Как разобрать по составу слово математика
Срочно, пж. дам 50 баллов. как за 30-40 минут выучить текст на две страницы?
Вставьте пропущенные знаки препинания. Я стал вспоминать как выглядели жёлтые глянцевые лаковые лепестки хотел представить как они выглядели если бы о … ни были написаны художником. Но представился мне не букет а наш летний луг где роскошным ковром расцветают эти цветочки в сырых местах. Вообще-то эти цветы настолько любят сырость что учёные дали им имя которое в переводе с латинского значит «лягушонок». И названы они так не потому что они чем-то похожи на лягушек или как-то связаны с ними а просто растут там где сыро и где бывает много лягушек. Вот почему по этим цветам можно узнать летом где текли через наш луг весенние воды и как они несли свою мутную влагу. Цветки из которых соткан ярко-жёлтый атласный ковёр небольшие но настолько красивы в своей удивительной скромности что невольно любуешься тоненькими нежными лепестками снаружи зеленоватыми внутри — жёлтыми блестящими будто лакированными. Однако напрасно красуются они напрасно манят своими сочными пятилопастными изящно вырезанными листьями потому что люди не собирают их в букеты а животные обходят стороной. Злой это цветок ядовитый.
!!!!!!СРОЧНО ОТДАЮ ВСЕ СВОИ БАЛЛЫ!!!!!
Выпишите предложение, в котором нужно поставить тире. (Знаки препинания внутри предложений не расставлены.) Нап
… ишите, на каком основании Вы сделали свой выбор.
1.
1) На его фасаде интересные часы.
2) На лесных полянках появляются проталины ковром разрастаются подснежники.
3) Как здесь красиво! говорят ребята.
4) В водоеме плещутся рыбки.
2.
1) На его фасаде интересные часы.
2) На лесных полянках появляются проталины ковром разрастаются подснежники.
3) Как здесь красиво! говорят ребята.
4) В водоеме плещутся рыбки.
3.
1) Сова житель полярных стран.
2) На зеленом фоне хвои краснеют сережки ольхи.
3) Облепили лампу мошки греют тоненькие ножки.
4) В октябре сбор даров лета калины рябины клюквы.
Чётко прочитайте, а затем запишите предложение заменяя числа словами и согласуя их с существительными6.Площадь в 375 квадратных метров.7. Высота 2750 … метров.8. Контейнер с 1 243 килограммами яблок.
Напишите, пожалуйста, 8 местоимений с чередующейся гласной.
СРОЧНО!!! этот разговор и его рисунок, в данных словосочетаниях надо обозначить вид подчинения словосочений
Скоро выпал первый снег, а река все еще не поддавалась холоду, потому что все, что замерзало по ночам, вода разбивала днем. можно схему и вид подчинен … ия, пожалуйста!!
Помогите Пожалуйста…
Помогите пожалуйста с домашним заданием упрожнение 253 9 класс
прогуляться и погулять в чем разница?
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.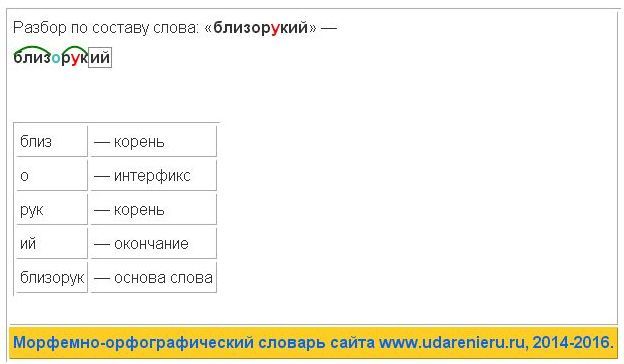
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Урок 37. обобщение знаний о составе слова — Русский язык — 3 класс
Конспект урока.
Русский язык. 3 класс
№ 37
Раздел. Основа слова.
Тема. Обобщение знаний о составе слова.
Перечень вопросов, рассматриваемых в теме
Знать, что такое приставка, корень, суффикс, окончание основа, находить в словах приставку, корень, суффикс, окончание, основу, выполнять разбор по составу слова, соотносить схему слова с соответствующим словом.
Тезаурус по теме (перечень терминов и понятий, введенных на данном уроке)
Корень, приставка, суффикс, окончание, основа, разбор слова по составу.
- В.П. Канакина, В.Г. Горецкий. Русский язык. 3 класс Учебник для общеобразовательных организаций. М.: Просвещение, 2017.
- В.П. Канакина, Русский язык. 3 класс Рабочая тетрадь. Пособие для общеобразовательных организаций. М.: Просвещение, 2017.
- В.П. Канакина, Русский язык. 3 класс. Проверочные работы. М.: Просвещение, 2017.
- В.П. Канакина, Русский язык. 3 класс. Тетрадь учебных достижений. М.: Просвещение, 2017.
Планируемые результаты
На этом уроке
Узнаем:
- что такое морфемный разбор, или разбор слова по составу;
Научимся:
- находить приставку, корень, суффикс, окончание, основа;
- выполнять морфемный разбор, или разбор по составу;
- соотносить схему слова с соответствующим словом.
Теоретический материал для самостоятельного изучения
Рассмотрим схему. О чём рассказывает данная схема? Составим рассказ на основе заданной схемы.
Как видно, данная схема отражает состав слова. В данном слове есть приставка, корень, суффикс, окончание и основа. На основе заданной схемы можно определить место каждой морфемы в слове. Приставка стоит перед корнем, суффикс стоит после корня, основу составляет приставка, корень, суффикс.
На этом уроке
Узнаем:
- что такое морфемный разбор, или разбор слова по составу;
Научимся:
- находить приставку, корень, суффикс, окончание, основа;
- выполнять морфемный разбор, или разбор по составу;
- соотносить схему слова с соответствующим словом.
Морфемика — это наука о частях слова. Морфемика изучает части слова: приставку, корень, суффикс, окончание, основу.
Для того, чтобы выполнить морфемный разбор слова (разбор по частям слова) нужно определить, какие части есть в слове.
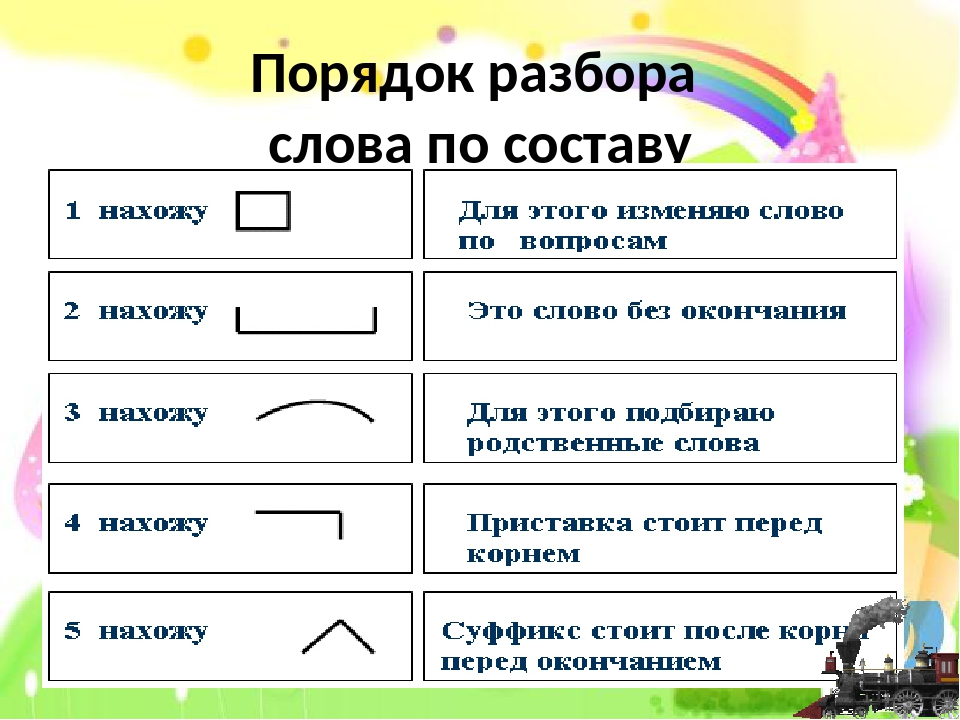
Определим порядок разбора слова по составу.
Как разобрать слово по составу?
- Прочитай и объясни смысл слова.
 Определи, к какой части речи относится слово. Изменяется оно или нет?
Определи, к какой части речи относится слово. Изменяется оно или нет? - Найди в слове окончание. Для этого измени слово: поездка, поездки, поездкой. Изменяемая часть – а. Это окончание. Выдели его знаком:
 Определи, к какой части речи относится слово. Изменяется оно или нет?
Определи, к какой части речи относится слово. Изменяется оно или нет?- Выдели в слове основу. Основа – это часть слова без окончания. Выделим основу:
- Найди в слове корень. Эля этого подбери однокоренные слова (поезди, езда, ездовой), сравни их, выдели общую часть. Это будет корень. Выдели его знаком::
- Найди в слове приставку (если она есть). Для этого подбери однокоренные слова без приставки или с другой приставкой (езда, заезд, приезд). Приставка стоит перед корнем. Выдели приставку.
- Найди в слове суффикс (если он есть). Он стоит после корня и служит для образования слова. Выдели его знаком: .
- Назови все значимые части слова.
Разбор заданий
Укажите все части слова (морфемы).
- Корень, суффикс, окончание.
- Приставка, корень, суффикс, окончание.
- Приставка, корень, суффикс, окончание, основа.
Правильный ответ
Приставка, корень, суффикс, окончание, основа.
Укажите слово, в котором есть суффикс и приставка.
- Лесной
- Столовая
- Прибрежный
Правильный ответ
Прибрежный
Повышенный уровень
Заполните таблицу. Распределите слова в 2 столбика: формы одного и того же слова, однокоренные слова.
Стол, столу, столовая, застолье, столе, столом.
Однокоренные слова | Формы слова |
Правильный ответ
Однокоренные слова | Формы слова |
Стол | столу |
столовая | столе |
застолье | столом |
Алгоритм разбора слова по составу. 3-й класс
Цели урока:
- научить детей определять части слова;
- развивать внимание, речь, наблюдательность;
- воспитывать интерес к процессу познания.

Задача: на основании полученных знаний о частях слова, провести самостоятельное выведение алгоритма разбора слова по составу.
I. Чистописание.
На какие соединения надо обратить внимание?
слакс отлапь ёсво дотлса зёбера кьвромо
II. Повторение словарных слов.
1) В чистописании мы писали не просто набор букв, а слова — анаграммы. Догадайтесь, какие это слова и впишите их в клеточки по порядку. Если все будет записано правильно, вы увидите “спрятавшееся” слово, которое подскажет тему урока.
класс
пальто
овёс
солдат
береза
морковь
- В какую группу можно объединить эти слова? (Словарные слова)
- Почему? (нельзя проверить написание какой-либо буквы)
III. Актуализация.
1) Найдите, спрятавшееся слово. (Состав)
Что можете сказать о слове “состав”? О его
значении? (6 букв, 6 звуков,
2 слога, имеет несколько значений)
Какие значения имеет слово “состав”? (состав вещества, офицерский
состав, состав поезда)
Что же обозначает это слово? (Соединение всех частей в целое)
Как вы думаете, какой состав будет интересовать нас? (состав слова)
Нас, конечно, интересует состав слова. Это тема нашего урока.
2) Что такое окончание? (Изменяемая часть слова)
Что такое суффикс? (Часть основы, которая стоит после корня)
Что такое приставка? (Часть основы, которая стоит перед корнем)
Что называют корнем слова? (Главная часть основы)
Что еще выделяем в слове? (Основа — часть слова, которая остается
если отделить окончание)
3) Подберите однокоренное слово к одному из
словарных слов, обозначающее название грибов.
подберезовики
Попробуйте найти знакомые части слова в слове “
(Графически дети записывают свои ответы)
Физминутка.
Мы показывали части слова графически, а теперь попробуем показать части слова вами. Поделитесь на пары. Я называю слово и его часть, а вы должны показать, как обозначается эта часть.
Повозка — воз, переделать — пере, корзинка — а, солнышко — ышк, деревянный — дерев, зимний — н.
IV. Постановка проблемы.
Почему вы решили, что –под- в слове “подберезовики и поделка” — это приставка? Докажите. (Потом идет корень, а перед корнем всегда приставка)
Так с чего же все-таки нужно начинать находить части слова?
Какую часть слова надо находить первой, какую следующей и почему? Я предлагаю вам установить порядок разбора слова по составу, т. е. вывести алгоритм.
V. Открытие нового знания.
1) Для этого поделимся на 3 команды. Каждая команда получает свое слово, думает, на листочке определяет и записывает свой порядок разбора слова по составу. Затем, выбираете 1 человека от команды, он на доске записывает свое слово и объясняет порядок разбора слова. Почему разбирать слово нужно именно так, а не иначе? Остальные слушают объяснение, согласны вы или нет, почему? 1 команда — подснежники, 2 команда - подсолнухи, 3 команда – посадка. Почему сначала находим окончание?
(Оно служит только для связи слов в предложении, смысл слова заключен в основе, а главное в основе — корень)
2) Посмотрим, какой алгоритм разбора слова по составу, записан в учебнике на с. 41. Прочтите, похоже на наш алгоритм. Докажите.
Разбор слова по составу.1.Измени слово и выдели в нем окончание.
2. Вы дел и основу слова.
3.Подбери однокоренные слова и выдели корень.
4.Выдели приставку.
5. Вы дел и суффикс.
3) Можно запомнить этот алгоритм, составив рифмовку:
Слово по составу верно разбирай:
Первым, окончание всегда выделяй,
На основу внимательно смотри,
Корень, поскорее, ты у нее найди,
Приставку и суффикс в конце определи.
Этим алгоритмом пользуются все ученики во всех школах.
4) Вернемся к нашим словам “подберезовики и поделка”, и уже соблюдая порядок разбора слова по составу, выделите в нем все его части.
- С чего начнем?
- Как найдем окончание? (изменим слово)
- Что осталось? (основа)
- Как правильно выделить корень? (Подобрать как можно больше однокоренных слов) Приставка — перед корнем, суффикс — после корня.
VI. Самостоятельная работа.
1) Шарады
Корень тот же, что и в слове сказка,
Суффикс тот же, что и в слове извозчик,
Приставка та же, что и в слове расход.
(Рассказчик)
Корень мой находится в цене.
В очерке найди приставку мне,
Суффикс мой в тетрадке все встречали.
Вся же — в дневнике я и в журнале.
(Оценка)
Запишем и найдем в слове его части.
2) Отгадаем загадки и разберем отгадки по составу. Золотое решето черных домиков полно; сколько черненьких домков, Столько беленьких жильцов, (подсолнух).
Еду — еду следу нету: режу — режу крови нету, (лодка).
У конька, у горбунка деревянные бока.
У него из — под копыт стружка
белая бежит, (рубанок).

— Вот по кругу друг за дружкой ходят дружно две подружки; не толкаясь, не мешая, быстро движется большая, (стрелки).
— Два брюшка, четыре ушка. Что это? (подушка).
— В брюхе — баня, в носу — решето, на голове — пуговица, одна рука — и та на спине, (чайник).
Весь день ползу я по дорожке, то выпущу, то спрячу рожки. Спешить домой я не спешу. Зачем спешить мне по- пустому? Свой дом я при себе ношу, и потому всегда я дома, (улитка)
— Покружилась звездочка в воздухе немножко, Села и растаяла на моей ладошке, (снежинка)
3) Учебник с. 44 упр. 47. (2 ученика у доски одновременно по вариантам) Задания выполняется по вариантам. Мысленно проведите ось симметрии. Левую сторону выполняет I вариант, правую — II.
Списать слова, разобрать их по составу. Задание выполняется самостоятельно, затем проверим.
| покупки | окраска |
| коровушка | засада |
| моряк | пересадка |
| побег | лисонька |
| грибники | забег |
VII. Итог урока.
Что мы открыли на уроке? Какое открытие сделали? (Алгоритм разбора состава слова) С помощью стихотворения вспомним порядок разбора слова по составу. Слово по составу верно разбирай:
Первым, окончание всегда выделяй,
На основу внимательно смотри,
Корень, поскорее, ты у нее найди,
Приставку и суффикс в конце определи.
VIII. Самооценка.
1) Возьмите листочки, где находится вертикальная линия.
Поставьте на ней крестик:
— на самом верху, если вы все поняли и можете самостоятельно разбирать слова по составу;
— посередине, если поняли, но сомневаетесь в своих силах;
— внизу, если не поняли, как разобрать слово по составу.
IX. Оценки.
X. Домашнее задание.
Проверочная работа по теме «Состав слова»
- Напиши, какие ты знаешь части слова.
Приставка, корень, суффикс, окончание.
- Закончи предложения:
- Приставка — это
- Окончание – это
- Суффикс – это
Приставка - это часть слова, которая стоит перед корнем. Приставки служат для образования новых слов. Окончание – это изменяемая часть слова. Окончание располагается в конце слова, и служит для связи слов в предложении и словосочетании. Окончание может быть нулевым. Оно не образует новых слов. Суффикс – это часть слова, которая находится после корня. Суффиксы служат для образования новых слов.
- Укажи слово, которое не является однокоренным среди данной группы:
- чайник, чайный, нечаянно, чай;
- легонько, легковой, залегать, облегчать;
- дело, делить, поделки, деловой.
1. чайник, чайный,нечаянно, чай; 2. легонько, легковой,залегать, облегчать; 3. дело,делить, поделки, деловой.
- Разбери слова по составу.
Заморозки, полет, грибник, вырубка.
- Образуй однокоренные слова при помощи суффиксов -еньк-, -очк-, -ок-.
- Серый волк,
- красная роза,
- теплый ветер.
Серый волк, серенький волчок. Красная роза, красненькая розочка.
 Теплый ветер, тепленький ветерок.
Теплый ветер, тепленький ветерок.
- Подбери однокоренные слова, выдели корни.
- Цвет,
- дуб,
- береза.
Цвет, цветной. Дуб, дубовая. Береза, березовый.
- Укажите слова, строение которых соответствует схеме:
приставка, корень, суффикс, окончание.
Крылышко, погрузка, поход, подснежник, лесок, пригородный.
Крылышко, погрузка, поход, подснежник, лесок, пригородный.
- Укажи слова, в которых частью корня является «на»:
Надежда, наломать, наземный, наружный.
Надежда, наломать, наземный, наружный.
- Выберите слова с приставками:
(За)ночевал, (за)спиной, (в)лез, (с)мылом, (по)работал, (через)лёд.
(За)ночевал, (за)спиной, (в)лез, (с)мылом, (по)работал, (через)лёд.
- Соотнеси слова и схемы слов:
а) дорога 1) ¬ ͡ ˄ □
б) дочка 2) ͡ □
в) заморозки 3) ͡ ˄ □
- Подбери однокоренное слово с непроизносимым согласным звуком, в корне слова:
- грустить,
- радость,
- счастье,
- прелесть,
- честь.
Грустить – грустный, радость – радостный, счастье – счастливый, прелесть – прелестный, честь – честный.
Разбор по составу слова «помощь»
Чтобы разобрать по составу слово «помощь», вначале определим, какой частью речи оно является. У каждой части речи в русском языке, как известно, имеется свой набор минимальных значимых частей, поэтому морфемный разбор начинаем именно с этого.
Ваша помощь мне необходима.
Слово «помощь» обозначает предметность и отвечает на вопрос что? Значит, это самостоятельная часть речи имя существительное, которое может менять свою грамматическую форму:
- нет (чего?) помощ-и,
- обращаюсь (за чем?) за помощь-ю.

Сравнив падежные формы, в начальной форме именительного падежа у этого существительного отметим наличие нулевого окончания.
Основа совпадает со всем словом без окончания — помощь-.
Далее возникает вопрос: есть в нём приставка? Чтобы выяснить это, обратимся к словообразованию:
мочь → помочь → помогать → помощь.
Да, есть в морфемном составе этого слова приставка. Она досталась этому существительному от производящего глагола.
Корнем является морфема -мощь, в чем убедимся, подобрав родственные слова:
- помощник
- помощница
- беспомощный
- беспомощность
В результате запишем школьный вариант морфемного разбора:
помощь — приставка/корень/окончание.
Для любознательных отметим, истины ради, что в составе этого существительного имеется еще одна морфема — нулевой суффикс, с помощью которого оно образовано от глагола «помогать». От него при словообразовании отсечены глагольный словообразовательный суффикс -а- и окончание:
помог/ать→ помощь
В результате такого творчества появилось новое слово, причём произошла смена части речи, что происходит при суффиксальном способе образования. За счет чего оно образовано ? С помощью нулевого суффикса.
Тогда схема морфемного состава исследуемого слова такова:
помощь 0 — приставка/корень/суффикс/окончание.
В итоге в составе анализируемого слова вместо двух видимых морфем за счет наличия морфем- «невидимок» их имеется ровно в два раза больше — четыре.
Скачать статью: PDFЛадыженская Т. А. 5 класс. Учебник №2, упр. 469, с. 30
469. Разберите устно по составу слова: фигурист, привозим, вносишь, сварщик, красноватая (жидкость), парашютистка — и письменно: (в) сарафанчике, уходит, шерстяным (шарфом), тихая, безлунная (ночь).
1. Фигурист. В слове фигурист нулевое окончание. Основа — фигурист-. Окончание указывает здесь на то, что имя существительное стоит в именительном падеже, в единственном числе.
2. Корень слова- -фигур-. Однокоренные слова: фигурный, фигуристка.
3. В слове фигурист суффикс -ист-. Он обозначает лиц (людей) по роду их занятий, по профессии.
1. Привозим. В слове привозим окончание -им. Основа — привоз-. Окончание указывает здесь на то, что глагол стоит в настоящем времени, 1-го лица, множественного числа.
2. Корень слова- -воз-. Однокоренные слова: возить, пово́зка.
3. В слове привозим есть приставка при-. Она имеет значение доведение действия до цели, до определенного места.
1. Вносишь. В слове вносишь окончание -ишь. Основа — внос-. Окончание указывает здесь на то, что глагол стоит в настоящем времени, 2-го лица, единственного числа.
2. Корень слова- -нос-. Однокоренные слова: носить, заносят.
3. В слове вносишь есть приставка в-. Она имеет значение направленности движения или действия внутрь.
1. Сварщик. В слове сварщик нулевое окончание. Основа — сварщик-. Окончание указывает здесь на то, что имя существительное стоит в именительном падеже единственного числа.
2. Корень слова- -вар-. Однокоренные слова: сварка, варить.
3. В слове сварщик суффикс -щик-. Он обозначает лиц (людей) по роду их занятий, по профессии.
В слове сварщик есть приставка с-. Она имеет значение явления, характеризующиеся соединением предметов.
Она имеет значение явления, характеризующиеся соединением предметов.
1. Красноватая (жидкость). В слове красноватая окончание -ая, основа красноват-. Окончание обозначает, что прилагательное стоит в женском роде, в именительном падеже, в единственном числе.
2. Корень слова- -красн-. Однокоренные слова: красный, покраснеть.
3. В слове красноватая суффикс -оват-. Он образует имена прилагательные, которые имеют значение «чуть-чуть такой»: красноватый — значит не совсем красный.
1. Парашютистка. В слове парашютистка окончание -а. Основа — парашютистк-. Окончание указывает здесь на то, что имя существительное стоит в именительном падеже единственного числа.
2. Корень слова- -парашют-. Однокоренные слова: парашют, парашютный.
3. В слове парашютистка суффикс -к-. Он обозначает лиц женского пола.
Ответы по русскому языку. 5 класс. Учебник. Часть 2. Ладыженская Т. А., Баранов М. Т., Тростенцова Л. А.
Ответы по русскому языку. 5 класс
Ладыженская Т. А. 5 класс. Учебник №2, упр. 469, с. 30
3.8 (76%) от 5 голосующих(PDF) Автоматическое решение проблем числовых слов с помощью семантического анализа и анализа
D.G. Бобров. 1964a. Ввод на естественном языке для компьютерной системы решения проблем
. Отчет MAC-
TR-1, Project MAC, Массачусетский технологический институт, Кембридж, июнь
D.G. Бобров. 1964b. Ввод на естественном языке для компьютерной системы решения проблем
. Кандидат наук. Диссертация,
Кандидат наук. Диссертация,
Математический факультет, Массачусетский технологический институт, Кембридж
D.L. Брайарс, Дж. Ларкин.1984. Интегрированная модель
навыков решения элементарных словесных задач. Познание и обучение,
,, 1984, 1 (3) 245-296.
Q. Cai и A. Yates. 2013. Масштабный семантический синтаксический анализ —
через сопоставление схем и расширение лексики. В
Ассоциация компьютерной лингвистики (ACL).
Х. Каррерас. и Л. Маркес. 2004. Введение в общую задачу
CoNLL-2004: разметка семантических ролей. В
Труды CoNLL.
Э. Чарняк. 1968. CARPS: программа, которая решает
задач по исчислению слов. Отчет MAC-TR-51, Pro-
ject MAC, Массачусетский технологический институт, Кембридж,
июляЭ. Чарняк. 1969. Компьютерное решение математических словарных задач
. В материалах международной совместной конференции
по искусственному интеллекту. Вашингтон, округ Колумбия,
стр. 303–316
Н. Хомский. 1956. Три модели для описания
языка. Теория информации, IRE Transactions on,
2 (3), 113-124.
С. Кларк и Дж. Карран. 2007. Эффективный статистический анализ
с широким охватом с помощью CCG и лог-линейных моделей.
Компьютерная лингвистика, 33 (4): 493-552.
Д. Дас, Д. Чен, A.F.T. Мартинс, Н. Шнайдер и
Н.А. Смит. 2014. Фрейм-семантический анализ. Com-
условная лингвистика 40: 1, страницы 9-56
Д. Деллароса. 1986. Компьютерное моделирование решения арифметических задач детей
dren. Поведение
Research Methods, Instruments, & Computers,
18: 147–154
V.Дурме, Т. Цянь и Л. Шуберт. 2008. Класс-
, управляемое извлечение атрибутов. В материалах 22-й Международной конференции по вычислительной технике
, том 1, стр. 921-928. Ассоциация
компьютерной лингвистики, 2008.
Дж. Эрли. 1970. Эффективный алгоритм разбора без контекста —
ритм. Сообщения ACM, 13 (2), 94-102.
Сообщения ACM, 13 (2), 94-102.
К.Дж. Филмор, К.Р. Джонсон и М.Р. Петрук. 2003 г.
Фон для FrameNet. Международный журнал
Лексикография, 16 (3).
К. Р. Флетчер. 1985. Понимание и решение арифметических задач
: компьютерное моделирование. Be-
havior Research Methods, Instruments, & Comput-
ers, 17: 565–571
D. Gildea, D. Jurafsky. 2002. Автоматическая разметка
семантических ролей. Компьютерная лингвистика, 28 (3).
М. Херст. 1992. Автоматическое получение гипонимов
из больших текстовых корпусов.На Четырнадцатой Международной конференции по компьютерной лингвистике
,
Нант, Франция.
М.Дж. Хоссейни, Х. Хаджиширзи, О. Эциони и Н. Куш-
человек. 2014. Учимся решать арифметические слова
Проблемы с категоризацией глаголов. В
ЕМНЛП’2014.
Д. Джурафски, Дж. Х. Мартин. 2000. Речь и язык
обработка. Pearson Education India.
Т. Касами. 1965. Эффективное распознавание и алгоритм синтаксического анализа
для контекстно-свободных языков
(Технический отчет).AFCRL. 65-758.
П. Кингсбери и М. Палмер. 2002. Из TreeBank в
PropBank. В трудах LREC.
Н. Кушман, Ю. Арци, Л. Зеттлемойер и Р. Барзи
lay. 2014. Учимся автоматически решать алгебру
словарных задач. В Proc. годового собрания
Ассоциации компьютерной лингвистики
(ACL).
Т. Квятковски, Э. Чой, Ю. Арци и Л. Цеттлемойер.
2013. Масштабирование семантических анализаторов с оперативным согласованием тологий
.В эмпирических методах обработки естественного языка
(EMNLP).
И. Лев, Б. Маккартни, К. Мэннинг и Р. Леви.
2004. Решение логических задач: от надежного перехода
к точной семантике. В материалах семинара
по значению и интерпретации текста. As-
Сообщество компьютерной лингвистики.
К. Лигуда, Т. Пфайффер. 2012. Моделирование математического слова
Моделирование математического слова
Проблемы с расширенными семантическими сетями.
НЛБД’2012, стр. 247–252.
Ю. Ма, Ю. Чжоу, Г. Цуй, Р. Юнь, Р. Хуан. 2010.
Кадровое исчисление для решения арифметических задач с несколькими шагами
сложения и вычитания слов. В Международном семинаре по образовательным технологиям
и информатике
, т. 2. С. 476–479.
L. Marquez, X. Carreras, K.C. Литковски, С. Сте-
венсон. 2008. Семантическая разметка ролей: введение в спецвыпуск.Компьютерная лингвистика,
34 (2).
А. Мукерджи и У. Гараин. 2008. Обзор методик
для автоматического понимания естественного языка
математических задач. Искусственный интеллект Re-
вид, 29 (2).
М. Паска, Д. Линь, Дж. Бигхэм, А. Лифчиц и А. Джайн.
2006. Организация и поиск во всемирной паутине
фактов — шаг первый: извлечение одного миллиона фактов
Задача. В AAAI (т.6. С. 1400–1405).
К.К. Шулер. 2005. VerbNet: широкий охват, com-
лексика цепляющих глаголов. Диссертация. http: // reposi-
tory.upenn.edu/dissertations/AAI3179808
1141
Алгоритм автоматического решения математических задач со словами с помощью машинного обучения
В течение долгого времени целью исследователей было автоматическое решение математических задач. проблемы со словами (Upadhyay & Chang, 2017). В тексте большинства математических задач со словами содержится вся информация, необходимая для ее решения, а это означает, что их можно легко решить без полного понимания значения слов.Тем не менее, они сочетают в себе простую для человека задачу, синтаксический анализ и понимание естественного языка, а также продвинутую математику, и выступают в качестве меры искусственного интеллекта (Clark & Etzioni, 2016).
Текущий стандарт для автоматического решения проблем со словами рекомендует решать проблемы со словами путем создания шаблонов и их решения (Upadhyay & Chang, 2017). Уравнения шаблона ограничены по объему и могут решать только уравнения, аналогичные тем, которые он уже видел — этого недостаточно, чтобы решать многоэтапные задачи.Другой опубликованный метод, называемый ARRIS, использует категоризацию глаголов (Hosseini, Hajishirzi, Etzioni & Kushman 2014). Методы категоризации глаголов становятся жертвами ошибок, связанных с ошибками синтаксического анализа, завершением набора, нерелевантной информацией и следствием, достигая точности только 70% в идеальных сценариях (Hosseini et. Al 2014).
Уравнения шаблона ограничены по объему и могут решать только уравнения, аналогичные тем, которые он уже видел — этого недостаточно, чтобы решать многоэтапные задачи.Другой опубликованный метод, называемый ARRIS, использует категоризацию глаголов (Hosseini, Hajishirzi, Etzioni & Kushman 2014). Методы категоризации глаголов становятся жертвами ошибок, связанных с ошибками синтаксического анализа, завершением набора, нерелевантной информацией и следствием, достигая точности только 70% в идеальных сценариях (Hosseini et. Al 2014).
Новое исследование показывает, что можно анализировать предложения с точностью 92,1% (Kong, Alberti, Andor, Bogatyy, & Weiss, 2017) с помощью моделей от последовательности к последовательности (Suskever, Vinyals & Le, 2017).Я предлагаю алгоритм, который использует модель от последовательности к последовательности, основанный на последних достижениях в технологии машинного обучения, для извлечения уравнений из текстовых задач.
Результаты этого исследования можно обобщить для улучшения личных помощников, таких как Siri от Apple или Google Assistant.
Материалы
——
Модель была построена с использованием Keras (Chollet F., 2015) и бэкэнда Tensorflow (Abadi et al., 2015).
Набор данных для обучения и проверки представляет собой смесь задач из MAWPS (Koncel-Kedziorski et al., 2016) и Dolphin 18k (Huang, Shi, Lin, Yin, & Ma, 2016) и состоит из около 5000 проблем при очистке. Набор данных для тестирования взят из Upadhyay S. & Change, 2016. Все наборы данных очищены и содержат только проблемы с правильными уравнениями, в которых используются числа из текста.
Из-за небольшого размера общедоступных корпусов задач со словами и высокой стоимости создания и маркировки новых, модель использует векторы слов spaCy (Honnibal & Montani, 2017) в качестве входных данных для уменьшения требований к обучающим данным.
Модель была обучена на ML Engine от Google — общедоступной облачной платформе для обучения нейронных сетей, построенной с помощью TensorFlow.
Sympy используется для решения сгенерированных уравнений, это система компьютерной алгебры Python с открытым исходным кодом (Meurer et al., 2017).
Источник алгоритма написан на Python 2.7
Все графики и визуальные элементы, созданные исследователем с использованием TensorBoard и Matplotlib (Hunter, 2007)
Процесс проектирования и объяснение
——
Первоначальный дизайн для «Решение слов» — это процесс, основанный на правилах.Он включал в себя синтаксический анализ предложения с помощью парсера естественного языка, классификацию каждого токена для создания дерева («классификацию»), а затем преобразование этого дерева с помощью ряда определенных шагов для «материализации» дерева в уравнение, готовое для использования с компьютерной алгеброй. система («овеществление»). Это оказалось проблематичным: английский не статичен даже с хорошо написанными словами. Попытка выбрать статический путь от дерева к уравнению практически невозможна.
Чтобы решить эту проблему, дизайн был изменен на объединение этапов классификации и реификации с использованием нейронной сети.Модели от последовательности к последовательности хорошо работают для машинного перевода (Wu et al., 2016), поэтому дизайн сети основан на модели от последовательности к последовательности.
Модель состоит из трех разделов: кодировщик, декодер и внимание. Секция кодировщика создает тензор, содержащий представление использования каждого слова в уравнении. Раздел внимания генерирует оценку важности каждого слова, которая используется для вычисления средневзвешенного значения закодированного представления для каждого вывода.Декодер декодирует внимание и выводит набор значений, каждое из которых соответствует либо операции, либо переменной, либо числу из входного предложения.
Вместо записи уравнений в стандартной нотации используется машинно-ориентированная префиксная нотация. Он снижает количество ошибок за счет присвоения числовых индексов переменным в уравнениях и может быть представлен с высокой плотностью информации.
Из-за ограничений доступных данных модель может генерировать только уравнения длиной менее 70 символов, используя однозначные числа, содержащиеся в первых 71 слове задачи.Предварительно обученные векторы слов из SpaCy используются в качестве входных данных, сокращая требования к данным.
Результаты
——
Лучшая модель набрала 94,09% посимвольной точности в тестовом наборе данных проблем. Это означает создание правильных уравнений для 25,74% проблем в наборе обучающих данных модели и 12,34% проблем вне набора обучающих данных модели.
Заключение
——
Компьютеры борются с проблемами понимания слов.По сравнению с другими моделями на реальных проблемах, SolveWords достигла точности 12,35%. В Huang et al. (2016), решатель с наивысшей точностью набрал около 15,9% при использовании модели, основанной на сходстве, которая может дать сбой за пределами области задач, на которых она была обучена. Поскольку SolveWords обрабатывает все предложение, его следует более точно тестировать на предмет проблем, в отличие от тех, которые он видел раньше, по сравнению с другими моделями, но отсутствие данных затрудняет проверку этого.
SolveWords получил 25 баллов по результатам тестирования.74% (и можно было бы получить больше со временем обучения), показатель того, что модель хорошо подходит для текстовых задач, но «переоснащается» (не удается обобщить) обучающих данных из-за отсутствия образцов. В будущем можно будет достичь более высокой точности с помощью этой модели, просто собрав больше данных для обучения, в идеале, по крайней мере, 30 000 задач (что было невозможно из-за бюджетных ограничений). Тем не менее, используя ограниченные общедоступные наборы данных, SolveWords представляет собой современную модель для решения текстовых проблем.
Описание слов — Найдите прилагательные для описания вещей
слов для описания ~ термин ~
Как вы, наверное, заметили, прилагательные к слову «термин» перечислены выше. Надеюсь, сгенерированный выше список слов для описания термина соответствует вашим потребностям.
Надеюсь, сгенерированный выше список слов для описания термина соответствует вашим потребностям.
Если вы получаете странные результаты, возможно, ваш запрос не совсем в правильном формате. В поле поиска должно быть простое слово или фраза, например «тигр» или «голубые глаза». Поиск слов, описывающих «людей с голубыми глазами», скорее всего, не даст результатов.Поэтому, если вы не получаете идеальных результатов, проверьте, не вводит ли ваш поисковый запрос «термин» в заблуждение таким образом.
Обратите также внимание на то, что если терминов прилагательных не так много или их совсем нет, то, возможно, в вашем поисковом запросе содержится значительная часть речи. Например, слово «синий» может быть как существительным, так и прилагательным. Это сбивает двигатель с толку, поэтому вы можете не встретить много прилагательных, описывающих его. Возможно, я исправлю это в будущем. Вам также может быть интересно: что за слово ~ термин ~?
Описание слов
Идея движка Describing Words возникла, когда я создавал движок для связанных слов (он похож на тезаурус, но дает вам гораздо более широкий набор из связанных слов, а не только синонимов).Играя с векторами слов и API «HasProperty» концептуальной сети, я немного повеселился, пытаясь найти прилагательные, которые обычно описывают слово. В конце концов я понял, что есть гораздо лучший способ сделать это: разбирать книги!
Project Gutenberg был первоначальным корпусом, но синтаксический анализатор стал более жадным и жадным, и в итоге я скармливал ему где-то около 100 гигабайт текстовых файлов — в основном художественной литературы, в том числе многих современных работ. Парсер просто просматривает каждую книгу и вытаскивает различные описания существительных.
Надеюсь, это больше, чем просто новинка, и некоторые люди действительно сочтут ее полезной для написания и мозгового штурма, но стоит попробовать сравнить два существительных, которые похожи, но отличаются в некотором значении — например, интересен пол: «женщина» против «мужчины» и «мальчик» против «девочки». При первоначальном быстром анализе кажется, что авторы художественной литературы как минимум в 4 раза чаще описывают женщин (в отличие от мужчин), используя термины, связанные с красотой (в отношении их веса, черт лица и общей привлекательности).Фактически, «красивая», возможно, является наиболее широко используемым прилагательным для женщин во всей мировой литературе, что вполне согласуется с общим одномерным представлением женщин во многих других формах СМИ. Если кто-то хочет провести дальнейшее исследование по этому поводу, дайте мне знать, и я могу предоставить вам гораздо больше данных (например, существует около 25000 различных записей для слова «женщина» — слишком много, чтобы показать здесь).
При первоначальном быстром анализе кажется, что авторы художественной литературы как минимум в 4 раза чаще описывают женщин (в отличие от мужчин), используя термины, связанные с красотой (в отношении их веса, черт лица и общей привлекательности).Фактически, «красивая», возможно, является наиболее широко используемым прилагательным для женщин во всей мировой литературе, что вполне согласуется с общим одномерным представлением женщин во многих других формах СМИ. Если кто-то хочет провести дальнейшее исследование по этому поводу, дайте мне знать, и я могу предоставить вам гораздо больше данных (например, существует около 25000 различных записей для слова «женщина» — слишком много, чтобы показать здесь).
Голубая окраска результатов отражает их относительную частоту. Вы можете навести курсор на элемент на секунду, и должна появиться оценка частоты.Сортировка по «уникальности» используется по умолчанию, и благодаря моему сложному алгоритму ™ она упорядочивает их по уникальности прилагательных к этому конкретному существительному относительно других существительных (на самом деле это довольно просто). Как и следовало ожидать, вы можете нажать кнопку «Сортировать по частоте использования», чтобы выбрать прилагательные по частоте их использования для этого существительного.
Особая благодарность разработчикам mongodb с открытым исходным кодом, который использовался в этом проекте.
Обратите внимание, что Describing Words использует сторонние скрипты (такие как Google Analytics и рекламные объявления), которые используют файлы cookie.Чтобы узнать больше, см. Политику конфиденциальности.
Математика для гуманитарных наук
Логика — это систематический образ мышления, который позволяет нам выводить новую информацию из старой информации и анализировать значения предложений. Вы неформально используете логику в повседневной жизни и, конечно же, в математике. Например, предположим, что вы работаете с определенным кругом, назовите его «Круг X», и вам доступны следующие две части информации.
- Окружность X имеет радиус, равный 3.
- Если любой круг имеет радиус r , то его площадь равна π r 2 квадратных единиц.
У вас нет проблем, сложив эти два факта вместе, чтобы получить:
- Круг X имеет площадь 9π квадратных единиц.
При этом вы используете логику для объединения существующей информации для получения новой информации. Поскольку основной задачей математики является получение новой информации, логика должна играть фундаментальную роль. Эта глава предназначена для того, чтобы вы в достаточной степени овладели логикой.
Важно понимать, что логика — это процесс правильного вывода информации, а , а не , просто вывод правильной информации. Например, предположим, что мы ошиблись и окружность X на самом деле имела радиус 4, а не 3. Давайте снова посмотрим на наш точно такой же аргумент.
- Окружность X имеет радиус, равный 3.
- Если любой круг имеет радиус r , то его площадь равна π r 2 квадратных единиц.
- Окружность X имеет площадь 9π квадратных единиц.
Предложение « Окружность X имеет радиус, равное 3. » теперь неверно, как и наш вывод: «Окружность X имеет площадь 9π квадратных единиц. »Но логика совершенно верна; информация была составлена правильно, даже если часть из них была ложной. Это различие между правильной логикой и правильной информацией важно, потому что часто важно проследить последствия неверного предположения. В идеале мы хотим, чтобы наша логика и наша информация были правильными, но дело в том, что это разные вещи.
При доказательстве теорем мы применяем логику к информации, которая считается очевидной истинной (например, « Любые две точки определяют ровно одну линию. ») или уже известна как истинная (например, теорема Пифагора). Если наша логика верна, то все, что мы выводим из такой информации, также будет правдой (или, по крайней мере, так же правдиво, как «очевидно правдивая» информация, с которой мы начали).
Заявления
Изучение логики начинается с утверждений. Утверждение — это предложение или математическое выражение, которое либо определенно истинно, либо определенно ложно.Вы можете думать об утверждениях как о фрагментах информации, которые являются правильными или неправильными. Таким образом, операторы — это фрагменты информации, к которым мы можем применить логику, чтобы произвести другие фрагменты информации (которые также являются операторами).
Пример 1
Вот несколько примеров утверждений. Все они верны.
Если круг имеет радиус r , то его площадь равна π r 2 квадратных единиц.
Каждое четное число делится на 2.
[латекс] 2 \ text {} {\ in} \ text {} \ mathbb {Z} \\ [/ latex] (2 — это элемент набора целых чисел (или, проще говоря, 2 — целое число).)
[латекс] \ sqrt {2} \ text {} {\ notin} \ text {} \ mathbb {Z} \\ [/ latex] (Квадратный корень из 2 не является целым числом.)
[латекс] \ mathbb {N} \ text {} {\ substeq} \ text {} \ mathbb {Z} \\ [/ latex] (Набор натуральных чисел является подмножеством набора целых чисел.)
Набор {0,1,2} состоит из трех элементов.
Некоторые прямоугольные треугольники равнобедренные.
Пример 2
Вот несколько дополнительных утверждений.Все они ложны.
Все прямоугольные треугольники равнобедренные.
5 = 2
[латекс] \ sqrt {2} \ text {} {\ notin} \ text {} \ mathbb {R} \\ [/ latex] (Квадратный корень из 2 не является действительным числом.)
[латекс] \ mathbb {Z} \ substeq \ mathbb {N} \\ [/ latex] (Набор целых чисел является подмножеством набора натуральных чисел.)
[латекс] {0,1,2} \ cap \ mathbb {N} = \ varnothing \\ [/ latex] (Пересечение множества {0,1,2} и натуральных чисел является пустым множеством.)
Пример 3
Здесь мы объединяем предложения или выражения, которые не являются операторами, с аналогичными выражениями, которые являются операторами.
| НЕ Заявления | Заявления |
|---|---|
| Добавьте 5 с обеих сторон. | Добавление 5 к обеим сторонам x — 5 = 37 дает x = 42. |
| [латекс] \ mathbb {Z} \\ [/ latex] (Набор целых чисел) | [латекс] 42 \ text {} {\ in} \ text {} \ mathbb {Z} \\ [/ latex] (42 — элемент набора целых чисел.) |
| 42 | 42 — это не число. |
| Каково решение 2 x = 84? | Решение 2 x = 84 равно 42. |
Пример 4
Мы часто будем использовать буквы P , Q , R и S для обозначения определенных утверждений. Когда нужно больше букв, мы можем использовать индексы. Вот еще утверждения, обозначенные буквами. Вы сами решаете, какие из них истинны, а какие — ложны.
P : для каждого целого числа n > 1 число 2 n -1 простое.
Q : Каждый полином степени n имеет не более n корней.
R : функция f ( x ) = x 2 является непрерывной.
S 1 : [латекс] \ mathbb {N} \ substeq \ varnothing \\ [/ latex]
S 2 : [латекс] {0, -1, -2} \ cap \ mathbb {N} = \ varnothing \\ [/ latex]
Обозначение утверждений буквами (как это было сделано выше) — очень полезное сокращение. При обсуждении конкретного утверждения, например «Функция f ( x ) = x 2 является непрерывной», удобно просто ссылаться на него как на R , чтобы избежать необходимости писать или произносить ее. много раз.
Операторы могут содержать переменные. Вот пример.
P : Если целое число x кратно 6, то x четно.
Это верное предложение. (Все числа, кратные 6, четны, поэтому независимо от того, каким кратным 6 оказывается целое число x , оно четное.) Поскольку предложение P определенно верно, это утверждение. Когда предложение или утверждение P содержит переменную, такую как x , мы иногда обозначаем его как P ( x ), чтобы указать, что в нем что-то говорится о x .Таким образом, приведенное выше утверждение можно обозначить как
.P ( x ): если целое число x кратно 6, тогда x четно.
Утверждение или предложение, включающее две переменные, можно обозначить как P ( x , y ) и т. Д.
Вполне возможно, что предложение, содержащее переменные, не будет утверждением. Рассмотрим следующий пример.
Q ( x ): целое число x четное.
Это заявление? Верно это или ложно, зависит от того, какое целое число x . Это верно, если x = 4, и false, если x = 7, и т. Д. Но без каких-либо оговорок относительно значения x невозможно сказать, является ли Q ( x ) истинным или ложным. Поскольку это не определенно верно или определенно ложно, Q ( x ) не может быть утверждением. Такое предложение, истинность которого зависит от значения одной или нескольких переменных, называется открытым предложением .Переменные в открытом предложении (или утверждении) могут представлять любой тип сущности, а не только числа. Вот открытое предложение, где переменные — это функции:
R ( f , g ): функция f является производной функции g .
Это открытое предложение верно, если f ( x ) = 2 x и g ( x ) = x 2 . Неверно, если f ( x ) = x 3 и g ( x ) = x 2 и т. Д.Мы отмечаем, что такое предложение, как R ( f , g ) (которое включает переменные), может быть обозначено как R ( f , g ) или просто R . Мы используем выражение R ( f , g ), когда хотим подчеркнуть, что предложение включает переменные.
Мы еще поговорим об открытых предложениях позже, а пока вернемся к утверждениям.
Утверждения везде в математике.п \\ [/ латекс].
Ферма считал это утверждение правдой. Он отметил, что может доказать, что это правда, за исключением того, что поле его записной книжки было слишком узким, чтобы вместить его доказательство. Сомнительно, что он действительно имел в виду правильное доказательство, поскольку после его смерти поколения блестящих математиков безуспешно пытались доказать, что его утверждение было истинным (или ложным). Наконец, в 1993 году Эндрю Уайлс из Принстонского университета объявил, что разработал доказательство. Уайлс работал над этой проблемой более семи лет, и его доказательство занимает сотни страниц.Мораль этой истории заключается в том, что некоторые истинные утверждения не являются очевидными.
Вот еще одно заявление, достаточно известное, чтобы его можно было назвать. Впервые она была сформулирована в XVIII веке немецким математиком Кристианом Гольдбахом и поэтому называется гипотезой Гольдбаха:
S : Каждое четное целое число больше 2 является суммой двух простых чисел.
Вы должны согласиться с тем, что S либо верно, либо неверно. Это кажется правдой, потому что, когда вы исследуете четные числа, которые больше 2, они кажутся суммой двух простых чисел: 4 = 2 + 2, 6 = 3 + 3, 8 = 3 + 5, 10 = 5 + 5. , 12 = 5 + 7, 100 = 17 + 83 и так далее.Но это не значит, что не существует большого четного числа, которое не являлось бы суммой двух простых чисел. Если такое число существует, то S ложно. Дело в том, что за более чем 260 лет, прошедших с тех пор, как Гольдбах впервые поставил эту проблему, никто так и не смог определить, правда это или ложь. Но поскольку это явно либо правда, либо ложь, S является утверждением.
Эта книга о методах, которые можно использовать, чтобы доказать, что S (или любое другое утверждение) истинно или ложно. Чтобы доказать, что утверждение истинно, мы начинаем с очевидных утверждений (или других утверждений, истинность которых доказана) и используем логику для вывода все более и более сложных утверждений, пока, наконец, не получим утверждение, такое как S .Конечно, некоторые утверждения труднее доказать, чем другие, и S , как известно, является сложным; мы сконцентрируемся на утверждениях, которые легче доказать.
Но суть в следующем: доказывая, что утверждения верны, мы используем логику, чтобы помочь нам понять утверждения и объединить фрагменты информации для создания новых фрагментов информации. В следующих нескольких разделах мы исследуем некоторые стандартные способы объединения операторов для формирования новых или разбиения на более простые операторы.
И, Или, Не
Слово «и» может использоваться для объединения двух операторов в новое утверждение. Рассмотрим, например, следующее предложение.
R 1 : Число 2 четное и число 3 нечетное.
Мы признаем это как истинное утверждение, основанное на нашем здравом смысле понимания значения слова «и». Обратите внимание, что R 1 состоит из двух более простых утверждений:
P : Число 2 четное.
Q : Число 3 нечетное.
Они объединены словом «и», чтобы сформировать более сложное утверждение R 1 . Утверждение R 1 утверждает, что P и Q оба верны. Поскольку и P , и Q на самом деле верны, утверждение R 1 также верно.
Если бы один или оба из P и Q были ложными, то R 1 было бы ложным.Например, каждое из следующих утверждений неверно.
R 2 : Число 1 четное и число 3 нечетное.
R 3 : число 2 четное и число 4 нечетное.
R 4 : Число 3 четное и число 2 нечетное.
Из этих примеров мы видим, что любые два оператора P и Q могут быть объединены в новый оператор « P и Q .«В духе использования букв для обозначения утверждений, мы теперь вводим специальный символ ∧ для обозначения слова« и ». Таким образом, если P и Q являются операторами, то P ∧ Q означает выражение « P и Q ». Утверждение P ∧ Q верно, если верны и P , и Q ; в противном случае это ложь. Это обобщено в следующей таблице, которая называется таблицей истинности .
| п. | Q | P ∧ Q |
|---|---|---|
| т | т | т |
| т | F | F |
| Ф | т | F |
| Ф | F | F |
В этой таблице T означает «Истина», а F означает «Ложь.”(T и F называются значениями истинности .) Каждая строка перечисляет одну из четырех возможных комбинаций или значений истинности для P и Q , а столбец, озаглавленный P ∧ Q , указывает, P ∧ Q верно или неверно в каждом случае.
Заявления также можно объединить с помощью слова «или». Рассмотрим следующие четыре утверждения.
S 1 : Число 2 четное или число 3 нечетное.
S 2 : Число 1 четное или число 3 нечетное.
S 3 : Число 2 четное или число 4 нечетное.
S 4 : Число 3 четное или число 2 нечетное.
В математике утверждение « P или Q » всегда понимается как означающее, что одно или оба из P и Q истинны. Таким образом, все утверждения S 1 , S 2 , S 3 верны, а S 4 — ложны.Символ ∨ используется для обозначения слова «или». Таким образом, если P и Q являются операторами, P ∨ Q представляет собой утверждение « P или Q ». Вот таблица истинности.
| п. | Q | P ∨ Q |
|---|---|---|
| т | т | т |
| т | F | т |
| Ф | т | т |
| Ф | F | F |
Важно знать, что значение «или», выраженное в приведенной выше таблице, отличается от того, как оно иногда используется в повседневном разговоре.Например, предположим, что сотрудник университета делает следующую угрозу:
Вы платите за обучение. или вы будете исключены из школы.
Вы понимаете, что это означает, что либо вы платите за обучение, либо вас исключат из школы, , но не одновременно . В математике мы никогда не используем слово «или» в таком смысле. Для нас «или» означает именно то, что указано в таблице для ∨. Таким образом, истинность P ∨ Q означает, что один или и из P , и Q истинны.Если нам когда-нибудь понадобится выразить тот факт, что ровно одно из P и Q истинно, мы используем одну из следующих конструкций:
P или Q , , но не то и другое вместе.
Либо P , либо Q .
Если бы сотрудник университета был математиком, он мог бы квалифицировать свое утверждение одним из следующих способов.
Оплатите обучение. или вы будете исключены из школы, , но не оба .
Либо вы платите за обучение, либо , либо вы будете исключены из школы.
В заключение этого раздела упомянем еще один способ получения новых операторов из старых. Учитывая любое утверждение P , мы можем сформировать новое утверждение « Неправда, что P ». Например, рассмотрим следующее утверждение.
Число 2 четное.
Это утверждение верно. Теперь измените его, вставив в начало слова «Это неправда»:
Неправда, что число 2 четное.
Это новое утверждение неверно.
В качестве другого примера, начиная с ложного утверждения «[latex] 2 \ in \ varnothing \\ [/ latex]» мы получаем истинное утверждение «Неверно, что [latex] 2 \ in \ varnothing \\ [/ latex ] ».
Мы используем символ ∼ для обозначения слов «Это неправда», поэтому ∼ P означает « Неправда, что P ». Мы часто читаем ∼ P просто как «не P ». В отличие от ∧ и ∨, которые объединяют два оператора, символ ∼ просто изменяет один оператор.Таким образом, его таблица истинности состоит всего из двух строк, по одной для каждого возможного значения истинности P .
Утверждение ∼ P называется отрицанием из P . Отрицание конкретного утверждения можно выразить разными способами. Рассмотрим
P : Число 2 четное.
Вот несколько способов выразить его отрицание.
∼ P : Неверно, что число 2 четное.
∼ P : Неверно, что число 2 четное.
∼ P : Число 2 не четное.
В этом разделе мы узнали, как комбинировать или изменять операторы с операциями ∧, ∨ и ∼. Конечно, мы также можем применить эти операции к открытым предложениям или смеси открытых предложений и утверждений. Например, ( x — четное целое число) ∧ (3 — нечетное целое число) — открытое предложение, которое представляет собой комбинацию открытого предложения и утверждения.
Условные утверждения
Есть еще один способ объединить два оператора.Предположим, мы имеем в виду конкретное целое число a . Рассмотрим следующее утверждение о a .
R : Если целое число a кратно 6, тогда a делится на 2.
Мы сразу же замечаем это как истинное утверждение, основываясь на наших знаниях о целых числах и значениях слов «если» и «то». Если целое число a кратно 6, тогда a четное, поэтому a делится на 2. Обратите внимание, что R состоит из двух более простых операторов:
P: целое число a кратно 6.
Q: Целое число a делится на 2.
R: Если P, то Q.
В общем, учитывая любые два утверждения P и Q , мы можем сформировать новое утверждение « Если P, то Q ». Это записывается символически как P ⇒ Q , что мы читаем как « Если P, то Q » или « P подразумевает Q ». Как и ∧ и ∨, символ ⇒ имеет очень специфическое значение. Когда мы утверждаем, что утверждение P ⇒ Q верно, мы имеем в виду, что , если P истинно , то Q также должно быть истинным.(Другими словами, мы имеем в виду, что условие P истинно, заставляет Q быть истинным.) Утверждение формы P ⇒ Q называется условным утверждением , потому что это означает, что Q будет истинным. при условии , что P является истинным.
Вы можете думать о P ⇒ Q как об обещании, что всякий раз, когда P истинно, Q также будет истинным. Есть только один способ нарушить это обещание (т.е. быть ложным), и это если P истинно, но Q ложно. Таким образом, таблица истинности обещания P ⇒ Q выглядит следующим образом:
| п. | Q | P ⇒ Q |
|---|---|---|
| т | т | т |
| т | F | F |
| Ф | т | т |
| Ф | F | т |
Возможно, вас беспокоит тот факт, что P ⇒ Q верно в последних двух строках этой таблицы.Вот пример, который убедит вас в правильности таблицы. Предположим, ваш профессор дает следующее обещание:
Если вы сдадите заключительный экзамен, то вы пройдете курс.
Ваш профессор дает обещание
(Вы сдаете экзамен) ⇒ (Вы сдаете курс).
При каких обстоятельствах она солгала? Есть четыре возможных сценария, в зависимости от того, сдали ли вы экзамен и прошли ли вы курс.Эти сценарии собраны в следующей таблице.
| Вы сдали экзамен | Вы прошли курс | (Вы сдаете экзамен) ⇒ (Вы сдаете курс) |
|---|---|---|
| т | т | т |
| т | F | F |
| Ф | т | т |
| Ф | F | т |
В первой строке описан сценарий, в котором вы сдали экзамен и проходили курс.Очевидно, профессор сдержала свое обещание, поэтому мы поместили T в третью колонку, чтобы указать, что она сказала правду. Во второй строке вы сдали экзамен, но ваш профессор поставил вам плохую оценку за курс. В этом случае она нарушила свое обещание, и F в третьем столбце указывает на то, что то, что она сказала, не соответствовало действительности.
Теперь рассмотрим третий ряд. В этом случае вы провалили экзамен, но все же прошли курс. Как такое могло случиться? Может быть, вашему профессору было жаль вас.Но это не значит, что она лгунья. Ее единственное обещание заключалось в том, что если вы сдадите экзамен, вы пройдете курс. Она не сказала, что сдача экзамена — единственный способ пройти курс . Поскольку она не лгала, значит, она сказала правду, поэтому в третьей колонке стоит T .
Наконец, посмотрите на четвертый ряд. В этом случае вы провалили экзамен и провалили курс. Ваш профессор не солгал; она сделала именно то, что обещала. Отсюда T в третьем столбце.
В математике всякий раз, когда мы встречаем конструкцию « Если P, то Q », это означает именно то, что выражает таблица истинности для ⇒. Но, конечно, есть и другие грамматические конструкции, которые также означают P ⇒ Q . Вот краткое изложение основных.
[латекс] {P} \ Rightarrow {Q} \ begin {cases} {\ text {If} P \ text {, then} Q.} \\ {Q \ text {if} P.} \\ {Q \ text {when} P.} \\ {Q \ text {, при условии, что} P.} \\ {\ text {Anywhere} P \ text {, тогда также} Q.} \\ {P \ text {является достаточным условие для} Q.} \\ {\ text {Для} Q \ text {достаточно, чтобы} P.} \\ {Q \ text {было необходимым условием для} P.} \\ {\ text {Для} P \ text { , необходимо, чтобы} Q.} \\ {P \ text {только если} Q.} \ end {case} \\ [/ latex]
Все они могут использоваться вместо (и означать то же самое, что и) « Если P, то Q ». Вам следует проанализировать значение каждого из них и убедиться, что он передает значение P ⇒ Q . Например, P ⇒ Q означает, что условие P выполняется достаточно (т.е.е., достаточно), чтобы сделать Q истинным; следовательно, « P является достаточным условием для Q ».
Формулировка может быть сложной. Часто повседневная ситуация, связанная с условным утверждением, может помочь прояснить это. Например, рассмотрим обещание вашего профессора:
(Вы сдаете экзамен) ⇒ (Вы сдаете курс)
Это означает, что ваша сдача экзамена является достаточным (хотя, возможно, и не необходимым) условием для прохождения курса. Таким образом, ваш профессор мог бы точно сформулировать свое обещание одним из следующих способов.
Сдача экзамена является достаточным условием для прохождения курса.
Чтобы пройти курс, достаточно сдать экзамен.
Однако, когда мы хотим сказать « Если P, то Q » в повседневном разговоре, мы обычно не выражаем это как « Q является необходимым условием для P » или « P, только если Q ». Но такие конструкции не редкость в математике. Чтобы понять, почему они имеют смысл, обратите внимание, что P ⇒ Q истинно означает, что невозможно, чтобы P было истинным, но Q ложно, поэтому для того, чтобы P было истинным, необходимо, чтобы Q верно; следовательно, « Q является необходимым условием для P .«А это означает, что P может быть истинным, только если Q истинно, то есть« P, только если Q ».
Двуусловные утверждения
Важно понимать, что P ⇒ Q не то же самое, что Q ⇒ P . Чтобы понять, почему, предположим, что a — некоторое целое число, и рассмотрим утверждения
. (a делится на 6) ⇒ (a делится на 2),
(a делится на 2) ⇒ (a делится на 6).
Первое утверждение утверждает, что если a делится на 6, то a делится на 2.Это, несомненно, верно, поскольку любое число, кратное 6, является четным и, следовательно, делится на 2. Второе утверждение утверждает, что если a делится на 2, то оно кратно 6. Это не обязательно верно для a = 4 (например, ) делится на 2, но не кратно 6. Следовательно, значения P ⇒ Q и Q ⇒ P в целом совершенно разные. Условное выражение Q ⇒ P называется , обратное от P ⇒ Q , поэтому условное выражение и его обратное выражают совершенно разные вещи.
Однако контрапозитив из P ⇒ Q , ~ Q ⇒ ~ P , эквивалентен P ⇒ Q . Аналогично, , обратный для P ⇒ Q , что составляет ~ P ⇒ ~ Q , эквивалентно обратному Q ⇒ P . В «Таблицах истинности для утверждений» мы узнаем, как показать эти эквивалентности с помощью таблицы истинности.
Но иногда, если P и Q — правильные утверждения, может случиться так, что P ⇒ Q и Q ⇒ P оба обязательно верны.Например, рассмотрим утверждения
. ( a четно) ⇒ ( a делится на 2),
( a делится на 2) ⇒ ( a четно).
Независимо от того, какое значение имеет , оба эти утверждения верны. Поскольку оба значения: P ⇒ Q и Q ⇒ P верны, отсюда следует, что ( P ⇒ Q ) ∧ ( Q ⇒ P ) верно.
Теперь мы вводим новый символ ⇔, чтобы выразить смысл утверждения ( P ⇒ Q ) ∧ ( Q ⇒ P ).Подразумевается, что выражение P ⇔ Q имеет то же значение, что и ( P ⇒ Q ) ∧ ( Q ⇒ P ). Согласно предыдущему разделу, Q ⇒ P читается как « P, если Q », а P ⇒ Q может читаться как « P, только если Q ». Поэтому мы произносим P ⇔ Q как « P, если и только если Q ». Например, учитывая целое число a, мы имеем истинное утверждение
( a четно) ⇔ ( a делится на 2),
, которое мы можем прочитать как « Integer a, даже тогда и только тогда, когда a делится на 2. ”
Таблица истинности для ⇔ показана ниже. Обратите внимание, что в первой и последней строках как P ⇒ Q, так и Q ⇒ P истинны (согласно таблице истинности для ⇒), поэтому (P ⇒ Q) ∧ (Q ⇒ P) истинно, и, следовательно, P ⇔ Q истинно. правда. Однако в двух средних строках одна из P ⇒ Q или Q ⇒ P ложна, поэтому (P ⇒ Q) ∧ (Q ⇒ P) ложно, что делает P ⇔ Q ложным.
| п. | Q | P ⇔ Q |
|---|---|---|
| т | т | т |
| т | F | F |
| Ф | т | F |
| Ф | F | т |
Сравните утверждение R : ( a четно) ⇔ ( a делится на 2) с этой таблицей истинности.Если , а — четное, то два утверждения по обе стороны от верны, поэтому согласно таблице R истинно. Если a нечетное, то два утверждения по обе стороны от ложны, и снова согласно таблице R истинно. Таким образом, R истинно независимо от того, какое значение имеет a. В общем случае, если P 30 Q истинно, значит, P и Q оба истинны или оба ложны.
Неудивительно, что есть много способов сказать P ⇔ Q на английском языке.Все следующие конструкции означают P ⇔ Q :
[латекс] {P} \ iff {Q} \ begin {cases} {P \ text {тогда и только тогда, когда} Q.} \\ {P \ text {является необходимым и достаточным условием для} Q.} \\ {\ text {For} P \ text {необходимо и достаточно, чтобы} Q.} \\ {\ text {If} P \ text {, то} Q \ text {, и наоборот.}} \ end {case} \\ [/ латекс]
Первые три из них просто объединяют конструкции из предыдущего раздела, чтобы выразить, что P ⇒ Q и Q ⇒ P .В последнем случае слова « и наоборот » означают, что в дополнение к истинности « Если P, то Q », обратное утверждение « Если Q, то P » также верно.
Таблицы истинности утверждений
Теперь вы должны знать таблицы истинности для ∧, ∨, ∼, ⇒ и ⇔. Они должны быть усвоены , а также запомнены. Вы должны тщательно понимать символы, поскольку теперь мы объединяем их, чтобы сформировать более сложные утверждения.
Например, предположим, что мы хотим передать, что одно или другое из P и Q истинно, но они не оба истинны.Ни один символ не выражает этого, но мы могли бы объединить их как
.( P ∨ Q ) ∧ ∼ ( P ∧ Q ),
, что буквально означает:
P или Q истинны, и это не тот случай, когда и P, и Q истинны.
Это утверждение будет истинным или ложным в зависимости от значений истинности P и Q . Фактически, мы можем составить таблицу истинности для всего утверждения. Начните как обычно с перечисления возможных истинных / ложных комбинаций P и Q в четырех строках.Выражение ( P ∨ Q ) ∧ ∼ ( P ∧ Q ) содержит отдельные утверждения ( P ∨ Q ) и ( P ∧ Q ), поэтому мы их значения истинности в третьем и четвертом столбцах. В пятом столбце перечислены значения для ∼ ( P ∧ Q ), и это просто противоположности соответствующих записей в четвертом столбце. Наконец, объединив третий и пятый столбцы с ∧, мы получим значения для ( P ∨ Q ) ∧ ∼ ( P ∧ Q ) в шестом столбце.
| п. | Q | ( P ∨ Q ) | ( P ∧ Q ) | ∼ ( P ∧ Q ) | ( P ∨ Q ) ∧ ∼ ( P ∧ Q ) |
|---|---|---|---|---|---|
| т | т | т | т | F | F |
| т | F | т | F | т | т |
| Ф | т | т | F | т | т |
| Ф | F | F | F | т | F |
Эта таблица истинности говорит нам, что ( P ∨ Q ) ∧ ∼ ( P ∧ Q ) верно именно тогда, когда истинны одно, но не оба из P и Q , поэтому он имеет то значение, которое мы задумали.(Обратите внимание, что три средних столбца нашей таблицы истинности являются просто «вспомогательными столбцами» и не являются необходимыми частями таблицы. При написании таблиц истинности вы можете опустить такие столбцы, если уверены в своей работе.)
В качестве другого примера рассмотрим следующее знакомое утверждение относительно двух действительных чисел x и y :
Произведение xy равно нулю тогда и только тогда, когда x = 0 или y = 0.
Это можно смоделировать как ( xy = 0) ⇔ ( x = 0 ∨ y = 0).Если ввести буквы P , Q и R для операторов xy = 0, x = 0 и y = 0, то получится P ⇔ ( Q ∨ R ). Обратите внимание, что круглые скобки здесь необходимы, поскольку без них мы не знали бы, следует ли читать утверждение как P ⇔ ( Q ∨ R ) или ( P ⇔ Q ) ∨ R .
Создание таблицы истинности для P ⇔ ( Q ∨ R ) влечет за собой строку для каждой комбинации T / F для трех утверждений P , Q и R .Восемь возможных комбинаций собраны в первых трех столбцах следующей таблицы.
| п. | Q | R | Q ∨ R | P ⇔ ( Q ∨ R ) |
|---|---|---|---|---|
| т | т | т | т | т |
| т | т | F | т | т |
| т | F | т | т | т |
| т | F | F | F | F |
| Ф | т | т | т | F |
| Ф | т | F | т | F |
| Ф | F | т | т | F |
| Ф | F | F | F | т |
Мы заполняем четвертый столбец, используя наши знания таблицы истинности для ∨.Наконец, пятый столбец заполняется путем объединения первого и четвертого столбцов с нашим пониманием таблицы истинности для ⇔. В итоговой таблице приведены истинные / ложные значения P ⇔ ( Q ∨ R ) для всех значений P , Q и R .
Обратите внимание, что когда мы подставляем различные значения для x и y , операторы P : xy = 0, Q : x = 0 и R : y = 0 имеют различные значения истинности, но утверждение P ⇔ ( Q ∨ R ) всегда верно.Например, если x = 2 и y = 3, то P , Q и R ложны. Этот сценарий описан в последней строке таблицы, и там мы видим, что P ⇔ ( Q ∨ R ) верно. Аналогично, если x = 0 и y = 7, тогда P и Q истинны, а R ложны, сценарий описан во второй строке таблицы, где снова P ⇔ ( Q ∨ R ) верно.Существует простая причина, по которой P ⇔ ( Q ∨ R ) верно для любых значений x и y : P ⇔ ( Q ∨ R ) представляет ( xy = 0) ⇔ ( x = 0 ∨ y = 0), что является истинным математическим утверждением . Это абсолютно невозможно, чтобы это было ложью.
Это может заставить вас задуматься о строках в таблице, где P ⇔ ( Q ∨ R ) ложно.Почему они там? Причина в том, что P ⇔ ( Q ∨ R ) также может представлять собой ложное утверждение. Чтобы понять, как это сделать, представьте, что в конце семестра ваш профессор дает следующее обещание.
Вы проходите класс тогда и только тогда, когда вы получаете «А» в финале или вы получаете «В» в финале.
Это обещание имеет форму P ⇔ ( Q ∨ R ), поэтому его истинностные значения сведены в таблицу выше. Представьте, что на экзамене вы получили «пятерку», но не прошли курс.Значит, ваш профессор, конечно, солгал вам. Фактически, P ложно, Q истинно, а R ложно. Этот сценарий отражен в шестой строке таблицы, и действительно, P ⇔ ( Q ∨ R ) ложно (т.е. это ложь).
Мораль этого примера заключается в том, что люди могут лгать, но истинные математические утверждения никогда не лгут.
Мы завершаем этот раздел словом об использовании круглых скобок. Символ ∼ аналогичен знаку минус в алгебре.Он отрицает предшествующее выражение. Таким образом, ∼ P ∨ Q означает (∼ P ) ∨ Q , а не ∼ ( P ∨ Q ). В ∼ ( P Q ) значение всего выражения P ∨ Q инвертируется.
Логическая эквивалентность
Рассматривая таблицу истинности для P ⇔ Q , вы, вероятно, заметили, что P ⇔ Q истинно именно тогда, когда P и Q оба истинны или оба ложны.Другими словами, P Q верно именно тогда, когда верно хотя бы одно из утверждений P ∧ Q или ∼ P ∧ ∼ Q . Это может побудить нас сказать, что P ⇔ Q означает то же самое, что ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q ).
Чтобы убедиться, что это действительно так, мы можем написать таблицы истинности для P ⇔ Q и ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q ).При этом более эффективно поместить эти два оператора в одну таблицу, как показано ниже. (В этой таблице есть вспомогательные столбцы для промежуточных выражений ∼ P , ∼ Q , ( P ∧ Q ) и (~ P ∧ ∼ Q ).)
| п. | Q | ∼ P | ∼ Q | ( P ∧ Q ) | (∼ P ∧ ∼ Q ) | ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q ) | P ⇔ Q |
|---|---|---|---|---|---|---|---|
| т | т | F | F | т | F | т | т |
| т | F | F | т | F | F | F | F |
| Ф | т | т | F | F | F | F | F |
| Ф | F | т | т | F | т | т | т |
Таблица показывает, что P ⇔ Q и ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q ) имеют одинаковое значение истинности, независимо от значений P и Q .Это как если бы P ⇔ Q и ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q ) были алгебраическими выражениями, которые равны независимо от того, что «вставлено в» переменные P и Q . Мы выражаем такое положение дел письмом
P ⇔ Q = ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q )
и заявив, что P ⇔ Q и ( P ∧ Q ) ∨ (∼ P ∧ ∼ Q ) логически эквивалентны .
В общем, два утверждения логически эквивалентны , если их значения истинности совпадают построчно в таблице истинности.
Логическая эквивалентность важна, потому что она может дать нам разные (и потенциально полезные) способы взглянуть на одно и то же. В качестве примера в следующей таблице показано, что P ⇒ Q логически эквивалентно (∼ Q ) ⇒ (∼ P ).
| п. | Q | ∼ P | ∼ Q | (∼ Q ) ⇒ (∼ P ) | P ⇒ Q |
|---|---|---|---|---|---|
| т | т | F | F | т | т |
| т | F | F | т | F | F |
| Ф | т | т | F | т | т |
| Ф | F | т | т | т | т |
Тот факт, что P ⇒ Q = (∼ Q ) ⇒ (∼ P ), полезен, потому что очень много теорем имеют вид P ⇒ Q .Как мы увидим в главе 5, доказательство такой теоремы может быть проще, если мы выразим ее в логически эквивалентной форме (∼ Q ) ⇒ (∼ P ).
Две пары логически эквивалентных утверждений встречаются снова и снова в этой книге и далее. Они достаточно распространены, чтобы их удостоить особое имя: законы ДеМоргана.
Факт: законы ДеМоргана
- ∼ ( P ∧ Q ) = (∼ P ) ∨ (∼ Q )
- ∼ ( P ∨ Q ) = (∼ P ) ∧ (∼ Q )
Первый из законов ДеМоргана подтверждается следующей таблицей.Вам предлагается проверить второе в одном из упражнений.
| п. | Q | ~ пол | ~ К | P ∧ Q | ∼ ( P ∧ Q ) | (∼ P ) ∨ (∼ Q ) |
|---|---|---|---|---|---|---|
| т | т | F | F | т | F | F |
| т | F | F | т | F | т | т |
| Ф | т | т | F | F | т | т |
| Ф | F | т | т | F | т | т |
Законы ДеМоргана на самом деле очень естественны и интуитивно понятны.Рассмотрим утверждение ∼ ( P ∧ Q ), которое мы можем интерпретировать как означающее, что неверны и P , и Q . Если это не так, что и P , и Q истинны, то по крайней мере один из P или Q является ложным, и в этом случае (∼ P ) ∨ (∼ Q ) является правда. Таким образом, ∼ ( P ∧ Q ) означает то же, что и (∼ P ) ∨ (∼ Q ).
Законы ДеМоргана могут быть очень полезными.Предположим, нам известно, что некое утверждение вида ∼ ( P ∨ Q ) верно. Второй из законов ДеМоргана говорит нам, что (∼ Q ) ∧ (∼ P ) также верно, следовательно, ∼ P и ∼ Q также верны. Возможность быстро получить такую дополнительную информацию может быть чрезвычайно полезной.
Вот краткое изложение некоторых важных логических эквивалентностей. Те, которые не сразу очевидны, можно проверить с помощью таблицы истинности.
[латекс] \ text {Контрапозитивный закон} \ begin {cases} P \ Rightarrow {Q} = (\ sim {Q}) \ Rightarrow (\ sim {P}) \ end {cases} \\ [/ latex]
[латекс] \ text {законы ДеМоргана} \ begin {cases} {\ sim (P \ land {Q}) = \ sim {P} \ lor \ sim {Q}} \\ {\ sim (P \ lor { Q}) = \ sim {P} \ land \ sim {Q}} \ end {case} \\ [/ latex]
[латекс] \ text {Коммутативные законы} \ begin {cases} {(P \ land {Q}) = {P} \ land {Q}} \\ {(P \ lor {Q}) = {P} \ lor {Q}} \ end {case} \\ [/ latex]
[латекс] \ text {Распределительные законы} \ begin {cases} {{P} \ land (Q \ lor {R}) = ({P} \ land {Q}) \ lor (P \ land {R}) } \\ {P \ lor (Q \ land {R}) = ({P} \ lor {Q}) \ land (P \ lor {R})} \ end {case} \\ [/ latex]
[латекс] \ text {Ассоциативные законы} \ begin {cases} {P \ land (Q \ land {R}) = (P \ land {Q}) \ land {R}} \\ {P \ lor (Q \ lor {R}) = (P \ lor {Q}) \ lor {R}} \ end {case} \\ [/ latex]
Обратите внимание, что закон распределения P ∧ ( Q ∨ R ) = ( P ∧ Q ) ∨ ( P ∧ R ) имеет ту же структуру, что и закон распределения p ( q + r ) = p · q + p · r от алгебры.Что касается ассоциативных законов, тот факт, что P ∧ ( Q ∧ R ) = ( P ∧ Q ) ∧ R , означает, что положение скобок не имеет значения, и мы можем записать это как P ∧ Q ∧ R без неоднозначности. Точно так же мы можем опустить скобки в таких выражениях, как P ∨ ( Q ∨ R ).
Но круглые скобки важны, когда есть сочетание ∧ и ∨, как в P ∨ ( Q ∧ R ).Действительно, P ∨ ( Q ∧ R ) и ( P ∨ Q ) ∧ R логически не эквивалентны .
Отрицательные утверждения
Для утверждения R утверждение ∼ R называется отрицанием из R . Если R — сложный оператор, то часто бывает так, что его отрицание ∼ R может быть записано в более простой или более полезной форме. Процесс нахождения этой формы называется , отрицая R .При доказательстве теорем часто бывает необходимо отрицать некоторые утверждения. Теперь мы исследуем, как это сделать.
Часть этой темы мы уже рассмотрели. Законы ДеМоргана
∼ (P ∧Q) = (∼ P) ∨ (∼ Q)
∼ (P ∨Q) = (∼ P) ∧ (∼ Q)
(от «Логической эквивалентности») можно рассматривать как правила, которые говорят нам, как отрицать утверждения P ∧Q и P ∨Q. Вот несколько примеров, которые иллюстрируют, как законы ДеМоргана используются для опровержения утверждений, содержащих «и» или «или».
Пример 5
Вы можете опровергнуть следующее утверждение.
R : Вы можете решить это факторингом или квадратной формулой.
Теперь R означает (Вы можете решить это факторингом) ∨ (Вы можете решить это с помощью Q.F.), который мы обозначим как P ∨ Q . Отрицание этого —
∼ ( P ∨ Q ) = (∼ P ) ∧ (∼ Q ).
Таким образом, на словах отрицание R равно
.∼ R : Вы не можете решить это факторингом, и вы не можете решить его квадратной формулой.
Может быть, вы сможете найти ∼ R , не обращаясь к законам ДеМоргана. Это хорошо; вы усвоили законы ДеМоргана и используете их неосознанно.
Пример 6
Мы опустим следующее предложение.
R : Оба числа x и y нечетные.
Это выражение означает ( x нечетно) ∧ ( y нечетно), поэтому его отрицание равно
~ [( x нечетное) ∧ ( y нечетное)] = ∼ ( x нечетное) ∨ ∼ ( y нечетное)
( x нечетное) ∧ ( y нечетное) = ( x четное) ∨ ( y четное).
Следовательно, отрицание R может быть выражено следующим образом:
∼ R: Число x четное или число y четное.
∼ R: По крайней мере, одно из x и y четное.
А теперь перейдем к проблеме немного другого рода. Часто бывает необходимо найти отрицание количественных утверждений. Например, рассмотрим ∼ (∀ x ∈ [латекс] \ mathbb {N} \\ [/ latex], P ( x )). Прочитав это словами, мы получим следующее:
Это не тот случай, когда P ( x ) верно для всех натуральных чисел x .
Это означает, что P ( x ) ложно хотя бы для одного x. В символах это ∃ x ∈ [latex] \ mathbb {N} \\ [/ latex], ∼ P ( x ). Таким образом, ∼ (∀ x ∈ [латекс] \ mathbb {N} \\ [/ latex], P ( x )) = ∃ x ∈ [латекс] \ mathbb {N} \\ [/ латекс], ∼ P ( x ). Точно так же вы можете предположить, что ∼ (∃ x ∈ [латекс] \ mathbb {N} \\ [/ latex], P ( x )) = ∀ x ∈ [латекс] \ mathbb { N} \\ [/ latex], ∼ P ( x ).Всего:
∼ (∀ x ∈ S , P ( x )) = ∃ x ∈ S , ∼ P ( x )
∼ (∃ x ∈ ∈ , P ( x )) = ∀ x ∈ S , ∼ P ( x )
Логический вывод
Предположим, мы знаем, что утверждение формы P ⇒ Q верно. Это говорит нам, что всякий раз, когда P истинно, Q также будет истинным.Само по себе P ⇒ Q истинность не говорит нам, что либо P , либо Q истинно (они оба могут быть ложными, или P может быть ложным, а Q истинным). Однако, если вдобавок мы знаем, что P истинно, то должно быть, что Q истинно. Это называется логическим выводом . : Имея два истинных утверждения, мы можем сделать вывод, что третье утверждение истинно. В этом случае истинные утверждения P ⇒ Q и P «складываются вместе», чтобы получить Q .Это описано ниже с P ⇒ Q и P , уложенными друг на друга линией, отделяющей их от Q . Предполагаемое значение состоит в том, что P ⇒ Q в сочетании с P дает Q .
Два других логических вывода перечислены выше. В каждом случае вы должны убедить себя (основываясь на вашем знании соответствующих таблиц истинности), что истинность утверждений над линией заставляет утверждение под линией быть истинным.
Ниже приведены некоторые дополнительные полезные логические выводы. Первый выражает очевидный факт, что если P и Q истинны, то утверждение P ∧ Q будет истинным. С другой стороны, истинность P 30 Q заставляет P (также Q ) быть истинным. Наконец, если P истинно, то P ∨ Q должно быть истинным, независимо от того, какое утверждение Q .
Эти выводы настолько интуитивно очевидны, что о них нет нужды упоминать.Однако они представляют собой определенные модели рассуждений, которые мы часто будем применять к предложениям в доказательствах, поэтому мы должны осознавать тот факт, что мы их используем.
Первые два утверждения в каждом случае называются «предпосылками», а последнее утверждение — «заключением». Объединяем помещения с ∧ («и»). Посылки вместе подразумевают заключение. Таким образом, первый аргумент будет иметь (( P ⇒ Q ) ∧ P ) ⇒ Q в качестве символического утверждения.
Важное примечание
Важно знать причины, по которым мы изучаем логику. Есть три очень веских причины. Во-первых, таблицы истинности, которые мы изучили, сообщают нам точные значения таких слов, как «и», «или», «не» и так далее. Например, всякий раз, когда мы используем или читаем конструкцию «Если…, то» в математическом контексте, логика сообщает нам, что именно имеется в виду. Во-вторых, правила вывода обеспечивают систему, в которой мы можем производить новую информацию (утверждения) из известной информации.Наконец, логические правила, такие как законы ДеМоргана, помогают нам правильно преобразовывать определенные утверждения в (потенциально более полезные) утверждения с тем же значением. Таким образом, логика помогает нам понять значение утверждений, а также порождает новые значимые утверждения.
Логика — это клей, который скрепляет цепочки утверждений и фиксирует точное значение определенных ключевых фраз, таких как конструкции «Если…, то» или «Для всех». Логика — это общий язык, которым пользуются все математики, поэтому мы должны твердо владеть им, чтобы писать и понимать математику.
Но, несмотря на свою фундаментальную роль, логика находится на заднем плане того, что мы делаем, а не на переднем крае. С этого момента красивые символы ∧, ∨, ⇒, ⇔, ∼, ∀ и ∃ пишутся редко. Но мы постоянно осознаем их значение. Читая или записывая предложение, связанное с математикой, мы анализируем его с помощью этих символов мысленно или на бумаге, чтобы понять истинное и недвусмысленное значение.
Определение математики Merriam-Webster
математика · электронная · математика | \ ˌMath-ˈma-tiks , Ma-thə- \ 1 : наука о числах и их операциях (см. Операционный смысл 5), взаимосвязи, комбинации, обобщения и абстракции, а также пространственные (см. Пространственное обозначение 1, смысл 7) конфигурации и их структура, измерения, преобразования и обобщения Алгебра, арифметика, исчисление, геометрия и тригонометрия — это разделы математики.2 : раздел, работа или использование математики математика физической химии
gunthercox / mathparse: библиотека Python для оценки математических уравнений естественного языка
GitHub — gunthercox / mathparse: библиотека Python для оценки математических уравнений естественного языкаБиблиотека Python для оценки математических уравнений естественного языка
Файлы
Постоянная ссылка Не удалось загрузить последнюю информацию о фиксации.Тип
Имя
Последнее сообщение фиксации
Время фиксации
Библиотека mathparse — это модуль Python, предназначенный для вычисления математических уравнений, содержащихся в строках.
Вот несколько примеров:
из mathparse import mathparse
mathparse.синтаксический анализ ('50 * (85/100) ')
>>> 42,5
mathparse.parse ('сто раз пятьдесят четыре', mathparse.codes.ENG)
>>> 5400
mathparse.parse ('(семь * девять) + 8 - (45 плюс два)', language = 'ENG')
>>> 24 Установка
Поддержка языков
Параметр языка должен быть установлен для оценки уравнения, в котором используются операторы слова. Код языка должен быть действующим кодом языка ISO 639-2.
История
См. Изменения в примечаниях к выпуску.
Около
Библиотека Python для оценки математических уравнений естественного языка
Темы
ресурсов
Лицензия
Вы не можете выполнить это действие в настоящее время. Вы вошли в систему с другой вкладкой или окном.Перезагрузите, чтобы обновить сеанс. Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.обширная математическая библиотека для JavaScript и Node.js
На этой странице описан синтаксис парсера выражений math.js. Он описывает как работать с доступными типами данных, функциями, операторами, переменными, и больше.
Отличия от JavaScript #
Синтаксический анализатор выражений math.js нацелен на математическую аудиторию, не аудитория программирования.Синтаксис аналогичен синтаксису большинства калькуляторов и математические приложения. Это тоже близко к JavaScript, хотя там несколько важных различий между синтаксисом синтаксического анализатора выражений и синтаксис нижнего уровня math.js. Различия:
- Нет необходимости в префиксе функций и констант пространством имен
math. *, вы можете просто ввестиsin (pi / 4). - Матричные индексы отсчитываются от единицы, а не от нуля.
- Есть операторы индекса и диапазона, которые позволяют более удобно получать
и установка индексов матрицы, например
A [2: 4, 1]. используется для возведения в степень, не побитовый xor. - Неявное умножение, например
2 pi, поддерживается и имеет особые правила. - Операторы отношения (
<,>,<=,> =,==и! =) связаны цепочкой, поэтому выражение5эквивалентно 5.
Операторы №
В анализаторе выражений есть операторы для всех распространенных арифметических операций, таких как как сложение и умножение.Синтаксический анализатор выражений использует обычный инфиксный обозначение операторов: оператор помещается между его аргументами. Круглые скобки могут использоваться для отмены приоритета операторов по умолчанию.
// используйте операторы
math.evaluate ('2 + 3') // 5
math.evaluate ('2 * 3') // 6
// используйте круглые скобки для отмены приоритета по умолчанию
math.evaluate ('2 + 3 * 4') // 14
math.evaluate ('(2 + 3) * 4') // 20
Доступны следующие операторы:
| Оператор | Имя | Синтаксис | Ассоциативность | Пример | Результат |
|---|---|---|---|---|---|
(, ) | Группировка | (х) | Нет | 2 * (3 + 4) | 14 |
[, ] | Матрица, индекс | [...] | Нет | [[1,2], [3,4]] | [[1,2], [3,4]] |
{, } | Объект | {...} | Нет | {a: 1, b: 2} | {a: 1, b: 2} |
, | Разделитель параметров | х, у | Слева направо | макс. (2, 1, 5) | 5 |
. | Право собственности на объект | obj.prop | Слева направо | obj = {a: 12}; obj.a | 12 |
; | Разделитель выписок | х; г | Слева направо | а = 2; b = 3; а * б | [6] |
; | Разделитель рядов | [х; y] | Слева направо | [1,2; 3,4] | [[1,2], [3,4]] |
\ n | Разделитель выписок | х \ п у | Слева направо | a = 2 \ n b = 3 \ n a * b | [2,3,6] |
+ | Добавить | х + у | Слева направо | 4 + 5 | 9 |
+ | Одинарный плюс | + у | Справа налево | +4 | 4 |
- | Вычесть | x - y | Слева направо | 7–3 | 4 |
- | Унарный минус | -г | Справа налево | -4 | -4 |
* | Умножить | х * у | Слева направо | 2 * 3 | 6 |
. | 2 | 7 | ||||
<< | Левый сдвиг | x << y | Слева направо | 4 << 1 | 8 |
>> | Правый арифметический сдвиг | x >> y | Слева направо | 8 >> 1 | 4 |
>>> | Логический сдвиг вправо | х >>> у | Слева направо | -8 >>> 1 | 2147483644 |
и | логический и | x и y | Слева направо | правда и ложь | ложный |
не | Логическое не | не | Справа налево | не соответствует действительности | ложный |
или | логический или | x или y | Слева направо | правда или ложь | правда |
xor | Логический xor | x xor y | Слева направо | true xor истина | ложный |
= | Переуступка | х = у | Справа налево | а = 5 | 5 |
? : | Условное выражение | х? г: г | Справа налево | 15> 100? 1: -1 | -1 |
: | Диапазон | x: y | Справа налево | 1: 4 | [1,2,3,4] |
до , дюйм | Преобразование единиц | x к y | Слева направо | 2 дюйма в см | 5.08 см |
== | равно | х == у | Слева направо | 2 == 4-2 | правда |
! = | Неравно | х! = У | Слева направо | 2! = 3 | правда |
< | Меньший | х <у | Слева направо | 2 <3 | правда |
> | Больше | x> y | Слева направо | 2> 3 | ложный |
<= | Smallereq | х <= у | Слева направо | 4 <= 3 | ложный |
> = | Largereq | х> = у | Слева направо | 2 + 4> = 6 | правда |
№ приоритета
Операторы имеют следующий приоритет, сверху вниз:
| Операторы | Описание |
|---|---|
(...) [...] {...} | Группировка Матрица Объект |
x (...) x [...] obj.prop : | Вызов функции Индекс матрицы Средство доступа к свойству Разделитель ключей / значений |
' | Матрица транспонированная |
! | Факториал |
^ , . | | Побитовый xor |
| | Побитовое или |
и | логический и |
xor | Логический xor |
или | логический или |
? , : | Условное выражение |
= | Переуступка |
, | Параметр и разделитель столбцов |
; | Разделитель рядов |
\ n , ; | Разделители выписок |
Функции #
Функции вызываются путем ввода их имени, за которым следует ноль или более аргументы заключены в круглые скобки.Все доступные функции перечислены на страница Функции.
math.evaluate ('sqrt (25)') // 5
math.evaluate ('log (10000, 3 + 7)') // 4
math.evaluate ('sin (pi / 4)') // 0.7071067811865475
Новые функции могут быть определены с помощью ключевого слова function . Функции могут быть
определяется несколькими переменными. Назначения функций ограничены: они могут
может быть определен только в одной строке.
константный синтаксический анализатор = math.parser ()
парсер.(pi * i) + 1 ') // ~ 0 (Эйлер)
Переменные можно определять с помощью оператора присваивания = , и их можно использовать
как константы.
константный синтаксический анализатор = math.parser ()
// определяем переменные
parser.evaluate ('a = 3.4') // 3.4
parser.evaluate ('b = 5/2') // 2,5
// использовать переменные
parser.evaluate ('a * b') // 8.5
Имена переменных должны:
- Начните с «альфа-символа»:
- Латинская буква (верхний или нижний регистр).Ascii:
a-z,A-Z - Знак подчеркивания. Ascii:
_ - Знак доллара. Ascii:
$ - Латинская буква с ударениями. Юникод:
\ u00C0-\ u02AF - Греческое письмо. Юникод:
\ u0370-\ u03FF - Буквенный символ. Юникод:
\ u2100-\ u214F - Математический буквенно-цифровой символ.Юникод:
\ u {1D400}-\ u {1D7FF}, исключая недопустимые кодовые точки
- Латинская буква (верхний или нижний регистр).Ascii:
- Содержит только буквенные символы (см. Выше) и цифры
0-9 - Не может быть одним из следующих:
mod,до,в,и,xor,или,не,конец. Некоторые из них можно назначить, но это не рекомендуется.
Можно настроить разрешенные буквенные символы, дополнительные сведения см. В разделе Настройка поддерживаемых символов.
Типы данных #
Синтаксический анализатор выражений поддерживает логические значения, числа, комплексные числа, единицы измерения, строки, матрицы и объекты.
Логические #
Логические значения true и false могут использоваться в выражениях.
// используйте логические значения
math.evaluate ('true') // правда
math.evaluate ('false') // ложь
math.evaluate ('(2 == 3) == false') // правда
Логические значения можно преобразовать в числа и строки и наоборот, используя
функции число и логическое , а строка .
// преобразование логических значений
math.evaluate ('число (истина)') // 1
math.evaluate ('string (false)') // «ложь»
math.evaluate ('boolean (1)') // истина
math.evaluate ('boolean ("false")') // ложь
Номера
Самый важный и основной тип данных в math.js - числа. В числах используется точка как десятичный знак. Числа можно вводить в экспоненциальной записи. Примеры:
// числа в math.js
math.evaluate ('2') // 2
математика.оценить ('3.14') // 3.14
math.evaluate ('1.4e3') // 1400
math.evaluate ('22e-3') // 0,022
Число можно преобразовать в строку и наоборот с помощью функций номер и строка .
// преобразовываем строку в число
math.evaluate ('число ("2.3")') // 2.3
math.evaluate ('строка (2.3)') // "2.3"
Math.js использует обычные числа JavaScript, которые представляют собой числа с плавающей запятой с ограниченная точность и ограниченный диапазон.Ограничения подробно описаны на странице Номера.
math.evaluate ('1e-325') // 0
math.evaluate ('1e309') // Бесконечность
math.evaluate ('- 1e309') // -Бесконечность
При вычислениях с числами с плавающей запятой очень легко можно получить ошибки округления:
// ошибка округления из-за ограниченной точности с плавающей запятой
math.evaluate ('0,1 + 0,2') // 0,30000000000000004
При выводе результатов можно использовать функцию math.format , чтобы скрыть
эти ошибки округления при выводе результатов для пользователя:
const ans = math.оценить ('0,1 + 0,2') // 0,30000000000000004
math.format (ans, {precision: 14}) // "0,3"
Числа могут быть выражены как двоичные, восьмеричные и шестнадцатеричные литералы:
math.evaluate ('0b11') // 3
math.evaluate ('0o77') // 63
math.evaluate ('0xff') // 255
Суффикс размера слова может использоваться для изменения поведения недесятичного литерала:
math.evaluate ('0xffi8') // -1
math.evaluate ('0xffffffffi32') // -1
математика.оценить ('0xfffffffffi32') // SyntaxError: строка «0xfffffffff» вне допустимого диапазона
Недесятичные числа могут включать точку счисления:
math.evaluate ('0b1.1') // 1,5
math.evaluate ('0o1.4') // 1,5
math.evaluate ('0x1.8') // 1,5
Числа могут быть отформатированы как двоичные, восьмеричные и шестнадцатеричные строки с использованием опции нотации функции формата :
math.evaluate ('format (3, {notation: "bin"})') // '0b11'
математика.оценить ('формат (63, {обозначение: "окт"})') // '0o77'
math.evaluate ('format (255, {notation: "hex"})') // '0xff'
math.evaluate ('формат (-1, {обозначение: "шестнадцатеричное"})') // '-0x1'
math.evaluate ('format (2.3, {notation: "hex"})') // '0x2.4cccccccccccc'
Функция формата принимает параметр wordSize для использования в сочетании с недвоичной нотацией:
math.evaluate ('format (-1, {notation: "hex", wordSize: 8})') // '0xffi8'
Функции bin , oct и hex являются сокращением для функции формата с соответствующим обозначением :
математ.оценить ('bin (-1)') // '-0b1'
math.evaluate ('bin (-1, 8)') // '0b11111111i8'
BigNumbers #
Math.js поддерживает BigNumbers для вычислений с произвольной точностью. Плюсы и минусы Number и BigNumber подробно описаны на странице. Числа.
BigNumbers медленнее, но имеют более высокую точность. Расчеты с большими числа поддерживаются только арифметическими функциями.
BigNumbers можно создать с помощью функции bignumber :
математ.оценить ('bignumber (0.1) + bignumber (0.2)') // BigNumber, 0,3
Тип номера по умолчанию анализатора выражения может быть изменен при создании экземпляра. из math.js. По умолчанию синтаксический анализатор выражений анализирует числа как BigNumber:
// Настройте тип числа: 'число' (по умолчанию), 'BigNumber' или 'Дробь'
math.config ({номер: 'BigNumber'})
// все числа анализируются как BigNumber
math.evaluate ('0,1 + 0,2') // BigNumber, 0,3
BigNumbers можно преобразовать в числа и наоборот с помощью функций номер и большой номер .2 = -1 . У комплексных чисел есть действительная и комплексная части, которые могут быть
извлекается с помощью функций re и im .
константный синтаксический анализатор = math.parser ()
// создаем комплексные числа
parser.evaluate ('a = 2 + 3i') // Комплексный, 2 + 3i
parser.evaluate ('b = 4 - i') // Комплексный, 4 - i
// получаем действительную и мнимую часть комплексного числа
parser.evaluate ('re (a)') // Число, 2
parser.evaluate ('im (a)') // Число, 3
// вычисления с комплексными числами
парсер.оценить ('a + b') // Комплекс, 6 + 2i
parser.evaluate ('a * b') // Комплекс, 11 + 10i
parser.evaluate ('i * i') // Число, -1
parser.evaluate ('sqrt (-4)') // Комплекс, 2i
Math.js не преобразует автоматически комплексные числа с мнимой частью
от нуля до чисел. Их можно преобразовать в число с помощью функции номер .
// преобразовываем комплексное число в число
константный синтаксический анализатор = math.parser ()
parser.evaluate ('a = 2 + 3i') // Комплексный, 2 + 3i
парсер.оценить ('b = a - 3i') // Комплекс, 2 + 0i
parser.evaluate ('number (b)') // Число, 2
parser.evaluate ('number (a)') // Ошибка: 2 + i недействительное число
Квартир #
math.js поддерживает единицы измерения. Единицы можно использовать в арифметических операциях. сложение, вычитание, умножение, деление и возведение в степень. Единицы также могут быть преобразованы из одной в другую. Обзор всех доступных единиц можно найти на странице Единицы измерения.
Единицы можно преобразовать с помощью оператора в или в .
// создаем отряд
math.evaluate ('5,4 кг') // Единица измерения, 5,4 кг
// конвертируем единицу
math.evaluate ('2 дюйма в см') // Единица измерения, 5,08 см
math.evaluate ('20 по Фаренгейту ') // Единица, ~ 68 по Фаренгейту
math.evaluate ('90 км / ч до м / с ') // Единица измерения, 25 м / с
// преобразовываем единицу в число
// Должен быть указан второй параметр с единицей измерения для экспортируемого числа
math.evaluate ('number (5 cm, mm)') // Число, 50
// расчеты с единицами
математика.2 * 5 с в миль / ч ') // Единица измерения, 109,72172512527 миль / ч
Струны #
Строки заключаются в двойные или одинарные кавычки. Строки можно объединить с помощью
function concat (не добавляя их с помощью + , как в JavaScript). Части
строка может быть получена или заменена с помощью индексов. Строки можно преобразовать
в число с помощью функции число , а числа можно преобразовать в строку
используя функцию string .
При установке значения символа в строке, символ, который был набор возвращается. Точно так же, когда установлен диапазон символов, этот диапазон символов возвращается.
константный синтаксический анализатор = math.parser ()
// создаем строку
parser.evaluate ('"привет"') // Строка, "привет"
// манипуляции со строками
parser.evaluate ('a = concat ("hello", "world")') // Строка, "hello world"
parser.evaluate ('size (a)') // Матрица [11]
парсер.оценить ('a [1: 5]') // Строка, "привет"
parser.evaluate ('a [1] = "H"') // Строка, "H"
parser.evaluate ('a [7:12] = "там!"') // Строка, "туда!"
parser.evaluate ('a') // Строка: «Привет!»
// преобразование строки
parser.evaluate ('number ("300")') // Число, 300
parser.evaluate ('string (300)') // Строка, "300"
Строки могут использоваться в функции оценивать , чтобы анализировать выражения внутри
синтаксический анализатор выражения:
математ.оценить ('оценить ("2 + 3")') // 5
Матрицы #
Матрицы могут быть созданы путем ввода ряда значений в квадратных скобках,
элементы разделяются запятой , .
Матрица типа [1, 2, 3] создаст вектор, одномерную матрицу с
размер [3] . Чтобы создать многомерную матрицу, матрицы могут быть вложены в
друг друга. Для упрощения создания двумерных матриц точка с запятой ; может использоваться для разделения строк в матрице.
// создаем матрицу
math.evaluate ('[1, 2, 3]') // Матрица, размер [3]
math.evaluate ('[[1, 2, 3], [4, 5, 6]]') // Матрица, размер [2, 3]
math.evaluate ('[[[1, 2], [3, 4]], [[5, 6], [7, 8]]]') // Матрица, размер [2, 2, 2]
// создаем двумерную матрицу
math.evaluate ('[1, 2, 3; 4, 5, 6]') // Матрица, размер [2, 3]
Другой способ создания заполненных матриц - использование функций нулей , единиц , идентификатор и диапазон .
// инициализируем матрицу единицами или нулями
math.evaluate ('zeros (3, 2)') // Матрица, [[0, 0], [0, 0], [0, 0]], размер [3, 2]
math.evaluate ('ones (3)') // Матрица, [1, 1, 1], размер [3]
math.evaluate ('5 * ones (2, 2)') // Матрица, [[5, 5], [5, 5]], размер [2, 2]
// создаем единичную матрицу
math.evaluate ('identity (2)') // Матрица, [[1, 0], [0, 1]], размер [2, 2]
// создаем диапазон
math.evaluate ('1: 4') // Матрица, [1, 2, 3, 4], размер [4]
математика.оценить ('0: 2: 10') // Матрица, [0, 2, 4, 6, 8, 10], размер [6]
Подмножество может быть извлечено из матрицы с помощью индексов и подмножества матрицы
можно заменить с помощью индексов. Индексы заключаются в квадратные скобки, а
содержат число или диапазон для каждого измерения матрицы. Диапазон может иметь
его начало и / или конец не определены. Если начало не определено, диапазон начнется
на 1, когда конец не определен, диапазон будет заканчиваться в конце матрицы.
Также доступна контекстная переменная end для обозначения конца
матрица.
ВАЖНО: индексы и диапазоны матриц работают иначе, чем индексы math.js в JavaScript: они основаны на единице с включенной верхней границей, как и большинство математические приложения.
parser = math.parser ()
// создаем матрицы
parser.evaluate ('a = [1, 2; 3, 4]') // Матрица, [[1, 2], [3, 4]]
parser.evaluate ('b = zeros (2, 2)') // Матрица, [[0, 0], [0, 0]]
parser.evaluate ('c = 5: 9') // Матрица, [5, 6, 7, 8, 9]
// заменяем подмножество в матрице
парсер.оценить ('b [1, 1: 2] = [5, 6]') // Матрица, [[5, 6], [0, 0]]
parser.evaluate ('b [2,:] = [7, 8]') // Матрица, [[5, 6], [7, 8]]
// выполняем вычисление матрицы
parser.evaluate ('d = a * b') // Матрица, [[19, 22], [43, 50]]
// получаем подмножество матрицы
parser.evaluate ('d [2, 1]') // 43
parser.evaluate ('d [2, 1: end]') // Матрица, [[43, 50]]
parser.evaluate ('c [end - 1: -1: 2]') // Матрица, [8, 7, 6]
Объекты
Объекты по математике.js работают так же, как в таких языках, как JavaScript и Python.
Объект заключен в квадратные скобки {, } и содержит набор
Пары ключ / значение, разделенные запятыми. Ключи и значения разделяются двоеточием : .
Ключи могут быть символом типа prop или строкой типа "prop" .
math.evaluate ('{a: 2 + 1, b: 4}') // {a: 3, b: 4}
math.evaluate ('{"a": 2 + 1, "b": 4}') // {a: 3, b: 4}
Объекты могут содержать объекты:
математ.оценить ('{a: 2, b: {c: 3, d: 4}}') // {a: 2, b: {c: 3, d: 4}}
Свойства объекта можно получить или заменить с помощью точечной нотации или скобок. обозначение. В отличие от JavaScript, при установке значения свойства весь объект возвращается, а не значение свойства
let scope = {
obj: {
опора: 42
}
}
// получаем свойства
math.evaluate ('obj.prop', scope) // 42
math.evaluate ('obj ["prop"]', scope) // 42
// установка свойств (возвращает весь объект, а не значение свойства!)
математика.оценить ('obj.prop = 43', scope) // {prop: 43}
math.evaluate ('obj ["prop"] = 43', scope) // {prop: 43}
scope.obj // {prop: 43}
Многострочные выражения #
Выражение может содержать несколько строк, а выражения могут быть распределены по
несколько строк. Строки могут быть разделены символом новой строки \ n или символом
точка с запятой ; . Вывод операторов, за которыми следует точка с запятой, будет скрыт от
вывод, а пустые строки игнорируются.Результат возвращается как ResultSet ,
с записью для каждого видимого утверждения.
// многострочное выражение
math.evaluate ('1 * 3 \ n 2 * 3 \ n 3 * 3') // ResultSet, [3, 6, 9]
// операторы точки с запятой скрыты от вывода
math.evaluate ('a = 3; b = 4; a + b \ n a * b') // ResultSet, [7, 12]
// одно выражение распространяется на несколько строк
math.evaluate ('a = 2 + \ n 3') // 5
math.evaluate ('[\ n 1, 2; \ n 3, 4 \ n]') // Матрица, [[1, 2], [3, 4]]
Результаты можно прочитать из ResultSet через свойство ResultSet.записи который является массивом , или путем вызова ResultSet.valueOf () , который возвращает
массив с результатами.
Неявное умножение #
Неявное умножение означает умножение двух символов, чисел или сгруппированного выражения в круглых скобках без использования оператора * . Этот тип синтаксиса позволяет более естественным способом вводить выражения. Например:
math.evaluate ('2 пи') // 6.283185307179586
math.evaluate ('(1 + 2) (3 + 4)') // 21
Круглые скобки анализируются как вызов функции, когда на
левая сторона, например sqrt (4) или obj.method (4) . В остальных случаях
круглые скобки интерпретируются как неявное умножение.
Math.js всегда будет оценивать неявное умножение перед явным умножением * , так что выражение x * y z анализируется как x * (y * z) .Math.js также дает неявному умножению более высокий приоритет, чем деление, , за исключением , когда деление соответствует шаблону [число] / [число] [символ] или [число] / [число] [левая скобка] . В этом особом случае сначала оценивается деление:
math.evaluate ('20 кг / 4 кг ') // 5 Оценивается как (20 кг) / (4 кг)
math.evaluate ('20 / 4 кг ') // 5 кг Рассчитывается как (20/4) кг
Поведение неявного умножения можно резюмировать с помощью этих правил приоритета операторов, перечисленных от самого высокого до самого низкого приоритета:
- Вызов функций:
[символ] [левая скобка] - Явное деление
/, когда деление соответствует этому шаблону:[число] / [число] [символ]или[число] / [число] [левая скобка] - Неявное умножение
- Все остальные деление
/и умножение*
Неявное умножение - дело сложное, поскольку может показаться двусмысленность в том, как будет оцениваться выражение.Опыт показал, что приведенные выше правила наиболее точно соответствуют намерениям пользователя при вводе выражений, которые можно интерпретировать по-разному. Также возможно, что эти правила могут быть изменены в будущих основных выпусках. Осторожно используйте неявное умножение. Если вам не нравится неопределенность, вносимая неявным умножением, используйте явные операторы * и круглые скобки, чтобы ваше выражение оценивалось так, как вы предполагали.
Вот еще несколько примеров использования неявного умножения:
| Выражение | Оценивается как | Результат |
|---|---|---|
| (1 + 3) pi | (1 + 3) * пи | 12.566370614359172 |
| (4–1) 2 | (4–1) * 2 | 6 |
| 3/4 мм | (3/4) * мм | 0,75 мм |
| 2 + 3 и | 2 + (3 * я) | 2 + 3i |
| (1 + 2) (4–2) | (1 + 2) * (4–2) | 6 |
| кв. |