Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
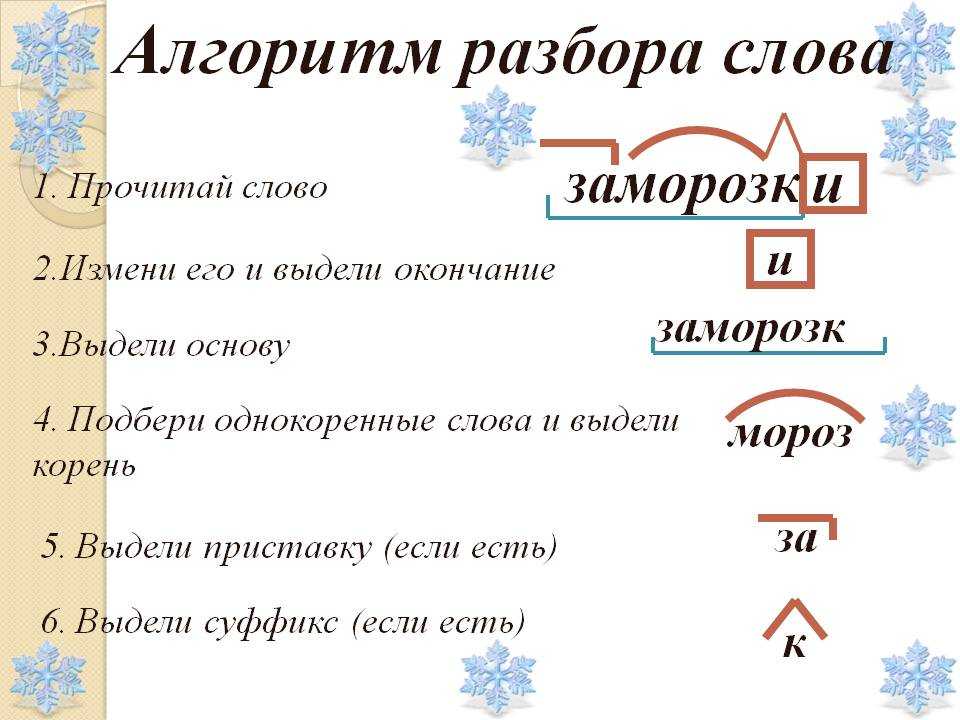
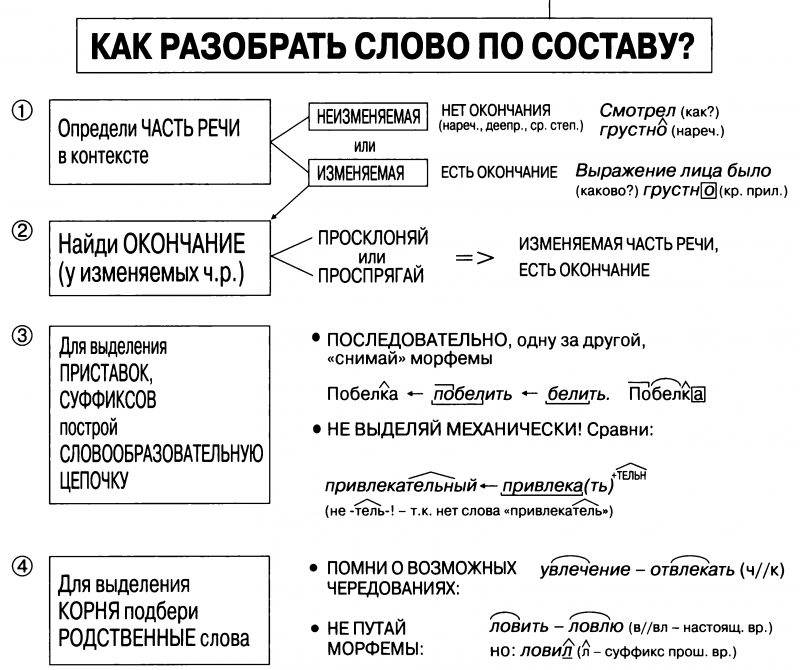
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.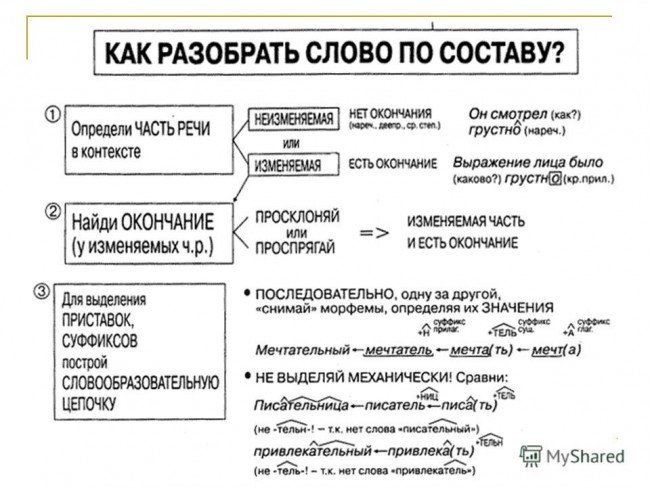
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться.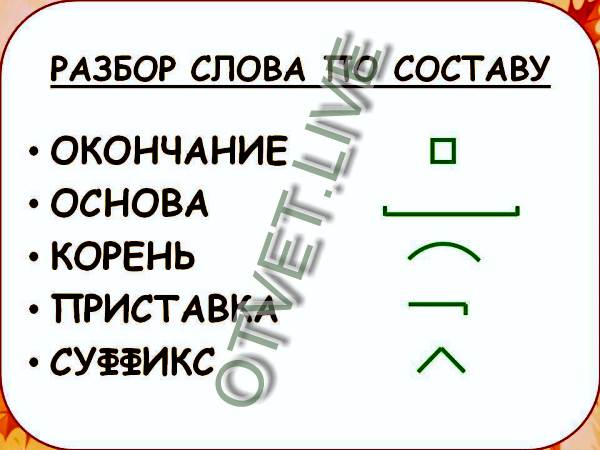 Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: планшет сейчас ппоорр сейчас евдозорь сейчас вимирати сейчас плетасо сейчас шлаквыд сейчас д р а с я н сейчас рисоп сейчас котовагин сейчас сагамри 1 секунда назад маршрут 1 секунда назад кратас 1 секунда назад к о м п а с 1 секунда назад кокуссинр 1 секунда назад враждае 1 секунда назад
Слова «совсем» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «совсем» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «совсем» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «совсем».
Содержимое:
- 1 Слоги в слове «совсем» деление на слоги
- 2 Как перенести слово «совсем»
- 3 Морфологический разбор слова «совсем»
- 4 Разбор слова «совсем» по составу
- 5 Сходные по морфемному строению слова «совсем»
- 6 Синонимы слова «совсем»
- 7 Антонимы слова «совсем»
- 8 Ударение в слове «совсем»
- 9 Фонетическая транскрипция слова «совсем»
- 10 Фонетический разбор слова «совсем» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «совсем»
- 12 Значение слова «совсем»
- 13 Как правильно пишется слово «совсем»
- 14 Ассоциации к слову «совсем»
Слоги в слове «совсем» деление на слоги
Количество слогов: 2
По слогам: со-всем
По правилам школьной программы слово «совсем» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Например, такой:
сов-сем
По программе института слоги выделяются на основе восходящей звучности:
со-всем
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
в примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «совсем»
со—всем
сов—сем
Морфологический разбор слова «совсем»
Часть речи:
Наречие
Грамматика:
часть речи: наречие;
отвечает на вопрос: Как?
Начальная форма:
совсем
Разбор слова «совсем» по составу
| совсем | корень |
совсем
Сходные по морфемному строению слова «совсем»
Сходные по морфемному строению слова
Синонимы слова «совсем»
1. вовсе
вовсе
2. окончательно
3. совершенно
4. весь
5. абсолютно
6. дочиста
7. дотла
8. напрочь
9. насквозь
10. насовсем
11. начисто
12. невозвратно
13. никак
14. нимало
15. нисколько
16. ничуть
17. целиком
18. навек
19. навеки
20. навсегда
21. нисколечко
22. решительно
23. ни чуточки
24. ни капли
25. ни капельки
26. ни крошки
27. ни крошечки
28. ни на волос
29. положительно
30. на веки веков
31. на веки вечные
32. вдрызг
33. вчистую
34. настежь
35. ровно
36. в корне
37. отнюдь
38. полностью
39. вполне
40. сплошь
41. во всем
42. всесторонне
43. целиком и полностью
44. радикально
45. радикальным образом
46. коренным образом
47. кардинально
48. до основания
49. всецело
50. до конца
51. во всех отношениях
52. в полном смысле слова
в полном смысле слова
53. в полной мере
54. от начала до конца
55. в полном объеме
56. во всем объеме
57. в пух и в прах
58. в пух и прах
59. ни в какой мере
60. ни в какой степени
61. ни в коей мере
62. ни в малейшей степени
63. ни вот столько
64. ни на грош
65. ни на йоту
66. ни на каплю
67. ни на копейку
68. ни на лепту
69. ни на маковое зерно
70. ни на полушку
71. далеко не
72. чисто
73. вдовень
74. вдокон
75. вдосек
76. водерень
Антонимы слова «совсем»
1. не совсем
2. вовсе не
3. совсем не
Ударение в слове «совсем»
совсе́м — ударение падает на 2-й слог
Фонетическая транскрипция слова «совсем»
[сафс’`эм]
Фонетический разбор слова «совсем» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| о | [а] | гласный, безударный | о |
| в | [ф] | согласный, глухой парный, твёрдый, шумный | в |
| с | [с’] | согласный, глухой парный, мягкий, шумный | с |
| е | [`э] | гласный, ударный | е |
| м | [м] | согласный, звонкий непарный (сонорный), твёрдый | м |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 6 букв и 6 звуков.
Буквы: 2 гласных буквы, 4 согласных букв.
Звуки: 2 гласных звука, 4 согласных звука.
Предложения со словом «совсем»
Совсем скоро она выполнит свои планы.
Источник: Энни Уэст, В объятиях незнакомца.
Я хоть и страшным забиякой был по молодости, но уж совсем чокнутым меня назвать было нельзя.
Источник: Юлия Галанина, Пропавшая шпага.
Деньги у вас есть и скупость совсем неуместна!
Источник: Татьяна Борщ, Лунный календарь для женщин на 2016 год + календарь стрижек, 2015.
Значение слова «совсем»
СОВСЕ́М , нареч. 1. Совершенно, полностью. Совсем новая вещь. Совсем темно. Совсем забыл. (Малый академический словарь, МАС)
Как правильно пишется слово «совсем»
Правописание слова «совсем»
Орфография слова «совсем»
Правильно слово пишется: совсем
Нумерация букв в слове
Номера букв в слове «совсем» в прямом и обратном порядке:
- 6
с
1 - 5
о
2 - 4
в
3 - 3
с
4 - 2
е
5 - 1
м
6
Ассоциации к слову «совсем»
Непохожий
Молоденький
Ослабелый
Недурной
Остылый
Иной
Никудышный
Неинтересный
Неопытный
Уместный
Юный
Неподходящий
Дряхлый
Стемнеть
Рассвести
Рехнуться
Спятить
Обессилеть
Свихнуться
Запутаться
Отчаяться
Разучиться
Выбиться
Распуститься
Отбиться
Выдохнуться
Сникнуть
Позабыть
Вязаться
Растеряться
Запутать
Замучить
Отвыкнуть
Обстоять
Измучить
Обезуметь
Ослабнуть
Осмелеть
Испортиться
Забыть
Развеселиться
Недавно
Близко
Необязательно
Некстати
По-иному
По-другому
Худо
По-детски
Несложно
Темно
Чуть-чуть
Недалеко
Светло
Нетрудно
Недурно
Недолго
Неплохо
Неинтересно
Ненамного
По-человечески
Наоборот
Непросто
Рядом
Скверно
Уместно
Stage One 10-X Parse Data // Прочие данные // Репозиторий программного обеспечения для бухгалтерского учета и финансов // Университет Нотр-Дам
** Загрузите заархивированные файлы данных здесь.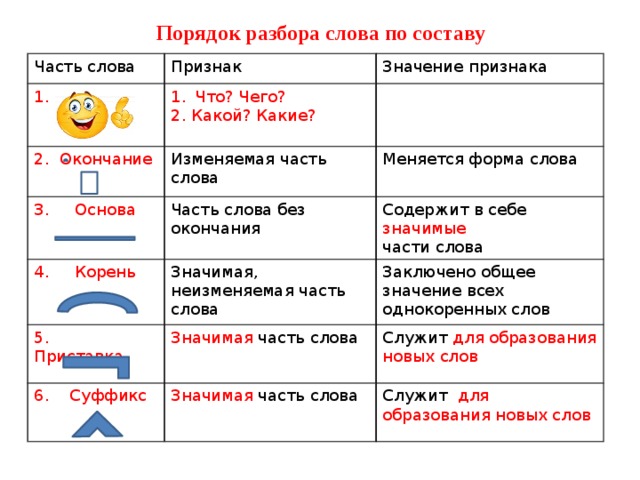 **
**
Документация по первому этапу анализа 10-X
Обновлено 201901
1. Автор: Профессор Билл Макдональд
Колледж бизнеса Мендосы
Университет Нотр-Дам
Notre Dame, IN 46556
2. Первый этап анализа
Определение
«10-X» представляет любую регистрацию ценных бумаг и бирж (SEC), которая является вариантом 10-K, например, 10-Q, 10-K/A, 10-K405 и т. д.[1] Эти ежегодные и ежеквартальные отчеты требуются любым эмитентом ценных бумаг, зарегистрированных в соответствии с Разделом 12 или в соответствии с Разделом 15 (d) SEC Закона о фондовых биржах от 1934 с поправками и в соответствии с требованиями к периодической и текущей отчетности Раздела 13 или 15(d)[2].
Назначение
Я предоставляю два основных источника данных, связанных с заявками 10-X, на веб-сайте EDGAR Комиссии по ценным бумагам и биржам (SEC). Первый помечен как «Разбор первого этапа», который по существу очищает каждый документ от посторонних материалов и подробно описан ниже. Отдельно я предоставляю данные, связанные со «Вторым этапом анализа», который анализирует каждый документ на токены и табулирует различные количества слов. Все эти данные доступны по адресу https://sraf.nd.edu/data/.
Значительная часть содержимого текстового файла EDGAR состоит из HTML-кода, встроенных PDF-файлов, jpg-файлов и других артефактов, которые обычно не представляют интереса. Полный размер некоторых из самых больших файлов превышает 400 МБ. Если для вашего исследования не требуются некоторые из этих артефактов, процесс синтаксического анализа можно сделать на порядки более эффективным, извлекая эти элементы и создавая сжатые версии файлов. Например, после анализа первого этапа размер самого большого файла составляет менее 5 МБ. Эти соображения наиболее актуальны для годовых и квартальных отчетов фирм (годовые и квартальные отчеты в соответствии с Разделом 13 раздела 15(d)), которые находятся в центре внимания этого процесса.
Эти соображения наиболее актуальны для годовых и квартальных отчетов фирм (годовые и квартальные отчеты в соответствии с Разделом 13 раздела 15(d)), которые находятся в центре внимания этого процесса.
Процесс
Все полные текстовые документы 10-X SEC загружаются за каждый год/квартал. В качестве предупредительного примечания: файлы сайта EDGAR в целом надежны, но, основываясь на прошлом опыте, я обнаружил, что они не совсем стабильны. Например, несколько лет назад один из файлов основного индекса был поврежден и содержал только часть полного индекса. Кроме того, в прошлом году пропало 110 файлов из четвертого квартала 2015 года. Я стараюсь проверять загрузки, используя прошлые версии данных, когда это возможно, чтобы избежать некоторых из этих ошибок.
Текстовая версия файлов, представленных на сервере SEC, представляет собой совокупность всей информации, представленной в удобных для браузера файлах, также перечисленных в EDGAR для конкретного файла. Например, в заявке IBM 10-K от 20120228 перечислены основной документ 10-K в формате HTML, десять приложений, четыре файла jpg (графика) и шесть файлов XBRL.[3] Все эти файлы также содержатся в одном текстовом файле со встроенным HTML, XBRL, экспонатами и графикой в кодировке ASCII.[4] В примере с IBM из 48 253 491 символов, содержащихся в файле, только около 7,6% приходится на 10-тысячный текст, включая экспонаты и таблицы. Код HTML составляет около 55% файла. Таблицы XBRL имеют очень высокое соотношение тегов к данным и составляют около 33% текстового файла. Остальные 27% файла относятся к графике в кодировке ASCII. Во многих случаях закодированные в формате ASCII файлы PDF, графики, xls или другие двоичные файлы, которые были закодированы, могут составлять более 90 % документа.
Например, в заявке IBM 10-K от 20120228 перечислены основной документ 10-K в формате HTML, десять приложений, четыре файла jpg (графика) и шесть файлов XBRL.[3] Все эти файлы также содержатся в одном текстовом файле со встроенным HTML, XBRL, экспонатами и графикой в кодировке ASCII.[4] В примере с IBM из 48 253 491 символов, содержащихся в файле, только около 7,6% приходится на 10-тысячный текст, включая экспонаты и таблицы. Код HTML составляет около 55% файла. Таблицы XBRL имеют очень высокое соотношение тегов к данным и составляют около 33% текстового файла. Остальные 27% файла относятся к графике в кодировке ASCII. Во многих случаях закодированные в формате ASCII файлы PDF, графики, xls или другие двоичные файлы, которые были закодированы, могут составлять более 90 % документа.
Поскольку в большинстве исследований текстового анализа основное внимание уделяется текстовому содержимому документа, анализ Stage One создает файлы, в которых все документы 10-X были проанализированы для исключения тегов разметки, графики в кодировке ASCII и таблиц. Мы исключаем таблицы, потому что они обычно не являются объектом анализа текста. Конечно, можно представить исследование, в котором любой из этих исключенных элементов может потребовать анализа исходных документов, однако сжатые файлы обеспечивают стандартизированный и эффективный способ облегчить эти исследования, сосредоточенные на тексте.
Мы исключаем таблицы, потому что они обычно не являются объектом анализа текста. Конечно, можно представить исследование, в котором любой из этих исключенных элементов может потребовать анализа исходных документов, однако сжатые файлы обеспечивают стандартизированный и эффективный способ облегчить эти исследования, сосредоточенные на тексте.
3. Метки разметки
Все теги исходного языка разметки (HTML, XBRL, XML) удаляются из исходного документа. Мы вставляем собственные теги разметки в заголовок в начале сжатого документа и теги, чтобы разграничить все экспонаты в документе. Структура системы тегов следующая:
- В начале каждого файла появляется следующая информация:
<Заголовок>
<Заголовок SEC>
… Весь текст, содержащийся в исходном заголовке SEC
Обратите внимание, что данные 
- Все экспонаты, которым предшествуют исходные теги «
EX-##», инкапсулируются в анализируемых файлах как:
… исходный текст
- Все экспонаты, которым предшествуют исходные теги «
4. Детали разбора
Каждый текстовый файл, загруженный из EDGAR, анализируется в следующей последовательности.
- Удалить сегменты в кодировке ASCII — из файла удаляются все теги
сегмента документа GRAPHIC, ZIP, EXCEL, JSON и PDF. Кодирование ASCII — это средство преобразования файлов двоичного типа в стандартные символы ASCII для облегчения передачи между различными аппаратными платформами. Относительно небольшая графика может создать значительный сегмент ASCII. Файлы, содержащие несколько графических изображений, могут быть на несколько порядков больше, чем файлы, содержащие только текстовую информацию. - Удалить теги,
, и . Хотя нам требуется некоторая информация HTML для последующего синтаксического анализа, файлы настолько велики (и обрабатываются как одна строка), что для повышения эффективности обработки мы сначала просто удалите часть форматирования HTML. 
- Удалить все XML — удаляются все внедренные XML-документы.
- Удалить все XBRL — удаляются все символы между
… .- Удалить верхний/нижний колонтитул SEC — все символы от начала исходного файла до (или в некоторых старых документах) удаляются из файла. Обратите внимание, однако, что информация заголовка сохраняется и включается в тегированные элементы, описанные в разделе 4.1. Кроме того, нижний колонтитул «——END PRIVACY-ENHANCED MESSAGE——», появляющийся в конце каждого документа, удаляется.
- Замените \&NBSP и \  пробелом.
- Замените \& и \& на «&»
- Удалить все оставшиеся ссылки на расширенные символы (ISO-8859-1, см. http://www.sec.gov/info/edgar/edgarfm-vol2-v34.pdf, раздел 5.2.2.6.
- Удалить таблицы — удаляются все символы между тегами
и
.- Обратите внимание, что некоторые фильтры используют табличные теги для разграничения абзацев текста, поэтому каждая потенциальная строка таблицы сначала очищается от всего HTML, а затем сравнивается количество числовых и буквенных символов. Для этого синтаксического анализа только строки, инкапсулированные в таблицу, где числовые символы/(буквенные + числовые символы) > 10% удаляются.
- В некоторых случаях пункт 7 и/или пункт 8 документации начинается с таблицы данных, где граница пункта 7 или 8 отображается в виде строки в строке таблицы. Таким образом, любая строка таблицы, содержащая «Элемент 7» или «Элемент 8» (без учета регистра), удаляется , а не .
- Обратите внимание, что некоторые фильтры используют табличные теги для разграничения абзацев текста, поэтому каждая потенциальная строка таблицы сначала очищается от всего HTML, а затем сравнивается количество числовых и буквенных символов.
- Tag Exhibits — на этом этапе процесса синтаксического анализа все экспонаты помечаются тегами, как описано в разделе 3.2.
- Удалить теги разметки — удалить все оставшиеся теги разметки (например, <…>).
- Удалены лишние переводы строки.
Загрузите заархивированные файлы 10-X здесь.
[1] В частности, включены следующие формы:
f_10K = [’10-K’, ’10-K405′, ’10KSB’, ’10-KSB’, ’10KSB40′]
f_10KA = [‘ 10-К/А», «10-К405/А», «10КСБ/А», «10-КСБ/А», «10КСБ40/А»]
f_10KT = [’10-KT’, ’10KT405′, ’10-KT/A’, ’10KT405/A’]
f_10Q = [’10-Q’, ’10QSB’, ’10-QSB’]
f_10QA = [’10-Q/A’, ’10QSB/A’, ’10-QSB/A’]
f_10QT = [’10-QT’, ’10-QT/A’]
Обратите внимание, что формы 10-KSB и 10-QSB на самом деле являются неправильно помеченными заявками, такими как NBG Radio (CIK=1059366, FilingDate=20020228).
Это относительно редко. Мы не включаем форму 20-F, которая требуется для иностранных компаний, менее 50% акций которых обращаются на бирже США.[2] Отличное описание сроков и распространения документов SEC предоставлено Rogers, Skinner, and Zechman (2017, Journal of Accounting Research ).
[3] XBRL (eXtensible Business Reporting Language) — это язык разметки. Вариант XML, связанный с HTML, обеспечивает семантический контекст для данных, сообщаемых в пределах 10-K. Например, одна строка в заявке Google 20111231 10-K содержит «
00
[4] Кодирование ASCII преобразует файлы двоичных данных в простые печатные символы ASCII, тем самым обеспечивая кросс-платформенное соответствие.
Преобразование из двоичного в обычный текст увеличивает размер исходного файла на несколько порядков.Разбирать, не проверять
⦿ функциональное программирование, haskell, типы
Исторически сложилось так, что я изо всех сил пытался найти краткий и простой способ объяснить, что значит практиковать дизайн, управляемый типами. Слишком часто, когда кто-то спрашивает меня: «Как вы пришли к такому подходу?» Я обнаружил, что не могу дать им удовлетворительный ответ. Я знаю, что это не просто пришло ко мне в видении — у меня итеративный процесс проектирования, который не требует выхватывания «правильного» подхода из воздуха — и все же мне не очень удалось донести этот процесс до других. .
Однако около месяца назад я размышлял в Твиттере о различиях, с которыми столкнулся при синтаксическом анализе JSON в языках со статической и динамической типизацией, и, наконец, понял, что искал. Теперь у меня есть один броский слоган, отражающий, что для меня значит дизайн, основанный на шрифтах, и, что еще лучше, он состоит всего из трех слов:
Анализировать, не проверять.
Суть шрифтового дизайна
Хорошо, признаюсь: если вы еще не знаете, что такое шрифтовой дизайн, мой броский слоган, вероятно, не так уж много значит для вас. К счастью, именно для этого и предназначена оставшаяся часть этого сообщения в блоге. Я собираюсь объяснить, что именно я имею в виду, в кровавых подробностях, но сначала нам нужно немного попрактиковаться в принятии желаемого за действительное.
Царство возможного
Одна из замечательных особенностей систем статического типа заключается в том, что они позволяют, а иногда даже легко отвечать на такие вопросы, как «Возможно ли написать эту функцию?» В качестве крайнего примера рассмотрим следующую сигнатуру типа Haskell:
foo :: Integer -> Void
Можно ли реализовать
foo? Тривиально ответ нет , так какVoid— это тип, который не содержит значений, поэтому для 9 это невозможно.0003 любая функция для получения значения типаVoid. 1 Этот пример довольно скучный, но вопрос становится намного интереснее, если мы выберем более реалистичный пример:head :: [a] -> a
Эта функция возвращает первый элемент из списка. Возможно ли реализовать? Звучит конечно не так, как будто он делает что-то очень сложное, но если мы попытаемся это реализовать, то компилятор не удовлетворится:
head :: [a] -> a голова (х:_) = х
предупреждение: [-Wincomplete-шаблоны] Совпадения с образцом не являются исчерпывающими В уравнении для «головы»: Образцы не совпадают: []Это сообщение полезно указывает на то, что наша функция является частичной , то есть она не определена для всех возможных входных данных. В частности, он не определен, когда ввод
[]пустой список. Это имеет смысл, так как невозможно вернуть первый элемент списка, если список пуст — возвращаемого элемента нет! Итак, что примечательно, мы узнаем, что эту функцию также невозможно реализовать.Вращение частичных функций всего
Для человека, работающего с динамически типизированным фоном, это может показаться запутанным. Если у нас есть список, мы вполне можем захотеть получить в нем первый элемент. И действительно, операция «получение первого элемента списка» не является невозможной в Haskell, просто требует небольшой дополнительной церемонии. Есть два разных способа исправить функцию головки
, и мы начнем с самого простого.Управление ожиданиями
Как установлено,
headявляется частичным, потому что нет элемента для возврата, если список пуст: мы дали обещание, которое не можем выполнить. К счастью, у этой дилеммы есть простое решение: мы можем ослабить наше обещание. Поскольку мы не можем гарантировать вызывающей стороне элемент списка, нам придется немного попрактиковаться в управлении ожиданиями: мы сделаем все возможное, чтобы вернуть элемент, если сможем, но мы оставляем за собой право вообще ничего не возвращать. В Haskell мы выражаем эту возможность с помощью Может бытьtype:head :: [a] -> Maybe a
Это дает нам свободу, необходимую для реализации
head— это позволяет нам вернутьНичегокогда мы обнаружим, что не можем произвести значение типаaв конце концов:head :: [a] -> Maybe a голова (x:_) = Просто x head [] = Ничего
Проблема решена, верно? На данный момент да… но у этого решения есть скрытая стоимость.
Возвращение
Может быть,несомненно удобен, когда нам реализацияголовка. Однако он становится значительно менее удобным, когда мы действительно хотим его использовать! Посколькуheadвсегда может вернутьNothing, бремя обработки этой возможности ложится на его вызывающих, и иногда такая передача ответственности может быть невероятно неприятной. Чтобы понять почему, рассмотрим следующий код:getConfigurationDirectories :: IO [FilePath] getConfigurationDirectories = сделать configDirsString <- getEnv "CONFIG_DIRS" пусть configDirsList = разделить ',' configDirsString когда (нулевой configDirsList) $ throwIO $ userError "CONFIG_DIRS не может быть пустым" чистый configDirsList главная :: IO () главное = делать configDirs <- getConfigurationDirectories case head configDirs of Просто cacheDir -> initializeCache cacheDir Ничего -> ошибка "никогда не должна происходить; уже проверенные configDirs не пусты"Когда
getConfigurationDirectoriesполучает список путей к файлам из среды, он заранее проверяет, не пуст ли этот список. Однако когда мы используем headвmainдля получения первого элемента списка, результатMaybe FilePathпо-прежнему требует от нас обработки случаяNothing, который, как мы знаем, никогда не произойдет! Это ужасно плохо по нескольким причинам:Во-первых, это просто раздражает. Мы уже проверили, что список не пуст, зачем нам загромождать наш код еще одной избыточной проверкой?
Во-вторых, это потенциально снижает производительность. Хотя стоимость избыточной проверки в этом конкретном примере тривиальна, можно представить более сложный сценарий, в котором избыточные проверки могут суммироваться, например, если они происходят в замкнутом цикле.
Наконец, что хуже всего, этот код является ошибкой, ожидающей своего появления! Что, если бы
getConfigurationDirectoriesбыли изменены, чтобы остановить проверку того, что список пуст, преднамеренно или непреднамеренно? Программист может не помнить об обновленииmain, и вдруг «невозможная» ошибка становится не только возможной, но и вероятной.
Необходимость в этой избыточной проверке, по сути, вынудила нас пробить дыру в нашей системе типов. Если бы мы могли статически доказать случай
Nothingневозможно, то модификацияgetConfigurationDirectories, которая прекращает проверку того, был ли список пустым, сделает доказательство недействительным и вызовет сбой времени компиляции. Однако, как написано, мы вынуждены полагаться на набор тестов или ручную проверку, чтобы обнаружить ошибку.Платить вперед
Очевидно, что наша модифицированная версия
головыоставляет желать лучшего. Как-то хотелось бы поумнее: если мы уже проверили, что список не пуст,headдолжен безоговорочно вернуть первый элемент, не заставляя нас обрабатывать заведомо невозможный случай. Как мы можем сделать это?Давайте еще раз посмотрим на исходную (частичную) сигнатуру типа для
head:head :: [a] -> a
В предыдущем разделе показано, что мы можем превратить эту сигнатуру частичного типа в полную, ослабив обещание, сделанное в возвращаемом типе.
Однако, поскольку мы не хотим этого делать, остается изменить только одно: тип аргумента (в данном случае [a]). Вместо того, чтобы ослаблять возвращаемый тип, мы можем усилить тип аргумента, исключив возможность того, чтоheadкогда-либо будет вызвана для пустого списка.Для этого нам нужен тип, представляющий непустые списки. К счастью, существующие 9Тип 0235 NonEmpty из
Data.List.NonEmptyименно такой. Он имеет следующее определение:data NonEmpty a = a :| [a]
Обратите внимание, что
NonEmpty aна самом деле просто кортеж изaи обычного, возможно пустого[a]. Это удобно моделирует непустой список, сохраняя первый элемент списка отдельно от конца списка: даже если компонент[a]равен[], компонентaвсегда должен присутствовать. Это составляетheadсовершенно тривиально реализовать: 2head :: NonEmpty a -> a head (x:|_) = x
В отличие от предыдущего, GHC принимает это определение без претензий — это определение всего , а не частично.
Мы можем обновить нашу программу, чтобы использовать новую реализацию:getConfigurationDirectories::IO (NonEmpty FilePath) getConfigurationDirectories = сделать configDirsString <- getEnv "CONFIG_DIRS" пусть configDirsList = разделить ',' configDirsString case непустой configDirsList of Просто nonEmptyConfigDirsList -> чистый nonEmptyConfigDirsList Ничего -> throwIO $ userError «CONFIG_DIRS не может быть пустым» главная :: IO () главное = делать configDirs <- getConfigurationDirectories initializeCache (главный configDirs)Обратите внимание, что избыточная проверка в
основнойтеперь полностью удалена! Вместо этого мы выполняем проверку ровно один раз, вgetConfigurationDirectories. Он создаетNonEmpty aиз[a], используя функциюnonEmptyизData.List.NonEmpty, которая имеет следующий тип:nonEmpty :: [a] -> Maybe (NonEmpty a)
Возможно,все еще там, но на этот раз мы справимся сНичего 9Случай 0236 очень рано в нашей программе: прямо в том же месте, где мы уже выполняли проверку ввода. После того, как эта проверка прошла, у нас теперь есть значение NonEmpty FilePath, которое сохраняет (в системе типов!) знание того, что список действительно непуст. Другими словами, вы можете думать о значении типаNonEmpty aкак о значении типа[a]плюс доказательство того, что список не пуст.Путем усиления типа аргумента до
headвместо того, чтобы ослабить тип его результата, мы полностью устранили все проблемы из предыдущего раздела:Код не имеет избыточных проверок, поэтому не может быть никаких накладных расходов на производительность.
Кроме того, если
getConfigurationDirectoriesизменится, чтобы прекратить проверку того, что список не пуст, его возвращаемый тип также должен измениться. Следовательно,mainне сможет выполнить проверку типов, предупредив нас о проблеме еще до того, как мы запустим программу!
Более того, тривиально восстановить старое поведение
headиз нового, составивheadсnonEmpty:head' :: [a] -> Maybe a голова' = fmap голова.
nonEmpty Обратите внимание, что обратное , а не верно: невозможно получить новую версию
headиз старой. В целом, второй подход лучше по всем осям.Сила синтаксического анализа
Вам может быть интересно, какое отношение приведенный выше пример имеет к заголовку этой записи в блоге. В конце концов, мы рассмотрели только два разных способа проверки того, что список не пуст, без синтаксического анализа. Эта интерпретация не является ошибочной, но я хотел бы предложить другую точку зрения: на мой взгляд, разница между проверкой и синтаксическим анализом почти полностью заключается в том, как сохраняется информация. Рассмотрим следующую пару функций:
validateNonEmpty :: [a] -> IO () validateNonEmpty (_:_) = чистый () validateNonEmpty [] = throwIO $ userError "список не может быть пустым" parseNonEmpty :: [a] -> IO (NonEmpty a) parseNonEmpty (x:xs) = чистый (x:|xs) parseNonEmpty [] = throwIO $ userError "список не может быть пустым"
Эти две функции почти идентичны: они проверяют, пуст ли заданный список, и если это так, прерывают программу с сообщением об ошибке.
Разница полностью заключается в типе возвращаемого значения: validateNonEmptyвсегда возвращает(), тип, который не содержит информации, ноparseNonEmptyвозвращаетNonEmpty a, уточнение типа ввода, которое сохраняет знания, полученные в системе типов. Обе эти функции проверяют одно и то же, ноparseNonEmptyдает вызывающей стороне доступ к полученной информации, аvalidateNonEmptyпросто отбрасывает ее.Эти две функции элегантно иллюстрируют два разных взгляда на роль статической системы типов:
validateNonEmptyдостаточно хорошо подчиняется проверке типов, но толькоparseNonEmptyв полной мере использует его преимущества. Если вы понимаете, почемуparseNonEmptyпредпочтительнее, вы понимаете, что я имею в виду под мантрой «разбирать, а не проверять». Тем не менее, возможно, вы скептически относитесь к имениparseNonEmpty. Действительно ли анализирует что-либо или просто проверяет ввод и возвращает результат? Хотя точное определение того, что значит синтаксический анализ или проверка чего-либо, является спорным, я считаю, чтоparseNonEmpty— полноценный синтаксический анализатор (хотя и очень простой).Подумайте: что такое синтаксический анализатор? На самом деле синтаксический анализатор — это просто функция, которая получает менее структурированный ввод и выдает более структурированный вывод. По своей природе синтаксический анализатор является частичной функцией — некоторые значения в домене не соответствуют никакому значению в диапазоне — поэтому все синтаксические анализаторы должны иметь некоторое представление об отказе. Часто на вход синтаксическому анализатору поступает текст, но это ни в коем случае не является обязательным требованием, и
parseNonEmpty— превосходный синтаксический анализатор: он разбирает списки на непустые списки, сигнализируя о сбое, завершая программу сообщением об ошибке.При таком гибком определении синтаксические анализаторы являются невероятно мощным инструментом: они позволяют выполнять проверки ввода заранее, прямо на границе между программой и внешним миром, и после того, как эти проверки были выполнены, их никогда не нужно проверять снова! Хаскеллеры хорошо осведомлены об этой силе и регулярно используют множество разных типов парсеров:
Библиотека aeson предоставляет тип
Parser, который можно использовать для анализа данных JSON в доменных типах.Аналогично, optparse-applicative предоставляет набор комбинаторов синтаксического анализа для анализа аргументов командной строки.
Библиотеки баз данных, такие как постоянные и postgresql-simple, имеют механизм анализа значений, хранящихся во внешнем хранилище данных.
Экосистема слуг построена на разборе типов данных Haskell из компонентов пути, параметров запроса, заголовков HTTP и многого другого.
Общим для всех этих библиотек является то, что они находятся на границе между вашим приложением Haskell и внешним миром. Этот мир говорит не в типах произведения и суммы, а в потоках байтов, так что не обойтись без парсинга. Выполнение такого синтаксического анализа заранее, до обработки данных, может значительно помочь избежать многих классов ошибок, некоторые из которых могут даже быть уязвимостями в системе безопасности.
Одним из недостатков такого подхода к предварительному анализу всего является то, что иногда требуется анализировать значения задолго до их фактического использования.
В языке с динамической типизацией это может затруднить синхронизацию логики синтаксического анализа и обработки без обширного покрытия тестами, многие из которых могут быть трудоемкими в обслуживании. Однако со статической системой типов проблема становится на удивление простой, как показано на примере 9.0235 NonEmpty Пример выше: если логика синтаксического анализа и обработки не синхронизирована, программа даже не скомпилируется.Опасность валидации
Надеюсь, к этому моменту вы хотя бы частично уверились в том, что синтаксический анализ предпочтительнее валидации, но у вас могут остаться сомнения. Действительно ли валидация настолько плоха, если система типов в любом случае заставит вас выполнять необходимые проверки? Может быть, отчет об ошибках будет немного хуже, но немного избыточной проверки не повредит, верно?
К сожалению, это не так просто. Специальная проверка приводит к явлению, которое теоретико-языковая область безопасности называет разбором дробовика .
В статье 2016 года «Семь башен Вавилона: таксономия ошибок LangSec и способы их устранения» авторы дают следующее определение: поперек обработки кода — бросая на вход тучу проверок и надеясь, без всякого систематического обоснования, что тот или иной отловит все «плохие» случаи.Далее они объясняют проблемы, присущие таким методам проверки:
Мгновенный анализ обязательно лишает программу возможности отклонять неверный ввод вместо его обработки. Запоздало обнаруженные ошибки во входном потоке приведут к тому, что некоторая часть недопустимых входных данных будет обработана, в результате чего состояние программы будет трудно точно предсказать.
Другими словами, программа, которая не анализирует все свои входные данные заранее, рискует воздействовать на допустимую часть входных данных, обнаруживая, что другая часть недействительна, и внезапно возникает необходимость откатить все изменения, которые она уже выполнила. чтобы сохранить последовательность.
Иногда это возможно, например, откат транзакции в СУБД, но в целом это может быть невозможно.Может быть не сразу очевидно, какое отношение разбор дробовика имеет к проверке — в конце концов, если вы делаете всю свою проверку заранее, вы снижаете риск разбора дробовика. Проблема в том, что подходы, основанные на проверке, чрезвычайно затрудняют или делают невозможным определение того, действительно ли все было проверено заранее или действительно могут произойти некоторые из этих так называемых «невозможных» случаев. Вся программа должна предполагать, что возбуждение исключения в любом месте не только возможно, но и регулярно необходимо.
Синтаксический анализ позволяет избежать этой проблемы, разделяя программу на две фазы — синтаксический анализ и выполнение — где сбой из-за недопустимого ввода может произойти только на первой фазе. По сравнению с этим набор оставшихся режимов отказа во время выполнения минимален, и с ними можно обращаться с необходимой осторожностью.
Анализ, а не проверка, на практике
До сих пор эта запись в блоге была чем-то вроде коммерческого предложения. «Ты, дорогой читатель, должен заниматься разбором!» он говорит, и если я сделал свою работу должным образом, по крайней мере, некоторые из вас проданы. Однако, даже если вы понимаете «что» и «почему», вы можете не чувствовать особой уверенности в том, «как».
Мой совет: сосредоточьтесь на типах данных.
Предположим, вы пишете функцию, которая принимает список кортежей, представляющих пары ключ-значение, и вдруг понимаете, что не знаете, что делать, если в списке есть повторяющиеся ключи. Одним из решений было бы написать функцию, которая утверждает, что в списке нет дубликатов:
checkNoDuplicateKeys :: (MonadError AppError m, Eq k) => [(k, v)] -> m ()
Однако , эта проверка ненадежна: ее очень легко забыть. Поскольку его возвращаемое значение не используется, его всегда можно опустить, и код, который в нем нуждается, все равно будет проверять тип.
Лучшее решение — выбрать структуру данных, которая запрещает дублирование ключей по своей конструкции, например, Карта. Настройте сигнатуру типа вашей функции, чтобы она принималаMapвместо списка кортежей, и реализуйте ее, как обычно.После того, как вы это сделаете, сайт вызова вашей новой функции, скорее всего, не пройдет проверку типов, поскольку ему все еще передается список кортежей. Если вызывающему объекту было присвоено значение через один из его аргументов или если он получил его из результата какой-либо другой функции, вы можете продолжить обновление типа из списка до
Mapна всем пути вверх по цепочке вызовов. В конце концов, вы либо доберетесь до места, где создается значение, либо найдете место, где дубликаты действительно должны быть разрешены. В этот момент вы можете вставить вызов модифицированной версииcheckNoDuplicateKeys:checkNoDuplicateKeys :: (MonadError AppError m, Eq k) => [(k, v)] -> m (Map k v)
Теперь проверку нельзя опускать, так как ее результат действительно необходим для продолжения программы!
Этот гипотетический сценарий подчеркивает две простые идеи:
Используйте структуру данных, которая делает недопустимые состояния непредставимыми.
Смоделируйте свои данные, используя наиболее точную структуру данных, какую только сможете. Если исключить конкретную возможность слишком сложно, используя кодировку, которую вы используете в настоящее время, рассмотрите альтернативные кодировки, которые могут более легко выразить интересующее вас свойство. Не бойтесь рефакторинга.Поднимите бремя доказывания как можно дальше, но не дальше. Превратите свои данные в наиболее точное представление, которое вам нужно, как можно быстрее. В идеале это должно происходить на границе вашей системы, до того, как будут обработаны любых данных. 3
Если одна конкретная ветвь кода в конечном итоге требует более точного представления части данных, проанализируйте данные в более точное представление, как только ветвь будет выбрана. Разумно используйте типы сумм, чтобы ваши типы данных отражали поток управления и адаптировались к нему.
Другими словами, пишите функции в представлении данных, которое вы хотите иметь, а не в представлении данных, которое вам дано.
Затем процесс проектирования превращается в упражнение по преодолению разрыва, часто работая с обоих концов, пока они не встретятся где-то посередине. Не бойтесь итеративно корректировать части дизайна по ходу работы, так как вы можете узнать что-то новое в процессе рефакторинга!Вот несколько дополнительных советов, расположенных в произвольном порядке:
Пусть ваши типы данных влияют на ваш код, не позволяйте вашему коду управлять вашими типами данных. Избегайте искушения просто вставить
Boolв запись где-нибудь, потому что это необходимо для функции, которую вы сейчас пишете. Не бойтесь рефакторить код, чтобы использовать правильное представление данных — система типов гарантирует, что вы покрыли все места, которые нужно изменить, и, скорее всего, избавит вас от головной боли позже.Обработка функций, возвращающих
м ()с глубоким подозрением. Иногда они действительно необходимы, так как могут выполнять обязательный эффект без значимого результата, но если основная цель этого эффекта — вызвать ошибку, вероятно, есть лучший способ.Не бойтесь анализировать данные в несколько проходов. Избегание парсерного анализа просто означает, что вы не должны воздействовать на входные данные до того, как они будут полностью проанализированы, а не то, что вы не можете использовать некоторые из входных данных, чтобы решить, как анализировать другие входные данные. Множество полезных парсеров являются контекстно-зависимыми.
Избегайте денормализованного представления данных, особенно , если оно изменчиво. Дублирование одних и тех же данных в нескольких местах приводит к тривиально представимому недопустимому состоянию: места не синхронизируются. Стремитесь к единственному источнику истины.
Держите денормализованные представления данных за границами абстракции. Если денормализация абсолютно необходима, используйте инкапсуляцию, чтобы гарантировать, что небольшой доверенный модуль несет единоличную ответственность за синхронизацию представлений.
Используйте абстрактные типы данных, чтобы сделать валидаторы «похожими» на парсеры. Иногда сделать недопустимое состояние действительно непредставимым просто непрактично, учитывая инструменты, предоставляемые Haskell, такие как обеспечение того, чтобы целое число находилось в определенном диапазоне. В этом случае используйте абстрактный
newtypeс интеллектуальным конструктором, чтобы «подделать» парсер из валидатора.
Как всегда, руководствуйтесь здравым смыслом. Вероятно, не стоит выбрасывать синглтоны и рефакторить все ваше приложение только для того, чтобы избавиться от одной единственной девятки.0235 ошибка «невозможно» звоните куда-нибудь — просто не забудьте относиться к этим ситуациям как к радиоактивному веществу, которым они являются, и обращайтесь с ними с соответствующей осторожностью. Если ничего не помогает, по крайней мере, оставьте комментарий, чтобы задокументировать инвариант для тех, кому нужно изменить код следующим.
Резюме, размышления и соответствующее чтение
Вот и все. Надеюсь, этот пост в блоге доказывает, что для использования преимуществ системы типов Haskell не требуется докторская степень и даже не требуется использование новейших и лучших языковых расширений GHC, хотя иногда они, безусловно, могут помочь! Иногда самым большим препятствием для использования Haskell в полной мере является простое знание того, какие варианты доступны, и, к сожалению, одним из недостатков небольшого сообщества Haskell является относительная нехватка ресурсов, которые документируют шаблоны проектирования и методы, которые стали общим знанием.
Ни одна из идей в этом сообщении не является новой. На самом деле основная идея — «написать полные функции» — концептуально довольно проста. Несмотря на это, мне невероятно сложно сообщать действенные и практические подробности о том, как я пишу код на Haskell. Легко потратить много времени на обсуждение абстрактных понятий, многие из которых весьма ценны!, не сообщая ничего полезного о процессе .
Я надеюсь, что это небольшой шаг в этом направлении.К сожалению, я не знаю очень много других ресурсов по этой конкретной теме, но я знаю один: я никогда не колеблясь рекомендую фантастический пост в блоге Мэтта Парсона Type Safety Back and Forth. Если вам нужен другой доступный взгляд на эти идеи, включая еще один работающий пример, я настоятельно рекомендую прочитать его. Для значительно более продвинутого взгляда на многие из этих идей я также могу порекомендовать статью Мэтта Нунана 2018 года Ghosts of Departed Proofs, в которой описывается несколько методов для захвата более сложных инвариантов в системе типов, чем я описал здесь.
В заключение я хочу сказать, что рефакторинг, описанный в этом блоге, не всегда прост. Примеры, которые я привел, просты, но реальная жизнь зачастую гораздо менее прямолинейна. Даже для тех, кто имеет опыт проектирования, основанного на типах, может быть действительно трудно зафиксировать определенные инварианты в системе типов, поэтому не считайте личным провалом, если вы не можете решить что-то так, как вам хотелось бы! Считайте принципы, изложенные в этом блоге, идеалами, к которым нужно стремиться, а не строгими требованиями, которым необходимо соответствовать.
Все, что имеет значение, это попробовать.Технически, в Haskell игнорируются «днища», конструкции, которые могут занимать любое значение . Это не «настоящие» значения (в отличие от
nullв некоторых других языках) — это такие вещи, как бесконечные циклы или вычисления, вызывающие исключения — и в идиоматическом Haskell мы обычно стараемся их избегать, поэтому рассуждения, которые притворяются, что они не не существует по-прежнему имеет значение. Но не верьте мне на слово — я позволю Даниэльссону и др. убедить вас в том, что быстрое и расплывчатое мышление морально правильно. ↩На самом деле
Data.List.NonEmptyуже предоставляет функциюheadс этим типом, но просто для иллюстрации мы перереализуем ее сами. ↩Иногда необходимо выполнить какую-либо авторизацию перед анализом пользовательского ввода, чтобы избежать атак типа «отказ в обслуживании», но это нормально: авторизация должна иметь относительно небольшую площадь поверхности и не должна вызывать каких-либо значительных изменений в состояние вашей системы.
- Удалить сегменты в кодировке ASCII — из файла удаляются все теги

 Для этого синтаксического анализа только строки, инкапсулированные в таблицу, где числовые символы/(буквенные + числовые символы) > 10% удаляются.
Для этого синтаксического анализа только строки, инкапсулированные в таблицу, где числовые символы/(буквенные + числовые символы) > 10% удаляются. Это относительно редко. Мы не включаем форму 20-F, которая требуется для иностранных компаний, менее 50% акций которых обращаются на бирже США.
Это относительно редко. Мы не включаем форму 20-F, которая требуется для иностранных компаний, менее 50% акций которых обращаются на бирже США. Преобразование из двоичного в обычный текст увеличивает размер исходного файла на несколько порядков.
Преобразование из двоичного в обычный текст увеличивает размер исходного файла на несколько порядков.
 1 Этот пример довольно скучный, но вопрос становится намного интереснее, если мы выберем более реалистичный пример:
1 Этот пример довольно скучный, но вопрос становится намного интереснее, если мы выберем более реалистичный пример:
 В Haskell мы выражаем эту возможность с помощью
В Haskell мы выражаем эту возможность с помощью  Однако когда мы используем
Однако когда мы используем 
 Однако, поскольку мы не хотим этого делать, остается изменить только одно: тип аргумента (в данном случае
Однако, поскольку мы не хотим этого делать, остается изменить только одно: тип аргумента (в данном случае  Мы можем обновить нашу программу, чтобы использовать новую реализацию:
Мы можем обновить нашу программу, чтобы использовать новую реализацию: После того, как эта проверка прошла, у нас теперь есть значение
После того, как эта проверка прошла, у нас теперь есть значение  nonEmpty
nonEmpty 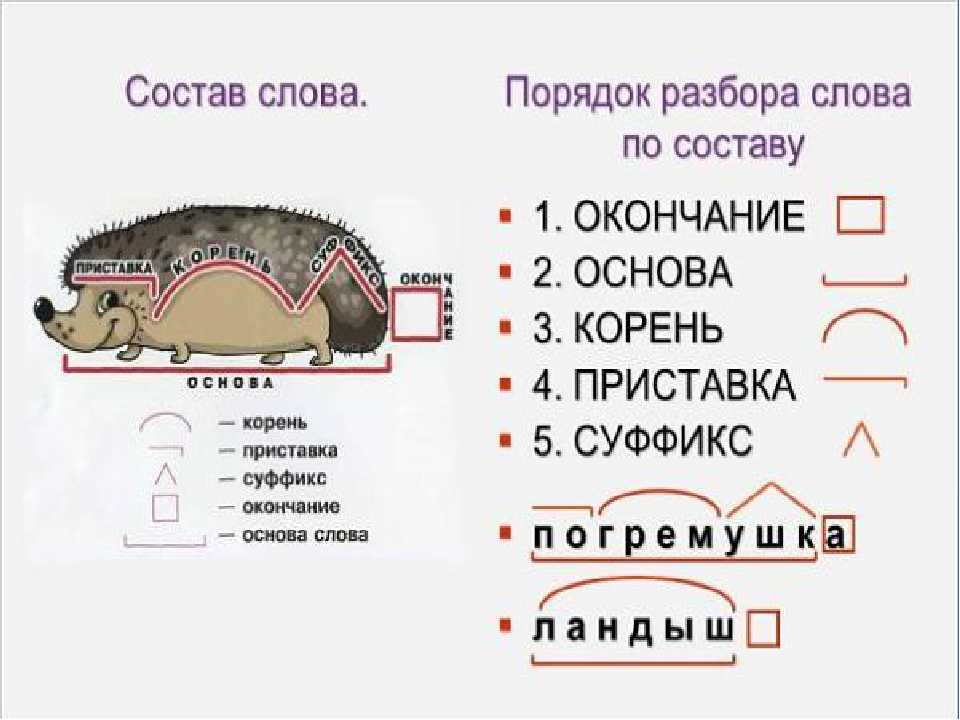 Разница полностью заключается в типе возвращаемого значения:
Разница полностью заключается в типе возвращаемого значения: 
 В языке с динамической типизацией это может затруднить синхронизацию логики синтаксического анализа и обработки без обширного покрытия тестами, многие из которых могут быть трудоемкими в обслуживании. Однако со статической системой типов проблема становится на удивление простой, как показано на примере 9.0235 NonEmpty Пример выше: если логика синтаксического анализа и обработки не синхронизирована, программа даже не скомпилируется.
В языке с динамической типизацией это может затруднить синхронизацию логики синтаксического анализа и обработки без обширного покрытия тестами, многие из которых могут быть трудоемкими в обслуживании. Однако со статической системой типов проблема становится на удивление простой, как показано на примере 9.0235 NonEmpty Пример выше: если логика синтаксического анализа и обработки не синхронизирована, программа даже не скомпилируется. В статье 2016 года «Семь башен Вавилона: таксономия ошибок LangSec и способы их устранения» авторы дают следующее определение: поперек обработки кода — бросая на вход тучу проверок и надеясь, без всякого систематического обоснования, что тот или иной отловит все «плохие» случаи.
В статье 2016 года «Семь башен Вавилона: таксономия ошибок LangSec и способы их устранения» авторы дают следующее определение: поперек обработки кода — бросая на вход тучу проверок и надеясь, без всякого систематического обоснования, что тот или иной отловит все «плохие» случаи. Иногда это возможно, например, откат транзакции в СУБД, но в целом это может быть невозможно.
Иногда это возможно, например, откат транзакции в СУБД, но в целом это может быть невозможно.
 Лучшее решение — выбрать структуру данных, которая запрещает дублирование ключей по своей конструкции, например,
Лучшее решение — выбрать структуру данных, которая запрещает дублирование ключей по своей конструкции, например,  Смоделируйте свои данные, используя наиболее точную структуру данных, какую только сможете. Если исключить конкретную возможность слишком сложно, используя кодировку, которую вы используете в настоящее время, рассмотрите альтернативные кодировки, которые могут более легко выразить интересующее вас свойство. Не бойтесь рефакторинга.
Смоделируйте свои данные, используя наиболее точную структуру данных, какую только сможете. Если исключить конкретную возможность слишком сложно, используя кодировку, которую вы используете в настоящее время, рассмотрите альтернативные кодировки, которые могут более легко выразить интересующее вас свойство. Не бойтесь рефакторинга. Затем процесс проектирования превращается в упражнение по преодолению разрыва, часто работая с обоих концов, пока они не встретятся где-то посередине. Не бойтесь итеративно корректировать части дизайна по ходу работы, так как вы можете узнать что-то новое в процессе рефакторинга!
Затем процесс проектирования превращается в упражнение по преодолению разрыва, часто работая с обоих концов, пока они не встретятся где-то посередине. Не бойтесь итеративно корректировать части дизайна по ходу работы, так как вы можете узнать что-то новое в процессе рефакторинга!


 Я надеюсь, что это небольшой шаг в этом направлении.
Я надеюсь, что это небольшой шаг в этом направлении. Все, что имеет значение, это попробовать.
Все, что имеет значение, это попробовать.