Морфологический разбор слова «современный»
Часть речи: Прилагательное
СОВРЕМЕННЫЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «СОВРЕМЕННЫЙ»
| Слово | Морфологические признаки |
|---|---|
| СОВРЕМЕННЫЙ |
|
| СОВРЕМЕННЫЙ |
|
Все формы слова СОВРЕМЕННЫЙ
СОВРЕМЕННЫЙ, СОВРЕМЕННОГО, СОВРЕМЕННОМУ, СОВРЕМЕННЫМ, СОВРЕМЕННОМ, СОВРЕМЕННАЯ, СОВРЕМЕННОЙ, СОВРЕМЕННУЮ, СОВРЕМЕННОЮ, СОВРЕМЕННОЕ, СОВРЕМЕННЫЕ, СОВРЕМЕННЫХ, СОВРЕМЕННЫМИ, СОВРЕМЕНЕН, СОВРЕМЕННА, СОВРЕМЕННО, СОВРЕМЕННЫ, СОВРЕМЕННЕЕ, СОВРЕМЕННЕЙ, ПОСОВРЕМЕННЕЕ, ПОСОВРЕМЕННЕЙ, СОВРЕМЕННЕЙШИЙ, СОВРЕМЕННЕЙШЕГО, СОВРЕМЕННЕЙШЕМУ, СОВРЕМЕННЕЙШИМ, СОВРЕМЕННЕЙШЕМ, СОВРЕМЕННЕЙШАЯ, СОВРЕМЕННЕЙШЕЙ, СОВРЕМЕННЕЙШУЮ, СОВРЕМЕННЕЙШЕЮ, СОВРЕМЕННЕЙШЕЕ, СОВРЕМЕННЕЙШИЕ, СОВРЕМЕННЕЙШИХ, СОВРЕМЕННЕЙШИМИ
Разбор слова по составу современный
современн
ый| Основа слова | современн |
|---|---|
| Приставка | со |
| Корень | врем |
| Суффикс | ен |
| Суффикс | н |
| Окончание | ый |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СОВРЕМЕННЫЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «современный»
1
Кажется, кто-то однажды сказал, что Париж – самый современный из древних городов, а Нью-Йорк – самый древний из современных, – сказал Генри.
Все прекрасное началось потом, Саймон Ван Бой, 2014г.2
И такой же современный – я чисто физически не могу быть современнее.
Энглби, Себастьян Фолкс, 2007г.3
Вырвись, современный человек, сын мой, из тисков современного города-спрута, запутавшего тебя в свои щупальца, выйди в чистое поле и оглянись кругом.
Последнее предупреждение Матушки-Земли о грядущей экологической катастрофе, Андрей Симонов, 2016г.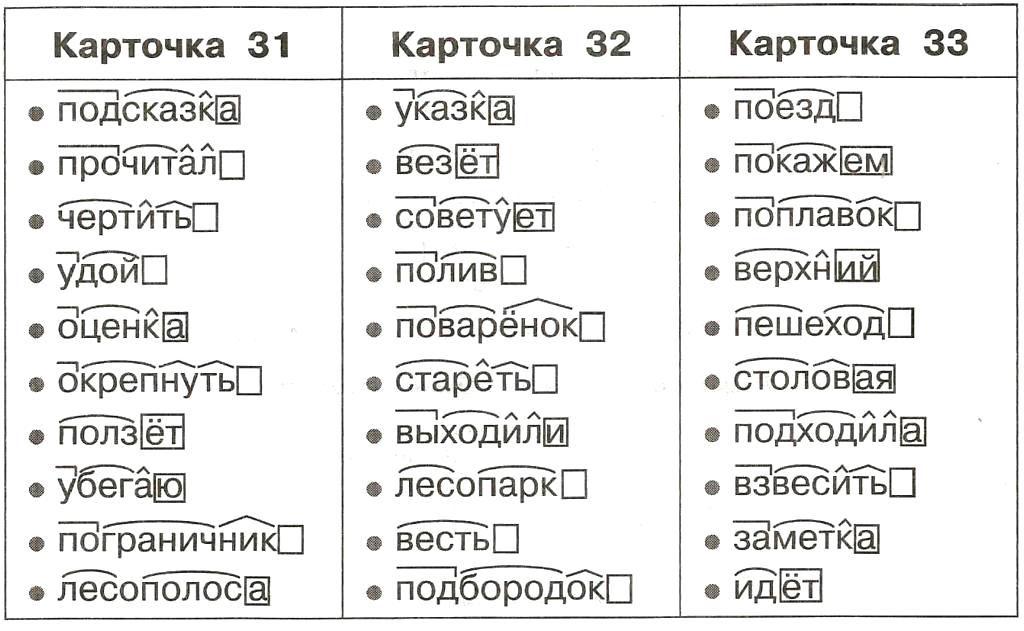
4
Странное дело, но в современный век технологий, рыцари оказались эффективней пехоты с самым современным оружием.
Летописи межмирья. Книга четвертая. Осколки, Александр Маяков5
Думаю что современный человек уже понимает что этот принцип лежит в основе современного мира и определяет всю жизнь.
People watching, Майкл СоснинНайти еще примеры предложений со словом СОВРЕМЕННЫЙ
1. Сделать фонетический разбор слова: (на) ящиках — 1-й вариант хвоей — 2-й вариант 2. Разобрать слова по составу: Беспокойное, озябших, сжимаясь – 1-й вариант старинный, современными, оборваться — 2-й вариант 3. Выписать по два словосочетания на все виды подчинительной связи и разобрать их: Из первого абзаца — 1-й вариант из второго абзаца — 2-й вариант 4.
 Сделать синтаксический разбор предложения: Подняв воротник кожаной куртки, Аня сидела на ящиках и, сжимаясь от холода, смотрела в темноту, где давно исчезли огоньки города. — 1-й вариант Уже в течение двух часов плот несло по быстрине, и не видно было ни берегов, ни неба.
Сделать синтаксический разбор предложения: Подняв воротник кожаной куртки, Аня сидела на ящиках и, сжимаясь от холода, смотрела в темноту, где давно исчезли огоньки города. — 1-й вариант Уже в течение двух часов плот несло по быстрине, и не видно было ни берегов, ни неба.Ответы 1
ящик
ящик
и.с
п п
сущ
лор
Знаешь ответ? Добавь его сюда!
Последние вопросы
- Математика
1 час назад
какое аниме посмотреть подскажите
- Физика
1 день назад
на стройплощадке идет возведение здания на 6 этаже стоит рабочий какие силы действуют на рабочего и на здание если s 100м² вес 70кг
- Химия
1 день назад
Помогите пожалуйста
- Геометрия
1 день назад
Помогите пожалуйста
1.
 2.
2.2. Напишите уравнение сферы с центром в точке A(-1;1;-1) проходящей через точку N(3;4;2)
- Математика
2 дня назад
Помогите решить пример,срочно!!!
фото прикрепила
- Физика
2 дня назад
помогите решить пожалуйста!!!
- Обществознание
4 дня назад
47×8:2×2 решите пж этот пример срочно!!! Можно не столбиком - Английский язык
5 дней назад
Помогите пожалуйста очень срочно буду благодарен
- Математика
6 дней назад
https://gamejolt.
- Математика
6 дней назад
что делать когда скучно
не пишите срать через окно и тому подобное
- Геометрия
7 дней назад
ПОМОГИТЕ С ГЕОМЕТРИЕЙ ПОЖАЛУЙСТА, желательно с рисунком
- Математика
7 дней назад
Ой лето😍😘
- Геометрия
8 дней назад
Помогите пожалуйста с геометрией срочно
- Математика
8 дней назад
84 баллов в скайсмарте ,это 5 или 4? - Геометрия
8 дней назад
Из вершины развернутого угла АВС проведен луч ВК и проведена биссектриса ВМ угла АВК.
Найдите угол АВМ, если угол СВК равен 54о
 2.
2.
 Найдите угол АВМ, если угол СВК равен 54о
Найдите угол АВМ, если угол СВК равен 54оPenn-Helsinki Parsed Corpus of Early Modern English: первые результаты синтаксического анализа и анализ
Seth Kulick, Невилл Райант, Beatrice Santorini
Abstract
Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), древовидный банк из 1,7 миллиона слов, который является важным ресурсом для исследований синтаксических изменений, имеет несколько свойств, которые создают потенциальные проблемы для технологий НЛП. . Мы описываем эти ключевые особенности PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представляем результаты для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к функционированию. восстановление тегов Gabbard et al. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона.
- Идентификатор антологии:
- 2022.findings-naacl.44
- Том:
- Выводы Ассоциации компьютерной лингвистики: NAACL 2022
- Месяц: 90 012 июля
- Год:
- 2022
- Адрес:
- Seattle, United States
- Место проведения:
- Findings
- SIG:
- Издатель:
- Association for Computational Linguistics
- Примечание: 90 036
- Страниц:
- 578–593
- Язык:
- URL:
- https://aclanthology.org/2022.findings-naacl. 44
- DOI:
- 10.18653/v 1/2022.findings-naacl.44
- Bibkey :
- Cite (ACL):
- Сет Кулик, Невилл Райант и Беатрис Санторини. 2022. Penn-Helsinki Parsed Corpus of Early Modern English: первые результаты синтаксического анализа и анализ. В выводах Ассоциации компьютерной лингвистики: NAACL 2022
- Процитируйте (неофициально):
- Penn-Helsinki Parsed Corpus of Early Modern English: результаты и анализ первого анализа (Kulick et al., Findings 2022)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2022.findings-naacl.44.pdf
- Видео:
- https://aclanthology.org/2022.findings-naacl.44.mp4 9 0010 Данные
- Пенн Трибэнк
 44
44PDF Процитировать Поиск Видео
- BibTeX
- MODS XML
- Конечная сноска
- Предварительно отформатировано
@inproceedings{kulick-etal-2022-penn,
title = "{P}enn-{H}elsinki Анализируемый корпус раннего {M}современного {E}нглиша: первые результаты анализа и анализ",
автор = "Кулик, Сет и
Райант, Невилл и
Санторини, Беатрис",
booktitle = "Выводы Ассоциации компьютерной лингвистики: NAACL 2022",
месяц = июль,
год = "2022",
address = "Сиэтл, США",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2022.findings-naacl.44",
doi = "10.18653/v1/2022.findings-naacl.44",
страницы = "578--593",
abstract = "Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), древовидный банк из 1,7 миллиона слов, который является важным ресурсом для исследований синтаксических изменений, обладает рядом свойств, которые создают потенциальные проблемы для технологий НЛП. Мы опишем эти ключевые функции PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представление результатов для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к восстановлению функциональных тегов Gabbard и др. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов. Parser будет использоваться для анализа Early English Books Online, корпуса из 1,5 миллиардов слов, чья полезность для изучения синтаксических изменений будет значительно увеличена с добавлением точных деревьев синтаксического анализа.
}
 org/2022.findings-naacl.44",
doi = "10.18653/v1/2022.findings-naacl.44",
страницы = "578--593",
abstract = "Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), древовидный банк из 1,7 миллиона слов, который является важным ресурсом для исследований синтаксических изменений, обладает рядом свойств, которые создают потенциальные проблемы для технологий НЛП. Мы опишем эти ключевые функции PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представление результатов для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к восстановлению функциональных тегов Gabbard и др. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов.
org/2022.findings-naacl.44",
doi = "10.18653/v1/2022.findings-naacl.44",
страницы = "578--593",
abstract = "Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), древовидный банк из 1,7 миллиона слов, который является важным ресурсом для исследований синтаксических изменений, обладает рядом свойств, которые создают потенциальные проблемы для технологий НЛП. Мы опишем эти ключевые функции PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представление результатов для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к восстановлению функциональных тегов Gabbard и др. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов.
<моды> <информация о заголовке> Penn-Helsinki Parsed Corpus of Early Modern English: первые результаты синтаксического анализа и анализ <название типа="личное">Сет Кулик <роль>автор <название типа="личное">Невилл Райант <роль>автор <название типа="личное">Беатрис Санторини <роль>автор <информация о происхождении>2022-07 текст <информация о заголовке> Выводы Ассоциации компьютерной лингвистики: NAACL 2022 <информация о происхождении>Ассоциация компьютерной лингвистики <место>Сиэтл, США публикация конференции Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), древовидный банк из 1,7 миллиона слов, который является важным ресурсом для исследований в области синтаксических изменений, обладает рядом свойств, которые создают потенциальные проблемы для технологий НЛП. kulick-etal-2022-penn 10. <местоположение>https://aclanthology.org/2022.findings-naacl.44 <часть> <дата>2022-07 <единица экстента="страница">578 <конец>593
 Мы описываем эти ключевые особенности PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представляем результаты для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к функционированию. восстановление тегов Gabbard et al. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов. Полученный синтаксический анализатор будет использоваться для анализа Early English Books Online, корпуса из 1,5 миллиарда слов, полезность которого для изучения синтаксических изменений будет значительно увеличена с добавлением точных деревьев синтаксического анализа.
Мы описываем эти ключевые особенности PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представляем результаты для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к функционированию. восстановление тегов Gabbard et al. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов. Полученный синтаксический анализатор будет использоваться для анализа Early English Books Online, корпуса из 1,5 миллиарда слов, полезность которого для изучения синтаксических изменений будет значительно увеличена с добавлением точных деревьев синтаксического анализа. 18653/v1/2022.findings-naacl.44
18653/v1/2022.findings-naacl.44%0 Материалы конференции %T Penn-Helsinki Parsed Corpus of Early Modern English: первые результаты синтаксического анализа и анализ %A Кулик, Сет %A Райант, Невилл %A Санторини, Беатрис %S Выводы Ассоциации компьютерной лингвистики: NAACL 2022 %D 2022 %8 июля %I Ассоциация компьютерной лингвистики %C Сиэтл, США %F kulick-etal-2022-penn %X The Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME), древовидный банк из 1,7 миллиона слов, который является важным ресурсом для исследований синтаксических изменений, имеет несколько свойств, которые создают потенциальные проблемы для технологий НЛП. Мы описываем эти ключевые особенности PPCEME, которые усложняют анализ, включая более широкий и разнообразный набор функциональных тегов, чем в Penn Treebank, и представляем результаты для этого корпуса с использованием модифицированной версии Berkeley Neural Parser и подхода к функционированию.
 восстановление тегов Gabbard et al. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов. Полученный синтаксический анализатор будет использоваться для анализа Early English Books Online, корпуса из 1,5 миллиарда слов, полезность которого для изучения синтаксических изменений будет значительно увеличена с добавлением точных деревьев синтаксического анализа.
%R 10.18653/v1/2022.findings-naacl.44
%U https://aclanthology.org/2022.findings-naacl.44
%U https://doi.org/10.18653/v1/2022.findings-naacl.44
%Р 578-593
восстановление тегов Gabbard et al. (2006). Хотя этот подход к восстановлению функционального тега дает разумные результаты, он в некотором смысле не подходит для синтаксических анализаторов на основе диапазона. Мы также представляем дополнительные доказательства важности предварительной подготовки в предметной области для контекстуализированных представлений слов. Полученный синтаксический анализатор будет использоваться для анализа Early English Books Online, корпуса из 1,5 миллиарда слов, полезность которого для изучения синтаксических изменений будет значительно увеличена с добавлением точных деревьев синтаксического анализа.
%R 10.18653/v1/2022.findings-naacl.44
%U https://aclanthology.org/2022.findings-naacl.44
%U https://doi.org/10.18653/v1/2022.findings-naacl.44
%Р 578-593
Markdown (неофициальный)
[Penn-Helsinki Parsed Corpus of Early Modern English: First Parsing Results and Analysis] (https://aclanthology.org/2022.findings-naacl.44) (Kulick et al., Findings 2022 )
- Penn-Helsinki Parsed Corpus of Early Modern English: первые результаты синтаксического анализа и анализ (Kulick et al. , Findings 2022)
 , Findings 2022)
, Findings 2022)ACL
- Сет Кулик, Невилл Райант и Беатрис Санторини. 2022. Penn-Helsinki Parsed Corpus of Early Modern English: первые результаты синтаксического анализа и анализ. В Выводы Ассоциации компьютерной лингвистики: NAACL 2022 , страницы 578–593, Сиэтл, США. Ассоциация компьютерной лингвистики.
Penn Parsed Corpora of Historical English
The Penn Parsed Corpora of Historical English запускает тексты и текстовые образцы британской английской прозы за всю ее историю — от самые ранние среднеанглийские документы до Первой мировой войны. Они включают три корпуса:
 и синтаксически аннотированный текст. Синтаксическая аннотация (разбор)
позволяет искать не только слова и словосочетания, но и
абстрактные синтаксические конструкции. Вся аннотация была тщательно
проверены экспертами-аннотаторами на предмет точности и согласованности.
корпуса предназначены для использования студентами и исследователями истории
английского языка, особенно исторический синтаксис языка, и они
общедоступны для отдельных лиц, исследовательских групп и библиотек. и синтаксически аннотированный текст. Синтаксическая аннотация (разбор)
позволяет искать не только слова и словосочетания, но и
абстрактные синтаксические конструкции. Вся аннотация была тщательно
проверены экспертами-аннотаторами на предмет точности и согласованности.
корпуса предназначены для использования студентами и исследователями истории
английского языка, особенно исторический синтаксис языка, и они
общедоступны для отдельных лиц, исследовательских групп и библиотек.Версия 2016 года добавляет 2 миллиона слов к современному британскому английскому языку. корпус, в общей сложности 3 миллиона слов, и включает в себя значительный количество исправлений к другим корпусам серии. Кроме того, было внесено несколько небольших изменений для упрощения руководство по аннотации.
Благодарности
В отношении перечисленных выше грантов любые мнения, выводы и
выводы или рекомендации, выраженные в этом материале, принадлежат
автора(ов) и не обязательно отражают взгляды Национального
Фонд гуманитарных наук или Национальный научный фонд. |
 Каталожный номер LDC
это LDC2020T16.
Потенциальные новые пользователи, будь то частные лица или учреждения, должны связаться с
НРС в
ldc AT ldc DOT upenn DOT edu. Так должно пройти
пользователи, желающие обновить лицензионные соглашения, выпущенные до 2016 г.
выпуска, которые должны четко указать свой статус бывших лицензиатов в своих
запрос.
Каталожный номер LDC
это LDC2020T16.
Потенциальные новые пользователи, будь то частные лица или учреждения, должны связаться с
НРС в
ldc AT ldc DOT upenn DOT edu. Так должно пройти
пользователи, желающие обновить лицензионные соглашения, выпущенные до 2016 г.
выпуска, которые должны четко указать свой статус бывших лицензиатов в своих
запрос. вопросы, связанные с лингвистикой, следует направлять Беатрис Санторини
at beatrice AT sas DOT upenn DOT upenn. Этот
также является адресом для отправки отчетов об ошибках аннотаций, чтобы мы могли
продолжать улучшать качество корпусов.
вопросы, связанные с лингвистикой, следует направлять Беатрис Санторини
at beatrice AT sas DOT upenn DOT upenn. Этот
также является адресом для отправки отчетов об ошибках аннотаций, чтобы мы могли
продолжать улучшать качество корпусов.