Латвия, Эстония и Литва возглавили рейтинг наиболее благоприятных для стартапов стран по версии Index Ventures Статьи редакции
{«id»:196025,»url»:»https:\/\/vc.ru\/offline\/196025-latviya-estoniya-i-litva-vozglavili-reyting-naibolee-blagopriyatnyh-dlya-startapov-stran-po-versii-index-ventures»,»title»:»\u041b\u0430\u0442\u0432\u0438\u044f, \u042d\u0441\u0442\u043e\u043d\u0438\u044f \u0438 \u041b\u0438\u0442\u0432\u0430 \u0432\u043e\u0437\u0433\u043b\u0430\u0432\u0438\u043b\u0438 \u0440\u0435\u0439\u0442\u0438\u043d\u0433 \u043d\u0430\u0438\u0431\u043e\u043b\u0435\u0435 \u0431\u043b\u0430\u0433\u043e\u043f\u0440\u0438\u044f\u0442\u043d\u044b\u0445 \u0434\u043b\u044f \u0441\u0442\u0430\u0440\u0442\u0430\u043f\u043e\u0432 \u0441\u0442\u0440\u0430\u043d \u043f\u043e \u0432\u0435\u0440\u0441\u0438\u0438 Index Ventures»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/offline\/196025-latviya-estoniya-i-litva-vozglavili-reyting-naibolee-blagopriyatnyh-dlya-startapov-stran-po-versii-index-ventures»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/offline\/196025-latviya-estoniya-i-litva-vozglavili-reyting-naibolee-blagopriyatnyh-dlya-startapov-stran-po-versii-index-ventures&title=\u041b\u0430\u0442\u0432\u0438\u044f, \u042d\u0441\u0442\u043e\u043d\u0438\u044f \u0438 \u041b\u0438\u0442\u0432\u0430 \u0432\u043e\u0437\u0433\u043b\u0430\u0432\u0438\u043b\u0438 \u0440\u0435\u0439\u0442\u0438\u043d\u0433 \u043d\u0430\u0438\u0431\u043e\u043b\u0435\u0435 \u0431\u043b\u0430\u0433\u043e\u043f\u0440\u0438\u044f\u0442\u043d\u044b\u0445 \u0434\u043b\u044f \u0441\u0442\u0430\u0440\u0442\u0430\u043f\u043e\u0432 \u0441\u0442\u0440\u0430\u043d \u043f\u043e \u0432\u0435\u0440\u0441\u0438\u0438 Index Ventures»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.

15 378 просмотров
Сыграем с Новой Зеландией!
В пятницу, 4 марта, женская национальная сборная России сыгрет второй матч на международном турнире «Кубок Алгарве». Соперником нашей команды станет Новая Зеландия. Поединок пройдет в городе Паршал, начало в 21:30 по московскому времени. На официальном сайте РФС пройдет текстовая онлайн-трансляция поединка.
На следующий день после тяжелейшей победы над Португалией россиянок ждал насыщенный день. С утра команда на теоретическом занятии вместе с тренерским штабом разобрала прошедший матч. Далее россиянки приняли участие в тренировке. Те футболистки, кто провели накануне на поле большую часть матча, посвятили занятие восстановлению, остальные работали в обычном режиме. Вечером игроки снова расположились в учебном классе где разобрали игру ближайшего соперника — сборной Новой Зеландии. Футболистки просмотрели нарезку эпизодов матча новозеландок с Бразилией, в котором южноамериканки праздновали минимальную победу 1:0.
Новая Зеландия занимает 16-е место в рейтинге ФИФА. Это единственная команда в нашей группе, которая дебютирует на «Кубке Алгарве». В 22-х предыдущих турнирах «футбольные папоротники» задействованы не были, как, впрочем, и Бельгия, выступающая в другом квартете.
Эта команда из далекой и экзотической страны – многократный триумфатор «Кубка наций», проходящего под эгидой Конфедерации футбола Океании. Она принимала участие в трех последних Чемпионатах мира, где останавливалась на групповой стадии, а также в двух Олимпиадах, причем последняя из них – в Лондоне, — завершилась для нее на четвертьфинальной стадии, где она уступила в два мяча будущему триумфатору сборной США. На предстоящих Олимпийских играх в Бразилии Новая Зеландия также будет представлена. Путевку на крупнейший международный форум «папоротники» завоевали месяц назад, выиграв двухматчевое противостояние с Папуа – Новой Гвинеей.
На предстоящих Олимпийских играх в Бразилии Новая Зеландия также будет представлена. Путевку на крупнейший международный форум «папоротники» завоевали месяц назад, выиграв двухматчевое противостояние с Папуа – Новой Гвинеей.
«Для нас «Кубок Алгарве» – это большая репетиция турнира в рамках Олимпийских игр, мы пытались попасть на соревнование в Португалии в течение многих лет. Это что-то новое для команды, что-то свежее, и это будет отличным вызовом для нас в преддверии Олимпиады. На групповом этапе «Кубка Алгарве» мы сыграем с тремя командами, которые демонстрируют три различных стиля игры. Это значит, что мы должны адаптировать то, что мы делаем и как мы делаем против каждой из трех сборных. Надеюсь, что мы сможем финишировать на вершине нашей группы, после чего сыграем с совершенно новым по стилю соперником в финальной игре плей-офф», — приводит слова главного тренера новозеландских футболисток 40-летнего британского специалиста Тони Ридингса официальный сайт Ассоциации футбола страны.
В Португалию прибыли многие из тех, кто ковал олимпийскую путевку для Новой Зеландии, в том числе многоопытный капитан «папоротников» — 26-летняя Эбби Эрцег, в активе которой более 100 матчей за национальную команду. Нужно отметить, что разменяли вторую сотню еще три игрока, которые попали в заявку на «Кубок Алгарве», — Риа Персивал, Эмбер Херн, Кэти Данкан. Интересно, что все эти девушки, как и большинство футболисток команды, выступают в Чемпионатах за пределами родной страны.
Национальные сборные России и Новой Зеландии встречались прежде считанное количество раз. За последние десять лет команды провели всего два матча, и оба состоялись на Кипре. Последний, прошедший в марте 2011 года, носил статус товарищеской встречи в рамках подготовки к международному турниру «Кубок Кипра» и завершился со счетом 3:1 в пользу нашей сборной, в составе которой уже в дебюте поединка дубль оформила Екатерина Сочнева, а после перерыва отличилась Елена Морозова. А двумя годами ранее, уже в рамках самого соревнования, российские футболистки тоже вязи верх над соперником – 4:2. Любопытно, что в той встрече в составе нашей команды хет-триком отметилась Елена Фомина, которая в настоящее время возглавляет ее, а еще один гол записала в свой актив ее нынешняя подопечная в сборной и в «Россиянке» Анна Кожникова.
Любопытно, что в той встрече в составе нашей команды хет-триком отметилась Елена Фомина, которая в настоящее время возглавляет ее, а еще один гол записала в свой актив ее нынешняя подопечная в сборной и в «Россиянке» Анна Кожникова.
Состав команды:
Вратари: Эрин Нейлер («Норвест Юнайтед» Новая Зеландия), Ребекка Роллс («3 Кингс Юнайтед» Новая Зеландия).
Защитники: Кэтрин Ботт («Форрест Хилл Милфорд Юнайтед» Новая Зеландия), Анна Грин («Малльбакен» Швеция), Мейкайла Мур («Норвест Юнайтед» Новая Зеландия), Риа Персивал («Йена» Германия), Эли Райли («Русенгорд» Швеция), Ребека Стотт («Мельбурн Сити» Австралия), Эбби Эрцег («Вестерн Нью-Йорк Флэш» США).
Полузащитники: Кэти Боуэн («Канзас Сити» США), Кэти Данкан («Цюрих» Швейцария), Кейт Лойе («Клодлендс Роверс» Новая Зеландия), Аннали Лонго («Кашмир Техникал» Новая Зеландия), Бэтси Хассетт («Вердер» Германия), Кирсти Яллоп («Малльбакен» Швеция).
Нападающие: Сара Грегориус («Сперанца Осака-Такацуки» Япония), Жасмин Перейра («3 Кингс Юнайтед» Новая Зеландия), Роузи Уайт («Ливерпуль» Англия), Эйми Филлипс («Форрест Хилл Милфорд Юнайтед» Новая Зеландия), Эмбер Херн («Йена» Германия).
Главный тренер – Тони Ридингс (Англия).
ТУРНИРНОЕ ПОЛОЖЕНИЕ
Новичок «Кайрата» и другие. Названа символическая сборная третьего тура КПЛ
Профессиональная футбольная лига Казахстана (ПФЛК) представила символическую сборную третьего тура OLIMPBET-чемпионата страны.
При формировании состава сборной учитывался не только общий индекс действий игроков, но и различные ключевые показатели, характерные для их позиций.
Список 11 лучших футболистов тура следующий:
Вратарь: Марко Милошевич, «Каспий»
Надежный матч отыграл страж ворот «Каспия» против талдыкорганского «Жетысу» (2:0).
Правый защитник: Эльдар Абдрахманов, «Акжайык»
Великолепно против «Ордабасы» (1:2) сыграл опытный крайний защитник Эльдар Абдрахманов. Он совершил пять чистых отборов и четыре перехвата, к тому же у игрока 100-процентный показатель выигранных единоборств в защите. Моментами ему удавалось выключать из игры одного из самых лучших дриблеров лиги Рубена Бриджидо. Индекс действий — 263.
Центральные защитники: Александар Симчевич, «Ордабасы»; Жарко Томашевич, «Астана»
Второй кряду качественный матч сыграл опытный игрок обороны «Ордабасы» Александр Симчевич. Серб выиграл в обороне 85 процентов единоборств, а также совершил шесть перехватов и 14 подборов. Нельзя не отметить высокую точность передач футболиста — 111 пасов нашли своих адресатов (96 процентов точности). Индекс действий — 285.
Согласно статистике, у Томашевича в игре с «Тоболом» (1:1) 75 процентов выигранных единоборств в защите. Также игрок «Астаны» совершил восемь перехватов и пять подборов. Под конец игры Томашевич ударом головой сравнял счет и помог столичной команде уйти от поражения. Индекс действий — 336.
Левый защитник: Максат Тайкенов, «Каспий»
Воспитанник актауского футбола в матче с «Жетысу» здорово смотрелся как в атаке, так и в защите. Тайкенов уверенно поддерживал атаки «Каспия» и создавал угрозу за счет индивидуальных качеств. Он семь раз успешно обыгрывал своего оппонента, сделал две ключевые передачи и отметился ассистом. Индекс действий — 259.
Опорный полузащитник: Стефан Букорац, «Каспий»
Букорац цементировал опорную зону своей команды в игре против «Жетысу» (2:0). Шесть из восьми попыток отбора мяча у серба были удачными. Стефан своевременно страховал своих защитников и выиграл в обороне 71 процент борьбы.
 Также в активе у опытного игрока две ключевые передачи. Индекс действий — 281.
Также в активе у опытного игрока две ключевые передачи. Индекс действий — 281.Правый полузащитник: Еркебулан Тунгышбаев, «Ордабасы»
Тунгышбаев, выйдя на замену в игре с «Акжайыком», качественно усилил игру в атаке. Активность игрока проявилась в двух удачных обводках и двух ударах, один из которых стал победным на последней добавленной минуте игры. Индекс действий — 300.
Атакующий полузащитник: Дарко Зорич, «Кызыл-Жар СК»
Главным действующим лицом «Кызыл-Жара» в атаке является балканец Дарко Зорич. В победном домашнем матче с «Шахтером» (2:0) Зорич совершил пять удачных обводок и сделал в штрафную шесть передач. Его активность была вознаграждена забитым голом. Индекс действий — 277.
Левый полузащитник: Руслан Валиуллин, «Тобол»
Валиуллин продолжает демонстрировать стабильность на старте нового сезона. В прошедшем туре у Руслана в активе: два чистых отбора, девять перехватов и пять подборов. К тому же латераль «Тобола» был полезен и в атаке, совершив четыре эффективных обводки и сделав три точные передачи в штрафную. Индекс действий — 262.
Нападающие: Жоао Пауло, «Ордабасы»; Хосе Канте, «Кайрат»
Самый опасный игрок шымкентской дружины в противостоянии с крепким уральским «Акжайыком» (2:1), как обычно, был активен. Жоао часто прибегал к дальним ударам, но сумел отличиться с пенальти. Всего бразилец нанес девять ударов по воротам соперника, а также сделал семь передач в штрафную. Индекс действий — 237.
Яркий дебют новичка «Кайрата» Хосе Канте запомнится надолго не только болельщикам алматинского клуба, но защитникам из «Тараза». Канте был активен в атаке и отличился по системе «гол+пас». Сначала он мастерским ударом вколотил мяч в угол ворот, затем ассистировал Вагнеру Лаву. Индекс действий — 259.
Ближайшие матчи пройдут в два дня. 9 апреля сыграют «Тараз» — «Шахтер», «Акжайык» — «Кызыл-Жар СК», «Актобе» — «Ордабасы», «Кайсар» — «Каспий», а 10-го числа встретятся «Астана» — «Атырау», «Кайрат» — «Туран», «Жетысу» — «Тобол». Турнирная таблица приведена по этой ссылке.
Турнирная таблица приведена по этой ссылке.
Хотите стать обладателем нового смартфона? Тогда участвуйте в конкурсах на Vesti.kz. Что для этого нужно? Все просто: собрать свою команду в «Дрим тим» и делать прогнозы в «Конкурсе прогнозов» на матчи чемпионата Казахстана по футболу. Победители двух конкурсов получат по смартфону!
разобрать слово по составу плещется
Какой тип речи представлен в данном тексте? Культура развивается в диалоге, и Пришвин — хотя и стоял особняком в литературе, даже дачи в Переделкине … у него не было и не участвовал он в писательских комиссиях, разве что в Малеевке бывал иногда,— не исключение, а скорее подтверждение этого правила. Писатель, которого с легкой руки законодательницы высокой литературной моды начала века Зинаиды Николаевны Гиппиус часто упрекали не только в бесчеловечности, но и в болезненном самолюбии и самолюбовании, при всей своей индивидуальности был насквозь диалогичен и только через диалоги и полемику и может быть оценён и понят. Поэтому писать о Пришвине — это писать об эпохе, в которой он жил, и о людях, с которыми он спорил, у кого учился, кого любил и кого недолюбливал. Это верно по отношению к биографии любого писателя, но к Пришвину приложимо вдвойне, потому что не одну, а несколько эпох прожил этот человек, родившийся в семидесятые годы XIX века и умерший в пятидесятые XX, много чему был свидетель и испытатель и всё, что видел, кропотливо заносил в свой великий Дневник — главное и до сих пор не прочитанное произведение, бережно сохраненное для нас его второй женой Валерией Дмитриевной. описание рассуждение повествование
К какому стилю относится данный текст?
Культура развивается в диалоге, и Пришвин — хотя и стоял особняком в литературе, даже дачи в Переделкине у нег
… о не было и не участвовал он в писательских комиссиях, разве что в Малеевке бывал иногда,— не исключение, а скорее подтверждение этого правила. Писатель, которого с легкой руки законодательницы высокой литературной моды начала века Зинаиды Николаевны Гиппиус часто упрекали не только в бесчеловечности, но и в болезненном самолюбии и самолюбовании, при всей своей индивидуальности был насквозь диалогичен и только через диалоги и полемику и может быть оценён и понят. Поэтому писать о Пришвине — это писать об эпохе, в которой он жил, и о людях, с которыми он спорил, у кого учился, кого любил и кого недолюбливал. Это верно по отношению к биографии любого писателя, но к Пришвину приложимо вдвойне, потому что не одну, а несколько эпох прожил этот человек, родившийся в семидесятые годы XIX века и умерший в пятидесятые XX, много чему был свидетель и испытатель и всё, что видел, кропотливо заносил в свой великий Дневник — главное и до сих пор не прочитанное произведение, бережно сохраненное для нас его второй женой Валерией Дмитриевной.
разговорный
научный
публицистический
художественный
официально-деловой
Поэтому писать о Пришвине — это писать об эпохе, в которой он жил, и о людях, с которыми он спорил, у кого учился, кого любил и кого недолюбливал. Это верно по отношению к биографии любого писателя, но к Пришвину приложимо вдвойне, потому что не одну, а несколько эпох прожил этот человек, родившийся в семидесятые годы XIX века и умерший в пятидесятые XX, много чему был свидетель и испытатель и всё, что видел, кропотливо заносил в свой великий Дневник — главное и до сих пор не прочитанное произведение, бережно сохраненное для нас его второй женой Валерией Дмитриевной.
разговорный
научный
публицистический
художественный
официально-деловой
Какой тип речи представлен в этом тексте? Однажды бедный немецкий ремесленник приехал по делу в богатый голландский город Амстердам. Загляделся он на
… окружающее богатство. Увидев большой и красивый дом, он спросил первого встречного: «Чей это дом, в окнах которого так много тюльпанов, нарциссов, роз?» Прохожий ответил: «Каннитферштан». По-голландски это значит: «Не могу вас понять». А немец подумал, что так звали владельца дома. «Видно, богат не на шутку этот Каннитферштан», — подумал немец. Потом он пришел на пристань. Там было много кораблей, а тюки с товарами были как горы. Немцу захотелось узнать, кому принадлежат эти корабли и товары. Он спросил об этом у матроса, который нес огромный тюк. Матрос угрюмо пробормотал: «Каннитферштан!» «Какой молодец этот Каннитферштан! — подумал немец. — С таким богатством ему не было трудно построить такой роскошный дом!» Шел немец назад и с горечью думал о том, сколько богатых на свете и как беден он. И какое было бы счастье, если бы он был богат, как Каннитферштан. И вдруг увидел он четырех лошадей в длинных черных попонах. Они везли гроб, а за гробом шли родные и друзья в траурной одежде. Вдали одиноко звенел погребальный колокол. Немец тихонько спросил одного из идущих за гробом, кого это хоронят. «Каннитферштан!» — был ответ. «Бедный Каннитферштан! — подумал немец. — Что осталось тебе от такого богатства? То же, что рано или поздно останется мне от моей бедности: саван и тесный гроб». И с тех пор, когда грусть посещала его и ему становилось досадно видеть счастье богатых людей, он всегда утешался, вспомнив о Каннитферштане, его несметном богатстве, пышном доме, большом корабле и — тесной могиле. описание повествование рассуждение
И с тех пор, когда грусть посещала его и ему становилось досадно видеть счастье богатых людей, он всегда утешался, вспомнив о Каннитферштане, его несметном богатстве, пышном доме, большом корабле и — тесной могиле. описание повествование рассуждение
Редактирование предложений. 1.В детстве особенно важно научиться любить природу и понять её красоту и тайну. ( ошибка в употреблении видовременной свя … зи глаголов)2. В эмиграции Марина Цветаева часто вспоминала и восхищалась поэзией Бориса Пастернака. (ошибка в построении предложения с однородными членами)3. Трое подростков, среди которых были двое девушек, о чём-то шумно спорили на крыльце «Дома торговли». (ошибка в употреблении имени числительного)4. А. С. Пушкин в романе в стихах «Евгении Онегине» рисует картины жизни Петербурга и Москвы.5. Те, кто читал роман Л. Н. Толстого «Война и мир», помнит описание Бородинского сражения.6. Каждый человек видит жизненный идеал по-своему, согласно своего характера и моральных устоев.
Укажите номера предложений, которые связаны с предыдущими при помощи личного местоимения. (1) Однажды я побывал в лесничестве. (2) Оно помещалось на … окраине городка над рекой. (3) Около дома, где помещалось лесничество, разросся по склону оврага тенистый сад. (4) По дну оврага протекала речушка. (5) Она была тихая, с ленивым течением и густыми зарослями по берегам. (6) В этих зарослях была протоптана к воде тропинка, а около неё стояла скамейка. (7) В свободные минуты лесничий Михаил Михайлович, Анюта и другие сотрудники лесничества любили немного посидеть на этой скамейке, посмотреть, как толчётся над водой мошкара и как заходящее солнце догорает на облаках, похожих на парусные корабли. 6 1 2 7 4 5 3
Сделайте морфологический разбор слова (со мной)
Какой тип речи представлен в предложениях 3—5? (1) Однажды я побывал в лесничестве. (2) Оно помещалось на окраине городка над рекой. (3) Около дома, г
… де помещалось лесничество, разросся по склону оврага тенистый сад. (4) По дну оврага протекала речушка. (5) Она была тихая, с ленивым течением и густыми зарослями по берегам. (6) В этих зарослях была протоптана к воде тропинка, а около неё стояла скамейка. (7) В свободные минуты лесничий Михаил Михайлович, Анюта и другие сотрудники лесничества любили немного посидеть на этой скамейке, посмотреть, как толчётся над водой мошкара и как заходящее солнце догорает на облаках, похожих на парусные корабли. повествование описание рассуждение
(4) По дну оврага протекала речушка. (5) Она была тихая, с ленивым течением и густыми зарослями по берегам. (6) В этих зарослях была протоптана к воде тропинка, а около неё стояла скамейка. (7) В свободные минуты лесничий Михаил Михайлович, Анюта и другие сотрудники лесничества любили немного посидеть на этой скамейке, посмотреть, как толчётся над водой мошкара и как заходящее солнце догорает на облаках, похожих на парусные корабли. повествование описание рассуждение
помогите пожалуйста. нужно подчеркнуть деепричастные обороты
К какому стилю относится данный текст? (1) Однажды я побывал в лесничестве. (2) Оно помещалось на окраине городка над рекой. (3) Около дома, где поме … щалось лесничество, разросся по склону оврага тенистый сад. (4) По дну оврага протекала речушка. (5) Она была тихая, с ленивым течением и густыми зарослями по берегам. (6) В этих зарослях была протоптана к воде тропинка, а около неё стояла скамейка. (7) В свободные минуты лесничий Михаил Михайлович, Анюта и другие сотрудники лесничества любили немного посидеть на этой скамейке, посмотреть, как толчётся над водой мошкара и как заходящее солнце догорает на облаках, похожих на парусные корабли. художественный официально-деловой разговорный научный публицистический
составьте план пожалуйста
Самый быстрый способ разобрать текст в Excel
Если вы хотите проанализировать такие строки, как & quot; Первый последний & quot; в отдельные столбцы, вам не нужно использовать причудливые формулы. В Excel есть инструмент, который упрощает работу.
В разделе «Экономьте время, используя функции Excel для левой, правой и средней строк» мы показали вам, как извлекать подстроки из левой, правой или середины строки с фиксированным количеством символов.Мы продолжили этот совет, предложив «Использование Excel Find и Mid для извлечения подстроки, когда вы не знаете начальную точку», что позволяет извлекать подстроки из строк различной длины.

В этой статье мы покажем вам самый быстрый и простой способ разбить строку на отдельные столбцы. Самое приятное то, что эта техника не требует никаких формул!
Если есть разделитель, Excel может проанализировать текст.
Недавно я заметил, что коллега редактировал электронную таблицу, содержащую записи, подобные тем, что показаны на рис. A .Ей дали эти необработанные данные и попросили просуммировать факсы и электронные письма.
К сожалению, цифры и метки были объединены в одну строку. Эта бедняжка вручную меняла номер и метки, и у нее было 700 строк данных.
| Рисунок A |
| Мы покажем вам простой способ отделить числа от меток в этих необработанных данных. |
К счастью, я смог прийти на помощь своей коллеге, показав ей, как использовать функцию Excel Text To Columns для автоматического анализа этого текста.Вот как это работает.
Сначала выберите столбец ячеек, содержащий необработанные данные, затем откройте меню «Данные» и выберите «Текст в столбцы». Когда вы это сделаете, Excel запустит мастер преобразования текста в столбцы.
Убедитесь, что выбран переключатель «С разделителями», и нажмите «Далее». Поскольку разделитель в этих необработанных данных — это просто пробел между числом и меткой, активируйте флажок для Пробела, как показано на Рис. B . (Отмените выбор вкладки, которая является выбором по умолчанию.)
| Рисунок B |
| Укажите мастеру, что нужно использовать пробелы как разделители для этих необработанных данных. |
Нажмите кнопку «Далее», если хотите перейти к следующему экрану мастера. Однако в подобных случаях вы можете просто нажать кнопку «Готово». Когда вы это сделаете, Excel преобразует эти метки в отдельные столбцы. Числа в левой части поля будут сохранены как значения, а строки будут скопированы в следующий столбец, как показано на рис. C .
C .
| Рисунок C |
| Всего несколькими щелчками мыши вы можете преобразовать столбец меток в столбцы данных. |
Строка с любым другим именем
Этот совет пригодится, если у вас есть столбец имен в формате Первый Последний и вы хотите отделить фамилии — просто укажите пробел в качестве разделителя. Инструмент «Текст в столбцы» «обрежет» эти строки по любому указанному вами разделителю, так что вам и вашим пользователям больше не потребуется повторно вводить данные в отдельные столбцы.
Tales of Excel-lence
Чтобы прокомментировать этот совет (или поделиться своим любимым трюком с Excel), оставьте комментарий ниже или напишите нам.
Каждую неделю Джефф Дэвис рассказывает об этом так, как будто он видит это из окопов поля битвы ИТ. И вы можете получить его отчет с передовой прямо на ваш адрес электронной почты. Подпишитесь на Jeff’s View от Ground Zero TechMail, и вы получите бонус в виде избранных Джеффом лучших материалов для Интернета, , эксклюзивно для подписчиков TechMail .
(PDF) Анализ формул Excel: грамматика и ее применение в 4 больших наборах данных: AIVALOGLOU et al.
РАЗБОР ФОРМУЛ EXCEL 23
Неизвестно, эквивалентны ли две контекстно-свободные грамматики, но на практике для этой цели успешно использовались несколько приемов
[28, 29].
Анализ формул в наборе данных показал, что большинство из них маленькие и простые, но
также существуют удивительно большие и сложные формулы с более чем 50 функциями или операциями.
С точки зрения функциональности, большинство формул включают как минимум одну функцию или операцию
, и почти половина из них содержит как минимум одну константу. Было обнаружено, что почти все формулы используют данные
из других ячеек, которые часто относятся к ячейкам разных листов и внешних файлов.Были обнаружены различные типы
ссылок: Ссылки в виде диапазонов ячеек используются часто, в одной четвертой из
формул, но объединений, пересечений и ссылок на именованные диапазоны, на горизонтальные и вертикальные диапазоны
и на ссылки -возвратные функции Excel встречаются редко. Менее чем в 0,1% формул мы
Менее чем в 0,1% формул мы
обнаружили несколько ссылок на листы, сложные диапазоны, структурированные ссылки или динамический обмен данными
ссылок.
ССЫЛКИ
1.Уинстон В. Возможности высшего образования. OR / MS Сегодня 2001; 28 (4): 8–10.
2. Использование компьютеров и Интернета на работе в 2003 году. Технический отчет, Бюро статистики труда США за 2005 год. URL
http://www.bls.gov/news.release/pdf/ciuaw.pdf.
3. Анализ использования компьютеров в 95 организациях в Европе, Северной Америке и Австралии. Технический отчет
, Wellnomics 2007. URL http://www.wellnomics.nl/assets/Uploads/WorkPace/
News / Wellnomics-white-paper-Comparison- of-Computer-Use- через-разные-
Страны .pdf.
4. Скафди Ч., Шоу М., Майерс Б.А. Оценка количества конечных пользователей и конечных пользователей-программистов. Proc. VL / HCC
’05, 2005 г .; 207–214.
5. Hermans F, Jansen B, Roy S, Aivaloglou E, Swidan A, Hoepelman D. Электронные таблицы — это код: Обзор
подходов к разработке программного обеспечения, применяемых к электронным таблицам. 23-я Международная конференция IEEE по программному обеспечению
Анализ, эволюция и реинжиниринг, 2016.
6. Белл Д., Парр М. Таблицы: повестка дня исследования.SIGPLAN Notices 1993; 28 (9): 26–28.
7. Херманс Ф., Пинцгер М., ван Дерсен А. Поддержка профессиональных пользователей электронных таблиц путем создания диаграмм выровненных потоков данных.
. Proc. ICSE ’11, 2011 г .; 451–460.
8. Сиодзава К., Окада К., Мацусита Ю. Трехмерная интерактивная визуализация зависимостей электронных таблиц между ячейками. Proc.
из INFOVIS, IEEE, 1999; 79–83.
9. Hermans F, Sedee B, Pinzger M, Deursen Av. Обнаружение клонов данных и визуализация в электронных таблицах.Материалы
Международной конференции по разработке программного обеспечения 2013 г., ICSE ’13, IEEE Press: Piscataway, NJ, USA, 2013;
292–301. URL http://dl.acm.org/citation.cfm?id=2486788.2486827.
URL http://dl.acm.org/citation.cfm?id=2486788.2486827.
10. Доу В., Чунг С.К., Гао Ц., Сюй Ц., Сюй Л., Вэй Дж. Обнаружение клонов таблиц и запахов в электронных таблицах. Материалы
24-го Международного симпозиума ACM SIGSOFT по основам разработки программного обеспечения 2016 г., FSE 2016,
ACM: Нью-Йорк, Нью-Йорк, США, 2016 г .; 787–798, DOI: 10.1145 / 2950290.2950359. URL http://doi.acm.org/
10.1145 / 2950290.2950359.
11. Херманс Ф., Пинцгер М., ван Дерсен А. Обнаружение и визуализация запахов между листами в электронных таблицах. Proc. из
ICSE ’12, 2012 г .; 441–451.
12. Cheung SC, Chen W, Liu Y, Xu C. Custodes: Автоматическая кластеризация ячеек электронной таблицы и обнаружение запаха с использованием сильных и слабых функций
. Материалы 38-й Международной конференции по разработке программного обеспечения, ICSE ’16,
ACM: Нью-Йорк, Нью-Йорк, США, 2016; 464–475, DOI: 10.1145 / 2884781.2884796. URL http://doi.acm.org/
10.1145 / 2884781.2884796.
13. Доу В., Сюй С, Чунг С.К., Вей Дж. Кашек: Обнаружение и восстановление массивов ячеек в электронных таблицах. IEEE Transactions
о программной инженерии, март 2017 г .; 43 (3): 226–251, DOI: 10.1109 / TSE.2016.2584059.
14. Hermans F, Dig D. Bumblebee: Среда рефакторинга для формул электронных таблиц. FSE 2014, 2014; 747–750.
15. Badame S, Dig D. Рефакторинг соответствует формулам электронных таблиц.Proc. ICSM 2012, IEEE, 2012; 399–409.
16. Германс Ф. Совершенствование методов тестирования электронных таблиц. Материалы конференции 2013 г. Центра перспективных исследований
по совместным исследованиям, CASCON ’13, IBM Corp .: Riverton, NJ, USA, 2013; 56–69.
17. Фишер М., Ротермель Г. Корпус электронных таблиц euses: общий ресурс для поддержки экспериментов с механизмами надежности электронных таблиц
. SIGSOFT Softw. Англ. Примечания май 2005 г .; 30 (4): 1–5, DOI: 10.1145/1082983.
1083242.
18. Климт Б., Ян Й. Enron corpus: новый набор данных для исследования классификации электронной почты. Машинное обучение: ECML
2004, т. 3201. Springer Berlin Heidelberg, 2004; 217–226, DOI: 10.1007 / 978-3-540-30115-8 \ _22.
19. Барик Т., Любик К., Смит Дж., Сланкас Дж., Мерфи-Хилл Э. Фьюз: воспроизводимый, расширяемый корпус из
электронных таблиц в масштабе Интернета. Proc. 12-й Рабочей конференции по репозиториям программного обеспечения для майнинга (Data Showcase), 2015 г.
20. Германс Ф. Машина Тьюринга. URL http://www.felienne.com/archives/2974.
21. Microsoft. Расширения Excel (.xlsx) к формату файла office open xml spreadsheetml. URL https: // msdn.
microsoft.com/en-us/library/dd922181(v=office.12).aspx.
22. Aivaloglou E, Hoepelman D, Hermans F. Грамматика для формул электронных таблиц, оцененных на двух больших наборах данных.
Анализ исходного кода и манипуляции (SCAM), 2015 15-я Международная рабочая конференция IEEE, 2015 г .;
121–130.
23. Microsoft. Функции Excel (по алфавиту). URL-адрес https://support.office.com/en-in/article/
Excel-functions-алфавитный-b3944572- 255d-4efb-bb96- c6d
e188.Copyright c
0000 John Wiley & Sons, Ltd. J. Softw. Evol. и Proc. (0000)
Подготовлено с использованием smrauth.cls DOI: 10.1002 / smr
Навыки Microsoft Office для резюме и сопроводительных писем
Работодатели во многих отраслях ожидают от соискателей навыков работы с Microsoft Office (MS).Даже с появлением Google Диска, популярного конкурента, Microsoft Office остается наиболее предпочтительным программным обеспечением для повышения производительности на предприятиях по всему миру. Возможно, вам не понадобится быть экспертом в MS Office для вашей следующей работы, но вы улучшите свои перспективы трудоустройства и будете рассматриваться для получения дополнительных должностей, если вы хотя бы знакомы с основами.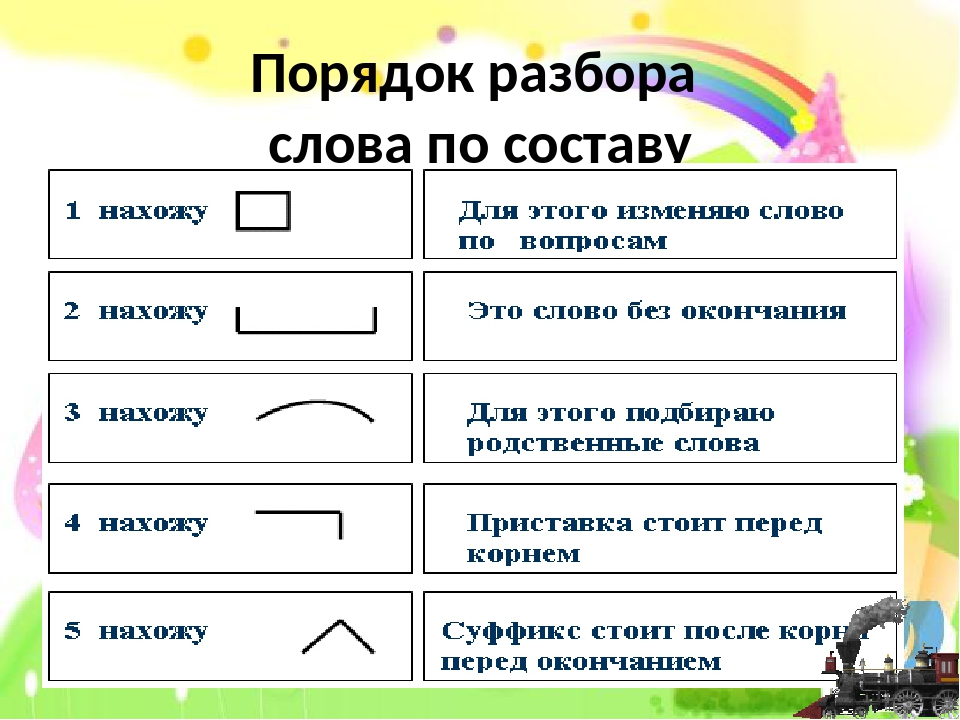
Более того, если вы подаете заявку на какую-либо административную должность, вам необходимо хорошо разбираться в использовании программ Office для решения повседневных задач.Скорее всего, ваш менеджер по найму будет рассчитывать на высокий уровень владения MS Office.
Для должностей высокого уровня ваш работодатель ожидает от вас хотя бы базового знания MS Word и MS Excel.
Какие навыки работы с Microsoft Office вам нужны?
MS Office включает в себя множество настольных приложений. Наиболее распространены Excel для электронных таблиц, Outlook для электронной почты, PowerPoint для презентаций и Word для обработки текста.
Хотя ваша следующая работа может использовать несколько приложений Microsoft Office, многие должности требуют ежедневного использования одного или обоих, MS Excel, MS Word и MS PowerPoint.Следующие ниже описания охватывают навыки в рамках этих программ, которые могут потребоваться работодателю, поэтому вы можете освежить их по мере необходимости и включить их в свое резюме.
Типы навыков работы с Microsoft Office
MS Excel
Вы можете получить дополнительное внимание от потенциальных работодателей, если сообщите им, что ваш уровень навыков в MS Excel включает знания и опыт использования следующих функций:
- Сводные таблицы: Вы можете управлять, сортировать и анализировать данные различными способами с помощью Excel, если вы в совершенстве владеете искусством создания сводной таблицы.Сводные таблицы выполняют автоматические действия, такие как сортировка и усреднение, чтобы помочь вам быстро анализировать данные, используя формулы, сортировки и другие функции, извлечение которых для анализа данных в противном случае заняло бы часы.
- Функции формул: Знание того, как использовать основные формулы в Excel, может помочь вам создавать электронные таблицы, которые принесут реальную пользу вашему работодателю.
 Ознакомьтесь с формулами для простых математических вычислений, а затем изучите часто используемые навыки, например, как связывать данные из одной электронной таблицы с другой, как находить информацию в больших наборах данных с помощью формул, таких как ВПР, и как использовать функции фильтра и промежуточных итогов. для сортировки и представления данных в визуально привлекательных форматах.
Ознакомьтесь с формулами для простых математических вычислений, а затем изучите часто используемые навыки, например, как связывать данные из одной электронной таблицы с другой, как находить информацию в больших наборах данных с помощью формул, таких как ВПР, и как использовать функции фильтра и промежуточных итогов. для сортировки и представления данных в визуально привлекательных форматах. - Форматирование: Нет правила, согласно которому электронные таблицы должны быть уродливыми или скучными. Таблицы, отформатированные с использованием одинакового размера шрифта, фирменных цветов и единообразного интервала, будут лучше восприняты коллегами и руководителями. Помимо основ создания визуально привлекательных электронных таблиц, Excel предоставляет множество вариантов форматирования, которые вы можете применить, чтобы сделать ваши данные более удобочитаемыми и эстетичными. Не стоит недооценивать силу удачно размещенного разделителя линий или умеренно применяемой цветовой схемы.
 Ознакомьтесь с формулами для простых математических вычислений, а затем изучите часто используемые навыки, например, как связывать данные из одной электронной таблицы с другой, как находить информацию в больших наборах данных с помощью формул, таких как ВПР, и как использовать функции фильтра и промежуточных итогов. для сортировки и представления данных в визуально привлекательных форматах.
Ознакомьтесь с формулами для простых математических вычислений, а затем изучите часто используемые навыки, например, как связывать данные из одной электронной таблицы с другой, как находить информацию в больших наборах данных с помощью формул, таких как ВПР, и как использовать функции фильтра и промежуточных итогов. для сортировки и представления данных в визуально привлекательных форматах.MS Word
Для письменного общения в бизнесе лучше всего использовать MS Word. Большинство работодателей будут искать кандидатов, которые могут выполнять следующие задачи в MS Word.
- Форматирование и настройка страницы: Многие люди не могут понять основы, казалось бы, трудных в использовании функций форматирования и настройки страниц MS Word. Вам будет очень полезно изучить основы этих функций, потому что они являются ключевыми для использования MS Office.Форматирование может включать в себя такие вещи, как настраиваемые повторяющиеся заголовки, несколько столбцов, нумерацию страниц, а также выбор шрифта и цвета.
- Создание и редактирование шаблонов: Создав то, что вам нравится, вы можете сохранить шаблон и повторно использовать его снова и снова.
- Использование SmartArt и текстовых полей: MSWord отлично подходит не только для текстовых документов. Это также полезно для таких вещей, как флаеры и вывески. Word позволяет легко создавать флаеры, если вы знаете, как использовать SmartArt и текстовые поля.Формы и текстовые поля иногда могут быть громоздкими, потому что сложнее заставить их перекрывать друг друга, и они могут иногда прыгать по странице, но как только вы освоите это и поймете причуды, вы станете мастером.
- Отслеживание изменений: Если вы просматриваете черновик чужой работы, важно иметь возможность использовать функцию отслеживания изменений, которая отображает любые изменения исходного текста, такие как добавленные или удаленные слова, или обновления форматирования Другим цветом подчеркнутым шрифтом.Также важно знать, как вставлять комментарии, и вы можете найти обе эти функции на вкладке «Обзор».
 Это также полезно для таких вещей, как флаеры и вывески. Word позволяет легко создавать флаеры, если вы знаете, как использовать SmartArt и текстовые поля.Формы и текстовые поля иногда могут быть громоздкими, потому что сложнее заставить их перекрывать друг друга, и они могут иногда прыгать по странице, но как только вы освоите это и поймете причуды, вы станете мастером.
Это также полезно для таких вещей, как флаеры и вывески. Word позволяет легко создавать флаеры, если вы знаете, как использовать SmartArt и текстовые поля.Формы и текстовые поля иногда могут быть громоздкими, потому что сложнее заставить их перекрывать друг друга, и они могут иногда прыгать по странице, но как только вы освоите это и поймете причуды, вы станете мастером.Если вы предпочитаете не использовать Photoshop или у вас нет доступа к профессиональному цифровому дизайну, MS Word и Publisher станут отличной альтернативой простым проектам визуального дизайна с использованием изображений, форм, цветов и других элементов дизайна.
MS PowerPoint
PowerPoint — это программное обеспечение для презентаций. Это позволяет дизайнеру создавать широкий спектр настраиваемых слайдов для проецирования на экран.Работодатели будут искать кандидатов, которые могут составить презентацию в PowerPoint, включающую текст, изображения, графику и таблицы. PowerPoint имеет множество функций, таких как тени, звуки и переходы между слайдами. Те, кто разбирается в PowerPoint, будут знать, как использовать правильные функции для акцента, не переусердствуя, не отвлекаясь.
- Пользовательские слайды и шаблоны: Работодателям нужен человек, который может создать привлекательный слайд с нуля и кто понимает основные элементы дизайна, такие как композиция, цвет и баланс.Успешный кандидат также сможет вводить новые данные в существующий шаблон.
- Анимация: Добавление анимации к тексту и изображениям добавляет яркости каждому слайду. Анимация позволяет элементам на странице увеличиваться, увеличиваться и уменьшаться. Работодатели предпочтут кандидатов, которые могут со вкусом и продуманно использовать эту функцию, не переусердствуя.
 Анимация позволяет элементам на странице увеличиваться, увеличиваться и уменьшаться. Работодатели предпочтут кандидатов, которые могут со вкусом и продуманно использовать эту функцию, не переусердствуя.
Анимация позволяет элементам на странице увеличиваться, увеличиваться и уменьшаться. Работодатели предпочтут кандидатов, которые могут со вкусом и продуманно использовать эту функцию, не переусердствуя.Работа с MS Office может быть интересной и полезной. Навыки Microsoft Office пригодятся практически в любой роли, но особенно на рабочем месте, где ценятся административные задачи.
Повысьте свои навыки и будьте готовы рассказать о том, что вы можете делать с MS Office на следующем собеседовании.
Дополнительные навыки работы с Microsoft Office
- MS Outlook
- Издатель MS
- Сертификаты MS
- OneDrive
- OneNote
- Графики
- Настройка параметров электронной почты
- Электронные визитные карточки
- Письменное сообщение
- Сотрудничество
- Организация цифровых файлов и папок
- Создание формы
- Создание этикеток
- Цифровые презентации
- Создание запроса
- Создание слайд-шоу
- Анализ данных
- Управление базой данных
- Фильтры электронной почты
- Вложения электронной почты
- Проверка грамматики
- Рассылка писем
- Параметры страницы
- Параметры печати
- Планирование
- Подписи электронной почты
- Обмен документами
- Проверка орфографии
- Дизайн
Как выделить свои навыки
ДОБАВЬТЕ СООТВЕТСТВУЮЩИЕ НАВЫКИ В ВАШЕ РЕЗЮМЕ: Для каждой работы требуются разные навыки и опыт, поэтому обязательно внимательно прочтите описание должности и сосредоточьтесь на соответствующих профессиональных навыках, перечисленных работодателем.
ОСНОВНЫЕ НАВЫКИ В ВАШЕМ ОБЛОЖНОМ ПИСЬМЕ: Используйте навыки, указанные выше, при создании письма. Для каждого навыка, который вы включаете, представьте, что вы проходите собеседование и вам нужно привести пример того, как вы использовали этот навык.
ИСПОЛЬЗУЙТЕ СЛОВА НАВЫКОВ В СВОЕЙ РАБОТЕ ИНТЕРВЬЮ: Во время собеседования будьте готовы обсудить функции, которые вам знакомы, и то, что вы можете делать.
Автоматизируйте скучную работу с помощью Python
В главе 13 вы узнали, как извлекать текст из документов PDF и Word.Эти файлы были в двоичном формате, что требовало специальных модулей Python для доступа к их данным. С другой стороны, файлы CSV и JSON — это просто текстовые файлы. Вы можете просмотреть их в текстовом редакторе, например в редакторе файлов IDLE. Но Python также поставляется со специальными модулями csv и json , каждый из которых предоставляет функции, которые помогут вам работать с этими форматами файлов.
CSV означает «значения, разделенные запятыми», а файлы CSV — это упрощенные электронные таблицы, хранящиеся в виде файлов с открытым текстом.Модуль Python csv упрощает синтаксический анализ файлов CSV.
JSON (произносится как «JAY-sawn» или «Jason» — неважно как, потому что в любом случае люди скажут, что вы произносите его неправильно) — это формат, в котором информация хранится в виде исходного кода JavaScript в файлах с открытым текстом.
(JSON — это сокращение от JavaScript Object Notation.) Вам не нужно знать язык программирования JavaScript, чтобы использовать файлы JSON, но формат JSON полезно знать, поскольку он используется во многих веб-приложениях.
Каждая строка в файле CSV представляет собой строку в электронной таблице, а ячейки в строке разделяются запятыми. Например, электронная таблица example.xlsx из http://nostarch.com/automatestuff/ в файле CSV будет выглядеть так:
05.04.2015 13:34, Яблоки, 73 05.04.2015 3:41, Вишня, 85 06.04.2015 12:46, Груши, 14 8.04.2015 8:59, Апельсины, 52 10.04.2015 2:07, Яблоки, 152 10.04.2015 18:10, Бананов, 23 10.04.2015 2:40, Клубника, 98
Я буду использовать этот файл для интерактивных примеров оболочки в этой главе.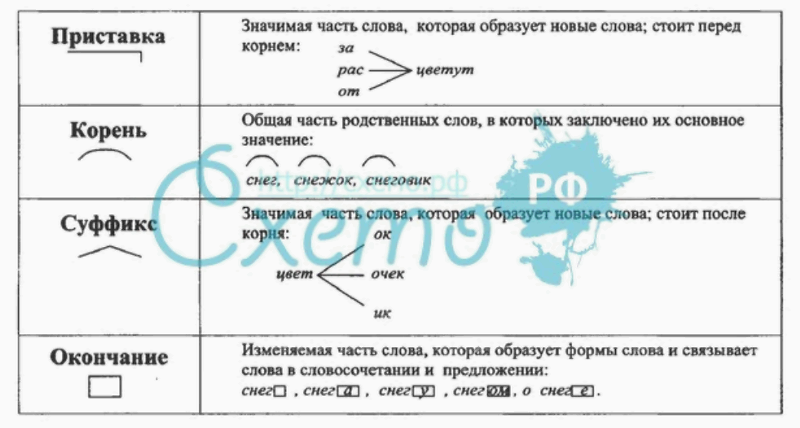 Вы можете загрузить example.csv из http://nostarch.com/automatestuff/ или ввести текст в текстовый редактор и сохранить его как example.csv .
Вы можете загрузить example.csv из http://nostarch.com/automatestuff/ или ввести текст в текстовый редактор и сохранить его как example.csv .
просты, в них отсутствуют многие функции электронной таблицы Excel. Например, файлы CSV
Не имеют типов для значений — все является строкой
Нет настроек размера или цвета шрифта
Нет нескольких листов
Невозможно указать ширину и высоту ячеек
Невозможно объединить ячейки
Не могут быть встроены в изображения или диаграммы
Преимущество файлов CSV — простота.Файлы CSV широко поддерживаются многими типами программ, их можно просматривать в текстовых редакторах (включая редактор файлов IDLE), и они представляют собой простой способ представления данных электронных таблиц. Формат CSV точно такой, как рекламируется: это просто текстовый файл со значениями, разделенными запятыми.
Поскольку файлы CSV — это просто текстовые файлы, у вас может возникнуть соблазн прочитать их как строку, а затем обработать эту строку, используя методы, которые вы изучили в главе 8. Например, поскольку каждая ячейка в файле CSV разделена запятой, возможно, вы могли бы просто вызвать метод split () для каждой строки текста, чтобы получить значения.Но не каждая запятая в файле CSV представляет собой границу между двумя ячейками. Файлы CSV также имеют собственный набор управляющих символов, позволяющих включать запятые и другие символы как часть значений . Метод split () не обрабатывает эти escape-символы. Из-за этих потенциальных ловушек вы всегда должны использовать модуль csv для чтения и записи файлов CSV.
Для чтения данных из файла CSV с помощью модуля csv необходимо создать объект Reader .Объект Reader позволяет перебирать строки в файле CSV.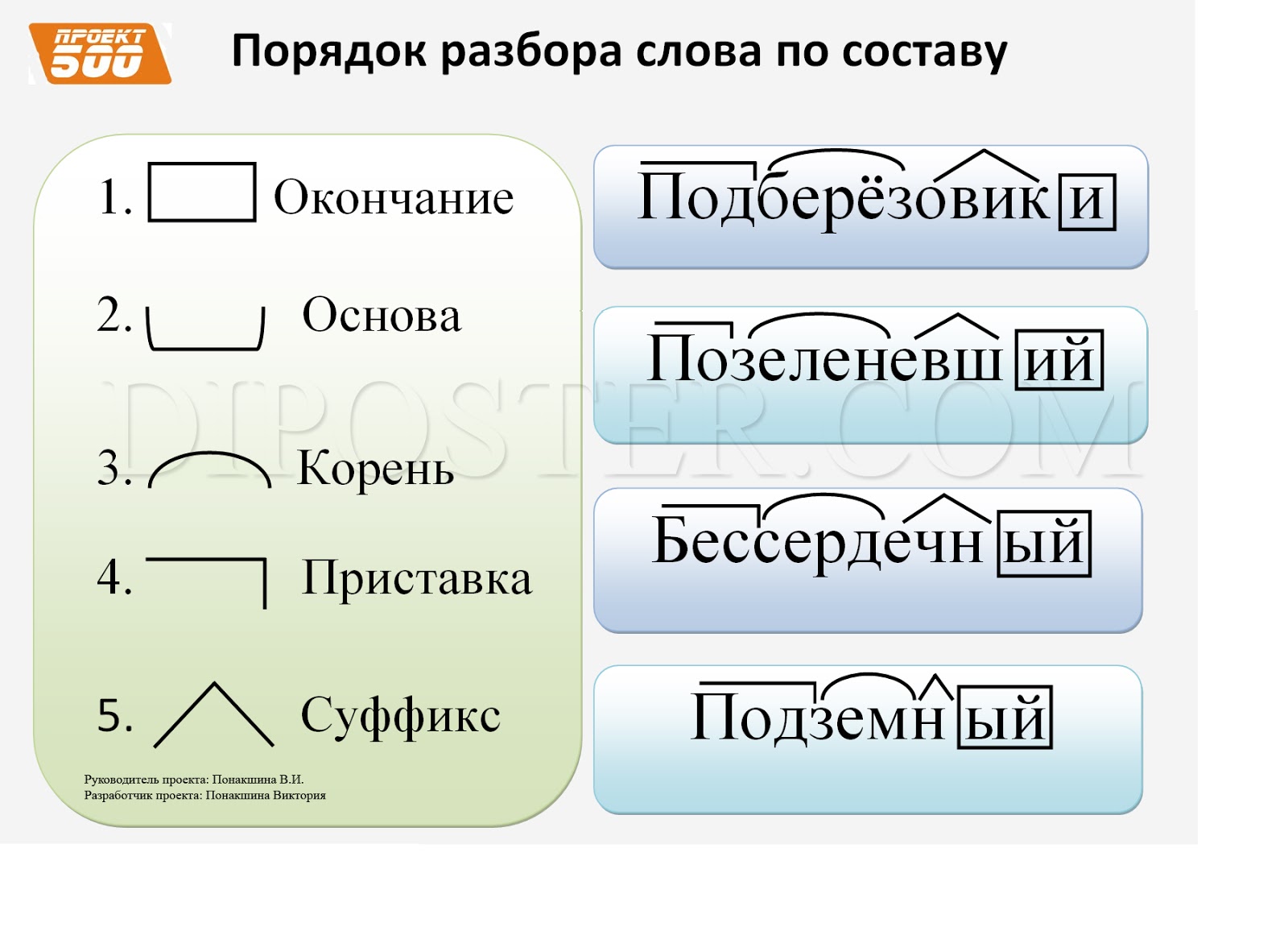 Введите в интерактивную оболочку следующее, с example.csv в текущем рабочем каталоге:
Введите в интерактивную оболочку следующее, с example.csv в текущем рабочем каталоге:
❶ >>> импорт csv
❷ >>> exampleFile = open ('example.csv')
❸ >>> exampleReader = csv.reader (exampleFile)
❹ >>> exampleData = list (exampleReader)
❹ >>> примерДанные
[['05.04.2015 13:34', 'Яблоки', '73'], ['05.04.2015 3:41', 'Вишни', '85'],
['4/6/2015 12:46', 'Груши', '14'], ['08.04.2015 8:59', 'Апельсины', '52'],
['4.10.2015 2:07', 'Яблоки', '152'], ['4.10.2015 18:10', 'Бананы', '23'],
['4.10.2015 2:40', 'Strawberries', '98']] Модуль csv поставляется с Python, поэтому мы можем импортировать его ❶ без предварительной установки.
Чтобы прочитать файл CSV с модулем csv , сначала откройте его с помощью функции open () ❷, как и любой другой текстовый файл. Но вместо вызова метода read () или readlines () для объекта File , который возвращает open () , передайте его функции csv.reader () ❸. Это вернет вам объект Reader . Обратите внимание, что вы не передаете строку имени файла напрямую в файл csv.reader () функция.
Самый прямой способ получить доступ к значениям в объекте Reader — преобразовать его в простой список Python, передав его в list () ❹. Использование list () для этого объекта Reader возвращает список списков, который вы можете сохранить в переменной, например, exampleData . При вводе exampleData в оболочку отображается список списков ❺.
Теперь, когда у вас есть CSV-файл в виде списка списков, вы можете получить доступ к значению в определенной строке и столбце с помощью выражения exampleData [row] [col] , где row — это индекс одного из списков в exampleData , а col — это индекс элемента, который вы хотите из этого списка. Введите в интерактивную оболочку следующее:
Введите в интерактивную оболочку следующее:
>>> exampleData [0] [0] '05.04.2015 13:34' >>> exampleData [0] [1] 'Яблоки' >>> exampleData [0] [2] '73' >>> exampleData [1] [1] 'Вишня' >>> exampleData [6] [1] 'Клубника'
exampleData [0] [0] входит в первый список и дает нам первую строку, exampleData [0] [2] входит в первый список и дает нам третью строку и так далее.
Чтение данных из объектов Reader в цикле for
Для больших файлов CSV вам нужно использовать объект Reader в цикле для . Это позволяет избежать загрузки всего файла в память сразу. Например, введите в интерактивную оболочку следующее:
>>> импорт CSV
>>> exampleFile = open ('example.csv')
>>> exampleReader = csv.reader (exampleFile)
>>> для строки в exampleReader:
print ('Row #' + str (exampleReader.line_num) + '' + str (строка))
Строка 1 ['05.04.2015 13:34', 'Яблоки', '73']
Строка № 2 ['05.04.2015 3:41', 'Вишня', '85']
Строка № 3 ['06.04.2015 12:46', 'Груши', '14']
Ряд № 4 ['8.04.2015 8:59', 'Апельсины', '52']
Строка 5 ['10.04.2015 2:07', 'Яблоки', '152']
Строка № 6 ['10.04.2015 18:10', 'Бананы', '23'].
Строка № 7 ['10.04.2015 2:40', 'Клубника', '98'] После того, как вы импортируете модуль csv и создадите объект Reader из файла CSV, вы можете перебирать строки в объекте Reader .Каждая строка представляет собой список значений, каждое из которых представляет собой ячейку.
Вызов функции print () печатает номер текущей строки и ее содержимое. Чтобы получить номер строки, используйте переменную line_num объекта Reader , которая содержит номер текущей строки.
Объект Reader можно зациклить только один раз. Чтобы повторно прочитать файл CSV, необходимо вызвать
Чтобы повторно прочитать файл CSV, необходимо вызвать csv.reader , чтобы создать объект Reader .
Объект Writer позволяет записывать данные в файл CSV. Чтобы создать объект Writer , вы используете функцию csv.writer () . Введите в интерактивную оболочку следующее:
>>> импорт CSV
❶ >>> outputFile = open ('output.csv', 'w', newline = '')
❷ >>> outputWriter = csv.writer (outputFile)
>>> outputWriter.writerow (['спам', 'яйца', 'бекон', 'ветчина'])
21 год
>>> outputWriter.writerow (['Привет, мир!', 'яйца', 'бекон', 'ветчина'])
32
>>> outputWriter.writerow ([1, 2, 3.141592, 4])
16
>>> outputFile.close () Сначала вызовите open () и передайте ему 'w' , чтобы открыть файл в режиме записи ❶. Это создаст объект, который затем можно передать в csv.writer () ❷, чтобы создать объект Writer .
В Windows вам также потребуется передать пустую строку для аргумента ключевого слова newline функции open () .По техническим причинам, выходящим за рамки этой книги, если вы забудете установить аргумент newline , строки в файле output.csv будут разделены двойным интервалом, как показано на рис. 14-1.
Рисунок 14-1. Если вы забудете аргумент ключевого слова newline = '' в open () , CSV-файл будет разделен двойным интервалом.
Метод writerow () для объектов Writer принимает аргумент списка. Каждое значение в списке помещается в отдельную ячейку выходного файла CSV.Возвращаемое значение writerow () — это количество символов, записанных в файл для этой строки (включая символы новой строки).
Этот код создает файл output. csv , который выглядит следующим образом:
csv , который выглядит следующим образом:
спам, яйца, бекон, ветчина «Привет, мир!», Яйца, бекон, ветчина 1,2,3.141592,4
Обратите внимание, как объект Writer автоматически экранирует запятую в значении 'Hello, world!' в двойных кавычках в CSV-файле. Модуль csv избавляет вас от необходимости решать эти особые случаи самостоятельно.
Аргументы ключевого слова разделителя и ограничителя строки
Допустим, вы хотите разделить ячейки символом табуляции вместо запятой и хотите, чтобы строки были разделены двойным интервалом. Вы можете ввести в интерактивную оболочку что-то вроде следующего:
>>> импорт CSV
>>> csvFile = open ('example.tsv', 'w', newline = '')
❶ >>> csvWriter = csv.writer (csvFile, delimiter = '\ t', lineterminator = '\ n \ n')
>>> csvWriter.writerow (['яблоки', 'апельсины', 'виноград'])
24
>>> csvWriter.writerow (['яйца', 'бекон', 'ветчина'])
17
>>> csvWriter.writerow (['спам', 'спам', 'спам', 'спам', 'спам', 'спам'])
32
>>> csvFile.close () Это изменяет символы разделителя и конца строки в вашем файле. Разделитель — это символ, который появляется между ячейками в строке. По умолчанию разделителем для файла CSV является запятая.Знак конца строки — это символ, который стоит в конце строки. По умолчанию терминатор строки — это новая строка. Вы можете изменить символы на другие значения, используя аргументы ключевого слова delimiter и lineterminator с csv.writer () .
Передача delimeter = '\ t' и lineterminator = '\ n \ n' ❶ изменяет символ между ячейками на табуляцию, а символ между строками на две новой строки. Затем мы трижды вызываем writerow () , чтобы получить три строки.
Будет создан файл с именем example.tsv со следующим содержимым:
яблоки апельсины виноград яйца бекон ветчина спам спам спам спам спам спам
Теперь, когда наши ячейки разделены табуляцией, мы используем расширение файла .tsv для значений, разделенных табуляцией.
Допустим, у вас скучная работа по удалению первой строки из нескольких сотен файлов CSV. Возможно, вы будете вводить их в автоматизированный процесс, требующий только данных, а не заголовков в верхней части столбцов.Вы, , можете открыть каждый файл в Excel, удалить первую строку и повторно сохранить файл, но это займет часы. Давайте вместо этого напишем программу.
Программа должна будет открыть каждый файл с расширением .csv в текущем рабочем каталоге, прочитать содержимое CSV-файла и переписать содержимое без первой строки в файл с тем же именем. Это заменит старое содержимое файла CSV новым содержимым без заголовка.
Примечание
Как всегда, всякий раз, когда вы пишете программу, которая изменяет файлы, обязательно сделайте резервную копию файлов, сначала на случай, если ваша программа не работает так, как вы ожидаете.Вы не хотите случайно стереть исходные файлы.
На высоком уровне программа должна делать следующее:
Найдите все файлы CSV в текущем рабочем каталоге.
Прочтите все содержимое каждого файла.
Запишите содержимое, пропуская первую строку, в новый файл CSV.
На уровне кода это означает, что программе потребуется выполнить следующие действия:
Перебирать список файлов из
os.listdir (), пропуская файлы, отличные от CSV.Создайте объект CSV
Readerи прочтите содержимое файла, используя атрибутline_num, чтобы определить, какую строку следует пропустить.Создайте объект CSV
Writerи запишите считанные данные в новый файл.

Для этого проекта откройте новое окно редактора файлов и сохраните его как removeCsvHeader.py .
Шаг 1. Цикл по каждому CSV-файлу
Первое, что нужно сделать вашей программе, — это перебрать список всех имен файлов CSV для текущего рабочего каталога. Сделайте так, чтобы ваш removeCsvHeader.py выглядел так:
#! python3
# removeCsvHeader.py - Удаляет заголовок из всех файлов CSV в текущем
# рабочий каталог.
импорт csv, os
os.makedirs ('headerRemoved', exist_ok = True)
# Перебрать каждый файл в текущем рабочем каталоге.для csvFilename в os.listdir ('.'):
если не csvFilename.endswith ('. csv'):
❶ continue # пропустить файлы не в формате CSV
print ('Удаление заголовка из' + csvFilename + '...')
# TODO: прочитать CSV-файл (пропуская первую строку).
# TODO: Запишите CSV-файл. Вызов os.makedirs () создаст папку headerRemoved , куда будут записаны все файлы CSV без заголовка. для петли на ос .listdir ('.') частично поможет вам, но он будет перебирать всех файлов в рабочем каталоге, поэтому вам нужно будет добавить код в начале цикла, который пропускает имена файлов, которые не заканчиваются на .csv . Оператор continue ❶ заставляет цикл for переходить к следующему имени файла, когда он сталкивается с файлом, отличным от CSV.
Так же, как выводит что-то во время работы программы, распечатайте сообщение о том, над каким CSV-файлом работает программа.Затем добавьте несколько комментариев TODO о том, что должна делать остальная часть программы.
Шаг 2. Прочтите CSV-файл
Программа не удаляет первую строку из файла CSV. Вместо этого он создает новую копию файла CSV без первой строки. Поскольку имя файла копии совпадает с именем исходного файла, копия перезапишет оригинал.
Программе потребуется способ отслеживать, зацикливается ли в данный момент первая строка. Добавьте следующее в removeCsvHeader.py .
#! python3
# removeCsvHeader.py - Удаляет заголовок из всех файлов CSV в текущем
# рабочий каталог.
- снип -
# Прочитать CSV-файл (пропуская первую строку).
csvRows = []
csvFileObj = открыть (csvFilename)
readerObj = csv.reader (csvFileObj)
для строки в считывателе Obj:
, если readerObj.line_num == 1:
continue # пропустить первую строку
csvRows.добавить (строка)
csvFileObj.close ()
# TODO: Запишите CSV-файл. Атрибут line_num объекта Reader может использоваться для определения, какую строку в CSV-файле он читает в данный момент. Другой цикл для будет перебирать строки, возвращенные из объекта CSV Reader , и все строки, кроме первой, будут добавлены к csvRows .
Поскольку цикл для повторяется по каждой строке, код проверяет, соответствует ли значение readerObj.line_num устанавливается на 1 . Если это так, он выполняет continue , чтобы перейти к следующей строке, не добавляя ее к csvRows . Для каждой последующей строки условием всегда будет False , и строка будет добавлена к csvRows .
Шаг 3. Запишите CSV-файл без первой строки
Теперь, когда csvRows содержит все строки, кроме первой, список необходимо записать в файл CSV в папке headerRemoved .Добавьте следующее в файл removeCsvHeader.py :
#! python3
# removeCsvHeader.py - Удаляет заголовок из всех файлов CSV в текущем
# рабочий каталог.
- снип -
# Перебрать каждый файл в текущем рабочем каталоге.
❶ для csvFilename в os.listdir ('.'):
если не csvFilename.endswith ('. csv'):
continue # пропустить файлы в формате, отличном от CSV
- снип -
# Записываем CSV-файл.
csvFileObj = open (os.path.join ('headerRemoved', csvFilename), 'w',
новая строка = '')
csvWriter = csv.writer (csvFileObj)
для строки в csvRows:
csvWriter.writerow (строка)
csvFileObj.close ()  ❶ для csvFilename в os.listdir ('.'):
если не csvFilename.endswith ('. csv'):
continue # пропустить файлы в формате, отличном от CSV
- снип -
# Записываем CSV-файл.
csvFileObj = open (os.path.join ('headerRemoved', csvFilename), 'w',
новая строка = '')
csvWriter = csv.writer (csvFileObj)
для строки в csvRows:
csvWriter.writerow (строка)
csvFileObj.close ()
❶ для csvFilename в os.listdir ('.'):
если не csvFilename.endswith ('. csv'):
continue # пропустить файлы в формате, отличном от CSV
- снип -
# Записываем CSV-файл.
csvFileObj = open (os.path.join ('headerRemoved', csvFilename), 'w',
новая строка = '')
csvWriter = csv.writer (csvFileObj)
для строки в csvRows:
csvWriter.writerow (строка)
csvFileObj.close () Объект CSV Writer запишет список в файл CSV в заголовке headerRemoved , используя csvFilename (который мы также использовали в программе чтения CSV).Это перезапишет исходный файл.
После создания объекта Writer мы перебираем подсписки, хранящиеся в csvRows , и записываем каждый подсписок в файл.
После выполнения кода внешний цикл for ❶ перейдет к следующему имени файла из os.listdir ('.') . Когда этот цикл завершится, программа будет завершена.
Чтобы протестировать вашу программу, загрузите removeCsvHeader.zip из http: // nostarch.com / automatestuff / и разархивируйте его в папку. Запустите программу removeCsvHeader.py в этой папке. Результат будет выглядеть так:
Удаление заголовка из NAICS_data_1048.csv ... Удаление заголовка из NAICS_data_1218.csv ... - снип - Удаление заголовка из NAICS_data_9834.csv ... Удаление заголовка из NAICS_data_9986.csv ...
Эта программа должна печатать имя файла каждый раз, когда она удаляет первую строку из файла CSV.
Идеи для похожих программ
Программы, которые вы могли бы написать для файлов CSV, аналогичны программам, которые вы могли бы написать для файлов Excel, поскольку они оба являются файлами электронных таблиц. Вы можете написать программы для выполнения следующих задач:
Вы можете написать программы для выполнения следующих задач:
Сравните данные между разными строками в файле CSV или между несколькими файлами CSV.
Скопируйте определенные данные из файла CSV в файл Excel или наоборот.
Проверьте файлы CSV на недопустимые данные или ошибки форматирования и предупредите пользователя об этих ошибках.
Считайте данные из файла CSV в качестве входных данных для ваших программ Python.
Нотация объектов JavaScript — популярный способ форматирования данных в виде единой удобочитаемой строки. JSON — это нативный способ написания структур данных программами JavaScript, который обычно напоминает то, что производит функция Python pprint () . Вам не нужно знать JavaScript, чтобы работать с данными в формате JSON.
Вот пример данных в формате JSON:
{"name": "Zophie", "isCat": правда,
«miceCaught»: 0, «napsTaken»: 37.5,
"felineIQ": null} JSON полезно знать, потому что многие веб-сайты предлагают контент JSON как способ взаимодействия программ с сайтом. Это известно как предоставление прикладного программного интерфейса (API) . Доступ к API аналогичен доступу к любой другой веб-странице через URL-адрес. Разница в том, что данные, возвращаемые API, отформатированы (например, с помощью JSON) для машин; Людям нелегко читать API.
Многие веб-сайты предоставляют свои данные в формате JSON.Facebook, Twitter, Yahoo, Google, Tumblr, Wikipedia, Flickr, Data.gov, Reddit, IMDb, Rotten Tomatoes, LinkedIn и многие другие популярные сайты предлагают API-интерфейсы для программ. Некоторые из этих сайтов требуют регистрации, которая почти всегда бесплатна. Вам нужно будет найти документацию о том, какие URL-адреса должна запрашивать ваша программа, чтобы получить нужные данные, а также общий формат возвращаемых структур данных JSON. Эта документация должна предоставляться любым сайтом, предлагающим API; если у них есть страница «Разработчики», поищите там документацию.
Используя API, вы можете писать программы, которые делают следующее:
Очистите необработанные данные с веб-сайтов. (Доступ к API часто бывает удобнее, чем загрузка веб-страниц и анализ HTML с помощью Beautiful Soup.)
Автоматически загружать новые сообщения из одной из ваших учетных записей в социальной сети и размещать их в другой учетной записи. Например, вы можете взять свои сообщения в Tumblr и опубликовать их в Facebook.
Создайте «энциклопедию фильмов» для своей личной коллекции фильмов, извлекая данные из IMDb, Rotten Tomatoes и Wikipedia и помещая их в один текстовый файл на своем компьютере.
Вы можете увидеть несколько примеров JSON API в ресурсах по адресу http://nostarch.com/automatestuff/ .
Модуль Python json обрабатывает все детали преобразования между строкой с данными JSON и значениями Python для функций json.loads () и json.dumps () . JSON не может хранить на каждые значений Python. Он может содержать значения только следующих типов данных: строки, целые числа, числа с плавающей запятой, логические значения, списки, словари и NoneType .JSON не может представлять объекты, специфичные для Python, такие как объекты File , объекты CSV Reader или Writer , объекты Regex или объекты Selenium WebElement .
Чтение JSON с помощью функции load ()
Чтобы преобразовать строку, содержащую данные JSON, в значение Python, передайте ее функции json.loads () . (Название означает «строка загрузки», а не «загрузка».) Введите в интерактивную оболочку следующее:
>>> stringOfJsonData = '{"name": "Zophie", "isCat": true, "miceCaught": 0,
"felineIQ": null} '
>>> импорт json
>>> jsonDataAsPythonValue = json. загружает (stringOfJsonData)
>>> jsonDataAsPythonValue
{'isCat': True, 'miceCaught': 0, 'name': 'Zophie', 'felineIQ': None}  загружает (stringOfJsonData)
>>> jsonDataAsPythonValue
{'isCat': True, 'miceCaught': 0, 'name': 'Zophie', 'felineIQ': None}
загружает (stringOfJsonData)
>>> jsonDataAsPythonValue
{'isCat': True, 'miceCaught': 0, 'name': 'Zophie', 'felineIQ': None} После импорта модуля json вы можете вызвать load () и передать ему строку данных JSON. Обратите внимание, что в строках JSON всегда используются двойные кавычки. Он вернет эти данные в виде словаря Python. Словари Python не упорядочены, поэтому пары ключ-значение могут отображаться в другом порядке при печати jsonDataAsPythonValue .
Запись JSON с помощью функции dumps ()
Функция json.dumps () (что означает «строка дампа», а не «дампы») преобразует значение Python в строку данных в формате JSON. Введите в интерактивную оболочку следующее:
>>> pythonValue = {'isCat': True, 'miceCaught': 0, 'name': 'Зофи',
'felineIQ': Нет}
>>> импорт json
>>> stringOfJsonData = json.дампы (pythonValue)
>>> строкаOfJsonData
'{"isCat": true, "felineIQ": null, "miceCaught": 0, "name": "Зофи"}' Значение может быть только одним из следующих основных типов данных Python: словарь, список, целое число, число с плавающей запятой, строка, логическое значение или Нет .
Проверка погоды кажется довольно тривиальной: откройте веб-браузер, щелкните адресную строку, введите URL-адрес веб-сайта с прогнозом погоды (или найдите его, а затем щелкните ссылку), дождитесь загрузки страницы, просмотрите все объявления, и так далее.
На самом деле, есть много скучных шагов, которые вы могли бы пропустить, если бы у вас была программа, которая загружала прогноз погоды на следующие несколько дней и распечатывала его в виде открытого текста. Эта программа использует модуль запросов из главы 11 для загрузки данных из Интернета.
В целом программа выполняет следующие функции:
Считывает запрошенное местоположение из командной строки.
Загрузки данных о погоде в формате JSON с OpenWeatherMap.орг.
Преобразует строку данных JSON в структуру данных Python.
Печать погоды на сегодня и следующие два дня.
Значит, в коде нужно будет сделать следующее:
Соедините строки в
sys.argv, чтобы получить местоположение.Позвоните по номеру
requests.get (), чтобы загрузить данные о погоде.Позвоните по телефону
json.load ()для преобразования данных JSON в структуру данных Python.Распечатать прогноз погоды.

Для этого проекта откройте новое окно редактора файлов и сохраните его как quickWeather.py .
Шаг 1. Получите местоположение из аргумента командной строки
Ввод для этой программы будет поступать из командной строки. Сделайте так, чтобы quickWeather.py выглядел так:
#! python3
# quickWeather.py - печатает погоду для местоположения из командной строки.
импортировать json, запросы, sys
# Вычислить местоположение из аргументов командной строки.
если len (sys.argv) <2:
print ('Использование: расположение quickWeather.py')
sys.exit ()
location = '' .join (sys.argv [1:])
# TODO: Загрузите данные JSON из API OpenWeatherMap.org.
# TODO: загрузить данные JSON в переменную Python. В Python аргументы командной строки хранятся в sys.argv список. После #! shebang line и import , программа проверит наличие более одного аргумента командной строки. (Напомним, что sys.argv всегда будет иметь хотя бы один элемент, sys.argv [0] , который содержит имя файла сценария Python.) Если в списке есть только один элемент, то пользователь не предоставил местоположение в командной строке, и перед завершением программы пользователю будет предоставлено сообщение об использовании.
Аргументы командной строки разделены пробелами.Аргумент командной строки San Francisco, CA сделает sys.argv удерживающим ['quickWeather.py', 'San', 'Francisco,', 'CA'] . Поэтому вызовите метод join () , чтобы объединить все строки, кроме первой, в sys.argv . Сохраните эту объединенную строку в переменной с именем location .
Шаг 2. Загрузите данные JSON
OpenWeatherMap.org предоставляет информацию о погоде в реальном времени в формате JSON. Ваша программа просто должна загрузить страницу по адресу http: // api.openweathermap.org/data/2.5/forecast/daily?q=
#! python3 # quickWeather.py - Распечатывает погоду для местоположения из командной строки. - снип - # Загрузите данные JSON из API OpenWeatherMap.org. url = 'http: //api.openweathermap.org/data/2.5/forecast/daily? Q =% s & cnt = 3'% (местоположение) ответ = запросы.получить (URL) response.raise_for_status () # TODO: загрузить данные JSON в переменную Python.
У нас есть расположение из наших аргументов командной строки. Чтобы создать URL-адрес, к которому мы хотим получить доступ, мы используем заполнитель % s и вставляем любую строку, хранящуюся в ячейке , в это место в строке URL-адреса. Мы сохраняем результат в url и передаем url на requests.get () . Вызов requests.get () возвращает объект Response , который можно проверить на наличие ошибок, вызвав raise_for_status () .Если исключение не возникает, загруженный текст будет в response.text .
Шаг 3. Загрузите данные JSON и распечатайте прогноз погоды
Переменная-член response. содержит большую строку данных в формате JSON. Чтобы преобразовать это значение в значение Python, вызовите функцию  text
text json.loads () . Данные JSON будут выглядеть примерно так:
{'город': {'координата': {'широта': 37,7771, 'долгота': -122,42},
'country': 'Соединенные Штаты Америки',
'id': '5391959',
'name': 'Сан-Франциско',
'популяция': 0},
'cnt': 3,
'cod': '200',
'list': [{'clouds': 0,
'град': 233,
'dt': 1402344000,
'влажность': 58,
'давление': 1012.23,
'скорость': 1,96,
'temp': {'day': 302,29,
"канун": 296,46,
'макс': 302,29,
'min': 289,77,
'утро': 294,59,
'night': 289.77},
'weather': [{'description': 'небо чистое',
'icon': '01d',
- снип - Вы можете увидеть эти данные, передав weatherData в pprint.pprint () .Вы можете проверить http://openweathermap.org/ для получения дополнительной документации о том, что означают эти поля. Например, в онлайн-документации будет указано, что 302,29 после «день» - это дневная температура по Кельвину, а не по Цельсию или Фаренгейту.
Описание погоды, которое вы хотите, следует после 'main' и 'description' . Чтобы аккуратно распечатать их, добавьте следующее в quickWeather.py .
! python3
# quickWeather.py - печатает погоду для местоположения из командной строки.
- снип -
# Загрузить данные JSON в переменную Python.
weatherData = json.loads (response.text)
# Распечатать описание погоды.
❶ w = weatherData ['список']
print ('Текущая погода в% s:'% (location))
print (w [0] ['weather'] [0] ['main'], '-', w [0] ['weather'] [0] ['description'])
печать ()
print ('Завтра:')
print (w [1] ['weather'] [0] ['main'], '-', w [1] ['weather'] [0] ['description'])
печать ()
print ('Послезавтра:')
print (w [2] ['weather'] [0] ['main'], '-', w [2] ['weather'] [0] ['description']) Обратите внимание, что код сохраняет weatherData ['list'] в переменной w , чтобы сэкономить время при вводе ❶.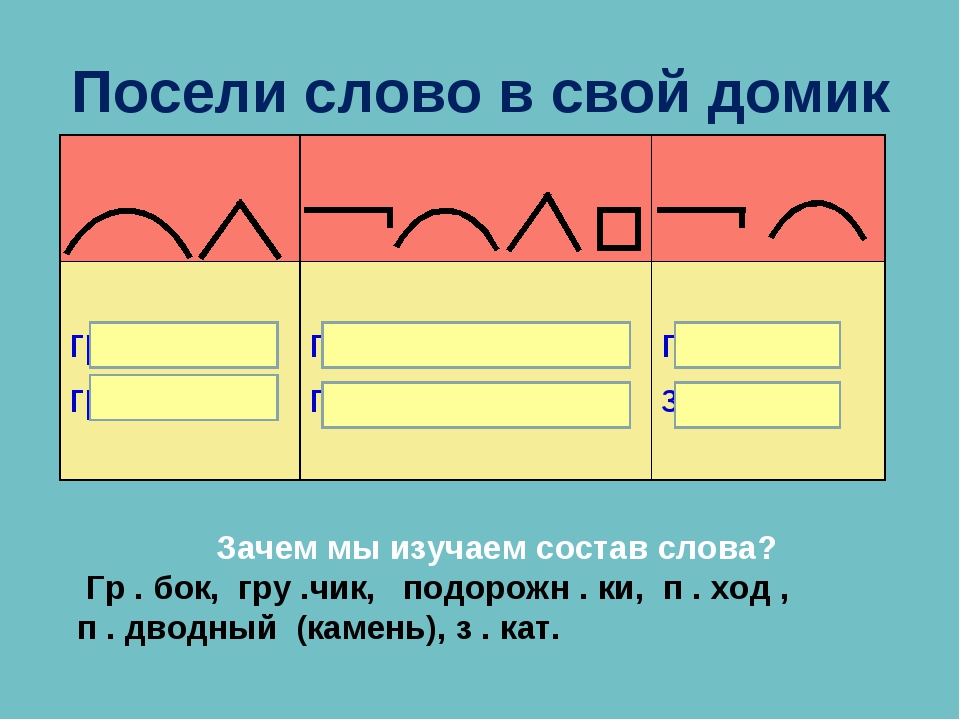 Вы используете
Вы используете w [0] , w [1] и w [2] для получения словарей на сегодня, завтра и послезавтра погоду соответственно. Каждый из этих словарей имеет ключ 'weather' , который содержит значение списка. Вас интересует первый элемент списка, вложенный словарь с еще несколькими ключами, с индексом 0. Здесь мы печатаем значения, хранящиеся в ключах 'main' и 'description' , через дефис.
Когда эта программа запускается с аргументом командной строки quickWeather.py San Francisco, CA , результат выглядит примерно так:
Текущая погода в Сан-Франциско, Калифорния: Ясно - небо ясное Завтра: Облака - мало облаков Послезавтра: Ясно - небо чисто
(Погода - одна из причин, почему мне нравится жить в Сан-Франциско!)
Идеи для похожих программ
Доступ к данным о погоде может лечь в основу многих типов программ. Вы можете создавать похожие программы для следующих целей:
Соберите прогнозы погоды для нескольких кемпингов или пешеходных маршрутов, чтобы узнать, на каком из них будет лучшая погода.
Запланируйте программу, чтобы регулярно проверять погоду и отправлять вам оповещения о заморозках, если вам нужно переместить растения в помещение. (В главе 15 рассказывается о расписании, а в главе 16 объясняется, как отправлять электронную почту.)
Получите данные о погоде с нескольких сайтов, чтобы показать все сразу, или рассчитайте и покажите среднее значение нескольких прогнозов погоды.
Почему Microsoft Word должен умереть
Ненавижу Microsoft Word.Я хочу, чтобы Microsoft Word умер. Я ненавижу Microsoft Word с пламенной страстью. Я ненавижу Microsoft Word так же, как Уинстон Смит ненавидел Большого Брата. Наши причины, что тревожно, не отличаются ...
Microsoft Word - тиран воображения, мелкий, лишенный воображения, непоследовательный диктатор, который не подходит для любого творческого писателя. Хуже того: это почти монополист, доминирующий в области обработки текстов. Его повсеместный почти монопольный статус заставил разработчиков программного обеспечения «промыть мозги» до такой степени, что немногие могут представить себе инструмент для обработки текстов, существующий как нечто иное, кроме как поверхностную имитацию Redmond Behemoth.Но что именно с этим не так?
Хуже того: это почти монополист, доминирующий в области обработки текстов. Его повсеместный почти монопольный статус заставил разработчиков программного обеспечения «промыть мозги» до такой степени, что немногие могут представить себе инструмент для обработки текстов, существующий как нечто иное, кроме как поверхностную имитацию Redmond Behemoth.Но что именно с этим не так?
Я использую текстовые редакторы и текстовые редакторы почти 30 лет. До доминирования Microsoft Word была эпоха, когда на открытом рынке идей соревновались различные радикально разные парадигмы подготовки и форматирования текста. Одной из первых и особенно эффективных комбинаций была идея текстового файла, содержащего встроенные команды или макросы, который можно было редактировать с помощью текстового редактора программиста (например, ed или teco или, позже, vi или emacs), а затем передавать в различные инструменты: автономные средства проверки орфографии, средства проверки грамматики и средства форматирования, такие как scribe, troff и latex, которые создают двоичное изображение страницы, которое можно загрузить на принтер.
Эти инструменты были быстрыми, мощными, элегантными и чрезвычайно требовательными к пользователю. Когда появились первые 8-битные персональные компьютеры (в основном состоящие из Apple II и конкурирующей экосистемы CP / M), программисты попытались разработать гибридный инструмент, называемый текстовым процессором: экранно-ориентированный редактор, скрывающий сложное и враждебное управление принтером. команды от автора, заменяя их видимыми выделенными символами на экране и показывая их только тогда, когда пользователь сказал программе «раскрыть коды».Такие программы, как WordStar, лидировали до тех пор, пока WordPerfect не вышел на рынок в начале 1980-х, добавив возможность редактировать два или более файлов одновременно в режиме разделенного экрана.
Затем, в конце 1970-х - начале 1980-х, исследовательские группы Массачусетского технологического института и исследовательского центра Xerox в Пало-Альто начали разработку инструментов, которые конкретизировали графический пользовательский интерфейс рабочих станций, таких как Xerox Star, а затем Apple Lisa и Macintosh (и наконец, имитатор Джонни, пришедшего в последнее время, Microsoft Windows). Между двумя фракциями вспыхнула непрекращающаяся война. Одна фракция хотела взять классическую модель встроенных кодов и обновить ее до графического растрового отображения: вы должны выделить часть текста и пометить ее как «курсив» или «полужирный», а текстовый процессор встроит управляющие коды в файла, и, когда пришло время распечатать файл, он изменил глифы шрифта, отправляемые на принтер в этой точке последовательности. Но другая группа хотела использовать гораздо более мощную модель: иерархические таблицы стилей.В системе таблиц стилей единицы текста - слова или абзацы - помечаются именем стиля, которое обладает набором атрибутов, которые применяются к фрагменту текста при его печати.
Между двумя фракциями вспыхнула непрекращающаяся война. Одна фракция хотела взять классическую модель встроенных кодов и обновить ее до графического растрового отображения: вы должны выделить часть текста и пометить ее как «курсив» или «полужирный», а текстовый процессор встроит управляющие коды в файла, и, когда пришло время распечатать файл, он изменил глифы шрифта, отправляемые на принтер в этой точке последовательности. Но другая группа хотела использовать гораздо более мощную модель: иерархические таблицы стилей.В системе таблиц стилей единицы текста - слова или абзацы - помечаются именем стиля, которое обладает набором атрибутов, которые применяются к фрагменту текста при его печати.
Microsoft была производителем программного обеспечения для персональных компьютеров в начале 1980-х, главным образом известна своим интерпретатором BASIC и операционной системой MS-DOS. Стив Джобс обратился к Биллу Гейтсу с просьбой написать приложения для новой системы Macintosh в 1984 году, и Билл согласился. Одной из его первых работ было создание первого текстового процессора WYSIWYG для персонального компьютера - Microsoft Word для Macintosh.Внутри бушевали споры: следует ли использовать управляющие коды или иерархические таблицы стилей? В конце концов, постановление вышло: Word должен реализовать и парадигмы форматирования. Несмотря на то, что они принципиально несовместимы, вы можете попасть в ужасный беспорядок, применив простое форматирование символов к документу, основанному на стилях, или наоборот. На самом деле слово было нарушено намеренно, с самого начала - и дальше стало только хуже.
В конце 1980-х - начале 1990-х годов Microsoft превратилась в гиганта с почти монопольным положением в мире программного обеспечения.Одна из его тактик стала известна (и вызывала опасения) во всей отрасли: обнимать и расширять. Если бы Microsoft столкнулась с успешным новым типом программного обеспечения, Microsoft купила бы одну из ведущих компаний в этом секторе, а затем бросила бы ресурсы на интеграцию своего продукта в собственную экосистему Microsoft, при необходимости сбросив ее по более низкой цене, чтобы вытеснить конкурентов из бизнеса. Microsoft Word вырос за счет появления новых подсистем: слияние писем, проверка орфографии, проверка грамматики, обработка схем. Все это когда-то было успешным кустарным производством с процветающим сообществом конкурирующих поставщиков продуктов, стремящихся производить более качественные продукты, которые захватили бы доли рынка друг друга.Но один за другим Microsoft входила в каждый сектор и встраивала в Word одного из конкурентов, тем самым убивая конкуренцию и подавляя инновации. Microsoft убила процессор схем в Windows; остановило развитие инструмента проверки грамматики, подавило проверку орфографии. Существует целое кладбище некогда обнадеживающих новых программных экосистем, имя ему - Microsoft Word.
Microsoft Word вырос за счет появления новых подсистем: слияние писем, проверка орфографии, проверка грамматики, обработка схем. Все это когда-то было успешным кустарным производством с процветающим сообществом конкурирующих поставщиков продуктов, стремящихся производить более качественные продукты, которые захватили бы доли рынка друг друга.Но один за другим Microsoft входила в каждый сектор и встраивала в Word одного из конкурентов, тем самым убивая конкуренцию и подавляя инновации. Microsoft убила процессор схем в Windows; остановило развитие инструмента проверки грамматики, подавило проверку орфографии. Существует целое кладбище некогда обнадеживающих новых программных экосистем, имя ему - Microsoft Word.
По мере роста продукта Microsoft развернула свою тактику охвата и расширения, чтобы вынудить пользователей выполнить обновление, заблокировав их в Word, путем изменения формата файла, который программа регулярно использовала.Ранние версии Word хорошо взаимодействовали с такими конкурентами, как Word Perfect, импортируя и экспортируя форматы файлов других программ. Но по мере установления доминирования Word Microsoft неоднократно меняла формат файла - с Word 95, Word 97 в 2000 году и снова в 2003 году и в последнее время. Каждая новая версия Word по умолчанию записывала новый формат файла, который не мог быть проанализирован старыми копиями программы. Если бы вам пришлось обмениваться документами с кем-либо еще, вы могли бы попробовать , чтобы заставить их отправлять и получать RTF - но по большей части обычные бизнес-пользователи никогда не разбирались в различных форматах файлов в «Сохранить как»... ", и поэтому, если вам нужно было работать с другими, вам приходилось платить Microsoft Danegeld на регулярной основе, даже если ни одна из новых функций не была вам полезна. Формат файла .doc также был запутан, намеренно или намеренно: вместо анализируемого документа, содержащего форматирование и макрометаданные, это был фактически дамп структур данных в памяти, используемых словом, с указателями на подпрограммы, которые обеспечивали форматирование или поддержку макросов. А «быстрое сохранение» ухудшало картину , добавив журнал изменений в состояние памяти приложения.Для синтаксического анализа файла .doc вам фактически нужно написать мини-реализацию Microsoft Word. Это не формат файла данных: это кошмар! В 21 веке они пытались улучшить картину, заменив ее схемой XML ... но каким-то образом им удалось ухудшить ситуацию, используя теги XML, которые ссылались на обратные вызовы в кодовой базе Word, а не представляли фактическую семантику документа. Трудно представить себе, что такая большая и [обычно] грамотно управляемая корпорация, как Microsoft, случайно совершит такую ошибку...
А «быстрое сохранение» ухудшало картину , добавив журнал изменений в состояние памяти приложения.Для синтаксического анализа файла .doc вам фактически нужно написать мини-реализацию Microsoft Word. Это не формат файла данных: это кошмар! В 21 веке они пытались улучшить картину, заменив ее схемой XML ... но каким-то образом им удалось ухудшить ситуацию, используя теги XML, которые ссылались на обратные вызовы в кодовой базе Word, а не представляли фактическую семантику документа. Трудно представить себе, что такая большая и [обычно] грамотно управляемая корпорация, как Microsoft, случайно совершит такую ошибку...
Это запланированное устаревание не имеет значения для большинства предприятий, поскольку средний срок службы делового документа составляет менее 6 месяцев. Но некоторые поля требуют сохранения документов. Право, медицина и литература - это области, в которых продолжительность жизни файла может измеряться десятилетиями, если не столетиями. Деловая практика Microsoft противоречит интересам этих пользователей.
Microsoft Word также не прост в использовании. Его интерфейс запутан, выполнен в стиле барокко, что делает легкое трудным, а трудное почти невозможным.Это гарантирует безопасность работы для гуру, а не прозрачность для адепта дзен, который хочет сосредоточиться на поставленной задаче, а не на инструменте, с помощью которого задача должна быть выполнена. Он навязывает свою собственную концепцию того, как документ должен быть структурирован для автора, структура, лучше всего подходящая для деловых писем и отчетов (задач, для которых он используется большинством пользователей). Его инструменты проверки и механизмы отслеживания изменений непонятны, содержат ошибки и не подходят для полноценной совместной подготовки документов; его средства обрисовки и маркировки прискорбно примитивны по сравнению с теми, которые требуются писателю или автору диссертации: и прокрустово диктат его средства проверки грамматики было бы просто забавным, если бы усердно-изощренный деловой стиль письма, который он предписывает, не был бы так широко распространен.
Но не поэтому я хочу, чтобы Microsoft Office умер.
Причина, по которой я хочу, чтобы Word умер, заключается в том, что, пока он не умер, это неизбежно . Я не пишу романы в Microsoft Word. Я использую множество других инструментов , от Scrivener (программа, предназначенная для управления структурой и редактирования больших составных документов, которая работает аналогично интегрированной среде разработки программиста, если бы Word был основным текстовым редактором) до классического текста. редакторы, такие как Vim.Но почему-то крупных издателей запугали, заставив поверить, что Word является непременным условием систем производства документов. Они исказили и исказили свой производственный процесс, используя файлы Microsoft Word .doc в качестве необработанной основы, даже несмотря на то, что этот формат файла плохо подходит для редактирования или набора текста. И они ожидают, что я интегрирую себя в рабочий процесс, ориентированный на Word, даже если это неподходящий, опасный и трудоемкий инструмент для работы. Это просто неизбежно.И что еще хуже, из-за его большой известности мы не замечаем возможности улучшения наших инструментов для создания документов. Это сдерживает нас уже почти 25 лет; Надеюсь, скоро мы найдем что-нибудь получше, чтобы занять его место.
/> PS: Пишу зарабатываю на жизнь. И если вам интересно посмотреть, что я пишу, моя последняя повесть «Эквид» поступит в продажу завтра (16 октября). Microsoft Word не участвовал в его создании; и вы можете купить ее как электронную книгу во всех обычных магазинах через меню здесь.
Как читать документы Word с помощью Python
В этом посте будет рассказано о том, как читать документы Word с помощью Python. Мы собираемся рассмотреть три разных пакета - docx2txt , docx и мой личный фаворит: docx2python .
Пакет docx2txt Давайте сначала поговорим о docx2text. Это пакет Python, который позволяет очищать текст и изображения из документов Word.Пример ниже читается в документе Word, содержащем Zen of Python. Как видите, после того, как мы импортировали docx2txt , все, что нам нужно, - это одна строка кода для чтения текста из документа Word. Мы можем прочитать документ, используя метод в пакете под названием process , который принимает имя файла в качестве входных данных. Обычный текст, элементы списка, текст гиперссылки и текст таблицы будут возвращены в одной строке.
Это пакет Python, который позволяет очищать текст и изображения из документов Word.Пример ниже читается в документе Word, содержащем Zen of Python. Как видите, после того, как мы импортировали docx2txt , все, что нам нужно, - это одна строка кода для чтения текста из документа Word. Мы можем прочитать документ, используя метод в пакете под названием process , который принимает имя файла в качестве входных данных. Обычный текст, элементы списка, текст гиперссылки и текст таблицы будут возвращены в одной строке.
импорт docx2txt
# читать в текстовом файле
результат = docx2txt.процесс ("zen_of_python.docx")
Что делать, если в файле есть изображения? В этом случае нам просто нужно немного подправить наш код. Когда мы запускаем метод process , мы можем передать дополнительный параметр, который указывает имя выходного каталога. Запуск docx2txt.process извлечет все изображения из документа Word и сохранит их в эту указанную папку. Текст из файла также будет извлечен и сохранен в переменной result .
импорт docx2txt
result = docx2txt.process ("zen_of_python_with_image.docx", "C: / путь / к / магазину / файлам")
Пример изображения
docx2txt также очистит любой текст из таблиц. Опять же, это будет возвращено в одну строку с любым другим текстом, найденным в документе, что означает, что этот текст будет труднее анализировать. Позже в этом посте мы поговорим о docx2python , который позволяет очищать таблицы в более структурированном формате.
Исходный код docx2txt получен из кода в пакете docx , который также можно использовать для очистки документов Word. docx - мощная библиотека для управления и создания документов Word, но также может (с некоторыми ограничениями) читать текст из файлов Word.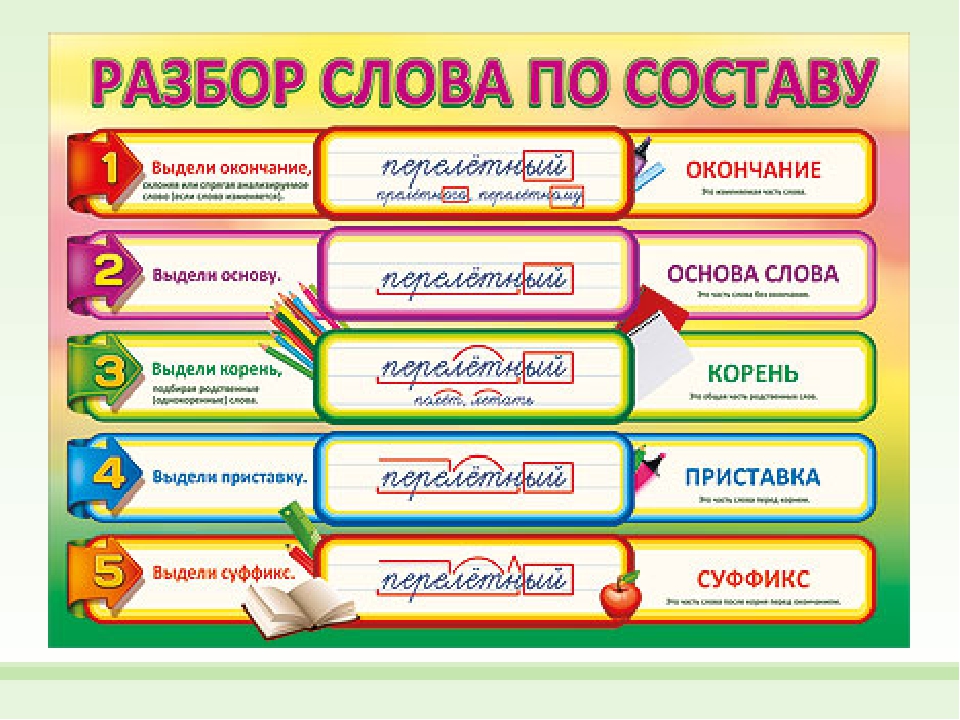
В приведенном ниже примере мы открываем подключение к нашему образцу файла Word с помощью метода docx.Document . Здесь мы просто вводим имя файла, к которому хотим подключиться.Затем мы можем очистить текст из каждого абзаца в файле, используя понимание списка в сочетании с doc.paragraphs . Это будет включать очистку отдельных строк, определенных в документе Word, для перечисленных элементов. В отличие от docx2txt , docx не может очищать изображения из документов Word. Кроме того, docx не будет очищать гиперссылки и текст в таблицах, определенных в документе Word.
импорт docx
# открываем подключение к документу Word
doc = docx.Документ ("zen_of_python.docx")
# читать в каждом абзаце файла
result = [p.text для p в doc.paragraphs]
Пакет docx2python docx2python - еще один пакет, который мы можем использовать для очистки документов Word. Он имеет некоторые дополнительные функции помимо docx2txt и docx . Например, он может вернуть текст, извлеченный из документа, в более структурированном формате. Давайте протестируем наш документ Word с помощью docx2python .Мы собираемся добавить в документ простую таблицу, чтобы мы могли извлечь и ее (см. Ниже).
docx2python содержит метод с таким же именем. Если мы вызовем этот метод с именем документа в качестве входных данных, мы вернем объект с несколькими атрибутами.
из docx2python импорт docx2python
# извлечь содержимое docx
doc_result = docx2python ('zen_of_python.docx')
Каждый атрибут предоставляет текст или информацию из файла.Например, представьте, что наш файл состоит из трех основных компонентов - текста, содержащего Дзен Python, таблицы и изображения. Если мы вызовем doc_result.body , каждый из этих компонентов будет возвращен как отдельные элементы в списке.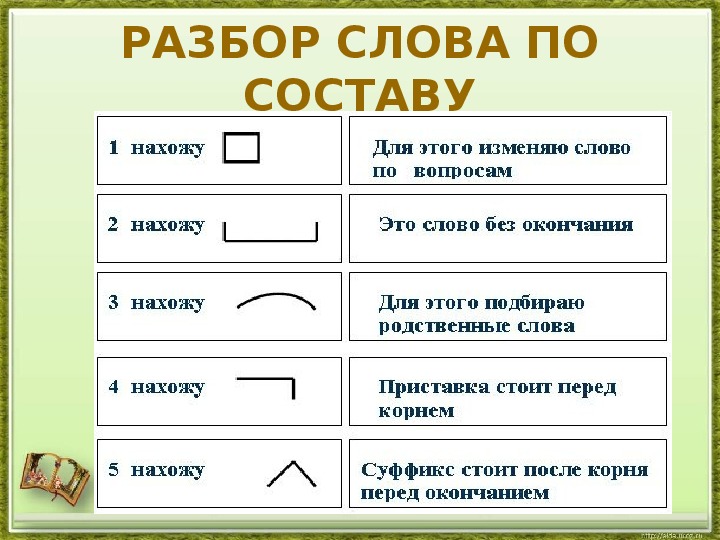
# получаем отдельные компоненты документа doc_result.body # получить текст из Zen of Python doc_result [0] # получить изображение doc_result [1] # получить текст таблицы doc_result [2]Очистка таблицы документа Word с помощью docx2python
Текстовый результат таблицы возвращается в виде вложенного списка, как вы можете видеть ниже.Каждая строка (включая заголовок) возвращается как отдельный подсписок. 0-й элемент списка относится к заголовку или 0-й строке таблицы. Следующий элемент относится к следующей строке в таблице и так далее. В свою очередь, каждое значение в строке возвращается как отдельный подсписок в соответствующем списке этой строки.
Мы можем преобразовать этот результат в табличный формат, используя pandas . Фрейм данных по-прежнему немного беспорядочный - каждая ячейка в фрейме данных представляет собой список, содержащий одно значение.Это значение также имеет несколько символов «\ t» (которые представляют собой табуляторы).
pd.DataFrame (doc_result.body [1] [1:])
Здесь мы используем метод applymap , чтобы применить лямбда-функцию ниже к каждой ячейке во фрейме данных. Эта функция получает индивидуальное значение в списке в каждой ячейке и удаляет все экземпляры «\ t».
импортировать панд как pd
pd.DataFrame (doc_result.body [1] [1:]). \
applymap (лямбда val: val [0].полоса ("\ t"))
Затем давайте изменим заголовки столбцов на те, которые мы видим в файле Word (который также был возвращен нам в doc_result.body ).
df.columns = [val [0] .strip ("\ t") для val в doc_result.body [1] [0]]
Извлечение изображений Мы можем извлечь изображения из файла Word с помощью атрибута images нашего объекта doc_result . doc_result.images состоит из словаря, где ключи - это имена файлов изображений (не записываются автоматически на диск), а соответствующие значения - файлы изображений в двоичном формате.
doc_result.images состоит из словаря, где ключи - это имена файлов изображений (не записываются автоматически на диск), а соответствующие значения - файлы изображений в двоичном формате.
тип (doc_result.images) # dict doc_result.images.keys () # dict_keys (['image1.png'])
Мы можем записать изображение в двоичном формате в физический файл следующим образом:
для ключа val в doc_result.images.items ():
f = open (ключ, "wb")
f.написать (val)
f.close ()
Выше мы просто перебираем ключи (имена файлов изображений) и значения (двоичные изображения) в словаре и записываем их в файл. В этом случае у нас есть только одно изображение в документе, поэтому мы просто записываем одно.
Прочие атрибутыРезультат docx2python имеет несколько других атрибутов, которые мы можем использовать для извлечения текста или информации из файла. Например, если мы хотим просто получить весь текст файла в одной строке (аналогично docx2txt ), мы можем запустить doc_result.текст .
# получить весь текст в одной строке doc_result.text
Помимо текста, мы также можем получить метаданные о файле, используя атрибут properties . Это возвращает такую информацию, как создатель документа, даты создания / последнего изменения и количество редакций.
doc_result.properties
Если документ, который вы очищаете, имеет верхние и нижние колонтитулы, вы также можете очистить их следующим образом (обратите внимание на единственную версию «header» и «footer»):
# получить заголовки doc_result.заголовок # получить нижние колонтитулы doc_result.footer
Сноски также можно извлечь следующим образом:
doc_result.footnotesПолучение HTML, возвращенного с помощью docx2python
Мы также можем указать, что хотим получить объект HTML, возвращенный с помощью метода docx2python , который поддерживает несколько типов тегов, включая шрифт (размер и цвет), курсив, полужирный и подчеркнутый текст. Нам просто нужно указать параметр «html = True».В приведенном ниже примере мы видим The Zen of Python жирным и подчеркнутым шрифтом. Соответственно этому, мы можем увидеть HTML-версию этого на втором снимке ниже. Функция HTML в настоящее время не поддерживает теги, связанные с таблицами, поэтому я бы рекомендовал использовать метод, который мы использовали выше, если вы хотите очистить таблицы от документов Word.
Нам просто нужно указать параметр «html = True».В приведенном ниже примере мы видим The Zen of Python жирным и подчеркнутым шрифтом. Соответственно этому, мы можем увидеть HTML-версию этого на втором снимке ниже. Функция HTML в настоящее время не поддерживает теги, связанные с таблицами, поэтому я бы рекомендовал использовать метод, который мы использовали выше, если вы хотите очистить таблицы от документов Word.
doc_html_result = docx2python ('zen_of_python.docx', html = True)
Надеюсь, вам понравился этот пост! Пожалуйста, ознакомьтесь с другими моими сообщениями о Python ниже или нажав здесь.
Распространенных синтаксических ошибок SQL и способы их устранения
В SQL Server Management Studio ошибки можно легко отследить с помощью встроенной панели Error List . Эту панель можно активировать в меню View или с помощью сочетаний клавиш Ctrl + \ и Ctrl + EНа панели «Список ошибок» отображаются синтаксические и семантические ошибки, обнаруженные в редакторе запросов.Чтобы перейти непосредственно к синтаксической ошибке SQL в редакторе сценариев, дважды щелкните соответствующую ошибку, отображаемую в Списке ошибок
.Ошибки ключевого слова SQL
Ошибки ключевых слов SQL возникают, когда одно из слов, которые язык запросов SQL резервирует для своих команд и предложений, написано с ошибкой. Например, если вы напишите «UPDTE» вместо «UPDATE», это приведет к ошибке
.В этом примере ключевое слово «ТАБЛИЦА» написано с ошибкой:
Как показано на изображении выше, выделено не только слово «TBLE», но и слова вокруг него.На изображении ниже показано, что эта простая ошибка приводит к выделению большого количества слов
.Фактически, всего 49 ошибок было зарегистрировано только из-за неправильного написания одного ключевого слова
Если пользователь хочет исправить все эти сообщенные ошибки, не найдя исходной, то, что начиналось как простая опечатка, становится гораздо большей проблемой
Также возможно, что все ключевые слова SQL написаны правильно, но их расположение не в правильном порядке. Например, инструкция «FROM Table_1 SELECT *» сообщит об ошибке синтаксиса SQL
.Порядок команд
Неправильное расположение ключевых слов обязательно вызовет ошибку, но неправильное расположение команд также может быть проблемой
Если пользователь, например, пытается создать новую схему в существующей базе данных, но сначала хочет проверить, существует ли уже схема с тем же именем, он должен написать следующую команду
Однако, несмотря на то, что каждая команда написана правильно и может выполняться отдельно без ошибок, в этой форме возникает ошибка
.Как указано в сообщении об ошибке, команда CREATE SCHEMA должна быть первой заданной командой.Правильный способ выполнения этих команд вместе выглядит так:
В кавычках
Другая распространенная ошибка, возникающая при написании проекта SQL, - использование двойных кавычек вместо одинарных. Для разделения строк используются одинарные кавычки. Например, здесь используются двойные кавычки вместо одинарных, что вызывает ошибку
.Замена кавычек на правильные, устраняет ошибку
Бывают ситуации, когда необходимо использовать двойные кавычки для написания некоторых общих кавычек, например
Как показано в предыдущем примере, это вызовет ошибку.Но это не означает, что нельзя использовать двойные кавычки, они просто должны быть внутри одинарных кавычек. Однако добавление одинарных кавычек в этом примере не решит проблему, но вызовет еще одну
Поскольку внутри этой цитаты есть апостроф, он ошибочно используется как конец строки. Все остальное считается ошибкой
Чтобы иметь возможность использовать апостроф внутри строки, он должен быть «экранирован», чтобы он не считался разделителем строки.Чтобы «избежать» апострофа, необходимо использовать другой апостроф рядом с ним, как показано ниже
Поиск синтаксических ошибок SQL
Поиск синтаксических ошибок SQL может быть сложной задачей, но есть несколько советов, как сделать это немного проще.