Контрольный диктант по теме «Имя прилагательное » 6 класс к УМК Т. Ладыженской | Учебно-методический материал по русскому языку (6 класс) на тему:
Опубликовано 28.01.2016 — 12:00 — Шевченко Гульнара Гарифуловна
Контрольный диктант составлен для итогового контроля по теме «Имя прилагательное», включает в себя грамматическое задание.
Скачать:
Предварительный просмотр:
Контрольный диктант с грамматическим заданием
по теме «Имя прилагательное»6 класс.
Диктант.
1.Было раннее туманное утро. 2.Над деревней раздавались петушиные крики.
3.Мы выехали, когда заря разгоралась. 4.В низине расстилался молочно-белый туман. 5.Дорога шла равнинной местностью. 6.По узкой тропинке среди темно-зеленых зарослей тростника пробирались к реке. 7.Покрытая росой трава касалась наших ног. 8.Мы расположились на отдых на песчаном берегу небольшой речонки. 9.Речка неширокая, но достаточно глубокая.
10.Солнце уже взошло, и на растениях блестела роса.11. Её капельки переливались на траве, как бусинки. 12.Лёгкий ветерок коснулся серебряной глади реки. 13.В прибрежных кустах проснулись утки.
14.Вскоре прибежали загорелые ребятишки и стали купаться. 15.Они позвали нас. 16.Мы приняли их предложение и с наслаждением окунулись в прохладную воду.
17.Утро было прекрасное, а впереди нас ожидал длинный день. 18.Мы провели его хорошо вместе с новыми друзьями.
Грамматическое задание
1. Из предложений 1-4 выпишите слово, в котором правописание Н и НН подчиняется правилу: «В отыменных прилагательных с суффиксами -АН-, -ЯН-, -ИН- пишется одна буква Н».
2. Из предложений 4-6 выпишите слова с чередующейся гласной в корне слова.
3. Из предложений 17-18 выпишите слово, приставку в котором можно заменить словом «очень».
4. Из предложений 6-7 выпишите слово с непроизносимой согласной в корне.
5. Из предложений 3-4 выпишите сложное прилагательное, обозначающее оттенок цвета.
6. Из предложения 13 выпишите именное словосочетание.
7. Среди предложений 1-3 найдите сложное. Напишите номер этого предложения.
8. Из предложений 1-2 выпишите притяжательное прилагательное.
Предварительный просмотр:
Контрольный диктант с грамматическим заданием
по теме «Имя прилагательное»6 класс.
ЛЕТНИЙ ДЕНЬ
Жарким июльским днем, когда луч солнца так жгуч, хочется найти место прохладнее. Далеко не легкое это дело. Из большого грушевого сада, который наполнен зноем, идешь через двор мимо собачьей будки и рыбацких сетей, поднимаешься на деревянное крыльцо и входишь в прохладный каменный дом.
Ставни прикрыты, и поэтому здесь царят тишина и таинственный полумрак. Приглядевшись, начинаешь различать длинную сероватую лавку, холщовую рубашку и кумачовую косынку на ней, глиняный кувшин на столе и другую бабушкину домашнюю утварь.
В первую минуту вздыхаешь с величайшим облегчением: что может быть лучше этой прохлады?.. …К вечеру, после утомительного знойного дня, собирается гроза.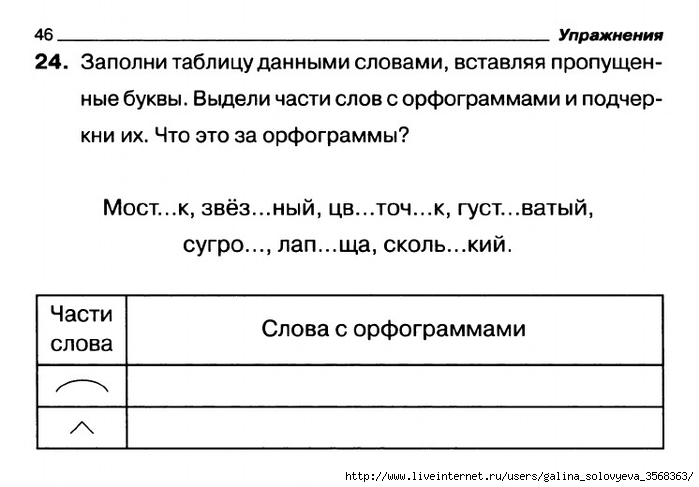 Порывистый северо-восточный ветер налетает на сад, доносит гусиные крики с реки и далекие раскаты грома. Дерзкие порывы теребят соломенную крышу сарая и гонят серо-синюю огромную тучу, закрывшую нежно-голубой небосвод. Вот уже дальний лес скрылся за туманной пеленой дождя…
Порывистый северо-восточный ветер налетает на сад, доносит гусиные крики с реки и далекие раскаты грома. Дерзкие порывы теребят соломенную крышу сарая и гонят серо-синюю огромную тучу, закрывшую нежно-голубой небосвод. Вот уже дальний лес скрылся за туманной пеленой дождя…
Грамматическое задание
1. Укажите морфемный состав слов:
I вариант: величайшим, гусиные, порывистый, птичьих, короче, хорош;
II вариант: прохладнее, собачьей, бабушкину, жгуч, нежно-голубой, тончайший.
2. Выполните морфологический разбор слов:
I вариант: прохладнее, собачьей, деревянное;
II вариант: глиняный, величайшим, гусиные.
Предварительный просмотр:
Контрольный диктант с грамматическим заданием
по теме «Имя прилагательное»6 класс.
Пятые сутки геолог пробирался через тайгу. Ненастье мешало ему двигаться быстрее, но сегодня снегопад прекратился.
Кончились запасы пищи, и теперь он питался шишками. Ножом он вытаскивал зернышки, набирал их в горсть и долго жевал.
Геолог расположился на ночлег под раскидистой елью, разложил костер около смолистого пня, набросал еловых веток и прилег прямо на них.
Языки пламени костра то замирали, то вспыхивали. От костра расстилался душистый дымок. Глаза слипались. Геолог чувствовал ужасную усталость. Он знал, что ему предстоит долгий и опасный путь через глухую местность.
Ночь преобразила лес. Сугробы снега превращались в причудливые фигурки.
Геолог прислушался и вдруг ясно услышал рев машин.
Он поднялся, затоптал костер и пошел на шум машин.
Выполните грамматические задания
1. Произведите синтаксический разбор предложения:
1 вариант
Ножом он вытаскивал зернышки, набирал их в горсть и долго жевал.
2 вариант
Геолог прислушался и вдруг ясно услышал рев машин.
2. Произведите морфологический разбор слов:
1 вариант
(Под) раскидистой (елью) –
Еловых (веток) –
2 вариант
В причудливые (фигурки) –
Смолистого (пня) –
3. Произведите морфемный разбор слов (по составу):
Произведите морфемный разбор слов (по составу):
1 вариант
Заячий, ближний, лисий, дядин, поздний
2 вариант
Сестрин, синий, песий, Юрьев, Петров
4. Образуйте все формы сравнительной степени слова (1 вариант)
Опасный –
Образуйте все формы превосходной степени слова (2 вариант)
Ужасный —
По теме: методические разработки, презентации и конспекты
Тексты контрольных диктантов для 6-9 классов
Тексты диктантов для 6-9 классов с дополнительными заданиями….
Тексты контрольных диктантов для 6-9 классов
6 класс. 1 четверть. Утром. Утром в низинах расстилался туман. Но вот из-за горизонта появляются солнце, и его лучи съедают серую пелену тумана. Со…
Тексты для контрольных диктантов в 5-8 классах
материал содеоржит тексты для проведения итогового контроля в 5-8 классах, к каждому тексту разработаны задания…
Итоговый контрольный диктант за курс 7 класса по русскому языку
Даннный конторольный итоговый диктант проводится в конце учебного года и позволяет проверить прочность и глубину знаний учащихся за курс 7 класса. …
…
Контрольный диктант «Спящая Ассоль» (7 класс, тема «Деепричастие»)
Контрольный диктант «Спящая Ассоль » проводится в 7 классе после изучения темы «Деепричастие » с целью контроля знаний учащихся….
Контрольные диктанты для учащихся 5 классов
В помощь учителю-русоведу…
Контрольные диктанты для 5-9 класса по краеведению.
Контрольные диктанты для 5-9 класса по краеведению….
Поделиться:
Все, что вам нужно знать
По мере того, как компании ищут способы улучшить связь со своими растущими многоязычными клиентами по всему миру, решение, к которому стремятся многие, — это машинный перевод.
Машинный перевод — это процесс преобразования текста с одного языка на другой с помощью программного обеспечения для автоматического перевода. Машина-переводчик автоматически переводит сложные выражения и идиомы с одного языка на другой. Хотя концепция кажется простой, ее реализация может быть сложной из-за различий в синтаксисе, семантике и грамматике различных языков мира. Независимо от того, является ли переводчик человеком или машиной, текст необходимо разбить на базовые элементы, чтобы полностью извлечь и точно восстановить сообщение на целевом языке. Вот почему для машинного переводчика крайне важно охватить все нюансы языка, включая региональные диалекты.
Источник перевода также усложняет его. Например, для фрагмента текста два разных инструмента автоматического перевода могут дать два разных результата. Параметры и правила, регулирующие работу машинного переводчика, будут влиять на его способность производить перевод, соответствующий смыслу исходного текста.
Целью любого машинного перевода является создание публикуемой работы без необходимости вмешательства человека. В настоящее время программное обеспечение для машинного перевода ограничено, и требуется, чтобы переводчик-человек вводил исходный текст. Однако достижения позволили машинному переводу извлекать синтаксис и грамматику из более широкой базы, создавая жизнеспособные переводы с непревзойденной скоростью.
Хотя концепция кажется простой, ее реализация может быть сложной из-за различий в синтаксисе, семантике и грамматике различных языков мира. Независимо от того, является ли переводчик человеком или машиной, текст необходимо разбить на базовые элементы, чтобы полностью извлечь и точно восстановить сообщение на целевом языке. Вот почему для машинного переводчика крайне важно охватить все нюансы языка, включая региональные диалекты.
Источник перевода также усложняет его. Например, для фрагмента текста два разных инструмента автоматического перевода могут дать два разных результата. Параметры и правила, регулирующие работу машинного переводчика, будут влиять на его способность производить перевод, соответствующий смыслу исходного текста.
Целью любого машинного перевода является создание публикуемой работы без необходимости вмешательства человека. В настоящее время программное обеспечение для машинного перевода ограничено, и требуется, чтобы переводчик-человек вводил исходный текст. Однако достижения позволили машинному переводу извлекать синтаксис и грамматику из более широкой базы, создавая жизнеспособные переводы с непревзойденной скоростью.
Автоматический перевод берет свое начало из работ арабского криптографа Аль-Кинди. Методы, которые он разработал для системного языкового перевода, также используются в современном машинном переводе. После Аль-Кинди развитие автоматического перевода медленно продолжалось на протяжении веков, вплоть до 1930-х годов. Один из самых заметных патентов в этой области был получен советским ученым Петром Троянским в 1933 году. Троянский продемонстрировал свою «машину для выбора и печати слов при переводе с одного языка на другой» в Академии наук СССР. Машинный переводчик Троянского состоял из пишущей машинки, кинокамеры и набора языковых карточек. Процесс перевода потребовал ряда шагов:
Шаг 1: Носитель языка оригинала упорядочил текстовые карточки в логическом порядке, сделал фотографию и ввел морфологические характеристики текста в пишущую машинку.
Шаг 2: Затем машина создала набор кадров, эффективно переводящих слова, с помощью ленты и фотопленки.
Шаг 3: Наконец, редактор, свободно владеющий целевым языком, просмотрел перевод и убедился, что он расположен в правильном порядке.
Академия наук СССР признала изобретение Троянского бесполезным. Несмотря на это, ученый продолжал попытки усовершенствовать свой машинный перевод, пока не скончался из-за болезни в 1950 году. Его машина оставалась непризнанной до 1956 года, когда его патент был заново открыт.
Следующее крупное достижение в машинном переводе произошло во время холодной войны. В 1954 году технологический гигант IBM начал эксперимент, в ходе которого его компьютерная система IBM 701 осуществила первый в мире автоматический перевод текста с русского на английский. Перевод состоял из 60 строк русской копии. Услышав новость о том, что в Соединенных Штатах была разработана система автоматического перевода, страны по всему миру начали инвестировать в свои собственные машинные переводчики.
Однако двенадцать лет спустя Консультативный комитет США по автоматической обработке языков (ALPAC) выступил с заявлением.

В основе машинного перевода лежат лингвистические правила. Эти правила направляют машину при обработке простых замен слов. Само по себе это не дает качественного перевода. Чтобы расширить возможности машинного переводчика, для разбора текста используется метод, основанный на правилах. Слова в каждой строке интерпретируются с использованием обширного лексикона, включая морфологические, синтаксические и семантические принципы.
Имея достаточно информации для создания всестороннего набора правил, машинный переводчик может создать приемлемый перевод с исходного языка на целевой язык — носитель целевого языка сможет расшифровать намерение. Однако успех зависит от наличия достаточного количества точных данных для создания связного перевода.
Машинный перевод на основе правил появился еще в 1970-х годах. Ученые и исследователи начали разработку машинного переводчика, используя лингвистическую информацию об исходном и целевом языках. Они достигли этого с помощью многоязычных словарей, используя информацию о семантических, морфологических и синтаксических закономерностях исходного языка для создания перевода. Существует три типа систем RBMT. 
Этот метод по-прежнему использует формат замены слов, что ограничивает область его применения. Хотя он упростил грамматические правила, он также увеличил количество словесных формул по сравнению с прямым машинным переводом. Межъязыковый машинный перевод Межъязыковый машинный перевод — это метод перевода текста с исходного языка на интерлингва, искусственный язык, разработанный для перевода слов и значений с одного языка на другой. Процесс межъязыкового машинного перевода включает преобразование исходного языка в интерлингва (промежуточное представление), а затем преобразование интерлингва перевода в целевой язык.
 Основное преимущество использования метода RBMT заключается в возможности воспроизведения переводов. Поскольку правила, диктующие переводы, учитывают морфологию, синтаксис и семантику, даже если перевод будет непонятным, он всегда будет одним и тем же. Это позволяет лингвистам и программистам адаптировать его для конкретных случаев использования, в которых идиомы и намерения кратки. Например, для этого метода могут подойти прогнозы погоды или технические руководства.
Главный недостаток RBMT заключается в том, что каждый язык включает в себя тонкие выражения, разговорные выражения и диалекты. В приложении необходимо учитывать бесчисленные правила и тысячи словарей языковых пар. Правила должны быть построены вокруг обширного лексикона, учитывая независимые морфологические, синтаксические и семантические атрибуты каждого слова.
Примеры включают:
Основное преимущество использования метода RBMT заключается в возможности воспроизведения переводов. Поскольку правила, диктующие переводы, учитывают морфологию, синтаксис и семантику, даже если перевод будет непонятным, он всегда будет одним и тем же. Это позволяет лингвистам и программистам адаптировать его для конкретных случаев использования, в которых идиомы и намерения кратки. Например, для этого метода могут подойти прогнозы погоды или технические руководства.
Главный недостаток RBMT заключается в том, что каждый язык включает в себя тонкие выражения, разговорные выражения и диалекты. В приложении необходимо учитывать бесчисленные правила и тысячи словарей языковых пар. Правила должны быть построены вокруг обширного лексикона, учитывая независимые морфологические, синтаксические и семантические атрибуты каждого слова.
Примеры включают: Английский: Английский язык наполнен неправильными глаголами и имеет три основных подмножества, которые необходимо учитывать: американский английский, британский английский и австралийский английский. Хотя эти три языка имеют общий словарный запас, каждый из них имеет свой собственный список исключений.
Хотя эти три языка имеют общий словарный запас, каждый из них имеет свой собственный список исключений.
Греческий: В греческом языке преобладает синтаксис SVO (подлежащее-глагол-дополнение). Однако он свободно и часто меняет порядок, а также опускает существительное, как это подразумевается в контексте сообщения.
Русский: Русский язык не имеет подлежащего, а это означает, что полное предложение не обязательно должно содержать подлежащее.
Чтобы построить функциональную систему RBMT, создатель должен тщательно продумать свой план развития. Одним из вариантов является вложение значительных средств в систему, позволяющую производить высококачественный контент при выпуске. Прогрессивная система – еще один вариант. Он начинается с некачественного перевода, и по мере добавления новых правил и словарей он становится более точным.
Хотя пользователи могут постоянно добавлять слова в словари и создавать подправила для каждого слова, этот метод нельзя назвать эффективным. Учет всех этих идиосинкразий, омонимов и фраз потребует значительных затрат времени.
Машинный перевод на основе примеров (EBMT)
Учет всех этих идиосинкразий, омонимов и фраз потребует значительных затрат времени.
Машинный перевод на основе примеров (EBMT)
Машинный перевод на основе примеров (EBMT) — это метод машинного перевода, в котором в качестве основной основы используются параллельные тексты, расположенные рядом, фраза к фразе (двуязычный корпус). Подумайте о знаменитом Розеттском камне, древней скале, содержащей указ короля Птолемея V Эпифана на трех разных языках. Розеттский камень раскрыл секреты иероглифов после того, как их значение было утеряно на протяжении многих веков. Иероглифы были расшифрованы параллельным демотическим письмом и древнегреческим текстом на камне, которые все еще понимались.
Япония вложила значительные средства в EBMT в 1980-х, когда он стал глобальным рынком автомобилей и электроники, и его экономика процветала. В то время как финансовые горизонты страны расширялись, немногие ее граждане говорили по-английски, а потребность в машинном переводе росла.
К сожалению, существующие методы перевода на основе правил не могут дать адекватных результатов, так как грамматическая структура японского и английского языков существенно различается.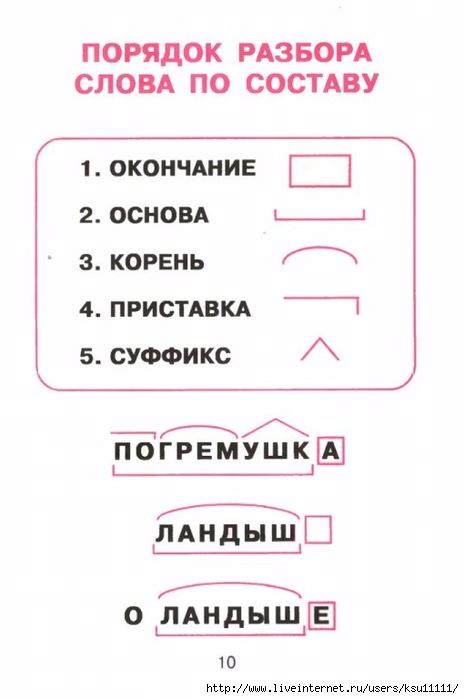 Чтобы решить эту проблему, в 1984 году Макото Нагао из Киотского университета обнаружил, что вместо дословного перевода метод фразы в фразу дает лучший перевод. С помощью этого метода, чем больше фраз вы добавите в базу данных, тем проще системе будет найти слово-заменитель.
Например, если простая фраза «Я хочу что-нибудь выпить» уже переведена на целевой язык, то перевод «Я хочу что-нибудь съесть» не требует дословного перевода всего предложения. слово. В словаре нужно найти только слово-заменитель «есть».
С EBMT вам нужно только расшифровать различия между фразами, найти неизвестные слова и надеяться, что исключения не существует. Этот метод значительно повысил доступность машинного перевода, поскольку сложные языковые правила, как правило, уже встроены в каждую фразу.
Статистический машинный перевод (SMT)
Чтобы решить эту проблему, в 1984 году Макото Нагао из Киотского университета обнаружил, что вместо дословного перевода метод фразы в фразу дает лучший перевод. С помощью этого метода, чем больше фраз вы добавите в базу данных, тем проще системе будет найти слово-заменитель.
Например, если простая фраза «Я хочу что-нибудь выпить» уже переведена на целевой язык, то перевод «Я хочу что-нибудь съесть» не требует дословного перевода всего предложения. слово. В словаре нужно найти только слово-заменитель «есть».
С EBMT вам нужно только расшифровать различия между фразами, найти неизвестные слова и надеяться, что исключения не существует. Этот метод значительно повысил доступность машинного перевода, поскольку сложные языковые правила, как правило, уже встроены в каждую фразу.
Статистический машинный перевод (SMT)
Примерно через полвека после внедрения EBMT Исследовательский центр Томаса Дж. Уотсона IBM продемонстрировал систему машинного перевода, полностью уникальную как для систем RBMT, так и для систем EBMT. Система SMT не полагается на правила или лингвистику для своих переводов. Вместо этого система подходит к языковому переводу через анализ закономерностей и вероятности.
Система SMT основана на языковой модели, которая вычисляет вероятность того, что фраза будет использована носителем языка. Затем он сопоставляет два языка, которые были разделены на слова, сравнивая вероятность того, что имелось в виду конкретное значение.
Например, SMT рассчитает вероятность того, что греческое слово «γραφείο (grafeío)» должно быть переведено либо на английское слово «офис», либо на «стол». Этот метод также используется для порядка слов. SMT предписывает более высокую синтаксическую вероятность фразе «Я попробую», а не «Я попробую».
Имейте в виду, что такие решения, как использование слова «офис» при переводе «γραφείο», не были продиктованы конкретными правилами, установленными программистом. Переводы зависят от контекста предложения. Машина определяет, что если одна форма используется чаще, то, скорее всего, это правильный перевод.
Система SMT не полагается на правила или лингвистику для своих переводов. Вместо этого система подходит к языковому переводу через анализ закономерностей и вероятности.
Система SMT основана на языковой модели, которая вычисляет вероятность того, что фраза будет использована носителем языка. Затем он сопоставляет два языка, которые были разделены на слова, сравнивая вероятность того, что имелось в виду конкретное значение.
Например, SMT рассчитает вероятность того, что греческое слово «γραφείο (grafeío)» должно быть переведено либо на английское слово «офис», либо на «стол». Этот метод также используется для порядка слов. SMT предписывает более высокую синтаксическую вероятность фразе «Я попробую», а не «Я попробую».
Имейте в виду, что такие решения, как использование слова «офис» при переводе «γραφείο», не были продиктованы конкретными правилами, установленными программистом. Переводы зависят от контекста предложения. Машина определяет, что если одна форма используется чаще, то, скорее всего, это правильный перевод. Метод SMT оказался значительно более точным и менее затратным, чем системы RBMT и EBMT. Система полагалась на большие объемы текста для получения жизнеспособных переводов, поэтому лингвистам не нужно было применять свой опыт.
Прелесть системы статистического машинного перевода заключается в том, что при ее создании всем переводам присваивается одинаковый вес. По мере того, как в машину вводится больше данных для построения закономерностей и вероятностей, потенциальные переводы начинают меняться. Это все еще заставляет нас задаться вопросом, как машина знает, что нужно преобразовать слово «γραφείο» в «стол» вместо «офис»? Это когда SMT разбит на подразделения. Словесный SMT Первая система статистического машинного перевода, представленная IBM под названием Model 1, разбивала каждое предложение на слова. Затем эти слова будут проанализированы, подсчитаны и им будет присвоен вес по сравнению с другими словами, в которые они могут быть переведены, без учета порядка слов.
Чтобы улучшить эту систему, IBM затем разработала модель 2.
Метод SMT оказался значительно более точным и менее затратным, чем системы RBMT и EBMT. Система полагалась на большие объемы текста для получения жизнеспособных переводов, поэтому лингвистам не нужно было применять свой опыт.
Прелесть системы статистического машинного перевода заключается в том, что при ее создании всем переводам присваивается одинаковый вес. По мере того, как в машину вводится больше данных для построения закономерностей и вероятностей, потенциальные переводы начинают меняться. Это все еще заставляет нас задаться вопросом, как машина знает, что нужно преобразовать слово «γραφείο» в «стол» вместо «офис»? Это когда SMT разбит на подразделения. Словесный SMT Первая система статистического машинного перевода, представленная IBM под названием Model 1, разбивала каждое предложение на слова. Затем эти слова будут проанализированы, подсчитаны и им будет присвоен вес по сравнению с другими словами, в которые они могут быть переведены, без учета порядка слов.
Чтобы улучшить эту систему, IBM затем разработала модель 2.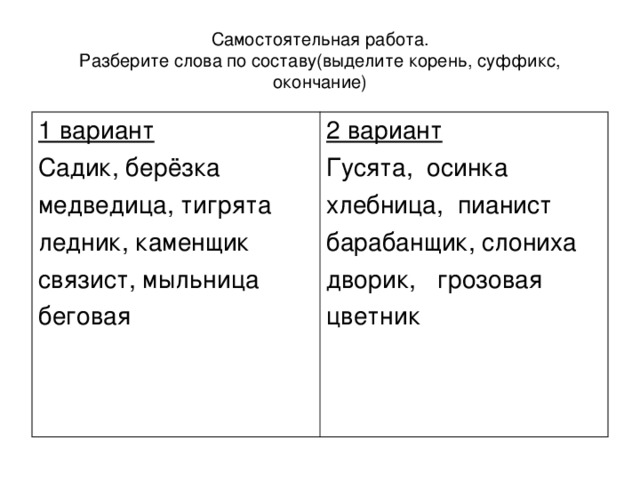 Эта обновленная модель учитывала синтаксис путем запоминания того, где слова были помещены в переведенное предложение.
Модель 3 еще больше расширила систему, включив два дополнительных шага. Во-первых, вставки NULL-токенов позволяли SMT определять, когда необходимо добавлять новые слова в его банк терминов. Второй шаг диктовал выбор грамматически правильного слова для каждого выравнивания слова-символа.
Модель 4 начала учитывать расположение слов. Поскольку языки могут иметь различный синтаксис, особенно когда речь идет о прилагательных и размещении существительных, Модель 4 приняла систему относительного порядка.
В то время как основанная на словах SMT обогнала предыдущие системы RBMT и EBMT, тот факт, что она почти всегда переводила «γραφειο» на «офис», а не на «стол», означала необходимость внесения основных изменений. Таким образом, его быстро вытеснил метод, основанный на фразах. SMT на основе фразы
Обновленная система статистического машинного перевода на основе фраз имеет характеристики, аналогичные системе перевода на основе слов.
Эта обновленная модель учитывала синтаксис путем запоминания того, где слова были помещены в переведенное предложение.
Модель 3 еще больше расширила систему, включив два дополнительных шага. Во-первых, вставки NULL-токенов позволяли SMT определять, когда необходимо добавлять новые слова в его банк терминов. Второй шаг диктовал выбор грамматически правильного слова для каждого выравнивания слова-символа.
Модель 4 начала учитывать расположение слов. Поскольку языки могут иметь различный синтаксис, особенно когда речь идет о прилагательных и размещении существительных, Модель 4 приняла систему относительного порядка.
В то время как основанная на словах SMT обогнала предыдущие системы RBMT и EBMT, тот факт, что она почти всегда переводила «γραφειο» на «офис», а не на «стол», означала необходимость внесения основных изменений. Таким образом, его быстро вытеснил метод, основанный на фразах. SMT на основе фразы
Обновленная система статистического машинного перевода на основе фраз имеет характеристики, аналогичные системе перевода на основе слов. Но в то время как последний разбивает предложения на компоненты слов, прежде чем переупорядочивать и взвешивать значения, алгоритм системы на основе фраз включает группы слов. Система построена на непрерывной последовательности «n» элементов из блока текста или речи. В терминах компьютерной лингвистики эти блоки фраз называются n-граммами.
Целью метода на основе фраз является расширение возможностей машинного перевода для включения n-грамм различной длины. Однако машина не вычисляет n-граммы так, как мы обрабатываем фразы. Вместо того, чтобы использовать лингвистические фразы, как мы это делаем в обычной речи, машина приближает свое статистическое ранжирование к фраземам, поскольку нормальные фразы не всегда строятся с использованием стандартного синтаксиса. Благодаря этим дополнениям машинный перевод заметно улучшился.
Этот метод был быстро принят крупными технологическими компаниями, такими как Google, Microsoft и Яндекс. На протяжении более десяти лет машинный перевод на основе фраз был стандартом языкового перевода, что делало все остальные методы устаревшими.
Но в то время как последний разбивает предложения на компоненты слов, прежде чем переупорядочивать и взвешивать значения, алгоритм системы на основе фраз включает группы слов. Система построена на непрерывной последовательности «n» элементов из блока текста или речи. В терминах компьютерной лингвистики эти блоки фраз называются n-граммами.
Целью метода на основе фраз является расширение возможностей машинного перевода для включения n-грамм различной длины. Однако машина не вычисляет n-граммы так, как мы обрабатываем фразы. Вместо того, чтобы использовать лингвистические фразы, как мы это делаем в обычной речи, машина приближает свое статистическое ранжирование к фраземам, поскольку нормальные фразы не всегда строятся с использованием стандартного синтаксиса. Благодаря этим дополнениям машинный перевод заметно улучшился.
Этот метод был быстро принят крупными технологическими компаниями, такими как Google, Microsoft и Яндекс. На протяжении более десяти лет машинный перевод на основе фраз был стандартом языкового перевода, что делало все остальные методы устаревшими. SMT на основе синтаксиса Другая форма SMT была основана на синтаксисе, хотя и не получила значительного распространения. Идея предложения на основе синтаксиса состоит в том, чтобы объединить RBMT с алгоритмом, который разбивает предложение на синтаксическое дерево или дерево синтаксического анализа. Этот метод был направлен на решение проблем с выравниванием слов, обнаруженных в других системах. Недостатки SMT Один из основных недостатков, который вы найдете в любой форме SMT, заключается в том, что если вы пытаетесь перевести текст, который отличается от основного корпуса, на котором построена система, вы столкнетесь с многочисленными аномалиями. Система также будет напрягаться, пытаясь рационализировать идиомы и разговорные выражения. Такой подход особенно невыгоден, когда речь идет о переводе малоизвестных или редких языков.
Неспособность SMT успешно переводить обычный язык означает, что его использование за пределами определенных технических областей ограничивает его охват рынка.
SMT на основе синтаксиса Другая форма SMT была основана на синтаксисе, хотя и не получила значительного распространения. Идея предложения на основе синтаксиса состоит в том, чтобы объединить RBMT с алгоритмом, который разбивает предложение на синтаксическое дерево или дерево синтаксического анализа. Этот метод был направлен на решение проблем с выравниванием слов, обнаруженных в других системах. Недостатки SMT Один из основных недостатков, который вы найдете в любой форме SMT, заключается в том, что если вы пытаетесь перевести текст, который отличается от основного корпуса, на котором построена система, вы столкнетесь с многочисленными аномалиями. Система также будет напрягаться, пытаясь рационализировать идиомы и разговорные выражения. Такой подход особенно невыгоден, когда речь идет о переводе малоизвестных или редких языков.
Неспособность SMT успешно переводить обычный язык означает, что его использование за пределами определенных технических областей ограничивает его охват рынка.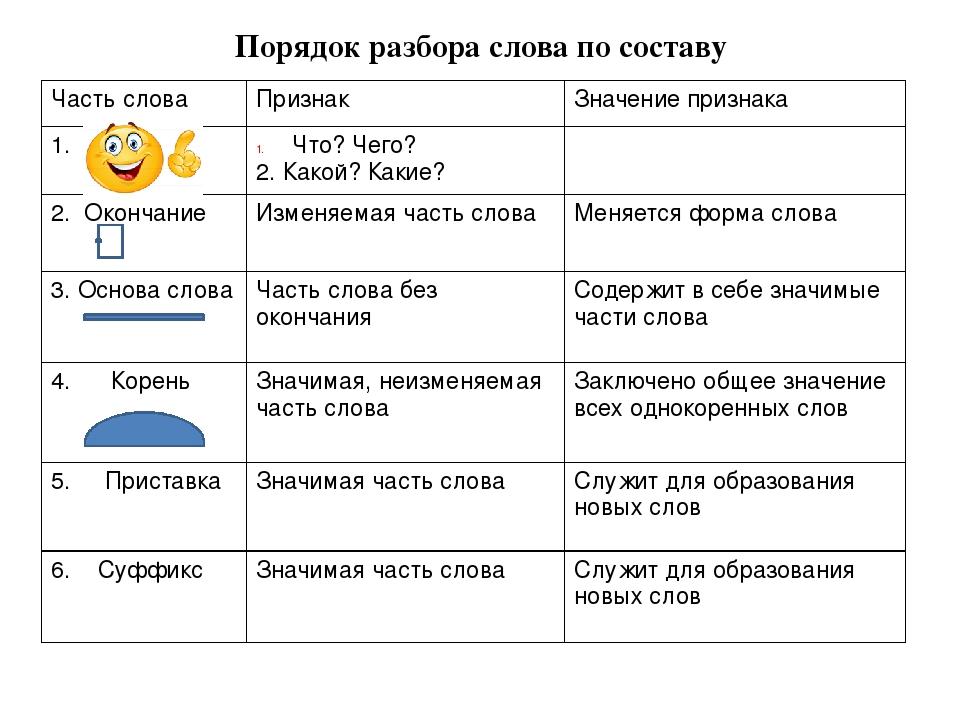 Хотя она намного превосходит RBMT, ошибки в предыдущей системе можно было легко выявить и исправить. Системы SMT значительно сложнее исправить, если вы обнаружите ошибку, так как всю систему необходимо переобучить.
Нейронный машинный перевод (NMT)
Хотя она намного превосходит RBMT, ошибки в предыдущей системе можно было легко выявить и исправить. Системы SMT значительно сложнее исправить, если вы обнаружите ошибку, так как всю систему необходимо переобучить.
Нейронный машинный перевод (NMT)
Системы SMT на основе фраз господствовали до 2016 года, после чего несколько компаний переключили свои системы на нейронный машинный перевод (NMT). С точки зрения эксплуатации NMT не сильно отличается от SMT прошлых лет. Развитие искусственного интеллекта и использование моделей нейронных сетей позволяет NMT отказаться от проприетарных компонентов, имеющихся в SMT.
NMT работает, обращаясь к обширной нейронной сети, которая обучена читать целые предложения, в отличие от SMT, которые разбирают текст на фразы. Это обеспечивает прямой сквозной конвейер между исходным языком и целевым языком. Эти системы развились до такой степени, что рекуррентные нейронные сети (RNN) организованы в архитектуру кодер-декодер. Это снимает ограничения на длину текста, гарантируя, что перевод сохранит свое истинное значение.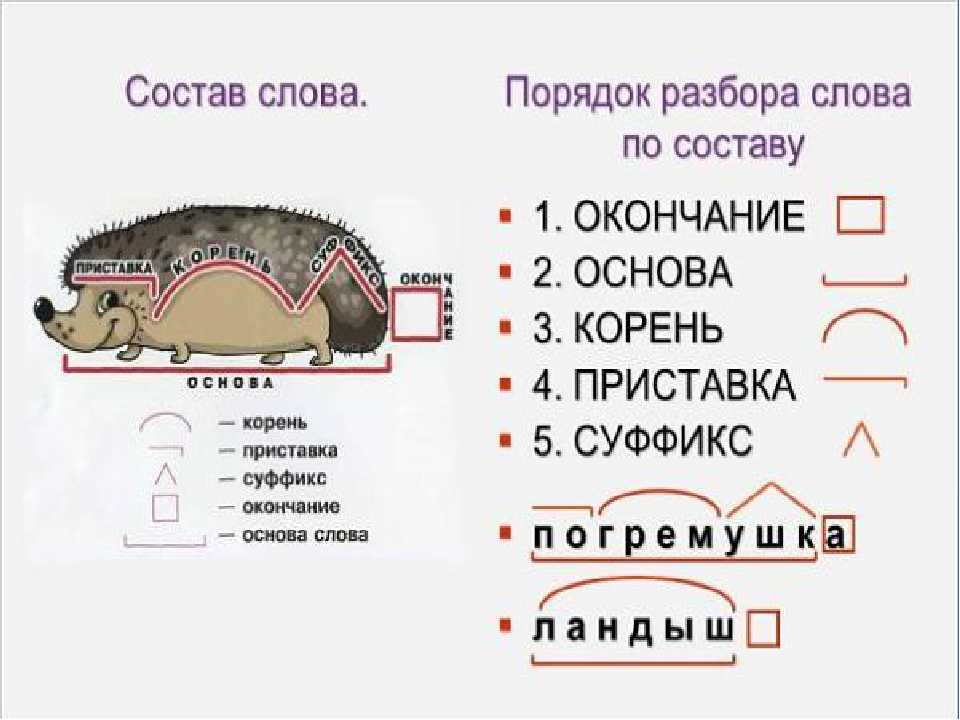 Эта архитектура кодер-декодер работает путем кодирования исходного языка в вектор контекста. Вектор контекста — это представление исходного текста фиксированной длины. Затем нейронная сеть использует систему декодирования для преобразования вектора контекста в целевой язык. Проще говоря, сторона кодирования создает описание исходного текста, размера, формы, действия и так далее. Сторона декодирования читает описание и переводит его на целевой язык.
В то время как многие системы NMT имеют проблемы с длинными предложениями или абзацами, такие компании, как Google, тщательно разработали архитектуру кодировщика-декодера RNN. Этот механизм внимания обучает модели анализировать последовательность первичных слов, в то время как выходная последовательность декодируется. Google — не единственная компания, внедрившая RNN для своего машинного переводчика. Apple использует RNN в качестве основы программного обеспечения для распознавания речи Siri.
Эта технология постоянно расширяется. Первоначально RNN был однонаправленным, рассматривая только слово перед ключевым словом.
Эта архитектура кодер-декодер работает путем кодирования исходного языка в вектор контекста. Вектор контекста — это представление исходного текста фиксированной длины. Затем нейронная сеть использует систему декодирования для преобразования вектора контекста в целевой язык. Проще говоря, сторона кодирования создает описание исходного текста, размера, формы, действия и так далее. Сторона декодирования читает описание и переводит его на целевой язык.
В то время как многие системы NMT имеют проблемы с длинными предложениями или абзацами, такие компании, как Google, тщательно разработали архитектуру кодировщика-декодера RNN. Этот механизм внимания обучает модели анализировать последовательность первичных слов, в то время как выходная последовательность декодируется. Google — не единственная компания, внедрившая RNN для своего машинного переводчика. Apple использует RNN в качестве основы программного обеспечения для распознавания речи Siri.
Эта технология постоянно расширяется. Первоначально RNN был однонаправленным, рассматривая только слово перед ключевым словом. Затем он стал двунаправленным, учитывая также предшествующее и последующее слово. В конце концов, NMT превзошел возможности SMT на основе фраз. NMT начал производить выходной текст, который содержал менее половины ошибок порядка слов и почти на 20% меньше словесных и грамматических ошибок, чем переводы SMT. NMT создан с учетом машинного обучения. Чем больше корпусов загружается в RNN, тем более адаптируемой она становится, что приводит к меньшему количеству ошибок.
Одним из основных преимуществ NMT по сравнению с системами SMT является то, что для перевода между двумя языками, не входящими в мировой лингва-франка, не требуется английский язык. При использовании SMT исходный язык сначала преобразуется в английский, а затем переводится на целевой язык. Этот метод привел к потере качества исходного текста в переводе на английский язык и к дополнительным ошибкам при переводе с английского на целевой язык.
Система NMT дополнительно усовершенствована функцией краудсорсинга. Когда пользователи взаимодействуют с Google Translate в Интернете, им предоставляется основной перевод с несколькими другими потенциальными переводами.
Затем он стал двунаправленным, учитывая также предшествующее и последующее слово. В конце концов, NMT превзошел возможности SMT на основе фраз. NMT начал производить выходной текст, который содержал менее половины ошибок порядка слов и почти на 20% меньше словесных и грамматических ошибок, чем переводы SMT. NMT создан с учетом машинного обучения. Чем больше корпусов загружается в RNN, тем более адаптируемой она становится, что приводит к меньшему количеству ошибок.
Одним из основных преимуществ NMT по сравнению с системами SMT является то, что для перевода между двумя языками, не входящими в мировой лингва-франка, не требуется английский язык. При использовании SMT исходный язык сначала преобразуется в английский, а затем переводится на целевой язык. Этот метод привел к потере качества исходного текста в переводе на английский язык и к дополнительным ошибкам при переводе с английского на целевой язык.
Система NMT дополнительно усовершенствована функцией краудсорсинга. Когда пользователи взаимодействуют с Google Translate в Интернете, им предоставляется основной перевод с несколькими другими потенциальными переводами. По мере того, как все больше людей выбирают один перевод вместо другого, система начинает изучать, какой вывод является наиболее точным. Это означает, что лингвисты и разработчики могут отступить и позволить сообществу оптимизировать NMT. Недостатки NMT Легко понять, почему NMT стал золотым стандартом, когда дело доходит до повседневного перевода. Это быстро, эффективно и постоянно расширяет возможности.
Главный вопрос – это его стоимость. NMT невероятно дороги по сравнению с другими системами машинного перевода. Они также требуют большего обучения, чем их аналоги SMT, и вы все равно столкнетесь с проблемами при работе с непонятными или сфабрикованными словами. Помимо этих недостатков, кажется, что NMT продолжит лидировать в отрасли.
По мере того, как все больше людей выбирают один перевод вместо другого, система начинает изучать, какой вывод является наиболее точным. Это означает, что лингвисты и разработчики могут отступить и позволить сообществу оптимизировать NMT. Недостатки NMT Легко понять, почему NMT стал золотым стандартом, когда дело доходит до повседневного перевода. Это быстро, эффективно и постоянно расширяет возможности.
Главный вопрос – это его стоимость. NMT невероятно дороги по сравнению с другими системами машинного перевода. Они также требуют большего обучения, чем их аналоги SMT, и вы все равно столкнетесь с проблемами при работе с непонятными или сфабрикованными словами. Помимо этих недостатков, кажется, что NMT продолжит лидировать в отрасли.
В попытке смягчить некоторые из наиболее распространенных проблем, возникающих в рамках одного метода машинного перевода, были разработаны подходы к полному объединению определенных функций или целых систем. Multi-Engine
Многоядерный подход объединяет две или более систем машинного перевода параллельно. Выходные данные на целевом языке представляют собой комбинацию окончательных выходных данных нескольких систем машинного перевода.
Генерация статистических правил
Выходные данные на целевом языке представляют собой комбинацию окончательных выходных данных нескольких систем машинного перевода.
Генерация статистических правил
Подход к генерации статистических правил представляет собой комбинацию накопленных статистических данных для создания формата правил. Основным принципом этого подхода является создание структуры лингвистических правил, аналогичной RBMT, с использованием обучающего корпуса, а не команды лингвистов. Недостаток этой системы такой же, как у стандартного SMT. Качество вывода зависит от его сходства с текстом в обучающем корпусе. Хотя это делает его отличным выбором, если он нужен в определенной области или области, он будет давать сбои и давать сбои, если применяется к другим областям. Мультипроход
Многопроходный подход — это альтернативный подход к многодвигательному подходу. Многомашинный подход работал с целевым языком через параллельные машинные переводчики для создания перевода, в то время как многопроходная система представляет собой последовательный перевод исходного языка. Исходный язык будет обрабатываться через систему RBMT и передаваться SMT для создания вывода на целевом языке.
Основанный на достоверности
Исходный язык будет обрабатываться через систему RBMT и передаваться SMT для создания вывода на целевом языке.
Основанный на достоверности
Метод, основанный на достоверности, подходит к переводу иначе, чем в других гибридных системах, поскольку он не всегда использует несколько машинных переводов. Этот тип системы обычно пропускает исходный язык через NMT, а затем получает оценку достоверности, указывающую вероятность того, что его перевод является правильным. Если оценка достоверности удовлетворительна, выдается вывод на целевом языке. В противном случае он передается на отдельный SMT, если перевод оказывается недостаточным.
В наши дни компаниям необходимо выйти на глобальный рынок. Им нужен доступ к переводчикам, которые могут создавать копии на нескольких языках быстрее и с меньшим количеством ошибок. Вот почему они обращаются к машинному переводу.
С помощью машинного перевода компании могут локализовать свои сайты электронной коммерции или создавать контент, доступный мировой аудитории.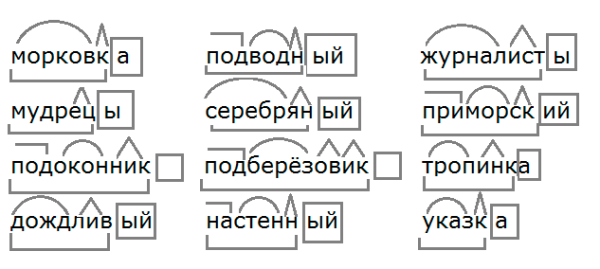 Это открывает рынок, гарантируя, что:
Это открывает рынок, гарантируя, что:
— Увеличение доходов.
— Клиенты счастливее.
— Снижение накладных расходов.
— Стратегия выхода на рынок реализуется быстрее.
Обычно компаниям приходится выбирать между качеством, эффективностью и ценой. К счастью, с Lilt вам не нужно идти на такие жертвы. Если вы хотите увидеть, как ваш бизнес может работать на мировой арене, технология NMT от Lilt поможет вам локализовать ваши сайты быстрее, лучше и с меньшими затратами. С Lilt у вас есть доступ к лучшим в мире людям-переводчикам и лучшей системе нейронного машинного перевода на базе искусственного интеллекта. Мы хотим, чтобы ваша компания росла, не меняя способов ведения бизнеса, поэтому мы разработали наши переводческие услуги, которые легко интегрируются в ваш текущий рабочий процесс. Специалисты по переводу Lilt работают с вашей командой, чтобы внести необходимые коррективы, чтобы вы могли сосредоточиться на том, что у вас получается лучше всего. Чтобы узнать больше о том, как Lilt может улучшить вашу локализацию, запросите демонстрацию сегодня!
Переводите с Lilt сегодня
парс-латиница — нпм
Анализатор естественного языка для языков с латинской графикой, который создает nlcst.
Содержание
- Что это?
- Когда я должен использовать это?
- Установить
- Использование
- API
-
ParseLatin()
-
- Алгоритм
- Типы
- Совместимость
- Связанные
- Пожертвовать
- Безопасность
- Лицензия
Что это?
Этот пакет предоставляет синтаксический анализатор, который принимает естественный язык латинского алфавита и создает синтаксическое дерево.
Когда я должен использовать это?
Если вы хотите вручную обрабатывать естественный язык как синтаксические деревья, используйте это.
Кроме того, вы можете использовать плагин retext retext-latin ,
который обертывает этот проект, чтобы также анализировать естественный язык на более высоком уровне
(проще) абстракция.
Старый английский язык («þā gewearþ þǣm hlāforde и þǣm hȳrigmannum wiþ ānum
penninge»), исландский («Hvað er að frétta»), французский («Où sont les Toilettes?»),
этот проект хорошо справляется с токенизацией.
Для английского и голландского языков вместо этого можно использовать parse-english и парс-голландский .
Вы можете использовать это для латинских шрифтов, таких как кириллица («Добро пожаловать!»), грузинский («როგორა ხარ?»), армянский («Շատ հաճելի է»), и тому подобное.
Установить
Этот пакет предназначен только для ESM. В Node.js (версии 14.14+ и 16.0+) установите с помощью npm:
npm install parse-latin
В Deno с esm.sh :
import {ParseLatin} from 'https://esm.sh /parse-latin@6' В браузерах с esm.sh :
Использовать
import {inspect} из 'unist-util-inspect'
импортировать {ParseLatin} из 'parse-latin'
const tree = new ParseLatin().parse('Простое предложение.')
console.log (проверить (дерево)) Выходы:
RootNode[1] (1:1–1:19, 0–18)
└─0 ParagraphNode[1] (1:1–1:19, 0–18)
└─0 SentenceNode[6] (1:1–1:19, 0–18)
├─0 WordNode[1] (1:1-1:2, 0-1)
│ └─0 TextNode "A" (1:1-1:2, 0-1)
├─1 WhiteSpaceNode " " (1:2-1:3, 1-2)
├─2 WordNode[1] (1:3-1:9, 2-8)
│ └─0 TextNode "простой" (1:3-1:9, 2-8)
├─3 WhiteSpaceNode " " (1:9-1:10, 8-9)
├─4 WordNode[1] (1:10–1:18, 9–17)
│ └─0 TextNode "предложение" (1:10-1:18, 9-17)
└─5 ПунктуацияУзел ". " (1:18-1:19, 17-18)
" (1:18-1:19, 17-18) 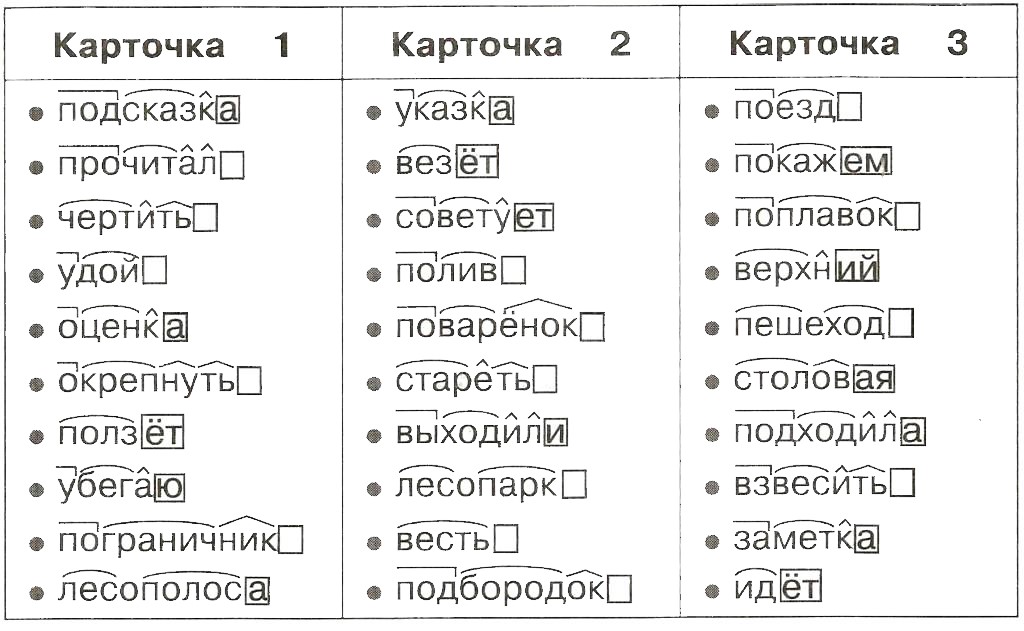 " (1:18-1:19, 17-18)
" (1:18-1:19, 17-18) API
Этот пакет экспортирует идентификатор ParseLatin .
Экспорта по умолчанию нет.
ParseLatin() Создать новый парсер.
ParseLatin#parse(value) Превратите естественный язык в синтаксическое дерево.
Параметры
-
значение(строка, необязательно) — значение для анализа
Возвращает
Дерево ( Корневой узел ).
Алгоритм
👉 Примечание : Самый простой способ увидеть, как
parse-latinанализирует, — это использовать онлайн-демонстрация синтаксического анализатора, которая показывает синтаксическое дерево, соответствующее набранный текст.
parse-latin разбивает текст на пробелы, знаки препинания, символы и слова
токены:
- «слово» — это одна или несколько букв или цифр Юникода
- «пробел» — это один или несколько пробельных символов Юникода
- «пунктуация» — это один или несколько знаков пунктуации Юникода
- «символ» является одним или несколькими из чего-либо еще
Затем он обрабатывает эти токены и объединяет их в синтаксическое дерево, добавляя
предложения и абзацы, где это необходимо.