Объекты данных и аннотации — Раздел
Содержание
- Документ
- Предложение
- Маркер
- Word
- Span
- ParseT ree
- Добавление новых свойств к объектам данных Stanza
На этой странице описаны объекты данных и аннотации, используемые в Stanza, и как они взаимодействуют друг с другом.
Document
Объект Document содержит аннотацию всего документа и автоматически генерируется, когда строка аннотируется Трубопровод . Он содержит набор из Sentence и сущностей (которые представлены как Span s) и может быть легко преобразован в собственный объект Python.
Документ содержит следующие свойства:
| Свойство | Тип | Описание |
|---|---|---|
str | Необработанный текст документа. | |
| предложения | List[Sentence] | Список предложений в этом документе. |
| сущности (энты) | List[Span] | Список сущностей в этом документе. |
| num_tokens | int | Общее количество токенов в этом документе. |
| num_words | int | Общее количество слов в этом документе. |
Документ также содержит следующие методы:
| Метод | Тип возврата | Описание |
|---|---|---|
Iterator[Word] | Итератор, возвращающий все слова в этом документе по порядку. | |
| iter_tokens | Iterator[Token] | Итератор, возвращающий все токены в этом документе по порядку. |
| to_dict | List[List[Dict]] | Создает дамп всего документа в виде списка словарей, где каждый словарь представляет токен, которые сгруппированы по предложениям в документе. |
| to_serialized | байт | Создает дамп (с рассолом) всего документа, включая текст, в массив байтов, содержащий список списка словарей для каждой лексемы в каждом предложении в документе. |
| from_serialized | Document | Метод класса для создания и инициализации нового документа из сериализованной строки, сгенерированной Document.to_serialized_string(). |
Sentence
Объект Sentence представляет предложение (сегментированное TokenizeProcessor или предоставленное пользователем) и содержит список Token в предложении, список всех его Word s, а также список сущностей в предложении (представленный как Диапазон с).
Предложение содержит следующие свойства:
| Свойство | Тип | Описание |
|---|---|---|
Document | «Обратный указатель» на родительский документ этого предложения. | |
| текст | str | Необработанный текст для этого предложения. |
| зависимости | Список[(Word,str,Word)] | Список зависимостей для этого предложения, где каждый элемент содержит заголовок Слово отношения зависимости, тип отношения зависимости и зависимое Слово в этом отношении. |
| токены | List[Token] | Список токенов в этом предложении. |
| слова | List[Word] | Список слов в этом предложении. |
| сущности (энты) | List[Span] | Список сущностей в этом предложении. |
| тональность | str | Значение тональности для этого предложения в виде строки. Обратите внимание, что только несколько языков имеют модель тональности. |
| округ | ParseTree | Выбор округа для этого предложения, как ParseTree. Обратите внимание, что только несколько языков имеют модель избирательного округа. Обратите внимание, что только несколько языков имеют модель избирательного округа. |
Предложение также содержит следующие методы:
| Метод | Тип возврата | Описание |
|---|---|---|
List[Dict] | Сбрасывает предложение в список словарей, где каждый словарь представляет токен в предложении. | |
| print_dependencies | Нет | Вывести синтаксические зависимости для этого предложения. |
| print_tokens | Нет | Распечатать токены для этого предложения. |
| print_words | Нет | Выведите слова для этого предложения. |
| tokens_string | str | Аналогично print_tokens , но вместо вывода токенов выгружает токены в строку. |
| слова_строка | стр | Аналогично print_words , но вместо того, чтобы печатать слова, выводит слова в строку. |
Token
Объект Token содержит токен и список лежащих в его основе синтаксических Word s. В случае, если токен представляет собой токен, состоящий из нескольких слов (например, французский au = à le ), токен будет иметь диапазон id , как описано в спецификациях формата CoNLL-U (например, 3-4 ), с его словами свойств, содержащим базовые Word s, соответствующий этим id s. В других случаях объект Token будет функционировать как простая оболочка вокруг одного объекта Word , где его свойство words является одноэлементным.
Токен содержит следующие свойства:
| Свойство | Тип | Описание |
|---|---|---|
Tuple[int] | Индекс этого токена в предложении, 1- основанный на. Этот индекс содержит два элемента (например, Этот индекс содержит два элемента (например, (1, 2) ), если соответствующий токен представляет собой токен из нескольких слов, в противном случае он содержит только один элемент (например, (1, ) ). | |
| текст | str | Текст этого токена. Пример: «The». |
| разное | str | Различные аннотации в отношении этого токена. Используется в конвейере для хранения, например, является ли токен токеном из нескольких слов. |
| слов | List[Word] | Список синтаксических слов, лежащих в основе этого токена. |
| start_char | int | Индекс начального символа для этого токена в необработанном тексте документа. Особенно полезно, если вы хотите выполнить детокенизацию в какой-то момент или применить аннотации к необработанному тексту. |
| end_char | int | Индекс конечного символа для этого токена в необработанном тексте документа. Особенно полезно, если вы хотите выполнить детокенизацию в какой-то момент или применить аннотации к необработанному тексту. Особенно полезно, если вы хотите выполнить детокенизацию в какой-то момент или применить аннотации к необработанному тексту. |
| ner | str | Тег NER этого токена в формате BIOES. Пример: «Б-ОРГ». |
Токен также содержит следующие методы:
| Метод | Тип возврата | Описание |
|---|---|---|
| to_dict | List[Dict] | Сбрасывает токен в список словарей, каждый словарь представляет одно из слов, лежащих в основе этого токена. |
| pretty_print | str | Выведите этот токен со словами, в которые он раскрывается, в одну строку. |
Word
Объект Word содержит синтаксическое слово и все его аннотации на уровне слова. В случае маркеров из нескольких слов (MWT) слова генерируются в результате применения MWTProcessor и используются во всех нижестоящих синтаксических анализах, таких как тегирование, лемматизация и синтаксический анализ. Если
Если Word является результатом расширения MWT, его текст обычно не будет найден во входном необработанном тексте. Помимо токенов, состоящих из нескольких слов, Word должны быть похожи на знакомые «токены», которые можно увидеть в других местах.
Word содержит следующие свойства:
| Свойство | Тип | Описание |
|---|---|---|
| id | int | Индекс этого слова в предложении, на основе 1 (индекс 0 зарезервирован для искусственного символа, представляющего корень синтаксического дерева). |
| текст | стр | Текст этого слова. Пример: «The». |
| лемма | стр | Лемма этого слова. |
| упос (поз) | стр | Универсальная часть речи этого слова. Пример: «СУЩЕСТВИТЕЛЬНОЕ». |
| xpos | str | Часть речи этого слова, связанная с банком деревьев. Пример: «ННП». Пример: «ННП». |
| подвиги | стр | Морфологические признаки этого слова. Пример: «Пол=женщина|человек=3». |
| head | int | Идентификатор синтаксического заголовка этого слова в предложении, основанный на 1 для фактических слов в предложении (0 зарезервирован для искусственного символа, представляющего корень синтаксического дерева ). |
| deprel | str | Отношение зависимости между этим словом и его синтаксическим заголовком. Пример: «нмод». |
| deps | str | Комбинация head и deprel, которая собирает всю информацию о синтаксических зависимостях. Видно в файлах CoNLL-U, выпущенных из универсальных зависимостей, не предсказанных нашим конвейером . |
| разное | стр | Разные аннотации к этому слову. Конвейер использует это поле, например, для внутреннего хранения информации о смещении символов. |
| родитель | Токен | «Обратный указатель» на родительский токен, частью которого является это слово. В случае токена, состоящего из нескольких слов, токен может быть родителем нескольких слов. |
Word также содержит следующие методы:
| Метод | Тип возврата | Описание |
|---|---|---|
| to_dict | Dict | Сбрасывает слово в словарь со всеми его информация. |
| pretty_print | str | Выводит слово в одну строку со всей его информацией. |
Span
Объект Span хранит атрибуты непрерывного фрагмента текста. Диапазон объектов (например, именованные сущности) может быть представлен как Span .
Пролет содержит следующие свойства:
| Свойство | Тип | Описание |
|---|---|---|
| doc | Document | «Обратный указатель» на родительский документ этого диапазона. |
| текст | стр | Текст этого промежутка. |
| токены | List[Token] | Список токенов, соответствующих этому диапазону. |
| слова | List[Word] | Список слов, соответствующих этому диапазону. |
| type | str | Тип объекта этого диапазона. Пример: «ЧЕЛОВЕК». |
| start_char | int | Смещение начального символа этого диапазона в документе. |
| end_char | int | Смещение конечного символа этого диапазона в документе. |
Span также содержит следующие методы:
| Метод | Тип возврата | Описание |
|---|---|---|
| to_dict | Dict | Сбрасывает диапазон в словарь, содержащий всю его информацию. |
| pretty_print | str | Печатает диапазон в одну строку со всей его информацией. |
ParseTree
Объект ParseTree представляет собой вложенную древовидную структуру, предназначенную для представления результатов анализатора групп. Каждый слой вложенности имеет следующие свойства:
| Свойство | Тип | Описание |
|---|---|---|
| этикетка | стр 900 53 | Метка внутреннего узла представляет тип скобки. Претерминалы имеют тег POS в качестве метки. Листья имеют текст слова в качестве метки. |
| дочерние элементы | List[ParseTree] | Дочерние элементы этой скобки. Претерминалы имеют одного потомка и представляют тег и слово. Листья представляют собой просто слово и не имеют потомков. |
Добавление новых свойств к объектам данных Stanza
Новое в версии 1. 1
1
Все объекты данных Stanza могут быть легко расширены, если вам нужно добавить к ним новые интересующие аннотации, либо с помощью нового процессора вы разработки или из написанного вами пользовательского кода.
Чтобы добавить новую аннотацию или свойство к объекту Stanza, скажем, Document , просто вызовите
Document.add_property('char_count', default=0, getter=lambda self: len(self.text), setter= Никто)
И тогда вы сможете получить доступ к свойству char_count из всех экземпляров класса Document . Интерфейс здесь должен быть знаком, если вы использовали свойства класса в Python или другом объектно-ориентированном языке — первый и единственный обязательный аргумент — это имя свойства, которое вы хотите создать, за которым следует по умолчанию
геттер для чтения значения свойства и сеттер для установки значения свойства.
По умолчанию все созданные свойства доступны только для чтения, если вы явно не назначите установщик . Базовая переменная для нового свойства называется _{property_name} , поэтому в нашем примере выше Stanza автоматически создаст переменную класса с именем _char_count для хранения значения этого свойства, если это необходимо. Это переменная, которую должны использовать ваши функции getter и setter , если это необходимо.
С ужасом в мыслях, формульный способ разбора предложений
Реклама
Продолжить чтение основной историиЧТО ДАЛЬШЕ
Ной Шахтман
- 9000 5
МОЖЕТ БЫТЬ английский в шестом классе оказался более полезным, чем вы думали. Одно из самых скучных грамматических упражнений используется, чтобы помочь найти потенциальных террористов и спасти компании.
Составление предложений с выделением подлежащего, глагола, дополнения, прилагательного и других частей речи десятилетиями было одним из основных предметов на уроках грамматики в средних и старших классах. Теперь, получив финансирование от Центрального разведывательного управления, калифорнийская фирма использует эту технику для проверки сообщений электронной почты и разговоров в чатах, которые могут быть богатым источником корпоративной и правительственной информации, которую сложно добыть.
Теперь, получив финансирование от Центрального разведывательного управления, калифорнийская фирма использует эту технику для проверки сообщений электронной почты и разговоров в чатах, которые могут быть богатым источником корпоративной и правительственной информации, которую сложно добыть.
Выяснение связей между людьми, местами и вещами — это то, с чем компьютерные алгоритмы справляются довольно хорошо, пока эта информация структурирована или классифицирована и помещена в базу данных. Например, просмотреть файл клиента компании для человека по имени Бондс довольно просто.
Но если данные неструктурированы — если слово «облигации» не классифицировано как имя игрока или инвестиционный вариант — поиск становится намного сложнее.
Для людей, занятых в бизнесе или на государственной службе, только около 20 процентов их информации хранится в официальных базах данных, отметил Ник Пейшенс, аналитик из 451 Group, исследовательской фирмы в области технологий. Остальное неструктурировано, спрятано в сообщениях электронной почты, журналах вызовов, заметках и мгновенных сообщениях.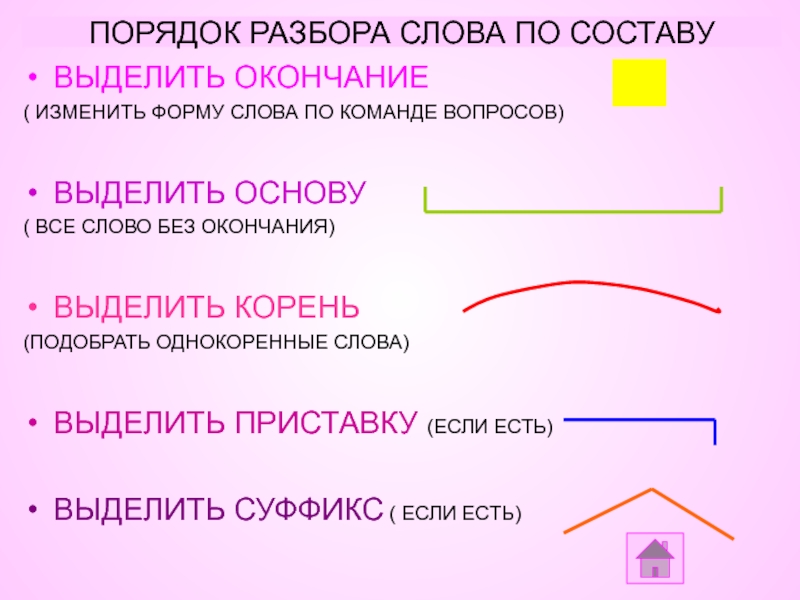
Компания Attensity, базирующаяся в Пало-Альто, штат Калифорния, и частично финансируемая In-Q-Tel, инвестиционным подразделением ЦРУ, разработала метод почти мгновенного анализа электронных документов и составления схем всех предложений внутри. («Моби Дик», например, занял все девять с половиной секунд.) Помечая предметы, глаголы и другие части речи, программное обеспечение Attensity придает документам определяемую структуру, позволяющую помещать их в базу данных. И это помогает превратить повседневную болтовню в актуальную и полезную информацию.
«Они берут язык, которым люди пользуются каждый день, и компилируют его так, чтобы его могла использовать машина», — сказал мистер Пейшенс. «И это позволяет людям начать использовать этот огромный объем интеллекта, который остался неиспользованным».
Компания Whirlpool, производитель бытовой техники, теперь использует программное обеспечение Attensity для сбора информации о 400 000 звонков в службу поддержки, которые компания получает каждый месяц.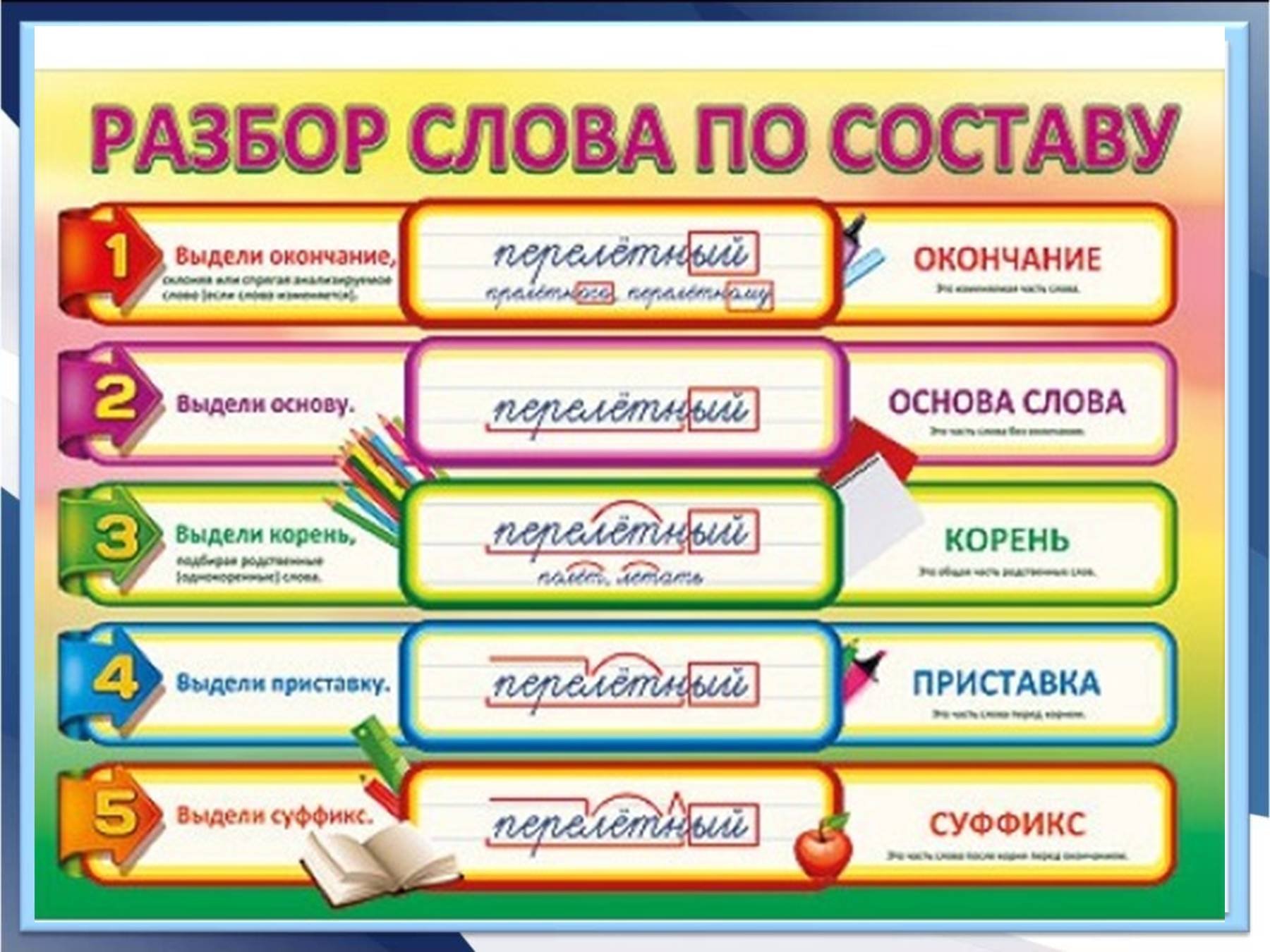
Том Велке, генеральный менеджер Whirlpool, сказал, что компания осознала, что ей нужна помощь, в марте 2002 года во время отзыва микроволновой печи. Машины загорались дугой, производя электрические искры, из-за чего еда внутри задымлялась.
Мистер Велке решил просмотреть записи последних звонков клиентов, выполнив поиск по словам «дуговой разряд» и «дым». Его команда нашла 18 500 совпадающих записей. Затем шесть человек провели выходные, читая результаты, и в итоге получили 700 звонков от клиентов, потенциально связанных с проблемой.
Для сравнения, г-н Велке прогнал те же записи через программу Attensity, которая недавно оплатила ему телефонный звонок.
«Он мог определить, дымит ли микроволновка, дымится ли курица или ест ли клиент копченую курицу», — сказал он. «Он нашел 542 экземпляра примерно за 10 секунд».
В настоящее время Whirlpool тратит четверть миллиона долларов в год на опыт Attensity, присоединяясь к таким компаниям, как John Deere, General Motors и Honeywell, в качестве клиентов Attensity.
Программное обеспечение помогает федеральным исследователям искать ключи к террористической и преступной деятельности в «текстах донесений со всего мира, полевых отчетах, газетных статьях и чатах», — сказал Дэвид Л. Бин, соучредитель Attensity. .
«В разведывательном сообществе имеется множество систем для шести степеней разделения, для сложения двух и двух», — сказал доктор Бин. «Но для этого им нужны структурированные данные. Мы даем им эту структуру».
Спецслужбы отказались обсуждать, используют ли они это программное обеспечение. Но Крис Александер, бывший аналитик разведки Центрального командования вооруженных сил США, отметил, что «внесение неструктурированной информации во все, что могло бы ее систематизировать, было бы очень полезным».
«У нас есть ребята, которые умеют взламывать жесткие диски», — сказал мистер Александр. «Получить информацию легко. Труднее всего поделиться ею и организовать ее так, чтобы все в агентстве, даже неспециалисты, могли ее использовать».
Однако алгоритмы Attensity могут сделать больше, чем подготовить документ к категоризации. Программное обеспечение определяет смысл предложений по мере их построения. Если слово «покупка» используется как глагол, человек, совершающий покупку, помечается как возможный покупатель. Если в качестве объекта используется фраза «пластиковая взрывчатка», субъект помечается как потенциальный враг.
На данный момент Attensity работает только с английским языком. На эту слабость быстро указывают конкуренты компании в мире структурирования данных.
Inxight Software из Саннивейла, Калифорния, например, производит программное обеспечение, которое превращает грамматические отношения в математические формулы, что позволяет анализировать документы на 31 языке. Intelliseek из Цинциннати извлекает объекты — имена собственные и места — из записей в блогах, чтобы классифицировать их. Программное обеспечение компании также будет характеризовать документ как положительный или отрицательный в зависимости от содержащихся в нем слов.
Intelliseek из Цинциннати извлекает объекты — имена собственные и места — из записей в блогах, чтобы классифицировать их. Программное обеспечение компании также будет характеризовать документ как положительный или отрицательный в зависимости от содержащихся в нем слов.
Oracle и другие крупные производители баз данных также встраивают некоторые ограниченные функции для извлечения информации из неструктурированных текстов. Но эти системы обычно полагаются на то, что человек, использующий их, обучает алгоритмы тому, что им нужно знать — что в юридическом документе, например, «поданы в суд» и «поданы обвинения» являются грубыми эквивалентами.
С программным обеспечением Attensity такого рода инструкции часто не нужны. «Внимательность показывает, как все слова соотносятся друг с другом — все действующие лица, объекты и действия в документе, а также то, как они связаны», — сказала Гейл фон Эккартсберг, представитель In-Q-Tel, которая также финансирует Inxight. и Intelliseek.