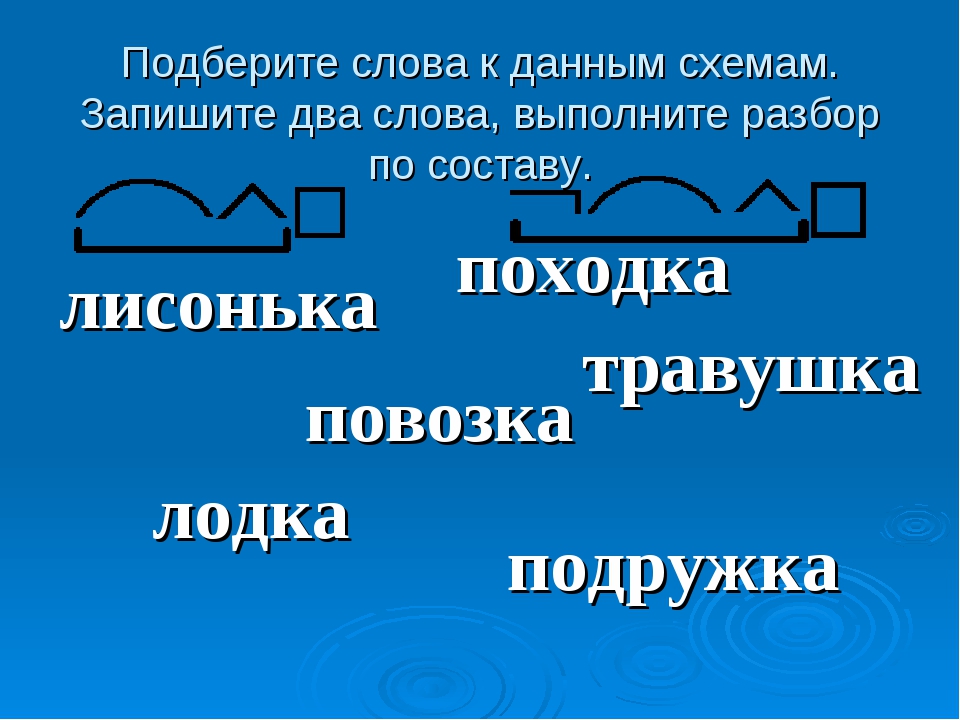
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Разбери по составу слова: низкие, отметили, перелетали.
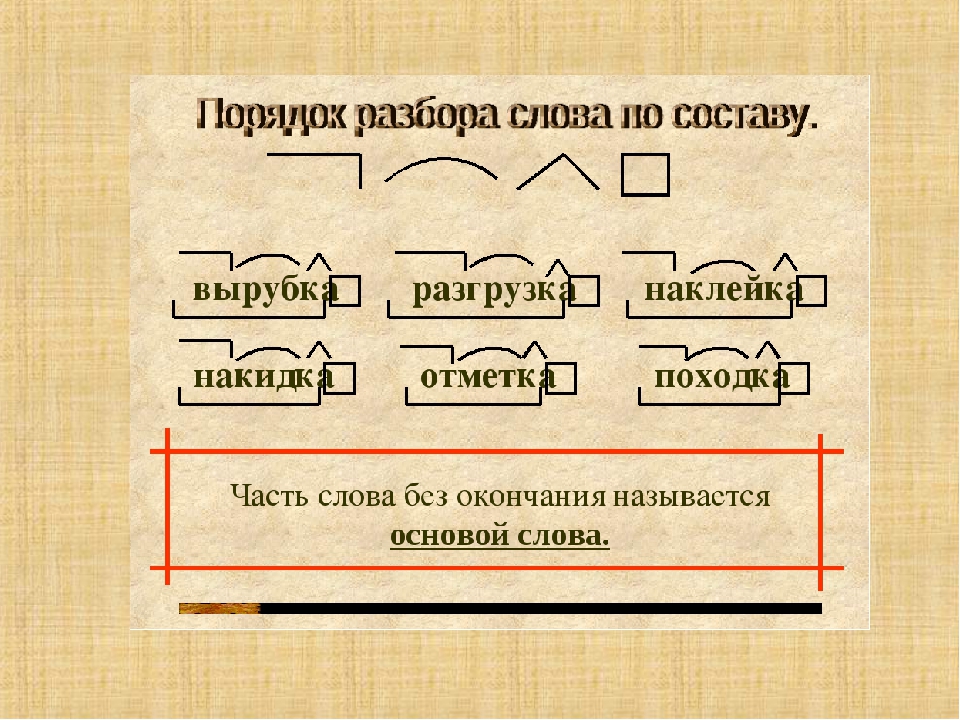
Морфемы составляют слова. Разбираем слово на составные по схеме при этом не всегда обнаружим корень, приставку, суффикс и окончание.
Есть слова только с корнем (суп) или несколькими корнями (двухсоткилометровый), 2-3 приставками (беспомощность, предрасположенность), тремя суффиксами (бесхитростный, убыточный).
Анализ состава слова
- Вопрос к слову определяет часть речи.
- Окончанием зовется изменяемая часть слова. Склоняя/спрягая слово, меняем его.
- Основа — остаток после отделения окончания.
 Корень, приставку и суффикс следует искать там.
Корень, приставку и суффикс следует искать там. - Корнем именуются общая часть родственных слов.
- В начале слова, перед корнем, найдем приставку.
- Суффикс стоит после корня, перед окончанием.
 Корень, приставку и суффикс следует искать там.
Корень, приставку и суффикс следует искать там.
Неизменяемые слова (жабо), наречия, деепричастия не имеют окончаний. В изменяемом слове не просматривается окончание нулевое (прилетел).
Суффикс порой находится не перед окончанием, постфикс «ся» (отметился). Суффикс не входит в состав основы в некоторых случаях (отметил).
Примеры разбора слов по составу
Слово «низкие»
- «Какие?» — прилагательное.
- Ищем окончание, изменяемую часть слова: «низкий», «низкая», «низкое» — «ие».
- Основа — «низк».
- Родственные слова: «низко», «низковатый»,
«низкокачественный», «низковато». Общая «низк» будет корнем. - Приставки нет.
- Суффикса нет.
«Перелетали»
- Глагол, потому что вопрос «что делали?».
- Изменяемая часть: «перелетал», перелетала», «перелетало» указывает на окончание «и».
- Основа в слове — «перелета».
- Родственные слова: «летать», «перелететь», «перелет», «взлет», полет», «влетать», «прилетать», «полет». Общая часть слов «лет» именуется корнем.
- Приставка — пре.
- Суффиксы: а, л.

«Отметили»
- «Что сделали?» — глагол.
- Ищем изменяемую часть: «отметило, «отметила», «отметил» — разыскали окончание «и».
- Основа — «отмети».
- Родственные слова: «отметиться», «метить», «заметить», «отметка», «отмечаться», «метка», «наметить», «разметить». Общая часть «мет» зовется корнем.
- Приставка — от.
- Суффиксы: и, л.
В словах»отметили», «пролетели» суффикс «л» употреблялся для формирования прошедшего времени глагола, составляющей основы он не является.
низко — фонетический (звуко-буквенный) разбор слова — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «низкий», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
НИЗКИЙ, ая, ое; зок, зка, зко, зки и зки; ниже; низший и (устар.) нижайший.
1. (зки). Малый по высоте, находящийся на небольшой высоте от земли, от какого-н. уровня. Низкая ограда. Низкое кресло. Низко (нареч.) лететь. Низкое место (низменное). Н. лоб (узкий, невысокий).
2. кр. ф. (зки). Меньший по высоте, чем нужно. Этот стол мне низок.
3. Не достигающий среднего уровня, средней нормы, небольшой, незначительный.Низкое давление. Низкая температура. Ток низкого напряжения. Низкие цены. Низкая квалификация. Н. уровень знаний. Низкая вода (стоящая ниже обычного уровня, отступившая от берегов).
4. Плохой, неудовлетворительный в качественном отношении. Н. сорт. Низкое качество. Быть низкого мнения о ком-чёмн.
Н. сорт. Низкое качество. Быть низкого мнения о ком-чёмн.
5. Подлый, бесчестный. Низкая личность. Н. поступок.
6. полн. ф. Неродовитый, не принадлежащий к господствующему, привилегированному классу (устар.). Низкое происхождение.
7. О стиле речи: не возвышенный, простой, обиходный (устар.). Н. слог.
8. О звуке, голосе: густой и насыщенный. Н. бас. Низкая нота.
9. нижайший, ая, ее. Почтительный, уважительный (устар.). Нижайшая просьба. Нижайшее почтение. Нижайший поклон (то же, что низкий поклон во 2 знач.).
• Низкий поклон 1) глубокий поклон, почти до земли; 2) кому, земной поклон, глубокая благодарность. Низкий поклон хлеборобам.
| уменьш. низенький, ая, ое (к 1 знач.).
| сущ. низость, и, ж. (к 5 знач.).
низость, и, ж. (к 5 знач.).
Фонетический (звуко-буквенный) разбор
ни́зкий
низкий — слово из 2 слогов: ни-зкий. Ударение падает на 1-й слог.
Транскрипция слова: [н’иск’ий’]
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
и — [и] — гласный, ударный
з — [с] — согласный, глухой парный, твёрдый (парный)
к — [к’] — согласный, глухой парный, мягкий (парный)
и — [и] — гласный, безударный
й — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
В слове 6 букв и 6 звуков.
Цветовая схема: низкий
Разбор слова «низкий» по составу
низкий
Части слова «низкий»: низк/ий
Часть речи: имя прилагательное
Состав слова:
низк — корень,
ий — окончание,
низк — основа слова.
низкий
Части слова «низкий»: низ/к/ий
Часть речи: имя прилагательное
Состав слова:
низ — корень,
к — суффикс,
ий — окончание,
низк — основа слова.
Морфологический разбор слова «низка»
Слово можно разобрать в 3 вариантах, в
зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Существительное
НИЗКА — неодушевленное
Начальная форма слова: «НИЗКА»
| Слово | Морфологические признаки |
|---|---|
| НИЗКА |
|
Все формы слова НИЗКА
НИЗКА, НИЗКИ, НИЗКЕ, НИЗКУ, НИЗКОЙ, НИЗКОЮ, НИЗОК, НИЗКАМ, НИЗКАМИ, НИЗКАХ
2 вариант разбора
Часть речи: Краткое прилагательное
НИЗКА — неодушевленное
Начальная форма слова: «НИЗОК»
| Слово | Морфологические признаки |
|---|---|
| НИЗКА |
|
Все формы слова НИЗКА
НИЗОК, НИЗКА, НИЗКУ, НИЗКОМ, НИЗКЕ, НИЗКИ, НИЗКОВ, НИЗКАМ, НИЗКАМИ, НИЗКАХ
3 вариант разбора
Часть речи: Существительное
НИЗКА — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НИЗКИЙ»
| Слово | Морфологические признаки |
|---|---|
| НИЗКА |
|
Все формы слова НИЗКА
НИЗКИЙ, НИЗКОГО, НИЗКОМУ, НИЗКИМ, НИЗКОМ, НИЗКАЯ, НИЗКОЙ, НИЗКУЮ, НИЗКОЮ, НИЗКОЕ, НИЗКИЕ, НИЗКИХ, НИЗКИМИ, НИЗОК, НИЗКА, НИЗКО, НИЗКИ, НИЖЕ, ПОНИЖЕ, НИЖАЙШИЙ, НАИНИЖАЙШИЙ, НИЗШИЙ, НАИНИЗШИЙ, НИЖАЙШЕГО, НАИНИЖАЙШЕГО, НИЗШЕГО, НАИНИЗШЕГО, НИЖАЙШЕМУ, НАИНИЖАЙШЕМУ, НИЗШЕМУ, НАИНИЗШЕМУ, НИЖАЙШИМ, НАИНИЖАЙШИМ, НИЗШИМ, НАИНИЗШИМ, НИЖАЙШЕМ, НАИНИЖАЙШЕМ, НИЗШЕМ, НАИНИЗШЕМ, НИЖАЙШАЯ, НАИНИЖАЙШАЯ, НИЗШАЯ, НАИНИЗШАЯ, НИЖАЙШЕЙ, НАИНИЖАЙШЕЙ, НИЗШЕЙ, НАИНИЗШЕЙ, НИЖАЙШУЮ, НАИНИЖАЙШУЮ, НИЗШУЮ, НАИНИЗШУЮ, НИЖАЙШЕЮ, НАИНИЖАЙШЕЮ, НИЗШЕЮ, НАИНИЗШЕЮ, НИЖАЙШЕЕ, НАИНИЖАЙШЕЕ, НИЗШЕЕ, НАИНИЗШЕЕ, НИЖАЙШИЕ, НАИНИЖАЙШИЕ, НИЗШИЕ, НАИНИЗШИЕ, НИЖАЙШИХ, НАИНИЖАЙШИХ, НИЗШИХ, НАИНИЗШИХ, НИЖАЙШИМИ, НАИНИЖАЙШИМИ, НИЗШИМИ, НАИНИЗШИМИ
Разбор слова по составу низка
| Основа слова | низк |
|---|---|
| Корень | низ |
| Суффикс | к |
| Окончание | а |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НИЗКА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти
синонимы к слову «низка»
Примеры предложений со словом «низка»
1
Пройдя мимо торговок, мы очутились перед низкой дверью трактира-низка в доме Ярошенко.
Москва и москвичи. Избранные главы, Владимир Гиляровский, 1926г.
2
Температура выше трупной, но еще низка.
Голова профессора Доуэля, Александр Беляев, 1937г.
3
Он знал по опыту прошлой зимы, что, как бы ни была низка температура, для ощущения тепла важно резкое изменение, контраст.
Колымские рассказы, Варлам Шаламов, 1954-1962г.
4
Действительно, таковая оказалась рядом, только дверь очень была низка.
Чудо Рождественской ночи, Сборник, 2008г.
5
Корпус был приземист, окна темноваты, парадная дверь тяжела и низка.
Смерть Вазир-Мухтара, Юрий Тынянов, 1928г.
Найти еще примеры предложений со словом НИЗКА
“Стоят” фонетический разбор | Грамота
При фонетическом разборе слова “стоят”, требуется рассмотреть и выделить определенные характерные черты каждого звукового значения по свойственным ему показателям, а также изучить правильное произношение, ударение и перенос словоформы в письменной речи.
Так происходит звуко-буквенный разбор слова “стоят”. Рассмотрим его по пунктам.
Фонетический разбор
Данный разбор требует соблюдения определенных правил и порядка:
- Итак, начинаем с того, из какого числа слогов состоит слово: сто/ят – состоит из 2-х слогов.
- Письменный перенос в данной лексеме полностью идентичен выделенным слогам: сто-ят.
- Обязательно определяем букву, которая стоит под ударением: стоЯт.
Транскрипция слова
Произносим словоформу “стоят”, чтобы верно определить звуковую транскрипцию: [стай’ат].
Звуко-буквенный разбор
На основе транскрипционного произношения соотносим каждую букву её звуковому значению, и смотрим сколько звуков и букв в слове “стоят”:
- с – [с] – стоит в значении согласного, обладает глухим звучанием в твёрдой парной форме;
- т – [т] – является одним из согласных, находится в глухом парном положении, выражает твёрдость;
- о – [а] – по признакам относится к гласным, не попадает под ударение;
- я – [й’] – выражается согласным звуком, всегда обладает звонким выражением, стоит в мягкой форме;
- – [а] – определяет гласное звучание в ударной позиции;
- т – [т] – имеет принадлежность к согласным, является парным глухим, обладает твёрдостью звука.
Проверь себя: “Играя” фонетический разбор слова
В слове “стоят” мы получаем 5 букв, а звуков на один больше – 6.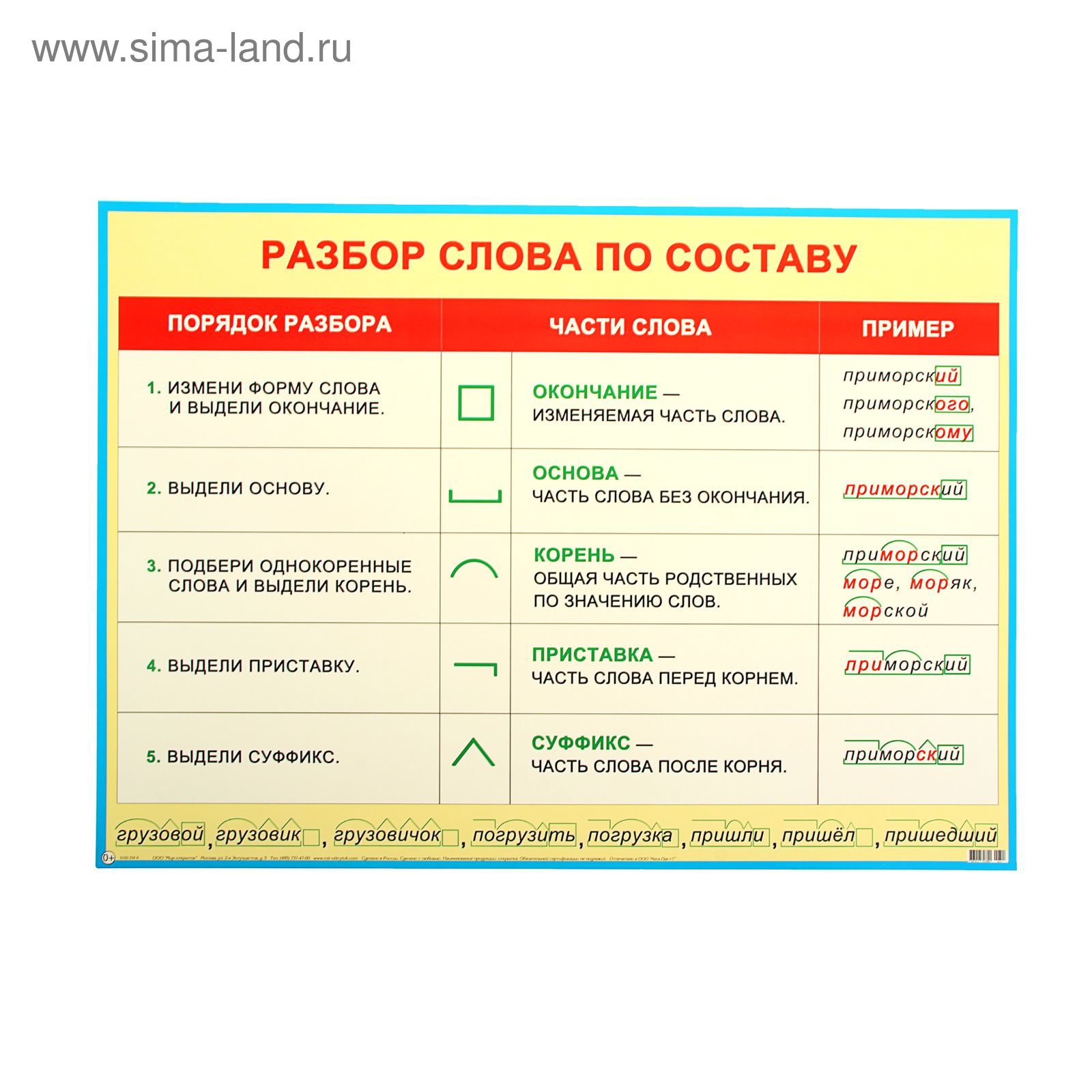
Обоснованием этому служит двойственный звук [й’а], образованный от гласной “я”.
В позиции без ударения буква “о” слышится звуком [а]. Он проверяется: стОя.
Раздел: Фонетика
Низкокачественный или низко качественный как правильно?
Правильно Низкокачественный – правильный вариант написания сложного прилагательного, пишется слитно. Согласно правилам русского языка слитно пишутся прилагательные, употребляемые в качестве научно-технических терминов. Часто первой частью таких прилагательных выступают слова высоко-, низко-: низкокачественный, высокоорганизованный,… Читать дальше »
Солнце стояло низко над горизонтом разобрать по членам предложения
Красный-пунцовый
Бирюзовый-голубой
Темный-черный
Жёлтый-золотой
Невиданный-небывалый
ПОняли -ударение на гласную букву О
В отличие от многих людей, я отношусь к компьютеру очень позитивно. Это — величайшее изобретение человечества! Люди создали универсальную машину, с помощью которой можно делать сто дел: читать, смотреть кино, рисовать, печатать, чертить, считать, находить полезную информацию, делать ретушь фотографии, создавать мультфильмы и видеоролики.Еще можно общаться с людьми у которых самые разные увлечения, которые живут хоть на другом конце планеты. Не нужно ограничиваться только теми людьми, кто живет в соседнем дворе, и навязывать себе их хобби.Я могу продолжать этот список до конца сочинения, чтобы было понятно, как полезен компьютер.Часто компьютер сравнивают с телевизором и говорят, что они оба крадут у человека время. Но у меня другое мнение. Да, долго сидеть перед компьютером вредно для здоровья и для личности, потому что человек не двигается, портит зрение и не общается с живыми людьми. Но в чем виноват компьютер?! Человек сам крадет у себя время, а не машина.Телевизор не полезен, потому что перед ним человек сидит пассивно. Сидит, пультом клацает, а ему показывают картинку.
Это — величайшее изобретение человечества! Люди создали универсальную машину, с помощью которой можно делать сто дел: читать, смотреть кино, рисовать, печатать, чертить, считать, находить полезную информацию, делать ретушь фотографии, создавать мультфильмы и видеоролики.Еще можно общаться с людьми у которых самые разные увлечения, которые живут хоть на другом конце планеты. Не нужно ограничиваться только теми людьми, кто живет в соседнем дворе, и навязывать себе их хобби.Я могу продолжать этот список до конца сочинения, чтобы было понятно, как полезен компьютер.Часто компьютер сравнивают с телевизором и говорят, что они оба крадут у человека время. Но у меня другое мнение. Да, долго сидеть перед компьютером вредно для здоровья и для личности, потому что человек не двигается, портит зрение и не общается с живыми людьми. Но в чем виноват компьютер?! Человек сам крадет у себя время, а не машина.Телевизор не полезен, потому что перед ним человек сидит пассивно. Сидит, пультом клацает, а ему показывают картинку. С компьютером другое дело! С ним все время надо действовать! Даже читать и писать все время приходится. Так даже интереснее, чем торчать у телевизора.А еще компьютер заставляет выбирать самому то, что действительно нужно. Если бы люди не учились выбирать, то перед монитором проводили бы всю жизнь.Компьютер в моей жизни занимает важное место, но я могу подолгу обходиться и без него. Просто надо все время помнить, что компьютер изобрели для того, чтобы облегчить жизнь, а не заменить ее. И чтобы расширить возможности человека, а не сузить их.
С компьютером другое дело! С ним все время надо действовать! Даже читать и писать все время приходится. Так даже интереснее, чем торчать у телевизора.А еще компьютер заставляет выбирать самому то, что действительно нужно. Если бы люди не учились выбирать, то перед монитором проводили бы всю жизнь.Компьютер в моей жизни занимает важное место, но я могу подолгу обходиться и без него. Просто надо все время помнить, что компьютер изобрели для того, чтобы облегчить жизнь, а не заменить ее. И чтобы расширить возможности человека, а не сузить их.
Двор — 4 буквы, 4 звука, 1 гласная, 3 согласные, 1 слог.
д-согласная, парная т\д, звонкая, твердая
в-согласная, парная в/ф, звонкая, твердая
о-гласная, ударная
р-согласная, непарная, звонкая, твердая
Морфологический разбор слова Низко.

Начальная форма, части речи, постоянные и непостоянные признаки
Выполним морфологический разбор слова «низко».
Слово можно разобрать двумя способами.
Выбор способа зависит от предложения или словосочетания в котором оно используется.
Слово состоит из двух слогов.
Ударение в слове «нИзко» падает на букву
«и».
1 способ
Часть речи
наречие
Синтаксическая роль
Обстоятельство
Морфологические признаки
Неизменяемое слово
2 способ
Часть речи
имя прилагательное
Синтаксическая роль
В зависимости от контекста
Морфологические признаки
| Постоянные признаки | качественное |
| Непостоянные признаки | краткая форма, средний род, единственное число |
| Начальная форма | низкий |
Фонетический (звуко-буквенный) разбор слова
н’`иска
Слово по слогам (2)
ни-зко
Перенос слова
ни-зко, низ-ко
Данный разбор был сделан с помощью искусственного интеллекта и может быть не правильным.
Результаты разбора могут быть использованы исключительно для самопроверки.
Если вы нашли ошибку, оставьте комментарий в форме ниже.
Ещё никто не оставил комментария, вы будете первым.
Написать комментарий
Спасибо за комментарий, он будет опубликован после проверки
Комплексные задания для подготовки к ВПР
Просмотр содержимого документа
«Комплексные задания для подготовки к ВПР»
Текст 1
1. (На) стали тёплые дни. 2. (На) высок…… д…рев…ях з…л…неют ярк…… листоч…ки. 3. Из-за син……… моря (к) нам прил…тели стр…жи и ласт…чки. 4. Они строят свои гнёзда под окнами нашего дом…ка в соседн…… лесу или осинов…… рощ…. 5. Ранн…… утром выйду в поле и (за) любуюсь необ…ятн……… просторами лугов. 6. Под лучами утренн……… солнца просыпаются птич…ки. 7. Длинные ветви берёзк… успели покрыться свеж…… л…ствой.
1. Сделай синтаксический разбор всех предложений (по возможности)
2. Назови номера предложений:
Назови номера предложений:
где есть однородные члены предложения________
где нет обстоятельства__________
где подлежащее выражено местоимением________
3. Найди имя существительное в форме мн.ч., П.п. в предложении 1-3__________
4. Выпиши слово, в котором звуков больше, чем букв (предложение 4)_________
5. Выпиши 2 слова, соответствующие схеме (из предложения 6)
6. Подбери синонимы к словам
Залюбуюсь __________________________просторами_______________________
7. Выпиши грамматическую основу предложения № 3
___________________________________________________
Текст 2
(На) голых ветках д…рев…евв…сят хлоп…я снега.
Из …врага к лесу в…дет крутой под…ем.
Быстро (с)…ехали лыжн…ки (с) горы и ок…зались в б…льшом сугробе.
Спиши, раскрывая скобки и вставляя пропущенные буквы. После каждого имени существительного в скобках запиши его склонение, число, падеж.
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Сделай синтаксический разбор всех предложений.
Разбери по составу слова с…ехали, лыжн…ки.
Выполни фонетический разбор слова под…ем.
_______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Текст 3
Солнце стояло низко. Его лучи играли на верхушке березки. Легкий ветерок качал гибкий тростник. Чудесная песенка щегла доносилась из близкого леса. Вскоре солнце село. Затих лес, заснул сад.
Его лучи играли на верхушке березки. Легкий ветерок качал гибкий тростник. Чудесная песенка щегла доносилась из близкого леса. Вскоре солнце село. Затих лес, заснул сад.
Выпиши из текста слова с орфограммами, орфограмму обозначь. В одном слове может быть несколько орфограмм.
Проверяемые безударные гласные в корне слова (6) | Непроверяемые безударные гласные в корне слова (3) | Проверяемые парные согласные в корне слова (6) | Непроизносимые согласные, сочетание сн (3) | Безударные падежные окончания им. сущ. (2) |
Сделай синтаксический разбор всех предложений.
Какое предложение не похоже на другие по своему строению? Почему ты так решила? ___________________________________________________________________Найди и выпиши слово с нулевым окончанием, слово с приставкой.
 Какое предложение не похоже на другие по своему строению? Почему ты так решила? ___________________________________________________________________
Какое предложение не похоже на другие по своему строению? Почему ты так решила? ______________________________________________________________________________________________________________________________________
Выпиши по 2 слова 1 и 2 склонения. ___________________________________________________________________
Выпиши по одному слову в И.п. _________________
Р.п._________________
В.п._________________
П.п._________________
6. Сделай фонетический разбор слова низко
__________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Итоговые контрольные диктанты
Итоговые контрольные диктанты
Автор: Богданова Н. Н.
Н.
Методическая копилка —
Русский язык
ИТОГОВЫЙ КОНТРОЛЬНЫЙ ДИКТАНТ 6 кл
Весеннее утро
Небо перед утренней зарей прояснилось. На нем нет туч и облаков. Над узкой речкой расстилается синий туман. В такую раннюю пору здесь ни с кем не встретиться. Предрассветная тишь долго не нарушается никакими звуками, ничьими голосами. В утреннем тумане ничего не видишь. Только тяжелая от росы трава низко прилегает к земле и блестит серебряными каплями. Но вот пробежал легкий ветерок. Раздается стук дятла, и лес наполняется птичьим пением. Из куста выскочил косой зайчонок и сбросил с веток капли росы.
Теперь уже нет опасности заблудиться в тумане. Поднимается горячее солнце. Оно бросает свои лучи на весеннюю землю. Никогда не бывает утро так прекрасно, как ранней весной. Легко дышишь, любуешься природой. (109 слов)
Грамматические задания:
1. Выполнить синтаксический разбор предложения:
Над узкой речкой расстилается синий туман.
2. Выполнить морфемный разбор слов:
расстилается, утренней, зайчонок
3. Выполнить морфологический разбор слова: дышишь
Итоговый контрольный диктант, 7 класс
Зеленых предгорий, поросших лесами, здесь не было и в помине. Горы показались неожиданно. Они начинались отвесной скалой, вздымавшейся ввысь. Ветер, вода в течение минувших веков немало потрудились над ней. Во многих местах были отчетливо заметны пласты разнородного камня, то лежавшие ровно, то немыслимо перекошенные и изломанные. Кое-где они напоминали искусно сделанную каменную кладку.
Стена, выходившая на север, никогда не освещалась солнцем, поэтому граница вечных снегов здесь спускалась низко. Задолго до нее деревья начинали мельчать и редеть, затем совсем пропадали. Под стеной лежала травянистая пустошь, и по ней тянулась дорога. Она тоже старалась не прижиматься вплотную к стене. Но жизнь ничто не может остановить. Даже по самой стене ползли вверх цепкие кустики, выросшие из семян, занесенных сюда птицами или ветром.
Даже по самой стене ползли вверх цепкие кустики, выросшие из семян, занесенных сюда птицами или ветром.
(119 слов)
(М. Семенова)
1. Выполнить синтаксический разбор предложения:
Ветер, вода в течение минувших веков немало потрудились над ней.
2. Выполнить морфемный разбор слов: поросших, каменную, прижиматься
3. Выполнить фонетический разбор слова: семян
определение, произношение, транскрипция, словоформы, примеры
существительное
— воздушная масса более низкого давления; часто приносит осадки (синоним: депрессия)
низкий уровень, приходящий за ночь с мокрым снегом и мокрым снегом
— британский политический карикатурист (родился в Новой Зеландии), создавший персонажа полковника Блимпа (1891-1963)
— низкий уровень или позиция или степень
фондовый рынок упал до нового минимума
— самого низкого передаточного числа передаточного числа в коробке передач автомобиля; используется для запуска машины (син. : первый)
: первый)
глагол
— сделать низкий шум, характерный для крупного рогатого скота (син .: му)
прилагательное
— очень низкий по громкости
низкий шум
низкий- тонированное бормотание прибоя
— необработанный характер
низкая комедия
— самого презренного типа (синоним: жалкий, низкий, жалкий, мерзкий, цинга)
низкий трюк, чтобы вытащить
низко подкрасться
— низкое или низкое по положению или качеству (синоним: скромный, скромный, скромный, маленький)
низкий приходской священник
— больше не хватает (синоним: истощено)
запасов мало
— покорено или приведен в низкое состояние или статус (синоним: сломленный, раздавленный, униженный)
низведенный
— наполненный меланхолией и унынием (синоним: синий, подавленный, подавленный, подавленный, подавленный, подавленный, мрачный, мрачный, низкий — воодушевленный)
а dverb
— в низком положении; у земли
сучья низко висели
Дополнительные примеры
В квартире низкие потолки.
У них есть дом в низине.
Дома построены на низком уровне.
Температура до 10 минус
Он лечится от низкого кровяного давления.
Малая доза лекарства
Заработок у нее невысокий.
Спрос на его книги остается низким.
Температура была ниже восьмидесятых.
У нас заканчивается запас топлива.
Солнце низко.
Они меня низко опускают.
Мы жили очень бедно.
В мае цена на какао упала до самого низкого уровня с 1975-76 гг.
Моральный дух был низким после последнего раунда сокращений рабочих мест.
Формы слова
глагол
I / you / we / they: low
he / she / it: low
причастие настоящего времени: мычание
прошедшее время: мычание
причастие прошедшего времени: мычание
существительное
единственное число: младшее
множественное число: младшее
прилагательное
сравнительное: низшее
превосходное: низшее
Следы фонологической памяти не содержат фонетической информации
В естественном языке звуки речи могут быть представлены на нескольких уровнях абстракции. В то время как звук по своей природе аналоговый и недискретный, язык дискретен и абстрактен. Представления, используемые в языковой обработке, должны преодолевать этот разрыв между непрерывным звуковым сигналом и дискретным лингвистическим представлением. На самом низком уровне звук можно смоделировать с помощью явных акустических представлений с информацией, полученной от слуховой сенсорной системы. На самом высоком уровне используются абстрактные фонологические представления с использованием специфической для языка информации, закодированной в функциях, в которых отсутствует явная информация о физических свойствах звука, таких как частота, амплитуда или продолжительность.Между этими двумя крайностями находится посреднический фонетический уровень , который использует специфичные для языка параметры, применяемые к акустической информации, такие как пороговые значения времени начала речи (VOT).
В то время как звук по своей природе аналоговый и недискретный, язык дискретен и абстрактен. Представления, используемые в языковой обработке, должны преодолевать этот разрыв между непрерывным звуковым сигналом и дискретным лингвистическим представлением. На самом низком уровне звук можно смоделировать с помощью явных акустических представлений с информацией, полученной от слуховой сенсорной системы. На самом высоком уровне используются абстрактные фонологические представления с использованием специфической для языка информации, закодированной в функциях, в которых отсутствует явная информация о физических свойствах звука, таких как частота, амплитуда или продолжительность.Между этими двумя крайностями находится посреднический фонетический уровень , который использует специфичные для языка параметры, применяемые к акустической информации, такие как пороговые значения времени начала речи (VOT).
Нас интересует роль, которую репрезентации на фонетическом и фонологическом уровнях играют на ранних стадиях слуховой обработки и восприятия речи.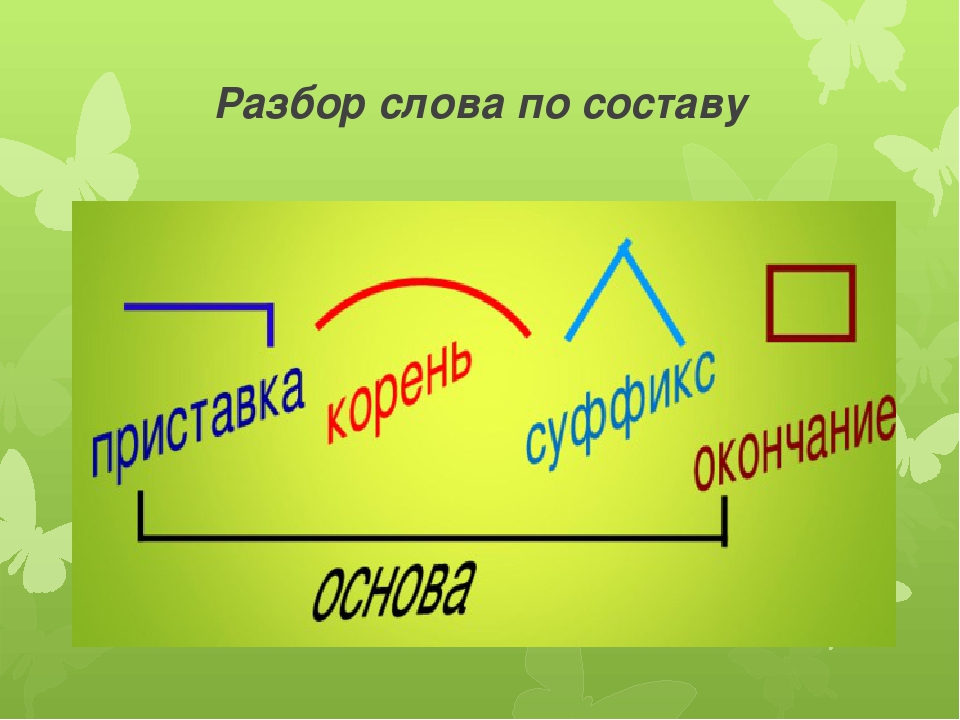 Конечная лингвистическая цель системы слухового восприятия — отнести звуки к категориям фонем, чтобы анализировать слова из речевого потока.Как только звук был отнесен к категории системой восприятия (например, / t /), фонетическая информация о звуке (его конкретный VOT или формантные значения) больше не является строго полезной для этой цели. Наш интерес в этом исследовании состоит в том, чтобы проверить, имеет ли слуховая кора доступ к дискретным представлениям фонологических категорий при прогнозировании входящих звуков речи.
Конечная лингвистическая цель системы слухового восприятия — отнести звуки к категориям фонем, чтобы анализировать слова из речевого потока.Как только звук был отнесен к категории системой восприятия (например, / t /), фонетическая информация о звуке (его конкретный VOT или формантные значения) больше не является строго полезной для этой цели. Наш интерес в этом исследовании состоит в том, чтобы проверить, имеет ли слуховая кора доступ к дискретным представлениям фонологических категорий при прогнозировании входящих звуков речи.
Мы сообщаем о результатах исследования, в котором использовались записи электроэнцефалографии (ЭЭГ) в различных стандартах странной парадигмы для выявления слуховых корковых реакций на основе фонологических представлений.Мы сравнили условия, различающиеся по фонетическому качеству, чтобы определить, присутствует ли фонетическая информация в следах памяти, используемых слуховой корой для предсказания входящих звуков, или эти следы памяти являются чисто фонологическими.
Фонетическая и фонологическая репрезентация
Особенностью, которая отличает фонетические категории от фонологических категорий, является наличие категориально-внутренней структуры по акустическим параметрам. Фонетические категории группируют звуки в соответствии с их акустическими свойствами, такими как VOT или формантные значения.Когда слушатели классифицируют звуки по некоторому акустическому континууму (например, VOT), появляется S-образная кривая вероятности. Звуки в этом континууме сгруппированы в отдельные фонетические категории с небольшой областью неопределенности между ними. Для континуума VOT для альвеолярных стопов на английском языке эта область находится между 30 и 40 мс (Lisker & Abramson, 1964, 1967; Stevens & Klatt, 1974). Этот тип категориального восприятия включает простую сортировку звуков по категориям на основе их фонетических свойств.Об этом свидетельствует тот факт, что этот эффект был обнаружен у доязыковых младенцев (Bertoncini & Bijeljac-Babic, 1987; Eimas, 1974), а также у таких животных, как шиншилла (Kuhl & Miller, 1975). Категориальное восприятие также было обнаружено в ответ на нелингвистические стимулы (J. D. Miller, Wier, Pastore, Kelly, & Dooling, 1976; Pastore et al., 1977).
Категориальное восприятие также было обнаружено в ответ на нелингвистические стимулы (J. D. Miller, Wier, Pastore, Kelly, & Dooling, 1976; Pastore et al., 1977).
Поскольку фонетические категории определяются в терминах этих акустических свойств, фонетическое представление каждого жетона сохранит эту подробную акустическую информацию.Эта информация о градиенте не содержится в фонологических представлениях, которые состоят из дискретных единиц, используемых для представления отдельных слов в долговременной памяти. Для доступа к лексическим элементам особые значения VOT не нужны — нам нужна только идентичность фонем, составляющих слово. Например, слово «кошка» может храниться в лексиконе с тремя фонемами / k /, / æ / и / t /, без каких-либо подробностей о фонетической реализации каждого звука.
Фонологические категории определяются просто функциями, такими как [-voice] или [+ coronal], и не имеют внутренней категориальной структуры.Фонологическое представление не различает a / t / 60 мс и a / t / 90 мс. Каждый токен / t / рассматривается точно так же: просто как член категории / t /. Мы используем термин «фонологические категории», потому что они являются мишенью для фонологических процессов, таких как ассимиляция, силлабификация и определение ударения (Kenstowicz, 1994). Эти процессы просто нацелены на членов всей фонологической категории, а градиентная фонетическая информация конкретного токена игнорируется.Фонемы также функционируют как связки «битов» с целью хранения информации, обеспечивая кодирование отдельных слов в долговременной памяти.
Каждый токен / t / рассматривается точно так же: просто как член категории / t /. Мы используем термин «фонологические категории», потому что они являются мишенью для фонологических процессов, таких как ассимиляция, силлабификация и определение ударения (Kenstowicz, 1994). Эти процессы просто нацелены на членов всей фонологической категории, а градиентная фонетическая информация конкретного токена игнорируется.Фонемы также функционируют как связки «битов» с целью хранения информации, обеспечивая кодирование отдельных слов в долговременной памяти.
Свидетельства фонетических и фонологических категорий
Ранние исследования восприятия речи показали, что слушатели могут различать представителей разных категорий легче, чем представителей той же категории (Liberman, Harris, Hoffman, & Griffith, 1957; Liberman, Harris, Kinney, & Lane, 1961). Однако было показано, что слушатели по-прежнему способны различать члены одной и той же фонетической категории, особенно гласные (Fry, Abramson, Eimas, & Liberman, 1962; Pisoni, 1973). Карни, Видин и Вимейстер (1977) обнаружили, что с обучением возможно хорошее внутрикатегориальное различение согласных звуков. Писони и Таш (1974) обнаружили более быстрое время реакции при различении пар стимулов с большими формантными различиями, даже если все различия относятся к категории. Это означает, что относительное акустическое расстояние между звуками было точно представлено в дополнение к их фонологической принадлежности к категории. Это убедительное доказательство того, что фонетические категории имеют градиентную структуру и что эта структура представлена слушателями при различении категорий.
Карни, Видин и Вимейстер (1977) обнаружили, что с обучением возможно хорошее внутрикатегориальное различение согласных звуков. Писони и Таш (1974) обнаружили более быстрое время реакции при различении пар стимулов с большими формантными различиями, даже если все различия относятся к категории. Это означает, что относительное акустическое расстояние между звуками было точно представлено в дополнение к их фонологической принадлежности к категории. Это убедительное доказательство того, что фонетические категории имеют градиентную структуру и что эта структура представлена слушателями при различении категорий.
Внутренняя структура фонетических категорий была продемонстрирована исследованиями, в которых слушатели оценивали качество категорий экземпляров (J. L. Miller & Volaitis, 1989; J. L. Miller, 1994; Volaitis & Miller, 1992). Эти результаты показывают, что фонетические категории определены вокруг прототипов, которые служат хорошими примерами этих категорий. Эти прототипы важны для определения пространства фонетической категории и являются важными якорями для обработки слуха.
Сэмюэл (1982) использовал адаптацию, чтобы показать структуру прототипа, обнаружив, что адаптация была более эффективной, если адаптер был близок к стоимости прототипа субъекта.Iverson и Kuhl (1995) и Kuhl (1991) показали «эффект магнетизма восприятия» у взрослых и младенцев, когда хорошие примеры фонетических категорий (то есть примеры, близкие к прототипу этой категории) заставляют соседние примеры казаться более похожими, что делает их труднее различить. Все это свидетельствует о том, что фонетическая информация доступна на всех этапах слуховой обработки и широко используется для вынесения суждений о поведенческих категориях (как мы должны предполагать, учитывая проблему инвариантности и сопоставление « многие к одному » между фонетическими образцами и фонологическими категориями). .Итак, наш вопрос, учитывая обширные свидетельства градуированной фонетической репрезентации, заключается в том, доступны ли дискретные фонологические категориальные репрезентации на всех этапах слуховой обработки.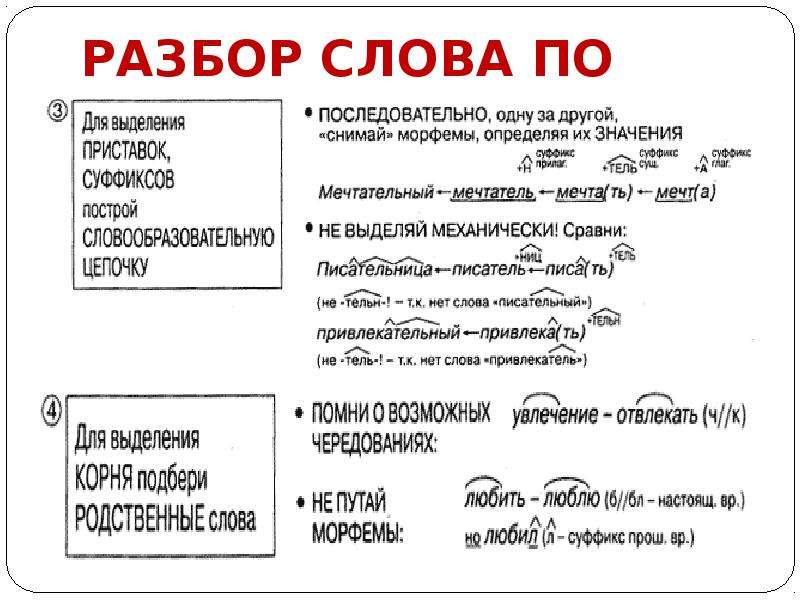
Электрофизиологические доказательства
Имеются также электрофизиологические доказательства различения как фонетических, так и фонологических категорий. Многие исследования обнаружили категоричные реакции мозга на стимулы в акустическом континууме (например, континууме VOT). Steinschneider et al. (1999) использовали многокомпонентные записи инвазивной ЭЭГ, чтобы показать категориальные нейронные реакции на континуум VOT.Их результаты показывают другую реакцию для согласных с VOT 0–20 мс, чем для согласных с VOT 40–80 мс. Simos et al. (1998) получили аналогичные категориальные ответы с помощью МЭГ.
В нескольких исследованиях слуховое восприятие изучали с использованием реакции отрицательного несоответствия (MMN), автоматической реакции на любое изменение слуховой стимуляции, генерируемой слуховой корой (Alho, 1995). MMN обычно вызывается в парадигме необычного, в которой повторяющаяся последовательность стандартного стимула прерывается необычным или девиантным стимулом. Появление этого нечастого девианта вызывает реакцию «неожиданности», которая проявляется как отрицательное отклонение по отношению к ответу на стандартный стимул.
Появление этого нечастого девианта вызывает реакцию «неожиданности», которая проявляется как отрицательное отклонение по отношению к ответу на стандартный стимул.
В соответствии с выводами Liberman et al. (1957, 1961), Шарма и Дорман (1999) обнаружили разницу между реакциями мозга на межкатегориальные и внутрикатегорийные контрасты. Для межкатегорийного контраста стандарт был озвучен / d / (30 мс VOT), а девиант — безмолвным / t / (50 мс VOT). Для контраста внутри категории стандарт был безголосым / t / (80 мс VOT), а девиант был безголосым / t / (60 мс VOT).Жетоны были разными в двух условиях, но относительное расстояние между стандартом и отклонением было идентичным (20 мс). Шарма и Дорман измерили более высокую амплитуду MMN-эффекта для межкатегорийного контраста, чем для внутрикатегорийного контраста, несмотря на идентичное фонетическое расстояние.
Winkler et al. (1999) записали ответы ЭЭГ на различия между категориями и внутри категорий в венгерских и финских гласных. В этом случае пары стандартного отклонения были идентичны, но два типа грамматики говорящих по-разному трактуют контраст.В финском языке / e / и / æ / относятся к разным категориям, тогда как в венгерском языке это различие не проводится. Контраст / e / — / æ / относится к категории для говорящих на финском языке, но внутри категории для говорящих на венгерском языке. Винклер и др. протестировали носителей финского языка, L2, говорящих на финском языке, и «наивных» венгров, не знающих финского языка. Они обнаружили, что амплитуды MMN были больше у субъектов, которые относились к контрасту как к межкатегориальному (финские говорящие на L1 и L2), чем у субъектов, которые относились к контрасту как внутри категории (наивные говорящие на венгерском).Dehaene-Lambertz (1997) аналогичным образом записал ответы ЭЭГ на межкатегорийные и внутрикатегорийные контрасты для носителей разных языков. Дехен-Ламбертц представила / d / — / ɖ / контраст с французскими и хинди говорящими. Во французском языке контраст находится внутри категории, а на хинди — между категориями.
В этом случае пары стандартного отклонения были идентичны, но два типа грамматики говорящих по-разному трактуют контраст.В финском языке / e / и / æ / относятся к разным категориям, тогда как в венгерском языке это различие не проводится. Контраст / e / — / æ / относится к категории для говорящих на финском языке, но внутри категории для говорящих на венгерском языке. Винклер и др. протестировали носителей финского языка, L2, говорящих на финском языке, и «наивных» венгров, не знающих финского языка. Они обнаружили, что амплитуды MMN были больше у субъектов, которые относились к контрасту как к межкатегориальному (финские говорящие на L1 и L2), чем у субъектов, которые относились к контрасту как внутри категории (наивные говорящие на венгерском).Dehaene-Lambertz (1997) аналогичным образом записал ответы ЭЭГ на межкатегорийные и внутрикатегорийные контрасты для носителей разных языков. Дехен-Ламбертц представила / d / — / ɖ / контраст с французскими и хинди говорящими. Во французском языке контраст находится внутри категории, а на хинди — между категориями. Дехайн-Ламбертц, как и Винклер и др., Обнаружили больший эффект несоответствия амплитуды для разных категорий, чем контраст внутри категории.
Дехайн-Ламбертц, как и Винклер и др., Обнаружили больший эффект несоответствия амплитуды для разных категорий, чем контраст внутри категории.
Разница в амплитуде, обнаруженная в этих исследованиях, предполагает, что амплитуда эффекта MMN имеет несколько источников.По крайней мере, как фонетическая дистанция, так и различие категорий вносят вклад в общую амплитуду эффекта. Тем не менее, эффект категории вносит гораздо больший вклад в общую амплитуду. Näätänen et al. (1997) записали ЭЭГ-ответы говорящих на финском языке на два разных контраста между категориями. Стандарт был / e /, а отклоняющимися от него были / ö / (фонема в финском языке) и / õ / (звук, не соответствующий категории фонем в финском языке). Näätänen et al. обнаружили, что реакция несоответствия на «прототип» девианта была больше, чем реакция на отклонение, не являющееся прототипом, даже при том, что последний имел большее акустическое отличие от стандарта.
Эти результаты, кажется, указывают на то, что слушатели относят звуки, встречающиеся в парадигме чудаков, к фонологическим категориям, хотя они не исключают интерпретацию фонетической категории. Хотя присутствует асимметрия — различия между заранее заданными границами вносят больший вклад в амплитуду несоответствия, чем произвольные различия — эти границы могут быть определены либо путем присвоения фонологической категории, либо посредством фонетической градации. С фонологической точки зрения, разница между / t / и / d / «больше», чем разница между двумя лексемами / t /.Принадлежность к разным категориям вызывает больший эффект несоответствия, чем принадлежность к одной и той же категории. С фонетической точки зрения разница между «плохим» образцом и «хорошим» образцом (когда один очень далек от значения прототипа, а другой намного ближе) — это «большая» разница, чем разница между двумя «хорошими» экземплярами. . В свете этого мы не можем быть уверены, что эти результаты соответствуют истинным фонологическим представлениям.
Хотя присутствует асимметрия — различия между заранее заданными границами вносят больший вклад в амплитуду несоответствия, чем произвольные различия — эти границы могут быть определены либо путем присвоения фонологической категории, либо посредством фонетической градации. С фонологической точки зрения, разница между / t / и / d / «больше», чем разница между двумя лексемами / t /.Принадлежность к разным категориям вызывает больший эффект несоответствия, чем принадлежность к одной и той же категории. С фонетической точки зрения разница между «плохим» образцом и «хорошим» образцом (когда один очень далек от значения прототипа, а другой намного ближе) — это «большая» разница, чем разница между двумя «хорошими» экземплярами. . В свете этого мы не можем быть уверены, что эти результаты соответствуют истинным фонологическим представлениям.
Различные стандарты
В нескольких исследованиях ЭЭГ использовался подход «различных стандартов» для усиления фонологических представлений. Различные стандарты обеспечивают простой способ выявления фонологических категорий путем введения фонетических вариаций в стандарты.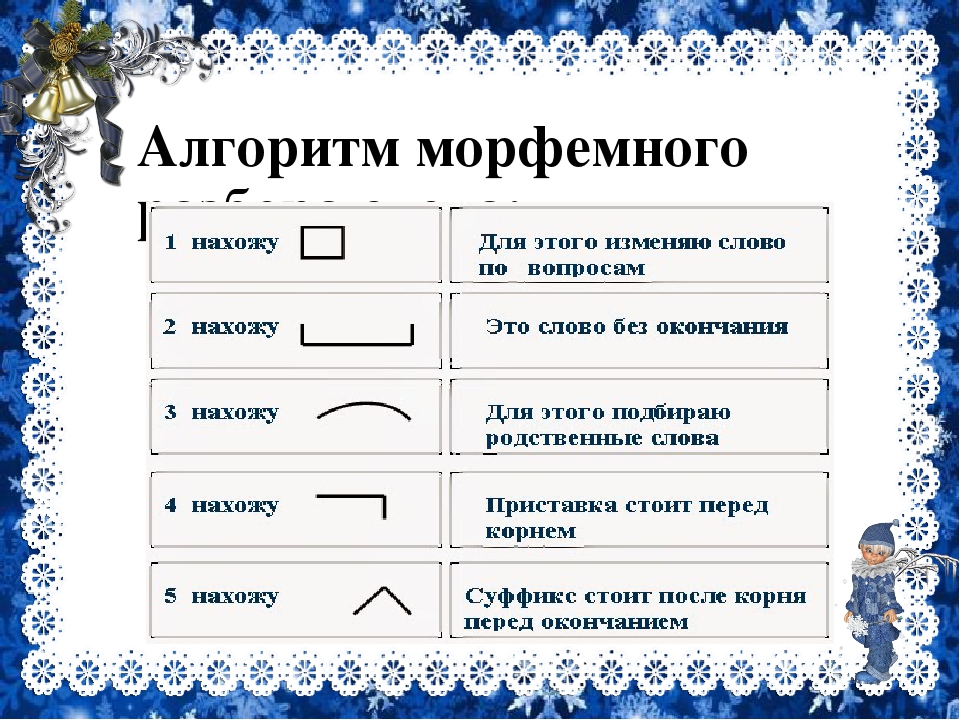 Если набор стандартов варьируется в пределах фонологической категории — скажем, изменяя VOT или частоту формант на небольшие количества — это ограничивает тип жизнеспособного представления трассировки памяти, которое может быть сгенерировано. След памяти может просто принять форму представления фонологической категории, потому что все стандарты относятся к одной и той же категории. В качестве альтернативы, трассировка памяти может включать изменяющуюся акустическую информацию в представление « ad hoc », которое вычисляет среднее значение или диапазон изменяющихся акустических значений.
Если набор стандартов варьируется в пределах фонологической категории — скажем, изменяя VOT или частоту формант на небольшие количества — это ограничивает тип жизнеспособного представления трассировки памяти, которое может быть сгенерировано. След памяти может просто принять форму представления фонологической категории, потому что все стандарты относятся к одной и той же категории. В качестве альтернативы, трассировка памяти может включать изменяющуюся акустическую информацию в представление « ad hoc », которое вычисляет среднее значение или диапазон изменяющихся акустических значений.
Phillips et al. (2000b) продемонстрировали, что слуховая кора получает доступ к фонологическим представлениям, измеряя реакцию мозга на фонологические и акустические состояния. См. Рис. 1 для обзора этих условий. Их фонологическое состояние изменяло стандарты в пределах одной категории ([+ voice]) и варьировало отклоняющихся в пределах другой категории ([-voice]). Изменение стандартов привело к тому, что стандарты были сохранены в фонологической памяти, и возникло несоответствие при обнаружении межкатегорийного девианта. Их акустическое состояние равномерно увеличивало значения VOT всех стимулов, так что некоторые стандарты теперь находились в диапазоне [+ voice], а некоторые — в диапазоне [-voice]. Поскольку стандарты (определяемые «частым» классом стимулов) больше не попадали в одну категорию, фонологический след памяти был невозможен. Они не наблюдали эффекта несоответствия в этом состоянии, что указывает на то, что ad hoc фонетической группировки стандартов не произошло. Это служит убедительным доказательством того, что слуховая кора имеет доступ к фонологическим репрезентациям в соответствии с парадигмой странностей с изменяющимися стандартами.
Их акустическое состояние равномерно увеличивало значения VOT всех стимулов, так что некоторые стандарты теперь находились в диапазоне [+ voice], а некоторые — в диапазоне [-voice]. Поскольку стандарты (определяемые «частым» классом стимулов) больше не попадали в одну категорию, фонологический след памяти был невозможен. Они не наблюдали эффекта несоответствия в этом состоянии, что указывает на то, что ad hoc фонетической группировки стандартов не произошло. Это служит убедительным доказательством того, что слуховая кора имеет доступ к фонологическим репрезентациям в соответствии с парадигмой странностей с изменяющимися стандартами.
Рис. 1
Два условия Phillips et al. (2000b). Стандарты отмечены черным цветом; девианты отмечены красным. Фонологические условия варьировали время начала голоса (VOT) стандартов в категории [+ voice]. Девиант не попал в эту категорию, что и вызвало MMN. Фонетическое состояние изменяло VOT стандартов на одинаковые величины, а разрыв между стандартами и отклонением был идентичен фонологическому состоянию. Однако все значения VOT были сдвинуты вверх, поэтому стандарты теперь находятся по обе стороны от границы VOT, отделяющей [+ voice] от [-voice].В этом состоянии MMN не обнаружен
Однако все значения VOT были сдвинуты вверх, поэтому стандарты теперь находятся по обе стороны от границы VOT, отделяющей [+ voice] от [-voice].В этом состоянии MMN не обнаружен
Эффекты
MMN были вызваны таким образом с помощью стандартов, записанных разными динамиками (Dehaene-Lambertz & Pena, 2001; Shestakova et al., 2002), стандартов с вариацией их формантной частоты F0 (Jacobsen & Schröger, 2004) и вариации VOT (Hestvik & Durvasula, 2016; Phillips, Pellathy, & Marantz, 2000a; Phillips, Pellathy, Marantz, et al., 2000b). Эулитц и Лахири (2004) и Хествик и Дурвасула (2016) использовали различные стандарты, чтобы задействовать дополнительные свойства фонем, а именно фонологическую недостаточную спецификацию.
Однако фонетические категории по-прежнему зависят от языковых параметров. Граница между / t / и / d / в английском языке хорошо установлена, и фонетическая группировка звуков в континууме VOT будет группироваться вокруг фонетических прототипов. Неспособность слуховой коры выполнить ad hoc группировку токенов в Phillips et al. исследование могло быть связано с их удаленностью от прототипов категории. Если токен находится на достаточно большом расстоянии от соответствующего фонетического прототипа, слуховая система больше не сможет отнести этот токен к необходимой категории.Другими словами, фонетическая группировка, по-видимому, подчиняется тем же ограничениям категорий, что и фонологическая группировка. Новую фонетическую группировку нельзя создать на лету.
исследование могло быть связано с их удаленностью от прототипов категории. Если токен находится на достаточно большом расстоянии от соответствующего фонетического прототипа, слуховая система больше не сможет отнести этот токен к необходимой категории.Другими словами, фонетическая группировка, по-видимому, подчиняется тем же ограничениям категорий, что и фонологическая группировка. Новую фонетическую группировку нельзя создать на лету.
Отсутствие эффекта несоответствия в «фонетическом» условии Филлипса и др. Демонстрирует, что ad hoc фонетическая группировка по категориям (например, токены, попадающие между 30 и 60 мс VOT) невозможны. Но остается вопрос, присутствует ли подробная фонетическая информация в следе памяти, или же изменение стандартов обязательно заставляет слуховую кору рассматривать каждый токен как идентичный член фонологической категории. Принадлежность к фонологической категории не подразумевает различия между ее членами. Все токены имеют равноценный статус. Однако принадлежность к фонетической категории оценивается. К членам фонетической категории можно относиться по-разному, в зависимости от качества их акустических свойств.
Однако принадлежность к фонетической категории оценивается. К членам фонетической категории можно относиться по-разному, в зависимости от качества их акустических свойств.
Целью настоящего исследования было определить, действительно ли слуховая кора имеет доступ к фонологическим категориям , когда стандарты различаются — категориям, в которых каждый токен, принадлежащий этой категории, рассматривается как идентичный — или доступ к фонетическим категориям — специфичным для языка категории, в которых разные токены имеют уникальный статус.Другими словами, использует ли слуховая кора представления фонологических категорий для прогнозирования входящих звуков речи, как предполагают Филлипс и др.? и последующие исследования?
Отрицательность несоответствия (MMN)
Этот вопрос будет рассмотрен с использованием парадигмы негативности несоответствия различных стандартов (MMN), чтобы увидеть, поддерживают ли участники мелкозернистую фонетическую информацию при прогнозировании фонологической категории. Несоответствие реакции — это функция способности слуховой коры делать прогнозы о входящих звуках.
Несоответствие реакции — это функция способности слуховой коры делать прогнозы о входящих звуках.
MMN — это отражение автоматической реакции мозга на любое изменение слуховой стимуляции, генерируемое слуховой корой (Alho, 1995). Поскольку он вызывается неожиданным слуховым изменением, MMN функционально является нейронным «неожиданным» ответом. Поскольку это происходит автоматически, ответ о несоответствии может быть вызван как в контексте присутствия, так и в контексте отсутствия (István Winkler, Czigler, Sussman, Horváth, & Balázs, 2005; Näätänen, 1979, 1985).
Чтобы слуховая кора реагировала на изменение слуховой стимуляции (и генерировала эффект MMN), она должна делать активные прогнозы относительно входящих звуков.Эти прогнозы основаны на представлении (называемом следом памяти), построенном из повторяющейся последовательности стандартных стимулов. Когда представлен девиант, входящая сенсорная информация «конфликтует» с предсказанием, сгенерированным представлением трассировки памяти, и вызывает ответ MMN (Иштван Винклер, Коуэн, Чипе, Циглер, & Нэатанен, 1996a; Иштвфин Винклер, Кармос, & Нэатанен, 1996b; Näätänen & Picton, 1987). Исследования со стимулами, маскирующими назад, предполагают, что этот след памяти устанавливается и сохраняется в слуховой сенсорной памяти.Представление трассировки памяти может сохраняться в течение нескольких секунд (Winkler, Schröger, & Cowan, 2001).
Исследования со стимулами, маскирующими назад, предполагают, что этот след памяти устанавливается и сохраняется в слуховой сенсорной памяти.Представление трассировки памяти может сохраняться в течение нескольких секунд (Winkler, Schröger, & Cowan, 2001).
Амплитуда эффекта MMN увеличивается, а латентность сокращается по мере увеличения амплитуды слуховых изменений (Näätänen, Paavilainen, Rinne, & Alho, 2007; Rinne, Särkkä, Degerman, Schröger, & Alho, 2006). Когда отклонение от стандарта отличается более чем по одному признаку, амплитуда MMN демонстрирует аддитивный эффект (Schröger, 1995; Wolff & Schröger, 2001). Это свидетельство того, что система обработки слуха чувствительна к мелкозернистым акустическим вариациям, и что эти детали могут быть закодированы в представлениях памяти.Это также свидетельствует о механизме оценки предсказания градиента. Когда входящий звук сравнивается с предсказанием, амплитуда реакции неожиданности (MMN) пропорциональна разнице между новым входящим звуком и представлением прошлых звуков (то есть, ошибка предсказания; см. Friston, 2005).
Friston, 2005).
Наше исследование сравнивало несоответствие ответов на два условия с разными расстояниями, операционализированное как расстояние между нечетным VOT и средним VOT стандартов.В обоих случаях стандарты будут токенами / t / с различными значениями VOT, а отклонение будет / d / с VOT 15 мс. Одним из условий будет состояние «низкого T», при котором стандартное значение VOT составляет 65 мс. Другим условием будет состояние «high-T», при котором стандартное значение VOT составляет 80 мс. Эти условия показаны на рис. 2.
Рис. 2
Два экспериментальных условия эксперимента 1. Сплошная черная линия представляет границу между [+ voice] и [-voice] (примерно на 35 мс).Пунктирная линия отделяет стандарты «High-T» от стандартов «Low-T». Каждое условие сравнивает стандарты [-голос] одной группы (высокий или низкий) с отклонением [+ голос]. Если представление содержит подробную фонетическую информацию (время начала голоса; VOT), будет разница в амплитуде между двумя условиями
Поскольку амплитуда эффекта несоответствия чувствительна к величине изменения между стимулами, мы прогнозируем «Эффект расстояния» основан на относительном расстоянии между отклоняющимся VOT и средним VOT стандартов. Такой эффект расстояния будет указывать на то, что слуховая кора может получить доступ только к фонетически градуированным представлениям (а не к представлениям фонологической категории). Если слуховая кора отслеживает эту информацию и кодирует ее в записи памяти, мы прогнозируем, что состояние с более высокими стандартами VOT вызовет более высокий эффект несоответствия амплитуды, чем состояние с более низкими стандартами VOT, из-за большего расстояния между девиантным и стандартов в состоянии «высокой температуры» (65 мс), чем в состоянии «низкой температуры» (50 мс).Однако, если слуховая кора использует фонологические представления категорий, в которых все члены категории рассматриваются по принципу «все или ничего» (т. Е. Все члены категории рассматриваются как идентичные), не должно быть разницы в амплитуде между двумя состояниями. .
Такой эффект расстояния будет указывать на то, что слуховая кора может получить доступ только к фонетически градуированным представлениям (а не к представлениям фонологической категории). Если слуховая кора отслеживает эту информацию и кодирует ее в записи памяти, мы прогнозируем, что состояние с более высокими стандартами VOT вызовет более высокий эффект несоответствия амплитуды, чем состояние с более низкими стандартами VOT, из-за большего расстояния между девиантным и стандартов в состоянии «высокой температуры» (65 мс), чем в состоянии «низкой температуры» (50 мс).Однако, если слуховая кора использует фонологические представления категорий, в которых все члены категории рассматриваются по принципу «все или ничего» (т. Е. Все члены категории рассматриваются как идентичные), не должно быть разницы в амплитуде между двумя состояниями. .
В большинстве исследований MMN этого типа сравнивается реакция мозга на / d / как на отклонение от ответа на / d / как на не-отклоняющееся. Это позволяет избежать путаницы из-за внутренней разницы в нейронных реакциях на звуки / d / и / t /. Поскольку стандарты и отклонения различаются по VOT, они могут вызывать различия в задержке, поскольку мозг реагирует на всплеск согласных и начало голоса в разное время. В классической парадигме MMN этой путаницы можно избежать, сравнивая целевые звуки как отклоняющиеся от тех же звуков как стандарты. Однако это не исключает возможности того, что эффект MMN является результатом рефрактерности нейронов. Повторная стимуляция популяций нейронов (например, популяции нейронов, которая реагирует на / t /) вызывает привыкание, при этом общая активация этой популяции со временем снижается (Butler, Spreng, & Keidel, 1969).Поскольку стандарты появляются чаще, чем отклоняющиеся, нейронные реакции более привычны к стандартам (и ослабляются), в то время как нервные реакции менее привычны к отклоняющимся.
Поскольку стандарты и отклонения различаются по VOT, они могут вызывать различия в задержке, поскольку мозг реагирует на всплеск согласных и начало голоса в разное время. В классической парадигме MMN этой путаницы можно избежать, сравнивая целевые звуки как отклоняющиеся от тех же звуков как стандарты. Однако это не исключает возможности того, что эффект MMN является результатом рефрактерности нейронов. Повторная стимуляция популяций нейронов (например, популяции нейронов, которая реагирует на / t /) вызывает привыкание, при этом общая активация этой популяции со временем снижается (Butler, Spreng, & Keidel, 1969).Поскольку стандарты появляются чаще, чем отклоняющиеся, нейронные реакции более привычны к стандартам (и ослабляются), в то время как нервные реакции менее привычны к отклоняющимся.
Чтобы контролировать оба этих эффекта, мы здесь используем парадигму «случайного контроля» Якобсена и Шрегера (2001, 2003) для выявления и измерения MMN. Вместо того, чтобы сравнивать девиантов непосредственно с самими собой в качестве стандартов, этот метод использует блок «случайного контроля», в котором появление целевого / d / звука имеет частоту, равную его частоте в блоках стандартного отклонения, но оно встроено в континуум случайно возникающих равновероятных стимулов. Сравнивая девиантный стимул сам с собой в условиях случайного контроля, мы можем контролировать присущие ему различия в ответе мозга между стандартными и девиантными стимулами и гарантировать, что ожидаемые MMN получены из сравнения памяти. Отклонение в контрольном условии будет служить средством контроля для вычисления эффекта несоответствия вместо стандартных стимулов.
Сравнивая девиантный стимул сам с собой в условиях случайного контроля, мы можем контролировать присущие ему различия в ответе мозга между стандартными и девиантными стимулами и гарантировать, что ожидаемые MMN получены из сравнения памяти. Отклонение в контрольном условии будет служить средством контроля для вычисления эффекта несоответствия вместо стандартных стимулов.
Волна разницы MMN, рассчитанная на основе стандартов и отклонений, имеет несколько основных источников. Один источник — это просто акустическое различие: акустически разные звуки активируют разные популяции нейронов.Другой источник — рефрактерность нейронов — повторная активация популяции нейронов приводит к привыканию, уменьшая амплитуду ответа. Это приводит к ослаблению реакции мозга до стандартов по сравнению с отклоняющимися. Другой источник — это нейронная реакция «неожиданности», которая является функцией неверного предсказания входящих звуков. Чтобы быть уверенным, что мы измеряем реакцию неожиданности, а не различия, возникающие из-за акустики и рефрактерности нейронов, мы используем сравнение с отклонением от нормы — сравнивая реакцию мозга с отклонением от стандартного отклоняющегося блока с отклоняющимся в случайных стандартах. блок управления.
блок управления.
% PDF-1.2
%
2 0 obj
>
поток
BT
/ F2 1 Тс
12,912 0 0 12,912 86,16 696,42 тм
0 г
/ GS1 GS
0,0024 Тс
[(A) -251,4 (T) 0,3 (HREE-ST) 93,2 (A) 55,3 (G) -0,3 (E) -222,8 (S) 0,8 (OLUTION) -232,8 (F) 0 (OR) -242,1 (ГИБКИЙ) ) -232,1 (V) 46 (O) -0,3 (CAB) 9,6 (ULAR) 36,7 (Y) -223,5 (S) 0,8 (PEECH)] TJ
11,8499 -1,2454 TD
0,0026 Тс
[(ПОНИМАЕТ) 93,4 (АНДИНГ)] TJ
/ T5 1 Тс
0,12 0 0 -0,12 352,44 685,02 тм
0 Tc
0 Tw
(1) Tj
/ F6 1 Тс
10,76 0 0 10,76 269,04 658,74 тм
0,0022 Тс
[(Gr) 12 (ace) -234,1 (C) 0,1 (завис)] TJ
/ F4 1 Тс
-4.0819 -1,9964 ТД
0,0019 Тс
[(Spok) 11.2 (en) -234.2 (Language) -234.4 (Systems) -233.6 (G) -1 (roup)] TJ
0,0446 -1,1599 TD
0,0018 Тс
[(Лаборатория) -234,3 (ж) 0,2 (или) -245,1 (Компьютер) -234 (Наука)] TJ
-0,9368 -1,171 ТД
0,0016 Тс
[(Массачусетс) -222,8 (Институт) -245,9 (из) -245,3 (Т) 66,1 (технология)] TJ
-0,1896 -1,171 ТД
0,0018 Тс
[(Кембридж,) — 238,9 (М) -1,4 (Ассачусетс) -222,6 (02139) -234,3 (США)] TJ
-2,5428 -1,1599 ТД
[(http: // www) 65,7 (. ) 6,4 (s) 0,4 (ls.) 6,3 (l) 0,9 (cs.) 6,3 (m) -1 (ит.) 6,3 (edu,) -227,9 (mailto: благодать) 10,8 (yc @ mit.) 6.4 (edu)] TJ
) 6,4 (s) 0,4 (ls.) 6,3 (l) 0,9 (cs.) 6,3 (m) -1 (ит.) 6,3 (edu,) -227,9 (mailto: благодать) 10,8 (yc @ mit.) 6.4 (edu)] TJ
/ F2 1 Тс
-3.8031 -2.7101 ТД
0,0025 Тс
[(ABSTRA) 55.4 (CT)] TJ
/ F4 1 Тс
8,966 0 0 8,966 57,6 541,98 тм
0,0022 Тс
[(Th) 7 (is) -371,7 (p) 7 (a) 4,5 (p) 7 (e) 4,5 (r) -387,5 (d) 7 (isc) 4,5 (u) 7 (sse) 4,5 (s) -385 (o) 7 (u) 7 (r) -387,5 (th) 7 (re) 4,5 (e) 4,5 (-) 0,6 (sta) 4,5 (g) 7 (e) -383,6 (a) 4,5 (p ) 7 (р) 7 (г) 0,6 (о) 7 (а) 4,5 (в) 4,5 (з) -394,5 (к) -367,7 (а) -383,6 (\ 003) -3,9 (д) 17,9 (х) 7 (ib) 7 (le) -370,2 (v) 20,4 (o) 7 (-)] TJ
0 -1,1911 ТД
-0,0033 Тс
[(каб.) 14.9 (ул.) -6.4 (ар) -4.9 (у) -319.7 (сек) -2.4 (пич) -319.7 (низ) -4.9 (сек) -2.4 (т) -6.4 (а) -1 (нди) -6,4 (нг) -346.5 (syst) -6.4 (em,) — 328.8 (w) -4 (hi) -6.4 (ch) -319.7 (can) -319.7 (det) -6.4 (ect) -327.6 (out) -6.4 (-) -4,9 (o) 1,5 (f) -4,9 (-)] ТДж
0 -1,2045 ТД
-0,0032 Тс
[(v) 15 (o) 1,6 (каб) 15 (ul) -6,3 (ar) -4,8 (y) -266,1 (\ () — 4,8 (O) -3,9 (O) 49,6 (V) -3,9 (\ )) — 259,1 (w) 9,5 (o) 1,6 (r) -4,8 (d) 1,6 (s,) — 275,2 (и) -279,4 (гипотеза) -6,3 (hesi) -6,3 (ze) -268,5 (t) -6,3 (h) 1,6 (ei) -6,3 (r) -272,5 (phonet) -6,3 (i) -6,3 (c) -268,5 (и) -266,1 (o) 1,6 (r) 8,6 (-)] TJ
Т *
-0,0035 Тс
[(t) -6,6 (hogr) -5,1 (афи) -6,6 (c) -456,2 (t) -6,6 (r) -5,1 (a) -1,2 (nscr) -5,1 (i) -6,6 (p) 1,3) (т) -6,6 (я) -6,6 (зав. ) — 877.7 (I) -5,1 (n) -440,3 (t) -6,6 (he) -442,8 (\ 002) -9,6 (r) -5,1 (st) -434,8 (st) -6,6 (возраст,) — 489,6 (w ) -4,2 (e) -442,8 (i) -6,6 (n) 1,3 (t) -6,6 (r) -5,1 (oduce) -456,2 (t) -6,6 (he)] TJ
) — 877.7 (I) -5,1 (n) -440,3 (t) -6,6 (he) -442,8 (\ 002) -9,6 (r) -5,1 (st) -434,8 (st) -6,6 (возраст,) — 489,6 (w ) -4,2 (e) -442,8 (i) -6,6 (n) 1,3 (t) -6,6 (r) -5,1 (oduce) -456,2 (t) -6,6 (he)] TJ
0 -1,1911 ТД
0,0024 Тс
[(c) 4,7 (o) 7,2 (lu) 7,2 (mn) 7,2 (-b) 7,2 (иг) 7,2 (ra) 4,7 (m) -210 (\ 002) -3,7 (n) 7,2 (ите) 4,7 ( -sta) 4,7 (te) -182,6 (tra) 4,7 (n) 7,2 (sd) 7,2 (u) 7,2 (c) 4,7 (e) 4,7 (r) -199,9 (\ (FST \)) — 173,2 (w) 1,7 (h) 7,2 (i) -0,7 (c) 4,7 (h) 7,2 (,) — 216 (w) 1,7 (h) 7,2 (ile) -182,6 (e) 4,7 (м) 4,1 (b) 7,2 (e) ) 4.7 (d) 7.2 (-)] ТДж
0 -1,2045 ТД
-0,0048 Тс
[(ди) -7,9 (нг)] ТДж
7,173 0 0 7,173 76,801 488.22 тм
0,0653 Тс
(ЭНДЖИ) Tj
8,966 0 0 8,966 104,038 488,22 тм
-0,0036 Тс
[(subl) -6,7 (e) 12,1 (x) 1,2 (i) -6,7 (cal) -354,6 (модель) -6,7 (s) -2,7 (,) — 369,2 (a) -1,3 (l) -6,7 ( s) -2,7 (o) -333,4 (s) -2,7 (uppor) -5,2 (t) -6,7 (s) -350,7 (pr) -5,2 (e) 25,5 (v) 1,2 (i) -6,7 (ousl) -6,7 (y) -360,2 (не показано)] TJ
-5,1791 -1,2045 ТД
-0,0038 Тс
[(dat) -6. 9 (a) -322. 7 (f) -5.4 (r) -5.4 (o) 1 (m) -336.6 (unkno) 27.8 (w) -4.5 (n) -347 (w) 8.9 (o) ) 1 (r) -5,4 (d) 1 (s.) — 530 (S) -9,9 (econdl) -6,9 (y) 67,9 (,) — 356,1 (t) -6,9 (h) 1 (e)] TJ
9 (a) -322. 7 (f) -5.4 (r) -5.4 (o) 1 (m) -336.6 (unkno) 27.8 (w) -4.5 (n) -347 (w) 8.9 (o) ) 1 (r) -5,4 (d) 1 (s.) — 530 (S) -9,9 (econdl) -6,9 (y) 67,9 (,) — 356,1 (t) -6,9 (h) 1 (e)] TJ
7,173 0 0 7,173 212,525 477,42 тм
0,0653 Тс
(ЭНДЖИ) Tj
8.966 0 0 8,966 239,642 477,42 тм
0,0025 Тс
[(mo) 7.3 (d) 7.3 (e) 4.8 (ls) -331.2 (u) 7.3 (tiliz) 4.8 (e)] TJ
-20,3027 -1,1911 ТД
-0,0037 Тс
[(gr) -5,3 (афема) -376,1 (i) -6,8 (n) 1,1 (f) -5,3 (o) 1,1 (r) -5,3 (m) -2 (at) -6,8 (i) -6,8 ( на,) — 382,7 (пр) -5,3 (о) 14,5 (в) 1,1 (и) -6,8 (г) 1,1 (и) -6,8 (п) 1,1 (г) -373,6 (т) -6,8 (и) — 6,8 (ght) -6,8 (er) -353,3 (l) -6,8 (i) -6,8 (ngui) -6,8 (st) -6,8 (i) -6,8 (c) -349,3 (const) -6,8 (r) — 5,3 (ai) -6,8 (nt) -368,1 (as)] TJ
0 -1,2045 ТД
-0,0013 Тс
[(колодец) -379,1 (ас) -375,2 (мгновенно) -388,5 (звук-буква) -391 (способность) -384,6 (во время) -384.6 (r) -2,9 (экогни -)] TJ
Т *
0,0029 Тс
[(tio) 7,7 (n) 7,7 (.) — 416,3 (Th) 7,7 (ird) 7,7 (l) -0,2 (y) 74,6 (,) — 282,4 (th) 7,7 (e) -289,2 (s) 3,8 ( y) 7,7 (lla) 5,2 (б) 7,7 (l) -0,2 (e) 5,2 (-) 1,3 (le) 32 (v) 21,1 (e) 5,2 (l) -294,6 (l) -0,2 (e) 18,6 (x) 7,7 (ic) 5,2 (a) 5,2 (l) -281,2 (u) 7,7 (n) 7,7 (it) -290,7 (o) 7,7 (f) -279,7 (th) 7,7 (e) -289,2 (\ 002) -3,2 (первый) -267,8 (с) 3,8 (ta) 5,2 (г) 7,7 (e) -289,2 (a) 5,2 (r) 1,3 (e)] TJ
0 -1,1911 ТД
0,0023 Тс
[(a) 4,6 (u) 7,1 (to) 7,1 (ma) 4,6 (tic) 4,6 (a) 4,6 (lly) -300,7 (d) 7,1 (e) 4,6 (ri) 26 (v) 20,5 (e) 4,6 (г) -300,7 (в) 7,1 (ia) -289,8 (а) 4,6 (н) -287,3 (итт) 4. 6 (ra) 4,6 (ti) 26 (v) 20,5 (e) -289,8 (p) 7,1 (r) 0,7 (o) 7,1 (c) 4,6 (e) 4,6 (d) 7,1 (u) 7,1 (r) 0,7 (д) -316,6 (т) -0,8 (о) -287,3 (о) 7,1 (п) 7,1 (тимиз) 4,6 (д) -289,8 (п) 7,1 (д) 4,6 (г) 14,1 (-)] ТДж
6 (ra) 4,6 (ti) 26 (v) 20,5 (e) -289,8 (p) 7,1 (r) 0,7 (o) 7,1 (c) 4,6 (e) 4,6 (d) 7,1 (u) 7,1 (r) 0,7 (д) -316,6 (т) -0,8 (о) -287,3 (о) 7,1 (п) 7,1 (тимиз) 4,6 (д) -289,8 (п) 7,1 (д) 4,6 (г) 14,1 (-)] ТДж
0 -1,2045 ТД
-0,0033 Тс
[(f) -4.9 (o) 1.5 (r) -4.9 (m) -1.6 (ance.) — 315.4 (T) -8 (h) 1.5 (e) -228.5 (s) -2.4 (econd -) — 4.9 (st) -6.4 (возраст) -241.9 (r) -4.9 (ecogni) -6.4 (zer) -232.4 (empl) -6.4 (o) 14.9 (y) 1.5 (s)] TJ
7,173 0 0 7,173 232,805 423,66 тм
0,0653 Тс
(ЭНДЖИ) Tj
8,966 0 0 8,966 259,083 423,66 тм
-0,0048 Тс
[(t) -7.9 (o) -214.1 (out) -7.9 (put)] TJ
-22,4709 -1,2045 ТД
-0,0011 Тс
[(а) -346.7 (w) 11,6 (ord) -357,6 (n) 3,7 (et) -4,2 (w) 11,6 (o) 3,7 (rk) -357,6 (whi) -4,2 (c) 1,2 (h) -344,3 (i) — 4,2 (s) -348,2 (p) 3,7 (arsed) -357,7 (b) 3,7 (y)] TJ
7,173 0 0 7,173 191,524 412,86 тм
0,0748 Тс
[(TI) 6,3 (N) 44,1 (A)] TJ
8,966 0 0 8,966 210,122 412,86 тм
-0,0042 Тс
[(,) — 343,1 (наш) -367,1 (нац) -7,3 (u) 0,6 (r) -5,8 (a) -1,9 (l) -355,2 (l) -7,3 (anguage)] TJ
-17. 0104 -1. 1911 ТД
0104 -1. 1911 ТД
-0,0032 Тс
[(\ () — 4.8 (N) -3.9 (L) -7.9 (\)) — 285.8 (пр) -4.8 (процессор) 35.4 (,) — 328.7 (i) -6.3 (n) -292.8 (st) -6,3 (возраст) -295,3 (t) -6,3 (час) -4,8 (ee.) — 435,8 (E) -7,9 (xper) -4,8 (i) -6,3 (ment) -6.3 (s) -310,1 (w) -3,9 (i) -6,3 (t) -6,3 (h) -279,5 (a)] TJ
7,173 0 0 7,173 245,046 402,18 тм
0,0748 Тс
[(J) 12,2 (U) 10,6 (P) 11,9 (I) 6,3 (TER)] TJ
8,966 0 0 8,966 278,402 402,18 тм
0,0007 Тс
(im-) Tj
-24,6256 -1,2045 ТД
-0,0033 Тс
[(пл) -6,4 (элемент) -6,4 (а) -1 (т) -6,4 (и) -6,4 (о) 1,5 (п) -266,2 (о) 1,5 (ж) -259,2 (т) -6,4 ( hi) -6,4 (s) -243,3 (s) -2,4 (yst) -6,4 (e) -1 (m) -269,2 (a) -1 (r) -4,9 (e) -255,2 (descr) -4,9 ( i) -6,4 (слой) -266,2 (i) -6,4 (n) -239,4 ([) — 4,9 (1) -11,9 (]) — 4,9 (.)] ТДж
/ F2 1 Тс
10,76 0 0 10,76 121,92 373,74 тм
0,0023 Тс
[(1.) — 996,8 (INTR) 32.9 (ODUCTION)] TJ
/ F4 1 Тс
8,966 0 0 8,966 57,6 357,78 тм
-0,0035 Тс
[(I) -5,1 (n) -306,5 (t) -6,6 (h) 1,3 (e) -295,6 (f) -5,1 (ut) -6,6 (ur) -5,1 (e,) — 329 (w) -) — 4,2 (e) -309 (f) -5,1 (o) 1,3 (r) -5,1 (e) -1,2 (см. ) -309 (c) -1,2 (on) 41,4 (v) 14,7 (e) -1,2 (r ) -5,1 (с) -2,6 (at) -6,6 (i) -6,6 (onal) -327,8 (s) -2,6 (yst) -6,6 (e) -1,2 (мс) -310,4 (capabl) -6,6 (e ) -322,4 (из) -299,5 (sup -)] ТДж
) -309 (c) -1,2 (on) 41,4 (v) 14,7 (e) -1,2 (r ) -5,1 (с) -2,6 (at) -6,6 (i) -6,6 (onal) -327,8 (s) -2,6 (yst) -6,6 (e) -1,2 (мс) -310,4 (capabl) -6,6 (e ) -322,4 (из) -299,5 (sup -)] ТДж
Т *
-0,0033 Тс
[(por) -4,9 (t) -6,4 (i) -6,4 (n) 1,5 (g) -199,2 (\ 003) -9,4 (e) 12,4 (x) 1,5 (i) -6,4 (b) 1,5 (l) ) -6.4 (e) -201.7 (v) 14.9 (o) 1.5 (cab) 14.9 (ul) -6.4 (ar) -4.9 (i) -6.4 (e) -1 (s,) — 208,3 (t) — 6.4 (h) 1,5 (at) -193,7 (i) -6,4 (s) -2,4 (,) — 208,3 (не известно) 28,3 (w) -4 (n) -226 (w) 9,4 (o) 1,5 (r) -4,9 (г) 1,5 (с) -203,2 (а) -1 (г) -4,9 (д) -188,3 (авт) -6,4 (о) 1,5 (мат) -6,4 (-)] ТДж
Т *
-0,0036 Тс
[(я) -6,7 (кал) -6,7 (л) -6,7 (у) -333,4 (дет) -6,7 (и т. д.) -6,7 (ред) -346,8 (ат) -341,2 (т) -6,7 (в) 1,2 (e) -335,8 (s) -2,7 (pok) 14,6 (en) -360,2 (i) -6,7 (nput) -6,7 (,) — 369,2 (a) -1,3 (nd) -346,8 (cor) -5,2 ( r) -5,2 (e) -1,3 (spondi) -6,7 (нг) -360,1 (акустика) -6,7 (i) -6,7 (c) -1,3 (,)] TJ
0 -1,1911 ТД
-0,0039 Тс
[(фонол) -7 (оги) -7 (кал) -368,3 (и) -333,7 (л) -7 (я) -7 (нгуи) -7 (ст) -7 (я) -7 (в) — 336. 1 (пр) -5,5 (опер) -5,5 (т) -7 (и) -7 (д) -1,6 (с) -337,6 (а) -1,6 (р) -5,5 (д) -336,1 (и) — 7 (n) 0,9 (f) -5,5 (e) -1,6 (r) -5,5 (r) -5,5 (e) -1,6 (d.) — 556,9 (F) -10 (r) -5,5 (om) — 336,7 (t) -7 (h) 0,9 (ese,)] ТДж
1 (пр) -5,5 (опер) -5,5 (т) -7 (и) -7 (д) -1,6 (с) -337,6 (а) -1,6 (р) -5,5 (д) -336,1 (и) — 7 (n) 0,9 (f) -5,5 (e) -1,6 (r) -5,5 (r) -5,5 (e) -1,6 (d.) — 556,9 (F) -10 (r) -5,5 (om) — 336,7 (t) -7 (h) 0,9 (ese,)] ТДж
0 -1,2045 ТД
-0,001 Тс
[() -373,4 (s) -0,1 (система) -387,4 (w) 11,7 (ould) -384,3 (предположить) -386,8 (буква) -363,9 (s) -0,1 (pellings,) — 420,2 (a) 1,3 (nd) -384,3 (дюйм) -370,9 (это) -361,5 (w) 11,7 (a) 1,3 (y) 70,7 (,)] TJ
Т *
-0,0037 Тс
[(t) -6,8 (h) 1,1 (e) -362,7 (l) -6,8 (e) 12 (x) 1,1 (i) -6,8 (c) -1,4 (on) -373,6 (i) -6,8 (s) ) -364,2 (динамика) -6,8 (кал) -6,8 (л) -6,8 (у) -387 (д) 12 (х) 1.1 (t) -6,8 (e) -1,4 (nded) -373,6 (w) -4,4 (i) -6,8 (t) -6,8 (h) -360,2 (ne) 25,4 (w) -379,2 (w) 9 ( или) -5,3 (ds) -377,6 (разговорный) 14,5 (en) -387 (at)] TJ
0 -1,1911 ТД
0,0016 Тс
[(re) 3,9 (c) 3,9 (o) 6,4 (g) 6,4 (n) 6,4 (itio) 6,4 (n) -355 (время) 3,9 (.) — 578,2 (At) -349,4 (p) 6,4 (r) ) 0 (e) 3,9 (s) 2,5 (e) 3,9 (n) 6,4 (t,) — 377,4 (sta) 3,9 (t) -1,5 (e) 3,9 (-) 0 (o) 6,4 (f-th) 6,4 (e) 3,9 (-a) 3,9 (rt) -336 (sy) 6,4 (ste) 3,9 (m) 3,3 (s) -345,5 (h) 6,4 (a) 17,3 (v) 19,8 (e) -344 ( lim -)] TJ
0 -1,2045 ТД
-0,0011 Тс
[(ited) -210. 4 (возможности) -214.4 (i) -4.2 (n) -197 (c) 1.2 (oping) -223.8 (with) -210.4 (unkno) 30.5 (wn) -223,8 (w) 11,6 (o) 3,7 (выстр.) — 313,2 (In) -210,4 (f) 10,7 (act,) — 219,5 (a) 1,2 (s) -214,4 (цитируется)] TJ
4 (возможности) -214.4 (i) -4.2 (n) -197 (c) 1.2 (oping) -223.8 (with) -210.4 (unkno) 30.5 (wn) -223,8 (w) 11,6 (o) 3,7 (выстр.) — 313,2 (In) -210,4 (f) 10,7 (act,) — 219,5 (a) 1,2 (s) -214,4 (цитируется)] TJ
Т *
-0,0033 Тс
[(i) -6,4 (n) -226 ([) — 4,9 (5) 1,5 (]) — 4,9 (,) — 235,1 (t) -6,4 (e) -1 (st) -233,9 (отправлено) -6,4 (ences) -256,7 (продолжение) -6,4 (ai) -6,4 (ni) -6,4 (нг) -239,4 (O) -4 (O) 49,5 (V) -231,5 (w) 9,4 (или) -4,9 (ds) ) -243,3 (может) -239,4 (суф) 21,9 (ж) -4,9 (эр) -232,4 (а) -241,9 (\ 002) 17,4 (в) 14,9 (д) -1 (-) — 4,9 (е) — 4,9 (o) 1,5 (l) -6,4 (d)] ТДж
0 -1,1911 ТД
0,0024 Тс
[(d) 7,2 (e) 18,1 (g) 7,2 (r) 0,8 (a) 4,7 (d) 7,2 (a) 4,7 (tio) 7,2 (n) -273,8 (i) -0,7 (n) -247,1 (r) ) 0,8 (д) 4,7 (в) 4,7 (о) 7.2 (g) 7,2 (n) 7,2 (itio) 7,2 (n) -273,9 (p) 7,2 (e) 4,7 (rfo) 7,2 (rma) 4,7 (n) 7,2 (c) 4,7 (e) 4,7 (.) — 349,9 (Вкл.) 7,2 (e) -262,9 (c) 4,7 (h) 7,2 (a) 4,7 (lle) 4,7 (n) 7,2 (g) 7,2 (e) -276,3 (is) -251 (to) -247,1 ( n) 7,2 (a) 4,7 (r) 14,2 (-)] TJ
0 -1,2045 ТД
-0,0037 Тс
[(r) -5,3 (o) 27,9 (w) -258,7 (t) -6,8 (hi) -6,8 (s) -257,1 (l) -6,8 (ar) 8,1 (ge) -242,3 (per) -5,3 ( f) -5,3 (o) 1,1 (r) -5,3 (m) -2 (ance) -282,4 (разрыв)] TJ
0 -1,7666 TD
0,0028 Тс
[(Pre) 31,9 (v) 7,6 (io) 7,6 (u) 7,6 (s) 3,7 (ly) 74,5 (,) — 550,2 (w) 2,1 (e) -490 (e) 5,1 (n) 47,7 (v) 7,6 (isio) 7,6 (n) 7,6 (e) 5,1 (d) -501 (a)] TJ
/ F6 1 Тс
12. 3398 0 TD
3398 0 TD
(два) Tj
/ F4 1 Тс
1.4454 0 TD
-0,0018 тс
[(-st) -4.9 (a) 0.5 (ge) -494.6 (archi) -4.9 (t) -4.9 (ect) -4.9 (ure) -494.6 (w) -2.5 (здесь) -494.6 (t) -) — 4.9 (h) 3 (e)] TJ
-13,7852 -1,1911 ТД
-0,0039 Тс
[(f) -5,5 (r) -5,5 (онт) -7 (-) — 5,5 (e) -1,6 (nd) -266,8 (конси) -7 (s) -3 (t) -7 (e) — 1,6 (d) -266,8 (o) 0,9 (f) -259,8 (a) -255,8 (domai) -7 (n -) — 5,5 (i) -7 (ndependent) -301,4 (r) -5,5 (ecogni) — 7 (zer) 34,7 (,) — 262,5 (a) -1,6 (nd) -266,8 (t) -7 (h) 0,9 (i) -7 (s)] TJ
0 -1,2045 ТД
-0,0028 Тс
[(w) 9,9 (a) -0,5 (s) -256,2 (i) -5,9 (nt) -5,9 (erf) 9 (aced) -252,3 (vi) -5,9 (a) -241,4 (a) -241,4) с) -1,9 (убв) 9,9 (порядк) -265.7 (n) 2 (et) -5.9 (w) 9.9 (o) 2 (rk) -252.3 (t) -5.9 (o) -238.9 (a) -241.4 (b) 2 (ack-end) -265.7 ( whi) -5,9 (c) -0,5 (h) -252,3 (i) -5,9 (ncor) 9 (-)] TJ
Т *
-0,0036 Тс
[(por) -5,2 (at) -6,7 (ed) -400,3 (const) -6,7 (r) -5,2 (ai) -6,7 (nt) -6,7 (s) -390,8 (f) -5,2 (r) -) — 5,2 (o) 1,2 (м) -376,6 (h) 1,2 (i) -6,7 (gher) 8,2 (-) — 5,2 (или) -5,2 (der) -406,7 (kno) 28 (w) -4,3 (l) -6,7 (край) -402,8 (кислый) -5,2 (цес,) — 436,2 (с) -2,7 (уч)] ТДж
0 -1,1911 ТД
-0,002 Тс
[(as) -308,9 (NL) -6,7 (,) — 300,7 (t) -5,1 (ai) -5,1 (l) -5,1 (o) 2,8 (красный) -305 (f) -3,6 (или) -311,4) (t) -5,1 (h) 2,8 (e) -307,5 (s) -1,1 (peci) -5,1 (\ 002) -8. 1 (в) -307,5 (домай) -5,1 (п.) — 488,1 (В) -305 ([2],) — 314,1 (ср) -307,5 (и) -5,1 (м) -0,3 (пл) -5,1 (ement) -5,1 (e) 0,3 (d)] TJ
1 (в) -307,5 (домай) -5,1 (п.) — 488,1 (В) -305 ([2],) — 314,1 (ср) -307,5 (и) -5,1 (м) -0,3 (пл) -5,1 (ement) -5,1 (e) 0,3 (d)] TJ
0 -1,2045 ТД
0,0022 Тс
[(а) -303,3 (п) 7 (ре) 4,5 (лимин) 7 (а) 4,5 (г) 0,6 (у) -300,8 (с) 3,1 (у) 7 (с) 3,1 (тэ) 4,5 (м) -317,3 (w) 1,5 (h) 7 (e) 4,5 (re) -303,3 (th) 7 (e) -303,3 (\ 002) -3,9 (первый) -295,3 (s) 3,1 (ta) 4,5 (g) 7 (e) -303,3 (o) 7 (n) 7 (l) -0,9 (y) -314,2 (u) 7 (tiliz) 4,5 (e) 4,5 (s) -304,7 (sy) 7 (lla) 4,5 ( б) 7 (л) -0,9 (д) 4,5 (-)] ТДж
Т *
-0,0039 Тс
[(l) -7 (e) 25,2 (v) 14,3 (e) -1,6 (l) -261,2 (l) -7 (i) -7 (ngui) -7 (st) -7 (i) -7 ( в) -242,5 (i) -7 (n) 0,9 (f) -5,5 (o) 0,9 (r) -5.5 (м) -2,2 (ат) -7 (i) -7 (на,) — 262,5 (комбинированный) -7 (n) 0,9 (i) -7 (n) 0,9 (g)] ТДж
7,173 0 0 7,173 200,044 169,74 тм
0,0653 Тс
(ЭНДЖИ) Tj
8,966 0 0 8,966 226,562 169,74 тм
0,0009 Тс
[([4) 5,7 (],) — 244,3 (th) 5,7 (e) -251 (s) 1,8 (u) 5,7 (b) 5,7 (l) -2,2 (e) 16,6 (x) 5,7 (ical)] TJ
-18,8439 -1,1911 ТД
-0,0038 Тс
[(модель) -6,9 (,) — 289,1 (т) -6,9 (огет) -6,9 (в) 1 (эр) -286,4 (ш) -4,5 (и) -6,9 (т) -6,9 (в) -280 (а) -269,1 (м) -2,1 (или) -5,4 (ф)] ТДж
6,276 0 0 6,276 164,64 162,3 тм
0 Tc
(2) Tj
8,966 0 0 8,966 170,88 159,06 тм
0,0019 Тс
[(триг. ) 6,7 (ра) 4,2 (м.) — 363,7 (чт) 6.7 (is) -278,3 (\ 002rst) -255,4 (sta) 4,2 (g) 6,7 (e) -276,8 (p) 6,7 (ro) 6,7 (d) 6,7 (u) 6,7 (c) 4,2 (e) 4,2 ( s)] TJ
) 6,7 (ра) 4,2 (м.) — 363,7 (чт) 6.7 (is) -278,3 (\ 002rst) -255,4 (sta) 4,2 (g) 6,7 (e) -276,8 (p) 6,7 (ro) 6,7 (d) 6,7 (u) 6,7 (c) 4,2 (e) 4,2 ( s)] TJ
-12,6339 -1,2045 ТД
-0,0035 Тс
[(a) -268,8 (фонет) -6,6 (i) -6,6 (c) -295,6 (нетто) -6,6 (w) 9,2 (или) -5,1 (k) -279,7 (w) -4,2 (hi) -6,6 (ch) -279,7 (gui) -6,6 (des) -283,7 (t) -6,6 (he) -268,8 (шепот) -5,1 (ch) -279,8 (i) -6,6 (n) -279,7 (st) -6,6 (возраст) -268,8 (t) -6,6 (w) 9,2 (o) 1,3 (.) — 382,5 (T) -8,2 (ее) -5,1 (e) -1,2 (-)] TJ
Т *
-0,0004 Тс
[(корма) -3,5 (e) 1,9 (r) 38,2 (,)] TJ
7,173 0 0 7,173 79,561 137,46 тм
0,0748 Тс
[(TI) 6,3 (N) 44,1 (A)] TJ
8,966 0 0 8,966 101,279 137.46 тм
-0,0039 Тс
[([) -5,5 (3) 0,9 (]) — 5,5 (,) — 382,9 (наш) -380,2 (N) -4,6 (L) -356,5 (модуль) -7 (e,) — 396,3 (и)] TJ
7,173 0 0 7,173 196,681 137,46 тм
0,0653 Тс
(ЭНДЖИ) Tj
8,966 0 0 8,966 224,159 137,46 тм
0,0025 Тс
[(mo) 7,3 (d) 7,3 (e) 4,8 (ls) -371,4 (a) 4,8 (r) 0,9 (e) -356,5 (tig) 7,3 (h) 7,3 (tly))] TJ
-18,5759 -1,1911 ТД
-0,0037 Тс
[(i) -6,8 (n) 1,1 (t) -6,8 (e) 12 (gr) -5,3 (at) -6,8 (ed) -373,6 (w) -4,4 (i) -6,8 (t) -6,8 ( h) 1,1 (i) -6,8 (n) -360,3 (a) -362,7 (s) -2,8 (i) -6,8 (ngl) -6,8 (e) -376,1 (s) -2,8 (ухо) -5,3 (ch ,) — 396,1 (т) -6,8 (о) -373,6 (п) 1,1 (г) -5,3 (выход) -376. 1 (\ 002) -9,8 (окончание) -368,1 (s) -2,8 (энт) -6,8 (e) -1,4 (nce) -389,5 (hy -)] TJ
1 (\ 002) -9,8 (окончание) -368,1 (s) -2,8 (энт) -6,8 (e) -1,4 (nce) -389,5 (hy -)] TJ
0 -1,2045 ТД
-0,0035 Тс
[(pot) -6.6 (heses.) — 623.4 (H) -4.2 (e) -1.2 (r) -5.1 (e) -1.2 (,) — 382.5 (w) -4.2 (e) -349.1 (e)] 12,2 (xt) -6,6 (конец) -360 (t) -6,6 (he) -349,1 (пр) -5,1 (e) 25,6 (v) 1,3 (i) -6,6 (ous) -377,4 (ar) -5,1 ( chi) -6.6 (t) -6.6 (ect) -6.6 (ur) -5.1 (e) -349.1 (w) -4.2 (i) -6.6 (t) -6.6 (h) -346.7 (some)] TJ
Т *
[(нет) 14,7 (v) 14,7 (e) -1,2 (l) -327,8 (e) -1,2 (улучшение) -6,6 (s) -350,6 (i) -6,6 (n) -319,9 (a)] TJ
/ F6 1 Тс
10,3456 0 TD
0,0031 Тс
[(th) 7,9 (r) 44,1 (e) 5,4 (e)] TJ
/ F4 1 Тс
2,0076 0 TD
0.0024 Tc
[(-sta) 4,7 (g) 7,2 (e) -316,5 (imp) 7,2 (l) -0,7 (e) 4,7 (m) 4,1 (e) 4,7 (n) 7,2 (ta) 4,7 (tio) 7,2 (n) ) 7,2 (.) — 523,8 (Th) 7,2 (e) 4,7 (s) 3,3 (e) -316,5 (a) 4,7 (re)] TJ
-12,3532 -1,1911 ТД
-0,0035 Тс
[(дези) -6,6 (гнед) -293,1 (т) -6,6 (о) -266,4 (е) -1,2 (набл) -6,6 (е) -282,2 (т) -6,6 (он) -268,8 (сист) — 6,6 (выс. ) -282,8 (t) -6,6 (o) -266,4 (det) -6,6 (ect) -287,6 (не известно) 28,1 (шир.) -4,2 (n) -293,1 (шир.) 9,2 (o) 1,3 (r ) -5,1 (г) 1,3 (с,) — 288,8 (гипотеза) -6,6 (ч -)] ТДж
) -282,8 (t) -6,6 (o) -266,4 (det) -6,6 (ect) -287,6 (не известно) 28,1 (шир.) -4,2 (n) -293,1 (шир.) 9,2 (o) 1,3 (r ) -5,1 (г) 1,3 (с,) — 288,8 (гипотеза) -6,6 (ч -)] ТДж
ET
q
93,36 0 0 -0,36 57,588 88,608 см
БИ
/ Вт 1
/ Ч 1
/ BPC 1
/ IM правда
/ F / CCF
/ DP>
ID P
Пример текста подсчета слов
5 февраля 2020 г. · Формула для подсчета отфильтрованных ячеек с определенным текстом (частичное совпадение). Чтобы подсчитать отфильтрованные ячейки, содержащие определенный текст, как часть содержимого ячейки, измените приведенные выше формулы следующим образом.Вместо того, чтобы сравнивать образец текста с диапазоном ячеек, ищите целевой текст, используя ISNUMBER и FIND, как описано в одном из … 21 июля 2014 г. · Затем мы создадим функцию с именем word_in_text (слово, текст). Эта функция возвращает True, если слово найдено в тексте, в противном случае возвращает False. def word_in_text (слово, текст): word = word. нижний () текст = текст. lower () match = re. search (word, text) if match: return True return False Например, при написании чека банки будут ссылаться только на слова для проверки цифр, написанных в другом месте чека.Когда выписывать числа. Чек — это наиболее распространенная ситуация, когда вам нужно будет выписать сумму, используя слова (в дополнение к цифрам в долларовом поле). 06 марта 2012 г. · Слово «Дата» и двоеточие; 5. Слово «Тема» (или Re :), за которым следует двоеточие, обозначает тему заметки. Кратко изложите тему, но убедитесь, что она передает суть заметки. Организация / написание: памятка записывается как непрерывный текст, организованный в абзацы. 3 июля 2008 г. · Может быть, 35 слов для шестиколонной газеты, такой как Pittsburgh Post-Gazette, и 40 слов для пятиколоночной газеты, такой как Philadelphia Inquirer.Опять же, это только приблизительные значения, потому что длина слова и разбивка графов влияют на общую сумму больше, чем на количество слов. 5 дюймов = 175-200 слов. 10 дюймов = 350-400 слов.
lower () match = re. search (word, text) if match: return True return False Например, при написании чека банки будут ссылаться только на слова для проверки цифр, написанных в другом месте чека.Когда выписывать числа. Чек — это наиболее распространенная ситуация, когда вам нужно будет выписать сумму, используя слова (в дополнение к цифрам в долларовом поле). 06 марта 2012 г. · Слово «Дата» и двоеточие; 5. Слово «Тема» (или Re :), за которым следует двоеточие, обозначает тему заметки. Кратко изложите тему, но убедитесь, что она передает суть заметки. Организация / написание: памятка записывается как непрерывный текст, организованный в абзацы. 3 июля 2008 г. · Может быть, 35 слов для шестиколонной газеты, такой как Pittsburgh Post-Gazette, и 40 слов для пятиколоночной газеты, такой как Philadelphia Inquirer.Опять же, это только приблизительные значения, потому что длина слова и разбивка графов влияют на общую сумму больше, чем на количество слов. 5 дюймов = 175-200 слов. 10 дюймов = 350-400 слов. 12 дюймов = 420-480 слов Пример домена. Этот домен предназначен для использования в иллюстративных примерах в документах. Вы можете использовать этот домен в литературе без предварительного согласования или запроса разрешения. Образцы текстовых файлов Подробнее. Текстовый файл — это обычный компьютерный файл, содержащий текст без какого-либо форматирования, например полужирного, курсивного и других форматов.Этот файл сохранен в формате .txt. Как открыть файлы .txt? .Txt файл открыт с помощью любого типа текстового редактора, и в каждой операционной системе доступно множество текстовых редакторов для открытия и редактирования текста … Dec 07, 2020 · Processing — это гибкий программный альбом для рисования и язык для обучения программированию в контексте изобразительного искусства. С 2001 года Processing продвигает грамотность в области программного обеспечения в изобразительном искусстве и визуальную грамотность в сфере технологий. Облако слов — это изображение, состоящее из слов, которые вместе напоминают облачную форму.
12 дюймов = 420-480 слов Пример домена. Этот домен предназначен для использования в иллюстративных примерах в документах. Вы можете использовать этот домен в литературе без предварительного согласования или запроса разрешения. Образцы текстовых файлов Подробнее. Текстовый файл — это обычный компьютерный файл, содержащий текст без какого-либо форматирования, например полужирного, курсивного и других форматов.Этот файл сохранен в формате .txt. Как открыть файлы .txt? .Txt файл открыт с помощью любого типа текстового редактора, и в каждой операционной системе доступно множество текстовых редакторов для открытия и редактирования текста … Dec 07, 2020 · Processing — это гибкий программный альбом для рисования и язык для обучения программированию в контексте изобразительного искусства. С 2001 года Processing продвигает грамотность в области программного обеспечения в изобразительном искусстве и визуальную грамотность в сфере технологий. Облако слов — это изображение, состоящее из слов, которые вместе напоминают облачную форму. Размер слова показывает, насколько оно важно, например как часто он появляется в тексте — его частота. Люди обычно используют облака слов, чтобы легко составлять резюме больших документов (отчеты, выступления), создавать произведения искусства по теме (подарки, демонстрации) или визуализировать данные … 30 марта 2014 г. · Продано более 1 миллиона копий. Обладатель премии «Книга года ECPA». Учебная Библия ESV была разработана, чтобы помочь вам глубже понять Библию. Созданная разноплановой командой из 95 ведущих библеистов и учителей из 9 стран, почти 20 деноминаций и 50 семинарий, колледжей и университетов, исследование ESV Study Библия, индексированная, имеет широкий набор инструментов для изучения, что делает ее… 1. Напишите программу, которая подсчитывает количество символов, включая слова и строки в файле. Программа предлагает пользователю ввести имя файла. Пример вывода выглядит следующим образом: Введите имя файла: narrative.txt Файл Sample.txt содержит 1732 символа, 204 слова и 70 строк.
Размер слова показывает, насколько оно важно, например как часто он появляется в тексте — его частота. Люди обычно используют облака слов, чтобы легко составлять резюме больших документов (отчеты, выступления), создавать произведения искусства по теме (подарки, демонстрации) или визуализировать данные … 30 марта 2014 г. · Продано более 1 миллиона копий. Обладатель премии «Книга года ECPA». Учебная Библия ESV была разработана, чтобы помочь вам глубже понять Библию. Созданная разноплановой командой из 95 ведущих библеистов и учителей из 9 стран, почти 20 деноминаций и 50 семинарий, колледжей и университетов, исследование ESV Study Библия, индексированная, имеет широкий набор инструментов для изучения, что делает ее… 1. Напишите программу, которая подсчитывает количество символов, включая слова и строки в файле. Программа предлагает пользователю ввести имя файла. Пример вывода выглядит следующим образом: Введите имя файла: narrative.txt Файл Sample.txt содержит 1732 символа, 204 слова и 70 строк. *** от c0deslayer *** Создать образец данных и выбрать текст. Если вы наберете = rand () в своем документе Word и затем нажмете Enter, Word создаст три абзаца. Вы можете использовать эти абзацы, чтобы попрактиковаться в изучении. На этих уроках вам будет предложено выбрать текст.В следующем упражнении вы узнаете, как создавать данные и как выбирать данные. 07 декабря 2020 г. · Processing — это гибкий программный блокнот и язык для обучения программированию в контексте изобразительного искусства. С 2001 года Processing продвигает грамотность в области программного обеспечения в изобразительном искусстве и визуальную грамотность в сфере технологий. улей> создать таблицу вики. wiki_word_counts как выбранное слово, count (1) count from people_wiki_sample боковой вид explode (split (text, »)) соблазнительно как группа слов по порядку слов по count desc; После запуска у меня в базе данных появилась новая таблица с именем wiki_word_counts.22 ноября 2013 г. · Большие данные — это относительно новая парадигма, и обработка данных является наиболее важной областью, на которой следует сосредоточить усилия в области развития.
*** от c0deslayer *** Создать образец данных и выбрать текст. Если вы наберете = rand () в своем документе Word и затем нажмете Enter, Word создаст три абзаца. Вы можете использовать эти абзацы, чтобы попрактиковаться в изучении. На этих уроках вам будет предложено выбрать текст.В следующем упражнении вы узнаете, как создавать данные и как выбирать данные. 07 декабря 2020 г. · Processing — это гибкий программный блокнот и язык для обучения программированию в контексте изобразительного искусства. С 2001 года Processing продвигает грамотность в области программного обеспечения в изобразительном искусстве и визуальную грамотность в сфере технологий. улей> создать таблицу вики. wiki_word_counts как выбранное слово, count (1) count from people_wiki_sample боковой вид explode (split (text, »)) соблазнительно как группа слов по порядку слов по count desc; После запуска у меня в базе данных появилась новая таблица с именем wiki_word_counts.22 ноября 2013 г. · Большие данные — это относительно новая парадигма, и обработка данных является наиболее важной областью, на которой следует сосредоточить усилия в области развития. Под большими данными понимается большой объем данных, который поступает из разных источников, таких как социальные сети, данные датчиков, мобильные данные, данные из Интернета и многие другие. 9 октября 2019 г. · Например, строка «Java Example.Hello» вернет количество слов как 2 с использованием шаблона «\\ s +», поскольку «Example» и «Hello» разделены не пробелом, а точкой. В то время как шаблон «\\ w +» вернет счетчик слов как 3, поскольку он соответствует словам, указанным ниже.18 января 2018 г. · В Stata вы можете использовать команду контракта для расчета частоты для переменных и сохранения результатов в новом наборе данных. Предположим, у вас есть следующие данные: Восстановить запись 1978 г. Загрузить образец текстового файла или фиктивный текстовый файл для вашего цель тестирования. Мы предоставляем вам текстовые файлы разного размера. Пример Hadoop WordCount — выполнение этапа сопоставления. Текст из входного текстового файла токенизируется в слова, чтобы сформировать пару значений ключа со всеми словами, присутствующими во входном текстовом файле.
Под большими данными понимается большой объем данных, который поступает из разных источников, таких как социальные сети, данные датчиков, мобильные данные, данные из Интернета и многие другие. 9 октября 2019 г. · Например, строка «Java Example.Hello» вернет количество слов как 2 с использованием шаблона «\\ s +», поскольку «Example» и «Hello» разделены не пробелом, а точкой. В то время как шаблон «\\ w +» вернет счетчик слов как 3, поскольку он соответствует словам, указанным ниже.18 января 2018 г. · В Stata вы можете использовать команду контракта для расчета частоты для переменных и сохранения результатов в новом наборе данных. Предположим, у вас есть следующие данные: Восстановить запись 1978 г. Загрузить образец текстового файла или фиктивный текстовый файл для вашего цель тестирования. Мы предоставляем вам текстовые файлы разного размера. Пример Hadoop WordCount — выполнение этапа сопоставления. Текст из входного текстового файла токенизируется в слова, чтобы сформировать пару значений ключа со всеми словами, присутствующими во входном текстовом файле. Ключ — это слово из входного файла со значением «1».Например, если вы рассмотрите предложение «Слон — это животное». 7 мая 2014 г. · Облако слов — это графическое представление часто используемых слов в коллекции текстовых файлов. Высота каждого слова на этом рисунке является показателем частоты встречаемости слова во всем тексте. К концу этой статьи вы сможете создать облако слов с помощью R для любого заданного набора текстовых файлов.
Ключ — это слово из входного файла со значением «1».Например, если вы рассмотрите предложение «Слон — это животное». 7 мая 2014 г. · Облако слов — это графическое представление часто используемых слов в коллекции текстовых файлов. Высота каждого слова на этом рисунке является показателем частоты встречаемости слова во всем тексте. К концу этой статьи вы сможете создать облако слов с помощью R для любого заданного набора текстовых файлов.
Количество слов важно, потому что оно влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи.С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).
— Подсчитайте «количество слов», как только вы напишете Ex. 1) Количество слов в заметках → 4 Пр. 2) я тебя. → 2 Пр. 3) вы живете в реальном времени ??? → 5 — Подсчитайте «общее количество» введенных символов, как только вы напишете Ex. 1) яблоко → 5 Пр. 2) Счетчик слов в примечаниях → 21 Пр. 3) я ручка. → 11 *) Разрывы строк не включаются в количество символов …
1) яблоко → 5 Пр. 2) Счетчик слов в примечаниях → 21 Пр. 3) я ручка. → 11 *) Разрывы строк не включаются в количество символов …
Одна из самых важных задач — это обобщение разговорного текста при прослушивании PTE.Подготовьте задание с образцами вопросов здесь.
Формула для подсчета отфильтрованных ячеек с определенным текстом (частичное совпадение) Чтобы подсчитать отфильтрованные ячейки, содержащие определенный текст, как часть содержимого ячейки, измените приведенные выше формулы следующим образом. Вместо того, чтобы сравнивать образец текста с диапазоном ячеек, ищите целевой текст с помощью ISNUMBER и FIND, как описано в одном из …
Загрузить образцы текстовых файлов и архивов Бесплатная загрузка различных текстовых примеров файлов и архивов.Файл CSV (файл значений, разделенных запятыми) обычно используется программами для работы с электронными таблицами, такими как Microsoft Excel или OpenOffice Calc.
21 февраля 2011 г. · Как программа IC, которая считывает некоторый текст из файла и подсчитывает количество одинаковых слов, количество слов, количество предложений, числа Подсчет количества текстовых документов, содержащих одно слово. Подсчитывает, сколько раз число повторяется и какие числа повторяются в C #
Уровень текста D — Литературный текст Образец текста от Clever Fox. В книге… Студент учится… разнообразным предложениям, содержащим до восьми-десяти слов.m любых знакомых слов, которые учащимся нужно быстро прочитать. слова с основными фонетическими образцами: согласные, диграфы и короткие гласные звуки.
Ведущий веб-сайт для обучения английскому языку. Высококачественные английские рабочие листы по пониманию прочитанного, частям речи, орфографии, соответствию, лексике, синонимам и антонимам, фонетике, временам глаголов, обучающим играм и многому другому.
Программа для выполнения таких операций, как подсчет символов, слов и строк файла, отображение файла в обратном порядке, изменение регистра и частоты конкретного слова в файле; Программа для подсчета определенного символа во входной строке определенное количество раз; Программа, которая примет строку текста из текстового файла; подсчитайте количество слов, строк и символов в…
.apply (Filter. By ((String word) ->! Word. IsEmpty ())) // Концепция № 3: Примените преобразование Count к нашей PCollection отдельных слов. Преобразование Count // возвращает новую коллекцию PCollection пар ключ / значение, где каждый ключ представляет // уникальное слово в тексте. Связанное значение — это количество вхождений для этого слова..apply (Count. PerElement ())
Подсчитайте количество гласных (A, E, I, O, U) в слове. Добавляйте 1 каждый раз, когда буква «y» звучит как гласный звук (A, E, I, O, U).Вычтите 1 для каждой беззвучной гласной (например, безмолвной «е» в конце слова). Вычтите 1 для каждого дифтонга или трифтонга в слове. Дифтонг: когда 2 гласные издают только 1 звук (au, oy, oo)
18 августа 2019 г. · Длина этого массива будет соответствовать количеству слов в строке. Если вас специально просят написать программу на Java без использования какого-либо метода API, вы можете использовать логику, в которой вы проверяете каждый символ строки, является ли он пробелом или нет.
11 июля 2020 г. · Выражения могут включать буквальное сопоставление текста, повторение, композицию шаблонов, ветвление и другие сложные правила.Большое количество проблем синтаксического анализа легче решить с помощью регулярного выражения, чем путем создания специального лексического анализатора и анализатора. Регулярные выражения обычно используются в приложениях, требующих обработки большого количества текста.
Проверьте количество слов, количество ключевых слов и частоту слов с помощью нашего бесплатного онлайн-счетчика. Вы получите полную разбивку всех ключевых слов, которые вы использовали в своем тексте, чтобы вы могли улучшить свою копию, чтобы избежать проблем с SEO. Вы также можете бесплатно разместить его в своем блоге или на веб-сайте.
18 июля 2003 г. · ÿ то, что я пытался сделать, — это прочитать текстовый файл и извлечь из него все слова, а затем создать матрицу текстового документа, для которой мне нужно иметь количество раз, когда каждое слово встречается в этом файле. Откройте App.Path & «\ Words1.txt» для ввода как # 3 Не используйте EOF (3) ÿ ÿ wordcount = wordcount + 1 ÿ ÿ Input # 3, nameIn (wordcount) ÿ ÿ ÿ ÿ Loop
Выберите 15- 25 слов, которые вам неизвестны из предоставленного списка. Найдите и запишите определение, часть речи и используйте новое слово в предложении из более чем 6 слов.Попрактикуйтесь в использовании нового слова. Напишите рассказ, открытку, письмо или создайте запись в дневнике, используя 15-25 слов в контексте.
Сумма может включать только слова в тексте, все слова (текст + заголовки + подписи) или слова плюс количество формул. Строгость правил для определения слов, вариантов и т. Д. При выборе расслабленного режима критерии того, что разрешено внутри слов и вариантов, смягчаются.
22 июля, 2016 · Встречая длинный документ Word, зрячие пользователи часто быстро прокручивают страницу и ищут большой жирный текст (заголовки), чтобы получить представление о его структуре и содержании.Пользователи программ чтения с экрана и других вспомогательных технологий также могут перемещаться по документам Word по структуре заголовков, если используются стили заголовков Word.
— Ваш доход, который мы не учитываем = Ваш исчисляемый доход. 2) Размер федерального пособия SSI — ваш исчисляемый доход = федеральное пособие SSI. СЛЕДУЮЩИЕ ПРИМЕРЫ ОСНОВАНЫ НА ПРИБОРНЫХ СУММАХ В ДОЛЛАРАХ: ПРИМЕР A — Федеральное пособие SSI только с НЕЗАРАБОТАННЫМ ДОХОДОМ. Общий ежемесячный доход = 300 долларов (пособие по социальному обеспечению)
4 июня 2017 г. · min_count = 1 — пороговое значение для слов.В модель будут включены только слова с более высокой частотой. size = 300 — количество измерений, в которых мы хотим представить наше слово. Это размер вектора слова. worker = 4 — используется для распараллеливания. # using модель
Чтобы использовать инструмент Word Count, просто выберите данные, затем щелкните меню макросов QI и выберите Word Count в подменю Data Mining. Инструмент Word Count проанализирует выделенный текст на слова и два -слова фразы, затем используйте сводную таблицу Excel, чтобы суммировать частоту фраз и отсортировать их в порядке убывания: количество слов убирается…
Режим живого программирования Visualize Execution …
Самый простой в мире калькулятор частоты слов. Просто вставьте текст в форму ниже, нажмите кнопку «Рассчитать частоту слов», и вы получите статистику слов. Нажмите кнопку, чтобы узнать количество слов. Никакой рекламы, ерунды и мусора.
Этот инструмент анализа текста предоставляет информацию о удобочитаемости и сложности текста, а также статистику частоты слов и количества символов. Может помочь переводчикам при расчете расценок для клиентов.Введите или вставьте текст для анализа в поле ниже, затем нажмите GO
Как я могу подсчитать количество строк, содержащих слово -> [com.java.Name abc]
Двоичный для штрих-кода
23 августа 2017 г. · В случае конечной точки нашего генератора штрих-кода мы возвращаем только 200, 400 и 500. Для состояния 200 нам нужно определить 2 заголовка ответа : Allow-Access-Control-Origin & Content-Type. Content-Type требуется, чтобы интеграция метода API Gateway могла сопоставить ответ изображения в кодировке Lambda base64 с правильным изображением Content-Type: image / png.
Когда я разбираю двоичный мат, у меня больше нет серого коврика. Но я думаю, что мог бы сохранить его, чтобы сравнить рядом, раз уж здесь не посреди ночи…;) В любом случае спасибо за вашу помощь!
16 апреля 2010 г. · Это сайт для преобразования из двоичных, восьмеричных, шестнадцатеричных и других оснований в преобразование оснований десятичных чисел. Мы также сталкивались с тайниками головоломок, в которых используются штрих-коды и даже более сложные матричные 2D штрих-коды. Штрих-коды можно использовать для кодирования чисел или текста.Вот ссылка на Википедию, которая описывает основы штрих-кодов.
Двоичный штрих-код CPC — это патентованная символика Почты Канады, используемая в операциях автоматической сортировки почты. Этот штрих-код печатается в правом нижнем углу каждого конверта с лицевой стороны.
Двоичные значения мэйнфрейма обычно не сохраняются так же, как двоичные данные ПК. Чтобы преобразовать их, нам, помимо прочего, необходимо знать тип двоичного поля, количество байтов или слов, а также порядок байтов и слов. COBOL Двоичные поля: эти поля хранятся в двоичном (машинном) формате с основанием 2.Обычно они представляют собой формат с дополнением до двух, в 2, 4 …
Оптическое распознавание символов или оптическое распознавание символов (OCR) — это электронное или механическое преобразование изображений печатного, рукописного или печатного текста в машинно-кодированный текст, независимо от того, из отсканированный документ, фотография документа, фотография сцены (например, текст на вывесках и рекламных щитах на альбомной фотографии) или из текста субтитров, наложенного на изображение (например: из …
11 декабря, 2020 · Код Грея — это форма двоичного кодирования, при которой переходы между последовательными числами отличаются только на один бит.Это полезное кодирование для уменьшения опасности аппаратных данных с помощью значений, которые быстро меняются и / или подключаются к более медленному оборудованию в качестве входных данных.
Список частот MURS
Имеется пять частот MURS, все зарезервированы в диапазоне VHF для бизнеса, личного пользования или пять каналов, запрограммированных на все пять частот MURS, и передает с полной мощностью 2 Вт, максимальная … MURS разрешен пять каналов, которые ранее использовались для промышленных / деловых радиослужб и были известны как частоты «цветных точек» в Части 90 Частоты канала и (полоса пропускания):
28 апреля 2019 · ПРОЦЕДУРА MURS / FRS Net Script — BARE BONES NET SCRIPT [КАЖДЫЙ СОСЕД, ЧТОБЫ ОПРЕДЕЛИТЬ, КАК ИСПОЛЬЗОВАТЬ СВОЮ СОБСТВЕННУЮ СЕТЬ — РЕКОМЕНДУЕТСЯ ПРОСЛУШИВАТЬ СЕТИ SER В ЧАСТОТЕ ДЛЯ ВЕТЧИНЫ ДЛЯ ПРОЦЕДУР] Используйте стандартный фонетический алфавит (например.г., Альфа, Браво и др.). Никакой милой фонетики. Используйте TICKLER СПИСОК ПРОБЛЕМ — FORMAT TANGO 9M. Le Monde.fr — 1-й информационный сайт. Журнальные и актуальные статьи в непрерывном режиме: International, France, Société, Economie, Culture, Environnement, Blogs …
2-Pack Amcrest ATR-22 Portable Radio Walkie Talkie Диапазон частот 400–470 МГц FM-трансивер 16 программируемых каналов, фонарик высокой мощности, рация, двусторонняя радиосвязь, сертификация FCC — черный цвет: 45,99 долларов США 1: 151,8200: 0,0000: 88.5: 88.5: 23: nn: nfm: 5.000: s: 084: murs 2: 151.8800: 0.0000: 88.5: 88.5: 23: nn: nfm: 5.000: s: 085: murs 3: 151.9400: 0.0000: 88.5: 88.5: 23: nn: nfm: 5.000: s: 086: blu dot: 154.5700: 0.0000: 88.5: 88.5: 23: nn: fm: 5.000: s: 087: grn dot: 154.6000: 0.0000: 88.5: 88.5: 23: nn: fm: 5.000: s: 088: красная точка: 151.6250: 0.0000: 88.5: 88.5: 23: nn: fm: 5.000: s: 089: pur dot: 151.9550: 0.0000: 88.5: 88.5: 23: nn: fm: 5.000: s: 090: brn dot: 464.5000 + 5.0000: 88.5 …
2-Pack Amcrest ATR-22 Портативная рация УВЧ-рация Диапазон частот 400-470 МГц FM-трансивер 16 программируемых каналов Фонарик высокой мощности Двусторонняя рация Сертифицировано FCC — черный 45 долларов.99 МУРС. Служба многопользовательской радиосвязи доступна для использования в личных или деловых целях. Набор из пяти частот, которые попадают в область VHF (Very High Frequency) и могут передаваться с мощностью 2 Вт.
Частоты многоцелевой радиослужбы (MURS): Многофункциональная радиослужба — это маломощная УКВ-служба ближнего действия для гражданского диапазона в диапазоне 150 МГц. МУРС предназначен для местной связи малого радиуса действия. Высота антенны ограничена 20 футами над строением или 60 футами над землей, в зависимости от того, что больше.Частоты и полоса пропускания канала MURS допускает нелицензированное использование на следующих 5 частотах и диапазонах: [см. 95,632 (a), (b)} 151,820 МГц, полоса пропускания: 11,25 кГц 151,880 МГц, полоса пропускания: 11,25 …
Как произносится LOW в Английский
Ваш браузер не поддерживает аудио в формате HTML5
Соединенное Королевство
Как произнести low adjective в британском английском
Ваш браузер не поддерживает аудио в формате HTML5
нас
Как произнести low adjective в американском английском
Ваш браузер не поддерживает аудио в формате HTML5
Соединенное Королевство
Как произнести low adverb в британском английском
Ваш браузер не поддерживает аудио в формате HTML5
нас
Как произнести low adverb в американском английском
Ваш браузер не поддерживает аудио в формате HTML5
Соединенное Королевство
Как произнести low verb в британском английском
Ваш браузер не поддерживает аудио в формате HTML5
нас
Как произнести low verb в американском английском
Ваш браузер не поддерживает аудио в формате HTML5
Соединенное Королевство
Как произнести low noun в британском английском
Ваш браузер не поддерживает аудио в формате HTML5
нас
Как произнести low noun в американском английском
.
Как разобрать по составу слово «чучело»?
В первую очередь отметим: лексема, предоставленная нам для анализа морфемного, – глагол, часть речи спрягаемая, употреблённая в личной форме, следовательно, имеющая флексию (окончание). Её-то, изменяемую морфему, мы выделим прежде всего, что позволит нам одновременно определить основу – неизменяемую часть данной лексемы.
Делаем сие просто – меняем словоформу и смотрим, что же при этом меняется и что остаётся неизменным:
- обраста-ю;
- обраста-ешь;
- обраста-ете.
Флексии в приведённых для сопоставления словоформах -Ю, -ЕШЬ, -ЕТЕ, а потому в глаголе разбираемом этой же значимой частью является -ЮТ, а основой в каждой словоформе, включая для разбора данную, – часть без флексии ОБРАСТА-.
Чтобы правильно выделить морфемы, входящие в основу, знакомимся с самыми близкими родственниками глагола обрастают – словами, имеющими с ним один и тот же корень, то есть общую часть всех однокоренных лексем, заключающую в себе основную семантику всех слов-родственников:
- про-раст-ают, раст-ут, за-раст-ёт, раст-ение;
- рост-ок, вы-рост, рост-овщик;
- вы-ращ-щенная, с-ращ-ение, вы-ращ-ивая;
- рос-ли, рос-лый, под-рос-ла.
В нашем глаголе вариант корня с А и СТ – РАСТ-.
Приведённая выше подборка наглядно демонстрирует: и перед корнем, и за ним в глаголе обрастают есть морфемы.
Впереди располагается префикс (по-школьному – приставка) ОБ-. Этот префикс имеет варианты О-, ОБО- и в данном случае обозначает
Такой же префикс и с такой же семантикой есть в глаголах обклеить, обмазать, обхватить, обсадить, обгородить, обмыть.
За корнем расположился один из суффиксов неопределённой формы
Выполнив разбор, мы выявили следующий морфемный состав глагола обрастают:
- флексия – -ют;
- основа – обраста-;
в составе основы:
- корень – раст-;
- префикс – об-;
- суффикс – -а-.
Завершает наш разбор его письменное оформление. Вот такое:
Диктант с грамматическим заданием по русскому языку для учащихся 3 класса.»Школа России»
Экзаменационная работа по русскому языку для учащихся 3 класса.
Программа «Школа России»
Диктант.
Приметы дождя.
Перед дождём бабочки залетают в двери домов и сараев. Широкие еловые лапы свисают вниз. Закрывают лепестки цветочные чашечки. Ласточки и стрижи летают низко над землёй. Урчат и квакают лягушки. Перестают трещать кузнечики, а муравьи спешат к своим домам. Сильнее пахнут цветы. Листья ивы плачут. С них стекают прозрачные капли. Пчёлы залетают в ульи. Дым от костра медленно плывёт над землёй.
(62 слова) По Н.Сладкову
Грамматические задания
Вариант 1.
Найти грамматическую основу в третьем предложении.
Над каждым словом в третьем предложении указать часть речи.
Выписать из предложения слова с проверяемой безударной гласной в корне.
Разобрать по составу слова: лепестки, цветочные.
Вариант 2.
Найти грамматическую основу в первом предложении.
Над каждым словом в первом предложении указать часть речи.
Выписать из предложения слова с проверяемой безударной гласной в корне.
Разобрать по составу слова: домов, еловые
Критерии оценивания
Диктант.
«5»- нет грамматических и пунктуационных ошибок.
«4»- 1, 2 грамматические и 1 пунктуационная ошибки.
«3»- 3-5 грамматических и 2-3 пунктуационных ошибок.
«2»- 6 и более грамматических ошибок; 5 грамматических и 3 пунктуационных ошибок.
Грамматические задания
«5»- нет ошибок.
«4»- 1- 2 ошибки.
«3»- 3 ошибки.
«2»- 4 ошибки и более.
Использованная литература
1.Сборник диктантов и проверочных работ по русскому языку.2-4 классы / Сост. Н.Н.Максимук, И.Ф.Яценко.- 2-е изд., перераб.- М.:ВАКО, 2013. 272 с.-
ISBN978-5-408-00993-0
Как разобрать по составу слова: разгадаешь, выделенный, прочитаешь?
Чтобы выполнить звуко-буквенный, или фонетический, разбор слова ручейки, вначале разделим его на слоги и поставим ударение:
ру-чей-ки.
Ударным является гласный третьего слога, из-за чего предыдущий гласный, оказавшийся в слабой позиции, искажается.
В итоге это существительное в форме множественного числа звучит вот так:
[р у ч’ и й’ к’ и].
Завершим звуко-буквенный, фонетический, разбор подсчетом букв и звуков, составляющих рассматриваемое слово: 7 букв и 7 звуков.
Тут люди не только общаются, но и зарабатывают. Заработок зависит напрямую от количества просмотров вопроса. Поэтому на этом сайте можно часто встретить много странных, казалось бы вопросов, если Вам интересно понять, как тут зарабатывают — почитайте правила.
В рамках морфемного разбора слова (разбор по составу) «научится», определим основу слова, корень, приставку, а также имеющийся в данном случае постфикс.
Начнём по порядку:
«на» является приставкой;
«уч» представляет собой корень слова;
«ит» является личным окончанием глагола 3 лица в единственном числе;
«ся» в конце слова — это «возвратный постфикс»
Основой же слова «научится» является «науч_ся».
Морфемный анализ слова на этом окончен.
Слово «приезжают» — глагол в настоящем времени. В прошедшем времени слово выглядит «приехали», а в будущем времени — «приедут».
В единственном числе «приезжает», во множественном — «приезжают». Отвечает слово на вопрос «что делают», а, следовательно, глагол несовершенного вида.
Морфемный разбор слова «приезжают» выглядит следующим образом:
Приставка «при», затем корень «езж», за корнем стоит суффикс из гласной буквы «а». А завершает слово окончание «ют». В единственном числе в слове окончание было бы «ет» («приезжает»). Ну и основной слова будет все слово целиком кроме окончание, то есть «приезжа».
Определим к какой части речи относится слово Яблоко задав к нему вопрос: Что это у тебя? — Яблоко. Это имя существительное
Начальная форма слова: Яблоко
Постоянными признаками будут: Яблоко — оно мое. Это существительное среднего рода и второго склонения. Яблоко — неодушевленное и нарицательное существительное
К непостоянным признакам относятся: стоит в единственном числе Яблоко-Яблоки, именительном или винительном падежах
В предложении оказывается подлежащим, либо дополнением
Пример предложения: Когда на голову Ньютону упало яблоко, он не стал винить яблоко в том, что позже придумал закон тяготения.
Сколько слов можно составить из младших
Общее количество слов, составленных из Lower = 24
Lower является допустимым словом в Scrabble с 8 очками. Нижний — допустимое слово в Word with Friends , имеющем 9 баллов. Нижний — это среднее слово из 5 , начинающееся с L и заканчивающееся на R. Ниже приведены всего 24 слова, составленные из этого слова.Анаграммы нижних
1). rowel
4 буквы Слова, состоящие из младших
1).орле 2). Лоу 3). знания 4). роль 5). носил
3-буквенные слова, состоящие из младших
1). должен 2). сова 3). ряд 4). руда 5). оле 6). низкий 7). горе 8). roe
Двухбуквенные слова, состоящие из младших
1). мы 2). wo 3). к 4). вл 5). или 6). э 7). ло 8). er 9). эль
См. Также: — Слова, начинающиеся с младшего
Слова, заканчивающиеся на младший
Слова, содержащие младший Младший смысл: — Сравн.Лоу- а. Пускать под собственным весом — как что-то подвешенное; подводить; как — опустить ведро в колодец; спустить парус или лодку; иногда — сносить; как — опустить флаг. Уменьшить высоту; как опустить забор или стену; опустить дымоход или башню. Давить как направление; как — опустить прицел ружья; сделать менее возвышенным по отношению к объекту; как — снизить амбиции — устремления — или надежды.
Инструменты для поиска слов
Поиск скрэбблаПоиск слов с друзьями
Поиск анаграмм
Решатель кроссвордов
Слова, составленные из добавления одной буквы в начале младшего
blower flower glower plower slowerСлова, образованного добавлением одной буквы в конце младшего
lowyСлова, составленные после изменения первой буквы на любую другую в нижней части
bower cower dower косилка power rower sower tower vowerСлова, составленные после изменения Последняя буква с любой другой буквой в нижнем регистре
lowed lowesПримечание : Есть 1 анаграмма слова ниже.Анаграммы — это значащие слова, составленные после перестановки всех букв слова.
Искать больше слов, чтобы посмотреть, сколько слов можно составить из них
Примечание В нижнем слове 2 гласных и 3 согласных буквы. L — 12-е, O — 15-е, W — 23-е, E — 5-е, R — 18-е, буквы алфавита.
Wordmaker — это веб-сайт, который сообщает вам, сколько слов вы можете составить из любого слова на английском языке. мы изо всех сил старались включить все возможные словосочетания данного слова.Это хороший сайт для тех, кто ищет анаграммы определенного слова. Анаграммы — это слова, составленные с использованием каждой буквы слова и имеющие ту же длину, что и исходное английское слово. Значения большинства слов также предоставлены для лучшего понимания слова. Классный инструмент для поклонников скрэббла и англоязычных пользователей, Word Maker быстро становится одним из самых популярных англоязычных справочников в сети.
слов, составленных с помощью Low, слов с низким, анаграмма Low
Этот веб-сайт требует JavaScript для правильной работы.
Пожалуйста, включите JavaScript в вашем браузере.
LOW — играбельное слово
`прилагательное
нижний, нижний
с относительно небольшим удлинением вверх
глагол
мычание, мычание, минимумы
для произнесения звуковой характеристики крупного рогатого скота
Из «LOW»
можно составить 5 игровых слов.Двухбуквенных слов (Найдено 3)
Слова из 3 букв (Найдено 2)
Комментарии
Что заставляло вас смотреть снизу вверх? Включите любые комментарии и вопросы, которые у вас есть по поводу этого слова.
Lowkey: простое слово, попавшее в наш словарь
Как развивается язык в Интернете? В этой серии статей по интернет-лингвистике Гретхен Маккалох рассказывает о последних нововведениях в онлайн-общении.
Вот слово, которое вы могли раньше не замечать: lowkey . Отличный пример — это твит:
когда тебе нужно привлечь внимание официанта
@Lin_Manuel @leslieodomjr @DaveedDiggs @ChrisisSingin pic.twitter.com/6HwxIdZIis
— Команда Гамильтона (@hamiltonssquad) 19 ноября 2015 г.
Хотя, конечно, фотография была изначально сделана по другим причинам, если мы предположим, что актеры на этой фотографии действительно пытались привлечь внимание официанта, это отличная иллюстрация того, как это выглядит, чтобы сделать что-то сдержанное.Они не кивают воображаемого официанта и не кричат, что что-то загорелось — нет, это не срочно, они играют хладнокровно, смотрят в глаза, ожидая, пока официант их заметит.
Совершенно ясно, откуда берется lowkey. Обычные словари, такие как Merriam-Webster, имеют сдержанный дефис, как в сдержанной партии.
сдержанный (прилагательное)
: тихий и расслабленный: не очень сильный, эмоциональный или заметный
На самом деле, даже в Городском словаре 2005 года есть слово «сдержанный» с тем же значением:
низкий ключ
держать что-нибудь сдержанное: не объявлять об этом; провести тихую встречу; напротив большой вечеринки или большой группы людей; не так много внимания, как обычная ночная жизнь, когда вы занимаетесь обычными делами.
Я ухожу сегодня вечером, но это довольно сдержанно; завтра работа, так что сегодня вечером будет сдержанное событие.
от донжамин 10 июня 2005 г.
Также есть «сдержанный», который используется в фотографии, где это означает «темный, с небольшим заполняющим светом или без него и высоким коэффициентом освещения», что может быть тем местом, где пришло «сдержанное» как «сдержанная вечеринка». из (источники неясны по этому поводу.)
В любом случае, есть четкая связь с новым lowkey: с точки зрения смысла, идеи тихого / расслабленного и своего рода / тонкого не так уж далеки друг от друга.Но в то время как старое сдержанное — прилагательное (сдержанная вечеринка, та вечеринка была сдержанной), новая сдержанная — это наречие. Это даже не так уж и ново — это появляется в Urban Dictionary за 2009 год:
Lowkey
Значение вродеЯ был в восторге от вечеринки.
Я был в восторге от вечеринки.от lUXURyLala 29 августа 2009 г.
1) Тайно или тайно
2) Немного или вроде
«Он переезжает в Чикаго через три недели, но семестр не закончится еще через семь недель.Он невысокий бросает учебу «.
«Не думал, что буду, но мне грустно, что мой сосед по комнате переезжает».
Наречие lowkey действительно распространено в Интернете, но я не нашел еще никого, кто бы его анализировал или комментировал, а также он еще не попал в словари ( psst , какие-нибудь лексикографы это читают?). Вот еще несколько примеров из твиттера:
«В поисках Немо» один из моих самых любимых фильмов
британцы настолько нетерпимы друг к другу, что мы все низко желаем смерти друг друга
Я бы хотел, чтобы один из моих маленьких фанатов влюбился в меня, чтобы мы могли любить сдержанные поцелуи и все такое
Когда ты грустишь, но пытаешься не заботиться
И в отличие от значения «сдержанная вечеринка», у нового lowkey также есть противоположность: highkey.Хотя highkey не так распространен, как lowkey, примеров все же есть. Люди в Твиттере часто используют его, чтобы говорить о безответных увлечениях:
lowkey влюблен в вас highkey никогда не дам вам знать
lowkey хочу отношений highkey не хочу разочаровываться
Я в восторге от вас, но пытаюсь сдержать вас
В некотором смысле вполне уместно, что lowkey существует уже как минимум шесть лет, но он не был задокументирован за пределами Urban Dictionary и нескольких малоизвестных сайтов.Мы просто ждали, когда мы это заметим.
Дислексия: По ту сторону мифа | Reading Rockets
Каждый пятый студент страдает дислексией. Недиагностированная дислексия или отсутствие специальных инструкций может привести к разочарованию, неуспеваемости и заниженной самооценке. Распространенные мифы о дислексии состоят в том, что дислексики читают в обратном порядке слова и буквы в обратном порядке. Хотя эти характеристики могут быть частью проблемы у некоторых людей, они НЕ являются наиболее распространенными или наиболее важными атрибутами.
Дислексия — это не болезнь! Слово дислексия происходит от греческого языка и означает бедный язык . Люди с дислексией плохо умеют читать, писать, правописание и / или математику, хотя у них есть способности и возможности учиться. Люди с дислексией могут учиться; они просто учатся по-другому. Часто говорят, что у этих людей с талантливым и продуктивным умом есть разница в изучении языка.
У моего ребенка дислексия?
Люди с дислексией обычно обладают некоторыми из следующих характеристик.
Затруднения с устной речью
- Позднее научиться говорить
- Затруднения с произношением слов
- Затруднения со словарным запасом или использованием соответствующей возрасту грамматики
- Затруднения в следовании указаниям
- Путаница с до / после, справа / слева и т. Д.
- Затруднения в изучении алфавита, детских стишков или песен
- Затруднения в понимании понятий и взаимосвязей
Затруднения с чтением
- Затруднения в обучении чтению
- Затруднения в определении или создании рифмующихся слов или подсчете слогов в словах (Фонологическая осведомленность)
- Затруднения со слухом и манипулированием звуками в словах (фонематическая осведомленность)
- Сложность различения разных звуков в словах (слуховая дискриминация)
- Затруднения в изучении звуков букв
- Затруднения в запоминании имен и / или порядка букв при чтении 9021 6 Меняет буквы или порядок букв при чтении
- Неправильно читает или пропускает обычные маленькие слова
- «Спотыкается» при чтении более длинных слов
- Плохое понимание прочитанного во время устного или тихого чтения
- Медленное, трудоемкое устное чтение
Проблемы с письменной речью
- Сложность воплощения идей на бумаге
- Многие орфографические ошибки
- Могут хорошо сдавать еженедельные орфографические тесты, но в повседневной работе встречается много орфографических ошибок
- Трудности с корректурой
Есть ли у моего ребенка другие связанные с этим нарушения обучения?
Ниже приведены характеристики связанных расстройств обучения.
Каждый наверняка сможет проверить одну или две из этих характеристик. Это не значит, что дислексия есть у всех. У человека с дислексией обычно есть несколько из этих характеристик, которые сохраняются с течением времени и мешают его обучению. Если ваш ребенок испытывает трудности, учится читать, и вы отметили некоторые из этих характеристик у своего ребенка, возможно, его или ее нужно обследовать на предмет дислексии и / или связанного с ней расстройства.
Затруднения с почерком (дисграфия)
- Неуверенность в правильности или леворукости
- Плохой или медленный почерк
- Беспорядочные и неорганизованные документы
- Затруднения при копировании
- Плохая мелкая моторика
(Нарушения с математикой
- )
- Трудности с точным счетом
- Могут переворачиваться числа
- Трудности с запоминанием математических фактов
- Трудности с копированием математических задач и организацией письменной работы
- Множество ошибок в расчетах
- Сложность сохранения математического словаря и / или понятий
Сложность с вниманием — Синдром дефицита внимания и гиперактивности)
- Невнимательность
- Различное внимание
- Отвлекаемость
- Импульсивно
- Избыточная активность
Проблемы с моторикой (диспраксия)
- Трудности в планировании движений и координации движений
- Затруднения в координации мышц для производства звуков
Затруднения с организацией
- Потеря бумаг
- Плохое чувство времени
- Забывает домашнее задание
- Неудачный стол
- Слишком много
- Работает медленно
- Вещи не видны out of mind «
Другие характеристики
- Сложность называния цветов, предметов и букв (быстрое наименование)
- Проблемы с памятью
- Требуется много раз видеть или слышать концепции, чтобы их усвоить
- Отвлекается на визуальные стимулы
- Тенденция к снижению успеваемости или успеваемости в школе
- Непостоянная работа в школе
- Учитель говорит: «Если бы только она старалась больше» или «Он ленив.«
- У родственников могут быть похожие проблемы
Какие инструкции нужны моему ребенку?
Дислексию и другие связанные с ней нарушения обучения невозможно« вылечить ». Правильное обучение способствует успеху чтения и облегчает многие трудности, связанные с расстройствами. лица с различиями в обучении должны быть:
- Явный — непосредственно обучает навыкам чтения, правописания и письма
- Систематический и совокупный — имеет определенную логическую последовательность введения понятий
- Структурированный — имеет ступенчатый- пошаговые процедуры для введения, анализа и практического применения концепций
- Мультисенсорный — задействует зрительный, слуховой и кинестетический каналы одновременно или в быстрой последовательности
Индивидуальные образовательные оценки
Согласно IDEA (федеральному закону о специальном образовании), a полные и бесплатные индивидуальных образовательных Оценка может быть запрошена в муниципальном школьном округе или государственной чартерной школе бесплатно для родителей, если есть подозрение на инвалидность и потребность в услугах специального образования.Вы должны написать директору специального образования в вашем школьном округе с копиями учителю вашего ребенка и директору школы вашего ребенка, чтобы запросить образовательную оценку.
Узнайте в вашем государственном образовательном агентстве, у школьной администрации, в региональном образовательном центре или в государственном образовательном агентстве какие-либо правила, специфичные для вашего штата. Для получения более подробной информации см. Www.nichcy.org/pubs1.htm.
Для постановки диагноза используется несколько различных тестов.Тестирование должно включать в себя следующее:
Тестирование интеллекта для определения:
- общей обучаемости вашего ребенка
Тестирование чтения для определения:
- навыков чтения слов
- словарного запаса
- понимания прочитанного — устного и немого
- навыки фонологической обработки (понимание звуков речи)
- навыки быстрого, автоматического называния
Тестирование письма для определения:
- понимания структуры предложения и абзаца
- уровень механики — орфография, грамматика, почерк
- мера содержания / идей
Тестирование устной речи для определения:
- слуховой обработки и понимания
- языковых экспрессивных навыков
- языковых навыков
Тестирование математики для определения:
- базовых навыков вычислений
- базовой концепции Understa nding
- навыки рассуждения и применение навыков
Как произносится ALLOW, LOW и другие слова, оканчивающиеся на -OW — Espresso English
Подробнее о курсе произношения
Здравствуйте, студенты! Это Шайна, ваша учительница из EspressoEnglish.net, а сегодня мы попрактикуемся в произношении слов, оканчивающихся на -ow.
Обязательно ознакомьтесь с моими курсами по произношению и теневым курсом , чтобы узнать больше о произношении, включая оценку вашего английского произношения.
Я заметил ошибку, которую некоторые мои ученики делают с этим словом: РАЗРЕШИТЬ. Они говорят это как «аллоэ», но на самом деле это произносится как «разрешить». Забавно, что слова low (противоположность high) и ниже (что означает «ниже») имеют один и тот же звук «о» в « no » — низкий, ниже.Но слово разрешить звучит как в слове теперь и как .
Так есть ли какое-то правило, когда произносить «ой» в каждом случае? К сожалению, не совсем. Английское произношение очень нерегулярное, и вам просто нужно запомнить индивидуальное произношение каждого слова.
Но когда я думал о словах, оканчивающихся на буквы -ow , я понял, что большинство слов с этим окончанием имеют звук «о» как в «нет» и «низкий».«Давайте попрактикуемся в некоторых из них — слушайте и повторяйте.
- окно
- глотать
- подушка
- колено
- стрела
- заимствовать
- мелкое
- поток
- косить
- буксир
Есть только несколько слов, оканчивающихся на -ow, которые произносятся вместе со звуком «как». Попрактикуемся:
- разрешить
- бровь
- эндов
- плуг
- обет
- вау
Как насчет слова, написанного BOW ? Это интересно, потому что у него два произношения с двумя разными значениями.Когда произносится лук как низкий , это существительное относится к изогнутому объекту, например, к луку и стрелам или к подарочному луку. Еще у нас есть радуга.
Лук и стрелы
Бант на подарок
Радуга
Когда произносится как «поклон», как «», это относится к действию сгибания или наклона вашего тела, чтобы уважать или почитать кого-то. В некоторых культурах кланяются в знак приветствия или в некоторых религиях.
В некоторых культурах вы поклоняетесь (ст.) В знак приветствия.
Спасибо, что попрактиковались в произношении вместе со мной! Я надеюсь, что вы присоединитесь к моему курсу произношения в американском английском, чтобы получить больше уроков, которые помогут вам практиковать все звуки английского языка и избежать ошибок произношения.
Лучшее качество для графики высокого разрешения (Microsoft Word)
Обратите внимание: Эта статья написана для пользователей следующих версий Microsoft Word: 2007, 2010, 2013, 2016, 2019 и Word в Office 365.Если вы используете более раннюю версию (Word 2003 или более раннюю), , этот совет может не сработать для вас . Чтобы посмотреть версию этого совета, написанную специально для более ранних версий Word, щелкните здесь: «Лучшее качество для графики с высоким разрешением».
Нина создает бланк, и она хочет использовать графику для адресной части бланка.Она сохранила текстовую часть как векторный файл EPS, думая, что это обеспечит наилучшее разрешение при вставке изображения в Word. Однако, когда она это сделала, файл EPS обрабатывается в Word так, как будто он имеет разрешение 72 dpi. Это делает исходный размер изображения (согласно Word) огромным, примерно 69 дюймов. Word автоматически подгоняет изображение к доступному пространству, что означает, что его размер изменяется до 11% от исходного. Полученная графика выглядит ужасно в Word; текст в графическом формате не выглядит таким четким или четким, как исходная текстовая версия адреса.Нина задается вопросом, как лучше всего встроить графику с высоким разрешением на свой бланк, чтобы он выглядел с той четкостью и ясностью, на которую она рассчитывала.
Здесь есть несколько проблем. Прежде всего, вы можете серьезно подумать о том, чтобы не использовать EPS для графики с высоким разрешением, которая в конечном итоге окажется в документе Word. EPS — это векторный формат, означающий, что графический файл состоит из множества отдельных «объектов», которые определены математически. Большинство программ, включая Word, не декодируют математические вычисления на экране, а вместо этого полагаются на предварительный просмотр изображения с низким разрешением.Этот предварительный просмотр создается программой, создавшей файл EPS, и обычно имеет низкое разрешение, например 72 точки на дюйм.
Когда вы используете Word для печати файла EPS, то, что вы видите на распечатке, зависит от типа используемого вами принтера. Если вы используете принтер PostScript (и правильный драйвер принтера), графика EPS будет напечатана правильно, поскольку PostScript может правильно декодировать файлы EPS. Если вы используете другой тип принтера — тот, который не понимает PostScript, — или если вы используете драйвер принтера, отличного от PostScript, с принтером PostScript, то то, что вы видите, будет тем, что вы видите на экране — изображение для предварительного просмотра в разрешении EPS.
Поскольку так много всего должно быть «правильным» для правильной работы файлов EPS с Word, лучше не полагаться на них без необходимости. Вместо этого выберите экспорт изображения в формат TIF с высоким разрешением. Обычно для большинства принтеров достаточно разрешения 300 или 600 точек на дюйм. В результате файл изображения будет довольно большим, но он будет таким же четким и ясным, как вы ожидаете. Причина в том, что Word может работать с файлами TIF и масштабировать их до любого необходимого размера.
Если большой размер файла является проблемой, вы можете попробовать следующее. Сначала экспортируйте изображение, используя такой формат, как PNG. У него отличное разрешение, но размеры файлов намного меньше, чем у соответствующих файлов TIF. Вам также следует рассмотреть возможность использования графической программы для изменения размера изображения до любого необходимого вам окончательного размера в документе Word.
Еще вам нужно настроить Word так, чтобы он не сжимал изображения. Word позволяет делать это в Word 2010 и более поздних версиях:
- Отобразить диалоговое окно «Параметры Word».(Щелкните вкладку «Файл» на ленте и нажмите кнопку «Параметры».)
- Щелкните «Дополнительно» в левой части диалогового окна.
- Прокрутите вниз до раздела Размер и качество изображения. (См. Рисунок 1.)
- Убедитесь, что для элемента управления «Установить целевой вывод по умолчанию» или «Разрешение по умолчанию» (в зависимости от версии Word) установлено значение 220 пикселей на дюйм.
- Щелкните OK.
Рисунок 1. Параметры изображения в диалоговом окне «Параметры Word».
Когда вы выполняете эти шаги, Word преобразует любые изображения с высоким разрешением в разрешение, указанное на шаге 4. Если разрешение 220 dpi недостаточно высокое для ваших нужд, вам следует (на шаге 4) нажать кнопку «Не сжимать». Флажок изображений. Если установлено, Word игнорирует все, что вы указали в элементе управления «Разрешение по умолчанию», и вместо этого включает любые вставленные изображения с их исходным разрешением. Это дает самое высокое разрешение (при условии, что ваши изображения имеют разрешение выше 220 dpi), но также приводит к самым большим размерам файлов документов.
Наконец, какой бы формат вы ни выбрали для своей графики, вы захотите использовать инструмент «Изображение» на вкладке «Вставка» на ленте, чтобы фактически вставить изображение в документ. Если вы вставите изображение вместо того, чтобы вставить его, Word может преобразовать изображение в растровую версию, которая не подходит для некоторых целей.
WordTips — ваш источник экономичного обучения работе с Microsoft Word. (Microsoft Word — самая популярная программа для обработки текстов в мире.) Этот совет (10218) применим к Microsoft Word 2007, 2010, 2013, 2016, 2019 и Word в Office 365. Вы можете найти версию этого совета для старого интерфейса меню Word здесь: Лучшее качество для графики с высоким разрешением .
Автор Биография
Аллен Вятт
Аллен Вятт — всемирно признанный автор, автор более чем 50 научно-популярных книг и многочисленных журнальных статей.Он является президентом Sharon Parq Associates, компании, предоставляющей компьютерные и издательские услуги. Узнать больше о Allen …
Сохранение настроек отображения / скрытия
Word позволяет отображать или скрывать непечатаемые символы в документе. Этот параметр конфигурации …
Открой для себя большеОпределение длины строки
Нужно узнать в макросе, какова длина конкретной текстовой строки? Вы можете выяснить это с помощью функции Len,…
Открой для себя большеЗащита отслеживаемых изменений
Track Changes — отличный инструмент для редакторов и соавторов при создании документов. Автор, ищущий перемен …
Открой для себя большеГлоссарий подросткового сленга: что это значит?
Если вам кажется, что вам нужен переводчик, чтобы понять вашего подростка, помощь уже в пути.
В рамках серии «Подростки рассказывают все» мы попросили подростков рассказать взрослой публике обо всех тех загадочных терминах, которые они произносят, когда говорят или пишут.
Приносим свои извинения, срок действия этого видео истек.
Возможно, вы слышали о «Netflix and Chill» — когда вы идете в дом своей второй половинки, чтобы посмотреть Netflix (подмигивает), но на самом деле это просто сеанс целования (или даже больше, ну!).
Или «bae», короткое слово для «младенец» или «ребенок» (или, согласно одной теории, сокращение от «Before Anyone Else»), которое вы используете, чтобы называть своего парня или девушку.
Но это еще не все. Гораздо больше.
Конечно, в подростковой речи нет ничего нового: у каждого поколения был свой язык.Только подумайте, как слово «великий» трансформировалось с годами: босс, крутой, крутой, плохой, бомба. А сегодня он «горит».
Подростки используют кодированный язык как выражение независимости, способ создать индивидуальность, отделенную от своих родителей, а иногда и держать родителей в неведении. Знание правильных слов также создает мгновенную связь для социальной группы, или «fam», последний жаргон для внутреннего круга.
«Fam — это люди, с которыми вы едете или умираете», — сказал Кеннеди.
«Итак, если вы идете по коридору, вы скажете:« Как дела, дружище? »- добавила Адела.
СВЯЗАННЫЕ С: Подростки рассказывают все: что они рассказывают о сексе, наркотиках и социальных сетях
Из-за социальных сетей сленг в наши дни быстро набирает обороты и быстрее выгорает. Как только слово становится популярным, оно мертво.
Готовы к ускоренному курсу подросткового языка? Начнем:
Глоссарий для подростков:
BAE — Термин нежности, «Перед кем-либо еще», также сокращенно от «младенец» или «младенец»
Базовый — Мейнстрим в негативном ключе
Bruh — Другой способ сказать братан
Кривая — Отвергнуть кого-то романтично
Мертвый — Когда вы настолько подавлены, вы чувствуете себя мертвым
Вниз в DM — Когда кто-то отправляет вам сообщения в социальных сетях вместо обмена сообщениями вы по телефону или разговариваете лично, часто с намерением установить связь
Fam — Друзья, с которыми вы ближе всего
Finna — Собираетесь / собираетесь, сокращенно от «привязки к»
Цели — Конечная цель — то, что вы пытаетесь сделать или кем быть, — конечная цель
GOAT — Величайший из всех времен
Gucci — Хорошо, круто
Высокий ключ — Люди говорят высокий ключ, когда они собираются сказать что-то, что они хотят, чтобы все знали о
Hundo P — 100 процентов, подтверждаю что-то
Я даже не могу — Когда вы так потрясены, вы не можете что-то понять
Я ‘ m weak — Это было забавно
Он горит — Это круто, это круто
Kek — Смеяться вслух
Сдержанно — Люди говорят тихо, когда собираются сказать то, что не делают Я не хочу, чтобы все знали о
На флике, на точке — Пригвожден
Peep — Чтобы взглянуть на что-нибудь
RT — Сделать ретвит, когда вы согласны с чем-то, кто-то говорит
Соленый — Горький из-за чего-то
Savage — Badass
Корабль — Сокращение от отношения, если вы «отправляете» двух человек, вы хотите, чтобы они были парой
Потягивая чай 9 0098 — Заниматься своими делами
Skurt — Уйти или уйти
Smash — Заняться случайным сексом
Straight fire — Горячо / модно
Отряд — Ваша группа друзей
Sus — Подозреваю, когда что-то подозрительно
Проведите пальцем влево — В Tinder, когда вам кто-то не нравится
Проведите вправо — В Tinder, когда кто-то вам понравится
TBH — Если честно
Жаждущий — Отчаянный
Бросок оттенка — Посмотри на кого-нибудь грязно или скажи что-нибудь гадкое
Флюиды — Атмосфера или чувство, которые есть у кого-то; Воскресенье означало лежать на диване и расслабляться
v.