Слова «человек» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «человек» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «человек» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «человек».
Содержимое:
- 1 Слоги в слове «человек» деление на слоги
- 2 Как перенести слово «человек»
- 3 Разбор слова «человек» по составу
- 4 Сходные по морфемному строению слова «человек»
- 5 Синонимы слова «человек»
- 6 Ударение в слове «человек»
- 7 Фонетическая транскрипция слова «человек»
- 8 Фонетический разбор слова «человек» на буквы и звуки (Звуко-буквенный)
- 9 Предложения со словом «человек»
- 10 Сочетаемость слова «человек»
- 11 Значение слова «человек»
- 12 Склонение слова «человек» по подежам
- 13 Как правильно пишется слово «человек»
Слоги в слове «человек» деление на слоги
Количество слогов: 3
По слогам: че-ло-век
Как перенести слово «человек»
че—ловек
чело—век
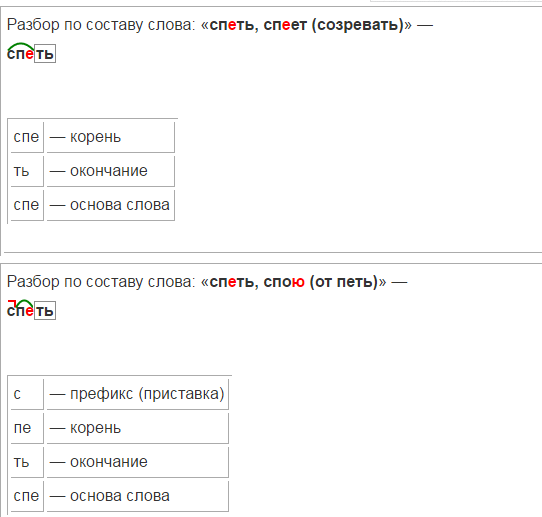
Разбор слова «человек» по составу
| человек | корень |
| ø | нулевое окончание |
человек
Сходные по морфемному строению слова «человек»
Сходные по морфемному строению слова
Синонимы слова «человек»
1. примат
примат
2. лицо
3. личность
4. особа
5. персона
6. индивид
7. индивидуум
8. душа
9. смертный
10. млекопитающее
11. муж
12. мужчина
13. фигура
14. парень
15. создание
16. субъект
17. существо
18. тип
19. титан
20. типаж
21. царь природы
22. двуногий
23. двуногое
24. рабочая сила
25. рабочая единица
26. некто
27. венец творения
28. слуга
Ударение в слове «человек»
челове́к — ударение падает на 3-й слог
Фонетическая транскрипция слова «человек»
[ч’илав’`эк]
Фонетический разбор слова «человек» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| ч | [ч’] | согласный, глухой непарный, мягкий, шипящий | ч |
| е | [и] | гласный, безударный | е |
| л | [л] | согласный, звонкий непарный (сонорный), твёрдый | л |
| о | [а] | гласный, безударный | о |
| в | [в’] | согласный, звонкий парный, мягкий | в |
| е | [`э] | гласный, ударный | е |
| к | [к] | согласный, глухой парный, твёрдый, шумный | к |
Число букв и звуков:
Буквы: 3 гласных буквы, 4 согласных букв.
Звуки: 3 гласных звука, 4 согласных звука.
Предложения со словом «человек»
Поступок этот мог бы дорого обойтись благородному молодому человеку.
Источник: Г. Г. Овдиенко, Подготовка к ЕГЭ. Русский язык и литература. Экзаменационное сочинение, 2015.
Первой объявленной цифрой погибших было 632 тысячи человек.
Источник: В. С. Бушин, Пятая колонна. Отпор клеветникам, 2014.
Но вот конечная граница жизни человека зафиксирована: ею считается его биологическая смерть (смерть головного мозга) (ч.
Источник: О. В. Леонтьев, Ответственность за преступления, совершаемые медицинскими работниками, 2008.
Сочетаемость слова «человек»
1. молодой человек
молодой человек
2. обычный человек
3. близкие люди
4. люди животных
5. люди мира
6. люди земли
7. большинство людей
8. жизнь человека
9. тысячи людей
10. люди говорят
11. люди поняли
12. люди думают
13. видеть человека
14. стать человеком
15. убить человека
16. (полная таблица сочетаемости)
Значение слова «человек»
ЧЕЛОВЕ́К , -а, мн. лю́ди и (устар. и шутл.) челове́ки, м. (косвенные падежи мн. ч. челове́к, челове́кам, челове́ками, о челове́ках употр. только в сочетании с количественными словами). 1. Живое существо, обладающее мышлением, речью, способностью создавать орудия и пользоваться ими в процессе общественного труда. (Малый академический словарь, МАС)
Склонение слова «человек» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн. ч. ч. |
|---|---|---|---|
| ИменительныйИм. | кто? | человек | люди |
| РодительныйРод. | кого? | человека | человек |
| ДательныйДат. | кому? | человеку | людям |
| ВинительныйВин. | кого? | человека | людей |
| ТворительныйТв. | кем? | человеком | людьми |
| ПредложныйПред. | о ком? | человеке | людях |
Как правильно пишется слово «человек»
Правописание слова «человек»
Орфография слова «человек»
Правильно слово пишется: челове́к
Нумерация букв в слове
Номера букв в слове «человек» в прямом и обратном порядке:
- 7
ч
1 - 6
е
2 - 5
л
3 - 4
о
4 - 3
в
5 - 2
е
6 - 1
к
7
Морфологический разбор слова «человек»
Часть речи: Существительное
ЧЕЛОВЕК — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ЧЕЛОВЕК»
| Слово | Морфологические признаки |
|---|---|
| ЧЕЛОВЕК |
|
| ЧЕЛОВЕК |
|
Все формы слова ЧЕЛОВЕК
ЧЕЛОВЕК, ЧЕЛОВЕКА, ЧЕЛОВЕКУ, ЧЕЛОВЕКОМ, ЧЕЛОВЕКЕ, ЛЮДИ, ЛЮДЕЙ, ЛЮДЯМ, ЧЕЛОВЕКАМ, ЛЮДЬМИ, ЧЕЛОВЕКАМИ, ЛЮДЯХ, ЧЕЛОВЕКАХ
Разбор слова по составу человек
человек
| Основа слова | человек |
|---|---|
| Корень | человек |
| Нулевое окончание |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ЧЕЛОВЕК» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «человек»
Примеры предложений со словом «человек»
1
И неадекватен русский человек просто потому, что в момент посещения Духа Святого
Выкидыш, Владислав Дорофеев
2
Это человек – птица, человек – амфибия и человек космоса.
Рассказы и повести. По мотивам романа «Новые кроманьонцы», Юрий Берков
3
Человек побуждает её работать, человек ставит ей задачи, человек добывает ей новые экспериментальные данные, строит гипотезы.
Рассказы и повести. По мотивам романа «Новые кроманьонцы», Юрий Берков
4
Подходит человек, хватает скалу, цепи снимаются, и человек не только поднимает скалу, но и сам вместе с нею взлетает на воздух.
Ариэль, Александр Беляев, 1941г.
5
И тогда вдруг обрывается насмешка – мгновение паузы – и вдруг перед вами третий человек, человек великого гнева.
Causeries. Правда об острове Тристан-да-Рунья, Владимир Евгеньевич Жаботинский, 1930г.
Найти еще примеры предложений со словом ЧЕЛОВЕК
Обработка естественного языка — это весело! | Адам Гейтги
Как компьютеры понимают человеческий язык
Эта статья является частью постоянной серии на NLP: Часть 1 , Часть 2 , Часть 3 , . Часть 4 , Часть 5 . Вы также можете прочитать версию этой статьи в переводе для читателей по номеру 普通话 или فارسی .
Часть 4 , Часть 5 . Вы также можете прочитать версию этой статьи в переводе для читателей по номеру 普通话 или فارسی .
Гигантское обновление: Я написал новую книгу на основе этих статей ! Он не только расширяет и обновляет все мои статьи, но и содержит массу совершенно нового контента и множество практических проектов по кодированию. Проверьте сейчас !
Компьютеры отлично подходят для работы со структурированными данными, такими как электронные таблицы и таблицы базы данных. Но мы, люди, обычно общаемся словами, а не таблицами. Это несчастье для компьютеров.
К сожалению, мы не живем в этой альтернативной версии истории, где все данные структурированы .Много информации в мире неструктурировано — необработанный текст на английском или другом человеческом языке. Как заставить компьютер понимать неструктурированный текст и извлекать из него данные?
Обработка естественного языка или НЛП — это подполе ИИ, которое направлено на то, чтобы компьютеры могли понимать и обрабатывать человеческие языки. Давайте проверим, как работает НЛП, и научимся писать программы, которые могут извлекать информацию из необработанного текста с помощью Python!
Давайте проверим, как работает НЛП, и научимся писать программы, которые могут извлекать информацию из необработанного текста с помощью Python!
Примечание. Если вам все равно, как работает НЛП, и вы просто хотите вырезать и вставить некоторый код, перейдите к разделу «Кодирование конвейера НЛП в Python».
С тех пор, как существуют компьютеры, программисты пытаются писать программы, которые понимают такие языки, как английский. Причина довольно очевидна — люди записывали информацию на протяжении тысячелетий, и было бы очень полезно, если бы компьютер мог читать и понимать все эти данные.
Компьютеры еще не могут по-настоящему понимать английский язык так, как это делают люди, но они уже могут многое! В некоторых ограниченных областях то, что вы можете делать с помощью НЛП, уже кажется волшебством. Возможно, вы сможете сэкономить много времени, применяя техники НЛП к своим собственным проектам.
Более того, последние достижения НЛП легко доступны через библиотеки Python с открытым исходным кодом, такие как spaCy, textacy и neurocoref. То, что вы можете сделать всего несколькими строками кода Python, просто потрясающе.
То, что вы можете сделать всего несколькими строками кода Python, просто потрясающе.
Процесс чтения и понимания английского языка очень сложен — и это даже не учитывая, что английский язык не следует логическим и последовательным правилам. Например, что означает этот заголовок новости?
«Природоохранные органы допрашивают владельца бизнеса по поводу незаконных поджогов угля».
Допрашивают ли регулирующие органы владельца бизнеса о незаконном сжигании угля? Или регуляторы буквально готовят владельца бизнеса? Как видите, парсинг английского на компьютере будет сложным.
Выполнение чего-либо сложного в машинном обучении обычно означает создание конвейера . Идея состоит в том, чтобы разбить вашу проблему на очень маленькие части, а затем использовать машинное обучение для решения каждой из них по отдельности. Затем, объединив несколько моделей машинного обучения, которые взаимодействуют друг с другом, вы сможете делать очень сложные вещи.
И это именно та стратегия, которую мы собираемся использовать для НЛП. Мы разобьем процесс понимания английского языка на небольшие части и посмотрим, как работает каждая из них.
Давайте посмотрим на кусок текста из Википедии:
Лондон — столица и самый густонаселенный город Англии и Соединенного Королевства. Расположенный на реке Темзе на юго-востоке острова Великобритания, Лондон на протяжении двух тысячелетий был крупным поселением. Он был основан римлянами, которые назвали его Лондиниум.
(Источник: статья Википедии «Лондон»)
Этот абзац содержит несколько полезных фактов. Было бы здорово, если бы компьютер мог прочитать этот текст и понять, что Лондон — это город, Лондон находится в Англии, Лондон был заселен римлянами и так далее. Но чтобы достичь этого, мы должны сначала научить наш компьютер самым основным понятиям письменного языка, а затем двигаться дальше.
Шаг 1: Сегментация предложений
Первым шагом в конвейере является разбиение текста на отдельные предложения. Это дает нам это:
Это дает нам это:
- «Лондон — столица и самый густонаселенный город Англии и Соединенного Королевства».
- «Лондон, стоящий на берегу Темзы на юго-востоке острова Великобритания, на протяжении двух тысячелетий был крупным поселением».
- «Он был основан римлянами, которые назвали его Лондиниум».
Можно предположить, что каждое предложение на английском языке — это отдельная мысль или идея. Гораздо проще написать программу для понимания одного предложения, чем для понимания целого абзаца.
Кодирование предложения Модель сегментации может быть такой же простой, как разделение предложений на части всякий раз, когда вы видите знак препинания. Но современные конвейеры НЛП часто используют более сложные методы, которые работают, даже если документ отформатирован неправильно.
Шаг 2. Токенизация Word
Теперь, когда мы разбили наш документ на предложения, мы можем обрабатывать их по одному. Начнем с первого предложения из нашего документа:
«Лондон — столица и самый густонаселенный город Англии и Соединенного Королевства».

Следующий шаг в нашем конвейере — разбить это предложение на отдельные слова или токенов . Это называется токенизацией . Вот результат:
«Лондон», «есть», «тот», «столица», «и», «наиболее густонаселенный», «город», «из», «Англия», «и «, «Объединенное королевство», «.»
Токенизацию легко сделать на английском языке. Мы просто будем разделять слова, когда между ними есть пробел. И мы также будем рассматривать знаки препинания как отдельные токены, поскольку знаки препинания также имеют значение.
Шаг 3: Предсказание частей речи для каждой лексемы
Далее мы рассмотрим каждую лексему и попытаемся угадать ее часть речи — существительное ли это, глагол, прилагательное и так далее. Знание роли каждого слова в предложении поможет нам понять, о чем идет речь в предложении.
Мы можем сделать это, вводя каждое слово (и несколько дополнительных слов вокруг него для контекста) в предварительно обученную модель классификации частей речи: Английские предложения, в которых часть речи каждого слова уже отмечена и учится воспроизводить это поведение.
Имейте в виду, что модель полностью основана на статистике — она на самом деле не понимает, что означают слова, как люди. Он просто умеет угадывать часть речи на основе похожих предложений и слов, которые он видел раньше.
После обработки всего предложения у нас будет такой результат:
Имея эту информацию, мы уже можем начать подбирать некоторый базовый смысл. Например, мы видим, что существительные в предложении включают «Лондон» и «столица», поэтому в предложении, вероятно, говорится о Лондоне.
Шаг 4: лемматизация текста
В английском (и большинстве языков) слова появляются в разных формах. Посмотрите на эти два предложения:
У меня был пони .
У меня было две пони .
В обоих предложениях говорится о существительном пони, , но в них используются разные склонения. При работе с текстом на компьютере полезно знать основную форму каждого слова, чтобы знать, что оба предложения говорят об одном и том же понятии. В противном случае строки «пони» и «пони» выглядят для компьютера как два совершенно разных слова.
В противном случае строки «пони» и «пони» выглядят для компьютера как два совершенно разных слова.
В НЛП мы называем этот процесс лемматизацией — определением самой основной формы или леммы каждого слова в предложении.
То же самое относится и к глаголам. Мы также можем лемматизировать глаголы, находя их корневую неспрягаемую форму. Таким образом, « У меня было два пони » становится « У меня [есть] два [пони]. »
Лемматизация обычно выполняется с помощью справочной таблицы леммных форм слов на основе их части речи и, возможно, с помощью некоторых пользовательских правил для обработки слов, которые вы никогда раньше не видели.
Вот как выглядит наше предложение после того, как лемматизация добавляет в корневую форму нашего глагола:
Единственное изменение, которое мы сделали, это превратили «is» в «be».
Шаг 5: Определение стоп-слов
Далее мы хотим рассмотреть важность каждого слова в предложении. В английском языке много слов-наполнителей, которые очень часто встречаются, например, «and», «the» и «a». При составлении статистики по тексту эти слова вносят много шума, поскольку они появляются гораздо чаще, чем другие слова. Некоторые конвейеры НЛП помечают их как 9.0037 стоп-слова — то есть слова, которые вы, возможно, захотите отфильтровать перед выполнением какого-либо статистического анализа.
В английском языке много слов-наполнителей, которые очень часто встречаются, например, «and», «the» и «a». При составлении статистики по тексту эти слова вносят много шума, поскольку они появляются гораздо чаще, чем другие слова. Некоторые конвейеры НЛП помечают их как 9.0037 стоп-слова — то есть слова, которые вы, возможно, захотите отфильтровать перед выполнением какого-либо статистического анализа.
Вот как выглядит наше предложение со стоп-словами, выделенными серым цветом:
Стоп-слова обычно идентифицируются путем простой проверки жестко заданного списка известных стоп-слов. Но не существует стандартного списка стоп-слов, подходящего для всех приложений. Список игнорируемых слов может варьироваться в зависимости от вашего приложения.
Например, если вы создаете поисковую систему для рок-групп, вам нужно убедиться, что вы не игнорируете слово «The». Дело в том, что слово «The» встречается не только во многих названиях групп, но и в знаменитом 19Рок-группа 80-х под названием The !
Шаг 6: Анализ зависимостей
Следующий шаг — выяснить, как все слова в нашем предложении связаны друг с другом. Это называется анализом зависимостей .
Это называется анализом зависимостей .
Цель состоит в том, чтобы построить дерево, которое назначит одно родительское слово каждому слову в предложении. Корень дерева будет главным глаголом в предложении. Вот как будет выглядеть начало дерева синтаксического анализа для нашего предложения:
Но мы можем пойти еще дальше. Помимо определения родительского слова для каждого слова, мы также можем предсказать тип отношения, существующего между этими двумя словами:
Это дерево синтаксического анализа показывает нам, что подлежащим в предложении является существительное « Лондон », и оно имеет отношение « быть » с « столица ». Наконец-то мы узнали кое-что полезное — Лондон — это столица ! И если бы мы следовали полному дереву синтаксического анализа для предложения (помимо того, что показано), мы бы даже узнали, что Лондон является столицей Соединенного Королевства .
Точно так же, как мы предсказывали части речи ранее, используя модель машинного обучения, синтаксический анализ зависимостей также работает, вводя слова в модель машинного обучения и выводя результат. Но синтаксический анализ зависимостей слов — особенно сложная задача, и для подробного объяснения потребуется целая статья. Если вам интересно, как это работает, отличное место для начала чтения — отличная статья Мэтью Хоннибала 9.0007 » Разбор английского языка в 500 строк Python » .
Но синтаксический анализ зависимостей слов — особенно сложная задача, и для подробного объяснения потребуется целая статья. Если вам интересно, как это работает, отличное место для начала чтения — отличная статья Мэтью Хоннибала 9.0007 » Разбор английского языка в 500 строк Python » .
Но, несмотря на примечание автора в 2015 году о том, что этот подход теперь является стандартным, на самом деле он устарел и даже больше не используется автором. В 2016 году Google выпустила новый анализатор зависимостей под названием Parsey McParseface , который превзошел предыдущие тесты с использованием нового подхода к глубокому обучению, который быстро распространился по всей отрасли. Затем, через год, они выпустили еще более новую модель под названием 9.0007 ParseySaurus , который еще больше улучшил ситуацию. Другими словами, методы синтаксического анализа по-прежнему являются активной областью исследований, они постоянно меняются и совершенствуются.
Также важно помнить, что многие английские предложения неоднозначны и их очень сложно разобрать. В таких случаях модель делает предположение на основе того, какая проанализированная версия предложения кажется наиболее вероятной, но она не идеальна, а иногда модель будет досадно ошибочной . Но со временем наши модели НЛП будут совершенствоваться в осмысленном анализе текста.
Хотите попробовать анализ зависимостей в собственном предложении? Здесь есть отличная интерактивная демонстрация от команды spaCy.
Шаг 6b: Поиск словосочетаний
До сих пор мы рассматривали каждое слово в нашем предложении как отдельную сущность. Но иногда имеет смысл сгруппировать слова, обозначающие одну идею или вещь. Мы можем использовать информацию из дерева синтаксического анализа зависимостей, чтобы автоматически группировать вместе слова, говорящие об одном и том же.
Например, вместо этого:
Мы можем сгруппировать словосочетания, чтобы получить это:
Сделаем мы этот шаг или нет, зависит от нашей конечной цели. Но часто это быстрый и простой способ упростить предложение, если нам не нужны дополнительные подробности о том, какие слова являются прилагательными, а вместо этого мы больше заботимся об извлечении полных идей.
Но часто это быстрый и простой способ упростить предложение, если нам не нужны дополнительные подробности о том, какие слова являются прилагательными, а вместо этого мы больше заботимся об извлечении полных идей.
Шаг 7: Распознавание именованных сущностей (NER)
Теперь, когда мы проделали всю эту тяжелую работу, мы наконец можем выйти за рамки школьной грамматики и начать извлекать идеи.
В нашем предложении есть следующие существительные:
Некоторые из этих существительных представляют реальные вещи в мире. Например, « Лондон» , «Англия» и «Великобритания» обозначают физические места на карте. Было бы здорово это обнаружить! С помощью этой информации мы могли бы автоматически извлечь список реальных мест, упомянутых в документе, используя НЛП.
Целью Распознавания именованных объектов или NER является обнаружение и обозначение этих существительных понятиями реального мира, которые они представляют. Вот как выглядит наше предложение после запуска каждого токена через нашу модель тегов NER:
Вот как выглядит наше предложение после запуска каждого токена через нашу модель тегов NER:
Но системы NER не просто выполняют простой поиск по словарю. Вместо этого они используют контекст того, как слово появляется в предложении, и статистическую модель, чтобы угадать, какой тип существительного представляет слово. Хорошая система NER может определить разницу между человеком « Brooklyn Decker » и местом « Brooklyn », используя контекстные подсказки.
Вот лишь некоторые из типов объектов, которые может маркировать типичная система NER:
- Имена людей
- Названия компаний
- Географическое расположение (как физическое, так и политическое)
- Названия продуктов
- Даты и время
- Денежные суммы
- Названия событий
NER имеет множество применений, поскольку позволяет легко собирать структурированные данные вне текста. Это один из самых простых способов быстро извлечь пользу из конвейера НЛП.
Хотите попробовать распознавание именованных объектов самостоятельно? Вот еще одна отличная интерактивная демонстрация от spaCy.
Шаг 8: Разрешение базовой ссылки
К этому моменту у нас уже есть полезное представление нашего предложения. Мы знаем части речи для каждого слова, как слова соотносятся друг с другом и какие слова говорят об именованных объектах.
Однако у нас осталась одна большая проблема. Английский язык полон местоимений — таких слов, как он , она и это . Это ярлыки, которые мы используем вместо того, чтобы выписывать имена снова и снова в каждом предложении. Люди могут отслеживать, что означают эти слова, в зависимости от контекста. Но наша модель НЛП не знает, что означают местоимения, потому что анализирует только одно предложение за раз.
Давайте посмотрим на третье предложение в нашем документе:
«Он был основан римлянами, которые назвали его Лондиниум».
Если мы проанализируем это с помощью нашего конвейера НЛП, мы узнаем, что «это» было основано римлянами. Но гораздо полезнее знать, что «Лондон» был основан римлянами.
Но гораздо полезнее знать, что «Лондон» был основан римлянами.
Как человек, читающий это предложение, вы можете легко понять, что « это» означает « Лондон» . Цель разрешения кореферентности состоит в том, чтобы выяснить это же отображение, отслеживая местоимения в предложениях. Мы хотим выяснить все слова, которые относятся к одному и тому же объекту.
Вот результат выполнения разрешения кореферентности в нашем документе для слова «Лондон»:
С кореферентной информацией в сочетании с деревом синтаксического анализа и информацией об именованных объектах мы должны быть в состоянии извлечь много информации из этого документа!
Разрешение Coreference — один из самых сложных шагов в нашем конвейере для реализации. Это даже сложнее, чем разбор предложений. Недавние достижения в области глубокого обучения привели к появлению новых подходов, которые стали более точными, но они еще не идеальны. Если вы хотите узнать больше о том, как это работает, начните здесь.
Хотите поиграть с разрешением со ссылкой? Посмотрите эту замечательную демонстрацию разрешения совместных ссылок от Hugging Face.
Вот обзор нашего полного конвейера NLP:
Разрешение Coreference — необязательный шаг, который не всегда выполняется.Ух ты, сколько шагов!
Примечание. Прежде чем мы продолжим, стоит упомянуть, что это шаги типичного конвейера НЛП, но вы будете пропускать шаги или менять их порядок в зависимости от того, что вы хотите сделать и как реализована ваша библиотека НЛП. Например, некоторые библиотеки, такие как spaCy, выполняют сегментацию предложений намного позже в конвейере, используя результаты синтаксического анализа зависимостей.
Так как же нам написать этот конвейер? Благодаря замечательным библиотекам Python, таким как spaCy, это уже сделано! Все шаги закодированы и готовы к использованию.
Во-первых, предполагая, что у вас уже установлен Python 3, вы можете установить spaCy следующим образом:
Затем код для запуска конвейера NLP на фрагменте текста выглядит так: список именованных сущностей и типов сущностей, обнаруженных в нашем документе:
Лондон (GPE)
Англия (GPE)
Великобритания (GPE)
река Темза (FAC)
Великобритания (GPE)
Лондон (GPE)
два тысячелетия (ДАТА)
Римляне (NORP)
Лондиниум (PERSON)
Вы можете посмотреть, что каждый из эти коды объектов означают здесь.
Обратите внимание, что он делает ошибку в «Londinium» и думает, что это имя человека, а не место. Вероятно, это связано с тем, что в обучающем наборе данных не было ничего похожего на это, и он сделал наилучшее предположение. Обнаружение именованных сущностей часто требует небольшой точной настройки модели, если вы анализируете текст, содержащий уникальные или специализированные термины, подобные этому.
Давайте возьмем идею обнаружения сущностей и переделаем ее, чтобы создать скруббер данных. Допустим, вы пытаетесь соблюдать новые правила конфиденциальности GDPR и обнаружили, что у вас есть тысячи документов с информацией, позволяющей установить личность, например с именами людей. Вам дали задание удалить все имена из ваших документов.
Просмотр тысяч документов и попытка отредактировать все имена вручную могут занять годы. Но с НЛП это проще простого. Вот простой скруббер, который удаляет все обнаруженные им имена:
И если вы запустите его, вы увидите, что он работает так, как ожидалось:
В 1950 году [УДАЛЕНО] опубликовал свою известную статью «Вычислительные машины и интеллект».В 1957 году [УДАЛЕНО]
Syntactic Structures произвел революцию в лингвистике с помощью «универсальной грамматики», основанной на правилах системы синтаксических структур.
 В 1957 году [УДАЛЕНО]
В 1957 году [УДАЛЕНО] То, что вы можете сделать с помощью spaCy прямо из коробки, довольно удивительно. Но вы также можете использовать проанализированные выходные данные spaCy в качестве входных данных для более сложных алгоритмов извлечения данных. Существует библиотека Python под названием textacy, которая реализует несколько распространенных алгоритмов извлечения данных поверх spaCy. Это отличная отправная точка.
Один из реализованных алгоритмов называется извлечением полуструктурированных операторов. Мы можем использовать его для поиска в дереве синтаксического анализа простых утверждений, в которых подлежащее — «Лондон», а глагол — форма «быть». Это должно помочь нам найти факты о Лондоне.
Вот как это выглядит в коде:
И вот что выводится:
Вот что я знаю о Лондоне: - столица и самый густонаселенный город Англии и Соединенного Королевства.
- крупное поселение на протяжении двух тысячелетий.

Может быть, это не слишком впечатляет. Но если вы запустите тот же код для всего текста статьи Лондонской Википедии, а не только для трех предложений, вы получите более впечатляющий результат:
Вот что я знаю о Лондоне: - столица и самый густонаселенный город Англии и Великобритания
- крупнейшее поселение на протяжении двух тысячелетий
- самый густонаселенный город мира примерно с 1831 по 1925 год
- вне всякого сравнения самый большой город в Англии
- все еще очень компактный
— крупнейший город мира примерно с 1831 по 1925 год
— резиденция правительства Соединенного Королевства
— уязвим для наводнений
— «один из самых зеленых городов мира» с более чем 40 процентами зеленых насаждений или открытой воды
— самый густонаселенный город и столичный регион Европейского Союза и второй по численности населения в Европе
- 19-й по величине город и 18-й по величине мегаполис в мире
- христианин, имеет большое количество церквей, особенно в лондонском Сити.
— также дом для значительных мусульманских, индуистских, сикхских и еврейских общин
— также дом для 42 индуистских храмов
— самый дорогой рынок офисной недвижимости в мире за последние три года, согласно отчету журнала World Property Journal (2015)
— один из самых дорогих офисных рынков в мире за последние три года выдающиеся финансовые центры мира как самое важное место для международных финансов
- лучший город в мире по рейтингу пользователей TripAdvisor
- крупный международный узел воздушного транспорта с самым загруженным городским воздушным пространством в мире
— центр национальной железнодорожной сети, 70 процентов железнодорожных рейсов которого начинаются или заканчиваются в Лондоне
— крупный глобальный центр обучения и исследований в области высшего образования, в котором сосредоточено самое большое количество высших учебных заведений в Европе
— дом дизайнеров Вивьен Вествуд, Гальяно, Стелла Маккартни, Маноло Бланик и Джимми Чу, среди прочих
- место действия многих литературных произведений
- крупный центр телевизионного производства со студиями, включая BBC Television Center, The Fountain Studios и The London Studios
- также центр городской музыки
- "самый зеленый город" Европы с 35 000 акров общественных парков, лесов и садов
- не столица Англии, так как в Англии нет собственного правительства

Теперь все становится интереснее ! Это довольно внушительный объем информации, которую мы собрали автоматически.
Чтобы получить дополнительные баллы, попробуйте установить библиотеку neurocoref и добавить разрешение Coreference Resolution в свой конвейер. Это даст вам еще несколько фактов, так как он поймает предложения, которые говорят об «этом», а не прямо упоминают «Лондон».
Что еще мы можем сделать?
Просматривая документы spaCy и textacy, вы увидите множество примеров того, как вы можете работать с проанализированным текстом. То, что мы видели до сих пор, — это всего лишь крошечный образец.
Вот еще один практический пример: представьте, что вы создаете веб-сайт, который позволяет пользователю просматривать информацию о каждом городе мира, используя информацию, которую мы извлекли в последнем примере.
Если бы у вас была функция поиска на веб-сайте, было бы неплохо автоматически заполнять общие поисковые запросы, как это делает Google:
Предложения автозаполнения Google для «Лондон» Но для этого нам нужен список возможных дополнений, которые можно предложить пользователю. Мы можем использовать НЛП для быстрого создания этих данных.
Мы можем использовать НЛП для быстрого создания этих данных.
Вот один из способов извлечения фрагментов часто упоминаемых существительных из документа:
Если вы запустите это в статье Лондонской Википедии, вы получите следующий вывод:
Собор Святого Павла
Роял Альберт Холл
лондонское метро
великий пожар
британский музей
лондонский глаз…. и т.д…..
Это лишь малая часть того, что вы можете сделать с помощью НЛП. В будущих постах мы поговорим о других приложениях НЛП, таких как классификация текстов, и о том, как такие системы, как Amazon Alexa, анализируют вопросы.
А пока установите spaCy и начните играть! Или, если вы не являетесь пользователем Python и в конечном итоге используете другую библиотеку НЛП, все идеи должны работать примерно одинаково.
Эта статья является частью продолжающейся серии статей о НЛП. Вы можете продолжить по телефону Часть 2 .
Если вам понравилась эта статья, подпишитесь на мою рассылку «Машинное обучение — это весело»! информационный бюллетень:
Вы также можете подписаться на меня в Твиттере по адресу @ageitgey, написать мне напрямую или найти меня на LinkedIn. Я хотел бы услышать от вас, если я могу помочь вам или вашей команде с машинным обучением.
Я хотел бы услышать от вас, если я могу помочь вам или вашей команде с машинным обучением.
Становление человеком | mysite
Розмари Риццо Парс представляет собой альтернативу как традиционным биомедицинским, так и биопсихосоциально-духовным подходам, представленным в других теориях ухода. Парсе впервые опубликовала свою теорию в 1981 как «Человек-живое-здоровье». Название было официально изменено на «теорию становления человека» в 1992 году, чтобы удалить термин «человек» после изменения словарного определения этого слова с его прежнего значения «человечество». Теория становления человека была разработана как теоретическая перспектива науки о человеке и превратилась в школу мысли (Parse, 1998) в традициях Дильтея, Хайдеггера, Сартра, Мерло-Понти и Гадамера. В 2014 году Parse опубликовал «Парадигму становления человека: трансформационное мировоззрение». Предположения, лежащие в основе парадигмы становления человека, определяют фундаментальные представления о человеческой вселенной, духе становления человека и качестве жизни.
Первая тема, СМЫСЛ, выражена в первом принципе человеческого становления, который гласит, что «Структурирование смысла – это отображение и оценка языка» (Parse, 2014, стр. 37). Этот принцип означает, что люди соучаствуют в создании того, что для них реально, как это показано в их выражении воплощения своих ценностей выбранным образом.
Вторая тема, РИТМИЧЕСКОСТЬ, выражена во втором принципе человеческого становления, который гласит, что «Настройка ритмических паттернов есть выявление-сокрытие и разрешение-ограничение соединения-разделения» (Parse, 2014, стр. 43) . Этот принцип означает, что живой парадокс включает в себя кажущиеся противоположные переживания, сосуществующие в ритмических паттернах. Это означает, что, живя от момента к моменту, человек показывает и не показывает возможности и ограничения, возникающие при движении вместе с другими и отдельно от них.
Третья тема, ПРЕВОСХОДСТВО, выражена в третьем принципе человеческого становления, который гласит, что «Сотрансцендирование с возможными есть приведение в действие и начало преобразования» (Parse, 2014, стр. 47). Этот принцип означает, что движение моментами настоящего есть проживание становления видимым-невидимым с двусмысленностью непрерывного изменения возникающего сейчас.
Темы и принципы становления человека пронизаны четырьмя постулатами: безграничности, парадокса, свободы и тайны (Parse, 2007, 2014). НЕОГРАНИЧЕННОСТЬ – это «неделимое безграничное знание, простирающееся до бесконечности, одновременное воспоминание и поиск с возникающим сейчас» (Parse, 2014, стр. 36). ПАРАДОКС – это «сложный ритм, выраженный в виде предпочтения паттерна» (Parse, 2014, стр. 36). Парадоксы — это не «противоположности, которые нужно примирить, или дилеммы, которые нужно преодолеть, а, скорее, живые ритмы» (Parse, 2007, стр. 309).). СВОБОДА — это «освобождение, истолкованное в контексте» (Parse, 2014, стр. 36). Люди свободны и постоянно выбирают способы быть в соответствии со своими ситуациями. ТАЙНА — это необъяснимое, то, что не может быть познано полностью однозначно» (Parse, 2014, стр. 36). Это непостижимая, невыразимая, непознаваемая природа неделимой, непредсказуемой, постоянно меняющейся человеческой вселенной (Parse, 2007, 2008).
36). Люди свободны и постоянно выбирают способы быть в соответствии со своими ситуациями. ТАЙНА — это необъяснимое, то, что не может быть познано полностью однозначно» (Parse, 2014, стр. 36). Это непостижимая, невыразимая, непознаваемая природа неделимой, непредсказуемой, постоянно меняющейся человеческой вселенной (Parse, 2007, 2008).
Медсестры и другие медицинские работники живут искусством человеческого становления в истинном присутствии с раскрытием просветляющего смысла, меняющимися ритмами и вдохновляющим выходом за пределы (Parse, 2014, стр. 92). Наука об искусстве проливает свет на значение универсальных жизненных переживаний, таких как надежда, лишение жизни изо дня в день, горе, страдание и мужество. Доктор Парс также сформулировал этические постулаты человеческого достоинства (Parse, 2010, 2014) и развитого сообщества (Parse, 2003, 2014), ведущего-следующего (Parse, 2008a, 2014), обучения-обучения (Parse, 2004, 2014), наставничество (Parse, 2008b, 2014) и семейные модели (Parse, 2009, 2014), которые используются во всем мире.