Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «рука», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
РУКА, и, вин. руку, мн. руки, рук, рукам, ж.
1. Одна из двух верхних конечностей человека от плеча до кончиков пальцев, а также от запястья до кончиков пальцев. Правая, левая р. Выронить из рук. Пожать руку кому-н. (в знак приветствия, благодарности). Поздороваться за руку (о рукопожатии). Руки не подавать кому-н. (в знак презрения не обмениваться рукопожатием). Вести за руку (держа за руку). Взяться за руки. Под руки вести (поддерживая с двух сторон под согнутые локти). Под руку идти с кем-н. (опираясь на чьюн. согнутую в локте руку). На руки взять кого-н. (посадить к себе на колени или, подняв, прижать к себе, обычно о ребёнке). На руках держать кого-н. (взяв на руки). На руках носить кого-н. (также перен.: холить, лелеять; разг.). Руки опустились у кого-н. (также перен.: пропало желание действовать, быть активным). В руки отдать кому-н. (самому, лично). На руку надеть. Не по руке перчатки (велики или малы). Золотые руки у кого-н. (умелые; разг.). Рукам воли не давай (не дерись, убери руки; разг.). Из рук выпустить (также перен.: упустить что-н., не воспользоваться чем-н. выгодным; разг.). Руки греть на чёмн. (перен.: наживаться на каком-н. деле; разг. неодобр.). Руки прочь от кого-чего-н.! (также перен.: требование не вмешиваться в чьин. дела). Р. не дрогнет у кого-н. (также перен.: легко решиться на что-н. плохое). За руку схватить кого-н. (также перен.: уличить, поймать на месте преступления; разг.
Под руку идти с кем-н. (опираясь на чьюн. согнутую в локте руку). На руки взять кого-н. (посадить к себе на колени или, подняв, прижать к себе, обычно о ребёнке). На руках держать кого-н. (взяв на руки). На руках носить кого-н. (также перен.: холить, лелеять; разг.). Руки опустились у кого-н. (также перен.: пропало желание действовать, быть активным). В руки отдать кому-н. (самому, лично). На руку надеть. Не по руке перчатки (велики или малы). Золотые руки у кого-н. (умелые; разг.). Рукам воли не давай (не дерись, убери руки; разг.). Из рук выпустить (также перен.: упустить что-н., не воспользоваться чем-н. выгодным; разг.). Руки греть на чёмн. (перен.: наживаться на каком-н. деле; разг. неодобр.). Руки прочь от кого-чего-н.! (также перен.: требование не вмешиваться в чьин. дела). Р. не дрогнет у кого-н. (также перен.: легко решиться на что-н. плохое). За руку схватить кого-н. (также перен.: уличить, поймать на месте преступления; разг. ). Твёрдая р. у кого-н. (перен.: уверен в себе, строг). В руках у кого-н. (также перен.: 1) имеется, наличествует. Доказательство в руках у следователя; 2) в полном подчинении, зависимости. Вся семья у неё в руках; 3) пойман. Преступник в руках у правосудия). В руках или в своих руках держать, иметь что-н. (также перен.: держать в своей власти, обладая чем-н.). В руках держать кого-н. (также перен.: в строгости; разг.). Руку приложить (также перен.: поставить свою подпись; устар.). В руки или в свои руки захватить, взять что-н. (также перен.: взять себе или под своё наблюдение, руководство). В руки взять кого-н. (также перен.: сделать более дисциплинированным, заставить повиноваться; разг.). В наших (моих, его) руках (также перен.: в нашей власти, возможностях; разг.). Всё или дело валится из рук (перен.: за что ни возьмись, ничего не получается, ни на что нет сил; разг.). В хорошие, плохие, чужие руки отдать, попасть или в хороших, плохих, чужих руках быть, находиться (перен.
). Твёрдая р. у кого-н. (перен.: уверен в себе, строг). В руках у кого-н. (также перен.: 1) имеется, наличествует. Доказательство в руках у следователя; 2) в полном подчинении, зависимости. Вся семья у неё в руках; 3) пойман. Преступник в руках у правосудия). В руках или в своих руках держать, иметь что-н. (также перен.: держать в своей власти, обладая чем-н.). В руках держать кого-н. (также перен.: в строгости; разг.). Руку приложить (также перен.: поставить свою подпись; устар.). В руки или в свои руки захватить, взять что-н. (также перен.: взять себе или под своё наблюдение, руководство). В руки взять кого-н. (также перен.: сделать более дисциплинированным, заставить повиноваться; разг.). В наших (моих, его) руках (также перен.: в нашей власти, возможностях; разг.). Всё или дело валится из рук (перен.: за что ни возьмись, ничего не получается, ни на что нет сил; разг.). В хорошие, плохие, чужие руки отдать, попасть или в хороших, плохих, чужих руках быть, находиться (перен. : к хорошим, плохим, чужим людям или у хороших, плохих, чужих людей; разг.). В одни руки продать, отпустить (перен.: одному покупателю; разг.). В руки само (сам) идёт (перен.: оказывается легко доступным, достижимым; разг.). В четыре руки играть (играть на рояле вдвоём). Голыми руками не возьмёшь кого-н. (перен.: о том, кто хитёр, увёртлив; разг.). Из рук в руки или с рук на руки передать кого-что-н. (перен.: непосредственно передать кому-н.). Из рук в руки переходить (перен.: переходить в обладание то к одному, то к другому попеременно). Под горячую руку попасть (в сердитую минуту, когда кто-н. раздражён, рассержен; разг.). Под руку попасть (перен.: 1) случайно попасться. Под руку попала интересная статья; 2) то же, что под горячую руку попасть; разг.). Под рукой (также перен.: в непосредственной близости, так, что удобно воспользоваться; разг.). Под руку говорить кому-н. (перен.: говорить, мешая тому, кто занят делом; разг.
: к хорошим, плохим, чужим людям или у хороших, плохих, чужих людей; разг.). В одни руки продать, отпустить (перен.: одному покупателю; разг.). В руки само (сам) идёт (перен.: оказывается легко доступным, достижимым; разг.). В четыре руки играть (играть на рояле вдвоём). Голыми руками не возьмёшь кого-н. (перен.: о том, кто хитёр, увёртлив; разг.). Из рук в руки или с рук на руки передать кого-что-н. (перен.: непосредственно передать кому-н.). Из рук в руки переходить (перен.: переходить в обладание то к одному, то к другому попеременно). Под горячую руку попасть (в сердитую минуту, когда кто-н. раздражён, рассержен; разг.). Под руку попасть (перен.: 1) случайно попасться. Под руку попала интересная статья; 2) то же, что под горячую руку попасть; разг.). Под рукой (также перен.: в непосредственной близости, так, что удобно воспользоваться; разг.). Под руку говорить кому-н. (перен.: говорить, мешая тому, кто занят делом; разг.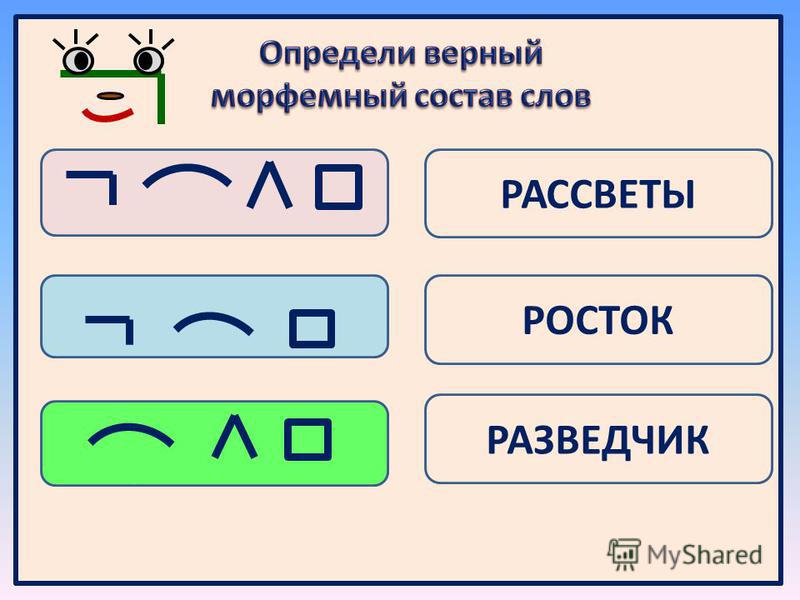 ). По рукам бить или ударить (также перен.: заключить сделку, договориться; прост.). По рукам дать кому-н. (также перен.: дать кому-н. острастку; разг.). На руках умереть чьих-н. или у кого-н. (перен.: в присутствии того, кто был рядом, близко). Подать, протянуть руку помощи (перен.: помочь; высок.). Поднять руку на кого-н. (перен.: покуситься ударить или убить кого-н.). Руками и ногами отбиваться, отпихиваться (также перен.: категорически отказываться; разг.). С руками и ногами (перен.: весь, целиком; разг.). Р. об руку идти (взявшись за руки; также перен.: действовать дружно, совместно). Рукой не достанешь кого-н. (также перен.: о том, кто достиг высокого положения, а также о том, кто далеко; разг.). Руку наложить на что-н. (перен.: завладеть чем-н.; разг. неодобр.). Р. не поднимается у кого на кого-что-н. (перен.: не хватает смелости, решительности сделать что-н.; разг.
). По рукам бить или ударить (также перен.: заключить сделку, договориться; прост.). По рукам дать кому-н. (также перен.: дать кому-н. острастку; разг.). На руках умереть чьих-н. или у кого-н. (перен.: в присутствии того, кто был рядом, близко). Подать, протянуть руку помощи (перен.: помочь; высок.). Поднять руку на кого-н. (перен.: покуситься ударить или убить кого-н.). Руками и ногами отбиваться, отпихиваться (также перен.: категорически отказываться; разг.). С руками и ногами (перен.: весь, целиком; разг.). Р. об руку идти (взявшись за руки; также перен.: действовать дружно, совместно). Рукой не достанешь кого-н. (также перен.: о том, кто достиг высокого положения, а также о том, кто далеко; разг.). Руку наложить на что-н. (перен.: завладеть чем-н.; разг. неодобр.). Р. не поднимается у кого на кого-что-н. (перен.: не хватает смелости, решительности сделать что-н.; разг. ). Руки развязать кому-н. (также перен.: дать возможность свободно действовать; разг.). Руки чешутся у кого-н. (также перен.: 1) хочется подраться; разг.; 2) на что и с неопр., хочется заняться каким-н. делом; разг. Руки чешутся на работу). Пройти через чьин. руки (перен.: быть предметом чьейн. деятельности, воздействия, внимания). Р. руку моет (посл. о тех, кто прикрывает неблаговидные дела друг друга). Чистыми руками делать что-н. (также перен.: не кривя душой, с чистой совестью).
). Руки развязать кому-н. (также перен.: дать возможность свободно действовать; разг.). Руки чешутся у кого-н. (также перен.: 1) хочется подраться; разг.; 2) на что и с неопр., хочется заняться каким-н. делом; разг. Руки чешутся на работу). Пройти через чьин. руки (перен.: быть предметом чьейн. деятельности, воздействия, внимания). Р. руку моет (посл. о тех, кто прикрывает неблаговидные дела друг друга). Чистыми руками делать что-н. (также перен.: не кривя душой, с чистой совестью).
2. перен. Почерк, подпись. Разобрать чьюн. руку. Неразборчивая р.
3. перен. Сторона, направление (разг.). На левой руке (слева). По правую руку от кого-чего-н. (справа).
4. перен. Человек, а также вообще те, кто оказывает кому-н. уверенную, но неявную помощь. Своя р. в министерстве у кого-н. У одного из кандидатов есть р. среди сильных мира сего.
Своя р. в министерстве у кого-н. У одного из кандидатов есть р. среди сильных мира сего.
5. руки какой. употр. в нек-рых выражениях в знач. того или иного вида, сорта, качества (разг.). Товар средней руки. Большой руки негодяй.
• Взять себя в руки заставить себя успокоиться.
Дело рук человеческих о том, что вполне осуществимо.
Дело рук чьих о том, кто виноват в чёмн.
Держать руку чью (устар. и разг.) быть чьимн. сторонником, поддерживать кого-н. в чёмн.
Живой рукой (прост.) быстро, живо. Беги живой рукой!
Из вторых (третьих) рук (узнать, получить сведения) не непосредственно от кого-н.
Из первых рук (узнать, получить сведения) из первоисточника, непосредственно от кого-н.
Из рук вон (плохо) (разг. ) очень плохо, никуда не годится.
) очень плохо, никуда не годится.
Из чужих рук смотреть (разг. неодобр.) быть в зависимости от других.
К рукам прибрать кого-что 1) присвоить или завладеть, захватить (разг. неодобр.). Прибрать к рукам чьён. наследство; 2) всецело подчинить себе кого-н. (разг.). Прибрать к рукам подчинённых.
Как рукой сняло что (разг.) совершенно прошло (обычно о боли).
На все руки мастер (разг.) всё умеет делать.
На руках 1) быть, иметься в наличии. Документы на руках; 2) у кого, на чьёмн. попечении. У него на руках большая семья.
На руки выдать что кому вручить.
На руку кому что (разг.) совпадает с чьимин. интересами, выгодно кому-н.
На руку нечист (разг. ) нечестен, вороват.
) нечестен, вороват.
Не покладая рук (разг.) усердно, без устали.
Не рука кому, с неопр. (прост.) не нужно, некстати, не следует. Ссориться с ним мне сейчас не рука.
Не с руки (разг.) 1) кому, о неудобном положении руки при каком-н. занятии. Писать лёжа не с руки; 2) не следует, не годится, не рука.
От руки написать пером, карандашом, в отличие от машинописного, печатного текста.
По рукам пойти (ходить) (разг.) переходить от одного к другому.
Просить чьей руки сделать предложение1 (в 3 знач.).
Руку (и сердце) предложить кому (устар.) то же, что просить чьейн. руки.
Руки не доходят до чего (разг.) не успевает кто-н. сделать что-н. из-за множества других дел. До уборки руки не доходят.
До уборки руки не доходят.
Рукой подать (разг.) очень близко. До дому рукой подать.
Свобода рук (книжн.) свобода действий.
Сон в руку (разг.) о сбывшемся сне.
С рук сбыть кого-что (разг.) избавиться от кого-чего-н.
С рук сойти (разг.) остаться безнаказанным. Шалость сошла с рук.
| уменьш. ручка, и, ж. (к 1 знач.). Сделать ручкой кому-н. (проститься; также перен.: исчезнуть, скрыться; разг. шутл.). За ручку водить кого-н. (также перен.: излишне опекать, лишать возможности действовать самостоятельно; неодобр.).
• До ручки дойти (разг.) до нищеты или до совершенно безвыходного состояния.
| ласк. рученька, и, ж. (к 1 знач.).
| уменьш.-ласк. ручонка, и, ж. (к 1 знач.).
ручонка, и, ж. (к 1 знач.).
| увел. ручища, и, ж. (к 1 знач.).
| прил. ручной, ая, ое (к 1 знач.).
Фонетический (звуко-буквенный) разбор
рука́
рука — слово из 2 слогов: ру-ка. Ударение падает на 2-й слог.
Транскрипция слова: [рука]
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
у — [у] — гласный, безударный
к — [к] — согласный, глухой парный, твёрдый (парный)
а — [а] — гласный, ударный
В слове 4 буквы и 4 звука.
Цветовая схема: рука
Разбор слова «рука» по составу
рука
Части слова «рука»: рук/а
Состав слова:
рук — корень,
а — окончание,
рук — основа слова.
Слова «руки» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «руки» на слоги для переноса.
Онлайн словарь Soosle. ru поможет: фонетический и морфологический разобрать слово «руки» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «руки».
ru поможет: фонетический и морфологический разобрать слово «руки» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «руки».
Содержимое:
- 1 Слоги в слове «руки» деление на слоги
- 2 Как перенести слово «руки»
- 3 Морфологический разбор слова «руки»
- 4 Разбор слова «руки» по составу
- 5 Сходные по морфемному строению слова «руки»
- 6 Синонимы слова «руки»
- 7 Ударение в слове «руки»
- 8 Фонетическая транскрипция слова «руки»
- 9 Фонетический разбор слова «руки» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «руки»
- 11 Сочетаемость слова «руки»
- 12 Значение слова «руки»
- 13 Как правильно пишется слово «руки»
- 14 Ассоциации к слову «руки»
Слоги в слове «руки» деление на слоги
Количество слогов: 2
По слогам: ру-ки
Как перенести слово «руки»
ру—ки
Морфологический разбор слова «руки»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: единственное, множественное;
падеж: родительный, именительный, винительный;
отвечает на вопрос: (нет/около) Чего?, (есть) Что?, (вижу/виню) Что?
Начальная форма:
рука
Разбор слова «руки» по составу
| рук | корень |
| а | окончание |
рука
Сходные по морфемному строению слова «руки»
Сходные по морфемному строению слова
Синонимы слова «руки»
1. грабли
грабли
2. грабки
3. обрезки
4. шуршики
5. пакши
6. растопырки
7. рычаги
8. шуршалки
9. щипанцы
10. щупальцы
11. цыпки
Ударение в слове «руки»
руки́ — ударение падает на 2-й слог
Фонетическая транскрипция слова «руки»
[рук’`и]
Фонетический разбор слова «руки» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| у | [у] | гласный, безударный | у |
| к | [к’] | согласный, глухой парный, мягкий, шумный | к |
| и | [`и] | гласный, ударный | и |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 4 буквы и 4 звука.
Буквы: 2 гласных буквы, 2 согласных букв.
Звуки: 2 гласных звука, 2 согласных звука.
Предложения со словом «руки»
– До завтра, – тихо ответил он и махнул рукой уже пустому проёму.
Вячеслав Шалыгин, Глаз Павлина, 1999.
– Мы наплодили кибернетических сущностей, создали армады боевых машин, а теперь, очнувшись, пытаемся протянуть руку друг другу, начинаем действовать сообща, хотя не так давно были заклятыми врагами.
Андрей Ливадный, Наемник. Грань возможного, 2010.
Зажав правую руку левой и ругаясь вполголоса, он плечом открыл дверь своей спальни.
Дж. К. Роулинг, Гарри Поттер и Дары Смерти, 2007.
Сочетаемость слова «руки»
1. правая рука
2. левая рука
3. дрожащая рука
4. руки ноги
5. рука человека
6. рука помощи
рука помощи
7. пальцы рук
8. кисти рук
9. движение руки
10. руки дрожали
11. руки тряслись
12. руки задрожали
13. взять кого-либо за руку
14. протянуть руку
15. держать себя в руках
16. (полная таблица сочетаемости)
Значение слова «руки»
РУКА́ , -и́, вин. ру́ку, мн. ру́ки, дат. рука́м, ж. 1. Каждая из двух верхних конечностей человека от плечевого сустава до кончиков пальцев. Заложить руки за спину. Скрестить руки на груди. (Малый академический словарь, МАС)
Как правильно пишется слово «руки»
Правильно слово пишется: ру́ки
Номера букв в слове «руки» в прямом и обратном порядке:
- 4
р
1 - 3
у
2 - 2
к
3 - 1
и
4
Ассоциации к слову «руки»
Лева
Пожатие
Взмах
Кисть
Эфес
Перчатка
Запястье
Перевязь
Талия
Вертел
Рукоять
Подлокотник
Предплечье
Вытянутый
Безвольный
Правый
Узловатый
Согнутый
Костлявый
Тыльный
Приветственный
Левый
Молитвенный
Всплеснуть
Махнуть
Замахать
Воздеть
Скрестить
Обвить
Обхватить
Упереть
Раскинуть
Заломить
Сцепить
Помахать
Высвободить
Сжимать
Протягивать
Повертеть
Подпереть
Взмахнуть
Махать
Пожимать
Протянуть
Обвиться
Потирать
Прибрать
Вытянуть
Придерживать
Зажать
Развести
Разжаться
Размахивать
Разжать
Просунуть
Забинтовать
Сжать
Растопырить
Зажимать
Взмахивать
Согнуть
Держать
Трястись
Чесаться
Опереться
Схватить
Засунуть
Обвивать
Стискивать
Сложить
Сунуть
Нащупать
Вертеть
Дотронуться
Пачкать
Ухватить
Вцепиться
Вырвать
Шарить
Затечь
Прижимать
Ухватиться
Прижать
Намотать
Умыть
Закинуть
Положить
Коснуться
Растирать
Вскидывать
Выдернуть
Дрожать
Нащупывать
Скрючить
Выронить
Пошарить
Предостерегающе
Бессильно
Крепко
Галантно
Слова «руках» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «руках» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «руках» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «руках».
Содержимое:
- 1 Слоги в слове «руках» деление на слоги
- 2 Как перенести слово «руках»
- 3 Морфологический разбор слова «руках»
- 4 Разбор слова «руках» по составу
- 5 Сходные по морфемному строению слова «руках»
- 6 Синонимы слова «руках»
- 7 Ударение в слове «руках»
- 8 Фонетическая транскрипция слова «руках»
- 9 Фонетический разбор слова «руках» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «руках»
- 11 Сочетаемость слова «руках»
- 12 Значение слова «руках»
- 13 Как правильно пишется слово «руках»
- 14 Ассоциации к слову «руках»
Слоги в слове «руках» деление на слоги
Количество слогов: 2
По слогам: ру-ках
Как перенести слово «руках»
ру—ках
Морфологический разбор слова «руках»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: множественное;
падеж: предложный;
отвечает на вопрос: (говорю/думаю) О чём?
Начальная форма:
рука
Разбор слова «руках» по составу
| рук | корень |
| а | окончание |
рука
Сходные по морфемному строению слова «руках»
Сходные по морфемному строению слова
Синонимы слова «руках»
1. ручища
ручища
2. фланг
3. сторона
4. рученька
5. ручка
6. ручонка
7. десница
8. шуйца
9. лапа
10. длань
11. кисть
12. пятерня
13. почерк
14. покровительство
15. конечность
16. лапка
17. связи
18. блат
19. знакомства
20. своя рука
21. сильная рука
22. стиль
23. манера
24. творческий почерк
25. весло
26. клешня
27. крюк
28. коряга
29. культя
30. культяпка
31. маховик
32. масёл
33. шатун
34. сучок
35. цапка
36. хэнд
37. хваталка
38. хапалка
39. цапалка
40. шершавка
41. цапля
42. черпалка
43. крыша
Ударение в слове «руках»
рука́х — ударение падает на 2-й слог
Фонетическая транскрипция слова «руках»
[рук`ах]
Фонетический разбор слова «руках» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| у | [у] | гласный, безударный | у |
| к | [к] | согласный, глухой парный, твёрдый, шумный | к |
| а | [`а] | гласный, ударный | а |
| х | [х] | согласный, глухой непарный, твёрдый, шумный | х |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 5 букв и 5 звуков.
Буквы: 2 гласных буквы, 3 согласных букв.
Звуки: 2 гласных звука, 3 согласных звука.
Предложения со словом «руках»
– До завтра, – тихо ответил он и махнул рукой уже пустому проёму.
Вячеслав Шалыгин, Глаз Павлина, 1999.
– Мы наплодили кибернетических сущностей, создали армады боевых машин, а теперь, очнувшись, пытаемся протянуть руку друг другу, начинаем действовать сообща, хотя не так давно были заклятыми врагами.
Андрей Ливадный, Наемник. Грань возможного, 2010.
Зажав правую руку левой и ругаясь вполголоса, он плечом открыл дверь своей спальни.
Дж. К. Роулинг, Гарри Поттер и Дары Смерти, 2007.
Сочетаемость слова «руках»
1. правая рука
2. левая рука
3. дрожащая рука
4. руки ноги
5. рука человека
6. рука помощи
рука помощи
7. пальцы рук
8. кисти рук
9. движение руки
10. руки дрожали
11. руки тряслись
12. руки задрожали
13. взять кого-либо за руку
14. протянуть руку
15. держать себя в руках
16. (полная таблица сочетаемости)
Значение слова «руках»
РУКА́ , -и́, вин. ру́ку, мн. ру́ки, дат. рука́м, ж. 1. Каждая из двух верхних конечностей человека от плечевого сустава до кончиков пальцев. Заложить руки за спину. Скрестить руки на груди. (Малый академический словарь, МАС)
Как правильно пишется слово «руках»
Орфография слова «руках»Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «руках» в прямом и обратном порядке:
Ассоциации к слову «руках»
Лева
Пожатие
Взмах
Кисть
Эфес
Перчатка
Запястье
Перевязь
Талия
Вертел
Рукоять
Подлокотник
Предплечье
Вытянутый
Безвольный
Правый
Узловатый
Согнутый
Костлявый
Тыльный
Приветственный
Левый
Молитвенный
Всплеснуть
Махнуть
Замахать
Воздеть
Скрестить
Обвить
Обхватить
Упереть
Раскинуть
Заломить
Сцепить
Помахать
Высвободить
Сжимать
Протягивать
Повертеть
Подпереть
Взмахнуть
Махать
Пожимать
Протянуть
Обвиться
Потирать
Прибрать
Вытянуть
Придерживать
Зажать
Развести
Разжаться
Размахивать
Разжать
Просунуть
Забинтовать
Сжать
Растопырить
Зажимать
Взмахивать
Согнуть
Держать
Трястись
Чесаться
Опереться
Схватить
Засунуть
Обвивать
Стискивать
Сложить
Сунуть
Нащупать
Вертеть
Дотронуться
Пачкать
Ухватить
Вцепиться
Вырвать
Шарить
Затечь
Прижимать
Ухватиться
Прижать
Намотать
Умыть
Закинуть
Положить
Коснуться
Растирать
Вскидывать
Выдернуть
Дрожать
Нащупывать
Скрючить
Выронить
Пошарить
Предостерегающе
Бессильно
Крепко
Галантно
Word2Vec для фраз — изучение встраивания более чем одного слова | Моше Хазум
Фото Александры на Unsplash Когда дело доходит до семантики, мы все знаем и любим знаменитый алгоритм Word2Vec [1] для создания вложений слов с помощью распределенных семантических представлений во многих приложениях НЛП, таких как NER, семантический анализ, классификация текста и многое другое.
Однако ограничением текущей реализации алгоритма Word2Vec является естественное поведение униграмм . В Word2Vec мы пытаемся предсказать данное слово на основе его контекста (CBOW) или предсказать окружающий контекст на основе данного слова (Skip-Gram). Но что, если мы хотим использовать термин «American Airlines» целиком? В этом посте я объясню, как создавать вложения для более чем униграмм, используя неконтролируемый текстовый корпус. Если вы знакомы с алгоритмом Word2Vec и встраиванием слов, вы можете пропустить первую часть этого поста.
В частности, мы рассмотрим:
- Введение в представление слов в задачах НЛП.
- Гипотеза распределения [2] и алгоритм Word2Vec.
- Изучение фраз из текста без присмотра.
- Как извлечь фразы, похожие на заданную фразу.
Компания Amenity Analytics, в которой я сейчас работаю, создает продукты Text Analytics, уделяя особое внимание области финансов. Это помогает предприятиям получать полезную информацию в огромных масштабах. Недавно мы выпустили новую поисковую систему на основе Elastic Search, чтобы помочь нашим клиентам получить более точное и целенаправленное представление своих данных. Изучив запросы пользователей в поисковой системе, мы заметили, что многие клиенты ищут финансовые термины, а наивного выполнения полнотекстового поиска по запросу недостаточно. Например, один термин, который много раз встречался в поисковых запросах пользователей, — это «точка перегиба».
Недавно мы выпустили новую поисковую систему на основе Elastic Search, чтобы помочь нашим клиентам получить более точное и целенаправленное представление своих данных. Изучив запросы пользователей в поисковой системе, мы заметили, что многие клиенты ищут финансовые термины, а наивного выполнения полнотекстового поиска по запросу недостаточно. Например, один термин, который много раз встречался в поисковых запросах пользователей, — это «точка перегиба».
Найдите определение «точки перегиба» в Investopedia:
«Точка перегиба — это событие, которое приводит к значительным изменениям в развитии компании, отрасли, сектора, экономики или геополитической ситуации и может считаться поворотным точка, после которой ожидается резкое изменение с положительными или отрицательными результатами»
Наши клиенты хотят видеть важные события в компаниях, за которыми они следят, поэтому нам нужно искать больше терминов с тем же значением, что и « Точка перегиба», например «Поворотный момент», «Переломный момент» и т. д.
д.
Представление слов
Наиболее гранулированными объектами языка являются символы, из которых формируются слова или токены. Слова (и символы) дискретны и символичны. Невозможно сказать, что «лабрадор» и «собака» каким-то образом связаны друг с другом, просто взглянув на слова как есть или взглянув на символы, которые их составляют.
Мешок слов (BOW)
Наиболее распространенным методом извлечения признаков для задач НЛП является метод набора слов (BOW). В пакете слов мы смотрим на гистограмму вхождений слов в данном корпусе без учета порядка. Часто мы ищем не только одно слово, но и биграммы («хочу»), триграммы («хочу») или n-граммы в общем случае. Это распространенный подход к нормализации счетчиков для каждого слова, потому что документы могут различаться по длине (в большинстве случаев).
Нормализованный ЛУК. Один из основных недостатков представления BOW заключается в том, что оно дискретно и не может отражать семантическую связь между словами.
Частота термина — обратная частота документа (TF-IDF)
Одним из результатов представления BOW является то, что оно дает оценку словам, которые встречались много раз, но многие из них не дают никакой значимой информации, например «к и от». Мы хотим различать слова, которые встречаются много раз и являются общими словами, от слов, которые встречаются много раз, но дают информацию о конкретном документе. Взвешивание векторов BOW является обычной практикой, и одним из наиболее часто используемых подходов к взвешиванию является TF-IDF (Manning et al., 2008).
Формула взвешивания TF-IDF. Существует множество вариаций TF-IDF, подробнее об этом можно прочитать здесь.Однако и BOW, и TF-IDF не могут фиксировать семантическое значение слов, поскольку они представляют слова или n-граммы дискретным образом.
Гипотеза распределения заключается в том, что слова, встречающиеся в одном и том же контексте, обычно имеют сходные значения [2]. Это основа семантического анализа текста. Идея, лежащая в основе этой гипотезы, заключается в том, что мы можем узнать значение слов, глядя на контекст, в котором они появляются. Легко заметить, что слово «играть» в предложении «Мальчик любит играть на улице» имеет другое значение, чем слово «играть» в предложении «Пьеса была фантастической». В целом слова, близкие к целевому слову, более информативны, но в некоторых случаях в предложениях существуют длительные зависимости между целевым словом и словами, которые «далеки» от него. За прошедшие годы было разработано множество подходов к изучению слова из его контекста, в том числе знаменитый Word2Vec, о котором пойдет речь в этом посте из-за его огромной популярности как в академических кругах, так и в отрасли.
Это основа семантического анализа текста. Идея, лежащая в основе этой гипотезы, заключается в том, что мы можем узнать значение слов, глядя на контекст, в котором они появляются. Легко заметить, что слово «играть» в предложении «Мальчик любит играть на улице» имеет другое значение, чем слово «играть» в предложении «Пьеса была фантастической». В целом слова, близкие к целевому слову, более информативны, но в некоторых случаях в предложениях существуют длительные зависимости между целевым словом и словами, которые «далеки» от него. За прошедшие годы было разработано множество подходов к изучению слова из его контекста, в том числе знаменитый Word2Vec, о котором пойдет речь в этом посте из-за его огромной популярности как в академических кругах, так и в отрасли.
Word2Vec
Гипотеза распределения является основной идеей Word2Vec. В Word2Vec у нас есть большой неконтролируемый корпус, и для каждого слова в корпусе мы пытаемся предсказать его по заданному контексту (CBOW) или пытаемся предсказать контекст по конкретному слову (Skip-Gram).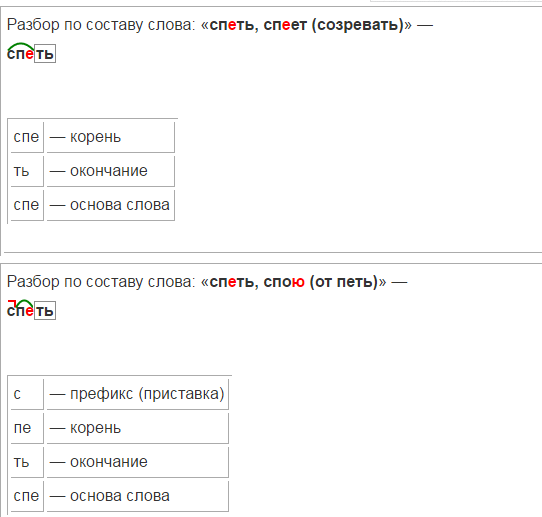 Word2Vec — это (неглубокая) нейронная сеть с одним скрытым слоем (с размерностью d) и функцией оптимизации Negative-Sampling или Hierarchical Softmax (подробнее можно прочитать в этой статье). На этапе обучения мы перебираем токены в корпусе (целевое слово) и смотрим на окно размером k (k слов с каждой стороны целевого слова, обычно со значениями от 2 до 10).
Word2Vec — это (неглубокая) нейронная сеть с одним скрытым слоем (с размерностью d) и функцией оптимизации Negative-Sampling или Hierarchical Softmax (подробнее можно прочитать в этой статье). На этапе обучения мы перебираем токены в корпусе (целевое слово) и смотрим на окно размером k (k слов с каждой стороны целевого слова, обычно со значениями от 2 до 10).
В конце обучения мы получим из сети следующую матрицу встраивания:
Матрица вложения после обучения Word2Vec Теперь каждое слово будет представлено не дискретным и разреженным вектором, а d-размерностью непрерывный вектор, и значение каждого слова будет отражаться его отношением к другим словам [5]. Причина этого заключается в том, что во время обучения, если два целевых слова имеют общий контекст, интуитивно вес сети для этих двух целевых слов будет близок друг к другу и, следовательно, к их совпадающим векторам. Таким образом, мы получаем представление распределения для каждого слова в корпусе, в отличие от подходов, основанных на подсчете (таких как BOW и TF-IDF). Из-за поведения распределения конкретное измерение в векторе не дает никакой ценной информации, но, рассматривая (распределительный) вектор в целом, можно выполнить множество задач подобия. Например, мы получаем, что V(«Король»)-V(«Мужчина»)+V(«Женщина) ~= V(«Королева») и V(«Париж»)-V(«Франция)+V(» Испания») ~= V(«Мадрид»). Кроме того, мы можем выполнить меры сходства, такие как косинус-сходство, между векторами и получить, что вектор слова «президент» будет близок к «Обаме», «Трамп», «генеральный директор», «председатель» и т. д.
Из-за поведения распределения конкретное измерение в векторе не дает никакой ценной информации, но, рассматривая (распределительный) вектор в целом, можно выполнить множество задач подобия. Например, мы получаем, что V(«Король»)-V(«Мужчина»)+V(«Женщина) ~= V(«Королева») и V(«Париж»)-V(«Франция)+V(» Испания») ~= V(«Мадрид»). Кроме того, мы можем выполнить меры сходства, такие как косинус-сходство, между векторами и получить, что вектор слова «президент» будет близок к «Обаме», «Трамп», «генеральный директор», «председатель» и т. д.
Как показано выше, мы можем выполнять множество задач на сходство слов, используя Word2Vec. Но, как мы упоминали выше, мы хотим сделать то же самое для более чем одного слова.
Мы можем легко создавать биграммы с нашим неконтролируемым корпусом и использовать их в качестве входных данных для Word2Vec. Например, предложение «Я шел сегодня в парк» будет преобразовано в «Я_шел_шел_сегодня_сегодня_в_парк», и каждая биграмма будет рассматриваться как униграмма в обучающей фразе Word2Vec. Это будет работать, но есть некоторые проблемы с этим подходом:
Это будет работать, но есть некоторые проблемы с этим подходом:
- Он выучит эмбеддинги только для биграмм, при этом многие из этих биграмм не имеют особого смысла (например, «walked_today») и мы пропустим эмбеддинги для униграмм, вроде «гулял» и « Cегодня».
- Работа только с биграммами создает очень разреженный корпус. Подумайте, например, о приведенном выше предложении «Сегодня я ходил в парк». Допустим, целевое слово — «walked_today», этот термин не очень распространен в корпусе, и у нас не будет много контекстных примеров, чтобы изучить репрезентативный вектор для этого термина.
Итак, как решить эту проблему? как мы извлекаем только значимые термины, сохраняя слова как униграммы, если их взаимная информация достаточно сильна? Как всегда ответ внутри вопроса — взаимная информация .
Взаимная информация (МИ)
Взаимная информация между двумя случайными величинами X и Y является мерой зависимости между X и Y. Формально:
Формально:
В нашем случае , X и Y представляют все биграммы в корпусе, такие что y идет сразу после x.
Точечная взаимная информация (PMI)
PMI – это мера зависимости между конкретным появлением x и y. Например: x=прошел, y=сегодня. Формально:
PMI конкретных вхождений x и y.Легко видеть, что когда два слова x и y встречаются вместе много раз, но не поодиночке, PMI(x;y) будет иметь высокое значение, в то время как оно будет иметь значение 0, если x и y полностью независимы.
Нормализованная поточечная взаимная информация (NPMI)
Хотя PMI является мерой зависимости появления x и y, у нас нет верхней границы его значений [3]. Нам нужна мера, которую можно сравнивать между всеми биграммами, поэтому мы можем выбирать только биграммы выше определенного порога. Мы хотим, чтобы показатель PMI имел максимальное значение 1 для идеально коррелированных слов x и y. Формально:
Формально:
Подход, управляемый данными
Другой способ извлечения фраз из текста — использование следующей формулы [4], которая учитывает количество униграмм и биграмм и коэффициент дисконтирования для предотвращения создания биграмм слишком редких слов. Формально:
Подробнее читайте в этой статье.Теперь, когда у нас есть способ извлекать значимые биграммы из большого неконтролируемого корпуса, мы можем заменить биграммы с NPMI выше определенного порога на одну униграмму, например: «точка перегиба» будет преобразована в « точка_перегиба». Легко создать триграммы, используя преобразованный корпус с биграммами и снова запустив процесс (с более низким порогом) для триграмм форм. Точно так же мы можем продолжить этот процесс до n-грамм с уменьшающимся порогом.
Наш корпус состоит примерно из 60 миллионов предложений, содержащих в общей сложности 1,6 миллиарда слов. Нам потребовался 1 час, чтобы построить биграммы с использованием подхода, управляемого данными. Наилучшие результаты достигаются при пороговом значении 7 и минимальном количестве сроков 5.
Наилучшие результаты достигаются при пороговом значении 7 и минимальном количестве сроков 5.
Мы измерили результаты с помощью набора оценок, который содержит важные биграммы, которые мы хотим идентифицировать, например, финансовые термины, имена людей (в основном генеральные и финансовые директора). города, страны и т. д. Используемая нами метрика — это простой отзыв: из наших извлеченных биграмм, каково покрытие в оценочном тесте. В этой конкретной задаче нас больше заботит отзыв, а не точность, поэтому мы позволили себе использовать относительно небольшой порог при извлечении биграмм. Мы принимаем во внимание, что наша точность может ухудшиться при снижении порога, и, в свою очередь, мы можем извлечь биграммы, которые не очень ценны, но это предпочтительнее, чем пропустить важные биграммы, при выполнении задачи расширения запроса.
Код примера
Чтение корпуса строка за строкой (мы предполагаем, что каждая строка содержит одно предложение) с эффективным использованием памяти: not line:
break
yield line
Очистите предложения, обрезав начальные и конечные пробелы, строчные буквы, удалив знаки препинания, удалив ненужные символы и сократив повторяющиеся пробелы в один пробел (обратите внимание, что это не обязательно, потому что позже мы будем токенизировать наше предложение через пробел): 9a-z0-9\s]’, », предложение)
return re. sub(r’\s{2,}’, ‘ ‘, предложение)
sub(r’\s{2,}’, ‘ ‘, предложение)
Маркировать каждую строку простым разделителем пробелов (более продвинутые методы для токенизации существуют, но токенизация с помощью простого пробела дала нам хорошие результаты и хорошо работает на практике), а также удалить стоп-слова. Удаление стоп-слов зависит от задачи, и в некоторых задачах НЛП сохранение стоп-слов дает лучшие результаты. Следует оценивать оба подхода. Для этой задачи мы использовали набор стоп-слов Spacy.
из spacy.lang.en.stop_words import STOP_WORDSdef tokenize(sentence):
вернуть [токен для токена в предложении.split(), если токен не в STOP_WORDS]
Теперь, когда у нас есть представления наших предложений в виде двумерной матрицы очищенных токенов, мы можем строить биграммы. Мы будем использовать библиотеку Gensim, которая действительно рекомендуется для семантических задач НЛП. К счастью, в Genim есть реализация для извлечения фраз, как с NPMI, так и с описанным выше подходом Миколова и др. на основе данных. Можно легко управлять гиперпараметрами, такими как определение минимального количества терминов, порога и оценки («по умолчанию» для подхода, основанного на данных, и «npmi» для NPMI). Обратите внимание, что значения различаются между двумя подходами, и это необходимо учитывать.
на основе данных. Можно легко управлять гиперпараметрами, такими как определение минимального количества терминов, порога и оценки («по умолчанию» для подхода, основанного на данных, и «npmi» для NPMI). Обратите внимание, что значения различаются между двумя подходами, и это необходимо учитывать.
из gensim.models.phrases import Phrases, Phraserdef build_phrases(sentences):
фразы = фразы(предложения,
min_count=5,
threshold=7,
progress_per=1000)
return Phraser(phrases)
После завершения создав модель фраз, мы можем легко сохранить ее и загрузить позже: может использовать его для извлечения биграмм для данного предложения:
def offer_to_bi_grams(phrases_model, предложение):
return ' '.join(phrases_model[sentence])
Мы хотим создать на основе нашего корпуса новый корпус со значимыми биграммами, объединенными вместе для последующего использования:
def Offerings_to_bi_grams(n_grams, input_file_name, output_file_name):
с open(input_file_name, 'r') as input_file_pointer:
с open(output_file_name, 'w+') as out_file:
для предложения в get_sentences(input_file_pointer):
clean_sentence = clean_sentence( предложение)
tokenized_sentence = tokenize(cleaned_sentence)
parsed_sentence = Offering_to_bi_grams(n_grams, tokenized_sentence)
out_file.write(parsed_sentence + '\n')
 write(parsed_sentence + '\n')
write(parsed_sentence + '\n') возможно, потребуется изменить гиперпараметры), как и раньше. Обучающая фраза будет рассматривать «точку перегиба» как одно слово и выучит распределенный d-мерный вектор, который будет близок к векторам таких терминов, как «точка перегиба» или «перегиб», что и является нашей целью!
В нашем корпусе из 1,6 миллиарда слов нам потребовался 1 час для построения биграмм и еще 2 часа для обучения Word2Vec (с пакетным Skip-Gram, размерностью 300, 10 эпохами, контекстом k=5, отрицательной выборкой 5, скорость обучения 0,01 и минимальное количество слов 5) на машине с 16 ЦП и 64 ОЗУ с использованием сервиса AWS Sagemaker. Отличный пример использования сервиса AWS Sagemaker для обучения Word2Vec в блокноте можно найти здесь.
Можно также использовать библиотеку Gensim для обучения модели Word2Vec, например здесь.
Например, при задании термина «точка перегиба» мы получаем следующие связанные термины, упорядоченные по их показателю косинусного сходства с их представленным вектором и вектором «точка_перегиба»:
«terms»: [
{
"term": "перегиб",
"score": 0,741
},
{
"term": "tipping_point",
"score": 0,667
},
{
"term": "inflexion_point",
"score": 0,637
},
{
"term": "hit_inflection",
"score": 0,624
},
{
"term": "точки перегиба",
"score": 0,606
},
{
"term": "достигнутый_перегиб",
"score": 0,583
},
{
"term": "вершина",
"оценка": 0,567
},
{
"термин": "достижение_изменения",
"оценка": 0,546
},
{
"термин": "достижение_опрокидывания",
"оценка": 0,518
},
{
"term": "hitting_inflection",
"score": 0,501
}
]
Некоторые из наших клиентов хотели увидеть влияние Черной пятницы на продажи компаний, поэтому, давая термин «Черная пятница Пятница» получаем:
"terms": [
{
"term": "cyber_monday",
"score": 0,815
},
{
"term": "thanksgiving_weekend",
"score": 0,679
},
{
"term": "праздничный_сезон",
"score": 0,645
},
{
"term": "thanksgiving_holiday",
"score": 0,643
},
{
"term": "valentine_day",
" оценка": 0,628
},
{
"термин": "день_матери",
"оценка": 0,628
},
{
"термин": "рождество",
"оценка": 0,627
},
{
"term": "shopping_cyber",
"score": 0,612
},
{
"term": "holiday_shopping",
"score": 0,608
},
{
"term": "праздник",
"счет": 0,605
}
]
Круто, не правда ли?
В этом посте мы рассмотрели различные подходы к представлению слов в задачах NLP (BOW, TF-IDF и Word Embeddings), узнали, как изучать представление слов из их контекста с помощью Word2Vec, увидели, как мы можем извлекать значимые фразы из заданного корпуса ( NPMI и подход, основанный на данных), и как преобразовать данный корпус, чтобы выучить похожие термины/слова для каждого из извлеченных терминов/слов с использованием алгоритма Word2Vec. Результаты этого процесса можно использовать в последующих задачах, таких как расширение запроса в задачах извлечения информации, классификация документов, кластеризация, ответы на вопросы и многие другие.
Результаты этого процесса можно использовать в последующих задачах, таких как расширение запроса в задачах извлечения информации, классификация документов, кластеризация, ответы на вопросы и многие другие.
Спасибо за внимание!
[1] Миколов, Т., Чен, К., Коррадо, Г.С., и Дин, Дж. (2013). Эффективная оценка представлений слов в векторном пространстве. CoRR, абс/1301.3781 .
[2] Харрис, З. (1954). Распределительная структура. Слово , 10 (23): 146–162.
[3] Баума, Г. (2009). Нормализованная (точечная) взаимная информация при извлечении словосочетаний.
[4] Миколов Т., Суцкевер И., Чен К., Коррадо Г.С. и Дин Дж. (2013). Распределенные представления слов и фраз и их композиционность. НИПС .
[5] Голдберг Ю., Херст Г., Лю Ю. и Чжан М. (2017). Нейросетевые методы обработки естественного языка. Компьютерная лингвистика, 44 , 193–195.
Faith Ringgold Publishing on Cloth – PARSE
Художественная карьера Faith Ringgold, насчитывающая более пяти десятилетий, включает в себя активную деятельность, писательскую деятельность, перформанс и создание картин, политических плакатов и лоскутных одеял. Родившаяся в Гарлеме, штат Нью-Йорк, в 1930 году, Рингголд — афроамериканская художница, которая была признана историком искусства Джулией Брайан-Уилсон в контексте Соединенных Штатов «одной из первых феминисток, которые включили текстиль в свою практику». 1 Ее опубликованные произведения включают многочисленные детские книги и мемуары « Мы пролетели над мостом » (1995). Несмотря на широкое признание, собственное признание Рингголд о том, что «я не могу жить в мире, не осознавая, что раса и пол влияют на все, что я делаю в своей жизни», представляет нам интерсекциональную политику, которая долгое время влияла на ее карьеру. 2 В этом письме я отхожу от некоторых наиболее хорошо отрепетированных аспектов карьеры Рингголда как активиста, 3 художник, 4 и перформанс, 5 , чтобы сосредоточиться на одном конкретном аспекте своей художественной практики: отношениях между текстом и текстилем, которые можно найти в стеганых одеялах Ринггольд, рассказывающих истории, и событиях, которые привели ее к использованию ткани в качестве поверхности.
Родившаяся в Гарлеме, штат Нью-Йорк, в 1930 году, Рингголд — афроамериканская художница, которая была признана историком искусства Джулией Брайан-Уилсон в контексте Соединенных Штатов «одной из первых феминисток, которые включили текстиль в свою практику». 1 Ее опубликованные произведения включают многочисленные детские книги и мемуары « Мы пролетели над мостом » (1995). Несмотря на широкое признание, собственное признание Рингголд о том, что «я не могу жить в мире, не осознавая, что раса и пол влияют на все, что я делаю в своей жизни», представляет нам интерсекциональную политику, которая долгое время влияла на ее карьеру. 2 В этом письме я отхожу от некоторых наиболее хорошо отрепетированных аспектов карьеры Рингголда как активиста, 3 художник, 4 и перформанс, 5 , чтобы сосредоточиться на одном конкретном аспекте своей художественной практики: отношениях между текстом и текстилем, которые можно найти в стеганых одеялах Ринггольд, рассказывающих истории, и событиях, которые привели ее к использованию ткани в качестве поверхности. на котором она могла бы опубликоваться.
на котором она могла бы опубликоваться.
В публичном диалоге с художественным руководителем Serpentine Galleries Гансом Ульрихом Обристом, сопровождавшим ее одноименную персональную выставку в Лондоне (6 июня — 8 сентября 2019 г.), Рингголд рассказала о реакции своего первоначального издателя на ранний набросок ее мемуаров, сначала названный Быть моей собственной женщиной , которая в конечном итоге будет опубликована как Мы пролетели над мостом :
Она [издатель] сказала, что это не ваша история. И я сказал, о боже мой. Во-первых, она сказала раньше, что собирается издать мою книгу. Я не знаю, почему она просто посмотрела на меня и решила, что моя книга будет односторонней. И это было не так. Итак, когда я дал ей свою автобиографию о том, как я вырос в Гарлеме и поступил в Городской колледж, и обо всех испытаниях и невзгодах, она решила, что это не твоя история. Потому что большинство писателей, чернокожих писательниц, которые писали свои рассказы в то время, писали рассказы обо всех ужасах, которые принесла им их жизнь.
 Что ж, извините. Моя жизнь не была ужасом. Меня не изнасиловали и не выбросили в окно, не избили и все такое. Этого не случилось со мной. Итак, что я должен делать? Придумать, чтобы меня опубликовали? И, возможно, некоторые из них сделали это тоже. Я не знаю. Но я решил, что хочу рассказать свою историю. 6
Что ж, извините. Моя жизнь не была ужасом. Меня не изнасиловали и не выбросили в окно, не избили и все такое. Этого не случилось со мной. Итак, что я должен делать? Придумать, чтобы меня опубликовали? И, возможно, некоторые из них сделали это тоже. Я не знаю. Но я решил, что хочу рассказать свою историю. 6 Когда Обрист спросила Рингголд, как она пришла к формату квилта рассказа, она вернулась к теме публикации: «Ну, как я могу опубликоваться? Как я могу получить свое слово там?» 7 «Это можно сделать, написав это на моем рисунке. Напиши это. Никто не может помешать мне сделать это. У меня есть слова на этот счет». 8
В то время как Рингголд рассказала о проблемах, с которыми она столкнулась при публикации своих мемуаров, Керли Рэйвен Холтон добавляет, что Рингголд «называли феминисткой, но она быстро напоминает нам, что феминистское движение не всегда искало лица, похожие на ее». 9 Американский искусствовед Алисса Аутер отмечает, что «стремление Рингголд и других художников-феминисток к художественной идентичности вне мейнстрима тесно связано с их законным желанием заниматься профессиональной деятельностью в мире искусства, враждебном их присутствию». 10 «В случае Рингголда это было утверждением расовой идентичности в искусстве, которое неизбежно ставило под сомнение маргинализацию Западом африканского искусства как ремесла». 11
10 «В случае Рингголда это было утверждением расовой идентичности в искусстве, которое неизбежно ставило под сомнение маргинализацию Западом африканского искусства как ремесла». 11
Вспоминая свое детство, Рингголд отмечает: «Я выросла в Гарлеме во время Великой депрессии. Это не значит, что я был беден и угнетен. Мы были защищены от угнетения и окружены любящей семьей». 12 В случае с Рингголд первоначальная «неспособность» ее биографии в глазах ее первоначального издателя описать опыт бедности или насилия, которого она на самом деле не пережила, вдохновила ее на решение вместо этого обратиться к написанию текстиль. «Позже Фейт заметит, что это было началом ее включения реального письменного текста в свою работу и, возможно, началом ее официальной карьеры писателя». 13 По иронии судьбы обращение к ткани как к месту публикации также вовлекло практику Рингголд в дебаты о ценности искусства и ремесла, которые рисковали усугубить маргинализацию, которую она уже испытала из-за своего пола и расы. Аутер отмечает: «Важно, что исследование Фейт Рингголд разделения искусства и ремесла продемонстрировало, что эти отношения определялись не только полом, но и расой, расширив феминистскую критику эстетической иерархии за пределы ее связи с домашней сферой». 14
Аутер отмечает: «Важно, что исследование Фейт Рингголд разделения искусства и ремесла продемонстрировало, что эти отношения определялись не только полом, но и расой, расширив феминистскую критику эстетической иерархии за пределы ее связи с домашней сферой». 14
Одеяло как рассказчик
Одеяла появляются в самых разных культурных контекстах и исторических моментах как рассказчики — иногда рассказчики по принуждению. При диктатуре генерала Пиночета в Чили (1973-1990) сшитых ткани арпиллера, вывезенных контрабандой из страны, объявили о пропаже без вести мужей, сыновей и братьев тех, кто сшил одежду, прежде чем другие формы сообщения, такие как радио и газетная бумага. 15 В Зимбабве такие проекты, как Weya Appliqués, сшитые в конце 1980-е и начало 2000-х годов также являются частью традиции рассказывания историй, первоначально финансируемой за счет туризма, но в конечном итоге затрагивающей такие темы, как эпидемия ВИЧ / СПИДа. 16 Совсем недавно такие выставки, как «Жизнь на полях» на острове Спайк, Бристоль, признали карьеру филиппинской американской художницы Пачиты Абад (1946–2004), чьи крупномасштабные работы сочетают в себе живопись и трапунто и имеют сходство с эстетикой Ринггольда. . 17 Сама Рингголд писала о работах Абад: «Путешествуя по всему миру, Абад создает свои работы с точки зрения цветной женщины со всего мира. Те из нас, кто также много путешествовал, знают, что творческие цветные женщины работают по всему миру, а не являются просто фигурами «меньшинства» в узких рамках западного мира искусства». 18
. 17 Сама Рингголд писала о работах Абад: «Путешествуя по всему миру, Абад создает свои работы с точки зрения цветной женщины со всего мира. Те из нас, кто также много путешествовал, знают, что творческие цветные женщины работают по всему миру, а не являются просто фигурами «меньшинства» в узких рамках западного мира искусства». 18
Но афроамериканский ученый Белл Хукс также предостерегает от огульных сравнений. Она призывает, не используя этот термин, к тому, что сегодня мы можем назвать признанием интерсекциональности на работе:
Работа чернокожих мастериц нуждается в особом феминистском критическом комментарии, учитывающем влияние расы, пола и класса.
 Многие чернокожие женщины стегали, несмотря на угнетающие экономические и социальные обстоятельства, которые часто требовали проявления творческого воображения способами, радикально отличными от таковых у белых женщин, особенно привилегированных женщин, у которых был больший доступ к материалам и времени. Часто чернокожие рабыни вяжут одежду как часть своего труда в белых семьях . 19
Многие чернокожие женщины стегали, несмотря на угнетающие экономические и социальные обстоятельства, которые часто требовали проявления творческого воображения способами, радикально отличными от таковых у белых женщин, особенно привилегированных женщин, у которых был больший доступ к материалам и времени. Часто чернокожие рабыни вяжут одежду как часть своего труда в белых семьях . 19 Крючки-предупреждения применимы к чтению лоскутных одеял Рингголд, чья семейная история связана с порабощенным трудом: «Вилли Поузи [мать Рингголд] описала, как наблюдала, как ее бабушка, Бетси Бингем, кипятила и отбеливала мешки для цветов, чтобы выровнять одеяла, которые она шила. Сьюзи Шеннон, мать Бетси, была рабыней в довоенной Флориде и шила одеяла в рамках своих обязанностей». 20
Текстильное производство, особенно хлопок, и американское рабство были взаимозависимыми. Как отмечает Свен Беккерт в своем обширном исследовании истории производства хлопка: «Хлопок буквально требовал охоты за рабочей силой и постоянной борьбы за контроль над ним […] сопутствующее физическое и психологическое насилие, связанное с содержанием миллионов людей в рабстве, имело центральное значение для расширения производства хлопка. хлопкового производства в Соединенных Штатах и промышленной революции в Великобритании». 21 Несмотря на то, что предупреждение Хукс верно в отношении семейной истории Рингголд, она также рискует навязать работу автобиографическим ожиданиям, подобно тому, как Рингголд начала публиковать . Стеганые одеяла, несмотря на всю их способность рассказывать истории, также подвергались завышенным требованиям относительно их повествовательного влияния.
хлопкового производства в Соединенных Штатах и промышленной революции в Великобритании». 21 Несмотря на то, что предупреждение Хукс верно в отношении семейной истории Рингголд, она также рискует навязать работу автобиографическим ожиданиям, подобно тому, как Рингголд начала публиковать . Стеганые одеяла, несмотря на всю их способность рассказывать истории, также подвергались завышенным требованиям относительно их повествовательного влияния.
Один из примеров преувеличения рассказывающего потенциала лоскутных одеял можно найти в вкладе лоскутных одеял в порабощенных людей, перемещающихся по Подземной железной дороге. 22 Жаклин Л. Тобин и Рэймонд Дж. Добард опубликовали широко оспариваемую книгу, в которой утверждалось, что стеганые одеяла буквально содержали коды выкройки, которые направляли порабощенных людей, которые путешествовали к своей свободе в американских штатах, где рабство было незаконным. 23 Предположение о том, что эти коды, пересказанные через устную историю, переданную одной из владелиц магазина лоскутных одеял Озеллой Уильямс в Чарльстоне, Южная Каролина, функционировали как закодированные карты, было широко оспорено, возможно, наиболее эффективно благодаря общему признанию того, что путешествие происходило пешком ночью. где висящие одеяла в качестве маркеров или карт не только вызвали бы подозрения, но и были бы недоступны для тех, кто путешествует под покровом темноты. 24 Как пишет Фергюс М. Бордевич:
где висящие одеяла в качестве маркеров или карт не только вызвали бы подозрения, но и были бы недоступны для тех, кто путешествует под покровом темноты. 24 Как пишет Фергюс М. Бордевич:
Большое значение Подземной железной дороги заключается не в причудливых легендах, а в разнообразной истории мужчин и женщин, черных и белых, которые заставили ее работать, и в далеком будущем. -достижение политических и моральных последствий содеянного. Подземная железная дорога была первым крупным движением массового гражданского неповиновения в стране после Американской революции, в котором тысячи граждан участвовали в активном подрыве федерального закона, а также первым массовым движением, отстаивавшим принцип личной ответственности за права человека других. Это было также первое в стране межрасовое политическое движение, которое с самого начала в 1790s присоединились к свободным чернокожим, белым аболиционистам, а иногда и к рабам в сотрудничестве, которое разрушило расовые табу .
 25
25 Написание Тобина и Добарда о подземной железной дороге превратило потенциал в факт, но в отсутствие существенных подтверждающих доказательств. Что касается многих других мировых примеров, то текстиль и, возможно, стеганые одеяла в частности заслуживают признания не только как рассказчики, но и как рассказчики, способные сообщать альтернативные и несанкционированные версии истории. Верно и обратное: одеяло как структура, метафора и символ появляется и способствует написанию художественной литературы.
Литературные стеганые одеяла
Стипендия о появлении лоскутного шитья в американской литературе включает чтение Элейн Шоуолтер сходства между лоскутным шитьем и повествовательными структурами в письмах американских женщин девятнадцатого и двадцатого веков. 26 Шоуолтер пишет: «Я хотел бы предположить, что знание техники соединения фрагментов в замысловатый и искусный рисунок может обеспечить контексты, в которых мы можем интерпретировать и понимать формы, значения и традиции повествования. Американское женское письмо». 27 Как и крючки, и несмотря на ее энтузиазм по поводу ряда обстоятельств, в которых происходило и имеет место стегание, 28 Шоуолтер призывает обратить внимание на конкретные контексты: «чтобы понять взаимосвязь между шитьем и письмом американских женщин, мы также должны деромантизировать искусство лоскутного одеяла, поместить его в его исторический контекст и отбросить многие сентиментальные стереотипы идеализированной, сестринской и неиерархической женской культуры, которые цепляются за него». 29
Американское женское письмо». 27 Как и крючки, и несмотря на ее энтузиазм по поводу ряда обстоятельств, в которых происходило и имеет место стегание, 28 Шоуолтер призывает обратить внимание на конкретные контексты: «чтобы понять взаимосвязь между шитьем и письмом американских женщин, мы также должны деромантизировать искусство лоскутного одеяла, поместить его в его исторический контекст и отбросить многие сентиментальные стереотипы идеализированной, сестринской и неиерархической женской культуры, которые цепляются за него». 29
Шоуолтер далеко не одинока в своем расследовании. Санни Падающий дождь использует аналогичную стратегию чтения, чтобы проследить структуру того, что она считает сумасшедшим лоскутным одеялом в романе Тони Моррисон « Возлюбленный » (1987):
Моррисон буквально создал сумасшедшее лоскутное одеяло. Каждый компонент сумасшедшего одеяла имеет аналог в романе. Диапазон литературных приемов, используемых для развития романа как сумасшедшего стеганого одеяла, включает в себя прямые утверждения о стеганых одеялах, цветах, тканях и лоскутном одеяле, а также об их значении в жизни персонажей.
 Но автор также создал очень тонкие техники для имитации структур квилтинга, техники, которые, как мне кажется, мог заметить только тот, кто разбирается в квилтинге — кто-то, кто ищет структуры, напоминающие безумное лоскутное одеяло. 30
Но автор также создал очень тонкие техники для имитации структур квилтинга, техники, которые, как мне кажется, мог заметить только тот, кто разбирается в квилтинге — кто-то, кто ищет структуры, напоминающие безумное лоскутное одеяло. 30 Я бы добавил, что одеяло в Возлюбленная существует не только в остатках ткани и стеганых структурах, которые Падающий дождь прослеживает на протяжении всего романа, но и в пятнах цвета, взятых с тела:
Ее прошлое было таким же, как ее настоящее — невыносимым, — и, поскольку она знала, что смерть — это что угодно, но только не забвение, она использовала немного оставшейся энергии для обдумывания цвета.
«Принесите немного лаванды, если она у вас есть. Розовый, если нет.
И Сете сделает ей что угодно, от ткани до собственного языка. Зима в Огайо была особенно суровой, если у вас был аппетит к цвету. Небо представляло собой единственную драму, и рассчитывать на горизонт Цинциннати как на главную радость жизни было поистине безрассудно .
 31
31 Роман Элис Уокер « Пурпурный цвет » (1982), вдохновивший Рингголда на создание романа Рингголд « Пурпурное одеяло » (1986), также придает текстилю и шитью значительное влияние на повествование. 32 Главный голос книги принадлежит Сели, причем большая часть книги рассказывается в переписке между Сели и ее сестрой Нетти, которая работает миссионером с вымышленным народом олинка в Африке. Одеяло используется, чтобы вызвать воспоминания о Коррин, работодателе и коллеге-миссионере Нетти, на смертном одре и подтвердить точное биологическое материнство. 33 Дизайн и пошив брюк дает Сели некоторые экономические и личные возможности в надомном производстве, которое она называет Folkpants Unlimited. 34 И важность визуальной красоты, обнаруживаемой как в текстиле, так и в похожих на текстиль фрагментах в Возлюбленный — видеть розовое зимой на языке — также очевидна в романе Уокера, когда Шуг, после того как познакомил Сели с ее собственной сексуальностью , замечает: «Я думаю, что это злит Бога, если вы идете по фиолетовому цвету где-нибудь в поле и не замечаете этого». 35
35
В ряде случаев крючки также относятся к стеганым одеялам в ее написании эссе. В версиях ее письма, опубликованных в Объект труда: искусство, ткань и культурное производство макет текста и «заплатки» появляются, а крючки напоминают об эстетическом наследии ее собственного детства. 36 Маленькие белые блоки, лишенные текста, первоначально акцентируют внимание на странице и нарушают ожидаемый ритм последовательных столбцов слов. По мере того, как Хукс пишет, некоторые пустые блоки начинают частично заполняться фрагментами изображений из лоскутных одеял Рингголда, изначально незавершенных, а затем наращиваемых по мере развития письма, предлагая еще один подход к историческим исследованиям Шоуолтера. 37
Одеяла с рассказами Фейт Рингголд
Стратегия Рингголд по публикации материалов на ткани появилась в 1980-х годах, примером чему служат рассказы о покрывалах, таких как Кто боится тети Джемаймы? (1983), Одеяло из истории изнасилования рабов (1985) и Пурпурное одеяло (1986). Использование ею текстильных материалов объясняется влиянием ее матери, Вилли Поузи Джонс, местного модельера, и просмотром Рингголд тханка картин. 38 Писатель-феминистка Мишель Уоллес, одна из двух дочерей Рингголд, размышляет о том, что ее мать «увидела в этих необрамленных свитках» тибетских и непальских тханка картин пятнадцатого века в Рейксмузеуме летом 1972 г. «решение ее проблемы в перемещение, хранение и транспортировка картин […] Картины на танках [так в оригинале] можно было свернуть». 39 Сама Рингголд объясняет в интервью 1975 года:
Использование ею текстильных материалов объясняется влиянием ее матери, Вилли Поузи Джонс, местного модельера, и просмотром Рингголд тханка картин. 38 Писатель-феминистка Мишель Уоллес, одна из двух дочерей Рингголд, размышляет о том, что ее мать «увидела в этих необрамленных свитках» тибетских и непальских тханка картин пятнадцатого века в Рейксмузеуме летом 1972 г. «решение ее проблемы в перемещение, хранение и транспортировка картин […] Картины на танках [так в оригинале] можно было свернуть». 39 Сама Рингголд объясняет в интервью 1975 года:
Кто сказал, что искусство — это масляная краска, натянутая на холст в художественных рамах? Я этого не говорил. Никто из тех, кто когда-либо был похож на меня, так не говорил, так какого черта я это делаю? Так что я просто остановился; а теперь я шью и все такое. Шитье традиционно было тем, чем занимались все женщины во всех культурах. Что случилось с этим? С политической точки зрения, я думаю, некоторые женщины, вероятно, сказали бы: «Я не хочу, чтобы меня помещали в сумку [] женского искусства… шитья».
 Хорошо, это ваш выбор… Я не хочу, чтобы меня сажали в мешок, где я думаю, что все искусство заключается в создании чего-то, что никто не может сдвинуть. Делать какую-то большую, монументальную, монолитную вещь, которую я даже не могу себе позволить… Феминистское искусство — это мягкое искусство, легкое искусство, искусство шитья. Это уникальный вклад женщин . 40
Хорошо, это ваш выбор… Я не хочу, чтобы меня сажали в мешок, где я думаю, что все искусство заключается в создании чего-то, что никто не может сдвинуть. Делать какую-то большую, монументальную, монолитную вещь, которую я даже не могу себе позволить… Феминистское искусство — это мягкое искусство, легкое искусство, искусство шитья. Это уникальный вклад женщин . 40 Уоллес отмечает, что серия «Изнасилование раба » (1972) «служит предшественником идеи, более полно задуманной в сюжетных стеганых одеялах 1980-х годов» благодаря использованию тканевой каймы, вдохновленной картинами тханка . и при поддержке швейных навыков матери Рингголд. Каждая работа в серии из трех частей содержит центральное живописное изображение раздетых и частично замаскированных листвой «африканских женщин, сопротивляющихся плену и сексуальному насилию». 41 Работы обрамлены окантовкой из кусочков ткани, что противоречит материальным ожиданиям от белого куба, чтобы соответствовать прямым углам и прямым краям. Возможно, ткань можно было бы сшить ровнее, а композиции — более сбалансированными, если бы была желательна такая эстетика. Эта обработка ткани, а не деталей шитья, является стилистической чертой, которая проходит через всю работу Ринггольда с тканью.
Возможно, ткань можно было бы сшить ровнее, а композиции — более сбалансированными, если бы была желательна такая эстетика. Эта обработка ткани, а не деталей шитья, является стилистической чертой, которая проходит через всю работу Ринггольда с тканью.
Но шитье, как утверждает Рингголд, не является «тем, чем занимаются все женщины во всех культурах». Уокер обращается к этому европейскому и североамериканскому стереотипу в конце 9 в.0272 Пурпурный цвет через диалог между Сели и Альбертом, мужем, которому отчим Сели фактически продал ее и который подверг ее изнасилованию, которые достигли некоторой формы примирения через их взаимную любовь и неприятие одной и той же женщиной. 42 Сели узнала благодаря миссионерской работе своей сестры в Африке, что текстильные традиции, такие как шитье, не организованы так, как она испытала в Америке, и пытается поделиться этими знаниями с Альбертом. Их диалог предлагает острую виньетку гендерных норм, с которыми они живут:
Мужчины и женщины не должны носить одно и то же, сказал он.
Так что я сказал, Вы должны сказать это мужчинам в Африке.
Что сказать? Он аст. Впервые он подумал о том, чем занимаются африканцы . […]
А мужчины и в Африке шьют, говорю я.
Да? Он аст.
Да, говорю я. Они не такие отсталые, как мужчины здесь.
Когда я рос, сказал он, я пытался шить вместе с мамой, потому что она всегда так делала. Но все надо мной смеялись. Но знаете, мне понравилось.
Ну, чувак, теперь я буду смеяться над тобой, сказал я. Вот, помоги мне зашить эти карманы.
Но я не знаю как, говорит он.
Я покажу тебе, сказал я. И я сделал.
Теперь сидим и шьем, разговариваем и курим трубки . 43
 Мужчины предлагают носить брюки.
Мужчины предлагают носить брюки. Рингголд позже сотрудничала со своей матерью над тем, что считается ее первым стеганым одеялом в 1980 году Echoes of Harlem . 44 Одеяло состоит из блоков нарисованных лиц без сопроводительного текста, которое Аутер описал как «сшитую сетку из кусочков ткани с сильными отсылками к афроамериканской традиции квилтинга в использовании остатков и импровизационном контрасте цвета. и узор», отметив, что позже Рингголд выразила сожаление по поводу того, что не последовала первоначальной идее своей матери относительно границы, «боясь, что узор будет выглядеть непрофессионально. Как только она пришла к пониманию того, как интерес ее матери к вышивке края стеганого одеяла от руки связан с афроамериканской традицией изготовления стеганых одеял, она пожалела, что не реализовала первоначальную идею». 45 В диалоге с Обристом Рингголд размышляет о содержании лоскутного одеяла:
и узор», отметив, что позже Рингголд выразила сожаление по поводу того, что не последовала первоначальной идее своей матери относительно границы, «боясь, что узор будет выглядеть непрофессионально. Как только она пришла к пониманию того, как интерес ее матери к вышивке края стеганого одеяла от руки связан с афроамериканской традицией изготовления стеганых одеял, она пожалела, что не реализовала первоначальную идею». 45 В диалоге с Обристом Рингголд размышляет о содержании лоскутного одеяла:
FR: В 1960-х годах в Гарлеме каждые пять минут на улице происходили беспорядки.
ХУО: Вы могли видеть беспорядки на улице, вы их пережили, но ни по телевидению, ни в газетах кадры не попали?
ФР: Нет, вообще ничего. Я не мог понять, что ты можешь стоять на улице и ничего не увидеть в новостях, когда вернешься домой. Мне пришло в голову, что кто-то скрывает информацию . 46
Наблюдение Ринггольда можно легко применить к другим контекстам, где производство текстиля предлагало ранние записи о насилии, например, к чилийскому arpilleras .
Джемайма Блейки (рис. А) не происходила из обычных людей. Ее бабушка и дедушка выкупили свободу из рабства в Новом Орлеане.
 Бабушка Джемайма Блейки — ее тоже звали тетя Джемайма — пекла торты и устраивала прекрасные вечеринки для владельцев плантаций в Луизиане. А дедушка Блейки тоже был первоклассным портным. По памяти он мог подогнать костюм как перчатку. Они были уверены, что умные люди, эти Блейки. И Джемайма была такой же, как они, трудолюбивой и богобоязненной до дня своей смерти.0273 .
Бабушка Джемайма Блейки — ее тоже звали тетя Джемайма — пекла торты и устраивала прекрасные вечеринки для владельцев плантаций в Луизиане. А дедушка Блейки тоже был первоклассным портным. По памяти он мог подогнать костюм как перчатку. Они были уверены, что умные люди, эти Блейки. И Джемайма была такой же, как они, трудолюбивой и богобоязненной до дня своей смерти.0273 . История продолжает рассказывать о браке Джемаймы с Большим Руфусом, несмотря на то, что ее родители запретили этот брак, ее переезде в Тампу, Флорида, и работе домработницей, пока молния буквально не ударит в дом, оставив Джемайму единственной выжившей. . Удар молнии создает наследство Джемайме и Большому Руфусу, которые переезжают со своими детьми в Нью-Йорк, где открывают ресторан. Затем история закручивается и закручивается через браки детей пары и дальнейший переезд, на этот раз в Новый Орлеан, прежде чем Джемайма и Большой Руфус погибнут в автокатастрофе, и их дети унаследуют. Талия Гума-Петерсон назвала это и многие другие рассказывающие Ринггольд стеганые одеяла примерами повествований, которые объединяют «элементы народных преданий и анекдотов с африканской и западноафриканской сказкой о дилемме, традиции, которые Рингголд усвоила из повествования ее матери», признавая, что Рингголд истории, как правило, остаются открытыми, редко подтверждая окончательный вывод или предлагая единственный правильный результат. 51 Кто боится тети Джемаймы? остается любопытной смесью фэнтези и морального смысла, и он запускает шаблон, который появляется во многих лоскутных одеялах повествования Рингголда.
51 Кто боится тети Джемаймы? остается любопытной смесью фэнтези и морального смысла, и он запускает шаблон, который появляется во многих лоскутных одеялах повествования Рингголда.
. имеет приоритет над изображениями», 52 с композицией, основанной на широком центре белого креста с текстом, заполняющим все, кроме четырех самых центральных квадратов, которые вместо этого заполнены человеческими фигурами. 53 Письменная история длиннее, чем многие другие примеры рассказов Рингголда, и рассказывает о матери и дочери, путешествующих на невольничьем корабле «Кариоль», самоубийстве матери после родов, утоплении вместе с ней насильника и о том, что Гума-Петерсон читает как еще одна открытая концовка. 54 Если Эхо Гарлема (1980) позволило Рингголд рассказать с помощью изображений ее личные воспоминания о людях в определенный момент истории, Одеяло «История об изнасиловании рабов» (1985) гораздо больше полагается на письменное слово для передачи повествования.
Год спустя « Пурпурное одеяло » (1986) представляет собой необычный пример того, как Рингголд явно черпала вдохновение из другого повествования: романа Элис Уокер, получившего Пулитцеровскую премию 9.0272 Пурпурный цвет (1982) и его последующая экранизация, снятая Стивеном Спилбергом (1985). Главные персонажи нарисованы высокими продолговатыми блоками, а отрывки из текста Уокера включены в панели аналогичного формата справа и слева от средней части лоскутного одеяла, обрамленные торсами других персонажей и окрашенными в галстук блоками сверху и снизу. 55 Включение Рингголд текста Уокера — это стратегия, которая нечасто встречается в ее работах. Исключения составляют часть 2 из 9Серия 0272 Jones Road (2010), в которой она цитирует известных исторических личностей: Мартина Лютера Кинга, Гарриет Табман и Соджорнер Трут. Гума-Петерсон пишет о «Пурпурное одеяло »: «В этой работе, как и в Одеяло «История изнасилования рабов », Рингголд претендует на повествовательный авторитет тройного черного женского голоса (ее собственного, Алисы Уокер и Сели [главного героя Уокера]). ) интерпретировать женский опыт через форму искусства (лоскутное одеяло), которую часто считают коллективным, анонимным творением». 56
Гума-Петерсон пишет о «Пурпурное одеяло »: «В этой работе, как и в Одеяло «История изнасилования рабов », Рингголд претендует на повествовательный авторитет тройного черного женского голоса (ее собственного, Алисы Уокер и Сели [главного героя Уокера]). ) интерпретировать женский опыт через форму искусства (лоскутное одеяло), которую часто считают коллективным, анонимным творением». 56
Сама Уокер остро подняла вопрос об анонимности афроамериканских лоскутных одеял:
в Смитсоновском институте в Вашингтоне, округ Колумбия, висит одеяло, не похожее ни на одно другое в мире […] Под этим одеялом я увидел записку, в которой говорится, что она была сделана «анонимной чернокожей женщиной из Алабамы сто лет назад». Если бы мы могли найти эту «анонимную» чернокожую женщину из Алабамы, она оказалась бы одной из наших бабушек — художницей, которая оставила свой след в единственных материалах, которые она могла себе позволить, и в единственном средстве, которое позволяло ей ее положение в обществе.
 использовать . 57
использовать . 57 Шоуолтер справедливо отмечает, что «шитье и выстегивание не были анонимными искусствами, хотя имена и личности производителей лоскутных одеял часто скрывались историей современного искусства и музейным кураторством». 58 Но и Уокер, и крючки предостерегают от забвения обстоятельств исторических традиций стегания в афроамериканской культуре.
Рисунок 5: Фейт Рингголд, Женщина на мосту №1 из 5: Тар-Бич , 1988, холст, акрил 74 x 69 см, Музей Соломона Р. Гуггенхайма, Нью-Йорк, изображение © и любезно предоставлено Фейт Рингголд Через шесть лет после Пурпурное одеяло чествует авторский голос Уокера, собственные письменные и стеганые голоса Рингголда объединяются в Tar Пляж (1988 г.), нарисованное сюжетное одеяло, которое сейчас находится в коллекции Музея Соломона Р. Гуггенхайма и является первым в серии из пяти названных «Женщины на мосту », и детская книга 59 с тем же названием (1991 г. ). 60 История Рингголд, рассказанная голосом восьмилетней Кэсси Луизы Лайтфут, напоминает о ее детстве, когда она спасалась летними вечерами от жары на (смоляной) крыше многоквартирного дома, где она жила в детстве. Представляя, как она смотрит высоко в небо, глядя вниз на крышу и близлежащий мост Джорджа Вашингтона, рассказчик объясняет: «Сон на Тар-Бич был волшебным. Лежа на крыше в ночи, со звездами и небоскребами вокруг меня, я чувствовал себя богатым, как будто мне принадлежало все, что я мог видеть. Мост был моим самым ценным достоянием». 61
). 60 История Рингголд, рассказанная голосом восьмилетней Кэсси Луизы Лайтфут, напоминает о ее детстве, когда она спасалась летними вечерами от жары на (смоляной) крыше многоквартирного дома, где она жила в детстве. Представляя, как она смотрит высоко в небо, глядя вниз на крышу и близлежащий мост Джорджа Вашингтона, рассказчик объясняет: «Сон на Тар-Бич был волшебным. Лежа на крыше в ночи, со звездами и небоскребами вокруг меня, я чувствовал себя богатым, как будто мне принадлежало все, что я мог видеть. Мост был моим самым ценным достоянием». 61
Далее в рассказе говорится, что дата открытия моста совпадает с датой рождения Рингголд, строительные работы ее отца на мосту сопровождались его безработицей и исключением из профсоюза, «потому что дедушка не был член.» 62 Панели с рукописным текстом появляются вверху и внизу квилта, а книжная версия сопровождается дополнительными иллюстрациями. 63 Расизм не исключен из повествования, но Рингголд нашел дидактический выход через формат детской литературы, сочетающей элементы автобиографии и художественной литературы.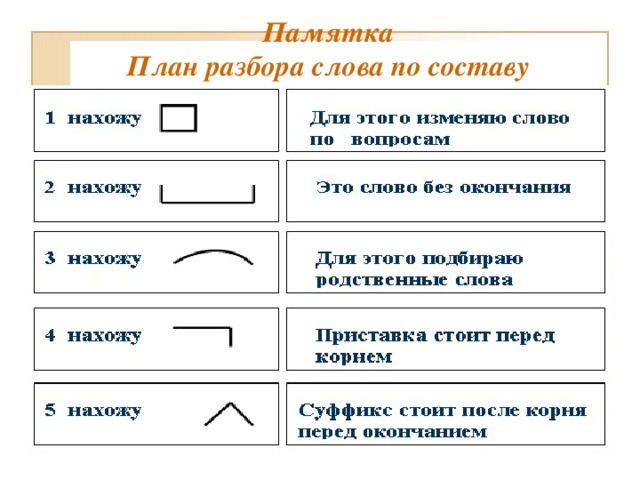
В то время как стратегия Рингголд по публикации на ткани началась с работ, сделанных в 1980-х годах, Мишель Уоллес размышляет о том, что публикация Tar Beach (1991), за которой последовали ее мемуары We Flew Over the Bridge (1995) «устранила срочность, которая изначально она хотела включить свои истории в свои лоскутные одеяла». 64 Тем не менее, она отказалась от художественного подхода. Coming to Jones Road Part 1 (1999-2000) и Part 2 (2009-2010), серия, даже называемая tankas в названиях некоторых работ части 2 — акрил на холсте, обрамленном тканевой каймой, включает текст, взятый у известных исторических личностей, таких как Мартин Лютер Кинг-младший, Гарриет Табман и Соджорнер Трут, которые создают фоновую рамку вокруг лица каждого человека. . Более поздние работы, особенно ее серия French Connection , продолжают смешивать литературные и художественные отсылки. 65
Рингголд продолжает создавать картины и ткани политического содержания. Акриловые полотна Американская коллекция № 1: Мы приехали в Америку (1997) 66 и Американская коллекция № 6: Флаг истекает кровью № 2 (1997) изображает, соответственно, океан черных тел, плывущих к черной статуе с дредами. Свободы и американский флаг, с которого капает красная кровь и который частично скрывает чернокожую женщину, которая стоит с двумя детьми, держащимися за ее талию. Сегодня, в возрасте почти девяноста лет, она продолжает творить, заработав статус признанной и знаменитой художницы. Но пересечение расы и пола, в случае Рингголд стереотипные предположения, которые впервые привели ее к публикации на ткани, ставят ее работу в сложные отношения с ремеслом. Аутер, чей раздел о Ринггольде в Веревка, войлок, нить называется «Художник, работающий в среде квилтинга» признает:
Акриловые полотна Американская коллекция № 1: Мы приехали в Америку (1997) 66 и Американская коллекция № 6: Флаг истекает кровью № 2 (1997) изображает, соответственно, океан черных тел, плывущих к черной статуе с дредами. Свободы и американский флаг, с которого капает красная кровь и который частично скрывает чернокожую женщину, которая стоит с двумя детьми, держащимися за ее талию. Сегодня, в возрасте почти девяноста лет, она продолжает творить, заработав статус признанной и знаменитой художницы. Но пересечение расы и пола, в случае Рингголд стереотипные предположения, которые впервые привели ее к публикации на ткани, ставят ее работу в сложные отношения с ремеслом. Аутер, чей раздел о Ринггольде в Веревка, войлок, нить называется «Художник, работающий в среде квилтинга» признает:
С одной стороны, изобретение Ринггольдом ненатянутого нарисованного изображения в тканевой рамке представляло собой критику границ и иерархий мир искусства, который повлиял на нее как на афроамериканскую художницу.
 С другой стороны, то, что она настаивает на том, чтобы называть эти работы «живописью», когда ставится под сомнение ценность их гибридности, также показывает столь же значительный вклад в успех в том же самом мире искусства. С точки зрения Ринггольда, цель преодоления или разрушения границ между искусством и ремеслом, важных для формального и политического значения данного произведения, могла быть достигнута только во имя искусства.0273 . 67
С другой стороны, то, что она настаивает на том, чтобы называть эти работы «живописью», когда ставится под сомнение ценность их гибридности, также показывает столь же значительный вклад в успех в том же самом мире искусства. С точки зрения Ринггольда, цель преодоления или разрушения границ между искусством и ремеслом, важных для формального и политического значения данного произведения, могла быть достигнута только во имя искусства.0273 . 67 Первоначальная порывистость Рингголд к публикации на ткани возникла из-за необходимости раскрыть жизнь большего подчинения, чем она испытала. Текстиль обеспечил полезный и в конечном итоге успешный путь в издательский мир, где она хотела, чтобы ее голос был услышан. Эффективность того значения, которое она придавала тому, чтобы ее лоскутные одеяла воспринимались как искусство, а не как ремесло, сегодня гораздо менее ясна. Вместо этого лоскутные одеяла Рингголд отмечают определенный этап в ее карьере — возможно, они интересны не столько тем, откуда и к чему они вели, сколько тем, как они стоят сами по себе.
Композиционное обобщение в семантическом разборе: наборы данных | Денис Луковников | Analytics Vidhya
Если вы скажете человеку, что 🦓 — это зебра, а 🐴 — это лошадь, а затем покажете несколько предложений со словом «лошадь» (например, «Лошадь — это млекопитающее» и «Сколько ног у лошади? ») человек также сможет мгновенно понимать похожие предложения и задавать аналогичные вопросы о лошадях. Это пример способности человека к новым сочетаниям ранее увиденных элементов и конструкций, что называется «композиционным обобщением».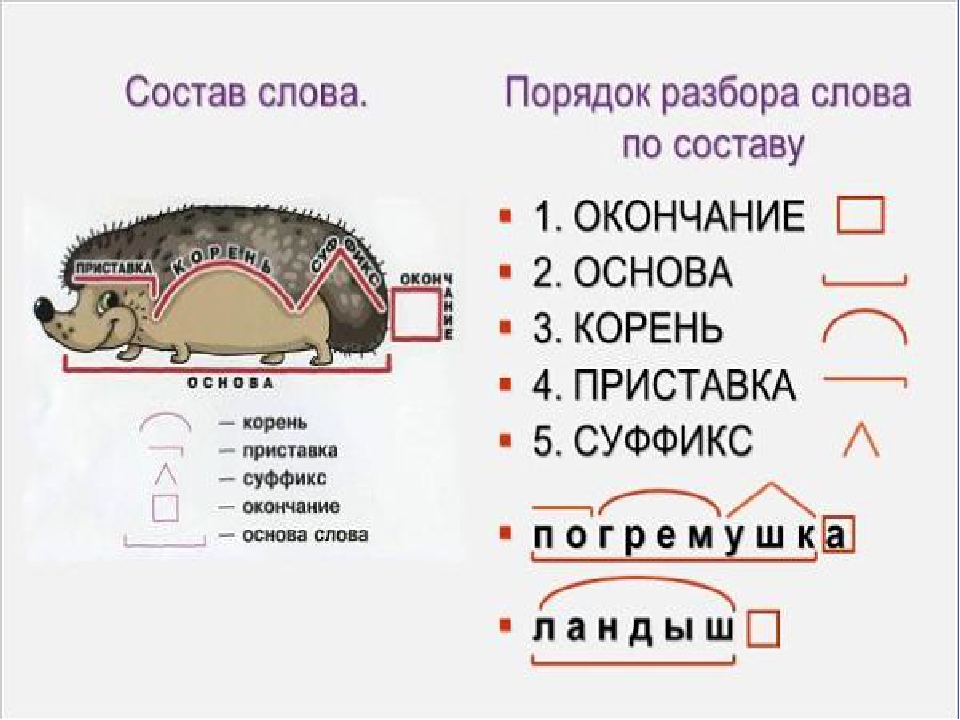
Хотя люди считают это само собой разумеющимся, нет уверенности в том, что наши модели НЛП обладают такой же способностью (спойлер: согласно многим документам, перечисленным ниже, у них это получается довольно плохо).
Измерение композиционного обобщения непросто и требует тщательного продумывания дизайна используемых наборов данных и их разбиений на обучение/тестирование. Тем не менее, благодаря некоторым (совсем недавним) замечательным работам, мы наблюдаем больший прогресс в этом вопросе, и, надеюсь, это еще не все.
Ниже мы рассмотрим некоторые существующие наборы данных.
(Lake and Baroni, ICML 2018)
Документ: https://arxiv.org/pdf/1711.00350.pdf
Это одно из первых исследований, указывающее на то, что существующие модели семантического анализа плохо обобщают новые комбинации. уже наблюдаемых элементов. Хотя используемые данные просты, статья указывает на очень интересную проблему современных систем. После публикации эта работа вдохновила на создание нескольких качественных работ, предлагающих различные решения проблемы, которые мы, надеемся, рассмотрим в будущем.
В этой работе создается набор данных, состоящий из последовательностей слов, соединенных с последовательностями простых инструкций (например, JUMP). Входные последовательности генерируются с использованием простой CFG, а соответствующие выходные последовательности генерируются с использованием простых правил. В SCAN есть примитивных команды (например, LTURN, JUMP), а также модификаторы и союзы, которые помогают композиционно построить последовательность действий. Пример задачи дается парой
- ( «дважды повернуть налево» , LTURN LTURN).
Итак, задача состоит в том, чтобы сопоставить последовательность «естественного языка» с последовательностью инструкций.
Авторы экспериментируют с различными архитектурами seq2seq на основе RNN, с вниманием и без внимания.
Было проведено три эксперимента с данными SCAN.
Во-первых, случайное разбиение доступных данных дает точность >99%. Высокая точность теста по-прежнему была достигнута с использованием лишь небольшой части обучающих примеров.
Затем авторы проверили, могут ли модели обобщаться до более длинных последовательностей . Примеры с самыми короткими последовательностями действий (выходами) использовались при обучении, а самые длинные — при тестировании. Все модели на этом сплите блестяще провалились (достигнув точности 20,8% 😮) и решили только тестовые примеры с кратчайшими последовательностями действий.
Наконец, авторы также экспериментируют с , «экстраполируя» примитив . Настройка такова, что определенная команда видится только как примитивный пример (например, «прыжок» → ПРЫЖОК) во время тренировки, в то время как все остальные команды видны в составных командах. В частности, тестировались только «повернуть налево» и «прыгнуть» , поскольку остальные варианты эквивалентны. Эксперименты показали, что вариант «повернуть налево» по-прежнему дает хорошие результаты (~ 90%), в то время как вариант «прыжок» полностью проваливается (~ 1% 🙊). Это различие объясняется тем, что если команда «повернуть налево» наблюдалась только изолированно (все остальные обучающие примеры не содержали этой команды во входных данных), то соответствующее ей действие LTURN наблюдалось при обучении в составе других команды (например, «иди налево и прыгни налево» ). В версии «прыжок» соответствующая команда JUMP при обучении вообще не наблюдалась.
Это различие объясняется тем, что если команда «повернуть налево» наблюдалась только изолированно (все остальные обучающие примеры не содержали этой команды во входных данных), то соответствующее ей действие LTURN наблюдалось при обучении в составе других команды (например, «иди налево и прыгни налево» ). В версии «прыжок» соответствующая команда JUMP при обучении вообще не наблюдалась.
Несмотря на то, что модель знала, что «прыгает» → ПРЫГАТЬ, и понимала различные выражения с другими действиями (например, « идти и повернуть направо» ), модель не могла понять «прыгать» в этих контекстах ( например, « прыгнуть и повернуть направо» ).
(Финеган-Доллак, ACL 2018)
Документ: https://arxiv.org/pdf/1806.09029.pdf
В этой работе авторы сосредотачиваются на (1) сложности запросов, утверждая, что для человеческих вопросов требуются более сложные запросы, чем в автоматически генерируемых наборах данных, и (2 ) разделение обучения/тестирования, где авторы утверждают, что стандартные разделения на самом деле не требуют обучения для создания новых шаблонов запросов.
При анализе наборов данных Text2SQL они обнаружили, что некоторые часто используемые имеют ограниченное количество шаблонов и что большие наборы данных не обязательно имеют пропорционально больше шаблонов запросов. Чтобы дополнительно изучить эффект, который это имеет, авторы пробуют простой подход на основе шаблонов, который автоматически идентифицирует шаблоны из обучающих данных, а во время теста назначает пример одного из этих шаблонов и заполняет его слоты. Эта базовая линия на основе шаблона достигает конкурентоспособной производительности с моделями seq2seq для нескольких наборов данных. Это вызывает беспокойство, потому что базовый план на основе шаблона не может обобщаться на новые шаблоны запросов по своей конструкции. Тем не менее, авторы обнаруживают, что seq2seq действительно демонстрирует некоторую способность обобщать за пределы шаблонов, наблюдаемых во время обучения.
Авторы также экспериментируют с другим разделением поезд/тест. Там, где обычно данные разбиваются таким образом, чтобы в тесте не встречалась пара (вопрос, запрос), которая происходила при обучении, авторы предлагают разделение на основе чисто шаблона запроса . Чтобы создать это разделение, они сначала анонимизируют сущности в запросах SQL и позволяют примерам с одним и тем же анонимным запросом быть только в обучении или тестировании. Это разделение оказалось гораздо более сложным для нескольких часто используемых наборов данных Text2SQL, что часто приводило к резкому снижению производительности. Это еще раз указывает на зависимость существующих моделей от запоминания шаблонов запросов.
Чтобы создать это разделение, они сначала анонимизируют сущности в запросах SQL и позволяют примерам с одним и тем же анонимным запросом быть только в обучении или тестировании. Это разделение оказалось гораздо более сложным для нескольких часто используемых наборов данных Text2SQL, что часто приводило к резкому снижению производительности. Это еще раз указывает на зависимость существующих моделей от запоминания шаблонов запросов.
Таким образом, эта работа показывает, что обычно используемая методология оценки для семантического разбора может игнорировать композиционную способность моделей к обобщению, которая в значительной степени может быть сведена к модели заполнения слотов.
(Keysers et al., ICLR 2020)
Статья: https://openreview.net/pdf?id=SygcCnNKwr
Состав атомарных и составных фраз. Источник. В то время как работа над SCAN предоставила первоначальные доказательства неспособности стандартных моделей seq2seq обобщать невидимые композиции, установка в SCAN была чрезвычайно простой, а в данных использовалась лишь наноскопическая часть языка. В этой работе авторы нацелены на более интересную универсальную настройку семантического анализа для ответов на вопросы по графам знаний. И пока СКАН тестировал «повернуть налево» и «прыгнуть» , эта работа следует более систематическому подходу, который генерирует расщепления на основе максимального расхождения соединений при минимизации расхождения атомов.
В этой работе авторы нацелены на более интересную универсальную настройку семантического анализа для ответов на вопросы по графам знаний. И пока СКАН тестировал «повернуть налево» и «прыгнуть» , эта работа следует более систематическому подходу, который генерирует расщепления на основе максимального расхождения соединений при минимизации расхождения атомов.
Оценка композиционности на основе распределения
Основная идея этой работы состоит в том, чтобы создать набор данных/контрольный показатель с разделением обучения/теста, который сводит к минимуму перекрытие между соединениями, наблюдаемыми во время обучения, и теми, которые наблюдаются во время тестирования, и в то же время гарантирует, что все компоненты (атомы) для построения этих составных фраз во время теста наблюдались во время обучения.
Атомарные фразы можно рассматривать как те фразы, значение которых нельзя далее разделить на состав некоторых составляющих элементов. Например, слово «лошадь» напрямую относится к животному 🐴 и не подлежит дальнейшему разложению. Другие фразы, такие как «возраст» (со ссылкой на предикат age(X, Y) ) и шаблоны вопросов (например, «Что такое <предикат> <сущности>» ) также считаются атомами. . Напротив, соединения — это фразы, из которых состоят эти атомы. Например, «Сколько лет лошади» составляет все три вышеуказанных атома.
Другие фразы, такие как «возраст» (со ссылкой на предикат age(X, Y) ) и шаблоны вопросов (например, «Что такое <предикат> <сущности>» ) также считаются атомами. . Напротив, соединения — это фразы, из которых состоят эти атомы. Например, «Сколько лет лошади» составляет все три вышеуказанных атома.
Чтобы проверить композиционное обобщение моделей seq2seq, расщепления тестовой последовательности определяются таким образом, чтобы расхождение между распределениями атомов было минимальным, а расхождение между распределениями композиционных фраз (составное расхождение) должно быть максимальным. Когда все атомы были обнаружены во время обучения, система не страдает от проблем со словарным запасом, которые привели бы к очевидным потерям производительности. Однако минимизация количества общих соединений между тестом и обучением проверяет модель на ее способность составлять уже наблюдаемые атомы новыми, ненаблюдаемыми способами.
Набор данных
Авторы создают большой набор данных семантического синтаксического анализа на основе Freebase и предоставляют три различных разделения обучающих тестов, которые максимизируют составное расхождение при минимизации атомарного расхождения. Набор данных формируется автоматически, но, судя по примерам, вопросы выглядят вполне естественно.
Набор данных формируется автоматически, но, судя по примерам, вопросы выглядят вполне естественно.
По стандартам семантического разбора набор данных очень велик: 239 357 вопросов, 228 149 запросов и 34 921 шаблон запросов. И ввод, и вывод предоставляются в разных форматах, где объекты упоминаются по их имени, идентификатору или просто заполнителю. Это означает, что вам не нужно беспокоиться о запуске сущностей, связывающих ¯\_(ツ)_/¯.
Вопросы на английском языке:
- «Агустин Альмодовар был исполнительным продюсером Deadfall?» M1»
И запросы приведены в SPARQL:
- «SELECT count(*) WHERE {ns:m.04lhs01 ns:film.producer.films_executive_produced ns: m.0gx0plf}»
- 0744
Также приведены версии-заполнители запросов SPARQL:
- «SELECT count(*) WHERE {M0 ns:film.producer. Films_executive_produced M1}”
При проведении экспериментов авторы используют версии, в которых сущности заменены заполнителями.
Набор данных создается автоматически с использованием набора правил. Во-первых, генерируется вопрос на естественном языке и соответствующая ему логическая форма. Затем логическая форма сопоставляется с запросом SPARQL. Логическая форма использует вариант логики описания ℰℒ (ℰℒ DL допускает только пересечения и кванторы существования). Приложения правил образуют DAG, а подграфы этого DAG, соответствующие соединениям, используются для измерения составного расхождения.
Эксперименты
Авторы проводят эксперименты по CFQ, а также по SCAN с тремя моделями: LSTM+Attention, Transformer и Universal Transformer. При использовании случайного разбиения, что обычно и делается, все три модели достигают очень высокой производительности (выше 95%). Однако, когда модели обучаются с использованием расщеплений MCD, результаты резко падают ниже 20%!!! 😮
Результаты теста с бумаги.Авторы приходят к выводу, что нормальные модели, которые обычно повсеместно используются для семантического разбора, на самом деле совсем плохи, когда видят новые комбинации уже виденных вещей.
Точность CFQ для разных базовых уровней при изменении степени расхождения соединений.Можно утверждать, что эти результаты являются ожидаемыми, поскольку распределения обучающих и тестовых данных резко различаются, и что модель даже не должна обрабатывать такое несоответствие.
С другой стороны, это не должно иметь значения, поскольку нам нужны семантические парсеры, способные создавать новые комбинации элементов.
(Shaw et al., 2020)
Документ: https://arxiv.org/pdf/2010.12725.pdf
В то время как критерий MCD CFQ обеспечивает хорошо обоснованное разделение, метод разделения CFQ полагается на входные и выходные данные, генерируемые набором правил. Это ограничивает применимость их критерия MCD только к синтетическим данным. В этой работе Shaw и соавт. предложить простую адаптацию MCD, которая вычисляет составную дивергенцию, используя только целевые представления (логические формы). Это позволяет находить расщепления TMCD также для уже существующих, созданных вручную примеров без каких-либо дополнительных аннотаций.
Этот показатель можно использовать для разделения существующих наборов данных (здесь используются GeoQuery и Spider). Авторы создают разделения, которые максимизируют TMCD, обеспечивая при этом, чтобы все атомы наблюдались хотя бы один раз во время обучения.
Для набора данных GeoQuery авторы используют версию FunQL и принимают все символы предикатов и сущностей как атомы. Составные — это комбинации родительских и дочерних символов в дереве FunQL. Обратите внимание, что соединения не обязательно должны быть полными (под)деревьями. Для SQL авторы берут отдельные токены как атомы и определяют составные части на основе разбора запросов CFG.
Дополнительный момент, на который обращают внимание авторы, заключается в том, что многие работы, посвященные композиционному обобщению, были оценены только с помощью SCAN и что их производительность на существующих стандартных наборах данных семантического анализа (таких как GeoQuery) может быть ниже номинала из-за компромиссов, сделанных для улучшения композиционное обобщение.
Наконец, авторы предлагают подход к семантическому анализу, в котором используется предварительно обученный преобразователь T5 seq2seq, а также автоматически индуцированный семантический анализатор на основе грамматики, о котором мы расскажем в следующей статье.
(Ким и Линзен, EMNLP 2020)
Документ: https://arxiv.org/pdf/2010.05465.pdf
Здесь авторы создают набор данных семантического анализа, который позволяет явно измерить пять лингвистически мотивированных типов обобщения. Это отличается от CFQ, который просто максимизирует сложное расхождение. Хотя COGS охватывает некоторые случаи (обобщение примитивов), использованные в предыдущих работах, диапазон категорий более широк.
Набор данных содержит предложения, соединенные с лямбда-выражениями. Предложения генерируются автоматически с использованием PCFG.
В наборе данных содержатся следующие категории обобщения:
1. Обобщение примитивов и других грамматических ролей:
Здесь есть два типа примеров:
а).
обучение только примитивам (атомам) и тестирование предложений, содержащих эти примитивы. Нарицательные существительные сопоставляются с унарными предикатами (например, «лошадь» → λx.horse(x) ), имена собственные сопоставляются с константами (например, «Rocinante» → ROCINANTE ), а глаголы сопоставляются с n-арными предикатами (пример из статьи: «like» → λx.λy.λe.like.agent(e,y) ∧ like.theme (е, х) ).Такие изолированные сопоставления наблюдаются только во время обучения. Во время тестирования эти примитивы используются в полном предложении вместе с другими константами и предикатами.
Обратите внимание, что это очень похоже на третий эксперимент SCAN, где проверяется обобщение примитивов, видимых только изолированно.
б). замена слова с дополнения на подлежащее. Например, если во время обучения наблюдается «лошадь съела морковку» (здесь речь идет об испытуемом «лошадь» ), то в тестовой выборке не будет примеров, где «лошадь» используется в качестве подлежащее, но будет пример, где «лошадь» используется как прямое дополнение (например, «Дон Кихот ехал на лошади» ).
2. Модифицированные словосочетания в другой синтаксической роли
Когда, например, именная группа (NP) изменяется с предложной группой (PP), мы получаем новую NP, которая может использоваться в тех же синтаксических ролях, что и исходная NP. Например, [the horse](NP) и [[the horse][on field]] (NP, состоящее из NP и PP), оба могут использоваться в предложении как дополнение или подлежащее.
Во время обучения COGS использует предложения с PP-модифицированными NP в качестве объекта, а во время тестирования PP-модифицированные NP используются в качестве субъекта.
3. Более глубокая рекурсия
Человеческий язык позволяет вкладывать фразы в другие фразы, что позволяет строить бесконечное количество выражений. Например, предложение может иметь один уровень вложенности: «Дон Кихот знал, что Росинант ел траву» , но это может быть и более глубокая: «Дон Кихот знал, что Санчо Панса знал, что Росинант ел траву» .
В COGS при обучении используется только до двух уровней вложенности, а в тестовых примерах этой категории используется строго три и более уровней. Это позволяет измерить способность моделей экстраполировать на более длинные предложения с определенными типами рекурсии. Обратите внимание, что это чем-то похоже на второй эксперимент SCAN, где в обучении использовались более короткие последовательности, а затем модель тестировалась на более длинных.
4. Чередование глаголов
Некоторые глаголы, которые могут употребляться в переходной форме ( «Дон Кихот накормил лошадь» ), также могут употребляться в пассивной форме ( «Лошадь накормили» ). Этот и другие шаблоны включены в набор данных COGS: конкретный глагол используется только одним способом (например, активным) в обучающем наборе, а в тестовом наборе используется только другим способом (например, пассивным).
5. Класс глагола
Прежде чем обсуждать последний, давайте возьмем…
Небольшой экскурс в глаголы и семантику:
Некоторые более лингвистически подкованные читатели, вероятно, уже знают это и могут уверенно пропустить это.
Для остальных вот небольшой обзор терминологии, чтобы помочь понять, что представляет собой эта пятая категория. Глаголы могут быть переходными , что означает, что у глагола есть подлежащее и дополнение (например, «Росинант [subj]🐴 съел траву [obj]🌿» ). Но глаголы также могут быть непереходными , что означает, что у них нет объекта (например, «Росинант [subj] съел» ).
Теперь давайте повторим семантические роли. Субъект и объект являются грамматическими ролями, и хотя они обычно коррелируют с нашим пониманием того, кто что с кем делает, они не всегда правильны. Чтобы правильно описать, что кто-то кому делает, что было бы буквальным «значением» описываемого действия, мы можем лучше использовать семантические роли. Кроме того, семантические роли также предоставляют более точную информацию о последствиях действия.
Основной Семантические роли (a.
k.a. ТЕМАТИЧЕСКИЕ Отношения). Мы больше всего заинтересованы в (1) Агент , (2) . ) Пациент , хотя есть несколько других, которые покрывают свой собственный кусок семантического пирога. Агент — это сущность в предложении, которая выполняет действие (например, «Росинант [Агент] ел траву». ). Роли «Тема» и «Пациент» являются получателями выполняемого действия, с той разницей, что состояние «Пациент» изменяется (например, «Росинант съел траву [Пациент]» ), а Тема — нет (например, «Росинант любит траву [Тема]»). ). Вернемся к глаголам. Среди непереходных глаголов есть неэргативные глаголы и неаккузативные глаголы. Неэргативный Глаголы – это глаголы, грамматический субъект которых также является их семантическим агентом (например, «Росинант съел» ) и невинительные глаголы — это глаголы, субъект которых является пациентом или темой, поэтому субъект сам страдает от действия (например, «Росинант исчез».
). Для последней категории «Класс глаголов» авторы отмечают, что грамматических ролей недостаточно для предсказания правильной структуры аргумента. Например, хотя и неэргативный, и неаккузативный глаголы кажутся синтаксически непереходными, подлежащее глагола в первом случае является Агентом, а во втором случае Темой или Пациентом, что также будет отражено в построенной логической форме.
Для проверки способности моделей семантического разбора к обобщению авторы включают случаи, когда определенный NP встречается только в одной роли при обучении и в другой при тестировании. Например, определенный NP наблюдается как субъект-агент (например, «Росинант» в «Росинант ел траву» ), но в наборе обобщения встречается как тематический субъект (например, «Росинант исчез 👻 .” )
Набор данных
Набор данных автоматически генерируется с использованием PCFG, и каждое предложение на естественном языке проходит этап автоматической обработки для создания логических форм.
Пример пары вопрос-логическая форма:
- «Кошка улыбнулась» → кот(х) ∧ улыбка.агент(у, х)
Наборы для обучения, разработки и тестирования содержат 24155, 3000 и 3000 экземпляров соответственно. Последние 155 примеров в обучающем наборе являются примитивами. Набор обобщений, который является тестовым набором, используемым для измерения композиционного обобщения, был создан с использованием другой PCFG и содержит 21000 примеров.
Результаты
Модели seq2seq на основе Transformer и LSTM были протестированы в экспериментах.
Как и ожидалось, результаты случайного тестирования (с использованием тестового набора из 3000 примеров) были близки к идеальным.
Однако производительность на наборе обобщений (набор тестов из 21 тыс. примеров, содержащих сложные случаи) была в среднем довольно низкой, с разными числами для разных случаев обобщения и высокой дисперсией между запусками. В целом, стандартные модели seq2seq сильно потерпели неудачу:
Авторы также провели анализ ошибок, сравнив лексический и структурный обобщение.
- 0744




 обучение только примитивам (атомам) и тестирование предложений, содержащих эти примитивы. Нарицательные существительные сопоставляются с унарными предикатами (например, «лошадь» → λx.horse(x) ), имена собственные сопоставляются с константами (например, «Rocinante» → ROCINANTE ), а глаголы сопоставляются с n-арными предикатами (пример из статьи: «like» → λx.λy.λe.like.agent(e,y) ∧ like.theme (е, х) ).
обучение только примитивам (атомам) и тестирование предложений, содержащих эти примитивы. Нарицательные существительные сопоставляются с унарными предикатами (например, «лошадь» → λx.horse(x) ), имена собственные сопоставляются с константами (например, «Rocinante» → ROCINANTE ), а глаголы сопоставляются с n-арными предикатами (пример из статьи: «like» → λx.λy.λe.like.agent(e,y) ∧ like.theme (е, х) ).

 Для остальных вот небольшой обзор терминологии, чтобы помочь понять, что представляет собой эта пятая категория.
Для остальных вот небольшой обзор терминологии, чтобы помочь понять, что представляет собой эта пятая категория.  k.a. ТЕМАТИЧЕСКИЕ Отношения). Мы больше всего заинтересованы в (1) Агент , (2) . ) Пациент , хотя есть несколько других, которые покрывают свой собственный кусок семантического пирога. Агент — это сущность в предложении, которая выполняет действие (например, «Росинант [Агент] ел траву». ). Роли «Тема» и «Пациент» являются получателями выполняемого действия, с той разницей, что состояние «Пациент» изменяется (например, «Росинант съел траву [Пациент]» ), а Тема — нет (например, «Росинант любит траву [Тема]»). ).
k.a. ТЕМАТИЧЕСКИЕ Отношения). Мы больше всего заинтересованы в (1) Агент , (2) . ) Пациент , хотя есть несколько других, которые покрывают свой собственный кусок семантического пирога. Агент — это сущность в предложении, которая выполняет действие (например, «Росинант [Агент] ел траву». ). Роли «Тема» и «Пациент» являются получателями выполняемого действия, с той разницей, что состояние «Пациент» изменяется (например, «Росинант съел траву [Пациент]» ), а Тема — нет (например, «Росинант любит траву [Тема]»). ). 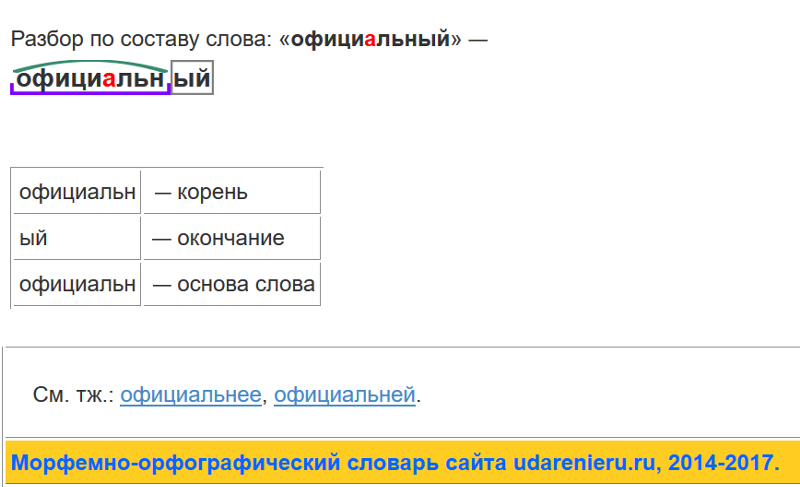 ).
). 
