Слова «петеньку» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «петеньку» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «петеньку» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «петеньку».
Содержимое:
- 1 Как перенести слово «петеньку»
- 2 Морфологический разбор слова «петеньку»
- 3 Разбор слова «петеньку» по составу
- 4 Предложения со словом «петеньку»
- 5 Значение слова «петеньку»
- 6 Как правильно пишется слово «петеньку»
Как перенести слово «петеньку»
пе—теньку
пете—ньку
петень—ку
Морфологический разбор слова «петеньку»
Часть речи:
Имя существительное
часть речи: имя существительное;
одушевлённость: одушевлённое;
род: мужской;
число: единственное;
падеж: винительный;
отвечает на вопрос: (нет/около/вижу) Кого?
Начальная форма:
петенька
Разбор слова «петеньку» по составу
| по | приставка |
| мал | корень |
| еньк | суффикс |
| у | суффикс |
помаленьку
Предложения со словом «петеньку»
А не видя поживы, его ватага начала помаленьку расползаться. Отряды таяли с каждым днём, и конунг ничего уже не мог с этим поделать.
Отряды таяли с каждым днём, и конунг ничего уже не мог с этим поделать.
Борис Васильев, Владимир Мономах, 2010.
Может быть, именно поэтому и личные отношения стали помаленьку
налаживаться.Наталья Никольская, Не ходите девки в лес.
Посему госпожа кардинал решила, что хорошего помаленьку, и перешла к активным действиям…
Татьяна Устименко, Сокровище двух миров, 2013.
Значение слова «петеньку»
ПОМАЛЕ́НЬКУ , нареч. Разг. То же, что понемногу. (Малый академический словарь, МАС)
Как правильно пишется слово «петеньку»
Правописание слова «петеньку»
Орфография слова «петеньку»
Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «петеньку» в прямом и обратном порядке:
Опубликовано: 2020-11-07
Популярные слова
воспитанник , беседами , взбежавшие , взъерошив , выскребу , высчитанною , вытравлявшей , вячеславом , гемолизом , геннадиевичи , гимнастерочку , домоустройство , завибрируют , завинчивающимся , павлиньего , парабеллумами , парковавшемся , перебираемыми , плакатная , подающее , подлетать , подросту , положительнейшего , помпонах , поохотившимся , пражского , прогульном , прокашливаться , проституируя , противогазовые , развернувшее , разделе , раскрутилось , раскусывают , расторгну , резервированного , реорганизовавшем , респонсорною , сильванер , солея
Урок путешествие «состав слова» 2 класс
Урок-путешествие
Состав слова (закрепление)
Русский язык.
2 класс.
Тема: Состав слова (обобщение)
Цели урока: закрепление знаний учащихся по изученной теме. Умение выделять части слова и последовательно выполнять разбор слова по составу. Развитие умения самостоятельно анализировать и оценивать свою работу. Способствование создания атмосферы хорошего настроения при организации работы на уроке. Воспитание активности и любознательности учащихся.
Ход урока
Организационный момент.
-Здравствуйте, ребята! Садитесь. Какое у вас настроение в начале урока? Выберите смайлик, который соответствует вашему настроению и приклейте его на дерево настроения.
Розовый – У меня хорошее настроение
Синий – У меня плохое настроение.
— Итак, с хорошим настроением мы начинаем урок.
Сообщение темы урока.
Чтобы тему урока узнать,
Надо запись расшифровать.
ССОЛСОТВААВ
— Правильно, тема нашего урока СОСТАВ СЛОВА
— Работать мы будем под девизом: Тот, кто знает части слова,
Тот напишет их толково!
— Ребята, на предыдущих уроках мы работали над составом слова.
— Что значит – разобрать слова по составу? (Находить части слов и выделять их)
— Какие части слов вы знаете? (окончание, основа слова, приставка, суффикс и корень)
— Сегодня на уроке мы закрепим знания о составе слов.
— Открываем тетради.
Я тетрадочку открою,
Под наклоном положу.
Я от вас друзья не скрою,
Ручку я вот так держу.
Сяду прямо, не согнусь.
За работу я возьмусь.
Сядьте ровно, аккуратно запишите число и классная работа.
— Ребята, сегодня у нас будет необычный урок, мы отправимся в путешествие. Посмотрите на слайд и попробуйте догадаться куда мы отправимся. Кто догадался?
(в космос)
— С какой буквы начинается это слово? (с согласной буквы К)
Дайте характеристику этой букве
(буква Ка имеет два звука: твёрдый – к, мягкий – кь. Согласный, глухой, парный (г-к).
Каллиграфическая минутка
— Посмотрите внимательно на слайд, найдите закономерность в написании букв и элементов. Аккуратно пропишите до конца строки.
— Итак, мы отправляемся с вами в космос. А кто знает значение этого слова?
(Космос – это пространство за пределами нашей планеты Земля).
— Посмотрите на слайд. Подумайте, какое слово «лишнее» и почему?
Подумайте, какое слово «лишнее» и почему?
(Косметика – это средства, с помощью которых люди ухаживают за собой, приводят себя в порядок)
— Какие слова остались? (однокоренные)
— Почему эти слова можно назвать однокоренными? (Они имеют общий корень и являются родственными, т.е. близкими по значению)
— Назовите общий корень в словах.
— Что такое космос мы выяснили, а какое значение имеют остальные слова?
(Космический – относящийся к космосу, космонавт — человек, совершающий полет в космос)
— Ребята, назовите имя первого человека, побывавшего в космосе. (Ю.А. Гагарин)
— А теперь назовите других космонавтов.
— А теперь можно и в путь.
Далекие звезды над нами горят,
Зовут они в гости хороших ребят.
Внимание! Взлет!
Наша ракета мчится вперед.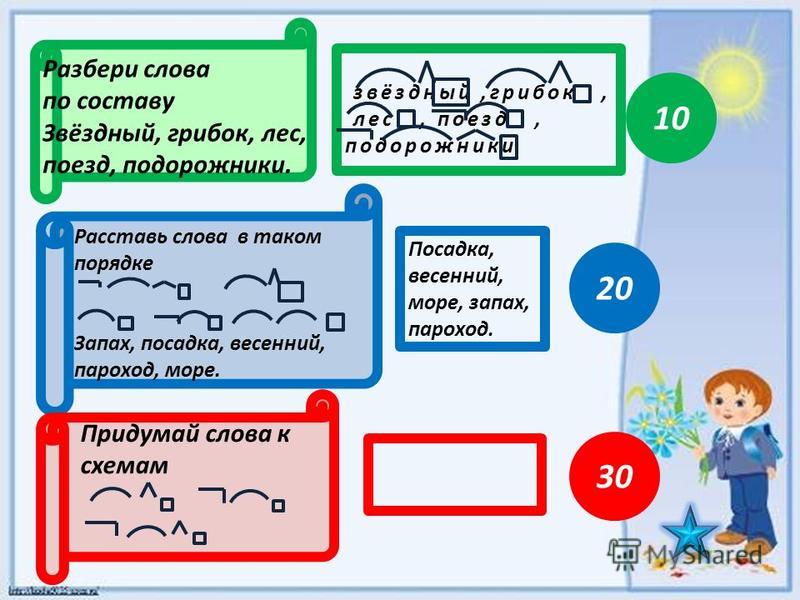
Прощально мигнут и растают вдали
Огни золотые любимой Земли.
— Как вы думаете, что мы сможем увидеть в космосе? (планеты, спутники, звезды…)
Работа в карточках
(звезд, звезды, звездами, о звездах)
— Аня прочти задание. (Выделите в словах окончание и основу слова)
— Что в слове нужно выделить в первую очередь?
— Что такое окончание? Как его выделить в слове?
(окончание – изменяемая часть слова, которая служит для связи слов в предложении. Чтобы выделить окончание в слове, нужно изменять слово)
— После окончание нужно выделить …… (основу слова)
— Что такое основа слова?
— Выполняйте задание в карточке. Работайте в парах, советуйтесь.
— Проверим. Прочитаем по очереди. (Образец на слайде)
(Образец на слайде)
Возле каждого из вас на парте лежит ракета – это лист оценок. Если вы выполнили работу верно, приклейте зелёный иллюминатор. Если есть одна или две ошибки, то приклейте жёлтый иллюминатор. Если задание выполнено неверно, нужно ещё подучить. Приклейте красный иллюминатор.
— Ребята, мы с вами приземлились на неизвестной планете. Посмотрите, на этой планете растут необычные деревья. Давайте вспомним, какие части есть у дерева? (корень, ствол, ветки, листья)
— А какая часть самая главная? (корень)
— Посмотрите на это дерево. Оно необычно тем, что оно – словообразовательное. Чтобы у дерева выросли ветви – слова, нам надо ответить на вопросы:
— Как вас называют в школе? (ученики)
— Почему вас так называют? (т.к. мы учимся)
— Как называют человека, который учит? (учитель)
— С какой пословицей мы работали на прошлом уроке? (ученье – свет, а неученье – тьма)
(ученье- это знания, неученье – это невежество)
— Какая часть в слове является главной? У слова так же, как и у дерева главная часть – корень.
— Почему корень – это главная часть слова? (В нём заключено общее значение родственных слов)
— Как в слове выделить корень? (надо подобрать однокоренные слова)
— Запишите эти слова с красной строки и выделите корень.
Самопроверка по образцу
— Поднимите руки у кого нет ни одной ошибки?
— Поднимите руки у кого есть одна ошибка?
— А теперь оцените свою работу. Возле каждого из вас на парте лежит ракета – это лист оценок. Если вы выполнили работу верно, приклейте зелёный иллюминатор. Если есть одна или две ошибки, то приклейте жёлтый иллюминатор. Если задание выполнено неверно, нужно ещё подучить. Приклейте красный иллюминатор.
— Ребята, на этой планете очень интересно. Здесь растут необычные растения.
— Посмотрите на цветы. Один очень похож на цветок, который растет в нашей местности. Какой? (ромашка)
Какой? (ромашка)
— А на этой планете такой цветок называется приставочным.
— Как вы думаете, почему? (на лепестках приставки)
— Что такое приставка? (приставка- это часть слова, которая стоит перед корнем и служит для образования новых слов)
— Образуйте с помощью этих приставок и корня -лить- новые слова, запишите их на новой строке, выделяя приставку.
— Проверьте друг у друга работу и оцените её. ВЗАИМОПРОВЕРКА КАРУСЕЛЬ
Оцените работу. Если вы выполнили работу верно, приклейте зелёный иллюминатор. Если есть одна или две ошибки, то приклейте жёлтый иллюминатор. Если задание выполнено неверно, нужно ещё подучить. Приклейте красный иллюминатор.
Физминутка
Встаньте дружно из-за парт
Разминке каждый будет рад!
Повернитесь вправо, влево,
А теперь, присядьте смело!
Поработаем ногами,
Раз, два, три!
Поработаем руками!
Раз, два, три!
Улыбнёмся: день хороший,
И похлопаем в ладоши!
— Ребята, посмотрите, за нами кто-то наблюдает. Это жители этой планеты. Им нужна наша помощь.
Это жители этой планеты. Им нужна наша помощь.
У них сломался мостик через реку. На одном берегу остались слова, а на другом – суффиксы.
— Ребята, давайте вспомним, что такое суффикс. (Суффикс – это часть слова, которая стоит после корня и служит для образования новых слов)
— Чтобы восстановить мостик, нужно присоединить суффиксы к словам. (устно)
(гнёздышко, совёнок, ветерок, берёзка, козочка)
— А теперь запишите полученные слова на новой строке и выделите суффикс.
Проверьте и оцените работу друг друга. (меняются др. с др.)
— Мост построен. Инопланетяне очень рады. Они говорят вам спасибо за помощь.
Вернёмся к листу оценок. Если вы выполнили работу верно, приклейте зелёный иллюминатор. Если есть одна или две ошибки, то приклейте жёлтый иллюминатор. Если задание выполнено неверно, нужно ещё подучить. Приклейте красный иллюминатор.
Приклейте красный иллюминатор.
— Ребята у вас на партах лежат карточки с частями слов. Возьмите их, постройтесь у доски в таком порядке, в каком нужно выполнять разбор слова по составу. (окончание, основа слова, корень, приставка, суффикс)
— А вы помните какой цифрой обозначается в учебнике разбор слова по составу?
— А теперь приклеим части слова в том порядке, в каком они стоят в составе слова.
— Я для вас подготовила вот такие памятки, чтобы вы всегда помнили, как и в каком порядке нужно выполнять разбор слова по составу. Эти памятки приклейте в узелки на память.
— А теперь проверим, чему мы научились на планете.
Работа у доски (схемы состава слов)
— Нужно взять карточку. Разобрать слово по составу и соотнести со схемой у доски.
Заросли кормушка листик запах с книгой
Пришкольный братишка дубок повар в садах
Наклейка лисичка лесник выход о доме
— К доске выходим по очереди
— Остальные ребята следите за правильностью выполнения разбора друг друга.
Оцените работу. Если вы выполнили работу верно, приклейте зелёный иллюминатор. Если есть одна или две ошибки, то приклейте жёлтый иллюминатор. Если задание выполнено неверно, нужно ещё подучить. Приклейте красный иллюминатор.
Итог:
— Ребята, давайте у человечков узнаем, как называется их планета. Чтобы узнать название планеты, надо отгадать кроссворд. Помните правило поднятой руки.
1. Изменяемая часть слова.
2. Часть слова, которая стоит перед корнем и служит для образования новых слов.
3. Часть слова, которая стоит после корня и служит для образования новых слов.
4. Общая часть однокоренных слов.
— Планета, на которой мы сегодня побывали, называется Планетой МОРФЕМ.
Морфемы – это части слов, которые мы сегодня выделяли.
— Как называются части слов? (МОРФЕМЫ)
— Какие морфемы вы знаете?
Возвращаться нам пора,
По местам мои друзья!
Из полета возвратились,
Мы на землю приземлились.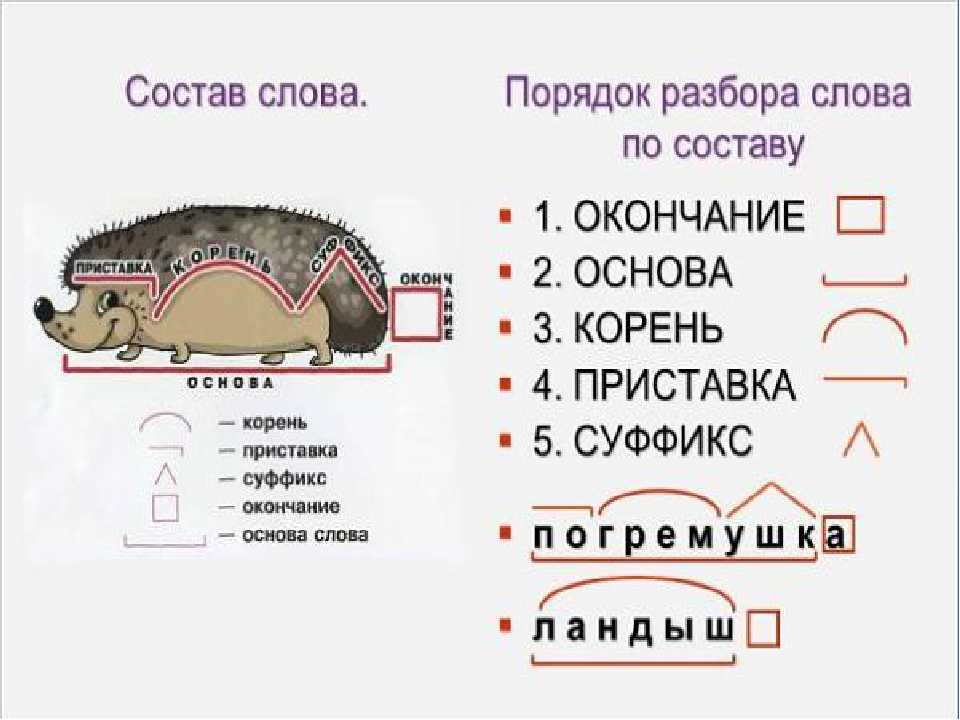
— Ребята, чем мы занимались сегодня на уроке?
Выставление оценок:
— А теперь посмотрите на свои листы оценок. Как вы оцените свою работу на уроке и почему?
Рефлексия
— Вам понравилось путешествие? Какое настроение у вас в конце урока? Покажите мне. Приклейте смайлик на дерево.
Жёлтый – мне было интересно на уроке. Я всё понял.
Зелёный – испытываю равнодушие. Я не всё понял.
Голубой – Мне было не интересно. Я ничего не понял.
Домашнее задание.
-Домашнее задание я для вас приготовила на карточках, которые лежат в ваших дневниках.
Прочитайте предложения. Спишите, в однокоренных словах выделите корень.
Под осиной растут подосиновики. В лесу работает лесник. Рыбак ловит рыбу. Муравьи живут в муравейнике.
— Спасибо за урок. Урок окончен. Можете идти на перемену.
Урок окончен. Можете идти на перемену.
Подходы к лемматизации с примерами в Python
Лемматизация — это процесс преобразования слова в его базовую форму. Разница между стеммингом и лемматизацией заключается в том, что лемматизация учитывает контекст и преобразует слово в его осмысленную базовую форму, тогда как стемминг просто удаляет несколько последних символов, что часто приводит к неправильному значению и орфографическим ошибкам.
Сравнение подходов к лемматизации в Python. Фото Ясмин Шрайбер
Содержание
1. Введение 2. Лемматизатор Wordnet 3. Лемматизатор Wordnet с соответствующим тегом POS 4. Лемматизатор spaCy 5. Лемматизатор TextBlob 6. Лемматизатор TextBlob с соответствующим тегом POS 7. Лемматизатор шаблонов 8. Лемматизатор Stanford CoreNLP 9. Лемматизация Gensim 10. TreeTagger 11 Сравнение NLTK, TextBlob, spaCy, Pattern и Stanford CoreNLP 12. Заключение
1. Введение
Лемматизация — это процесс преобразования слова в его базовую форму.
Разница между определением основы и лемматизацией заключается в том, что при лемматизации учитывается контекст и преобразуется слово в его осмысленную базовую форму, в то время как при определении основы просто удаляются последние несколько символов, что часто приводит к неправильному значению и орфографическим ошибкам.
Например, лемматизация правильно идентифицирует базовую форму слова «забота» как «забота», в то время как определение корня отрезает часть «инг» и преобразует ее в автомобиль. «Забота» -> Лемматизация -> «Забота» «Забота» -> Основание -> «Автомобиль»
Кроме того, иногда одно и то же слово может иметь несколько разных «лемм». Таким образом, в зависимости от контекста, в котором оно используется, вы должны определить тег «часть речи» (POS) для слова в этом конкретном контексте и извлечь соответствующую лемму.
Примеры реализации приведены в следующих разделах. Сегодня мы увидим, как реализовать лемматизацию, используя следующие пакеты Python.
- Лемматизатор Wordnet
- Лемматизатор Spacy
- TextBlob
- Образец зажимов
- Stanford CoreNLP
- Генсим Лемматизатор
- Тритеггер
2. Лемматизатор Wordnet с NLTK
Wordnet — это большая, бесплатно и общедоступная лексическая база данных для английского языка, предназначенная для установления структурированных семантических отношений между словами.
Он также предлагает возможности лемматизации и является одним из первых и наиболее часто используемых лемматизаторов.
NLTK предлагает к нему интерфейс, но вы должны сначала загрузить его, чтобы использовать. Следуйте приведенным ниже инструкциям, чтобы установить nltk и загрузить wordnet .
# Как установить и импортировать NLTK
# В терминале или в приглашении:
# pip установить nltk
# # Загрузите Wordnet через NLTK в консоли Python:
импортировать нлтк
nltk.download('wordnet')
Для лемматизации необходимо создать экземпляр WordNetLemmatizer() и вызвать lemmatize() работает с одним словом.
импорт нлтк
из nltk.stem импортировать WordNetLemmatizer
# Запустите лемматизатор Wordnet
лемматизатор = WordNetЛемматизатор()
# Лемматизация одного слова
print(lemmatizer.lemmatize("летучие мыши"))
#> летучая мышь
print(lemmatizer.lemmatize("являются"))
#> являются
печать (lemmatizer.lemmatize («ноги»))
#> стопа
Лемматизируем простое предложение. Сначала мы разбиваем предложение на слова, используя nltk.word_tokenize , а затем вызываем lemmatizer.lemmatize() на каждое слово. Это можно сделать в понимании списка (цикл for внутри квадратных скобок для создания списка).
# Определите предложение, которое нужно лемматизировать предложение = «Полосатые летучие мыши лучше всего висят на ногах» # Tokenize: разбить предложение на слова word_list = nltk.word_tokenize(предложение) печать (слово_список) #>['The', 'полосатый', 'летучие мыши', 'есть', 'висит', 'на', 'их', 'лапы', 'для', 'лучший'] # Лемматизировать список слов и соединить lemmatized_output = ' '.join([lemmatizer.lemmatize(w) для w в word_list]) печать (lemmatized_output) #> Полосатая летучая мышь лучше всего висит на ноге
 join([lemmatizer.lemmatize(w) для w в word_list])
печать (lemmatized_output)
#> Полосатая летучая мышь лучше всего висит на ноге
join([lemmatizer.lemmatize(w) для w в word_list])
печать (lemmatized_output)
#> Полосатая летучая мышь лучше всего висит на ноге
Приведенный выше код является простым примером использования лемматизатора wordnet для слов и предложений.
Обратите внимание, что это не помогло. Потому что «есть» не преобразуется в «быть», а «висит» не преобразуется в «висит», как ожидалось.
Полное мастерство машинного обучения
Вы хотите изучать AI / ML, как опытные специалисты по данным?
Перейти от нуля к работе с признанной сертификацией. Решайте проекты с реальными данными компании и осваивайте искусственный интеллект и машинное обучение.
Да, хочу. Возьми меня туда!
Полное овладение машинным обучением
Пройдите путь от нуля до готовности к работе с признанной сертификацией. Получите мышление, уверенность и навыки, которые делают Data Scientist очень ценным.
Да, хочу. Возьми меня туда!
Это можно исправить, если мы предоставим правильный тег «часть речи» (тег POS) в качестве второго аргумента для lemmatize() .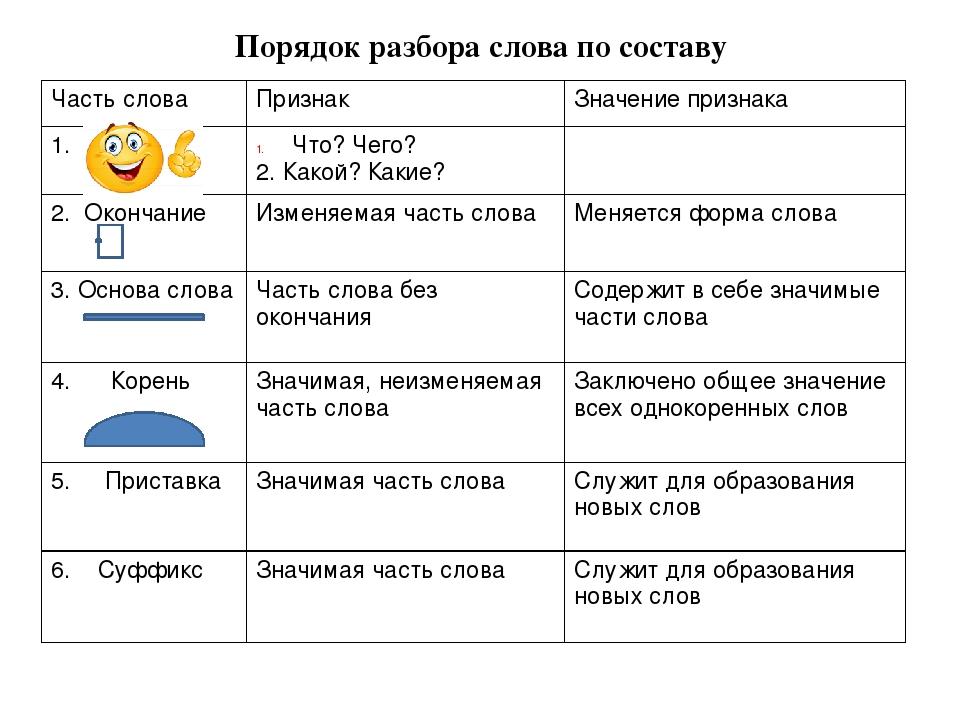
Иногда одно и то же слово может иметь несколько лемм в зависимости от значения/контекста.
print(lemmatizer.lemmatize("полосы", 'v'))
#> полоса
print(lemmatizer.lemmatize("полосы", 'n'))
#> полоса
3. Лемматизатор Wordnet с соответствующим POS-тегом
Для больших текстов может оказаться невозможным вручную указать правильный POS-тег для каждого слова.
Итак, вместо этого мы найдем правильный POS-тег для каждого слова, сопоставим его с правильным входным символом, который принимает WordnetLemmatizer, и передадим его в качестве второго аргумента в lemmatize() .
Итак, как получить POS-тег для данного слова?
В nltk он доступен через метод nltk.pos_tag()
печать (nltk.pos_tag (['ноги']))
#> [('ноги', 'ННС')]
печать (nltk.pos_tag (nltk.word_tokenize (предложение)))
#> [('The', 'DT'), ('полосатый', 'JJ'), ('летучие мыши', 'NNS'), ('are', 'VBP'), ('висящий', 'VBG '), ('на', 'В'), ('их', 'PRP$'), ('ножки', 'ННС'), ('для', 'В'), ('лучший', ' JJS')]
nltk. возвращает кортеж с тегом POS. Ключевым моментом здесь является сопоставление POS-тегов NLTK с форматом, который примет лемматизатор wordnet. Функция  pos_tag()
pos_tag() get_wordnet_pos() , определенная ниже, выполняет эту работу по сопоставлению.
# Лемматизировать с POS-тегом
из nltk.corpus импортировать wordnet
защита get_wordnet_pos (слово):
"""Сопоставьте тег POS с первым символом, который lemmatize() принимает"""
тег = nltk.pos_tag([word])[0][1][0].upper()
tag_dict = {"J": wordnet.ADJ,
"N": wordnet.СУЩЕСТВИТЕЛЬНОЕ,
"V": wordnet.ГЛАГОЛ,
"R": wordnet.ADV}
вернуть tag_dict.get(тег, wordnet.NOUN)
# 1. Инициализировать лемматизатор
лемматизатор = WordNetЛемматизатор()
# 2. Лемматизируйте одно слово с соответствующим тегом POS
слово = 'ноги'
print(lemmatizer.lemmatize(слово, get_wordnet_pos(слово)))
# 3. Лемматизируйте предложение с соответствующим тегом POS
предложение = «Полосатые летучие мыши лучше всего висят на ногах»
print([lemmatizer. lemmatize(w, get_wordnet_pos(w)) для w в nltk.word_tokenize(предложение)])
#> ['The', 'раздеть', 'летучая мышь', 'быть', 'повесить', 'на', 'их', 'нога', 'за', 'лучший']
 lemmatize(w, get_wordnet_pos(w)) для w в nltk.word_tokenize(предложение)])
#> ['The', 'раздеть', 'летучая мышь', 'быть', 'повесить', 'на', 'их', 'нога', 'за', 'лучший']
lemmatize(w, get_wordnet_pos(w)) для w в nltk.word_tokenize(предложение)])
#> ['The', 'раздеть', 'летучая мышь', 'быть', 'повесить', 'на', 'их', 'нога', 'за', 'лучший']
4. Лемматизация spaCy
spaCy — это относительно новый инструмент в этой области, который позиционируется как мощное промышленное ядро НЛП.
Он поставляется с готовыми моделями, которые могут анализировать текст и вычислять различные функции, связанные с НЛП, с помощью одного единственного вызова функции.
Конечно, это также дает лемму слова. Прежде чем мы начнем, давайте установим spaCy и загрузим модель «en».
# Установить spaCy (запустить в терминале/подсказке)
импорт системы
!{sys.executable} -m pip install spacy
# Скачать модель spaCy 'en'
!{sys.executable} -m spacy скачать ru
spaCy по умолчанию определяет тег части речи и присваивает соответствующую лемму. Он поставляется с кучей готовых моделей, где «en», который мы только что скачали выше, является одним из стандартных для английского языка.
импортное пространство
# Инициализировать пространственную модель en, оставив только компонент тега, необходимый для лемматизации.
nlp = spacy.load('en', disable=['parser', 'ner'])
предложение = «Полосатые летучие мыши лучше всего висят на ногах»
# Разобрать предложение, используя загруженный объект модели 'en' `nlp`
документ = nlp (предложение)
# Извлекаем лемму для каждого токена и соединяем
" ".join([token.lemma_ для токена в документе])
#> 'стриптиз-биту повесить на -PRON- ногу навсегда'
Он сделал все лемматизации, которые Wordnet Lemmatizer поставил с правильным тегом POS. Кроме того, он также лемматизировал «лучший» в «хороший». Хороший! Вы увидите, что символ -PRON- появляется всякий раз, когда пробел обнаруживает местоимение.
5. TextBlob Lemmatizer
TexxtBlob также является мощным, быстрым и удобным пакетом НЛП. Используя объекты Word и TextBlob , довольно просто анализировать и лемматизировать слова и предложения соответственно.
# pip установить textblob из textblob импортировать TextBlob, Word # Лемматизировать слово слово = 'полосы' ш = слово (слово) w.lemmatize () #> полоса
Однако, чтобы лемматизировать предложение или абзац, мы анализируем его с помощью TextBlob и вызываем функцию lemmatize() для проанализированных слов.
# Лемматизировать предложение предложение = «Полосатые летучие мыши лучше всего висят на ногах» отправлено = TextBlob(предложение) " ". join([w.lemmatize() для w в send.words]) #> 'Полосатая летучая мышь лучше всего висит на ноге'
С самого начала он не очень хорошо работал, потому что, как и NLTK, TextBlob также использует wordnet для внутренних целей. Итак, давайте передадим соответствующий POS-тег в метод lemmatize() .
6. Лемматизатор TextBlob с соответствующим POS-тегом
# Определите функцию для лемматизации каждого слова с его POS-тегом
def lemmatize_with_postag (предложение):
отправлено = TextBlob(предложение)
tag_dict = {"J": 'а',
«Н»: «н»,
«В»: «в»,
«Р»: «р»}
words_and_tags = [(w, tag_dict. get(pos[0], 'n')) для w, pos в send.tags]
lemmatized_list = [wd.lemmatize(tag) для wd, тег в words_and_tags]
вернуть " ".join (лемматизированный_список)
# Лемматизировать
предложение = «Полосатые летучие мыши лучше всего висят на ногах»
lemmatize_with_postag(предложение)
#> 'Полосатая летучая мышь лучше всего будет висеть на ноге'
 get(pos[0], 'n')) для w, pos в send.tags]
lemmatized_list = [wd.lemmatize(tag) для wd, тег в words_and_tags]
вернуть " ".join (лемматизированный_список)
# Лемматизировать
предложение = «Полосатые летучие мыши лучше всего висят на ногах»
lemmatize_with_postag(предложение)
#> 'Полосатая летучая мышь лучше всего будет висеть на ноге'
get(pos[0], 'n')) для w, pos в send.tags]
lemmatized_list = [wd.lemmatize(tag) для wd, тег в words_and_tags]
вернуть " ".join (лемматизированный_список)
# Лемматизировать
предложение = «Полосатые летучие мыши лучше всего висят на ногах»
lemmatize_with_postag(предложение)
#> 'Полосатая летучая мышь лучше всего будет висеть на ноге'
7. Pattern Lemmatizer
Pattern by CLiPs — универсальный модуль со многими полезными возможностями НЛП.
шаблон установки !pip
Если у вас возникли проблемы при установке шаблона, ознакомьтесь с известными проблемами на github. Я сам столкнулся с этой проблемой при установке на mac.
шаблон импорта из pattern.en лемма импорта, лексема предложение = "Полосатые летучие мыши висели на ногах и питались лучшей рыбой" " ".join([лемма(wd) для wd в предложении.split()]) #> 'полосатая летучая мышь будет висеть на ногах и есть лучшую рыбу'
Вы также можете просмотреть возможные лексемы для каждого слова.
# Лексем для каждого слова [лексема (wd) для wd в предложении.split()] #> [['the', 'thes', 'thing', 'thed'], #> ['полоса', 'полоса', 'полоса', 'полосатый'], #> ['bat', 'bats', 'batting', 'batted'], #> ['быть', 'есть', 'есть', 'есть', 'быть', 'было', 'были', 'было', #> . «нет», «не», «не есть», «не было», «не было»], #> ['висит', 'зависает', 'зависает', 'зависает'], #> ['он', 'онс', 'онинг', 'онед'], #> ['их', 'их', 'их', 'их'], #> ['ноги', 'ноги', 'ноги', 'ноги'], #> ['и', 'и', 'и', 'и'], #> ['есть', 'есть', 'есть', 'есть', 'есть'], #> ['лучший', 'лучший', 'лучший', 'лучший'], #> ['fishes', 'fishing', 'fishesed']]
Вы также можете получить лемму, проанализировав текст.
из разбора импорта pattern.en
print(parse('Полосатые летучие мыши висели на ногах и питались лучшей рыбой',
лемматы = Истина, теги = Ложь, куски = Ложь))
#>The/DT/полосатые/JJ/полосатые летучие мыши/NNS/летучие мыши были/VBD/висят/VBG/висят на/IN/на их/PRP$/их
#> ноги/NNS/ноги и/CC/и ели/VBD/есть лучшие/JJ/лучшие рыбы/NNS/рыбы
8.
 Лемматизация Stanford CoreNLP
Лемматизация Stanford CoreNLPStandford CoreNLP — популярный инструмент NLP, изначально реализованный на Java. Вокруг него написано множество оберток для Python. Тот, который я использую ниже, довольно удобен в использовании.
Но перед этим вам необходимо загрузить Java и программное обеспечение Standford CoreNLP.
Перед тем, как перейти к коду лемматизации, убедитесь, что у вас есть следующие требования: Шаг 1: Установлена Java 8. Вы можете загрузить и установить со страницы загрузки Java. Пользователи Mac могут проверить версию Java, набрав java -version в терминале. Если 1.8+, то нормально.
В противном случае выполните следующие действия.
варить обновление варить установить jenv варить бочку установить java
Шаг 2: Загрузите программное обеспечение Standford CoreNLP и разархивируйте его.
Шаг 3: Запустите сервер Stanford CoreNLP с терминала. Как? cd в папку, которую вы только что разархивировали, и запустите следующую команду в терминале:
cd stanford-corenlp-full-2018-02-27 java -mx4g -cp "*" edu.
 stanford.nlp.pipeline.StanfordCoreNLPServer -annotators "tokenize,ssplit,pos,lemma,parse,sentiment" -port 9000 -timeout 30000
stanford.nlp.pipeline.StanfordCoreNLPServer -annotators "tokenize,ssplit,pos,lemma,parse,sentiment" -port 9000 -timeout 30000
Это запустит StanfordCoreNLPServer, прослушивающий порт 9000.
Теперь мы готовы извлечь леммы на python. В stanfordcorenlp , лемма встроена в выходные данные метода annotate() объекта соединения StanfordCoreNLP (см. код ниже).
# Запустите `pip install stanfordcorenlp`, чтобы установить пакет stanfordcorenlp
из stanfordcorenlp импорт StanfordCoreNLP
импортировать json
# Подключиться к серверу CoreNLP, который мы только что запустили
nlp = StanfordCoreNLP('http://localhost', порт=9000, время ожидания=30000)
# Определяем свойства, необходимые для получения леммы
реквизит = {'аннотаторы': 'поз, лемма',
'трубопроводный язык': 'en',
'выходной формат': 'json'}
предложение = "Полосатые летучие мыши висели на ногах и питались лучшей рыбой"
parsed_str = nlp.annotate (предложение, свойства = реквизит)
parsed_dict = json. loads(parsed_str)
parsed_dict
#> {'предложения': [{'индекс': 0,
#> 'токены': [{'после': ' ',
#> 'до': '',
#> 'characterOffsetBegin': 0,
#> 'characterOffsetEnd': 3,
#> 'индекс': 1,
#> 'lemma': 'the', << ----------- ЛЕММА
#> 'originalText': 'The',
#> 'поз': 'ДТ',
#> 'слово': 'The'},
#> {'после': ' ',
#> 'до': ' ',
#> 'characterOffsetBegin': 4,
#> 'characterOffsetEnd': 11,
#> 'индекс': 2,
#> 'лемма': 'полосатый', << ----------- ЛЕММА
#> 'originalText': 'полосатый',
#> 'поз': 'JJ',
#> 'слово': 'полосатый'},
#> {'после': ' ',
#> 'до': ' ',
#> 'characterOffsetBegin': 12,
#> 'characterOffsetEnd': 16,
#> 'индекс': 3,
#> 'lemma': 'bat', << ----------- ЛЕММА
#> 'originalText': 'летучие мыши',
#> 'поз': 'ННС',
#> 'слово': 'летучие мыши'}
#> ...
#> ...
 loads(parsed_str)
parsed_dict
#> {'предложения': [{'индекс': 0,
#> 'токены': [{'после': ' ',
#> 'до': '',
#> 'characterOffsetBegin': 0,
#> 'characterOffsetEnd': 3,
#> 'индекс': 1,
#> 'lemma': 'the', << ----------- ЛЕММА
#> 'originalText': 'The',
#> 'поз': 'ДТ',
#> 'слово': 'The'},
#> {'после': ' ',
#> 'до': ' ',
#> 'characterOffsetBegin': 4,
#> 'characterOffsetEnd': 11,
#> 'индекс': 2,
#> 'лемма': 'полосатый', << ----------- ЛЕММА
#> 'originalText': 'полосатый',
#> 'поз': 'JJ',
#> 'слово': 'полосатый'},
#> {'после': ' ',
#> 'до': ' ',
#> 'characterOffsetBegin': 12,
#> 'characterOffsetEnd': 16,
#> 'индекс': 3,
#> 'lemma': 'bat', << ----------- ЛЕММА
#> 'originalText': 'летучие мыши',
#> 'поз': 'ННС',
#> 'слово': 'летучие мыши'}
#> ...
#> ...
loads(parsed_str)
parsed_dict
#> {'предложения': [{'индекс': 0,
#> 'токены': [{'после': ' ',
#> 'до': '',
#> 'characterOffsetBegin': 0,
#> 'characterOffsetEnd': 3,
#> 'индекс': 1,
#> 'lemma': 'the', << ----------- ЛЕММА
#> 'originalText': 'The',
#> 'поз': 'ДТ',
#> 'слово': 'The'},
#> {'после': ' ',
#> 'до': ' ',
#> 'characterOffsetBegin': 4,
#> 'characterOffsetEnd': 11,
#> 'индекс': 2,
#> 'лемма': 'полосатый', << ----------- ЛЕММА
#> 'originalText': 'полосатый',
#> 'поз': 'JJ',
#> 'слово': 'полосатый'},
#> {'после': ' ',
#> 'до': ' ',
#> 'characterOffsetBegin': 12,
#> 'characterOffsetEnd': 16,
#> 'индекс': 3,
#> 'lemma': 'bat', << ----------- ЛЕММА
#> 'originalText': 'летучие мыши',
#> 'поз': 'ННС',
#> 'слово': 'летучие мыши'}
#> ...
#> ...
Вывод nlp.annotate() был преобразован в dict с использованием json.loads .
Теперь нужная нам лемма встроена парой слоев внутрь parsed_dict .
Итак, здесь нам нужно просто значение леммы из каждого словаря.
Я использую приведенные ниже списки, чтобы добиться цели.
lemma_list = [v для d в parsed_dict['предложения'][0]['токены'] для k,v в d.items(), если k == 'лемма'] " ".join(лемма_список) #> 'полосатая летучая мышь висит на ноге и ест лучшую рыбу'
Давайте обобщим эту замечательную функцию, чтобы обрабатывать большие абзацы.
из stanfordcorenlp импорт StanfordCoreNLP
импортировать json, строку
def lemmatize_corenlp (conn_nlp, предложение):
реквизит = {
«аннотаторы»: «pos, lemma»,
'трубопроводный язык': 'en',
'выходной формат': 'json'
}
# разбить на слова
посылает = conn_nlp.word_tokenize (предложение)
# удалить знаки препинания из токенизированного списка
sents_no_punct = [s вместо s в сообщениях, если s не в строке.пунктуация]
# формировать предложение
предложение2 = " ".join(sents_no_punct)
# аннотировать, чтобы получить лемму
parsed_str = conn_nlp.annotate (предложение2, свойства = реквизит)
parsed_dict = json. loads(parsed_str)
# извлечь лемму для каждого слова
lemma_list = [v для d в parsed_dict['предложения'][0]['токены'] для k,v в d.items(), если k == 'лемма']
# составить предложение и вернуть его
вернуть " ".join(lemma_list)
# установить соединение и вызвать `lemmatize_corenlp`
nlp = StanfordCoreNLP('http://localhost', порт=9000, время ожидания=30000)
lemmatize_corenlp (conn_nlp = nlp, предложение = предложение)
#> 'полосатая летучая мышь висит на ноге и ест лучшую рыбу'
 loads(parsed_str)
# извлечь лемму для каждого слова
lemma_list = [v для d в parsed_dict['предложения'][0]['токены'] для k,v в d.items(), если k == 'лемма']
# составить предложение и вернуть его
вернуть " ".join(lemma_list)
# установить соединение и вызвать `lemmatize_corenlp`
nlp = StanfordCoreNLP('http://localhost', порт=9000, время ожидания=30000)
lemmatize_corenlp (conn_nlp = nlp, предложение = предложение)
#> 'полосатая летучая мышь висит на ноге и ест лучшую рыбу'
loads(parsed_str)
# извлечь лемму для каждого слова
lemma_list = [v для d в parsed_dict['предложения'][0]['токены'] для k,v в d.items(), если k == 'лемма']
# составить предложение и вернуть его
вернуть " ".join(lemma_list)
# установить соединение и вызвать `lemmatize_corenlp`
nlp = StanfordCoreNLP('http://localhost', порт=9000, время ожидания=30000)
lemmatize_corenlp (conn_nlp = nlp, предложение = предложение)
#> 'полосатая летучая мышь висит на ноге и ест лучшую рыбу'
9. Gensim Lemmatize
Gensim предоставляет средства лемматизации на основе пакета шаблона .
Его можно реализовать с помощью метода lemmatize() в модуле utils .
По умолчанию lemmatize() разрешает использовать только теги «JJ», «VB», «NN» и «RB».
из gensim.utils импортировать лемматизировать
предложение = "Полосатые летучие мыши висели на ногах и питались лучшей рыбой"
lemmatized_out = [wd.decode('utf-8'). split('/')[0] для wd в lemmatize(предложение)]
#> ['полосатый', 'летучая мышь', 'быть', 'повесить', 'нога', 'есть', 'лучший', 'рыба']
 split('/')[0] для wd в lemmatize(предложение)]
#> ['полосатый', 'летучая мышь', 'быть', 'повесить', 'нога', 'есть', 'лучший', 'рыба']
split('/')[0] для wd в lemmatize(предложение)]
#> ['полосатый', 'летучая мышь', 'быть', 'повесить', 'нога', 'есть', 'лучший', 'рыба']
10. TreeTagger
Treetagger — это тегировщик частей речи для многих языков.
И это также дает лемму слова.
Вам необходимо загрузить и установить само программное обеспечение TreeTagger, чтобы использовать его, выполнив указанные шаги.
# pip установить treetaggerwrapper
импортировать treetaggerwrapper как ttpw
tagger = ttpw.TreeTagger(TAGLANG='en', TAGDIR='/Users/ecom-selva.p/Documents/MLPlus/11_Lemmatization/treetagger')
tags = tagger.tag_text("Полосатые летучие мыши висели на ногах и питались лучшей рыбой")
lemmas = [t.split('\t')[-1] для t в тегах]
#> ['the', 'полосатый', 'летучая мышь', 'быть', 'повесить', 'на', 'их', 'нога', 'и', 'есть', 'хорошо', 'рыба' ] Treetagger действительно хорошо справляется с преобразованием «лучшего» в «хорошее», а также для других слов. Для дальнейшего чтения обратитесь к документации TreeTaggerWrapper.
11. Сравнение NLTK, TextBlob, spaCy, Pattern и Stanford CoreNLP
Давайте запустим лемматизацию, используя 5 реализаций для следующего предложения, и сравним результат.
предложение = """После нападения мышей заботливые фермеры отправились в Дели в поисках лучших условий жизни.
Полиция Дели во вторник обстреляла протестующих фермеров из водометов и слезоточивого газа.
ломать баррикады своими автомобилями, автомобилями и тракторами."""
# НЛТК
из nltk.stem импортировать WordNetLemmatizer
лемматизатор = WordNetЛемматизатор()
pprint(" ".join([lemmatizer.lemmatize(w, get_wordnet_pos(w)) для w в nltk.word_tokenize(предложение) если w не в string.punctuation]))
# ('После нападения мышей фермер отправится в Дели за хорошей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и снарядом со слезоточивым газом '
# 'протест фермера, они пытаются сломать баррикаду своим автомобилем и '
# 'трактор')
# Просторный
импортировать просторный
nlp = spacy.load('en', disable=['parser', 'ner'])
документ = nlp (предложение)
pprint(" ". join([token.lemma_ для токена в документе]))
# («следите за нападением мышей, позаботьтесь о фермере, отправляйтесь в Дели за хорошими условиями жизни»
# '. Полиция Дели во вторник обстреляла протестующих из водометов и слезоточивого газа
# 'фермер как -PRON- попробуй сломать баррикаду с -PRON- машиной, автомобилем и '
# 'трактор.')
# Текстовый Блоб
pprint (lemmatize_with_postag (предложение))
# ('После того, как фермер позаботится о нападении мышей, отправляйтесь в Дели за хорошей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и снарядом со слезоточивым газом '
# 'протест фермера, они пытаются сломать баррикаду своим автомобилем и '
# 'трактор')
# Шаблон
лемма импорта из pattern.en
pprint(" ".join([лемма(wd) для wd в предложении.split()]))
# ('следите за атаками мышей, позаботьтесь о фермере, отправляйтесь в Дели, чтобы жить лучше'
# 'условия. Полиция Дели во вторник открыла огонь из водометов и слезоточивого снаряда
# 'протест фермера, они пытаются сломать баррикаду своими автомобилями, автомобилями и '
# 'тракторы. ')
# Стэнфорд
pprint (lemmatize_corenlp (conn_nlp = conn_nlp, предложение = предложение))
# ('следуй за фермером, атакующим мышь, отправляйся в Дели за лучшей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и слезоточивым снарядом '
# 'протест фермера, когда они пытаются сломать баррикаду с помощью своего автомобиля и '
# 'трактор')
 join([token.lemma_ для токена в документе]))
# («следите за нападением мышей, позаботьтесь о фермере, отправляйтесь в Дели за хорошими условиями жизни»
# '. Полиция Дели во вторник обстреляла протестующих из водометов и слезоточивого газа
# 'фермер как -PRON- попробуй сломать баррикаду с -PRON- машиной, автомобилем и '
# 'трактор.')
# Текстовый Блоб
pprint (lemmatize_with_postag (предложение))
# ('После того, как фермер позаботится о нападении мышей, отправляйтесь в Дели за хорошей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и снарядом со слезоточивым газом '
# 'протест фермера, они пытаются сломать баррикаду своим автомобилем и '
# 'трактор')
# Шаблон
лемма импорта из pattern.en
pprint(" ".join([лемма(wd) для wd в предложении.split()]))
# ('следите за атаками мышей, позаботьтесь о фермере, отправляйтесь в Дели, чтобы жить лучше'
# 'условия. Полиция Дели во вторник открыла огонь из водометов и слезоточивого снаряда
# 'протест фермера, они пытаются сломать баррикаду своими автомобилями, автомобилями и '
# 'тракторы.
join([token.lemma_ для токена в документе]))
# («следите за нападением мышей, позаботьтесь о фермере, отправляйтесь в Дели за хорошими условиями жизни»
# '. Полиция Дели во вторник обстреляла протестующих из водометов и слезоточивого газа
# 'фермер как -PRON- попробуй сломать баррикаду с -PRON- машиной, автомобилем и '
# 'трактор.')
# Текстовый Блоб
pprint (lemmatize_with_postag (предложение))
# ('После того, как фермер позаботится о нападении мышей, отправляйтесь в Дели за хорошей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и снарядом со слезоточивым газом '
# 'протест фермера, они пытаются сломать баррикаду своим автомобилем и '
# 'трактор')
# Шаблон
лемма импорта из pattern.en
pprint(" ".join([лемма(wd) для wd в предложении.split()]))
# ('следите за атаками мышей, позаботьтесь о фермере, отправляйтесь в Дели, чтобы жить лучше'
# 'условия. Полиция Дели во вторник открыла огонь из водометов и слезоточивого снаряда
# 'протест фермера, они пытаются сломать баррикаду своими автомобилями, автомобилями и '
# 'тракторы. ')
# Стэнфорд
pprint (lemmatize_corenlp (conn_nlp = conn_nlp, предложение = предложение))
# ('следуй за фермером, атакующим мышь, отправляйся в Дели за лучшей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и слезоточивым снарядом '
# 'протест фермера, когда они пытаются сломать баррикаду с помощью своего автомобиля и '
# 'трактор')
')
# Стэнфорд
pprint (lemmatize_corenlp (conn_nlp = conn_nlp, предложение = предложение))
# ('следуй за фермером, атакующим мышь, отправляйся в Дели за лучшей жизнью'
# 'Состояние полиции Дели во вторник обстреляло водометами и слезоточивым снарядом '
# 'протест фермера, когда они пытаются сломать баррикаду с помощью своего автомобиля и '
# 'трактор')
12. Заключение
Итак, это методы, которые вы можете использовать, когда беретесь за проект НЛП.
Я был бы рад узнать, есть ли у вас какие-либо новые подходы или предложения в ваших комментариях.
Приятного обучения!
Лучшее первое слово в Wordle… по математике – Эндрю Стил
Перейти к содержимому
Можете ли вы рассчитать лучшее начальное слово?
Опубликовано
Прочтите мою книгу Ageless: новая наука о старении без старения !
 youtube.com/embed/YEoCBnQwdzM?enablejsapi=1&origin=https://andrewsteele.co.uk&autoplay=0&cc_load_policy=0&cc_lang_pref=&iv_load_policy=1&loop=0&modestbranding=1&rel=1&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=1&" title="YouTube player" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen="" data-no-lazy="1" data-skipgform_ajax_framebjll="">
youtube.com/embed/YEoCBnQwdzM?enablejsapi=1&origin=https://andrewsteele.co.uk&autoplay=0&cc_load_policy=0&cc_lang_pref=&iv_load_policy=1&loop=0&modestbranding=1&rel=1&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=1&" title="YouTube player" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen="" data-no-lazy="1" data-skipgform_ajax_framebjll=""> Wordle может показаться игрой слов, но на самом деле это математическая игра. Вместо того, чтобы спорить о лучшем вступительном слове, почему бы не вычислить его с помощью теории информации?
Большое спасибо Tran Nguyen за всю ее помощь с этим видео… в частности, за то, что вдохновила нас на графики, показывающие энтропию различных начальных слов. А также большое спасибо Джейсону Лишке за то, что он открыл исходный код его кода для решения Wordle, который я безжалостно взломал, чтобы выполнить вычисления для этого видео!
Вы можете найти таблицу оптимальных вступительных слов в соответствии с этим методом ниже:
Лучшие вступительные слова
| Легкая режим | СРЕДНЯ | ALL ALL ALL ALL SARWLAD. | все слова | общие слова | ранг | слово | получается выиграть | слово | получается выиграть | слово получается | 2 | 2 | получается | word | turns to win | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. | REAST | 3.604 | TRACE | 3.625 | TRAPE | 3.805 | TRACE | 3.840 | ||||||||||||||||||||||||||||||
| 2. | TRACE | 3.608 | CRANE | 3.635 | PRATE | 3.808 | SLATE | 3.841 | ||||||||||||||||||||||||||||||
| 3. | CRANE | 3.610 | ROAST | 3.638 | SALET | 3.811 | LEAST | 3.846 | ||||||||||||||||||||||||||||||
| 4. | CARLE | 3.611 | SLATE | 3.640 | LEANT | 3.812 | LEANT | 3.850 | ||||||||||||||||||||||||||||||
5. | TORSE | 3.613 | TRICE | 3.641 | REAST | 3.814 | TRAIN | 3.851 | ||||||||||||||||||||||||||||||
| 6. | RANCE | 3.614 | CRATE | 3.642 | TRACE | 3.815 | PRATE | 3.852 | ||||||||||||||||||||||||||||||
| 7. | SALET | 3.614 | SLANT | 3.648 | CRANE | 3.816 | SLANT | 3,852 | ||||||||||||||||||||||||||||||
| 8. | Сланец | 3,616 | Старе | 3,648 | 2 | 3,818 | 3,818 | 3,818 | 3,818 | 3,818 | 3,818 | 3,818 | 3,648 | .0317 | ||||||||||||||||||||||||
| 9. | SNARE | 3.617 | LEAST | 3.651 | SLATE | 3.827 | CRANE | 3.855 | ||||||||||||||||||||||||||||||
10. | CRATE | 3.620 | PRATE | 3.653 | CRATE | 3.829 | TALES | 3.857 | ||||||||||||||||||||||||||||||
| 11. | LEAST | 3.620 | REACT | 3.654 | CARET | 3.829 | TRIPE | 3.862 | ||||||||||||||||||||||||||||||
| 12. | TRONE | 3.620 | CORSE | 3.655 | CARLE | 3.829 | SPATE | 3.863 | ||||||||||||||||||||||||||||||
| 13. | CARET | 3.621 | CADRE | 3.655 | TRICE | 3.829 | PLATE | 3.864 | ||||||||||||||||||||||||||||||
| 14. | ROAST | 3.621 | TRADE | 3.656 | PRASE | 3.830 | TRICE | 3.864 | ||||||||||||||||||||||||||||||
| 15. | CARTE | 3.621 | TRAIN | 3.657 | SLANE | 3.832 | DEALT | 3. 866 866 | ||||||||||||||||||||||||||||||
| 16. | ROSET | 3.621 | DEALT | 3.657 | PEART | 3.832 | TRIES | 3.866 | ||||||||||||||||||||||||||||||
| 17. | PRASE | 3.622 | SNARE | 3.657 | ARTEL | 3.833 | TRAIL | 3.867 | ||||||||||||||||||||||||||||||
| 18. | TRINE | 3.622 | LANCE | 3.657 | RESAT | 3.834 | STALE | 3,868 | ||||||||||||||||||||||||||||||
| 19. | TOILE | 3.623 | CARET | 3,658 | TRAGION | 3,8359 | .0317 | |||||||||||||||||||||||||||||||
| 20. | TRICE | 3.623 | STALE | 3.660 | PARSE | 3.835 | TRADE | 3.870 | ||||||||||||||||||||||||||||||
| 21. | SLART | 3.625 | SLICE | 3.660 | REIST | 3.836 | LANCE | 3.870 | ||||||||||||||||||||||||||||||
22. | PARSE | 3.625 | STORE | 3.660 | CARTE | 3.838 | CLEAT | 3.871 | ||||||||||||||||||||||||||||||
| 23. | TRADE | 3.626 | SCALE | 3.661 | REACT | 3.838 | CARET | 3.873 | ||||||||||||||||||||||||||||||
| 24. | SOREL | 3.627 | TRIPE | 3.662 | CARSE | 3.838 | TRIAL | 3.873 | ||||||||||||||||||||||||||||||
| 25. | STARE | 3.627 | STILE | 3.664 | SETAL | 3.839 | CREST | 3.875 | ||||||||||||||||||||||||||||||
| 26. | RAINE | 3.628 | TRAIL | 3.664 | TORSE | 3.839 | SCALE | 3.875 | ||||||||||||||||||||||||||||||
| 27. | SLANE | 3.628 | LEANT | 3.664 | TRINE | 3.840 | PLANE | 3. 876 876 | ||||||||||||||||||||||||||||||
| 28. | REACT | 3.631 | TEARS | 3.666 | SLART | 3.841 | REACT | 3.877 | ||||||||||||||||||||||||||||||
| 29. | CARSE | 3.633 | SAINT | 3.667 | TEALS | 3.841 | LEARN | 3.883 | ||||||||||||||||||||||||||||||
| 30. | PEART | 3.634 | SPATE | 3.668 | TRIES | 3.841 | NACRE | 3.884 | ||||||||||||||||||||||||||||||
| 31. | REIST | 3.634 | RAISE | 3.669 | EARNT | 3.844 | PEARL | 3.884 | ||||||||||||||||||||||||||||||
| 32. | TRAPE | 3.634 | PARSE | 3.670 | STALE | 3,844 | Cadre | 3,885 | ||||||||||||||||||||||||||||||
| 33. | Heart | 3,635 | Cater | 3,635 | 3,635 | 3,635 | 3,635 | . 0352 0352 | 3.885 | |||||||||||||||||||||||||||||
| 34. | ARTEL | 3.635 | CRAPE | 3.670 | TERAS | 3.844 | CASTE | 3.886 | ||||||||||||||||||||||||||||||
| 35. | EARST | 3.635 | PLATE | 3.671 | ALERT | 3.845 | TREAD | 3.886 | ||||||||||||||||||||||||||||||
| 36. | RONTE | 3.635 | PLANE | 3.671 | RANCE | 3.847 | ROAST | 3.887 | ||||||||||||||||||||||||||||||
| 37. | STALE | 3.635 | SNORE | 3.671 | CATER | 3.848 | ALERT | 3.888 | ||||||||||||||||||||||||||||||
| 38. | PRATE | 3.636 | AROSE | 3.672 | STANE | 3.849 | HEART | 3.888 | ||||||||||||||||||||||||||||||
| 39. | RAILE | 3.636 | NITRE | 3.672 | ALTER | 3. 849 849 | STARE | 3.888 | ||||||||||||||||||||||||||||||
| 40. | TASER | 3.636 | SIREN | 3.673 | TEARS | 3.850 | CORSE | 3.889 | ||||||||||||||||||||||||||||||
| 41 . | SOARE | 3,637 | TARGE | 3,673 | ROAT | 3,850 | PARSE | 3,850 | .0352 | 3.637 | ALTER | 3.674 | SANER | 3.851 | TAPER | 3.891 | ||||||||||||||||||||||
| 43. | TEARS | 3.637 | CREST | 3.674 | LEARN | 3.852 | SNARE | 3.891 | ||||||||||||||||||||||||||||||
| 44. | ANTRE | 3.638 | TRIED | 3.674 | TRONE | 3.852 | TRIED | 3.891 | ||||||||||||||||||||||||||||||
| 45. | LEANT | 3.638 | CLEAT | 3.675 | ROAST | 3.853 | TEARS | 3. 892 892 | ||||||||||||||||||||||||||||||
| 46. | ROATE | 3.638 | TRIAL | 3.676 | STARE | 3.853 | NEARS | 3.892 | ||||||||||||||||||||||||||||||
| 47. | TARES | 3.640 | SCARE | 3.677 | HEART | 3.854 | LITRE | 3.892 | ||||||||||||||||||||||||||||||
| 48. | AROSE | 3.641 | TREAD | 3.678 | ORATE | 3.854 | STEAL | 3.892 | ||||||||||||||||||||||||||||||
| 49. | EARNT | 3.641 | СЛАНКА | 3.678 | TASER | 3,854 | CATER | 3,893 | ||||||||||||||||||||||||||||||
| 50. | ||||||||||||||||||||||||||||||||||||||
| 50. | ||||||||||||||||||||||||||||||||||||||
| 50. | ||||||||||||||||||||||||||||||||||||||
| 50. | ||||||||||||||||||||||||||||||||||||||
| . | LATER | 3.854 | STILE | 3.894 | ||||||||||||||||||||||||||||||||||
| 51. | PARLE | 3.642 | GRATE | 3. 679 679 | EARST | 3.854 | TENOR | 3.895 | ||||||||||||||||||||||||||||||
| 52. | RESAT | 3.642 | NACRE | 3.679 | TARES | 3.855 | RINSE | 3.896 | ||||||||||||||||||||||||||||||
| 53. | SLIER | 3.643 | TRIES | 3.679 | ROSET | 3.855 | SAINT | 3.896 | ||||||||||||||||||||||||||||||
| 54. | STORE | 3.643 | CLEAR | 3.680 | SNARE | 3.856 | SLICE | 3.896 | ||||||||||||||||||||||||||||||
| 55. | STIRE | 3.645 | PEARL | 3.680 | STORE | 3.857 | SORTA | 3.897 | ||||||||||||||||||||||||||||||
| 56. | PAIRE | 3.648 | ALONE | 3.682 | TOILE | 3.857 | ALTER | 3.897 | ||||||||||||||||||||||||||||||
| 57. | CATER | 3. 648 648 | STAIR | 3.682 | SCARE | 3.857 | STAIR | 3.897 | ||||||||||||||||||||||||||||||
| 58. | ORATE | 3.649 | ALIEN | 3.682 | PARLE | 3.858 | SIREN | 3.898 | ||||||||||||||||||||||||||||||
| 59. | SANER | 3.649 | HEART | 3.682 | ANTRE | 3.859 | RATES | 3.899 | ||||||||||||||||||||||||||||||
| 60. | SETAL | 3.649 | LATER | 3.682 | SERAL | 3.859 | SCARE | 3.899 | ||||||||||||||||||||||||||||||
| 61. | ARIEL | 3.650 | SPARE | 3.682 | STRAE | 3.859 | SHALE | 3.899 | ||||||||||||||||||||||||||||||
| 62. | ALERT | 3.650 | CASTE | 3.683 | RATEL | 3.860 | SNORE | 3.900 | ||||||||||||||||||||||||||||||
63. | SERAL | 3.651 | ALERT | 3.683 | ALINE | 3.860 | SPARE | 3.901 | ||||||||||||||||||||||||||||||
| 64. | ALTER | 3.651 | TALES | 3.684 | ARETS | 3.862 | LATER | 3.901 | ||||||||||||||||||||||||||||||
| 65. | SCARE | 3.651 | AISLE | 3.685 | LITRE | 3.862 | NITRE | 3.901 | ||||||||||||||||||||||||||||||
| 66. | LIANE | 3.652 | CARES | 3.685 | SOREL | 3.863 | GRATE | 3.902 | ||||||||||||||||||||||||||||||
| 67. | RATEL | 3.652 | RINSE | 3.686 | TALER | 3.865 | IRATE | 3.902 | ||||||||||||||||||||||||||||||
| 68. | COATE | 3.653 | RATES | 3.686 | ALIEN | 3,867 | CLEAR | 3. 903 903 | ||||||||||||||||||||||||||||||
| 69. | 3,653 | LEANG | 3,687 | 3,687 | 3,657 | 3,653 | 3,653 | 3,653 | 0352 | 3.904 | ||||||||||||||||||||||||||||
| 70. | TALER | 3.654 | IRATE | 3.689 | RATES | 3.869 | ALIEN | 3.906 | ||||||||||||||||||||||||||||||
| 71. | AISLE | 3.655 | SAUTE | 3.690 | ARIEL | 3.870 | SATED | 3.910 | ||||||||||||||||||||||||||||||
| 72. | ALINE | 3.656 | TENOR | 3.690 | REALS | 3.870 | TARGE | 3.911 | ||||||||||||||||||||||||||||||
| 73. | ALONE | 3.656 | TAPER | 3.690 | LIANE | 3.872 | ASTER | 3.912 | ||||||||||||||||||||||||||||||
74. | SAINE | 3.656 | SOLAR | 3.691 | STEAR | 3.872 | CANOE | 3.912 | ||||||||||||||||||||||||||||||
| 75. | ARISE | 3.657 | GLARE | 3.692 | PAIRE | 3.873 | NARES | 3.913 | ||||||||||||||||||||||||||||||
| 76. | LATER | 3.657 | SORTA | 3.693 | STIRE | 3.874 | RENAL | 3.913 | ||||||||||||||||||||||||||||||
| 77 . | IRATE | 3.657 | PATER | 3.694 | RAINE | 3.875 | BLARE | 3.914 | ||||||||||||||||||||||||||||||
| 78. | TRIES | 3.658 | STEAL | 3.695 | IRATE | 3.876 | LITER | 3.914 | ||||||||||||||||||||||||||||||
| 79. | ALIEN | 3.659 | LITRE | 3.695 | SAUTE | 3.878 | CARES | 3. 916 916 | ||||||||||||||||||||||||||||||
| 80. | TEALS | 3.660 | SATED | 3.696 | ALONE | 3.880 | ALONE | 3.921 | ||||||||||||||||||||||||||||||
| 81. | TERAS | 3.660 | CANOE | 3.697 | RAILE | 3.880 | THANE | 3.923 | ||||||||||||||||||||||||||||||
| 82. | SAICE | 3.661 | SUITE | 3.698 | SHARE | 3.883 | SAUTE | 3.923 | ||||||||||||||||||||||||||||||
| 83. | SAUTE | 3.662 | THANE | 3.698 | LARES | 3.884 | LASER | 3.924 | ||||||||||||||||||||||||||||||
| 84. | RATES | 3.662 | BLARE | 3.698 | RALES | 3.885 | SOLAR | 3.925 | ||||||||||||||||||||||||||||||
| 85. | SHARE | 3.663 | NARE | 3,700 | Урат | 3,885 | Hater | 3,926 | ||||||||||||||||||||||||||||||
86. | до | .0352 | SLIER | 3.887 | ARISE | 3.927 | ||||||||||||||||||||||||||||||||
| 87. | LITRE | 3.663 | SHARE | 3.702 | COATE | 3.888 | AISLE | 3.927 | ||||||||||||||||||||||||||||||
| 88. | ARETS | 3.666 | LASER | 3.702 | SOARE | 3.888 | RAISE | 3.928 | ||||||||||||||||||||||||||||||
| 89. | TALES | 3.666 | HATER | 3.703 | RAISE | 3.889 | GLARE | 3.928 | ||||||||||||||||||||||||||||||
| 90. | LEARN | 3.667 | ASTER | 3.704 | LASER | 3.889 | ANISE | 3.930 | ||||||||||||||||||||||||||||||
| 91. | URATE | 3. 672 672 | LOSER | 3.705 | TOISE | 3.892 | LOSER | 3.932 | ||||||||||||||||||||||||||||||
| 92. | ARLES | 3.674 | ANISE | 3.708 | SAINE | 3.894 | ATONE | 3.934 | ||||||||||||||||||||||||||||||
| 93. | REALO | 3.674 | ATONE | 3.710 | ARLES | 3,895 | САБЕР | 3,937 | ||||||||||||||||||||||||||||||
| 94. | Стеар | 3,674 | 3,714 | .0352 | 3.940 | |||||||||||||||||||||||||||||||||
| 95. | REALS | 3.675 | ORIEL | 3.716 | OATER | 3.898 | SUITE | 3.943 | ||||||||||||||||||||||||||||||
| 96. | LARES | 3.678 | SHEAR | 3.717 | AISLE | 3.899 | ORIEL | 3.951 | ||||||||||||||||||||||||||||||
| 97. | RALES | 3.679 | NEARS | 3.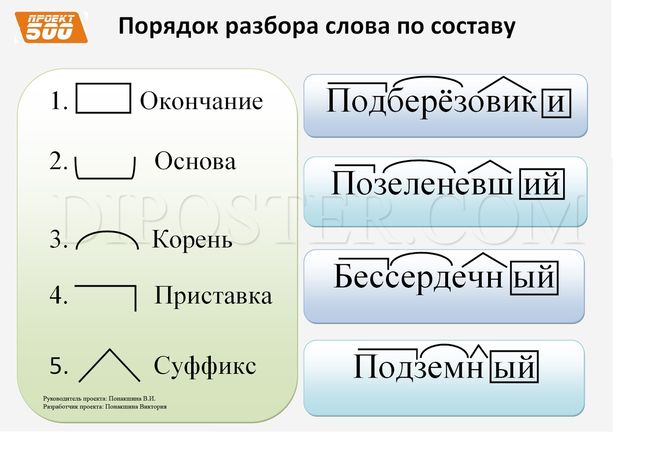 | ||||||||||||||||||||||||||||||||||
