Разбор слов по составу, морфемный разбор
wordmap
Разбор слов по составу
Каждое слово состоит из составных частей. Выделение этих частей – и есть разбор слов по составу. Его также называют «морфемный разбор слов». Чтобы научиться делать такой разбор быстро и безошибочно, необходимо первым делом понять, какие части слов бывают, и как они определяются.
Кстати, чтобы сделать грамотный морфемный разбор слов, особенно если вы столкнулись со сложными словами, будет нелишним использовать специальные словари морфемных разборов. Они могут быть электронными, ими легко и удобно пользоваться в режиме онлайн, например – на нашем сайте.
Разбираем поэтапно
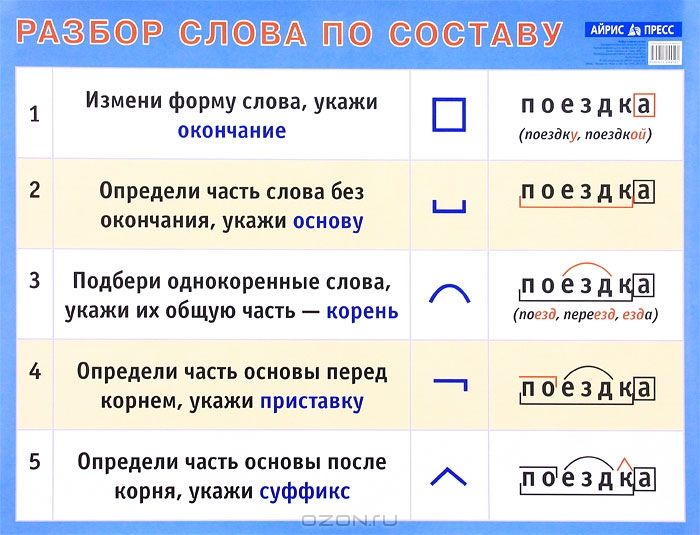
Морфемный разбор слова необходимо делать в определенной последовательности:
- Для начала, выпишите слово и выясните, к какой части речи оно относится. Если это, к примеру, наречие – знайте, что оно не будет иметь окончания и других частей, так как не изменяется.
- Определите окончание, если оно вообще есть.

- Далее стоит определить основу. Это та часть, у которой нет окончания. Например, слово «городской»: тут окончание «ой», и основа «городск».
- Как видите, основа может содержать в себе суффикс и даже приставку.
- Находим приставку, если таковая имеется. К примеру, слово «застолье»: после того, как вы определили основу «стол», вы безтруда найдете приставку «за».
- Определяем суффикс. Эта часть слова стоит сразу после основы (корня» и нужна, чтобы образовать новое слово. Например, был стол – стал столик. В этом случае «ик» — суффикс (окончания нет). Был лес – стал лесок, или лесник.
- Последний этап – найти корень слова. Это та часть, которая не изменяется. В случае со столом, «стол» и есть корень. Чтобы определить корень, найдите однокоренные слова.

Каждая часть выделяется графически, с помощью особых значков. Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Особенности, которые следует знать
Морфемный анализ – процесс, который может показаться слишком простым, а может и наоборот, вызывать ряд сложностей. Вот, что стоит всегда знать и учитывать:
- Нельзя начинать разбор с поиска корня, даже если на первый взгляд он очевиден. Это может привести к ошибке, так что начинать всегда следует с окончания. Часто этап определения корня стоит вторым в плане, но все же вернее именно заканчивать разбор этим этапом, так как это – наиболее безошибочный путь.
- Не стоит путать слова с нулевым окончанием, и те, которые не имеют окончаний. Ведь нулевое окончание – это по сути такая же часть речи, а слово, не имеющее окончаний – не изменяется вовсе. Например, это наречия, деепричастия, сравнительные степени прилагательных и некоторые исключения.
Чтобы научиться делать морфемный разбор грамотно, не забывайте пользоваться электронными словарями, которые доступны на нашем сайте. Это удобно, и позволит вам научиться разбирать слова безошибочно!
Только что искали:
качество 4 секунды назад
арст 6 секунд назад
судачения 14 секунд назад
паридене 15 секунд назад
искаженность 21 секунда назад
ккаасдл 25 секунд назад
нгунгуру 27 секунд назад
работники 30 секунд назад
сабра 31 секунда назад
вспенивающейся 39 секунд назад
компьютерам 41 секунда назад
там 42 секунды назад
цагерский муниципалитет 42 секунды назад
врач-менеджер 43 секунды назад
любить своих родителей 43 секунды назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | искаженность | 50 слов | 12 минут назад | 95. 68.114.220 68.114.220 |
| Игрок 2 | фарширование | 43 слова | 49 минут назад | 95.68.114.220 |
| Игрок 3 | бессовестный | 28 слов | 1 час назад | 95.68.114.220 |
| Игрок 4 | упиливание | 30 слов | 1 час назад | 95.68.114.220 |
| Игрок 5 | пситтакозавр | 0 слов | 2 часа назад | 83.149.47.171 |
| Игрок 6 | остов | 0 слов | 13 часов назад | 95.78.192.95 |
| Игрок 7 | конвон | 0 слов | 13 часов назад | 178.71.171.79 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | одержание | 200:194 | 1 час назад | 176. 59.99.89 59.99.89 |
| Игрок 2 | гигроскоп | 121:134 | 2 часа назад | 178.90.177.217 |
| Игрок 3 | шарик | 56:47 | 2 часа назад | 46.249.26.38 |
| Игрок 4 | катет | 55:49 | 3 часа назад | 46.249.26.38 |
| Игрок 5 | шелковина | 85:95 | 3 часа назад | 178.90.177.217 |
| Игрок 6 | латин | 57:51 | 3 часа назад | 46.249.26.38 |
| Игрок 7 | кумач | 0:0 | 3 часа назад | 46.249.26.38 |
| Играть в Балду! | ||||
| Имя | Игра | Откуда | ||
|---|---|---|---|---|
| Лиза | На одного | 10 вопросов | 11 часов назад | 85. 249.17.26 249.17.26 |
| Бомба фантатмк | На одного | 20 вопросов | 15 часов назад | 188.19.48.93 |
| О | На одного | 20 вопросов | 15 часов назад | 188.19.48.93 |
| Мушка | На двоих | 5 вопросов | 1 день назад | 79.105.117.50 |
| Б | На одного | 10 вопросов | 2 дня назад | 194.226.26.86 |
| Диор | На одного | 5 вопросов | 2 дня назад | 84.54.118.162 |
| Аоя | На одного | 15 вопросов | 3 дня назад | 178.46.85.49 |
| Играть в Чепуху! | ||||
«Расчёт» или «рассчёт» — как правильно пишется слово?
В русском языке есть много трудных для написания слов. Одним из них является существительное «расчёт» или «рассчёт», которое активно используется в речи. Не всем понятно, как его правильно употреблять, с точки зрения грамматики. Разберёмся в этом вопросе ниже.
Одним из них является существительное «расчёт» или «рассчёт», которое активно используется в речи. Не всем понятно, как его правильно употреблять, с точки зрения грамматики. Разберёмся в этом вопросе ниже.
Читайте в статье
- Как пишется правильно: «расчёт» или «рассчёт»?
- Значение слова
- Морфемный разбор слова «расчёт»
- Примеры предложений
- Синонимы слова «расчет»
- Неправильное написание слова «расчет»
- Заключение
Как пишется правильно: «расчёт» или «рассчёт»?
Нормативным считается написание с одной согласной «с» – «расчёт».
Желание написать двойную согласную «сс» возникает по той причине, что изучаемая лексема образована от глагола «рассчитывать». Однако морфемный разбор лексемы «расчёт» доказывает, что писать удвоенную «с» не нужно. Для быстрого запоминания приведём простое правило: если в слове корень «чёт» (с «ё / е»), то всегда следует писать только одну «с» в префиксе.
Значение слова
Рассматриваемое слово многозначное. Приведём его основные лексические значения:
- «Определение количества выплат».
- «Польза от кого-либо, выгода от ситуации».
- «Предположение», «намерение».
- «Денежная компенсация за товар или услугу».
- «Деньги, которые выплачиваются сотруднику при увольнении».
Примечательно, что лексема «расчёт» наиболее часто употребляется в финансовой сфере.
Морфемный разбор слова «расчёт»
Отметим, что анализируемое слово – неодушевлённое существительное мужского рода единственного числа и второго склонения. В первую очередь выделим префикс «рас» (например, как в подобных «раскрасить», «раскрошить», «расклеить»). Затем подберём родственные слова, чтобы выделить корневую морфему. К ним отнесём: «расчётливо», «расчётливость», «подсчёт», «расчётный» и др. На основании этого выделим главную часть слова, в которой заключено его основное лексическое значение – корень «чёт».
Таким образом, «рас» – префикс, «чёт» – корень и нулевое окончание.
расчётПримеры предложений
Приведём примеры контекстов со словом «расчёт», чтобы навсегда запомнить его правописание:
- Елена Степановна поругалась с начальством, поэтому уволилась и попросила расчёт.
- На сегодняшний день безналичный расчёт является популярным средством оплаты.
- Секретарь помогла мне произвести расчёт пособия по уходу за ребёнком.
- Расчёт тарифов на газ со следующего месяца будет проводиться по-другому.
- У компании был расчёт на то, что сотрудники выиграют проект.
- Мама предупреждала меня, что нужно брать в расчёт не только семью, но и друзей.
- Расчёт площади дома оказался неверным, поэтому пришлось начинать сначала.
- Евгений предпочитает работать только за наличный расчёт.
- Его расчёт был на то, что скоро стемнеет, а утром кражу уже никто не сможет обнаружить.
- Расчёт полковника оказался верен: враг был повержен, территории освобождены, недруги взяты в плен.
- Дима попросил меня помочь произвести расчёт строительных материалов.

Синонимы слова «расчет»
Неправильное написание слова «расчет»
Нельзя писать слово с двумя буквами «сс» – «рассчёт». Также неграмотно употреблять такие варианты – «расчот», «разчот», «разчёт».
Заключение
Таким образом, выбрать единственный нормативный вариант написания «расчёт» или «рассчёт» не так трудно, как может показаться на первый взгляд. Для этого достаточно выполнить морфемный разбор этой лексемы и запомнить, что на стыке префикса и корня будет писаться только одна буква «с» – «расчёт». Если всё-таки возникнут сомнения, рекомендуется уточнить правописание в орфографическом словаре.
Простой калькулятор синтаксического анализа.
 Пару месяцев назад искал… | by Ali Erbay Чтение: 5 мин.
Пару месяцев назад искал… | by Ali Erbay Чтение: 5 мин.·
24 августа 2021 г. Photo by Mert Kahveci on UnsplashПару месяцев назад я искал некоторые проблемы с кодом, которые нужно решить, и нашел проблему, которая кажется простой.
Вот оно,
Создайте функцию, которая вычисляет и возвращает значение целочисленного выражения, заданного в виде строки, разделенной пробелами.
вычислить ("2 + 3") Поддерживаются 4 основных оператора: сложение (+), вычитание (-), умножение (*) и деление
вычисление("3 * 2 + 1") Поддерживаются как положительные, так и отрицательные целые числа.
calculate("3 * -2 + 6") Первым и самым простым решением этой проблемы может быть использование встроенной eval() функции Javascript. Да, он анализирует входную строку и запускается как код Javascript. Но нам не нравится eval() , да и вообще его использование считается опасным, так что лучше не привыкать к нему.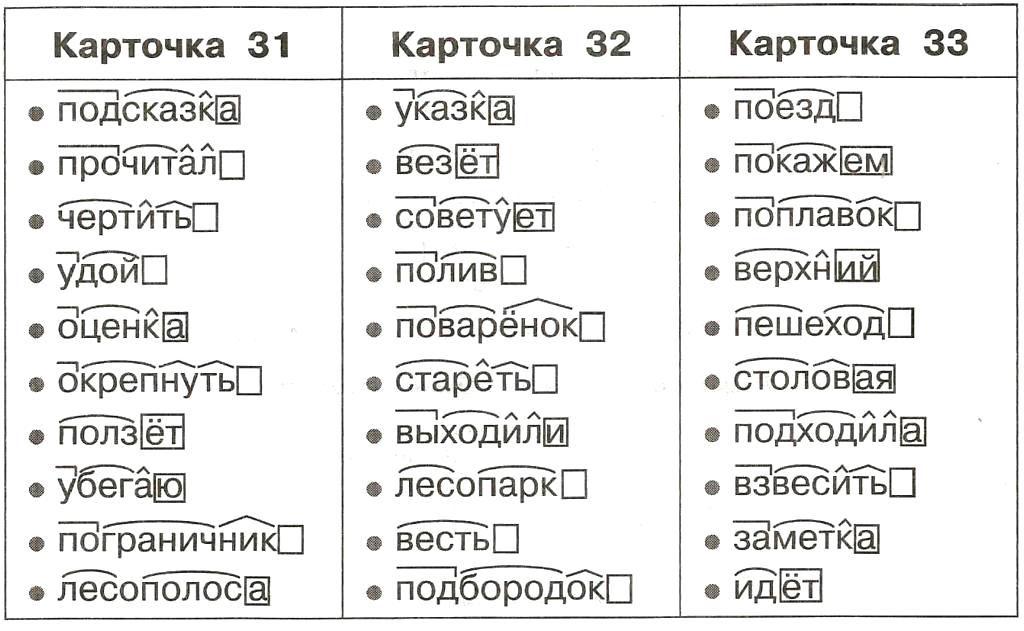 Мы обнаружим некоторые другие варианты, но сначала давайте напишем тестовый код с помощью Jest, я сделаю несколько утверждений, а также покрою некоторые крайние случаи для ввода функции.
Мы обнаружим некоторые другие варианты, но сначала давайте напишем тестовый код с помощью Jest, я сделаю несколько утверждений, а также покрою некоторые крайние случаи для ввода функции.
Я добавлю некоторую очистку ввода, чтобы выдавать ошибки, когда предоставлены некоторые неправильные входные данные, это не обязательно, но я воспринял это как часть задачи по обработке крайних случаев.
Это предложение решения состоит из двух вложенных циклов for и решает строку вычисления, подчиняясь правилам приоритета математических операций.
Вверху я проверяю правильность ввода с помощью уродливого регулярного выражения, которое можно было бы сделать немного лучше, но оно все еще работает для наших целей. Я также должен указать, что это повредит производительности функции, если мы помещаем большие входные данные с очень длинными строками, потому что вызовы Regex, как правило, дороги с точки зрения вычислительных ресурсов. Затем мне нужно было определить возможные математические операнды для нашего использования в порядке их приоритета.
Как обычно делает студент, функция сначала выбирает математические операторы с наивысшим операционным приоритетом, в данном случае умножение и деление, и выполняет поиск во входной строке слева направо (по-прежнему подчиняясь приоритету операций). Пока он не встретит операнд умножения или деления, он продолжает помещать исходные элементы строки вычисления в промежуточный массив с именем NyCalc, , когда он встречает умножение или деление, он выполняет вычисление с предыдущим элементом и элементом после операнда и помещает результат в промежуточный массив NyCalc.
2 + 4 * 4 / 2 - 1 + 3 * 3
становится
2 + 8 - 1 + 9
Теперь внешний цикл функции переключится на вторую пару операндов и сократит исходный массив из слева направо до результата с одним числом.
18
Эта реализация проходит тесты, но поиск лучшего решения или подходящего решения привел меня к исследованию синтаксических анализаторов. Я не выпускник компьютерных наук, поэтому у меня было довольно слабое понимание концепции парсера.
Термин , анализирующий , происходит от латинского pars ( orationis ), что означает часть (речи). В вычислительной лингвистике этот термин используется для обозначения формального анализа компьютером предложения или другой строки слов на его составляющие, в результате чего дерево синтаксического анализа показывает их синтаксическую связь друг с другом. Наш синтаксический анализатор будет читать ввод слева направо и пытаться установить связи между элементами в соответствии с нашим правилом грамматики.
Синтаксический анализатор должен создать абстрактное синтаксическое дерево, где каждый узел дерева обозначает математическую операцию, такую как сложение, умножение и т. д.
Пример абстрактного синтаксического дерева Чтобы получить это дерево, нам нужно определить правила грамматики, которым мы будем следовать при анализе входной строки. Одно из решений разбора выражений рекурсивным спуском состоит в том, чтобы создать новый нетерминал для каждого уровня приоритета. Следующие постановки необходимы для определения правила грамматики;
Следующие постановки необходимы для определения правила грамматики;
Pnum : Number
Pmuldiv : Pnum{('*'|'/')Pnum}
Paddsub : Pmuldiv{('+'|'-')Pmuldiv}
{ и } включают в себя части произведений, которые могут быть повторяется 0 или более раз и | разделяет альтернативы. В соответствии с этими правилами мы можем сформулировать синтаксический анализ, применив простой лексер split() для токенизации ввода и проверки достоверности ввода, а затем обработки функций для уровней приоритета.
splitString функция является токенизатором и в то же время выполняет проверку ввода, это не идеально, поскольку здесь следует применять разделение проблем, мы займемся этим позже.
В определении функции parse есть определения функций checkPos и jumpNext , которые позволяют нам двигаться вперед по входной строке и возвращать фактический токен, на котором мы находимся. parseNum , parseAddSub , 9Функции 0031 parseMulDiv помогают нам отслеживать токены входной строки один за другим и возвращать объекты, содержащие структуру дерева синтаксического анализа.
Синтаксический анализатор выполнит один проход слева направо по checkPos без возврата, pos — это индекс следующего токена, поэтому мы начинаем с 0 и увеличиваем его по мере продвижения. jumpNext потребляет один токен, перемещая pos к следующему.
Точка входа процесса разбора начинается с parseAddSub , так как это самый низкий приоритет в нашей модели калькулятора.
Давайте еще раз взглянем на дерево абстрактного синтаксиса;
Абстрактное синтаксическое дерево Целочисленные значения будут отображаться в конечных узлах, а внутренние узлы представляют операторы.
Для оценки синтаксического дерева можно использовать рекурсивный подход.
Если вы все еще здесь, мы можем сделать простое улучшение, чтобы избавиться от этого длинного выражения RegEx для проверки ввода. Вот что мы собираемся сделать, мы дадим нашему парсеру проверять ввод на ходу. Мы не будем пытаться проверить весь ввод, даже не начав синтаксический анализ.
Мы не будем пытаться проверить весь ввод, даже не начав синтаксический анализ.
Я только что добавил функцию isNumber для проверки ввода в функции parseNumber .
Что нам нужно сделать, если мы хотим добавить возведение в степень в наш калькулятор?
Во-первых, нам нужно переоценить наше правило грамматики, затем нам нужно добавить новую продукцию с правильным уровнем приоритета. На обычном жаргоне информатики возведение в степень в математике правоассоциативное, мы должны отразить это в нашем производстве.
Pnum: номер 9'Pexp}
Pmuldiv : Pexp{('*'|'/')Pexp}
Paddsub : Pmuldiv{('+'|'-')Pmuldiv}
Обратите внимание, что левоассоциативный и правоассоциативный операторы относиться по-разному; левоассоциативные операторы используются в цикле, а правоассоциативные операторы обрабатываются праворекурсивным производством.
parseExp Для экспоненциального операнда предусмотрена функция. Теперь давайте обновим рекурсивную функцию финального вычисления.
Теперь давайте обновим рекурсивную функцию финального вычисления.
Заключительные слова
Вот, мы написали синтаксический анализатор, который подчиняется правилам грамматики и строит абстрактное синтаксическое дерево с достаточным количеством информации для выполнения вычислений с помощью рекурсивной функции.
Это была отличная практика и возможность узнать больше о концепциях информатики. Моей следующей целью было бы понять и прочитать больше о парсерах и компиляторах в целом. Я только слегка поцарапал поверхность, но всем нужно с чего начать!
Калькуляторсимволов в слова
Как использовать наш калькулятор символов для слов
Просто введите количество символов в поле с надписью «Введите число» под полем «Символы». Наш конвертер символов в слова будет автоматически обновляться, чтобы предоставить вам диапазон из двух чисел, низкую оценку слов и высокую оценку.
Вам нужен конвертер символов в страницы?
У нас также есть конвертер символов в страницы справа.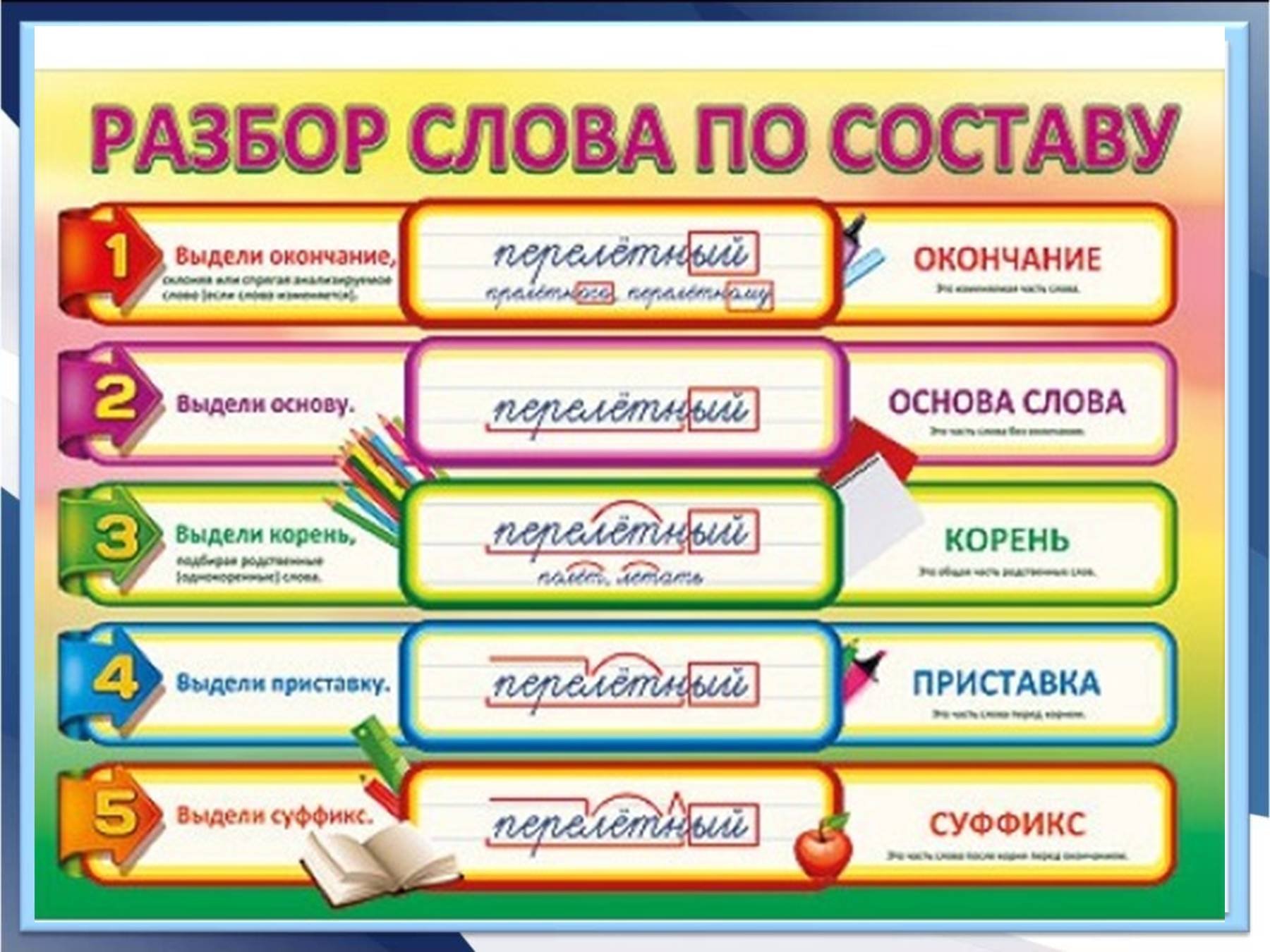 Это даст вам диапазон предполагаемого количества страниц. Имейте в виду, что этот калькулятор символов на страницу будет рассчитывать количество страниц на основе текста, набранного шрифтом Times New Roman размером 12 пунктов с двойным интервалом.
Это даст вам диапазон предполагаемого количества страниц. Имейте в виду, что этот калькулятор символов на страницу будет рассчитывать количество страниц на основе текста, набранного шрифтом Times New Roman размером 12 пунктов с двойным интервалом.
Сколько символов в слове?
В среднем текст содержит от 5 до 6,5 символов на слово, включая пробелы и знаки препинания.
Например, «Великий Гэтсби» содержит в среднем 5,44 символа в слове.
«Гарри Поттер и Философский камень» содержит в среднем 5,55 символов в слове.
Типичная статья New York Times содержит в среднем 6,05 символов на слово.
Имейте в виду, что оценка, которую он дает, включает пробелы. Чтобы получить оценку без пробелов, просто вычтите 1 из оценки. Например, вместо среднего диапазона от 5 до 6,5 символов на слово диапазон без пробелов будет составлять от 4 до 5,5 символов на слово. Затем вы должны разделить общее количество символов на 4, чтобы получить нижний диапазон, и разделить общее количество символов на 5,5, чтобы получить верхний диапазон.
Как рассчитывается оценка
Как упоминалось ранее, большая часть текста содержит от 5 до 6,5 символов на слово. Наш инструмент оценки разделит ваше количество символов на 6,5, чтобы получить первое число в диапазоне, и разделит ваше количество символов на 5, чтобы получить конечное число в диапазоне.
Например, если вы введете 1000 символов выше, вы получите примерный диапазон от 154 до 200 слов. Первое число в диапазоне (154 слова) получается путем деления 1000 на 6,5. Последнее число в диапазоне (200 слов) получается путем деления 1000 на 5.
Если вы введете в поле выше что-либо, не являющееся числом, например, букву или символ, вы получите ответ «Неверный номер». Если это произойдет, просто удалите то, что вы набрали, и повторите попытку, убедившись, что на этот раз вы вводите только цифры.
Как сделать текст более читабельным?
Представьте, что вы начинаете читать текст и теряетесь в середине предложения. Хорошо, вы не сосредоточены и должны перечитать абзац еще раз. И, может быть, еще один. В лучшем случае через несколько раз вы «спотыкаетесь» о длинных неупотребительных словах, не можете уловить основную мысль и просто бросаете читать. Такая ситуация всем знакома и причина тому — плохая читабельность.
И, может быть, еще один. В лучшем случае через несколько раз вы «спотыкаетесь» о длинных неупотребительных словах, не можете уловить основную мысль и просто бросаете читать. Такая ситуация всем знакома и причина тому — плохая читабельность.
Что такое читабельность и длина слова?
Удобочитаемость определяет, насколько легко обычному человеку читать текст. Удобочитаемость зависит от нескольких факторов, влияющих на восприятие текста: длина предложения, структура предложения и, конечно же, длина слова. Длина слова означает использование длинных или коротких слов, которые определяют восприятие и общее понимание текста.
Длинные слова и короткие слова
С точки зрения удобочитаемости короткие слова преобладают над длинными в большинстве текстов. Причины просты и очевидны. Встречая длинные и сложные слова, читатель склонен терять понимание и понимание.
Длинные и даже незнакомые слова трудно читать, поэтому снижается вероятность того, что читатель дочитает текст до конца. Напротив, короткие слова знакомы, легко читаются и запоминаются. Они увеличивают понимание и обеспечивают чтение до конца.
Напротив, короткие слова знакомы, легко читаются и запоминаются. Они увеличивают понимание и обеспечивают чтение до конца.
Когда использовать короткие или длинные слова?
Хотя мы определяем короткие слова как более эффективные для улучшения понимания, было бы несправедливо утверждать, что у длинных слов есть только минусы. Прежде всего, выбор коротких или длинных слов зависит от контекста и целевой аудитории. Конечно, если вы пишете рекламный текст, статью, сообщение в блоге или историю в маркетинговых целях, следует учитывать длину слова.
Если ваша цель — сделать основное сообщение понятным максимальному количеству людей, то лучше выбирать короткие слова ради понимания и лучшего вовлечения.
Однако, работая над профессиональным информационным бюллетенем, ориентированным на специалистов в какой-либо области, подготавливая научную книгу или написав презентацию, посвященную любой нишевой теме, вы должны учитывать, что «громкие слова» могут быть лучше для этого типа аудитории.
Чтобы для какой-то цели казаться более пафосным и вычурным, писатель может выбирать длинные слова вместо коротких. То же самое относится к исследованиям, академическим статьям или кейсам, которые обычно основаны на академическом стиле письма с обилием длинных слов.
Как сделать текст более читаемым?
Если вы хотите, чтобы ваше письмо было более читабельным для ваших целей, лучше выбирать короткие и общеупотребительные слова. Чем больше знакомых слов вы выберете, тем понятнее будет читателям.
Что еще более важно, короткие или даже односложные слова улучшают понимание и не оставляют читателю возможности упустить основную мысль текста. Кроме того, существуют как бесплатные, так и платные онлайн-инструменты, такие как Grammarly, Readable или Hemingway, которые позволяют вам проверить оценку удобочитаемости вашего письма. Обычно он предлагает полезные предложения по замене потенциально трудных слов для обычного читателя.
Таким образом, глубокое знание целевой аудитории и цели написания, правильный выбор стиля и полезные инструменты обеспечат высокую оценку читабельности.