Номер №504 — ГДЗ по Русскому языку 5 класс: Ладыженская Т.А.
войтирегистрация
- Ответкин
- Решебники
- 5 класс
- Русский язык
- Ладыженская
- Номер №504
НАЗАД К СОДЕРЖАНИЮ
2012г.ВыбранВыбрать ГДЗ (готовое домашние задание из решебника) на Номер №504 по учебнику Русский язык. 5 класс. Учебник для общеобразовательных учреждений 1, 2 части. М. Т. Баранов, Т.А. Ладыженская, Л. А. Тростенцова и др.; Просвещение, 2012г..
2019г.ВыбранВыбрать
ГДЗ (готовое домашние задание из решебника) на Номер №504 по учебнику Русский язык. 5 класс. Учебник для общеобразовательных организаций в 2 частях. Т.А. Ладыженская, М. Т. Баранов, Л. А. Тростенцова и др.; Просвещение, 2019г.
Т. Баранов, Л. А. Тростенцова и др.; Просвещение, 2019г.
Условие 20122019г.
Cменить на 2012 г.
Cменить на 2019 г.
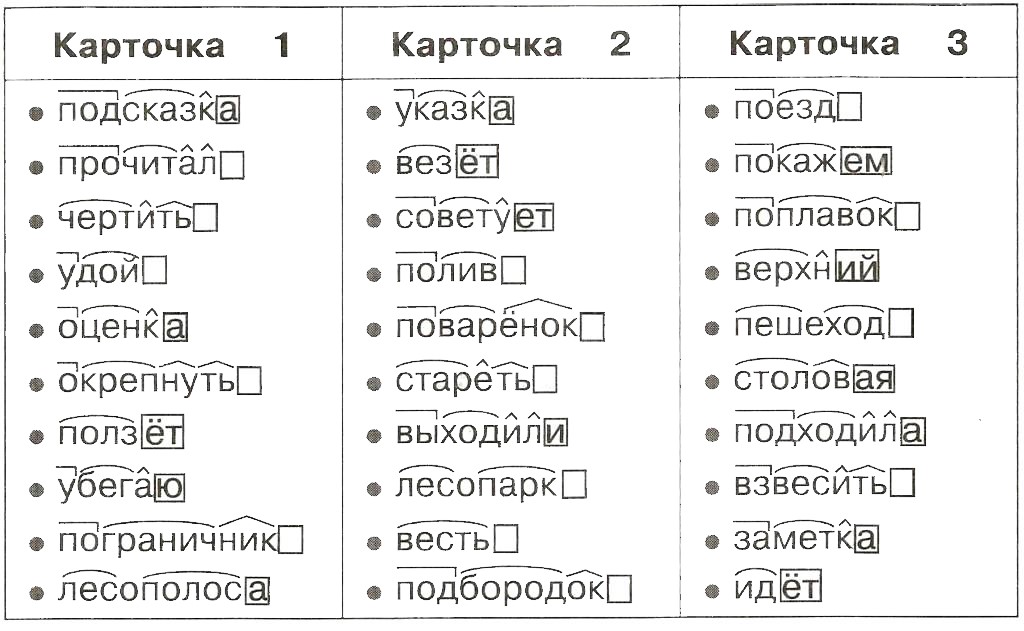
С существительными мышь, путь, рояль, фамилия, повидло, яблоко составьте такие словосочетания или предложения, в которых отчётливо определялся бы их род.
I. Какие из приведённых слов соответствуют схеме?
Заморозка, пришкольный, набережная, глоточек, взломщик, льдинка, работник, обход, щекастый.
II. Образуйте цепочки слов по образцу. Какое слово лишнее? Образец. Виноград — виноградина — виноградинка.
Горох, снег, изюм, солома.
Решение 1
Смотреть подробное решение
Решение 2
Смотреть подробное решение
Сообщить об ошибке в решении
Подробное решение
Рекомендовано
Белый фонпереписывать в тетрадь
Цветной фонтеория и пояснения
Решение 1
Смотреть подробное решение
Сообщить об ошибке в решении
Подробное решение
Рекомендовано
Белый фонпереписывать в тетрадь
Цветной фонтеория и пояснения
Решение 3
Смотреть подробное решение
Решение 4
Смотреть подробное решение
Решение 5
Смотреть подробное решение
ГДЗ по Русскому языку 5 класс: Ладыженская Т. А.
А.
Издатель: Т.А. Ладыженская, М. Т. Баранов, Л. А. Тростенцова, 2012г. / 2019г.
ГДЗ по Русскому языку 5 класс: Разумовская М.М.
Издатель: М.М. Разумовская, С.И. Львова, В.И. Капинос. 2012-2018г.
Сообщить об ошибке
Выберите тип ошибки:
Решено неверно
Опечатка
Плохое качество картинки
Опишите подробнее
в каком месте ошибка
Ваше сообщение отправлено
и скоро будет рассмотрено
ОК, СПАСИБО
[email protected]
© OTVETKIN.INFO
Классы
Предметы
Погода в Новоалтайске сегодня, прогноз погоды Новоалтайск на сегодня, Новоалтайск (городской округ), Алтайский край, Россия
GISMETEO: Погода в Новоалтайске сегодня, прогноз погоды Новоалтайск на сегодня, Новоалтайск (городской округ), Алтайский край, РоссияПерейти на мобильную версию
Сейчас
6:39
−12 10
По ощущению −20 -4
Вс, 19 фев
Сегодня
−139
−621
Пн, 20 фев
Завтра
−147
−425
100
400
700
1000
1300
1600
1900
2200
−916
−1112
−139
−1210
−818
−621
−719
−916
Скорость ветра, м/cкм/ч
0-1 0-4
0-1 0-4
0-1 0-4
1-4 4-14
0-3 0-11
0-1 0-4
Осадки, мм
Распечатать. ..
..
Снег
Вс, 19 фев, сегодня
Пн, 20
100
400
700
1000
1300
1600
1900
2200
Выпадающий снег, см
Высота снежного покрова, см
36,1
36,1
36,1
36,1
37
37,5
37,2
37,2
/Ветер, м/скм/ч
Вс, 19 фев, сегодня
Пн, 20
100
400
700
1000
1300
1600
1900
2200
Порывы
—
—
АвтоДавление, мм рт. ст.гПа
Вс, 19 фев, сегодня
Пн, 20
100
400
700
1000
1300
1600
1900
2200
7561008
7561008
7581010
7581010
7581010
7571009
7581010
7591012
Влажность, %
Вс, 19 фев, сегодня
Пн, 20
100
400
700
1000
1300
1600
1900
2200
85
92
86
85
85
82
86
92
Солнце и Луна
Вс, 19 фев, сегодня
Пн, 20
Долгота дня: 10 ч 2 мин
Восход — 8:37
Заход — 18:39
Сегодня день на 4 минуты длиннее, чем вчера
Луна стареющая, 7%
Заход — 13:50 (17 февраля)
Восход — 8:17
Полнолуние — 7 марта, через 18 дней
Ультрафиолетовый индекс, баллы
Вс, 19 фев, сегодня
Пн, 20
100
400
700
1000
1300
1600
1900
2200
Геомагнитная активность, Кп-индекс
Вс, 19 фев, сегодня
Пн, 20
100
400
700
1000
1300
1600
1900
2200
Осадки
Температура
Ветер
Облачность
Бажево
Белоярск
Солнечное
Березовка
Зудилово
Санниково
Боровиха
Фирсово
Правда
Казачий
Барнаул
Повалиха
Сибирский
Покровка
Лосиха
Кислуха
Логовское
Баюновские Ключи
Бешенцево
Костяки
Сибирский
Ползуново
Лесная Поляна
Казенная Заимка
5 вещей, которые нужно сделать при первом входе в Parse.
 ly
lyВы только что впервые вошли в Parse.ly… поздравляю! Что теперь? Вот пять вещей, которые вы должны сделать прежде всего:
- Добавьте букмарклет Parse.ly в свой браузер
- Настройте обзорный экран
- Настройте свой первый запланированный отчет
- Настройте свое первое оповещение
- Создайте свой первый сохраненный вид
Преимущество: Экономия времени при доступе к панели управления Parse.ly
Если вы используете Google Chrome, первое, что мы рекомендуем вам сделать, это добавить в браузер букмарклет «Открыть в Parse.ly». Это позволит вам перейти с любой страницы контента на вашем веб-сайте прямо на соответствующую страницу с информацией о публикации в Parse.ly всего одним щелчком мыши.
Чтобы настроить это, посетите этот справочный документ, нажмите зеленую кнопку с надписью «Открыть в Parse.ly» и перетащите ссылку с кнопки на панель закладок. Теперь букмарклет Parse.ly находится на панели закладок вашего браузера.
Теперь букмарклет Parse.ly находится на панели закладок вашего браузера.
С установленным букмарклетом перейдите на любую страницу вашего сайта, нажмите на ссылку букмарклета, которую вы только что создали, и вы автоматически попадете на соответствующую страницу с информацией о публикации в Parse.ly.
2. Настройте обзорный экранПреимущество: Быстро оценивайте производительность и действуйте быстрее
Обзорный экран — это первый экран, который вы увидите, открыв панель инструментов Parse.ly. Вы увидите моментальный снимок того, на что обращает внимание ваша аудитория и как ваш контент работает в режиме реального времени, поэтому вы сразу поймете, куда направить свои усилия.
Вы можете настроить три столбца в нижней части экрана «Обзор», чтобы показать эффективность вашего контента в любых терминах или показателях, которые вы хотите. Щелкните значок шестеренки над каждым из столбцов, чтобы открыть панель настроек, затем выберите, какую статистику и списки отображать.
Выбранные вами настройки будут сохранены в вашем браузере и будут отображаться каждый раз, когда вы открываете Parse.ly.
Вы также можете настроить остальную часть экрана «Обзор», щелкнув значок шестеренки в правом верхнем углу страницы.
Вот несколько идей по настройке экрана «Обзор» для различных ролей.
3. Настройте свой первый запланированный отчетПреимущество: Автоматически держите вашу команду на одной странице
Затем настройте ежедневный или еженедельный отчет, который показывает, что произошло с вашим контентом за предыдущий период времени. Отчеты можно отправлять кому угодно, и они настраиваются по метрике, частоте и категории.
В зависимости от вашей роли и типа организации, в которой вы работаете, вы можете настроить различные базовые и расширенные отчеты, которые помогут вам выполнять свою работу.
В отчете Top Listings показаны самые популярные сообщения, видео, авторы, разделы, теги или рефереры. Вы можете выбрать показатель, период времени и количество объявлений для отображения. Если вы курируете команду из нескольких писателей, настройте отчет, в котором будет показано, как работает каждый автор.
Вы можете выбрать показатель, период времени и количество объявлений для отображения. Если вы курируете команду из нескольких писателей, настройте отчет, в котором будет показано, как работает каждый автор.
Подробный отчет представляет собой сводку данных по конкретному автору, разделу, тегу или всему сайту. Это идет немного глубже, помимо списка того, что работает, чтобы помочь вам понять модели трафика и почему определенные истории были такими же хорошими, как они.
В отчете «Статистика с течением времени» показано, как изменился трафик для определенного автора, раздела, тега или всего сайта. Вы узнаете, как та или иная инициатива изменила эффективность с течением времени, сколько историй публиковалось каждый день, в какие дни недели было больше вовлеченности и т. д. : Оптимизация в режиме реального времени
Оповещения информируют вас о заметном трафике вашего контента без необходимости постоянно проверять панель инструментов Parse.ly. Вы можете получать оповещения в браузере, на мобильном телефоне, в Slack или по электронной почте, когда сообщения получают значительно больше трафика, чем обычно.
Вы можете настроить оповещение с любой страницы со значком мегафона в левом верхнем углу.
Чтобы настроить оповещение для какой-либо новости, находящейся в тренде на вашем сайте, начните с экрана «Обзор», нажмите на мегафон, выберите тип оповещения и следуйте инструкциям. Синий мегафон указывает на то, что оповещение было настроено.
5. Создайте свой первый сохраненный видПреимущество: Сориентируйте свою команду и сэкономьте время
Сохраненные представления дают вам возможность делать закладки на страницах информационной панели внутри Parse.ly для быстрого доступа. После того как вы настроите комбинацию фильтров, которые вы считаете полезными, сохраните представление, чтобы вам не приходилось повторно выполнять эти настройки каждый раз, когда вы используете панель мониторинга.
Возможно, вы хотите быстро увидеть, какие истории в определенном разделе получили наибольшее количество трафика с Facebook за последнюю неделю. Или, может быть, вы хотите отслеживать определенную группу авторов на одном экране.
Или, может быть, вы хотите отслеживать определенную группу авторов на одном экране.
Настройте страницу так, как вы хотите, а затем сохраните представление, чтобы вы могли вернуться к нему в любое время, нажав на звездочку в меню в правом верхнем углу экрана:
Вы также можете нажать кнопку «Руководство», чтобы быстро переходить к предлагаемым представлениям. Это дает вам другие способы думать и смотреть на ваш контент, а также показывает вам настройки панели инструментов для настройки этих представлений.
У вас есть вопросы или вы хотите узнать больше о том, как получить максимальную отдачу от Parse.ly? Обратитесь за дополнительной помощью к нашей команде экспертов по контент-аналитике!
Как выполнить сегментацию предложения или токенизацию предложения с помощью spaCy | NLP Series
Сегментация предложения или токенизация предложения — это процесс идентификации различных предложений среди группы слов. Библиотека Spacy, предназначенная для обработки естественного языка, выполняет сегментацию предложений с гораздо большей точностью. Однако давайте сначала поговорим о том, как мы, люди, определяем начало и конец предложения? В основном с помощью знаков препинания, верно? И в большинстве случаев мы говорим, что предложение заканчивается точкой «.». Таким образом, с этой основной идеей мы бы сказали, что можем разделить строку на основе точки и получить разные предложения. Как вы думаете, этой логики будет достаточно, чтобы получить все токены предложения?
Однако давайте сначала поговорим о том, как мы, люди, определяем начало и конец предложения? В основном с помощью знаков препинания, верно? И в большинстве случаев мы говорим, что предложение заканчивается точкой «.». Таким образом, с этой основной идеей мы бы сказали, что можем разделить строку на основе точки и получить разные предложения. Как вы думаете, этой логики будет достаточно, чтобы получить все токены предложения?
Что делать, если в предложениях есть сокращения, например, рассмотрим предложение «U.K. имеет две точки в аббревиатуре». В этом случае наш мозг натренирован таким образом, что не будет считать точки между аббревиатурой окончанием предложения. Однако он продолжает читать, пока не достигнет точки, которая фактически заканчивает предложение. Теперь посмотрите, в этом случае наша логика разделения полностью выйдет из строя. Здесь нам нужно обучение модели с нуля в текстовом корпусе или использование некоторых предварительно обученных моделей и их настройка в соответствии с нашими конкретными потребностями. Spacy предоставляет разные модели для разных языков. Я буду объяснять концепцию в отношении модели английского языка. Для поддержки других языков и инструкций по установке обратитесь к документации, доступной на официальном сайте spacy.io.
Spacy предоставляет разные модели для разных языков. Я буду объяснять концепцию в отношении модели английского языка. Для поддержки других языков и инструкций по установке обратитесь к документации, доступной на официальном сайте spacy.io.
Итак, в этом посте мы узнаем, как работает сегментация предложений и как установить пользовательские правила сегментации.
Jupyter Notebook Sentence-SegmentationDownload
#Выполнить стандартный импорт
import spacy
nlp = spacy.load('en_core_web_sm') # Загрузить английскую модель
string1 = "Это первое предложение. Это второе предложение. Это это третье предложение».
doc = nlp(string1)
для отправленных в doc.sents:
print(sent)
Отправка документов является генератором Объект-генератор не может производить вывод/сегментацию, пока он не будет вызван. Например, если есть объект списка, вы можете перебирать его и печатать элементы один за другим. Также вы можете распечатать вывод, используя индексирование, такое как список [0], список [1] и т. д., не вызывая его явно, даже не зацикливаясь на нем.
Также вы можете распечатать вывод, используя индексирование, такое как список [0], список [1] и т. д., не вызывая его явно, даже не зацикливаясь на нем.
Но это не относится к объектам-генераторам. Таким образом, документ не сегментируется до тех пор, пока не будет вызвано doc.sents . Это означает, что там, где вы могли бы напечатать второй токен Doc (словный токен) с print(doc[1]) , вы не можете вызвать «второе предложение Doc» с помощью print(doc.sents[1]) :
Давайте попробуем распечатать второе предложение таким же образом и посмотрим, что произойдет .
для отправленных в doc.sents:
print(sent)
Однако вы можете также создать коллекцию предложений, запустив doc.sents и сохранение результата в список:
doc_sents = [отправлено для отправки в doc.sents]
doc_sents
ПРИМЕЧАНИЕ : list(doc.sents) также работает. Мы показываем понимание списка, поскольку оно позволяет вам передавать условные операторы.
print(list(doc.sents))
print(list(doc.sents)[0])
sends представляют собой диапазоны, в которых сохранены начальные и конечные указатели токеновсодержит текст из исходного объекта Doc. На самом деле это просто спаны с начальным и конечным указателями токенов. Назначая указатели начального и конечного токенов, spaCy распознает токены предложений.
Добавление правил | Определяемое пользователем начало и конец предложения
Встроенный в spaCy генератор предложений полагается на синтаксический анализ зависимостей и пунктуацию в конце предложения для определения правил сегментации. Мы можем добавить собственные правила, но они должны быть добавлены до создания объекта Doc, так как именно здесь происходит синтаксический анализ токенов начала сегмента:
#Назначение токенов запуска происходит во время обработки конвейера nlp в soacy.
doc2 = nlp(u'Это первое предложение. Это начало второго предложения.Это начало третьего предложения.')
 Это начало третьего предложения.')
Это начало третьего предложения.') для токена в doc2:
print(token.is_sent_start, ' '+token.text)
Обратите внимание, что мы не запускали doc2.sents , и тем не менее token.is_sent_start было установлено в True на двух токенах в Док. Это означает, что инициализация маркера начала и конца предложения происходит во время самого конвейера nlp.
Давайте добавим точку с запятой к нашим существующим правилам сегментации. То есть всякий раз, когда генератор предложений встречает точку с запятой, следующая лексема должна начинать новый сегмент.
ПОВЕДЕНИЕ #SPACY ПО УМОЛЧАНИЮ
doc3 = nlp(u'"Руководство делает все правильно; руководство делает правильные вещи." - Питер Друкер')
для отправленных в doc3.sents:
print(sent)
nlp = spacy.load(' en_core_web_sm') #Сброс модели #ДОБАВИТЬ НОВОЕ ПРАВИЛО В КОНВЕЙЕР
def set_custom_Sentence_end_points(doc):
для токена в doc[:-1]:
if token.
doc[token .i+1].is_sent_start = True
return doc
 text == ';':
text == ';': nlp.add_pipe(set_custom_Sentence_end_points, before='parser')
nlp.pipe_names
Новое правило должно быть запущено до анализа документа.
# Повторно запустить создание объекта Doc:
doc4 = nlp(u'"Руководство делает все правильно; руководство делает правильные вещи." - Питер Друкер')
для отправленных в doc4.sents:
print(sent )
Почему бы не изменить токен напрямую?
Почему бы просто не установить для .is_sent_start значение True на существующих токенах?
Изменение правил
В некоторых случаях требуется заменить Stenencizer по умолчанию spaCy нашим собственным набором правил. В этом разделе мы увидим, как раскладчик по умолчанию разбивается на периоды. Затем мы заменим это поведение генератором предложений, который разрывается на разрывы строк.
nlp = spacy.load('en_core_web_sm') # сброс к исходному
mystring = u"Это предложение. Это другое.\n\nЭто \nтретье предложение."
#SPACY ПОВЕДЕНИЕ ПО УМОЛЧАНИЮ:
doc = nlp(mystring)
для отправленных в doc.sents:
print([token.text для отправленного токена]) 9
start = 0 = word.i
visible_newline = False
elif word.text.startswith('\n'): # обрабатывает несколько вхождений
see_newline = True
yield doc[start:] # обрабатывает последнюю группу токенов
sbd = SentenceSegmenter(nlp .vocab, стратегия=split_on_newlines)
nlp.add_pipe(sbd)  Это другое.\n\nЭто \nтретье предложение."
Это другое.\n\nЭто \nтретье предложение." Хотя функцию split_on_newlines можно назвать как угодно, важно использовать имя sbd для SentenceSegmenter.
doc = nlp(mystring)
для отправленных в doc.sents:
print([token.text для отправленного токена])
Здесь мы видим, что периоды больше не влияют на сегментацию, влияют только разрывы строк. Это было бы уместно, например, при работе с длинным списком твитов.
Это все о сегментации предложений с использованием spaCy.