Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: м е о р е б т сейчас тихорецк 1 секунда назад угадай слова афвгваа 1 секунда назад к с и о к м к 1 секунда назад минтулаз 1 секунда назад рикноаа 1 секунда назад о р к е с т р 1 секунда назад масло 1 секунда назад д ласк 1 секунда назад т е р а к т 2 секунды назад банятис 2 секунды назад м у к а ш 2 секунды назад закуска 2 секунды назад возница 2 секунды назад нссук 2 секунды назад
Морфологический разбор слова «настольный»
Часть речи: Прилагательное
НАСТОЛЬНЫЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАСТОЛЬНЫЙ»
| Слово | Морфологические признаки |
|---|---|
| НАСТОЛЬНЫЙ |
|
| НАСТОЛЬНЫЙ |
|
Все формы слова НАСТОЛЬНЫЙ
НАСТОЛЬНЫЙ, НАСТОЛЬНОГО, НАСТОЛЬНОМУ, НАСТОЛЬНЫМ, НАСТОЛЬНОМ, НАСТОЛЬНАЯ, НАСТОЛЬНОЙ, НАСТОЛЬНУЮ, НАСТОЛЬНОЮ, НАСТОЛЬНОЕ, НАСТОЛЬНЫЕ, НАСТОЛЬНЫХ, НАСТОЛЬНЫМИ, НАСТОЛЕН, НАСТОЛЬНА, НАСТОЛЬНО, НАСТОЛЬНЫ, НАСТОЛЬНЕЕ, НАСТОЛЬНЕЙ, ПОНАСТОЛЬНЕЕ, ПОНАСТОЛЬНЕЙ
Разбор слова по составу настольный
настольн
ый| Основа слова | настольн |
|---|---|
| Приставка | на |
| Корень | столь |
| Суффикс | н |
| Окончание | ый |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАСТОЛЬНЫЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «настольный»
1
Всё остальное время мальчишки играли в настоящий настольный теннис и ненастоящий (настольный же) футбол.
Куток, или Хроники лядовской автостанции, Игорь Леонидович Волков, 2007г.2
Настольный календарь, настольные часы, барометр, термометр – все это настолько загружало стол, что пользоваться им для работы было бы невозможно.
Вечное возвращение. Книга 1: Повести, Сборник, 2016г.3
Иванов перелистал настольный календарь.
Водители, Анатолий Рыбаков, 1949–1950г.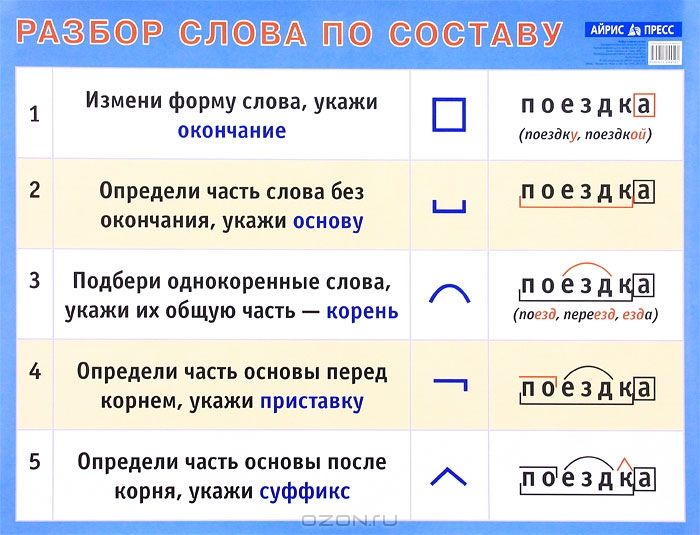
4
Она достала из сумочки дамские сигареты, закурив, бросила взгляд на настольный ежедневник.
Моряк, которого разлюбило море, Юкио Мисима, 1963г.5
Катцер посмотрел в настольный календарь, где отмечал время деловых встреч.
Две недели в другом городе. Вечер в Византии, Ирвин Шоу, 1960, 1973г.Все еще анализирует строки User-Agent для ваших моделей машинного обучения? | by Sergey Mastitsky
Опубликовано в·
Чтение: 9 мин.·
26 октября 2020 г. Photo by Emile Perron on UnsplashИнформация, содержащаяся в строке User-Agent s могут быть эффективно представлены с использованием низкоразмерных вложений, а затем используется в последующих задачах машинного обучения.

Когда пользователь взаимодействует с веб-сайтом, браузер отправляет HTTP-запросы на сервер для получения необходимого контента, отправки данных или выполнения других действий. Такие запросы обычно содержат несколько заголовков, т. е. пар символов «ключ-значение», которые определяют параметры данного запроса. Строка User-Agent (далее именуемая «UAS») — это заголовок HTTP-запроса, описывающий программное обеспечение, действующее от имени пользователя (рис. 1).
Рисунок 1. Браузер выступает в роли агента пользователя при отправке запросов на сервер. Строка User-Agent описывает свойства браузера. Первоначальной целью UAS было согласование контента , то есть механизм определения наилучшего контента для обслуживания пользователя в зависимости от информации, содержащейся в соответствующем UAS (например, формат изображения, язык документа, кодировка текста и т. д.). .). Эта информация обычно включает сведения о среде, в которой работает браузер (устройство, операционная система и ее версия, языковой стандарт), механизме и версии браузера, механизме и версии макета и т. д. (рис. 2).
д. (рис. 2).
Несмотря на то, что обслуживание разных веб-страниц для разных браузеров в настоящее время считается плохой идеей, у UAS все еще есть много практических приложений. Самый распространенный из них — веб-аналитика , т. е. составление отчетов о составе трафика для оптимизации эффективности веб-сайта. Другим вариантом использования является управление веб-трафиком , которое включает в себя блокировку нежелательных поисковых роботов, снижение нагрузки на веб-сайт от нежелательных посетителей, предотвращение мошенничества с кликами и другие подобные задачи. Благодаря богатой информации, которую они содержат, UAS также может служить источником данных для Приложения машинного обучения . Однако последнему варианту использования до сих пор не уделялось должного внимания. Здесь я рассматриваю эту проблему и обсуждаю эффективный способ создания информативных функций из моделей UAS для машинного обучения. Эта статья представляет собой краткое изложение доклада, который я недавно представил на двух конференциях — Почему R? и Корпоративные приложения языка R . Данные и код, используемые в примерах, описанных ниже, доступны на GitHub.
Эта статья представляет собой краткое изложение доклада, который я недавно представил на двух конференциях — Почему R? и Корпоративные приложения языка R . Данные и код, используемые в примерах, описанных ниже, доступны на GitHub.
Элементы UAS часто могут служить полезными заменителями характеристик пользователя, таких как образ жизни, техническая подкованность и даже достаток. Например, пользователь, который обычно посещает веб-сайт с мобильного устройства высокого класса, вероятно, отличается от пользователя, посещающего тот же веб-сайт из Internet Explorer на настольном компьютере под управлением Windows XP. Наличие прокси-серверов на основе UAS для таких характеристик может быть особенно ценным, когда для пользователя недоступна другая демографическая информация (например, когда новый, неизвестный человек посещает веб-сайт).
В некоторых приложениях также может быть полезно различать человеческий и нечеловеческий веб-трафик. В некоторых случаях это легко сделать, поскольку автоматические поисковые роботы используют упрощенный формат UAS, который включает слово «бот» (например, Googlebot/2. ). . Однако некоторые сканеры не следуют этому соглашению (например, боты Facebook содержат слово  1 (+http://www.google.com/bot.html)
1 (+http://www.google.com/bot.html) facebookexternalhit в своем UAS), и для их идентификации требуется словарь поиска.
Одним, казалось бы, простым способом создания функций машинного обучения из UAS является применение синтаксического анализатора , извлечение отдельных элементов UAS, а затем горячее кодирование этих элементов. Этот подход может хорошо работать в простых случаях, когда только высокоуровневые и легко идентифицируемые элементы UAS нуждаются в преобразовании в функции. Например, относительно легко определить тип аппаратного обеспечения пользовательского агента (мобильное, настольное, серверное и т. д.). Для такого рода разработки функций можно использовать несколько высококачественных парсеров на основе регулярных выражений (например, см. проект «ua-parser» и его реализации для выбора языков).
Однако описанный выше подход быстро становится непрактичным, когда нужно использовать все элементы, составляющие БАС, и извлечь из них максимум информации. Этому есть две основные причины:
Этому есть две основные причины:
- Существующие рекомендации по форматированию заголовков User-Agent никак не соблюдаются, и в реальном мире можно встретить самые разные спецификации UAS. В результате последовательный анализ UAS, как известно, сложен. Более того, каждый день появляются новые устройства и версии операционных систем и браузеров, что превращает обслуживание качественных парсеров в сложнейшую задачу.
- Количество возможных элементов БАС и их комбинаций астрономически велико. Даже если бы их можно было закодировать в горячем режиме, результирующая матрица данных была бы чрезвычайно разреженной и слишком большой, чтобы поместиться в память компьютеров, которые обычно используются учеными данных в наши дни.
Чтобы преодолеть эти проблемы, можно применить метод уменьшения размерности и представить UAS в виде векторов фиксированного размера, минимизируя при этом потерю исходной информации. Эта идея, конечно, не нова, и поскольку UAS — это просто строки текста, этого можно достичь, используя различные методы обработки естественного языка. В своих проектах я часто обнаруживал, что алгоритм fastText, разработанный исследователями из Facebook (Bojanowski et al. 2016), дает особенно полезные решения.
В своих проектах я часто обнаруживал, что алгоритм fastText, разработанный исследователями из Facebook (Bojanowski et al. 2016), дает особенно полезные решения.
Описание алгоритма fastText выходит за рамки этой статьи. Однако, прежде чем мы приступим к примерам, стоит упомянуть некоторые практические преимущества этого метода:
- он не требователен к данным, т. е. хорошо работающую модель можно обучить только на нескольких тысячах примеров;
- хорошо работает с короткими и структурированными документами, такими как UAS;
- , как следует из названия, обучается быстро;
- хорошо справляется с «словами вне словаря», т.е. может генерировать осмысленные векторные представления (эмбеддинги) даже для строк, которые не были замечены во время обучения.
Официальная реализация fastText доступна в виде отдельной библиотеки C++ и оболочки Python. Обе эти библиотеки хорошо документированы и просты в установке и использовании. Широко используемая библиотека Python gensim имеет собственную реализацию алгоритма. Ниже я покажу, как можно также обучать модели fastText в R.
Ниже я покажу, как можно также обучать модели fastText в R.
Существует несколько оболочек R вокруг библиотеки fastText C++ (см.0037 fastTextR ). Однако, пожалуй, самый простой способ обучения и использования моделей fastText в R — это вызов официальных привязок Python через пакет reticulate . Импорт модуля fasttext Python в среду R можно выполнить следующим образом:
# Сначала установите `fasttext`
# (см. `package
# (сначала установите, если необходимо):
require(reticulate)# Убедитесь, что `fasttext` доступен для R:
py_module_available("fasttext")
## [1] TRUE# Import `fasttext`:
ft <- import("fasttext")# Затем вызовите необходимые методы, используя
# стандартную нотацию `$`,
# например: `ft$train_supervised()`
Примеры, описанные ниже, основаны на выборке из 200 000 уникальных UAS из базы данных whatismybrowser.com (рис. 3).
Рис. 3. Пример UAS, использованный в примерах в этой статье. Данные хранятся в текстовом файле, где каждая строка содержит один UAS. Обратите внимание, что все UAS были приведены к нижнему регистру, и никакая другая предварительная обработка не применялась.
Данные хранятся в текстовом файле, где каждая строка содержит один UAS. Обратите внимание, что все UAS были приведены к нижнему регистру, и никакая другая предварительная обработка не применялась. Обучить неконтролируемую модель fastText в R так же просто, как вызвать команду, подобную следующей:
lr = 0,05,
dim = 32L, # размерность вектора
ws = 3L,
minCount = 1L,
minn = 2L,
maxn = 6L,
neg = 3L,
wordNgrams = 2L,
потеря = «нс «,
эпоха = 100л,
нить = 10л
)
9Аргумент 0037 dim в приведенной выше команде указывает размерность пространства встраивания. В этом примере мы хотим преобразовать каждый UAS в вектор размера 32. Другие аргументы управляют процессом обучения модели ( lr — скорость обучения, loss, — функция потерь, epoch, — количество эпох и т. д. .). Чтобы понять значение всех аргументов, обратитесь к официальной документации fastText.
После обучения модели легко вычислить вложения для новых случаев (например, из тестового набора). В следующем примере показано, как это сделать (клавиша здесь — 9).0037 m_unsup$get_sentence_vector() , который возвращает вектор, усредненный по вложениям отдельных элементов, составляющих данный UAS):
В следующем примере показано, как это сделать (клавиша здесь — 9).0037 m_unsup$get_sentence_vector() , который возвращает вектор, усредненный по вложениям отдельных элементов, составляющих данный UAS):
test_data <- readLines("./data/test_data_unsup.txt") emb_unsup <- test_data %> %
lapply(., function(x) {
m_unsup$get_sentence_vector(text = x) %>%
t(.) %>% as.data.frame(.)
}) %>%
bind_rows(.) %>%
setNames(., paste0("f", 1:32))
# Распечатка первых 5 значений
# векторов (размером 32)
# которые представляют первые 3 UAS
# из тестового набора: emb_unsup[1:3, 1:5]
## f1 f2 f3 f4 f5
## 1 0.197 -0.03726 0.147 0.153 0.0423
## 2 0.182 0. 00307 0,147 0,101 0,0326
## 3 0,101 -0,28220 0,189 0,202 -0,1623
Но как узнать, хороша ли обученная неконтролируемая модель? Конечно, один из способов проверить это — подключить векторные представления UAS, полученные с помощью этой модели, к последующей задаче машинного обучения и оценить качество полученного решения. Однако, прежде чем переходить к последующей задаче моделирования, можно также визуально оценить, насколько хороши встраивания fastText. Хорошо известные графики tSNE (Maaten & Hinton 2008; см. также это видео на YouTube) могут быть особенно полезными.
Однако, прежде чем переходить к последующей задаче моделирования, можно также визуально оценить, насколько хороши встраивания fastText. Хорошо известные графики tSNE (Maaten & Hinton 2008; см. также это видео на YouTube) могут быть особенно полезными.
На рис. 4 показан трехмерный график tSNE вложений, рассчитанных для UAS из тестового набора с использованием указанной выше модели fastText. Хотя эта модель была обучена без присмотра, она смогла создать вложения, отражающие важные свойства исходных строк User-Agent. Например, можно увидеть хорошее разделение баллов по типу оборудования.
Для обучения контролируемой модели fastText по определению требуются помеченные данные. Именно здесь существующие синтаксические анализаторы UAS часто могут оказать большую помощь, поскольку их можно использовать для быстрой маркировки тысяч обучающих примеров. Алгоритм fastText поддерживает как мультиклассовые, так и мультиметочные классификаторы. Ожидаемый формат (по умолчанию) для меток:
Алгоритм fastText поддерживает как мультиклассовые, так и мультиметочные классификаторы. Ожидаемый формат (по умолчанию) для меток: __label__ . Метки, отформатированные таким образом (и потенциально разделенные пробелом в случае модели с несколькими метками), должны добавляться перед каждым документом в обучающем наборе данных.
Предположим, нас интересуют вложения, которые подчеркивают различия UAS в зависимости от типа оборудования. На рис. 5 показан пример размеченных данных, которые подходят для обучения соответствующей модели.
Рисунок 5. Пример размеченных данных, подходящих для обучения контролируемой модели fastText.Команда R, необходимая для обучения контролируемой модели fastText на таких размеченных данных, аналогична тому, что мы видели ранее:
m_sup <- ft$train_supervised(
input = "./data/train_data_sup.txt",
lr = 0,05,
dim = 32L, # размерность вектора
ws = 3L,
minCount = 1L,
minCountLabel = 10L, # мин.появление метки
minn = 2L,
max n = 6L,
отрицательный = 3L ,
wordNgrams = 2L,
loss = "softmax", # функция потерь
epoch = 100L,
thread = 10L
)
 появление метки
появление метки Мы можем оценить результирующую контролируемую модель, рассчитав точность, отзыв и показатель f1 в маркированном тесте набор. Эти показатели можно рассчитать для всех ярлыков или для отдельных ярлыков. Например, вот показатели качества для БАС, соответствующих метке «мобильный»:
metrics <- m_sup$test_label("./data/test_data_sup.txt")
metrics["__label__mobile"]## $`__label__mobile`
## $`__label__mobile`$precision
## [1] 0.998351 9009 1 # #
## $`__label__mobile`$recall
## [1] 0.9981159
##
## $`__label__mobile`$f1score
## [1] 0.9982334 Визуальная проверка графика tSNE для этой контролируемой модели также подтверждает его высокое качество: мы видим четкое разделение тестов по типу оборудования (рис. 6). Это неудивительно, поскольку при обучении контролируемой модели мы предоставляем вспомогательную информацию, которая помогает алгоритму создавать вложения для конкретных задач.
Эта статья продемонстрировала, что обширная информация, содержащаяся в UAS, может быть эффективно представлена с использованием низкоразмерных вложений. Модели для создания таких вложений можно обучать как в режиме без учителя, так и в режиме с учителем. Неконтролируемые встраивания являются общими и поэтому могут использоваться в любой последующей задаче машинного обучения. Однако, когда это возможно, я бы рекомендовал обучать контролируемую модель для конкретной задачи. Одним особенно полезным алгоритмом для представления UAS в виде векторов фиксированного размера является fastText. Его реализации доступны на всех основных языках, используемых в настоящее время специалистами по данным.
Ищете аналогичный анализ или моделирование ваших данных? Я предоставляю консультационные услуги по науке о данных, поэтому свяжитесь с нами! Сборка
— я получаю сообщение об ошибке MIPS «spim: (parser) синтаксическая ошибка» при выполнении кода
спросил
Изменено 2 года, 2 месяца назад
Просмотрено 837 раз
Вот мой код:
.
 data
num1: .word # переменная num1
num2: .word # переменная num2
max: .word # максимальная переменная
msg: .asciiz "Введите целое число" # msg
msg2: .asciiz "Большее значение равно " # msg2
.текст
основной:
la $a0, msg # печатает msg
ли $v0, 4
системный вызов
la $v0, 5 # читает данные
системный вызов
# загружает адрес num1 в $t0
la $t0, число1
# перемещаем содержимое $v0 в $t0
переместить $t0,$v0
la $a0, msg # напечатать сообщение
ли $v0, 4
системный вызов
la $v0, 5 # прочитать данные
системный вызов
# загружает адрес num1 в $t1
ла $t1, число2
# перемещает содержимое $v0 в $t1
переместить $t1,$v0
# загружает адрес max в t2
la $t2, макс.
# если $t0 (число1) > $t2 (число2), выполнить, если часть/метка
bgt $t0,$t1,if # перейти к метке if
# еще
еще:
# перемещает содержимое $t1 (num2) в $t2 (max)
переместить $t2,$t1
la $a0, msg2 # напечатать msg2
ли $v0, 4
системный вызов
ход $a0, $t2 # вывести макс.
data
num1: .word # переменная num1
num2: .word # переменная num2
max: .word # максимальная переменная
msg: .asciiz "Введите целое число" # msg
msg2: .asciiz "Большее значение равно " # msg2
.текст
основной:
la $a0, msg # печатает msg
ли $v0, 4
системный вызов
la $v0, 5 # читает данные
системный вызов
# загружает адрес num1 в $t0
la $t0, число1
# перемещаем содержимое $v0 в $t0
переместить $t0,$v0
la $a0, msg # напечатать сообщение
ли $v0, 4
системный вызов
la $v0, 5 # прочитать данные
системный вызов
# загружает адрес num1 в $t1
ла $t1, число2
# перемещает содержимое $v0 в $t1
переместить $t1,$v0
# загружает адрес max в t2
la $t2, макс.
# если $t0 (число1) > $t2 (число2), выполнить, если часть/метка
bgt $t0,$t1,if # перейти к метке if
# еще
еще:
# перемещает содержимое $t1 (num2) в $t2 (max)
переместить $t2,$t1
la $a0, msg2 # напечатать msg2
ли $v0, 4
системный вызов
ход $a0, $t2 # вывести макс. ли $v0, 1
системный вызов
li $v0, 10 # выход
системный вызов
# если
если:
# перемещает содержимое $t0 (num1) в $t2 (max)
переместить $t2,$t0
la $a0, msg2 # напечатать msg2
ли $v0, 4
системный вызов
ход $a0, $t2 # вывести макс.
ли $v0, 1
системный вызов
li $v0, 10 # выход
системный вызов
ли $v0, 1
системный вызов
li $v0, 10 # выход
системный вызов
# если
если:
# перемещает содержимое $t0 (num1) в $t2 (max)
переместить $t2,$t0
la $a0, msg2 # напечатать msg2
ли $v0, 4
системный вызов
ход $a0, $t2 # вывести макс.
ли $v0, 1
системный вызов
li $v0, 10 # выход
системный вызов
Каждый раз, когда я пытаюсь запустить этот код в QTSpim, я получаю сообщение об ошибке «spim: (парсер) синтаксическая ошибка в строке 3 файла C:/Users/danie/Desktop/program_1.asm .word # num1 variable»
Что я делаю не так? Спасибо
- сборка
- mips
- qtspim
- spim
Вы хотите, чтобы .word 0 выдавало одно 32-битное слово со значением 0 .
.word без операндов зарезервирует 0 байтов пространства для этого пустого списка инициализаторов слов . (Вот как некоторые другие ассемблеры на самом деле обрабатывают это, не выдавая ошибок. ) Так что это похоже на
) Так что это похоже на uint32_t array[] = {}; в C1, как объявление массива из 0 элементов.
Это не то, что кому-то нужно (нормальный человек просто пропустил бы .word , если бы он просто хотел поставить несколько меток на один и тот же адрес), так что кажется, что ассемблер SPIM мешает вам написать что-то бесполезное и рассматривает это как ошибка. Я думаю, может быть, вы можете представить себе макрос, который ничего не расширяет для некоторых конфигураций, возможно, поэтому другие ассемблеры предпочитают не ошибаться и обрабатывать .word как список из нуля или более значений слов вместо одного или более.
Сноска 1: За исключением C, два массива не могут иметь один и тот же адрес, даже если они пусты, или, по крайней мере, GCC избегает этого. GCC действительно испускает некоторые дополнения после пустого массива: https://godbolt.org/z/5GMT6e
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через FacebookОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.