Морфологический разбор слова «ранним»
Часть речи: Прилагательное
РАННИМ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «РАННИЙ»
| Слово | Морфологические признаки |
|---|---|
| РАННИМ |
|
| РАННИМ |
|
| РАННИМ |
|
Все формы слова РАННИМ
РАННИЙ, РАННЕГО, РАННЕМУ, РАННИМ, РАННЕМ, РАННЯЯ, РАННЕЙ, РАННЮЮ, РАННЕЮ, РАННЕЕ, РАННИЕ, РАННИХ, РАННИМИ, РАНЬШЕ, ПОРАНЬШЕ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «РАННИМ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «ранним»
1
Сплю я ранним—ранним утром в своей постели, и вдруг слышу – открывается входная дверь.
За Тем Рубежом, Рауфа Кариева, 2019г.
2
Тем ранним—ранним утром она задыхалась и бормотала: «Никакой «Скорой помощи».
Андеграунд, или Герой нашего времени, Владимир Маканин, 1998г.
3
Я проснулась ранним—ранним утром.
Предпоследний день грусти, Елена Сазанович
4
Как-то ранним—ранним утром приходит на приём к моему приятелю-урологу дама.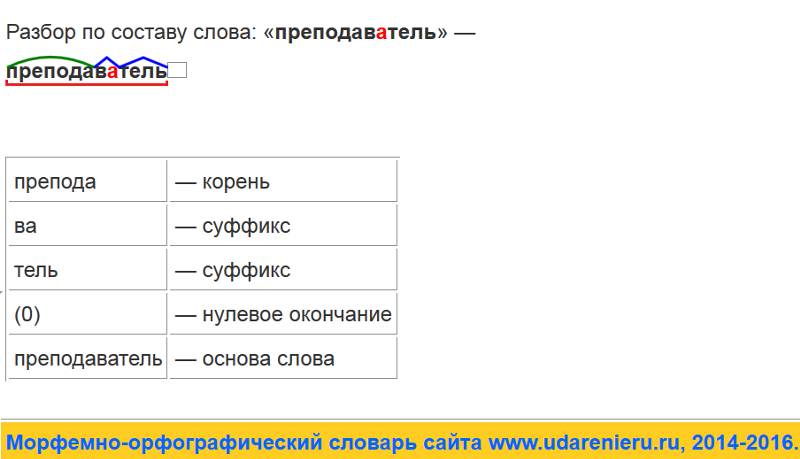
Акушер-ХА! (сборник), Татьяна Соломатина, 2009г.
5
Надо ли говорить, что судака и щучку для них дедушка поймал собственноручно ранним—ранним утром того же дня.
Девочки. Женщины, Юлия Панина
Найти еще примеры предложений со словом РАННИМ
Итоговый контрольный диктант по русскому языку в 4 классе
Материал опубликовала
#4 класс #Русский язык #Учебно-методические материалы #Презентация #Учитель начальных классов #Школьное образование
Итоговый диктант по русскому языку в 4 классе Ю.В.Мурашко, учитель начальных классов МБОУ СОШ с.Первомайское
Содержание Текст диктанта (для учителя) Работа с лексическим значением слов Работа с основной мыслью текста Предварительная работа с орфограммами (обобщенный вариант) Грамматическое задание Анализ орфографических ошибок (2 урок)
Последние денёчки
Ранним мартовским утром проснулось солнце. Отдёрнуло оно лёгкую кисею облаков и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Около берёзки свежий снежок бросили, холмы молочным туманом укрыли. А в лесочке ледяные сосульки на соснах развесили. Радостно ребятишки бегут по последнему снежку.
Поглядело светило на эти проказы и стало землю пригревать. Лёд и снег сразу потускнели. По лесной ложбинке побежал весёлый говорливый ручеёк. Он бежал и пел свою песенку о весне.
Отдёрнуло оно лёгкую кисею облаков и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Около берёзки свежий снежок бросили, холмы молочным туманом укрыли. А в лесочке ледяные сосульки на соснах развесили. Радостно ребятишки бегут по последнему снежку.
Поглядело светило на эти проказы и стало землю пригревать. Лёд и снег сразу потускнели. По лесной ложбинке побежал весёлый говорливый ручеёк. Он бежал и пел свою песенку о весне.
Работа с лексическим значением слов Кисея — прозрачная тонкая легкая ткань (перен. что-л., напоминающее такую ткань) Проказы – шалости, проделки
Работа с лексическим значением слов Потускнели – стали недостаточно яркими, прозрачными Ложбинка — небольшое продолговатое углубление на чем-либо, в чем-либо
Определите основную мысль текста «Последние денёчки»
Основная мысль текста (идея) –
это реализация авторского замысла (т. е. то, чему хотел научить автор, для чего он написал текст)
е. то, чему хотел научить автор, для чего он написал текст)
Основная мысль текста Несмотря на то, что все времена года по-своему хороши, в природе все на своих местах и всему свое время. А природа прекрасна в любое время года.
Орфограммы Проверяемая безударная гласная в корне Парный согласный в корне слова Гласный после шипящего Мягкий и твердый знаки Безударные падежные окончания имён существительных Безударные личные окончания глаголов Безударные окончания прилагательных Правописание – чк, — чн Правописание приставок и предлогов Непроверяемое написание слов (словарные слова)
Грамматическое задание Выполнить разбор по членам предложения последнего предложения в тексте и указать части речи Выполнить разбор слов как частей речи: взглянуло, молочным, (за) ночь Разобрать слова по составу: ранним, пригревать, песенку
Работа с орфограммами
Проверяемая безударная гласная в корне Взгл…нуло – взгляд, з…ма – зимы, нав…ли – навёл, сн…жок – снег, х…лмы – холм, (в) л…сочке – лес, л…дяные – лёд, б…гут – бег, св…тило – свет, пригр…вать – греть, в…сёлый – весело, г…ворливый – говор, руч…ёк – ручей, (о) в…сне – вёсны
Парный гласный в корне слова Лё…кую – лёгок, моро… — морозец, берё…ки – берёза, сне…ку – снежок, лё… — льда, сне… — снега
Гласный после шипящего Свеж…й Непроверяемое написание слов (словарные слова) Облака, мороз, около, берёзки, ребятишки
Правописание «ь» и «ъ» знаков
Ноч… (ж. р., 3 скл.), сосул…ки, проснулос…, пригреват…
Правописание -чк, — чн
Молоч(…)ным, (в) лесоч(…)ке
р., 3 скл.), сосул…ки, проснулос…, пригреват…
Правописание -чк, — чн
Молоч(…)ным, (в) лесоч(…)ке
Безударные падежные окончания имён существительных Утром (Т.п), кисею (В.п), туманом (Т.п), (в) лесочке (П.п), светило (ср.р, Им.п.), (по) ложбинке (П.п), (о) весне (П.п)
Безударные окончания имен прилагательных Ранним (Т.п), мартовским (Т.п.), лёгкую (В.п.), (по) последнему (Д.п.), (по) лесной (Д.п.)
Безударные личные окончания глаголов Отдёрнуло (ср.р.), взглянуло (ср.р.), поглядело (ср.р.), стало пригревать (ср.р.) Правописание приставок Проснулось, отдёрнуло, взглянуло, развесили, поглядело, пригревать, потускнели, побежал
Непроизносимый согласный Со…нце – солнечный, радос…но – радость
Спасибо за работу на уроке
Создание чиптюнов с помощью марковских моделей
За последний год или около того несколько любопытных обстоятельств загнали меня в кроличью нору алгоритмического сочинения музыки. Сначала интригующий вопрос о классификации подлинных и поддельных пианино, затем блестящий профессор, написавший оперу о жизни Алана Тьюринга, и, наконец, одаренный аспирант, задающий наводящие вопросы о модели OpenAI VQ-VAE, — все это заставило меня все больше интересоваться созданием музыки с помощью машинное обучение. После того, как я поделился некоторыми первыми результатами своих исследований, несколько друзей захотели узнать больше. Этот пост — моя попытка поделиться некоторыми путями, которыми я шел, и изложить несколько относительно простых способов начать работу с автоматическим созданием музыки.
Сначала интригующий вопрос о классификации подлинных и поддельных пианино, затем блестящий профессор, написавший оперу о жизни Алана Тьюринга, и, наконец, одаренный аспирант, задающий наводящие вопросы о модели OpenAI VQ-VAE, — все это заставило меня все больше интересоваться созданием музыки с помощью машинное обучение. После того, как я поделился некоторыми первыми результатами своих исследований, несколько друзей захотели узнать больше. Этот пост — моя попытка поделиться некоторыми путями, которыми я шел, и изложить несколько относительно простых способов начать работу с автоматическим созданием музыки.
Чтобы все было как можно проще, в посте ниже описывается, как можно использовать базовые марковские модели для создания MIDI-аудио. Сначала мы рассмотрим, как работают марковские модели, построив простую модель генерации текста примерно в дюжине строк Python. Затем мы обсудим, как можно преобразовать MIDI-данные в текстовые последовательности, что позволит нам использовать тот же подход модели Маркова для создания MIDI-аудио. Наконец, чтобы немного оживить ситуацию, мы преобразуем наши сгенерированные MIDI-файлы в звуковую форму волны чиптюна с танцевальным битом в стиле диско. Давайте погрузимся!
Наконец, чтобы немного оживить ситуацию, мы преобразуем наши сгенерированные MIDI-файлы в звуковую форму волны чиптюна с танцевальным битом в стиле диско. Давайте погрузимся!
Построение марковских моделей
Хотя термин «марковская модель» используется для описания широкого круга статистических моделей, практически все марковские модели следуют простому основному правилу: модель генерирует последовательность выходных данных, и каждый элемент последовательности зависит только от предшествующего элемента последовательности. По одному слову марковская модель может предсказать следующее слово в последовательности. Учитывая пиксель, марковская модель может предсказать следующий пиксель в последовательности. Учитывая элемент в последовательности, марковская модель может предсказать следующий элемент в последовательности.
В качестве примера давайте создадим марковскую модель, которая может выполнять простую задачу генерации текста. Наша цель будет состоять в том, чтобы обучить модель, используя пьесы Уильяма Шекспира, а затем использовать эту модель для создания нового текста псевдошекспировской пьесы.
Первый гражданин: Прежде чем мы продолжим, выслушайте меня. Все: Говори, говори. Первый гражданин: Вы все решили скорее умереть, чем голодать? Все: Решено. решено.
Как видите, текст имеет обычный формат, в котором имя персонажа предшествует его речи. Чтобы помочь нашей модели распознавать эти границы речи персонажей, давайте добавим токены START и END до и после каждой речи, например:
from collections import defaultdict
# прочитать файл
текст = открыть('крошечный Шекспир.txt').Читать()
# добавить START перед каждым выступлением и END после
formatted = text.replace('\n\n', 'КОНЕЦ \n\nНАЧАЛО')
# создаем полную строку обучающих данных
training_data = 'НАЧАЛО' + отформатировано + 'КОНЕЦ' Если вы напечатаете training_data , вы увидите, что оно включает слово START перед каждым выступлением и слово END после каждого выступления:
START Первый гражданин: Прежде чем мы продолжим, выслушайте меня.КОНЕЦ НАЧАТЬ Все: Говори, говори. КОНЕЦ СТАРТ Первый гражданин: Вы все решили скорее умереть, чем голодать? КОНЕЦ НАЧАТЬ Все: Решено. решено. КОНЕЦ
 КОНЕЦ
НАЧАТЬ Все:
Говори, говори. КОНЕЦ
СТАРТ Первый гражданин:
Вы все решили скорее умереть, чем голодать? КОНЕЦ
НАЧАТЬ Все:
Решено. решено. КОНЕЦ
КОНЕЦ
НАЧАТЬ Все:
Говори, говори. КОНЕЦ
СТАРТ Первый гражданин:
Вы все решили скорее умереть, чем голодать? КОНЕЦ
НАЧАТЬ Все:
Решено. решено. КОНЕЦ
Эти маркеры START и END помогут нашей модели узнать, как выглядит правильная речь, чтобы она могла создавать новые речи, имеющие тот же формат, что и наши обучающие речи.
Подготовив данные для обучения, мы можем теперь обучить нашу модель. Для этого нам просто нужно создать словарь, в котором мы сопоставляем каждое слово со списком слов, которые за ним следуют. Например, учитывая последовательность 1 2 1 3 , наш словарь будет выглядеть так: {1: [2,3], 2: [1]} . Этот словарь говорит нам, что за значением 1 следуют 2 и 3, а за значением 2 следует только 1. За значением 3 ничего не следует, потому что это последний токен в нашей последовательности. Давайте создадим этот словарь, используя наши текстовые данные Шекспира:
из коллекций импортировать defaultdict # разделяем наши тренировочные данные на список слов слова = training_data.
 split(' ')
# next_words будет хранить список слов, следующих за словом
next_words = defaultdict(список)
# проверять каждое слово до последнего, но не включая его
для word_index, слово в enumerate(words[:-1]):
# указывает, что за первым словом следует следующее
next_words[word].append(words[word_index+1] )
split(' ')
# next_words будет хранить список слов, следующих за словом
next_words = defaultdict(список)
# проверять каждое слово до последнего, но не включая его
для word_index, слово в enumerate(words[:-1]):
# указывает, что за первым словом следует следующее
next_words[word].append(words[word_index+1] ) Это все, что нужно для обучения марковской модели!
Если мы рассмотрим next_words мы обнаружим, что он сопоставляет каждый ключ со списком слов, за которым следует. Значения этого словаря содержат дубликаты по дизайну. Если за словом «to» часто следует слово «be», но слово «страдать» следует только один раз, то при наличии слова «to» наша модель должна с большей вероятностью предсказывать «быть», чем «страдать». . Говоря более изящно, наш словарь next_words представляет взвешенные вероятности того, что определенное слово следует за другим конкретным словом. Чтобы сгенерировать новые последовательности, мы просто будем выбирать из этих взвешенных вероятностей и собирать последовательность текста слово за словом.
А теперь самое интересное. Давайте используем модель для генерации новых речей. Для этого мы запустим следующий цикл 100 раз. Сначала мы случайным образом выберем слово, которое следует за токеном START. Имена персонажей всегда следуют за токеном START, поэтому первое слово в каждой речи будет содержать имя персонажа. Затем мы будем использовать next_words , чтобы случайным образом выбрать одно из слов, которое появляется после имени выбранного персонажа. Например, если выбранный нами персонаж — «Клавдий», на этом шаге мы случайным образом выберем одно из слов, которое следует сразу за словом «Клавдий» (то есть одно из слов, с которых Клавдий начинает одну из своих речей). Затем мы случайным образом выбираем слово, которое следует за этим последним словом. Мы будем продолжать в том же духе, пока не нажмем токен END, после чего завершим речь. Мы можем реализовать эту операцию в коде следующим образом:
случайный импорт # генерируем 100 образцов из модели для i в диапазоне (100): # инициализируем строку, которая будет хранить наш вывод вывод = '' # выбрать случайное слово, следующее за START слово = random.
 choice(next_words['START'])
# продолжаем выбирать следующее слово, пока не нажмем маркер END
пока слово != 'КОНЕЦ':
# добавить текущее слово в вывод
вывод += слово + ''
# получить следующее слово в последовательности
слово = случайный.выбор(следующие_слова[слово])
# отображаем вывод
печать (output.strip(), '\n')
choice(next_words['START'])
# продолжаем выбирать следующее слово, пока не нажмем маркер END
пока слово != 'КОНЕЦ':
# добавить текущее слово в вывод
вывод += слово + ''
# получить следующее слово в последовательности
слово = случайный.выбор(следующие_слова[слово])
# отображаем вывод
печать (output.strip(), '\n') Это все, что нужно для выборки из марковской модели! Вывод этого блока должен выглядеть как набор сумасшедших, бормочущих шекспировскую чепуху:
.
БЭКИНГЕМ:
По пути посмотреть.
Я соизволил,
С твоим обещанием прошло:
Я ограничиваю тебя желанной милостью твоей,
Я предсказываю мою.
МАРСИЙ:
Пусть эти люди скажут, что вы должны
изменить этого второго Грисселя,
И римский лагерь провести его с вашей душой
Сгенерированный текст выглядит псевдошекспировским! Теперь давайте посмотрим, сможем ли мы обучить некоторые марковские модели, которые генерируют музыкальные выражения.
Создание музыки с помощью марковских моделей
Как оказалось, мы можем использовать практически ту же стратегию, что и выше, для создания музыки с помощью марковских моделей. Для этого нам просто нужно преобразовать аудиофайл в текстовый файл. Для достижения этой цели мы можем разобрать миди-файл и преобразовать каждую ноту в файле в слово. Фантастическая библиотека music21 на языке Python, написанная лабораторией Майкла Скотта Катберта в Массачусетском технологическом институте, значительно упрощает эту задачу. Мы можем установить music21 и все зависимости, которые мы будем использовать ниже, следующим образом:0003
пункт установить музыку21 == 7.1.0 pip установить nltk == 3.6.2 pip установить довольно-миди == 0.2.9 пип установить scipy == 1.4.0 установка пипа https://github.com/duhaime/nesmdb/archive/python-3-support.zip
После установки music21 мы можем использовать функцию ниже, чтобы преобразовать ambrosia.midi (очаровательная мелодия из 8-битной игры Nintendo Ultima III) в строку. Вот миди-файл, и вот как мы преобразуем его в строку:
Вот миди-файл, и вот как мы преобразуем его в строку:
из music21.note import Примечание.
импортировать музыку21
определение midi_to_string (midi_path):
# разбираем музыкальную информацию, хранящуюся в миди-файле
счет = music21.converter.parse(
midi_path, # установить путь к миди-файлу
quantizePost=True, # квантовать длину ноты
QuarterLengthDivisors=(4,3)) # устанавливаем допустимую длину нот
# s будет хранить последовательность нот в виде строки
с = ''
# сохранить запись о последнем смещении времени, которое было замечено в счете
последнее_смещение = 0
# перебираем каждую ноту в партитуре
для n в score.flat.notes:
# измеряем время между этой нотой и предыдущей
дельта = n.offset - last_offset
# получить продолжительность этой ноты
продолжительность = n.duration.components[0].type
# сохранить время начала этой заметки
last_offset = n.смещение
# если прошло какое-то время, добавить токен ожидания
если дельта: s += 'w_{} '. format(delta)
# добавляем токены для каждой ноты (или каждой ноты в аккорде)
примечания = [n], если isinstance(n, примечание), иначе n.notes
для я в примечаниях:
# добавить это нажатие клавиши в последовательность
s += 'n_{}_{} '.format(i.pitch.midi, продолжительность)
вернуть с
s = midi_to_string('ambrosia.midi')  format(delta)
# добавляем токены для каждой ноты (или каждой ноты в аккорде)
примечания = [n], если isinstance(n, примечание), иначе n.notes
для я в примечаниях:
# добавить это нажатие клавиши в последовательность
s += 'n_{}_{} '.format(i.pitch.midi, продолжительность)
вернуть с
s = midi_to_string('ambrosia.midi')
format(delta)
# добавляем токены для каждой ноты (или каждой ноты в аккорде)
примечания = [n], если isinstance(n, примечание), иначе n.notes
для я в примечаниях:
# добавить это нажатие клавиши в последовательность
s += 'n_{}_{} '.format(i.pitch.midi, продолжительность)
вернуть с
s = midi_to_string('ambrosia.midi') Блок выше превращает ambrosia.midi в строку s . В этой строке каждая нота в ambrosia.midi представлена токеном, который начинается с «n_», а каждая пауза между нотами представлена токеном, который начинается с «w_». Если мы напечатаем s , мы сможем более четко увидеть строковое представление наших MIDI-данных:
>>> print(s) w_1.0 n_65_квартал n_38_half w_0,5 n_62_восьмой ...
Эта строка указывает, что файл начинается с полного такта паузы. Затем мы играем ноты 65 и 38 в течение четверти такта и половины такта соответственно, затем ждем половину такта, затем играем ноту 62 в течение восьмого такта и так далее. Таким образом, используя только два типа токенов («n_» и «w_»), мы можем записывать каждое нажатие клавиши, которое должно быть воспроизведено, а также продолжительность времени между этими нажатиями клавиш. Мы оставляем длительности нот в дробной форме, чтобы предотвратить усечение с плавающей запятой.
Таким образом, используя только два типа токенов («n_» и «w_»), мы можем записывать каждое нажатие клавиши, которое должно быть воспроизведено, а также продолжительность времени между этими нажатиями клавиш. Мы оставляем длительности нот в дробной форме, чтобы предотвратить усечение с плавающей запятой.
Чтобы проверить, работает ли это преобразование, давайте обратим процесс и преобразуем строку s в новый миди-файл. Если оба преобразования прошли успешно, мы должны ожидать, что новый миди-файл будет звучать как исходный файл ambrosia.midi. К счастью, music21 также упрощает преобразование струнных инструментов в миди:
из фракций import Fraction
определение string_to_midi(s):
# инициализируем последовательность, в которую мы будем добавлять ноты
поток = музыка21.поток.поток()
# отслеживать последнее наблюдаемое время
время = 1
# перебираем каждый токен в нашей строке
для я в s.split():
# если токен начинается с 'n' это заметка
если i. startswith('n'):
# определить ноту и ее продолжительность
примечание, продолжительность = i.lstrip('n_').split('_')
# создать новый объект заметки
n = music21.note.Note (int (note))
# указать продолжительность ноты
n.duration.type = продолжительность
# добавить заметку в поток
stream.insert(время, n)
# если токен начинается с 'w', это ожидание
Элиф i.startswith('w'):
# добавляем продолжительность ожидания к текущему времени
время += float(Дробь(i.lstrip('w_')))
# вернуть созданный нами поток
обратный поток
миди = string_to_midi(s)  startswith('n'):
# определить ноту и ее продолжительность
примечание, продолжительность = i.lstrip('n_').split('_')
# создать новый объект заметки
n = music21.note.Note (int (note))
# указать продолжительность ноты
n.duration.type = продолжительность
# добавить заметку в поток
stream.insert(время, n)
# если токен начинается с 'w', это ожидание
Элиф i.startswith('w'):
# добавляем продолжительность ожидания к текущему времени
время += float(Дробь(i.lstrip('w_')))
# вернуть созданный нами поток
обратный поток
миди = string_to_midi(s)
startswith('n'):
# определить ноту и ее продолжительность
примечание, продолжительность = i.lstrip('n_').split('_')
# создать новый объект заметки
n = music21.note.Note (int (note))
# указать продолжительность ноты
n.duration.type = продолжительность
# добавить заметку в поток
stream.insert(время, n)
# если токен начинается с 'w', это ожидание
Элиф i.startswith('w'):
# добавляем продолжительность ожидания к текущему времени
время += float(Дробь(i.lstrip('w_')))
# вернуть созданный нами поток
обратный поток
миди = string_to_midi(s) Как видите, вышеприведенный блок просто меняет операции, выполненные в midi_to_string , преобразуя каждый токен в миди-ноту. Получившийся миди-файл действительно должен звучать так же, как миди, с которого мы начали:
Теперь приступаем! Отсюда все, что нам нужно сделать, чтобы обучить марковскую модель строковому представлению нашего MIDI-файла. Для этого давайте преобразуем марковскую модель, которую мы использовали выше, в функцию многократного использования:
from collections import defaultdict из nltk импортировать ngrams импортировать случайный определение марков (s, sequence_length = 6, output_length = 250): # марковская модель поезда d = defaultdict(список) # создать список списков, где подсписки содержат последовательности слов токены = список (ngrams (s.
 split (), sequence_length))
# сохранить карту из токена в следующие за ним токены
для idx я в перечислении (токены [:-1]):
d[i].append(токены[idx+1])
# пример из марковской модели
l = [random.choice(токены)]
в то время как len(l) < output_length:
l.append(random.choice(d.get(l[-1], токены)))
# форматируем результат в строку
return ' '.join([' '.join(i) для i в l])
# образец новой строки из s, затем преобразование этой строки в midi
сгенерированный_миди = string_to_midi (марков (ы))
# сохранить миди-данные в "generated.midi"
сгенерированный_миди.write('миди', 'сгенерированный.миди')
split (), sequence_length))
# сохранить карту из токена в следующие за ним токены
для idx я в перечислении (токены [:-1]):
d[i].append(токены[idx+1])
# пример из марковской модели
l = [random.choice(токены)]
в то время как len(l) < output_length:
l.append(random.choice(d.get(l[-1], токены)))
# форматируем результат в строку
return ' '.join([' '.join(i) для i в l])
# образец новой строки из s, затем преобразование этой строки в midi
сгенерированный_миди = string_to_midi (марков (ы))
# сохранить миди-данные в "generated.midi"
сгенерированный_миди.write('миди', 'сгенерированный.миди')
Если мы запустим функцию markov , мы получим новую строку, содержащую последовательность нот, выраженную в текстовом виде. Затем мы можем преобразовать эту строку в правильный миди-файл, используя функцию string_to_midi , которую мы определили выше. Результат звучит как пара пьяных матросов, плачущих на пианино:
Хорошая новость: если вам не нравится этот звук, вы можете просто перезапустить функцию markov , пока не получите хранителя. Однако, прежде чем изгонять наш образец, давайте попробуем пропустить его через мясорубку чиптюна, о чем мы напишем ниже.
Однако, прежде чем изгонять наш образец, давайте попробуем пропустить его через мясорубку чиптюна, о чем мы напишем ниже.
Марковские модели и чиптюны
Крис Донахью, блестящий постдок в области компьютерных наук в Стэнфордском университете, выполнил сложнейшую задачу по преобразованию исходного 8-битного синтезатора Nintendo, или «блока обработки звука», в простой API, представленный в Python. пакет nesmdb. Nesmdb экспортирует функцию midi_to_wav , которая преобразует миди-файл в ностальгический 8-битный звук, передающий чистую энергию оригинальных саундтреков NES. В дальнейшем мы будем использовать эту функцию для преобразования миди-файла в аудио сигнал чиптюна.
from pretty_midi import Instrument as Tone из nesmdb.convert импортировать midi_to_wav из music21.note импортировать ноту импортировать pretty_midi, математику, scipy def midi_to_nintendo_wav (midi_path, длина = нет, скаляр = 0,3): # создать список тонов и время, когда каждый из них свободен тона = [Tone(0, name=n) для n в ['p1', 'p2', 'tr', 'no']] для t в тонах: t.
 free = 0
# получить время начала и окончания каждой ноты в `midi_path`
счет = music21.converter.parse(midi_path)
для n в score.flat.notes[:length]:
for i in [n] if isinstance(n, Note) else n.notes:
start = n.offset * скаляр
конец = начало + (n.seconds * скаляр)
# определить позицию индекса первого свободного тона
tone_index = Нет
для индекса t в перечислении (тона [: 3]):
если t.free <= start:
если тон_индекс равен Нет: тон_индекс = индекс
t.свободно = 0
если tone_index равен None: продолжить
тоны[tone_index].free = конец
# воспроизвести миди-ноту выбранным тоном
тоны[tone_index].notes.append(pretty_midi.Note(
скорость=10,
шаг=i.pitch.midi,
старт=старт,
конец = конец))
# добавить барабаны: 1 = бочка, 8 = малый барабан, 16 = хай-хэт
для i в диапазоне (math.ceil (конец * 8)):
нота = тоны[3].notes.append(pretty_midi.Note(
скорость=10,
шаг=1, если (i%4) == 0, иначе 8, если (i%4) == 2, иначе 16,
начало=(i/2 * скаляр),
конец=(i/2 * скаляр) + 0,1))
миди = pretty_midi.
free = 0
# получить время начала и окончания каждой ноты в `midi_path`
счет = music21.converter.parse(midi_path)
для n в score.flat.notes[:length]:
for i in [n] if isinstance(n, Note) else n.notes:
start = n.offset * скаляр
конец = начало + (n.seconds * скаляр)
# определить позицию индекса первого свободного тона
tone_index = Нет
для индекса t в перечислении (тона [: 3]):
если t.free <= start:
если тон_индекс равен Нет: тон_индекс = индекс
t.свободно = 0
если tone_index равен None: продолжить
тоны[tone_index].free = конец
# воспроизвести миди-ноту выбранным тоном
тоны[tone_index].notes.append(pretty_midi.Note(
скорость=10,
шаг=i.pitch.midi,
старт=старт,
конец = конец))
# добавить барабаны: 1 = бочка, 8 = малый барабан, 16 = хай-хэт
для i в диапазоне (math.ceil (конец * 8)):
нота = тоны[3].notes.append(pretty_midi.Note(
скорость=10,
шаг=1, если (i%4) == 0, иначе 8, если (i%4) == 2, иначе 16,
начало=(i/2 * скаляр),
конец=(i/2 * скаляр) + 0,1))
миди = pretty_midi. PrettyMIDI (разрешение = 22050)
midi.instruments.extend (тоны)
# сохранить длину миди, преобразовать в двоичный файл, а затем в wav
time_signature = pretty_midi.TimeSignature (1, 1, конец)
midi.time_signature_changes.append(time_signature)
midi.write('chiptune.midi')
вернуть midi_to_wav(open('chiptune.midi', 'rb').read())
# преобразовать нашу сгенерированную миди-последовательность в пустой массив
wav = midi_to_nintendo_wav('сгенерированный.midi')
# сохранить массив numpy в виде wav-файла
scipy.io.wavfile.write('сгенерированный.wav', 44100, wav)
PrettyMIDI (разрешение = 22050)
midi.instruments.extend (тоны)
# сохранить длину миди, преобразовать в двоичный файл, а затем в wav
time_signature = pretty_midi.TimeSignature (1, 1, конец)
midi.time_signature_changes.append(time_signature)
midi.write('chiptune.midi')
вернуть midi_to_wav(open('chiptune.midi', 'rb').read())
# преобразовать нашу сгенерированную миди-последовательность в пустой массив
wav = midi_to_nintendo_wav('сгенерированный.midi')
# сохранить массив numpy в виде wav-файла
scipy.io.wavfile.write('сгенерированный.wav', 44100, wav) Исходный синтезатор NES поддерживал пять параллельных звуковых дорожек: две дорожки пульсовой волны («p1», «p2»), дорожку треугольной волны («tr»), дорожку шума («no») и семплирование. трек, который не реализован в nesmdb. В приведенной выше функции мы просто назначаем каждую ноту из входного миди-файла первой неиспользуемой дорожке в нашем синтезаторе (исключая дорожку «нет», которой позже в функции назначается танцевальный бит). Конечно, есть более умные способы назначения нот на треки синтезатора, но мы будем использовать этот подход для простоты. Вот некоторые примеры результатов:
Конечно, есть более умные способы назначения нот на треки синтезатора, но мы будем использовать этот подход для простоты. Вот некоторые примеры результатов:
Если вам интересно попробовать создать собственное аудио, не стесняйтесь попробовать этот блокнот Colab, который загрузит файл ambrosia.midi и обработает его, используя шаги, описанные выше. В этой записной книжке есть ячейка, чтобы упростить загрузку пользовательских MIDI-файлов для обработки.
Идем дальше с марковскими MIDI-данными
Предшествующее обсуждение предназначено только для того, чтобы служить относительно простым способом начать генерировать звук с помощью марковских моделей. Мы едва поцарапали поверхность того, что возможно. Если вас интересует автоматическое создание музыки, вы можете поэкспериментировать с более сложными методами выборки текста, такими как сеть LSTM или модель преобразования, такая как GPT2. Также может быть интересно обучить вашу модель с большим набором данных, таких как набор MIDI-данных Colin Raffel Lakh (возможно, с удалением треков ударных и преобразованием каждого обучающего файла в общий относительный мажор, чтобы предотвратить переобучение).
Если вы создадите забавный звук, используя некоторые из этих методов, свяжитесь с нами! Я хотел бы услышать от вас.
* * *
Я хотел бы поблагодарить Кристин Макливи, чей проект Clara впервые познакомил меня с идеей преобразования MIDI-файлов в текстовые данные, и профессора Мэтью Саттора из Йельской школы драмы, чья опера I Am Alan Тьюринг вдохновил меня продолжить работу над алгоритмической композицией музыки.
Грамматика структуры фраз - Лингвистика
Введение
Грамматики структуры фраз моделируют внутреннюю структуру предложения в терминах иерархически организованного представления. Например, предложение У каждого мальчика есть велосипед состоит из именной группы ( каждый мальчик ) и глагольной группы ( имеет велосипед ), где первое состоит из определителя ( каждые ). ) и существительное ( мальчик ), а последнее из глагола ( имеет ) и именное словосочетание ( велосипед ), которое, в свою очередь, состоит из определителя ( a ) и существительного ( велосипед ). Структура становится явной с помощью помеченных скобок, как в (S (NP (Det каждый ) (N мальчик )) (VP (V имеет ) (NP (Det a ) (N велосипед ) ))) или по дереву. Грамматики фразовой структуры были введены Ноамом Хомским в 1950-х годах, опираясь на традицию непосредственного анализа составляющих в постблумфилдовском структурализме. Они играли ключевую роль в трансформационной грамматике (ТГ) до конца 19 века.60-х, в основном как описательный прием. Сдвиг к обобщению привел к более абстрактной версии, широко известной как синтаксис X-bar, основной компонент генеративного синтаксиса на протяжении 1970-х и 1980-х годов. Внедрение минималистской программы в 1990-х годах привело к дальнейшей абстракции, включая, среди прочего, фактическое устранение правил построения фраз. В нетрансформационной грамматике, зародившейся в 1970-х годах, грамматики структуры фраз продолжают процветать, особенно в лексико-функциональной грамматике (LFG) и грамматике структуры фраз, управляемой головой (HPSG).
Структура становится явной с помощью помеченных скобок, как в (S (NP (Det каждый ) (N мальчик )) (VP (V имеет ) (NP (Det a ) (N велосипед ) ))) или по дереву. Грамматики фразовой структуры были введены Ноамом Хомским в 1950-х годах, опираясь на традицию непосредственного анализа составляющих в постблумфилдовском структурализме. Они играли ключевую роль в трансформационной грамматике (ТГ) до конца 19 века.60-х, в основном как описательный прием. Сдвиг к обобщению привел к более абстрактной версии, широко известной как синтаксис X-bar, основной компонент генеративного синтаксиса на протяжении 1970-х и 1980-х годов. Внедрение минималистской программы в 1990-х годах привело к дальнейшей абстракции, включая, среди прочего, фактическое устранение правил построения фраз. В нетрансформационной грамматике, зародившейся в 1970-х годах, грамматики структуры фраз продолжают процветать, особенно в лексико-функциональной грамматике (LFG) и грамматике структуры фраз, управляемой головой (HPSG). Хотя грамматики структуры фраз в основном используются в синтаксисе, они также играют роль в других областях лингвистики: они обеспечивают структурную основу для композиционной интерпретации предложений в семантике и для определения просодических единиц в фонологии. Их роль в морфологии является яблоком раздора: в трансформационной грамматике наименьшими единицами анализа являются морфемы, так что PS-грамматики простираются ниже уровня слов. Нетрансформационные грамматики, напротив, занимают лексикалистскую позицию и рассматривают слова как синтаксические атомы, оставляя выражение сублексических регулярностей другим приемам, таким как лексические правила. Формальные свойства грамматик структуры фраз изучались в математической лингвистике. Они играют ключевую роль в компьютерной лингвистике и обработке естественного языка. Их актуальность для исследования обработки человеческого языка изучается в психолингвистике.
Хотя грамматики структуры фраз в основном используются в синтаксисе, они также играют роль в других областях лингвистики: они обеспечивают структурную основу для композиционной интерпретации предложений в семантике и для определения просодических единиц в фонологии. Их роль в морфологии является яблоком раздора: в трансформационной грамматике наименьшими единицами анализа являются морфемы, так что PS-грамматики простираются ниже уровня слов. Нетрансформационные грамматики, напротив, занимают лексикалистскую позицию и рассматривают слова как синтаксические атомы, оставляя выражение сублексических регулярностей другим приемам, таким как лексические правила. Формальные свойства грамматик структуры фраз изучались в математической лингвистике. Они играют ключевую роль в компьютерной лингвистике и обработке естественного языка. Их актуальность для исследования обработки человеческого языка изучается в психолингвистике.
Общие обзоры и учебники
Грамматики структуры фраз обеспечивают формальную нотацию для анализа внутренней структуры предложений. Их происхождение и их роль в лингвистике прослеживаются в Graffi 2001 и Matthews 1993. Они играют ключевую роль в порождающей грамматике. Учебники обычно вводят либо трансформационный, либо нетрансформационный подходы, но есть и такие, которые охватывают оба, например, Borsley 1999, Carnie 2011 и Müller 2016.
Их происхождение и их роль в лингвистике прослеживаются в Graffi 2001 и Matthews 1993. Они играют ключевую роль в порождающей грамматике. Учебники обычно вводят либо трансформационный, либо нетрансформационный подходы, но есть и такие, которые охватывают оба, например, Borsley 1999, Carnie 2011 и Müller 2016.
Borsley, Robert D. 1999. Теория синтаксиса: единый подход . 2 изд. Лондон: Рутледж.
Поэтапно знакомит с основными понятиями синтаксической теории, систематически сравнивая их трактовку в рамках трансформационного управления и связывания (GB) и в обобщенной грамматике структуры фраз / грамматике структуры фраз, управляемой головой (GPSG/HPSG). Содержит упражнения.
Карни, Эндрю. 2011. Современный синтаксис: Учебник . Кембридж, Великобритания: Кембриджский унив. Нажимать.
DOI: 10.1017/CBO9780511780738
Целью является объединение лучших идей минимализма, HPSG и лексико-функциональной грамматики (LFG).
Содержит упражнения.Граффи, Джорджио. 2001. 200 лет синтаксиса: критический обзор . Амстердам: Джон Бенджаминс.
DOI: 10.1075/sihols.98
Широкий исторический обзор, охватывающий как девятнадцатый, так и двадцатый века, вплоть до Минималистской программы включительно (Хомский 19).95, цитируется в разделе Bare Phrase Structure and the Minimalist Program с 1995 г.). Непосредственный составной анализ представлен в главе о методах синтаксического описания.
Мэтьюз, Питер. 1993. Теория грамматики в Соединенных Штатах: от Блумфилда до Хомского . Кембридж, Великобритания: Кембриджский унив. Нажимать.
DOI: 10.1017/CBO9780511620560
Взгляд с высоты птичьего полета на историю лингвистики в Северной Америке, охватывающий период с 1900 по 1990 г. Прослеживается развитие и преемственность трех ведущих идей: автономии синтаксиса (от значения), взгляда на предложения как на линейные конфигурации морфем и взгляда на грамматику как на генетически унаследованную систему универсальных принципов.
 Содержит упражнения.
Содержит упражнения.