Морфологический разбор слова «сургуч»
Часть речи: Существительное
СУРГУЧ — неодушевленное
Начальная форма слова: «СУРГУЧ»
| Слово | Морфологические признаки |
|---|---|
| СУРГУЧ |
|
| СУРГУЧ |
|
Все формы слова СУРГУЧ
СУРГУЧ, СУРГУЧА, СУРГУЧУ, СУРГУЧОМ, СУРГУЧЕ, СУРГУЧИ, СУРГУЧЕЙ, СУРГУЧАМ, СУРГУЧАМИ, СУРГУЧАХ
Разбор слова по составу сургуч
сургуч
| Основа слова | сургуч |
|---|---|
| Корень | сургуч |
| Нулевое окончание |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СУРГУЧ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «сургуч»
Примеры предложений со словом «сургуч»
1
Схрумкал папка в кулаке сургуч на бутылке, крошки сургуча в пепельницу из ладони высыпал, открыл бутылку, разлил водку по стаканам, сидит, ждёт.
Была бы дочь Анастасия (моление), Василий Иванович Аксёнов, 2018г.
2
Горлышко было запечатано потрескавшимся темным сургучом или чем-то похожим на сургуч.
Дом певчих птиц, Юлия Климова, 2019г.
3
Господин Кириллов, войдя, засветил свечу и из своего чемодана, стоявшего в углу и еще не разобранного, достал конверт, сургуч и хрустальную печатку.
Бесы, Федор Достоевский, 1871г.
4
Вот вам конверт, вот сургуч, бумажки понадобится – и бумажки дадим.
На горах, Павел Мельников-Печерский, 1875-1881г.
5
Старик самодовольно улыбнулся и послал Настеньку принести ему из кабинета сургуч и печать.
Тысяча душ, Алексей Феофилактович Писемский, 1858г.
Найти еще примеры предложений со словом СУРГУЧ
Измерение композиционного обобщения — блог Google AI
Автор: Марк ван Зи, инженер-программист, Google Research
Люди способны изучать значение нового слова, а затем применять его в других языковых контекстах.
Обычный подход к измерению композиционного обобщения в системах машинного обучения (ML) заключается в разделении данных обучения и тестирования на основе свойств, которые интуитивно коррелируют с композиционной структурой. Например, один из подходов состоит в том, чтобы разделить данные на основе последовательностей длиной — обучающий набор состоит из коротких примеров, а тестовый набор состоит из более длинных примеров. В другом подходе используется паттернов последовательности 9.0006 , что означает, что разделение основано на случайном назначении кластеров примеров, использующих один и тот же шаблон, либо для обучающих, либо для тестовых наборов. Например, вопросы « Кто снял Фильм1 » и « Кто снял Фильм2 » попадают в шаблон « Кто снял <ФИЛЬМ> », поэтому они будут сгруппированы вместе. Еще один метод использует протянутых примитивов — некоторые лингвистические примитивы очень редко проявляются при обучении (например, глагол «прыгать»), но очень заметны при тестировании. Хотя каждый из этих экспериментов полезен, не сразу ясно, какой эксперимент является «лучшей» мерой композиционности. Можно ли систематически разработать «оптимальный» композиционный эксперимент по обобщению?
В другом подходе используется паттернов последовательности 9.0006 , что означает, что разделение основано на случайном назначении кластеров примеров, использующих один и тот же шаблон, либо для обучающих, либо для тестовых наборов. Например, вопросы « Кто снял Фильм1 » и « Кто снял Фильм2 » попадают в шаблон « Кто снял <ФИЛЬМ> », поэтому они будут сгруппированы вместе. Еще один метод использует протянутых примитивов — некоторые лингвистические примитивы очень редко проявляются при обучении (например, глагол «прыгать»), но очень заметны при тестировании. Хотя каждый из этих экспериментов полезен, не сразу ясно, какой эксперимент является «лучшей» мерой композиционности. Можно ли систематически разработать «оптимальный» композиционный эксперимент по обобщению?
В статье «Измерение композиционного обобщения: всеобъемлющий метод на реалистичных данных» мы пытаемся ответить на этот вопрос, введя самый крупный и наиболее полный тест композиционного обобщения с использованием реалистичных задач понимания естественного языка, в частности, семантического разбора и ответов на вопросы. В этой работе мы предлагаем метрику — составное расхождение — которая позволяет количественно оценить, насколько разделение поезд-тест измеряет композиционную способность к обобщению системы ML. Мы анализируем композиционную способность обобщения трех последовательностей для последовательностей архитектур ML и обнаруживаем, что они не могут композиционно обобщаться. Мы также выпускаем набор данных Compositional Freebase Questions, используемый в работе, в качестве ресурса для исследователей, желающих улучшить эти результаты.
В этой работе мы предлагаем метрику — составное расхождение — которая позволяет количественно оценить, насколько разделение поезд-тест измеряет композиционную способность к обобщению системы ML. Мы анализируем композиционную способность обобщения трех последовательностей для последовательностей архитектур ML и обнаруживаем, что они не могут композиционно обобщаться. Мы также выпускаем набор данных Compositional Freebase Questions, используемый в работе, в качестве ресурса для исследователей, желающих улучшить эти результаты.
Измерение композиционности
Чтобы измерить способность системы к композиционному обобщению, мы начинаем с предположения, что мы понимаем основополагающие принципы создания примеров. Например, мы начинаем с правил грамматики, которых мы должны придерживаться при создании вопросов и ответов. Затем мы проводим различие между атомами и соединениями . Атомы являются строительными блоками, которые используются для создания примеров и 9Соединения 0005 представляют собой конкретные (потенциально неполные) композиции этих атомов. Например, на приведенном ниже рисунке каждая коробка представляет собой атом (например,
Например, на приведенном ниже рисунке каждая коробка представляет собой атом (например,
| Построение составных предложений (составных) из строительных блоков (атомов). |
Тогда идеальный эксперимент по композиционности должен иметь подобное распределение атомов , т. е. распределение слов и подфраз в обучающей выборке максимально похоже на их распределение в тестовой выборке, но с различное составное распределение . Чтобы измерить композиционное обобщение в ответе на вопрос о домене фильма, можно, например, подготовить и проверить следующие вопросы: entity>» появляются как в обучающем, так и в тестовом наборах, соединения разные.
Набор данных Compositional Freebase Questions
Чтобы провести точный эксперимент по композиционности, мы создали набор данных Compositional Freebase Questions (CFQ), простой, но реалистичный, большой набор данных вопросов и ответов на естественном языке, созданных на основе общедоступных знаний Freebase. база. CFQ можно использовать для задач ввода/вывода текста, а также для семантического анализа. В наших экспериментах мы фокусируемся на семантическом разборе, где вводом является вопрос на естественном языке, а выводом — запрос, который при выполнении на Freebase дает правильный результат. CFQ содержит около 240 тыс. примеров и почти 35 тыс. шаблонов запросов, что делает его значительно больше и сложнее, чем сопоставимые наборы данных — примерно в 4 раза больше, чем у WikiSQL, и примерно в 17 раз больше шаблонов запросов, чем сложные веб-вопросы. Особое внимание было уделено тому, чтобы вопросы и ответы были естественными. Мы также количественно оцениваем сложность синтаксиса в каждом примере, используя метрику «уровень сложности» ( 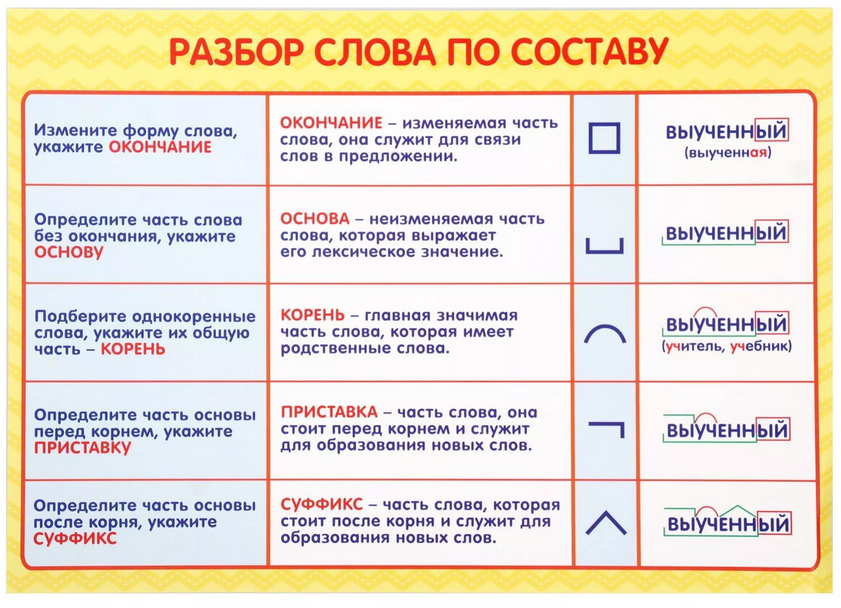
Эксперименты по композиционному обобщению на CFQ
Для данного разделения поезд-тест, если составные распределения набора поездов и тестов очень похожи, то их составное расхождение будет близко к 0, что указывает на то, что они не сложные тесты на композиционное обобщение. Составная дивергенция, близкая к 1, означает, что наборы обучающих тестов содержат много разных соединений, что делает его хорошим тестом для композиционного обобщения. Таким образом, составная дивергенция охватывает понятие «различное распределение соединений», как и хотелось.
Мы алгоритмически генерируем разбиения обучающих тестов, используя набор данных CFQ, которые имеют сложное расхождение в диапазоне от 0 до 0,7 (максимум, которого мы смогли достичь). Мы фиксируем расхождение атомов очень маленьким. Затем для каждого разделения мы измеряем производительность трех стандартных архитектур машинного обучения — LSTM+внимание, Transformer и Universal Transformer. Результаты показаны на графике ниже.
Результаты показаны на графике ниже.
| Составное расхождение и точность для трех архитектур машинного обучения. Существует удивительно сильная отрицательная корреляция между составным расхождением и точностью. |
Мы измеряем производительность модели, сравнивая правильные ответы с выходной строкой, заданной моделью. Все модели достигают точности более 95%, когда составное расхождение очень мало. Средняя точность разбиения с наибольшим составным расхождением составляет менее 20% для всех архитектур, а это означает, что даже большой обучающий набор с одинаковым распределением атомов между обучением и тестом недостаточен для того, чтобы архитектуры хорошо обобщались. Для всех архитектур существует сильная отрицательная корреляция между составным расхождением и точностью. Это, по-видимому, указывает на то, что составная дивергенция успешно улавливает основную трудность этих архитектур ML для композиционного обобщения.
Потенциально многообещающими направлениями будущей работы могут быть применение неконтролируемого предварительного обучения языку ввода или выходным запросам или использование более разнообразных или более целенаправленных архитектур обучения, таких как синтаксическое внимание. Также было бы интересно применить этот подход к другим областям, таким как визуальное мышление, т.е. основанный на CLEVR, или расширить наш подход к более широким подмножествам понимания языка, включая использование двусмысленных конструкций, отрицаний, квантификации, компаративов, дополнительных языков и других вертикальных областей. Мы надеемся, что эта работа вдохновит других на использование этого эталона для расширения возможностей композиционного обобщения обучающихся систем.
синтаксическая грамматика — Google
AlleBilderVideosBücherMapsNewsShopping
suchoptionen
Tipp: Begrenze diesuche auf deutschsprachige Ergebnisse. Du kannst deinesuchsprache in den Einstellungen ändern.
Unter Syntax (altgriechisch σύνταξις syntaxis, von σύν syn ‚zusammen’ und τάξις taxis ‚Ordnung, Reihenfolge’) versteht man allgemein ein Regelsystem zur Kombination elementarer Zeichen zu zusammengesetzten Zeichen in natürlichen oder künstlichen Zeichensystemen.
Синтаксис — Википедия
de.wikipedia.org › wiki › Синтаксис
Hervorgehobene Snippets
Что такое синтаксис? Изучите значение и правила с примерами
www.grammarly.com › блог › синтаксис
29.04.2022 · В лингвистике синтаксис – это расположение или порядок слов, определяемый как стилем автора, так и грамматическими правилами. Как работает синтаксис? Большинство …
Грамматика и синтаксис: в чем разница? — ProWritingAid
prowritingaid.com › грамматика и синтаксис
01.05.2022 · Синтаксис – это подразделение грамматики. Грамматика включает в себя всю систему правил языка, включая синтаксис. Синтаксис касается того, как …
Грамматика и синтаксис: различия между грамматикой и синтаксисом
www. masterclass.com › статьи › грамматика и синтаксис
masterclass.com › статьи › грамматика и синтаксис
15.09.2021 · Синтаксис – это расположение слов внутри структура предложения. Подмножество грамматики, синтаксис представляет собой набор правил, описывающих порядок слов и …
Разница между синтаксисом и грамматикой (со сравнительной таблицей)
keydifferences.com › разница-между-синтаксисом-ан… и фразы для формирования правильного предложения на конкретном языке. Это …
Различия в грамматике и синтаксисе и основные характеристики | YourDictionary
gram.yourdictionary.com › Vs.
Грамматические правила и шаблоны определяют способы использования синтаксических частей предложения. Например, каждое предложение должно включать подлежащее и сказуемое.
Синтаксис / Грамматика — deutsch.info
deutsch.info › грамматика › синтаксис
Порядок слов в главном предложении. Предложение состоит из подлежащего (лица или предмета, осуществляющего действие), сказуемого (финитного глагола) и, возможно, других элементов.
Natalie faulenzt nicht gern: = Натали любит бездельничать
Ich gehe heute ins Kino: = Сегодня я иду в кино
Unser Vater spielt gern Теннис: = Наш отец любит играть в теннис
синтаксис | грамматика | Британика
www.britannica.com › … › Языки
синтаксис, расположение слов в предложениях, предложениях и фразах, а также изучение построения предложений и отношения их компонентов …
Синтаксис — Википедия
en.wikipedia.org › wiki › Синтаксис
Чтобы узнать о других значениях, см. Синтаксис (значения). «Структура предложения» перенаправляется сюда. Информацию о структуре предложения в традиционной грамматике см. в статье Предложение предложения …
Определение и примеры синтаксиса — Грамматика английского языка — ThoughtCo
www.thoughtco.com › Английский язык › Грамматика английского языка
24.01.2020 · В лингвистике «синтаксис» относится к правилам, которые определяют, как слова объединяются в фразы, пункты и предложения.