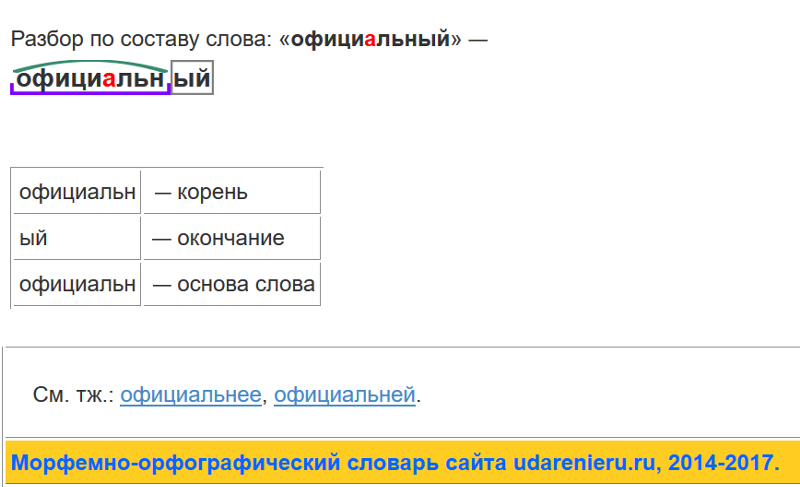
РАЗОБРАТЬ ПО СОСТАВУ ПРИСТАВКА КОРЕНЬ И Т.Д 1.Заросши… -reshimne.ru
Новые вопросы
Ответы
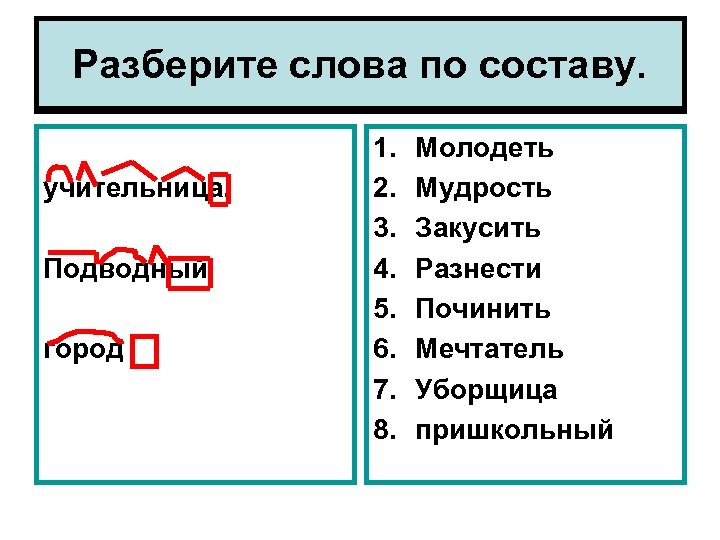
приставка [за] + корень [рос] + суффикс [ш] + окончание [их]
приставка [со] + корень [хран] + суффикс [и] + суффикс [л] + окончание [и]
приставка [про] + приставка [в] + приставка [а] + корень [лива] + окончание [ют] + постфикс [ся]
1. За- — приставка
-рос- — корень
-ш — суффикс
-их — окончание
Заросш- — основа.
2. Со- — приставка
-хран- — корень
-и — суффикс
-л — суффикс
-и — окончание
Сохранил- — основа.
3. Про- — приставка
-вал- — корень
-ива — суффикс (т. к. оно подчиняется правилу написания -ыва(-ива) и -ова(-ева) у инфинитива и прошедшего времени)
-ют — окончание
-ся — постфикс
Провалива-ø-ся — основа.
Похожие вопросы
!2. Определите типы придаточных в предложениях 6 и 16.
(6) И не только у окружающих, но даже у далеких, которых никогда не увидит: это они своими налогами оплачивают его врачей, учителей, стадионы и библиотеки, куда потом будут ходить, ит. д.
д.
(16) Общество начинает требовать, чтобы они работали и содержали хотя бы самих себя.
!…
Выписать все словосочетания из предложения и указать их вид и способ связи «На следующий день князь Андрей поехал к Растовым и провел у них весь день» Сделайте срочно!!!…
1)Выпишите слово которое соответствует схеме приставка-корень-суффикс-окончание.
Приветливый вспыхнула замолкать непригодный заново
2) В каком слове нет суффикса -щик-
Табельщик кровельщик подлещик мусорщик
Расскажут подземный безвкусица уко… СИНТАКСИЧЕСКИЙ РАЗБОР
Если смотреть на них откуда-нибудь с возвышенности, можно отлично видеть сохранившийся уровень воды, линию берега, острова. …
…
Помогите очень нужно Прямую речь перестройте в косвенную. 1) Радиолокатор в рубке капитана показывал: «Впереди по курсу движения корабля находится неизвестное препятствие». 2) «В рисунках художника отражена вся история северного края», — отмечали посетители выставки. 3) «Дешевое дороже обходится!» — открыл мне житейскую тайну Владик….
Я отправился домой через потемневшие поля, медленно вдыхая пахучий воздух , и пришёл в свою комнату . Разбор полный предложения…Математика
Литература
Алгебра
Русский язык
Геометрия
Английский язык
Химия
Физика
Биология
Другие предметы
История
Обществознание
Окружающий мир
ГеографияУкраїнська мова
Українська література
Қазақ тiлi
Беларуская мова
Информатика
Экономика
Право
Французский язык
Немецкий язык
МХК
ОБЖ
Психология
Тест по русскому языку.
 Повторение пройденного во 2 классе | Тест по русскому языку по теме:
Повторение пройденного во 2 классе | Тест по русскому языку по теме:3 класс Повторение пройденного в 1 – 2 классах.
1.Отметьте слово, в котором все согласные глухие.
Визг
Тропка
Испуг
Гараж
2. Отметьте слова, в которых проверочным является слово светлый.
Свет
Светит
Светленький
Световой (год)
Светлячок
Светлица
3.Отметьте слово, в котором все звуки соответствуют буквам.
Стрела
Прорубь
Удача
Рябина
4.Отметьте строку слов с ударением на последнем слоге.
Коклюш, столько, средства.
Документ, ревень, ремень.
Статуя, жаворонок, алфавит.
5.Отметьте слова, для которых проверочным будет слово цвет.
Цветной
Цветение
Цветок
Расцветка
Зацвели
Процветает
Отцвели
6. Отметьте слово, в котором все звуки соответствуют буквам.
Пестрый
Посадка
Грипп
Подставка.
7. Укажите строку, в словах которой звуков меньше, чем букв.
Укажите строку, в словах которой звуков меньше, чем букв.
Классный, пейзаж, стекло.
Помощь, кроссовки, большой.
Стальной, галчонок, мышонок.
8. Отметьте строку, в каждом слове которой звуков больше, чем букв.
Больные, змейка, вьюга.
Вьюн, колье, пьеса.
Ястреб, як, поехал.
9. Отметьте слова, в которых произношение расходится с написанием.
Посадка
Кольцо
Фуражка
Палатка
Пыль
Ватрушка
10. Отметьте слово, в котором есть твердый согласный звук.
Щавель
Деревья
Пищать
Денек
11. Сколько звуков и букв в слове маяк? Отметьте правильный ответ.
5звуков, 3 буквы
3звука, 5 букв
4звука, 4 буквы
5звуков, 4 буквы.
12.Отметьте неправильный ответ. В слове комната…
3 слога
Второй слог ударный
3гласных звука
2 звонких согласных.
13. В каких случаях буквы е, ё, ю, я могут обозначать два звука? Отметьте правильные ответы.
В начале слова.
После согласных звуков для обозначения их мягкости.
После гласных.
После ъ и ь.
14. Отметьте два слова, в которых нет звука [й,]
Березка
Маяк
Зеленеть
Змей
15. Отметьте строку, в каждом слове которой букв больше, чем звуков.
Ярмарка, тростник, конфета.
Морковь, известный, ранний.
Сонный, соленый, вкусный.
16. Отметьте слово, в котором звуков больше, чем букв.
Яблоко
Звездный
Осенний
Крылья.
3класс Однокоренные слова. Состав слова.
- Какие части слова участвуют в образовании новых слов? Отметьте правильный ответ.
Приставка, корень, суффикс, окончание.
Приставка, корень, окончание.
Приставка, суффикс
Корень, суффикс, окончание.
2.Отметьте правильные утверждения.
Слово гулять образовано от слова гул.
Слово метить образовано от слова метка.
Слово рыбалка образовано от слова рыба.
Слово побелка образовано от слова белка.
3.Отметьте слова, которые являются формой слова свет.
Светит
Светлица
Светлячок
(На) свету
Светлый
Светом
4.Отметьте строку с названием части слова, которая служит для связи слов в предложении.
Приставка, корень, суффикс, окончание.
Приставка, корень, окончание.
Окончание.
Корень, суффикс.
5.Отметьте строку, в каждом слове которой нулевое окончание.
Столик, окно, дерево.
Стон, ночь, смелость.
Зверь, медведица, волчонок.
6. Отметьте строку, в которой все слова однокоренные.
Поле, полевой, полить, поляна.
Лень, ленится, бездельник, ленивый.
Силушка, силач, великан, сильный.
Свет, светлячок, светленький, светит.
7. Отметьте слова с приставкой с-.
Спросить. Сбежать.
Свой Слезливый.
Ставить. Смотреть.
3 класс Однокоренные слова. Состав слова.
1.Отметьте пару слов, в которой не происходит смена ( чередования) согласных звуков в корне.
Бежит – бегун
Кричать – крикнул
Пилить – пилит
Сок – сочный
2.Отметьте строку с предлогами.
(Вы) летел, (вы) рубка, (вы)стрел.
(За) кричала, (за) качала, (за) молчала.
(За) домом, (за) столом, (за) светом.
3.Отметьте слова без приставки.
Покупка
Посуда
Поговорка
Пословица
Полевой
4. отметьте слово непроизносимым согласным в корне.
Загадка
Ложка
Подсадка
Сердце
Сонный
Подставка
5.Отметьте однокоренное слово, в котором буква согласного звука требует проверки.
Проводка
Ведёт
Проводит
Водный
Водоворот
Проводник
6.Отметьте слова с приставкой.
Составить Соломка Соскок
7.Отметьте суффикс, указывающий на профессию человека.
— ат — ик — ник — ок
3 класс Безударные гласные в корне слова.
1.Укажите слова, в которых нет буквы безударного гласного в корне.
Горушка
Горец
Гористая
Горный
Горка
2.Укажите слово с буквой а безударного гласного в корне.
В..зить
К..рмить
Т..щить
Д..лить
3.Отметьте слово, в котором букву безударного гласного нельзя проверить ударением.
Пост..ять
Прог..в..рить
Р..бина
В..твистый
Ск..листый
4.Отметьте способы проверки букв безударных гласных звуков в корне.
Изменить форму слова.
Разобрать слово по составу.
Обозначить ударение.
Подобрать однокоренное слово.
5.Отметьте в глаголе букву а безударного гласного в корне.
Пос..дела ( голова)
Расп..вают (песни)
Прил..скать( котёнка)
Сп..шит ( домой)
6.Укажите слово с буквой я безударного гласного в корне.
Поч..рнел
Выт..нуть
Ст..мнело
Приз..млился
Пот..нет
Т. .снение
.снение
3 класс Имя существительное.
1.Отметьте имя существительное, отличающееся от других родом.
Олень
Конь
Медведь
Рысь
Гусь
Лось
Глухарь
Соболь
2.Отметьте имя существительное с буквой а в корне, проверяемой ударением.
Окраска
Инженер
Засветило
Зеркала
Повозка
Пробежал
3.Отметьте лишнее слово.
Речь Печь
Мощь Степь
4.Отметьте имя существительное, у которого нет формы единственного числа.
Коньки
Лыжи
Каникулы
Птицы
Деревья
Столбы
5.Что нужно сделать, чтобы определить род имен существительных?
Поставить вопрос.
Определить, что это слово обозначает.
Выяснить, к какому слову это слово относится.
Подобрать нужное местоимение.
6.Отметьте существительное, у которого не пишется ь.
Гуаш… Мелоч… лож…
Кирпич… мыш… полноч…
3 класс Имя прилагательное.
1.Отметьте лишнее слово.
Сладкий
Робкий
Морозный
Гладкий
2.Отметьте правильное утверждение.
Имя прилагательное – это член предложения.
Имя прилагательное – это часть речи.
Имя прилагательное – это часть слова.
3.Отметьте имя прилагательное в форме множественного числа.
Дремучий (лес)
Вкусное (мороженое)
Светлые (поляны)
Синяя (лента)
4.Отметьте пары прилагательных, близких по смыслу.
Тяжёлый – лёгкий
Нежный – ласковый
Сладкий – горький
Красивый – привлекательный
5. Отметьте неправильное утверждение.
Имена прилагательные согласуются с именами существительными в роде и числе.
Имена прилагательные изменяются по родам и числам.
Имена прилагательные не изменяются по родам.
6. Отметьте два имени прилагательных с приставками.
Срочный вызов.
Задумчивый взгляд.
Прекрасный вид.
Прелестный ребёнок.
7. Отметьте имя прилагательное, которое подойдёт к имени существительному.
…….привет
Дружный
Дружеский
Дружественный
……….поколение
Старое
Старинное
старшее
3 класс Глагол.
1.Отметьте глагол в форме прошедшего времени.
Стучит
Ворчу
Говорить
Светила (лампа)
2.Укажите вопросы, на которые отвечают глаголы в начальной форме.
Что делает? Что сделать?
Что делать? Что сделает?
3.Отметьте правильное утверждение.
Глагол – член предложения, который обозначает действие или состояние предмета и отвечает на вопросы: « что делать?», « что сделать?».
Глагол – часть речи, которая обозначает признак предмета и отвечает на вопросы: «какой?», «что делает?».
Глагол – часть речи, которая обозначает действие или состояние предмета и отвечает на вопросы: «что делать?», «что сделать?».
4.Отметьте правильное утверждение.
Глаголы изменяются по временам и числам.
Глаголы прошедшего времени не изменяются по родам и числам.
Глаголы прошедшего времени изменяются по родам и числам.
5.Как изменяются глаголы? Отметьте правильный ответ.
По числам, падежам, временам.
По родам, числам, падежам.
По падежам, числам, временам.
По временам, числам, родам.
6.Отметьте глаголы в форме настоящего времени.
Наступила
Бережёт
Сидит
Свистела
Засветит
Подбежит.
7.Отметьте глаголы с буквой безударного гласного в корне.
Посадить.
Высадка.
Зелень.
Бегут.
Запомнит.
Малахит.
Шелестят.
Свистит.
Ворчат.
Вставь одинаково звучащие предлоги и приставки.между предлогом исловом вставляй подходящие по смыслу слова. клеить конверт .скочить сцены
Ответы
Oks099 02.07.2020 09:20Заклеить конверт,соскочить со сцены как то так
ПОКАЗАТЬ ОТВЕТЫ
Юсик1854
02. 07.2020 09:20
07.2020 09:20
Заклеить конверт, соскочить со сцены
ПОКАЗАТЬ ОТВЕТЫ
kari2018 17.10.2020 20:34
Прийти к дому, приплыть к берегу, приехать в город, приехал к улице
ПОКАЗАТЬ ОТВЕТЫ
СерсеяЛаннистер 17.10.2020 20:34
Пойти по улице, отплыть от берега, доехать до дома, поехал по городу.
ПОКАЗАТЬ ОТВЕТЫ
MashaBendyuk
17. 10.2020 20:34
10.2020 20:34
Поехал погороду поехал поулице
ПОКАЗАТЬ ОТВЕТЫ
zeinalovazahra 17.10.2020 20:34
ПОДойти
ПОДплыть
НАехать
НАехал
ОТ дома
ОТ берега
ДО города
ДО улицы
ПОКАЗАТЬ ОТВЕТЫ
aigul666 17.10.2020 20:34
ПЕРЕЧИТАТЬ,ПЕРЕПИСАТЬ,ПЕРЕСКАЗАТЬ,ПЕРЕНОСИТЬ
ПОКАЗАТЬ ОТВЕТЫ
трифон1
17. 10.2020 20:34
10.2020 20:34
Отойти от дома
отплыть от берега
въехать в город
поехал по улице
ПОКАЗАТЬ ОТВЕТЫ
Не совсем понятно задание. Напиши, как написано в задании в учебнике.
ПОКАЗАТЬ ОТВЕТЫ
0Assistant0 17.10.2020 20:34
Наклеить на конверт, соскочить со сцены, внёс в комнату, спрыгнул с крылечка.
ПОКАЗАТЬ ОТВЕТЫ
kat2000T
17. 10.2020 20:34
10.2020 20:34
наклеить марку на конверт
соскочить быстро со сцены
внёс диван в комнату
cпрыгнул котёнок с крылечка
ПОКАЗАТЬ ОТВЕТЫ
Настюша1лавруша 17.10.2020 20:34
Идти до дома; плыть до берега.
ехать по городу; ехал по улице
ПОКАЗАТЬ ОТВЕТЫ
win66123 17.10.2020 20:34
Дойти до дома, переплыть до берега.
ПОКАЗАТЬ ОТВЕТЫ
julyyushchenko
17.
Дойти до дома Доплыть до берега Въехать в город Поехал по улице
ПОКАЗАТЬ ОТВЕТЫ
Ghasty 17.10.2020 20:34
Дойти до дома доплыть до берега доехать до города проехал по улице
ПОКАЗАТЬ ОТВЕТЫ
авяпвяа 17.10.2020 20:34
Дойти до (моего) дома.
до (этого)берега
в (наш) город
на (Московской) улице
доплыть
поехать
уехал
я правильно поняла задание?
ПОКАЗАТЬ ОТВЕТЫ
azavidov00
17. 10.2020 20:34
10.2020 20:34
До ехать
Страна
Поехать
Столица
ПОКАЗАТЬ ОТВЕТЫ
bogdanpavlovi 17.10.2020 20:34
Внес в комнату, в первом случае в -это приставка, а во втором- предлог
ПОКАЗАТЬ ОТВЕТЫ
sashadedarewa 17.10.2020 20:34
пройти дома,переплыть, проехать город,
ПОКАЗАТЬ ОТВЕТЫ
liza45683liza 17.10.2020 20:34
пройти дома, переплыть берега, проехать город, поехал к улице
ПОКАЗАТЬ ОТВЕТЫ
Vilaan1972
17. 10.2020 20:34
10.2020 20:34
ответ к заданию по русскому языку
ПОКАЗАТЬ ОТВЕТЫ
Тупой7А 17.10.2020 20:34
наклеить марку на конверт
соскочить быстро со сцены
внёс диван в комнату
cпрыгнул котёнок с крылечка
Объяснение:
ПОКАЗАТЬ ОТВЕТЫ
sofiapel68p08lqa 17.10.2020 20:34
дойти,
доплыть,
доехать.
ПОКАЗАТЬ ОТВЕТЫ
мышка72
17. 10.2020 20:34
10.2020 20:34
Пройти по дому
Проплыть берега
Приехать в город
Проехать по улице
ПОКАЗАТЬ ОТВЕТЫ
Другие вопросы по теме Русский язык
leranik4 21.05.2019 06:30
Сочинение на тему как я убираюсь в комнате…
7Оля8 19.08.2019 05:10
Что обозначают безличные предложения?…
ivankisa12 24.04.2019 18:26
Составьте сочинение-рассуждение на тему самый важный день в году составить самим не брать из интернета. заранее . 20 ….
заранее . 20 ….
DaniilEzhov036 30.06.2019 06:20
5пословиц поговорок с условным наклонением…
yakovlev59 09.07.2019 10:50
Ялюблю булки,плюшки,батоны и кекс! я люблю хлеб, и торт, и пирожные,и пряники. а ещё я люблю кильки,сайру,судака в маринаде, бычки в томате, частик в собственном…
89109949335 21.04.2019 20:41
Определите стилистическую окраску слова зафиксировано . подберите и запишите синоним (синонимы) к этому слову. …
…
Анека1111111 25.04.2021 18:33
2. Запишите текст из 3 предложений на тему «День Защитников Украины».…
НикаНик1111 27.06.2019 08:50
Предумайте предложение со словосочетанием отломать кусочек…
КириллПос 21.06.2019 06:20
Где нужно надо поставить запятую. 1) поезд шел не останавливаясь. 2)поев он собирался отдохнуть. 3)но вспомнив о намеченных планах он отказался. 4)пришел приказ действовать…
А22222222
11. 05.2021 20:22
05.2021 20:22
СОР №4 «День Победы»памагит если смогу скрины отправлюну памагит…
Самый точный в мире синтаксический анализатор становится открытым исходным кодом
Эта структура кодирует, что Алиса и Боб — существительные, а пила — глагол. Основной глагол пила является корнем предложения, а Алиса является подлежащим (nsubj) пила , а Боб является его прямым дополнением (добж). Как и ожидалось, Parsey McParseface правильно анализирует это предложение, но также понимает следующий более сложный пример:
Эта структура снова кодирует тот факт, что Алиса и Боб являются субъектом и объектом соответственно пилы , кроме того, что Алиса модифицируется относительным предложением с глаголом , читающим , что пила модифицируется временным модификатором вчера , и так далее. Грамматические отношения, закодированные в структурах зависимостей, позволяют нам легко восстановить ответы на различные вопросы, например кого увидела Алиса? , кто видел Боба? , о чем читала Алиса? или когда Алиса увидела Боба? .
Грамматические отношения, закодированные в структурах зависимостей, позволяют нам легко восстановить ответы на различные вопросы, например кого увидела Алиса? , кто видел Боба? , о чем читала Алиса? или когда Алиса увидела Боба? .
Почему синтаксический анализ так сложен для компьютеров?
Одна из основных проблем, делающих синтаксический анализ настолько сложным, заключается в том, что человеческие языки демонстрируют значительный уровень неоднозначности. Предложения средней длины — скажем, 20 или 30 слов — нередко содержат сотни, тысячи или даже десятки тысяч возможных синтаксических структур. Парсер естественного языка должен каким-то образом просмотреть все эти альтернативы и найти наиболее правдоподобную структуру с учетом контекста. В качестве очень простого примера, предложение Алиса ехала по улице на своей машине имеет как минимум два возможных разбора зависимостей:
Первый соответствует (правильной) интерпретации, когда Алиса едет на своей машине; второй соответствует (абсурдной, но возможной) интерпретации, где улица находится в ее машине. Двусмысленность возникает из-за того, что предлог в может модифицировать либо водила , либо улица ; этот пример является примером того, что называется двусмысленностью прикрепления предложной фразы .
Двусмысленность возникает из-за того, что предлог в может модифицировать либо водила , либо улица ; этот пример является примером того, что называется двусмысленностью прикрепления предложной фразы .
Люди прекрасно справляются с двусмысленностью почти до такой степени, что проблема становится незаметной; задача состоит в том, чтобы компьютеры делали то же самое. Множественные двусмысленности, подобные этим, в более длинных предложениях сговорились, чтобы дать комбинаторный взрыв в количестве возможных структур для предложения. Обычно подавляющее большинство этих структур крайне неправдоподобны, но, тем не менее, возможны и должны быть каким-то образом отброшены синтаксическим анализатором.
SyntaxNet применяет нейронные сети к проблеме неоднозначности. Входное предложение обрабатывается слева направо, при этом зависимости между словами постепенно добавляются по мере рассмотрения каждого слова в предложении. В каждый момент обработки может быть возможно много решений — из-за неоднозначности — и нейронная сеть выставляет баллы конкурирующим решениям на основе их правдоподобия. По этой причине очень важно использовать поиск луча в модели. Вместо того, чтобы просто принимать первое лучшее решение в каждой точке, на каждом шаге сохраняется несколько частных гипотез, причем гипотезы отбрасываются только тогда, когда рассматривается несколько других гипотез более высокого ранга. Пример последовательности решений слева направо, которая приводит к простому синтаксическому анализу, показан ниже для предложения Я забронировал билет в Google .
По этой причине очень важно использовать поиск луча в модели. Вместо того, чтобы просто принимать первое лучшее решение в каждой точке, на каждом шаге сохраняется несколько частных гипотез, причем гипотезы отбрасываются только тогда, когда рассматривается несколько других гипотез более высокого ранга. Пример последовательности решений слева направо, которая приводит к простому синтаксическому анализу, показан ниже для предложения Я забронировал билет в Google .
Кроме того, как описано в нашей статье, крайне важно плотно интегрировать обучение и поиск для достижения максимальной точности предсказания. Parsey McParseface и другие модели SyntaxNet — одни из самых сложных сетей, которые мы обучали с помощью платформы TensorFlow в Google. Учитывая некоторые данные из поддерживаемого Google проекта Universal Dependencies, вы можете обучить модель синтаксического анализа на своем собственном компьютере.
Итак, насколько точен Parsey McParseface?
На стандартном тесте, состоящем из случайно выбранных предложений английской новостной ленты (20-летний Penn Treebank), Parsey McParseface восстанавливает индивидуальные зависимости между словами с более чем 9Точность 4%, что превосходит наши собственные предыдущие современные результаты, которые уже были лучше, чем любой предыдущий подход. Хотя в литературе нет явных исследований о человеческой деятельности, мы знаем из наших собственных проектов аннотации, что лингвисты, обученные этой задаче, соглашаются в 96-97% случаев. Это говорит о том, что мы приближаемся к человеческим возможностям, но только на правильно сформированном тексте. Предложения, взятые из Интернета, намного сложнее анализировать, как мы узнали из Google WebTreebank (выпущенного в 2011 году). Parsey McParseface набрал чуть более 9 баллов0% точности синтаксического анализа в этом наборе данных.
Хотя в литературе нет явных исследований о человеческой деятельности, мы знаем из наших собственных проектов аннотации, что лингвисты, обученные этой задаче, соглашаются в 96-97% случаев. Это говорит о том, что мы приближаемся к человеческим возможностям, но только на правильно сформированном тексте. Предложения, взятые из Интернета, намного сложнее анализировать, как мы узнали из Google WebTreebank (выпущенного в 2011 году). Parsey McParseface набрал чуть более 9 баллов0% точности синтаксического анализа в этом наборе данных.
Хотя точность не идеальна, она, безусловно, достаточно высока, чтобы быть полезной во многих приложениях. Основным источником ошибок на этом этапе являются такие примеры, как описанная выше двусмысленность прикрепления предложной фразы, которая требует знания реального мира (например, что улица вряд ли находится в автомобиле) и глубоких контекстуальных рассуждений. Машинное обучение (и, в частности, нейронные сети) добились значительного прогресса в разрешении этих неоднозначностей. Но наша работа все еще ограничена: мы хотели бы разработать методы, которые могут познать мир и обеспечить одинаковое понимание естественного языка в 9 странах мира.0003 все языка и контекста.
Но наша работа все еще ограничена: мы хотели бы разработать методы, которые могут познать мир и обеспечить одинаковое понимание естественного языка в 9 странах мира.0003 все языка и контекста.
Для начала просмотрите код SyntaxNet и загрузите модель парсера Parsey McParseface. Удачного разбора от главных разработчиков, Криса Альберти, Дэвида Вайса, Даниэля Андора, Майкла Коллинза и Слава Петрова.
Автор: Слав Петров, старший научный сотрудник
В Google мы тратим много времени на размышления о том, как компьютерные системы могут читать и понимать человеческий язык, чтобы разумно обрабатывать его. Сегодня мы рады поделиться плодами нашего исследования с более широким сообществом, выпустив SyntaxNet, среду нейронной сети с открытым исходным кодом, реализованную в TensorFlow, которая обеспечивает основу для систем понимания естественного языка (NLU). Наш релиз включает в себя весь код, необходимый для обучения новых моделей SyntaxNet на ваших собственных данных, а также Parsey McParseface , анализатор английского языка, который мы подготовили для вас и который вы можете использовать для анализа английского текста.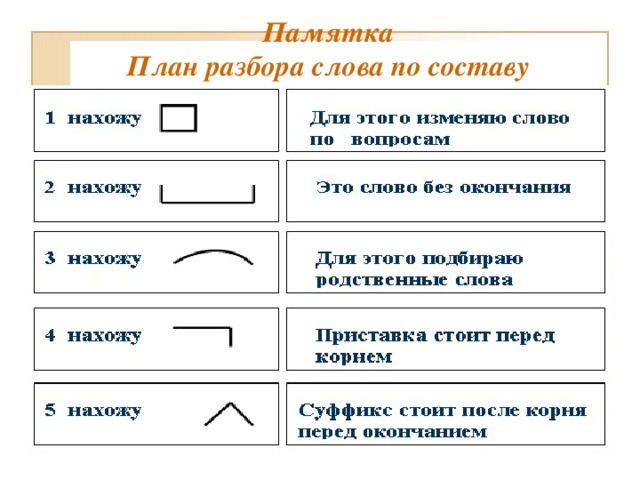
Parsey McParseface построен на мощных алгоритмах машинного обучения, которые учатся анализировать лингвистическую структуру языка и могут объяснить функциональную роль каждого слова в данном предложении. Поскольку Parsey McParseface является самой точной такой моделью в мире, мы надеемся, что она будет полезна разработчикам и исследователям, интересующимся автоматическим извлечением информации, переводом и другими основными приложениями NLU.
Как работает SyntaxNet?
SyntaxNet представляет собой структуру для того, что известно в академических кругах как синтаксический анализатор , который является ключевым первым компонентом во многих системах NLU. Получив предложение в качестве входных данных, он помечает каждое слово тегом части речи (POS), который описывает синтаксическую функцию слова, и определяет синтаксические отношения между словами в предложении, представленные в дереве синтаксического анализа зависимостей. Эти синтаксические отношения напрямую связаны с основным значением рассматриваемого предложения. В качестве очень простого примера рассмотрим следующее дерево зависимостей для Алиса увидела Боба :
В качестве очень простого примера рассмотрим следующее дерево зависимостей для Алиса увидела Боба :
Эта структура кодирует, что Алиса и Боб являются существительными, а видели глаголом. Основной глагол пила является корнем предложения, а Алиса является подлежащим (nsubj) пила , а Боб является его прямым дополнением (добж). Как и ожидалось, Parsey McParseface правильно анализирует это предложение, но также понимает следующий более сложный пример:
Эта структура снова кодирует тот факт, что Алиса и Боб являются субъектом и объектом соответственно пилы , кроме того, что Алиса модифицируется относительным предложением с глаголом , читающим , что пила модифицируется временным модификатором вчера , и так далее. Грамматические отношения, закодированные в структурах зависимостей, позволяют нам легко восстановить ответы на различные вопросы, например кого увидела Алиса? , кто видел Боба? , о чем читала Алиса? или когда Алиса увидела Боба? .

Почему синтаксический анализ так сложен для компьютеров?
Одна из основных проблем, делающих синтаксический анализ настолько сложным, заключается в том, что человеческие языки демонстрируют значительный уровень неоднозначности. Предложения средней длины — скажем, 20 или 30 слов — нередко содержат сотни, тысячи или даже десятки тысяч возможных синтаксических структур. Парсер естественного языка должен каким-то образом просмотреть все эти альтернативы и найти наиболее правдоподобную структуру с учетом контекста. В качестве очень простого примера, предложение Алиса ехала по улице на своей машине имеет как минимум два возможных разбора зависимостей:
Первый соответствует (правильной) интерпретации, когда Алиса едет на своей машине; второй соответствует (абсурдной, но возможной) интерпретации, где улица находится в ее машине. Двусмысленность возникает из-за того, что предлог в может модифицировать либо водила , либо улица ; этот пример является примером того, что называется двусмысленностью прикрепления предложной фразы .
Люди прекрасно справляются с двусмысленностью почти до такой степени, что проблема становится незаметной; задача состоит в том, чтобы компьютеры делали то же самое. Множественные двусмысленности, подобные этим, в более длинных предложениях сговорились, чтобы дать комбинаторный взрыв в количестве возможных структур для предложения. Обычно подавляющее большинство этих структур крайне неправдоподобны, но, тем не менее, возможны и должны быть каким-то образом отброшены синтаксическим анализатором.
SyntaxNet применяет нейронные сети к проблеме неоднозначности. Входное предложение обрабатывается слева направо, при этом зависимости между словами постепенно добавляются по мере рассмотрения каждого слова в предложении. В каждый момент обработки может быть возможно много решений — из-за неоднозначности — и нейронная сеть выставляет баллы конкурирующим решениям на основе их правдоподобия. По этой причине очень важно использовать поиск луча в модели. Вместо того, чтобы просто принимать первое лучшее решение в каждой точке, на каждом шаге сохраняется несколько частных гипотез, причем гипотезы отбрасываются только тогда, когда рассматривается несколько других гипотез более высокого ранга.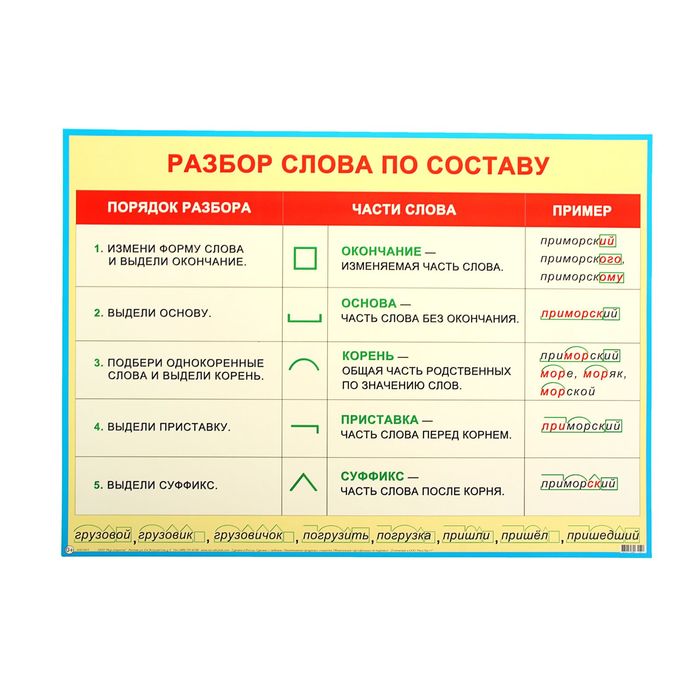 Пример последовательности решений слева направо, которая приводит к простому синтаксическому анализу, показан ниже для предложения Я забронировал билет в Google .
Пример последовательности решений слева направо, которая приводит к простому синтаксическому анализу, показан ниже для предложения Я забронировал билет в Google .
Итак, насколько точен Parsey McParseface?
На стандартном тесте, состоящем из случайно выбранных предложений английской новостной ленты (20-летний Penn Treebank), Parsey McParseface восстанавливает индивидуальные зависимости между словами с более чем 9Точность 4%, что превосходит наши собственные предыдущие современные результаты, которые уже были лучше, чем любой предыдущий подход. Хотя в литературе нет явных исследований о человеческой деятельности, мы знаем из наших собственных проектов аннотации, что лингвисты, обученные этой задаче, соглашаются в 96-97% случаев. Это говорит о том, что мы приближаемся к человеческим возможностям, но только на правильно сформированном тексте. Предложения, взятые из Интернета, намного сложнее анализировать, как мы узнали из Google WebTreebank (выпущенного в 2011 году). Parsey McParseface набрал чуть более 9 баллов0% точности синтаксического анализа в этом наборе данных.
Хотя в литературе нет явных исследований о человеческой деятельности, мы знаем из наших собственных проектов аннотации, что лингвисты, обученные этой задаче, соглашаются в 96-97% случаев. Это говорит о том, что мы приближаемся к человеческим возможностям, но только на правильно сформированном тексте. Предложения, взятые из Интернета, намного сложнее анализировать, как мы узнали из Google WebTreebank (выпущенного в 2011 году). Parsey McParseface набрал чуть более 9 баллов0% точности синтаксического анализа в этом наборе данных.
Хотя точность не идеальна, она, безусловно, достаточно высока, чтобы быть полезной во многих приложениях. Основным источником ошибок на этом этапе являются такие примеры, как описанная выше двусмысленность прикрепления предложной фразы, которая требует знания реального мира (например, что улица вряд ли находится в автомобиле) и глубоких контекстуальных рассуждений. Машинное обучение (и, в частности, нейронные сети) добились значительного прогресса в разрешении этих неоднозначностей.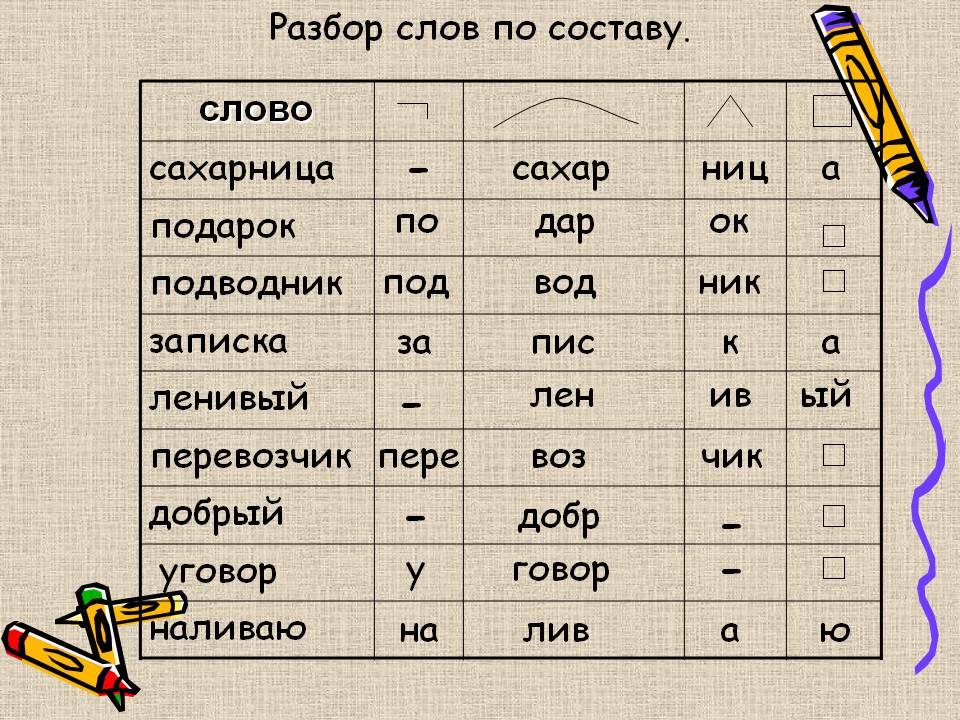 Но наша работа все еще ограничена: мы хотели бы разработать методы, которые могут познать мир и обеспечить одинаковое понимание естественного языка в 9 странах мира.0003 все языка и контекста.
Но наша работа все еще ограничена: мы хотели бы разработать методы, которые могут познать мир и обеспечить одинаковое понимание естественного языка в 9 странах мира.0003 все языка и контекста.
Для начала просмотрите код SyntaxNet и загрузите модель парсера Parsey McParseface. Удачного разбора от главных разработчиков, Криса Альберти, Дэвида Вайса, Даниэля Андора, Майкла Коллинза и Слава Петрова.
Анализ зависимостей для малоресурсного языка (тагальский)
D Анализ зависимостей является одним из самых важные задачи в обработке естественного языка. Это позволяет нам формально понять структуру и смысл предложения, основанные на отношениях его слова. В этом блоге я расскажу о том, как мы можем обучать и оценивать синтаксический анализатор малоресурсного языка, такого как тагальский, мой родной язык.
Разбор предложения требует от нас идентификации его главного и зависимых .
голова обычно самое важное слово, в то время как зависимые существуют только для того, чтобы
изменить его. Возьмем это предложение, «Эта девушка — моя сестра», например:
Возьмем это предложение, «Эта девушка — моя сестра», например:
- Каждая стрелка представляет зависимости между словами и то, как они связаны,
т. е. X является $RELATION Y (например,
detдля определителя,possдля притяжательного,nsubjдля именной темы). - Самое важное слово в этом предложении
девочка. Все остальные слова по желанию; они существуют только для того, чтобы модифицировать это существенное слово. я могу оставить другие биты и просто скажите «Эта девушка», и это все равно будет относиться к тот же предмет.
Вы можете многое сделать с этой информацией. Например, вы можете использовать
дерево зависимостей, чтобы намекнуть на модель распознавания именованных объектов (NER), где существительное
фразы есть. В анализе настроений вы можете использовать голову и ее модификаторы для
получить хорошее представление об общей полярности текста. В поиске можно использовать разобранный
дерево для улучшения ранжирования результатов. Вы всегда можете увидеть парсер зависимостей
как часть конвейера НЛП или как основной компонент приложения НЛП.
Вы всегда можете увидеть парсер зависимостей
как часть конвейера НЛП или как основной компонент приложения НЛП.
На банках деревьев и языках с низким уровнем ресурсов
Какими бы крутыми они ни были, обучение парсера зависимостей требует много аннотированные данные. Обычно они имеют форму деревьев, и один из их самые большие запасы — универсальные зависимости (УД) проект. Однако не все языки имеют одинаковое количество размеченной информации. Языки с низким ресурсом (LRL) часто получают более короткий конец палки с точки зрения доступности данных и объем.
Для тагальского языка у вас есть только два варианта выбора деревьев:
ТРГ 1 (Шахтнер и Отанес, 1983 г., и Самсон С., 2020 г.) и
Угнаян
(Акино и де Леон, 2020 г.). Первый содержит 128
предложения и 734 токена, а последний имеет 94 предложения и 1011 токенов.
Это не так уж и много, особенно если сравнить их с некоторыми английскими деревьями, такими как
Атис
или ESL, с
почти в 50 раз больше токенов, чем у нас. 2
2
| Берега деревьев | предложений | Жетоны | Источник | Информация на этикетке |
|---|---|---|---|---|
| ТРГ | 128 | 734 | Тагальский справочник по грамматике | Леммы, УПОС, Особенности, Отношения |
| Угнаян | 94 | 1011 | Портал учебных ресурсов DepEd | Леммы, УПОС, Отношения |
Тогда возникает вопрос: как мы можем надежно обучить и оценить модель из малоресурсного языка?
- Для обучения вроде бы можно обучить парсер и получить приличный
точность примерно со 100 предложениями (Nivre, et al, 2017), поэтому мы будем придерживаться деревьев, которые
у нас есть. Мы будем использовать конфигурацию обучения spaCy по умолчанию, которую вы можете найти
в этом
репозиторий.

- Для оценки мы будем выполнять как одноязычные, так и многоязычные проверки для наши данные. Первый влечет за собой простую 10-кратную перекрестную проверку. для нашей модели (согласно рекомендациям руководства UD), в то время как последняя включает в себя псевдо-переносной подход к обучению, при котором мы обучаем синтаксический анализатор на более крупном языковая модель с тагальским банком деревьев в качестве нашего тестового набора.

Моя общая цель — продемонстрировать, что можно создать достойный тагальский язык. парсер зависимостей с объемом данных, которые у нас были, и выделить пробелы которые мешают нам достичь того же уровня плотности информации, что и другие языки.
Обучение синтаксического анализатора зависимостей с использованием spaCy
Банк дерева универсальных зависимостей (UD) имеет определенный формат. Для каждого предложения обычно вы найдете что-то вроде этого:
# sent_id = schachter-otanes-60-0 # текст = Гумирование анг Бата.
 # text_en = Ребенок проснулся.
1 Gumising gising ГЛАГОЛ _ Аспект=Исполнение|Настроение=Индия|Голос=Действие 0 корень _ Блеск=пробуждённый
2 ang ADP _ Case=Nom 3 case _ Gloss=the
3 bata bata СУЩЕСТВИТЕЛЬНОЕ _ _ 1 nsubj _ Gloss=child|SpaceAfter=No
4 . . ПУНКТ _ _ 1 точка _ _
# text_en = Ребенок проснулся.
1 Gumising gising ГЛАГОЛ _ Аспект=Исполнение|Настроение=Индия|Голос=Действие 0 корень _ Блеск=пробуждённый
2 ang ADP _ Case=Nom 3 case _ Gloss=the
3 bata bata СУЩЕСТВИТЕЛЬНОЕ _ _ 1 nsubj _ Gloss=child|SpaceAfter=No
4 . . ПУНКТ _ _ 1 точка _ _
- В первых нескольких строках вы получите некоторые метаданные, такие как уникальный идентификатор предложения, полный текст и его английский перевод.
- Для пронумерованных строк вы увидите лингвистические аннотации для каждого токена (например, «гумизинг», «анг» и др.). Для каждого токена вам обычно предоставляется его лемматизация (базовая форма), часть речи (POS) тег, лексический Особенности, и другие морфологические Информация.
Эти аннотации упакованы в файл .conllu файл
формат, который вы можете открыть, используя
любой текстовый редактор. С помощью spaCy мы можем легко разобрать это на
объект Python, которым можно управлять программно:
python -m spacy convert path/to/annotations.
 conllu path/to/save/ \
--converter conllu
--n-отправляет 1
--merge-подтокены
conllu path/to/save/ \
--converter conllu
--n-отправляет 1
--merge-подтокены
Вы могли заметить, что для аннотаций на тагальском языке у нас есть только тестовый набор,
то есть файлы были названы как tl_trg-ud-test и tl_ugnayan-ud-test . Этот
рекомендуется
разделить на
проекта универсальных зависимостей и является распространенным сценарием для
языки.
«Если у вас меньше 20 тысяч слов. Вариант A: оставить все как тестовые данные. Пользователям придется пройти 10-кратную перекрестную проверку, если они захотят на ней тренироваться». (UD: выпуск данных Контрольный список)
Существует множество фреймворков для обучения, 3 , но для этого мы будем использовать spaCy. работа. Мы будем использовать конфиг и проект система, потому что я лично считаю, что это удобно и легко. Вы можете найти полную проект в этом Github репозиторий.
spaCy имеет продуманный конвейер для обучения парсера зависимостей, и большая часть
он зависит от модели токена-вектора (Tok2Vec)
состоит из встраивания и сети CNN. Теггер, морфологизатор и синтаксический анализатор
все слушают эту модель Tok2Vec. Возможна замена этой модели Tok2Vec
с трансформатором на основе Transformer, но для целей этого блога мы будем использовать
вариант по умолчанию. Если вы хотите узнать больше об этом шаблоне слушателя, я
настоятельно рекомендую посмотреть на разработчика
документы
Теггер, морфологизатор и синтаксический анализатор
все слушают эту модель Tok2Vec. Возможна замена этой модели Tok2Vec
с трансформатором на основе Transformer, но для целей этого блога мы будем использовать
вариант по умолчанию. Если вы хотите узнать больше об этом шаблоне слушателя, я
настоятельно рекомендую посмотреть на разработчика
документы
Рисунок : Проект трубопровода spaCy (Источник: веб-сайт spaCy)
Если вы используете этот spaCy
проект, то вы можете обучать
парсер, запустив spacy project run [имя] до команды train .
Это обучает два парсера зависимостей для каждого банка деревьев. Вы даже можете увидеть полностью
тренировочная конфигурация в этом
файл.
Наконец, вы должны увидеть обученные модели в /training/${treebank}/model-best каталог. Вы можете получить доступ к этому аналогично тому, как вы получаете доступ к другим моделям spaCy:
импортировать пространство nlp = spacy.load («обучение/UD_Tagalog-TRG/модель-лучшая») text = "Накакаин ка на ба?" # ТН: Ты поел? документ = нлп (текст)
Отсюда мы можем использовать displaCy для визуализировать зависимости для данного текста:
от spacy import displacy displacy.
 render(doc,) # https://localhost:5000
render(doc,) # https://localhost:5000
(перевод) Ты поел?
Давайте попробуем это на других предложениях вне тренировочного набора):
(перевод) : Вам больше не нужно меня спрашивать.
Проверено! И обратите внимание, что мы используем небольшое количество предложений. (почти сотня) для обучения этого парсера. Конечно, мы не в стране конфет, и есть несколько предложений, где наш синтаксический анализатор работает плохо:
(перевод) : Посмотри мне в глаза, разве ты не видишь?
В этом примере такие слова, как мата (глаз/глаза) и aking (мой) были неправильно помечен. Первое должно быть существительным, а второе должно быть местоимением. Но довольно интересно, что помимо этих двух слов, наш парсер уже достаточно прилично.
Конечно, нам нужен лучший способ оценить эту модель, а не пробовать
случайные фразы. 4 В следующем разделе мы будем использовать как одноязычные, так и
межъязыковая оценка для наших двух моделей. Это должно дать нам понимание не
только наших моделей, но и наших деревьев.
Это должно дать нам понимание не
только наших моделей, но и наших деревьев.
Одноязычная и межъязыковая оценка
Для оценки наших деревьев мы проведем как одноязычную, так и межъязыковую оценку:
- Одноязычная оценка : мы проведем 10-кратную перекрестную проверку для нашей модели. затем сообщите среднее значение по всем показателям. Ради интереса я также собираюсь проверить, насколько хорошо модель, обученная на другом дереве, работает на другом (и наоборот).
- Межъязыковая оценка : с помощью определенного показателя мы определяем пять (5) языков которые типологически похожи на тагальский и имеют большие берега деревьев. Мы будем обучать модель для каждого чужого банка деревьев и использовать TRG и Ugnayan в качестве тестовых наборов.
Что касается наших метрик, мы будем измерять следующее:
-
TOKEN_ACC: точность токенизатора, т. е. насколько хорошо он может определить правильные токены данного текста. -
POS_ACC: точность атрибутов токена. -
MORPH_ACC: общая точность нашего морфологизатора на основе формата Universal Dependencies FEATS. -
DEP_UAS / DEP_LAS: точность парсера зависимостей. Бывший оценка немаркированного вложения, в то время как последнее называется помеченным вложением оценка (Нивре и Фанг, 2017).

Стоит измерять другие атрибуты нашей модели, даже если нас интересует только с разбором зависимостей. Я не особо заморачивался с NER, потому что у меня есть подозреваю, что он не будет работать хорошо, учитывая размер наших данных.
Одноязычная оценка
Я выполнил 10-кратную перекрестную проверку для наборов данных TRG и Ugnayan. я также было любопытно, как каждая модель будет работать с другим набором данных, поэтому я обучил модель для одного и использовал другой в качестве тестового набора.
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| Угнаян | 0,998 | 0,819 | 0,995 | 0,810 | 0,667 | 0,409 |
| ТРГ | 1. 000 000 | 0,843 | 0,749 | 0,833 | 0,846 | 0,554 |
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| ТРГ на Угнаян | 0,997 | 0,563 | 0,364 | 0,538 | 0,472 | 0,240 |
| Угнаян на TRG | 1.000 | 0,789 | 0,424 | 0,779 | 0,793 | 0,572 |
TRG как банк деревьев хорошо работает по большинству показателей по сравнению с Ugnayan. Однако,
интересно, что с последним можно обучить довольно приличную модель. Ты
можете изучить эти модели, используя демонстрацию ниже.
Однако,
интересно, что с последним можно обучить довольно приличную модель. Ты
можете изучить эти модели, используя демонстрацию ниже.
Межъязыковая оценка
Для межъязыковой оценки я обучил модель на другом языке и использовали наши тагальские деревья в качестве тестового набора. Мои критерии выбора этих языки следующие: они должны быть (1) ближе к тагальскому и (2) должен иметь приличный объем данных (не малоресурсный).
В первом случае я использовал метрику расстояния, чтобы идентифицировать языки, которые типологически похож на тагальский (Agić, 2017). 5 В этом случае, это индонезийский (id), вьетнамский (vi), румынский (ro), украинский (uk), и каталонский (ок.).
Затем я зашел в их репозитории UD и проверил, есть ли в них существующие
обучающие и оценочные наборы данных. К счастью, у всех так, поэтому я пошел дальше.
и обучили модель анализировать наши тагальские деревья. Результаты
интересно: точность токенов хорошая, но точность тегера и парсера оставляет желать лучшего. много лучшего.
много лучшего.
TRG Treebank
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| ID-GSD | 1.000 | 0,374 | 0,320 | 0,000 | 0,342 | 0,151 |
| ви-втб | 1.000 | 0,306 | 0,423 | 0,000 | 0,309 | 0,143 |
| ро-ррт | 0,999 | 0,392 | 0,198 | 0,000 | 0,304 | 0,098 |
| Великобритания-Ю | 1.000 | 0,185 | 0,177 | 0,000 | 0,539 | 0,188 |
| ка-анкора | 0,999 | 0,284 | 0,057 | 0,015 | 0,261 | 0,081 |
Угнаян Трибанк
| TOKEN_ACC | POS_ACC | МОРФ_АКК | ТАГ_АКК | DEP_UAS | DEP_LAS | |
|---|---|---|---|---|---|---|
| ID-GSD | 0,997 | 0,310 | 0,803 | 0,000 | 0,251 | 0,058 |
| ви-втб | 0,997 | 0,256 | 0,986 | 0,000 | 0,199 | 0,049 |
| ро-ррт | 0,992 | 0,332 | 0,275 | 0,000 | 0,279 | 0,085 |
| Великобритания-Ю | 0,998 | 0,151 | 0,123 | 0,000 | 0,300 | 0,084 |
| ка-анкора | 0,994 | 0,267 | 0,301 | 0,025 | 0,242 | 0,041 |
Что удивительно, так это то, как индонезийские и вьетнамские морфологизаторы
хорошо выступил в Угаяне. Возможно, это связано с их принадлежностью к одному
Австронезийская языковая семья как тагальский? Вы можете исследовать эти модели, используя
демо ниже.
Возможно, это связано с их принадлежностью к одному
Австронезийская языковая семья как тагальский? Вы можете исследовать эти модели, используя
демо ниже.
Демонстрация Streamlit
Вот веб-демонстрация парсера зависимостей и тега POS для всех тагальских и зарубежные модели. Вы можете ввести любое предложение на тагальском, и это даст вам проанализированная информация в удобном именно.
Обратите внимание, что иногда при выборе параметра «Свернуть фразы» возникает ошибка. в языке нет реализации блока существительных. Это так ожидаемо игнорировать это пока. Конечно, вы также можете улучшить языковую поддержку spaCy. внедряя чанкеры существительных в те языки.
Заключение
В этом сообщении мы рассмотрели, как обучить и оценить анализатор зависимостей. для малоресурсного языка, такого как тагальский. Мы также узнали, что:
- Парсеры зависимостей позволяют нам понять структуру и значение
предложения через связь их слов. Эти отношения затем могут
использоваться для нескольких последующих задач обработки естественного языка.
- Можно использовать банк деревьев для обучения парсера зависимостей. Универсальные зависимости (UD) служит хорошим хранилищем для таких. spaCy, это проще и удобнее для анализа и обучения на основе этих наборов данных.
- Языки с низким уровнем ресурсов слишком малы, чтобы в UD они делегировались только как «тестовый набор». Тем не менее, мы все еще можем оценить парсеры из этих деревьев с помощью k-кратной перекрестной проверки или путем сравнения с более крупными зарубежными модели.

Работая над этим проектом, я понял, сколько работы еще предстоит улучшить
лингвистический анализ тагальского языка. Конечно, проще всего сказать, что «мы
нужно больше данных», но аннотирование и маркировка деревьев требует
домен-экспертиза. 6 Если вы использовали spaCy, вам также может понадобиться
Напишите блокировщик существительных, который извлекает базовые словосочетания из парсера. Истинный
достаточно, большая часть этого усилия включает песчаную работу.
Наконец, вы можете рассматривать этот пост в блоге как репродукцию статьи «Анализ в отсутствие родственных языков: оценка малоресурсных парсеров зависимостей на Тагальский» (Акино и де Леон, 2020). Здесь они использовали строфа и UDPipe, но я хочу чтобы проверить, как это работает с spaCy. Это связанные документы график также был полезен в качестве отправной точки для дальнейшего чтения.
Если вам интересно посмотреть код и наборы данных, используемые в этом проекте, тогда не стесняйтесь зайти на Github репозиторий.
Ссылки
- Желько, А. Выбор межъязыкового парсера для Языки с низким ресурсом. В: Материалы семинара NoDaLiDa 2017 по Универсальные зависимости , стр. 1-10, Гетеборг, Швеция, Ассоциация Компьютерная лингвистика.
- Акино, А. и де Леон, Ф. Разбор в
отсутствие связанных языков: оценка парсеров зависимостей с низким уровнем ресурсов на
тагальский. В Материалы четвертого семинара по универсальным зависимостям
(UDW 2020) , стр. 8-15, ACL.
- Драйер, М. и Хаспелмат, М. Атлас мира Языковые структуры онлайн . Институт эволюционной антропологии Макса Планка, Лейпциг.
- Луи, М. и Болдуин, T.langid.py: готовый Инструмент определения языка. В: Труды системы ACL 2012. Демонстрации , страницы 25-30, остров Чеджу, Корея. Ассоциация для Компьютерная лингвистика.
- Нивр, Дж., Земан, Д., Гинтер Ф., Тайерс, Ф. Учебное пособие об универсальных зависимостях: добавление нового языка в UD. Представлено на 15-й конференции Европейского отделения Ассоциации компьютерной лингвистики , 2017.
- Нивр, Дж. и Фанг С-Т. Универсальная зависимость Оценка. В: Материалы семинара NoDaLiDa 2017 по универсальному Зависимости , страницы 86-95, Гетеборг, Швеция. Ассоциация вычислительных Лингвистика
- Schachter, P. and Otanes, F.Tagalog Ссылка Грамматика. Калифорнийский университет Press , 1983.
 8-15, ACL.
8-15, ACL.Сноски
Этот банк деревьев получил свое название от Tagalog Reference Grammar (TRG) автора Шахтер и Отанес.
Большая часть текстов в дереве TRG была удалена.
из этого источника. ↩И мы говорим только о древовидных банках универсальных зависимостей для английского языка. В инвентаре Linguistic Data Consortium у вас есть Penn treebank и OntoNotes с почти более миллиона слов каждый! ↩
Другие наборы инструментов для разбора зависимостей включают UDPipe (который в моем исследовании доступен только для R), и Стэнфорд Станца
деппарструбопровод. ↩Помимо первого предложения, последние два были текстами песен группы. называется Головки-ластики . первый взят из песни Huwag mo nang Itanong , а второй прибыл из Алапаап . Я определенно испортил перевод, так что прошу прощения за что! ↩
Он основан на инструменте идентификации языка (LangID) Луи и Болдуина.
(2012 г.) в сочетании с некоторыми функциями Атласа мира.
языковых структур (WALS) (Dryer and Haspelmath, 2013). ↩Не говоря уже о том, что эти источники данных должны быть коммерчески выгодными. лицензии: вы хотели бы избежать текстов с авторскими правами и т. д. ↩
 Большая часть текстов в дереве TRG была удалена.
из этого источника. ↩
Большая часть текстов в дереве TRG была удалена.
из этого источника. ↩ (2012 г.) в сочетании с некоторыми функциями Атласа мира.
языковых структур (WALS) (Dryer and Haspelmath, 2013). ↩
(2012 г.) в сочетании с некоторыми функциями Атласа мира.
языковых структур (WALS) (Dryer and Haspelmath, 2013). ↩REGEX для разбора слов и положительного/отрицательного количества…
core.noscript.text
Этикетки
- ААХ
1 - ААХ Добро пожаловать
2 - Академия
21 - АДАПТ
87 - Добавить столбец
1 - Добавить новый столбец
1 - Настройки администратора
1 - Администрация
34 - Adobe
162 - Расширенная аналитика
1 - Появление кода
5 - Псевдоним Менеджер
96 - Альтерикс
1 - Альтерикс 2020. 1
4 - Альтерикс Академия
3 - Альтерикс Аналитика
1 - Центр аналитики Alteryx
2 - Введение в сообщество Alteryx — студент MSA в CSUF
1 - Альтерикс Коннект
1 - Альтерикс Дизайнер
79 - Альтерикс Двигатель
1 - Галерея Альтерикс
1 - Концентратор Альтерикс
1 - альтерикс с открытым исходным кодом
1 - Alteryx Post ответ
1 - Альтерикс Практика
129 - Alteryx SDK API
1 - Команда Альтерикс
1 - Инструменты Alteryx
1 - АльтериксФорГуд
1 - Амазонка s3
183 - Двигатель AMP
96 - АНАЛИТИКА ИННОВАЦИЙ
1 - Поддержка аналитических приложений
1 - Аналитические приложения
18 - Аналитические приложения ACT
1 - Аналитика
2 - Анализатор
19 - Объявление
4 - API
1204 - Приложение
2 - Добавить поля
1 - Приложения
1386 - Процесс архивации
1 - АРИМА
1 - Присвоение метаданных CSV
1 - Аутентификация
4 - Автоматическое обновление
1 - банковское дело
1 - Кодировка Base64
1 - Базовая отчетность по таблицам
1 - Пакетный макрос
1288 - Новичок
1 - Анализ поведения
237 - Лучшие практики
2556 - BI + аналитика + наука о данных
1 - Книжный червь
2 - Ошибка
631 - Ошибки и проблемы
1 - Расчет рабочих дней
1 - Калгари
90 - КАСС
70 - Человек-кошка
1 - Категория Приложения
1 - Категория Соединители
1 - Категория Документация
1 - Категория Вход Выход
2 - Категория Predictive
1 - Категория Пространственная
1 - Категория Временной ряд
3 - Преобразование категории
1 - Сертификация
4 - Связанное приложение
252 - Вызов
17 - Диаграмма
1 - Клиенты
5 - Кластеризация
1 - Распространенные варианты использования
3445 - Связь
1 - Сообщество
263 - Объединить
1 - Условный столбец
1 - Условный оператор
1 - СОЕДИНИТЕ И РЕШИТЕ
1 - Соединители
1292 - Содержит
1 - Содержание
1 - Управление контентом
8 - Конкурс
6 - Начало разговора
22 - копия
1 - COVID-19
4 - Создайте новую электронную таблицу, используя существующий набор данных
. 1 - Управление учетными данными
3 - Любопытный*Маленький
1 - Функция пользовательской формулы
1 - Пользовательские инструменты
1400 - Создание приборной панели
1 - Анализ данных
1 - Анализ данных
2 - Аналитика данных
1 - Вызов данных
103 - Очистка данных
5 - Соединение данных
1 - Исследование данных
2682 - Загрузка данных
1 - Наука о данных
31 - Подключение к базе данных
2356 - Подключения к базе данных
6 - Наборы данных
4078 - Дата
2 - Дата и время
3 - формат даты
1 - Выбор даты
2 - Дата Время
2707 - Формат даты
1 - даты
1 - дата и время разбор
2 - Дефект
10 - Демографический анализ
197 - Дизайнер
1 - Дизайнерское облако
121 - Интеграция дизайнера
109 - Разработчик
3154 - Инструменты разработчика
2661 - Обсуждение
2 - Документация
471 - Человек-собака
3 - Скачать
1086 - Дублирует ряды
1 - Дублирование строк
1 - Динамический
1 - Динамический ввод
1 - Динамическое имя
1 - Динамическая обработка
2643 - динамическая замена
1 - динамически создавать таблицы для входных файлов
1 - Электронная почта
716 - Уведомление по электронной почте
1 - Инструмент электронной почты
2 - Встроить
1 - встроенный
1 - Двигатель
88 - Улучшение
4 - Улучшения
2 - Сообщение об ошибке
2260 - Сообщения об ошибках
6 - ЭТС
1 - События
205 - Эксель
1 - Excel динамически объединяет
1 - Макрос Excel
1 - Пользователи Excel
1 - Исследователь
5 - Выражение
1606 - извлечь данные
1 - Запрос функции
4 - Фильтр
1 - фильтр присоединиться
1 - Финансовые услуги
1 - гурман
4 - Формула
2 - формула или фильтр
1 - Инструмент формулы
4 - Формулы
2 - удовольствие
5 - Нечеткое совпадение
710 - Нечеткое соответствие
1 - Галерея
573 - Генерал
176 - Общее предложение
4 - Создание формул строк и многострочных формул
1 - Создать строки
1 - Начало работы
1 - Google Аналитика
182 - группировка
1 - Руководство
16 - Всем привет !
2 - Справка
3651 - Как раскрасить поля в строке на основе значения в другом столбце
1 - Как сделать
1 - Hub20. 4
2 - Я новичок в Альтерикс.
1 - идентификатор
1 - В базе данных
1122 - В базе данных
1 - Введите
3998 - Входные данные
2 - Вход Выход
3 - Вставка новых строк
1 - Установить
4 - Установка
407 - Интерфейс
3 - Инструменты интерфейса
1670 - Введение
7 - Итеративный макрос
980 - Соединитель Jira
1 - Присоединяйтесь к
1772 - база знаний
1 - Лицензии
1 - Лицензирование
246 - Список бегунов
1 - Погрузчики
20 - Загрузчики SDK
3 - Оптимизатор местоположения
79 - Поиск
1 - Машинное обучение
171 - Макрос
2 - Макросы
2767 - Картирование
1 - Маркето
25 - соответствие
1 - Слияние
1 - МонгоДБ
83 - Создание нескольких переменных
1 - MultiRowFormula
1 - Нужна помощь
1 - нужна помощь: как найти определенную строку во всех столбцах excel и вернуть этот clmn
1 - Нужна помощь по формуле Tool
1 - сеть
1 - Эквивалент функции NetworkDays
1 - Новый инструмент
1 - Новости
1 - Не твое дело
1 - Не по теме
15 - Управление финансов
1 - Нефть и газ
1 - Оптимизация
700 - Открытый энтузиаст
1 - Выход
4633 - Выходные данные
1 - пакет
1 - Разобрать
2021 - Сопоставление шаблонов
1 - Люди Человек
5 - процентили
1 - PowerBI
195 - практические упражнения
1 - Предиктивный
2 - Прогнозный анализ
1263 - Прогнозная аналитика
1 - Подготовка
5009 - Предписывающая аналитика
235 - Опубликовать
280 - Питон
652 - Qlik
57 - квартили
1 - Вопрос
15 - Вопросы
2 - Квадратные значения R
1 - Инструмент R
681 - RE GEX конвертировать
1 - проблема с обновлением
1 - Регулярное выражение
1908 - Удалить столбец
1 - Отчетность
2055 - Ресурс
16 - RestAPI
1 - Управление ролями
3 - Выполнить команду
564 - Запуск рабочих процессов
12 - Время выполнения
1 - Продажи
301 - Расписание
1 - Расписание рабочих процессов
3 - Планировщик
448 - Ученый
3 - Поиск
3 - Поиск отзывов
16 - Сервер
463 - Настройки
914 - Установка и конфигурация
93 - SFTP
1 - Sharepoint
440 - Делюсь
2 - Умный лист
1 - Снежинка
1 - Пространственный
1 - Пространственный анализ
784 - студент
9 - Проблема со стилем
1 - Итого
1 - Системное администрирование
2 - Таблица
549 - Таблицы
1 - Технология
1 - Интеллектуальный анализ текста
299 - Миниатюра
1 - Четверг Мысль
11 - Временной ряд
442 - Прогнозирование временных рядов
1 - Советы и хитрости
3805 - Улучшение инструмента
9 - Инструменты
1 - Интересующая тема
44 - Трансформация
2954 - Транспонировать
1 - Твиттер
50 - Удасити
139 - Уникальный
2 - Не уверен на подходе
1 - Обновления
3 - Обновления
1 - URL-адрес
1 - Варианты использования
1 - Дизайн взаимодействия с пользователем
2 - Пользовательский интерфейс
47 - Управление пользователями
5 - Видео
2 - ВидеоID
1 - ВПР
1 - Еженедельное испытание
1 - Распределение Вейбулла Weibull.
 1
1  1
1 4
4 