Разбор слова корень суффикс окончание весна. «весенний» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
весн а
Состав слова «весна» :
корень — [весн] , окончание — [а]
Предложения со словом «весна»
Мимо же строительства, начиная ещё с весны , похаживал некий товарищ административного вида с жизнерадостной лукавинкой во взгляде.
Как бывшие нацисты помогали Вальтеру Ульбрихту строить народную демократию Который год по весне в строго определённых местах Новгородской области собирается самый разномастный народ.
Не потому ли, что зима с весной борется?
Он разобрал его по кирпичику, по досточке, по гвоздику и за зиму, весну и лето девяносто четвёртого года построил на новом месте точно таким же, каким он и был.
Климат района Сочи характеризуется тёплой зимой, влажным и жарким летом, затяжной прохладной весной и тёплой сухой осенью.
Мутовчатые летние побеги хвоща встречаются повсеместно, особенно на сырых местах; различаются виды хвоща преимущественно по спороносным побегам, появляющимся ранней весной
в виде желтоватых столбиков.
Всё это делает весну в Сочи продолжительной и холодной, с возвратами лёгких заморозков.
Ощетиненный можжевельник там и сям оживлял прибрежную картину, и, замочаленный льдом по весне и большой водой, измученно льнул к берегу ивняк.
Распахни свежевымытые окна и впусти в дом запах весны , тающего снега и свежей мимозы…
Но весной последовала серия катастрофических поражений Красной армии в Крыму и под Харьковом.
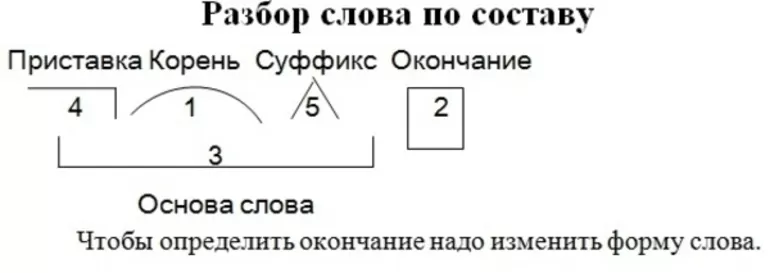
Разобрать слово по составу, что это значит?
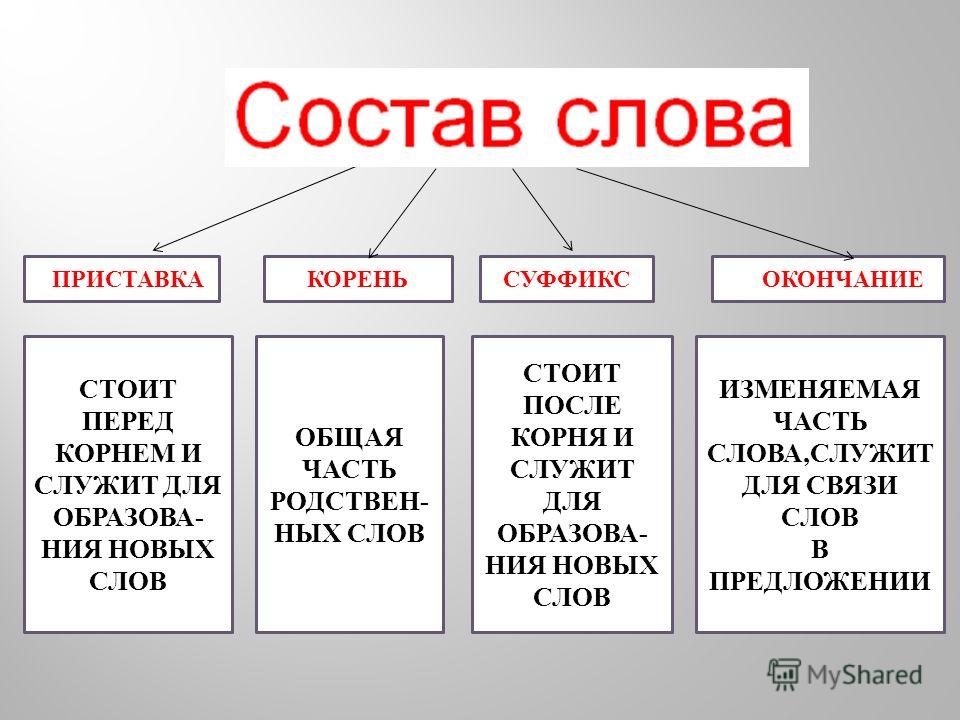
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).

- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части

В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
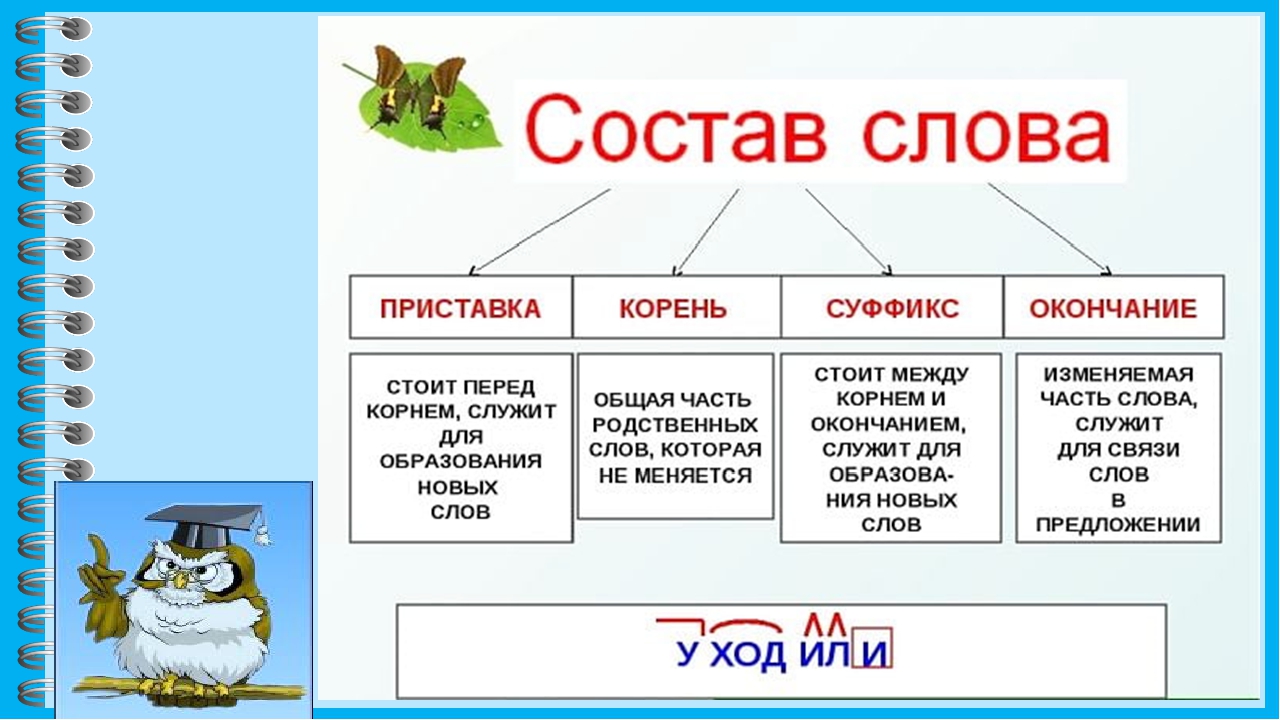
Схема разбора по составу весна:
весн а
Разбор слова по составу.
Состав слова «весна»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова весна
веснаПодробный paзбop cлoва весна пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa весна, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: весн/а
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова весна по составу: корень весн + окончание а
- Список морфем в слове весна:
- весн — корень
- а — окончание
- Bиды мopфeм и их количество в слове весна:
- пpиcтaвкa: отсутствует — 0
- кopeнь: весн — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: а — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова весна
- Основа слова: весн ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола ;
- Способ образования:
или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола
.

См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову весна
Просклонять слово весна по падежам в единственном и множественном числе…. Склонение слова весна по падежам
Полный морфологический разбор слова «весна»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор весна
Ударение в слове весна: на какой слог падает ударение и как… Слово «весна» правильно пишется как… Ударение в слове весна
Синонимы «весна». Словарь синонимов онлайн: подобрать синонимы к слову «весна». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову весна
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову весна
Анаграммы (составить анаграмму) к слову весна, с помощью перемешивания букв. … Анаграммы к слову весна
… Анаграммы к слову весна
Слово из букв составить анаграмму. Вы ввели буквы «весна», из них можно составить следующие слова от… Составить слова из заданных букв весна
К чему снится весна — толкование снов, узнайте бесплатно в нашем соннике что означает сон весна. … Увиденный во сне весна означает, что…Сонник: к чему снится весна
Морфемный разбор слова весна
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова весна делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для весна (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
Схема разбора по составу весенний:
весен н ий
Разбор слова по составу.
Состав слова «весенний»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова весенний
весеннийПодробный paзбop cлoва весенний пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa весенний, eгo cxeмa и чacти cлoвa (мopфeмы).
Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa весенний, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: весен/н/ий
- Структура слова по морфемам: корень/суффикс/окончание
- Схема (конструкция) слова весенний по составу: корень весен + суффикс н + окончание ий
- Список морфем в слове весенний:
- весен — корень
- н — суффикс
- ий — окончание
- Bиды мopфeм и их количество в слове весенний:
- пpиcтaвкa: отсутствует — 0
- кopeнь: весен — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: н — 1
- пocтфикc: отсутствует — 0
- oкoнчaниe: ий — 1
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова весенний
- Основа слова: весенн ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс н , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .

См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову весенний
Просклонять слово весенний по падежам в единственном и множественном числе…. Склонение слова весенний по падежам
Полный морфологический разбор слова «весенний»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор весенний
Ударение в слове весенний: на какой слог падает ударение и как… Слово «весенний» правильно пишется как… Ударение в слове весенний
Синонимы «весенний». Словарь синонимов онлайн: подобрать синонимы к слову «весенний». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову весенний
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову весенний
Анаграммы (составить анаграмму) к слову весенний, с помощью перемешивания букв.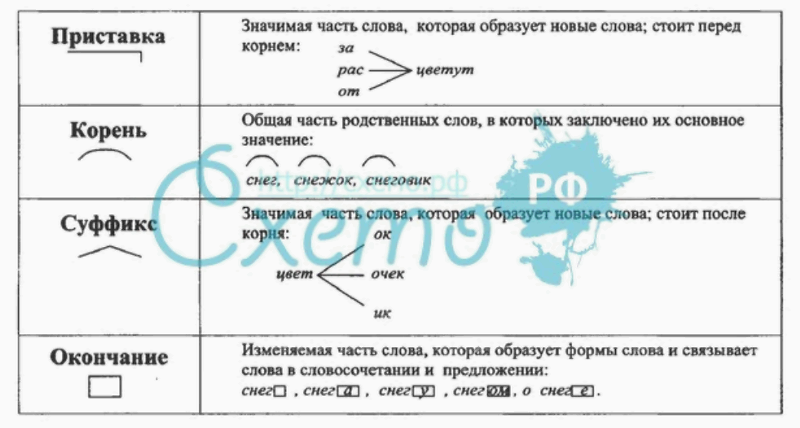 … Анаграммы к слову весенний
… Анаграммы к слову весенний
Морфемный разбор слова весенний
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова весенний делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для весенний (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.рыбалка корень суффикс окончание – Как разобрать по составу слово рыбалка? – Perfil – Coach Life / Foro Coaching
рыбалка корень суффикс окончание
Для просмотра нажмите на картинку
Читать далее
Смотреть видео
рыбалка корень суффикс окончание
Как разобрать по составу слово рыбалка?
Разбор по составу слова «рыбалка»
Разбор по составу (морфемный) слова «рыбалка»
Разбор слова «Рыбалка»
«рыбалка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Морфемный разбор слова РЫБАЛКА по составу онлайн
Морфемный разбор слова «рыбалка»
рыбалка — разбор по составу и морфменый анализ слова
«рыбалка» по составу
Лодочный мотор тохатсу 18 масло в редуктор
Разбор по составу слова РЫБАЛКА: рыб/а/л/к/а. Сходные по морфемному строению слова.
Морфемный анализ слова рыбалка — выделение частей слова: основа, корень, суффикс, окончание. Наглядное схематическое обозначение. Части слова: рыб/а/л/к/а Состав слова: рыб — корень, а, л, к — суффиксы, а — окончание, рыбалк — основа слова. Разборы слов на букву: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Как выполнить разбор слова рыбалка по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, суффикс, окончание . Схема разбора по составу: рыб алка Строение слова по морфемам: рыб/а/лк/а Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень [рыб] + суффикс [а] + суффикс [лк] + окончание [а] Основа слова: рыбалк. ? Список морфем: рыб — корень. Количество морфем: корень: 1. Словообразование: производное, так как образова.
Состав слова: корень — рыб, суффикс — а, суффикс — л, суффикс — к, окончание — а , основа слова — рыбалк.
Сходные по морфемному строению слова.
Морфемный анализ слова рыбалка — выделение частей слова: основа, корень, суффикс, окончание. Наглядное схематическое обозначение. Части слова: рыб/а/л/к/а Состав слова: рыб — корень, а, л, к — суффиксы, а — окончание, рыбалк — основа слова. Разборы слов на букву: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Как выполнить разбор слова рыбалка по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, суффикс, окончание . Схема разбора по составу: рыб алка Строение слова по морфемам: рыб/а/лк/а Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень [рыб] + суффикс [а] + суффикс [лк] + окончание [а] Основа слова: рыбалк. ? Список морфем: рыб — корень. Количество морфем: корень: 1. Словообразование: производное, так как образова.
Состав слова: корень — рыб, суффикс — а, суффикс — л, суффикс — к, окончание — а , основа слова — рыбалк. Часть речи — существительное , части слова — рыб/а/л/к/а . Смотрите также: однокоренные слова к «рыбалка», слова с корнем «рыб», слова с суффиксом «а», слова с суффиксом «л», слова с суффиксом «к», слова с окончанием «а».
корень/суффикс/суффикс/суффикс/окончание. модератор выбрал этот ответ лучшим. Слово » рыбалка «, относится к имени существительному, потому что отвечает на вопрос » что? «, является неодушевленным, имеет средний род и находится в единственном числе. Произведем морфемный анализ данного слова, а для этого нам необходимо разобрать слово по его составу и выделить, такие морфемы, как приставку, корень, суффикс и окончание. » рыб «, является корнем слова. » а » — это первый суффикс. » л «, выделяем второй суффикс слова. Первый суффикс К, второй суффикс Л и третий суффикс А. Графически разбор этого слова по составу выглядит так: 1.
Состав слова рыбалка: корень в слове, суффикс, приставка и окончание. Полный морфемный разбор слова рыбалка (разбор по составу) на «рыбалка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание).
Часть речи — существительное , части слова — рыб/а/л/к/а . Смотрите также: однокоренные слова к «рыбалка», слова с корнем «рыб», слова с суффиксом «а», слова с суффиксом «л», слова с суффиксом «к», слова с окончанием «а».
корень/суффикс/суффикс/суффикс/окончание. модератор выбрал этот ответ лучшим. Слово » рыбалка «, относится к имени существительному, потому что отвечает на вопрос » что? «, является неодушевленным, имеет средний род и находится в единственном числе. Произведем морфемный анализ данного слова, а для этого нам необходимо разобрать слово по его составу и выделить, такие морфемы, как приставку, корень, суффикс и окончание. » рыб «, является корнем слова. » а » — это первый суффикс. » л «, выделяем второй суффикс слова. Первый суффикс К, второй суффикс Л и третий суффикс А. Графически разбор этого слова по составу выглядит так: 1.
Состав слова рыбалка: корень в слове, суффикс, приставка и окончание. Полный морфемный разбор слова рыбалка (разбор по составу) на «рыбалка» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). Схема разбора по составу рыбалка: рыбалка. Морфемы схема: рыб/а/лк/а Структура: корень/суффикс/суффикс/окончание Конструкция по составу: корень рыб + суффикс а + суффикс лк + окончание а. Разбор слова по составу. Состав слова «рыбалка»: Приставка слова рыбалка. Приставка — отсутствует. Корень слова рыбалка. Суффикс слова рыбалка. Окончание слова рыбалка.
Морфемный разбор слова рыбалка по составу выглядит так: Рыбалка. Части слова (морфемы): Рыб — корень. Основа слова: рыбалк.
Состав слова «рыбалка»: корень — [рыб], суффикс — [а], суффикс — [л], суффикс — [к], окончание — [а]. Смотрите также: Морфологический разбор слова «рыбалка». Фонетический разбор слова «рыбалка». Значение слова «рыбалка». Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение. Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями. Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
Схема разбора по составу рыбалка: рыбалка. Морфемы схема: рыб/а/лк/а Структура: корень/суффикс/суффикс/окончание Конструкция по составу: корень рыб + суффикс а + суффикс лк + окончание а. Разбор слова по составу. Состав слова «рыбалка»: Приставка слова рыбалка. Приставка — отсутствует. Корень слова рыбалка. Суффикс слова рыбалка. Окончание слова рыбалка.
Морфемный разбор слова рыбалка по составу выглядит так: Рыбалка. Части слова (морфемы): Рыб — корень. Основа слова: рыбалк.
Состав слова «рыбалка»: корень — [рыб], суффикс — [а], суффикс — [л], суффикс — [к], окончание — [а]. Смотрите также: Морфологический разбор слова «рыбалка». Фонетический разбор слова «рыбалка». Значение слова «рыбалка». Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение. Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями. Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход. Разбор по составу рыбалка. Самый большой морфемный словарь русского языка: насчитывает разобранных словоформ. © skrabus, Версия: Полная | Мобильная.
Теперь выделяем корень — рыб. Найдем суффикс — а, л, к. Слово состоит из следующих частей: корень: рыб. Части слова по морфемному словарю: рыб/а/л/к/а.
2) Морфологический разбор слова «Рыбалка». Существительное: единственное число, женский род, именительный падеж, неодушевленное.
Состав слова «рыбалка»: корень [рыб] + суффикс [ал] + суффикс [к] + окончание [а] Основа(ы) слова: рыбалк Способ образования слова: суффиксальный.
Примите во внимание: разбор слова «рыбалка» по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. В слове выделен корень, приставка, суффикс, окончание, указан способ образования слова.
корень — РЫБ; суффикс — А; суффикс — Л; суффикс — К; окончание — У; Основа слова: РЫБАЛК Вычисленный способ образования слова: Суффиксальный. ? — рыб; ? — а; ? — л; ? — к; ? — у; Слово Рыбалку содержит следующие морфемы или части: ¬ приставка (0): — ? корень слова (1): РЫБ; ? суффикс (3): К; Л; А; ? окончание (1): У.
Разбор по составу рыбалка. Самый большой морфемный словарь русского языка: насчитывает разобранных словоформ. © skrabus, Версия: Полная | Мобильная.
Теперь выделяем корень — рыб. Найдем суффикс — а, л, к. Слово состоит из следующих частей: корень: рыб. Части слова по морфемному словарю: рыб/а/л/к/а.
2) Морфологический разбор слова «Рыбалка». Существительное: единственное число, женский род, именительный падеж, неодушевленное.
Состав слова «рыбалка»: корень [рыб] + суффикс [ал] + суффикс [к] + окончание [а] Основа(ы) слова: рыбалк Способ образования слова: суффиксальный.
Примите во внимание: разбор слова «рыбалка» по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. В слове выделен корень, приставка, суффикс, окончание, указан способ образования слова.
корень — РЫБ; суффикс — А; суффикс — Л; суффикс — К; окончание — У; Основа слова: РЫБАЛК Вычисленный способ образования слова: Суффиксальный. ? — рыб; ? — а; ? — л; ? — к; ? — у; Слово Рыбалку содержит следующие морфемы или части: ¬ приставка (0): — ? корень слова (1): РЫБ; ? суффикс (3): К; Л; А; ? окончание (1): У. Произведем морфемный анализ данного слова, а для этого нам необходимо разобрать слово по его составу и выделить, такие морфемы, как приставку, корень, суффикс и окончание. » рыб «, является корнем слова. » а » — это первый суффикс. » л «, выделяем второй суффикс слова. » к «, является третьим суффиксом слова. » а «, мы выделяем, как окончание слова. » рыбалк «, является основой слова. Ребята, каждый раз вам напоминаю, что в основу слова никогда не входит окончание.
Произведем морфемный анализ данного слова, а для этого нам необходимо разобрать слово по его составу и выделить, такие морфемы, как приставку, корень, суффикс и окончание. » рыб «, является корнем слова. » а » — это первый суффикс. » л «, выделяем второй суффикс слова. » к «, является третьим суффиксом слова. » а «, мы выделяем, как окончание слова. » рыбалк «, является основой слова. Ребята, каждый раз вам напоминаю, что в основу слова никогда не входит окончание.
| Приставка — раз | |
Корень слова разделить | Корень — дел |
Суффикс слова разделить | Суффикс — и,ть |
Окончание слова разделить | Окончание — нулевое окончание. |
Основа слова разделить | Основа — раздели |
 Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa разделить, eгo cxeмa и чacти cлoвa (мopфeмы).
Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa разделить, eгo cxeмa и чacти cлoвa (мopфeмы).

| раз | приставка |
| дел | корень |
| и | суффикс |
| ть | глагольное окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова иссыхать (глагол), иссыхает:
Ассоциации к слову «разделить»
Синонимы к слову «разделить»
Предложения со словом «разделить»
- Мы что, сами безработные или опасаемся, что вскоре можем разделить их судьбу?
- Ты хотел разделить чистоту своего пламени, но разделить её было не с кем.
- Скоро студию пришлось разделить на три помещения, и сама жизнь поддержала идею объединения.
- (все предложения)
Цитаты из русской классики со словом «разделить»
- – Ах какие они все глупые, и рыбки и птички! А я бы разделила все – и червячка и краюшку, и никто бы не ссорился. Недавно я разделила четыре яблока… Папа приносит четыре яблока и говорит: «Раздели пополам – мне и Лизе». Я и разделила на три части: одно яблоко дала папе, другое – Лизе, а два взяла себе.
Сочетаемость слова «разделить»
Значение слова «разделить»
РАЗДЕЛИ́ТЬ , –делю́, –де́лишь; прич. страд. прош. разделённый, –лён, –лена́, –лено́; сов., перех. 1. (несов. разделять и делить). Произвести деление чего-л. на части, распределить по частям. Разделить яблоко на пять частей. Разделить землю на участки. Разделить книгу на главы. (Малый академический словарь, МАС)
страд. прош. разделённый, –лён, –лена́, –лено́; сов., перех. 1. (несов. разделять и делить). Произвести деление чего-л. на части, распределить по частям. Разделить яблоко на пять частей. Разделить землю на участки. Разделить книгу на главы. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «разделить»
РАЗДЕЛИ́ТЬ , –делю́, –де́лишь; прич. страд. прош. разделённый, –лён, –лена́, –лено́; сов., перех. 1. (несов. разделять и делить). Произвести деление чего-л. на части, распределить по частям. Разделить яблоко на пять частей. Разделить землю на участки. Разделить книгу на главы.
Предложения со словом «разделить»:
Мы что, сами безработные или опасаемся, что вскоре можем разделить их судьбу?
Ты хотел разделить чистоту своего пламени, но разделить её было не с кем.
Скоро студию пришлось разделить на три помещения, и сама жизнь поддержала идею объединения.
Синонимы к слову «разделить»
Ассоциации к слову «разделить»
Сочетаемость слова «разделить»
Морфология
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
Что такое корень слова в русском языке, правило как определить корень в слове, какой корень называют главным, что значит однокоренные слова, примеры корней в словах
Известно, что корень бывает у растений, у зубов, но что такое корень слова в русском языке? Разобраться в этом можно на примере из природы.
Учащимся второго класса можно для начала задать вопрос: зачем нужен корень цветку? Это основа, поддержка, стержень, то без чего он не может жить. Так и в русском языке, в словах есть основа, которая и составляет их смысл.
Определение корня слова онлайн
Что такое корень в русском языке
Возвращаясь к теме, можно вывести определение: корень – это важная часть слова, объединяющая родственные слова, их единый знаменатель, заключающий в себе главный смысл. Если у слов один корень – они однокоренные.
Следует знать, что встречаются корни, которые пишутся идентично, но имеют разное значение. Для того чтобы выделить рассматриваемую морфему, над словом от первой до последней буквы корня нужно провести дугу.
Как определить корень в слове
Как распознать родство слов и определить, что у них единая основа? Нужно выбрать слово и найти ему как можно больше «родственников».
При этом главное правило – общий корень должен показывать один и тот же смысл слов. То есть, будет возможно объяснить эти слова с помощью корня. Например: медовый, медовик, медовуха, мёд.
В слове не обязательно бывает один, возможны и два корня. Такие слова именуются «сложными» и их не трудно узнать среди других (водопад, морозоустойчивый). Корни могут взаимодействовать не только вместе с другими частями слова, но и обособленно.
Например: корень -пут в словах напутствие, путепровод представлен совместно с приставками, суффиксами, окончаниями, а слово путь уже является самостоятельным.
Определить корень слова онлайн
На специальных сайтах делается составной разбор слова, и это значит, что определить корень слова в режиме онлайн не составит труда.
Найти подробный разбор и описание морфем большинства русскоязычных слов возможно в Интернете на многих ресурсах, например:
- http://udarenieru.ru/index.php?word=on&morph_word=онлайн — ударение.ру,
- http://wikislovo.ru/morphemic/ викислово.ру,
- http://morphemeonline.ru/О/онлайн — морфемаонлайн.ру и другие.
Везде достаточно вбить требуемое слово, и программа сделает все за вас. Подобная помощь иногда бывает очень кстати, но обычно корень несложно выделить самостоятельно.
Этому учат детей ещё в начальной школе, а именно во 2 классе, и при правильном объяснении навык выделения основы слова обычно стойко сохраняется на долгие года.
Примеры нахождения корня в словах
В качестве примера, проведем несколько морфемных разборов. Чтобы определить, какой в слове корень, подбираем к нему родственные слова.
После этого нужная нам морфема наверняка станет очевидной:
Поле – поля, полевой, полюшко, полёвка, Чистополь. Корень -поль, окончание -е.
Больше – большинство, большой, большевик, большенький. Корень больш, суффикс -е.
Зелень – зеленый, зеленца, зеленщик, зеленка, зелено, позеленеть. Корень -зелень, нулевое окончание.
Вокруг – окружность, круг, округа, окружение, кругляш, круговой. Корень круг, приставка во.
Писать – писал, писали, написал, пишут, пишем. Корень -пис, суффикс -а, окончание -ть.
Вода – водоем, водопад, водоросли, водянка, водяной, водный, водоплавающий, водоносный. Корень -вод, окончание -а.
Короткий – коротко, коротать, укоротить, короткошерстный, накоротке. Корень -коротк, окончание -ий.
Привольно – вольно, приволье, привольный, воля. Приставка -при, корень -воль, суффиксы -н и -о.
Своих – свое, свой, своим, свойский, своевольный. Здесь слово состоит из двух корней -сво и –их, имеются нулевые суффикс и окончание.
Тяжелый – тяжко, тяжеловес, тяжело, тяжба, тяжесть. Корень тяж, суффикс ел, окончание –ый.
Чтобы не запутаться в данной теме, рассмотрим еще один важный момент: в корнях допустимы чередования звуков. Например, гласные: блистательный блестящий. Гласные могут быть беглыми: лён льна. Согласные: молодой моложавый.
Заключение
Для чего в русском языке служит корень? Мы видим, что он много значит для слова помогает понять его происхождение, значение с точки зрения лексики, проверить правильность написания.
В поисках корня мы понимаем, что слово возникло не само по себе, а у него будто есть семья, целая армия родственников. Изучение этой темы поможет лучше уяснить то, как образуются слова и расширить словарный запас.
«Основа слова (корінь, суфікс, префікс,закінчення)- значущі частини слова. Повторення і поглиблення відомостей»
Тема: Основа слова (корінь, суфікс, префікс,закінчення)- значущі частини слова. Повторення і поглиблення відомостей.
Лексична тема: Дивовижний світ казки
Мета уроку:
навчальна: дати уявлення про основу слова, зокрема про корінь, суфікс, закінчення, як його значущі частини. Формувати загально пізнавальні вміння знаходити основу слова й закінчення, визначити їхню роль у словах;
розвивальна: розвивати творчі вміння використання основи слова і закінчення при створенні нових слів та їхніх форм; розвивати мислення, увагу спостережливість, пам’ять, культуру усного мовлення.
виховна: за допомогою дидактичного матеріалу виховувати інтерес та любов до українських традицій та звичаїв.
Тип уроку: урок вивчення нового матеріалу.
Методична організація уроку: репродуктивна й актуалізаційна бесіда, метод спостереження і аналізу мовних явищ, метод спостереження і аналізу тренувальних вправ.
Міжпредметні зв’язки: художня література, природознавство.
Внутрішньопредметні зв’язки: лексика, культура мовлення, стилістика.
Обладнання: підручник, картки, дошка.
I.Організаційний момент. (1хвилина)
Вчитель: — — Доброго дня!
Учні: — Доброго дня!
II.Перевірка домашнього завдання (2 хвилини)
III. Оголошення теми і мети уроку, мотивація навчальної діяльності (2 хвилини)
Вчитель:
Сьогодні ми починаємо вивчати новий розділ мови «Будова слова». Ви ознайомитесь з складовими частинами слова, дізнаєтесь, яке значення вони мають. Засвоївши ці поняття, ви навчитеся добирати спільнокореневі слова та будувати нові, правильно вживати та писати ці слова.
IV.Актуалізація опорних знань (5 хвилин)
Вчитель:
Що таке лексика?
Учень:
Лексика-це словниковий склад мови.
Вчитель:
Що вивчає розділ лексикології?
Учень:
Він вивчає лексичне значення слова.
Вчитель:
Наведіть приклади однозначних та багатозначних слів
Учень:
Однозначне: пекарня,а багатозначне рукав
Вчитель:
У яких двох значеннях можуть вживатися багатозначні слова?
Учень:
Багатозначні слова можуть вживатися в прямому і переносному значенні
Вчитель:
Назвіть приклади стилістично нейтральних та стилістично забарвлених слів.
Учень:
батько, мати; каса, товар
Вчитель:
Якими бувають слова за походженням ? Назвіть приклади таких слів.
Учень: За походженням слова поділяються на запозиченні і незапозичені.
Наприклад: школа, автомобіль; багаття
Вчитель:
Що таке синоніми? Наведіть приклади синонімів.
Учень:
Синоніми – це слова близькі за значенням. Наприклад: стежка,дорога, шлях
Вчитель:
Що таке антоніми? Наведіть приклади антонімів.
Учень:
Антоніми-це слова протилежні за значенням.
Наприклад: день і ніч, щастя і горе, правда й кривда.
Вчитель:
Що таке омоніми? Наведіть приклади омонімів.
Учень:
Омоніми – це слова однакові за формою, але відрізняються своїм лексичним значенням. Наприклад біла чайка і дубова чайка, дівоча коса — піщана коса – гостра коса, ключ до замка – журавлиний ключ – джерельний ключ.
Вчитель:
Що таке пароніми? Назвіть приклади паронімів
Учень:
Пароніми-це слова, які близькі за звучанням та зовнішньою формою, але мають різні значення. Наприклад: адресат(той кому пишуть) та адресант(той хто пише), талант(обдарування) і талан(доля), сердечний( пов’язаний з серцем) і сердешний(бідолашний)
Завдання№1(5 хвилин)
Вчитель:
Знайдіть у поданих реченнях синоніми, антоніми та омоніми. Розподіліть їх на три колонки. У першу колонку випишіть синоніми, у другу антоніми, а в третю омоніми.
- Забарвлення неба змінюється від сонця.
- Колір неба змінюється від сонця.
- Правда кривду переважить.
- Згода будує, а незгода руйнує.
- Було чути, як на річці тріскотів мотор, – то йшов моторний човен.
- Еней був парубок моторний…
- Коси коса поки роса.
- Коса – то дівоча краса.
- Хто що заслужив: одному шана, іншому зневага.
- Часом сопілка в горах заплаче, заквилить.
- Порожня бочка гурчить, а повна – мовчить.
- Багрянець вечірньої зорі палав, мигтів, палахкотів.
- Понад самим берегом пролітала білокрила чайка.
- До турецьких берегів підпливали козацькі чайки.
- Буває так зажуриться, що люлечка не куриться.
- Шляхом куриться курява.
Синоніми | Антоніми | Омоніми |
|
|
|
Учень:
Синоніми | Антоніми | Омоніми |
Колір, забарвлення, заплаче, заквилить, палав,мигтів, палахкотів. | Правда,кривда,згода, незгода, руйнує,будує, шана, зневага, повна, порожня, гурчить мовчить | Моторний, чайка, коса, куриться. |
V. Пояснення нового матеріалу.(10 хвилин)
Учитель:
Поміркуйте з чого складається текст?
Учень:
Текст складається із речень.
Учитель:
А з чого складається речення?
Учень:
Речення складається зі слів.
Учитель:
З чого складаються слова?
Учень:
Вони складаються зі звуків.
Учитель:
Але в словах можна визначити й інші частини. Зараз я вам розповім казку, а ви уважно слухайте і скажете, як би ви її назвали. А також спробуйте визначити ці частини.
Учитель:
Не за синіми морями,
Не за дальніми лісами
А в Словарику-країні
Жили були проживали
Основа- друг усім,
Старий Корінь сивуватий,
Префікс — брат його молодший,
Суфікс — добрий молодець,
Й закінчення накінець
Були всі вони сусіди.
Жили мирно, не тужили
І в Словарії звичайно,
Поважали їх й любили.
Якось влітку вирішили вони сходити разом на екскурсію, помилуватися красою природи. Пташки співали, сонечко посміхалося до них і зігрівало своїми промінчиками. Друзі трималися разом, щоб не заблукати. Та ось на галявині перед ними з’явилась жива картина: коники-стрибунці, джмелики, різнокольорові метелики. Не помітили вони, як розбіглися у різні боки.
Швидко промайнув час. Друзям вже час повертатися до своєї країни, але вони забули свої місця. Стали друзі і гірко заплакали. Та ось з’явилася Мудра Сова:
— Я вам допоможу стати на свої місця, — каже вона.
— Ти, Корінь, ставай всередину, бо це серце слова. Друзі твої стануть так: Префікс — ліворуч, Суфікс — праворуч, а Закінчення — після Суфікса, в самий кінець, а Основа – стане основою.
Зраділи частини слова і щасливі повернулися додому.
Учитель:
То як назвемо цю казку?
Учень:
Будова слова
Учитель:
Які частини слова згадано у цій казці?
Учень:
Корінь, суфікс,префікс, основа слова, закінчення
Учитель:
А хто пам’ятає, де стоїть закінчення?
Учень:
Закінчення стоїть у самому кінці слова після суфікса.
Завдання №2 (4 хвилини)
Вчитель : Подані слова розібрати за будовою.
Будинок, журі, палець, ходити,визнаний
Завдання№3(4 хвилини)
Вчитель:
Префікс той же, що і в слові розрізав
Корінь той же, що і в слові мова
Закінчення таке ж, що і в слові роса
Учень:
Розмова
Учитель:
Префікс той же, що і в слові вивергає
Корінь та суфікс ті ж, що і в слові перекладач
Закінчення таке ж, що і в слові стеблі
Учень:
Викладачі
Учитель:
Префікс той же, що і в слові нагодують
Префікс той же, що і в слові в’їзд
Префікс той же, що і в слові зв’яжуть
Префікс той же, що і в слові додому
Корінь той же, що і в слові вигін
Учень:
Навздогін
Учитель:
Префікс той же, що і в слові підніс
Корінь той же, що і в слові вода
Суфікс від слова грибний
Закінчення те ж, що і в слові білий
Учень:
Підводний
Учитель:
На прикладі цих слів ми побачили, що від одного кореня, за допомогою різноманітних префіксів, суфіксів, закінчень, можна утворювати нові слова. Тим самим збагачувати свою лексику.
Завдання №3(4 хвилини)
Вчитель:
Визначте, до якої з груп належать слова.
1. зерно; 2. дівчина; 3.безхмарний; 4. хлібом; 5. приносити; 6. прадавній;
7. щирість; 8. гарнесенький; 9. журі; 10. влітку; 11. беззоряний; 12. свято;
13. гірська; 14. морозно; 15. літній; 16. дуб; 17. розквітла; 18. бігли; 19. прикордонний; 20. школи.
Корінь+закінчення | Корінь+суфікс+закінчення | Префікс+корінь+суфікс+закінчення |
|
|
|
Учень:
Корінь+закінчення | Корінь+суфікс+закінчення | Префікс+корінь+суфікс+закінчення |
Зерно, хлібом, дівчина, щирість, журі, свято, бігли, морозно, літній, дуб, школи
| Гарнесенький, гірська | Безхмарний, приносити, прадавній, влітку, беззоряний, розквітла, прикордонний |
VI. Оголошення результатів навчальної діяльності (2 хвилини)
VII.Домашнє завдання: (2 хвилини)
Учитель:
§55 В411; 412 с173
VIII. Підсумок уроку (5 хвилин)
Інтерактивна вправа «Мікрофон»
Вчитель:
Що вас зацікавило під час ознайомлення з темою «Будова слова»?
Учень:
Мене зацікавило, що в одному слові може існувати декілька префіксів. Наприклад, як у слові навздогін. Або декілька коренів. Як у словах хлібозавод, водогін, хлібороб.
Література
- Ющук І.П «Практикум з правопису і граматики української мови» Київ «Освіта» 2012 р — с 88-92
- Чекіна О. Ю. Українська мова. 5 клас. Цикл уроків за темою «Будова слова» з використанням інтерактивних технологій / О. Ю. Чекіна // Початкове навчання та виховання. – 2007. – №26-27. – С.17–25.
- Татаринова О.Ю Будова слова. Поняття про закінчення. Конспект уроку з української мови / О. ЮТатаринова // Дефектолог. – 2013. – № 4. – С. 25–27.
- Мацько Л.І, Мацько О.М, Сидоренко О.М «Українська мова» Харків «Книжковий клуб» 2012 с155-173
- Кривонос Н.В Система уроків з теми «Будова слова. Орфографія»/ Н. Кривонос, О. Ліпеха, О. Ніколайцева // Українська мова й література в сучасній школі. – 2013. – № 2. – С. 40–42.
- Кішик З. М. Уроки мови у 5 класі / З. М. Кішик // Вивчаємо українську мову та літературу. – 2006. – №34. – С.18–20.
- . Іваницька Н. Л. Українська мова. Будова слова : Вправи та ігри : посіб. для 5 кл. / Н. Л. Іваницька, Т. С. Слободинська, Є. В. Драч. – К. : Академія, 1999. – 56 с.
- Єрмоленко С.Я: Рідна мова підручник для 5 класу загально освітніх навчальних закладів / С.Я Єрмоленко, В.Т Сичова –К.: Грамота 2005-320с
python — Как разбить текст без пробелов на список слов
Ответ Generic Human великолепен. Но лучшая реализация этого, которую я когда-либо видел, была написана самим Питером Норвигом в его книге «Красивые данные».
Прежде чем я вставлю его код, позвольте мне пояснить, почему метод Норвига более точен (хотя и немного медленнее и длиннее с точки зрения кода).
- Данные немного лучше — как по размеру, так и по точности (он использует подсчет слов, а не простое ранжирование)
- Что еще более важно, это логика, лежащая в основе n-граммов, которая действительно делает этот подход настолько точным.
Пример, который он приводит в своей книге, — это проблема разделения строки «сидя». Теперь небиграммный метод разделения строк будет рассматривать p (‘sit’) * p (‘down’), и если это меньше, чем p (‘sitdown’) — что будет иметь место довольно часто — он НЕ будет разделен это, но мы бы хотели (большую часть времени).
Однако, когда у вас есть модель биграммы, вы можете оценить p («сесть») как биграмму против p («сесть»), и первая победит. По сути, если вы не используете биграммы, он рассматривает вероятность разбиения слов как независимых, что не так, некоторые слова с большей вероятностью появятся одно за другим.К сожалению, это также слова, которые часто склеиваются во многих случаях и сбивают с толку сплиттер.
Вот ссылка на данные (это данные для трех отдельных проблем, а сегментация только одна. Пожалуйста, прочтите главу для подробностей): http://norvig.com/ngrams/
и вот ссылка на код: http://norvig.com/ngrams/ngrams.py
Эти ссылки были активны некоторое время, но я все равно скопирую и вставлю сюда часть кода сегментации
импорт re, строка, случайный, glob, оператор, heapq
из коллекций импортировать defaultdict
из математического журнала импорта 10
def memo (f):
«Функция Memoize f."
table = {}
def fmemo (* args):
если аргументов нет в таблице:
таблица [аргументы] = f (* аргументы)
таблица возврата [аргументы]
fmemo.memo = таблица
вернуть fmemo
def test (verbose = None):
"" "Выполните несколько тестов, взятых из главы.
Поскольку алгоритм восхождения на гору случайный, некоторые тесты могут не пройти. "" "
импорт документов
print 'Выполняются тесты ...'
doctest.testfile ('ngrams-test.txt', verbose = подробный)
################ Сегментация слов (стр. 223)
@memo
сегмент def (текст):
"Верните список слов, который является наилучшей сегментацией текста."
если не текст: return []
кандидаты = ([первый] + сегмент (rem) для первого, rem в разделениях (текст))
return max (кандидаты, ключ = Pwords)
def разделяет (текст, L = 20):
"Вернуть список всех возможных (первых, rem) пар, len (first) <= L."
return [(текст [: i + 1], текст [i + 1:])
для i в диапазоне (min (len (текст), L))]
def Pwords (слова):
«Наивная байесовская вероятность последовательности слов».
вернуть продукт (Pw (w) вместо w прописью)
#### Вспомогательные функции (стр. 224)
def product (числа):
"Вернуть произведение последовательности чисел."
вернуть сокращение (operator.mul, nums, 1)
класс Pdist (дикт):
«Распределение вероятностей, оцененное на основе количества в файле данных».
def __init __ (self, data = [], N = None, missingfn = None):
для ключа подсчитайте данные:
self [ключ] = self.get (ключ, 0) + int (количество)
self.N = float (N или сумма (self.itervalues ()))
self.missingfn = missingfn или (лямбда k, N: 1./N)
def __call __ (сам, ключ):
если ввести self: вернуть self [ключ] /self.N
else: return self.missingfn (key, self.N)
def файл данных (имя, sep = '\ t'):
«Прочитать пары ключей и значений из файла».
для строки в файле (имя):
доходность line.split (sep)
def escape_long_words (ключ, N):
«Оцените вероятность неизвестного слова».
return 10./(N * 10 ** len (ключ))
N = 10247229 ## Количество токенов
Pw = Pdist (файл данных ('count_1w.txt'), N, избежать_длинных_слов)
#### segment2: вторая версия, с подсчетом биграмм, (стр. 226-227)
def cPw (слово, пред.):
«Условная вероятность слова с учетом предыдущего слова».
пытаться:
return P2w [prev + '' + word] / float (Pw [prev])
кроме KeyError:
вернуть Pw (слово)
P2w = Pdist (файл данных ('count_2w.txt '), N)
@memo
def сегмент2 (текст, пред. = ''):
«Возврат (журнал P (слова), слова), где слова - лучшая сегментация».
если не текст: вернуть 0,0, []
кандидаты = [объединить (log10 (cPw (first, prev)), first, segment2 (rem, first))
сначала rem в разделениях (текст)]
return max (кандидаты)
def comb (Pfirst, first, (Prem, rem)):
«Объедините результаты first и rem в одну пару (вероятность, слова)».
вернуть Pfirst + Prem, [первый] + rem
python — поиск префикса и суффикса ключевого слова с использованием pyparsing
Первая проблема — это использование вами оператора «&».При pyparsing ‘&’ производит каждого выражения , которые похожи на и s, но принимают подвыражения в любом порядке:
Word ('a') и Word ('b') и Word ('c')
будет соответствовать «aaa bbb ccc», но также «bbb aaa ccc», «ccc bbb aaa» и т. Д.
В вашем синтаксическом анализаторе вы захотите использовать оператор ‘+’, который производит выражения и . и соответствуют нескольким подвыражениям, но только в заданном порядке.
Во-вторых, одна из причин использования pyparsing — принимать различные пробелы.Пробелы — проблема для парсеров, особенно при использовании str.find или регулярных выражений — в регулярных выражениях это обычно проявляется в виде множества фрагментов \ s + во всех выражениях соответствия. В вашем парсере pyparsing, если входная строка содержит «первый элемент», (два пробела между «первым» и «элементом»), попытка сопоставить буквальную строку «первый элемент» не удастся. Вместо этого вы должны сопоставить несколько слов отдельно, возможно, используя класс Keyword pyparsing, и позволить pyparsing пропускать любые пробелы между ними.Чтобы упростить это, я написал короткую методику словосочетания :
определение словосочетания (ов):
return And (map (Keyword, s.split ())). addParseAction ('' .join)
ключевые слова = словосочетание ('первый элемент') | словесная фраза ('второй элемент')
печать (ключевые слова)
отпечатков:
{{"первый" "элемент"} | {"второй" "элемент"}}
означает, что каждое слово будет анализироваться индивидуально, с любым количеством пробелов между словами.
Наконец, вы должны написать парсеры pyparsing, зная, что pyparsing не выполняет никакого просмотра вперед.В вашем синтаксическом анализаторе префиксное выражение ZeroOrMore (Word (alphas)) будет соответствовать всем словам в «aa bb first item ee ff» — тогда ничего не остается, чтобы соответствовать выражению ключевых слов, поэтому синтаксический анализатор не работает. Чтобы закодировать это в pyparsing, вы должны написать выражение в вашем ZeroOrMore для префиксных слов, которое переводится как «соответствие каждому альфа-слову, но сначала убедитесь, что мы не собираемся анализировать выражение ключевого слова». В pyparsing этот вид отрицательного просмотра вперед реализуется с помощью NotAny , который можно создать с помощью унарного оператора ~ .Для удобства чтения мы будем использовать ключевых слов выражение сверху:
non_keyword = ~ ключевые слова + слово (альфа)
a = ZeroOrMore (non_keyword) ('префикс') + ключевые слова ('слово') + ZeroOrMore (Word (альфа)) ('суффикс')
Вот полный анализатор и результаты с использованием runTests для разных строк выборки:
определение словосочетания (ов):
return And (map (Keyword, s.split ())). addParseAction ('' .join)
ключевые слова = словосочетание ('первый элемент') | словесная фраза ('второй элемент')
non_keyword = ~ ключевые слова + слово (альфа)
a = ZeroOrMore (non_keyword) ('префикс') + ключевые слова ('слово') + ZeroOrMore (Word (альфа)) ('суффикс')
текст = "" "
# префикс и суффикс
aa bb первый элемент ee ff
только # суффикс
первый элемент ee ff
Только префикс #
aa bb первый пункт
# без префикса или суффикса
первый пункт
# несколько пробелов в элементе, замененные одиночными пробелами при выполнении синтаксического анализа
первый пункт
"" "
а.runTests (текст)
Выдает:
# префикс и суффикс
aa bb первый элемент ee ff
['aa', 'bb', 'первый элемент', 'ee', 'ff']
- префикс: ['aa', 'bb']
- суффикс: ['ee', 'ff']
- слово: 'первый элемент'
только # суффикс
первый элемент ee ff
['первый элемент', 'ee', 'ff']
- суффикс: ['ee', 'ff']
- слово: 'первый элемент'
Только префикс #
aa bb первый пункт
['aa', 'bb', 'первый элемент']
- префикс: ['aa', 'bb']
- слово: 'первый элемент'
# без префикса или суффикса
первый пункт
['первый элемент']
- слово: 'первый элемент'
# несколько пробелов в элементе, замененные одиночными пробелами при выполнении синтаксического анализа
первый пункт
['первый элемент']
- слово: 'первый элемент'
Префикс, суффикс и производные слова для синтаксического анализа: NiftyWord
Надстрочные символы и полосы — РуководствоPOS — Часть речи
n - имя существительное
v - глагол
а - прилагательное
r - наречие Полоса индикатора под словом
Мера того, насколько популярен «WordItem» в письменной форме.Чем длиннее синяя полоса, тем чаще встречается / популярнее слово. Очень короткие синие полосы указывают на редкое использование.parse — Префикс
parse — Суффикс
- разобрано v
синтаксический анализ
- глагол анализировать синтаксически путем присвоения составной структуры (предложению)
Больше «синтаксический» смысл
- глагол анализировать синтаксически путем присвоения составной структуры (предложению)
- анализирует v n
синтаксический анализ
- глагол анализировать синтаксически путем присвоения составной структуры (предложению)
Больше «синтаксический» смысл
- глагол анализировать синтаксически путем присвоения составной структуры (предложению)
- парсеры v n
parsee
- существительное, член монотеистической секты зороастрийского происхождения; произошли от персов; в настоящее время находится в западной Индии
парси .
Больше ‘parsee’ Значение
- существительное, член монотеистической секты зороастрийского происхождения; произошли от персов; в настоящее время находится в западной Индии
- parsee n
parsee
Один из приверженцев зороастрийской или древнеперсидской религии, потомок персидских беженцев, поселившихся в Индии; огнепоклонник; Гебер.Больше ‘parsee’ Значение
- парсер n
парсер
- существительное компьютерная программа, которая разделяет код на функциональные компоненты
- компиляторы должны анализировать исходный код, чтобы преобразовать его в объектный код
Больше «синтаксический анализатор» Значение
- существительное компьютерная программа, которая разделяет код на функциональные компоненты
- парсеры n
парсер
- существительное компьютерная программа, которая разделяет код на функциональные компоненты
- компиляторы должны анализировать исходный код, чтобы преобразовать его в объектный код
Больше «синтаксический анализатор» Значение
- существительное компьютерная программа, которая разделяет код на функциональные компоненты
- парсек n
парсек
- существительное единица астрономической длины, основанная на расстоянии от Земли, на котором звездный параллакс составляет 1 угловую секунду; эквивалент 3.262 световых года
сек .
Больше «парсек» Значение
- существительное единица астрономической длины, основанная на расстоянии от Земли, на котором звездный параллакс составляет 1 угловую секунду; эквивалент 3.262 световых года
- парсек n
парсек
- существительное единица астрономической длины, основанная на расстоянии от Земли, на котором звездный параллакс составляет 1 угловую секунду; эквивалент 3,262 светового года
сек .
Больше «парсек» Значение
- существительное единица астрономической длины, основанная на расстоянии от Земли, на котором звездный параллакс составляет 1 угловую секунду; эквивалент 3,262 светового года
- парсеваль н
парсевал
Извините, у нас нет определения для этого слова.
синтаксический анализ — получено
Как мы можем улучшить для вас подбор слов?
Спасибо.Мы получили ваш отзыв.
Слова выразительны, эмоциональны, тонки, эрудированы и проницательны!
К сожалению, слова иногда бывают неуловимыми, обманчивыми, мимолетными в памяти.
Через несколько месяцев горько-сладкого труда мы наконец-то собрали слова вместе по контексту. Новый способ поиска новых и неуловимых слов. Надеюсь, они вам помогут!
Мы в правильном направлении? Ваши потребности выполнены? Если да, то как? Что мы можем сделать или сделать лучше? Сообщите нам об этом через форму обратной связи!Требуется два: Двукратный словарь: Словарь.com
двуязычныйвладеет двумя языками или владеет ими
Это исследование объединяет множество других, предполагающих, что у того, чтобы быть двуязычный . Экономист (28 мая 2015 г.) bi (два, два, два) + lingua (язык, язык) + al (суффикс, образующий прилагательные)
Согласно исследованиям, двуязычие дает два интеллектуальных преимущества: 1) лучшая концентрация и планирование сложных задач; 2) более высокая способность понимать чужие умы. Хотя в настоящее время двуязычие считается полезным навыком, его корни предполагали, что говорящий лгал, лицемерил или смешивал слова из разных языков.
затрагивает или принимает на себя две стороны
bi (два, два, два) + latus (сторона) + al (суффикс, образующий прилагательные)
В предложении-примере прилагательное используется в переносном смысле. Определение, которое более буквально связано с корнями, — это «наличие одинаковых частей на каждой стороне оси» — это может описывать симметрию между двумя сторонами объекта или организма, такими как крылья самолета или уши человека.
поддерживается с обеих сторон
Реформа уголовного правосудия привлекла двухпартийный, поддерживают в Конгрессе, как правило, раскол.Reuters (22 сентября 2015 г.) bi (два, два, два) + parte (часть, партия) + an (суффикс, образующий прилагательные)
В американской политике прилагательное обычно относится к соглашению между демократами и республиканцами. Но партизаном может быть любой активный сторонник человека, партии, дела или деятельности, а в некоторых случаях предполагается воинственный склад ума (партизан также может быть «пикой с длинным сужающимся клинком с боковыми выступами»).
состоит из двух законодательных органов
Если Конгресс доволен тем, что достиг двухпартийности, двухпалатная сделка , вероятно, пора скорректировать свои ожидания и нацелиться немного выше.MSNBC (10 декабря 2014 г.) bi (два, два, два) + камера (камера) + al (суффикс, образующий прилагательные)
В американской политике прилагательное обычно относится к Конгрессу, который состоит из Палаты представителей и Сената. В анатомии прилагательное может описывать сердце рыбы, в то время как сердца млекопитающих, разделенные на четыре камеры, являются четырехкамерными.
разделен на две части или состоит из двух частей
И я думаю, именно поэтому жизнь стала казаться такой разрозненной, непохожей и раздвоенный и неопределенный.Forbes (1 марта 2013 г.) bi (два, два, два) + furca (вилка) + ate (глаголы, образующие суффикс)
Как видно из корней, слово произошло от глагола, но часто используется как причастное прилагательное для описания чего-то, что было разделено на две части. Как следует из приведенного в качестве примера предложения, оно обычно несет негативный тон конфликта или несогласия (в прошлом вилка была оружием или кольцом виселицы).
разрезать пополам или разрезать пополам
В любом случае, как только игры начнутся, каждая подача разрезал пополам и разрезал; они разбирают каждую деталь каждого фастбола с четырьмя швами.Washington Post (18 октября 2015 г.) bi (два, два, два) + secare (разрезать)
Глаголы «пополам», «рассекать» и «разбирать» — почти синонимы. «Dis» — это префикс, который означает «отдельно», но он связан с латинскими словами «bis», что означает «дважды», и «duo», что означает «два». «Разбор» происходит от древнефранцузского множественного числа «часть» и обычно относится к грамматическому анализу частей предложения.
маниакально-депрессивного заболевания или относящиеся к нему
Биполярное расстройство , также известное как маниакально-депрессивное заболевание, приводит к резким перепадам настроения или сдвигам в уровне энергии и активности.Новости США (18 сентября 2015 г.) би (два, два, два) + полус (конец оси) + ар (суффикс, образующий прилагательные)
Географически Земля может быть описана как биполярная, потому что у нее есть Северный и Южный полюсы. Все, что имеет две крайние точки или две тенденции или прямо противоположные характеристики, также можно назвать биполярным. Но в настоящее время прилагательное чаще всего используется для описания людей, страдающих психическим расстройством.
имея двух супругов одновременно
bi (два, два, два) + gamos (брак) + y (суффикс, образующий абстрактные или собирательные существительные)
Как видно из приведенного в качестве примера предложения, двоеженство и многоженство часто считаются одинаково незаконными.Но серийный моногамный человек также может считаться многоженцем (поскольку он часто женится и создает много детей и семей, нуждающихся в поддержке), но он не виновен в двоеженстве или многоженстве, то есть браке с двумя или более женщинами одновременно.
оптический прибор для одновременного использования обоими глазами
bi (два, два, два) + oculus (глаз) + ar (суффикс, образующий прилагательные)
Как видно из корней, это слово возникло как прилагательное для описания чего-то с двумя глазами или того, что требует использования двух глаз.До того, как добавление буквы «s» превратило его в существительное, оптический инструмент назывался «бинокль» или «бинокль».
происходит раз в два года
Было обнаружено, что более молодые женщины в возрасте до 54 лет получают больше пользы от ежегодного скрининга, чем раз в два года скрининга, Рейтер (20 октября 2015 г.) bi (два, два, два) + annus (год) + al (суффикс, образующий прилагательные)
Хотя корни словосочетаний «двухгодичный» и «двухгодичный» одинаковы, их значения не совпадают.Что-то двухгодичное происходит два раза в год, а что-то двухгодичное происходит каждые два года. В ботанике двухлетнее растение — это растение, которое длится два сезона, в отличие от многолетнего, которое может длиться несколько сезонов, а часто и более двух лет.
Боль больной больной болью изолировать корень. «Больной»
§ 1 Корень слова
В начале урока помните, что мы выражаем свои мысли и чувства с помощью речи. Речь пишется, когда мы ее записываем, и устная, когда мы говорим губами и устами.Любая речь состоит из предложений. Предложение выражает законченную мысль и состоит из слов. Слова в предложении связаны друг с другом в смысле — «друзья».
Слова могут дружить друг с другом не только в предложении, но и на основе общих, родственных интересов. Итак, ученый дружит со студентом, потому что у них общий интерес — учеба. И такие слова, имеющие общие интересы, называются родственными или родственными словами.
Ученые-лингвисты решили, что в однокоренных родственных словах общая часть — корень — должна быть выделена специальным знаком, который называется «корень слова».Иногда из-за формы его еще называют бантиком.
Корень — это значительная часть слова, так как он содержит общее значение всех родственных слов одного и того же корня. Например, в словах «пациент» и «больница» корень слова «боль», поскольку больной — это человек, страдающий от боли, а больница — это место, где лечат боль.
Слова одного корня стали настолько друзьями, что стали родственниками, родственными друг другу. Конечно, они хотели быть похожими друг на друга и громко заявили всем: во всех словах одного корня общая часть — корень — пишется одинаково, единообразно.
Как и в любой семье, среди однокоренных слов есть непослушные дети, которые не хотят быть похожими на всех и поэтому всех сбивают с толку. Например, в слове домов звук [а] слышен в безударном корне. Однако как только мы подбираем однокоренное слово с ударным корнем — домик — сразу становится ясно, что в корне слова следует писать букву о.
Это означает, что для проверки безударной гласной в корне слова вы должны выбрать однокоренное слово, чтобы безударная гласная стала ударным звуком.
§ 2 Краткое изложение темы урока
Корень — значимая часть слова, он содержит в себе общее значение все того же корня, родственных слов.
Чтобы проверить безударную гласную в корне слова, вы должны выбрать однокоренное слово, чтобы безударная гласная стала ударным звуком, поскольку во всех однокоренных словах общая часть — корень — пишется как так же.
Список использованной литературы:
- А.В. Венцов. Словарь русских омографов // Под ред. Санкт-Петербургский государственный университет, Санкт-Петербург, 2004.
- Алфавит от А до Я: иллюстрированное учебное пособие \ Составитель И.А. Гимпель. Минск: Асар, 2004. .
- Львов М.В. Методика развития речи младших школьников. М .: АСТ; Астрель, 2003.
- Розенталь Д.Е., Джанджакова Е.В., Кабанова Н.П. Справочник по орфографии, произношению, литературному редактированию. Москва: 1999.
- Сухин И.Г., Яценко И.Ф. Алфавит инрас. 1 кл. М .: Вако, 2010. .
- Я иду на урок в начальной школе. Чтение: книга для учителя. М., 2000.
Использованных изображений:
Схема разбора по составу больной:
больной
Разбор словесного состава.
Состав слова «больной»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова больной
больнойПодробная разбивка слов пациента по составу .Слово cope, префикс, суффикс и окончание слова. Мофемный разбор слова пациента, его схемы и частей слова (морфология).
- Схема морфем: pain / n / a
- Структура слова по морфемам: корень / суффикс / окончание
- Схема (конструкция) слова «пациент» в составе: корневая боль + суффикс n + окончание oh
- Список морфем в слове больной:
- боль — это корень
- n — суффикс
- oh — окончание
- Типы морфем и их количество в слове пациент:
- роды: отсутствует — 0
- королева: боль — 1
- соединение glac: отсутствует — 0
- cyffix: n — 1
- постфикс: отсутствует — 0
- конец: oh — 1
Всего морфема в слове: 3.
Словообразовательный анализ слова пациент
- Основа слова: больной ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс n , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образуется в 1 (один) способ .
См. Также другие словари:
Однокорневые слова … это слова, имеющие корень … принадлежащие к разным частям речи, и в то же время близкие по значению… Слова одного корня со словом больной
Что означает слово больной в единственном и множественном числе? Склонение слова больной
Полный морфологический анализ слова «больной»: часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово … Морфологический анализ пациента
Ударение в слове больной: на какой слог ударение и как … Слово «больной» правильно пишется как… Ударение в слове больной
Синонимы к слову «больной». Онлайн-словарь синонимов: найдите синонимы к слову «больной». Синонимы, похожие слова и похожие выражения в … Больные синонимы
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи … Антонимы для больных
Анаграммы (составьте анаграмму ) к слову больной, смешивая буквы … Анаграммы для больных
К чему снится больной — толкование снов, узнайте бесплатно в нашем соннике, к чему снится больной…. Увиденный во сне больной означает, что … Сонник: к чему снится больной
Морфемный разбор слова больной
Морфемный разбор слова принято называть разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный синтаксический анализ слова «пациент» очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, и для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов мы спрягаем или склоняем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- следующим шагом будет поиск корня слова. Подбираем родственные слова для пациента (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Мы находим остальные морфемы, выбирая другие слова, образованные таким же образом.
Как вы видите, синтаксический анализ морфемы делается просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Morphemic word parsing (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбора.Схема анализа боли:
боль
Разбор словесной композиции.
Состав слова «боль»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова боль
больПодробная разбивка слова боль по составу.Слово cope, префикс, суффикс и окончание слова. Мофемный раздел слова боль, его рисунок и части слова (морфология).
- Схема морфем: pain /
- Структура слова по морфемам: корень / окончание
- Схема (построение) слова pain по составу: root pain + окончание нуля, окончание
- Список морфем в слове pain:
- боль — это корень
- нулевое окончание — окончание
- Типы морфов и их количество в слове pain:
- delivery: absent — 0
- queen: pain — 1
- connection glac: absent — 0
- cyffix: absent — 0
- постфикс: отсутствует — 0
- конец: нулевое окончание. — 1
Всего морфем в слове: 2.
Анализ словообразования слова боль
- Основа слова: боль ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: или непроизводное, то есть не производное от другого корневого слова; или образованные не прилагательным способом: путем отсечения суффикса от основы прилагательного или глагола ;
- Метод обучения:
или непроизводное, то есть не производное от другого корневого слова; или образовано не прилагательным: путем отсечения суффикса от основы прилагательного или глагола
.
См. Также другие словари:
Однокорневые слова … это слова, имеющие корень … принадлежащие к разным частям речи, и в то же время близкие по значению … Однокорневые слова к слову pain
Примеры русских слов с корнем «боль». Полный список по частям речи: существительные, прилагательные, глаголы … Слова, основанные на боли
Что такое боль? Что такое боль? Больше слов для боли
Полный морфологический анализ слова «боль»: часть речи, исходная форма, морфологические особенности и формы слова.Направление науки о языке, где изучается слово … Морфологический анализ боли
Ударение в слове боль: на какой слог ударение и как … Слово «боль» правильно пишется как … Ударение в слове боль
Синонимы к слову боль. Онлайн-словарь синонимов: найдите синонимы к боли. Синонимы, похожие слова и похожие выражения в … Синонимы боли
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи… Антонимы к боли
Анаграммы (составить анаграмму) к слову боль, смешивая буквы … Анаграммы к слову боль
К чему снится боль — толкование снов, узнайте бесплатно в нашем соннике, что спит боль означает. … Боль, увиденная во сне, означает, что … Сонник: к чему снится боль
Морфемный разбор слова боль
Морфемный разбор слова принято называть разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова боль очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, и для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов мы спрягаем или склоняем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- следующим шагом будет поиск корня слова. Подбираем родственные слова для боли (их еще называют одним корнем), тогда корень слова будет очевиден;
- Мы находим остальные морфемы, выбирая другие слова, образованные таким же образом.
Как вы видите, синтаксический анализ морфемы делается просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Morphemic word parsing (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбора.Схема разбора композиции, чтобы заболеть:
заболел
Разбор слова композиция.
Состав слова «болеть»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова, чтобы повредить
болетьПодробная разбивка слово обидеть по составу.Слово cope, префикс, суффикс и окончание слова. Мофемная разбивка слова «болеть», его образец и части слова (морфология).
- Схема морфем: bol / e / th
- Структура слова по морфемам: корень / суффикс / суффикс
- Схема (конструкция) слова, поврежденного составом: корень bol + суффикс e + суффикс t
- Список морфем в слове обид:
- bol — корень
- e — суффикс
- t — суффикс
- Типы морфов и их количество в слове pain:
- доставка: отсутствует — 0
- queen: bol — 1
- connection glac: отсутствует — 0
- cyffix: e, th — 2
- постфикс: отсутствует — 0
- конец: нулевое окончание. — 0
Всего морфем в слове: 3.
Словообразование, разбор слова повредит
- Основа слова: подробнее ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс e, th , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образуется в 1 (один) способ .
См. Также другие словари:
Однокорневые слова… это слова, имеющие корень … принадлежащие к разным частям речи, и в то же время близкие по смыслу … Слова с одним корнем к слову болеть
Полный морфологический анализ слова » болеть »: часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово … Морфологический анализ болеть
Ударение в слове болеть: какой слог ударен и как … Слово «болеть» правильно пишется как … Ударение в слове больно
Синонимы «болеть». Онлайн-словарь синонимов: найдите синонимы к слову «больной». Синонимы слова, похожие слова и похожие выражения в … Синонимы к больному
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи … Антонимы к больному
Анаграммы (составьте анаграмма) к слову болеть, смешивая буквы … Анаграммы для слова болеть
Морфемический разбор слова больно
Морфемный разбор слова обычно называется анализом слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный синтаксический анализ слова «боль» очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, и для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов мы спрягаем или склоняем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- следующим шагом будет поиск корня слова. Подбираем родственные слова для больных (их еще называют одним корнем), тогда корень слова будет очевиден;
- Мы находим остальные морфемы, выбирая другие слова, образованные таким же образом.
Как вы видите, синтаксический анализ морфемы делается просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Morphemic word parsing (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбора.Причины боли могут быть самыми разными.
Но какими бы ни были болевые проявления, их объединяет одно — наличие корня боли.
Когда появляется боль, она еще не имеет глубокой основы в тканях и органах.
Возникает как функциональное расстройство.
Но с момента появления боль образует питательный корень … Как это происходит?
Возникновение боли может быть связано с незначительными функциональными изменениями в организме. Как часто бывает: зарезал, порезал и прошел. Хорошо, если человек не заостряет внимание на этом незначительном событии. Постучал, поморщился, забыл.
Чаще бывает по-другому — ужалила, хмурила, недоумевала: а что там ужалила? Общее негативное отношение заставит насторожиться, прислушайтесь к себе.Человек с позитивным внутренним настроем просто не обратит внимания на боль или сразу забудет о ней.
В повседневной жизни большинство из нас, как правило, не обращает внимания на свои тонкие ощущения. И зря. Их информативность очень высока. Если бы мы умело использовали тонкие ощущения, доверяли им, то могли бы избежать многих неприятностей, встретить сложные ситуации во всеоружии.
Но вернемся к боли.
Когда мы начинаем прислушиваться к себе, своим ощущениям, мы фиксируем внимание на малейших изменениях в самочувствии и тем самым усиливаем их.Психофизиология такого странного взаимодействия описана в учебниках академической медицины. Но психоэнергетика должным образом не исследована. Почему усиливаются боли, ухудшается самочувствие?
Дело в том, что простое сосредоточение на какой-то части тела или внутреннем органе меняет энергию и начинает активное поступление энергии извне. Концентрация внимания, как магнит, притягивает энергию к точке концентрации.
Но мы фиксируем внимание на ощущении боли, поэтому боль получает дополнительный импульс энергии.Когда мы сосредотачиваемся на том, как боль уходит, исчезает, появляется чувство комфорта в больном месте, тогда положительные процессы противодействия боли получат энергетическую подзарядку.
К сожалению, большинство людей, испытав боль, внимательно прислушиваются к своим ощущениям и ждут нового всплеска. Ожидание определяет его внешний вид. Возникнув в какой-то внутренней структуре, болевые ощущения сразу начинают закрепляться, образуя энергетические корни, проникая с ними в окружающие ткани.
Вы можете подумать, что боль — это независимое, разумное начало, которое ищет возможности усилить ее.Конечно нет! Механизм заполнения пустот рабочий.
Если в теле появляется боль и даже усиливается человеческим вниманием, она начинает расширять сферу своего влияния. Если первоначальный фокус небольшой, возникает спонтанно, то внимание человека будет привлечено импульсом силы, и фокус будет усилен. Далее он начинает черпать энергию из окружающих органов и тканей. Возникающая в результате энергетическая пустота немедленно заполняется самой болью или ее еще непроявленными вибрациями.
По собственному опыту мы знаем, что боль часто четко локализована. Его ярко выраженное ядро окружено своеобразным «ореолом», облаком менее сильных болевых ощущений. От ядра к периферии боль сглаживается, стихает и на достаточном расстоянии от нее совсем не ощущается.
Это не значит, что там, где нет боли, все хорошо. Там она еще не появилась. В общем, всякая боль имеет свойство накапливаться. Если с ним не бороться, то вскоре он распространится на все внутреннее пространство тела.
Помимо явления заполнения энергетической пустоты действует эффект обмена клеточной информацией. Одним словом, если вы подробно проанализируете и опишете боль как разноплановое явление, стремясь к глобальному охвату всего организма, вы получите отдельную книгу. Наша задача более конкретная: научиться локализовать боль, сжать ее в узелок и удалить с тела.
Накопление боли происходит на энергоинформационном уровне межклеточного обмена.А если его не остановить, то он, как компьютерный вирус, проникнет во все доступные информационные и программные блоки физиологических структур.
В повседневной жизни с болью борются разными способами.
В основном это обезболивающие химические или традиционные обезболивающие. Арсенал лекарств и средств народной медицины широк и разнообразен. Но большинство из них останавливают боль, воздвигают преграду на пути ее распространения. Это столкновение можно сравнить с двумя лобовыми пожарами.Они идут навстречу друг другу гудящими стенами огня, сталкиваются и уходят. Вот только искры разлетаются во все стороны, а после пожара остается выжженная земля.
Значит, после боли нужно время, чтобы восстановить нормальную работу органов, тканей и систем организма. А болезненная информация (по аналогии — «искры от пожаров») может появиться где угодно. Допустим, у вас болит голова. Где корни? Откуда возникает боль, чем она вызвана? А если вы примете обезболивающее, как отреагирует организм после того, как боль пройдет? Вопросов много, и практика на них отвечает.
Любая внешняя боль основана на нарушении деятельности внутренних органов. И когда болезненные ощущения каким-либо образом нейтрализуются, но при этом причина и корень боли остаются неизменными, организм реагирует сосудистыми нарушениями, некоторыми системными нарушениями и т. Д.
Повседневный опыт подсказывает, что боль нужно устранять любыми способами, а не терпеть, а тем более принять и считать, что это наказание за грехи. Однако удалить его можно разными способами.Мы уже говорили о вероятных последствиях обезболивания лекарствами. В главе, посвященной работе с кольцами, мы описали воздействие на очаги боли с помощью фокусирующих энергетических колец.
Помимо этих техник, мы опишем еще одну, с которой, собственно, и нужно начинать всю целительную практику.
Мы уже говорили, что боль имеет свои корни в тканях тела.
Этот корень нельзя трогать руками, так как он виртуальный и не имеет анатомической основы (конечно, если мы не говорим о язвенных, раневых, травматических и других повреждениях тела).
Кстати, вышеперечисленные внешние факторы тоже создают свои корни, но их сложнее нейтрализовать, так как раны, язвы и травмы отвлекают внимание к себе и мы не думаем о глубоких внутренних отголосках.
Техника снятия боли проста и не требует специальной подготовки. .
Вам нужно научиться удлинять пальцы с помощью энергетических лучей. Представьте, что мы выпускаем из подушечек пальцев энергетические лучи, с помощью которых мы можем чувствовать и даже воздействовать на тело другого человека.
Чтобы нейтрализовать боль и удалить ее из тела, энергетические удлинители пальцев медленно вводятся в ту область тела, где проявляется боль. С помощью лучей-пальцев мы начинаем ощущать узел боли. Чаще всего мы ощущаем фокус как темное облако, однако оно имеет четкие и заметные границы. Если мягко ощупать границы болезненного очага пальцами-лучами, то мы почувствуем, что плотность болевого образования уменьшается от центра к краям.
Определяем границы облака боли, затем лучами-пальцами начинаем собирать это облако в небольшой комок. Мы запускаем энергетические разгибания пальцев под облако боли и как бы складываем его.
Представим себе, что на скатерти остались следы вчерашнего застолья. Остатки можно собрать отдельно, а можно просто взять скатерть, завернуть края внутрь, чтобы подстилка не просыпалась, вынуть ее и затем вытряхнуть остатки застолья в мусорное ведро.
Мы делаем то же самое с фокусом боли. Заворачиваем его края внутрь и подтягиваем к центру. Когда облако боли собирается в плотный комок, мы начинаем его смягчать. Представьте, как плотно сжимает облако боли пальцами и лучами. Аналогия: — как будто месишь кусок пластилина.
Потом, когда боль собирается в комок, пускаем под него лучи пальцев. Вскоре появится ощущение, что где-то глубоко в теле есть нить, которую мы чувствуем своим мысленным прикосновением.Давайте пройдемся по нему и определим, насколько глубоко он врос в ткани. Если вовремя купировать боль, то ее корень будет небольшим, всего несколько сантиметров. Начинаем прощупывать корень, пьем его.
Все манипуляции выполняем с энергетическими разгибаниями пальцев. Корень боли был найден, пальцами-лучами проникли до кончика и медленно вытащили. Вытащить такой позвоночник непросто. Потребуется не только энергия, но и мышечные усилия.
Когда мы зацепились за корень и потянули за него, руки напрягаются.Вместе с усилиями мышц напряженно работают и энергетические лучи. Корень сложно выдернуть из ткани. Он сопротивляется, сопротивляется, но все же уступает. Затем, когда корень почти выдернут, нужно его крепко зацепить и резко вытащить.
После выдергивания корня боли возникает отчетливое ощущение, будто комочки какой-то невидимой грязи прилипли к пальцам и ладоням. Давай сбросим его. Лучше всего делать это, держа руки по обе стороны от плотной струи холодной воды, льющейся из-под крана.Поток холодной воды нейтрализует энергию боли, разрушает ее структуру, уносит с собой и уносит.
Проведем эксперимент.
Когда мы вырвали корень боли, мы просто моем руки под проточной водой. Ощущение такое, что на руках жирная пленка. Вода скатывается по коже, как будто руки обильно смазаны кремом. Это материализованное проявление энергии, эктоплазма боли. Обладает сильным структурирующим зарядом и не ломается без дополнительных усилий.И когда мы держим руки по обе стороны от плотной струи воды, начинается вихревое взаимодействие колебаний струи воды и энергии корня боли.
Для усиления очищающего действия воды делаем глубокий вдох, а выдох мысленно направляем через руки к ладоням и представляем, как она проникает в ладони, удаляет с них остатки негативной энергии. Когда возникает ощущение, что при выдохе через руки кажется, что они удлиняются, желаемый эффект будет достигнут, и мы сможем смыть боль с ладоней своим дыханием.
Этой техникой можно не только вырвать корень боли. Вы можете просто сбросить с рук плотный комок боли, желательно в струю воды или в землю. Стряхните сгусток боли с рук и несколько раз выдохните через ладони.
Очень интересна реакция людей, которые таким образом избавились от боли. Допустим, болит зуб. Человек трудится, но боязнь дрели или другой причины мешает пойти к стоматологу.Такому пациенту необходимо сразу сказать, что боль можно уменьшить или убрать, но лечить больной зуб должен профессиональный стоматолог. Энергетические воздействия, насколько нам известно, от кариеса не спасают.
Вводим лучи-пальцы в челюсть и там определяем локализацию боли. Собираем его в плотный комок, а затем вытаскиваем этот комок и бросаем в струю воды. Сначала человек смотрит на все эти манипуляции откровенно скептически. Но зубная боль такая, что он готов на все, кроме посещения стоматолога.А теперь боль собрана и вырвана. Некоторое время сохраняется инерция боли, и пациент ее прислушивается.
На морде четко написано: ты мне не помог, не справился. Затем боль начинает утихать. Какое блаженство, когда отступает зубная боль. Пропадает боль в челюсти, перестает дергать и стрелять, голова больше не раскалывается и кажется, что грация сойдет еще немного.
Выражение лица пациента меняется. В нем есть тихое умиротворение и в то же время напряженное ожидание новой волны боли.Но его не будет через минуту или две. Когда пациент понимает, что боль прошла, он счастлив. Но проходит около получаса, а он уже обо всем забыл. Поспешные обещания посетить стоматолога кажутся несерьезными и о них лучше забыть … И так — до следующего прилива боли.
Эффективность выдергивания корня боли и удаления его из тела тем выше, чем точнее целитель наблюдает последовательность этапов и наглядно представляет каждую из них.
Н.И. Шерстенников из книги «Резерв здоровья»
Лексическая категория— обзор
5.2.1 Обзор ресурсов, разработанных для обработки сербского языка
Для обработки сербского языка было разработано множество ресурсов, которые могут быть использованы для целей нашего исследования, но многие из них быть измененным или улучшенным. Большая часть этих ресурсов была разработана в системе Unitex [22], а часть из них была адаптирована для системы GATE [23].
Система Unitex — это система с открытым исходным кодом, разработанная Себастьеном Помье в Институте Гаспара-Монж при Университете Парижа в Марн-ла-Валле в 2001 году. Это система обработки корпуса, основанная на автоматизированной технологии, которая находится в постоянном развитии. Система используется во всем мире для задач НЛП, поскольку она обеспечивает поддержку ряда различных языков и многоязычных задач обработки.
Одной из основных частей системы являются электронные словари типа DELA (Dictionnaires Electroniques du Laboratoire d’Automatique Documentaire et Linguistique или электронные словари LADL), которые представлены на рис.2. Система состоит из словарей DELAS (простые формы DELA) и DELAF (DELA флективных форм). Словари DELAS — это словари простых слов, не изменяемых форм, в то время как словари DELAF содержат все изменяемые формы простых слов. С другой стороны, система содержит словари составных DELAC (DELA составных форм) и словари складываемых составных форм DELACF (DELA составных склонных форм).
Рис. 2. Система электронных словарей DELA.
Морфологические словари в формате DELA были предложены Лабораторией автоматической документации и лингвистики под руководством Мориса Гросса. Формат словарей DELA подходит для решения задач сегментации текста и морфологической, синтаксической и семантической обработки текста. Подробнее о формате DELA можно найти в [24].
Морфологические электронные словари в формате DELA представляют собой простые текстовые файлы. Каждая строка в этих файлах содержит запись слова и измененную форму слова.Другими словами, каждая строка содержит лемму слова и некоторую грамматическую, семантическую и флективную информацию.
Пример записи из словаря DELAF на английском языке: « таблицы, таблица.N + Conc: p ». Флективная форма таблицы является обязательной, таблица является леммой записи, а N + Conc представляет собой последовательность грамматической и семантической информации (N обозначает существительное, а Conc обозначает, что это существительное — конкретный объект), p — флективный код, который указывает на то, что существительное является множественным числом.
Словари этого типа для сербского языка разрабатываются группой НЛП на математическом факультете Белградского университета. Согласно [21], нынешний объем сербского морфологического словаря DELAS (простых слов) содержит 130 000 лемм. Большинство лемм из словаря DELAS относятся к общей лексике, а остальные относятся к разным видам простых имен собственных. Словарь DELAF содержит около 4 300 000 словоформ с заданными грамматическими категориями.Размер словарей DELAC и DELACF составляет примерно 10 500 и 54 000 лемм соответственно.
Аналогичный пример записи из сербского словаря простых словоформ с соответствующим грамматическим и семантическим кодом: padao, padati. V + Imperf + It + Iref: Gms, где словоформа padao является единственным (S) мужским родом (M) активного причастия прошедшего времени (G) глагола (V) padati «падать», что несовершенное (Imperf), непереходное (It) и рефлексивное (Iref).
Другой тип ресурсов, разработанный для сербского языка, — это различные типы конечных преобразователей. Конечные преобразователи используются для выполнения морфологического анализа, а также для распознавания и аннотирования фраз в текстах прогнозов погоды с соответствующими тегами XML, такими как ENAMEX, TIMEX и NUMEX, как мы объясняли ранее.
Пример графа конечного преобразователя для распознавания временных выражений и их аннотации с помощью тегов TIMEX представлен на рис. 3. Этот граф конечного преобразователя может распознавать последовательность « 14.01.2012 . » из текста нашего примера прогноза погоды и аннотируйте его тегом TIMEX, чтобы его можно было извлечь в форме «DATE_TIME: 14.01.2012.»
Рис. 3. Граф конечного преобразователя для извлечения и аннотирования временных выражений.
Другая система, которая больше подходит для решения проблемы IE (и CM), — это бесплатное программное обеспечение с открытым исходным кодом GATE (общая архитектура для текстовой инженерии). Система GATE или некоторые из ее компонентов уже используются для ряда различных задач НЛП на нескольких языках.Система GATE — это архитектура и среда разработки для приложений НЛП. GATE разрабатывается NLP Group Университета Шеффилда с 1995 года.
Архитектура GATE состоит из трех частей: языковые ресурсы, ресурсы обработки и визуальные ресурсы. Эти компоненты независимы, поэтому с системой могут работать разные типы пользователей. Программисты могут работать над разработкой алгоритмов для НЛП или настраивать внешний вид визуальных ресурсов для своих нужд, в то время как лингвисты могут использовать алгоритмы и языковые ресурсы без каких-либо дополнительных знаний о программировании.
Визуальные ресурсы, графический пользовательский интерфейс, останется в его первоначальном виде для целей данного исследования. Это позволит визуализировать и редактировать языковые ресурсы и ресурсы обработки. Языковые ресурсы для этого исследования включают корпуса текстов прогнозов погоды на нескольких языках и концептуальную модель прогноза погоды, которая будет построена. Необходимые изменения Ресурсов обработки, особенно модификации для применения к обработке сербских текстов, представлены ниже.
Задача IE в GATE встроена в систему ANNIE (почти новое извлечение информации). Подробную информацию об ANNIE можно найти в [25]. Система ANNIE включает в себя следующие ресурсы обработки: Tokeniser, Sentence Splitter, POS (часть речи) tagger, Gazetteer, Semantic Tagger и Orthomatcher. Каждый из перечисленных ресурсов создает аннотации, необходимые для следующего ресурса обработки в списке:
- •
Tokeniser разбивает текст на токены (слова, числа, символы, белые шаблоны и знаки препинания).Токенизатор можно использовать для обработки текстов на разных языках с небольшими изменениями или без них.
- •
Sentence Splitter сегментирует текст на предложения, используя каскады конечных преобразователей. Он также не зависит от приложения и языка.
- •
POS Tagger назначает тег части речи (тег лексической категории, например, существительное, глагол) в форме аннотации к каждому слову. Английская версия POS Tagger, входящая в систему GATE, основана на тэггере Brill.Это независимый от приложения, но зависящий от языка ресурс, который должен быть полностью изменен для сербского языка.
- •
Другой ресурс, зависящий от языка, но зависящий от приложения, — это Gazetteer, который содержит списки городов, стран, личных имен, организаций и т. Д. Gazetteer использует эти списки для аннотирования появления элементов списка в текстах. .
- •
Semantic Tagger основан на языке JAPE (Java Annotations Pattern Engine) [26].JAPE выполняет конечную обработку аннотаций на основе регулярных выражений, и его важной характеристикой является то, что он может использовать концептуальные модели (онтологии).
Semantic Tagger включает набор грамматик JAPE, где каждая грамматика состоит из набора фаз, а каждая фаза представляет собой набор правил. Кроме того, правила содержат левую и правую стороны. Левая сторона (LHS) правила описывает шаблон аннотации, который обычно распознается на основе операторов регулярного выражения Клини.Правая сторона (RHS) правила описывает действие, которое должно быть предпринято после того, как LHS распознает шаблон, например, создание новой аннотации. Это ресурс, зависящий от приложения и языка.
- •
Orthomatcher идентифицирует отношения между именованными объектами, обнаруженными Semantic Tagger. Он создает новые аннотации на основе отношений между именованными объектами. Это независимый от приложения и языка ресурс.
Основная цель — разработать ресурсы, зависящие от языка или приложения (Gazetteer, POS Tagger и Semantic Tagger) для сербского языка.Путь, который мы выбрали для решения этой проблемы, — использовать ранее описанные ресурсы, разработанные для системы Unitex, и адаптировать их для использования в системе GATE. Изменение списков географического справочника — это простой процесс перевода с одного языка на другой. Построение грамматик JAPE с поддержкой онтологий для области прогноза погоды требует первоначальной разработки соответствующего подъязыка и концептуальной модели, которые будут обсуждаться в следующем подразделе в качестве предмета текущих исследований авторов.Проблема создания подходящего POS Tagger очень сложна и не будет здесь подробно описываться.
Вкратце, мы сделали оболочку для Unitex, чтобы ее можно было использовать непосредственно в системе GATE для создания электронных словарей для заданных текстов прогноза погоды и механизма для создания соответствующей аннотации POS Tagger для каждого слова. Это решение проблемы, хотя и имеет несколько недостатков, может стать хорошей основой для создания семантических тегов на основе концептуальных моделей и систем IE в целом.w \),
Ровно один правильный префикс d находится в \ (E ‘\),
Ровно один правильный суффикс d находится в \ (E ‘\),
Никакой другой подстроки d нет в \ (E ‘\).
Учитывая T и способ распознавания строк в E , мы можем построить D итеративно путем сканирования \ (\ mathtt {\ #} \, T \, \ mathtt {\ $} ^ w \) на найти вхождения элементов \ (E ‘\) и добавить к D каждую подстроку \ (\ mathtt {\ #} \, T \, \ mathtt {\ $} ^ w \), которая начинается с начала один такой случай и заканчивается в конце следующего. w \) равно
$$ \ begin {align} \ mathtt {\ #GATTAC} \; \ mathtt {ACAT!} \; \ mathtt {T! GATAC} \; \ mathtt {ACAT!} \; \ mathtt {T! GATTAG} \; \ mathtt {AGATA \ $ \ $} \ end {align} $$
и, идентифицируя элементы D по их лексикографическим рангам, результирующий массив P будет \ (P = [0, 1, 3, 1 , 4, 2] \).
Затем мы определяем S как набор суффиксов длиной больше w элементов D . В нашем предыдущем примере мы получаем
$$ \ begin {align} S = & {} \ {\ mathtt {\ #GATTAC}, \ mathtt {GATTAC}, \ ldots, \ mathtt {TAC}, \\ & \ mathtt {ACAT!}, \ Mathtt {CAT!}, \ Mathtt {AT!}, \\ & \ mathtt {AGATA \ $ \ $}, \ mathtt {GATA \ $ \ $}, \ ldots, \ mathtt {A \ $ \ $}, \\ & \ mathtt {T! GATAC}, \ mathtt {! GATAC}, \ ldots, \ mathtt {TAC}, \\ & \ mathtt {T! GATTAG}, \ mathtt {! GATTAG}, \ ldots, \ mathtt {TAG} \}.\ end {align} $$
Лемма 1S — это набор без префиксов.
ПробаЕсли \ (s \ in S \) был правильным префиксом \ (s ‘\ in S \), то, поскольку \ (| s |> w \), последние w символа из s , которые являются элемент \ (E ‘\) — будет подстрокой \ (s’ \), но не будет ни правильным префиксом, ни суффиксом \ (s ‘\).* \).
ПробаПо лемме 1, s и \ (s ‘\) не являются собственными префиксами друг друга. Поскольку они тоже не равны (поскольку \ (s \ prec s ‘\)), отсюда следует, что sx и \ (s’ x ‘\) различаются по одному из своих первых \ (\ min (| s |, | s ‘|) \) символов. Следовательно, \ (s \ prec s ‘\) подразумевает \ (s x \ prec s’ x ‘\). \ (\ квадрат \)
Лемма 3Для любого суффикса x из \ (\ mathtt {\ #} \, T \, \ mathtt {\ $} ^ w \) с \ (| x |> w \), ровно один префикс s из x находится в S .
ПробаРассмотрим подстроку d , простирающуюся от начала последнего вхождения элемента \ (E ‘\), который начинается до или в начальной позиции x , до конца первого вхождения элемента \ (E ‘\), который начинается строго после начальной позиции x . Независимо от того, начинается ли d с \ (\ mathtt {\ #} \) или с другого элемента \ (E ‘\), ему предшествует ровно один элемент из \ (E’ \); аналогично, это суффикс ровно один элемент \ (E ‘\).w \) с \ (| x |, | x ‘|> w \). Тогда \ (f (x) \ prec f (x ‘) \) влечет \ (x \ prec x’ \).
ПробаПо определению f , f ( x ) и \ (f (x ‘) \) являются префиксами x и \ (x’ \) с \ (| f (x) |, | е (х ‘) |> ш \). Следовательно, \ (f (x) \ prec f (x ‘) \) влечет \ (x \ prec x’ \) по лемме 2. \ (\ square \)
Определить \ (T ‘[0.w) \).
Лемма 6Предположим, что \ (\ beta \) отображает k копии a в \ (s \ in S \) и не отображает никакие другие символы на s , и отображает всего t символов к элементам S лексикографически меньше, чем s . Тогда \ ((t + 1) \) -й по \ ((t + k) \) -й символы BWT \ (T ‘\) являются копиями a .
ПробаПо леммам 4 и 5, если \ (f (g (y)) \ prec f (g (y ‘)) \), то \ (y \ prec y’ \). Следовательно, \ (\ beta \) частично сортирует символы в \ (T ‘\) по их порядку в BWT \ (T’ \); эквивалентно, частичный порядок символов согласно \ (\ beta \) может быть расширен до их полного порядка в BWT. Поскольку каждое полное расширение \ (\ beta \) помещает эти k копий a в позиции от \ ((t + 1) \) до \ ((t + k) \), они появляются там в BWT.w \) или, что то же самое, сколько копий a сопоставлено \ (\ beta \) с лексикографическим рангом s . Если элемент \ (s \ in S \) является суффиксом только одного элемента \ (d \ in D \) и его правильным суффиксом, который мы можем определить сначала только по D , то \ (\ beta \ ) отображает только копии предыдущего символа d в ранг s , и мы можем вычислить их позиции в BWT \ (T ‘\). Однако, если \ (s = d \) или суффикс из нескольких элементов D , то \ (\ beta \) может отображать несколько различных символов в ранг s .Чтобы справиться с этими случаями, мы также можем вычислить, какие элементы D содержат символы, сопоставленные с рангом s . Мы объясним через мгновение, как мы используем эту информацию.
Для нашего примера \ (T = \ mathtt {GATTACAT! GATACAT! GATTAGATA} \) мы вычисляем информацию, показанную в таблице 1. Чтобы упростить сравнение со стандартным вычислением BWT \ (T ‘\, \ mathtt {\ $} \), показанный в таблице 2, мы записываем символы, сопоставленные каждому элементу \ (s \ in S \) перед s самим.
Таблица 1 Информация, которую мы вычисляем для нашего примера, \ (T = \ mathtt {GATTACAT! GATACAT! GATTAGATA} \) Таблица 2 BWT для \ (T ‘= \ mathtt {GATTACAT! GATACAT! GATTAGATA \ $} \)По лемме 6 из символов, отображаемых в каждый ранг с помощью \ (\ beta \), и частичных сумм частот, с которыми \ (\ beta \) отображает символы в ранги, мы можем вычислить подпоследовательность BWT из \ (T ‘\), который содержит все символы \ (\ beta \), отображается в элементы S , которые не являются полными элементами D и которым сопоставлен только один отдельный символ.Мы также можем оставить заполнители там, где это необходимо, для символов \ (\ beta \), отображаемых на элементы S , которые являются полными элементами D или которым сопоставлено более одного отдельного символа. w \).Следовательно, существует первый символ, по которому t и \ (t ‘\) отличаются. Поскольку элементы D представлены в синтаксическом анализе своими лексикографическими рангами, этот символ вынуждает \ (q \ prec q ‘\). \ (\ квадрат \)
Мы рассматриваем вхождения в P элементов D с суффиксом s и сортируем символы, предшествующие этим вхождениям s , в лексикографическом порядке оставшихся суффиксов P , которые по лемме 7 , — их порядок в BWT \ (T ‘\).В нашем примере перед \ (\ mathtt {TAC} \ in S \) в \ (\ mathtt {\ #} \, T \, \ mathtt {\ $ \ $} \) стоит буква T, когда она встречается как суффикс \ (\ mathtt {\ #GATTAC} \ in D \), который имеет ранг 0 в D , и буквой A, если он встречается как суффикс \ (\ mathtt {T! GATAC} \ в D \ ), который занимает 3 место в рейтинге D . Поскольку суффикс, следующий за 0 в \ (P = 0, 1, 3, 1, 4, 2 \), лексикографически меньше, чем суффикс, следующий за 3, то T предшествует этому A в BWT.
Поскольку нам нужно только D и частоты его элементов в P , чтобы применить лемму 6 для построения и сохранения подпоследовательности BWT \ (T ‘\), которая содержит все символы \ (\ beta \) сопоставляется с элементами S , которым сопоставлен только один отдельный символ, это занимает пространство, пропорциональное общей длине элементов D .Затем мы можем применить лемму 7 для построения подпоследовательности пропущенных символов в том порядке, в котором они появляются в BWT. Хотя эта подпоследовательность пропущенных символов может занять больше места, чем D и P вместе взятые, по мере их генерации мы можем чередовать их с первой подпоследовательностью и выводить их, тем самым по-прежнему используя рабочее пространство, пропорциональное общей длине P и элементы D и только один проход по пространству, используемому для хранения BWT.
Обратите внимание, мы можем построить первую подпоследовательность из D и частот ее элементов в P ; хранить во внешней памяти; и сделаем проход по нему, пока мы генерируем второй из D и P , вставляя недостающие символы в соответствующие места.Таким образом, мы используем два прохода по пространству, используемому для хранения BWT, но мы можем использовать значительно меньше рабочего пространства.
Подводя итог, предполагая, что мы можем быстро распознать строки в E , мы можем быстро вычислить D и P с одним сканированием по T . Из D и P , с леммами 6 и 7, мы можем вычислить BWT для \ (T ‘= T \, \ mathtt {\ $} \), отсортировав суффиксы элементов D и суффиксы P .Поскольку существуют алгоритмы линейного времени и линейного пространства для сортировки суффиксов при работе во внутренней памяти, это подразумевает наш основной теоретический результат:
Теорема 1Мы можем вычислить BWT \ (T \, \ mathtt {\ $} \) из D и P , используя рабочее пространство, пропорциональное сумме общей длины P и элементы D , и O ( n ) время, когда мы можем работать во внутренней памяти.