охват семантического графа и изучение отрывков из документов. В материалах Национальной конференции по искусственному интеллекту (AAAI), 2005.
- Саймон Х. Корстон-Оливер, Эрик Ринггер, Майкл Гамон и Ричард Кэмпбелл. 2004. Целенаправленное обобщение электронной почты. В материалах семинара ACL 2004 «Разветвляется обобщение текста», Барселона, Испания.
- Люси Вандервенде, Микеле Банко и Арул Менезес. 2004. Генерация сводок, ориентированных на события.В Рабочих заметках конференции Document Understanding 2004
- Юрий Лесковец, Наташа Милич-Фрайлинг, Марко Гробельник. Извлечение сводных предложений на основе семантического графика документа. Технический отчет Microsoft Research MSR-TR-2005-07, 2005.
- Юрий Лесковец, Марко Гробельник и Наташа Милич-Фрайлинг. 2004. Изучение подструктур семантических графов документов для обобщения документов. В материалах семинара по анализу ссылок и обнаружению групп (LinkKDD), 2004 г.
- Саймон Корстон-Оливер.2001. Сжатие текста для отображения на очень маленьких экранах. В материалах семинара по автоматическому обобщению, NAACL 2001.
Оценка
Entailment
Построение базы знаний / Извлечение информации / Анализ текста
- Кумаран, Ранбер Макин, Виджай Паттисапу, Шайк Шариф, Гэри Качмарчик и Люси Вандервенде. 2006. Автоматическое извлечение синонимической информации. В Семинар «Онтологии в текстовых технологиях», Оснабрюк, Германия , декабрь 2006 г.
- Крис Квирк, Паллави Чоудхури, Майкл Гамон и Люси Вандервенде.Запись MSR-NLP в BioNLP Shared Task 2011. В материалах семинара BioNLP Shared Task 2011.
Исправление орфографии
Поиск информации
Интеллектуальные агенты
- Саймон Корстон-Оливер, Эрик Ринггер, Майкл Гамон и Ричард Кэмпбелл. 2004 г. Интеграция электронной почты и списков задач. На Первой конференции по электронной почте и защите от спама (CEAS), 2004 г., Труды
- Тим Пэк и Эрик Хорвиц. 1999. Неопределенность, полезность и недопонимание: теоретико-решающий взгляд на обоснование в диалоговых системах.В техническом отчете AAAI FS-99-03.
- Хуа Ли, Доу Шэнь, Бэнью Чжан, Чжэн Чен и Цян Ян. 2006. Добавление семантики в кластеризацию электронной почты. В материалах Шестой Международной конференции по интеллектуальному анализу данных (ICDM’06).
- Гохан Тур, Ануп Деорас и Дилек Хаккани-Тур. 2014. Обнаружение высказываний вне домена, адресованных виртуальному персональному помощнику. In Proceedings of Interspeech , ISCA - Международная ассоциация речевой коммуникации, сентябрь 2014 г.
Заявка на получение образования
- Ли Шварц, Такако Айкава и Мишель Пахуд.2004. Инструменты динамического изучения языка. Материалы симпозиума InSTIL / ICALL 2004 г., июнь 2004 г.
- Такако Айкава, Ли Шварц и Мишель Пахуд. 2005 .NLP Story Maker. В материалах конференции Second Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics 21-23 апреля 2005 г., Познань, Польша
Настроение
Идентификация авторства
- Английский язык и разработка ядра: Карен Дженсен, Джордж Хайдорн, Стивен Д.Ричардсон, Диана Петерсон, Люси Вандервенде, Джозеф Пентерудакис, Билл Долан, Дебора Кофлин, Ли Шварц, Саймон Корстон Оливер, Эрик Ринггер, Рич Кэмпбелл, Арул Менезес, Крис Квирк
- Французский : Мартина Петтенаро, Джесси Пинкхэм, Мартина Сметс
- Испанский : Мариса Хименес, Кармен Лозано, Маите Мелеро
- Немецкий : Майкл Гамон, Том Ройтер
- Японский : Такако Айкава, Крис Брокетт, Хисами Сузуки
- Китайский : Терренс Пэн, Анди Ву, Цзян Цзысинь
- Корейский : Джи Ын Ким, Конг Джу Ли
Парсинг | Энциклопедия.com
PARSING [От глагола parse , от латинского pars / partis часть, абстрагированная от фразы pars orationis часть речи].1. Анализ СООБЩЕНИЯ на его составные части, более или менее детальное определение синтаксических отношений и частей речи.
2. Описание СЛОВА в предложении, определение его части речи, словоизменительной формы и синтаксической функции.
Парсинг раньше был центральным элементом преподавания ГРАММАТИКИ во всем англоязычном мире и широко рассматривался как основа для использования и понимания письменного языка.Когда многие люди говорят о формальной грамматике в школах, они имеют в виду преподавание , синтаксический анализ и CLAUSE ANALYSIS, которое практически прекратилось в начальном и среднем образовании в англоязычном мире в 1960-х годах, а в высшем образовании на смену ему пришло высшее образование. лингвистический анализ. Аргумент против традиционного синтаксического анализа состоит из трех частей: он продвигает старомодные описания языка, основанные на грамматических категориях LATIN; что студенты не получают от этого никакой пользы; и что это источник разочарования и скуки как для студентов, так и для учителей.Аргумент в пользу синтаксического анализа состоит из четырех частей: он раскрывает структуру речи и письма, дисциплинированно тренирует ум, позволяет людям говорить об использовании языка и помогает в изучении и обсуждении иностранных языков. Компромиссная позиция заключается в том, что формальное обсуждение SYNTAX и функции может быть полезным, но оно должно уступать место свободному выражению и достижению уверенности, а не доминировать в еженедельной рутине. Когда компьютер разбирает, он анализирует строку символов, чтобы связать группы в строке с синтаксическими единицами грамматики.Компьютеры делают это в основном для языков программирования, но иногда и для английского. Языки программирования определяются простыми, но точными грамматиками, и для перевода этих языков на машинный язык необходимо знать, какие правила применяются к каждому оператору. Типичные грамматики для компьютерных языков берут несколько десятков правил и анализируют ввод со скоростью несколько секунд на каждое утверждение. Грамматика для таких языков разработана таким образом, чтобы быть недвусмысленной: для каждого утверждения возможен только один «синтаксический анализ».Ученые-информатики часто думают о применении аналогичных методов к естественному языку, но такой язык, как английский, требует сотен или тысяч правил, не соответствует аккуратным математическим моделям, которые позволяют быстро анализировать компьютерные языки, часто содержит двусмысленность и еще не были описаны достаточно подробно, чтобы машина могла успешно их проанализировать.звуковых сигналов помогают слушателям по-разному разбирать слова на разных языках - Psychonomic Society Featured Content
Слышать, как другие люди говорят на иностранном языке, может вызвать головокружение.Как они могут так быстро говорить? Почему они не делают паузы между словами, как это делаем мы? На самом деле говорящие на иностранном языке действительно делают паузу: но, несмотря на то, как это звучит для нас на нашем родном языке, разговорный язык не прерывается аккуратно тишиной между словами.
Не уверены? Взгляните на рисунок ниже, который отображает слуховую речь, называемую спектрограммой. Спектрограмма отображает частоту по оси Y и время по оси X. Более темные полосы указывают на большую интенсивность звука на этой частоте; более белые области указывают на тишину.Посмотрите, сможете ли вы выяснить, где в этом потоке могут быть разрывы слов.
Вот подсказка, есть четыре английских слова. (Чтобы получить ответ, перейдите по этой ссылке).
Ясно, что периоды молчания в английской речи не соответствуют перерывам между словами. Это означает, что, когда мы слышим незнакомый язык, мы не можем разбирать слова, прислушиваясь к периодам молчания. Но означает ли это, что информации о переносах слов вообще нет в звуковом потоке?
Взгляните на видео ниже, в котором используются обычные английские фонемы, но они смешиваются вместе.Это все еще звучит так, как будто вы слышите слова, несмотря на то, что они (и предложения, которые они образуют) не имеют значения:
Недавняя статья Михаила Ордина и его коллег в Memory and Cognition подчеркивает два аспекта структуры разговорной речи, которые могут позволить людям сегментировать слова непосредственно из информации, содержащейся в речи. Один аспект - вероятность перехода - очень согласован между языками. Второе - последнее удлинение - может отличаться в зависимости от языка.
Вероятность перехода - это вероятность того, что один слог произойдёт сразу после другого. В разных языках пары слогов могут встречаться рядом друг с другом чаще в словах, чем между словами. Например, слова «салат» и «огурец» легко поддаются синтаксическому анализу, поскольку слоги «са» и «парень» чаще встречаются вместе в одном слове, чем «ад» и «кук», что приводит к интерпретации « салат из огурцов », а не« салат из огурцов ». После длительного знакомства с языком эти вероятности перехода могут быть изучены неявно.
Окончательное удлинение - это увеличение продолжительности последнего слога во фразе. То есть последний звук во фразе будет удлинен, давая слушателю слуховой сигнал о том, что предложение закончилось.
Хотя это могут делать носители всех языков, Ордин и его коллеги отмечают, что продолжительность также является признаком лексического ударения. Позвольте Майку Майерсу продемонстрировать.
Как вы понимаете, emPHAsis удлиняет и ударный слог, что может помешать окончательному удлинению.
В то время как все языки имеют более высокую вероятность перехода внутри слов, чем между словами, разные языки имеют тенденцию подчеркивать разные слоги. В своем исследовании Ордин и его коллеги выбрали носителей четырех языков, которые варьируются в зависимости от того, где акцент обычно делается на словах. Немецкий обычно делает ударение на первом слоге; Баскский язык сильно различается; в испанском и итальянском языках ударение делается на предпоследний слог (вспомните лазанья или буррито ).
Исследователи предсказали, что при изучении нового языка это предпоследнее удлинение в испанском и итальянском языках повлияет на вероятность перехода.Чтобы проверить это, исследователи создали совершенно новый «язык», состоящий из шести трехсложных слов, состоящих из уникальных комбинаций слогов («вапута» и «дубипо»). Отдельные слоги в словах не повторялись. Это означало, что каждый раз, когда вы слышали «ва», сразу же следовало «пу». С другой стороны, каждый раз, когда вы слышите «та», вероятность того, что за ним последует «ду», составляет только 16%, потому что в остальных 84% случаев за ним следует другое слово (которое начинается с другой слог).Таким образом, вероятность перехода между словами была 100% и намного ниже.
Участники должны были прослушать потоки этих слов, а затем выполнить задание, в котором они должны были выбрать «слово» на языке, который они только что выучили. Только с учетом вероятности перехода участники на всех языках выучили слова выше вероятности, отвечая правильно примерно в 65% случаев (см. «Без удлинения» на рисунке ниже). Ясно, что вероятностей перехода достаточно, чтобы участники могли довольно быстро уловить разделение слов.
Как это взаимодействует с акцентом? Чтобы проверить это, участники выучили еще три «языка». В этих языках теперь для каждого слова удлинялся один из трех слогов. Напомним, что говорящие по-испански и по-итальянски ожидают, что акцент будет падать на предпоследний слог в их родных языках. Если этот сигнал мешает информации из вероятности перехода, они должны быть нарушены, когда другие слоги удлиняются, но помогают, когда удлиняются предпоследний слог.
Для итальянцев, по крайней мере, это то, что обнаружили исследователи (на рисунке ниже обратите внимание, что ромбы ниже для начального удлинения, но выше для предпоследнего). Другими словами, ударение на предпоследнем слоге («vapuTA dubiPO bolaTU») говорило говорящим по-итальянски «va puTAdu biPObo», что нарушало вероятности перехода. Ударный слог мешал вероятностям перехода, предлагая другую возможность синтаксического анализа.
Речь сложная.Это одна из причин, по которым процессоры естественного языка, такие как Siri, с трудом понимают вас. Исследование того, как разные языки решают эту проблему, может выявить, что может вызвать сбой в работе процессора естественного языка у носителей разных языков. Это также помогает объяснить естественную стратегию общения с людьми, не говорящими по-английски: речь. очень. медленно. Мы подчеркиваем паузы между словами, потому что они на самом деле не паузы.
В языке меня примечательно то, как много разных способов решения проблемы коммуникации люди.Мы слышим язык, но не оставляем слышимых пробелов между словами, единицами значения. Вместо этого мозг должен их вывести. Мы видим язык в письменной форме и можем не только различать едва воспринимаемые визуальные символы, но и мгновенно обрабатывать их, восстанавливать слуховой код, к которому они относятся, и в конечном итоге извлекать значение. По крайней мере, в письменной речи пробелы между словами четко разграничены. Это, конечно, обобщения. Исследования, подобные исследованию Ордина и его коллег, подтверждают важность рассмотрения идиосинкразии отдельных языков при выявлении универсальных свойств.
Статья, на которой сосредоточено внимание в этом посте:
Ордин М., Полянская Л., Лака И., & Неспор М. (2017). Межъязыковые различия в использовании длительности сигналов для сегментации нового языка.